ОБЛАСТЬ ТЕХНИКИ
[001] Настоящее изобретение в общем относится к компьютерным системам, а более конкретно - к системам и способам обнаружения полей в документе.
УРОВЕНЬ ТЕХНИКИ
[002] На изображении может быть изображен документ или его часть. Документ может состоять из различных типов элементов, включая поля. На механизм обработки изображений может быть возложена задача обнаружения полей на изображении документа.
РАСКРЫТИЕ ИЗОБРЕТЕНИЯ
[003] В соответствии с одним или несколькими вариантами реализации настоящего изобретения способ, описанный в примере, может включать в себя: получение набора данных для обучения, содержащего несколько изображений документа, причем каждое из нескольких изображений документа сопоставляется с соответствующими метаданными, определяющими поле документа, содержащее переменный текст; формирование путем обработки нескольких изображений документа первой тепловой карты, представленной структурой данных, содержащей несколько элементов тепловой карты, соответствующих нескольким пикселям изображения документа, причем в каждом элементе тепловой карты хранится счетчик некоторого количества изображений документа, в котором поле документа содержит пиксель изображения документа, связанный с элементом тепловой карты; получение изображения входного документа; и определение в пределах изображения входного документа области-кандидата, содержащей поле документа, причем область-кандидат содержит несколько пикселей изображения входного документа, соответствующих элементам тепловой карты, удовлетворяющим пороговому условию.
[004] В соответствии с одним или несколькими вариантами реализации настоящего изобретения система, описанная в примере, может включать в себя: запоминающее устройство для хранения инструкций; устройство обработки, соединенное с запоминающим устройством, причем устройство обработки предназначено для выполнения инструкций для: получения набора данных для обучения, содержащего несколько изображений документа, причем каждое из нескольких изображений документа сопоставляется с соответствующими метаданными, определяющими поле документа, содержащее переменный текст; формирования путем обработки нескольких изображений документа первой тепловой карты, представленной структурой данных, содержащей несколько элементов тепловой карты, соответствующих нескольким пикселям изображения документа, причем в каждом элементе тепловой карты хранится счетчик некоторого количества изображений документа, в котором поле документа содержит пиксель изображения документа, связанный с элементом тепловой карты; получения изображения входного документа; и определения в пределах изображения входного документа области-кандидата, содержащей поле документа, причем область-кандидат содержит несколько пикселей изображения входного документа, соответствующих элементам тепловой карты, удовлетворяющим пороговому условию.
[005] В соответствии с одним или несколькими вариантами реализации настоящего изобретения энергонезависимый машиночитаемый носитель, описанный в примере, может содержать инструкции, при выполнении которых устройством обработки данных устройство обработки данных: получает набор данных для обучения, содержащий несколько изображений документа, причем каждое из нескольких изображений документа сопоставляется с соответствующими метаданными, определяющими поле документа, содержащее переменный текст; формирует путем обработки нескольких изображений документа первую тепловую карту, представленную структурой данных, содержащей несколько элементов тепловой карты, соответствующих нескольким пикселям изображения документа, причем в каждом элементе тепловой карты хранится счетчик некоторого количества изображений документа, в котором поле документа содержит пиксель изображения документа, связанный с элементом тепловой карты; получает изображение входного документа; определяет внутри изображения входного документа область-кандидат, содержащую поле документа, причем область-кандидат содержит несколько пикселей изображения входного документа, соответствующих элементам тепловой карты, удовлетворяющим пороговому условию.
[006] В соответствии с одним или несколькими вариантами реализации настоящего изобретения способ, описанный в примере, может включать в себя: получение набора данных для обучения, содержащего несколько документов, причем каждый из нескольких документов соотносится с несколькими размеченными пользователем полями; для данного поля из нескольких размеченных пользователем полей в данном документе из нескольких документов, установление того, повторяется ли в одном или нескольких дополнительных документах существующая в данном документе конкретная комбинация относительных положений одного или нескольких дополнительных размеченных пользователем полей относительно данного поля; указание неправильности выделения данного поля, если установлено, что конкретная комбинация не повторяется в любых дополнительных документах; установление наличия в двух или более других документах другой комбинации относительных положений дополнительных одного или нескольких полей, размеченных пользователем, относительно данного поля, если установлено, что конкретная комбинация повторяется в одном или нескольких дополнительных документах, причем указание данного поля как размеченного правильно, если установлено, что другая комбинация не существует в двух или более других документах; и указание данного поля как размеченного непоследовательно, если установлено, что данная комбинация существует в двух или более других документах.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[007] Настоящее изобретение иллюстрируется на примере, без каких бы то ни было ограничений; его сущность становится понятной при рассмотрении приведенного ниже подробного описания изобретения в сочетании с чертежами, на которых:
[008] На Фиг. 1 изображена высокоуровневая компонентная диаграмма иллюстративной системной архитектуры, соответствующая одному или нескольким вариантам реализации настоящего изобретения.
[009] На Фиг. 2 показана блок-схема высокого уровня примерного способа обнаружения полей в документе, соответствующая одному или нескольким вариантам реализации настоящего изобретения.
[0010] На Фиг. 3 показана блок-схема различных компонент примерной системы обнаружения полей в документе, соответствующая одному или нескольким вариантам реализации настоящего изобретения.
[0011] На Фиг. 4А-4В показаны примеры тепловых карт, использованных при выполнении обнаружения полей в документе, соответствующие одному или нескольким вариантам реализации настоящего изобретения.
[0012] На Фиг. 5 показан иллюстративный пример оценки внутреннего формата поля, соответствующий одному или нескольким вариантам реализации настоящего изобретения.
[0013] На Фиг. 6 показан иллюстративный пример документов с обнаруженными полями, соответствующий одному или нескольким вариантам реализации настоящего изобретения.
[0014] На Фиг. 7 показана блок-схема примерного способа обнаружения полей в документе, соответствующая одному или нескольким вариантам реализации настоящего изобретения.
[0015] На Фиг. 8 изображена примерная компьютерная система, которая может выполнять любой из описанных в настоящей заявке способов, соответствующих одному или нескольким вариантам реализации настоящего изобретения.
ОПИСАНИЕ ИЗОБРЕТЕНИЯ
[0016] Описываются варианты применения для обнаружения поля документа. «Поле» относится к участку внутри документа (например, прямоугольный участок), таким образом, что этот участок обозначается как местоуказатель, куда могут быть внесены переменные данные, создавая тем самым новый экземпляр типа документа (например, счет-фактура, поручение и т.д.). Поля, как правило, встречаются в документах-формах. В документе могут быть различные поля, такие как текстовые поля (содержащие цифры, числа, буквы, слова, предложения), графические поля (содержащие логотип или любое другое изображение), таблицы (содержащие строки, столбцы, ячейки) и так далее.
[0017] В настоящей заявке «электронный документ» (также называемый просто «документом» в настоящей заявке) может означать любой документ, изображение которого может быть доступно для вычислительной системы. Изображением может быть отсканированное изображение, сфотографированное изображение или любое другое отображение документа, которое может быть преобразовано в форму данных, доступную для компьютера. Например, «электронный документ» может относиться к файлу, содержащему один или несколько элементов цифрового содержимого, которые могут быть визуально отображены для обеспечения визуального представления электронного документа (например, на дисплее или в печатном виде). В соответствии с различными вариантами применения настоящего изобретения документ может соответствовать любому подходящему электронному формату файла, такому как PDF, DOC, ODT, JPEG и др.
[0018] «Документ» может представлять собой финансовый, юридический или любой другой документ, например, документ, созданный путем заполнения полей алфавитно-цифровыми символами (например буквами, словами, цифрами) или изображениями. «Документ» может представлять собой документ, который распечатан, набран или написан от руки (например путем заполнения стандартной формы). «Документ» может представлять собой документ-форму, который имеет различные поля, такие как текстовые поля (содержащие цифры, числа, буквы, слова, предложения), графическое поле (содержащее логотип или любое другое изображение), таблицы (имеющие строки, столбцы, ячейки) и так далее. Примеры различных типов документов, которые имеют поля, включают в себя договоры, счета-фактуры, финансовые документы, визитные карточки, удостоверения личности, заявки на кредиты, приказы/выписки, бухгалтерские документы, отчетные документы, отчеты о патентном поиске, различные бланки компании и т.д.
[0019] Поля можно найти в различных видах документов, таких как счета-фактуры, финансовые документы, визитные карточки, удостоверения личности, заявления на получение кредита и т.д. Оптическое распознавание символов (OCR) такого документа может включать в себя предварительный этап определения всех полей, содержащихся в документе, который может быть выполнен нейронными сетями, прошедшими обучение на большом числе (например тысячах) образцов документов, включающих в себя поля. Однако такой подход не обеспечивает обнаружения полей с достаточной точностью для различных типов документов, использующих универсальные образцы документов, поскольку документы могут существенно отличаться друг от друга. Таким образом, для обучения нейронных сетей может потребоваться большое количество документов каждого типа. Такие способы обнаружения полей требуют длительной и обширной подготовки с большим количеством операций, выполняемых вручную, не обладают гибкостью и потенциально могут приводить к разглашению конфиденциальных данных. Более того, эти способы также требуют точной разметки каждого документа. Однако, когда для разметки документов используются операции, выполняемые вручную, пользователи часто пропускают или неправильно размечают поля, что делает документы непригодными для использования в качестве обучающих образцов. Кроме того, чтобы устранить последствия такой неправильной разметки, пользователю может потребоваться повторить разметку или разметить дополнительные документы того же типа, чтобы начать обучение заново. В некоторых случаях пользователь также не может выполнить разметку правильно, так как он может не знать, где находится конкретное поле в документе, или поле не определяется описательным словом. Например, пользователь может иметь намерение разметить поле «total», которое, как ожидается, будет заполнено числом. Однако если поле не определяется словом «total», или пользователь не может найти слово «total», или в силу других причин, пользователь может вместо этого разметить другое поле, содержащее символы, визуально сходные с ожидаемым содержимым поля «total», например, другое поле, содержащее цифры.
[0020] Варианты реализации настоящего изобретения устраняют вышеупомянутые и другие недостатки, обеспечивая механизмы обнаружения полей в документе без необходимости разметки большого количества документов вручную для обучения нейронной сети. Механизмы могут обеспечить быстрое обучение обучаемой модели на небольшом наборе данных, например, наборе данных, включающем не более десяти документов конкретного типа с размеченными полями. После обучения модели для конкретного класса документов она используется для обнаружения полей в других пользовательских документах того же класса.
[0021] В одном из вариантов применения варианты реализации настоящего изобретения обеспечивают обучение нейронной сети с использованием небольшого количества размеченных документов, которые будут использоваться в качестве обучающих документов. Эти документы могут содержать метаданные, определяющие одно или несколько полей документа на основе пользовательской разметки, указывающей на расположение соответствующих полей документа. Обнаружение полей основано на определении пространственного распределения полей по отношению к визуальным опорным элементам в обучающих документах. После получения изображений документов получается текст из изображений документов, а также различные знаки, в том числе слова, из текста в изображениях документов. Опорные элементы на изображении документа могут быть использованы для определения расположения размеченных полей. Любой структурный элемент, относящийся к макету документа, может быть использован в качестве опорного. Опорный элемент может включать в себя предопределенные визуальные элементы, такие как предопределенное слово (например, ключевые слова, слова пользовательского словаря), предопределенный графический элемент (например, визуальный разделитель, логотип) и т.д. на изображениях документа. Опорные элементы на изображениях документа могут быть определены путем сопоставления слов из пользовательского словаря и (или) слов, которые появляются на данном документе (или в корпусе документов) с частотой, превышающей предопределенную пороговую частоту. Например, счет-фактура может содержать название компании, итоги, сроки оплаты и т.д. в качестве опорных элементов в зависимости от частоты, с которой эти ключевые слова могут появляться в документах данного типа. Расположение различных полей документа может быть определено относительно опорного элемента.
[0022] Для каждого поля в наборе данных для обучения может быть сформирована тепловая карта по каждому опорному элементу. «Тепловая карта» представляет собой набор числовых элементов, составленных таким образом, чтобы значение каждого элемента определялось конкретной функцией, вычисляемой по координатам изображения, отражающим положение элемента. В некоторых вариантах применения тепловая карта может быть представлена прямоугольной матрицей, каждый элемент которой соответствует конкретному пикселю поблизости от опорного элемента таким образом, что значение, связанное с каждым пикселем, отражает количество обучающих документов, в которых данное поле содержит этот пиксель. Числовые значения элементов тепловой карты могут быть кодированы цветом для визуализации (отсюда и пошло название термина), однако этот шаг был бы излишним для обучения нейронных сетей, в которых используются не цвета, а числовые значения.
[0023] Соответственно, на обучающем этапе могут быть сформированы тепловые карты относительно небольшого набора обучающих документов, которые сопровождаются метаданными («разметкой») с указанием положений и названий полей документа. Затем сформированные тепловые карты можно будет использовать для определения положений полей в других документах. В некоторых вариантах применения система, работающая в соответствии с вариантами реализации настоящего изобретения, может определить в изображении входного документа область-кандидат на каждое интересующее поле на основе тепловых карт, построенных для этого поля в отношении одного или нескольких опорных элементов. Каждая определенная область-кандидат будет включать в себя пиксели изображения входного документа, соответствующие элементам тепловой карты, удовлетворяющим пороговому условию (например когда их соответствующие значения превышают пороговое значение, когда выбрана заранее определенная доля пикселей, имеющих наибольшие значения, и т.д.).
