ОБЛАСТЬ ТЕХНИКИ, К КОТОРОЙ ОТНОСИТСЯ ИЗОБРЕТЕНИЕ
Изобретение относится к компьютерному зрению, глубоким нейронным сетям, реконструкции 3D-изображения
Описание уровня техники
3D-реконструкция лиц активно развивается десятилетиями для отслеживания и выравнивания лиц [11,13], распознавания лиц [2,41], и порождающего моделирования [17,22,23,27,32,40]. Во всех этих сценариях, статистические сеточные модели (также известные как параметрические модели) [3] остаются в числе широко используемых инструментов [8]. Такие модели выдвигают сильную гипотезу в отношении пространства возможных реконструкций. Традиционные параметрические модели для человеческих голов состоят из оснащенных сеток [20], которые поддерживают широкий диапазон анимаций с жесткими движениями для челюсти, шеи и глазных яблок, а также через освобожденную форму и коэффициенты выражения. Однако, они обеспечивают реконструкции только для областей лица, ушей, шеи и лба, что ограничивает сферу применения. Включение в эти параметрические модели полной реконструкции головы (т.е. волос и одежды) возможно, но для этого современные подходы требуют собирать значительно больше обучающих данных в форме 3D-сканов. Вместо этого, предлагается пользоваться существующими крупномасштабными массивами данных [6] по-прежнему используемых видеозаписей согласно парадигме обучения путем синтеза без использования каких-либо дополнительных 3D-сканов.
Нейронные 3D модели человеческой головы.
Хотя параметрические модели обеспечивают достаточное качество реконструкции для многих нижерасположенных приложений, они не способны моделировать очень мелкие детали, необходимые для фотореалистического моделирования. В последние годы, подходы, моделирующие очень сложную геометрию и/или внешний вид людей с использованием глубоких нейронных сетей высокой емкости. Некоторые из этих работ используют сильные характерные для человека гипотезы [9, 24, 32, 35]. Другие подгоняют сети высокой емкости к данным без использования таких гипотез [16, 22, 23, 25, 27, 29, 30]. Методы в этом классе отличаются типом структуры данных, используемых для представления геометрии, а именно, сеточной [9,22,23], точечной [25,44] и неявной моделей [24, 27, 29, 30, 32, 35].
Сеточные модели вероятно представляют наиболее удобный класс методов для нижерасположенных приложений. Они обеспечивают более высокое качество рендеризации и более высокую временную устойчивость, чем точечная нейронная рендеризация. Также, в отличие от методов на основе неявной геометрии, сеточные методы позволяют сохранять топологию и возможности риггинга, и также гораздо быстрее в ходе подгонки и/или рендеризации. Однако в настоящее время сеточные методы либо сильно ограничивают диапазон деформаций [9], что делает невыполнимым изучение сложной геометрии, наподобие волос или одежды, либо действуют в многоразовом сценарии и требуют избыточного количества 3D-сканов в качестве обучающих данных [22, 23]. Предложенный способ также основан на сетке, но позволяет прогнозировать сложные деформации без 3D-контроля, подъем ограничений предыдущих работ.
Разовые нейронные модели головы.
Достижения в нейронных сетях также привели к развитию методов, которые напрямую прогнозируют изображения с использованием больших сверточных сетей, работающих в области 2D-изображений, практически без базовой 3D геометрии [36,45,46] или с очень грубой 3D геометрией [43]. Эти методы достигают традиционного реализма [43], используются по-прежнему используемые изображения или видеозаписи без 3D аннотаций для обучения, и могут создавать аватары из единственного изображения. Однако отсутствие явной геометрической модели делает эти модели несовместимыми со многими приложениями реального мира, и ограничивает диапазон положений камеры, которыми можно манипулировать этими методами.
Нейронная рендеризация сетки.
В последнее время возникли подходы, объединяющие явные структуры данных (облака или сетки точек) со сгенерированными нейронными изображениями. Для сеточной геометрии, этот способ был впервые представлен и популяризирован системой отсроченной нейронной рендеризации [39]. Этот класс методов также базируется на последних достижения в дифференцируемой рендеризации сетки [19, 21, 33]. Нейронная рендеризация сетки использует 2D сверточные сети для моделирования сложных фотометрических свойств поверхностей, и достигает высокого реализма рендеров с мелкими деталями, даже когда такие детали отсутствуют в базовой геометрической модели. Во время этой работы, авторы адаптируют эти достижения к моделированию человеческой головы и объединяют их с обучением на основе больших массивов данных по-прежнему используемых видеозаписей.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
Персонифицированные аватары человека становятся ключевой технологией в нескольких областях применения, например, дистанционное присутствие, виртуальные миры, онлайн-торговля. Во многих случаях, достаточно персонифицировать только часть тела аватара. Затем остальные части тела могут либо выбираться из некоторой библиотеки активов, либо исключаться из интерфейса. Для этого, многие приложения требуют персонификации на уровне головы, т.е. создания персональных моделей головы. Создание персонифицированных голов является важным и жизнеспособным промежуточным этапом между персонификацией только лица (что часто бывает недостаточно) и созданием персонифицированных полнотельных моделей, что является значительно более сложной задачей, что ограничивает качество результирующих моделей и/или требует обременительного сбора данных.
Получение аватаров человека из единственной фотографии (“одноразовый”) обеспечивает наибольшее удобство для пользователей, и тем не менее является особенно многообещающим и требует сильных гипотез в отношении геометрии и внешнего вида человека. Для лиц давно известны параметрические модели для обеспечения хороших решений персонификации [3]. Модели лица также могут обучаться из сравнительно небольшого массива данных 3D-сканов и представляют геометрию с использованием сеток и внешний вид с использованием текстур, что делает такие модели совместимыми с многими приложениями и конвейерами компьютерной графики. С другой стороны, параметрические модели лица невозможно тривиально распространить на всю область головы вследствие большой геометрической изменчивости нелицевых частей, например, волос и шеи. Во время этой работы, параметрическое сеточное моделирование распространяется на человеческие головы. Для обучения повышенной геометрической и фотометрической изменчивости (по сравнению с лицами), параметрические модели обучаются напрямую из большого массива данных по-прежнему используемых видеозаписей [6]. Нейронные сети используются для параметризации как геометрии, так и внешнего вида. Для моделирования внешнего вида, авторы следуют парадигме отсроченной нейронной рендеризации [39] и используют комбинацию нейронных текстур и сетей рендеризации. Инфраструктура нейронной рендеризации [33] используется для обеспечения сквозного обучения и для достижения высокого визуального реализма результирующих моделей головы. После обучения, обе геометрическая нейронная сеть и нейронная сеть внешнего вида могут опираться на информацию, извлеченную из единственной фотографии, обеспечивая одноразовую генерацию реалистических аватаров.
Получение аватаров человека из единственной фотографии (“одноразовый”) обеспечивает наибольшее удобство для пользователей, и тем не менее является особенно многообещающим и требует сильных гипотез в отношении геометрии и внешнего вида человека. Для лиц давно известны параметрические модели для обеспечения хороших решений персонификации [3]. Модели лица также могут обучаться из сравнительно небольшого массива данных 3D-сканов и представляют геометрию с использованием сеток и внешний вид с использованием текстур, что делает такие модели совместимыми с многими приложениями и конвейерами компьютерной графики. С другой стороны, параметрические модели лица невозможно тривиально распространить на всю область головы вследствие большой геометрической изменчивости нелицевых частей, например, волос и шеи.
Во время этой работы, параметрическое сеточное моделирование распространяется на человеческие головы. Для обучения повышенной геометрической и фотометрической изменчивости (по сравнению с лицами), параметрические модели обучаются напрямую из большого массива данных по-прежнему используемых видеозаписей [6]. Нейронные сети используются для параметризации как геометрии, так и внешнего вида. Для моделирования внешнего вида, авторы следуют парадигме отсроченной нейронной рендеризации [39] и используют комбинацию нейронных текстур и сетей рендеризации. Инфраструктура нейронной рендеризации [33] используется для обеспечения сквозного обучения и для достижения высокого визуального реализма результирующих моделей головы. После обучения, обе геометрическая нейронная сеть и нейронная сеть внешнего вида могут опираться на информацию, извлеченную из единственной фотографии, обеспечивая одноразовую генерацию реалистических аватаров.
