Область техники, к которой относится изобретение
Раскрытие сущности относится к классификации биологической ткани с использованием вычислительной системы, включающей в себя способ и соответствующую компьютерную программу и компьютерную систему.
Уровень техники
Исследование и классификация биологической ткани представляют собой часть процедур онкологического обследования (скрининга). Например, в случае обследования на предмет рака шейки матки, может выполняться кольпоскопия, при которой шейка матки непосредственно просматривается, и одно или более изображений из нее захватываются. Это обеспечивает возможность идентификации и классификации патологических изменений в шейке матки в зависимости от их риска таким образом, что могут выполняться надлежащие биопсии или лечение. Такая классификация, в общем, выполняется специалистами-медиками.
В частности, хорошо работающая технология кольпоскопии описывается в международной патентной публикации номер WO-01/72214, в которой агент, дифференцирующий патологию (в частности, разбавленная уксусная кислота), наносится на биологическую ткань. Это вызывает переходный оптический эффект, в частности, отбеливание ткани, который может просматриваться непосредственно, а также в захваченном изображении. Кроме того, может выполняться анализ переходных процессов и/или спектральный анализ одного или более захваченных изображений, в частности, измерение диффузионной отражательной способности, и такие данные могут предоставляться специалисту-медику, чтобы помогать при его анализе. Кольпоскопы с использованием этой технологии продаются компанией DYSIS Medical Limited.
Компьютерный искусственный интеллект применяется к медицинским классификациям в ряде предметных областей, таких как магнитно-резонансная визуализация (MRI) и радиологические изображения. Также рассматривается применение технологий искусственного интеллекта к классификации биологической ткани, такой как классификация патологических изменений шейки матки. Работа "An Observational Study of Deep Learning and Automated Evaluation of Cervical Images for Cancer Screening", авторы Hu и другие, J Natl Cancer Inst 2019 (doi: 10.1093/jnci/djy225) изучает автоматизированную оценку "цервикограмм" (изображений шейки матки, снятых с помощью пленочной камеры с фиксированным фокусным расстоянием и с кольцевой подсветкой, примерно через минуту после нанесения разбавленной уксусной кислоты на эпителий шейки матки), чтобы идентифицировать предраковые и раковые патологические изменения для обследования шейки матки по месту жительства. В этом подходе, цервикограмма предоставляется в качестве ввода в алгоритм на основе глубокого обучения, в частности, в более быструю сверточную нейронную сеть на основе областей (более быструю R-CNN). Алгоритм выполняет обнаружение объекта (шейки), извлечение признаков (вычисление признаков объекта) и классификацию как положительной или отрицательной для высокозлокачественной неоплазии шейки матки (прогнозирование количественного показателя вероятности случая). Этот способ, при изучении на популяции для обследования, достигает площади под кривой (AUC) в 0,91, которая превышает исходную интерпретацию цервикограмм (AUC 0,69) идентичного набора данных, при идентификации случаев предракового состояния или рака.
Работа "Multimodal Deep Learning for Cervical Dysplasia Diagnosis", авторов Xu и другие, Medical Image Computing and Computer-Assisted Intervention - MICCAI 2016, Lecture Notes in Computer Science, том 9901, Springer, Cham, рассматривает применение машинного обучения к диагностике дисплазии шейки матки. В этом подходе, изображение шейки, захваченное после нанесения 5%-й уксусной кислоты на эпителий шейки матки, предоставляется в качестве ввода в глубокую нейронную сеть. Помимо этого, клинические результаты других медицинских тестов и другие данные относительно исследуемого предоставляются в качестве вводов таким образом, что нейронная сеть имеет многомодальные вводы. Структура, заключающая в себе несколько сверточных нейронных сетевых уровней, используется для изучения признаков изображений, и различные модальности комбинируются с использованием объединенных полностью соединенных нейронных сетевых уровней. Сообщается, что эта технология обеспечивает окончательный диагноз с чувствительностью в 87,83% при 90%-ой специфичности.
Такие технологии могут быть полезными для специалистов-медиков, в частности, в развивающихся странах, в которых обследование шейки матки недоступно, но предоставление более клинически полезных выводов из искусственного интеллекта, таких как картирование и градация по степени злокачественности заболевания для точного размещения биопсии, требуется для того, чтобы улучшать способность специалиста-медика корректно диагностировать и предоставлять подходящее лечение или последующий контроль при необходимости.
Сущность изобретения
С учетом вышеуказанного описания уровня техники, раскрытие сущности предоставляет способ для классификации биологической ткани с использованием вычислительной системы по пункту 1 формулы, компьютерной программы по пункта 27 формулы и вычислительной системы, заданной посредством пункта 28 формулы. Дополнительные признаки детализируются в зависимых пунктах формулы изобретения и в данном документе.
Данные изображений, содержащие множество изображений зоны исследования биологической ткани (в частности, шейки исследуемого объекта), принимаются в вычислительной системе. Каждое изображение захватывается в различные моменты времени в течение периода, в который местное применение дифференцирующего агента для выявления патологии к зоне исследования ткани вызывает переходные оптические эффекты. В частности, дифференцирующий агент для выявления патологии может содержать уксусную кислоту (типично разбавленную уксусную кислоту, обычно до 3-5%) таким образом, что переходные оптические эффекты могут содержать ацетоотбеливающий эффект (хотя другие дифференцирующие агенты и/или оптические эффекты могут быть возможными, например, с использованием молекулярной диагностики). Зона исследования может подвергаться воздействию оптического излучения, которое может быть широкополосным (для большей части или всего оптического спектра) или узкополосным (ограниченным одной или диапазоном конкретных длин волн, задающих только один или ограниченный диапазон цветов, возможно включающий в себя ультрафиолетовый диапазон и/или инфракрасный диапазон), в течение периода захвата изображений. Изображения, захваченные после применения агента (например, с предварительно определенными и/или регулярными интервалами), в силу этого могут показывать развитие переходных оптических эффектов. Принимаемые данные изображений (которые могут подвергаться обработке изображений, как пояснено ниже) предоставляются в качестве ввода в алгоритм машинного обучения (работающий в вычислительной системе). Алгоритм машинного обучения выделяет одну из множества классификаций для ткани. Шейка также может сегментироваться, например, на основе применения одной или более масок (например, заданных посредством распознавания морфологии или извлечения признаков) и/или на основе локальных классификаций, применяемых для ткани. Таким образом, ткань может классифицироваться на дискретные и заданные подзоны для зоны исследования ткани, в частности, с различной классификацией, выделяемой для каждого сегмента шейки. Классификации могут задаваться посредством шкалы значений с непрерывным диапазоном (к примеру, 0-1 или 0-100) или набора дискретных вариантов, которые могут включать в себя множество тегов заболевания (например: "отрицательный" по сравнению с "положительный", или, например: "низкий риск"; "средний риск"; "высокий риск", конкретные состояния заболевания, например: "CIN1", "CIN2", "CIN3", либо наличие одной или более характеристик морфологии, к примеру, наличие атипичных сосудов, резких границ патологических изменений или заболевания, к примеру, постоянное или плотное ацетоотбеливание).
В подходе, раскрытом в данном документе, может достигаться автоматическая классификация в живом организме (in vivo) или в пробирке (in vitro) биологической ткани. Использование множества изображений, снятых в ходе развития переходных оптических эффектов, позволяет обеспечивать существенное улучшение по чувствительности и/или специфичности классификации по сравнению с известными способами. Чувствительность и специфичность может означать способность идентифицировать дисплазию шейки матки и/или неоплазию шейки матки. Чувствительность в силу этого означает способность корректно идентифицировать ткани, отображающие дисплазию шейки матки и/или неоплазию шейки матки. Специфичность в силу этого означает способность корректно идентифицировать ткани, которые не отображают дисплазию шейки матки и/или неоплазию шейки матки. В зависимости от контекста применения, вывод может быть сфокусирован на максимизации чувствительности или специфичности или работе при пороговом значении, которое может быть оптимальным для одного или обоих из означенного. Хотя классификация может представляться на основе исследуемого/ткани в целом, изобретение обеспечивают идентификацию областей ткани, которые подозреваются как предраковые или раковые. Это может быть преимущественным для направления на биопсию или на лечение, в том числе и на хирургическую резекцию. Эти участки могут браться на биопсию, чтобы подтверждать идентификацию. Успешная реализация такой системы может приводить к тому, что взятие биопсии становится необычным во многих или в большинстве случаев. Например, пациент может непосредственно направляться на реабилитацию на плановое обследование или на лечение, на основе вывода такой классификации. Кроме того, вывод алгоритма машинного обучения может быть более клинически полезным, чем для существующих подходов, как поясняется ниже. Технология может реализовываться как способ, компьютерная программа, программируемые аппаратные средства, компьютерная система и/или в системе для исследования ткани (к примеру, в кольпоскопической системе).
Например, вычислительная система, работающая с возможностью классификации ткани, может содержать: ввод для приема данных изображений; и процессор для работы с алгоритмом машинного обучения. В вариантах осуществления, она дополнительно содержит модуль сбора изображений для захвата оптических изображений (например, необработанных изображений), на которых основаны данные изображений. Модуль сбора изображений может быть расположен удаленно от процессора. В некоторых проектных решениях, процессор содержит множество обрабатывающих устройств, каждое из которых работает с частью алгоритма машинного обучения (например, распределенным способом). В таком случае, модуль сбора изображений может быть расположен удаленно, по меньшей мере, от одного из обрабатывающих устройств. Ниже поясняются подходы, применимые к любой из возможных реализаций в соответствии с раскрытием сущности (в качестве этапов способа или программы и/или в качестве структурных признаков).
Данные изображений, предоставленные в качестве ввода в алгоритм машинного обучения, могут извлекаться из захваченных оптических изображений, которые представляют собой необработанные изображения, снятые посредством модуля сбора изображений (который может составлять часть компьютерной системы либо который может быть внешним). Например, оптические (необработанные) изображения могут масштабироваться (например, на основе фокусного расстояния для соответствующего оптического изображения). Это может обеспечивать возможность множеству изображений для одной ткани иметь шкалу, идентичную шкале другой ткани. Каждое из изображений может иметь идентичную пиксельную компоновку (т.е. идентичный размер и форму изображений). Совмещение множества изображений может достигаться посредством применения одного или более преобразований к оптическим изображениям. Артефакты могут удаляться из оптических изображений посредством анализа и/или обработки изображений. Изображения могут разбиваться или подразделяться на патчи (например, на смежный блок пикселов, предпочтительно двумерных), которые могут формировать данные изображений. Патчи могут быть перекрывающимися, например, патчи, созданные с шагом, меньшим размера патча, что позволяет увеличивать разрешение.
Дополнительный ввод в алгоритм машинного обучения может быть основан на обработке каждого из множества изображений, чтобы извлекать индивидуально адаптированные признаки, на основе математических функций, описывающих локальный цвет, градиент и текстуру, хотя также могут предполагаться другие характеристики. Это может осуществляться по отдельности для подчастей изображения, заданных в качестве патчей блока пикселов (например, квадратного блока в 8×8, 16×16, 32×32 пикселов или с другими размерами, прямоугольного блока либо другой формы блока). Каждое изображение может разбиваться на определенное число патчей с шагом между ними, который может составлять 4, 8, 16, 32 пиксела (при этом другие размеры также являются возможными). Как отмечено выше, патчи могут предоставляться в качестве данных изображений, предоставленных в качестве ввода в алгоритм машинного обучения.
Картографические данные, содержащие соответствующий аналитический индекс для каждого пиксела, могут получаться в компьютерной системе. Аналитические индексы извлекаются из множества изображений, например, на основе одного или более из следующего: максимальная интенсивность для пиксела по множеству изображений; время для того, чтобы достигать максимальной интенсивности для пиксела; и суммирование интенсивности для пиксела по множеству изображений (которое может включать в себя суммирование со взвешиванием, например, чтобы предоставлять площадь зоны под кривой зависимости интенсивности от времени захвата изображений). Каждый из этих параметров может быть ограничен предварительно определенной полосой пропускания спектра, и/или несколько таких параметров (идентичного или различного типа) могут использоваться, каждый из которых предназначен для различных полос пропускания спектра. Данные для идентичного пиксела для нескольких изображений могут подгоняться к кривой, и эта кривая может использоваться для того, чтобы получать параметр. Это обуславливает полезные параметры, выбранные из одного или более из следующего: площадь под кривой (интеграл), площадь под кривой вплоть до максимальной интенсивности ("площадь до максимума"), (подогнанный или средний) наклон кривой вплоть до максимальной интенсивности, (подогнанный или средний) наклон кривой после максимальной интенсивности. Конкретные параметры, полезные в настоящем изобретении, поясняются в WO 2008/001037, полностью содержащемся в данном документе по ссылке. Комбинирование со взвешиванием нескольких параметров (различных типов и/или для различных полос пропускания спектра) может использоваться для того, чтобы устанавливать аналитические индексы. Аналитические индексы могут представлять показатель диффузионной отражательной способности. Преимущественно, картографические данные могут предоставляться в качестве дополнительного ввода в алгоритм машинного обучения, например, в качестве дополнительного ввода изображений.
Алгоритм машинного обучения преимущественно содержит нейронную сеть и более предпочтительно глубокую нейронную сеть (содержащую больше одного скрытого уровня), хотя могут рассматриваться реализации с использованием неглубокой нейронной сети. Глубокая нейронная сеть необязательно содержит одно или более из следующего: сверточная нейронная сеть; полностью соединенная нейронная сеть; и рекуррентная нейронная сеть, но также могут рассматриваться другие типы сетей. Глубокая нейронная сеть может содержать один или более сверточных нейронных сетевых уровней. Алгоритм машинного обучения предпочтительно является многомодальным в том, что он может принимать данные изображений и без изображений в качестве вводов для обучения и тестирования.
В вариантах осуществления, изображения обрабатываются, чтобы идентифицировать и/или количественно определять один или более извлеченных признаков и/или, по меньшей мере, одну морфологическую характеристику, к примеру, одно или более из следующего: атипичные сосуды; мозаицизм; и пунктация. Один или более извлеченных признаков и/или, по меньшей мере, одна морфологическая характеристика могут предоставляться в качестве дополнительного ввода в алгоритм машинного обучения. В менее предпочтительном подходе, это может обеспечивать возможность разделения изображений на патчи (на основе одного или более извлеченных признаков и/или, по меньшей мере, одной морфологической характеристики).
