ОБЛАСТЬ ТЕХНИКИ
[001] Настоящее изобретение относится в целом к обработке изображений, а более конкретно - к системам и способам создания изображений документов и их обработке для последующего использования, включая использование для обучения моделей машинного обучения.
УРОВЕНЬ ТЕХНИКИ
[002] Машинное обучение позволяет вычислительным системам обучаться выполнять задачи, исходя из наблюдаемых данных. Алгоритмы машинного обучения могут позволить вычислительным системам обучаться без явного программирования. Методы машинного обучения могут включать, в том числе, нейронные сети, обучение деревьев решений, глубокое обучение и т.д. Модель машинного обучения, например, нейронная сеть, может использоваться в решениях, относящихся к распознаванию образов, включая оптическое распознавание символов. Наблюдаемые данные в случае распознавания образов могут быть множеством изображений. Нейронная сеть, таким образом, может быть снабжена обучающими выборками изображений, по которым нейронная сеть может научиться распознаванию изображений.
РАСКРЫТИЕ ИЗОБРЕТЕНИЯ
[003] В соответствии с одним или более вариантами реализации настоящего изобретения пример способа создания разметки изображения документа может включать: получение с помощью вычислительной системы множества изображений, содержащих один или более документов; выявление одной или более ключевых точек в каждом из множества изображений; добавление каждого из множества изображений в один или более кластеров, добавление в один или более кластеров включает добавление одной или более ключевых точек каждого из множества изображений к одному или более индексов, связанных с одним или более кластерами, где минимальное количество одной или более ключевых точек соответствует существующим ключевым точкам в одном или более индексах; после обнаружения насыщенности кластера из одного или более кластеров анализ каждого из изображений кластера как изображения-кандидата для генерации эталонного изображения, где анализ включает разметку вдоль границ документа, имеющегося на изображении-кандидате; верификация правильности генерации разметки путем сравнения разметки с границами изображенного документа на нескольких других изображения кластера; и выбор изображения-кандидата в качестве эталонного изображения, если разметка была верифицирована больше заранее определенного количества раз; и использование эталонного изображения, обнаруживающего разметку документа вдоль границ документа, присутствующего на исходном изображении.
[004] В соответствии с одним или более вариантами реализации настоящего изобретения пример системы создания разметки изображения документа может включать: память и процессор, соединенный с памятью, реализованный с возможностью выполнения следующих операций: получение с помощью вычислительной системы множества изображений, содержащих один или более документов; выявление одной или более ключевых точек в каждом из множества изображений; добавление каждого из множества изображений в один или более кластеров, добавление в один или более кластеров включает добавление одной или более ключевых точек каждого из множества изображений к одному или более индексов, связанных с одним или более кластерами, где минимальное количество одной или более ключевых точек соответствует существующим ключевым точкам в одном или более индексах; после обнаружения насыщенности кластера из одного или более кластеров анализ каждого из изображений кластера как изображения-кандидата для генерации эталонного изображения, где анализ включает разметку вдоль границ документа, имеющегося на изображении-кандидате; верификация правильности генерации разметки путем сравнения разметки с границами изображенного документа на нескольких других изображениях кластера; и выбор изображения-кандидата в качестве эталонного изображения, если разметка была верифицирована больше заранее определенного количества раз; и использование эталонного изображения, обнаруживающего разметку документа вдоль границ документа, присутствующего на исходном изображении; и добавление исходного изображения, содержащего разметку документа, в обучающую выборку изображений для обучения модели машинного обучения.
[005] В соответствии с одним или более вариантами реализации настоящего изобретения пример постоянного машиночитаемого носителя данных может включать исполняемые команды, которые при исполнении их обрабатывающим устройством приводят к выполнению обрабатывающим устройством операций, включающих в себя: получение с помощью вычислительной системы множества изображений, содержащих один или более документов; выявление одной или более ключевых точек в каждом из множества изображений; добавление каждого из множества изображений в один или более кластеров, добавление в один или более кластеров включает добавление одной или более ключевых точек каждого из множества изображений к одному или более индексам, связанных с одним или более кластерами, где минимальное количество одной или более ключевых точек соответствует существующим ключевым точкам в одном или более индексах; после обнаружения насыщенности кластера из одного или более кластеров анализ каждого из изображений кластера как изображения-кандидата для генерации эталонного изображения, где анализ включает разметку вдоль границ документа, имеющегося на изображении-кандидате; верификация правильности генерации разметки путем сравнения разметки с границами изображенного документа на нескольких других изображениях кластера; и выбор изображения-кандидата в качестве эталонного изображения, если разметка была верифицирована больше заранее определенного количества раз; и использование эталонного изображения, обнаруживающего разметку документа вдоль границ документа, присутствующего на исходном изображении; и добавление исходного изображения, содержащего разметку документа, в обучающую выборку изображений для обучения модели машинного обучения.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[006] Настоящее изобретение иллюстрируется с помощью примеров, а не способом ограничения, и может быть лучше понято при рассмотрении приведенного ниже описания предпочтительных вариантов реализации в сочетании с чертежами, на которых:
[007] На Фиг. 1А приведена схема компонентов верхнего уровня для примера архитектуры системы в соответствии с одним или более вариантами реализации настоящего изобретения.
[008] На Фиг. 1В приведена блок-схема иллюстративного примера способа создания разметки изображения документа в соответствии с одним или более вариантами реализации настоящего изобретения.
[009] На Фиг. 2 показаны примеры документов в соответствии с одним или более вариантами реализации настоящего изобретения.
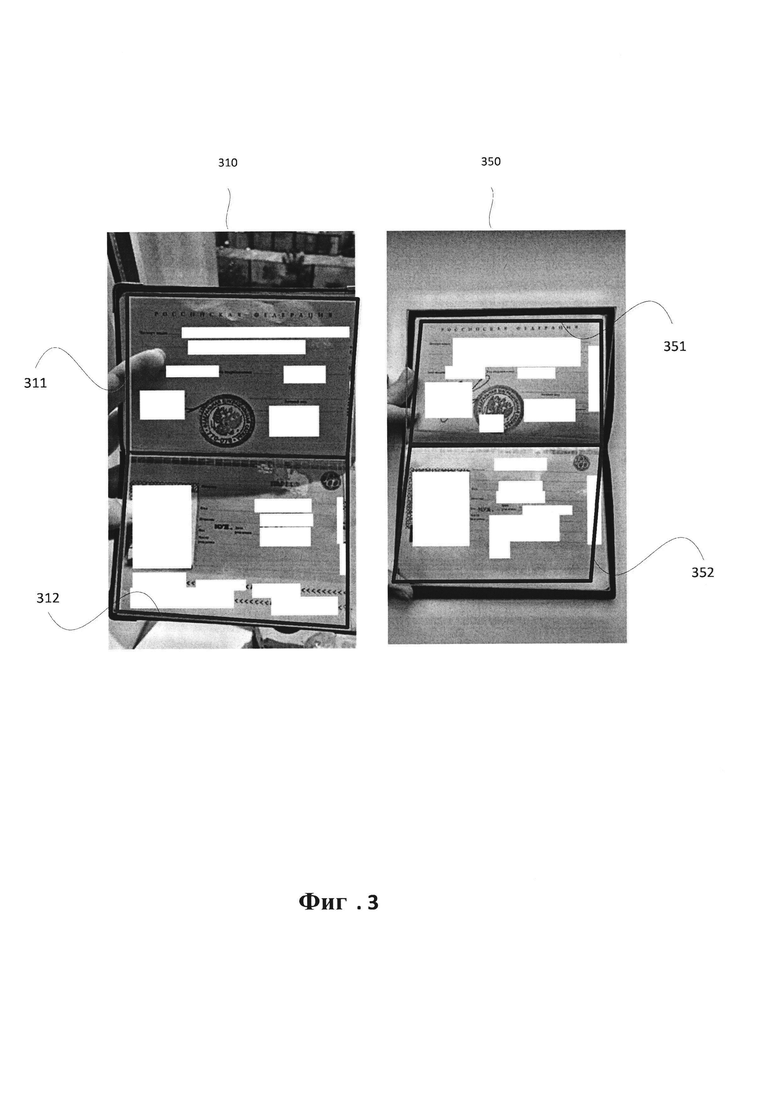
[0010] На Фиг. 3 иллюстрируется пример обнаружения границ на двух изображениях документа в соответствии с одним или более вариантами реализации настоящего изобретения.
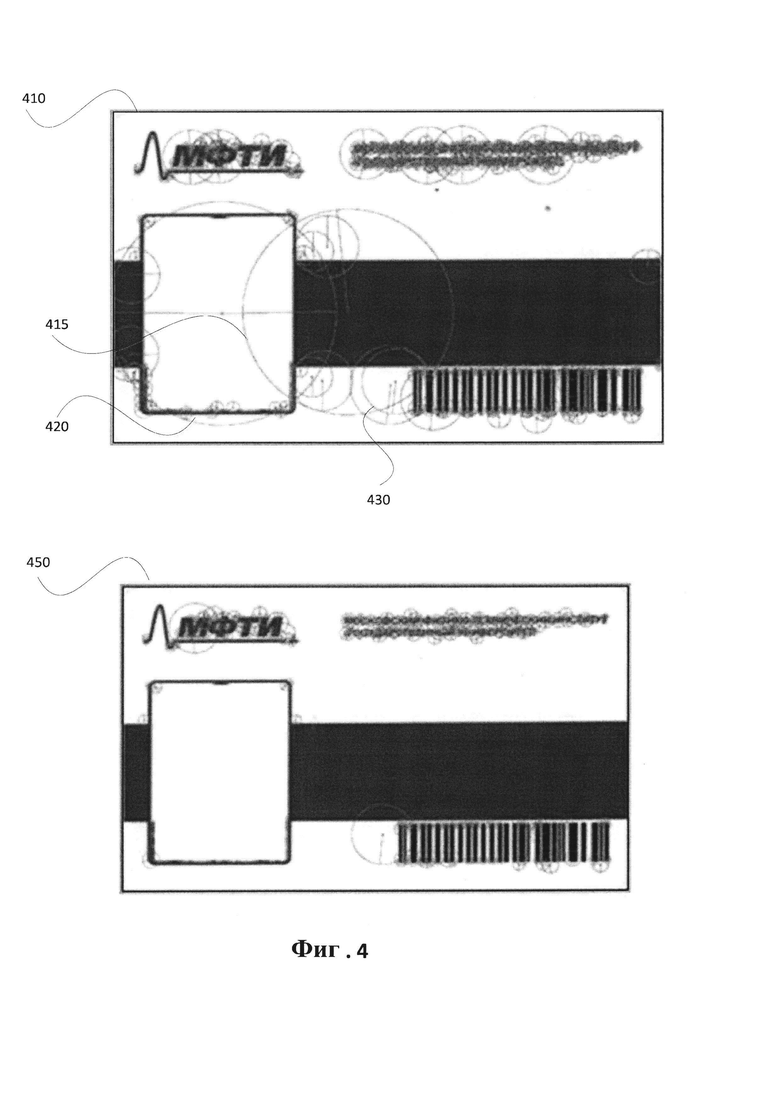
[ООН] На Фиг. 4 иллюстрируется пример фильтрации излишних ключевых точек изображения в соответствии с одним или более вариантами реализации настоящего изобретения.