Насколько известно, данная система является первой, которая способна создавать реалистические персонифицированные модели человеческой головы в формате оснащенной сетки из единственной фотографии. Это отличает данную модель от растущего класса подходов, которые восстанавливают нейронные аватары головы, которые нуждаются в явной геометрии [36, 43, 45, 46], из другого большого класса подходов, которые могут персонифицировать область лица, но не всю голову [3,9,17,40], и от коммерческих систем, которые создают не фотореалистические аватары типа сетки из единственного изображения [1,31]. Помимо полной модели, авторы также рассматривают ее упрощение на основании базиса линейного блендшейпа и показывают, как такое упрощение и соответствующий упреждающий предсказатель для коэффициентов блендшейпа могут обучаться (на одном и том же массиве данных видео).
Предложен способ 3D-реконструкции человеческой головы для получения рендера изображения человека, с использованием единственного исходного изображения, в котором форма лица, извлеченная из единственного исходного изображения, ориентация головы, выражение лица, извлеченное из произвольного целевого изображения, способ, осуществляемый на устройстве, имеющем CPU, внутреннюю память с изображениями, RAM, причем способ содержит следующие этапы:
a) считывание единственного исходного изображения из памяти устройства, и кодирование, посредством первой сверточной нейронной сети, исходное изображение в нейронную текстуру того же пространственного размера, что и исходное изображение, но с увеличенным количеством каналов, которая содержит локальные персональные детали;
b) параллельно, оценивание формы лица, выражения лица и ориентации головы посредством переобученной системы DECA в отношении исходного и целевого изображений, и обеспечение начальной сетки как множества лиц и множество начальных вершин;
c) обеспечение спрогнозированной сетки для нелицевых частей сетки головы, причем этап обеспечения содержит:
- рендеризацию начальной сетки в xyz-координатную текстуру,
- сцепление xyz-координатной текстуры и нейронной текстуры,
- обработку с помощью второй сети в латентную геометрическую карту,
- билинейную фильтрацию латентной геометрической карты с использованием координат текстуры для получения признака, зависящего от вершины,
- декодирование признака, зависящего от вершины, посредством многослойного перцептрона для прогнозирования 3D-смещения для каждой вершины,
- добавление спрогнозированного 3D-смещения к начальным вершинам для получения 3D-реконструкции человеческой головы в виде спрогнозированной сетки;
d) растеризацию 3D-реконструкции человеческой головы для обработки результата посредством третьей сети для получения рендера изображения человека.
По меньшей мере один из нескольких модулей может осуществляться через модель AI. Функция, связанная с AI, может осуществляться через энергонезависимую память, энергозависимую память и процессор. Процессор может включать в себя один или несколько процессоров. При этом, один или несколько процессоров могут быть процессором общего назначения, например, центральным процессором (CPU), процессором приложений (AP) и т.п., чисто графический процессор, например, графический процессор (GPU), визуальный процессор (VPU) и/или процессор, предназначенный для AI, например, нейронный процессор (NPU).
Один или несколько процессоров управляют обработкой входных данных в соответствии с заранее заданным правилом работы или моделью искусственного интеллекта (AI), хранящейся в энергонезависимой памяти и энергозависимой памяти. Заранее заданное правило работы или модель искусственного интеллекта обеспечивается путем тренировки или обучения.
Здесь, обеспечение путем обучения означает, что, путем применения алгоритма обучения к нескольким обучающим данным, создается заранее заданное правило работы или модель AI с желаемой характеристикой. Обучение может осуществляться в самом устройстве, в котором осуществляется AI согласно варианту осуществления, и может осуществляться через отдельный сервер/систему.
Модель AI может состоять из нескольких слоев нейронной сети. Каждый слой имеет несколько весовых значений, и осуществляет операцию слоя путем вычисления предыдущего слоя и операцию нескольких весов. Примеры нейронных сетей включают в себя, но без ограничения, сверточную нейронную сеть (CNN), глубокую нейронную сеть (DNN), рекуррентную нейронную сеть (RNN), ограниченную машину Больцмана (RBM), глубокая сеть доверия (DBN), двунаправленная рекуррентная глубокая нейронная сеть (BRDNN), порождающие состязательные сети (GAN) и глубокие Q-сети.
Алгоритм обучения - это способ обучения заранее определенного целевого устройства (например, робота) с использованием нескольких обучающих данных, чтобы предписывать, позволять или управлять целевым устройством, чтобы делать определение или предсказание. Примеры алгоритмов обучения включают в себя, но без ограничения, контролируемое обучение, неконтролируемое обучение, полуконтролируемое обучение или обучение с подкреплением.
При этом, вышеописанный способ, осуществляемый электронным устройством, может осуществляться с использованием модели искусственного интеллекта.
Согласно изобретению, предложенный метод распознавания может получать выходные данные, распознающие изображение с использованием данных изображений в качестве входных данных для модели искусственного интеллекта. Модель искусственного интеллекта можно получить путем обучения. Здесь, "полученный путем обучения" означает, что заранее заданное правило работы или модель искусственного интеллекта, выполненная с возможностью осуществления желаемого признака (или цели) получается обучением базовой модели искусственного интеллекта с множественными фрагментами обучающих данных посредством алгоритма обучения. Модель искусственного интеллекта может включать в себя несколько слоев нейронной сети. Каждый из множества слоев нейронной сети включает в себя несколько весовых значений и осуществляет вычисление нейронной сети путем вычисления между результатом вычисления предыдущим слоем и несколькими весовыми значениями.
Визуальное понимание - это метод распознавания и обработки вещей человеческим зрением и включает в себя, например, распознавание объекта, отслеживание объекта, извлечение изображения, распознавание человека, распознавание сцены, 3D-реконструкция /локализация или улучшение изображения.
ЧЕРТЕЖИ
Вышеупомянутые и/или другие аспекты можно лучше понять из описания иллюстративных вариантов осуществления со ссылкой на прилагаемые чертежи, в которых:
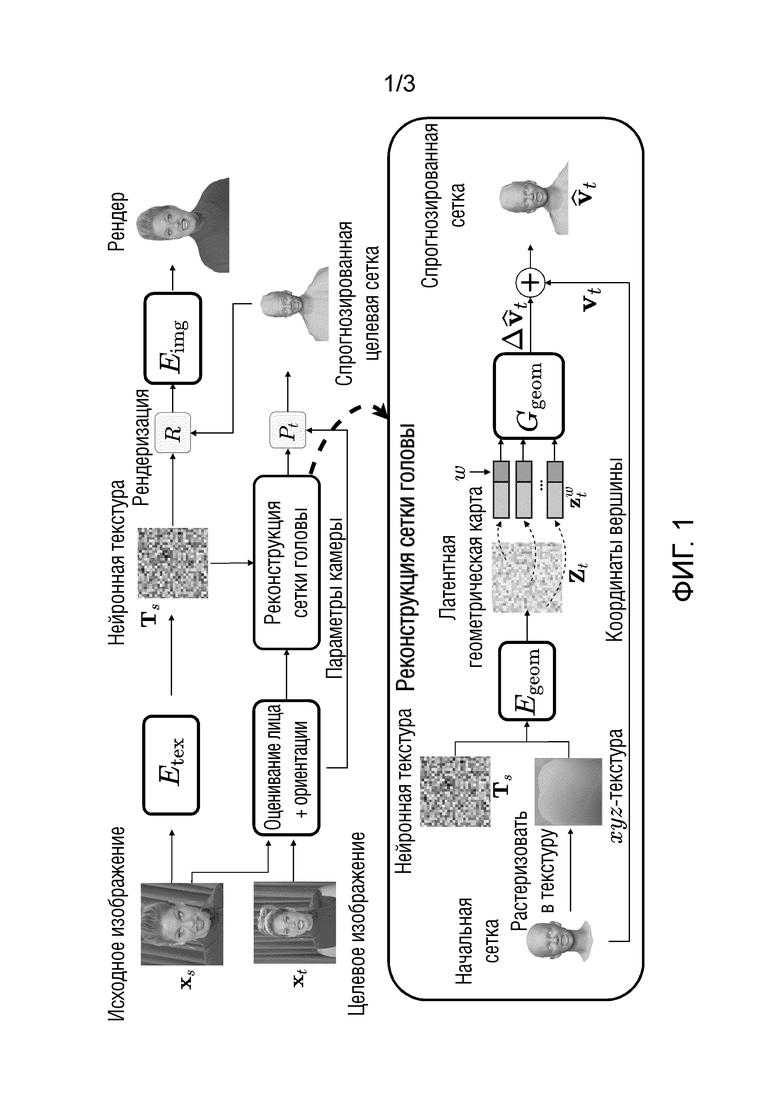
фиг. 1 схематически иллюстрирует предложенный метод 3D-реконструкции человеческих голов с использованием единственной фотографиии в форме многоугольной сетки.
