ОБЛАСТЬ ТЕХНИКИ
[1] Настоящее техническое решение, в общем, относится к области защиты данных, а более конкретно к обезличиванию конфиденциальных данных с сохранением структуры данных в текстовых документах.
УРОВЕНЬ ТЕХНИКИ
[2] В настоящее время в любой организации существуют ограничения на хранение и обработку конфиденциальных данных. Так, организации обязаны хранить и обрабатывать конфиденциальные данные в определенных базах данных и обеспечивать полную сохранность таких данных, например, в соответствии с законодательными актами, такими как Федеральный закон "О персональных данных", Федеральный закон "О банках и банковской деятельности" и т.д. Конфиденциальные данные содержат персональные данные клиентов и сотрудников, сведения, составляющие банковскую и коммерческую тайну, сведения о медицинском страховании, медицинские записи и т.д., что объясняет такие высокие требования к их обработке и распространению, и, соответственно, не позволяет использовать такие данные во внешних структурах. При этом, у организаций сохраняется потребность и необходимость в применении таких данных, например, при разработке и тестировании программного обеспечения, для передачи третьим лицам, таким как агентства по переводу документов, консалтинговые, аудиторские компании, для использования в разработке моделей искусственного интеллекта и т.д.
[3] Одним из способов применения конфиденциальных данных во внешних источниках, известный из уровня техники, является обезличивание конфиденциальных данных. Так, конфиденциальные данные подвергаются необратимой модификации, исключающей возможность отнести эти данные к конкретному субъекту прямым или косвенным образом.
[4] Однако, такой подход неприменим в сферах, где требуется сохранение целостности структуры данных, таких как высокая релевантность, синтаксические и морфологические особенности данных, например, при создании AI-моделей, переводе документов подрядчиками, прототипировании аналитического приложения или витрины данных, ввиду невозможности корректного перевода и/или точного обучения модели.
[5] Так, из уровня техники, также известно решение, раскрытое в заявке на патент США №US 2012131075 A1 (MAWDSLEY GARY [GB], et al.), опубл. 24.05.2012. Указанное решение, в частности, раскрывает способ обратимой анонимизации персональных данных, хранящихся в базе данных, в котором для подмножества элементов данных определяют отклонение каждого из указанных элементов данных в подмножестве относительно справочных элементов данных и присваивают идентификаторы отклонения каждому из указанных определенных отклонений в указанных данных для анонимизации элементов данных в указанном подмножестве данных; создают таблицу преобразования, отображающую указанные элементы данных в указанном подмножестве на указанные идентификаторы отклонения; сохраняют упомянутую таблицу перевода; и хранят упомянутые идентификаторы отклонения, определяющих упомянутые анонимизированные элементы данных.
[6] Недостатками такого решения является низкая точность и эффективность обезличивания данных в сферах, где требуется сохранение целостности данных, из-за невозможности применения способа на неструктурированных данных, осуществления распознавания конфиденциальной информации на основе правил, что может привести к пропуску данных, которые не учтены в правилах, а также невозможности сохранения форматирования данных и их семантических и морфологических особенностей.
[7] Общими недостатками существующих решений является отсутствие точного и эффективного способа обезличивания данных в текстовых документах, обеспечивающего возможность сохранения формата стиля и структуры данных, а также позволяющего обнаруживать данные, которые раньше не встречалась. Кроме того, такого рода решение должно обеспечивать семантическую структуру данных и осуществлять проверку контрольных разрядов некоторых типов данных. Также, такое решение должно обеспечивать возможность выполнения обратимого обезличивания.
РАСКРЫТИЕ ИЗОБРЕТЕНИЕ
[8] Данное техническое решение направлено на устранение недостатков, присущих существующим решениям, известным из уровня техники.
[9] Решаемой технической проблемой в данном техническом решении является создание нового и эффективного способа обезличивания конфиденциальных данных в текстовых документах.
[10] Основным техническим результатом, проявляющимся при решении вышеуказанной проблемы, является обеспечение возможности сохранения стилистической, семантической, лексической и морфологической структуры данных в текстовых документах при их обезличивании.
[11] Дополнительным техническим результатом, является повышение точности обезличивания данных в текстовых документах, за счет определения конфиденциальных данных в текстовых документах с помощью модели машинного обучения.
[12] Указанные технические результаты достигаются благодаря осуществлению способа обезличивания конфиденциальных данных в текстовых документах с сохранением структуры данных, содержащий этапы, на которых:
a) получают документ, содержащий текстовые данные;
b) сегментируют текстовые данные, полученные на этапе а), причем в ходе сегментации данные разбиваются по границам изменения форматирования текста на части текста, и присваивают указанным частям текста порядковую позицию в тексте;
c) токенизируют текстовые данные, полученные на этапе а), и присваивают порядковые позиции в тексте каждому токену;
d) выполняют векторизацию токенов, полученных на этапе с);
e) осуществляют обработку векторных представлений токенов, полученных на этапе d), с помощью модели машинного обучения на базе нейронной сети, обученной на наборах конфиденциальных данных, в ходе которой осуществляется определение принадлежности каждого токена к категории конфиденциальных данных;
f) обезличивают данные, относящиеся к токенам с конфиденциальными данными, причем в ходе обезличивания данные заменяют на данные из той же категории с сохранением структуры данных;
g) формируют список замен, включающий указания порядковых позиций токенов с конфиденциальными данными в тексте, порядковых позиций изменения границ форматирования частей текста, обезличенные данные, соответствующие конфиденциальным данным;
h) заменяют исходные конфиденциальные данные в текстовом документе, на обезличенные данные по списку замен, причем в процессе замены обезличенные данные форматируют в соответствии с позициями изменения форматирования частей текста.
[13] В одном из частных примеров осуществления способа текстовые данные получают в виде неструктурированного текстового документа.
[14] В другом частном примере осуществления способа категории конфиденциальных данных представляют собой, по меньшей мере, одно из:
• числовые сущности;
• именованные сущности.
[15] В другом частном примере осуществления способа числовые сущности представляют, по меньшей мере, одно из: основной номер держателя карты, номер ИНН, номер телефона, номер счета, номер страхового свидетельства, IP - адрес, MAC - адрес.
[16] В другом частном примере осуществления способа именованные сущности представляют собой, по меньшей мере, одно из: персоны, локации, организации.
[17] В другом частном примере осуществления способа структурой данных является соответствие формата, вида и смыслового содержания конфиденциальных и обезличенных данных.
[18] В другом частном примере осуществления способа обезличенные данные для числовых сущностей генерируются с сохранением идентифицирующих признаков.
[19] В другом частном примере осуществления способа обезличенные данные для именованных сущностей приводятся к соответствующей конфиденциальным данным морфологической форме.
[20] В другом частном примере осуществления способа повторяющиеся конфиденциальные данные обезличиваются одинаковыми данными.
[21] Кроме того, заявленные технические результаты достигаются за счет системы обезличивания конфиденциальных данных в текстовых документах с сохранением структуры данных, содержащих:
• по меньшей мере один процессор;
• по меньшей мере одну память, соединенную с процессором, которая содержит машиночитаемые инструкции, которые при их выполнении по меньшей мере одним процессором обеспечивают выполнение способа обезличивания конфиденциальных данных в текстовых документах с сохранением структуры данных.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[22] Признаки и преимущества настоящего технического решения станут очевидными из приводимого ниже подробного описания и прилагаемых чертежей, на которых:
[23] Фиг. 1 иллюстрирует блок-схему выполнения заявленного способа.
