Область техники, к которой относится изобретение
Варианты осуществления, согласно изобретению, относятся к динамическим потокам битов в стиле VR (виртуальной реальности)/AR (дополненной реальности), например, с использованием трех типов пакетов, с использованием пакетов обновлений сцен с условием обновления, с использованием временной метки и/или с использованием информации ячеек.
Уровень техники
Чтобы предоставлять иммерсивное восприятие для VR- и/или AR-вариантов применения, недостаточно предоставлять пространственное восприятие при просмотре, но также нужно и пространственное восприятие для слуха. В качестве примера, чтобы удовлетворять такую потребность, разрабатываются аудиотехнологии с шестью степенями свободы (6DoF). В этом отношении, сложно разрабатывать потоки битов и соответствующие кодеры и декодеры, которые обеспечивают иммерсивное восприятие для слуха высокой четкости, при одновременной применимости с целесообразными полосами пропускания.
Следовательно, желательно задавать концепцию, которая обеспечивает лучший компромисс между достижимым впечатлением для слуха от подготовленной посредством рендеринга аудиосцены, эффективностью передачи данных, используемых для рендеринга аудиосцены, и эффективностью декодирования и/или рендеринга данных.
Это достигается посредством предмета изобретения, охарактеризованного в независимых пунктах формулы изобретения настоящей заявки.
Дополнительные варианты осуществления согласно предмету изобретения представлены посредством зависимых пунктов формулы изобретения настоящей заявки.
Сущность изобретения
Ниже по тексту, поясняются варианты осуществления согласно первому аспекту изобретения. Варианты осуществления согласно первому аспекту изобретения могут быть основаны на использовании трех типов пакетов. Варианты осуществления согласно первому аспекту изобретения, например, могут содержать пакеты обновлений сцен и/или пакеты рабочих данных сцен. Варианты осуществления согласно первому аспекту изобретения могут содержать MPEG-H-совместимые пакеты либо могут предоставлять или содержать MPEG-H-совместимые декодеры, кодеры и/или потоки битов.
Варианты осуществления согласно изобретению, содержат аудиодекодер для обеспечения декодированного и необязательно подготовленного посредством рендеринга аудиопредставления на основе кодированного аудиопредставления. Аудиодекодер выполнен с возможностью пространственно подготавливать посредством рендеринга один или более аудиосигналов и принимать множество пакетов с различными типами пакетов, например, имеющих типы пакетов, которые являются совместимыми с определением MPEG-H MHAS-пакетов, причем пакеты содержат один или более пакетов конфигурирования сцен, например, пакет конфигурирования сцен, например, mpegiSceneConfig[] (иногда также обозначенный в качестве "mpeghiSceneConfig[]"), предоставляющий конфигурационную информацию модуля рендеринга, задающую использование объектов сцены и/или использование характеристик сцены, например, задающую то, когда или при каком условии различные объекты сцены и/или характеристики сцены должны использоваться в процессе рендеринга, например, с использованием определения ячеек. Концепция ячеек, например, является, в частности, важной для практической реализации поддержки подсцен. Подсцены, например, представляют собой части сцены, которые являются релевантными в определенной точке времени в сцене или в определенной окрестности/близости к предварительно заданным местоположениям сцены. В этих случаях, термин "ячейка" и "подсцена" может использоваться синонимично.
Необязательно, пакет конфигурирования сцен, например, может задавать то, какие пакеты рабочих данных сцен требуются в данной точке в пространстве и времени. В качестве другого необязательного признака, пакет конфигурирования сцен, например, может задавать то, из чего пакеты рабочих данных сцен могут извлекаться.
Кроме того, пакеты содержат один или более пакетов обновлений сцен, например, mpegiSceneUpdate[] (иногда также обозначенный в качестве "mpeghiSceneUpdate[]"), задающих обновление, например, изменение метаданных сцены для рендеринга, (например, изменение одного или более значений метаданных; например, изменение параметра объекта сцены или изменение характеристики сцены; например, изменение метаданных сцены, которое возникает во время воспроизведения). Необязательно, один или более пакетов обновлений сцен, например, могут задавать одно или более условий для обновления сцен.
Кроме того, пакеты содержат один или более пакетов рабочих данных сцен (например, mpegiScenePayload, иногда также обозначенный в качестве "mpeghiScenePayload"), содержащих определения одного или более объектов сцены и/или определения одной или более характеристик сцены (например, коллективные метаданные; например, метаданные, которые требуются для рендеринга одной или более аудиосцен; например, геометрические метаданные, описывающие аудиосцену для рендеринга, и/или параметрические инструкции рендеринга для рендеринга, и/или метаданные аудиоэлементов, описывающие один или более аудиоэлементов в аудиосцене для рендеринга; например, директивы и/или геометрии, и/или метаданные аудиоэффектов; например, метаданные реверберации и/или метаданные ранних отражений, и/или метаданные дифракции; например, mpegiScenePayload (иногда также обозначенный в качестве "mpeghiScenePayload"), например, в MHASPacketPayload()).
Помимо этого, аудиодекодер выполнен с возможностью выбирать определения одного или более объектов сцены и/или определения одной или более характеристик сцены, которые включаются в пакеты рабочих данных сцен для рендеринга, в зависимости от конфигурационной информации модуля рендеринга, которая необязательно может включаться в пакеты конфигурирования сцен. В качестве другого необязательного признака, ячейки могут использоваться для того, чтобы выбирать то, какие объекты сцены и/или характеристики сцены должны использоваться
Кроме того, аудиодекодер выполнен с возможностью обновлять одни или более метаданных сцены (например, один или более параметров рендеринга, обозначенных посредством "targetId", при этом новые значения одного или более параметров рендеринга могут быть обозначены посредством "attribute") в зависимости от контента одного или более пакетов обновлений сцен.
В качестве примера, аудиодекодер дополнительно может содержать функциональность модуля рендеринга либо может содержать модуль рендеринга или модуль подготовки посредством рендеринга. Следовательно, в контексте некоторых вариантов осуществления, аудиодекодер может быть синонимичным с модулем рендеринга, например, модулем рендеринга с функциональностью декодирования.
Авторы изобретения выяснили, что использование, по меньшей мере, трех отличающихся типов пакетов, а именно, пакетов конфигурирования сцен, пакетов обновлений сцен и пакетов рабочих данных сцен, может обеспечивать возможность эффективно предоставлять, передавать, сохранять и/или обновлять метаданные для вариантов применения для комплексного и динамического кодирования аудио, например, для динамических 6DoF-аудиосцен.
В качестве примера, пакеты конфигурирования сцен могут содержать или предоставлять релевантную информацию для декодера (или модуля рендеринга), чтобы конфигурировать себя. В частности, они, например, могут содержать инструкции в отношении того, какие пакеты рабочих данных сцен требуются в любой данной точке в пространстве (например, в пространственной позиции в аудиосцене или в сценарии рендеринга) и/или во времени, и необязательно, в отношении того, из чего они могут извлекаться, например, из выделенного обратного клиент-серверного канала.
Пакеты рабочих данных сцен, с другой стороны, например, могут представлять собой контейнер для коллективных метаданных, которые могут представлять собой метаданные, которые не могут непосредственно быть связанными с временной шкалой аудиопотока, но являются обязательными или полезными для рендеринга, например, комплексных и динамических аудиосцен, к примеру, 6DoF-аудиосцен. Пакеты рабочих данных могут содержать, например, геометрическую информацию акустически релевантных объектов, присутствующих в аудиосцене, параметрические инструкции рендеринга и/или дополнительные метаданные аудиоэлементов, например, свойства отражений или дифракции. Другими словами, пакеты рабочих данных, например, могут содержать направленности, геометрии и специальные метаданные для отдельных аудиоэффектов, таких как реверберация, ранние отражения или дифракция.
Кроме того, авторы изобретения выяснили, что может быть преимущественным задавать третий класс пакетов, а именно, пакеты обновлений сцен для того, чтобы обновлять вышеописанные метаданные сцены. Они, например, могут обеспечивать возможность указывать условие, при котором обновление выполняется (например, на основе времени и/или на основе информации местоположения, и/или на основе интерактивных триггеров), и изменение, внесенное в сцену.
Простыми словами и в качестве примера, варианты осуществления согласно изобретению, могут быть основаны на идее предоставлять метаданные сцены для задания акустически релевантных элементов и/или атрибутов сцены в пакетах рабочих данных сцен. Чтобы предоставлять информацию относительно того, как соответствующая рабочая информация должна обрабатываться, и/или того, когда и/или где (например, в аудиосцене или в сценарии рендеринга) соответствующая рабочая информация должна использоваться, пакеты конфигурирования сцен могут использоваться для того, чтобы задавать модуль рендеринга или декодер в соответствующей конфигурации. Чтобы иметь возможность обновлять такие метаданные, пакеты обновлений сцен могут использоваться для того, чтобы предоставлять информацию относительно обновления и необязательно условия обновления.
Следовательно, "измеренная" (например, реальная) аудиосцена может точно реконструироваться, или виртуальная аудиосцена может подготавливаться посредством рендеринга реалистично с использованием рабочей информации, при этом конфигурация декодера или модуля рендеринга, а также передача, сохранение, распределение и обновление информации могут выполняться эффективно на основе вышеописанного разделения на различные типы пакетов.
Другими словами, использование трех различных типов пакетов, включающих в себя пакеты конфигурирования сцен, пакеты рабочих данных сцен и пакеты обновлений сцен, обеспечивает возможность очень эффективной передачи и оценки информации сцен (например, информации объектов сцен и информации характеристик сцен), поскольку аудиодекодер может определять, на основе одного или более пакетов конфигурирования сцен, то, какие пакеты рабочих данных сцен или какая информация из пакетов рабочих данных сцен требуется. Соответственно, аудиодекодер, например, может использовать информацию пакетов конфигурирования сцен для того, чтобы принимать решение в отношении того, какие пакеты рабочих данных сцен следует сохранять и/или оценивать, и аудиодекодер, например, в некоторых случаях также может использовать пакеты конфигурирования сцен для того, чтобы определять то, какие пакеты рабочих данных сцен следует запрашивать из поставщика пакетов рабочих данных сцен (например, из сервера). Помимо этого, пакеты обновлений сцен могут обеспечивать возможность эффективной передачи в служебных сигналах изменений информации сцен и в силу этого способствовать высокой эффективности передачи и обработки информации сцен.
Согласно дополнительным вариантам осуществления изобретения, аудиодекодер выполнен с возможностью определять конфигурацию рендеринга на основе пакета конфигурирования сцен. Необязательно, пакет конфигурирования сцен, например, может означать глобальный пакет рабочих данных с использованием globalPayloadId, и пакет конфигурирования сцен, например, может означать отдельные рабочие данные (или отдельные пакеты рабочих данных) с использованием концепции ячеек, которая ассоциирует payloadIds с ячейками. Кроме того, аудиодекодер выполнен с возможностью определять обновление конфигурации рендеринга на основе одного или более пакетов обновлений сцен.
Ячейки могут предоставлять пространственную и/или временную сегментацию аудиосцены, при этом текущая позиция слушателя, для которого подготавливается посредством рендеринга аудиосцена, может инициировать запрос или использование соответствующих пакетов рабочих данных, например, задающих метаданные относительно акустически релевантных объектов в сцене, например, пространственно расположенной в зоне, ассоциированной с ячейкой, например, активной в текущее время воспроизведения.
Согласно дополнительным вариантам осуществления изобретения, один или более пакетов обновлений сцен, например, mpegiSceneUpdate (иногда также обозначенный в качестве "mpeghiSceneUpdate()"), содержат перечисление элементов метаданных сцены, которые должны изменяться, например, перечисление, имеющее переменное число элементов метаданных сцены, которые должны изменяться, и переменное упорядочение элементов метаданных сцены, которые должны изменяться. Помимо этого, перечисление содержит, для одного или более элементов метаданных, которые должны изменяться, идентификатор метаданных, например, targetId, и значение обновления метаданных, например, attribute. Необязательно, аудиодекодер может быть выполнен с возможностью избирательно обновлять метаданные сцены, включенные в перечисление.
Авторы изобретения выяснили, что это может обеспечивать возможность эффективно указывать то, какие элементы метаданных должны обновляться, и обновлять их.
Согласно дополнительным вариантам осуществления изобретения, аудиодекодер выполнен с возможностью получать определения одного или более объектов сцены и/или определения одной или более характеристик сцены из одного или более пакетов рабочих данных сцен.
Как пояснено выше, авторы изобретения выяснили, что пакеты рабочих данных сцен могут обеспечивать возможность эффективно задавать акустически релевантные объекты сцены и/или характеристики сцены. На основе этих элементов и/или характеристик, может выполняться реалистичный рендеринг звуковых окружений.
Согласно дополнительным вариантам осуществления изобретения, один или более пакетов рабочих данных сцен содержат перечисление рабочих данных, задающих объекты сцены и/или характеристики сцены, например, перечисление, имеющее переменное число рабочих данных и переменное упорядочение рабочих данных. Кроме того, аудиодекодер выполнен с возможностью оценивать перечисление рабочих данных, задающих объекты сцены и/или характеристики сцены.
Перечисление рабочих данных может обеспечивать возможность простого выбора того, какие рабочие данные, например, элемент рабочих данных, следует в данный момент рассматривать. Кроме того, перечисление, используемое посредством пакета обновлений сцен, может соответствовать перечислению пакета рабочих данных сцены для простого выбора того, какой элемент рабочих данных следует обновлять.
Согласно дополнительным вариантам осуществления изобретения, идентификатор рабочих данных, например, идентификатор ассоциирован с рабочими данными в пакете рабочих данных сцены, и аудиодекодер выполнен с возможностью оценивать идентификатор рабочих данных для указанных рабочих данных, чтобы принимать решение в отношении того, должны или нет указанные рабочие данные, например, определение определенного данного объекта сцены и/или определенных характеристик сцены, использоваться для рендеринга, например, с использованием конфигурационной информации модуля рендеринга, задающей использование объектов сцены и/или использование характеристик сцены.
Авторы изобретения выяснили, что использование идентификатора рабочих данных может обеспечивать возможность эффективно выбирать то, какие рабочие данные следует рассматривать для рендеринга.
Согласно дополнительным вариантам осуществления изобретения, один или более пакетов обновлений сцен задают условие для обновления сцен, и аудиодекодер выполнен с возможностью оценивать то, удовлетворяется или нет условие для обновления сцен, заданное в пакете обновлений сцен для того, чтобы принимать решение в отношении того, должно или нет осуществляться обновление сцен.
Следовательно, эффективные обновления сцен могут выполняться. Использование условных обновлений может обеспечивать возможность выполнять упомянутые обновления быстро, после того, как условие удовлетворяется, например, без необходимости сначала запрашивать соответствующую информацию обновления, когда условие удовлетворяется. Следовательно, такие обновления, содержащие информацию относительно самого обновления и инициирующего условия, могут передаваться в декодер до того, как они требуются, так что декодер может просто "ожидать" до тех пор, пока критерий не удовлетворяется.
Согласно дополнительным вариантам осуществления изобретения, один или более пакетов обновлений сцен задают интерактивное инициирующее условие, например, такое условие, что пользователь предпринимает определенное действие, которое выходит за рамки простого перемещения в сцене; например, такое условие, что пользователь выдает предварительно определенную команду или активирует предварительно определенную кнопку. Кроме того, аудиодекодер выполнен с возможностью оценивать то, удовлетворяется или нет интерактивное инициирующее условие, чтобы принимать решение в отношении того, должно или нет осуществляться обновление сцен.
Следовательно, реалистичный рендеринг аудиоокружений может предоставляться, при этом может учитываться даже реальное пользовательское взаимодействие по таймеру, например, с окружением (например, нажатие кнопки, например, запуск виртуально имитируемой машины, который вызывает изменение акустических свойств сцены).
Согласно дополнительным вариантам осуществления изобретения, один или более пакетов конфигурирования сцен и один или более пакетов обновлений сцен, и один или более пакетов рабочих данных сцен являются совместимыми с определением MPEG-H MHAS-пакетов. Необязательно, аудиодекодер может быть выполнен с возможностью идентифицировать один или более пакетов конфигурирования сцен и один или более пакетов обновлений сцен, и один или более пакетов рабочих данных сцен в потоке пакетов, например, с использованием синтаксического анализа потоков битов, адаптированного к определению MPEG-H MHAS-пакетов.
Это может обеспечивать возможность простой интеграции в существующих инфраструктурах кодирования.
Согласно дополнительным вариантам осуществления изобретения, один или более пакетов конфигурирования сцен и один или более пакетов обновлений сцен, и один или более пакетов рабочих данных сцен содержат идентификатор типа пакета, например, MHASPacketType, метку пакета, например, MHASPacketLabel, информацию длины пакетов, например, MHASPacketLength, и рабочие данные пакета, например, MHASPAcketPayload. Необязательно, аудиодекодер может быть выполнен с возможностью оценивать идентификатор типа пакета, чтобы отличать пакеты с различными типами пакетов.
В качестве примера, метка пакета может предоставлять индикатор того, какие пакеты принадлежат друг другу. Например, с использованием различных меток, различные трехмерные конфигурационные MPEG-H-аудиоструктуры могут назначаться конкретным последовательностям трехмерных MPEG-H-единиц аудиодоступа. Информация длины пакетов может указывать длину рабочих данных пакета. Авторы изобретения выяснили, что использование такой структуры данных может обеспечивать возможность эффективной обработки пакетов.
Согласно дополнительным вариантам осуществления изобретения, аудиодекодер выполнен с возможностью извлекать один или более пакетов конфигурирования сцен, один или более пакетов обновлений сцен и один или более пакетов рабочих данных сцен из потока битов, содержащего множество MPEG-H-пакетов, включающих в себя пакеты, представляющие один или более аудиоканалов, которые должны подготавливаться посредством рендеринга.
Необязательно, аудиодекодер, например, может быть выполнен с возможностью извлекать один или более пакетов конфигурирования сцен, один или более пакетов обновлений сцен и один или более пакетов рабочих данных сцен из перемеженной последовательности пакетов (например, из перемеженной последовательности MHAS-пакетов) содержащей пакеты с различными типами, например, с использованием идентификаторов типов пакетов и/или меток пакетов, включенных в пакеты.
Варианты осуществления согласно изобретению, могут использоваться в контексте MPEG-H-аудиопотоков. Следовательно, варианты осуществления согласно изобретению, могут быть совместимыми с существующими инфраструктурами потоковой передачи аудио. Кроме того, варианты осуществления, например, могут поддерживать множество различных вариантов для того, чтобы предоставлять пакеты (например, с перемежением). В качестве примера, предоставление перемеженным способом может обеспечивать возможность поддерживать размер соответствующих пакетов низким, что может быть преимущественным для некоторых, например, широковещательных каналов.
Согласно дополнительным вариантам осуществления изобретения, аудиодекодер выполнен с возможностью принимать один или более пакетов конфигураций сцен через широковещательный поток, например, через широковещательный поток с низкой скоростью передачи битов. Авторы изобретения выяснили, что, например, для вариантов применения со множеством пользователей, пакеты конфигурирования сцен могут предоставляться эффективно через широковещательный поток.
Согласно дополнительным вариантам осуществления изобретения, аудиодекодер выполнен с возможностью запрашивать один или более пакетов рабочих данных сцен из поставщика пакетов, например, с использованием обратного канала с поставщиком пакетов, например, в ответ на определение, посредством аудиодекодера, того, что один или более пакетов рабочих данных сцен либо контент одного или более пакетов рабочих данных сцен требуются для рендеринга.
Например, на основе пакетов конфигурирования сцен, декодер может определять то, какие пакеты рабочих данных необходимы (например, посредством определения сначала конфигурации модуля рендеринга, которая может указывать то, какие элементы метаданных необходимы, или то, какие рабочие данные необходимы), и в силу этого может запрашивать их. Это, например, может обеспечивать возможность освобождать от нагрузки широковещательный канал и повторно выделять отдельно релевантную (например, для конкретного декодера или слушателя, для которого декодер подготавливает посредством рендеринга аудиосцену) передачу информации в одноадресный и/или многоадресный канал.
Согласно дополнительным вариантам осуществления изобретения, аудиодекодер выполнен с возможностью запрашивать один или более пакетов рабочих данных сцен из поставщика пакетов с использованием идентификатора рабочих данных, например, с использованием идентификатора, ассоциированного с элементом рабочих данных. Альтернативно, аудиодекодер выполнен с возможностью запрашивать один или более пакетов рабочих данных сцен из поставщика пакетов с использованием идентификатора пакета, например, с использованием идентификатора, ассоциированного с пакетом рабочих данных сцены.
Следовательно, согласно вариантам осуществления, пакеты рабочих данных сцен могут идентифицироваться с использованием идентификатора рабочих данных, например, представляющего рабочие данные соответствующего пакета рабочих данных, либо с использованием идентификатора пакета. Это может обеспечивать возможность эффективного запроса информации.
Согласно дополнительным вариантам осуществления изобретения, аудиодекодер выполнен с возможностью предвидеть, например, с использованием прогнозирования, то, какие одна или более структур данных, например, какие один или более PayloadElements потребуются или предположительно должны требоваться, например, с использованием прогнозирования того, какая ячейка станет активной следующей или имеет заданную вероятность стать активной следующей, и запрашивать одну или более структур данных или один или более пакетов рабочих данных сцен, содержащих упомянутую одну или более структур данных, до того, как структуры данных фактически требуются.
Авторы изобретения выяснили, что такое прогнозирование, например, может выполняться для того, чтобы обеспечивать гладкое или плавное реконструирование аудиосцен, например, чтобы удостоверяться в отношении того, что времена буферизации не требуются. Например, неожиданные падения полосы пропускания могут уменьшаться на основе своевременного предвидения необходимых структур данных и в силу этого их передачи до того, как они требуются.
Согласно дополнительным вариантам осуществления изобретения, аудиодекодер выполнен с возможностью предоставлять информацию, например, информацию позиции или информацию времени воспроизведения, или время в сцене, указывающую, по меньшей мере, неявно то, какие один или более пакетов рабочих данных сцен требуются или потребуются в течение предварительно определенного периода времени, в поставщик пакетов, например, чтобы за счет этого обеспечивать возможность поставщику пакетов избирательно предоставлять, например, с использованием передачи "точка-точка", пакеты, которые требуются посредством аудиодекодера или которые потребуются посредством аудиодекодера в течение предварительно определенного периода времени, в аудиодекодер.
Следовательно, далее предоставленный поток битов может оптимизироваться таким образом, чтобы учитывать передачу запрашиваемых пакетов рабочих данных сцен. Кроме того, таким способом может определяться диспетчеризация, которая обеспечивает возможность надежно удовлетворять временным ограничениям, например, так что гарантированно обеспечивается либо, по меньшей мере, является очень вероятным то, что необходимая информация присутствует в декодере, когда она требуется.
В общем, следует отметить, что поставщик пакетов, например, может представлять собой кодер согласно любому из вариантов осуществления, раскрытых в данном документе.
Согласно дополнительным вариантам осуществления изобретения, один или более пакетов обновлений сцен, например, mpegiSceneUpdate[] (иногда также обозначенный в качестве "mpeghiSceneUpdate[]"), задают обновление метаданных сцены для рендеринга, например, изменение параметра объекта сцены или изменение характеристики сцены и содержат представление одного или более условий обновления. Кроме того, аудиодекодер выполнен с возможностью оценивать то, удовлетворяются либо нет одно или более условий обновления, и избирательно обновлять одни или более метаданных сцены в зависимости от контента одного или более пакетов обновлений сцен, если одно или более условий обновления удовлетворяются, например, чтобы за счет этого определять сценарий рендеринга, соответствующий временной метке.
Следовательно, пакеты обновлений сцен могут предоставлять не только само обновление, но также и условие, когда и/или где (например, пространственно в акустической сцене и/или в каких рабочих данных, соответственно) следует выполнять обновление. Следовательно, информация обновления может предоставляться до того, как обновление необходимо, за счет этого обеспечивая возможность предотвращать времена буферизации и обеспечивать возможность адаптации аудиосцен в реальном времени. В качестве примера, условие может представлять собой открытие двери, так что когда пользователь в VR-окрестностях открывает дверь, сцена может сразу обновляться относительно акустически измененных характеристик.
Ниже по тексту, поясняются варианты осуществления, связанные с оборудованием для обеспечения кодированного аудиопредставления, например, с кодером. Следует отметить, что такие варианты осуществления могут быть основаны на соображениях, идентичных или аналогичных, или соответствующих соображениям вышеуказанных вариантов осуществления, связанных с декодером. Следовательно, нижеприведенные варианты осуществления могут содержать признаки, функциональности и подробности, идентичные, аналогичные или соответствующие признакам, функциональностям и подробностям вышеуказанных раскрытых вариантов осуществления, как отдельно, так и в комбинации.
Следовательно, дополнительные варианты осуществления согласно изобретению содержат оборудование, например, аудиокодер или аудиосервер, для обеспечения кодированного аудиопредставления, при этом оборудование выполнено с возможностью предоставлять информацию для пространственного рендеринга одного или более аудиосигналов, и при этом оборудование выполнено с возможностью предоставлять множество пакетов с различными типами пакетов, например, имеющих типы пакетов, которые являются совместимыми с определением MPEG-H MHAS-пакетов.
Кроме того, пакеты содержат один или более пакетов конфигурирования сцен, например, пакет конфигурирования сцен, например, mpegiSceneConfig[] (иногда также обозначенный в качестве "mpeghiSceneConfig"), предоставляющий конфигурационную информацию модуля рендеринга, задающую использование объектов сцены и/или использование характеристик сцены, например, задающую то, когда или при каком условии различные объекты сцены и/или характеристики сцены должны использоваться в процессе рендеринга, например, с использованием определения ячеек.
Кроме того, пакеты содержат один или более пакетов обновлений сцен, например, mpegiSceneUpdate[] (иногда также обозначенный в качестве "mpeghiSceneUpdate"), задающих обновление метаданных сцены для рендеринга, например, изменение одного или более значений метаданных; например, изменение параметра объекта сцены или изменение характеристики сцены, например, изменение одного или более значений метаданных.
Помимо этого, пакеты содержат один или более пакетов рабочих данных сцен, содержащих определения одного или более объектов сцены и/или определения одной или более характеристик сцены, например, коллективные метаданные; например, метаданные, которые требуются для рендеринга одной или более аудиосцен; например, геометрические метаданные, описывающие аудиосцену для рендеринга, и/или параметрические инструкции рендеринга для рендеринга, и/или метаданные аудиоэлементов, описывающие один или более аудиоэлементов в аудиосцене для рендеринга.
Согласно дополнительным вариантам осуществления изобретения, оборудование выполнено с возможностью предоставлять конфигурационную информацию модуля рендеринга, которая включается в пакеты конфигурирования сцен, так что конфигурационная информация модуля рендеринга задает выбор определений одного или более объектов сцены и/или определений одной или более характеристик сцены, которые включаются в пакеты рабочих данных сцен для рендеринга.
Следовательно, аудиосцена может подготавливаться или подготавливается посредством рендеринга иммерсивным способом и/или с высоким уровнем детальности.
Согласно дополнительным вариантам осуществления изобретения, оборудование выполнено с возможностью предоставлять один или более пакетов обновлений сцен таким образом, что контент одного или более пакетов обновлений сцен задает обновление одних или более метаданных сцены.
Согласно дополнительным вариантам осуществления изобретения, оборудование выполнено с возможностью предоставлять пакет конфигурирования сцен, так что пакет конфигурирования сцен определяет конфигурацию рендеринга, и оборудование выполнено с возможностью предоставлять пакеты обновлений сцен, так что пакеты обновлений сцен задают обновление конфигурации рендеринга.
Согласно дополнительным вариантам осуществления изобретения, оборудование выполнено с возможностью предоставлять один или более пакетов конфигурирования сцен и один или более пакетов обновлений сцен, и один или более пакетов рабочих данных сцен таким образом, что один или более пакетов конфигурирования сцен и один или более пакетов обновлений сцен, и один или более пакетов рабочих данных сцен являются совместимыми с определением MPEG-H MHAS-пакетов.
Согласно дополнительным вариантам осуществления изобретения, оборудование выполнено с возможностью предоставлять один или более пакетов конфигурирования сцен и один или более пакетов обновлений сцен, и один или более пакетов рабочих данных сцен таким образом, что один или более пакетов конфигурирования сцен и один или более пакетов обновлений сцен, и один или более пакетов рабочих данных сцен содержат идентификатор типа пакета, например, MHASPacketType, метку пакета, например, MHASPacketLabel, информацию длины пакетов, например, MHASPacketLength, и рабочие данные пакета, например, MHASPAcketPayload.
Согласно дополнительным вариантам осуществления изобретения, оборудование выполнено с возможностью предоставлять один или более пакетов конфигурирования сцен и один или более пакетов обновлений сцен, и один или более пакетов рабочих данных сцен в потоке битов, содержащем множество MPEG-H-пакетов, например, перемеженным способом, включающих в себя пакеты, представляющие один или более аудиоканалов, которые должны подготавливаться посредством рендеринга.
Необязательно, аудиодекодер, например, может быть выполнен с возможностью извлекать один или более пакетов конфигурирования сцен, один или более пакетов обновлений сцен и один или более пакетов рабочих данных сцен из перемеженной последовательности пакетов (например, из перемеженной последовательности MHAS-пакетов) содержащей пакеты с различными типами, например, с использованием идентификаторов типов пакетов и/или меток пакетов, включенных в пакеты.
Следовательно, меньшие части данных, например, могут передаваться перемеженным способом. Например, в широковещательном сценарии, это может обеспечивать возможность поддерживать скорость передачи данных широковещательного потока битов низкой. В таком случае, в качестве примера, пакеты рабочих данных могут необязательно предоставляться с использованием отдельного клиент-серверного канала.
Согласно дополнительным вариантам осуществления изобретения, оборудование выполнено с возможностью предоставлять пакеты конфигураций сцен через широковещательный поток, например, через широковещательный поток с низкой скоростью передачи битов и необязательно предоставлять пакеты рабочих данных сцен в зависимости от времени в сцене и/или в зависимости от позиции пользователя.
Согласно дополнительным вариантам осуществления изобретения, оборудование выполнено с возможностью предоставлять один или более пакетов рабочих данных сцен в ответ на запрос из аудиодекодера, например, в ответ на определение, посредством аудиодекодера, того, что один или более пакетов рабочих данных сцен либо контент одного или более пакетов рабочих данных сцен требуются для рендеринга, например, "по запросу". Это может обеспечивать возможность эффективного обеспечения пакетов рабочих данных.
Согласно дополнительным вариантам осуществления изобретения, оборудование выполнено с возможностью предоставлять один или более пакетов рабочих данных сцен в ответ на запрос из аудиодекодера, содержащий идентификатор рабочих данных, например, с использованием идентификатора, ассоциированного с элементом рабочих данных. Альтернативно, оборудование выполнено с возможностью предоставлять один или более пакетов рабочих данных сцен в ответ на запрос из аудиодекодера, содержащий идентификатор пакета, например, с использованием идентификатора, ассоциированного с пакетом рабочих данных сцены.
Согласно дополнительным вариантам осуществления изобретения, оборудование выполнено с возможностью предоставлять один или более пакетов рабочих данных сцен в ответ на информацию, например, информацию позиции или информацию времени воспроизведения, или время в сцене, указывающую, например, по меньшей мере, неявно то, какие один или более пакетов рабочих данных сцен требуются или потребуются в течение предварительно определенного периода времени, например, так что оборудование может избирательно предоставлять, например, с использованием передачи "точка-точка", пакеты, которые требуются посредством аудиодекодера или которые потребуются посредством аудиодекодера в течение предварительно определенного периода времени, в аудиодекодер.
Согласно дополнительным вариантам осуществления изобретения, оборудование выполнено с возможностью предоставлять один или более пакетов обновлений сцен таким образом, что один или более пакетов обновлений сцен, например, mpegiSceneUpdate[] (иногда также обозначенный в качестве "mpeghiSceneUpdate"), задают обновление метаданных сцены для рендеринга, например, изменение параметра объекта сцены или изменение характеристики сцены и содержат представление одного или более условий обновления.
Согласно дополнительным вариантам осуществления изобретения, оборудование выполнено с возможностью повторять предоставление пакета конфигурирования сцен или даже последовательности пакета конфигурирования сцен и одного или более пакетов рабочих данных сцен, и необязательно также одного или более пакетов обновлений сцен, периодически. Это может обеспечивать возможность простой подстройки для соответствующего декодера или модуля рендеринга.
Согласно дополнительным вариантам осуществления изобретения, оборудование выполнено с возможностью предоставлять пакет конфигурирования сцен, так что пакет конфигурирования сцен задает то, какие пакеты рабочих данных сцен требуются в данной точке в пространстве и времени.
Согласно дополнительным вариантам осуществления изобретения, оборудование выполнено с возможностью предоставлять пакет конфигурирования сцен, так что пакет конфигурирования сцен задает то, из чего пакеты рабочих данных сцен могут извлекаться. Следовательно, соответствующие декодеры или модули рендеринга могут отдельно запрашивать соответствующие необходимые пакеты рабочих данных.
Согласно дополнительным вариантам осуществления изобретения, оборудование выполнено с возможностью предоставлять пакеты обновлений сцен, так что пакеты обновлений сцен задают условие для обновления сцен.
Согласно дополнительным вариантам осуществления изобретения, оборудование выполнено с возможностью предоставлять пакеты обновлений сцен таким образом, что пакеты обновлений сцен задают интерактивное инициирующее условие (например, такое условие, что пользователь предпринимает определенное действие, которое выходит за рамки простого перемещения в сцене; например, такое условие, что пользователь выдает предварительно определенную команду или активирует предварительно определенную кнопку) для обновления сцен.
Согласно дополнительным вариантам осуществления изобретения, оборудование выполнено с возможностью адаптировать упорядочение определений одного или более объектов сцены и/или определений одной или более характеристик сцены в пакетах рабочих данных сцен в зависимости от того, когда и/или где определения одного или более объектов сцены и/или определения одной или более характеристик сцены необходимы посредством модуля рендеринга.
Это может обеспечивать возможность эффективно диспетчеризовать передачу рабочих данных, описывающих объекты сцены или характеристики. В качестве примера, на основе времени в сцене или времени воспроизведения, релевантность акустически релевантных объектов может определяться, и в силу этого порядок передачи может задаваться. В качестве другого примера, на основе позиции слушателя в виртуальной акустической сцене, акустически релевантные объекты, близкие к этой позиции, могут передаваться раньше, на основе их переупорядочения таким образом, что, например, в случае если инициирующее пространственное условие слушателя удовлетворяется, сцена может подготавливаться посредством рендеринга с высокой детальностью без прерывания (Простыми словами: В случае если слушатель перемещается в другую позицию поблизости от своего фактического местоположения, соответствующая информация для акустических характеристик новой позиции, например, может быть доступна сразу).
Согласно дополнительным вариантам осуществления изобретения, оборудование выполнено с возможностью адаптировать упорядочение определений одного или более объектов сцены и/или определений одной или более характеристик сцены в пакетах рабочих данных сцен в зависимости от важности определений одного или более объектов сцены и/или определений одной или более характеристик сцены для модуля рендеринга.
Следовательно, упорядочение, например, может выбираться согласно акустическому воздействию соответствующего объекта или характеристики. Это дополнительно может обеспечивать возможность включать концепцию уровня детальности согласно вариантам осуществления.
Согласно дополнительным вариантам осуществления изобретения, оборудование выполнено с возможностью адаптировать упорядочение определений одного или более объектов сцены и/или определений одной или более характеристик сцены в пакетах рабочих данных сцен в зависимости от ограничения по размеру пакетов.
Следовательно, варианты осуществления могут обеспечивать возможность распределять определения объектов сцены и/или характеристик сцены, чтобы предоставлять требуемые размеры пакетов для их передачи, например, обеспечивая возможность реализовывать небольшие размеры пакетов, с тем чтобы эффективно предоставлять их перемеженным способом с другими пакетами.
Согласно дополнительным вариантам осуществления изобретения, оборудование выполнено с возможностью предоставлять пакеты рабочих данных, содержащие сравнительно низкий уровень детальности, сначала, и предоставлять пакеты рабочих данных, содержащие сравнительно более высокий уровень детальности, позднее.
Это может обеспечивать возможность сначала предоставлять минимальный объем информации для рендеринга сцены, которая может детализироваться позднее, например, при условии достаточно хорошего канала связи. Следовательно, аудиосцена может предоставляться надежным способом.
Согласно дополнительным вариантам осуществления изобретения, оборудование выполнено с возможностью разделять определения одного или более объектов сцены и/или определения одной или более характеристик сцены (например, коллективные метаданные; например, метаданные, которые требуются для рендеринга одной или более аудиосцен; например, геометрические метаданные, описывающие аудиосцену для рендеринга, и/или параметрические инструкции рендеринга для рендеринга, и/или метаданные аудиоэлементов, описывающие один или более аудиоэлементов в аудиосцене для рендеринга) на множество пакетов рабочих данных сцен, например, на пакеты рабочих данных сцен, которые являются релевантными в различных точках во времени (например, в различные времена воспроизведения) и/или в различных местоположениях в пространстве сцены.
Кроме того, оборудование выполнено с возможностью предоставлять различные пакеты рабочих данных сцен в различные моменты времени, например, в различные моменты времени в соответствии с определением того, в какое время воспроизведения и/или в какой позиций внутри сцены требуются характеристики сцены, содержащиеся в соответствующих пакетах рабочих данных сцен.
Соответственно, авторы изобретения выяснили, что, простыми словами, разброс меньших пакетов рабочих данных может обеспечивать возможность предоставлять эффективный поток битов.
Согласно дополнительным вариантам осуществления изобретения, оборудование выполнено с возможностью предоставлять пакеты конфигурирования сцен для того, чтобы разлагать сцену на множество пространственных областей, например, площадей или объемов; например, пространственных областей, содержащих форму, которая задается посредством геометрического объекта, в котором различные метаданные рендеринга являются допустимыми.
Авторы изобретения выяснили, что разложение сцен на множество пространственных областей может обеспечивать возможность эффективно оркестровать или диспетчеризовать, или манипулировать активацией акустически релевантных элементов, например, представленных в рабочих данных, например, относительно времени и/или пространства, чтобы предоставлять реалистичную акустическую сцену. В качестве примера, ячейки, например, как пояснено в контексте дополнительных вариантов осуществления, могут использоваться для такого разложения сцен, а также для концепции уровня детальности в силу этого, в качестве примера, для разделения аудиосцены в пространстве и/или во времени на различные ячейки, которые, например, могут перекрываться, так что одна ячейка может предоставлять детализацию информации для акустических элементов, ассоциированных с другой ячейкой.
Ниже по тексту, поясняются варианты осуществления, связанные со способами для обеспечения декодированного и кодированного аудиопредставления. Следует отметить, что такие варианты осуществления могут быть основаны на соображениях, идентичных или аналогичных, или соответствующих соображениям вышеуказанных вариантов осуществления, связанных с оборудованием. Следовательно, нижеприведенные варианты осуществления могут содержать признаки, функциональности и подробности, идентичные, аналогичные или соответствующие признакам, функциональностям и подробностям вышеуказанных раскрытых вариантов осуществления, как отдельно, так и в комбинации.
Дополнительные варианты осуществления согласно изобретению, содержат способ для обеспечения декодированного и необязательно подготовленного посредством рендеринга аудиопредставления на основе кодированного аудиопредставления. Способ содержит пространственный рендеринг одного или более аудиосигналов и прием множества пакетов с различными типами пакетов, например, имеющих типы пакетов, которые являются совместимыми с определением MPEG-H MHAS-пакетов.
Кроме того, пакеты содержат один или более пакетов конфигурирования сцен, например, пакет конфигурирования сцен, например, mpegiSceneConfig[] (иногда также обозначенный в качестве "mpeghiSceneConfig"), предоставляющий конфигурационную информацию модуля рендеринга, задающую использование объектов сцены и/или использование характеристик сцены, например, задающую то, когда или при каком условии различные объекты сцены и/или характеристики сцены должны использоваться в процессе рендеринга, например, с использованием определения ячеек.
Необязательно, пакет конфигурирования сцен, например, может задавать то, какие пакеты рабочих данных сцен требуются в данной точке в пространстве и времени, и пакет конфигурирования сцен, например, может задавать то, из чего пакеты рабочих данных сцен могут извлекаться.
Помимо этого, пакеты содержат один или более пакетов обновлений сцен, например, mpegiSceneUpdate[] (иногда также обозначенный в качестве "mpeghiSceneUpdate"), задающих обновление, например, изменение метаданных сцены для рендеринга, например, изменение одного или более значений метаданных; например, изменение параметра объекта сцены или изменение характеристики сцены; например, изменение метаданных сцены, которое возникает во время воспроизведения. Необязательно, один или более пакетов обновлений сцен, например, могут задавать одно или более условий для обновления сцен.
Кроме того, пакеты содержат один или более пакетов рабочих данных сцен, содержащих определения одного или более объектов сцены и/или определения одной или более характеристик сцены, например, коллективные метаданные; например, метаданные, которые требуются для рендеринга одной или более аудиосцен; например, геометрические метаданные, описывающие аудиосцену для рендеринга, и/или параметрические инструкции рендеринга для рендеринга, и/или метаданные аудиоэлементов, описывающие один или более аудиоэлементов в аудиосцене для рендеринга; например, директивы и/или геометрии, и/или метаданные аудиоэффектов; например, метаданные реверберации и/или метаданные ранних отражений, и/или метаданные дифракции.
Кроме того, способ содержит выбор определений одного или более объектов сцены и/или определений одной или более характеристик сцены, которые включаются в пакеты рабочих данных сцен для рендеринга, в зависимости от конфигурационной информации модуля рендеринга, которая, например, может включаться в пакеты конфигурирования сцен, при этом, например, ячейки могут использоваться для того, чтобы выбирать то, какие объекты сцены и/или характеристики сцены должны использоваться.
Кроме того, способ содержит обновление одних или более метаданных сцены, например, одного или более параметров рендеринга, обозначенных посредством "targetId", при этом новые значения одного или более параметров рендеринга обозначаются посредством "attribute" в зависимости от контента одного или более пакетов обновлений сцен.
Дополнительные варианты осуществления согласно изобретению, содержат способ для обеспечения кодированного аудиопредставления, при этом способ содержит предоставление информации для пространственного рендеринга одного или более аудиосигналов и предоставление множества пакетов с различными типами пакетов, например, имеющих типы пакетов, которые являются совместимыми с определением MPEG-H MHAS-пакетов.
Пакеты содержат один или более пакетов конфигурирования сцен, например, пакет конфигурирования сцен, например, mpegiSceneConfig[] (иногда также обозначенный в качестве "mpeghiSceneConfig"), предоставляющий конфигурационную информацию модуля рендеринга, задающую использование объектов сцены и/или использование характеристик сцены, например, задающую то, когда или при каком условии различные объекты сцены и/или характеристики сцены должны использоваться в процессе рендеринга, например, с использованием определения ячеек.
Кроме того, пакеты содержат один или более пакетов обновлений сцен, например, mpegiSceneUpdate[] (иногда также обозначенный в качестве "mpeghiSceneUpdate"), задающих обновление метаданных сцены для рендеринга, например, изменение одного или более значений метаданных; например, изменение параметра объекта сцены или изменение характеристики сцены.
Кроме того, пакеты содержат один или более пакетов рабочих данных сцен, содержащих определения одного или более объектов сцены и/или определения одной или более характеристик сцены, например, коллективные метаданные; например, метаданные, которые требуются для рендеринга одной или более аудиосцен; например, геометрические метаданные, описывающие аудиосцену для рендеринга, и/или параметрические инструкции рендеринга для рендеринга, и/или метаданные аудиоэлементов, описывающие один или более аудиоэлементов в аудиосцене для рендеринга.
Дополнительные варианты осуществления согласно изобретению, содержат компьютерную программу для осуществления способа согласно любому из вариантов осуществления, раскрытых в данном документе, когда компьютерная программа выполняется на компьютере.
Ниже по тексту, поясняются варианты осуществления, связанные с потоками битов. Следует отметить, что такие варианты осуществления могут быть основаны на соображениях, идентичных или аналогичных, или соответствующих соображениям вышеуказанных вариантов осуществления, связанных с оборудованием и/или способами. Следовательно, нижеприведенные варианты осуществления могут содержать признаки, функциональности и подробности, идентичные, аналогичные или соответствующие признакам, функциональностям и подробностям вышеуказанных раскрытых вариантов осуществления, как отдельно, так и в комбинации.
Дополнительные варианты осуществления согласно изобретению, содержат поток битов, представляющий аудиоконтент, причем поток битов содержит множество пакетов с различными типами пакетов, например, имеющих типы пакетов, которые являются совместимыми с определением MPEG-H MHAS-пакетов.
Пакеты содержат один или более пакетов конфигурирования сцен, например, пакет конфигурирования сцен, например, mpegiSceneConfig[] (иногда также обозначенный в качестве "mpeghiSceneConfig"), предоставляющий конфигурационную информацию модуля рендеринга, задающую использование объектов сцены и/или использование характеристик сцены, например, задающую то, когда или при каком условии различные объекты сцены и/или характеристики сцены должны использоваться в процессе рендеринга, например, с использованием определения ячеек.
Необязательно, пакет конфигурирования сцен, например, может задавать то, какие пакеты рабочих данных сцен требуются в данной точке в пространстве и времени, и пакет конфигурирования сцен, например, может задавать то, из чего пакеты рабочих данных сцен могут извлекаться.
Кроме того, пакеты содержат один или более пакетов обновлений сцен, например, mpegiSceneUpdate[] (иногда также обозначенный в качестве "mpeghiSceneUpdate"), задающих обновление, например, изменение метаданных сцены для рендеринга, например, изменение одного или более значений метаданных; например, изменение параметра объекта сцены или изменение характеристики сцены; например, изменение метаданных сцены, которое возникает во время воспроизведения. Необязательно, один или более пакетов обновлений сцен, например, могут задавать одно или более условий для обновления сцен.
Кроме того, пакеты содержат один или более пакетов рабочих данных сцен, содержащих определения одного или более объектов сцены и/или определения одной или более характеристик сцены, например, коллективные метаданные; например, метаданные, которые требуются для рендеринга одной или более аудиосцен; например, геометрические метаданные, описывающие аудиосцену для рендеринга, и/или параметрические инструкции рендеринга для рендеринга, и/или метаданные аудиоэлементов, описывающие один или более аудиоэлементов в аудиосцене для рендеринга; например, директивы и/или геометрии, и/или метаданные аудиоэффектов; например, метаданные реверберации и/или метаданные ранних отражений, и/или метаданные дифракции.
Помимо этого, поток битов необязательно может дополняться посредством любых элементов потока битов, раскрытых в данном документе, как отдельно, так и в комбинации.
Дополнительные варианты осуществления содержат аудиодекодер для обеспечения декодированного аудиопредставления на основе кодированного аудиопредставления, при этом аудиодекодер выполнен с возможностью пространственно подготавливать посредством рендеринга один или более аудиосигналов и принимать множество пакетов с различными типами пакетов, причем пакеты содержат один или более пакетов конфигурирования сцен, предоставляющих конфигурационную информацию модуля рендеринга, задающую объекты сцены и/или характеристики сцены, причем пакеты содержат один или более пакетов обновлений сцен, задающих обновление метаданных сцены для рендеринга, причем пакеты содержат один или более пакетов рабочих данных сцен, содержащих определения одного или более объектов сцены и/или определения одной или более характеристик сцены.
Кроме того, аудиодекодер выполнен с возможностью выбирать определения одного или более объектов сцены и/или определения одной или более характеристик сцены, которые включаются в пакеты рабочих данных сцен для рендеринга, и обновлять одни или более метаданных сцены в зависимости от контента одного или более пакетов обновлений сцен.
Следует отметить, что такой изобретаемый декодер может содержать идентичные, аналогичные или соответствующие признаки, функциональности и подробности относительно любых из вышеуказанных раскрытых вариантов осуществления или относительно любых из других вариантов осуществления, раскрытых в данном документе, как отдельно, так и в комбинации.
Ниже по тексту, поясняются варианты осуществления согласно второму аспекту изобретения. Варианты осуществления согласно второму аспекту изобретения могут быть основаны на использовании пакетов обновлений сцен с условием обновления и/или основаны на использовании пакетов обновлений сцен с условием обновления и другими признаками.
Варианты осуществления согласно второму аспекту могут содержать признаки, функциональности и подробности вариантов осуществления первого аспекта изобретения, и наоборот, как отдельно, так и в комбинации.
Варианты осуществления согласно изобретению, содержат аудиодекодер для обеспечения декодированного и необязательно подготовленного посредством рендеринга аудиопредставления на основе кодированного аудиопредставления, при этом аудиодекодер выполнен с возможностью пространственно подготавливать посредством рендеринга один или более аудиосигналов. Аудиодекодер выполнен с возможностью принимать множество пакетов с различными типами пакетов, например, имеющих типы пакетов, которые являются совместимыми с определением MPEG-H MHAS-пакетов.
Кроме того, пакеты содержат один или более пакетов конфигурирования сцен, например, пакет конфигурирования сцен, например, mpegiSceneConfig[] (иногда также обозначенный в качестве "mpeghiSceneConfig"), предоставляющий конфигурационную информацию модуля рендеринга, например, задающую использование объектов сцены и/или использование характеристик сцены, например, задающую то, когда или при каком условии различные объекты сцены и/или характеристики сцены должны использоваться в процессе рендеринга.
Кроме того, пакеты содержат один или более пакетов обновлений сцен, например, mpegiSceneUpdate[] (иногда также обозначенный в качестве "mpeghiSceneUpdate"), задающих обновление метаданных сцены для рендеринга, например, изменение параметра объекта сцены или изменение характеристики сцены и содержащих представление одного или более условий обновления.
Помимо этого, аудиодекодер выполнен с возможностью оценивать то, удовлетворяются либо нет одно или более условий обновления, например, заданных в пакетах обновлений сцен, и избирательно обновлять одни или более метаданных сцены в зависимости от контента одного или более пакетов обновлений сцен, если одно или более условий обновления удовлетворяются.
Авторы изобретения выяснили, что аудиосцена может обновляться эффективно с использованием обновлений метаданных в форме пакетов обновлений сцен. Пакеты обновлений сцен в силу этого содержат представления условий обновления, так что декодер, например, может принимать пакет обновлений сцен до того, как обновление непосредственно должно выполняться, за счет этого ослабляя временные ограничения передачи. Оборудование затем может выполнять обновление, когда соответствующее условие удовлетворяется.
Это может обеспечивать возможность эффективно рассматривать предварительно определенные, инициированные акустические воздействия в аудиосцене. Например, в VR-окрестностях, пользователь может открывать дверь, за счет этого изменяя акустические характеристики виртуального помещения. Следовательно, открытие двери может инициировать обновление. Информация относительно акустической "механики" открытия двери в силу этого может передаваться до того, как дверь открывается.
Следовательно, виртуальная акустическая сцена может предоставляться с высокой степенью реализма и в реальном времени при одновременном упрощении передачи информации обновления метаданных.
Кроме того, следует подчеркнуть, что одно преимущество этого подхода, например, может представлять собой агрегирование не только информации обновления, но также и инициирующей информации обновления в форме условий обновления в пакетах обновлений сцен, обеспечивая возможность предоставлять самосогласованную и/или самодостаточную, и/или самополагающуюся информацию обновления.
Кроме того, аудиодекодер может реагировать на различные события, заданные посредством условий обновления (например, на локальные события, возникающие на стороне аудиодекодера, инициирующие обновление), и не ограничен предварительно определенной временной эволюцией сцены. Таким образом, использование пакетов обновлений сцен способствует очень хорошему выражению для слуха при поддержании требуемой скорости передачи битов обоснованно небольшой.
Согласно дополнительным вариантам осуществления изобретения, аудиодекодер выполнен с возможностью оценивать временное условие, например, временное инициирующее условие; например, заданное посредством startTimestamp, который включается в пакет обновлений сцен для того, чтобы принимать решение в отношении того, должны либо нет одни или более метаданных сцены обновляться в зависимости от контента одного или более пакетов обновлений сцен, например, в зависимости от перечисления элементов метаданных сцены, которые должны изменяться, например, указываться посредством ссылки посредством "targetId" и соответствующих новых значений, например, заданных посредством "attribute".