Одна или более характеристик исследуемого объекта (каждая из которых связана с исследуемым объектом, из которого исходит биологическая ткань) могут предоставляться в качестве другого ввода в алгоритм машинного обучения. Например, характеристики исследуемого объекта могут содержать: факторы риска объекта исследуемого и/или результаты клинических тестов исследуемого объекта. Факторы риска исследуемого объекта могут включать в себя одно или более из следующего: возраст исследуемого объекта; статус на предмет курения исследуемого объекта; статус вакцинации против HPV; число сексуальных партнеров; использование презервативов; и количество родов для исследуемого объекта. Результаты клинических тестов исследуемого объекта могут содержать одно или более из следующего: предшествующий результат цитологии; предшествующий результат теста на папилломавирус человека (HPV); предшествующий результат HPV-теста типирования; предшествующая информация лечения шейки матки; и предшествующая история обследования на предмет рака или предраковых состояний шейки матки.
Преимущественно, алгоритм машинного обучения выделяет одну из множества классификаций для каждого из одного или более сегментов ткани. Сегмент или сегменты могут идентифицироваться из данных изображений с использованием алгоритма машинного обучения, например, чтобы идентифицировать отдельные исследуемые области или патологические изменения. Часть изображений, соответствующих шейке, может идентифицироваться в некоторых вариантах осуществления, что может обеспечивать возможность определения подходящих сегментов. Например, классификации могут принимать форму диагностических тегов. В другом варианте, классификации могут иметь форму "тепловой карты" изображения ткани (которое представляет собой выходное изображение, преимущественно на основе множества изображений), в которой интенсивность и/или цвет каждого пиксела служит индикатором классификации для этого пиксела, предпочтительно вероятностной классификации для пиксела. В другом варианте, вывод классификации может иметь форму тега риска, за счет чего зона тканей ярко выделяется (например, посредством ограничительной рамки) как "нет риска", "низкий риск" или "высокий риск". Необязательно, также может выделяться полная классификация для ткани. Она может быть основана на классификациях, выделяемых для сегмента или результата (отдельной) параллельной модели машинного обучения.
Алгоритм машинного обучения преимущественно обучается на основе соответствующего множества изображений и соответствующей выделяемой классификации (или классификаций, если применимо) для каждой из множества других биологических тканей. Число других биологических тканей может быть большим, например, по меньшей мере, 500, 1000, 2000 или 5000. Выделяемая классификация может быть, к примеру, такой, в которой конкретная область (или группа из нескольких областей) каждой ткани характеризуется посредством показаний гистопатологии.
Алгоритм машинного обучения также может постоянно и/или динамически обучаться (инкрементное обучение) с использованием таких способов, как обучение с переносом и избирательное переобучение (к примеру, как описано в работе "Lifelong Learning with Dynamically Expandable Networks", авторов Yoon и др., ICLR 2018), посредством предоставления определенной пользователями (или на основе баз данных) классификации для ткани (к примеру, предоставленной специалистом-медиком, например, из биопсии или эксцизионного лечения с гистологией или субъективной оценки) в алгоритм машинного обучения (и/или в версию алгоритма машинного обучения, работающего во второй компьютерной системе). Если алгоритм машинного обучения предоставляется распределенным способом, первая часть может предоставляться локально для модуля сбора изображений, а вторая часть может предоставляться более удаленно. Обе части могут допускать выделение классификаций. Непрерывно продолжаемое (динамическое) обучение может применяться только ко второй части, в частности, периодически и может включать данные из нескольких различных первых частей. Первая часть может представлять собой фиксированный алгоритм, который может обновляться (с интервалами, например, после множества классификаций или конкретной продолжительности).
Краткое описание чертежей
Изобретение может реализовываться на практике рядом способов, и ниже описываются предпочтительные варианты осуществления только в качестве примера и со ссылкой на прилагаемые чертежи, на которых:
Фиг. 1 показывает принципиальную схему вычислительной системы в соответствии с раскрытием сущности;
Фиг. 2 схематично иллюстрирует процесс в соответствии с раскрытием сущности;
Фиг. 3 схематично иллюстрирует блок-схему последовательности операций способа, иллюстрирующую технологию для экспериментальной системы в соответствии с раскрытием сущности;
Фиг. 4 схематично иллюстрирует известную модель классификации по принципу случайного леса;
Фиг. 5 схематично показывает известную архитектуру на основе искусственной нейронной сети;
Фиг. 6 схематично иллюстрирует известную архитектуру на основе долгого кратковременного запоминающего устройства;
Фиг. 7A, 7B, 7C и 7D показывают индикаторные тепловые карты для первых примерных биологических тканей, обработанных посредством известного способа (фиг. 7A) или в соответствии с технологией по фиг. 4-6 (фиг. 7B, 7C и 7D); и
Фиг. 8A, 8B, 8C и 8D показывают индикаторные тепловые карты для вторых примерных биологических тканей, обработанных посредством известного способа (фиг. 8A) или в соответствии с технологией по фиг. 4-6 (фиг. 8B, 8C и 8D).
Подробное описание предпочтительных вариантов осуществления
Ссылаясь сначала на фиг. 1, показывается принципиальная схема вычислительной системы в соответствии с раскрытием сущности. Вычислительная система содержит: модуль 10 сбора изображений; локальный процессор 15; основной сервер 20; базу 30 данных идентификационных данных; базу 40 данных визуализации. Локальный интерфейс 12 соединяет модуль 10 сбора изображений с локальным процессором 15. Интерфейс 22 обработки соединяет локальный процессор 15 с основным сервером 20. Первый интерфейс 32 передачи идентификационных данных соединяет базу 30 данных идентификационных данных с локальным процессором 15, и второй интерфейс 34 передачи идентификационных данных соединяет базу 30 данных идентификационных данных с основным сервером 20. Первый интерфейс 42 передачи данных изображений соединяет базу 40 данных визуализации с локальным процессором 15, и второй интерфейс 44 передачи данных изображений соединяет базу 40 данных визуализации с основным сервером 20. Следует отметить, что вычислительная система по фиг. 1 включает части, которые могут быть отличными от компьютера, например, составляющие часть оптической системы и/или электронной системы управления. Тем не менее, они все должны считаться частью вычислительной системы для целей этого раскрытия сущности.
Модуль 10 сбора изображений представляет собой блок кольпоскопической визуализации, для захвата и сбора оптических изображений зоны исследования, в частности, шейки матки. Хотя основной вариант осуществления настоящего изобретения относится к кольпоскопической системе, и предусмотрены значительные и явные преимущества, применимые к такой системе, следует понимать, что реализация, описанная в данном документе, может использоваться для других типов системы для исследования и/или визуализации биологической ткани. Модуль 10 сбора изображений управляется посредством локального процессора 15, который может включать в себя пользовательский интерфейс, например, содержащий средства управления и/или дисплей. База 30 данных идентификационных данных используется для того, чтобы сохранять идентификационные данные пациента. Во время исследования, локальный процессор может взаимодействовать с базой 30 данных идентификационных данных с использованием первого интерфейса 32 передачи идентификационных данных, чтобы извлекать идентификационные данные для исследуемого пациента. Изображения, собранные во время исследования, сохраняются в базе 40 данных визуализации через первый интерфейс 42 передачи данных изображений. Идентификатор пациента может сохраняться с изображениями пациентов, чтобы обеспечивать возможность перекрестных ссылок с информацией, сохраненной в базе 30 данных идентификационных данных.
В качестве части процесса исследования, разбавленная уксусная кислота местно применяется к шейке, что вызывает ацетоотбеливающий эффект. Изображения шейки снимаются во время процесса ацетоотбеливания. Инициирование захвата изображений возникает после применения разбавленной уксусной кислоты и дополнительно может возникать до и во время применения (чтобы предоставлять опорное изображение). Цель или зона исследования, включающая в себя шейку, освещается. Свойства освещения типично стандартизируются и количественно определяются с точки зрения характеристик пучка, цветового профиля и интенсивности. Последовательности оптических изображений шейки захватываются во времени для целей количественного определения любых изменений оптических свойств эпителия шейки матки. Типично, изображения снимаются в предварительно определенные времена относительно времени, в которое применяется разбавленная уксусная кислота. Предварительно определенные времена могут иметь регулярные интервалы либо могут быть более частыми сначала и менее частыми в дальнейшем. Эти изображения сохраняются в базе 40 данных визуализации, как пояснено выше. Изображения могут захватываться и/или сохраняться в форме дискретных изображений и/или в качестве видеоформата или потока и необязательно также отображаются с использованием пользовательского интерфейса локального процессора 15 (имеющего один или более экранов), что может обеспечивать возможность оператору также выполнять исследование. Модуль сбора изображений калибруется таким образом, что он имеет стандартизированные и измеримые характеристики (такие как поле зрения и/или цветовой профиль, и/или реакцию на интенсивность света). Фокусное расстояние для каждого изображения известно и сохранено. Оптические изображения могут захватывать широкий частотный спектр или узкий частотный спектр (например, ограниченный одной или более конкретных полос оптических частот, каждая из которых меньше полного оптического спектра, к примеру, конкретными цветами или группами цветов).
Обработка "необработанных" оптических изображений (термин "оптические изображения" в данном документе типично означает необработанные изображения или такие изображения до завершения обработки и/или анализа изображений) может осуществляться в локальном процессоре 15 и/или на основном сервере 20, например, в форме подсистемы анализа изображений. Одна форма обработки представляет собой стандартизацию размера изображений. Для оптической системы с фиксированной фокусной длиной, она может достигаться со ссылкой на фокусное расстояние для каждого оптического изображения. Типично, фокусное расстояние для каждого из оптических изображений идентичной зоны исследования должно быть идентичным (в частности, при использовании кольпоскопического оборудования, как описано в международной патентной публикации номер WO-01/72214, в которой относительная позиция между тканью и оптической головкой устройства остается почти постоянной во время захвата нескольких изображений). С использованием соответствующего фокусного расстояния для оптического изображения, изображение может масштабироваться до стандартного размера (таким образом, что каждый пиксел соответствует стандартной физической длине). Это обеспечивает возможность сравнения изображений, снятых для различных тканей. Тем не менее, если используется менее преимущественное кольпоскопическое оборудование, в котором относительная позиция между тканью и оптической головкой оборудования может варьироваться, множество изображений могут масштабироваться для того, чтобы стандартизировать их размер.
Типичное разрешение для калибровки изображений составляет 1024×768 или 2048×1536, но другие разрешения являются возможными. Другая форма обработки представляет собой совмещение изображений со ссылкой на характерный признак, показанный в изображении, такой как шейка. Цель такого совмещения состоит в том, чтобы компенсировать естественные движения, к примеру, смещения и сжатия, во время захвата оптических изображений. Такое совмещение может осуществляться посредством идентификации одного или более характерных признаков в каждом из изображений и сравнения изображений на основе идентификации признаков, чтобы определять параметры преобразования (к примеру, для перемещения в пространстве, вращения, увеличения или деформации), чтобы достигать совмещения признаков через стек изображений. Стандартные технологии обработки изображений затем могут использоваться для того, чтобы реализовывать преобразования на основе определенных параметров преобразования. Дополнительная форма обработки изображений может включать в себя алгоритм для того, чтобы обрабатывать необработанные оптические изображения или постобработанные изображения, с тем чтобы идентифицировать зону шейки на фоне (исследуемую область). Артефакты, которые могут сосуществовать на изображениях, такие как отражения, могут идентифицироваться и удаляться, в другой форме обработки. Распознавание шаблонов дополнительно может идентифицировать морфологические характеристики, к примеру, одно или более из следующего: атипичные сосуды; мозаицизм; и пунктация. Типично, используются все формы технологии обработки изображений, но только поднабор может применяться в некоторых вариантах осуществления. Кроме того, различные формы обработки могут выполняться в различных частях системы. Обработанные изображения находятся в высококачественном JPEG- или PNG-формате и в цветовом RGB-режиме (но могут допускаться другие форматы). Показатели качества могут использоваться для того, чтобы обеспечивать возможность идентификации проблем с изображениями, таких как зоны, которые демонстрируют блики или другие артефакты, и несфокусированные изображения. Это может обеспечивать возможность их исключения из анализа и/или предоставления обратной связи пользователям.
В последние годы, искусственный интеллект (AI) возникает в качестве испытанного способа, который реализуется в ряде областей человеческой жизнедеятельности, включающих в себя варианты применения в медицине и здравоохранении. Усовершенствованные алгоритмы, разработанные в научном сообществе, обеспечивают перспективу более точных и эффективных процессов. Применение AI для обработки медицинских изображений, в частности, с использованием изображения шейки, к которой применяется процесс ацетоотбеливания, уже рассматривается. Теперь следует признавать то, что применение (например, сбор и анализ) нескольких изображений шейки во время процесса ацетоотбеливания может значительно повышать производительность AI. Это может быть обусловлено выявлением такого удивительного факта, что в переходных оптических эффектах, таких как ацетоотбеливающий эффект, эффект может отличаться не только в конце процесса, но также и в ходе самого процесса. Наблюдение только одного момента процесса предоставляет некоторую информацию относительно биологической ткани, в частности, шейки в этом случае. Тем не менее, поскольку процесс может не быть равномерным для шейки, наблюдение всего процесса может предоставлять значительную дополнительную информацию, которая может быть, в частности, полезной при корректной классификации оптических эффектов и их смысла для биологической ткани. AI, предоставляемый с несколькими изображениями процесса, в силу этого может обеспечивать возможность кольпоскопическому способу идентифицировать и/или характеризовать зоны, подозрительные на предмет неоплазии шейки матки.
AI в системе по фиг. 1 предоставляется как в локальном процессоре 15, так и на основном сервере 20. Обе системы имеют возможность осуществлять доступ ко множеству изображений шейки, захваченных во время процесса ацетоотбеливания и сохраненных в базе 40 данных визуализации. Локальный процессор использует фиксированный AI-алгоритм, который обеспечивает возможность немедленной классификации шейки на основе изображений. Основной сервер 20 использует AI-алгоритм, который обновляется более регулярно, предпочтительно в пакетах результатов (другими словами, алгоритм непрерывно и динамически обучается из пакетов данных), и, менее предпочтительно, может обновляться с каждым новым исследованием. Чтобы осуществлять это, AI-алгоритм на основном сервере 20 может иметь различную структуру и/или параметризацию по сравнению с фиксированным AI, и эта разность может увеличиваться во времени по мере того, как дополнительное обучение предоставляется в AI-алгоритм на основном сервере 20. Локальный процессор 15 использует фиксированный AI-алгоритм, который может обновляться с интервалами, предпочтительно с использованием AI-алгоритма, обученного на основном сервере, в частности, после того как он развивается в установившееся состояние. Фиксированный AI-алгоритм может предоставлять более быстрые результаты, чем AI-алгоритм, работающий на основном сервере 20. Основной сервер 20 может быть облачным таким образом, что он имеет возможность собирать и анализировать наборы данных изображений шейки матки из нескольких удаленных устройств. Обучающий набор в силу этого может быть большим и иметь возможность захватывать разности, получающиеся в результате, например, демографических изменений или изменений программ обследования.
