Область раскрытия
[1] Настоящий документ относится к кодированию видео или изображений на основе отображения яркости.
Связанная область техники
[2] В последнее время, потребность в изображениях/видео высокого разрешения, высокого качества, таких как изображения/видео сверхвысокой четкости (UHD) 4K или 8K или выше, возросла в различных областях. Так как данные изображения/видео имеют высокое разрешение и высокое качество, количество информации или битов, подлежащих передаче, увеличивается относительно существующих данных изображения/видео, и таким образом, передача данных изображения с использованием носителей, таких как существующая проводная/беспроводная широкополосная линия или существующий носитель хранения, или хранение данных изображения/видео с использованием существующего носителя хранения повышают затраты на передачу и затраты на хранение.
[3] К тому же, интерес и потребность в иммерсивных медиа, таких как контент или голограммы виртуальной реальности (VR) и искусственной реальности (AR), в последнее время возросли, и возросла трансляция изображения/видео, имеющих характеристики, отличные от изображений реальности, таких как игровые изображения.
[4] Соответственно, требуется высокоэффективная технология сжатия изображения/видео, чтобы эффективно сжимать, передавать, хранить и воспроизводить информацию изображений/видео высокого разрешения, высокого качества, имеющих различные характеристики, как описано выше.
[5] К тому же, процесс отображения яркости с масштабированием цветности (LMCS) выполняется, чтобы улучшить эффективность сжатия и чтобы повысить субъективное/объективное визуальное качество, и обсуждается уменьшение вычислительной сложности в процессе LMCS.
Краткое описание сущности изобретения
[6] В соответствии с вариантом осуществления настоящего документа, обеспечены способ и устройство для повышения эффективности кодирования изображения.
[7] В соответствии с вариантом осуществления настоящего документа, обеспечены способ и устройство эффективного применения фильтрации.
[8] В соответствии с вариантом осуществления настоящего документа, обеспечены способ и устройство эффективного применения LMCS.
[9] В соответствии с вариантом осуществления настоящего документа, кодовые слова LMCS (или их диапазон) могут быть ограничены.
[10] В соответствии с вариантом осуществления настоящего документа, может использоваться один коэффициент остаточного масштабирования цветности, непосредственно сигнализируемый в масштабировании цветности LMCS.
[11] В соответствии с вариантом осуществления настоящего документа, может использоваться линейное отображение (линейное LMCS).
[12] В соответствии с вариантом осуществления настоящего документа, информация о точках поворота, требуемых для линейного отображения, может явно сигнализироваться.
[13] В соответствии с вариантом осуществления настоящего документа, гибкое число бинов может использоваться для отображения яркости.
[14] В соответствии с вариантом осуществления настоящего документа, процесс выведения индекса для обратного отображения яркости и/или остаточного масштабирования цветности может быть упрощен.
[15] В соответствии с вариантом осуществления настоящего документа, обеспечен способ декодирования видео/изображения, выполняемый устройством декодирования.
[16] В соответствии с вариантом осуществления настоящего документа, обеспечено устройство декодирования для выполнения декодирования видео/изображения.
[17] В соответствии с вариантом осуществления настоящего документа, обеспечен способ кодирования видео/изображения, выполняемый устройством кодирования.
[18] В соответствии с вариантом осуществления настоящего документа, обеспечено устройство кодирования для выполнения кодирования видео/изображения.
[19] В соответствии с одним вариантом осуществления настоящего документа, обеспечен считываемый компьютером цифровой носитель хранения, в котором хранится закодированная информация видео/изображения, сгенерированная в соответствии со способом кодирования видео/изображения, раскрытым в по меньшей мере одном из вариантов осуществления настоящего документа.
[20] В соответствии с вариантом осуществления настоящего документа, обеспечен считываемый компьютером цифровой носитель хранения, в котором хранится закодированная информация или закодированная информация видео/изображения, побуждающая устройство декодирования выполнять способ декодирования видео/изображения, раскрытый в по меньшей мере одном из вариантов осуществления настоящего документа.
Полезные результаты
[21] В соответствии с вариантом осуществления настоящего документа, общая эффективность сжатия изображения/видео может быть улучшена.
[22] В соответствии с вариантом осуществления настоящего документа, субъективное/объективное визуальное качество может быть улучшено за счет эффективной фильтрации.
[23] В соответствии с вариантом осуществления настоящего документа, процесс LMCS для кодирования изображения/видео может эффективно выполняться.
[24] В соответствии с вариантом осуществления настоящего документа, возможно минимизировать ресурсы/затраты (программного обеспечения или аппаратных средств), требуемые для процесса LMCS.
[25] В соответствии с вариантом осуществления настоящего документа, реализация аппаратных средств для процесса LMCS может быть облегчена.
[26] В соответствии с вариантом осуществления настоящего документа, операция деления, требуемая для выведения кодовых слов LMCS при отображении (повторном формировании), может быть устранена или минимизирована путем ограничения кодовых слов LMCS (или их диапазона).
[27] В соответствии с вариантом осуществления настоящего документа, задержка в соответствии с идентификацией кусочного индекса может быть устранена с использованием одного коэффициента остаточного масштабирования цветности.
[28] В соответствии с вариантом осуществления настоящего документа, процесс остаточного масштабирования цветности может выполняться без зависимости от (восстановления) блока яркости с использованием линейного отображения в LMCS, и, таким образом, задержка в масштабировании может быть устранена.
[29] В соответствии с вариантом осуществления настоящего документа, эффективность отображения в LMCS может повышаться.
[30] В соответствии с вариантом осуществления настоящего документа, сложность LMCS может уменьшаться за счет упрощения процесса выведения индекса обратного отображения для обратного отображения яркости и/или остаточного масштабирования цветности, и, таким образом, эффективность кодирования видео/изображения может повышаться.
Краткое описание чертежей
[31] Фиг. 1 иллюстрирует пример системы кодирования видео/изображения, к которой могут применяться варианты осуществления настоящего документа.
[32] Фиг. 2 является диаграммой, схематично иллюстрирующей конфигурацию устройства кодирования видео/изображения, к которому могут применяться варианты осуществления настоящего документа.
[33] Фиг. 3 является диаграммой, схематично иллюстрирующей конфигурацию устройства декодирования видео/изображения, к которому могут применяться варианты осуществления настоящего документа.
[34] Фиг. 4 показывает примерную иерархическую структуру для закодированного изображения/видео.
[35] Фиг. 5 иллюстрирует примерную иерархическую структуру CVS в соответствии с вариантом осуществления настоящего документа.
[36] Фиг. 6 иллюстрирует примерную структуру LMCS в соответствии с вариантом осуществления настоящего документа.
[37] Фиг. 7 иллюстрирует структуру LMCS в соответствии с другим вариантом осуществления настоящего документа.
[38] Фиг. 8 показывает график, представляющий примерное прямое отображение.
[39] Фиг. 9 является блок-схемой последовательности операций, иллюстрирующей способ для выведения индекса остаточного масштабирования цветности в соответствии с вариантом осуществления настоящего документа.
[40] Фиг. 10 иллюстрирует линейную аппроксимацию точек поворота в соответствии с вариантом осуществления настоящего документа.
[41] Фиг. 11 иллюстрирует один пример линейного повторного формирования (или линейного переформирования, линейного отображения) в соответствии с вариантом осуществления настоящего документа.
[42] Фиг. 12 показывает пример линейного прямого отображения в варианте осуществления настоящего документа.
[43] Фиг. 13 показывает пример обратного прямого отображения в варианте осуществления настоящего документа.
[44] Фиг. 14 и фиг. 15 схематично показывают пример способа кодирования видео/изображения и связанные компоненты в соответствии с вариантом(ами) осуществления настоящего документа.
[45] Фиг. 16 и фиг. 17 схематично показывают пример способа декодирования изображения/видео и связанные компоненты в соответствии с вариантом осуществления настоящего документа.
[46] Фиг. 18 показывает пример системы стриминга контента, к которой могут применяться варианты осуществления, раскрытые в настоящем документе.
Описание примерных вариантов осуществления
[47] Настоящий документ может модифицироваться в различных формах, и его конкретные варианты осуществления будут описаны и показаны на чертежах. Однако варианты осуществления не предназначены ограничивать настоящий документ. Термины, используемые в последующем описании, используются, чтобы только описывать конкретные варианты осуществления, но не предназначены ограничивать настоящий документ. Выражение в единственном числе включает в себя выражение во множественном числе, если только оно не читается явно иначе. Термины, такие как “включать в себя” и “иметь”, предназначены указывать, что признаки, числа, этапы, операции, элементы, компоненты или их комбинации, используемые в следующем описании, существуют, и, таким образом, должно быть понятно, что возможность существования или добавления одного или более других признаков, чисел, этапов, операций, элементов, компонентов или их комбинация не исключается.
[48] Между тем, каждая конфигурация на чертежах, описанная в настоящем документе, показана независимо для удобства описания касательно разных функций характеристик и не означает, что каждая конфигурация реализуется как отдельные аппаратные средства или отдельное программное обеспечение. Например, два или более компонентов из каждого компонента могут комбинироваться для образования одного компонента, или один компонент может делиться на множество компонентов. Варианты осуществления, в которых каждый компонент является интегрированным и/или отдельным, также включены в объем раскрытия настоящего документа.
[49] Далее, примеры настоящего варианта осуществления будут описаны подробно со ссылкой на прилагаемые чертежи. К тому же, одинаковые ссылочные позиции используются, чтобы указывать одинаковые элементы на всех чертежах, и те же самые описания одинаковых элементов будут опущены.
[50] Фиг. 1 иллюстрирует пример системы кодирования видео/изображения, к которой могут применяться варианты осуществления настоящего документа.
[51] Со ссылкой на фиг. 1, система кодирования видео/изображения может включать в себя первое устройство (устройство-источник) и второе устройство (устройство приема). Устройство-источник может передавать закодированную информацию или данные видео/изображения на устройство приема через цифровой носитель хранения или сеть в виде файла или потока.
[52] Устройство-источник может включать в себя источник видео, устройство кодирования и передатчик. Устройство приема может включать в себя приемник, устройство декодирования и устройство рендеринга (визуализации). Устройство кодирования может называться устройством кодирования видео/изображения, и устройство декодирования может называться устройством декодирования видео/изображения. Передатчик может быть включен в устройство кодирования. Приемник может быть включен в устройство декодирования. Устройство визуализации может включать в себя дисплей, и дисплей может быть сконфигурирован как отдельное устройство или внешний компонент.
[53] Источник видео может получать видео/изображение через процесс захвата, синтеза или генерации видео/изображения. Источник видео может включать в себя устройство захвата видео/изображения и/или устройство генерации видео/изображения. Устройство захвата видео/изображения может включать в себя, например, одну или несколько камер, архивы видео/изображений, включающие в себя ранее захваченные видео/изображения, и тому подобное. Устройство генерации видео/изображения может включать в себя, например, компьютеры, планшеты и смартфоны и может (электронным способом) генерировать видео/изображения. Например, виртуальное видео/изображение может генерироваться через компьютер или тому подобное. В этом случае, процесс захвата видео/изображения может быть заменен на процесс генерации связанных данных.
[54] Устройство кодирования может кодировать введенное видео/изображение. Устройство кодирования может выполнять последовательность процедур, таких как предсказание, преобразование и квантование для компактности и эффективности кодирования. Закодированные данные (закодированная информация видео/изображения) могут выводиться в виде битового потока.
[55] Передатчик может передавать закодированное изображение/информацию изображения или данные, выведенные в виде битового потока, на приемник устройства приема через цифровой носитель хранения или сеть в виде файла или потока. Цифровой носитель хранения может включать в себя различные носители хранения, такие как USB, SD, CD, DVD, Blu-ray, HDD, SSD и тому подобное. Передатчик может включать в себя элемент для генерации медиа-файла посредством предопределенного формата файла и может включать в себя элемент для передачи через сеть вещания/связи. Приемник может принимать/извлекать битовый поток и передавать принятый битовый поток на устройство декодирования.
[56] Устройство декодирования может декодировать видео/изображение путем выполнения последовательности процедур, таких как деквантование, обратное преобразование и предсказание, соответствующих операции устройства кодирования.
[57] Устройство визуализации может визуализировать декодированное видео/изображение. Визуализированное видео/ изображение может отображаться посредством дисплея.
[58] Настоящий документ относится к кодированию видео/изображения. Например, способ/вариант осуществления, раскрытый в настоящем документе, может применяться к способу, раскрытому в стандарте многоцелевого кодирования видео (VVC), стандарте существенного кодирования видео (EVC), стандарте AOMedia Видео 1 (AV1), стандарте кодирования аудио/видео 2-го поколения (AVS2) или стандарте кодирования видео/изображения следующего поколения (например, H.267, H.268 или тому подобное).
[59] Настоящий документ предлагает различные варианты осуществления кодирования видео/изображения, и варианты осуществления выше могут также выполняться в комбинации друг с другом, если не специфицировано иное.
[60] В настоящем документе, видео может относиться к последовательности изображений по времени. Картинка обычно относится к единице, представляющей одно изображение в конкретном временном кадре, и вырезка/мозаичный элемент относится к единице, составляющей часть картинки в терминах кодирования. Вырезка/мозаичный элемент может включать в себя одну или более единиц дерева кодирования (CTU). Одна картинка может состоять из одной или более вырезок/мозаичных элементов. Одна картинка может состоять из одной или более групп мозаичных элементов. Одна группа мозаичных элементов может включать в себя один или более мозаичных элементов. “Кирпичик” может представлять прямоугольную область строк CTU в пределах мозаичного элемента в картинке. Мозаичный элемент может разбиваться на множество кирпичиков, каждый из которых может состоять из одной или более строк CTU в пределах мозаичного элемента. Мозаичный элемент, который не разбивается на множество кирпичиков, может также называться кирпичиком. Сканирование кирпичиков может представлять конкретный последовательный порядок CTU, разбивающих картинку, причем CTU могут быть упорядочены в растровом сканировании CTU в пределах кирпичика, и кирпичики в пределах мозаичного элемента могут быть упорядочены последовательно в растровом сканировании кирпичиков мозаичного элемента, и мозаичные элементы в картинке могут быть упорядочены последовательно в растровом сканировании мозаичных элементов картинки. Мозаичный элемент является прямоугольной областью CTU в пределах конкретного столбца мозаичного элемента и конкретной строки мозаичного элемента в картинке. Столбец мозаичного элемента является прямоугольной областью CTU, имеющей высоту, равную высоте картинки, и ширину, специфицированную синтаксическими элементами в наборе параметров картинки. Строка мозаичного элемента является прямоугольной областью CTU, имеющей высоту, специфицированную синтаксическими элементами в наборе параметров картинки, и ширину, равную ширине картинки. Сканирование мозаичного элемента является конкретным последовательным упорядочиванием CTU, разбивающих картинку, в котором CTU упорядочены последовательно в растровом сканировании CTU в мозаичном элементе, причем мозаичные элементы в картинке упорядочены последовательно в растровом сканировании мозаичных элементов картинки. Вырезка включает в себя целое число кирпичиков картинки, которые могут содержаться исключительно в одной единице NAL. Вырезка может состоять из некоторого количества полных мозаичных элементов или только последовательности полных кирпичиков одного мозаичного элемента. В настоящем документе, группа мозаичных элементов и вырезка могут использоваться взаимозаменяемым образом. Например, в настоящем документе, группа мозаичных элементов/заголовок группы мозаичных элементов может называться вырезкой/заголовком вырезки.
[61] Между тем, одна картинка может делиться на две или более под-картинок. Под-картинка может представлять собой прямоугольную область одной или более вырезок в пределах картинки.
[62] Пиксел или пел может означать наименьшую единицу, составляющую одну картинку (или изображение). Также, ‘выборка’ может использоваться как термин, соответствующий пикселу. Выборка может, в общем, представлять пиксел или значение пиксела и может представлять только пиксел/значение пиксела компонента яркости или только пиксел/значение пиксела компонента цветности.
[63] Единица может представлять базовую единицу обработки изображения. Единица может включать в себя по меньшей мере одно из конкретной области картинки и информации, относящейся к области. Одна единица может включать в себя один блок яркости и два блока цветности (например, cb, cr). Единица может использоваться взаимозаменяемо с терминами, такими как блок или область в некоторых случаях. В общем случае, блок M×N может включать в себя выборки (или массивы выборок) или набор (или массив) коэффициентов преобразования M столбцов и N строк. Альтернативно, выборка может означать значение пиксела в пространственной области, и когда такое значение пиксела преобразуется в частотную область, оно может означать коэффициент преобразования в частотной области.
[64] В настоящем документе, “A или B” может означать “только A”, “только B” или “как A, так и B”. Другими словами, “A или B” в настоящем документе может интерпретироваться как “A и/или B”. Например, в настоящем документе “A, B или C (A, B или C)” означает “только A”, “только B”, “только C” или “любая комбинация A, B и C”.
[65] Слеш (/) или запятая, используемые в настоящем документе, могут означать “и/или”. Например, “A/B” может означать “A и/или B”. Соответственно, “A/B” может означать “только A”, “только B” или “как A, так и B”. Например, “A, B, C” может означать “A, B или C”.
[66] В настоящем документе, “по меньшей мере одно из A и B” может означать “только A”, “только B” или “как A, так и B”. Также, в настоящем документе, выражение “по меньшей мере одно из A или B” или “по меньшей мере одно из A и/или B” может интерпретироваться так же, как “по меньшей мере одно из A и B”.
[67] Также, в настоящем документе, “по меньшей мере одно из A, B и C” означает “только A, “только B”, “только C” или “любая комбинация A, B и C”. Также, “по меньшей мере одно из A, B или C” или “по меньшей мере одно из A, B и/или C” может означать “по меньшей мере одно из A, B и C”.
[68] Также, круглые скобки, используемые в настоящем документе, могут означать “например”. Конкретно, когда указано “предсказание (интра-предсказание)”, “интра-предсказание” может предлагаться как пример “предсказания”. Другими словами, “предсказание” в настоящем документе не ограничено “интра-предсказанием”, и “интра-предсказание” может предлагаться в качестве примера “предсказания”. Также, даже когда указано “предсказание (т.е., интра-предсказание)”, “интра-предсказание” может предлагаться как пример “предсказания”.
[69] Технические признаки, которые отдельно описаны в одном чертеже в настоящем документе, могут быть реализованы по отдельности или вместе.
[70] Фиг. 2 является диаграммой, схематично иллюстрирующей конфигурацию устройства кодирования видео/изображения, к которому могут применяться варианты осуществления настоящего документа. Далее, то, что называется устройством кодирования видео, может включать в себя устройство кодирования изображения.
[71] Со ссылкой на фиг. 2, устройство 200 кодирования включает в себя модуль 210 разбиения изображения, предсказатель 220, остаточный процессор (процессор остатка) 230 и энтропийный кодер 240, сумматор 250, фильтр 260 и память 270. Предсказатель 220 может включать в себя интер-предсказатель 221 и интра-предсказатель 222. Процессор 230 остатка может включать в себя преобразователь 232, квантователь 233, деквантователь 234 и обратный преобразователь 235. Процессор 230 остатка может дополнительно включать в себя вычитатель 231. Сумматор 250 может называться реконструктором или генератором восстановленного блока. Модуль 210 разбиения изображения, предсказатель 220, процессор 230 остатка, энтропийный кодер 240, сумматор 250 и фильтр 260 могут быть сконфигурированы по меньшей мере одним компонентом аппаратных средств (например, чипсетом кодера или процессором) в соответствии с вариантом осуществления. К тому же, память 270 может включать в себя буфер декодированной картинки (DPB) или может быть сконфигурирована цифровым носителем хранения. Компонент аппаратных средств может дополнительно включать в себя память 270 как внутренний/внешний компонент.
[72] Модуль 210 разбиения изображения может разбивать входное изображение (или картинку или кадр), введенное в устройство 200 кодирования в один или более процессоров. Например, процессор может называться единицей кодирования (CU). В этом случае, единица кодирования может рекурсивно разбиваться в соответствии со структурой квадродерева-двоичного дерева- троичного дерева (QTBTTT) из единицы дерева кодирования (CTU) или наибольшей единицы кодирования (LCU). Например, одна единица кодирования может разбиваться на множество единиц кодирования большей глубины на основе структуры квадродерева, структуры двоичного дерева и/или троичного дерева. В этом случае, например, структура квадродерева может применяться первой, и структура двоичного дерева и/или структура троичного дерева может применяться позже. Альтернативно, структура двоичного дерева может применяться первой. Процедура кодирования в соответствии с настоящим раскрытием может выполняться на основе конечной единицы кодирования, которая больше не разбивается. В этом случае, наибольшая единица кодирования может использоваться как конечная единица кодирования на основе эффективности кодирования в соответствии с характеристиками изображения, или если необходимо, единица кодирования может рекурсивно разбиваться на единицы кодирования большей глубины, и единица кодирования, имеющая оптимальный размер, может использоваться как конечная единица кодирования. Здесь, процедура кодирования может включать в себя процедуру предсказания, преобразования и восстановления, которые будут описаны далее. В качестве примера, процессор может дополнительно включать в себя единицу предсказания (PU) или единицу преобразования (TU). В этом случае, единица предсказания и единица преобразования могут разделяться или разбиваться из вышеупомянутой конечной единицы кодирования. Единица предсказания может представлять собой единицу предсказания выборки, и единица преобразования может представлять собой единицу для выведения коэффициента преобразования и/или единицу для выведения остаточного сигнала из коэффициента преобразования.
[73] Единица может использоваться взаимозаменяемо с терминами, такими как блок или область в некоторых случаях. В общем случае, блок M×N может представлять набор выборок или коэффициентов преобразования, состоящих из M столбцов и N строк. Выборка может, в общем, представлять пиксел или значение пиксела, может представлять только пиксел/значение пиксела компонента яркости или представлять только пиксел/значение пиксела компонента цветности. Выборка может использоваться как термин, соответствующий одной картинке (или изображению) для пиксела или пела.
[74] В устройстве 200 кодирования, сигнал предсказания (предсказанный блок, массив выборок предсказания), выведенный из интер-предсказателя 221 или интра-предсказателя 222, вычитается из входного сигнала изображения (исходного блока, исходного массива выборок), чтобы сгенерировать остаточный сигнал (остаточный блок, остаточный массив выборок), и сгенерированный остаточный сигнал передается на преобразователь 232. В этом случае, как показано, модуль для вычитания сигнала предсказания (предсказанного блока, массива выборок предсказания) из входного сигнала изображения (исходного блока, исходного массива выборок) в кодере 200 может называться вычитателем 231. Предсказатель может выполнять предсказание на блоке, подлежащем обработке (далее называемом текущим блоком), и генерировать предсказанный блок, включающий в себя выборки предсказания для текущего блока. Предсказатель может определять, применяется ли интра-предсказание или интер-предсказание на текущем блоке или на основе CU. Как описано далее в описании каждого режима предсказания, предсказатель может генерировать различную информацию, относящуюся к предсказанию, такую как информация режима предсказания, и передавать сгенерированную информацию на энтропийный кодер 240. Информация о предсказании может кодироваться в энтропийном кодере 240 и выводиться в форме битового потока.
[75] Интра-предсказатель 222 может предсказывать текущий блок путем ссылки на выборки в текущей картинке. Указанные выборки могут быть расположены по соседству с текущим блоком или могут быть разнесены в соответствии с режимом предсказания. В интра-предсказании, режимы предсказания могут включать в себя множество ненаправленных режимов и множество направленных режимов. Ненаправленный режим может включать в себя, например, режим DC и планарный режим. Направленный режим может включать в себя, например, 33 направленных режима предсказания или 65 направленных режимов предсказания в соответствии со степенью детализации направления предсказания. Однако это только пример, больше или меньше направленных режимов предсказания могут использоваться в зависимости от настроек. Интра-предсказатель 222 может определять режим предсказания, применяемый к текущему блоку, путем использования режима предсказания, применяемого к соседнему блоку.
[76] Интер-предсказатель 221 может выводить предсказанный блок для текущего блока на основе опорного блока (опорного массива выборок), специфицированного вектором движения на опорной картинке. Здесь, чтобы уменьшить количество информации движения, передаваемой в режиме интер-предсказания, информация движения может предсказываться в единицах блоков, подблоков или выборках на основе корреляции информации движения между соседним блоком и текущим блоком. Информация движения может включать в себя вектор движения и индекс опорной картинки. Информация движения может дополнительно включать в себя информацию направления интер-предсказания (предсказание L0, предсказание L1, Bi-предсказание и т.д.). В случае интер-предсказания, соседний блок может включать в себя пространственный соседний блок, представленный в текущей картинке, и временной соседний блок, представленный в опорной картинке. Опорная картинка, включающая в себя опорный блок, и опорная картинка, включающая в себя временной соседний блок, могут быть одинаковыми или разными. Временной соседний блок может называться совместно расположенным опорным блоком, co-located CU (colCU) и т.п., и опорная картинка, включающая в себя временной соседний блок, может называться совместно расположенной картинкой (colPic). Например, интер-предсказатель 221 может конфигурировать список кандидатов информации движения на основе соседних блоков и генерировать информацию, указывающую, какой кандидат используется, чтобы вывести вектор движения и/или индекс опорной картинки текущего блока. Интер-предсказание может выполняться на основе различных режимов предсказания. Например, в случае режима пропуска и режима объединения, интер-предсказатель 221 может использовать информацию движения соседнего блока как информацию движения текущего блока. В режиме пропуска, в отличие от режима объединения, остаточный сигнал может не передаваться. В случае режима предсказания вектора движения (MVP), вектор движения соседнего блока может использоваться как предсказатель вектора движения, и вектор движения текущего блока может указываться путем сигнализации разности векторов движения.
[77] Предсказатель 220 может генерировать сигнал предсказания на основе различных способов предсказания, описанных ниже. Например, предсказатель может не только применять интра-предсказание или интер-предсказание, чтобы предсказать один блок, но также одновременно применять как интра-предсказание, так и интер-предсказание. Это может называться комбинированным интер- и интра-предсказанием (CIIP). К тому же, предсказатель может быть основан на режиме предсказания внутри-блочного копирования (IBC) или режиме палитры для предсказания блока. Режим предсказания IBC или режим палитры могут использоваться для кодирования контента изображения/видео игры или тому подобного, например, кодирования контента экрана (SCC). IBC в основном выполняет предсказание в текущей картинке, но может выполняться аналогично интер-предсказанию тем, что опорный блок выводится в текущей картинке. То есть, IBC может использовать по меньшей мере один из методов интер-предсказания, описанных в настоящем раскрытии. Режим палитры может рассматриваться как пример интра-кодирования или интра-предсказания. Когда режим палитры применяется, значение выборки в пределах картинки может сигнализироваться на основе информации о таблице палитры и индексе палитры.