Авторы изобретения выяснили, что триггер обновления, например, может предоставляться не только посредством события, но и также посредством временной синхронизации. Следовательно, снова, пакет обновлений сцен может содержать информацию относительно самого обновления и времени или временного отрезка для того, чтобы определять время, когда следует выполнять обновление. Следовательно, акустическое изменение во времени, например, может учитываться эффективно.
Согласно дополнительным вариантам осуществления изобретения, временное условие задает начальный момент времени, например, с использованием элемента startTimestamp потока битов. Альтернативно, временное условие задает временной интервал, например, с использованием начального времени и конечного времени.
Кроме того, аудиодекодер выполнен с возможностью осуществлять обновление одних или более метаданных сцены, например, в соответствии с определением, включенным в соответствующий пакет обновлений сцен, в ответ на обнаружение, например, сразу в ответ на обнаружение или с использованием временной задержки, заданной в соответствующем пакете обновлений сцен, того, что текущее время воспроизведения, например, время в сцене, достигает начального момента времени или находится после начального момента времени.
Альтернативно, аудиодекодер выполнен с возможностью осуществлять обновление одних или более метаданных сцены, например, в соответствии с определением, включенным в соответствующий пакет обновлений сцен, в ответ на обнаружение того, что текущее время воспроизведения, например, время в сцене, находится в пределах временного интервала.
Следовательно, в зависимости от конкретной реализации, точка во времени, когда обновление должно выполняться, либо, простыми словами, "таймер" до тех пор, пока обновление не должно выполняться, например, может предоставляться, обеспечивая возможность эффективного обновления метаданных.
Согласно дополнительным вариантам осуществления изобретения, аудиодекодер выполнен с возможностью оценивать пространственное условие, например, инициирующее пространственное условие, которое включается в пакет обновлений сцен, например, пространственное условие, заданное посредством ссылки на геометрическое определение; например, пространственное условие, заданное посредством geometryId, чтобы принимать решение в отношении того, должны либо нет одни или более метаданных сцены обновляться в зависимости от контента одного или более пакетов обновлений сцен, например, в зависимости от перечисления элементов метаданных сцены, которые должны изменяться, например, указываться посредством ссылки посредством "targetId" и соответствующих новых значений, например, заданных посредством "attribute".
Следовательно, обновление в зависимости от пространственного местоположения в акустической сцене может указываться эффективно.
Согласно дополнительным вариантам осуществления изобретения, пространственное условие задает геометрический элемент, например, с использованием ссылки на геометрическое определение, при этом упомянутое геометрическое определение, например, может включаться в элемент рабочих данных сцены.
Кроме того, аудиодекодер выполнен с возможностью осуществлять обновление одних или более метаданных сцены, например, в соответствии с определением, включенным в соответствующий пакет обновлений сцен, в ответ на обнаружение, например, сразу в ответ на обнаружение, или, например, с использованием временной задержки, заданной в соответствующем пакете обновлений сцен, того, что текущая позиция достигает геометрического элемента (например, достигает одномерной границы, заданной посредством геометрического элемента, или достигает двумерной границы, заданной посредством геометрического объекта, или достигает трехмерной границы, заданной посредством геометрического объекта), либо в ответ на обнаружение, например, сразу в ответ на обнаружение, или, например, с использованием временной задержки, заданной в соответствующем пакете обновлений сцен, того, что текущая позиция находится внутри геометрического элемента, например, внутри двумерного геометрического элемента или внутри трехмерного геометрического элемента.
В качестве примера, пользователь VR-окрестностей может перемещаться через VR-помещение, которое разделяется на акустические зоны, например, задается посредством геометрических элементов, таких как прямоугольники. Когда пользователь входит в новую акустическую зону, эта зона может обновляться, чтобы точно описывать соответствующие акустические свойства, за счет этого обеспечивая возможность иммерсивного пользовательского восприятия. Таким образом, только текущая релевантная акустическая зона, возможно, должна обновляться.
Согласно дополнительным вариантам осуществления изобретения, аудиодекодер выполнен с возможностью оценивать то, удовлетворяется или нет интерактивное инициирующее условие, которое например, может задаваться в пакете обновлений сцен (например, такое условие, что пользователь предпринимает определенное действие, которое выходит за рамки простого перемещения в сцене; например, такое условие, что пользователь выдает предварительно определенную команду или активирует предварительно определенную кнопку, например, заданную посредством флага "fireOn"), чтобы принимать решение в отношении того, должны либо нет одни или более метаданных сцены обновляться в зависимости от контента одного или более пакетов обновлений сцен.
Как пояснено выше, например, в контексте первого аспекта изобретения, акустическая сцена в силу этого может обновляться эффективно.
Согласно дополнительным вариантам осуществления изобретения, аудиодекодер выполнен с возможностью оценивать комбинацию, например, комбинацию "AND" либо другую булеву комбинацию двух или более условий обновления, и аудиодекодер выполнен с возможностью избирательно обновлять одни или более метаданных сцены в зависимости от контента одного или более пакетов обновлений сцен, если комбинированное условие обновления удовлетворяется, например, если два или более условия обновления удовлетворяются.
Авторы изобретения выяснили, что оценка взаимосвязанных или сцепленных условий обновления может обеспечивать возможность эффективного обновления акустической сцены, например, аудиосцены, например, сценария рендеринга.
Согласно дополнительным вариантам осуществления изобретения, аудиодекодер выполнен с возможностью оценивать временное условие обновления и пространственное условие обновления. Альтернативно, аудиодекодер выполнен с возможностью оценивать временное условие обновления и интерактивное условие обновления.
Следовательно, условия обновления могут указываться с высокой гибкостью, обеспечивая возможность повышать эффективность и/или адаптивность обновления.
Согласно дополнительным вариантам осуществления изобретения, аудиодекодер выполнен с возможностью оценивать информацию задержки, например, задержку, который включается в пакет обновлений сцен; и аудиодекодер выполнен с возможностью задерживать обновление одних или более метаданных сцены в зависимости от контента одного или более пакетов обновлений сцен в соответствии с информацией задержки в ответ на обнаружение того, что одно или более условий обновления удовлетворяются.
Некоторые изменения акустической сцены могут инициироваться посредством события, после чего возникает задержка, например, запаздывание во времени. Такое изменение может быть включено в обновление акустической сцены эффективно, на основе вышеописанного подхода.
Согласно дополнительным вариантам осуществления изобретения, аудиодекодер выполнен с возможностью оценивать флаг, например, hasTemporalCondition, в пакете обновлений сцен, указывающий то, задается или нет временное условие обновления в пакете обновлений сцен. Альтернативно или помимо этого, аудиодекодер выполнен с возможностью оценивать флаг, например, hasSpatialCondition, в пакете обновлений сцен, указывающий то, задается или нет пространственное условие обновления в пакете обновлений сцен. Необязательно, аудиодекодер выполнен с возможностью обеспечивать комбинирование "AND" условий, присутствие которых указывается посредством соответствующих флагов.
Следовательно, в декодер может предоставляться информация в отношении того, должно либо нет временное и/или пространственное условие обновления рассматриваться, с использованием флагов и в силу этого с низкими усилиями по передаче служебных сигналов.
Согласно дополнительным вариантам осуществления изобретения, аудиодекодер выполнен с возможностью оценивать флаг, например, "имеет задержку", например, флаг, указывающий "имеет задержку", в пакете обновлений сцен, указывающий то, задается или нет информация задержки в пакете обновлений сцен.
Следовательно, индикатор того, должна рассматриваться или нет задержка, может предоставляться с низкими усилиями по передаче служебных сигналов.
Согласно дополнительным вариантам осуществления изобретения, пакет обновлений сцен содержит представление (например, перечисление, при этом число записей перечисления, например, может указываться посредством параметра потока битов, например, посредством numOfModifications) множества модификаций одного или более параметров одного или более объектов сцены и/или одной или более характеристик сцены.
Необязательно, параметры или характеристики сцены, которые должны модифицироваться (или обновляться), например, обозначаются с помощью "targetId", и соответствующие новые значения параметров или характеристик сцены, например, обозначаются с помощью "attribute".
Помимо этого, аудиодекодер выполнен с возможностью применять модификации в ответ на обнаружение того, что одно или более условий обновления удовлетворяются.
Согласно дополнительным вариантам осуществления изобретения, пакет обновлений сцен содержит информацию траектории, которая, например, может быть ассоциирована с параметром объекта сцены, который должен изменяться, или, например, с характеристикой сцены, которая должна изменяться, например, содержащую isTrajectory, interpolationType, numPoints, time[n] и value[n].
Помимо этого, аудиодекодер выполнен с возможностью обновлять соответствующие метаданные сцены, с которыми ассоциирована информация траектории, с использованием варьирования параметров, например, плавного интерполированного варьирования параметров согласно траектории, например, временной эволюции, заданной посредством информации траектории, при этом аудиодекодер, например, может определять траекторию на основе множества опорных точек.
Следовательно, даже комплексное обновление, например, может параметризоваться или представляться с низкими усилиями с использованием траектории, сокращая усилия по передаче служебных сигналов. Следовательно, необязательно, на основе опорных точек, траектория и в силу этого обновление метаданных может интерполироваться.
Согласно дополнительным вариантам осуществления изобретения, аудиодекодер выполнен с возможностью оценивать информацию (например, флаг isTrajectory; например, информацию, которая включается в пакет обновлений сцен), указывающую то, используется или нет обновление на основе траектории метаданных сцены, с тем чтобы активировать или деактивировать обновление на основе траектории метаданных сцены.
Согласно дополнительным вариантам осуществления изобретения, аудиодекодер выполнен с возможностью оценивать информацию типа интерполяции, которая например, может указывать линейную интерполяцию и/или кубическую интерполяцию, и/или поведение по принципу дискретизации и запоминания, включенную в пакет обновлений сцен, например, информацию interpolationType, чтобы определять тип интерполяции между двумя или более опорными точками траектории, при этом опорные точки, например, могут задаваться посредством информации времени (например, time[n]), ассоциированной с соответствующими опорными точками, и посредством информации значений (например, value[n]), ассоциированной с соответствующими опорными точками.
Следовательно, в зависимости от требуемой траектории, подходящий тип интерполяции может выбираться. Кроме того, хороший компромисс между вычислительной сложностью для интерполяции траектории и точностью требуемой траектории может достигаться на основе варианта выбора типа интерполяции.
Согласно дополнительным вариантам осуществления изобретения, аудиодекодер выполнен с возможностью оценивать информацию опорных точек (например, информацию опорных точек, содержащую информацию относительно числа опорных точек; например, информацию опорных точек, содержащую одно или более значений time[n] и value[n]), описывающих траекторию, при этом информация опорных точек, например, может описывать множество опорных точек для временного варьирования метаданных сцены, например, с использованием пар информации времени опорных точек и информации значений опорных точек.
Авторы изобретения выяснили, что опорные точки могут обеспечивать возможность описывать траекторию и в силу этого правило обновления с низкими вычислительными затратами и/или затратами на передачу.
Ниже по тексту, поясняются варианты осуществления, связанные с оборудованием для обеспечения кодированного аудиопредставления, например, с кодером. Следует отметить, что такие варианты осуществления могут быть основаны на соображениях, идентичных или аналогичных, или соответствующих соображениям вышеуказанных вариантов осуществления, связанных с декодером. Следовательно, нижеприведенные варианты осуществления могут содержать признаки, функциональности и подробности, идентичные, аналогичные или соответствующие признакам, функциональностям и подробностям вышеуказанных раскрытых вариантов осуществления, как отдельно, так и в комбинации.
Дополнительные варианты осуществления согласно изобретению содержат оборудование, например, аудиокодер или аудиосервер, для обеспечения кодированного аудиопредставления, при этом оборудование выполнено с возможностью предоставлять информацию для пространственного рендеринга одного или более аудиосигналов, и при этом оборудование выполнено с возможностью предоставлять множество пакетов с различными типами пакетов, например, имеющих типы пакетов, которые являются совместимыми с определением MPEG-H MHAS-пакетов.
Кроме того, пакеты содержат один или более пакетов конфигурирования сцен, например, пакет конфигурирования сцен, например, mpegiSceneConfig[] (иногда также обозначенный в качестве "mpeghiSceneConfig"), предоставляющий конфигурационную информацию модуля рендеринга, например, задающую использование объектов сцены и/или использование характеристик сцены, например, задающую то, когда или при каком условии различные объекты сцены и/или характеристики сцены должны использоваться в процессе рендеринга.
Помимо этого, пакеты содержат один или более пакетов обновлений сцен, например, mpegiSceneUpdate[] (иногда также обозначенный в качестве "mpeghiSceneUpdate"), задающих обновление метаданных сцены для рендеринга, например, изменение параметра объекта сцены или изменение характеристики сцены и содержащих представление одного или более условий обновления.
Согласно дополнительным вариантам осуществления изобретения, оборудование выполнено с возможностью предоставлять пакет обновлений сцен таким образом, что пакет обновлений сцен содержит представление временного условия, например, временного инициирующего условия; например, заданного посредством startTimestamp, для обновления одних или более метаданных сцены в зависимости от контента пакета обновлений сцен, например, в зависимости от перечисления элементов метаданных сцены, которые должны изменяться, например, указываться посредством ссылки посредством "targetId" и соответствующих новых значений, например, заданных посредством "attribute".
Согласно дополнительным вариантам осуществления изобретения, временное условие задает начальный момент времени, например, с использованием элемента startTimestamp потока битов. Альтернативно, временное условие задает временной интервал, например, с использованием начального времени и конечного времени.
Согласно дополнительным вариантам осуществления изобретения, оборудование выполнено с возможностью предоставлять пакет обновлений сцен, так что пакет обновлений сцен содержит представление пространственного условия, например, инициирующего пространственного условия, например, пространственного условия, заданного посредством ссылки на геометрическое определение; например, пространственного условия, заданного посредством geometryId, для обновления одних или более метаданных сцены в зависимости от контента пакета обновлений сцен, например, в зависимости от перечисления элементов метаданных сцены, которые должны изменяться, например, указываться посредством ссылки посредством "targetId" и соответствующих новых значений, например, заданных посредством "attribute".
Согласно дополнительным вариантам осуществления изобретения, пространственное условие задает геометрический элемент, например, с использованием ссылки на геометрическое определение, при этом упомянутое геометрическое определение, например, может включаться в элемент рабочих данных сцены.
Согласно дополнительным вариантам осуществления изобретения, оборудование выполнено с возможностью предоставлять пакет обновлений сцен, так что пакет обновлений сцен содержит представление интерактивного инициирующего условия, которое, например, может задаваться в пакете обновлений сцен (например, такого условия, что пользователь предпринимает определенное действие, которое выходит за рамки простого перемещения в сцене; например, такого условия, что пользователь выдает предварительно определенную команду или активирует предварительно определенную кнопку, например, заданную посредством флага "fireOn") для обновления одних или более метаданных сцены в зависимости от контента пакета обновлений сцен, например, в зависимости от перечисления элементов метаданных сцены, которые должны изменяться, например, указываться посредством ссылки посредством "targetId" и соответствующих новых значений, например, заданных посредством "attribute".
Согласно дополнительным вариантам осуществления изобретения, оборудование выполнено с возможностью предоставлять пакет обновлений сцен, так что пакет обновлений сцен содержит представление комбинации, например, комбинации "AND" либо другой булевой комбинации двух или более условий обновления.
Согласно дополнительным вариантам осуществления изобретения, оборудование выполнено с возможностью предоставлять пакет обновлений сцен, так что пакет обновлений сцен содержит информацию задержки, например, задержку, задающую необходимость задерживать обновление одних или более метаданных сцены в зависимости от контента одного или более пакетов обновлений сцен в ответ на обнаружение того, что одно или более условий обновления удовлетворяются.
Согласно дополнительным вариантам осуществления изобретения, оборудование выполнено с возможностью предоставлять пакет обновлений сцен, так что пакет обновлений сцен содержит флаг, например, hasTemporalCondition, указывающий то, задается или нет временное условие обновления в пакете обновлений сцен. Альтернативно или помимо этого, оборудование выполнено с возможностью предоставлять пакет обновлений сцен, так что пакет обновлений сцен содержит представление флага, например, hasSpatialCondition, указывающего то, задается или нет пространственное условие обновления в пакете обновлений сцен.
Согласно дополнительным вариантам осуществления изобретения, оборудование выполнено с возможностью предоставлять пакет обновлений сцен таким образом, что пакет обновлений сцен содержит флаг, например, "имеет задержку", например, флаг "имеет задержку", указывающий то, задается или нет информация задержки в пакете обновлений сцен.
Согласно дополнительным вариантам осуществления изобретения, оборудование выполнено с возможностью предоставлять пакет обновлений сцен, так что пакет обновлений сцен содержит представление, например, перечисление, при этом число записей перечисления, например, может указываться посредством параметра потока битов, например, посредством numOfModifications, из множества модификаций одного или более параметров одного или более объектов сцены и/или одной или более характеристик сцены.
Согласно дополнительным вариантам осуществления изобретения, оборудование выполнено с возможностью предоставлять пакет обновлений сцен, так что пакет обновлений сцен содержит информацию траектории, которая, например, может быть ассоциирована с параметром объекта сцены, который должен изменяться, или с характеристикой сцены, которая должна изменяться, например, содержащую isTrajectory, interpolationType, numPoints, time[n] и value[n].
Кроме того, информация траектории описывает необходимость обновлять соответствующие метаданные сцены, с которыми ассоциирована информация траектории, с использованием варьирования параметров, например, плавного интерполированного варьирования параметров согласно траектории, например, временной эволюции, заданной посредством информации траектории, при этом аудиодекодер, например, может определять траекторию на основе множества опорных точек.
Согласно дополнительным вариантам осуществления изобретения, оборудование выполнено с возможностью предоставлять пакет обновлений сцен, так что информация траектории содержит информацию, например, флаг isTrajectory; например, информацию, которая включается в пакет обновлений сцен, указывающую то, используется или нет обновление на основе траектории метаданных сцены, с тем чтобы активировать или деактивировать обновление на основе траектории метаданных сцены.
Согласно дополнительным вариантам осуществления изобретения, оборудование выполнено с возможностью предоставлять пакет обновлений сцен, так что информация траектории содержит информацию типа интерполяции, которая например, может указывать линейную интерполяцию и/или кубическую интерполяцию, и/или поведение по принципу дискретизации и запоминания, включенную в пакет обновлений сцен, например, информацию interpolationType, чтобы определять тип интерполяции между двумя или более опорными точками траектории, при этом опорные точки, например, могут задаваться посредством информации времени (например, time[n]), ассоциированной с соответствующими опорными точками, и посредством информации значений (например, value[n]), ассоциированной с соответствующими опорными точками.
Согласно дополнительным вариантам осуществления изобретения, оборудование выполнено с возможностью предоставлять пакет обновлений сцен, так что информация траектории содержит информацию опорных точек, например, информацию опорных точек, содержащую информацию относительно числа опорных точек; например, информацию опорных точек, содержащую одно или более значений time[n] и value[n], описывающих траекторию, при этом информация опорных точек, например, может описывать множество опорных точек для временного варьирования метаданных сцены, например, с использованием пар информации времени опорных точек и информации значений опорных точек.
Ниже по тексту, поясняются варианты осуществления, связанные со способами для обеспечения декодированного и кодированного аудиопредставления. Следует отметить, что такие варианты осуществления могут быть основаны на соображениях, идентичных или аналогичных, или соответствующих соображениям вышеуказанных вариантов осуществления, связанных с оборудованием. Следовательно, нижеприведенные варианты осуществления могут содержать признаки, функциональности и подробности, идентичные, аналогичные или соответствующие признакам, функциональностям и подробностям вышеуказанных раскрытых вариантов осуществления, как отдельно, так и в комбинации.
Дополнительные варианты осуществления согласно изобретению, содержат способ для обеспечения декодированного и необязательно подготовленного посредством рендеринга аудиопредставления на основе кодированного аудиопредставления, при этом способ содержит пространственный рендеринг одного или более аудиосигналов и прием множества пакетов с различными типами пакетов, например, имеющих типы пакетов, которые являются совместимыми с определением MPEG-H MHAS-пакетов.
Кроме того, пакеты содержат один или более пакетов конфигурирования сцен, например, пакет конфигурирования сцен, например, mpegiSceneConfig[] (иногда также обозначенный в качестве "mpeghiSceneConfig"), предоставляющий конфигурационную информацию модуля рендеринга (например, задающую использование объектов сцены и/или использование характеристик сцены, например, задающую то, когда или при каком условии различные объекты сцены и/или характеристики сцены должны использоваться в процессе рендеринга).
Помимо этого, пакеты содержат один или более пакетов обновлений сцен, например, mpegiSceneUpdate[] (иногда также обозначенный в качестве "mpeghiSceneUpdate"), задающих обновление метаданных сцены для рендеринга, например, изменение параметра объекта сцены или изменение характеристики сцены и содержащих представление одного или более условий обновления.
Кроме того, способ содержит оценку того, удовлетворяются либо нет одно или более условий обновления, например, заданных в пакетах обновлений сцен, и избирательное обновление одних или более метаданных сцены в зависимости от контента одного или более пакетов обновлений сцен, если одно или более условий обновления удовлетворяются.
Дополнительные варианты осуществления согласно изобретению содержат способ для обеспечения кодированного аудиопредставления, при этом способ содержит предоставление множества пакетов с различными типами пакетов, например, имеющих типы пакетов, которые являются совместимыми с определением MPEG-H MHAS-пакетов.
Кроме того, пакеты содержат один или более пакетов конфигурирования сцен, например, пакет конфигурирования сцен, например, mpegiSceneConfig[] (иногда также обозначенный в качестве "mpeghiSceneConfig"), предоставляющий конфигурационную информацию модуля рендеринга (например, задающую использование объектов сцены и/или использование характеристик сцены, например, задающую то, когда или при каком условии различные объекты сцены и/или характеристики сцены должны использоваться в процессе рендеринга).
Помимо этого, пакеты содержат один или более пакетов обновлений сцен, например, mpegiSceneUpdate[] (иногда также обозначенный в качестве "mpeghiSceneUpdate"), задающих обновление метаданных сцены для рендеринга, например, изменение параметра объекта сцены или изменение характеристики сцены и содержащих представление одного или более условий обновления.
Дополнительные варианты осуществления согласно изобретению, содержат компьютерную программу для осуществления способа согласно любому из вариантов осуществления, когда компьютерная программа выполняется на компьютере.
Ниже по тексту, поясняются варианты осуществления, связанные с потоками битов. Следует отметить, что такие варианты осуществления могут быть основаны на соображениях, идентичных или аналогичных, или соответствующих соображениям вышеуказанных вариантов осуществления, связанных с оборудованием и/или способами. Следовательно, нижеприведенные варианты осуществления могут содержать признаки, функциональности и подробности, идентичные, аналогичные или соответствующие признакам, функциональностям и подробностям вышеуказанных раскрытых вариантов осуществления, как отдельно, так и в комбинации.
Дополнительные варианты осуществления согласно изобретению, содержат поток битов, представляющий аудиоконтент, при этом поток битов содержит множество пакетов с различными типами пакетов, например, имеющих типы пакетов, которые являются совместимыми с определением MPEG-H MHAS-пакетов.
Кроме того, пакеты содержат один или более пакетов конфигурирования сцен, например, пакет конфигурирования сцен, например, mpegiSceneConfig[] (иногда также обозначенный в качестве "mpeghiSceneConfig"), предоставляющий конфигурационную информацию модуля рендеринга (например, задающую использование объектов сцены и/или использование характеристик сцены, например, задающую то, когда или при каком условии различные объекты сцены и/или характеристики сцены должны использоваться в процессе рендеринга).
Помимо этого, пакеты содержат один или более пакетов обновлений сцен, например, mpegiSceneUpdate[] (иногда также обозначенный в качестве "mpeghiSceneConfigUpdate"), задающих обновление метаданных сцены для рендеринга, например, изменение параметра объекта сцены или изменение характеристики сцены и содержащих представление одного или более условий обновления.
В качестве примера, поток битов необязательно может дополняться посредством любых элементов потока битов, раскрытых в данном документе, как отдельно, так и в комбинации.
Ниже по тексту, поясняются варианты осуществления согласно третьему аспекту изобретения. Варианты осуществления согласно третьему аспекту изобретения могут быть основаны на использовании временной метки и/или основаны на оценке информации временной метки и других признаков.
Варианты осуществления согласно третьему аспекту могут содержать признаки, функциональности и подробности вариантов осуществления первого и/или второго аспекта изобретения, и, соответственно, наоборот, как отдельно, так и в комбинации.
Варианты осуществления согласно изобретению содержат аудиодекодер для обеспечения декодированного и необязательно подготовленного посредством рендеринга аудиопредставления на основе кодированного аудиопредставления. Аудиодекодер выполнен с возможностью пространственно подготавливать посредством рендеринга один или более аудиосигналов и принимать множество пакетов с различными типами пакетов, например, имеющих типы пакетов, которые являются совместимыми с определением MPEG-H MHAS-пакетов, причем пакеты содержат множество пакетов конфигурирования сцен, например, пакет конфигурирования сцен, например, mpegiSceneConfig[] (иногда также обозначенный в качестве "mpeghiSceneConfig"), предоставляющий конфигурационную информацию модуля рендеринга, задающую временную эволюцию сценария рендеринга, например, задающую использование объектов сцены и/или использование характеристик сцены, например, задающую то, когда или при каком условии различные объекты сцены и/или характеристики сцены должны использоваться в процессе рендеринга, и содержащую информацию временных меток.
Кроме того, аудиодекодер выполнен с возможностью оценивать информацию временных меток и задавать конфигурацию рендеринга в качестве сценария рендеринга, соответствующего временной метке с использованием конфигурационной информации модуля рендеринга, например, когда аудиодекодер подстраивается под поток.
Авторы изобретения выяснили, что аудиосцена, имеющая временную эволюцию, может подготавливаться посредством рендеринга эффективно посредством регулирования конфигурации модуля рендеринга соответствующего декодера. Следовательно, в декодер, например, может предоставляться пакет конфигурирования сцен, который предоставляет конфигурационную информацию модуля рендеринга, задающую временную эволюцию сценария рендеринга, например, аудиосцены.
Следовательно, информация может предоставляться в декодер, который задает то, когда следует использовать соответствующую конфигурацию модуля рендеринга, например, предоставленную в пакете конфигурирования сцен для того, чтобы хорошо подготавливать посредством рендеринга аудиосцену или сценарий рендеринга.
Следовательно, пакеты конфигурирования сцен содержат информацию временных меток. Следовательно, после оценки информации временных меток, декодер или модуль рендеринга, например, может задавать конфигурацию рендеринга, которая является подходящей для рендеринга сценария рендеринга в определенной точке во времени, например, заданной посредством информации временных меток. Например, если время воспроизведения совпадает или превышает время, заданное посредством информации временных меток, конфигурация модуля рендеринга, например, может активироваться.
Конфигурация модуля рендеринга, например, может задавать то, какие акустически релевантные объекты или характеристики сцены должны рассматриваться для точного рендеринга аудиосцены.
Следовательно, например, на основе опорной точки во времени и информации разности времен, извлеченной из информации временных меток, либо необязательно непосредственно, например, может определяться точка во времени, в которой соответствующая конфигурация модуля рендеринга, предоставленная посредством пакетов конфигурирования сцен, должна использоваться. Соответственно, временная метка, например, может представлять собой любой объект информации, подходящей для задания точки во времени, в которой соответствующая конфигурация модуля рендеринга должна использоваться.
Это может обеспечивать возможность эффективно включать изменения акустической сцены, которые инициируются посредством точки во времени или посредством истекшего времени.
Кроме того, следует подчеркнуть, что одно преимущество этого подхода, например, может представлять собой агрегирование не только конфигурационной информации (например, в отношении того, как задавать конфигурацию модуля рендеринга), но также и инициирующей информации в форме временной информации относительно адаптации (например, в отношении того, когда задавать конфигурацию модуля рендеринга). Это может обеспечивать возможность предоставлять самосогласованную и/или самодостаточную, и/или самополагающуюся информацию обновления.
Помимо этого, следует отметить, что пакет конфигурирования сцен необязательно может содержать информацию относительно того, какие пакеты рабочих данных (например, mpegiScenePayload (иногда также обозначенный в качестве "mpeghiScenePayload")), как пояснено выше, могут требоваться в данный момент времени и/или пространство. Следовательно, информация относительно временной эволюции сценария рендеринга необязательно также может использоваться для того, чтобы адаптировать метаданные, например, акустически релевантных объектов и/или характеристик сцены, например, заданных в пакетах рабочих данных, на основе информации временной синхронизации.
Таким образом, информация временных меток обеспечивает то, что конфигурация рендеринга надлежащим образом задается и соответствует (или находится в совмещении с) фактическому времени воспроизведения.
В качестве примера, конфигурация рендеринга может содержать, например, в числе другой информации, например, информации пользовательского ввода и/или предшествующей информации ввода, и/или предшествующей пакетной информации, информацию или настройку на основе конфигурационной информации модуля рендеринга.
Согласно дополнительным вариантам осуществления изобретения, аудиодекодер выполнен с возможностью оценивать информацию временных меток, когда аудиодекодер пропускает один или более предшествующих пакетов конфигурирования сцен потока, либо, когда аудиодекодер подстраивается под поток.
Помимо этого, аудиодекодер выполнен с возможностью задавать время воспроизведения или необязательно время в сцене в зависимости от информации временных меток, включенной в пакет конфигурирования сцен.
Следовательно, декодер, например, может эффективно определять и в силу этого задавать текущее время воспроизведения, например, время (например, относительное время или абсолютное время), в течение которого ассоциированная аудиоинформация должна отображаться, например, после возмущения либо при присоединении к потоку заново или при присоединении к потоку снова.
Согласно дополнительным вариантам осуществления изобретения, аудиодекодер выполнен с возможностью выполнять либо, необязательно эквивалентно, восстанавливать или реконструировать временную разработку сцены для рендеринга вплоть до времени воспроизведения или, например, до времени в сцене, заданного посредством информации временных меток, когда аудиодекодер пропускает один или более предшествующих пакетов конфигурирования сцен потока, либо, когда аудиодекодер подстраивается под поток.
Следовательно, в качестве примера, декодер или модуль рендеринга может не отставать от хода обновлений, например, обновлений метаданных, на основе пакетов конфигурирования сцен, например, с учетом информации временных меток.
Согласно дополнительным вариантам осуществления изобретения, аудиодекодер выполнен с возможностью получать информацию временной шкалы, которая включается в пакет, например, в пакет конфигурирования сцен; например, в пакет mpegiSceneConfig() (иногда также обозначенный в качестве "mpeghiSceneConfig").
Кроме того, аудиодекодер выполнен с возможностью оценивать информацию временной метки с использованием информации временной шкалы, при этом аудиодекодер, например, может быть выполнен с возможностью оценивать информацию временной метки на временной шкале, заданной посредством информации временной шкалы; при этом, например, информация временной шкалы конфигурирует интерпретацию информации временной метки и необязательно также интерпретацию другой информации времени относительно источника тактовых сигналов аудиодекодера или модуля рендеринга. Следовательно, информация времени или информация временной синхронизации может предоставляться и определяться эффективно.
Согласно дополнительным вариантам осуществления изобретения, аудиодекодер выполнен с возможностью определять, в зависимости от информации временных меток, то, какие объекты сцены должны использоваться для рендеринга. Следовательно, временно зависимые смены сцен, которые могут моделироваться посредством объектов, могут представляться эффективно.
Согласно дополнительным вариантам осуществления изобретения, аудиодекодер выполнен с возможностью оценивать пакет конфигурирования сцен, который задает эволюцию сцены для рендеринга, начиная с точки времени, которая находится перед временем, заданным посредством информации временных меток.
Помимо этого, аудиодекодер выполнен с возможностью извлекать конфигурацию сцены, ассоциированную с точкой во времени, заданной посредством информации временных меток, на основе информации в пакете конфигурирования сцен.
Следовательно, эволюция обновления аудиосцены, перед временем информации временных меток, например, может рассматриваться посредством аудиодекодера, чтобы определять конфигурацию сцены, которая присутствует во время временной метки. Следовательно, подстройка аудиодекодера в аудиопотоке является возможной без наличия самосогласованной конфигурационной информации сцен, ассоциированной со временем информации временных меток. Это может уменьшать скорость передачи битов при предоставлении хорошего восприятия для слуха.
Согласно дополнительным вариантам осуществления изобретения, аудиодекодер выполнен с возможностью извлекать конфигурацию сцены, ассоциированную с точкой во времени, заданной посредством информации временных меток, с использованием одного или более пакетов обновлений сцен и, например, предпочтительно также с использованием информации в пакете конфигурирования сцен.
Следовательно, варианты осуществления предоставляют хорошую гибкость относительно конфигурационной информации модуля рендеринга, предоставляющей пакеты.
Согласно дополнительным вариантам осуществления изобретения, пакеты конфигурирования сцен и необязательно один или более пакетов обновлений сцен, и один или более пакетов рабочих данных сцен являются совместимыми с определением MPEG-H MHAS-пакетов.
Следовательно, варианты осуществления согласно изобретению, могут использоваться вместе или в соответствии с существующими инфраструктурами или стандартами кодирования аудио.
Согласно дополнительным вариантам осуществления изобретения, пакеты конфигурирования сцен и необязательно один или более пакетов обновлений сцен, и один или более пакетов рабочих данных сцен содержат идентификатор типа пакета, например, MHASPacketType, метку пакета, например, MHASPacketLabel, информацию длины пакетов, например, MHASPacketLength, и рабочие данные пакета, например, MHASPAcketPayload.
В качестве примера, метка пакета может предоставлять индикатор того, какие пакеты принадлежат друг другу. Например, с использованием различных меток, различные трехмерные конфигурационные MPEG-H-аудиоструктуры могут назначаться конкретным последовательностям трехмерных MPEG-H-единиц аудиодоступа. Информация длины пакетов может указывать длину рабочих данных пакета. Авторы изобретения выяснили, что использование такой структуры данных может обеспечивать возможность эффективной обработки пакетов.
Согласно дополнительным вариантам осуществления изобретения, аудиодекодер выполнен с возможностью извлекать один или более пакетов конфигурирования сцен и необязательно один или более пакетов обновлений сцен, и один или более пакетов рабочих данных сцен из потока битов, содержащего множество MPEG-H-пакетов, включающих в себя пакеты, представляющие один или более аудиоканалов, которые должны подготавливаться посредством рендеринга.
Необязательно, аудиодекодер, например, может быть выполнен с возможностью извлекать один или более пакетов конфигурирования сцен, один или более пакетов обновлений сцен и один или более пакетов рабочих данных сцен из перемеженной последовательности пакетов (например, из перемеженной последовательности MHAS-пакетов) содержащей пакеты с различными типами, например, с использованием идентификаторов типов пакетов и/или меток пакетов, включенных в пакеты.
Следовательно, меньшие части данных, например, могут передаваться перемеженным способом. Например, в широковещательном сценарии, это может обеспечивать возможность поддерживать скорость передачи данных широковещательного потока битов низкой.
Согласно дополнительным вариантам осуществления изобретения, аудиодекодер выполнен с возможностью принимать один или более пакетов конфигураций сцен через широковещательный поток, например, через широковещательный поток с низкой скоростью передачи битов.
Это, например, может обеспечивать возможность распределения конфигурационной информации модуля рендеринга во множество декодеров или модулей рендеринга с ограниченным использованием ресурсов передачи.
Согласно дополнительным вариантам осуществления изобретения, аудиодекодер выполнен с возможностью подстраиваться под широковещательный поток и определять время воспроизведения на основе временной метки первого пакета конфигурирования сцен, идентифицированного посредством аудиодекодера после подстройки.
Авторы изобретения выяснили, что посредством обеспечения возможности определения временной метки на основе первого пакета конфигурирования сцен, идентифицированного посредством аудиодекодера после подстройки, аудиодекодер может быстро задавать корректное текущее время воспроизведения, с тем чтобы корректно подготавливать посредством рендеринга аудиоинформацию.
Ниже по тексту, поясняются варианты осуществления, связанные с оборудованием для обеспечения кодированного аудиопредставления, например, с кодером. Следует отметить, что такие варианты осуществления могут быть основаны на соображениях, идентичных или аналогичных, или соответствующих соображениям вышеуказанных вариантов осуществления, связанных с декодером. Следовательно, нижеприведенные варианты осуществления могут содержать признаки, функциональности и подробности, идентичные, аналогичные или соответствующие признакам, функциональностям и подробностям вышеуказанных раскрытых вариантов осуществления, как отдельно, так и в комбинации.
Дополнительные варианты осуществления согласно изобретению содержат оборудование, например, аудиокодер или аудиосервер, для обеспечения кодированного аудиопредставления, при этом оборудование выполнено с возможностью предоставлять информацию для пространственного рендеринга одного или более аудиосигналов.
Кроме того, оборудование выполнено с возможностью предоставлять множество пакетов с различными типами пакетов, например, имеющих типы пакетов, которые являются совместимыми с определением MPEG-H MHAS-пакетов, причем пакеты содержат множество пакетов конфигурирования сцен, например, пакет конфигурирования сцен, например, mpegiSceneConfig[] (иногда также обозначенный в качестве "mpeghiSceneConfig"), предоставляющий конфигурационную информацию модуля рендеринга, задающую временную эволюцию сценария рендеринга, например, задающую использование объектов сцены и/или использование характеристик сцены, например, задающую то, когда или при каком условии различные объекты сцены и/или характеристики сцены должны использоваться в процессе рендеринга, и содержащую информацию временных меток.
Согласно дополнительным вариантам осуществления изобретения, оборудование выполнено с возможностью предоставлять, в одном из пакетов, например, в пакете конфигурирования сцен, информацию временной шкалы, при этом информация временной метки предоставляется в представлении, связанном с информацией временной шкалы.
Согласно дополнительным вариантам осуществления изобретения, оборудование выполнено с возможностью предоставлять пакеты конфигурирования сцен и необязательно один или более пакетов обновлений сцен, и один или более пакетов рабочих данных сцен таким образом, что пакеты конфигурирования сцен и необязательно один или более пакетов обновлений сцен, и один или более пакетов рабочих данных сцен являются совместимыми с определением MPEG-H MHAS-пакетов.
Согласно дополнительным вариантам осуществления изобретения, оборудование выполнено с возможностью предоставлять пакеты конфигурирования сцен и необязательно один или более пакетов обновлений сцен, и один или более пакетов рабочих данных сцен таким образом, что пакеты конфигурирования сцен и необязательно один или более пакетов обновлений сцен, и один или более пакетов рабочих данных сцен содержат идентификатор типа пакета, например, MHASPacketType, метку пакета, например, MHASPacketLabel, информацию длины пакетов, например, MHASPacketLength, и рабочие данные пакета, например, MHASPAcketPayload.
Согласно дополнительным вариантам осуществления изобретения, оборудование выполнено с возможностью предоставлять поток битов, содержащий множество MPEG-H-пакетов, также, в качестве примера, обозначенных в качестве MHAS или MHAS-потока, включающих в себя пакеты, представляющие один или более аудиоканалов, которые должны подготавливаться посредством рендеринга, и один или более пакетов конфигурирования сцен, и необязательно один или более пакетов обновлений сцен, и один или более пакетов рабочих данных сцен.
Согласно дополнительным вариантам осуществления изобретения, оборудование выполнено с возможностью предоставлять поток битов, содержащий множество MPEG-H-пакетов, также, в качестве примера, обозначенных в качестве MHAS или MHAS-потока, включающих в себя пакеты, представляющие один или более аудиоканалов, которые должны подготавливаться посредством рендеринга, и один или более пакетов конфигурирования сцен, и необязательно один или более пакетов обновлений сцен, и один или более пакетов рабочих данных сцен, перемеженным способом.
Согласно дополнительным вариантам осуществления изобретения, оборудование выполнено с возможностью периодически повторять пакет конфигурирования сцен, например, с изменением только временной метки, например, периодически повторять пакет конфигурирования сцен с одним или более пакетов рабочих данных сцен (например, рабочие данные 1, рабочие данные 2) и одним или более пакетов, представляющих один или более аудиоканалов, которые должны подготавливаться посредством рендеринга (например, MPEGH3DA-кадр) (и необязательно также с одним или более пакетов обновлений сцен) между двумя последующими пакетами конфигурирования сцен, например, периодически повторять пакет конфигурирования сцен с одним или более пакетов, представляющих один или более аудиоканалов, которые должны подготавливаться посредством рендеринга (например, MPEGH3DA-кадр) (и необязательно также с одним или более пакетов обновлений сцен) между двумя последующими пакетами конфигурирования сцен, которые предоставляет оборудование.
Это может обеспечивать возможность эффективной процедуры подстройки для декодеров или модулей рендеринга, присоединяющихся к потоку.
Согласно дополнительным вариантам осуществления изобретения, оборудование выполнено с возможностью периодически повторять, например, в широковещательном потоке битов, пакет конфигурирования сцен, необязательно с изменением только временной метки, с одним или более пакетов рабочих данных сцен, например, рабочие данные 1, рабочие данные 2, и одним или более пакетов, представляющих один или более аудиоканалов, которые должны подготавливаться посредством рендеринга, например, MPEGH3DA-кадр, и необязательно также с одним или более пакетов обновлений сцен, между двумя последующими пакетами конфигурирования сцен.
Согласно дополнительным вариантам осуществления изобретения, оборудование выполнено с возможностью периодически повторять, например, в широковещательном потоке битов, пакет конфигурирования сцен, необязательно с изменением или обновляться только временной метки, с одним или более пакетов, представляющих один или более аудиоканалов, которые должны подготавливаться посредством рендеринга, например, MPEGH3DA-кадр, и необязательно также с одним или более пакетов обновлений сцен, между двумя последующими пакетами конфигурирования сцен.
Кроме того, оборудование выполнено с возможностью предоставлять или запрашивать один или более пакетов рабочих данных сцен по запросу, например, по запросу аудиодекодера или модуля рендеринга.
Необязательно, оборудование может быть выполнено с возможностью периодически повторять пакет конфигурирования сцен с одним или более пакетов, представляющих один или более аудиоканалов, которые должны подготавливаться посредством рендеринга (например, MPEGH3DA-кадр) (и необязательно также с одним или более пакетов обновлений сцен) между двумя последующими пакетами конфигурирования сцен, при этом, например, оборудование предоставляет пакеты рабочих данных сцен только по запросу.
Следовательно, пакеты конфигурирования сцен, например, могут представлять собой небольшие пакеты, и соответствующий декодер или модуль рендеринга может определять, например, на основе упомянутых пакетов конфигурирования сцен, то, какие пакеты рабочих данных необходимы, может запрашивать их через обратный канал, например, из вышеописанного оборудования, которое может быть выполнено с возможностью предоставлять их. Следовательно, скорость передачи данных широковещательных потоков битов может поддерживаться низкой.
Согласно дополнительным вариантам осуществления изобретения, оборудование выполнено с возможностью предоставлять, например, периодически множество в других отношениях идентичных пакетов конфигурирования сцен, отличающихся, например, только по информации временных меток.
Следовательно, например, только информация временных меток может обновляться. Следовательно, усилия по адаптации могут поддерживаться низкими при одновременном предоставлении информации относительно текущего времени воспроизведения.
Согласно дополнительным вариантам осуществления изобретения, оборудование выполнено с возможностью адаптировать информацию временных меток ко времени воспроизведения, например, ко времени в сцене.
Согласно дополнительным вариантам осуществления изобретения, оборудование выполнено с возможностью адаптировать информацию временных меток ко времени воспроизведения, например, к независимому времени воспроизведения, например, к намеченному времени воспроизведения, например, к независимому времени воспроизведения; например, ко времени в сцене информации сцен для рендеринга, включенной в пакеты, которые предоставляются посредством оборудования во временном окружении соответствующего пакета конфигурирования сцен, в который включается соответствующая информация временных меток.
Ниже по тексту, поясняются варианты осуществления, связанные со способами для обеспечения декодированного и кодированного аудиопредставления. Следует отметить, что такие варианты осуществления могут быть основаны на соображениях, идентичных или аналогичных, или соответствующих соображениям вышеуказанных вариантов осуществления, связанных с оборудованием. Следовательно, нижеприведенные варианты осуществления могут содержать признаки, функциональности и подробности, идентичные, аналогичные или соответствующие признакам, функциональностям и подробностям вышеуказанных раскрытых вариантов осуществления, как отдельно, так и в комбинации.
Дополнительные варианты осуществления согласно изобретению содержат способ для обеспечения декодированного и необязательно подготовленного посредством рендеринга аудиопредставления на основе кодированного аудиопредставления, при этом способ содержит пространственный рендеринг одного или более аудиосигналов и прием множества пакетов с различными типами пакетов, например, имеющих типы пакетов, которые являются совместимыми с определением MPEG-H MHAS-пакетов, причем пакеты содержат множество пакетов конфигурирования сцен, например, пакет конфигурирования сцен, например, mpegiSceneConfig[] (иногда также обозначенный в качестве "mpeghiSceneConfig"), предоставляющий конфигурационную информацию модуля рендеринга, задающую временную эволюцию сценария рендеринга, например, задающую использование объектов сцены и/или использование характеристик сцены, например, задающую то, когда или при каком условии различные объекты сцены и/или характеристики сцены должны использоваться в процессе рендеринга, и содержащую информацию временных меток.
Кроме того, способ содержит оценку информации временных меток и задание конфигурации рендеринга в качестве сценария рендеринга, соответствующего временной метке, с использованием конфигурационной информации модуля рендеринга, например, когда аудиодекодер подстраивается под поток.
Дополнительные варианты осуществления согласно изобретению содержат способ для обеспечения кодированного аудиопредставления, при этом способ содержит предоставление информации для пространственного рендеринга одного или более аудиосигналов и предоставление множества пакетов с различными типами пакетов, например, имеющих типы пакетов, которые являются совместимыми с определением MPEG-H MHAS-пакетов, причем пакеты содержат множество пакетов конфигурирования сцен, например, пакет конфигурирования сцен, например, mpegiSceneConfig[] (иногда также обозначенный в качестве "mpeghiSceneConfig"), предоставляющий конфигурационную информацию модуля рендеринга, задающую временную эволюцию сценария рендеринга, например, задающую использование объектов сцены и/или использование характеристик сцены, например, задающую то, когда или при каком условии различные объекты сцены и/или характеристики сцены должны использоваться в процессе рендеринга, и содержащую информацию временных меток.
Дополнительные варианты осуществления согласно изобретению, содержат компьютерную программу для осуществления способа согласно любому из вариантов осуществления, когда компьютерная программа выполняется на компьютере.
Ниже по тексту поясняются варианты осуществления, связанные с потоками битов. Следует отметить, что такие варианты осуществления могут быть основаны на соображениях, идентичных или аналогичных, или соответствующих соображениям вышеуказанных вариантов осуществления, связанных с оборудованием и/или способами. Следовательно, нижеприведенные варианты осуществления могут содержать признаки, функциональности и подробности, идентичные, аналогичные или соответствующие признакам, функциональностям и подробностям вышеуказанных раскрытых вариантов осуществления, как отдельно, так и в комбинации.
Дополнительные варианты осуществления согласно изобретению содержат поток битов, представляющий аудиоконтент, причем поток битов содержит множество пакетов с различными типами пакетов, например, имеющих типы пакетов, которые являются совместимыми с определением MPEG-H MHAS-пакетов, причем пакеты содержат множество пакетов конфигурирования сцен, например, пакет конфигурирования сцен, например, mpegiSceneConfig[] (иногда также обозначенный в качестве "mpeghiSceneConfig"), предоставляющий конфигурационную информацию модуля рендеринга, задающую временную эволюцию сценария рендеринга, например, задающую использование объектов сцены и/или использование характеристик сцены, например, задающую то, когда или при каком условии различные объекты сцены и/или характеристики сцены должны использоваться в процессе рендеринга, и содержащую информацию временных меток.
В качестве примера, поток битов необязательно может дополняться посредством любых элементов потока битов, раскрытых в данном документе, как отдельно, так и в комбинации.
Дополнительные варианты осуществления изобретения содержат аудиодекодер для обеспечения декодированного аудиопредставления на основе кодированного аудиопредставления, при этом аудиодекодер выполнен с возможностью пространственно подготавливать посредством рендеринга один или более аудиосигналов и принимать множество пакетов с различными типами пакетов, причем пакеты содержат множество пакетов конфигурирования сцен, предоставляющих конфигурационную информацию модуля рендеринга.
Кроме того, аудиодекодер выполнен с возможностью оценивать информацию временных меток и задавать конфигурацию рендеринга в качестве сценария рендеринга, соответствующего временной метке.
Следует отметить, что такой изобретаемый декодер может содержать идентичные, аналогичные или соответствующие признаки, функциональности и подробности относительно любых из вышеуказанных раскрытых вариантов осуществления или относительно любых из других вариантов осуществления, раскрытых в данном документе, как отдельно, так и в комбинации.
Ниже по тексту, поясняются варианты осуществления согласно четвертому аспекту изобретения. Варианты осуществления согласно четвертому аспекту изобретения могут быть основаны на использовании информации ячеек.
Варианты осуществления согласно четвертому аспекту могут содержать признаки, функциональности и подробности вариантов осуществления первого, второго и/или третьего аспекта изобретения, и наоборот, как отдельно, так и в комбинации.
Варианты осуществления согласно изобретению содержат аудиодекодер для обеспечения декодированного и необязательно подготовленного посредством рендеринга аудиопредставления на основе кодированного аудиопредставления, при этом аудиодекодер выполнен с возможностью пространственно подготавливать посредством рендеринга один или более аудиосигналов, которые, например, могут кодироваться в кодированном аудиопредставлении.
Кроме того, аудиодекодер выполнен с возможностью принимать пакет конфигурирования сцен, например, пакет конфигурирования сцен, который является совместимым с определением MPEG-H MHAS-пакетов, например, пакет конфигурирования сцен, например, mpegiSceneConfig[] (иногда также обозначенный в качестве "mpeghiSceneConfig"), предоставляющий конфигурационную информацию модуля рендеринга, например, задающую использование объектов сцены и/или использование характеристик сцены, например, задающую то, когда или при каком условии различные объекты сцены и/или характеристики сцены должны использоваться в процессе рендеринга.
Помимо этого, пакет конфигурирования сцен содержит информацию ячеек (например, информацию numCells, указывающую число ячеек и, для каждой ячейки, определение одного или более условий в ячейке (например, начальной временной метки и необязательно конечной временной метки или геометрического идентификатора) и определение одних или более рабочих данных сцен (например, payloadId[i][j] и/или ссылки на пакет обновлений сцен (например, updateId[i])) (при этом, например, но не обязательно, информация ячеек может представлять собой информацию ячеек подсцены), задающих одну или более ячеек, например, предпочтительно множество ячеек, и необязательно также определение, или, например, задающую один или более аудиопотоков.
Кроме того, информация ячеек задает ассоциирование между одной или более, например, временных и/или пространственных ячеек, например, имеющих индекс i ячейки, и соответствующей одной или более структур данных (например, рабочих данных или пакетов рабочих данных (например, mpegiScenePayload (иногда также обозначенный в качестве "mpeghiScenePayload")); например, payloadId[i][j]; например, рабочих данных, задающих объекты сцены и/или характеристики сцены; например, структур данных, задающих источники звука и/или рассеивающие объекты, и/или рассеивающие поверхности, и/или вызывающие затухание объекты, и/или вызывающие затухание поверхности, и/или параметры материала, и/или характеристики реверберации, и/или порталы, и/или ранние отражения, и/или позднюю реверберацию, и/или характеристики дифракции, и/или акустические материалы, и/или геометрические элементы в сцене, например, идентифицированной посредством идентификатора структуры данных или идентификатора рабочих данных; например, идентифицированной посредством payloadId), ассоциированных с одной или более ячеек, например, с использованием ссылки на рабочие данные пакета рабочих данных сцены, представляющего одну или более соответствующих структур данных и задающего сценарий рендеринга (например, но не обязательно, сценарий рендеринга подсцен).
Помимо этого, аудиодекодер выполнен с возможностью оценивать информацию ячеек, чтобы определять то, какие структуры данных, например, какие рабочие данные сцен, идентифицированные посредством payloadId[i][j], должны использоваться для пространственного рендеринга, например, в различные моменты времени или в различных позициях слушателя, при этом упомянутые структуры данных, например, могут включаться в пакеты рабочих данных сцен.
Авторы изобретения выяснили, что на основе определения ячеек, сценарий рендеринга, содержащий структуры данных, может задаваться эффективно. Как пояснено выше, ячейки, например, могут представлять собой временные и/или пространственные ячейки. Другими словами, аудиосцена, например, аспект аудиосцены, такой как акустически релевантные объекты, может разделяться или отделяться, или сегментироваться во времени и/или в пространстве.
