Перекрестная ссылка на родственные заявки
Данная заявка заявляет приоритет предварительной заявки на патент США № 62/927790, поданной 30 октября 2019 г., и предварительной заявки на патент США № 63/086465, поданной 1 октября 2020 г., каждая из которых включена в настоящий документ посредством ссылки во всей своей полноте.
Область техники, к которой относится изобретение
Настоящее изобретение в целом относится к обработке аудиосигнала. В частности, настоящее изобретение относится к способам обработки пространственного аудиосигнала (пространственной аудиосцены) для генерирования сжатого представления пространственного аудиосигнала и к способам обработки сжатого представления пространственного аудиосигнала для генерирования восстановленного представления пространственного аудиосигнала.
Уровень техники
Человеческий слух позволяет слушателям воспринимать окружающую их среду в форме пространственной аудиосцены, вследствие чего термин «пространственная аудиосцена» используется в настоящем документе для отсылки к акустической среде вокруг слушателя или акустической среде, воспринимаемой слушателем в уме.
В то время как опыт человека связан с пространственными аудиосценами, процесс записи и воспроизведения аудио включает захват, обработку, передачу и проигрывание аудиосигналов или аудиоканалов. Термин «аудиопоток» используется для отсылки к набору из одного или более аудиосигналов, в частности, тогда, когда аудиопоток предназначен для представления пространственной аудиосцены.
Аудиопоток можно проиграть для слушателя с помощью электроакустических преобразователей или посредством других средств для предоставления одному или более слушателям опыта прослушивания в форме пространственной аудиосцены. Обычно целью практикующих специалистов в области аудиозаписи и аудиохудожников является создание аудиопотоков, предназначенных для предоставления слушателю опыта конкретной пространственной аудиосцены.
Аудиопоток может сопровождаться связанными данными, которые называют метаданными, которые оказывают содействие процессу проигрывания. Сопроводительные метаданные могут содержать зависящую от времени информацию, которую можно использовать для воздействия на изменения обработки, применяемой в ходе процесса проигрывания.
В дальнейшем термин «захваченный аудиоопыт» может использоваться для отсылки к аудиопотоку с добавлением каких-либо связанных метаданных.
В некоторых применениях метаданные состоят исключительно из данных, указывающих намеченную схему расположения громкоговорителей для проигрывания. Часто эти метаданные опускают в предположении, что схема расположения динамиков для проигрывания является стандартизованной. В этом случае захваченный аудиоопыт состоит исключительно из аудиопотока. Примером одного такого захваченного аудиоопыта является 2-канальный аудиопоток, записанный на компакт-диске, при этом предполагается, что намеченная система проигрывания имеет форму двух громкоговорителей, расположенных перед слушателем.
Альтернативно захваченный аудиоопыт в форме основанного на сцене многоканального аудиосигнала может предназначаться для представления слушателю путем обработки аудиосигналов с помощью матрицы микширования для генерирования набора сигналов динамиков, каждый из которых может впоследствии проигрываться соответственным громкоговорителем, при этом громкоговорители могут произвольно располагаться в пространстве вокруг слушателя. В этом примере матрица микширования может генерироваться на основе априорных знаний об основанном на сцене формате и о схеме расположения динамиков для проигрывания.
Примером основанного на сцене формата является амбиофония высшего порядка (HOA), и примерный способ вычисления соответствующих матриц микширования приведен в документе «Ambisonics», Franz Zotter и Matthias Frank, ISBN: 978-3-030-17206-0, глава 3, который посредством ссылки включен в настоящий документ.
Обычно такие основанные на сцене форматы содержат большое количество каналов или аудиообъектов, что приводит к сравнительно высоким требованиям к полосе пропускания или хранилищам данных при передаче или хранении пространственных аудиосигналов в этих форматах.
Поэтому существует потребность в компактных представлениях пространственных аудиосигналов, представляющих пространственные аудиосцены. Это применимо как к основанным на каналах, так и к основанным на объектах пространственным аудиосигналам.
Сущность изобретения
В настоящем изобретении предложены способы обработки пространственного аудиосигнала для генерирования сжатого представления пространственного аудиосигнала, способы обработки сжатого представления пространственного аудиосигнала для генерирования восстановленного представления пространственного аудиосигнала, соответствующие устройство, программы и считываемые компьютером носители данных.
Один аспект настоящего изобретения относится к способу обработки пространственного аудиосигнала для генерирования сжатого представления пространственного аудиосигнала. Пространственный аудиосигнал может представлять собой, например, многоканальный сигнал или основанный на объектах сигнал. Сжатое представление может представлять собой компактное представление или представление уменьшенного размера. Способ может включать анализ пространственного аудиосигнала для определения направлений поступления для одного или более аудиоэлементов в аудиосцене (пространственной аудиосцене), представленной пространственным аудиосигналом. Аудиоэлементы могут представлять собой доминирующие аудиоэлементы. Эти (доминирующие) аудиоэлементы могут относиться, например, к (доминирующим) акустическим объектам, (доминирующим) источникам звука или (доминирующим) акустическим составляющим в аудиосцене. Один или более аудиоэлементов могут содержать от одного до десяти аудиоэлементов, например, четыре аудиоэлемента. Направления поступления могут соответствовать местоположениям на единичной сфере, указывающим воспринимаемые местоположения аудиоэлементов. Способ может дополнительно включать для по меньшей мере одного частотного поддиапазона (например, для всех частотных поддиапазонов) пространственного аудиосигнала определение соответственных указателей мощности сигнала, связанной с определенными направлениями поступления. Способ может дополнительно включать генерирование метаданных, содержащих информацию о направлениях и информацию об энергиях, причем информация о направлениях содержит указатели определенных направлений поступления одного или более аудиоэлементов, и информация об энергиях содержит соответственные указатели мощности сигнала, связанной с определенными направлениями поступления. Способ может дополнительно включать генерирование основанного на каналах аудиосигнала с предварительно установленным количеством каналов на основе пространственного аудиосигнала. Основанный на каналах аудиосигнал может называться микшированным аудиосигналом или микшированным аудиопотоком. Понятно, что количество каналов основанного на каналах аудиосигнала может быть меньше количества каналов или количества объектов пространственного аудиосигнала. Способ может также дополнительно включать вывод, в виде сжатого представления пространственного аудиосигнала, основанного на каналах аудиосигнала и метаданных. Метаданные могут относиться к потоку метаданных.
Таким образом, можно сгенерировать сжатое представление пространственного аудиосигнала, содержащее лишь ограниченное количество каналов. Также, путем надлежащего использования информации о направлениях и информации об энергиях, декодер может генерировать восстановленную версию исходного пространственного аудиосигнала, которая представляет собой очень хорошее приближение исходного пространственного аудиосигнала в том, что касается представления исходной пространственной аудиосцены.
В некоторых вариантах осуществления анализ пространственного аудиосигнала может основываться на множестве частотных поддиапазонов пространственного аудиосигнала. Например, анализ может основываться на полном частотном диапазоне пространственного аудиосигнала (т. е. на полном сигнале). То есть анализ может основываться на всех частотных поддиапазонах.
В некоторых вариантах осуществления анализ пространственного аудиосигнала может включать применение анализа сцены к пространственному аудиосигналу. Тем самым можно надежным и эффективным образом определить доминирующие аудиоэлементы (их направления) в аудиосцене.
В некоторых вариантах осуществления пространственный аудиосигнал может представлять собой многоканальный аудиосигнал. Альтернативно пространственный аудиосигнал может представлять собой основанный на объектах аудиосигнал. В этом случае способ может дополнительно включать преобразование основанного на объектах аудиосигнала в многоканальный аудиосигнал перед применением анализа сцены. Это позволяет содержательно применять инструментальные средства анализа сцены к аудиосигналу.
В некоторых вариантах осуществления указатель мощности сигнала, связанной с заданным направлением поступления, может относиться к доле мощности сигнала в частотном поддиапазоне для заданного направления поступления относительно общей мощности сигнала в частотном поддиапазоне.
В некоторых вариантах осуществления указатели мощности сигнала могут определяться для каждого из множества частотных поддиапазонов. В этом случае они могут относиться, для заданного направления поступления и заданного частотного поддиапазона, к доле мощности сигнала в заданном частотном поддиапазоне для заданного направления поступления относительно общей мощности сигнала в заданном частотном поддиапазоне. В частности, указатели мощности сигнала могут определяться для каждого поддиапазона, тогда как определение (доминирующих) направлений поступления может выполняться в отношении полного сигнала (т. е. на основе всех частотных поддиапазонов).
В некоторых вариантах осуществления анализ пространственного аудиосигнала, определение соответственных указателей мощности сигнала и генерирование основанного на каналах аудиосигнала могут выполняться для каждого временного отрезка. Соответственно, сжатое представление может генерироваться и выводиться для каждого из множества временных отрезков посредством подвергнутого понижающему микшированию аудиосигнала и метаданных (блока метаданных) для каждого временного отрезка. Альтернативно или дополнительно анализ пространственного аудиосигнала, определение соответственных указателей мощности сигнала и генерирование основанного на каналах аудиосигнала могут выполняться на основе частотно-временного представления пространственного аудиосигнала. Например, вышеупомянутые этапы могут выполняться на основе дискретного преобразования Фурье (такого как, например, STFT) пространственного аудиосигнала. То есть для каждого временного отрезка (временного блока) вышеупомянутые этапы могут выполняться на основе элементов разрешения по времени и частоте (элементов разрешения FFT) пространственного аудиосигнала, т. е. на основе коэффициентов Фурье пространственного аудиосигнала.
В некоторых вариантах осуществления пространственный аудиосигнал может представлять собой основанный на объектах аудиосигнал, содержащий множество аудиообъектов и связанных векторов направлений. Тогда способ может дополнительно включать генерирование многоканального аудиосигнала путем панорамирования аудиообъектов в предварительно установленный набор аудиоканалов. При этом каждый аудиообъект могут панорамировать в предварительно установленный набор аудиоканалов в соответствии с его вектором направления. Дополнительно основанный на каналах аудиосигнал может представлять собой подвергнутый понижающему микшированию сигнал, сгенерированный путем применения операции понижающего микширования к многоканальному аудиосигналу. Например, многоканальный аудиосигнал может представлять собой сигнал амбиофонии высшего порядка.
В некоторых вариантах осуществления пространственный аудиосигнал может представлять собой многоканальный аудиосигнал. Тогда основанный на каналах аудиосигнал может представлять собой подвергнутый понижающему микшированию сигнал, сгенерированный путем применения операции понижающего микширования к многоканальному аудиосигналу.
Другой аспект настоящего изобретения относится к способу обработки сжатого представления пространственного аудиосигнала для генерирования восстановленного представления пространственного аудиосигнала. Сжатое представление может содержать основанный на каналах аудиосигнал с предварительно установленным количеством каналов и метаданные. Метаданные могут содержать информацию о направлениях и информацию об энергиях. Информация о направлениях может содержать указатели направлений поступления одного или более аудиоэлементов в аудиосцене (пространственной аудиосцене). Информация об энергиях может содержать, для по меньшей мере одного частотного поддиапазона, соответственные указатели мощности сигнала, связанной с направлениями поступления. Способ может включать генерирование аудиосигналов одного или более аудиоэлементов на основе основанного на каналах аудиосигнала, информации о направлениях и информации об энергиях. Способ может дополнительно включать генерирование остаточного аудиосигнала, в котором по существу отсутствует один или более аудиоэлементов, на основе основанного на каналах аудиосигнала, информации о направлениях и информации об энергиях. Остаточный сигнал может быть представлен в таком же аудиоформате, как основанный на каналах аудиосигнал, например, может содержать такое же количество каналов.
В некоторых вариантах осуществления указатель мощности сигнала, связанной с заданным направлением поступления, может относиться к доле мощности сигнала в частотном поддиапазоне для заданного направления поступления относительно общей мощности сигнала в частотном поддиапазоне.
В некоторых вариантах осуществления информация об энергиях может содержать указатели мощности сигнала для каждого из множества частотных поддиапазонов. Тогда указатель мощности сигнала может относиться, для заданного направления поступления и заданного частотного поддиапазона, к доле мощности сигнала в заданном частотном поддиапазоне для заданного направления поступления относительно общей мощности сигнала в заданном частотном поддиапазоне.
В некоторых вариантах осуществления способ может дополнительно включать панорамирование аудиосигналов одного или более аудиоэлементов в набор каналов выходного аудиоформата. Способ может также дополнительно включать генерирование восстановленного многоканального аудиосигнала в выходном аудиоформате на основе панорамированного одного или более аудиоэлементов и остаточного сигнала. Выходной аудиоформат может относиться к выходному представлению, например, такому как НОА или любой другой подходящий многоканальный формат. Генерирование восстановленного многоканального аудиосигнала может включать повышающее микширование остаточного сигнала в набор каналов выходного аудиоформата. Генерирование восстановленного многоканального аудиосигнала может дополнительно включать сложение панорамированного одного или более аудиоэлементов и подвергнутого повышающему микшированию остаточного сигнала.
В некоторых вариантах осуществления генерирование аудиосигналов одного или более аудиоэлементов может включать определение коэффициентов обратной матрицы  микширования для отображения основанного на каналах аудиосигнала в промежуточное представление, содержащее остаточный аудиосигнал и аудиосигналы одного или более аудиоэлементов, на основе информации о направлениях и информации об энергиях. Промежуточное представление может также называться раздельным или разделяемым представлением или гибридным представлением.
микширования для отображения основанного на каналах аудиосигнала в промежуточное представление, содержащее остаточный аудиосигнал и аудиосигналы одного или более аудиоэлементов, на основе информации о направлениях и информации об энергиях. Промежуточное представление может также называться раздельным или разделяемым представлением или гибридным представлением.
В некоторых вариантах осуществления определение коэффициентов обратной матрицы микширования может включать определение, для каждого из одного или более аудиоэлементов, вектора  панорамирования для панорамирования аудиоэлемента в каналы основанного на каналах аудиосигнала на основе направления
панорамирования для панорамирования аудиоэлемента в каналы основанного на каналах аудиосигнала на основе направления  поступления аудиоэлемента. Указанное определение коэффициентов обратной матрицы микширования может дополнительно включать определение матрицы
поступления аудиоэлемента. Указанное определение коэффициентов обратной матрицы микширования может дополнительно включать определение матрицы  микширования, которую будут использовать для отображения остаточного аудиосигнала и аудиосигналов одного или более аудиоэлементов в каналы основанного на каналах аудиосигнала на основе определенных векторов панорамирования. Указанное определение коэффициентов обратной матрицы микширования может дополнительно включать определение ковариационной матрицы
микширования, которую будут использовать для отображения остаточного аудиосигнала и аудиосигналов одного или более аудиоэлементов в каналы основанного на каналах аудиосигнала на основе определенных векторов панорамирования. Указанное определение коэффициентов обратной матрицы микширования может дополнительно включать определение ковариационной матрицы  для промежуточного представления на основе информации об энергиях. Определение ковариационной матрицы может дополнительно основываться на определенных векторах
для промежуточного представления на основе информации об энергиях. Определение ковариационной матрицы может дополнительно основываться на определенных векторах  панорамирования. Указанное определение коэффициентов обратной матрицы микширования может также дополнительно включать определение коэффициентов обратной матрицы микширования на основе матрицы микширования и ковариационной матрицы .
панорамирования. Указанное определение коэффициентов обратной матрицы микширования может также дополнительно включать определение коэффициентов обратной матрицы микширования на основе матрицы микширования и ковариационной матрицы .
В некоторых вариантах осуществления матрица микширования может определяться в соответствии с  . Здесь
. Здесь  может представлять собой единичную матрицу
может представлять собой единичную матрицу  , где
, где  указывает количество каналов основанного на каналах сигнала,
указывает количество каналов основанного на каналах сигнала,  может представлять собой вектор панорамирования для
может представлять собой вектор панорамирования для 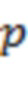 -го аудиоэлемента со связанным направлением
-го аудиоэлемента со связанным направлением 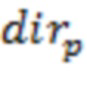 поступления, который будет панорамировать (например, отображать) -й аудиоэлемент в каналов основанного на каналах сигнала, где
поступления, который будет панорамировать (например, отображать) -й аудиоэлемент в каналов основанного на каналах сигнала, где  указывает соответственный один из одного или более аудиоэлементов, и
указывает соответственный один из одного или более аудиоэлементов, и 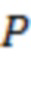 указывает общее количество из одного или более аудиоэлементов. Соответственно, матрица может представлять собой матрицу
указывает общее количество из одного или более аудиоэлементов. Соответственно, матрица может представлять собой матрицу 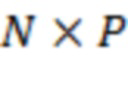 . Матрица может определяться для каждого из множества временных отрезков
. Матрица может определяться для каждого из множества временных отрезков 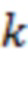 . В этом случае матрица и направления поступления будут характеризоваться индексом , указывающим временной отрезок, например,
. В этом случае матрица и направления поступления будут характеризоваться индексом , указывающим временной отрезок, например, 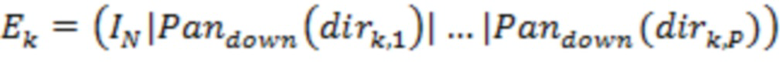 . Хотя предложенный способ может действовать на основе полос, матрица может являться одинаковой для всех частотных поддиапазонов.
. Хотя предложенный способ может действовать на основе полос, матрица может являться одинаковой для всех частотных поддиапазонов.
