ОБЛАСТЬ ТЕХНИКИ
[0001] Заявленное техническое решение в общем относится к области защиты данных, а в частности к способу и системе выявления данных, подверженных деанонимизации, в обезличенном наборе данных.
УРОВЕНЬ ТЕХНИКИ
[0002] В настоящее время в любой организации существуют ограничения на хранение и обработку конфиденциальных данных. Так, организации обязаны хранить и обрабатывать конфиденциальные данные в определенных базах данных и обеспечивать полную сохранность таких данных, например, в соответствии с законодательными актами, такими как Федеральный закон "О персональных данных", Федеральный закон "О банках и банковской деятельности" и т.д.
[0003] При этом, у организаций сохраняется потребность и необходимость в применении таких данных, например, при разработке и тестировании программного обеспечения, для передачи третьим лицам, таким как агентства по переводу документов, консалтинговые, аудиторские компании, для использования в разработке моделей искусственного интеллекта и т.д.
[0004] Так, наиболее применимым способом решения указанной проблемы, обеспечивающий возможность распространять конфиденциальные данные во внешние контуры, является обезличивание конфиденциальных данных. Так, конфиденциальные данные подвергаются модификации, исключающей возможность отнести эти данные к конкретному субъекту прямым или косвенным образом, что, соответственно, позволяет использовать такие данные при взаимодействии с внешними источниками, например, для разработки моделей машинного обучения, проведения соревнований и т.д.
[0005] Однако, несмотря на то, что данные обезличены, в ряде случаев существует риск идентифицировать субъект данных даже в обезличенном наборе данных. Так, обезличенные данные могут содержать разнообразные значения с точки зрения диапазонов значений, что, соответственно, может привести к возникновению аномальных значений, т.е. значений, существенно отличающихся от других значений в наборе данных. При этом, объединение таких данных с другими датасетами, например, публичными, может привести к деобезличиванию обезличенных данных, т.е. анализ двух изначально несвязанных наборов данных позволяет установить субъект данных в обезличенном наборе данных, что, как следствие, может привести к утечке конфиденциальных данных, что является недопустимым в определенных отраслях организации.
[0006] Так, из уровня техники известно решение, раскрытое в заявке на патент США №US 2022\0004544 Al (NIPPON TELEGRAPH & TELEPHONE [JP]), опубл. 06.06.2022. Указанное решение, в частности, раскрывает способ анонимизации данных посредством оценки взаимосвязей между данными и ценности данных, подлежащих анонимизации.
[0007] Недостатком указанного решения является невозможность применения указанного подхода к уже обезличенному набору данных, т.е. невозможность определения отклонений в уже обезличенном наборе данных, которые позволяют идентифицировать субъекта в обезличенном наборе данных. Кроме того, указанный подход не предполагает и не описывает возможность анализа наборов данных на наличие существенно отличающихся значений, которые не имеют временной зависимости и являются корректными значениями, а не ошибками/выбросами.
[0008] Общими недостатками существующих решений является отсутствие эффективного способа выявления данных, подверженных деанонимизации, в обезличенном наборе данных, обеспечивающим снижение риска деобезличивания таких данных. Кроме того, такого рода решение позволяет определять, в обезличенных наборах данных, существенно отличающиеся значения, которые не имеют временной зависимости и являются корректными значениями, а не ошибками/выбросами, что соответственно, также повышает защищенность данных.
РАСКРЫТИЕ ИЗОБРЕТЕНИЯ
[0009] В заявленном техническом решении предлагается новый подход к выявлению данных, подверженных деанонимизации, в обезличенном наборе данных.
[0010] Таким образом, решается техническая проблема создания нового и эффективного способа выявления данных, подверженных деанонимизации, в обезличенном наборе данных.
[0011] Техническим результатом, достигающимся при решении данной проблемы, является повышение эффективности защиты данных, за счет выявления данных, подверженных деанонимизации.
[0012] Дополнительным техническим результатом, проявляющимся при решении вышеуказанной проблемы, является снижение риска деобезличивания обезличенных данных.
[0013] Указанные технические результаты достигаются благодаря осуществлению способа выявления данных, подверженных деанонимизации, в обезличенном наборе данных, содержащего этапы, на которых:
a) получают набор структурированных обезличенных данных;
b) формируют, на основе данных, полученных на этапе а), усеченный набор данных, причем указанный усеченный набор содержит по меньшей данные из набора структурированных обезличенных данных, которые не являются идентификационными значениями;
c) осуществляют кластеризацию данных, полученных на этапе b), в ходе которой выполняют:
i. определение соседних точек, на основе допустимого расстояния между точками;
ii. объединение точек, полученных на шаге i, в по меньшей мере один кластер;
d) определяют данные, на основе данных, полученных на этапе с), не отнесенные ни к одному из сформированных кластеров;
e) формируют набор данных, подверженных деанонимизации, на основе данных, полученных на этапе d);
f) изменяют данные, подверженные деанонимизации.
[0014] В одном из частных примеров осуществления способа идентификационные значения представляют собой, по меньшей мере, ИНН, номер счета, номер телефона.
[0015] В другом частном примере осуществления способа усеченный набор данных формируется с помощью модели машинного обучения на базе нейронной сети, обученной на распознавания идентификационных значений.
[0016] В другом частном примере осуществления способа изменение данных, подверженных деанонимизации включает в себя по меньшей мере одно из:
a) сглаживание данных, подверженных деанонимизации;
b) удаление данных, подверженных деанонимизации.
[0017] В другом частном примере осуществления способа сглаживание данных, подверженных деанонимизации представляет собой по меньшей мере замену данных, подверженных деанонимизации на среднее или медианное, или модальное значение.
[0018] Кроме того, заявленные технические результаты достигаются за счет выявления данных, подверженных деанонимизации, в обезличенном наборе данных, содержащая:
- по меньшей мере один процессор;
- по меньшей мере одну память, соединенную с процессором, которая содержит машиночитаемые инструкции, которые при их выполнении по меньшей мере одним процессором обеспечивают выполнение способа по любому из п.п. 1-5.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0019] Признаки и преимущества настоящего изобретения станут очевидными из приводимого ниже подробного описания изобретения и прилагаемых чертежей.
