Уровень техники
Область техники, к которой относится изобретение
[1] Настоящее раскрытие относится к технологии кодирования изображений, а более конкретно, к преобразованию для матричного внутреннего прогнозирования при кодировании изображений.
Описание предшествующего уровня техники
[2] В последнее время, спрос на высококачественное изображение/видео высокого разрешения, к примеру, 4K, 8K либо изображения/видео еще более сверхвысокой четкости (UHD), растет в различных областях техники. По мере того, как разрешение или качество изображений/видео становится более высоким, относительно больший объем информации или число битов передается, чем для традиционных данных изображений/видео. Следовательно, если данные изображений/видео передаются через такую среду, как существующая проводная/беспроводная широкополосная линия, либо сохраняются на унаследованном от прошлого носителе хранения данных, затраты на передачу и хранение серьезно увеличиваются.
[3] Кроме того, растет интерес и спрос в отношении контента виртуальной реальности (VR) и искусственной реальности (AR) и иммерсивного мультимедиа, к примеру, голограммы; а также растет широковещательная передача изображений/видео, демонстрирующих характеристики изображений/видео, отличающиеся от характеристик фактического изображения/видео, к примеру, игровых изображений/видео.
[4] Следовательно, требуется высокоэффективная технология сжатия изображений/видео для того, чтобы эффективно сжимать и передавать, сохранять или воспроизводить высококачественные изображения/видео высокого разрешения, демонстрирующие различные характеристики, как описано выше.
Сущность изобретения
[5] Согласно варианту осуществления настоящего документа, предоставляются способ и оборудование для повышения эффективности кодирования изображений/видео.
[6] Согласно варианту осуществления настоящего документа, предоставляются способ и оборудование для преобразования блока, к которому матричное внутреннее прогнозирование (MIP) применяется при кодировании изображений.
[7] Согласно варианту осуществления настоящего документа, предоставляются способ и оборудование для передачи в служебных сигналах индекса преобразования для блока, к которому применяется MIP.
[8] Согласно варианту осуществления настоящего документа, предоставляются способ и оборудование для передачи в служебных сигналах индекса преобразования для блока, к которому не применяется MIP.
[9] Согласно варианту осуществления настоящего документа, предоставляются способ и оборудование для логического вывода индекса преобразования для блока, к которому применяется MIP.
[10] Согласно варианту осуществления настоящего документа, предоставляются способ и оборудование для преобразования в двоичную форму или кодирования индекса преобразования для блока, к которому применяется MIP.
[11] Согласно варианту осуществления настоящего документа, предоставляется способ декодирования видео/изображений, осуществляемый посредством оборудования декодирования.
[12] Согласно варианту осуществления настоящего документа, предоставляется оборудование декодирования для выполнения декодирования видео/изображений.
[13] Согласно варианту осуществления настоящего документа, предоставляется способ кодирования видео/изображений, осуществляемый посредством оборудования кодирования.
[14] Согласно варианту осуществления настоящего документа, предоставляется оборудование кодирования для выполнения кодирования видео/изображений.
[15] Согласно варианту осуществления настоящего документа, предоставляется компьютерно-читаемый цифровой носитель хранения данных, сохраняющий кодированную информацию видео/изображений, сформированную согласно способу кодирования видео/изображений, раскрытому по меньшей мере в одном из вариантов осуществления этого документа.
[16] Согласно варианту осуществления настоящего документа, предоставляется компьютерно-читаемый цифровой носитель хранения данных, сохраняющий кодированную информацию или кодированную информацию видео/изображений, инструктирующую оборудованию декодирования осуществлять способ декодирования видео/изображений, раскрытый по меньшей мере в одном из вариантов осуществления этого документа.
[17] Согласно настоящему документу, общая эффективность сжатия изображений/видео может повышаться.
[18] Согласно настоящему документу, индекс преобразования для блока, к которому применяется матричное внутреннее прогнозирование (MIP), может эффективно передаваться в служебных сигналах.
[19] Согласно настоящему документу, индекс преобразования для блока, к которому применяется MIP, может эффективно кодироваться.
[20] Согласно настоящему документу, индекс преобразования для блока, к которому применяется MIP, может логически выводиться без отдельной передачи в служебных сигналах индекса преобразования.
[21] Согласно настоящему документу, в случае если применяются MIP и низкочастотное неразделимое преобразование (LFNST), помехи между ними могут минимизироваться, оптимальная эффективность кодирования может поддерживаться, и сложность может уменьшаться.
[22] Преимущества, которые могут получаться через подробный пример настоящего документа, не ограничены преимуществами, перечисленными выше. Например, могут быть предусмотрены различные технические эффекты, которые могут пониматься или логически выводиться специалистами в данной области техники из настоящего документа. Соответственно, подробные преимущества настоящего документа не ограничены преимуществами, явно указанными в настоящем документе, и могут включать в себя различные преимущества, которые могут пониматься или логически выводиться из технических признаков настоящего документа.
Краткое описание чертежей
[23] Фиг. 1 схематично иллюстрирует пример системы кодирования видео/изображений, к которой является применимым настоящий документ.
[24] Фиг. 2 является схемой, схематично поясняющей конфигурацию оборудования кодирования видео/изображений, к которому является применимым настоящий документ.
[25] Фиг. 3 является схемой, схематично поясняющей конфигурацию оборудования декодирования видео/изображений, к которому является применимым настоящий документ.
[26] Фиг. 4 схематично иллюстрирует технологию множественного преобразования согласно варианту осуществления настоящего документа.
[27] Фиг. 5 примерно иллюстрирует внутренние направленные режимы в 65 направлениях прогнозирования.
[28] Фиг. 6 и 7 являются схемами, поясняющими RST согласно варианту осуществления настоящего документа.
[29] Фиг. 8 примерно иллюстрирует контекстно-адаптивное двоичное арифметическое кодирование (CABAC) для кодирования синтаксических элементов.
[30] Фиг. 9 является схемой, поясняющей MIP для блока 8×8.
[31] Фиг. 10 является блок-схемой последовательности операций, поясняющей способ, к которому применяются MIP и LFNST.
[32] Фиг. 11 и 12 схематично иллюстрируют способ кодирования видео/изображений и пример связанных компонентов согласно варианту(ам) осуществления настоящего документа.
[33] Фиг. 13 и 14 схематично иллюстрируют способ декодирования видео/изображений и пример связанных компонентов согласно варианту(ам) осуществления настоящего документа.
[34] Фиг. 15 иллюстрирует пример системы потоковой передачи контента, к которой являются применимыми варианты осуществления, раскрытые в настоящем документе.
Подробное описание вариантов осуществления
[35] Настоящее раскрытие может модифицироваться в различных формах, и его конкретные варианты осуществления описываются и иллюстрируются на чертежах. Тем не менее, эти варианты осуществления не предназначены для ограничения раскрытия. Термины, используемые в нижеприведенном описании, используются для того, чтобы просто описывать конкретные варианты осуществления, но не имеют намерение ограничивать раскрытие. Выражение единственного числа включает в себя выражение множественного числа, до тех пор, пока они четко трактуются по-разному. Такие термины, как "включать в себя" и "иметь", предназначены для того, чтобы указывать то, что существуют признаки, числа, этапы, операции, элементы, компоненты либо комбинации вышеозначенного, используемые в нижеприведенном описании, и в силу этого следует понимать, что не исключается возможность наличия или добавления одного или более других признаков, чисел, этапов, операций, элементов, компонентов либо комбинаций вышеозначенного.
[36] Помимо этого, каждая конфигурация чертежей, описанных в этом документе, является независимой иллюстрацией для пояснения функций в качестве признаков, которые отличаются друг от друга, и не означает то, что каждая конфигурация реализуется посредством взаимно различных аппаратных средств или различного программного обеспечения. Например, две или более конфигураций могут комбинироваться, чтобы формировать одну конфигурацию, и одна конфигурация также может разделяться на несколько конфигураций. Без отступления от сущности этого документа, варианты осуществления, в которых конфигурации комбинируются и/или разделяются, включаются в объем формулы изобретения.
[37] В дальнейшем в этом документе подробно описываются примеры настоящего варианта осуществления со ссылкой на прилагаемые чертежи. Помимо этого, аналогичные ссылки с номерами используются для того, чтобы указывать аналогичные элементы на всех чертежах, и идентичные описания аналогичных элементов опускаются.
[38] Этот документ относится к кодированию видео/изображений. Например, способы/варианты осуществления, раскрытые в этом документе, могут относиться к стандарту универсального кодирования видео (VVC) (ITU-T (Rec. (H.266), к стандарту кодирования видео/изображений следующего поколения после VVC либо к другим связанным с кодированием видео стандартам (например, к стандарту высокоэффективного кодирования видео (HEVC) (ITU-T (Rec. (H.265), к стандарту фундаментального кодирования видео (EVC), к AVS2-стандарту и т.п.).
[39] Этот документ предлагает различные варианты осуществления кодирования видео/изображений, и вышеуказанные варианты осуществления также могут выполняться в комбинации между собой, если не указано иное.
[40] В этом документе, видео может означать последовательность изображений во времени. Кадр, в общем, означает единицу, представляющую одно изображение в конкретном временном кинокадре, и срез/плитка означает единицу, составляющую часть кадра с точки зрения кодирования. Срез/плитка может включать в себя одну или более единиц дерева кодирования (CTU). Один кадр может состоять из одного или более срезов/плиток. Один кадр может состоять из одной или более групп плиток. Одна группа плиток может включать в себя одну или более плиток.
[41] Пиксел или пел может означать наименьшую единицу, составляющую один кадр (или изображение). Кроме того, "выборка" может использоваться в качестве термина, соответствующего пикселу. Выборка, в общем, может представлять пиксел или значение пиксела и может представлять только пиксел/пиксельное значение компонента сигнала яркости либо только пиксел/пиксельное значение компонента сигнала цветности.
[42] Единица может представлять базовую единицу обработки изображений. Единица может включать в себя по меньшей мере одно из конкретной области кадра и информации, связанной с областью. Одна единица может включать в себя один блок сигналов яркости и два блока сигналов цветности (например, Cb, Cr). Единица может использоваться взаимозаменяемо с такими терминами, как блок или зона в некоторых случаях. В общем случае, блок MxN может включать в себя выборки (или массивы выборок) либо набор (или массив) коэффициентов преобразования из M столбцов и N строк. Альтернативно, выборка может означать пиксельное значение в пространственной области и когда такое пиксельное значение преобразуется в частотную область, это может означать коэффициент преобразования в частотной области.
[43] В этом документе, термин "/" и "," должен интерпретироваться как указывающий "и/или". Например, выражение "A/B" может означать "A и/или B". Дополнительно, "A, B" может означать "A и/или B". Дополнительно, "A/B/C" может означать "по меньшей мере одно из A, B и/или C". Кроме того, "A/B/C" может означать "по меньшей мере одно из A, B и/или C".
[44] Дополнительно, в документе, термин "или" должен интерпретироваться как указывающий "и/или". Например, выражение "A или B" может содержать 1) только A, 2) только B и/или 3) как A, так и B. Другими словами, термин "или" в этом документе должен интерпретироваться как указывающий "дополнительно или альтернативно".
[45] В настоящем описании изобретения, "по меньшей мере одно из A и B" может означать "только A", "только B" или "как A, так и B". Кроме того, в настоящем описании изобретения, выражение "по меньшей мере одно из A или B" или "по меньшей мере одно из A и/или B" может интерпретироваться идентично "по меньшей мере одно из A и B".
[46] Дополнительно, в настоящем описании изобретения, "по меньшей мере одно из A, B и C" может означать "только A", "только B", "только C" либо "любая комбинация A, B и C". Кроме того, "по меньшей мере одно из A, B или C" или "по меньшей мере одно из A, B и/или C" может означать "по меньшей мере одно из A, B и C".
[47] Дополнительно, круглые скобки, используемые в настоящем описании изобретения, могут означать "например". В частности, в случае если "прогнозирование (внутреннее прогнозирование)" выражается, может указываться то, что "внутреннее прогнозирование" предлагается в качестве примера "прогнозирования". Другими словами, термин "прогнозирование" в настоящем описании изобретения не ограничен "внутренним прогнозированием", и может указываться то, что "внутреннее прогнозирование" предлагается в качестве примера "прогнозирования". Дополнительно, даже в случае, если "прогнозирование (т.е. внутреннее прогнозирование)" выражается, может указываться то, что "внутреннее прогнозирование" предлагается в качестве примера "прогнозирования".
[48] В настоящем описании изобретения, технические признаки, отдельно поясненные на одном чертеже, могут реализовываться отдельно либо могут реализовываться одновременно.
[49] Фиг. 1 иллюстрирует пример системы кодирования видео/изображений, к которой может применяться раскрытие настоящего документа.
[50] Ссылаясь на фиг. 1, система кодирования видео/изображений может включать в себя исходное устройство и приемное устройство. Исходное устройство может передавать кодированную информацию или данные видео/изображений в приемное устройство через цифровой носитель хранения данных или сеть в форме файла или потоковой передачи.
[51] Исходное устройство может включать в себя видеоисточник, оборудование кодирования и передатчик. Приемное устройство может включать в себя приемник, оборудование декодирования и модуль рендеринга. Оборудование кодирования может называться "оборудованием кодирования видео/изображений", и оборудование декодирования может называться "оборудованием декодирования видео/изображений". Передатчик может включаться в оборудование кодирования. Приемник может включаться в оборудование декодирования. Модуль рендеринга может включать в себя дисплей, и дисплей может быть сконфигурирован как отдельное устройство или внешний компонент.
[52] Видеоисточник может получать видео/изображение посредством процесса захвата, синтезирования или формирования видео/изображения. Видеоисточник может включать в себя устройство захвата видео/изображений и/или устройство формирования видео/изображений. Устройство захвата видео/изображений может включать в себя, например, одну или более камер, архивы видео/изображений, включающие в себя ранее захваченные видео/изображения, и т.п. Устройство формирования видео/изображений может включать в себя, например, компьютеры, планшетные компьютеры и смартфоны и может (электронно) формировать видео/изображения. Например, виртуальное видео/изображение может формироваться через компьютер и т.п. В этом случае, процесс захвата видео/изображений может заменяться посредством процесса формирования связанных данных.
[53] Оборудование кодирования может кодировать входное видео/изображение. Оборудование кодирования может выполнять последовательность процедур, таких как прогнозирование, преобразование и квантование, для эффективности сжатия и кодирования. Кодированные данные (кодированная информация видео/изображений) могут выводиться в форме потока битов.
[54] Передатчик может передавать информацию или данные кодированных изображений/изображений, выводимую в форме потока битов, в приемник приемного устройства через цифровой носитель хранения данных или сеть в форме файла или потоковой передачи. Цифровой носитель хранения данных может включать в себя различные носители хранения данных, такие как USB, SD, CD, DVD, Blu-Ray, HDD, SSD и т.п. Передатчик может включать в себя элемент для формирования мультимедийного файла через предварительно определенный формат файлов и может включать в себя элемент для передачи через широковещательную передачу/сеть связи. Приемник может принимать/извлекать поток битов и передавать принимаемый поток битов в оборудование декодирования.
[55] Оборудование декодирования может декодировать видео/изображение посредством выполнения последовательности процедур, таких как деквантование, обратное преобразование и прогнозирование, соответствующих работе оборудования кодирования.
[56] Модуль рендеринга может подготавливать посредством рендеринга декодированное видео/изображение. Подготовленное посредством рендеринга видео/изображение может отображаться через дисплей.
[57] Фиг. 2 является схемой, принципиально иллюстрирующей конфигурацию оборудования кодирования видео/изображений, к которому может применяться раскрытие настоящего документа. В дальнейшем в этом документе, то, что называется "оборудованием кодирования видео", может включать в себя оборудование кодирования изображений.
[58] Ссылаясь на фиг. 2, оборудование 200 кодирования может включать в себя и конфигурироваться с помощью модуля 210 сегментации изображений, модуля 220 прогнозирования, остаточного процессора 230, энтропийного кодера 240, сумматора 250, фильтра 260 и запоминающего устройства 270. Модуль 220 прогнозирования может включать в себя модуль 221 взаимного прогнозирования и модуль 222 внутреннего прогнозирования. Остаточный процессор 230 может включать в себя преобразователь 232, квантователь 233, деквантователь 234 и обратный преобразователь 235. Остаточный процессор 230 дополнительно может включать в себя вычитатель 231. Сумматор 250 может называться "модулем восстановления" или "формирователем восстановленных блоков". Модуль 210 сегментации изображений, модуль 220 прогнозирования, остаточный процессор 230, энтропийный кодер 240, сумматор 250 и фильтр 260, которые описываются выше, могут конфигурироваться посредством одного или более аппаратных компонентов (например, наборов микросхем или процессоров кодера) согласно варианту осуществления. Помимо этого, запоминающее устройство 270 может включать в себя буфер декодированных кадров (DPB) и также может конфигурироваться посредством цифрового носителя хранения данных. Аппаратный компонент дополнительно может включать в себя запоминающее устройство 270 в качестве внутреннего/внешнего компонента.
[59] Модуль 210 сегментации изображений может разбивать входное изображение (или кадр, кинокадр), вводимое в оборудование 200 кодирования, на одну или более единиц обработки. В качестве примера, единица обработки может называться "единицей кодирования (CU)". В этом случае, единица кодирования может рекурсивно разбиваться согласно структуре в виде дерева квадрантов, двоичного дерева и троичного дерева (QTBTTT) из единицы дерева кодирования (CTU) или наибольшей единицы кодирования (LCU). Например, одна единица кодирования может разбиваться на множество единиц кодирования большей глубины на основе структуры в виде дерева квадрантов, структуры в виде двоичного дерева и/или структуры в виде троичного дерева. В этом случае, например, сначала применяется структура в виде дерева квадрантов, и впоследствии может применяться структура в виде двоичного дерева и/или структура в виде троичного дерева. Альтернативно, также сначала может применяться структура в виде двоичного дерева. Процедура кодирования согласно настоящему раскрытию может выполняться на основе конечной единицы кодирования, которая более не разбивается. В этом случае, на основе эффективности кодирования согласно характеристикам изображений и т.п., максимальная единица кодирования может непосредственно использоваться в качестве конечной единицы кодирования, или при необходимости, единица кодирования может рекурсивно разбиваться на единицы кодирования большей глубины, так что единица кодирования, имеющая оптимальный размер, может использоваться в качестве конечной единицы кодирования. Здесь, процедура кодирования может включать в себя такую процедуру, как прогнозирование, преобразование и восстановление, которая описывается ниже. В качестве другого примера, единица обработки дополнительно может включать в себя единицу прогнозирования (PU) или единицу преобразования (TU). В этом случае, каждая из единицы прогнозирования и единицы преобразования может разбиваться или сегментироваться из вышеуказанной конечной единицы кодирования. Единица прогнозирования может представлять собой единицу выборочного прогнозирования, и единица преобразования может представлять собой единицу для логического вывода коэффициента преобразования и/или единицу для логического вывода остаточного сигнала из коэффициента преобразования.
[60] Единица может взаимозаменяемо использоваться с таким термином, как блок или зона, в некоторых случаях. Обычно, блок MxN может представлять выборки, состоящие из M столбцов и N строк или группы коэффициентов преобразования. Выборка, в общем, может представлять пиксел или значение пиксела и также может представлять только пиксел/пиксельное значение компонента сигнала яркости, а также представлять только пиксел/пиксельное значение компонента сигнала цветности. Выборка может использоваться в качестве термина, соответствующего пикселу или пелу, конфигурирующему один кадр (или изображение).
[61] Вычитатель 231 может формировать остаточный сигнал (остаточный блок, остаточные выборки или массив остаточных выборок) посредством вычитания прогнозного сигнала (прогнозированный блок, прогнозные выборки или массив прогнозных выборок), вывод из модуля 220 прогнозирования из сигнала входного изображения (исходный блок, исходные выборки или массив исходных выборок) и сформированный остаточный сигнал передается в преобразователь 232. Модуль 220 прогнозирования может выполнять прогнозирование для целевого блока обработки (далее называемого "текущим блоком") и формировать прогнозированный блок, включающий в себя прогнозные выборки для текущего блока. Модуль 220 прогнозирования может определять то, применяется либо нет внутреннее прогнозирование или взаимное прогнозирование, для текущего блока или в единицах CU. Как описано ниже в описании каждого режима прогнозирования, модуль прогнозирования может формировать различные виды информации, связанной с прогнозированием, к примеру, информацию режима прогнозирования, и передавать сформированную информацию в энтропийный кодер 240. Информация относительно прогнозирования может кодироваться в энтропийном кодере 240 и выводиться в форме потока битов.
[62] Модуль 222 внутреннего прогнозирования может прогнозировать текущий блок со ссылкой на выборки в пределах текущего кадра. Выборки, на которые ссылаются, могут быть расположены как граничащие с текущим блоком либо также могут быть расположены на большом расстоянии от текущего блока согласно режиму прогнозирования. Режимы прогнозирования при внутреннем прогнозировании могут включать в себя множество ненаправленных режимов и множество направленных режимов. Ненаправленный режим может включать в себя, например, DC-режим или планарный режим. Направленный режим может включать в себя, например, 33 режима направленного прогнозирования или 65 режимов направленного прогнозирования согласно точной степени направления прогнозирования. Тем не менее, это является иллюстративным, и режимы направленного прогнозирования, которые больше или меньше вышеуказанного числа, могут использоваться согласно настройке. Модуль 222 внутреннего прогнозирования также может определять режим прогнозирования, применяемый к текущему блоку, посредством использования режима прогнозирования, применяемого к соседнему блоку.
[63] Модуль 221 взаимного прогнозирования может логически выводить прогнозированный блок текущего блока на основе опорного блока (массива опорных выборок), указываемого посредством вектора движения для опорного кадра. В это время, чтобы снижать объем информации движения, передаваемой в режиме взаимного прогнозирования, информация движения может прогнозироваться в единицах блоков, субблоков или выборок на основе корреляции информации движения между соседним блоком и текущим блоком. Информация движения может включать в себя вектор движения и индекс опорного кадра. Информация движения дополнительно может включать в себя информацию направления взаимного прогнозирования (L0-прогнозирование, L1-прогнозирование, бипрогнозирование и т.п.). В случае взаимного прогнозирования, соседний блок может включать в себя пространственный соседний блок, существующий в текущем кадре, и временной соседний блок, существующий в опорном кадре. Опорный кадр, включающий в себя опорный блок, и опорный кадр, включающий в себя временной соседний блок, могут быть идентичными друг другу или отличающимися друг от друга. Временной соседний блок может упоминаться под таким названием, как "совместно размещенный опорный блок", "совместно размещенная CU (colCU)" и т.п., и опорный кадр, включающий в себя временной соседний блок, также может называться "совместно размещенным кадром (colPic)". Например, модуль 221 взаимного прогнозирования может конфигурировать список возможных вариантов информации движения на основе соседних блоков и формировать информацию, указывающую то, какой возможный вариант используется для того, чтобы извлекать вектор движения и/или индекс опорного кадра текущего блока. Взаимное прогнозирование может выполняться на основе различных режимов прогнозирования, и, например, в случае режима пропуска и режима объединения, модуль 221 взаимного прогнозирования может использовать информацию движения соседнего блока в качестве информации движения текущего блока. В случае режима пропуска, остаточный сигнал может не передаваться, в отличие от режима объединения. Режим прогнозирования векторов движения (MVP) может указывать вектор движения текущего блока посредством использования вектора движения соседнего блока в качестве предиктора вектора движения и передачи в служебных сигналах разности векторов движения.
[64] Модуль 220 прогнозирования может формировать прогнозный сигнал на основе различных способов прогнозирования, описанных ниже. Например, модуль прогнозирования может не только применять внутреннее прогнозирование или взаимное прогнозирование для того, чтобы прогнозировать один блок, но также и одновременно применять как внутренние прогнозирование, так и взаимное прогнозирование. Это может называться "комбинированным взаимным и внутренним прогнозированием (CIIP)". Помимо этого, модуль прогнозирования может выполнять внутриблочное копирование (IBC) для прогнозирования блока. Внутриблочное копирование может использоваться для кодирования изображений контента/движущихся изображений игры и т.п., например, для кодирования экранного контента (SCC). IBC по существу выполняет прогнозирование в текущем кадре, но оно может выполняться аналогично взаимному прогнозированию, в котором опорный блок извлекается в текущем кадре. Таким образом, IBC может использовать по меньшей мере одну из технологий взаимного прогнозирования, описанных в настоящем документе.
[65] Прогнозный сигнал, сформированный через модуль 221 взаимного прогнозирования и/или модуль 222 внутреннего прогнозирования, может использоваться для того, чтобы формировать восстановленный сигнал или формировать остаточный сигнал. Преобразователь 232 может формировать коэффициенты преобразования посредством применения технологии преобразования к остаточному сигналу. Например, технология преобразования может включать в себя по меньшей мере одно из дискретного косинусного преобразования (DCT), дискретного синусного преобразования (DST), преобразования на основе графа (GBT) или условно нелинейного преобразования (CNT). Здесь, GBT означает преобразование, полученное из графа, когда информация взаимосвязи между пикселами представляется посредством графа. CNT означает преобразование, полученное на основе прогнозного сигнала, сформированного с использованием всех ранее восстановленных пикселов. Помимо этого, процесс преобразования может применяться к квадратным пиксельным блокам, имеющим идентичный размер, или может применяться к блокам, имеющим переменный размер, а не квадратный.
