ОБЛАСТЬ ТЕХНИКИ
Настоящее техническое решение относится к области информационных технологий, в частности, к системе сжатия искусственных нейронных сетей (НС) на основе итеративного применения тензорных аппроксимаций.
УРОВЕНЬ ТЕХНИКИ
Из уровня техники известны решения, которые предлагают использовать матрицы, подобные Теплицевым для аппроксимации тензоров весов в Recursive Neural Networks (RNN) и Long Short-Term Memory (LSTM). Данные методы базируются на довольно сильном предположении о структуре тензора весов. В случае невыполнения данного предположения компрессия данным методом может быть невозможна. Такие решения, например, раскрыты в следующих документах: US20170076196A1 (МПК G06N3/04, опубл. 2017-03-16); CN107038476A (МПК G06N3/04, опубл. 2017-08-11).
Кроме того, из уровня техники известны решения, которые предлагают сокращение количества фильтров в сверточных слоях путем их удаления. Несмотря на то, что данный метод сокращает количество нейронов в нейронной сети, он не использует в полной мере структурные свойства тензора, поэтому компрессия такими методами менее интенсивна. Такие решения раскрыты в следующих документах: CN107392305A (МПК G06N3/04, опубл. 2017-11-24); US201716346313A1 (МПК G06N3/04, опубл. 2019-09-12); CN201910338123А (МПК G06K9/62, опубл. 2019-08-27).
Из патента US20160217369A1 (МПК G06N3/08, опубл. 2016-07-28) известно решение, описывающее способ сжатия нейронной сети. Известное решение включает замену по меньшей мере одного слоя в нейронной сети множеством сжатых слоев для создания сжатой нейронной сети; вставку нелинейности между сжатыми слоями сжатой сети; и тонкую настройка сжатой сети путем обновления значений веса по меньшей мере в одном из сжатых слоев.
Из уровня техники известно решение, описывающее способ сжатия сверточных нейронных сетей, основанный на разложении Таккера и анализе главных компонент (CN110032951A, МПК G06K9/00, опубл. 2019-07-19). При этом способ использует весовой тензор текущего слоя и весовой тензор двух соседних слоев, когда выбирается ранг, и сжатие между слоями больше не является полностью независимым. Выбор ранга является более разумным благодаря информации между смежными уровнями. И, чтобы решить проблему увеличения глубины сети с помощью метода сжатия, основанного на разложении Таккера, разложение Таккера и метод анализа главных компонентов объединяются для сжатия весового тензора каждого сверточного слоя, так что исходная глубина сети сохраняется, а проблемы исчезновения градиента и т.п., вызванные значительным увеличением количества сетевых уровней, исключаются.
Недостатками известных из уровня техник решений является то, что они выполняют сжатие каждого слоя один раз, что влечет резкое уменьшение числа параметров и значительное падение качества, которое затрудняет последующую процедуру тонкой настройки (путем корректировки параметров НС методом обратного распространения ошибки) с целью восстановления исходного качества модели.
Заявленное решение не обладает этим недостатком, так как слои НС можно сжимать несколько раз подряд, т.е. не допускать резкого падения качества предсказаний модели после одной итерации сжатия и тем самым упрощать процедуру тонкой настройки (выполняемую после очередного сжатия слоев).
Таким образом, основным отличием заявленного решения от известных из уровня техники, базирующихся на тензорных аппроксимациях, является то, что оно позволяет проводить сжатие итеративно.
Как результат, при заданном качестве такая процедура позволяет достичь большей степени компрессии, чем неитеративные аналоги.
Более того, в заявленную систему сжатия входят компоненты, не встречающиеся у аналогов. В качестве одного из режимов автоматического выбора ранга используется Байесовский подход с последующим ослабление ранга.
Также в заявленной системе присутствует возможность сжатия сверточного слоя НС путем поиска аппроксимации не для исходного веса слоя, а для его модификации, полученной за счет переиндексации элементов веса.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
Нейронные сети доказали свою эффективность для классификации и сегментации изображений, обнаружения объектов на изображении. Тем не менее, современные сверточные НС содержат сотни миллионов параметров, что препятствует их эффективной работе на встраиваемых системах, характерными признаками которых является ограниченность памяти и мощностей, доступных для использования.
Технической проблемой, на решение которой направлено заявленное техническое решение, является создание системы сжатия искусственных НС на основе итеративного применения тензорных аппроксимаций.
Техническим результатом, достигаемым при решении вышеуказанной технической проблемы, является эффективное сжатие НС, что позволяет уменьшить размер НС, сохраняя качество ее предсказаний.
Данный результат позволяет решать задачу сжатия более эффективно с точки зрения использования ресурсов клиентских устройств, например, мобильных телефонов. Это может иметь решающее значение для систем с ограниченным хранилищем данных. Кроме того, это облегчает распространение приложений через Интернет. Сжатие уменьшает количество вычислений и, следовательно, уменьшает потребление энергии.
В заявленном решении используется итеративный подход к сжатию, который основан на чередовании двух процедур: сжатия слоев НС и восстановления качества предсказаний НС.
При этом параметры сжатия ищутся автоматически, а именно, для каждого слоя автоматически ищется ранг тензорного разложения, который используется при аппроксимации весового тензора и определяет структуру сжатого слоя. Такой алгоритм ускоряет сверточные НС и уменьшает размер модели без снижения оригинальной точности.
Заявленный результат достигается за счет осуществления системы сжатия искусственных НС на основе итеративного применения тензорных аппроксимаций, содержащей:
устройство сжатия, которое состоит из модуля автоматического определения параметров сжатия (модуль rank selector) и модуля, осуществляющего замену параметров сверточных/полносвязных слоев НС на их малоранговую аппроксимацию, полученную с помощью тензорных/матричных разложений (модуль tensor approximator), и
устройство тонкой настройки, при этом:
• устройство сжатия принимает на вход НС, модуль rank selector автоматически для каждого сверточного/полносвязного слоя НС подбирает ранг тензорного разложения, который используется при аппроксимации весового тензора, после чего модуль tensor approximator осуществляет замену веса слоя на его малоранговую аппроксимацию так, что суммарное число параметров новых тензоров меньше, чем число параметров в исходном тензоре,
в результате чего при первой обработке сверточного/полносвязного слоя устройством сжатия исходный слой заменяется на декомпозированный слой, который представляет собой последовательность нескольких сверточных/полносвязных слоев, при этом веса новых слоев инициализируются факторами тензорного разложения, с помощью которого выполнена аппроксимация, при повторной обработке уже декомпозированного слоя число сверточных/полносвязных слоев не изменяется, но число параметров в каждой составляющей декомпозированного слоя уменьшается в силу уменьшения ранга аппроксимации;
• устройство тонкой настройки принимает на вход преобразованную НС и выдает на выход оптимизированную НС, обладающую лучшей предсказательной способностью за счет корректировки параметров модели, которая производится методом обратного распространения ошибки с использованием базы данных.