[24] Фиг. 2 иллюстрирует блок-схему выполнения способа обратимого обезличивания данных.
[25] Фиг. 3 иллюстрирует блок-схему выполнения способа деобезличивания данных
[26] Фиг. 4 иллюстрирует пример системы автоматического обезличивания конфиденциальных данных.
[27] Фиг. 5 иллюстрирует пример системы автоматического обратимого обезличивания конфиденциальных данных.
[28] Фиг. 6 иллюстрирует пример вычислительного устройства для реализации заявленных систем.
ОСУЩЕСТВЛЕНИЕ ИЗОБРЕТЕНИЯ
[29] Заявленное техническое решение предлагает новых подход, обеспечивающий обезличивание конфиденциальных данных в текстовых документах. Основной особенностью заявленного решения является обеспечение возможности обезличивания конфиденциальных данных в текстовых документах с сохранением структуры обезличенных данных, за счет сохранения стилистической структуры конфиденциальных данных и обезличивания данных с сохранением семантической, лексической и морфологической формы данных. Кроме того, реализация настоящего технического решения, повышает точность обезличивания данных, за счет реализации модели машинного обучения на базе нейронной сети, обеспечивающей поиск конфиденциальных данных, которые раньше не встречались, в том числе в неструктурированных данных. Также, еще одним дополнительным преимуществом, достигаемым при использовании заявленного решения, является возможность выполнения как обратимого обезличивания данных, так и необратимого обезличивания данных.
[30] Заявленное техническое решение может выполняться, например, системой, машиночитаемым носителем, сервером и т.д. В данном техническом решении под системой подразумевается, в том числе компьютерная система, ЭВМ (электронно-вычислительная машина), ЧПУ (числовое программное управление), ПЛК (программируемый логический контроллер), компьютеризированные системы управления и любые другие устройства, способные выполнять заданную, четко определенную последовательность операций (действий, инструкций).
[31] Под устройством обработки команд подразумевается электронный блок либо интегральная схема (микропроцессор), исполняющая машинные инструкции (программы).
[32] Устройство обработки команд считывает и выполняет машинные инструкции (программы) с одного или более устройства хранения данных, например, таких устройств, как оперативно запоминающие устройства (ОЗУ) и/или постоянные запоминающие устройства (ПЗУ). В качестве ПЗУ могут выступать, но, не ограничиваясь, жесткие диски (HDD), флеш-память, твердотельные накопители (SSD), оптические носители данных (CD, DVD, BD, MD и т.п.) и др.
[33] Программа - последовательность инструкций, предназначенных для исполнения устройством управления вычислительной машины или устройством обработки команд.
[34] Термин «инструкции», используемый в этой заявке, может относиться, в общем, к программным инструкциям или программным командам, которые написаны на заданном языке программирования для осуществления конкретной функции, такой как, например, получение и обработка данных, формирование профиля пользователя, прием и передача сигналов, анализ принятых данных, идентификация пользователя и т.п. Инструкции могут быть осуществлены множеством способов, включающих в себя, например, объектно-ориентированные методы. Например, инструкции могут быть реализованы, посредством языка программирования С++, Java, Python, различных библиотек (например, "MFC"; Microsoft Foundation Classes) и т.д. Инструкции, осуществляющие процессы, описанные в этом решении, могут передаваться как по проводным, так и по беспроводным каналам передачи данных, например, Wi-Fi, Bluetooth, USB, WLAN, LAN и т.п.
[35] На Фиг. 1 представлена блок схема способа 100 обезличивания конфиденциальных данных в текстовых документах, который раскрыт поэтапно более подробно ниже. Указанный способ 100 заключается в выполнении этапов, направленных на обработку различных цифровых данных. Обработка, как правило, выполняется с помощью системы, которая может представлять, например, сервер, компьютер, мобильное устройство, вычислительное устройство и т.д. Более подробно элементы системы раскрыты на Фиг. 6. В одном частном варианте осуществления, также может выполняться системой 400, которая более подробно раскрыта ниже.
[36] Под термином конфиденциальные данные в данном решении стоит понимать данные, доступ к которым ограничен в соответствии с политиками безопасности организаций и/или законодательными актами. Так, конфиденциальные данные могут представлять персональные данные, сведения, составляющие банковскую и коммерческую тайну, ФИО сотрудников и клиентов, партнеров и поставщиков, адреса, номера телефонов, адреса электронных почтовый ящиков, номера социального страхования, информация о банковских картах, номер ИНН, регистрационный номер машины, номер БИК, IP-адрес, данные геолокации, номер документа о браке, номер документа об образовании, дата, URL-адрес, МАС-адрес, номер трудовой книжки, номер военного билета, код ОКПО и т.д., не ограничиваясь.
[37] Обезличивание данных - действия, в результате которых становится невозможным без использования дополнительной информации определить принадлежность конфиденциальных данных конкретному субъекту конфиденциальных данных.
[38] На этапе 110 происходит получение документа, содержащего текстовые данные.
[39] На указанном этапе 110 документ, содержащий текстовые данные, поступает в систему, например, систему 400. В одном частном варианте осуществления, документ может быть загружен в систему 400 посредством сети связи, такой как Интернет, ЛВС и т.д. В еще одном частном варианте осуществления, документ может быть импортирован непосредственно из флэш-накопителя и/или встроенной памяти системы 400. Под документом, содержащим текстовые данные в данном решении следует понимать любой файл данных, содержащий текстовые данные. Так, документ может представлять собой любой неструктурированный документ, например, файл формата Word, PDF, текстовый документ, фотографию, оцифрованный документ, файл электронной почты и т.д.
[40] Далее способ 100 переходит к этапу 120.
[41] На этапе 120 сегментируют текстовые данные, полученные на этапе 110, причем в ходе сегментации данные разбиваются по границам изменения форматирования текста на части текста, и присваивают указанным частям текста порядковую позицию в тексте.
[42] Как уже отмечалось выше, стиль форматирования является существенным в определенных задачах, связанных с обработкой данных, например, при разработке моделей искусственного интеллекта (ИИ), переводе текста и т.д. При этом, известные системы обезличивания данных не предполагают и не содержат такой возможности в связи с тем, что стили форматирования текста не привязаны непосредственно к тексту, а содержатся в сопутствующих данных документа, например, в метаданных. Кроме того, некоторые модели машинного обучения также учитывают форматирование данных, что соответственно повышает точность самого процесса обучения.
[43] Соответственно, для реализации указанной возможности в заявленном способе предложен следующий подход. Указанный подход, в одном частном варианте осуществления, решает, как проблему предоставления сторонним разработчикам обезличенных данных, так и обеспечивает формирование точной и максимально приближенной, в том числе и по стилю форматирования, выборки данных для обучения модели.