[78] Сигнал предсказания, сгенерированный предсказателем (включающим в себя интер-предсказатель 221 и/или интра-предсказатель 222), может использоваться, чтобы генерировать восстановленный сигнал или чтобы генерировать остаточный сигнал. Преобразователь 232 может генерировать коэффициенты преобразования путем применения метода преобразования к остаточному сигналу. Например, метод преобразования может включать в себя по меньшей мере одно из дискретного косинусного преобразования (DCT), дискретного синусного преобразования (DST), преобразования Карунена-Лоэва (KLT), преобразования на основе графа (GBT) или условно-нелинейного преобразования (CNT). Здесь, GBT означает преобразование, полученное из графа, когда информация отношения между пикселами представлена графом. CNT относится к преобразованию, сгенерированному на основе сигнала предсказания, сгенерированного с использованием всех ранее восстановленных пикселов. К тому же, процесс преобразования может применяться к квадратным блокам пикселов, имеющим одинаковый размер, или может применяться к блокам, имеющим переменный размер, а не квадратным.
[79] Квантователь 233 может квантовать коэффициенты преобразования и передавать их на энтропийный кодер 240, и энтропийный кодер 240 может кодировать квантованный сигнал (информацию о квантованных коэффициентах преобразования) и выводить битовый поток. Информация о квантованных коэффициентах преобразования может называться информацией остатка. Квантователь 233 может переупорядочивать квантованные коэффициенты преобразования типа блока в форму одномерного вектора на основе порядка сканирования коэффициентов и генерировать информацию о квантованных коэффициентах преобразования на основе квантованных коэффициентов преобразования в форме одномерного вектора. Информация о коэффициентах преобразования может генерироваться. Энтропийный кодер 240 может выполнять различные способы кодирования, такие как, например, экспоненциальное кодирование Голомба, контекстно-адаптивное кодирование с переменной длиной (CAVLC), контекстно-адаптивное двоичное арифметическое кодирование (CABAC) и тому подобное. Энтропийный кодер 240 может кодировать информацию, необходимую для восстановления видео/изображения, отличную от квантованных коэффициентов преобразования (например, значения синтаксических элементов и т.д.), вместе или отдельно. Закодированная информация (например, закодированная информация видео/изображения) может передаваться или сохраняться в единицах NAL (уровень сетевой абстракции) в форме битового потока. Информация видео/изображения может дополнительно включать в себя информацию о различных наборах параметров, таких как набор параметров адаптации (APS), набор параметров картинки (PPS), набор параметров последовательности (SPS) или набор параметров видео (VPS). К тому же, информация видео/изображения может дополнительно включать в себя общую информацию ограничения. В настоящем раскрытии, информация и/или синтаксические элементы, передаваемые/сигнализируемые от устройства кодирования на устройство декодирования, могут быть включены в информацию видео/картинки. Информация видео/изображения может кодироваться посредством вышеописанной процедуры кодирования и включаться в битовый поток. Битовый поток может передаваться по сети или может сохраняться в цифровом носителе хранения. Сеть может включать в себя сеть вещания и/или сеть связи, и цифровой носитель хранения может включать в себя различные носители хранения, такие как USB, SD, CD, DVD, Blu-ray, HDD, SSD и тому подобное. Передатчик (не показан), передающий сигнал, выведенный из энтропийного кодера 240, и/или модуль хранения (не показан), хранящий сигнал, могут быть включены как внутренний/внешний элемент устройства 200 кодирования, и альтернативно, передатчик может быть включен в энтропийный кодер 240.
[80] Квантованные коэффициенты преобразования, выведенные из квантователя 233, могут использоваться, чтобы генерировать сигнал предсказания. Например, остаточный сигнал (остаточный блок или остаточные выборки) может восстанавливаться путем применения деквантования и обратного преобразования к квантованным коэффициентам преобразования деквантователем 234 и обратным преобразователем 235. Сумматор 250 добавляет восстановленный остаточный сигнал к сигналу предсказания, выведенному из интер-предсказателя 221 или интра-предсказателя 222, чтобы сгенерировать восстановленный сигнал (восстановленную картинку, восстановленный блок, восстановленный массив выборок). Если отсутствует остаток для блока, подлежащего обработке, например, в случае, где применяется режим пропуска, предсказанный блок может использоваться как восстановленный блок. Сумматор 250 может называться реконструктором или генератором восстановленного блока. Сгенерированный восстановленный сигнал может использоваться для интра-предсказания следующего блока, подлежащего обработке, в текущей картинке и может использоваться для интер-предсказания следующей картинки посредством фильтрации, как описано ниже.
[81] Между тем, отображение яркости с масштабированием цветности (LMCS) может применяться во время кодирования и/или восстановления картинки.
[82] Фильтр 260 может улучшать субъективное/объективное качество изображения путем применения фильтрации к восстановленному сигналу. Например, фильтр 260 может генерировать модифицированную восстановленную картинку путем применения различных способов фильтрации к восстановленной картинке и сохранять модифицированную восстановленную картинку в памяти 270, конкретно, DPB памяти 270. Различные способы фильтрации могут включать в себя, например, фильтрацию деблокирования, адаптивное смещение выборки, адаптивный контурный фильтр, двунаправленный фильтр и тому подобное. Фильтр 260 может генерировать различную информацию, относящуюся к фильтрации, и передавать сгенерированную информацию на энтропийный кодер 240, как описано далее в описании каждого способа фильтрации. Информация, относящаяся к фильтрации, может кодироваться энтропийным кодером 240 и выводиться в форме битового потока.
[83] Модифицированная восстановленная картинка, передаваемая в память 270, может использоваться как опорная картинка в интер-предсказателе 221. Когда интер-предсказание применяется посредством устройства кодирования, можно избежать рассогласования предсказания между устройством 200 кодирования и устройством 300 декодирования, и эффективность кодирования может улучшаться.
[84] DPB памяти 270 DPB может хранить модифицированную восстановленную картинку для использования в качестве опорной картинки в интер-предсказателе 221. Память 270 может хранить информацию движения блока, из которой выводится (или кодируется) информация движения в текущей картинке, и/или информацию движения блоков в картинке, которые уже были восстановлены. Сохраненная информация движения может передаваться на интер-предсказатель 221 и использоваться как информация движения пространственного соседнего блока или информация движения временного соседнего блока. Память 270 может хранить восстановленные выборки восстановленных блоков в текущей картинке и может переносить восстановленные выборки на интра-предсказатель 222.
[85] Фиг. 3 является схематичной диаграммой, иллюстрирующей конфигурацию устройства декодирования видео/изображения, к которому может применяться вариант(ы) осуществления настоящего раскрытия.
[86] Со ссылкой на фиг. 3, устройство 300 декодирования может включать в себя энтропийный декодер 310, процессор 320 остатка, предсказатель 330, сумматор 340, фильтр 350, память 360. Предсказатель 330 может включать в себя интер-предсказатель 331 и интра-предсказатель 332. Процессор 320 остатка может включать в себя деквантователь 321 и обратный преобразователь 321. Энтропийный декодер 310, процессор 320 остатка, предсказатель 330, сумматор 340 и фильтр 350 могут быть сконфигурированы компонентом аппаратных средств (например, чипсетом декодера или процессором) в соответствии с вариантом осуществления. К тому же, память 360 может включать в себя буфер декодированной картинки (DPB) или может быть сконфигурирована цифровым носителем хранения. Компонент аппаратных средств может дополнительно включать в себя память 360 как внутренний/внешний компонент.
[87] Когда битовый поток, включающий в себя информацию видео/изображения, вводится, устройство 300 декодирования может восстанавливать изображение, соответствующее процессу, в котором информация видео/изображения обрабатывается в устройстве кодирования согласно фиг. 2. Например, устройство 300 декодирования может выводить единицы/блоки на основе информации, относящейся к разбиению блока, полученной из битового потока. Устройство 300 декодирования может выполнять декодирование с использованием процессора, применяемого в устройстве кодирования. Таким образом, процессор декодирования может представлять собой единицу кодирования, например, и единица кодирования может разбиваться в соответствии со структурой квадродерева, структурой двоичного дерева и/или структурой троичного дерева из единицы дерева кодирования или наибольшей единицы кодирования. Одна или более единиц преобразования могут выводиться из единицы кодирования. Восстановленный сигнал изображения, декодированный и выведенный посредством устройства 300 декодирования, может воспроизводиться посредством устройства воспроизведения.
[88] Устройство 300 декодирования может принимать сигнал, выведенный из устройства кодирования согласно фиг. 2 в форме битового потока, и принятый сигнал может декодироваться посредством энтропийного декодера 310. Например, энтропийный декодер 310 может выполнять синтаксический анализ битового потока, чтобы вывести информацию (например, информацию видео/изображения), необходимую для восстановления изображения (или восстановления картинки). Информация видео/изображения может дополнительно включать в себя информацию о различных наборах параметров, таких как набор параметров адаптации (APS), набор параметров картинки (PPS), набор параметров последовательности (SPS) или набор параметров видео (VPS). К тому же, информация видео/изображения может дополнительно включать в себя общую информацию ограничения. Устройство декодирования может дополнительно декодировать картинку на основе информации о наборе параметров и/или общей информации ограничения. Сигнализированная/принятая информация и/или синтаксические элементы, описанные далее в настоящем раскрытии, могут быть декодированы для декодирования процедуры декодирования и получены из битового потока. Например, энтропийный декодер 310 кодирует информацию в битовом потоке на основе способа кодирования, такого как экспоненциальное кодирование Голомба, CAVLC или CABAC, и выводит синтаксические элементы, требуемые для восстановления изображения, и квантованные значения коэффициентов преобразования для остатка. Более конкретно, способ энтропийного декодирования CABAC может принимать бин, соответствующий каждому синтаксическому элементу в битовом потоке, определять контекстную модель с использованием информации декодирования целевого синтаксического элемента, информации декодирования для декодирования целевого блока или информации символа/бина, декодированного на предыдущей стадии, и выполнять арифметическое декодирование на бине путем предсказания вероятности появления бина в соответствии с определенной контекстной моделью, и генерировать символ, соответствующий значению каждого синтаксического элемента. В этом случае, способ энтропийного декодирования CABAC может обновлять контекстную модель с использованием информации декодированного символа/бина для контекстной модели следующего символа/бина после определения контекстной модели. Информация, относящаяся к предсказанию, среди информации, декодированной энтропийным декодером 310, может предоставляться на предсказатель (интер-предсказатель 332 и интра-предсказатель 331), и значение остатка, на котором энтропийное декодирование было выполнено в энтропийном декодере 310, то есть, квантованные коэффициенты преобразования и связанная информация параметров, может вводиться в процессор 320 остатка. Процессор 320 остатка может выводить остаточный сигнал (остаточный блок, остаточные выборки, остаточный массив выборок). К тому же, информация о фильтрации среди информации, декодированной энтропийным декодером 310, может предоставляться на фильтр 350. Между тем, приемник (не показан) для приема сигнала, выведенного из устройства кодирования, может быть дополнительно сконфигурирован как внутренний/внешний элемент устройства 300 декодирования, или приемник может быть компонентом энтропийного декодера 310. Между тем, устройство декодирования в соответствии с настоящим раскрытием может называться устройством декодирования видео/изображения/картинки, и устройство декодирования может классифицироваться на декодер информации (декодер информации видео/изображения/картинки) и декодер выборки (декодер выборки видео/изображения/картинки). Декодер информации может включать в себя энтропийный декодер 310, и декодер выборки может включать в себя по меньшей мере одно из деквантователя 321, обратного преобразователя 322, сумматора 340, фильтра 350, памяти 360, интер-предсказателя 332 и интра-предсказателя 331.
[89] Деквантователь 321 может деквантовать квантованные коэффициенты преобразования и выводить коэффициенты преобразования. Деквантователь 321 может переупорядочивать квантованные коэффициенты преобразования в форме двумерного блока. В этом случае, переупорядочивание может выполняться на основе порядка сканирования коэффициентов, выполняемого в устройстве кодирования. Деквантователь 321 может выполнять деквантование на квантованных коэффициентах преобразования с использованием параметра квантования (например, информации размера шага квантования) и получать коэффициенты преобразования.
[90] Обратный преобразователь 322 обратно преобразует коэффициенты преобразования, чтобы получить остаточный сигнал (остаточный блок, остаточный массив выборок).
[91] Предсказатель может выполнять предсказание на текущем блоке и генерировать предсказанный блок, включающий в себя выборки предсказания для текущего блока. Предсказатель может определять, применяется ли интра-предсказание или интер-предсказание к текущему блоку, на основе информации о предсказании, выведенной из энтропийного декодера 310, и может определять конкретный режим интра/интер-предсказания.
[92] Предсказатель 320 может генерировать сигнал предсказания на основе различных способов предсказания, описанных ниже. Например, предсказатель может не только применять интра-предсказание или интер-предсказание, чтобы предсказывать один блок, но также одновременно применять интра-предсказание и интер-предсказание. Это может называться комбинированным интер- и интра-предсказанием (CIIP). К тому же, предсказатель может быть основан на режиме предсказания внутри-блочного копирования (IBC) или режиме палитры для предсказания блока. Режим предсказания IBC или режим палитры могут использоваться для кодирования контента изображения/видео игры или тому подобного, например, кодирования контента экрана (SCC). IBC в основном выполняет предсказание в текущей картинке, но может выполняться аналогично интер-предсказанию тем, что опорный блок выводится в текущей картинке. То есть, IBC может использовать по меньшей мере один из методов интер-предсказания, описанных в настоящем раскрытии. Режим палитры может рассматриваться как пример интра-кодирования или интра-предсказания. Когда режим палитры применяется, значение выборки в пределах картинки может сигнализироваться на основе информации о таблице палитры и индексе палитры.
[93] Интра-предсказатель 331 может предсказывать текущий блок путем ссылки на выборки в текущей картинке. Указанные выборки могут быть расположены по соседству с текущим блоком или могут быть разнесены в соответствии с режимом предсказания. В интра-предсказании, режимы предсказания могут включать в себя множество ненаправленных режимов и множество направленных режимов. Интра-предсказатель 331 может определять режим предсказания, применяемый к текущему блоку, с использованием режима предсказания, применяемого к соседнему блоку.
[94] Интер-предсказатель 332 может выводить предсказанный блок для текущего блока на основе опорного блока (опорного массива выборок), специфицированного вектором движения на опорной картинке. В этом случае, чтобы уменьшить количество информации движения, передаваемой в режиме интер-предсказания, информация движения может предсказываться в единицах блоков, подблоков или выборок на основе корреляции информации движения между соседним блоком и текущим блоком. Информация движения может включать в себя вектор движения и индекс опорной картинки. Информация движения может дополнительно включать в себя информацию направления интер-предсказания (предсказание L0, предсказание L1, Bi-предсказание и т.д.). В случае интер-предсказания, соседний блок может включать в себя пространственный соседний блок, представленный в текущей картинке, и временной соседний блок, представленный в опорной картинке. Например, интер-предсказатель 332 может конфигурировать список кандидатов информации движения на основе соседних блоков и выводить вектор движения текущего блока и/или индекс опорной картинки на основе принятой информации выбора кандидата. Интер-предсказание может выполняться на основе различных режимов предсказания, и информация о предсказании может включать в себя информацию, указывающую режим интер-предсказания для текущего блока.
[95] Сумматор 340 может генерировать восстановленный сигнал (восстановленную картинку, восстановленный блок, восстановленный массив выборок) путем добавления полученного остаточного сигнала к сигналу предсказания (предсказанному блоку, предсказанному массиву выборок), выведенному из предсказателя (включающего в себя интер-предсказатель 332 и/или интра-предсказатель 331). Если отсутствует остаток для блока, подлежащего обработке, например, когда применяется режим пропуска, предсказанный блок может использоваться как восстановленный блок.
[96] Сумматор 340 может называться реконструктором или генератором восстановленного блока. Сгенерированный восстановленный сигнал может использоваться для интра-предсказания следующего блока, подлежащего обработке в текущей картинке, может выводиться посредством фильтрации, как описано ниже, или может использоваться для интер-предсказания следующей картинки.
[97] Между тем, отображение яркости с масштабированием цветности (LMCS) может применяться в процессе декодирования картинки.
[98] Фильтр 350 может улучшать субъективное/объективное качество изображения путем применения фильтрации к восстановленному сигналу. Например, фильтр 350 может генерировать модифицированную восстановленную картинку путем применения различных способов фильтрации к восстановленной картинке и сохранять модифицированную восстановленную картинку в памяти 360, конкретно, DPB памяти 360. Различные способы фильтрации могут включать в себя, например, фильтрацию устранения блочности, адаптивное смещение выборки, адаптивный контурный фильтр, двунаправленный фильтр и тому подобное.
[99] (Модифицированная) восстановленная картинка, хранящаяся в DPB памяти 360, может использоваться как опорная картинка в интер-предсказателе 332. Память 360 может хранить информацию движения блока, из которого выводится (или декодируется) информация движения в текущей картинке, и/или информацию движения блоков в картинке, которые уже были восстановлены. Сохраненная информация движения может передаваться на интер-предсказатель 260 для использования в качестве информации движения пространственного соседнего блока или информации движения временного соседнего блока. Память 360 может хранить восстановленные выборки восстановленных блоков в текущей картинке и переносить восстановленные выборки на интра-предсказатель 331.
[100] В настоящем документе, варианты осуществления, описанные в фильтре 260, интер-предсказателе 221 и интра-предсказателе 222 устройства 200 кодирования, могут быть теми же самыми или соответственно применяться, чтобы соответствовать фильтру 350, интер-предсказателю 332 и интра-предсказателю 331 устройства 300 декодирования. То же может также применяться к модулю 332 и интра-предсказателю 331.
[101] Как описано выше, в кодировании видео, предсказание выполняется, чтобы повысить эффективность сжатия. Посредством этого, возможно сгенерировать предсказанный блок, включающий в себя выборки предсказания для текущего блока, который является блоком, подлежащим кодированию. Здесь, предсказанный блок включает в себя выборки предсказания в пространственной области (или области пикселов). Предсказанный блок выводится одинаково из устройства кодирования и устройства декодирования, и устройство кодирования декодирует информацию (информацию остатка) об остатке между исходным блоком и предсказанным блоком, а не исходное значение выборки самого исходного блока. Путем сигнализации на устройство, эффективность кодирования изображения может быть повышена. Устройство декодирования может выводить остаточный блок, включающий в себя остаточные выборки, на основе информации остатка, и генерировать восстановленный блок, включающий в себя восстановленные выборки, путем суммирования остаточного блока и предсказанного блока, и генерировать восстановленную картинку, включающую в себя восстановленные блоки.
[102] Информация остатка может генерироваться в процессах преобразования и квантования. Например, устройство кодирования может выводить остаточный блок между исходным блоком и предсказанным блоком и выполнять процесс преобразования на остаточных выборках (остаточном массиве выборок), включенных в остаточный блок, чтобы вывести коэффициенты преобразования, и затем, путем выполнения процесса квантования на коэффициентах преобразования, выводить квантованные коэффициенты преобразования, чтобы сигнализировать остаток, относящийся к информации, на устройство декодирования (посредством битового потока). Здесь, информация остатка может включать в себя информацию местоположения, метод преобразования, ядро преобразования и параметр квантования, информацию значения квантованных коэффициентов преобразования и т.д. Устройство декодирования может выполнять процесс деквантования/обратного преобразования на основе информации остатка и выводить остаточные выборки (или остаточные блоки). Устройство декодирования может генерировать восстановленную картинку на основе предсказанного блока и остаточного блока. Устройство кодирования может также деквантовать/обратно преобразовывать квантованные коэффициенты преобразования для ссылки для интер-предсказания более поздней картинки, чтобы вывести остаточный блок и сгенерировать на его основе восстановленную картинку.
[103] В настоящем документе, по меньшей мере одно из квантования/деквантования и/или преобразования/обратного преобразования может опускаться. Когда квантование/деквантование опускается, квантованный коэффициент преобразования может называться коэффициентом преобразования. Когда преобразование/ обратное преобразование опускается, коэффициенты преобразования могут называться коэффициентами или остаточными коэффициентами или могут по-прежнему называться коэффициентами преобразования для единообразия выражения.
[104] В настоящем документе, квантованный коэффициент преобразования и коэффициент преобразования могут называться коэффициентом преобразования и масштабированным коэффициентом преобразования, соответственно. В этом случае, информация остатка может включать в себя информацию о коэффициенте(ах) преобразования, и информация о коэффициенте(ах) преобразования может сигнализироваться через синтаксис кодирования остатка. Коэффициенты преобразования могут выводиться на основе информации остатка (или информации о коэффициенте(ах) преобразования), и масштабированные коэффициенты преобразования могут выводиться через обратное преобразование (масштабирование) на коэффициентах преобразования. Остаточные выборки могут выводиться на основе обратного преобразования (преобразования) масштабированных коэффициентов преобразования. Это может быть применено/выражено также в других частях настоящего документа.
[105] Интра-предсказание может относиться к предсказанию, которое генерирует выборки предсказания для текущего блока на основе опорных выборок в картинке, которой принадлежит текущий блок (далее называемой текущей картинкой). Когда интра-предсказание применяется к текущему блоку, соседние опорные выборки, подлежащие использованию для интра-предсказания текущего блока, могут выводиться. Соседние опорные выборки текущего блока могут включать в себя выборки, смежные с левой границей текущего блока, имеющего размер nW×nH, и всего 2×nH выборок, соседних снизу-слева, выборки, смежные с верхней границей текущего блока, и всего 2×nW выборок, соседних сверху-справа, и одну выборку, соседнюю сверху-слева от текущего блока. Альтернативно, соседние опорные выборки текущего блока могут включать в себя множество верхних соседних выборок и множество левых соседних выборок. К тому же, соседние опорные выборки текущего блока могут включать в себя всего nH выборок, смежных с правой границей текущего блока, имеющего размер nW×nH, всего nW выборок, смежных с нижней границей текущего блока, и одну выборку, соседнюю снизу-справа от текущего блока.
[106] Однако, некоторые из соседних опорных выборок текущего блока могут еще не быть декодированными или доступными. В этом случае, декодер может конфигурировать соседние опорные выборки для использования для предсказания путем замены выборок, которые недоступны, на доступные выборки. Альтернативно, соседние опорные выборки, подлежащие использованию для предсказания, могут быть сконфигурированы через интерполяцию доступных выборок.
[107] Когда соседние опорные выборки выводятся, (i) выборка предсказания может выводиться на основе среднего или интерполяции соседних опорных выборок текущего блока, и (ii) выборка предсказания может выводиться на основе опорной выборки, представленной в конкретном направлении (предсказания), для выборки предсказания среди периферийных опорных выборок текущего блока. Случай (i) может называться ненаправленным режимом или не-угловым режимом, и случай (ii) может называться направленным режимом или угловым режимом.
[108] Более того, выборка предсказания может также генерироваться посредством интерполяции между второй соседней выборкой и первой соседней выборкой, расположенными в направлении, противоположном направлению предсказания режима интра-предсказания текущего блока, на основе выборки предсказания текущего блока среди соседних опорных выборок. Случай выше может называться интра-предсказанием линейной интерполяции (LIP). К тому же, выборки предсказания цветности могут генерироваться на основе выборок яркости с использованием линейной модели. Этот случай может называться режимом LM.
[109] К тому же, временная выборка предсказания текущего блока может выводиться на основе отфильтрованных соседних опорных выборок, и по меньшей мере одна опорная выборка, выведенная в соответствии с режимом интра-предсказания среди существующих соседних опорных выборок, то есть, неотфильтрованных соседних опорных выборок, и временная выборка предсказания могут взвешенно суммироваться, чтобы вывести выборку предсказания текущего блока. Случай выше может называться зависимым от положения интра-предсказанием (PDPC).
[110] К тому же, линия опорной выборки, имеющая самую высокую точность предсказания среди соседних линий множества опорных выборок текущего блока, может выбираться, чтобы вывести выборку предсказания с использованием опорной выборки, расположенной в направлении предсказания на соответствующей линии, и затем линия опорной выборки, используемая здесь, может указываться (сигнализироваться) на устройство декодирования, тем самым выполняя кодирование интра-предсказания. Случай выше может называться интра-предсказанием с множеством опорных линий (MRL) или интра-предсказанием на основе MRL.
[111] К тому же, интра-предсказание может выполняться на основе одного и того же режима интра-предсказания путем деления текущего блока на вертикальные или горизонтальные подразбиения, и соседние опорные выборки могут выводиться и использоваться в единице подразбиения. То есть, в этом случае, режим интра-предсказания для текущего блока равным образом применяется к подразбиениям, и выполнение интра-предсказания может быть улучшено в некоторых случаях путем выведения и использования соседних опорных выборок в единице подразбиения. Такой способ предсказания может называться интра-подразбиениями (ISP) или интра-предсказанием на основе ISP.
[112] Вышеописанные способы интра-предсказания могут называться типом интра-предсказания отдельно от режима интра-предсказания. Тип интра-предсказания может называться различными терминами, такими как метод интра-предсказания или дополнительный режим интра-предсказания. Например, тип интра-предсказания (или дополнительный режим интра-предсказания) может включать в себя по меньшей мере одно из вышеописанных LIP, PDPC, MRL и ISP. Общий способ интра-предсказания за исключением специального типа интра-предсказания, такого как LIP, PDPC, MRL или ISP, может называться нормальным типом интра-предсказания. Нормальный тип интра-предсказания может, в общем, применяться, когда специальный тип интра-предсказания не применяется, и предсказание может выполняться на основе режима интра-предсказания, описанного выше. Между тем, пост-фильтрация может выполняться на выведенной предсказанной выборке по мере необходимости.
[113] Конкретно, процедура интра-предсказания может включать в себя этап определения режима/типа интра-предсказания, этап вывода соседней опорной выборки и этап вывода выборки предсказания на основе режима/типа интра-предсказания. К тому же, этап пост-фильтрации может выполняться на выведенной предсказанной выборке, по мере необходимости.
