ОБЛАСТЬ ТЕХНИКИ
[1] Настоящее техническое решение, в общем, относится к области защиты данных, а более конкретно к распознаванию данных, составляющих коммерческую тайну, в текстовых документах.
УРОВЕНЬ ТЕХНИКИ
[2] В настоящее время в любой организации существуют ограничения на хранение, обработку и распространение конфиденциальных данных. Недопущение распространения конфиденциальной информации является важной проблемой в сфере информационной безопасности, т.к. ее утечка может повлечь за собой серьезные последствия. В связи с этим, распознавание конфиденциальной информации является одной из важнейших проблем в данной области техники.
[3] Кроме того, к некоторым видам конфиденциальной информации дополнительно применяются установленные законодательством требования по защите и обращению, регулирующие обработку такой информации, например, Федеральный закон от 29.07.2004 N 98-ФЗ «О коммерческой тайне» (далее - ФЗ-98) регулирует отношения, связанные с установлением, изменением и прекращением режима коммерческой тайны в отношении информации, которая имеет действительную или потенциальную коммерческую ценность в силу неизвестности ее третьим лицам. Так, в соответствии с законодательством, при реализации режима коммерческой тайны (КТ) надлежит организовать ряд мер по охране конфиденциальной информации, к которым относится: ограничение доступа к информации, составляющей коммерческую тайну (ИКТ); учет лиц, получивших доступ к ИКТ; регулирование отношений по использованию ИКТ; проставление грифа «Коммерческая тайна» на носителях ИКТ и включение его в состав реквизитов документов, содержащих ИКТ, в том числе электронных.
[4] В связи с тем, что гриф «Коммерческая тайна» не всегда проставляется владельцем данных или проставляется некорректно, необходимо выявлять документы, реально содержащие ИКТ и одновременно не содержащие необходимого в таких случаях грифа «Коммерческая тайна», в целях исполнения обязанностей законного обладателя ИКТ и выполнения требований ст. 10 Ф3-98: внесения грифа «Коммерческая тайна», ограничение доступа к ИКТ и учет лиц, которым такой доступ предоставлен. При этом, основной сложностью при распознавании информации, содержащей коммерческую тайну, является отсутствие конкретных категорий информации, относящихся к ИКТ, что, соответственно, не позволяет применять существующие подходы по поиску конфиденциальных данных, ввиду их непригодности к поиску информации, содержащей ИКТ, но при этом не относящейся к стандартным категориям конфиденциальных данных.
[5] Так, из уровня техники известен подход, основанный на ручном распознавании такой информации в документах.
[6] К недостаткам такого подхода можно отнести низкую точность распознавания ИКТ, ввиду необходимости наличия сотрудников, разбирающихся в нормативных документах по коммерческой тайне. Кроме того, такой подход сильно подвержен влиянию человеческого фактора.
[7] Из уровня техники также известно решение, раскрытое в патенте Китая № CN 111259116 A (Beijing Luoan Technology Со Ltd), опубл. 16.01.2020. Указанное решение, в частности, раскрывает способ обнаружения данных, составляющих коммерческую тайну на основе обнаружения чувствительных данных.
[8] Недостатками указанного решения является низкая точность обнаружения данных, составляющих ИКТ, ввиду нахождения ИКТ в данных, не являющихся конфиденциальными.
[9] Общими недостатками известных решений является низкая точность и эффективность распознавания информации, содержащей коммерческую тайну, в текстовых документах, ввиду необходимости учета семантического контекста распознаваемых данных. Кроме того, такого рода решение должно обеспечивать возможность безопасной передачи данных за счет автоматического выявления документов, содержащих ИКТ, но не имеющих соответствующего грифа.
РАСКРЫТИЕ ИЗОБРЕТЕНИЕ
[10] Данное техническое решение направлено на устранение недостатков, присущих существующим решениям, известным из уровня техники.
[11] Решаемой технической проблемой в данном техническом решении является создание нового и эффективного способа распознавания данных, составляющих коммерческую тайну, в текстовых документах.
[12] Техническим результатом, проявляющимся при решении вышеуказанной проблемы, является повышение точности распознавания данных, содержащих коммерческую тайну, за счет использования семантического контекста распознаваемых данных.
[13] Указанные технические результаты достигаются благодаря осуществлению распознавания данных, составляющих коммерческую тайну, в текстовых документах, содержащий этапы, на которых:
a) получают документ, содержащий текстовые данные;
b) сегментируют текстовые данные, полученные на этапе а), причем в ходе сегментации текстовые данные разбивают на предложения;
c) токенизируют текстовые данные, причем в ходе токенизации перед каждым предложением добавляют служебный токен;
d) выполняют векторизацию токенов, полученных на этапе с);
e) осуществляют обработку векторных представлений токенов, полученных на этапе
d), с помощью модели машинного обучения на базе нейронной сети, обученной на наборах данных, содержащих коммерческую тайну, в ходе которой выполняют:
i. определение близости каждого вектора с векторами всех других токенов в предложении;
ii. формирование вектора для каждого токена, учитывающего контекстуальное отношение;
iii. объединение сформированных векторов в общий вектор предложения, образованный в результате преобразования служебного токена;
iv. определение принадлежности общего вектора к категории коммерческой тайны;
f) присваивают документу, содержащему коммерческую тайну, метку наличия коммерческой тайны.
[14] В одном из частных примеров осуществления способа общий вектор формируется по меньшей мере посредством алгоритма конкатенации среднего или максимального объединения.
[15] В другом частном примере осуществления способа категория коммерческой тайны представляет собой по меньшей мере одну из следующих категорию:
a) перспективные и стратегические коммерческие замыслы, планы по расширению;
b) программы исследований и перспективных разработок, ключевые идеи научно-исследовательских и опытно-конструкторских работ.
[16] В другом частном примере осуществления способ дополнительно содержит этап определения принадлежности документа к коммерческой тайне.
[17] В другом частном примере осуществления способа принадлежность документа к коммерческой тайне определяется на основе доли предложений с коммерческой тайной относительно общего количества предложений документа.
[18] Кроме того, заявленные технические результаты достигаются за счет системы распознавания данных, составляющих коммерческую тайну, в текстовых документах, содержащая:
• по меньшей мере один процессор;
• по меньшей мере одну память, соединенную с процессором, которая содержит машиночитаемые инструкции, которые при их выполнении по меньшей мере одним процессором обеспечивают выполнение способа распознавания данных, составляющих коммерческую тайну, в текстовых документах.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[19] Признаки и преимущества настоящего технического решения станут очевидными из приводимого ниже подробного описания и прилагаемых чертежей, на которых:
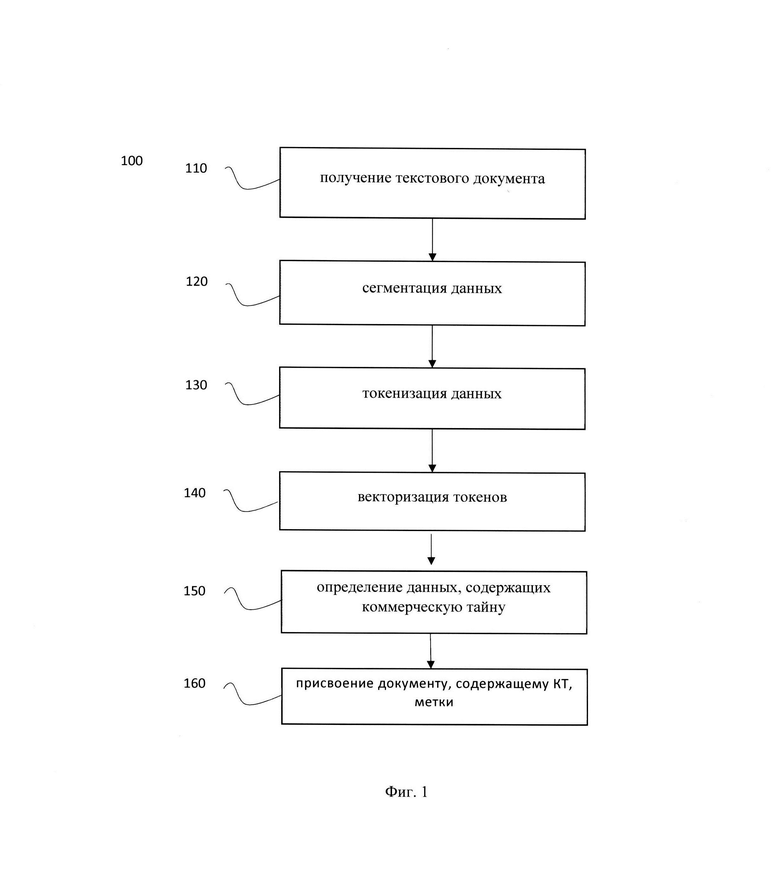
[20] Фиг. 1 иллюстрирует блок-схему выполнения заявленного способа.
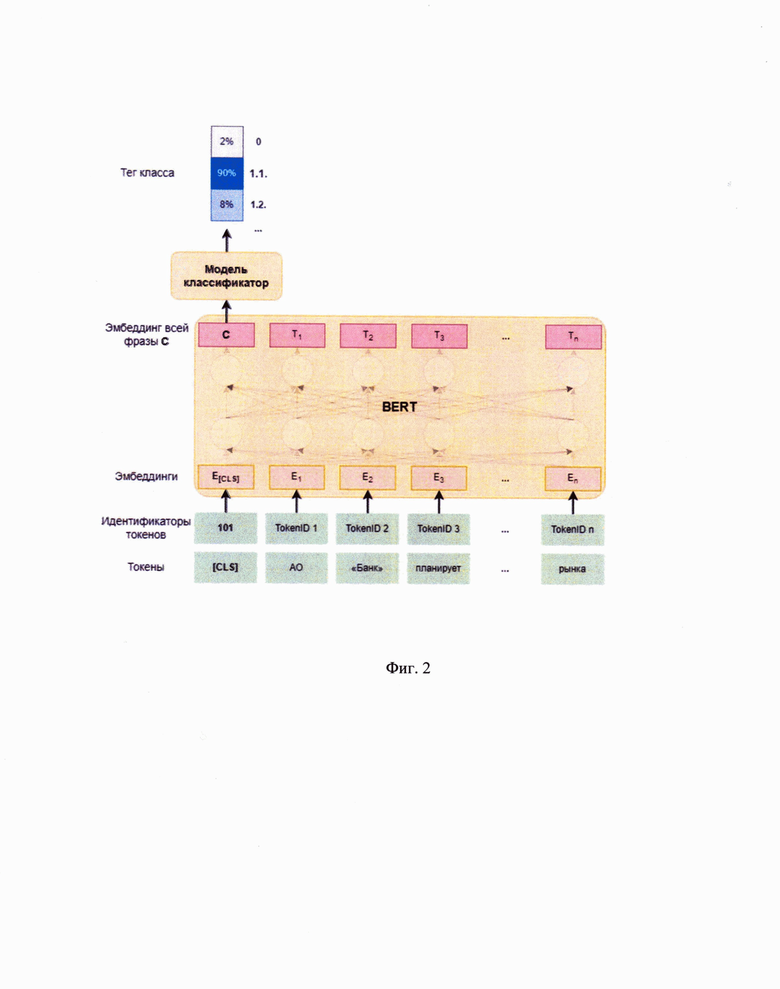
[21] Фиг. 2 иллюстрирует пример реализации механизма внимания.
[22] Фиг. 3 иллюстрирует пример вычислительного устройства для реализации заявленных систем.
ОСУЩЕСТВЛЕНИЕ ИЗОБРЕТЕНИЯ
[23] Заявленное техническое решение предлагает новых подход, обеспечивающий новый и эффективный способ распознавания данных, содержащих коммерческую тайну, в текстовых документах. Основной особенностью заявленного решения является обеспечение возможности распознавания данных, содержащих коммерческую тайну, в текстовых документах, за счет внедрения механизма внутреннего внимания, позволяющего учитывать контекстуальные отношения между словами и предложениями текстового файла. Кроме того, реализация настоящего технического решения, повышает точность распознавания наличия коммерческой тайны в текстовых файлах, за счет реализации модели машинного обучения на базе нейронной сети, обеспечивающей поиск сложных зависимостей и возможности распознавания фраз, содержащих коммерческую тайну, которые ранее не встречались в документах. Также, еще одним дополнительным преимуществом, достигаемым при использовании заявленного решения, является возможность обеспечения безопасной передачи данных, за счет автоматического выявления документов, содержащих ИКТ, но не имеющих соответствующего грифа, и, соответственно, применения политик ограничения передачи данных к таким документам в реальном времени.
[24] Заявленное техническое решение может выполняться, например, системой, машиночитаемым носителем, сервером и т.д. В данном техническом решении под системой подразумевается, в том числе компьютерная система, ЭВМ (электронно-вычислительная машина), ЧПУ (числовое программное управление), ПЛК (программируемый логический контроллер), компьютеризированные системы управления и любые другие устройства, способные выполнять заданную, четко определенную последовательность операций (действий, инструкций).
[25] Под устройством обработки команд подразумевается электронный блок либо интегральная схема (микропроцессор), исполняющая машинные инструкции (программы).
[26] Устройство обработки команд считывает и выполняет машинные инструкции (программы) с одного или более устройства хранения данных, например, таких устройств, как оперативно запоминающие устройства (ОЗУ) и/или постоянные запоминающие устройства (ПЗУ). В качестве ПЗУ могут выступать, но, не ограничиваясь, жесткие диски (HDD), флеш-память, твердотельные накопители (SSD), оптические носители данных (CD, DVD, BD, MD и т.п.) и др.
[27] Программа - последовательность инструкций, предназначенных для исполнения устройством управления вычислительной машины или устройством обработки команд.
[28] Термин «инструкции», используемый в этой заявке, может относиться, в общем, к программным инструкциям или программным командам, которые написаны на заданном языке программирования для осуществления конкретной функции, такой как, например, получение и обработка данных, формирование профиля пользователя, прием и передача сигналов, анализ принятых данных, идентификация пользователя и т.п. Инструкции могут быть осуществлены множеством способов, включающих в себя, например, объектно-ориентированные методы. Например, инструкции могут быть реализованы, посредством языка программирования С++, Java, Python, различных библиотек (например, "MFC"; Microsoft Foundation Classes) и т.д. Инструкции, осуществляющие процессы, описанные в этом решении, могут передаваться как по проводным, так и по беспроводным каналам передачи данных, например, Wi-Fi, Bluetooth, USB, WLAN, LAN и т.п.
[29] На Фиг. 1 представлена блок схема способа 100 распознавания данных, составляющих коммерческую тайну, в текстовых документах, который раскрыт поэтапно более подробно ниже. Указанный способ 100 заключается в выполнении этапов, направленных на обработку различных цифровых данных. Обработка, как правило, выполняется с помощью системы, которая может представлять, например, сервер, компьютер, мобильное устройство, вычислительное устройство и т.д, дополненное аппаратным и/или программно-аппаратным блоком, реализующим настоящий способ 100. Более подробно элементы системы раскрыты на Фиг. 3.
[30] Под термином коммерческая тайна или информация, составляющая коммерческую тайну (ИКТ), в данном решении стоит понимать данные любого характера (производственные, технические, экономические, организационные и другие), в том числе о результатах интеллектуальной деятельности в научно-технической сфере, а также данные о способах осуществления профессиональной деятельности, которые имеют действительную или потенциальную коммерческую ценность в силу неизвестности их третьим лицам, к которым у третьих лиц нет свободного доступа на законном основании и в отношении которых обладателем таких сведений введен режим коммерческой тайны. Так, данные, составляющие коммерческую тайну, могут не содержать данных, доступ к которым ограничен в соответствии с политиками безопасности организаций и/или законодательными актами, таких как персональные данные, сведения, составляющие банковскую тайну, например, ФИО сотрудников и клиентов, партнеров и поставщиков, адреса, номера телефонов, адреса электронных почтовый ящиков, номера социального страхования, информация о банковских картах, номер ИНН, регистрационный номер машины, номер БИК, IP-адрес, данные геолокации, номер документа о браке, номер документа об образовании, дата, URL-адрес, МАС-адрес, номер трудовой книжки, номер военного билета, код ОКПО и т.д., не ограничиваясь, но при этом иметь критическое значение для организации, например, данные о планах развития компании, данные структуре компании и т.д.
[31] Как указывалось выше, сложность обнаружения в текстовых документах данных, содержащих коммерческую тайну, является отсутствие четких категорий данных, которые относятся к КТ, ввиду чего, известные из уровня техники системы, направленные на распознавание именно конфиденциальных данных, малопригодны и/или вообще не способны распознавать такого рода данные. Так, например, к данным, содержащим КТ, могут относиться перспективные и стратегические замыслы компаний, при этом, для каждой конкретной компании и/или организации, такие данные могут иметь совершенно разные категории, т.е. могут значительно отличаться друг от друга.
[32] Настоящее техническое решение призвано решить указанные проблемы.
[33] На этапе 110 происходит получение документа, содержащего текстовые данные.
[34] На указанном этапе 110 документ, содержащий текстовые данные, поступает в систему, например, систему 200. В одном частном варианте осуществления, документ может быть загружен в систему 200 посредством сети связи, такой как Интернет, ЛВС и т.д. В еще одном частном варианте осуществления, документ может быть импортирован непосредственно из флэш-накопителя и/или встроенной памяти системы 200. Под документом, содержащим текстовые данные в данном решении следует понимать любой файл данных, содержащий текстовые данные. Так, документ может представлять собой любой неструктурированный документ, например, файл формата Word, PDF, текстовый документ, фотографию, оцифрованный документ, файл электронной почты и т.д.
[35] Далее способ 100 переходит к этапу 120.
[36] На этапе 120 сегментируют текстовые данные, полученные на этапе 110, причем в ходе сегментации, причем в ходе сегментации текстовые данные разбивают на предложения.
[37] Указанный этап 120 может выполняться, например, посредством поиска технических символов в тексте (например, точка, восклицательный знак, вопросительный знак и т.д.), с учетом деления указанных символов на группы, и т.д. В еще одном частном варианте осуществления, текст может разбивается на фразы, которые могут быть выражены предложениями, словосочетаниями, абзацами или отдельными словами. Например, текст «АО «Банк» планирует приобрести ключевой пакет акций организации АО «Фирма», чтобы занять большую часть рынка. Детали сделки обсуждаются.» разобьется на предложения «АО «Банк» планирует приобрести ключевой пакет акций организации АО «Фирма», чтобы занять большую часть рынка.» и «Детали сделки обсуждаются.». Выбор между уровнем сегментации текста определяется тем, насколько детально необходимо понимать, где в тексте находится КТ. Наиболее приемлемым уровнем является сегментация на предложения.
[38] Далее, фразы очищаются от служебных символов и концевых знаков препинания.
[39] Например, предложение «АО «Банк» планирует приобрести ключевой пакет акций организации АО «Фирма», чтобы занять большую часть рынка.» очистится от концевой точки и примет вид «АО «Банк» планирует приобрести ключевой пакет акций организации АО «Фирма», чтобы занять большую часть рынка».
[40] Под извлечением текста из документа в данном решении следует понимать выделение из текстового документа определенных частей текста и сохранение указанных частей в памяти системы 200, например, в виде файла данных, Т.е. на указанном этапе 120 исходный текст преобразуется в несколько частей, в соответствии с уровнем сегментации. В еще одном частном варианте осуществления, в качестве инструмента определения начала и конца части (фразы, предложения), могут использоваться как внутренние средства документа, обеспечивающие подсчет символов в тексте, например, текстовые редакторы, так и инструменты, например, программные средства для анализа текстовых документов, в том числе и встроенные в систему 200.
[41] Таким образом, на указанном этапе 120 выполняют сегментацию текстовых данных.
[42] Далее способ 100 переходит к этапу 130.
[43] На этапе 130 выполняют токенизацию текстовых данных, причем в ходе токенизации перед каждым предложением добавляют служебный токен.
[44] На этапе 130 выполняется обработка полученных текстовых данных. Входной текст токенизируется, т.е. сегментируется на части, например, на предложения, слова или символы. Под токеном в данном решении следует понимать последовательность символов в документе, которая имеет значение для анализа. Так, токенами могут являться, например, отдельные слова, части слов и т.д. Токенизация на предложения может проводиться при помощи, например, лексических анализаторов, таких как razdel, rusenttokenize, NLTK и т.д. Лексический анализ - это процесс аналитического разбора входной последовательности символов на распознанные группы (лексемы) с целью получения на выходе идентифицированных последовательностей, называемых «токенами». Кроме того, токенизация входного текста может быть осуществлена на основе регулярных выражений. Для специалиста в данной области техники очевидно, что может быть применен любой лексический анализатор известный из уровня техники и данное решение не ограничивается приведенными выше примерами. Стоит отметить, что в одном частном варианте осуществления, токену присваивается позиция в тексте и соответствующий порядковый номер.
[45] Основной особенностью данного этапа 130 является то, что перед каждым предложением, полученном на этапе 120, добавляется служебный токен. Так, в одном частном варианте осуществления, служебный токен добавляется перед каждой фразой, полученной на этапе 120.
[46] Служебный токен представляет собой некоторое фиксированное числовое значение, получаемое из обученной таблицы токенов, содержащей числовое представление для словесных токенов, в виду того, что модель работает с числами. При этом, служебный токен как таковой не имеет смысловой интерпретации на какой-либо язык. Указанный токен необходим для получения эмбеддинга всей фразы и ее классификации. Также в конфигурациях модели указывается, какой токен будет являться служебным, т.е. сводным токеном для механизма внутреннего внимания. Так, каждый токен заменяется на свой идентификатор из таблицы токенов обученной модели. Кроме того, указанный служебный токен необходим для корректной работы механизма внимания, учитывающего контекстуальные отношения между словами внутри фразы/предложения.
[47] На этапе 140 выполняют векторизацию токенов, полученных на этапе 130.
[48] На указанном этапе 140 выполняется векторизация каждого токена, полученного в процессе токенизации, например, с помощью эмбеддингов (embeddings) или прямого кодирования (one hot encoding). Так, например, при токенизации, каждый токен, представлен в словаре своим индексом, отображающий позицию в указанном словаре. Таким образом, каждый токен представляет индекс в словаре, и, соответственно процесс векторизации осуществляется путем замены каждого токена на его индекс в словаре. Затем индексы группируются с учетом разряженности словаря и семантической близости токенов. Для специалиста в данной области техники будет очевидно, что для векторизации токенов могут применять и другие алгоритмы векторизации, например, с помощью алгоритмов TransformersBertEmbedder, Word2vec, fastText и т.д., не ограничиваясь. Указанный процесс векторизации является подготовительным этапом к обработке данных моделью машинного обучения, выполняющей распознавание конфиденциальных данных (этап 150).
[49] Так, в еще одном частном варианте осуществления, в качестве векторов могут быть представлены эмбеддинги BERT, GLoVe, ELMo, word2vec и других нейросетевых архитектур, вектора TF-IDF и т.д., не ограничиваясь приведенными примерами. При этом, стоит отметить, что в эмбеддинге токена учитывается его значение и позиция в тексте.
[50] Далее способ 100 переходит к этапу 150
[51] На этапе 150 осуществляют обработку векторных представлений токенов с помощью модели машинного обучения на базе нейронной сети, обученной на наборах данных, содержащих коммерческую тайну, в ходе которой осуществляется определение принадлежности каждого токена к категории конфиденциальных данных.
[52] Для обработки неструктурированных данных и определения в неструктурированном тексте данных, содержащих коммерческую тайну, была разработана и применена модель машинного обучения. Особенностью указанной модели машинного обучения является механизм внимания. Так, с помощью нейронной сети и механизма внимания обеспечивается возможность анализа эмбеддингов сразу всех токенов во всех направлениях, благодаря чему модель машинного обучения извлекает из фразы не просто категорированные данные, а контекстуальные отношения между словами. Обработка текста во всех направлениях позволяет учитывать контекст слов относительно как предыдущих, так и последующих слов. Механизм внимания (attention) в свою очередь обеспечивает возможность выделения более значимых токенов во всей фразе и учета взаимосвязи каждого токена с каждым другим токеном из всей фразы. Таким образом формируются новые эмбеддинги токенов, учитывающие контекст, в том числе и эмбеддинг служебного токена, учитывающий контекст сразу всего предложения.
[53] Обучение модели МО производилось на заранее размеченных данных. На момент создания модели был использован датасет (набор данных) из размеченных конфиденциальных данных, состоящий из более чем 100 тысяч фраз, представленных 2,5 миллионами токенов. Набор данных сформирован по оригинальным текстовым документам, содержащим персональные данные, сведения, составляющие банковскую и коммерческую тайну, и т.д. Обучение модели распознаванию конфиденциальных данных в текстовых документах заключалось в определении классов предложений в тексте, т.е. категорий коммерческой тайны (а) перспективные и стратегические коммерческие замыслы; b) программы исследований и перспективных разработок и др.). При разметке данных каждому предложению, представленному набором токенов, проставляется тег, соответствующий категории коммерческой тайны. Если предложение не относится к коммерческой тайне, то проставляется нулевой тег. Датасет может быть представлен, например, в виде упорядоченного списка токенов, сгруппированного по предложениям. Для специалиста в данной области техники очевидно, что может быть применена любая схема разметки и представления датасета известная из уровня техники и данное решение не ограничивается приведенными выше примерами. Для обучения модели МО использовалось 80% токенов из датасета, а для расчета метрик качества - 20%. Обучение производилось на 5 эпохах.
[54] Основная метрика качества модели МО, взвешенная по классам F1 мера, составляет около 93%. При этом разброс между полнотой (recall) и точностью (precision) не превышает 0,8%, что говорит о высоком уровне качества модели как с точки зрения безопасности - низкая вероятность пропустить конфиденциальную информацию, так и с точки зрения конечного пользователя - малое количество ложных обнаружений конфиденциальной информации. Степень падения метрики качества при аугментации текстов на уровне символов, показывающая стабильность модели, не превышает 5%.
[55] Указанная модель машинного обучения на базе нейронной сети была успешно внедрена и протестирована в организации в рабочих процессах подразделений.
[56] Рассмотрим более подробно принцип работы механизма внимания в модели машинного обучения на базе нейронной сети. Так, на Фиг. 2 показан пример работы модели с механизмом внимания. В одном частном варианте осуществления, в качестве нейронной сети может быть использована, например, нейронная сеть архитектуры трансформер (Transformer), с механизмом многослойного внутреннего внимания (multi-head self-attention).
[57] Более подробно, механизм внимания описывается формулой 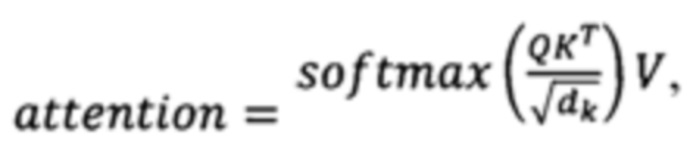 где Q - вектор запроса, K - вектор ключа, V - вектор значения, dk - размерность векторов.
где Q - вектор запроса, K - вектор ключа, V - вектор значения, dk - размерность векторов.
[58] Векторы Q, K и V получаются путем перемножения эмбеддинга токена на соответствующие матрицы, полученные при предварительном обучении модели. Поскольку в действительности вычисления производятся над векторными представлениями нескольких токенов, то Q, K и V являются матрицами, и перед расчетом произведения Q и K матрицу K необходимо транспонировать. Вектор ключа и вектор значения служат для представления токена, а вектор запроса показывает значимость данного токена относительно других. Функция softmax, выраженная формулой 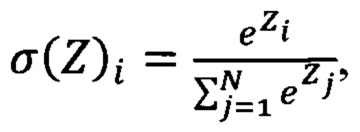 где i и j - индексы элемента вектора в диапазоне от 1 до N, служит для нормализации, т.е. преобразует вектор Z размерности N к вектору σ той же размерности, где все координаты нормированного вектора σi выражены числом в интервале от 0 до 1, а их сумма равна единице.
где i и j - индексы элемента вектора в диапазоне от 1 до N, служит для нормализации, т.е. преобразует вектор Z размерности N к вектору σ той же размерности, где все координаты нормированного вектора σi выражены числом в интервале от 0 до 1, а их сумма равна единице.
[59] Эмбеддинги токенов, учитывающие контекстуальные отношения, объединяются в общий эмбеддинг всей фразы, представленный эмбеддингом служебного токена. Данный эмбеддинг может формироваться по различным алгоритмам, например, путем конкатенации среднего (mean pooling) и максимального объединения (max pooling). Max pooling получается выбором эмбеддинга токена с максимальным значением во всей фразе, a mean pooling усреднением эмбеддингов всех токенов фразы.
[60] Далее с помощью нейронной сети, обученной на наборах текстов, содержащих коммерческую тайну, и эмбеддинга фразы (эмбеддинг служебного токена) модель относит фразу к определенному пункту перечня ИКТ. Например, 1.1. Перспективные и стратегические коммерческие замыслы, планы по расширению или 1.2. Программы исследований и перспективных разработок, ключевые идеи научно-исследовательских и опытно-конструкторских работ.Если фраза не относится к ИКТ, то проставляется нулевой тег.[61] Например, продолжая пример, рассмотренный выше, полученная фраза будет классифицироваться следующим образом:

[62] Таким образом, для учета контекстуальных отношений между словами при поиске КТ, после разбиения текста на слова (токены), вычисляются их вектора (эмбеддинги). Затем вектор каждого слова сравнивается с векторами всех других слов в предложении и анализируется их близость, благодаря чему извлекаются контекстуальные отношения между словами. За счет этого у каждого слова получается новый вектор, учитывающий контекст. Затем вектора всех слов объединяются в один общий вектор, по сути содержащий контекст всего предложения.
[63] В одном частном варианте осуществления, указанную последовательность действий повторяют заданное количество раз. Такой подход позволяет учитывать разные взаимосвязи между словами. Так, в еще одном частном варианте осуществления, указанный подход повторяют 12 раз с разными предобученными весами. Специалисту в данной области техники очевидно, что количество повторений может принимать любое целое положительное число и зависит от количества слоев нейронной сети. Продолжая рассматривать данную особенность, с каждым повторением, новый вектор предложения учитывает взаимосвязи текущего слоя и всех предыдущих. Таким образом, на выходе имеем вектор предложения, который учитывает контекст по различным взаимосвязям слов.
[64 [Предложенный подход учета контекстуальных отношений слов позволяет с высокой точностью определять взаимосвязи не соседних слов, в составе предложения.
[65] Кроме того, в еще одном частном варианте осуществления, обеспечивается возможность выделения конкретных предложений, содержащих коммерческую тайну, например, для последующего обезличивания. Т.е. возможность определения именно предложений, а не просто классификации всего документа целиком, обеспечивает более глубокий контроль за передаваемыми данными и позволяет обезличить данные, содержащие коммерческую тайну, не предотвращая передачу всего документа.
[66] Кроме того, в еще одном частном варианте осуществления, после определения данных, содержащих КТ, указанные данные могут извлекаться для последующей обработки, например, в защищенную память системы 200 для дальнейшего их обезличивания.
[67] Возвращаясь к шагам этапа 150, на первом шаге происходит определение близости каждого вектора с векторами всех других токенов в предложении.
[68] Как указывалось выше, для определения близости каждого вектора с векторами других токенов в предложении, определяют вектора Q, K и V. Вектор ключа K и вектор значения V служат для представления токена, а вектор запроса Q показывает значимость данного токена относительно других. Вектора берутся из матриц модели, сформированных во время ее обучения. Функция softmax, служит для нормализации, т.е. преобразует вектор Z размерности N к вектору σ той же размерности, где все координаты нормированного вектора σi выражены числом в интервале от 0 до 1, а их сумма равна единице. Чем ближе к 1 вычисленный по формуле 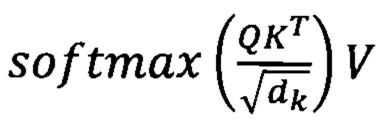 вес вектора токена, тем большее значение он оказывает на вектор токена, относительно которого осуществляются вычисления, и тем более близки эти токены с точки зрения контекста. Новый вектор токена с учетом контекста формируется суммированием произведений весов и значений остальных векторов токенов фразы.
вес вектора токена, тем большее значение он оказывает на вектор токена, относительно которого осуществляются вычисления, и тем более близки эти токены с точки зрения контекста. Новый вектор токена с учетом контекста формируется суммированием произведений весов и значений остальных векторов токенов фразы.
[69] Например, во фразе «Стратегический замысел о покупке перспективной компании и продаже убыточной организации» вектор токена «покупке» имеет больший вес относительно вектора токена «компании», чем относительно вектора токена «организации». Таким образом, механизм внимания определяет, что речь идет о покупке компании, а не организации. Суммируя все взаимосвязи между векторами токенов фразы, формируется векторное представление контекста, на основе которого определяется принадлежность фразы коммерческой тайне.
[70] Далее, на шаге два, полученные на первом шаге вектора циклически проходят по слоям нейросети, где подвергаются преобразованиям аналогичным шагу один. Наличие нескольких слоев нейросети с механизмом внимания позволяет извлечь больше признаков, влияющих на контекстуальные отношения токенов. Так, например, в одном частном варианте осуществления, на указанном шаге два, может быть совершено, например, двенадцать повторений.
[71] На шаге три объединяют сформированные вектора в общий вектор предложения. Указанный общий вектор представляет собой эмбеддинг служебного токена, учитывающий контекст всего предложения. Эмбеддинги токенов, учитывающие контекстуальные отношения, объединяются в общий эмбеддинг всей фразы, представленный эмбеддингом служебного токена. Данный эмбеддинг может формироваться по различным алгоритмам, например, путем конкатенации среднего (mean pooling) и максимального объединения (max pooling). Max pooling получается выбором эмбеддинга токена с максимальным значением во всей фразе, a mean pooling усреднением эмбеддингов всех токенов фразы. Продолжая пример из шага 1, формируется общий эмбеддинг всей фразы (векторное представление служебного токена), учитывающий контекст того, что в данной фразе речь идет о перспективных замыслах и расширении.
[72] На шаге четыре происходит определение принадлежности общего вектора к категории коммерческой тайны.
[73] Далее с помощью нейронной сети, обученной на наборах текстов, содержащих коммерческую тайну, и эмбеддинга фразы (эмбеддинг служебного токена) модель относит фразу к определенному пункту перечня ИКТ. Например, 1.1. Перспективные и стратегические коммерческие замыслы, планы по расширению или 1.2. Программы исследований и перспективных разработок, ключевые идеи научно-исследовательских и опытно-конструкторских работ. Если фраза не относится к ИКТ, то проставляется нулевой тег. Классификатор нейронной сети, определяющий принадлежность фразу к определенному пункту перечня ИКТ, может быть представлен линейным классификатором, условным случайным полем (CRF) или любым другим решением, известным из области техники. Продолжая пример, классификатор на основе эмбеддинга, содержащего контекст о перспективных замыслах по расширению, относит фразу к пункту 1.1. Перспективные и стратегические коммерческие замыслы, планы по расширению перечня ИКТ.
[74] Таким образом, на указанном этапе 150 из текстового документа распознаются и извлекаются фразы/предложения, содержащие коммерческую тайну. В еще одном частном варианте осуществления, фразам или предложениям, содержащим коммерческую тайну, присваивается категория коммерческой тайны, как это было указано выше.
[75] Далее, на этапе 160 присваивают документу, содержащему коммерческую тайну, метку наличия коммерческой тайны.
[76] Так, на указанном этапе 160 на основе исходного документа и фраз с соответствующими тегами, проставленными в результате обработки документа на этапе 150, формируется отчет, в котором выделяются фразы, содержащие ИКТ. Указанный отчет может быть сформирован, например, в графическом интерфейсе пользователя. В еще одном частном варианте осуществления документу, содержащему коммерческую тайну, присваивается метка (гриф) -коммерческая тайна.
[77] Так, указанная метка может характеризовать разрешенные каналы передачи данных внутри организации, круг лиц, имеющий доступ к таким данным и другие действия с документами, обусловленные защитой такого документа от попадания к третьим лицам.
[78] В одном частном варианте осуществления, после определения документа, содержащего ИКТ, для присваивания указанному документу метки, с документа снимается цифровой слепок (хэш). Указанный слепок содержит сведения о документе, например, о наличии ИКТ, владельце документа (пользователе) и т.д. Соответственно указанный хэш далее собирается, сохраняется и обрабатывается централизованно, в системе безопасности компании. Так, при передачи любого документа внутри сети, в том числе и документа, содержащего ИКТ, его хэш запрашивается системой безопасности и сравнивается со списком хешей документов, содержащих ИКТ. Указанная система, в частности, обеспечивает управление доступом, передачей, шифрованием, т.е. обеспечивает безопасную передачу и обработку такого документа. Кроме того, благодаря такой системе безопасности реализуется политика управления режимом ИКТ и соблюдения требований ст. 10 Ф3-98 (учет лиц, грифование, ограничение доступа).
[79] Так, в еще одном частном варианте осуществления, указанное решение может быть встроено в каналы передачи данных организации. Соответственно перед отправкой документов, указанные документы будут проверяться на наличие данных, содержащих коммерческую тайну. Если факт попытки передачи таких данных, содержащих метку ИКТ, зафиксирован, то передача документа блокируется.
[80] Таким образом, в вышеприведенных материалах был описан способ распознавания данных, содержащих коммерческую тайну, в текстовых документах.
[81] Теперь рассмотрим сценарий применения некоторых вариантов заявленного решения.
[82] Так, одним из сценариев применения может являться выявление данных, содержащих коммерческую тайну. Как указывалось выше, сложность такой процедуры заключается в том, что коммерческой тайной могут являться данные, не относящиеся к чувствительным как таковым. Например, предложение «Банк планирует провести поглощение ключевой металлургической компании». Как видно, указанное предложение не содержит данных, защищаемых законом о персональных данных или о банковской тайне, но при этом, исходя из контекста, данное выражение относится к коммерческой тайне, т.к. содержит перспективные и стратегические коммерческие замыслы, планы по расширению. Т.е. особенностью указанного способа 100 является возможность распознавания указанных данных, даже при отсутствии в документе чувствительных данных.
[83] Продолжая указанный пример, система, такая как система 200, может быть интегрирована в каналы передачи организации, например, в почтовый клиент и т.д. Соответственно все документы, передаваемые через такой канал, проходят через указанную систему. Для определения наличия данных, содержащих коммерческую тайну, а также предотвращения распространения таких данных, документ сегментируется на предложения (этап 120), токенизируется, причем в ходе токенизации перед каждым предложением добавляется служебный токен (этап 130). Далее, указанные токены векторизуются (этап 140) и обрабатываются (этап 150).
[84] Как указывалось выше, одной из особенностей заявленного технического решения является применение механизма внимания, обеспечивающего возможность учета контекстуальных отношений токенов предложения (семантическую связь), позволяющую повысить точность распознавания ИКТ в документах, в том числе за счет возможности выявления предложений, как приведено выше в примере. Для этого, на первом шаге обработки данных, определяют близость каждого вектора с векторами всех других токенов в предложении. Так, на указанном шаге вычисляется близость каждого вектора к остальным в рамках предложения. Стоит отметить, что указанное действие выполняется вместе с служебным токеном. Например, если предложение состоит из двух слов, то оно будет иметь следующую структуру [cls] t1 t2, где [cls] - вектор служебного токена, a t1 и t2 -векторное предоставление токенов предложения. Соответственно для каждого векторного представления токена вычисляется его близость с остальными. В данном случае вектора токена t1 по отношению к [cls] и t2, вектора токена t2 по отношению к [cls] и t1 и вектора токена [cls ] по отношению к t1 и t2. Результат такого вычисления будет содержать новый вектор для каждого токена, построенный с учетом близости указанного токена к остальным. Соответственно, на шаге два указанная процедура циклически повторяется заданное количество раз, например, двенадцать, для получившихся новых векторов, причем на каждом шаге берутся вектора из предыдущего шага. Стоит отметить, что циклическое повторение необходимо для обеспечения учета всех взаимосвязей (семантических связей/контекстуальных отношений) между словами. Далее, на шаге три получившиеся вектора объединяются в общий вектор предложения, на основе которого, на шаге четыре происходит определение принадлежности общего вектора к категории коммерческой тайны.
[85] Возвращаясь к приведенному примеру, если при обработке документа, данные содержат ИКТ, например, одну из приведенных выше категорий ИКТ, то документу присваивается цифровая метка. Указанная метка передается в систему безопасности. Кроме того, в еще одном частном варианте осуществления, если документ содержит ИКТ, однако не был изначально промаркирован соответствующим грифом, а был выявлен в процессе анализа, то система, такая как система 200, блокирует передачу такого документа. В еще одном частном варианте осуществления, пользователю направляется уведомление о недопустимости передачи такой информации. Кроме того, как указывалось выше, на основе данной метки обеспечивается дальнейшее распространение и обработка документа.
[86] В еще одном частном варианте осуществления, настоящий способ 100 может реализовывать распознавание конкретных предложений в тексте, содержащих ИКТ, т.е. осуществлять классификацию текста по предложениям. При использовании такого подхода, также может вычисляться доля предложений с ИКТ относительно общего количества предложений. На основе указанной доли может определяться ложное срабатывание алгоритма. Так, например, при выявлении в 1 предложении данных, содержащих ИКТ, при общем количестве предложений в 2000, будет принято решение о ложном срабатывании алгоритма и документ будет откатегорирован как не содержащий ИКТ. Напротив, если в обрабатываемом документе распознано 9 предложений с ИКТ из 10 (90%), то документ будет считаться содержащим ИКТ. Указанные особенности также позволяют повысить точность распознавания ИКТ в текстовых документах.
[87] На Фиг. 3 представлена система 200, реализующая этапы заявленного способа 100. [88] В общем случае система 200 содержит такие компоненты, как: один или более процессоров 201, по меньшей мере одну память 202, средство хранения данных 203, интерфейсы ввода/вывода 204, средство В/В 205, средство сетевого взаимодействия 206, которые объединяются посредством универсальной шины.
[89] Процессор 201 выполняет основные вычислительные операции, необходимые для обработки данных при выполнении способа 100. Процессор 201 исполняет необходимые машиночитаемые команды, содержащиеся в оперативной памяти 202.
[90] Память 202, как правило, выполнена в виде ОЗУ и содержит необходимую программную логику, обеспечивающую требуемый функционал.
[91] Средство хранения данных 203 может выполняться в виде HDD, SSD дисков, рейд массива, флэш-памяти, оптических накопителей информации (CD, DVD, MD, Blue-Ray дисков) и т.п.Средства 203 позволяют выполнять долгосрочное хранение различного вида информации, например, истории таблицы подстановок, таблицы форматирования и т.п.
[92] Для организации работы компонентов системы 200 и организации работы внешних подключаемых устройств применяются различные виды интерфейсов В/В 204. Выбор соответствующих интерфейсов зависит от конкретного исполнения вычислительного устройства, которые могут представлять собой, не ограничиваясь: PCI, AGP, PS/2, IrDa, Fire Wire, LPT, COM, SATA, IDE, Lightning, USB (2.0, 3.0, 3.1, micro, mini, type C), TRS/Audio jack (2.5, 3.5, 6.35), HDMI, DVI, VGA, Display Port, RJ45, RS232 и т.п.
[93] Выбор интерфейсов 204 зависит от конкретного исполнения системы 200, которая может быть реализована на базе широко класса устройств, например, персональный компьютер, мейнфрейм, ноутбук, серверный кластер, тонкий клиент, смартфон, сервер и т.п.
[94] В качестве средств В/В данных 205 может использоваться: клавиатура, джойстик, дисплей (сенсорный дисплей), монитор, сенсорный дисплей, тач-пад, манипулятор мышь, световое перо, стилус, сенсорная панель, трекбол, динамики, микрофон, средства дополненной реальности, оптические сенсоры, планшет, световые индикаторы, проектор, камера, средства биометрической идентификации (сканер сетчатки глаза, сканер отпечатков пальцев, модуль распознавания голоса) и т.п.
[95] Средства сетевого взаимодействия 206 выбираются из устройств, обеспечивающих сетевой прием и передачу данных, например, Ethernet карту, WLAN/Wi-Fi модуль, Bluetooth модуль, BLE модуль, NFC модуль, IrDa, RFID модуль, GSM модем и т.п. С помощью средств 606 обеспечивается организация обмена данными между, например, системой 200, представленной в виде сервера и вычислительным устройством пользователя, на котором могут отображаться полученные данные (обезличенный текстовый документ) по проводному или беспроводному каналу передачи данных, например, WAN, PAN, ЛВС (LAN), Интранет, Интернет, WLAN, WMAN или GSM.
[96] Представленные материалы заявки раскрывают предпочтительные примеры реализации технического решения и не должны трактоваться как ограничивающие иные, частные примеры его воплощения, не выходящие за пределы испрашиваемой правовой охраны, которые являются очевидными для специалистов соответствующей области.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ И СИСТЕМА ОБЕЗЛИЧИВАНИЯ КОНФИДЕНЦИАЛЬНЫХ ДАННЫХ | 2022 |
|
RU2804747C1 |
| СПОСОБ И СИСТЕМА ОБЕЗЛИЧИВАНИЯ КОНФИДЕНЦИАЛЬНЫХ ДАННЫХ | 2022 |
|
RU2802549C1 |
| СПОСОБ И СИСТЕМА КЛАССИФИКАЦИИ ТЕКСТА | 2022 |
|
RU2818693C2 |
| СПОСОБ И СИСТЕМА ПОЛУЧЕНИЯ ВЕКТОРНЫХ ПРЕДСТАВЛЕНИЙ ДАННЫХ В ТАБЛИЦЕ С УЧЁТОМ СТРУКТУРЫ ТАБЛИЦЫ И ЕЁ СОДЕРЖАНИЯ | 2024 |
|
RU2839037C1 |
| СИСТЕМА И СПОСОБ АУГМЕНТАЦИИ ОБУЧАЮЩЕЙ ВЫБОРКИ ДЛЯ АЛГОРИТМОВ МАШИННОГО ОБУЧЕНИЯ | 2020 |
|
RU2758683C2 |
| СПОСОБ И СИСТЕМА ВЫЯВЛЕНИЯ КОНФИДЕНЦИАЛЬНЫХ ДАННЫХ | 2023 |
|
RU2838508C2 |
| СПОСОБ И СИСТЕМА ГЕНЕРАЦИИ ТЕКСТА | 2023 |
|
RU2817524C1 |
| СПОСОБ И СИСТЕМА ГЕНЕРАЦИИ ТЕКСТА ДЛЯ ЦИФРОВОГО АССИСТЕНТА | 2022 |
|
RU2796208C1 |
| СПОСОБ И СИСТЕМА ИЗВЛЕЧЕНИЯ ИМЕНОВАННЫХ СУЩНОСТЕЙ | 2021 |
|
RU2823914C2 |
| СПОСОБ И СИСТЕМА ПЕРЕФРАЗИРОВАНИЯ ТЕКСТА | 2023 |
|
RU2814808C1 |
Изобретение относится к области распознавания данных. Техническим результатом является повышение точности распознавания данных, содержащих коммерческую тайну, а также возможность обеспечения безопасной передачи данных за счет автоматического выявления документов, содержащих коммерческую тайну, и применения политик ограничения передачи таких документов в реальном времени. Способ распознавания данных, составляющих коммерческую тайну, в текстовых документах содержит этапы, на которых: получают документ, содержащий текстовые данные; сегментируют текстовые данные на предложения; токенизируют текстовые данные, перед каждым предложением добавляют служебный токен; выполняют векторизацию токенов; осуществляют обработку векторных представлений токенов с помощью модели машинного обучения на базе нейронной сети, обученной на наборах данных, содержащих коммерческую тайну, на основе механизма внутреннего внимания, позволяющего учитывать контекстуальные отношения между словами и предложениями текстового файла; присваивают документу, содержащему коммерческую тайну, метку наличия коммерческой тайны. 2 н. и 4 з.п. ф-лы, 3 ил., 1 табл.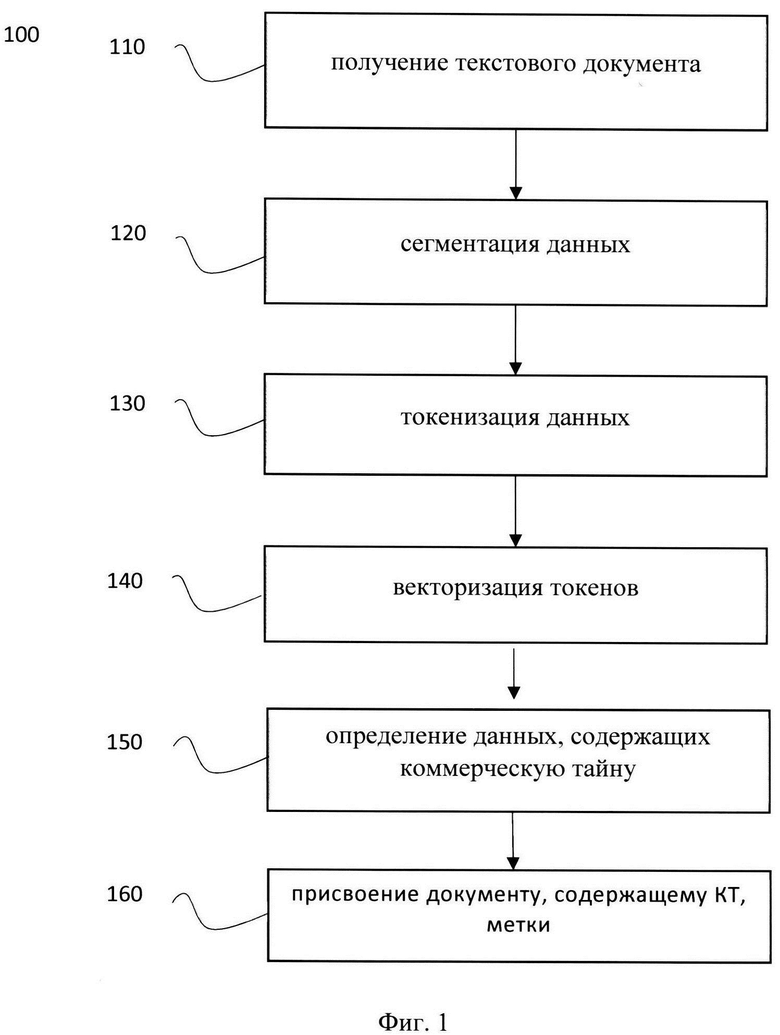
1. Способ распознавания данных, составляющих коммерческую тайну, в текстовых документах, содержащий этапы, на которых:
a) получают документ, содержащий текстовые данные;
b) сегментируют текстовые данные, полученные на этапе а), причем в ходе сегментации текстовые данные разбивают на предложения;
c) токенизируют текстовые данные, причем в ходе токенизации перед каждым предложением добавляют служебный токен;
d) выполняют векторизацию токенов, полученных на этапе с);
e) осуществляют обработку векторных представлений токенов, полученных на этапе d), с помощью модели машинного обучения на базе нейронной сети, обученной на наборах данных, содержащих коммерческую тайну, в ходе которой выполняют:
i. определение близости каждого вектора с векторами всех других токенов в предложении посредством определения весов векторов токенов относительно других векторов токенов в предложении;
ii. формирование вектора для каждого токена, учитывающего контекстуальное отношение, посредством суммирования произведений весов и значений векторов токенов предложения;
iii. объединение сформированных векторов в общий вектор предложения, образованный в результате преобразования служебного токена на основе объединения векторов токенов, учитывающих контекст;
iv. определение принадлежности общего вектора к категории коммерческой тайны;
f) присваивают документу, содержащему коммерческую тайну, метку наличия коммерческой тайны посредством хеширования документа, содержащего коммерческую тайну, причем указанная метка определяет разрешенные каналы передачи данных и круг лиц, имеющий доступ к данным, составляющим коммерческую тайну.
2. Способ по п. 1, характеризующийся тем, что общий вектор формируется по меньшей мере посредством алгоритма конкатенации среднего или максимального объединения.
3. Способ по п. 1, характеризующийся тем, что категория коммерческой тайны представляет собой по меньшей мере одну из следующих категорий:
i. перспективные и стратегические коммерческие замыслы, планы по расширению;
ii. программы исследований и перспективных разработок, ключевые идеи научно-исследовательских и опытно-конструкторских работ.
4. Способ по п. 1, характеризующийся тем, что дополнительно содержит этап определения принадлежности документа к коммерческой тайне.
5. Способ по п. 4, характеризующийся тем, что принадлежность документа к коммерческой тайне определяется на основе доли предложений с коммерческой тайной относительно общего количества предложений документа.
6. Система распознавания данных, составляющих коммерческую тайну, в текстовых документах, содержащая:
• по меньшей мере один процессор;
• по меньшей мере одну память, соединенную с процессором, которая содержит машиночитаемые инструкции, которые при их выполнении по меньшей мере одним процессором обеспечивают выполнение способа по любому из пп. 1-5.
| СПОСОБ И СИСТЕМА КЛАССИФИКАЦИИ ДАННЫХ ДЛЯ ВЫЯВЛЕНИЯ КОНФИДЕНЦИАЛЬНОЙ ИНФОРМАЦИИ В ТЕКСТЕ | 2019 |
|
RU2755606C2 |
| Способ получения продуктов конденсации фенолов с формальдегидом | 1924 |
|
SU2022A1 |
| CN 116702765 A, 05.09.2023 | |||
| US 9483532 B1, 01.11.2016 | |||
| СПОСОБ И СИСТЕМА ОБЕЗЛИЧИВАНИЯ КОНФИДЕНЦИАЛЬНЫХ ДАННЫХ | 2022 |
|
RU2802549C1 |
| Способ карбонизации растворов алюминатов | 1934 |
|
SU42047A1 |
| Тепловая изоляция | 1934 |
|
SU39466A1 |
| CN 111259116 A, 09.06.2020. | |||