AI может реализовываться в локальном процессоре 15 и/или на основном сервере 20 в качестве программного модуля. Этот AI содержит алгоритм машинного обучения. Типично, он использует нейронные сети и может представлять собой глубокую нейронную сеть (которая содержит более одного скрытого уровня). Более конкретно, могут использоваться полностью соединенная нейронная сеть (fcNN), рекуррентная нейронная сеть (RNN) или сверточная нейронная сеть (CNN) либо комбинации их или другие типы нейронных сетей в ансамблевых схемах. В самом базовом варианте осуществления, AI содержит данные из нескольких изображений, захваченных во время ацетоотбеливающего эффекта, как поясняется ниже. Тем не менее, дополнительные данные предпочтительно также предоставляются в AI. В этом случае, AI может содержать многомодальную нейронную сеть, которая может комбинировать данные изображений и без изображений.
Изображения, предоставленные в AI, могут представлять собой временные ряды "необработанных" изображений, захваченных посредством оптической системы. Тем не менее, изображения более типично должны предоставляться с постобработкой "необработанных" оптических изображений, в частности, после масштабирования и/или совмещения посредством программного алгоритма и/или после обработки для одного или более из следующего: идентификация шейки; удаление артефактов; и распознавание шаблонов. Необработанные и постобработанные изображения могут предоставляться в качестве вводов в некоторых реализациях. Полный набор захваченных изображений или поднабор для набора изображений (в любом случае, с или без последующей обработки) может предоставляться в качестве ввода в AI. Например, необработанные или постобработанные изображения могут подразделяться на патчи, которые могут предоставляться в качестве данных изображений. Размеры патчей и/или число предоставленных патчей могут варьироваться между изображениями. Извлечение признаков и/или другая обработка, описанная в данном документе, может применяться к патчам, а не к полному или целому изображению.
Один дополнительный ввод в AI может быть основан на дополнительной обработке данных для данных изображений (типично на постобработке "необработанных" оптических изображений, в частности, чтобы достигать идентичного масштабирования и совмещения). Эта дополнительная обработка данных может использоваться для того, чтобы измерять характеристики диффузионной отражательной способности в изображениях, и может выполняться в локальном процессоре 15 и/или на основном сервере 20. Первоначально, пиксельные значения (к примеру, интенсивности) могут извлекаться из совмещенных изображений и снабжаться ссылкой согласно времени, в которое захвачено изображение (которое может представлять собой абсолютное время либо задаваться относительно времени, в которое разбавленная уксусная кислота местно применяется). Различные параметры затем вычисляются из пиксельных значений с разрешением по времени, такие как интенсивность, время до достижения максимальной интенсивности и площадь под кривой зависимости пиксельного значения от времени (т.е. интеграл пиксельного значения во времени). Эти параметры могут вычисляться в одной или более полос спектра и/или для всех или подвыборки пикселов изображений. Хотя параметры могут быть основаны непосредственно на захваченных пиксельных значениях с разрешением по времени, параметры вместо этого могут вычисляться с использованием промежуточных значений, вычисленных из пиксельных значений с разрешением по времени. Например, промежуточные значения могут определяться посредством подгонки извлеченных пиксельных значений с разрешением по времени к математической функции (к примеру, к линейной функции, кривой или экспоненциалу). Затем коэффициенты этой функции могут использоваться для того, чтобы вычислять различные параметры, такие как максимальная интенсивность, время до достижения максимальной интенсивности и площадь под кривой зависимости пиксельного значения от времени. Такие параметры могут использоваться в качестве конкретных вводов в AI, которые могут представлять уровень диффузионной отражательной способности. В другом подходе, параметры могут использоваться для того, чтобы вычислять одно числовое значение индекса в расчете на пиксел, например, из одного параметра или из комбинирования со взвешиванием параметров. Одно числовое значение индекса в расчете на пиксел затем может предоставляться в качестве ввода в AI. Альтернативно, цвет из псевдоцветовой шкалы может назначаться каждому пикселу на основе его значения индекса, и параметрическая псевдоцветовая карта может формироваться посредством иллюстрации соответствующего псевдоцвета по каждому пикселу изображения шейки матки. Затем эта параметрическая псевдоцветовая карта может предоставляться в качестве ввода в AI.
Один дополнительный ввод в AI может быть основан на дополнительной обработке данных для данных изображений (типично на постобработке "необработанных" оптических изображений, в частности, чтобы достигать идентичного масштабирования и совмещения). Это может осуществляться по отдельности для подчастей изображения, которые могут задаваться как патчи в 8×8 или 16×16 или 32×32 пикселов (при этом другие формы и/или размеры патчей также являются возможными). Каждое изображение может разбиваться на определенное число патчей с шагом между ними, который может составлять 4, 8, 16, 32 пиксела (при этом другие размеры также являются возможными). Таким образом, каждый патч может иметь частичное перекрытие со своими соседними патчами, и большое число патчей может извлекаться из каждого изображения или части изображения. Эта дополнительная обработка данных может использоваться для того, чтобы извлекать индивидуально адаптированные или ручные признаки, на основе математических функций, описывающих локальный цвет, градиент и текстуру (при этом другие типы функций также являются возможными). Затем эти признаки могут предоставляться в качестве ввода в AI.
Другие формы информации могут предоставляться в качестве одного или более дополнительных вводов в AI, например, с использованием информации, сохраненной в базе 30 данных идентификационных данных. Эта информация может включать в себя одно или более из следующего: демографические данные пациента; факторы риска пациента; предыдущая информация истории болезни; и результаты клинических тестов. Демографические данные пациента могут содержать, например, возраст пациента во время исследования (или то, что возраст превышает предварительно заданное пороговое значение). Факторы риска пациента могут включать в себя: статус на предмет курения для пациента (к примеру, одно из "не курит", "регулярно курит", "курит время от времени" или "курил в прошлом"); сексуальный статус и/или история для пациента; использование презервативов во время полового акта (к примеру, одно из "всегда", "иногда" или "никогда"); статус вакцинации против HPV; и количество родов для пациента (с точки зрения того, были или нет роды, и/или числа родов). Результаты клинических тестов пациента могут содержать, по меньшей мере, одно или любую комбинацию следующего: предшествующие результаты цитологии; предшествующие результаты HPV-теста; предшествующие результаты HPV-теста типирования; предшествующая информация лечения шейки матки; и предшествующая история обследования на предмет и/или для диагностики рака или предраковых состояний шейки матки. Возможные результаты цитологии могут представлять собой одно из следующего (упорядочено по серьезности): "нормальный", "ASCUS (граничная линия"), "LSIL (мягкий дискариоз)", "ASC-H", "умеренный дискариоз", "сильный дискариоз (HSIL)", "подозрение на железистые изменения" или "подозрение на инвазивный рак". Возможные результаты для HPV-тестов могут представлять собой одно из "отрицательный", "HR-положительный", "16-положительный", "16/18-положительный" или другой.
В общих чертах, в силу этого может рассматриваться способ для классификации (в живом организме или в пробирке) биологической ткани, такой как шейка матки, с использованием вычислительной системы. Данные изображений, содержащие множество изображений зоны исследования биологической ткани, принимаются в вычислительной системе. Каждое из множества изображений захватывается в различные моменты времени в течение периода, в который местное применение дифференцирующего агента для выявления патологии (в частности, содержащего уксусную кислоту, которая предпочтительно разбавляется) к зоне исследования ткани. Это вызывает переходные оптические эффекты, такие как отбеливание, которое может представлять собой ацетоотбеливание (если используется уксусная кислота). Принимаемые данные изображений предоставляются в качестве ввода в алгоритм машинного обучения, работающий в вычислительной системе (в частности, например, на одном или более процессоров вычислительной системы). Алгоритм машинного обучения, который преимущественно содержит нейронную сеть и более предпочтительно глубокую нейронную сеть, выполнен с возможностью выделять одну из множества классификаций для ткани. В предпочтительном варианте осуществления, алгоритм машинного обучения выполнен с возможностью выделять одну из множества классификаций для каждого из множества сегментов ткани, которая преимущественно может представляться в форме тепловой карты, указывающей классификации (как подробнее пояснено ниже). Способ может реализовываться как компьютерная программа.
В другом смысле, может рассматриваться вычислительная система, работающая с возможностью классификации ткани, содержащая: ввод, выполненный с возможностью принимать данные изображений, содержащие множество изображений зоны исследования биологической ткани; и процессор, выполненный с возможностью работать с алгоритмом машинного обучения, выполненным с возможностью выделять одну из множества классификаций для ткани на основе данных изображений. Каждое из множества изображений захватывается в различные моменты времени в течение периода, в который местное применение дифференцирующего агента для выявления патологии к зоне исследования ткани вызывает переходные оптические эффекты.
До предоставления дополнительных сведений по реализации предпочтительного конкретного варианта осуществления, в дальнейшем поясняются некоторые необязательные и/или преимущественные признаки этого обобщенного способа и/или компьютерной системы. Такие признаки типично могут применяться к любому аспекту.
Множество изображений (или оптические изображение, из которых извлекаются множество изображений, также называемые "необработанными изображениями"), в общем, захватываются с интервалами (которые могут быть регулярными, но не обязательно) в предварительно определенную длительность, в течение периода, в который местное применение дифференцирующего агента для выявления патологии к зоне исследования ткани вызывает переходные оптические эффекты. По меньшей мере, одно изображение биологической ткани до местного применения дифференцирующего агента для выявления патологии к зоне исследования ткани, вызывающего переходные оптические эффекты, может захватываться (базовое опорное изображение), и оно может предоставляться в качестве дополнительного ввода в алгоритм машинного обучения. Зона исследования преимущественно подвергается воздействию широкополосного оптического излучения в течение периода, в который местное применение дифференцирующего агента для выявления патологии к зоне исследования ткани вызывает переходные оптические эффекты. Широкополосное оптическое излучение предпочтительно имеет полосу пропускания на основе переходных оптических эффектов, например, полосу пропускания, которая вызывает то, что ацетоотбеливающий эффект является видимым в захваченных изображениях. Уровень освещения яркости изображения, достигаемый посредством оптического излучения, может точно характеризоваться относительно интенсивности падающего света и расстояния между источником света и целью. Широкополосное оптическое излучение может охватывать целый оптический спектр, по меньшей мере, в 90%, 80%, 75%, 70%, 60% или в большую часть (50%) оптического спектра. Узкополосное оптическое излучение может использоваться в некоторых случаях, например, для определенных дифференцирующих агентов для выявления патологии (к примеру, в молекулярной диагностике, например, с использованием флуоресцеиновых маркеров). В этом случае, узкополосное оптическое излучение может охватывать менее 50%, 40%, 30%, 20% или 10% от оптического спектра, например, ограниченного одним цветом, таким как ультрафиолетовый диапазон или инфракрасный диапазон.
Процессор вычислительной системы может содержать одно обрабатывающее устройство или множество обрабатывающих устройств. Каждое обрабатывающее устройство необязательно выполнено с возможностью работать с частью алгоритма машинного обучения (например, распределенным способом). Обрабатывающие устройства могут быть расположены в различных (удаленных) местоположениях.
Множество оптических изображений (необработанные изображения) зоны исследования биологической ткани преимущественно захватываются. Это может достигаться с использованием модуля сбора изображений (содержащего надлежащим образом смонтированную камеру и/или под управлением процессора). Модуль сбора изображений необязательно находится удаленно от процессора, на котором работает алгоритм машинного обучения (или, по меньшей мере, от одного из обрабатывающих устройств, если используются несколько обрабатывающих устройств).
Множество изображений из данных изображений может извлекаться из множества оптических (необработанных) изображений. Необязательно, одно или более из множества оптических изображений предоставляются в качестве дополнительного ввода в алгоритм машинного обучения. Преимущественно, модуль сбора изображений калибруется, например, с регулярными интервалами или после предварительно определенного числа захватов изображений и/или исследований отдельных биологических тканей (или пациентов). Каждое оптическое изображение может захватываться с соответствующим фокусным расстоянием. Фокусные расстояния могут быть идентичными. Оптическое изображение затем может масштабироваться на основе фокусного расстояния и опорного расстояния, чтобы предоставлять соответствующее одно из множества изображений, в частности, таким образом, что шкала каждого из множества изображений находится на предварительно определенном уровне. Каждое оптическое изображение предпочтительно преобразуется таким образом, чтобы предоставлять совмещение зоны исследования в пределах множества изображений. Дополнительно или альтернативно, каждое оптическое изображение может обрабатываться для того, чтобы удалять один или более артефактов или типов артефактов. Множество изображений могут обрабатываться для того, чтобы идентифицировать часть из множества изображений, соответствующих предварительно определенному органу. Например, если биологическая ткань содержит шейку, множество изображений могут обрабатываться для того, чтобы идентифицировать часть из множества изображений, соответствующих шейке. В некоторых вариантах осуществления, множество изображений могут обрабатываться для того, чтобы идентифицировать и/или количественно определять, по меньшей мере, один извлеченный признак и/или, по меньшей мере, одну морфологическую характеристику, к примеру, одно или более из следующего: атипичные сосуды; мозаицизм; и пунктация. Извлеченный признак или признаки и/или морфологическая характеристика или характеристики могут предоставляться в качестве дополнительного ввода (или дополнительных вводов) в алгоритм машинного обучения.