Вес сверточного слоя в нашем случае представляет собой четырехмерный тензор, а вес полносвязного слоя является матрицей (двумерным тензором).
ОПИСАНИЕ ЧЕРТЕЖЕЙ
Реализация изобретения будет описана в дальнейшем в соответствии с прилагаемыми чертежами, которые представлены для пояснения сути изобретения и никоим образом не ограничивают область изобретения. К заявке прилагаются следующие чертежи:
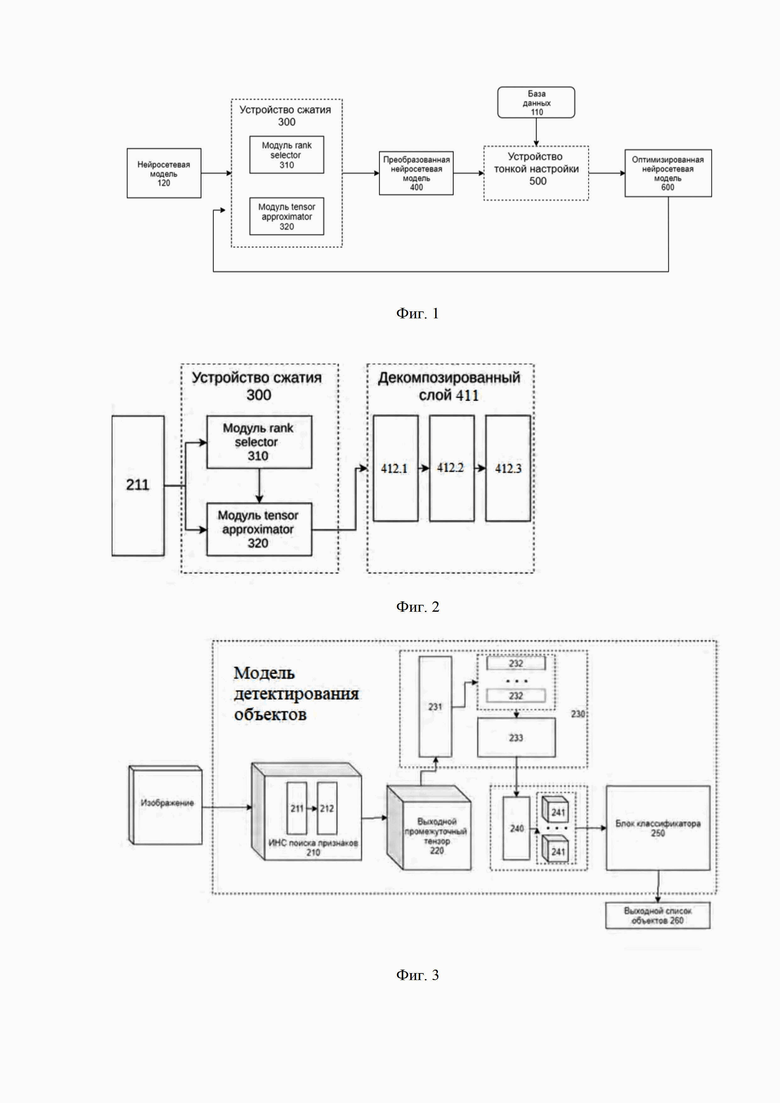
Фиг. 1 иллюстрирует пример системы сжатия искусственных НС на основе итеративного применения тензорных аппроксимаций;
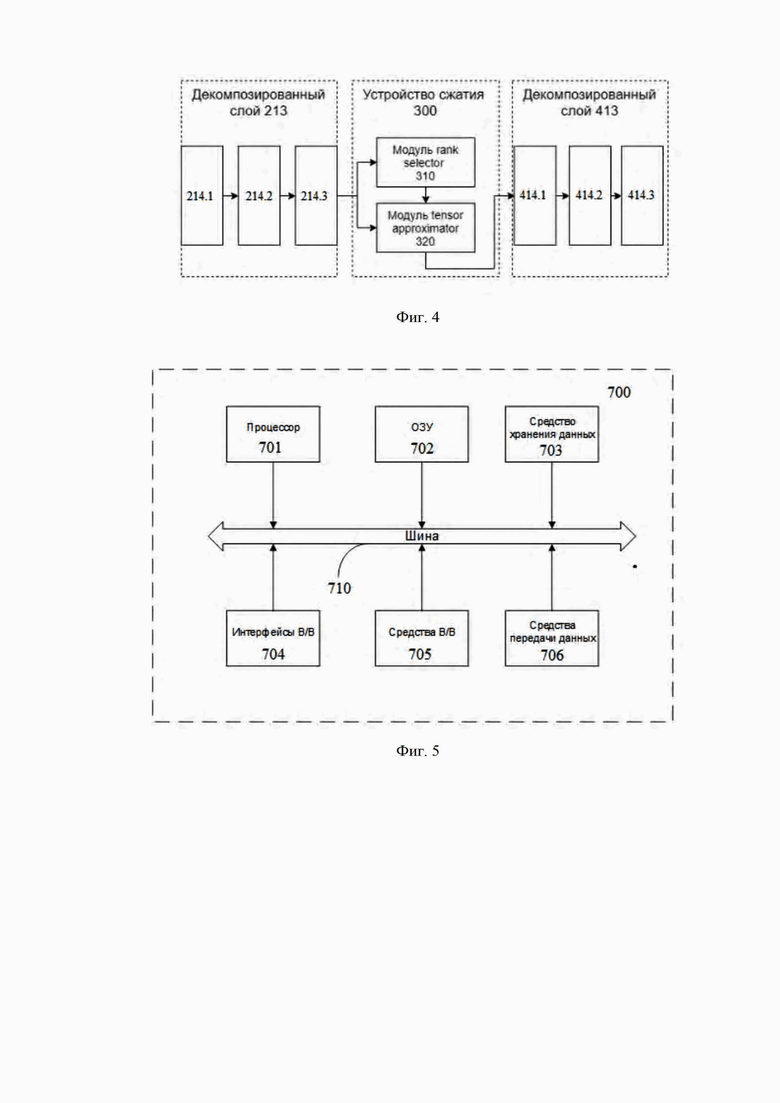
Фиг. 2 иллюстрирует работу устройства сжатия на примере одного сверточного слоя;
Фиг. 3 иллюстрирует модель детектирования объектов, на примере которой показана работа системы сжатия;
Фиг. 4 иллюстрирует описание сжатия декомпозированного слоя;
Фиг. 5 иллюстрирует пример общей схемы компьютерного устройства.