[66] Квантователь 233 может квантовать коэффициенты преобразования и передавать их в энтропийный кодер 240, и энтропийный кодер 240 может кодировать квантованный сигнал (информацию относительно квантованных коэффициентов преобразования) и выводить поток битов. Информация относительно квантованных коэффициентов преобразования может называться "остаточной информацией". Квантователь 233 может перекомпоновывать блочные квантованные коэффициенты преобразования в одномерную векторную форму на основе порядка сканирования коэффициентов и формировать информацию относительно квантованных коэффициентов преобразования на основе квантованных коэффициентов преобразования в одномерной векторной форме. Энтропийный кодер 240 может осуществлять различные способы кодирования, такие как, например, кодирование экспоненциальным кодом Голомба, контекстно-адаптивное кодирование переменной длины (CAVLC), контекстно-адаптивное двоичное арифметическое кодирование (CABAC) и т.п. Энтропийный кодер 240 может кодировать информацию, необходимую для восстановления видео/изображений вместе с или отдельно из квантованных коэффициентов преобразования (например, значения синтаксических элементов и т.п.). Кодированная информация (например, кодированная информация видео/изображений) может передаваться или сохраняться в единицах слоя абстрагирования от сети (NAL) в форме потока битов. Информация видео/изображений дополнительно может включать в себя информацию относительно различных наборов параметров, таких как набор параметров адаптации (APS), набор параметров кадра (PPS), набор параметров последовательности (SPS) или набор параметров видео (VPS). Помимо этого, информация видео/изображений дополнительно может включать в себя общую информацию ограничений. В настоящем документе, передаваемые в служебных сигналах/передаваемые информация и/или синтаксические элементы, которые описываются ниже, могут кодироваться через вышеописанную процедуру кодирования и включаться в поток битов. Поток битов может передаваться через сеть или может сохраняться на цифровом носителе хранения данных. Здесь, сеть может включать в себя широковещательную сеть и/или сеть связи, и цифровой носитель хранения данных может включать в себя различные носители хранения данных, такие как USB, SD, CD, DVD, Blu-Ray, HDD, SSD и т.п. Передатчик (не проиллюстрирован), передающий сигнал, выводимый из энтропийного кодера 240, и/или модуль хранения (не проиллюстрирован), сохраняющий сигнал, могут быть сконфигурированы в качестве внутреннего/внешнего элемента оборудования 200 кодирования, и альтернативно, передатчик может включаться в энтропийный кодер 240.
[67] Квантованные коэффициенты преобразования, выводимые из квантователя 233, могут использоваться для того, чтобы формировать прогнозный сигнал. Например, остаточный сигнал (остаточный блок или остаточные выборки) может восстанавливаться посредством применения деквантования и обратного преобразования к квантованным коэффициентам преобразования через деквантователь 234 и обратный преобразователь 235. Сумматор 250 суммирует восстановленный остаточный сигнал с прогнозным сигналом, выводимым из модуля 220 прогнозирования, чтобы формировать восстановленный сигнал (восстановленный кадр, восстановленные выборки или массив восстановленных выборок). Если отсутствует остаток для целевого блока для обработки, к примеру, в случае, когда режим пропуска применяется, прогнозированный блок может использоваться в качестве восстановленного блока. Сформированный восстановленный сигнал может использоваться для внутреннего прогнозирования следующего целевого блока для обработки в текущем кадре и может использоваться для взаимного прогнозирования следующего кадра посредством фильтрации, как описано ниже.
[68] Между тем, преобразование сигнала яркости с масштабированием сигнала цветности (LMCS) может применяться в ходе процесса кодирования и/или восстановления кадров.
[69] Фильтр 260 может повышать субъективное/объективное качество изображений посредством применения фильтрации к восстановленному сигналу. Например, фильтр 260 может формировать модифицированный восстановленный кадр посредством применения различных способов фильтрации к восстановленному кадру и сохранять модифицированный восстановленный кадр в запоминающем устройстве 270, а именно, в DPB запоминающего устройства 270. Различные способы фильтрации могут включать в себя, например, фильтрацию для удаления блочности, дискретизированное адаптивное смещение (SAO), адаптивный контурный фильтр, билатеральный фильтр и т.п. Фильтр 260 может формировать различные виды информации, связанной с фильтрацией, и передавать сформированную информацию в энтропийный кодер 290, как описано ниже в описании каждого способа фильтрации. Информация, связанная с фильтрацией, может кодироваться посредством энтропийного кодера 290 и выводиться в форме потока битов.
[70] Модифицированный восстановленный кадр, передаваемый в запоминающее устройство 270, может использоваться в качестве опорного кадра в модуле 221 взаимного прогнозирования. Когда взаимное прогнозирование применяется посредством оборудования кодирования, рассогласование прогнозирования между оборудованием 200 кодирования и оборудованием декодирования может исключаться, и эффективность кодирования может повышаться.
[71] DPB запоминающего устройства 270 может сохранять модифицированный восстановленный кадр для использования в качестве опорного кадра в модуле 221 взаимного прогнозирования. Запоминающее устройство 270 может сохранять информацию движения блока, из которой информация движения в текущем кадре извлекается (или кодируется), и/или информацию движения уже восстановленных блоков в кадре. Сохраненная информация движения может передаваться в модуль 221 взаимного прогнозирования для использования в качестве информации движения пространственного соседнего блока или информации движения временного соседнего блока. Запоминающее устройство 270 может сохранять восстановленные выборки восстановленных блоков в текущем кадре и может передавать восстановленные выборки в модуль 222 внутреннего прогнозирования.
[72] Фиг. 3 является схемой для схематичного пояснения конфигурации оборудования декодирования видео/изображений, к которому может применяться раскрытие настоящего документа.
[73] Ссылаясь на фиг. 3, оборудование 300 декодирования может включать в себя и конфигурироваться с помощью энтропийного декодера 310, остаточного процессора 320, модуля 330 прогнозирования, сумматора 340, фильтра 350 и запоминающего устройства 360. Модуль 330 прогнозирования может включать в себя модуль 331 взаимного прогнозирования и модуль 332 внутреннего прогнозирования. Остаточный процессор 320 может включать в себя деквантователь 321 и обратный преобразователь 322. Энтропийный декодер 310, остаточный процессор 320, модуль 330 прогнозирования, сумматор 340 и фильтр 350, которые описываются выше, могут конфигурироваться посредством одного или более аппаратных компонентов (например, наборов микросхем или процессоров декодера) согласно варианту осуществления. Дополнительно, запоминающее устройство 360 может включать в себя буфер декодированных кадров (DPB) и может конфигурироваться посредством цифрового носителя хранения данных. Аппаратный компонент дополнительно может включать в себя запоминающее устройство 360 в качестве внутреннего/внешнего компонента.
[74] Когда поток битов, включающий в себя информацию видео/изображений, вводится, оборудование 300 декодирования может восстанавливать изображение в ответ на процесс, в котором информация видео/изображений обрабатывается в оборудовании кодирования, проиллюстрированном на фиг. 2. Например, оборудование 300 декодирования может извлекать единицы/блоки на основе связанной с разбиением на блоки информации, полученной из потока битов. Оборудование 300 декодирования может выполнять декодирование с использованием единицы обработки, применяемой для оборудования кодирования. Следовательно, единица обработки для декодирования, например, может представлять собой единицу кодирования, и единица кодирования может разбиваться согласно структуре в виде дерева квадрантов, структуре в виде двоичного дерева и/или структуре в виде троичного дерева из единицы дерева кодирования или максимальной единицы кодирования. Одна или более единиц преобразования могут извлекаться из единицы кодирования. Помимо этого, восстановленный сигнал изображения, декодированный и выводимый посредством оборудования 300 декодирования, может воспроизводиться посредством оборудования воспроизведения.
[75] Оборудование 300 декодирования может принимать сигнал, выводимый из оборудования кодирования по фиг. 2 в форме потока битов, и принимаемый сигнал может декодироваться через энтропийный декодер 310. Например, энтропийный декодер 310 может синтаксически анализировать поток битов, чтобы извлекать информацию (например, информацию видео/изображений), необходимую для восстановления изображений (или восстановления кадров). Информация видео/изображений дополнительно может включать в себя информацию относительно различных наборов параметров, таких как набор параметров адаптации (APS), набор параметров кадра (PPS), набор параметров последовательности (SPS) или набор параметров видео (VPS). Помимо этого, информация видео/изображений дополнительно может включать в себя общую информацию ограничений. Оборудование декодирования дополнительно может декодировать кадр на основе информации относительно набора параметров и/или общей информации ограничений. Передаваемая в служебных сигналах/принимаемая информация и/или синтаксические элементы, описанные далее в этом документе, могут декодироваться, может декодировать процедуру декодирования и получаться из потока битов. Например, энтропийный декодер 310 декодирует информацию в потоке битов на основе способа кодирования, такого как кодирование экспоненциальным кодом Голомба, CAVLC или CABAC, и выходных синтаксических элементов, требуемых для восстановления изображений, и квантованных значений коэффициентов преобразования для остатка. Более конкретно, способ энтропийного CABAC-декодирования может принимать элемент разрешения, соответствующий каждому синтаксическому элементу в потоке битов, определять контекстную модель посредством использования информации целевого синтаксического элемента декодирования, информации декодирования целевого блока декодирования или информации символа/элемента разрешения, декодированного на предыдущей стадии, и выполнять арифметическое декодирование для элемента разрешения посредством прогнозирования вероятности появления элемента разрешения согласно определенной контекстной модели и формировать символ, соответствующий значению каждого синтаксического элемента. В этом случае, способ энтропийного CABAC-декодирования может обновлять контекстную модель посредством использования информации декодированного символа/элемента разрешения для контекстной модели следующего символа/элемента разрешения после определения контекстной модели. Информация, связанная с прогнозированием, из информации, декодированной посредством энтропийного декодера 310, может предоставляться в модуль 330 прогнозирования, и информация относительно остатка, для которого энтропийное декодирование выполнено в энтропийном декодере 310, т.е. квантованные коэффициенты преобразования и связанная информация параметров, может вводиться в деквантователь 321. Помимо этого, информация относительно фильтрации из информации, декодированной посредством энтропийного декодера 310, может предоставляться в фильтр 350. Между тем, приемник (не проиллюстрирован) для приема сигнала, выводимого из оборудования кодирования, может быть дополнительно сконфигурирован в качестве внутреннего/внешнего элемента оборудования 300 декодирования, или приемник может представлять собой составляющий элемент энтропийного декодера 310. Между тем, оборудование декодирования согласно настоящему документу может называться "оборудованием декодирования видео/изображений/кадров", и оборудование декодирования может классифицироваться на информационный декодер (декодер информации видео/изображений/кадров) и выборочный декодер (декодер выборок видео/изображений/кадров). Информационный декодер может включать в себя энтропийный декодер 310, и выборочный декодер может включать в себя по меньшей мере одно из деквантователя 321, обратного преобразователя 322, модуля 330 прогнозирования, сумматора 340, фильтра 350 и запоминающего устройства 360.
[76] Деквантователь 321 может деквантовать квантованные коэффициенты преобразования, с тем чтобы выводить коэффициенты преобразования. Деквантователь 321 может перекомпоновывать квантованные коэффициенты преобразования в двумерной блочной форме. В этом случае, перекомпоновка может выполняться на основе порядка сканирования коэффициентов, выполняемого посредством оборудования кодирования. Деквантователь 321 может выполнять деквантование для квантованных коэффициентов преобразования с использованием параметра квантования (например, информации размера шага квантования) и получать коэффициенты преобразования.
[77] Обратный преобразователь 322 обратно преобразует коэффициенты преобразования, чтобы получать остаточный сигнал (остаточный блок, массив остаточных выборок).
[78] Модуль 330 прогнозирования может выполнять прогнозирование текущего блока и формировать прогнозированный блок, включающий в себя прогнозные выборки текущего блока. Модуль прогнозирования может определять то, применяется внутреннее прогнозирование, или применяется взаимное прогнозирование к текущему блоку, на основе информации относительно прогнозирования, выводимой из энтропийного декодера 310, и определять конкретный режим внутреннего/взаимного прогнозирования.
[79] Модуль прогнозирования может формировать прогнозный сигнал на основе различных способов прогнозирования, описанных ниже. Например, модуль прогнозирования может не только применять внутреннее прогнозирование или взаимное прогнозирование для того, чтобы прогнозировать один блок, но также и одновременно применять внутреннее прогнозирование и взаимное прогнозирование. Это может называться "комбинированным взаимным и внутренним прогнозированием (CIIP)". Помимо этого, модуль прогнозирования может выполнять внутриблочное копирование (IBC) для прогнозирования блока. Внутриблочное копирование может использоваться для кодирования изображений контента/движущихся изображений игры и т.п., например, для кодирования экранного контента (SCC). IBC по существу выполняет прогнозирование в текущем кадре, но оно может выполняться аналогично взаимному прогнозированию, в котором опорный блок извлекается в текущем кадре. Таким образом, IBC может использовать по меньшей мере одну из технологий взаимного прогнозирования, описанных в настоящем документе.
[80] Модуль 332 внутреннего прогнозирования может прогнозировать текущий блок посредством ссылки на выборки в текущем кадре. Выборки для ссылки могут быть расположены в окружении текущего блока или могут быть расположены с разнесением относительно текущего блока согласно режиму прогнозирования. При внутреннем прогнозировании, режимы прогнозирования могут включать в себя множество ненаправленных режимов и множество направленных режимов. Модуль 332 внутреннего прогнозирования может определять режим прогнозирования, который должен применяться к текущему блоку, посредством использования режима прогнозирования, применяемого к соседнему блоку.
[81] Модуль 331 взаимного прогнозирования может извлекать прогнозированный блок для текущего блока на основе опорного блока (массива опорных выборок), указываемого посредством вектора движения для опорного кадра. В этом случае, чтобы уменьшать объем информации движения, передаваемой в режиме взаимного прогнозирования, информация движения может прогнозироваться в единицах блоков, субблоков или выборок на основе корреляции информации движения между соседним блоком и текущим блоком. Информация движения может включать в себя вектор движения и индекс опорного кадра. Информация движения дополнительно может включать в себя информацию относительно направления взаимного прогнозирования (L0-прогнозирование, L1-прогнозирование, бипрогнозирование и т.п.). В случае взаимного прогнозирования, соседний блок может включать в себя пространственный соседний блок, существующий в текущем кадре, и временной соседний блок, существующий в опорном кадре. Например, модуль 331 взаимного прогнозирования может конструировать список возможных вариантов информации движения на основе соседних блоков и извлекать вектор движения текущего блока и/или индекс опорного кадра на основе принимаемой информации выбора возможных вариантов. Взаимное прогнозирование может выполняться на основе различных режимов прогнозирования, и информация относительно прогнозирования может включать в себя информацию, указывающую режим взаимного прогнозирования для текущего блока.
[82] Сумматор 340 может формировать восстановленный сигнал (восстановленный кадр, восстановленный блок или массив восстановленных выборок) посредством суммирования полученного остаточного сигнала с прогнозным сигналом (прогнозированным блоком или массивом прогнозированных выборок), выводимым из модуля 330 прогнозирования. Если отсутствует остаток для целевого блока обработки, к примеру, в случае, когда режим пропуска применяется, прогнозированный блок может использоваться в качестве восстановленного блока.
[83] Сумматор 340 может называться "модулем восстановления" или "формирователем восстановленных блоков". Сформированный восстановленный сигнал может использоваться для внутреннего прогнозирования следующего блока, который должен обрабатываться в текущем кадре, и, как описано ниже, также может выводиться посредством фильтрации либо также может использоваться для взаимного прогнозирования следующего кадра.
[84] Между тем, преобразование сигнала яркости с масштабированием сигнала цветности (LMCS) также может применяться в процессе декодирования кадров.
[85] Фильтр 350 может повышать субъективное/объективное качество изображений посредством применения фильтрации к восстановленному сигналу. Например, фильтр 350 может формировать модифицированный восстановленный кадр посредством применения различных способов фильтрации к восстановленному кадру и сохранять модифицированный восстановленный кадр в запоминающем устройстве 360, а именно, в DPB запоминающего устройства 360. Различные способы фильтрации могут включать в себя, например, фильтрацию для удаления блочности, дискретизированное адаптивное смещение, адаптивный контурный фильтр, билатеральный фильтр и т.п.
[86] (Модифицированный) восстановленный кадр, сохраненный в DPB запоминающего устройства 360, может использоваться в качестве опорного кадра в модуле 331 взаимного прогнозирования. Запоминающее устройство 360 может сохранять информацию движения блока, из которой информация движения в текущем кадре извлекается (или декодируется), и/или информацию движения уже восстановленных блоков в кадре. Сохраненная информация движения может передаваться в модуль 331 взаимного прогнозирования, так что она используется в качестве информации движения пространственного соседнего блока или информации движения временного соседнего блока. Запоминающее устройство 360 может сохранять восстановленные выборки восстановленных блоков в текущем кадре и передавать восстановленные выборки в модуль 332 внутреннего прогнозирования.
[87] В настоящем описании изобретения, варианты осуществления, описанные в модуле 330 прогнозирования, деквантователе 321, обратном преобразователе 322 и фильтре 350 оборудования 300 декодирования, также могут применяться идентичным способом или соответственно модулю 220 прогнозирования, деквантователю 234, обратному преобразователю 235 и фильтру 260 оборудования 200 кодирования.
[88] Между тем, как описано выше, при выполнении кодирования видео, прогнозирование выполняется для того, чтобы повышать эффективность сжатия. Через это, может формироваться прогнозированный блок, включающий в себя прогнозные выборки для текущего блока, в качестве блока, который должен кодироваться (т.е. целевого блока кодирования). Здесь, прогнозированный блок включает в себя прогнозные выборки в пространственной области (или пиксельной области). Прогнозированный блок извлекается идентично в оборудовании кодирования и оборудовании декодирования, и оборудование кодирования может передавать в служебных сигналах информацию (остаточную информацию) относительно остатка между исходным блоком и прогнозированным блоком, а не значение исходной выборки исходного блока, в оборудование декодирования, за счет этого повышая эффективность кодирования изображений. Оборудование декодирования может извлекать остаточный блок, включающий в себя остаточные выборки на основе остаточной информации, суммировать остаточный блок и прогнозированный блок, чтобы формировать восстановленные блоки, включающие в себя восстановленные выборки, и формировать восстановленный кадр, включающий в себя восстановленные блоки.
[89] Остаточная информация может формироваться через процедуру преобразования и квантования. Например, оборудование кодирования может извлекать остаточный блок между исходным блоком и прогнозированным блоком, выполнять процедуру преобразования для остаточных выборок (массива остаточных выборок), включенных в остаточный блок, чтобы извлекать коэффициенты преобразования, выполнять процедуру квантования для коэффициентов преобразования, чтобы извлекать квантованные коэффициенты преобразования и связанную с сигналами остаточную информацию в оборудование декодирования (через поток битов). Здесь, остаточная информация может включать в себя информацию значений квантованных коэффициентов преобразования, информацию местоположения, технологию преобразования, ядро преобразования, параметр квантования и т.п. Оборудование декодирования может выполнять процедуру деквантования/обратного преобразования на основе остаточной информации и извлекать остаточные выборки (или остаточные блоки). Оборудование декодирования может формировать восстановленный кадр на основе прогнозированного блока и остаточного блока. Кроме того, для ссылки для взаимного прогнозирования изображения позднее, оборудование кодирования также может деквантовать/обратно преобразовывать квантованные коэффициенты преобразования, чтобы извлекать остаточный блок и формировать восстановленный кадр на его основе.
[90] Фиг. 4 схематично иллюстрирует технологию множественного преобразования согласно настоящему документу.
[91] Ссылаясь на фиг. 4, преобразователь может соответствовать преобразователю в оборудовании кодирования по фиг. 2, как описано выше, и обратный преобразователь может соответствовать обратному преобразователю в оборудовании кодирования по фиг. 2 или обратному преобразователю в оборудовании декодирования по фиг. 3, как описано выше.
[92] Преобразователь может извлекать коэффициенты (первичного) преобразования посредством выполнения первичного преобразования на основе остаточной выборки (массива остаточных выборок) в остаточном блоке (S410). Такое первичное преобразование может называться "базовым преобразованием". Здесь, первичное преобразование может быть основано на множественном выборе преобразования (MTS), и в случае, если множественное преобразование применяется в качестве первичного преобразования, оно может называться "множественным базовым преобразованием".
[93] Например, множественное базовое преобразование может представлять способ преобразования посредством дополнительного использования дискретного косинусного преобразования (DCT) тип 2 (DCT-II), дискретного синусного преобразования (DST) тип 7 (DST-VII), DCT-типа 8 (DCT-VIII) и/или DST-типа 1 (DST-I). Таким образом, множественное базовое преобразование может представлять способ преобразования для преобразования остаточного сигнала (или остаточного блока) пространственной области в коэффициенты преобразования (или коэффициенты первичного преобразования) частотной области на основе множества ядер преобразования, выбранных из DCT-типа 2, DST-типа 7, DCT-типа 8 и DST-типа 1. Здесь, коэффициенты первичного преобразования могут называться "временными коэффициентами преобразования на стороне преобразователя".
[94] Другими словами, в случае если существующий способ преобразования применяется, преобразование пространственной области для остаточного сигнала (или остаточного блока) в частотную область может применяться на основе DCT-типа 2, и коэффициенты преобразования могут формироваться. Тем не менее, в отличие от этого, в случае если множественное базовое преобразование применяется, преобразование пространственной области для остаточного сигнала (или остаточного блока) в частотную область может применяться на основе DCT-типа 2, DST-типа 7, DCT-типа 8 и/или DST-типа 1, и коэффициенты преобразования (или коэффициенты первичного преобразования) могут формироваться. Здесь, DCT-тип 2, DST-тип 7, DCT-тип 8 и DST-тип 1 могут называться "типом преобразования", "ядром преобразования" или "базой преобразования". Типы DCT/DST-преобразования могут задаваться на основе базисных функций.
[95] В случае, если множественное базовое преобразование выполняется, ядро вертикального преобразования и/или ядро горизонтального преобразования для целевого блока могут выбираться из числа ядер преобразования, вертикальное преобразование для целевого блока может выполняться на основе ядра вертикального преобразования, и горизонтальное преобразование для целевого блока может выполняться на основе ядра горизонтального преобразования. Здесь, горизонтальное преобразование может представлять преобразование для горизонтальных компонентов целевого блока, и вертикальное преобразование может представлять преобразование для вертикальных компонентов целевого блока. Ядро вертикального преобразования/ядро горизонтального преобразования может адаптивно определяться на основе режима прогнозирования и/или индекса преобразования целевого блока (CU или субблока), включающего в себя остаточный блок.
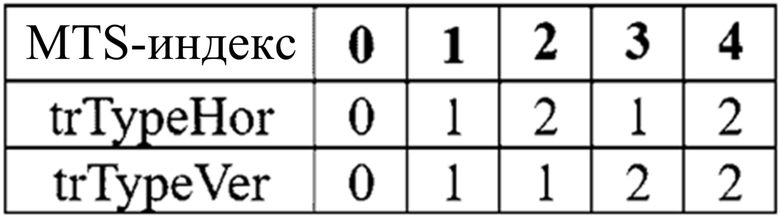
[96] Дополнительно, например, в случае выполнения первичного преобразования посредством применения MTS, конкретные базисные функции могут быть сконфигурированы как указанные значения, и в случае вертикального преобразования или горизонтального преобразования, взаимосвязь преобразования для ядра преобразования может быть сконфигурирована посредством комбинирования того, какие базисные функции применяются. Например, в случае если ядро преобразования горизонтального направления представляется посредством trTypeHor, и ядро преобразования вертикального направления представляется посредством trTypeVer, trTypeHor или trTypeVer, имеющее значение 0, может быть сконфигурировано как DCT2, и trTypeHor или trTypeVer, имеющее значение 1, может быть сконфигурировано как DCT7; trTypeHor или trTypeVer, имеющее значение 2, может быть сконфигурировано как DCT8.
[97] Дополнительно, например, чтобы указывать любой из нескольких наборов ядер преобразования, MTS-индекс может кодироваться, и информация MTS-индекса может передаваться в служебных сигналах в оборудование декодирования. Здесь, MTS-индекс может представляться как синтаксический элемент tu_mts_idx или синтаксический элемент mts_idx. Например, если MTS-индекс равен 0, он может представлять то, что значения trTypeHor и trTypeVer равны 0, и если MTS-индекс равен 1, он может представлять то, что значения trTypeHor и trTypeVer равны 1. Если MTS-индекс равен 2, он может представлять то, что значение trTypeHor равно 2, и значение trTypeVer равно 1, и если MTS-индекс равен 3, он может представлять то, что значение trTypeHor равно 1, и значение trTypeVer равно 2. Если MTS-индекс равен 4, он может представлять то, что значения trTypeHor и trTypeVer равны 2. Например, набор ядер преобразования согласно MTS-индексу может представляться так, как указано в следующей таблице.
[98] Табл. 1
[99] Преобразователь может извлекать модифицированные коэффициенты (вторичного) преобразования посредством выполнения вторичного преобразования на основе коэффициентов (первичного) преобразования (S420). Первичное преобразование может представлять собой преобразование пространственной области в частотную область, и вторичное преобразование может представлять преобразование в более сжимающее выражение посредством использования корреляции, существующей между коэффициентами (первичного) преобразования.
[100] Например, вторичное преобразование может включать в себя неразделимое преобразование. В этом случае, вторичное преобразование может называться "неразделимым вторичным преобразованием (NSST)" или "зависимым от режима неразделимым вторичным преобразованием (MDNSST)". Неразделимое вторичное преобразование может представлять преобразование для формирования модифицированных коэффициентов преобразования (или коэффициентов вторичного преобразования) для остаточного сигнала посредством вторичного преобразования коэффициентов (первичного) преобразования, извлекаемых через первичное преобразование на основе матрицы неразделимого преобразования. Здесь, вертикальное преобразование и горизонтальное преобразование могут не применяться отдельно (или независимо) относительно коэффициентов (первичного) преобразования на основе матрицы неразделимого преобразования, но могут применяться одновременно.
[101] Другими словами, неразделимое вторичное преобразование может представлять способ преобразования для перекомпоновки, например, двумерных сигналов (коэффициентов преобразования) в одномерный сигнал через конкретно определенное направление (например, направление сначала по строкам или направление сначала по столбцам), без разделения коэффициентов (первичного) преобразования на вертикальные компоненты и горизонтальные компоненты, и последующего формирования модифицированных коэффициентов преобразования (или коэффициентов вторичного преобразования) на основе матрицы неразделимого преобразования.
[102] Например, направление (или порядок) сначала по строкам может представлять компоновку блока MxN в линии в порядке "первая строка - N-ая строка", и направление (или порядок) сначала по столбцам может представлять компоновку блока MxN в линии в порядке "первый столбец - M-ый столбец". Здесь, M и N могут представлять ширину (W) и высоту (H) блока и могут быть положительными целыми числами.