[0024] Выбранные области-кандидаты могут затем рассматриваться как положения соответствующих полей, например, путем применения технологий оптического распознавания символов (OCR) к фрагментам снимков, лежащим внутри областей-кандидатов. В некоторых вариантах применения извлеченное содержимое каждого поля документа можно оценивать с помощью ВРЕ (Byte Pair Encoding, кодирование пар байтов) токенов, оценивая различия (например евклидовы расстояния) между ВРЕ токеном, представляющим извлеченное содержимое данного поля входного документа, и ВРЕ токенами, вычисленными для этого же поля в обучающих документах, ВРЕ токен относится к числовому вектору, представляющему входной текст. В некоторых вариантах применения вектор может быть представлен в виде эмбеддинга промежуточного представления входного текста так, что в промежуточном представлении может использоваться искусственный алфавит, каждый символ которого может кодировать подстроку из одного или нескольких символов входного текста, как более подробно описано ниже. Встраиваемые данные формируются таким образом, что семантически близкие входные данные будут выдавать численно близкие встраиваемые данные.
[0025] Соответственно, если вычисленное расстояние между ВРЕ токеном, представляющим содержимое, извлеченное из поля-кандидата, и ВРЕ токеном(и), представляющими одно и то же поле в наборе данных для обучения, меньше порогового значения, то вероятность того, что это поле будет обнаружено правильно, относительно велика, и поле кандидата может быть принято для извлечения информации. Описанные в настоящей заявке технологии позволяют автоматически обнаруживать поле в документах с помощью искусственного интеллекта. Описанные в настоящей заявке системы и способы представляют собой значительные улучшения в обеспечении более точного и эффективного обнаружения полей в документах. В способах применяются обучаемые модели, которые могут быть обучены на небольшом количестве (например, менее десяти) образцов документов обнаруживать и классифицировать поля, обеспечивая при этом высокое качество. Эти способы позволяют ускорить и повысить качество проверки данных. Кроме того, способы могут также служить руководством для пользователей, если пользователь мог неточно разметить поле или забыть его разметить. Способы позволяют выявить ошибочную разметку документа, выполненную пользователем, а также эффективно исправить и восстановить отсутствующую разметку полей. Кроме того, данные способы позволяют выбрать подмножество размеченных документов, содержащих полную и последовательную разметку, что, в свою очередь, может позволить обучить дополнительные, более точные модели.
[0026] Различные варианты реализации вышеупомянутых способов и систем подробно описаны ниже в виде примеров, а не ограничений.
[0027] На Фиг. 1 изображена высокоуровневая компонентная диаграмма иллюстративной системной архитектуры 100, соответствующая одному или нескольким вариантам реализации настоящего изобретения. Системная архитектура 100 включает в себя вычислительное устройство 120, хранилище 160 и сервер 150, подключенный к сети 130. Сеть 130 может быть общедоступной сетью (например, интернет), частной сетью (например локальная вычислительная сеть (LAN) или глобальная вычислительная сеть (WAN)), или их комбинацией.
[0028] Вычислительное устройство 120 может выполнять обнаружение полей на изображении документа. В одном из вариантов применения вычислительное устройство 120 может представлять собой настольный компьютер, ноутбук, смартфон, планшетный компьютер, сервер, сканер или любое подходящее вычислительное устройство, способное реализовать описанные в настоящей заявке технологии. Вычислительное устройство 120 может получать одно или несколько изображений. Например, изображение 110 может быть получено вычислительным устройством 120. Изображение 110 может включать в себя изображение документа, страницы документа или части страницы документа. Страница документа или часть страницы документа, представленная на изображении 110, может включать в себя одно или несколько полей с переменным текстом. В примере может потребоваться обнаружение различных полей документа внутри документа. Изображение 110 может быть предоставлено в качестве входного для вычислительного устройства 120.
[0029] В одном из вариантов применения вычислительное устройство 120 может включать в себя детектор 122 полей. Детектор 122 полей может включать в себя инструкции, хранящиеся на одном или нескольких материальных машиночитаемых носителях информации вычислительного устройства 120 и исполняемые одним или несколькими устройствами обработки вычислительного устройства 120. В одном из вариантов применения детектор 122 полей может формировать в качестве выходных данных некоторое количество обнаруженных полей, содержимое, извлеченное из обнаруженных полей, и (или) выходной документ с некоторым количеством обнаруженных полей и содержимым, соответствующим обнаруженным полям. В одном из вариантов применения детектор 122 полей может использовать обученную модель 140 машинного обучения, которая обучена обнаружению полей в изображении 110. Модель 140 машинного обучения можно обучать с помощью обучающего набора изображений. В некоторых случаях модель 140 машинного обучения может быть частью детектора 122 полей или же доступ к ней можно получить на другой машине (например, на сервере 150) посредством детектора 122 полей. На основе выходных данных (например, тепловых карт, соответствующих пикселям изображения) обученной модели 140 машинного обучения, детектор 122 полей может определить на входном изображении 110 область-кандидат, которая обнаруживается как конкретное поле. Детектор 122 полей может также извлекать слова, относящиеся к обнаруженному полю.
[0030] Сервер 150 может представлять собой сервер, установленный в стойку, может быть компьютером-маршрутизатором, персональным компьютером, карманным персональным компьютером, мобильным телефоном, ноутбуком, планшетным компьютером, фотоаппаратом, видеокамерой, нетбуком, настольным компьютером, медиацентром или любой комбинацией вышеперечисленного. Сервер 150 может включать в себя устройство 151 обучения обнаружению полей. Модель 140 машинного обучения может обозначать образцы модели, созданные устройством 151 обучения обнаружению полей с использованием обучающих данных, которые включают в себя обучающие входные данные и соответствующие заданные выходные данные (правильные ответы на соответствующие обучающие входные данные). Во время обучения можно найти закономерности в обучающих данных, которые привязывают обучающие входные данные к заданному выходному результату (ответ, который необходимо предсказать), и впоследствии используются моделью 140 машинного обучения для будущих предсказаний. Как более подробно описано ниже, модель 140 машинного обучения может состоять, например, из одного уровня линейных или нелинейных операций (например, метод опорных векторов Support Vector Machine [SVM]) или может быть глубокой сетью, т.е. модель машинного обучения, состоящая из нескольких уровней нелинейных операций). Примерами глубоких сетей являются нейронные сети, включая сверточные нейронные сети, рекуррентные нейронные сети с одним или несколькими скрытыми слоями, а также полностью связанные нейронные сети.
[0031] Модель 140 машинного обучения может быть обучена устанавливать вероятность принадлежности пикселей изображений к определенному полю документа, как будет описано ниже. После обучения модели 140 машинного обучения ее можно подключить к детектору 122 полей для анализа изображения 110. Например, детектор 122 полей может запросить тепловые карты для некоторого количества ключевых слов на изображении 110. В некоторых примерах модель 140 может состоять из сверточной нейронной сети. Детектор 122 полей может получить один или несколько выходных результатов от обученной модели 140 машинного обучения. Выходной результат может представлять собой набор гипотез о расположении полей документа на основе тепловых карт.
[0032] Хранилище 160 может представлять собой постоянное хранилище, способное хранить изображение 110, тепловые карты, опорные элементы и точки, гипотезы о полях документа, обнаруженные поля и выходные изображения, а также структуры данных для присвоения меток, организации и индексации изображения 110. Хранилище 160 может размещаться на одном или нескольких устройствах хранения, таких как основная память, магнитные или оптические диски, ленты или жесткие диски, NAS, SAN и так далее. Несмотря на то, что хранилище 160 изображено отдельно от вычислительного устройства 120, в одном варианте применения хранилище 160 может быть частью вычислительного устройства 120. В некоторых вариантах применения хранилище 160 может быть сетевым файловым сервером, в то время как в других вариантах применения хранилище 160 может быть другим типом постоянного хранилища, таким как объектно-ориентированная база данных, реляционная база данных и т.д., которое может быть размещено на сервере или на одной или нескольких различных машинах, соединенных по сети 130 или подключенных к ней.
[0033] На Фиг. 2 показана блок-схема высокого уровня примерного способа 200 обнаружения полей в документе, соответствующая одному или нескольким вариантам реализации настоящего изобретения. С высокого уровня работа системы может быть логически разделена на 2 этапа. Первый этап - этап 220 обучения, второй этап - этап 230 обнаружения поля входного документа. Этап 220 обучения может принимать в качестве входных данных различные документы 210, содержащие различные поля. На примере Фиг. 2 документы 210 включают в себя шаблон 212 банковского счета, сберегательный вклад 214, квитанцию 216, счет-фактуру 218 и др. В каждом из документов 210 содержится несколько полей. Например, шаблон 212 банковского счета включает в себя поля в виде таблицы 212а с двумя столбцами и несколькими строками, счет 218 включает в себя графическое поле с логотипом 218а, текстовое поле с цифрами 218b и др. При получении документов 210 на этапе 220 обучения каждый тип документов обрабатывается, чтобы система могла обучаться по разметке полей в этих документах. Одна или несколько моделей могут быть получены на этапе 220 обучения для обнаружения полей в документах. На этапе 230 обнаружения полей входного документа система обрабатывает входной документ с целью выявления структуры входного документа, обнаружения поля (полей) внутри входного документа на основе моделей, полученных на этапе 220 обучения, и извлекает поля с его содержимым.
[0034] На Фиг. 3 показана блок-схема различных компонент примерной системы 300 обнаружения полей в документе, соответствующая одному или нескольким вариантам реализации настоящего изобретения. В некоторых вариантах применения пользователь, например, человек-пользователь или пользователь-компьютерная система, может определить небольшое количество документов, содержащих одно или несколько полей. Пользователь может определить каждый тип документа, в котором выполняется обнаружение поля с помощью системы 300. В одном варианте применения пользователь может разметить поля в определенных документах. Для разметки поля пользователь может рисовать линии, круги, рамки, прямоугольники или другие фигуры, выделять или иным образом создавать разметку на части документа или вокруг нее, чтобы обозначить участок как определенное поле. Пользователь может разметить несколько полей, на которых нужно провести обучение для их обнаружения по каждому документу, например, поля «Total» и «Адрес». Кроме того, пользовательская разметка может включать в себя также определение размеченных полей (например, «Дата», «Total» и т.д.). «Небольшое количество» в том виде, в каком оно используется в настоящей заявке, может представлять собой, например, 3-5 документов. В примере пользователем размечено не более десяти документов определенного типа. Пользователь может разметить все поля в документе или разметить выборочные поля на документе. Каждое поле определяется и размечается независимо от других полей документа.
[0035] В некоторых вариантах применения пользователь может затем загрузить определенные документы в систему 300 в виде электронных документов. Электронными документами могут быть отсканированные изображения, сфотографированные изображения или любое другое отображение документа, которое может быть преобразовано в форму данных, доступную для компьютера. Загруженные документы в настоящей заявке называются изображениями 310 документов. В одном варианте применения пользователь может загружать документы, которые уже содержат размеченные поля. В другом варианте применения пользователь может осуществлять электронную разметку изображений 310 документов с помощью пользовательского интерфейса системы 300. Например, используя интерфейс пользователя, пользователь может указать (например, щелчком мыши, перетаскиванием, другими жестами и т.п.) на часть документа, содержащую требуемое слово, числа и т.д., и в дальнейшем система может автоматически разметить окружающие границы поля. В некоторых вариантах применения полученные документы могут быть автоматически сгруппированы в различные предварительные кластеры таким образом, чтобы в каждом кластере были похожие документы, что, в свою очередь, может помочь пользователю правильно разметить поля. Система 300 связывает каждое изображение документа из изображений 310 документа с метаданными, определяющими конкретное поле документа по разметке на изображении документа. В некоторых примерах метаданные определяют поле документа, содержащее текст переменной. В некоторых вариантах применения система 300 относит каждое изображение 310 документа к конкретному классу документа с помощью блока 320 классификации документов. Например, изображения документа могут быть отнесены к конкретному классу на основании сходства характеристик документов. В одном из примеров изображения документа могут быть классифицированы на основании имени продавца, связанного с документом. Для каждого класса в системе 300 собирается небольшая подборка изображений документа (например 2-6 изображений документа).
