ОБЛАСТЬ ТЕХНИКИ
Настоящее техническое решение относится к области вычислительной техники, в частности к способам распознавания видеопотока и обнаружения объектов.
УРОВЕНЬ ТЕХНИКИ
Из уровня техники известно решение, выбранное в качестве наиболее близкого аналога RU 2484529 (C1), опубл. 10.06.2013. В данном решении раскрыт способ ранжирования видеоданных, включающий получение видеоданных с, по крайней мере, одной видеокамеры или сенсора и передачу отсортированных видеоданных по каналам связи, по крайней мере, одному пользователю и/или, по крайней мере, в одно хранилище, характеризующийся тем, что вначале из полученных исходных видеоданных выделяют фрагменты, соответствующие, по крайней мере, одному объекту и/или событию, затем вычисляют признаки каждого фрагмента, которые влияют на оценку приоритета фрагмента и/или используются при поиске фрагментов в хранилище, далее оценивают приоритет каждого фрагмента с учетом его признаков, потом сортируют фрагменты в соответствии с приоритетом каждого из них и передают по каналам связи, по крайней мере, одному пользователю и/или, по крайней мере, в одно хранилище полученную приоритетную очередь фрагментов или один фрагмент с наибольшим приоритетом.
Приведенное выше известное из уровня техники решение направлено на решение проблемы видеоаналитики.
Предлагаемое решение направлено на устранение недостатков современного уровня техники и отличается от известных ранее тем, что предложенное решение не требует дополнительных вычислительных ресурсов и времени на обучение каждого детектора при использовании много детекторного подхода для обнаружения разных комбинаций объектов.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
Технической проблемой, на решение которой направлено заявленное решение, является создание способа распознавания видеопотока и обнаружения объектов.
Технический результат заключается в повышении качества и эффективности распознавания видеопотока и обнаружения объектов.
Дополнительным техническим результатом является увеличение производительности вычислительной системы/сервера при решении поставленной задачи (т.е. позволяет производить обработку с получением результата (продукта) за меньшее количество времени), тем самым снижая нагрузку на центральные процессоры вычислительных устройств, за счет уменьшения количества обрабатываемых запросов.
Заявленные результаты достигаются за счет осуществления способа распознавания видеопотока и обнаружения объектов содержащего этапы, на которых:
с видеокамеры, располагаемой на системе видеонаблюдения, осуществляют трансляцию видеопотока на сервер;
модуль подготовки изображения, с использованием вычислительных мощностей сервера, осуществляет обработку видеопотока, полученного от видеокамеры и подготовку изображений для последующей обработки детектором;
детектор, с использованием вычислительных мощностей сервера, осуществляет, слоями извлечения признаков объектов «Backbone», единых для всех обнаруживаемых N комбинаций объектов, формирование карты признаков объектов, которая поступает N число нейронных сетей «Head», архитектурно зависимых от вида сети «Backbone, которая осуществляет предсказание охватывающей рамки на основе обработки карты признаков и классификацию объектов для каждой отдельно взятой комбинации детектируемых объектов;
на выходе из детектора, с использованием вычислительных мощностей сервера, формируются параметры охватывающие рамки и класс объекта, которые направляются в модуль формирования отчетов по каждой комбинации объектов обнаружения.
ОПИСАНИЕ ЧЕРТЕЖЕЙ
Реализация изобретения будет описана в дальнейшем в соответствии с прилагаемыми чертежами, которые представлены для пояснения сути изобретения и никоим образом не ограничивают область изобретения. К заявке прилагаются следующие чертежи:
Фиг. 1 иллюстрирует схему обучения и организации работы решения для детектирования с 4-х комбинаций объектов.
Фиг. 2 иллюстрирует архитектору детекторов с выделением Backbone и Head.