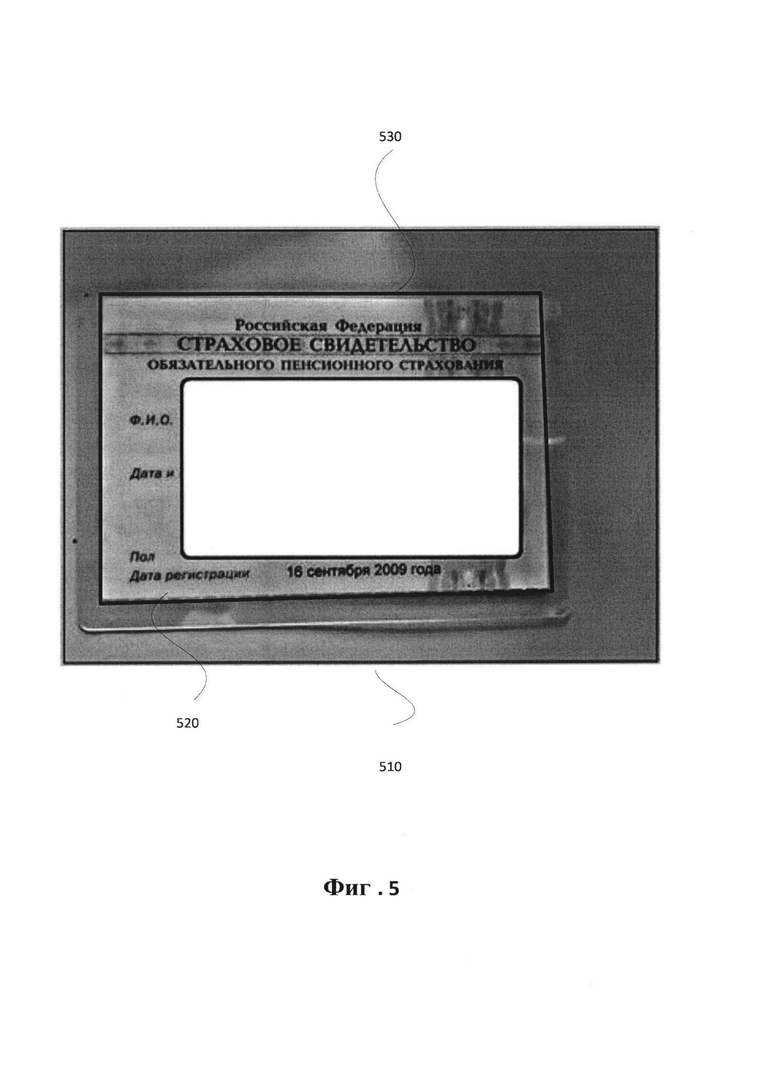
[0012] На Фиг. 5 приведен пример эталонного изображения с разметкой в соответствии с одним или более вариантами реализации настоящего изобретения.
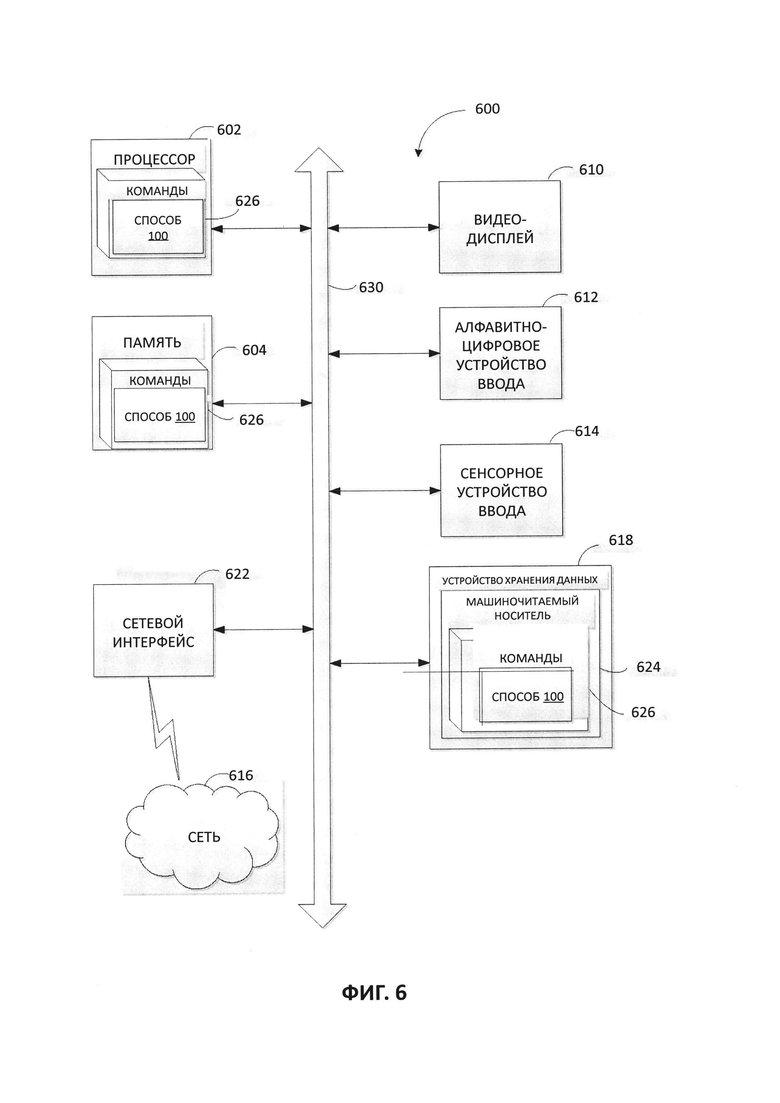
[0013] На Фиг. 6 представлена подробная схема компонентов примера вычислительной системы, внутри которой исполняются инструкции, которые вызывают выполнение вычислительной системой любого из одного или более способов, рассматриваемых в этом документе.
ОСУЩЕСТВЛЕНИЕ ИЗОБРЕТЕНИЯ
[0014] В настоящем документе описываются способы и системы создания разметки изображений документов для обучающего набора изображений для использования в модели машинного обучения.
[0015] В настоящем документе термин «вычислительная система» означает устройство обработки данных, оснащенное универсальным процессором, памятью и по меньшей мере одним интерфейсом связи. Примерами вычислительных систем, в которых могут использоваться способы, описанные в настоящем документе, являются, в частности, настольные компьютеры, ноутбуки, планшетные компьютеры и смартфоны.
[0016] В приведенном ниже описании термин «документ» должен толковаться расширительно, как относящийся к широкому спектру носителей текста, включая, помимо прочего, печатные или написанные от руки бумажные документы, баннеры, постеры, знаки, рекламные щиты и (или) другие физические объекты, несущие видимые символы текста на одной или более поверхностях. В приведенном ниже описании термин «изображение документа» относится к изображению как минимум части исходного документа (например, страницы бумажного документа).
[0017] Документ может быть печатным документом, цифровым документом и т.д. В отличие от печатных документов, которые по своей сути представляют собой изображения, электронные документы содержат последовательности цифровых кодов символов и знаков естественного языка. Может быть желательно преобразовать печатные документы, поскольку электронные документы имеют перед печатными документами преимущества по стоимости, возможностям передачи и рассылки, простоте редактирования и изменения, а также по надежности хранения. Для получения цифровых изображений печатных документов (то есть содержащих текст документов) используются различные способы. Цифровые изображения печатных документов, полученные с помощью электронных сканеров, портативных устройств и мобильных вычислительных устройств (таких как смартфоны, цифровые камеры, видеокамеры, планшеты, портативные компьютеры и т.д.), могут обрабатываться в системах распознавания изображений. Кроме того, цифровые изображения могут обрабатываться вычислительными системами оптического распознавания символов, включая приложения для оптическое распознавание символов, для получения электронных документов, соответствующих печатным документам.