[0036] В некоторых вариантах применения подблок 330 выбора слов системы 300 представляет собой подмодуль, использующий эвристический алгоритм для анализа текста документа. Текст может быть проанализирован по выбранным словам в макете документа на основе типов символов, таких как буквы, цифры, разделители и т.д. Эвристика может включать в себя решение задач экспериментальным методом и (или) методом проб и ошибок. Типичный эвристический алгоритм выводится с помощью некоторой функции, которая включается в систему для поиска решения, часто с использованием деревьев решений. Алгоритм может включать в себя шаги по настройке весов ветвей дерева решений в зависимости от вероятности того, что ветвь приведет к узлу конечной цели. Здесь эвристика может быть использована для разделения строк текста на группы одного типа символов. Например, каскадная классификация текстовых фрагментов в документе может быть представлена с помощью графа. Текстовые фрагменты являются узлами графа. Узлы графа соединяются ребрами (логические связи между текстовыми фрагментами). Граф может быть проанализирован и модифицирован для дальнейшей разбивки текстовых фрагментов, которые были изначально определены в каждом узле. Например, фрагмент текста, содержащий как буквы, так и цифры, можно разделить на два новых узла, чтобы отделить буквы от цифр. В одном варианте применения блок 330 получает текст из изображения 310 документа и разделяет текст документа на непрерывную подпоследовательность символов. Подпоследовательности символов могут относиться к одному и тому же типу символов. Например, типы символов могут включать в себя буквы, цифры и разделители. В подблоке 330 можно разделить текст на отдельные слова. В подблоке 330 можно получить все возможные слова в изображении 310 документа.
[0037] В некоторых вариантах применения система 300 использует блок 340 классификации компонент полей для классификации каждого слова в изображении 310 документа в зависимости от вероятности включения этого слова в конкретное поле. В некоторых вариантах применения опорные элементы на изображении документа используются для определения расположения поля документа. Любой структурный элемент, относящийся к макету документа, может быть использован в качестве опорного. Опорный элемент может включать в себя предопределенное слово (например, ключевое слово), предопределенный графический элемент (например визуальный разделитель, логотип) и т.д. В некоторых вариантах применения набор опорных элементов может быть получен с помощью обучающей выборки изображений документа. В некоторых примерах на основе обучающих документов может быть сформирован специальный словарь «часто встречающихся слов». Часто встречающиеся слова - это список слов, сгруппированных по частоте возникновения в составе корпуса документов (например, обучающие образцы документов). Например, часто встречающиеся слова могут быть сгруппированы в виде рейтингового списка. В некоторых примерах опорные элементы на изображениях документа могут быть определены путем сопоставления часто встречающихся слов, появляющихся на одном или нескольких изображениях документа, с частотой, превышающей предопределенную пороговую частоту. В некоторых примерах опорные элементы могут быть определены по пользовательским словарям слов, различным разделителям словесных символов, штампам и другим предопределенным текстовым и (или) визуальным элементам на изображении документа.
[0038] Опорный элемент может действовать как точка фокусировки, по отношению к которой определяется расположение поля документа. Например, центр прямоугольного участка, охватывающего часто встречающееся слово на изображении документа, может быть определен как расположение опорного элемента на этом изображении документа. В других примерах любое другое место, соответствующее опорному элементу, может быть обозначено как место расположения опорного элемента. На примере Фиг. 2 в качестве расположения опорного элемента «totaltotal» можно использовать расположение (например центр) прямоугольного участка 218с, окружающего слово «totaltotal» в документе 218.
[0039] В некоторых вариантах применения расположение поля документа (также называемого здесь «областью поля») может определяться по отношению к опорному элементу. На примере Фиг. 2 расположение поля документа (например расположение номеров 218b), соответствующего опорному элементу «total», может определяться по отношению к расположению опорного элемента «totaltotal» в документе. Для каждого изображения документа в обучающем наборе изображений документа (например изображения 310 документа) расположение поля документа можно получить на основе разметки изображения документа обучающего образца. В одном варианте применения система 300 связывает метаданные с конкретным полем документа на основе разметки пользователя на документе. Метаданные могут определять расположение поля документа относительно опорного элемента. Например, метаданные для конкретного размеченного изображения документа могут указывать на то, что расположение поля документа находится на 50 пикселей вправо от расположения опорного элемента на изображении документа. Расположение поля документа может быть выражено в виде диапазона расположений, количества пикселей и т.д. Расположение поля документа может включать в себя область на изображении документа. Областью может являться участок внутри изображения документа. У области может быть конкретная геометрическая форма, в том числе, например, в виде прямоугольника, четырехугольника, эллипса, круга, иного многоугольника и т.п. Расположение поля документа может относиться к области на изображении документа, содержащегося в поле документа.
[0040] В некоторых вариантах применения для установления вероятности включения слова на изображении документа в конкретное поле используется тепловая карта. Для каждого заданного поля в наборе данных для обучения может быть сформирована тепловая карта по каждому опорному элементу. «Тепловая карта» представляет собой набор числовых элементов, составленных таким образом, чтобы значение каждого элемента определялось конкретной функцией, вычисляемой по координатам изображения, отражающим положение элемента. В некоторых вариантах применения тепловая карта может быть представлена прямоугольной матрицей в виде таблицы, сетки и т.д. Каждый элемент тепловой карты соответствует конкретному пикселю поблизости от опорного элемента таким образом, что значение, связанное с каждым пикселем, отражает количество обучающих документов, в которых данное поле содержит этот пиксель. Тепловая карта может быть представлена с использованием различных структур данных. Например, тепловая карта может быть представлена с использованием гистограмм, диаграмм, таблиц с ячейками, графов, чертежей и т.д. Тепловая карта - это технология визуализации данных, которая показывает величину явления с использованием цвета в двух измерениях. Числовые значения элементов тепловой карты могут быть кодированы цветом для визуализации (отсюда и пошло название термина), однако этот шаг был бы излишним для обучения нейронных сетей, в которых используются не цвета, а числовые значения.
[0041] В некоторых вариантах применения тепловая карта может быть сформирована для каждого опорного элемента в наборе изображений 310 обучающего документа. Тепловая карта формируется с использованием расположения поля документа относительно опорного элемента на основе метаданных для изображений обучающего документа. Например, расположение поля документа может быть представлено конкретными пикселями на изображении, включенным в рамку, окружающую поле документа, как это определено разметкой на изображении документа. Тепловая карта представлена структурой данных, включающей в себя несколько элементов тепловой карты. Например, тепловую карту можно создать, разделив изображение на прямоугольную сетку с заданным размером ячейки в пикселях. В данном примере сетка представляет собой структуру данных тепловой карты, а ячейки - элементы тепловой карты. Изображение, используемое для тепловой карты, может соответствовать каждому из изображений обучающего документа, а каждый из нескольких элементов тепловой карты может соответствовать каждому из некоторого количества пикселей изображения документа соответствующего изображения обучающего документа. В примере для каждой пары опорных элементов и расположения поля документа в обучающем наборе изображений документа ячейка заполняется значением, равным доле участка, занимаемого областью для поля документа, содержащегося в ячейке.
[0042] В одном варианте применения для выбранного опорного элемента, для которого строится тепловая карта, в каждом из изображений обучающего документа устанавливается относительное расположение поля, соответствующего опорному элементу. Например, на гипотетическом изображении первого обучающего документа в 50 пикселях справа от расположения опорного элемента «total» можно найти числовое значение «$1000». Для структуры данных тепловой карты для опорного элемента «total» устанавливается, входит ли каждый пиксель изображения документа на первом изображении, соответствующий каждому элементу тепловой карты (например ячейке), в расположение поля документа, определяемое разметкой на изображении документа. Если какой-либо пиксель изображения документа полностью содержится в расположении поля документа (например в области, покрытой полем документа), элементу тепловой карты, соответствующему этому пикселю изображения документа, присваивается значение «1». Например, значение ячейки устанавливается равным «1», когда ячейка соответствует пикселю изображения в документе, содержащемуся в размеченной части изображения документа, покрывающего область для «$1000». Значение ячейки устанавливается равным «0», если оно соответствует пикселю изображения в документе, не занятому областью поля «$1000». В одном из вариантов применения значение, установленное в ячейке, указывает на количество изображений документа, в котором поле содержит пиксель, соответствующий элементу тепловой карты. Таким образом, элемент тепловой карты хранит счетчик количества изображений документа, в котором поле документа содержит пиксель изображения документа, связанный с элементом тепловой карты.
[0043] Система 300 продолжает обновлять тепловую карту для выбранного опорного элемента, используя следующее изображение документа в обучающем наборе изображений документа. Значения элементов тепловой карты обновляются, чтобы можно было добавить новые значения, отражающие следующее изображение документа. Например, если значение конкретной ячейки на тепловой карте уже было установлено на «1», а ячейка соответствует пикселю изображения в следующем документе, который содержится в области поля «$1000», то значение ячейки увеличивается на значение «1» и равняется значению «2». Система 300 продолжает агрегацию значений элемента тепловой карты для каждого из изображений документа в обучающем наборе изображений документа для определения пикселей изображения, содержащихся в конкретном поле документа. В некоторых вариантах применения конечной гистограммой относительного расположения выбранного опорного элемента считается среднее арифметическое значений в соответствующих ячейках тепловых карт.
[0044] В некоторых вариантах применения система 300 может обновлять тепловую карту для выбранного опорного элемента, чтобы она могла включить в себя значения элементов тепловой карты, которые относятся к другому полю документа. То есть для выбранного опорного элемента, для которого строится тепловая карта, определяется расположение другого поля из всех изображений обучающего документа. Расположение определяется относительно выбранного опорного элемента тепловой карты. Например, расположение «invoice date», внесенное относительно опорного элемента «total», можно определить на тепловой карте, установив значение элементов тепловой карты на «1», где элементы тепловой карты соответствуют пикселям изображения, которые содержатся в поле «invoice date» на первом обучающем изображении. Сходным образом значения элементов тепловой карты агрегируются для каждого дополнительного изображения документа в обучающем наборе для расположения поля «invoice date» относительно опорного элемента «totaltotal». Таким образом, тепловая карта для выбранного опорного элемента может определять потенциальные расположения каждого поля документа по отношению к выбранному опорному элементу. Соответственно, на этапе обучения могут быть сформированы тепловые карты относительно небольшого набора обучающих документов, которые сопровождаются метаданными, указывающими расположение полей документа. Сформированные тепловые карты впоследствии можно будет использовать для определения расположений полей в других документах.
[0045] На Фиг. 4А показан пример тепловой карты 401 для выбранного опорного элемента. Опорный элемент 410 представляет собой предопределенное ключевое слово «date», которое встречается в обучающем наборе изображений документа. Тепловая карта 401 определяет расположение различных полей документа относительно элемента 410. Опорный элемент 410 показан пунктирными линиями, так как опорный элемент не является частью структуры 420 данных сетки, которая представляет собой тепловую карту 401. Скорее, опорный элемент 410 представляет собой положение на сетке, которое соответствует расположению ключевого слова «date» на обучающем наборе изображений документа. Элементы тепловой карты, такие как ячейки 431 и 432, соответствуют пикселям изображения в изображениях обучающего документа, которые содержатся в различных полях документа. В примере ячейка 432 показана темнее чем ячейка 433, что указывает на то, что счетчик для ячейки 432 имеет большее значение, чем счетчик для ячейки 433, что, в свою очередь, указывает на то, что большее количество изображений документа имеют пиксели изображения, соответствующие ячейке 432, содержащейся в соответствующем поле, а не ячейке 433. Сходным образом, на Фиг. 4В показан пример тепловой карты 402 для выбранного опорного элемента 411 с ключевым словом «Total» и расположениями различных полей, определенных по отношению к опорному элементу 411, обозначенному заштрихованными ячейками. В этом примере ячейка 442 показана темнее ячейки 443. На Фиг. 4А и 4В показана структура данных сетки, используемая для изображенных на ней тепловых карт. В примере размер сетки представляет собой гиперпараметр, например, 64×64 пикселя. Гиперпараметр также имеет другое значение, например, 32×32 пикселей, 16×16 пикселей и т.д. Гипер параметр можно выбрать из значений, которые зависят, например, от самого документа (количество размеченных полей, размер текста и т.д.), макета документа и т.п.
[0046] В некоторых вариантах применения система 300 использует характеристики тепловой карты для классификации каждого возможного слова, найденного на изображениях 310 документа, с целью определения вероятности того, что это слово будет содержаться в конкретной области поля. Классификация состоит из положительных и отрицательных примеров. Положительными примерами являются слова, включенные в конкретную область поля в соответствии с координатами поля (например ось х, ось у) в документе. Отрицательными примерами являются все слова, которые не включены в конкретную область поля. В качестве локализующих признаков гипотезы, формируемой блоком 340 классификации компонент полей, используются расположения конкретных областей полей, определенных на тепловых картах по отношению к опорным элементам. На выходе блока 340 формируется один или несколько наборов гипотез о компонентах полей. Гипотезы могут указывать на вероятное расположение поля документа в пределах документа по отношению к опорному элементу. Вероятное расположение устанавливается на основе положительных примеров, выявленных с помощью тепловых карт.
[0047] В некоторых вариантах применения система 300 оценивает внутренний формат извлеченного содержимого определенных полей в обучающем наборе изображений 310 документа с помощью токенов ВРЕ (кодирование пар байтов). Токен ВРЕ относится к числовому вектору, представляющему собой входной текст. В некоторых вариантах применения вектор может быть представлен в виде встраивания промежуточного представления входного текста так, что в промежуточном представлении может использоваться искусственный алфавит, каждый символ которого может кодировать подстроку из одного или нескольких символов входного текста, как более подробно описано ниже. Встраиваемые данные формируются таким образом, что семантически близкие входные данные будут выдавать численно близкие встраиваемые данные.