[114] Когда применяется интра-предсказание, режим интра-предсказания, применяемый к текущему блоку, может определяться с использованием режима интра-предсказания соседнего блока. Например, устройство декодирования может выбирать один из наиболее вероятных кандидатов режима (mpm) из списка mpm, выведенного на основе режима интра-предсказания соседнего блока (например, левого и/или верхнего соседних блоков) текущего блока на основе принятого индекса mpm, и выбирать один из других оставшихся режимов интра-предсказания, не включенных в кандидаты mpm (и планарный режим), на основе оставшейся информации режима интра-предсказания. Список mpm может быть сконфигурирован, чтобы включать или не включать в себя планарный режим в качестве кандидата. Например, если список mpm включает в себя планарный режим в качестве кандидата, список mpm может иметь шесть кандидатов. Если список mpm не включает в себя планарный режим в качестве кандидата, список mpm может иметь три кандидата. Когда список mpm не включает в себя планарный режим в качестве кандидата, флаг не-планарный (например, intra_luma_not_planar_flag), указывающий, не является ли режим интра-предсказания текущего блока планарным режимом, может сигнализироваться. Например, флаг mpm может сигнализироваться первым, и индекс mpm и флаг не-планарный могут сигнализироваться, когда значение флага mpm равно 1. К тому же, индекс mpm может сигнализироваться, когда значение флага не-планарный равно 1. Здесь, список mpm сконфигурирован, чтобы не включать планарный режим в качестве кандидата, не должен сигнализировать сначала флаг не-планарный, чтобы проверить, является ли он планарным режимом, поскольку планарный режим всегда рассматривается как mpm.
[115] Например, то, находится ли режим интра-предсказания, применяемый к текущему блоку, в кандидатах mpm (и планарном режиме) или в оставшемся режиме, может указываться на основе флага mpm (например, Intra_luma_mpm_flag). Значение 1 флага mpm может указывать, что режим интра-предсказания для текущего блока находится в кандидатах mpm (и планарном режиме), и значение 0 флага mpm может указывать, что режим интра-предсказания для текущего блока не находится в кандидатах mpm (и планарном режиме). Значение 0 флага не-планарный (например, Intra_luma_not_planar_flag) может указывать, что режим интра-предсказания для текущего блока является планарным режимом, и значение 1 флага не-планарный может указывать, что режим интра-предсказания для текущего блока не является планарным режимом. Индекс mpm может сигнализироваться в форме синтаксического элемента mpm_idx или intra_luma_mpm_idx, и оставшаяся информация режима интра-предсказания может сигнализироваться в форме синтаксического элемента rem_intra_luma_pred_mode или intra_luma_mpm_remainder. Например, оставшаяся информация режима интра-предсказания может индексировать оставшиеся режимы интра-предсказания, не включенные в кандидаты mpm (и планарный режим), среди всех режимов интра-предсказания по порядку числа режимов предсказания, чтобы указать один из них. Режим интра-предсказания может представлять собой режим интра-предсказания для компонента (выборки) яркости. Далее, информация режима интра-предсказания может включать в себя по меньшей мере одно из флага mpm (например, Intra_luma_mpm_flag), флага не-планарный (например, Intra_luma_not_planar_flag), индекса mpm (например, mpm_idx или intra_luma_mpm_idx) и оставшейся информации режима интра-предсказания (rem_intra_luma_pred_mode или intra_luma_mpm_remainder). В настоящем документе, список МРМ может называться различными терминами, такими как список кандидатов MPM и candModeList. Когда MIP применяется к текущему блоку, отдельный флаг mpm (например, intra_mip_mpm_flag), индекс mpm (например, intra_mip_mpm_idx) и оставшаяся информация режима интра-предсказания (например, intra_mip_mpm_remainder) для MIP могут сигнализироваться, а флаг не-планарный не сигнализируется.
[116] Другими словами, в общем, когда разделение блока выполняется на изображении, текущий блок и соседний блок, подлежащие кодированию, имеют аналогичные характеристики изображения. Поэтому, текущий блок и соседний блок с высокой вероятностью имеют один и тот же или аналогичный режим интра-предсказания. Таким образом, кодер может использовать режим интра-предсказания соседнего блока, чтобы кодировать режим интра-предсказания текущего блока.
[117] Например, кодер/декодер может конфигурировать список наиболее вероятных режимов (MPM) для текущего блока. Список МРМ может также называться списком кандидатов MPM. Здесь, MPM может относиться к режиму, используемому, чтобы улучшать эффективность кодирования с учетом сходства между текущим блоком и соседним блоком в кодировании режима интра-предсказания. Как описано выше, список МРМ может быть сконфигурирован, чтобы включать в себя планарный режим, или может быть сконфигурирован, чтобы исключать планарный режим. Например, когда список МРМ включает в себя планарный режим, число кандидатов в списке МРМ может составлять 6. И, если список МРМ не включает в себя планарный режим, число кандидатов в списке МРМ может составлять 5.
[118] Кодер/декодер может конфигурировать список МРМ, включающий в себя 5 или 6 MPM.
[119] Чтобы сконфигурировать список МРМ, могут рассматриваться три типа режимов: интра-режимы по умолчанию, соседние интра-режимы и выведенные интра-режимы.
[120] Для соседних интра-режимов, могут рассматриваться два соседних блока, т.е. левый соседний блок и верхний соседний блок.
[121] Как описано выше, если список МРМ сконфигурирован не включать в себя планарный режим, планарный режим исключается из списка, и число кандидатов списка МРМ может устанавливаться в 5.
[122] К тому же, ненаправленный режим (или не-угловой режим) среди режимов интра-предсказания может включать в себя режим DC на основе среднего соседних опорных выборок текущего блока или планарный режим на основе интерполяции.
[123] Когда интер-предсказание применяется, предсказатель устройства кодирования/устройства декодирования может выводить выборку предсказания путем выполнения интер-предсказания в единицах блоков. Интер-предсказание может представлять собой предсказание, выводимое способом, который зависит от элементов данных (например, значений выборки или информации движения) картинки(ок), отличной от текущей картинки. Когда интер-предсказание применяется к текущему блоку, предсказанный блок (массив выборок предсказания) для текущего блока может выводиться на основе опорного блока (опорного массива выборок), специфицированного вектором движения на опорной картинке, указанной индексом опорной картинки. Здесь, чтобы уменьшить количество информации движения, передаваемой в режиме интер-предсказания, информация движения текущего блока может предсказываться в единицах блоков, подблоков или выборках на основе корреляции информации движения между соседним блоком и текущим блоком. Информация движения может включать в себя вектор движения и индекс опорной картинки. Информация движения может дополнительно включать в себя информацию типа интер-предсказания (предсказание L0, предсказание L1, Bi-предсказание и т.д.). В случае интер-предсказания, соседний блок может включать в себя пространственный соседний блок, представленный в текущей картинке, и временной соседний блок, представленный в опорной картинке. Опорная картинка, включающая в себя опорный блок, и опорная картинка, включающая в себя временной соседний блок, могут быть одинаковыми или разными. Временной соседний блок может называться совместно расположенным опорным блоком, совместно расположенной CU (colCU) и т.п., и опорная картинка, включающая в себя временной соседний блок, может называться совместно расположенной картинкой (colPic). Например, список кандидатов информации движения может быть сконфигурирован на основе соседних блоков текущего блока, и информация флага или индекса, указывающая, какой кандидат выбран (используется), может сигнализироваться, чтобы вывести вектор движения и/или индекс опорной картинки текущего блока. Интер-предсказание может выполняться на основе различных режимов предсказания. Например, в случае режима пропуска и режима объединения, информация движения текущего блока может быть той же самой, что и информация движения соседнего блока. В режиме пропуска, в отличие от режима объединения, остаточный сигнал может не передаваться. В случае режима предсказания вектора движения (MVP), вектор движения выбранного соседнего блока может использоваться как предсказатель вектора движения, и вектор движения текущего блока может сигнализироваться. В этом случае, вектор движения текущего блока может выводиться с использованием суммы предсказателя вектора движения и разности векторов движения.
[124] Информация движения может включать в себя информацию движения L0 и/или информацию движения L1 в соответствии с типом интер-предсказания (предсказание L0, предсказание L1, Bi-предсказание и т.д.). Вектор движения в направлении L0 может называться вектором движения L0 или MVL0, и вектор движения в направлении L1 может называться вектором движения L1 или MVL1. Предсказание на основе вектора движения L0 может называться предсказанием L0, предсказание на основе вектора движения L1 может называться предсказанием L1, и предсказание на основе вектора движения L0 и вектора движения L1, может называться bi-предсказанием. Здесь, вектор движения L0 может указывать вектор движения, ассоциированный со списком L0 опорных картинок (L0), и вектор движения L1 может указывать вектор движения, ассоциированный со списком L1 опорных картинок (L1). Список L0 опорных картинок может включать в себя картинки, которые являются более ранними в порядке вывода, чем текущая картинка, как опорные картинки, и список L1 опорных картинок может включать в себя картинки, которые являются более поздними в порядке вывода, чем текущая картинка. Предыдущие картинки могут называться прямыми (опорными) картинками, и последующие картинки могут называться обратными (опорными) картинками. Список L0 опорных картинок может дополнительно включать в себя картинки, которые являются более поздними в порядке вывода, чем текущая картинка, как опорные картинки. В этом случае, предыдущие картинки могут индексироваться первыми в списке L0 опорных картинок, и последующие картинки могут индексироваться позже. Список L1 опорных картинок может дополнительно включать в себя картинки, предшествующие в порядке вывода текущей картинке, как опорные картинки. В этом случае, последующие картинки могут индексироваться первыми в списке 1 опорных картинок, и предыдущие картинки могут индексироваться позже. Порядок вывода может соответствовать порядку подсчета порядка картинок (POC).
[125] Фиг. 4 показывает примерную иерархическую структуру для закодированного изображения/видео.
[126] Со ссылкой на фиг. 4, закодированное изображение/видео делится на уровень кодирования видео (VCL), который проводит процесс декодирования изображения/видео, подсистему, которая передает и сохраняет закодированную информацию, и NAL (уровень сетевой абстракции), отвечающий за функцию и представленный между VCL и подсистемой.
[127] В VCL, генерируются данные VCL, включающие в себя данные сжатого изображения (данные вырезки), или могут генерироваться набор параметров, включающий в себя набор параметров картинки (PSP), набор параметров последовательности (SPS) и набор параметров видео (VPS) или сообщение информации дополнительной оптимизации (SEI), дополнительно требуемое для процесса декодирования изображения.
[128] В NAL, единица NAL может генерироваться путем добавления информации заголовка (заголовка единицы NAL) к полезной нагрузке последовательности необработанных байтов (RBSP), генерируемой в VCL. В этом случае, RBSP относится к данным вырезки, набору параметров, сообщению SEI и т.д., генерируемыми в VCL. Заголовок единицы NAL может включать в себя информацию типа единицы NAL, специфицированную в соответствии с данными RBSP, включенными в соответствующую единицу NAL.
[129] Как показано на чертеже, единица NAL может классифицироваться на единицу VCL NAL и единицу не-VCL NAL в соответствии с RBSP, сгенерированным в VCL. Единица VCL NAL может означать единицу NAL, которая включает в себя информацию об изображении (данные вырезки) об изображении, и единица не-VCL NAL может означать единицу NAL, которая включает в себя информацию (набор параметров или сообщение SEI), требуемую для декодирования изображения.
[130] Вышеописанные единица VCL NAL и единица не-VCL NAL могут передаваться через сеть путем прикрепления информации заголовка в соответствии со стандартом данных подсистемы. Например, единица NAL может преобразовываться в формат данных предопределенного стандарта, такой как формат файла H.266/VVC, транспортный протокол в реальном времени (RTP), транспортный поток (TS) и т.д., и передаваться через различные сети.
[131] Как описано выше, единица NAL может быть специфицирована при помощи типа единицы NAL в соответствии со структурой данных RBSP, включенной в соответствующую единицу NAL, и информация о типе единицы NAL может храниться и сигнализироваться в заголовке единицы NAL.
[132] Например, единица NAL может классифицироваться на тип единицы VCL NAL и тип единицы не-VCL NAL в соответствии с тем, включает ли в себя единица NAL информацию (данные вырезки) об изображении. Тип единицы VCL NAL может классифицироваться в соответствии с характером и типом картинок, включенных в единицу VCL NAL, и тип единицы не-VCL NAL может классифицироваться в соответствии с типами наборов параметров.
[133] Описанное далее представляет собой пример типа единицы NAL, специфицированной в соответствии с типом набора параметров, включенного в тип единицы не-VCL NAL.
[134] - Единица NAL APS (набор параметров адаптации): Тип для единицы NAL, включающей в себя APS
[135] - Единица NAL DPS (набор параметров декодирования): Тип для единицы NAL, включающей в себя DPS
[136] - Единица NAL VPS (набор параметров видео): Тип для единицы NAL, включающей в себя VPS
[137] - Единица NAL SPS (набор параметров последовательности): Тип для единицы NAL, включающей в себя SPS
[138] - Единица NAL PPS (набор параметров картинки) NAL: Тип для единицы NAL, включающей в себя PPS
[139] - Единица NAL PH (заголовок картинки): Тип для единицы NAL, включающей в себя PH
[140] Вышеупомянутые типы единицы NAL могут иметь синтаксическую информацию для типов единицы NAL, и синтаксическая информация может храниться и сигнализироваться в заголовке единицы NAL. Например, синтаксическая информация может представлять собой nal_unit_type, и типы единицы NAL могут быть специфицированы значением nal_unit_type.
[141] Между тем, как описано выше, одна картинка может включать в себя множество вырезок, и одна вырезка может включать в себя заголовок вырезки и данные вырезки. В этом случае, один заголовок картинки может дополнительно добавляться к множеству вырезок (набору заголовка вырезки и данных вырезки) в одной картинке. Заголовок картинки (синтаксис заголовка картинки) может включать в себя информацию/параметры, обычно применяемые к картинке. В настоящем документе, вырезка может быть смешана или заменена на группу мозаичных элементов. Также, в настоящем документе, заголовок вырезки может быть смешан или заменен на заголовок группы мозаичных элементов.
[142] Заголовок вырезки (синтаксис заголовка вырезки) может включать в себя информацию/параметры, которые могут обычно применяться к вырезке. APS (синтаксис APS) или PPS (синтаксис PPS) может включать в себя информацию/параметры, которые могут обычно применяться к одной или более вырезкам или картинкам. SPS (синтаксис SPS) может включать в себя информацию/параметры, которые могут обычно применяться к одной или более последовательностям. VPS (синтаксис VPS) может включать в себя информацию/параметры, которые могут обычно применяться ко множеству уровней. DPS (синтаксис DPS) может включать в себя информацию/параметры, которые могут обычно применяться ко всему видео. DPS может включать в себя информацию/параметры, относящиеся к конкатенации закодированной последовательности видео (CVS). Синтаксис высокого уровня (HLS) в настоящем документе может включать в себя по меньшей мере одно из синтаксиса APS, синтаксиса PPS, синтаксиса SPS, синтаксиса VPS, синтаксиса DPS и синтаксиса заголовка вырезки.
[143] В настоящем документе, изображение/информация изображения, закодированные устройством кодирования и сигнализированные на устройство декодирования в форме битового потока, включают в себя не только информацию, относящуюся к разбиению в картинке, информацию интер/интра-предсказания, информацию остатка, информацию внутриконтурной фильтрации и т.д., но также информацию, включенную в заголовок вырезки, информацию, включенную в APS, информацию, включенную в PPS, информацию, включенную в SPS, и/или информацию, включенную в VPS.
[144] Между тем, чтобы скомпенсировать разницу между исходным изображением и восстановленным изображением вследствие ошибки, возникающей в процессе кодирования сжатия, таком как квантование, процесс внутриконтурной фильтрации может выполняться на восстановленных выборках или восстановленных картинках, как описано выше. Как описано выше, внутриконтурная фильтрация может выполняться фильтром устройства кодирования и фильтром устройства декодирования, и могут применяться фильтр устранения блочности, SAO и/или адаптивный контурный фильтр (ALF). Например, процесс ALF может выполняться после того, как завершены процесс фильтрации устранения блочности и/или процесс SAO. Однако, даже в этом случае, процесс фильтрации устранения блочности и/или процесс SAO могут опускаться.
[145] Между тем, чтобы повысить эффективность кодирования, отображение яркости с масштабированием цветности (LMCS) может применяться, как описано выше. LMCS может упоминаться как контурный формирователь (повторное формирование). Чтобы повысить эффективность кодирования, управление LMCS и/или сигнализация относящейся к LMCS информации могут выполняться иерархически.
[146] Фиг. 5 иллюстрирует примерную иерархическую структуру CVS в соответствии с вариантом осуществления настоящего документа. Закодированная последовательность видео (CVS) может включать в себя набор параметров последовательности (SPS), набор параметров картинки (PPS), заголовок группы мозаичных элементов, данные мозаичного элемента и/или CTU. Здесь, заголовок группы мозаичных элементов и данные мозаичного элемента могут называться заголовком вырезки и данными вырезки, соответственно.
[147] SPS может включать в себя флаги, предназначенные для задействования инструментов, подлежащих использованию в CVS. К тому же, к SPS можно обращаться при помощи PPS, включающего в себя информацию о параметрах, которые меняются для каждой картинки. Каждая из закодированных картинок может включать в себя один или более закодированных мозаичных элементов прямоугольной области. Мозаичные элементы могут группироваться на растровые сканирования, образующие группы мозаичных элементов. Каждая группа мозаичных элементов инкапсулирована с информацией заголовка, называемой заголовком группы мозаичных элементов. Каждый мозаичный элемент состоит из CTU, содержащей закодированные данные. Здесь данные могут включать в себя значения исходной выборки, значения выборки предсказания и его компоненты яркости и цветности (значения выборок предсказания яркости и значения выборок предсказания цветности).
[148] Фиг. 6 иллюстрирует примерную структуру LMCS в соответствии с вариантом осуществления настоящего документа. Структура 600 LMCS на фиг. 6 включает в себя часть 610 внутриконтурного отображения компонентов яркости на основе адаптивных кусочно-линейных (адаптивных PWL) моделей и часть 620 зависимого от яркости остаточного масштабирования цветности для компонентов цветности. Блоки деквантования и обратного преобразования 611, восстановления 612 и интра-предсказания 613 части 610 внутриконтурного отображения представляют процессы, применимые в отображенной (переформированной) области. Блоки контурных фильтров 615, компенсации движения или интер-предсказания 617 части 610 внутриконтурного отображения и блоки восстановления 622, интра-предсказания 623, компенсации движения или интер-предсказания 624, контурных фильтров 625 части 620 остаточного масштабирования цветности представляют процессы, применимые в исходной (не-отображенной, не-переформированной) области.
[149] Как проиллюстрировано на фиг. 6, когда LMCS включено, может применяться по меньшей мере один из процесса 614 обратного отображения (повторного формирования), процесса 618 прямого отображения (повторного формирования) и процесса 621 масштабирования цветности. Например, процесс обратного отображения может применяться к (восстановленной) выборке яркости (или выборкам яркости или массиву выборок яркости) в восстановленной картинке. Процесс обратного отображения может выполняться на основе кусочного индекса (обратной) функции выборки яркости. Кусочный индекс (обратной) функции может идентифицировать фрагмент, которому принадлежит выборка яркости. Выводом процесса обратного отображения является модифицированная (восстановленная) выборка яркости (или модифицированные выборки яркости или массив модифицированных выборок яркости). LMCS может включаться или выключаться на уровне группы мозаичных элементов (или вырезки), картинки или выше.
[150] Процесс прямого отображения и/или процесс масштабирования цветности могут применяться, чтобы сгенерировать восстановленную картинку. Картинка может содержать выборки яркости и выборки цветности. Восстановленная картинка с выборками яркости может называться восстановленной картинкой яркости, и восстановленная картинка с выборками цветности может называться восстановленной картинкой цветности. Комбинация восстановленной картинки яркости и восстановленной картинки цветности может называться восстановленной картинкой. Восстановленная картинка яркости может генерироваться на основе процесса прямого отображения. Например, если интер-предсказание применяется к текущему блоку, прямое отображение применяется к выборке предсказания яркости, выведенной на основе (восстановленной) выборки яркости в опорной картинке. Поскольку (восстановленная) выборка яркости в опорной картинке генерируется на основе процесса обратного отображения, прямое отображение может применяться к выборке предсказания яркости, таким образом, может выводиться отображенная (переформированная) выборка предсказания яркости. Процесс прямого отображения может выполняться на основе кусочного индекса функции выборки предсказания яркости. Кусочный индекс функции может выводиться на основе значения выборки предсказания яркости или значения выборки яркости в опорной картинке, используемой для интер-предсказания. Если интра-предсказание (или внутриблочное копирование (IBC)) применяется к текущему блоку, прямое отображение не является обязательным, поскольку процесс обратного отображения еще не применялся к восстановленным выборкам в текущей картинке. (Восстановленная) выборка яркости в восстановленной картинке яркости генерируется на основе отображенной выборки предсказания яркости и соответствующей остаточной выборки яркости.
[151] Восстановленная картинка цветности может генерироваться на основе процесса масштабирования цветности. Например, (восстановленная) выборка цветности в восстановленной картинке цветности может выводиться на основе выборки цветности предсказания и остаточной выборки цветности (cres) в текущем блоке. Остаточная выборка цветности (cres) выводится на основе (масштабированной) остаточной выборки цветности (cresScale), и коэффициента остаточного масштабирования цветности (cScaleInv может упоминаться как varScale) для текущего блока. Коэффициент остаточного масштабирования цветности может вычисляться на основе значений переформированной выборки предсказания яркости для текущего блока. Например, коэффициент масштабирования может вычисляться на основе среднего значения ave(Y'pred) яркости значений Y'pred переформированной выборки предсказания яркости. Для ссылки, на фиг. 6, (масштабированная) остаточная выборка цветности, выведенная на основе обратного преобразования/ деквантования, может упоминаться как cresScale, и остаточная выборка цветности, выведенная путем выполнения процесса (обратного) масштабирования в (масштабированную) остаточную выборку цветности, может упоминаться как cres.
[152] Фиг. 7 иллюстрирует структуру LMCS в соответствии с другим вариантом осуществления настоящего документа. Фиг. 7 описана со ссылкой на фиг. 6. Здесь, главным образом, описана разница между структурой LMCS по фиг. 7 и структурой 600 LMCS по фиг. 6. Часть внутриконтурного отображения и часть зависимого от яркости остаточного масштабирования цветности на фиг. 7 могут работать так же (аналогично), как и часть 610 внутриконтурного отображения и часть 620 зависимого от яркости остаточного масштабирования цветности на фиг. 6.
[153] Со ссылкой на фиг. 7, коэффициент остаточного масштабирования цветности может выводиться на основе восстановленных выборок яркости. В этом случае, среднее значение (avgYr) яркости может быть получено (выведено) на основе соседних восстановленных выборок яркости вне восстановленного блока, а не внутренних восстановленных выборок яркости восстановленного блока, и коэффициент остаточного масштабирования цветности выводится на основе среднего значения (avgYr) яркости. Здесь, соседние восстановленные выборки яркости могут быть соседними восстановленными выборками яркости текущего блока или могут быть соседними восстановленными выборками яркости единиц данных виртуального конвейера (VPDU), включающих в себя текущий блок. Например, когда интра-предсказание применяется к целевому блоку, восстановленные выборки могут выводиться на основе выборок предсказания, которые выводятся на основе интра-предсказания. В другом примере, когда интер-предсказание применяется к целевому блоку, прямое отображение применяется к выборкам предсказания, которые выведены на основе интер-предсказания, и восстановленные выборки генерируются (выводятся) на основе переформированных (или прямо отображенных) выборок предсказания яркости.
[154] Информация видео/изображения, сигнализированная через битовый поток, может включать в себя параметры LMCS (информацию о LMCS). Параметры LMCS могут быть сконфигурированы как синтаксис высокого уровня (HLS, включающий в себя синтаксис заголовка вырезки) или тому подобное. Подробное описание и конфигурация параметров LMCS будут описаны далее. Как описано выше, синтаксические таблицы, описанные в настоящем документе (и последующих вариантах осуществления), могут быть сконфигурированы/закодированы на стороне кодера и сигнализироваться на сторону декодера посредством битового потока. Декодер может выполнять синтаксический анализ/ декодировать информацию о LMCS (в форме синтаксических компонентов) в синтаксических таблицах. Один или более вариантов осуществления, которые будут описаны ниже, могут комбинироваться. Кодер может кодировать текущую картинку на основе информации о LMCS, и декодер может декодировать текущую картинку на основе информации о LMCS.
[155] Внутриконтурное отображение компонентов яркости может регулировать динамический диапазон сигнала ввода путем перераспределения кодовых слов по динамическому диапазону, чтобы улучшить эффективность сжатия. Для отображения яркости, могут использоваться функция прямого отображения (повторного формирования) (FwdMap) и функция обратного отображения (повторного формирования) (InvMap), соответствующая функции прямого отображения (FwdMap). Функция FwdMap может сигнализироваться с использованием кусочно-линейных моделей, например, кусочно-линейная модель может иметь 16 фрагментов или бинов. Фрагменты могут иметь равную длину. В одном примере, функция InvMap не должна сигнализироваться и вместо этого выводится из функции FwdMap. То есть, обратное отображение может быть функцией прямого отображения. Например, функция обратного отображения может быть математически построена как симметричная функция прямого отображения, как отражается линией y=x.
[156] Внутриконтурное повторное формирование (яркости) может использоваться, чтобы отображать входные (выборки) значения яркости на измененные значения в переформированной области. Переформированные значения могут кодироваться и затем отображаться обратно на исходную (не-отображенную, не-переформированную) область после восстановления. Чтобы скомпенсировать взаимодействие между сигналом яркости и сигналом цветности, может применяться остаточное масштабирование цветности. Внутриконтурное повторное формирование выполняется путем специфицирования синтаксиса высокого уровня для модели формирователя. Синтаксис модели формирователя может сигнализировать кусочно-линейную модель (модель PWL). Например, синтаксис модели формирователя может сигнализировать модель PWL с 16 бинами или фрагментами равной длины. Прямая поисковая таблица (FwdLUT) и/или обратная поисковая таблица (InvLUT) могут выводиться на основе кусочно-линейной модели. Например, модель PWL предварительно вычисляет прямую (FwdLUT) и обратную (InvLUT) поисковые таблицы (LUT) с 1024 записями. В качестве примера, когда прямая поисковая таблица FwdLUT выведена, обратная поисковая таблица InvLUT может выводиться на основе прямой поисковой таблицы FwdLUT. Прямая поисковая таблица FwdLUT может отображать входные значения Yi яркости на измененные значения Yr, и обратная поисковая таблица InvLUT может отображать измененные значения Yr на восстановленные значения Y'i. Восстановленные значения Y′i могут выводиться на основе входных значений яркости Yi.
[157] В одном примере, SPS может включать в себя синтаксис Таблицы 1 ниже. Синтаксис Таблицы 1 может включать в себя sps_reshaper_enabled_flag как инструмент, задействующий флаг. Здесь, sps_reshaper_enabled_flag может использоваться, чтобы специфицировать, используется ли формирователь в закодированной последовательности видео (CVS). То есть, sps_reshaper_enabled_flag может быть флагом для включения повторного формирования в SPS. В одном примере, синтаксис Таблицы 1 может быть частью SPS.
[158] [Таблица 1]