В некоторых вариантах осуществления ковариационная матрица может определяться как диагональная матрица в соответствии с 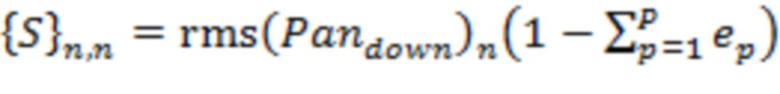 для
для  и
и 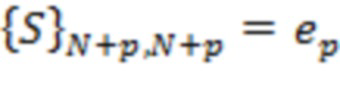 для
для  . Здесь
. Здесь  может представлять собой мощность сигнала, связанную с направлением поступления -го аудиоэлемента. Матрица может определяться для каждого из множества временных отрезков и/или для каждого из множества частотных поддиапазонов
может представлять собой мощность сигнала, связанную с направлением поступления -го аудиоэлемента. Матрица может определяться для каждого из множества временных отрезков и/или для каждого из множества частотных поддиапазонов  . В этом случае матрица и мощности сигнала будут характеризоваться индексом , указывающим временной отрезок, и/или индексом , указывающим частотный поддиапазон, например,
. В этом случае матрица и мощности сигнала будут характеризоваться индексом , указывающим временной отрезок, и/или индексом , указывающим частотный поддиапазон, например,  для и
для и 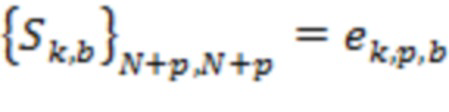 для .
для .
В некоторых вариантах осуществления определение коэффициентов обратной матрицы микширования на основе матрицы микширования и ковариационной матрицы может включать определение псевдообратной матрицы на основе матрицы микширования и ковариационной матрицы .
В некоторых вариантах осуществления обратная матрица микширования может определяться в соответствии с 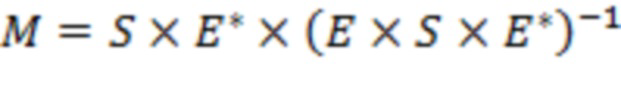 . Здесь «
. Здесь « » указывает матричное произведение, и «
» указывает матричное произведение, и « » указывает сопряженную транспозицию матрицы. Обратная матрица микширования может определяться для каждого из множества временных отрезков и/или для каждого из множества частотных поддиапазонов . В этом случае матрицы и могут характеризоваться индексом , указывающим временной отрезок, и/или индексом , указывающим частотный поддиапазон, и матрица может характеризоваться индексом , указывающим временной отрезок, например,
» указывает сопряженную транспозицию матрицы. Обратная матрица микширования может определяться для каждого из множества временных отрезков и/или для каждого из множества частотных поддиапазонов . В этом случае матрицы и могут характеризоваться индексом , указывающим временной отрезок, и/или индексом , указывающим частотный поддиапазон, и матрица может характеризоваться индексом , указывающим временной отрезок, например, 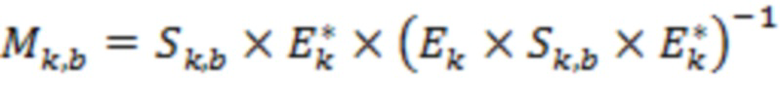 .
.
В некоторых вариантах осуществления основанный на каналах аудиосигнал может представлять собой сигнал амбиофонии первого порядка.
Другой аспект относится к устройству, содержащему процессор и запоминающее устройство, соединенное с процессором, при этом процессор приспособлен для осуществления всех этапов способов в соответствии с любым из вышеупомянутых аспектов и вариантов осуществления.
Другой аспект настоящего изобретения относится к программе, содержащей команды, которые при исполнении процессором предписывают процессору осуществить все этапы вышеупомянутых способов.
Еще один аспект настоящего изобретения относится к считываемому компьютером носителю данных, на котором хранится вышеупомянутая программа.
Дополнительные варианты осуществления настоящего изобретения включают эффективный способ представления пространственной аудиосцены в форме микшированного аудиопотока и потока метаданных направлений, причем поток метаданных направлений содержит данные, указывающие местоположение направленных звуковых элементов в пространственной аудиосцене, и данные, указывающие мощность каждого направленного звукового элемента в нескольких поддиапазонах относительно общей мощности пространственной аудиосцены в этом поддиапазоне. Другие дополнительные варианты осуществления относятся к способам определения потока метаданных направлений на основании входной пространственной аудиосцены и способам создания воссозданной аудиосцены из потока метаданных направлений и связанного микшированного аудиопотока.
В некоторых вариантах осуществления используется способ представления пространственной аудиосцены в более компактной форме как компактной пространственной аудиосцены, содержащей микшированный аудиопоток и поток метаданных направлений, при этом указанный микшированный аудиопоток состоит из одного или более аудиосигналов, и при этом указанный поток метаданных направлений состоит из временной последовательности блоков метаданных направлений, причем каждый из указанных блоков метаданных направлений связан с соответствующим временным отрезком в указанных аудиосигналах, и при этом указанная пространственная аудиосцена содержит один или более направленных звуковых элементов, каждый из которых связан с соответственным направлением поступления, и при этом каждый из указанных блоков метаданных направлений содержит:
• информацию о направлениях, указывающую указанные направления поступления для каждого из указанных направленных звуковых элементов, и
• информацию о долях энергии в полосах, указывающую энергию в каждом из указанных направленных звуковых элементов относительно энергии в указанном соответствующем временном отрезке в указанных аудиосигналах, для каждого из указанных направленных звуковых элементов и для каждого из набора из двух или более поддиапазонов.
В некоторых вариантах осуществления используется способ обработки компактной пространственной аудиосцены, содержащей микшированный аудиопоток и поток метаданных направлений, для получения раздельного пространственного аудиопотока, содержащего набор из одного или более сигналов аудиообъектов, и остаточного потока, при этом указанный микшированный аудиопоток состоит из одного или более аудиосигналов, и при этом указанный поток метаданных направлений состоит из временной последовательности блоков метаданных направлений, причем каждый из указанных блоков метаданных направлений связан с соответствующим временным отрезком в указанных аудиосигналах, при этом для каждого из множества поддиапазонов способ включает:
• определение коэффициентов матрицы демикширования (обратной матрицы микширования) на основании информации о направлениях и информации о долях энергии в полосах, содержащейся в потоке метаданных направлений, и
• микширование с использованием указанной матрицы демикширования указанных аудиосигналов для получения указанного раздельного пространственного аудиопотока.
В некоторых вариантах осуществления используется способ обработки пространственной аудиосцены для получения компактной пространственной аудиосцены, содержащей микшированный аудиопоток и поток метаданных направлений, при этом указанная пространственная аудиосцена содержит один или более направленных звуковых элементов, каждый из которых связан с соответственным направлением поступления, и при этом указанный поток метаданных направлений состоит из временной последовательности блоков метаданных направлений, причем каждый из указанных блоков метаданных направлений связан с соответствующим временным отрезком в указанных аудиосигналах, причем указанный способ включает:
• этап определения указанного направления поступления для одного или более указанных направленных звуковых элементов на основании анализа указанной пространственной аудиосцены,
• этап определения того, какую долю от общей энергии в указанной пространственной сцене вносит энергия в каждом из указанных направленных звуковых элементов, и
• этап обработки указанной пространственной аудиосцены для получения указанного микшированного аудиопотока.
Понятно, что вышеупомянутые этапы могут быть реализованы подходящими средствами или блоками, которые, в свою очередь, могут быть реализованы, например, с помощью одного или более компьютерных процессоров.
Будет также понятно, что признаки устройства и этапы способа можно взаимно заменять многими методами. В частности, детали раскрытого способа (раскрытых способов) могут быть реализованы соответствующим устройством, и наоборот, как будет понятно специалисту. Кроме того, понятно, что любое из приведенных выше утверждений в отношении способа (способов) аналогично применимо к соответствующему устройству, и наоборот.
Краткое описание графических материалов
Примерные варианты осуществления настоящего изобретения проиллюстрированы в качестве примера на сопроводительных графических материалах, на которых аналогичные ссылочные номера указывают одинаковые или подобные элементы, и на которых:
фиг. 1 схематически иллюстрирует пример компоновки кодера, генерирующего сжатое представление пространственной аудиосцены, и соответствующего декодера для генерирования воссозданной аудиосцены из сжатого представления в соответствии с вариантами осуществления настоящего изобретения,
фиг. 2 схематически иллюстрирует другой пример компоновки кодера, генерирующего сжатое представление пространственной аудиосцены, и соответствующего декодера для генерирования воссозданной аудиосцены из сжатого представления в соответствии с вариантами осуществления настоящего изобретения,
фиг. 3 схематически иллюстрирует пример генерирования сжатого представления пространственной аудиосцены в соответствии с вариантами осуществления настоящего изобретения,
фиг. 4 схематически иллюстрирует пример декодирования сжатого представления пространственной аудиосцены для образования воссозданной аудиосцены в соответствии с вариантами осуществления настоящего изобретения,
фиг. 5 и фиг. 6 представляют собой блок-схемы, иллюстрирующие примеры способов обработки пространственной аудиосцены для генерирования сжатого представления пространственной аудиосцены в соответствии с вариантами осуществления настоящего изобретения,
фиг. 7 – фиг. 11 схематически иллюстрируют примеры деталей генерирования сжатого представления пространственной аудиосцены в соответствии с вариантами осуществления настоящего изобретения,
фиг. 12 схематически иллюстрирует пример деталей декодирования сжатого представления пространственной аудиосцены для образования воссозданной аудиосцены в соответствии с вариантами осуществления настоящего изобретения,
фиг. 13 представляет собой блок-схему, иллюстрирующую пример способа декодирования сжатого представления пространственной аудиосцены для образования воссозданной аудиосцены в соответствии с вариантами осуществления настоящего изобретения,
фиг. 14 представляет собой блок-схему, иллюстрирующую детали способа, представленного на фиг. 13,
фиг. 15 представляет собой блок-схему, иллюстрирующую другой пример способа декодирования сжатого представления пространственной аудиосцены для образования воссозданной аудиосцены в соответствии с вариантами осуществления настоящего изобретения, и
фиг. 16 схематически иллюстрирует устройство для генерирования сжатого представления пространственной аудиосцены и/или декодирования сжатого представления пространственной аудиосцены для образования воссозданной аудиосцены в соответствии с вариантами осуществления настоящего изобретения.
Подробное описание
В целом настоящее изобретение относится к обеспечению возможности хранения и/или передачи пространственной аудиосцены с использованием уменьшенного объема данных.
Ниже будут описаны концепции аудиообработки, которые можно использовать в контексте настоящего изобретения.
Функции панорамирования
Многоканальный аудиосигнал (или аудиопоток) может быть образован путем панорамирования отдельных звуковых элементов (или аудиоэлементов, аудиообъектов) в соответствии с линейным законом микширования. Например, если набор из  аудиообъектов представлен с помощью сигналов,
аудиообъектов представлен с помощью сигналов, 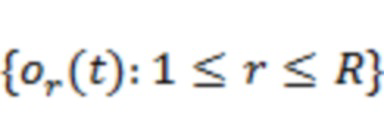 , то многоканальный панорамированный микшированный сигнал
, то многоканальный панорамированный микшированный сигнал 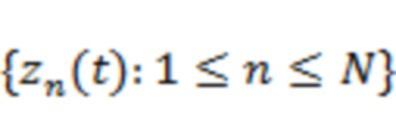 можно образовать следующим образом:
можно образовать следующим образом:
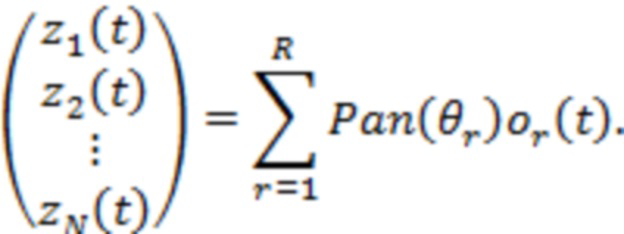 (1)
(1)
Функция  панорамирования представляет вектор-столбец, содержащий
панорамирования представляет вектор-столбец, содержащий 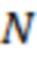 масштабных коэффициентов (коэффициентов усиления при панорамировании), указывающих коэффициенты усиления, которые используются для микширования сигнала объекта,
масштабных коэффициентов (коэффициентов усиления при панорамировании), указывающих коэффициенты усиления, которые используются для микширования сигнала объекта, 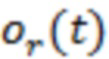 , для образования многоканального вывода, и причем
, для образования многоканального вывода, и причем  указывает местоположение соответственного объекта.
указывает местоположение соответственного объекта.
Одной возможной функцией панорамирования является функция панорамирования «Амбиофония первого порядка» (FOA). Пример функции панорамирования FOA имеет вид:
 (2)
(2)
Альтернативной функцией панорамирования является функция панорамирования «Амбиофония третьего порядка» (3OA). Пример функции панорамирования 3OA имеет вид:
 (3)
(3)
Понятно, что настоящее изобретение не ограничивается функциями панорамирования FOA или НОА, и что можно учесть использование других функций панорамирования, которые понятны специалисту.
Кратковременное преобразование Фурье
Аудиопоток, состоящий из одного или более аудиосигналов, можно преобразовать, например, в форму кратковременного преобразования Фурье (STFT). Для этого дискретное преобразование Фурье можно применить к (необязательно обработанным методом окна) временным отрезкам аудиосигналов (например, каналов, сигналов аудиообъектов) аудиопотока. Применение этого процесса к аудиосигналу  можно выразить следующим образом:
можно выразить следующим образом:
 (4)
(4)
Понятно, что STFT представляет собой пример частотно-временного преобразования, и что настоящее изобретение не следует ограничивать преобразованиями STFT.
В уравнении (4) переменная 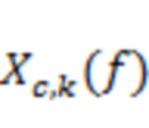 указывает кратковременное преобразование Фурье канала
указывает кратковременное преобразование Фурье канала  (
( ) для временного отрезка
) для временного отрезка 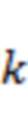 (
( ) аудиосигнала в элементах
) аудиосигнала в элементах 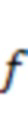 (
( ) разрешения по частоте, где
) разрешения по частоте, где 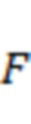 указывает количество элементов разрешения по частоте, полученных с помощью дискретного преобразования Фурье. Будет понятно, что термины, используемые в настоящем документе, приведены в качестве примера, и что конкретные детали реализации различных способов STFT (в том числе различных оконных функций) могут являться известными в данной области техники. Временной отрезок аудио можно установить, например, как диапазон отсчетов аудио с центром в окрестности
указывает количество элементов разрешения по частоте, полученных с помощью дискретного преобразования Фурье. Будет понятно, что термины, используемые в настоящем документе, приведены в качестве примера, и что конкретные детали реализации различных способов STFT (в том числе различных оконных функций) могут являться известными в данной области техники. Временной отрезок аудио можно установить, например, как диапазон отсчетов аудио с центром в окрестности 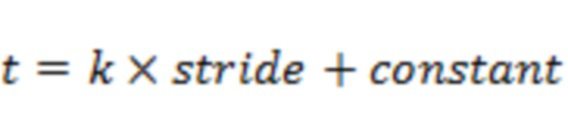 так, что временные отрезки равномерно разнесены по времени с интервалом, равным
так, что временные отрезки равномерно разнесены по времени с интервалом, равным  .
.
Числовые значения STFT (такие как  ,
,  , …,
, …, 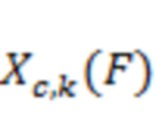 ) могут называться элементами разрешения FFT.
) могут называться элементами разрешения FFT.
Дополнительно форму STFT можно преобразовать в аудиопоток. Результирующий аудиопоток может представлять собой приближение исходного входного сигнала и может иметь вид:

Анализ на основе полос частот
Характеристические данные можно образовать из аудиопотока, причем характеристические данные связаны с несколькими полосами частот (частотными поддиапазонами), причем полоса (поддиапазон) установлена (установлен) областью частотного диапазона.
Например, мощность (power) сигнала в канале потока в полосе  частот (где количество полос равно
частот (где количество полос равно  , и
, и  ), где полоса охватывает элементы
), где полоса охватывает элементы  разрешения FFT, можно вычислить в соответствии с:
разрешения FFT, можно вычислить в соответствии с:
 (6)
(6)
В соответствии с более общим примером полосу  частот можно установить с помощью весового вектора
частот можно установить с помощью весового вектора  , который приписывает весовые коэффициенты каждому элементу разрешения по частоте так, что альтернативное вычисление мощности в полосе может иметь вид:
, который приписывает весовые коэффициенты каждому элементу разрешения по частоте так, что альтернативное вычисление мощности в полосе может иметь вид:
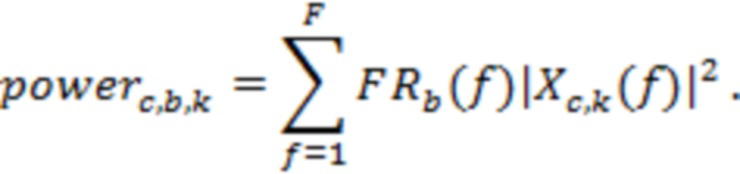 (7)
(7)
В дополнительном обобщении уравнения (7) STFT потока, состоящего из 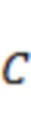 аудиосигналов, может обрабатываться для получения ковариации в нескольких полосах, причем ковариация
аудиосигналов, может обрабатываться для получения ковариации в нескольких полосах, причем ковариация 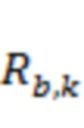 представляет собой матрицу
представляет собой матрицу 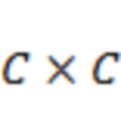 , и причем элемент
, и причем элемент 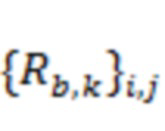 вычисляется в соответствии с:
вычисляется в соответствии с:
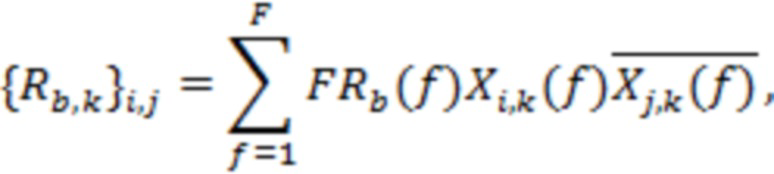 (8)
(8)
где 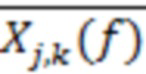 представляет комплексно-сопряженную величину
представляет комплексно-сопряженную величину 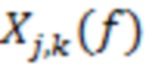 .
