Описание предшествующего уровня техники
В настоящее время, в связи с резким ростом числа мультимедийных данных, существует острая необходимость в разработке интеллектуальных методов для их обработки и организации [1]. Например, все большее внимание привлекает задача автоматической организации фото и видеоальбомов [2, 3]. Различные системы организации фотографий позволяют пользователям группировать и маркировать фотографии и видео, чтобы можно было осуществлять поиск среди большого количества изображений в медиатеке [4]. Наиболее типичная обработка фотоальбома включает в себя группирование (кластеризацию) лиц, при этом каждый кластер можно автоматически маркировать такими атрибутами лиц, как возраст (год рождения) и пол [5]. Следовательно, типичная задача заключается в том, чтобы при наличии большого количества неразмеченных изображений лиц можно было сгруппировать эти изображения по отдельным людям (личностям) [4] и предсказать возраст и пол каждого человека [6].
Эту задачу обычно решают с помощью глубоких сверточных нейронных сетей (СНС, CNN) [7]. Сначала выполняется кластеризация фотографий и видео, на которых изображен один и тот же человек, с помощью известных методов идентификации [10] и верификации [8, 9] лиц. Атрибуты (возраст, пол, раса, эмоции) выявленных лиц можно распознавать с помощью других СНС [5, 6]. Хотя такой подход работает довольно хорошо, он требует использования нескольких разных СНС, что увеличивает время обработки, особенно если надо обработать фотоальбом на мобильных платформах в автономном режиме. Кроме того, каждая СНС изучает собственное представление лица, качество которого может быть ограничено небольшим размером обучающего набора или шумом в обучающих данных. Последняя проблема имеет особенно важное значение для предсказания возраста, где значения возраста зачастую определены некорректно.
Вполне очевидно, что можно использовать близость этих задач обработки лиц для извлечения эффективных представлений (индивидуальных характерных признаков) лиц, что способствует повышению их индивидуальных результатов. Например, в одной СНС можно одновременно реализовать детектирование лиц, ключевых точек лиц, оценку позы и распознавание пола [11].
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
Таким образом, целью настоящего изобретения является повышение эффективности кластеризации лиц и распознавания атрибутов лиц путем обучения представлений лиц с предварительным обучением СНС для задачи идентификации лиц из предварительно собранной базы данных. В изобретении предложено расширение с несколькими выходами для СНС с низкой вычислительной сложностью и затратам памяти, например, MobileNet [12], которую предварительно обучают выполнять распознавание лиц с использованием набора данных VGGFace2 [13]. Дополнительные слои этой сети дообучаются на распознавание атрибутов лиц, например, используя наборы данных Adience [5] и IMDB-Wiki [6]. И, наконец, предложен новый подход к группированию лиц. Этот подход позволяет решить несколько проблем обработки альбомов фотографий и видео реального мира.
Настоящее изобретение предусматривает автоматическое выделение людей и их атрибутов (пол, возраст, этническая принадлежность, эмоции) из альбома фотографий и видео. Авторы изобретения предлагают двухэтапный подход, в котором СНС сначала одновременно предсказывает атрибуты лиц из всех фотографий и дополнительно извлекает представления лиц, подходящие для идентификации лиц. Эффективную СНС предварительно обучают выполнять распознавание лиц с дополнительным распознаванием атрибутов лиц (возраста, пола и т.п.). На втором этапе данного подхода извлеченные лица группируются с помощью методов иерархической агломеративной кластеризации. Возраст и пол человека в каждом кластере оцениваются путем агрегирования предсказаний для отдельных фотографий. Качество кластеризации лиц, обеспечиваемое изобретением, сопоставимо с существующими нейронными сетями, однако изобретательский подход значительно дешевле в реализации вычислений. Более того, указанный подход характеризуется более точным распознаванием атрибутов лиц на основе видео по сравнению с известными моделями.
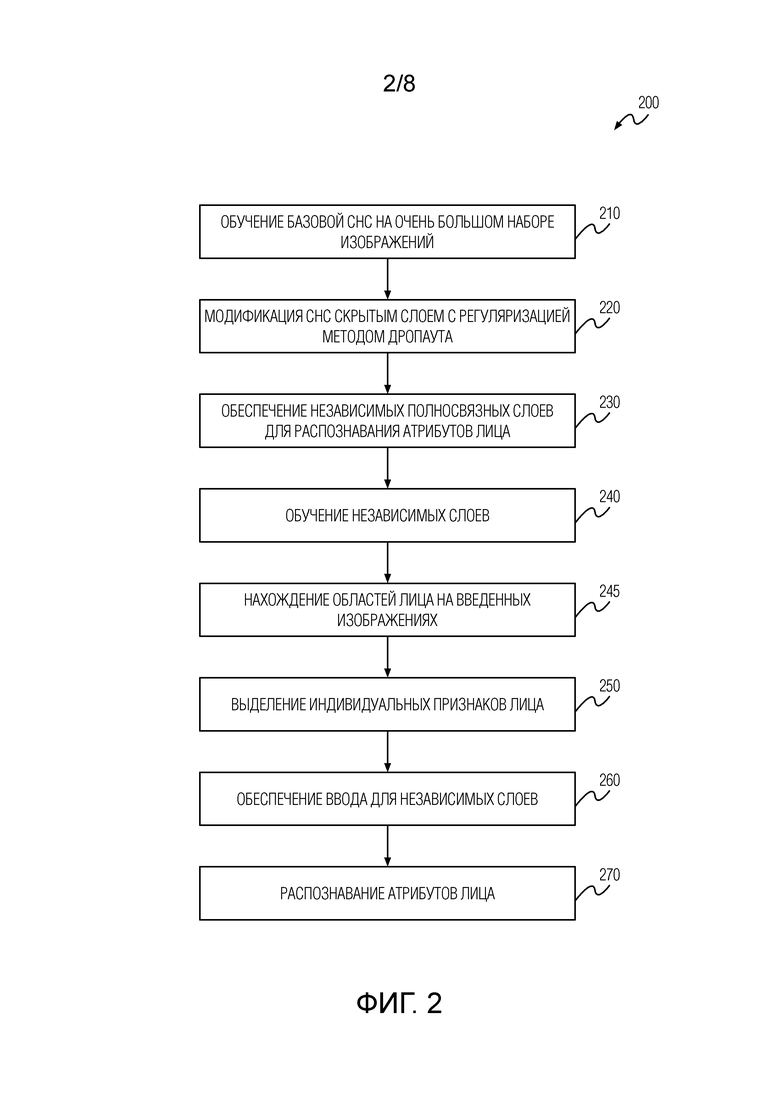
Согласно первому аспекту изобретения предложен компьютерно-реализуемый способ одновременного распознавания атрибутов лиц (например, одного или более из возраста, пола, расы или этнической принадлежности, или эмоций) и идентификации личности в цифровых изображениях. Данный способ содержит этапы, на которых: обучают базовую СНС на предварительно выбранном наборе изображений; модифицируют СНС посредством обеспечения по меньшей мере одного скрытого слоя с регуляризацией методом дропаута; обеспечивают над этим по меньшей мере одним скрытым слоем независимые полносвязные слои для распознавания атрибутов лиц, причем каждый из этих независимых слоев соответствует конкретному одному из атрибутов лиц и имеет соответствующую нелинейность; обучают независимые полносвязные слои, причем при обучении поочередно используют подмножество (батч) обучающих данных, относящееся только к тому одному из независимых слоев, который подвергается обучению; извлекают посредством слоев базовой СНС из, по меньшей мере, частей одного или нескольких входных изображений индивидуальные характерные признаки, пригодные для идентификации лиц; обеспечивают ввод для независимых полносвязных слоев посредством, по меньшей мере, скрытого слоя, используя извлеченные индивидуальные характерные признаки; и распознают атрибуты лиц, соответственно, посредством независимых полносвязных слоев на основе ввода из по меньшей мере одного скрытого слоя.
Базовой СНС предпочтительно является СНС с низкой вычислительной сложностью и затратам памяти (например, MobileNet v1/v2).
Каждый батч обучающих данных предпочтительно имеет соответствующую метку, указывающую на конкретный атрибут лица, к которому данный батч относится.
Способ может дополнительно содержать этапы, на которых: детектируют на одном или нескольких входных изображениях области, ассоциированные с лицами, и используют эти области в качестве упомянутых, по меньшей мере, частей одного или нескольких входных изображений. Детектирование предпочтительно выполняют посредством каскадного классификатора или метода MTCNN (многозадачной каскадной сверточной нейронной сети).
Согласно второму аспекту изобретения предложен компьютерно-реализуемый способ организации цифрового фотоальбома и/или цифрового видеоальбома, причем фотоальбом содержит множество фотографий, а видеоальбом содержит множество видеофайлов. Упомянутый способ содержит этапы, на которых: выбирают множество кадров в каждом видеофайле из множества видеофайлов; детектируют в каждом из выбранных кадров и/или на каждой фотографии из множества фотографий области, ассоциированные с лицами; извлекают индивидуальные характерные признаки и атрибуты всех лиц, используя способ согласно первому аспекту изобретения, при этом детектированные области используются в качестве входных изображений; для каждого видеофайла в множестве видеофайлов осуществляют кластеризацию извлеченных индивидуальных характерных признаков и атрибутов, ассоциированных с каждым лицом из лиц, детектированных в видеофайле, в один кластер и вычисляют средние индивидуальные характерные признаки и средние атрибуты лиц для каждого кластера видеофайла; и группируют фотографии и/или видеофайлы посредством совместной кластеризации индивидуальных характерных признаков, извлеченных из фотографий, и средних индивидуальных характерных признаков, вычисленных для видеофайлов, и на основе по меньшей мере одного усредненного атрибута лиц, вычисленного для каждого кластера из соответствующих атрибутов и/или средних атрибутов лиц, ассоциированных с кластером.
Детектирование предпочтительно выполняют посредством каскадного классификатора или метода MTCNN. Выбор предпочтительно включает в себя выбор с фиксированной частотой четких кадров видеофайла. По меньшей мере один усредненный атрибут лиц предпочтительно вычисляют, используя подходящий метод агрегации, такой как простое голосование или максимизация средних апостериорных вероятностей на выходах СНС. Вычисление средних индивидуальных характерных признаков предпочтительно включает в себя вычисление нормированного среднего извлеченных индивидуальных характерных признаков.