Каждое из множества изображений задается посредством соответствующего набора пикселов, и необязательно, каждый из наборов пикселов имеет идентичную пиксельную компоновку. В предпочтительном варианте осуществления, получаются картографические данные, содержащие соответствующий аналитический индекс для каждого пиксела пиксельной компоновки, причем аналитические индексы извлекаются из множества изображений. Предпочтительно, аналитический индекс для пиксела формируется на основе, по меньшей мере, одного параметра, извлекаемого из множества изображений. По меньшей мере, один параметр необязательно ограничивается предварительно определенной полосой пропускания спектра, и если извлекаются несколько параметров, они могут содержать первый параметр, ограниченный первой предварительно определенной полосой пропускания спектра, и второй параметр, ограниченный второй предварительно определенной полосой пропускания спектра (отличающейся от первой предварительно определенной полосы пропускания спектра). Каждый параметр может определяться на основе точных данных пиксела и/или посредством подгонки данных для пиксела по множеству изображений к линии или кривой и определения параметра из кривой. Аналитический индекс для каждого пиксела может быть основан на одном параметре или комбинировании со взвешиванием нескольких параметров. По меньшей мере, один параметр содержит, например, одно или более из следующего: максимальная интенсивность для пиксела по множеству изображений; время для того, чтобы достигать максимальной интенсивности для пиксела; и суммирование или суммирование со взвешиванием интенсивности для пиксела по множеству изображений. Суммирование со взвешиванием интенсивности для пиксела по множеству изображений может использовать весовые коэффициенты на основе времени захвата для каждого из множества изображений, например, на их относительном времени захвата. Это может обеспечивать возможность вычисления интеграции интенсивности во времени (или площади под кривой зависимости интенсивности от времени). Картографические данные (или, по меньшей мере, один или более аналитических индексов) могут предоставляться в качестве дополнительного ввода в алгоритм машинного обучения.
В некоторых вариантах осуществления, одна или более характеристик исследуемого объекта предоставляются в качестве ввода в алгоритм машинного обучения. Каждая характеристика исследуемого объекта может быть связана с исследуемым объекта, из которого исходит биологическая ткань. Например, одна или более характеристик исследуемого объекта могут содержать одно или более из следующего: факторы риска исследуемого (к примеру, одно или более из следующего: возраст исследуемого; статус на предмет курения исследуемого; статус HPV-вакцинации исследуемого; использование презервативов во время полового акта; и количество родов для исследуемого); и результаты клинических тестов исследуемого (например, одно или более из следующего: предшествующий результат цитологии; предшествующий результат HPV-теста; предшествующий результат HPV-теста типирования; предшествующая информация лечения шейки матки; и предшествующая история обследования на предмет и/или диагностики рака или предраковых состояний шейки матки).
Далее поясняются дополнительные сведения по реализации. Ссылаясь теперь на фиг. 2, схематично проиллюстрирован процесс кольпоскопического анализа в соответствии с раскрытием сущности. Как показано в левой стороне иллюстрации, начальный этап в процессе представляет собой захват, подготовку и анализ изображений 100. Первоначально, исходные изображения 102 захватываются, они затем обрабатываются, чтобы формировать совмещенные изображения 104, и параметрическая псевдоцветовая карта 106 формируется. Они предоставляются в качестве вводов на этап 110 AI-обработки. Также в качестве ввода на этап 110 AI-обработки предоставляются данные без изображений 120, которые могут включать в себя: информацию 121 возраста; статус 122 на предмет курения; HPV-статус 123; и статус 124 прохождения теста Папаниколау. Другие и/или дополнительные вводы также являются возможными, как пояснено в данном документе.
AI (в частности, алгоритм, работающий на основном сервере 20) обучается, чтобы классифицировать ткань, из которой захвачены изображения в некотором смысле. Различные наборы данных могут использоваться для того, чтобы обучать различные аспекты AI. Тип или типы данных, используемых для обучения, типично могут включать в себя любое одно или более из типа или типов данных, используемых для классификации. В одной реализации, AI выполнен с возможностью предоставлять классификацию интраэпителиальной неоплазии шейки матки (CIN), на основе обучающих данных, содержащих изображения и релевантную классификацию из точно охарактеризованного набора случаев с пациентом с известными зонами биопсии и результатами гистопатологии. В частности, это представляет собой набор случаев с известными участками, которые берутся на биопсию, и результаты гистологии биопсий преимущественно известны. Примечания опытных экспертов на предмет подозрительных зон также могут быть доступными, и они могут предоставляться в качестве дополнительных обучающих данных. В определенных реализациях, набор случаев подвергнут эксцизионному лечению, и доступно подробное картирование для их гистологии, включающей в себя несколько секций в расчете на лечебный образец, которое также может предоставляться в качестве обучающих данных. AI может классифицировать шейку по шкале риска, при этом различные уровни этой шкалы соответствуют общему риску наличия у пациента различных степеней злокачественности CIN (например, по шкале 0-1,0-100 или 1-100 на целочисленной или непрерывной шкале). Различные пороговые значения на этой шкале могут выбираться с возможностью подстраивать конечную производительность или предоставлять непосредственный индикатор "нет риска", "низкий риск" или "высокий риск". В другом варианте осуществления, AI может непосредственно предоставлять результаты в классификациях, например, "нормальный", "CIN1", "CIN2", "CIN3", "AIS" или "инвазивный рак" (один из множества тегов заболевания).
Обучающие наборы данных могут предоставляться из клинических испытаний. Они могут включать в себя одно или более синхронизированных по времени (динамических) изображений шейки с ацетоотбеливанием (в их исходной и совмещенной форме), составляющих данные, чтобы предоставлять параметрическую псевдоцветовую карту для изображений, результаты гистологии (с местоположениями биопсии, если известны), а также базовые характеристики пациента (возраст, цитологию, HPV, статус на предмет курения, предыдущую историю заболевания и т.п.). Набор данных пациента может включать в себя набор изображений, захваченных во время исследования, с опорным изображением (до применения уксусной кислоты) и всеми последующими (после уксусной кислоты) синхронизированными по времени изображениями (вплоть до 24). Разрешение изображений может составлять 1024×768, 1600×1200 или 2800×2100, при этом другие разрешения также являются возможными. Дополнительно или альтернативно, набор данных пациента может включать в себя набор изображений, совмещенных посредством алгоритма обработки изображений, который может содержать опорное изображение (до применения уксусной кислоты) и все последующие (после уксусной кислоты) синхронизированные по времени изображения (вплоть до 24). Разрешение совмещенных изображений, например, может составлять 1024×768 или 2048×1536. Типичное разрешение для параметрической псевдоцветовой карты, например, составляет 1024×768 или 2048×1536. Результаты гистологии могут представлять собой одно из следующего (упорядочено по серьезности): "нормальный", "CIN1", "CIN2", "CIN3", "AIS", "инвазивный рак".
Хотя одна классификация для ткани может выводиться из AI, другие варианты также являются возможными. В конкретной реализации, AI анализирует и может сегментировать изображение шейки для каждого пациента, исследуемого с помощью системы. Изображение может сегментироваться предварительно определенным способом либо на основе идентификации риска патологических изменений или заболевания, и это необязательно может осуществляться за рамками алгоритма машинного обучения. Каждый сегмент шейки затем классифицируется по шкале риска для оцененного риска для различных степеней злокачественности CIN (как пояснено выше) или для того, чтобы предоставлять классификацию из одного из определенного числа дискретных состояний заболевания. Необязательно, AI также может классифицировать каждый пиксел и/или сегмент в соответствии с определенным наличием морфологической характеристики. Это может представлять собой промежуточный вывод AI, который может использоваться для того, чтобы определять дополнительные классификации, но не должен обязательно предоставляться в качестве вывода пользователю.
Результаты AI-сегментации и классификации могут отображаться в качестве вероятностной "тепловой карты" (параметрической псевдоцветовой карты), в качестве вывода AI. Это показано как вывод 130 AI на фиг. 2. Тепловая карта, выводимая из AI (которая отличается от параметрической псевдоцветовой карты, сформированной посредством обработки изображений, как описано выше, и которая может использоваться в качестве ввода в AI), затем преимущественно отображается в графической форме в качестве наложения на изображения шейки матки системному оператору во время исследования (например, через локальный процессор 15), чтобы упрощать считывание показаний и принятие клинических решений. Разрешение тепловой карты может быть идентичным масштабированным изображениям, предоставленным в качестве ввода в AI (такое как, например, 1024×768 или 2048×1536). Эта (или аналогичная обработка изображений) может обеспечивать возможность наложения вывода тепловой AI-карты на изображение шейки, захваченное во время исследования (например, постобработки). Такая "тепловая карта" может иметь значительную клиническую полезность (к примеру, для идентификации участка биопсии или эксцизионного лечения).
Результаты AI-сегментации и классификации альтернативно могут отображаться в качестве ограничительной рамки, которая указывает зоны, которые достигают количественного показателя классификации выше предварительно заданного порогового значения в качестве вывода AI. Например, она может представлять собой индикатор "нет риска", "низкий риск" или "высокий риск" или непосредственно с тегом заболевания, например: "нормальный"; "CIN1"; "CIN2"; "CIN3"; "AIS"; или "инвазивный рак".
Для каждого результата, который он формирует, AI-модуль также может вычислять прилагаемый доверительный интервал или другой показатель точности, которая может иметь графическую или числовую форму.
Подход, поясненный в этом раскрытии сущности, должен повышать точность и производительность кривой рабочих характеристик приемного устройства (ROC). Она может измеряться в качестве AUC (площади под кривой), которая за счет ROC-кривой иллюстрирует частоту истинноположительных суждений в зависимости от частоты ложноположительных суждений, и в силу этого иллюстрирует комбинированную производительность чувствительности и специфичности. Производительность AI может определяться посредством сравнения AI-классификации с экспериментально полученными проверочными данными (результатами гистологии) для каждого протестированного пациента и характеризует сравнение в качестве одного из следующего: истинноположительное суждение (TP); ложноположительное суждение (FP); истинноотрицательное суждение (TN); и ложноотрицательное суждение (FN). Основные показатели для сравнения могут представлять собой общую точность, чувствительность и специфичность. Вторичные показатели могут включать в себя положительные и отрицательные прогнозирующие значения.
Со ссылкой на общий смысл, поясненный выше, в некоторых вариантах осуществления может рассматриваться возможность того, что алгоритм машинного обучения выполнен с возможностью выделять одну из множества классификаций для каждого из одного или более сегментов ткани. Один или более сегментов ткани необязательно идентифицируются из данных изображений, например, с использованием алгоритма машинного обучения. Альтернативно, сегменты могут быть основаны на числе пикселов в каждом изображении из данных изображений. Может формироваться (и необязательно отображаться) выходное изображение, показывающее зону исследования биологической ткани на основе данных изображений и указывающее классификацию, выделяемую для каждого из множества сегментов ткани. Например, это может принимать форму тепловой карты. Таким образом, множество сегментов ткани могут представлять подзоны для зоны исследования биологической ткани. Эти подзоны могут задаваться и разграничиваться относительно других подзон на основе одной или более масок, извлечения признаков и/или общей классификации, выделяемой для конкретной подзоны. Это означает то, что форма и размер подзон в этом случае могут определяться посредством признаков и/или классификаций, применяемых для ткани (и в силу этого могут не быть равномерными по размеру или форме). Соответственно, повышенная производительность может измеряться на основе способности применять отдельные классификации к различным частям ткани (в противоположность полной классификации тканей).
Классификация может выделяться для (всей или полной) ткани на основе классификации, выделяемой для одного или более сегментов ткани (или из комбинации классификаций, выделяемых для нескольких сегментов, к примеру, из взвешенной суммы). Дополнительно или альтернативно, классификация, выделяемая для (всей или полной) ткани, может быть основана на алгоритме, отличающемся от алгоритма машинного обучения, например, на другой параллельной модели. Классификации могут быть дискретными или задаваться посредством шкалы значений с непрерывным диапазоном (например, в качестве вероятности, уровня риска или количественного показателя, такого как наличие определенного условия).
Алгоритм машинного обучения (или версия, работающая во второй компьютерной системе, которая может быть удаленной от компьютерной системы) может обучаться на основе соответствующего множества изображений и соответствующей выделяемой классификации для каждой из множества других биологических тканей (которые могут захватываться в различные моменты времени в течение периода, в который местное применение дифференцирующего агента для выявления патологии к зоне исследования ткани вызывает переходные оптические эффекты). Число других биологических тканей может составлять, по меньшей мере, 100, 500, 1000 или 5000 в некоторых случаях. Необязательно, определенная пользователями (или на основе баз данных) классификация для ткани может предоставляться в алгоритм машинного обучения для дополнительного обучения. Она может быть основана на одном или обоих из биопсии с известным результатом гистологии либо на клинической оценке прекрасно обученного специалиста-медика. Такие классификации могут предоставляться вручную (например, непосредственно врачом, специалистом-медиком или техническим специалистом), и/или они могут автоматически извлекаться из базы данных, например, медицинских карт пациентов, которые могут составлять часть входного набора данных. Классификации затем могут вводиться в базу данных (или другую базу данных, из которой частично или полностью извлечен набор данных) вручную.
В некоторых вариантах осуществления, классификация может выделяться для ткани с использованием первого алгоритма машинного обучения, работающего в первом процессоре вычислительной системы. В некоторых случаях, первый процессор является локальным для модуля сбора изображений, который используется для того, чтобы захватывать множество оптических (необработанных) изображений зоны исследования биологической ткани, из которой извлекаются множество изображений. Необязательно, классификация также может выделяться для ткани с использованием второго (другого) алгоритма машинного обучения, работающего во втором процессоре вычислительной системы. Дополнительно или альтернативно, второй алгоритм машинного обучения (описанный выше в качестве версии алгоритма машинного обучения) может обучаться, например, с использованием классификации или классификаций, идентифицированных посредством первого алгоритма машинного обучения. Второй процессор предпочтительно является удаленным от модуля сбора изображений, и в определенных случаях, первый процессор также может быть удаленным. Второй алгоритм машинного обучения преимущественно имеет другую структуру и/или параметризацию по сравнению с первым алгоритмом машинного обучения. В некоторых вариантах осуществления, классификация, выделяемая в первом процессоре, может предоставляться в качестве ввода во второй процессор.
В варианте осуществления, второй алгоритм машинного обучения может обучаться посредством предоставления определенной пользователями (или на основе баз данных) классификации для ткани во второй алгоритм машинного обучения (например, из биопсии с известной гистологией, как пояснено выше). Тем не менее, первый алгоритм машинного обучения необязательно не обучается посредством предоставления определенной пользователями (или на основе баз данных) классификации для ткани в первый алгоритм машинного обучения. Таким образом, (быстрый и/или менее сложный) алгоритм машинного обучения может предоставляться без обучения (т.е. фиксированный алгоритм), при этом (более медленный и/или более сложный) алгоритм машинного обучения предоставляется с непрерывным динамическим обучением (инкрементным обучением), например, на основе предоставления дополнительных данных. В соответствии с непрерывным динамическим обучением, например, второй алгоритм машинного обучения может содержать, для каждой из множества зон исследования одной или более биологических тканей, одно или более из следующего: множество изображений зоны исследования (предоставляемых в алгоритм машинного обучения, работающий на компьютерной системе); одно или более местоположений биопсии (выполняемых для этой зоны исследования); множество классификаций для каждого из множества сегментов ткани, выделяемой посредством первого алгоритма машинного обучения (работающего в компьютерной системе, т.е. локального алгоритма); и результаты гистопатологии для ткани. Алгоритм машинного обучения без обучения может быть локальным для захвата изображений, и/или алгоритм машинного обучения с непрерывным динамическим обучением может быть удаленным для захвата изображений. Процесс непрерывного динамического обучения преимущественно выполняется периодически. Преимущественно, процесс может включать данные из нескольких отдельных устройств захвата изображений (каждое из которых имеет соответствующий локальный алгоритм машинного обучения). Первый алгоритм машинного обучения (фиксированный алгоритм) может время от времени обновляться.