.
В другом примере можно использовать полосовые фильтры для образования фильтрованных сигналов, представляющих исходный аудиопоток, в полосах частот в соответствии с характеристиками полосовых фильтров. Например, аудиосигнал 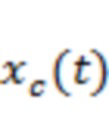 можно подвергнуть фильтрации для получения
можно подвергнуть фильтрации для получения 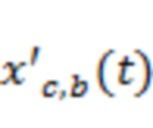 , который представляет собой сигнал с энергией, преимущественно полученной из полосы сигнала , и тогда альтернативный способ вычисления ковариации потока в полосе для временного блока (соответствующего временным отсчетам
, который представляет собой сигнал с энергией, преимущественно полученной из полосы сигнала , и тогда альтернативный способ вычисления ковариации потока в полосе для временного блока (соответствующего временным отсчетам 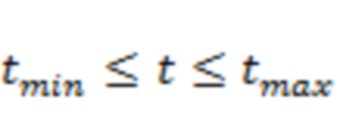 ) можно выразить как:
) можно выразить как:
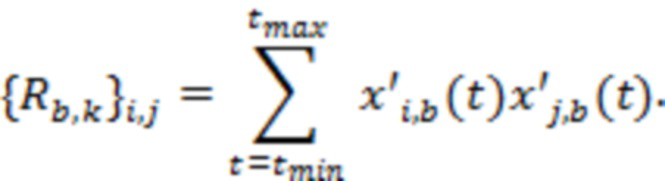 (9)
(9)
Микширование на основе полос частот
Аудиопоток, состоящий из  каналов, может обрабатываться для получения аудиопотока, состоящего из
каналов, может обрабатываться для получения аудиопотока, состоящего из 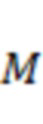 каналов, в соответствии с матрицей
каналов, в соответствии с матрицей 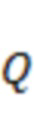 линейного микширования
линейного микширования 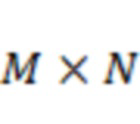 , так что:
, так что:
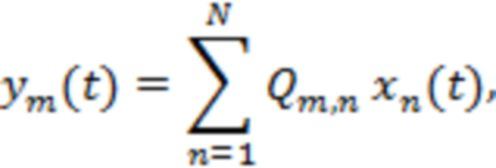 (10)
(10)
что можно записать в матричной форме как:
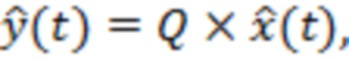 (11)
(11)
где  относится к вектору-столбцу, образованному из элементов:
относится к вектору-столбцу, образованному из элементов:  .
.
Дополнительно альтернативный способ микширования можно реализовать в области STFT, при этом матрица может принимать разные значения в каждом временном блоке и в каждой полосе частот. В этом случае обработку можно рассматривать как приблизительно имеющую вид:
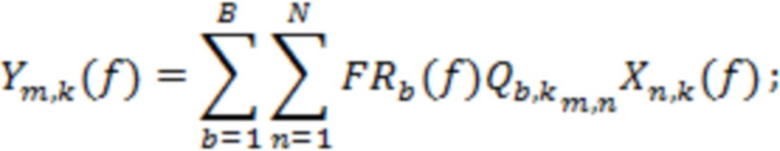 (12)
(12)
или в матричной форме:
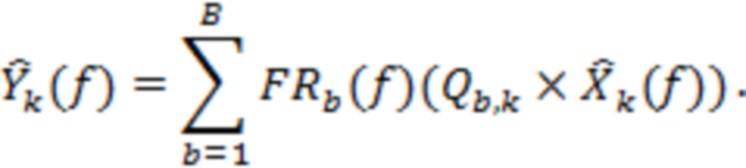 (13)
(13)
Будет понятно, что для получения поведения, эквивалентного обработке, описанной в уравнении (13), можно использовать альтернативные способы.
Примерные реализации
Ниже будут более подробно описаны примерные реализации способов и устройства в соответствии с вариантами осуществления настоящего изобретения.
В общих чертах, способы в соответствии с вариантами осуществления настоящего изобретения представляют пространственную аудиосцену в форме микшированного аудиопотока и потока метаданных направлений, причем поток метаданных направлений содержит данные, указывающие местоположение направленных звуковых элементов в пространственной аудиосцене, и данные, указывающие мощность каждого направленного звукового элемента в нескольких поддиапазонах относительно общей мощности пространственной аудиосцены в этом поддиапазоне. Дополнительные способы в соответствии с вариантами осуществления настоящего изобретения относятся к определению потока метаданных направлений на основании входной пространственной аудиосцены и к созданию воссозданной (например, восстановленной) аудиосцены из потока метаданных направлений и связанного микшированного аудиопотока.
Примеры способов в соответствии с вариантами осуществления настоящего изобретения являются эффективными (например, в том, что касается уменьшения количества данных для хранения или передачи) при представлении пространственной звуковой сцены. Пространственную аудиосцену можно представить с помощью пространственного аудиосигнала. Указанные способы можно реализовать путем установления формата хранения или передачи (например, формата «Компактный пространственный аудиопоток»), который состоит из микшированного аудиопотока и потока метаданных (например, потока метаданных направлений).
Микшированный аудиопоток содержит несколько аудиосигналов, передающих сокращенное представление пространственной звуковой сцены. Поэтому микшированный аудиопоток может относиться к основанному на каналах аудиосигналу с предварительно установленным количеством каналов. Понятно, что это количество каналов основанного на каналах аудиосигнала меньше количества каналов или количества аудиообъектов пространственного аудиосигнала. Например, основанный на каналах аудиосигнал может представлять собой аудиосигнал амбиофонии первого порядка. Иначе говоря, компактный пространственный аудиопоток может содержать микшированный аудиопоток в форме представления звукового поля в виде амбиофонии первого порядка.
Поток метаданных (направлений) содержит метаданные, устанавливающие пространственные свойства пространственной звуковой сцены. Метаданные направлений могут состоять из последовательности блоков метаданных направлений, при этом каждый блок метаданных направлений содержит метаданные, указывающие свойства пространственной звуковой сцены в соответствующем временном отрезке в микшированном аудиопотоке.
В целом метаданные содержат информацию о направлениях и информацию об энергиях. Информация о направлениях содержит указатели направлений поступления одного или более (доминирующих) аудиоэлементов в аудиосцене. Информация об энергиях содержит, для каждого направления поступления, указатель мощности сигнала, связанной с определенными направлениями поступления. В некоторых реализациях указатели мощности сигнала могут быть предусмотрены для одной, некоторых или каждой из множества полос (частотных поддиапазонов). Кроме того, метаданные могут предусматриваться для каждого из множества последовательных временных отрезков, например, в форме блоков метаданных.
В одном примере метаданные (метаданные направлений) включают метаданные, которые указывают свойства пространственной звуковой сцены по нескольким полосам частот, причем метаданные устанавливают:
• одно или более направлений (например, направлений поступления), указывающих местоположение аудиообъектов (аудиоэлементов) в пространственной звуковой сцене, и
• долю энергии (или мощности сигнала) в каждой полосе частот, отнесенную к соответственному аудиообъекту (например, отнесенную к соответственному направлению).
Ниже будут представлены детали определения информации о направлениях и информации об энергиях.
Фиг. 1 схематически показывает пример компоновки, в которой используются варианты осуществления настоящего изобретения. В частности, на фигуре показана компоновка 100, в которой пространственная аудиосцена 10 вводится в кодер 200 сцены, генерирующий микшированный аудиопоток 30 и поток 20 метаданных направлений. Пространственная аудиосцена 10 может быть представлена пространственным аудиосигналом или пространственным аудиопотоком, который вводится в кодер 200 сцены. Микшированный аудиопоток 30 и поток 20 метаданных направлений совместно образуют пример компактной пространственной аудиосцены, т. е. сжатое представление пространственной аудиосцены 10 (или пространственного аудиосигнала).
Сжатое представление, т. е. микшированный аудиопоток 30 и поток 20 метаданных направлений, вводится в декодер 300 сцены, который генерирует восстановленную аудиосцену 50. Аудиоэлементы, существующие в пространственной аудиосцене 10, будут представлены в микшированном аудиопотоке 30 в соответствии с функцией панорамирования микшированного сигнала.
Фиг. 2 схематически показывает другой пример компоновки, в которой используются варианты осуществления настоящего изобретения. В частности, на фигуре показана альтернативная компоновка 110, в которой компактная пространственная аудиосцена, состоящая из микшированного аудиопотока 30 и потока 20 метаданных направлений, дополнительно кодируется путем доставки микшированного аудиопотока 30 в аудиокодер 35 для получения аудиопотока 37, кодированного с пониженной битовой скоростью передачи данных, и путем доставки потока 20 метаданных направлений в кодер 25 метаданных для получения кодированного потока 27 метаданных. Аудиопоток 37, кодированный с пониженной битовой скоростью передачи данных, и кодированный поток 27 метаданных совместно образуют кодированную (кодированную с пониженной битовой скоростью передачи данных) пространственную аудиосцену.
Кодированную пространственную аудиосцену можно восстановить путем, в первую очередь, применения аудиопотока 37, кодированного с пониженной битовой скоростью передачи данных, и кодированного потока 27 метаданных в соответственных декодерах 36 и 26 для получения восстановленного микшированного аудиопотока 38 и восстановленного потока 28 метаданных направлений. Восстановленные потоки 38, 28 могут являться идентичными или приблизительно равными соответственным потокам 30, 20. Восстановленный микшированный аудиопоток 38 и восстановленный поток 28 метаданных направлений могут декодироваться декодером 300 для получения восстановленной аудиосцены 50.
Фиг. 3 схематически иллюстрирует пример компоновки для генерирования аудиопотока, кодированного с пониженной битовой скоростью передачи данных, и кодированного потока метаданных из входной пространственной аудиосцены. В частности, на фигуре показана компоновка 150 кодера 200 сцены, доставляющего поток 20 метаданных направлений и микшированный аудиопоток 30 в соответственные кодеры 25, 35 для получения кодированной пространственной аудиосцены 40, которая содержит аудиопоток 37, кодированный с пониженной битовой скоростью передачи данных, и кодированный поток 27 метаданных. Кодированный пространственный аудиопоток 40 предпочтительно выполнен так, что он подходит для хранения и/или передачи с пониженными требованиями к данным по сравнению с данными, необходимыми для хранения/передачи исходной пространственной аудиосцены.
Фиг. 4 схематически иллюстрирует пример компоновки для генерирования восстановленной пространственной аудиосцены из аудиопотока, кодированного с пониженной битовой скоростью передачи данных, и кодированного потока метаданных. В частности, на фигуре показана компоновка 160, в которой кодированный пространственный аудиопоток 40, состоящий из аудиопотока 37, кодированного с пониженной битовой скоростью передачи данных, и кодированного потока 27 метаданных, доставляется в качестве ввода в декодеры 36, 26 для получения микшированного аудиопотока 38 и потока 28 метаданных направлений соответственно. Затем потоки 38, 28 обрабатываются декодером 300 сцены для получения восстановленной аудиосцены 50.
Ниже будут описаны детали генерирования компактной пространственной аудиосцены, т.е. сжатого представления пространственной аудиосцены (или пространственного аудиосигнала / пространственного аудиопотока).
Фиг. 5 представляет собой блок-схему примера способа 500 обработки пространственного аудиосигнала для генерирования сжатого представления пространственного аудиосигнала. Способ 500 включает этапы S510–S550.
На этапе S510 пространственный аудиосигнал подвергают анализу для определения направлений поступления для одного или более аудиоэлементов (например, доминирующих аудиоэлементов) в аудиосцене (пространственной аудиосцене), представленной с помощью пространственного аудиосигнала. Эти (доминирующие) аудиоэлементы могут относиться, например, к (доминирующим) акустическим объектам, (доминирующим) источникам звука или (доминирующим) акустическим составляющим в аудиосцене. Анализ пространственного аудиосигнала может включать или может относиться к применению анализа сцены к пространственному аудиосигналу. Понятно, что специалисту известен диапазон подходящих инструментальных средств анализа сцены. Направления поступления, определенные на этом этапе, могут соответствовать местоположениям на единичной сфере, указывающим (воспринимаемые) местоположения аудиоэлементов.
В соответствии с приведенным выше описанием анализа на основе полос частот, анализ пространственного аудиосигнала на этапе S510 может основываться на множестве частотных поддиапазонов пространственного аудиосигнала. Например, анализ может основываться на полном частотном диапазоне пространственного аудиосигнала (т.е. на полном сигнале). То есть анализ может основываться на всех частотных поддиапазонах.
На этапе S520 для по меньшей мере одного частотного поддиапазона пространственного аудиосигнала определяют соответственные указатели мощности сигнала, связанной с определенными направлениями поступления.
На этапе S530 генерируют метаданные, содержащие информацию о направлениях и информацию об энергиях. Информация о направлениях содержит указатели определенных направлений поступления одного или более аудиоэлементов. Информация об энергиях содержит соответственные указатели мощности сигнала, связанной с определенными направлениями поступления. Метаданные, генерируемые на этом этапе, могут относиться к потоку метаданных.
На этапе S540 на основе пространственного аудиосигнала генерируют основанный на каналах аудиосигнал с предварительно установленным количеством каналов.
Наконец, на этапе S550 основанный на каналах аудиосигнал и метаданные выводят в виде сжатого представления пространственного аудиосигнала.
Понятно, что приведенные выше этапы могут выполняться в любом порядке или параллельно друг другу до тех пор, пока порядок этапов обеспечивает доступность необходимого ввода для каждого этапа.
Обычно можно считать, что пространственная сцена (или пространственный аудиосигнал) состоит из суммы акустических сигналов, падающих на слушателя с набора направлений относительно положения прослушивания. Поэтому пространственную аудиосцену можно смоделировать как набор из акустических объектов, причем объект  (
(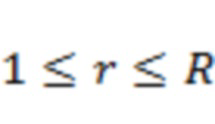 ) связан с аудиосигналом
) связан с аудиосигналом 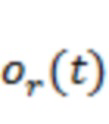 , падающим в положение прослушивания с направления поступления, установленного вектором
, падающим в положение прослушивания с направления поступления, установленного вектором 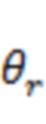 направления. Вектор направления может также представлять собой зависящий от времени вектор
направления. Вектор направления может также представлять собой зависящий от времени вектор 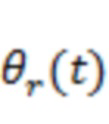 направления.
направления.
Таким образом, в соответствии с некоторыми реализациями пространственный аудиосигнал (пространственный аудиопоток) может быть установлен как основанный на объектах пространственный аудиосигнал (основанная на объектах пространственная аудиосцена) в форме набора аудиосигналов и связанных векторов направлений:
(14)
Дополнительно в соответствии с некоторыми реализациями пространственный аудиосигнал (пространственный аудиопоток) может быть установлен в выражении сигналов 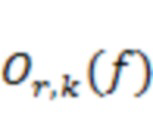 кратковременного преобразования Фурье в соответствии с уравнением (4), а векторы направлений могут быть определены в соответствии с индексом блока, так что:
кратковременного преобразования Фурье в соответствии с уравнением (4), а векторы направлений могут быть определены в соответствии с индексом блока, так что:
(15)
Альтернативно пространственный аудиосигнал (пространственный аудиопоток) может быть представлен в выражении основанного на каналах пространственного аудиосигнала (основанной на каналах пространственной аудиосцены). Основанный на каналах поток состоит из набора аудиосигналов, при этом каждый аудиообъект из пространственной аудиосцены микшируется в каналы в соответствии с функцией панорамирования ( ) согласно уравнению (1). Например, -канальная основанная на каналах пространственная аудиосцена
) согласно уравнению (1). Например, -канальная основанная на каналах пространственная аудиосцена 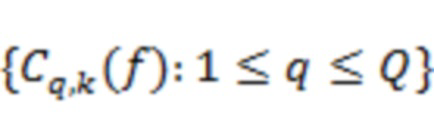 может быть образована из основанной на объектах пространственной аудиосцены в соответствии с:
может быть образована из основанной на объектах пространственной аудиосцены в соответствии с:
 (16)
(16)
Будет понятно, что многие свойства основанной на каналах пространственной аудиосцены определяются выбором функции панорамирования, и, в частности, длина () вектора-столбца, возвращаемого функцией панорамирования, будет определять количество аудиоканалов, содержащихся в основанной на каналах пространственной аудиосцене. В общем, более высококачественное представление пространственной аудиосцены можно реализовать с помощью основанной на каналах пространственной аудиосцены, содержащей большее количество каналов.
Например, на этапе S540 способа 500 пространственный аудиосигнал (пространственная аудиосцена) может обрабатываться для создания основанного на каналах аудиосигнала (основанного на каналах потока) в соответствии с уравнением (16). Функцию панорамирования можно выбрать так, чтобы создать представление пространственной аудиосцены с относительно низким разрешением. Например, функция панорамирования может быть выбрана как функция «Амбиофония первого порядка» (FOA), например, установленная в уравнении (2). Поэтому сжатое представление может представлять собой компактное представление, или представление уменьшенного размера.