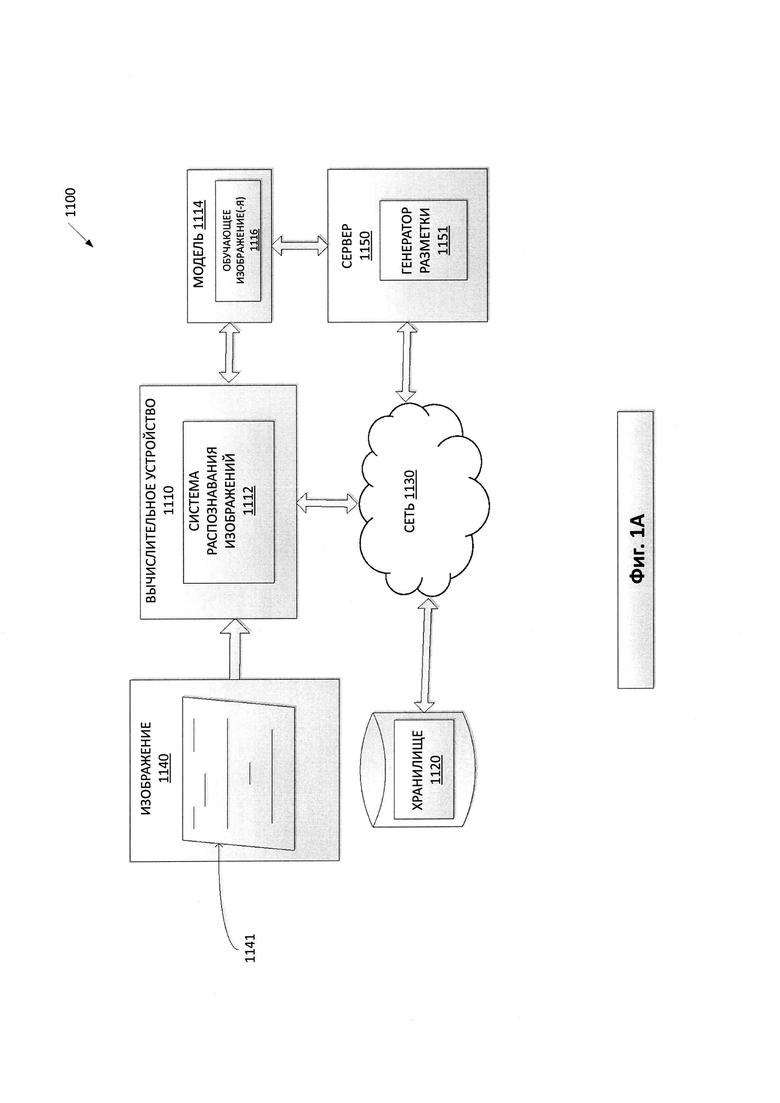
[0018] Распознавание изображений, включая оптическое распознавание символов, может выполняться моделями машинного обучения. Например, нейронную сеть можно использовать в качестве модели машинного обучения для распознавания образов. Модель машинного обучения может поставляться с примерами изображения документов в качестве обучающих выборок изображений, на которых может проходить обучение модель машинного обучения. Эти изображения могут включать цифровые изображения, полученные с помощью электронных сканеров, портативных и мобильных устройств, как описано выше. Эти изображения могут быть связаны с шумом, нестандартным положением и ориентацией считывающего устройства относительно считываемого документа, оптическим размытием, мешающими объектами, фоновым изображением за интересующим нас документом, а также с другими дефектами и зависимостями. Чтобы обучать модель машинного обучения на примерах изображений, примеры изображений должны быть размечены для идентификации на изображении интересующего нас документа. Разметка может производиться вдоль границ интересующего нас документа на изображении. Однако разметка этих изображений вручную может привести к неэффективности, неточности, предрасположенности к ошибкам, медленной работе и трудоемкости. Кроме того, если обучающая выборка для выбранной модели машинного обучения требует большого количества (то есть сотен или тысяч) изображений документов, разметка документов на изображениях вручную может значительно увеличивать затраты и (или) перекрывать преимущества от использования модели машинного обучения.
[0019] Описанные в настоящем документе системы и способы представляют значительные улучшения за счет автоматического создания разметки на множестве обучающих изображений. Описанные в настоящем документе системы и способы представляют улучшения за счет классификации и кластеризации сходных изображений документов, исходя из ключевых точек, выявленных на изображениях, и выбора эталонного изображения для каждого кластера. Разметка эталонного изображения может создаваться вдоль границ документа или его частей, присутствующих на изображении, правильность разметки может быть верифицирована путем сравнения разметки эталонного изображения с разметкой других документов, имеющихся на других изображениях кластера. Таким образом, описанные в настоящем документе системы и способы могут эффективно использоваться для обработки различных изображений документов, включая изображения, полученные портативными и мобильными вычислительными устройствами, которые оборудованы фото- или видеокамерами, и автоматически размечать эти документы на изображениях. Разметка изображения документа может быть создана без участия людей, а также независимо верифицирована на правильность, что повышает эффективность и точность, а также сводит к минимуму затраты ресурсов. Автоматическое создание разметки позволяет включить в обучающую выборку изображений огромное количество различных типов документов и изображений, что повышает точность и полноценность системы распознавания изображений. Обработка изображений эффективно повышает качество распознавания изображений, компенсируя различные искажения изображений. Качество распознавания изображений, производимого системами и способами по настоящему изобретению, обеспечивает значительное повышение точности оптического распознавания символов (OCR) по сравнению с обычными способами получения изображения.
[0020] В одном из иллюстративных примеров представлена вычислительная система, реализующая способы настоящего изобретения, может получать множество изображений, содержащих документы. Обработка изображений может включать поиск ключевых точек в каждом из множества изображений. Каждое из множества изображений может быть добавлено в один или более кластеров, исходя из метрики схожести для ключевых точек изображений. Каждое из изображений кластера может быть проанализировано для построения эталонного изображения. Разметка может создаваться вдоль границ документа, присутствующего на эталонном изображении. Излишние ключевые точки эталонного изображения могут фильтроваться с использованием соответствующего алгоритма, например, стабильного метода оценки параметров модели на основе случайных выборок (RANSAC) или адаптивного RANSAC, частотного фильтра и т.д. Например, излишние ключевые точки вне разметки документа могут быть удалены путем отсечения излишних ключевых точек документа. Подобная фильтрация может выполняться по мере исполнения различных этапов осуществления способа. Вычислительная система может верифицировать правильность выполнения разметки, подтвердив выбор эталонного изображения. Кластеры могут быть уточнены путем исключения кластеров, для которых уже был получен размеченный эталон, кроме того, можно отфильтровать дублирующиеся кластеры. После получения эталона разметки изображения документа эталонное изображение можно использовать для выявления разметки документа на дополнительных случайных входящих изображениях, содержащих документы схожего типа с документами на эталонном изображении. Разметка изображения документа на эталонном изображении, а также разметка документа на любых других случайных изображениях с использованием эталонного изображения может быть автоматически создана моделью машинного обучения без участия человека путем добавления эталонного изображения и (или) случайного изображения к обучающей выборке изображения для обучения модели машинного обучения. Модель машинного обучения может быть машиной опорных векторов, нейронной сетью и т.д. После обучения модель машинного обучения может быть использована для автоматически выявляемой разметки изображений на новом изображении, содержащем документ. Документ далее может быть обработан системой распознавания образов для распознавания содержимого внутри разметки документа.
[0021] Различные аспекты упомянутых выше способов и систем подробно описаны ниже в этом документе с помощью примеров, а не способом ограничения.
[0022] На Фиг. 1А изображена схема компонентов верхнего уровня для примера системной архитектуры 1100 в соответствии с одним или более вариантами реализации настоящего изобретения. Системная архитектура 1100 включает вычислительное устройство 1110, хранилище 1120 и сервер 1150, подключенный к сети 1130. Сеть 1130 может быть общественной сетью (например, Интернет), частной сетью (например, локальная сеть (LAN) или распределенной сетью (WAN)), а также их комбинацией.
[0023] Вычислительное устройство 1110 может выполнять распознавание образов, включая распознавание символов. Вычислительное устройство 1110 может быть настольным компьютером, портативным компьютером, смартфоном, планшетным компьютером, сервером, сканером или любым подходящим вычислительным устройством, которое в состоянии использовать технологии, описанные в этом изобретении. Изображение 1140 может быть получено вычислительным устройством 1110. В одном из примеров изображение 1140 может быть цифровым изображением печатного документа 1141. Изображение 1140 может содержать документ с одним или более предложениями, каждое из которых содержит одно или более слов, состоящих из одного или более символов. Распознавание символов, выполняемое вычислительным устройством 1110, может включать распознавание одного или более символов документа.
[0024] Изображение 1140 может быть получено любым подходящим способом. Например, вычислительное устройство 1110 может получить цифровую копию изображения 1140 путем сканирования документа 1141 или фотографирования документа 1141. Кроме того, в тех вариантах реализации изобретения, где вычислительное устройство 1110 представляет собой сервер, клиентское устройство, которое подключается к серверу по сети ИЗО, может загружать цифровую копию изображения 1140 на сервер. В тех вариантах реализации изобретения, где вычислительное устройство 1110 является клиентским устройством, соединенным с сервером по сети 1130, клиентское устройство может загружать изображение 140 с сервера. Изображение 1140 может содержать документ в одной или более своих частей. В одном из примеров изображение 1140 может содержать документ 1141 во всей его полноте. В другом примере изображение 1140 может содержать часть документа 1141. В еще одном примере изображение 1140 может содержать несколько частей документа 1141.
[0025] Изображение 1140 может использоваться для обучения набора моделей машинного обучения или может быть новым изображением, для которого следует выполнить распознавание. Соответственно, на предварительных этапах обработки изображение 1140, включающее документ 1141, можно подготовить для обучения набора моделей машинного обучения или для последующего распознавания. Например, в изображении 1140 могут быть выявлены границы документа 1141, так что будет возможно выполнить оптическое распознавание символов для части внутри границ документа 1141. Разметка документа может быть создана для документа 1141 вдоль линий границ документа 1141.
[0026] Вычислительное устройство 1100 может содержать систему распознавания изображений 1112. Система распознавания изображений 1112 может содержать инструкции, сохраненные на одном или более физических машиночитаемых носителях данных вычислительного устройства 1110 и выполняемые на одном или более устройствах обработки вычислительного устройства 1110. В одном из вариантов осуществления система распознавания изображений 1112 может использовать набор обученных моделей машинного обучения 1114, которые обучены и используются для распознавания образа 1140, включая содержимое документа 1141 на изображении 1140. Этот набор моделей машинного обучения 1114 может быть обучен на обучающей выборке изображений 1116. Обучающая выборка изображений может быть создана из полученного изображения 1140. Система распознавания изображений 1112 также может предварительно обрабатывать полученные изображения перед использованием этих изображений для обучения моделей машинного обучения 1114 и (или) применения набора обученных моделей машинного обучения 1114 к изображениям. В некоторых вариантах реализации набор обученных моделей машинного обучения 1114 может быть частью системы распознавания изображений 1112 или может быть доступен для обращения с другой машины (например, сервера 1150) через систему распознавания образов 1112. На основе результата работы набора обученных моделей машинного обучения 1114 система распознавания изображений 1112 может распознавать объекты на изображении 1140, например, содержимое документа, включая одно или более предполагаемых слов, предложений, логотипов и т.д. из документа 1141.