Далее поясняются экспериментальные результаты. Выполняемые эксперименты поясняются со ссылкой на фиг. 3, на котором схематично проиллюстрирована блок-схема последовательности операций способа, детализирующая технологию для экспериментальной системы. Эта блок-схема последовательности операций способа указывает рабочий конвейер, после этапа выбора наборов данных пациента, которые удовлетворяют базовым критериям качества (таким как хорошо сфокусированные изображения, последовательность готовых изображений, отсутствие существенных артефактов и известные результаты биопсии). Во-первых, снабжение примечаниями 200 изображений для обучения (пометка зон биопсии и добавление в конец меток заболевания) выполняется посредством анализа изображений и видео процедуры биопсии для точного размещения меток на ткани. После этого выполняется формирование масок 210, содержащее извлечение соответствующих масок изображения. Извлечение патчей 220 затем выполняется для 17 моментов времени. Извлечение признаков 230 содержит извлечение признаков из каждой зоны биопсии и по отдельности для всех патчей. Технология 240 условной подстановки данных затем выполнена, чтобы учитывать все отсутствующие значения. Этап 250 на основе схемы глубокого обучения содержит установление и обучение трех различных схем машинного обучения для вычисления вероятностей для каждого патча. В завершение, формирование тепловых карт 260 получается в результате выводов схем глубокого обучения для тестовых случаев. Тестовые случаи подготавливаются аналогично тому, что описано посредством технологии по фиг. 3. Единственная разница заключается в том, что модели не знают статус заболевания зоны биопсии (т.е. при снабжении примечаниями 200), а вместо этого должны прогнозировать его.
Набор данных получен из существующего клинического испытания с использованием цифрового кольпоскопа, изготовленного компанией DYSIS Medical Limited, с картированием на основе динамической спектральной визуализации (DSI), и включает в себя 222 пациента с 396 независимыми биопсиями. 1Местоположения биопсий известны, и биопсии включают в себя визуально выбранные биопсии, биопсии на основе DSI-карты и случайные биопсии из зон, которые кажутся нормальными врачу. Набор данных каждого пациента содержит 17 изображений, которые включают в себя опорное изображение (предварительное ацетоотбеливание) и 16 последующих изображений в стандартные моменты времени. Изображения использованы в качестве ввода, после того, как они точно совмещены (совмещены), чтобы компенсировать перемещения (смещения, сжатия и т.п.).
Для двоичной классификации результатов, биопсии разделены согласно их гистологической градации по степени злокачественности на два класса: нормальная/низкая степень злокачественности (NLG) (включающая в себя результаты "отрицательный" и "CIN1") в качестве "отрицательного" класса; и высокая степень злокачественности (HG) ("CIN2", "CIN3", "AIS", "инвазивный рак") в качестве "положительного" класса. Она представляет собой клинически значимую классификацию и является согласованной с классификацией, используемой в большинстве кольпоскопических исследований.
Набор данных вручную разбит пациентом на 80% для обучающего набора, 10% для проверки достоверности и 10% для независимого тестирования. Для этого разбиения, рассматриваются число биопсий в расчете на одного пациента и процентная доля низкозлокачественных и высокозлокачественных биопсий, чтобы создавать аналогичные распределения по пациентам в наборах для проверки достоверности и тестовых наборах. Оставшиеся пациенты используются для обучения. Обучающий набор включает в себя 172 пациента и 306 биопсий, проверка достоверности включает в себя 25 пациентов и 46 биопсий, и тестовый набор включает в себя 25 пациентов и 44 биопсии.
Зоны биопсии каждого изображения отдельно снабжаются примечаниями (пространственно помечаются и отмечаются по степени злокачественности заболевания). Каждая биопсия классифицирована согласно своей гистопатологической степени злокачественности заболевания как "нормальный", "CIN1", "CIN2", "CIN3", "AIS" или "инвазивный рак".
После снабжения примечаниями, соответствующие маски (т.е. площадь изображения) каждой биопсии извлекаются. На основе этих масок, патчи извлекаются для 17 совмещенных изображений для различных моментов времени. Патчи первоначально извлечены с различными размерами в 16×16, 32×32 и 64×64 пикселов и с различными шагами в 8, 16, 32 и 64 пиксела, чтобы обеспечивать возможность изучения того, какие комбинации работают лучше всего.
Из каждого патча, извлекаются множество ручных признаков, на основе локального цвета, градиента и текстуры для применения в качестве ввода в алгоритмах машинного обучения (см. работы: Tao Xu и другие “Multi-feature based benchmark for cervical dysplasia classification evaluation”, "Pattern Recognit.", март 2017 года; 63: 468-475; Kim E, Huang X. "A data driven approach to cervigram image analysis and classification", Color Medical Image analysis, Lecture Notes in Computational Vision and Biomechanics", 2013; 6:1-13; и Song D, Kim E, Huang X, и другие, "Multi-modal entity coreference for cervical dysplasia diagnosis", IEEE Trans on Medical Imaging, TMI. 2015; 34(1):229-245). Это приводит к общему числу в 1374 признака для каждого патча и момента времени. Признаки, которые извлекаются, являются очень варьирующимися по абсолютным величинам значений, единицам и диапазону, так что они все нормализованы по шкале 0-1:
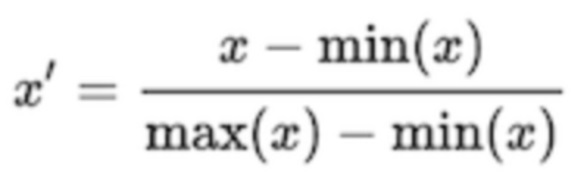 .
.
После извлечения признаков, применяется условная подстановка данных (см. работу Welch, G. Bishop, "An Introduction to the Kalman Filter", SIGGRAPH 2001 Course 8, 1995 год), чтобы компенсировать некоторые недостающие признаки в размытых и неправильно совмещенных патчах. Достоверность способа условной подстановки проверена отдельно. Данные структурированы таким образом, что для каждого пациента, предоставлена матрица моментов времени из каждого патча, извлеченного из зон(ы) биопсии, относительно значений каждого из извлеченных признаков (включающих в себя условно подставленные признаки) для каждого из патчей.
Ниже поясняются модели машинного обучения, используемые при анализе. Данные, как описано выше, используются в качестве ввода в три различных классификатора машинного обучения: случайный лес (RF); полностью соединенная нейронная сеть (FNN); и нейронная сеть на основе долгого кратковременного запоминающего устройства (LSTM), которая представляет собой тип рекуррентной нейронной сети, RNN.
Ссылаясь далее на фиг 4, схематично проиллюстрирована известная модель классификации по принципу случайного леса. Случайные леса или случайные леса решений представляют собой ансамблевый способ обучения для классификации, регрессии и других задач, который работает посредством составления множества деревьев решений во времени обучения и вывода класса, который представляет собой режим классов (классификацию) либо среднее прогнозирование (регрессию) отдельных деревьев (см. работу Ho, Tin Kam, "Random Decision Forests", Proceedings of the 3rd International Conference on Document Analysis and Recognition, Montreal, QC, 14-16 августа 1995 года, стр. 278-282). Случайные леса решений корректируют тенденцию деревьев решений на предмет их сверхподгонки к обучающему набору. Чтобы реализовывать классификатор случайного леса (RF), используются Python-библиотека Scikit-Learn и 150 модулей оценки (деревьев решений).
Ссылаясь теперь на фиг. 5, схематично показывается известная архитектура на основе искусственной нейронной сети (ANN). ANN (также называемая "нейронной сетью" или "NN") представляет собой парадигму обработки информации, которая обусловлена способом, которым биологические нервные системы, такие как мозг, обрабатывают информацию. Ключевой элемент представляет собой новую структуру системы обработки информации. Она состоит из большого числа очень взаимосвязанных обрабатывающих элементов (нейронов), работающих согласованно, чтобы разрешать конкретные проблемы. NN, как и люди, обучаются на примере. NN сконфигурирована для конкретного варианта применения, такого как распознавание шаблонов или классификация данных, посредством процесса обучения. Обучение в биологических системах заключает в себе регулирования для синаптических соединений, которые существуют между нейронами. Это также верно для NN.
Нейронные сети, с их способностью извлекать смысл из сложных или неточных данных, могут использоваться для того, чтобы извлекать шаблоны и обнаруживать тренды, которые являются слишком сложными для восприятия людьми или посредством других компьютерных технологий. Обученная нейронная сеть может рассматриваться в качестве "эксперта" в категории информации, которая ей предоставлена для анализа. Этот эксперт затем может использоваться для того, чтобы предоставлять проекции с учетом новых интересующих ситуаций и отвечать на вопросы "что, если". Для случая нейронных сетей, используется инфраструктура машинного обучения с открытым исходным кодом TensorFlow (RTM) Python. После настройки гиперпараметров и небольшого сеточного поиска, используется полностью соединенная сеть с 3 уровнями по 50 единиц каждый и с уровнем функции мягкого максимума с 2 единицами в качестве выходного уровня.
Хотя NN может представлять собой полезное инструментальное средство для такой классификации, следует признавать то, что люди не начинают свое размышление с нуля в каждом обстоятельстве. Традиционные NN не могут использовать информацию из предыдущего обучения, что кажется недостатком. Рекуррентные нейронные сети (RNN) разрешают эту проблему. Они представляют собой сети с контурами в них, позволяющими информации "постоянно сохраняться". RNN может рассматриваться в качестве нескольких копий идентичной сети, каждая из которых пересылает сообщение в последующий элемент.
Далее следует обратиться к фиг. 6, на котором схематично иллюстрируется известная базовая архитектура на основе долгого кратковременного запоминающего устройства (LTSM). LSTM представляют собой специальный вид RNN, допускающей изучение долговременных зависимостей. LSTM явно проектируются с возможностью исключать проблему долговременных зависимостей. Идентичный процесс, что и в ANN, используется для реализации классификатора для случая LSTM. Более конкретно, после оптимизации гиперпараметров и сеточного поиска, обнаружено, что наилучшая модель состоит из следующего: два LSTM-уровня с 20 единицами каждый; и функция мягкого максимума с 2 единицами в качестве выходного уровня.
Помимо этого, последовательности ансамблевых схем классификации разработаны, с использованием среднего вероятностей для каждого патча всей возможной комбинации трех классификаторов. В частности, четыре комбинации протестированы для RF+NN+LSTM, RF+NN, RF+LSTM и NN+LSTM для 25 тестовых пациентов для биопсий.
Также разработаны последовательности средневзвешенных схем вероятностей. Более конкретно, "неглубокая нейронная сеть" обучены с комбинированными вероятностями проверки достоверности согласно каждой ансамблевой схеме, в то время как вероятности проверки достоверности извлечены отдельно из каждой вышеуказанной главной модели (RF, NN и LSTM). В отличие от глубокой NN, неглубокая NN имеет только один скрытый уровень.
Архитектуры первоначально испытаны в различных комбинациях размера патча и шага, чтобы оценивать то, какой подход должно работать лучше всего с учетом размера масок изображений и признаков. Обнаружено что комбинация размера патча в 32×32 с шагом в 8 пикселов работает лучше всего, так что она приспособлена для подстройки всех моделей и формирования результатов.
Ниже поясняется выполнение каждого из протестированных подходов со ссылкой на фиг. 7A-7D и 8A-8D, на которых показаны индикаторные тепловые карты, например, обработанные биологические ткани. Вероятности уровня патча, которые вычисляются посредством трех базовых классификаторов (RF, NN и LSTM) для масок изображений (т.е. зон биопсии) в тестовом наборе, используются для того, чтобы конструировать показанные соответствующие тепловые карты. Модели не "видели" эти случаи до этого и не знали их результаты. Вероятность, назначенная каждому пикселу тепловой карты, представляет собой среднее ее значения во всех патчах, которые включают ее в себя. В качестве индикатора, представляются тепловые карты для двух из 25 тестовых случаев, каждая из которых использует три различных технологии машинного обучения (фиг. 7B, 7C, 7D и фиг. 8B, 8C, 8D), вместе с соответствующей DSI-картой из исходного исследования (фиг. 7A и 8A).
Для клинической оценки классификации, прогнозирования для каждой зоны биопсии посредством каждого способа классифицированы на два класса: NLG (нормальная или низкая степень злокачественности) и HG (высокая степень злокачественности). Это осуществляется для каждого отдельного случая посредством визуальной оценки, и если тепловая карта биопсии содержит вероятности, большие 0,5 (которые представляют собой красный, желтый или белый цвет), то прогнозирование для этой биопсии классифицируется как HG, иначе она считается NLG.
Обращаясь сначала к фиг. 7A, область 301 показывает биопсийную зону с результатом с высокой степенью злокачественности (HG), и область 302 показывает биопсийную зону с результатом с отрицательной/низкой степенью злокачественности (NLG) (статус биопсийных тканей подтвержден посредством гистологической градации по степени злокачественности). Меньшие круговые примечания в биопсийных зонах (областях 301 и 302) представляют примечания врача из исходного исследования. DSI-карта не может ярко выделять зону в области 301 в качестве потенциальной HG и корректно классифицирует область 302 как нормальную/низкую степень злокачественности. Ссылаясь на фиг. 7B, показывается тепловая карта с выводами RF-алгоритма, как пояснено выше. Здесь, область 303 высокой вероятности идентифицируется в идентичной области с областью 301, но ничего не появляется в области 304, которая представляет собой идентичную зону тканей с областью 302. Ссылаясь на фиг. 7C, показывается тепловая карта с выводами NN-алгоритма, как пояснено выше. Область 305 высокой вероятности идентифицируется в идентичной зоне тканей с областью 301, и область 306 низкой вероятности идентифицируется в идентичной зоне тканей с областью 302. Ссылаясь на фиг. 7D, показывается тепловая карта с выводами LSTM-алгоритма, как пояснено выше. Более четкая область 307 высокой вероятности идентифицируется в идентичной зоне тканей с областью 301, и более четкая область низкой вероятности 308 появляется в идентичной зоне тканей с областью 302. Это показывает повышение производительности трех алгоритмов машинного обучения относительно стандартного DSI-алгоритма, поскольку они корректно ярко выделяют зону результата биопсии HG, а также корректно прогнозируют зону NLG-результата биопсии.