Фиг. 6 представляет собой блок-схему, представляющую другую формулировку способа 600 генерирования компактного представления пространственной аудиосцены. В способ 600 доставляют входной поток в форме пространственной аудиосцены или основанного на сцене потока, и он генерирует в качестве компактного представления компактную пространственную аудиосцену. Для этого способ 600 включает этапы S610–S660. При этом этап S610 можно рассматривать как соответствующий этапу S510, этап 620 можно рассматривать как соответствующий этапу S520, этап S630 можно рассматривать как соответствующий этапу S540, этап S650 можно рассматривать как соответствующий этапу S530, и этап S660 можно рассматривать как соответствующий этапу S550.
На этапе S610 входной поток подвергают анализу для определения доминирующих направлений поступления.
На этапе S620 для каждой полосы (частотного поддиапазона) определяют долю энергии, выделяемой каждому направлению, относительно общей энергии в потоке в этой полосе.
На этапе S630 образуют подвергнутый понижающему микшированию поток, содержащий несколько аудиоканалов, представляющих пространственную аудиосцену.
На этапе S640 подвергнутый понижающему микшированию поток кодируют для образования сжатого представления потока.
На этапе S650 информацию о направлениях и информацию о долях энергии кодируют для образования кодированных метаданных.
Наконец, на этапе S660 кодированный подвергнутый понижающему микшированию поток объединяют с кодированными метаданными для образования компактной пространственной аудиосцены.
Понятно, что приведенные выше этапы могут выполняться в любом порядке или параллельно друг другу до тех пор, пока порядок этапов обеспечивает доступность необходимого ввода для каждого этапа.
Фиг. 7 - фиг. 11 схематически иллюстрируют примеры деталей генерирования сжатого представления пространственной аудиосцены в соответствии с вариантами осуществления настоящего изобретения. Понятно, что особенности, например, анализа пространственного аудиосигнала для определения направлений поступления, определения указателей мощности сигнала, связанной с определенными направлениями поступления, генерирования метаданных, содержащих информацию о направлениях и информацию об энергиях, и/или генерирования основанного на каналах аудиосигнала с предварительно установленным количеством каналов, как описано ниже, могут не зависеть от конкретной компоновки системы и могут применяться, например, в любых компоновках, показанных на фиг. 7 – фиг. 11, или любых подходящих альтернативных компоновках.
Фиг. 7 схематически иллюстрирует первый пример деталей генерирования сжатого представления пространственной аудиосцены. В частности, фиг. 7 показывает кодер 200 сцены, в котором пространственная аудиосцена 10 обрабатывается с помощью функции 203 понижающего микширования для получения -канального микшированного аудиопотока 30 в соответствии, например, с этапами S540 и S630. В некоторых вариантах осуществления функция 203 понижающего микширования может включать процесс панорамирования в соответствии с уравнением (1) или уравнением (16), при этом выбрана следующая функция панорамирования при понижающем микшировании:  . Например, в качестве функции панорамирования при понижающем микшировании можно выбрать функцию панорамирования «Амбиофония первого порядка»:
. Например, в качестве функции панорамирования при понижающем микшировании можно выбрать функцию панорамирования «Амбиофония первого порядка»: 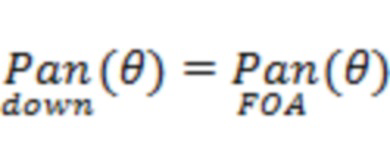 , и тогда
, и тогда 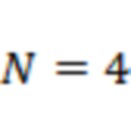 .
.
Для каждого временного отрезка аудио анализ 202 сцены принимает в качестве ввода пространственную аудиосцену и определяет направления поступления вплоть до 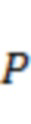 доминирующих акустических составляющих в пространственной аудиосцене в соответствии, например, с этапами S510 и S610. Типичные значения для составляют от 1 до 10, и предпочтительное значение для равно
доминирующих акустических составляющих в пространственной аудиосцене в соответствии, например, с этапами S510 и S610. Типичные значения для составляют от 1 до 10, и предпочтительное значение для равно 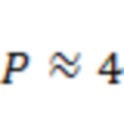 . Соответственно, один или более аудиоэлементов, определенных на этапе S510, могут содержать от одного до десяти аудиоэлементов, например, четыре аудиоэлемента.
. Соответственно, один или более аудиоэлементов, определенных на этапе S510, могут содержать от одного до десяти аудиоэлементов, например, четыре аудиоэлемента.
Анализ 202 сцены генерирует поток 20 метаданных, состоящий из информации 21 о направлениях и информации 22 о долях энергии в полосах (информации об энергиях). Необязательно анализ 202 сцены может также доставлять коэффициенты 207 в функцию 203 понижающего микширования для обеспечения возможности модификации подвергнутого понижающему микшированию сигнала.
Без предполагаемого ограничения анализ пространственного аудиосигнала (например, на этапе S510), определение соответственных указателей мощности сигнала (например, на этапе S520) и генерирование основанного на каналах аудиосигнала (например, на этапе S540) могут выполнять для каждого временного отрезка, например, в соответствии с приведенным выше описанием преобразований STFT. Это предполагает, что сжатое представление будет генерироваться и выводиться для каждого из множества временных отрезков посредством подвергнутого понижающему микшированию аудиосигнала и метаданных (блока метаданных) для каждого временного отрезка.
Для каждого временного отрезка информация 21 о направлениях (например, воплощенная посредством направлений поступления одного или более аудиоэлементов) может принимать форму векторов 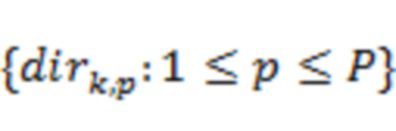 направлений. Вектор
направлений. Вектор  направления указывает направление, связанное с индексом доминирующего объекта, и может быть представлен в выражении единичных векторов:
направления указывает направление, связанное с индексом доминирующего объекта, и может быть представлен в выражении единичных векторов:
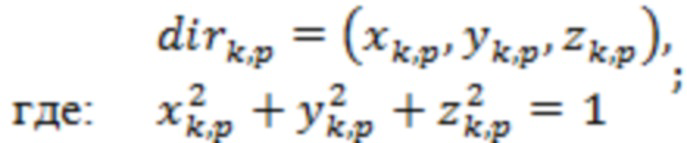 (17)
(17)
или в выражении сферических координат:
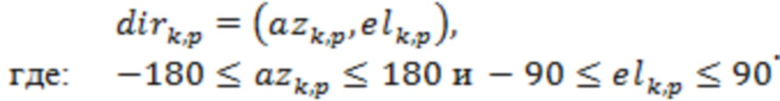 (18)
(18)
В некоторых вариантах осуществления соответственные указатели мощности сигнала, определяемые на этапе S520, принимают форму доли мощности сигнала. То есть указатель мощности сигнала, связанной с заданным направлением поступления в частотном поддиапазоне, относится к доле мощности сигнала в частотном поддиапазоне для заданного направления поступления относительно общей мощности сигнала в частотном поддиапазоне.
Дополнительно в некоторых вариантах осуществления указатели мощности сигнала определяются для каждого из множества частотных поддиапазонов (т. е. для каждого поддиапазона). Тогда они относятся, для заданного направления поступления и заданного частотного поддиапазона, к доле мощности сигнала в заданном частотном поддиапазоне для заданного направления поступления относительно общей мощности сигнала в заданном частотном поддиапазоне. В частности, хотя указатели мощности сигнала можно определить для каждого поддиапазона, определение (доминирующих) направлений поступления по-прежнему может выполняться в отношении полного сигнала (т. е. на основе всех частотных поддиапазонов).
Также дополнительно в некоторых вариантах осуществления анализ пространственного аудиосигнала (например, на этапе S510), определение соответственных указателей мощности сигнала (например, на этапе S520) и генерирование основанного на каналах аудиосигнала (например, на этапе S540) выполняют на основе частотно-временного представления пространственного аудиосигнала. Например, вышеупомянутые этапы и другие этапы при необходимости могут выполняться на основе дискретного преобразования Фурье (такого как, например, STFT) пространственного аудиосигнала. Например, для каждого временного отрезка (временного блока) вышеупомянутые этапы могут выполняться на основе элементов разрешения по времени и частоте (элементов разрешения FFT) пространственного аудиосигнала, т.е. на основе коэффициентов Фурье пространственного аудиосигнала.
При условии вышесказанного, для каждого временного отрезка и для каждого индекса (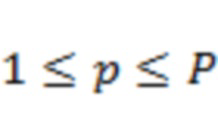 ) доминирующего объекта информация 22 о долях энергии в полосах может содержать значение
) доминирующего объекта информация 22 о долях энергии в полосах может содержать значение  доли для каждой полосы из набора полос (). Значение доли определяется для временного отрезка в соответствии с:
доли для каждой полосы из набора полос (). Значение доли определяется для временного отрезка в соответствии с:
 (19)
(19)
Значение доли может представлять долю энергии в области пространства в окрестности направления 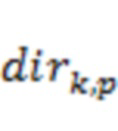 , так что энергию множества акустических объектов в исходной пространственной аудиосцене можно объединить для представления одной доминирующей акустической составляющей, приписанной направлению . В некоторых вариантах осуществления энергия всех акустических объектов в сцене может быть взвешена с использованием весовой функции
, так что энергию множества акустических объектов в исходной пространственной аудиосцене можно объединить для представления одной доминирующей акустической составляющей, приписанной направлению . В некоторых вариантах осуществления энергия всех акустических объектов в сцене может быть взвешена с использованием весовой функции 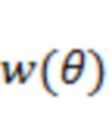 на основе угловой разности, которая предоставляет больший весовой коэффициент для направления
на основе угловой разности, которая предоставляет больший весовой коэффициент для направления 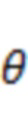 , близкого к , и меньший весовой коэффициент для направления , удаленного от . Разности между направлениями можно считать близкими при угловых разностях меньше, например,
, близкого к , и меньший весовой коэффициент для направления , удаленного от . Разности между направлениями можно считать близкими при угловых разностях меньше, например,  , и удаленными при угловых разностях больше, например,
, и удаленными при угловых разностях больше, например,  . В альтернативных вариантах осуществления весовая функция может быть выбрана на основе альтернативных вариантов выбора близких/удаленных угловых разностей.
. В альтернативных вариантах осуществления весовая функция может быть выбрана на основе альтернативных вариантов выбора близких/удаленных угловых разностей.
В целом входной пространственный аудиосигнал, для которого генерируется сжатое представление, может представлять собой, например, многоканальный аудиосигнал или основанный на объектах аудиосигнал. В последнем случае способ генерирования сжатого представления пространственного аудиосигнала будет дополнительно включать этап преобразования основанного на объектах аудиосигнала в многоканальный аудиосигнал перед применением анализа сцены (например, перед этапом S510).
В примере, представленном на фиг. 7, входной пространственный аудиосигнал может представлять собой многоканальный аудиосигнал. Тогда основанный на каналах аудиосигнал, генерируемый на этапе S540, будет представлять собой подвергнутый понижающему микшированию сигнал, сгенерированный путем применения операции понижающего микширования к многоканальному аудиосигналу.
Фиг. 8 схематически иллюстрирует другой пример деталей генерирования сжатого представления пространственной аудиосцены. В этом случае входной пространственный аудиосигнал может представлять собой основанный на объектах аудиосигнал, содержащий множество аудиообъектов и связанных векторов направлений. В этом случае способ генерирования сжатого представления пространственного аудиосигнала включает генерирование многоканального аудиосигнала в качестве промежуточного преставления или промежуточной сцены путем панорамирования аудиообъектов в предварительно установленный набор аудиоканалов, при этом каждый аудиообъект панорамируют в предварительно установленный набор аудиоканалов в соответствии с его вектором направления. Таким образом, фиг. 8 показывает альтернативный вариант осуществления кодера 200 сцены, в котором пространственная аудиосцена 10 вводится в преобразователь 201, который генерирует промежуточную сцену 11 (например, воплощенную посредством многоканального сигнала). Промежуточную сцену 11 можно создать в соответствии с уравнением (1), причем функцию панорамирования выбирают так, что скалярное произведение векторов 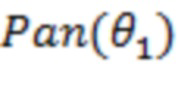 и
и 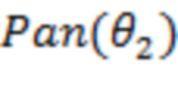 коэффициентов усиления при панорамировании приблизительно представляет весовую функцию на основе угловой разности, как описано выше.
коэффициентов усиления при панорамировании приблизительно представляет весовую функцию на основе угловой разности, как описано выше.
В некоторых вариантах осуществления функция панорамирования, используемая в преобразователе 201, представляет собой функцию 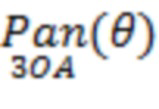 панорамирования «Амбиофония третьего порядка», как показано в уравнении (3). Соответственно, многоканальный аудиосигнал может представлять собой, например, сигнал амбиофонии высшего порядка.
панорамирования «Амбиофония третьего порядка», как показано в уравнении (3). Соответственно, многоканальный аудиосигнал может представлять собой, например, сигнал амбиофонии высшего порядка.
Промежуточная сцена 11 затем вводится в анализ 202 сцены. Анализ 202 сцены может определять направления доминирующих акустических объектов в пространственной аудиосцене на основании анализа промежуточной сцены 11. Определение доминирующих направлений можно выполнить путем оценки энергии в наборе направлений, при этом доминирующее направление представляет наибольшая оценочная энергия.
Информация 22 о долях энергии в полосах для временного отрезка может содержать значение доли для каждой полосы , полученное на основании энергии в полосе промежуточной сцены 11 в каждом направлении , относительно общей энергии в полосе промежуточной сцены 11 во временном отрезке .
В этом случае микшированный аудиопоток 30 (например, основанный на каналах аудиосигнал) компактной пространственной аудиосцены (например, компактного представления) представляет собой подвергнутый понижающему микшированию сигнал, сгенерированный путем применения функции 203 понижающего микширования (операции понижающего микширования) к пространственной аудиосцене.
Фиг. 10 показывает альтернативную компоновку кодера сцены, содержащего преобразователь 201 для преобразования пространственной аудиосцены 10 в основанный на сцене промежуточный формат 11. Промежуточный формат 11 вводится в анализ 202 сцены и в функцию 203 понижающего микширования. В некоторых вариантах осуществления функция 203 понижающего микширования может содержать функцию матричного микширования с коэффициентами, приспособленными для преобразования промежуточного формата 11 в микшированный аудиопоток 30. То есть в этом случае микшированный аудиопоток 30 (например, основанный на каналах аудиосигнал) компактной пространственной аудиосцены (например, компактного представления) может представлять собой подвергнутый понижающему микшированию сигнал, сгенерированный путем применения функции 203 понижающего микширования (операции понижающего микширования) к промежуточной сцене (например, многоканальному аудиосигналу).
В альтернативном варианте осуществления, показанном на фиг. 11, пространственный кодер 200 может принимать ввод в форме основанного на сцене ввода 11, при этом акустические объекты представлены в соответствии с законом панорамирования. В некоторых вариантах осуществления функция панорамирования может представлять собой функцию панорамирования «Амбиофония высшего порядка». В одном примерном варианте осуществления функция панорамирования представляет собой функцию панорамирования «Амбиофония третьего порядка».
В другом альтернативном варианте осуществления, проиллюстрированном на фиг. 9, пространственная аудиосцена 10 преобразовывается с помощью преобразователя 201 в пространственном кодере 200 для получения промежуточной сцены 11, которая вводится в функцию 203 понижающего микширования. В анализ 202 сцены доставляет ввод из пространственной аудиосцены 10.
Фиг. 12 схематически иллюстрирует пример деталей декодирования сжатого представления пространственной аудиосцены для образования воссозданной аудиосцены в соответствии с вариантами осуществления настоящего изобретения. В частности, на фигуре показан декодер 300 сцены, содержащий функцию 302 демикширования, которая принимает микшированный аудиопоток 30 и генерирует раздельный пространственный аудиопоток 70. Раздельный пространственный аудиопоток 70 состоит из сигналов 90 доминирующих объектов и остаточного потока 80. Остаточный декодер 81 принимает ввод из остаточного потока 80 и создает декодированный остаточный поток 82. Функция 91 панорамирования объектов принимает ввод из сигналов 90 доминирующих объектов и создает поток 92 панорамированных объектов. Декодированный остаточный поток 82 и поток 92 панорамированных объектов суммируются 75 для получения воссозданной аудиосцены 50.
Дополнительно фиг. 12 показывает информацию 21 о направлениях и информацию 22 о долях энергии в полосах, которая вводится в вычислитель 301 матрицы демикширования, определяющий матрицу 60 демикширования (обратную матрицу микширования) для использования функцией 302 демикширования.
Ниже будут описаны детали обработки компактной пространственной аудиосцены (например, сжатого представления пространственного аудиосигнала) для генерирования восстановленного представления пространственного аудиосигнала.
Фиг. 13 представляет собой блок-схему примера способа 1300 обработки сжатого представления пространственного аудиосигнала для генерирования восстановленного представления пространственного аудиосигнала. Понятно, что сжатое представление содержит основанный на каналах аудиосигнал (например, воплощенный посредством микшированного аудиопотока 30) с предварительно установленным количеством каналов и метаданные, причем метаданные содержат информацию о направлениях (например, воплощенную посредством информации 21 о направлениях) и информацию об энергиях (например, воплощенную посредством информации 22 о долях энергии в полосах), причем информация о направлениях содержит указатели направлений поступления одного или более аудиоэлементов в аудиосцене, и информация об энергиях содержит, для по меньшей мере одного частотного поддиапазона, соответственные указатели мощности сигнала, связанной с направлениями поступления. Например, основанный на каналах аудиосигнал может представлять собой сигнал амбиофонии первого порядка. Способ 1300 включает этапы S1310 и S1320, а также необязательно этапы S1330 и S1340. Понятно, что эти этапы могут выполняться, например, декодером 300 сцены, представленным на фиг. 12.