Другими словами, метаданные, например, могут становиться обязательными (a) в конкретной точке во времени или (b) в конкретном местоположении в пространстве. Концепция "ячеек" предоставляет, например, способ для того, чтобы указывать то, в какое время и/или в каком местоположении определенные пакеты рабочих данных требуются для рендеринга сцены.
Ячейки могут содержать границы ячеек, задающие геометрию ячейки в пространственной акустической сцене. Ячейка, например, может быть активной, когда слушатель находится в пределах границ ячеек и/или когда слушатель находится в пределах границ ячеек в определенное время. Границы ячеек, например, могут представлять собой произвольную геометрию, но примитивные геометрии (такие как ограничивающие прямоугольники с совмещением по осям) могут быть предпочтительными для эффективной реализации.
Простыми словами и в качестве примера, ячейки могут предоставлять "пакетирование" для структур данных, например, в форме рабочих данных, например, задающих объекты сцены и/или характеристики сцены, так что эти элементы ассоциированы с конкретной зоной и/или временем в акустической сцене, и так что эти элементы могут активироваться или учитываться простым способом, например, посредством активации соответствующей ячейки.
Кроме того, ячейки могут быть перекрывающимися, например, реализующими подход на основе уровня детальности, так что первая ячейка предоставляет приблизительную информацию относительно акустически релевантных элементов аудиосцены, которая детализируется посредством перекрывающихся ячеек, предоставляющих более подробную информацию.
В качестве примера, на основе информации ячеек, необязательно включенной в пакеты рабочих данных, декодер в силу этого может выбирать то, какие рабочие данные необходимы для рендеринга аудиосцены, например, на основе временного или пространственного условия информации ячеек. Таким образом, декодер может только запрашивать выбор рабочих данных, которые могут использоваться и/или сохраняться.
Таким образом, эффективность может увеличиваться, поскольку меньшее количество рабочих данных, возможно, должны запрашиваться и оцениваться, что может уменьшать соответствующую требуемую скорость передачи битов между кодером и декодером.
Кроме того, в качестве примера, поскольку пакеты конфигурирования сцен могут содержать информацию ячеек, которая необязательно может распределяться в качестве небольших пакетов потоков битов в широковещательном канале, может предоставляться хорошая доступность такой фундаментальной информации рендеринга, например, для эффективного выбора рабочих данных, что может повышать эффективность концепции изобретения.
Согласно дополнительным вариантам осуществления изобретения, информация ячеек содержит временное определение, например, временное условие данной ячейки, например, ячейки, имеющей индекс i ячейки, например, информацию начального времени и/или информацию конечного времени; например, начальную временную метку и/или конечную временную метку; например, startTimestamp[i] и/или endTimestamp[i].
Кроме того, аудиодекодер выполнен с возможностью оценивать временное определение данной ячейки, чтобы определять то, должны либо нет одна или более структур данных, ассоциированных с данной ячейкой, например, идентифицированной посредством payloadId[i][j], рассматриваться (например, использоваться) в пространственном рендеринге, при этом аудиодекодер, например, может быть выполнен с возможностью избирательно использовать структуру(ы) данных, ассоциированную с данной ячейкой, если текущее время воспроизведения удовлетворяет временному определению (например, временному условию) данной ячейки.
Следовательно, временная информация (например, временная эволюция) аудиосцены, например, может быть легко включена в процедуру рендеринга, на основе концепции ячеек.
Согласно дополнительным вариантам осуществления изобретения, информация ячеек содержит пространственное определение, например, пространственное условие данной ячейки, например, прямое геометрическое определение или ссылку на определение геометрического объекта; например, геометрический идентификатор; например, geometryId[i].
Помимо этого, аудиодекодер выполнен с возможностью оценивать пространственное определение данной ячейки, чтобы определять то, должны либо нет одна или более структур данных, ассоциированных с данной ячейкой, например, идентифицированной посредством payloadId[i][j], рассматриваться (например, использоваться) в пространственном рендеринге.
Необязательно, аудиодекодер, например, может быть выполнен с возможностью избирательно использовать структуру(ы) данных, ассоциированную с данной ячейкой, если текущая позиция слушателя удовлетворяет пространственному определению (например, пространственному условию) данной ячейки.
Следовательно, пространственная информация относительно аудиосцены, например, может быть легко включена в процедуру рендеринга, на основе концепции ячеек.
Согласно дополнительным вариантам осуществления изобретения, аудиодекодер выполнен с возможностью оценивать информацию числа ячеек, например, numCells, которая включается в пакет конфигурирования сцен для того, чтобы определять число ячеек.
Согласно дополнительным вариантам осуществления изобретения, информация ячеек содержит флаг, например, isTimed[i], указывающий то, содержит либо нет информация ячеек временное определение ячейки или пространственное определение ячейки.
Кроме того, аудиодекодер выполнен с возможностью оценивать флаг, указывающий то, содержит либо нет информация ячеек временное определение ячейки или пространственное определение ячейки, например, чтобы извлекать условие, когда одна или более структур данных, ассоциированных с соответствующей ячейкой, должны использоваться для пространственного рендеринга.
Флаги, например, могут передаваться и оцениваться с низкими вычислительными усилиями и с низкими требованиями относительно ресурсов передачи.
Согласно дополнительным вариантам осуществления изобретения, информация ячеек содержит ссылку геометрической структуры, например, geometryId[i], чтобы задавать ячейку, при этом геометрическая структура, например, может задаваться в пакете рабочих данных.
Кроме того, аудиодекодер выполнен с возможностью оценивать ссылку геометрической структуры, чтобы получать геометрическое определение ячейки.
Использование ссылочной информации, например, может обеспечивать возможность задавать множество комплексных геометрий, выбор которых может указываться посредством ссылочной информации, например, с использованием списка или таблицы поиска, которая может быть общей как для кодера, так и для декодера, так что передача подробной информации, задающей саму геометрию, может опускаться.
В общем, следует отметить, что ячейки, например, могут задавать пространственное и/или временное разделение аудиосцены, содержащей акустически релевантные элементы, которые могут описываться с использованием элементов рабочих данных. Следовательно, ячейки могут быть ассоциированы с рабочими данными или с пакетами рабочих данных. Тем не менее, сами ячейки могут необязательно также представлять акустически релевантные объекты, при этом их геометрия, например, может представлять геометрию элемента.
Согласно дополнительным вариантам осуществления изобретения, аудиодекодер выполнен с возможностью получать определение геометрической структуры, например, геометрической структуры, указываемой посредством ссылки посредством geometryId, который задает геометрическую границу ячейки, из глобального пакета рабочих данных, при этом ссылка на глобальный пакет рабочих данных, например, может включаться в пакет конфигурирования сцен, и при этом глобальный пакет рабочих данных, например, может задавать структуры данных, такие как объекты сцены и/или характеристики сцены, которые используются в нескольких ячейках и/или которые должны быть глобально доступными.
Авторы изобретения выяснили, что геометрические структуры и, например, очень часто используемые геометрические структуры могут задаваться эффективно посредством глобального определения, в силу чего глобального пакета рабочих данных, который может быть глобально доступным.
Согласно дополнительным вариантам осуществления изобретения, аудиодекодер выполнен с возможностью идентифицировать одну или более текущих, например, временных и/или пространственных ячеек, например, с использованием текущего времени воспроизведения и/или текущей позиции и необязательно временных и/или пространственных определений ячеек.
Кроме того, аудиодекодер выполнен с возможностью выполнять пространственный рендеринг, например, избирательно, с использованием одной или более структур данных, например, рабочих данных, ассоциированных с одной или более идентифицированных текущих ячеек, и необязательно также с использованием одних или более глобально требуемых рабочих данных.
В качестве примера, текущая ячейка, например, может представлять собой активную ячейку, в силу чего ячейку, для которой ассоциированные метаданные, например, рабочие данные могут учитываться для рендеринга аудиосцены. Соответственно, только ограниченное количество ячеек, возможно, должно активироваться, так что усилия по передаче служебных сигналов и вычислительные усилия могут быть ограничены.
Авторы изобретения выяснили, что только часть доступных ячеек, возможно, должна активироваться и/или учитываться, например, для определенного слушателя (например, пространственно в определенном местоположении) и/или, например, для текущего времени воспроизведения аудиосцены.
Согласно дополнительным вариантам осуществления изобретения, аудиодекодер выполнен с возможностью идентифицировать одну или более текущих, например, временных и/или пространственных ячеек, например, с использованием текущего времени воспроизведения и/или текущей позиции и необязательно временных и/или пространственных определений ячеек.
Кроме того, аудиодекодер выполнен с возможностью выполнять пространственный рендеринг, например, избирательно, с использованием одного или более объектов сцены (например, аудиоисточников и/или рассеивающих объектов, и/или вызывающих затухание объектов, и/или преград) и/или характеристик сцены (например, характеристик материала и/или характеристик распространения, и/или характеристик дифракции, и/или характеристик отражения), ассоциированных с одной или более идентифицированных текущих ячеек, и необязательно также с использованием одних или более глобально требуемых рабочих данных.
Согласно дополнительным вариантам осуществления изобретения, аудиодекодер выполнен с возможностью выбирать объекты сцены и/или характеристики сцены, которые должны рассматриваться, например, использоваться в пространственном рендеринге в зависимости от информации ячеек.
Согласно дополнительным вариантам осуществления изобретения, аудиодекодер выполнен с возможностью определять то, в какой одной или более, например, пространственно перекрывающихся пространственных ячеек находится текущая позиция, например, текущая позиция слушателя, например, с использованием границ ячеек, которые, например, могут задаваться в одних или более глобально требуемых рабочих данных, например, чтобы за счет этого получать идентифицированные ячейки.
Кроме того, аудиодекодер выполнен с возможностью выполнять пространственный рендеринг, например, избирательно, с использованием одного или более объектов сцены, например, аудиоисточников и/или рассеивающих объектов, и/или вызывающих затухание объектов, и/или преград, и/или характеристик сцены, например, характеристик материала и/или характеристик распространения, и/или характеристик дифракции, и/или характеристик отражения, ассоциированных с одной или более идентифицированных текущих ячеек, и необязательно также с использованием одних или более глобально требуемых рабочих данных.
Это может обеспечивать возможность эффективно подготавливать посредством рендеринга аудиосцену.
Согласно дополнительным вариантам осуществления изобретения, аудиодекодер выполнен с возможностью определять одни или более рабочих данных, например, рабочих данных, описывающих объекты сцены и/или характеристики сцены; например, рабочих данных mpegiPayloadElement() (иногда также обозначенный в качестве "mpeghiPayloadElement"), ассоциированных с одной или более текущих ячеек, например, имеющих индекс i ячейки, на основе перечисления идентификаторов рабочих данных, например, for(j=0; j<numPayloads[i]; j++){payloadId[i][j];}, включенных в определение ячейки для ячейки.
Помимо этого, аудиодекодер выполнен с возможностью выполнять пространственный рендеринг с использованием определенных одних или более рабочих данных, например, с оставлением других рабочих данных, ассоциированных с другими ячейками, нерассмотренными/заброшенными.
Следовательно, в качестве примера, ячейки могут быть ассоциированы с рабочими данными, которые, например, могут задавать метаданные, которые могут использоваться для того, чтобы включать акустически релевантные элементы в акустическую сцену. Следовательно, на основе идентификации соответствующей ячейки, выбор рабочих данных, которые должны рассматриваться, может выполняться (и выбор того, какие рабочие данные следует оставлять нерассмотренным), за счет этого повышая эффективность рендеринга аудио.
Согласно дополнительным вариантам осуществления изобретения, аудиодекодер выполнен с возможностью выполнять пространственный рендеринг с использованием информации из одного или более пакетов обновлений сцен, например, mpegiSceneUpdate (иногда также обозначенный в качестве "mpeghiSceneUpdate"), которые ассоциированы с одной или более текущих ячеек и которые, например, могут идентифицироваться, например, с использованием ссылки updateId[i], в определениях ячеек для ячеек, при этом обновление сцен, заданное посредством пакета обновлений сцен, например, может содержать активацию и/или деактивацию одного или более объектов сцены.
В качестве примера, обновления могут быть ассоциированы с определенными ячейками или элементами, например, элементами рабочих данных, ассоциированными с определенной ячейкой, соответственно. Следовательно, обновления сцен могут указываться эффективно на основе ссылки на соответствующую ячейку.
Согласно дополнительным вариантам осуществления изобретения, аудиодекодер выполнен с возможностью обновлять сцену для рендеринга с использованием информации из одного или более пакетов обновлений сцен, например, пакета обновлений сцен, обозначенного посредством updateId[], ассоциированного с данной ячейкой, в ответ на нахождение того, что данная ячейка становится активной, например, в ответ на нахождение того, что позиция достигает или входит в область, ассоциированную с ячейкой, и/или в ответ на нахождение того, что время воспроизведения достигает времени или временного интервала, ассоциированного с ячейкой, или входит во временной интервал, ассоциированный с ячейкой.
Следовательно, акустически релевантные элементы сцены, например, могут обновляться, когда они необходимы для рендеринга сцены для рендеринга, например, аудиосцены. Авторы изобретения выяснили, что на основе состояния активации ячейки, потребность в предоставлении актуальной версии акустических метаданных может указываться эффективно.
Согласно дополнительным вариантам осуществления изобретения, информация ячеек содержит ссылку, например, updateId[i], для и/или на пакет обновлений сцен, например, mpegiSceneUpdate[] (иногда также обозначенный в качестве "mpeghiSceneUpdate"), задающий обновление метаданных сцены для рендеринга, например, изменение параметра объекта сцены или изменение характеристики сцены и необязательно содержащий представление одного или более условий обновления.
Кроме того, аудиодекодер выполнен с возможностью избирательно выполнять обновление метаданных сцены, заданных в данном пакете обновлений сцен, в ответ на обнаружение того, что ячейка, содержащая ссылку на данный пакет обновлений сцен, становится активной, например, так что аудиодекодер использует оценку информации ячеек, чтобы определять то, какие объекты сцены и/или характеристики сцены должны использоваться для пространственного рендеринга, а также определять, посредством ссылки на пакет обновлений сцен, то, какое обновление метаданных сцены должно осуществляться в ответ на активацию ячейки.
Следовательно, на основе информации ячеек пакет обновлений сцен, ассоциированный с соответствующей ячейкой, может запрашиваться и/или получаться. В качестве примера, после активации ячейки, метаданные, ассоциированные с ячейкой, могут обновляться на основе указываемого посредством ссылки пакета обновлений сцен. Следовательно, метаданные могут обновляться эффективно.
Согласно дополнительным вариантам осуществления изобретения, один или более пакетов обновлений сцен содержат представление одного или более условий обновления, и аудиодекодер выполнен с возможностью оценивать то, удовлетворяются либо нет одно или более условий обновления, например, заданных в пакетах обновлений сцен, и избирательно обновлять одни или более метаданных сцены в зависимости от контента одного или более пакетов обновлений сцен, если одно или более условий обновления удовлетворяются, например, так что предусмотрено, например, два механизма для инициирования обновления одних или более метаданных сцены в зависимости от контента одного или более пакетов обновлений сцен, а именно, инициирование с использованием ячейки, заданной в пакете конфигурирования сцен, и инициирование с использованием условия, заданного в самом пакете обновлений сцен.
Следовательно, акустическая сцена может обновляться эффективно. Варианты осуществления могут обеспечивать возможность задавать и предоставлять гибкие инициирующие условия, так что эффективное инициирование обновления может предоставляться для множества различных вариантов применения.
Согласно дополнительным вариантам осуществления изобретения, аудиодекодер выполнен с возможностью оценивать временное условие, например, временное инициирующее условие; например, заданное посредством startTimestamp, который включается в пакет обновлений сцен для того, чтобы принимать решение в отношении того, должны либо нет одни или более метаданных сцены обновляться в зависимости от контента одного или более пакетов обновлений сцен, например, в зависимости от перечисления элементов метаданных сцены, которые должны изменяться, например, указываться посредством ссылки посредством "targetId" и соответствующих новых значений, например, заданных посредством "attribute".
Кроме того, временное условие задает начальный момент времени, например, с использованием элемента startTimestamp потока битов, или временное условие задает временной интервал, например, с использованием начального времени и конечного времени.
Помимо этого, аудиодекодер выполнен с возможностью осуществлять обновление одних или более метаданных сцены, например, в соответствии с определением, включенным в соответствующий пакет обновлений сцен, в ответ на обнаружение, например, сразу в ответ на обнаружение или с использованием временной задержки, заданной в соответствующем пакете обновлений сцен, того, что текущее время воспроизведения, например, время в сцене, достигает начального момента времени или находится после начального момента времени.
Альтернативно, аудиодекодер выполнен с возможностью осуществлять обновление одних или более метаданных сцены, например, в соответствии с определением, включенным в соответствующий пакет обновлений сцен, в ответ на обнаружение того, что текущее время воспроизведения, например, время в сцене, находится в пределах временного интервала.
Альтернативно или помимо этого, аудиодекодер выполнен с возможностью оценивать пространственное условие, например, инициирующее пространственное условие, которое включается в пакет обновлений сцен, например, пространственное условие, заданное посредством ссылки на геометрическое определение; например, пространственное условие, заданное посредством geometryId, чтобы принимать решение в отношении того, должны либо нет одни или более метаданных сцены обновляться в зависимости от контента одного или более пакетов обновлений сцен, например, в зависимости от перечисления элементов метаданных сцены, которые должны изменяться, например, указываться посредством ссылки посредством "targetId" и соответствующих новых значений, например, заданных посредством "attribute".
Следовательно, обновления, например, могут инициироваться посредством временного условия и/или посредством пространственного условия, предоставляя хорошую гибкость для реализации условия обновления и в силу этого обеспечивая возможность эффективно обновлять акустическую сцену.
Согласно дополнительным вариантам осуществления изобретения, пространственное условие в пакете обновлений сцен задает геометрический элемент, например, с использованием ссылки на геометрическое определение, при этом упомянутое геометрическое определение, например, может включаться в элемент рабочих данных сцены.
Помимо этого, аудиодекодер выполнен с возможностью осуществлять обновление одних или более метаданных сцены, например, в соответствии с определением, включенным в соответствующий пакет обновлений сцен, в ответ на обнаружение, например, сразу в ответ на обнаружение, или, например, с использованием временной задержки, заданной в соответствующем пакете обновлений сцен, того, что текущая позиция достигает геометрического элемента, например, достигает одномерной границы, заданной посредством геометрического элемента, или, например, достигает двумерной границы, заданной посредством геометрического объекта, или, например, достигает трехмерной границы, заданной посредством геометрического объекта, либо в ответ на обнаружение, например, сразу в ответ на обнаружение, или, например, с использованием временной задержки, заданной в соответствующем пакете обновлений сцен, того, что текущая позиция находится внутри геометрического элемента, например, внутри двумерного геометрического элемента или внутри трехмерного геометрического элемента.
Следовательно, авторы изобретения выяснили, что пространственное условие может представлять или задавать геометрический элемент, например, в форме ячейки. Геометрический элемент, например, может представлять собой пространственную часть аудиосцены, например, сценария рендеринга. Следовательно, акустически релевантные метаданные могут определяться, в качестве примера, на основе позиции слушателя или пользователя, для которого аудиосцена подготавливается посредством рендеринга, так что метаданные, ассоциированные с геометрическим элементом, причем метаданные необязательно описывают акустически релевантные элементы или характеристики сцены, могут быть релевантными, если слушатель или пользователь находится близко или даже внутри геометрического элемента. Чтобы за счет этого подготавливать посредством рендеринга аудиосцену с высоким качеством, метаданные, ассоциированные с таким геометрическим элементом (например, метаданные, описывающие элементы, которые пространственно размещаются вокруг или внутри геометрического элемента в аудиосцене), могут обновляться.
Согласно дополнительным вариантам осуществления изобретения, аудиодекодер выполнен с возможностью оценивать то, удовлетворяется или нет интерактивное инициирующее условие, которое например, может задаваться в пакете обновлений сцен (например, такое условие, что пользователь предпринимает определенное действие, которое выходит за рамки простого перемещения в сцене; например, такое условие, что пользователь выдает предварительно определенную команду или активирует предварительно определенную кнопку, например, заданную посредством флага "fireOn"), чтобы принимать решение в отношении того, должны либо нет одни или более метаданных сцены обновляться в зависимости от контента одного или более пакетов обновлений сцен.
Следовательно, обновления с инициированием по событиям могут быть включены в рендеринг аудиосцены. Это, например, может быть, в частности, преимущественным в контексте VR-вариантов применения, например, в которых имитируется цифровой близнец объекта, такого как машина или здание. Акустическое окружение может изменяться на основе взаимодействия с цифровым близнецом объекта, а не исключительно на основе относительной позиции по отношению к объекту или времени в имитации.
Согласно дополнительным вариантам осуществления изобретения, аудиодекодер выполнен с возможностью оценивать информацию ячеек, чтобы определять то, в какое время, например, в какое время воспроизведения и/или в какой зоне позиции слушателя какие структуры данных, например, какие рабочие данные, обозначенные посредством идентификатора рабочих данных, например, payloadId, требуются или должны, например, использоваться для пространственного рендеринга.
Следовательно, информация ячеек может представлять собой компактную информацию, которая обеспечивает возможность определять или ассоциировать, или соединять акустически релевантную информацию аудиосцены (например, местоположение (например, зону), время (например, время воспроизведения) и акустические характеристики (например, заданные посредством рабочих данных) в местоположении и во времени), в силу этого обеспечивая возможность эффективного рендеринга аудиосцены.
Согласно дополнительным вариантам осуществления изобретения, аудиодекодер выполнен с возможностью пространственно подготавливать посредством рендеринга один или более аудиосигналов с использованием первого набора объектов сцены и/или характеристик сцены, например, с использованием объектов сцены и/или характеристик сцены, указываемых посредством ссылки в информации ячеек, ассоциированной с первой ячейкой, и необязательно глобальных объектов сцены и/или характеристик сцены, которые применяются ко всем ячейкам, когда позиция слушателя находится в первой пространственной области, например, в первой ячейке.
Кроме того, аудиодекодер выполнен с возможностью пространственно подготавливать посредством рендеринга один или более аудиосигналов с использованием второго набора объектов сцены и/или характеристик сцены, например, с использованием объектов сцены и/или характеристик сцены, указываемых посредством ссылки в информации ячеек, ассоциированной со второй ячейкой, и необязательно глобальных объектов сцены и/или характеристик сцены, которые применяются ко всем ячейкам, когда позиция слушателя находится во второй пространственной области, например, во второй ячейке.
Помимо этого, первый набор объектов сцены и/или характеристик сцены предоставляет более детальный пространственный рендеринг по сравнению со вторым набором объектов сцены и/или характеристик сцены, например, поскольку первый набор объектов сцены и/или характеристик сцены содержит большее число объектов сцены и/или характеристик сцены, чем второй набор объектов сцены и/или характеристик сцены, при этом, например, первая вторая пространственная область может находиться ближе к источникам звука, чем первая пространственная область.
Авторы изобретения выяснили, что концепция уровня детальности может обеспечивать возможность эффективного рендеринга аудиосцены. В качестве примера, разложение по уровню детальности (LoD) акустической сцены может выполняться: Например, далеко от геометрической структуры, приблизительное геометрическое представление структуры может быть достаточным (например, с небольшим числом отражающих поверхностей), тогда как близко к идентичной структуре, отражения на геометрической структуре и другие эффекты, связанные с геометрической акустикой, должны подготавливаться посредством рендеринга с более высоким LoD (например, с большим числом отражающих поверхностей). Это, например, может достигаться посредством указания одной ячейки для окрестности рассматриваемой геометрии, включающей в себя геометрическое представление с высоким LoD, и одной ячейки для оставшейся сцены, включающей в себя геометрическое представление с низким LoD.
Следовательно, в общем, ячейки могут быть перекрывающимися и/или даже содержащими или содержащими друг друга. Следовательно, следует отметить, что, в общем, ячейки могут использоваться для того, чтобы задавать различные степени обобщения или абстрагирования аудиосцены. Например, первая ячейка может быть ассоциирована с приблизительными метаданными для рендеринга аудиосцены в местоположении и, например, во времени активации ячейки. Вторая перекрывающаяся ячейка может предоставлять детализированную или дополнительную информацию метаданных для более точного рендеринга аудиосцены.
Уровень детальности в силу этого может масштабироваться не только посредством расстояния до определенного элемента, но также и относительно доступной полосы пропускания и/или других требований, которые могут задавать масштабирование уровня детальности необходимым или преимущественным.
Следовательно, аудиосцена может подготавливаться посредством рендеринга с переменным уровнем детализации.
Согласно дополнительным вариантам осуществления изобретения, аудиодекодер выполнен с возможностью запрашивать один или более пакетов рабочих данных сцен, которые, например, могут содержать структуры данных, указываемые посредством ссылки в информации ячеек, из поставщика пакетов, например, с использованием обратного канала с поставщиком пакетов, например, в ответ на определение, посредством аудиодекодера, того, что один или более пакетов рабочих данных сцен либо контент одного или более пакетов рабочих данных сцен требуются для рендеринга.
Следовательно, трафик в широковещательном канале, например, может уменьшаться, поскольку соответствующий декодер может отдельно запрашивать только пакеты рабочих данных, необходимые для себя.
Согласно дополнительным вариантам осуществления изобретения, аудиодекодер выполнен с возможностью идентифицировать одну или более структур данных, которые должны использоваться для пространственного рендеринга, с использованием идентификатора рабочих данных, например, payloadId[i], который включается в информацию ячеек.
На основе идентификатора рабочих данных, структуры данных, например, могут идентифицироваться эффективно.
Согласно дополнительным вариантам осуществления изобретения, аудиодекодер выполнен с возможностью запрашивать один или более пакетов рабочих данных сцен из поставщика пакетов, например, с использованием обратного канала с поставщиком пакетов, например, в ответ на определение, посредством аудиодекодера, на основе информации ячеек, того, что один или более пакетов рабочих данных сцен либо контент одного или более пакетов рабочих данных сцен требуются для рендеринга.
Авторы изобретения выяснили, что, например, в широковещательном сценарии, трафик в широковещательном канале может уменьшаться, если декодеры или модули рендеринга выполнены с возможностью и в силу этого, например, отвечают за то, чтобы идентифицировать и запрашивать пропущенные пакеты рабочих данных сцен, например, через отдельный канал.
Согласно дополнительным вариантам осуществления изобретения, аудиодекодер выполнен с возможностью запрашивать один или более пакетов рабочих данных сцен из поставщика пакетов с использованием идентификатора рабочих данных, который включается в информацию ячеек, например, с использованием идентификатора, ассоциированного с элементом рабочих данных.
Альтернативно, аудиодекодер выполнен с возможностью запрашивать один или более пакетов рабочих данных сцен из поставщика пакетов с использованием идентификатора пакета, например, с использованием идентификатора, ассоциированного с пакетом рабочих данных сцены.
Идентификаторы рабочих данных и/или пакетов, например, могут представлять собой эффективное средство для того, чтобы идентифицировать и запрашивать пропущенные пакеты рабочих данных сцен, за счет этого обеспечивая возможность поддерживать затраты на передачу запросов низкими.
Согласно дополнительным вариантам осуществления изобретения, аудиодекодер выполнен с возможностью предвидеть, например, с использованием прогнозирования, то, какие одна или более структур данных, например, какие один или более PayloadElements потребуются или предположительно должны требоваться, например, с использованием прогнозирования того, какая ячейка станет активной следующей или имеет заданную вероятность стать активной следующей, с использованием информации ячеек, и запрашивать одну или более структур данных или один или более пакетов рабочих данных сцен, содержащих упомянутую одну или более структур данных, до того, как структуры данных фактически требуются.
Следовательно, временные ограничения для передачи соответствующих структур данных могут ослабляться. Это, например, может быть, в частности, преимущественным в сценариях, в которых аудиосцена должна подготавливаться посредством рендеринга в реальном времени, и/или в которых аудиосцена может изменяться в реальном времени, но прогнозируемым способом, например, когда априори общеизвестно, что, либо, по меньшей мере, может моделироваться то, как событие инициирует последующие дальнейшие события, которые изменяют акустические характеристики сцены.
Согласно дополнительным вариантам осуществления изобретения, аудиодекодер выполнен с возможностью извлекать рабочие данные, идентифицированные посредством информации ячеек, из потока битов, например, из пакетов рабочих данных потока битов, например, из пакетов рабочих данных широковещательного потока битов.
Согласно дополнительным вариантам осуществления изобретения, аудиодекодер выполнен с возможностью отслеживать требуемые структуры данных, например, рабочие данные, идентифицированные посредством идентификатора payloadId[i] рабочих данных, с использованием информации ячеек.
Следовательно, декодер, например, может, по меньшей мере, приблизительно всегда быть актуальным, например, вплоть до времени в сцене или до времени воспроизведения, например, относительно акустически релевантных элементов сцены. Это может обеспечивать возможность использования небольших, инкрементных обновлений, использование которых, например, может уменьшать затраты на передачу.
Согласно дополнительным вариантам осуществления изобретения, аудиодекодер выполнен с возможностью избирательно отбрасывать одну или более структур данных, например, рабочие данные, идентифицированные посредством идентификатора payloadId[i] рабочих данных, в зависимости от информации ячеек, например, в ответ на нахождение, с использованием информации ячеек, того, что текущее время воспроизведения находится после временного интервала (заданного в информации ячеек), в течение которого структура данных требуется, и/или в ответ на нахождение того, что текущая позиция слушателя находится достаточно далеко от геометрической границы ячейки для ячейки, в рамках которой требуется структура данных.
Следовательно, информация аудиосцен может обновляться эффективно, на основе разделения акустической сцены либо ее аспектов этого на ячейки.
Согласно дополнительным вариантам осуществления изобретения, информация ячеек задает подразделение на основе информации местоположения и/или на основе времени сцены для рендеринга.
Это может обеспечивать возможность уменьшать сложность сценария рендеринга.
Согласно дополнительным вариантам осуществления изобретения, аудиодекодер выполнен с возможностью получать определение, например, временных и/или пространственных ячеек на основе структуры конфигурационных данных сцен, например, пакета конфигурирования сцен, например, SceneConfig, при этом структура конфигурационных данных сцен может быть расположена в начале файла или потока, и при этом структура конфигурационных данных сцен необязательно может повторяться в потоке, при этом декодер, например, может быть выполнен с возможностью синтаксически анализировать файл или поток для пакета конфигурирования сцен.
Авторы изобретения выяснили, что определения ячеек могут предоставляться эффективно, с использованием изобретаемых структур конфигурационных данных сцен.
Согласно дополнительным вариантам осуществления изобретения, аудиодекодер выполнен с возможностью запрашивать одну или более структур данных, например, рабочие данные или пакеты рабочих данных, с использованием соответствующих идентификаторов структур данных, например, идентификаторов рабочих данных или идентификаторов пакетов рабочих данных, например, payloadId.
Помимо этого, аудиодекодер выполнен с возможностью извлекать идентификаторы структур данных для структур данных, которые должны запрашиваться с использованием информации ячеек, например, посредством идентификации того, в какой ячейке или ячейках находится текущая позиция, и необязательно посредством обеспечения сообщения с запросом, содержащего идентификаторы структур данных, ассоциированные с одной или более идентифицированных ячеек; например, посредством идентификации одной или более ячеек, которые ассоциированы с информацией текущего времени, и посредством обеспечения сообщения с запросом, содержащего идентификаторы структур данных, ассоциированные с одной или более идентифицированных ячеек.
Как пояснено выше, в качестве примера, посредством реализации структур обеспечения данных на основе запросов, трафик в широковещательном канале может уменьшаться.
Согласно дополнительным вариантам осуществления изобретения, аудиодекодер выполнен с возможностью предвидеть, например, с использованием прогнозирования, то, какие одна или более структур данных потребуются или предположительно должны требоваться, например, с использованием прогнозирования того, какая ячейка станет активной следующей или имеет заданную вероятность стать активной следующей, и запрашивать одну или более структур данных до того, как структуры данных фактически требуются.
Как пояснено выше, это, например, может ослаблять временные ограничения на передачу требуемых структур данных, например, в вариантах применения в реальном времени.
Согласно дополнительным вариантам осуществления изобретения, аудиодекодер выполнен с возможностью извлекать одну или более структур данных, например, рабочие данные или пакеты рабочих данных, с использованием соответствующих идентификаторов структур данных, например, идентификаторов рабочих данных или идентификаторов пакетов рабочих данных, например, payloadId.
Помимо этого, аудиодекодер выполнен с возможностью извлекать идентификаторы структур данных для структур данных, которые должны извлекаться и необязательно оцениваться, с использованием информации ячеек.
Согласно дополнительным вариантам осуществления изобретения, аудиодекодер выполнен с возможностью извлекать метаданные, требуемые для рендеринга, например, для рендеринга комплексных и/или динамических 6DoF-аудиосцен, из пакета рабочих данных, например, из пакета "рабочих данных сцены".
Необязательно, пакет рабочих данных сцены может содержать множество элементов рабочих данных, например, mpegiPayloadElement (иногда также обозначенный в качестве "mpeghiPayloadElement"), которым назначаются идентификаторы элементов рабочих данных, например, идентификатор.
Ниже по тексту, поясняются варианты осуществления, связанные с оборудованием для обеспечения кодированного аудиопредставления, например, с кодером. Следует отметить, что такие варианты осуществления могут быть основаны на соображениях, идентичных или аналогичных, или соответствующих соображениям вышеуказанных вариантов осуществления, связанных с декодером. Следовательно, нижеприведенные варианты осуществления могут содержать признаки, функциональности и подробности, идентичные, аналогичные или соответствующие признакам, функциональностям и подробностям вышеуказанных раскрытых вариантов осуществления, как отдельно, так и в комбинации.
Дополнительные варианты осуществления согласно изобретению содержат оборудование, например, аудиокодер или аудиосервер, для обеспечения кодированного аудиопредставления, при этом оборудование выполнено с возможностью предоставлять информацию для пространственного рендеринга одного или более аудиосигналов и предоставлять множество пакетов с различными типами пакетов, например, имеющих типы пакетов, которые являются совместимыми с определением MPEG-H MHAS-пакетов.
Кроме того, оборудование выполнено с возможностью предоставлять пакет конфигурирования сцен, например, пакет конфигурирования сцен, который является совместимым с определением MPEG-H MHAS-пакетов, например, пакет конфигурирования сцен, например, mpegiSceneConfig[] (иногда также обозначенный в качестве "mpeghiSceneConfig"), предоставляющий конфигурационную информацию модуля рендеринга, например, задающую использование объектов сцены и/или использование характеристик сцены, например, задающую то, когда или при каком условии различные объекты сцены и/или характеристики сцены должны использоваться в процессе рендеринга.
Помимо этого, пакет конфигурирования сцен содержит информацию ячеек (например, информацию numCells, указывающую число ячеек и, для каждой ячейки, определение одного или более условий в ячейке (например, начальной временной метки и необязательно конечной временной метки или геометрического идентификатора) и определение одних или более рабочих данных сцен (например, payloadId[i][j] и/или ссылки на пакет обновлений сцен (например, updateId[i])), задающих одну или более ячеек, предпочтительно множества ячеек, и необязательно также определение одного или более аудиопотоков.
Кроме того, информация ячеек задает ассоциирование между одной или более, например, временных и/или пространственных ячеек, например, имеющих индекс i ячейки, и соответствующей одной или более структур данных (например, рабочих данных или пакетов рабочих данных; например, payloadId[i][j]; например, рабочих данных, задающих объекты сцены и/или характеристики сцены; например, структур данных, задающих источники звука и/или рассеивающие объекты, и/или рассеивающие поверхности, и/или вызывающие затухание объекты, и/или вызывающие затухание поверхности, и/или параметры материала, и/или характеристики реверберации, и/или порталы, и/или ранние отражения, и/или позднюю реверберацию, и/или характеристики дифракции, и/или акустические материалы, и/или геометрические элементы в сцене, например, идентифицированной посредством идентификатора структуры данных или идентификатора рабочих данных; например, идентифицированной посредством payloadId), ассоциированных с одной или более ячеек, например, с использованием ссылки на рабочие данные пакета рабочих данных сцены, представляющего одну или более соответствующих структур данных и задающего сценарий рендеринга.
Аудиодекодер необязательно может предоставлять любой из пакетов, раскрытых в данном документе, также относительно аудиокодера, как отдельно, так и в комбинации. Кроме того, информация ячеек, например, может содержать любую из характеристик, раскрытых в данном документе, также относительно аудиодекодера, как отдельно, так и в комбинации.
Согласно дополнительным вариантам осуществления изобретения, оборудование выполнено с возможностью повторять предоставление пакета конфигурирования сцен или, например, даже последовательности пакета конфигурирования сцен и одного или более пакетов рабочих данных сцен, и необязательно также одного или более пакетов обновлений сцен, периодически. Альтернативно или помимо этого, оборудование выполнено с возможностью предоставлять один или более пакетов рабочих данных сцен по запросу, например, по запросу аудиодекодера или модуля рендеринга.
Простыми словами и в качестве примера, ответственность в отношении того, чтобы распределять пакеты конфигурирования сцен, может удовлетворяться посредством кодера. Необязательно, кодер также может определять, когда следует предоставлять какие пакеты рабочих данных, и, например, может широковещательно передавать их либо или их часть, например, периодически, например, вместе с пакетами конфигурирования сцен. С другой стороны, декодер может явно требовать необходимые рабочие данные, так что соответствующие пакеты рабочих данных необязательно предоставляются только по запросу, например, через одноадресный канал.
Согласно дополнительным вариантам осуществления изобретения, оборудование выполнено с возможностью предоставлять один или более пакетов рабочих данных сцен, которые содержат одну или более структур данных, указываемых посредством ссылки в информации ячеек.
Согласно дополнительным вариантам осуществления изобретения, оборудование выполнено с возможностью предоставлять пакеты рабочих данных сцен, с учетом того, когда структуры данных, включенные в пакеты рабочих данных сцен, необходимы посредством аудиодекодера в соответствии с информацией ячеек.
Следовательно, в качестве примера, кодер может удостоверяться однозначно или, по меньшей мере, с большой вероятностью в том, что необходимая информация находится в декодере или модуле рендеринга своевременно, например, чтобы предотвращать времена буферизации или акустические запаздывания.
Согласно дополнительным вариантам осуществления изобретения, аудиокодер или декодер выполнен с возможностью предоставлять информацию первой ячейки, задающую первый набор объектов сцены и/или характеристик сцены для рендеринга сцены, когда позиция слушателя находится в первой пространственной области, например, в первой ячейке.
Кроме того, аудиокодер или декодер выполнен с возможностью предоставлять информацию второй ячейки, задающую второй набор объектов сцены и/или характеристик сцены для рендеринга сцены, когда позиция слушателя находится во второй пространственной области, например, во второй ячейке.
Первый набор объектов сцены и/или характеристик сцены предоставляет более детальный пространственный рендеринг по сравнению со вторым набором объектов сцены и/или характеристик сцены, например, поскольку первый набор объектов сцены и/или характеристик сцены содержит большее число объектов сцены и/или характеристик сцены, чем второй набор объектов сцены и/или характеристик сцены, при этом, например, первая вторая пространственная область может находиться ближе к источникам звука, чем первая пространственная область.
Согласно дополнительным вариантам осуществления изобретения, оборудование выполнено с возможностью использовать различные определения ячеек, чтобы управлять пространственным рендерингом с различным уровнем детальности, например, в зависимости от того, находится позиция слушателя в первой ячейке или второй ячейке, при этом, например, ячейка, которая находится относительно ближе к источнику звука, может содержать больше структур данных (например, структур данных, описывающих отражающие поверхности и/или поглощающие поверхности, и/или рассеивающие объекты, и/или поглощающие объекты и т.д.), чем ячейка, которая находится относительно дальше от источника звука.
Авторы изобретения выяснили, что использование различных определений ячеек или даже различных категорий определений ячеек может обеспечивать возможность эффективно реализовывать концепцию уровня детальности, так что качество рендеринга аудиосцены может быть масштабируемым.
Ниже по тексту, поясняются варианты осуществления, связанные со способами для обеспечения декодированного и кодированного аудиопредставления. Следует отметить, что такие варианты осуществления могут быть основаны на соображениях, идентичных или аналогичных, или соответствующих соображениям вышеуказанных вариантов осуществления, связанных с оборудованием. Следовательно, нижеприведенные варианты осуществления могут содержать признаки, функциональности и подробности, идентичные, аналогичные или соответствующие признакам, функциональностям и подробностям вышеуказанных раскрытых вариантов осуществления, как отдельно, так и в комбинации.
Дополнительные варианты осуществления согласно изобретению содержат способ для обеспечения декодированного и необязательно подготовленного посредством рендеринга аудиопредставления на основе кодированного аудиопредставления, при этом способ содержит пространственный рендеринг одного или более аудиосигналов, который например, может кодироваться в кодированном аудиопредставлении.
Помимо этого, способ содержит прием пакета конфигурирования сцен, например, пакета конфигурирования сцен, который является совместимым с определением MPEG-H MHAS-пакетов, например, пакета конфигурирования сцен, например, mpegiSceneConfig[] (иногда также обозначенного в качестве "mpeghiSceneConfig"), предоставляющего конфигурационную информацию модуля рендеринга, например, задающую использование объектов сцены и/или использование характеристик сцены, например, задающую то, когда или при каком условии различные объекты сцены и/или характеристики сцены должны использоваться в процессе рендеринга.
Кроме того, пакет конфигурирования сцен содержит информацию ячеек, например, информацию numCells, указывающую число ячеек и, для каждой ячейки, определение одного или более условий в ячейке (например, начальной временной метки и необязательно конечной временной метки или геометрического идентификатора) и определение одних или более рабочих данных сцен (например, payloadId[i][j] и/или ссылки на пакет обновлений сцен (например, updateId[i]), задающих одну или более ячеек, например, предпочтительно множества ячеек, и необязательно также определение одного или более аудиопотоков.
Помимо этого, информация ячеек задает ассоциирование между одной или более, например, временных и/или пространственных ячеек, например, имеющих индекс i ячейки, и соответствующей одной или более структур данных (например, рабочих данных или пакетов рабочих данных; например, payloadId[i][j]; например, рабочих данных, задающих объекты сцены и/или характеристики сцены; например, структур данных, задающих источники звука и/или рассеивающие объекты, и/или рассеивающие поверхности, и/или вызывающие затухание объекты, и/или вызывающие затухание поверхности, и/или параметры материала, и/или характеристики реверберации, и/или порталы, и/или ранние отражения, и/или позднюю реверберацию, и/или характеристики дифракции, и/или акустические материалы, и/или геометрические элементы в сцене, например, идентифицированной посредством идентификатора структуры данных или идентификатора рабочих данных; например, идентифицированной посредством payloadId), ассоциированных с одной или более ячеек, например, с использованием ссылки на рабочие данные пакета рабочих данных сцены, представляющего одну или более соответствующих структур данных и задающего сценарий рендеринга.
Кроме того, способ содержит оценку информации ячеек, чтобы определять то, какие структуры данных, например, какие рабочие данные сцен, идентифицированные посредством payloadId[i][j], должны использоваться для пространственного рендеринга, например, в различные моменты времени или в различных позициях слушателя, при этом упомянутые структуры данных, например, могут включаться в пакеты рабочих данных сцен.
Дополнительные варианты осуществления согласно изобретению содержат способ, например, аудиокодер или для аудиокодера либо аудиосервер или для аудиосервера, для обеспечения кодированного аудиопредставления, при этом способ содержит предоставление информации для пространственного рендеринга одного или более аудиосигналов и предоставление множества пакетов с различными типами пакетов, например, имеющих типы пакетов, которые являются совместимыми с определением MPEG-H MHAS-пакетов.
Кроме того, способ содержит предоставление пакета конфигурирования сцен, например, пакета конфигурирования сцен, который является совместимым с определением MPEG-H MHAS-пакетов, например, пакета конфигурирования сцен, например, mpegiSceneConfig[] (иногда также обозначенного в качестве "mpeghiSceneConfig"), предоставляющего конфигурационную информацию модуля рендеринга, например, задающую использование объектов сцены и/или использование характеристик сцены, например, задающую то, когда или при каком условии различные объекты сцены и/или характеристики сцены должны использоваться в процессе рендеринга.
Кроме того, пакет конфигурирования сцен содержит информацию ячеек (например, информацию numCells, указывающую число ячеек и, для каждой ячейки, определение одного или более условий в ячейке (например, начальной временной метки и необязательно конечной временной метки или геометрического идентификатора) и определение одних или более рабочих данных сцен (например, payloadId[i][j] и/или ссылки на пакет обновлений сцен (например, updateId[i])), задающих одну или более ячеек, например, предпочтительно из множества ячеек, и необязательно также определение одного или более аудиопотоков.
Кроме того, информация ячеек задает ассоциирование между одной или более, например, временных и/или пространственных ячеек, например, имеющих индекс i ячейки, и соответствующей одной или более структур данных (например, рабочих данных или пакетов рабочих данных; например, payloadId[i][j]; например, рабочих данных, задающих объекты сцены и/или характеристики сцены; например, структур данных, задающих источники звука и/или рассеивающие объекты, и/или рассеивающие поверхности, и/или вызывающие затухание объекты, и/или вызывающие затухание поверхности, и/или параметры материала, и/или характеристики реверберации, и/или порталы, и/или ранние отражения, и/или позднюю реверберацию, и/или характеристики дифракции, и/или акустические материалы, и/или геометрические элементы в сцене, например, идентифицированной посредством идентификатора структуры данных или идентификатора рабочих данных; например, идентифицированной посредством payloadId), ассоциированных с одной или более ячеек, например, с использованием ссылки на рабочие данные пакета рабочих данных сцены, представляющего одну или более соответствующих структур данных и задающего сценарий рендеринга.
Дополнительные варианты осуществления согласно изобретению, содержат компьютерную программу для осуществления способа согласно любому из вариантов осуществления, раскрытых в данном документе, когда компьютерная программа выполняется на компьютере.
Ниже по тексту поясняются варианты осуществления, связанные с потоками битов. Следует отметить, что такие варианты осуществления могут быть основаны на соображениях, идентичных или аналогичных, или соответствующих соображениям вышеуказанных вариантов осуществления, связанных с оборудованием и/или способами. Следовательно, нижеприведенные варианты осуществления могут содержать признаки, функциональности и подробности, идентичные, аналогичные или соответствующие признакам, функциональностям и подробностям вышеуказанных раскрытых вариантов осуществления, как отдельно, так и в комбинации.
Дополнительные варианты осуществления согласно изобретению содержат поток битов, представляющий аудиоконтент, причем поток битов содержит множество пакетов с различными типами пакетов, например, имеющих типы пакетов, которые являются совместимыми с определением MPEG-H MHAS-пакетов, причем пакеты содержат пакет конфигурирования сцен, например, пакет конфигурирования сцен, который является совместимым с определением MPEG-H MHAS-пакетов, например, пакет конфигурирования сцен, например, mpegiSceneConfig[] (иногда также обозначенный в качестве "mpeghiSceneConfig"), предоставляющий конфигурационную информацию модуля рендеринга, например, задающую использование объектов сцены и/или использование характеристик сцены, например, задающую то, когда или при каком условии различные объекты сцены и/или характеристики сцены должны использоваться в процессе рендеринга.
Кроме того, пакет конфигурирования сцен содержит информацию ячеек, например, информацию numCells, указывающую число ячеек и, для каждой ячейки, определение одного или более условий в ячейке (например, начальной временной метки и необязательно конечной временной метки или геометрического идентификатора) и определение одних или более рабочих данных сцен (например, payloadId[i][j] и/или ссылки на пакет обновлений сцен (например, updateId[i]), задающих одну или более ячеек, например, предпочтительно множества ячеек, и необязательно также определение одного или более аудиопотоков.
Кроме того, информация ячеек задает ассоциирование между одной или более, например, временных и/или пространственных ячеек, например, имеющих индекс i ячейки, и соответствующей одной или более структур данных (например, рабочих данных или пакетов рабочих данных; например, payloadId[i][j]; например, рабочих данных, задающих объекты сцены и/или характеристики сцены; например, структур данных, задающих источники звука и/или рассеивающие объекты, и/или рассеивающие поверхности, и/или вызывающие затухание объекты, и/или вызывающие затухание поверхности, и/или параметры материала, и/или характеристики реверберации, и/или порталы, и/или ранние отражения, и/или позднюю реверберацию, и/или характеристики дифракции, и/или акустические материалы, и/или геометрические элементы в сцене, например, идентифицированной посредством идентификатора структуры данных или идентификатора рабочих данных; например, идентифицированной посредством payloadId), ассоциированных с одной или более ячеек, например, с использованием ссылки на рабочие данные пакета рабочих данных сцены, представляющего одну или более соответствующих структур данных и задающего сценарий рендеринга.
В качестве примера, поток битов необязательно может дополняться посредством любых элементов потока битов, раскрытых в данном документе, как отдельно, так и в комбинации.
Дополнительные варианты осуществления согласно изобретению содержат аудиодекодер для обеспечения декодированного аудиопредставления на основе кодированного аудиопредставления, при этом аудиодекодер выполнен с возможностью принимать множество пакетов с различными типами пакетов, причем пакеты содержат один или более пакетов конфигурирования сцен, предоставляющих конфигурационную информацию модуля рендеринга, причем пакеты содержат один или более пакетов обновлений сцен, задающих обновление метаданных сцены для рендеринга.
Кроме того, аудиодекодер выполнен с возможностью оценивать то, удовлетворяются либо нет одно или более условий обновления, и избирательно обновлять одни или более метаданных сцены в зависимости от контента одного или более пакетов обновлений сцен, если одно или более условий обновления удовлетворяются.
Следует отметить, что такой изобретаемый декодер может содержать идентичные, аналогичные или соответствующие признаки, функциональности и подробности относительно любых из вышеуказанных раскрытых вариантов осуществления или относительно любых из других вариантов осуществления, раскрытых в данном документе, как отдельно, так и в комбинации.
Краткое описание чертежей
Чертежи необязательно начерчены в масштабе, вместо этого акцент, в общем, делается на иллюстрации принципов изобретения. В нижеприведенном описании, различные варианты осуществления изобретения описываются со ссылкой на нижеприведенные чертежи, на которых:
Фиг. 1 показывает схематичный вид аудиодекодера согласно вариантам осуществления первого аспекта изобретения;
Фиг. 2 показывает схематичный вид аудиодекодера с дальнейшими дополнительными, необязательными признаками, согласно вариантам осуществления первого аспекта изобретения;
Фиг. 3 показывает схематичный вид кодера согласно вариантам осуществления первого аспекта изобретения;
Фиг. 4 показывает принципиальную блок-схему способа для обеспечения декодированного аудиопредставления на основе кодированного аудиопредставления согласно вариантам осуществления первого аспекта изобретения;
Фиг. 5 показывает принципиальную блок-схему способа для обеспечения кодированного аудиопредставления, согласно вариантам осуществления первого аспекта изобретения;
Фиг. 6 показывает схематичный вид аудиодекодера согласно вариантам осуществления второго аспекта изобретения;
Фиг. 7 показывает схематичный вид кодера согласно вариантам осуществления второго аспекта изобретения;
Фиг. 8 показывает принципиальную блок-схему способа для обеспечения декодированного аудиопредставления на основе кодированного аудиопредставления согласно вариантам осуществления второго аспекта изобретения;
Фиг. 9 показывает принципиальную блок-схему способа для обеспечения кодированного аудиопредставления, согласно вариантам осуществления второго аспекта изобретения;
Фиг. 10 показывает схематичный вид аудиодекодера согласно вариантам осуществления третьего аспекта изобретения;
Фиг. 11 показывает схематичный вид кодера согласно вариантам осуществления третьего аспекта изобретения.