[159] В одном примере, семантика синтаксических элементов sps_seq_parameter_set_id и sps_reshaper_enabled_flag может быть такой, как показано в Таблице 2 ниже.
[160] [Таблица 2]

[161] В одном примере, заголовок группы мозаичных элементов или заголовок вырезки может включать в себя синтаксис Таблицы 3 или Таблицы 4 ниже.
[162] [Таблица 3]
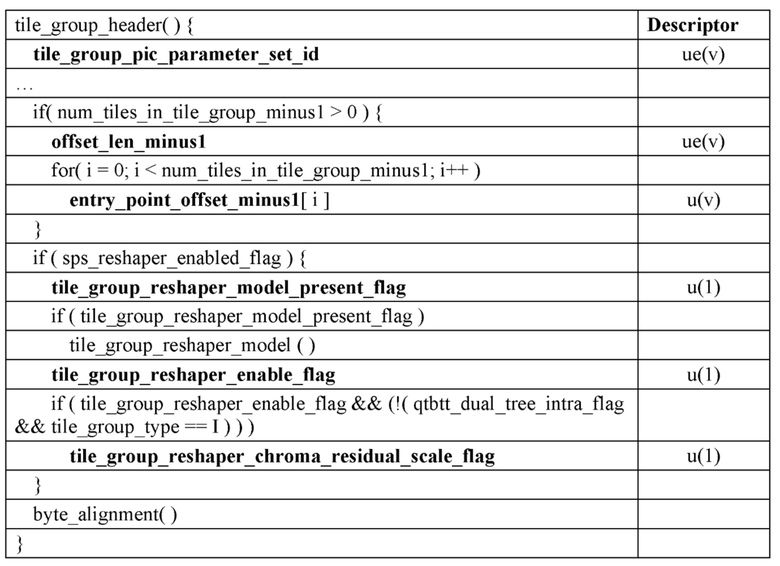
[163] [Таблица 4]
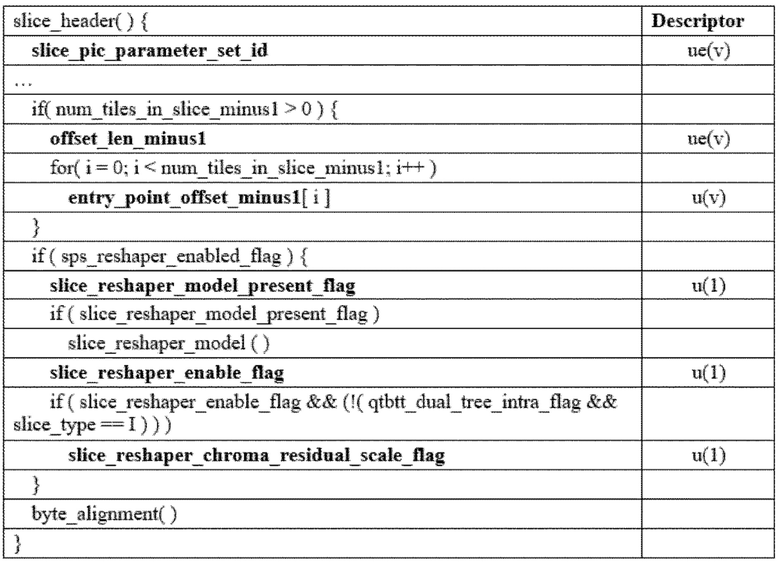
[164] Семантика синтаксических элементов, включенных в синтаксис Таблицы 3 или Таблицы 4, может включать в себя, например, содержимое, раскрытое в следующих таблицах.
[165] [Таблица 5]