Фиг. 2 иллюстрирует качественное сравнение иллюстративных случаев для массива данных H3DS.
фиг. 3 иллюстрирует сравнение рендеров на массиве данных VoxCeleb2. Задача состоит в восстановлении исходного изображения на основании выражения и ориентации изображения водителей.
ПОДРОБНОЕ ОПИСАНИЕ
Предложенное изобретение обеспечивает 3D-реконструкцию человеческих голов в форме многоугольной сетки с использованием единственного изображения с возможностями анимации и реалистической рендеризации для новых положений головы. Другими словами, предложенное изобретение обеспечивает 3D-реконструкцию человеческой головы, с использованием единственного исходного изображения xs, в котором форма лица, извлеченная из единственного исходного изображения xs, ориентация головы, выражение лица, извлеченное из произвольного целевого изображения xt, которые можно брать из памяти устройства и из любого подходящего источника информации, включая интернет.Это решение можно использовать как для настольных компьютеров, так и для мобильных устройств (смартфонов) с графическим процессором. Также для реализации предложенного изобретения можно использовать компьютерно-считываемый носитель, а именно, компьютерно-считываемый носитель, содержащий программу, в ходе выполнения которой предложенный метод осуществляется на компьютере.
Предложенный алгоритм осуществляет 3D-реконструкцию изображения человеческой головы и ее реалистическую рендеризацию, включая возможности изменения ориентации и выражения.
Предложенное изобретение обеспечивает способ, который совместно обучается генерировать фотореалистические рендеры человеческих голов, а также оценивать их 3D сетки с использованием только единственного исходного изображения xs и без какого-либо 3D-контроля.
На этапе обучения используется крупномасштабный массив данных [6] по-прежнему используемых видеозаписей (видеотрансляций) с говорящими дикторами. Предполагается, что все кадры в каждой видеозаписи изображают одного и того же человека в одном и том же окружении (заданным освещением, прической и одеждой человека).
На каждом этапе обучения, выбирается два произвольных кадра xs и xt из произвольного обучающегося видео. Цель состоит в реконструкции и рендеризации целевого изображения 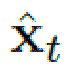 при условии, что
при условии, что
a) персональные детали и форма лица, извлекаются из исходного изображения xs, а также
b) ориентация головы, выражение лица и ориентация камеры, оцениваются из целевого изображения xt.
Окончательные потери при реконструкции распространяются и используются для обновления параметров компонентов модели.
После обучения, можно создавать персонифицированную модель головы, оценивая все параметры из единственного изображения. Затем эту модель можно анимировать с использованием параметров отслеживания лиц, извлеченных из любой последовательности говорящих голов, и рендеризовать из диапазона точек обзора аналогично присутствующих в обучающем массиве данных.
Способ осуществляется в два этапа. Первый этап включает в себя обучение параметров алгоритма с использованием большого массива данных (видеозаписей говорящих людей). После этого установка обученного алгоритма возможна на менее способных устройствах, наподобие настольных компьютеров и смартфонов.
В случае аппаратной реализации, целевым устройством может быть любой мобильный телефон с достаточными вычислительными ресурсами или любое другое потребительское устройство, которое может требовать такого синтеза изображения (например, телевизор). Чтобы действовать правильно, такое устройство должно иметь CPU, внутреннюю память с изображениями, RAM и GPU. Нейронный процессор также может быть включен для ускорения вычислений. Входное изображение считывается из памяти, выходное изображение записывается в память и отображается на экране.
Фиг. 1 схематически иллюстрирует предложенный метод 3D-реконструкции человеческих голов в форме многоугольной сетки с использованием единственного изображения (фотографии). Хотя применение обученной модели осуществляется с использованием описанного алгоритма, процесс обучения задает параметры четырех нейронных сетей, обозначенных здесь и на фиг. 1 следующим образом: Etex, Eimg, Egeom, Ggeom. Их обучение осуществляется с использованием алгоритма обратного распространения и алгоритма дифференцируемой рендеризации, оба из которых общедоступны. Функция потерь, используемая в ходе обучения, состоит из фотометрических и геометрических членов.
Ключевой признак, отличающий предложенный метод от альтернативных состоит в использовании только 2D-контроля на геометрии, что позволяет обучать предложенный метод на первичных видеозаписях без каких-либо конкретно собранных данных наподобие синтетических рендеров или 3D-сканов. Используемыми данными являются видеозаписи с говорящими головами, поэтому они сами не являются 3D-данными, но люди поворачиваются с головами.
Новизна предложенного способа состоит в получении 3D-реконструкции путем деформации многоугольной сетки, полученной из параметрической модели, с использованием нейронных сетей. Это позволяет осуществлять 3D-реконструкцию с использованием единственного изображения во время записи.
Для реализации 3D-реконструкции с помощью обученной модели авторам понадобилось устройство с графическим процессором, а также библиотеки, которые поддерживают сверточные слои и другие связанные модули, например, нелинейности и нормализации.
Для получения обученной модели, требуется сервер с множественными графическими процессорами.
Предложенный подход, представленный на фиг.1, состоит из двух главных стадий: (a) отсроченной нейронной рендеризации и (b) реконструкции сетки головы.
В предложенной модели, совместно используются множественные нейронные сети, которые осуществляют рендеризацию и реконструкцию сетки. Конвейер обучения выполняется следующим образом (фиг. 1):
- оценивание латентной текстуры.
Исходное изображение xs кодируется в нейронную текстуру Ts, которая содержит локальные персональные детали (описывающие как локальный внешний вид, так и геометрию). Кодирование осуществляется сверточной нейронной сетью Etex.
- оценивание лица и 3D ориентации.
Параллельно, применяется переобученная система DECA [9] для реконструкции лиц как к исходному xs, так и целевому изображению xt (фиг. 1 блок “оценивание лица+ориентации”). DECA оценивает формы лица, выражения лица и положения головы и использует модель головы FLAME [20], и заранее заданную топологию сетки и блендшейпы, обученные на основе 3D-сканов. Используют форма лица из исходного изображения xs, а также выражение лица и ориентацию камеры из целевого изображения xt, обеспечивая начальную сетку как множество лиц и множество начальных вершин для дальнейшей обработки.
- реконструкция сетки головы (это показано на фиг. 1 в окруженной области справа (b)).
Вершины сетки DECA (начальная сетка на фиг. 1) с персонифицированной областью лица и общими нелицевыми частями рендеризуются в xyz-координатную текстуру (xyz-текстуру на фиг. 1) с использованием заранее заданного отображения текстуры. xyz-текстура и нейронная текстура Ts сцепляются и обрабатываются сетью U-Net [34] Egeom в новую текстурную карту (латентную геометрическую карту на фиг. 1) Zt. Это позволяет независимо генерировать смещения для каждой вершины сетки.