Фиг. 12 показывает принципиальную блок-схему способа для обеспечения декодированного аудиопредставления на основе кодированного аудиопредставления согласно вариантам осуществления третьего аспекта изобретения;
Фиг. 13 показывает принципиальную блок-схему способа для обеспечения кодированного аудиопредставления, согласно вариантам осуществления третьего аспекта изобретения;
Фиг. 14 показывает схематичный вид аудиодекодера согласно вариантам осуществления четвертого аспекта изобретения;
Фиг. 15 показывает схематичный вид кодера согласно вариантам осуществления третьего аспекта изобретения;
Фиг. 16 показывает принципиальную блок-схему способа для обеспечения декодированного аудиопредставления на основе кодированного аудиопредставления согласно вариантам осуществления четвертого аспекта изобретения;
Фиг. 17 показывает принципиальную блок-схему способа для обеспечения кодированного аудиопредставления, согласно вариантам осуществления четвертого аспекта изобретения;
Фиг. 18 показывает схематичный вид первого потока битов согласно вариантам осуществления изобретения;
Фиг. 19 показывает схематичный вид второго потока битов согласно вариантам осуществления изобретения;
Фиг. 20 показывает схематичный вид третьего потока битов согласно вариантам осуществления изобретения; и
Фиг. 21 показывает принципиальную блок-схему обзора архитектуры согласно вариантам осуществления изобретения.
Подробное описание вариантов осуществления
Идентичные или эквивалентные элементы либо элементы с идентичной или эквивалентной функциональностью обозначаются в нижеприведенном описании посредством идентичных или эквивалентных ссылок с номерами даже при появлении на различных чертежах.
В нижеприведенном описании, множество деталей изложено с тем, чтобы предоставлять более полное пояснение вариантов осуществления настоящего изобретения. Тем не менее, специалистам в данной области техники должно быть очевидным, что варианты осуществления настоящего изобретения могут быть использованы на практике без этих конкретных деталей. В других случаях, известные структуры и устройства показаны в форме блок-схемы, а не подробно, чтобы не затруднять понимание вариантов осуществления настоящего изобретения. Помимо этого, признаки различных вариантов осуществления, описанных далее, могут комбинироваться между собой, если прямо не указано иное.
Фиг. 1 показывает схематичный вид аудиодекодера согласно вариантам осуществления первого аспекта изобретения. Фиг. 1 показывает аудиодекодер 100, который выполнен с возможностью предоставлять декодированное и, как показано, необязательно подготовленное посредством рендеринга аудиопредставление 106 на основе кодированного аудиопредставления 102. Аудиодекодер 100 содержит модуль 110 подготовки посредством рендеринга, который выполнен с возможностью пространственно подготавливать посредством рендеринга один или более аудиосигналов. Следовательно, модуль 110 подготовки посредством рендеринга необязательно может содержать модуль декодирования, который может быть выполнен с возможностью декодировать кодированное аудиопредставление, чтобы получать один или более аудиосигналов. Тем не менее, в качестве другого варианта, как показано с помощью штрихпунктирных линий, аудиодекодер 100 может содержать модуль 120 декодирования, в который может предоставляться кодированное аудиопредставление 102 и который может предоставлять один или более аудиосигналов в модуль 110 подготовки посредством рендеринга.
Кроме того, аудиодекодер 100 выполнен с возможностью принимать множество пакетов 104 с различными типами пакетов, причем пакеты содержат один или более пакетов конфигурирования сцен, предоставляющих конфигурационную информацию модуля рендеринга, задающую использование объектов сцены и/или использование характеристик сцены, а также один или более пакетов обновлений сцен, задающих обновление метаданных 130 сцены для рендеринга, и один или более пакетов рабочих данных сцен, содержащих определения одного или более объектов сцены и/или определения одной или более характеристик сцены.
Следовательно, на основе пакетов конфигурирования сцен, конфигурация модуля рендеринга модуля 110 подготовки посредством рендеринга может задаваться и/или регулироваться. На основе конфигурации модуля рендеринга, модуль 110 подготовки посредством рендеринга может определять то, какой объект сцены и/или характеристики сцены должны рассматриваться.
Такие объекты и/или характеристики, например, могут задаваться с использованием метаданных 130. Как пояснено выше, на основе пакетов обновлений сцен, упомянутые метаданные 130 могут обновляться для рендеринга.
В качестве примера, на основе пакетов рабочих данных сцен, новые определения объектов сцены и/или характеристик сцены могут добавляться в метаданные 130 для модуля 110 подготовки посредством рендеринга и/или могут предоставляться непосредственно в модуль 110 подготовки посредством рендеринга.
Соответственно, модуль 110 подготовки посредством рендеринга выполнен с возможностью выбирать определения одного или более объектов сцены и/или определения одной или более характеристик сцены, которые включаются в пакеты рабочих данных сцен для рендеринга, в зависимости от конфигурационной информации модуля рендеринга. Помимо этого, как пояснено выше, декодер 100 выполнен с возможностью обновлять одни или более метаданных 130 сцены в зависимости от контента одного или более пакетов обновлений сцен.
Простыми словами и в качестве примера, декодер 100 может принимать кодированное аудиопредставление 102. Это кодированное аудиопредставление может декодироваться, чтобы получать аудиоинформацию. Аудиоинформация, например, может содержать информацию относительно спектральных коэффициентов аудиосигнала.
Тем не менее, для точной реконструкции аудиосцены или, например, для иммерсивного акустического чувства в VR- или AR-окружении, дополнительные эффекты, возможно, должны учитываться. Следовательно, декодер 100 может быть выполнен с возможностью учитывать метаданные 130 для рендеринга аудиоинформации.
Эти метаданные, например, могут содержать или описывать или связываться с объектами данных, которые дополнительно могут задавать характеристики или элементы, например, объекты акустической сцены. Метаданные, например, могут задавать элементы, например, в пространстве и/или во времени, которые могут вызывать акустически релевантные эффекты, такие как реверберация, отражение и т.п.
Чтобы использовать концепцию аудиометаданных эффективным способом, пакеты 104 предоставляются в декодер 100. Авторы изобретения выяснили, что различение, по меньшей мере, на три типа пакетов, например, может быть преимущественным.
Пакеты конфигурирования сцен, например, могут предоставлять информацию относительно того, какие акустические элементы и/или характеристики должны рассматриваться, например, в определенном местоположении в аудиосцене или в определенное время. Чтобы включать изменения акустически релевантных элементов, пакеты обновлений сцен, например, вводятся, так что соответствующие метаданные могут изменяться.
Пакеты рабочих данных сцен, с другой стороны, например, могут содержать информацию и/или определения акустически релевантных элементов, например, объектов или самих характеристик сцены, которые могут быть релевантными для рендеринга аудиосигнала. Выбор элементов рабочих данных может выполняться на основе конфигурационной информации сцен.
Кроме того, следует подчеркнуть, что вышеописанные и показанные метаданные 130 являются необязательными. Модуль подготовки посредством рендеринга, например, может подбирать и рассматривать только акустически релевантные элементы, заданные посредством пакетов рабочих данных, предоставленных в декодер 100. Их выбор, например, может выполняться посредством конфигурации рендеринга, которая может адаптироваться на основе пакетов конфигурирования сцен.
Кроме того, следует отметить, что разделение входящих сигналов на пакеты 104 и кодированном аудиопредставлении 102 представляет собой пример. Кодированное аудиопредставление может предоставляться в качестве части пакетов 104, например, в качестве MPEGH3DA-кадра, например, в форме пакета, например, содержащего информацию относительно спектральных аудиокоэффициентов. С другой стороны, декодер 100, например, может принимать только кодированное аудиопредставление, содержащее, в дополнение к аудиоинформации или аудиосигналу, пакеты 104, как пояснено выше, содержащие конфигурационные данные, данные обновлений и метаданные. Следовательно, необязательный модуль 120 декодирования может быть выполнен с возможностью декодировать кодированные пакеты, альтернативно или помимо этого.
В качестве необязательного признака, декодер 100 выполнен с возможностью определять конфигурацию рендеринга, например, с использованием модуля 110 подготовки посредством рендеринга или необязательного модуля оценки (например, как пояснено в контексте по фиг. 2) на основе пакета конфигурирования сцен для того, чтобы определять обновление конфигурации рендеринга модуля 110 подготовки посредством рендеринга на основе одного или более пакетов обновлений сцен.
Следовательно, пакет конфигурирования сцен, например, может содержать полный набор конфигурационных параметров и на их основе, например, инкрементные обновления могут предоставляться или выполняться на основе пакетов обновлений сцен.
Необязательно, один или более пакетов обновлений сцен могут содержать перечисление элементов метаданных сцены, которые должны изменяться, и перечисление может содержать, для одного или более элементов метаданных, которые должны изменяться, идентификатор метаданных и значение обновления метаданных. Следовательно, необязательно, метаданные 130 могут организовываться на основе идентификатора, например, числа и одного или более значений. Такое значение может изменяться согласно значению обновления метаданных.
В качестве другого необязательного признака, аудиодекодер 100, например, модуль 110 подготовки посредством рендеринга декодера 100, выполнен с возможностью получать определения одного или более объектов сцены и/или определения одной или более характеристик сцены, например, в качестве примера метаданных.
Далее следует обратиться к фиг. 2. Фиг. 2 показывает схематичный вид аудиодекодера с дальнейшими дополнительными, необязательными признаками, согласно вариантам осуществления первого аспекта изобретения. Фиг. 2 показывает аудиодекодер 200, который содержит модуль 210 подготовки посредством рендеринга, необязательный модуль 220 декодирования и метаданные 230, как пояснено в контексте по фиг. 1, а также соответствующие декодированные и кодированные аудиопредставления 202, 206 и пакеты 204.
В качестве необязательного признака, аудиодекодер 200 содержит модуль 240 оценки. Необязательно, один или более пакетов рабочих данных сцен (например, включенных в пакеты 204) содержат перечисление рабочих данных, задающих объекты сцены и/или характеристики сцены. Кроме того, аудиодекодер 100 выполнен с возможностью оценивать, например, с использованием модуля 240 оценки, перечисление рабочих данных, задающих объекты сцены и/или характеристики сцены.
В качестве другого необязательного признака, идентификатор рабочих данных ассоциирован с рабочими данными в пакете рабочих данных сцены, и аудиодекодер, например, модуль 240 оценки этого, может быть выполнен с возможностью оценивать идентификатор рабочих данных для указанных рабочих данных, чтобы принимать решение в отношении того, должны или нет указанные рабочие данные использоваться для рендеринга в модуле 210 подготовки посредством рендеринга.
Следовательно, необязательно, информация относительно пакетов 204 необязательно может предоставляться в модуль 210 подготовки посредством рендеринга исключительно через модуль 240 оценки.
В качестве другого необязательного признака, один или более пакетов обновлений сцен задают условие для обновления сцен, и аудиодекодер, например, его модуль 240 оценки выполнен с возможностью оценивать то, удовлетворяется или нет условие для обновления сцен, заданное в пакете обновлений сцен для того, чтобы принимать решение в отношении того, должно или нет осуществляться обновление сцен. Следовательно, в качестве примера, метаданные 230 могут регулироваться, и/или конфигурация рендеринга модуля 210 подготовки посредством рендеринга может регулироваться.
В качестве другого необязательного признака, один или более пакетов обновлений сцен задают интерактивное инициирующее условие, и аудиодекодер, например, его модуль 240 оценки выполнен с возможностью оценивать то, удовлетворяется или нет интерактивное инициирующее условие, чтобы принимать решение в отношении того, должно или нет осуществляться обновление сцен. Следовательно, в качестве примера, метаданные 230 могут обновляться, и/или модулю 210 подготовки посредством рендеринга может инструктироваться регулировать рендеринг и/или конфигурацию рендеринга. Инициирующее условие, например, может представлять собой условие на основе событий, например, кроме или в дополнение к условию на основе информации местоположения и/или на основе времени.
В качестве другого необязательного признака, один или более пакетов конфигурирования сцен и один или более пакетов обновлений сцен, и один или более пакетов рабочих данных сцен и в силу этого, в качестве примера, пакеты 204 являются совместимыми с определением MPEG-H MHAS-пакетов.
В качестве другого необязательного признака, один или более пакетов конфигурирования сцен и один или более пакетов обновлений сцен, и один или более пакетов рабочих данных сцен содержат идентификатор типа пакета, например, MHASPacketType, метку пакета, например, MHASPacketLabel, информацию длины пакетов, например, MHASPacketLength, и рабочие данные пакета, например, MHASPacketPayload. В качестве примера, аудиодекодер 200 необязательно может быть выполнен с возможностью, например, с использованием модуля 240 оценки, оценивать идентификатор типа пакета, чтобы отличать пакеты с различными типами пакетов. Следовательно, декодер может отличать различные пакеты для последующей обработки.
В качестве другого необязательного признака, аудиодекодер 200 содержит модуль 250 извлечения. В качестве другого необязательного признака, аудиодекодер 200, например, его модуль 250 извлечения, выполнен с возможностью извлекать один или более пакетов конфигурирования сцен, один или более пакетов обновлений сцен и один или более пакетов рабочих данных сцен из потока 208 битов, содержащего множество MPEG-H-пакетов, включающих в себя пакеты, представляющие один или более аудиоканалов, которые должны подготавливаться посредством рендеринга.
В качестве примера, кодированное аудиопредставление 202 может содержать или может представлять собой информацию относительно аудиоканалов, которые должны подготавливаться посредством рендеринга. Как пояснено выше, кодированное аудиопредставление 202 также может представлять собой пакет. Необязательно, модуль 250 извлечения может быть выполнен с возможностью, как показано, извлекать кодированное аудиопредставление 202 из потока 208 битов, отделенного от пакетов 204.
С другой стороны, следует отметить, что разделение входящих сигналов на пакеты 204 и кодированное аудиопредставление 202 представляет собой пример. Кодированное аудиопредставление может предоставляться в качестве части пакетов 204, например, в качестве MPEGH3DA-кадра, например, в форме пакета, например, содержащего информацию относительно спектральных аудиокоэффициентов. С другой стороны, декодер 200, например, может принимать только кодированное аудиопредставление, содержащее, в дополнение к аудиоинформации или аудиосигналу, пакеты 204, как пояснено выше, содержащие конфигурационные данные, данные обновлений и метаданные.
В качестве другого необязательного признака, поток 208 битов может представлять собой широковещательный поток битов. Следовательно, декодер 200 может быть выполнен с возможностью принимать один или более пакетов конфигураций сцен через широковещательный поток. Тем не менее, следует отметить, что пакеты 204 могут приниматься посредством декодера 204 через различные потоки битов. Потоки битов могут содержать широковещательные потоки битов, а также одноадресные потоки битов, например, для запроса на передачу в выделенный сервер или кодер.
В качестве другого необязательного признака, декодер 200 содержит запрашивающий модуль 260. Необязательно, аудиодекодер 200 выполнен с возможностью, например, с использованием запрашивающего модуля 260, запрашивать один или более пакетов рабочих данных сцен из поставщика пакетов. Следовательно, декодер 200 может предоставлять запрос 201. Соответственно, пакеты рабочих данных сцен могут приниматься посредством декодера через отдельный поток битов (не показан), например, одноадресный поток битов, через канал, который используется для передачи запроса 201.
Для запроса одного или более пакетов рабочих данных сцен, декодер 200 необязательно может использовать идентификатор рабочих данных, например, с использованием идентификатора, ассоциированного с элементом рабочих данных или идентификатором пакета, например, с использованием идентификатора, ассоциированного с пакетом рабочих данных сцены. Следовательно, запрос 201 может содержать такие идентификаторы.
В качестве другого необязательного признака, декодер 200 содержит модуль 270 предвидения. В качестве необязательного признака, аудиодекодер 200 выполнен с возможностью предвидеть, например, прогнозировать, например, с использованием модуля 270 предвидения, то, какие одна или более структур данных потребуются или предположительно должны требоваться, и запрашивать одну или более структур данных или один или более пакетов рабочих данных сцен, содержащих упомянутую одну или более структур данных, до того, как структуры данных фактически требуются.
Следовательно, модуль 270 предвидения, например, может предоставлять информацию в запрашивающий модуль 260 для задания запроса 201.
В качестве другого необязательного признака, аудиодекодер, например, запрашивающий модуль 260, выполнен с возможностью предоставлять информацию, например, запрос 201, указывающий то, какие один или более пакетов рабочих данных сцен требуются или потребуются в течение предварительно определенного периода времени, в поставщик пакетов, например, кодер согласно вариантам осуществления.
В качестве необязательного признака, один или более пакетов обновлений сцен (например, пакетов 204) задают обновление метаданных сцены, например, метаданных 230, для рендеринга и содержат представление одного или более условий обновления. Кроме того, в качестве необязательного признака, аудиодекодер 200, например, его модуль 240 оценки выполнен с возможностью оценивать то, удовлетворяются либо нет одно или более условий обновления, и избирательно обновлять одни или более метаданных сцены, например, метаданные 230, в зависимости от контента одного или более пакетов обновлений сцен, если одно или более условий обновления удовлетворяются.
Далее следует обратиться к фиг. 3. Для краткости и, как пояснено выше, следует отметить, что варианты осуществления согласно изобретению, содержат кодеры с соответствующими признаками согласно декодерам и в силу этого декодеру, показанному на фиг. 1. Следовательно, кодер может содержать только необходимые признаки, чтобы предоставлять сигналы, принимаемые посредством декодера 100 на фиг. 1, и обрабатывать их для того, чтобы предоставлять декодированное аудиопредставление 106, вообще без необязательных признаков. Тем не менее, любые из необязательных признаков, функциональностей и подробностей, раскрытых выше в контексте фиг. 1 и 2, могут присутствовать, соответственно (например, соответствующим способом) в кодере согласно вариантам осуществления, отдельно или в комбинации. То же касается признаков, функциональностей и подробностей декодеров и/или кодеров других аспектов изобретения.
Фиг. 3 показывает схематичный вид кодера согласно вариантам осуществления первого аспекта изобретения. Кодер 300 выполнен с возможностью предоставлять поток 302 битов (например, аналогичный или соответствующий, или идентичный потоку 208 битов, как показано на фиг. 2), при этом поток битов, например, может содержать кодированное аудиопредставление. В частности, кодер 300 выполнен с возможностью предоставлять информацию для пространственного рендеринга одного или более аудиосигналов, которая включается в поток 302 битов. Следовательно, поток 302 битов содержит множество пакетов 322 с различными типами пакетов.
Для обеспечения потока битов и в силу этого вышеуказанных информационных объектов, кодер 300 содержит поставщик 310 потоков битов, в который предоставляются пакеты 322.
Как показано, кодер 300 необязательно может содержать модуль 320 предоставления пакетов. Кодер 300 выполнен с возможностью предоставлять, например, с использованием модуля 320 предоставления пакетов, пакеты 322. Пакеты 322 содержат один или более пакетов конфигурирования сцен, предоставляющих конфигурационную информацию модуля рендеринга, задающую использование объектов сцены и/или использование характеристик сцены, один или более пакетов обновлений сцен, задающих обновление метаданных сцены для рендеринга, и один или более пакетов рабочих данных сцен, содержащих определения одного или более объектов сцены и/или определения одной или более характеристик сцены.
В качестве примера, аудиосигнал 304, который должен кодироваться, может предоставляться в кодер 300. Аудиосигнал может содержать выборки временной области и/или спектральные значения, например, речевого и/или музыкального сигнала. Необязательно (не показано), если этот сигнал уже кодируется, этот сигнал может непосредственно предоставляться в поставщик 310 потоков битов, чтобы включаться в поток битов, например, вместе с пакетами 322.
Пакеты 322 могут предоставляться посредством модуля предоставления пакетов различными способами. Например, модуль 320 предоставления пакетов может предоставлять пакеты 322 на основе информации сцен, которая задает акустическую сцену и которая может быть предварительно задана или которая может получаться посредством модуля предоставления пакетов.
Например, для вариантов применения в стиле виртуальной реальности, на основе виртуальной модели (например, акустической сцены), акустически релевантные виртуальные объекты могут определяться, чтобы моделировать или представлять акустическую сцену (акустическую сцену, например, содержащую виртуальную модель с акустически релевантными виртуальными объектами и аудиосигналом), с использованием пакетов. Необязательно, (необязательный) модуль 330 анализа может поддерживать определение акустически релевантных виртуальных объектов или их характеристик (так что, например, характеристики аудиосигнала могут использоваться для того, чтобы дополнять и/или детализировать виртуальную модель акустической сцены, например, посредством обеспечения информации относительно позиции источника звука).
Следовательно, информация для поддержки определения соответствующих пакетов 322 может предоставляться из необязательного модуля 330 анализа в модуль 320 предоставления пакетов. Например, модуль 320 предоставления пакетов может управлять виртуальной моделью, или в него может предоставляться информация относительно виртуальной модели.
В качестве другого примера, в контексте вариантов применения в стиле дополненной реальности, аудиосигнал 304, который должен кодироваться, может предоставляться в кодер 300 и может содержать выборки временной области и/или спектральные значения, например, речевого и/или музыкального сигнала. Тем не менее, необязательно аудиосигнал 304 дополнительно может содержать (или переносить) пространственную информацию (например, в неявной форме) реальной аудиосцены, которая должна дополняться, например, информацию позиции измеренного аудиоисточника в сцене, например, пользователя, который говорит. Такая информация и, необязательно помимо этого, виртуальная информация наложения (например, информация для того, чтобы добавлять акустически релевантные виртуальные объекты в реальную сцену, чтобы дополнять реальную сцену) может извлекаться и/или анализироваться, и/или применяться посредством необязательного модуля 330 анализа, чтобы моделировать или представлять сцену с использованием пакетов. Следовательно, как пояснено выше, информация для определения соответствующих пакетов 322 может предоставляться в модуль 320 предоставления пакетов. В качестве примера, модуль 330 анализа может определять, на основе пространственной информации в аудиосигнале 304, то, какие акустически релевантные объекты сцены должны рассматриваться или обновляться, или подготавливаться посредством рендеринга, чтобы предоставлять требуемое восприятие для слуха.
Тем не менее, следует отметить, что кодер 300 необязательно может не содержать модуль анализа, так что, например, информация относительно пакетов 322 может предоставляться в кодер 300 из внешнего модуля, например, модуля, управляющего виртуальной или дополненной сценой.
В качестве дополнительного пояснения вышеприведенного примера, аудиосигнал 304, который должен кодироваться, может предоставляться в кодер 300, причем он может представлять собой аудиосигнал из пространственной аудиосцены и необязательно дополнительно может содержать пространственную информацию относительно аудиосцены. Следовательно, в качестве необязательного признака, кодер 300 содержит модуль 330 анализа. Модуль 330 анализа выполнен с возможностью анализировать информацию, предоставляемую из аудиосцены, чтобы определять или аппроксимировать представление аудиосцены. В качестве примера, аудиосцена, например, может моделироваться с использованием метаданных, например, описывающих объекты сцены и/или характеристики сцены, которые могут использоваться вместе со спектральными коэффициентами аудиосигнала, чтобы предоставлять иммерсивное представление аудиосцены для слушателя.
Следует отметить, что метаданные, например, могут быть основаны на цифровой модели аудиосцены (например, для случаев применения в стиле виртуальной реальности) и/или на анализе фактической сцены, в которой аудиосигнал записывается (например, для случаев применения в стиле дополненной реальности).
На основе этого, в качестве примера, соответствующие пакеты конфигурирования сцен, пакеты обновлений сцен и пакеты рабочих данных сцен могут определяться и предоставляться.
В качестве примера, модуль 320 предоставления пакетов в силу этого может дополнительно предоставлять пакеты, содержащие упомянутую спектральную информацию аудиосигнала, например, в форме пакетов, представляющих один или более аудиоканалов, которые должны подготавливаться посредством рендеринга (например, необязательно таких пакетов, как MPEGH3DA-кадры), которые могут представлять собой часть пакетов 322.
Необязательно, аудиосигнал 304, например, может предоставляться непосредственно в модуль 320 предоставления пакетов и/или в поставщик 310 потоков битов. В качестве примера, если аудиосигнал 304 уже кодируется, может уже содержать заданные пакеты 322, так что эти пакеты, например, могут только извлекаться в модуле 322 предоставления пакетов для того, чтобы кодироваться, например, повторно кодироваться в поставщике 310 потоков битов. Информация аудиосигналов, например, за исключением информации метаданных, например, может предоставляться в форме пакетов или непосредственно на основе аудиосигнала 304 в поставщик 310 потоков битов.
Кроме того, следует отметить, что модуль 330 анализа также необязательно может быть выполнен с возможностью определять или аппроксимировать виртуальную акустическую сцену, причем аудиосигнал 304, например, представляет только непосредственно акустический сигнал (например, его спектральные коэффициенты, например, измеренные посредством гарнитуры пользователя VR-помещения), при этом дополнительные пространственные характеристики сцены могут быть основаны на виртуальной модели окрестностей в виртуальной акустической сцене и, например, основаны на позиции пользователя в виртуальных окрестностях. Например, в виртуальном конференц-зале, характеристики отражения виртуальных стен и/или характеристики демпфирования виртуального ковра могут быть включены в качестве метаданных, например, описывающих объекты сцены, на основе виртуальной акустической модели стены или ковра, например, относительно позиции слушателя, а не на основе реального измерения.
В качестве другого необязательного признака, кодер 300, например, модуль 320 предоставления пакетов, выполнен с возможностью предоставлять конфигурационную информацию модуля рендеринга, которая включается в пакеты конфигурирования сцен, так что конфигурационная информация модуля рендеринга задает выбор определений одного или более объектов сцены и/или определений одной или более характеристик сцены (например, заданных посредством метаданных, например, как показано на фиг. 2, метаданные 230), которые включаются в пакеты рабочих данных сцен для рендеринга.
В качестве другого необязательного признака, кодер 300, например, модуль 320 предоставления пакетов, выполнен с возможностью предоставлять один или более пакетов обновлений сцен, так что контент одного или более пакетов обновлений сцен задает обновление одних или более метаданных сцены.
В качестве другого необязательного признака, кодер 300, например, модуль 320 предоставления пакетов, выполнен с возможностью предоставлять пакет конфигурирования сцен, так что пакет конфигурирования сцен определяет конфигурацию рендеринга, и предоставлять пакеты обновлений сцен, так что пакеты обновлений сцен задают обновление конфигурации рендеринга. Следовательно, в качестве примера, на основе пакета конфигурирования сцен, могут предоставляться параметры модуля рендеринга, а на основе пакетов обновлений сцен, обновления параметров модуля рендеринга, например, инкрементные обновления.
Кроме того, в качестве другого необязательного признака, кодер 300, например, модуль 320 предоставления пакетов, выполнен с возможностью предоставлять один или более пакетов конфигурирования сцен и один или более пакетов обновлений сцен, и один или более пакетов рабочих данных сцен таким образом, что один или более пакетов конфигурирования сцен и один или более пакетов обновлений сцен, и один или более пакетов рабочих данных сцен являются совместимыми с определением MPEG-H MHAS-пакетов.
В качестве другого необязательного признака, кодер 300, например, модуль 320 предоставления пакетов, выполнен с возможностью предоставлять один или более пакетов конфигурирования сцен и один или более пакетов обновлений сцен, и один или более пакетов рабочих данных сцен таким образом, что один или более пакетов конфигурирования сцен и один или более пакетов обновлений сцен, и один или более пакетов рабочих данных сцен содержат идентификатор типа пакета, например, MHASPacketType, метку пакета, например, MHASPacketLabel, информацию длины пакетов, например, MHASPacketLength, и рабочие данные пакета, например, MHASPacketPayload.
Соответственно, в качестве необязательного признака, поток 302 битов, например, может содержать множество MPEG-H-пакетов, включающих в себя пакеты, представляющие один или более аудиоканалов, которые должны подготавливаться посредством рендеринга. Следовательно, кодер 300, например, поставщик 310 потоков битов, может быть выполнен с возможностью предоставлять один или более пакетов конфигурирования сцен и один или более пакетов обновлений сцен, и один или более пакетов рабочих данных сцен в потоке битов, например, перемежаемом с MPEG-H-пакетами.
Кроме того, кодер 300 (в общем оборудовании для кодирования) может, необязательно, предоставлять поток битов через широковещательный поток. Тем не менее, следует отметить, что кодер 300, например, поставщик 310 потоков битов, необязательно может быть выполнен с возможностью предоставлять некоторые пакеты через широковещательный поток битов, например, через необязательно показанный широковещательный поток 306 битов, а некоторые пакеты через нешироковещательный поток битов, например, 302. Например, широковещательный поток 306 битов может содержать пакеты конфигурирования сцен. С другой стороны, поток 302 битов, например, может адресовать конкретного пользователя и в силу этого может содержать конкретные пакеты рабочих данных. Соответственно, кодер 300 может предоставлять широковещательный поток 306 битов и множество отдельных потоков 302 битов, например, через множество сервер-клиентских каналов.
В качестве другого необязательного признака, кодер 300 содержит запрашивающий модуль 340. Кодер 300 может принимать запрос 308 (например, соответствующий запросу 201, показанному на фиг. 2), например, из декодера и в силу этого может предоставлять один или более пакетов рабочих данных сцен в ответ на запрос 308. Следовательно, запрашивающий модуль 340 может перенаправлять такой запрос в модуль 320 предоставления пакетов и/или в поставщик 310 потоков битов, чтобы предоставлять пакеты и кодировать их в поток битов.
Один или более пакетов рабочих данных сцен, например, могут идентифицироваться с использованием идентификатора рабочих данных и/или идентификатора пакета. Другими словами, кодер 300 может быть выполнен с возможностью предоставлять один или более пакетов рабочих данных сцен в ответ на запрос 308 из аудиодекодера, содержащий идентификатор рабочих данных, либо в ответ на запрос 308 из аудиодекодера, содержащий идентификатор пакета.
Запрос 308 содержит, в качестве необязательного признака, например, в дополнение или в качестве альтернативы вышеуказанному, информацию, указывающую, по меньшей мере, неявно то, какие один или более пакетов рабочих данных сцен требуются или потребуются в течение предварительно определенного периода времени. Следовательно, запрашивающий модуль 340 необязательно может диспетчеризовать своевременную передачу запрашиваемых пакетов.
В качестве другого необязательного признака, кодер 300 выполнен с возможностью, например, с использованием модуля 320 предоставления пакетов, предоставлять один или более пакетов обновлений сцен таким образом, что один или более пакетов обновлений сцен задают обновление метаданных сцены для рендеринга и содержат представление одного или более условий обновления.
В качестве примера, модуль 330 анализа может определять метаданные сцены, необходимые для представления или аппроксимации аудиосцены. На основе текущих используемых метаданных в соответствующем декодере, модуль анализа может предоставлять информацию в модуль 320 предоставления пакетов, чтобы задавать или определять пакеты обновлений сцен для того, чтобы предоставлять информацию обновления метаданных в соответствующий декодер. Кроме того, обновления могут быть условными, например, относительно времени, местоположения в аудиосцене и/или события (например, открытия окна пользователем в VR-помещении).
В качестве другого необязательного признака, кодер 300 выполнен с возможностью повторять предоставление пакета конфигурирования сцен периодически, например, в широковещательном потоке 306 битов, например, чтобы обеспечивать возможность эффективной подстройки новых декодеров.
В качестве другого необязательного признака, кодер 300 выполнен с возможностью, например, с использованием модуля 320 предоставления пакетов, предоставлять пакет конфигурирования сцен, так что пакет конфигурирования сцен задает то, какие пакеты рабочих данных сцен требуются в данной точке в пространстве и времени. Другими словами, и в качестве примера, на основе анализа акустической сцены может определяться конфигурация, которая задает то, в какой момент во времени и/или в пространстве и/или относительно какого условия, какие рабочие данные, например, представляющие метаданные, задающие акустически релевантные объекты и/или характеристики, могут быть необходимыми или являются преимущественными для задания или повторного создания аудиосцены.
В качестве другого необязательного признака, кодер 300 выполнен с возможностью, например, с использованием модуля 320 предоставления пакетов, предоставлять пакет конфигурирования сцен, так что пакет конфигурирования сцен задает то, из чего пакеты рабочих данных сцен могут извлекаться. Следовательно, на основе пакета конфигурирования сцен, например, из широковещательного канала, декодер может отдельно запрашивать соответствующие пакеты рабочих данных, например, через одноадресный канал.
Как пояснено выше и в качестве необязательного признака, кодер 300 выполнен с возможностью, например, с использованием модуля 320 предоставления пакетов, предоставлять пакеты обновлений сцен, так что пакеты обновлений сцен задают условие для обновления сцен. Необязательно, пакеты обновлений сцен могут задавать интерактивное инициирующее условие для обновления сцен.
Кроме того, в качестве другого необязательного признака, кодер 300, например, с использованием модуля 320 предоставления пакетов, выполнен с возможностью адаптировать упорядочение определений одного или более объектов сцены и/или определений одной или более характеристик сцены в пакетах рабочих данных сцен в зависимости от того, когда и/или где определения одного или более объектов сцены и/или определения одной или более характеристик сцены необходимы посредством модуля рендеринга или декодера.
В качестве другого необязательного признака, оборудование 300, например, с использованием модуля 320 предоставления пакетов, выполнено с возможностью адаптировать упорядочение определений одного или более объектов сцены и/или определений одной или более характеристик сцены в пакетах рабочих данных сцен в зависимости от важности определений одного или более объектов сцены и/или определений одной или более характеристик сцены для модуля рендеринга.
Необязательно, упорядочение определений одного или более объектов сцены и/или определений одной или более характеристик сцены в пакетах рабочих данных сцен может задаваться в зависимости от ограничения по размеру пакетов.
В качестве другого необязательного признака, оборудование выполнено с возможностью предоставлять пакеты рабочих данных, содержащие сравнительно низкий уровень детальности, сначала, и предоставлять пакеты рабочих данных, содержащие сравнительно более высокий уровень детальности, позднее. В качестве примера, модуль 330 анализа может "разбивать" аудиосцену, которая должна кодироваться, с различными степенями детальности или детализации. В соответствии с этим, сначала приблизительная информация относительно аудиосцены может предоставляться, а позднее более точная информация.
Кроме того, в качестве необязательного признака, оборудование 300, например, с использованием модуля 330 анализа, выполнено с возможностью разделять определения одного или более объектов сцены и/или определения одной или более характеристик сцены на множество пакетов рабочих данных сцен и предоставлять различные пакеты рабочих данных сцен в различные моменты времени. В соответствии с вышеуказанным, некоторые объекты сцены или характеристики могут оказывать большее влияние на аудиосцену и в силу этого могут сразу предоставляться для рендеринга аудиосцены. Другие объекты или характеристики, например, могут требоваться только для детализации акустического восприятия и в силу этого могут передаваться, если вычислительные ресурсы и/или ограничения по полосе пропускания обеспечивают возможность этого.
В качестве другого необязательного признака, оборудование 300, например, с использованием модуля 330 анализа, выполнено с возможностью предоставлять пакеты конфигурирования сцен для того, чтобы разлагать сцену на множество пространственных областей, в которых другие метаданные рендеринга являются допустимыми. Следовательно, декодер, адресующий конкретного пользователя в конкретном местоположении аудиосцены, может избирательно запрашивать только допустимые метаданные, что позволяет повышать эффективность.
Фиг. 4 показывает принципиальную блок-схему способа для обеспечения декодированного аудиопредставления на основе кодированного аудиопредставления согласно вариантам осуществления первого аспекта изобретения.
Способ 400 содержит пространственный рендеринг, 410, одного или более аудиосигналов и прием, 420, множества пакетов с различными типами пакетов, причем пакеты содержат один или более пакетов конфигурирования сцен, предоставляющих конфигурационную информацию модуля рендеринга, задающую использование объектов сцены и/или использование характеристик сцены, причем пакеты содержат один или более пакетов обновлений сцен, задающих обновление метаданных сцены для рендеринга, и причем пакеты содержат один или более пакетов рабочих данных сцен, содержащих определения одного или более объектов сцены и/или определения одной или более характеристик сцены.
Способ дополнительно содержит выбор, 430, определений одного или более объектов сцены и/или определений одной или более характеристик сцены, которые включаются в пакеты рабочих данных сцен, для рендеринга в зависимости от конфигурационной информации модуля рендеринга, и обновление, 440, одних или более метаданных сцены в зависимости от контента одного или более пакетов обновлений сцен.
Фиг. 5 показывает принципиальную блок-схему способа для обеспечения кодированного аудиопредставления, согласно вариантам осуществления первого аспекта изобретения. Способ 500 содержит предоставление, 510, информации для пространственного рендеринга одного или более аудиосигналов и предоставление, 520, множества пакетов с различными типами пакетов, причем пакеты содержат один или более пакетов конфигурирования сцен, предоставляющих конфигурационную информацию модуля рендеринга, задающую использование объектов сцены и/или использование характеристик сцены, причем пакеты содержат один или более пакетов обновлений сцен, задающих обновление метаданных сцены для рендеринга, и причем пакеты содержат один или более пакетов рабочих данных сцен, содержащих определения одного или более объектов сцены и/или определения одной или более характеристик сцены.
Далее следует обратиться к фиг. 2-3. Поток 208 битов по фиг. 2 и, соответственно, поток 302 и/или 306 битов по фиг. 3 представляют аудиоконтент. Варианты осуществления согласно изобретению, содержат потоки битов, к примеру, вышеуказанные потоки битов. Если обобщать, такие потоки битов содержат множество пакетов с различными типами пакетов, причем пакеты содержат один или более пакетов конфигурирования сцен, предоставляющих конфигурационную информацию модуля рендеринга, задающую использование объектов сцены и/или использование характеристик сцены, причем пакеты содержат один или более пакетов обновлений сцен, задающих обновление метаданных сцены для рендеринга, и причем пакеты содержат один или более пакетов рабочих данных сцен, содержащих определения одного или более объектов сцены и/или определения одной или более характеристик сцены.
Фиг. 6 показывает схематичный вид аудиодекодера согласно вариантам осуществления второго аспекта изобретения. Фиг. 6 показывает аудиодекодер 600 для обеспечения декодированного аудиопредставления 606 на основе кодированного аудиопредставления 602. Декодер 600 содержит, в качестве необязательного признака, модуль 610 подготовки посредством рендеринга, который выполнен с возможностью пространственно подготавливать посредством рендеринга один или более аудиосигналов. Следовательно, модуль 610 подготовки посредством рендеринга необязательно может содержать модуль декодирования, который может быть выполнен с возможностью декодировать кодированное аудиопредставление, чтобы получать один или более аудиосигналов. Тем не менее, в качестве другого варианта, как показано с помощью штрихпунктирных линий, аудиодекодер 600 может содержать модуль 620 декодирования, в который может предоставляться аудиопредставление 602 и который может предоставлять один или более аудиосигналов в модуль 610 подготовки посредством рендеринга.
Кроме того, аудиодекодер 600 выполнен с возможностью принимать множество пакетов 604 с различными типами пакетов, причем пакеты 604 содержат один или более пакетов конфигурирования сцен, предоставляющих конфигурационную информацию модуля рендеринга, причем пакеты 604 содержат один или более пакетов обновлений сцен, задающих обновление метаданных сцены для рендеринга и содержащих представление одного или более условий обновления.
Следовательно, на основе пакетов конфигурирования сцен, конфигурация модуля рендеринга модуля 610 подготовки посредством рендеринга может задаваться и/или регулироваться. На основе конфигурации модуля рендеринга, модуль 610 подготовки посредством рендеринга может определять то, какой объект сцены и/или характеристики сцены должны рассматриваться.
Такие объекты и/или характеристики, например, могут задаваться с использованием метаданных 630. Как пояснено выше, на основе пакетов обновлений сцен, упомянутые метаданные 630 могут обновляться для рендеринга.
Кроме того, аудиодекодер 600 выполнен с возможностью оценивать, с использованием необязательного модуля 640 оценки, то, удовлетворяются либо нет одно или более условий обновления, и избирательно обновлять одни или более метаданных 130 сцены в зависимости от контента одного или более пакетов обновлений сцен, если одно или более условий обновления удовлетворяются.
Следовательно, другими словами, и в качестве примера, декодер 600 может принимать кодированное аудиопредставление 602, которое декодируется, например, с использованием модуля 620 декодирования и подготавливается посредством рендеринга с использованием модуля 610 подготовки посредством рендеринга. Рендеринг выполняется на основе конфигурации модуля рендеринга, которая задается на основе одного или более пакетов конфигурирования сцен, которые предоставляются в декодер 600 в дополнение к аудиопредставлению 602.
Кроме того, пакеты 604, предоставленные в декодер 600, содержат информацию относительно обновления сцен, которая содержит информацию относительно обновления метаданных, используемых посредством модуля 610 подготовки посредством рендеринга. Тем не менее, в дополнение к непосредственно данным обновлений, условия обновления предоставляются, так что декодер может оценивать условия и может обновлять метаданные, используемые для рендеринга, когда заданные критерии удовлетворяются.
Как показано на фиг. 6, модуль 640 оценки может инструктировать обновлению метаданных 630, например, определений самих объектов сцены и/или характеристик сцены. Необязательно, модуль 640 оценки может инструктировать адаптации в модуле подготовки посредством рендеринга к тому, чтобы выбирать другие объекты метаданных или обновлять метаданные через модуль подготовки посредством рендеринга. Тем не менее, такая дополнительная функциональность или тракт передачи сигналов может быть необязательной.
С другой стороны, следует отметить, что разделение входящих сигналов на пакеты 604 и кодированное аудиопредставление 602 представляет собой пример. Кодированное аудиопредставление может предоставляться в качестве части пакетов 604, например, в качестве MPEGH3DA-кадров, например, в форме пакетов, например, содержащих информацию относительно спектральных аудиокоэффициентов. С другой стороны, декодер 600, например, может принимать только кодированное аудиопредставление, содержащее, в дополнение к аудиоинформации или аудиосигналу, пакеты 604, как пояснено выше, содержащие конфигурационные данные и данные обновлений. Следовательно, необязательный модуль 620 декодирования может быть выполнен с возможностью декодировать кодированные пакеты альтернативно или помимо этого.
Необязательно, декодер 600, например, с использованием модуля 640 оценки, выполнен с возможностью оценивать временное условие, которое включается в пакет обновлений сцен для того, чтобы принимать решение в отношении того, должны либо нет одни или более метаданных 630 сцены обновляться в зависимости от контента одного или более пакетов обновлений сцен.
В качестве примера, временное условие может задавать начальный момент времени или временной интервал, и декодер 600, например, с использованием модуля 640 оценки, может быть выполнен с возможностью осуществлять обновление одних или более метаданных сцены в ответ на обнаружение того, что текущее время воспроизведения достигает начального момента времени или находится после начального момента времени, или осуществлять обновление одних или более метаданных 630 сцены в ответ на обнаружение того, что текущее время воспроизведения находится в пределах временного интервала.
В качестве другого необязательного признака, например, помимо или альтернативно вышеуказанному, декодер 600, например, с использованием модуля 640 оценки, может быть выполнен с возможностью оценивать пространственное условие, которое включается в пакет обновлений сцен для того, чтобы принимать решение в отношении того, должны либо нет одни или более метаданных сцены обновляться в зависимости от контента одного или более пакетов обновлений сцен.
Необязательно, пространственное условие задает геометрический элемент, и аудиодекодер 600, например, с использованием модуля 640 оценки, выполнен с возможностью осуществлять обновление одних или более метаданных 630 сцены в ответ на обнаружение того, что текущая позиция достигает геометрического элемента, либо в ответ на обнаружение того, что текущая позиция находится внутри геометрического элемента.
Следовательно, в качестве необязательного признака, декодер 600 может быть выполнен с возможностью принимать дополнительную информацию 608, которая может содержать информацию относительно такой текущей позиции. Позиция, например, может представлять собой позицию слушателя, для которого декодер подготавливает посредством рендеринга акустическую сцену в упомянутой сцене. Тем не менее, следует отметить, что декодер 600 также может определять такую информацию на основе предоставленных пакетов 604, например, с использованием модуля 640 оценки
Кроме того, декодер 600, например, модуль 640 оценки, может быть выполнен с возможностью оценивать то, удовлетворяется или нет интерактивное инициирующее условие, чтобы принимать решение в отношении того, должны либо нет одни или более метаданных сцены обновляться в зависимости от контента одного или более пакетов обновлений сцен. В качестве примера, открытие окна пользователем в виртуальном помещении может изменять акустические характеристики помещения, и в силу этого, на основе инициирующих метаданных "открытие окна", например, элемент, представляющий акустические характеристики стены, может изменяться на стену с отверстием (=окном). Это событие может передаваться в декодер, в качестве примера, через дополнительную информацию 608. Тем не менее, декодер необязательно может содержать такую информацию или извлекать такую информацию самостоятельно.
В качестве другого необязательного признака, аудиодекодер 600, например, модуль 640 оценки, выполнен с возможностью оценивать комбинацию двух или более условий обновления и избирательно обновлять одни или более метаданных 130 сцены в зависимости от контента одного или более пакетов обновлений сцен, если комбинированное условие обновления удовлетворяется.
Соответственно, в качестве необязательного признака, аудиодекодер 600, например, модуль 640 оценки, должен быть выполнен с возможностью оценивать временное условие обновления и пространственное условие обновления либо оценивать временное условие обновления и интерактивное условие обновления. Согласно вариантам осуществления может, рассматриваться любая комбинация пространственного, временного условия и/или условия на основе событий.
В качестве другого необязательного признака, аудиодекодер, например, модуль 640 оценки, выполнен с возможностью оценивать информацию задержки, которая включается в пакет обновлений сцен, и задерживать обновление одних или более метаданных 130 сцены в зависимости от контента одного или более пакетов обновлений сцен в соответствии с информацией задержки в ответ на обнаружение того, что одно или более условий обновления удовлетворяются.
Кроме того, в качестве необязательного признака, аудиодекодер 600, например, модуль 640 оценки, выполнен с возможностью оценивать флаг в пакете обновлений сцен, указывающий то, задается или нет временное условие обновления в пакете обновлений, сцен и/или оценивать флаг в пакете обновлений сцен, указывающий то, задается или нет пространственное условие обновления в пакете обновлений сцен.
Соответственно, аудиодекодер 600, например, модуль 640 оценки выполнен с возможностью оценивать флаг в пакете обновлений сцен, указывающий то, задается или нет информация задержки в пакете обновлений сцен.
В качестве другого необязательного признака, пакет обновлений сцен содержит представление множества модификаций одного или более параметров одного или более объектов сцены и/или одной или более характеристик сцены, и аудиодекодер 600 выполнен с возможностью применять модификации, например, к метаданным 630, задающим такие объекты или характеристики, в ответ на обнаружение, например, с использованием модуля 640 оценки, того, что одно или более условий обновления удовлетворяются.
В качестве другого необязательного признака, пакет обновлений сцен содержит информацию траектории, и аудиодекодер 600, например, с использованием модуля 640 оценки, выполнен с возможностью обновлять соответствующие метаданные 130 сцены, с которыми ассоциирована информация траектории, с использованием варьирования параметров согласно траектории, заданной посредством информации траектории.
Следовательно, следует отметить, что модуль 640 оценки может быть выполнен с возможностью выполнять любые из вышеописанных обновлений, например, обновления метаданных. Следовательно, модуль 640 оценки может содержать модуль обновления, который не показан для простоты. Необязательно, декодер 600 может содержать отличающийся модуль обновления, который выполнен с возможностью принимать результат оценки из модуля 640 оценки и выполнять соответствующее обновление.
В качестве другого необязательного признака, аудиодекодер 600, например, модуль 640 оценки, выполнен с возможностью оценивать информацию, указывающую то, используется или нет обновление на основе траектории метаданных 630 сцены, с тем чтобы активировать или деактивировать обновление на основе траектории метаданных сцены.
В качестве другого необязательного признака, аудиодекодер 600, например, модуль 640 оценки, выполнен с возможностью оценивать информацию типа интерполяции, включенную в пакет обновлений сцен для того, чтобы определять тип интерполяции между двумя или более опорными точками траектории
Соответственно, в качестве необязательного признака, аудиодекодер 600, например, модуль 640 оценки, выполнен с возможностью оценивать информацию опорных точек, описывающую траекторию.
Следует отметить, что декодер 600 может содержать любые из признаков, как пояснено в контексте декодеров, как показано на фиг. 1 и 2, как отдельно, так и в комбинации. Например, декодер 600 необязательно может содержать модуль извлечения, модуль предвидения и/или запрашивающий модуль (и в силу этого соответствующие функциональности). Кроме того, декодер 600 может быть выполнен с возможностью принимать и обрабатывать пакеты рабочих данных, как описано в контексте по фиг. 1 и 2, например, в качестве части пакетов 604. Наоборот, декодеры 100 и 200 из фиг. 1 и 2 могут содержать любые из признаков, как пояснено в контексте декодера, как показано на фиг. 6, например, средство принимать дополнительную информацию и использовать ее в модуле оценки.
Далее следует обратиться к фиг. 7. Для краткости и, как пояснено выше, следует отметить, что варианты осуществления согласно изобретению, содержат кодеры с соответствующими признаками согласно декодерам и в силу этого декодеру, показанному на фиг. 6. Следовательно, кодер может содержать только необходимые признаки, чтобы предоставлять обязательные сигналы, принимаемые посредством декодера 600 на фиг. 6, и обрабатывать их для того, чтобы предоставлять декодированное аудиопредставление 606, вообще без необязательных признаков. Тем не менее, любые из необязательных признаков, функциональностей и подробностей, раскрытых выше, могут присутствовать, соответственно, в кодере согласно вариантам осуществления, отдельно или в комбинации. То же касается признаков, функциональностей и подробностей декодеров и/или кодеров других аспектов изобретения.
Фиг. 7 показывает схематичный вид кодера согласно вариантам осуществления второго аспекта изобретения. Кодер 700 выполнен с возможностью предоставлять поток 702 битов, при этом поток битов, например, может содержать кодированное аудиопредставление. В частности, кодер 700 выполнен с возможностью предоставлять информацию для пространственного рендеринга одного или более аудиосигналов, которая включается в поток 702 битов. Следовательно, поток 702 битов содержит множество пакетов 722 с различными типами пакетов.
Для обеспечения потока 702 битов и в силу этого вышеуказанных информационных объектов, кодер 700 содержит необязательный поставщик 710 потоков битов, в который предоставляются пакеты 722.
Как показано, кодер 700 необязательно может содержать модуль 720 обеспечения пакетов. Кодер 700 выполнен с возможностью, например, с использованием модуля 720 предоставления пакетов, предоставлять пакеты 722. Пакеты 722 содержат один или более пакетов конфигурирования сцен, предоставляющих конфигурационную информацию модуля рендеринга, и один или более пакетов обновлений сцен, задающих обновление метаданных сцены для рендеринга и содержащих представление одного или более условий обновления.
В качестве примера, аудиосигнал 704, который должен кодироваться, может предоставляться в кодер 700. Аудиосигнал может содержать выборки временной области и/или спектральные значения, например, речевого и/или музыкального сигнала. Необязательно (не показано), если этот сигнал уже кодируется, этот сигнал может непосредственно предоставляться в поставщик 710 потоков битов, чтобы включаться в поток битов, например, вместе с пакетами 722.
Пакеты 722 могут предоставляться посредством модуля предоставления пакетов различными способами. Например, модуль 720 предоставления пакетов может предоставлять пакеты 722 на основе информации сцен, которая задает акустическую сцену и которая может быть предварительно задана или которая может получаться посредством модуля предоставления пакетов.
Например, для вариантов применения в стиле виртуальной реальности, на основе виртуальной модели (например, акустической сцены), акустически релевантные виртуальные объекты могут определяться, чтобы моделировать или представлять акустическую сцену (акустическую сцену, например, содержащую виртуальную модель с акустически релевантными виртуальными объектами и аудиосигналом), с использованием пакетов. Необязательно, (необязательный) модуль 730 анализа может поддерживать определение акустически релевантных виртуальных объектов или их характеристик (так что, например, характеристики аудиосигнала могут использоваться для того, чтобы дополнять и/или детализировать виртуальную модель акустической сцены, например, посредством обеспечения информации относительно позиции источника звука).
Следовательно, информация для поддержки определения соответствующих пакетов 722 может предоставляться из необязательного модуля 730 анализа в модуль 720 предоставления пакетов. Например, модуль 720 предоставления пакетов может управлять виртуальной моделью, или в него может предоставляться информация относительно виртуальной модели.
В качестве другого примера, в контексте вариантов применения в стиле дополненной реальности, аудиосигнал 704, который должен кодироваться, может предоставляться в кодер 700 и может содержать выборки временной области и/или спектральные значения, например, речевого и/или музыкального сигнала. Тем не менее, необязательно аудиосигнал 704 дополнительно может содержать (или переносить) пространственную информацию (например, в неявной форме) реальной аудиосцены, которая должна дополняться, например, информацию позиции измеренного аудиоисточника в сцене, например, пользователя, который говорит. Такая информация и, необязательно помимо этого, виртуальная информация наложения (например, информация для того, чтобы добавлять акустически релевантные виртуальные объекты в реальную сцену, чтобы дополнять реальную сцену) может извлекаться и/или анализироваться, и/или применяться посредством необязательного модуля 730 анализа, чтобы моделировать или представлять сцену с использованием пакетов. Следовательно, как пояснено выше, информация для определения соответствующих пакетов 722 может предоставляться в модуль 720 предоставления пакетов. В качестве примера, модуль 730 анализа может определять, на основе пространственной информации в аудиосигнале 704, то, какие акустически релевантные объекты сцены должны рассматриваться или обновляться, или подготавливаться посредством рендеринга, чтобы предоставлять требуемое восприятие для слуха.