На этапе S1310 на основе основанного на каналах аудиосигнала, информации о направлениях и информации об энергиях генерируют аудиосигналы одного или более аудиоэлементов.
На этапе S1320 на основе основанного на каналах аудиосигнала, информации о направлениях и информации об энергиях генерируют остаточный аудиосигнал, в котором по существу отсутствует один или более аудиоэлементов. Здесь остаточный сигнал может быть представлен в таком же аудиоформате, как основанный на каналах аудиосигнал, например, может содержать такое же количество каналов, как основанный на каналах аудиосигнал.
На необязательном этапе S1330 аудиосигналы одного или более аудиоэлементов панорамируют в набор каналов выходного аудиоформата. Здесь выходной аудиоформат может относиться к выходному представлению, например, такому как НОА, или любому другому подходящему многоканальному формату.
На необязательном этапе S1340 восстановленный многоканальный аудиосигнал в выходном аудиоформате генерируют на основе панорамированного одного или более аудиоэлементов и остаточного сигнала. Генерирование восстановленного многоканального аудиосигнала может включать повышающее микширование остаточного сигнала в набор каналов выходного аудиоформата. Генерирование восстановленного многоканального аудиосигнала может дополнительно включать сложение панорамированного одного или более аудиоэлементов и подвергнутого повышающему микшированию остаточного сигнала.
Понятно, что приведенные выше этапы могут выполняться в любом порядке или параллельно друг другу до тех пор, пока порядок этапов обеспечивает доступность необходимого ввода для каждого этапа.
В соответствии с приведенным выше описанием способов обработки пространственной аудиосцены для генерирования сжатого представления пространственной аудиосцены, указатель мощности сигнала, связанной с заданным направлением поступления, может относиться к доле мощности сигнала в частотном поддиапазоне для заданного направления поступления относительно общей мощности сигнала в частотном поддиапазоне.
Кроме того, в некоторых вариантах осуществления информация об энергиях может содержать указатели мощности сигнала для каждого из множества частотных поддиапазонов. Тогда указатель мощности сигнала может относиться, для заданного направления поступления и заданного частотного поддиапазона, к доле мощности сигнала в заданном частотном поддиапазоне для заданного направления поступления относительно общей мощности сигнала в заданном частотном поддиапазоне.
Генерирование аудиосигналов одного или более аудиоэлементов на этапе S1310 может включать определение коэффициентов обратной матрицы микширования для отображения основанного на каналах аудиосигнала в промежуточное представление, содержащее остаточный аудиосигнал и аудиосигналы одного или более аудиоэлементов, на основе информации о направлениях и информации об энергиях. Промежуточное представление может также называться раздельным или разделяемым представлением или гибридным представлением.
Детали указанного определения коэффициентов обратной матрицы микширования будут описаны ниже со ссылкой на блок-схему, представленную на фиг. 14. Способ 1400, проиллюстрированный с помощью этой блок-схемы, включает этапы S1410–S1440.
На этапе S1410 для каждого из одного или более аудиоэлементов определяют вектор  панорамирования для панорамирования аудиоэлемента в каналы основанного на каналах аудиосигнала на основе направления
панорамирования для панорамирования аудиоэлемента в каналы основанного на каналах аудиосигнала на основе направления 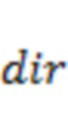 поступления аудиоэлемента.
поступления аудиоэлемента.
На этапе S1420 на основе определенных векторов панорамирования определяют матрицу  микширования, которую будут использовать для отображения остаточного аудиосигнала и аудиосигналов одного или более аудиоэлементов в каналы основанного на каналах аудиосигнала.
микширования, которую будут использовать для отображения остаточного аудиосигнала и аудиосигналов одного или более аудиоэлементов в каналы основанного на каналах аудиосигнала.
На этапе S1430 на основе информации об энергиях определяют ковариационную матрицу для промежуточного представления. Определение ковариационной матрицы может дополнительно основываться на определенных векторах панорамирования.
Наконец, на этапе S1440 коэффициенты обратной матрицы микширования определяют на основе матрицы микширования и ковариационной матрицы .
Понятно, что приведенные выше этапы могут выполняться в любом порядке или параллельно друг другу до тех пор, пока порядок этапов обеспечивает доступность необходимого ввода для каждого этапа.
Возвращаясь к фиг. 12, вычислитель 301 матрицы демикширования вычисляет матрицу 60 демикширования (обратную матрицу микширования) 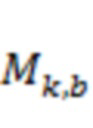 в соответствии с процессом, который включает следующие этапы.
в соответствии с процессом, который включает следующие этапы.
1. Входными данными в вычислитель матрицы демикширования, для временного отрезка , являются информация 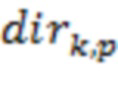 () о направлениях и информация
() о направлениях и информация 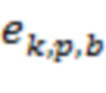 ( и
( и 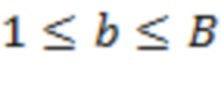 ) о долях энергии в полосах. представляет количество доминирующих акустических составляющих, и
) о долях энергии в полосах. представляет количество доминирующих акустических составляющих, и 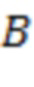 указывает количество полос частот.
указывает количество полос частот.
2. Для каждой полосы матрицу  демикширования вычисляют в соответствии с:
демикширования вычисляют в соответствии с:
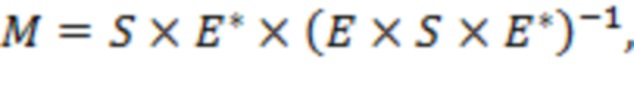 (20)
(20)
где «» указывает матричное произведение, и «» указывает сопряженную транспозицию матрицы. Например, вычисление в соответствии с уравнением (20) может соответствовать этапу S1440.
Матрицу демикширования можно определить для каждого из множества временных отрезков и/или для каждого из множества частотных поддиапазонов . В этом случае матрицы и будут характеризоваться индексом , указывающим временной отрезок, и/или индексом , указывающим частотный поддиапазон, и матрица будет характеризоваться индексом , указывающим временной отрезок, например:
 (20a)
(20a)
Обычно определение коэффициентов обратной матрицы микширования на основе матрицы микширования и ковариационной матрицы может включать определение псевдообратной матрицы на основе матрицы микширования и ковариационной матрицы . Один пример такой псевдообратной матрицы приведен в уравнениях (20) и (20a).
В уравнении (20) матрица 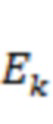 (матрица микширования) образована путем объединения друг с другом единичной матрицы
(матрица микширования) образована путем объединения друг с другом единичной матрицы  (
( ) и столбцов, образованных путем применения функции панорамирования к направлениям каждой из доминирующих акустических составляющих:
) и столбцов, образованных путем применения функции панорамирования к направлениям каждой из доминирующих акустических составляющих:
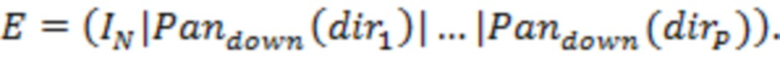 (21)
(21)
В уравнении (21) – единичная матрица , где указывает количество каналов основанного на каналах сигнала.  – вектор панорамирования для -го аудиоэлемента со связанным направлением поступления, который будет панорамировать -й аудиоэлемент в каналов основанного на каналах сигнала, где указывает соответственный один из одного или более аудиоэлементов, и указывает общее количество из одного или более аудиоэлементов. Вертикальные линии в уравнении (21) указывают операцию пополнения матрицы. Соответственно, матрица представляет собой матрицу .
– вектор панорамирования для -го аудиоэлемента со связанным направлением поступления, который будет панорамировать -й аудиоэлемент в каналов основанного на каналах сигнала, где указывает соответственный один из одного или более аудиоэлементов, и указывает общее количество из одного или более аудиоэлементов. Вертикальные линии в уравнении (21) указывают операцию пополнения матрицы. Соответственно, матрица представляет собой матрицу .
Дополнительно матрицу можно определить для каждого из множества временных отрезков . В этом случае матрица и направления поступления будут характеризоваться индексом , указывающим временной отрезок, например:
 (21a)
(21a)
Если предложенный способ действует на основе полос, матрица может являться одинаковой для всех частотных поддиапазонов.
В соответствии с этапом S1420 матрица представляет собой матрицу микширования, которую будут использовать для отображения остаточного аудиосигнала и аудиосигналов одного или более аудиоэлементов в каналы основанного на каналах аудиосигнала. Как видно из уравнений (21) и (21a), матрица основана на векторах панорамирования, определенных на этапе S1410.
В уравнении (20) матрица  представляет собой диагональную матрицу
представляет собой диагональную матрицу 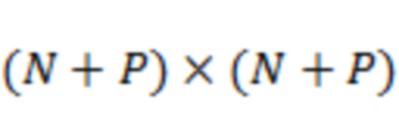 . Ее можно рассматривать как ковариационную матрицу для промежуточного представления. Ее коэффициенты можно вычислить на основе информации об энергиях в соответствии с этапом S1430. Первые диагональных элементов имеют вид:
. Ее можно рассматривать как ковариационную матрицу для промежуточного представления. Ее коэффициенты можно вычислить на основе информации об энергиях в соответствии с этапом S1430. Первые диагональных элементов имеют вид:
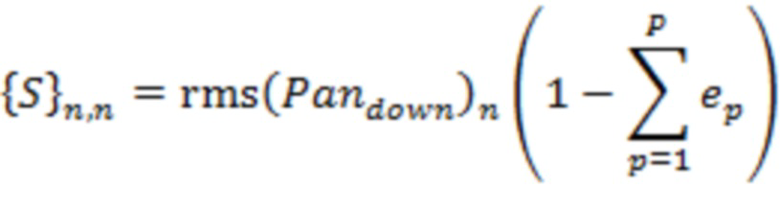 (22)
(22)
для  , а остальные диагональных элементов имеют вид:
, а остальные диагональных элементов имеют вид:
(23)
для , где представляет собой мощность сигнала, связанную с направлением поступления -го аудиоэлемента.
Ковариационную матрицу можно определить для каждого из множества временных отрезков и/или для каждого из множества частотных поддиапазонов . В этом случае ковариационная матрица и мощности  сигнала будут характеризоваться индексом , указывающим временной отрезок, и/или индексом , указывающим частотный поддиапазон. Первые диагональных элементов будут иметь вид:
сигнала будут характеризоваться индексом , указывающим временной отрезок, и/или индексом , указывающим частотный поддиапазон. Первые диагональных элементов будут иметь вид:
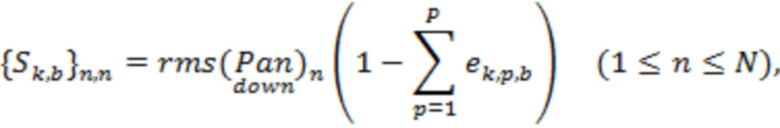 (22a)
(22a)
а остальные диагональных элементов будут иметь вид:
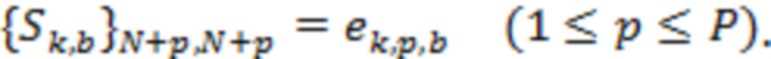 (23a)
(23a)
В предпочтительном варианте осуществления матрица демикширования применяется функцией 302 демикширования для получения раздельного пространственного аудиопотока 70 (в качестве примера промежуточного представления) в соответствии с вышеописанной реализацией этапа S1310, при этом первые каналов представляют собой остаточный поток 80, а остальные каналов представляют доминирующие акустические составляющие.
 -канальный раздельный пространственный поток 70
-канальный раздельный пространственный поток 70 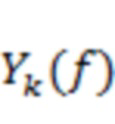 , -канальные сигналы 90
, -канальные сигналы 90  доминирующих объектов (в качестве примеров аудиосигналов одного или более аудиоэлементов, сгенерированных на этапе S1310) и -канальный остаточный поток 80
доминирующих объектов (в качестве примеров аудиосигналов одного или более аудиоэлементов, сгенерированных на этапе S1310) и -канальный остаточный поток 80  (в качестве примера остаточного аудиосигнала, сгенерированного на этапе S1320) вычисляются на основании -канального микшированного аудиосигнала 30
(в качестве примера остаточного аудиосигнала, сгенерированного на этапе S1320) вычисляются на основании -канального микшированного аудиосигнала 30 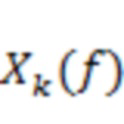 в соответствии с:
в соответствии с:
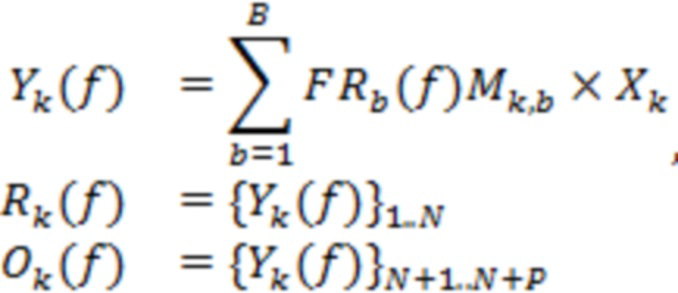 (24)
(24)
при этом сигналы представлены в форме STFT, выражение 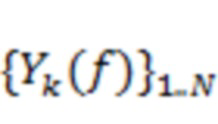 указывает N-канальный сигнал, образованный из каналов 1..N сигнала , и
указывает N-канальный сигнал, образованный из каналов 1..N сигнала , и 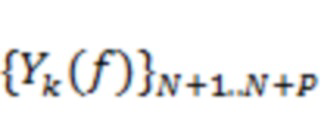 указывает Р-канальный сигнал, образованный из каналов N+1..N+P сигнала . Специалистам будет понятно, что применение матрицы может выполняться в соответствии с альтернативными способами, известными в данной области техники, которые обеспечивают приближенную функцию, эквивалентную функции в уравнении (24).
указывает Р-канальный сигнал, образованный из каналов N+1..N+P сигнала . Специалистам будет понятно, что применение матрицы может выполняться в соответствии с альтернативными способами, известными в данной области техники, которые обеспечивают приближенную функцию, эквивалентную функции в уравнении (24).
В дополнение к вышесказанному, в некоторых вариантах осуществления количество доминирующих акустических составляющих может быть приспособлено для принятия разных значений для каждого временного отрезка, так что  может зависеть от индекса временного отрезка. Например, анализ 202 сцены в кодере 200 сцены может определять значение для каждого временного отрезка. Обычно количество доминирующих акустических составляющих может зависеть от времени. Выбор (или ) может включать компромисс между скоростью передачи метаданных и качеством восстановленной аудиосцены.
может зависеть от индекса временного отрезка. Например, анализ 202 сцены в кодере 200 сцены может определять значение для каждого временного отрезка. Обычно количество доминирующих акустических составляющих может зависеть от времени. Выбор (или ) может включать компромисс между скоростью передачи метаданных и качеством восстановленной аудиосцены.
Возвращаясь к фиг. 12, пространственный декодер 300 генерирует -канальную воссозданную аудиосцену 50, при этом -канальный поток связан с выходной функцией 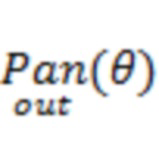 панорамирования. Это может осуществляться в соответствии с вышеописанным этапом S1340. Примеры выходных функций панорамирования включают функции стереофонического панорамирования, функции амплитудного панорамирования на векторной основе, известные в данной области техники, и функции панорамирования «Амбиофония высшего порядка», известные в данной области техники.
панорамирования. Это может осуществляться в соответствии с вышеописанным этапом S1340. Примеры выходных функций панорамирования включают функции стереофонического панорамирования, функции амплитудного панорамирования на векторной основе, известные в данной области техники, и функции панорамирования «Амбиофония высшего порядка», известные в данной области техники.
Например, функция 91 панорамирования объектов на фиг. 12 может быть приспособлена для создания -канального потока 92  панорамированных объектов в соответствии с:
панорамированных объектов в соответствии с:
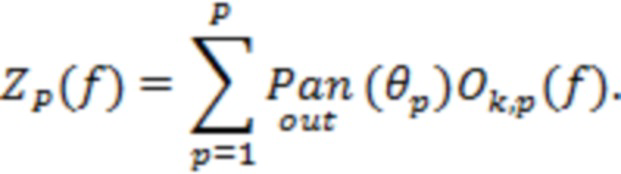 (25)
(25)
Фиг. 15 представляет собой блок-схему, представляющую альтернативную формулировку способа 1500 декодирования компактной пространственной аудиосцены для получения воссозданной аудиосцены. Способ 1500 включает этапы S1510–S1580.
На этапе S1510 принимают компактную пространственную аудиосцену и извлекают кодированный подвергнутый понижающему микшированию поток и кодированный поток метаданных.
На этапе S1520 кодированный подвергнутый понижающему микшированию поток декодируют для образования подвергнутого понижающему микшированию потока.
На этапе S1530 кодированный поток метаданных декодируют для образования информации о направлениях и информации о долях энергии.
На этапе S1540 на основании информации о направлениях и информации о долях энергии образуют матрицу демикширования для каждой полосы.
На этапе S1550 подвергнутый понижающему микшированию поток обрабатывают в соответствии с матрицей демикширования для образования раздельного потока.
На этапе S1560 сигналы объектов извлекают из раздельного потока и панорамируют для получения сигналов панорамированных объектов в соответствии с информацией о направлениях и требуемым выходным форматом.
На этапе S1570 остаточные сигналы извлекают из раздельного потока и обрабатывают для создания декодированных остаточных сигналов в соответствии с требуемым выходным форматом.
Наконец, на этапе S1580 сигналы панорамированных объектов и декодированные остаточные сигналы объединяют для образования воссозданной аудиосцены.
