Область ТЕХНИКИ
[1] По меньшей мере один из настоящих вариантов осуществления в общем относится, например, к способу или устройству для кодирования или декодирования видео и, более конкретно, к способу или устройству для выбора кандидата предсказателя из набора множества кандидатов предсказателя для компенсации движения на основе модели движения, такой как, например, аффинная модель, для кодера видео или декодера видео.
Предшествующий уровень техники
[2] Чтобы достичь высокой эффективности сжатия, схемы кодирования изображения и видео обычно применяют предсказание, включающее в себя предсказание вектора движения и преобразование для использования с выгодой пространственной и временной избыточности в видео контенте. Обычно, интра- (внутрикадровое) или интер (межкадровое) предсказание применяется, чтобы использовать разрабатывать внутри- или межкадровую корреляцию, тогда различия между исходным изображением и предсказанным изображением, часто обозначаемыми как ошибки предсказания или остатки предсказания, преобразуются, квантуются и энтропийно кодируются. Чтобы воссоздать видео, сжатые данные декодируются посредством обратных процессов, соответствующих энтропийному кодированию, квантованию, преобразованию и предсказанию.
[3] Недавнее дополнение к технологии высокого сжатия включает в себя использование модели движения на основе аффинного моделирования. В частности, аффинное моделирование используется для компенсации движения для кодирования и декодирования видеоизображений. В общем, аффинное моделирование представляет собой модель, использующую по меньшей мере два параметра, такие как, например, два вектора движения контрольной точки (CPMV), представляющие движение в соответственных углах блока изображения, что позволяет выводить поле движения для целого блока изображения, чтобы имитировать, например, вращение и гомотетию (зум).
Краткое описание сущности изобретения
[4] В соответствии с общим аспектом по меньшей мере одного варианта осуществления, представлен способ для кодирования видео, содержащий: определение, для блока, кодируемого в изображении, набора кандидатов предсказателя (предиктора), имеющего множество кандидатов предсказателя; выбор кандидата предсказателя из набора кандидатов предсказателя; определение для выбранного кандидата предсказателя из набора кандидатов предсказателя одного или нескольких соответствующих векторов движения контрольной точки для блока; определение для выбранного кандидата предсказателя, на основе одного или нескольких соответствующих векторов движения контрольной точки, соответствующего поля движения на основе модели движения для выбранного кандидата предсказателя, причем соответствующее поле движения идентифицирует векторы движения, используемые для предсказания подблоков кодируемого блока; кодирование блока на основе соответствующего поля движения для выбранного кандидата предсказателя из набора кандидатов предсказателя; и кодирование индекса для выбранного кандидата предсказателя из набора кандидатов предсказателя.
[5] В соответствии с другим общим аспектом по меньшей мере одного варианта осуществления, представлен способ для декодирования видео, содержащий: прием, для блока, декодируемого на изображении, индекса, соответствующего конкретному кандидату предсказателя; определение, для конкретного кандидата предсказателя, одного или нескольких соответствующих векторов движения контрольной точки для декодируемого блока; определение для конкретного кандидата предсказателя, на основе одного или нескольких соответствующих векторов движения контрольной точки, соответствующего поля движения на основе модели движения, причем соответствующее поле движения идентифицирует векторы движения, используемые для предсказания подблоков декодируемого блока; и декодирование блока на основе соответствующего поля движения.
[6] В соответствии с другим общим аспектом по меньшей мере одного варианта осуществления, представлено устройство для кодирования видео, содержащее: средство для определения, для блока, кодируемого на изображении, набора кандидатов предсказателя, имеющего множество кандидатов предсказателя; средство для выбора кандидата предсказателя из набора кандидатов предсказателя; средство для определения для выбранного кандидата предсказателя, на основе одного или нескольких соответствующих векторов движения контрольной точки, соответствующего поля движения на основе модели движения для выбранного кандидата предсказателя, причем соответствующее поле движения идентифицирует векторы движения, используемые для предсказания подблоков кодируемого блока; средство для кодирования блока на основе соответствующего поля движения для выбранного кандидата предсказателя из набора кандидатов предсказателя; и средство для кодирования индекса для выбранного кандидата предсказателя из набора кандидатов предсказателя.
[7] В соответствии с другим общим аспектом по меньшей мере одного варианта осуществления, представлено устройство для декодирования видео, содержащее: средство для приема, для блока, декодируемого в изображении, индекса, соответствующего конкретному кандидату предсказателя; средство для определения, для конкретного кандидата предсказателя, одного или нескольких соответствующих векторов движения контрольной точки для декодируемого блока; средство для определения для конкретного кандидата предсказателя, на основе одного или нескольких соответствующих векторов движения контрольной точки, соответствующего поля движения на основе модели движения, причем соответствующее поле движения идентифицирует векторы движения, используемые для предсказания подблоков декодируемого блока; и средство для декодирования блока на основе соответствующего поля движения.
[8] В соответствии с другим общим аспектом по меньшей мере одного варианта осуществления, обеспечено устройство для кодирования видео, содержащее: один или несколько процессоров и по меньшей мере одну память. Причем один или несколько процессоров сконфигурированы, чтобы: определять, для блока, кодируемого в изображении, набор кандидатов предсказателя, имеющий множество кандидатов предсказателя; выбирать кандидат предсказателя из набора кандидатов предсказателя; определять для выбранного кандидата предсказателя из набора кандидатов предсказателя, один или несколько соответствующих векторов движения контрольной точки для блока; определять для выбранного кандидата предсказателя, на основе одного или нескольких соответствующих векторов движения контрольной точки, соответствующее поле движения на основе модели движения для выбранного кандидата предсказателя, причем соответствующее поле движения идентифицирует векторы движения, используемые для предсказания подблоков кодируемого блока; кодировать блок на основе соответствующего поля движения для выбранного кандидата предсказателя из набора кандидатов предсказателя; и кодировать индекс для выбранного кандидата предсказателя из набора кандидатов предсказателя. По меньшей мере одна память предназначена для хранения, по меньшей мере временно, закодированного блока и/или закодированного индекса.
[9] В соответствии с другим общим аспектом по меньшей мере одного варианта осуществления, обеспечено устройство для декодирования видео, содержащее: один или несколько процессоров и по меньшей мере одну память. При этом один или несколько процессоров сконфигурированы, чтобы: принимать, для блока, декодируемого в изображении, индекс, соответствующий конкретному кандидату предсказателя; определять, для конкретного кандидата предсказателя, один или несколько соответствующих векторов движения контрольной точки для декодируемого блока; определять для конкретного кандидата предсказателя, на основе одного или нескольких соответствующих векторов движения контрольной точки, соответствующее поле движения на основе модели движения, причем соответствующее поле движения идентифицирует векторы движения, используемые для предсказания подблоков декодируемого блока; и декодировать блок на основе соответствующего поля движения. По меньшей мере одна память предназначена для хранения, по меньшей мере временно, декодированного блока.
[10] В соответствии с общим аспектом по меньшей мере одного варианта осуществления, представлен способ для кодирования видео, содержащий: определение, для блока, кодируемого в изображении, набора кандидатов предсказателя; определение для каждого из множества кандидатов предсказателя из набора кандидатов предсказателя одного или нескольких соответствующих векторов движения контрольной точки для блока; определение для каждого из множества кандидатов предсказателя, на основе одного или нескольких соответствующих векторов движения контрольной точки, соответствующего поля движения на основе модели движения для каждого из множества кандидатов предсказателя из набора кандидатов предсказателя; оценивание множества кандидатов предсказателя в соответствии с одним или несколькими критериями и на основе соответствующего поля движения; выбор кандидата предсказателя из множества кандидатов предсказателя на основе оценивания; и кодирование блока на основе выбранного кандидата предсказателя из набора кандидатов предсказателя.
[11] В соответствии с общим аспектом по меньшей мере одного варианта осуществления, представлен способ для декодирования видео, содержащий извлечение, для блока, декодируемого в изображении, индекса, соответствующего выбранному кандидату предсказателя. При этом выбранный кандидат предсказателя выбирается в кодере посредством: определения, для блока, кодируемого в изображении, набора кандидатов предсказателя; определения для каждого из множества кандидатов предсказателя из набора кандидатов предсказателя одного или нескольких соответствующих векторов движения контрольной точки для кодируемого блока; определения для каждого из множества кандидатов предсказателя, на основе одного или нескольких соответствующих векторов движения контрольной точки, соответствующего поля движения на основе модели движения для каждого из множества кандидатов предсказателя из набора кандидатов предсказателя; оценивания множества кандидатов предсказателя в соответствии с одним или несколькими критериями и на основе соответствующего поля движения; выбора кандидата предсказателя из множества кандидатов предсказателя на основе оценивания; и кодирования индекса для выбранного кандидата предсказателя из набора кандидатов предсказателя. Способ дополнительно содержит декодирование блока на основе индекса, соответствующего выбранному кандидату предсказателя.
[12] В соответствии с другим общим аспектом по меньшей мере одного варианта осуществления, способ может дополнительно содержать: оценивание множества кандидатов предсказателя в соответствии с одним или несколькими критериями и на основе соответствующих полей движения для каждого из множества кандидатов предсказателя; и выбор кандидата предсказателя из множества кандидатов предсказателя на основе оценивания.
[13] В соответствии с другим общим аспектом по меньшей мере одного варианта осуществления, устройство может дополнительно содержать: средство для оценивания множества кандидатов предсказателя в соответствии с одним или несколькими критериями и на основе соответствующих полей движения для каждого из множества кандидатов предсказателя; и средство для выбора кандидата предсказателя из множества кандидатов предсказателя на основе оценивания.
[14] В соответствии с другим общим аспектом по меньшей мере одного варианта осуществления, один или несколько критериев основаны на определении искажения-скорости, соответствующем одному или нескольким из множества кандидатов предсказателя из набора кандидатов предсказателя.
[15] В соответствии с другим общим аспектом по меньшей мере одного варианта осуществления, декодирование или кодирование блока на основе соответствующего поля движения содержит декодирование или кодирование, соответственно, на основе предсказателей для подблоков, предсказателей, указываемых векторами движения.
[16] В соответствии с другим общим аспектом по меньшей мере одного варианта осуществления, набор кандидатов предсказателя содержит пространственные кандидаты и/или временные кандидаты кодируемого или декодируемого блока.
[17] В соответствии с другим общим аспектом по меньшей мере одного варианта осуществления, модель движения представляет собой аффинную модель.
[18] В соответствии с другим общим аспектом по меньшей мере одного варианта осуществления, соответствующее поле движения для каждого положения (x, y) внутри кодируемого или декодируемого блока определяется посредством:
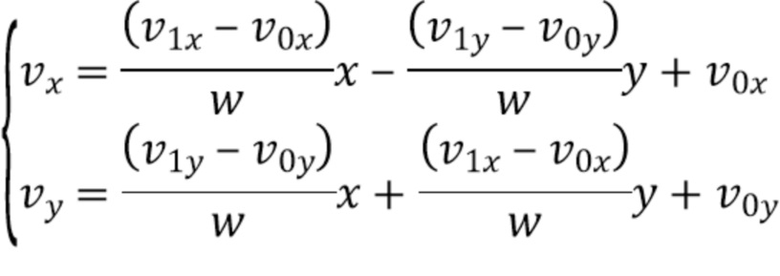
причем (v0x, v0y) и (v1x, v1y) представляют собой векторы движения контрольной точки, используемые, чтобы генерировать соответствующее поле движения, (v0x, v0y) соответствует вектору движения контрольной точки верхнего левого угла кодируемого или декодируемого блока, (v1x, v1y) соответствует вектору движения контрольной точки верхнего правого угла кодируемого или декодируемого блока, и w представляет собой ширину кодируемого или декодируемого блока.
[19] В соответствии с другим общим аспектом по меньшей мере одного варианта осуществления, число пространственных кандидатов составляет по меньшей мере 5.
[20] В соответствии с другим общим аспектом по меньшей мере одного варианта осуществления, один или несколько дополнительных векторов движения контрольной точки добавляются для определения соответствующего поля движения на основе функции определенного одного или нескольких соответствующих векторов движения контрольной точки.
[21] В соответствии с другим общим аспектом по меньшей мере одного варианта осуществления, функция включает в себя одно или несколько из: 1) среднего, 2) взвешенного среднего, 3) уникального среднего, 4) усреднения, 5) медианы или 6) однонаправленной части одного из вышеуказанных 1)-6) для определенных одного или нескольких соответствующих векторов движения контрольной точки.
[22] В соответствии с другим общим аспектом по меньшей мере одного варианта осуществления, представлен не-временный считываемый компьютером носитель, содержащий содержимое данных, генерируемое в соответствии со способом или устройством согласно любому из предшествующих описаний.
[23] В соответствии с другим общим аспектом по меньшей мере одного варианта осуществления, обеспечен сигнал, содержащий видео данные, генерируемые в соответствии со способом или устройством согласно любому из предшествующих описаний.
[24] Один или несколько из настоящих вариантов осуществления также обеспечивают считываемый компьютером носитель хранения, имеющий сохраненные на нем инструкции для кодирования или декодирования видео данных в соответствии с любым из способов, описанных выше. Настоящие варианты осуществления также обеспечивают считываемый компьютером носитель хранения, имеющий сохраненный на нем битовый поток, генерируемый в соответствии со способами, описанными выше. Настоящие варианты осуществления также обеспечивают способ и устройство для передачи битового потока, генерируемого в соответствии со способами, описанными выше. Настоящие варианты осуществления также обеспечивают компьютерный программный продукт, включающий в себя инструкции для выполнения любого из описанных способов.
Краткое описание чертежей
[25] Фиг. 1 иллюстрирует блок-схему варианта осуществления кодера видео HEVC (высокоэффективного кодирования видео).
[26] Фиг. 2A представляет собой графический пример, иллюстрирующий генерацию стандартного образца HEVC.
[27] Фиг. 2B представляет собой графический пример, иллюстрирующий направления интра-предсказания в HEVC.
[28] Фиг. 3 иллюстрирует блок-схему варианта осуществления декодера видео HEVC.
[29] Фиг. 4 иллюстрирует пример принципов единицы дерева кодирования (CTU) и дерева кодирования (CT) для представления сжатого изображения HEVC.
[30] Фиг. 5 иллюстрирует пример разделений единицы дерева кодирования (CTU) на единицы кодирования (CU), единицы предсказания (PU) и единицы преобразования (TU).
[31] Фиг. 6 иллюстрирует пример аффинной модели в качестве модели движения, используемой в модели совместного исследования (JEM).
[32] Фиг. 7 иллюстрирует пример поля аффинного вектора движения на основе под-CU 4×4, используемого в модели совместного исследования (JEM).
[33] Фиг. 8A иллюстрирует примеры кандидатов предсказания вектора движения для аффинных интер-CU.
[34] Фиг. 8B иллюстрирует пример кандидатов предсказания вектора движения в режиме аффинного объединения.
[35] Фиг. 9 иллюстрирует пример пространственного вывода аффинных векторов движения контрольной точки в случае модели движения режима аффинного объединения.
[36] Фиг. 10 иллюстрирует примерный способ в соответствии с общим аспектом по меньшей мере одного варианта осуществления.
[37] Фиг. 11 иллюстрирует другой примерный способ в соответствии с общим аспектом по меньшей мере одного варианта осуществления.
[38] Фиг. 12 также иллюстрирует другой примерный способ в соответствии с общим аспектом по меньшей мере одного варианта осуществления.
[39] Фиг. 13 также иллюстрирует другой примерный способ в соответствии с общим аспектом по меньшей мере одного варианта осуществления.
[40] Фиг. 14 иллюстрирует пример известного процесса для оценивания режима аффинного объединения интер-CU в JEM.
[41] Фиг. 15 иллюстрирует пример процесса для выбора кандидата предсказателя в режиме аффинного объединения в JEM.
[42] Фиг. 16 иллюстрирует пример распространенных аффинных полей движения через кандидат предсказателя аффинного объединения, расположенный слева от текущего кодируемого или декодируемого блока.
[43] Фиг. 17 иллюстрирует пример распространенных аффинных полей движения через кандидат предсказателя аффинного объединения, расположенный сверху и справа от текущего кодируемого или декодируемого блока.
[44] Фиг. 18 иллюстрирует пример процесса выбора кандидата предсказателя в соответствии с общим аспектом по меньшей мере одного варианта осуществления.
[45] Фиг. 19 иллюстрирует пример процесса для формирования набора множества кандидатов предсказателя в соответствии с общим аспектом по меньшей мере одного варианта осуществления.
[46] Фиг. 20 иллюстрирует пример процесса вывода CPMV верхнего левого и верхнего правого углов для каждого кандидата предсказателя в соответствии с общим аспектом по меньшей мере одного варианта осуществления.
[47] Фиг. 21 иллюстрирует пример дополненного набора пространственных кандидатов предсказателя в соответствии с общим аспектом по меньшей мере одного варианта осуществления.
[48] Фиг. 22 иллюстрирует другой пример процесса для формирования набора множества кандидатов предсказателя в соответствии с общим аспектом по меньшей мере одного варианта осуществления.
[49] Фиг. 23 также иллюстрирует другой пример процесса для формирования набора множества кандидатов предсказателя в соответствии с общим аспектом по меньшей мере одного варианта осуществления.
[50] Фиг. 24 иллюстрирует пример того, как временные кандидаты могут использоваться для кандидатов предсказателя в соответствии с общим аспектом по меньшей мере одного варианта осуществления.
[51] Фиг. 25 иллюстрирует пример процесса добавления векторов движения среднего CPMV, вычисленных из сохраненного кандидата CPMV, в конечный набор кандидатов CPMV в соответствии с общим аспектом по меньшей мере одного варианта осуществления.
[52] Фиг. 26 иллюстрирует блок-схему примерного устройства, в котором могут быть реализованы различные аспекты вариантов осуществления.
Подробное описание
[53] Фиг. 1 иллюстрирует примерный кодер 100 высокоэффективного кодирования видео (HEVC). HEVC представляет собой стандарт сжатия, разработанный совместной сотрудничающей командой по кодированию видео (JCT-VC) (см., например, “ITU-T H.265 TELECOMMUNICATION STANDARDIZATION SECTOR OF ITU (10/2014), SERIES H: AUDIOVISUAL AND MULTIMEDIA SYSTEMS, Infrastructure of audiovisual services - Coding of moving video, High efficiency video coding, Recommendation ITU-T H.265”).
[54] В HEVC, чтобы закодировать последовательность видео с одним или несколькими изображениями, изображение разбивается на один или несколько слайсов, при этом каждый слайс может включать в себя один или несколько сегментов слайса. Сегмент слайса организован в единицы кодирования, единицы предсказания и единицы преобразования.