Тем не менее, следует отметить, что кодер 700 необязательно может не содержать модуль анализа, так что, например, информация относительно пакетов 722 может предоставляться в кодер 700 из внешнего модуля, например, модуля, управляющего виртуальной или дополненной сценой.
В качестве дополнительного пояснения вышеприведенного примера, аудиосигнал 704, который должен кодироваться, может предоставляться в кодер 700, причем он может представлять собой аудиосигнал из пространственной аудиосцены и необязательно дополнительно может содержать пространственную информацию относительно аудиосцены. Следовательно, необязательно кодер 700 может содержать модуль 730 анализа. Модуль 730 анализа может быть выполнен с возможностью анализировать информацию, предоставляемую из аудиосцены, чтобы определять или аппроксимировать представление аудиосцены. В качестве примера, аудиосцена может представляться с использованием метаданных, например, описывающих объекты сцены и/или характеристики сцены, которые могут использоваться вместе со спектральными коэффициентами, чтобы предоставлять иммерсивное представление аудиосцены для слушателя.
На основе этого, в качестве примера, соответствующие пакеты конфигурирования сцен и пакеты обновлений сцен, содержащие условия обновления, могут определяться и предоставляться с использованием модуля 720 предоставления пакетов, чтобы предоставлять конфигурационную информацию модуля рендеринга для рендеринга аудиосцены и обновлений метаданных, чтобы указывать эволюцию аудиосцены или, например, изменение восприятия аудиосцены для слушателя в аудиосцене, например, относительно пространства, времени и/или дополнительных условий.
Следует отметить, что метаданные, например, могут быть основаны на цифровой модели аудиосцены (например, для случаев применения в стиле виртуальной реальности) и/или на анализе фактической сцены, в которой аудиосигнал записывается (например, для случаев применения в стиле дополненной реальности).
В качестве примера, модуль 720 предоставления пакетов дополнительно может предоставлять пакеты, содержащие упомянутую спектральную информацию аудиосигнала, например, в форме пакетов, представляющих один или более аудиоканалов, которые должны подготавливаться посредством рендеринга (например, необязательно таких пакетов, как MPEGH3DA-кадры), которые представляют собой представлять собой часть пакетов 722.
Необязательно, аудиосигнал 704, например, может предоставляться непосредственно в модуль 720 предоставления пакетов и/или в поставщик 710 потоков битов. В качестве примера, аудиосигнал 704 может уже содержать заданные пакеты 722, так что эти пакеты могут только извлекаться в модуле 722 предоставления пакетов для того, чтобы кодироваться в поставщике 710 потоков битов. Информация аудиосигналов, например, за исключением информации метаданных, например, может предоставляться в форме пакетов или непосредственно на основе аудиосигнала 304 в поставщик 710 потоков битов.
Кроме того, следует отметить, что модуль 730 анализа также может определять или аппроксимировать виртуальную акустическую сцену, причем аудиосигнал 704, например, представляет только непосредственно акустический сигнал, при этом дополнительные пространственные характеристики сцены могут быть основаны на виртуальной модели окрестностей в виртуальной акустической сцене, например, с использованием информации относительно позиции пользователя в виртуальных окрестностях. Например, в виртуальном конференц-зале, характеристики отражения виртуальных стен или характеристики демпфирования виртуального ковра могут быть включены в качестве метаданных на основе виртуальной акустической модели стены или ковра, например, относительно позиции слушателя, а не на основе реального измерения.
В качестве необязательного признака, кодер 700, например, модуль 720 предоставления пакетов, выполнен с возможностью предоставлять пакет обновлений сцен, так что пакет обновлений сцен содержит представление временного условия для обновления одних или более метаданных сцены в зависимости от контента пакета обновлений сцен. Например, на основе результата модуля 730 анализа, кодер 700 может определять или выводить то, что аудиосцена, которая должна кодироваться, может изменяться согласно временной эволюции, и в силу этого может передавать такую информацию, например, моделирование, через передачу соответствующих данных обновлений и временного условия.
В качестве другого необязательного признака, временное условие задает начальный момент времени или временной интервал.
Соответственно, в качестве другого необязательного признака, модуль 730 анализа, в качестве примера, выполнен с возможностью определять то, что аудиосцена, которая должна кодироваться, содержит пространственную зависимость, и в силу этого может передавать такую информацию через передачу соответствующих данных обновлений и пространственного условия. Следовательно, оборудование 700 необязательно выполнено с возможностью предоставлять пакет обновлений сцен, так что пакет обновлений сцен содержит представление пространственного условия для обновления одних или более метаданных сцены в зависимости от контента пакета обновлений сцен.
В качестве другого необязательного признака, пространственное условие задает геометрический элемент. Модуль анализа в силу этого может моделировать аудиосцену эффективно с использованием таких геометрических элементов.
В качестве другого необязательного признака, кодер 700, например, модуль 720 предоставления пакетов, выполнен с возможностью предоставлять пакет обновлений сцен, так что пакет обновлений сцен содержит представление интерактивного инициирующего условия для обновления одних или более метаданных сцены в зависимости от контента пакета обновлений сцен.
Необязательно, оборудование 700, например, модуль 720 предоставления пакетов, выполнено с возможностью предоставлять пакет обновлений сцен, так что пакет обновлений сцен содержит представление комбинации двух или более условий обновления.
В качестве другого необязательного признака, оборудование 700, например, модуль 720 предоставления пакетов, выполнено с возможностью предоставлять пакет обновлений сцен, так что пакет обновлений сцен содержит информацию задержки, задающую необходимость задерживать обновление одних или более метаданных сцены в зависимости от контента одного или более пакетов обновлений сцен в ответ на обнаружение того, что одно или более условий обновления удовлетворяются.
Необязательно, оборудование 700, например, модуль 720 предоставления пакетов, выполнено с возможностью предоставлять пакет обновлений сцен, так что пакет обновлений сцен содержит флаг, указывающий то, задается или нет временное условие обновления в пакете обновлений сцен, и/или представление флага, указывающее то, задается или нет пространственное условие обновления в пакете обновлений сцен.
В качестве другого необязательного признака, оборудование 700, например, модуль 720 предоставления пакетов, выполнено с возможностью предоставлять пакет обновлений сцен, так что пакет обновлений сцен содержит флаг, указывающий то, задается или нет информация задержки в пакете обновлений сцен.
В качестве другого необязательного признака, оборудование 700, например, модуль 720 предоставления пакетов, выполнено с возможностью предоставлять пакет обновлений сцен, так что пакет обновлений сцен содержит представление множества модификаций одного или более параметров одного или более объектов сцены и/или одной или более характеристик сцены.
Необязательно, оборудование 700, например, модуль 720 предоставления пакетов, выполнено с возможностью предоставлять пакет обновлений сцен, так что пакет обновлений сцен содержит информацию траектории, описание информации траектории, чтобы обновлять соответствующие метаданные сцены, с которыми ассоциирована информация траектории, с использованием варьирования параметров согласно траектории, заданной посредством информации траектории.
В качестве примера, модуль 730 анализа может быть выполнен с возможностью определять то, что изменение акустически релевантного объекта или характеристики аудиосцены, которая должна кодироваться, может моделироваться или аппроксимироваться с использованием обновления метаданных согласно информации траектории, и в силу этого может быть выполнен с возможностью уменьшать усилия по передаче служебных сигналов для такой информации обновления посредством ее представления в форме информации траектории.
В качестве другого необязательного признака, оборудование 700, например, модуль 720 предоставления пакетов, выполнено с возможностью предоставлять пакет обновлений сцен, так что информация траектории содержит информацию, указывающую то, используется или нет обновление на основе траектории метаданных сцены, с тем чтобы активировать или деактивировать обновление на основе траектории метаданных сцены.
В качестве другого необязательного признака, оборудование 700, например, модуль 720 предоставления пакетов, выполнено с возможностью предоставлять пакет обновлений сцен, так что информация траектории содержит информацию типа интерполяции, включенную в пакет обновлений сцен.
В качестве другого необязательного признака, оборудование 700, например, модуль 720 предоставления пакетов, выполнено с возможностью предоставлять пакет обновлений сцен, так что информация траектории содержит информацию опорных точек, описывающую траекторию.
Фиг. 8 показывает принципиальную блок-схему способа для обеспечения декодированного аудиопредставления на основе кодированного аудиопредставления согласно вариантам осуществления второго аспекта изобретения. Способ 800 содержит пространственный рендеринг, 810, одного или более аудиосигналов и прием, 820, множества пакетов с различными типами пакетов, причем пакеты содержат один или более пакетов конфигурирования сцен, предоставляющих конфигурационную информацию модуля рендеринга, причем пакеты содержат один или более пакетов обновлений сцен, задающих обновление метаданных сцены для рендеринга и содержащих представление одного или более условий обновления.
Кроме того, способ 800 содержит оценку 830 того, удовлетворяются либо нет одно или более условий обновления, и избирательное обновление одних или более метаданных сцены в зависимости от контента одного или более пакетов обновлений сцен, если одно или более условий обновления удовлетворяются.
Фиг. 9 показывает принципиальную блок-схему способа для обеспечения кодированного аудиопредставления, согласно вариантам осуществления второго аспекта изобретения. Способ 900 содержит предоставление 910 множества пакетов с различными типами пакетов, причем пакеты содержат один или более пакетов конфигурирования сцен, предоставляющих конфигурационную информацию модуля рендеринга, и причем пакеты содержат один или более пакетов обновлений сцен, задающих обновление метаданных сцены для рендеринга и содержащих представление одного или более условий обновления.
Далее следует обратиться к фиг. 7. Поток 702 битов по фиг. 7 представляет аудиоконтент. Варианты осуществления согласно изобретению, содержат потоки битов, к примеру, вышеуказанный поток битов. Если обобщать, такой поток битов содержит множество пакетов с различными типами пакетов, причем пакеты содержат один или более пакетов конфигурирования сцен, предоставляющих конфигурационную информацию модуля рендеринга, и причем пакеты содержат один или более пакетов обновлений сцен, задающих обновление метаданных сцены для рендеринга и содержащих представление одного или более условий обновления.
Фиг. 10 показывает схематичный вид аудиодекодера согласно вариантам осуществления третьего аспекта изобретения. Фиг. 10 показывает аудиодекодер 1000 для обеспечения декодированного аудиопредставления 1006 на основе кодированного аудиопредставления 602. Декодер 1000 содержит модуль 1010 подготовки посредством рендеринга, который выполнен с возможностью пространственно подготавливать посредством рендеринга один или более аудиосигналов. Следовательно, модуль 1010 подготовки посредством рендеринга необязательно может содержать модуль декодирования, который может быть выполнен с возможностью декодировать кодированное аудиопредставление, чтобы получать один или более аудиосигналов. Тем не менее, в качестве другого варианта, как показано с помощью штрихпунктирных линий, аудиодекодер 1000 может содержать модуль 1020 декодирования, в который может предоставляться аудиопредставление 1002 и который может предоставлять один или более аудиосигналов в модуль 1010 подготовки посредством рендеринга.
Кроме того, аудиодекодер 1000 выполнен с возможностью принимать множество пакетов 1004 с различными типами пакетов, причем пакеты 1004 содержат множество пакетов конфигурирования сцен, предоставляющих конфигурационную информацию модуля рендеринга, задающую временную эволюцию сценария рендеринга и содержащую информацию временных меток.
Кроме того, аудиодекодер 1000 выполнен с возможностью, с использованием модуля 1020 оценки, оценивать информацию временных меток и задавать конфигурацию рендеринга модуля 1010 подготовки посредством рендеринга как сценарий рендеринга, соответствующий временной метке, с использованием конфигурационной информации модуля рендеринга.
С другой стороны, следует отметить, что разделение входящих сигналов на пакеты 1004 и кодированное аудиопредставление 1002 представляет собой пример. Кодированное аудиопредставление может предоставляться в качестве части пакетов 1004, например, в качестве MPEGH3DA-кадра, например, в форме пакета, например, содержащего информацию относительно спектральных аудиокоэффициентов. С другой стороны, декодер 1000, например, может принимать только кодированное аудиопредставление, содержащее, в дополнение к аудиоинформации или аудиосигналу, пакеты 1004, как пояснено выше, содержащие конфигурационные данные, данные обновлений и метаданные. Следовательно, необязательный модуль 1020 декодирования может быть выполнен с возможностью декодировать кодированные пакеты, альтернативно или помимо этого.
В качестве необязательного признака, аудиодекодер 1000, например, модуль 1020 оценки, выполнен с возможностью оценивать информацию временных меток, когда аудиодекодер пропускает один или более предшествующих пакетов конфигурирования сцен потока, либо когда аудиодекодер подстраивается под поток. Кроме того, аудиодекодер 1000 выполнен с возможностью задавать время воспроизведения, например, в модуле 1010 подготовки посредством рендеринга, в зависимости от информации временных меток, включенной в пакет конфигурирования сцен.
В качестве другого необязательного признака, аудиодекодер 1000, например, модуль 1010 подготовки посредством рендеринга, выполнен с возможностью выполнять временную разработку сцены для рендеринга вплоть до времени воспроизведения, заданного посредством информации временных меток, когда аудиодекодер пропускает один или более предшествующих пакетов конфигурирования сцен потока, либо когда аудиодекодер подстраивается под поток.
В качестве другого необязательного признака, аудиодекодер 1000 выполнен с возможностью получать информацию временной шкалы, которая включается в пакет, и оценивать, например, с использованием модуля 1020 оценки, информацию временной метки с использованием информации временной шкалы.
В качестве другого необязательного признака, аудиодекодер 1000, например, модуль 1020 оценки, выполнен с возможностью определять, в зависимости от информации временных меток, то, какие объекты сцены должны использоваться для рендеринга. На основе такого определения, конфигурация модуля рендеринга модуля 1010 подготовки посредством рендеринга может адаптироваться соответствующим образом.
Необязательно, модуль 1010 подготовки посредством рендеринга может принимать или выбирать объекты сцены или характеристики сцены для рендеринга из элементов набора метаданных, например, как показано на фиг. 1, 2 и/или 6.
В качестве другого необязательного признака, аудиодекодер 1000, например, с использованием модуля 1020 оценки, выполнен с возможностью оценивать пакет конфигурирования сцен, который задает эволюцию сцены для рендеринга, начиная с точки времени, которая находится перед временем, заданным посредством информации временных меток. Кроме того, аудиодекодер 1000, например, его модуль 1020 оценки выполнен с возможностью извлекать конфигурацию сцены, ассоциированную с точкой во времени, заданной посредством информации временных меток, на основе информации в пакете конфигурирования сцен.
Соответственно, такая конфигурация сцены, например, может предоставляться в модуль 1010 подготовки посредством рендеринга.
В качестве другого необязательного признака, аудиодекодер 1000, например, с использованием модуля 1020 оценки, выполнен с возможностью извлекать конфигурацию сцены, ассоциированную с точкой во времени, заданной посредством информации временных меток, с использованием одного или более пакетов обновлений сцен.
Соответственно, пакеты 1004 могут необязательно содержать один или более пакетов обновлений сцен.
В качестве другого необязательного признака, пакеты конфигурирования сцен являются совместимыми с определением MPEG-H MHAS-пакетов.
В качестве другого необязательного признака, пакеты конфигурирования сцен содержат идентификатор типа пакета, метку пакета, информацию длины пакетов и рабочие данные пакета.
В качестве другого необязательного признака, аудиодекодер 1000 выполнен с возможностью извлекать один или более пакетов конфигурирования сцен из потока битов, содержащего множество MPEG-H-пакетов, включающих в себя пакеты, представляющие один или более аудиоканалов, которые должны подготавливаться посредством рендеринга. Следовательно, декодер 1000 необязательно может содержать модуль извлечения, например, как показано на фиг. 2.
В качестве необязательного признака, аудиодекодер 1000 выполнен с возможностью принимать один или более пакетов конфигураций сцен через широковещательный поток.
В качестве другого необязательного признака, аудиодекодер 1000 выполнен с возможностью подстраиваться под широковещательный поток и определять время воспроизведения на основе временной метки первого пакета конфигурирования сцен, идентифицированного посредством аудиодекодера после подстройки.
Далее следует обратиться к фиг. 11. Для краткости и, как пояснено выше, следует отметить, что варианты осуществления согласно изобретению, содержат кодеры с соответствующими признаками согласно декодеру, показанному на фиг. 10. Следовательно, кодер может содержать только необходимые признаки, чтобы предоставлять обязательные сигналы, принимаемые посредством декодера 1000 на фиг. 10, и обрабатывать их для того, чтобы предоставлять декодированное аудиопредставление 1006, вообще без необязательных признаков. Тем не менее, любые из необязательных признаков, функциональностей и подробностей, раскрытых выше, могут присутствовать, соответственно, в кодере согласно вариантам осуществления, отдельно или в комбинации. То же касается признаков, функциональностей и подробностей декодеров и/или кодеров других аспектов изобретения.
Фиг. 11 показывает схематичный вид кодера согласно вариантам осуществления третьего аспекта изобретения. Кодер 1100 выполнен с возможностью предоставлять поток 1102 битов, при этом поток битов, например, может содержать кодированное аудиопредставление. В частности, кодер 1100 выполнен с возможностью предоставлять информацию для пространственного рендеринга одного или более аудиосигналов, которая включается в поток битов. Следовательно, поток 1102 битов содержит множество пакетов 1122 с различными типами пакетов.
Для обеспечения потока 1102 битов и в силу этого вышеуказанных информационных объектов, кодер 1100 содержит поставщик 1110 потоков битов, в который предоставляются пакеты 1122.
Как показано, кодер 1100 может содержать модуль 1120 предоставления пакетов. Кодер 1100 выполнен с возможностью, например, с использованием модуля 1120 предоставления пакетов, предоставлять пакеты 1122. Пакеты 1122 содержат множество пакетов конфигурирования сцен, предоставляющих конфигурационную информацию модуля рендеринга, задающую временную эволюцию сценария рендеринга и содержащую информацию временных меток.
Следовательно, как показано на фиг. 11, упомянутая информация временных меток может предоставляться в модуль 1120 предоставления пакетов посредством необязательного модуля 1140 предоставления информации времени.
В качестве примера, аудиосигнал 1104, который должен кодироваться, может предоставляться в кодер 1100. Аудиосигнал может содержать выборки временной области и/или спектральные значения, например, речевого и/или музыкального сигнала. Необязательно (не показано), если этот сигнал уже кодируется, этот сигнал может непосредственно предоставляться в поставщик 1110 потоков битов, чтобы включаться в поток битов, например, вместе с пакетами 1122.
Пакеты 1122 могут предоставляться посредством модуля предоставления пакетов различными способами. Например, модуль 1120 предоставления пакетов может предоставлять пакеты 322 на основе информации сцен, которая задает акустическую сцену и которая может быть предварительно задана или которая может получаться посредством модуля предоставления пакетов.
Например, для вариантов применения в стиле виртуальной реальности, на основе виртуальной модели (например, акустической сцены), акустически релевантные виртуальные объекты могут определяться, чтобы моделировать или представлять акустическую сцену (акустическую сцену, например, содержащую виртуальную модель с акустически релевантными виртуальными объектами и аудиосигналом), с использованием пакетов. Необязательно, (необязательный) модуль 1130 анализа может поддерживать определение акустически релевантных виртуальных объектов или их характеристик (так что, например, характеристики аудиосигнала могут использоваться для того, чтобы дополнять и/или детализировать виртуальную модель акустической сцены, например, посредством обеспечения информации относительно позиции источника звука).
Следовательно, информация для поддержки определения соответствующих пакетов 1122 может предоставляться из необязательного модуля 1130 анализа в модуль 1120 предоставления пакетов. Например, модуль 1120 предоставления пакетов может управлять виртуальной моделью, или в него может предоставляться информация относительно виртуальной модели.
В качестве другого примера, в контексте вариантов применения в стиле дополненной реальности, аудиосигнал 1104, который должен кодироваться, может предоставляться в кодер 1100 и может содержать выборки временной области и/или спектральные значения, например, речевого и/или музыкального сигнала. Тем не менее, необязательно аудиосигнал 1104 дополнительно может содержать (или переносить) пространственную информацию (например, в неявной форме) реальной аудиосцены, которая должна дополняться, например, информацию позиции измеренного аудиоисточника в сцене, например, пользователя, который говорит. Такая информация и, необязательно помимо этого, виртуальная информация наложения (например, информация для того, чтобы добавлять акустически релевантные виртуальные объекты в реальную сцену, чтобы дополнять реальную сцену) может извлекаться и/или анализироваться, и/или применяться посредством необязательного модуля 1130 анализа, чтобы моделировать или представлять сцену с использованием пакетов. Следовательно, как пояснено выше, информация для определения соответствующих пакетов 1122 может предоставляться в модуль 1120 предоставления пакетов. В качестве примера, модуль 1130 анализа может определять, на основе пространственной информации в аудиосигнале 1104, то, какие акустически релевантные объекты сцены должны рассматриваться или обновляться, или подготавливаться посредством рендеринга, чтобы предоставлять требуемое восприятие для слуха.
Тем не менее, следует отметить, что кодер 1100 необязательно может не содержать модуль анализа, так что, например, информация относительно пакетов 1122 может предоставляться в кодер 1100 из внешнего модуля, например, модуля, управляющего виртуальной или дополненной сценой.
В качестве дополнительного пояснения вышеприведенного примера, аудиосигнал 1104 может представлять собой аудиосигнал из пространственной аудиосцены и необязательно дополнительно может содержать пространственную информацию относительно аудиосцены. Следовательно, необязательно кодер 1100 может содержать модуль анализа 1130. Модуль анализа 1130, например, может быть выполнен с возможностью анализировать информацию, предоставляемую из аудиосцены, чтобы определять или аппроксимировать представление аудиосцены. В качестве примера, аудиосцена может представляться с использованием метаданных, например, описывающих объекты сцены и/или характеристики сцены, которые могут использоваться вместе со спектральными коэффициентами аудиосигнала, чтобы предоставлять иммерсивное представление аудиосцены для слушателя.
Следует отметить, что метаданные, например, могут быть основаны на цифровой модели аудиосцены (например, для случаев применения в стиле виртуальной реальности) и/или на анализе фактической сцены, в которой аудиосигнал записывается (например, для случаев применения в стиле дополненной реальности).
На основе этого, в качестве примера, соответствующие пакеты конфигурирования сцен, пакеты обновлений сцен и пакеты рабочих данных сцен могут определяться и предоставляться.
В качестве примера, модуль 1120 предоставления пакетов в силу этого может дополнительно предоставлять пакеты, содержащие упомянутую спектральную информацию аудиосигнала, например, в форме пакетов, представляющих один или более аудиоканалов, которые должны подготавливаться посредством рендеринга, которые в силу этого могут необязательно включаться в пакеты 1122.
Необязательно, аудиосигнал 1104 может предоставляться непосредственно в модуль 1120 предоставления пакетов и/или в поставщик 1110 потоков битов. В качестве примера, аудиосигнал 1104 может уже содержать заданные пакеты 1122, так что эти пакеты могут только извлекаться в модуле 1122 предоставления пакетов для того, чтобы кодироваться в поставщике 1110 потоков битов. Информация аудиосигналов, например, за исключением информации метаданных, может предоставляться в форме пакетов или непосредственно на основе аудиосигнала 1104 в поставщик 1110 потоков битов.
Кроме того, следует отметить, что модуль 1130 анализа также может определять или аппроксимировать виртуальную акустическую сцену, причем аудиосигнал 1104, например, представляет только непосредственно акустический сигнал, при этом дополнительные пространственные характеристики сцены могут быть основаны на виртуальной модели окрестностей в виртуальной акустической сцене и, например, основаны на позиции пользователя в виртуальных окрестностях. Например, в виртуальном конференц-зале, характеристики отражения виртуальных стен или характеристики демпфирования виртуального ковра могут быть включены в качестве метаданных на основе виртуальной акустической модели стены или ковра, например, относительно позиции слушателя, а не на основе реального измерения.
Необязательно, информация временных меток может извлекаться через анализ аудиосигнала 1104, например, как указано посредством пунктирной линии, либо, например, может определяться или задаваться, например, независимо. Необязательно, информация временных меток может предоставляться в качестве другого входного сигнала кодера 1100.
Необязательно, оборудование 1100 выполнено с возможностью предоставлять, например, с использованием модуля 1140 предоставления информации времени, в одном из пакетов информацию временной шкалы, при этом информация временной метки предоставляется в представлении, связанном с информацией временной шкалы.
В качестве другого необязательного признака, оборудование 1100, например, модуль 1120 предоставления пакетов, выполнено с возможностью предоставлять пакеты конфигурирования сцен, так что пакеты конфигурирования сцен являются совместимыми с определением MPEG-H MHAS-пакетов.
В качестве другого необязательного признака, оборудование 1100, например, модуль 1120 предоставления пакетов, выполнено с возможностью предоставлять пакеты конфигурирования сцен, так что пакеты конфигурирования сцен содержат идентификатор типа пакета, метку пакета, информацию длины пакетов и рабочие данные пакета.
В качестве другого необязательного признака, оборудование 1100, например, поставщик потоков битов 1120, выполнено с возможностью предоставлять поток 1102 битов, содержащий множество MPEG-H-пакетов, включающих в себя пакеты, представляющие один или более аудиоканалов, которые должны подготавливаться посредством рендеринга, и один или более пакетов конфигурирования сцен.
Соответственно, пакеты 1122 могут содержать упомянутые MPEG-H-пакеты, которые, например, могут предоставляться посредством модуля 1120 предоставления пакетов.
В качестве другого необязательного признака, оборудование 1100, например, поставщик 1110 потоков битов, выполнено с возможностью предоставлять поток 1102 битов, содержащий множество MPEG-H-пакетов, включающих в себя пакеты, представляющие один или более аудиоканалов, которые должны подготавливаться посредством рендеринга, и один или более пакетов конфигурирования сцен перемеженным способом.
В качестве другого необязательного признака, оборудование 1100 выполнено с возможностью периодически повторять пакет конфигурирования сцен.
В качестве другого необязательного признака, оборудование 1100 выполнено с возможностью периодически повторять пакет конфигурирования сцен с одним или более пакетов рабочих данных сцен и одним или более пакетов, представляющих один или более аудиоканалов, которые должны подготавливаться посредством рендеринга между двумя последующими пакетами конфигурирования сцен.
Следовательно, модуль 1120 предоставления пакетов необязательно может быть выполнен с возможностью предоставлять пакеты рабочих данных сцен для их кодирования с использованием поставщика 1110 потоков битов.
В качестве другого необязательного признака, оборудование 1100 выполнено с возможностью периодически повторять пакет конфигурирования сцен с одним или более пакетов, представляющих один или более аудиоканалов, которые должны подготавливаться посредством рендеринга между двумя последующими пакетами конфигурирования сцен. Кроме того, оборудование 1100 выполнено с возможностью предоставлять один или более пакетов рабочих данных сцен по запросу.
Следовательно, оборудование 1100 содержит, в качестве необязательного признака, запрашивающий модуль 1150, который выполнен с возможностью принимать такой запрос 1108. Запрашивающий модуль 1150 в силу этого может предоставлять информацию относительно запроса в модуль 1120 предоставления пакетов, чтобы предоставлять один или более пакетов рабочих данных сцен, и необязательно в поставщик 1110 потоков битов, чтобы кодировать их в потоке 1102 битов.
В качестве другого необязательного признака, оборудование выполнено с возможностью предоставлять множество в других отношениях идентичных пакетов конфигурирования сцен, отличающихся по информации временных меток.
В качестве другого необязательного признака, оборудование 1100, например, модуль 1140 предоставления информации времени, выполнено с возможностью адаптировать информацию временных меток ко времени воспроизведения. Необязательно, кодер 1100 может принимать информацию относительно времени воспроизведения в качестве входного сигнала или может выводить или определять время воспроизведения на основе аудиосигнала, например, с использованием модуля анализа 1130.
В качестве другого необязательного признака, оборудование 1100 выполнено с возможностью адаптировать информацию временных меток ко времени воспроизведения информации сцен для рендеринга, включенной в пакеты, которые предоставляются посредством оборудования во временном окружении соответствующего пакета конфигурирования сцен, в который включается соответствующая информация временных меток.
Фиг. 12 показывает принципиальную блок-схему способа для обеспечения декодированного аудиопредставления на основе кодированного аудиопредставления согласно вариантам осуществления третьего аспекта изобретения. Способ 1200 содержит пространственный рендеринг, 1210, одного или более аудиосигналов и прием, 1220, множества пакетов с различными типами пакетов, причем пакеты содержат множество пакетов конфигурирования сцен, предоставляющих конфигурационную информацию модуля рендеринга, задающую временную эволюцию сценария рендеринга и содержащую информацию временных меток. Способ дополнительно содержит оценку, 1230, информации временных меток и задание конфигурации рендеринга в качестве сценария рендеринга, соответствующего временной метке, с использованием конфигурационной информации модуля рендеринга.
Фиг. 13 показывает принципиальную блок-схему способа для обеспечения кодированного аудиопредставления, согласно вариантам осуществления третьего аспекта изобретения. Способ 1300 содержит предоставление, 1310, информации для пространственного рендеринга одного или более аудиосигналов и предоставление, 1320, множества пакетов с различными типами пакетов, причем пакеты содержат множество пакетов конфигурирования сцен, предоставляющих конфигурационную информацию модуля рендеринга, задающую временную эволюцию сценария рендеринга и содержащую информацию временных меток.
Далее следует обратиться к фиг. 11. Поток 1102 битов по фиг. 11 представляет аудиоконтент. Варианты осуществления согласно изобретению, содержат потоки битов, к примеру, вышеуказанный поток битов. Если обобщать, такой поток битов содержит множество пакетов с различными типами пакетов, причем пакеты содержат множество пакетов конфигурирования сцен, предоставляющих конфигурационную информацию модуля рендеринга, задающую временную эволюцию сценария рендеринга и содержащую информацию временных меток.
Фиг. 14 показывает схематичный вид аудиодекодера согласно вариантам осуществления четвертого аспекта изобретения. Фиг. 14 показывает аудиодекодер 1400 для обеспечения декодированного аудиопредставления 1406 на основе кодированного аудиопредставления 1402. Декодер 1400 содержит, в качестве необязательного признака, модуль 1410 подготовки посредством рендеринга, который выполнен с возможностью пространственно подготавливать посредством рендеринга один или более аудиосигналов. Следовательно, модуль 1410 подготовки посредством рендеринга необязательно может содержать модуль декодирования, который может быть выполнен с возможностью декодировать кодированное аудиопредставление, чтобы получать один или более аудиосигналов. Тем не менее, в качестве другого варианта, как показано с помощью штрихпунктирных линий, аудиодекодер 1400 может содержать модуль 1420 декодирования, в который может предоставляться аудиопредставление 1402 и который может предоставлять один или более аудиосигналов в модуль 1410 подготовки посредством рендеринга.
Кроме того, аудиодекодер 1400 выполнен с возможностью принимать пакеты 1404, причем пакеты 1404 содержат пакет конфигурирования сцен, предоставляющий конфигурационную информацию модуля рендеринга, при этом пакет конфигурирования сцен содержит информацию ячеек подсцены, задающую одну или более ячеек, при этом информация ячеек задает ассоциирование между одной или более ячеек и соответствующей одной или более структур 1430 данных, ассоциированных с одной или более ячеек и задающих сценарий рендеринга.
Следовательно, на основе пакетов конфигурирования сцен, конфигурация модуля рендеринга модуля 1410 подготовки посредством рендеринга может задаваться и/или регулироваться. Кроме того, аудиодекодер 1400, например, с использованием показанного необязательного модуля 1440 оценки, выполнен с возможностью оценивать информацию ячеек, чтобы определять то, какие структуры 1430 данных должны использоваться для пространственного рендеринга в модуле 1410 подготовки посредством рендеринга.
Следовательно, другими словами, и в качестве примера, декодер 600 может принимать кодированное аудиопредставление 1402, которое декодируется, например, с использованием модуля 1420 декодирования и подготавливается посредством рендеринга с использованием модуля 1410 подготовки посредством рендеринга. Рендеринг выполняется на основе конфигурации модуля рендеринга, которая задается на основе пакета конфигурирования сцен, который предоставляется в декодер 1400 в дополнение к аудиопредставлению 4102.
Кроме того, с использованием модуля 1440 оценки, информация ячеек может извлекаться из конфигурационной информации, так что на основе информации ячеек, например, задающей часть аудиосцены или сцены для рендеринга, или сценария рендеринга в пространстве и/или во времени, структуры данных, релевантные для рендеринга аудиосигнала, могут выбираться для и/или предоставляться в модуль 1410 подготовки посредством рендеринга.
Следовательно, необязательно, модуль 1440 оценки может инструктировать адаптации в модуле подготовки посредством рендеринга к тому, чтобы выбирать другие структуры данных, например, через тракт передачи прямых сигналов в модуль 1410 подготовки посредством рендеринга.
С другой стороны, следует отметить, что разделение входящих сигналов на пакеты 1404 и кодированное аудиопредставление 1402 представляет собой пример. Кодированное аудиопредставление может предоставляться в качестве части пакетов 1404, например, в качестве MPEGH3DA-кадра, например, в форме пакета, например, содержащего информацию относительно спектральных аудиокоэффициентов и/или аудиоканалов, которые должны подготавливаться посредством рендеринга. С другой стороны, декодер 1400, например, может принимать только кодированное аудиопредставление, содержащее, в дополнение к аудиоинформации или аудиосигналу, пакеты 1404, как пояснено выше, содержащие конфигурационные данные и, необязательно помимо этого, данные обновлений и метаданные, при этом метаданные могут представлять собой пример структур данных, например, задающих акустически релевантные объекты и/или характеристики аудиосцены, которая должна подготавливаться посредством рендеринга. Кроме того, соответственно, необязательный модуль 1420 декодирования может быть выполнен с возможностью декодировать кодированные пакеты альтернативно или помимо этого.
В качестве необязательного признака, информация ячеек содержит временное определение данной ячейки, и аудиодекодер 1400, например, с использованием модуля 1400 оценки, выполнен с возможностью оценивать временное определение данной ячейки, чтобы определять то, должны либо нет одна или более структур данных, ассоциированных с данной ячейкой, рассматриваться (например, использоваться) в пространственном рендеринге, например, в модуле 1410 подготовки посредством рендеринга.
В качестве другого необязательного признака, информация ячеек содержит пространственное определение данной ячейки, и аудиодекодер 1400, например, с использованием модуля 1440 оценки, выполнен с возможностью оценивать пространственное определение данной ячейки, чтобы определять то, должны либо нет одна или более структур данных, ассоциированных с данной ячейкой, рассматриваться (например, использоваться) в пространственном рендеринге, например, в модуле 1410 подготовки посредством рендеринга.
В качестве другого необязательного признака, аудиодекодер 1400, например, с использованием модуля 1400 оценки, выполнен с возможностью оценивать информацию числа ячеек, которая включается в пакет конфигурирования сцен для того, чтобы определять число ячеек.
В качестве другого необязательного признака, информация ячеек содержит флаг, указывающий то, содержит либо нет информация ячеек временное определение ячейки или пространственное определение ячейки, и аудиодекодер 1400 выполнен с возможностью оценивать, например, с использованием модуля 1400 оценки, флаг, указывающий то, содержит либо нет информация ячеек временное определение ячейки или пространственное определение ячейки.
В качестве другого необязательного признака, информация ячеек содержит ссылку геометрической структуры, чтобы задавать ячейку, и аудиодекодер, например, с использованием модуля 1440 оценки, выполнен с возможностью оценивать ссылку геометрической структуры, чтобы получать геометрическое определение ячейки.
В качестве другого необязательного признака, аудиодекодер 1400 выполнен с возможностью получать, например, с использованием модуля 1440 оценки, определение геометрической структуры, которая задает геометрическую границу ячейки, из глобального пакета рабочих данных. Следовательно, пакеты 1404 могут содержать такой глобальный пакет рабочих данных, который может предоставляться через широковещательный поток битов.
В качестве другого необязательного признака, аудиодекодер 1400 выполнен с возможностью идентифицировать, например, с использованием модуля 1440 оценки, одну или более текущих ячеек, и аудиодекодер 1400 выполнен с возможностью выполнять пространственный рендеринг, например, с использованием модуля 1410 подготовки посредством рендеринга, с использованием одной или более структур данных, например, из множества структур данных, например, 1430, ассоциированных с одной или более идентифицированных текущих ячеек.
В качестве другого необязательного признака, аудиодекодер 1400 выполнен с возможностью идентифицировать, например, с использованием модуля 1440 оценки, одну или более текущих ячеек, и аудиодекодер 1400 выполнен с возможностью выполнять пространственный рендеринг, например, с использованием модуля 1410 подготовки посредством рендеринга, с использованием одного или более объектов сцены и/или характеристик сцены, ассоциированных с одной или более идентифицированных текущих ячеек. В качестве примера, набор объектов данных может быть ассоциирован с текущей ячейкой или ячейками, причем структуры данных, например, содержат метаданные, задающие акустически релевантные объекты и/или характеристики сцены, которая должна подготавливаться посредством рендеринга.
В качестве другого необязательного признака, аудиодекодер 1400 выполнен с возможностью выбирать, например, с использованием модуля 1440 оценки, объекты сцены и/или характеристики сцены, которые должны рассматриваться в пространственном рендеринге в зависимости от информации ячеек.
В качестве другого необязательного признака, аудиодекодер 1400 выполнен с возможностью определять, например, с использованием модуля 1440 оценки, то, в какой одной или более пространственных ячеек находится текущая позиция, и аудиодекодер выполнен с возможностью выполнять пространственный рендеринг, например, с использованием модуля 1410 подготовки посредством рендеринга, с использованием одного или более объектов сцены и/или характеристик сцены, ассоциированных с одной или более идентифицированных текущих ячеек.
Как необязательно показано, декодер 1400 может быть выполнен с возможностью принимать дополнительную информацию 1408. Дополнительная информация может содержать информацию относительно текущей позиции. Необязательно, декодер 1400 альтернативно может быть выполнен с возможностью выводить или определять информацию относительно текущей позиции, например, слушателя или пользователя, для которого сценарий рендеринга, например, акустическая сцена подготавливается посредством рендеринга, внутренне, например, без приема выделенного ввода для этого.
В качестве другого необязательного признака, аудиодекодер 1400 выполнен с возможностью определять одни или более рабочих данных, например, рабочих данных, описывающих объекты сцены и/или характеристики сцены, ассоциированные с одной или более текущих ячеек, на основе перечисления идентификаторов рабочих данных, включенных в определение ячейки для ячейки; и аудиодекодер 1400 выполнен с возможностью выполнять пространственный рендеринг, например, с использованием модуля 1410 подготовки посредством рендеринга, с использованием определенных одних или более рабочих данных.
Необязательно, рабочие данные могут предоставляться в качестве пакетов рабочих данных, так что пакеты 1404 могут необязательно содержать их. В качестве примера, рабочие данные пакетов рабочих данных могут быть ассоциированы или могут задавать метаданные, информация которых может представляться посредством структур 1430 данных.
В качестве другого необязательного признака, аудиодекодер выполнен с возможностью выполнять пространственный рендеринг, например, с использованием модуля 1410 подготовки посредством рендеринга, с использованием информации из одного или более пакетов обновлений сцен, которые ассоциированы с одной или более текущих ячеек. Следовательно, пакеты 1404 дополнительно могут содержать пакеты обновлений сцен.
В качестве другого необязательного признака, аудиодекодер 1400 выполнен с возможностью обновлять сцену для рендеринга, например, аудиосценарий, который должен подготавливаться посредством рендеринга, с использованием информации из одного или более пакетов обновлений сцен, ассоциированных с данной ячейкой, в ответ на нахождение того, что данная ячейка становится активной. В качестве примера, ячейка может становиться активной, когда ее ассоциированная информация метаданных и/или ассоциированные структуры данных являются акустически значительно релевантными, что может иметь место, если пространственное местоположение слушателя находится в или внутри ячейки.
В качестве другого необязательного признака, информация ячеек содержит ссылку для и/или на пакет обновлений сцен, задающий обновление метаданных сцены, например, описывающих или содержащих, или представляющих собой структуры 1430 данных, для рендеринга, и аудиодекодер 1400 выполнен с возможностью избирательно выполнять обновление метаданных сцены, заданных в данном пакете обновлений сцен, в ответ на обнаружение того, что ячейка, содержащая ссылку на данный пакет обновлений сцен, становится активной.
Другими словами, и в качестве примера, модуль 1440 оценки может определять то, что ячейка является активной, например, поскольку пользователь пространственно находится в подготовленной посредством рендеринга аудиосцене в пределах геометрических границ ячейки, и в силу этого может выполнять обновление метаданных сцены, ассоциированных с активной ячейкой, на основе пакета обновлений, на который он ссылается посредством информации ячеек, соответствующей активной ячейке.
В качестве другого необязательного признака, один или более пакетов обновлений сцен содержат представление одного или более условий обновления, и аудиодекодер, например, с использованием модуля 1440 оценки, выполнен с возможностью оценивать то, удовлетворяются либо нет одно или более условий обновления, и избирательно обновлять одни или более метаданных сцены, например, структуры 1430 данных, в зависимости от контента одного или более пакетов обновлений сцен, если одно или более условий обновления удовлетворяются.
В качестве другого необязательного признака, аудиодекодер 1400 выполнен с возможностью оценивать, например, с использованием модуля 1440 оценки, временное условие, которое включается в пакет обновлений сцен для того, чтобы принимать решение в отношении того, должны либо нет одни или более метаданных сцены, например, структуры 1430 данных, обновляться в зависимости от контента одного или более пакетов обновлений сцен, которые, например, могут включаться в пакеты 1404.
Временное условие необязательно задает начальный момент времени, либо временное условие альтернативно и необязательно задает временной интервал.
Аудиодекодер 1400, например, выполнен с возможностью осуществлять обновление одних или более метаданных сцены, например, структуры 1430 данных, в ответ на обнаружение того, что текущее время воспроизведения достигает начального момента времени или находится после начального момента времени.
Альтернативно, аудиодекодер 1400 необязательно выполнен с возможностью осуществлять обновление одних или более метаданных сцены, например, структуры 1430 данных, в ответ на обнаружение того, что текущее время воспроизведения находится в пределах временного интервала.
Альтернативно или помимо этого, аудиодекодер необязательно выполнен с возможностью оценивать, например, с использованием модуля 1440 оценки, пространственное условие, которое включается в пакет обновлений сцен для того, чтобы принимать решение в отношении того, должны либо нет одни или более метаданных сцены обновляться в зависимости от контента одного или более пакетов обновлений сцен.
В качестве другого необязательного признака, пространственное условие в пакете обновлений сцен, например, включенном в пакеты 1404, задает геометрический элемент, и аудиодекодер 1400 выполнен с возможностью осуществлять обновление одних или более метаданных сцены, например, представленных, по меньшей мере, частично с использованием структур 1430 данных, в ответ на обнаружение того, что текущая позиция достигает геометрического элемента, либо в ответ на обнаружение того, что текущая позиция находится внутри геометрического элемента.
В качестве другого необязательного признака, аудиодекодер 1400 выполнен с возможностью оценивать, например, с использованием модуля 1440 оценки, то, удовлетворяется или нет интерактивное инициирующее условие, чтобы принимать решение в отношении того, должны либо нет одни или более метаданных сцены, например, описывающих структуры 1430 данных, обновляться в зависимости от контента одного или более пакетов обновлений сцен, например, включенных в пакеты 1404.
В качестве другого необязательного признака, аудиодекодер 1400 выполнен с возможностью оценивать, например, с использованием модуля 1440 оценки, информацию ячеек, чтобы определять то, в какое время и/или в какой зоне позиции слушателя какие структуры данных требуются.
В качестве другого необязательного признака, аудиодекодер 1400 выполнен с возможностью пространственно подготавливать посредством рендеринга, например, с использованием модуля 1410 подготовки посредством рендеринга, один или более аудиосигналов с использованием первого набора объектов сцены и/или характеристик сцены, когда позиция слушателя находится в первой пространственной области, и аудиодекодер выполнен с возможностью пространственно подготавливать посредством рендеринга один или более аудиосигналов с использованием второго набора объектов сцены и/или характеристик сцены, когда позиция слушателя находится во второй пространственной области.
Первый набор объектов сцены и/или характеристик сцены необязательно предоставляет более детальный пространственный рендеринг по сравнению со вторым набором объектов сцены и/или характеристик сцены.
Структуры 1430 данных могут содержать или описывать, или представлять информацию относительно объектов сцены и/или характеристик сцены и могут содержать или описывать, или представлять такую информацию с различными уровнями детальности относительно их акустического воздействия на сцену. Например, на основе пространственного расстояния позиции слушателя от определенных объектов сцены и/или характеристик сцены, различный уровень их детальности может рассматриваться для рендеринга.
В качестве другого необязательного признака, аудиодекодер 1400 выполнен с возможностью запрашивать один или более пакетов рабочих данных сцен из поставщика пакетов. Следовательно, кодер 1400 содержит, в качестве необязательного признака, запрашивающий модуль 1460 для предоставления запроса 1401.
В качестве другого необязательного признака, аудиодекодер 1400 выполнен с возможностью идентифицировать, например, с использованием модуля 1440 оценки, одну или более структур данных, которые должны использоваться для пространственного рендеринга, с использованием идентификатора рабочих данных, который включается в информацию ячеек.
В качестве другого необязательного признака, аудиодекодер 1400 выполнен с возможностью запрашивать, например, с использованием запрашивающего модуля 1460, один или более пакетов рабочих данных сцен из поставщика пакетов, например, кодера согласно вариантам осуществления.
В качестве другого необязательного признака, аудиодекодер 1400 выполнен с возможностью запрашивать, например, с использованием запрашивающего модуля 1460, один или более пакетов рабочих данных сцен из поставщика пакетов с использованием идентификатора рабочих данных, который включается в информацию ячеек, или аудиодекодер выполнен с возможностью запрашивать, например, с использованием запрашивающего модуля 1460, один или более пакетов рабочих данных сцен из поставщика пакетов с использованием идентификатора пакета. Необязательно, соответствующий идентификатор рабочих данных и/или идентификатор пакета могут определяться посредством модуля 1440 оценки и предоставляться в запрашивающий модуль 1460.
В качестве другого необязательного признака, аудиодекодер 1400 выполнен с возможностью предвидеть, например, с использованием необязательно показанного модуля 1470 предвидения, то, какие одна или более структур данных потребуются или предположительно должны требоваться с использованием информации ячеек, например, с использованием результата оценки информации ячеек модуля 1440 оценки, и запрашивать одну или более структур данных или один или более пакетов рабочих данных сцен, содержащих упомянутую одну или более структур данных, до того, как структуры данных фактически требуются, например, посредством передачи запроса 1401 с использованием запрашивающего модуля 1460.
В качестве другого необязательного признака, аудиодекодер 1400 выполнен с возможностью извлекать рабочие данные, идентифицированные посредством информации ячеек, из потока битов. Следовательно, декодер 1400 необязательно может содержать модуль извлечения, например, как показано на фиг. 2, в который может предоставляться инструкция извлечения из модуля 1440 оценки, на основе результата оценки информации ячеек.
В качестве другого необязательного признака, аудиодекодер 1400 выполнен с возможностью отслеживать требуемые структуры данных с использованием информации ячеек, например, на основе результата оценки модуля 1440 оценки.
В качестве другого необязательного признака, аудиодекодер 1400 выполнен с возможностью избирательно отбрасывать одну или более структур 1430 данных в зависимости от информации ячеек. В качестве примера, отброшенные структуры данных из множества структур данных могут не рассматриваться для рендеринга или могут даже удаляться, например, в запоминающем устройстве декодера 1400.
В качестве другого необязательного признака, информация ячеек задает подразделение на основе информации местоположения и/или на основе времени сцены для рендеринга (аудиосцены, сценария рендеринга).
В качестве другого необязательного признака, аудиодекодер 1400 выполнен с возможностью получать определение ячеек на основе структуры конфигурационных данных сцен, например, на основе ее оценки с использованием модуля 1440 оценки.
В качестве другого необязательного признака, аудиодекодер 1400 выполнен с возможностью запрашивать, например, с использованием запрашивающего модуля 1460, одну или более структур данных, и аудиодекодер 1400 выполнен с возможностью извлекать идентификаторы структур данных для структур данных, которые должны запрашиваться с использованием информации ячеек, например, с использованием модуля 1440 оценки.
В качестве другого необязательного признака аудиодекодер 1400 выполнен с возможностью предвидеть, например, с использованием модуля 1470 предвидения, то, какие одна или более структур данных потребуются или предположительно должны требоваться, и запрашивать одну или более структур данных, например, с использованием запрашивающего модуля 1460 до того, как структуры данных фактически требуются.
В качестве другого необязательного признака, аудиодекодер 1400 выполнен с возможностью извлекать одну или более структур данных с использованием соответствующих идентификаторов структур данных, например, с использованием модуля 1440 оценки, и аудиодекодер 1400 выполнен с возможностью извлекать идентификаторы структур данных для структур данных, которые должны извлекаться, с использованием информации ячеек.
В качестве другого необязательного признака, аудиодекодер 1400 выполнен с возможностью извлекать метаданные, требуемые для рендеринга, из пакета рабочих данных, например, с использованием модуля 1440 оценки. Следовательно, пакеты 1404 могут необязательно содержать такие пакеты рабочих данных. Тем не менее, следует отметить, что декодер 1400 может быть выполнен с возможностью принимать множество потоков битов, например, из широковещательных и/или одноадресных каналов,
Далее следует обратиться к фиг. 15. Для краткости и, как пояснено выше, следует отметить, что варианты осуществления согласно изобретению, содержат кодеры с соответствующими признаками согласно декодеру, показанному на фиг. 14. Следовательно, кодер может содержать только необходимые признаки, чтобы предоставлять обязательные сигналы, принимаемые посредством декодера 1400 на фиг. 14, и обрабатывать их для того, чтобы предоставлять декодированное аудиопредставление 1406, вообще без необязательных признаков. Тем не менее, любые из необязательных признаков, функциональностей и подробностей, раскрытых выше, могут присутствовать, соответственно, в кодере согласно вариантам осуществления, отдельно или в комбинации. То же касается признаков, функциональностей и подробностей декодеров и/или кодеров других аспектов изобретения.
Фиг. 15 показывает схематичный вид кодера согласно вариантам осуществления четвертого аспекта изобретения. Кодер 1500 выполнен с возможностью предоставлять поток 1502 битов, при этом поток битов, например, может содержать кодированное аудиопредставление. В частности, кодер 1500 выполнен с возможностью предоставлять информацию для пространственного рендеринга одного или более аудиосигналов, которая включается в поток 1502 битов. Следовательно, поток 1502 битов содержит множество пакетов 1522 с различными типами пакетов.
Для обеспечения потока 1502 битов и в силу этого вышеуказанных информационных объектов, кодер 1500 содержит поставщик 1510 потоков битов, в который необязательно предоставляются пакеты 1522.
Как показано, кодер 1500 может содержать модуль 1520 предоставления пакетов для обеспечения пакетов 1522. Пакеты 1522 содержат пакет конфигурирования сцен, предоставляющий конфигурационную информацию модуля рендеринга. Кроме того, пакет конфигурирования сцен содержит информацию ячеек, задающую одну или более ячеек, при этом информация ячеек задает ассоциирование между одной или более ячеек и соответствующей одной или более структур данных, ассоциированных с одной или более ячеек и задающих сценарий рендеринга.
В качестве примера, аудиосигнал 1504, который должен кодироваться, может предоставляться в кодер 1500. Аудиосигнал может содержать выборки временной области и/или спектральные значения, например, речевого и/или музыкального сигнала. Необязательно (не показано), если этот сигнал уже кодируется, этот сигнал может непосредственно предоставляться в поставщик 1510 потоков битов, чтобы включаться в поток битов, например, вместе с пакетами 1522.