[166] [Таблица 6]

[167] В качестве одного примера, когда флаг, задействующий повторное формирование (т.е., sps_reshaper_enabled_flag), синтаксически анализируется в SPS, заголовок группы мозаичных элементов может синтаксически анализировать дополнительные данные (т.е., информацию, включенную в Таблицу 5 или 6), которые используются для создания поисковых таблиц (FwdLUT и/или InvLUT). Для этого, статус флага формирователя SPS (sps_reshaper_enabled_flag) может сначала проверяться в заголовке вырезки или заголовке группы мозаичных элементов. Когда sps_reshaper_enabled_flag истинно (или 1), дополнительный флаг, т.е., tile_group_reshaper_model_present_flag (или slice_reshaper_model_present_flag) может синтаксически анализироваться. Цель tile_group_reshaper_model_present_flag (или slice_reshaper_model_present_flag) может состоять в том, чтобы указывать наличие модели повторного формирования. Например, когда tile_group_reshaper_model_present_flag (или slice_reshaper_model_present_flag) истинно (или 1), может указываться, что формирователь представлен для текущей группы мозаичных элементов (или текущей вырезки). Когда tile_group_reshaper_model_present_flag (или slice_reshaper_model_present_flag) ложно (или 0), может указываться, что формирователь не представлен для текущей группы мозаичных элементов (или текущей вырезки).
[168] Если формирователь представлен и формирователь включен в текущей группе мозаичных элементов (или текущей вырезке), модель формирователя (т.е., tile_group_reshaper_model() или slice_reshaper_model()) может обрабатываться. В дополнение к этому, дополнительный флаг, tile_group_reshaper_enable_flag (или slice_reshaper_enable_flag) может также синтаксически анализироваться. tile_group_reshaper_enable_flag (или slice_reshaper_enable_flag) может указывать, используется ли модель повторного формирования для текущей группы мозаичных элементов (или вырезки). Например, если tile_group_reshaper_enable_flag (или slice_reshaper_enable_flag) равен 0 (или ложно), может указываться, что модель повторного формирования не используется для текущей группы мозаичных элементов (или текущей вырезки). Если tile_group_reshaper_enable_flag (или slice_reshaper_enable_flag) равен 1 (или истинно), может указываться, что модель повторного формирования используется для текущей группы мозаичных элементов (или вырезки).
[169] В качестве одного примера, tile_group_reshaper_model_present_flag (или slice_reshaper_model_present_flag) может быть истинно (или 1), и tile_group_reshaper_enable_flag (или slice_reshaper_enable_flag) может быть ложно (или 0). Это означает, что модель повторного формирования представлена, но не используется в текущей группе мозаичных элементов (или вырезке). В этом случае, модель повторного формирования может использоваться в будущих группах мозаичных элементов (или вырезках). В качестве примера, tile_group_reshaper_enable_flag может быть истинно (или 1), и tile_group_reshaper_model_present_flag может быть ложно (или 0). В таком случае, декодер использует формирователь из предыдущей инициализации.
[170] Когда модель повторного формирования (т.е., tile_group_reshaper_model() или slice_reshaper_model()) и tile_group_reshaper_enable_flag (или slice_reshaper_enable_flag) синтаксически проанализированы, может определяться (оцениваться), представлены ли условия, необходимые для масштабирования цветности. Условия выше включают в себя условие 1 (текущая группа мозаичных элементов/вырезка не была интра-кодирована) и/или условие 2 (текущая группа мозаичных элементов/вырезка не была разбита на две отдельных структуры квадродерева кодирования для яркости и цветности, т.е. структура блока для текущей группы мозаичных элементов/вырезки не является структурой двойного дерева). Если условие 1 и/или условие 2 истинно и/или tile_group_reshaper_enable_flag (или slice_reshaper_enable_flag) истинно (или 1), то tile_group_reshaper_chroma_residual_scale_flag (или slice_reshaper_chroma_residual_scale_flag) может синтаксически анализироваться. Когда tile_group_reshaper_chroma_residual_scale_flag (или slice_reshaper_chroma_residual_scale_flag) включено (если 1 или истинно), может указываться, что остаточное масштабирование цветности включено для текущей группы мозаичных элементов (или вырезки). Когда tile_group_reshaper_chroma_residual_scale_flag (или slice_reshaper_chroma_residual_scale_flag) выключено (если 0 или ложно), может указываться, что остаточное масштабирование цветности отключено для текущей группы мозаичных элементов (или вырезки).
[171] Цель модели повторного формирования группы мозаичных элементов состоит в том, чтобы синтаксически анализировать данные, которые будут необходимы для создания поисковых таблиц (LUT). Эти LUT создаются на основе идеи, что распределение допустимого диапазона значений яркости может быть разделено на множество бинов (например, 16 бинов), которые могут быть представлены с использованием набора системы 16 PWL уравнений. Поэтому, любое значение яркости, которое лежит в пределах данного бина, может отображаться на измененное значение яркости.
[172] Фиг. 8 показывает график, представляющий примерное прямое отображение. На фиг. 8, пять бинов проиллюстрированы в качестве примера.
[173] Со ссылкой на фиг. 8, ось x представляет входные значения яркости, и ось y представляет измененные выходные значения яркости. Ось x делится на 5 бинов или вырезок, каждый бин имеет длину L. То есть, пять бинов, отображаемых на измененные значения яркости, имеют одну и ту же длину. Прямая поисковая таблица (FwdLUT) может создаваться с использованием данных (т.е., данных формирователя), доступных из заголовка группы мозаичных элементов, и поэтому отображение может облегчаться.
[174] В одном варианте осуществления, могут вычисляться выходные точки поворота, ассоциированные с индексами бинов. Выходные точки поворота могут устанавливать (маркировать) минимальную и максимальную границы диапазона вывода повторного формирования кодового слова яркости. Процесс вычисления выходных точек поворота может выполняться путем вычисления кусочно-кумулятивной функции распределения (CDF) числа кодовых слов. Выходной диапазон поворота может сегментироваться на основе максимального числа бинов, подлежащих использованию, и размера поисковой таблицы (FwdLUT или InvLUT). В качестве одного примера, выходной диапазон поворота может сегментироваться на основе произведения максимального числа бинов и размера поисковой таблицы (размер LUT * максимальное число индексов бинов). Например, если произведение максимального числа бинов и размеров поисковой таблицы составляет 1024, выходной диапазон поворота может сегментироваться в 1024 входов. Этот зубец выходного диапазона поворота может выполняться (применяться или достигаться) на основе (с использованием) коэффициента масштабирования. В одном примере, коэффициент масштабирования может выводиться на основе Уравнения 1 ниже.
[175] [Уравнение 1]
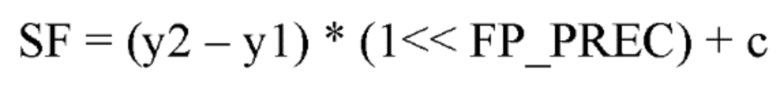
[176] В Уравнении 1, SF обозначает коэффициент масштабирования, и y1 и y2 обозначают выходные точки поворота, соответствующие каждому бину. Также, FP_PREC и c могут быть предопределенными постоянными. Коэффициент масштабирования, определенный на основе Уравнения 1, может называться коэффициентом масштабирования для прямого повторного формирования.
[177] В другом варианте осуществления, в отношении обратного повторного формирования (обратного отображения), для определенного диапазона бинов, подлежащих использованию (т.е., от reshaper_model_min_bin_idx до reshape_model_max_bin_idx), входные переформированные точки поворота, которые соответствуют отображенным точкам поворота прямого LUT, и отображенные обратные выходные точки поворота (заданные индексом бина с учетом * числа исходных кодовых слов), выводятся. В другом примере, коэффициент SF масштабирования может выводиться на основе Уравнения 2 ниже.
[178] [Уравнение 2]