ДЕТАЛЬНОЕ ОПИСАНИЕ ИЗОБРЕТЕНИЯ
В приведенном ниже подробном описании реализации изобретения приведены многочисленные детали реализации, призванные обеспечить отчетливое понимание настоящего изобретения. Однако, квалифицированному в предметной области специалисту, будет очевидно каким образом можно использовать настоящее изобретение, как с данными деталями реализации, так и без них. В других случаях хорошо известные методы, процедуры и компоненты не были описаны подробно, чтобы не затруднять понимание особенностей настоящего изобретения.
Кроме того, из приведенного изложения будет ясно, что изобретение не ограничивается приведенной реализацией. Многочисленные возможные модификации, изменения, вариации и замены, сохраняющие суть и форму настоящего изобретения, будут очевидными для квалифицированных в предметной области специалистов.
Ниже будут описаны термины и понятия, необходимые для осуществления настоящего технического решения.
База данных (БД) - совокупность данных, организованных в соответствии с концептуальной структурой, описывающей характеристики этих данных и взаимоотношения между ними, причем такое собрание данных, которое поддерживает одну или более областей применения (ISO/IEC 2382:2015, 2121423 «database»).
Нейронная сеть (далее - НС) - вычислительная или логическая схема, построенная из процессорных элементов, являющихся упрощенными функциональными моделями нейронов. Существуют сторонние библиотеки, позволяющих эффективно работать с искусственными нейронными сетями, которые находятся в открытом доступе (например, PyTorch, TensorFlow).
Слой нейронной сети (англ. layer) - совокупность нейронов сети, объединяемых по особенностям их функционирования.
Преобразование данных в моделях классификации изображений и детектирования объектов осуществляется за счет обработки данных слоями нейронной сети. Архитектура вычислений в уровне техники известна как архитектура сверточной искусственной нейронной сети. На данный момент множество задач компьютерного зрения успешно решается с помощью данного инструмента.
Механизм обработки входного изображения с помощью сверточной НС представляет собой чередование обработки линейными (сверточные, полносвязные), нелинейными, MaxPooling слоями.
Обработка данных сверточным слоем состоит из последовательного применения операции свертки к входному тензору: трехмерный входной тензор с размерами (H,W,Cin) преобразуется путем последовательного скалярного умножения участков тензора, размера (K1,K2,Cin,Cout) каждый, на ядро сверточного слоя - четырехмерный тензор весов с размерами (K1,K2,Cin,Cout).
В данном случае, (H,W) это ширина и высота, а Cin -число каналов входного тензора, (K1,K2) - пространственные размеры ядра свертки, а Cout - число выходных каналов свертки. В результате применения данной операции, полученный тензор имеет размерность (H,W,Cout). Кроме того, часть слоев применяет операцию свертки не к каждому участку входного тензора, сдвигая по H и W на 1 пиксель каждый раз, но с произвольным сдвигом (англ. stride). В таком случае размер выходного тензора будет (Hnew,Wnew,Cout).
Механизм работы полносвязного слоя искусственной НС состоит из последовательного применения следующих преобразований входного вектора размерности L: вектор умножается на матрицу весов размерности (M, L) и результат суммируется с вектором смещения размерности M.
Кроме того, после каждого линейного слоя следует нелинейное преобразования полученного вектора (нелинейный слой).
Еще один тип слоя - MaxPooling, который копирует максимальные элементы участков входного тензора, имеющих размер (K,K,Cin). Данный слой обычно используется для уменьшения обрабатываемого тензора в 2 раза по высоте и ширине.
Тензор, являющийся результатом обработки одного из слоев, называется выходом скрытого слоя и отправляется в качестве входного тензора следующей компоненте искусственной нейронной сети (т.е. отправляется на обработку следующему скрытому слою).
Ниже приведено описание алгоритма в общих чертах (Фиг 1).
Создание более глубоких и сложных нейросетевых моделей обусловлено необходимостью получать модели с лучшей предсказательной способностью. Однако, такие сети содержат десятки миллионов параметров и часто не могут быть эффективно реализованы на переносных и мобильных устройствах из-за их вычислительной мощности и ограничений памяти. Таким образом, существует проблема, связанная с хранением и работой в режиме реального времени современных нейросетевых моделей, в частности моделей для классификации и детектирования по видеоданным.
Методы, основанные на матричных и тензорных аппроксимациях низкого ранга, обеспечивают хорошее сжатие [1, 2, 3, 4]. Однако все предыдущие подходы следуют одной и той же схеме: разовое сжатие со значительной потерей качества модели, и последующая тонкая настройка для восстановления качества.
Заявленное решение существенно улучшает вышеупомянутые схемы, применяя сжатие и тонкую настройку не один раз, а итеративно, используя при этом автоматический подбор параметров сжатия.
На Фиг. 1 представлен общий вид основных элементов заявленной системы (100) для осуществления сжатия НС на основе многошаговых тензорных аппроксимаций. Система (100) включает в себя базу данных (110), НС (120), устройство сжатия НС (300), преобразованную НС (400), устройство тонкой настройки НС (500), оптимизированную НС (600).
Получение оптимизированной, в части занимаемой памяти и скорости работы, НС (600) с помощью заявленной технической системы происходит путем чередования двух шагов: обработки НС с помощью устройства сжатия (300) и обработки НС с помощью устройства тонкой настройки (500). Итеративное повторение этих двух шагов позволяет постепенно сжимать НС и сохранять качество предсказаний результирующей модели на уровне, превышающим качество моделей, полученных с помощью существующих аналогов.
Чередование шагов завершается, когда-либо число операций, выполняемых оптимизированной НС (600) при обработке сигнала, либо число параметров модели, либо ее предсказательное качество не опустится ниже заданного порога. Пороги задаются перед началом работы системы (100), как, соответственно, максимальное число операций/параметров и максимальное падение качества НС, которые считаются допустимыми.
Устройство сжатия (300) принимает на вход НС (120) и выдает на выход преобразованную НС (400), которая содержит меньшее число параметров и требует меньшее число операций для обработки сигнала. Сжатие происходит за счет уменьшения числа параметров в сверточных и полносвязных слоях НС (120).
Устройство тонкой настройки (500) принимает на вход преобразованную НС (400), являющуюся результатом работы устройства сжатия и выдает на выход оптимизированную НС (600), обладающую лучшей предсказательной способностью. Качество предсказаний НС (120) улучшается за счет корректировки параметров модели, которая производится методом обратного распространения ошибки с использованием базы данных (110).
Работа устройства сжатия (300) заключается в последовательном применении двух модулей:
• модуля rank selector (310);
• модуля tensor approximator (320).
Параметры (вес) сверточного слоя представляют собой четырехмерный тензор. Вес полносвязного слоя является матрицей (двумерным тензором). Построение аппроксимации исходного тензора с помощью тензорного разложения означает, что мы находим новые тензоры (факторы) такие, что каждый элемент исходного тензора есть некая линейная функция от элементов новых тензоров. Каждое тензорное разложение характеризуется значением ранга, т.е. параметром, от которого зависят размеры найденных факторов.
Аппроксимация называется малогранговой, если суммарное число параметров новых тензоров меньше, чем число параметров в исходном тензоре.
Таким образом, обработка НС устройством сжатия (300) заключается в том, что для каждого сверточного/полносвязного слоя НС, модуль rank selector (310) автоматически подбирает ранг тензорного разложения, которое далее используется модулем tensor approximator (320) для замены веса слоя на его малоранговую аппроксимацию.
Получается, что при первой обработке сверточного/полносвязного слоя устройством сжатия (300) исходный слой заменяется на декомпозированный слой (411), который представляет собой последовательность нескольких сверточных/полносвязных слоев (веса новых слоев инициализируются факторами тензорного разложения, с помощью которого выполнена аппроксимация). При повторной обработке уже декомпозированного слоя (411) устройством сжатия (300) число сверточных/полносвязных слоев не изменяется, но число параметров в каждой составляющей (412) декомпозированного слоя (411) уменьшается в силу уменьшения ранга аппроксимации.
Предлагаемая система (100) может быть использована для сжатия и ускорения работы любых НС, содержащих сверточные и полносвязные слои.
Модули tensor approximator (320) и rank selector (310) могут функционировать в нескольких режимах, что позволяет более оптимальное использование устройства сжатия (300) в зависимости от цели сжатия (либо избавление от избыточных параметров модели, либо получение модели с наименьшим числом параметров/выполняемых операций с плавающей точкой, демонстрирующей качество предсказаний не ниже заданного уровня).
Система сжатия (100) использует новый Байесовского подход для автоматического подбора ранга в качестве одного из режимов работы модуля rank selector (310). Также, модуль tensor approximator (320) включает себе режим (не встречающийся ранее у аналогов), в котором тензорная аппроксимация ищется не для исходного веса слоя, а для тензора, являющегося его модификацией, полученной за счет переиндексации элементов веса.
Ключевым отличием предлагаемой системы сжатия (100) от существующих аналогов является итеративность, то есть поочередная обработка НС устройством сжатия (300) и устройством тонкой настройки (500).
Итеративный подход позволяет получать модели с качеством предсказаний, как у сжатых моделей, являющихся результатом работы аналогов, и содержащих при этом меньшее число параметров.
Ниже приведено описание того, как сжимается один слой.
Модуль tensor approximator (320) для сжатия слоев НС может функционировать в трех режимах: “Tucker-2”/“СP-3”/“Truncated-SVD”, которые соответствуют поиску аппроксимации весового тензора в формате Tucker decomposition/Canonical polyadic decomposition/Singular Value Decomposition (см. [14]).
Ниже приведена схема сжатия сверточного слоя НС (Фиг. 2).
Каждому сверточному слою соответствует 4-x мерный тензор весов (K, K, Cin, Cout). Модуль автоматического подбора параметров (310) определяет ранг тензорного разложения, который далее используется модулем сжатия (320) для аппроксимации тензора весов (ниже подробно будет раскрыта работа модуля (310)).
Модуль сжатия (320) производит замену 4-х мерного тензора на найденную аппроксимацию, что эквивалентно замене исходного сверточного слоя на последовательность трех сверточных слоев с меньшими весовыми тензорами.
Модуль сжатия (320), работающий в режиме “Tucker-2”, аппроксимирует 4-х мерный тензор весов W размера (K, K, Cin, Cout) с помощью 4-х мерного тензора W2 меньшего размера (K, K, R1, R2), R1< Cin, R2< Cout и двух матриц размера (Cin, Rin) и (Cout, Rout), соответственно (т.е. аппроксимируем с помощью тензорного разложения Tucker-2 ранга (R1, R2)). Далее, элементы матриц используются для создания двух 4-х мерных тензоров W1 и W3 размера (1, 1, Cin, R1) и (1, 1, R2, Cout), соответственно.
Таким образом, обработка входного тензора сверточным слоем с весовым тензором W заменяется на последовательную обработку входного тензора тремя сверточными слоями с весовыми тензорами W1, W2, W3.
В режиме CP-3 модуль сжатия (320) заменяет новые слои на три слоя с размерами (1, 1, Cin, R), (K, K, 1, R), (1, 1, R, Cout). Это происходит в результате следующих шагов.
Сначала 4-х мерный тензор весов (K, K, Cin, Cout) преобразуется в 3-х мерный (K*K, Cin, Cout) за счет переиндексации элементов. Затем 3-х мерный тензор аппроксимируется с помощью трех матриц размера (Cin, R), (K*K, R), (Cout, R) (т.е. аппроксимируем с помощью тензорного разложения CP-3 ранга R). Далее, элементы матриц используются для создания трех 4-х мерных тензоров W1, W2 и W3 размера (1, 1, Cin, R), (K, K, 1, R) и (1, 1, R, Cout), соответственно.
Таким образом, обработка входного тензора сверточным слоем с весовым тензором W заменяется на последовательную обработку входного тензора тремя сверточными слоями с весовыми тензорами W1, W2, W3, где второй слой представляет собой поканальную свертку.
Ниже приведена схема сжатия полносвязного слоя НС.
Каждому полносвязному слою соответствует 2-х мерный тензор весов (Cin, Cout). Модуль автоматического определения параметров сжатия (310) определяет ранг тензорного разложения R и модуль (320) производит замену 2-х мерного тензора на найденную с помощью “Truncated-SVD” аппроксимацию. Т.е. исходный слой заменяется на последовательность двух полносвязных с меньшими весовыми тензорами (Cin, R), (R, Cout).