[44] После получения текстового документа системой 400, указанная система 400, извлекает текст из документа частями так, чтобы сохранить исходные стили форматирования документа. Под извлечением текста из документа в данном решении следует понимать выделение из текстового документа определенных частей текста и сохранение указанных частей в памяти системы 400, например, в виде файла данных, Т.е. на указанном этапе 120 исходный текст преобразуется в несколько частей, разбитых по границам изменения форматирования. Под форматированным текстом в данном решении понимается результат процесса оформления страницы, абзаца, строки, символа документа. Так, стилем форматирования текста может являться изменение цвета, подчеркивание, выделение курсивом, начертание, изменение отступов, регистров и т.д., определенных слов, символов, абзацев в текстовом документе. Стиль форматирования текста может определяться посредством разметки XML («расширяемый язык разметки»), которая может хранится, например, в файле текстового документа, являться машиночитаемым приложением к текстовому документу и т.д. Стоит отметить, что особенностью данного этапа является то, что текст разбивается не на целые слова и/или токены окруженные разметкой XML, а разбивается именно по границам изменения форматирования разметки. Такой подход обеспечивает избегание нарушения стилей и дальнейшее неправильное применение стилей к обезличенным частям.
[45] Рассмотрим пример извлечения текста в соответствии с указанным этапом 120. Так, следующий текст: «Иванов Иван получил карту 4485 2911 2679 2812 в ООО «Бетта». Теперь Ивану доступны онлайн платежи, с чем его поздравил Андрей.» будет преобразован на несколько частей, разбитых по границам изменения форматирования (таблица 1).


[46] Как видно из таблицы 1, символ Б является частью слова Бетта, однако имеет другой стиль форматирования, и, соответственно, вынесен в отдельную часть текста. Для специалиста в данной области техники будет очевидно, что, хотя пример приведен на основе регистра и подчеркивания символа, данный подход применим для любого изменения форматирования текста.
[47] После получения частей текста, указанным частям присваиваются индексы начала и конца в рамках общего текста. Указанные индексы в дальнейшем необходимы для преобразования обезличенных данных в исходный стиль форматирования.
[48] В качестве инструмента определения начала и конца части текста (длина текста), могут использоваться как внутренние средства документа, обеспечивающие подсчет символов в тексте, например, текстовые редакторы, так и инструменты, например, программные средства для анализа текстовых документов, в том числе и встроенные в систему 400.
[49] Итак, продолжая предыдущий пример, указанным частям текста будут присвоены следующие индексы (таблица 2):
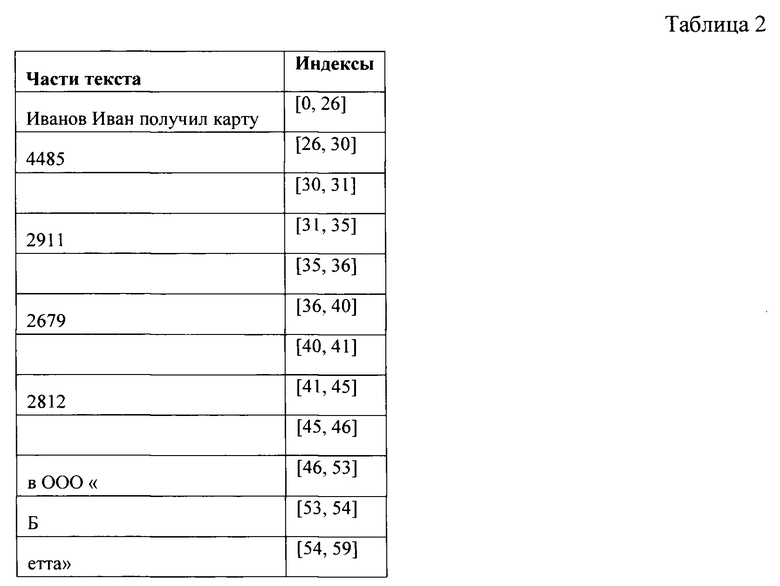

[50] Таким образом, на указанном этапе 120 выполняют сегментацию текстовых данных и присваивают указанным частям текста порядковую позицию в тексте.
[51] Далее способ 100 переходит к этапу 130.
[52] На этапе 130 выполняют токенизацию текстовых данных, полученных на этапе 110, и присваивают порядковые позиции в тексте каждому токену.
[53] На этапе 130 выполняется обработка полученных текстовых данных. Входной текст токенизируется, т.е. сегментируется на части, например, на предложения, слова или символы. Под токеном в данном решении следует понимать последовательность символов в документе, которая имеет значение для анализа. Так, токенами могут являться, например, отдельные слова, части слов и т.д. Токенизация на предложения может проводиться при помощи, например, лексических анализаторов, таких как razdel, rusenttokenize, NLTK и т.д. Лексический анализ - это процесс аналитического разбора входной последовательности символов на распознанные группы (лексемы) с целью получения на выходе идентифицированных последовательностей, называемых «токенами». Кроме того, токенизация входного текста может быть осуществлена на основе регулярных выражений. Для специалиста в данной области техники очевидно, что может быть применен любой лексический анализатор известный из уровня техники и данное решение не ограничивается приведенными выше примерами. После процесса токенизации, по аналогии с присвоением индексов начала и конца на этапе 120, токенам текста присваиваются начальный и конечный индекс.Как указывалось выше, определение позиции слова в текстовом документе может быть выполнено, например, при помощи анализаторов текста.
[54] При этом, стоит отметить, что в процессе токенизации текста стили форматирования текста будут стерты, т.к. указанный процесс не может учитывать стиль текста в документе.
[55] Продолжая приведенный выше пример, представленный текст будет разбит на следующие токены, которым будут присвоены следующие индексы (таблица 3):

[56] На этапе 140 выполняют векторизацию токенов, полученных на этапе 130.
[57] На указанном этапе 140 выполняется векторизация каждого токена, полученного в процессе токенизации, например, с помощью эмбеддингов (embeddings) или прямого кодирования (one hot encoding). Так, например, при токенизации, каждый токен, представлен в словаре своим индексом, отображающий позицию в указанном словаре. Таким образом, каждый токен представляет индекс в словаре, и, соответственно процесс векторизации осуществляется путем замены каждого токена на его индекс в словаре. Затем индексы группируются с учетом разряженности словаря и семантической близости токенов. Для специалиста в данной области техники будет очевидно, что для векторизации токенов могут применять и другие алгоритмы векторизации, например, с помощью алгоритмов TransformersBertEmbedder, Word2vec, fastText и т.д., не ограничиваясь. Указанный процесс векторизации является подготовительным этапом к обработке данных моделью машинного обучения, выполняющей распознавание конфиденциальных данных (этап 150).
[58] На этапе 150 осуществляют обработку векторных представлений токенов, с помощью модели машинного обучения на базе нейронной сети, обученной на наборах конфиденциальных данных, в ходе которой осуществляется определение принадлежности каждого токена к категории конфиденциальных данных.
[59] Для обработки неструктурированных данных и определения в неструктурированном тексте конфиденциальных данных была разработана и применена модель машинного обучения. Указанная модель предназначена для решения задачи классификации текста (задача NER). Распознавание именованных сущностей (Named-entity recognition, NER) - это подзадача извлечения информации, которая направлена на поиск и классификацию упоминаний именованных сущностей в неструктурированном тексте по заранее определенным категориям, таким как имена лиц, организации, местоположения, денежные значения, проценты и т.д.