Латентная геометрическая карта фильтруется билинейно с использованием координат текстуры 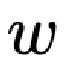 ( -
( - 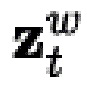 на фиг. 1) для получения признака, зависящего от вершины. Затем 3D-смещения для каждой вершины сетки независимо декодируются многослойным перцептроном Ggeom, который прогнозирует 3D-смещение
на фиг. 1) для получения признака, зависящего от вершины. Затем 3D-смещения для каждой вершины сетки независимо декодируются многослойным перцептроном Ggeom, который прогнозирует 3D-смещение  для каждой вершины. На этом этапе персонифицированная модель реконструируется для нелицевых частей сетки головы (спрогнозированной сетки
для каждой вершины. На этом этапе персонифицированная модель реконструируется для нелицевых частей сетки головы (спрогнозированной сетки  ) на фиг. 1). Реконструкции совместимы с топологией/связностью сетки FLAME [20].
) на фиг. 1). Реконструкции совместимы с топологией/связностью сетки FLAME [20].
- Отсроченная нейронная рендеризация. Персонифицированная сетка головы (спрогнозированная сетка) рендеризуется с использованием оператора ориентации Pt (который поворачивает и транслирует сетку к целевой ориентации), оцененной DECA (блоком “оценивание лица+ориентации” на фиг. 1) для целевого изображения и с наложенной нейронной текстурой Tx. Результирующий рендер обрабатывается декодированием (рендеризацией R на фиг.1) сети U-Net Eimg для получения спрогнозированного изображения 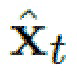 и маски сегментирования
и маски сегментирования 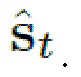
В ходе обучения, реконструкция сравнивается с истинным изображением/маской, и потери используются для обновления компонентов предложенной системы.
Ниже авторы сначала обеспечивают детали каждой стадии во время обучения. Заряд они рассматривают детали обучения и потери при обучении. Авторы также рассматривают оценивание упрощенной модели, причем геометрия модельной головы с использованием базиса формы линейной комбинации.
предложенный метод использует заранее заданную сетку головы с соответствующими координатами текстуры xyz. Также описанный процесс реконструкции сетки не изменяет топологию лица или координаты текстуры из отдельных вершин. В частности, авторы используют модель головы FLAME [20], которая имеет N базовых вершин 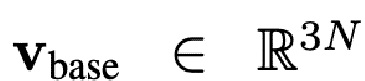 , и два множества K и L базисных векторов, которые кодируют форму
, и два множества K и L базисных векторов, которые кодируют форму 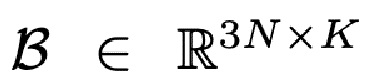 и выражение
и выражение 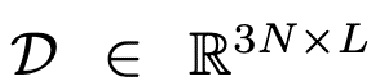 . Реконструкция осуществляется в две стадии: сначала базисные векторы комбинируются с использованием двух векторов линейных коэффициентов φ и ψ, и затем функция W скиннинга на основе линейной комбинации [20] применяется с параметрами θ, которая поворачивает группы вершин вокруг линейно оцененных соединений. Окончательная реконструкция в мировых координатах может выражаться следующим образом:
. Реконструкция осуществляется в две стадии: сначала базисные векторы комбинируются с использованием двух векторов линейных коэффициентов φ и ψ, и затем функция W скиннинга на основе линейной комбинации [20] применяется с параметрами θ, которая поворачивает группы вершин вокруг линейно оцененных соединений. Окончательная реконструкция в мировых координатах может выражаться следующим образом:
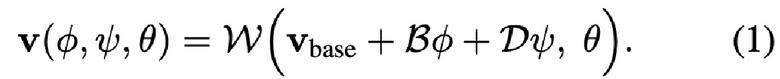
В предыдущих работах [40], эти параметры оценивались посредством фотометрической оптимизаци. Более недавно, начали появляться методы на основе обучения [9], позволяющие осуществлять одновидовую реконструкцию. Во время этой работы, авторы используют переобученную систему DECA [9], которая обеспечивает начальную реконструкцию головы (в форме параметров FLAME).
В ходе обучения, авторы применяют DECA как к исходному изображению 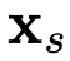 , так и к целевому изображению
, так и к целевому изображению 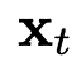 . Затем параметры формы лица из исходного изображения совместно с параметрами выражения, ориентации головы и ориентации камеры из целевого изображения используются для реконструкции начальных вершин
. Затем параметры формы лица из исходного изображения совместно с параметрами выражения, ориентации головы и ориентации камеры из целевого изображения используются для реконструкции начальных вершин 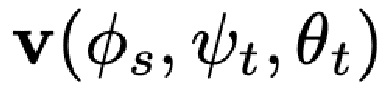 FLAME, а также оценивания матрицы
FLAME, а также оценивания матрицы 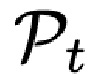 камеры.
камеры.
Вершины vt FLAME, оцененные посредством DECA, обеспечивают хорошие реконструкции для области лица, но не дает никаких персональных деталей в остальных частях головы (волосы, одежда). Для исправления, прогнозируются персональные смещения сетки для нелицевых областей при сохранении формы лица, спрогнозированной DECA. Области уха дополнительно исключены, поскольку их геометрия в начальной сетке (множестве лиц и множестве начальных вершин) слишком сложны для обучения из по-прежнему используемых массивов данных видео.
Эти смещения сетки оцениваются в два этапа. Сначала кодируются как текстура вершин, так и нейронная текстура Ts в текстурную карту Zt латентной геометрии через сеть UNet Egeom. Благодаря этому созданная латентная карта может содержать как позиции начальных вершин vt, и их семантику, обеспеченную нейронной текстурой.
Из Zt получаем векторы посредством билинейной интерполяции с фиксированными координатами текстуры w. Затем векторы 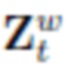 и их координаты
и их координаты  сцепляются и передаются через многослойный перцептрон Ggeom независимо для каждой вершины в сетке для прогнозирования смещений
сцепляются и передаются через многослойный перцептрон Ggeom независимо для каждой вершины в сетке для прогнозирования смещений  . Затем эти смещения обнуляются для областей лица и уха, и окончательная реконструкция в мировых координатах получается следующим образом:
. Затем эти смещения обнуляются для областей лица и уха, и окончательная реконструкция в мировых координатах получается следующим образом:

Уравнение (2) характеризует добавление спрогнозированного 3D-смещения к начальным вершинам для получения 3D-реконструкции человеческой головы в виде спрогнозированной сетки.
Отсроченная нейронная рендеризация
Рендеризуются вершины 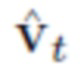 реконструированной головы с использованием топологии и координат текстуры
реконструированной головы с использованием топологии и координат текстуры 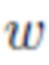 из модели FLAME с наложенной нейронной текстурой Ts. Для этого используется дифференцируемый рендеризатор R сетки [33] с матрицей Pt камеры, оцененной посредством DECA для целевого изображения xt.
из модели FLAME с наложенной нейронной текстурой Ts. Для этого используется дифференцируемый рендеризатор R сетки [33] с матрицей Pt камеры, оцененной посредством DECA для целевого изображения xt.
Результирующая растеризация обрабатывается сетью рендеризации (декодирования) Eimg для получения спрогнозированного изображения  и маски
и маски 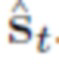 сегментирования. Eimg состоит из двух Unet, которые по отдельности декодируют изображение и маску. Результатом отсроченной нейронной рендеризации является реконструкция целевого изображения и его маски , которые сравнивается с эталонными данными изображение xt и маской st через фотометрические потери.
сегментирования. Eimg состоит из двух Unet, которые по отдельности декодируют изображение и маску. Результатом отсроченной нейронной рендеризации является реконструкция целевого изображения и его маски , которые сравнивается с эталонными данными изображение xt и маской st через фотометрические потери.
Задачи обучения
В предложенном подходе производится обучение геометрии без какого-либо эталонного 3D-контроля в ходе обучения или предварительного обучения (поверх свойственного оценивателя DECA). Для этого используются два типа задач: геометрические потери 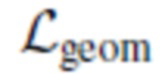 на основе сегментации и фотометрические потери
на основе сегментации и фотометрические потери 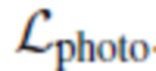 .
.
Назначение в явном виде подмножества вершин сетки областям шеи и волос позволяет значительно повысить качество окончательной деформации. Это позволяет представить топологической гипотезы для спрогнозированных смещений. В наших прогнозах, волосы не имеют отверстия и топологически эквивалентны полусфере (диску), тогда как шея и одежда эквивалентны цилиндру. В отсутствие этой явной гипотезы, предложенный метод не может генерировать согласованные с видом реконструкции.