[103] Например, неразделимое вторичное преобразование может применяться к левой верхней области блока, состоящего из коэффициентов (первичного) преобразования (далее блока коэффициентов преобразования). Например, если ширина (W) и высота (H) блока коэффициентов преобразования равны или больше 8, неразделимое вторичное преобразование 8×8 может применяться к левой верхней зоне 8×8 блока коэффициентов преобразования. Дополнительно, если ширина (W) и высота (H) блока коэффициентов преобразования равны или больше 4 и меньше 8, неразделимое вторичное преобразование 4×4 может применяться к левой верхней зоне min(8, W) x min(8, H) блока коэффициентов преобразования. Тем не менее, варианты осуществления не ограничены этим, и, например, даже если такое условие, что ширина (W) и высота (H) блока коэффициентов преобразования равны или больше 4, удовлетворяется, неразделимое вторичное преобразование 4×4 может применяться к левой верхней зоне min(8, W) x min(8, H) блока коэффициентов преобразования.
[104] В частности, например, в случае, когда входной блок 4×4 используется, неразделимое вторичное преобразование может выполняться следующим образом.
[105] Входной блок X 4×4 может представляться следующим образом.
[106] уравнение 1
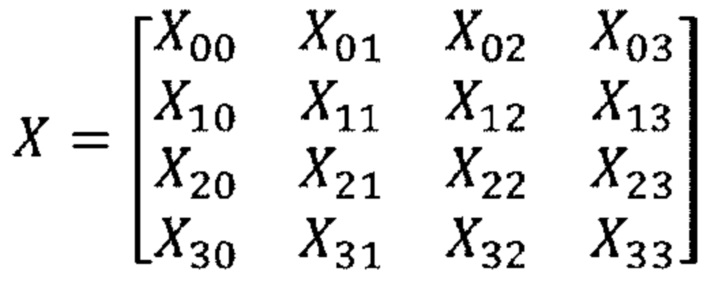
[107] Например, векторная форма X может представляться следующим образом.
[108] уравнение 2
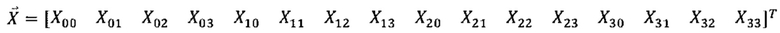
[109] Ссылаясь на уравнение 2, 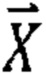 может представлять вектор X, и двумерный блок X в уравнении 1 может перекомпоновываться и представляться в качестве одномерного вектора в соответствии с порядком сначала по строкам.
может представлять вектор X, и двумерный блок X в уравнении 1 может перекомпоновываться и представляться в качестве одномерного вектора в соответствии с порядком сначала по строкам.
[110] В этом случае, вторичное неразделимое преобразование может вычисляться следующим образом.
[111] уравнение 3
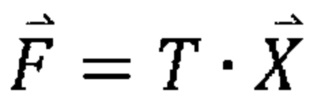
[112] Здесь,  может представлять вектор коэффициентов преобразования, и T может представлять матрицу (неразделимого) преобразования 16×16.
может представлять вектор коэффициентов преобразования, и T может представлять матрицу (неразделимого) преобразования 16×16.
[113] На основе уравнения 3, , имеющий размер 16×1, может извлекаться, и может реорганизовываться в качестве блока 4×4 через порядок сканирования (горизонтальный, вертикальный или диагональный). Тем не менее, вышеописанное вычисление является примерным, и чтобы уменьшать вычислительную сложность неразделимого вторичного преобразования, гиперкубическое преобразование Гивенса (HyGT) и т.п. может использоваться для того, чтобы вычислять неразделимое вторичное преобразование.
[114] Между тем, при неразделимом вторичном преобразовании, ядро преобразования (либо база преобразования или тип преобразования) может выбираться зависимым от режима способом. Здесь, режим может включать в себя режим внутреннего прогнозирования и/или режим взаимного прогнозирования.
[115] Например, как описано выше, NSST может выполняться на основе преобразования 8×8 или преобразования 4×4, определенного на основе ширины (W) и высоты (H) блока коэффициентов преобразования. Например, если W и H равны или больше 8, преобразование 8×8 может представлять преобразование, которое может применяться к зоне 8×8, включенной в соответствующий блок коэффициентов преобразования, и зона 8×8 может представлять собой левую верхнюю зону 8×8 в соответствующем блоке коэффициентов преобразования. Дополнительно, аналогично, если W и H равны или больше 4, преобразование 4×4 может представлять преобразование, которое может применяться к зоне 4×4, включенной в соответствующий блок коэффициентов преобразования, и зона 4×4 может представлять собой левую верхнюю зону 4×4 в соответствующем блоке коэффициентов преобразования. Например, матрица ядра преобразования 8×8 может представлять собой матрицу 64×64/16×64, и матрица ядра преобразования 4×4 может представлять собой матрицу 16×16/8×16.
[116] В этом случае, для выбора ядра преобразования на основе режима, два ядра неразделимого вторичного преобразования в расчете на набор для преобразования для неразделимого вторичного преобразования могут быть сконфигурированы относительно всех из преобразования 8×8 и преобразования 4×4, и могут предоставляться четыре набора для преобразования. Таким образом, четыре набора для преобразования могут быть сконфигурированы относительно преобразования 8×8, и четыре набора для преобразования могут быть сконфигурированы относительно преобразования 4×4. В этом случае, каждый из четырех наборов для преобразования для преобразования 8×8 может включать в себя два ядра преобразования 8×8, и каждый из четырех наборов для преобразования для преобразования 4×4 может включать в себя два ядра преобразования 4×4.
[117] Тем не менее, размер субблока преобразования, число наборов и число ядер преобразования в наборе являются примерными, и может использоваться размер, отличный от 8×8 или 4×4, либо n наборов могут быть сконфигурированы, и k ядер преобразования могут быть включены в каждый набор. Здесь, n и k могут быть положительными целыми числами.
[118] Например, набор для преобразования может называться "NSST-набором", и ядро преобразования в NSST-наборе может называться "NSSAT-ядром". Например, выбор конкретного набора из наборов для преобразования может выполняться на основе режима внутреннего прогнозирования целевого блока (CU или субблока).
[119] Например, режим внутреннего прогнозирования может включать в себя два режима ненаправленного или неуглового внутреннего прогнозирования и 65 режимов направленного или углового внутреннего прогнозирования. Режимы ненаправленного внутреннего прогнозирования могут включать в себя режим планарного внутреннего прогнозирования номер 0 и режим внутреннего DC-прогнозирования номер 1, и режимы направленного внутреннего прогнозирования могут включать в себя 65 режимов внутреннего прогнозирования (номер 2-66). Тем не менее, это является примерным, и вариант осуществления согласно настоящему документу может применяться даже к случаю, в котором предоставляется другое число режимов внутреннего прогнозирования. Между тем, в некоторых случаях, режим внутреннего прогнозирования номер 67 дополнительно может использоваться, и режим внутреннего прогнозирования номер 67 может представлять режим на основе линейной модели (LM).
[120] Фиг. 5 примерно иллюстрирует внутренние направленные режимы в 65 направлениях прогнозирования.
[121] Ссылаясь на фиг. 5, режимы могут разделяться на режимы внутреннего прогнозирования, имеющие горизонтальную направленность, и режимы внутреннего прогнозирования, имеющие вертикальную направленность относительно режима внутреннего прогнозирования номер 34, имеющего левое верхнее диагональное направление прогнозирования. На фиг. 5, H и V могут означать горизонтальную направленность и вертикальную направленность, соответственно, и номера от -32 до 32 могут представлять смещения в единицах 1/32 для позиции на сетке выборок. Оно может представлять смещение для значения индекса режима.
[122] Например, режимы внутреннего прогнозирования номер 2-33 могут иметь горизонтальную направленность, и режимы внутреннего прогнозирования номер 34-66 имеют вертикальную направленность. Между тем, с технической точки зрения, режим внутреннего прогнозирования номер 34 может считаться не имеющим ни горизонтальной направленности, ни вертикальной направленности, но может классифицироваться как принадлежащий горизонтальной направленности с точки зрения определения набора для преобразования для вторичного преобразования. Это обусловлено тем, что входные данные транспонируются и используются относительно вертикальных направленных режимов, симметричных относительно режима внутреннего прогнозирования номер 34, и способ компоновки входных данных для горизонтального направленного режима используется относительно режима внутреннего прогнозирования номер 34. Здесь, транспозиция входных данных может означать конфигурацию данных NxM таким способом, что строки становятся столбцами, и столбцы становятся строками относительно двумерных блочных данных MxN.
[123] Дополнительно, режим внутреннего прогнозирования номер 18 и режим внутреннего прогнозирования номер 50 могут представлять режим горизонтального внутреннего прогнозирования и режим вертикального внутреннего прогнозирования, соответственно, и режим внутреннего прогнозирования номер 2 может называться "режимом правого верхнего диагонального внутреннего прогнозирования", поскольку прогнозирование выполняется в направлении вверх и вправо с левым опорным пикселом. В идентичном контексте, режим внутреннего прогнозирования номер 34 может называться "режимом правого нижнего диагонального внутреннего прогнозирования", и режим внутреннего прогнозирования номер 66 может называться "режимом левого нижнего диагонального внутреннего прогнозирования".
[124] Между тем, если определяется то, что конкретный набор используется для неразделимого преобразования, одно из k ядер преобразования в конкретном наборе может выбираться через индекс неразделимого вторичного преобразования. Например, оборудование кодирования может извлекать индекс неразделимого вторичного преобразования, представляющий конкретное ядро преобразования, на основе проверки искажения в зависимости от скорости передачи (RD) и может передавать в служебных сигналах индекс неразделимого вторичного преобразования в оборудование декодирования. Например, оборудование декодирования может выбирать одно из k ядер преобразования в конкретном наборе на основе индекса неразделимого вторичного преобразования. Например, NSST-индекс, имеющий значение 0, может представлять первое ядро неразделимого вторичного преобразования, NSST-индекс, имеющий значение 1, может представлять второе ядро неразделимого вторичного преобразования, и NSST-индекс, имеющий значение 2, может представлять третье ядро неразделимого вторичного преобразования. Альтернативно, NSST-индекс, имеющий значение 0, может представлять то, что первое неразделимое вторичное преобразование не применяется к целевому блоку, и NSST-индекс, имеющий значение 1-3, может указывать три ядра преобразования, как описано выше.
[125] Преобразователь может выполнять неразделимое вторичное преобразование на основе выбранных ядер преобразования и может получать модифицированные коэффициенты (вторичного) преобразования. Модифицированные коэффициенты преобразования могут извлекаться в качестве квантованных коэффициентов преобразования через вышеописанный квантователь и могут кодироваться с возможностью передаваться в служебных сигналах в оборудование декодирования, и могут передаваться в деквантователь/обратный преобразователь в оборудовании кодирования.
[126] Между тем, если вторичное преобразование опускается, как описано выше, коэффициенты (первичного) преобразования, которые представляют собой выводы первичного (разделимого) преобразования, могут извлекаться в качестве квантованных коэффициентов преобразования через квантователь, как описано выше, и могут кодироваться с возможностью передаваться в служебных сигналах в оборудование декодирования и могут передаваться в деквантователь/обратный преобразователь в оборудовании кодирования.
[127] Снова ссылаясь в фиг. 4, обратный преобразователь может выполнять последовательность процедур в обратном порядке по отношению к процедурам, выполняемым посредством вышеописанного преобразователя. Обратный преобразователь может принимать (деквантованные) коэффициенты преобразования, извлекать коэффициенты (первичного) преобразования посредством выполнения вторичного (обратного) преобразования (S450) и получать остаточный блок (остаточные выборки) посредством выполнения первичного (обратного) преобразования относительно коэффициентов (первичного) преобразования (S460). Здесь, коэффициенты первичного преобразования могут называться "модифицированными коэффициентами преобразования на стороне обратного преобразователя". Как описано выше, оборудование кодирования и/или оборудование декодирования могут формировать восстановленный блок на основе остаточного блока и прогнозированного блока и могут формировать восстановленный кадр на его основе.
[128] Между тем, оборудование декодирования дополнительно может включать в себя модуль определения применения/неприменения вторичного обратного преобразования (или элемент для определения того, следует или нет применять вторичное обратное преобразование), и модуль определения вторичного обратного преобразования (или элемент для определения вторичного обратного преобразования). Например, модуль определения применения/неприменения вторичного обратного преобразования может определять то, следует или нет применять вторичное обратное преобразование. Например, вторичное обратное преобразование может представлять собой NSST или RST, и модуль определения применения/неприменения вторичного обратного преобразования может определять то, следует или нет применять вторичное обратное преобразование, на основе флага вторичного преобразования, синтаксически проанализированного или полученного из потока битов. Альтернативно, например, модуль определения применения/неприменения вторичного обратного преобразования может определять то, следует или нет применять вторичное обратное преобразование, на основе коэффициента преобразования остаточного блока.
[129] Модуль определения вторичного обратного преобразования может определять вторичное обратное преобразование. В этом случае, модуль определения вторичного обратного преобразования может определять вторичное обратное преобразование, применяемое к текущему блоку, на основе набора для NSST-(или RST-)преобразования, указываемого в соответствии с режимом внутреннего прогнозирования. Альтернативно, способ определения вторичного преобразования может определяться в зависимости от способа определения первичного преобразования. Альтернативно, различные комбинации первичного преобразования и вторичного преобразования могут определяться в соответствии с режимом внутреннего прогнозирования. Например, модуль определения вторичного обратного преобразования может определять зону, к которой вторичное обратное преобразование применяется, на основе размера текущего блока.
[130] Между тем, если вторичное (обратное) преобразование опускается, как описано выше, остаточный блок (остаточные выборки) может получаться посредством приема (деквантованных) коэффициентов преобразования и выполнения первичного (разделимого) обратного преобразования. Как описано выше, оборудование кодирования и/или оборудование декодирования могут формировать восстановленный блок на основе остаточного блока и прогнозированного блока и могут формировать восстановленный кадр на его основе.
[131] Между тем, в настоящем документе, чтобы уменьшать объем вычислений и требуемый объем запоминающего устройства, вызываемые посредством неразделимого вторичного преобразования, сокращенное вторичное преобразование (RST), имеющее уменьшенный размер матрицы (ядра) преобразования, может применяться к понятию NSST.
[132] В настоящем документе, RST может означать (упрощенное) преобразование, выполняемое относительно остаточных выборок для целевого блока, на основе матрицы преобразования, размер которой уменьшается в соответствии с коэффициентом упрощения. В случае выполнения этого объем вычислений, требуемый во время преобразования, может уменьшаться вследствие уменьшения размера матрицы преобразования. Таким образом, RST может использоваться для того, чтобы разрешать проблему сложности вычислений, возникающую во время преобразования блока, имеющего большой размер, или неразделимого преобразования.
[133] Например, RST может называться с помощью различных терминов, таких как "сокращенное преобразование", "сокращенное вторичное преобразование", "преобразование с сокращением", "упрощенное преобразование" или "простое преобразование", и названия, с помощью которых называется RST, не ограничены перечисленными примерами. Дополнительно, RST главным образом выполняется в низкочастотной области, включающей в себя коэффициенты, которые не равны 0 в блоке преобразования, и в силу этого может называться "низкочастотным неразделимым преобразованием (LFNST)".
[134] Между тем, в случае если вторичное обратное преобразование выполняется на основе RST, обратный преобразователь 235 оборудования 200 кодирования и обратный преобразователь 322 оборудования 300 декодирования могут включать в себя обратный RST-модуль, извлекающий модифицированные коэффициенты преобразования на основе обратного RST для коэффициентов преобразования, и обратный первичный преобразователь, извлекающий остаточные выборки для целевого блока на основе обратного первичного преобразования для модифицированных коэффициентов преобразования. Обратное первичное преобразование означает обратное преобразование относительно первичного преобразования, применяемого к остатку. В настоящем документе, извлечение коэффициентов преобразования на основе преобразования может означать извлечение коэффициентов преобразования посредством применения соответствующего преобразования.
[135] Фиг. 6 и 7 являются схемами, поясняющими RST согласно варианту осуществления настоящего документа.
[136] Например, фиг. 6 может представлять собой чертеж, поясняющий то, что прямое сокращенное преобразование применяется, и фиг. 7 может представлять собой чертеж, поясняющий то, что обратное сокращенное преобразование применяется. В настоящем документе, целевой блок может представлять текущий блок, остаточный блок или блок преобразования в зависимости от того, кодирование чего выполняется.
[137] Например, в RST, N-мерный вектор может преобразовываться в R-мерный вектор, расположенный в другом пространстве, и матрица сокращенного преобразования может определяться. Здесь, N и R могут быть положительными целыми числами, и R может быть меньше N. N может означать квадрат длины одной стороны блока, к которому применяется преобразование, или общее число коэффициентов преобразования, соответствующих блоку, к которому применяется преобразование, и коэффициент упрощения может означать значение R/N. Коэффициент упрощения может называться с помощью различных терминов, таких как "сокращенный коэффициент", "коэффициент сокращения", "упрощенный коэффициент" или "простой коэффициент". Между тем, R может называться "уменьшенным коэффициентом", и в некоторых случаях, коэффициент упрощения может означать R. Дополнительно, в некоторых случаях, коэффициент упрощения может означать N/R-значение.
[138] Например, коэффициент упрощения или уменьшенный коэффициент может передаваться в служебных сигналах через поток битов, но не ограничен этим. Например, предварительно заданные значения для коэффициента упрощения или уменьшенного коэффициента могут сохраняться в оборудовании 200 кодирования и оборудовании 300 декодирования, и в этом случае, коэффициент упрощения или уменьшенный коэффициент может не передаваться в служебных сигналах отдельно.
[139] Например, размер (RxN) матрицы упрощенного преобразования может быть меньше размера (NxN) матрицы регулярного преобразования и может задаваться в следующем уравнении.
[140] уравнение 4

[141] Например, матрица T в блоке сокращенного преобразования, проиллюстрированном на фиг. 6, может представлять матрицу TRxN уравнения 4. Как показано на фиг. 6, в случае если остаточные выборки для целевого блока умножаются на матрицу TRxN упрощенного преобразования, коэффициенты преобразования для целевого блока могут извлекаться.
[142] Например, в случае если размер блока, к которому применяется преобразование, составляет 8×8, и R равен 16 (т.е. R/N=16/64=1/4), RST согласно фиг. 6 может выражаться посредством матричной операции, как указано в нижеприведенном уравнении 5. В этом случае, запоминающее устройство и операция умножения могут уменьшаться приблизительно до 1/4 посредством коэффициента упрощения.
[143] В настоящем документе, матричная операция может пониматься как операция получения вектора-столбца посредством размещения матрицы слева от вектора-столбца и умножения матрицы и вектора-столбца.
[144] уравнение 5

[145] В уравнении 5, r1-r64 могут представлять остаточные выборки для целевого блока. Альтернативно, например, они могут представлять собой коэффициенты преобразования, сформированные посредством применения первичного преобразования. На основе результата операции уравнения 5, коэффициенты ci преобразования для целевого блока могут извлекаться.
[146] Например, в случае если R равен 16, коэффициенты c1-c16 преобразования для целевого блока могут извлекаться. Если матрица преобразования, имеющая размер 64×64 (NxN), через применение регулярного преобразования, а не RST, умножается на остаточные выборки, имеющие размер 64×1 (Nx1), 64 (N) коэффициента преобразования для целевого блока могут извлекаться, но поскольку RST применяется, только 16 (N) коэффициентов преобразования для целевого блока могут извлекаться. Поскольку общее число коэффициентов преобразования для целевого блока уменьшается с N до R, объем данных, которые оборудование 200 кодирования передает в оборудование 300 декодирования, может уменьшаться, и в силу этого эффективность передачи между оборудованием 200 кодирования и оборудованием 300 декодирования может повышаться.
[147] С учетом размера матрицы преобразования, поскольку размер матрицы регулярного преобразования составляет 64×64 (NxN), и размер матрицы упрощенного преобразования уменьшается до 16×64 (RxN), использование запоминающего устройства при выполнении RST может уменьшаться в отношении R/N по сравнению со случаем, в котором регулярное преобразование выполняется. Дополнительно, по сравнению с числом (NxN) операций умножения, при использовании матрицы регулярного преобразования, использование матрицы упрощенного преобразования может сокращать число операций умножения (RxN) в отношении R/N.
[148] В варианте осуществления, преобразователь 232 оборудования 200 кодирования может извлекать коэффициенты преобразования для целевого блока посредством выполнения первичного преобразования и вторичного преобразования на основе RST для остаточных выборок для целевого блока. Коэффициенты преобразования могут передаваться в обратный преобразователь оборудования 300 декодирования, и обратный преобразователь 322 оборудования 300 декодирования может извлекать модифицированные коэффициенты преобразования на основе обратного сокращенного вторичного преобразования (RST) для коэффициентов преобразования и может извлекать остаточные выборки для целевого блока на основе обратного первичного преобразования модифицированных коэффициентов преобразования.
[149] Размер обратной RST-матрицы TNxR согласно варианту осуществления может составлять NxR, что меньше размера NxN матрицы регулярного обратного преобразования, и может иметь транспонированную взаимосвязь с матрицей TRxN упрощенного преобразования, проиллюстрированной в уравнении 4.
[150] Матрица Tt в блоке сокращенного обратного преобразования, проиллюстрированном на фиг. 7, может представлять обратную RST-матрицу TRxNT. Здесь, надстрочный индекс T может представлять транспонирование. Как показано на фиг. 7, в случае если коэффициенты преобразования для целевого блока умножаются на обратную RST-матрицу TRxNT, модифицированные коэффициенты преобразования для целевого блока или остаточные выборки для целевого блока могут извлекаться. Обратная RST-матрица TRxNT может выражаться как (TRxN)TNxR.
[151] Более конкретно, в случае если обратное RST применяется в качестве вторичного обратного преобразования, модифицированные коэффициенты преобразования для целевого блока могут извлекаться посредством умножения коэффициентов преобразования для целевого блока на обратную RST-матрицу TRxNT. Между тем, обратное RST может применяться в качестве обратного первичного преобразования, и в этом случае, остаточные выборки для целевого блока могут извлекаться, когда обратная RST-матрица TRxNT умножается на коэффициенты преобразования для целевого блока.
[152] В варианте осуществления, в случае если размер блока, к которому применяется обратное преобразование, составляет 8×8, и R равен 16 (т.е. R/N=16/64=1/4), RST согласно фиг. 7 может выражаться посредством матричной операции, как указано в нижеприведенном уравнении 6.
[153] уравнение 6

[154] В уравнении 6, c1-c16 могут представлять коэффициенты преобразования для целевого блока; rj, представляющий модифицированные коэффициенты преобразования для целевого блока или остаточные выборки для целевого блока, может извлекаться на основе результата операции уравнения 6. Таким образом, r1-rN, представляющие модифицированные коэффициенты преобразования для целевого блока или остаточные выборки для целевого блока, могут извлекаться.
[155] С учетом размера матрицы обратного преобразования, поскольку размер матрицы регулярного обратного преобразования составляет 64×64 (NxN), и размер матрицы упрощенного обратного преобразования уменьшается до 64×16 (NxR), использование запоминающего устройства при выполнении обратного RST может уменьшаться в отношении R/N по сравнению со случаем, в котором регулярное обратное преобразование выполняется. Дополнительно, по сравнению с числом (NxN) операций умножения, при использовании матрицы регулярного обратного преобразования, использование матрицы упрощенного обратного преобразования может уменьшать число (NxR) операций умножения в отношении R/N.
[156] Между тем, наборы для преобразования могут конфигурироваться и применяться даже относительно RST 8×8. Таким образом, соответствующее RST 8×8 может применяться в соответствии с набором для преобразования. Поскольку один набор для преобразования состоит из двух или трех ядер преобразования в соответствии с режимом внутреннего прогнозирования, он может быть выполнен с возможностью выбирать одно из четырех преобразований, что как максимум включает в себя даже случай, в котором вторичное преобразование не применяется. При преобразовании, когда вторичное преобразование не применяется, можно считать, что единичная матрица применяется. Если предполагается, что индекс 0, 1, 2 или 3 задается для четырех преобразований (например, индекс номер 0 может выделяться случаю, в котором единичная матрица, т.е. вторичное преобразование, не применяется), преобразование, которое должно применяться, может быть обозначено посредством передачи в служебных сигналах синтаксического элемента, которая представляет собой NSST-индекс, в каждый блок коэффициентов преобразования. Таким образом, через NSST-индекс NSST 8×8 может быть обозначено для левого верхнего блока 8×8, и в RST-конфигурации, RST 8×8 может быть обозначено. NSST 8×8 и RST 8×8 могут представлять преобразования, допускающие применение к зоне 8×8, включенной в соответствующий блок коэффициентов преобразования в случае, если W и H целевого блока, который становится целью преобразования, равны или больше 8, и зона 8×8 может представлять собой левую верхнюю зону 8×8 в соответствующем блоке коэффициентов преобразования. Аналогично, NSST 4×4 и RST 4×4 могут представлять преобразования, допускающие применение к зоне 4×4, включенной в соответствующий блок коэффициентов преобразования в случае, если W и H целевого блока равны или больше 4, и зона 4×4 может представлять собой левую верхнюю зону 4×4 в соответствующем блоке коэффициентов преобразования.
[157] Между тем, например, оборудование кодирования может извлекать поток битов посредством кодирования значения синтаксического элемента или квантованных значений коэффициента преобразования для остатка на основе различных способов кодирования, таких как экспоненциальный код Голомба, контекстно-адаптивное кодирование переменной длины (CAVLC), контекстно-адаптивное двоичное арифметическое кодирование (CABAC) и т.п. Дополнительно, оборудование декодирования может извлекать значение синтаксического элемента или квантованных значений коэффициента преобразования для остатка на основе различных способов кодирования, таких как кодирование экспоненциальным кодом Голомба, CAVLC, CABAC и т.п.
[158] Например, вышеописанные способы кодирования могут выполняться в качестве контента, который описывается ниже.
[159] Фиг. 8 примерно иллюстрирует контекстно-адаптивное двоичное арифметическое кодирование (CABAC) для кодирования синтаксического элемента.