[55] В настоящей заявке, термины “реконструированный” и “декодированный” могут использоваться взаимозаменяемо, термины “закодированный” или “кодированный” могут использоваться взаимозаменяемо, и термины “изображение” и “кадр” могут использоваться взаимозаменяемо. Обычно, но не обязательно, термин “реконструированный” используется на стороне кодера, в то время как “декодированный” используется на стороне декодера.
[56] Спецификация HEVC проводит различие между “блоками” и “единицами”, где “блок” обращается к конкретной области в массиве выборок (например, яркость, Y), а “единица” включает в себя совмещенные блоки всех закодированных цветовых компонентов (Y, Cb, Cr или монохром), синтаксические элементы и данные предсказания, которые ассоциированы с блоками (например, векторы движения).
[57] Для кодирования, изображение разбивается на блоки дерева кодирования (CTB) квадратной формы с конфигурируемым размером, и последовательный набор блоков дерева кодирования группируется в слайс. Единица дерева кодирования (CTU) содержит CTB закодированных цветовых компонентов. CTB представляет собой корень разбиения квадродерева на блоки кодирования (CB), и блок кодирования может разбиваться на один или несколько блоков предсказания (PB) и формирует корень разбиения квадродерева в блоки преобразования (TB). Соответственно блоку кодирования, блоку предсказания и блоку преобразования, единица кодирования (CU) включает в себя единицы предсказания (PU) и структурированный в виде дерева набор единиц преобразования (TU), PU включает в себя информацию предсказания для всех компонентов цвета, и TU включает в себя структуру синтаксиса кодирования остатка для каждого компонента цвета. Размер CB, PB и TB компонента яркости применяется к соответствующей CU, PU и TU. В настоящей заявке, термин “блок” может использоваться, чтобы ссылаться, например, на любое из CTU, CU, PU, TU, CB, PB и TB. К тому же, “блок” может также использоваться, чтобы ссылаться на макроблок и разбиение, как специфицировано в H.264/AVC или других стандартах кодирования видео, и в более общем смысле, чтобы ссылаться на массив данных различных размеров.
[58] В примерном кодере 100, изображение кодируется элементами кодера, как описано ниже. Изображение, подлежащее кодированию, обрабатывается в единицах CU. Каждая CU кодируется с использованием интра- или интер-режима. Когда CU кодируется в интра-режиме, она выполняет интра-предсказание (160). В интер-режиме, выполняются оценка (175) и компенсация (170) движения. Кодер решает (105), какой из интра-режима или интер-режима следует использовать для кодирования CU, и указывает интра-/интер-решение посредством флага режима предсказания. Остатки предсказания вычисляются посредством вычитания (110) предсказанного блока из блока исходного изображения.
[59] CU в интра-режиме предсказываются из реконструированных соседних выборок в пределах одного и того же слайса. Набор из 35 интра-режимов предсказания доступен в HEVC, включая DC, планарный и 33 угловых режима предсказания. Опора интра-предсказания реконструируется из строки и столбца, смежных с текущим блоком. Опора продолжается по двукратному размеру блока в горизонтальном и вертикальном направлениях с использованием доступных выборок из ранее реконструированных блоков. Когда угловой режим предсказания используется для интра-предсказания, опорные выборки могут копироваться вдоль направления, указанного угловым режимом предсказания.
[60] Применимый режим интра-предсказания яркости для текущего блока может кодироваться с использованием двух разных опций. Если применимый режим включен в сформированный список трех наиболее вероятных режимов (MPM), режим сигнализируется посредством индекса в списке MPM. В противном случае, режим сигнализируется посредством бинаризации фиксированной длины индекса режима. Три наиболее вероятных режима выводятся из режимов интра-предсказания верхних и левых соседних блоков.
[61] Для интер-CU, соответствующий блок кодирования дополнительно разбивается на один или несколько блоков предсказания. Интер-предсказание выполняется на уровне PB, и соответствующая PU содержит информацию о том, как выполняется интер-предсказание. Информация движения (т.е., вектор движения и индекс опорного изображения) могут сигнализироваться в двух способах, а именно, “режиме объединения” и “расширенного предсказания вектора движения (AMVP)”.
[62] В режиме объединения, кодер или декодер видео формирует список кандидатов на основе уже закодированных блоков, и кодер видео сигнализирует индекс для одного из кандидатов в списке кандидатов. На стороне декодера, вектор движения (MV) и индекс опорного изображения реконструируются на основе сигнализированного кандидата.
[63] Набор возможных кандидатов в режиме объединения состоит из пространственных соседних кандидатов, временного кандидата и генерируемых кандидатов. Фиг. 2A показывает положения пяти пространственных кандидатов {a1, b1, b0, a0, b2} для текущего блока 210, причем a0 и a1 находятся слева от текущего блока, и b1, b0, b2 находятся сверху текущего блока. Для каждого положения кандидата, доступность проверяется в соответствии с порядком a1, b1, b0, a0, b2, и затем удаляется избыточность в кандидатах.
[64] Вектор движения совмещенного местоположения в опорном изображении может использоваться для вывода временного кандидата. Применимое опорное изображение выбирается на основе слайса и указывается в заголовке слайса, и опорный индекс для временного кандидата устанавливается в iref=0. Если расстояние (td) POC между изображением совмещенной PU и опорным изображением, из которого предсказывается совмещенная PU, является тем же самым, что и расстояние (tb) между текущим изображением и опорным изображением, содержащим совмещенную PU, совмещенный вектор mvcol движения может использоваться непосредственно в качестве временного кандидата. В противном случае, масштабированный вектор движения, tb/td*mvcol, используется в качестве временного кандидата. В зависимости от того, где расположена текущая PU, совмещенная PU определяется местоположением выборки внизу справа или в центре текущей PU.
[65] Максимальное число кандидатов объединения, N, задается в заголовке слайса. Если число кандидатов объединения больше, чем N, используются только первые N-1 пространственных кандидатов и временной кандидат. В противном случае, если число кандидатов объединения меньше, чем N, набор кандидатов заполняется до максимального числа N генерируемыми кандидатами в качестве комбинаций уже представленных кандидатов, или нулевыми кандидатами. Кандидаты, используемые в режиме объединения, могут упоминаться как “кандидаты объединения” в настоящей заявке.
[66] Если CU указывает режим пропуска, применимый индекс для кандидата объединения указывается, только если список кандидатов объединения больше, чем 1, и никакая дополнительная информация не закодирована для CU. В режиме пропуска, вектор движения применяется без обновления остатка.
[67] В AMVP, кодер или декодер видео формирует списки кандидатов на основе векторов движения, определенных из уже закодированных блоков. Кодер видео затем сигнализирует индекс в списке кандидатов, чтобы идентифицировать предсказатель вектора движения (MVP), и сигнализирует разность векторов движения (MVD). На стороне декодера, вектор движения (MV) реконструируется как MVP+MVD. Применимый индекс опорного изображения также явно кодируется в синтаксисе PU для AMVP.
[68] Только два пространственных кандидата движения выбираются в AMVP. Первый пространственный кандидат движения выбирается из левых положений {a0, a1}, а второй из верхних положений {b0, b1, b2}, при поддержке порядка поиска, как указано в двух наборах. Если число кандидатов вектора движения не равно двум, временной кандидат MV может включаться. Если набор кандидатов все еще не заполнен полностью, то используются нулевые векторы движения.
[69] Если индекс опорного изображения пространственного кандидата соответствует индексу опорного изображения для текущей PU (т.е., используется один и тот же индекс опорного изображения или они оба используют долгосрочные опорные изображения, независимо от списка опорных изображений), вектор движения пространственного кандидата используется непосредственно. В противном случае, если оба опорных изображений являются краткосрочными, вектор движения кандидата масштабируется в соответствии с расстоянием (tb) между текущим изображением и опорным изображением текущей PU и расстоянием (td) между текущим изображением и опорным изображением пространственного кандидата. Кандидаты, используемые в режиме AMVP, могут упоминаться как “кандидаты AMVP” в настоящей заявке.
[70] Для простоты обозначения, блок, тестируемый в режиме “объединения” на стороне кодера, или блок, декодированный в режиме “объединения” на стороне декодера, обозначается как блок “объединения”, а блок, тестируемый в режиме AMVP на стороне кодера, или блок, декодированный в режиме AMVP на стороне декодера, обозначается как блок “AMVP”.
[71] Фиг. 2B иллюстрирует примерное представление вектора движения с использованием AMVP. Для текущего блока 240, подлежащего кодированию, вектор движения (MVcurrent) может быть получен через оценку движения. С использованием вектора движения (MVleft) из левого блока 230 и вектора движения (MVabove) из верхнего блока 220, предсказатель вектора движения может выбираться из MVleft и MVabove как MVPcurrent. Разность векторов движения затем может вычисляться как MVDcurrent=MVcurrent-MVPcurrent.
[72] Предсказание компенсации движения может выполняться с использованием одного или двух опорных изображений для предсказания. В P-слайсах, только одна опора предсказания может использоваться для интер-предсказания, обеспечивая возможность одиночного (уни-) предсказания для блока предсказания. В B-слайсах доступны два списка опорных изображений, и могут использоваться одиночное предсказание или двойное (би-) предсказание. В двойном предсказании используется одно опорное изображение из каждого из списков опорных изображений.
[73] В HEVC, точность информации движения для компенсации движения составляет одну четверть выборки (также упоминается как четверть пела (пиксела) или ¼ пела) для компонента яркости и одну восьмую выборки (также упоминается как 1/8 пела) для компонентов цветности для конфигурации 4:2:0. 7-отводный или 8-отводный фильтр интерполяции используется для интерполяции положений дробной выборки, т.е., 1/4, 1/2 и 3/4 местоположений полной выборки как в горизонтальном, так и в вертикальном направлении могут рассматриваться для яркости.
[74] Остатки предсказания затем преобразуются (125) и квантуются (130). Квантованные коэффициенты преобразования, а также векторы движения и другие элементы синтаксиса энтропийно кодируются (145) для вывода битового потока. Кодер может также пропускать преобразование и применять квантование непосредственно к непреобразованному сигналу остатка на основе TU 4×4. Кодер может также обходить как преобразование, так и квантование, т.е., остаток кодируется непосредственно без применения процесса преобразования или квантования. В прямом кодировании PCM, никакое предсказание не применяется, и выборки единицы кодирования непосредственно кодируются в битовый поток.
[75] Кодер декодирует закодированный блок, чтобы обеспечить опору для дальнейших предсказаний. Квантованные коэффициенты преобразования подвергаются обратному квантованию (деквантуются) (140) и обратно преобразуются (150), чтобы декодировать остатки предсказания. Посредством комбинирования (155) декодированных остатков предсказания и предсказанного блока реконструируется блок изображения. Контурные фильтры (165) применяются к реконструированному изображению, например, чтобы выполнить фильтрацию устранения блочности/SAO (адаптивное к выборке смещение), чтобы уменьшить артефакты кодирования. Отфильтрованное изображение сохраняется в буфере (180) опорных изображений.
[76] Фиг. 3 иллюстрирует блок-схему примерного декодера 300 видео HEVC. В примерном декодере 300, битовый поток декодируется посредством элементов декодера, как описано ниже. Декодер 300 видео в общем выполняет проход декодирования взаимно обратно по отношению к проходу кодирования, как описано на фиг. 1, который выполняет декодирование видео как часть кодирования данных видео.
[77] В частности, вход декодера включает в себя битовый поток видео, который может генерироваться посредством кодера 100 видео. Битовый поток сначала энтропийно декодируется (330) для получения коэффициентов преобразования, векторов движения и другой закодированной информации. Коэффициенты преобразования деквантуются (340) и обратно преобразуются (350), чтобы декодировать остатки предсказания. Посредством комбинирования (355) декодированных остатков предсказания и предсказанного блока, реконструируется блок изображения. Предсказанный блок может быть получен (370) из интра-предсказания (360) или скомпенсированного по движению предсказания (т.е., интер-предсказания) (375). Как описано выше, AMVP и методы режима объединения могут использоваться, чтобы вывести векторы движения для компенсации движения, что может использовать фильтры интерполяции для вычисления интерполированных значений для суб-целочисленных выборок опорного блока. Контурные фильтры (365) применяются к реконструированному изображению. Отфильтрованное изображение сохраняется в буфере (380) опорных изображений.
[78] Как упомянуто, в HEVC применяется скомпенсированное по движению временное предсказание, чтобы использовать избыточность, которая существует между последовательными видеоизображениями. Для этого вектор движения ассоциируется с каждой единицей предсказания (PU). Как объяснено выше, каждая CTU представлена посредством кодового дерева в сжатой области. Это представляет собой деление квадродерева для CTU, где каждый лист называется единицей кодирования (CU), и проиллюстрировано на фиг. 4 для CTU 410 и 420. Каждой CU затем придаются некоторые параметры интра- или интер-предсказания в качестве информации предсказания. Для этого, CU может быть пространственно разбита на одну или несколько единиц предсказания (PU), причем каждой PU назначается некоторая информация предсказания. Режим интра- или интер-кодирования назначается на уровне CU. Эти принципы дополнительно проиллюстрированы на фиг. 5 для примерных CTU 500 и CU 510.
[79] В HEVC, один вектор движения назначается каждой PU. Этот вектор движения используется для скомпенсированного по движению временного предсказания рассматриваемой PU. Поэтому, в HEVC, модель движения, которая связывает предсказанный блок и его опорный блок, состоит просто из преобразования (трансляции) или вычисления на основе опорного блока и соответствующего вектора движения.
[80] Чтобы улучшить HEVC, опорная JEM (модель совместного исследования) программного обеспечения и/или документации разрабатывается Объединенной группой исследования видео (JVET). В одной версии JEM (например, “Algorithm Description of Joint Exploration Test Model 5”, Document JVET-E1001_v2, Joint Video Exploration Team of ISO/IEC JTC1/SC29/WG11, 5th meeting, 12-20 January 2017, Geneva, CH), некоторые дополнительные модели движения поддерживаются для улучшения временного предсказания. Для этого, PU может быть пространственно разделена на под-PU, и может использоваться модель, чтобы назначать каждой под-PU выделенный вектор движения.
[81] В более недавних версиях JEM (например, “Algorithm Description of Joint Exploration Test Model 2”, Document JVET-B1001_v3, Joint Video Exploration Team of ISO/IEC JTC1/SC29/WG11, 2nd meeting, 20-26 February 2016, San Diego, USA”), CU больше не определяется, чтобы разделяться на PU или TU. Вместо этого, могут использоваться более гибкие размеры CU, и некоторые данные движения непосредственно назначаются каждой CU. В этом новом проекте кодека в новых версиях JEM, CU может быть разделена на под-CU, и вектор движения может вычисляться для каждой под-CU разделенной CU.
[82] Одна из новых моделей движения, представленных в JEM, состоит в использовании аффинной модели в качестве модели движения для представления векторов движения в CU. Используемая модель движения проиллюстрирована на фиг. 6 и представлена Уравнением 1, как показано ниже. Аффинное поле движения содержит следующие значения компонентов вектора движения для каждого положения (x, y) внутри рассматриваемого блока 600 на фиг. 6:
Уравнение 1: аффинная модель движения, используемая, чтобы генерировать поле движения внутри CU для предсказания,
причем (v0x, v0y) и (v1x, v1y) представляют собой векторы движения контрольной точки, используемые, чтобы генерировать соответствующее поле движения, (v0x, v0y) соответствует вектору движения контрольной точки верхнего левого угла кодируемого или декодируемого блока, (v1x, v1y) соответствует вектору движения контрольной точки верхнего правого угла кодируемого или декодируемого блока, и w представляет собой ширину кодируемого или декодируемого блока.
[83] Чтобы уменьшить сложность, вектор движения вычисляется для каждого подблока (под-CU) 4×4 рассматриваемой CU 700, как проиллюстрировано на фиг. 7. Аффинный вектор движения вычисляется из векторов движения контрольной точки для каждого центрального положения каждого подблока. Полученный MV представляется с точностью 1/16 пел. В результате, компенсация единицы кодирования в аффинном режиме состоит в скомпенсированном по движению предсказании каждого подблока со своим собственным вектором движения. Эти векторы движения для подблоков показаны соответственно как стрелка для каждого из подблоков на фиг. 7.
[84] Поскольку в JEM начальные числа сохраняются в пределах соответствующих подблоков 4×4, аффинный режим может использоваться только для CU с шириной и высотой больше 4 (чтобы иметь независимые подблоки для каждого начального числа). Например, в CU 64×4 существует только один левый подблок для сохранения верхнего левого и нижнего левого начальных чисел, и в CU 4×32 существует только один верхний подблок для верхнего левого и верхнего правого начальных чисел; в JEM невозможно корректно сохранить начальные числа в такой тонкой CU. При помощи нашего предложения, поскольку начальные числа сохраняются отдельно, обеспечивается возможность обработки такой тонкой CU с шириной или высотой, равной 4.
[85] Со ссылкой вновь на фиг. 7, аффинная CU определяется своей ассоциированной аффинной моделью, составленной из трех векторов движения, называемых начальные числами аффинной модели, как векторы движения от верхнего левого, верхнего правого и нижнего левого углов CU (v0, v1 и v2 на фиг. 7). Эта аффинная модель тогда позволяет осуществлять вычисление поля аффинного вектора движения в пределах CU, которое выполняется на основе подблока 4×4 (черные векторы движения на фиг. 7). В JEM, эти начальные числа привязаны к верхнему левому, верхнему правому и нижнему левому подблокам 4×4 в рассматриваемой CU. В предложенном решении, начальные числа аффинной модели сохраняются отдельно в качестве информации движения, ассоциированной с целой CU (подобно флагу IC, например). Модель движения, таким образом, становится развязанной от векторов движения, используемых для действительной компенсации движения на уровне блока 4×4. Такое новое сохранение может позволить сохранять полное поле вектора движения на уровне подблока 4×4. Оно также позволяет использовать аффинную компенсацию движения для блока размером 4 по ширине или высоте.
[86] Аффинная компенсация движения может использоваться двумя способами в JEM: аффинный интер- (AF_INTER) режим и режим аффинного объединения. Они представлены в следующих разделах.
[87] Аффинный интер- (AF_INTER) режим: CU в режиме AMVP, размер которой больше, чем 8×8, может предсказываться в аффинном интер-режиме. Это сигнализируется посредством флага в битовом потоке. Генерация аффинного поля движения для этой интер-CU включает в себя определение векторов движения контрольной точки (CPMV), которые получают декодером посредством сложения дифференциала вектора движения и предсказания вектора движения точки управления (CPMVP). CPMVP представляют собой пару кандидатов вектора движения, соответственно взятых из набора (A, B, C) и (D, E), проиллюстрированного на фиг. 8A для текущей кодируемой или декодируемой CU 800.