[0048] На Фиг. 5 показан иллюстративный пример оценки 500 внутреннего формата поля, соответствующий одному или нескольким вариантам реализации настоящего изобретения. В некоторых вариантах применения для оценки внутреннего формата обнаруженного поля система 300 использует токены ВРЕ. В традиционных системах токены ВРЕ обычно используются в задачах обработки естественного языка. Варианты реализации настоящего изобретения используют токены ВРЕ для оценки внутреннего формата поля для более точного и уверенного обнаружения полей документа. Использование токенов ВРЕ для оценки приводит к значительному улучшению механизма обнаружения полей путем повышения качества и скорости обнаружения полей в документах.
[0049] В некоторых вариантах применения в рамках оценки 500 внутреннего формата поля использование токенов 510 ВРЕ позволяет получить характеристики, описывающие внутренний формат содержимого (например переменный текст, слова) обнаруженных полей на изображениях документа. В системе 300 может использоваться механизм маркирования строк многоязычного словаря 520 токенов ВРЕ. Словарь 520 может включать в себя предварительно обученные эмбеддинги 530 и словарь 540 предварительно обученного конкретного списка слов по частоте употребления. Как эмбеддинги 530, так и словарь 540 предварительно обучены на теле текстовых полей существующей базы данных разметок. В примере среднее арифметическое встраиваемых объектов принимается за вектор 550 признаков объекта текстовой строки токенов, входящих в строку.
[0050] В некоторых вариантах применения токены ВРЕ используются для содержимого обнаруженных полей в обучающем наборе данных (например изображения обучающего документа). Как отмечалось выше, искусственный алфавит символов может быть получен для использования в качестве токенов ВРЕ (например в кодировках). Алфавит включает в себя отдельные символы и токены из двух символов, трех символов и т.д. В примере алфавит может включать в себя тысячу и более символов, представляющих различные комбинации символов. Каждое слово или символы в слове могут быть представлены в изображениях обучающего документа с помощью символов из производного алфавита, представляющего слово или символы для получения маркированного содержимого. Затем выводятся вставки ВРЕ, которые являются векторным выражением токенов ВРЕ. Слова в наборе обучающих документов, которые семантически ближе друг к другу (например «1000» и «2000»), будут производить численно близкие вставки (например евклидово расстояние между двумя векторами меньше предопределенного значения). Например, в одном документе в поле «total» может стоять «1000», а в другом документе в поле «total» может стоять «2000». При применении токенов ВРЕ к этим значениям вставки ВРЕ будут близки друг к другу. В результате можно будет подтвердить, что значения правильно определены как содержимое поля «total». При обработке системой входного документа для обнаружения полей учитывается суммарное (например среднеквадратическое, среднее и т.д.) значение токенов ВРЕ для значений «1000» и «2000» обучающего документа для сравнения со значениями в обнаруженных полях входного документа. Если обнаруженное поле содержит значение (например «2500»), чья вставка ВРЕ близка к суммарному значению ВРЕ в обучающих документах, то обнаружение поля может быть подтверждено с большей степенью вероятности. Можно указать пороговый диапазон, чтобы установить, близко ли значение во входном документе к агрегированному значению. Кроме того, если обнаруженное поле содержит несколько слов, аналогичным образом можно использовать токены ВРЕ для сравнения с опорной вставкой обнаруженного поля.
[0051] Возвращаясь к Фиг. 3, в некоторых вариантах применения система 300 применяет блок 350 классификации связей между компонентами к полученным гипотезам из блока 340. Для каждой пары компонент (например слов) блок 350 вычисляет оценку совместного нахождения пары в гипотетическом поле документа. Например, гипотетическое поле может включать в себя несколько слов, например, поле адреса, которое включает в себя номер улицы, название улицы, город, штат, страну и т.д. Кроме того, возможные расположения полей, которые были определены на тепловых картах, могут включать в себя несколько слов. Соответственно, каждая гипотеза включает в себя последовательность одного или нескольких слов из нескольких слов, соответствующих расположению поля.
[0052] В некоторых вариантах применения система 300 применяет блок 360 фильтрации и оценки гипотез к полученным данным из блока 350. Блок 360 использует дополнительные параметры поля для фильтрации и оценки гипотез, полученных из блока 350. Например, дополнительные параметры могут включать в себя многостраничный индикатор (например для указания того, что поле находится более чем на одной странице документа), односторонний индикатор (например для указания того, что содержимое находится только на одной стороне документа), двусторонний индикатор (например для указания того, что содержимое находится на обеих сторонах документа), максимальный и минимальный размер геометрического поля, а также другие признаки как по отдельности, так и в сочетании друг с другом. В одном варианте применения параметры могут быть установлены пользователем системы 300. Например, пользователь может задать параметр, при котором содержимое поля будет многострочным или однострочным. В примере пользователь может задать параметр, указывающий, что поле «дата» или «total» в документе счет-фактуры может быть представлено только одной строкой. В другом варианте применения система 300 может задавать параметр, связанный с типом документа. Например, система 300 может задавать такие параметры, как геометрические параметры поля, пороговые значения и т.д. Эти параметры могут быть определены эвристическим методом. Типичный эвристический алгоритм получается при использовании некоторой функции, входящей в систему для поиска решения, часто с использованием деревьев решений. Алгоритм может включать в себя шаги по корректировке массы ветвей дерева решений в зависимости от вероятности того, что ветвь приведет к узлу конечной цели. В системе 300 также могут использоваться различные комбинации параметров или способов. Кроме того, в системе 300 могут использоваться линейные классификаторы, основанные на логистической регрессии (например обученные классификаторы, основанные на градиентном бустинге) в качестве классификатора компонент и классификатора гипотез для поля документа.
[0053] В некоторых вариантах применения в системе 300 для оценки общего качества полученных гипотез используется блок 370 оценки и анализа качества гипотез. В некоторых примерах гипотезы берутся из блока 360. В других примерах гипотезы могут браться из другого блока системы 300. Для оценки качества гипотез в системе могут быть определены различные пороговые значения. Например, набор слов может быть определен как находящийся в «уверенной» группе, когда вероятность того, что набор слов относится к какому-либо полю на выходе классификации, является выше заданного порогового значения. Например, заданное пороговое значение может быть 0,5, 0,4 или другим значением, которое было установлено с помощью экспертного метода, такого как оценка документа тестового образца, или значением, которое является единичным заданным гиперпараметром (например параметром, полученным на основе предварительного распределения).
[0054] Оценка качества гипотезы может включать в себя определение «уверенности» слова и слов, которые «надежно» связаны с уверенным словом. Для оценки выбирается стартовая компонента из гипотез, а для ограничения поиска других слов выбирается область поиска вокруг гипотез. Например, для начала построения одной или нескольких гипотез выбирается одно или несколько «уверенных» слов. Областью поиска считается описывающий слово прямоугольник с границами, которые отстают на расстояние заданного максимального размера поля от границ стартовой компоненты. Затем собирается «уверенная цепочка» гипотез, включающая все слова, «надежно» связанные со стартовой компонентой, лежащей в зоне поиска. Затем собираются и оцениваются окончательные одна или несколько гипотез, которые включают в себя все слова из зоны поиска, которые «надежно» связаны со всеми компонентами «уверенной цепочки». «Надежность» связи слов может быть установлена с помощью эвристически настраиваемого порогового значения, например, определение того, какое значение выше настроенного порогового значения принимается как надежно связанное, какое значение ниже настроенного порогового значения принимается как ненадежно связанное и т.д. Например, заданное пороговое значение может быть получено путем обучения на большой выборке данных, поступивших от клиента, с помощью подходящего метода машинного обучения, а также путем проверки его значения с помощью перекрестной проверки или другого подходящего метода. Кроме того, дальнейший анализ документов может быть выполнен путем сравнения полей гипотезы с самым высоким качеством по сравнению с другими гипотезами.
[0055] В некоторых вариантах применения система 300 использует блок обнаружения и извлечения полей 380 для обнаружения и классификации полей на другом входном документе (документах) 380. Система 300 может определять поля в соответствии с выбранными гипотезами потенциальных полей со значением качества, отвечающим определенному порогу качества, и (или) полученными результатами анализа по внутреннему формату содержимого в пределах потенциальных полей. Например, когда система 300 получает входной документ 380 для обнаружения и извлечения полей, система 300 может обнаруживать поля на входном документе 380, классифицировать поля и извлекать содержимое в пределах обнаруженных полей. В некоторых примерах система 300 может автоматически загружать изображение документа с обнаруженными полями и извлеченным содержимым в хранилище данных и (или) программный портал. На Фиг. 6 показан иллюстративный пример входного документа 600 с обнаруженными полями 610, соответствующий одному или нескольким вариантам реализации настоящего изобретения. Система 300 обнаруживает поля 610 на основе гипотез, полученных с помощью обучающего набора изображений документа.
[0056] Возвращаясь к Фиг. 3, в некоторых вариантах применения система 300 может получить изображение входного документа и может определить в пределах изображения входного документа область-кандидат для каждого поля, представляющего интерес, на основе тепловых карт, построенных для этого поля, в отношении одного или нескольких опорных элементов. Каждая определенная область-кандидат будет включать в себя пиксели изображения входного документа, соответствующие элементам тепловой карты, удовлетворяющим пороговому условию (например когда их соответствующие значения превышают пороговое значение, когда выбрана заранее определенная доля пикселей, имеющих наибольшие значения, и т.д.). Выбранные области-кандидаты могут затем рассматриваться как положения соответствующих полей, например, путем применения технологий оптического распознавания символов (OCR) к фрагментам снимков, лежащим внутри областей-кандидатов.
[0057] В некоторых примерах две или более тепловых карт могут быть использованы для обнаружения полей, в которых каждая тепловая карта построена для разных опорных элементов. Например, для обнаружения расположения конкретного поля (например поля, соответствующего опорному элементу «Invoice #», в дальнейшем именуемого полем «Invoice #») на новом входном изображении документа 380 ключевые слова из изображения документа сначала определяются с помощью словаря ключевых слов. Например, к определенным ключевым словам могут относиться «Date», «Total», «Balance due», «Due date» и т.д. Система 300 выбирает тепловые карты для каждого из ключевых слов и определяет вероятное положение для конкретного поля на изображении документа. Например, система 300 выбирает тепловую карту для опорного элемента «Date» и определяет вероятное положение конкретного поля (например поле « Invoice #») по отношению к опорному элементу «Date». Вероятное положение поля определяется на основе гипотез, сформированных на основе значений элементов тепловой карты, находящихся выше пороговых значений. Аналогичным образом система 300 выбирает тепловую карту для опорного элемента «Total» и определяет вероятное положение конкретного поля (например поля «Invoice #») по отношению к опорному элементу «Total» и т.д. для тепловых карт различных ключевых слов, найденных во входном документе. Затем система 300 сравнивает тепловые карты и определяет пересечение возможных точек, определенных с помощью различных тепловых карт. Система 300 выбирает одну или несколько точек на входном документе, которые соответствуют максимальному количеству пересекающихся тепловых карт, и определяет область, включая точки как область-кандидат на конкретное поле (например поле «Invoice #») на изображении входного документа. Пороговый номер может быть указан для количества пересекающихся точек. Если количество пересекающихся точек на тепловых картах соответствует пороговому количеству или превышает его, то выбранный участок должен быть включен в область-кандидат. Соответственно, область-кандидат определяется в качестве конкретного поля во входном документе.
[0058] В некоторых вариантах применения содержимое, извлеченное из каждого обнаруженного поля документа, может оцениваться с помощью токенов ВРЕ посредством определения различий (например евклидовых расстояний) между токеном ВРЕ, представляющим извлеченное содержимое данного поля входного документа, и токенами ВРЕ, вычисленными для этого же поля в обучающих документах. Если расчетное расстояние между токеном ВРЕ, представляющим содержимое, извлеченное из поля-кандидата, и совокупностью (например среднеквадратическое значение, среднее) токена (токенов) ВРЕ, представляющего одно и то же поле в наборе данных для обучения, меньше порогового значения, то вероятность того, что поле будет обнаружено правильно, относительно велика, и поле-кандидат может быть принято для извлечения информации.
[0059] В некоторых вариантах применения выходные данные различных модулей могут быть подключены для априорного анализа документа (например документов таких типов, как счета-фактуры, таблицы, квитанции, ключи-значения и т.д.). Могут также использоваться пользовательские правила, которые описывают знания о природе входного документа (например код страны, номер страницы и т.п.).
[0060] В некоторых вариантах применения после получения большого набора документов (например нескольких тысяч документов) система 300 может повторить процесс обучения, но с ошибками, определенными в процессе обнаружения полей. Это может еще больше повысить качество обнаружения полей.