Для оценивания геометрических потерь, вычисляются две отдельные маски заполнения с использованием операции мягкой растеризации [21]. Сначала 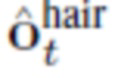 вычисляется с отсоединенными вершинами шеи, благодаря чему, градиент течет через эту маску только к смещениям, соответствующим вершинам волос, и затем вычисляется с отсоединенными вершинами волос.Согласовывается маска заполнения волос с эталонной маской
вычисляется с отсоединенными вершинами шеи, благодаря чему, градиент течет через эту маску только к смещениям, соответствующим вершинам волос, и затем вычисляется с отсоединенными вершинами волос.Согласовывается маска заполнения волос с эталонной маской 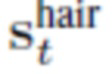 (которая покрывает волосы, лицо и уши), и маску заполнения шеи с полной маской st сегментирования:
(которая покрывает волосы, лицо и уши), и маску заполнения шеи с полной маской st сегментирования:
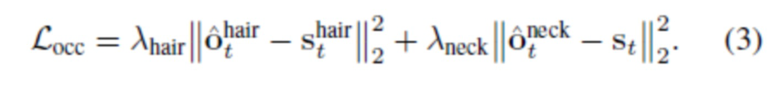
Также используется вспомогательная функция Chamfer loss, позволяющая гарантировать, что спрогнозированные вершины сетки покрывают голову более равномерно. В частности, 2D-координаты вершин сетки, спроецированной в целевое изображение, согласуются с маской сегментирования головы. Обозначим подмножество спрогнозированных вершин сетки, наблюдаемых в целевом изображении, как 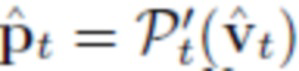 , и количество этих вершин как Nt, благодаря чему
, и количество этих вершин как Nt, благодаря чему 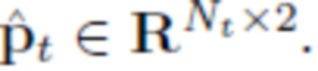 Заметим, что оператор
Заметим, что оператор 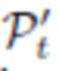 здесь не только совершает преобразование камеры, но и отбрасывает координату z вершины проецируемой сетки. Для вычисления потерь, выбирается Nt 2D-точек из маски сегментирования st и оцениваем функцию Chamfer distance между отфильтрованным множеством точек pt и проекциями вершин:
здесь не только совершает преобразование камеры, но и отбрасывает координату z вершины проецируемой сетки. Для вычисления потерь, выбирается Nt 2D-точек из маски сегментирования st и оцениваем функцию Chamfer distance между отфильтрованным множеством точек pt и проекциями вершин:
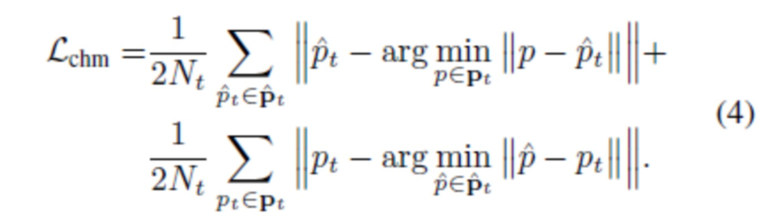
Наконец, регуляризуют обученную геометрию с использованием штрафной функции Лапласа [37]. Первоначально устанавливается, что регуляризующие смещения 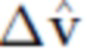 работают лучше, чем регуляризующие полные координаты
работают лучше, чем регуляризующие полные координаты 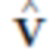 и приняли этот подход для всех экспериментов. Версию лапласовой функции потерять можно выразить в виде:
и приняли этот подход для всех экспериментов. Версию лапласовой функции потерять можно выразить в виде:

где 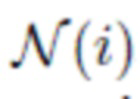 обозначает множество индексов для вершин, соседствующих с i-ой вершиной в сетке.
обозначает множество индексов для вершин, соседствующих с i-ой вершиной в сетке.
Окончательные геометрические потери, которые используются 4 для обучения реконструкции сетки головы, выражаются в виде:
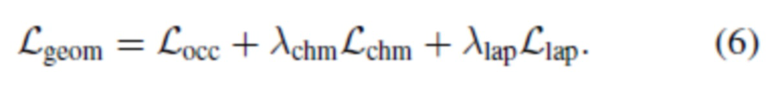
Фотометрическая оптимизация согласует полученное и эталонное изображения. Члены фотометрических потерь позволяют не только получить фотореалистические рендеры, но и помогают в обучении правильной геометрической реконструкции. Фотометрические члены включают в себя перцептивные потери [15], потери при распознавании лиц [5] и состязательные потери в режиме нескольких разрешений [10, 42]. Также используется Dice-функция потерь [28] для согласования масок сегментирования. Поэтому используется следующая комбинацию потерь:
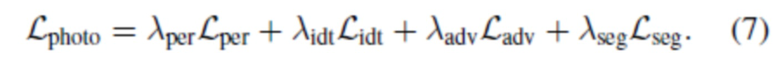
Окончательной задачей является сумма геометрических и фотометрических потерь:
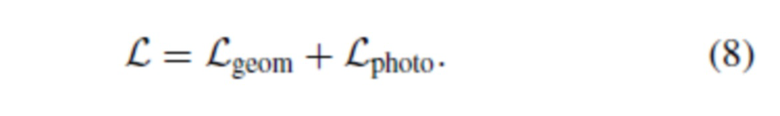
Модель линейных деформаций
Помимо предложенной выше полной нелинейной модели, рассматривается упрощенная параметрическая модель с линейным базисом смещений. Хотя эта модель аналогична параметрическим моделям [20,47], авторы все же не используют 3D-сканы для обучения и, напротив, получают линейную модель путем “дистилляции” нелинейной модели. Также обучается упреждающий регрессор, который прогнозирует линейные коэффициенты из входного изображения.
Мотивация для обучения этой дополнительной модели состоит в том, чтобы показать, что деформации, обученные предложенным методом, можно аппроксимировать с использованием системы со значительно более низкой емкости. Такую простую модель регрессии может быть проще применять для интерфейса на низкопроизводительных устройствах.
Для обучения линейной модели, сначала получается базис смещений 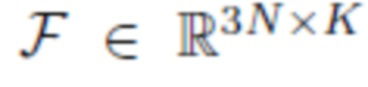 , аналогичный используемому в параметрической модели FLAME. Этот базис получается путем применения низкораногового PCA [12] к матрице смещений
, аналогичный используемому в параметрической модели FLAME. Этот базис получается путем применения низкораногового PCA [12] к матрице смещений 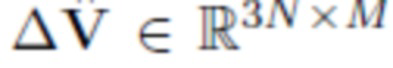 , вычисленной с использованием M изображений из массива данных. Согласно [20], отбрасывается большинство базисных векторов и оставляем только K компонентов, соответствующих максимальным сингулярным значениям. Затем аппроксимированную вершину смещения
, вычисленной с использованием M изображений из массива данных. Согласно [20], отбрасывается большинство базисных векторов и оставляем только K компонентов, соответствующих максимальным сингулярным значениям. Затем аппроксимированную вершину смещения 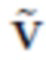 для каждого изображения можно оценивать согласно следующему выражению:
для каждого изображения можно оценивать согласно следующему выражению:

где η можно получить путем применения матрицы F псевдообратного преобразования базиса к соответствующим смещениям 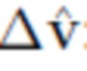 :
:
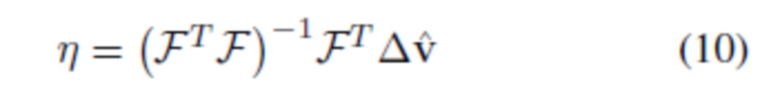
Затем регрессивная сеть обучается путем оценивания вектора базисных коэффициентов 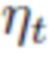 , для данного изображения
, для данного изображения 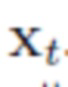 . Для этого, потери, выраженные среднеквадратичной ошибкой (MSE),
. Для этого, потери, выраженные среднеквадратичной ошибкой (MSE), 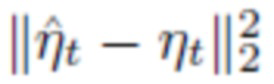 , между оцененными коэффициентами и эталоном минимизируются.