[160] Например, в процессе CABAC-кодирования, если входной сигнал представляет собой синтаксический элемент, который не представляет собой двоичное значение, значение входного сигнала может преобразовываться в двоичное значение через преобразование в двоичную форму. Дополнительно, если входной сигнал уже представляет собой двоичное значение (т.е. если значение входного сигнала представляет собой двоичное значение), преобразование в двоичную форму может не выполняться, и входной сигнал может использоваться как есть. Здесь, каждое двоичное число 0 или 1, составляющее двоичное значение, может называться "элементом разрешения". Например, если двоичная строка после преобразования в двоичную форму представляет собой 110, каждое из 1, 1 и 0 может представляться как один элемент разрешения. Элемент(ы) разрешения для одного синтаксического элемента может представлять значение синтаксического элемента. Преобразование в двоичную форму может быть основано на различном способе преобразования в двоичную форму, таком как процесс преобразования в двоичную форму усеченным кодом Райса или процесс преобразования в двоичную форму кодом фиксированной длины, и способ преобразования в двоичную форму для целевого синтаксического элемента может быть предварительно задан. Процедура преобразования в двоичную форму может выполняться посредством модуля преобразования в двоичную форму в энтропийном кодере.
[161] После этого, преобразованные в двоичную форму элементы выборки синтаксического элемента могут вводиться в механизм регулярного кодирования или механизм обходного кодирования. Механизм регулярного кодирования оборудования кодирования может выделять контекстную модель, которая отражает значение вероятности относительно соответствующего элемента разрешения, и кодировать соответствующий элемент разрешения на основе выделяемой контекстной модели. Механизм регулярного кодирования оборудования кодирования может обновлять контекстную модель для соответствующего элемента разрешения после выполнения кодирования относительно соответствующих элементов разрешения. Элементы разрешения, кодируемые в качестве вышеописанного контента, могут представляться как контекстно-кодированные элементы разрешения.
[162] Между тем, в случае если преобразованные в двоичную форму элементы выборки синтаксического элемента вводятся в механизм обходного кодирования, они могут кодироваться следующим образом. Например, механизм обходного кодирования оборудования кодирования может опускать процедуру для оценки вероятности относительно входного элемента выборки и процедуру для обновления вероятностной модели, применяемые к элементу разрешения после кодирования. В случае если обходное кодирование применяется, оборудование кодирования может кодировать входной элемент выборки посредством применения регулярного распределения вероятностей вместо выделения контекстной модели, и за счет этого может повышаться скорость кодирования. Элемент разрешения, кодируемый в качестве вышеописанного контента, может представляться как обходной элемент разрешения.
[163] Энтропийное декодирование может представлять процесс для выполнения процесса, идентичного вышеописанному энтропийному кодированию, в обратном порядке.
[164] Оборудование декодирования (энтропийный декодер) может декодировать кодированную информацию изображений/видео. Информация изображений/видео может включать в себя связанную с сегментацией информацию, связанную с прогнозированием информацию (например, информацию разделения взаимного/внутреннего прогнозирования, информацию режима внутреннего прогнозирования, информацию режима взаимного прогнозирования и т.п.), остаточную информацию или связанную с внутриконтурной фильтрацией информацию либо может включать в себя различные синтаксические элементы из нее. Энтропийное кодирование может выполняться в единицах синтаксического элемента.
[165] Оборудование декодирования может выполнять преобразование в двоичную форму целевых синтаксических элементов. Здесь, преобразование в двоичную форму может быть основано на различных способах преобразования в двоичную форму, таких как процесс преобразования в двоичную форму усеченным кодом Райса или процесс преобразования в двоичную форму кодом фиксированной длины, и способ преобразования в двоичную форму для целевого синтаксического элемента может быть предварительно задан. Оборудование декодирования может извлекать доступные строки элементов разрешения (возможные варианты строк элементов разрешения) для доступных значений целевых синтаксических элементов через процедуру преобразования в двоичную форму. Процедура преобразования в двоичную форму может выполняться посредством модуля преобразования в двоичную форму в энтропийном декодере.
[166] Оборудование декодирования может сравнивать извлеченную строку элементов разрешения с доступными строками элементов разрешения для соответствующих синтаксических элементов при последовательном декодировании или синтаксическом анализе соответствующих элементов разрешения на предмет целевых синтаксических элементов из входного бита(ов) в потоке битов. Если извлеченная строка элементов разрешения равна одной из доступных строк элементов разрешения, значение, соответствующее соответствующей строке элементов разрешения, извлекается в качестве значения соответствующего синтаксического элемента. Если нет, оборудование декодирования может повторно выполнять вышеописанную процедуру после дополнительного синтаксического анализа следующего бита в потоке битов. Посредством такого процесса, можно выполнять передачу в служебных сигналах конкретной информации (или конкретного синтаксического элемента) в потоке битов с использованием бита переменной длины даже без использования начального бита или конечного бита соответствующей информации. Через это, относительно меньший бит может выделяться относительно меньшего значения, и в силу этого может повышаться общая эффективность кодирования.
[167] Оборудование декодирования может выполнять декодирование на основе контекстных моделей или обходное декодирование соответствующих элементов разрешения в строке элементов разрешения из потока битов на основе технологии энтропийного кодирования, такой как CABAC или CAVLC.
[168] В случае если синтаксический элемент декодируется на основе контекстной модели, оборудование декодирования может принимать элемент разрешения, соответствующий синтаксическому элементу, через поток битов, может определять контекстную модель за счет использования синтаксического элемента и декодирования информации целевого блока декодирования или соседнего блока либо информации символов/элементов разрешения, декодированной на предыдущей стадии, и может извлекать значение синтаксического элемента посредством выполнения арифметического декодирования элемента разрешения через прогнозирование вероятности появления принимаемого элемента разрешения в соответствии с определенной контекстной моделью. После этого, контекстная модель следующего декодируемого элемента разрешения может обновляться на основе определенной контекстной модели.
[169] Контекстная модель может выделяться и обновляться посредством контекстно-кодированных (регулярно кодированных) элементов разрешения, и контекстная модель могут указываться на основе индекса контекста (ctxIdx) или приращения индекса контекста (ctxInc). CtxIdx может извлекаться на основе ctxInc. В частности, например, ctxIdx, представляющий контекстную модель для каждого из регулярно кодированных элементов разрешения, может извлекаться посредством суммы ctxInc и смещения индекса контекста (ctxIdxOffset). Например, ctxInc может извлекаться по-иному посредством элементов разрешения. ctxIdxOffset может представляться как наименьшее значение ctxIdx. Обычно, ctxIdxOffset может представлять собой значение, используемое для того, чтобы отличать ее от контекстных моделей для других синтаксических элементов, и контекстная модель для одного синтаксического элемента может разделяться или извлекаться на основе ctxInc.
[170] В процедуре энтропийного кодирования, может определяться то, следует выполнять кодирование через механизм регулярного кодирования или выполнять кодирование через механизм обходного кодирования, и, соответственно, тракт кодирования может переключаться. Энтропийное декодирование может выполнять процесс, идентичный энтропийному кодированию, в обратном порядке.
[171] Между тем, например, в случае если выполняется обходное декодирование синтаксического элемента, оборудование декодирования может принимать элемент разрешения, соответствующий синтаксическому элементу, через поток битов, и может декодировать входной элемент выборки посредством применения регулярного распределения вероятностей. В этом случае, оборудование декодирования может опускать процедуру извлечения контекстной модели синтаксического элемента и процедуру обновления контекстной модели, применяемые к элементу разрешения после декодирования.
[172] Как описано выше, остаточная выборка может извлекаться в качестве квантованных коэффициентов преобразования через процессы преобразования и квантования. Квантованные коэффициенты преобразования могут называться "коэффициентами преобразования". В этом случае, коэффициенты преобразования в блоке могут передаваться в служебных сигналах в форме остаточной информации. Остаточная информация может включать в себя синтаксис или синтаксический элемент относительно остаточного кодирования. Например, оборудование кодирования может кодировать остаточную информацию и может выводить ее в форме потока битов, и оборудование декодирования может декодировать остаточную информацию из потока битов и может извлекать остаточные (квантованные) коэффициенты преобразования. Как описано ниже, остаточная информация может включать в себя синтаксические элементы, представляющие то, применяется или нет преобразование к соответствующему блоку, то, где находится местоположение последнего эффективного коэффициента преобразования в блоке, то, существует или нет эффективный коэффициент преобразования в субблоке, либо то, каким является размер/знак эффективного коэффициента преобразования.
[173] Между тем, например, модуль прогнозирования в оборудовании кодирования по фиг. 2 или модуль прогнозирования в оборудовании декодирования по фиг. 3 может выполнять внутреннее прогнозирование. В дальнейшем подробнее описывается внутреннее прогнозирование следующим образом.
[174] Внутреннее прогнозирование может представлять прогнозирование для формирования прогнозных выборок для текущего блока на основе опорных выборок в кадре (далее "текущий кадр"), которому принадлежит текущий блок. В случае если внутреннее прогнозирование применяется к текущему блоку, соседние опорные выборки, которые должны использоваться для внутреннего прогнозирования текущего блока, могут извлекаться. Соседние опорные выборки текущего блока могут включать в себя выборку, смежную с левой границей текущего блока, имеющего размер nWxnH, и сумму 2xnH выборок, граничащих с левой нижней частью, выборки, смежной с верхней границей текущего блока, и сумму 2xnW выборок, граничащих с правой верхней частью, и одну выборку, граничащую с левой верхней частью относительно текущего блока. Альтернативно, соседние опорные выборки текущего блока могут включать в себя верхнюю соседнюю выборку нескольких столбцов и левую соседнюю выборку нескольких строк. Альтернативно, соседние опорные выборки текущего блока могут включать в себя сумму nH выборок, смежных с правой границей текущего блока, имеющего размер nWxnH, сумму nH выборок, смежных с правой границей текущего блока, сумму nW выборок, смежных с нижней границей текущего блока, и одну выборку, граничащую с правым нижним из текущего блока.
[175] Тем не менее, некоторые соседние опорные выборки текущего блока могут быть еще не декодированы или могут не быть доступными. В этом случае, декодер может конфигурировать соседние опорные выборки, которые должны использоваться для прогнозирования, через подстановку доступных выборок вместо недоступных выборок. Альтернативно, соседние опорные выборки, которые должны использоваться для прогнозирования, могут быть сконфигурированы через интерполяцию доступных выборок.
[176] В случае если соседние опорные выборки извлекаются, (i) прогнозная выборка может логически выводиться на основе среднего или интерполяции соседних опорных выборок текущего блока, и (ii) прогнозная выборка может логически выводиться на основе опорной выборки, существующей в конкретном направлении (прогнозирования) относительно прогнозной выборки из соседних опорных выборок текущего блока. Случай (i) может называться "ненаправленным режимом" или "неугловым режимом", и случай (ii) может называться "направленным режимом" или "угловым режимом".
[177] Дополнительно, прогнозная выборка может формироваться через интерполяцию между первой соседней выборкой и второй соседней выборкой, расположенной в противоположном направлении относительно направления прогнозирования режима внутреннего прогнозирования текущего блока, на основе прогнозной выборки текущего блока из соседних опорных выборок. Вышеописанный случай может называться "внутренним прогнозированием с линейной интерполяцией (LIP)". Дополнительно, выборки прогнозирования сигналов цветности могут формироваться на основе выборок сигнала яркости с использованием линейной модели. Этот случай может называться "режимом на основе линейной модели (LM)". Альтернативно, прогнозная выборка текущего блока может извлекаться посредством извлечения временной прогнозной выборки текущего блока на основе фильтрованных соседних опорных выборок и выполнения взвешенного суммирования временной прогнозной выборки и по меньшей мере одной опорной выборки, извлекаемой в соответствии с режимом внутреннего прогнозирования, из нефильтрованных соседних опорных выборок. Вышеописанный случай может называться "позиционно-зависимым внутренним прогнозированием (PDPC)". Альтернативно, внутреннее прогнозирующее кодирование может выполняться в способе для извлечения прогнозной выборки с использованием опорной выборки, расположенной в направлении прогнозирования в опорной выборочной линии, имеющей наибольшую точность прогнозирования, посредством выбора соответствующей линии из соседних множественных опорных выборочных линий текущего блока, и для указания (передачи в служебных сигналах) опорной выборочной линии, используемой в это время, в оборудование декодирования. Вышеописанный случай может называться "внутренним прогнозированием на основе множественной опорной линии (MRL)" или "внутренним прогнозированием на основе MRL". Дополнительно, при выполнении внутреннего прогнозирования на основе идентичных режимов внутреннего прогнозирования через разделение текущего блока на вертикальные или горизонтальные субсегменты, соседние опорные выборки могут извлекаться и использоваться в единицах субсегментов. Таким образом, режим внутреннего прогнозирования для текущего блока может в равной степени применяться к субсегментам и в этом случае, поскольку соседние опорные выборки извлекаются и используются в единицах субсегмента, производительность внутреннего прогнозирования может повышаться в некоторых случаях. Этот способ прогнозирования может называться "внутренним прогнозированием на основе внутренних субсегментов (ISP) или на основе ISP".
[178] Вышеописанные способы внутреннего прогнозирования могут называться "типом внутреннего прогнозирования" в отличие от режима внутреннего прогнозирования. Тип внутреннего прогнозирования может называться с помощью различных терминов, таких как "технология внутреннего прогнозирования" или "дополнительный режим внутреннего прогнозирования". Например, тип внутреннего прогнозирования (или дополнительный режим внутреннего прогнозирования) может включать в себя по меньшей мере одно из LIP, PDPC, MRL и ISP, как описано выше. Общий способ внутреннего прогнозирования, за исключением конкретного типа внутреннего прогнозирования, такого как LIP, PDPC, MRL или ISP, может называться "типом нормального внутреннего прогнозирования". В случае если вышеописанный конкретный тип внутреннего прогнозирования не применяется, тип нормального внутреннего прогнозирования, в общем, может применяться, и прогнозирование может выполняться на основе вышеописанного режима внутреннего прогнозирования. Между тем, по мере необходимости постфильтрация для извлеченной прогнозной выборки может выполняться.
[179] Другими словами, процедура внутреннего прогнозирования может включать в себя определение режима/типа внутреннего прогнозирования, извлечение соседних опорных выборок и извлечение прогнозных выборок на основе режима/типа внутреннего прогнозирования. Дополнительно, по мере необходимости, постфильтрация для извлеченной прогнозной выборки может выполняться.
[180] Между тем, из вышеописанных типов внутреннего прогнозирования, ISP может разделять текущий блок в горизонтальном направлении или вертикальном направлении и может выполнять внутреннее прогнозирование в единицах разделенных блоков. Таким образом, ISP может извлекать субблоки посредством разделения текущего блока в горизонтальном направлении или вертикальном направлении и может выполнять внутреннее прогнозирование для каждого из субблоков. В этом случае, восстановленный блок может формироваться посредством выполнения кодирования/декодирования в единицах разделенных субблоков, и восстановленный блок может использоваться в качестве опорного блока следующего разделенного субблока. Здесь, субблок может называться "внутренним субсегментом".
[181] Например, в случае если ISP применяется, текущий блок может разделяться на два или четыре субблока в вертикальном или горизонтальном направлении на основе размера текущего блока.
[182] Например, чтобы применять ISP, флаг, представляющий то, следует или нет применять ISP, может передаваться в единицах блоков, и в случае, если ISP применяется к текущему блоку, флаг, представляющий то, является тип сегментации горизонтальным или вертикальным, т.е. то, представляет направление сегментации собой горизонтальное направление или вертикальное направление, может кодироваться/декодироваться. Флаг, представляющий то, следует или нет применять ISP, может называться "ISP-флагом", и ISP-флаг может представляться как синтаксический элемент intra_subpartitions_mode_flag. Дополнительно, флаг, представляющий тип сегментации, может называться "флагом ISP-сегментации", и флаг ISP-сегментации может представляться как синтаксический элемент intra_subpartitions_split_flag.
[183] Например, посредством ISP-флага или флага ISP-сегментации, может представляться информация, представляющая то, что ISP не применяется к текущему блоку (IntraSubPartitionsSplitType==ISP_NO_SPLIT), информация, представляющая сегментацию в горизонтальном направлении (IntraSubPartitionsSplitType==ISP_HOR_SPLIT), информация, представляющая сегментацию в вертикальном направлении (IntraSubPartitionsSplitType==ISP_VER_SPLIT). Например, ISP-флаг или флаг ISP-сегментации может называться "связанной с ISP информацией" относительно субсегментации блока.
[184] Между тем, в дополнение к вышеописанным типам внутреннего прогнозирования, аффинное линейное взвешенное внутреннее прогнозирование (ALWIP) может использоваться. ALWIP может называться "линейным взвешенным внутренним прогнозированием (LWIP)", "матричным взвешенным внутренним прогнозированием (MWIP)" или "матричным внутренним прогнозированием (MIP)". В случае если ALWIP применяется к текущему блоку, i) с использованием соседних опорных выборок, для которых процедура усреднения выполнена, ii) процедура матрично-векторного умножения может выполняться, и iii) по мере необходимости, прогнозные выборки для текущего блока могут извлекаться посредством дополнительного выполнения процедуры горизонтальной/вертикальной интерполяции.
[185] Режимы внутреннего прогнозирования, используемые для ALWIP, могут представлять собой вышеописанное внутреннее LIP-, PDPC-, MRL- или ISP-прогнозирование, но могут быть сконфигурированы по-другому по сравнению с режимами внутреннего прогнозирования, используемыми при нормальном внутреннем прогнозировании. Режим внутреннего прогнозирования для ALWIP может называться "ALWIP-режимом". Например, в соответствии с режимом внутреннего прогнозирования для ALWIP, матрица и смещение, используемые в матрично-векторном умножении, могут быть сконфигурированы по-другому. Здесь, матрица может называться "(аффинной) матрицей весовых коэффициентов", и смещение может называться "(аффинным) вектором смещения" или "(аффинным) вектором сдвига". В настоящем документе, режим внутреннего прогнозирования для ALWIP может называться "ALWIP-режимом", "ALWIP-режимом внутреннего прогнозирования", "LWIP-режимом", "LWIP-режимом внутреннего прогнозирования", "MWIP-режимом", "MWIP-режимом внутреннего прогнозирования", "MIP-режимом" или "MIP-режимом внутреннего прогнозирования". Ниже описывается подробный ALWIP-способ.
[186] Фиг. 9 является схемой, поясняющей MIP для блока 8×8.
[187] Чтобы прогнозировать выборки прямоугольного блока, имеющего ширину W и высоту H, MIP может использовать выборки, граничащие с левой границей блока, и выборки, граничащей с верхней границей. Здесь, выборки, граничащие с левой границей, могут представлять выборки, расположенные в одной линии, смежной с левой границей блока, и могут представлять восстановленные выборки. Выборки, граничащие с верхней границей, могут представлять выборки, расположенные в одной линии, смежной с верхней границей блока, и могут представлять восстановленные выборки.
[188] Например, если восстановленные выборки не доступны, восстановленные выборки, аналогично внутреннему прогнозированию в предшествующем уровне техники, могут формироваться или извлекаться и могут использоваться.
[189] Прогнозный сигнал (или прогнозные выборки) может формироваться на основе процесса усреднения, процесса матрично-векторного умножения и процесса (линейной) интерполяции.
[190] Например, процесс усреднения может представлять собой процесс для извлечения выборок из границы через усреднение. Например, если ширина W и высота H выборок равны 4, извлекаемые выборки могут представлять собой четыре выборки и могут представлять собой 8 выборок в другом случае. Например, на фиг. 9, bdryleft и bdrytop могут представлять извлеченные левые выборки и верхние выборки, соответственно.
[191] Например, процесс матрично-векторного умножения может представлять собой процесс выполнения матрично-векторного умножения с усредненными выборками в качестве вводов. Дополнительно, смещение может добавляться. Например, на фиг. 9, Ak может представлять матрицу, bk может представлять смещение, и bdryred может представлять собой сокращенный сигнал для выборок, извлеченных через процесс усреднения. Дополнительно, bdryred может представлять собой сокращенную информацию относительно bdryleft и bdrytop. Результат может представлять собой сокращенный прогнозный сигнал predred для набора субдискретизированных выборок в исходном блоке.
[192] Например, процесс (линейной) интерполяции может представлять собой процесс, в котором прогнозный сигнал формируется в оставшихся местоположениях из прогнозного сигнала для набора, субдискретизированного посредством линейной интерполяции. Здесь, линейная интерполяция может представлять одну линейную интерполяцию в соответствующих направлениях. Например, линейная интерполяция может выполняться на основе сокращенного прогнозного сигнала predred, помеченного серым цветом в блоке на фиг. 9, и соседних граничных выборок, и за счет этого все прогнозные выборки в блоке могут извлекаться.
[193] Например, матрицы (Ak на фиг. 9) и векторы смещения (bk на фиг. 9), требуемые для того, чтобы формировать прогнозный сигнал (либо выборки блоков прогнозирования или прогнозные выборки), могут получаться из трех наборов S0, S1 и S2. Например, набор S0 может состоять из 18 матриц (A0i, i=0, 1, ...,1, ..., 17) и 18 векторов смещения (b0i, i=0, 1, ..., 17). Здесь, каждая из 18 матриц может иметь 16 строки и 4 столбцов, и каждый из 18 векторов смещения может иметь 16 размера. Матрицы и векторы смещения набора S0 могут использоваться для блока, имеющего размер 4×4. Например, набор S1 может состоять из 10 матриц (A1i, i=0, 1, ..., 9) и 10 векторов смещения (b1i, i=0, 1, ..., 9). Здесь, каждая из 10 матриц может иметь 16 строки и 8 столбцов, и каждый из 10 векторов смещения может иметь 16 размера. Матрицы и векторы смещения набора S1 могут использоваться для блока, имеющего размер 4×8, 8×4 или 8×8. Например, набор S2 может состоять из 6 матриц (A2i, i=0, 1, ..., 5) и 6 векторов смещения (b2i, i=0, 1, ..., 5). Здесь, каждая из 6 матриц может иметь 64 строки и 8 столбцов, и каждый из 6 векторов смещения может иметь 64 размера. Матрицы и векторы смещения набора S2 могут использоваться для всех оставшихся блоков.
[194] Между тем, в варианте осуществления настоящего документа, информация LFNST-индекса может передаваться в служебных сигналах относительно блока, к которому применяется MIP. Альтернативно, оборудование кодирования может формировать поток битов посредством кодирования информации LFNST-индекса для преобразования блока, к которому применяется MIP, и оборудование декодирования может получать информацию LFNST-индекса для преобразования блока, к которому применяется MIP, посредством синтаксического анализа или декодирования потока битов.
[195] Например, информация LFNST-индекса может представлять собой информацию для различения набора LFNST-преобразования в соответствии с числом преобразований, составляющих набор для преобразования. Например, оптимальное LFNST-ядро может выбираться относительно блока, в котором внутреннее прогнозирование, к которому MIP применяется на основе информации LFNST-индекса. Например, информация LFNST-индекса может представляться как синтаксический элемент st_idx или синтаксический элемент lfnst_idx.
[196] Например, информация LFNST-индекса (или синтаксический элемент st_idx) может включаться в синтаксис, как указано в следующих таблицах.
[197] Табл. 2
[198] Табл. 3
[199] Табл. 4
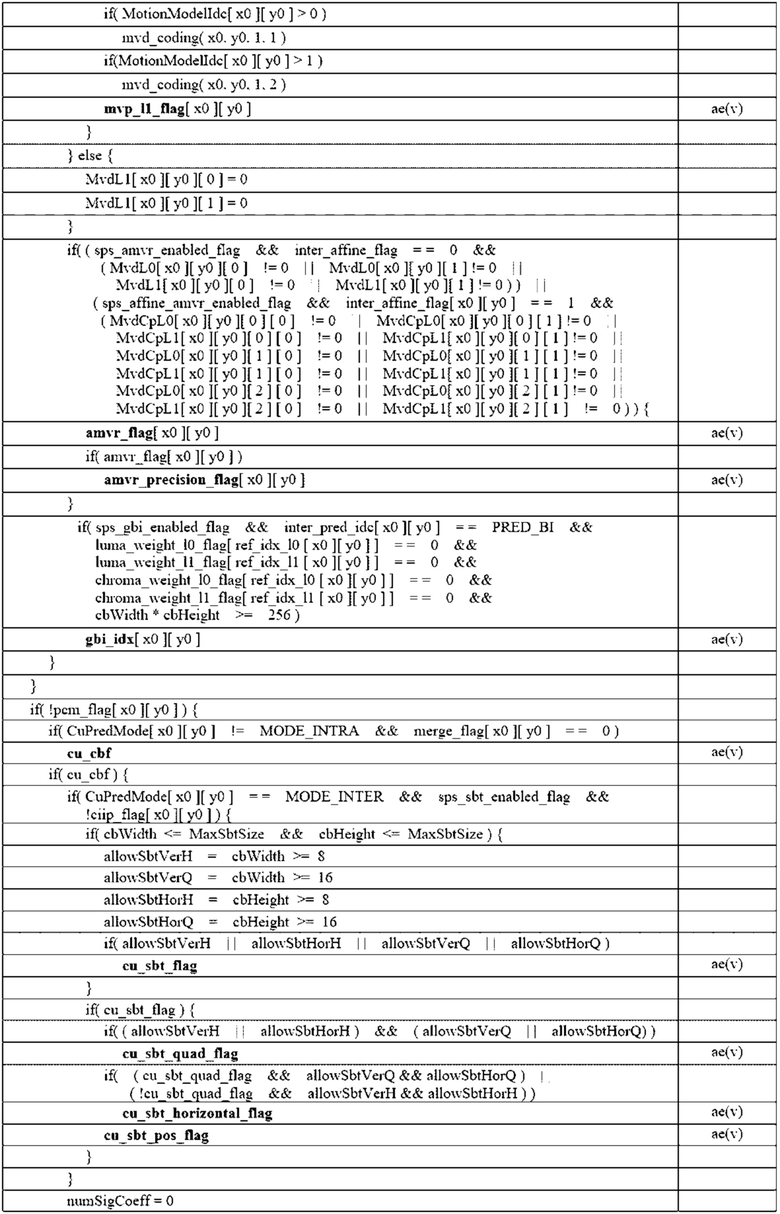
[200] Табл. 5

[201] Таблицы 2-5, как описано выше, могут последовательно представлять один синтаксис или информацию.
[202] Например, в таблицах 2-5, информация или семантика, представленная посредством синтаксического элемента intra_mip_flag, синтаксического элемента intra_mip_mpm_flag, синтаксического элемента intra_mip_mpm_idx, синтаксического элемента intra_mip_mpm_remainder или синтаксического элемента st_idx, может быть такой, как указано в следующей таблице.