[0061] В некоторых вариантах применения система 3400 может установить точность пользовательской разметки на обучающих документах и исправить любую обнаруженную неточность. Документы с настраиваемой разметкой полей принимаются в качестве обучающих входных данных. Разметка в партии может быть полной (правильной), частичной, непоследовательной (одни и те же поля размечены в разных местах), ошибочной. Эта разметка представляет собой именно ту разметку, которую выполнил пользователь. Для каждого размеченного поля определяются возможные стабильные комбинации относительного положения других полей на основе разметки других полей, поиска этих полей системой, а также различных ключевых слов (часто встречающихся слов, входящих в область поля). Относительное положение полей может устанавливаться по абсолютному расположению (например по тому, как оно относится к документу, на котором находится поле, например, номер строки или обозначение пикселей на документе) или по относительному расположению (например по сравнению с конкретным элементом на документе, например, поле «total» находится на 100 пикселей вправо от поля «date»), или по зоне (например диапазону) приемлемого расположения (распределения) конкретных полей или ключевых слов (например указание на то, что поле «client number» должно всегда находиться слева от поля «client name» и не дальше 100 пикселей от него, в противном случае оно не считается значением данного поля). Поля, для которых существуют стабильные комбинации других полей и ключевых слов и для которых эти комбинации повторяются или соотносятся от документа к документу, считаются стабильными и, возможно, правильно размеченными. Поля, для которых не найдены стабильные закономерности, считаются либо неправильно размеченными, либо размеченными единично. Поля одного и того же типа (например «total») с разными стабильными структурами или комбинациями на разных наборах документов считаются либо непоследовательными (если это документы одного и того же кластера или продавца), либо обнаруживают неоднородность документов, на которых они расположены. Таким образом, система может проверить правильность полученной разметки и предсказать разметку с высоким уровнем уверенности при первом запуске системы с небольшим количеством документов, необходимых для начала обучения системы, при условии, что система содержит универсальную предварительно обученную модель машинного обучения разметке, содержащую стандартные правила в отношении предполагаемых типов пользовательских документов. В дальнейшем при сборе статистики пользовательской разметки модель обучается на пользовательских документах в обратном направлении, зная стабильные комбинации полей и ключевых слов, система может определить области возможного расположения неразмеченных полей или неправильно размеченных полей и давать пользователю подсказки. Например, система может предоставить подсказки о том, как правильно разметить конкретный документ, или загрузить подборку документов, где разметка явно неверна и нуждается в исправлении.
[0062] На Фиг. 7 представлена блок-схема одного наглядного примера способа сегментации документа на блоки различных типов, соответствующего одному или нескольким вариантам реализации настоящего изобретения. Способ 700 и (или) каждая из его отдельных функций, процедур, подпрограмм или операций может выполняться одним или несколькими процессорами компьютерной системы (например моделью компьютерной системы 800 на Фиг. 8), выполняющими этот способ. В некоторых вариантах применения способ 700 может выполняться одним потоком обработки. В другом варианте применения способ 700 может выполняться двумя или более потоками обработки, каждый из которых выполняет одну или несколько отдельных функций, процедур, подпрограмм или операций способа. Например, потоки обработки, реализующие способ 700, могут быть синхронизированы (например с помощью семафоров, критических секций и (или) других механизмов синхронизации потоков). В другом варианте применения потоки обработки, осуществляющие способ 700, могут выполняться асинхронно по отношению друг к другу. Поэтому если на Фиг. 7 и связанном с ней описании перечислены операции способа 700 в конкретном порядке, различные варианты применения способа могут выполнять по меньшей мере некоторые из описанных операций параллельно и (или) в произвольно выбранном порядке. В одном из вариантов применения способ 700 может быть выполнен одним или несколькими различными компонентами, изображенными на Фиг. 1, такими как детектор 122 полей, устройство 151 обучения обнаружению полей и др.
[0063] На шаге 710 компьютерная система, применяющая данный способ, может получить набор данных для обучения. Набор данных для обучения может содержать несколько изображений документа. Каждое из нескольких изображений документа может быть связано с соответствующими метаданными, определяющими поле документа. Поле документа может содержать символы, такие как переменный текст. Для каждого из нескольких изображений документа метаданные могут определить размеченное расположение поля документа, соответствующее этому полю документа.
[0064] На шаге 720 компьютерная система может сформировать первую тепловую карту. Тепловая карта может быть представлена структурой данных (например сеткой, графиком и т.д.). Структура данных может включать в себя несколько элементов тепловой карты (например ячеек), соответствующих нескольким пикселям изображения документа. В некоторых примерах каждый элемент тепловой карты содержит счетчик. Счетчик может указать некоторое количество изображений документа, в которых поле документа содержит пиксель изображения документа, связанный с элементом тепловой карты.
[0065] На шаге 730 компьютерная система может получить изображение входного документа. На шаге 740 компьютерная система может определить область-кандидат в пределах изображения входного документа. Изображение-кандидат может содержать поле документа. В некоторых примерах область-кандидат содержит несколько пикселей изображения входного документа. В некоторых примерах пиксели изображения входного документа соответствуют элементам тепловой карты, удовлетворяющим пороговому условию.
[0066] В некоторых примерах область-кандидат определяется с помощью нескольких тепловых карт. Несколько тепловых карт могут содержать первую тепловую карту и одну или несколько дополнительных тепловых карт. Каждая из нескольких тепловых карт определяет потенциальное расположение поля документа, соответствующего этому полю документа. Каждая из нескольких тепловых карт определяет потенциальное расположение поля документа относительно соответствующего опорного элемента в каждой из нескольких тепловых карт. В некоторых примерах соответствующий опорный элемент содержит предопределенное слово (например ключевое слово «Date») или предопределенный графический элемент (например визуальный разделитель, логотип и т.д.).
[0067] Кроме того, на этапе обучения компьютерная система может извлекать содержимое каждого изображения обучающего документа, где это содержимое включено в потенциальное расположение поля документа (например содержимое «1000», «2000» и «1500», соответственно, в каждом документе, где это содержимое содержится в потенциальном расположении поля «total»). Затем компьютерная система может проанализировать содержимое каждого изображения документа с помощью токенов ВРЕ. В одном варианте применения для анализа содержимого компьютерная система может представлять содержимое каждого изображения документа с помощью токенов ВРЕ для получения маркированного содержимого для каждого изображения документа. Компьютерная система может формировать векторное представление (например ВРЕ эмбеддинги) маркированного содержимого для каждого изображения документа. Компьютерная система может вычислить расстояние (например евклидово расстояние) между парой эмбеддингов (например эмбеддингов, представляющих «1000» и «2000») из двух из нескольких изображений документа. Если установлено, что расстояние меньше предопределенного значения, то компьютерная система указывает, что потенциальное расположение поля документа, вероятно, является верным. На этапе обнаружения полей входного документа при обнаружении поля-кандидата (например «total») на входном документе с помощью обучающей модели может быть извлечено содержимое (например «2899») обнаруженного поля, а также могут быть сформированы ВРЕ эмбеддинги извлеченного содержимого. Можно рассчитать суммарное значение ВРЕ эмбеддингов в содержимое (например содержимое «1000», «2000» и «1500» в обучающих документах) поля в наборе обучающих документов. Если вычисленное расстояние между токеном ВРЕ, представляющим содержимое, извлеченное из обнаруженного поля на входном документе, и совокупным токеном (токенами) ВРЕ, представляющим то же самое поле в наборе обучающих данных, меньше порогового значения, то вероятность того, что поле обнаружено правильно, относительно велика, и поле-кандидат может быть принято в качестве обнаруженного поля и выбрано для извлечения информации.
[0068] На Фиг. 8 в качестве примера изображена компьютерная система 800, которая может выполнять любой из описанных в настоящей заявке способов, соответствующих одному или нескольким вариантам реализации настоящего изобретения. В одном из примеров компьютерной системе 800 может соответствовать вычислительное устройство, способное реализовать способ 700 на Фиг. 7. Компьютерная система 800 может быть подключена (например по сети) к другим компьютерным системам в локальной сети, интранете, экстранете или интернете. Компьютерная система 800 может работать в качестве сервера в сетевой среде клиент-сервер. Компьютерной системой 800 может быть персональный компьютер (ПК), планшетный компьютер, приставка (STB), карманный персональный компьютер (КПК), мобильный телефон, камера, видеокамера или любое устройство, способное выполнить набор инструкций (последовательных или иных), определяющих действия, которые должны быть предприняты этим устройством. Кроме того, хотя иллюстрируется только одна компьютерная система, под термином «компьютер» понимается также любая совокупность компьютеров, которые по отдельности или совместно выполняют набор (или несколько наборов) инструкций для реализации одного или нескольких способов, рассматриваемых в настоящей заявке.
[0069] Примерная вычислительная система 800 включает в себя устройство 802 обработки, память 804 (например память только для чтения (ROM), флэш-память, память динамического произвольного доступа (DRAM), например, синхронную DRAM (SDRAM)), а также устройство 818 хранения данных, которые обмениваются данными друг с другом по шине 830.
[0070] Устройство 802 обработки представляет собой одно или несколько устройств обработки общего назначения, таких как микропроцессор, центральный процессор и т.п. В частности, устройство 802 обработки может быть микропроцессором со сложным набором команд (CISC), микропроцессором с сокращенным набором команд (RISC), микропроцессором с командными словами сверхбольшой длины (VLIW) или процессором, реализующим другие наборы команд, или процессорами, реализующими комбинацию наборов команд. Устройство 802 обработки может также быть одним или несколькими специализированными устройствами обработки, такими как специализированная интегральная схема (ASIC), программируемая логическая интегральная схема (FPGA), процессор для цифровой обработки сигналов (DSP), сетевой процессор и т.п. Устройство 802 обработки настроено на выполнение инструкций для выполнения операций и шагов, описанных в настоящей заявке.
[0071] Компьютерная система 800 может также включать в себя устройство 822 сопряжения с сетью. Компьютерная система 800 может также включать в себя блок 810 видеодисплея (например жидкокристаллический дисплей (LCD) или катодно-лучевую трубку (CRT)), устройство 812 ввода алфавитно-цифровых данных (например клавиатуру), устройство 814 управления курсором (например мышь) и устройство 816 формирования сигнала (например сеть). В одном наглядном примере блок 810 видеодисплея, устройство 812 ввода алфавитно-цифровых данных и устройство 814 управления курсором могут быть объединены в один компонент или устройство (например сенсорный LCD дисплей).
[0072] Устройство 818 хранения данных может включать в себя машиночитаемый носитель 824, на котором хранятся инструкции 826, содержащие любую из описанных в настоящей заявке методик или функций. Инструкции 826 могут также находиться, полностью или хотя бы частично, в памяти 804 и (или) в устройстве 802 обработки во время их выполнения компьютерной системой 800, памятью 804 и устройством 802 обработки, которые являются также машиночитаемыми носителями. Далее инструкции 826 могут передаваться или приниматься по сети через устройство 822 сопряжения с сетью.
[0073] В то время как машиночитаемый носитель 824 информации показан в иллюстративных примерах в виде единого носителя, термин «машиночитаемый носитель информации» следует понимать как включающий в себя один или несколько носителей информации (например централизованную или распределенную базу данных и (или) связанные с ней кэши и серверы), на которых хранится один или несколько наборов инструкций. Термин «машиночитаемый носитель информации» также означает любой носитель информации, который способен хранить, кодировать или переносить набор инструкций для выполнения машиной и который заставляет машину выполнять одну или несколько методик настоящего изобретения. Соответственно, термин «машиночитаемый носитель информации» включает в себя, в частности, полупроводниковую память, оптические и магнитные носители.
[0074] Хотя представленные в настоящей заявке процедуры выполнения различных способов показаны и описаны в конкретном порядке, порядок выполнения каждого способа может быть изменен так, чтобы некоторые процедуры могли выполняться в обратном порядке или так, чтобы некоторая процедура могла выполняться, по крайней мере частично, одновременно с другими процедурами. В некоторых вариантах применения инструкции или подпроцедуры отдельных процедур могут прерываться и (или) чередоваться.
[0075] Следует понимать, что приведенное выше описание должно быть иллюстративным, а не ограничивающим. Многие другие варианты применения будут очевидны для специалистов в данной области техники после прочтения и понимания вышеприведенного описания. Следовательно, объем изобретения должен устанавливаться со ссылкой на прилагаемые пункты формулы изобретения вместе с полным объемом эквивалентов, на которые такие пункты могут распространяться.
[0076] В вышеуказанном описании приведены многочисленные детали. Однако для специалиста в данной области техники будет очевидно, что варианты реализации настоящего изобретения могут применяться без этих конкретных подробностей. В некоторых случаях известные структуры и устройства показаны в виде блок-схемы, а не описаны в подробностях, чтобы не затруднить восприятие настоящего изобретения.
[0077] Некоторые части приведенных выше подробных описаний представлены в виде алгоритмов и символических представлений операций с битами данных в памяти компьютера. Эти алгоритмические описания и представления являются средствами, используемыми специалистами в области обработки данных, для наиболее эффективной передачи существа своей работы другим специалистам в данной области техники. Алгоритм здесь и в целом задуман как самосогласованная последовательность шагов, приводящая к желаемому результату. Это те шаги, которые требуют физических манипуляций с физическими величинами. Обычно, хотя и не всегда, эти величины принимают форму электрических или магнитных сигналов, которые можно хранить, передавать, объединять, сравнивать и иным образом использовать. Было доказано, что иногда, в основном по причинам общего использования, удобно называть эти сигналы битами, значениями, элементами, символами, знаками, терминами, числами и т.п.