, между оцененными коэффициентами и эталоном минимизируются.
предложенный метод обучается на массиве данных VoxCeleb2 [6] видеозаписей. Этот крупномасштабный массив данных содержит порядка 105 видеозаписей 103 разных дикторов. Он широко используется [7,43,45] для обучения моделей говорящей головы. Однако главным недостатком этого массива данных является смешанное качество видеозаписей и тяжелое смещение к фронтальным положениям.
Для решения этих общеизвестных ограничений, этот массив данных обрабатывается с использованием готовой модели анализа качества изображения [38] и сети 3D выравнивания лиц [4]. Затем фильтруются данные, которые имеют низкое качество и сходный поворот головы. Наш окончательный обучающий массив данных имеет ≈ 15000 последовательностей. Заметим, что фильтрация/обрезка не полностью решают проблему смещения поворота головы, и предложенный метод все же лучше всего работает во фронтальных видах.
Также используется массив данных H3DS [32] фотографий с соответствующими 3D-сканами для оценивания качества реконструкций головы.
Детали реализации
В экспериментах использовали обучение в две стадии. На первой стадии, обучаются все сети в течение 1⋅105 итераций, но применяют смещения только к вершинам волос и запрещают шею и 2D Chamfer loss. Используются следующие веса: λhair=100, λper=1, λidt=0,1, λadv=0,1, λseg=10. После этого начинается оценивание смещения для вершин шеи, и обучение в течение дополнительно 5⋅104 итераций. Снижают потери на сегментировании волос (λhair=10) и разрешают шею и 2D Chamfer loss (λneck=10, λchm=0,01). Также применяли разные штрафные функции к вершинам, которые соответствуют областям шеи и волос в ходе обучения. Для вершин шеи задано λlap=10, тогда как для вершин волос, задано λlap=1.
Обучали предложенные модели с разрешением 256 × 256 с использованием ADAM [18] при фиксированной частоте обучения 10−4, β1=0, β2=0,999 и размере партии 32. За дополнительными деталями следует обратиться к вспомогательным материалам.
Оценивание
3D-реконструкция.
Хотя ни один из двух методов не дает хороших результатов, вероятно, ROME (предложенный метод) обеспечивает более реалистические рендеры, а также лучше согласует геометрию головы, чем H3D-Net в одноразовом режиме. Важным преимуществом ROME является то, что результирующие аватары готовы для анимации.
Предложенное качество реконструкции головы оценивается с использованием нового массива данных H3DS [32]. По сравнению с традиционным методом H3D-Net реконструкции головы [32], который использует знаковые функции расстояния для представления геометрии. Несмотря на обеспечение высокого качества реконструкции в сценарии прореженных видов, их подход имеет ряд ограничений. Например, H3D-Net требует массива данных полных сканеров головы для формирования гипотез о формах головы. Дополнительно, он не имеет встроенных возможностей анимации и требует тонкой настройки каждой сцены, хотя предложенный метод работает с упреждением.
Производится сравнение с H3D-Net в одновидовом сценарии, который является естественным для предложенного метода, но выходит за пределы возможностей, указанных авторами в оригинальной публикации [32]. Однако H3D-Net является системой, ближайшей к нашей по возможностям одновидовой реконструкции (из всех систем, где присутствуют либо их код, или результаты).
Фиг. 2 иллюстрирует качественное сравнение иллюстративных случаев для массива данных H3DS. Каждый столбец: 1-й - исходное изображение, 2-й - результат рендеризации H3D-Net [32], 3-й результат предложенной рендеризации, 4-й - эталонная сетка (из массива данных H3D), 5-й - спрогнозированная сетка H3D-Net, 6-й - спрогнозированная сетка ROME (предложенный метод). Оценивается предложенный метод и H3D-Net для реконструкции фронтального и бокового вида. Обратим внимание на значительную переподгонку H3D-Net к наблюдаемой геометрии волос, тогда как предложенная модель делает реконструкции более устойчивыми к смене точки обзора.
В целом, сравнивались предложенные модели на всех сканах, доступных в испытательном наборе массива данных H3DS, и каждый скан реконструировался из 3 разных точек обзора. Измеренное среднее Chamfer distance по всем сканам равно 15,1 мм для H3D-Net, и 13,2 мм для предложенного метода.
Фиг. 3 иллюстрирует сравнение рендеров на массиве данных VoxCeleb2. Задача состоит в восстановлении исходного изображения на основании выражения и ориентации изображения водителей. Здесь рассмотрены разнообразные примеры в отношении изменения ориентации для выделения различий в производительности сравниваемых методов. Для больших поворотов ориентации головы, чисто нейронные методы (FOMM, Bi-Layer) борются за поддержание согласованного качества.
В сравнении, предложенный метод рендеризации (ROME) создает изображения, более устойчивые к изменениям ориентации. Общеизвестно, что для малых изменений ориентации, нейронные методы демонстрируют меньший разрыв в идентичности, чем ROME (нижняя строка), и общее превосходство нашего способа в отношении качество рендеризации.
Дополнительно, представлен метод FLAMETex, который используется в традиционных одноразовых системах реконструкции лиц [9], но известен для персонификации аватара на уровне головы.
Оценивается качество предложенных рендеров на подмножестве отказа массива данных VoxCeleb2. Используется сценарий перекрестного сравнения для качественного сравнения для выделения возможностей анимации предложенного метода и сценарий самоуправления для количественного сравнения.
Сначала сравниваются с системой рендеризации FLAMETex [20], которая работает в явном виде с рендеризацией сетки. Из исходного изображения, FLAMETex оценивает альбедо через базис RGB-текстур, и затем объединяет его со спрогнозированным зависящим от сцены затенения. Напротив, наш способ прогнозирует рендеризованное изображение напрямую и избегает сложности явного разложения альбедо-затенение.
Затем проводится сравнение с общедоступными негеометрическими методами рендеризации, обученные на одном и том же массиве данных. Для этого предложенное решение использует модель движения первого порядка (FOMM) [36] и модель аватара Bi-Layer [45]. Обе эти системы обходят явное оценивание 3D геометрии и опираются только на обучение структуры сцены через параметры порождающих сверточных сетей. Другие способы [7,43], которые внутренне используют некоторые 3D структуры, например, повороты камеры, выходили за пределы объема нашего сравнения, вследствие недоступности переобученных моделей.
Представлены качественное сравнение на фиг. 3, и количественное сравнение через произвольно отфильтрованное подмножество отказа VoxCeleb2 в таблице 1.
Таблица 1 представляет количественные результаты на массиве данных VoxCeleb2 в режиме самореконструкции. Предложенная система ROME преобладает над FOMM (в наиболее перцептивно-правдоподобных метриках LPIPS), когда положения фильтруются, чтобы включать в себя только большие изменения.
Вышеприведенные варианты осуществления являются иллюстративными и не подлежат рассмотрению как ограничительные. Кроме того, описание иллюстративных вариантов осуществления служит для иллюстрации, но не для ограничения объема формулы изобретения, и многие альтернативы, модификации и вариации будут очевидны специалистам в данной области техники.
Ссылки
[1] AvatarSDK. https://avatarsdk.com/.
[2] V. Blanz, S. Romdhani, and T. Vetter. Face identification across different poses and illuminations with a 3d morphable model. Proceedings of Fifth IEEE International Conference on Automatic Face Gesture Recognition, pages 202- 207, 2002.
[3] V. Blanz and T. Vetter. A morphable model for the synthesis of 3d faces. In SIGGRAPH ’99, 1999.
[4] A. Bulat and G. Tzimiropoulos. How far are we from solving the 2d & 3d face alignment problem? (and a dataset of 230,000 3d facial landmarks). In International Conference on Computer Vision, 2017.
[5] Q. Cao, L. Shen, W. Xie, O. M. Parkhi, and A. Zisserman. Vggface2: A dataset for recognising faces across pose and age. 2018 13th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2018), pages 67-74, 2018.
[6] J. S. Chung, A. Nagrani, and A. Zisserman. Voxceleb2: Deep speaker recognition. In INTERSPEECH, 2018.