[179] В Уравнении 2, SF обозначает коэффициент масштабирования, x1 и x2 обозначают входные точки поворота, и y1 и y2 обозначают выходные точки поворота, соответствующие каждому фрагменту (бину) (выходные точки поворота обратного отображения). Здесь, входные точки поворота могут представлять точки поворота, отображаемые на основе прямой поисковой таблицы (FwdLUT), и выходные точки поворота могут представлять точки поворота, обратно отображенные на основе обратной поисковой таблицы (InvLUT). Также, FP_PREC может быть предопределенным постоянным значением. FP_PREC из Уравнения 2 может быть тем же или отличным от FP_PREC из Уравнения 1. Коэффициент масштабирования, определенный на основе Уравнения 2, может называться коэффициентом масштабирования для обратного повторного формирования. При обратном повторном формировании, разбиение входных точек поворота может выполняться на основе коэффициента масштабирования Уравнения 2. Коэффициент SF масштабирования используется для сегментации диапазона входных точек поворота. На основе сегментированных входных точек поворота, индексам бинов в диапазоне от 0 до минимального индекса бина (reshaper_model_min_bin_idx) и/или от минимального индекса бина (reshaper_model_min_bin_idx) до максимального индекса бина (reshape_model_max_bin_idx) назначаются значения поворота соответственно минимальному и максимальному значениям бинов.
[180] Таблица 7 ниже показывает синтаксис модели формирователя в соответствии с вариантом осуществления. Модель формирователя может называться моделью повторного формирования или моделью LMCS. Здесь, модель формирователя была описана для примера как формирователь группы мозаичных элементов, но настоящий документ не ограничен этим вариантом осуществления. Например, модель формирователя может быть включена в APS, или модель формирователя группы мозаичных элементов может называться моделью формирователя вырезки или данными LMCS. Также, префикс reshaper_model или Rsp может использоваться взаимозаменяемо с lmcs. Например, в следующих таблицах и описании ниже, reshaper_model_min_bin_idx, reshaper_model_delta_max_bin_idx, reshaper_model_max_bin_idx, RspCW, RsepDeltaCW могут использоваться взаимозаменяемо с lmcs_min_bin_idx, lmcs_delta_cs_bin_idx, lmx, lmcs_delta_csDcselta_idx, lmx, соответственно.
[181] [Таблица 7]