[0078] Однако следует иметь в виду, что все эти и аналогичные термины должны ассоциироваться с соответствующими физическими величинами и являться просто удобными обозначениями, применяемыми к этим величинам. Если не указано иное, то исходя из всего последующего обсуждения, становится понятно, что такие часто встречающиеся в дискуссии термины, как «получение», «установление», «выбор», «хранение», «настройка» и т.п., относятся к действиям и процессам компьютерной системы или аналогичного электронного вычислительного устройства, которое управляет и преобразует данные, представленные в виде физических (электронных) величин в регистрах и памяти компьютерной системы, в другие данные, аналогичным образом представленные как физические величины в памяти или регистрах компьютерной системы, или в других подобных устройствах хранения, передачи или отображения информации.
[0079] Настоящее изобретение также относится к устройству для выполнения операций, описанных в настоящей заявке. Это устройство может быть специально сконструировано для требуемых целей или может содержать компьютер общего назначения, выборочно активированный или переконфигурированный компьютерной программой, хранящейся в компьютере. Подобная компьютерная программа может храниться на машиночитаемом носителе информации, в частности, таком как дискеты, оптические диски, компакт-диски, магнитооптические диски, постоянная память (ROM), оперативная память (RAM), стираемая программируемая постоянная память (EPROM), электрически стираемая программируемая постоянная память (EEPROM), магнитные или оптические карты или любые другие носители информации, пригодные для хранения электронных инструкций, каждый из которых подключен к системной шине компьютера.
[0080] Представленные в настоящей заявке алгоритмы и дисплеи по своей природе не связаны с каким-либо конкретным компьютером или другим устройством. В соответствии с содержащимися в настоящей заявке методическими указаниями, с программами могут использоваться различные системы общего назначения, но для выполнения требуемых методических этапов целесообразным может оказаться создание узкоспециализированного устройства. Для различных подобных систем нужная структура будет соответствовать требованиям, изложенным в описании. Кроме того, варианты реализации настоящего изобретения не рассматриваются в контексте какого-либо конкретного языка программирования. Очевидно, что для реализации настоящего изобретения, описанного в настоящей заявке, могут использоваться различные языки программирования.
[0081] Варианты реализации настоящего изобретения могут быть предоставлены в виде компьютерного программного продукта или программного обеспечения, которое может включать в себя машиночитаемый носитель с сохраненными на нем инструкциями, который может быть использован для программирования компьютерной системы (или других электронных устройств) для выполнения процесса в соответствии с настоящим изобретением. Машиночитаемый носитель включает в себя любую процедуру хранения или передачи информации в форме, пригодной для чтения машиной (например компьютером). Например, к машиночитаемым (например пригодным для чтения компьютером) носителям относятся пригодные для чтения машиной (например компьютером) носители информации (например постоянная память (ROM), оперативная память (RAM), носители информации на магнитных дисках, оптические носители информации, устройства флэш-памяти и т.д.).
[0082] Слова «пример» или «примерный» используются в настоящей заявке в качестве примера, образца или иллюстрации. Любой вариант реализации или образец, описанный в настоящей заявке с характеристикой «пример» или «примерный», не обязательно должен рассматриваться как предпочтительный или преимущественный по сравнению с другими вариантами реализации или образцами. Использование слов «пример» или «примерный», скорее, предназначено для представления концепции в приложении к конкретному случаю. В том виде, в каком термин «или» используется в настоящей заявке, он означает включающее «или», а не исключающее «или». То есть, если не указано иное или не ясно из контекста, «X включает в себя А или В» используется для обозначения любой из естественных включающих перестановок. То есть, если X включает в себя А; X включает в себя В; или X включает в себя и А, и В, то в любом из вышеперечисленных случаев формулировка «X включает в себя А или В» считается истинной. Кроме того, неопределенные артикли «а» и «an», используемые в настоящей заявке на английском языке, и прилагаемые пункты формулы изобретения должны обычно толковаться как означающие «один или несколько», если только не указано иное или не ясно из контекста, что они должны быть приведены в форме единственного числа. Кроме того, использование в тексте термина «вариант применения», «один вариант применения» или «один из вариантов применения» не должно означать один и тот же вариант применения, если только он не описан в качестве такового. Кроме того, термины «первый», «второй», «третий», «четвертый» и т.д., используемые в настоящей заявке, означают метки для разграничения различных элементов и не обязательно имеют порядковое значение в соответствии с их числовым обозначением.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБЫ И СИСТЕМЫ ИДЕНТИФИКАЦИИ ПОЛЕЙ В ДОКУМЕНТЕ | 2021 |
|
RU2774653C1 |
| ГЕНЕРАЦИЯ РАЗМЕТКИ ИЗОБРАЖЕНИЙ ДОКУМЕНТОВ ДЛЯ ОБУЧАЮЩЕЙ ВЫБОРКИ | 2017 |
|
RU2668717C1 |