Ссылаясь на фиг. 8A, показаны две биопсийных зоны 310 и 311, которые имеют высокую степень злокачественности (HG). Меньшие круговые примечания внутри (или с пересечением) биопсийных зон 310 и 311 представляют примечания врача из исходного исследования. Статус биопсийных тканей подтвержден посредством гистологической градации по степени злокачественности. DSI-карта ярко выделяет одну из двух областей (биопсийную зону 310) в качестве потенциальной HG, но не может ярко выделять область 311 в качестве HG. Ссылаясь на фиг. 8B, показывается тепловая карта с выводами RF-алгоритма, как пояснено выше. Здесь, область 312 высокой вероятности идентифицируется в идентичной области с одной из биопсийных HG-зон, и область 313 в некоторой степени более низкой вероятности идентифицируется в идентичной области с другой из биопсийных HG-зон. Ссылаясь на фиг. 8C, показывается тепловая карта с выводами NN-алгоритма, как пояснено выше. Область 314 высокой вероятности идентифицируется в идентичной области с одной из биопсийных HG-зон, и область 315 более низкой вероятности идентифицируется в идентичной области с другой из биопсийных HG-зон. Ссылаясь на фиг. 8D, показывается тепловая карта с выводами LSTM-алгоритма, как пояснено выше. Область 316 высокой вероятности идентифицируется в идентичной области с одной из биопсийных HG-зон, и область 317 высокой вероятности также появляется в идентичной области с другой из биопсийных HG-зон. Повышение производительности LSTM-алгоритма в силу этого наблюдается относительно RF- и NN-алгоритмов, а также исходного DSI-алгоритма.
С учетом относительно небольшого числа случаев и несбалансированного характера набора данных, чтобы обобщать производительность с одним показателем выдержки, "сбалансированная точность" используется для того, чтобы классифицировать a) биопсии и b) пациентов корректно в качестве нормальной/низкой степени злокачественности по сравнению с высокой степенью злокачественности. Сбалансированная точность (называемая ниже просто "точностью") представляет собой среднее число случаев, которые корректно классифицированы в каждом классе. Она эффективно представляет собой среднее между чувствительностью и специфичностью и предоставляет более глобальную выдержку, чем только чувствительность и специфичность.
При анализе по уровням биопсии (т.е. каждая биопсия рассматривается и анализируется в качестве отдельной единицы), точность RF- и NN-классификаторов составляет 81%, тогда как для LSTM она составляет 84%. Для сравнения, в идентичном наборе данных, исходная DSI-карта достигает 57%-й точности. Для анализа по уровням пациента на основе результатов зон биопсии, каждый пациент считается "HG", когда, по меньшей мере, одна биопсия представляет собой HG. RF и NN достигают 77%-й точности, LSTM достигает 70%, тогда как точность исходной DSI-карты составляет 59%.
Точность для анализа на уровне биопсии средних ансамблевых схем варьируется от 77% (RF+NN) до 83% (RF+LSTM, NN+LSTM и RF+NN+LSTM). Для анализа на уровне пациента, точность всех схем составляет 81%. Точность для анализа на уровне биопсии средневзвешенных ансамблевых схем составляет 77% (RF+NN+LSTM), 79% (RF+LSTM), 86% (RF+NN) и 88% (NN+LSTM). Для анализов на уровне пациента, точность схем составляет 77% (RF+NN+LSTM и RF+NN) и 81% (RF+LSTM и NN+LSTM).
Модели машинного обучения, которые разработаны в этом проекте с подтверждением концепции, достигают общей повышенной производительности относительно существующей DSI-карты в картировании и классификации зон тканей в качестве нормальной/низкой степени злокачественности по сравнению с высокой степенью злокачественности, демонстрируя клинический вариант применения, который может использоваться для того, чтобы дополнительно улучшать поддержку решений по выбору участков биопсии и клиническому лечению.
Включение больших наборов данных для обучения и тестирования моделей может быть полезным. Также могут рассматриваться другие эффекты выбора признаков и размеров патчей. Дополнительные данные и факторы риска, которые доступны для каждого пациента, представляют собой настройку яркости кольпоскопического освещения в исходной совокупности изображений и возраст пациента, результаты обследования (цитология, hrHPV, HPV16, HPV18) и статус на предмет курения. Они также могут использоваться в качестве ввода в модели, что позволяет дополнительно повышать производительность.
При обучении на большом наборе данных, модели могут использоваться для того, чтобы вычислять тепловые карты не только для зон биопсии, но и для всей шейки, а также адаптироваться к существованию артефактов.
Признаки, используемые для обучения моделей в эксперименте, описанном выше, извлечены из каждого момента времени по отдельности, и их временная зависимость предположительно получается посредством сетей. В другом варианте осуществления, проектное решение по признакам, которые следует извлекать, может включать в себя элемент времени таким образом, что признак представляет собой функцию от характеристики во времени.
Применение сверточных нейронных сетей (CNN) независимо или в качестве части ансамблевой схемы также является возможным, например, как комбинации RNN с CNN. Ключевой модуль этой схемы может представлять собой рекуррентные сверточные уровни (RCL), которые вводят рекуррентное соединение на сверточный уровень. За счет этих соединений сеть может развиваться во времени, хотя ввод является статическим, и на каждую единицу оказывают влияние ее соседние единицы. Другой пример представляет собой использование CNN с изображением в один момент времени в качестве ввода, который формирует вероятность классификации для пациента. Показано, что это позволяет формировать точные результаты, которые затем могут подаваться в другой нейронный сетевой классификатор (например, NN или RNN) в качестве дополнительного ввода вместе с последовательностью изображений. Еще один другой пример представляет собой использование различных CNN, чтобы оценивать каждое отдельное изображение в последовательности по отдельности и комбинацию их отдельных выводов в другую нейронную сеть, например, RNN или LSTM, чтобы предоставлять конечный вывод. Использование CNN может не требовать извлечения ручных признаков, как описано выше, поскольку признаки могут извлекаться посредством самой сети.
Хотя выше описаны конкретные варианты осуществления, специалисты в данной области техники должны принимать во внимание, что различные модификации и изменения являются возможными. Например, может рассматриваться включение различных типов обработки изображений и классификаторов машинного обучения в различные схемы. Как отмечено выше, раскрытие сущности, в общем, направлено на исследование ткани шейки матки с использованием процесса ацетоотбеливания, но может реализовываться для исследования и/или классификации других биологических тканей с использованием дифференцирующего агента для выявления патологии. Например, хотя предпочтительно используется разбавленная уксусная кислота, другие типы кислоты могут использоваться вместо этого для конкретных целей. Технология также может быть подходящей для классификации с использованием молекулярной диагностики. Хотя предпочтительный вариант осуществления использует захваченные изображения живого организма, также могут рассматриваться реализации, которые используют захваченные изображения в пробирке. В некоторых вариантах осуществления, неполный набор данных для пациента может предоставляться в качестве ввода в AI.
Раскрыта конкретная компоновка локальных и удаленных процессоров, но специалисты в данной области техники должны принимать во внимание, что возможны различные компоновки процессоров. Например, один или более процессоров могут предоставляться только локально относительно модуля захвата изображений. Альтернативно, один или более процессоров могут предоставляться только удаленно относительно модуля захвата изображений. Может использоваться компьютерный облачный анализ или необлачный анализ. В частности, реализация может рассматриваться с первым и вторым алгоритмами машинного обучения, предоставленными удаленно относительно модуля захвата изображений, при этом первый алгоритм машинного обучения является фиксированным, а второй алгоритм машинного обучения имеют непрерывно продолжаемое обучение (способом, описанным выше).
Другой тип нейронных сетевых структур или алгоритмов машинного обучения может быть предусмотрен. Структуры алгоритмов машинного обучения могут быть одномодальными (с приемом только данных изображений в качестве ввода) или многомодальными (с приемом как данных изображений, так и данных без изображений в качестве вводов). Хотя выше результаты AI (т.е. выходное изображение) отображаются в качестве вероятностной тепловой карты, могут быть возможными другие выводы (в форматах данных или визуализациях).
| название | год | авторы | номер документа |
|---|---|---|---|
| ОПТИЧЕСКОЕ РАСПОЗНАВАНИЕ СИМВОЛОВ ПОСРЕДСТВОМ КОМБИНАЦИИ МОДЕЛЕЙ НЕЙРОННЫХ СЕТЕЙ | 2020 |
|
RU2768211C1 |
| СПОСОБ ВЫЯВЛЕНИЯ ОНКОЗАБОЛЕВАНИЙ В ОРГАНАХ МАЛОГО ТАЗА И СИСТЕМА ДЛЯ РЕАЛИЗАЦИИ СПОСОБА | 2023 |
|
RU2814790C1 |
| Способ и система диагностирования патологических изменений в биоптате предстательной железы | 2021 |
|
RU2757256C1 |
| ДЕТЕКТИРОВАНИЕ БАРКОДОВ НА ИЗОБРАЖЕНИЯХ | 2018 |
|
RU2695054C1 |
| СПОСОБ И СИСТЕМА ДЛЯ ВЫЯВЛЕНИЯ ОБЪЕМНЫХ ОБРАЗОВАНИЙ ПОЧЕК НА КОМПЬЮТЕРНЫХ ТОМОГРАММАХ БРЮШНОЙ ПОЛОСТИ | 2024 |
|
RU2839531C1 |
| ОТБОР ИЗОБРАЖЕНИЙ ДЛЯ ОПТИЧЕСКОГО ИССЛЕДОВАНИЯ ШЕЙКИ МАТКИ | 2012 |
|
RU2633320C2 |
| МЕТОДИКА ПРИМЕНЕНИЯ СРЕДСТВ ИСКУССТВЕННОГО ИНТЕЛЛЕКТА ДЛЯ ИНТЕРПРЕТАЦИИ РЕЗУЛЬТАТОВ, ПОЛУЧЕННЫХ МЕТОДОМ ВЫСОКОРАЗРЕШАЮЩЕЙ КОМПЬЮТЕРНОЙ ТОМОГРАФИИ (ВРКТ), ДЛЯ ДИАГНОСТИКИ ИНТЕРСТИЦИАЛЬНЫХ ЗАБОЛЕВАНИЙ ЛЕГКИХ ЧЕЛОВЕКА (ИЗЛ) | 2023 |
|
RU2827804C1 |
| СПОСОБ И СИСТЕМА АВТОМАТИЗИРОВАННОЙ ДИАГНОСТИКИ СОСУДИСТЫХ ПАТОЛОГИЙ НА ОСНОВАНИИ ИЗОБРАЖЕНИЯ | 2020 |
|
RU2741260C1 |
| СПОСОБ И СИСТЕМА ИДЕНТИФИКАЦИИ НОВООБРАЗОВАНИЙ НА РЕНТГЕНОВСКИХ ИЗОБРАЖЕНИЯХ | 2020 |
|
RU2734575C1 |
| СИСТЕМА И СПОСОБ ДЛЯ ОБУЧАЮЩИХСЯ МОДЕЛЕЙ ПЛАНОВ РАДИОТЕРАПЕВТИЧЕСКОГО ЛЕЧЕНИЯ С ПРОГНОЗИРОВАНИЕМ РАСПРЕДЕЛЕНИЙ ДОЗЫ РАДИОТЕРАПИИ | 2017 |
|
RU2719028C1 |
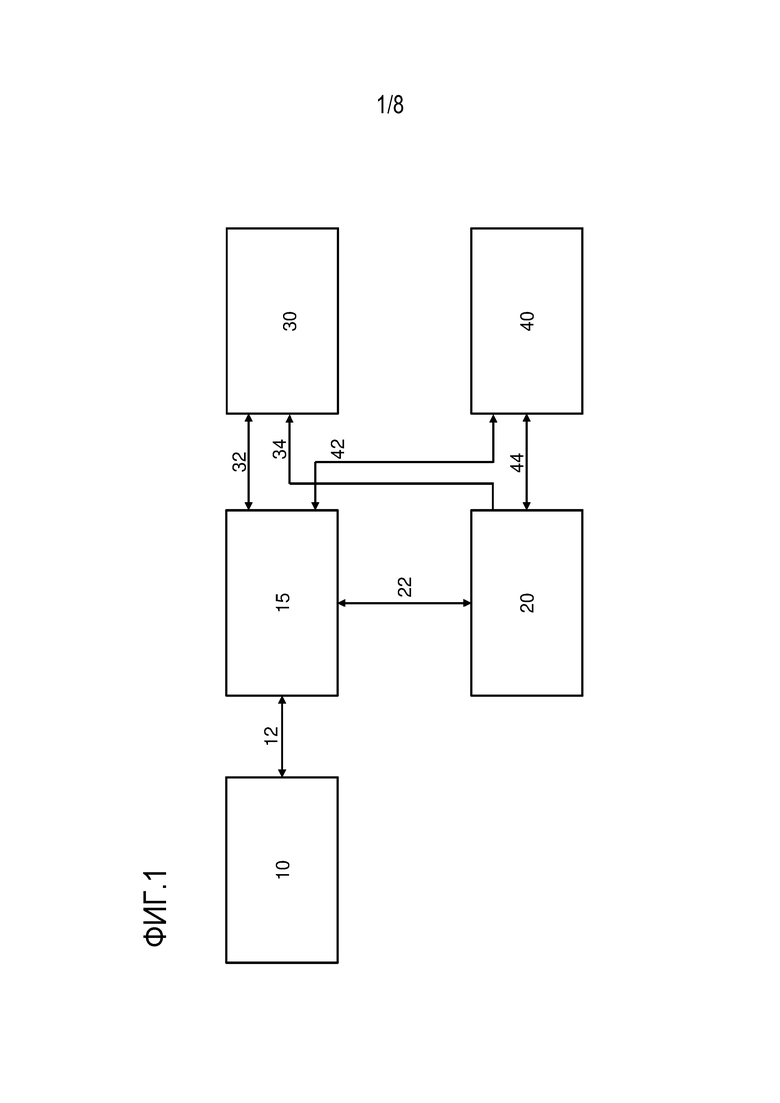
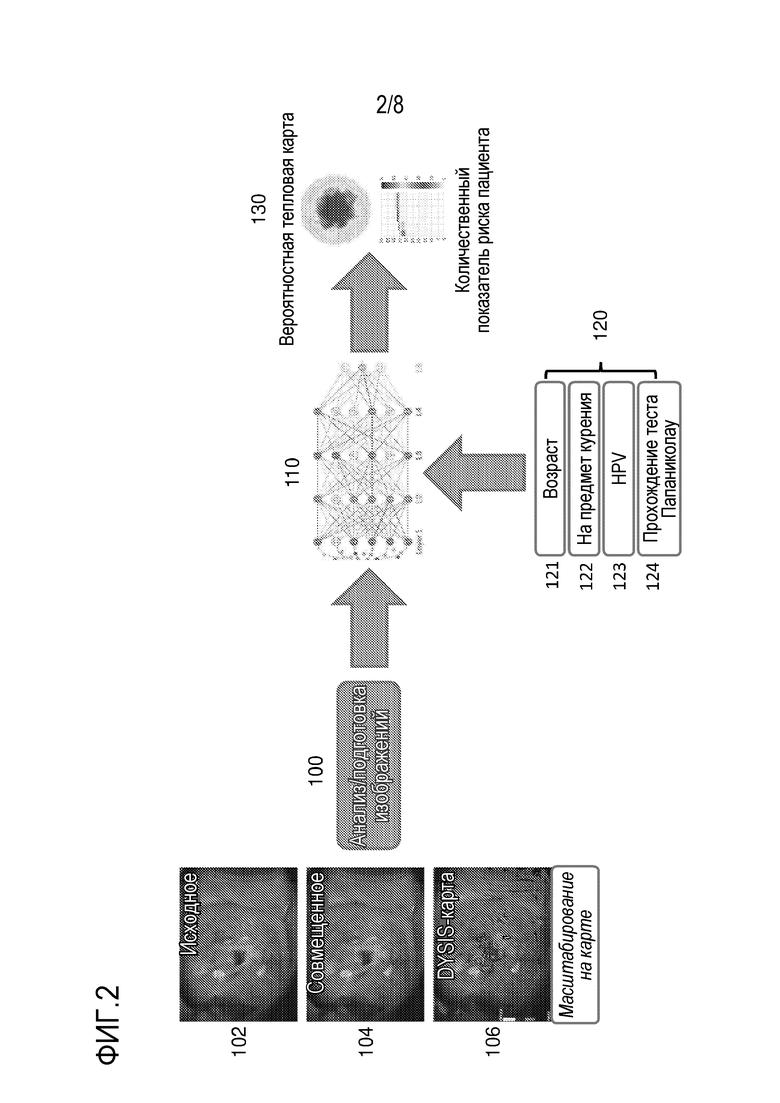

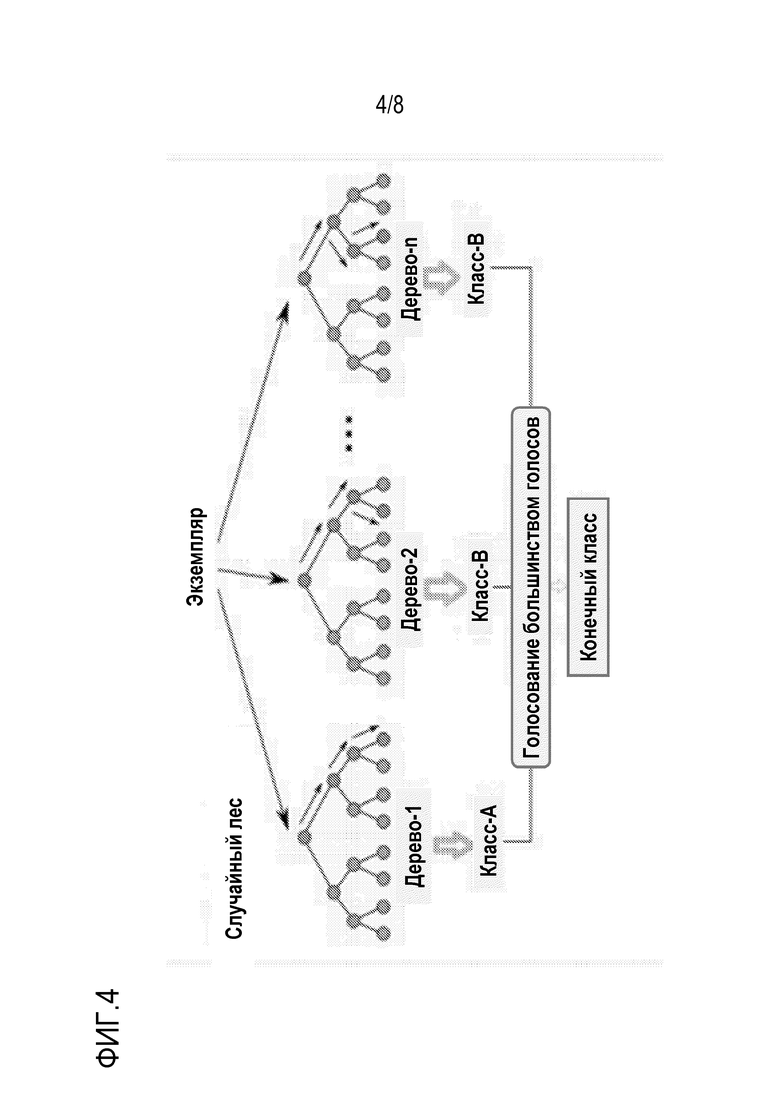
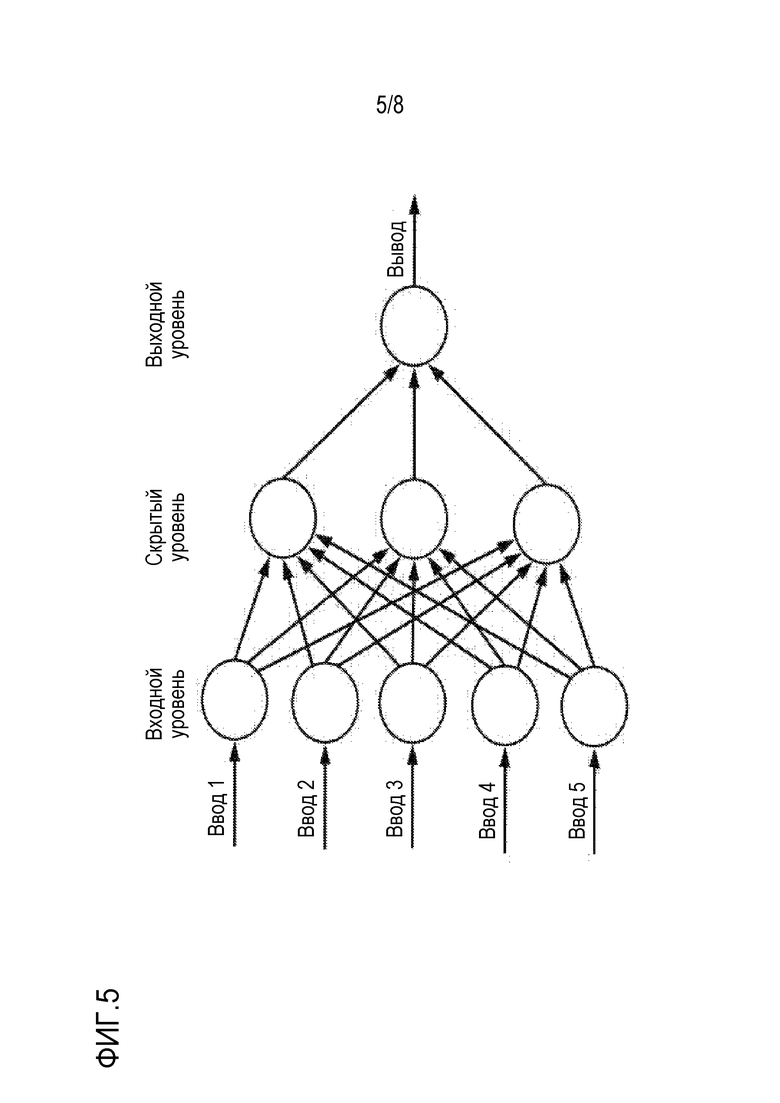
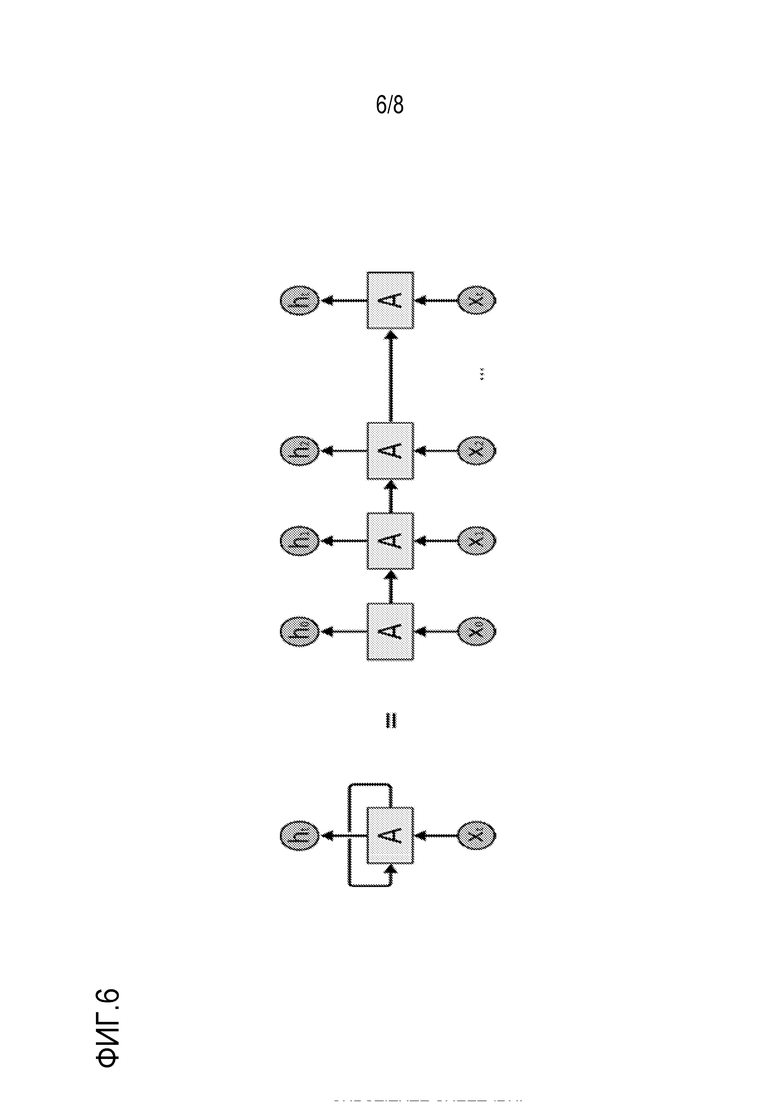
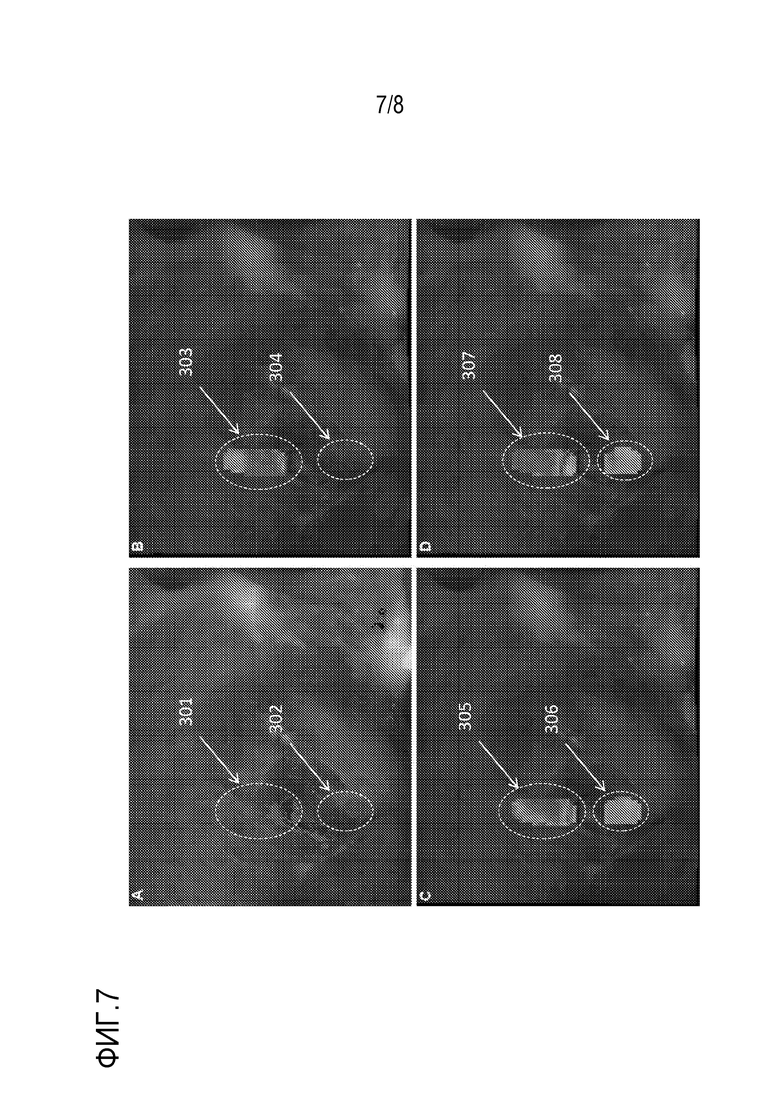
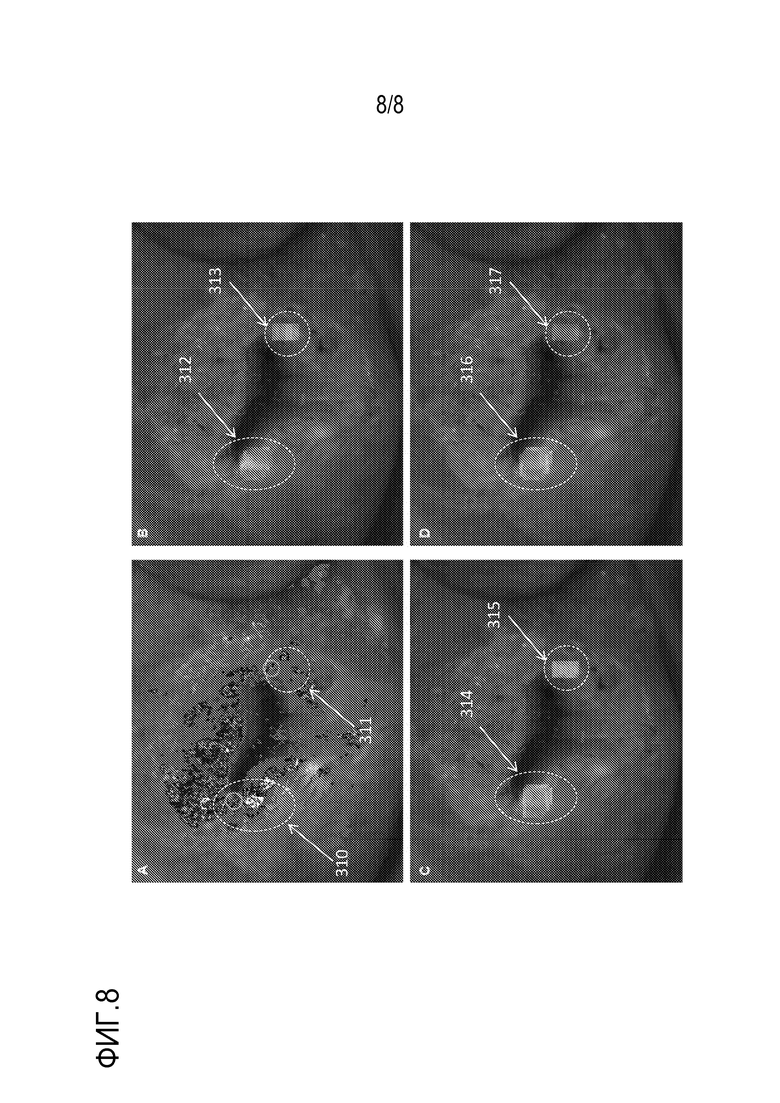
Изобретение относится к средствам для классификации биологической ткани. Техническим результатом является повышение точности классификации биологической ткани. Способ для классификации биологической ткани реализуется с использованием вычислительной системы. Данные изображений, содержащие множество изображений зоны исследования биологической ткани, принимаются в вычислительной системе. Каждое из множества изображений захватывается в различные моменты времени в течение периода, в который местное применение дифференцирующего агента для выявления патологии к зоне исследования ткани вызывает переходные оптические эффекты. Принимаемые данные изображений предоставляются в качестве ввода в алгоритм машинного обучения, работающий в вычислительной системе. Алгоритм машинного обучения выполнен с возможностью выделять одну из множества классификаций для каждого из множества сегментов ткани. 2 н. и 25 з.п. ф-лы, 8 ил.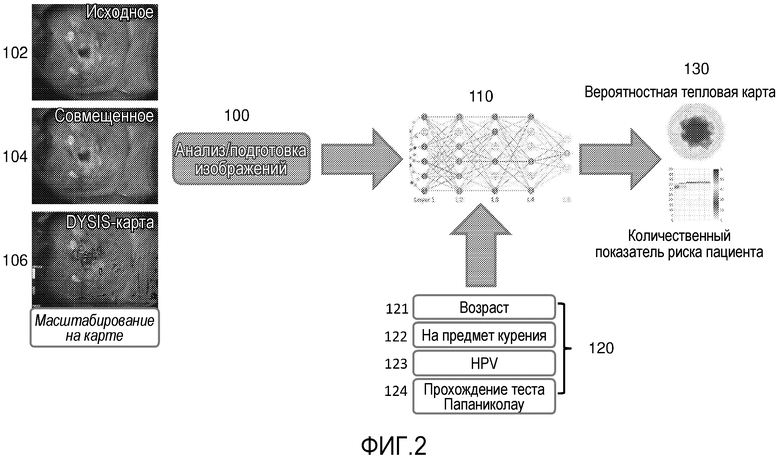
1. Способ для классификации биологической ткани с использованием вычислительной системы, при этом способ содержит этапы, на которых:
- принимают, в вычислительной системе, данные изображений, содержащие множество изображений зоны исследования биологической ткани, причем каждое из множества изображений захватывается в различные моменты времени в течение периода, в который местное применение дифференцирующего агента для выявления патологии к зоне исследования ткани вызывает переходные оптические эффекты; и
- предоставляют принимаемые данные изображений в качестве ввода в алгоритм машинного обучения, работающий в вычислительной системе, причем алгоритм машинного обучения содержит глубокую нейронную сеть и выполнен с возможностью идентифицировать множество сегментов ткани и выделять одну из множества классификаций для каждого из множества сегментов ткани; и
- при этом множество классификаций задаются посредством шкалы значений в непрерывном диапазоне, служащей индикатором вероятности состояния заболевания.
2. Способ по п. 1, в котором биологическая ткань содержит шейку матки.
3. Способ по п. 1 или 2, в котором:
- по меньшей мере одно изображение из множества изображений захватывается в начале периода до появления переходных оптических эффектов; и/или
- по меньшей мере часть из множества изображений захватывается с интервалами в предварительно определенную длительность в течение периода местного применения дифференцирующего агента для выявления патологии.
4. Способ по любому из предшествующих пунктов, в котором зона исследования подвергается воздействию оптического излучения в течение периода, в который местное применение дифференцирующего агента для выявления патологии к зоне исследования ткани вызывает переходные оптические эффекты.
5. Способ по любому из предшествующих пунктов, в котором дифференцирующий агент для выявления патологии содержит кислоту.
6. Способ по любому из предшествующих пунктов, дополнительно содержащий этап, на котором:
- захватывают множество оптических изображений зоны исследования биологической ткани с использованием модуля сбора изображений, причем множество изображений из данных изображений извлекаются из множества оптических изображений.
7. Способ по любому из предшествующих пунктов, в котором предусмотрено одно или более из следующего:
- каждое из множества изображений извлекается из соответствующего начального изображения, преобразованного таким образом, чтобы предоставлять совмещение зоны исследования в пределах множества изображений;
- каждое из множества изображений извлекается из соответствующего начального изображения, обработанного для того, чтобы удалять один или более артефактов; и
- данные изображений, предоставленные в качестве ввода в алгоритм машинного обучения, содержат, для каждого из множества изображений, множество патчей, извлекаемых из соответствующего начального изображения.
8. Способ по любому из предшествующих пунктов, в котором биологическая ткань содержит шейку матки, при этом способ дополнительно содержит этап, на котором обрабатывают множество изображений, чтобы идентифицировать часть из множества изображений, соответствующих шейке матки.
9. Способ по любому из предшествующих пунктов, в котором каждое из множества изображений задается посредством соответствующего набора пикселов, причем каждый из наборов пикселов имеет идентичную пиксельную компоновку, при этом способ дополнительно содержит этапы, на которых:
- получают, в вычислительной системе, картографические данные, причем картографические данные содержат соответствующий аналитический индекс для каждого пиксела пиксельной компоновки, причем аналитические индексы извлекаются из множества изображений; и
- предоставляют картографические данные в качестве ввода в алгоритм машинного обучения; и