Совместную кластеризацию предпочтительно выполняют с использованием иерархической агломеративной кластеризации для получения кластеров, каждый из которых включает в себя индивидуальные характерные признаки одного или нескольких лиц. Совместная кластеризация предпочтительно включает в себя корректировку кластеров, при которой отфильтровываются неподходящие кластеры. Неподходящими кластерами могут быть кластеры с числом элементов меньше, чем первое предопределенное пороговое значение, или кластеры, ассоциированные с фотографиями/видеофайлами, даты съемки которых отличаются меньше, чем на второе предопределенное пороговое значение.
До этапа совместной кластеризации способ может дополнительно содержать этапы, на которых: оценивают год рождения, относящийся к каждому из лиц, путем вычитания возраста в атрибутах, ассоциированных с данным лицом, из даты создания файла, содержащего фотографию или видеофайл, в котором было детектировано упомянутое лицо. В этом случае при совместной кластеризации предпочтительно предотвращают кластеризацию в один и тот же кластер индивидуальных характерных признаков тех людей, чьи годы рождения отличаются больше, чем на предопределенный порог.
Способ может дополнительно содержать этап, на котором отображают сгруппированные фотографии и/или видеофайлы вместе с соответствующими усредненными атрибутами лиц.
Согласно третьему аспекту изобретения предложено вычислительное устройство. Вычислительное устройство содержит: по меньшей мере один процессор и память, выполненную с возможностью хранения машиноисполняемых команд, которые при их исполнении по меньшей мере одним процессором предписывают вычислительному устройству выполнять способ согласно второму аспекту изобретения.
Согласно четвертому аспекту изобретения предложен машиночитаемый носитель данных, на котором хранятся машиноисполняемые команды. Исполняемые команды при их исполнении вычислительным устройством предписывают вычислительному устройству выполнять способ согласно второму аспекту изобретения.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Фиг. 1 - поясняющий вид, на котором схематически изображена сверточная нейронная сеть с несколькими выходами, подходящая для одновременного распознавания атрибутов лиц и идентификации личности согласно изобретению.
Фиг. 2 - блок-схема, схематически изображающая способ одновременного распознавания атрибутов лиц и идентификации личности в цифровых изображениях согласно изобретению.
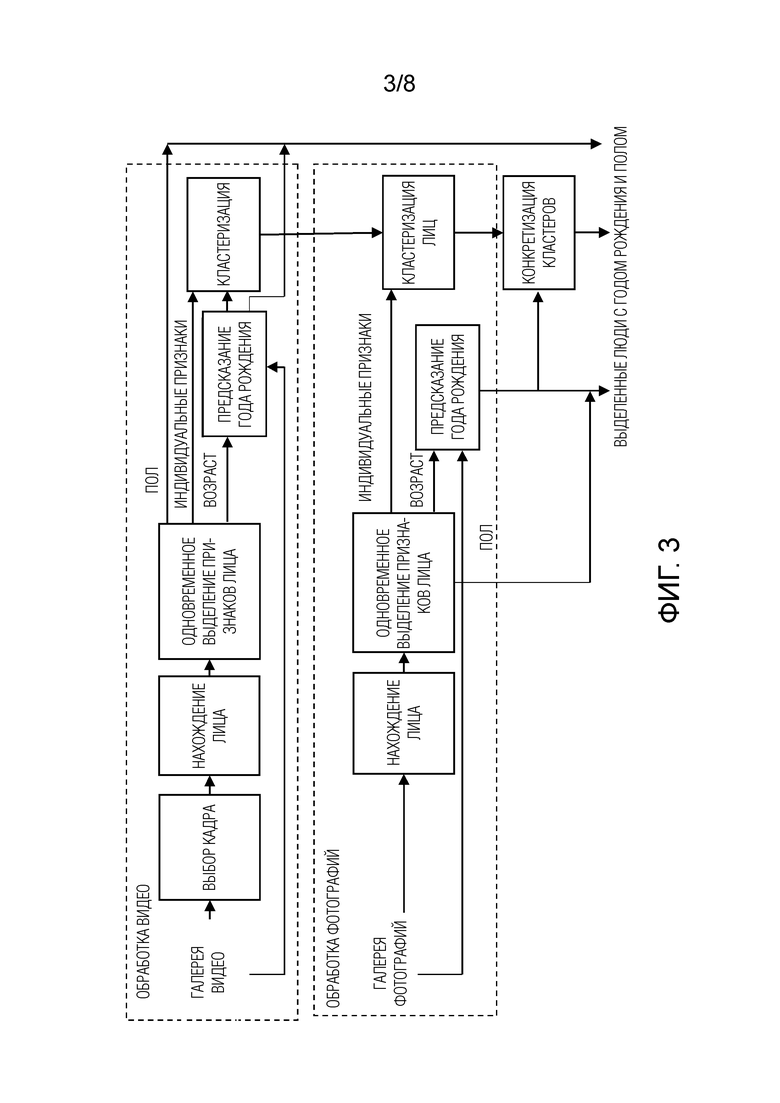
Фиг. 3 - блок-схема, схематически изображающая общий поток данных при работе СНС согласно изобретению для организации альбомов с фотографиями и видео.
Фиг. 4 - блок-схема, схематически изображающая способ организации цифрового фотоальбома и/или цифрового видеоальбома согласно изобретению.
Фиг. 5a-5c - примерные виды частичной реализации предложенного метода в мобильном приложении.
Фиг. 6 - высокоуровневая блок-схема варианта пользовательского устройства, приспособленного выполнять операции в соответствии с настоящим изобретением.
ПОДРОБНОЕ ОПИСАНИЕ ИЗОБРЕТЕНИЯ
СНС с множеством выходов для одновременного распознавания атрибутов лиц и идентификации личности
Изобретение предназначено для решения нескольких различных задач аналитики лиц. Лицевые области получают в каждом цифровом изображении с помощью любого подходящего детектора лиц, например, обычного многовидового каскадного классификатора Виолы-Джонса или более точных методов на основе СНС [14]. Задача распознавания пола - это задача бинарной классификации, в которой полученное изображение лица причисляется к одному из двух классов (мужскому и женскому). Распознавание эмоций - это задача многоклассовой классификации с тремя классами (положительным, отрицательным, нейтральным) или семью типами основных эмоций (гнев, отвращение, страх, радость, печаль, удивление, нейтральность). Распознавание расы (этнической принадлежности) также является задачей многоклассовой классификации с такими классами, как белые, европеоидная, негроидная, монголоидная, латиноамериканцы, жители Ближнего Востока и т.д. Предсказание возраста является частным случаем регрессивной задачи, хотя иногда его рассматривают как многоклассовую классификацию, например, имеющую N=100 различных классов, так что требуется предсказать, имеет ли наблюдаемый человек возраст 1, 2, ... или 100 лет [6]. В таком случае эти задачи становятся очень похожими и могут быть решены с помощью традиционных методов глубокого обучения. А именно, собирается большой набор данных изображений лиц людей с известными атрибутами лиц, например, IMDB-Wiki [6] или UTKFace. После этого обучают глубокую СНС решать эту задачу классификации. Полученные в результате сети можно применять для пресказания возраста и пола, когда дано новое изображение лица.
Другая проблема заключается в том, что задача идентификации лиц значительно отличается от распознавания атрибутов лиц. Рассматривается случай обучения без учителя, при котором изображения лиц из фотоальбома должны приписываться одному из C > 1 людей (личностей). Число С людей обычно неизвестно. Размер R обучающей выборки обычно довольно мал для обучения сложного классификатора (например, глубокой СНС). Следовательно, можно применить адаптацию предметной области [7]: каждое изображение описывается вектором характерных признаков с использованием глубокой СНС. Чтобы получить этот вектор, СНС предварительно обучается с учителем идентифицировать лица из большого набора данных, например, CASIA-WebFace, VGGFace/VGGFace2 или MS-Celeb-1M. При подаче каждого r-го изображения галереи (r = 1, 2, …, R) в качестве ввода данной СНС L2-нормированные выходы на одном из последних слоев используются в качестве D-мерного вектора характерных признаков  этого r-го изображения. И наконец, можно использовать любой подходящий метод кластеризации, например, иерархическую агломеративную кластеризацию [15], для принятия окончательного решения для этих векторов характерных признаков.
этого r-го изображения. И наконец, можно использовать любой подходящий метод кластеризации, например, иерархическую агломеративную кластеризацию [15], для принятия окончательного решения для этих векторов характерных признаков.
В большинстве научных исследований каждая из вышеупомянутых задач решается соответствующей независимой СНС, даже несмотря на необходимость решения всех указанных задач. В результате, обработка каждого изображения лица отнимает много времени, особенно для автономных мобильных приложений. Настоящее изобретение позволяет решить все эти задачи с помощью одной и той же СНС. В частности, авторы изобретения предполагают, что индивидуальные характерные признаки, извлеченные во время идентификации лиц, могут быть достаточно содержательными для любого анализа лиц. Например, было показано, что признаки VGGFace [16] можно использовать для повышения точности визуального распознавания эмоций [17, 18]. Принимая во внимание то, что основным требованием является возможность использования разрабатываемой СНС на мобильных платформах, авторы изобретения предлагают непосредственную модификацию СНС с низкой вычислительной сложностью и затратам памяти (например, MobileNet v1/v2 [12]), которая в данном документе именуется как "базовая СНС". Этот аспект раскрыт ниже со ссылками на фиг. 1.
Первые слои предложенной сети, которые образованы базовой СНС, предварительно обученной на данных ImageNet, извлекают представления, пригодные для идентификации лиц. Эти представления преобразуются на по меньшей мере одном скрытом полносвязном слое, который является предпоследним слоем предложенной сети, для построения более мощных классификаторов атрибутов лиц. После каждого скрытого полносвязного слоя добавляется специальный слой регуляризации методом дропаута, чтобы предотвратить переобучение на обучающую выборку и улучшить возможности обобщения модели нейронной сети. Для каждого предсказанного атрибута лица, к отдельному выходному полносвязному слою добавляется соответствующая нелинейная функция активации, например, softmax для мультиклассовой классификации (предсказание возраста, распознавание эмоции и расовой принадлежности) или логистическая сигмоида для бинарной классификации по полу. Эксперименты показали, что по меньшей мере один новый скрытый слой с регуляризацией методом дропаута после извлечения индивидуальных характерных признаков слегка повышает точность распознавания атрибутов лиц.