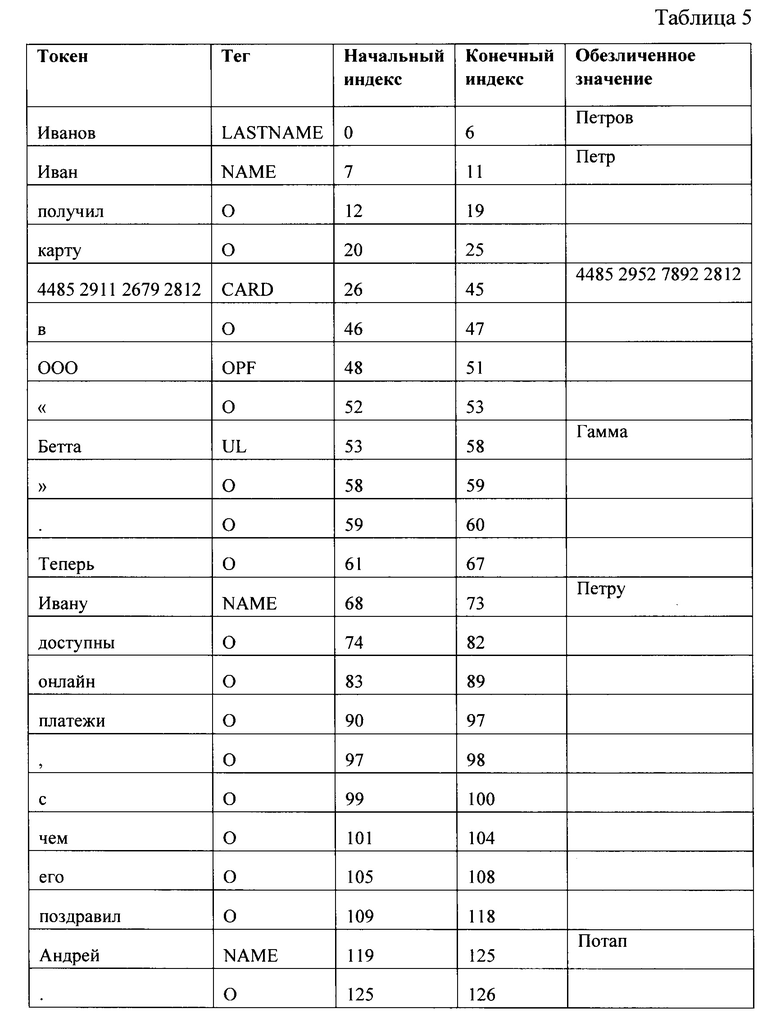
[60] Обучение модели МО производилось на заранее размеченных данных. На момент создания модели был использован датасет (набор данных) из размеченных конфиденциальных данных, состоящий из более чем 2 миллионов токенов. Набор данных сформирован по оригинальным текстовым документам, содержащим персональные данные, сведения, составляющие банковскую и коммерческую тайну, и т.д. Обучение модели распознаванию конфиденциальных данных в текстовых документах заключалось в определении классов именованных сущностей в тексте (ФИО, номер банковской карты, номер социального страхования и т.д.). В качестве схемы для разметки данных может применятся, например, ВIO/IOВ-схема, BILUO-схема и т.д., не ограничиваясь. Датасет может быть представлен, например, в виде упорядоченного списка токенов, отделенных разделителем от класса именованной сущности, например, символом пробела. Для специалиста в данной области техники очевидно, что может быть применена любая схема разметки и представления датасета известная из уровня техники и данное решение не ограничивается приведенными выше примерами. Для обучения модели МО использовалось 80% токенов из датасета, а для расчета метрик качества - 20%.
[61] Основная метрика качества модели МО, взвешенная по классам F1 мера, составляет около 95,3%, что превышает результаты автоматического машинного обучения (AutoML) более чем на 15%. При этом разброс между полнотой (recall) и точностью (precision) не превышает 0,8%, что говорит о высоком уровне качества модели как с точки зрения безопасности - низкая вероятность пропустить конфиденциальную информацию, так и с точки зрения конечного пользователя - малое количество ложных обнаружений конфиденциальной информации. Степень падения метрики качества при аугментации текстов на уровне символов, показывающая стабильность модели, не превышает 5%.
[62] Указанная модель машинного обучения на базе нейронной сети была успешно внедрена и протестирована в организации в рабочих процессах подразделений.
[63] В одном частном варианте осуществления, в качестве нейронной сети может быть использована, например, нейронная сеть архитектуры трансформер (Transformer), рекуррентная нейронная сеть (RNN) и т.д., не ограничиваясь. Особенностью указанной модели машинного обучения является возможность эффективного распознавания конфиденциальных данных в текстовых документах, в том числе благодаря анализу семантической близости токенов.
[64] Таким образом, на этапе 150 выполняют, с помощью представленной обученной модели машинного обучения, обработку данных, осуществляя распознавание конфиденциальных данных. Продолжая пример, результат обработки данных будет иметь следующий вид (таблица 4):


[65] Так, из указанных текстовых данных извлекаются конфиденциальные данные с присвоенной категорией, к которой указанные данные относятся. Например, как видно из таблицы 4, все данные, относящиеся к конфиденциальным, помечены тегами - короткими строками, которые взаимно однозначно соответствуют видам конфиденциальных данных. Тэги соответствуют категории, присвоенной указанным данным, например, CARD - номер карты, NAME - имя и т.д. Тэги пишутся на латинице, для того, чтобы они имели общий вид на всех кодировках.
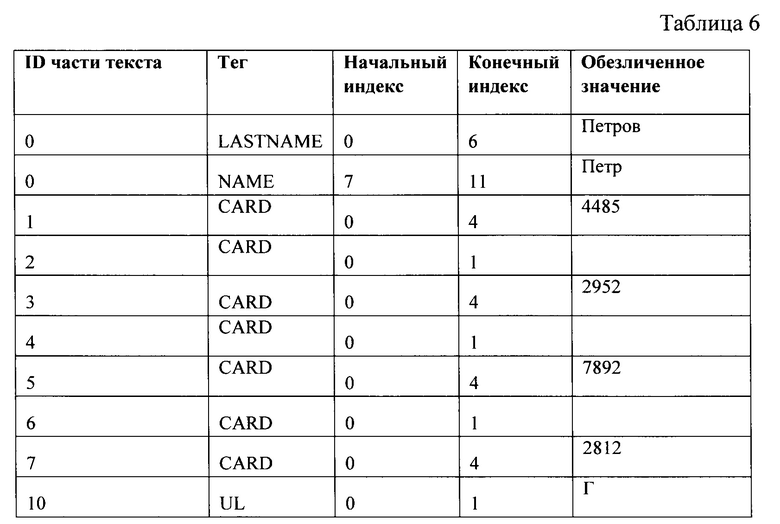
[66] В одном частном варианте осуществления, категории конфиденциальных данных, которые присваиваются текстовым данным представляют собой, по меньшей мере категорию данных числовых сущностей и категорию данных именованных сущностей. Указанный этап может выполняться моделью машинного обучения и является грубой классификацией, когда данные разделяют на числовые и именованные сущности, для последующей идентификации типа конфиденциальных данных, например, с помощью мультиклассовой классификации (Multiclass classification), распознавания именованных сущностей (NER) и т.д. Указанное разделение необходимо для выбора корректного алгоритма обезличивания, соответствующего типу конфиденциальных данных, и для установления более жестких требований к сохранению морфологических особенностей именованных сущностей. Так, после отнесения данных к числовым, может быть определен тип числовых данных. Числовые сущности могут представлять, следующие данные: Основной номер держателя карты (PAN), Номер ИНН ФЛ, Номер ИНН ЮЛ, Номер дома, Номер ДУЛ, Номер счета ФЛ, Номер счета ЮЛ, Телефон, Номер ОГРНИП, Номер ОГРН, Номер СНИЛС, Номер полиса ОМС, Паспорт транспортного средства, Номер БИК, IP-адрес, Номер социального страхования SNN, Идентификационный номер работодателя EIN, Индивидуальный номер налогоплательщика ITIN, Данные геолокации, Номер документа о браке, Номер документа об образовании, Дата, Номер трудовой книжки, Номер военного билета, Код ОКПО, IMEI и т.д. Для повышения точности распознавания конфиденциальных данных, в настоящем решении, также применяется процедура проверки контрольных разрядов к числовым сущностям. Алгоритм проверки контрольных разрядов проверяет данные на соответствие контрольным разрядам, которые обычно вычисляются с помощью алгоритма Луна или других алгоритмов. Алгоритм Луна - алгоритм вычисления контрольной цифры некоторых видов данных. Не является криптографическим средством, а предназначен в первую очередь для выявления ошибок, вызванных непреднамеренным искажением данных. Контрольный разряд используется в различных номерах, таких как: номера банковских карт, СНИЛС, ОКПО, ОГРН, ИНН и т.д. не ограничиваясь. Контрольный разряд необходим, для того, чтобы исключить вероятность некорректного распознавания типа конфиденциальных данных.
