ПЕРЕКРЕСТНАЯ ССЫЛКА НА РОДСТВЕННЫЕ ЗАЯВКИ
По настоящей заявке на патент испрашивается приоритет по дате подачи предварительной заявки США № 60/784510, поданной 20 марта 2006.
ПРЕДШЕСТВУЮЩИЙ УРОВЕНЬ ТЕХНИКИ
Данные стали важным ресурсом почти в каждом приложении независимо от того, является ли оно, например, производственным (LOB) приложением, просматривающим продукты и формирующим заказы, или приложением личной информационной системы (PIM), планирующим встречи между людьми. Приложения все более и более становятся ориентированными на данные - они планируют существенную часть своего восприятия в плане дизайна и времени выполнения, вокруг запрашивания данных, манипулирования данными и их представления. Многие из этих приложений имеют дело с данными с расширенной семантикой, например структурной целостностью, ограничениями на данные, связями между данными и так далее. При разработке процедурного кода современных приложений затрачиваются значительные усилия на предохранение семантики данных.
Рассмотрим, например, приложение LOB. Как правило, такое приложение имеет дело с Customers (Клиенты), Orders (Заказы), OrderLines (Строки Заказа), Suppliers (Поставщики), Products (Продукты), Employees (Служащие), Shippers (Грузоотправители), Invoices (Счета-фактуры) и так далее. Каждое из этих понятий представляет отдельный расширенный тип данных со специальной структурой. Например, тип Customer (Клиент) имеет такие элементы, как CustomerID (Идентификатор Клиента), Company Name (Название Компании), Contact Name (Имя Представителя) и Address (Адрес), тип Order (Заказ) имеет такие элементы, как OrderID (Идентификатор Заказа), CustomerID (Идентификатор Клиента), OrderDate (Дата Заказа), OrderLines (Строки Заказа), DueDate (Дата Выполнения) и т.д. К любому из вышеупомянутых также могут предъявляться требования, например, для Address (Адреса) может требоваться PostalCode (Почтовый Код), который для США должен быть почтовым индексом США, который состоит из пяти символов, и каждый символ является цифрой между нулем и девятью. В Канаде PostalCode (Почтовый Код) должен иметь вид "ANA NAN", где A - буква, и N - число. Соответственно при моделировании почтовых кодов не достаточно просто определить его как строку (string) - на эту строку должны быть наложены дополнительные ограничения, ограничивающие диапазон возможных значений, которые она может принимать. Кроме того, между данными обычно существуют связи. Например, Order (Заказ) всегда может иметь связанного с ним Customer (Клиент), это связь - многие (Order)-к-одному (Customer). Products (Продукты) и Suppliers (Поставщики) имеют связь многие-ко-многим, потому что несколько продуктов могут поставляться одним поставщиком, и несколько поставщиков могут торговать идентичным продуктом.
Модель данных описывает структуру и семантику и связи между различными элементами данных, которые являются частью приложения. Хотя реляционные модели и системы очень успешно управляют данными, они не могут перехватывать модели данных приложений. Общепринятые клиент-серверные приложения передают на исполнение запросы и операции персистентности (по созданию и поддержке перманентных объектов) на своих данных в системы баз данных. Система базы данных управляет данными в виде строк и таблиц, в то время как приложение управляет данными в виде конструкций высокоуровневого языка программирования, например классов и расширенных типов данных. Рассогласование нагрузки в услугах манипулирования данными между приложением и звеном базы данных было допустимо в общепринятых системах. С появлением сервис-ориентированных архитектур (SOA), серверов приложений и многозвенных приложений потребность в расширенных услугах обработки и доступа к данным, которые хорошо интегрированы со средами программирования и могут работать в любом звене, увеличилась чрезвычайно.
Большинство приложений и сред разработки приложений создают свою собственную модель данных на основе систем, базирующихся на реляционной модели данных, для связывания рассогласования нагрузки между данными и средой прикладного программирования. Это потому, что большинству приложений, LOB, PIM, Information Worker (информационный работник) или другим, требуются такие концепции модели данных, как расширенная структура, связи, поведения и расширяемость. Эти концепции модели данных не поддерживаются в достаточной мере существующими моделями данных, и, кроме того, в настоящее время не существует соответствующих языков запросов для доступа к данным, если они будут организованы согласно более расширенной модели данных.
Современные иллюстративные кандидаты на метамодель данных включают в себя версию 1999 языка структурированных запросов (SQL99), общеязыковую среду исполнения (CLR), унифицированный язык моделирования (UML) и определение XML схем (XSD). Однако CLR является объектно-ориентированной средой императивного программирования времени выполнения и не имеет собственной модели данных или понятий ограничения целостности, связей или персистентности. В SQL99 отсутствуют такие концепции моделирования данных, как связи, и у него нет хорошей интеграции с языками программирования. Спецификация XSD не поддерживает такие концепции, как ключи, связи и персистентность, и является сложной и имеет громоздкое отображение в модели и реляционной базы данных, и времени выполнения. UML является слишком общим: в нем от разработчиков приложений требуется добавлять точную семантику, особенно для персистентности.
В промышленности существует неудовлетворенная потребность в модели данных и соответствующей интегрированной среде поддержки, которая обеспечивает лучший доступ приложений к расширенным типам данных. Также существует потребность в расширяемом языке запросов с поддержкой расширенных типов данных, который может поддерживаться такой моделью данных.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
С учетом указанных выше недостатков в данной области техники настоящее изобретение обеспечивает расширяемый язык запросов с поддержкой для расширенных типов данных. В этом документе обсуждаются различные иллюстративные признаки обеспеченного языка запросов. Кроме того, система может содержать приложение, сконфигурированное для формирования запросов согласно языку запросов. Также обеспечена платформа для обработки запросов, которые сформированы согласно обеспеченному языку запросов. Платформа, в общем, содержит уровень сервисов объектов, уровень поставщика отображения и связующий уровень, который может в конечном счете обеспечить интерфейс со множеством доступных в промышленном масштабе баз данных.
ПЕРЕЧЕНЬ ЧЕРТЕЖЕЙ
Системы и способы для расширяемого языка запросов с поддержкой для расширенных типов данных также описаны в соответствии с настоящим изобретением согласно прилагаемым чертежам, в которых:
На фиг.1 изображена архитектура поддержки приложения для приложений, осуществляющих доступ к данным согласно системам и способам, обеспеченным в этом документе.
Фиг.2 - главные компоненты архитектуры CDP, и, в частности, на ней изображен конвейер запроса, который может проводить запросы, сделанные с использованием расширяемого языка запросов, для расширенных типов данных, обсуждаемых более подробно ниже.
На фиг.3 изображено представление Outlook группировки по дате (group by date), аналогичное дружественному представлению с группировкой, формируемому с использованием вычисляемого метода согласно изобретению.
ПОДРОБНОЕ ОПИСАНИЕ
Для обеспечения полного понимания различных вариантов осуществления изобретения в следующем описании и чертежах изложены конкретные детали. Однако во избежание излишнего затруднения понимания различных вариантов осуществления изобретения в следующем раскрытии не изложены определенные общеизвестные детали, часто связанные с вычислением и программированием. Кроме того, специалистам будет понятно, что они могут на практике осуществить другие варианты осуществления изобретения без одной или нескольких деталей, описанных ниже. Наконец, несмотря на то, что в следующем раскрытии различные способы описаны согласно этапам и последовательностям, описание как таковое предназначено для обеспечения четкой реализации вариантов осуществления изобретения, и этапы и последовательности этапов не следует воспринимать как обязательные для практического применения этого изобретения.
Во-первых, в этом описании обеспечены иллюстративная модель данных и соответствующие механизмы поддержки данных, которые могут быть использованы в иллюстративных вариантах осуществления систем и способов, которые включают язык запросов с поддержкой для расширенных типов данных, как описано в этом документе. Далее, обсуждается множество новых признаков и аспектов иллюстративного языка запросов, изложенного в этом документе, и которым придается большое значение. Подробная спецификация иллюстративного языка запросов изложена в Приложении A, и расширения к нему изложены в Приложении B. Как будет понятно специалистам в данной области техники, подробные реализации включают в себя много новых и полезных признаков.
Иллюстративная модель данных и соответствующие механизмы поддержки данных
Иллюстративная модель данных и соответствующие механизмы поддержки данных могут быть включены в ряд таких технологий, как объекты данных Active X для платформы управляемого кода (ADO.NET), которая предназначена для обеспечения единообразного доступа к таким источникам данных, как сервер языка структурированных запросов (SQL) MICROSOFT®, а также к источникам данных, выставленных через связывание и встраивание объектов для базы данных (OLE DB) и расширяемый язык разметки (XML). Клиентские приложения совместного использования данных могут использовать ADO.NET для соединения с этими источниками данных и отыскания, обработки и обновления данных.
ADO.NET аккуратно разлагает доступ к данным из манипулирования данными в дискретные компоненты, которые могут использоваться отдельно или последовательно. ADO.NET включает в себя поставщиков данных.NET Framework для соединения с базой данных, исполнения команд и извлечения результатов. Эти результаты или обрабатываются непосредственно, или помещаются в объект DataSet ADO.NET для выставления их пользователю способом для данного случая, объединенными с данными из нескольных источников, или (удаленно) между звеньями. Объект DataSet ADO.NET может также использоваться независимо от поставщика данных.NET Framework для управления данными, локальными для приложения или поставляемыми из XML. Соответственно ADO.NET обеспечивает функциональные возможности разработчикам, пишущим управляемый код, подобный функциональным возможностям, обеспеченным разработчикам собственной COM технологией объектов данных Active X (ADO), знакомой специалистам в данной области техники.
В одном варианте осуществления платформа ADO.Net может быть расширена для обеспечения расширенного набора служб данных для приложений - по всему множеству таких сред разработки приложений, как интегрированные среды PIM и интегрированные среды LOB - для получения доступа к данным, их обработки и управления ими способом, который хорошо интегрирован со средой прикладного программирования. На фиг.1 изображено размещение этих функциональных возможностей в архитектуре поддержки приложения. Платформа общих данных (CDP) 100 может реализовывать ряд таких технологий, как платформа ADO.Net. Платформа общих данных (CDP) 100 и соответствующие технологии подробно обсуждаются в патентной заявке США 11/171905.
Архитектура поддержки приложения фиг.1 может включить в себя, например, источник 110 данных, например SQL SERVER®, WinFS® или базу данных ORACLE®; CDP 100, который обеспечивает службы расширенных данных для приложения и сред разработки приложений; набор услуг интегрированной среды, например UAF 120 и интегрированной среды 130 LOB, которые расширяют и дополняют функциональные возможности CDP 100; набор классов данных, например 122, 132, 140, которые инкапсулируют функциональные возможности интегрированной среды и общую логику приложения; и любое количество приложений 150, 160, 170, которые используют функциональные возможности, обеспеченные CDP 100 и интегрированными средами 120, 130, и/или классов 122, 132, 140.
Модель данных, которая поддерживается CDP 100, может содержать, например, модель данных сущностей-объектов (Entity Data Model, EDM), разработанную корпорацией MICROSOFT®, Редмонд, штат Вашингтон. EDM расширяет реляционную модель данных для приспособления нескольких сред разработки приложений, например LOB, PIM, Management (Управление) и т.д. EDM определяет абстракцию расширенного объекта для данных, моделирует расширенную семантику, например, связи данных, минимизирует рассогласование между структурами приложения и моделью данных, поддерживает определенные поведения приложения, поддерживает основные реляционные концепции, расширенные типы с наследованием и связи, и в целом обеспечивает концепции моделирования, которые перехватывают семантику данных независимо от звеньев развертывания и складов данных. EDM может быть включена в такие технологии, как ADO.NET.
На фиг.2 изображены главные компоненты архитектуры CDP 100, и, в особенности, на ней изображен конвейер запроса, который может (проводить) запросы, сделанные с использованием расширяемого языка запросов, для расширенных типов данных, обсуждаемых более подробно ниже. Термин "eSQL" будет использоваться в этом документе для ссылки на расширяемый язык запросов для расширенных типов данных, вариант осуществления которых подробно изложен ниже. На фиг.2 также изображено, как запрос плавно проходит через различные компоненты CDP 100.
Во-первых, приложение 200 выдает запрос поставщику 210 сервисов объектов как запрос eSQL. Поставщик 210 сервисов объектов может содержать службу 211 синтаксического анализатора, который анализирует запрос и преобразует его в каноническое дерево, и отображающие трансформации 212, которые выполняют любые отображающие трансляции (из модели данных приложения в EDM, как предусмотрено в этом документе) на каноническом дереве. Поставщик сервисов объектов далее может передавать каноническое дерево поставщику 220 отображения.
Поставщик 220 отображения инкапсулирует реляционные отображающие функциональные возможности объекта. Он содержит отображающие трансформации 222, которые выполняют отображающие трансляции на каноническом дереве. Поставщик отображения передает каноническое дерево в связующее устройство 230 для посреднических услуг.
Связующее средство 230 может содержать компонент 231 услуг компенсации запроса, который разлагает каноническое дерево и выполняет любые компенсации модели данных, затем передает одно или несколько канонических деревьев поставщику 240 накопителей.
Поставщик 240 хранилища транслирует каноническое дерево на его родной диалект, например на диалект SQL, например SQL 2000 или SQL 2005, или в формат встроенной базы данных или WinFS. Поставщик 240 хранилища исполняет запрос и возвращает сообщение, например сообщение, которое может быть отформатировано для передачи в интерфейс DataReader ("DataReader") или из него в связующее устройство 230.
Связующее средство 230 содержит услугу 232 ассемблирования результата/значения, которая ассемблирует, в случае необходимости, результаты из потенциально нескольких DataReader, возвращенных поставщиком 240 хранилищ. Результатом этой операции, выполненной 232, является единый DataReader в терминах пространства EDM.
Далее поставщик 220 отображения просто возвращает DataReader из связующего устройства 230 поставщику 210 сервисов объектов. Сервисы 210 объектов транслируют результаты поставщика 220 отображения в объектное пространство. Поставщик 221 сервисов объектов содержит компонент 213, который дополнительно осуществляет результаты как объекты и кэширует эти объекты в таблице идентификации. Наконец, приложение 200 использует результирующий DataReader.
Более конкретно, согласно нескольким существенным аспектам EDM, EDM, в целом, создается согласно четырем базовым концепциям: типы, экземпляры, сущности-объекты и связи. Эти концепции можно проиллюстрировать с использованием примера типичного приложения LOB. Такое приложение имеет дело с различными видами данных, например заказом, клиентом, строками заказа, адресом, поставщиком, продуктом, служащим и так далее.
В иллюстративном использовании EDM данные Customer можно рассматривать как сущность-объект. Сущность-объект представляет элемент данных верхнего уровня, с которым работает приложение. Customer может иметь несколько полей: CustomerID, CompanyName, ContactName, Address и Phone (Телефон). Каждое поле имеет тип, который определяет структуру данных, входящих в это поле. Например, CustomerID может быть строкой (string) фиксированной длины. Поля CompanyName и ContactName также могут иметь тип string. Customer непосредственно также имеет тип; так как Customer является сущностью-объектом, то этот тип можно назвать типом сущности-объекта.
Поле Address может отличаться от других полей: оно обладает внутренней структурой в виде других полей, например City (Город), State (Штат) и PostalCode. В EDM тип такого поля, как Address называют составным типом. Напротив, типы CustomerID, CompanyName и ContactName все могут быть простыми типами.
Поле Phone может состоять из нескольких номеров телефона, каждый из которых является строкой. Его называют коллекцией.
Тип определяет структуру данных и определенные ограничения на значения. Фактические данные хранятся в экземплярах этих типов. Каждый, кто знаком с объектно-ориентированным программированием, проведет очевидную аналогию: типы и экземпляры подобны классам и объектам соответственно.
И Customer, и Address сходны в том смысле, что у них обоих есть внутренняя структура: они состоят из нескольных полей. Но семантически и в отношении функционирования Customer отличается от Address. Customer действует как единица для запроса, операций обмена данными, транзакций, персистентности (создания и поддержания перманентных объектов) и совместного использования. Address, с другой стороны, всегда функционирует в пределах Customer и нельзя ссылаться или каким-либо другим способом воздействовать на него независимо. В EDM такие элементы данных верхнего уровня называются объектами. Все другие данные рассматниваются как встроенные в сущности-объекты.
Теперь рассмотрим иллюстративные данные Order. Бизнес-правила могут требовать, чтобы каждый заказ имел соответствующего клиента. Это моделируют посредством связи между сущность-объектом Order и сущность-объектом Customer. Существуют различные виды связей, поддерживаемых EDM. Связь между Order и Customer называется ассоциация. Ассоциации, как правило, используют для моделирования одноранговых связей между сущностями-объектами.
Каждый заказ может состоять из нескольких строк заказа. Например, если вы заказываете пять книг на AMAZON.COM®, то данные о каждой книге составляют строку заказа. Это моделируется как другой вид связи, композиция. Каждый OrderLine в пределах композиции является сущностью-объектом.
Иллюстративные новые признаки eSQL
Далее обсуждается множество новых признаков и аспектов иллюстративного языка запросов, которым придается большое значение. В общем, язык eSQL и его расширения, предоставленные ниже, могут быть реализованы в системе, например, описанной выше согласно фиг.1 и фиг.2, хотя специалистам в данной области техники будет понятно, что различные новые системы и способы, связанные с нижеописанным иллюстративным вариантом осуществления, также могут быть реализованы в других контекстах.
Спецификация eSQL, заданная ниже, содержит множество новых признаков, которые включают в себя, например, представление запросов и утверждений языка манипулирования данными (DMLs - термин "запрос", используемый в этом документе, относится к запросам и DMLs) в терминах языка моделирования данных с поддержкой для расширенных типов данных (расширенный язык моделирования данных), например EDM, канонические деревья команд (CTree), которые представляют программный способ определения запросов и DMLs в терминах расширенного языка моделирования данных, функциональные возможности связующего устройства, которые выполняют компенсацию для конкретных поставщиков посредством манипулирования каноническими запросами, использование развертывания вида для изящного объединения способа отображения OR по всей семантике расширенного языка моделирования данных с запросом и обновлениями. И способность расширить базовый язык запросов через расширения, которыми управляют из метаданных. Кроме того, иллюстративные новые аспекты спецификаций eSQL, изложенные ниже, включают в себя следующее.
Первоклассная поддержка для коллекций: иллюстративный вариант осуществления eSQL, обеспеченный в этом документе, разработан подобным SQL и обеспечивает преимущества перед SQL. В общем, ранние версии SQL (SQL 92 и более ранние) были в основном сконцентрированы на таблице. Таблицы обрабатывали, как первоклассные сущности-объекты, а строки/столбцы обрабатывали, как второклассные. И, конечно, не было никакого понятия о коллекциях. SQL 99 и более поздние диалекты обеспечивают поддержку для коллекций, но эта поддержка была настроена на SQL 92. Доказательство, например, тяжеловесные добавления наподобие unnest, apply и т.п.