Обучение модели выполняется постепенно. Сначала базовую СНС обучают идентифицировать лица, используя очень большой набор данных, например VGGFace2 с тремя миллионами фотографий 10000 людей [13]. Затем последний слой классификации удаляется, а веса основной СНС фиксируются неизменными. И, наконец, оставшиеся последние слои обучаются распознаванию атрибутов лиц. Обучающие фотографии не обязательно должны содержать все имеющиеся атрибуты, поскольку согласно изобретению обучение задач распознавания атрибутов лиц происходит поочередно с использованием подмножеств (батчей) различных обучающих изображений и имеющихся наборов данных. Поскольку возрастные группы в наборе данных IMDB-Wiki [6] очень несбалансированы, обученные модели могут работать некорректно для лиц очень молодых или пожилых людей. Поэтому предусмотрен вариант изобретения, в котором добавляются все (15000) изображений из набора данных Adience [5]. Так как указанный набор данных содержит только возрастные интервалы, например, ʺ(0-2)ʺ, ʺ(60-100)ʺ, все изображения из такого интервала приписываются к среднему возрасту, например ʺ1ʺ или ʺ80ʺ, соответственно.
Следует отметить, что не все изображения в IMDB-Wiki содержат информацию о возрасте и поле одновременно. Более того, в данных Adience пол иногда неизвестен. В результате, число лиц с информацией о возрасте и поле в несколько раз меньше общего числа изображений лиц. И наконец, данные о поле для разных возрастов также очень несбалансированы. Поэтому авторы предлагают обучать все выходы СНС (см. фиг. 1) независимо, используя различные обучающие данные для классификации возраста и пола. В частности, в настоящем изобретении предусмотрены меняющиеся батчи с метками возраста, пола, расы и эмоций, так что обучается только соответствующая часть сети: например, веса полносвязного слоя, ассоциированные с выводом возраста модели, не обновляются для батча с информацией о поле.
Обсуждаемый выше подход дополнительно проиллюстрирован со ссылками на фиг. 2, на которой изображена блок-схема последовательности операций способа (200) одновременного распознавания атрибутов лиц (т.е. одного или нескольких из возраста, пола, расовой или этнической принадлежности, или эмоций) и идентификации личности в цифровых изображениях согласно изобретению.
На этапе 210 базовую СНС обучают на имеющемся очень большом наборе изображений. Как указано выше, базовая СНС предпочтительно представляет собой СНС с низкой вычислительной сложностью и затратам памяти, например, MobileNet v1/v2.
На этапе 220 модифицируют СНС, обеспечивая по меньшей мере один скрытый слой регуляризации методом дропаута поверх слоев базовой СНС.
После этого, на этапе 230 поверх упомянутого по меньшей мере одного скрытом слоя обеспечиваются независимые полносвязные слои для распознавания атрибутов лиц. Каждый из этих независимых слоев соответствует конкретному атрибуту лица и имеет конкретную нелинейность.
На этапе 240 осуществляют обучение этих независимых полносвязных слоев. При обучении поочередно используют подмножество (батч) обучающих данных, относящийся только к одному из независимых слоев, обучаемому в данное время. Здесь следует отметить, что каждый батч обучающих данных может иметь соответствующую метку, указывающую конкретный атрибут лица, к которому данный батч относится.
Затем на вход модифицированной и обученной СНС подают одно или несколько входных изображений.
На этапе 250 слои базовой СНС извлекают из, по меньшей мере, частей введенных изображений индивидуальные характерные признаки, подходящие для идентификации лиц.
Этапу 250 обычно предшествует этап 245, на котором во входных изображениях детектируют области, ассоциированные с лицами, например, с помощью метода MTCNN, и эти области затем используются в качестве упомянутых частей входных изображений.
На этапе 260 скрытый слой СНС предоставляет ввод для независимых полносвязных слоев, используя извлеченные индивидуальные характерные признаки.
И наконец, на этапе 270 атрибуты лиц соответственно распознаются независимыми полносвязными слоями на основе ввода от скрытого слоя.
Предложенная СНС имеет следующие преимущества. Прежде всего, она очень эффективна, так как позволяет использовать СНС с высокой вычислительной скоростью и низкими затратами памяти (например, базовую сеть MobileNet) в качестве базовой СНС и одновременно решать все вышеупомянутые задачи распознавания возраста, пола, этнической принадлежности, эмоций и идентификации личности, без необходимости применения нескольких разных СНС. Во-вторых, в отличие от общедоступных наборов данных, обычно используемых для задач распознавания атрибутов лиц, которые имеют довольно малый объем и низкое качество, в предложенной модели используется потенциал очень больших качественных наборов данных для идентификации лиц для изучения высококачественных представлений лиц. Кроме того, скрытый слой между индивидуальными характерными признаками и выходами дополнительно объединяет знания, необходимые для классификации атрибутов лиц. В результате, эта модель позволяет повысить точность распознавания атрибутов лиц по сравнению с моделями, основывающимися на обучении только на специфических наборах данных.
Предлагаемое устройство для организации фото и видеоальбомов
На фиг. 3 изображена функциональная схема использования СНС (см. фиг. 1, 2) для организации альбомов с фотографиями и видео согласно изобретению.
В этом варианте осуществления изобретения детектирование лиц на каждой фотографии осуществляют с помощью, например, метода MTCNN. Затем СНС выполняет прямой проход согласно изобретению в отношении всех найденных лиц Xr для извлечения D индивидуальных характерных признаков и классификации атрибутов лиц (например, возраста и пола). После этого все полученные векторы индивидуальных характерных признаков группируются в кластеры. Так как число людей в фотоальбомах обычно неизвестно, для этой цели используется иерархическая агломеративная кластеризация [15]. При корректировке кластеров сохраняются только довольно большие кластеры с минимальным количеством лиц. Пол, эмоции, раса и год рождения человека в каждом кластере оцениваются с помощью соответствующих методов агрегации, например, простого голосования или максимизации средних апостериорных вероятностей на выходах СНС (см. фиг. 1). Например, можно применить правило умножения [19] в предположении независимости всех изображений лиц 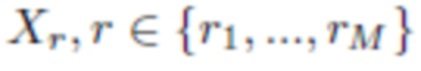 в кластере:
в кластере:

где N - общее число классов, а 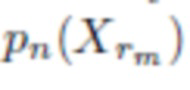 - n-й выход СНС для входного изображения
- n-й выход СНС для входного изображения 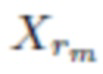 .
.
Эту же процедуру повторяют для всех видеофайлов. В каждом видеофайле выбирается только каждый из, например, 3-5 кадров; извлекаются индивидуальные характерные признаки всех выявленных лиц, и сначала в кластеры группируются только лица, выявленные в этом клипе.
После этого вычисляют нормированное среднее индивидуальных характерных признаков всех кластеров [2] и добавляют его к набору данных {Xr}, чтобы характерные признаки всех фотографий и отдельных людей, идентифицированных на всех видео, обрабатывались вместе.
Тем не менее, предсказание возраста просто путем максимизации выходных данных из соответствующего выхода (выходов) СНС не является точным из-за несбалансированности обучающего набора. Добавление данных Adience приводит к решению в пользу одного из классов большинства. Поэтому авторы предлагают агрегировать выходные данные 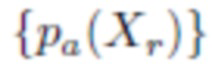 выходов апостериорных вероятностей возраста. Однако, как было обнаружено экспериментально, агрегация всех результатов снова не обеспечивает достаточной точности, потому что большинство людей в обучающем наборе имеет возраст 20-40 лет. Поэтому предлагается выбрать только
выходов апостериорных вероятностей возраста. Однако, как было обнаружено экспериментально, агрегация всех результатов снова не обеспечивает достаточной точности, потому что большинство людей в обучающем наборе имеет возраст 20-40 лет. Поэтому предлагается выбрать только  индексов
индексов  максимальных выходов и вычислить ожидаемое среднее
максимальных выходов и вычислить ожидаемое среднее 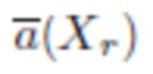 для каждого изображения лица Xr в галерее, используя нормированные выходы полносвязного слоя СНС, использующегося для предсказания возраста, следующим образом:
для каждого изображения лица Xr в галерее, используя нормированные выходы полносвязного слоя СНС, использующегося для предсказания возраста, следующим образом:
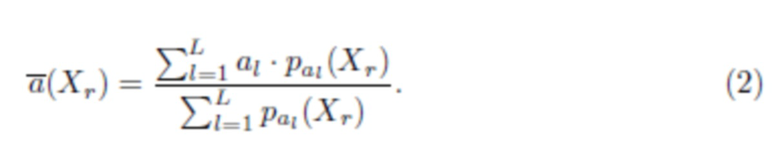
Затем оценивается год рождения, ассоциированный с каждым лицом, путем вычитания предсказанного возраста из даты создания соответствующего файла изображения. Это позволит организовывать очень большие альбомы, собранные за много лет. Кроме того, предсказанный год рождения используется в качестве дополнительного признака с особым весом при анализе кластеров, чтобы частично преодолеть известное сходство маленьких детей в семье.
И наконец, в блоке корректировки кластеров применяется несколько дополнительных эвристик (см. фиг. 3). Во-первых, специально помечаются разные лица, присутствующие на одной фотографии. Поскольку такие лица должны содержаться в разных кластерах, дополнительно выполняется полная кластеризация каждого кластера лиц. Матрица расстояний строится специально таким образом, чтобы расстояния между лицами на одной фотографии были установлены на максимальное значение, которое намного превышает порог, применяемый при формировании кластеров. Более того, самые важные кластеры не должны содержать фото/видео, снятые в один день. Следовательно, устанавливается определенный порог для количества дней между самой ранней и самой старой фотографией в кластере, чтобы устранить неоднозначность большого количества лиц, не представляющих интерес.