[67] Соответственно, именованные сущности также могут быть поделены по типу сущностей. Так, именованные сущности могут представлять: персоны, локации, организации, например, Фамилия, Имя, Отчество, Должность, Полное и краткое наименование юридического лица, логин, улица, город и т.д.
[68] Указанные извлеченные сущности могут сохраняться, например, в защищенной памяти системы 400 для дальнейшего их обезличивания. В одном частном варианте осуществления, токены с одинаковыми тегами конфиденциальных данных объединяются в единый токен (например, токены, характеризующие номер банковской карты). Так, токены, принадлежащие тегу CARD могут быть объединены в единый токен. Кроме того, в еще одном частном варианте осуществления, одинаковые токены с одинаковым классом также могут быть идентифицированы и помечены для дальнейшей заменены на одинаковые обезличенные значения, например, одно и тоже встречающееся имя будет обезличено одним и тем же значением.
[69] Таким образом, на указанном этапе 150 из текстового документа извлекаются все сущности, содержащие конфиденциальную информацию.
[70] Далее, на этапе 160 выполняется обезличивание данных, относящихся к токенам с конфиденциальными данными, причем в ходе обезличивания данные заменяют на данные из той же категории с сохранением структуры данных.
[71] Так, после определения типа конфиденциальных данных, способ 100 переходит к этапу 160. На этапе 160 выполняется обезличивание определенных конфиденциальных данных с сохранением структуры данных. Основной особенностью заявленного технического решения является возможность обезличивания данных с сохранением морфологических особенностей, структуры текста и с заменой одинаковых сущностей на одинаковые обезличенные значения. Указанная возможность позволяет использовать обезличивание для тех задач, где важны морфологические особенности и смысл текста, например, обучение моделей искусственного интеллекта, перевод текста и т.д. Под сохранением структуры текста понимается псевдонимизация конфиденциальных данных, при которой конфиденциальные или личные данные заменяются данными того же типа, пола и языка/региона. Например, женское имя заменяется другим женским именем, распространенным в местной культуре, улица заменяется на улицу со схожей морфологической и фонетической структурой, например, Екатерина заменяется на Елизавету, и т.д. Для указанного процесса на основе типа конфиденциальных данных в словаре, например, базе данных системы 400, содержащий набор данных для обезличивания, определяются схожие атрибуты с фрагментом текстовых данных, подлежащему замене. Например, при сопоставлении атрибутов Иванова Ивана, атрибут Елена Смит будет обладать низкой степенью схожести, т.к. указанные данные обладают разными классами (пол. муж. и жен.) и национальностями (Смит этнически принадлежит к немецкой национальности). При этом, атрибут Петров Петр будет иметь высокую степень схожести, т.к. пол и национальность совпадает. Как указывалось выше, определение типа данных в категории может быть выполнено на этапе 150 с помощью модели машинного обучения. Кроме того, в одном частном варианте осуществления, часть текстовых данных может быть заменена данными с равнозначным количеством букв, например, слово «два» может быть обезличено как «три». Указанная особенность может быть достигнута посредством заранее размеченной базы данных, содержащей указания на вышеперечисленные структурные особенности текста (например, база данных может хранить разделы, относящиеся к персональным данным по национальностям, половому признаку и т.д.), т.е. база данных может представлять собой таблицу с идентифицированными именем столбца и типом данных.
[72] Кроме того, в еще одном частном варианте осуществления, конфиденциальные данные, представленные датами, могут сдвигаются на фиксированное смещение, например, на 1, 10 дней и т.д. Указанная особенность позволяет получить репрезентативные данные, например, для обучающего набора данных, где дата совершения события может являться критичной, например, в задачах поиска аномальных событий.
[73] Стоит отметить, что для указанных задач анонимизации в системе 400 дополнительно могут содержаться классификаторы типов данных, например, контекстные классификаторы, классификаторы морфологического анализа, комбинация указанных классификаторов и т.д. Указанные классификаторы выполнены с возможностью определения конкретного типа данных (подкласса данных), к которым относятся данные (национальность, географическая принадлежность и т.д.). Более подробно пример классификатора раскрыт в статье, найденной в Интернет, см. https://arxiv.org/abs/1708.07903. Так, например, классификаторы морфологического анализа такие как pymorphy2 и др. могут включать в себя классификатор типов на основе префиксов и суффиксов или классификатор типов на основе подслов и составных слов. Классификация по национальности и этнической принадлежности может осуществляться, например, с помощью NamePrism и других классификаторов, использующих закономерности гомофилии, но не ограничивающихся ими.
[74] Так, продолжая этап 160, обезличенные значения с сохранением косвенно идентифицирующих признаков генерируются для токенов, относящихся к типу и категории конфиденциальных данных. В одном частном варианте осуществления, для числовых сущностей значения могут генерироваться на основе заданных шаблонов. Так, например, для номеров телефонов, шаблон будет содержать код страны и количество цифр номера. Например, для России код страны является +7, соответственно номера телефонов, содержащиеся в конфиденциальных данных и начинающиеся на +7, будут заменены с сохранением указанного кода. Для специалиста в данной области техники очевидно, что указанные особенности могут быть сохранены и для других числовых сущностей (ИНН, социальное страхование и т.д.).
[75] В еще одном частном варианте осуществления, как указывалось выше, именованные сущности обезличиваются в соответствии с нужной морфологической формой для токенов, относящихся к конфиденциальным данным с помощью хранилища обезличенных данных (например, базы данных). Так, указанная база данных или словарь изначально наполнены уникальными данными в нормальной форме и сгруппированы по видам конфиденциальной информации: Имя, Фамилия, Должность и т.д.
[76] Так, данные из текстового документа, приведенные в примере выше, будут заменены на следующие данные (таблица 5):
[77] Как видно из таблицы, тип данных CARD, был обезличен с сохранением структуры, а именно были сохранены первые 6 цифр, обозначающие банковский идентификационный номер, и последние 4 цифры, служащие для идентификации карты и проверки ее подлинности с помощью контрольного разряда. Кроме того, имена, фамилии, названия юридического лица также были обезличены с сохранением структуры данных.