[203] Табл. 6
- intra_mip_flag[x0][y0], равный 1, указывает то, что тип внутреннего прогнозирования для выборок сигнала яркости представляет собой матричное внутреннее прогнозирование; intra_mip_flag[x0][y0], равный 0, указывает то, что тип внутреннего прогнозирования для выборок сигнала яркости не представляет собой матричное внутреннее прогнозирование.
Когда intra_mip_flag[x0][y0] не присутствует, он может логически выводиться как равный 0.
Синтаксические элементы intra_mip_mpm_flag[x0][y0], intra_mip_mpm_idx[x0][y0] и intra_mip_mpm_remainder[x0][y0] указывают режим матричного внутреннего прогнозирования для выборок сигнала яркости. Индексы x0, y0 массивов указывают местоположение (x0, y0) левой верхней выборки сигнала яркости рассматриваемого блока кодирования относительно левой верхней выборки сигнала яркости кинокадра.
Когда intra_mip_mpm_flag[x0][y0] равен 1, режим матричного внутреннего прогнозирования логически выводится из соседней внутренне прогнозированной единицы кодирования.
Когда intra_mip_mpm_flag[x0][y0] не присутствует, он может логически выводиться как равный 1.
- st_idx[x0][y0] указывает то, какие ядра преобразования (LFNST-ядра) применяются к LFNST для текущего блока, st_idx может указывать одно из ядер преобразования в наборе LFNST-преобразования, которое может определяться на основе внутреннего/взаимного прогнозирования и/или размера блока текущего блока.
[204] Например, синтаксический элемент intra_mip_flag может представлять информацию относительно того, применяется либо нет MIP к выборкам сигнала яркости или текущему блоку. Дополнительно, например, синтаксический элемент intra_mip_mpm_flag, синтаксический элемент intra_mip_mpm_idx или синтаксический элемент intra_mip_mpm_remainder может представлять информацию относительно режима внутреннего прогнозирования, который должен применяться к текущему блоку в случае, если MIP применяется. Дополнительно, например, синтаксический элемент st_idx может представлять информацию относительно ядра преобразования (LFNST-ядра), которое должно применяться к LFNST для текущего блока. Таким образом, синтаксический элемент st_idx может представлять собой информацию, представляющую одно из ядер преобразования в наборе LFNST-преобразования. Здесь, синтаксический элемент st_idx может представляться как синтаксический элемент lfnst_idx или информация LFNST-индекса.
[205] Фиг. 10 является блок-схемой последовательности операций, поясняющей способ, к которому применяются MIP и LFNST.
[206] Между тем, другой вариант осуществления настоящего документа может не передавать в служебных сигналах информацию LFNST-индекса относительно блока, к которому применяется MIP. Дополнительно, оборудование кодирования может формировать поток битов посредством кодирования информации изображений, за исключением информации LFNST-индекса для преобразования блока, к которому применяется MIP, и оборудование декодирования может синтаксически анализировать или декодировать поток битов и может выполнять процесс преобразования блока без информации LFNST-индекса для преобразования блока, к которому применяется MIP.
[207] Например, если информация LFNST-индекса не передается в служебных сигналах, информация LFNST-индекса может логически выводиться в качестве значения по умолчанию. Например, информация LFNST-индекса, логически выведенная в качестве значения по умолчанию, может представлять собой значение 0. Например, информация LFNST-индекса, имеющая значение 0, может представлять то, что LFNST не применяется к соответствующему блоку. В этом случае, поскольку информация LFNST-индекса не передается, объем в битах для кодирования информации LFNST-индекса может уменьшаться. Дополнительно, сложность может уменьшаться за счет предотвращения одновременного применения MIP и LFNST, и в силу этого время задержки также может уменьшаться.
[208] Ссылаясь на фиг. 10, может сначала определяться то, применяется или нет MIP к соответствующему блоку. Таким образом, может определяться то, равно 1 или 0 либо нет значение синтаксического элемента intra_mip_flag (S1000). Например, если значение синтаксического элемента intra_mip_flag равно 1, он может считаться представляющим собой "истина" или "Да", и это может представлять то, что MIP применяется к соответствующему блоку. Соответственно, MIP-прогнозирование может выполняться для соответствующего блока (S1010). Таким образом, блок прогнозирования для соответствующего блока может извлекаться посредством выполнения MIP-прогнозирования. После этого, процедура обратного первичного преобразования может выполняться (S1020), и процедура внутреннего восстановления может выполняться (S1030). Другими словами, остаточный блок может извлекаться посредством выполнения обратного первичного преобразования относительно коэффициентов преобразования, полученных из потока битов, и восстановленный блок может формироваться на основе блока прогнозирования согласно MIP-прогнозированию и остаточному блоку. Таким образом, информация LFNST-индекса для блока, к которому применяется MIP, может не включаться. Дополнительно, LFNST может не применяться к блоку, к которому применяется MIP.
[209] Дополнительно, например, если значение синтаксического элемента intra_mip_flag равно 0, он может считаться представляющим собой "ложь" или "Нет", и это может представлять то, что MIP не применяется к соответствующему блоку. Таким образом, традиционное внутреннее прогнозирование может применяться к соответствующему блоку (S1040). Таким образом, блок прогнозирования для соответствующего блока может извлекаться посредством выполнения традиционного внутреннего прогнозирования. После этого, может определяться то, применяется или нет LFNST к соответствующему блоку, на основе информации LFNST-индекса. Другими словами, может определяться то, больше 0 или нет значение синтаксического элемента st_idex (S1050). Например, если значение синтаксического элемента st_idex больше 0, процедура обратного LFNST-преобразования может выполняться с использованием ядра преобразования, представленного посредством синтаксического элемента st_idex (S1060). Дополнительно, если значение синтаксического элемента st_idex не превышает 0, оно может представлять то, что LFNST не применяется к соответствующему блоку, и процедура обратного LFNST-преобразования может не выполняться. После этого, процедура обратного первичного преобразования может выполняться (S1020), и процедура внутреннего восстановления может выполняться (S1030). Другими словами, остаточный блок может извлекаться посредством выполнения обратного первичного преобразования относительно коэффициентов преобразования, полученных из потока битов, и восстановленный блок может формироваться на основе блока прогнозирования согласно традиционному внутреннему прогнозированию и остаточному блоку.
[210] В общих словах, если MIP применяется, блок MIP-прогнозирования может формироваться без декодирования информации LFNST-индекса, и конечный сигнал внутреннего восстановления может формироваться посредством применения обратного первичного преобразования к принимаемому коэффициенту.
[211] Напротив, если MIP не применяется, информация LFNST-индекса может декодироваться, и если значение флага (либо информации LFNST-индекса или синтаксического элемента st_idx) больше 0, конечный сигнал внутреннего восстановления может формироваться посредством применения обратного LFNST-преобразования и обратного первичного преобразования относительно принимаемого коэффициента.
[212] Например, для вышеописанной процедуры, информация LFNST-индекса (или синтаксический элемент st_idx) может включаться в синтаксис или информацию изображений на основе информации (или синтаксического элемента intra_mip_flag) относительно того, применяется или нет MIP, и может передаваться в служебных сигналах. Дополнительно, информация LFNST-индекса (или синтаксический элемент st_idx) может избирательно конфигурироваться/синтаксически анализироваться/передаваться в служебных сигналах/передаваться/приниматься со ссылкой на информацию (или синтаксический элемент intra_mip_flag) относительно того, применяется или нет MIP. Например, информация LFNST-индекса может представляться как синтаксический элемент st_idx или синтаксический элемент lfnst_idex.
[213] Например, информация LFNST-индекса (или синтаксический элемент st_idx) может включаться так, как указано в нижеприведенной таблице 7.
[214] Табл. 7

[215] Например, ссылаясь на таблицу 7, синтаксический элемент st_idx может включаться на основе синтаксического элемента intra_mip_flag. Другими словами, если значение синтаксического элемента intra_mip_flag равно 0 (!intra_mip_flag), синтаксический элемент st_idx может включаться.
[216] Дополнительно, например, информация LFNST-индекса (или синтаксический элемент lfnst_idx) может включаться так, как указано в нижеприведенной таблице 8.
[217] Табл. 8

[218] Например, ссылаясь на таблицу 8, синтаксический элемент lfnst_idx может включаться на основе синтаксического элемента intra_mip_flag. Другими словами, если значение синтаксического элемента intra_mip_flag равно 0 (!intra_mip_flag), синтаксический элемент lfnst_idx может включаться.
[219] Например, ссылаясь на таблицу 7 или таблицу 8, синтаксический элемент st_idx или синтаксический элемент lfnst_idx может включаться на основе связанной с режимом на основе внутренних субсегментов (ISP) информации относительно субсегментации блока. Например, связанная с ISP информация может включать в себя ISP-флаг или флаг ISP-сегментации, и за счет этого может представляться информация относительно того, выполняется или нет субсегментация относительно блока. Например, информация относительно того, выполняется или нет субсегментация, может представляться как IntraSubPartitionsSplitType, ISP_NO_SPLIT может представлять то, что субсегментация не выполняется, ISP_HOR_SPLIT может представлять то, что субсегментация выполняется в горизонтальном направлении, и ISP_VER_SPLIT может представлять то, что субсегментация выполняется в вертикальном направлении.
[220] Связанная остаточная информация может включать в себя информацию LFNST-индекса на основе MIP-флага и связанной с ISP информации.
[221] Между тем, в другом варианте осуществления настоящего документа, информация LFNST-индекса может логически выводиться относительно блока, к которому применяется MIP, без отдельной передачи в служебных сигналах. Дополнительно, оборудование кодирования может формировать поток битов посредством кодирования информации изображений, за исключением информации LFNST-индекса, чтобы преобразовывать блок, к которому применяется MIP, и оборудование декодирования может синтаксически анализировать или декодировать поток битов, логически выводить и получать информацию LFNST-индекса, чтобы преобразовывать блок, к которому применяется MIP, и выполнять процесс преобразования блока на его основе.
[222] Таким образом, информация LFNST-индекса может не декодироваться относительно соответствующего блока, но через процесс логического вывода, индекс для сегментации преобразований, составляющих набор LFNST-преобразования, может определяться. Дополнительно, через процесс логического вывода, может определяться то, что отдельное оптимизированное ядро преобразования используется для блока, к которому применяется MIP. В этом случае, оптимальное LFNST-ядро может выбираться относительно блока, к которому применяется MIP, и объем в битах для его кодирования может уменьшаться.
[223] Например, информация LFNST-индекса может логически выводиться на основе по меньшей мере одной из информации индекса опорной линии для внутреннего прогнозирования, информации режима внутреннего прогнозирования, информации размера блока или информации MIP-применения/неприменения.
[224] Между тем, в другом варианте осуществления настоящего документа, информация LFNST-индекса для блока, к которому применяется MIP, может преобразовываться в двоичную форму, чтобы передаваться в служебных сигналах. Например, число применимых LFNST-преобразований может отличаться в зависимости от того, применяется или нет MIP к текущему блоку, и для этого, способ преобразования в двоичную форму для получения информации LFNST-индекса может избирательно переключаться.
[225] Например, одно LFNST-ядро может использоваться относительно блока, к которому применяется MIP, и это ядро может представлять собой одно из LFNST-ядер, применяемых к блоку, к которому не применяется MIP. Дополнительно, используемое существующее LFNST-ядро может не использоваться для блока, к которому применяется MIP, но отдельное ядро, оптимизированное для блока, к которому применяется MIP, может задаваться и использоваться.
[226] В этом случае, поскольку сокращенное число LFNST-ядер используется относительно блока, к которому применяется MIP, по сравнению с числом LFNST-ядер для блока, к которому не применяется MIP, служебная информация вследствие передачи в служебных сигналах информации LFNST-индекса может уменьшаться, и сложность может уменьшаться.
[227] Например, информация LFNST-индекса может использовать способ преобразования в двоичную форму, как указано в следующей таблице.
[228] Табл. 9
[229] Ссылаясь на таблицу 9, например, синтаксический элемент st_idx может преобразовываться в двоичную форму в усеченный код Райса (TR) в случае, если MIP не применяется к соответствующему блоку, в случае intra_mip_flag[][]=="ложь", или в случае, если значение синтаксического элемента intra_mip_flag равно 0. В этом случае, например, cMax, который представляет собой входной параметр, может иметь значение 2, и cRiceParam может иметь значение 0.
[230] Дополнительно, например, синтаксический элемент st_idx может преобразовываться в двоичную форму в фиксированную длину (FL) в случае, если MIP применяется к соответствующему блоку, в случае intra_mip_flag[][]=="истина", или в случае, если значение синтаксического элемента intra_mip_flag равно 1. В этом случае, например, cMax, который представляет собой входной параметр, может иметь значение 1.
[231] Здесь, синтаксический элемент st_idx может представлять информацию LFNST-индекса и может представляться как синтаксический элемент lfnst_idx.
[232] Между тем, в другом варианте осуществления настоящего документа, связанная с LFNST информация может передаваться в служебных сигналах относительно блока, к которому применяется MIP.
[233] Например, информация LFNST-индекса может включать в себя один синтаксический элемент и может представлять информацию относительно того, применяется или нет LFNST на основе одного синтаксического элемента, и информацию относительно вида ядра преобразования, используемого для LFNST. В этом случае, информация LFNST-индекса может представляться, например, как синтаксический элемент st_idx или синтаксический элемент lfnst_idx.
[234] Дополнительно, например, информация LFNST-индекса может включать в себя один или более синтаксических элементов и может представлять информацию относительно того, применяется или нет LFNST, на основе одного или более синтаксических элементов, и информацию относительно вида ядра преобразования, используемого для LFNST. Например, информация LFNST-индекса может включать в себя два синтаксических элемента. В этом случае, информация LFNST-индекса может включать в себя синтаксический элемент, представляющий информацию относительно того, применяется или нет LFNST, и синтаксический элемент, представляющий информацию относительно вида ядра преобразования, используемого для LFNST. Например, информация относительно того, применяется или нет LFNST, может представляться как LFNST-флаг и может представляться как синтаксический элемент st_flag или синтаксический элемент lfnst_flag. Дополнительно, например, информация относительно вида ядра преобразования, используемого для LFNST, может представляться как флаг индекса ядра преобразования и может представляться как синтаксический элемент st_idx_flag, синтаксический элемент st_kernel_flag, синтаксический элемент lfnst_idx_flag или синтаксический элемент lfnst_kernel_flag. Например, в случае если информация LFNST-индекса включает в себя один или более синтаксических элементов, как описано выше, информация LFNST-индекса может называться "связанной с LFNST информацией".
[235] Например, связанная с LFNST информация (например, синтаксический элемент st_flag или синтаксический элемент st_idx_flag) может включаться так, как указано в нижеприведенной таблице 10.
[236] Табл. 10
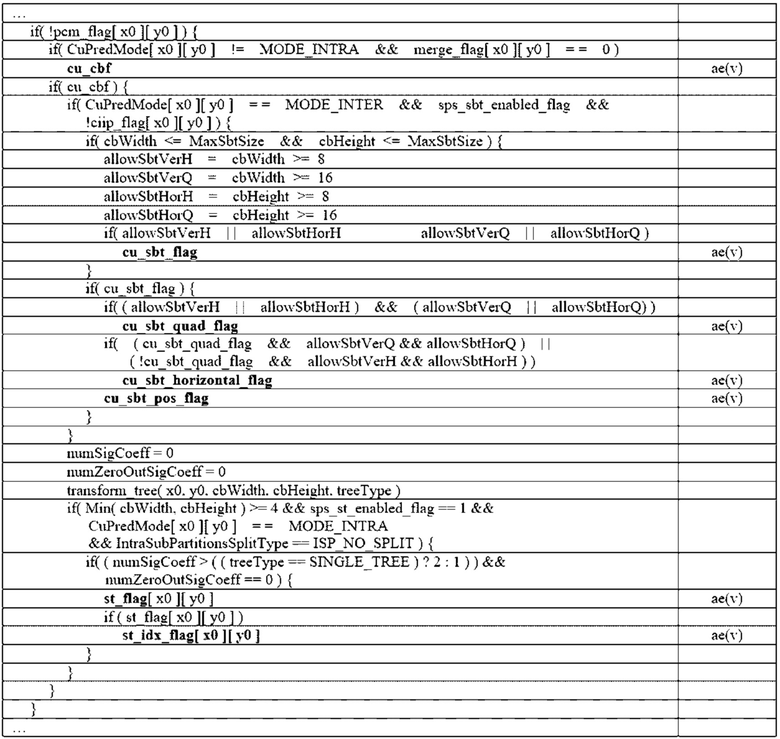
[237] Между тем, блок, к которому применяется MIP, может использовать другое число LFNST-преобразований (ядер) из того из блока, к которому не применяется MIP. Например, блок, к которому применяется MIP, может использовать только одно ядро LFNST-преобразования. Например, одно ядро LFNST-преобразования может представлять собой одно из LFNST-ядер, применяющихся к блоку, к которому не применяется MIP. Дополнительно, вместо использования существующего LFNST-ядра, используемого относительно блока, к которому применяется MIP, отдельное ядро, оптимизированное для блока, к которому применяется MIP, может задаваться и использоваться.
[238] В этом случае, информация (например, флаг индекса ядра преобразования) относительно вида ядра преобразования, используемого для LFNST, из связанной с LFNST информации, может избирательно передаваться в служебных сигналах в зависимости от того, применяется или нет MIP, и связанная с LFNST информация в это время может включаться, например, так, как указано в нижеприведенной таблице 11.
[239] Табл. 11

[240] Другими словами, ссылаясь на таблицу 11, информация (или синтаксический элемент st_idx_flag) относительно вида ядра преобразования, используемого для LFNST, может включаться на основе информации (или синтаксического элемента intra_mip_flag) относительно того, применяется или нет MIP к соответствующему блоку. Дополнительно, например, синтаксический элемент st_idx_flag может передаваться в служебных сигналах в !intra_mip_flag в случае, если MIP не применяется к соответствующему блоку.
[241] Например, в таблице 10 или таблице 11, информация или семантика, представленная посредством синтаксического элемента st_flag или синтаксического элемента st_idx_flag, может быть такой, как указано в следующей таблице.
[242] Табл. 12
- st_flag[x0][y0] указывает то, применяется вторичное преобразование или нет; st_flag[x0][y0], равный 0, указывает то, что вторичное преобразование не применяется. Индексы x0, y0 массивов указывают местоположение (x0, y0) верхней левой выборки рассматриваемого блока преобразования относительно верхней левой выборки кадра.
Когда st_flag[x0][y0] не присутствует, st_idx[x0][y0] логически выводится равным равный 0.
- st_idx_flag[x0][y0] указывает то, какое ядро вторичного преобразования применяется между двумя возможными вариантами ядер в выбранном наборе для преобразования. Индексы x0, y0 массивов указывают местоположение (x0, y0) верхней левой выборки рассматриваемого блока преобразования относительно верхней левой выборки кадра.
Когда st_idx_flag[x0][y0] не присутствует, st_idx[x0][y0] логически выводится равным равный 0.
[243] Например, синтаксический элемент st_flag может представлять информацию относительно того, применяется или нет вторичное преобразование. Например, если значение синтаксического элемента st_flag равно 0, оно может представлять то, что вторичное преобразование не применяется, тогда как если 1, оно может представлять то, что вторичное преобразование применяется. Например, синтаксический элемент st_idx_flag может представлять информацию относительно применяемого ядра вторичного преобразования из двух возможных вариантов ядер в выбранном наборе для преобразования.
[244] Например, для связанной с LFNST информации, может использоваться способ преобразования в двоичную форму, как указано в следующей таблице.
[245] Табл. 13
[246] Ссылаясь на таблицу 13, например, синтаксический элемент st_flag может преобразовываться в двоичную форму на основе FL. Например, в этом случае, cMax, который представляет собой входной параметр, может иметь значение 1. Дополнительно, например, синтаксический элемент st_idx_flag может преобразовываться в двоичную форму на основе FL. Например, в этом случае, cMax, который представляет собой входной параметр, может иметь значение 1.
[247] Например, ссылаясь на таблицу 10 или таблицу 11, дескриптор синтаксического элемента st_flag или синтаксического элемента st_idx_flag может представлять собой ae(v). Здесь, ae(v) может представлять контекстно-адаптивное арифметическое энтропийное кодирование. Дополнительно, синтаксический элемент, для которого дескриптор представляет собой ae(v), может представлять собой контекстно-адаптивно арифметически энтропийно кодированный синтаксический элемент. Таким образом, контекстно-адаптивное арифметическое энтропийное кодирование может применяться к связанной с LFNST информации (например, синтаксическому элементу st_flag или синтаксическому элементу st_idx_flag). Дополнительно, связанная с LFNST информация (например, синтаксический элемент st_flag или синтаксический элемент st_idx_flag) может представлять собой информацию или синтаксический элемент, к которому применяется контекстно-адаптивное арифметическое энтропийное кодирование. Дополнительно, связанная с LFNST информация (например, элементы разрешения из строки элементов разрешения синтаксического элемента st_flag или синтаксического элемента st_idx_flag) может кодироваться/декодироваться на основе вышеописанного CABAC и т.п. Здесь, контекстно-адаптивное арифметическое энтропийное кодирование может представляться как кодирование на основе контекстных моделей, контекстное кодирование или регулярное кодирование.
[248] Например, приращение индекса контекста (ctxInc) связанной с LFNST информации (например, синтаксического элемента st_flag или синтаксического элемента st_idx_flag) или ctxInc в соответствии с местоположением элемента разрешения синтаксического элемента st_flag или синтаксического элемента st_idx_flag может выделяться или определяться так, как указано в таблице 14. Дополнительно, как указано в таблице 14, контекстная модель может выбираться на основе ctxInc в соответствии с местоположением элемента разрешения синтаксического элемента st_flag или синтаксического элемента st_idx_flag, который выделяется или определяется так, как указано в таблице 14.
[249] Табл. 14
[250] Ссылаясь на таблицу 14, например (элемент разрешения из строки элементов разрешения или первый элемент разрешения) синтаксический элемент st_flag может использовать две контекстных модели (или ctxIdx), и контекстная модель может выбираться на основе ctxInc наличие значения 0 или 1. Дополнительно, например, обходное кодирование может применяться к (элементу разрешения из строки элементов разрешения или первый элемент разрешения) синтаксическому элементу st_idx_flag. Дополнительно, кодирование может выполняться посредством применения регулярного распределения вероятностей.
[251] Например, ctxInc (элемента разрешения из строки элементов разрешения или первый элемент разрешения) синтаксического элемента st_flag может определяться на основе нижеприведенной таблицы 15.
[252] Табл. 15
9.5.4.2.8. Процесс извлечения ctxInc для синтаксического элемента st_flag
Вводы в этот процесс представляют собой индекс cIdx цветового компонента, местоположение (x0, y0) сигнала яркости или сигнала цветности, указывающее левую верхнюю выборку текущего блока кодирования сигналов яркости или сигналов цветности относительно левой верхней выборки текущего кадра в зависимости от cIdx, тип treeType дерева и индекс tu_mts_idx[x0][y0] множественного выбора преобразования. Вывод этого процесса представляет собой ctxInc.
Назначение ctxInc указывается следующим образом:
- ctxInc=(tu_mts_idx[x0][y0]=0 andand treeType!=SINGLE_TREE)?1:0
[253] Ссылаясь на таблицу 15, например, ctxInc (элемента разрешения из строки элементов разрешения или первый элемент разрешения) синтаксического элемента st_flag может определяться на основе MTS-индекса (или синтаксического элемента tu_mts_idx) либо информации типа дерева (treeType). Например, ctxInc может извлекаться в качестве 1 в случае, если значение MTS-индекса равно 0, и тип дерева не представляет собой одиночное дерево. Дополнительно, ctxInc может извлекаться в качестве 0 в случае, если значение MTS-индекса не равно 0, или тип дерева представляет собой одиночное дерево.
[254] В этом случае, поскольку сокращенное число LFNST-ядер используется относительно блока, к которому применяется MIP, по сравнению с числом LFNST-ядер для, к которому не применяется MIP, служебная информация вследствие передачи служебных сигналов информации LFNST-индекса может уменьшаться, и сложность может уменьшаться.
[255] Между тем, в другом варианте осуществления настоящего документа, LFNST-ядро может логически выводиться и использоваться относительно блока, к которому применяется MIP. Таким образом, LFNST-ядро может логически выводиться без отдельной передачи в служебных сигналах информации относительно LFNST-ядра. Дополнительно, оборудование кодирования может формировать поток битов посредством кодирования информации изображений, за исключением информации LFNST-индекса, чтобы преобразовывать блок, к которому применяется MIP, и информации относительно (вида) ядра преобразования, подходящего для LFNST, и оборудование декодирования может синтаксически анализировать или декодировать поток битов, логически выводить и получать информацию LFNST-индекса, чтобы преобразовывать блок, к которому применяется MIP, и информацию относительно ядра преобразования, используемого для LFNST, и выполнять процесс преобразования блока на его основе.
[256] Таким образом, информация LFNST-индекса для соответствующего блока или информации относительно ядра преобразования, используемого для LFNST, может не декодироваться, но через процесс логического вывода индекс для сегментации преобразований, составляющих набор LFNST-преобразования, может определяться. Дополнительно, через процесс логического вывода, может определяться то, что отдельное оптимизированное ядро преобразования используется для блока, к которому применяется MIP. В этом случае, оптимальное LFNST-ядро может выбираться относительно блока, к которому применяется MIP, и объем в битах для его кодирования может уменьшаться.
[257] Например, информация LFNST-индекса или информация относительно ядра преобразования, используемого для LFNST, может логически выводиться на основе по меньшей мере одной из информации индекса опорной линии для внутреннего прогнозирования, информации режима внутреннего прогнозирования, информации размера блока или информации MIP-применения/неприменения.
[258] В вышеописанных вариантах осуществления настоящего документа, преобразование в двоичную форму кодом фиксированной длины (FL) может представлять способ преобразования в двоичную форму с фиксированной длиной, к примеру, с конкретным числом битов, и конкретное число битов может быть предварительно задано или может представляться на основе cMax. Преобразование в двоичную форму усеченным двоичным кодом (TU) может представлять способ преобразования в двоичную форму с переменной длиной, без присоединения 0 в случае, если число символов, предназначенных для выражения с использованием 1, число которых не меньше числа символы и один 0, равно максимальной длине, и максимальная длина может представляться на основе cMax. Преобразование в двоичную форму усеченным кодом Райса (TR) может представлять способ преобразования в двоичную форму в форме, в которой префикс и суффикс соединяются между собой, к примеру, как TU+FL, с использованием информации максимальной длины и сдвига, и в случае, если информация сдвига имеет значение 0, он может быть равным TU. Здесь, максимальная длина может представляться на основе cMax, и информация сдвига может представляться на основе cRiceParam.