[0027] Сервер 1150 может быть стоечным сервером, маршрутизатором, персональным компьютером, карманным персональным компьютером, мобильным телефоном, портативным компьютером, планшетным компьютером, фотокамерой, видеокамерой, нетбуком, настольным компьютером, медиацентром или их сочетанием. Сервер 1150 может содержать генератор разметки 1151. Набор моделей машинного обучения 1114 может сослаться на артефакты модели, например, обучающие изображения 1116, которые были размечены генератором разметки 1151. Для того чтобы обучить набор моделей машинного обучения 1114 распознавать документы на изображениях, обучающее изображение 1116 нуждается в идентификации документа внутри изображения 1116 путем разметки документа, присутствующего на изображении 1116. Генератор разметки 1151 может создавать разметку вдоль границ документа, присутствующего на изображении 1116, и предоставлять набор моделей машинного обучения 1114 с изображением 1116, которое содержит разметку. Набор моделей машинного обучения 1114 может быть составлен, например, из одного уровня линейных или нелинейных операций (например, машины опорных векторов [SVM]) или может представлять собой глубокую сеть, то есть модель машинного обучения, составленную из нескольких уровней нелинейных операций. Примерами глубоких сетей являются нейронные сети, включая сверточные нейронные сети, рекуррентные нейронные сети с одним или более скрытыми слоями и полносвязные нейронные сети.
[0028] Набор моделей машинного обучения 1114 может быть обучен распознаванию содержимого изображения 1140 и документа 1141 с использованием обучающих данных. После обучения набора моделей машинного обучения 1114 набор моделей машинного обучения 1114 может быть использован в системе распознавания изображений 1112 для анализа новых изображений. Например, система распознавания изображений 1112 может получать на входе изображение документа 1141, полученное из изображения 1140, для анализа с помощью набора моделей машинного обучения 1114. Система распознавания изображений 1112 может получать один или более итоговых результатов от набора обученных моделей машинного обучения и может извлекать из итоговых результатов одно или более предполагаемых результатов для документа 1141. В одном из примеров эти предполагаемые результаты могут содержать вероятную последовательность слов, и каждое слово может содержать вероятную последовательность символов.
[0029] Хранилище 1120 может быть постоянной памятью, которая в состоянии сохранять изображение 1140 и (или) документ 1141, а также структуры данных для разметки, организации и индексации содержимого документа 1141. Хранилище 1120 может располагаться на одном или более запоминающих устройствах, таких как основная память, магнитные или оптические запоминающие устройства на основе дисков, лент или твердотельных накопителей, NAS, SAN и т.д. Несмотря на то, что хранилище изображено отдельно от вычислительного устройства 1110, в одной из реализаций изобретения хранилище 1120 может быть частью вычислительного устройства 1110. В некоторых вариантах реализации хранилище 1120 может представлять собой подключенный к сети файловый сервер, в то время как в других вариантах реализации изобретения хранилище содержимого 1120 может представлять собой какой-либо другой тип энергонезависимого запоминающего устройства, например, объектно-ориентированной базы данных, реляционной базы данных и т.д., которая может находиться на сервере или одной или более различных машинах, подключенных к нему через сеть 1130.
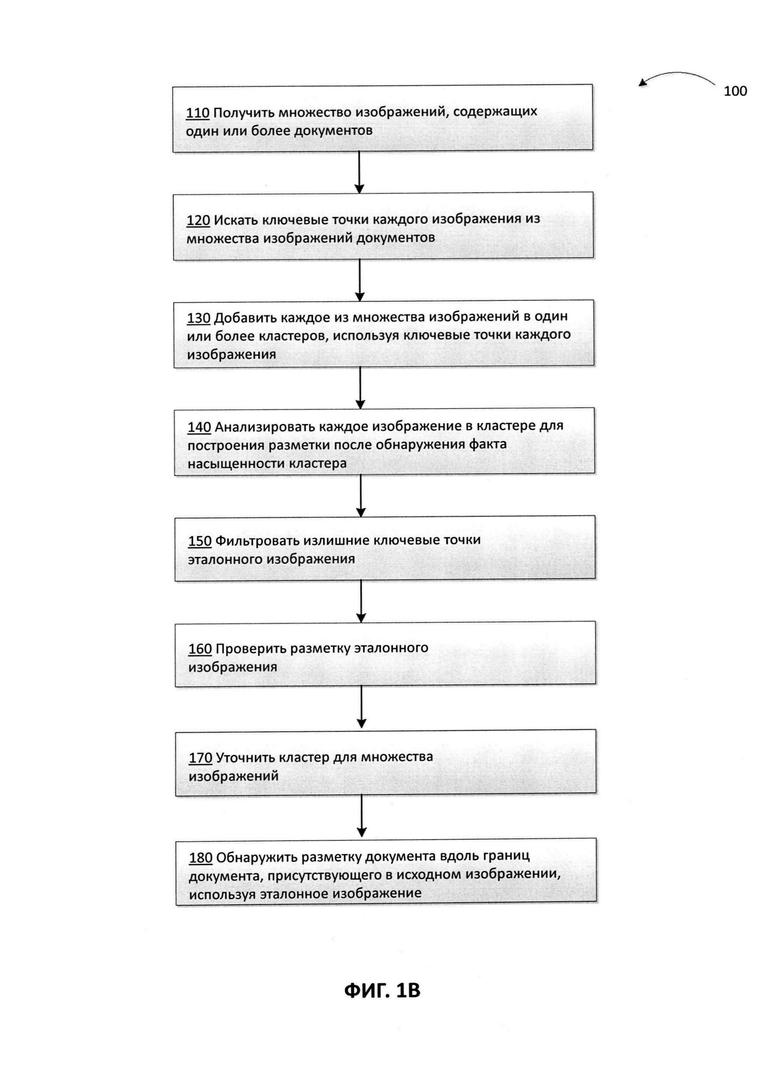
[0030] На Фиг. 1В приведена блок-схема иллюстративного примера способа 100 создания разметки изображения документа для множества документов в соответствии с одним или более вариантами реализации настоящего изобретения. Способ 100 и (или) каждая из его отдельно взятых функций, процедур, подпрограмм или операций могут осуществляться с помощью одного или более процессоров вычислительной системы (например, вычислительной системы 600 на Фиг. 6), реализующей этот способ. В некоторых реализациях способ 100 может быть реализован в одном потоке обработки. В качестве альтернативы способ 100 может выполняться с использованием двух и более потоков обработки, при этом каждый поток выполняет одну или более отдельных функций, стандартных программ, подпрограмм или операций способа. В одном из иллюстративных примеров потоки обработки, в которых реализован способ 100, могут быть синхронизированы (например, с использованием семафоров, критических секций и (или) других механизмов синхронизации потоков). При альтернативном подходе потоки обработки, реализующие способ (100), могут выполняться асинхронно по отношению друг к другу. Таким образом, несмотря на то что Фиг. 1В и соответствующее описание содержат перечень действий для способа 100 в определенном порядке, в различных вариантах осуществления способа по меньшей мере некоторые из описанных операций могут выполняться параллельно и (или) в произвольно выбранном порядке. В одном из вариантов осуществления способ 100 может быть осуществлен с помощью генератора разметки 1151 на Фиг. 1В.
[0031] На шаге ПО вычислительная система, реализующая способ, может получить множество изображений документов. Это множество изображений может содержать различные типы документов. Например, различные типы документов могут включать, не ограничиваясь этим, паспорт, водительские права, идентификационные карты, страховое свидетельство, сертификаты и т.д. Например, на Фиг. 2 приведены различные документы 210, 220, 230, 240, 250 и 260. Эти документы могут быть печатными документами. Цифровые изображения этих документов могут быть получены с помощью различных способов и устройств, таких как электронный сканер, смартфон, цифровая камера и т.д. Получение изображений может быть выполнено с помощью фото- или видеокамер. Цифровые изображения, содержащие документ, могут поступать в вычислительную систему в виде множества изображений документов.
[0032] Изменение положения устройства получения изображений относительно исходного документа может привести к разнице в углах, масштабе изображения, различным оптическим искажениям изображения, вызванным различиями в углах съемки, разному положению исходного документа на кадре изображения и (или) разному положению различных визуальных артефактов, таких как блики или тени. Кроме того, различия в условиях получения изображений могут быть вызваны разницей в скорости затвора, диафрагме, фокусном расстоянии и (или) наличием внешних объектов, как минимум частично перекрывающих исходный документ, что может привести к различиям в яркости, резкости, бликам, смазам и (или) другим особенностям изображения и визуальным артефактам. Эти факторы могут наложиться на трудности, существующие между различными изображениями одного и того же или похожих документов.
[0033] Каждое из множества изображений может содержать документ или одну или более его частей. В одном из примеров изображение может содержать документ полностью. В другом примере изображение может содержать часть документа. Например, изображение может содержать половину документа, например, половину страницы паспорта. Некоторые из множества изображений могут содержать один и тот же документ, некоторые могут содержать документы похожих типов, а некоторые могут содержать документы совершенно разных типов. Некоторые из этих документов могут иметь много общих характеристик, признаков или элементов, у других документов их небольшое количество. Изображения, которые могут содержать один и тот же документ, могут иметь больше всего общих признаков, однако могут оставаться различными по многим причинам, например, из-за различного положения устройство формирования изображения, вариации условий формирования изображения и т.д., как было указано выше. Документы одного типа могут иметь значительное количество общих признаков. Например, документы 230, 250 и 260 на Фиг. 2 представляют собой примеры водительских прав и их признаки, такие как фотографии, идентификационные номера, подписи, логотипы, заголовки и т.д., которые могут совпадать. Документ другого типа, например, документы 210 и 220, по сравнению с документами 230, 250 и 260, могут иметь некоторое количество одинаковых признаков, но множество признаков не будут совпадать. Например, документ 210 содержит логотип 212, и документ 250 также содержит логотип 252. Однако эти два документа также имеют множество других признаков, которые не пересекаются.
[0034] Множество изображений могут быть получены из различных источников. Например, изображения могут находиться в существующей папке или вычислительной системе, в динамическом хранилище квитанций в распределенной системе, в одиночной системе в паспортном столе, на сервере дорожной полиции и т.д. Эти изображения могут содержать документы, такие как логотипы, государственные регистрационные знаки автотранспорта, баннеры и т.д. Изображение может содержать одиночный документ, несколько страниц одного документа или несколько документов. Множество изображений могут быть введены в вычислительную систему, реализующую способы, описанные в настоящем документе. Изображения могут вводиться по одному за раз, один за другим или пакетом.
[0035] На шаге 120 вычислительная система может выполнить поиск ключевых точек каждого изображения из множества изображений документов. Для представления каждого изображения с целью поиска ключевых точек в изображениях можно использовать модель «мешка визуальных слов» (BoW - «Bag of visual words»). Изображение может содержать различные признаки. В модели BoW признаки изображения рассматриваются как визуальные слова. «Мешок визуальных слов» определяется как вектор счетчиков вхождений в словарь локальных признаков изображения. Таким образом, эмпирическое распределение визуальных слов может быть выявлено путем пересчета вхождений каждого визуального слова в визуальный словарь в определенном изображении.