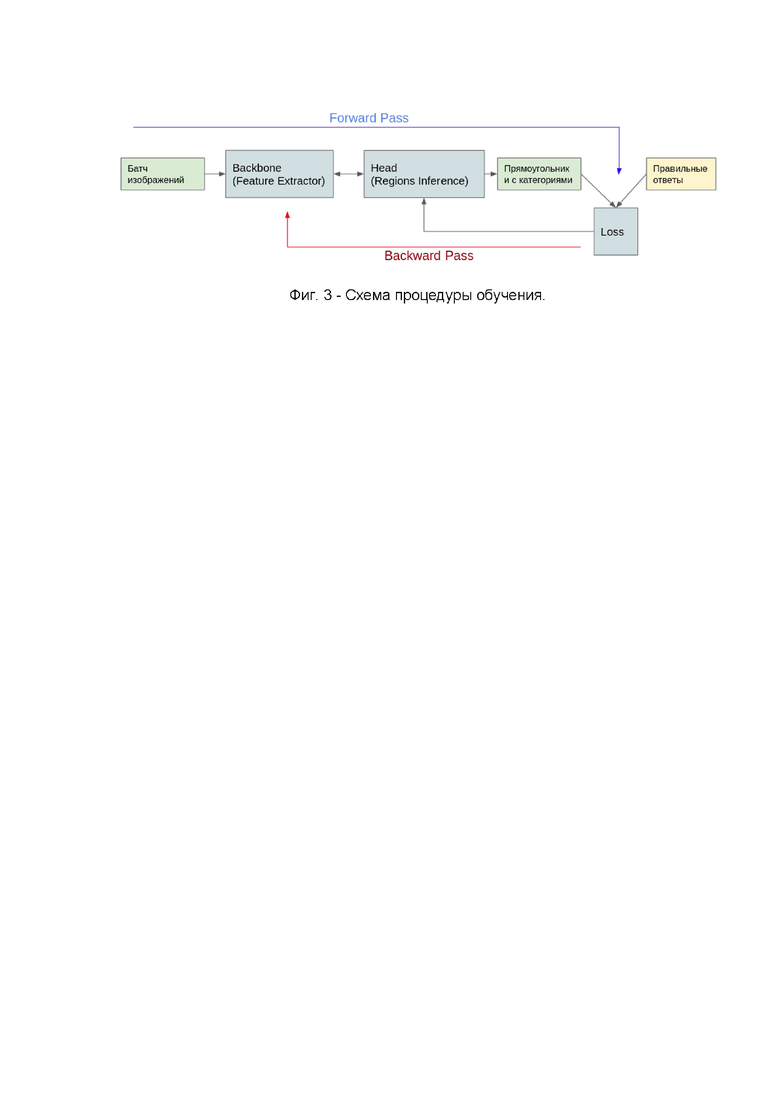
Фиг. 3 иллюстрирует схему процедуры обучения.
Фиг. 4 иллюстрирует схему процедуры обучения нейросети с одной Backbone и несколькими Heads.
Фиг. 5 иллюстрирует общую структурную блок-схему предлагаемого способа.
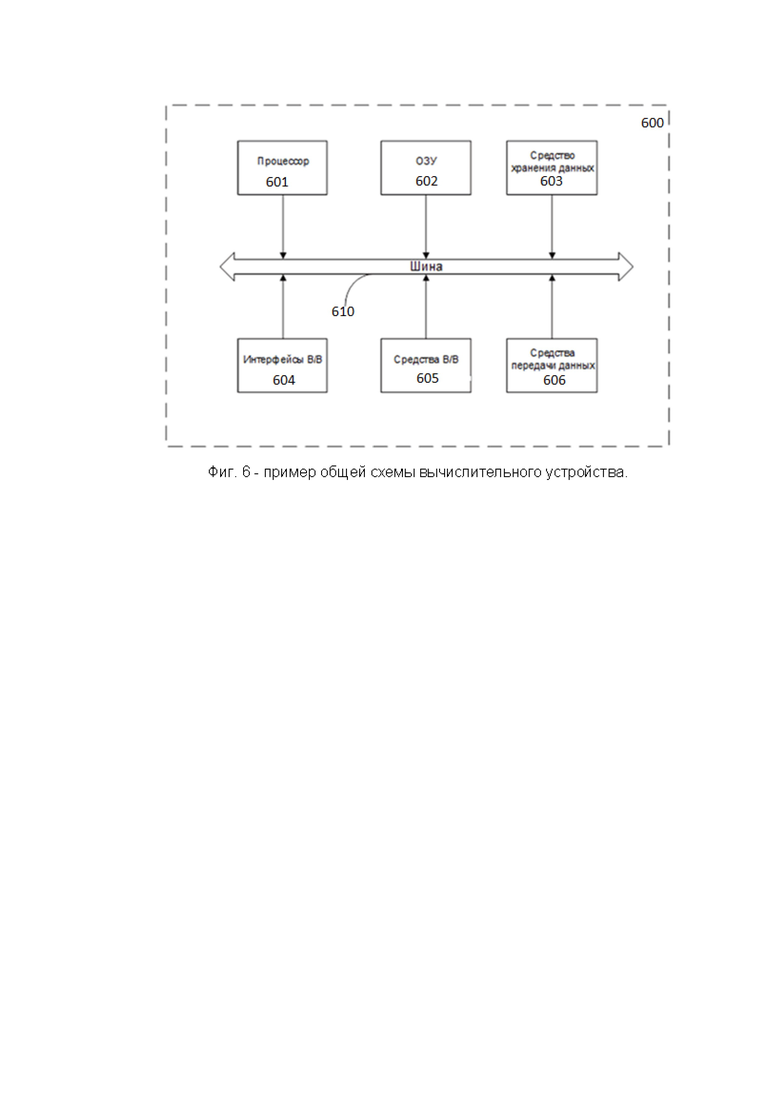
Фиг. 6 иллюстрирует пример общей схемы вычислительного устройства.
ДЕТАЛЬНОЕ ОПИСАНИЕ ИЗОБРЕТЕНИЯ
В приведенном ниже подробном описании реализации изобретения приведены многочисленные детали реализации, призванные обеспечить отчетливое понимание настоящего изобретения. Однако, квалифицированному в предметной области специалисту, будет очевидно каким образом можно использовать настоящее изобретение как с данными деталями реализации, так и без них. В других случаях хорошо известные методы, процедуры и компоненты не были описаны подробно, чтобы не затруднять излишне понимание особенностей настоящего изобретения.
Кроме того, из приведенного изложения будет ясно, что изобретение не ограничивается приведенной реализацией. Многочисленные возможные модификации, изменения, вариации и замены, сохраняющие суть и форму настоящего изобретения, будут очевидными для квалифицированных в предметной области специалистов.
Процесс внедрения решения видеоаналитики сопряжен с тем, что детектируемые объекты отличаются от места к месту внедрения и для этого требуется дополнительное обучение детекторов или создание новых - в случае если в месте внедрения, требуется детектировать свой набор объектов, отсутствующий в первоначальном варианте (коробочном варианте).
Кроме того, в процессе эксплуатации решения видеоаналитики может возникнуть необходимость детектировать дополнительные объекты и для этого также потребуются применение новых детекторов, что предполагает их обучение.
Существенная часть решений видеоаналитики решает задачу детектирования основного объекта и сопутствующих ему других различных объектов, т.е. основной детектируемый объект, служит объединяющим признаком для остальных одновременно детектируемых с ним объектов. Таким общим объектом может быть: человек, транспортное средство (автомобиль, самолет, корабль) и т.д., а сопутствующим объектом может быть: голова в каске, кисть с перчаткой, колесо автомобиля, надстройка для антенны, номерной знак автомобиля и т.д.
Предположим, что внедряется/развивается решение, в котором необходимо детектировать N комбинаций объектов.
1)  Есть/Нет),
Есть/Нет),  Есть/Нет),
Есть/Нет), 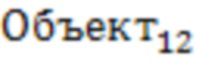 , (Есть/Нет)…,
, (Есть/Нет)…,  (Есть/Нет);
(Есть/Нет);
2) Есть/Нет),  Есть/Нет),
Есть/Нет),  , (Есть/Нет)…,
, (Есть/Нет)…,  (Есть/Нет);
(Есть/Нет);
……
N) Есть/Нет),  Есть/Нет),
Есть/Нет), 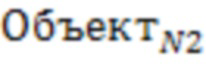 , (Есть/Нет)…,
, (Есть/Нет)…,  (Есть/Нет).
(Есть/Нет).
Объект является общим и объединяющим для всех остальных для каждой из комбинаций.
Допустим, что для каждой из N комбинаций имеются «сильные» размеченные датасеты (более 10 тыс. изображений), наличие которых с высокой вероятностью гарантирует получение качественных детекторов.
Стандартный подход предполагает использование этих датасетов для обучения детекторов. Прогоняется датасет, вычисляется невязка (ошибка) и с использованием метода обратного распространения градиента отптимизируются веса. В итоге получаем N независимых детекторов для детектирования каждой из N комбинаций объектов.
Для наглядности, в качестве примера, на фиг. 1 представлена схема обучения и организации работы решения по детектированию 4-х комбинаций объектов (решение в котором используется 4 детектора). Основная проблема при работе такого решения - это увеличение потребления вычислительных мощностей, а именно при работе решения эти детекторы будут последовательно вызываться на каждый кадр, что будет занижать FPS (Frames per second - количество кадров в секунду). Для примера с 4-мя детекторами (фиг. 1), обрабатываемое количество кадров в единицу времени упадет в 4 раза, что приведет к тому, что для поддержания той скорости обработки потребуется увеличить расходы на физические устройства (вычислители).
Так, например, если один детектор на одной видеокарте может обрабатывать 20 камер со скоростью 5 FPS (минимально допустимая для трекинга), то наличие в решении четырех детекторов, снижает возможное количество камер, которые могут обрабатываться одной видеокартой в 4 раза, т.е. до 5 видеокамер.
Альтернативным вариантом является создание одного детектора для всех комбинаций сразу. Для его создания необходим соответствующий датасет, который нельзя получить простым объединением уже имеющихся размеченных датасетов. Это обусловлено тем, что датасеты могут содержать общие объекты, которые в одном датасете размечены, а в другом не размечены, и возникает задача в каждом из датасете провести работу до разметки по каждому из объектов. Это трудоемкий и длительный процесс во времени, который увеличит время внедрения решения, а в случае развития решения замедлят его.
Например, качественный датасет для обучения нового детектора содержит не менее 10 000 изображений и число детектируемых категорий более 15, то сборка и разметка такого датасета тремя разметчиками занимает срок от 3-х месяцев. В случае до разметки задача не менее сложная.
Таким образом, при внедрении решения, в котором необходимо детектировать N комбинаций объектов под каждую комбинацию делается свой детектор, что требует при работе их в решении дополнительных вычислительных ресурсов или, если обучается/дообучается один детектор для всех комбинаций объектов сразу, но это требует значительного времени на сборку и разметку соответствующего датасета.
В качестве альтернативы способу использования нескольких детекторов или способу обучения одного детектора для всех N комбинаций объектов предлагается способ, который позволяет объединять независимые детекторы в один, за счет создания единой признаковой базы и с несколькими выходами и тем самым избежать недостатков, присущих первым двум.
Способ позволяет объединять детекторы не зависимо от архитектуры детектора и будет действовать для всех популярных архитектур:
1) Faster-RCNN with Region Proposal Network (Shaoqing Ren, Kaiming He, Ross Girshick, Jian Sun, Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks, 2015, https://arxiv.org/abs/1506.01497).
2) Cascade RCNN with Feature Pyramid Network (Zhaowei Cai, and Nuno Vasconcelos, Cascade R-CNN: High Quality Object Detection and Instance Segmentation, 2019, https://arxiv.org/pdf/1906.09756.pdf).
3) Retina Net (Paul F. Jaeger, Simon A. A. Kohl, Sebastian Bickelhaupt, Fabian Isensee, Tristan Anselm Kuder, Heinz-Peter Schlemmer, Klaus H. Maier-Hein, Retina U-Net: Embarrassingly Simple Exploitation of Segmentation Supervision for Medical Object Detection, 2018, https://arxiv.org/abs/1811.08661).
4) Yolo v1/v2/v3/v4/v5 (Alexey Bochkovskiy, Chien-Yao Wang, Hong-Yuan Mark Liao, YOLOv4: Optimal Speed and Accuracy of Object Detection, 2020, https://arxiv.org/abs/2004.10934).
5) Single Shot Detector (Wei Liu, Dragomir Anguelov, Dumitru Erhan, Christian Szegedy, Scott Reed, Cheng-Yang Fu, Alexander C. Berg, SSD: Single Shot MultiBox Detector, 2016, https://arxiv.org/abs/1512.02325).
Не важно, двухшаговый детектор (Faster RCNN, Cascade RCNN) или одношаговый (Retina, Yolo, SSD), имеется ли вывод прямоугольников с нескольких мест нейронной сети (Cascade RCNN, Yolo v2/v3/v4/v5) или с одного (Faster RCNN, Yolo v1). Всякую архитектуру детектора можно представить в виде двух частей: «Backbone» и «Head» (рис. 2).
Backbone - набор сверточных слоев без полносвязанных. На выходе Backbone будет карта признаков - по сути, многомерное изображение, где каждый пиксель представляет собой многомерный вектор чисел с плавающей точкой и у каждого такого пикселя будет своя область видимости (Receptive Field). Область видимости определяет область пикселей на исходном изображении, которая потенциально может повлиять на вектор признаков. Например, популярны следующие архитектуры в качестве Backbone:
1) Vgg16/Vgg19 (Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton, «ImageNet Classification with Deep Convolutional Neural Networks», https://papers.nips.cc/paper/2012/file/c399862d3b9d6b76c8436e924a68c45b-Paper.pdf).
2) ResNet50/101/151 (Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun, «Deep Residual Learning for Image Recognition», https://arxiv.org/abs/1512.03385).
3) ResNext50/101/151 (Saining Xie, Ross Girshick, Piotr Dollár, Zhuowen Tu, Kaiming He, «Aggregated Residual Transformations for Deep Neural Networks», https://arxiv.org/abs/1611.05431).
4) Inception (Liang-Chieh Chen, Yukun Zhu, George Papandreou, Florian Schroff, Hartwig Adam, «Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation», https://arxiv.org/abs/1802.02611).
Head - архитектурно зависимая нейронная сеть (от вида сети Backbone), отвечающая за предсказание охватывающей рамки, классификацию объектов для отдельно взятой комбинации детектируемых объектов.
Каждый элемент архитектуры детектора (Backbone и Head) описывается своим набором слоев, из которых состоит нейронная сеть, связями между Backbone и Head, функцией невязки (loss functions, их может быть несколько) и процедурой обучения.
Процедура обучения для каждой архитектуры описывает Forward Pass для вывода (Inference) и Backward Pass (оптимизация весов нейронной сети для уменьшения невязки).
На каждую итерацию обучения выбирается случайный набор изображений, по ним делается Forward Pass, вычисляется заданный Loss и вычисляется Backward Pass.
В случае Cascade RCNN или Faster RCNN на одну итерацию может быть несколько Forward Pass и Backward Pass с разными loss функциями - одна для тренировки модуля Region Proposal Network (RPN), другая для тренировки Fast RCNN. Но общая схема оптимизации весов не меняется.
Суть способа заключается в совмещении нескольких детекторов в единую сеть, с одной сетью для извлечения признаков Backbone и с несколькими выходами Headi для каждого i-го датасета - комбинации объектов (рис.4). Число Headi определяется числом комбинаций объектов N.
Алгоритм обучения нейросети с одной Backbone и несколькими Head похож на обучение обычной сверточной нейросети. Единственное, обучение осуществляется отдельно для каждого датасета, т.е. Headi.
На каждой итерации обучения:
1) Выбираем датасет i.
2) Формируем случайным образом батч из датасета i.
3) Запускаем Forward Pass, который проходит через Backbone и через Head i.
4) Вычисляем невязку по ответам из выбранного батча (из датасета i).
5) Методом обратного распространения градиента оптимизируем веса нейронной сети: веса Backbone и веса Head i.
6) Повторяем процедуру для всех датасетов.
В случае если детектор двухшаговый, то шаги 1-5 нужно выполнить и для первого, и для второго шага с соответствующими loss-функциями.
Важно (как и в описании выше), чтобы датасеты (комбинации детектируемых объектов) содержали хотя бы один общий объект, который служит объединяющим признаком для остальных одновременно детектируемых с ним объектов.
Ожидаемые положительные технические эффекты.
1. Высокая скорость работы (скорость детекции) по сравнению с традиционной организацией решения по детектированию N комбинаций объектов N детекторами.
Backbone представляет собой самую тяжелую часть в любом детекторе, в ней происходит до 80% всех GPU-вычислений. Таким образом, на этапе эксплуатации модели за счет единой признаковой базы будет осуществляться значительное ускорение инференса.
Так, например, если скорость инференса составляет X мс и количество датасетов равно N, в обычном случае мы имеем скорость:
N*X.
В случае единой сети скорость инференса составляет:
k*X + N*(1-k)*X,
где k - это процент GPU-вычислений, который выпадает на Backbone в заданной архитектуре детектора, т.е использование предлагаемого способа позволит создать нейросеть, которая будет работать в N/( k + N*(1-k)) раза быстрее.
Например, для четырех датасетов ускорение может составить 2,5 раза.
2. За счет расширения выборки детектируемых объектов ожидается, что будет улучшено качество работы нейросети.
Теоретическое обоснование этого заключается в том, что процесс обучения такой нейросети близок к методу обучения с частичным привлечением учителя (Semi-Supervised Learning), который часто приводит к улучшению качества, по сравнению с обычном Supervised Learning. Semi-Supervised подразумевает обучение на неразмеченных данных.
В предлагаемом решении каждая голова (Head) детектора строго будет обучаться на определенном датасете (т.е. Supervised), однако Backbone будет обучаться сразу на всех датасетах, и признаки будут более сложные, как в том случае, если обучались на одном датасете, т.е. с точки зрения конкретной головы и конкретной loss функции, данные с других датасетов могут восприниматься как Unsupervised обучение. В конечном итоге получаем комбинированный вариант Semi-Supervised (Supervised + Unsupervised).
3. Предложенный способ предполагает обработку произвольного количества комбинаций объектов, которые нужно дополнительно детектировать (датасетов для обучения).
Один раз запрограммировав архитектуру и процедуру обучения, в процессе конкретной эксплуатации такой нейросети, можно быстро наращивать число «голов» нейросети (Heads), соответствующих дополнительному количеству комбинаций объектов, которые нужно детектировать и проводить ее дообучение соответствующими датасетами.
При этом с точки зрения трудозатрат количество дополнительных комбинаций объектов, которые требуется детектрировать, не будет иметь значения, т.е. трудозатраты на запуск обучения на 4-х датасетах и на 10-ти будут одинаковые. В этом и будет заключатся автоматизация создания/развития такой нейросети.
Примеры практического применения.
Внедрение решений видеоаналитики или развития уже внедренного решения видеоаналитики сопряжено с тем, что требуется дополнительное обучение детекторов или создание новых детекторов. Для понимания, кейсы упрощены.
Пример 1. У пользователя при внедрении решения видеоаналитики по мониторингу за ношением персоналом средств индивидуальной защиты (СИЗ) имеется потребность для детектирования объектов, которых нет в базовом пакете.
Вариант 2. У клиента в процессе эксплуатации решения видеоаналитики появилась потребность детектировать новые объекты, дополнительно или вместо уже детектируемых.
Стандартные подходы предполагают или создание под каждую потребность - обнаружение нового объекта своего детектора, который затем встраивается в решение или создание нового детектора, который будет обнаруживать дополнительно новые объекты.
И первый, и второй походы являются ресурсоемкими. При создании нового дополнительного детектора и встраивание его в решение, увеличивается потребление вычислительных мощностей, что при определенных ситуациях может критически ограничить скорость работы решения. Создание общего одного детектора для обнаружения всех объектов требует сборки общего детектора - «до разметки» новых объектов на существующем датасете и «доразметки» уже обнаруживаемыми объектами в датасете новых объектов - это длительный во времени процесс, который может занять месяцы.
На фиг. 5 далее будет представлена общая структурная блок-схема предлагаемого способа с техническими элементами, реализующими его.
1 - Система видеонаблюдения.
2 - Видеокамера, основной элемент системы видеонаблюдения и источник изображений.
3 - Сервер (выделенный вычислительный ресурс/мощность), предназначенный для проведения вычислений при обработке изображений детектором. Как правило основу вычислительных мощностей сервера составляют GPU видеокарты. 4 - Модуль, осуществляющий обработку видеопотока от видеокамеры и подготовку изображений (выделение отдельных регионов, масштабирование изображения или выделенных регионов под размер (высота×ширина пикселей), который требуется для подачи на вход той или иной нейросети и т.д.) для последующей обработки в Детекторе. Данный модуль может, в том числе выделять отдельные кадры, когда в видеопотоке имеется движение. 5 - Изображение - видеопоток (поток кадров отражающий ситуацию в месте наблюдения с использованием системы видеонаблюдения), который подготовлен для подачи для последующей обработки на сервере (вычислительном ресурсе). 6 - Детектор - нейросеть или совокупность нейросетей различной архитектуры (в зависимости от решаемой задачи), предназначенная для решения задачи обнаружения объектов, задач сегментации и классификации. Наибольшее популярные для задач обнаружения объектов используются следующие архитектуры нейросетей:
1) Faster-RCNN with Region Proposal Network (Shaoqing Ren, Kaiming He, Ross Girshick, Jian Sun, Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks, 2015, https://arxiv.org/abs/1506.01497).
2) Cascade RCNN with Feature Pyramid Network (Zhaowei Cai, and Nuno Vasconcelos, Cascade R-CNN: High Quality Object Detection and Instance Segmentation, 2019, https://arxiv.org/pdf/1906.09756.pdf).
3) Retina Net (Paul F. Jaeger, Simon A. A. Kohl, Sebastian Bickelhaupt, Fabian Isensee, Tristan Anselm Kuder, Heinz-Peter Schlemmer, Klaus H. Maier-Hein, Retina U-Net: Embarrassingly Simple Exploitation of Segmentation Supervision for Medical Object Detection, 2018, https://arxiv.org/abs/1811.08661).
4) Yolo v1/v2/v3/v4/v5 (Alexey Bochkovskiy, Chien-Yao Wang, Hong-Yuan Mark Liao, YOLOv4: Optimal Speed and Accuracy of Object Detection, 2020, https://arxiv.org/abs/2004.10934).
5) Single Shot Detector (Wei Liu, Dragomir Anguelov, Dumitru Erhan, Christian Szegedy, Scott Reed, Cheng-Yang Fu, Alexander C. Berg, SSD: Single Shot MultiBox Detector, 2016, https://arxiv.org/abs/1512.02325).
7 - Backbone - CNN-сеть какого-либо типа, которая осуществляет вычисления признаков изображения. На выходе Backbone формируется карта признаков - по сути, многомерное изображение, где каждый пиксель представляет собой многомерный вектор чисел с плавающей точкой, и у каждого такого пикселя будет своя область видимости (Receptive Field). Область видимости определяет область пикселей на исходном изображении, которая потенциально может повлиять на вектор признаков. Например, популярны следующие архитектуры в качестве Backbone:
1) Vgg16/Vgg19 (Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton, «ImageNet Classification with Deep Convolutional Neural Networks», https://papers.nips.cc/paper/2012/file/c399862d3b9d6b76c8436e924a68c45b-Paper.pdf);
2) ResNet50/101/151 (Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun, «Deep Residual Learning for Image Recognition», https://arxiv.org/abs/1512.03385);
3) ResNext50/101/151 (Saining Xie, Ross Girshick, Piotr Dollár, Zhuowen Tu, Kaiming He, «Aggregated Residual Transformations for Deep Neural Networks», https://arxiv.org/abs/1611.05431);
4) Inception (Liang-Chieh Chen, Yukun Zhu, George Papandreou, Florian Schroff, Hartwig Adam, «Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation», https://arxiv.org/abs/1802.02611).
8 - Head - архитектурно зависимая нейронная сеть (от вида сети Backbone), отвечающая за предсказание охватывающей рамки, классификацию объектов и определение его маски для отдельно взятой комбинации детектируемых объектов. Количество Head определяется количеством комбинаций объектов N.
9 - Результат обработки изображения детектором: обнаружение объектов, их классификация и определение охватывающей рамки.
10 - Модуль, использующий результаты обработки изображения детектором и информацию, полученную из других источников для формирования формализованных и настроенных пользователем отчетов и демонстрации изображения с нанесенной на него рамкой, охватывающей обнаруженный объект. Сформированные отчеты и демонстрация отчетов осуществляется в личном кабинете пользователя.
11 - Средства отображения - технические средства, посредством которых пользователь осуществляет просмотр/ознакомление с отчетом и изображениями в личном кабинете.
12 - Личный кабинет выполнен, как web ресурс или, как мобильное приложение (iOS, Android или какой-либо другой операционной системы).
Видеопоток из видеокамеры (2) системы видеонаблюдения (1) поступает в модуль подготовки изображения (4), где осуществляется изменение размера, разрешения, формата кадра и т.д. в зависимости от требований к обрабатываемым изображениям в детекторе, в том числе могут выделяться отдельные кадры, на которых имеется движение.
После предварительной подготовки изображение 5 поступает в детектор 6. Первоначально изображение 5 поступает на набор сверточных слоев - Backbone (7), количество и обработка изображения которыми определяется типом нейросети, лежащей в основе детектора. На выходе Backbone (7) формируется карта признаков, которая поступает на совокупность архитектурно зависимых от типа Backbone нейросетей Head (8), при этом число Head (8) определяется числом комбинаций объектов, которые необходимо обнаружить на изображении.
На выходе Head (8) формируются параметры охватывающей рамки и класс объекта, которые затем поступают в программный модуль формирования отчетов по объектам обнаружения: видео (кадры) с рамками обнаруженных объектов и отчеты по обнаружению объектов.
Модуль подготовки изображения (4), Детектор (6), Модуль формирования отчетов (10) используют вычислительные мощности (3) для решения поставленных задач.
Пользователь системы видеоаналитики, может ознакомится с Отчетами в личном кабинете (12) посредством средства отображения - доступа в личный кабинет: персональный компьютер, ноутбук, мобильный телефон и т.д. (11).
На Фиг. 2 далее будет представлена общая схема вычислительного устройства (200), обеспечивающего обработку данных, необходимую для реализации заявленного решения.
В общем случае устройство (200) содержит такие компоненты, как: один или более процессоров (201), по меньшей мере одну память (202), средство хранения данных (203), интерфейсы ввода/вывода (204), средство В/В (205), средства сетевого взаимодействия (206).
Процессор (201) устройства выполняет основные вычислительные операции, необходимые для функционирования устройства (200) или функциональности одного или более его компонентов. Процессор (201) исполняет необходимые машиночитаемые команды, содержащиеся в оперативной памяти (202).
Память (202), как правило, выполнена в виде ОЗУ и содержит необходимую программную логику, обеспечивающую требуемый функционал.
Средство хранения данных (203) может выполняться в виде HDD, SSD дисков, рейд массива, сетевого хранилища, флэш-памяти, оптических накопителей информации (CD, DVD, MD, Blue-Ray дисков) и т.п. Средство (203) позволяет выполнять долгосрочное хранение различного вида информации, например, вышеупомянутых файлов с наборами данных пользователей, базы данных, содержащих записи измеренных для каждого пользователя временных интервалов, идентификаторов пользователей и т.п.
Интерфейсы (204) представляют собой стандартные средства для подключения и работы с серверной частью, например, USB, RS232, RJ45, LPT, COM, HDMI, PS/2, Lightning, FireWire и т.п.
Выбор интерфейсов (204) зависит от конкретного исполнения устройства (200), которое может представлять собой персональный компьютер, мейнфрейм, серверный кластер, тонкий клиент, смартфон, ноутбук и т.п.
В качестве средств В/В данных (205) в любом воплощении системы, реализующей описываемый способ, должна использоваться клавиатура. Аппаратное исполнение клавиатуры может быть любым известным: это может быть, как встроенная клавиатура, используемая на ноутбуке или нетбуке, так и обособленное устройство, подключенное к настольному компьютеру, серверу или иному компьютерному устройству. Подключение при этом может быть, как проводным, при котором соединительный кабель клавиатуры подключен к порту PS/2 или USB, расположенному на системном блоке настольного компьютера, так и беспроводным, при котором клавиатура осуществляет обмен данными по каналу беспроводной связи, например, радиоканалу, с базовой станцией, которая, в свою очередь, непосредственно подключена к системному блоку, например, к одному из USB-портов. Помимо клавиатуры, в составе средств В/В данных также может использоваться: джойстик, дисплей (сенсорный дисплей), проектор, тачпад, манипулятор мышь, трекбол, световое перо, динамики, микрофон и т.п.
Средства сетевого взаимодействия (206) выбираются из устройства, обеспечивающий сетевой прием и передачу данных, например, Ethernet карту, WLAN/Wi-Fi модуль, Bluetooth модуль, BLE модуль, NFC модуль, IrDa, RFID модуль, GSM модем и т.п. С помощью средств (205) обеспечивается организация обмена данными по проводному или беспроводному каналу передачи данных, например, WAN, PAN, ЛВС (LAN), Интранет, Интернет, WLAN, WMAN или GSM.
Компоненты устройства (200) сопряжены посредством общей шины передачи данных (210).
В настоящих материалах заявки было представлено предпочтительное раскрытие осуществление заявленного технического решения, которое не должно использоваться как ограничивающее иные, частные воплощения его реализации, которые не выходят за рамки испрашиваемого объема правовой охраны и являются очевидными для специалистов в соответствующей области техники.
| название | год | авторы | номер документа |
|---|---|---|---|
| МЕТОД ДЛЯ ВЫДЕЛЕНИЯ И КЛАССИФИКАЦИИ ТИПОВ КЛЕТОК КРОВИ С ПОМОЩЬЮ ГЛУБОКИХ СВЕРТОЧНЫХ НЕЙРОННЫХ СЕТЕЙ | 2019 |
|
RU2732895C1 |
| СИСТЕМА РАСПОЗНАВАНИЯ ИЗОБРАЖЕНИЯ: BEORG SMART VISION | 2020 |
|
RU2777354C2 |
| Бортовая система технического зрения рельсового транспортного средства | 2023 |
|
RU2804565C1 |
| Программно-аппаратный комплекс выявления опасного приближения рабочей штанги к стенкам бассейна ядерного топлива на основе видеонаблюдения | 2023 |
|
RU2828724C1 |
| СПОСОБ РАСПОЗНАВАНИЯ ЛИЦА НА СИСТЕМАХ КОНТРОЛЯ И УПРАВЛЕНИЯ ДОСТУПОМ | 2021 |
|
RU2765439C1 |
| ПРОГРАММНО-АППАРАТНЫЙ КОМПЛЕКС АВТОМАТИЧЕСКОЙ СОРТИРОВКИ ТВЕРДЫХ ОТХОДОВ | 2023 |
|
RU2814860C1 |
| Способ автоматического анализа визуальных данных и интеллектуальная портативная видеосистема для его реализации | 2022 |
|
RU2788481C1 |
| СПОСОБ И УСТРОЙСТВО ФИКСАЦИИ ТРЕВОЖНЫХ СОБЫТИЙ НА СЛУЖЕБНОМ ТРАНСПОРТНОМ СРЕДСТВЕ | 2021 |
|
RU2770862C1 |
| СИСТЕМА КОМПЬЮТЕРНОГО ЗРЕНИЯ В РИТЕЙЛЕ | 2022 |
|
RU2785327C1 |
| СИСТЕМА СЖАТИЯ ИСКУССТВЕННЫХ НЕЙРОННЫХ СЕТЕЙ НА ОСНОВЕ ИТЕРАТИВНОГО ПРИМЕНЕНИЯ ТЕНЗОРНЫХ АППРОКСИМАЦИЙ | 2019 |
|
RU2734579C1 |




Изобретение относится к способу распознавания видеопотока и обнаружения объектов. Технический результат заключается в повышении скорости и точности обнаружения объектов на изображении. Способ содержит этапы, на которых с видеокамеры, располагаемой на системе видеонаблюдения, осуществляют трансляцию видеопотока на сервер; осуществляют обработку видеопотока, полученного от видеокамеры, и подготовку изображений для последующей обработки детектором с помощью модуля подготовки изображения сервера; с помощью детектора, состоящего из сверточной нейронной сети «Backbone» и связанных с ней нейронных сетей «Head», архитектурно зависимых от вида сети «Backbone, с использованием вычислительных мощностей сервера, осуществляют извлечение посредством нейронной сети «Backbone» признаков объектов, единых для всех обнаруживаемых N комбинаций объектов, и формирование карты признаков объектов, которая поступает на нейронные сети «Head», при этом количество нейронных сетей «Head» равно количеству комбинаций объектов N, классификацию посредством нейронных сетей «Head» объектов на изображениях для каждой отдельно взятой комбинации детектируемых объектов и формирование охватывающих рамок для классифицированных объектов на основе обработки полученной карты признаков объектов; на выходе из детектора, с помощью модуля формирования отчетов сервера, получают сформированные параметры охватывающих рамок и классы объектов для формирования и отправки отчета на средства отображения пользователя. 6 ил.
Способ распознавания видеопотока и обнаружения объектов, содержащий этапы, на которых:
с видеокамеры, располагаемой на системе видеонаблюдения, осуществляют трансляцию видеопотока на сервер;
осуществляют обработку видеопотока, полученного от видеокамеры, и подготовку изображений для последующей обработки детектором с помощью модуля подготовки изображения сервера;
с помощью детектора, состоящего из сверточной нейронной сети «Backbone» и связанных с ней нейронных сетей «Head», архитектурно зависимых от вида сети «Backbone, с использованием вычислительных мощностей сервера, осуществляют:
извлечение посредством нейронной сети «Backbone» признаков объектов, единых для всех обнаруживаемых N комбинаций объектов, и формирование карты признаков объектов, которая поступает на нейронные сети «Head», при этом количество нейронных сетей «Head» равно количеству комбинаций объектов N,
классификацию посредством нейронных сетей «Head» объектов на изображениях для каждой отдельно взятой комбинации детектируемых объектов и формирование охватывающих рамок для классифицированных объектов на основе обработки полученной карты признаков объектов;
на выходе из детектора, с помощью модуля формирования отчетов сервера, получают сформированные параметры охватывающих рамок и классы объектов для формирования и отправки отчета на средства отображения пользователя.
| Kaiming He и др., "Mask R-CNN", 20.03.2017, доступно - https://arxiv.org/pdf/1703.06870v1.pdf | |||
| Kaiming He и др., "Deep Residual Learning for Image Recognition", 10.12.2015, доступно - https://arxiv.org/pdf/1512.03385.pdf | |||
| Tsung-Yi Lin и др., "Feature Pyramid Networks for Object Detection", 19.04.2017, доступно - |