[78] Стоит отметить, что в одном частном варианте реализации, при обратимом процессе обезличивания данных, таблица замен сохраняется в защищенное хранилище данных, памяти 400.
[79] Таким образом, на указанном этапе 160 выполняют обезличивание данных, относящихся к токенам с конфиденциальными данными, причем в ходе обезличивания данные заменяют на данные из той же категории с сохранением структуры данных (пола, национальной принадлежности и т.д.). [80] Далее способ переходит к этапу 170.
[81] На этапе 170 формируют список замен, включающий указания порядковых позиций токенов с конфиденциальными данными в тексте, порядковых позиций изменения границ форматирования частей текста, обезличенные данные, соответствующие конфиденциальным данным.
[82] На этапе 170, на основе сформированной таблицы замен, таблицы форматирования и порядковых позиций токенов в тексте (индексы начала и конца), составляется список замен на обезличенные значения для частей текста. Список замен содержит указание на порядковый номер части текста, граничные индексы замены в рамках части текста, вид найденных конфиденциальных данных и обезличенное значение. Если конфиденциальный токен представлен несколькими частями текста, то обезличенное значение разбивается на соответствующее количество частей.
[83] Указанный список также может быть сформирован в системе 400.
[84] Список замен для приведенного примера будет выглядеть следующим образом (таблица 6):

[85] На этапе 180 заменяют исходные конфиденциальные данные в текстовом документе, на обезличенные данные по списку замен, причем в процессе замены обезличенные данные форматируют в соответствии с позициями изменения форматирования частей текста.
[86] Так, в исходном документе части текста заменяются на обезличенные значения по списку замен, который был сформирован на этапе 170. Таким образом сохраняется исходное форматирование документа.
[87] Например, текст из примера после обезличивания будет выглядеть следующим образом: «Петров Петр получил карту 4485 2952 7892 2810 в ООО «Гамма». Теперь Петру доступны онлайн платежи, с чем его поздравил Потап.»
[88] В одном частном варианте осуществления, если выбран обратимый режим обезличивания, то, как указывалось выше, в системе 400 сохраняется таблица подстановок, например, в защищенной области памяти. В этом случае система 400 выполнена с возможностью восстановления исходных сущностей из обезличенных значений. [89] После замены частей текста, содержащих конфиденциальные данные, на обезличенные данные, система 400 выполнена с возможностью формирования нового текстового документа и предоставления указанного документа пользователю системы и/или выгрузки документа в сеть Интернет.
[90] Рассмотрим более подробно вариант реализации заявленного изобретения, относящийся к обратимому обезличиванию.
[91] Более подробно способ 200 обратимого обезличивания конфиденциальных данных в текстовых документах с сохранением структуры показан на фиг. 2.
[92] На этапе 210 система, такая так система 500 получает текстовый документ. Указанный этап аналогичен этапу 110, и, соответственно, для получения документа могут быть использованы приведенные выше средства.
[93] На этапе 220 выполняется сегментация текстовых данных, полученные на этапе 210, причем в ходе сегментации данные разбиваются по границам изменения форматирования текста на части текста, и присваивают указанным частям текста порядковую позицию в тексте.
[94] На этапе 230 выполняют токенизацию текстовых данных, полученные на этапе 210, и присваивают порядковые позиции в тексте каждому токену.
[95] На этапе 240 выполняют векторизацию токенов, полученных на этапе 230.
[96] На этапе 250 осуществляют обработку векторных представлений токенов, полученных на этапе 240, с помощью модели машинного обучения на базе нейронной сети, обученной на наборах конфиденциальных данных, в ходе которой осуществляется определение принадлежности каждого токена к категории конфиденциальных данных.
[97] На этапе 260 обезличивают данные, относящиеся к токенам с конфиденциальными данными, причем в ходе обезличивания данные заменяют на данные из той же категории с сохранением структуры данных.
[98] На этапе 270 формируют таблицу подстановок, характеризующую соответствие конфиденциальных данных и обезличенных данных, и сохраняют указанную таблицу в память. В частности, указанную таблицу подстановок сохраняют в защищенную память системы 500, например, в хранилище данных 506. Указанная особенность позволяет в дальнейшем деобезличить обезличенные данные, т.е. восстановить исходные данные в документе.
[99] На этапе 280 формируют список замен, включающий указания порядковых позиций конфиденциальных данных в тексте, порядковых позиций изменения границ форматирования частей текста, обезличенные данные, соответствующие конфиденциальным данным. Указанный список также может быть сохранен в хранилище 406.
[100] На этапе 290 заменяют исходные конфиденциальные данные, на обезличенные данные по списку замен, причем в процессе замены обезличенные данные форматируют в соответствии с позициями изменения форматирования частей текста. После замены конфиденциальных данных на обезличенные, система 500 может сформировать новый текстовый документ.
[101] Как было указано выше, основной особенностью обратимого обезличивания является возможность восстановления в текстовом документе исходных конфиденциальных данных. Такая потребность может возникать, например, при переводе текста за пределами организации. Так, если требуется перевести договор, содержащий конфиденциальные данные, наличие таких данных будет влиять на контекст перевода, и, соответственно, нерелевантные обезличенные данные могут привести к некорректному переводу. Кроме того, после предоставления переведенного документа, требуется восстановить исходные данные. Соответственно, в еще одном частном варианте осуществления заявленное решение раскрывает способ 300 деобезличивания данных, раскрытый более подробно на Фиг. 3.
[102] Так, указанный способ 300 может являться обратным процессом к этапам способа 200.
[103] На этапе 310 в систему, например, систему 500 поступает текстовый документ в виде файла данных, обезличенный в соответствии с этапами способа 200. В одном частном варианте, документ может быть загружен в систему 500.
[104] На этапе 320 система 500, определяет в текстовом документе обезличенные данные, которые необходимо деобезличить, с помощью таблицы подстановок.
[105] Указанный этап 320 основан на таблице подстановок, сохраненной в процессе обезличивания документа. Так, в текстовом документе определяются все сущности, содержащиеся в таблице подстановок, например, ФИО, название организации и т.д. и для последующей замены на конфиденциальные данные, которые содержались в исходном документе. Стоит отметить, что процесс определения сущностей, подлежащих деобезличиванию может быть выполнен с помощью поиска порядковых индексов по указанной таблице подстановок.
[106] Далее, на этапе 330 осуществляют процесс замены обезличенных данных на конфиденциальные данные в соответствии с таблицей подстановок.
[107] На указанном этапе 330 все обезличенные значения заменяют на исходные конфиденциальные данные. В ходе процесса деобезличивания стиль документа не затрагивается, что обеспечивает получение исходного документа с сохранением стиля форматирования.
[108] Так, например, после преобразования обезличенного документа третьими лицами, указанный документ загружают в систему 500. Т.е. получают текстовый документ, обезличенный в соответствии с этапами способа 200. Далее, на основе списка замен, хранящегося в системе, определяют в текстовом документе обезличенные данные, которые необходимо деобезличить, с помощью таблицы подстановок. После этого, осуществляют процесс замены обезличенных данных на конфиденциальные данные в соответствии с таблицей подстановок.