[259] Фиг. 11 и 12 схематично иллюстрируют способ кодирования видео/изображений и пример связанных компонентов согласно варианту(ам) осуществления настоящего документа.
[260] Способ, раскрытый на фиг. 11, может выполняться посредством оборудования кодирования, раскрытого на фиг. 2 или фиг. 12. В частности, например, S1100-S1120 по фиг. 11 могут выполняться посредством модуля 220 прогнозирования оборудования кодирования по фиг. 12, и S1130-S1150 по фиг. 11 могут выполняться посредством остаточного процессора 230 оборудования кодирования по фиг. 12, и S1160 по фиг. 11 может выполняться посредством энтропийного кодера 240 оборудования кодирования по фиг. 12. Дополнительно, хотя не проиллюстрировано на фиг. 11, модуль 220 прогнозирования оборудования кодирования на фиг. 12 может извлекать прогнозные выборки или связанную с прогнозированием информацию, остаточный процессор 230 оборудования кодирования может извлекать остаточную информацию из исходных выборок или прогнозных выборок, и энтропийный кодер 240 оборудования кодирования может формировать поток битов из остаточной информации или связанной с прогнозированием информации. Способ, раскрытый на фиг. 11, может включать в себя вышеописанные варианты осуществления настоящего документа.
[261] Ссылаясь на фиг. 11, оборудование кодирования может определять тип внутреннего прогнозирования текущего блока (S1100) и может формировать информацию типа внутреннего прогнозирования для текущего блока на основе типа внутреннего прогнозирования (S1110). Например, оборудование кодирования может определять тип внутреннего прогнозирования текущего блока с учетом функции затрат на искажение в зависимости от скорости передачи (RD). Информация типа внутреннего прогнозирования может представлять информацию относительно того, следует применять тип нормального внутреннего прогнозирования с использованием опорной линии, смежной с текущим блоком, режим на основе множественной опорной линии (MRL) с использованием опорной линии, которая не является смежной с текущим блоком, режим на основе внутренних субсегментов (ISP), выполняющий субсегментацию для текущего блока, или матричное внутреннее прогнозирование (MIP) с использованием матрицы.
[262] Например, информация типа внутреннего прогнозирования может включать в себя MIP-флаг, представляющий то, применяется или нет MIP к текущему блоку. Дополнительно, например, информация типа внутреннего прогнозирования может включать в себя связанную с режимом на основе внутренних субсегментов (ISP) информацию относительно субсегментации ISP для текущего блока. Например, связанная с ISP информация может включать в себя ISP-флаг, представляющий то, применяется или нет ISP к текущему блоку, или флаг ISP-сегментации, представляющий направление сегментации. Дополнительно, например, информация типа внутреннего прогнозирования может включать в себя MIP-флаг и связанную с ISP информацию. Например, MIP-флаг может представлять синтаксический элемент intra_mip_flag. Дополнительно, например, ISP-флаг может представлять синтаксический элемент intra_subpartitions_mode_flag, и флаг ISP-сегментации может представлять синтаксический элемент intra_subpartitions_split_flag.
[263] Дополнительно, хотя не проиллюстрировано на фиг. 11, например, оборудование кодирования может определять режим внутреннего прогнозирования для текущего блока и может формировать информацию внутреннего прогнозирования для текущего блока на основе режима внутреннего прогнозирования. Например, оборудование кодирования может определять режим внутреннего прогнозирования с учетом RD-затрат. Информация режима внутреннего прогнозирования может представлять режим внутреннего прогнозирования, который должен применяться к текущему блоку, из режимов внутреннего прогнозирования. Например, режимы внутреннего прогнозирования могут включать в себя режимы внутреннего прогнозирования номер 0-66. Например, режим внутреннего прогнозирования номер 0 может представлять планарный режим, и режим внутреннего прогнозирования номер 1 может представлять DC-режим. Дополнительно, режимы внутреннего прогнозирования номер 2-66 могут представляться как режимы направленного или углового внутреннего прогнозирования и могут представлять направления для ссылки. Дополнительно, режимы внутреннего прогнозирования номер 0 и номер 1 могут представляться как режимы ненаправленного или неуглового внутреннего прогнозирования. Подробное пояснение означенного приведено со ссылкой на фиг. 5.
[264] Например, оборудование кодирования может формировать связанную с прогнозированием информацию для текущего блока, и связанная с прогнозированием информация может включать в себя информацию режима внутреннего прогнозирования и/или информацию типа внутреннего прогнозирования.
[265] Оборудование кодирования может извлекать прогнозные выборки текущего блока на основе типа внутреннего прогнозирования (S1120). Дополнительно, например, оборудование кодирования может формировать прогнозные выборки на основе режима внутреннего прогнозирования и/или типа внутреннего прогнозирования. Дополнительно, оборудование кодирования может формировать прогнозные выборки на основе связанной с прогнозированием информации.
[266] Оборудование кодирования может формировать остаточные выборки текущего блока на основе прогнозных выборок (S1130). Например, оборудование кодирования может формировать остаточные выборки на основе исходных выборок (например, сигнала входного изображения) и прогнозных выборок. Дополнительно, например, оборудование кодирования может формировать остаточные выборки на основе разности между исходными выборками и прогнозными выборками.
[267] Оборудование кодирования может извлекать коэффициенты преобразования для текущего блока на основе остаточных выборок (S1140). Например, оборудование кодирования может извлекать коэффициенты преобразования посредством выполнения первичного преобразования на основе остаточных выборок. Дополнительно, например, оборудование кодирования может извлекать временные коэффициенты преобразования посредством выполнения первичного преобразования на основе остаточных выборок и может извлекать коэффициенты преобразования посредством применения LFNST к временным коэффициентам преобразования. Например, в случае если LFNST применяется, оборудование кодирования может формировать информацию LFNST-индекса. Таким образом, оборудование кодирования может формировать информацию LFNST-индекса на основе ядра преобразования, используемого для того, чтобы извлекать коэффициенты преобразования.
[268] Оборудование кодирования может формировать связанную остаточную информацию на основе коэффициентов преобразования (S1150). Например, оборудование кодирования может извлекать квантованные коэффициенты преобразования посредством выполнения квантования на основе коэффициентов преобразования. Дополнительно, оборудование кодирования может формировать информацию относительно квантованных коэффициентов преобразования на основе квантованных коэффициентов преобразования. Дополнительно, связанная остаточная информация может включать в себя информацию относительно квантованных коэффициентов преобразования.
[269] Оборудование кодирования может кодировать информацию типа внутреннего прогнозирования и связанную остаточную информацию (S1160). Например, связанная остаточная информация может включать в себя информацию относительно квантованных коэффициентов преобразования, как описано выше. Дополнительно, например, связанная остаточная информация может включать в себя информацию LFNST-индекса. Дополнительно, например, связанная остаточная информация может не включать в себя информацию LFNST-индекса.
[270] Например, связанная остаточная информация может включать в себя информацию LFNST-индекса, представляющую информацию относительно неразделимого преобразования для низкочастотных коэффициентов преобразования текущего блока. Дополнительно, например, связанная остаточная информация может включать в себя информацию LFNST-индекса на основе MIP-флага или размера текущего блока. Дополнительно, например, связанная остаточная информация может включать в себя информацию LFNST-индекса на основе MIP-флага или информации относительно текущего блока. Здесь, информация относительно текущего блока может включать в себя по меньшей мере одно из размера текущего блока, информации древовидной структуры, представляющей одиночное дерево или сдвоенное дерево, флага LFNST-активации или связанной с ISP информации. Например, MIP-флаг может представлять собой одно из множества условий для определения того, включает или нет связанная остаточная информация в себя информацию LFNST-индекса, и посредством других условий, таких как размер текущего блока, в дополнение к MIP-флагу, связанная остаточная информация может включать в себя информацию LFNST-индекса. Тем не менее, в дальнейшем в этом документе, пояснение приводится для MIP-флага. Здесь, информация LFNST-индекса может представляться как информация индекса преобразования. Дополнительно, информация LFNST-индекса может представляться как синтаксический элемент st_idx или синтаксический элемент lfnst_idx.
[271] Например, связанная остаточная информация может включать в себя информацию LFNST-индекса на основе MIP-флага, представляющего то, что MIP не применяется. Дополнительно, например, связанная остаточная информация может не включать в себя информацию LFNST-индекса на основе MIP-флага, представляющего то, что MIP применяется. Таким образом, в случае если MIP-флаг представляет то, что MIP применяется к текущему блоку (например, в случае если значение синтаксического элемента intra_mip_flag равно 1), связанная остаточная информация может не включать в себя информацию LFNST-индекса, и в случае, если MIP-флаг представляет то, что MIP не применяется к текущему блоку (например, в случае если значение синтаксического элемента intra_mip_flag равно 0), связанная остаточная информация может включать в себя информацию LFNST-индекса.
[272] Дополнительно, например, связанная остаточная информация может включать в себя информацию LFNST-индекса на основе MIP-флага и связанной с ISP информации. Например, в случае если MIP-флаг представляет то, что MIP не применяется к текущему блоку (например, в случае если значение синтаксического элемента intra_mip_flag равно 0), связанная остаточная информация может включать в себя информацию LFNST-индекса со ссылкой на связанную с ISP информацию (IntraSubPartitionsSplitType). Здесь, IntraSubPartitionsSplitType может представлять то, что ISP не применяется (ISP_NO_SPLIT), ISP применяется в горизонтальном направлении (ISP_HOR_SPLIT), или ISP применяется в вертикальном направлении (ISP_VER_SPLIT), и он может извлекаться на основе ISP-флага или флага ISP-сегментации.
[273] Например, поскольку MIP-флаг представляет то, что MIP применяется к текущему блоку, информация LFNST-индекса может логически выводиться или извлекаться для использования, и в этом случае, связанная остаточная информация может не включать в себя информацию LFNST-индекса. Таким образом, оборудование кодирования может не передавать в служебных сигналах информацию LFNST-индекса. Например, информация LFNST-индекса может логически выводиться или извлекаться для использования на основе по меньшей мере одного из информации индекса опорной линии для текущего блока, информации режима внутреннего прогнозирования текущего блока, информации размера текущего блока и MIP-флага.
[274] Дополнительно, например, информация LFNST-индекса может включать в себя LFNST-флаг, представляющий то, применяется или нет неразделимое преобразование для низкочастотных коэффициентов преобразования текущего блока, и/или флаг индекса ядра преобразования, представляющий ядро преобразования, применяемое к текущему блоку, из возможных вариантов ядер преобразования. Таким образом, хотя информация LFNST-индекса может представлять информацию относительно неразделимого преобразования для низкочастотных коэффициентов преобразования текущего блока на основе одного синтаксического элемента или одного фрагмента информации, она также может представлять информацию на основе двух синтаксических элементов или двух фрагментов информации. Например, LFNST-флаг может представляться как синтаксический элемент st_flag или синтаксический элемент lfnst_flag, и флаг индекса ядра преобразования может представляться как синтаксический элемент st_idx_flag, синтаксический элемент st_kernel_flag, синтаксический элемент lfnst_idx_flag или синтаксический элемент lfnst_kernel_flag. Здесь, флаг индекса ядра преобразования может включаться в информацию LFNST-индекса на основе LFNST-флага, представляющего то, что неразделимое преобразование применяется, и MIP-флага, представляющего то, что MIP не применяется. Таким образом, в случае если LFNST-флаг представляет то, что неразделимое преобразование применяется, и MIP-флаг представляет то, что MIP применяется, информация LFNST-индекса может включать в себя флаг индекса ядра преобразования.
[275] Например, поскольку MIP-флаг представляет то, что MIP применяется к текущему блоку, LFNST-флаг и флаг индекса ядра преобразования могут логически выводиться или извлекаться для использования, и в этом случае, связанная остаточная информация может не включать в себя LFNST-флаг и флаг индекса ядра преобразования. Таким образом, оборудование кодирования может не передавать в служебных сигналах LFNST-флаг и флаг индекса ядра преобразования. Например, LFNST-флаг и флаг индекса ядра преобразования могут логически выводиться или извлекаться для использования на основе по меньшей мере одного из информации индекса опорной линии для текущего блока, информации режима внутреннего прогнозирования текущего блока, информации размера текущего блока и MIP-флага.
[276] Например, в случае если связанная остаточная информация включает в себя информацию LFNST-индекса, информация LFNST-индекса может представляться через преобразование в двоичную форму. Например, информация LFNST-индекса (например, синтаксический элемент st_idx или синтаксический элемент lfnst_idx) может представляться через преобразование в двоичную форму усеченным кодом Райса (TR) на основе MIP-флага, представляющего то, что MIP не применяется, и информация LFNST-индекса (например, синтаксический элемент st_idx или синтаксический элемент lfnst_idx) может представляться через преобразование в двоичную форму кодом фиксированной длины (FL) на основе MIP-флага, представляющего то, что MIP применяется. Таким образом, в случае если MIP-флаг представляет то, что MIP не применяется к текущему блоку (например, в случае если синтаксический элемент intra_mip_flag равен 0 или представляет собой "ложь"), информация LFNST-индекса (например, синтаксический элемент st_idx или синтаксический элемент lfnst_idx) может представляться через преобразование в двоичную форму на основе TR, и в случае, если MIP-флаг представляет то, что MIP применяется к текущему блоку (например, в случае если синтаксический элемент intra_mip_flag равен 1 или представляет собой "истина"), информация LFNST-индекса (например, синтаксический элемент st_idx или синтаксический элемент lfnst_idx) может представляться через преобразование в двоичную форму на основе FL.
[277] Дополнительно, например, в случае если связанная остаточная информация включает в себя информацию LFNST-индекса, и информация LFNST-индекса включает в себя LFNST-флаг и флаг индекса ядра преобразования, LFNST-флаг и флаг индекса ядра преобразования могут представляться через преобразование в двоичную форму кодом фиксированной длины (FL).
[278] Например, информация LFNST-индекса может представляться как (элемент разрешения) строка элементов разрешения через вышеописанное преобразование в двоичную форму, и посредством ее кодирования, может формироваться бит, битовая строка или поток битов.
[279] Например, (первый) элемент разрешения из строки элементов разрешения LFNST-флага может кодироваться на основе контекстного кодирования, и контекстное кодирование может выполняться на основе значения приращения индекса контекста для LFNST-флага. Здесь, контекстное кодирование представляет собой кодирование, выполняемое на основе контекстной модели, и может называться "регулярным кодированием". Дополнительно, контекстная модель может представляться посредством индекса ctsIdx контекста, и индекс контекста может представляться на основе приращения ctxInc индекса контекста и смещения ctxIdxOffset индекса контекста. Например, значение приращения индекса контекста может представляться как один из возможных вариантов, включающих в себя 0 и 1. Например, значение приращения индекса контекста может определяться на основе MTS-индекса (например, синтаксического элемента mts_idx или синтаксического элемента tu_mts_idx), представляющего набор ядер преобразования, который должен использоваться для текущего блока, из наборов ядер преобразования, и информации типа дерева, представляющей структуру сегментации текущего блока. Здесь, информация типа дерева может представлять одиночное дерево, представляющее то, что структуры сегментации компонента сигнала яркости и компонент сигнала цветности текущего блока равны друг другу, или сдвоенное дерево, представляющее то, что структуры сегментации компонента сигнала яркости и компонент сигнала цветности текущего блока отличаются друг от друга.
[280] Например, (первый) элемент разрешения из строки элементов разрешения флага индекса ядра преобразования может кодироваться на основе обходного кодирования. Здесь, обходное кодирование может представлять то, что контекстное кодирование выполняется на основе регулярного распределения вероятностей, и эффективность кодирования может повышаться посредством опускания процедуры обновления контекстного кодирования.
[281] Дополнительно, хотя не проиллюстрировано на фиг. 11, например, оборудование кодирования может формировать восстановленные выборки на основе остаточных выборок и прогнозных выборок. Дополнительно, восстановленный блок и восстановленный кадр могут извлекаться на основе восстановленных выборок.
[282] Например, оборудование кодирования может формировать информацию потока битов или кодированную информацию посредством кодирования информации изображений, включающей в себя все или части вышеописанных фрагментов информации (или синтаксических элементов). Дополнительно, оборудование кодирования может выводить информацию в форме потока битов. Дополнительно, поток битов или кодированная информация может передаваться в оборудование декодирования через сеть или носитель хранения данных. Дополнительно, поток битов или кодированная информация может сохраняться на компьютерно-читаемом носителе хранения данных, и поток битов или кодированная информация может формироваться посредством вышеописанного способа кодирования изображений.
[283] Фиг. 13 и 14 схематично иллюстрируют способ декодирования видео/изображений и пример связанных компонентов согласно варианту(ам) осуществления настоящего документа.
[284] Способ, раскрытый на фиг. 13, может осуществляться посредством оборудования декодирования, раскрытого на фиг. 3 или фиг. 14. В частности, например, S1300 по фиг. 14 может выполняться посредством энтропийного декодера 310 оборудования декодирования по фиг. 14, и S1310 и S1320 по фиг. 13 могут выполняться посредством остаточного процессора 320 оборудования декодирования по фиг. 14. Дополнительно, хотя не проиллюстрировано на фиг. 13, энтропийный декодер 310 оборудования декодирования по фиг. 14 может извлекать связанную с прогнозированием информацию или остаточную информацию из потока битов, остаточный процессор 320 оборудования декодирования может извлекать остаточные выборки из остаточной информации, модуль 330 прогнозирования оборудования декодирования может извлекать прогнозные выборки из связанной с прогнозированием информации, и сумматор 340 оборудования декодирования может извлекать восстановленный блок или восстановленный кадр из остаточных выборок или прогнозных выборок. Способ, раскрытый на фиг. 13, может включать в себя вышеописанные варианты осуществления настоящего документа.
[285] Ссылаясь на фиг. 13, оборудование декодирования может получать информацию типа внутреннего прогнозирования для текущего блока и связанной остаточной информации из потока битов (S1300). Например, оборудование декодирования может получать информацию типа внутреннего прогнозирования или связанную остаточную информацию посредством синтаксического анализа или декодирования потока битов. Здесь, поток битов может называться "кодированной информацией (изображений)".
[286] Например, оборудование декодирования может получать связанную с прогнозированием информацию из потока битов, и связанная с прогнозированием информация может включать в себя информацию режима внутреннего прогнозирования и/или информацию типа внутреннего прогнозирования. Например, оборудование декодирования может формировать прогнозные выборки для текущего блока.
[287] Информация режима внутреннего прогнозирования может представлять режим внутреннего прогнозирования, который должен применяться к текущему блоку, из режимов внутреннего прогнозирования. Например, режимы внутреннего прогнозирования могут включать в себя режимы внутреннего прогнозирования номер 0-66. Например, режим внутреннего прогнозирования номер 0 может представлять планарный режим, и режим внутреннего прогнозирования номер 1 может представлять DC-режим. Дополнительно, режимы внутреннего прогнозирования номер 2-66 могут представляться как режимы направленного или углового внутреннего прогнозирования и могут представлять направления для ссылки. Дополнительно, режимы внутреннего прогнозирования номер 0 и номер 1 могут представляться как режимы ненаправленного или неуглового внутреннего прогнозирования. Подробное пояснение означенного приведено со ссылкой на фиг. 5.
[288] Дополнительно, информация типа внутреннего прогнозирования может представлять информацию относительно того, следует применять тип нормального внутреннего прогнозирования с использованием опорной линии, смежной с текущим блоком, режим на основе множественной опорной линии (MRL) с использованием опорной линии, которая не является смежной с текущим блоком, режим на основе внутренних субсегментов (ISP), выполняющий субсегментацию для текущего блока, или матричное внутреннее прогнозирование (MIP) с использованием матрицы.
[289] Например, оборудование декодирования может получать связанную остаточную информацию из потока битов. Здесь, связанная остаточная информация может представлять информацию, используемую для того, чтобы извлекать остаточные выборки, и может включать в себя информацию относительно остаточных выборок, связанную с (обратным) преобразованием информацию и/или связанную с (обратным) квантованием информацию. Например, связанная остаточная информация может включать в себя информацию относительно квантованных коэффициентов преобразования.
[290] Например, информация типа внутреннего прогнозирования может включать в себя MIP-флаг, представляющий то, применяется или нет MIP к текущему блоку. Дополнительно, например, информация типа внутреннего прогнозирования может включать в себя связанную с режимом на основе внутренних субсегментов (ISP) информацию относительно субсегментации ISP для текущего блока. Например, связанная с ISP информация может включать в себя ISP-флаг, представляющий то, применяется или нет ISP к текущему блоку, или флаг ISP-сегментации, представляющий направление сегментации. Дополнительно, например, информация типа внутреннего прогнозирования может включать в себя MIP-флаг и связанную с ISP информацию. Например, MIP-флаг может представлять синтаксический элемент intra_mip_flag. Дополнительно, например, ISP-флаг может представлять синтаксический элемент intra_subpartitions_mode_flag, и флаг ISP-сегментации может представлять синтаксический элемент intra_subpartitions_split_flag.
[291] Например, связанная остаточная информация может включать в себя информацию индекса низкочастотного неразделимого преобразования (LFNST), представляющую информацию относительно неразделимого преобразования для низкочастотных коэффициентов преобразования текущего блока. Дополнительно, например, связанная остаточная информация может включать в себя информацию LFNST-индекса на основе MIP-флага или размера текущего блока. Дополнительно, например, связанная остаточная информация может включать в себя информацию LFNST-индекса на основе MIP-флага или информации относительно текущего блока. Здесь, информация относительно текущего блока может включать в себя по меньшей мере одно из размера текущего блока, информации древовидной структуры, представляющей одиночное дерево или сдвоенное дерево, флага LFNST-активации или связанной с ISP информации. Например, MIP-флаг может представлять собой одно из множества условий для определения того, включает или нет связанная остаточная информация в себя информацию LFNST-индекса, и посредством других условий, таких как размер текущего блока, в дополнение к MIP-флагу, связанная остаточная информация может включать в себя информацию LFNST-индекса. Тем не менее, в дальнейшем в этом документе, пояснение приводится для MIP-флага. Здесь, информация LFNST-индекса может представляться как информация индекса преобразования. Дополнительно, информация LFNST-индекса может представляться как синтаксический элемент st_idx или синтаксический элемент lfnst_idx.
[292] Например, связанная остаточная информация может включать в себя информацию LFNST-индекса на основе MIP-флага, представляющего то, что MIP не применяется. Дополнительно, например, связанная остаточная информация может не включать в себя информацию LFNST-индекса на основе MIP-флага, представляющего то, что MIP применяется. Таким образом, в случае если MIP-флаг представляет то, что MIP применяется к текущему блоку (например, в случае если значение синтаксического элемента intra_mip_flag равно 1), связанная остаточная информация может не включать в себя информацию LFNST-индекса, и в случае, если MIP-флаг представляет то, что MIP не применяется к текущему блоку (например, в случае если значение синтаксического элемента intra_mip_flag равно 0), связанная остаточная информация может включать в себя информацию LFNST-индекса.
[293] Дополнительно, например, связанная остаточная информация может включать в себя информацию LFNST-индекса на основе MIP-флага и связанной с ISP информации. Например, в случае если MIP-флаг представляет то, что MIP не применяется к текущему блоку (например, в случае если значение синтаксического элемента intra_mip_flag равно 0), связанная остаточная информация может включать в себя информацию LFNST-индекса со ссылкой на связанную с ISP информацию (IntraSubPartitionsSplitType). Здесь, IntraSubPartitionsSplitType может представлять то, что ISP не применяется (ISP_NO_SPLIT), ISP применяется в горизонтальном направлении (ISP_HOR_SPLIT), или ISP применяется в вертикальном направлении (ISP_VER_SPLIT), и он может извлекаться на основе ISP-флага или флага ISP-сегментации.
[294] Например, поскольку MIP-флаг представляет то, что MIP применяется к текущему блоку, информация LFNST-индекса может логически выводиться или извлекаться для использования в случае, если связанная остаточная информация не включает в себя информацию LFNST-индекса, т.е. в случае, если информация LFNST-индекса не передается в служебных сигналах. Например, информация LFNST-индекса может извлекаться на основе по меньшей мере одного из информации индекса опорной линии для текущего блока, информации режима внутреннего прогнозирования текущего блока, информации размера текущего блока и MIP-флага.
[295] Дополнительно, например, информация LFNST-индекса может включать в себя LFNST-флаг, представляющий то, применяется или нет неразделимое преобразование для низкочастотных коэффициентов преобразования текущего блока, и/или флаг индекса ядра преобразования, представляющий ядро преобразования, применяемое к текущему блоку, из возможных вариантов ядер преобразования. Таким образом, хотя информация LFNST-индекса может представлять информацию относительно неразделимого преобразования для низкочастотных коэффициентов преобразования текущего блока на основе одного синтаксического элемента или одного фрагмента информации, она также может представлять информацию на основе двух синтаксических элементов или двух фрагментов информации. Например, LFNST-флаг может представляться как синтаксический элемент st_flag или синтаксический элемент lfnst_flag, и флаг индекса ядра преобразования может представляться как синтаксический элемент st_idx_flag, синтаксический элемент st_kernel_flag, синтаксический элемент lfnst_idx_flag или синтаксический элемент lfnst_kernel_flag. Здесь, флаг индекса ядра преобразования может включаться в информацию LFNST-индекса на основе LFNST-флага, представляющего то, что неразделимое преобразование применяется, и MIP-флага, представляющего то, что MIP не применяется. Таким образом, в случае если LFNST-флаг представляет то, что неразделимое преобразование применяется, и MIP-флаг представляет то, что MIP применяется, информация LFNST-индекса может включать в себя флаг индекса ядра преобразования.
[296] Например, поскольку MIP-флаг представляет то, что MIP применяется к текущему блоку, LFNST-флаг и флаг индекса ядра преобразования могут логически выводиться или извлекаться в случае, если связанная остаточная информация не включает в себя LFNST-флаг и флаг индекса ядра преобразования, т.е. LFNST-флаг и флаг индекса ядра преобразования не передаются в служебных сигналах. Например, LFNST-флаг и флаг индекса ядра преобразования могут извлекаться на основе по меньшей мере одного из информации индекса опорной линии для текущего блока, информации режима внутреннего прогнозирования текущего блока, информации размера текущего блока и MIP-флага.