Понятно, что приведенные выше этапы могут выполняться в любом порядке или параллельно друг другу до тех пор, пока порядок этапов обеспечивает доступность необходимого ввода для каждого этапа.
Выше были описаны способы обработки пространственного аудиосигнала для генерирования сжатого представления пространственного аудиосигнала, а также способы обработки сжатого представления пространственного аудиосигнала для генерирования восстановленного представления пространственного аудиосигнала. Дополнительно настоящее изобретение также относится к устройству для осуществления этих способов. Пример такого устройства 1600 схематически проиллюстрирован на фиг. 16. Устройство 1600 может содержать процессор 1610 (например, центральный процессор (CPU), графический процессор (GPU), процессор цифровой обработки сигналов (DSP), одну или более специализированных интегральных микросхем (ASIC), одну или более радиочастотных интегральных микросхем (RFIC) или любую их комбинацию) и запоминающее устройство 1620, соединенное с процессором 1610. Процессор может быть приспособлен для осуществления некоторых или всех этапов способов, описанных во всем настоящем описании. Если устройство 1600 действует в качестве кодера (например, кодера сцены), оно может принимать в качестве ввода 1630, например, пространственный аудиосигнал (т. е. пространственную аудиосцену). Затем устройство 1600 может генерировать в качестве вывода 1640 сжатое представление пространственного аудиосигнала. Если устройство 1600 действует в качестве декодера (например, декодера сцены), оно может принимать в качестве ввода 1630 сжатое представление. Затем устройство может генерировать в качестве вывода 1640 воссозданную аудиосцену.
Устройство 1600 может представлять собой компьютер-сервер, компьютер-клиент, персональный компьютер (PC), планшетный PC, телевизионную приставку (STB), персональный цифровой помощник (PDA), сотовый телефон, смартфон, устройство веб-интерфейса, сетевой маршрутизатор, коммутатор, или мост, или любую машину, выполненную с возможностью исполнения команд (последовательных или других), которые задают действия, которые должны быть предприняты этим устройством. Дополнительно, в то время как на фиг. 16 проиллюстрировано только одно устройство 1600, настоящее изобретение следует связывать с любым набором устройств, которые по отдельности или вместе исполняют команды для выполнения любой одного или более методологий, обсужденных в настоящем документе.
Настоящее изобретение дополнительно относится к программе (например, компьютерной программе), содержащей команды, которые при исполнении процессором предписывают процессору осуществить некоторые или все этапы способов, описанных в настоящем документе.
Также дополнительно настоящее изобретение относится к считываемому компьютером (или считываемому машиной) носителю данных, на котором хранится вышеупомянутая программа. В настоящем документе термин «считываемый компьютером носитель данных» включает, но без ограничения, хранилища данных, например, в форме твердотельных запоминающих устройств, оптических носителей и магнитных носителей.
Обсуждения дополнительных конфигураций
Если прямо не заявлено иное, как очевидно из следующих обсуждений, следует понимать, что во всем настоящем описании обсуждения, в которых используются такие термины, как «обработка», «вычисление», «расчет», «определение», «анализ» или т. п., относятся к действию и/или процессам компьютера, или вычислительной системы, или аналогичных электронных вычислительных устройств, которые совершают манипуляции и/или преобразование данных, представленных в виде физических, например, электронных, величин, в другие данные, аналогично представленные в виде физических величин.
Сходным образом, термин «процессор» может относиться к любому устройству или части устройства, которая обрабатывает электронные данные, например, из регистров и/или запоминающего устройства, для преобразования этих электронных данных в другие электронные данные, которые, например, могут храниться в регистрах и/или запоминающем устройстве. «Компьютер», или «вычислительная машина», или «вычислительная платформа» может содержать один или более процессоров.
Методологии, описанные в настоящем документе, в одном примерном варианте осуществления приспособлены для выполнения одним или более процессорами, принимающими считываемый компьютером код (также называемый считываемым машиной), содержащий набор команд, которые при исполнении одним или более процессорами осуществляют по меньшей мере один из способов, описанных в настоящем документе. Включен любой процессор, приспособленный для (последовательного или иного) исполнения набора команд, которые определяют предпринимаемые действия. Так, одним из примеров является типичная система обработки, которая содержит один или более процессоров. Каждый процессор может содержать одно или более из CPU, графического процессора и программируемого блока DSP. Система обработки может дополнительно содержать подсистему запоминающих устройств, содержащую основное RAM, и/или статическое RAM, и/или ROM. Для обеспечения связи между компонентами может быть включена подсистема шин. Система обработки дополнительно может представлять собой распределенную систему обработки с процессорами, связанными посредством сети. Если для системы обработки требуется дисплей, такой дисплей может включать, например, жидкокристаллический дисплей (LCD) или дисплей с катодно-лучевой трубкой (CRT). Если требуется ввод данных вручную, система обработки также содержит устройство ввода, такое как одно или более из буквенно-цифрового блока ввода, такого как клавиатура, координатно-указательного устройства, такого как мышь, и т. д. Система обработки может также охватывать систему хранения данных, такую как блок дисковода. Система обработки в некоторых конфигурациях может содержать устройство вывода звука и устройство сетевого интерфейса. Таким образом, подсистема запоминающих устройств содержит считываемый компьютером носитель данных, несущий считываемый компьютером код (например, программное обеспечение), который содержит набор команд для предписания выполнить, при исполнении одним или более процессорами, один или более способов, описанных в настоящем документе. Следует отметить, что если способ включает несколько элементов, например, несколько этапов, то, если это не отмечено специально, никакое упорядочение этих элементов не подразумевается. Программное обеспечение может находиться на жестком диске или может также находиться, полностью или по меньшей мере частично, на RAM и/или в процессоре во время его исполнения компьютерной системой. Таким образом, запоминающее устройство и процессор также составляют считываемый компьютером носитель данных, несущий считываемый компьютером код. Кроме того, считываемый компьютером носитель данных может образовывать компьютерный программный продукт или может содержаться в нем.
В альтернативных примерных вариантах осуществления один или более процессоров действуют как автономное устройство или могут быть соединены, например, посредством сети, с другим процессором (другими процессорами) в объединенную в сеть развернутую систему, причем один или более процессоров могут работать в качестве сервера или клиентской машины в сетевой среде типа клиент-сервер или в качестве одноранговой машины в одноранговой или распределенной сетевой среде. Один или более процессоров могут образовывать персональный компьютер (PC), планшетный PC, персональный цифровой помощник (PDA), сотовый телефон, устройство веб-интерфейса, сетевой маршрутизатор, коммутатор, или мост, или любую машину, выполненную с возможностью исполнять набор команд (последовательный или другой), которые задают действия, которые должны быть предприняты этой машиной.
Следует отметить, что термин «машина» следует также воспринимать как включающий любой набор машин, которые вместе или по отдельности исполняют набор (или несколько наборов) команд для выполнения любой одной или более методологий, описанных в настоящем документе.
Таким образом, один примерный вариант осуществления каждого из способов, описанных в настоящем документе, имеет форму считываемого компьютером носителя данных, несущего набор команд, например, компьютерную программу, которая предназначена для исполнения на одном или более процессорах, например, одном или более процессорах, которые составляют часть компоновки веб-сервера. Поэтому, как будет понятно специалистам в данной области техники, примерные варианты осуществления настоящего изобретения могут быть осуществлены как способ, устройство, такое как устройство специального назначения, устройство, такое как система обработки данных, или считываемый компьютером носитель данных, например, компьютерный программный продукт. Считываемый компьютером носитель данных несет считываемый компьютером код, содержащий набор команд, которые при исполнении на одном или более процессорах предписывает процессору или процессорам реализовать способ. Соответственно, аспекты настоящего изобретения могут принимать форму способа, полностью аппаратного примерного варианта осуществления, полностью программного примерного варианта осуществления или примерного варианта осуществления, сочетающего аспекты программного и аппаратного обеспечения. Кроме того, настоящее изобретение может принимать форму носителя данных (например, компьютерного программного продукта на считываемом компьютером носителе данных), несущего считываемый компьютером программный код, реализованный на носителе.
Программное обеспечение может дополнительно передаваться или приниматься по сети с помощью устройства сетевого интерфейса. Несмотря на то что носитель данных в примерном варианте осуществления представляет собой единственный носитель данных, термин «носитель данных» следует воспринимать как включающий единственный носитель данных или множество носителей данных (например, централизованную или распределенную базу данных и/или связанные устройства кэш-памяти и сервера), которые хранят один или более наборов команд. Термин «носитель данных» также следует воспринимать как включающий любой носитель данных, приспособленный для хранения, кодирования или переноса набора команд, предназначенных для исполнения одним или более процессорами и предписывающих одному или более процессорам выполнить любую одну или более методологий настоящего изобретения. Носитель данных может принимать множество форм, включая, но без ограничения, энергонезависимые носители данных, энергозависимые носители данных и среды передачи данных. Энергонезависимые носители данных включают, например, оптические, магнитные диски и магнитооптические диски. Энергозависимые носители данных включают динамическое запоминающее устройство, такое как основное запоминающее устройство. Среды передачи данных включают коаксиальные кабели, медный провод и оптоволоконные кабели, включая провода, которые содержат подсистему шин. Среды передачи данных могут также принимать форму акустических или световых волн, таких как волны, которые генерируются во время радиоволновой и инфракрасной передач данных. Например, термин «носитель данных» следует, соответственно, воспринимать как включающий, но без ограничения, твердотельные запоминающие устройства, компьютерный продукт, реализованный на оптическом и магнитном носителях; среду, переносящую распространяющийся сигнал, обнаруживаемый по меньшей мере одним процессором или одним или более процессорами и представляющий собой набор команд, которые при исполнении реализуют способ; и среду передачи данных в сети, переносящую распространяющийся сигнал, обнаруживаемый по меньшей мере одним процессором из одного или более процессоров и представляющий собой набор команд.
Следует понимать, что обсужденные этапы способов выполняются в одном примерном варианте осуществления надлежащим процессором (или надлежащими процессорами) системы обработки (например, компьютерной системы), исполняющей команды (считываемый компьютером код), хранящиеся в хранилище данных. Также следует понимать, что настоящее изобретение не ограничивается никакой конкретной реализацией или программным техническим решением и что настоящее изобретение можно реализовать с использованием любых надлежащих технических решений для реализации функциональных возможностей, описанных в настоящем документе. Настоящее изобретение не ограничивается никакими конкретными языком программирования или операционной системой.
Отсылка во всем настоящем описании к «одному примерному варианту осуществления», «некоторым примерным вариантам осуществления» или «примерному варианту осуществления» означает, что конкретные признак, конструкция или характеристика, описанные в связи с примерным вариантом осуществления, включены в по меньшей мере один примерный вариант осуществления настоящего изобретения. Поэтому появления фраз «в одном примерном варианте осуществления», «в некоторых примерных вариантах осуществления» или «в примерном варианте осуществления» в различных местах по всему настоящему описанию не обязательно относятся к одному и тому же примерному варианту осуществления. Кроме того, конкретные признаки, конструкции или характеристики могут комбинироваться в одном или более примерных вариантах осуществления любым подходящим образом, что должно быть очевидно из настоящего описания для специалиста в данной области техники.
В контексте настоящего документа, если не указано иное, использование порядковых числительных «первый», «второй», «третий» и т. д. для описания обычного объекта просто указывает на то, что производится ссылка на различные экземпляры сходных объектов, и они не предназначены для обозначения того, что объекты, описанные таким образом, должны находиться в заданной последовательности будь то во времени, в пространстве, по рангу или в ином смысле.
В приведенной ниже формуле изобретения и в настоящем описании любой из терминов «содержащий», «состоящий из» или «который содержит» является открытым термином, что означает включение по меньшей мере следующих за ним элементов/признаков, но не исключение остальных. Поэтому термин «содержащий» при его использовании в формуле изобретения не следует интерпретировать как ограничивающий в отношении средств, или элементов, или этапов, перечисляемых после него. Например, объем выражения «устройство, содержащее А и В» не следует ограничивать устройствами, состоящими только из элементов А и В. Любой из используемых в настоящем документе терминов «включающий» или «который включает» также представляет собой открытый термин, который также означает включение по меньшей мере элементов/признаков, следующих за этим термином, но не исключение остальных. Таким образом, «включающий» является синонимом и означает «содержащий».
Следует понимать, что в приведенном выше описании примерных вариантов осуществления настоящего изобретения различные признаки настоящего изобретения иногда группируются вместе в один примерный вариант осуществления, фигуру или их описание для выбора оптимального пути описания и для обеспечения понимания одного или более различных аспектов изобретения. Такой способ раскрытия, однако, не следует интерпретировать как отражающий намерение того, что формула изобретения требует большего количества признаков, чем те, которые явно перечислены в каждом пункте формулы изобретения. Вместо этого, как отражает нижеследующая формула изобретения, аспекты настоящего изобретения заключаются менее чем во всех признаках одного вышеописанного примерного варианта осуществления. Поэтому формула изобретения, следующая за разделом «Описание», таким образом, явно включена в этот раздел «Описание», причем каждый пункт формулы изобретения самостоятельно представляет собой отдельный примерный вариант осуществления настоящего изобретения.
Кроме того, несмотря на то, что некоторые примерные варианты осуществления, описанные в настоящем документе, включают одни, а не другие признаки, включенные в другие примерные варианты осуществления, комбинации признаков из различных примерных вариантов осуществления подразумеваются как находящиеся в пределах объема настоящего изобретения и образующие другие примерные варианты осуществления, как должно быть понятно специалистам в данной области техники. Например, в нижеследующей формуле изобретения любые заявленные примерные варианты осуществления могут применяться в любой комбинации.
В приведенном в настоящем документе описании изложено множество конкретных деталей. Однако следует понимать, что примерные варианты осуществления настоящего изобретения могут применяться на практике без этих конкретных деталей. В других случаях хорошо известные способы, конструкции и технологии не показаны подробно, чтобы не затруднять понимание данного описания.
Таким образом, в то время как здесь описано то, что рассматривается как лучшие варианты осуществления настоящего изобретения, специалистам в данной области будет понятно, что в них могут вноситься другие и дополнительные модификации без отступления от идеи настоящего изобретения, и подразумевается, что все указанные изменения и модификации заявляются как находящиеся в пределах объема настоящего изобретения. Например, любые приведенные выше формулы являются только примерами процедур, которые могут использоваться. Функциональные возможности могут добавляться к структурным схемам или исключаться из них, а операции могут быть подвержены взаимному обмену между функциональными блоками. Этапы могут добавляться к способам или исключаться из способов, описанных в пределах объема настоящего изобретения.
Дополнительные аспекты, варианты осуществления и примерные реализации настоящего изобретения станут очевидными из перечисленных ниже пронумерованных примерных вариантов осуществления (EEE).
EEE 1 относится к способу представления пространственной аудиосцены как компактной пространственной аудиосцены, содержащей микшированный аудиопоток и поток метаданных направлений, при этом указанный микшированный аудиопоток состоит из одного или более аудиосигналов, и при этом указанный поток метаданных направлений состоит из временной последовательности блоков метаданных направлений, причем каждый из указанных блоков метаданных направлений связан с соответствующим временным отрезком в указанных аудиосигналах, и при этом указанная пространственная аудиосцена содержит один или более направленных звуковых элементов, каждый из которых связан с соответственным направлением поступления, и при этом каждый из указанных блоков метаданных направлений содержит: (a) информацию о направлениях, указывающую указанные направления поступления для каждого из указанных направленных звуковых элементов, и (b) информацию о долях энергии в полосах, указывающую энергию в каждом из указанных направленных звуковых элементов относительно энергии в указанном соответствующем временном отрезке в указанных аудиосигналах, для каждого из указанных направленных звуковых элементов и для каждого из набора из двух или более поддиапазонов.
EEE 2 относится к способу в соответствии с EEE 1, в котором (a) указанная информация о долях энергии в полосах указывает свойства указанной пространственной аудиосцены в каждом из нескольких указанных поддиапазонов, и (b) для по меньшей мере одного направления поступления данные, содержащиеся в указанной информации о направлениях, указывают свойства указанной пространственной аудиосцены в кластере из двух или более указанных поддиапазонов.
EEE 3 относится к способу обработки компактной пространственной аудиосцены, содержащей микшированный аудиопоток и поток метаданных направлений, для получения раздельного пространственного аудиопотока, содержащего набор из одного или более сигналов аудиообъектов, и остаточного потока, при этом указанный микшированный аудиопоток состоит из одного или более аудиосигналов, и при этом указанный поток метаданных направлений состоит из временной последовательности блоков метаданных направлений, причем каждый из указанных блоков метаданных направлений связан с соответствующим временным отрезком в указанных аудиосигналах, при этом для каждого из множества поддиапазонов способ включает: (a) определение коэффициентов матрицы демикширования на основании информации о направлениях и информации о долях энергии в полосах, содержащейся в потоке метаданных направлений, и (b) микширование с использованием указанной матрицы демикширования указанного микшированного аудиопотока для получения указанного раздельного пространственного аудиопотока.
EEE 4 относится к способу в соответствии с EEE 3, в котором каждый из указанных блоков метаданных направлений содержит: (a) информацию о направлениях, указывающую направления поступления для каждого из указанных направленных звуковых элементов, и (b) информацию о долях энергии в полосах, указывающую энергию в каждом из указанных направленных звуковых элементов относительно энергии в указанном соответствующем временном отрезке в указанных аудиосигналах, для каждого из указанных направленных звуковых элементов и для каждого из набора из двух или более поддиапазонов.