[88] Режим аффинного объединения: в режиме аффинного объединения, флаг уровня CU указывает, применяет ли CU объединения аффинную компенсацию движения. Если да, то первая доступная соседняя CU, которая была закодирована в аффинном режиме, выбирается среди упорядоченного набора положений-кандидатов A, B, C, D, E согласно фиг. 8B для текущей кодируемой или декодируемой CU 880. Отметим, что этот упорядоченный набор положений-кандидатов в JEM является тем же самым, что и в случае пространственных соседних кандидатов в режиме объединения в HEVC, как показано на фиг. 2A и объяснено ранее.
[89] Когда первая соседняя CU в аффинном режиме получена, затем выводятся или вычисляются 3 CPMV 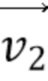 ,
, 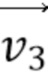 и
и 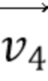 из верхнего левого, верхнего правого и нижнего левого углов соседней аффинной CU. Например, фиг. 9 показывает, что эта первая определенная соседняя CU 910 в аффинном режиме находится в положении A на фиг. 8B для текущей кодируемой или декодируемой CU 900. На основе этих трех CPMV соседней CU 910, два CPMV верхнего левого и верхнего правого углов текущей CU 900 выводятся, как описано далее:
из верхнего левого, верхнего правого и нижнего левого углов соседней аффинной CU. Например, фиг. 9 показывает, что эта первая определенная соседняя CU 910 в аффинном режиме находится в положении A на фиг. 8B для текущей кодируемой или декодируемой CU 900. На основе этих трех CPMV соседней CU 910, два CPMV верхнего левого и верхнего правого углов текущей CU 900 выводятся, как описано далее:
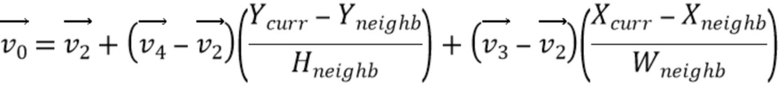
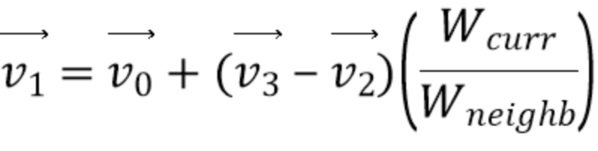
Уравнение 2: вывод CPMV текущей CU на основе трех векторов движения контрольной точки выбранной соседней CU
[90] Когда получены векторы 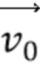 и
и 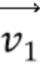 движения контрольной точки текущей CU, поле движения внутри текущей кодируемой или декодируемой CU вычисляется на основе под-CU 4×4, посредством модели Уравнения 1, как описано выше в связи с фиг. 6.
движения контрольной точки текущей CU, поле движения внутри текущей кодируемой или декодируемой CU вычисляется на основе под-CU 4×4, посредством модели Уравнения 1, как описано выше в связи с фиг. 6.
[91] Соответственно, общий аспект по меньшей мере одного варианта осуществления нацелен на улучшение характеристик режима аффинного объединения в JEM, так что характеристики сжатия рассматриваемого кодека видео могут быть улучшены. Поэтому, по меньшей мере в одном варианте осуществления, представлены расширенные и усовершенствованные устройство и способ аффинной компенсации движения, например, для единиц кодирования, которые кодируются в режиме аффинного объединения. Предложенный расширенный и усовершенствованный аффинный режим включает в себя оценивание множества кандидатов предсказателя в режиме аффинного объединения.
[92] Как обсуждалось ранее, в текущей JEM, первая соседняя CU, закодированная в режиме аффинного объединения среди окружающих CU, выбирается для предсказания аффинной модели движения, ассоциированной с текущей кодируемой или декодируемой CU. То есть, кандидат первой соседней CU среди упорядоченного набора (A, B, C, D, E) на фиг. 8B, который кодируется в аффинном режиме, выбирается для предсказания аффинной модели движения текущей CU.
[93] Соответственно, по меньшей мере один вариант осуществления выбирает кандидат предсказания аффинного объединения, который обеспечивает лучшую эффективность кодирования при кодировании текущей CU в режиме аффинного объединения, вместо использования только первого в упорядоченном наборе, как отмечено выше. Таким образом, усовершенствования этого варианта осуществления, на общем уровне, содержат, например:
- формирование набора множества кандидатов аффинного объединения предсказателя, который, по всей вероятности, будет обеспечивать хороший набор кандидатов для предсказания аффинной модели движения CU (для кодера/декодера);
- выбор одного предсказателя для вектора движения контрольной точки текущей CU среди сформированного набора (для кодера/декодера); и/или
- сигнализацию/декодирование индекса предсказателя вектора движения контрольной точки текущей CU (для кодера/декодера).
[94] Соответственно, фиг. 10 иллюстрирует примерный способ 1000 кодирования в соответствии с общим аспектом по меньшей мере одного варианта осуществления. В 1010, способ 1000 определяет, для блока, кодируемого в изображении, набор кандидатов предсказателя, имеющий множество кандидатов предсказателя. В 1020, способ 1000 выбирает кандидата предсказателя из набора кандидатов предсказателя. В 1030, способ 1000 определяет для выбранного кандидата предсказателя из набора кандидатов предсказателя один или несколько соответствующих векторов движения контрольной точки для блока. В 1040, способ 1000 определяет для выбранного кандидата предсказателя, на основе одного или нескольких соответствующих векторов движения контрольной точки, соответствующее поле движения на основе модели движения для выбранного кандидата предсказателя, причем соответствующее поле движения идентифицирует векторы движения, используемые для предсказания подблоков кодируемого блока. В 1050, способ 1000 кодирует блок на основе соответствующего поля движения для выбранного кандидата предсказателя из набора кандидатов предсказателя. В 1060, способ 1000 кодирует индекс для выбранного кандидата предсказателя из набора кандидатов предсказателя.
[95] Фиг. 11 иллюстрирует другой примерный способ 1100 кодирования в соответствии с общим аспектом по меньшей мере одного варианта осуществления. В 1110, способ 1100 определяет, для блока, кодируемого в изображении, набор кандидатов предсказателя. В 1120, способ 1100 определяет для каждого из множества кандидатов предсказателя из набора кандидатов предсказателя один или несколько соответствующих векторов движения контрольной точки для блока. В 1130, способ 1100 определяет для каждого из множества кандидатов предсказателя, на основе одного или нескольких соответствующих векторов движения контрольной точки, соответствующее поле движения на основе модели движения для каждого из множества кандидатов предсказателя из набора кандидатов предсказателя. В 1140, способ 1100 оценивает множество кандидатов предсказателя в соответствии с одним или несколькими критериями и на основе соответствующего поля движения. В 1150, способ 1100 выбирает кандидат предсказателя из множества кандидатов предсказателя на основе оценки. В 1160, способ 1100 кодирует индекс для выбранного кандидата предсказателя из набора кандидатов предсказателя.
[96] Фиг. 12 иллюстрирует примерный способ 1200 декодирования в соответствии с общим аспектом по меньшей мере одного варианта осуществления. В 1210, способ 1200 принимает, для блока, декодируемого в изображении, индекс, соответствующий конкретному кандидату предсказателя. В различных вариантах осуществления, конкретный кандидат предсказателя был выбран в кодере, и индекс позволяет выбирать один из множества кандидатов предсказателя. В 1220, способ 1200 определяет, для конкретного кандидата предсказателя, один или несколько соответствующих векторов движения контрольной точки для декодируемого блока. В 1230, способ 1200 определяет для конкретного кандидата предсказателя, на основе одного или нескольких соответствующих векторов движения контрольной точки, соответствующее поле движения. В различных вариантах осуществления, поле движения основано на модели движения, причем соответствующее поле движения идентифицирует векторы движения, используемые для предсказания подблоков декодируемого блока. В 1240, способ 1200 декодирует блок на основе соответствующего поля движения.
[97] Фиг. 13 иллюстрирует другой примерный способ 1300 декодирования в соответствии с общим аспектом по меньшей мере одного варианта осуществления. В 1310, способ 1300 извлекает, для блока, декодируемого на изображении, индекс, соответствующий выбранному кандидату предсказателя. Как также показано в 1310, выбранный кандидат предсказателя был выбран в кодере посредством: определения, для блока, кодируемого на изображении, набора кандидатов предсказателя; определения для каждого из множества кандидатов предсказателя из набора кандидатов предсказателя одного или нескольких соответствующих векторов движения контрольной точки для кодируемого блока; определения для каждого из множества кандидатов предсказателя, на основе одного или нескольких соответствующих векторов движения контрольной точки, соответствующего поля движения на основе модели движения для каждого из множества кандидатов предсказателя из набора кандидатов предсказателя; оценивания множества кандидатов предсказателя в соответствии с одним или несколькими критериями и на основе соответствующего поля движения; выбора кандидата предсказателя из множества кандидатов предсказателя на основе оценивания; и кодирования индекса для выбранного кандидата предсказателя из набора кандидатов предсказателя. В 1320, способ 1300 декодирует блок на основе индекса, соответствующего выбранному кандидату предсказателя.
[98] Фиг. 14 иллюстрирует подробности варианта осуществления процесса 1400, используемого, чтобы предсказывать аффинное поле движения текущей CU, кодируемой или декодируемой в существующем режиме аффинного объединения в JEM. Входом 1401 в этот процесс 1400 является текущая единица кодирования, для которой желательно сгенерировать аффинное поле движения подблоков, как показано на фиг. 7. В 1410, CPMV аффинного объединения для текущего блока получают с выбранным кандидатом предсказателя, как объяснено выше в связи, например, с фиг. 6, фиг. 7, фиг. 8B и фиг. 9. Вывод этого кандидата предсказателя также поясняется более подробно далее со ссылкой на фиг. 15.
[99] В результате, в 1420, верхний левый и верхний правый векторы 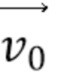 и
и 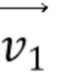 движения контрольной точки затем используются, чтобы вычислять аффинное поле движения, ассоциированное с текущей CU. Это состоит в вычислении вектора движения для каждого подблока 4×4 в соответствии с Уравнением 1, как объяснено выше. В 1430 и 1440, когда поле движения получено для текущей CU, осуществляется временное предсказание текущей CU с использованием компенсации движения на основе подблока 4×4 и затем OBMC (компенсация движения с перекрывающимися блоками). В 1450 и 1460, текущая CU кодируется и реконструируется, последовательно с данными остатка и без них. Режим выбирается на конкурентной основе по критерию RD, и этот режим используется, чтобы кодировать текущую CU, и индекс для этого режима также кодируется в различных вариантах осуществления.
движения контрольной точки затем используются, чтобы вычислять аффинное поле движения, ассоциированное с текущей CU. Это состоит в вычислении вектора движения для каждого подблока 4×4 в соответствии с Уравнением 1, как объяснено выше. В 1430 и 1440, когда поле движения получено для текущей CU, осуществляется временное предсказание текущей CU с использованием компенсации движения на основе подблока 4×4 и затем OBMC (компенсация движения с перекрывающимися блоками). В 1450 и 1460, текущая CU кодируется и реконструируется, последовательно с данными остатка и без них. Режим выбирается на конкурентной основе по критерию RD, и этот режим используется, чтобы кодировать текущую CU, и индекс для этого режима также кодируется в различных вариантах осуществления.
[100] В по меньшей мере одной реализации, используется флаг остатка. В 1450, флаг активируется (noResidual=0), указывая, что кодирование выполнено с данными остатка. В 1460, текущая CU полностью закодирована и реконструирована (с остатком), давая соответствующую стоимость RD. Затем флаг деактивируется (1480, 1485, noResidual=1), указывая, что кодирование произведено без данных остатка, и процесс возвращается к 1460, где CU кодируется (без остатка), давая соответствующую стоимость RD. Самая низкая стоимость RD (1470, 1475) между двумя предыдущими указывают, должен ли остаток кодироваться или нет (нормально или пропустить). Способ 1400 заканчивается в 1499. Затем эта лучшая стоимость RD конкурирует с другими режимами кодирования. Определение скорости-искажения будет пояснено более подробно ниже.
[101] Фиг. 15 показывает подробности варианта осуществления процесса 1500, используемого, чтобы предсказывать одну или несколько контрольных точек аффинного поля движения текущей CU. Процесс состоит в поиске (1510, 1520, 1530, 1540, 1550) CU, которая была закодирована/декодирована в аффинном режиме, среди пространственных положений (A, B, C, D, E) на фиг. 8B. Если никакое из найденных пространственных положений не закодировано в аффинном режиме, то переменная, указывающая число положений- кандидатов, например, numValidMergeCand, устанавливается (1560) в 0. В противном случае, выбирается (1515, 1525, 1535, 1545, 1555) первое положение, которое соответствует CU в аффинном режиме. Процесс 1500 тогда состоит в вычислении векторов движения контрольной точки, которые будут использоваться позже для генерации аффинного поля движения, назначенного текущей CU, и установке (1580) numValidMergeCand в 1. Это вычисление контрольной точки происходит следующим образом. Определяется CU, которая содержит выбранное положение. Она представляет собой одну из соседних CU текущей CU, как объяснено выше. Далее, 3 CPMV , и от верхнего левого, верхнего правого и нижнего левого углов внутри выбранной соседней CU выводятся (или определяются), как объяснено выше в связи с фиг. 9. Наконец, верхний левый и верхний правый CPMV 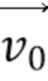 и
и 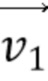 текущей CU выводятся (1570), в соответствии с Уравнением 1, как объяснено выше в связи с фиг. 6. Способ 1500 заканчивается в 1599.
текущей CU выводятся (1570), в соответствии с Уравнением 1, как объяснено выше в связи с фиг. 6. Способ 1500 заканчивается в 1599.
[102] Авторы настоящего изобретения выявили, что один аспект существующего процесса аффинного объединения, описанного выше, состоит в том, что он систематически использует один и только один предсказатель вектора движения для распространения аффинного поля движения от окружающей казуальной (причинно-обусловленной) (т.е., уже закодированной или декодированной) и соседней CU в направлении текущей CU. В различных ситуациях, авторы настоящего изобретения дополнительно установили, что этот аспект может быть неблагоприятным, поскольку, например, он не выбирает оптимальный предсказатель вектора движения. Более того, выбор этого предсказателя состоит только из первой казуальной и соседней CU, закодированной в аффинном режиме, в упорядоченном наборе (A, B, C, D, E), как уже отмечено выше. В других ситуациях, авторы настоящего изобретения дополнительно установили, что этот ограниченный выбор может быть неблагоприятным, поскольку, например, может быть доступным лучший предсказатель. Поэтому, существующий процесс в текущей JEM не учитывает тот факт, что несколько потенциальных казуальных и соседних CU вокруг текущей CU могли также использовать аффинное движение и что другая CU, отличная от первой обнаруженной как использовавшей аффинное движение, может быть лучшим предсказателем для информации движения текущей CU.
[103] Таким образом, авторы настоящего изобретения выявили потенциальные преимущества в нескольких способах для улучшения предсказания аффинных векторов движения текущей CU, которые не использовались существующими кодеками JEM. В соответствии с общим аспектом по меньшей мере одного варианта осуществления, такие преимущества, обеспеченные в настоящих моделях движения, можно видеть, и они проиллюстрированы на фиг. 16 и фиг. 17, как объяснено ниже.
[104] Как на фиг. 16, так и на фиг. 17, текущая кодируемая или декодируемая CU представляет собой большую единицу в середине, соответственно, 1610 на фиг. 16 и 1710 на фиг. 17. Два потенциальных кандидата предсказателя соответствуют положениям A и C на фиг. 8B и показаны соответственно как кандидаты 1620 предсказателя на фиг. 16 и кандидаты 1720 предсказателя на фиг. 17. В частности, фиг. 16 иллюстрирует потенциальные поля движения текущего кодируемого иди декодируемого блока 1610, если выбранный кандидат предсказателя расположен в левом положении (положение A на фиг. 8B). Подобным образом, фиг. 17 иллюстрирует потенциальные поля движения текущего кодируемого или декодируемого блока 1710, если выбранный кандидат предсказателя расположен в правом и верхнем положении (т.е., положении C на фиг. 8B). Как показано на иллюстративных чертежах, в зависимости от того, какой предсказатель аффинного объединения выбран, разные наборы векторов движения для подблоков могут генерироваться для текущей CU. Поэтому, авторы настоящего изобретения установили, что один или несколько критериев, таких как, например, оптимизированный выбор на основе искажения-скорости (RD) между этими двумя кандидатами, могут помочь в улучшении выполнения кодирования/декодирования текущей CU в режиме аффинного объединения.
[105] Поэтому, один общий аспект по меньшей мере одного варианта осуществления состоит в выборе лучшего кандидата предсказателя движения для выведения CPMV текущей кодируемой или декодируемой CU, среди набора множества кандидатов. На стороне кодера, кандидат, используемый, чтобы предсказывать текущий CPMV, выбирается в соответствии с критерием стоимости искажения-скорости, в соответствии с одним аспектом одного примерного варианта осуществления. Его индекс затем кодируется в выводимом битовом потоке для декодера, в соответствии с другим аспектом другого примерного варианта осуществления.
[106] В соответствии с другим аспектом другого примерного варианта осуществления, в декодере, может формироваться набор кандидатов, и предсказатель может выбираться из набора таким же образом, что и на стороне кодера. В таком варианте осуществления, нет необходимости кодировать индекс в потоке битов вывода. Другой вариант осуществления декодера избегает формирования набора кандидатов или по меньшей мере избегает выбора предсказателя из набора, как в кодере, и просто декодирует индекс, соответствующий выбранному кандидату, из битового потока для выведения соответствующих релевантных данных.
[107] В соответствии с другим аспектом другого примерного варианта осуществления, CPMV, используемые в нем, не ограничены двумя верхним правым и верхним левым положениями текущей кодируемой или декодируемой CU, как показано на фиг. 6. Другие варианты осуществления содержат, например, только один вектор или более двух векторов, и положения этих CPMV находятся, например, в положениях других углов или в любых положениях внутри или вне текущего блока, пока возможно выводить поле движения, например, в положении(ях) центра угловых подблоков 4×4 или внутреннего угла угловых подблоков 4×4.
[108] В примерном варианте осуществления, исследуемый набор потенциальных предсказателей кандидата идентичен набору положений (A, B, C, D, E), используемому, чтобы выводить предсказатель CPMV в существующем режиме аффинного объединения в JEM, как проиллюстрировано на фиг. 8B. Фиг. 18 иллюстрирует подробности одного примерного процесса 1800 выбора для выбора лучшего кандидата для предсказания аффинной модели движения текущей CU в соответствии с общим аспектом этого варианта осуществления. Однако другие варианты осуществления используют набор положений предсказателя, который отличается от A, B, C, D, E и который может включать в себя меньше или больше элементов в наборе.