[297] Например, в случае если связанная остаточная информация включает в себя информацию LFNST-индекса, информация LFNST-индекса может представляться через преобразование в двоичную форму. Например, информация LFNST-индекса (например, синтаксический элемент st_idx или синтаксический элемент lfnst_idx) может извлекаться через преобразование в двоичную форму усеченным кодом Райса (TR) на основе MIP-флага, представляющего то, что MIP не применяется, и информация LFNST-индекса (например, синтаксический элемент st_idx или синтаксический элемент lfnst_idx) может извлекаться через преобразование в двоичную форму кодом фиксированной длины (FL) на основе MIP-флага, представляющего то, что MIP применяется. Таким образом, в случае если MIP-флаг представляет то, что MIP не применяется к текущему блоку (например, в случае если синтаксический элемент intra_mip_flag равен 0 или представляет собой "ложь"), информация LFNST-индекса (например, синтаксический элемент st_idx или синтаксический элемент lfnst_idx) может извлекаться через преобразование в двоичную форму на основе TR, и в случае, если MIP-флаг представляет то, что MIP применяется к текущему блоку (например, в случае если синтаксический элемент intra_mip_flag равен 1 или представляет собой "истина"), информация LFNST-индекса (например, синтаксический элемент st_idx или синтаксический элемент lfnst_idx) может извлекаться через преобразование в двоичную форму на основе FL.
[298] Дополнительно, например, в случае если связанная остаточная информация включает в себя информацию LFNST-индекса, и информация LFNST-индекса включает в себя LFNST-флаг и флаг индекса ядра преобразования, LFNST-флаг и флаг индекса ядра преобразования могут извлекаться через преобразование в двоичную форму кодом фиксированной длины (FL).
[299] Например, информация LFNST-индекса может извлекать возможные варианты через вышеописанное преобразование в двоичную форму, может сравнивать элементы разрешения, представленные посредством синтаксического анализа или декодирования потока битов, с возможными вариантами, и за счет этого информация LFNST-индекса может получаться.
[300] Например, (первый) элемент разрешения из строки элементов разрешения LFNST-флага может извлекаться на основе контекстного кодирования, и контекстное кодирование может выполняться на основе значения приращения индекса контекста для LFNST-флага. Здесь, контекстное кодирование представляет собой кодирование, выполняемое на основе контекстной модели, и может называться "регулярным кодированием". Дополнительно, контекстная модель может представляться посредством индекса ctsIdx контекста, и индекс контекста может извлекаться на основе приращения ctxInc индекса контекста и смещения ctxIdxOffset индекса контекста. Например, значение приращения индекса контекста может извлекаться в качестве одного из возможных вариантов, включающих в себя 0 и 1. Например, значение приращения индекса контекста может извлекаться на основе MTS-индекса (например, синтаксического элемента mts_idx или синтаксического элемента tu_mts_idx), представляющего набор ядер преобразования, который должен использоваться для текущего блока, из наборов ядер преобразования, и информации типа дерева, представляющей структуру сегментации текущего блока. Здесь, информация типа дерева может представлять одиночное дерево, представляющее то, что структуры сегментации компонента сигнала яркости и компонент сигнала цветности текущего блока равны друг другу, или сдвоенное дерево, представляющее то, что структуры сегментации компонента сигнала яркости и компонент сигнала цветности текущего блока отличаются друг от друга.
[301] Например, (первый) элемент разрешения из строки элементов разрешения флага индекса ядра преобразования может извлекаться на основе обходного кодирования. Здесь, обходное кодирование может представлять то, что контекстное кодирование выполняется на основе регулярного распределения вероятностей, и эффективность кодирования может повышаться посредством опускания процедуры обновления контекстного кодирования.
[302] Оборудование декодирования может извлекать коэффициенты преобразования для текущего блока на основе связанной остаточной информации (S1310). Например, связанная остаточная информация может включать в себя информацию относительно квантованных коэффициентов преобразования, и оборудование декодирования может извлекать квантованные коэффициенты преобразования для текущего блока на основе информации относительно квантованных коэффициентов преобразования. Например, оборудование декодирования может извлекать коэффициенты преобразования для текущего блока посредством выполнения деквантования квантованных коэффициентов преобразования.
[303] Оборудование декодирования может формировать остаточные выборки текущего блока на основе коэффициентов преобразования (S1320). Например, оборудование декодирования может формировать остаточные выборки из коэффициентов преобразования на основе информации LFNST-индекса. Например, в случае если информация LFNST-индекса включается в связанную остаточную информацию, или информация LFNST-индекса логически выводится или извлекается, LFNST может выполняться относительно коэффициентов преобразования в соответствии с информацией LFNST-индекса, и модифицированные коэффициенты преобразования могут извлекаться. После этого, оборудование декодирования может формировать остаточные выборки на основе модифицированных коэффициентов преобразования. Дополнительно, например, в случае если информация LFNST-индекса не включается в связанную остаточную информацию, либо представляется то, что LFNST не выполняется, оборудование декодирования может не выполнять LFNST относительно коэффициентов преобразования, но может формировать остаточные выборки на основе коэффициентов преобразования.
[304] Хотя не проиллюстрировано на фиг. 13, например, оборудование декодирования может формировать восстановленные выборки на основе прогнозных выборок и остаточных выборок. Дополнительно, например, восстановленный блок и восстановленный кадр могут извлекаться на основе восстановленных выборок.
[305] Например, оборудование декодирования может получать информацию изображений, включающую в себя все или части вышеописанных фрагментов информации (или синтаксических элементов), посредством декодирования потока битов или кодированной информации. Дополнительно, поток битов или кодированная информация может сохраняться на компьютерно-читаемом носителе хранения данных и может инструктировать осуществление вышеописанного способа декодирования.
[306] Хотя способы описываются на основе блок-схемы последовательности операций способа, на которой этапы или блоки перечисляются в последовательности в вышеописанных вариантах осуществления, этапы настоящего документа не ограничены определенным порядком, и определенный этап может выполняться на другом этапе или в другом порядке либо одновременно относительно того, что описано выше. Дополнительно, специалисты в данной области техники должны понимать, что этапы блок-схем последовательности операций способа не являются единственно возможными, и другой этап может включаться, либо один или более этапов на блок-схеме последовательности операций способа могут удаляться без влияния на объем настоящего раскрытия.
[307] Вышеуказанный способ согласно настоящему раскрытию может осуществляться в форме программного обеспечения, и оборудования кодирование и/или оборудование декодирования согласно настоящему раскрытию могут включаться в устройство для выполнения обработки изображений, например, в телевизор, компьютер, смартфон, абонентскую приставку, устройство отображения и т.п.
[308] Когда варианты осуществления настоящего раскрытия реализуются посредством программного обеспечения, вышеуказанный способ может реализовываться посредством модуля (процесса или функции), который выполняет вышеуказанную функцию. Модуль может сохраняться в запоминающем устройстве и выполняться посредством процессора. Запоминающее устройство может устанавливаться внутри или снаружи процессора и может соединяться с процессором через различные известные средства. Процессор может включать в себя специализированную интегральную схему (ASIC), другие наборы микросхем, логическую схему и/или устройство обработки данных. Запоминающее устройство может включать в себя постоянное запоминающее устройство (ROM), оперативное запоминающее устройство (RAM), флэш-память, карту памяти, носитель хранения данных и/или другое устройство хранения данных. Другими словами, варианты осуществления согласно настоящему раскрытию могут реализовываться и выполняться на процессоре, микропроцессоре, контроллере или микросхеме. Например, функциональные модули, проиллюстрированные на соответствующих чертежах, могут реализовываться и выполняться на компьютере, процессоре, микропроцессоре, контроллере или микросхеме. В этом случае, информация относительно реализации (например, информация относительно инструкций) или алгоритмы могут сохраняться на цифровом носителе хранения данных.
[309] Помимо этого, оборудование декодирования и оборудование кодирования, к которым применяется вариант(ы) осуществления настоящего документа, могут включаться в широковещательное мультимедийное приемо-передающее устройство, терминал мобильной связи, видеоустройство системы домашнего кинотеатра, видеоустройство системы цифрового кинотеатра, камеру наблюдения, устройство проведения видеочатов и устройство связи в реальном времени, к примеру, видеосвязи, мобильное устройство потоковой передачи, носитель хранения данных, записывающую видеокамеру, поставщик услуг на основе технологии "видео по запросу (VoD)", видеоустройство поверх сетей (OTT), поставщик услуг потоковой передачи по Интернету, трехмерное видеоустройство, устройство в стиле виртуальной реальности (VR), устройство в стиле дополненной реальности (AR), телефонное видеоустройство, терминал в транспортном средстве (например, терминал в транспортном средстве (в том числе в автономном транспортном средстве), терминал в воздушном судне или терминал в морском судне) и медицинское видеоустройство; и могут использоваться для того, чтобы обрабатывать сигнал изображения или данные. Например, OTT-видеоустройство может включать в себя игровую консоль, Blu-Ray-проигрыватель, телевизор с доступом в Интернет, систему домашнего кинотеатра, смартфон, планшетный PC и цифровое записывающее видеоустройство (DVR).
[310] Помимо этого, способ обработки, к которому применяется вариант(ы) осуществления настоящего документа, может формироваться в форме программы, выполняемой посредством компьютера, и может сохраняться на компьютерно-читаемом носителе записи. Мультимедийные данные, имеющие структуру данных согласно варианту(ам) осуществления настоящего документа, также могут сохраняться на компьютерно-читаемом носителе записи. Компьютерно-читаемый носитель записи включает в себя все виды устройств хранения данных и устройств распределенного хранения данных, на которых сохраняются компьютерно-читаемые данные. Компьютерно-читаемый носитель записи может включать в себя, например, Blu-Ray-диск (BD), универсальную последовательную шину (USB), ROM, PROM, EPROM, EEPROM, RAM, CD-ROM, магнитную ленту, гибкий диск и оптическое устройство хранения данных. Компьютерно-читаемый носитель записи также включает в себя среды, осуществленные в форме несущей волны (например, передачи по Интернету). Помимо этого, поток битов, сформированный посредством способа кодирования, может сохраняться на компьютерно-читаемом носителе записи или передаваться через сеть проводной или беспроводной связи.
[311] Помимо этого, вариант(ы) осуществления настоящего документа может осуществляться в качестве компьютерного программного продукта на основе программного кода, и программный код может выполняться на компьютере согласно варианту(ам) осуществления настоящего документа. Программный код может сохраняться на компьютерно-читаемом носителе.
[312] Фиг. 15 представляет пример системы потоковой передачи контента, к которой может применяться вариант осуществления настоящего документа.
[313] Ссылаясь на фиг. 15, система потоковой передачи контента, к которой применяются варианты осуществления настоящего документа, в общем, может включать в себя сервер кодирования, потоковый сервер, веб-сервер, хранилище мультимедиа, пользовательское устройство и устройство ввода мультимедиа.
[314] Сервер кодирования функционирует для того, чтобы сжимать в цифровые данные контент, вводимый из устройств ввода мультимедиа, таких как смартфон, камера, записывающая видеокамера и т.п., чтобы формировать поток битов и передавать его на потоковый сервер. В качестве другого примера, в случае если устройство ввода мультимедиа, такое как смартфон, камера, записывающая видеокамера и т.п., непосредственно формирует поток битов, сервер кодирования может опускаться.
[315] Поток битов может формироваться посредством способа кодирования или способа формирования потоков битов, к которому применяются варианты осуществления настоящего документа. Кроме того, потоковый сервер может временно сохранять поток битов в процессе передачи или приема потока битов.
[316] Потоковый сервер передает мультимедийные данные в абонентское устройство на основе запроса пользователя через веб-сервер, который функционирует в качестве инструментария, который информирует пользователя в отношении того, какая услуга предусмотрена. Когда пользователь запрашивает услугу, которую пользователь хочет, веб-сервер передает запрос на потоковый сервер, и потоковый сервер передает мультимедийные данные пользователю. В этом отношении, система потоковой передачи контента может включать в себя отдельный сервер управления, и в этом случае, сервер управления функционирует для того, чтобы управлять командами/ответами между соответствующим оборудованием в системе потоковой передачи контента.