[109] Таким образом, в вышеприведенных материалах был описан способ обезличивания конфиденциальных данных в текстовых документах с сохранением структуры данных.
[110] Теперь рассмотрим сценарий применения некоторых вариантов заявленного решения.
[111] Так, одним из сценариев применения может являться перевод подрядчиками договоров, соглашений и других документов организации. Как было отмечено ранее, для осуществления перевода, переводчику требуется контекст и смысловое содержание данных, кроме того, при переводе также учитываются лексические и морфологические особенности текста.
[112] Таким образом, для реализации заявленного изобретения, документ, подлежащий переводу, загружается посредством интерфейса пользователя (например, интерфейса 501) в систему, такую как система 500. Далее, система 500 сегментирует текстовые данные, например, в соответствии с этапом 120 или этапом 220, токенизирует и векторизует исходные данные (этапы 130 и 140 или этапы 230 и 240) и выполняет обработку векторизованных токенов посредством модели машинного обучения, обученной на распознавание конфиденциальных данных (этап 150 или этап 250). Причем конфиденциальные данные распознаются по типам и категориям данных (этап 160 или этап 260). После этого, выполняется обезличивание конфиденциальных данных и формирование списка замен (этапы 170 и 180). Кроме того, если выбрано обратимое обезличивание, то в таком случае таблица подстановок дополнительно сохраняется в защищенную память системы, например, системы 500. (этапы 270 и 280). Последним этапом работы системы 500 является осуществление замены конфиденциальных данных в соответствии со списком замен в текстовом документе (этап 190 или этап 290). Как видно из представленного описания примера, указанный способ может быть выполнен и системой 400, в случае необратимого обезличивания. При этом, обезличенные конфиденциальные данные сохраняют структуру данных, а именно, стиль форматирования, морфологические, лексические и семантические особенности. Сформированный новый документ с обезличенными данными далее может быть отображен в пользовательском интерфейсе и/или выгружен в виде файла данных. Указанный файл далее может быть направлен переводчикам.
[113] Соответственно, после выполнения перевода, измененный файл данных может быть загружен в систему для замены обезличенных данных на исходные конфиденциальные данные.
[114] Кроме того, стоит отметить, что сохранение стилей форматирования является критичным для некоторых сфер. Так, например, некоторые автоматизированные системы хранят документы во внутреннем представлении, причем стиль документа учитывается указанными системами, поэтому если стили документов будут отличаться, то система не сможет соотнести исходный и обезличенный документ. Также, стили в документах могут использоваться как часть стандартизированных форм или для выделения ключевой информации, например, без сохранения стилей переводчик не сможет применять их в своей работе, а значит не сможет выдать корректный перевод. Также, стиль форматирования может учитываться в области разработки искусственного интеллекта. Так, кроме самого этапа обучения существует этап парсинга документа и подготовки данных. Если не сохранять стили, то они и не будут учитываться при парсинге, что в дальнейшем приведет к некорректной подготовке данных и неправильному обучению моделей. Т.е. одним из преимуществ раскрытого изобретения является возможность встраивания нового инструмента в уже существующие процессы, где происходит взаимодействие с документами, имеющими определенные стили. Удаление этих стилей может привести к нарушению работы автоматизированных систем, снижению качества обработки информации, нарушению стандартов.
[115] На Фиг. 6 представлена система 600, реализующая этапы заявленного способа (100).
[116] В общем случае система 600 содержит такие компоненты, как: один или более процессоров 601, по меньшей мере одну память 602, средство хранения данных 603, интерфейсы ввода/вывода 604, средство В/В 605, средство сетевого взаимодействия 606, которые объединяются посредством универсальной шины.
[117] Процессор 601 выполняет основные вычислительные операции, необходимые для обработки данных при выполнении способа 100. Процессор 601 исполняет необходимые машиночитаемые команды, содержащиеся в оперативной памяти 602. [118] Память 602, как правило, выполнена в виде ОЗУ и содержит необходимую программную логику, обеспечивающую требуемый функционал.
[119] Средство хранения данных 603 может выполняться в виде HDD, SSD дисков, рейд массива, флэш-памяти, оптических накопителей информации (CD, DVD, MD, Blue-Ray дисков) и т.п.Средства 603 позволяют выполнять долгосрочное хранение различного вида информации, например, истории таблицы подстановок, таблицы форматирования и т.п.[120] Для организации работы компонентов системы 600 и организации работы внешних подключаемых устройств применяются различные виды интерфейсов В/В 604. Выбор соответствующих интерфейсов зависит от конкретного исполнения вычислительного устройства, которые могут представлять собой, не ограничиваясь: PCI, AGP, PS/2, IrDa, FireWire, LPT, COM, SATA, IDE, Lightning, USB (2.0, 3.0, 3.1, micro, mini, type C), TRS/Audio jack (2.5, 3.5, 6.35), HDMI, DVI, VGA, Display Port, RJ45, RS232 и т.п.
[121] Выбор интерфейсов 604 зависит от конкретного исполнения системы 600, которая может быть реализована на базе широко класса устройств, например, персональный компьютер, мейнфрейм, ноутбук, серверный кластер, тонкий клиент, смартфон, сервер и т.п.
[122] В качестве средств В/В данных 605 может использоваться: клавиатура, джойстик, дисплей (сенсорный дисплей), монитор, сенсорный дисплей, тач-пад, манипулятор мышь, световое перо, стилус, сенсорная панель, трекбол, динамики, микрофон, средства дополненной реальности, оптические сенсоры, планшет, световые индикаторы, проектор, камера, средства биометрической идентификации (сканер сетчатки глаза, сканер отпечатков пальцев, модуль распознавания голоса) и т.п.
[123] Средства сетевого взаимодействия 606 выбираются из устройств, обеспечивающий сетевой прием и передачу данных, например, Ethernet карту, WLAN/Wi-Fi модуль, Bluetooth модуль, BLE модуль, NFC модуль, IrDa, RFID модуль, GSM модем и т.п.С помощью средств 606 обеспечивается организация обмена данными между, например, системой 600, представленной в виде сервера и вычислительным устройством пользователя, на котором могут отображаться полученные данные (обезличенный текстовый документ) по проводному или беспроводному каналу передачи данных, например, WAN, PAN, ЛВС (LAN), Интранет, Интернет, WLAN, WMAN или GSM.
[124] На фиг. 4 показан частный случай реализации системы 600.
[125] Указанная система 400 состоит из графического пользовательского интерфейса 401, модуля управления 402, модуля обезличивания 403, модуля распознавания конфиденциальной информации 404.
[126] Модули 402-404 могут являться программно-аппаратными средствами и могут представлять собой, по меньшей мере, сервер, компьютер и т.д., выполняющий предписанную ему функцию. Кроме того, для специалиста очевидно, что указанные модули могут быть реализованы с помощью по меньшей мере одного процессора и могут являться логическими модулями. Так, модуль распознавания конфиденциальной информации (КИ) 404 может содержать модель машинного обучения и предназначен для определения категорий и типов конфиденциальной информации (этап 150). Модуль 403 соответственно выполнен с возможностью замены определенных конфиденциальных данных на обезличенные данные. В одном частном варианте осуществления, указанный модуль 403 также может содержать средства классификации типов конфиденциальной информации и базу данных с наборами данных для обезличивания.
[127] На фиг. 5 показан еще один частный случай реализации системы 600.