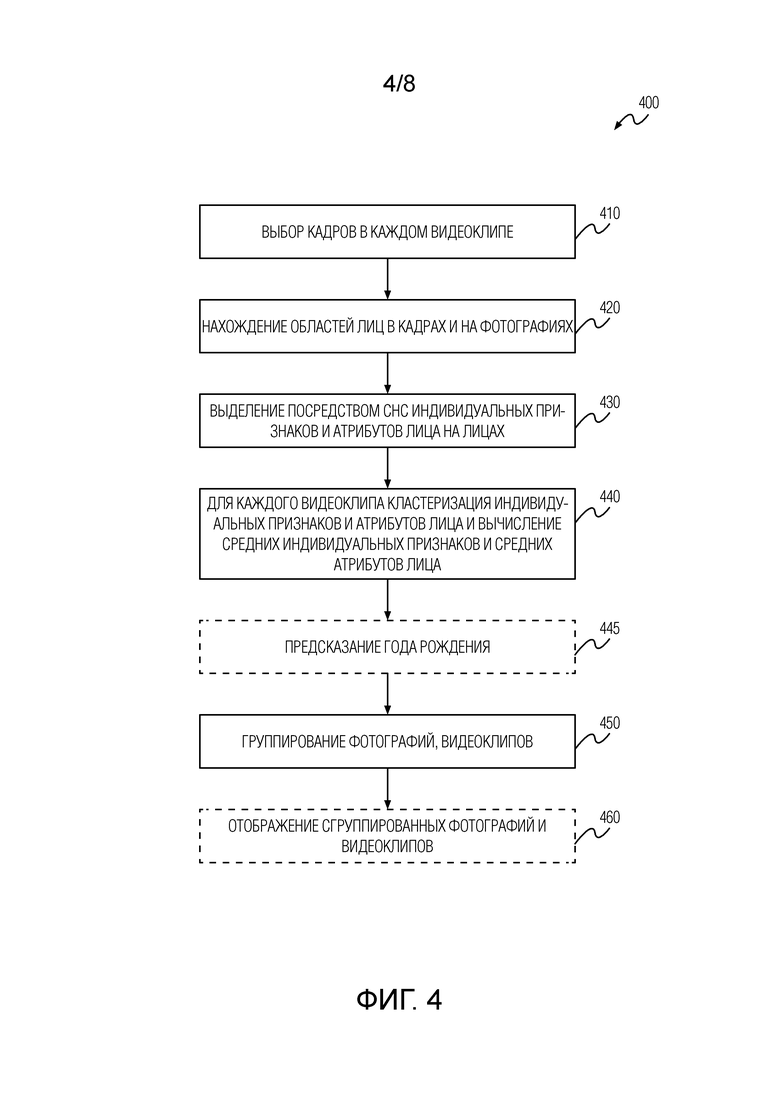
Обсуждаемый выше подход дополнительно проиллюстрирован со ссылкой на фиг. 4, на которой изображена блок-схема последовательности операций способа (400) организации цифрового фотоальбома и/или цифрового видеоальбома в соответствии с настоящим изобретением.
На этапе 410 выбирают несколько кадров в каждом видеофайле из множества видеофайлов, включенных в видеоальбом. На этапе 410 предпочтительно выбираются с фиксированной частотой четко различимые кадры видеофайла.
На этапе 420 детектируют ассоциированные с лицами области в каждом из кадров, выбранных на этапе 410, и/или на каждой фотографии из множества фотографий, включенных в фотоальбом. Этот этап можно выполнять с помощью какого-либо каскадного классификатора или с помощью метода MTCNN.
На этапе 430 выявленные области используются в качестве входных изображений для СНС согласно изобретению (см. фиг. 1), и эта СНС извлекает индивидуальные характерные признаки и атрибуты всех лиц путем выполнения соответствующего способа согласно изобретению (см. фиг. 2).
Затем для каждого видеофайла в соответствующем альбоме на этапе 440 группируют в один кластер извлеченные индивидуальные характерные признаки и атрибуты, ассоциированные с каждым лицом из лиц, найденных в упомянутом видеофайле. Затем, на этапе 440 для каждого кластера видеофайла вычисляют средние индивидуальные характерные признаки и средние атрибуты лиц. Средние индивидуальные характерные признаки можно получить путем вычисления нормированного среднего извлеченных индивидуальных характерных признаков.
На этапе 450 фотографии и/или видеофайлы группируются посредством совместной кластеризации индивидуальных характерных признаков, извлеченных из фотографий, и средних индивидуальных характерных признаков, вычисленных для видеофайлов, и на основе по меньшей мере одного усредненного атрибута лиц, вычисленного для каждого кластера, из соответствующих атрибутов и/или средних атрибутов лиц, ассоциированных с данным кластером. Усредненные атрибуты лиц можно вычислить с помощью соответствующего метода агрегации, например, простого голосования или максимизации средних апостериорных вероятностей на выходах СНС. Упомянутая совместная кластеризация предпочтительно выполняется с использованием иерархической агломеративной кластеризации для получения кластеров, каждый из которых включает в себя индивидуальные характерные признаки одного или нескольких лиц.
Этап 450 может включать в себя подэтап (не показан на фиг. 4), на котором кластеры корректируются для фильтрации неподходящих кластеров. Неподходящими кластерами могут быть, например, кластеры с числом элементов меньше некоторого предопределенного порога или кластеры, ассоциированные с фотографиями/видеофайлами, даты съемки которых отличаются меньше, чем на другой предопределенный порог.
Этапу 450 может предшествовать этап 445, на котором оценивается год рождения каждого из лиц путем вычитания возраста в атрибутах, ассоциированных с данным лицом, из даты создания фото/видеофайла, в котором было детектировано упомянутое лицо. В этом случае на этапе 450 можно дополнительно предотвратить кластеризацию в один и тот же кластер индивидуальных характерных признаков лиц, чьи годы рождения отличаются более, чем на некоторый предопределенный порог.
Способ может дополнительно включать в себя этап 460, на котором сгруппированные фотографии и/или видеофайлы вместе с соответствующими усредненными атрибутами лиц отображаются соответствующим образом через блок отображения конкретного пользовательского устройства.
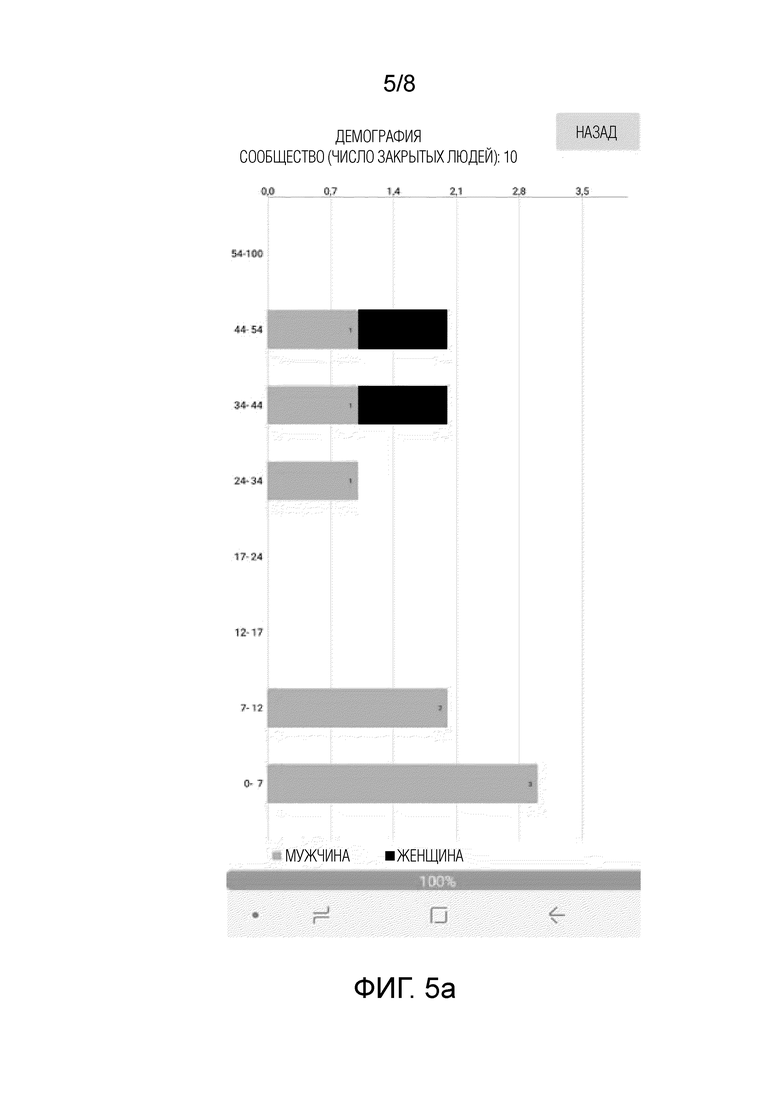
Подход, описанный выше со ссылками на фиг. 1-4, предпочтительно реализуется в специальном мобильном приложении для Android (фиг. 5). Это приложение может работать в автономном режиме, не требуя подключения к Интернету. Приложение последовательно обрабатывает все фотографии из галереи в фоновом режиме. Панель демографии отображает расположенные друг над другом гистограммы (см. фиг. 5(а)) атрибутов лиц членов семьи и друзей, которые присутствуют, по меньшей мере, на 3 фотографиях из галереи. Нажатие на каждую черную или серую полоску на горизонтальной гистограмме на фиг. 5(а) приводит к отображению списка всех фотографий конкретного человека (см. фиг. 5(б)). При этом важно отметить, что в данном приложении в форме отображения фотографии предпочтительно представлены полностью, а не только выделенные на них лица, так что в данной форме могут присутствовать фотографии, содержащие несколько человек. Если имеется несколько человек с одинаковым диапазоном пола и возраста, то в верхней части формы отображения может быть предусмотрен счетчик с изменяющимся значением, который можно использовать для выбора конкретного человека по ассоциированному порядковому номеру (см. фиг. 5c).