Ниже приведено описание сжатия декомпозированного слоя (213) (Фиг. 4).
При повторной обработке уже декомпозированного слоя (213) устройством сжатия (300) число сверточных/полносвязных слоев не изменяется, но число параметров в каждой составляющей (214) декомпозированного слоя (213) уменьшается в силу уменьшения ранга аппроксимации. Таким образом, устройство сжатия (300) выдает декомпозированный слой (413).
Описание автоматического подбора ранга.
Модуль rank selector (310) для автоматического определения параметров сжатия может функционировать в двух режимах: “bayesian” и “threshold”.
Режим “bayesian”.
Автоматический подбор рангов в режиме ‘bayesian’ производится с помощью Байесовского подхода. Для удобства введем два обозначения: экстремальный ранг и ослабленный ранг.
Экстремальный ранг - это значение, при котором малоранговая аппроксимация весового тензора не является избыточной.
Ослабленный ранг - это значение, при котором определенное количество избыточности сохраняется в аппроксимации тензора после разложения.
В Байесовском подходе, во-первых, выполняется поиск экстремального ранга с помощью GAS EVBMF (Глобальное аналитическое решение эмпирической вариационной байесовской матричной факторизации, см. [13]), а во-вторых, производится ослабление ранга (т.е. увеличение значения экстремального ранга).
GAS EVBMF может автоматически находить ранг матрицы, выполняя байесовский вывод, однако он предоставляет субоптимальное решение.
В отличие от решения [2], в заявленном решении используется GAS EVBMF не для того, чтобы установить ранг для аппроксимации весового тензора R, а только для определения экстремального ранга (т.е. Rextr = Revbmf). Чтобы определить экстремальный ранг с помощью GAS EVBMF для аппроксимации в тензорном формате Tucker-2, в заявленном решении применяем его по-отдельности к двум разверткам тензора весов (т.е. к двум матрицам, которые получаются из 4-х мерного тензора путем переиндексации элементов, и имеют значение одной из размерностей равным числу каналов).
Ослабленный ранг Rweak зависит линейно от экстремального ранга и служит для сохранения большей избыточности в аппроксимации тензора.
R = Rweak облегчает тонкую настройку и дает шаг сжатия с большей точностью.
Ослабленный ранг определяется следующим образом: Rweak = Rinit - w * (Rinit - Rextr), где w - гиперпараметр, называемый коэффициентом ослабления, 0 <w <1, и Rinit - изначальный ранг тензора. Это приводит к Rextr ≤ Rweak ≤ Rinit.
Оптимальное значение для w находится в диапазоне: 0,5≤w≤0,9. Если начальный ранг меньше 21, в заявленном решении алгоритм считает такие ядра достаточно маленькими и не сжимает их.
Автоматический подбор рангов в режиме “threshold” определяет ранг разложения для каждого слоя как минимальный ранг, при котором качество всей модели не падает ниже заданного пользователем порога качества.
Описание устройства тонкой настройки
Устройство настройки НС.
После процедуры сжатия модели измеряется ее качество на валидационной выборке (например, PASCAL VOC val [12]) и происходит процесс обучения модели с помощью устройства тонкой настройки (500):
Целевой набор данных должен состоять из изображений и аннотаций, содержащих информацию о правильных позициях объекта, его класса, координат обрамляющего прямоугольника (bounding box) и, опционально, маски для сегментации.
Для изображений из обучающей выборки и их аннотаций, вычисляется результат работы НС. Подсчитывается сконструированная особым образом функция потерь, учитывающая точность определения класса и границ объекта.
Подробное описание функции потерь см. в статье [11].
С помощью метода обратного распространения ошибки, избранным методом оптимизации (стохастическим градиентным спуском с моментом 0.9, с начальным коэффициентом скорости обучений (learning rate) 0.01) происходит подстройка весов всей модели. Процесс повторяется несколько эпох до тех пор, пока не будет достигнуто желаемое качество модели или не будет достигнуто максимальное установленное число итераций.
В экспериментах с Faster R-CNN [11] использовалось число итераций равное 180’000, с уменьшением в 10 раз коэффициента скорости обучения на 120’000 и 160’000 шагах.
Модель и результаты обучения сохраняются и на этом процедуру настройки можно считать завершенной и алгоритм переходит к следующему этапу.
База данных и обработка данных.
Предварительная обработка данных является частью комплексной системы сжатия НС, в частности, моделей компьютерного зрения.
Для модулей, решающих задачу классификации изображений, распознавания образов (детектирования объектов), сегментации или любой другой задачи компьютерного зрения требуется загрузить на вычислительное устройство наборы данных, содержащие изображения и аннотации в установленном формате.
Для задачи распознавания образов и работы с наборами данных в формате COCO (Common Objects in Context) [9] и PascalVOC [12], а также для задачи классификации изображений с набором данных в формате Imagenet, CIFAR SVHN, STL10, система (110) осуществляет загрузку данных и их интерпретацию.
Далее, для выбранной задачи требуется загрузить целевую модель НС (120) для ее дальнейшего сжатия. Система (100) позволяет использовать предобученные модели, распространяемые в установленном формате, содержащие информацию о значениях весов каждого слоя нейронной сети. После загрузки, целевая модель обладает следующими характеристиками:
вычислительная сложность, в количестве операций с плавающей точкой;
количество параметров;
скорость исполнения на целевой архитектуре;
точность в рамках задачи и тестовой подвыборки набора данных (например, test set COCO-2017 [9]).
Точность для каждой задачи имеет различный математический смысл. В задаче классификации качество модели оценивается метрикой accuracy (долей правильных предсказаний модели), в задаче детектирования объектов - метрикой mAP, ее описание представлено в источнике [7].
Ниже приведен выбор режимов функционирования устройства сжатия.
Выбор режима функционирования устройства сжатия (300) зависит от критериев, накладываемых на сжатую модель.
Если целью сжатия является избавление от избыточных параметров модели, то модулю rank selector (310) стоит использовать режиме “bayesian”, модуль tensor approximator (320) работает в режиме “Tucker-2” для сверточных слоев нейронной сети и режиме “Truncated-SVD” для сверточных слоев с ядром (1, 1, Cin, Cout) и для полносвязных слоев.
Если ставится цель получить модель с наименьшим числом параметров/операций с плавающей точкой, демонстрирующую качество не ниже заданного уровня, то следует выбирать следующие режимы. Для модуля rank selector (310) - режим “threshold”, для модуля tensor approximator (320) - CP-3 для сверточных слоев нейронной сети и “Truncated-SVD” для сверточных слоев с ядром (1, 1, Cin, Cout) и для полносвязных слоев.
Ниже приведен пример работы модели детектирования объектов (см. фиг. 3).
НС детектирования объектов Faster R-CNN [11], на которой в заявленном решении демонстрируется эффективная работа системы (100) автоматического сжатия, состоит из нескольких частей:
• Backbone. Искусственная НС поиска признаков (210). Архитектура сети состоит из последовательности, сконструированной из сверточных, нелинейных и MaxPooling [6] слоев (например, это может быть архитектура сети ResNet [5] или VGG [10]). Результат прохождения через каждый слой - промежуточный трехмерным тензор.
На Фиг. 3 показан сверточный слой (211) и трехмерный тензор (212), являющийся выходом слоя (211).
Сеть принимает на вход трехканальное, предварительно нормированное RGB изображение размера (h,w,3). Результатом прохождения через сеть является выходной промежуточный трехмерный тензор (220) размера (H,W,1024).
• Выходной тензор (220) сети backbone поступает в блок region proposal network (230), в который входит искусственная НС (231), предсказывающая регионы потенциального нахождения объектов (232), и блок (233), осуществляющий фильтрацию пересекающихся регионов.
• НС (231) состоит из светрочного слоя с ядром (3х3х1024х1024) и двух параллельно выполняющихся сверточных слоев: objectness layer с ядром (1х1х1024хnum_anchors) и bbox_rpn layer с ядром (1х1х1024х(4*num_achors)), где num_anchors - число заданных заранее якорных областей или anchors (прямоугольные рамки с фиксированным заранее соотношением сторон). Обычно используются рамки трех размеров с тремя разными соотношениями сторон: (1:1, 1:2, 2:1), то есть num_anchors=9.
Для архитектуры Faster R-CNN ResNet 50 C4 размеры рамок - [8x8, 16x16, 32x32] (для соотношения сторон 1:1) пикселя на выходном промежуточном слое, что соответствует 128, 256 и 512 пикселям на исходном изображении соответственно. Эти значения являются эвристическими и работают в предположении, что большинство объектов хорошо вписываются в такие рамки. Для каждой якорной области далее делается предсказание о наличии объекта внутри этой области (с помощью objectness layer, результат которого в тексте обозначается как o), а также с помощью bbox_rpn layer вычисляются поправки к границам якорной области, а именно, смещение области (Δx, Δy) и изменение высоты и ширины области (t_h, t_w).
• В результате, выходы (231) интерпретируются, как набор потенциально обнаруженных объектов, так называемый список предсказанных областей интереса (regions of interests) (232). Каждый элемент данного списка (называемый также RoI) соответствует одной области и представляется в виде [(o, x, y, h, w)], где o - вероятность наличия объекта в данной области (мера objectness), x,y - координаты левого верхнего угла региона, h, w - высота и ширина региона.
• Затем все регионы интереса проходят процедуру non-maximum-supression (233), заключающуюся в фильтрации пересекающихся регионов. Несколько раз подряд выполняется следующая операция. Выбирается регион с максимальным значением меры o (objectness) и для него вычисляется мера пересечения с каждым из оставшихся регионов, IoU (Intersection over union, пересечение по объединению - общепринятая метрика качества детекции объектов, см. определение, например, в [7]). Регионы, для которых IoU превышает порог 0.7, отбрасываются.
Затем операция повторяется для очередного региона из оставшихся. При достижении заданного числа регионов или по достижении порога по objectness, процедура non-maximum-supression завершается. Отобранные регионы интереса поступают далее на обработку следующей части модели детектирования.
• Отобранные список регионов поступает в блок RoIPooling (240), где происходит интерполяция участка тензора признаков, соответствующего каждому RoI в тензор фиксированного размера, в данном случае 14x14x512 (241). Точное описание метода интерполяции см. в статье [8].
• Затем каждый такой тензор (241) поступает в блок классификатора, называемый head (250). Входной тензор проходит через несколько сверточных слоев, затем трехмерный тензор промежуточного слоя разворачивается в одномерный вектор и поступает на два параллельных полносвязных слоя: классификатор (с нелинейностью softmax, которая переводит вектор в аналог вектора вероятностей, где каждый элемент неотрицателен и сумма всех равна единице) размера n_classes+1 и регрессор (линейный) размера 4*(n_classes+1). Число n_classes - количество распознаваемых классов объектов (20 для PascalVOC и 80 для COCO). Один символ для каждого класса соответствует вероятности, а 4 значения из регрессора - смещениям рамки относительно начального приближения.
• Таким образом, для каждого входного изображения, устройство возвращает список (260) из наиболее вероятного класса (c) и координат рамки, окружающей объект (x,y,h,w).
В архитектуре детектирования Faster R-CNN, на которой демонстрируется работа системы сжатия (100), только слои из блока backbone модифицируются с помощью устройства сжатия (300).
Оптимизированная нейросетевая модель.
После итеративного повторения вышеуказанных процедур сжатия и настройки модели, архитектура искусственной нейронной сети изменяется и в конечном виде представляет собой исходную архитектуру с измененными выбранными сверточными слоями (один сверточный слой преобразуется в три слоя, как описано выше)
В итоге число параметров и число операций меняется, однако качество всей сети сохраняется в желаемом пределе.
В случае описанной выше модели детектирования объектов на изображении, когда backbone имеет архитектуру сетей ResNet или VGG, заявленная система при работе модуля rank selector в режиме ‘bayesian’ и модуля tensor approximator в режиме ‘Tucker-2’ позволяет получить сжатые модели, которые в 1.5 раз легче и имеют качество предсказаний на 0.4% лучше, чем у исходных.
На Фиг. 5 представлен пример общего вида вычислительной системы (700), на базе которой может быть реализована система итеративного сжатия нейронной сети (100).
В общем виде система (700) содержит объединенные общей шиной информационного обмена один или несколько процессоров (701), средства памяти, такие как ОЗУ (702) и ПЗУ (703), интерфейсы ввода/вывода (704), устройства ввода/вывода (705), и устройство для сетевого взаимодействия (706).
Процессор (701) (или несколько процессоров, многоядерный процессор и т.п.) может выбираться из ассортимента устройств, широко применяемых в настоящее время, например, таких производителей, как: Intel™, AMD™, Apple™, Samsung Exynos™, MediaTEK™, Qualcomm Snapdragon™ и т.п.
ОЗУ (702) представляет собой оперативную память и предназначено для хранения исполняемых процессором (701) машиночитаемых инструкций для выполнение необходимых операций по логической обработке данных. ОЗУ (702), как правило, содержит исполняемые инструкции операционной системы и соответствующих программных компонент (приложения, программные модули и т.п.). При этом, в качестве ОЗУ (702) может выступать доступный объем памяти графической карты или графического процессора.
ПЗУ (703) представляет собой одно или более устройств постоянного хранения данных, например, жесткий диск (HDD), твердотельный накопитель данных (SSD), флэш-память (EEPROM, NAND и т.п.), оптические носители информации (CD-R/RW, DVD-R/RW, BlueRay Disc, MD) и др.
Для организации работы компонентов системы (700) и организации работы внешних подключаемых устройств применяются различные виды интерфейсов В/В (704). Выбор соответствующих интерфейсов зависит от конкретного исполнения вычислительного устройства, которые могут представлять собой, не ограничиваясь: PCI, AGP, PS/2, IrDa, FireWire, LPT, COM, SATA, IDE, Lightning, USB (2.0, 3.0, 3.1, micro, mini, type C), TRS/Audio jack (2.5, 3.5, 6.35), HDMI, DVI, VGA, Display Port, RJ45, RS232 и т.п.
Для обеспечения взаимодействия пользователя с вычислительной системой (700) применяются различные средства (705) В/В информации, например, клавиатура, дисплей (монитор), сенсорный дисплей, тач-пад, джойстик, манипулятор мышь, световое перо, стилус, сенсорная панель, трекбол, динамики, микрофон, средства дополненной реальности, оптические сенсоры, планшет, световые индикаторы, проектор, камера, средства биометрической идентификации (сканер сетчатки глаза, сканер отпечатков пальцев, модуль распознавания голоса) и т.п.
Средство сетевого взаимодействия (706) обеспечивает передачу данных посредством внутренней или внешней вычислительной сети, например, Интранет, Интернет, ЛВС и т.п. В качестве одного или более средств (706) может использоваться, но не ограничиваться: Ethernet карта, GSM модем, GPRS модем, LTE модем, 5G модем, модуль спутниковой связи, NFC модуль, Bluetooth и/или BLE модуль, Wi-Fi модуль и др.
Дополнительно могут применяться также средства спутниковой навигации в составе системы (700), например, GPS, ГЛОНАСС, BeiDou, Galileo.
Конкретный выбор элементов системы (700) для реализации различных программно-аппаратных архитектурных решений может варьироваться с сохранением обеспечиваемого требуемого функционала.
В настоящих материалах заявки было представлено предпочтительное раскрытие осуществление заявленного технического решения, которое не должно использоваться как ограничивающее иные, частные воплощения его реализации, которые не выходят за рамки испрашиваемого объема правовой охраны и являются очевидными для специалистов в соответствующей области техники.
Библиография:
[1] Jaderberg, M., Vedaldi, A., & Zisserman, A. (2014). Speeding up convolutional neural networks with low rank expansions. CoRR, abs/1405.3866.
[2] Kim, Y. D., Park, E., Yoo, S., Choi, T., Yang, L., & Shin, D. (2015). Compression of deep convolutional neural networks for fast and low power mobile applications. International Conference on Learning Representations.
[3] Lebedev, V., Ganin, Y., Rakhuba, M., Oseledets, I., and Lempitsky, V. (2015). Speeding-up convolutional neural networks using fine-tuned cp-decomposition. International Conference on Learning Representations.
[4] X. Zhang, J. Zou, K. He, and J. Sun. (2016). Accelerating deep convolutional networks for classification and detection. IEEE Transactions on Pattern Analysis and Machine Intelligence, 38(10):1943–1955.
[5] He, K., Zhang, X., Ren, S., & Sun, J. (2016). Deep residual learning for image recognition. Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition. https://doi.org/10.1109/CVPR.2016.90.
[6] Nagi, J., Ducatelle, F., Di Caro, G. A., Cireşan, D., Meier, U., Giusti, A., Gambardella, L. M. (2011). Max-pooling convolutional neural networks for vision-based hand gesture recognition. 2011 IEEE International Conference on Signal and Image Processing Applications, ICSIPA 2011. https://doi.org/10.1109/ICSIPA.2011.6144164.
[7] mAP (mean Average Precision) for Object Detection - Jonathan Hui - Medium https://medium.com/@jonathan_hui/map-mean-average-precision-for-object-detection-45c121a31173.
[8] Girshick, R. (2015). Fast R-CNN. Proceedings of the IEEE International Conference on Computer Vision. https://doi.org/10.1109/ICCV.2015.169.
[9] Tsung-Yi Lin, Genevieve Patterson, Matteo R. Ronchi, Yin Cui, Michael Maire, Serge Belongie, … Piotr Dollár. (2018). COCO - Common Objects in Context. COCO Dataset, 740–741. Retrieved from http://cocodataset.org/#home.
[10] Simonyan, K., & Zisserman, A. (2015). Very deep convolutional networks for large-scale image recognition. 3rd International Conference on Learning Representations, ICLR 2015 - Conference Track Proceedings.
[11] Ren, S., He, K., Girshick, R., & Sun, J. (2017). Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Transactions on Pattern Analysis and Machine Intelligence. https://doi.org/10.1109/TPAMI.2016.2577031.
[12] Everingham, M., Van Gool, L., Williams, C. K. I., Winn, J., & Zisserman, A. (2010). The pascal visual object classes (VOC) challenge. International Journal of Computer Vision. https://doi.org/10.1007/s11263-009-0275-4.
[13] Nakajima, S., Tomioka R., Sugiyama, M., and Babacan, S. D.. (2012). Perfect dimensionality recovery by variational Bayesian PCA. In Advances in Neural Information Processing Systems, pages 971–979.
[14] Cichocki, A., Lee, N., Oseledets, I., Phan, A. H., Zhao, Q., & Mandic, D. P. (2016). Tensor networks for dimensionality reduction and large-scale optimization: Part 1 low-rank tensor decompositions. Foundations and Trends® in Machine Learning, 9(4-5), 249-429.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ СЖАТИЯ И ХРАНЕНИЯ ТРЕХМЕРНЫХ ДАННЫХ (ВАРИАНТЫ) | 2020 |
|
RU2753591C1 |
| БЫСТРОЕ ВЫЧИСЛЕНИЕ СВЕРТОЧНОЙ НЕЙРОННОЙ СЕТИ | 2018 |
|
RU2722473C1 |
| Способ автоматической классификации рентгеновских изображений с использованием масок прозрачности | 2019 |
|
RU2716914C1 |
| Способ распознавания речевых эмоций при помощи 3D сверточной нейронной сети | 2023 |
|
RU2816680C1 |
| СПОСОБ И УСТРОЙСТВО АДАПТИВНОГО АВТОМАТИЗИРОВАННОГО УПРАВЛЕНИЯ СИСТЕМОЙ ОТОПЛЕНИЯ, ВЕНТИЛЯЦИИ И КОНДИЦИОНИРОВАНИЯ | 2021 |
|
RU2784191C1 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ КОМПИЛЯЦИИ НЕЙРОННЫХ СЕТЕЙ | 2024 |
|
RU2835757C1 |
| СПОСОБ ОБРАБОТКИ ДАННЫХ ПОСРЕДСТВОМ НЕЙРОННОЙ СЕТИ, ПОДВЕРГНУТОЙ ДЕКОМПОЗИЦИИ С УЧЕТОМ ОБЪЕМА ПАМЯТИ ВЫЧИСЛИТЕЛЬНОГО УСТРОЙСТВА (ВАРИАНТЫ), И КОМПЬЮТЕРНО-ЧИТАЕМЫЙ НОСИТЕЛЬ | 2023 |
|
RU2820172C1 |
| Способ и устройство для измерения характеристик колонки породы для создания модели поровой системы | 2020 |
|
RU2812143C1 |
| СПОСОБ ИДЕНТИФИКАЦИИ УЧАСТКОВ СВЯЗЫВАНИЯ БЕЛКОВЫХ КОМПЛЕКСОВ | 2020 |
|
RU2743316C1 |
| СПОСОБЫ РЕКОНСТРУКЦИИ КАРТЫ ГЛУБИНЫ И ЭЛЕКТРОННОЕ ВЫЧИСЛИТЕЛЬНОЕ УСТРОЙСТВО ДЛЯ ИХ РЕАЛИЗАЦИИ | 2020 |
|
RU2745010C1 |
Изобретение относится к системе сжатия искусственных нейронных сетей. Технический результат заключается в повышении эффективности сжатия искусственных нейронных сетей. Система содержит устройство сжатия, содержащее модуль автоматического определения параметров сжатия (модуль rank selector) и модуль, осуществляющий замену параметров сверточных/полносвязных слоев НС на их малоранговую аппроксимацию, полученную с помощью тензорных/матричных разложений (модуль tensor approximator), и устройство тонкой настройки, при этом устройство сжатия принимает на вход НС, модуль rank selector автоматически для каждого сверточного/полносвязного слоя НС подбирает ранг тензорного разложения, который используется при аппроксимации весового тензора, после чего модуль tensor approximator осуществляет замену веса слоя на его малоранговую аппроксимацию так, что суммарное число параметров новых тензоров меньше, чем число параметров в исходном тензоре, а устройство тонкой настройки принимает на вход преобразованную НС от устройства сжатия и выдает на выход оптимизированную НС, обладающую лучшей предсказательной способностью за счет корректировки параметров модели, которая производится методом обратного распространения ошибки с использованием базы данных. 1 з.п. ф-лы, 5 ил.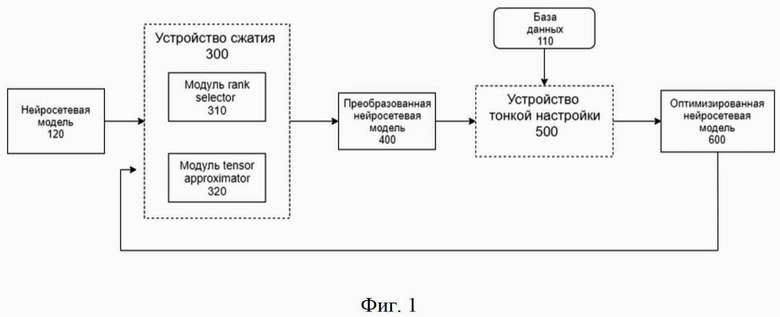
1. Система сжатия искусственных нейронных сетей (НС) на основе итеративного применения тензорных аппроксимаций, содержащая: устройство сжатия, которое состоит из модуля автоматического определения параметров сжатия (модуль rank selector) и модуля, осуществляющего замену параметров сверточных/полносвязных слоев НС на их малоранговую аппроксимацию, полученную с помощью тензорных/матричных разложений (модуль tensor approximator), и устройство тонкой настройки, при этом:
• устройство сжатия принимает на вход НС, модуль rank selector автоматически для каждого сверточного/полносвязного слоя НС подбирает ранг тензорного разложения, который используется при аппроксимации весового тензора, после чего модуль tensor approximator осуществляет замену веса слоя на его малоранговую аппроксимацию так, что суммарное число параметров новых тензоров меньше, чем число параметров в исходном тензоре,
в результате чего при первой обработке сверточного/полносвязного слоя устройством сжатия исходный слой заменяется на декомпозированный слой, который представляет собой последовательность нескольких сверточных/полносвязных слоев, при этом веса новых слоев инициализируются факторами тензорного разложения, с помощью которого выполнена аппроксимация, при повторной обработке уже декомпозированного слоя число сверточных/полносвязных слоев не изменяется, но число параметров в каждой составляющей декомпозированного слоя уменьшается в силу уменьшения ранга аппроксимации;
• устройство тонкой настройки принимает на вход преобразованную НС от устройства сжатия и выдает на выход оптимизированную НС, обладающую лучшей предсказательной способностью за счет корректировки параметров модели, которая производится методом обратного распространения ошибки с использованием базы данных.
2. Система по п. 1, характеризующаяся тем, что вес сверточного слоя представляет собой четырехмерный тензор, а вес полносвязного слоя является матрицей (двумерным тензором).
| БАЙЕСОВСКОЕ РАЗРЕЖИВАНИЕ РЕКУРРЕНТНЫХ НЕЙРОННЫХ СЕТЕЙ | 2018 |
|
RU2702978C1 |
| CN 109766995 A, 17.05.2019 | |||
| Токарный резец | 1924 |
|
SU2016A1 |
| CN 110032951 A, 19.07.2019 | |||
| Автомобиль-сани, движущиеся на полозьях посредством устанавливающихся по высоте колес с шинами | 1924 |
|
SU2017A1 |
| CN 107516129 A, 26.12.2017. | |||