| ОБУЧЕНИЕ НЕЙРОННЫХ СЕТЕЙ С ИСПОЛЬЗОВАНИЕМ ФУНКЦИЙ ПОТЕРЬ, ОТРАЖАЮЩИХ ЗАВИСИМОСТИ МЕЖДУ СОСЕДНИМИ ТОКЕНАМИ | 2018 |
|
RU2721190C1 |
| ИЗВЛЕЧЕНИЕ ПОЛЕЙ С ПОМОЩЬЮ НЕЙРОННЫХ СЕТЕЙ БЕЗ ИСПОЛЬЗОВАНИЯ ШАБЛОНОВ | 2019 |
|
RU2737720C1 |
| ИСПОЛЬЗОВАНИЕ ГЛУБИННОГО СЕМАНТИЧЕСКОГО АНАЛИЗА ТЕКСТОВ НА ЕСТЕСТВЕННОМ ЯЗЫКЕ ДЛЯ СОЗДАНИЯ ОБУЧАЮЩИХ ВЫБОРОК В МЕТОДАХ МАШИННОГО ОБУЧЕНИЯ | 2016 |
|
RU2636098C1 |
| УСТРОЙСТВО И СПОСОБ ДЛЯ АНАЛИЗА МЕДИЦИНСКИХ ИЗОБРАЖЕНИЙ | 2022 |
|
RU2806982C1 |
| СЕГМЕНТАЦИЯ ТЕКСТА | 2017 |
|
RU2666277C1 |
| ОБНАРУЖЕНИЕ ТЕКСТОВЫХ ПОЛЕЙ С ИСПОЛЬЗОВАНИЕМ НЕЙРОННЫХ СЕТЕЙ | 2018 |
|
RU2699687C1 |
| МНОГОЭТАПНОЕ ОБУЧЕНИЕ МОДЕЛЕЙ МАШИННОГО ОБУЧЕНИЯ ДЛЯ РАНЖИРОВАНИЯ РЕЗУЛЬТАТОВ ПОИСКА | 2021 |
|
RU2824338C2 |
| Автоматическое извлечение именованных сущностей из текста | 2014 |
|
RU2665239C2 |
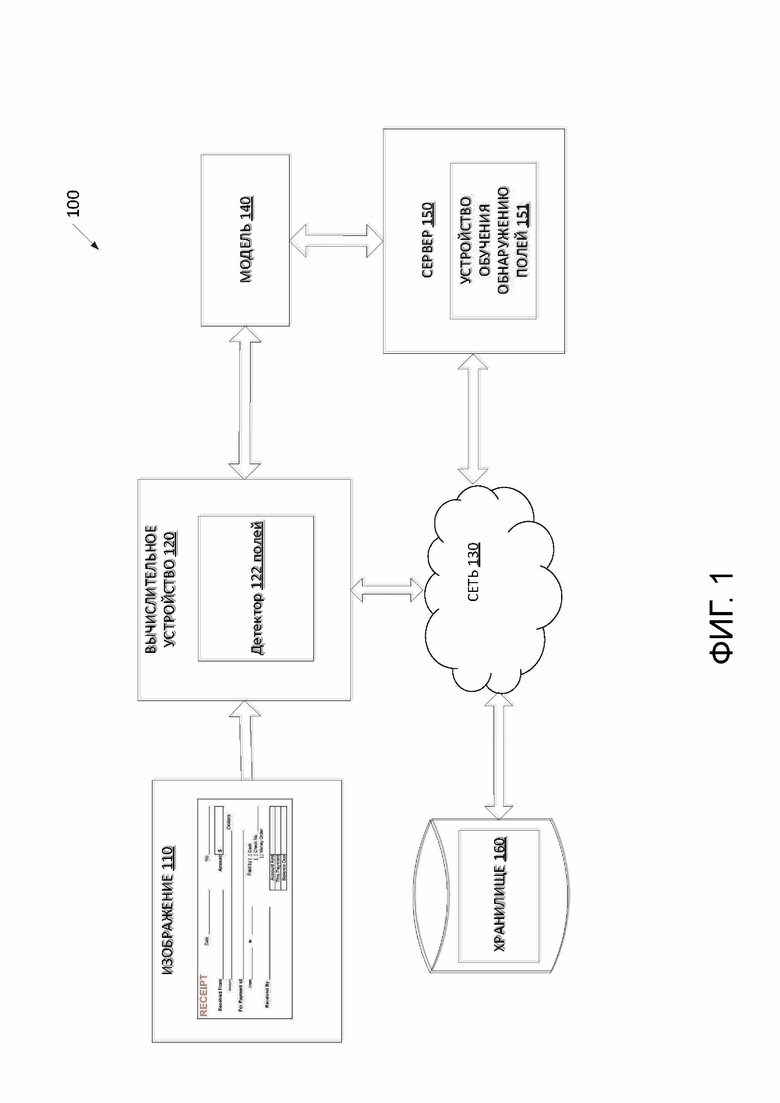
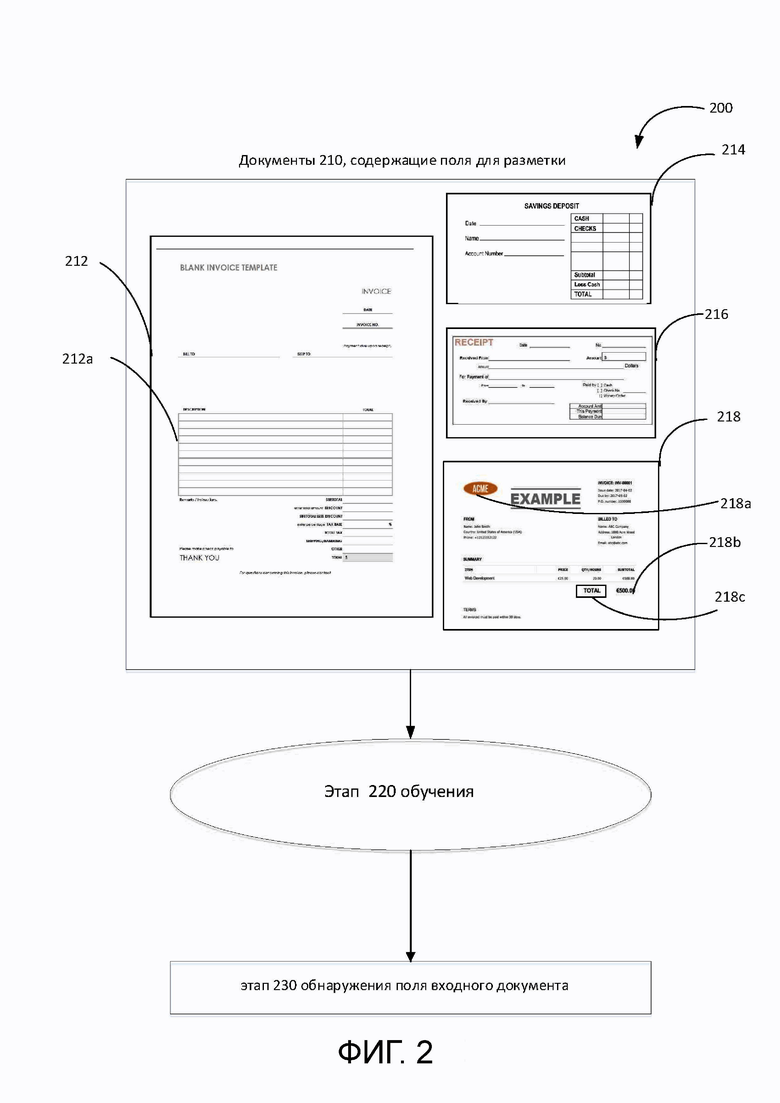
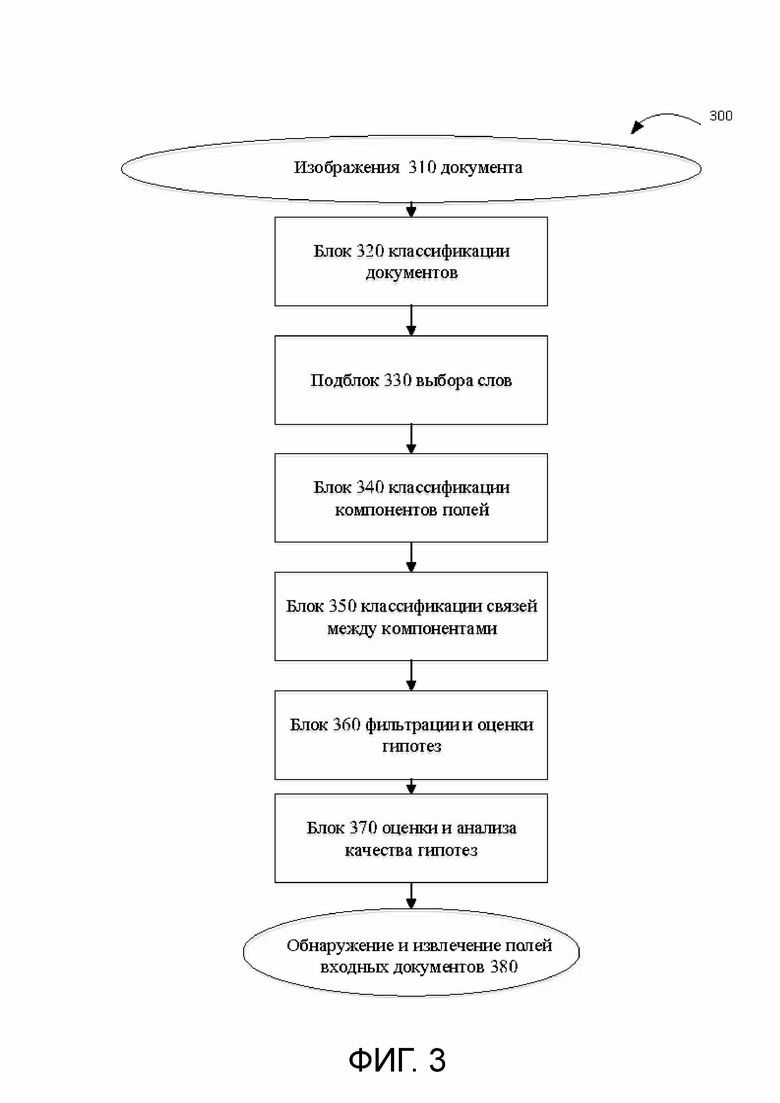
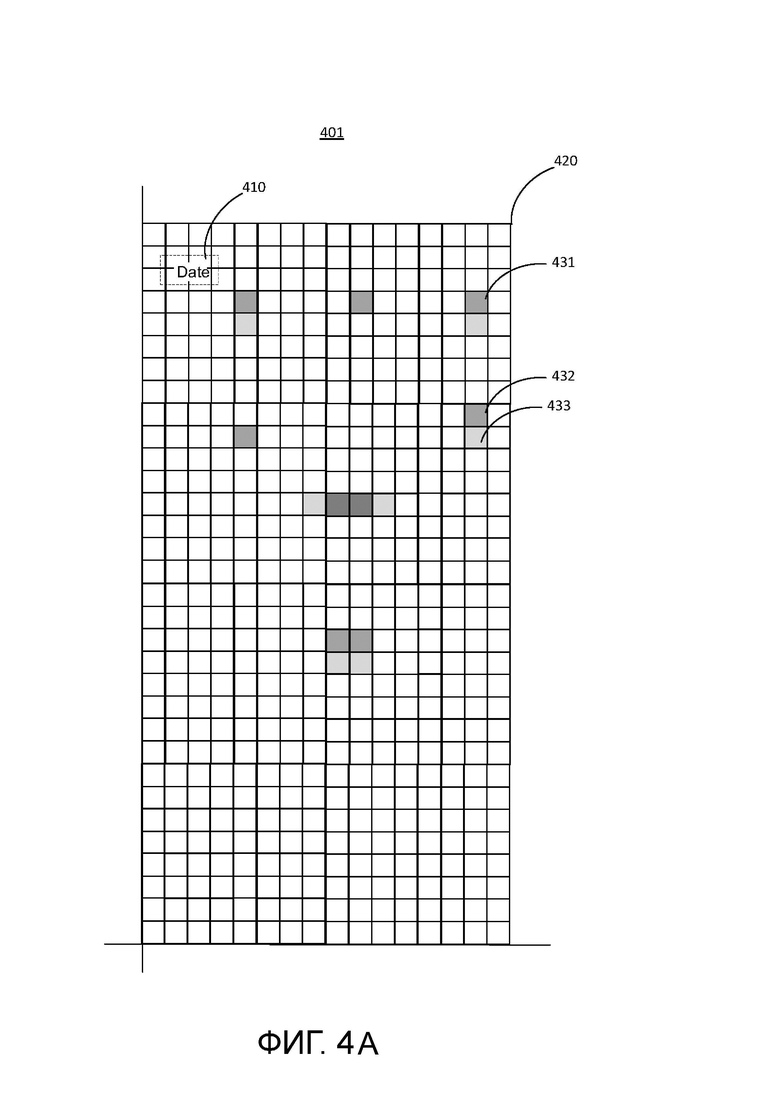
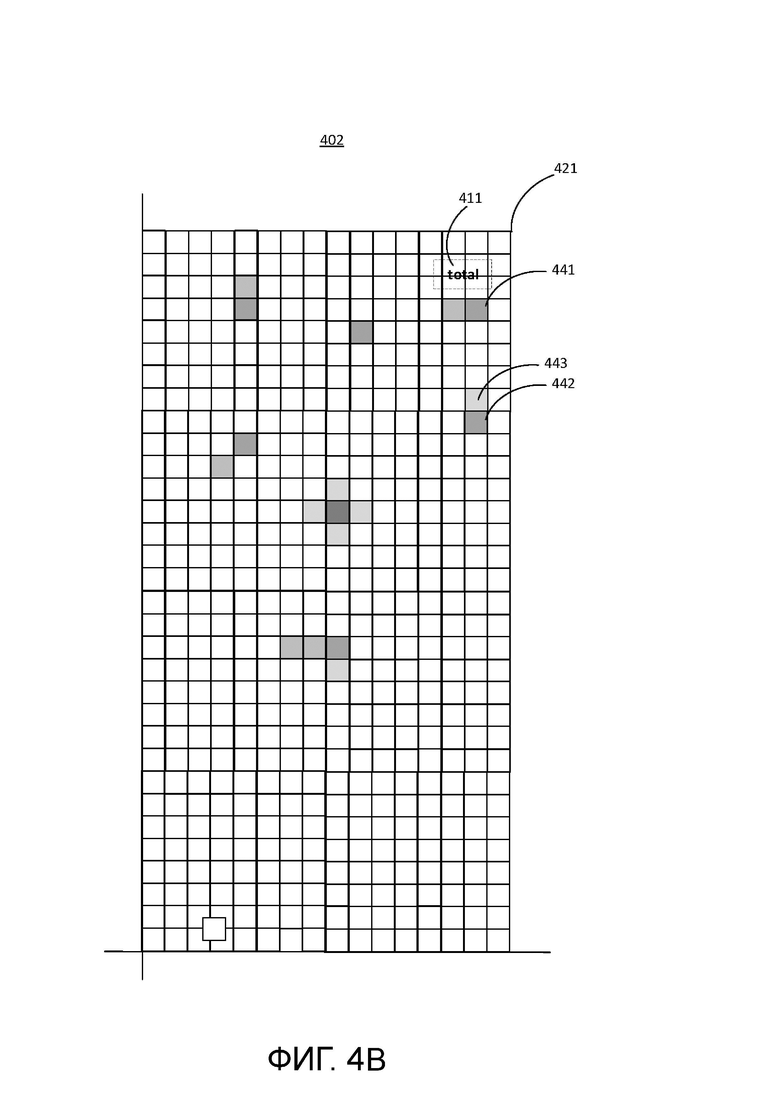
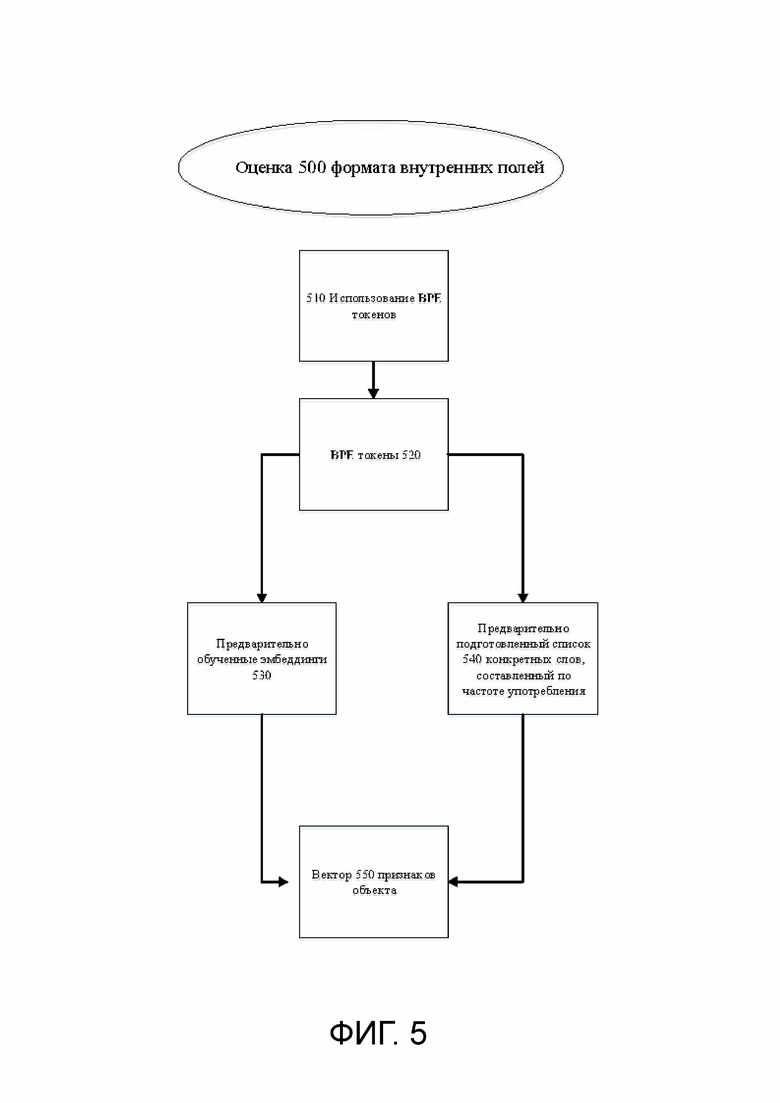
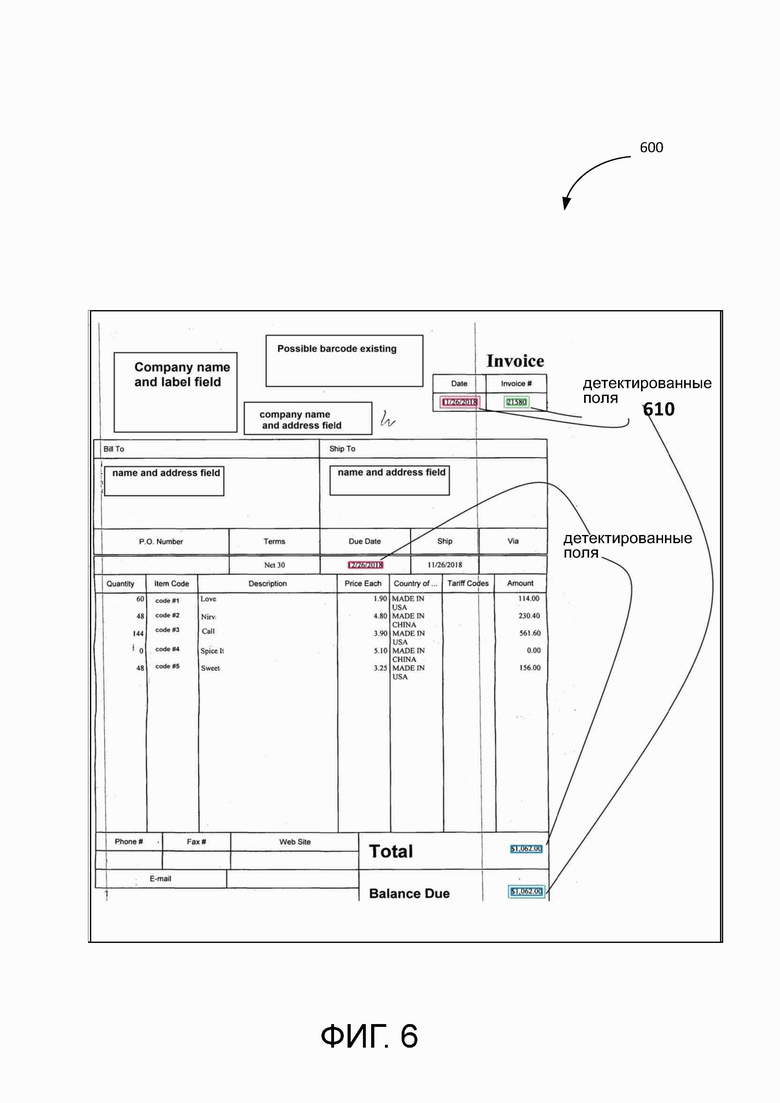
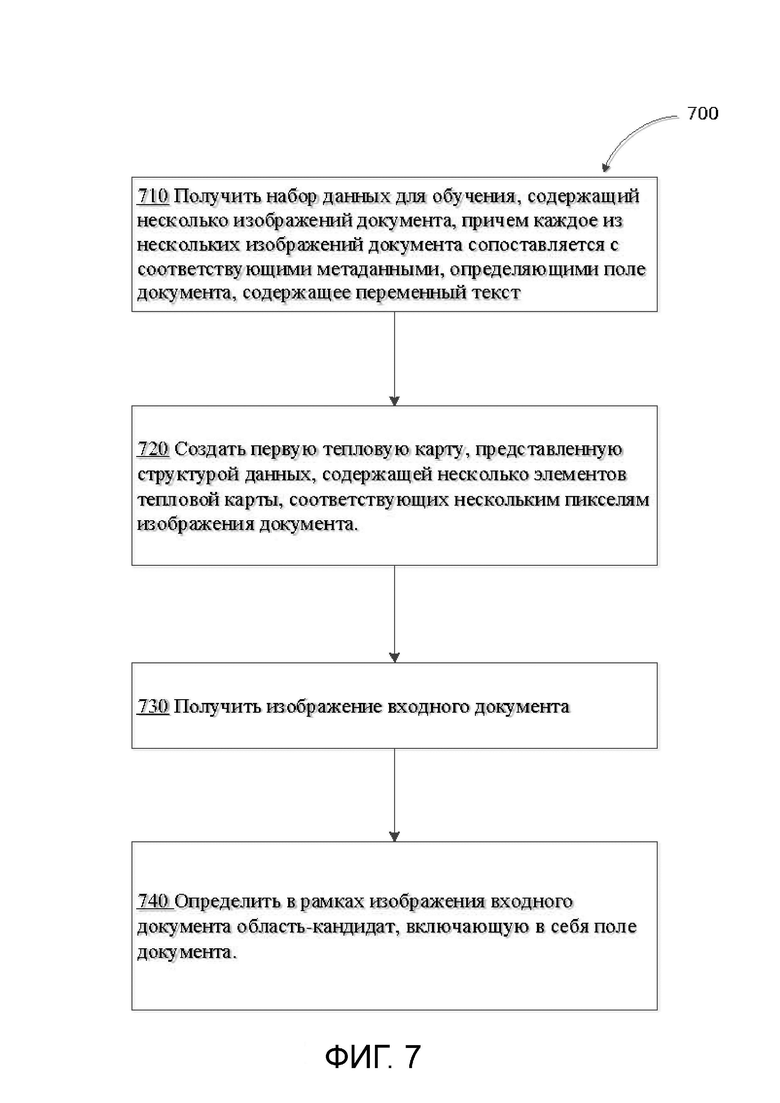
Изобретение относится к системам и способам обнаружения полей в документе. Технический результат – более точная идентификация полей в документе. Системы и способы раскрываются для получения набора данных для обучения, содержащего несколько изображений документа, причем каждое из нескольких изображений документа сопоставляется с соответствующими метаданными, определяющими поле документа, содержащее переменный текст; формирования путем обработки нескольких изображений документа первой тепловой карты, представленной структурой данных, содержащей несколько элементов тепловой карты, соответствующих нескольким пикселям изображения документа, причем в каждом элементе тепловой карты хранится счетчик некоторого количества изображений документа, в котором поле документа содержит пиксель изображения документа, связанный с элементом тепловой карты; получения изображения входного документа и определения в пределах изображения входного документа области-кандидата, содержащей поле документа, причем область-кандидат содержит несколько пикселей изображения входного документа, соответствующих элементам тепловой карты, удовлетворяющих пороговому условию. 3 н. и 12 з.п. ф-лы, 9 ил.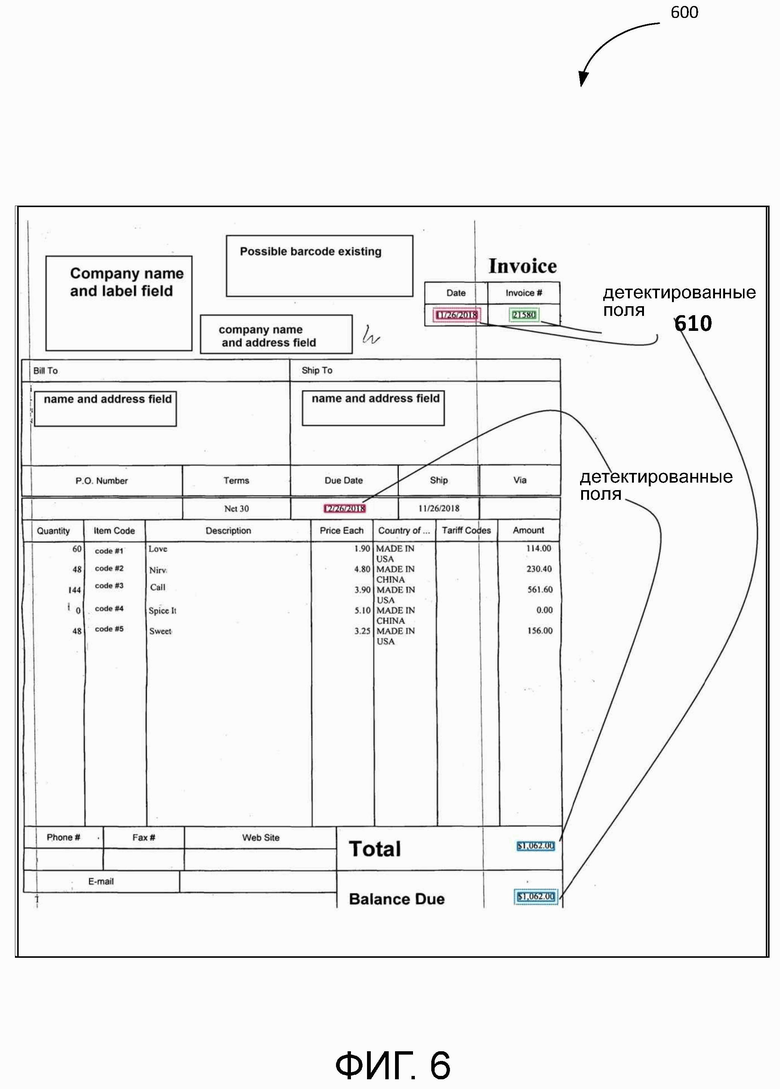
1. Способ обнаружения полей документа, включающий:
получение набора данных для обучения, содержащего несколько изображений документа, причем каждое из нескольких изображений документа ассоциировано с соответствующими метаданными набора данных для обучения, где метаданные определяют размеченное расположение поля документа, соответствующее полю документа для каждого из указанных нескольких изображений документа, содержащее переменный текст;
генерацию путем обработки нескольких изображений документа первой тепловой карты, представленной структурой данных, содержащей несколько элементов тепловой карты, соответствующих нескольким пикселям изображения документа, причем в каждом элементе тепловой карты хранится счетчик количества изображений документа, в котором поле документа содержит пиксель изображения документа, ассоциированный с элементом тепловой карты, где указанная тепловая карта определяет потенциальное расположение поля документа относительно соответствующего опорного элемента в ней;
получение изображения входного документа; и
определение в изображении входного документа области-кандидата, содержащей поле документа, причем область-кандидат содержит несколько пикселей изображения входного документа, соответствующих элементам тепловой карты, удовлетворяющих пороговому условию.
2. Способ по п.1, в котором область-кандидат определяется с помощью нескольких тепловых карт, причем несколько тепловых карт содержат первую тепловую карту и одну или несколько дополнительных тепловых карт, причем каждая из нескольких тепловых карт определяет потенциальное место расположения поля документа, соответствующее полю документа.
3. Способ по п.2, в котором каждая из нескольких тепловых карт определяет потенциальное расположение поля документа относительно соответствующего опорного элемента в каждой из нескольких тепловых карт.
4. Способ по п.3, в котором соответствующий опорный элемент содержит одно или более предопределенных слов или предопределенных графических элементов.
5. Способ по п.2, дополнительно включающий в себя:
извлечение содержимого каждого из нескольких изображений документа, при этом содержимое включается в потенциальное расположение поля документа; и
анализ содержимого каждого изображения документа с помощью токенов байтового парного кодирования (BPE).
6. Способ по п.5, в котором анализируется содержимое, включает в себя:
представление содержимого каждого изображения документа с помощью токенов BPE для получения маркированного содержимого для каждого изображения документа;
формирование векторного представления маркированного содержимого для каждого изображения документа;
вычисление расстояния между парой векторного представления токенизированного содержимого двух из нескольких изображений документа и
указание того, что потенциальное расположение поля документа, скорее всего, является правильным, если установлено, что расстояние меньше предопределенного значения.
7. Система обнаружения полей документа, включающая в себя:
запоминающее устройство для хранения инструкций;
устройство обработки, сопряженное с запоминающим устройством, причем устройство обработки предназначено для исполнения инструкций для:
получения набора данных для обучения, содержащего несколько изображений документа, причем каждое из нескольких изображений документа ассоциировано с соответствующими метаданными набора данных для обучения, где метаданные определяют размеченное расположение поля документа, соответствующее полю документа для каждого из указанных нескольких изображений документа, содержащее переменный текст, определяющих поле документа, содержащее переменный текст;
генерации путем обработки нескольких изображений документа первой тепловой карты, представленной структурой данных, содержащей несколько элементов тепловой карты, соответствующих нескольким пикселям изображения документа, причем в каждом элементе тепловой карты хранится счетчик количества изображений документа, в котором поле документа содержит пиксель изображения документа, ассоциированный с элементом тепловой карты, где указанная тепловая карта определяет потенциальное расположение поля документа относительно соответствующего опорного элемента в ней;
получения изображения входного документа и
определения в изображении входного документа области-кандидата, содержащей поле документа, причем область-кандидат содержит несколько пикселей изображения входного документа, соответствующих элементам тепловой карты, удовлетворяющих пороговому условию.
8. Система по п.7, в которой область-кандидат определяется с помощью нескольких тепловых карт, причем несколько тепловых карт содержат первую тепловую карту и одну или более дополнительных тепловых карт, причем каждая из нескольких тепловых карт определяет потенциальное место расположения поля документа, соответствующее полю документа.
9. Система по п.7, в которой соответствующий опорный элемент содержит одно или несколько предопределенных слов или предопределенных графических элементов.
10. Система по п.7, в которой устройство обработки дополнительно выполняет:
извлечение содержимого каждого из нескольких изображений документа, при этом содержимое включается в потенциальное расположение поля документа; и
анализ содержимого каждого изображения документа с помощью токенов байтового парного кодирования (BPE).
11. Система по п.10, в которой для анализа содержимого устройство обработки выполняет:
представление содержимого каждого изображения документа с помощью токенов BPE для получения токенизированного содержимого для каждого изображения документа;
формирование векторного представления токенизированного содержимого для каждого изображения документа;
вычисление расстояния между парой векторного представления токенизированного содержимого двух из нескольких изображений документа и
указание того, что потенциальное расположение поля документа, скорее всего, является правильным, если установлено, что расстояние меньше предопределенного значения.
12. Энергонезависимый машиночитаемый носитель данных, содержащий инструкции, при исполнении которых устройством обработки данных устройство обработки данных:
получает набор данных для обучения, содержащий несколько изображений документа, причем каждое из нескольких изображений документа ассоциировано с соответствующими метаданными набора данных для обучения, где метаданные определяют размеченное расположение поля документа, соответствующее полю документа для каждого из указанных нескольких изображений документа, содержащее переменный текст;
генерирует путем обработки нескольких изображений документа первую тепловую карту, представленную структурой данных, содержащей несколько элементов тепловой карты, соответствующих нескольким пикселям изображения документа, причем в каждом элементе тепловой карты хранится счетчик количества изображений документа, в котором поле документа содержит пиксель изображения документа, ассоциированный с элементом тепловой карты, где указанная тепловая карта определяет потенциальное расположение поля документа относительно соответствующего опорного элемента в ней;
получает изображение входного документа и
определяет в изображении входного документа область-кандидат, содержащую поле документа, причем область-кандидат содержит несколько пикселей изображения входного документа, соответствующих элементам тепловой карты, удовлетворяющих пороговому условию.
13. Носитель по п.12, в котором область-кандидат определяется с помощью нескольких тепловых карт, причем несколько тепловых карт содержат первую тепловую карту и одну или более дополнительных тепловых карт, причем каждая из нескольких тепловых карт определяет потенциальное место расположения поля документа, соответствующее полю документа.
14. Носитель по п.12, в котором соответствующий опорный элемент содержит одно или несколько предопределенных слов или предопределенных графических элементов.
15. Носитель по п.12, в котором устройство обработки выполняет:
извлечение содержимого каждого из нескольких изображений документа, при этом содержимое включается в потенциальное расположение поля документа; и
анализ содержимого каждого изображения документа с помощью токенов байтового парного кодирования (BPE).
| US 10679085 B2, 06.09.2020 | |||
| Способ восстановления спиралей из вольфрамовой проволоки для электрических ламп накаливания, наполненных газом | 1924 |
|
SU2020A1 |
| EP 3437019 B1, 30.09.2020 | |||
| Обработка электронных документов для распознавания инвойсов | 2014 |
|
RU2679209C2 |
| ИЗВЛЕЧЕНИЕ ПОЛЕЙ С ПОМОЩЬЮ НЕЙРОННЫХ СЕТЕЙ БЕЗ ИСПОЛЬЗОВАНИЯ ШАБЛОНОВ | 2019 |
|
RU2737720C1 |