[182] Семантика синтаксических элементов, включенных в синтаксис Таблицы 7, может включать в себя, например, содержимое, раскрытое в следующей таблице.
[183] [Таблица 8]

[184] 
[185] Процесс обратного отображения для выборки яркости в соответствии с настоящим документом может быть описан в форме документа стандарта, как показано в Таблице ниже.
[186] [Таблица 9]

[187] Идентификация процесса кусочного индекса функции для выборки яркости в соответствии с настоящим документом может быть описана в форме документа стандарта, как показано в Таблице ниже. В Таблице 10, idxYInv может называться индексом обратного отображения, и индекс обратного отображения может выводиться на основе восстановленных выборок яркости (lumaSample).
[188] [Таблица 10]

[189] Отображение яркости может выполняться на основе вышеописанных вариантов осуществления и примеров, и вышеописанные синтаксис и компоненты, включенные в них, могут быть только примерными представлениями, и варианты осуществления в настоящем документе не ограничены вышеупомянутыми таблицами или уравнениями. Далее описан способ для выполнения остаточного масштабирования цветности (масштабирования для компонентов цветности остаточных выборок) на основе отображения яркости.
[190] (Зависимое от яркости) остаточное масштабирование цветности предназначено для компенсации взаимодействия между сигналом яркости и его соответствующими сигналами цветности. Например, то, включено ли или нет остаточное масштабирование цветности, также сигнализируется на уровне группы мозаичных элементов. В одном примере, если отображение яркости включено и если разбиение двойного дерева (также известное как отдельное дерево цветности) не применяется к текущей группе мозаичных элементов, дополнительная метка сигнализируется, чтобы указывать, включено или нет зависимое от яркости остаточное масштабирование цветности. В другом примере, когда отображение яркости не используется или когда разбиение двойного дерева используется в текущей группе мозаичных элементов, зависимое от яркости остаточное масштабирование цветности выключено. В другом примере, зависимое от яркости остаточное масштабирование цветности всегда выключено для блоков цветности, у которых площадь меньше или равна 4.
[191] Остаточное масштабирование цветности может быть основано на среднем значении соответствующего блока предсказания яркости (компонента яркости блока предсказания, к которому применяется режим интра-предсказания и/или режим интер-предсказания). Операции масштабирования на стороне кодера и/или стороне декодера могут быть реализованы при помощи целочисленной арифметики с фиксированной запятой на основе Уравнения 3 ниже.
[192] [Уравнение 3]

[193] В Уравнении 3, c обозначает остаток цветности (остаточную выборку цветности, компонент цветности остаточной выборки), c' обозначает масштабированную остаточную выборку цветности (масштабированный компонент цветности остаточной выборки), s обозначает коэффициент остаточного масштабирования цветности, и CSCALE_FP_PREC обозначает (предопределенное) постоянное значение, чтобы специфицировать степень точности. Например, CSCALE_FP_PREC может составлять 11. Коэффициент масштаба остатка цветности вычисляется из ChromaScaleCoef[idxS], где idxS определяется соответствующим средним значением яркости TU в переформированной области.
[194] Фиг. 9 является блок-схемой последовательности операций, иллюстрирующей способ для вывода индекса остаточного масштабирования цветности в соответствии с вариантом осуществления настоящего документа. Способ на фиг. 9 может выполняться на основе фиг. 6, и таблиц, уравнений, переменных, массивов и функций, включенных в описание, относящееся к фиг. 6.
[195] На этапе S910, может определяться, является ли режим предсказания для текущего блока режимом интра-предсказания или режимом интер-предсказания, на основе информации режима предсказания. Если режим предсказания является режимом интра-предсказания, текущий блок или выборки предсказания текущего блока рассматриваются как находящиеся в переформированной (отображенной) области. Если режим предсказания является режимом интер-предсказания, текущий блок или выборки предсказания текущего блока рассматриваются как находящиеся в исходной (не-отображенной, не-переформированной) области.
[196] На этапе S920, когда режим предсказания является режимом интра-предсказания, среднее текущего блока (или выборки предсказания яркости текущего блока) может вычисляться (выводиться). То есть, среднее текущего блока в уже переформированной области вычисляется непосредственно. Среднее может также называться средним значением, средним или усредненным значением.
[197] На этапе S921, когда режим предсказания является режимом интер-предсказания, прямое повторное формирование (прямое отображение) может выполняться (применяться) на выборках предсказания яркости текущего блока. Через прямое повторное формирование, выборки предсказания яркости на основе режима интер-предсказания могут отображаться из исходной области в переформированную область. В одном примере, прямое повторное формирование выборок предсказания яркости может выполняться на основе модели повторного формирования, описанной при помощи Таблицы 7 выше.
[198] На этапе S922, среднее прямых переформированных (прямых отображенных) выборок предсказания яркости может вычисляться (выводиться). То есть, может выполняться процесс усреднения для прямого переформированного результата.
[199] На этапе S930, может вычисляться индекс остаточного масштабирования цветности. Когда режим предсказания является режимом интра-предсказания, индекс остаточного масштабирования цветности может вычисляться на основе среднего выборок предсказания яркости. Когда режим предсказания является режимом интер-предсказания, индекс остаточного масштабирования цветности может вычисляться на основе среднего прямых переформированных выборок предсказания яркости.
[200] В варианте осуществления, индекс остаточного масштабирования цветности может вычисляться на основе контурного синтаксиса. Таблица ниже показывает пример для контура синтаксиса для вывода (вычисления) индекса остаточного масштабирования цветности.
[201] [Таблица 11]

[202] В Таблице 11, idxS представляет индекс остаточного масштабирования цветности, idxFound представляет индекс, идентифицирующий, получен ли индекс остаточного масштабирования цветности, удовлетворяющий условию оператора if, S представляет предопределенное постоянное значение, и MaxBinIdx представляет максимальный разрешенный индекс бина. ReshapPivot[idxS+1] может выводиться на основе Таблицы 7 и/или 8, описанной выше.
[203] В варианте осуществления, коэффициент остаточного масштабирования цветности может выводиться на основе индекса остаточного масштабирования цветности. Уравнение 4 является примером для вывода коэффициента остаточного масштабирования цветности.
[204] [Уравнение 4]
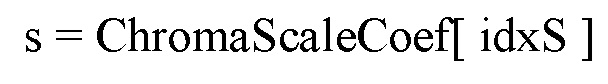
[205] В Уравнении 4, s представляет коэффициент остаточного масштабирования цветности, и ChromaScaleCoef может быть переменной (или массивом), выведенной на основе Таблицы 7 и/или 8, описанной выше.
[206] Как описано выше, может быть получено среднее значение яркости опорных выборок, и коэффициент остаточного масштабирования цветности может выводиться на основе среднего значения яркости. Как описано выше, остаточная выборка компонента цветности может масштабироваться на основе коэффициента остаточного масштабирования цветности, и выборка восстановления компонента цветности может генерироваться на основе масштабированной остаточной выборки компонента цветности.
[207] В одном варианте осуществления настоящего документа, предложена структура сигнализации для эффективного применения вышеописанного LMCS. В соответствии с этим вариантом осуществления настоящего документа, например, данные LMCS могут быть включены в HLS (т.е., APS), и через информацию заголовка (т.е., заголовок картинки, заголовок вырезки), которая представляет собой более низкий уровень APS, модель LMCS (модель формирователя) может адаптивно выводиться путем сигнализации ID APS, которое называется информацией заголовка. Модель LMCS может выводиться на основе параметров LMCS. Также, например, множество APS ID может сигнализироваться через информацию заголовка, и посредством этого, разные модели LMCS могут применяться в единицах блоков в пределах одной и той же картинки/вырезки.
[208] В одном варианте осуществления в соответствии с настоящим документом, предложен способ для эффективного выполнения операции, требуемой для LMCS. В соответствии с семантикой, описанной выше в Таблице 8, операция деления на длину фрагмента lmcsCW[i] (также обозначаемого RspCW[i] в настоящем документе) требуется для выведения InvScaleCoeff[i]. Длина фрагмента обратного отображения может не быть степенью 2, что означает, что деление не может выполняться посредством битового сдвига.
[209] Например, вычисление InvScaleCoeff может требовать до 16 делений на вырезку. В соответствии с Таблицей 8, описанной выше, для кодирования 10 битов, диапазон lmcsCW[i] составляет от 8 до 511, поэтому, чтобы реализовать операцию деления на lmcsCW[i] с использованием LUT, размер LUT должен составлять 504. Также, для кодирования 12 битов, диапазон lmcsCW[i] составляет от 32 до 2047, поэтому размер LUT должен составлять 2016, чтобы реализовать операцию деления на lmcsCW[i] с использованием LUT. То есть, деление является затратным в аппаратной реализации, поэтому желательно по возможности избегать деления.
[210] В одном аспекте этого варианта осуществления, lmcsCW[i] может быть ограничено как кратное фиксированного числа (или предварительно определенного числа). Соответственно, поисковая таблица (LUT) (емкость или размер LUT) для деления может быть уменьшена. Например, если lmcsCW[i] становится кратным 2, размер LUT для замены процесса деления может уменьшаться вполовину.
[211] В другом аспекте этого варианта осуществления, предложено, что для кодирования с кодированием более высокой внутренней битовой глубины, в дополнение к существующим ограничениям “значение lmcsCW[i] должно находиться в диапазоне от (OrgCW>>3) до (OrgCW<<3−1)”, дополнительным ограничением должно быть то, что lmcsCW[i] кратно 1<<(BitDepthY-10), если битовая глубина кодирования выше, чем 10. Здесь, BitDepthY может представлять собой битовую глубину яркости. Соответственно, возможное число lmcsCW[i] не будет меняться с битовой глубиной кодирования, и размер LUT, необходимый для вычисления InvScaleCoeff, не увеличивается для более высокой глубины кодирования. Например, для внутренней битовой глубины кодирования 12 битов, ограничение lmcsCW[i] является кратным 4, тогда LUT для замены процесса деления будет той же самой, что и LUT, подлежащая использованию для кодирования 10 битов. Этот аспект может быть реализован отдельно, но он может также быть реализован в комбинации с вышеупомянутым аспектом.
[212] В другом аспекте этого варианта осуществления, lmcsCW[i] может быть ограничено более узким диапазоном. Например, lmcsCW[i] может быть ограничено в пределах диапазона от (OrgCW>>1) до (OrgCW<<1)-1. Тогда для кодирования 10 битов, диапазон lmcsCW[i] может составлять [32, 127], и поэтому необходима только LUT, имеющая размер 96, для вычисления InvScaleCoeff.
[213] В другом аспекте настоящего варианта осуществления, lmcsCW[i] аппроксимироваться ближайшими числами, являющимися степенью 2, и использоваться при разработке формирователя. Соответственно, деление в обратном отображении может выполняться (и заменяться) битовым сдвигом.
[214] В одном варианте осуществления в соответствии с настоящим документом, предложено ограничение диапазона кодовых слов LMCS. В соответствии с Таблицей 8, описанной выше, значения кодовых слов LMCS находятся в диапазоне от (OrgCW>>3) до (OrgCW<<3)-1. Этот диапазон кодовых слов является слишком широким. Это может приводить к проблеме визуального артефакта, когда существуют большие разности между RspCW [i] и OrgCW.
[215] В соответствии с одним вариантом осуществления согласно настоящему документу, предложено ограничивать кодовое слово отображения LMCS PWL более узким диапазоном. Например, диапазон lmcsCW[i] может находиться в диапазоне от (OrgCW>>1) до (OrgCW<<1)-1.
[216] В одном варианте осуществления в соответствии с настоящим документом, использование одного коэффициента остаточного масштабирования цветности предложено для остаточного масштабирования цветности в LMCS. Существующий способ для вывода коэффициента остаточного масштабирования цветности использует среднее значение соответствующего блока яркости и выводит наклон каждого фрагмента обратного отображения яркости как соответствующий коэффициент масштабирования. К тому же, процесс для идентификации кусочного индекса требует доступности соответствующего блока яркости, это приводит к проблеме задержки. Это нежелательно для аппаратной реализации. В соответствии с этим вариантом осуществления настоящего документа, масштабирование в блоке цветности может не зависеть от значения блока яркости, и может не требоваться идентифицировать кусочный индекс. Поэтому, процесс остаточного масштабирования цветности в LMCS может выполняться без проблемы задержки.
[217] В одном варианте осуществления в соответствии с настоящим документом, один коэффициент масштабирования цветности может выводиться как из кодера, так и декодера на основе информации яркости LMCS. Когда модель яркости LMCS принята, коэффициент остаточного масштабирования цветности может обновляться. Например, когда модель LMCS обновляется, один коэффициент остаточного масштабирования цветности может обновляться.
[218] Таблица ниже показывает пример для получения одного коэффициента масштабирования цветности в соответствии с настоящим вариантом осуществления.
[219] [Таблица 12]