[0036] Для каждого изображения в множестве изображений, представляемого «мешком визуальных слов», можно извлечь ряд ключевых точек. Ключевые точки могут быть местами или точками на изображении, расположенными внутри изображения. Ключевые точки изображения могут соответствовать различным признакам визуальных слов в мешке визуальных слов этого изображения. Ключевые точки могут быть особыми инвариантными признаками изображения. В каждом изображении может быть выявлено и извлечено определенное количество ключевых точек. Определенное количество может быть заранее определенным числовым значением или процентом от общего количества ключевых точек в изображении. Выявленные ключевые точки могут быть центрами масс (центроидами) слов в мешке визуальных слов изображения.
[0037] В одном из иллюстративных примеров вычислительная система может искать ключевые точки в изображении документа 240, приведенном на Фиг. 2. В результате поиска вычислительная система может выявлять в изображении признаки или визуальные слова, и ключевые точки, соответствующие этим признакам. Например, как показано на Фиг. 4, вычислительная система может выявлять ключевые точки, проиллюстрированные множеством окружностей на изображении 410 документа 250 (показан на Фиг. 2), например, ключевые точки 415, 420 и 430.
[0038] Для каждой обнаруженной ключевой точки может быть определен один или более дескрипторов ключевых точек, представленных векторами, описывающими данные изображения в визуальной близости от этой ключевой точки. Для упрощения сопоставления ключевых точек на нескольких изображениях дескрипторы ключевых точек можно выбрать инвариантными по отношению к освещенности, шуму, положению и поворотам камеры и (или) другим факторам, которые могут включать искажение изображения. В различных иллюстративных примерах для выявления ключевых точек и получения соответствующих им дескрипторов могут использоваться один или более способов, например, масштабно-инвариантная трансформация признаков (SIFT), аффинная SIFT (ASIFT), робастные ускоренные признаки (SURF), Oriented FAST и Rotated BRIEF (ORB) и др.
[0039] Применение алгоритма SIFT к изображению, например, может создавать набор ключевых точек, которые могут быть особыми точками изображения, с координатами (х, y) относительно осей координат изображения, обычно параллельных верхней и левой границами изображения. Эти точки выбираются так, чтобы они были относительно инвариантными к преобразованию изображения, масштабированию и повороту, а также частично инвариантными к изменениям освещения и аффинным проекциям. Кроме извлечения ключевых точек изображения, из изображения могут извлекаться дополнительные признаки, такие как наличие или отсутствие других фотографий, углов, пятен и т.д. Дальнейшие способы вычисления дескрипторов ключевых точек и извлечения дополнительных признаков могут быть реализованы в соответствии с одним или более аспектами, описанными в United States Patent Application №15/279,903, она в полном объеме включена в настоящий документ.
[0040] На шаге 130 вычислительная система может добавить каждое из множества изображений в один или более кластеров, используя ключевые точки каждого изображения. Кластеризация может включать разбивку набора изображений на группы. Группы могут быть связаны с ключевыми точками изображений и дескрипторами ключевых точек. В некоторых вариантах осуществления кластеризация может проводиться таким образом, что внутри каждой группы могут находиться изображения, соответствующие заданной метрике схожести. В одном из вариантов осуществления может быть определена метрика качества кластера, в соответствии с которой производится кластеризация. Например, метрика качества кластера может характеризоваться мерой точности и полноты. В одном из вариантов осуществления от кластера может требоваться иметь минимальное значение точности и (или) полноты. Точность можно определить как количество изображений, правильно отнесенных к данному кластеру, деленное на общее количество изображений в кластере. Полноту можно определить как количество изображений, правильно отнесенных к данному кластеру, деленное на общее количество изображений, которые могут быть правильно отнесены к данному кластеру. Точность и полнота, используемые в осуществлении изобретения, могут быть выражены следующим образом:


[0041] Каждое из множества изображений может быть сгруппировано в один или более кластеров по одному изображению за раз. В одном из вариантов осуществления каждый кластер может быть связан с индексом. Для каждого изображения из множества изображений выявленные ключевые точки изображений могут быть добавлены в индекс, связанный с кластером. В качестве иллюстративного примера ключевые точки могут быть добавлены в индекс локально-чувствительного хэширования (LSH). LSH уменьшает размерность данных высокой размерности и исходных элементов так, что сходные элементы с высокой вероятностью распределяются по одним и тем же группам. Индекс LSH включает построение гиперплоскостей для ключевых точек. Гиперплоскость представляет собой подпространство одной размерности, меньшей чем окружающее пространство. То есть, если пространство 3-мерное, его гиперплоскости будут 2-мерными плоскостями, а если пространство 2-мерное, его гиперплоскости будут 1-мерными линиями.
[0042] В некоторых вариантах осуществления выявленные ключевые точки изображения добавляются в один или более индексов, связанных с одним или более кластеров. Например, могут использоваться несколько индексов LSH. В одном из примеров могут использоваться несколько индексов LSH с различными заранее заданными параметрами. Заранее заданные параметры определяют номер гиперплоскости и количество ключевых точек данного индекса.
[0043] В одном из вариантов осуществления выявленные ключевые точки изображения, которое в настоящий момент кластеризуется, могут быть оценены во взаимосвязи с одним или более существующих индексов. Выявленные ключевые точки могут добавляться к данному индексу, если дескрипторы ключевых точек текущего изображения совпадают с дескрипторами существующих ключевых точек, включенных в данный индекс. В некоторых вариантах осуществления дескрипторы текущего изображения и центроид внутри данного индекса могут считаться совпадающими, если некоторое минимальное число ключевых точек текущего изображения совпадает с существующими ключевыми точками данного индекса.
[0044] В отдельных вариантах осуществления для оценки соответствия двух ключевых точек друг другу вычисляется расстояние Хэмминга между двумя ключевыми точками. Расстояние Хэмминга измеряет количество несоответствий между двумя векторами. Например, расстояние Хэмминга между двумя строками одинаковой длины равно количеству позиций, в которых соответствующие символы различны. В некоторых вариантах осуществления, если расстояние Хэмминга между дескрипторами ключевых точек определенной ключевой точки текущего изображения и определенной ключевой точки данного индекса меньше заранее указанного порогового значения, эти две ключевые точки могут считаться совпадающими или соответствующими друг другу. В отдельных вариантах осуществления совпадающие пары могут фильтроваться в соответствии с заданным расстоянием Хэмминга. Фильтрация может свести к минимуму ложные совпадения.
[0045] В одном из вариантов осуществления один или более индексов могут инициализироваться. Инициализация может включать присвоение индексам начальных значений. Значение хэша может назначаться дескриптору ключевой точки в зависимости от индекса, к которому она принадлежит.
[0046] В некоторых вариантах осуществления оценка ключевых точек текущего изображения может производиться по отношению ко всем существующим индексам, связанные с одним или более кластерами. Если ключевые точки текущего изображения считаются совпадающими (то есть одинаковыми) с ключевыми точками более чем одного индекса, совпадающие ключевые точки текущего изображения могут быть добавлены в любой индекс, где имеется совпадение. Если совпадения отсутствуют, может быть создан новый кластер, и ключевые точки могут быть добавлены к индексу, связанному с новым кластером.
[0047] Оценка следующих изображений из множества изображений может осуществляться через любой из существующих индексов. Ключевые точки последующих изображений могут сравниваться с ключевыми точками существующих индексов в соответствии с вариантами осуществления, описанными выше. Если ключевые точки соответствуют ключевым точкам каких-либо индексов, ключевые точки следующего изображения могут быть добавлены к каждому из соответствующих индексов.
[0048] В отдельных вариантах осуществления можно собирать статистику о количестве дескрипторов, входящих в каждый кластер, из набора дескрипторов ключевых точек. В качестве иллюстративного примера для записи статистики о вхождении дескрипторов в кластер можно использовать таблицу дескрипторы-кластеры. В некоторых вариантах осуществления статистика о вхождении дескрипторов может использоваться для приписывания изображений к конкретному кластеру. Например, вычислительная система может добавлять изображение к определенному кластеру, если этот определенный кластер имеет большое количество дескрипторов, совпадающих с изображением. В некоторых вариантах осуществления могут быть установлены определенные критерии для выявления большого количества совпадений. Вычислительная система может использовать в качестве критерия числовое значение или процент совпадений. В отдельных вариантах осуществления если изображение назначается отдельному кластеру на основании большого количества совпадений ключевых точек, ключевые точки изображения, которые изначально не принадлежали к индексу, связанному с этим отдельным кластером, также могут быть добавлены в индекс и помечены как принадлежащие к этому кластеру.
[0049] В некоторых вариантах осуществления ключевые точки изображения могут соответствовать более чем одному индексу, связанному с более чем одним кластером. Изображение может быть добавлено к каждому из этих кластеров, с которым имеются совпадения, и ключевые точки могут быть добавлены к каждому из соответствующих индексов. В некоторых вариантах осуществления, если изображение добавляется в заранее определенное количество или процент кластеров, это изображение может быть добавлено во все существующие кластеры. В некоторых вариантах осуществления при отсутствии совпадений изображения с существующими кластерами, для изображения может быть создан новый кластер, и изображение может быть добавлено в этот новый кластер. В качестве иллюстративного примера отсутствии совпадений изображения с существующими кластерами может встретиться, если признаки изображения отличаются от признаков всех ранее включенных в кластеры изображений.
[0050] В отдельных вариантах осуществления вычислительная система может определять критерий или меру совпадения, с использованием которой может производиться определение, добавлять ли изображение в кластер. В качестве иллюстративного примера вычислительная система может настроить меру М, так что если больше М % ключевых точек изображения находится в кластере С, то вычислительная система назначает кластер С всем ключевым точкам изображения. Этот критерий может быть равен 60%, 70%, 80% или другой настраиваемой величине. В другом примере вычислительная система может настроить меру К, так, что если больше К % ключевых точек изображения не добавлены к одному из существующих кластеров, создается новый кластер для всех ключевых точек изображения. В еще одном примере вычислительная система может настроить число N, так, что если все ключевые точки изображения добавлены в более чем N кластеров, вычислительная система может удалить эти ключевые точки из индекса. Мера М, мера К и (или) число N могут настраиваться или заранее определяться компьютерной системой.