[317] Потоковый сервер может принимать контент из хранилища мультимедиа и/или сервера кодирования. Например, в случае если контент принимается из сервера кодирования, контент может приниматься в реальном времени. В этом случае, потоковый сервер может сохранять поток битов в течение предварительно определенного периода времени, чтобы плавно предоставлять услугу потоковой передачи.
[318] Например, абонентское устройство может включать в себя мобильный телефон, смартфон, переносной компьютер, цифровой широковещательный терминал, персональное цифровое устройство (PDA), портативный мультимедийный проигрыватель (PMP), навигационное устройство, грифельный планшетный PC, планшетный PC, ультрабук, носимое устройство (например, терминал в виде часов (интеллектуальные часы), терминал в виде очков (интеллектуальные очки), наголовный дисплей (HMD)), цифровой телевизор, настольный компьютер, систему цифровых информационных табло и т.п.
[319] Каждый из серверов в системе потоковой передачи контента может работать в качестве распределенного сервера, и в этом случае, данные, принимаемые посредством каждого сервера, могут обрабатываться распределенным способом.
[320] Пункты формулы изобретения в настоящем описании могут комбинироваться различными способами. Например, технические признаки в пунктах формулы изобретения на способ настоящего описания могут комбинироваться с возможностью реализовываться или выполняться в оборудовании, и технические признаки в пунктах формулы изобретения на оборудование могут комбинироваться с возможностью реализовываться или выполняться в способе. Дополнительно, технические признаки в пункте(ах) формулы изобретения на способ и пункте(ах) формулы изобретения на оборудование могут комбинироваться с возможностью реализовываться или выполняться в оборудовании. Дополнительно, технические признаки в пункте(ах) формулы изобретения на способ и пункте(ах) формулы изобретения на оборудование могут комбинироваться с возможностью реализовываться или выполняться в способе.
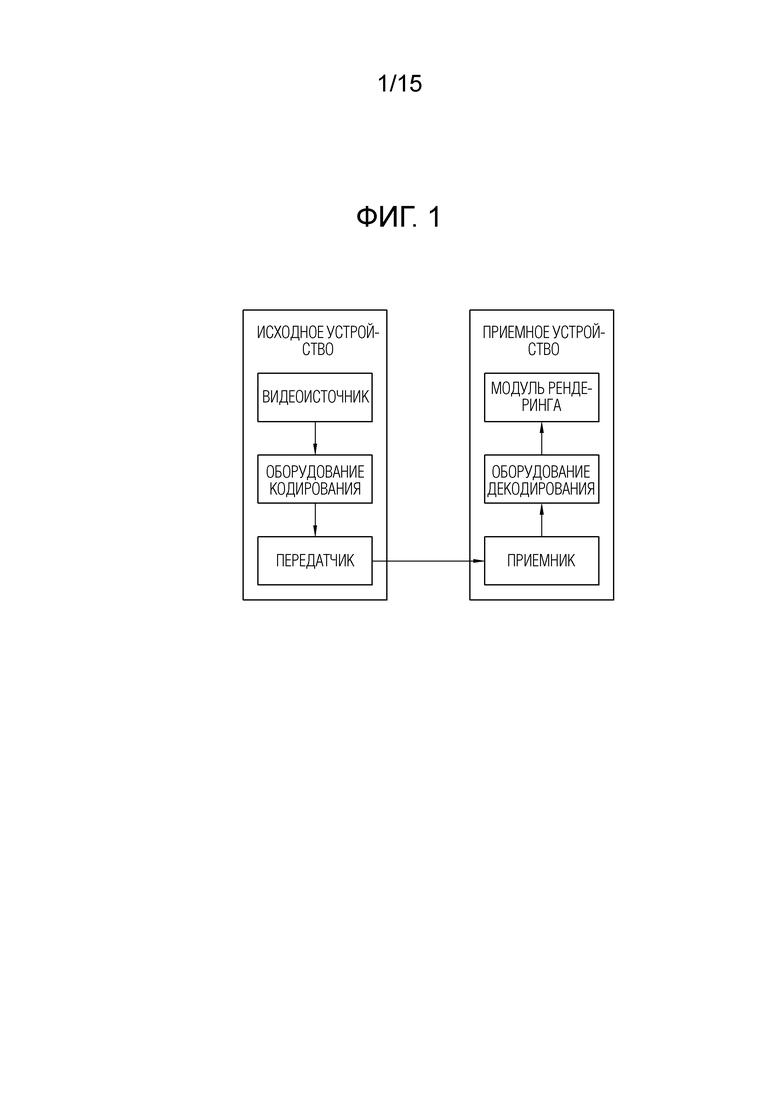

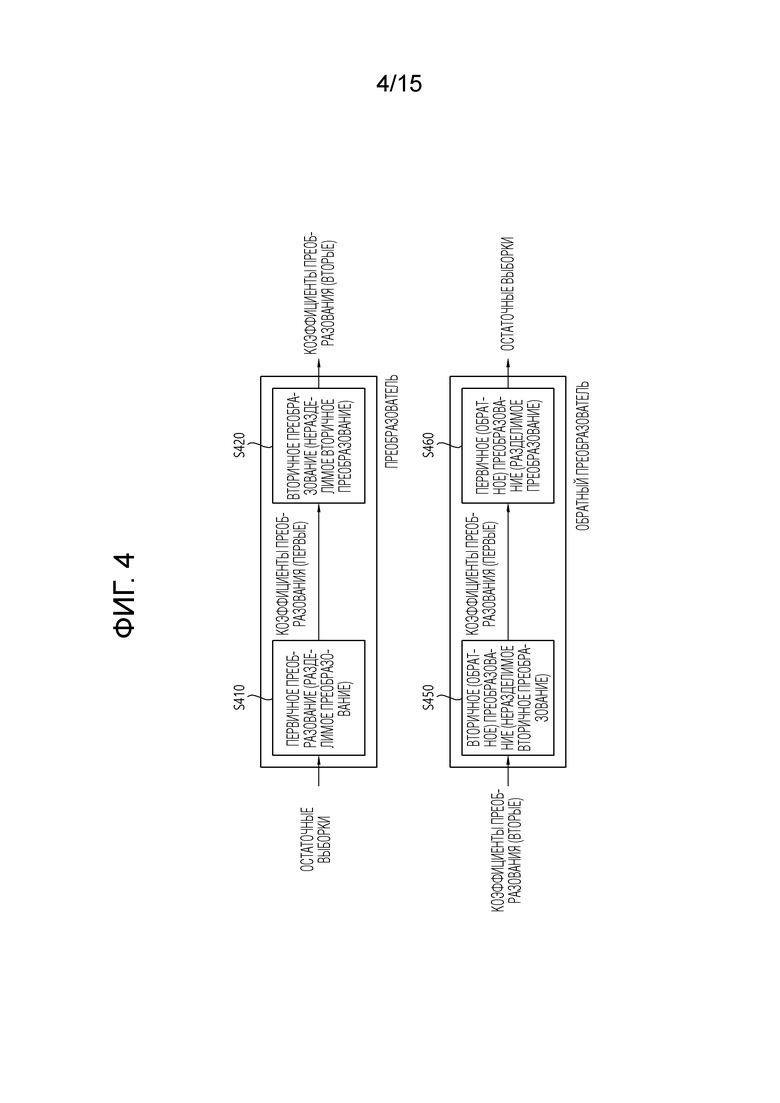
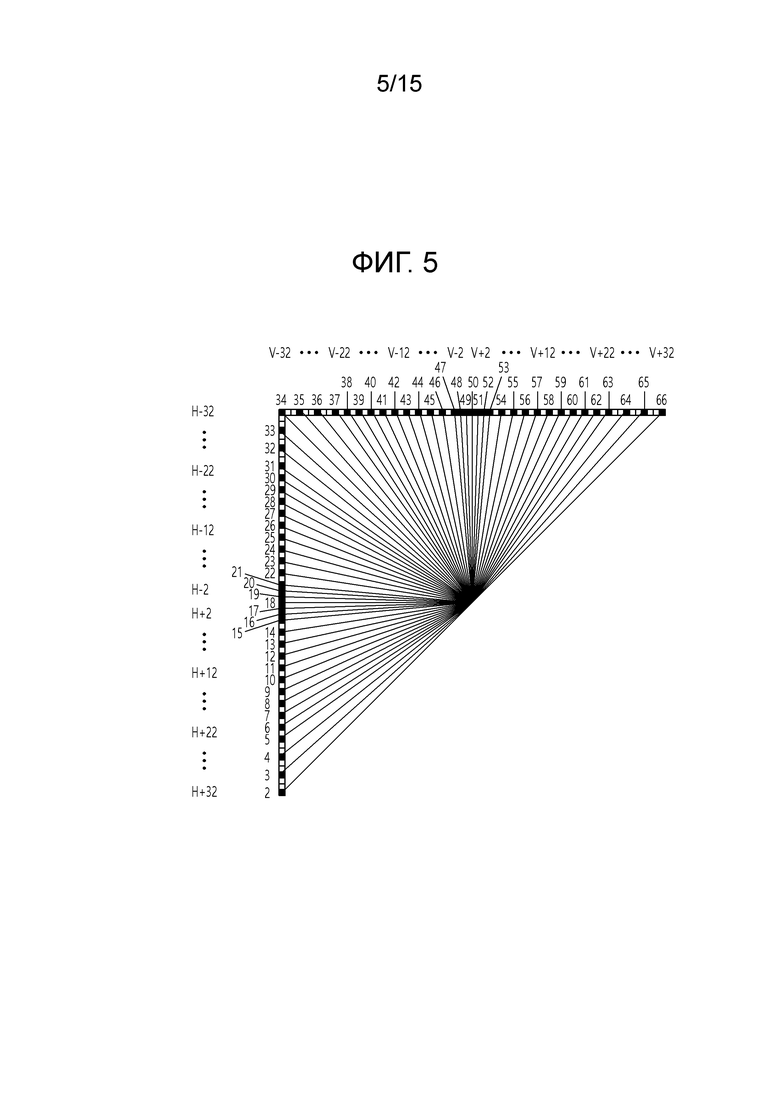

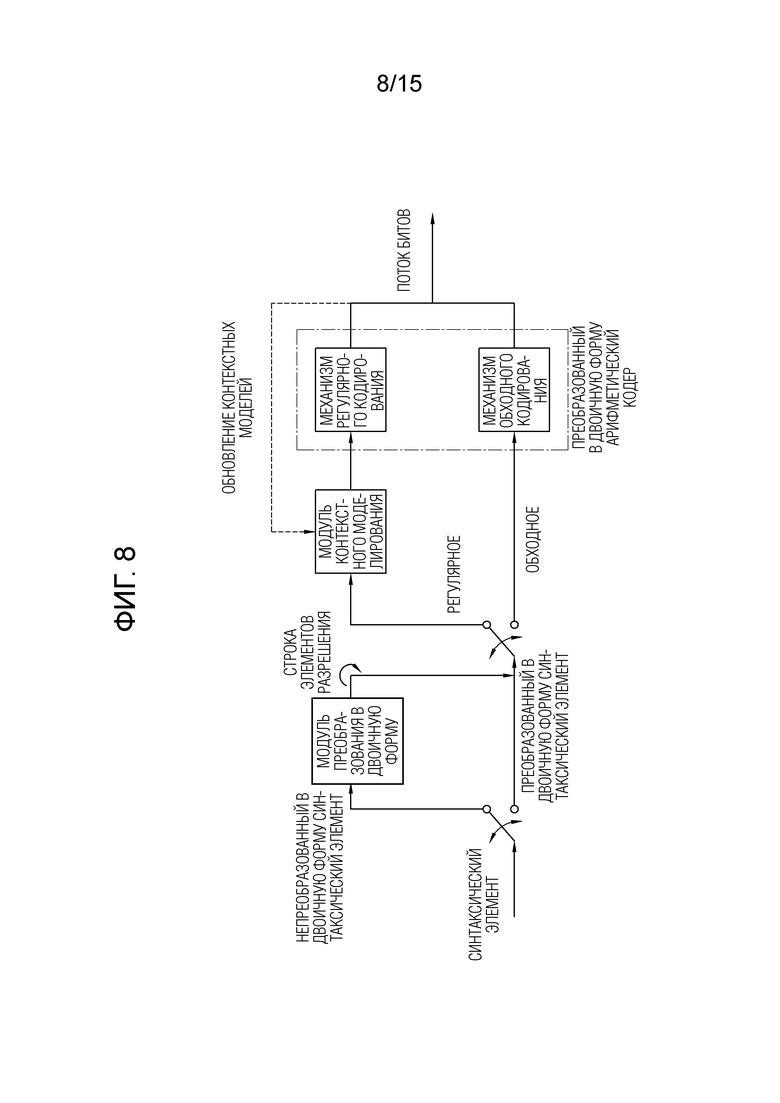
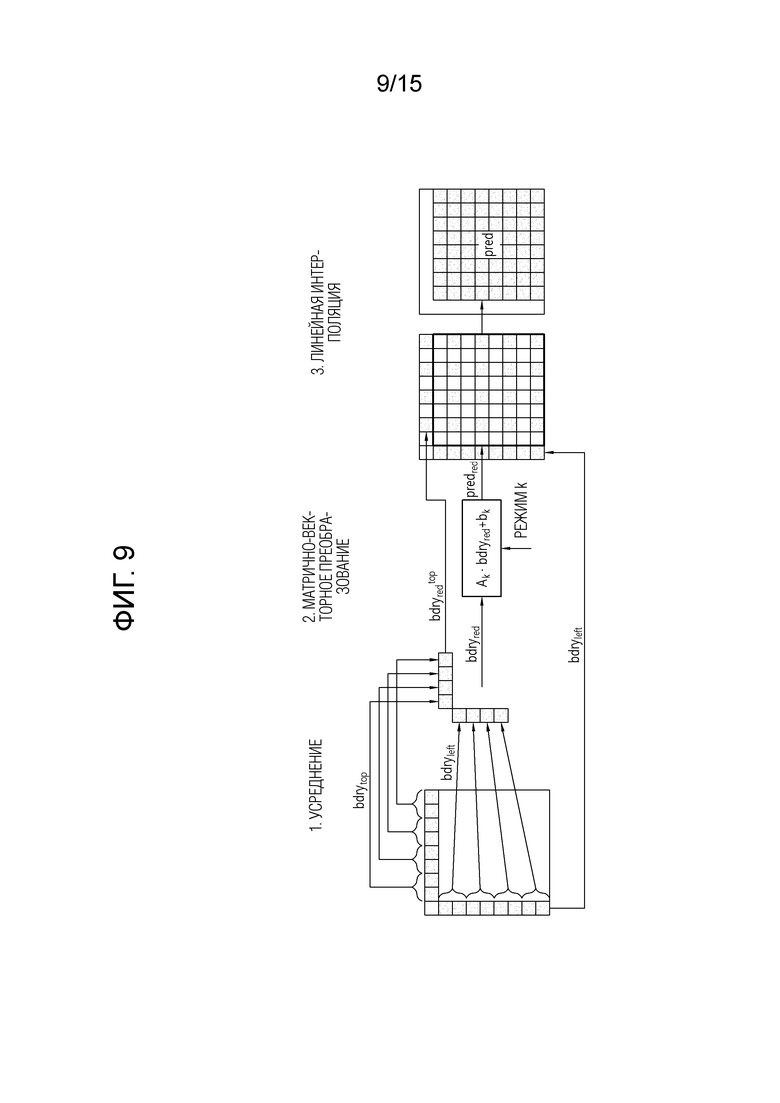
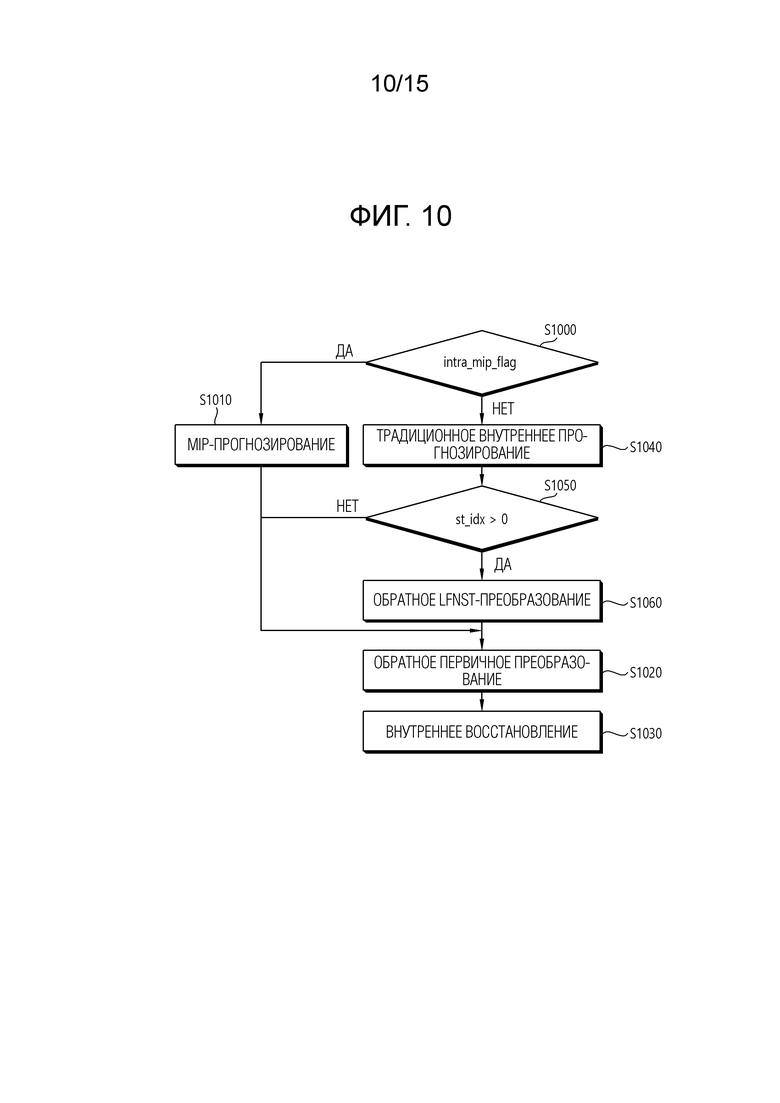
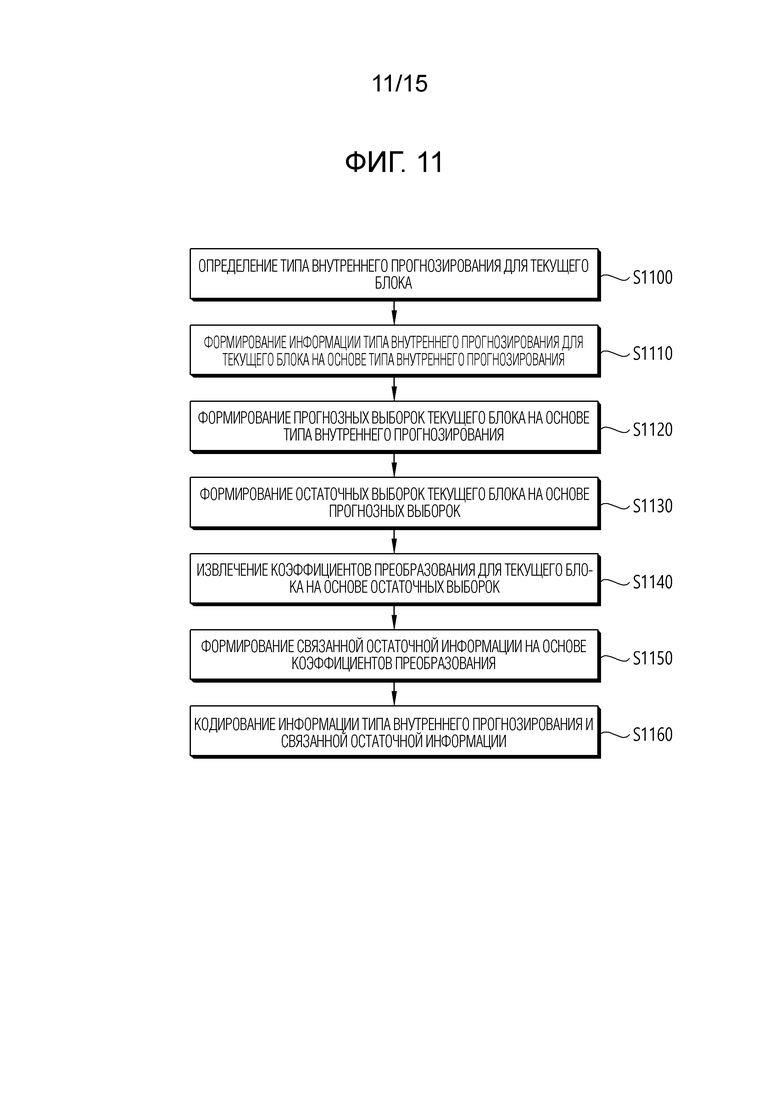
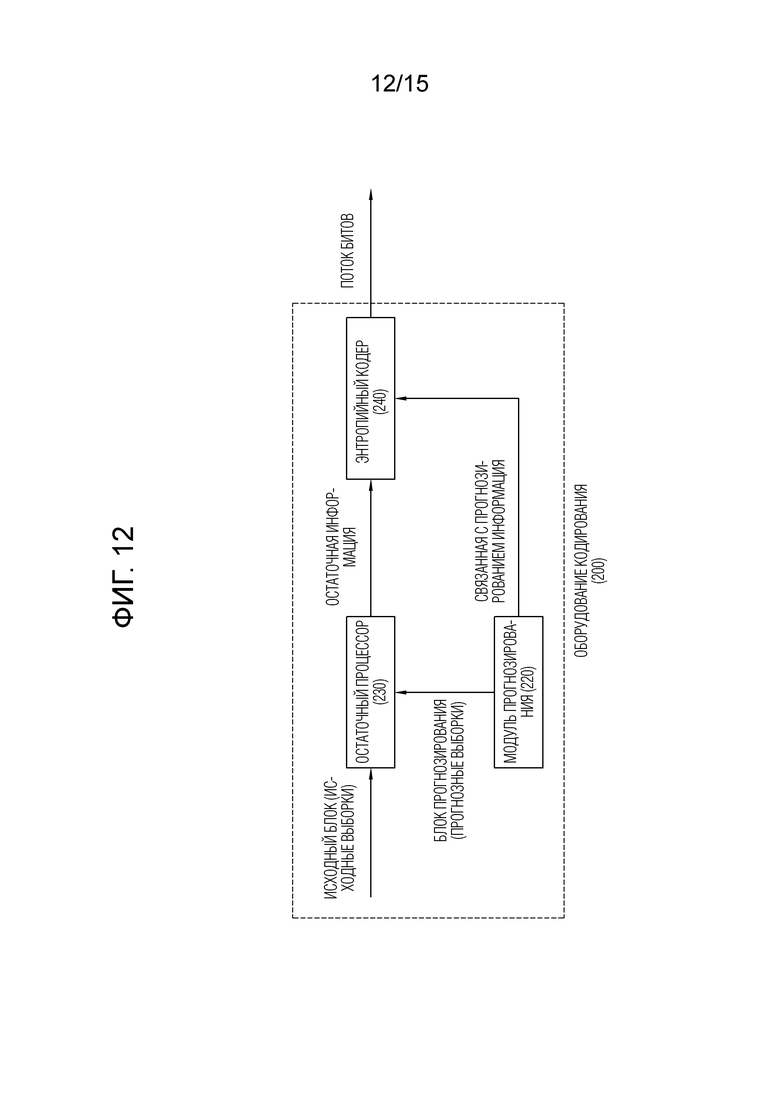
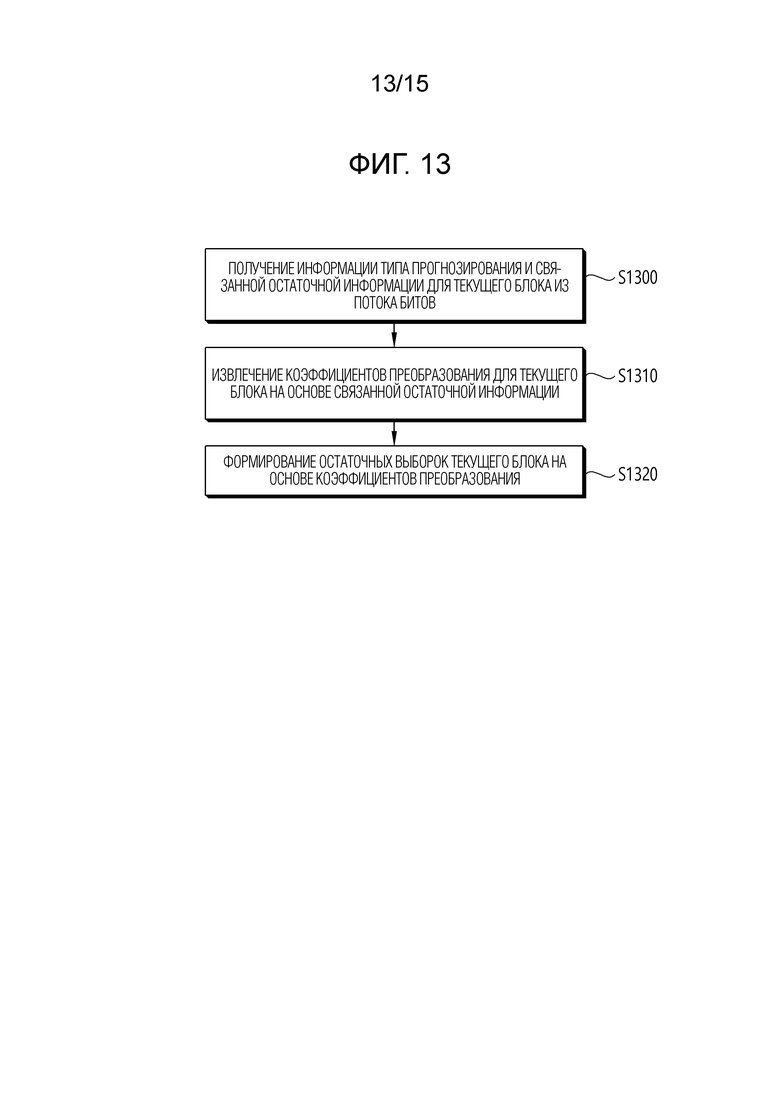
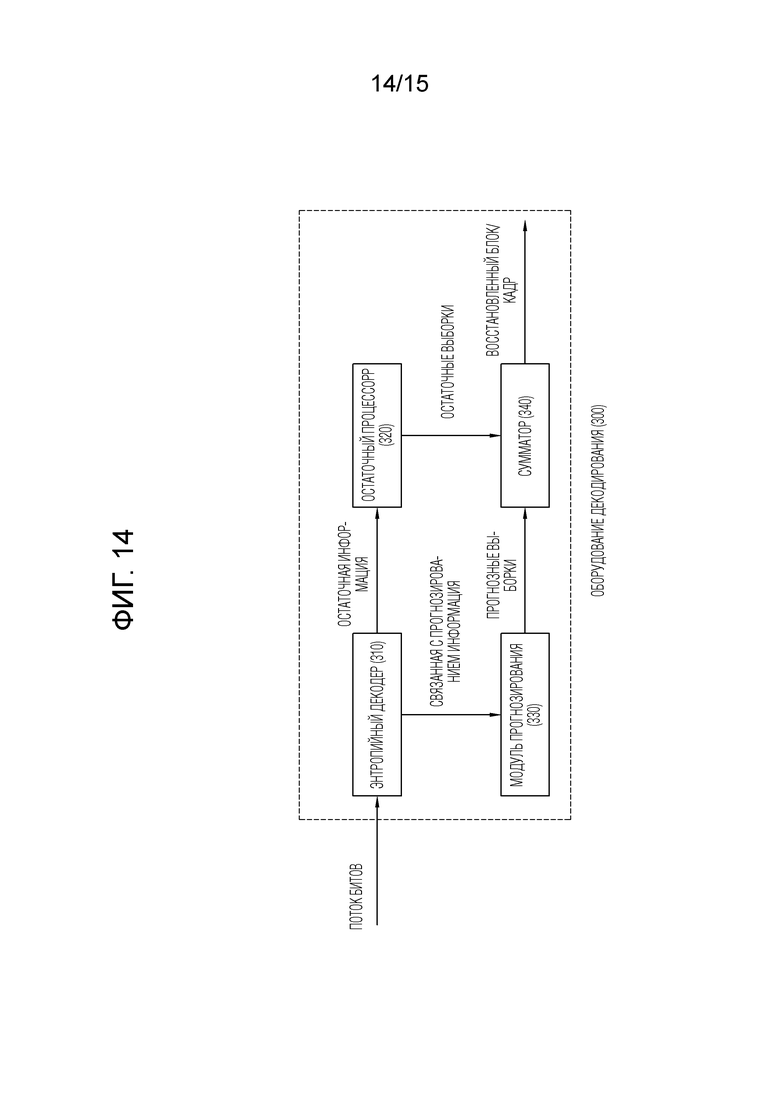
Изобретение относится к средствам для кодирования изображений. Технический результат заключается в повышении эффективности кодирования. Определяют тип внутреннего прогнозирования для текущего блока. Формируют информацию типа внутреннего прогнозирования для текущего блока на основе типа внутреннего прогнозирования. Извлекают прогнозные выборки текущего блока на основе типа внутреннего прогнозирования. Формируют остаточные выборки текущего блока на основе прогнозных выборок. Извлекают коэффициенты преобразования для текущего блока на основе остаточных выборок. Формируют связанную остаточную информацию на основе коэффициентов преобразования. Кодируют информацию типа внутреннего прогнозирования и связанную остаточную информацию. Информация типа внутреннего прогнозирования включает в себя флаг матричного внутреннего прогнозирования (MIP), представляющий то, применяется или нет MIP к текущему блоку. Связанная остаточная информация включает в себя информацию индекса низкочастотного неразделимого преобразования (LFNST) для текущего блока на основе MIP-флага. 4 н. и 9 з.п. ф-лы, 15 ил.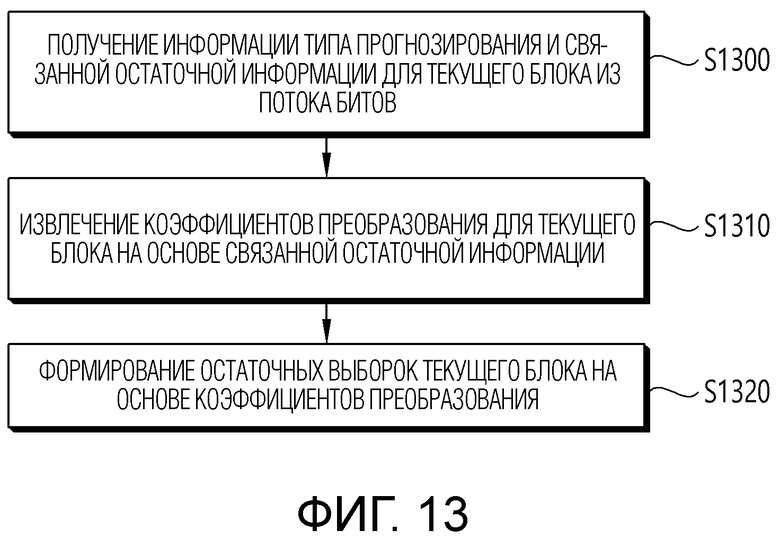
1. Способ декодирования изображений, осуществляемый посредством оборудования декодирования, при этом способ содержит этапы, на которых:
- получают информацию типа внутреннего прогнозирования и связанную остаточную информацию для текущего блока из потока битов;
- извлекают коэффициенты преобразования для текущего блока на основе информации относительно квантованных коэффициентов преобразования, включенных в связанную остаточную информацию; и
- формируют остаточные выборки текущего блока на основе коэффициентов преобразования,
при этом информация типа внутреннего прогнозирования включает в себя флаг матричного внутреннего прогнозирования (MIP), представляющий то, применяется или нет MIP к текущему блоку,
при этом связанная остаточная информация включает в себя информацию индекса низкочастотного неразделимого преобразования (LFNST) для текущего блока на основе MIP-флага,
при этом остаточные выборки формируются из коэффициентов преобразования на основе информации LFNST-индекса,
при этом порядок синтаксического анализа MIP-флага предшествует порядку синтаксического анализа информации LFNST-индекса,
при этом на основании значения MIP-флага, не равного 1, связанная остаточная информация включает в себя информацию LFNST-индекса и
при этом информация LFNST-индекса сконфигурирована в синтаксисе единицы кодирования на основе MIP-флага.
2. Способ декодирования изображений по п. 1, в котором информация типа внутреннего прогнозирования дополнительно включает в себя связанную с режимом на основе внутренних субсегментов (ISP) информацию относительно субсегментации текущего блока, и
при этом связанная остаточная информация включает в себя информацию LFNST-индекса на основе MIP-флага и связанной с ISP информации.
3. Способ декодирования изображений по п. 1, в котором информация LFNST-индекса извлекается через преобразование в двоичную форму усеченным кодом Райса (TR).
4. Способ декодирования изображений по п. 1, в котором информация LFNST-индекса содержит LFNST-флаг, представляющий то, применяется или нет неразделимое преобразование для низкочастотных коэффициентов преобразования текущего блока, и флаг индекса ядра преобразования, представляющий ядро преобразования, применяемое к текущему блоку, из возможных вариантов ядер преобразования.
5. Способ декодирования изображений по п. 4, в котором флаг индекса ядра преобразования включается в информацию LFNST-индекса на основе LFNST-флага, представляющего то, что неразделимое преобразование применяется, и MIP-флага, представляющего то, что MIP не применяется.
6. Способ декодирования изображений по п. 4, в котором LFNST-флаг и флаг индекса ядра преобразования извлекаются через преобразование в двоичную форму кодом фиксированной длины (FL).
7. Способ декодирования изображений по п. 4, в котором первый элемент разрешения из строки элементов разрешения LFNST-флага извлекается на основе контекстного кодирования, контекстное кодирование выполняется на основе значения приращения индекса контекста для LFNST-флага и значение приращения индекса контекста извлекается в качестве одного из возможных вариантов, включающих в себя 0 и 1, и
при этом первый элемент разрешения из строки элементов разрешения флага индекса ядра преобразования извлекается на основе обходного кодирования.
8. Способ декодирования изображений по п. 7, в котором значение приращения индекса контекста извлекается на основе индекса множественного выбора преобразования (MTS), представляющего набор ядер преобразования, который должен использоваться для текущего блока, из наборов ядер преобразования, и информации типа дерева, представляющей структуру сегментации текущего блока.
9. Способ кодирования изображений, осуществляемый посредством оборудования кодирования, при этом способ содержит этапы, на которых:
- определяют тип внутреннего прогнозирования для текущего блока;
- формируют информацию типа внутреннего прогнозирования для текущего блока на основе типа внутреннего прогнозирования;
- извлекают прогнозные выборки текущего блока на основе типа внутреннего прогнозирования;
- формируют остаточные выборки текущего блока на основе прогнозных выборок;
- извлекают коэффициенты преобразования для текущего блока на основе остаточных выборок;
- формируют связанную остаточную информацию на основе коэффициентов преобразования и
- кодируют информацию типа внутреннего прогнозирования и связанную остаточную информацию,
при этом информация типа внутреннего прогнозирования включает в себя флаг матричного внутреннего прогнозирования (MIP), представляющий то, применяется или нет MIP к текущему блоку,
при этом связанная остаточная информация включает в себя информацию индекса низкочастотного неразделимого преобразования (LFNST), представляющую информацию относительно неразделимого преобразования низкочастотных коэффициентов преобразования текущего блока на основе MIP-флага,
при этом информация LFNST-индекса формируется на основе ядра преобразования, используемого для того, чтобы извлекать коэффициенты преобразования,
при этом порядок синтаксического анализа MIP-флага предшествует порядку синтаксического анализа информации LFNST-индекса,
при этом на основании значения MIP-флага, не равного 1, связанная остаточная информация включает в себя информацию LFNST-индекса и
при этом информация LFNST-индекса сконфигурирована в синтаксисе единицы кодирования на основе MIP-флага.
10. Способ декодирования изображений по п. 1, в котором связанная остаточная информация включает в себя информацию LFNST-индекса дополнительно на основе флага LFNST-активации, представляющего то, что LFNST активируется, и
при этом информация LFNST-индекса сконфигурирована в синтаксисе единицы кодирования дополнительно на основе флага LFNST-активации.
11. Способ декодирования изображений по п. 1, в котором связанная остаточная информация включает в себя информацию LFNST-индекса дополнительно на основе минимального значения из ширины и высоты текущего блока, равного или выше 4, и
при этом информация LFNST-индекса сконфигурирована в синтаксисе единицы кодирования дополнительно на основе минимального значения.
12. Энергонезависимый компьютерно-читаемый носитель хранения данных, сохраняющий поток битов, сформированный посредством способа кодирования, при этом способ содержит:
- определение типа внутреннего прогнозирования для текущего блока;
- формирование информации типа внутреннего прогнозирования для текущего блока на основе типа внутреннего прогнозирования;
- извлечение прогнозных выборок текущего блока на основе типа внутреннего прогнозирования;
- формирование остаточных выборок текущего блока на основе прогнозных выборок;
- извлечение коэффициентов преобразования для текущего блока на основе остаточных выборок;
- формирование связанной остаточной информации на основе коэффициентов преобразования и
- кодирование информации типа внутреннего прогнозирования и связанной остаточной информации,
при этом информация типа внутреннего прогнозирования включает в себя флаг матричного внутреннего прогнозирования (MIP), представляющий то, применяется или нет MIP к текущему блоку,
при этом связанная остаточная информация включает в себя информацию индекса низкочастотного неразделимого преобразования (LFNST), представляющую информацию относительно неразделимого преобразования низкочастотных коэффициентов преобразования текущего блока на основе MIP-флага,
при этом информация LFNST-индекса формируется на основе ядра преобразования, используемого для того, чтобы извлекать коэффициенты преобразования,
при этом порядок синтаксического анализа MIP-флага предшествует порядку синтаксического анализа информации LFNST-индекса,
при этом на основании значения MIP-флага, не равного 1, связанная остаточная информация включает в себя информацию LFNST-индекса и
при этом информация LFNST-индекса сконфигурирована в синтаксисе единицы кодирования на основе MIP-флага.
13. Способ передачи данных для изображения, при этом способ содержит этапы, на которых:
- получают поток битов для изображения, поток битов формируется посредством выполнения определения типа внутреннего прогнозирования для текущего блока, формирования информации типа внутреннего прогнозирования для текущего блока на основе типа внутреннего прогнозирования, извлечения прогнозных выборок текущего блока на основе типа внутреннего прогнозирования, формирования остаточных выборок текущего блока на основе прогнозных выборок, извлечения коэффициентов преобразования для текущего блока на основе остаточных выборок, формирования связанной остаточной информации на основе коэффициентов преобразования и кодирования информации типа внутреннего прогнозирования и связанной остаточной информации, чтобы формировать поток битов; и
- передают данные, содержащие поток битов,
при этом информация типа внутреннего прогнозирования включает в себя флаг матричного внутреннего прогнозирования (MIP), представляющий то, применяется или нет MIP к текущему блоку,
при этом связанная остаточная информация включает в себя информацию индекса низкочастотного неразделимого преобразования (LFNST), представляющую информацию относительно неразделимого преобразования низкочастотных коэффициентов преобразования текущего блока на основе MIP-флага,
при этом информация LFNST-индекса формируется на основе ядра преобразования, используемого для того, чтобы извлекать коэффициенты преобразования,
при этом порядок синтаксического анализа MIP-флага предшествует порядку синтаксического анализа информации LFNST-индекса,
при этом на основании значения MIP-флага, не равного 1, связанная остаточная информация включает в себя информацию LFNST-индекса и
при этом информация LFNST-индекса сконфигурирована в синтаксисе единицы кодирования на основе MIP-флага.
| Способ получения цианистых соединений | 1924 |
|
SU2018A1 |
| Способ получения цианистых соединений | 1924 |
|
SU2018A1 |
| Автомобиль-сани, движущиеся на полозьях посредством устанавливающихся по высоте колес с шинами | 1924 |
|
SU2017A1 |
| Способ получения цианистых соединений | 1924 |
|
SU2018A1 |
| US 9661338 B2, 23.05.2017 | |||
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |