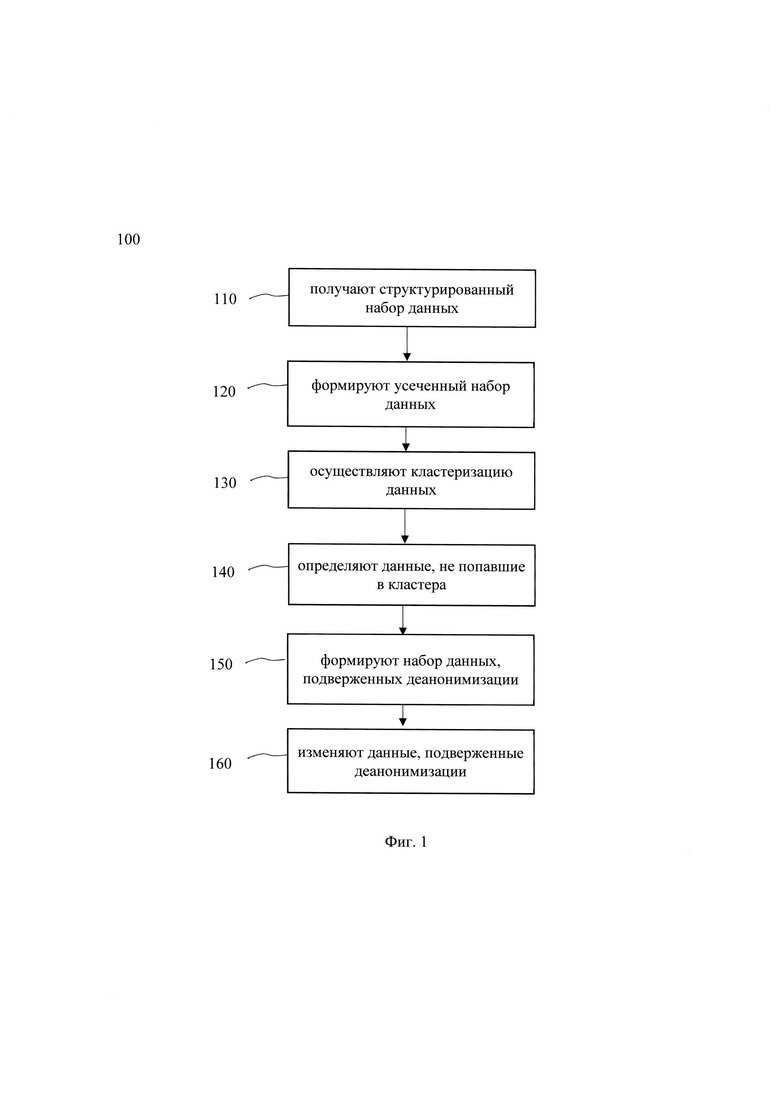
[0020] Фиг. 1 иллюстрирует блок-схему выполнения способа выявления данных, подверженных деанонимизации, в обезличенном наборе данных.
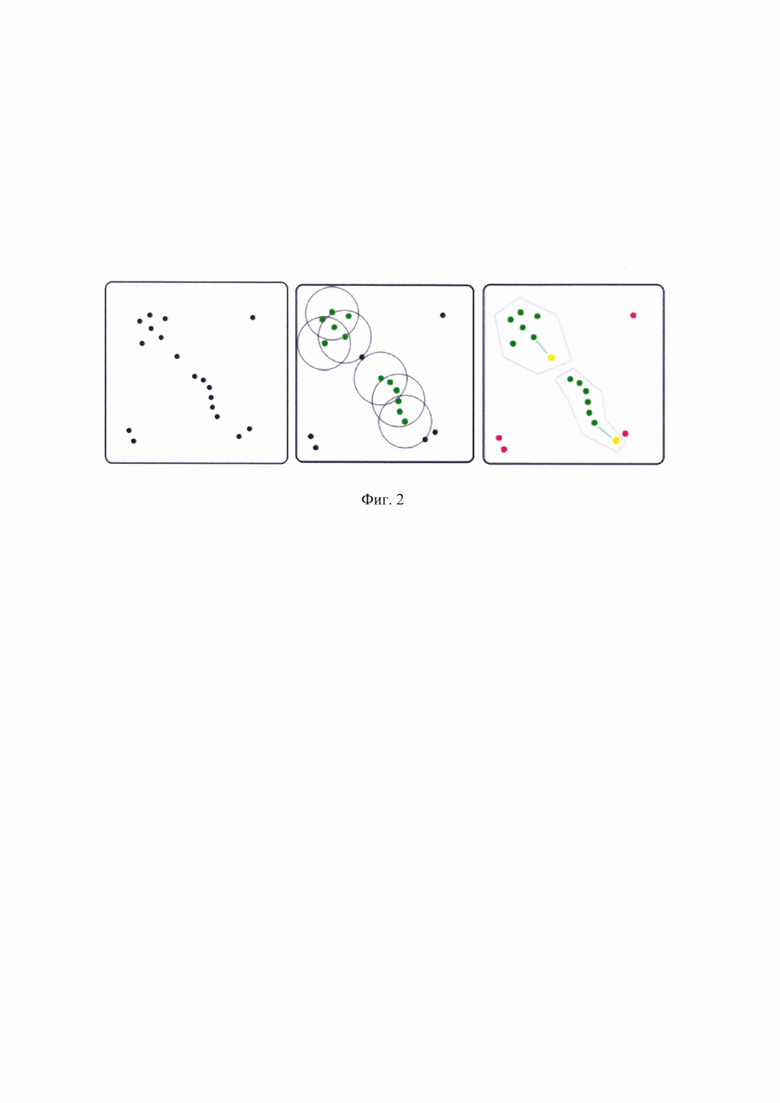
[0021] Фиг. 2 иллюстрирует пример кластеризации данных.
[0022] Фиг. 3 иллюстрирует пример общего вида вычислительного устройства, которое обеспечивает реализацию заявленного решения.
ОСУЩЕСТВЛЕНИЕ ИЗОБРЕТЕНИЯ
[0023] Ниже будут описаны понятия и термины, необходимые для понимания данного технического решения.
[0024] Модель в машинном обучении (МО) - совокупность методов искусственного интеллекта, характерной чертой которых является не прямое решение задачи, а обучение в процессе применения решений множества сходных задач.
[0025] Заявленное техническое решение предлагает новый подход, обеспечивающий выявление данных, подверженных деанонимизации, в обезличенном наборе данных, что, как следствие, снижает риск деобезличивания таких данных и повышает защищенность данных. Так, указанное решение позволяет определять, в обезличенных наборах данных, существенно отличающиеся значения, которые не имеют временной зависимости и являются корректными значениями, а не ошибками/выбросами.
[0026] Заявленное техническое решение может быть реализовано на компьютере, в виде автоматизированной информационной системы (АИС) или машиночитаемого носителя, содержащего инструкции для выполнения вышеупомянутого способа.
[0027] Техническое решение также может быть реализовано в виде распределенной компьютерной системы или вычислительного устройства.
[0028] В данном решении под системой подразумевается компьютерная система, ЭВМ (электронно-вычислительная машина), ЧПУ (числовое программное управление), ПЛК (программируемый логический контроллер), компьютеризированные системы управления и любые другие устройства, способные выполнять заданную, четко определенную последовательность вычислительных операций (действий, инструкций).
[0029] Под устройством обработки команд подразумевается электронный блок либо интегральная схема (микропроцессор), исполняющая машинные инструкции (программы).
[0030] Устройство обработки команд считывает и выполняет машинные инструкции (программы) с одного или более устройства хранения данных, например, таких устройств, как оперативно запоминающие устройства (ОЗУ) и/или постоянные запоминающие устройства (ПЗУ). В качестве ПЗУ могут выступать, но, не ограничиваясь, жесткие диски (HDD), флэш-память, твердотельные накопители (SSD), оптические носители данных (CD, DVD, BD, MD и т.п.) и др.
[0031] Программа- последовательность инструкций, предназначенных для исполнения устройством управления вычислительной машины или устройством обработки команд.
[0032] Термин «инструкции», используемый в этой заявке, может относиться, в общем, к программным инструкциям или программным командам, которые написаны на заданном языке программирования для осуществления конкретной функции, такой как, например, кодирование и декодирование текстов, фильтрация, ранжирование, трансляция текстов в диалоговую систему и т.п. Инструкции могут быть осуществлены множеством способов, включающих в себя, например, объектно-ориентированные методы. Например, инструкции могут быть реализованы, посредством языка программирования, С++, Java, Python, различных библиотек (например, MFC; Microsoft Foundation Classes) и т.д. Инструкции, осуществляющие процессы, описанные в этом решении, могут передаваться как по проводным, так и по беспроводным каналам передачи данных, например, Wi-Fi, Bluetooth, USB, WLAN, LAN и т.п.
[0033] На Фиг. 1 представлена блок схема способа 100 выявления данных, подверженных деанонимизации, в обезличенном наборе данных, который раскрыт поэтапно более подробно ниже. Указанный способ 100 заключается в выполнении этапов, направленных на обработку различных цифровых данных. Обработка, как правило, выполняется с помощью системы, которая может представлять, например, сервер, компьютер, мобильное устройство, вычислительное устройство и т.д. Более подробно элементы системы раскрыты на Фиг. 3. В одном частном варианте осуществления, способ 100 может выполняться системой 200, которая более подробно раскрыта ниже.
[0034] Под термином конфиденциальные данные (чувствительные данные) в данном решении стоит понимать данные, доступ к которым ограничен в соответствии с политиками безопасности организаций и/или законодательными актами. Так, конфиденциальные данные могут содержать как идентификационные значения, так и идентификационные сущности, например, к идентификационным сущностям могут относиться персональные данные, такие как ФИО, адрес. К идентификационным значениям могут относиться ИНН, номер телефона и т.д. Стоит отметить, что данное решение не ограничивается представленными примерами и в качестве идентификационных данных могут быть использованы любые конфиденциальные данные, такие как сведения, составляющие банковскую и коммерческую тайну, ФИО сотрудников и клиентов, партнеров и поставщиков, адреса, номера телефонов, адреса электронных почтовых ящиков, номера социального страхования, информация о банковских картах, номер ИНН, регистрационный номер машины, номер БИК, IP-адрес, данные геолокации, номер документа о браке, номер документа об образовании, дата, URL-адрес, МАС-адрес, номер трудовой книжки, номер военного билета, код ОКПО и т.д., не ограничиваясь.
[0035] Под обезличенными данными следует понимать данные, принадлежность которых конкретному субъекту конфиденциальных данных невозможно определить без дополнительной информации. Соответственно обезличивание данных - действия, в результате которых становится невозможным без использования дополнительной информации определить принадлежность конфиденциальных данных конкретному субъекту конфиденциальных данных.
[0036] Под данными, подверженными деанонимизации (аномальные данные) следует понимать значения, которые существенно отличаются от других значений в наборе данных, не имеют временной зависимости и являются корректными значениями, а не ошибками/выбросами.
[0037] На этапе 110 получают набор структурированных обезличенных данных.
[0038] На указанном этапе 110 система, такая как система 200 получает по меньшей мере один документ, например, в виде файла данных, содержащий обезличенные данные. В одном частном варианте осуществления, обезличенный набор данных представляет собой структурированный набор данных, например, набор данных в табличном представлении. Данные в табличном представлении хранят структурированные данные в виде колонок, в каждой из которой хранится более ли менее однородная информация (один и тот же вид информации). Например, в одной колонке содержатся данные о фамилии клиента, а в другой колонке - номер его телефона. Получение файла данных может осуществляться посредством открытых каналов передачи данных, например, ЛВС (локально-вычислительная сеть). Кроме того, файл данных может быть загружен в систему, например, систему 200 через интерфейсы ввода\вывода, например, USB. В еще одном частном варианте осуществления, набор данных может являться неструктурированным набором данных. В еще одном частном варианте осуществления, набор структурированных обезличенных данных может представлять собой документ, такой как текстовый документ с разделами данных.
[0039] На этапе 120 формируют, на основе данных, полученных на этапе 110, усеченный набор данных, причем указанный усеченный набор содержит по меньшей мере данные, которые не являются идентификационными значениями.
[0040] На указанном этапе 120, из набора данных отбираются данные, которые при этом не являются идентификационными значениями. Так, в одном частном варианте осуществления, из набора выделяются числовые значения, которые не являются идентификационными значениями (ИНН, номер счета, номер телефона и т.д.). Так, в еще одном частном варианте осуществления, могут быть отобраны данные, представленные в текстовом виде, например, после обработки данных с помощью МО, обученной на классификацию данных. Стоит отметить, что усеченный набор данных формируется на основе обезличенного структурированного набора данных, следовательно, в еще одном частном варианте осуществления выделение данных, не являющихся идентификационными, может происходить посредством анализа заголовков разделов или посредством анализа названий колонок (если набор данных представлен в табличном виде). Соответственно, посредством анализа колонок, для формирования усеченного набора данных, из набора данных могут быть исключены все колонки, относящиеся к идентификационной информации. Так, в еще одном частном варианте осуществления, из структурированного набора данных могут быть отобраны колонки, содержащие только числовые значения, которые при этом не содержат идентификационных значений (ИНН, номер счета, номер телефона и т.д.). Стоит отметить, что идентификационные числовые значения могут представлять числовые сущности, связанные с объектом персональных данных. Так, например, числовые сущности могут представлять, по меньшей мере, одно из: основной номер держателя карты, номер ИНН, номер телефона, номер счета, номер страхового свидетельства, IP - адрес, MAC - адрес и т.д. Соответственно, именованные сущности могут представлять собой адрес, ФИО и т.д. Таким образом, посредством исключения идентификационных данных, представленных либо в виде числовых сущностей, либо в виде именованных сущностей, формируется усеченный набор данных. Хотя в качестве примера указывается один из двух видов сущностей, определяемых для исключения из набора данных, по отдельности, для специалиста в данной области техники будет очевидно, что при наличии в документе колонок, содержащих как именованные, так и числовые сущности, указанные подходы могут быть использованы в комбинации. Например, посредством определения наличия идентификационных данных, будь то числовые или именованные, в по меньшей мере одной колонке.
[0041] Также, в одном частном варианте осуществления, усеченный набор данных может быть получен, например, посредством поиска регулярных выражений, например, посредством исключения данных, относящихся к идентификационным. В еще одном частном варианте осуществления идентификационные данные определяются посредством определения категории данных, содержащейся в столбце. Так, продолжая пример для структурированных данных, при помощи поиска регулярных выражений, из документа могут быть исключены все столбцы, относящиеся к идентификационным данным.