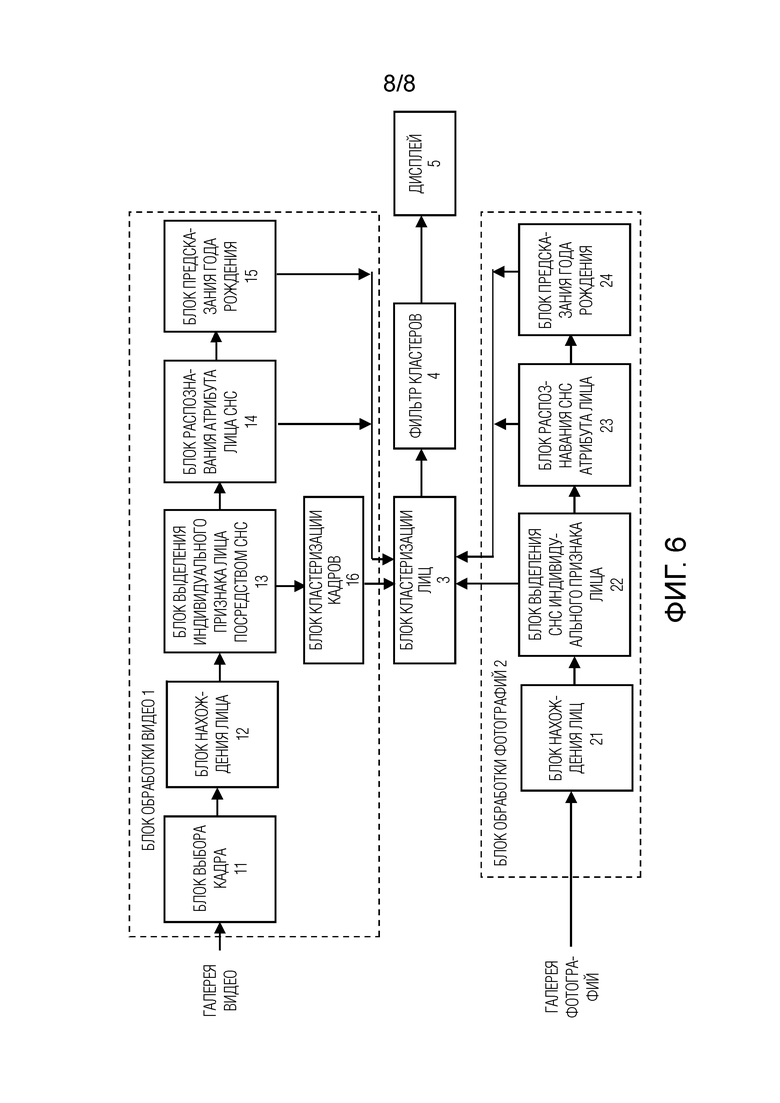
На фиг. 6 показано пользовательское устройство 600, в котором могут быть реализованы описанные выше варианты осуществления настоящего изобретения. Примерное пользовательское устройство содержит, по меньшей мере: блок 610 обработки видео, блок 620 обработки фотографий, блок 630 кластеризации лиц, блок фильтрации 640 кластеров и дисплей 650.
Блок 610 обработки видео включает в себя блок 611 выбора кадра, блок 612 детектирования лиц, блок 613 извлечения индивидуальных характерных признаков на основе СНС, блок 614 распознавания атрибутов лиц на основе СНС, блок 615 предсказания года рождения и блок 616 кластеризации кадров. Блок 620 обработки фотографий включает в себя блок 621 детектирования лиц, блок 622 извлечения индивидуальных характерных признаков на основе СНС, блок 623 распознавания атрибутов лиц на основе СНС и блок 24 предсказания года рождения. Перечисленные выше компоненты пользовательского устройства могут быть связаны, как показано на фиг. 6. Следует понимать, что хотя блок 610 обработки видео и блок 622 обработки фотографий показаны на фиг. 6 как содержащие отдельные блоки 612 и 621 детектирования лиц, отдельные блоки 613 и 622 распознавания индивидуальных характерных признаков на основе СНС, отдельные блоки 614 и 623 распознавания атрибутов лиц на основе СНС, отдельные блоки 615 и 624 предсказания года рождения, в других вариантах пользовательского устройства 600 блок 610 обработки видео и блок 620 обработки фотографий могут преимущественно использовать совместно один и тот же блок извлечения индивидуальных характерных признаков и блок распознавания атрибутов лиц на основе СНС, блок предсказания года рождения и блок детектирования лиц. Кроме того, пользовательское устройство может не содержать некоторые из проиллюстрированных компонентов или содержать дополнительные компоненты для обеспечения выполнения операций описанных способов.
Пользовательское устройство 600 работает следующим образом. В блок 11 выбора кадров, выполненный с возможностью извлечения высококачественных кадров, вводится галерея видеофайлов пользователя. Блок 612 детектирования лиц выполнен с возможностью детектирования ограничивающих рамок областей лица в выбранных видеокадрах. Блок 613 извлечения индивидуальных характерных признаков на основе СНС и блок 614 распознавания атрибутов лиц на основе СНС выполнены с возможностью осуществления прямого прохода в СНС согласно изобретению (см. фиг. 1), чтобы одновременно извлекать индивидуальные характерные признаки и, по меньшей мере, некоторые из таких атрибутов лиц, как возраст, пол, этническая принадлежность и эмоции (см. фиг. 2). Блок 615 предсказания года рождения выполнен с возможностью вычисления года рождения, ассоциированного с извлеченными лицами, с учетом дат модификации соответствующих видеофайлов и предсказанных возрастов. Блок 616 кластеризации кадров предназначен для объединения идентичных лиц, найденных в различных кадрах одного и того же видеофайла.
Далее описывается часть пользовательского устройства 600, отвечающая за обработку фотографий из галереи. Все фотографии вводятся в блок 621 детектирования лиц. Блок 621 детектирования лиц выполнен с возможностью выявления области (областей) лиц в снятом изображении и изменения размера этой области (областей) лиц. Блок 622 извлечения индивидуальных характерных признаков на основе СНС и блок 623 распознавания атрибутов лиц на основе СНС выполнены с возможностью осуществления прямого прохода в СНС согласно изобретению (см. фиг. 1). Блок 24 предсказания года рождения выполнен с возможностью оценки года рождения, ассоциированного с извлеченными лицами.
Далее описывается остальная часть пользовательского устройства 600, отвечающая за анализ демографической информации. Блок 630 кластеризации лиц выполнен с возможностью группирования индивидуальных характерных признаков, полученных на выходах блока 616 кластеризации кадров и блока 622 извлечения индивидуальных характерных признаков на основе СНС. Блок 630 кластеризации лиц может быть выполнен с возможностью дополнительного использования извлеченных атрибутов лиц, чтобы предотвратить объединение лиц со значительно различающимися предсказаниями года рождения при использовании выходов блоков 615, 624 предсказания года рождения. Блок 640 фильтрации кластеров выполнен с возможностью отфильтровывания неподходящих кластеров, например, кластеров с малым числом элементов или кластеров с фотографиями/видео, сделанными в один день. Полученные группы лиц и их атрибуты можно отправить в блок 650 отображения для предоставления пользователю желаемого визуального вывода (см. например, фиг. 5). С другой стороны, указанные группы и ассоциированные с ними атрибуты можно отправить в специальный блок обработки (не показан) пользовательского устройства 600, который выполнен с возможностью принятия решения о допустимости дальнейших взаимодействий между пользователем и пользовательским устройством на основе результатов распознавания в отношении данного пользователя, и в зависимости от этого решения разрешить или запретить эти взаимодействия пользователю.
Как видно из приведенного выше обсуждения, компоненты пользовательского устройства 600 по существу выполняют способы согласно настоящему изобретению, обсуждавшиеся со ссылками на фиг. 1-4.
В зависимости от различных вариантов изобретения пользовательское устройство может быть одним из смартфона, планшетного персонального компьютера (ПК), устройства для чтения электронных книг, настольного ПК, ноутбука, нетбука, карманного персонального компьютера (КПК), цифровой камеры или носимого электронного устройства (например, наголовного дисплея (НГД), электронных очков или умных часов).
Компоненты, описанные со ссылкой на фиг. 6, могут быть реализованы в программном обеспечении, хранящемся на одном или нескольких машиночитаемых носителях данных в вычислительном устройстве пользователя и исполняемом одним или несколькими блоками обработки данных (центральный процессор (ЦП) и т.п.), включенными в состав для реализации структур и выполнения операций согласно изобретению, обсуждавшихся выше со ссылками на фиг. 1-5. Следует отметить, что пользовательское устройство может дополнительно содержать другие известные аппаратные, программные или программно-аппаратные компоненты.
Результаты экспериментов по кластеризации лиц
В данном подразделе представлены экспериментальные исследования предлагаемой системы (см. фиг. 1, 3) в задачах кластеризации лиц для изображений, собранных в неконтролируемых условиях съемки. Индивидуальные характерные признаки, извлеченные базовой MobileNet (см. фиг. 1), сравниваются с известными СНС, подходящими для распознавания лиц, в частности, VGGFace (VGGNet-16) [16] и VGGFace2 (ResNet-50) [13]. VGGFace, VGGFace2 и MobileNet выделяют неотрицательные функции D=4096, D=2048 и D=1024 в выходе слоев ʺfc7ʺ, ʺpool5_7×7_s1ʺ и ʺreshape_1/Meanʺ из 224×224 RGB изображений, соответственно.
Все методы иерархической кластеризации из библиотеки SciPy используются с евклидовым (L2) расстоянием между векторами индивидуальных характерных признаков. Поскольку центроидный метод и метод связи Уорда показали очень низкую эффективность во всех случаях, результаты сообщаются только для одиночных, средних, полных, взвешенных и медианных методов иерархической кластеризации. Кроме того, авторы применили упорядоченную кластеризацию [20], которая была специально разработана для организации лиц в фотоальбомах. Параметры всех методов кластеризации были настроены с использованием 10% каждого набора данных. Следующие метрики кластеризации оцениваются с использованием библиотеки scikit-learn: ARI (Adjusted Rand Index), AMI (Adjusted Mutual Information), однородности (homogeneity) и полноты (completeness). Кроме того, оценивается отношение среднего числа выделенных кластеров K к количеству людей C и BCubed F-мера. Последняя метрика широко применяется в различных задачах группирования лиц [4, 21].
При испытании изобретения использовались следующие экспериментальные данные:
- Подмножество набора данных LFW (Labeled Faces in the Wild) [22], задействованная в протоколе идентификации лиц [23]. Во всех методах кластеризации используются C=596 человек, у которых есть по меньшей мере два изображения в базе данных LFW и по меньшей мере одно видео в базе данных YTF (YouTube Faces) (люди в базе данных YTF являются подгруппой тех, кто есть в LFW).
- набор данных из коллекции Gallagher Collection Person Dataset [24], который содержит 931 лиц с C=32 личностями на каждом из 589 изображений. Поскольку этот набор данных содержит только положения глаз, сначала детектируются лица с помощью метода MTCNN [14], и выбирается человек с наибольшим пересечением его/ее области лица с заданной областью глаз. Если это лицо не найдено, выделяется квадратная область с размером, выбранным как 1,5 расстояния между глазами.
- набор данных Grouping Faces in the Wild (GFW) [4] с предварительно найденными изображениями лиц из 60 альбомов реальных пользователей китайского портала социальной сети. Размер альбома варьируется от 120 до 3600 лиц с максимальным числом C=321 различных человек.
В таблице 1, таблице 2 и таблице 3 представлены средние значения метрик эффективности кластеризации для наборов данных LFW, Gallagher и GFW, соответственно.