Пакеты 1522 могут предоставляться посредством модуля предоставления пакетов различными способами. Например, модуль 1520 предоставления пакетов может предоставлять пакеты 1522 на основе информации сцен, которая задает акустическую сцену и которая может быть предварительно задана или которая может получаться посредством модуля предоставления пакетов.
Например, для вариантов применения в стиле виртуальной реальности, на основе виртуальной модели (например, акустической сцены), акустически релевантные виртуальные объекты могут определяться, чтобы моделировать или представлять акустическую сцену (акустическую сцену, например, содержащую виртуальную модель с акустически релевантными виртуальными объектами и аудиосигналом), с использованием пакетов. Необязательно, (необязательный) модуль 1530 анализа может поддерживать определение акустически релевантных виртуальных объектов или их характеристик (так что, например, характеристики аудиосигнала могут использоваться для того, чтобы дополнять и/или детализировать виртуальную модель акустической сцены, например, посредством обеспечения информации относительно позиции источника звука).
Следовательно, информация для поддержки определения соответствующих пакетов 1522 может предоставляться из необязательного модуля 1530 анализа в модуль 1520 предоставления пакетов. Например, модуль 1520 предоставления пакетов может управлять виртуальной моделью, или в него может предоставляться информация относительно виртуальной модели.
В качестве другого примера, в контексте вариантов применения в стиле дополненной реальности, аудиосигнал 1504, который должен кодироваться, может предоставляться в кодер 1500 и может содержать выборки временной области и/или спектральные значения, например, речевого и/или музыкального сигнала. Тем не менее, необязательно аудиосигнал 1504 дополнительно может содержать (или переносить) пространственную информацию (например, в неявной форме) реальной аудиосцены, которая должна дополняться, например, информацию позиции измеренного аудиоисточника в сцене, например, пользователя, который говорит. Такая информация и, необязательно помимо этого, виртуальная информация наложения (например, информация для того, чтобы добавлять акустически релевантные виртуальные объекты в реальную сцену, чтобы дополнять реальную сцену) может извлекаться и/или анализироваться, и/или применяться посредством необязательного модуля 1530 анализа, чтобы моделировать или представлять сцену с использованием пакетов. Следовательно, как пояснено выше, информация для определения соответствующих пакетов 1522 может предоставляться в модуль 1520 предоставления пакетов. В качестве примера, модуль 1530 анализа может определять, на основе пространственной информации в аудиосигнале 1504, то, какие акустически релевантные объекты сцены должны рассматриваться или обновляться, или подготавливаться посредством рендеринга, чтобы предоставлять требуемое восприятие для слуха.
Тем не менее, следует отметить, что кодер 1500 необязательно может не содержать модуль анализа, так что, например, информация относительно пакетов 1522 может предоставляться в кодер 1500 из внешнего модуля, например, модуля, управляющего виртуальной или дополненной сценой.
В качестве дополнительного пояснения вышеприведенного примера, аудиосигнал 1504 может представлять собой аудиосигнал из пространственной аудиосцены и необязательно дополнительно может содержать пространственную информацию относительно аудиосцены. Следовательно, необязательно кодер 1500 может содержать модуль 1530 анализа. Модуль 1530 анализа может быть выполнен с возможностью анализировать информацию, предоставляемую из аудиосцены, чтобы определять или аппроксимировать представление аудиосцены. В качестве примера, аудиосцена может представляться с использованием структур метаданных и/или структур данных (например, структур данных, содержащих или представляющих собой метаданные), например, описывающих объекты сцены и/или характеристики сцены, которые могут использоваться вместе со спектральными коэффициентами аудиосигнала, чтобы предоставлять иммерсивное представление аудиосцены для слушателя.
Следует отметить, что метаданные, например, могут быть основаны на цифровой модели аудиосцены (например, для случаев применения в стиле виртуальной реальности) и/или на анализе фактической сцены, в которой аудиосигнал записывается (например, для случаев применения в стиле дополненной реальности).
На основе этого, в качестве примера, соответствующие пакеты конфигурирования сцен, пакеты обновлений сцен и пакеты рабочих данных сцен, например, могут определяться и предоставляться.
В качестве примера, модуль 1520 предоставления пакетов в силу этого может дополнительно предоставлять пакеты, содержащие упомянутую спектральную информацию аудиосигнала, например, в форме пакетов, представляющих один или более аудиоканалов, которые должны подготавливаться посредством рендеринга (например, необязательно таких пакетов, как MPEGH3DA-кадры), которые могут представлять собой часть пакетов 1522.
В качестве другого необязательного признака, кодер 1500 содержит модуль 1540 задания информации ячеек, который выполнен с возможностью задавать или определять информацию относительно ассоциирования между одной или более ячеек и соответствующей одной или более структур данных и предоставлять ее в модуль 1520 предоставления пакетов. Как необязательно показано, такое ассоциирование может выполняться на основе анализа для аудиосигнала 1504, с использованием модуля 1530 анализа. Тем не менее, такая информация необязательно может предоставляться в кодер 1500.
Необязательно, аудиосигнал 1504 может предоставляться непосредственно в модуль 1520 предоставления пакетов и/или в поставщик 1510 потоков битов. В качестве примера, аудиосигнал 1504 может уже содержать заданные пакеты 1522, так что эти пакеты могут только извлекаться в модуле 1522 предоставления пакетов для того, чтобы кодироваться в поставщике 1510 потоков битов. Информация аудиосигналов, например, за исключением информации метаданных, например, может предоставляться в форме пакетов или непосредственно на основе аудиосигнала 1504 в поставщик 1510 потоков битов.
Кроме того, следует отметить, что модуль 1530 анализа также может определять или аппроксимировать виртуальную акустическую сцену, причем аудиосигнал 1504, например, представляет только непосредственно акустический сигнал, при этом дополнительные пространственные характеристики сцены могут быть основаны на виртуальной модели окрестностей в виртуальной акустической сцене и, например, основаны на позиции пользователя в виртуальных окрестностях. Например, в виртуальном конференц-зале, характеристики отражения виртуальных стен или характеристики демпфирования виртуального ковра могут быть включены в качестве метаданных на основе виртуальной акустической модели стены или ковра, например, относительно позиции слушателя, а не на основе реального измерения.
С другой стороны, следует отметить, что аудиокодер 1500 необязательно может предоставлять любой из пакетов, раскрытых в данном документе, также относительно любого из аудиодекодеров и/или кодеров, раскрытых в данном документе, как отдельно, так и в комбинации. Кроме того, информация ячеек, например, может содержать любую из характеристик, раскрытых в данном документе, также относительно аудиодекодера, как отдельно, так и в комбинации.
В качестве необязательного признака, оборудование 1500 выполнено с возможностью повторять предоставление пакета конфигурирования сцен периодически и/или предоставлять один или более пакетов рабочих данных сцен по запросу.
Следовательно, кодер 1500 необязательно содержит запрашивающий модуль 1550, который выполнен с возможностью принимать запрос 1508. Запрашивающий модуль 1550 в силу этого может инструктировать модулю 1520 предоставления пакетов предоставлять пакеты 1522, включающие в себя пакеты рабочих данных сцен, и как необязательно показано, поставщику 1510 потоков битов кодировать их в поток 1502 битов. Как пояснено выше, кодер 1500 также может быть выполнен с возможностью предоставлять множество потоков битов, например, широковещательных и одноадресных потоков битов, при этом глобальные данные заголовка могут повторяться в широковещательном потоке битов, и запрашиваемые структуры данных, пакеты рабочих данных, метаданные или любой информационный объект, отдельно необходимый для рендеринга, могут предоставляться через одноадресный поток битов.
В качестве другого необязательного признака, оборудование 1500, например, с использованием модуля 1520 предоставления пакетов, выполнено с возможностью предоставлять один или более пакетов рабочих данных сцен, которые содержат одну или более структур данных, указываемых посредством ссылки в информации ячеек.
В качестве другого необязательного признака, оборудование 1500 выполнено с возможностью предоставлять пакеты рабочих данных сцен, с учетом того, когда структуры данных, включенные в пакеты рабочих данных сцен, необходимы посредством аудиодекодера в соответствии с информацией ячеек.
В качестве другого необязательного признака, аудиокодер 1500 выполнен с возможностью предоставлять информацию первой ячейки, задающую первый набор объектов сцены и/или характеристик сцены для рендеринга сцены, когда позиция слушателя, например, необязательно предоставленная в кодер 1500 в качестве сигнала дополнительного ввода или неявно определенная посредством кодера на основе аудиосигнала, находится в первой пространственной области (например, как определено посредством модуля 1530 анализа), и аудиокодер выполнен с возможностью предоставлять информацию второй ячейки, задающую второй набор объектов сцены и/или характеристик сцены для рендеринга сцены, когда позиция слушателя находится во второй пространственной области. Кроме того, первый набор объектов сцены и/или характеристик сцены предоставляет более детальный пространственный рендеринг по сравнению со вторым набором объектов сцены и/или характеристик сцены.
В качестве другого необязательного признака, оборудование 1500 выполнено с возможностью использовать различные определения ячеек, чтобы управлять пространственным рендерингом с различным уровнем детальности.
Фиг. 16 показывает принципиальную блок-схему способа для обеспечения декодированного аудиопредставления на основе кодированного аудиопредставления согласно вариантам осуществления четвертого аспекта изобретения. Способ 1600 содержит пространственный рендеринг, 1610, одного или более аудиосигналов и прием, 1620, пакета конфигурирования сцен, предоставляющего конфигурационную информацию модуля рендеринга, при этом пакет конфигурирования сцен содержит информацию ячеек, задающую одну или более ячеек, при этом информация ячеек задает ассоциирование между одной или более ячеек и соответствующей одной или более структур данных, ассоциированных с одной или более ячеек и задающих сценарий рендеринга. Кроме того, способ содержит оценку, 1630, информации ячеек, чтобы определять то, какие структуры данных должны использоваться для пространственного рендеринга
Фиг. 17 показывает принципиальную блок-схему способа для обеспечения кодированного аудиопредставления, согласно вариантам осуществления четвертого аспекта изобретения. Способ 1700 содержит предоставление, 1710, информации для пространственного рендеринга одного или более аудиосигналов, предоставление, 1720, множества пакетов с различными типами пакетов и предоставление пакета конфигурирования сцен, и предоставление, 1730, конфигурационной информация модуля рендеринга, при этом пакет конфигурирования сцен содержит информацию ячеек, задающую одну или более ячеек, при этом информация ячеек задает ассоциирование между одной или более ячеек и соответствующей одной или более структур данных, ассоциированных с одной или более ячеек и задающих сценарий рендеринга.
Далее следует обратиться к фиг. 15. Поток 1502 битов по фиг. 15 представляет аудиоконтент. Варианты осуществления согласно изобретению, содержат потоки битов, к примеру, вышеуказанный поток битов. Если обобщать, такой поток битов содержит множество пакетов с различными типами пакетов, причем пакет конфигурирования сцен предоставляет конфигурационную информацию модуля рендеринга, при этом пакет конфигурирования сцен содержит информацию ячеек, задающую одну или более ячеек, при этом информация ячеек задает ассоциирование между одной или более ячеек и соответствующей одной или более структур данных, ассоциированных с одной или более ячеек и задающих сценарий рендеринга.
С другой стороны, следует отметить, что варианты осуществления согласно изобретению, описываются сегментированно на четыре изобретаемых аспекта. Следует отметить, что такое подразделение изобретения служит для того, чтобы упрощать понимание сущности изобретения и ограничивать избыточность. Следовательно, необходимо подчеркнуть, что любая функциональность, признак и/или подробность варианта осуществления согласно любому аспекту изобретения может быть включена в любой другой вариант осуществления идентичного или другого аспекта изобретения, в комбинации или отдельно. В идентичной сущности, следует отметить, что признаки, функциональности и подробности кодеров могут использоваться взаимозаменяемо для изобретаемых декодеров, и наоборот. То же применимо к подробностям изобретаемых потоков битов и способов.
Кроме того, следует отметить, что варианты осуществления согласно изобретению, содержат декодеры и/или модуль рендеринга. Декодер согласно вариантам осуществления может содержать функциональность модуля рендеринга; тем не менее, варианты осуществления могут содержать архитектуры, в которых две функциональности реализуются в различных объектах. В вышеприведенном пояснении, пояснены некоторые варианты осуществления, в которых декодеры используются взаимозаменяемо с модулями рендеринга, например, предоставляющих такую функциональность, помимо этого. Тем не менее, следует отметить, что это должно пониматься как пример. Функциональности, которые поясняются выше в одном объекте, например, в модулях подготовки посредством рендеринга декодеров, могут разбиваться на два отдельных объекта, а именно, на декодер и модуль рендеринга, причем модуль рендеринга, в качестве примера, содержит модули подготовки посредством рендеринга. Соответственно, входные и выходные сигналы могут разделяться.
Ниже по тексту, раскрываются дополнительные варианты осуществления изобретения. Нижеприведенные варианты осуществления могут использоваться в контексте либо для динамических VR/AR-потоков аудиобитов, например, с использованием трех типов пакетов, например, с использованием пакетов обновлений сцен с условием обновления, например, с использованием временной метки, например, с использованием информации ячеек.
Комментарии
Ниже по тексту, различные изобретаемые варианты осуществления и аспекты описываются в "Сущности изобретения", в главе "Новый подход" и в главе "Предпочтительный вариант осуществления", и в главе "Примеры вариантов применения", и в главе "Аспекты изобретения". Кроме того, дополнительные необязательные подробности описываются в приложении.
Кроме того, дополнительные варианты осуществления задаются посредством прилагаемой формулы изобретения.
Следует отметить, что любые варианты осуществления, определенные посредством формулы изобретения, могут необязательно дополняться посредством любых из подробностей (признаков и функций), описанных выше и в остальной части описания.
Кроме того, варианты осуществления, описанные выше, могут необязательно использоваться отдельно и также могут дополняться посредством любых из признаков в другой части описания, либо посредством любого признака, включенного в формулу изобретения, либо посредством любого признака, раскрытого в остальной части описания.
Кроме того, следует отметить, что отдельные аспекты, описанные в данном документе, могут использоваться отдельно или в комбинации. Таким образом, подробности могут добавляться в каждый из упомянутых отдельных аспектов без добавления подробностей в другой из упомянутых аспектов.
Кроме того, признаки и функциональности, раскрытые в данном документе по отношению к способу, необязательно также могут использоваться в оборудовании (выполненном с возможностью выполнять такую функциональность). Кроме того, любые признаки и функциональности, раскрытые в данном документе относительно оборудования, необязательно также могут использоваться в соответствующем способе. Другими словами, способы, раскрытые в данном документе, необязательно могут дополняться посредством любых из признаков и функциональностей, описанных относительно оборудования.
Кроме того, любые из признаков и функциональностей, описанных в данном документе, могут реализовываться в аппаратных средствах или в программном обеспечении либо с использованием комбинации аппаратных средств и программного обеспечения, как описано в разделе "Альтернативы реализации".
Кроме того, следует отметить, что поток аудиобитов [или, эквивалентно, кодированное аудиопредставление] необязательно может дополняться посредством любых из признаков, функциональностей и подробностей, раскрытых в данном документе, как отдельно, так и в комбинации.
Кроме того, как упомянуто выше, следует отметить, что варианты осуществления, раскрытые в контексте декодера, могут содержать соответствующие признаки, функциональности и подробности соответствующего кодера, отдельно или в комбинации, и наоборот.
Помимо этого, в общем, варианты осуществления согласно изобретению, могут содержать пакеты рабочих данных, содержащие одни или более рабочих данных, при этом пакеты рабочих данных и рабочие данные могут представлять собой примеры структур данных. Структуры данных также могут представлять собой пакеты других типов.
Рабочая информация может содержать метаданные, например, информацию для аудиосцены, которая не связана непосредственно с временной шкалой соответствующего аудиопотока, такую как акустически релевантная геометрия, параметрические инструкции рендеринга и информация относительно аудиоэлементов.
В качестве примера, метаданные могут содержать или могут представлять собой информацию относительно акустически релевантных объектов и/или характеристик.
Следовательно, пакеты рабочих данных и, соответственно, рабочие данные могут содержать определения одного или более объектов сцены и/или определения одной или более характеристик сцены и в силу этого определения метаданных.
1. Сущность изобретения
Аспект изобретения направлен на проектирование потоков битов, например, для аудиовариантов применения с шестью степенями свободы (6DoF), так что, например, передача пакетов потоков битов может гибко адаптироваться к практическому варианту использования, например, автономному рендерингу, потоковой передаче, широковещательной передаче или клиент-серверной схеме на месте.
Другие аспекты изобретения также раскрываются в данном документе.
2. Традиционные решения и их недостаток
Традиционные решения представляют собой проектные решения по потокам битов, содержащиеся в MPEG-аудиокодеках, таких как MPEG-H. В таких потоках битов, пакеты данных, например, главным образом передаются из отправителя ("кодера") в декодер/модуль рендеринга. Непосредственно в модуле рендеринга, пользовательская интерактивность может формировать дополнительные пакеты, которые используются статическим способом для рендеринга аудиоконтента. Примеры представляют собой данные слежения за положением головы или значения уровня для индивидуально настроенного аудиомикширования.
Обнаружено, что аудиоварианты применения с шестью степенями свободы (6DoF) иногда требуют динамической интерактивности в VR/AR-аудиовариантах применения. Обнаружено, что передача 6DoF-метаданных должна (или иногда обязательно должна) учитывать это для того, чтобы быть эффективной.
Обнаружено, что передача всех необходимых метаданных из отправителя в приемник/модуль рендеринга заранее в качестве заблаговременных коллективных данных должна представлять собой простой и удобный способ работы, но сопровождается огромным пиком в скорости передачи данных и некоторой задержкой на передачу до того, как фактический рендеринг может начинаться.
Обнаружено, что в определенном варианте применения, это простое решение является даже невозможным, если, например, дополнительная эволюция сцены является неизвестной в начальное время при запуске рендеринга.
Согласно аспекту, варианты осуществления согласно изобретению, могут использоваться в таких сценариях и вариантах применения.
Тем не менее, согласно другому аспекту, варианты осуществления изобретения также могут использоваться в различных сценариях и вариантах применения.
3. Новый подход
Согласно аспекту, изобретаемая концепция потока битов, например, учитывает повышенный уровень интерактивности, который является внутренне присущим в аудиовариантах применения с шестью степенями свободы (6DoF), и, например, в частности, для массовой динамической интерактивности в VR/AR-аудиовариантах применения, в которых, например, требуемые метаданные сильно решительно зависят от локальной позиции пользователя, пользовательского взаимодействия (например, нажатия виртуальных кнопок и т.д.) и/или от временной шкалы виртуальной сцены. Следовательно, согласно аспекту, преимущественно проектировать поток битов гибким способом таким образом, что, например, передача пакетов потоков битов может гибко адаптироваться к практическому варианту использования, например, автономному рендерингу, потоковой передаче, широковещательной передаче или клиент-серверной схеме на месте.
4. Предпочтительный вариант осуществления
4.1. Типы пакетов
Согласно аспекту изобретения, изобретаемый поток битов представляет собой расширение MHAS: MPEG-H-аудиопоток. В дополнение к существующим типам MHAS-пакетов, например, указываются три новых типов пакетов, которые, например, обеспечивают возможность сохранять и передавать метаданные для комплексных и динамических 6DoF-аудиосцен.
Конфигурирование сцен
Пакет конфигурирования сцен, например, представляет собой "заголовок" MPEG-I-потока битов и, например, может периодически повторяться в потоке битов для произвольного доступа. Он предоставляет, например, всю релевантную информацию для модуля рендеринга, чтобы конфигурировать себя. В частности, он, например, может содержать инструкции в отношении того, какие пакеты рабочих данных сцен требуются в любой данной точке в пространстве и времени, и (необязательно) в отношении того, из чего они могут извлекаться.
Обновление сцен
Обновления сцен (т.е. изменения в метаданных сцен, которые возникают во время воспроизведения), например, могут передаваться с использованием пакета обновлений сцен. Это обеспечивает возможность, например, указывать условие, при котором обновление выполняется (например, триггеры на основе времени и/или на основе информации местоположения и/или интерактивные триггеры), и изменение, внесенное в сцену.
Рабочие данные сцены
Пакет рабочих данных сцены, например, представляет собой контейнер для всех коллективных метаданных в потоке битов.
Коллективные метаданные, например, представляют собой все метаданные, которые не могут непосредственно быть связанными с временной шкалой аудиопотока, но являются обязательными (или полезными) для рендеринга, например, комплексных и динамических 6DoF-аудиосцен, включающие в себя, например, (акустически релевантную) геометрию, параметрические инструкции рендеринга и метаданные аудиоэлементов. Пакет может содержать, например, направленности, геометрии и специальные метаданные для отдельных аудиоэффектов, таких как реверберация, ранние отражения или дифракция.
Распределение рабочих данных в пакеты рабочих данных сцен, например, может организовываться посредством кодера, с учетом, например, того, когда и где метаданные необходимы посредством модуля рендеринга, какие метаданные являются существенно важными для рендеринга, а также максимального размера пакета и т.д.
Помимо этого, (необязательная) концепция "уровня детальности" отдельных модулей должна обеспечивать возможность разбрасывать большие рабочие данные (например, геометрию) по более длительному периоду в широковещательном сценарии. В (необязательном) сервер-клиентском сценарии, рабочие данные, например, могут загружаться через отдельный канал.
4.2. Синтаксис пакетов (подробности являются необязательными),


Примечания:
- Обновление входного формата для кодера (EIF) с длительностью представляет собой просто частный случай линейной интерполяции (необязательный)
- Необязательный interpolationType, например, может быть линейным, по принципу "дискретизация и запоминание", кубическим и т.д.
- Необязательный "ListenerProximityCondition" из EIF, например, выражается в качестве пространственного условия
- Например, комбинации пространственных условий и временных условий покрывают все
- Необязательно: Временные условия могут обновляться во временные диапазоны на последующей стадии
- Индикаторы параметров могут необязательно удаляться полностью (например, после CfP), поскольку обновления, например, может конструироваться просто с возможностью содержать модифицированный объект и новое значение.



4.3. Рабочие данные, ячейки и разложение подсцен (необязательные аспекты и примеры)
- Пакет рабочих данных сцены ("пакет рабочих данных" ниже по тексту), например, представляет собой контейнер для всех коллективных метаданных, которые не могут непосредственно быть связанными с временной шкалой аудиопотока, но, например, являются обязательными (или полезными), например, для рендеринга комплексных и динамических 6DoF-аудиосцен, включающие в себя, например, (акустически релевантную) геометрию, параметрические инструкции рендеринга и метаданные аудиоэлементов.
- В простейшем случае, все коллективные метаданные для сцены, например, могут содержаться в одном пакете рабочих данных, который, например, передается в декодер перед началом воспроизведения сцены. Это, например, представляет собой предпочтительный способ для передачи на основе файлов, при этом пакет рабочих данных, например, может быть расположен в начале файла.
- Тем не менее, в сценарии потоковой передачи, например, может быть преимущественным разбивать коллективные метаданные на несколько пакетов рабочих данных, например, с тем чтобы не допускать крупной передачи до того, как воспроизведение сцены может начинаться.
- Метаданные, например, могут становиться обязательными (a) в конкретной точке во времени или (b) в конкретном местоположении в пространстве. Необязательная концепция "ячеек" предоставляет, например, способ для того, чтобы указывать то, в какое время и/или в каком местоположении определенные пакеты рабочих данных требуются для рендеринга сцены.
Например, все ячейки сцены задаются в пакете конфигурирования сцен, т.е., например, либо располагаются в начале файла, либо повторяются периодически в MHAS-потоке, например, чтобы разрешать произвольный доступ. Декодер может (или даже должен, в некоторых случаях), например, синтаксически анализировать пакет конфигурирования сцен сначала, чтобы определять, например, то, какие пакеты рабочих данных требуются до того, как воспроизведение сцены может начинаться.
- Геометрия, которая указывает, например, объем, в котором ячейка на основе информации местоположения является активной, называется "границами ячеек". Ячейка, например, является активной, когда слушатель находится внутри границ ячеек. Границы ячеек, например, могут представлять собой произвольную геометрию, но примитивные геометрии (такие как ограничивающие прямоугольники с совмещением по осям) являются предпочтительными для эффективной реализации.
- Необязательно, набор из нуля или более глобально требуемых рабочих данных содержит, например, коллективные метаданные, т.е., например, всегда требуемые для надлежащего рендеринга сцены (например, содержащие геометрии, которые указывают границы ячеек).
- Например, в зависимости от профилей рендеринга, различные рабочие данные могут требоваться для данной ячейки. Таким образом, например, упрощенная геометрия может предоставляться для профилей с низкой сложностью.
- Этот документ не указывает (или не требует) то, как пакеты рабочих данных достигают декодера. Существуют несколько возможностей (которые, например, могут использоваться в комбинации с вариантами осуществления изобретения):
a) Согласно необязательному аспекту, декодер может запрашивать пакеты рабочих данных посредством идентификатора, например, из отдельного канала (например, на основе TCP/IP). В этом случае, например, именно декодер должен осуществлять выборку пакетов рабочих данных таким образом, что содержащиеся метаданные доступны, когда они становятся обязательными для воспроизведения сцены.
b) Согласно необязательному аспекту, пакеты рабочих данных перемежаются с MHAS-потоком, например, в широковещательном сценарии. Рабочие данные, которые становятся обязательными в последующей точке во времени после начала сцены, например, могут встраиваться в поток до того, как они становятся обязательными. Тем не менее, когда произвольный доступ разрешается, это, например, может требовать повторяющейся передачи требуемых пакетов рабочих данных с регулярными интервалами, что приводит к тому, что этот способ становится неподходящим для сцен с большими объемами коллективных метаданных в некоторых случаях.
c) Согласно необязательному аспекту, в "персонифицированном" одноадресном потоке, отправитель, например, может удостоверяться в отношении того, что пакеты рабочих данных встраиваются в MHAS-поток до того, как они становятся обязательными.
- (Может быть: Согласно необязательному аспекту, декодер может отслеживать то, какие рабочие данные являются устаревшими, посредством наблюдения конечной временной метки ячеек на основе времени, а также ячеек на основе информации местоположения, которые более не являются активными).
- Чтобы иллюстрировать концептуальные возможности ячеек, например, в крайнем случае, каждая акустически релевантная геометрия и аудиоэлемент могут пакетироваться в отдельный пакет рабочих данных, например, с отдельной, возможно перекрывающейся ячейкой на основе информации местоположения, например, на основе перцепционной релевантности в сцене. Например, таким образом, каждая геометрия рассматривается только для геометрических акустических эффектов, и/или каждый аудиоэлемент является активным только тогда, когда он является фактически перцепционно релевантным, например, в текущей позиции слушателя.
- Согласно необязательному аспекту, концепция также может быть использована для разложения по уровню детальности (LoD) сцены: Например, далеко от геометрической структуры, приблизительное геометрическое представление структуры может быть достаточным (например, с небольшим числом отражающих поверхностей), тогда как близко к идентичной структуре, отражения на геометрической структуре и другие эффекты, связанные с геометрической акустикой, должны подготавливаться посредством рендеринга с более высоким LoD (например, с большим числом отражающих поверхностей). Это, например, может достигаться посредством указания одной ячейки для окрестности рассматриваемой геометрии, включающей в себя геометрическое представление с высоким LoD, и одной ячейки для оставшейся сцены, включающей в себя геометрическое представление с низким LoD.
- Имеются, например, два варианта для разложения подсцен (т.е. деактивации определенных элементов, когда они являются перцепционно нерелевантными):
a) Рендеринг объектов сцены (например, аудиоэлементов и геометрий) должен осуществляться только в том случае, если они находятся в текущем релевантном пакете рабочих данных;
b) Соответствующее обновление сцен обеспечивает возможность, например, активировать и деактивировать объекты сцены. Для этого, в дополнение к EIF-спецификации, геометриям, возможно, например, требуется флаг "isActive".
- Например, акустические окружения (например, для параметрического описания поздней реверберации) могут быть конгруэнтными с ячейками на основе информации местоположения, но не обязательно.
4.4. Примечания по пакету обновлений сцен (необязательные аспекты и примеры)
- Для каждого параметра с непрерывным диапазоном значений, необязательно может указываться тип интерполяции. Тип интерполяции, например, может быть линейным, по принципу "дискретизация и запоминание", кубическим и т.д., и соответствующая кривая интерполяции, например, конструируется из данных опорных точек.
4.5. Примечания по пакету конфигурирования сцен (необязательные аспекты и примеры; рабочие данные являются необязательными),
- sceneSize (необязательный) - Конфигурирует масштабирование позиций в сцене. Это обеспечивает возможность, например, изменять число битов, требуемых для того, чтобы кодировать позицию, когда наибольшее ожидаемое значение для любой координаты меньше.
- timeScale (необязательный) - конфигурирует интерпретацию временной метки относительно источника тактовых сигналов модуля рендеринга.
- currentTime (необязательный) - временная метка этой конфигурации на данной временной шкале. В потоковом сценарии, он может использоваться для того, чтобы задавать время для нового приемника.
- numSceneObjects (необязательный) - число объектов сцены (например, аудиоэлементов+привязок/преобразований+геометрии) в сумме, например, включающей в себя все подсцены. Он, например, может использоваться для того, чтобы извлекать диапазон идентификаторов для объектов сцены и предварительно выделять ресурсы в модуле рендеринга.
- globalPayloadId (необязательный) - идентификатор MHAS-пакета пакета рабочих данных, который содержит артефакты, которые глобально требуются для конфигурирования модуля рендеринга и рендеринга сцены. Он включает в себя, например, геометрии, чтобы описывать границы ячеек. Также может быть равен "none".
- Audio Streams (необязательный) - преобразование из идентификаторов внутренних MPEG-I-потоков в источник, который, например, может представлять собой либо физический входной PCM-канал (для "локально захваченного аудио"), либо некоторую адресацию трехмерных MPEG-H-каналов аудиокадров. Необязательная ветвь "isLocallyCaptured", например, может использоваться для CfP-конфигурации каналов. Номера каналов должны, например, оставлять достаточное пространство для HOA. Кроме того, аудиопоток, например, может (необязательно) помечаться в качестве "динамического воспроизведения". В этом случае, весь аудиоконтент должен, например, загружаться и декодироваться заранее, так что триггер динамического воспроизведения может выполняться без задержки. Кроме того, данные для каждого аудиопотока могут необязательно содержать информацию относительно возможно требуемой компенсации задержки.
- Cells (необязательный) - ячейки обеспечивают возможность подразделения на основе информации местоположения и/или на основе времени сцены. Например, каждая ячейка (a) ссылается на геометрию посредством идентификатора, который описывает объем, при котором одни или несколько рабочих данных становятся обязательными, и/или (b) ссылается на временную метку, в которой рабочие данные (е) становятся обязательными. Помимо этого, необязательно может указываться посредством ссылки идентификатор соответствующего необязательного SceneUpdate, который объединяет в пакет все модификации сцены, которые должны происходить, когда триггер ячейки выполняется. Геометрия ячеек на основе информации местоположения необязательно может быть перекрывающейся. См. также раздел 4.3.
5. Примеры вариантов применения (подробности являются необязательными),
Ниже по тексту, представляются три примера, которые основаны на предпочтительном варианте осуществления синтаксиса потока битов. Примеры направлены на три различных варианта использования, в которых MHAS-пакеты изобретаемого потока битов MPEG-I-метаданных комбинируются с MHAS-пакетами, которые содержат MPEG-H-аудиопоток ("MPEGH3DA-кадр"). Например, MPEG-H-аудиопоток транспортирует аудиоматериал (каналы, объекты и HOA-сигналы), который подготавливается посредством рендеринга посредством MPEG-I-декодера/модуля рендеринга с использованием MPEG-I-метаданных в 6DoF-аудиосцену.
Ниже по тексту, поясняются варианты осуществления, направленные на MHAS-потоки на основе файлов (раскрываются примеры, подробности являются необязательными).
Следует обратиться к фиг. 18. Фиг. 18 показывает схематичный вид первого потока битов согласно вариантам осуществления изобретения. Поток 1800 битов содержит пакет 1810 конфигурирования сцен, множество пакетов 1820, 1830 рабочих данных сцен и множество пакетов 1840, 1850, содержащих часть аудиопотока или аудиопоток, например, MPEG-H-аудиопоток. Как показано на фиг. 18, пакет 1810 конфигурирования сцен необязательно может содержать информацию относительно состояния и/или настроек 1812, для соответствующего декодера или модуля рендеринга, и дополнительную информацию 1814, содержащую информацию ячеек, указывающую (например, с использованием идентификатора пакета рабочих данных) то, какие пакеты рабочих данных сцен необходимы для какой ячейки, и такую информацию, как счетчик Sphere и счетчик ObjSrc и т.д.
Первый пакет 1820 рабочих данных сцены содержит, в качестве примера, информацию относительно геометрии 1822, анимационную информацию 1824 и информацию относительно аудиоэлемента 1826. Второй пакет 1830 рабочих данных сцены содержит, в качестве примера, информацию 1832, 1834, 1836 относительно трех геометрий и информацию 1838 материала.
Следовательно, ячейка 1, как указано в пакете 1810 конфигурирования сцен, может быть ассоциирована с множеством акустически релевантной информации, например, с геометрической информацией, идентифицированной посредством индексов 12, 3, 4 и 5, с анимационной информацией, идентифицированной посредством индекса 27, с информацией аудиоэлементов, идентифицированной посредством индекса 1, и с информацией материала, идентифицированной посредством индекса 1. Следовательно, чтобы подготавливать посредством рендеринга аудиосцену корректно, если ячейка 1 является активной, пакеты 1820 и 1830 рабочих данных, содержащие информацию относительно этих элементов, могут быть необходимы. Например, аудиодекодер может использовать идентификаторы пакетов рабочих данных, ассоциированные с соответствующей ячейкой, чтобы определять то, какие пакеты рабочих данных должны оцениваться (или извлекаться и/или запрашиваться из источника данных).
В качестве другого необязательного признака, пакет 1 рабочих данных, 1820, может содержать приблизительное описание геометрии элемента ячеек, который может детализироваться посредством геометрической информации пакета 1830 рабочих данных.
Соответственно, декодер может использовать детализированную геометрическую информацию только в некоторых случаях (например, в случае если определенная ячейка является активной). Например, когда ячейка 1 является активной, информация информационных пакетов 1820 и 1830 может использоваться, но когда ячейка 2 является активной, декодер может использовать информацию пакета 1820 рабочих данных, но пренебрегать информацией пакета 1830 рабочих данных.
В качестве другого примера, пакеты рабочих данных, например, могут задавать геометрию ячейки и в силу этого геометрическую структуру ячейки, например, как задано посредством информации 1822, 1832, 1834, 1836.
В потоковом варианте применения потока, данные, например, принимаются из одного потока или считываются из файла. Например, пакет конфигурирования MPEG-I-сцен и пакеты рабочих данных передаются сначала, после чего передается определенное число пакетов MPEG-H-аудиопотоков. С периодическими интервалами, например, отражаемыми в обновленных временных метках, содержащихся в конфигурационном пакете, эта последовательность пакетов необязательно может повторяться, чтобы обеспечивать возможность произвольного доступа или "подстраиваться" под MPEG-I-сцену. Этот вариант применения обеспечивает, например, широковещательную передачу, поскольку все необходимые данные передаются. В качестве отрицательной стороны, скорость передачи данных широковещательных потоков битов в некоторых случаях является довольно большой, поскольку большие пакеты рабочих данных отправляются и повторяются периодически.
Ниже по тексту, поясняются варианты осуществления, направленные на широковещательные MHAS-потоки (например, с клиент-серверным каналом для пакетов рабочих данных) (примеры означенного, подробности являются необязательными).
Следует обратиться к фиг. 19. Фиг. 19 показывает схематичный вид изобретаемого потока 1900 битов, содержащего множество пакетов 1910, 1920 конфигурирования сцен и множество пакетов 1930, 1940, содержащих аудиопоток, например, MPEG-H-аудиопоток.
В клиент-серверном варианте применения, просто, например, небольшие пакеты конфигурирования сцен, например, 1910, 1920, и пакеты MPEG-H-аудиопотоков, например, 1930, 1940, например, принимаются из широковещательного потока или считываются из файла.
Следовательно, например, просто небольшой пакет конфигурирования MPEG-I-сцен отправляется и повторяется с периодическими интервалами, например, с обновленными временными метками (например, пакет 1910 равен 1920, за исключением информации временных меток). MPEG-I-декодер/модуль рендеринга, например, может определять из реестра, содержащегося, например, в пакете конфигурирования сцен, то, какие пакеты рабочих данных, 1950, необходимы для того, чтобы входить в сцену в данной временной метке или виртуальном местоположении, и, например, запрашивают только эти пакеты рабочих данных через обратный канал из сервера, например, кодера, только один раз. В силу этого, скорость передачи данных широковещательных потоков битов, например, поддерживается низкой по сравнению с первым сценарием.
Ниже по тексту, поясняются варианты осуществления, направленные на широковещательный MHAS-поток (например, с клиент-серверным каналом для пакетов рабочих данных) и с динамическими изменениями сцены (пример означенного, подробности являются необязательными).
Следует обратиться к фиг. 20. Фиг. 20 показывает схематичный вид изобретаемого потока 2000 битов, содержащего пакеты 2010 конфигурирования сцен, множество пакетов 2020, 2030, содержащих аудиопоток, например, MPEG-H-аудиопоток, и пакет 2040 обновлений сцен, содержащий, в качестве примера, информацию временных меток, например, для указания точки во времени, когда само обновление, например, ассоциирование индекса объекта и модификации, должно выполняться.
Кроме того, показаны пакеты 2050 рабочих данных, которые, например, могут запрашиваться через обратный канал.
Например, широковещательные потоки обоих типов дополнительно могут содержать пакеты обновлений сцен, например, 2040, в любой точке в последовательности пакетов. Сам пакет обновлений содержит, например, информацию относительно своего выполнения, например, время, в которое он должен применяться (например, сразу, если временная метка меньше или равна времени приема в сцене), либо если какой-либо другой триггер (например, пользовательское взаимодействие, такое как манипулирование виртуальными объектами или вход в определенное местоположение в виртуальном пространстве) может активировать это обновление.
Все потоки, например, могут содержать MHAS-пакеты синхронизации MPEG-H-аудиопотоков в выбранных точках во времени или через регулярные временные интервалы, например, чтобы обеспечивать возможность отрезания потока битов в произвольных точках и находить следующий допустимый пакет конфигурирования сцен для того, чтобы начинать процесс декодирования/рендеринга.
6. Аспекты изобретения
Оборудование/способ для передачи, например, метаданных с шестью степенями свободы (6DoF) для аудиовариантов применения.
- Три различных типа пакетов, которые разделяют:
- o конфигурацию,
- o динамические обновления,
-o полезные рабочие данные.
- Типы пакетов являются совместимыми с определением MPEG-H MHAS-пакетов (необязательный аспект, также является применимым независимо).
- Схема для того, чтобы совмещать эти пакеты в качестве заблаговременных коллективных данных (необязательный аспект, также является применимым независимо)
- Схема для того, чтобы повторять последовательность этих пакетов периодически для широковещательных вариантов применения (необязательный аспект, также является применимым независимо)
- Схема для того, чтобы отправлять конфигурационные пакеты только в широковещательном потоке с низкой скоростью передачи битов и предоставлять пакеты рабочих данных c высокой скоростью передачи битов по запросу через обратный канал (необязательный аспект, также является применимым независимо)
- Схема для того, чтобы отправлять конфигурационные пакеты только в широковещательном потоке с низкой скоростью передачи битов и предоставлять пакеты рабочих данных c высокой скоростью передачи битов в зависимости от времени в сцене и позиции пользователя (необязательный аспект, также является применимым независимо)
- Схема для того, чтобы отправлять конфигурационные пакеты только в широковещательном потоке с низкой скоростью передачи битов и предоставлять пакеты рабочих данных c высокой скоростью передачи битов по запросу для подсцен VR/AR-сцены (необязательный аспект, также является применимым независимо)
- Схема для того, чтобы перемежать аудио (MPEG-H-пакеты) и метаданные с шестью степенями свободы (6DoF) в общем потоке битов (необязательный аспект, также является применимым независимо)
- Схема для того, чтобы разделять коллективные метаданные на отдельные порции (пакеты рабочих данных), которые являются релевантными в различных точках во времени или в различных местоположениях в пространстве сцены (необязательный аспект, также применимыми независимо),
- Схема для того, чтобы предоставлять различные метаданные для различных требований по уровню детальности в отдельных пакетах рабочих данных (необязательный аспект)
- Схема для того, чтобы изменять 6DoF-аудиосцену с динамическими обновлениями, встраиваемыми в широковещательный поток, которые изменяют одно или несколько значений метаданных (необязательный аспект)
- Схема для того, чтобы разлагать 6DoF-аудиосцену на объемы произвольной формы, в которой различные метаданные являются допустимыми (необязательный аспект)
Дополнительные аспекты изобретения задаются посредством вышеприведенных примеров и содержат, например, поток битов, содержащий один или более признаков, упомянутых выше, и аудиодекодер, содержащий один или более признаков, упомянутых выше.
Приложение: Определение пакетов MPEG-I 6DoF MHAS-потоков (пример, подробности являются необязательными)
Общее представление
Этот раздел задает пакет данных MPEG-I-сцен, который соответствует формату MPEG-H 3DA MHAS-потока, который стандартизируется для того, чтобы транспортировать трехмерные MPEG-H-аудиоданные.
Синтаксис
Основные синтаксические MHAS-элементы
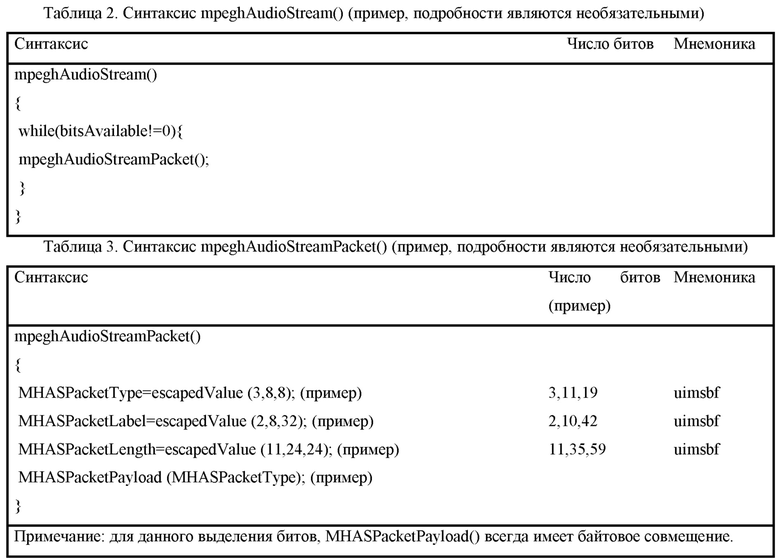
Семантика
MHASPacketLabel - Этот (необязательный) элемент предоставляет индикатор того, какие пакеты принадлежат друг другу. Например, с использованием различных меток, различные трехмерные конфигурационные MPEG-H-аудиоструктуры могут назначаться конкретным последовательностям трехмерных MPEG-H-единиц аудиодоступа.
MHASPacketLength - Этот (необязательный) элемент указывает длину MHASPacketPayload() в байтах.
MHASPacketPayload() - (Необязательные) рабочие данные для фактического MHASPacket.
Согласно аспекту изобретения, MPEG-I вводит, например, три дополнительных MHASPacketType в качестве MHASPacketPayload для существующего MPEG-H 3DA MHAS-потока, чтобы транспортировать данные, необходимые для 6DoF-рендеринга MPEG-H-аудиоконтента (например, каналы, объекты, HOA-сигналы). MHASPacketLabel этого пакета, например, используется для того, чтобы соединять MPEG-H 3DA-аудиоконтент с его ассоциированными 6DoF-данными сцены.
Таблица 4. Значение MHASPacketType (примеры)
mpegiSceneConfig() - MPEG-I-структура данных для конфигурации
mpegiSceneUpdate - MPEG-I-структура данных для обновления
mpegiScenePayload() - MPEG-I-структура данных для рабочих данных параметров
Синтаксис escapedValue(),заданный в ISO/IEC 23003-3:

Ниже по тексту, подробно поясняются варианты осуществления согласно изобретению.
В общем, варианты осуществления согласно изобретению могут быть направлены на воспроизведение иммерсивного аудио, например, на иммерсивное MPEG-I-аудио, например, с перемещением с 6 степенями свободы (6DoF) слушателя в аудиосцене, обеспечивающей восприятие виртуальной акустики в имитации виртуальной реальности (VR) и/или дополненной реальности (AR). Аудиоэффекты и явления, известные из акустики реального мира, такие как, например, локализация, затухание в зависимости от расстояния, отражения, реверберация, загораживание, дифракция и доплеровский эффект, например, могут моделироваться посредством декодера или модуля рендеринга, который управляется через метаданные, передаваемые в потоке битов, с дополнительным вводом интерактивных позиционных данных слушателей.
Наряду с другими частями MPEG-I (т.е. с частью 4, "Immersive Video", с частью 5, "Visual Volumetric Video-based Coding (V3C) and Video-based Point Cloud Compression", и с частью 2, "Systems Support"), варианты осуществления могут поддерживать, например, полное аудиовизуальное VR- или AR-представление, в котором пользователь, например, может осуществлять навигацию и взаимодействовать с имитируемым окружением с использованием 6DoF, причем это представляет собой пространственную навигацию (x, y, z) и ориентацию головы пользователя (наклон относительно вертикальной оси, наклон в продольном направлении, наклон в поперечном направлении).
Хотя VR-представления могут вызывать такое чувство, что пользователь фактически присутствует в виртуальном мире, AR может предоставлять насыщение реального мира посредством виртуальных элементов, которые воспринимаются прозрачно в качестве части реального мира. Пользователь, например, может взаимодействовать с виртуальной сценой или виртуальными элементами и, в ответ, вызывать звуки, которые воспринимаются как реалистичные и совпадающие с восприятием пользователей в реальном мире.
Варианты осуществления согласно изобретению, предоставляют средство для рендеринга интерактивного аудиопредставления в реальном времени, например, аудиосцену, например, сценарий рендеринга, например, аудиосценарий, при разрешении пользователю иметь 6DoF-перемещение. Варианты осуществления могут в силу этого содержать использование метаданных и/или структур данных для того, чтобы поддерживать этот рендеринг и синтаксис потока битов, который обеспечивает эффективное хранение и потоковую передачу иммерсивного аудиоконтента.
Следует отметить, что согласно вариантам осуществления, в общем, динамические обновления сцен могут содержать обновление, инициированное посредством внешнего объекта, который включает в себя значения атрибутов, которые должны обновляться. Метаданные могут содержать входные параметры и параметры состояния, например, даже все входные параметры и параметры состояния, которые используются для того, чтобы вычислять акустические события виртуального окружения. Модуль рендеринга может представлять собой программное обеспечение, например, все программное обеспечение, используемое для рендеринга. Инициированное обновление сцен может представлять собой обновление сцен, инициированное, например, вручную, например, на основе событий из внешнего объекта и выполняемое посредством модуля рендеринга или, например, рассматриваемое посредством декодера, сразу после приема триггера.
В качестве примера, следующая мнемоника может задаваться, чтобы описывать различные типы данных, используемые в кодированных рабочих данных потока битов согласно вариантам осуществления.
bslbf - Битовая строка, левый бит первый, при этом "левый" представляет собой порядок, в котором битовые строки записываются в ISO/IEC 14496 (все части). Битовые строки могут записываться в качестве строки единиц и нулей в одинарных кавычках, например, '1000 0001'. Пробелы в битовой строке служат для простоты чтения и не имеют значимости.
uimsbf - Целое число без знака, старший бит первый.
vlclbf - Код переменной длины, левый бит первый, при этом "левый" означает порядок, в котором коды переменной длины записываются.
tcimsbf - Целое число в двоичном дополнительном коде, старший (знаковый) бит первый.
Добавлена новая мнемоника. Эта мнемоника является временной и используется только в течение периода разработки MPEG-I-потока битов. Намерение состоит в том, чтобы удалять ее в будущем. Следующая мнемоника добавлена.
cstring - Строка в стиле языка C; последовательность ASCII-символов, в байтах, завершаемая нулевым байтом (0×00).
float - число с плавающей запятой с точностью до одного знака согласно IEEE 754.
Модуль рендеринга или декодер согласно вариантам осуществления, например, может работать с глобальной частотой дискретизации, например, в 48 кГц. Входные PCM-аудиоданные с другими частотами дискретизации должны быть или, например, могут повторно дискретизироваться в 48 кГц перед обработкой. Блок-схема обзора архитектуры согласно вариантам осуществления, например, обзора MPEG-I-архитектуры, показана на фиг 21. Краткий схематичный вид иллюстрирует то, как, модуль рендеринга необязательно соединяется с внешними модулями, такими как потоки битов MPEG-H 3DA-кодированных аудиоэлементов, MPEG-I-поток битов метаданных и другие интерфейсы. MPEG-H 3DA-кодированные аудиоэлементы декодируются посредством MPEG-H 3DA-декодера. Следует отметить, что декодер необязательно может содержать модуль рендеринга либо может содержать, другими словами, функциональность модуля рендеринга. Декодированное аудио затем подготавливается посредством рендеринга вместе с MPEG-I-потоком битов, который описывается ниже. MPEG-I-поток битов может переносить описание аудиосцен и другие метаданные, необязательно используемые посредством модуля рендеринга. Помимо этого, модуль рендеринга имеет необязательно интерфейсы, доступные для осуществления доступа к информации окружения потребления доступа, обновлениям сцен во время воспроизведения, пользовательским взаимодействиям и информации позиции пользователя.
Ниже по тексту, следует обратиться к вариантам осуществления, направленным на транспортировку иммерсивного MPEG-I-аудио. Следовательно, следующий раздел может называться "Транспортировка иммерсивного MPEG-I-аудио"
Общее представление
Варианты осуществления, направленные на MPEG-I-аудио, например, могут содержать три дополнительных значения MHASPacketType и ассоциированные MHASPacketPayload для существующего MPEG-H 3DA MHAS-потока, чтобы транспортировать данные, например, необходимые данные, для 6DoF-рендеринга MPEG-H-аудиоконтента (например, каналы, объекты, HOA-сигналы). MHASPacketLabel этих пакетов, например, может использоваться для того, чтобы соединять MPEG-H 3DA-аудиоконтент с его ассоциированными 6DoF-данными сцены. MHAS-пакеты MHASPacketType PACTYP_MPEGI_CFG, PACTYP_MPEGI_UPD и PACTYP_MPEGI_PLD встраивают 6DoF-данные сцены MPEG-I, mpegiSceneConfig, mpegiSceneUpdate и mpegiScenePayload в MHASPacketPayload().
Пакет mpegiSceneConfig, например, может представлять собой облегченный пакет для MPEG-I-потока битов. Он, например, может предоставлять всю релевантную информацию для модуля рендеринга, чтобы конфигурировать себя для инициализации. Он, например, может предоставлять преобразование между идентификаторами для всех объектов в сцене таким образом, что модуль рендеринга может транслировать целочисленные идентификаторы, передаваемые из пакетов обновлений и рабочих данных, в человекочитаемые строковые идентификаторы. В сценариях, в которых боковые каналы присутствуют, конфигурационный пакет, например, может или должен детализировать местоположения боковых каналов и то, какие пакеты рабочих данных доступны через упомянутые боковые каналы или обратный канал, например, через одноадресный поток битов.
Пакет mpegiSceneUpdate передает L1-, L2- (т.е. изменения объектов в сцене, которые известны, когда поток начинается) и L3-обновления (т.е. изменения объектов в сцене, которые являются неизвестными, когда поток начинается).
Пакет mpegiScenePayload, например, может представлять собой основной контейнер для всех "коллективных" метаданных в потоке битов MPEG-I-аудио. Он может содержать или содержать, например, направленности, геометрии и другие метаданные для отдельных аудиоэффектов, таких как реверберация, ранние отражения или дифракция. Распределение рабочих данных в пакеты рабочих данных сцен, например, может организовываться посредством кодера, с учетом того, когда и где метаданные необходимы посредством модуля рендеринга, какие метаданные являются существенно важными для рендеринга, а также максимального размера пакета и т.д. В сервер-клиентском сценарии, рабочие данные, например, могут загружаться через отдельный канал, например, обратный канал. Для чистых широковещательных сценариев, размеры рабочих данных, например, могут ограничиваться, чтобы экономить полосу пропускания.