[109] Как показано в 1801, входом этого примерного варианта 1800 осуществления является информация текущей кодируемой или декодируемой CU. В 1810, формируется набор множества кандидатов аффинного объединения предсказателя, в соответствии с алгоритмом 1500 на фиг. 15, который был пояснен выше. Алгоритм 1500 на фиг. 15 включает в себя сбор всех соседних положений (A, B, C, D, E), показанных на фиг. 8A, которые соответствуют казуальной CU, которая была закодирована в аффинном режиме, в набор кандидатов для предсказания аффинного движения текущей CU. Таким образом, вместо остановки при обнаружении казуальной аффинной CU, процесс 1800 сохраняет все возможные кандидаты для распространения аффинной модели движения от казуальной CU на текущую CU для всех из множества кандидатов предсказателя движения в наборе.
[110] Когда процесс на фиг. 15 выполнен, как показано в 1810 на фиг. 18, процесс 1800 на фиг. 18, в 1820, вычисляет CPMV верхнего левого и верхнего правого угла, предсказанные из каждого кандидата набора, обеспеченного в 1810. Это процесс 1820 дополнительно детализирован и проиллюстрирован на фиг. 19.
[111] Вновь, фиг. 19 показывает детали 1820 на фиг. 18 и включает в себя цикл по каждому кандидату, определенному и найденному из предшествующего этапа (1810 на фиг. 18). Для каждого кандидата предсказателя аффинного объединения, определяется CU, которая содержит пространственное положение этого кандидата. Затем для каждого опорного списка L0 и L1 (в основе B-слайса), векторы и движения контрольной точки, используемые для формирования поля движения текущей CU, выводятся в соответствии с Уравнением 2. Эти два CPMV для каждого кандидата сохраняются в наборе CPMV кандидата.
[112] Когда процесс согласно фиг. 19 выполнен и процесс возвращается к фиг. 18, выполнятся цикл 1830 по каждому кандидату предсказателя аффинного объединения. Он может выбирать, например, кандидата CPMV, который приводит к самой низкой стоимости скорости-искажения. Внутри цикла 1830, по каждому кандидату используется другой цикл 1840, который аналогичен процессу, как показано на фиг. 14, чтобы кодировать текущую CU с каждым кандидатом CPMV, как пояснено выше. Алгоритм согласно фиг. 14 заканчивается, когда все кандидаты были оценены, и его выход может содержать индекс лучшего предсказателя. Как указано ранее, в качестве примера, кандидат с минимальной стоимостью скорости-искажения может выбираться в качестве лучшего предсказателя. Различные варианты осуществления используют лучший предсказатель, чтобы кодировать текущую CU, и некоторые варианты осуществления также кодируют индекс для лучшего предсказателя.
[113] Один пример определения стоимости скорости-искажения определяется, как описано далее, как он известен специалисту в данной области техники:
RDcost=D+λ×R
причем D представляет искажение (обычно расстояние L2) между исходным блоком и реконструированным блоком, полученным путем кодирования и декодирования текущей CU с рассматриваемым кандидатом; R представляет стоимость скорости, например, число битов, генерируемых путем кодирования текущего блока с рассматриваемым кандидатом; λ представляет собой параметр Лагранжа, который представляет целевую скорость, с которой кодируется последовательность видео.
[114] Другой примерный вариант осуществления описан ниже. Этот примерный вариант осуществления нацелен на дополнительное улучшение характеристик кодирования режима аффинного объединения путем расширения набора кандидатов аффинного объединения по сравнению с существующей JEM. Этот примерный вариант осуществления может исполняться на стороне как кодера, так и декодера аналогичным образом, чтобы расширять набор кандидатов. Соответственно, в одном неограничивающем аспекте, некоторые дополнительные кандидаты предсказателя могут использоваться, чтобы формировать набор множества кандидатов аффинного объединения. Дополнительные кандидаты могут браться из дополнительных пространственных положений, таких как, например, A’ 2110 и B’ 2120, окружающих текущую CU 2100, как проиллюстрировано на фиг. 21. Другие варианты осуществления используют еще дополнительно пространственные положения вдоль или вблизи одного из краев текущей CU 2100.
[115] Фиг. 22 иллюстрирует примерный алгоритм 2200, который соответствует варианту осуществления с использованием дополнительных пространственных положений A’ 2110 и B’ 2120, как показано на фиг. 21 и описано выше. Например, алгоритм 2200 включает в себя тестирование нового положения-кандидата A’, если положение А не является действительным кандидатом предсказания аффинного объединения (например, не находится в CU, закодированной в аффинном режиме) в 2210-2230 на фиг. 22. Подобным образом, например, он также тестирует положение B’, если положение B не обеспечивает какого-либо действительного кандидата (например, не находится в CU, закодированной в аффинном режиме) в 2240-2260 на фиг. 22. Остальные аспекты примерного процесса 2200 для формирования набора кандидатов аффинного объединения являются по существу неизменными по сравнению с фиг. 19, как показано и пояснено ранее.
[116] В другом примерном варианте осуществления, существующие положения-кандидаты объединения рассматриваются сначала перед оцениванием заново добавленных положений. Добавленные положения оцениваются, только если набор кандидатов содержит меньше кандидатов, чем максимальное число кандидатов объединения, например, 5 или 7. Максимальное число может быть предопределенным или представлять собой переменную. Этот примерный вариант осуществления описан подробно посредством примерного алгоритма 2300 согласно фиг. 23.
[117] В соответствии с другим примерным вариантом осуществления, дополнительные кандидаты, называемые временными кандидатами, добавляются в набор кандидатов предсказателя. Эти временные кандидаты могут использоваться, например, если пространственные кандидаты не были обнаружены, как описано выше, или в варианте, если размер набора кандидатов аффинного объединения не достиг максимального значения, как описано выше. Другие варианты осуществления используют временные кандидаты перед добавлением пространственных кандидатов в набор. Например, временные кандидаты для предсказания векторов движения контрольной точки текущей CU могут выводиться из одного или нескольких опорных изображений, доступных или используемых для текущего изображения. Временные кандидаты могут браться, например, в положениях, соответствующих нижней правой соседней CU текущей CU в каждом из опорных изображений. Это соответствует положению-кандидату F 2410 для текущей кодируемой или декодируемой CU 2400, как показано на фиг. 24.
[118] В варианте осуществления, например, для каждого опорного изображения каждого списка опорных изображений, испытывается аффинный флаг, ассоциированный с блоком в положении F 2410 на фиг. 24 в рассматриваемом опорном изображении. Если истинно, то соответствующая CU, содержащаяся в этом опорном изображении, добавляется в текущий набор кандидатов аффинного объединения.
[119] В дополнительном варианте, временные кандидаты извлекаются из опорных изображений в пространственном положении, соответствующем верхнему левому углу текущей CU 2400. Это положение соответствует положению-кандидату G 2420 на фиг. 24.
[120] В дополнительном варианте, временные кандидаты извлекаются из опорных изображений в положении, соответствующем нижней правой соседней CU. Затем, если набор кандидатов содержит меньше кандидатов, чем предварительно фиксированное максимальное число кандидатов объединения, например, 5 или 7, выводятся временные кандидаты, соответствующие верхнему левому углу G 2420 текущей CU. В других вариантах осуществления, временные кандидаты получают из положения, на одном или нескольких опорных изображениях, соответствующего другой части (отличной от G 2420) текущей CU 2400 или соответствующего другой соседней CU (отличной от F 2410) текущей CU 2400.
[121] Дополнительно, примерный процесс вывода для векторов движения контрольной точки на основе временного кандидата осуществляется, как описано ниже. Для каждого временного кандидата, содержащегося в сформированном наборе, идентифицируется блок (tempCU), содержащий временной кандидат в своем опорном изображении. Затем три CPMV , и , расположенных в верхнем левом, верхнем правом и нижнем левом углах идентифицированной временной CU, масштабируются. Это масштабирование учитывает отношение между POC (отсчет порядка изображения) tempCU, POC опорного изображения tempCU (разность обозначается tempDist), POC текущей CU и POC опорного изображения текущей CU (разность обозначается curDist). Например, CPMV могут масштабироваться отношением расстояний (tempDist/curDist). Когда эти три масштабированных CPMV получены, два вектора движения контрольной точки для текущей CU выводятся в соответствии с Уравнением 2, как описано выше.
[122] Другой примерный вариант осуществления включает в себя добавление средней пары векторов движения контрольной точки, вычисленной как функция векторов движения контрольной точки, выведенных из каждого кандидата. Примерный процесс здесь поясняется подробно посредством примерного алгоритма 2500, показанного на фиг. 25. Цикл 2510 используется для каждого кандидата предсказателя аффинного объединения в наборе, сформированном для рассматриваемого списка опорных изображений.
[123] Затем в 2520, для каждого списка Lx опорных изображений, последовательно равных L0 и затем L1 (если в B-слайсе), если текущий кандидат имеет действительные CPMV для списка Lx:
Инициализировать пару векторов движения 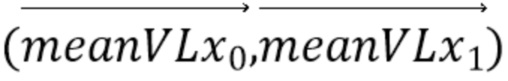 в
в 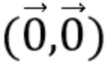
Для каждого кандидата
- вывести CPMV 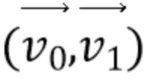 из текущих CPMV кандидата в соответствии с Уравнением 2.
из текущих CPMV кандидата в соответствии с Уравнением 2.
- добавить к паре ;
разделить пару векторов движения на число кандидатов для списка Lx;
назначить индекс опорного изображения векторам движения 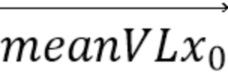 и
и 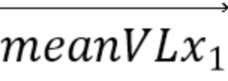 , равный минимальному индексу опорного изображения среди всех кандидатов каждого списка соответственно (Вектор относится к списку 0, и его ассоциированный опорный индекс установлен в минимальный опорный индекс, наблюдаемый среди всех кандидатов в списке 0. Вектор является тем же самым, за исключением того, что применяется к списку 1.);
, равный минимальному индексу опорного изображения среди всех кандидатов каждого списка соответственно (Вектор относится к списку 0, и его ассоциированный опорный индекс установлен в минимальный опорный индекс, наблюдаемый среди всех кандидатов в списке 0. Вектор является тем же самым, за исключением того, что применяется к списку 1.);
добавить полученную среднюю пару векторов движения к набору CPMV кандидатов для генерации аффинного поля движения текущей CU для списка Lx.
[124] С использованием алгоритма 2500 и/или других вариантов осуществления, набор кандидатов аффинного объединения дополнительно обогащается и содержит среднюю информацию движения, вычисленную из CPMV, выведенного для каждого кандидата, вставленного в набор кандидатов, в соответствии с предыдущими вариантами осуществления, как описано в предшествующих разделах.
[125] Поскольку возможно, что несколько кандидатов приводят к одному и тому же CPMV для текущей CU, вышеупомянутый средний кандидат может приводить к взвешенной усредненной паре векторов CPMV движения. Разумеется, процесс, описанный выше, может вычислять усредненное значение CPMV, собранных до сих пор, независимо от их уникальности в полном наборе CPMV. Поэтому, вариант этого варианта осуществления состоит в добавлении снова другого кандидата в набор кандидатов предсказания CPMV. Он состоит в добавлении усредненного CPMV набора уникальных собранных CPMV (помимо взвешенного среднего CPMV, как описано выше). Это обеспечивает дополнительный CPMV кандидат в наборе кандидатов предсказателя для формирования аффинного поля движения текущей CU.
[126] Например, рассмотрим ситуацию, в которой следующие пять пространственных кандидатов все являются доступными и аффинными (L, T, TR, BL, TL). Однако, 3 левых положения (L, BL, TL) находятся в пределах одной и той же соседней CU. В каждом пространственном положении, мы можем получить CPMV кандидат. Затем, первое среднее равно сумме этих 5 CPMV, разделенной на 5 (даже хотя несколько являются идентичными). Во втором среднем, рассматриваются только разные CPMV, поэтому 3 левых (L, BL, TL) рассматриваются только один раз, и второе среднее равно 3 разным CPMV (L, T, TR), разделенным на 3. В первом среднем, избыточные CPMV добавляются 3 раза, что дает больший вес для избыточных CPMV. С использованием уравнений, мы можем записать, что среднее1 = (L+T+TR+BL+TL)/5 при L=BL=TL, поэтому среднее1 = (3*L+T+TL)/5, в то время как среднее2 = (L+T+TL)/3.
[127] Два ранее описанных средних кандидата являются двунаправленными, поскольку рассматриваемый кандидат сохраняет один вектор движения для опорного изображения в списке 0 и другой в списке 1. В другом варианте, можно суммировать однонаправленные средние. Из взвешенного и уникального среднего, четыре однонаправленных кандидата могут формироваться путем подбора векторов движения из списка 0 и списка 1 независимо.
[128] Одно преимущество примерных способов расширения набора кандидатов, описанных в настоящей заявке, состоит в увеличении разнообразия в наборе векторов движения контрольной точки кандидатов, которые могут использоваться, чтобы формировать аффинное поле движения, ассоциированное с данной CU. Таким образом, настоящие варианты осуществления обеспечивают технологическое достижение в технологии вычислений для кодирования и декодирования видео контента. Например, настоящие варианты осуществления улучшают характеристику скорости-искажения, обеспечиваемую режимом кодирования аффинного объединения в JEM. Таким образом, характеристика скорости-искажения в целом рассматриваемого кодека видео была улучшена.
[0129] Дополнительный примерный вариант осуществления может быть обеспечен, чтобы модифицировать процесс согласно фиг. 18. Вариант осуществления включает в себя быструю оценку характеристики каждого кандидата CPMV через следующее приближенное вычисление искажения и скорости. Соответственно, для каждого кандидата в наборе CPMV, вычисляется поле движения текущей CU, и выполняется временное предсказание на основе подблока 4×4 текущей CU. Затем искажение вычисляется как SATD между предсказанной CU и исходной CU. Стоимость скорости получают как приблизительное число битов, связанных с сигнализацией индекса объединения рассматриваемого кандидата. Грубую (приблизительную) стоимость RD затем получают для каждого кандидата. Итоговый выбор основан на приблизительной стоимости RD в одном варианте осуществления. В другом варианте осуществления, поднабор кандидатов подвергается полному поиску RD, т.е. кандидаты, которые имеют самую низкую приблизительную стоимость RD, затем подвергаются полному поиску RD. Преимущество этих вариантов осуществления состоит в том, что они ограничивают повышение сложности на стороне кодера, которое возникает из поиска лучшего кандидата предсказателя аффинного объединения.
[130] Также, в соответствии с другим общим аспектом по меньшей мере одного варианта осуществления, аффинный интер-режим, как описано ранее, может также быть улучшен при помощи всех решений, представленных здесь, за счет наличия расширенного списка аффинных кандидатов предсказателя. Как описано выше в связи с фиг. 8A, один или несколько CPMVP аффинной интер-CU выводятся из соседних векторов движения независимо от их режима кодирования. Поэтому, тогда становится возможным извлечь выгоду из аффинных соседей с их аффинной моделью для создания одного или нескольких CPMVP текущей аффинной интер-CU, как в режиме аффинного объединения, как описано выше. В этом случае, рассматриваемые аффинные кандидаты могут представлять собой тот же самый список, что и описанный выше для режима аффинного объединения (например, не ограниченный только пространственными кандидатами).
[131] Соответственно, набор множества кандидатов предсказателя обеспечивается для улучшения сжатия/декомпрессии, обеспечиваемого текущим HEVC и JEM, путем использования лучших кандидатов предсказателя. Процесс будет более эффективным, и выигрыш кодирования будет наблюдаться, даже если может потребоваться передавать вспомогательный индекс.
[132] В соответствии с общим аспектом по меньшей мере одного варианта осуществления, набор кандидатов аффинного объединения (с по меньшей мере 7 кандидатами как в режиме объединения) составлен из, например:
- Пространственных кандидатов из (A, B, C, D, E),
- Временных кандидатов нижнего правого совмещенного положения, если менее 5 кандидатов в списке,
- Временных кандидатов совмещенного положения, если менее 5 кандидатов в списке,
- Взвешенного среднего,
- Уникального среднего,
- Однонаправленных средних из взвешенного среднего, если взвешенное среднее является двунаправленным и если менее 7 кандидатов в списке,
- Однонаправленных средних из уникального среднего, если уникальное среднее является двунаправленным и если менее 7 кандидатов в списке.
[133] Также, в случае AMVP, кандидаты предсказателя могут браться из, например:
- Пространственных кандидатов из набора (A, B, C, D, E),
- Вспомогательных пространственных кандидатов из (A’, B’),
- Временных кандидатов нижнего правого совмещенного положения.
[134] Таблица 1 и Таблица 2 ниже показывают улучшения по JEM 4.0 (параллельно) с использованием примерных вариантов осуществления некоторых из настоящих предлагаемых решений. Каждая таблица показывает результаты величин уменьшений скорости для одного из примерных вариантов осуществления, как описано выше. В частности, Таблица 1 показывает улучшения, когда 5 пространственных кандидатов (A, B, C, D, E), показанных на фиг. 8B, используются в качестве набора множества кандидатов предсказателя в соответствии с примерным вариантом осуществления, описанным выше. Таблица 2 показывает улучшения для примерного варианта осуществления, когда следующий порядок кандидатов предсказателя используется, как описано выше: сначала пространственные кандидаты, затем временные кандидаты, если число кандидатов все еще меньше, чем 5, затем средние и, наконец, однонаправленные средние, если число кандидатов все еще меньше, чем 7. Соответственно, например, Таблица 2 показывает, что для этого варианта осуществления, уменьшения скорости для выборок Y, U, V составляют соответственно уменьшения скорости на 0,22%, 0,26% и 0,12% BD (Метрика Бьентегарда) для класса D, почти без увеличения во временах выполнения кодирования и декодирования (т.е., 100% и 101% соответственно). Таким образом, настоящие примерные варианты осуществления улучшают эффективность сжатия/декомпрессии при поддержании затрат по вычислительной сложности по существующим реализациям JEM.
Таблица 1. Результаты выбора RDO лучшего CPMV с использованием пространственных кандидатов по JEM 4.0

Таблица 2. Результаты выбора RDO лучшего CPMV с использованием пространственных, временных, средних и затем однонаправленных средних кандидатов по JEM 4.0

[135] Фиг. 26 иллюстрирует блок-схему примерной системы 2600, в которой могут быть реализованы различные аспекты примерных вариантов осуществления. Система 2600 может быть воплощена как устройство, включающее в себя различные компоненты, описанные ниже, и сконфигурирована, чтобы выполнять процессы, описанные выше. Примеры таких устройств включают в себя, но без ограничения, персональные компьютеры, ноутбуки, смартфоны, планшеты, цифровые мультимедийные телевизионные приставки, цифровые телевизионные приемники, персональные системы видео записи, подсоединенные бытовые электронные приборы и серверы. Система 2600 может быть коммуникативно связана с другими аналогичными системами и с дисплеем посредством канала связи, как показано на фиг. 26 и известно специалистам в данной области техники для реализации всех или части примерных систем видео, описанных выше.