EEE 5 относится к способу в соответствии с EEE 3, в котором (a) для каждого из указанных блоков метаданных направлений указанную информацию о направлениях и указанную информацию о долях энергии в полосах используют для образования матрицы , представляющей приближенную ковариацию указанного раздельного пространственного аудиопотока, и (a) указанную информацию о долях энергии в полосах используют для образования матрицы , представляющей матрицу повторного микширования, которая устанавливает преобразование указанного раздельного пространственного аудиопотока в микшированный аудиопоток, и (b) указанную матрицу  демикширования вычисляют в соответствии с
демикширования вычисляют в соответствии с 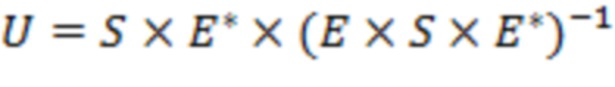 .
.
EEE 6 относится к способу в соответствии с EEE 5, в котором матрица представляют собой диагональную матрицу.
EEE 7 относится к способу в соответствии с EEE 3, в котором (a) указанный остаточный поток обрабатывают для получения восстановленного остаточного потока, (b) каждый из указанных сигналов аудиообъектов обрабатывают для получения соответствующего потока восстановленных объектов, и (c) указанный восстановленный остаточный поток и каждый из указанных потоков восстановленных объектов объединяют для образования воссозданных аудиосигналов, при этом указанные восстановленные аудиосигналы содержат направленные звуковые элементы в соответствии с указанной компактной пространственной аудиосценой.
EEE 8 относится к способу в соответствии с EEE 7, в котором указанные воссозданные аудиосигналы содержат два сигнала для представления слушателю через преобразователи на каждом или вблизи каждого уха для обеспечения бинаурального опыта пространственной аудиосцены, содержащей направленные звуковые элементы, в соответствии с указанной компактной пространственной аудиосценой.
EEE 9 относится к способу в соответствии с EEE 7, в котором указанные воссозданные аудиосигналы содержат несколько сигналов, которые представляют пространственную аудиосцену в форме сферических гармонических функций панорамирования.
EEE 10 относится к способу обработки пространственной аудиосцены для получения компактной пространственной аудиосцены, содержащей микшированный аудиопоток и поток метаданных направлений, при этом указанная пространственная аудиосцена содержит один или более направленных звуковых элементов, каждый из которых связан с соответственным направлением поступления, и при этом указанный поток метаданных направлений состоит из временной последовательности блоков метаданных направлений, причем каждый из указанных блоков метаданных направлений связан с соответствующим временным отрезком в указанных аудиосигналах, причем указанный способ предусматривает: (a) средства для определения указанного направления поступления для одного или более указанных направленных звуковых элементов на основании указанной пространственной аудиосцены, (b) средства для определения того, какую долю от общей энергии в указанной пространственной сцене вносит энергия в каждом из указанных направленных звуковых элементов, и (c) средства для обработки указанной пространственной аудиосцены для получения указанного микшированного аудиопотока.
| название | год | авторы | номер документа |
|---|---|---|---|
| Аудиоустройство и способ обработки аудио | 2019 |
|
RU2823573C1 |
| Аудиоустройство и способ обработки аудио | 2019 |
|
RU2815366C2 |
| Аудиоустройство и способ обработки аудио | 2019 |
|
RU2815621C1 |
| Аудиоустройство и способ обработки аудио | 2019 |
|
RU2798414C2 |
| УСТРОЙСТВО, СПОСОБ И КОМПЬЮТЕРНАЯ ПРОГРАММА ДЛЯ КОДИРОВАНИЯ, ДЕКОДИРОВАНИЯ, ОБРАБОТКИ СЦЕНЫ И ДРУГИХ ПРОЦЕДУР, ОТНОСЯЩИХСЯ К ОСНОВАННОМУ НА DirAC ПРОСТРАНСТВЕННОМУ АУДИОКОДИРОВАНИЮ | 2018 |
|
RU2759160C2 |
| ОБРАБОТКА АУДИОДАННЫХ НА ОСНОВЕ КАРТЫ НАПРАВЛЕННОЙ ГРОМКОСТИ | 2019 |
|
RU2771833C1 |
| ОПТИМИЗАЦИЯ ДОСТАВКИ ЗВУКА ДЛЯ ПРИЛОЖЕНИЙ ВИРТУАЛЬНОЙ РЕАЛЬНОСТИ | 2018 |
|
RU2750505C1 |
| ОБРАБОТКА АУДИОДАННЫХ НА ОСНОВЕ КАРТЫ НАПРАВЛЕННОЙ ГРОМКОСТИ | 2023 |
|
RU2826539C1 |
| ОПТИМИЗАЦИЯ ДОСТАВКИ ЗВУКА ДЛЯ ПРИЛОЖЕНИЙ ВИРТУАЛЬНОЙ РЕАЛЬНОСТИ | 2022 |
|
RU2801698C2 |
| ОБРАБОТКА АУДИОДАННЫХ НА ОСНОВЕ КАРТЫ НАПРАВЛЕННОЙ ГРОМКОСТИ | 2019 |
|
RU2798019C2 |
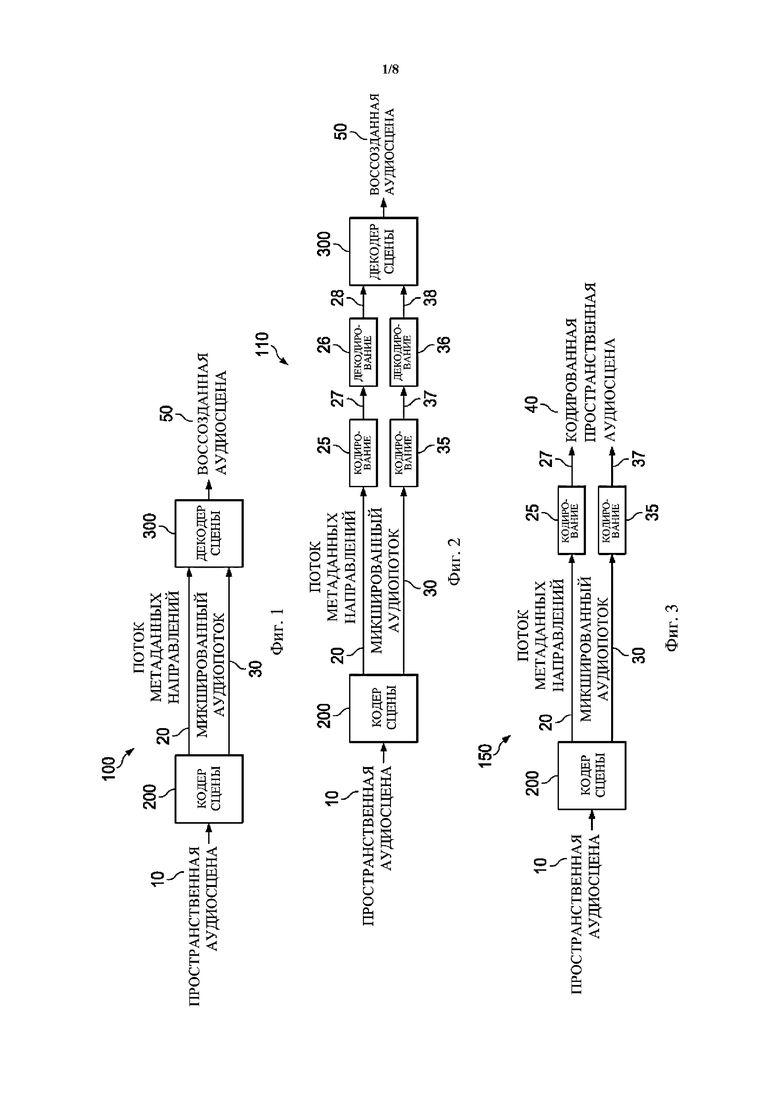

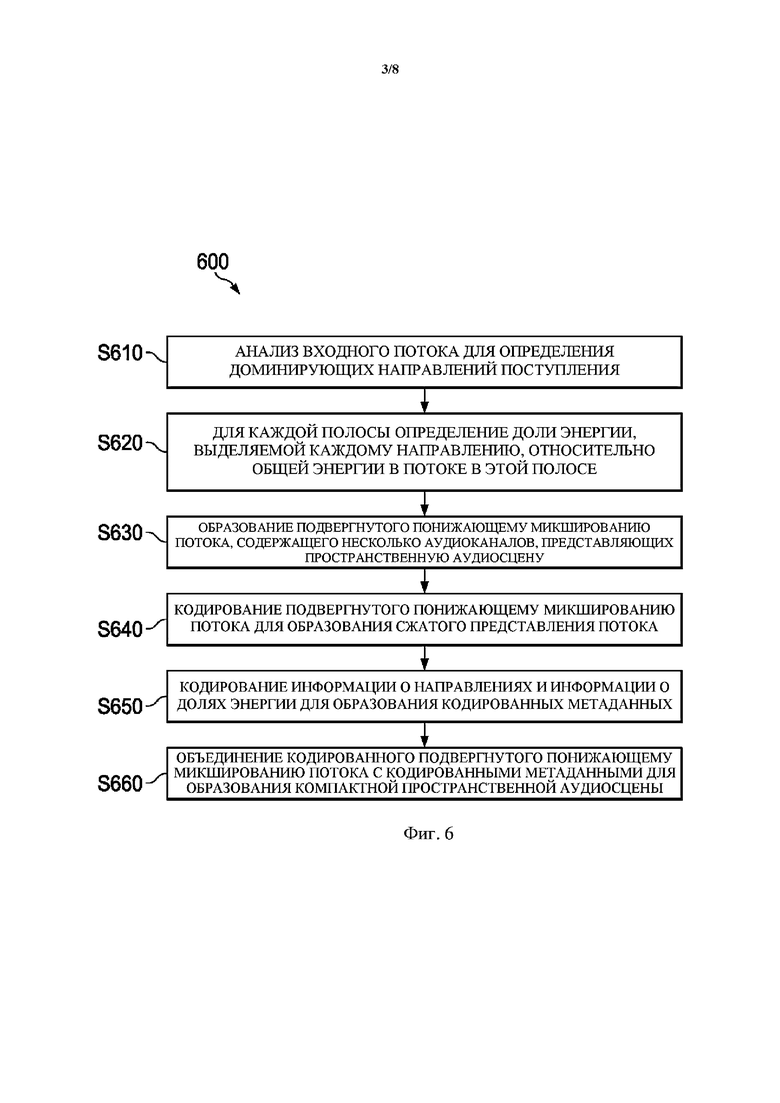

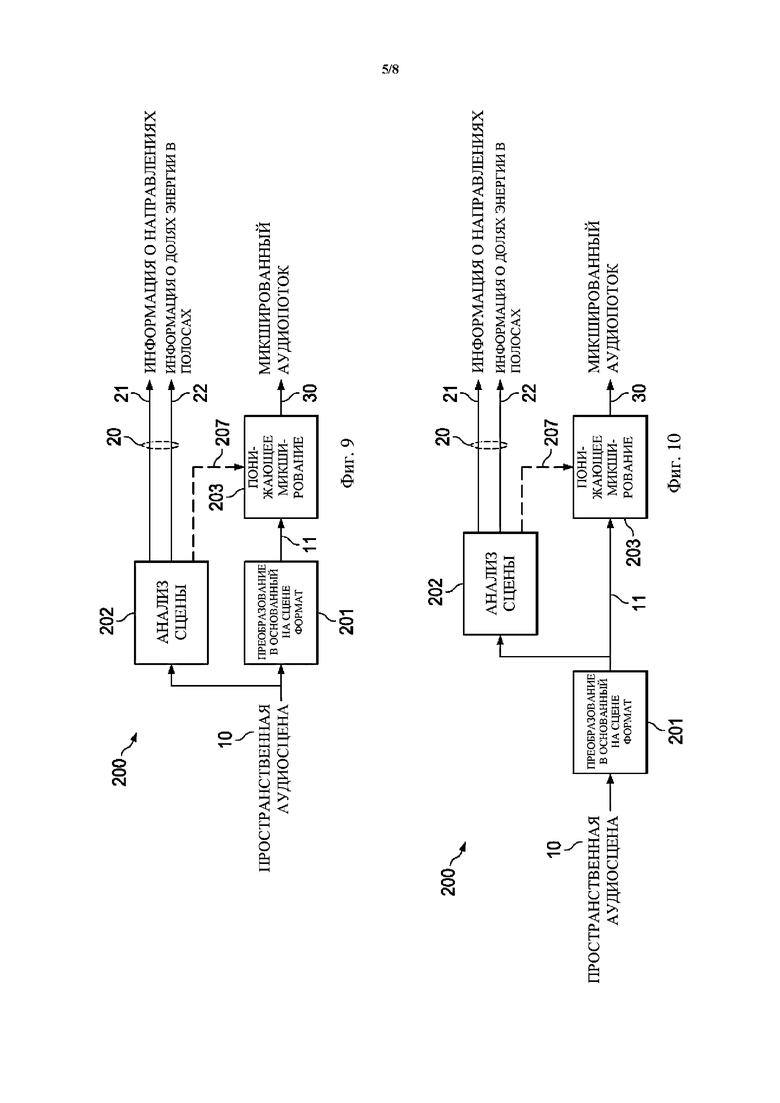
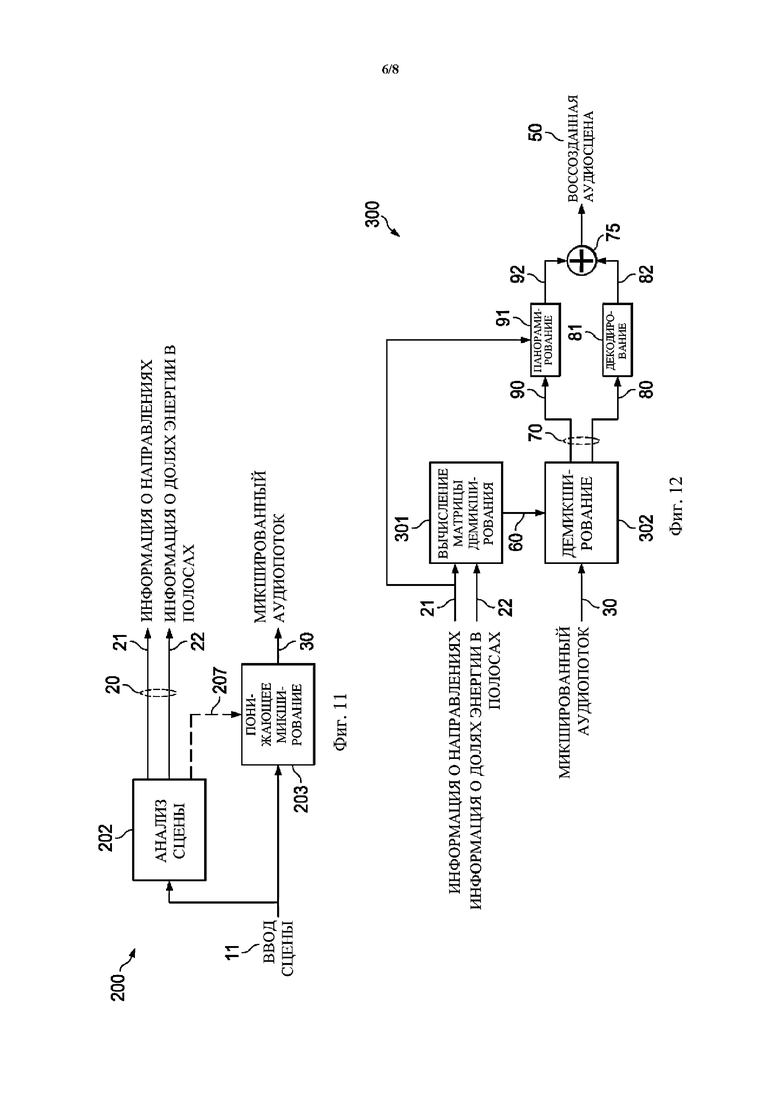
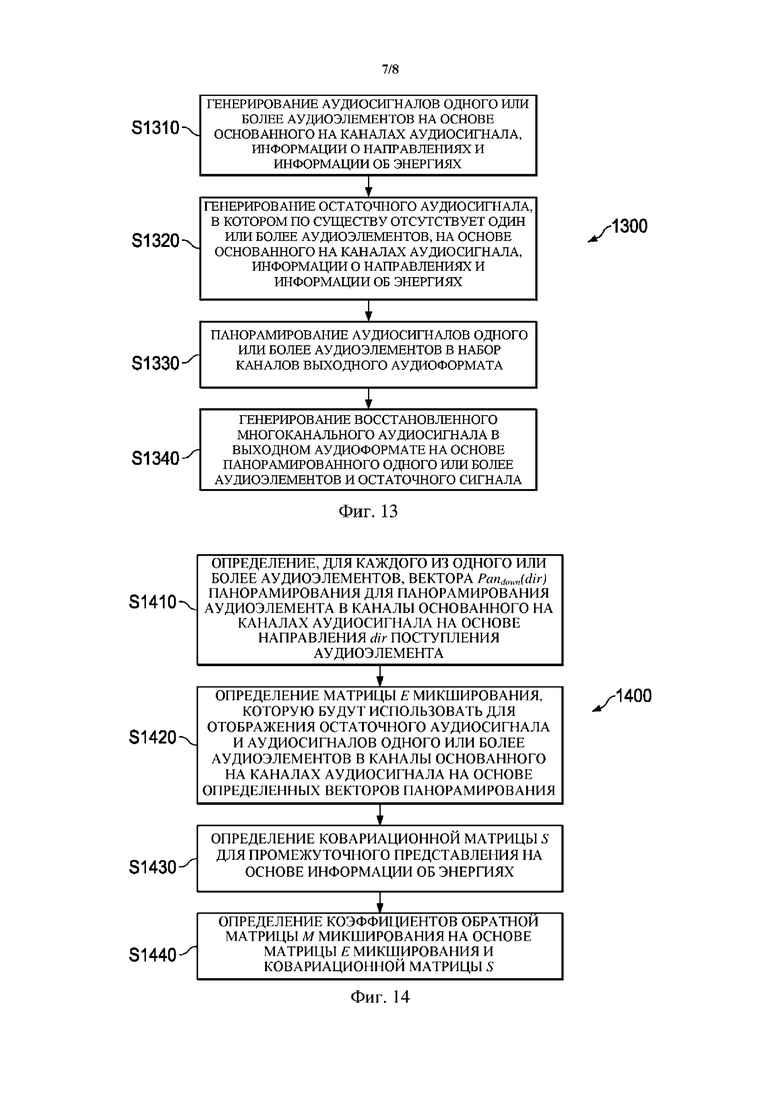
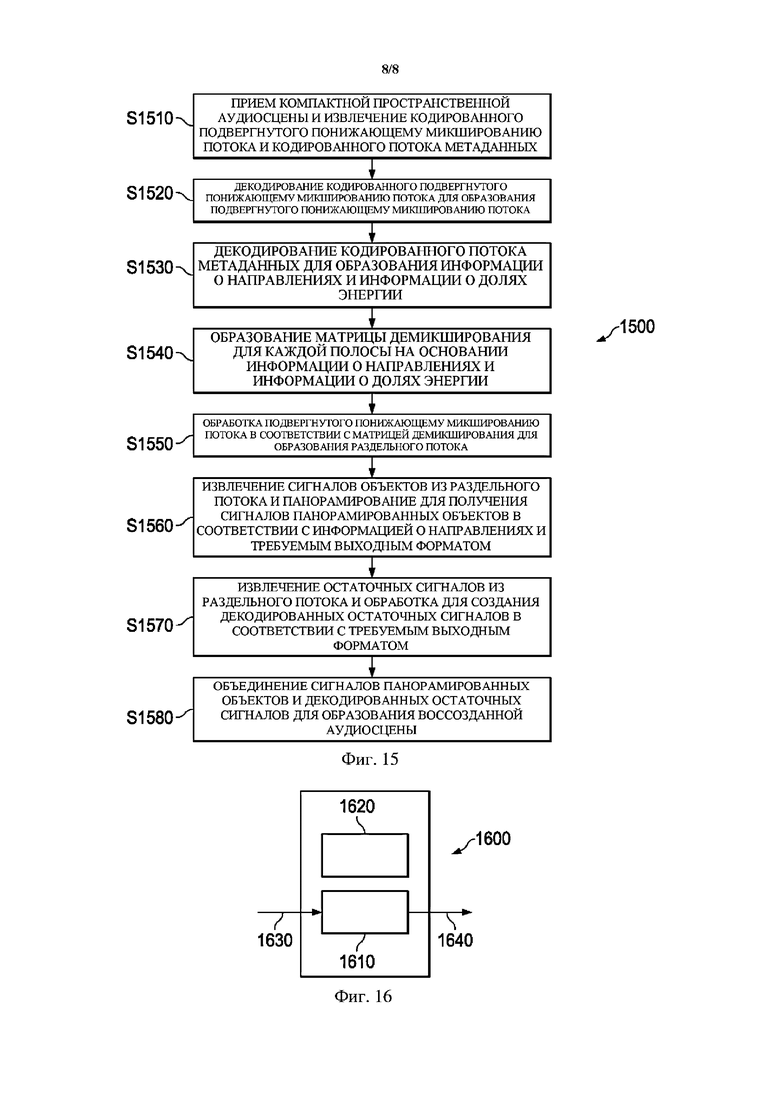
Изобретение относится к области вычислительной техники для обработки аудиосигналов. Технический результат заключается в снижении требований к полосе пропускания или хранилищам данных при передаче или хранении пространственных аудиосигналов. Технический результат достигается за счет этапов, на которых выполняют: анализ пространственного аудиосигнала для определения направлений поступления для одного или более аудиоэлементов в аудиосцене, представленной пространственным аудиосигналом; для по меньшей мере одного частотного поддиапазона пространственного аудиосигнала определение соответственных указателей мощности сигнала, связанной с определенными направлениями поступления; генерирование метаданных, содержащих информацию о направлениях и информацию об энергиях, причем информация о направлениях содержит указатели определенных направлений поступления одного или более аудиоэлементов, и информация об энергиях содержит соответственные указатели мощности сигнала, связанной с определенными направлениями поступления; генерирование основанного на каналах аудиосигнала с предварительно установленным количеством каналов на основе пространственного аудиосигнала; и вывод, в виде сжатого представления пространственного аудиосигнала, основанного на каналах аудиосигнала и метаданных. 2 н. и 18 з.п. ф-лы, 16 ил.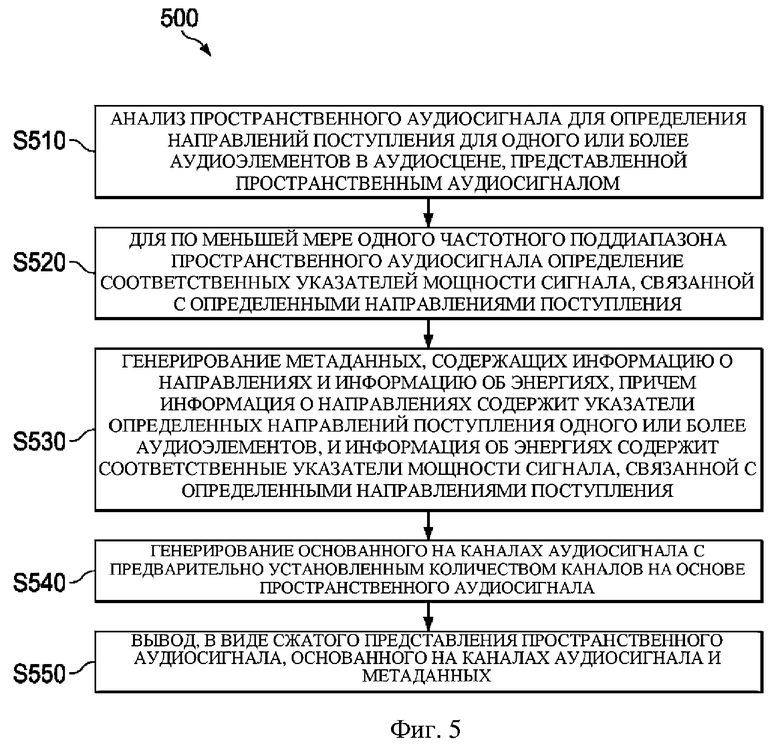
1. Способ обработки пространственного аудиосигнала для генерирования сжатого представления пространственного аудиосигнала, причем способ включает:
анализ пространственного аудиосигнала для определения направлений поступления для одного или более аудиоэлементов в аудиосцене, представленной пространственным аудиосигналом;
для по меньшей мере одного частотного поддиапазона пространственного аудиосигнала определение соответственных указателей мощности сигнала, связанной с определенными направлениями поступления;
генерирование метаданных, содержащих информацию о направлениях и информацию об энергиях, причем информация о направлениях содержит указатели определенных направлений поступления одного или более аудиоэлементов, и информация об энергиях содержит соответственные указатели мощности сигнала, связанной с определенными направлениями поступления;
генерирование основанного на каналах аудиосигнала с предварительно установленным количеством каналов на основе пространственного аудиосигнала; и
вывод, в виде сжатого представления пространственного аудиосигнала, основанного на каналах аудиосигнала и метаданных.
2. Способ по п. 1, отличающийся тем, что анализ пространственного аудиосигнала основан на множестве частотных поддиапазонов пространственного аудиосигнала.
3. Способ по п. 1, отличающийся тем, что анализ пространственного аудиосигнала включает применение анализа сцены к пространственному аудиосигналу.
4. Способ по п. 3, отличающийся тем, что пространственный аудиосигнал представляет собой многоканальный аудиосигнал; или
при этом пространственный аудиосигнал представляет собой основанный на объектах аудиосигнал, и способ дополнительно включает преобразование основанного на объектах аудиосигнала в многоканальный аудиосигнал перед применением анализа сцены.
5. Способ по п. 1, отличающийся тем, что указатель мощности сигнала, связанной с заданным направлением поступления, относится к доле мощности сигнала в частотном поддиапазоне для заданного направления поступления относительно общей мощности сигнала в частотном поддиапазоне.
6. Способ по п. 1, отличающийся тем, что указатели мощности сигнала определяют для каждого из множества частотных поддиапазонов, и они относятся, для заданного направления поступления и заданного частотного поддиапазона, к доле мощности сигнала в заданном частотном поддиапазоне для заданного направления поступления относительно общей мощности сигнала в заданном частотном поддиапазоне.