В сервер-клиентском варианте применения, MHASPacketType PACTYP_MPEGI_CFG, например, может или должен периодически перемежаться с MHAS-аудиопакетами в широковещательном потоке, но большие пакеты PACTYP_MPEGI_PLD должны отправляться или, например, могут отправляться только по запросу.
Чтобы синхронизироваться с широковещательным потоком, MHAS-пакет PACTYP_SYNC синхронизации, например, может или должен вставляться перед каждым пакетом mpegiSceneConfig(). Рабочие данные MPEG-I-сцены, например, могут пакетироваться в один или более пакетов mpegiScenePayload(). Точно детализированное перемежение между MPEG-I-метаданными и аудиоконтентом, например, может достигаться посредством распределения MPEG-I-метаданных в перемежение MPEG-I-метаданных по нескольким пакетам рабочих данных.
Ниже по тексту, приводятся определения для и согласно вариантам осуществления изобретения. Следовательно, следующий раздел может называться "Определения".
Следует обратиться к синтаксису согласно вариантам осуществления.
Во-первых, общая информация предоставляется, например, относительно синтаксиса.
Синтаксис потока битов согласно вариантам осуществления может быть основан на ISO/IEC ISO/IEC 23008-3 (MPEG-H, часть 3), раздел 5. Примеры модификаций и изменений в существующий синтаксис потока битов перечисляются ниже.
В окружениях, которые требуют байтового совмещения, конфигурационные элементы или элементы рабочих данных иммерсивного MPEG-I-аудио, которые не составляют целое число байтов по длине, например, могут дополняться в конце, чтобы достигать целочисленного числа байтов. Это указывается посредством функции ByteAlign().
Следовательно, варианты осуществления согласно изобретению, например, кодеры и/или декодеры могут содержать или использовать следующий синтаксис:
MHAS-синтаксис


Конфигурация сцен
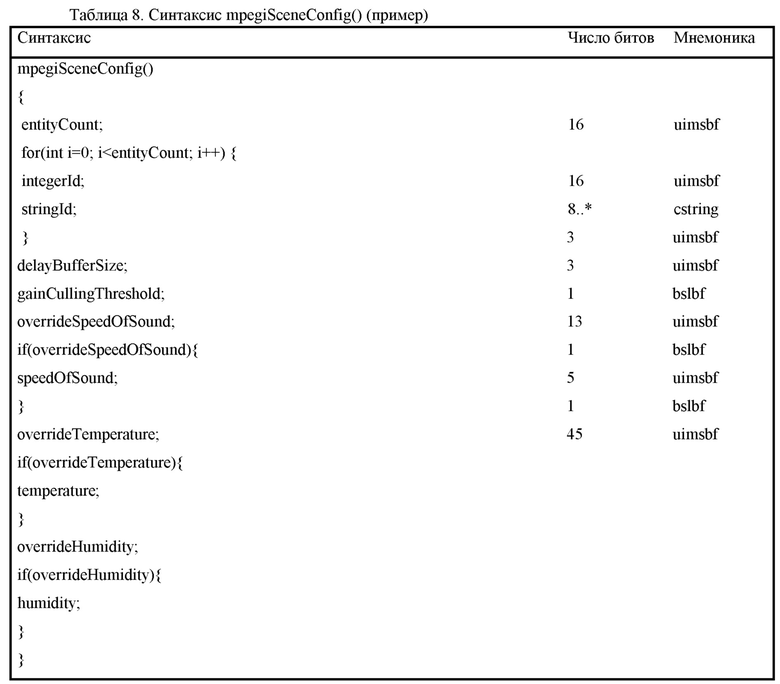
Обновление сцен
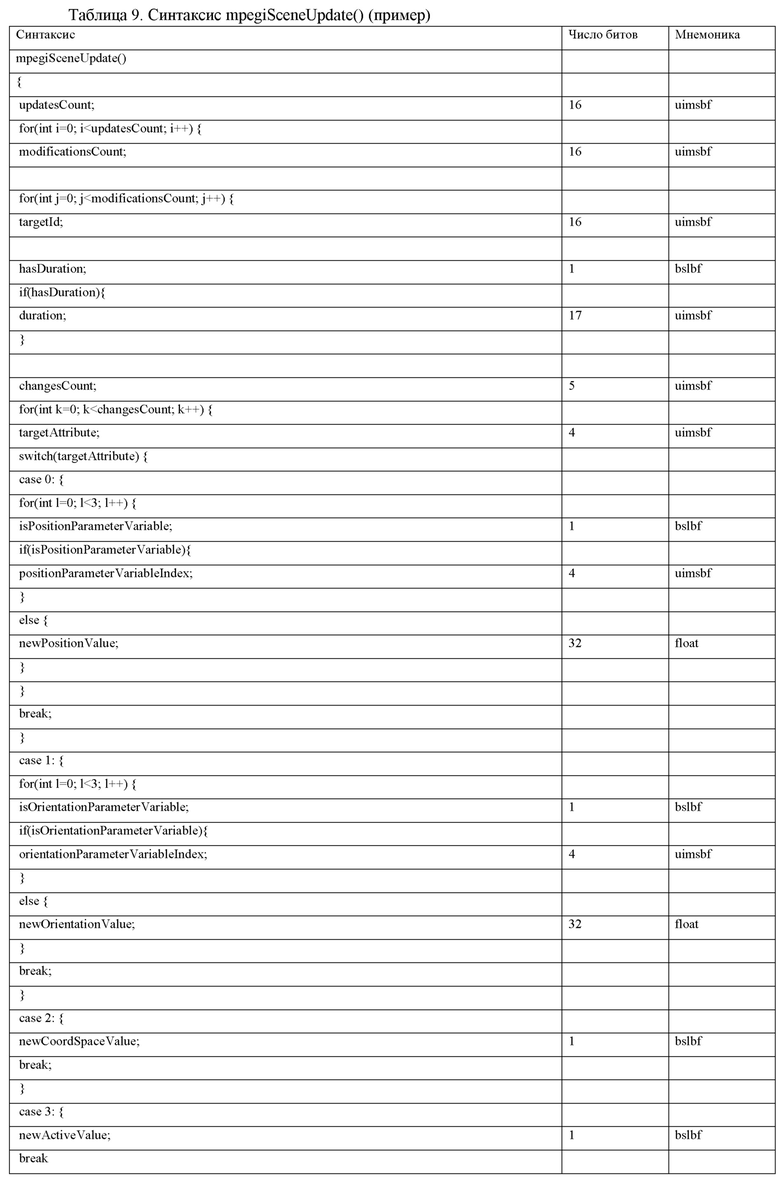
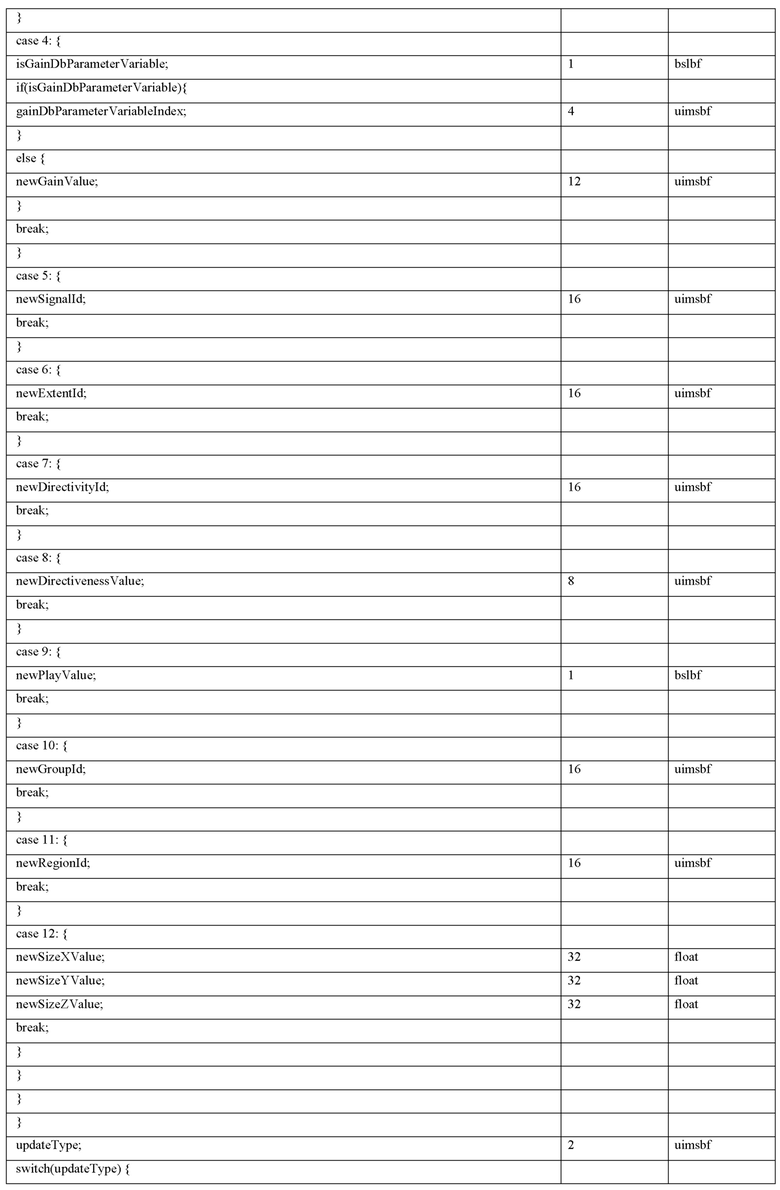
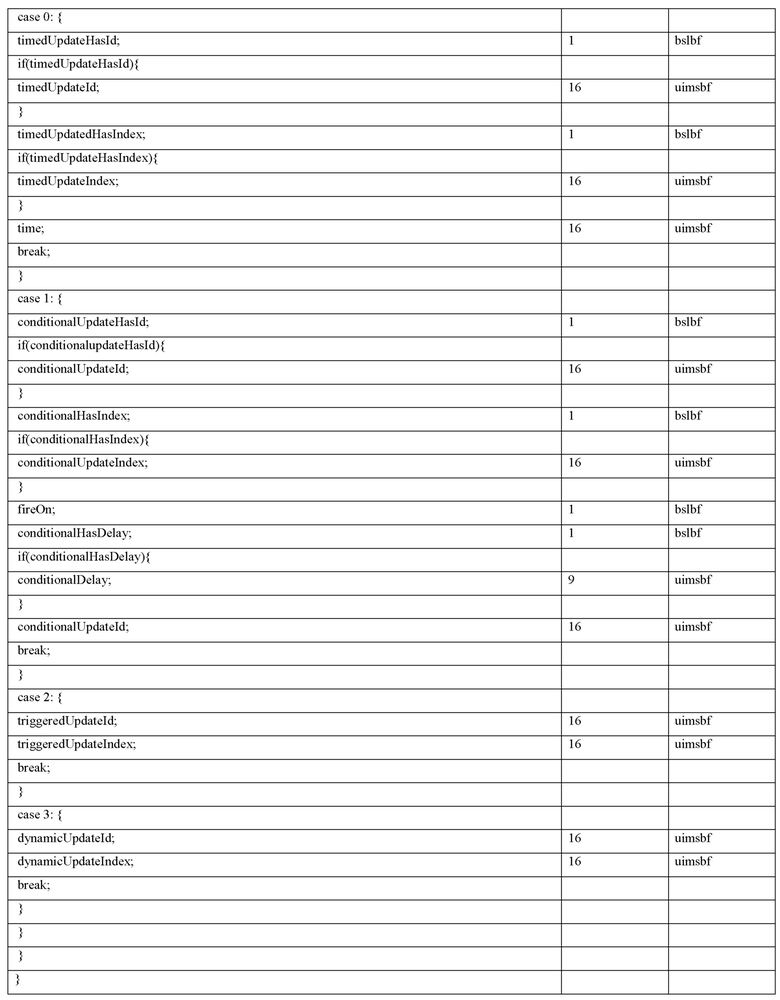
Рабочие данные сцены


Семантика
Варианты осуществления согласно изобретению, могут содержать или использовать следующую семантику:
bitstreamIdentifier - Это целое число, например, может представлять "MPEGI" в форме строки на языке C. Оно, например, может использоваться для целей разработки, чтобы верифицировать MPEG-I-потоки битов. Это представляет собой механизм предотвращения для случайного считывания других файлов.
bitstreamVersion - Это целое число, например, может представлять номер версии для этого потока битов. Целое число может изменяться вместе с синтаксисом, чтобы обеспечивать то, что модуль рендеринга может корректно декодировать этот поток битов. Оно, например, может главным образом использоваться для целей разработки в то время, когда синтаксис находится в состоянии изменения.
MHASPacketLabel - Этот элемент, например, может предоставлять индикатор того, какие пакеты принадлежат друг другу. Например, с использованием различных меток, различные трехмерные конфигурационные MPEG-H-аудиоструктуры могут назначаться конкретным последовательностям трехмерных MPEG-H-единиц аудиодоступа.
MHASPacketLength - Этот элемент, например, может указывать длину пакета в байтах.
Таблица 11. Значение MHASPacketType (пример)
mpegiSceneConfig() - MPEG-I-структура данных для конфигурации
mpegiSceneUpdate - MPEG-I-структура данных для обновления
mpegiScenePayload() - MPEG-I-структура данных для рабочих данных параметров
payloadId - Это целое число, например, может быть уникальным идентификатором пакета рабочих данных. Оно, например, может быть служить для того, чтобы отличать его от других пакетов рабочих данных.
payloadCount - Это целое число, например, может указывать то, сколько рабочих данных в данный момент присутствует в этом пакете.
payloadType - Это целое число, например, может обозначать тип текущих рабочих данных.
Элементы рабочих данных, перечисленные в таблице 18, как показано далее, например, могут задаваться согласно следующему необязательному синтаксису:
Синтаксис рабочих данных направленности






Таблица 18. Значение payloadType (пример)
payloadLabel - Этот элемент, например, может использоваться для того, чтобы группировать несколько рабочих данных.
payloadLength - Этот элемент, например, может быть длиной рабочих данных в байтах.
entityCount - Это целое число, например, может представлять число объектов, которые существуют с идентификаторами.
integerId - Это целое число, например, может представлять заново извлеченное целое число из строкового идентификатора. Все значения integerId, например, могут или должны быть уникальными.
stringId - Эта строка, например, может быть исходной строкой, содержащейся во входном формате для кодера для этого объекта. Намерение, например, может состоять в том, чтобы преобразовывать строки в целые числа таким образом, что остальная часть потока битов может использовать целые числа в качестве идентификаторов в размер потока битов. Все значения stringId, например, могут или должны быть уникальными.
delayBufferSize - Этот элемент, например, может задавать размер буферов задержки на распространение. Размер, например, может или должен быть достаточно большим для того, чтобы обрабатывать наибольшую задержку на распространение, которая может возникать в сцене.
Таблица 19. Значение delayBufferSize (пример)
gainCullingThreshold - Этот элемент, например, может устанавливать пороговое значение, при котором, например, может деактивироваться элемент рендеринга с большим затуханием (например, вследствие большого затухания в зависимости от расстояния). Пороговый коэффициент g деактивации, например, может вычисляться из значения v, где g=10v-10. Когда v располагается в диапазоне между 0 и 7, это, например, может приводить к пороговому значению деактивации между -100 дБ и -30 дБ при приращениях в 10 дБ.
overrideSpeedOfSound - Этот флаг, например, может указывать то, переопределяется или нет скорость по умолчанию звука (340 м/с), используемая для вычисления задержки на распространение, для этой сцены.
speedOfSound - Это значение, например, может задавать скорость звука.
overrideTemperature - Этот флаг, например, может указывать то, может или нет температура по умолчанию (20°C), используемая для вычисления среднего затухания, например, переопределяться для этой сцены.
temperature - Это значение, например, может задавать температуру. Температура T в °C, например, может вычисляться из значения v, где T=5v-50.
overrideHumidity - Этот флаг, например, может указывать то, может или нет влажность по умолчанию (40%), используемая для вычисления среднего затухания, например, переопределяться для этой сцены.
humidity - Это значение, например, может задавать влажность. Влажность H в %, например, может вычисляться из значения v с 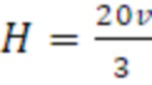 .
.
updatesCount - Это целое число, например, может быть числом обновлений в этих рабочих данных.
modificationsCount - Это целое число, например, может быть числом модификаций в этом обновлении.
targetId - Это целое число, например, может быть уникальным идентификатором целевого объекта, который модифицируется.
hasDuration - Этот флаг, например, может указывать то, возникает или нет модификация в течение периода времени.
duration - Это значение, например, может быть общей длительностью модификации в секундах. Диапазон, например, может составлять между 0,0 и 180,0. Чтобы деквантовать его в значение с плавающей запятой, следующее уравнение, например, может использоваться::
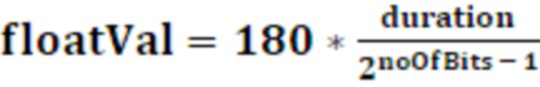 (1)
(1)
changesCount - Это целое число, например, может представлять то, сколько изменений значения возникает в этой модификации.
targetAttribute - Это целое число, например, может указывать то, какой атрибут, например, может модифицироваться.
Таблица 20. Значение channelSourceMode (пример)
isPositionParameterVariable - Этот флаг, например, может указывать то, исходит или нет значение из платформы оценки.
positionParameterVariableIndex - Это целое число, например, может быть индексом канала значений обновления, который подается из платформы оценки.
newPositionValue - Это число с плавающей запятой, например, может быть новым значением позиции в метрах для целевого объекта.
isOrientationParameterVariable - Этот флаг, например, может указывать то, исходит или нет значение из платформы оценки.
rientationParameterVariableIndex - Это целое число, например, может быть индексом канала значений обновления, который подается из платформы оценки.
newOrientationValue - Это число с плавающей запятой, например, может быть новым значением ориентации в градусах для целевого объекта.
newCoordSpaceValue - Этот флаг, например, может быть новым значением координированного пространства для целевого объекта.
Таблица 21. Значение newCoordSpaceValue (пример)
newActiveValue - Этот флаг, например, может (де-)активировать рендеринг целевого объекта.
isGainDbParameterVariable - Этот флаг, например, может указывать то, исходит или нет значение из платформы оценки.
gainDbParameterVariableIndex - Это целое число, например, может быть индексом канала значений обновления, который подается из платформы оценки.
newGainValue - Это значение, например, может быть новым значением усиления для целевого объекта. Оно располагается в диапазоне между -127,0 и 127,0. Чтобы деквантовать его в значение с плавающей запятой, следующее уравнение, например, может использоваться:
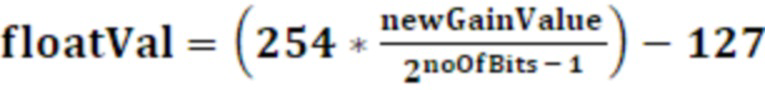 (2)
(2)
newSignalId - Это целое число, например, может быть новым уникальным идентификатором аудиопотока для целевого объекта.
newExtentId - Это целое число, например, может быть новым уникальным геометрическим идентификатором для атрибута протяженности целевого объекта.
newDirectivityId - Это целое число, например, может быть новым уникальным идентификатором направленности для направленности источника целевого объекта.
newDirectivenessValue - Это значение, например, может быть новым значением направленности для целевого объекта. Оно, например, может располагаться в диапазоне между 0,0 и 20,0. Чтобы деквантовать его в значение с плавающей запятой, следующее уравнение, например, может использоваться:
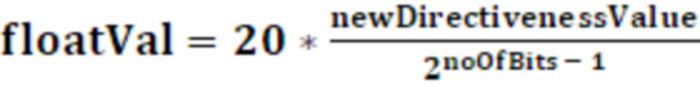 (3)
(3)
newPlayValue - Этот флаг, например, может указывать новое значение воспроизведения для целевого объекта.
newGroupId - Это целое число, например, может представлять новую уникальную группу HOA для целевого источника HOA.
newRegionId - Это целое число, например, может представлять новый уникальный геометрический идентификатор для атрибута области целевого объекта.
newSizeXValue - Это число с плавающей запятой, например, может представлять новый атрибут размера (м) на оси X для целевого примитивного объекта.
newSizeYValue - Это число с плавающей запятой, например, может представлять новый атрибут размера (м) на оси Y для целевого примитивного объекта.
newSizeZValue - Это число с плавающей запятой, например, может представлять новый атрибут размера (м) в оси Z для целевого примитивного объекта.
updateType - Это целое число, например, может указывать обновление, которое может иметь следующие типы: синхронизированное по времени, условное, динамическое или инициированное.
Таблица 22. Значение updateType (пример)
timedUpdateHasId - Этот флаг, например, может указывать то, имеет или нет синхронизированное по времени обновление уникальный идентификатор.
timedUpdateId - Это целое число, например, может указывать уникальный идентификатор для этого синхронизированного по времени обновления.
timedUpdateHasIndex - Этот флаг, например, может указывать то, имеет или нет синхронизированное по времени обновление значение индекса.
timedUpdateIndex - Это целое число, например, может быть значением индекса для этого синхронизированного по времени обновления.
time - Это значение, например, может быть точкой во времени, в которой начинается обновление. Оно, например, может располагаться в диапазоне между 0,0 и 180,0. Чтобы деквантовать его в значение с плавающей запятой, следующее уравнение, например, может использоваться:
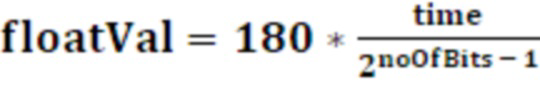 (4)
(4)
conditionalUpdateHasId - Этот флаг, например, может указывать то, имеет или нет это условное обновление уникальный идентификатор.
conditonalUpdateId - Это целое число, например, может быть уникальным идентификатором для этого условного обновления.
conditionalUpdateIndex - Это целое число, например, может быть значением индекса для этого условного обновления.
fireOn - Этот флаг, например, может определять то, когда это обновление инициируется. Он, например, может инициироваться, когда состояние этого значения достигается.
conditonalHasDelay - Этот флаг, например, может указывать то, задерживается или нет условное обновление после триггера.
conditionalDelay - Это значение, например, может быть задержкой в секундах между триггером обновления и актуализацией самого обновления. Оно, например, может располагаться в диапазоне между 0,0 и 10,0. Чтобы деквантовать его в значение с плавающей запятой, следующее уравнение, например, может использоваться:
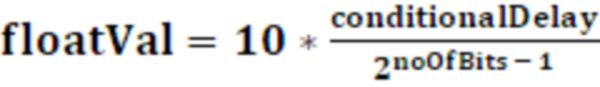 (5)
(5)
conditonId - Это целое число, например, может быть уникальным идентификатором условия близости слушателя, на который инициируется это обновление.
triggeredUpdateId - Это целое число, например, может быть уникальным идентификатором для этого инициированного обновления.
triggeredUpdateIndex - Это целое число, например, может быть значением индекса для этого инициированного обновления.
dynamicUpdateId - Это целое число, например, может быть уникальным идентификатором для этого динамического обновления.
dynamicUpdateIndex - Это целое число, например, может быть значением индекса для этого динамического обновления.
Дополнительные комментарии
В качестве примера, декодеры согласно изобретению могут содержать контроллер сцен, который например, может представлять собой центральный компонент для поддержания 6DoF-представления сцены, включающего в себя все аудиоэлементы и геометрии. Он, например, может запоминать состояние сцены и, например, может обрабатывать все гое внутренние и внешние модификации посредством обновлений, которые, например, могут приниматься через поток битов или интерфейс локальных обновлений. Если сцена представляет собой AR-сцену, контроллер сцен дополнительно считывает LSDF, описывающий акустические свойства и привязочные позиции пространства для прослушивания, которые интегрируются в состояние сцены.
В качестве примера, модуль оценки, как пояснено выше, может содержать или может представлять собой контроллер сцен.
В качестве примера, декодеры согласно изобретению могут содержать состояние сцены, которое например, может и необязательно всегда отражает текущее состояние множества объектов или даже всех объектов в сцене, включающих метаданные из множества источников, включающие в себя поток битов, LSDF (формат описания пространства для прослушивания) и локальные обновления. Объекты, например, могут представляться как объекты сцены (SO). В качестве примера, только контроллер сцен, например, может быть выполнен с возможностью модифицировать состояние сцены, тогда как все другие компоненты в модуле рендеринга, например, модуль подготовки посредством рендеринга декодера, могут иметь доступ только для чтения к состоянию сцены и всем SO.
Компоненты, например, также могут подписываться на изменения состояния сцены и отдельных SO, так что обратный вызов вызывается, когда атрибуты модифицируются. Для этого, компонент, например, может быть выполнен с возможностью реализовывать интерфейсы SceneStateObserver и SceneObjectObserver. Обратный вызов SceneStateObserver, например, может вызываться, когда SO добавляется или удаляется из состояния сцены.
Пример:
class SceneStateObserver {
public:
virtual ~SceneStateObserver(){};
virtual void sceneStateAttached(const SceneState*sceneState)=0;
virtual void sceneStateDetached()=0;
virtual void sceneObjectAdded(SceneObject*object)=0;
virtual void sceneObjectRemoved(SceneObject*object)=0;
};
Обратный вызов SceneObjectObserver уведомляет относительно любых модификаций отдельных SO.
class SceneObjectObserver {
public:
virtual ~SceneObjectObserver(){};
enum class Property {
Position,
Activity,
Directivity,
Gain,
DistanceModel,
AudioStream,
Extent,
Referencedistance,
Staticity
};
virtual void objectChanged(SceneObject*obj, Property modification)=0;
};
Согласно вариантам осуществления, любой аудиоэлемент, геометрия, преобразование и слушатель в сцене, например, могут представляться как объект сцены (SO). Каждый SO, например, может иметь, по меньшей мере, атрибуты, указываемые в таблице 23.
Таблица 23. Объекты сцены
Кроме того, обновление (например, как пояснено в контексте пакетов обновлений сцен) может представлять собой совокупность модификаций метаданных объектов сцены. Контроллер сцен, например, реализованный в или представляющий собой модуль оценки и/или модуль подготовки посредством рендеринга, может обеспечивать возможность обновлений в состоянии сцены, например, через следующие средства:
1. Пакеты обновлений сцен в потоке битов, например, могут содержать информацию относительно изменений отдельных объектов в сцене (например, как пояснено выше). Они могут обеспечивать возможность немедленных обновлений, предварительно заданных обновлений, обновлений на основе информации местоположения или времени и интерполированных обновлений.
a. Немедленные обновления: Сцена, например, с использованием модуля оценки, например, может обновлять состояние сцены, например, как только пакет обновлений сцен принимается из интерфейса передачи потоков битов.
b. Предварительно заданные обновления: Указанный пакет модификаций, например, может передаваться и инициироваться локально посредством данного идентификатора.
c. Одиночные обновления на основе информации местоположения или времени: Сцена, например, с использованием модуля оценки, например, может оценивать ранее принимаемые критерии на основе информации местоположения и времени и может обновлять состояние сцены, если критерии требуют изменения метаданных.
d. Интерполированные обновления: Сцена, например, с использованием модуля оценки, например, может оценивать ранее принимаемые и запускаемые траектории метаданных и может обновлять состояние сцены, соответственно.
2. API локальных обновлений для других систем и компонентов в декодере (например, как пояснено ниже по тексту).
Оценка критериев на основе информации местоположения и времени, а также интерполяция, например, может выполняться в отдельном подпроцессе, созданном посредством контроллера сцен. Подпроцесс, например, может или даже должен работать с темпом, по меньшей мере, в 100 выполнений в секунду.
Временные интерполяции, например, могут инициироваться посредством предварительно заданных обновлений, обновлений на основе информации местоположения или локальных обновлений, когда обновление содержит или содержит длительность, и, например, необязательно могут всегда представлять собой линейные интерполяция. Временные интерполяции, например, могут прекращаться, когда сцена циклично выполняется. Начальное значение для временной интерполяции, например, может быть, необязательно всегда, значением свойства метаданных в то время, когда обновление инициируется, без учета задержки.
Поведение, например, может быть неопределенным, когда свойство SO-метаданных изменяется с несколькими типами обновлений одновременно, например, когда источник объектов перемещается по синхронизированной по времени траектории, его местоположение, например, не может изменяться посредством локального обновления.
Внешние компоненты и подсистемы декодера, например, могут конструировать локальные обновления, чтобы изменять метаданные объектов сцены. Обновление (пример):
struct Modification {
std::string entityId;
std::string attributeName;
Variant targetValue;
bool teleport=false;
};
struct Update {
double timestamp=-1;
std::vector<Modification>modifications;
};
Временная метка, например, может приводиться во времени в сцене. Если текущее время в сцене, когда обновление принимается, больше временной метки обновления, обновление, например, может выполняться необязательно сразу. Кроме того, каждое обновление, например, может содержать или содержать список модификаций, каждая из которых необязательно состоит из или содержит:
- entityId, который соответствует строковому идентификатору объекта, используемого в EIF. Зарезервированный идентификатор "listener", например, может использоваться для того, чтобы обновлять, например, позицию слушателя через идентичный API с другими объектами,
- attributeName, который например, может быть или даже должен быть именем атрибута, используемого в EIF,
- targetValue, тип данных которого, например, может зависеть от атрибута, и
- Флаг teleport, чтобы указывать неинтерполированные модификации местоположения объекта, затрагивая, например, задержку на распространение.
Кроме того, декодеры или модули рендеринга согласно вариантам осуществления могут содержать диспетчер потоков (например, в изобретаемом модуле оценки или модуле подготовки посредством рендеринга), который может быть выполнен с возможностью осуществлять доступ к аудиопотокам, например, посредством или с использованием идентификатора, который может указываться посредством ссылки в потоке битов или во внешних обновлениях. Источник аудиопотоков, например, может быть переменным и может представлять собой либо локальный PCM-поток, либо декодированный MPEG-H-аудиопоток из потока битов.
Доступ к аудиопотокам, например, может осуществляться на основе кадров. Компоненты в модуле рендеринга, например, могут создавать StreamAccessBuffer, который может быть ассоциирован с определенным аудиопотоком, и блок выборок, например, может записываться в свой буфер запоминающего устройства для каждого обработанного кадра аудиопотока. Доступ к потокам, например, может поддерживать поиск в аудиопотоке. Диспетчер потоков, например, может подвергаться плавному переходу между аудиопотоками, если поток, к которому осуществляют доступ, изменяется.
Пример:
class StreamBuffer {
RealFrameand getFrame();
const RealFrameand getFrame() const;
};
class StreamAccessBuffer:public StreamBuffer
{
void setStream(const std::stringand id, double t=0,0);
void play();
void stop();
void seekTo(double t);
void setLoop(bool shouldLoop);
std::size_t getReadPosition() const;
inline const std::stringand getStreamId() const;
};
Компоненты, например, также могут создавать пустые экземпляры StreamBuffer, которые могут иметь идентичные свойства с StreamAccessBuffer, но контент может или, например, даже должен управляться посредством владеющего компонента.
Кроме того, декодеры согласно вариантам осуществления необязательно содержат компонент обмена тактовыми сигналами (например, в изобретаемом модуле оценки), который может обеспечивать возможность синхронизировать время в сцене с внешним хронометром. В автономном случае, реализация InternalClock интерфейса тактовых сигналов, например, может использовать системные часы CPU (например, std::chrono::steady_clock), чтобы определять время в секундах, которое прошло с момента начала сцены. Текущее время InternalClock, например, может синхронизироваться с подпроцессом аудиобоработки посредством подсчета числа выборок, которые воспроизведены с момента начала сцены.
class Clock {
public:
virtual ~Clock(){};
virtual double getCurrentTime()=0;
virtual void start()=0;
virtual void stop()=0;
virtual bool isRunning()=0;
virtual void sync(double t)=0;
};
Декодеры согласно изобретению, могут быть выполнены с возможностью выполнять многопоточную обработку, например, с использованием изобретаемого модуля оценки. Контроллер сцен, например, может создавать отдельный подпроцесс, чтобы обрабатывать обновления на основе времени и информации местоположения, необязательно, а также интерполяции. Процедура обновления в этом подпроцессе может или, например, должна выполняться на частоте, по меньшей мере, в 100 Гц.
Наблюдение состояния сцены и SO, например, может быть только для чтения. Обратные вызовы модуля наблюдения, например, могут вызываться из подпроцесса, в котором инициируется обновление. Компонент наблюдения может или даже должен обеспечивать безопасность подпроцессов обратного вызова.
Процедура Clock::sync() может или даже должна быть ориентирована на многопотоковое исполнение относительно параллельных вызовов в getCurrentTime.
Доступ к StreamBuffers и StreamAccessBuffers, например, может осуществляться только в подпроцессе аудиобоработки. Диспетчер потоков, например, может обеспечивать то, что StreamAccessBuffers содержат корректные выборки в начале каждого обратного вызова подпроцесса аудиобоработки.
Согласно дополнительным вариантам осуществления изобретения, кодеры, например, могут синтаксически анализировать файл описания сцен во входном формате для кодера (EIF) для иммерсивного аудио в считываемые структуры данных и, например, могут формировать различные категории вспомогательной информации, а также описания сцен. В завершение, кодеры, например, могут кодировать и преобразовывать в последовательную форму данные, чтобы создавать файл MHAS-потоков битов.
В этом потоке битов, кодер, например, может представлять различные категории вспомогательной информации в качестве отдельных элементов рабочих данных, объединенных в MHAS-пакет рабочих данных. Эти рабочие данные, например, могут использоваться для того, чтобы насыщать каскады модуля рендеринга или декодера дополнительными данными для более высококачественного рендеринга. Вспомогательная информация, например, может зачастую представляться как пара - идентификатор объекта, авторски разработанный в описании сцен, связанный с самой вспомогательной информацией. Например, кодер формирует параметры реверберации и связывает их с каждым идентификатором AcousticEnvironment, найденным в описании сцен. AcousticEnvironment, например, может описывать акустические условия во всей сцене или в определенной пространственной зоне, например, посредством акустических параметров (реверберации) помещения.
В качестве примера, состояние сцены, как пояснено выше, может сохраняться, определяться посредством и/или предоставляться с использованием модуля анализа и/или модуля оценки согласно вариантам осуществления изобретения.
Альтернативы реализации
Хотя некоторые аспекты описаны в контексте оборудования, очевидно, что эти аспекты также представляют описание соответствующего способа, при этом блок или устройство соответствует этапу способа либо признаку этапа способа. Аналогично, аспекты, описанные в контексте этапа способа, также представляют описание соответствующего блока или элемента, или признака соответствующего оборудования. Некоторые или все этапы способа могут выполняться посредством (или с использованием) аппаратного оборудования, такого как, например, микропроцессор, программируемый компьютер либо электронная схема. В некоторых вариантах осуществления, один или более из самых важных этапов способа могут выполняться посредством этого оборудования.
В зависимости от определенных требований к реализации, варианты осуществления изобретения могут реализовываться в аппаратных средствах или в программном обеспечении. Реализация может выполняться с использованием цифрового носителя хранения данных, например, гибкого диска, DVD, Blu-Ray, CD, ROM, PROM, EPROM, EEPROM или флэш-памяти, имеющего сохраненные электронно считываемые управляющие сигналы, которые взаимодействуют (или допускают взаимодействие) с программируемой компьютерной системой таким образом, что осуществляется соответствующий способ. Следовательно, цифровой носитель хранения данных может быть машиночитаемым.
Некоторые варианты осуществления согласно изобретению, содержат носитель данных, имеющий электронночитаемые управляющие сигналы, которые допускают взаимодействие с программируемой компьютерной системой таким образом, что осуществляется один из способов, описанных в данном документе.
В общем, варианты осуществления настоящего изобретения могут реализовываться как компьютерный программный продукт с программным кодом, при этом программный код выполнен с возможностью осуществления одного из способов, когда компьютерный программный продукт выполняется на компьютере. Программный код, например, может сохраняться на машиночитаемом носителе.
Другие варианты осуществления содержат компьютерную программу для осуществления одного из способов, описанных в данном документе, сохраненную на машиночитаемом носителе.
Другими словами, вариант осуществления изобретаемого способа в силу этого представляет собой компьютерную программу, имеющую программный код для осуществления одного из способов, описанных в данном документе, когда компьютерная программа выполняется на компьютере.
Следовательно, дополнительный вариант осуществления изобретаемых способов представляет собой носитель хранения данных (цифровой носитель хранения данных или машиночитаемый носитель), содержащий записанную компьютерную программу для осуществления одного из способов, описанных в данном документе. Носитель данных, цифровой носитель хранения данных или носитель с записанными данными типично является материальным и/или энергонезависимым.
Следовательно, дополнительный вариант осуществления изобретаемого способа представляет собой поток данных или последовательность сигналов, представляющих компьютерную программу для осуществления одного из способов, описанных в данном документе. Поток данных или последовательность сигналов, например, может быть выполнена с возможностью передачи через соединение для передачи данных, например, через Интернет.
Дополнительный вариант осуществления содержит средство обработки, например, компьютер или программируемое логическое устройство, выполненное с возможностью осуществлять один из способов, описанных в данном документе.
Дополнительный вариант осуществления содержит компьютер, имеющий установленную компьютерную программу для осуществления одного из способов, описанных в данном документе.
Дополнительный вариант осуществления согласно изобретению, содержит оборудование или систему, выполненную с возможностью передавать (например, электронно или оптически) компьютерную программу для осуществления одного из способов, описанных в данном документе, в приемное устройство. Приемное устройство, например, может представлять собой компьютер, мобильное устройство, запоминающее устройство и т.п. Оборудование или система, например, может содержать файловый сервер для передачи компьютерной программы в приемное устройство.
В некоторых вариантах осуществления, программируемое логическое устройство (например, программируемая пользователем вентильная матрица) может использоваться для того, чтобы выполнять часть или все из функциональностей способов, описанных в данном документе. В некоторых вариантах осуществления, программируемая пользователем вентильная матрица может взаимодействовать с микропроцессором, чтобы осуществлять один из способов, описанных в данном документе. В общем, способы предпочтительно осуществляются посредством любого аппаратного оборудования.
Оборудование, описанное в данном документе, может реализовываться с использованием аппаратного оборудования либо с использованием компьютера, либо с использованием комбинации аппаратного оборудования и компьютера.
Оборудование, описанное в данном документе, или любые компоненты оборудования, описанного в данном документе, могут реализовываться, по меньшей мере, частично в аппаратных средствах и/или в программном обеспечении.
Способы, описанные в данном документе, могут осуществляться с использованием аппаратного оборудования либо с использованием компьютера, либо с использованием комбинации аппаратного оборудования и компьютера.
Способы, описанные в данном документе, или любые компоненты оборудования, описанного в данном документе, могут выполняться, по меньшей мере, частично посредством аппаратных средств и/или посредством программного обеспечения.
Вышеописанные варианты осуществления являются просто иллюстративными в отношении принципов настоящего изобретения. Следует понимать, что модификации и изменения компоновок и подробностей, описанных в данном документе, должны быть очевидными для специалистов в данной области техники. Следовательно, они подразумеваются как ограниченные только посредством объема нижеприведенной формулы изобретения, а не посредством конкретных подробностей, представленных посредством описания и пояснения вариантов осуществления в данном документе.
В качестве общего замечания, следует отметить, что префикс "mpegi", который используется, например, в обозначении элементов потока битов и т.п., необязательно может заменяться посредством префикса "mpeghi", и наоборот, при этом, например, префикс "mpeghi" может быть синонимичным с префиксом "mpegi".