[128] Указанная система 500 состоит из графического пользовательского интерфейса 501, модуля управления 502, модуля обезличивания 503, модуля распознавания конфиденциальной информации 504, модуля управления таблицей подстановок 505, хранилища данных 506.
[129] Модули 502-506 могут являться программно-аппаратными средствами и могут представлять собой, по меньшей мере, сервер, компьютер и т.д., выполняющий предписанную ему функцию. Кроме того, для специалиста очевидно, что указанные модули могут быть реализованы с помощью по меньшей мере одного процессора и могут являться логическими модулями. Так, модуль распознавания конфиденциальной информации (КИ) 504 может содержать модель машинного обучения и предназначен для определения категорий и типов конфиденциальной информации (этап 250). Модуль 503 соответственно выполнен с возможностью замены определенных конфиденциальных данных на обезличенные данные. В одном частном варианте осуществления, указанный модуль 503 также может содержать средства классификации типов конфиденциальной информации и базу данных с наборами данных для обезличивания. Хранилище 506 может представлять удаленный сервер, встроенную защищенную память и/или защищенную область в памяти и т.д.
[130] Представленные материалы заявки раскрывают предпочтительные примеры реализации технического решения и не должны трактоваться как ограничивающие иные, частные примеры его воплощения, не выходящие за пределы испрашиваемой правовой охраны, которые являются очевидными для специалистов соответствующей области.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ И СИСТЕМА ОБЕЗЛИЧИВАНИЯ КОНФИДЕНЦИАЛЬНЫХ ДАННЫХ | 2022 |
|
RU2804747C1 |
| СПОСОБ И СИСТЕМА РАСПОЗНАВАНИЯ ИНФОРМАЦИИ, СОСТАВЛЯЮЩЕЙ КОММЕРЧЕСКУЮ ТАЙНУ | 2024 |
|
RU2841161C1 |
| СПОСОБ И СИСТЕМА ВЫЯВЛЕНИЯ ДАННЫХ, ПОДВЕРЖЕННЫХ ДЕАНОНИМИЗАЦИИ, В ОБЕЗЛИЧЕННОМ НАБОРЕ ДАННЫХ | 2024 |
|
RU2837785C1 |
| СПОСОБ И СИСТЕМА ВЫЯВЛЕНИЯ КОНФИДЕНЦИАЛЬНЫХ ДАННЫХ | 2023 |
|
RU2838508C2 |
| СПОСОБ И СИСТЕМА ПЕРЕФРАЗИРОВАНИЯ ТЕКСТА | 2023 |
|
RU2814808C1 |
| СПОСОБ И СИСТЕМА ГЕНЕРАЦИИ ТЕКСТА | 2023 |
|
RU2817524C1 |
| СПОСОБ И СИСТЕМА ГЕНЕРАЦИИ ТЕКСТА ДЛЯ ЦИФРОВОГО АССИСТЕНТА | 2022 |
|
RU2796208C1 |
| СПОСОБ И СИСТЕМА КЛАССИФИКАЦИИ ТЕКСТА | 2022 |
|
RU2818693C2 |
| СПОСОБ И СИСТЕМА КЛАССИФИКАЦИИ ДАННЫХ ДЛЯ ВЫЯВЛЕНИЯ КОНФИДЕНЦИАЛЬНОЙ ИНФОРМАЦИИ В ТЕКСТЕ | 2019 |
|
RU2755606C2 |
| СПОСОБ УПРАВЛЕНИЯ АВТОМАТИЗИРОВАННОЙ СИСТЕМОЙ ПРАВОВЫХ КОНСУЛЬТАЦИЙ | 2019 |
|
RU2718978C1 |





Изобретение относится к области защиты данных, а более конкретно к обратимому обезличиванию конфиденциальных данных с сохранением структуры данных в текстовых документах. Техническим результатом является обеспечение возможности сохранения стилистической, семантической, лексической и морфологической структуры данных в текстовых документах при их обезличивании, повышение точности обезличивания данных в текстовых документах за счет определения конфиденциальных данных в текстовых документах с помощью модели машинного обучения. Способ обратимого обезличивания конфиденциальных данных в текстовых документах с сохранением структуры данных содержит этапы, на которых: получают документ с текстовыми данными; сегментируют и токенизируют текстовые данные, выполняют векторизацию токенов; определяют принадлежности каждого токена к категории конфиденциальных данных с помощью модели машинного обучения; обезличивают данные, относящиеся к токенам с конфиденциальными данными с сохранением структуры данных; формируют таблицу подстановок и список замен; заменяют исходные конфиденциальные данные в текстовом документе на обезличенные данные по списку замен, причем обезличенные данные форматируют в соответствии с позициями изменения форматирования частей текста. 2 н.п. ф-лы, 6 ил., 6 табл.
1. Способ обратимого обезличивания конфиденциальных данных в текстовых документах с сохранением структуры данных, содержащий этапы, на которых:
a) получают документ, содержащий текстовые данные;
b) сегментируют текстовые данные, полученные на этапе а), причем в ходе сегментации данные разбиваются по границам изменения форматирования текста на части текста, и присваивают указанным частям текста порядковую позицию в тексте;
c) токенизируют текстовые данные, полученные на этапе а), и присваивают порядковые позиции в тексте каждому токену;
d) выполняют векторизацию токенов, полученных на этапе с);
e) осуществляют обработку векторных представлений токенов, полученных на этапе d), с помощью модели машинного обучения на базе нейронной сети, обученной на наборах конфиденциальных данных, в ходе которой осуществляется определение принадлежности каждого токена к категории конфиденциальных данных;
f) обезличивают данные, относящиеся к токенам с конфиденциальными данными, причем в ходе обезличивания данные заменяют на данные из той же категории с сохранением структуры данных;
g) формируют таблицу подстановок, характеризующую соответствие конфиденциальных данных и обезличенных данных, и сохраняют указанную таблицу в память;
h) формируют список замен, включающий указания порядковых позиций конфиденциальных данных в тексте, порядковых позиций изменения границ форматирования частей текста, обезличенные данные, соответствующие конфиденциальным данным;
i) заменяют исходные конфиденциальные данные на обезличенные данные по списку замен, причем в процессе замены обезличенные данные форматируют в соответствии с позициями изменения форматирования частей текста.
2. Способ деобезличивания данных в текстовых документах, содержащий этапы, на которых:
а) получают текстовый документ, обезличенный в соответствии с этапами способа по п. 1;
b) определяют в текстовом документе обезличенные данные, которые необходимо деобезличить, с помощью таблицы подстановок;
c) осуществляют процесс замены обезличенных данных на конфиденциальные данные в соответствии с таблицей подстановок.
| US 20200334381 A1, 22.10.2020 | |||
| US 7386550 B2, 10.06.2008 | |||
| US 20120131075 A1, 24.05.2012 | |||
| Способ обеспечения конфиденциальности при поточной операторской электронной обработке бумажных документов и программное обеспечение для его реализации | 2017 |
|
RU2661327C1 |
| СПОСОБ ГАРАНТИРОВАННОГО ОБЕЗЛИЧИВАНИЯ ЭЛЕКТРОННЫХ ДОКУМЕНТОВ | 2014 |
|
RU2629445C2 |
| Способ передачи анонимных данных недоверенной стороне | 2020 |
|
RU2754967C1 |