Метод средней связи (average linkage) является наилучшим методом согласно большинству метрик кластерного анализа. Использование упорядоченного расстояния [20] нецелесообразно из-за довольно низкой эффективности. Более того, это расстояние требует дополнительного порогового параметра для упорядоченного расстояния на уровне кластера. И наконец, вычислительная сложность такой кластеризации в 3-4 раза ниже по сравнению с другими методами иерархической агломеративной кластеризации. Одним из наиболее важных заключений на данный момент является то, что обученная MobileNet (см. фиг. 1) в большинстве случаев более точна, чем широко используемый дескриптор VGGFace. Как и ожидалось, качество представленной в ней модели несколько ниже по сравнению с глубокой сетью СНС ResNet-50, обученной на том же наборе данных VGGFace2.
Таблица 1. Результаты кластеризации, подмножество LFW (C=596 человек)
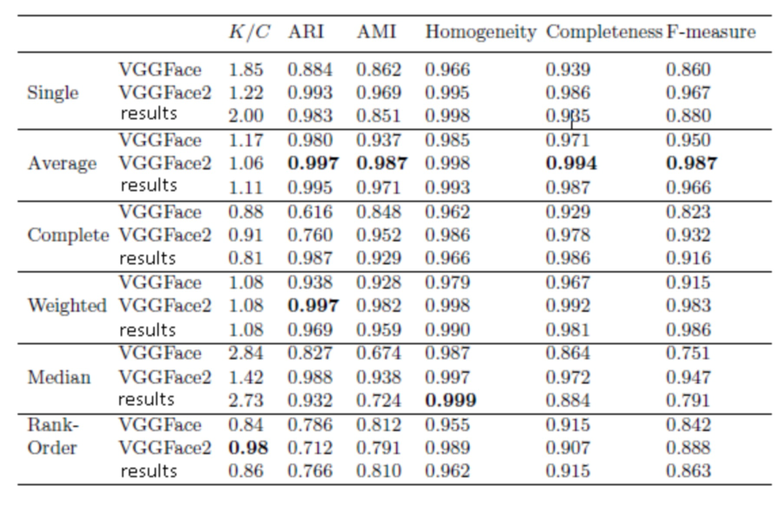
Таблица 2. Результаты кластеризации, набор данных Gallagher (C=32 человека)
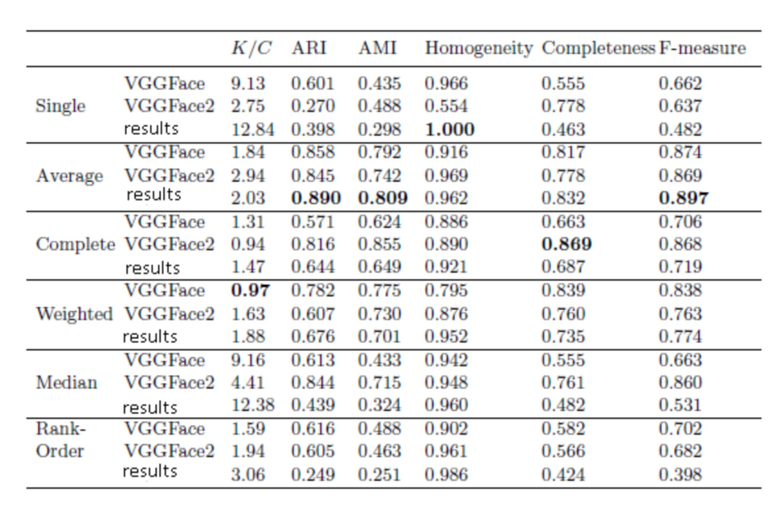 Таблица 3. Результаты кластеризации, набор данных GFW (в среднем, C=46 человек)
Таблица 3. Результаты кластеризации, набор данных GFW (в среднем, C=46 человек)
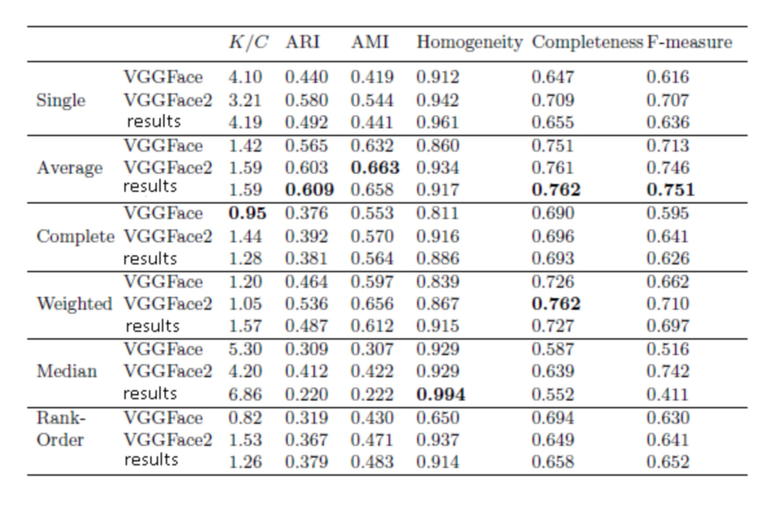
Следует отметить, что предложенная авторами изобретения нейросетевая модель достигла самой высокой F-меры BCubed для наиболее сложного набора данных GFW (0,751). Эта величина немного выше, чем лучшая BCubed F-мера (0,745), о которой сообщалось в первоначальной статье [4]. Однако с практической точки зрения наиболее важным преимуществом данной модели является чрезвычайно низкие вычислительная сложность и затраты памяти. Например, предсказание в данной модели осуществляется в 5-10 раз быстрее, чем в VGGFace и VGGFace2. Кроме того, размерность вектора признаков в 2-4 раза ниже, что приводит к более быстрому вычислению матрицы расстояний в методе кластеризации. Эта модель также позволяет одновременно предсказывать атрибуты наблюдаемого изображения лица. Это утверждение подтверждается в следующем подразделе.
Результаты экспериментов по распознаванию атрибутов лиц на основе видео
В данном подразделе предложенная модель сравнивается со следующими известными СНС для предсказания возраста/пола:
1. Age_net/gender_net [25], обученная на наборе данных Adience [5]
2. Сеть Deep expectation (DEX) VGG16, обученная на довольно большом наборе данных IMDB-Wiki [6]
Кроме того, анализируются два специальных случая модели на основе MobileNet (см. фиг. 1). Во-первых, модель сжимается с использованием стандартных преобразований графа при квантовании в Tensorflow. Во-вторых, все слои в этой модели дообучают на предсказание возраста и пола. Хотя такое дообучение, по-видимому, снижает точность идентификации лица по индивидуальным характерным признакам на выходе базовой сети MobileNet, она вызывает повышение валидационной точности на 1% и 2% для классификации по полу и возрасту, соответственно.
Эксперименты выполнялись на ноутбуке MacBook 2016 Pro (ЦП: 4xCore i7 2,2 ГГц, ОЗУ: 16 ГБ) и двух мобильных телефонах, в частности: 1) Honor 6C Pro (ЦП: MT6750 4×1 ГГц и 4×2,5 ГГц, ОЗУ: 3 ГБ); и 3) Samsung S9+(процессор: 4×2,7 ГГц, Mongoose M3 и 4×1,8 ГГц, Cortex-A55, ОЗУ: 6 ГБ). В таблице 4 представлены размер файла модели и среднее время обработки для одного изображения лица.
Таблица 4. Анализ производительности СНС
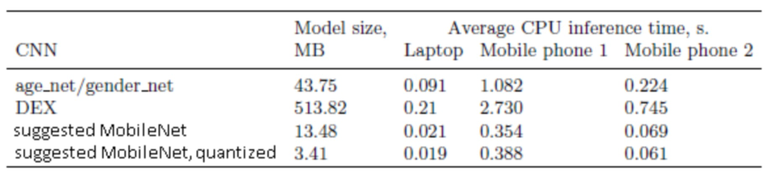
Как и ожидалось, сети MobileNets в несколько раз быстрее, чем более глубокие сверточные сети, и им требуется меньше памяти для хранения их весов. Хотя квантование уменьшает размер модели в 4 раза, оно не уменьшает время обработки изображений. И наконец, хотя время вычислений для ноутбука значительно меньше по сравнению с выводом в мобильных телефонах, все их более современные модели ("Мобильный телефон 2") стали более пригодными для распознавания изображений в автономном режиме. Фактически, предлагаемая модель требует всего 60 мс для извлечения индивидуальных характерных признаков и распознавания всех атрибутов лиц (возраста, пола и т.д.), что позволяет осуществлять на этом устройстве комплексную аналитику альбомов лиц.
В следующих экспериментах сравнивается точность моделей в распознавании пола и предсказании возраста. Были использованы следующие наборы видеоданных:
- Eurecom Kinect [26], который содержит 9 фотографий для каждого из 52 человек (14 женщин и 38 мужчин).
- база данных Indian Movie Face (IMFDB) [27] с 332 видеофайлами, содержащими 63 мужчин и 33 женщин. Предусмотрено всего четыре возрастные категории: "Ребенок" (0-15 лет), "Молодой" (16-35), "Среднего возраста" (36-60) и "Старый" (60+).
- Acted Facial Expressions in the Wild (AFEW) из конкурса аудиовизуального распознавания эмоций EmotiW 2018 (Emotions recognition in the wild) [28]. Содержит 1165 видеофайлов. Лицевые области детектируются с помощью метода MTCNN [14].
- IARPA Janus Benchmark A (IJB-A) [29] с общим количеством кадров более 13000 на 1165 видеофайлах. В этом наборе данных имеется только информация о поле.
При распознавании пола на основе видео сначала классифицируется пол в каждом видеокадре. После этого используются две простые стратегии агрегации, а именно: простое голосование и правило умножения (1). В таблице 5 представлены полученные точности.