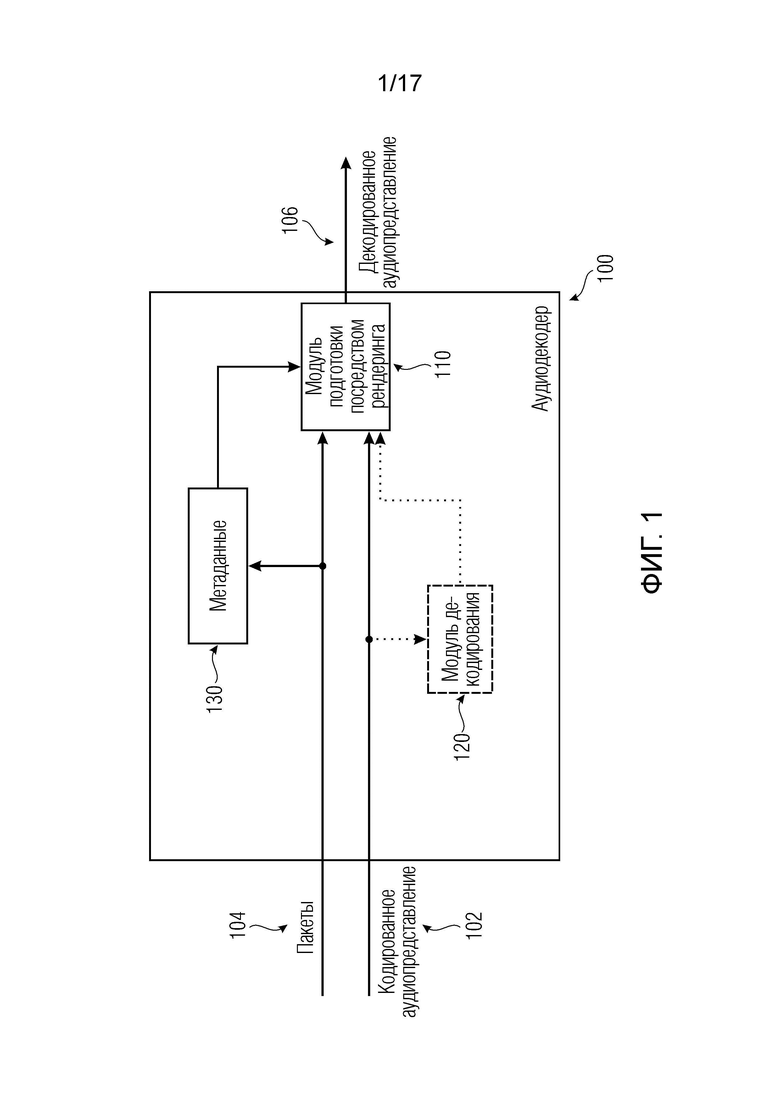
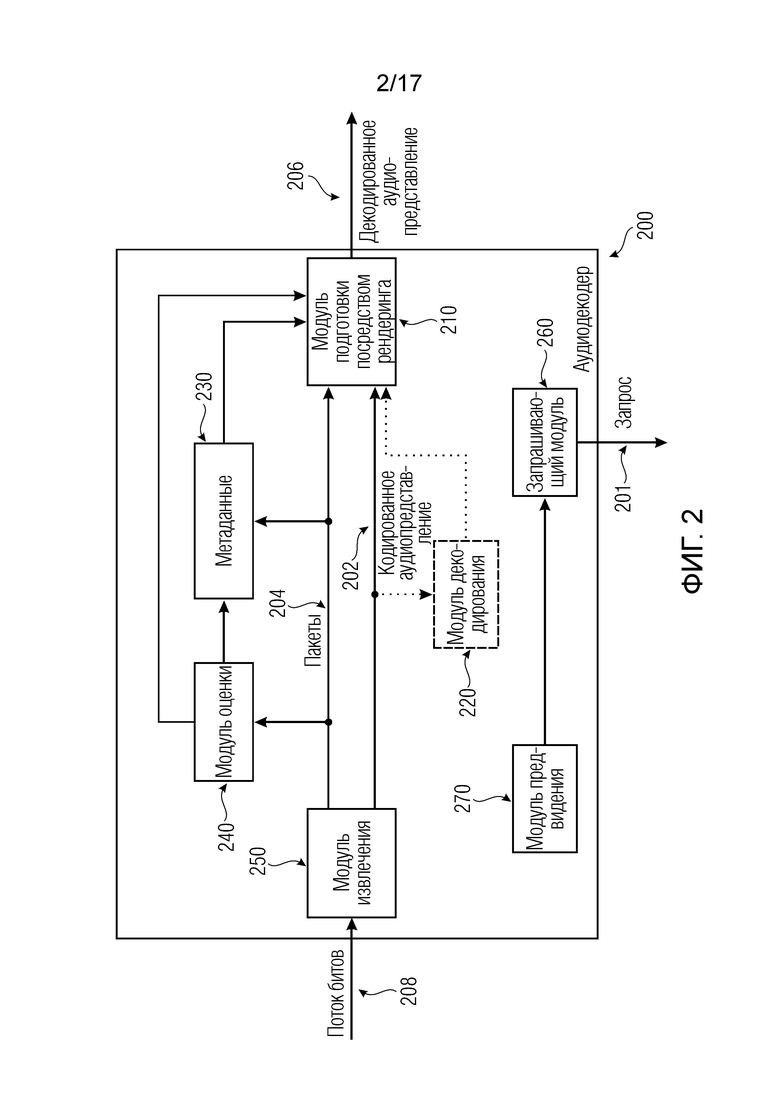
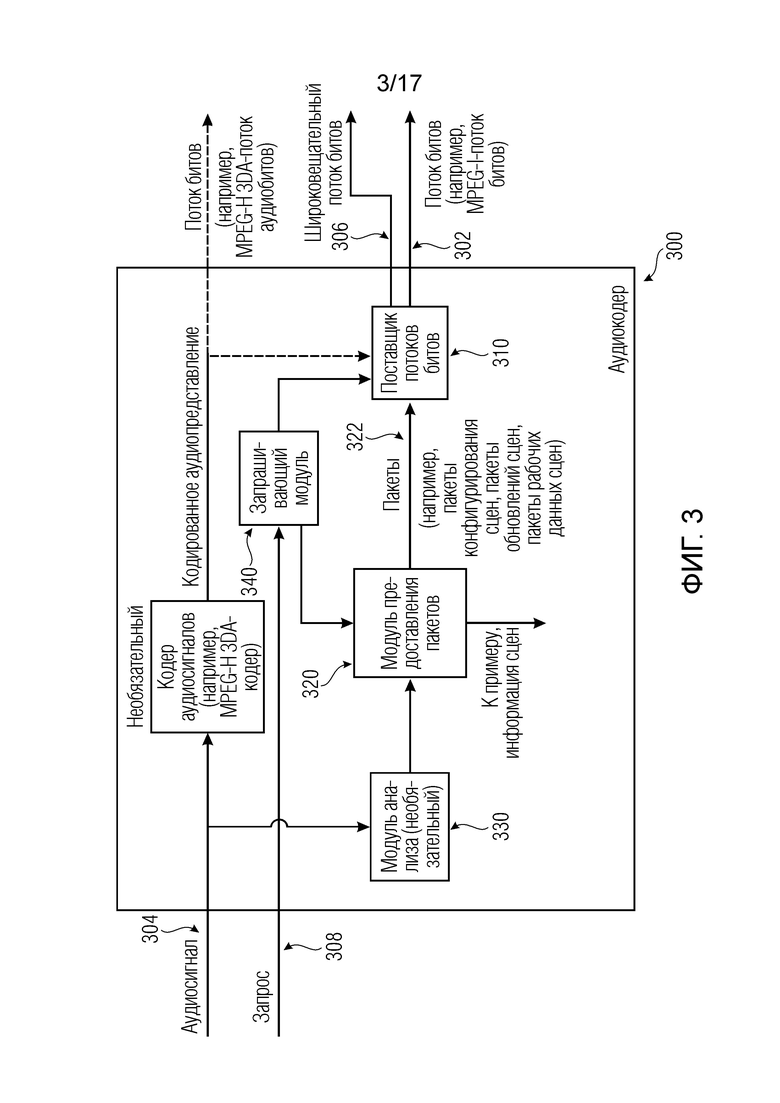
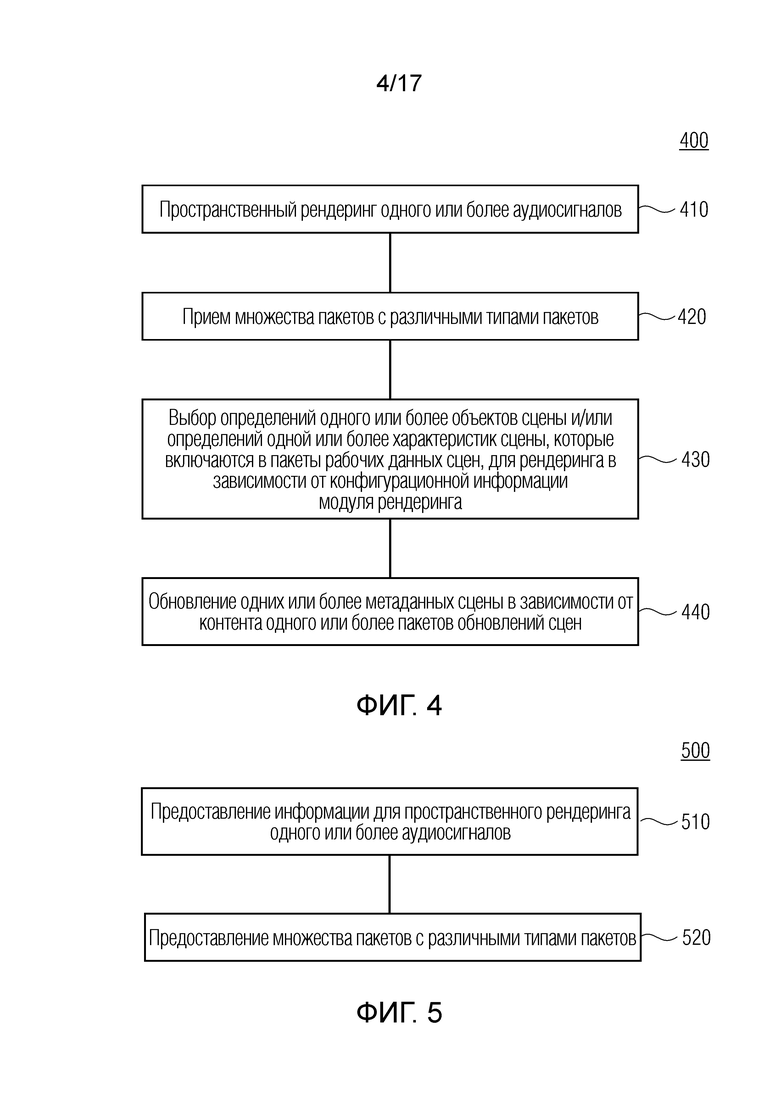
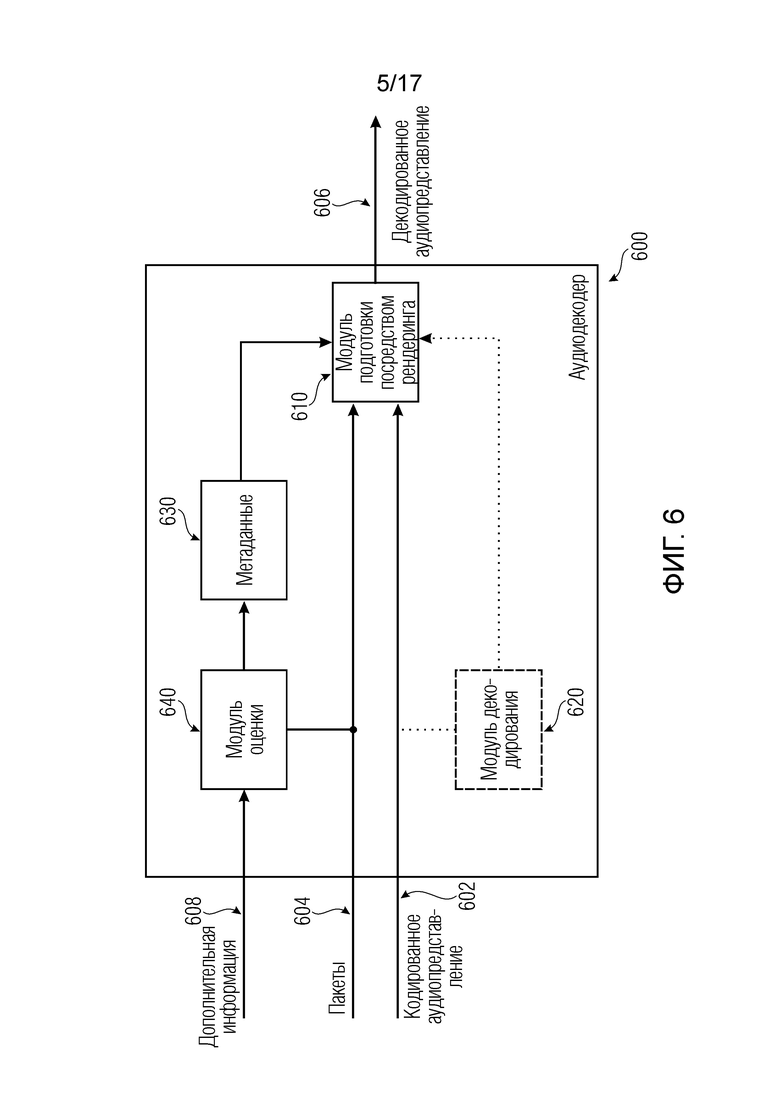
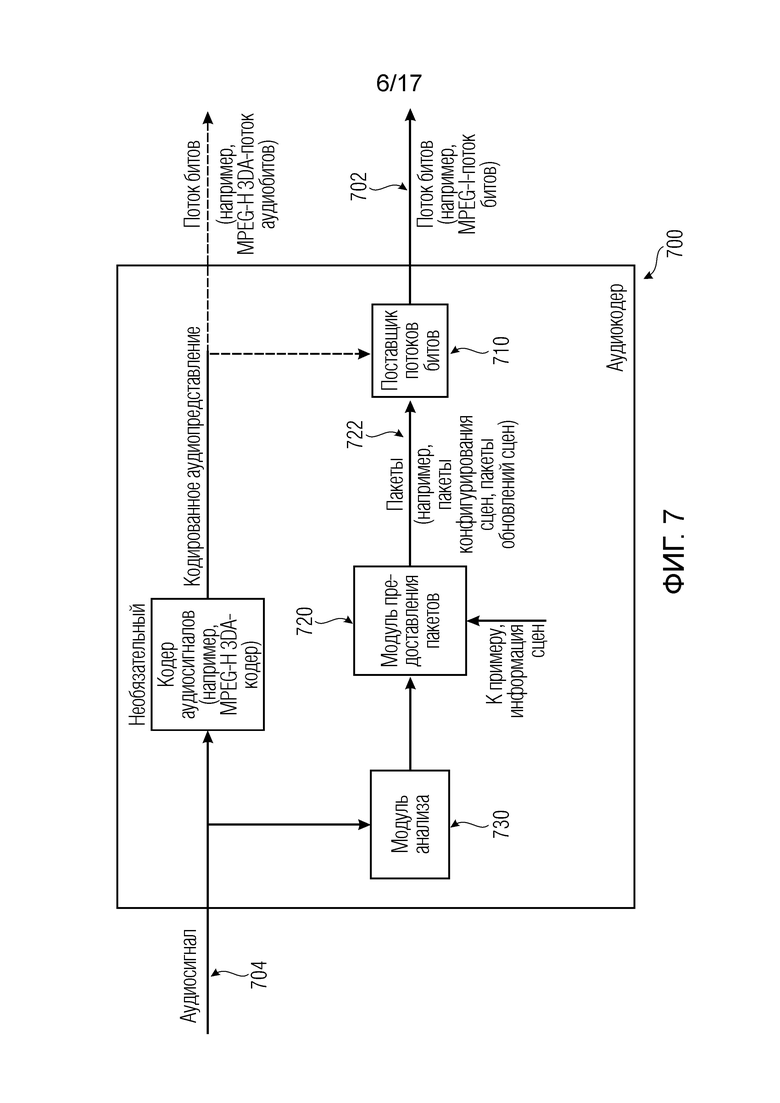
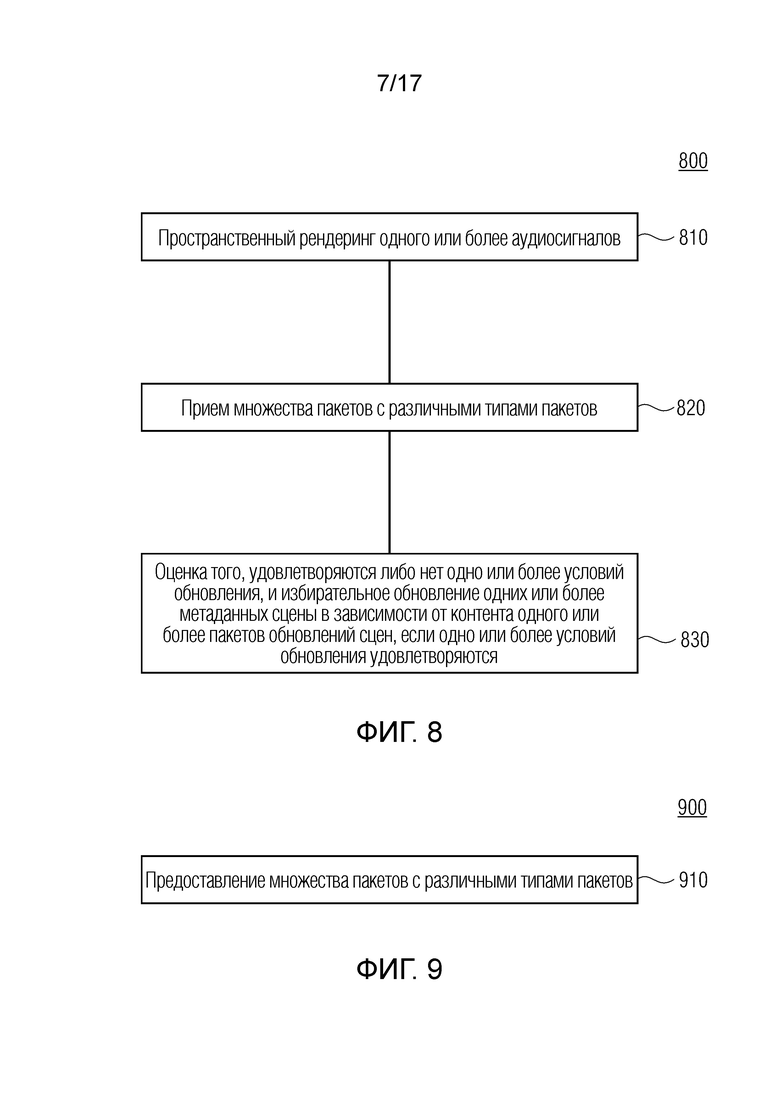
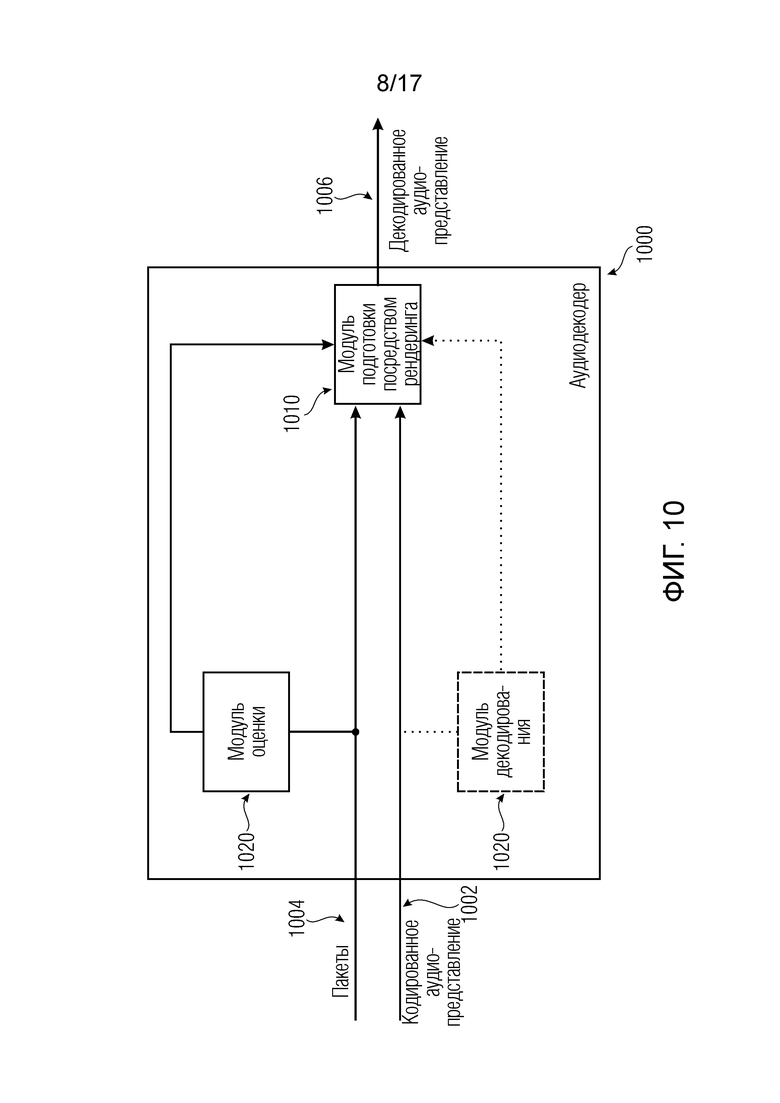
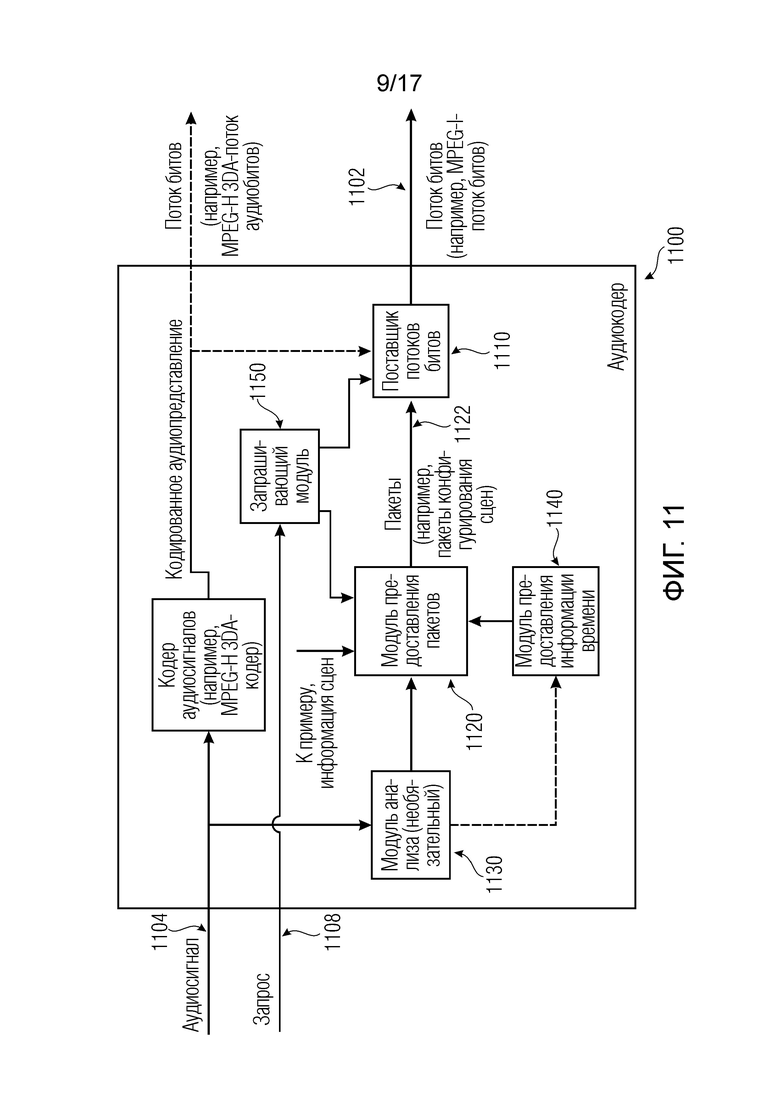
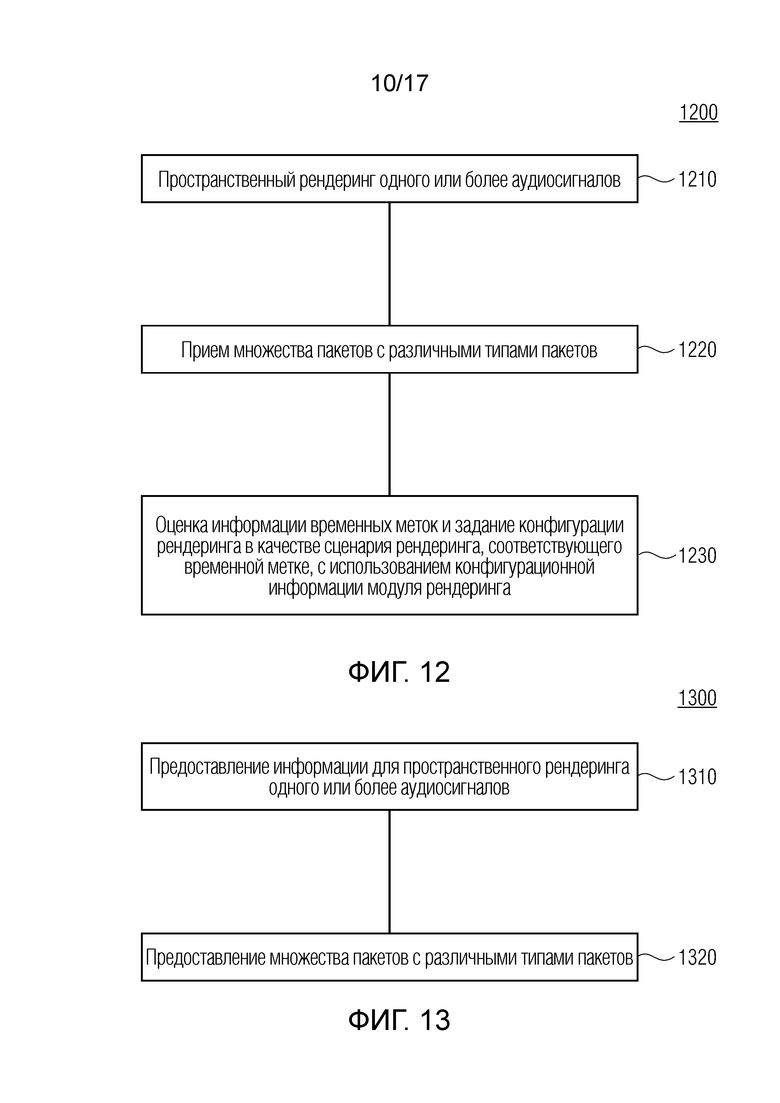
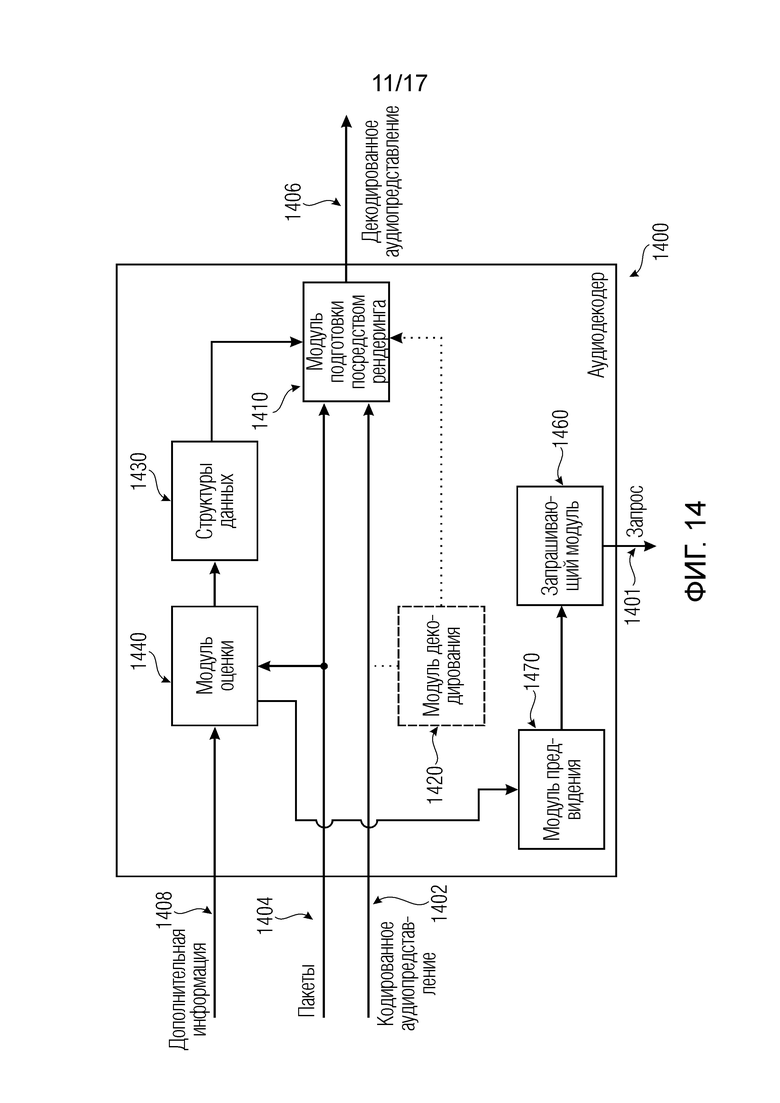
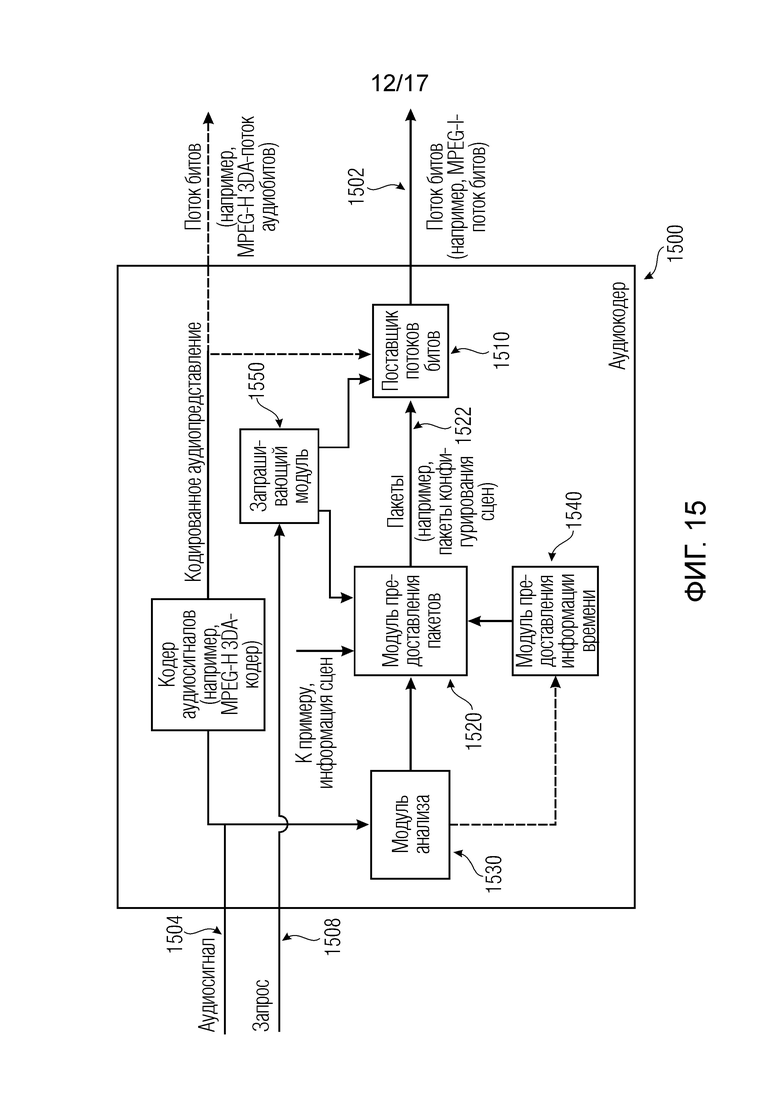
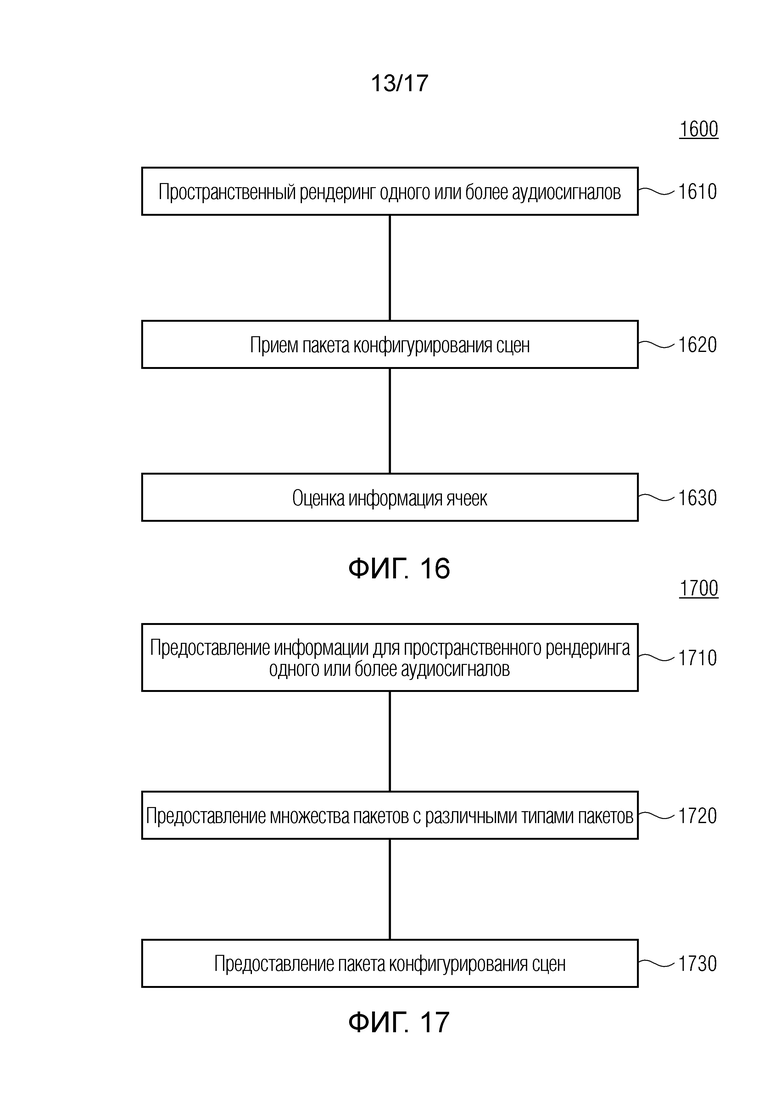
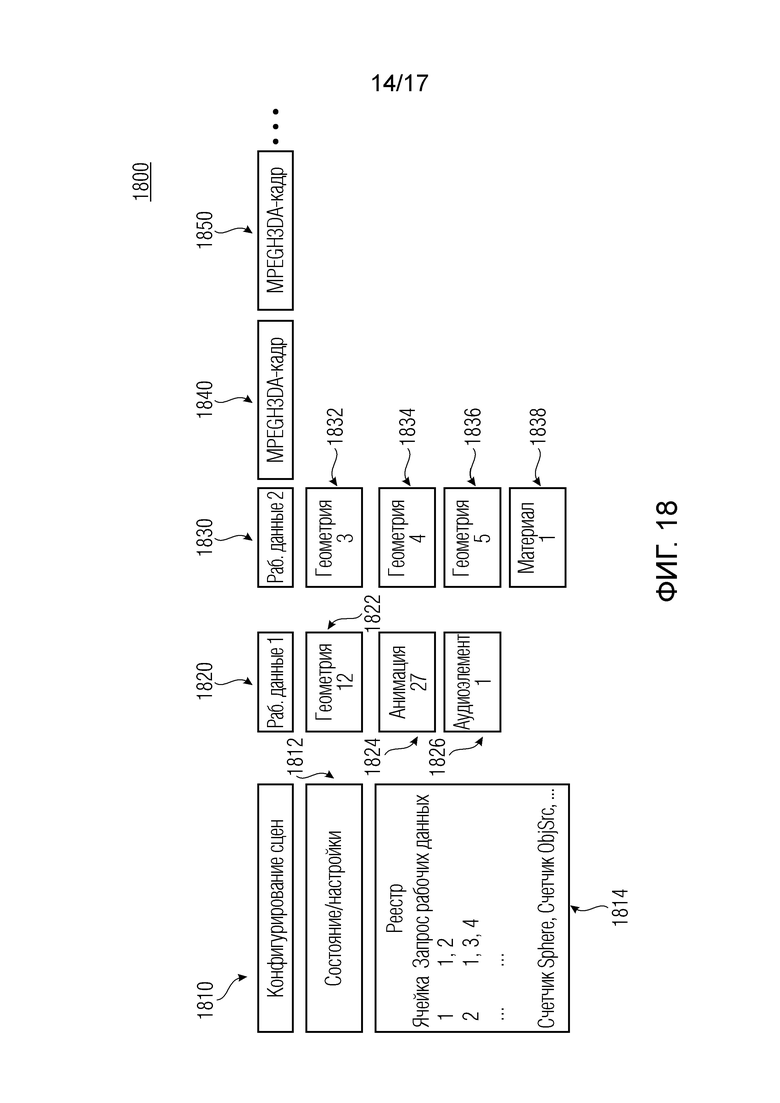
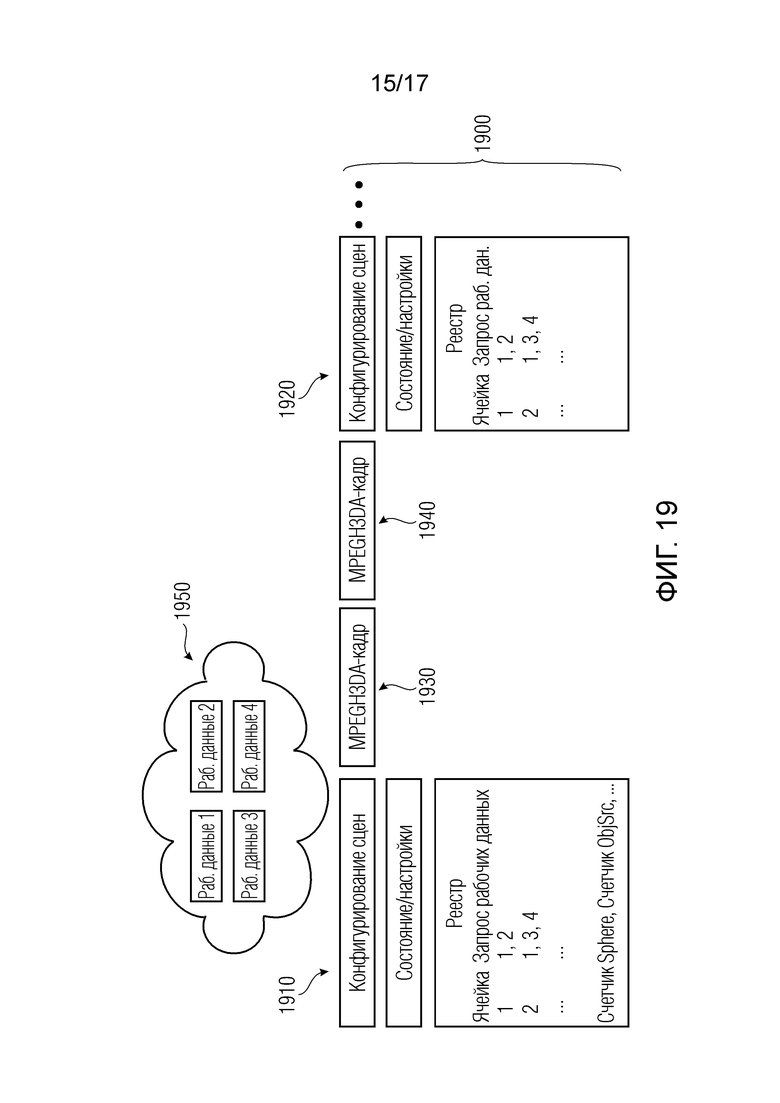
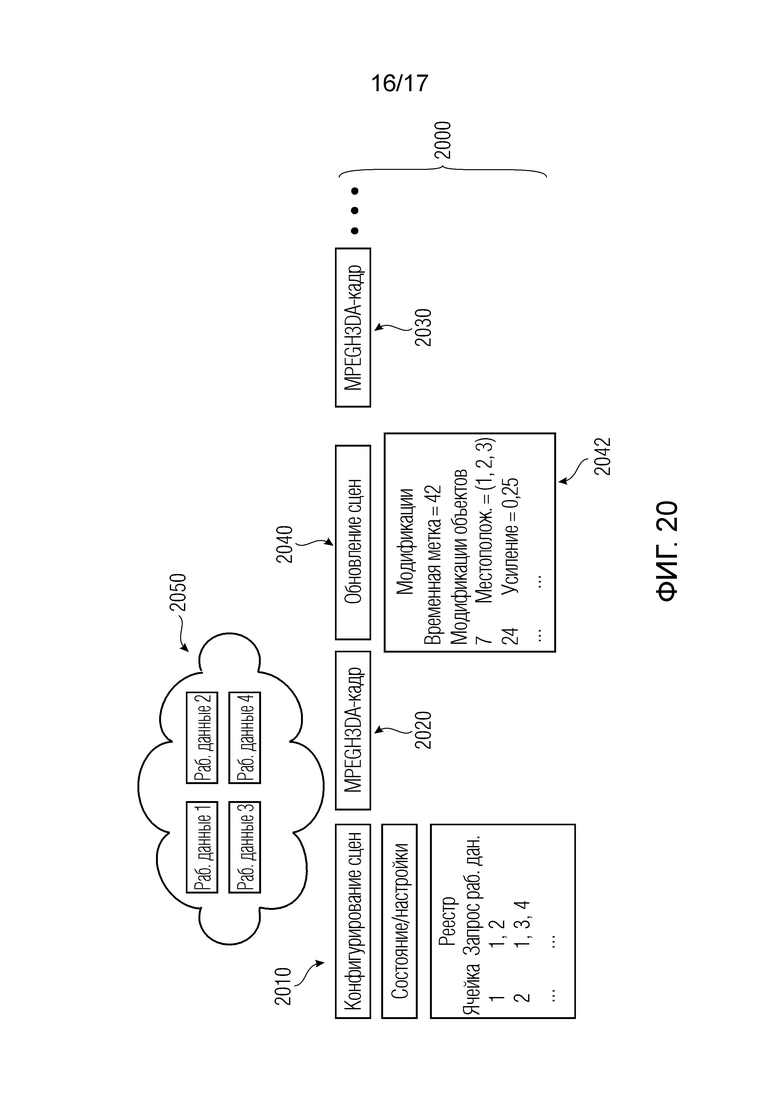
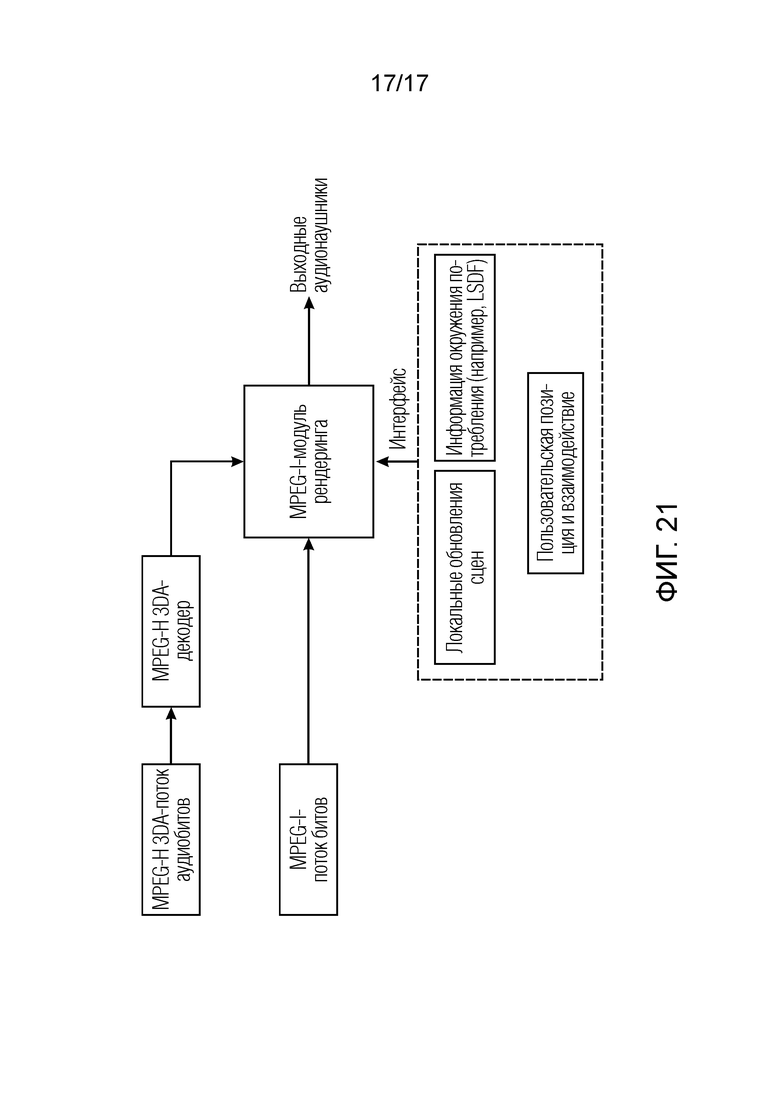
Изобретение относится к области обработки аудиоданных. Технический результат заключается в обеспечении иммерсивного восприятия для слуха высокой четкости при одновременной применимости с целесообразными полосами пропускания. Технический результат достигается за счет этапов, на которых подготавливают посредством пространственного рендеринга один или более аудиосигналов; принимают пакет конфигурирования сцен, предоставляющий конфигурационную информацию модуля рендеринга, при этом пакет конфигурирования сцен содержит информацию ячеек, задающую одну или более ячеек, при этом информация ячеек задает ассоциирование между одной или более ячеек и соответствующей одной или более структур данных, ассоциированных с одной или более ячеек и задающих сценарий рендеринга; оценивают информацию ячеек, чтобы определять то, какие структуры данных должны использоваться для пространственного рендеринга. 7 н. и 39 з.п. ф-лы, 21 ил., 26 табл.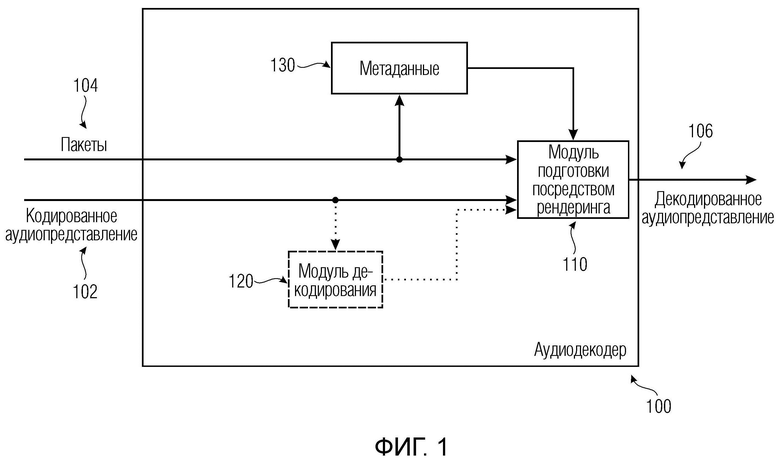
1. Аудиодекодер (1400) для обеспечения декодированного аудиопредставления на основе кодированного аудиопредставления,
при этом аудиодекодер выполнен с возможностью пространственно подготавливать посредством рендеринга один или более аудиосигналов;
при этом аудиодекодер выполнен с возможностью принимать пакет конфигурирования сцен, предоставляющий конфигурационную информацию модуля рендеринга,
при этом пакет конфигурирования сцен содержит информацию ячеек подсцены, задающую одну или более ячеек,
при этом информация ячеек задает ассоциирование между одной или более ячеек и соответствующей одной или более структур данных, ассоциированных с одной или более ячеек и задающих сценарий рендеринга подсцен;
при этом аудиодекодер выполнен с возможностью оценивать информацию ячеек, чтобы определять то, какие структуры данных должны использоваться для пространственного рендеринга.
2. Аудиодекодер (1400) по п. 1,
в котором информация ячеек содержит временное определение данной ячейки, и
при этом аудиодекодер выполнен с возможностью оценивать временное определение данной ячейки, чтобы определять то, должны либо нет одна или более структур данных, ассоциированных с данной ячейкой, рассматриваться в пространственном рендеринге.
3. Аудиодекодер (1400) по п. 1 или 2,
в котором информация ячеек содержит пространственное определение данной ячейки; и
при этом аудиодекодер выполнен с возможностью оценивать пространственное определение данной ячейки, чтобы определять то, должны либо нет одна или более структур данных, ассоциированных с данной ячейкой, рассматриваться в пространственном рендеринге.
4. Аудиодекодер (1400) по одному из пп. 1-3,
при этом аудиодекодер выполнен с возможностью оценивать информацию числа ячеек, которая включается в пакет конфигурирования сцен для того, чтобы определять число ячеек.
5. Аудиодекодер (1400) по одному из пп. 1-4,
в котором информация ячеек содержит флаг, указывающий то, содержит либо нет информация ячеек временное определение ячейки или пространственное определение ячейки; и
при этом аудиодекодер выполнен с возможностью оценивать флаг, указывающий то, содержит либо нет информация ячеек временное определение ячейки или пространственное определение ячейки.
6. Аудиодекодер (1400) по одному из пп. 1-5,
в котором информация ячеек содержит ссылку геометрической структуры, чтобы задавать ячейку; и
при этом аудиодекодер выполнен с возможностью оценивать ссылку геометрической структуры, чтобы получать геометрическое определение ячейки.
7. Аудиодекодер (1400) по п. 6,
при этом аудиодекодер выполнен с возможностью получать определение геометрической структуры, которая задает геометрическую границу ячейки, из глобального пакета рабочих данных.
8. Аудиодекодер (1400) по одному из пп. 1-7,
при этом аудиодекодер выполнен с возможностью идентифицировать одну или более текущих ячеек; и
при этом аудиодекодер выполнен с возможностью выполнять пространственный рендеринг с использованием одной или более структур (1430) данных, ассоциированных с одной или более идентифицированных текущих ячеек.
9. Аудиодекодер (1400) по одному из пп. 1-8,
при этом аудиодекодер выполнен с возможностью идентифицировать одну или более текущих ячеек; и
при этом аудиодекодер выполнен с возможностью выполнять пространственный рендеринг с использованием одного или более объектов (1430) сцены и/или характеристик сцены, ассоциированных с одной или более идентифицированных текущих ячеек.
10. Аудиодекодер (1400) по одному из пп. 1-9,
при этом аудиодекодер выполнен с возможностью выбирать объекты сцены и/или характеристики сцены, которые должны рассматриваться в пространственном рендеринге, в зависимости от информации ячеек.
11. Аудиодекодер (1400) по одному из пп. 1-10,
при этом аудиодекодер выполнен с возможностью определять то, в какой одной или более пространственных ячеек находится текущая позиция; и
при этом аудиодекодер выполнен с возможностью выполнять пространственный рендеринг с использованием одного или более объектов сцены и/или характеристик сцены, ассоциированных с одной или более идентифицированных текущих ячеек.
12. Аудиодекодер (1400) по одному из пп. 1-11,
при этом аудиодекодер выполнен с возможностью определять одни или более рабочих данных, ассоциированных с одной или более текущих ячеек, на основе перечисления идентификаторов рабочих данных, включенных в определение ячейки для ячейки; и
при этом аудиодекодер выполнен с возможностью выполнять пространственный рендеринг с использованием определенных одних или более рабочих данных.
13. Аудиодекодер (1400) по одному из пп. 1-12,
при этом аудиодекодер выполнен с возможностью выполнять пространственный рендеринг с использованием информации из одного или более пакетов обновлений сцен, которые ассоциированы с одной или более текущих ячеек.
14. Аудиодекодер (1400) по одному из пп. 1-13,
при этом аудиодекодер выполнен с возможностью обновлять сцену для рендеринга с использованием информации из одного или более пакетов обновлений сцен, ассоциированных с данной ячейкой, в ответ на нахождение того, что данная ячейка становится активной.
15. Аудиодекодер (1400) по одному из пп. 1-14,
в котором информация ячеек содержит ссылку на пакет обновлений сцен, задающий обновление метаданных сцены для рендеринга; и
при этом аудиодекодер выполнен с возможностью избирательно выполнять обновление метаданных сцены, заданных в данном пакете обновлений сцен, в ответ на обнаружение того, что ячейка, содержащая ссылку на данный пакет обновлений сцен, становится активной.
16. Аудиодекодер (1400) по одному из пп. 1-15,
в котором один или более пакетов обновлений сцен содержат представление одного или более условий обновления, и
при этом аудиодекодер выполнен с возможностью оценивать то, удовлетворяются либо нет одно или более условий обновления, и избирательно обновлять одни или более метаданных сцены в зависимости от контента одного или более пакетов обновлений сцен, если одно или более условий обновления удовлетворяются.
17. Аудиодекодер (1400) по одному из пп. 1-16,
при этом аудиодекодер выполнен с возможностью оценивать временное условие, которое включается в пакет обновлений сцен для того, чтобы принимать решение в отношении того, должны либо нет одни или более метаданных сцены обновляться в зависимости от контента одного или более пакетов обновлений сцен;
при этом временное условие задает начальный момент времени, или
при этом временное условие задает временной интервал;
при этом аудиодекодер выполнен с возможностью осуществлять обновление одних или более метаданных сцены в ответ на обнаружение того, что текущее время воспроизведения достигает начального момента времени или находится после начального момента времени, или
при этом аудиодекодер выполнен с возможностью осуществлять обновление одних или более метаданных сцены в ответ на обнаружение того, что текущее время воспроизведения находится в пределах временного интервала; и/или
при этом аудиодекодер выполнен с возможностью оценивать пространственное условие, которое включается в пакет обновлений сцен для того, чтобы принимать решение в отношении того, должны либо нет одни или более метаданных сцены обновляться в зависимости от контента одного или более пакетов обновлений сцен.
18. Аудиодекодер (1400) по п. 17,
в котором пространственное условие в пакете обновлений сцен задает геометрический элемент; и
при этом аудиодекодер выполнен с возможностью осуществлять обновление одних или более метаданных сцены в ответ на обнаружение того, что текущая позиция достигает геометрического элемента, либо в ответ на обнаружение того, что текущая позиция находится внутри геометрического элемента.
19. Аудиодекодер (1400) по одному из пп. 1-16,
при этом аудиодекодер выполнен с возможностью оценивать то, удовлетворяется или нет интерактивное инициирующее условие, чтобы принимать решение в отношении того, должны либо нет одни или более метаданных сцены обновляться в зависимости от контента одного или более пакетов обновлений сцен.
20. Аудиодекодер (1400) по одному из пп. 1-19,
при этом аудиодекодер выполнен с возможностью оценивать информацию ячеек, чтобы определять то, в какое время и/или в какой зоне позиции слушателя какие структуры данных требуются для пространственного рендеринга.
21. Аудиодекодер (1400) по одному из пп. 1-20,
при этом аудиодекодер выполнен с возможностью пространственно подготавливать посредством рендеринга один или более аудиосигналов с использованием первого набора объектов сцены и/или характеристик сцены, когда позиция слушателя находится в первой пространственной области, и
при этом аудиодекодер выполнен с возможностью пространственно подготавливать посредством рендеринга один или более аудиосигналов с использованием второго набора объектов сцены и/или характеристик сцены, когда позиция слушателя находится во второй пространственной области,
при этом первый набор объектов сцены и/или характеристик сцены предоставляет более детальный пространственный рендеринг по сравнению со вторым набором объектов сцены и/или характеристик сцены.
22. Аудиодекодер (1400) по одному из пп. 1-21,
при этом аудиодекодер выполнен с возможностью запрашивать (1401, 1508) один или более пакетов рабочих данных сцен из поставщика пакетов.
23. Аудиодекодер (1400) по одному из пп. 1-22,
при этом аудиодекодер выполнен с возможностью идентифицировать одну или более структур данных, которые должны использоваться для пространственного рендеринга, с использованием идентификатора рабочих данных, который включается в информацию ячеек.
24. Аудиодекодер (1400) по одному из пп. 1-23,
при этом аудиодекодер выполнен с возможностью запрашивать (1401, 1508) один или более пакетов рабочих данных сцен из поставщика пакетов.
25. Аудиодекодер (1400) по одному из пп. 1-24,
при этом аудиодекодер выполнен с возможностью запрашивать (1401, 1508) один или более пакетов рабочих данных сцен из поставщика пакетов с использованием идентификатора рабочих данных, который включается в информацию ячеек, или
при этом аудиодекодер выполнен с возможностью запрашивать один или более пакетов рабочих данных сцен из поставщика пакетов с использованием идентификатора пакета.
26. Аудиодекодер (1400) по одному из пп. 1-25,
при этом аудиодекодер выполнен с возможностью предвидеть то, какие одна или более структур данных потребуются или предположительно должны требоваться с использованием информации ячеек, и запрашивать (1401, 1508) одну или более структур данных или один или более пакетов рабочих данных сцен, содержащих упомянутую одну или более структур данных, до того, как структуры данных фактически требуются.
27. Аудиодекодер (1400) по одному из пп. 1-26,
при этом аудиодекодер выполнен с возможностью извлекать рабочие данные, идентифицированные посредством информации ячеек, из потока битов.
28. Аудиодекодер (1400) по одному из пп. 1-27,
при этом аудиодекодер выполнен с возможностью отслеживать требуемые структуры данных с использованием информации ячеек.
29. Аудиодекодер (1400) по одному из пп. 1-28,
при этом аудиодекодер выполнен с возможностью избирательно отбрасывать одну или более структур данных в зависимости от информации ячеек.
30. Аудиодекодер (1400) по одному из пп. 1-29,
в котором информация ячеек задает подразделение на основе информации местоположения и/или на основе времени сцены для рендеринга.
31. Аудиодекодер (1400) по одному из пп. 1-30,
при этом аудиодекодер выполнен с возможностью получать определение ячеек на основе структуры конфигурационных данных сцен.
32. Аудиодекодер (1400) по одному из пп. 1-31,
при этом аудиодекодер выполнен с возможностью запрашивать (1401, 1508) одну или более структур данных с использованием соответствующих идентификаторов структур данных,
при этом аудиодекодер выполнен с возможностью извлекать идентификаторы структур данных для структур данных, которые должны запрашиваться с использованием информации ячеек.
33. Аудиодекодер (1400) по одному из пп. 1-32,
при этом аудиодекодер выполнен с возможностью предвидеть то, какие одна или более структур данных потребуются или предположительно должны требоваться, и запрашивать (1401, 1508) одну или более структур данных до того, как структуры данных фактически требуются.
34. Аудиодекодер (1400) по одному из пп. 1-33,
при этом аудиодекодер выполнен с возможностью извлекать одну или более структур данных с использованием соответствующих идентификаторов структур данных,
при этом аудиодекодер выполнен с возможностью извлекать идентификаторы структур данных для структур данных, которые должны извлекаться, с использованием информации ячеек.
35. Аудиодекодер (1400) по одному из пп. 1-34,
при этом аудиодекодер выполнен с возможностью извлекать метаданные, требуемые для рендеринга, из пакета рабочих данных.
36. Оборудование (1500) для обеспечения кодированного аудиопредставления,
при этом оборудование выполнено с возможностью предоставлять информацию для пространственного рендеринга одного или более аудиосигналов,
при этом оборудование выполнено с возможностью предоставлять множество пакетов (1404, 1522) с различными типами пакетов,
при этом оборудование выполнено с возможностью предоставлять пакет конфигурирования сцен, предоставляющий конфигурационную информацию модуля рендеринга,
при этом пакет конфигурирования сцен содержит информацию ячеек, задающую одну или более ячеек,
при этом информация ячеек задает ассоциирование между одной или более ячеек и соответствующей одной или более структур данных, ассоциированных с одной или более ячеек и задающих сценарий рендеринга.
37. Оборудование (1500) по п. 36,
при этом оборудование выполнено с возможностью повторять предоставление пакета конфигурирования сцен периодически, и/или
при этом оборудование выполнено с возможностью предоставлять один или более пакетов рабочих данных сцен по запросу.
38. Оборудование (1500) по одному из пп. 36, 37,
при этом оборудование выполнено с возможностью предоставлять один или более пакетов рабочих данных сцен, которые содержат одну или более структур данных, указываемых посредством ссылки в информации ячеек.
39. Оборудование (1500) по п. 38,
при этом оборудование выполнено с возможностью предоставлять пакеты рабочих данных сцен с учетом того, когда структуры данных, включенные в пакеты рабочих данных сцен, необходимы посредством аудиодекодера в соответствии с информацией ячеек.
40. Оборудование (1500) по одному из пп. 36-39,
в котором аудиокодер выполнен с возможностью предоставлять информацию первой ячейки, задающую первый набор объектов сцены и/или характеристик сцены для рендеринга сцены, когда позиция слушателя находится в первой пространственной области, и
при этом аудиокодер выполнен с возможностью предоставлять информацию второй ячейки, задающую второй набор объектов сцены и/или характеристик сцены для рендеринга сцены, когда позиция слушателя находится во второй пространственной области, и
при этом первый набор объектов сцены и/или характеристик сцены предоставляет более детальный пространственный рендеринг по сравнению со вторым набором объектов сцены и/или характеристик сцены.
41. Оборудование (1500) по одному из пп. 36-40,
при этом оборудование выполнено с возможностью использовать различные определения ячеек, чтобы управлять пространственным рендерингом с различным уровнем детальности.
42. Способ (1600) для обеспечения декодированного аудиопредставления на основе кодированного аудиопредставления,
при этом способ содержит этап, на котором подготавливают посредством пространственного рендеринга (1610) один или более аудиосигналов,
при этом способ содержит этап, на котором принимают (1620) пакет конфигурирования сцен, предоставляющий конфигурационную информацию модуля рендеринга,
при этом пакет конфигурирования сцен содержит информацию ячеек, задающую одну или более ячеек,
при этом информация ячеек задает ассоциирование между одной или более ячеек и соответствующей одной или более структур данных, ассоциированных с одной или более ячеек и задающих сценарий рендеринга;
при этом способ содержит этап, на котором оценивают (1630) информацию ячеек, чтобы определять то, какие структуры данных должны использоваться для пространственного рендеринга.
43. Способ (1700) для обеспечения кодированного аудиопредставления,
при этом способ содержит этап, на котором предоставляют (1710) информацию для пространственного рендеринга одного или более аудиосигналов,
при этом способ содержит этап, на котором предоставляют (1720) множество пакетов (1404, 1522) с различными типами пакетов,
при этом способ содержит этап, на котором предоставляют (1730) пакет конфигурирования сцен, предоставляющий конфигурационную информацию модуля рендеринга,
при этом пакет конфигурирования сцен содержит информацию ячеек, задающую одну или более ячеек,
при этом информация ячеек задает ассоциирование между одной или более ячеек и соответствующей одной или более структур данных, ассоциированных с одной или более ячеек и задающих сценарий рендеринга.
44. Энергонезависимый машиночитаемый носитель, содержащий записанную на нем компьютерную программу для осуществления способа по п. 42, когда компьютерная программа работает на компьютере.
45. Энергонезависимый машиночитаемый носитель, содержащий записанную на нем компьютерную программу для осуществления способа по п. 43, когда компьютерная программа работает на компьютере.
46. Аудиодекодер, для обеспечения декодированного аудиопредставления на основе кодированного аудиопредставления,
при этом аудиодекодер выполнен с возможностью принимать множество пакетов с различными типами пакетов,
причем пакеты содержат один или более пакетов конфигурирования сцен, предоставляющих конфигурационную информацию модуля рендеринга,
причем пакеты содержат один или более пакетов обновлений сцен, задающих обновление метаданных сцены для рендеринга,
при этом аудиодекодер выполнен с возможностью оценивать то, удовлетворяются либо нет одно или более условий обновления, и избирательно обновлять одни или более метаданных сцены в зависимости от контента одного или более пакетов обновлений сцен, если одно или более условий обновления удовлетворяются.
| Устройство для закрепления лыж на раме мотоциклов и велосипедов взамен переднего колеса | 1924 |
|
SU2015A1 |
| Колосоуборка | 1923 |
|
SU2009A1 |
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |
| Колосоуборка | 1923 |
|
SU2009A1 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ РЕНДЕРИНГА ЗВУКОВОГО СИГНАЛА И КОМПЬЮТЕРНО-ЧИТАЕМЫЙ НОСИТЕЛЬ ИНФОРМАЦИИ | 2015 |
|
RU2646320C1 |