7. Способ по п. 1, отличающийся тем, что анализ пространственного аудиосигнала, определение соответственных указателей мощности сигнала и генерирование основанного на каналах аудиосигнала выполняют для каждого временного отрезка.
8. Способ по п. 1, отличающийся тем, что анализ пространственного аудиосигнала, определение соответственных указателей мощности сигнала и генерирование основанного на каналах аудиосигнала выполняют на основе частотно-временного представления пространственного аудиосигнала.
9. Способ по п. 1, отличающийся тем, что пространственный аудиосигнал представляет собой основанный на объектах аудиосигнал, содержащий множество аудиообъектов и связанных векторов направлений;
при этом способ дополнительно включает генерирование многоканального аудиосигнала путем панорамирования аудиообъектов в предварительно установленный набор аудиоканалов, при этом каждый аудиообъект панорамируют в предварительно установленный набор аудиоканалов в соответствии с его вектором направления; и
при этом основанный на каналах аудиосигнал представляет собой подвергнутый понижающему микшированию сигнал, сгенерированный путем применения операции понижающего микширования к многоканальному аудиосигналу.
10. Способ по п. 1, отличающийся тем, что пространственный аудиосигнал представляет собой многоканальный аудиосигнал; и
при этом основанный на каналах аудиосигнал представляет собой подвергнутый понижающему микшированию сигнал, сгенерированный путем применения операции понижающего микширования к многоканальному аудиосигналу.
11. Способ обработки сжатого представления пространственного аудиосигнала для генерирования восстановленного представления пространственного аудиосигнала, при этом сжатое представление содержит основанный на каналах аудиосигнал с предварительно установленным количеством каналов и метаданные, причем метаданные содержат информацию о направлениях и информацию об энергиях, причем информация о направлениях содержит указатели направлений поступления одного или более аудиоэлементов в аудиосцене, и информация об энергиях содержит, для по меньшей мере одного частотного поддиапазона, соответственные указатели мощности сигнала, связанной с направлениями поступления, причем способ включает:
генерирование аудиосигналов одного или более аудиоэлементов на основе основанного на каналах аудиосигнала, информации о направлениях и информации об энергиях; и
генерирование остаточного аудиосигнала, в котором по существу отсутствует один или более аудиоэлементов, на основе основанного на каналах аудиосигнала, информации о направлениях и информации об энергиях.
12. Способ по п. 11, отличающийся тем, что указатель мощности сигнала, связанной с заданным направлением поступления, относится к доле мощности сигнала в частотном поддиапазоне для заданного направления поступления относительно общей мощности сигнала в частотном поддиапазоне.
13. Способ по п. 11, отличающийся тем, что информация об энергиях содержит указатели мощности сигнала для каждого из множества частотных поддиапазонов, и при этом указатель мощности сигнала относится, для заданного направления поступления и заданного частотного поддиапазона, к доле мощности сигнала в заданном частотном поддиапазоне для заданного направления поступления относительно общей мощности сигнала в заданном частотном поддиапазоне.
14. Способ по п. 11, отличающийся тем, что дополнительно включает:
панорамирование аудиосигналов одного или более аудиоэлементов в набор каналов выходного аудиоформата; и
генерирование восстановленного многоканального аудиосигнала в выходном аудиоформате на основе панорамированного одного или более аудиоэлементов и остаточного сигнала.
15. Способ по п. 11, отличающийся тем, что генерирование аудиосигналов одного или более аудиоэлементов включает:
определение коэффициентов обратной матрицы 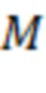 микширования для отображения основанного на каналах аудиосигнала в промежуточное представление, содержащее остаточный аудиосигнал и аудиосигналы одного или более аудиоэлементов, на основе информации о направлениях и информации об энергиях.
микширования для отображения основанного на каналах аудиосигнала в промежуточное представление, содержащее остаточный аудиосигнал и аудиосигналы одного или более аудиоэлементов, на основе информации о направлениях и информации об энергиях.
16. Способ по п. 15, отличающийся тем, что определение коэффициентов обратной матрицы микширования включает:
определение, для каждого из одного или более аудиоэлементов, вектора  панорамирования для панорамирования аудиоэлемента в каналы основанного на каналах аудиосигнала на основе направления
панорамирования для панорамирования аудиоэлемента в каналы основанного на каналах аудиосигнала на основе направления 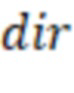 поступления аудиоэлемента;
поступления аудиоэлемента;
определение матрицы  микширования, которую будут использовать для отображения остаточного аудиосигнала и аудиосигналов одного или более аудиоэлементов в каналы основанного на каналах аудиосигнала на основе определенных векторов панорамирования;
микширования, которую будут использовать для отображения остаточного аудиосигнала и аудиосигналов одного или более аудиоэлементов в каналы основанного на каналах аудиосигнала на основе определенных векторов панорамирования;
определение ковариационной матрицы  для промежуточного представления на основе информации об энергиях; и
для промежуточного представления на основе информации об энергиях; и
определение коэффициентов обратной матрицы микширования на основе матрицы микширования и ковариационной матрицы .
17. Способ по п. 16, отличающийся тем, что матрицу микширования определяют в соответствии с:
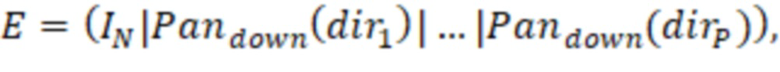
где  представляет собой единичную матрицу
представляет собой единичную матрицу 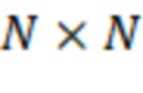 , причем
, причем  указывает количество каналов основанного на каналах сигнала,
указывает количество каналов основанного на каналах сигнала,  представляет собой вектор панорамирования для
представляет собой вектор панорамирования для  -го аудиоэлемента со связанным направлением
-го аудиоэлемента со связанным направлением 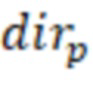 поступления, который будет панорамировать -й аудиоэлемент в каналов основанного на каналах сигнала, причем
поступления, который будет панорамировать -й аудиоэлемент в каналов основанного на каналах сигнала, причем  указывает соответственный один из одного или более аудиоэлементов, и
указывает соответственный один из одного или более аудиоэлементов, и  указывает общее количество из одного или более аудиоэлементов.
указывает общее количество из одного или более аудиоэлементов.
18. Способ по п. 17, отличающийся тем, что ковариационную матрицу определяют как диагональную матрицу в соответствии с:
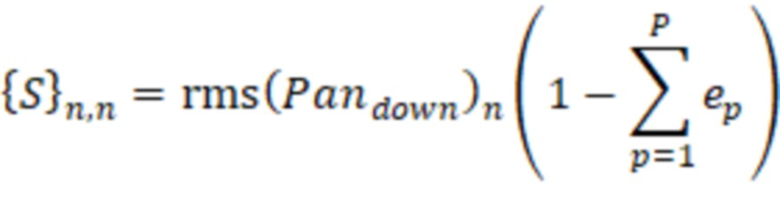
для 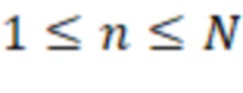 ; и
; и

для 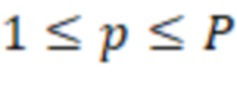 ,
,
где  представляет собой мощность сигнала, связанную с направлением поступления -го аудиоэлемента.
представляет собой мощность сигнала, связанную с направлением поступления -го аудиоэлемента.
19. Способ по п. 16, отличающийся тем, что определение коэффициентов обратной матрицы микширования на основе матрицы микширования и ковариационной матрицы включает определение псевдообратной матрицы на основе матрицы микширования и ковариационной матрицы.
20. Способ по п. 16, отличающийся тем, что обратную матрицу микширования определяют в соответствии с:
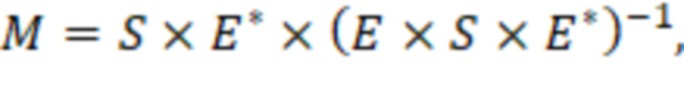
где « » указывает матричное произведение, и «
» указывает матричное произведение, и « » указывает сопряженную транспозицию матрицы.
» указывает сопряженную транспозицию матрицы.
| Пресс для выдавливания из деревянных дисков заготовок для ниточных катушек | 1923 |
|
SU2007A1 |
| Способ получения цианистых соединений | 1924 |
|
SU2018A1 |
| Автомобиль-сани, движущиеся на полозьях посредством устанавливающихся по высоте колес с шинами | 1924 |
|
SU2017A1 |
| Способ защиты переносных электрических установок от опасностей, связанных с заземлением одной из фаз | 1924 |
|
SU2014A1 |
| ПАРАМЕТРИЧЕСКОЕ КОДИРОВАНИЕ И ДЕКОДИРОВАНИЕ МНОГОКАНАЛЬНЫХ АУДИОСИГНАЛОВ | 2015 |
|
RU2704266C2 |