Таблица 5. Точность распознавания пола
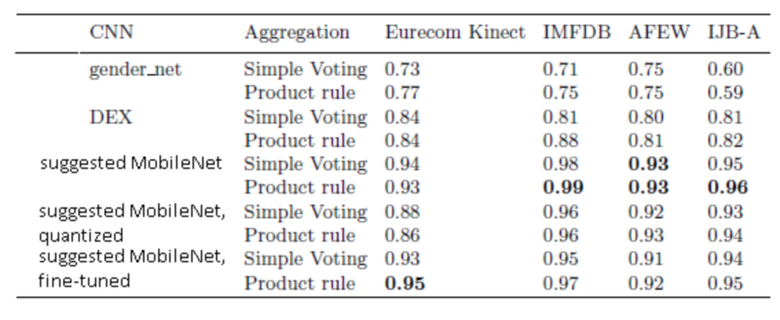
Во-первых, предложенные модели намного более точны, чем известные СНС. Этот факт можно объяснить предварительным обучением базовой MobileNet на задаче идентификации лиц с очень большим набором данных, что облегчает извлечение высококачественных представлений лиц. Во-вторых, использование правила умножения обычно приводит к уменьшению частоты ошибок на 1-2% по сравнению с простым голосованием. В-третьих, дообученная версия модели обеспечивает наименьшую частоту ошибок только для набора данных Kinect и менее точна на 1-3% в других случаях. И наконец, хотя сжатие СНС позволяет значительно уменьшить размер модели (см. таблицу 4), оно снижает коэффициент распознавания на величину до 7%.
В таблице 6 представлены последние результаты экспериментов по предсказанию возраста.
Таблица 6. Точность предсказания возраста

Для наборов данных Kinect и AFEW (с известным возрастом) считается распознавание возраста корректным, если разность между реальным и предсказанным возрастом не превышает 5 лет. Агрегация предсказаний возраста по отдельным видеокадрам осуществляется посредством: 1) простого голосования, 2) максимизации произведения апостериорных вероятностей возраста (1) и 3) усреднения ожидаемого значения (3) с выбором L=3 лучших предсказаний в каждом кадре.
Можно отметить, что и здесь эти модели более точны практически во всех случаях. Модели DEX сопоставимы с сетями СНС только для набора данных AFEW. Наименьшие коэффициенты ошибок получены для расчета ожидаемого значения предсказаний возраста. Например, этот расчет на 2% и 8% точнее, чем простое голосование для данных Kinect и AFEW. Этот эффект особенно заметен для изображений IMFDB, в которых ожидаемое значение приводит к повышению коэффициента распознавания на величину до 45%.
Представленные выше описания вариантов осуществления изобретения являются иллюстративными и подразумевают возможность модификации конфигураций и реализаций в рамках объема настоящего описания. Например, хотя варианты изобретения описаны в общем со ссылками на фиг. 1-6, эти описания являются лишь примерными. Несмотря на то, что изобретение было раскрыто на языке, специфичном для конструктивных признаков или технологических действий, следует понимать, что объем, определяемый прилагаемой формулой изобретения, не обязательно ограничен описанными выше конкретными признаками или действиями. Напротив, описанные выше конкретные признаки и действия раскрыты в качестве примерных форм реализации формулы изобретения. Изобретение также не ограничено проиллюстрированным порядком этапов выполнения способа, и специалист сможет изменить этот порядок без творческих усилий. Некоторые или все этапы способа могут выполняться последовательно или одновременно. Некоторые этапы способов могут быть опущены. Соответственно, объем изобретения ограничен только следующей формулой изобретения.
Литература
1. Manju, A., Valarmathie, P.: Organizing multimedia big data using semantic based video content extraction technique. In: Soft-Computing and Networks Security (ICSNS), 2015 International Conference on, IEEE (2015) 1-4
2. Sokolova, A.D., Kharchevnikova, A.S., Savchenko, A.V.: Organizing multimedia data in video surveillance systems based on face verification with convolutional neural networks. In: International Conference on Analysis of Images, Social Networks and Texts, Springer (2017) 223-230
3. Zhang, Y.J., Lu, H.: A hierarchical organization scheme for video data. Pattern Recognition 35(11) (2002) 2381-2387
4. He, Y., Cao, K., Li, C., Loy, C.C.: Merge or not? Learning to group faces via imitation learning. arXiv preprint arXiv:1707.03986 (2017)
5. Eidinger, E., Enbar, R., Hassner, T.: Age and gender estimation of unfiltered faces. IEEE Transactions on Information Forensics and Security 9(12) (2014) 2170-2179
6. Rothe, R., Timofte, R., Van Gool, L.: DEX: Deep expectation of apparent age from a single image. In: Proceedings of the IEEE International Conference on Computer Vision Workshops. (2015) 10-15
7. Goodfellow, I., Bengio, Y., Courville, A.: Deep learning. MIT press (2016)
8. Crosswhite, N., Byrne, J., Stauffer, C., Parkhi, O., Cao, Q., Zisserman, A.: Template adaptation for face verification and identification. In: Automatic Face & Gesture Recognition (FG 2017), 2017 12th IEEE International Conference on, IEEE (2017) 1-8
9. Wang, F., Cheng, J., Liu, W., Liu, H.: Additive margin softmax for face verification. IEEE Signal Processing Letters 25(7) (2018) 926-930
10. Savchenko, A.V., Belova, N.S.: Unconstrained face identification using maximum likelihood of distances between deep off-the-shelf features. Expert Systems with Applications 108 (2018) 170-182
11. Ranjan, R., Patel, V.M., Chellappa, R.: Hyperface: A deep multi-task learning framework for face detection, landmark localization, pose estimation, and gender recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence (2017)
12. Howard, A.G., Zhu, M., Chen, B., Kalenichenko, D., Wang, W., Weyand, T., Andretto, M., Adam, H.: MobileNets: Efficient convolutional neural networks for mobile vision applications. arXiv preprint arXiv:1704.04861 (2017)
13. Cao, Q., Shen, L., Xie, W., Parkhi, O.M., Zisserman, A.: VGGFace2: A dataset for recognising faces across pose and age. In: Automatic Face & Gesture Recognition (FG 2018), 2018 13th IEEE International Conference on, IEEE (2018) 67-74
14. Zhang, K., Zhang, Z., Li, Z., Qiao, Y.: Joint face detection and alignment using multitask cascaded convolutional networks. IEEE Signal Processing Letters 23(10) (2016) 1499-1503
15. Aggarwal, C.C., Reddy, C.K.: Data clustering: algorithms and applications. CRC press (2013)
16. Parkhi, O.M., Vedaldi, A., Zisserman, A., et al.: Deep face recognition. In: BMVC. Volume 1. (2015) 6
17. Kaya, H., Gurpinar, F., Salah, A.A.: Video-based emotion recognition in the wild using deep transfer learning and score fusion. Image and Vision Computing 65 (2017) 66-75
18. Rassadin, A., Gruzdev, A., Savchenko, A.: Group-level emotion recognition using transfer learning from face identification. In: Proceedings of the 19th ACM International Conference on Multimodal Interaction, ACM (2017) 544-548
19. Kittler, J., Hatef, M., Duin, R.P., Matas, J.: On combining classifiers. IEEE Transactions on Pattern Analysis and Machine Intelligence 20(3) (1998) 226-239
20. Zhu, C., Wen, F., Sun, J.: A rank-order distance based clustering algorithm for face tagging. In: Computer Vision and Pattern Recognition (CVPR), 2011 IEEE Conference on, IEEE (2011) 481-488
21. Zhang, Z., Luo, P., Loy, C.C., Tang, X.: Joint face representation adaptation and clustering in videos. In: European conference on computer vision, Springer (2016) 236-251
22. Learned-Miller, E., Huang, G.B., RoyChowdhury, A., Li, H., Hua, G.: Labeled faces in the wild: A survey. In: Advances in face detection and facial image analysis. Springer (2016) 189-248
23. Best-Rowden, L., Han, H., Otto, C., Klare, B.F., Jain, A.K.: Unconstrained face recognition: Identifying a person of interest from a media collection. IEEE Transactions on Information Forensics and Security 9(12) (2014) 2144-2157
24. Gallagher, A.C., Chen, T.: Clothing cosegmentation for recognizing people. In: Computer Vision and Pattern Recognition, 2008. CVPR 2008. IEEE Conference on, IEEE (2008) 1-8
25. Levi, G., Hassner, T.: Age and gender classification using convolutional neural networks. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops. (2015) 34-42
26. Min, R., Kose, N., Dugelay, J.L.: Kinectfacedb: A Kinect database for face recognition. IEEE Transactions on Systems, Man, and Cybernetics: Systems 44(11) (2014) 1534-1548
27. Setty, S., Husain, M., Beham, P., Gudavalli, J., Kandasamy, M., Vaddi, R., Hemadri, V., Karure, J., Raju, R., Rajan, B., et al.: Indian movie face database: a benchmark for face recognition under wide variations. In: Fourth National Conference on Computer Vision, Pattern Recognition, Image Processing and Graphics (NCVPRIPG), IEEE (2013) 1-5
28. Klare, B.F., Klein, B., Taborsky, E., Blanton, A., Cheney, J., Allen, K., Grother, P., Mah, A., Jain, A.K.: Pushing the frontiers of unconstrained face detection and recognition: Iarpa janus benchmark a. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. (2015) 1931-1939
29. Dhall, A., et al.: Collecting large, richly annotated facial-expression databases from movies. IEEE Multimedia (2012).