[7] M. C. Doukas, S. Zafeiriou, and V. Sharmanska. Headgan: Video-and-audio-driven talking head synthesis. ArXiv, abs/2012.08261, 2020.
[8] B. Egger, W. Smith, A. Tewari, S. Wuhrer, M. Zollh¨ofer, T. Beeler, F. Bernard, T. Bolkart, A. Kortylewski, S. Romdhani, C. Theobalt, V. Blanz, and T. Vetter. 3d morphable face models-past, present, and future. ACM Transactions on Graphics (TOG), 39:1 - 38, 2020.
[9] Y. Feng, H. Feng, M. J. Black, and T. Bolkart. Learning an animatable detailed 3d face model from in-the-wild images. ACM Transactions on Graphics (TOG), 40:1 - 13, 2020.
[10] I. J. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. C. Courville, and Y. Bengio. Generative adversarial nets. In NIPS, 2014.
[11] J. Guo, X. Zhu, Y. Yang, F. Yang, Z. Lei, and S. Z. Li. Towards fast, accurate and stable 3d dense face alignment. In Proceedings of the European Conference on Computer Vision (ECCV), 2020.
[12] N. Halko, P.-G. Martinsson, and J. A. Tropp.Finding structure with randomness: Probabilistic algorithms for constructing approximate matrix decompositions. SIAM Rev., 53:217-288, 2011.
[13] T. Hassner, S. Harel, E. Paz, and R. Enbar. Effective face frontalization in unconstrained images. 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 4295-4304, 2015.
[14] K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 770-778, 2016.
[15] J. Johnson, A. Alahi, and L. Fei-Fei. Perceptual losses for real-time style transfer and super-resolution. In ECCV, 2016.
[16] P. Kellnhofer, L. Jebe, A. Jones, R. P. Spicer, K. Pulli, and G. Wetzstein. Neural lumigraph rendering. 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 4285-4295, 2021.
[17] H. Kim, P. Garrido, A. Tewari, W. Xu, J. Thies, M. Niesner, P. P´erez, C. Richardt, M. Zoll¨ofer, and C. Theobalt. Deep video portraits. ACM Transactions on Graphics (TOG), 37(4):163, 2018.
[18] D. P. Kingma and J. Ba. Adam: A method for stochastic optimization. CoRR, abs/1412.6980, 2015.
[19] S. Laine, J. Hellsten, T. Karras, Y. Seol, J. Lehtinen, and T. Aila. Modular primitives for high-performance differentiable rendering. ACM Transactions on Graphics, 39(6), 2020.
[20] T. Li, T. Bolkart, M. J. Black, H. Li, and J. Romero. Learning a model of facial shape and expression from 4d scans. ACM Transactions on Graphics (TOG), 36:1 - 17, 2017.
[21] S. Liu, T. Li, W. Chen, and H. Li. Soft rasterizer: A differentiable renderer for image-based 3d reasoning. 2019 IEEE/CVF International Conference on Computer Vision (ICCV), pages 7707-7716, 2019.
[22] S. Lombardi, J. M. Saragih, T. Simon, and Y. Sheikh. Deep appearance models for face rendering. ACM Transactions on Graphics (TOG), 37:1 - 13, 2018.
[23] S. Lombardi, T. Simon, J. M. Saragih, G. Schwartz, A. M. Lehrmann, and Y. Sheikh. Neural volumes. ACM Transactions on Graphics (TOG), 38:1 - 14, 2019.
[24] S. Lombardi, T. Simon, G. Schwartz, M. Zollhoefer, Y. Sheikh, and J. M. Saragih. Mixture of volumetric primitives for efficient neural rendering. ACM Transactions on Graphics (TOG), 40:1 - 13, 2021.
[25] Q. Ma, S. Saito, J. Yang, S. Tang, and M. J. Black. Scale: Modeling clothed humans with a surface codec of articulated local elements. In CVPR, 2021.
[26] L. Mescheder, A. Geiger, and S. Nowozin. Which Training Methods for GANs do actually Converge? In Proc. ICML, 2018.
[27] B. Mildenhall, P. P. Srinivasan, M. Tancik, J. T. Barron, R. Ramamoorthi, and R. Ng. Nerf: Representing scenes as neural radiance fields for view synthesis. In ECCV, 2020.
[28] F. Milletari, N. Navab, and S.-A. Ahmadi. V-net: Fully convolutional neural networks for volumetric medical image segmentation. 2016 Fourth International Conference on 3D Vision (3DV), pages 565-571, 2016.
[29] M. Oechsle, S. Peng, and A. Geiger. Unisurf: Unifying neural implicit surfaces and radiance fields for multi-view reconstruction. ArXiv, abs/2104.10078, 2021.
[30] J. J. Park, P. R. Florence, J. Straub, R. A. Newcombe, and S. Lovegrove. Deepsdf: Learning continuous signed distance functions for shape representation. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 165-174, 2019.
[31] Pinscreen. https://www.pinscreen.com/.
[32] E. Ramon, G. Triginer, J. Escur, A. Pumarola, J. G. Giraldez, X. G. i Nieto, and F. Moreno-Noguer. H3d-net: Few-shot high-fidelity 3d head reconstruction. ArXiv, abs/2107.12512,2021.
[33] N. Ravi, J. Reizenstein, D. Novotny, T. Gordon, W.-Y. Lo, J. Johnson, and G. Gkioxari. Accelerating 3d deep learning with pytorch3d. arXiv:2007.08501, 2020.
[34] O. Ronneberger, P. Fischer, and T. Brox. U-net: Convolutional networks for biomedical image segmentation. In MICCAI, 2015.
[35] S. Saito, T. Simon, J. M. Saragih, and H. Joo. Pifuhd: Multilevel pixel-aligned implicit function for high-resolution 3d human digitization. 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 81-90,2020.
[36] A. Siarohin, S. Lathuili`ere, S. Tulyakov, E. Ricci, and N. Sebe. First order motion model for image animation. ArXiv, abs/2003.00196, 2019.
[37] O. Sorkine-Hornung. Laplacian mesh processing. In Eurographics,2005.
[38] S. Su, Q. Yan, Y. Zhu, C. cui Zhang, X. Ge, J. Sun, and Y. Zhang. Blindly assess image quality in the wild guided by a self-adaptive hyper network. 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 3664-3673, 2020.
[39] J. Thies, M. Zollh¨ofer, and M. Niesner. Deferred neural rendering: Image synthesis using neural textures. arXiv: Computer Vision and Pattern Recognition, 2019.
[40] J. Thies, M. Zollh¨ofer, M. Stamminger, C. Theobalt, and M. Niesner. Face2face: Real-time face capture and reenactment of rgb videos. In Proc. Computer Vision and Pattern Recognition (CVPR), IEEE, 2016.
[41] A. Tran, T. Hassner, I. Masi, and G. G. Medioni. Regressing robust and discriminative 3d morphable models with a very deep neural network. 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 1493-1502, 2017.
[42] T.-C. Wang, M.-Y. Liu, J.-Y. Zhu, A. Tao, J. Kautz, and B. Catanzaro. High-resolution image synthesis and semantic manipulation with conditional gans. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8798-8807, 2018.
[43] T.-C. Wang, A. Mallya, and M.-Y. Liu. One-shot freeview neural talking-head synthesis for video conferencing. 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 10034-10044, 2021.
[44] I. Zakharkin, K. Mazur, A. Grigoriev, and V. S. Lempitsky. Point-based modeling of human clothing. ArXiv, abs/2104.08230, 2021.
[45] E. Zakharov, A. Ivakhnenko, A. Shysheya, and V. S. Lempitsky. Fast bi-layer neural synthesis of one-shot realistic head avatars. In ECCV, 2020.
[46] E. Zakharov, A. Shysheya, E. Burkov, and V. S. Lempitsky. Few-shot adversarial learning of realistic neural talking head models. 2019 IEEE/CVF International Conference on Computer Vision (ICCV), pages 9458-9467, 2019.