[0051] В некоторых вариантах осуществления при добавлении нового изображения в кластер, кластер может отслеживаться для обнаружения факта насыщенности кластера. Мера насыщенности кластера может настраиваться или заранее определяться компьютерной системой. Кластер может считаться насыщенным, когда в кластере окажется определенное количество изображений. Вычислительная система может определить предельное количество изображений, при котором кластер считается насыщенным. В одном из примеров кластер может считаться насыщенным, если кластер содержит 12, 13, 14, 15 или другое настраиваемое или заранее заданное количество изображений.
[0052] На шаге 140 вычислительная система может анализировать каждое изображение в кластере для построения разметки после обнаружения факта насыщенности кластера. Если кластер насыщен, перед построением эталонного изображения может быть выполнена проверка внутриклассовой геометрии всех изображений в кластере. Эталонное изображение может быть создано в кластере после внутриклассовой верификации геометрии используемых изображений, например, по алгоритму RANSAC для совпадающих пар. В отдельных вариантах осуществления каждое из изображений документа может последовательно рассматриваться в качестве изображения-кандидата для построения эталонного изображения. В некоторых вариантах осуществления вдобавок к ключевым точкам, уже извлеченным для проведения кластеризации, из изображения могут быть извлечены дополнительные ключевые точки. Например, могут быть извлечены фотография или дополнительное количество ключевых точек, ассоциированных с документом, присутствующим на изображении.
[0053] В некоторых вариантах осуществления анализ изображений для построения эталона может включать сравнение каждого изображения-кандидата документа со всеми остальными изображениями документа. Ключевые точки текущего кандидата могут сравниваться с ключевыми точками всех остальных изображений документа в кластере. Сравнение может определить одно из изображений документа как наилучшим образом совпадающее со всеми изображениями в кластере. В качестве иллюстративного примера может использоваться алгоритм Быстрой библиотеки для аппроксимации ближайших соседей (FLANN) на основе k-d деревьев. Библиотека FLANN содержит коллекцию алгоритмов, оптимизированных для быстрого поиска ближайших соседей в больших наборах данных. K-d дерево - это структура данных для разбиения пространства, позволяющая организовывать точки в k-мерном пространстве. При использовании библиотеки FLANN можно выбрать из кластера исходное изображение для построения эталонного изображения. Если применять этот алгоритм, можно сравнить исходное изображение с каждым из оставшихся изображений в кластере, чтобы найти ближайшее совпадающее изображение. Каждое последующее изображение можно сравнивать с другими изображениями в кластере таким же образом, пока из агрегированного сравнения не будет получено наилучшее совпадение. Другие алгоритмы подобного рода могут включать, не ограничиваясь этим, SIFT, BRISK-LSH и т.д. В некоторых вариантах осуществления оставшиеся фотографии, извлеченные из изображения, могут использоваться при построении эталонного изображения, однако дополнительные фотографии или другие признаки могут не быть необходимы для идентификации изображения как эталонного изображения.
[0054] В одном из вариантов осуществления вычислительная система может использовать для построения эталонного изображения исходное идентифицированное изображение. В отдельных вариантах осуществления эталонное изображение может содержать изображение документа, содержащее выровненный документ. В одном из примеров изображение документа может содержать только статические поля. Статическое поле может быть полем, которое присуще определенному типу документов. Статическое поле может включать признаки изображения, общие для всех документов определенного типа документов. Примеры статических полей могут включать поле «фотография» для водительских прав, поле «имя» для паспортов и т.д. В некоторых вариантах осуществления эталонное изображение может не содержать каких-либо дополнительных признаков, отличающихся от признаков приведенного здесь документа. В некоторых вариантах осуществления эталонное изображение может быть построено с использованием следующих способов, реализованных в соответствии с одним или более аспектами, описанными в United States Patent Application №15/279,903, которая включена в настоящий документ.
[0055] В одном из вариантов осуществления эталонное изображение строится с использованием изображения документа кластера, вычислительная система может определить разметку для идентификации документа, присутствующего на эталонном изображении. Например, может быть создана разметка вдоль границ документа, присутствующего на эталонном изображении. Эта разметка может использоваться в качестве стандартной эталонной разметки, которая может применяться для разметки документов аналогичного типа. В одном из вариантов осуществления может быть запущен механизм для определения границ документа. Как показано на Фиг. 3, вычислительная система может выявить границы документа, присутствующего на изображении 310, где границы представлены в виде рамок 311 и 312. Аналогично, для документа, присутствующего на изображении 350, границы представлены в виде рамок 351 и 352. Дальнейшие способы поиска границ могут быть реализованы в соответствии с одним или более аспектами, описанными в United States Patent Application №15/195,759, она в полном объеме включена в настоящий документ.
[0056] На шаге 150 вычислительная система может отфильтровать излишние ключевые точки из эталонного изображения. Излишние ключевые точки могут переполнить память. В различных иллюстративных примерах для выявления точек-выбросов в наборе ключевых точек эталонного изображения и отсечения этих выбросов могут использоваться один или более способов, например, стабильного метода оценки параметров модели на основе случайных выборок (RANSAC) или адаптивного RANSAC, частотного фильтра и т.д. Например, на Фиг. 4 показано эталонное изображение 410 до фильтрации излишних ключевых точек, к которым относятся, например, ключевые точки 415, 420 и т.д. На Фиг. 4 также показано отфильтрованное эталонное изображение 450, на котором, например, отсутствуют излишние ключевые точки 415 и 420, которые были отфильтрованы с эталонного изображения 410.
[0057] На шаге 160 вычислительная система может верифицировать разметку эталонного изображения. В одном из вариантов осуществления разметка может быть верифицирована путем сравнения разметки с границами аналогичных документов, присутствующих на других изображениях. Изображения для сравнения с эталонным изображением могут быть выбраны из того же кластера, что и эталонное изображение. В некоторых вариантах осуществления для этой цели может выбираться случайный набор изображений. Количество изображений может быть настраиваемым. В некоторых вариантах осуществления отмечаются ложно-правдивые совпадающие пары изображений. В одном из иллюстративных примеров, если расстояние от позиции углов разметки в первом изображении превышает, например, 10% от размера изображения до углов (разметки) на следующем изображении, эта разметка может быть признана ложно-правдивым совпадением. В одном из вариантов осуществления разметка эталонного изображения может считаться правильно выполненной, а значит верифицированной, если разметка совпадает с определенной граничной величиной (например, 50%) других размеченных документов, с которыми сравнивается эталонное изображение. В другом варианте осуществления, если разметка эталонного изображения была подтверждена другими размеченными документами больше заранее установленного количества раз, эта разметка считается верифицированной как размеченное эталонное изображение.
[0058] Эталонное изображение может включать разметку документа, имеющегося на эталонном изображении, как идентифицированную и верифицированную вычислительной системой. В одном из иллюстративных примеров, как показано на Фиг. 5, изображение 510 идентифицировано как эталонное изображение, и может быть создана разметка для документа 520, имеющегося на этом изображении, эта разметка представлена рамкой 530 вдоль границы документа.
[0059] На шаге 170 вычислительная система может уточнить кластеры для множества изображений. Уточнение может включать фильтрацию дополнительных индексов, связанных с кластером, после получения эталонного изображения. В одном варианте осуществления, если найдено подтвержденное эталонное изображение для разметки документа, все кластеры проверяются, чтобы выявить наличие в них эталонного изображения. Если эталонное изображение обнаружено хотя бы в одном или более дополнительных кластеров, то кластер, содержащий это изображение, может быть исключен. Этот тип уточнения кластеров позволяет динамически уменьшать размерность вычислительной системы путем итеративной обработки следующих наборов изображений.
[0060] На шаге 180 вычислительная система может обнаруживать разметку документа вдоль границ документа, присутствующего в исходном изображении, используя эталонное изображение. Например, исходное изображение может включать случайное изображение. Документ, присутствующий на исходном изображении, может быть документом того же типа, что и документ на эталонном изображении. Вычислительная система может добавить исходное изображение в обучающую выборку изображений для обучения модели машинного обучения. Вычислительная система может также добавить эталонное изображение к обучающей выборке изображений.
[0061] В некоторых вариантах реализации за счет использования эталонного изображения можно обнаруживать границы случайных изображений, содержащих документы схожих типов. Например, может быть возможно обнаруживать границы документов того же типа в других случайных изображениях, исходя из отношения масштабов документов и углов между основными направлениями. В одном из вариантов осуществления изображение может поступать в вычислительную систему для обнаружения границ. Из исходного изображения могут быть извлечены ключевые точки, и для каждой ключевой точки могут быть вычислены дескрипторы ключевых точек. Дескриптор исходного изображения может сравниваться с дескрипторами обученного эталонного изображения с разметкой. Например, сравнение может использовать k-d деревья, адаптивный RANSAC и др. алгоритмы, как было описано раньше. В одном из примеров сравнение может включать выбор наилучшей модели трансформации М, для которой вычислительная система может получить набор ключевых точек, удовлетворяющих модели. Модель М может быть выражена как:
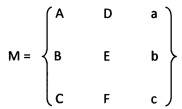
где М - матрица аффинного преобразования к однородным координатам (х, y),
А, В, D и Е - нормализованные коэффициенты (то есть коэффициенты аффинного преобразования без сдвига) однородных координат (х, y),
С и F - аффинное преобразование с отклонением,
а и b - простое преобразование, и
с - нормализованный коэффициент, который обеспечивает разрешимость системы уравнений.
[0062] Модель преобразования М является видом в двухмерном пространстве. Например, с 4 парами точек можно написать 8 уравнений. Таким образом, для ранее описанной модели преобразования вычислительная система может взять с=1.
[0063] Для каждой точки X из набора ключевых точек может быть создано уравнение следующего вида:
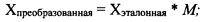
где Хпреобразованная представляет преобразованную точку X исходного изображения; и
Хэталонная представляет точку X эталонной точки.
[0064] Описанное выше преобразование для исходного изображения может использоваться с переопределенной системой. В одном из примеров проблема оптимизации, относящаяся к вычислению, была решена путем использования одного из методов, например, метода наименьших квадратов (МНК) с начальным приближением М. Полученное преобразование можно применить к точкам углов (то есть угловым точкам) эталонного изображения, в результате могут быть получены соответствующие точки исходных изображений (то есть искаженных изображений). Перспективное искажение может быть устранено, например, использованием подходящего метода. В одном из примеров подходящий метод коррекции перспективных искажений может быть реализован в соответствии с одним или более аспектами, описанными в упоминавшемся выше документе United States Patent Application №15/279,903.
[0065] Кроме того, вычислительная система может обнаруживать новые изображения документов, вводимые в систему, и выявлять эталонные изображения для этих изображений. Таким образом, система может динамически развиваться по мере ввода в систему новых изображений. Эталонное изображение может динамически переобучаться при добавлении в вычислительную систему новых наборов изображений документов. В одном из вариантов осуществления переобучение может включать установку счетчика, указывающего количество изображений. В одном из вариантов осуществления количество изображений может быть заранее определенным числом. Например, количество изображений может быть установлено в 30 или 45 изображений. В другом примере количество изображений может быть связано с мерой насыщенности. Например, количество может быть равно мере насыщенности, умноженной на два или три. В таком случае, если мера насыщенности равна 15 изображениям, а счетчик указывает, что установленное количество изображений втрое больше меры насыщенности, количество для переобучения будет равно 45 изображений. После достижения значения счетчика может быть сделана попытка переобучить эталонное изображение. Если переобучение эталонного изображения невозможно, например, потому что не удается верифицировать разметку эталонного изображения, может оставаться возможность вернуться к предыдущему эталонному изображению. Если переобучение прошло успешно, новое переобученное эталонное изображение скорее всего будет иметь улучшенное качество. Вычислительная система также может установить ограничение для переобучения, например, максимальное число, такое, что когда это максимальное число будет достигнуто, вычислительная система может не производить дальнейших попыток переобучить эталон кластера. Например, вычислительная система может определить максимальное число в 3 или 4 раза больше меры насыщенности, так что после того, как кластер будет насыщен больше 3 или 4 раз, вычислительная система может не производить дальнейших попыток переобучения эталона.
[0066] Вычислительная система также может быть в состоянии классифицировать документы, используя механизмы кластеризации, описанные в данном осуществлении изобретения. Кроме того, вычислительная система может автоматически обрезать контур документов на эталонном изображении.
[0067] На Фиг. 6 представлена подробная схема компонентов примера вычислительной системы, внутри которой исполняются инструкции, которые вызывают выполнение вычислительной системой любого из способов или более способов, рассматриваемых в этом документе. Вычислительная система 600 может быть соединена с другой вычислительной системой по локальной сети, корпоративной сети, сети экстранет или сети Интернет. Вычислительная система 600 может работать в качестве сервера или клиента в сетевой среде «клиент/сервер», или в качестве однорангового вычислительного устройства в одноранговой (или распределенной) сетевой среде. Вычислительная система 600 может быть представлена персональным компьютером (ПК), планшетным ПК, телевизионной приставкой (STB), карманным ПК (PDA), сотовым телефоном или любой вычислительной системой, способной выполнять набор команд (последовательно или иным образом), определяющих операции, которые должны быть выполнены этой вычислительной системой. Кроме того, хотя показана только одна вычислительная система, термин «вычислительная система» также может включать любую совокупность вычислительных систем, которые отдельно или совместно выполняют набор (или несколько наборов) команд для выполнения одной или более методик, обсуждаемых в настоящем документе.
[0068] Пример вычислительного устройства 600 включает в себя процессор 602, оперативную память 604 (например, постоянное запоминающее устройство (ПЗУ) или динамическую оперативную память (DRAM)) и устройство хранения данных 618, которые взаимодействуют друг с другом через шину 630.
[0069] Процессор 602 может быть представлен одним или более универсальными устройствами обработки данных, например, микропроцессором, центральным процессором и т.д. В частности, процессор 602 может представлять собой микропроцессор с полным набором команд (CISC), микропроцессор с сокращенным набором команд (RISC), микропроцессор с командными словами сверхбольшой длины (VLIW), процессор, реализующий другой набор команд или процессоры, реализующие комбинацию наборов команд. Процессор 602 также может представлять собой одно или более устройств обработки специального назначения, например, заказную интегральную микросхему (ASIC), программируемую пользователем вентильную матрицу (FPGA), процессор цифровых сигналов (DSP), сетевой процессор и т.п. Процессор 602 выполнен с возможностью исполнения инструкций 626 для выполнения операций и функций способа 100 создания разметки изображений документа, как описано выше в этом документе.
[0070] Вычислительная система 600 может дополнительно включать устройство сетевого интерфейса 622, устройство визуального отображения 610, устройство ввода символов 612 (например, клавиатуру) и устройство ввода в виде сенсорного экрана 614.
[0071] Устройство хранения данных 618 может включать машиночитаемый носитель данных 624, в котором хранится один или более наборов команд 626, в которых реализован один или более методов или функций, описанных в данном варианте реализации изобретения. Команды 626 во время выполнения их в вычислительной системе 600, также могут находиться полностью и (или) по меньшей мере частично в основной памяти 604 и (или) в процессоре 602, при этом оперативная память 604 и процессор 602 также составляют машиночитаемый носитель данных. Команды 626 также могут передаваться или приниматься по сети 616 через устройство сетевого интерфейса 622.
[0072] В отдельных вариантах осуществления инструкции 626 могут включать инструкции способа 100 генерации разметки изображения документа, как описано выше в этом документе. В то время как машиночитаемый носитель данных 624 показан в примере на Фиг. 6 как единый носитель, термин «машиночитаемый носитель данных» следует понимать как единый носитель либо множество таких носителей (например, централизованную или распределенную базу данных и (или) соответствующие кэши и серверы), в которых хранится один или более наборов команд. Термин «машиночитаемый носитель данных» также может включать любой носитель, который может хранить, кодировать или содержать набор команд для выполнения машиной и который обеспечивает выполнение машиной любой одной или более методик настоящего изобретения. Поэтому термин «машиночитаемый носитель данных» относится, помимо прочего, к твердотельным запоминающим устройствам, а также к оптическим и магнитным носителям.
[0073] Способы, компоненты и функции, описанные в этом документе, могут быть реализованы с помощью дискретных компонентов оборудования либо они могут быть встроены в функции других компонентов оборудования, например ASICS (специализированная заказная интегральная схема), FPGA (программируемая логическая интегральная схема), DSP (цифровой сигнальный процессор) или аналогичных устройств. Кроме того, способы, компоненты и функции могут быть реализованы с помощью модулей встроенного программного обеспечения или функциональных схем аппаратного обеспечения. Способы, компоненты и функции также могут быть реализованы с помощью любой комбинации аппаратного обеспечения и программных компонентов либо исключительно с помощью программного обеспечения.
[0074] В приведенном выше описании изложены многочисленные детали. Однако любому специалисту в этой области техники, ознакомившемуся с этим описанием, должно быть очевидно, что настоящее изобретение может быть осуществлено на практике без этих конкретных деталей. В некоторых случаях хорошо известные структуры и устройства показаны в виде блок-схем без детализации, чтобы не усложнять описание настоящего изобретения.
[0075] Некоторые части описания предпочтительных вариантов реализации изобретения представлены в виде алгоритмов и символического представления операций с битами данных в запоминающем устройстве компьютера. Такие описания и представления алгоритмов представляют собой средства, используемые специалистами в области обработки данных, что обеспечивает наиболее эффективную передачу сущности работы другим специалистам в данной области. В контексте настоящего описания, как это и принято, алгоритмом называется логически непротиворечивая последовательность операций, приводящих к желаемому результату. Операции подразумевают действия, требующие физических манипуляций с физическими величинами. Обычно, хотя и необязательно, эти величины принимают форму электрических или магнитных сигналов, которые можно хранить, передавать, комбинировать, сравнивать и выполнять другие манипуляции. Иногда удобно, прежде всего для обычного использования, описывать эти сигналы в виде битов, значений, элементов, символов, терминов, цифр и т.д.
[0076] Однако следует иметь в виду, что все эти и подобные термины должны быть связаны с соответствующими физическими величинами и что они являются лишь удобными обозначениями, применяемые к этим величинам. Если явно не указано обратное, принимается, что в последующем описании термины «определение», «вычисление», «расчет», «получение», «определение», «изменение», «создание» и т.п. относятся к действиям и процессам вычислительной системы или аналогичной электронной вычислительной системы, которая использует и преобразует данные, представленные в виде физических (например, электронных) величин в реестрах и устройствах памяти вычислительной системы, в другие данные, также представленные в виде физических величин в устройствах памяти или реестрах вычислительной системы или иных устройствах хранения, передачи или отображения такой информации.
[0077] Настоящее изобретение также относится к устройству для выполнения операций, описанных в настоящем документе. Такое устройство может быть специально сконструировано для требуемых целей, либо оно может представлять собой универсальный компьютер, который избирательно приводится в действие или дополнительно настраивается с помощью программы, хранящейся в памяти компьютера. Такая компьютерная программа может храниться на машиночитаемом носителе данных, например, помимо прочего, на диске любого типа, включая дискеты, оптические диски, CD-ROM и магнитно-оптические диски, постоянные запоминающие устройства (ПЗУ), оперативные запоминающие устройства (ОЗУ), СППЗУ, ЭППЗУ, магнитные или оптические карты и носители любого типа, подходящие для хранения электронной информации.
[0078] Следует понимать, что приведенное выше описание призвано иллюстрировать, а не ограничивать сущность изобретения. Специалистам в данной области техники после прочтения и уяснения приведенного выше описания станут очевидны и различные другие варианты реализации изобретения. Исходя из этого область применения изобретения должна определяться с учетом прилагаемой формулы изобретения, а также всех областей применения эквивалентных способов, на которые в равной степени распространяется формула изобретения.

Изобретение относится к созданию разметки изображения документа. Технический результат заключается в расширении арсенала средств того же назначения. Пример способа включает выявление ключевых точек в каждом из множества изображений; добавление каждого из множества изображений в один или более кластеров, добавление включает добавление ключевых точек одного или более индексов, связанных с кластерами, где минимальное количество одной или более ключевых точек соответствует ключевым точкам в индексах; анализ каждого из изображений кластера как изображения-кандидата для генерации путем генерации разметки вдоль границ документа, имеющегося на изображении-кандидате; верификация разметки путем сравнения разметки с границами изображенного документа на нескольких других изображениях кластера; и выбор изображения-кандидата в качестве эталонного изображения, если разметка была верифицирована больше заранее определенного количества раз; и обнаружение разметки документа вдоль границ документа, присутствующего на исходном изображении, с помощью эталонного изображения. 3 н. и 18 з.п. ф-лы, 7 ил.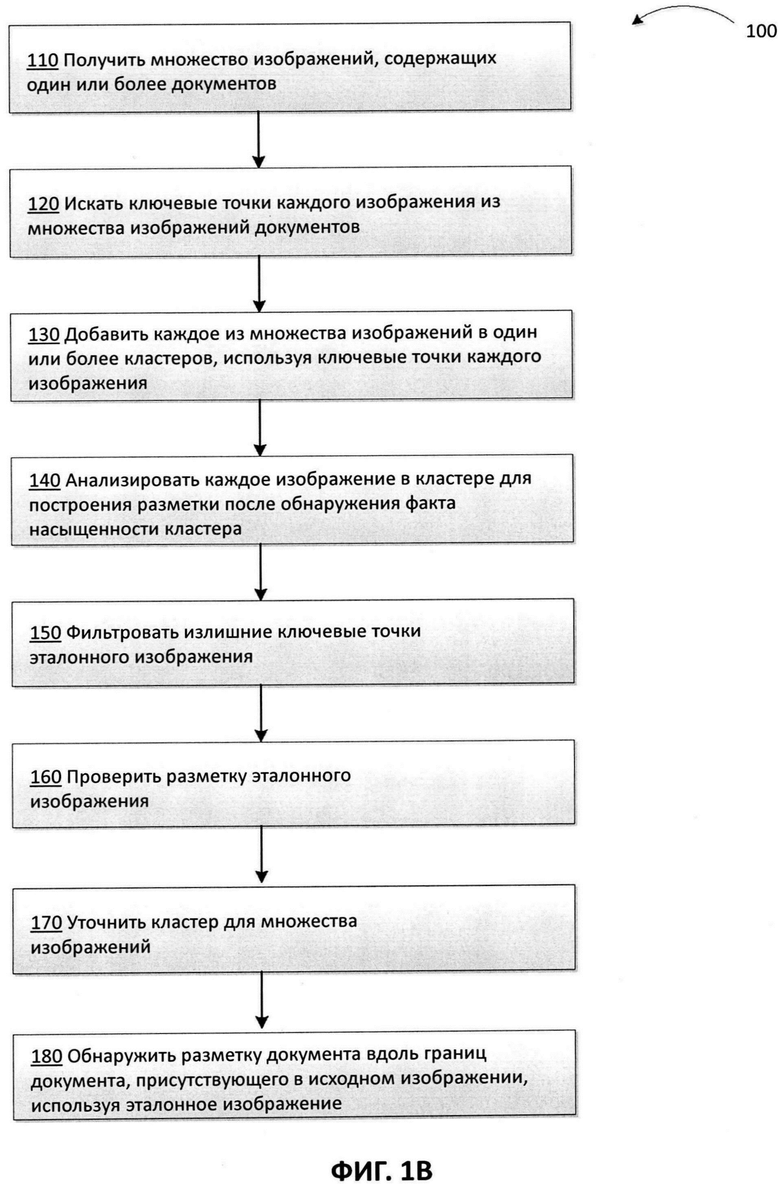
1. Способ автоматической разметки изображений, включающий:
получение с помощью вычислительной системы множества изображений, содержащих один или несколько документов;
выявление одной или более ключевых точек в каждом из множества изображений;
добавление каждого из множества изображений в один или более кластеров, добавление в один или более кластеров включает добавление одной или более ключевых точек каждого из множества изображений к одному или более индексам, связанным с одним или более кластерами, где минимальное количество одной или более ключевых точек соответствует существующим ключевым точкам в одном или более индексах;
после обнаружения насыщенности кластера из одного или более кластеров, анализ каждого из изображений кластера как изображения-кандидата для генерации эталонного изображения, где анализ включает:
разметку вдоль границ документа, имеющегося на изображении-кандидате;
верификацию правильности генерации разметки путем сравнения разметки с границами изображенного документа на ряде других изображений кластера; и
выбор изображения-кандидата в качестве эталонного изображения, если разметка была верифицирована больше заранее определенного количества раз; и
использование эталонного изображения для обнаружения разметки документа вдоль границ документа, имеющегося на входном изображении.
2. Способ по п. 1, дополнительно включающий:
добавление входного изображения, содержащего разметку документа, в обучающую выборку изображений для обучения модели машинного обучения.
3. Способ по п. 1, дополнительно включающий:
добавление эталонного изображения, включающего разметку, в обучающую выборку изображений для обучения модели машинного обучения.
4. Способ по п. 1, дополнительно включающий:
после выбора эталонного изображения обнаружение того факта, что по меньшей мере один дополнительный кластер из одного или более кластеров включает эталонное изображение, и
удаление по меньшей мере одного дополнительного кластера из одного или более кластеров.
5. Способ по п. 1, дополнительно включающий добавление изображения из множества изображений в новый кластер, где минимальное число из одной или более ключевых точек изображения не соответствуют существующим ключевым точкам одного или более индексов, связанных с одним или более кластерами.
6. Способ по п. 1, отличающийся тем, что один или более индексов включают ключевые точки, имеющие заданную метрику схожести.
7. Способ по п. 1, отличающийся тем, что одна или более ключевых точек соответствуют существующим ключевым точкам в одном или более индексах, с точки зрения расстояния Хэмминга, между одной или более ключевыми точками и существующими ключевыми точками.
8. Способ по п. 1, отличающийся тем, что один или более индексов создаются с использованием различных заранее установленных параметров.
9. Способ по п. 1, отличающийся тем, что сравнение разметки множества других изображений из кластера включает индикацию ложно-правдивых совпадений.
10. Способ по п. 1, отличающийся тем, что обнаружение насыщенности кластера включает обнаружение того факта, что в кластере имеется предельное количество изображений.
11. Способ по п. 1, отличающийся тем, что одна или более выявленных ключевых точек в каждом из множества изображений представляют центроиды слов в мешке визуальных слов (BoW) для каждого из множества изображений.
12. Способ по п. 1, отличающийся тем, что один или более индексов, связанных с одним или более кластерами, включают индекс локально-чувствительного хэширования (LSH).
13. Способ по п. 1, дополнительно включающий:
после обнаружения насыщенности кластера выполнение проверки внутриклассовой геометрии всех изображений в кластере перед построением эталонного изображения.
14. Способ по п. 1, отличающийся тем, что выявление одной или более ключевых точек в каждом из множества изображений включает вычисление одного или более дескрипторов ключевых точек для одной или более ключевых точек.
15. Система автоматической разметки изображений, включающая:
память;
процессор, связанный с данной памятью, причем этот процессор выполнен с возможностью:
выявления одной или более ключевых точек в каждом из множества изображений;
определения одного или более кластеров, содержащих одно или более изображений из множества изображений, определение одного или более кластеров включает добавление одной или более ключевых точек каждого из множества изображений в один или более индексов, связанных с одним или более кластерами, где минимальное количество одной или более ключевых точек соответствует существующим ключевым точкам в одном или более индексах;
обнаружения насыщенности кластера из одного или более кластеров, если кластер достиг предельного количества изображений;
после обнаружения насыщенности кластера анализ каждого из изображений кластера как изображения-кандидата для генерации эталонного изображения, где анализ включает:
разметку вдоль границ документа, имеющегося на изображении-кандидате;
верификацию правильности генерации разметки путем сравнения разметки с границами изображенного документа на ряде других изображений кластера; и
выбор изображения-кандидата в качестве эталонного изображения, если разметка была верифицирована больше заранее определенного количества раз; и при помощи эталонного документа, обнаружение разметки вдоль границ документа, имеющегося на входном изображении.
16. Система по п. 15, отличающаяся тем, что процессор дополнительно выполнен с возможностью выполнять добавление изображения из множества изображений в новый кластер, где минимальное число из одной или более ключевых точек изображения не соответствуют существующим ключевым точкам одного или более индексов, связанных с одним или более кластерами.
17. Система по п. 15, отличающаяся тем, что определение факта соответствия одной или более ключевых точек существующим ключевым точкам в одном или более индексах производится, с точки зрения расстояния Хэмминга, между одной или более ключевыми точками и существующими ключевыми точками.
18. Система по п. 15, отличающаяся тем, что эталонное изображение включает статические поля.
19. Машиночитаемый постоянный носитель данных, содержащий исполняемые команды, которые при их выполнении процессорным устройством побуждают это устройство:
получать множество изображений, связанных с документами;
выявлять одну или более ключевых точек в каждом из множества изображений;
добавлять каждое из множества изображений в один или более кластеров, добавление в один или более кластеров включает добавление одной или более ключевых точек каждого из множества изображений к одному или более индексам, связанным с одним или более кластерами, где минимальное количество одной или более ключевых точек соответствует существующим ключевым точкам в одном или более индексах;
после обнаружения насыщенности кластера из одного или более кластеров анализировать каждое из изображений кластера как изображение-кандидат для генерации эталонного изображения, где анализ включает:
разметку вдоль границ документа, имеющегося на изображении-кандидате;
верификацию правильности генерации разметки путем сравнения разметки с границами изображенного документа на ряде других изображений кластера; и
выбирать изображение-кандидат в качестве эталонного изображения, если разметка была верифицирована больше заранее определенного количества раз; и
использовать эталонное изображение для обнаружения разметки документа вдоль границ документа, имеющегося на входном изображении.
20. Носитель данных по п. 19, отличающийся тем, что один или более кластеров включают изображения, имеющие заданную метрику схожести.
21. Носитель данных по п. 19, отличающийся тем, что обрабатывающее устройство дополнительно выполнено с возможностью добавления входного изображения, включающего разметку документа, к обучающей выборке изображений для обучения нейронной сети.
| КЛАССИФИКАЦИЯ ИЗОБРАЖЕНИЙ ДОКУМЕНТОВ НА ОСНОВАНИИ КОНТЕНТА | 2014 |
|
RU2571545C1 |
| СРАВНЕНИЕ ДОКУМЕНТОВ С ИСПОЛЬЗОВАНИЕМ ДОСТОВЕРНОГО ИСТОЧНИКА | 2014 |
|
RU2597163C2 |
| ОЧИЩАЮЩЕЕ СРЕДСТВО (ВАРИАНТЫ) | 1990 |
|
RU2104331C1 |
| US 4471386 A1,11.09.1984. | |||