| название | год | авторы | номер документа |
|---|---|---|---|
| РАСПОЗНАВАНИЕ СОБЫТИЙ НА ФОТОГРАФИЯХ С АВТОМАТИЧЕСКИМ ВЫДЕЛЕНИЕМ АЛЬБОМОВ | 2020 |
|
RU2742602C1 |
| СПОСОБ АУДИОВИЗУАЛЬНОГО РАСПОЗНАВАНИЯ СРЕДСТВ ИНДИВИДУАЛЬНОЙ ЗАЩИТЫ НА ЛИЦЕ ЧЕЛОВЕКА | 2022 |
|
RU2791415C1 |
| Быстрый двухслойный нейросетевой синтез реалистичных изображений нейронного аватара по одному снимку | 2020 |
|
RU2764144C1 |
| Способ 3D-реконструкции человеческой головы для получения рендера изображения человека | 2022 |
|
RU2786362C1 |
| СПОСОБ ПОЛУЧЕНИЯ НИЗКОРАЗМЕРНЫХ ЧИСЛОВЫХ ПРЕДСТАВЛЕНИЙ ПОСЛЕДОВАТЕЛЬНОСТЕЙ СОБЫТИЙ | 2020 |
|
RU2741742C1 |
| СПОСОБ И СИСТЕМА ДЛЯ ОПРЕДЕЛЕНИЯ МЕСТОПОЛОЖЕНИЯ ВЫСОКОСКОРОСТНОГО ПОЕЗДА В НАВИГАЦИОННОЙ СЛЕПОЙ ЗОНЕ НА ОСНОВЕ МЕТЕОРОЛОГИЧЕСКИХ ПАРАМЕТРОВ | 2020 |
|
RU2771515C1 |
| СПОСОБ ИДЕНТИФИКАЦИИ ЧЕЛОВЕКА ПО ИЗОБРАЖЕНИЮ ЕГО ЛИЦА | 2006 |
|
RU2304307C1 |
| СПОСОБ ОБНАРУЖЕНИЯ ЛИЦ НА ИЗОБРАЖЕНИИ С ПРИМЕНЕНИЕМ КАСКАДА КЛАССИФИКАТОРОВ | 2010 |
|
RU2427911C1 |
| Способ идентификации измененного лица человека | 2023 |
|
RU2804261C1 |
| СПОСОБ ОТСЛЕЖИВАНИЯ, ОБНАРУЖЕНИЯ И ИДЕНТИФИКАЦИИ ИНТЕРЕСУЮЩИХ ОБЪЕКТОВ И АВТОНОМНОЕ УСТРОЙСТВО C ЗАЩИТОЙ ОТ КОПИРОВАНИЯ И ВЗЛОМА ДЛЯ ИХ ОСУЩЕСТВЛЕНИЯ | 2021 |
|
RU2789609C1 |



Изобретение относится к области распознавания лиц на цифровых изображениях. Технический результат заключается в повышении эффективности кластеризации лиц и распознавания атрибутов лиц путем обучения представлений лиц с предварительным обучением сверточной нейронной сети (СНС) для задачи идентификации лиц из предварительно собранной базы данных. Предложен способ одновременного распознавания атрибутов лиц и идентификации личности для организации фото и/или видеоальбомов, основанный на модификации эффективной сверточной нейронной сети (СНС), которая извлекает представления лиц, пригодные для выполнения задач идентификации лиц и распознавания атрибутов (возраст, пол, этническая принадлежность, эмоции и т.д.). Способ позволяет решать все задачи одновременно, не требуя дополнительных СНС. В результате обеспечивается очень быстрая система анализа лиц. 4 н. и 15 з.п. ф-лы, 6 табл., 6 ил.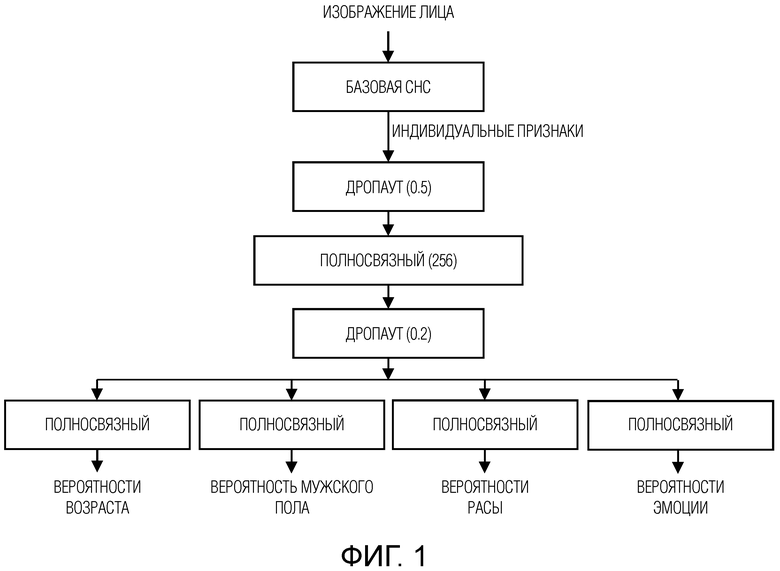
1. Компьютерно-реализуемый способ одновременного распознавания атрибутов лиц и идентификации личности на цифровых изображениях, содержащий этапы, на которых:
обучают базовую сверточную нейронную сеть (СНС) на предварительно выбранном наборе изображений;
модифицируют СНС посредством обеспечения по меньшей мере одного скрытого слоя с регуляризацией методом дропаута;
обеспечивают поверх по меньшей мере одного скрытого слоя независимые полносвязные слои для распознавания атрибутов лиц, причем каждый из этих независимых слоев соответствует соответственному одному из атрибутов лиц и имеет соответственную нелинейность;
обучают независимые полносвязные слои, причем при обучении поочередно используют подмножество обучающих данных, относящееся только к тому одному из независимых слоев, который подвергается обучению;
извлекают посредством слоев базовой СНС из, по меньшей мере, частей одного или нескольких входных изображений индивидуальные характерные признаки, пригодные для идентификации лиц;
обеспечивают ввод для независимых полносвязных слоев посредством по меньшей мере одного скрытого слоя, используя извлеченные индивидуальные характерные признаки; и
распознают атрибуты лиц соответственно посредством независимых полносвязных слоев на основе ввода с по меньшей мере одного скрытого слоя.
2. Способ по п.1, в котором базовой СНС является СНС с низкой вычислительной сложностью и затратами памяти.
3. Способ по п.2, в котором СНС с низкой вычислительной сложностью и затратами памяти является MobileNet v1/v2.
4. Способ по п.1, в котором атрибутами лиц являются одно или более из возраста, пола, расы или этнической принадлежности и эмоций.
5. Способ по п.1, в котором каждое подмножество обучающих данных имеет соответствующую метку, указывающую конкретный атрибут лица, к которому данное подмножество относится.
6. Способ по п.1, дополнительно содержащий этапы, на которых:
детектируют на одном или нескольких входных изображениях области, ассоциированные с лицами; и
используют эти области в качестве упомянутых, по меньшей мере, частей одного или нескольких входных изображений.
7. Способ по п.6, в котором упомянутое детектирование выполняют посредством каскадного классификатора или метода MTCNN.
8. Компьютерно-реализуемый способ организации цифрового фотоальбома и/или цифрового видеоальбома, причем фотоальбом содержит множество фотографий, а видеоальбом содержит множество видеофайлов, при этом способ содержит этапы, на которых:
выбирают множество кадров в каждом видеофайле из множества видеофайлов;
детектируют в каждом из выбранных кадров и/или на каждой фотографии из множества фотографий области, ассоциированные с лицами;
извлекают индивидуальные характерные признаки и атрибуты всех лиц, используя способ по п.1, причем детектированные области используются в качестве входных изображений;
для каждого видеофайла в множестве видеофайлов кластеризуют извлеченные индивидуальные характерные признаки и атрибуты лиц, ассоциированные с каждым лицом из лиц, детектированных в видеофайле, в один кластер и вычисляют средние индивидуальные характерные признаки и средние атрибуты лиц для каждого кластера видеофайла; и
группируют фотографии и/или видеофайлы посредством совместной кластеризации индивидуальных характерных признаков, извлеченных из фотографий, и средних индивидуальных характерных признаков, вычисленных для видеофайлов, и на основе по меньшей мере одного усредненного атрибута лиц, вычисленного для каждого кластера из соответствующих атрибутов и/или средних атрибутов лиц, ассоциированных с данным кластером.
9. Способ по п.8, в котором упомянутое детектирование выполняют посредством каскадного классификатора или метода MTCNN.
10. Способ по п.8, в котором при упомянутом выборе выбирают с фиксированной частотой четкие кадры видеофайла.
11. Способ по п.8, в котором
упомянутую совместную кластеризацию выполняют посредством использования иерархической агломеративной кластеризации для получения кластеров, каждый из которых включает в себя индивидуальные характерные признаки одного или нескольких лиц, и
данная совместная кластеризация содержит этап, на котором корректируют кластеры таким образом, чтобы отфильтровать неподходящие кластеры.
12. Способ по п.11, в котором неподходящими кластерами являются кластеры с числом элементов меньше, чем первое заранее определенное пороговое значение, или кластеры, ассоциированные с фотографиями/видеофайлами, даты съемки которых отличаются меньше, чем на второе заранее определенное пороговое значение.
13. Способ по п.8, в котором
атрибуты лиц содержат, по меньшей мере, возраст;
при этом способ дополнительно содержит, до этапа совместной кластеризации, этап, на котором оценивают год рождения, относящийся к каждому из лиц, путем вычитания возраста в атрибутах, ассоциированных с данным лицом, из даты создания файла, содержащего фотографию или видеофайл, в котором было детектировано упомянутое лицо;
причем данная совместная кластеризация содержит этап, на котором предотвращают кластеризацию в один и тот же кластер индивидуальных характерных признаков тех людей, чьи годы рождения отличаются больше, чем на заранее определенный порог.
14. Способ по п.8, в котором упомянутый по меньшей мере один усредненный атрибут лиц вычисляют, используя подходящий метод агрегации.
15. Способ по п.14, в котором упомянутый подходящий метод агрегации относится к простому голосованию или максимизации средних апостериорных вероятностей на выходах СНС.
16. Способ по п.8, в котором при упомянутом вычислении средних индивидуальных характерных признаков вычисляют нормированное среднее извлеченных индивидуальных характерных признаков.
17. Способ по п.8, дополнительно содержащий этап, на котором отображают сгруппированные фотографии и/или видеофайлы вместе с соответствующими усредненными атрибутами лиц.
18. Вычислительное устройство, содержащее:
по меньшей мере один процессор, и
память, приспособленную для хранения машиноисполняемых команд, которые при их исполнении по меньшей мере процессором предписывают вычислительному устройству выполнять способ по п.8.
19. Машиночитаемый носитель данных, на котором хранятся машиноисполняемые команды, которые при их исполнении вычислительным устройством предписывают вычислительному устройству выполнять способ по п.8.
| US 20180032866 A1, 01.02.2018 | |||
| CN 107292267 A, 24.10.2017 | |||
| НЕЙРОННАЯ СЕТЬ КОНЕЧНОГО КОЛЬЦА | 2003 |
|
RU2279132C2 |
| СПОСОБ ОБУЧЕНИЯ ИСКУССТВЕННОЙ НЕЙРОННОЙ СЕТИ | 2014 |
|
RU2566979C1 |
| Микропрофилометр для оценки и исследования чистоты обработки поверхности | 1954 |
|
SU115098A1 |
| СПОСОБ, УСТРОЙСТВО И СЕРВЕР РАСПОЗНАВАНИЯ КОНФИДЕНЦИАЛЬНОЙ ФОТОГРАФИИ | 2015 |
|
RU2622874C1 |
| WO 2005024718 A1, 17.03.2005. | |||