[47] S. Zuffi, A. Kanazawa, T. Berger-Wolf, and M. J. Black. Three-d safari: Learning to estimate zebra pose, shape, and texture from images ”in the wild”, 2019.
| название | год | авторы | номер документа |
|---|---|---|---|
| МОДЕЛИРОВАНИЕ ЧЕЛОВЕЧЕСКОЙ ОДЕЖДЫ НА ОСНОВЕ МНОЖЕСТВА ТОЧЕК | 2021 |
|
RU2776825C1 |
| СПОСОБ СОЗДАНИЯ АНИМИРУЕМОГО АВАТАРА ЧЕЛОВЕКА В ПОЛНЫЙ РОСТ ИЗ ОДНОГО ИЗОБРАЖЕНИЯ ЧЕЛОВЕКА, ВЫЧИСЛИТЕЛЬНОЕ УСТРОЙСТВО И МАШИНОЧИТАЕМЫЙ НОСИТЕЛЬ ДЛЯ ЕГО РЕАЛИЗАЦИИ | 2023 |
|
RU2813485C1 |
| СПОСОБ ВИЗУАЛИЗАЦИИ 3D ПОРТРЕТА ЧЕЛОВЕКА С ИЗМЕНЕННЫМ ОСВЕЩЕНИЕМ И ВЫЧИСЛИТЕЛЬНОЕ УСТРОЙСТВО ДЛЯ НЕГО | 2021 |
|
RU2757563C1 |
| НЕЙРОННАЯ ТОЧЕЧНАЯ ГРАФИКА | 2019 |
|
RU2729166C1 |
| Быстрый двухслойный нейросетевой синтез реалистичных изображений нейронного аватара по одному снимку | 2020 |
|
RU2764144C1 |
| НЕЙРОСЕТЕВОЙ ПЕРЕНОС ВЫРАЖЕНИЯ ЛИЦА И ПОЗЫ ГОЛОВЫ С ИСПОЛЬЗОВАНИЕМ СКРЫТЫХ ДЕСКРИПТОРОВ ПОЗЫ | 2020 |
|
RU2755396C1 |
| ТЕКСТУРИРОВАННЫЕ НЕЙРОННЫЕ АВАТАРЫ | 2019 |
|
RU2713695C1 |
| Повторный синтез изображения, использующий прямое деформирование изображения, дискриминаторы пропусков и основанное на координатах реконструирование | 2019 |
|
RU2726160C1 |
| ВИЗУАЛИЗАЦИЯ РЕКОНСТРУКЦИИ 3D-СЦЕНЫ С ИСПОЛЬЗОВАНИЕМ СЕМАНТИЧЕСКОЙ РЕГУЛЯРИЗАЦИИ НОРМАЛЕЙ TSDF ПРИ ОБУЧЕНИИ НЕЙРОННОЙ СЕТИ | 2023 |
|
RU2825722C1 |
| Способ синтеза двумерного изображения сцены, просматриваемой с требуемой точки обзора, и электронное вычислительное устройство для его реализации | 2020 |
|
RU2749749C1 |


Изобретение относится к способу 3D-реконструкции человеческой головы для получения рендера изображения человека. Технический результат заключается в возможности генерации реалистичного изображения человеческой головы. В способе используют единственное исходное изображение, причем форма лица извлекается из единственного исходного изображения, ориентация головы, выражение лица извлекаются из произвольного целевого изображения, причем способ осуществляется на устройстве, имеющем CPU, внутреннюю память с изображениями, RAM, причем способ содержит этапы, на которых: a) считывают единственное исходное изображение из памяти устройства и кодируют, посредством первой сверточной нейронной сети, исходное изображение в нейронную текстуру того же пространственного размера, что и исходное изображение, но с увеличенным количеством каналов, которая содержит локальные персональные детали; b) параллельно оценивают форму лица, выражение лица и ориентацию головы посредством переобученной системы DECA в отношении исходного и целевого изображений, и обеспечивают начальную сетку как множество лиц и множество начальных вершин; c) обеспечивают спрогнозированную сетку для нелицевых частей сетки головы, причем на этапе обеспечения: рендеризуют начальную сетку в xyz-координатную текстуру, сцепляют xyz-координатную текстуру и нейронную текстуру, обрабатывают с помощью второй сети в латентную геометрическую карту, билинейно фильтруют латентную геометрическую карту с использованием координат текстуры для получения признака, зависящего от вершины, декодируют признак, зависящий от вершины, посредством многослойного перцептрона для прогнозирования 3D-смещения для каждой вершины, добавляют спрогнозированное 3D-смещение к начальным вершинам для получения 3D-реконструкции человеческой головы в виде спрогнозированной сетки; d) растеризуют 3D-реконструкцию человеческой головы для обработки результата посредством третьей сети для получения рендера изображения человека. 3 ил., 1 табл.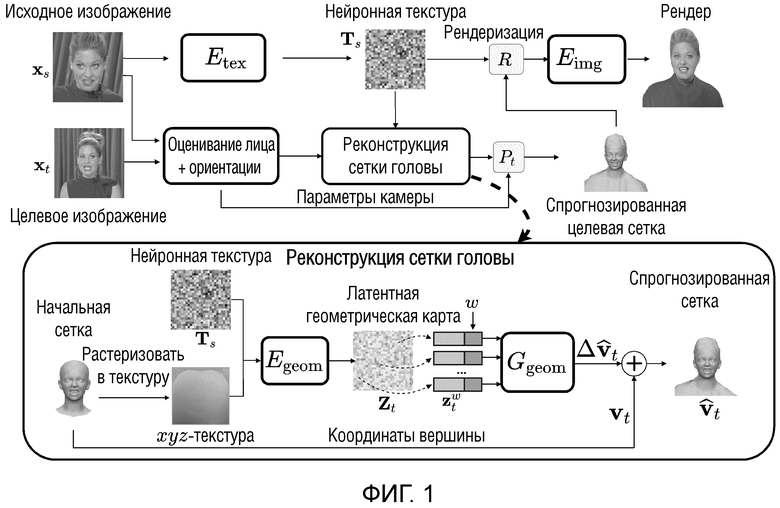
Способ 3D-реконструкции человеческой головы для получения рендера изображения человека с использованием единственного исходного изображения, причем форма лица извлекается из единственного исходного изображения, ориентация головы, выражение лица извлекаются из произвольного целевого изображения, причем способ осуществляется на устройстве, имеющем CPU, внутреннюю память с изображениями, RAM, причем способ содержит этапы, на которых:
a) считывают единственное исходное изображение из памяти устройства и кодируют, посредством первой сверточной нейронной сети, исходное изображение в нейронную текстуру того же пространственного размера, что и исходное изображение, но с увеличенным количеством каналов, которая содержит локальные персональные детали;
b) параллельно оценивают форму лица, выражение лица и ориентацию головы посредством переобученной системы DECA в отношении исходного и целевого изображений, и обеспечивают начальную сетку как множество лиц и множество начальных вершин;
c) обеспечивают спрогнозированную сетку для нелицевых частей сетки головы, причем на этапе обеспечения:
- рендеризуют начальную сетку в xyz-координатную текстуру,
- сцепляют xyz-координатную текстуру и нейронную текстуру,
- обрабатывают с помощью второй сети в латентную геометрическую карту,
- билинейно фильтруют латентную геометрическую карту с использованием координат текстуры для получения признака, зависящего от вершины,
- декодируют признак, зависящий от вершины, посредством многослойного перцептрона для прогнозирования 3D-смещения для каждой вершины,
- добавляют спрогнозированное 3D-смещение к начальным вершинам для получения 3D-реконструкции человеческой головы в виде спрогнозированной сетки;
d) растеризуют 3D-реконструкцию человеческой головы для обработки результата посредством третьей сети для получения рендера изображения человека.
| Nikhila Ravi et al., "Accelerating 3D Deep Learning with PyTorch3D", 16.07.2020, URL: https://arxiv.org/pdf/2007.08501 | |||
| Yao Feng et al., "Learning an Animatable Detailed 3D Face Model from In-The-Wild Images", 07.12.2020, URL: https://arxiv.org/pdf/2012.04012v1 | |||
| Justus Thies et al., "Deferred Neural Rendering: Image Synthesis using Neural |