Напротив, в одном варианте осуществления eSQL обрабатывает коллекции как первоклассные сущности-объекты. Например, выражения с коллекциями являются допустимыми в предложении from. Нет необходимости использовать синтаксические структуры unnest, подзапросы "in" и "exists" были обобщены для обработки любых коллекций - подзапрос просто является одним из видов коллекции, для выполнения этих операций предназначены конструкции eSQL "e1 in e2" и "exists(e)". Кроме того, многие из операций над множествами (set) (union (объединение), intersect (пересечение), except (исключение)) оперируют коллекциями. Операции join (соединение) также оперируют коллекциями.
Все является выражением: Стандартный SQL всегда имел двухуровневую систему - подзапросы (таблицы) и выражения (строки, столбцы). В одном варианте осуществления, для обеспечения первоклассной поддержки коллекций и вложенных коллекций, eSQL принимает намного более цельную модель - все является выражением. Например, все следующие запросы eSQL являются допустимыми:
1+2*3
"abc"
row(1 as a, 2 as b)
{ 1, 3, 5}
e1 union all e2
distinct(e1)
Единообразная обработка подзапросов. Так как SQL функционирует исходя из своего сконцентрированного на таблице представления о мире, то, как правило, у него существует тенденция интерпретировать подзапросы в контексте. Например, в SQL, считается, что подзапрос в предложении from является мультимножеством (таблицей), в то время как идентичный подзапрос, используемый в предложении select, считается скалярным подзапросом. Аналогично, подзапрос, используемый слева от оператора in, считается скалярным подзапросом, в то время как справа ожидается подзапрос мультимножества.
В одном варианте осуществления eSQL устраняет эти различия. Существует однообразная интерпретация выражения, которая не зависит от контекста, в котором оно используется. eSQL может считать все подзапросы подзапросами мультимножества. Если требуется скалярное значение из подзапроса, то eSQL может обеспечивать оператор element (элемент), который оперирует коллекцией (в данном случае подзапросом), и извлекать значение одного элемента из коллекции.
Избежание беспричинных неявных приведений типов данных: побочным эффектом, связанным с описанной выше проблемой, является склонность к неявному преобразованию подзапросов в скалярное значение. А именно, в SQL, мультимножество строк с одним полем неявно преобразуется в скалярное значение, типом данных которого является тип данных поля. Напротив, варианты осуществления eSQL не поддерживают это неявное приведение типа данных. eSQL может обеспечивать оператор element для извлечения значения одного элемента из коллекции и предложение select value (выбрать значение) для избежания создания упаковщика строк на протяжении выражения запроса.
Select_Value - избежание от неявного упаковщика строк: SQL до некоторой степени неоднозначен относительно обработки результата запроса. Предложение select в подзапросе SQL неявно создает упаковщика строк вокруг элементов этого предложения. Это, конечно, означает, что мы не можем создавать коллекции из скалярных величин или объектов - каждая коллекция является коллекцией строк (с одним полем, в случае необходимости). С обеспечением возможности неявного приведение типов данных между типом строк с одним полем и значением одиночного элемента идентичного типа данных.
В одном варианте осуществления eSQL обеспечивает предложение select value для пропуска неявного создания строки. В предложении select value может быть указан только один элемент. При использовании такого предложения вокруг элементов предложения select ни один упаковщик строк не создается, и может быть создана коллекция требуемой формы. eSQL также обеспечивает конструктор строки для создания произвольных строк. Так, select value row(e1, e2, ...) является точным эквивалентом select e1, e2, ...
В другом варианте осуществления в семантике select можно избежать создания строки для случая одного элемента, и при необходимости явно использовать конструктор строки. Если предложение select содержит несколько элементов, то оно продолжает вести себя, как в SQL.
В альтернативном и более изящном подходе не допускаются конструкции вида "select e1, e2 from...", и вместо них всегда неизбежно используется "select row(e1, e2) from...".
Корреляция слева и совмещение имен: В стандартном SQL выражения в заданной области видимости (одиночное предложение наподобие select, from и т.д.) не могут ссылаться на выражения, определенные ранее в идентичной области видимости. Некоторые диалекты SQL, в том числе T-SQL, действительно поддерживают их ограниченные формы в предложении from, но синтаксис для использования таких конструкций тяжеловесен и требует операций apply и unnest.
В одном варианте осуществления в eSQL обобщены корреляции слева в предложении from, и они обрабатываются однообразно. Выражения в предложении from могут ссылаться на более ранние определения (определения слева) в идентичном предложении без необходимости использования специальной синтаксической структуры. eSQL также налагает дополнительные ограничения на запросы, в том числе на предложения group-by. Выражения в предложении select, предложении having и т.д. таких запросов могут ссылаться на ключи group-by только через их псевдонимы. Конструкции наподобие следующих - которые допустимы в SQL - недопустимы в eSQL:
select t.x + t.y from T as t group by t.x + t.y
В eSQL будет правильно сделать это следующим образом:
select k from T as t group by (t.x + t.y) as k
Ссылка на столбцы (свойства) таблиц (коллекции): В одном варианте осуществления, все ссылки на столбец в eSQL должны быть уточнены посредством псевдонима таблицы. Следующая конструкция (предполагается, что "a" является допустимым столбцом таблицы "T") допустима в SQL, но не допустима в eSQL:
select a from T
Одобренной формой в eSQL является:
select t.a as a from T as t
При использовании неуточненных ссылок существует несколько проблем. Они могут быть неоднозначными. При развитии схемы возникают проблемы с внешним/внутренним перехватом, и, кроме того, они усложняют реализацию. Во избежание этих проблем хорошо спроектированные запросы в SQL уже используют уточненные ссылки на столбцы. В eSQL просто обеспечивается выполнение этой рекомендации, и это не усложняет язык.
Навигация по объектам: SQL использует нотацию "." для ссылки на столбцы (строку) таблицы. В одном варианте осуществления в eSQL эта нотация расширена (снова, в основном, позаимствовано из языков программирования) для поддержки навигации по свойствам объекта. Например, если "p" является выражением типа Person: p.Address.City является синтаксической структурой eSQL для ссылки на город (city) адреса (address) этого человека (person). Многие диалекты SQL уже поддерживают эту синтаксическую структуру.
Навигация по коллекциям: SQL не обеспечивает простого механизма для навигации по вложенным коллекциям. В одном варианте осуществления eSQL обеспечивает синтаксические сокращения для обработки этих случаев. Оператор .. в eSQL обеспечивает возможность проекции выражения из коллекции. Например, "a..b", на самом деле, является синтаксическим упрощением для "select value t.b from a as t". Аналогично, "a..b..(c*2)" является синтаксическим упрощением для "select value t2.c*2 from a as t1, t1.b as t2".
Оператор ".?" в eSQL обеспечивает возможность пользователям отсекать элементы из коллекции. Он подобен оператору "[]" в XPath. Конструкция вида "a.? p", на самом деле, является сокращением для "select value t from a as t where p". Например, "p.?(id = 1)", на самом деле, означает "select value p0 from p as p0 where p0.id = 1".
При работе с наследованием часто бывает полезной возможность выбора экземпляров подтипа из коллекции экземпляров супертипа. Оператор oftype в eSQL (подобный oftype в Последовательностях (Sequences) C#) обеспечивает эту возможность. Логически, oftype(c,T) эквивалентно "select value treat(x as T) from c as x where x is of T".
Отказ от *: SQL поддерживает неуточненную синтаксическую структуру * как псевдоним для всей строки и уточненную синтаксическую структуру * (t.*) как сокращение для полей этой таблицы. Кроме того, SQL допускает специальный агрегат count(*), который включает в себя нули. Хорошо спроектированные запросы в SQL не используют такие синтаксические структуры (по меньшей мере, варианты "select *" и "select t.*"). Использование "*" опасно при развитии схемы. Часть проблемы состоит в том, что в SQL не было никакого способа для пользователя выбрать все строки.
В одном варианте осуществления eSQL не поддерживает конструкцию "*". Запросы SQL типа "select * from T" и "select T1.* from T1, T2..." могут быть выражены в eSQL как "select value t from T as t" и "select value t1 from T1 as t1, T2 as t2..." соответственно. Кроме того, эти конструкции обрабатывают наследование (замещаемость значения) изящно, в то время как варианты "select *" ограничены свойствами верхнего уровня заявленного типа. Варианты осуществления eSQL также не поддерживают агрегат count(*). Вместо этого для обработки этого случая он поддерживает конструкцию count(group).
Изменения для group by: Как описано ранее, в одном варианте осуществления, eSQL поддерживает совмещение имен ключей group-by, и корреляции слева среди этих ключей. На самом деле выражения в предложении select и предложении having должны ссылаться на ключи group by только через их псевдонимы. Предложение group-by неявно создает агрегат nest для каждого раздела group-by - это выражение называют "группа" ("group"). Для выполнения агрегирования агрегатные функции в списке выбора и т.д. должны ссылаться на это выражение. Например:
select kl, count(group), sum(group..(t.a))
from T as t
group by t.b + t.c as k1
является синтаксисом eSQL для следующего запроса SQL:
select b + c, count(*), sum(a)
from T
group by b + c
Агрегаты на основе коллекции: Агрегаты SQL трудны для понимания. В одном варианте осуществления eSQL поддерживает два вида агрегатов. Агрегаты на основе коллекции оперируют коллекциями и формируют агрегированный результат. Они могут появляться в любом месте запроса, и им не требуется предложение group-by. Например, следующий запрос eSQL допустим:
select t.a as a, count({1,2,3}) as b from T as t
В одном варианте осуществления eSQL также поддерживает агрегаты в стиле SQL, и неявно преобразует их в агрегаты на основе коллекции (на основе коллекции "group"). Например, следующий запрос на eSQL допустим:
select a, sum(t.b) from T as t group by t.a as a;
и внутри транслируется в запрос вида:
select a, sum(group..(t.b)) as b from T as t group by t.a as a.
В одном варианте осуществления eSQL не поддерживает агрегат count(*). Вместо него используют конструкцию count(group).
Insert (Вставить): В одном варианте осуществления утверждение INSERT..VALUES eSQL отличается от T-SQL. В отличие от T-SQL, eSQL не обеспечивает возможности указания списка столбцов в insert. Для этого существуют две причины. Во-первых, у EDM нет концепции значений по умолчанию для столбцов; во-вторых, подход списка столбцов плохо подходит для обработки наследования (замещаемость значения).
Delete, Update (Удалить, Обновить): В отличие от T-SQL, в одном варианте осуществления eSQL не обеспечивает возможности дополнительного предложения from в утверждениях delete и update. Для утверждений delete это не представляет проблемы, так как запрос может быть написан с подзапросом. Однако для утверждений update дополнительное предложение from также помогает в формировании новых значений, используемых в предложении Set.
Извлеченные свойства и методы: Язык запросов WINDOWS® (WinQL) обеспечивает возможность навигации по коллекциям через оператор ".", если у самой коллекции нет свойства с идентичным именем. WinQL также обеспечивает возможность отфильтровывания элементов коллекции через конструкцию "[]" - подобно OPath. В одном варианте осуществления eSQL с этой целью использует оператор ".?" и "..". И опять же, развитие схемы (и внутренний перехват) является основной причиной того, что eSQL делает выбор в пользу различия между навигацией по коллекциям и навигацией по объектам. И eSQL преднамеренно избегает использования "[]" для предикатов, чтобы избежать проблем двусмысленности.
Семантика order-by: В WinQL определено, что предложение order by обрабатывается до предложения select. Это является отличием от SQL, где предложение order by логически обрабатывается после предложения select. В одном варианте осуществления eSQL может быть ближе к SQL в этом отношении, в то время как в WinQL существует более схожий с XQuery подход. Любой подход разумен, и до некоторой степени модель WinQL лучше; однако подход WinQL может быть не настолько лучше, чтобы оправдать изменение стиля работы пользователей SQL.
SQL-92 фактически ограничивает предложение order by так, что оно может содержать только ссылки на элементы предложения select. Большинство реализаций обеспечивает возможность ссылаться в предложении order by на другие элементы, которые в настоящее время находятся в области видимости. В одном варианте осуществления eSQL может следовать последнему стилю.
В дополнение к конкретным реализациям, явно изложенным в этом документе, другие аспекты и реализации будут очевидны для специалистов в данной области техники из рассмотрения описания изобретения, раскрытого в этом документе. Подразумевается, что описание изобретения и иллюстрированные реализации рассматриваются только как примеры, при этом истинный объем и сущность изобретения изложены в следующей формуле изобретения.
ПРИЛОЖЕНИЕ A: Подробная спецификация иллюстративного языка запросов
Далее изложена только иллюстративная спецификация для иллюстративного языка запросов, рассмотренного в этом документе. Вслед за нижеописанной спецификацией описывается иллюстративная спецификация для расширений к подобному языку запросов.
1 Функциональный реферат
1.1 Описание проблемной области
CDP обеспечивает инфраструктуру реляционного отображения объектов, которая может быть использована приложениями и интегрированными средами. WinFS обеспечивает интегрированный опыт хранения информации для широкого многообразия приложений для настольных компьютеров. И WinFS, и CDP основаны на модели данных сущностей-объектов (EDM). EDM является расширенной реляционной моделью данных, которая поддерживает основные реляционные концепции, расширенные типы с наследованием и связи. Пользователи должны иметь возможность выдавать расширенные запросы по их данным, выраженным в терминах EDM.
Несмотря на то, что SQL исторически был предпочтительным языком запросов для доступа к базе данных, у него существует много недостатков. Отсутствие поддержки для расширенных типов, неортогональные конструкции и т.д. - только некоторые из них. eSQL пытается решить многие из этих проблем, связанных с SQL. eSQL разработан подобным SQL и обеспечивает некоторую дополнительную инфраструктуру и усовершенствования на основе SQL.
И WinFS, и CDP усиливают существующие.NET технологии доступа к данным - ADO.NET - для доступа к данным и манипулирования ими. Поставщик данных.NET обеспечивает до некоторой степени однообразный способ доступа к данным из любого источника данных через Connections (соединения), Commands (команды), интерфейсы DataReader и другие подобные объекты. Команды для поставщика данных.NET выражаются в виде строк и должны быть на родном диалекте поставщика (более конкретно, источника данных, на который выходит поставщик). Как часть усилий CDP/WinFS, будут обеспечены три новых поставщика - поставщик объектов, поставщик EDM и поставщик WinFS, и все они будут использовать eSQL как родной диалект.
2 Обзор и принципы разработки
2.1 Принципы разработки
Первоклассная поддержка для коллекций и объектов. eSQL должен облегчить пользователям осуществление без швов запроса по их объектам и коллекциям.
Ортогональность
Конструкции в eSQL должны быть ортогональными. Не должно быть никаких контекстных интерпретаций по использованию данной конструкции.
Компонуемость
Конструкции в eSQL должны быть компонуемыми внутри других конструкций.
Подобие SQL
eSQL должен оставаться языком, подобным SQL в максимально возможной степени. Если отступление от SQL не является необходимым (например, когда это требуется согласно вышеуказанным аргументам), eSQL должен сохранять в точности конструкции SQL.
3 Обзор языка
eSQL включает в себя понятие выражения. Выражением, как и в других языках программирования, является конструкция, которую можно вычислять для получения значения. Запросом eSQL является любое допустимое выражение. eSQL обеспечивает следующие виды выражений.
3.1 Литералы
Литерал, как и в большинстве языков программирования, является просто постоянным значением. eSQL оказывает собственную поддержку для строковых и числовых литералов и специального нулевого литерала (который имеет непривязанный тип данных).
3.2 Параметры
Параметры в eSQL обеспечивают возможность выражениям (и запросам) ссылаться на значения, определенные вне запроса.
3.3 Ссылки на переменные
Ссылки на переменные в eSQL обеспечивают возможность выражениям ссылаться на другие выражения, которые были определены (и именованы) раньше в идентичной области видимости.
3.4 Встроенные операторы
eSQL обеспечивает небольшой набор встроенных операторов. Он включает в себя такие арифметические операторы, как +,-,*,/, операторы сравнения (<,>..), логические операторы (and, or, not и т.д.), и некоторые другие операторы (case, between и т.д.).
3.5 Функции
В eSQL не определены какие-либо собственные встроенные функции. Выражения функций eSQL обеспечивают возможность использования любой определенной пользователем функции (которая является видимой для eSQL).
3.6 Навигация по объектам, методы
Эти выражения eSQL обеспечивают возможность ссылаться на свойства и методы объекта и манипулировать ими естественным образом.
3.7 Агрегатные функции
Агрегатные функции в eSQL, как и их прототипы в SQL, обеспечивают возможность операций свертывания на коллекциях. eSQL поддерживает агрегат nest и любой определенный пользователем агрегат. Агрегатные функции eSQL основаны на коллекции, так как они могут использоваться в любом месте выражения. eSQL также поддерживает основанные на группе агрегаты, подобные имеющимся в SQL, которые можно использовать только в выражениях запроса.
3.8 Конструкторы
eSQL обеспечивает три вида конструкторов. Конструкторы строки могут использоваться для создания безымянного значения структурного типа (запись). Конструкторы объекта (конструкторы в C# и т.д.) могут использоваться для создания (именованных) определяемых пользователем объектов. Конструкторы мультимножества могут использоваться для создания мультимножеств других значений.
3.9 Операции над типом
eSQL обеспечивает операции, которые обеспечивают возможность запрашивать тип выражения (значения) и манипулировать им. Сюда входят такие операции опроса, как is of (подобная выражению is в C#), приведения к супертипу-подтипу наподобие treat (выражение as в C#) и oftype (метод OfType в Последовательностях (Sequences) C#) и операторы преобразований наподобие cast.
3.10 Операторы множества
eSQL обеспечивает расширенный набор операций над множествами. Он включает в себя операторы над множествами, подобные имеющимся в SQL, наподобие union, intersect, except и exists. Кроме того, eSQL поддерживает операторы для удаления дубликатов (distinct), проверки членства (in), соединений (join).
3.11 Выражения запроса
Выражения запроса представляют классические запросы SQL select-from-where-...
4 Детали языка - Выражения eSQL
4.1 Литералы
Null
Литерал null используется для представления нулевого значения для любого типа. Литерал null считается непривязанным, то есть он совместим с любым типом. Литералы null с определенным типом могут быть созданы через оператор Cast по литералу null:

Правила относительно того, где могут использоваться непривязанные литералы null, см. в разделе 9.6.
Булевы (Boolean)
Булевы литералы представлены ключевыми словами true (истина) и false (ложь).
Целочисленные (Integer) (Int32, Int64)
Целочисленные литералы могут иметь тип Int32 или Int64. Литерал Int32 - это последовательность цифр. Литерал Int64 - это последовательность цифр, за которой следует L верхнего регистра.
С фиксированной точкой (Decimal)
Число с фиксированной точкой (decimal) - это последовательность цифр, точка '.' и другая последовательность цифр, за которой следует М верхнего регистра.
С плавающей точкой с одинарной точностью (Float), с плавающей точкой с двойной точностью (Double)
Число с плавающей точкой с двойной точностью - это последовательность цифр, точка '.' и другая последовательность цифр, за которой следует экспонента. Число с плавающей точкой с одинарной точностью (или float) имеет синтаксис числа с плавающей точкой с двойной точностью, за которым следует f нижнего регистра.
Строковые (String)
Строка - это последовательность символов, заключенных в кавычки. Кавычки могут быть или обе одинарными кавычками ('), или обе двойными кавычками ("). Цитируемые идентификаторы (quoted identifier) могут быть представлены посредством [] или "". По умолчанию, допускается только стиль [], а конструкции "" обрабатываются как строковые литералы. Синтаксический анализатор SQL может допускать цитируемые идентификаторы в стиле "" (которыми будут управлять опции синтаксического анализатора - за рамками этого документа); в этом случае строковые литералы могут использовать только одинарные кавычки. См. раздел 9.1.2 для получения дополнительной информации об этом:

Другие литералы
eSQL в исходном формате не поддерживает литералы других типов данных (DateTime, Guid и т.д.)
4.2 Параметры
Параметры - это переменные, которые определены вне языка запросов, обычно через API для связывания, используемого базовым языком. У каждого параметра существует имя и тип. Имена параметров описываются с символом @ в качестве префикса перед именем для устранения их неоднозначного толкования с именами свойств или другими именами, определенными в пределах запроса. API для связывания базового языка обеспечивает интерфейсы API для связывания параметров. В следующем примере представлено использование параметра в выражении:
select c from customers as c where c.Name = @name
4.3 Переменная
Выражение переменная - это ссылка на (именованное) выражение, определенное ранее в текущей области видимости. Ссылка на переменную должна быть допустимым идентификатором, как определено в 6. В следующем примере представлено использование переменной в выражении:
select c from customers as c
4.4 Встроенные операторы
eSQL обеспечивает некоторое количество следующих встроенных операторов.
4.4.1 Арифметические
Арифметические операторы определены для числовых примитивов, например Int32, Int16, Int64, Double, Single и Decimal. Для двуместных операторов, до применения оператора имеет место неявное повышение типа операндов. Типы результатов всех арифметических операторов идентичны повышенным типам операндов. Суммирование также определено для строки и действует как конкатенация.
4.4.2 Сравнения
Операторы сравнения определены для числовых примитивов, например Byte, Int32, Int16, Int64, Double, Single и Decimal; String и DateTime. До применения оператора сравнения имеет место неявное повышение типа операндов. Операторы сравнения в результате всегда дают булеву (константу).
Равенство и неравенство определены для булева типа и любого типа объекта, который имеет идентификационную информацию. Объекты с идентификационной информацией, не являющиеся примитивами, считаются равными, если их идентификационная информация одинакова.
4.4.3 Логические
Логические операторы определены только для булевых типов - и всегда возвращают булев тип.
4.4.4 Case
Выражение case имеет семантику, подобную имеющейся для выражения case в TSQL. Выражение case используется для создания последовательности условных проверок для определения, какое выражение приводит к надлежащему результату.
Если b1, b2, ..., bn-1 являются выражениями типа Boolean и e1, e2, ..., en являются выражениями некоторого типа S, то следующее выражение являются допустимым выражением case, результатом которого является одно значение типа S.
case
when b1 then e1
when b2 then e2
...
[else vn]
end
В этой форме выражения case используется последовательность из одного или нескольких булевых выражений для определения надлежащего результирующего выражения. Первое when-выражение, в результате вычисления которого получится значение true, приведет к соответствующему выражению then. Остальные выражения не вычисляются. Если ни одно из условий when не выполняется, то результатом является результат вычисления выражения else (если таковое существует) или null (если не существует выражения else). Отметим, что может иметь место неявное повышение типа среди различных выражений результата (e1, e2, ... en, vn) для определения фактического типа результата выражения case.
4.4.5 Between
Выражение between имеет семантику, идентичную семантике выражения between в SQL. Оно определяет, находится ли значение результата данного выражения между нижней границей и верхней границей:
e1 between e2 and e3
Если e1, e2 и e3 все являются выражениями некоторого типа T, то вышеупомянутое выражение является допустимым выражением оператора between. Выражение between является сокращенным написанием двух операторов сравнения идентичного значения. Синтаксическая структура between удобна, если e1 является сложным выражением:
e1>=e2 and e1<=e3
Выражение not-between может использоваться для обозначения выражения, противоположного выражению between:
e1 not between e2 and e3 →
e1<e2 or e1>e3
4.4.6 Like
Семантика выражения like идентична описанной для TSQL. В нем определяется, соответствует ли строка образцу, и результатом является true, если строка соответствует (образцу), и false, если она не соответствует (образцу). Если match, pattern и escape все являются выражениями, имеющими тип String, то следующие выражения являются допустимыми выражениями like, результатом которых является булево значение:
match like pattern
match not like pattern
match like pattern escape escape
match not like pattern escape escape
Синтаксис строки pattern идентичен синтаксису строки образца в TSQL.
4.4.7 Проверка (на равенство) null
Оператор is null используется для определения, является ли результатом выражения значение null. Если в результате вычисления этого выражения получается значение null, то результатом (всего) выражения является значение true. В противном случае результатом (всего) выражения является значение false. Если e является выражением этого (that), то следующие выражения являются допустимыми выражениями, результатом которых является булева (константа):
e is null
e is not null
Используйте оператор is null для определения, не равняется ли null элемент внешнего соединения (outer join):
select c from cs as c left outer join as ds d
where d is not null and d.x=@x
Используйте оператор is null для определения, имеет ли член фактическое значение или нет:
select c from cs as c where c.x is not null
4.5 Доступ к члену
Доступ к члену также обычно известен как оператор точка. Используйте оператор доступа к члену для получения значения свойства или поля экземпляра объекта. Если m является членом типа T, который имеет тип М, и t является экземпляром типа T, то t.m является допустимым выражением доступа к члену, которое приводит к значению типа М:
select p.Name.FirstName from Person as p;
4.6 Вызов метода
Вызов метода является явным вызовом метода. Он в результате приводит к вызову метода. Методы могут быть методами экземпляра (некоторого) типа, статическими методами (некоторого) типа или глобальными статическими методами, то есть автономной функцией.
Если m является методом типа T, который возвращает тип М и имеет параметры типов (P1, P2, ..., Pn), и t является экземпляром типа T, а e1 является выражением типа P1 и так далее, то t.m (e1, e2, ..., en) является допустимым вызовом метода, результатом которого является значение типа М.
Если m является методом типа T, который возвращает тип М и имеет параметры типов (P1, P2, ..., Pn), и qn является уточненным именем, которое ссылается на тип T, а e1 является выражением типа P1 и так далее, то qn.m (e1, e2, ..., en) является допустимым вызовом статического метода, результатом которого является значение типа М.
Если m является методом типа T, который возвращает тип М и имеет параметры типов (P1, P2, ..., Pn), и qn является уточненным именем, которое ссылается на префикс пространства имен метода, а e1 является выражением типа P1 и так далее, то qn.m (e1, e2, ..., en) является допустимым вызовом статического метода, результатом которого является значение типа М.
Примером вызова метода, который может появиться в запросе eSQL, может быть использование методов, встроенных в типы данных примитивов:
select tsql.substring(c.Naine, 0, 2) from customers c
4.6.1 Разрешение перегрузки
Несколько методов могут быть определены с идентичным именем. Для определения, на какой метод ссылается данное выражение, следуйте этим правилам. Первое примененное в последовательности правило, результатом которого является только один метод, определяет разрешающий метод.
1. Существует метод с идентичным количеством параметров.
2. Метод, где тип каждого аргумента точно соответствует типу параметра или является литералом null.
3. Метод, где тип каждого аргумента точно соответствует типу параметра или является его подтипом, или аргумент является литералом null. Метод с наименьшим количеством преобразований подтипа.
4. Метод, где тип каждого аргумента точно соответствует типу параметра, является его подтипом или может быть повышен до типа аргумента, или аргумент является литералом null. Метод с наименьшим количеством повышений и преобразований подтипа.
5. Выражение вызова метода неоднозначно.
Отметим, что, даже если с использованием этих правил может быть выделен один метод, аргументы тем не менее могут не соответствовать параметрам. Если это так, то в аргументах допущена ошибка.
4.7 Перечисления
Перечисления являются целыми числовыми значениями со строгим контролем типов, на которые ссылаются по имени. Перечисление обозначается с использованием уточненного имени, ссылающегося на тип перечисления, за которым следует оператор точка и имя перечисления. Если qn является уточненным именем некоторого перечисления E, и en является именем значения перечисления, то qn.en является допустимой ссылкой на перечисление:
Color.Red
4.8 Операции над типом
eSQL обеспечивает несколько операций для работы с типами значений выражения.
4.8.1 Is Of
Посредством выражения Is оf проверяют, является ли выражение экземпляром указанного типа.
e is of (T)
e is not of (T)
e is of (only T)
e is not of (only T)
Если e имеет некоторый тип S во время компиляции, и S является подтипом/супертипом T, то вышеуказанные выражения являются допустимыми выражениями и возвращают результат булева типа. Если во время выполнения определено, что типом e является T (или некоторый подтип T), то e is of T возвращает True. Если e равно null во время выполнения, то это выражение возвращает null; в противном случае результатом этого выражения является False.
Если указан модификатор only, то указанное выражение возвращает true, только если e имеет точно тип T, а не какой-либо из его подтипов. Выражения e is not of (T) и e is not of (only T) синтаксически эквивалентны not(e is of (T)) и not(e is of (only T)) соответственно. Если S не является ни подтипом, ни супертипом T, то это выражение вызывает ошибку во время компиляции.
4.8.1.1 Treat
Посредством выражения treat делается попытка изменить тип данного выражения на супертип/подтип:
treat (e as T)
Если e имеет тип S, и T является подтипом S, или S является подтипом T, то вышеупомянутое выражение является допустимым выражением treat, и его результатом является значение типа T. Если ни S, ни T не являются подтипом друг друга, то это выражение приводит к ошибке во время компиляции. Если e имеет тип Employee, и Manager является подтипом Employee, то результатом следующего выражения является значение, равное e, но имеющее тип Manager вместо Employee:
treat (e as Manager)
Если значение e на самом деле не имеет типа Manager, то результатом упомянутого выражения является значение null.
4.8.1.2 Cast
Выражение cast имеет семантику, подобную имеющейся для выражения convert в TSQL. Выражение cast используется для преобразования значения одного типа в значение другого типа. Язык поддерживает только определенные преобразования типов:
cast (e as T)
Если e имеет некоторый тип S, и S является преобразуемым к T, то вышеупомянутое выражение является допустимым выражением cast. T должен быть примитивом (скалярным типом). Использование выражения cast считается явным преобразованием. При явных преобразованиях данные могут усекаться или может теряться точность. Список допустимых выражений cast, поддерживаемых eSQL, описан в разделе 10.5.
4.8.1.3 OfType
В выражении OfType указывается выражение типа, которое обеспечивается для выполнения проверки типа по каждому элементу коллекции. Выражение OfType создает новую коллекцию указанного типа, содержащую только те элементы, которые оказались эквивалентными или этому типу, или его подтипу.
Если ts является коллекцией типа collection<S>, и T является подтипом S, то OfType(ts,T) является выражением типа collection<T>, результатом которого является коллекция всех элементов e из ts, в которой индивидуальный тип e, Te, является подтипом T. Выражение OfType является сокращением следующего выражения запроса:
select value treat (t as T) from ts as t where t is of T
С учетом того, что Manager является подтипом Employee, следующее выражение создает коллекцию только из объектов manager из коллекции объектов employee:
OfType (employees, Manager)
Также можно повышать тип коллекции с использованием фильтра типа:
OfType (executives, Manager)
Так как все объекты executive являются объектами manager, результирующая коллекция все еще содержит все исходные объекты executive, хотя эта коллекция теперь имеет тип коллекции объектов manager. Невозможно выполнить общеизвестное недопустимое приведение типа. Следующее выражение вызывает ошибку во время компиляции (конечно, предполагается, что Address не является подтипом/супертипом Employee):
OfType (employees, Address)
4.9 Ссылки
eSQL поддерживает следующие операторы для ссылок.
4.9.1 Ref
При применении оператора Ref к переменной корреляции для множества сущностей-объектов (entityset) создается ссылка на сущность-объект из этой коллекции. Например, следующий запрос возвращает ссылки на каждый Order:
select ref (o) from Orders as o
Следующие использования оператора ref являются недопустимыми - переменная корреляции должна осуществлять разрешение в множество объектов-сущностей в текущей области видимости:
select ref(o) from (select value o from Orders as o) as o
4.9.2 CreateRef
Оператор CreateRef может использоваться для создания ссылок на сущность-объект в множестве сущностей-объектов (entityset). Первым аргументом этого оператора является идентификатор (не строковый литерал) множества сущностей объектов (entityset), и вторым аргументом является выражение с типом записи, которое соответствует ключевым свойствам типа сущность-объекта:
select ref(BadOrders, row(o. Id)) from Orders as o
Выражение с типом записи должно быть по структуре эквивалентным типу ключа для сущности-объекта, то есть оно должно иметь идентичный номер и типы полей в идентичном порядке c ключами сущности-объекта - имена полей являются несоответствующими.
4.9.3 Key
Оператор Key является противоположным оператору CreateRef и может использоваться для выделения ключевой части выражения с типом ref. Возвращаемым типом оператора Key является тип записи - с одним полем для каждого ключа сущности-объекта, и в идентичном порядке:
select key(ref (BadOrders, row(o.Id))) from Orders as o
4.9.4 Deref
Оператор Deref разыменовывает значение ссылки и обеспечивает результат этого разыменования:
select deref(o.CustRef) from Orders as o
Если r является ссылкой типа ref<T>, то Deref(r) является выражением типа T, результатом которого является сущность-объект, на который ссылается r. Если значением ссылки является null, или ссылка является висячей, то есть адресата ссылки не существует, то результатом оператора Deref является null.
4.9.5 Разыменование атрибута
По ссылкам можно осуществлять навигацию через оператор ".".
В следующем фрагменте извлекается свойство Id (из Customer) посредством навигации через свойство CustRef:
select o.CustRef.Id from Orders as o
Если значением ссылки является null, или ссылка является висячей, то есть адресата ссылки не существует, то результатом является null.
4.10 Конструкторы
eSQL обеспечивает 3 вида конструкторов - конструкторы строки, конструкторы объекта и конструкторы мультимножества.
4.10.1 Конструкторы строки
Конструкторы строки могут использоваться для создания безымянной записи структурного типа из одного или нескольких значений. Типом результата конструктора строки является тип строки - типы полей которой соответствуют типам значений, используемым для создания упомянутой строки. Например, нижеприведенное выражение:
row (l as a, "abc" as b, a+34 as c)
обеспечивает значение типа Record(a int, b string, c int).
Все выражения в конструкторе строки должны иметь псевдоним - если псевдоним не обеспечен, то eSQL пытается сформировать псевдоним через правила использования псевдонимов, указанные в 0. Выражения в конструкторе строки могут не ссылаться на псевдонимы, определенные ранее (слева) в этом конструкторе.
Недопустимо, чтобы два выражения в одном конструкторе строки имели идентичный псевдоним. Для извлечения полей из записи можно использовать оператор точка (.) (подобно извлечению свойств объекта).
4.10.2 Конструкторы NamedType (инициализаторы NamedType)
eSQL допускает использование конструкторов (инициализаторов) именованного типа для создания экземпляров именованных сложных типов и/или типов сущностей-объектов. В приведенном ниже выражении создается экземпляр типа Person (в предположении, что тип Person имеет эти два атрибута):
person ("abc", 12)
Предполагается, что аргументы конструктора находятся в порядке, идентичном объявлению атрибутов типа.
4.10.3 Конструкторы коллекции
Конструктор multiset создает экземпляр мультимножества из списка значений. Все значения в конструкторе должны иметь взаимно совместимый тип T, и конструктор создает коллекцию типа Multiset<T>. Приведенные ниже выражения создают мультимножество целых чисел:
multiset (1, 2, 3)
{1, 2, 3}
4.11 Операции над множествами
В этом разделе содержится множество операторов над множествами.
4.11.1 Distinct
Выражение distinct используется для преобразования коллекции объектов в множество посредством создания новой коллекции, из которой удалены все дублирующие ссылки. Если c является коллекцией типа collection<T>, то distinct(c) является допустимым выражением distinct, результатом которого является коллекция типа collection<T>, в которой нет дубликатов. Тип T должен допускать сравнение на равенство. Выражение distinct является сокращением выражения select:
distinct (c) -> select value distinct c from c
4.11.2 Flatten
Выражение flatten используется для преобразования коллекции коллекций в упрощенную коллекцию со всеми одинаковыми элементами, без вложенной структуры. Если c является коллекцией типа collection<collection<T>>, то flatten(c) является допустимым выражением flatten, результатом которого является новая коллекция типа collection<T>. Выражение flatten является сокращением использования выражения select:
flatten(c) -> select value c2 from c as cl, cl.it as c2
4.11.3 Exists
Выражение exists имеет семантику, идентичную семантике выражения exists в TSQL. Оно определяет, пуста коллекция или нет. Если коллекция не пуста, то выражение exists возвращает true, в противном случае оно возвращает false. Если c является коллекцией типа collection<T>, то exists(c) является допустимым выражением exists, результатом которого является одиночное значение типа Boolean.
4.11.4 In
Оператор in используется для проверки значения на членство в коллекции. Значение выражения слева от ключевого слова 'in' ищется в коллекции, представленной выражением справа. Если e является выражением с типом T, и ts является коллекцией с типом Collection<S>, и S и T находятся в отношении супертип/подтип, то следующие выражения являются допустимыми выражениями оператора in:
e in ts
e not in ts
В следующем примере имя "Bob" ищется в наборе имен клиентов:
'Bob' in customerNames
Если это значение находится в коллекции, то результатом этого оператора in является значение true. Если значением является null, или коллекция - null, то результатом этого оператора in является значение null. В противном случае результатом этого оператора in является значение false. Результатом отрицательной формы (not) этого оператора является противоположное значение.
4.11.5 Union. Union All
Выражения union и union all в eSQL имеют семантику, идентичную их эквивалентам в TSQL. UnionAll создает коллекцию, которая содержит объединенные содержимые этих двух коллекций (с дубликатами). Union создает коллекцию с удаленными дубликатами.
Если c1 является коллекцией типа Collection<T>, и c2 является коллекцией типа Collection<S>, где М является общим супертипом T и S, то c1 union c2 и c1 union all c2 являются допустимыми выражениями union, результатом которых является коллекция типа Collection<M>.
В следующем примере идентифицируется множество всех клиентов (customers), которые или живут в Вашингтоне, или являются хорошими клиентами. В первом выражении удаляются какие бы то ни было дубликаты (например, хороший клиент, который также живет в Вашингтоне), в то время как во втором выражении сохраняются все дубликаты:
goodCustomers union WashingtonCustomers
goodCustomers union all WashingtonCustomers
4.11.6 Intersect
Выражение Intersect имеет семантику, идентичную семантике выражения intersect в TSQL. Оно определяет пересечение двух коллекций. Если c1 является коллекцией типа Collection<T>, и c2 является коллекцией типа Collection<S>, где М является общим супертипом T и S, то c1 intersect c2 является допустимым выражением intersect, результатом которого является коллекция типа Collection<M>. В следующем примере идентифицируется множество всех клиентов (customers), которые живут в Вашингтоне и являются хорошими клиентами.
goodCustomers intersect WashingtonCustomers
4.11.7 Except
Выражение Except имеет семантику, идентичную семантике выражения except в TSQL. Оно определяет одностороннюю разность двух коллекций. Если c1 является коллекцией типа Collection<T>, и c2 является коллекцией типа Collection<S>, где М является общим супертипом T и S, то c1 except c2 является допустимым выражением except, результатом которого является коллекция типа Collection<T>. В следующем примере идентифицируется множество всех клиентов (customers), которые не являются плохими заказчиками:
allCustomers except badCustomers
4.11.8 Overlaps
Выражение overlaps определяет, есть ли у двух коллекций общий член. Если c1 является коллекцией типа Collection<T>, и c2 является коллекцией типа Collection<S>, где М является общим супертипом T и S, то c1 overlaps c2 является допустимым выражением overlaps, результат которого имеет булев (Boolean) тип. В следующем примере проверяется, является ли любой вашингтонский клиент хорошим клиентом:
WashingtonCustomers overlaps goodCustomers и он является синтаксическим сокращением для:
exists (WashingtonCustomers intersect goodCustomers)
4.11.9 Element
Посредством выражения element извлекают элемент из коллекции одного элемента. Если c является коллекцией типа collection<T>, то element(c) является допустимым выражением element, результатом которого является экземпляр типа T. В следующем примере делается попытка извлечь один элемент из множества плохих клиентов:
element (badCustomers)
Если коллекция пуста или имеет несколько элементов, то выражение element возвращает null.
4.12 Навигация по коллекциям
eSQL обеспечивает несколько синтаксических конструкций, которые предусматривают более простую обработку коллекций.
4.12.1 Проекция
Оператор.. (проекция из коллекции) используется для проекции элементов за пределы коллекции. Если c является коллекцией типа Collection<T>, и p является свойством T с типом Q, то c..p создает коллекцию типа Collection<Q>. Более широко, если c является коллекцией типа Collection<T>, и e является некоторым выражением типа Q, то c..e создает коллекцию типа Collection<Q>, содержащую результат вычисления e для каждого элемента c. В следующем примере получают названия заглавными буквами всех отделов:
Departments..(upper(name)) и он является сокращением для следующего запроса:
select value upper(d.name) from Departments as d
4.12.2 Фильтрация
Оператор.? (фильтрация коллекции) используется для отфильтровывания элементов из коллекции. Если c является коллекцией типа Collection<T>, и e является булевым выражением с типом Q, то c.?e создает коллекцию типа Collection<T>, содержащую только те элементы c, которые удовлетворяют предикату e. В следующем примере получают набор всех отделов, которые базируются в Сиэтле:
Departments.?(location = 'Seattle') и он является сокращением для следующего запроса:
select value d from Departments as d where d.location='Seattle'
4.12.3 Упрощенная проекция
Оператор... (упрощенная проекция из коллекции) используется для проекции элементов за пределы вложенной коллекции. Более широко, если c является коллекцией типа Collection<Collection<T>>, и e является некоторым выражением типа Q, то c...e создает коллекцию типа Collection<Q>, содержащую сначала результат первого упрощения c, и затем вычисления e для каждого элемента c. В следующем примере получают имена заглавными буквами всех служащих, в предположении, что Employees является свойством вычисленного множества Department:
Departments.Employees...(upper(Name)) и он является сокращением для следующего запроса:
select value upper(e.name) from Departments as d, d.Employees as e
4.12.4 Упрощенная фильтрация
Оператор..? (упрощенной фильтрации коллекции) используется для отфильтровывания элементов из вложенной коллекции. Более широко, если c является коллекцией типа Collection<Collection<T>>, и e является некоторым булевым выражением, то c..?e создает коллекцию типа Collection<T>, содержащую результат сперва упрощения c, и затем отфильтровывания тех элементов результата, которые не удовлетворяют e. В следующем примере получают множество всех служащих, зарплата которых больше 10000, в предположении, что Employees является свойством вычисленного множества Department:
Departments.Employees..?(salary>10000) и он является сокращением для следующего запроса:
select value e
from Departments as d, d.Employees as e
where e.salary > 10000
Правила обзора данных
Во всех вышеупомянутых случаях, при навигации по коллекции типа Collection<T>, создается новая область видимости, и текущий элемент коллекции связан с переменной it. Для удобства с точки зрения синтаксиса, также предполагается, что свойства (и методы) T находится в области видимости, но они рассматриваются как сокращения для доступа к члену через переменную it. Например:
Departments..Name -> Departments..(it.Name)
4.13 Агрегатные функции
Агрегатами являются выражения, которые преобразуют последовательность входных значений (обычно, но не обязательно, в одно значение). Они обычно используются вместе с предложением group-by выражения select и имеют ограничения на то, где они могут фактически использоваться. Каждая агрегатная операция определена для одного или нескольких типов. eSQL не определяет набор агрегатов. Для обработки агрегатных функций он просто полагается на окружающее пространство метаданных.
Агрегаты на основе коллекции
Агрегаты на основе коллекции являются агрегатами, вычисляемыми по конкретному набору значений. Например, данные заказы являются коллекцией всех заказов, можно вычислить самую раннюю дату отправки посредством следующего выражения:
min(orders..ShipDate)
Выражения в агрегатах на основе коллекции вычисляются с использованием текущей окружающей области видимости разрешения имен.
Агрегаты на основе группы
Агрегаты на основе группы вычисляются по группе, определеной предложением group-by. Для каждой группы в результате вычисляется отдельный агрегат с использованием элементов в каждой группе в качестве входных данных для вычисления агрегата. При использовании в выражении select предложения group-by, в предложении order-by или проекции могут присутствовать только имена выражения группировки, агрегаты или константные выражения. В следующем примере вычисляется средняя величина заказа каждого продукта:
select p, avg(o1.Quantity) from orderLines as o1
group by o1.Product as p
Агрегаты на основе группы просто являются сокращениями (для сохранения совместимости с SQL) выражений на основе коллекции. Приведенные выше примеры, на самом деле, транслируют в:
select p, avg(group..(o1.Quantity)) from orderLines as ol
group by ol.Product as p, где выражение группы ссылается на агрегат nest, неявно созданный предложением group-by. В выражении select можно иметь агрегат на основе группы без явного предложения group-by. Все элементы будут обрабатываться как одна группа, эквивалентная случаю определения группировки на основе константы:
select avg(ol.Quantity) from orderLines as ol →
select avg(group..(ol.Quantity)) from orderLines as ol group by 1
Выражения в агрегате на основе группы вычисляются с использованием области видимости разрешения имен, которая видима для выражения предложения where.
Для сохранения вида и функций SQL на входе агрегатов на основе группы можно также указывать модификатор distinct или all. Если указан модификатор distinct, то до вычисления агрегата из входной коллекции агрегата устраняются дубликаты. Если указан модификатор all (или не указано никакого модификатора), то устранение дубликатов не выполняется. Модификатор distinct, на самом деле, является синтаксическим сокращением оператора distinct:
avg(distinct ol.Quantity) →
avg(distinct(ol.Quantity))
Проведение различия между агрегатами на основе группы и на основе коллекции
Агрегаты на основе коллекции являются предпочтительным способом определения агрегатов в eSQL. Однако для уменьшения усилий по переходу для пользователей SQL также поддерживаются агрегаты на основе группы. Аналогично, для стиля работы, как в SQL, поддерживается указание distinct (или all) в качестве модификаторов на входе агрегата, но предпочтительным механизмом является использование вместо этого оператора distinct(). Различие в политике разрешения имен между агрегатами на основе коллекции и на основе группы может потребовать, чтобы в реализации были сделаны попытки анализа для обеих областей видимости. Принцип состоит в том, чтобы, в первую очередь, одобрять интерпретацию как агрегата на основе коллекции, и, во вторую очередь, - агрегата на основе группы.
4.14 Неподдерживаемые выражения
4.14.1 Количественные предикаты
SQL обеспечивает возможность конструкций вида:
sal > all (select salary from employees)
sal > any (select salary from employees) eSQL не поддерживает такие конструкции. Вышеупомянутые выражения могут быть выражены в eSQL как:
not exists(employees.? (sal > it.salary))
exists (employees.?(sal > it.salary))
или:
not exists (select 0 from employees as e where sal > e.salary)
exists (select O from employees as e where sal > e.salary) eSQL может быть расширен количественными выражениями.
4.14.2 *
SQL поддерживает использование "*" в качестве синтаксического сокращения в предложении select, указывающего, что все столбцы должны быть спроецированы вне.
5 Детали языка - выражения запроса
Выражение запроса является самым универсальным выражением в eSQL и больше всего распространено у программистов, знакомых с SQL. В нем много различных операторов запроса вместе скомбинированы в одной синтаксической структуре. Многие из этих операторов могут быть указаны самостоятельно; однако ни один не является столь выразительным как при комбинировании в выражении запроса. Если не указано обратное, то выражение select ведет себя подобно утверждению select в TSQL.
Выражение запроса формируют из последовательности предложений, которые применяют последовательные операции к коллекции объектов. Они основаны на предложениях, идентичных встречающимся в стандартном утверждении select в SQL; select, from, where, group by, having и order by.
В своей самой простой форме выражение запроса обозначается ключевым словом select, за которым следует список проекции, ключевое слово from, выражение источника, ключевое слово where и, наконец, фильтрующее условие:
select m from c where e
В этом примере c является коллекцией объектов некоторого типа T, m является членом T с типом М, и e является булевым выражением, в котором могут быть ссылки на один или несколько членов T. Запрос создает новую коллекцию объектов с типом М.
5.1 Предложение from
В основном, семантика предложения from идентична описанной для TSQL. Однако в ее синтаксисе намного меньше ограничений, который допускает любое выражение языка, результатом которого является коллекция, являющаяся допустимым источником. Предложение from является разделенным запятыми списком из одного или нескольких элементов предложения from. Предложение from может быть использовано для указания одного или нескольких источников для выражение select. Самой простой формой предложения from является одиночное выражение, идентифицирующее коллекцию и псевдоним:
from C as c
В общем, выражение select работает c каждым элементом коллекции источника по порядку. Это называется итерацией. В выражениях в списке select или предложении where могут быть ссылки на свойства текущего элемента с использованием псевдонимов коллекции как переменных, ссылающихся на элемент.
5.1.1 Элемент предложения from
Каждый элемент предложения from ссылается на коллекцию источника в запросе. eSQL поддерживает следующие классы элементов предложения from.
5.1.1.1 Простой элемент предложения from
Самой простой формой элемента предложения from является одиночное выражение, идентифицирующее коллекцию и псевдоним:
C as c
Указание псевдонима необязательно - альтернативным обозначением вышеупомянутого элемента предложения from может быть:
С
Если псевдоним не указан, то eSQL пытается сформировать псевдоним на основе выражения коллекции. См. 0 описанный далее.
5.1.1.2 Элемент join (соединение) предложения from
Элемент join предложения from представляет соединение двух элементов предложения from. eSQL поддерживает перекрестные соединения (cross join), внутренние соединения (inner join), левые и правые внешние соединения (left outer join и right outer join) и полные внешние соединения (full outer join) - все аналогично T-SQL. Как и в T-SQL, два элемента предложения from, включенные в соединение, должны быть независимыми - они не могут быть коррелированными. В этих случаях могут быть использованы CrossApply/OuterApply.
Перекрестные соединения
Выражение cross join формирует декартово произведение двух коллекций:
C as c cross join D as d
Внутреннее соединение
inner join формирует ограниченное декартово произведение двух коллекций:
C as c [inner] join D as d on e
Это выражение обрабатывает комбинацию каждого элемента левой коллекции, образующего пару с каждым элементом правой коллекции, где условие on является истинным. Условие on должно всегда быть указано.
Левое внешнее соединение, правое внешнее соединение
Выражение outer join формирует ограниченное декартово произведение двух коллекций:
C as c left outer join D as d on e
Это выражение обрабатывает комбинацию каждого элемента левой коллекции, образующего пару с каждым элементом правой коллекции, где условие on является истинным. Если условие on является ложным, то выражение, тем не менее, обрабатывает один экземпляр левого элемента, образующего пару с правым элементом со значением null. Правые внешние соединения могут быть выражены аналогичным образом.
Полное внешнее соединение
Явное full outer join формирует ограниченное декартово произведение двух коллекций:
C as c full outer join D as d on e
Это выражение обрабатывает комбинацию каждого элемента левой коллекции, образующего пару с каждым элементом правой коллекции, где условие on является истинным. Если условие on является ложным, то выражение, тем не менее, обрабатывает один экземпляр левого элемента, образующего пару с правым элементом со значением null, и один экземпляр правого элемента, образующего пару с левым элементом со значением null.
Примечания
Для сохранения совместимости с Sql-92, TSql, ключевое слово outer является дополнительным. Так, "left join", "right join" и "full join" являются синонимами "left outer join", "right outer join" и "full outer join".
Предложение ON должно использоваться для внутреннего и внешнего соединений; оно является недопустимым для перекрестных соединений.
5.1.1.3 Элемент предложения from apply
eSQL поддерживает два вида Apply - CrossApply и OuterApply. cross apply создает уникальную пару каждого элемента левой коллекции с элементом коллекции, созданной при вычислении правого выражения. При cross apply правое выражение является функцией левого элемента:
select c, f from C as c cross apply fn(c) as f
Поведение cross apply аналогично описанному для списка join. Если результатом вычисления правого выражения является пустая коллекция, то cross apply не создает пары для этого экземпляра левого элемента.
outer apply аналогично cross apply за исключением того, что пара все же создается, даже когда результатом вычисления правого выражения является пустая коллекция:
select c, f from C as c outer apply fn(c) as f
Примечание: В отличие от TSql, нет необходимости в явном этапе unnest.
5.1.2 Несколько коллекций в предложении from
В предложении from может быть указано несколько коллекций, разделенных запятыми. В таких случаях предполагается, что коллекции соединены вместе. Думайте о них как о n-стороннем перекрестном соединении.
5.1.3 Корреляция слева
Элементы в предложении from могут ссылаться на элементы, указанные ранее. В нижеприведенном примере C и D являются независимыми коллекциями, в то время как c.Names зависит от C:
from C as c, D as d, c.Names as e это логически эквивалентно:
from (C as c join D as d) cross apply c.Names as e
5.1.4 Семантика
Логически, коллекции в предложении from по предположению являются частью n-стороннего перекрестного соединения - одностороннее перекрестное соединение является вырожденным случаем. Псевдонимы в предложении from обрабатываются слева направо и добавляются к текущей области видимости для дальнейших ссылок. Предполагается, что предложение from создает мультимножество строк - с одним полем для каждого элемента в предложении from, и представляющих один элемент из этого элемента коллекции.
В вышеприведенном примере предложение from логически создает мультимножество строк типа Row(c, d, e), где предполагается, что поля c, d и e имеют тип элемента C, D и c.Names. eSQL вводит псевдоним для каждого простого элемента предложения from в области видимости. Например, в нижеприведенном запросе:
from (C as c join D as d) cross apply c.Names as e именами, введенными в область видимости, являются c, d и e. В отличие от имеющегося в SQL, предложение from вводит в область видимости только псевдонимы. Любые ссылки на столбцы (свойства) этих коллекций должны быть уточнены псевдонимом.
5.2 Предложение where
Семантика предложения where идентична описанной для TSQL. Оно ограничивает объекты, созданные выражением запроса, посредством ограничения элементов коллекций источника до тех, которые удовлетворяют условию:
select c from cs as c where e
Выражение e должно иметь булев тип. Предложение where применяется непосредственно после предложения from, перед группировкой, упорядочением или проекцией. Все имена элементов, определенные в предложении from являются видимыми для выражения предложения where.
5.3 Предложение group by
Семантика предложения group-by аналогична описанной для TSQL. Можно указать одно или несколько выражений, значения которых используются для сбора в группу элементов источника с целью вычисления агрегатов:
select e1, count (c.d1) from c group by e1, e2, ..., en
Результат каждого выражения в предложении group by должен быть вычислен с некоторым типом, для которого можно провести сравнение на равенство. Эти типы, в большинстве случаев, являются скалярными примитивами, например числами, строками и датами. Можно использовать составные типы как условия group-by, если для этих типов определено понятие равенства. Нельзя сгруппировать (group by) коллекцию.
После определения предложения group, явно или неявно (на основании предложения having в запросе), текущая область видимости скрывается, и вводится новая область видимости.
В предложении select, предложении having и предложении order-by больше нельзя ссылаться на имена элемента, указанные в предложении from. Ссылаться можно только на выражения группировки непосредственно. Для этого можно присвоить новые имена (псевдонимы) каждому выражению группировки. Если для выражения группировки не определен ни один псевдоним, то eSQL пытается сформировать один (псевдоним) посредством правил формирования псевдонимов в 0:
select g1, g2, ..., gn from c as c1
group by e1 as g1, e2 as g2, ..., en as gn
Выражения в предложении group-by могут не ссылаться на имена, определенные ранее в идентичном предложении.
Кроме группировки имен в предложении select, предложении having и предложении order-by можно также указывать агрегаты. Агрегат содержит выражение, которое вычисляется для каждого элемента группы. Агрегатный оператор преобразует значения всех этих выражений (обычно, но не всегда, в одно значение). В агрегатном выражении можно делать ссылку на первоначальные имена элемента, видимые в родительской области видимости, или на любое из новых имен, введенных в предложении group-by непосредственно. Хотя агрегаты появляются в предложении select, предложении having и предложении order-by, они фактически вычисляются в области видимости, идентичной (области видимости) выражений группировки:
select name, sum(o.Price * o.Quantity) as total
from orderLines as o
group by o.Product as name
В этом запросе используется предложение group-by для создания отчета о ценах всех заказанных продуктов с разбивкой по продуктам. В нем дается имя 'name' продукту как часть выражения группировки, и затем делается ссылка на это имя в списке select. В нем также указан агрегат 'sum' в списке select, внутри которого делается ссылка на количество и цену в строке (line) заказа.
Именованные группы
Сами группы могут иметь имена. Когда группе дается имя, то в область видимости вводится новое имя, которое ссылается на коллекцию объектов, которые формируют экземпляр группы. Сама группа является агрегатом - агрегатом nest - который просто объединяет все элементы, соответствующие критериям для группы, в мультимножество. Логически, предложение group by выполняет группировку на основе ключей и неявного агрегата nest - один для каждой группы - который содержит коллекцию неключевых столбцов для этой группы.
Последующие ссылки на агрегаты - агрегаты на основе группы - транслируются в агрегаты на основе коллекции, где рассматриваемая коллекция является агрегатом nest, созданным предложением group by:
select name, sum(o.Price * o.Quantity) as total, mygroup
from orderLines o
group mygroup by o.Product as name
В этом примере в предложении group-by идентифицируется группа mygroup, и на нее существует ссылка в списке select. Имя mygroup ссылается на коллекцию экземпляров OrderLine, которые формируют одну группу. Каждая строка результирующей коллекции будет иметь три свойства: name, total и mygroup.
Нет необходимости всегда определять свое собственное имя для группы. Даже без указания такового к группе всегда можно получить доступ с использованием группы name:
select name, sum (o.Price * o.Quantity) as total, group
from orderliness o
group by o.Product as name
5.4 Предложение having
Предложение having используется для указания дополнительного условия фильтрации результата группировки. Если в запросе не указано ни одного предложения group-by, то неявно предполагается "group by 1" - группа из одного множества. Предложение having действует аналогично предложению where за исключением того, что оно применяется после операции group-by. Это означает, что в предложении having можно делать ссылку только на псевдонимы и агрегаты группировки:
select name, sum(o.Price * o.Quantity) as total
from orderLines o
group by o.Product as name
having sum(o.Quantity) > 1
Этот пример идентичен примеру group-by за исключением того, что предложение having ограничивает группы до только тех, которые заключают в себе несколько единиц продукта.
5.5 Предложение select
Список из одного или нескольких выражений после ключевого слова select известен как список select или более формально как проекция. Самой общей формой проекции является одно выражение. Если выбирают некоторый член m из коллекции c, то создается новая коллекция из всех значений m для каждого элемента c:
select c.m from c
Например, если customers (клиенты) являются коллекцией типа customer (клиент), который имеет свойство Name, имеющее тип "string" (строка), то выбор Name из customers в результате дает коллекцию строк:
select c.Name from customers as c
Предложения выбора значения и строки
eSQL поддерживает два варианта предложения select (выбрать). Первый вариант - выбор строки - идентифицируется ключевым словом select и может использоваться для указания одного или нескольких элементов, которые должны быть спроецированы вне. Неявно, к элементам добавляется упаковщик строки, так что в итоге результатом выражения запроса всегда является мультимножество строк - с соответствующими полями. Для каждого выражения при выборе строки должен быть указан псевдоним. Если не указано ни одного псевдонима, то eSQL пытается сформировать псевдоним с использованием правил использования псевдонимов, описанных в 0.
Другой вариант предложения select - выбор значения - идентифицируется ключевым словом select value и обеспечивает возможность указания только одного элемента, и упаковщик строки не добавляется.
Выбор строки всегда можно выразить в терминах выбора значения. Например:
select 1 as a1, "abc" as b, a+34 as c →
select value row(l as a, "abc" as b, a+34 as c)
Модификаторы distinct и all
Оба варианта select обеспечивают возможность указания модификатора distinct или all. Если указан модификатор distinct, то дубликаты устраняются из коллекции, созданной выражением запроса (до и с включением в себя предложения select). Если указан модификатор all, то устранение дубликатов не выполняется.
Эти модификаторы сохранены только для совместимости с SQL. eSQL вместо них предлагает использование оператора distinct, но поддерживает эти варианты, и прозрачно транслирует выражение:
select distinct c.al, c.a2 from T as a →
distinct (select c.al, c.a2 from T as a)
Семантика
Предложение select вычисляется после вычисления предложений from, clause, group by и having. В предложении select можно ссылаться только на элементы, (находящиеся) в настоящее время в области видимости (через предложение from или из внешних областей видимости). Если было указано предложение group-by, то в предложении select допускается ссылаться только на псевдонимы для группировки (group by) по ключам. Ссылка на элементы предложения from допускается только как часть агрегатных функций.
5.5.1 Отклонения от SQL
Отсутствие поддержки для *
eSQL не поддерживает использование * (группового символа) или уточненного * для указания на то, что все предложение from (или все столбцы из таблицы) должны быть спроецированы вне. Даже в SQL, в хорошо спроектированных запросах избегают этих конструкций, так как у них могут быть неожиданные побочные эффекты при развитии схем. В eSQL вместо них допускается в запросах проецировать вне все записи посредством ссылок на псевдонимы коллекции из предложения from. Следующий запрос SQL:
select * from T1, T2
в eSQL намного лучше выражать посредством следующей конструкции:
select t1, t2 from T1 as t1, T2 as t2
5.6 Предложение order by
В предложении order-by можно указывать одно или несколько выражений, которые определяют упорядочение элементов в результате. Предложение order-by логически применяется к результату предложения select. В нем можно ссылаться на элементы в списке select через их псевдонимы. Кроме того, в нем также можно ссылаться на другие переменные, которые в настоящее время находятся в области видимости. Однако, если select_clause (предложение select) было определено с модификатором distinct, то в предложении order-by можно ссылаться только на псевдонимы из предложения select:
select c as cl from cs as c order by cl.e1, c.e2, ..., c.en
Результат каждого выражения в предложении order-by должен быть вычислен с некоторым типом, для которого можно провести сравнение на неравенство для упорядочения (меньше чем или больше чем и т.д.). Эти типы, в основном, являются скалярными примитивами, например числами, строками и датами.
Для каждого выражения в предложении order-by можно дополнительно указывать критерий сортировки. Можно указать ASC (или DESC) для указания на необходимость сортировки по возрастанию (или сортировки по убыванию) для конкретного выражения. Кроме того, для выражений строкового типа, можно определять предложение COLLATE для указания на использование для сортировки строкового сопоставления.
Позиционная спецификация, например order by 3, может использоваться для указания на соответствующий (третий) элемент в списке select, не поддерживается.
6 Детали языка - команда
6.1 Команда
Команда eSQL является термином, используемым для запроса всего запроса. Команда может быть выражением запроса, например выражением select, или утверждением, используемым для вставки, удаления или обновления объектов. Команда логически состоит из трех частей.
- Необязательный пролог (prolog)
- Необязательное предложение WITH
- Запрос или утверждение (языка) DML.
Например, предположим, что существует тип с именем Customer и коллекция экземпляров Customer с именем customers. Все следующее команды являются допустимыми:
customers.?(Name = 'Bob')
select c.Name, c. Phone from customers c
6.1.1 Прологи команды
В (необязательном) прологе команды можно указывать набор используемых пространств имен. Они будут описаны далее в разделе о пространствах имен.
6.1.2 Предложение WITH
eSQL поддерживает предложение WITH как префикс к любому запросу (или утверждению (языка) DML). Синтаксическая структура предложения WITH следующая:
withClause::= WITH <common-table-expr> [, <common-table-expr>]*
<common-table-expr>::= <simpleIdentifier> AS <paranthesizedExpr>
Примечания
В определениях <common-table-expr> можно ссылаться на общепринятые выражения таблицы, определенные ранее в предложении WITH. Например, допустимо следующее определение:
WITH tab1 as (...), tab2 as (select t from tab1 as t)
6.2 Утверждение запроса
Утверждение запроса является просто выражением.
6.3 Утверждение (языка) DML
Утверждения (языка) DML описаны в следующем разделе.
7 (Язык) DML
eSQL поддерживает утверждения (языка) DML insert, update и delete.
7.1.1 Insert
Команда INSERT в eSQL очень похожа на утверждение INSERT в стандартном SQL:
[WithClause] Insert [into] <container> [<with parent>] FROM <expr>
[WithClause] Insert [into] <container> [<with parent>] FROM <query_expr>:
[WithClause] Insert [into] <container> [<with parent>] VALUES <expr>
Семантика
<container> представляет любой контейнер данных. Множества сущностей-объектов (EntitySets) являются самым логическим контейнером.
<expr>/<query_expr> является мультимножеством (в первых двух случаях), которое формирует множество значений для вставки в контейнер. В третьем случае (предложение VALUES), <expr> имеет тип элемента контейнера.
WithClause определяется в последующих разделах.
With-parent-clause описывается в последующих разделах.
Примеры
Insert into NewCustomers select o from OldCustomers as o
Insert into NewCustomers from Multiset(Customer(...), Customer(...),...)
-- Все следующее утверждения эквивалентны:
Insert into NewCustomers from Multiset{Customer(...)}
Insert into NewCustomers select c from Multiset{Customer(...)} as c
Insert into NewCustomers from {Customer(...)}
Insert into NewCustomers values Customer(...)
Insert into NewCustomers values (Customer(...))
Примечания
Утверждение INSERT..VALUES eSQL немного отличается от T-SQL. Например, круглые скобки вокруг значения являются необязательными и не интерпретируются как конструктор строки, когда присутствуют.
В отличие от T-SQL, eSQL не обеспечивает возможности указания списка столбцов для утверждения Insert.
7.1.2 Delete
Команда DELETE в eSQL похожа на утверждение DELETE в стандартном SQL:
[WithClause] Delete [from] <container> [as <alias>]
[<with-parent-clause>] [where <expr>]
Семантика
<container> представляет любой контейнер данных. Множества сущностей-объектов (EntitySets) являются самым логическим контейнером.
<expr> является предикатом, то есть булева типа.
<with-parent-clause> определяется далее
Примеры
Delete from NewCustomers as n where n.id>10
Delete from NewCustomers
Примечания
В отличие от T-SQL, в утверждении DELETE в eSQL не допускается несколько предложений from. Вместо этого используется подзапрос.
7.1.3 Update
Утверждение update в eSQL концептуально похоже на утверждение UPDATE в стандартном SQL:
Update_statement::= [WithClause]
UPDATE<container> [as <alias>]
[<with-parent-clause>]
[<set_clauses>] [<apply-clauses>]
[where <expr>]
<set_clauses>::= SET <set_clause> [,<set_clause>]*
<set_clause>::= <field-expr> EQUAL <expr>
<field-expr>::= <expr>
Семантика
<container> представляет любой контейнер данных. Множества сущностей-объектов (EntitySets) являются самым логическим контейнером.
<expr> является предикатом, то есть булева типа.
<field-expr> является выражением с 1 значением, то есть оно может быть ссылкой на столбец, ссылкой на свойство столбца или выражением TREAT, включающим в себя такое свойство.
<with-parent-clause> определяется далее
Примеры
UPDATE NewCustomers as n
SET n.name.firstName = UPPER(n.name.firstName),
TREAT(n.address as
InternationalAddress).countrycode = 'US'
WHEHERE n.name like 'ABC%'
Примечания
В отличие от T-SQL, в утверждении UPDATE в eSQL не допускается несколько предложений from. Вместо этого используется подзапрос.
В утверждении UPDATE атрибут может быть модифицирован не более одного раза.
7.2 (Язык) DML для связей EDM
В EDM вводится понятие RelationshipSets (множества связей) как коллекции экземпляров связи. Связи и ассоциации и композиции моделируются через эти RelationshipSets.
7.2.1 Ассоциации
Общим образцом использования является то, что сначала создают экземпляры сущностей-объектов, и затем создают связи между сущностями-объектами посредством вставки в RelationshipSet. В следующем примере демонстрируются DMLs в таком relationshipset. Предположим, что существуют два типа сущностей-объектов Order и Customer (с EntitySets - Orders и Customers). Кроме того, предположим, что существует связь OrderCustomer между этими двумя сущностями-объектами, и OrderCustomerSet как relationshipset:
-- Вставить связь между Order и Customer
Insert into OrderCustomerSet
Select OrderCiastomer (ref(o), ref(c))
From Customers as c, Orders as o
Where o.Id = 123 and c.Name = 'ABC'
-- Удалить связь между Order и Customer
Delete from OrderCustomerSet as oc
Where oc.Order.Id = 123
7.2.2 Композиции
RelationshipSets, соответствующие композициям, также являются обновляемыми. Необходимо сначала создать родительский экземпляр сущности-объекта. В отличие от ассоциаций, однако, не существует отдельного этапа создания дочернего экземпляра. При вставке в Composition RelationshipSet автоматически создается дочерний экземпляр. Примеры этого включают в себя:
-- Вставка новых строк (line) в существующий заказ
Insert into OrderLineSet.Line
with parent (element.(select ref(o) from Orders as o
where o.Id = 20))
select Line (...) from...
-- модифицирование существующего элемента строки (line)
Update OrderLineSet.Line as 1
with parent (element(select ref(o) from Orders as o
where o.Id = 20))
Set 1.description = …
Where …
-- удаление существующего элемента строки (line)
Delete OrderLineSet.Line as 1
with parent (element(select ref(o) from Orders as o
where o.Id = 20))
where 1.description =...
Примечания: специальное предложение "with parent as" для модифицирования композиции.
8 eSQL Misc
8.1 Рекурсивные запросы
eSQL обеспечивает возможность поддержки рекурсивных запросов посредством обеспечения возможности определению таблицы (paranthesizedExpr) ссылаться на себя. Например:
WITH tab1 as (multiset(1, 2, 3, 4, 5)),
tab2 as (
multiset (1)
union all
select t2
from tab2 as t2, tab1 as t1
where t2 = t1
)
select t from tab1 as t В eSQL не даются никакие гарантии по поводу завершения рекурсии.
8.2 Поддержка связей EDM
В EDM вводится понятие RelationshipSets - которые являются логическими эквивалентами таблиц ссылок в SQL. RelationshipSets можно запрашивать точно так же, как и другие коллекции. Кроме того, eSQL поддерживает навигационных помощников для более простой навигации по связям. Общий вид навигационного помощника следующий:
Select o.Id, o->OrderCustomer.Customer
From Orders as o, где OrderCustomer - имя связи, и Customer - имя конца клиента связи.
8.3 Комментарии
eSQL поддерживает комментарии стиля T-SQL. Комментарии eSQL могут иметь следующие формы:
-- это комментарий
/* это тоже комментарий */
Комментарии могут использоваться в любом месте, где ожидается разделитель.
Символы комментария в стиле "--" (двойной дефис) могут использоваться на одной строке с кодом, который будет исполняться, или одни на строке. Все от двойных дефисов до конца строки является частью комментария.
/*... */ (пары символов косая черта-звездочка). Эти символы комментария могут использоваться на одной строке с кодом, который будет исполняться, одни на строке или даже внутри исполняемого кода. Все от открывающей комментарий пары (/*) до закрывающей комментарий пары (*/) считается частью комментария. Эти комментарии могут располагаться на нескольких строках.
9 Разрешение имен в eSQL и другие правила
9.1 Идентификаторы
Идентификаторы в eSQL используются для представления псевдонимов выражения, ссылок на переменную, свойств объектов, функций и т.д. Идентификаторы в eSQL могут быть двух видов.
9.1.1 Простой идентификатор
Простой идентификатор является просто последовательностью алфавитно-цифровых (и подчеркивания) символов
Первый символ идентификатора должен быть буквой, a-z или A-Z.
9.1.2 Цитируемые идентификаторы
Цитируемым идентификатором является любая последовательность символов, окруженных квадратными скобками или двойными кавычками. Заданной по умолчанию кавычкой является квадратная скобка. Двойные кавычки могут использоваться как символ цитирования только тогда, когда синтаксический анализатор для eSQL допускает это - управляющие этим точные опции синтаксического анализатора остаются на усмотрение синтаксического анализатора. Также заметим, что, когда двойные кавычки могут использоваться как символ цитирования, они не могут использоваться для строковых литералов - строковые литералы тогда всегда должны будут использовать одинарные кавычки.
Цитируемые идентификаторы обеспечивают возможность определять идентификаторы с символами, которые обычно не допустимы в идентификаторах. Все символы между квадратными скобками (или кавычками) считаются частью идентификатора, в том числе все пробелы. Цитируемый идентификатор может не включать в себя следующие символы:
Новой строки
Переводов каретки
Табуляций
Возврата на один символ
[(только в случае кавычек в стиле []),
Можно создавать имена свойства с другими обычно запрещенными символами:
select c.ContactName as [Contact Name] from customers as c
select c.ContactName as "Contact Name" from customers as c
Можно использовать цитируемый идентификатор для обозначения идентификатора, который обычно рассматривается как зарезервированное слово языка. Например, если тип Email имеет свойство с именем 'from', то можно устранить неоднозначность его и зарезервированного слова 'from' с использованием квадратных скобок:
select e.[from] from emails as e
Можно использовать цитируемый идентификатор справа от оператора точка:
select t from ts as t where t.[a property] == 2
Для использования символа, идентичного символу закрывающей кавычки в идентификаторе, его используют дважды. Например:
select t from ts as t where t.[a bc]]] == 2 соответственно выделяют идентификатор abc].
9.2 Чувствительность к регистру
Все ключевые слова в eSQL нечувствительны к регистру (как в SQL). Идентификаторы могут быть чувствительными или нечувствительными к регистру в зависимости от определенных опций синтаксического анализатора. Ключевые слова в eSQL всегда нечувствительны к регистру.
9.3 Правила использования псевдонимов
В eSQL рекомендовано указывать псевдонимы в запросах каждый раз, когда они необходимы. Псевдонимы необходимы в следующих конструкциях:
Поля конструктора строки
Элементы в предложении from выражения запроса
Элементы в предложении select выражения запроса
Элементы в предложении group by выражения запроса
Аргументы в выражении join
Допустимые псевдонимы
Любой простой идентификатор или цитируемый идентификатор является допустимым псевдонимом.
Формирование псевдонима
Если псевдоним не указан, то eSQL пытается сформировать псевдоним на основе нескольких простых правил.
Если выражение (для которого псевдоним не определен) является простым или цитируемым идентификатором, то этот идентификатор используется как псевдоним. Например:
row(a, [b]) -> row(a as a, [b] as [b])
Если выражение является более сложным выражением, но последний компонент этого выражения является простым идентификатором, то этот идентификатор используется как псевдоним. Например:
row( a.a1, b.[b1]) -> row(a.a1 as a1, b.[b1] as [b1])
В противном случае во время компиляции возникает исключительная ситуация.
9.4 Правила обзора данных
Правила обзора данных определяют, когда конкретные переменные видимы в языке запросов. Некоторые выражения или утверждения вводят новые имена. Правила обзора данных определяют, где эти имена могут использоваться, и когда или где новое объявление с именем, идентичным другому, может скрывать его предшественника.
Когда имена определены, то говорят, что они определены в пределах области видимости. Область видимости покрывает область запроса. Все ссылки на имена или выражения в пределах определенной области видимости могут видеть имена, определенные в пределах этой области видимости. До начала области видимости и после ее конца на имена, определенные в пределах этой области видимости, нельзя ссылаться.
Области видимости могут быть вложенными. Части языка вводят новые области видимости, покрывающие области, которые могут содержать другие выражения языка, которые также вводят области видимости. Когда области видимости вложены, можно делать ссылки на имена, определенные в пределах самой внутренней области видимости, внутри которой находится ссылка, а также на любые имена, определенные в любых внешних областях видимости. Любые две области видимости, определенные в пределах идентичной области видимости, считаются "братскими" областями видимости. Нельзя делать ссылки на имена, определенные в пределах "братских" областей видимости.
Если в пределах внутренней области видимости объявлено имя, которое соответствует имени, объявленному во внешней области видимости, то ссылки в пределах этой области видимости или в пределах областей видимости, объявленных в пределах этой области видимости, относятся только к недавно объявленному имени. Имя во внешней области видимости является скрытым. На имена нельзя ссылаться до их определения, даже в пределах идентичной области видимости.
Глобальные имена могут существовать как часть среды выполнения программы. Сюда могут включаться имена перманентных коллекций или переменных среды. Эта область видимости, которая содержит их, является самой внешней областью видимости. Параметры не находятся в области видимости. Так как ссылки на параметры включают в себя специальный синтаксис, имена параметров не вступают в конфликт с другими именами в запросе.
9.4.1 Выражения запроса
В выражении запроса вводится новая область видимости. Имена, определенные в предложении from, вводятся в область видимости from в порядке появления, слева направо. В выражениях списка join можно ссылаться на имена, определенные ранее в (этом) списке. Открытые (public) свойства (поля, и т.д.) элементов, идентифицированных в предложении from, не добавляются к области видимости from - на них всегда необходимо ссылаться через имя с уточнением псевдонимом. Обычно, все части выражения select считаются находящимися в пределах области видимости from.
Предложение group-by также вводит новую "братскую" область видимости. Каждая группа может иметь имя группы, которое ссылается на коллекцию элементов в группе. Каждое выражение группировки также вводит новое имя в область видимости группы. Кроме того, агрегат nest (или именованная группа) также добавляется в область видимости. Сами выражения группировки находятся в пределах области видимости from. Однако, когда (используется) предложение group-by, считается, что список select (проекция), предложение having и предложение order-by находятся в пределах области видимости группы, а не области видимости from. Агрегаты обрабатываются специальным образом, и они описаны ниже.
Список select может вводить новые имена в область видимости, по порядку. В выражениях проекции справа можно ссылаться на проецируемые имена слева. В предложении orderby можно ссылаться на имена (псевдонимы), указанные в списке select. Порядок вычисления предложений в пределах выражения select определяет порядок, в котором имена вводятся в область видимости. Сначала вычисляется предложение from, далее предложение where, предложение группировки, предложение having, предложение select и, наконец, предложение order-by.
Обработка агрегата
eSQL поддерживает две вида агрегатов - агрегаты на основе коллекции и агрегаты на основе группы. Агрегаты на основе коллекции являются предпочтительной конструкцией в eSQL, в то время как агрегаты на основе группы поддерживаются просто для совместимости с SQL.
При разрешении агрегата eSQL сначала пытается обработать его как агрегат на основе коллекции. Если это не удается, то eSQL трансформирует ввод агрегата в ссылку на агрегат nest и пытается разрешить это новое выражение. Например:
avg(t.c) → avg(group..(t.e))
9.4.2 Операции Фильтрации/проецирования из коллекции
Для операторов Фильтрации/проецирования из коллекции (.., ..., .? и ..?), создается новая область видимости для проекции/предиката, и в область видимости неявно добавляется имя it для представления каждого элемента коллекции. Кроме того, для простоты, открытые (public) члены элемента коллекции также добавляются в область видимости - и опять же, только на время вычисления проекции/предиката. Например:
Departments.. Name
Departments..(it.Name) создает мультимножество имен отдела - где предполагается, что каждый Department (отдел) имеет свойство Name (имя).
9.5 Пространства имен
eSQL вводит пространства имен для решения проблемы конфликтов имен для глобальных идентификаторов, например, имена типа множества сущностей-объектов, функции и т.д. Поддержка пространства имен в eSQL очень похожа на модель CLR. eSQL обеспечивает предложение using, которое может быть использовано в прологе команды (Command). Обеспечены два вида предложения using - с уточненными пространствами имен (где обеспечивается более короткий псевдоним для пространства имен) и неуточненными пространствами имен:
using System.Data.TSql;
using tsql=System.Data.TSql;
Правила разрешения имен
Если идентификатор не может быть разрешен в локальных областях видимости, тогда eSQL пытается найти имя в глобальных областях видимости, то есть пространствах имен. eSQL сначала пытается сопоставить идентификатор (префикс) с одним из уточненных пространств имен. Если существует соответствие, то eSQL пытается разрешить оставшуюся часть идентификатора в указанном пространстве имен - если соответствие не найдено, то возникает исключительная ситуация:

Далее eSQL пытается исследовать все неуточненные пространства имен (указанные в прологе) для идентификатора. Если идентификатор можно найти ровно в одном пространстве имен, то возвращается это положение. Если несколько пространств имен имеют идентификатор, соответствующий этому, то возникает исключительная ситуация. Если нельзя идентифицировать ни одного пространства имен для этого идентификатора, тогда eSQL передает имя в следующую внешнюю область видимости (объект Command/Connection):
using System.Data.TSql;
select substr(p.Name) from Person as p
Отличие от модели CLR
Стоит обратиться к одному отличию от модели CLR. В CLR можно использовать частично уточненные пространства имен - в eSQL это не допустимо. Например, в C #, следующее допустимо, в то время как эквивалент в eSQL не допустим:
using System.Data.TSql
void main() {
int x = Y.Z.Foo (); -- ссылка на метод Foo
of class Z in
-- пространство имен
System.Data.TSql.Y
}
Использование ADO.NET
Посредством команд (Commands) ADO.NET выражают утверждения запросов/DML. Команды (Commands) могут быть надстроены над объектами Connection. Как часть объектов Command и Connection также могут быть указаны пространства имен. Если eSQL не может разрешить идентификатор непосредственно в пределах запроса, то исследуются внешние пространства имен (посредством аналогичных правил). Запрос, объекты Command и Connection формируют кольца пространств имен - где сначала исследуется каждое кольцо.
9.6 Литералы null и формирование логического вывода о типе
Как описано ранее, литералы null совместимы с любым типом в системе типов eSQL. Однако для формирования правильного логического вывода для типа литерала null в eSQL налагаются определенные ограничения на то, где литерал null может использоваться. Применяются следующие правила
(Литералы) null с определенным типом
(Литералы) null с определенным типом, то есть "cast(null as Int16)" можно использовать везде; в дальнейшем нет никакой необходимости в формировании логического вывода о типе, так как в это время тип известен.
Непривязанные литералы null
Непривязанные литералы null могут использоваться в следующих контекстах:
Как аргумент выражения cast/treat - это является рекомендуемым механизмом для создания выражения null с определенным типом.
Аргумент метода или функции (применяются стандартные правила перегрузки, и если нельзя выбрать ни одной перегрузки, то возникает ошибка трансляции).
Как один из аргументов арифметического выражения, например, +, -,, /. Другой(ие) аргумент(ы) не могут быть литералами null; в противном случае формирование логического вывода о типе не возможно.
Как один из аргументов логического выражения (and/or/not) - известно, что все аргументы булева типа.
Как аргумент выражения "is null" или "is not null" - выражения "null is null" и "null is not null" допустимы (но неразумны)
Как один или несколько аргументов выражения like - ожидается, что все аргументы являются строками.
Как один или несколько аргументов конструктора именованного типа.
Как один или несколько аргументов конструктора мультимножества. Однако, по меньшей мере, один аргумент конструктора мультимножества должен быть выражением, отличным от литерала null.
Как один или несколько выражений then/else в выражении case. По меньшей мере, одно из выражений then/else должно быть выражением, отличным от литерала null.
Непривязанные литералы null не могут использоваться в других ситуациях. Некоторые из этих ситуаций (не исчерпывающий; включающий в себя только для иллюстрации) включают в себя
Аргументы конструктора строки.
Примечания
Выражения is null и is not null считаются специальными.
10 Система типов eSQL
eSQL оперирует экземплярами и создает экземпляры модели данных сущностей-объектов (EDM). В этом документе нет подробного изложения EDM; вместо этого раскрывается несколько элементов, представляющих особый интерес.
10.1 Типы строк
Строки (также известные как кортежи) являются структурными согласно членству. Структура строки зависит от последовательности с определенным типом и именованных членов, из которых она состоит. Строка является InlineType EDM - она не имеет никакой идентификационной информации и из нее нельзя наследовать.
Экземпляры идентичного типа строки эквивалентны, если эквивалентны соответствующие члены. Строки не имеют никакого поведения, кроме их структурной эквивалентности.
У строк нет никакого эквивалента в общеязыковой среде исполнения. Результатом запросов могут быть структуры, содержащие строки или коллекции строк.
API, осуществляющий связь между запросами eSQL и базовым языком, определяет, как реализуются строки в результате запроса. В ADO.NET, строки появляются как DataRecords (записи данных).
10.2 Коллекции
Коллекции представляют ноль или большее количество экземпляров других объектов. EDM поддерживает несколько видов коллекций - в том числе мультимножества, списки и т.д. Этот документ имеет дело только с мультимножествами.
10.3 Возможность принимать значение null (Nullability)
В EDM возможность принимать значение null (nullability) является ограничением на свойство, а не аспектом типа непосредственно. Каждый тип в EDM может принимать значение null. Литералы null в eSQL считаются совместимыми с любым типом в EDM.
10.3.1 Семантика null
Литералы null в eSQL ведут себя очень схоже с литералами null в TSql. А именно большинство выражений, которые оперируют литералом null, возвращают литералы null. Сюда входят:
Арифметические выражения
Логические выражения
Выражения типа
Следующие выражения могут не возвращать литералы null, когда один или несколько их аргументов являются литералом null:
Конструкторы (тип, строка, мультимножество)
Функции/методы
Операторы is null и is not null
Другие
10.4 Неявное повышение типа
eSQL определяет множество общепринятых двухместных и одноместных операторов, например суммирование, умножение и отрицание для примитивных типов данных, например, целое число, число с плавающей точкой с одинарной точностью и строка. Обычно двуместные операторы, например суммирование, оперируют более чем двумя экземплярами идентичного типа данных. Однако иногда допустимо запрашивать работу оператора с более чем с двумя экземплярами различного типа; например суммирование и целое число и число с плавающей точкой с одинарной точностью.
Для того чтобы это работало, тип одного из этих двух операндов должен быть повышен до типа другого. В общем, этим типом является тип с самой высокой точностью, поэтому при преобразовании нет никакой потери данных. При некоторых обстоятельствах для обеспечения отсутствия потери данных типы обоих операндов повышаются до третьего типа.
В следующей таблице перечислены неявные повышения типа, встроенные в язык. В первом столбце перечислен исходный тип, а во втором столбце перечислены ближайшие повышения, которые могут быть сделаны для указанного типа. Например, Int16 может быть повышен до Int32. Хотя он также может быть повышен до Int64, так как и Int32 может быть повышен до Int64.
Типы, которые не перечислены или перечислены как не имеющие 'ни одного' повышения, не могут быть повышены неявно.
Если необходимо знать правильное повышение типа при попытке суммирования Int16 с числом с плавающей точкой с одинарной точностью, то можно посмотреть в таблицу и увидеть, что Int16 действительно повышается до типа с плавающей точкой с одинарной точностью, хотя тип с плавающей точкой с одинарной точностью не повышается до Int16. Следовательно, Int16 будет повышен до типа с плавающей точкой с одинарной точностью, чтобы можно было суммировать два числа с плавающей точкой с одинарной точностью.
Немного более сложным примером является и суммирование Int32 с числом с плавающей точкой с одинарной точностью. Отметим, что и Int32 не будет повышен до типа с плавающей точкой с одинарной точностью, и тип с плавающей точкой с одинарной точностью не будет повышен до Int32. Однако и Int32 и тип с плавающей точкой с одинарной точностью будут повышены до типа с плавающей точкой с двойной точностью. Следовательно, типы обоих операндов повышают до типа с плавающей точкой с двойной точностью, и суммируются два числа с плавающей точкой с двойной точностью.
10.5 Допустимые преобразования типов
Следующая таблица является таблицей допустимых преобразований между примитивными типами данных.
11 Связывания базового языка
Связыванием базового языка является API, посредством которого взаимодействуют с eSQL. eSQL был разработан как язык запросов, к которому из базового языка программирования получают доступ через API способом, аналогичным тому, посредством которого программисты получают доступ к текущей (версии) TSQL с использованием доступа к данным Microsoft API. В принципе, запрашиваемые данные находятся где-нибудь вне области базового языка, в базе данных или другой перманентной памяти или структуре данных, которая непрозрачна для обычных операторов языка.
Предпочтительным механизмом доступа к данным для eSQL является ADO.NET. Объект Command в ADO.NET имеет свойство CommandText (которое можно вставлять в строку запроса eSQL). Метод Execute объекта Command возвращает DataReader (который поддерживает интерфейс IEnumerator). DataReader логически является коллекцией DataRecords, где DataRecord представляет один элемент результата.
12 Грамматика
12.1 Команда
command::= [prolog] [withClause] (query|dml)
prolog::= {NamespaeeDecl;} *
NamespaceDecl::=using(AliasedNamspaceDecl| UnaliasedNamespaceDecl)
AliasedNamespaceDecl::= simpleIdentifier = идентификатор
UnaliasedNamespaceDecl::= идентификатор
withClause::= with withclauseItemList
withClauseltemList::= withClauseItem
|withClauseltemList, withClauseItem
withClauseItem::= simpleIdentifier as paranthesizedExpr
12.2 (Язык) DML
dml::=insert|update|delete
insert expr::= insert [into].expr[with-parent-clause] from
|insert [into] expr [with-parent-clause]
queryExpr |insert [into] expr [with-parent-clause]
values expr
delete::= delete [from] aliasedExpr [with-parent-clause] [where expr]
update::= update aliasedExpr [with-parent-clause]
set [where expr]
with-parent-clause::= withparent parenthesizedExpr
set-clause::= set.set-clause-item-list
set-clause-item-list::= set-clause_item|
set-clause-item-list, set-clause-item
set-clause-item::= simple-set-clause-item
simple-set-clause-item::= expr=expr
12.3 Выражения запроса





ПРИЛОЖЕНИЕ B: Подробная спецификация расширений в иллюстративном языке запросов
1 Обзор
1.1 Цель
В этом документе приводится подробное описание расширений (функции) в языке запросов eSQL для WinFS/CDP.
eSQL обеспечивает поддержку для вызова функции, но не обеспечивает своих собственных встроенных функций. (Операторы наподобие +, - и т.д. обрабатываются по-другому, и предполагается, что они поддерживаются в языке непосредственно). Пользователи языков наподобие T-SQL и других диалектов SQL привыкли к расширенному набору встроенных функций. Целью этого документа является описание того, как eSQL может быть расширен для удовлетворения этим требованиям.
В основном, все функции в eSQL обрабатываются одинаково: как определяемые пользователем функции. eSQL использует пространства имен для определения различных контейнеров функций образом, подобным использованию пространств имен для контейнерных типов. Поставщики могут определять такие пространства имен с ассоциированным набором функций и делать их доступными пользователям eSQL через услуги метаданных. В этом документе внимание сосредоточено на конкретном наборе встроенных функций, доступных из SQL-сервера и WinFS, и пространствах имен, через которые они делаются доступными.
В этом документе не рассматривается вопрос относительно того, как поставщики обеспечивают этот список функций, и как они загружаются остальной частью системы.
Эти расширения сгруппированы по поставщикам накопителей, которые их поддерживают. Список поставщиков следующий:
1. SQL-сервер 2000.
2. SQL-сервер 2005. Этот поставщик поддерживает все функции 2000 SQL
3. WinFS. Этот поставщик поддерживает все функции SQL 2000 и SQL 2005
Эти функциональные возможности суммированы в следующей таблице:

ческие функции
(Частич-ная поддерж-ка)
Случаи частичной поддержки, перечисленные в вышеуказанной таблице, см. в последующих разделах документа.
1.2 Механизм расширения
Подробности механизма расширения eSQL, которые обеспечивают функциональные возможности расширения, можно найти в разделе 9.4 (Пространства имен) спецификации языка eSQL. Отметим, что отдельные пространства имен не поддерживаются; за дальнейшими подробностями обращайтесь к спецификации языка eSQL.
Пространства имен могут быть импортированы в запрос с использованием предложения using eSQL. С другой стороны, одно или несколько пространств имен можно определить вне границ запроса, например, как часть объектов Command/Connection.
1.3 Выполнение расширения
Выполнение запроса (в том числе функций расширения) всегда происходит в памяти. Кроме того, если не отмечено другое, ожидается, что семантика функций расширения будет идентичной имеющейся на сервере. Синтаксические анализаторы eSQL проверяют правильность сигнатуры вызовов функций; однако любая семантическая проверка выполняется в базовой памяти.
2 Рабочий план
2.1 Агрегаты
Агрегатные функции выполняют вычисление на мультимножестве значений и возвращают одно значение. За исключением COUNT агрегатные функции игнорируют значения null. Поддерживаются следующие доступные функции SQL:
При вычислении значения агрегатные функции игнорируют значения null (за исключением count (подсчет)). Также отметим, что count(*) не поддерживается. Агрегатные функции могут использоваться в предикате и в определении проекции. Кроме того, агрегаты поддерживают режим "distinct" (аналогичный поддержке SQL) для типов данных, которые поддерживают равенство. Тип возвращаемого результата этих функций основан на типе свойства (property), которое исполняется функцией. Так, например, avg(int) возвращает int. Он может и не быть ожидаемым, поскольку возвращаемым средним от 2,3 будет 2, а не 2.5. Чтобы избежать этого, пользователь должен явно привести свойство к типу, у которого есть нужная точность, например avg(cast(intProperty as double)).
2.1.1 Пространство имен
Эти функции находятся в пространстве имен System.Data.Tsql.Aggregates.
2.1.2 Примеры
using System.Data.TSql.Aggregates;
select count (i.Children) as Count
from Items as i;
select max (i.DisplayName)
from Items as i
group by i.Gender;
2.1.3 Поддерживаемые платформы
Поддерживается на: SQL 2000, SQL 2005 и WinFS.
2.2 Строковые функции
Эти скалярные функции выполняют операцию над строковым входным значением и возвращают строковое или числовое значение.
Отметим, что у всех строковых функций есть единственные относительные индексы.
2.2.1 Пространство имен
Эти функции находятся в пространстве имен System.Data.Tsql.String.
2.2.2 Примеры
using System.Data.String;
select substring (reverse (i.DisplayName), 1, 5)
from Items as i
2.2.3 Поддерживаемые платформы
Поддерживается на: SQL 2000, SQL 2005 и WinFS.
2.3 Математические функции
Эти скалярные функции выполняют общепринятый набор математических операций.
2.3.1 Пространство имен
Эти функции находятся в пространстве имен System.Data.Tsql.Math.
2.3.2 Примеры
using System.Data.TSql.Math;
select PI()
from Items as i
2.3.3 Поддерживаемые платформы
Поддерживается на: SQL 2000, SQL 2005 и WinFS.
2.4 Функции даты
Эти скалярные функции выполняют операцию над входным значением даты и времени и возвращают строковое, числовое значение или значение даты и времени:
2.4.1 Пространство имен
Эти функции находятся в пространстве имен System.Data.Tsql.Date.
2.4.2 Примеры
Часть дата (datepart) необходимо определять как строковый литерал:
using System.Data.TSql.Date;
select i
from Items as i
where i.MpdifiedTime > dateadd('day', -10, i.ModifiedTime)
2.4.3 Поддерживаемые платформы
Поддерживается на: SQL 2000, SQL 2005 и WinFS.
2.5 Системные функции
Существует набор системных функций, которые меняются согласно платформе, которая функционирует в пространстве имен System.Data.TSql.System. Они суммированы в следующей таблице:
В следующих разделах представлена более подробная информация для конкретных функций.
2.5.1 Soundex & Difference
Функция Soundex преобразует к функции Soundex T-SQL и используется для преобразования буквенной строки в четырехсимвольный код для нахождения созвучных слов или имен. Первым символом кода является первый символ символьного выражения (character_expression), а со второго по четвертый символами кода являются числа. Гласные в character_expression игнорируются, если они не являются первым символом строки. Строковые функции могут быть вложенными. Ее синтаксис следующий:
String soundex(string character_expression)
Difference возвращает разность между значением SOUNDEX двух символьных выражений как целое число. Эта функция может быть полезной при сортировке имен согласно произношению, например. Ее синтаксис следующий:
Далее приведены примеры использования soundex и difference в запросе:

//получить длину данных DisplayName для всех элементов

2.5.1.1 Поддерживаемые платформы
Поддерживается на: SQL 2000, SQL 2005 и WinFS.
2.5.2 Datalength
Функция Datalength используется для возвращения размера свойств (как int (целое число)). Она преобразует к функции datalength SQL. Ее синтаксис следующий:
int datalenght(property)
В случае, когда свойство не имеет значения (то есть null), возвращаемым значением является ноль *not*null (не null). Это противоположно тому, как работает функция datalength SQL. Далее приведены примеры использования datalength в запросе:
using System.Data.TSql.System;
//получить длину данных DisplayName для всех элементов
select WinFS.Datalength(i.DisplayName)
from Items as i
//получить длину данных тела сообщения
select sum(datalength(m.Body..Content)),
m.Subject
from OfType(Items, Message) as m
2.5.2.1 Поддерживаемые платформы
Поддерживается на: SQL 2005 и WinFS.
2.6 Функции XML
Поддержка для запросов XML обеспечивается через функции расширения. Обеспечены следующие функции расширения:

2.6.1 Пространство имен
Эти функции находятся в пространстве имен System.Data.Tsql.XML.
2.6.2 Примеры
using System.Data.TSql.XML;
select i
from Items as i
where Exist(i.XMLProperty, '//text()')
2.6.3 Поддерживаемые платформы
Поддерживается на: SQL 2005 и WinFS.
2.7 Функции WinFS
2.7.1 Полнотекстовые запросы (только WinFS)
WinFS должен поддерживать две TVF - Contains (содержит) и FreeText (текст на естественном языке) (две перегрузки для каждой) - для полнотекстового поиска. Эти функции преобразуются в функциональные возможности в MSSearch:
Все эти функции возвращают мультимножество строк - каждая с двумя полями. Поле ItemId является Guid и является id (идентификатором) Item (элемента), который соответствовал полнотекстовому предикату. Поле Rank является рангом для этого элемента. Результат не сортируется по Rank - для достижения этого в запросе должно явно использоваться (предложение) order by.
Contains
Contains моделирует предикат Contains MSSearch. Аргумент containsQuery должен соответствовать синтаксису, определенному предикатом Contains MSSearch. Аргумент propName должен соответствовать синтаксису, используемому для определения свойства search (поиск) во время инсталляции схемы WinFS.
FreeText
FreeText моделирует предикат FreeText MSSearch. Аргумент freeTextQuery должен соответствовать синтаксису, определенному предикатом FreeText MSSearch. Аргумент propName должен соответствовать синтаксису, используемому для определения свойства search (поиск) во время инсталляции схемы WinFS.
Примечания
В eSQL не интерпретируется ни один из аргументов. В нем только обеспечивается то, что они должны быть строками.
2.7.1.1 Механизм
Инсталляция схемы
Когда инсталлируется схема WinFS, идентифицируются и сохраняются в скомпонованном блоке клиента любые свойства поиска. Синтаксис спецификации свойства следующий:
Обработка запроса
Как упомянуто ранее, в eSQL не интерпретируются аргументы этих функций. Более конкретно, во время выполнения WinFS - который анализирует запрос - не выполняются проверки, кроме обеспечения того, что параметры являются строками.
Поставщик WinFS ответственен за интерпретацию аргумента propertyName - возможно как часть SqlGen, который ищет соответствующее свойство id в скомпонованном блоке клиента и затем транслирует его в эквивалентный вызов TVF в памяти. (Функции) TVF памяти будут иметь сигнатуры, которые похожи на:

2.7.1.2 Пространство имен
Эти функции находятся в пространстве имен System.Data.Tsql.WinFS.
2.7.1.3 Примеры
В следующих примерах иллюстрируется использование этих функций:

2.7.1.4 Поддерживаемые платформы
Поддерживается на: WinFS.
2.7.2 SumString (только WinFS)
Агрегат SumString (который преобразует в UDF памяти с именем SumString) обеспечивает возможность конкатенировать содержимые коллекции строк в одну строку с разделителем. Это полезно для некоторых сценариев приложения, в том числе отображения списка 'Кому' получателей сообщения в одном текстовом поле.
Это расширение eSQL является агрегатной функцией, аналогичной count, sum, max и т.д. и может быть применено к строковым свойствам в InlineObjectCollections, ItemFragmentCollections, ExtensionCollections и любому строковому свойству в результате операции Group. Синтаксис этого агрегата следующий:
string SumString (MuItiset<string> coll)
где коллекция должна быть коллекцией строк.
2.7.2.1 Пространство имен
Эти функции находятся в пространстве имен System.Data.Tsql.WinFS.
2.7.2.2 Примеры
Далее приведен пример использования SumString в запросе:
using System.Data.TSql.WinFS;
// Конкатенировать список ParticipantEAddress вместе
select
SumString(m.Participants.?(ParticipantType=Sender
.. ParticipantEAddress.Address),
m.Subject
from OfType(Items, Message) as m
2.7.2.3 Поддерживаемые платформы
Поддерживается на: WinFS.
2.7.3 NormalizeDigits (только WinFS)
Агрегат NormalizeDigits (который преобразует в UDF памяти с именем normalizedigits) обеспечивает возможность сортировать строки в формате, аналогичном сортировке в оболочке windows. Синтаксис этой функции следующий:
string NormalizeDigits (string property, int maxLength)
2.7.3.1 Пространство имен
Эти функции находятся в пространстве имен System.Data.Tsql.WinFS.
2.7.3.2 Примеры
Далее приведен пример использования SumString в запросе:
using System.Data.TSql.WinFS;
// упорядочить элементы с использованием этой функции
select i.ItemId, i.NamespaceName
from Items as i
order by NormalizeDigits(i.NamespaceName, 4000)
2.7.3.3 Поддерживаемые платформы
Поддерживается на: WinFS.
3 Загрузка пространства имен
Все пространства имен, описанные в этом документе, должны автоматически загружаться при соединении с поставщиком SqlClient. Не должно быть требования явного использования предложения "using".
4 Вычисляемые методы и свойства
Язык запросов eSQL поддерживает механизм расширения, посредством которого на свойства, которые добавляются в неполный класс O-Space (то есть непреобразуемые свойства), можно ссылаться в запросах. Эти свойства требуют, чтобы выражение eSQL было связано с ними через атрибут. Это выражение затем заменяется везде, где на это свойство ссылаются в запросе.
В выражении eSQL, которое обеспечивается, можно ссылаться на другие вычисляемые свойства и методы, другие преобразуемые свойства и другие функции, которые указаны в декларации Поставщика.
4.1 Вычисляемые свойства
System.Data.Objects.CalculatedAttribute может быть добавлен к Property (свойство), который определен только в клиентском классе (не преобразуемое свойство), для обеспечения возможности ссылки свойства в запросах.
Тип Property CLR должен соответствовать типу, возвращаемому выражением eSQL. Если тип возвращаемого результата выражения является типом, который может принимать значение null (nullable), тогда свойство должно быть объявлено как тип, который может принимать значение null (nullable). Выполнение этого ограничения обеспечено инфраструктурой, и будет "выброшена" исключительная ситуация. Если тип возвращаемого результата выражения является коллекцией, тогда Property должен иметь тип Query<T>.
Свойство ItemSize в Item является фактическим примером вычисляемого свойства, которое существует в схеме (Schema) в настоящее время. Далее приведен пример использования этого свойства:
// В следующем (примере) в конкретной папке отыскиваются все документы, которые больше, чем 10 КБ (-10000 байтов)
Quary<Item> searcher = wd.Items.Source.Where("it.ItemSize > 100000");
Это свойство будет отмечено посредством следующего атрибута:
[Calculated (Expression = "System.Storage.Item.GetItemSize(ItemId)")]
public int IteraSize {get;}
В вышеуказанном выражении ссылаются на функцию в декларации поставщика, которая преобразует к функции на стороне памяти.
PrimaryEmailAddress является примером свойства, которое можно вычислять исходя из схемы, и теперь посредством этих функциональных возможностей может быть заявлен и спроецирован через eSQL. Это свойство может возвращать Адрес электронной почты (Email) человека (Person), отмеченного посредством первичного ключевого слова (Primary Keyword). В следующем коде иллюстрируется, как определять это свойство PrimaryEmailAddress, чтобы обеспечить возможность его запроса посредством eSQL:
public partial class PersonItem:...
{
…
// Припишите свойство PrimaryEmailAddress
// @keyword ссылается на вычисляемый параметр [Calculated(Expressions ®
"using System.Storage.Contacts;
element (select value e
from this.EAddresses as e
where e is of SmtpEmailAddress
and exists (select 1
from e.Keywords
where Value=@keyword)))")]
[Calculated-Parameter (Name="keyword",
Value="System.Storage.Contacts.Primary")]
public SmtpEmailAddrβss PrimaryEmailAddress
{
get
{
foreach(SmtpEmailAddress smtpEA in
EAddresses.OfType<SmtpEmailAddress>())
{
foreach(Keyword k in smtpEA.Keywords)
{
if (k Value == "System.Storage.Contacts.Primary")
return smtpEA;
}
}
}
}
}
Далее это свойство может использоваться в запросе следующим образом:
Querγ<Person> searcher = wd.Items.Source.OfType<Person>().Where(" PrimaryEmailAddress.Address = 'rameshn@microsoft.com'");
Person person = searcher.GetSingle(); //Note the GetSingle is being added as a DCR
// Это свойство может быть спроецировано следующим образом: Query<DataRecord> projection = wd.Items.Source.OfType<Person>().Select ("it.DisplayName, it.PrimaryEmailAddress");
// Перечислить результаты
foreach(DataRecord records in projection)
{
string displayName = (string) record ["DisplayName"];
SmtpEmailAddress primaryEmailAddress = {SmtpEmailAddress) record["PrimaryEmailAddress"];
}
Примечания относительно выражения eSQL:
Префикс "this" должен использоваться для ссылки на другие свойства (Properties)/методы (Methods) (преобразованные или вычисленные) в экземпляре.
Правильность выражения проверяется только во время выполнения.
Может быть задано любое допустимое выражение eSQL, в том числе предложение using.
Вычисляемые параметры (Parameters) должны иметь префикс @ для ссылки на них в выражении
4.2 Вычисляемые методы
Аналогично вычисляемым свойствам можно также обеспечить возможность использования методов, определенных в неполных классах, в eSQL. System.Data.Objects.CaclulatedAttribute может быть добавлен в метод, способом, аналогичным добавлению его в свойство. Следующая семантика и ограничения относятся к вычисляемым методам:
Родовые (например, X<T>) методы в настоящее время не поддерживаются в eSQL, то есть параметр родового типа не будет использоваться в выражении eSQL.
Ключевое слово C# params, которое обеспечивает возможность переменного количества параметров метода, не поддерживается в вычисляемых методах.
Полиморфизм вычисляемых методов в настоящее время не поддерживается.
В настоящее время нет поддержки определенных вне приватных или внутренних вычисляемых методов, то есть API должен иметь доступ к свойству/методу.
В общем, рекурсивные вызовы в вычисляемых методах не поддерживаются.
Перегрузка вычисляемых методов посредством значений параметров (типов) в настоящее время не поддерживается.
Тип возвращаемого значения метода должен соответствовать типу, возвращаемому выражением eSQL.
Если тип возвращаемого результата выражения является типом, который может принимать значение null (nullable), тогда метод должен быть объявлен как возвращающий тип, который может принимать значение null (nullable). Выполнение этого ограничения обеспечено инфраструктурой, и будет "выброшена" исключительная ситуация.
Если тип возвращаемого результата выражения является коллекцией, тогда тип возвращаемого значения метода должен быть типом Query<T>.
Скрытие методов посредством указания оператора new не поддерживается.
Виртуальные методы не поддерживаются.
Методы, которые возвращают void, не поддерживаются
Параметры метода не требуют префикса для ссылки на них в выражении
Далее приведен пример использования вычисляемого метода. Сценарий в нем должен сформировать дружественное представление с группировкой, аналогичное представлению Outlook группировки по дате (group by date), как изображено на фиг.3.
В следующем коде this инкапсулируется в методе для возможности его многократного использования в другом месте:
public partial class Message:...
{
// В этом методе возвращаются служащие (employees) Организации (Organization)
// Работодатель (employer) в выражении ссылается на параметр метода employer
[Calculated(Expression= ®"
using System.Data.TSql.Date;
case
when datediff ('hour', this.ReceivedTime, date) < 0
then 'Future'
when datediff ('hour', this. ReceivedTime, date) < 24
then 'Today'
when datediff ('hour', this.ReceivedTime, date) between 24 and 48
then 'Yesterday'
when datediff ('hour', this.ReceivedTime, date) between 48 and (24*(datepart('weekday', date)))
then datename (weekday, this. ReceivedTime)
when datediff('hour', this.ReceivedTime, date) between
(24*(datepart('weekday',date))) and (24*(datepart('weekday', date))) + (7*24) then
'Last Week'
when datediff('hour', this. ReceivedTime, date) between
(24*(datepart('weekday',date)))+(7*24) and
(24 * (datepart ('будний день', дата))) + (14*24)
then 'Two Weeks Ago'
when datediff('hour', this.ReceivedTime, date) between
(24*(datepart('weekday', date)))+(14*24) and
(24*(datepart('weekday', date)))+(21*24)
then 'Three Weeks Ago'
when datediff('hour', this.ReceivedTime, date) between
(24*(datepart('weekday', date)))+(21*24) and
(24*(datepart('weekday',date)))+(84*24) and
datediff('month', this.ReceivedTime, date) < 2
then 'Last Month' else 'Older'
end as RelativeDate")]
public string GetReceivedTimeName (DateTime date)
{
// При реализации этого метода для совместимости необходимо сделать логику, аналогичную этому выражению
…
}
}
Далее это может использоваться для группировки результатов следующим образом:
// Создать запрос по сообщениям для группировки по имени (Name) ReceivedTime
Query<DataRecord> projection =
context.Items.Source.OfType<message>().Select("
it.Subject,it.GetReceivedTimeName(@date) as RelativeDate",new
QueryParameter("date",DateTime.Now)).GroupBy( "RelativeDate");
// Перечислить результаты
foreach (DataRecord record in projection)
{
…
}
4.3 Атрибуты Calculated & CacluatedParameter
System.Data.Objects.CalculatedAttribute определяется следующим образом:
namespace System.Data.Objects
{
[System.Attributeusage (AttributeTargets. Property |
AttributeTarge ts.Method)]
public class CalculatedAttribute: Attribute
{
public string Expression {get; set;}
public CalculatedAfctribute (string expression);
}
}
Этот атрибут определяет следующие свойства:
Expression (Выражение). Свойство Expression должно содержать допустимое выражение eSQL, которое проецирует значение. Это значение впоследствии может использоваться в другом выражении. Более подробную информацию относительно того, как определять именованные параметры в выражениях, см. ниже.
System.Data.Objects.CalculatedParameterAttribute
определяется следующим образом:
namespace System.Data.Objects
[AttrjbuteUsage(AttributeTargets.Property] AttributeTargets.Method,
AllowMultiple = true)]
public class CalculatedParameterAttribute: Attribute
{
public string Name {get; set;}
public object Value {get; set;}
public CalculatedParameterAttribute();
}
}
Этот атрибут определяет следующие свойства:
Name (Имя). Имя параметра, как на него ссылаются в свойстве Expression вычисляемого атрибута (Calculated Attribute).
Value (Значение). Значение параметра определяется свойством Name (имя).
Именованные параметры, определенные в CalculatedAttribute, следуют этим семантическим конструкциям:
Ссылки на вычисляемые параметры должен иметь префикс @
Порядок определения CalculatedParameterAttribute и CalculatedAttribute не имеет значения.
Имена параметров должны быть уникальными по всем именам параметров метода и другим именованным параметрам, определенным CalculatedParameterAttribute в методе.
Для вычисляемого свойства любые именованные параметры в выражении должны быть определены CalculatedParameterAttribute.
В следующем примере иллюстрируется использование вышеупомянутых классов атрибутов:
public partial class Parson:...
{
// @year в выражении ссылается на именованный параметр year, обеспеченный
// CalculatedParameterAttribute
[Calculated(Expression= @"
using System.Data.TSql.Date;
(@year - year(this.BirthDate)")]
[CalculatedParameter(Name="year", Value=System.DateTime.Year)]
public int GetRoughAge()
{…}
}
| название | год | авторы | номер документа |
|---|---|---|---|
| АРХИТЕКТУРА ОТОБРАЖЕНИЯ С ПОДДЕРЖАНИЕМ ИНКРЕМЕНТНОГО ПРЕДСТАВЛЕНИЯ | 2007 |
|
RU2441273C2 |
| СПОСОБЫ И СИСТЕМЫ ЗАГРУЗКИ ДАННЫХ В ХРАНИЛИЩА ВРЕМЕННЫХ ДАННЫХ | 2012 |
|
RU2599538C2 |
| МОДЕЛЬ ДАННЫХ ДЛЯ ОБЪЕКТНО-РЕЛЯЦИОННЫХ ДАННЫХ | 2006 |
|
RU2421798C2 |
| СИСТЕМЫ И СПОСОБЫ СОПРЯЖЕНИЯ ПРИКЛАДНЫХ ПРОГРАММ С ПЛАТФОРМОЙ ХРАНЕНИЯ НА ОСНОВЕ СТАТЕЙ | 2003 |
|
RU2412461C2 |
| СИСТЕМЫ И СПОСОБЫ МОДЕЛИРОВАНИЯ ДАННЫХ В ОСНОВАННОЙ НА ПРЕДМЕТАХ ПЛАТФОРМЕ ХРАНЕНИЯ | 2003 |
|
RU2371757C2 |
| СПОСОБ УПРАВЛЕНИЯ СИСТЕМОЙ РЕЛЯЦИОННОЙ БАЗЫ ДАННЫХ | 2005 |
|
RU2409848C2 |
| СПОСОБ УПРАВЛЕНИЯ РЕЛЯЦИОННОЙ СИСТЕМОЙ БАЗЫ ДАННЫХ | 2006 |
|
RU2419862C2 |
| ОБЪЕДИНЕНИЕ МНОГОМЕРНЫХ ВЫРАЖЕНИЙ И РАСШИРЕНИЙ ГЛУБИННОГО АНАЛИЗА ДАННЫХ ДЛЯ ИЗВЛЕЧЕНИЯ ИНФОРМАЦИИ ИЗ КУБОВ OLAP | 2005 |
|
RU2398273C2 |
| Способ параллельного выполнения операции JOIN при обработке больших структурированных высокоактивных данных | 2020 |
|
RU2755568C1 |
| Способ для разграничения доступа к данным в базе данных | 2018 |
|
RU2682010C1 |
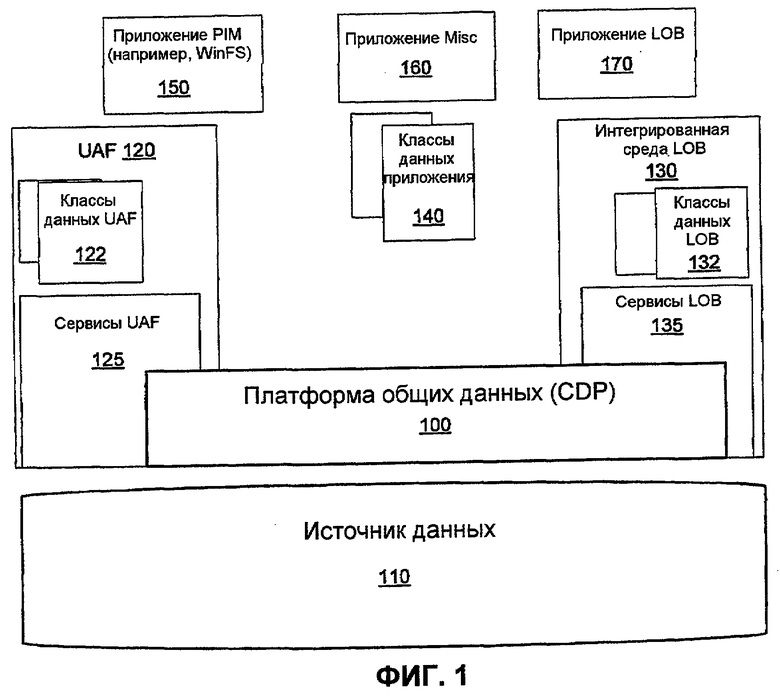

Изобретение относится к области запросов баз данных. Техническим результатом является расширение функциональных возможностей системы для обработки запроса приложения на данные за счет обеспечения языка запросов с поддержкой расширенных типов данных. Система для обработки запроса приложения на данные содержит: процессор; уровень сервисов объектов, который принимает запрос, причем этот запрос содержит выражение коллекции, содержащее, по меньшей мере, подзапросы таблицы и выражения в предложении from запроса базы данных, выраженного в любой одной из множества моделей данных приложений, и перехватывает семантику данных независимо от складов данных и звеньев развертывания для модели данных сущностей-объектов, содержащей коллекцию типов данных, относящихся к базам данных и не относящихся к базам данных; уровень сервисов объектов, который обобщает запросы для коллекций типов данных; уровень поставщика отображения, который обеспечивает множество отображающих трансформаций для трансформации запроса в каноническое дерево выражений; и связующий уровень, который преобразует каноническое дерево выражений в модифицированное дерево выражений и выполняет компенсацию модели данных. 4 н. и 17 з.п. ф-лы, 3 ил.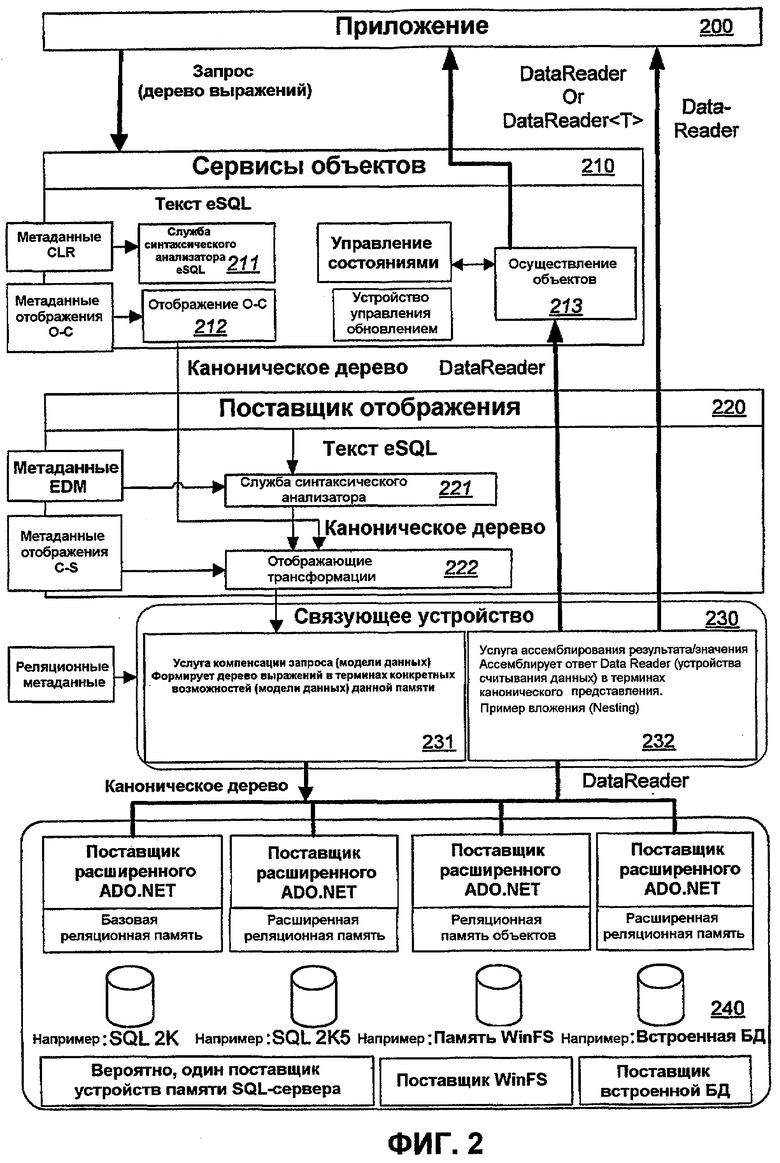
1. Система для обработки запроса приложения на данные, содержащая:
процессор;
уровень сервисов объектов, который принимает запрос, причем этот запрос содержит выражение коллекции, содержащее, по меньшей мере, подзапросы таблицы и выражения в предложении from запроса базы данных, выраженного в любой одной из множества моделей данных приложений, и перехватывает семантику данных независимо от складов данных и звеньев развертывания для модели данных сущностей-объектов, содержащей коллекцию типов данных, относящихся к базам данных и не относящихся к базам данных;
уровень сервисов объектов, который обобщает запросы для коллекций типов данных, относящихся к базам данных и не относящихся к базам данных, используя расширения, управляемые из метаданных, ассоциированных с каждым типом данных в коллекции, для создания единообразных выражений для каждого типа данных в коллекции;
уровень поставщика отображения, который обеспечивает множество отображающих трансформаций для трансформации запроса в каноническое дерево выражений, представляющее запрос базы данных, и отображения всех данных из модели данных сущностей-объектов, причем отображенная модель данных сущностей-объектов содержит выражение для каждого объекта-сущности в пределах коллекции типов данных, относящихся к базам данных и не относящихся к базам данных; и
связующий уровень, который преобразует каноническое дерево выражений в модифицированное дерево выражений и выполняет компенсацию модели данных, причем модифицированное дерево выражений адаптируется к по меньшей мере одному требованию первой базы данных или склада данных,
при этом связующий уровень сконфигурирован для преобразования дерева выражений в любую из множества функциональных возможностей модели данных, адаптированных к требованиям любой из множества баз данных, и сконфигурирован для возврата результата на связующий уровень.
2. Система по п.1, в которой запрос также содержит операцию над множествами, выбранную из группы, содержащей объединение, пересечение и исключение, причем эта операция над множествами оперирует коллекциями.
3. Система по п.1, в которой запрос также содержит операцию соединения, которая оперирует коллекциями.
4. Компьютерно-реализуемый способ обработки запроса приложения на данные, содержащий этапы, на которых:
принимают запрос посредством реализуемого процессором уровня сервисов объектов, причем этот запрос содержит операцию над множествами, выбранную из группы, содержащей объединение, пересечение и исключение, причем упомянутая операция над множествами оперирует коллекциями, содержащими, по меньшей мере, подзапросы таблицы и выражения в предложении from запроса базы данных для типов данных, относящихся к базам данных и не относящихся к базам данных, для создания единообразных выражений для каждого типа данных в коллекции;
обобщают запросы для коллекций типов данных, относящихся к базам данных и не относящихся к базам данных, используя расширения, управляемые из метаданных, ассоциированных с каждым типом данных в коллекции, для создания единообразных выражений для каждого типа данных в коллекции;
обеспечивают посредством уровня поставщика отображения множество отображающих трансформаций для трансформации запроса в каноническое дерево выражений, представляющее запрос базы данных, и отображения всех данных из модели данных сущностей-объектов, причем отображенная модель данных сущностей-объектов содержит выражение для каждого объекта-сущности в пределах коллекции типов данных, относящихся к базам данных и не относящихся к базам данных;
преобразуют посредством связующего уровня каноническое дерево выражений в модифицированное дерево выражений и выполняют компенсацию модели данных, причем модифицированное дерево выражений адаптируется к по меньшей мере одному требованию первой базы данных и любого из множества складов данных;
при этом связующий уровень сконфигурирован для преобразования дерева выражений в любую из множества функциональных возможностей модели данных, адаптированных к требованиям любой из множества баз данных или поставщиков хранилища, и сконфигурирован для возврата результата на связующий уровень.
5. Система по п.4, в которой запрос также содержит операцию соединения, которая оперирует коллекциями.
6. Машиночитаемый носитель, содержащий машиноисполняемые инструкции для обработки запроса приложения на данные, причем этими машиноисполняемыми инструкциями при их исполнении процессором реализуются действия, согласно которым:
принимают запрос на операцию соединения, которая оперирует коллекциями, содержащими, по меньшей мере, подзапросы таблицы и выражения в предложении from запроса базы данных, выраженного в любой одной из множества моделей данных приложений, и перехватывает семантику данных независимо от складов данных и звеньев развертывания для модели данных сущностей-объектов, содержащей коллекцию типов данных, относящихся к базам данных и не относящихся к базам данных;
обобщают запросы для коллекций типов данных, относящихся к базам данных и не относящихся к базам данных, используя расширения, управляемые из метаданных, ассоциированных с каждым типом данных в коллекции, для создания единообразных выражений для каждого типа данных в коллекции;
обеспечивают множество отображающих трансформаций для трансформации запроса в каноническое дерево выражений, представляющее запрос базы данных, и отображения всех данных из модели данных сущностей-объектов, причем отображенная модель данных сущностей-объектов содержит выражение для каждого объекта-сущности в пределах коллекции типов данных, относящихся к базам данных и не относящихся к базам данных; и
преобразуют посредством связующего уровня каноническое дерево выражений в модифицированное дерево выражений и выполняют компенсацию модели данных, причем модифицированное дерево выражений адаптируется к по меньшей мере одному требованию первой базы данных или любого из множества складов данных,
при этом связующий уровень сконфигурирован для преобразования дерева выражений в любую из множества функциональных возможностей модели данных, адаптированных к требованиям любой из множества баз данных, и сконфигурирован для возврата результата на связующий уровень.
7. Компьютерная система, содержащая приложение, сконфигурированное запрашивать данные из базы данных, причем это приложение формирует запрос согласно языку запросов, при этом данный язык запросов содержит, по меньшей мере, следующие характеристики:
упомянутый язык запросов обеспечивает возможность использовать выражение коллекции, содержащее, по меньшей мере, подзапросы таблицы и выражения в предложении from запроса базы данных, выраженного в любой одной из множества моделей данных приложений, и перехватывает семантику данных независимо от складов данных и звеньев развертывания для модели данных сущностей-объектов, содержащей коллекцию типов данных, относящихся к базам данных и не относящихся к базам данных;
упомянутый язык запросов обеспечивает возможность использовать уровень сервисов объектов для обобщения запросов для коллекций типов данных, относящихся к базам данных и не относящихся к базам данных, используя расширения, управляемые из метаданных, ассоциированных с каждым типом данных в коллекции, для создания единообразных выражений для каждого типа данных в коллекции;
упомянутый язык запросов инициирует уровень поставщика отображения, который обеспечивает множество отображающих трансформаций для трансформации выражения коллекции в каноническое дерево выражений, представляющее запрос базы данных;
упомянутый язык запросов обеспечивает возможность использования операции над множествами, выбранной из группы, содержащей объединение, пересечение и исключение, причем упомянутая операция над множествами оперирует коллекциями посредством предоставления синтаксического оператора для обеспечения возможности проецирования выражения из коллекции, содержащей, по меньшей мере, подзапросы таблицы и выражения в предложении from запроса базы данных, для типов данных, относящихся к базам данных и не относящихся к базам данных, для создания единообразных выражений для каждого типа данных в коллекции;
упомянутый язык запросов обеспечивает возможность использования операции соединения, которая оперирует коллекциями, и отображение всех данных из модели данных сущностей-объектов, причем отображенная модель данных сущностей-объектов содержит выражение для каждого объекта-сущности в пределах коллекции типов данных, относящихся к базам данных и не относящихся к базам данных.
8. Компьютерная система по п.7, в которой упомянутый язык запросов также требует, чтобы каждый запрос содержал по меньшей мере одно выражение.
9. Компьютерная система по п.8, в которой каждое выражение имеет однообразную интерпретацию, которая не зависит от контекста, в котором оно используется.
10. Компьютерная система по п.7, в которой упомянутый язык запросов также обеспечивает возможность использования следующих выражений:
1+2*3
"abc"
row(1 as a, 2 as b)
{1,3,5}
el union all e2
distinct(el)
11. Компьютерная система по п.7, в которой упомянутый язык запросов рассматривает все подзапросы как подзапросы мультимножества.
12. Компьютерная система по п.7, в которой если из подзапроса требуется скалярное значение, то упомянутый язык запросов требует, чтобы упомянутое приложение обеспечило оператор element (элемент), который оперирует коллекцией.
13. Компьютерная система по п.7, в которой упомянутый язык запросов также обеспечивает возможность использования оператора element (элемент) для извлечения значения одного элемента из коллекции и предложения select value (выбрать значение) для избежания создания упаковщика строк на протяжении выражения запроса.
14. Компьютерная система по п.7, в которой упомянутый язык запросов также обеспечивает возможность использования предложения select value для пропуска неявного создания строки.
15. Компьютерная система по п.7, в которой упомянутый язык запросов также обеспечивает возможность использования конструктора строки для создания произвольных строк так, чтобы утверждение select value row (e1, е2, …) было точным эквивалентом утверждения select e1, e2, …
16. Компьютерная система по п.7, в которой упомянутый язык запросов также обеспечивает возможность использования выражения запроса, которое обобщает корреляции слева в предложении from и обрабатывает их единообразно.
17. Компьютерная система по п.7, в которой упомянутый язык запросов требует, чтобы все ссылки на столбцы были уточнены псевдонимом таблицы.
18. Компьютерная система по п.7, в которой упомянутый язык запросов также обеспечивает возможность использования синтаксического сокращения для обработки навигации по коллекции, причем это сокращение использует оператор., для обеспечения возможности проекции выражения из коллекции так, чтобы "а..b" было эквивалентом "select value t.b from a as t" (выбрать значение t.b из а в качестве t).
19. Компьютерная система по п.7, в которой упомянутый язык запросов также обеспечивает возможность использования совмещения имен ключей group-by и корреляции слева среди таких ключей.
20. Компьютерная система по п.7, в которой упомянутый язык запросов также обеспечивает возможность использования двух видов агрегатов: агрегата на основе коллекции, который оперирует коллекциями и формирует агрегированный результат, и агрегата в стиле языка структурированных запросов (SQL), причем упомянутый механизм неявно преобразует агрегаты в стиле SQL в агрегаты на основе коллекции.
21. Компьютерная система по п.7, в которой упомянутый язык запросов также обеспечивает возможность использования утверждения INSERT..VALUES и упомянутое утверждение не обеспечивает возможность указания списка столбцов в упомянутом утверждении INSERT..VALUES.
| US 6578046 В2, 10.06.2003 | |||
| US 6792420 В2, 14.09.2004 | |||
| Способ обработки целлюлозных материалов, с целью тонкого измельчения или переведения в коллоидальный раствор | 1923 |
|
SU2005A1 |
| АППАРАТ ДЛЯ ИЗВЛЕЧЕНИЯ ЭФИРНЫХ МАСЕЛ ИЗ ДЕСТИЛЛЯЦИОННЫХ ВОД | 1933 |
|
SU36541A1 |