[136] Различные варианты осуществления системы 2600 включают в себя по меньшей мере один процессор 2610, сконфигурированный, чтобы исполнять инструкции, загруженные в него для реализации различных процессов, как обсуждалось выше. Процессор 2610 может включать в себя встроенную память, интерфейс ввода/вывода и различные другие схемы, как известно в данной области техники. Система 2600 может также включать в себя по меньшей мере одну память 2620 (например, устройство энергозависимой памяти, устройство энергонезависимой памяти). Система 2600 может дополнительно включать в себя устройство 2640 хранения, которое может включать в себя энергонезависимую память, включая, но без ограничения, EEPROM, ROM, PROM, RAM, DRAM, SRAM, флэш-память, накопитель на магнитном диске и/или накопитель на оптическом диске. Устройство 2640 хранения может содержать внутреннее устройство хранения, присоединенное устройство хранения и/или доступное через сеть устройство хранения, в качестве неограничивающих примеров. Система 2600 может также включать в себя модуль 2630 кодера/декодера, сконфигурированный, чтобы обрабатывать данные для обеспечения закодированного видео и/или декодированного видео, и модуль 2630 кодера/декодера может включать в себя свои собственные процессор и память.
[137] Модуль 2630 кодера/декодера представляет модуль(и), который может быть включен в устройство для выполнения функций кодирования и/или декодирования. Как известно, такое устройство может включать в себя один или оба из модулей кодирования и декодирования. Дополнительно, модуль 2630 кодера/декодера может быть реализован как отдельный элемент системы 2600 или может быть встроен в один или несколько процессоров 2610 в качестве комбинации аппаратных средств и программного обеспечения, как известно специалистам в данной области техники.
[138] Программный код, подлежащий загрузке на один или несколько процессоров 2610 для выполнения различных процессов, описанных здесь выше, может храниться в устройстве 2640 хранения и затем загружаться на память 2620 для исполнения процессорами 2610. В соответствии с примерными вариантами осуществления, одно или несколько из процессора(ов) 2610, памяти 2620, устройства 2640 хранения и модуля 2630 кодера/декодера может хранить один или несколько различных элементов во время выполнения вышеописанных процессов, включая, но без ограничения, входное видео, декодированное видео, битовый поток, уравнения, формулы, матрицы, переменные, операции и операционную логику.
[139] Система 2600 может также включать в себя интерфейс 2650 связи, который обеспечивает возможность связи с другими устройствами посредством канала 2660 связи. Интерфейс 2650 связи может включать в себя, но без ограничения, приемопередатчик, сконфигурированный, чтобы передавать и принимать данные из канала 2660 связи. Интерфейс 2650 связи может включать в себя, но без ограничения, модем или сетевую карту и канал 2650 связи может быть реализован в проводной и/или беспроводной среде. Различные компоненты системы 2600 могут быть соединены или коммуникативно связаны вместе (не показано на фиг. 26) с использованием различных подходящих соединений, включая, но без ограничения, внутренние шины, провода и печатные платы.
[140] Примерные варианты осуществления могут выполняться посредством компьютерного программного обеспечения, реализуемого процессором 2610 или аппаратными средствами или посредством комбинации аппаратных средств и программного обеспечения. В качестве неограничивающего примера, примерные варианты осуществления могут быть реализованы одной или несколькими интегральными схемами. Память 2620 может быть любого типа, подходящего для технической среды, и может быть реализована с использованием любой подходящей технологии хранения данных, такой как оптические устройства памяти, магнитные устройства памяти, устройства памяти на полупроводниковой основе, фиксированная память и съемная память, в качестве неограничивающих примеров. Процессор 2610 может быть любого типа, подходящего для технической среды, и может включать в себя один или несколько микропроцессоров, универсальных компьютеров, специализированных компьютеров и процессоров на основе многоядерной архитектуры, в качестве неограничивающих примеров.
[141] Реализации, описанные здесь, могут быть осуществлены, например, в способе или процессе, устройстве, программе программного обеспечения, потоке данных или сигнале. Даже если обсуждается только в контексте одной формы реализации (например, обсуждается только как способ), реализация обсуждаемых признаков может также быть осуществлена в других формах (например, устройстве или программе). Устройство может быть реализовано, например, в подходящих аппаратных средствах, программном обеспечении и прошивке. Способы могут быть реализованы, например, в устройстве, таком как, например, процессор, который относится к устройствам обработки в общем, включая, например, компьютер, микропроцессор, интегральную схему или программируемое логическое устройство. Процессоры также включают в себя устройства связи, такие как, например, компьютеры, сотовые телефоны, портативные/персональные цифровые ассистенты (“PDA”) и другие устройства, которые облегчают обмен информацией между конечными пользователями.
[142] Более того, специалист в данной области техники может с легкостью понять, что примерный кодер 100 HEVC, показанный на фиг. 1, и примерный декодер HEVC, показанный на фиг. 3, могут быть модифицированы в соответствии с вышеописанными решениями настоящего раскрытия, чтобы реализовать раскрытые усовершенствования существующих стандартов HEVC для достижения лучшего сжатия/декомпрессии. Например, энтропийное кодирование 145, компенсация 170 движения и оценка 175 движения в примерном кодере 100 согласно фиг. 1 и энтропийное декодирование 330 и компенсация 375 движения в примерном декодере согласно фиг. 3 могут быть модифицированы в соответствии с раскрытыми решениями для реализации одного или нескольких примерных аспектов настоящего раскрытия, включая обеспечение улучшенного предсказания аффинного объединения для существующей JEM.
[143] Ссылка на “один вариант осуществления” или “вариант осуществления”, или “одну реализацию”, или “реализацию”, а также другие их вариации означает, что конкретный признак, структура, характеристика и так далее, описанные в связи с вариантом осуществления, включены по меньшей мере в один вариант осуществления. Таким образом, фраза “в одном варианте осуществления” или “в варианте осуществления”, или “в одной реализации”, или “в реализации”, а также любые другие вариации, появляющиеся в различных местах в спецификации, не обязательно все ссылаются на один и тот же вариант осуществления.
[144] Дополнительно, настоящая заявка или ее формула изобретения могут ссылаться на “определение” различных частей информации. Определение информации может включать в себя одно или несколько из, например, оценивания информации, вычисления информации, предсказания информации или извлечения информации из памяти.
[145] Дополнительно, настоящая заявка или ее формула изобретения могут ссылаться на “доступ к” различным частям информации. Доступ к информации может включать в себя одно или несколько из, например, приема информации, извлечения информации (например, из памяти), сохранения информации, обработки информации, передачи информации, перемещения информации, копирования информации, стирания информации, вычисления информации, определения информация, предсказания информации или оценивания информации.
[146] Дополнительно, настоящая заявка или ее формула изобретения могут ссылаться на “прием” различных частей информации. Прием, как и “доступ”, интерпретируется как широкий термин. Прием информации может включать в себя одно или несколько из, например, доступа к информации или извлечения информации (например, из памяти). Дополнительно, “прием” обычно используется, тем или иным образом, во время операций, таких как, например, сохранение информации, обработка информации, передача информации, перемещение информации, копирование информации, стирание информации, вычисление информации, определение информации, предсказание информации или оценивание информации.
[0147] Как будет очевидно специалисту в данной области техники, реализации могут формировать различные сигналы, отформатированные, чтобы переносить информацию, которая может, например, сохраняться или передаваться. Информация может включать в себя, например, инструкции для выполнения способа или данные, сформированные одной из описанных реализаций. Например, сигнал может быть отформатирован, чтобы переносить битовый поток описанного варианта осуществления. Такой сигнал может быть отформатирован, например, как электромагнитная волна (например, с использованием радиочастотного участка спектра) или как сигнал основной полосы. Форматирование может включать в себя, например, кодирование потока данных и модуляцию несущей закодированным потоком данных. Информация, которую переносит сигнал, может представлять собой, например, аналоговую или цифровую информацию. Сигнал может передаваться по самым различным проводным или беспроводным линиям связи, как известно. Сигнал может сохраняться на считываемом процессором носителе.
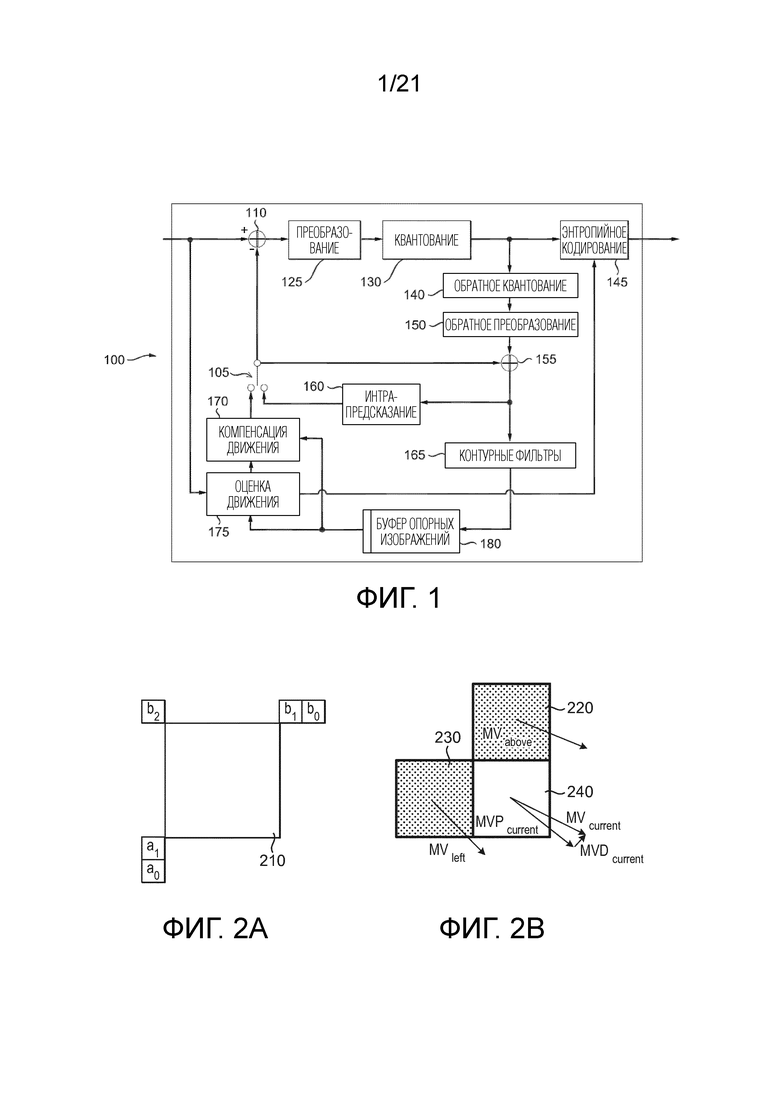
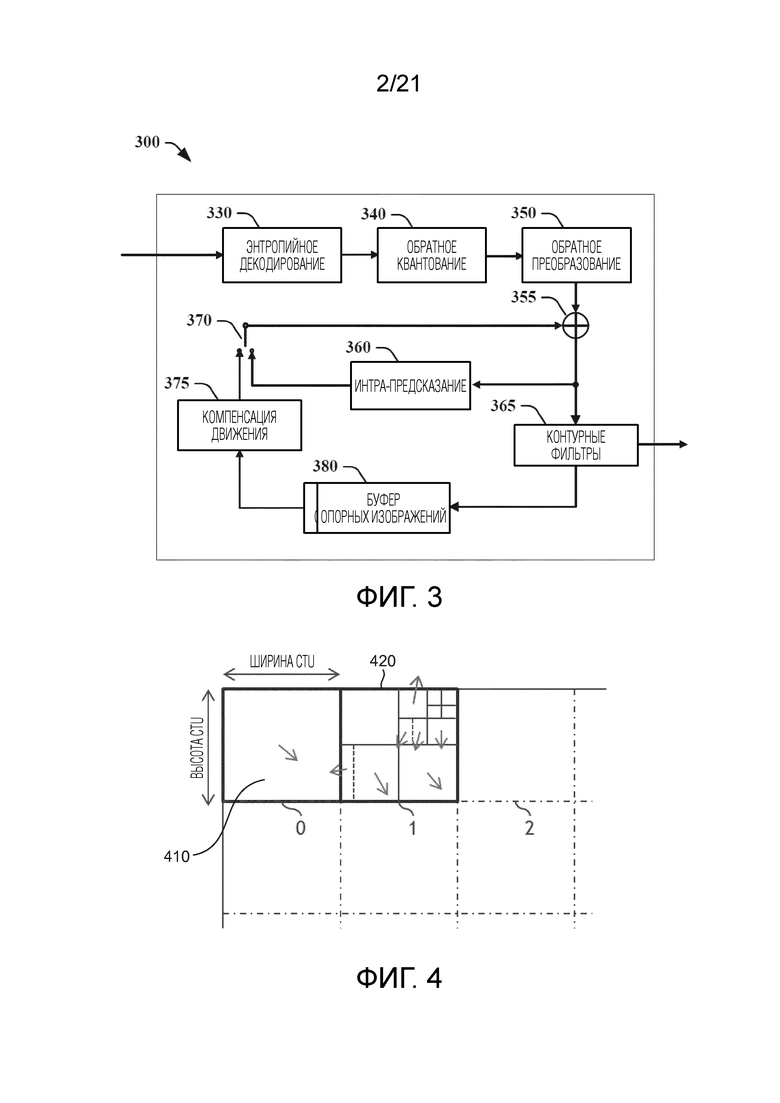
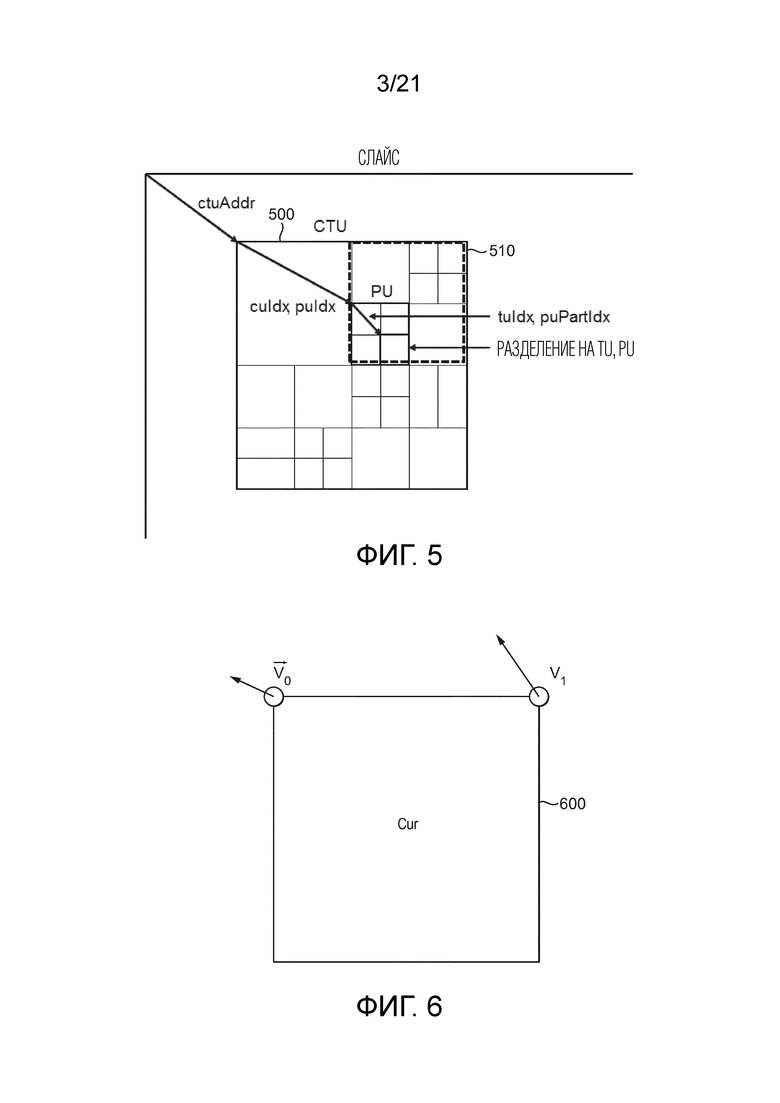
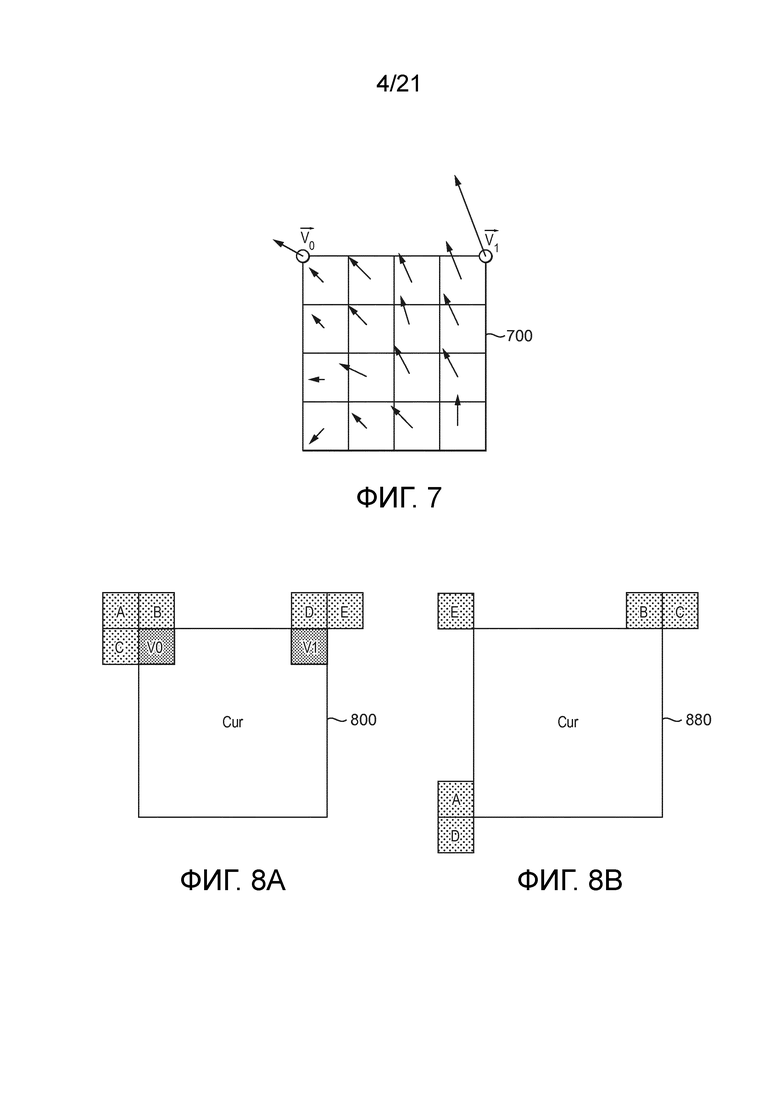
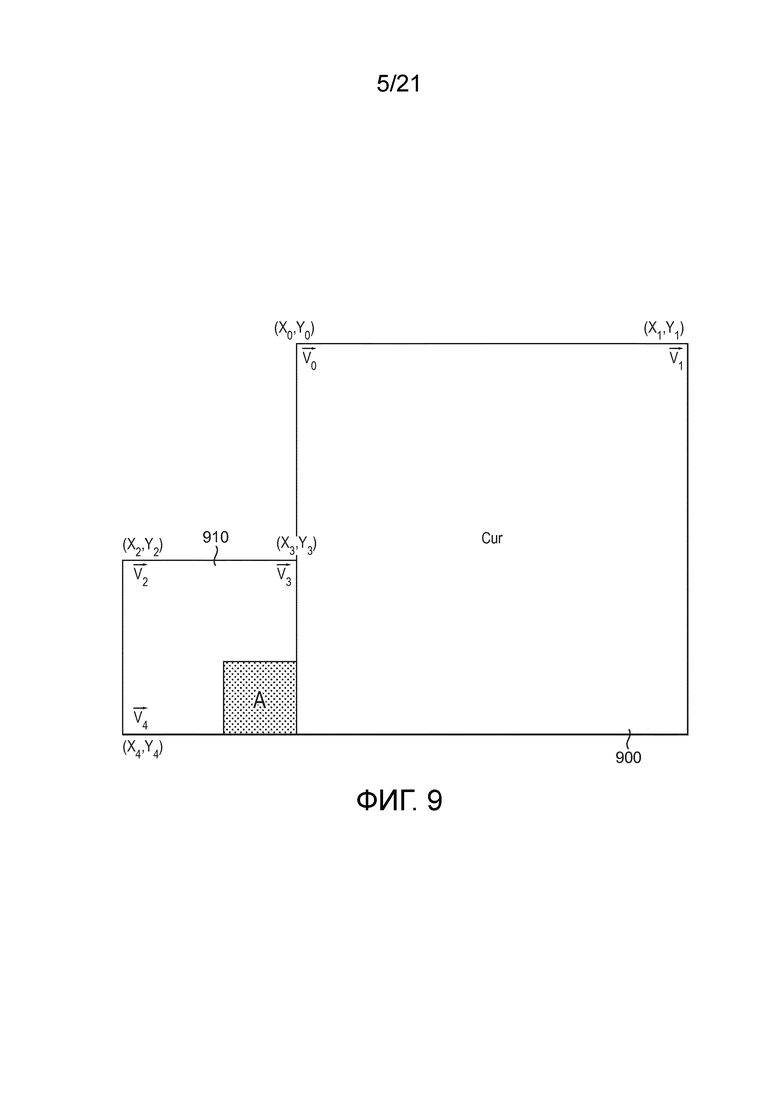
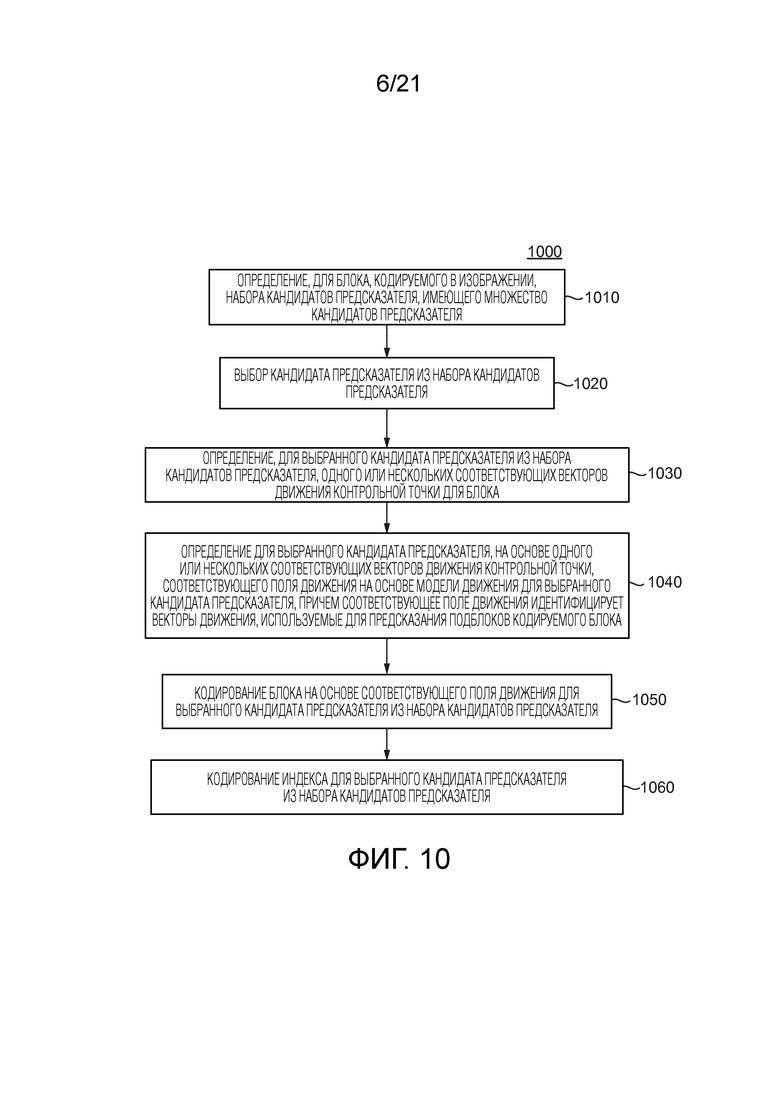
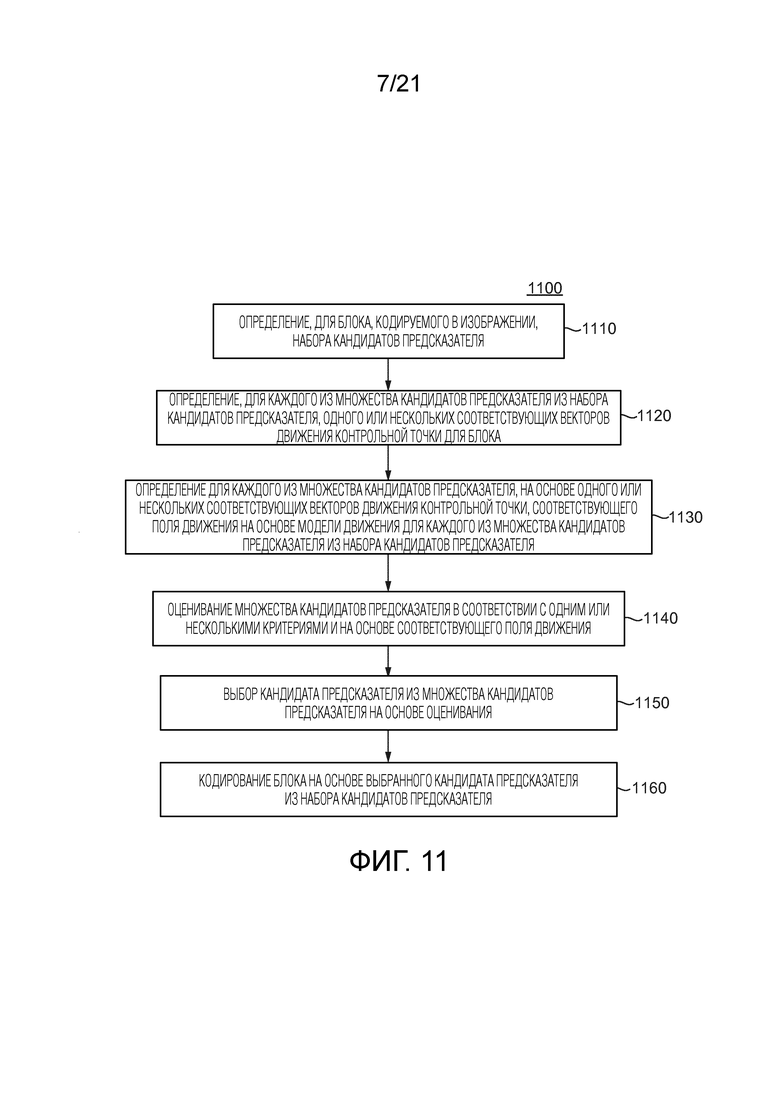
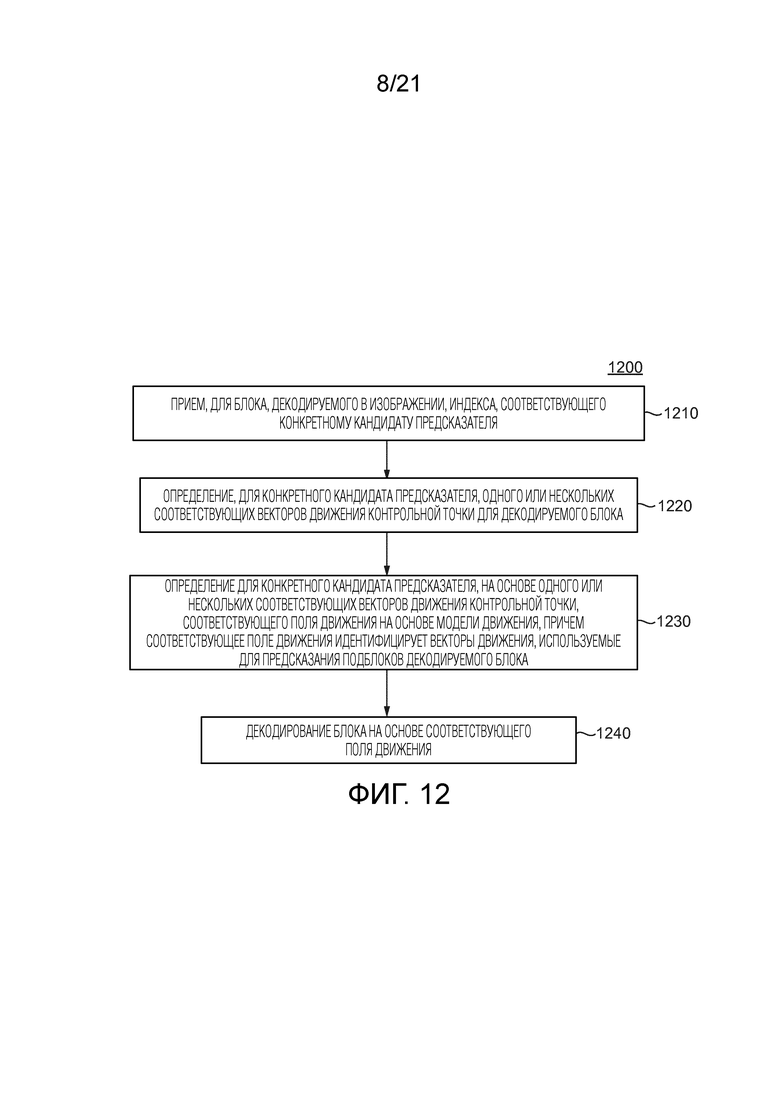
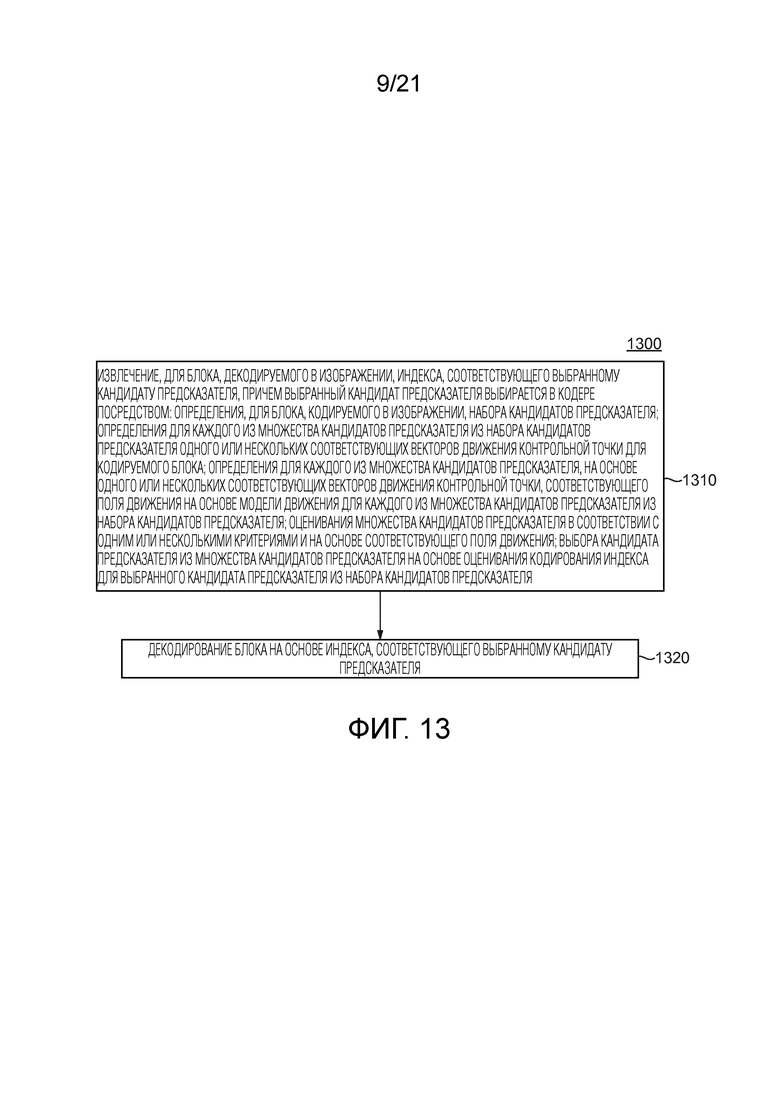
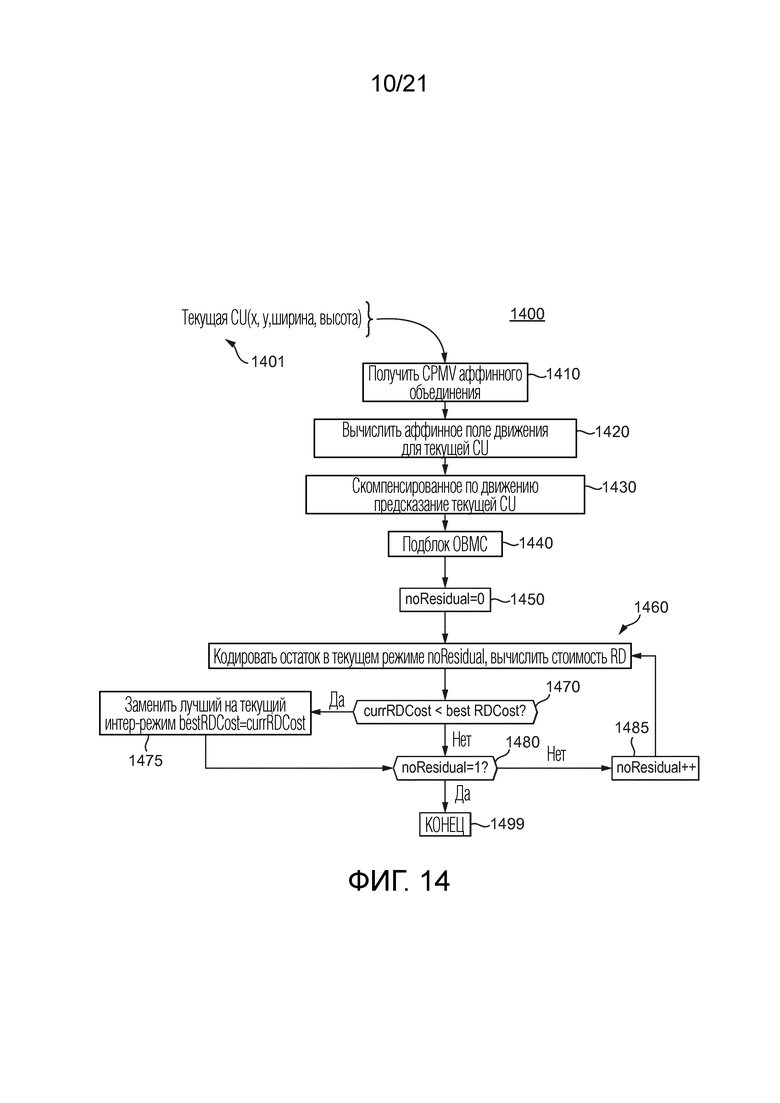
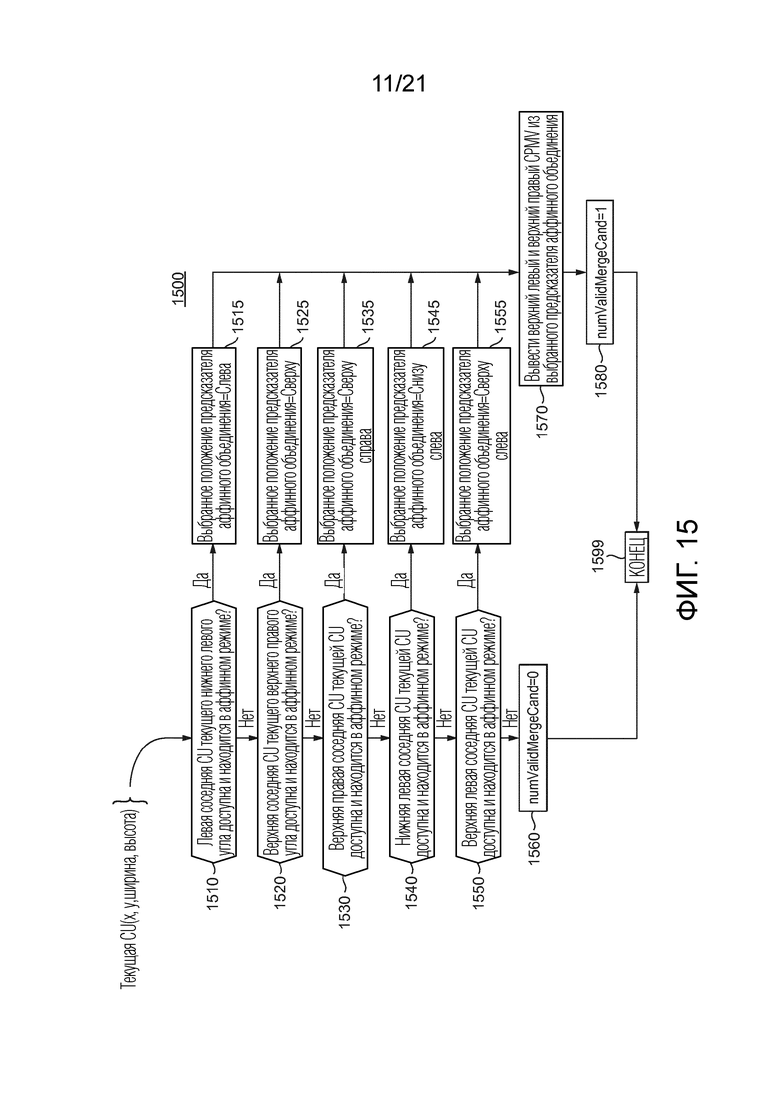
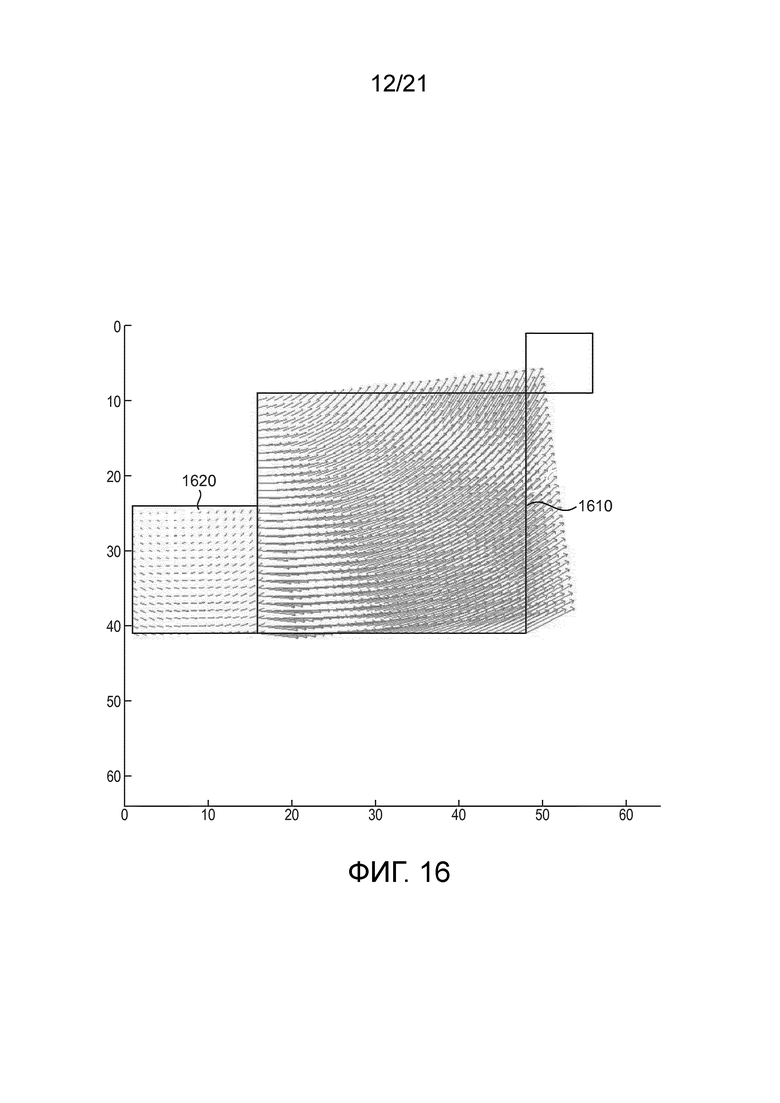
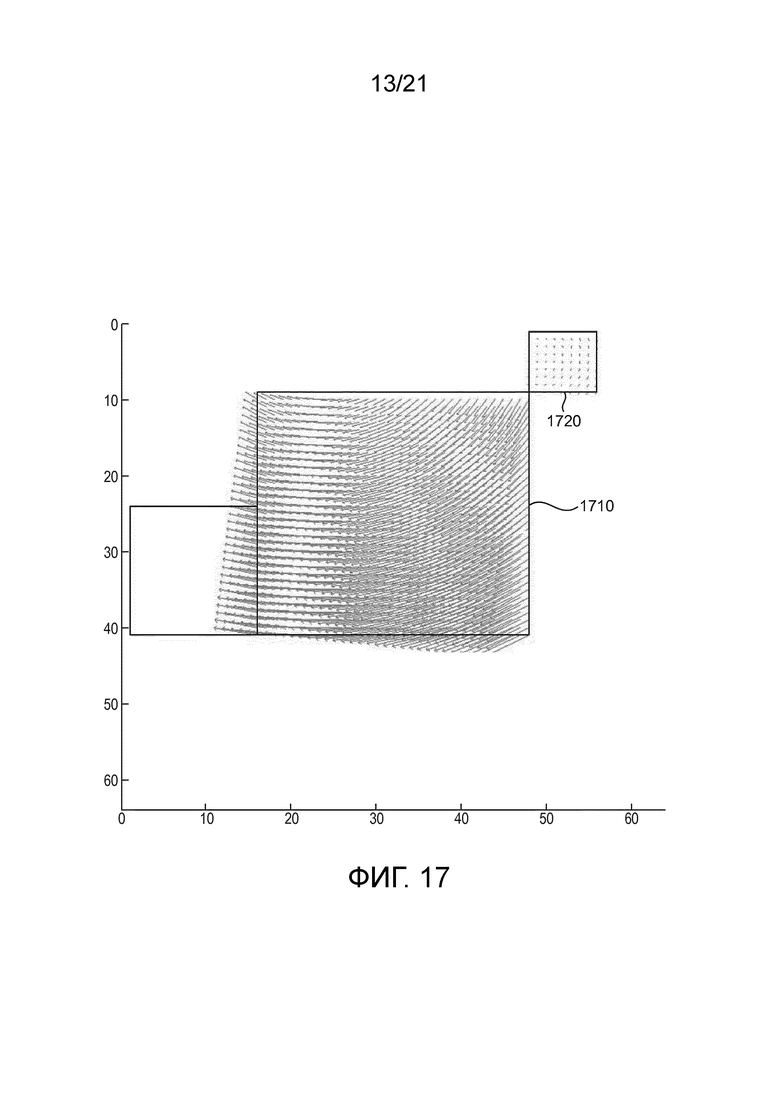
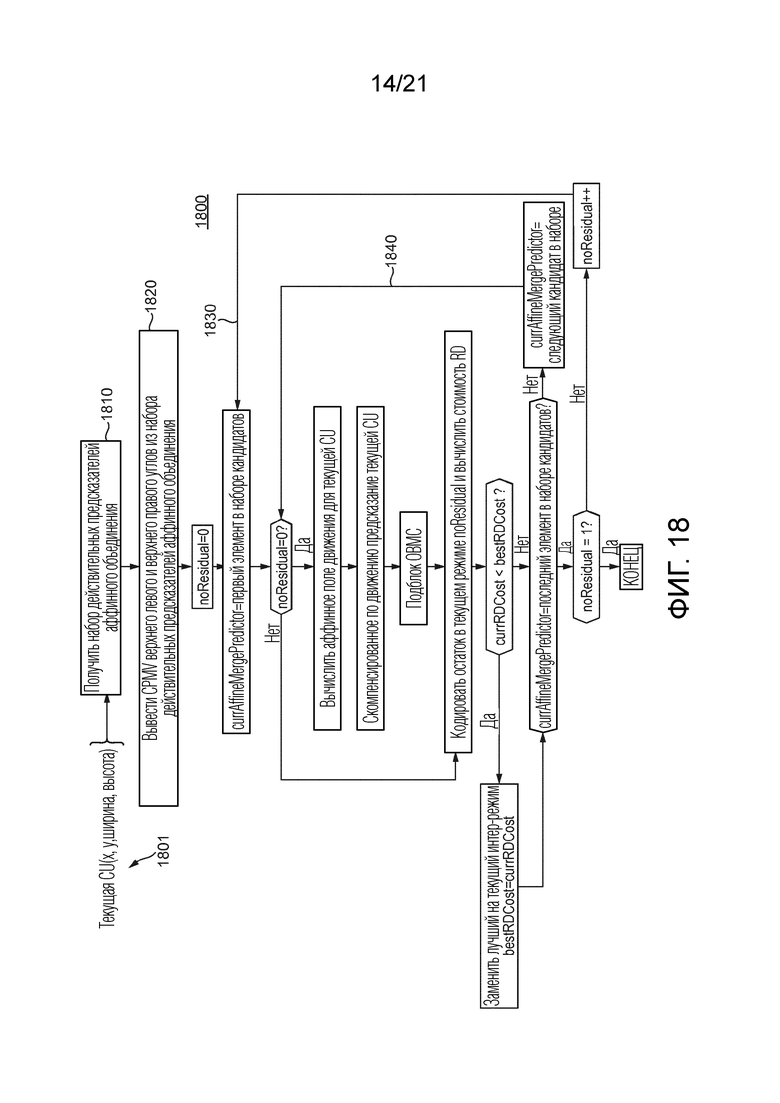
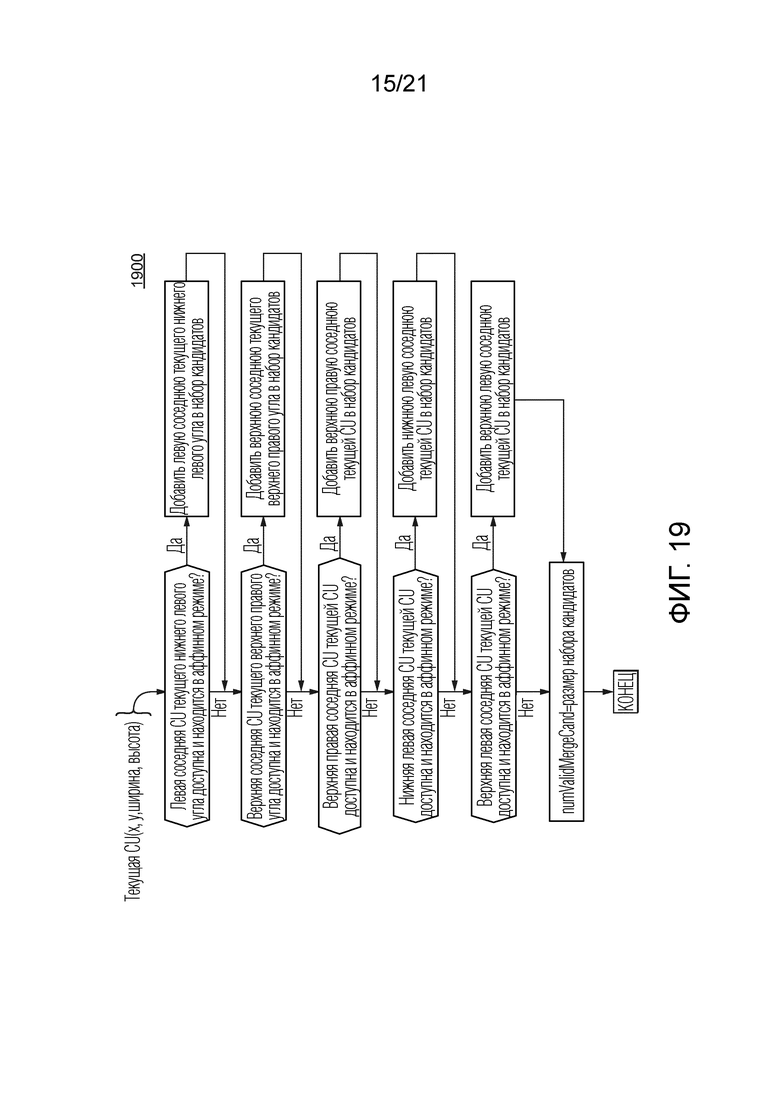
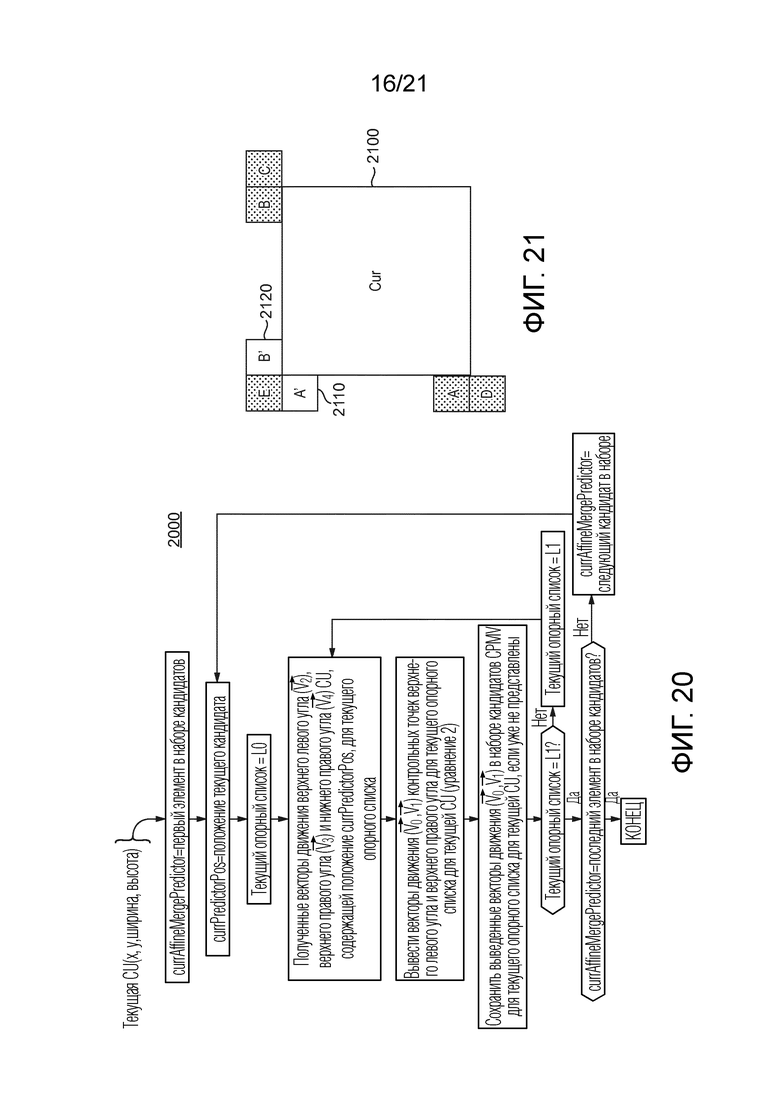
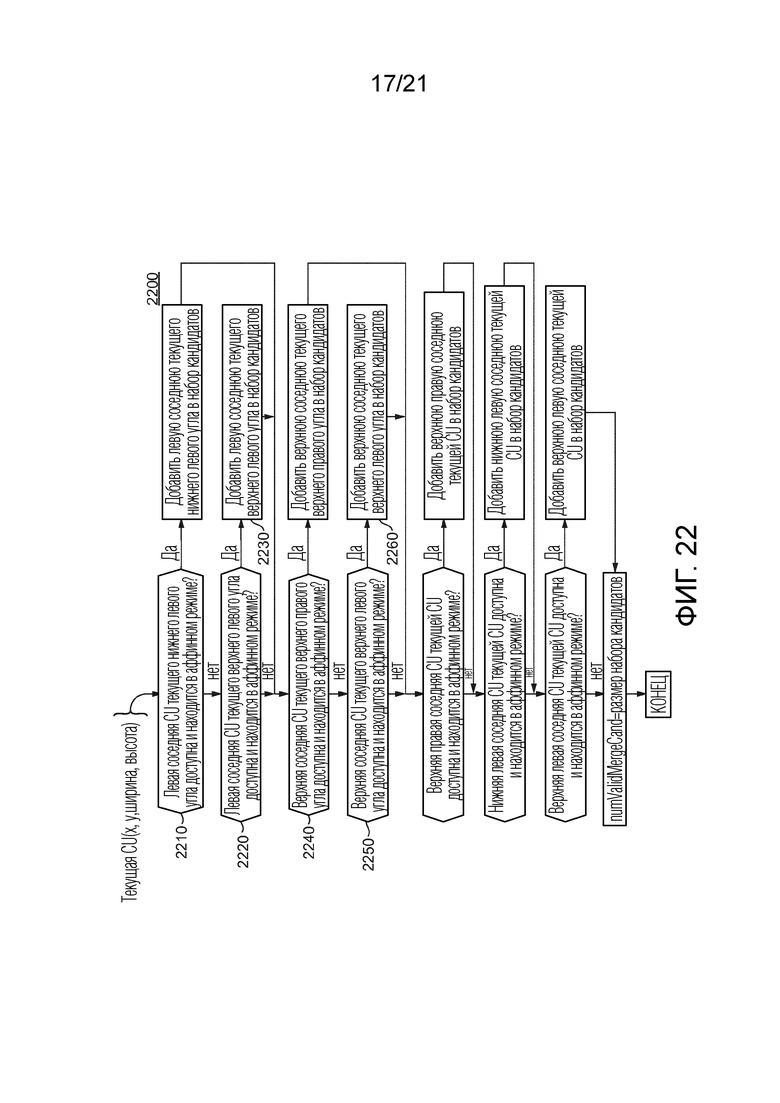
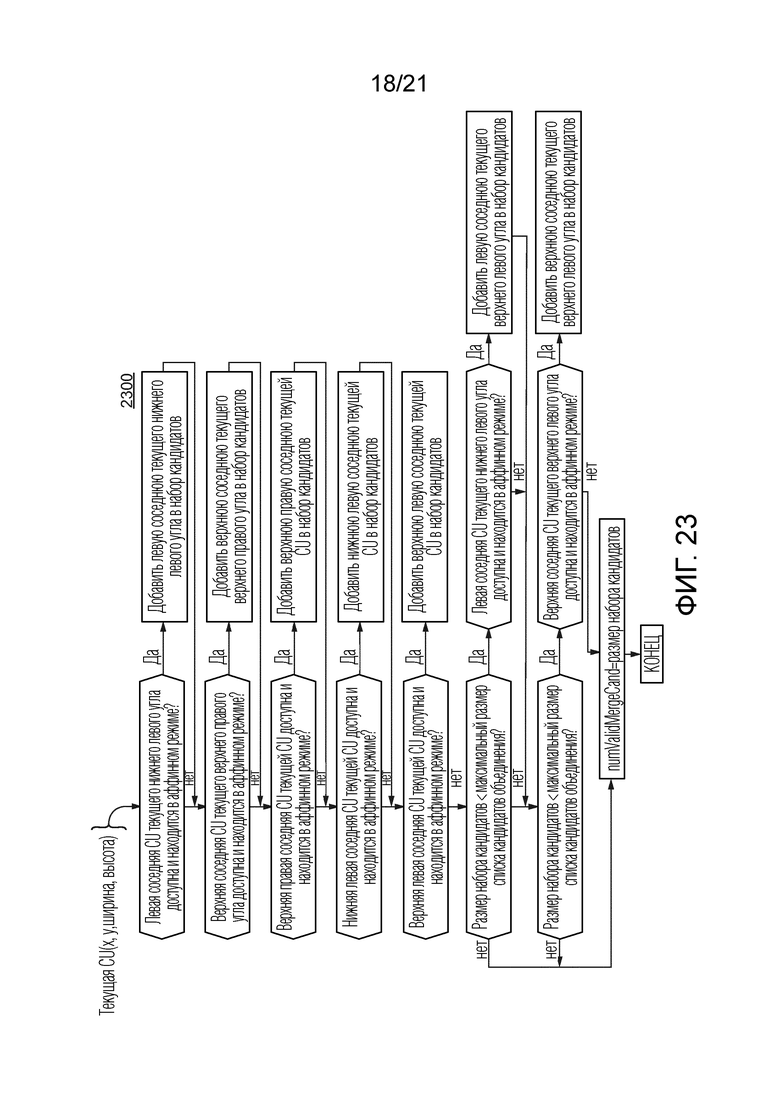
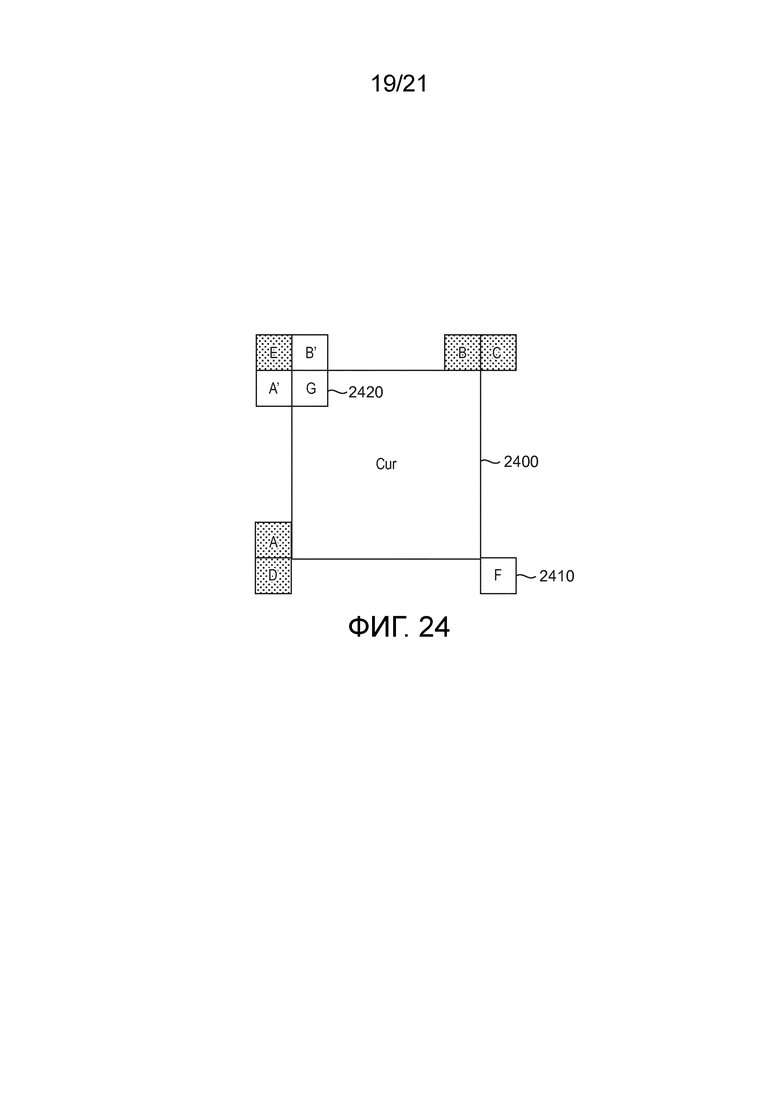
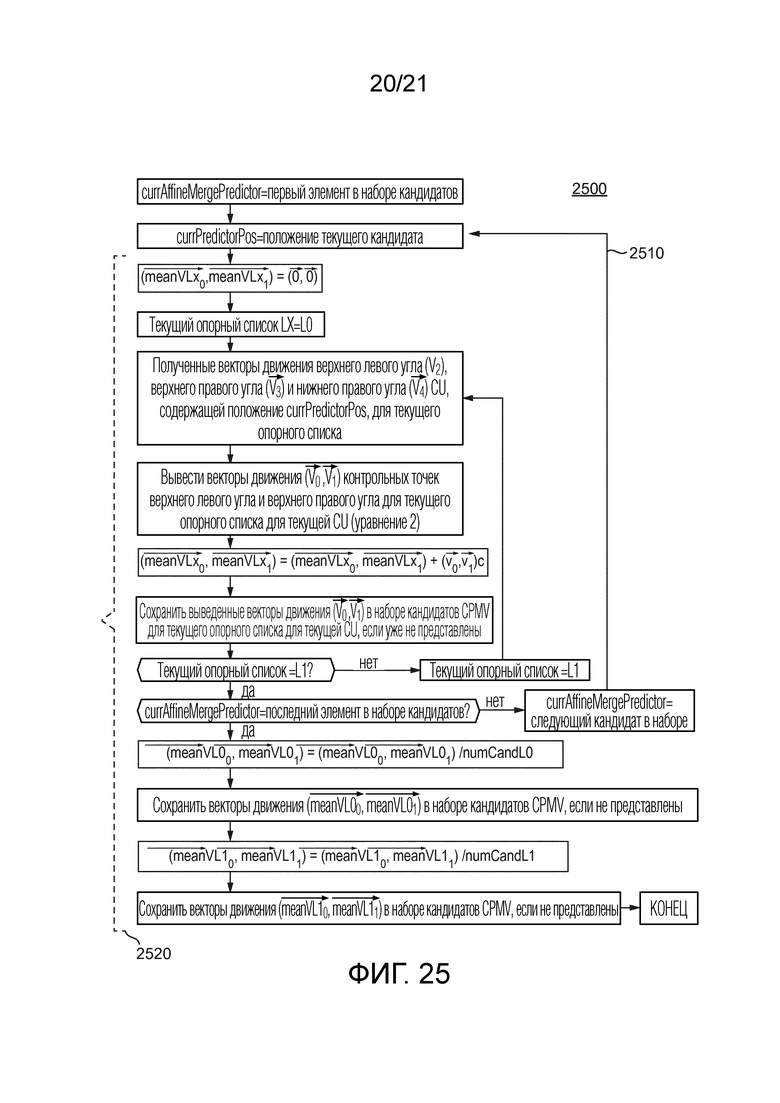
Изобретение относится к средствам для кодирования и декодирования видео. Технический результат заключается в повышении эффективности кодирования. Осуществляют доступ к набору кандидатов предсказателя, причем кандидат предсказателя соответствует пространственному или временному соседнему блоку, который был закодирован. Выбирают кандидата предсказателя из набора кандидатов предсказателя. Осуществляют доступ к набору векторов движения контрольной точки, сохраняемому для упомянутого выбранного кандидата предсказателя. При этом набор векторов движения контрольной точки сохраняется отдельно от векторов движения всех подблоков упомянутого выбранного кандидата предсказателя. При этом упомянутые векторы движения всех подблоков упомянутого выбранного кандидата предсказателя получены с использованием упомянутого набора векторов движения контрольной точки для упомянутого выбранного кандидата предсказателя на основе аффинной модели движения. При этом упомянутые векторы движения всех подблоков упомянутого выбранного кандидата предсказателя предназначены для компенсации движения упомянутого выбранного кандидата предсказателя. 4 н. и 12 з.п. ф-лы, 28 ил., 2 табл.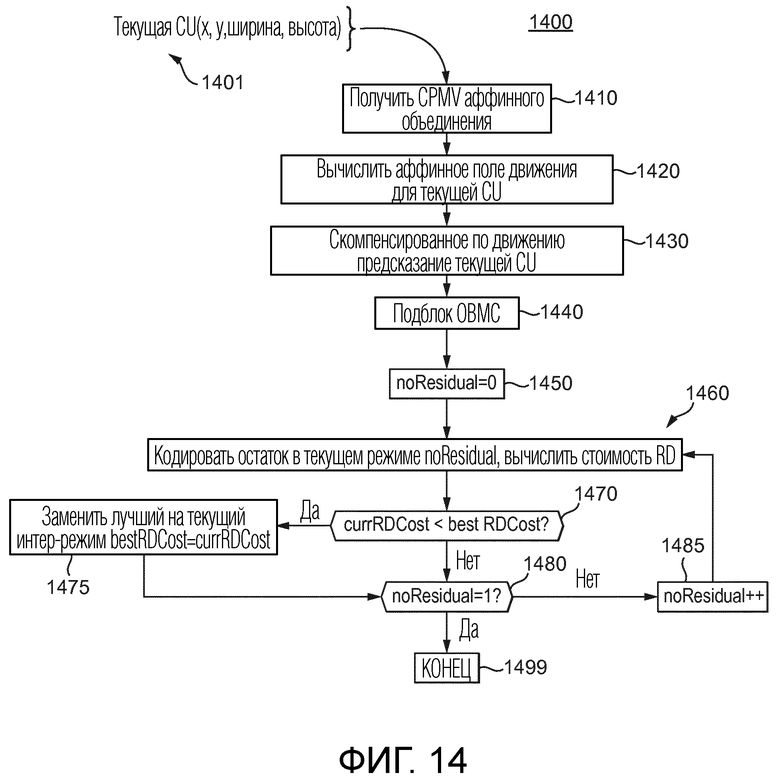
1. Способ для кодирования видео, содержащий:
осуществление доступа, для блока, кодируемого в изображении, к набору кандидатов предсказателя, имеющему множество кандидатов предсказателя, причем кандидат предсказателя соответствует пространственному или временному соседнему блоку, который был закодирован;
выбор кандидата предсказателя из набора кандидатов предсказателя;
осуществление доступа к набору векторов движения контрольной точки, сохраняемому для упомянутого выбранного кандидата предсказателя, при этом упомянутый набор векторов движения контрольной точки для упомянутого выбранного кандидата предсказателя сохраняется отдельно от векторов движения всех подблоков упомянутого выбранного кандидата предсказателя, при этом упомянутые векторы движения всех подблоков упомянутого выбранного кандидата предсказателя получены с использованием упомянутого набора векторов движения контрольной точки для упомянутого выбранного кандидата предсказателя на основе аффинной модели движения, и при этом упомянутые векторы движения всех подблоков упомянутого выбранного кандидата предсказателя предназначены для компенсации движения упомянутого выбранного кандидата предсказателя;
получение, с использованием упомянутого набора векторов движения контрольной точки для выбранного кандидата предсказателя, к которому осуществлен доступ, набора векторов движения контрольной точки для блока;
получение, на основе набора векторов движения контрольной точки для упомянутого блока, поля движения упомянутого блока на основе упомянутой аффинной модели движения, причем поле движения для упомянутого блока идентифицирует векторы движения, используемые для предсказания всех подблоков кодируемого блока, при этом упомянутый набор векторов движения контрольной точки для упомянутого блока сохраняется отдельно от упомянутых векторов движения упомянутого поля движения для упомянутого блока;
кодирование блока на основе поля движения для упомянутого блока; и
кодирование индекса для выбранного кандидата предсказателя из набора кандидатов предсказателя.
2. Способ по п. 1, причем упомянутый блок имеет размер 4 по ширине или высоте.
3. Способ по п. 1, причем упомянутый блок кодируется в режиме аффинного объединения.
4. Способ по п. 1, причем сохраненные векторы движения поля движения предназначены для компенсации движения блока.
5. Способ для декодирования видео, содержащий:
осуществление доступа, для блока, декодируемого в изображении, к индексу, соответствующему кандидату предсказателя из множества кандидатов предсказателя, при этом кандидат предсказателя соответствует пространственному или временному соседнему блоку, который был декодирован;
осуществление доступа к набору векторов движения контрольной точки, сохраненному для упомянутого выбранного кандидата предсказателя, при этом упомянутый набор векторов движения контрольной точки для упомянутого выбранного кандидата предсказателя сохраняется отдельно от векторов движения всех подблоков упомянутого выбранного кандидата предсказателя, при этом упомянутые векторы движения всех подблоков упомянутого выбранного кандидата предсказателя получают с использованием упомянутого набора векторов движения контрольной точки для упомянутого выбранного кандидата предсказателя на основе аффинной модели движения, и при этом упомянутые векторы движения всех подблоков упомянутого выбранного кандидата предсказателя предназначены для компенсации движения упомянутого выбранного кандидата предсказателя;
получение, с использованием упомянутого набора векторов движения контрольной точки для кандидата предсказателя, к которому осуществлен доступ, набора векторов движения контрольной точки для декодируемого блока;
получение, на основе набора векторов движения контрольной точки для упомянутого блока, поля движения для упомянутого блока на основе аффинной модели движения, причем поле движения для упомянутого блока идентифицирует векторы движения, используемые для предсказания всех подблоков декодируемого блока, при этом упомянутый набор векторов движения контрольной точки для упомянутого блока сохраняется отдельно от упомянутых векторов движения упомянутого поля движения для упомянутого блока; и
декодирование блока на основе поля движения.
6. Способ по п. 5, причем упомянутый блок имеет размер 4 по ширине или высоте.
7. Способ по п. 5, причем упомянутый блок декодируется в режиме аффинного объединения.
8. Способ по п. 5, причем сохраненные векторы движения поля движения предназначены для компенсации движения блока.
9. Устройство для кодирования видео, содержащее:
один или несколько процессоров, причем упомянутые один или несколько процессоров сконфигурированы, чтобы:
осуществлять доступ, для блока, кодируемого в изображении, к набору кандидатов предсказателя, имеющему множество кандидатов предсказателя, причем кандидат предсказателя соответствует пространственному или временному соседнему блоку, который был закодирован;
выбирать кандидат предсказателя из набора кандидатов предсказателя;
осуществлять доступ к набору векторов движения контрольной точки, сохраненному для упомянутого выбранного кандидата предсказателя, при этом упомянутый набор векторов движения контрольной точки для упомянутого выбранного кандидата предсказателя сохранен отдельно от векторов движения всех подблоков упомянутого выбранного кандидата предсказателя, при этом упомянутые векторы движения всех подблоков упомянутого выбранного кандидата предсказателя получены с использованием упомянутого набора векторов движения контрольной точки для упомянутого выбранного кандидата предсказателя на основе аффинной модели движения, и при этом упомянутые векторы движения всех подблоков упомянутого выбранного кандидата предсказателя предназначены для компенсации движения упомянутого выбранного кандидата предсказателя;
получать, с использованием упомянутого набора векторов движения контрольной точки для выбранного кандидата предсказателя из набора кандидатов предсказателя, к которому осуществлен доступ, набор векторов движения контрольной точки для блока;
получать, на основе набора векторов движения контрольной точки для упомянутого блока, поле движения упомянутого блока на основе упомянутой аффинной модели движения, причем поле движения для упомянутого блока идентифицирует векторы движения, используемые для предсказания всех подблоков кодируемого блока, при этом упомянутый набор векторов движения контрольной точки для упомянутого блока сохраняется отдельно от упомянутых векторов движения упомянутого поля движения для упомянутого блока;
кодировать блок на основе поля движения для упомянутого блока; и
кодировать индекс для выбранного кандидата предсказателя из набора кандидатов предсказателя.
10. Устройство по п. 9, причем упомянутый блок имеет размер 4 по ширине или высоте.
11. Устройство по п. 9, причем упомянутый блок кодируется в режиме аффинного объединения.
12. Устройство по п. 9, причем сохраненные векторы движения поля движения предназначены для компенсации движения блока.
13. Устройство для декодирования видео, содержащее:
один или несколько процессоров, причем один или несколько процессоров сконфигурированы, чтобы:
осуществлять доступ, для блока, декодируемого в изображении, к индексу, соответствующему кандидату предсказателя из множества кандидатов предсказателя, причем кандидат предсказателя соответствует пространственному или временному соседнему блоку, который был декодирован;
осуществлять доступ к набору векторов движения контрольной точки, сохраненному для упомянутого выбранного кандидата предсказателя, при этом упомянутый набор векторов движения контрольной точки для упомянутого выбранного кандидата предсказателя сохраняется отдельно от векторов движения всех подблоков упомянутого выбранного кандидата предсказателя, при этом упомянутые векторы движения всех подблоков упомянутого выбранного кандидата предсказателя получают с использованием упомянутого набора векторов движения контрольной точки для упомянутого выбранного кандидата предсказателя на основе аффинной модели движения, и при этом упомянутые векторы движения всех подблоков упомянутого выбранного кандидата предсказателя предназначены для компенсации движения упомянутого выбранного кандидата предсказателя;
получать, с использованием упомянутого набора векторов движения контрольной точки для кандидата предсказателя, к которому осуществлен доступ, набор векторов движения контрольной точки для декодируемого блока;
получать, на основе набора векторов движения контрольной точки для упомянутого блока, поле движения для упомянутого блока на основе упомянутой аффинной модели движения, причем поле движения для упомянутого блока идентифицирует векторы движения, используемые для предсказания всех подблоков декодируемого блока, при этом упомянутый набор векторов движения контрольной точки для упомянутого блока сохраняется отдельно от упомянутых векторов движения упомянутого поля движения для упомянутого блока; и
декодировать блок на основе поля движения.
14. Устройство по п. 13, причем упомянутый блок имеет размер 4 по ширине или высоте.
15. Устройство по п. 13, причем упомянутый блок декодируется в режиме аффинного объединения.
16. Устройство по п. 13, причем сохраненные векторы движения поля движения предназначены для компенсации движения блока.
| HAN HUANG et al., "Affine SKIP and DIRECT modes for efficient video coding", VISUAL COMMUNICATIONS AND IMAGE PROCESSING (VCIP), опубл | |||
| Печь для сжигания твердых и жидких нечистот | 1920 |
|
SU17A1 |
| Автомобиль-сани, движущиеся на полозьях посредством устанавливающихся по высоте колес с шинами | 1924 |
|
SU2017A1 |
| Способ подготовки стальных резервуаров под эмалирование | 1987 |
|
SU1528812A1 |
| US 7567617 B2, 28.09.2009 | |||
| DE 69623342 T2, 17.04.2003 | |||
| СМАЗЫВАЮЩИЙ СТЕРЖЕНЬ | 2010 |
|
RU2466894C2 |
| СПОСОБ АВТОМАТИЧЕСКОГО ИЗВЛЕЧЕНИЯ ИНДЕКСОВ КЛЮЧЕВЫХ КАДРОВ ДЛЯ РАСШИРЕНИЯ ВИДЕОДАННЫХ | 2014 |
|
RU2577486C2 |