- при этом аналитический индекс для пиксела формируется на основе по меньшей мере одного параметра, извлекаемого из множества изображений, причем по меньшей мере один параметр содержит одно или более из следующего: максимальная интенсивность для пиксела по множеству изображений; время для того, чтобы достигать максимальной интенсивности для пиксела; и суммирование или суммирование со взвешиванием интенсивности для пиксела по множеству изображений.
10. Способ по п. 9, в котором предусмотрено одно или более из следующего:
- параметр по меньшей мере из одного параметра ограничен предварительно определенной полосой пропускания спектра;
- каждый параметр по меньшей мере из одного параметра определяется посредством подгонки данных для пиксела по множеству изображений к линии или кривой и определения по меньшей мере одного параметра из линии или кривой; и
- при этом аналитический индекс для каждого пиксела основан на комбинировании со взвешиванием множества по меньшей мере из одного параметра.
11. Способ по любому из предшествующих пунктов, дополнительно содержащий этап, на котором:
- обрабатывают множество изображений, чтобы идентифицировать по меньшей мере одну морфологическую характеристику и/или по меньшей мере один извлеченный признак.
12. Способ по п. 11, дополнительно содержащий этап, на котором:
- предоставляют по меньшей мере одну морфологическую характеристику и/или извлеченный признак в качестве ввода в алгоритм машинного обучения.
13. Способ по любому из предшествующих пунктов, в котором алгоритм машинного обучения содержит нейронную сеть, и при этом предусмотрено одно или оба из следующего:
- нейронная сеть содержит одно либо комбинацию следующего: сверточная нейронная сеть; полностью соединенная нейронная сеть; и рекуррентная нейронная сеть; и
- нейронная сеть является многомодальной.
14. Способ по любому из предшествующих пунктов, дополнительно содержащий этап, на котором:
- предоставляют одну или более характеристик исследуемого, причем каждая характеристика исследуемого связана с объектом, из которого исходит биологическая ткань, в качестве ввода в алгоритм машинного обучения.
15. Способ по п. 14, в котором одна или более характеристик исследуемого содержат одно или более из следующего: факторы риска исследуемого; предшествующая информация истории болезни исследуемого; и результаты клинических тестов исследуемого.
16. Способ по п. 15, в котором факторы риска исследуемого содержат одно или более из следующего: возраст исследуемого; статус на предмет курения исследуемого; статус предшествующей HPV-вакцинации исследуемого; информация относительно использования презерватива во время полового акта для исследуемого; и количество родов для исследуемого; и/или в котором результаты клинических тестов исследуемого содержат одно или более из следующего: предшествующий результат цитологии; предшествующий результат HPV-теста; предшествующий результат HPV-теста типирования; предшествующая информация лечения шейки матки; и предшествующая история обследования на предмет и/или диагностики рака или предраковых состояний шейки матки.
17. Способ по любому из предшествующих пунктов, дополнительно содержащий этап, на котором:
- выделяют одну из множества классификаций для всей ткани на основе классификации, выделяемой для множества сегментов ткани, и/или на основе алгоритма, отличающегося от алгоритма машинного обучения.
18. Способ по любому из предшествующих пунктов, в котором множество классификаций дополнительно задаются посредством множества тегов заболевания.
19. Способ по любому из предшествующих пунктов, в котором множество классификаций дополнительно указывают наличие по меньшей мере одной морфологической характеристики.
20. Способ по любому из предшествующих пунктов, дополнительно содержащий этап, на котором:
- формируют выходное изображение, показывающее зону исследования биологической ткани на основе данных изображений и указывающее классификацию, выделяемую для каждого из множества сегментов ткани.
21. Способ по любому из предшествующих пунктов, дополнительно содержащий один или более из следующих этапов, на которых:
- обучают алгоритм машинного обучения на основе соответствующего множества изображений и соответствующей выделяемой классификации для каждой из множества других биологических тканей;
- обучают алгоритм машинного обучения посредством предоставления определенной пользователями или на основе баз данных классификации для ткани в алгоритм машинного обучения или в версию алгоритма машинного обучения, работающего во второй компьютерной системе; и
- предоставляют непрерывное динамическое обучение для алгоритма машинного обучения или версии алгоритма машинного обучения, работающего во второй компьютерной системе.
22. Способ по любому из предшествующих пунктов, дополнительно содержащий этапы, на которых:
- выделяют одну из множества классификаций для ткани с использованием первого алгоритма машинного обучения, работающего в первом процессоре вычислительной системы;
- выделяют одну из множества классификаций для ткани с использованием второго алгоритма машинного обучения, работающего во втором процессоре вычислительной системы; и
- обучают второй алгоритм машинного обучения посредством предоставления определенной пользователями или на основе баз данных классификации для ткани во второй алгоритм машинного обучения, причем первый алгоритм машинного обучения не обучается посредством предоставления определенной пользователями или на основе баз данных классификации для ткани в первый алгоритм машинного обучения.
23. Способ по п. 22, дополнительно содержащий этап, на котором:
- обновляют первый алгоритм машинного обучения.
24. Вычислительная система, работающая с возможностью классификации ткани, содержащая:
- интерфейс ввода, выполненный с возможностью принимать данные изображений, содержащие множество изображений зоны исследования биологической ткани, причем каждое из множества изображений захватывается в различные моменты времени в течение периода, в который местное применение дифференцирующего агента для выявления патологии к зоне исследования ткани вызывает переходные оптические эффекты; и
- процессор, выполненный с возможностью работать с алгоритмом машинного обучения, выполненным с возможностью идентифицировать множество сегментов ткани и выделять одну из множества классификаций для каждого из множества сегментов ткани на основе данных изображений, причем алгоритм машинного обучения содержит глубокую нейронную сеть; и
- при этом множество классификаций задаются посредством шкалы значений в непрерывном диапазоне, служащей индикатором вероятности состояния заболевания.
25. Вычислительная система по п. 24, дополнительно содержащая:
- модуль сбора изображений, выполненный с возможностью захватывать множество оптических изображений зоны исследования биологической ткани, причем принимаемые данные изображений основаны на множестве оптических изображений, захваченных посредством модуля сбора изображений.
26. Вычислительная система по п. 25, в которой:
- модуль сбора изображений расположен удаленно от процессора, на котором работает алгоритм машинного обучения; или
- процессор содержит множество обрабатывающих устройств, причем каждое обрабатывающее устройство выполнено с возможностью работать с частью алгоритма машинного обучения, и при этом модуль сбора изображений расположен удаленно по меньшей мере от одного из множества обрабатывающих устройств.
27. Вычислительная система по любому из пп. 24-26, выполненная с возможностью осуществлять способ по любому из пп. 1-23.
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| EP 1978867 B1, 25.05.2011 | |||
| Способ получения цианистых соединений | 1924 |
|
SU2018A1 |
| СЕГМЕНТАЦИЯ ТКАНЕЙ ЧЕЛОВЕКА НА КОМПЬЮТЕРНОМ ИЗОБРАЖЕНИИ | 2017 |
|
RU2654199C1 |
| СПОСОБ И СИСТЕМЫ ДЛЯ ОПРЕДЕЛЕНИЯ ПАРАМЕТРОВ И КАРТОГРАФИРОВАНИЯ ПОРАЖЕНИЙ ТКАНИ | 2001 |
|
RU2288636C2 |

