ОБЛАСТЬ ТЕХНИКИ
[0001] Заявленное техническое решение в общем относится к области защиты данных, а в частности к способу и системе выявления и классификации конфиденциальных данных в структурированных документах.
УРОВЕНЬ ТЕХНИКИ
[0002] В настоящее время крупные предприятия хранят, обрабатывают и передают огромные объемы данных, включая конфиденциальные данные, используемые в процессе функционирования предприятия. Такие конфиденциальные данные могут являться сведениями ограниченного доступа, к которым относятся, в частности, персональные данные клиентов и сотрудников, сведения, составляющие банковскую и коммерческую тайну. Одновременно с этим, предприятия обязаны обеспечивать полную сохранность и безопасность конфиденциальных данных во избежание утечек и обеспечения информационной безопасности предприятия в целом, например, в соответствии с Федеральным законом "О персональных данных", Федеральным законом "О банках и банковской деятельности", Федеральным законом "О коммерческой тайне" и т.д., которые накладывают ограничения на передачу и способы хранения такого рода данных. Кроме того, поскольку большинство предприятий работают в среде облачных вычислений, а объем больших данных увеличивается, предприятия сталкиваются с проблемой непреднамеренных утечек конфиденциальных данных, например, ввиду передачи конфиденциальных данных по открытым каналам и т.д., следовательно, испытывают трудности с принятием соответствующих мер для защиты конфиденциальных данных.
[0003] Таким образом, в организациях возникает необходимость в определении сведений ограниченного доступа и их классификации (категорирование информации), чтобы в зависимости от категории конфиденциальных данных предотвратить непреднамеренную передачу и удовлетворить требования к хранению таких данных.
[0004] Существует ряд способов выявления конфиденциальных данных в организациях, например, с помощью алгоритмов искусственного интеллекта. Данные представляются в виде файлов, содержащих данные в табличном формате (структурированные данные). Такой формат характеризуется огромным количеством значений, стоящих на пересечениях строк и колонок. На основе указанных алгоритмов можно реализовать категорирование каждого конкретного значения и, таким образом, всего файла.
[0005] К недостаткам таких методов относится низкая точность категорирования конфиденциальных данных, и, как следствие низкая точность определения конфиденциальных данных в файлах, т.к. ввиду формата данных (структурированные данные), вероятность неправильно категорировать весь файл крайне высока даже при неправильном категорировании одного значения в файле. Например, если предположить, что вероятности категорирования значений одинаковые и равны 0.999, то при расчете вероятности возникновения ошибки в таблице, состоящей из 10 колонок и 1000 строк, значение приближается к 1 и рассчитывается как Perr=1 - 0.99910000. Таким образом, при категорировании файлов, содержащих огромное количество значений в табличном формате, вероятность неправильного категорирования всего файла, приближается к 1, т.е. правильно категорировать файл практически невозможно.
[0006] Кроме того, из уровня техники известно решение, раскрытое в патенте США №US 8635691 В2 (VOGEL D J [US] et al.), опубл. 21.01.2014. Указанное решение, в частности, раскрывает способ выявления конфиденциальных данных в документах и осуществление последующей проверки данных для устранения ложных срабатываний при выявлении конфиденциальных данных, причем устранение ложных срабатываний осуществляется при помощи сравнения собранных данных с шаблонами ложноположительных конфиденциальных данных.
[0007] Недостатками указанного решения является низкая точность устранения ложных срабатываний при выявлении конфиденциальных данных из-за сильно применения шаблонов, которые, очевидно, физически не могут охватывать все возможные типы конфиденциальных и ложно конфиденциальных данных. Также, такое решение не предназначено для работы со структурированными документами, в которых содержатся миллионы записей. Кроме того, указанное решение не предполагает возможность категорирования (классификации) конфиденциальных данных, при которой, устранение ложных срабатываний указанным способом становится практически невозможным.
[0008] Общими недостатками существующих решений является отсутствие эффективного способа выявления и категорирования конфиденциальных данных в структурированных документах, обеспечивающего высокую точность, за счет устранения ложных срабатываний в процессе выявления и категорирования. Также, такого рода решения должно обеспечивать высокую точность категорирования документа за счет удаления ошибок категорирования отдельных значений внутри документа. Кроме того, такого рода решение позволяет существенно снизить, объем ручных проверок файлов, содержащих данные в табличном представлении.
РАСКРЫТИЕ ИЗОБРЕТЕНИЯ
[0009] В заявленном техническом решении предлагается новый подход к выявлению и классификации (категорирование) конфиденциальных данных в структурированных документах. В данном техническом решении используется алгоритм устранения ложных срабатываний, который позволяет повысить точность классификации и выявления конфиденциальных данных.
[0010] Таким образом, решается техническая проблема создания нового и эффективного способа выявления и классификации конфиденциальных данных.
[0011] Техническим результатом, достигающимся при решении данной проблемы, является повышение точности выявления конфиденциальных данных в структурированных документах.
[0012] Дополнительным техническим результатом, проявляющимся при решении вышеуказанной проблемы, является снижение ложных срабатываний при выявлении конфиденциальных данных.
[0013] Указанные технические результаты достигаются благодаря осуществлению способа устранения ложных срабатываний в системе выявления и классификации конфиденциальных данных, выполняющегося по меньшей мере одним вычислительным устройством, и содержащего этапы, на которых:
a) получают набор структурированных документов, содержащих данные в табличном виде;
b) осуществляют поиск конфиденциальных данных в документе и их категорирование по меньшей мере с помощью модели машинного обучения на базе нейронной сети, обученной на категорированных наборах конфиденциальных данных, в ходе которого осуществляется:
• определение конфиденциальных данных в каждой ячейке таблицы структурированного документа;
• определение тега, соответствующего типу конфиденциальной информации, для каждой ячейки столбца структурированного документа;
• определение тегов, соответствующих типу конфиденциальной информации, для каждого столбца структурированного документа на основе тегов ячеек, содержащихся в столбце;
• формирование категорированного конфиденциального набора данных, на основе определенных тегов;
c) формируют, на основе данных, полученных на этапе b), первый и второй набор конфиденциальных данных, содержащий правильно и ложно определенные типы конфиденциальных данных;
d) определяют, на основе второго набора данных, значения допустимости входа типа конфиденциальной информации, отличного от типа конфиденциальной информации, присвоенного столбцу;
e) определяют, на основе значения допустимости входа, определенного на этапе d), пороговые значения допустимости входа типов конфиденциальной информации;
f) сохраняют пороговые значения допустимости входа типов конфиденциальной информации в модель машинного обучения системы выявления и классификации конфиденциальных данных;
g) настраивают параметры модели машинного обучения в соответствии с пороговыми значениями.
[0014] Кроме того, заявленные технические результаты достигаются за счет способа выявления и классификации конфиденциальных данных в структурированных документах, выполняющегося по меньшей мере одним вычислительным устройством, и содержащего этапы, на которых:
a) получают по меньшей мере один структурированный документ, содержащий данные в табличном виде;
b) осуществляют обработку данных, полученных на этапе а), по меньшей мере с помощью модели машинного обучения на базе нейронной сети, настроенной в соответствии с этапами способа по п. 1, в ходе которой осуществляется:
i. определение конфиденциальных данных в каждой ячейки таблицы структурированного документа;
ii. определение тега, соответствующего типу конфиденциальной информации для каждой ячейки столбца структурированного документа;
iii. присвоение тега, соответствующего типу конфиденциальной информации, столбцам на основе тегов для ячеек этого столбца;
iv. сравнение, в каждом столбце, содержания тегов с типом конфиденциальной информации с пороговым значением для каждого такого тега, соответствующего типу конфиденциальных данных;
i. определение по меньшей мере одного тега столбца на основе результатов сравнения с пороговым значением, полученным на шаге iv;
c) выполнение классификации структурированного документа на основе сравнения проставленных тегов каждого столбца документа;
d) отправка классифицированного документа в систему безопасности для передачи по каналам связи в соответствии с требованиями безопасности.
[0015] Кроме того, заявленные технические результаты достигаются за счет системы устранения ложных срабатываний, содержащей:
- по меньшей мере один процессор;
- по меньшей мере одну память, соединенную с процессором, которая содержит машиночитаемые инструкции, которые при их выполнении по меньшей мере одним процессором обеспечивают выполнение способа устранения ложных срабатываний.
[0016] Кроме того, заявленные технические результаты достигаются за счет системы выявления и классификации конфиденциальных данных в структурированных документах, содержащей:
- по меньшей мере один процессор;
- по меньшей мере одну память, соединенную с процессором, которая содержит машиночитаемые инструкции, которые при их выполнении по меньшей мере одним процессором обеспечивают выполнение способа выявления и классификации конфиденциальных данных в структурированных документах.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0017] Признаки и преимущества настоящего изобретения станут очевидными из приводимого ниже подробного описания изобретения и прилагаемых чертежей.
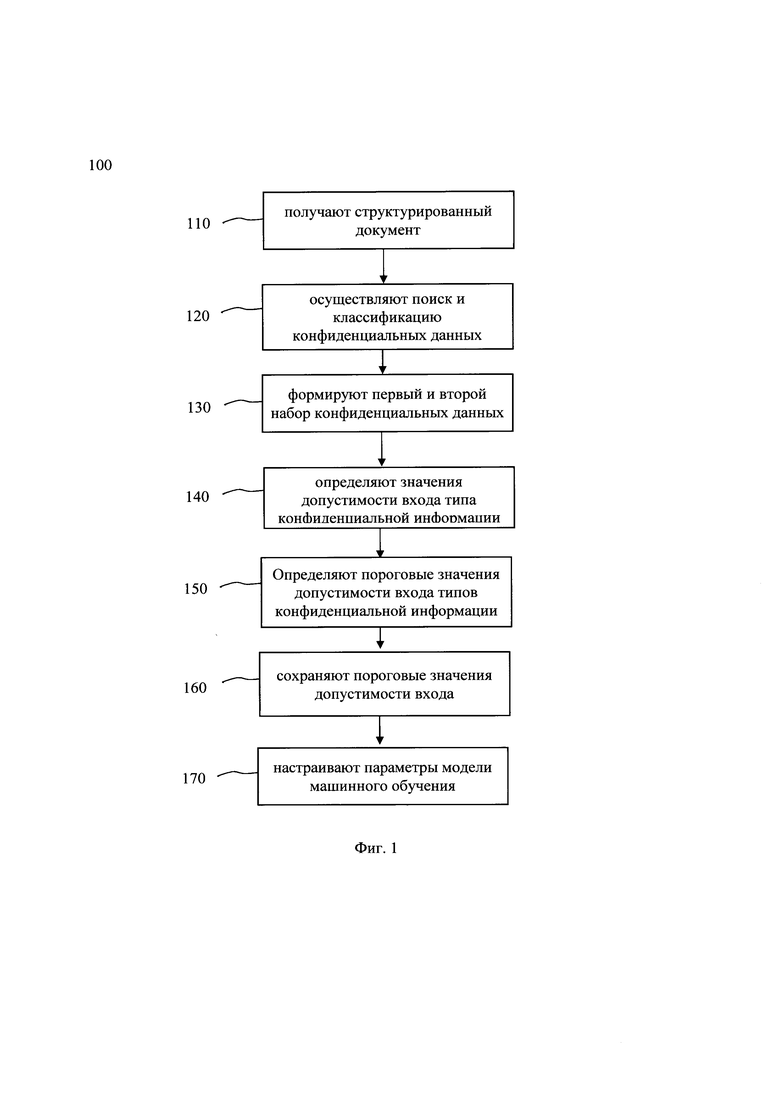
[0018] Фиг. 1 иллюстрирует блок-схему выполнения способа устранения ложных срабатываний в системе выявления и классификации конфиденциальных данных.
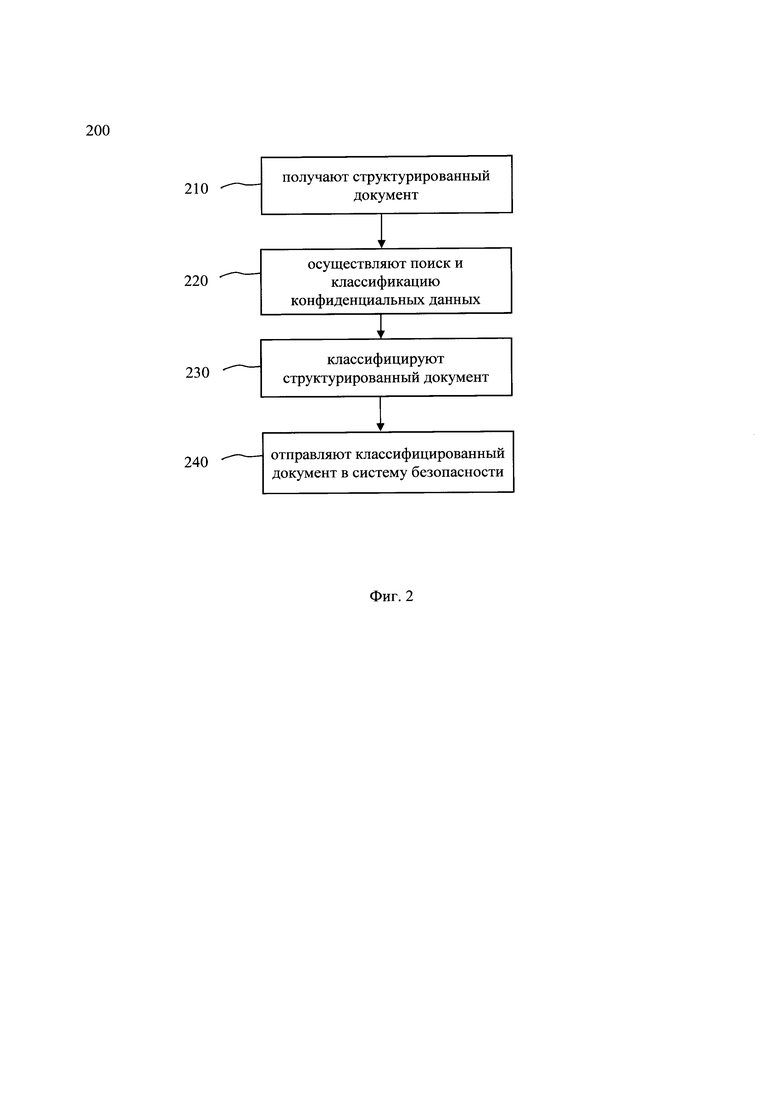
[0019] Фиг. 2 иллюстрирует блок-схему выполнения способа выявления и классификации конфиденциальных данных.
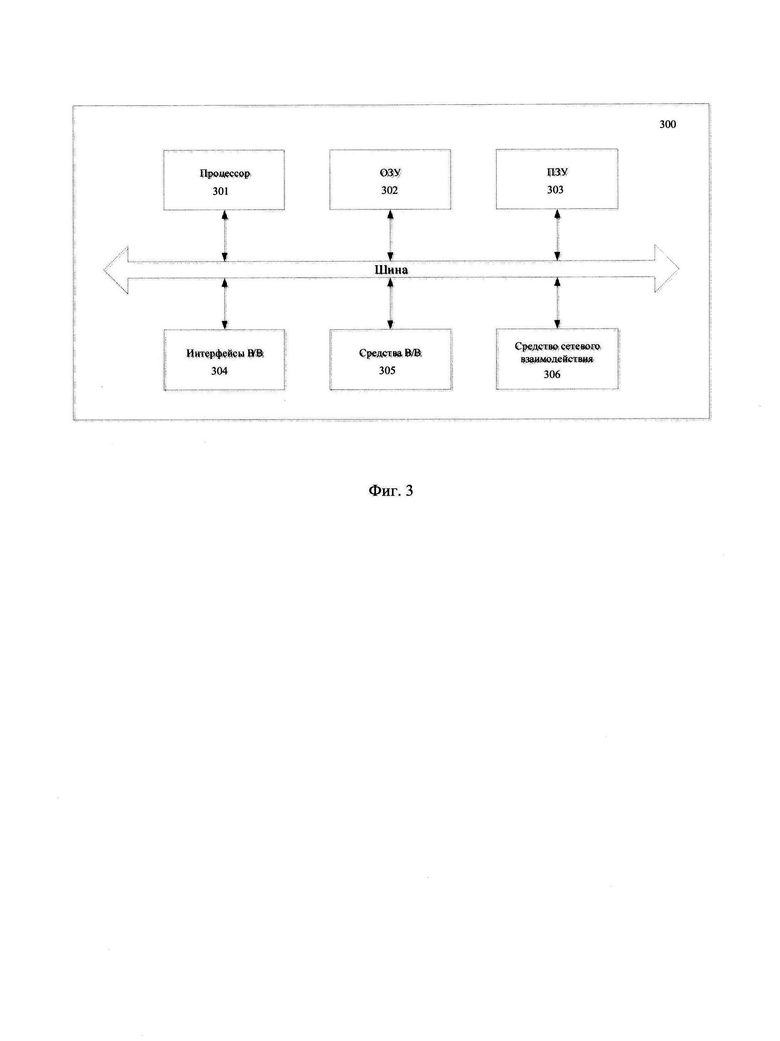
[0020] Фиг. 3 иллюстрирует пример общего вида вычислительного устройства, которое обеспечивает реализацию заявленного решения.
ОСУЩЕСТВЛЕНИЕ ИЗОБРЕТЕНИЯ
[0021] Ниже будут описаны понятия и термины, необходимые для понимания данного технического решения.
[0022] Модель в машинном обучении (МО) - совокупность методов искусственного интеллекта, характерной чертой которых является не прямое решение задачи, а обучение в процессе применения решений множества сходных задач.
[0023] Заявленное техническое решение предлагает новый подход, обеспечивающий повышение точности выявления и классификации конфиденциальных данных, заключающийся в устранении ложных срабатываний (удаление ошибок категорирования отдельных значений) в процессе классификации. Одной из особенностей заявленного технического решения является возможность проведения категорирования файлов, содержащих данные в табличной форме с высокой точностью.
[0024] Заявленное техническое решение может быть реализовано на компьютере, в виде автоматизированной информационной системы (АИС) или машиночитаемого носителя, содержащего инструкции для выполнения вышеупомянутого способа. [0025] Техническое решение также может быть реализовано в виде распределенной компьютерной системы или вычислительного устройства.
[0026] В данном решении под системой подразумевается компьютерная система, ЭВМ (электронно-вычислительная машина), ЧПУ (числовое программное управление), ПЛК (программируемый логический контроллер), компьютеризированные системы управления и любые другие устройства, способные выполнять заданную, четко определенную последовательность вычислительных операций (действий, инструкций).
[0027] Под устройством обработки команд подразумевается электронный блок либо интегральная схема (микропроцессор), исполняющая машинные инструкции (программы).
[0028] Устройство обработки команд считывает и выполняет машинные инструкции (программы) с одного или более устройства хранения данных, например, таких устройств, как оперативно запоминающие устройства (ОЗУ) и/или постоянные запоминающие устройства (ПЗУ). В качестве ПЗУ могут выступать, но, не ограничиваясь, жесткие диски (HDD), флэш-память, твердотельные накопители (SSD), оптические носители данных (CD, DVD, BD, MD и т.п.) и др.
[0029] Программа - последовательность инструкций, предназначенных для исполнения устройством управления вычислительной машины или устройством обработки команд.
[0030] Термин «инструкции», используемый в этой заявке, может относиться, в общем, к программным инструкциям или программным командам, которые написаны на заданном языке программирования для осуществления конкретной функции, такой как, например, кодирование и декодирование текстов, фильтрация, ранжирование, трансляция текстов в диалоговую систему и т.п. Инструкции могут быть осуществлены множеством способов, включающих в себя, например, объектно-ориентированные методы. Например, инструкции могут быть реализованы, посредством языка программирования, С++, Java, Python, различных библиотек (например, MFC; Microsoft Foundation Classes) и т.д. Инструкции, осуществляющие процессы, описанные в этом решении, могут передаваться как по проводным, так и по беспроводным каналам передачи данных, например Wi-Fi, Bluetooth, USB, WLAN, LAN и т.п.
[0031] На Фиг. 1 представлена блок-схема способа 100 устранения ложных срабатываний в системе выявления и классификации конфиденциальных данных, который раскрыт поэтапно более подробно ниже. Указанный способ 100 заключается в выполнении этапов, направленных на обработку различных цифровых данных. Обработка, как правило, выполняется с помощью системы, которая может представлять, например, сервер, компьютер, мобильное устройство, вычислительное устройство и т.д. Более подробно элементы системы раскрыты на Фиг. 3. В одном частном варианте осуществления, способ 100 может выполняться системой 300, которая более подробно раскрыта ниже.
[0032] Под термином конфиденциальные данные (чувствительные данные) в данном решении стоит понимать данные, доступ к которым ограничен в соответствии с политиками безопасности организаций и/или законодательными актами. Так, конфиденциальные данные могут представлять персональные данные, сведения, составляющие банковскую и коммерческую тайну, ФИО сотрудников и клиентов, партнеров и поставщиков, адреса, номера телефонов, адреса электронных почтовый ящиков, номера социального страхования, информация о банковских картах, номер ИНН, регистрационный номер машины, номер БИК, IP-адрес, данные геолокации, номер документа о браке, номер документа об образовании, дата, URL-адрес, МАС-адрес, номер трудовой книжки, номер военного билета, код ОКПО и т.д., не ограничиваясь.
[0033] Под устранением ложных срабатываний (удаление ошибок классификации отдельных значений) следует понимать - ошибочное и/или некорректное определение категории конфиденциальных данных или отнесение/не отнесение конфиденциальных/не конфиденциальных данных к какой-либо категории конфиденциальных. Появление ложных срабатываний в процессе классификации конфиденциальных данных может привести как к утечкам особо критичной конфиденциальной информации, например, при дальнейшей передачи данных по открытым каналам, так и к инцидентам информационной безопасности.
[0034] Под классификацией конфиденциальных данных понимается присвоение конфиденциальным данным тега/тегов (короткая строка, которая взаимно однозначно соответствуют видам конфиденциальной информации) из предварительно определенного набора тегов. Теги однозначно описывают отношение конфиденциальных данных к определенному типу, например, тег CARD - номер карты, NAME - имя и т.д. Теги пишутся на латинице, для того, чтобы они имели общий вид на всех кодировках. Виды конфиденциальной информации входят в одну из категорий законодательно регулируемых данных, например, персональные данные, банковская тайна, коммерческая тайна и т.д. Кроме того, классификация конфиденциальных данных может осуществляться по критичности конфиденциальных данных, так, конфиденциальные данные могут быть разделены на несколько категорий, характеризующих требования к их распространению и обработке (наиболее критичные - номера карт, ФИО, критичные - номер телефона, менее критичные - индекс и т.д.).
[0035] На этапе 110 получают по меньшей мере один структурированный документ, содержащий данные в табличном виде.
[0036] На указанном этапе 110 система выявления и классификации конфиденциальных данных получает по меньшей мере один документ, например, в виде файла данных, содержащего данные в табличном представлении. Данные в табличном представлении хранят структурированные данные в виде колонок, в каждой из которой хранится более ли менее однородная информация (один и тот же вид информации). Например, в одной колонке содержатся данные о фамилии клиента, а в другой колонке - номер его телефона. Получение файла данных может осуществляться посредством открытых каналов передачи данных, например, ЛВС (локально-вычислительная сеть). Кроме того, файл данных может быть загружен в систему, например, систему 300 выявления и классификации конфиденциальных данных через интерфейсы ввода/вывода, например, USB.
[0037] На этапе 120 осуществляют поиск конфиденциальных данных в документе и их классификацию.
[0038] На указанном этапе 120, на первом шаге, в каждой ячейке таблицы структурированного документа определяется наличие конфиденциальных данных. На втором шаге определяется тег, соответствующий типу конфиденциальной информации, для каждой ячейки столбца структурированного документа. На третьем шаге выполняют определение тега, соответствующего типу конфиденциальной информации, для каждого столбца структурированного документа на основе тегов ячеек, содержащихся в столбце. На четвертом шаге формируют категорированный конфиденциальный набор данных, на основе определенных тегов.
[0039] Так, в одном частном варианте осуществления, используются алгоритмы поиска, основанные на правилах и регулярных выражениях. В еще одном частном варианте осуществления, поиск конфиденциальных данных выполняется с помощью модели машинного обучения на базе нейронной сети, обученной на категорированных наборах конфиденциальных данных.
[0040] Так, продолжая частный вариант реализации, в качестве модели машинного обучения была разработана и обучена модель выявления и классификации конфиденциальных данных. Указанная модель предназначена для решения задачи классификации текста (задача NER). Распознавание именованных сущностей (Named-entity recognition, NER) - это подзадача извлечения информации, которая направлена на поиск и классификацию упоминаний именованных сущностей по заранее определенным категориям, таким как имена лиц, организации, местоположения, денежные значения, проценты и т.д.
[0041] Обучение модели МО производилось на заранее размеченных данных. На момент создания модели был использован датасет (набор данных) из размеченных конфиденциальных данных, состоящий из более миллиона токенов. Набор данных сформирован по оригинальным значениям табличных данных, содержащим персональные данные, сведения, составляющие банковскую и коммерческую тайну, и т.д. Обучение модели распознаванию конфиденциальных данных в структурированных документах заключалось в определении конфиденциальных данных и классификации таких данных по категориям (ФИО, номер банковской карты, номер социального страхования и т.д.). В качестве схемы для разметки данных может применятся, например, BIO/IOB-схема, BILUO-схема и т.д., не ограничиваясь. Датасет может быть представлен, например, в виде упорядоченного списка токенов, отделенных разделителем от класса именованной сущности, например, символом пробела. Для специалиста в данной области техники очевидно, что может быть применена любая схема разметки и представления датасета известная из уровня техники и данное решение не ограничивается приведенными выше примерами. Для обучения модели МО использовалось 80% токенов из датасета, а для расчета метрик качества - 20%.
[0042] Основная метрика качества модели МО, взвешенная по классам F1 мера, составляет около 97,9%, что превышает результаты автоматического машинного обучения (AutoML) более чем на 15%. При этом разброс между полнотой (recall) и точностью (precision) не превышает 0,8%, что говорит о высоком уровне качества модели как с точки зрения безопасности - низкая вероятность пропустить конфиденциальную информацию, так и с точки зрения конечного пользователя - малое количество ложных обнаружений конфиденциальной информации. Степень падения метрики качества при аугментации текстов на уровне символов, показывающая стабильность модели, не превышает 5%.
[0043] Указанная модель машинного обучения на базе нейронной сети была успешно внедрена и протестирована в организации в рабочих процессах подразделений.
[0044] В одном частном варианте осуществления, в качестве нейронной сети может быть использована, например, нейронная сеть архитектуры трансформер (Transformer), рекуррентная нейронная сеть (RNN) и т.д., не ограничиваясь.
[0045] Поиск и классификация конфиденциальных данных в структурированном документе с помощью модели машинного обучения может выполняться посредством токенизации, векторизации и обработки указанных данных. Так, входные данные токенизируются, т.е. сегментируется на части, например, на слова или символы. Под токеном в данном решении следует понимать последовательность символов в документе, которая имеет значение для анализа. Так, токенами могут являться, например, отдельные слова, части слов и т.д. Токенизация на предложения может проводиться при помощи, например, лексических анализаторов, таких как razdel, rusenttokenize, NLTK и т.д. Лексический анализ - это процесс аналитического разбора входной последовательности символов на распознанные группы (лексемы) с целью получения на выходе идентифицированных последовательностей, называемых «токенами». Кроме того, токенизация входного текста может быть осуществлена на основе регулярных выражений. Для специалиста в данной области техники очевидно, что может быть применен любой лексический анализатор известный из уровня техники и данное решение не ограничивается приведенными выше примерами.
[0046] Далее выполняется векторизация каждого токена, полученного в процессе токенизации, например, с помощью эмбеддингов (embeddings) или прямого кодирования (one hot encoding). Так, например, при токенизации, каждый токен, представлен в словаре своим индексом, отображающий позицию в указанном словаре. Таким образом, каждый токен представляет индекс в словаре, и, соответственно процесс векторизации осуществляется путем замены каждого токена на его индекс в словаре. Затем индексы группируются с учетом разряженности словаря и семантической близости токенов. Для специалиста в данной области техники будет очевидно, что для векторизации токенов могут применять и другие алгоритмы векторизации, например, с помощью алгоритмов TransformersBertEmbedder, Word2vec, fastText и т.д., не ограничиваясь. Указанный процесс векторизации является подготовительным этапом к обработке данных моделью машинного обучения, выполняющей выявление и классификацию конфиденциальных данных.
[0047] Таким образом, на этапе 120, например, посредством модели машинного обучения, обученной на категорированных наборов конфиденциальных данных, выполняют поиск конфиденциальных данных в ячейках, присвоения тега каждой ячейки, присвоение тега столбцу с ячейками на основе тегов ячеек и формирование набора классифицированных конфиденциальных данных.
Пример классификации структурированного документа, содержащего 17 колонок, приведен в таблице 1.
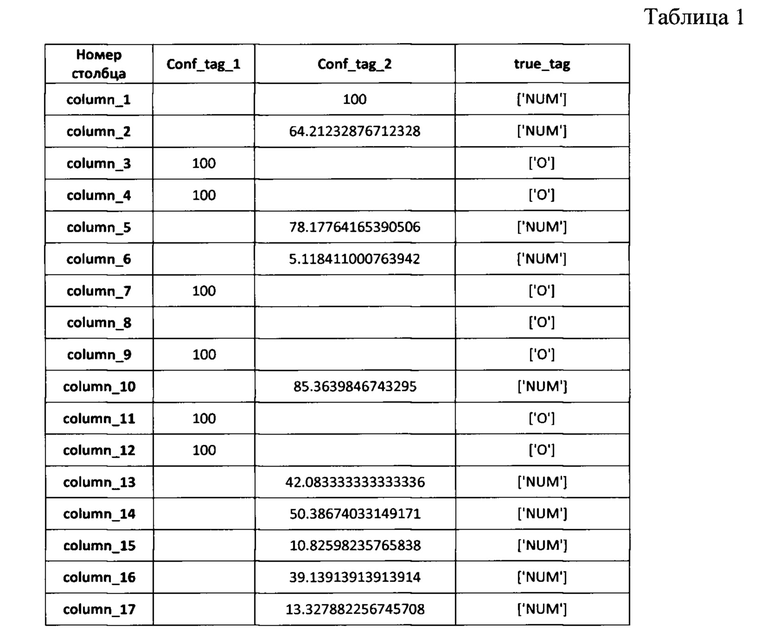
[0048] Так, в указанном варианте осуществления, колонки, размеченные тегами -conf tag представляют собой категорию конфиденциальных данных, относящуюся либо к числовым конфиденциальным данным, либо к именным, например, О или NUM. Стоит отметить, что категория О является категорией именованных сущностей, например, ФИО, Адрес, Место жительства и т.д., а категория NUM представляет собой числовые категории конфиденциальной информации, например, ИНН, номер карты и т.д. В еще одном частном варианте осуществления, con-tag может представлять конкретную категорию конфиденциальной информации, например, NAME, INN, CARD и т.д. Очевидно, что вместо двух тэгов, представленных в качестве примера, в реализации настоящего технического решения, классификация конфиденциальных данных может осуществляться непосредственно по множеству категорий. Указанный пример приведен для описания общего принципа работы.
[0049] При этом, значение, определенное для каждого conf tag представляет процент вхождения каждого типа конфиденциальной информации в колонку от общего значения (для NUM будут учитываться только числовые значения колонки и т.д.).
[0050] Колонка, размеченная тэгом True_tag, представляет собой категорию конфиденциальных данных, присвоенную рассматриваемой колонке (column_l - column 17 и т.д.)
[0051] Таким образом, формируется набор классифицированных конфиденциальных данных.
[0052] Далее способ 100 переходит к этапу 130.
[0053] На этапе 130 формируют, на основе данных, полученных на этапе 120, первый и второй набор конфиденциальных данных, содержащий правильно и ложно определенные типы конфиденциальных данных.
[0054] Поскольку при категорировании значений в одной колонке мы можем выяснить, что большинство значений относятся к одному виду, и при этом есть некоторое кол-во значений, которые относятся к другому виду, то при стандартных методах классификации, указанной колонке будет присвоен неверный класс (например, по виду конфиденциальных данных, которые ниже по степени критичности). Это может привести к утечке критичных конфиденциальных данных. Кроме того, на практике, встречаются колонки, содержащие разную длину и/или разный тип (например, часть колонки содержит текстовые данные, а часть числовые, также, часть может представлять из себя смешанный набор символов, состоящий как из цифр, так и букв). Также, к появлению неверно классифицированных конфиденциальных данных, может привести полное совпадение структуры выражения (численного или смешанного). Указанная особенность свойственна при поиске конфиденциальной информации с помощью регулярных выражений и методах, основанных на них (например, вычисление контрольных сумм). Кроме того, еще одной проблемой, при поиске и классификации конфиденциальных данных с помощью алгоритмов машинного обучения может относится к схожему по написанию выражению. При анализе похожих по написанию текстовых выражений (например, морфологическое сходство, регистр и др.) схожие слова могут быть отнесены к некорректным категориям. Поскольку информация представлена в структурированном виде, каждая запись в таблице - самостоятельное выражение, не имеющее контекста справа или слева, поэтому обучить модели более точно определять вид конфиденциальной информации невозможно (например, схожесть адресов, а именно наименований улиц и фамилий).
[0055] Все вышеперечисленные особенности как раз относятся к ложным срабатываниям. Для устранения указанных ошибок при классификации конфиденциальных данных, настоящее техническое решение предлагает новый подход, основанный на определении пороговых значений, которые характеризуют уровень, при котором считается, что вид информации некоторых значений определен ложно в анализируемом столбце.
[0056] Так, для определения пороговых значений, полученные на этапе 120, данные разделяются на значения, которые относятся к корректно определенным тегам и которые относятся к ложным срабатываниям AI-модели и регулярных выражений.
[0057] Для отнесения значения к ложному или правдивому результату может быть использована система автоматической проверки результатов классификации, реализованная на базе вычислительного устройства, раскрытого на фиг. 3.
[0058] Так, например, полученные результаты отправляются на проверку, в ходе которой осуществляется сопоставление полученных результатов с эталонными результатами для обрабатываемого документа. Например, в качестве эталонных результатов может быть использован заранее размеченный массив данных. Соответственно после классификации конфиденциальных данных, указанные результаты сравниваются с эталонными результатами. Кроме того, виды информации и статистические значения для них, которые определены для колонки корректно, с точки зрения работы AI-модели и регулярных выражений относятся в ряд с правдивыми значениями. Остальные теги и значения для них относятся к ряду с ложными результатами.
[0059] Далее на этапе 140 определяют, на основе второго набора данных, содержащего ложноположительные результаты, значения допустимости входа типа конфиденциальной информации, отличного от типа конфиденциальной информации, присвоенного столбцу.
[0060] Для этого выполняется анализ ряда с ложными срабатываниями.
[0061] Проверяются гипотезы о нормальности распределения ряда по всем проанализированным колонкам, с помощью следующих тестов:
[0062] Тест Шапиро-Вилко, который пригоден для относительно небольших выборок (менее или равных 1000 наблюдений). Нулевая гипотеза данного критерия: случайная величина распределена нормально. Статистика критерия имеет вид:
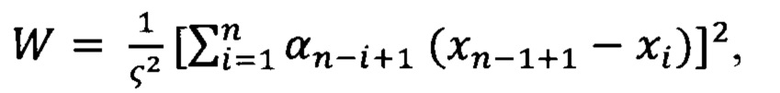
где 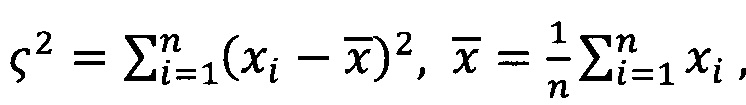 коэффициент
коэффициент 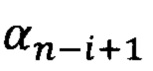 является табличным.
является табличным.
Если рассчитанное статистическое значение W меньше табличного для заданного уровня значимости (в нашем случае, 5%), то нулевая гипотеза о нормальности распределения отклоняется.
[0063] Тест Д'Агостино, основан на преобразованиях эксцесса и асимметрии, показывает, насколько распределение отклонено от нормального. Как и в прошлом тесте, нулевая гипотеза предполагает, что случайная величина относится к нормальному распределению. Если полученное значение p-value мало относительно выбранного уровня значимости (5%), скорее всего данные не относятся к нормальному распределению. Значение критерия рассчитывается следующим образом:
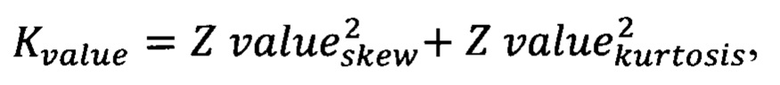 т.е. представляет собой комбинацию преобразованных значений эксцесса и асимметрии.
т.е. представляет собой комбинацию преобразованных значений эксцесса и асимметрии.
[0064] Тест Андерсона-Дарлинга, который чаще всего используется для обнаружения отклонения от нормальности максимального и минимального значений распределения. Значение статистики рассчитывается следующим образом:
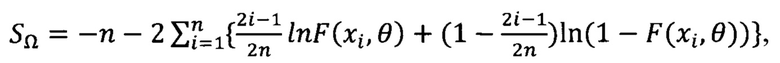 критическое значение критерия является табличным (α2(R*)), нулевая гипотеза не отвергается, если для полученных значений
критическое значение критерия является табличным (α2(R*)), нулевая гипотеза не отвергается, если для полученных значений 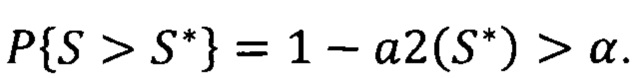 Данный критерий рассчитывается для 5 уровней значимости (α=[15, 10, 5, 2.5, 1]).
Данный критерий рассчитывается для 5 уровней значимости (α=[15, 10, 5, 2.5, 1]).
[0065] Таким образом, на этапе 140 определяют значения допустимости входа типа конфиденциальной информации, отличного от типа конфиденциальной информации, присвоенного столбцу.
[0066] Далее способ 100 переходит к этапу 150.
[0067] На этапе 150 определяют на основе значения допустимости входа, определенного на этапе 140, пороговые значения допустимости входа типов конфиденциальной информации.
[0068] Результаты тестов используются для принятия решения о схожести ряда с нормальным распределением. Для выборок используются следующие комбинации результатов тестов на нормальность:
[0069] Для небольших выборок (менее или равных 1000 наблюдений) наибольший вес имеет тест Шапиро-Вилко, общая комбинация принимает вид:
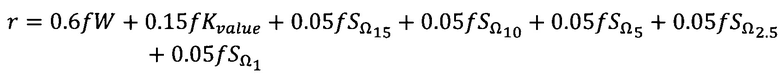
[0070] Для больших выборок (более 1000 наблюдений) больший вес имеют критерии оценивающие схожесть распределения с нормальным, опираясь на отклонения максимальных и минимальных значений, общая комбинация принимает вид:
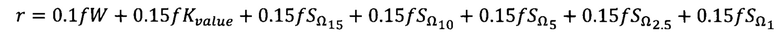
[0071] В обоих комбинациях f с последующим обозначением критериев представляет собой бинарную величину, где 1 означает, что нулевая гипотеза о «нормальности» распределения случайной величины не отвергается. Максимальное значение комбинации критериев равно 1, в случае, если все тесты показали, что распределение можно считать нормальным, в таком случае пороговое статистическое значение принимается равным 80-му перцентилю по ошибочным определениям классов. Минимальное значение равно 0, характеризует случай, когда все тесты на схожесть с нормальным распределением показали, что нулевая гипотеза отвергается, в таком случае пороговое значение принимается равным значению 99-му перцентилю, исходя из предположения, что возможно минимальное количество рассчитанных значений для категорируемых колонок превышает допустимый порог по ложным срабатываниям в категорировании ячеек колонки.
[0072] В случае, если комбинация принимает значение между 0 и 1, пороговое значение определяется по следующей схеме:
- вычисляются статистические значения: мода, медиана, среднее
- если эти 3 значения равны, то и пороговым назначается оно
- если мода не нулевая и не равна медиане или среднему значению, то рекомендуется в качестве порогового значения принять моду
- во всех остальных случаях, в качестве порога устанавливается значения 99-го перцентиля.
[0073] После того как определены рекомендации для пороговых значений, для анализа берется ряд с правдивыми значениями. Определяется минимальное правдивое значение для анализируемого ряда.
[0074] В случае если минимальное значение оказывается больше рекомендуемого порогового значения, запускается цикл уменьшения рекомендуемого значения исходя из процентильных значений с шагом уменьшения 0.1.
[0075] Далее на этапе 160 сохраняют пороговые значения допустимости входа типов конфиденциальной информации в модель машинного обучения системы выявления и классификации конфиденциальных данных.
[0076] Полученные пороговые значения далее сохраняются в модель машинного обучения. Указанный этап 160 может выполняться посредством предоставления файла с пороговыми значениями в модель машинного обучения.
[0077] Далее на этапе 170 настраивают параметры модели машинного обучения в соответствии с пороговыми значениями.
[0078] На указанном этапе 170 определенные пороговые значения далее устанавливаются в модель машинного обучения, выполняющую классификацию и выявление конфиденциальных данных.
[0079] За счет определенных пороговых значений, обеспечивается исключение ложных срабатываний в процессе классификации конфиденциальных данных, что, соответственно, значительно повышает защищенность данных в организации.
[0080] Далее рассмотрим пример реализации способа 100.
[0081] Рассмотрим пример с 10000 наблюдениями, их можно представить в виде 10 колонок по 1000 независимых наблюдений. Значит, вероятности событий Аеrr (ошибочно) и Atrue (корректно) определить классы наблюдений в колонке представляют собой: P(Aerr)=1 - 0.9991000=0.63, помимо этого P(Atrue)=0.9991000=0.37.
[0082] Далее, если внести предположение об однородности наблюдений в колонке, которое удовлетворяется, когда рассчитанное пороговое значение превышает фактическое значение доли классов относительно всей колонки, появляется возможность повысить вероятность корректного определения классов в анализируемой колонке. Также, в рассматриваемом ниже примере вводится предположение, что минимальное правдивое значение ложно определенных видов конфиденциальной информации равно 0. Поэтому уменьшение процентильного значения не производится.
[0083] Предположим, распределение накопленных ложных значений по классам в колонке нормальное, тогда за порог принимается значение 99-го перцентиля, значит в 1% проанализированных колонок фактическое значение доли классов превышало пороговое, значит предположение об однородности данных отвергается и расчет вероятности корректного/ложного определения классов в колонке совпадает с примером выше и равны: 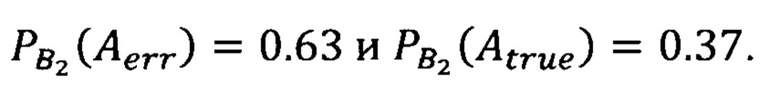 В остальных 99% случаев вероятность соответствует следующим значениям:
В остальных 99% случаев вероятность соответствует следующим значениям: 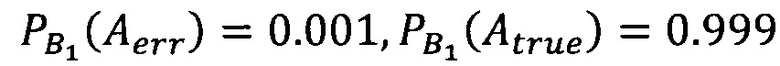 .
.
[0084] В таком случае, вероятность правильно категорировать всю колонку таблицы рассчитывается следующим образом:
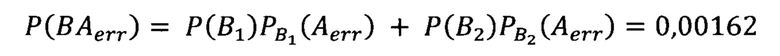
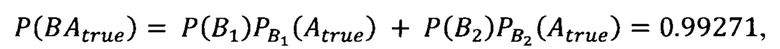
где P(B1)=0.99, а Р(В2)=0.1, т.е. В1 и В2 - события удовлетворения и отклонения предположения об однородности данных в колонках.
[0085] Продолжая пример, приведен непосредственно расчет порогового значения.
[0086] Так, например, в качестве исходных данных были получены следующие данные: имелось 10 колонок, каждая из которых содержит с по меньшей мере 1000 значений. Рассмотрим одну из 10 колонок с 1000 наблюдений, которые изначально являются числовыми (т.е. предполагается, что в колонке содержатся только числовые значения, например, ИНН физ. лиц). Стоит отметить, что 1000 наблюдений выбрано для простоты и удобства раскрытия данного примера и может являться любым значением, следовательно, не может ограничивать настоящее техническое решение. При классификации указанных значений, например, как было описано выше, выявлено 2 вида конфиденциальной информации: число (NUM) и ИНН физ. лица (INNFL).
[0087] В обычном случае, наиболее критичная информация, в рассматриваемой колонке - ИНН (относится к персональным данным) будет характеризовать всю колонку и оказывать влияние на категорию конфиденциальных данных для всего набора данных. Однако, при применении пороговых значений, т.е. реализации заявленного технического решения, система будет выполнять следующие действия. Поскольку все значения в колонке были определены как числовые, количество ячеек в которых были обнаружены ИНН будет поделено на количество непустых ячеек (того же типа, что и ИНН - числового) в рассматриваемой колонке. Допустим, в рассматриваемом примере эта величина получилась равной 0,123. При этом, в соответствии с этапами способа 100, для категории конфиденциальной информации ИНН было получено пороговое значение, равное 0,15. Следовательно, найденные 12,3 процента тегов INNFL, обнаруженные при классификации значений указанной колонки, относятся к ложноположительной (т.е. неверно определенной) категории и исключаются системой из влияющих на категорию колонки и всего документа.
[0088] Далее рассмотрим определение порогового значения на примере: для тега INNFL накоплена статистика с ложными срабатываниями в данных, которые категорировались ранее:

Помимо этого, накоплена статистика с правдивыми значениями определения тега для ИНН физ. лица в ячейках рассматриваемой колонки:

[0089] Для определения порогового значения, как указывалось выше, ряд с ложными срабатываниями анализируется на нормальность, например, используя разные тесты, раскрытые на этапе 140.
[0090] Поскольку рассматриваемый ряд со значениями ложных срабатываний содержит менее 1000 наблюдений, наибольшее влияние на конечное решение оказывает тест Шапиро-Вилко. По имеющимся данным 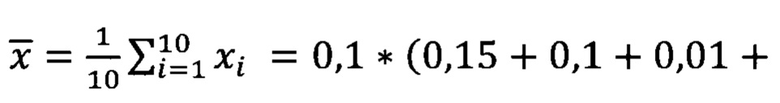
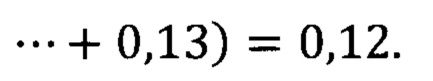
[0091] Следовательно, нормальность будет определена, по следующей формуле:
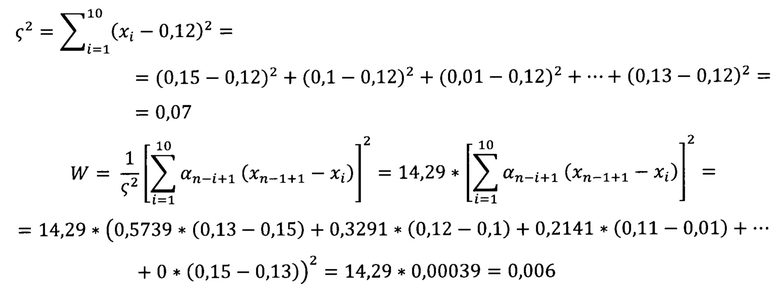
[0092] При 5-процентном уровне значимости табличное значение статистики равно 0,842. Поскольку рассчитанное значение меньше табличного (0,006<0,8423), то гипотеза о нормальности ряда отклоняется.
[0093] Соответственно, этап 140 выполняет следующий тест на нормальность - тест Д'Агостино. В нашем рассматриваемом примере:
Kvalue=1-704256, для которого p-value= - 0.041, что меньше 0,05, значит данные, скорее всего, не имеют нормальный вид.
[0094] Также производится проверка по третьему тесту, в рассматриваемом примере для всех уровней значимости а нулевая гипотеза о нормальности данных отвергается, значит в комбинации для маломерных данных мы получили минимальное значение 0, в таком случае пороговое значение принимается, равным 99-му перцентилю, и равно 0,15.
[0095] Таким образом, введение пороговых значений и предположения об однородности колонок повышает вероятность корректного категорирования колонки (с 0,37 до 0,9927) в 2,68 раза. Помимо этого, переход к анализу колонок с использованием пороговых значений для однородных данных позволил верно категорировать файлы, рассматриваемой структуры и удовлетворяющие описанным условиям, с вероятностью близкой к 1.
[0096] Таким образом, за определенный временной промежуток, в течение которого происходит сбор статистики, для каждого из определяемых видов информации сформированы 2 числовых ряда: со статистикой по ложным и правдивым результатам.
[0097] На фиг. 2 представлена блок-схема способа 200 выявления и классификации конфиденциальных данных в структурированных документах, который раскрыт поэтапно более подробно ниже. Указанный способ 200 заключается в выполнении этапов, направленных на обработку различных цифровых данных. Обработка, как правило, выполняется с помощью системы выявления и классификации, которая также может представлять, например, сервер, компьютер, мобильное устройство, вычислительное устройство и т.д. Более подробно элементы системы раскрыты на фиг. 3
[0098] На этапе 210 получают по меньшей мере один структурированный документ, содержащий данные в табличном виде.
[0099] На указанном этапе 210, система классификации и выявления конфиденциальных данных получает по меньшей мере один документ, например, в виде файла данных, содержащего данные в табличном представлении. Данные в табличном представлении хранят структурированные данные в виде колонок, в каждой из которой хранится более ли менее однородная информация (один и тот же вид информации). Так, система выявления и классификации конфиденциальных данных может представлять собой систему 300, которая может являться, например, сервером, вычислительным устройством и т.д. Так, на этапе 210, с помощью интерфейса, например, GUI, системы классификации и выявления конфиденциальных данных, может быть загружен структурированный документ, например, в формате XLS. Кроме того, в еще одном частном варианте осуществления, документ может быть получен посредством сетевого взаимодействия, например, через ЛВС. Кроме того, в еще одном частном варианте осуществления, структурированный документ может быть получен через интерфейс ввода/вывода.
[0100] На этапе 220 осуществляют обработку данных, полученных на этапе 210, по меньшей мере с помощью модели машинного обучения на базе нейронной сети, настроенной в соответствии с этапами способа 100, в ходе которой осуществляется определение конфиденциальных данных в каждой ячейки таблицы структурированного документа; определение тега, соответствующего типу конфиденциальной информации для каждой ячейки столбца структурированного документа; присвоение тега, соответствующего типу конфиденциальной информации, столбцам на основе тегов для ячеек этого столбца; сравнение, в каждом столбце, содержания тегов с типом конфиденциальной информации с пороговым значением для каждого такого тега, соответствующего типу конфиденциальных данных; определение по меньшей мере одного тега столбца на основе результатов сравнения с пороговым значением.
[0101] Так, на указанном этапе 220, с помощью модели машинного обучения, обученной на выявление и классификацию конфиденциальных данных и настроенную (модифицированную) в соответствии с полученными пороговыми значениями для каждого класса конфиденциальных данных, осуществляется категорирование каждой колонки в структурированном документе, однако, как было указано выше, итоговый класс колонке присваивается с учетом пороговых значений для каждой категории конфиденциальных данных, содержащихся в этой колонке.
[0102] На этапе 230 классифицируют структурированный документ на основе сравнения проставленных тегов каждого столбца документа.
[0103] На указанном этапе 230, на основе данных, полученных на этапе 220, присваивается итоговый класс всему структурированному документу.
[0104] Так, в одном частном варианте осуществления, каждый класс столбца (колонки) сравнивается по степени критичности с другими классами столбцов и документу присваивается класс, соответствующий самому критичному классу из столбцов. В еще одном частном варианте осуществления, классификация документа может содержать указание на конкретные части, соответствующие разной степени критичных данных, которые содержатся в столбцах. Так, итоговый класс может содержать множество наборов данных, распределенных по степени критичности.
[0105] На этапе 240 отправляют классифицированный документ в систему безопасности для передачи по каналам связи в соответствии с требованиями безопасности.
[0106] На указанном этапе 240 классифицированный документ отправляется в систему безопасности. Система безопасности может представлять собой систему безопасности организации, обеспечивающую правила распространения, хранения, передачи конфиденциальных данных. Так, например, система безопасности, после получения документа, содержащего критичные данные, может устанавливать и отслеживать соответствие требований к распространению такого файла. Например, при попытке передачи классифицированного файла, содержащего критичные данные, третьим лицам, система безопасности может запретить передачу такого файла и направить уведомление пользователю и/или временно заблокировать его. Кроме того, в еще одном частном варианте осуществления, на основе класса, присвоенного файлу, могут быть установлены политики безопасности, определяющие возможность допуска пользователей к указанному файлу. Для специалиста в данной области техники очевидно, что наличие класса конфиденциальных данных позволяет осуществлять и другие, известные из уровня техники, процедуры, обеспечивающие защищенность данных организации.
[0107] Таким образом, в заявленном техническом решении раскрыт способ выявления и классификации конфиденциальных данных, обеспечивающий высокую точность классификации за счет устранения ложных срабатываний, и, как следствие, повышающий защищенность данных в организации.
[0108] На Фиг. 3 представлен пример общего вида вычислительного устройства 300, на базе которого реализуются система выявления и классификации конфиденциальных данных и система устранения ложных срабатываний, которые обеспечивают реализацию заявленных способов 100 и 200 или является частью компьютерной системы, например, сервером, персональным компьютером, частью вычислительного кластера, обрабатывающим необходимые данные для осуществления заявленного технического решения.
[0109] В общем случае устройство 300 содержит такие компоненты, как: один или более процессоров 301, по меньшей мере одну память 302, средство хранения данных 303, интерфейсы ввода/вывода 304, средство В/В 305, средство сетевого взаимодействия 306, которые объединяются посредством универсальной шины.
[0110] Процессор 301 выполняет основные вычислительные операции, необходимые для обработки данных при выполнении способа 100 или способа 200. Процессор 301 исполняет необходимые машиночитаемые команды, содержащиеся в оперативной памяти 502.
[0111] Память 302, как правило, выполнена в виде ОЗУ и содержит необходимую программную логику, обеспечивающую требуемый функционал.
[0112] Средство хранения данных 303 может выполняться в виде HDD, SSD дисков, рейд массива, флэш-памяти, оптических накопителей информации (CD, DVD, MD, Blue-Ray дисков) и т.п. Средства 303 позволяют выполнять долгосрочное хранение различного вида информации, например, пороговых значений, классифицированных данных и т.п.
[0113] Для организации работы компонентов устройства 300 и организации работы внешних подключаемых устройств применяются различные виды интерфейсов В/В 304. Выбор соответствующих интерфейсов зависит от конкретного исполнения вычислительного устройства, которые могут представлять собой, не ограничиваясь: PCI, AGP, PS/2, IrDa, Fire Wire, LPT, COM, SATA, IDE, Lightning, USB (2.0, 3.0, 3.1, micro, mini, type C), TRS/Audio jack (2.5, 3.5, 6.35), HDMI, DVI, VGA, Display Port, RJ45, RS232 и т.п.
[0114] Выбор интерфейсов 304 зависит от конкретного исполнения устройства 300, которая может быть реализована на базе широко класса устройств, например, персональный компьютер, мейнфрейм, ноутбук, серверный кластер, тонкий клиент, смартфон, сервер и т.п.
[0115] В качестве средств В/В данных 305 может использоваться: клавиатура, джойстик, дисплей (сенсорный дисплей), монитор, сенсорный дисплей, тачпад, манипулятор мышь, световое перо, стилус, сенсорная панель, трекбол, динамики, микрофон, средства дополненной реальности, оптические сенсоры, планшет, световые индикаторы, проектор, камера, средства биометрической идентификации (сканер сетчатки глаза, сканер отпечатков пальцев, модуль распознавания голоса) и т.п.
[0116] Средства сетевого взаимодействия 306 выбираются из устройств, обеспечивающий сетевой прием и передачу данных, например, Ethernet карту, WLAN/Wi-Fi модуль, Bluetooth модуль, BLE модуль, NFC модуль, IrDa, RFID модуль, GSM модем и т.п. С помощью средств 305 обеспечивается организация обмена данными между, например, устройством 300, представленной в виде сервера и вычислительным устройством пользователя, на котором могут отображаться полученные данные (классифицированный структурированных документ) по проводному или беспроводному каналу передачи данных, например, WAN, PAN, ЛВС (LAN), Интранет, Интернет, WLAN, WMAN или GSM.
[0117] Конкретный выбор элементов устройства 300 для реализации различных программно-аппаратных архитектурных решений может варьироваться с сохранением обеспечиваемого требуемого функционала.
[0118] Представленные материалы заявки раскрывают предпочтительные примеры реализации технического решения и не должны трактоваться как ограничивающие иные, частные примеры его воплощения, не выходящие за пределы испрашиваемой правовой охраны, которые являются очевидными для специалистов соответствующей области техники. Таким образом, объем настоящего технического решения ограничен только объемом прилагаемой формулы.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ И СИСТЕМА КЛАССИФИКАЦИИ ДАННЫХ ДЛЯ ВЫЯВЛЕНИЯ КОНФИДЕНЦИАЛЬНОЙ ИНФОРМАЦИИ | 2019 |
|
RU2759786C1 |
| СПОСОБ И СИСТЕМА ВЫЯВЛЕНИЯ ДАННЫХ, ПОДВЕРЖЕННЫХ ДЕАНОНИМИЗАЦИИ, В ОБЕЗЛИЧЕННОМ НАБОРЕ ДАННЫХ | 2024 |
|
RU2837785C1 |
| СПОСОБ И СИСТЕМА КЛАССИФИКАЦИИ ДАННЫХ ДЛЯ ВЫЯВЛЕНИЯ КОНФИДЕНЦИАЛЬНОЙ ИНФОРМАЦИИ В ТЕКСТЕ | 2019 |
|
RU2755606C2 |
| СПОСОБ И СИСТЕМА РАСПОЗНАВАНИЯ ИНФОРМАЦИИ, СОСТАВЛЯЮЩЕЙ КОММЕРЧЕСКУЮ ТАЙНУ | 2024 |
|
RU2841161C1 |
| Система предотвращения утечки информации и способ предотвращения утечки информации | 2024 |
|
RU2830388C1 |
| СПОСОБ И СИСТЕМА ОБЕЗЛИЧИВАНИЯ КОНФИДЕНЦИАЛЬНЫХ ДАННЫХ | 2022 |
|
RU2804747C1 |
| СПОСОБ И СИСТЕМА ОБЕЗЛИЧИВАНИЯ КОНФИДЕНЦИАЛЬНЫХ ДАННЫХ | 2022 |
|
RU2802549C1 |
| СПОСОБ ОПРЕДЕЛЕНИЯ ПРОФИЛЯ ПОЛЬЗОВАТЕЛЯ МОБИЛЬНОГО УСТРОЙСТВА НА САМОМ МОБИЛЬНОМ УСТРОЙСТВЕ И СИСТЕМА ДЕМОГРАФИЧЕСКОГО ПРОФИЛИРОВАНИЯ | 2016 |
|
RU2647661C1 |
| Система и способ обнаружения фишинговых веб-страниц | 2024 |
|
RU2836604C1 |
| Способ классификации текстовой информации электронного вида на предмет наличия конфиденциальных данных | 2024 |
|
RU2834318C1 |
Изобретение относится к вычислительной технике. Технический результат заключается в повышении точности выявления конфиденциальных данных в структурированных документах. Способ выявления конфиденциальных данных в структурированных документах содержит этапы, на которых: a) получают структурированный документ, содержащий данные в табличном виде; b) осуществляют обработку данных с помощью модели машинного обучения на базе нейронной сети, обученной на выявление конфиденциальных данных, в ходе которой осуществляется: определение конфиденциальных данных в каждой ячейке таблицы структурированного документа; определение тега, соответствующего типу конфиденциальной информации для каждой ячейки столбца структурированного документа; присвоение тега столбцам на основе тегов для ячеек этого столбца; сравнение, в каждом столбце, содержания тегов с пороговым значением для каждого такого тега, соответствующего типу конфиденциальных данных; определение тега столбца на основе результатов сравнения; c) присваивают степень критичности структурированному документу; d) отправляют классифицированный документ в систему безопасности. 2 н.п. ф-лы, 3 ил., 1 табл.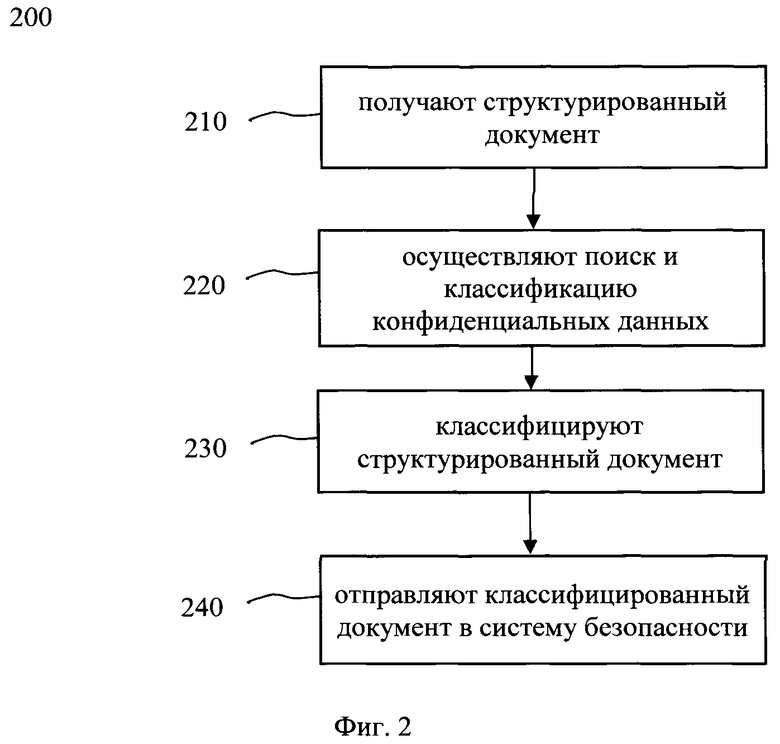
1. Способ выявления конфиденциальных данных в структурированных документах, выполняющийся по меньшей мере одним вычислительным устройством и содержащий этапы, на которых:
a) получают по меньшей мере один структурированный документ, содержащий данные в табличном виде;
b) осуществляют обработку данных, полученных на этапе а), по меньшей мере с помощью модели машинного обучения на базе нейронной сети, обученной на выявление конфиденциальных данных, причем указанная модель содержит пороговые значения допустимости входа типа конфиденциальной информации, отличного от типа конфиденциальной информации, присвоенного столбцу, в ходе которой осуществляется:
i. определение конфиденциальных данных в каждой ячейке таблицы структурированного документа;
ii. определение тега, соответствующего типу конфиденциальной информации для каждой ячейки столбца структурированного документа;
iii. присвоение тега, соответствующего типу конфиденциальной информации, столбцам на основе тегов для ячеек этого столбца;
iv. сравнение, в каждом столбце, содержания тегов с типом конфиденциальной информации с пороговым значением для каждого такого тега, соответствующего типу конфиденциальных данных;
v. определение по меньшей мере одного тега столбца на основе результатов сравнения, полученных на шаге iv;
c) присваивают степень критичности структурированному документу на основе сравнения проставленных тегов каждого столбца документа;
d) отправляют классифицированный документ в систему безопасности для передачи по каналам связи в соответствии с требованиями безопасности.
2. Система выявления и классификации конфиденциальных данных в структурированных документах, содержащая:
по меньшей мере один процессор;
по меньшей мере одну память, соединенную с процессором, которая содержит машиночитаемые инструкции, которые при их выполнении по меньшей мере одним процессором обеспечивают выполнение способа по п. 1.
| US 20200410116 A1, 31.12.2020 | |||
| US 20140188921 A1, 03.07.2014 | |||
| US 20160292445 A1, 06.10.2016 | |||
| Способ корректировки параметров модели машинного обучения для определения ложных срабатываний и инцидентов информационной безопасности | 2020 |
|
RU2763115C1 |
| Система и способ снижения нагрузки на сервис обнаружения вредоносных приложений | 2019 |
|
RU2739833C1 |