[0042] В еще одном частном варианте осуществления, усеченный набор данных может быть получен посредством модели машинного обучения на базе нейронной сети, обученной на распознавание идентификационных данных, например, числовых сущностей, именованных сущностей, их комбинации. Так, указанный этап может выполняться моделью машинного обучения и является грубой классификацией, когда данные разделяют на числовые и именованные сущности, для последующей идентификации типа конфиденциальных данных, например, с помощью мультиклассовой классификации (Multiclass classification), распознавания именованных сущностей (NER) и т.д. В еще одном частном варианте осуществления, для повышения точности распознавания конфиденциальных данных, в настоящем решении, также могут применяться процедуры проверки контрольных разрядов к числовым сущностям, например, алгоритм проверки контрольных разрядов, такой, как алгоритм Луна. Контрольный разряд используется в различных номерах, таких как: номера банковских карт, СНИЛС, ОКПО, ОГРН, ИНН и т.д. не ограничиваясь. Контрольный разряд необходим, для того, чтобы исключить вероятность некорректного распознавания типа идентификационных (конфиденциальных) данных.
[0043] Таким образом, на этапе 120 формируется усеченный набор данных, например, в табличной форме, сформированный путем исключения колонок, содержащих идентификационную информацию, например, текстовую информацию, колонки, которые содержат числовые идентификационные данные, например, с помощью анализа наименований колонок, например, используюя алгоритмы поиска, основанные на правилах и регулярных выражениях. Как указывалось выше, в еще одном частном варианте осуществления, поиск конфиденциальных данных выполняется с помощью модели машинного обучения на базе нейронной сети, обученной на распознавание конфиденциальных данных. Специалисту в данной области техники будет очевидно, что при формировании усеченного набора данных из неструктурированных документов будет применяться подход, основанный на модели машинного обучения.
[0044] Далее, на этапе 130 осуществляют кластеризацию данных, полученных на этапе 120, с помощью модели машинного обучения на базе нейронной сети или алгоритма анализа плотности наблюдений: определение соседних точек, на основе допустимого расстояния между точками; объединение точек в по меньшей мере один кластер.
[0045] Как указывалось выше, сложность обнаружения данных, подверженных деанонимизации, заключается в том, что указанные данные являются, по сути, корректными данными. Однако, ввиду того, что указанные данные существенно отличаются от других данных внутри одной категории, то в совокупности, например, с публичными данными, такие данные могут быть деобезличины. Соответственно, для обнаружения таких «отклонений» необходимо выявить данные, которые существенно отличаются от аналогичных данных в рамках одной категории/типа. Для этого, на этапе 130 был предложен подход, основанный на кластеризации данных.
[0046] Стоит отметить, что подход, основанный на кластеризации обеспечивает возможность поиска данных, в зависимости от их близости друг к другу, вне зависимости от входного типа данных, что существенно повышает качество по сравнению с применением других подходов.
[0047] В одном частном варианте осуществления, перед кластеризацией данных, усеченный набор данных, полученный на этапе 120, обрабатывается и нормализуется.
[0048] Так, при обработке реальных массивов данных, в некоторых ячейках могут присутствовать пропущенные значения. Для повышения точности кластеризации, такие пропущенные значения могут заполняться медианным, или любым другим значением, которое будет подходить для дальнейшего анализа данных, например, средним значением по всей колонке, поскольку в таком случае минимизируется смещение при кластеризации. Далее, указанный датасет без пропусков может нормализоваться, например, с помощью алгоритма sklearn.preprocessing.MaxAbsScaler. Этот способ масштабирует и преобразует каждый ряд данных по отдельности, так что максимальное абсолютное значение каждой колонки равно 1,0. Таким образом, не происходит сдвига/центрирования данных и сохраняется разреженность данных.
[0049] Далее, на этапе 130, осуществляют кластеризацию усеченного набора данных. Так, для задачи бинарной классификации числовых данных, с помощью кластеризации, где классы характеризуют наличие или отсутствие аномалий в данных, может быть использован алгоритм DBSCAN, основанный на анализе плотности данных, в которых может содержаться шум, который и будет являться данными, подверженными деанонимизации.
[0050] В еще одном частном варианте осуществления, алгоритм кластеризации может представлять, например, алгоритм спектральной кластеризации, алгоритм IsolationForest (лес изоляций) и т.д. не ограничиваясь.
[0051] Так, в еще одном частном варианте осуществления, в качестве модели машинного обучения может быть использована модель машинного обучения, обученная на выявление аномальных данных в обезличенных наборах данных. Так, указанная модель предназначается для кластеризации данных и выявления данных, выходящих за пределы всех кластеров.
[0052] Рассмотрим вариант реализации модели машинного обучения. В случае, если анализируемые данные содержат колонки с текстовой информацией, которую также необходимо учитывать для решения задачи поиска аномальных значений, их необходимо преобразовать в числовой вектор. Для этого может быть использована нейронная сеть, обученная реконструировать входные данные. Так, для преобразования текстовых данных может быть использована модель автоэнкодер - это модель, применяемая для эффективного воссоздания входного сигнала на выходе, путем кодирования входа в минимальное по размеру представление, используя входящие в его архитектуру энкодер - для сжатия и декодер - для "разжатия". Уровень узкого места автокодировщика можно использовать в качестве низкоразмерного представления данных, которые затем можно кластеризовать с помощью традиционных методов.
[0053] Рассмотрим более подробно порядок шагов, необходимый для реализации вышеуказанного подхода:
[0054] На первом шаге осуществляют преобразование текстовой информации в числовые векторы данных. Для этого может быть использован подход TF-IDF или любой другой метод представления данных.
[0055] На следующем шаге создается (обучается) модель автоэнкодера.
[0056] На третьем шаге, с помощью обученной модели извлекается скрытое пространство, которое будет представлять уменьшенную версию исходных данных.
[0057] Так, на указанном шаге извлекается результат энкодера (что является уменьшенным числовым представлением текстовых данных). Указанных выход, далее, объединяется с существующим датасетом (с нормированными числовыми значениями). При этом дополнение таким числовым результатом энкодера делается для каждой текстовой колонки.
[0058] Далее, уменьшенная версия данных, описывающих текстовую информацию объединяется с преобразованными числовыми данными анализируемого набора данных. Полученный объединенный набор данных используется для кластеризации и поиска аномальных значений.
[0059] Определение параметров для алгоритма кластеризации производилось на заранее размеченных данных. На момент создания модели был использован датасет (набор данных) из набора таблиц с несбалансированными данными, ввиду необходимости решения задач поиска аномалий, которые по своему происхождению не могут быть сбалансированы (как отдельный класс) с другими классами проанализированного датасета. Алгоритм позволяет сформировать (объединить точки, которые расположены друг к другу достаточно плотно) кластеры из значений данных.
[0060] Основная метрика качества модели МО, метрика F1 мера, составляет около 0,89, Recall - 0,891, Precision - 0,894. При этом, метрика Fl-мера является более приоритетной, чем метрики Precision и Recall поскольку она является компромиссным значением между ними. Так, с точки зрения области защиты данных важно не пропустить значения, по которым возможно деобезличить данные (важен Recall). С точки зрения пользователя важно не найти избыточное количество аномалий (важен Precision), поскольку придется удалить или изменить данные, что приведет к потере изначальной целостности данных. Поэтому в качестве целевой выбрана сбалансированная метрика по этим двум показателям - F1-мера.
[0061] Указанная модель машинного обучения была успешно внедрена и протестирована в организации в рабочих процессах подразделений.
[0062] В одном частном варианте осуществления, в качестве нейронной сети может быть использована, например, нейронная сеть архитектуры трансформер (Transformer), рекуррентная нейронная сеть (RNN) и т.д., не ограничиваясь.
[0063] Стоит отметить, что кластеризация может выполняться как для общего сформированного датасета (с нормированными числовыми значениями и закодированными текстовыми), так и для каждого по отдельности (т.е. отдельно числовой, отдельно текстовый).
[0064] Для кластеризации данных, в заявленном решении, модель машинного обучения осуществляет следующую последовательность действий.
[0065] Как показано на Фиг. 2, для кластеризации данных, объединяются точки (значения усеченного набора данных), которые расположены друг к другу достаточно плотно. Для определения степени плотности используются следующие параметры: радиус, в котором происходит выявление соседних точек (допустимое расстояние между точками); минимальное число соседних точек в кластере (количество точек которое образует кластер).
[0066] Алгоритм начинается с произвольной точки. Если одна из точек не имеет заданное количество соседей, то она помечается как шум. Позже, такая точка может быть найдена в окрестности другой точки. Если в результате прохождения алгоритма по всем значениям, точка не оказывается ни в одном из кластеров, указанная точка помечается как не принадлежащая ни одному из кластеров.
[0067] Рассматриваются все точки, помеченные как соседние, если рядом с ним недостаточное количество соседей, то это край кластера. С помощью такого подхода рассматриваем все точки из исходных данных.
[0068] Отдельно необходимо обратить внимание на точки «границ», которые могут быть границей сразу нескольких кластеров. В задаче детекции аномалий не важно к какому из кластеров будет отнесена точка, поэтому она присваивается к первому по порядку.
[0069] Если все точки «границ» уже относятся к какому-то кластеру, то оставшиеся точки, которые не отнесены ни к одной из групп данных - это аномалии, т.е. данные, подверженные деанонимизации.
[0070] Некоторые точки могут находиться на границе нескольких кластеров. В задаче детекции аномалий точку можно отнести к любому кластеру, поскольку основная задача -выявить аномальные значения. Все оставшиеся точки, которые не отнесены ни к одному из кластеров - это аномалии.
[0071] Рассмотрим более подробно параметры допустимого расстояния между точек -eps - радиус, внутри которого происходит поиск соседних точек После того, как из таблицы отобраны числовые колонки для анализа на наличие аномалий, числовые данные нормализуются по методологии max_abs_scaler. Поскольку максимальное абсолютное значение каждой будет равно 1,0. В данном подходе используется кастомизированная функция 
[0072] Минимальное число соседних точек - min_samples - минимальное число соседних точек. Так, в одном частном варианте осуществления минимальное количество одной группы из всех данных должно быть не менее 3%, в случае, если 3% выборки больше 3 в количественном выражении, иначе устанавливается значение 3. Итеративным образом выявлено значение 27,5%, которое показало себя наилучшим образом на обучающей выборке.
[0073] В еще одном частном варианте осуществления может быть использован статистический подход при малом количестве данных, например, менее пяти колонок.
[0074] При статистическом подходе каждая колонка анализируется отдельно, если хотя бы в одной обнаружено аномальное значение, то весь датасет помечается, как содержащий аномальное(-ые) значение(-я). Алгоритм может содержать следующие этапы:
[0075] Проверку данных анализируемой колонки на нормальность распределения:
[0076] Если распределение нормальное, для обнаружения аномалий используется подход, основанный на проверке гипотезы о наличии аномального отклонения в выборке.
[0077] Если предположение о нормальности распределения данных отклоняется, то применяется метод кластеризации одномерных данных, основанный на анализе отсортированных данных на предмет прироста каждого последующего значения, если такой прирост достаточно велик и при этом не относится к новому кластеру, то такое значение считается аномальным.
[0078] Таким образом, на этапе 130, например, посредством модели машинного обучения, выполняют кластеризацию усеченного набора данных.
[0079] Далее, на этапе 140 определяют данные, на основе данных, полученных на этапе 130, не отнесенные ни к одному из сформированных кластеров.
[0080] На указанном этапе 140, из сформированных кластеризованных данных определяются данные, не попавшие ни в один кластер.
[0081] Так, как указывалось выше, поскольку данные, подверженные деанонимизации, по своему происхождению не могут быть сбалансированы (как отдельный класс) с другими классами датасета, то на указанном этапе 140 отбираются все значения, не привязанные к какому-либо кластеру. Кроме того, в одном частном варианте осуществления, значения, не попавшие в кластер, сопоставляются с конкретными данными, содержащимися в документе. Так, например, значения, не попавшие в кластер, сопоставляются с конкретными данными таблицы. В еще одном частном варианте осуществления может проводиться дополнительная проверка отобранных значений, например, на предмет соответствия категории, в которой такое значение содержится.
[0082] Далее, на этапе 150 формируют набор данных, подверженных деанонимизации, на основе данных, полученных на этапе 140.
[0083] На указанном этапе 150 формируется подвыборка данных, подверженных деанонимизации. В одном частном варианте осуществления подвыборка данных может быть представлена в виде отчета с указанием данных, в которых обнаружены аномальные значения, с помощью которых данные потенциально могут быть деобезличены.
[0084] На этапе 160 изменяют данные, подверженные деанонимизации.
[0085] Далее, на этапе 160 осуществляют изменение данных для повышения защищенности данных и снижения риска деобезличивания данных. Так, изменение данных может представлять сглаживание данных или удаление данных, причем удаление может быть реализовано как на уровне наблюдения, так и атрибута. Конкретный способ изменения данных может зависеть от степени критичности и характера данных, передаваемых внешним источникам. В одном частном варианте осуществления, если данные подлежат использованию, например, в соревновательных целях, то может быть применен способ удаления данных. Данные, признанные аномальными (подверженными деанонимизации), могут быть удалены из документа. В еще одном частном варианте осуществления, удаленные данные могут быть заменены на среднее/медианное/модальное значение категории указанных данных, например, столбца.
[0086] В еще одном частном варианте осуществления к данным, подверженным деанонимизации может быть применен алгоритм сглаживания, например, адаптированные методы скользящего/экспоненциального сглаживания. Указанный способ позволяет сохранить размерность данных по сравнению с удалением данных.
[0087] После изменения данных, указанные данные могут быть переданы во внешний контур, например, для проведения соревнований, исследования, разработки моделей машинного обучения и т.д.
[0088] В еще одном частном варианте осуществления указанный способ 100 может выполняться в системе безопасности организации, такой как система кибербезопасности.
[0089] Так, этапы заявленного способа 100 могут выполняться при попытке передачи данных во внешний, по отношению к организации, контур. При передаче документа, система может определять, содержится ли в документе данные, подверженные деобезличиванию.
[0090] Если данные содержатся, то соответственно пользователю может быть предложено изменить данные определенным способом (сгладить, удалить). После устранения аномалий в данных, документ может быть разрешен к отправке.
[0091] Далее рассмотрим пример реализации способа 100.
[0092] В качестве примера рассмотрим передачу из банка, согласно договору, данных для исследований сектора логистики и доставок. Данные при этом передаются без указания конкретной организации, но с рейтингом, присвоенным банком этим организациям. Документ, содержащий обезличенные данные, представляет собой структурированный документ, содержащий обезличенное наименование компаний, рейтинг, среднее количество транзакций (Таблица 1).
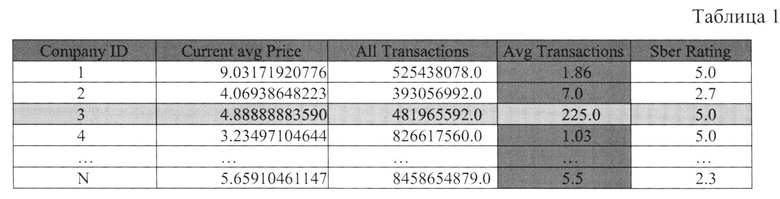
[0093] Как видно, среднее количество транзакций (Avg Transactions) у компании с ID 3 аномально отличается от всех остальных компаний.
[0094] При этом некоторой консалтинговой компанией были проведены публичные маркетинговые исследования рынка этих же компаний (Таблица 2):
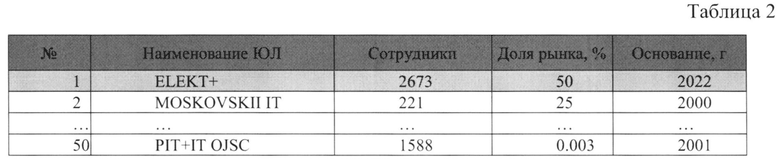
[0095] Как видно из данного исследования, есть компания, которая выделяется из всех, владея 50% рынка. Это компания ELEKT+. Соответственно, анализируя данные по транзакциям в банковских данных можно установить, что компания с ID 3 чрезвычайно выделяется по среднему количеству транзакций в день по сравнению с остальными организациями. Таким образом, на основе анализа двух изначально несвязанных наборов данных можно установить, что компания ELEKT+ и есть компания с ID 3, а также позволяет раскрыть конфиденциальную информацию компании, например, Сбера: присвоенный им score-балл (Sber Rating)
[0096] Соответственно, для минимизации риска деобезличивания, пример реализации которого описан выше, используется подход, раскрытый в способе 100, позволяющий определить в обезличенных данных наличие аномальных значений, с помощью которых можно явно идентифицировать субъект данных.
[0097] Для этого, на этапе 110, документ поступает в систему, такую как система безопасности. Как указывалось выше, указанный документ может поступать в систему при попытке отправить его за внешний контур организации.
[0098] На этапе 120 система формирует усеченный набор данных, причем указанный усеченный набор содержит по меньшей мере разделы документа с числовыми значениями, которые не являются идентификационными значениями.
[0099] В представленном примере усеченный набор будет содержать все колонки, за исключением колонки с названием компании, т.к. указанная колонка будет отнесена к идентификационной информации.
[0100] Далее, на этапе 130 выполняется кластеризация данных.
[0101] По итогу кластеризации значения компании ID 3 не попадут ни в один из кластеров, т.к. сильно отличаются по плотности относительно других.
[0102] Соответственно, на этапе 140 такое значение выбирается из данных.
[0103] На этапе 150 формируется набор данных, содержащих данные, подверженные деанонимизации. В нашем случае это данные компании ID 3.
[0104] На этапе 160 выполняется изменение данных для исключения деобезличивания данных и повышения безопасности данных. Как указывалось выше, может быть использован один из двух способов изменения данных. Так, например, данные компании ID 3 могут быть удалены и заменены, например, средними значениями по соответствующим столбцам.
[0105] Далее, система безопасности может разрешить передачу файла, содержащего измененные данные.
[0106] Далее рассмотрим систему, реализующую заявленный способ 100.
[0107] На Фиг. 3 представлен пример общего вида вычислительного устройства 300, на базе которого реализуются система выявления данных, подверженных деанонимизации, в обезличенном наборе данных, которая обеспечивает реализацию заявленного способа 100 или является частью компьютерной системы, например, сервером, персональным компьютером, частью вычислительного кластера, обрабатывающим необходимые данные для осуществления заявленного технического решения.
[0108] В одном частном варианте осуществления система выявления данных, подверженных деанонимизации, может состоять из таких модулей, как модуль поиска конфиденциальной информации, модуль поиска данных, подверженных деанонимизации, модуль изменения данных. Указанные модули могут являться частью системы безопасности организации и быть реализованы на базе устройства, такого как устройство 300.
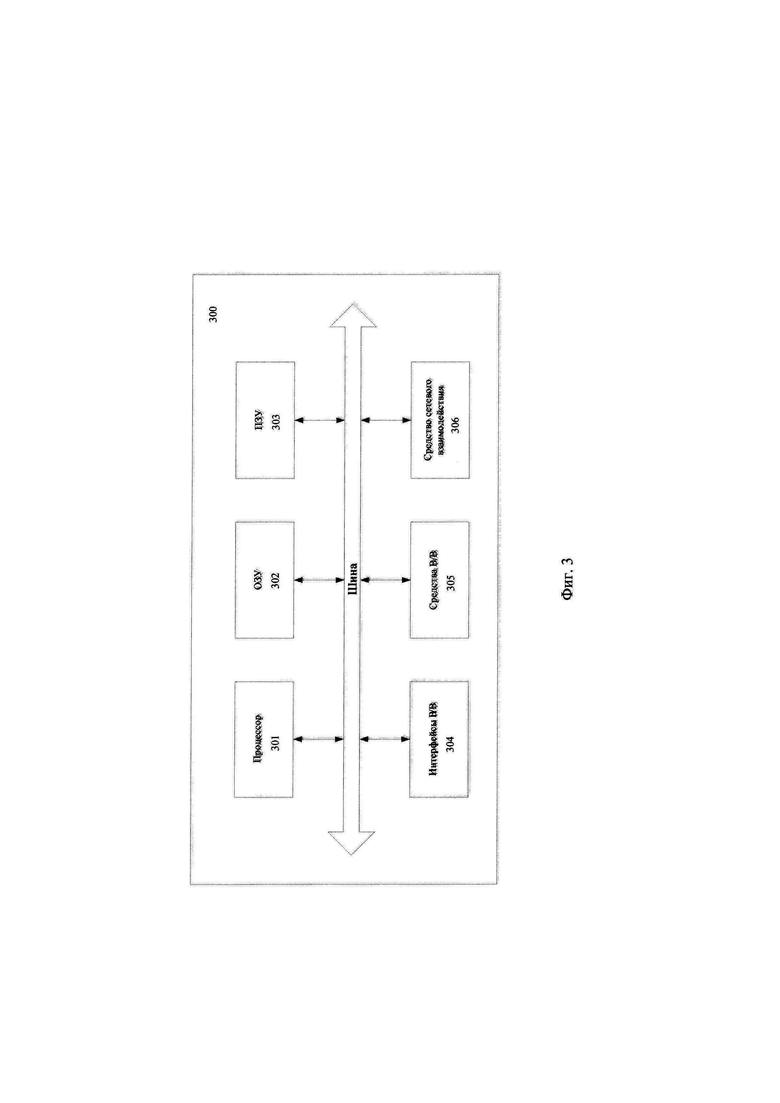
[0109] В общем случае устройство 300 содержит такие компоненты, как: один или более процессоров 301, по меньшей мере одну память 302, средство хранения данных 303, интерфейсы ввода/вывода 304, средство В/В 305, средство сетевого взаимодействия 306, которые объединяются посредством универсальной шины.
[0110] Процессор 301 выполняет основные вычислительные операции, необходимые для обработки данных при выполнении способа 100 или способа 200. Процессор 301 исполняет необходимые машиночитаемые команды, содержащиеся в оперативной памяти 302.
[0111] Память 302, как правило, выполнена в виде ОЗУ и содержит необходимую программную логику, обеспечивающую требуемый функционал.
[0112] Средство хранения данных 303 может выполняться в виде HDD, SSD дисков, рейд массива, флэш-памяти, оптических накопителей информации (CD, DVD, MD, Blue-Ray дисков) и т.п. Средства 303 позволяют выполнять долгосрочное хранение различного вида информации, например, данных, подверженных деанонимизации и т.п.
[0113] Для организации работы компонентов устройства 300 и организации работы внешних подключаемых устройств применяются различные виды интерфейсов В/В 304. Выбор соответствующих интерфейсов зависит от конкретного исполнения вычислительного устройства, которые могут представлять собой, не ограничиваясь: PCI, AGP, PS/2, IrDa, FireWire, LPT, COM, SAT A, IDE, Lightning, USB (2.0, 3.0, 3.1, micro, mini, type C), TRS/Audio jack (2.5, 3.5, 6.35), HDMI, DVI, VGA, Display Port, RJ45, RS232 и т.п.
[0114] Выбор интерфейсов 304 зависит от конкретного исполнения устройства 300, которая может быть реализована на базе широко класса устройств, например, персональный компьютер, мейнфрейм, ноутбук, серверный кластер, тонкий клиент, смартфон, сервер и т.п.
[0115] В качестве средств В/В данных 305 может использоваться: клавиатура, джойстик, дисплей (сенсорный дисплей), монитор, сенсорный дисплей, тачпад, манипулятор мышь, световое перо, стилус, сенсорная панель, трекбол, динамики, микрофон, средства дополненной реальности, оптические сенсоры, планшет, световые индикаторы, проектор, камера, средства биометрической идентификации (сканер сетчатки глаза, сканер отпечатков пальцев, модуль распознавания голоса) и т.п.
[0116] Средства сетевого взаимодействия 306 выбираются из устройств, обеспечивающий сетевой прием и передачу данных, например, Ethernet карту, WLAN/Wi-Fi модуль, Bluetooth модуль, BLE модуль, NFC модуль, IrDa, RFID модуль, GSM модем и т.п.С помощью средств 305 обеспечивается организация обмена данными между, например, устройством 300, представленной в виде сервера и вычислительным устройством пользователя, на котором могут отображаться полученные данные по проводному или беспроводному каналу передачи данных, например, WAN, PAN, ЛВС (LAN), Интранет, Интернет, WLAN, WMAN или GSM.
[0117] Конкретный выбор элементов устройства 300 для реализации различных программно-аппаратных архитектурных решений может варьироваться с сохранением обеспечиваемого требуемого функционала.
[0118] Представленные материалы заявки раскрывают предпочтительные примеры реализации технического решения и не должны трактоваться как ограничивающие иные, частные примеры его воплощения, не выходящие за пределы испрашиваемой правовой охраны, которые являются очевидными для специалистов соответствующей области техники. Таким образом, объем настоящего технического решения ограничен только объемом прилагаемой формулы.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ И СИСТЕМА ОБЕЗЛИЧИВАНИЯ КОНФИДЕНЦИАЛЬНЫХ ДАННЫХ | 2022 |
|
RU2802549C1 |
| СПОСОБ И СИСТЕМА ОБЕЗЛИЧИВАНИЯ КОНФИДЕНЦИАЛЬНЫХ ДАННЫХ | 2022 |
|
RU2804747C1 |
| СПОСОБ И СИСТЕМА ВЫЯВЛЕНИЯ КОНФИДЕНЦИАЛЬНЫХ ДАННЫХ | 2023 |
|
RU2838508C2 |
| СПОСОБ И СИСТЕМА ДЛЯ ГЕНЕРАЦИИ СИНТЕТИЧЕСКИХ ДАННЫХ | 2023 |
|
RU2824524C1 |
| СПОСОБ И СИСТЕМА КЛАССИФИКАЦИИ ДАННЫХ ДЛЯ ВЫЯВЛЕНИЯ КОНФИДЕНЦИАЛЬНОЙ ИНФОРМАЦИИ В ТЕКСТЕ | 2019 |
|
RU2755606C2 |
| Способ обезличивания персональных данных | 2021 |
|
RU2780957C1 |
| СПОСОБ И СИСТЕМА РАСПОЗНАВАНИЯ ИНФОРМАЦИИ, СОСТАВЛЯЮЩЕЙ КОММЕРЧЕСКУЮ ТАЙНУ | 2024 |
|
RU2841161C1 |
| СПОСОБ ВАЛИДАЦИИ ОБЕЗЛИЧЕННЫХ ПОЛЬЗОВАТЕЛЬСКИХ ДАННЫХ | 2024 |
|
RU2837045C1 |
| СПОСОБ И СИСТЕМА ВЫЯВЛЕНИЯ ОБФУСЦИРОВАННЫХ ВРЕДОНОСНЫХ КОМАНД В СИСТЕМНОЙ КОНСОЛИ ОПЕРАЦИОННОЙ СИСТЕМЫ | 2024 |
|
RU2838483C1 |
| СПОСОБ И СИСТЕМА КЛАССИФИКАЦИИ ДАННЫХ ДЛЯ ВЫЯВЛЕНИЯ КОНФИДЕНЦИАЛЬНОЙ ИНФОРМАЦИИ | 2019 |
|
RU2759786C1 |
Изобретение относится к области защиты данных, а в частности к способу и системе выявления данных, подверженных деанонимизации, в обезличенном наборе данных. Техническим результатом является повышение эффективности защиты данных за счет выявления данных, подверженных деанонимизации. Указанный технический результат достигается благодаря осуществлению способа выявления данных, подверженных деанонимизации, в обезличенном наборе данных, содержащего этапы, на которых получают набор структурированных обезличенных данных; формируют усеченный набор данных, причем указанный усеченный набор содержит по меньшей мере разделы документа с числовыми значениями, которые не являются идентификационными значениями; осуществляют кластеризацию данных, в ходе которой выполняют: определение соседних точек на основе допустимого расстояния между точками; объединение точек в по меньшей мере один кластер; определяют данные не отнесенные ни к одному из сформированных кластеров; формируют набор данных, подверженных деанонимизации; изменяют данные, подверженные деанонимизации. 2 н. и 6 з.п. ф-лы, 3 ил., 2 табл.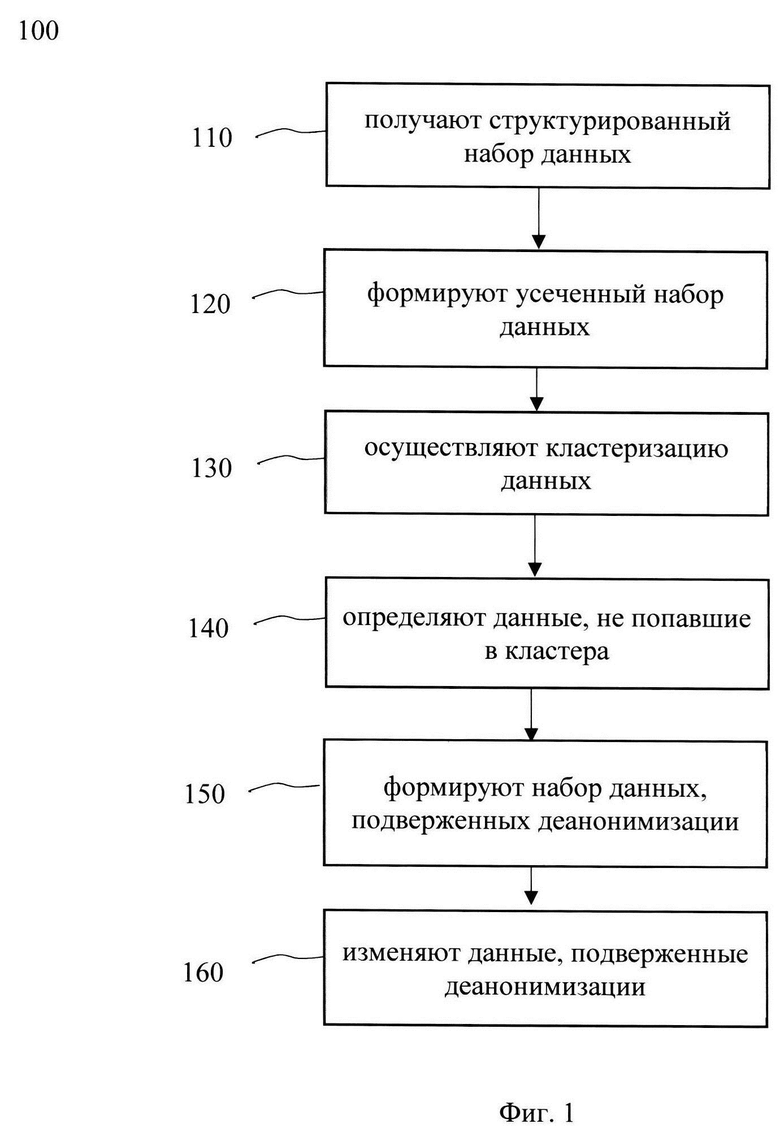
1. Способ выявления данных, подверженных деанонимизации, в обезличенном наборе данных, содержащий этапы, на которых:
a) получают набор структурированных обезличенных данных;
b) формируют, на основе данных, полученных на этапе а), усеченный набор данных, причем указанный усеченный набор содержит по меньшей мере данные из набора структурированных обезличенных данных, которые не являются идентификационными данными;
c) осуществляют кластеризацию данных, полученных на этапе b), в ходе которой выполняют:
i) определение соседних точек, на основе допустимого расстояния между точками;
ii) объединение точек, полученных на шаге i), в по меньшей мере один кластер;
d) определяют данные, на основе данных, полученных на этапе с), не отнесенные ни к одному из сформированных кластеров;
e) формируют набор данных, подверженных деанонимизации, на основе данных, полученных на этапе d);
f) изменяют данные, подверженные деанонимизации.
2. Способ по п. 1, характеризующийся тем, что идентификационные данные представляют собой идентификационные значения и/или идентификационные сущности.
3. Способ по п. 2, характеризующийся тем, что идентификационные значения представляют собой, по меньшей мере, ИНН, номер счета, номер телефона.
4. Способ по п. 2, характеризующийся тем, что идентификационные сущности представляют собой по меньшей мере ФИО, адрес.
5. Способ по п. 1, характеризующийся тем, что усеченный набор данных формируется с помощью модели машинного обучения на базе нейронной сети, обученной на распознавание идентификационных значений.
6. Способ по п. 1, характеризующийся тем, что изменение данных, подверженных деанонимизации включает в себя по меньшей мере одно из:
a) сглаживание данных, подверженных деанонимизации;
b) удаление данных, подверженных деанонимизации.
7. Способ по п. 6, характеризующийся тем, что сглаживание данных, подверженных деанонимизации, представляет собой по меньшей мере замену данных, подверженных деанонимизации, на среднее, или медианное, или модальное значение.
8. Система выявления данных, подверженных деанонимизации, в обезличенном наборе данных, содержащая:
- по меньшей мере один процессор;
- по меньшей мере одну память, соединенную с процессором, которая содержит машиночитаемые инструкции, которые при их выполнении по меньшей мере одним процессором обеспечивают выполнение способа по любому из пп. 1-7.
| Способ получения продуктов конденсации фенолов с формальдегидом | 1924 |
|
SU2022A1 |
| Способ получения продуктов конденсации фенолов с формальдегидом | 1924 |
|
SU2022A1 |
| CN 110334548 A, 15.10.2019 | |||
| Способ получения продуктов конденсации фенолов с формальдегидом | 1924 |
|
SU2022A1 |
| СПОСОБ ДЕАНОНИМИЗАЦИИ ПОЛЬЗОВАТЕЛЕЙ СЕТИ ИНТЕРНЕТ | 2021 |
|
RU2782705C1 |
| СПОСОБ И СИСТЕМА ОБЕЗЛИЧИВАНИЯ КОНФИДЕНЦИАЛЬНЫХ ДАННЫХ | 2022 |
|
RU2802549C1 |