[220] Со ссылкой на Таблицу 12, один коэффициент масштабирования цветности (например, ChromaScaleCoeff или ChromaScaleCoeffSingle) может быть получен путем усреднения наклонов обратного отображения яркости всех фрагментов в пределах lmcs_min_bin_idx и lmcs_max_bin_idx.
[221] Фиг. 10 иллюстрирует линейную аппроксимацию точек поворота в соответствии с вариантом осуществления настоящего документа. На фиг. 10, показаны точки P1, Ps и P2 поворота. Следующие варианты осуществления или их примеры будут описаны при помощи фиг. 10.
[222] В примере этого варианта осуществления, один коэффициент масштабирования цветности может быть получен на основе линейного приближения отображения яркости PWL между точками lmcs_min_bin_idx и lmcs_max_bin_idx+1 поворота. То есть, обратный наклон линейного отображения может использоваться как коэффициент остаточного масштабирования цветности. Например, линейная линия 1 на фиг. 10 может быть прямой линией, соединяющей точки P1 и P2 поворота. Со ссылкой на фиг. 10, в P1, входное значение составляет x1, и отображенное значение составляет 0, и в P2, входное значение составляет x2, и отображенное значение составляет y2. Обратный наклон (обратный масштаб) линейной линии 1 составляет (x2-x1)/y2, и один коэффициент ChromaScaleCoeffSingle масштабирования цветности может вычисляться на основе входных значений и отображенных значений точек P1, P2 поворота и следующего уравнения.
[223] [Уравнение 5]
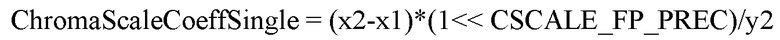
[224] В Уравнении 5, CSCALE_FP_PREC представляет коэффициент сдвига, например, CSCALE_FP_PREC может представлять собой предопределенное постоянное значение. В одном примере, CSCALE_FP_PREC может составлять 11.
[225] В другом примере в соответствии с этим вариантом осуществления, со ссылкой на фиг. 10, входное значение в точке поворота Ps составляет min_bin_idx+1, и отображенное значение в точке поворота Ps составляет ys. Соответственно, обратный наклон (обратный масштаб) линейной линии 1 может вычисляться как (xs-x1)/ys, и один коэффициент ChromaScaleCoeffSingle масштабирования цветности может вычисляться на основе входных значений и отображенных значений точек поворота P1, Ps и следующего уравнения.
[226] [Уравнение 6]

[227] В Уравнении 6, CSCALE_FP_PREC представляет коэффициент сдвига (коэффициент для битового сдвига), например, CSCALE_FP_PREC может представлять собой предопределенное постоянное значение. В одном примере, CSCALE_FP_PREC может составлять 11, и битовый сдвиг для обратного масштаба может выполняться на основе CSCALE_FP_PREC.
[228] В другом примере в соответствии с этим вариантом осуществления, один коэффициент остаточного масштабирования цветности может выводиться на основе линии линейной аппроксимации. Пример для вывода линии линейной аппроксимации может включать в себя линейное соединение точек поворота (т.е., lmcs_min_bin_idx, lmcs_max_bin_idx+1). Например, результат линейной аппроксимации может быть представлен кодовыми словами отображения PWL. Отображенное значение y2 в P2 может быть суммой кодовых слов всех бинов (фрагментов), и разность между входным значением в P2 и входным значением в P1 (x2-x1) составляет OrgCW*(lmcs_max_bin_idx-lmcs_min_bin_idx+1) (для OrgCW, см. Таблицу 8 выше). Таблица ниже показывает пример получения одного коэффициента масштабирования цветности в соответствии с вышеописанным вариантом осуществления.
[229] [Таблица 13]

[230] Со ссылкой на Таблицу 13, один коэффициент масштабирования цветности (например, ChromaScaleCoeffSingle) может быть получен из двух точек поворота (т.е., lmcs_min_bin_idx, lmcs_max_bin_idx). Например, обратный наклон линейного отображения может использоваться как коэффициент масштабирования цветности.
[231] В другом примере этого варианта осуществления, один коэффициент масштабирования цветности может быть получен путем линейной аппроксимации точек поворота, чтобы минимизировать ошибку (или среднеквадратичную ошибку) между линейной аппроксимацией и существующим отображением PWL. Этот пример может быть более точным, чем просто соединение двух точек поворота в lmcs_min_bin_idx и lmcs_max_bin_idx. Существует много способов найти оптимальное линейное отображение, и такой пример описан ниже.
[232] В одном примере, параметры b1 и b0 уравнения y=b1*x+b0 линейной аппроксимации для минимизации суммы наименьшей квадратичной ошибки могут вычисляться на основе Уравнений 7 и/или 8 ниже.
[233] [Уравнение 7]

[234] [Уравнение 8]

[235] В Уравнении 7 и 8, x является исходными значениями яркости, и y является переформированными значениями яркости, и  и
и  являются средним x и y, и xi и yi представляют значения i-ых точек поворота.
являются средним x и y, и xi и yi представляют значения i-ых точек поворота.
[236] Со ссылкой на фиг. 10, другая простая аппроксимация для идентификации линейного отображения задается следующим образом:
[237] - Получить линейную линию 1 путем соединения точек поворота отображения PWL в lmcs_min_bin_idx и lmcs_max_bin_idx+1, вычисленных lmcs_pivots_linear[i] этой линейной линии при входных значениях кратных OrgW.
[238] - Суммировать разности между отображенными значениями точек поворота с использованием линейной линии 1 и с использованием отображения PWL.
[239] - Получить среднюю разность avgDiff.
[240] - Отрегулировать последнюю точку поворота линейной линии в соответствии со средней разностью, например, 2*avgDiff.
[241] - Использовать обратный наклон отрегулированной линейной линии как масштаб остатка цветности.
[242] В соответствии с вышеописанной линейной аппроксимацией, коэффициент масштабирования цветности (т.е., обратный наклон прямого отображения) может выводиться (получаться) на основе Уравнения 9 или 10 ниже.
[243] [Уравнение 9]

[244] [Уравнение 10]

[245] В вышеописанных уравнениях, lmcs_pivots_lienar[i] может представлять собой отображенные значения линейного отображения. При линейном отображении, все фрагменты отображения PWL между минимальным и максимальным индексами бинов могут иметь одно и то же кодовое слово LMCS (lmcsCW). То есть, lmcs_pivots_linear[lmcs_min_bin_idx+1] может быть тем же самым, что и lmcsCW[lmcs_min_bin_idx].
[246] Также, в Уравнениях 9 и 10, CSCALE_FP_PREC представляет коэффициент сдвига (коэффициент для битового сдвига), например, CSCALE_FP_PREC может представлять собой предопределенное постоянное значение. В одном примере, CSCALE_FP_PREC может составлять 11.
[247] С одним коэффициентом остаточного масштабирования цветности (ChromaScaleCoeffSingle), больше нет необходимости вычислять среднее соответствующего блока яркости, находить индекс в линейном отображении PWL, чтобы получить коэффициент остаточного масштабирования цветности. Соответственно, эффективность кодирования с использованием остаточного масштабирования цветности может быть повышена. Это не только устраняет зависимость от соответствующего блока яркости, решает проблему задержки, но также уменьшает сложность.
[248] В другом варианте осуществления настоящего документа, кодер может определять параметры, относящиеся к одному коэффициенту масштабирования цветности, и сигнализировать параметры на декодер. При сигнализации, кодер может использовать другую информацию, доступную в кодере, чтобы вывести коэффициент масштабирования цветности. Этот вариант осуществления нацелен на устранение проблемы задержки остаточного масштабирования цветности.
[249] Например, другой пример для идентификации линейного отображения, подлежащего использованию для определения остаточного коэффициента масштабирования цветности, задается следующим образом:
[250] - Путем соединения точек поворота отображения PWL в lcs_min_bin_idx и lmcs_max_bin_idx+1, вычисленных lmcs_pivots_linear[i] из этой линейной линия при входных значениях, кратных OrgW
[251] - Получить взвешенную сумму разностей между отображенными значениями точек поворота с использованием линейной линии 1 и значениями отображения яркости PWL. Вес может быть основан на статистике кодера, такой как гистограмма бина.
[252] - Получить взвешенную усредненную разность avgDiff.
[253] - Отрегулировать последнюю точку поворота линейной линии 1 в соответствии с взвешенной усредненной разностью, например, 2*avgDiff.
[254] - Использовать обратный наклон отрегулированной линейной линии, чтобы вычислить масштаб остатка цветности.
[255] Таблица ниже показывает примеры синтаксисов для сигнализации значения y для вывода коэффициента масштабирования цветности.
[256] [Таблица 14]

[257] В Таблице 14, синтаксический элемент lmcs_chroma_scale может специфицировать один коэффициент (остаточного) масштабирования цветности, используемый для остаточного масштабирования цветности LMCS (ChromaScaleCoeffSingle=lmcs_chroma_scale). То есть, информация о коэффициенте остаточного масштабирования цветности может непосредственно сигнализироваться, и сигнализированная информация может выводиться как коэффициент остаточного масштабирования цветности. Другими словами, значение сигнализированной информации о коэффициенте остаточного масштабирования цветности может (непосредственно) выводиться как значение одного коэффициента остаточного масштабирования цветности. Здесь, синтаксический элемент lmcs_chroma_scale может сигнализироваться вместе с другими данными LMCS (т.е. синтаксическим элементом, относящимся к абсолютному значению и знаку кодового слова, и т.д.).
[258] Альтернативно, кодер может сигнализировать только необходимые параметры, чтобы вывести коэффициент остаточного масштабирования цветности в декодере. Чтобы вывести коэффициент остаточного масштабирования цветности в декодере, требуется входное значение x и отображенное значение y. Поскольку значение x является длиной бина и является известным числом, его не нужно сигнализировать. В сущности, только значение y должно сигнализироваться, чтобы вывести коэффициент остаточного масштабирования цветности. Здесь, значение y может быть отображенным значением любой точки поворота в линейном отображении (т.е., отображенные значения P2 или Ps на фиг. 10).
[259] Следующие таблицы показывают примеры сигнализации отображенных значений для вывода коэффициента остаточного масштабирования цветности.
[260] [Таблица 15]

[261] [Таблица 16]

[262] Один из синтаксисов Таблиц 15 и 16, описанных выше, может использоваться, чтобы сигнализировать значение y в любых линейных точках поворота, специфицированных кодером и декодером. То есть, кодер и декодер могут выводить значение y с использованием одного и того же синтаксиса.
[263] Сначала, описан вариант осуществления в соответствии с Таблицей 15. В Таблице 15, lmcs_cw_linear может обозначать отображенное значение при Ps или P2. То есть, в варианте осуществления в соответствии с Таблицей 15, фиксированное число может сигнализироваться через lmcs_cw_linear.
[264] В примере в соответствии с этим вариантом осуществления, если lmcs_cw_linear обозначает отображенное значение одного бина (т.е. lmcs_pivots_linear[lmcs_min_bin_idx+1] в Ps согласно фиг. 10), коэффициент масштабирования цветности может выводиться на основе следующего уравнения.
[265] [Уравнение 11]

[266] В другом примере в соответствии с этим вариантом осуществления, если lmcs_cw_linear обозначает lmcs_max_bin_idx+1 (т.е. lmcs_pivots_linear[lmcs_max_bin_idx+1] в P2 согласно фиг. 10), коэффициент масштабирования цветности может выводиться на основе следующего уравнения.
[267] [Уравнение 12]

[268] В вышеописанных уравнениях, CSCALE_FP_PREC представляет коэффициент сдвига (коэффициент для битового сдвига), например, CSCALE_FP_PREC может представлять собой предопределенное постоянное значение. В одном примере, CSCALE_FP_PREC может составлять 11.
[269] Далее, описан вариант осуществления в соответствии с Таблицей 16. В этом варианте осуществления, lmcs_cw_linear может сигнализироваться как значение дельта относительно фиксированного числа (т.е. lmcs_delta_abs_cw_linear, lmcs_delta_sign_cw_linear_flag). В примере этого варианта осуществления, когда lmcs_cw_linear представляет отображенное значение в lmcs_pivots_linear[lmcs_min_bin_idx+1] (т.е. Ps согласно фиг. 10), lmcs_cw_linear_delta и lmcs_cw_linear могут выводиться на основе следующих уравнений.
[270] [Уравнение 13]

[271] [Уравнение 14]

[272] В другом примере этого варианта осуществления, когда lmcs_cw_linear представляет отображенное значение в lmcs_pivots_linear[lmcs_max_bin_idx+1] (т.е. P2 согласно фиг. 10), lmcs_cw_linear_delta и lmcs_cw_linear могут выводиться на основе следующих уравнений.
[273] [Уравнение 15]
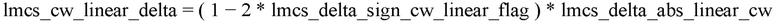
[274] [Уравнение 16]

[275] В вышеописанных уравнениях, OrgCW может представлять собой значение, выведенное на основе Таблицы 8, описанной выше.
[276] Фиг. 11 иллюстрирует один пример линейного повторного формирования (или линейного переформирования, линейного отображения) в соответствии с вариантом осуществления настоящего документа. То есть, в этом варианте осуществления, предложено использование линейного формирователя в LMCS. Например, пример на фиг. 11 может относиться к прямому линейному повторному формированию (отображению).
[277] В существующем примере, LMCS может использовать кусочно-линейное отображение с фиксированными 16 фрагментами. Это усложняет схему формирователя, поскольку резкий переход между точками поворота может вызывать нежелательный артефакт. Также, для обратного отображения яркости формирователя, необходимо идентифицировать кусочный индекс функции. Процесс идентификации кусочного индекса функции является процессом итерации с множеством сравнений. Более того, для остаточного масштабирования цветности с использованием соответствующего среднего блока яркости, также необходим такой процесс идентификации кусочного индекса яркости. Это не только имеет проблему сложности, это также вызывает задержку остаточного масштабирования цветности в зависимости от восстановления всего блока яркости. Чтобы решить эту проблему, использование линейного формирователя предложено для LMCS.
[278] Со ссылкой на фиг. 11, линейный формирователь может включать в себя две точки поворота т.е., P1 и P2. P1 и P2 могут представлять входное и отображенное значения, например, P1 может составлять (min_input, 0) и P2 может составлять (max_input, max_mapped). Здесь, min_input представляет минимальное входное значение, и max_input представляет максимальное входное значение. Любые входные значения, меньшие или равные min_input, отображаются в 0, любые входные значения, большие max_input, отображаются в max_mapped. Любые входные значения яркости в пределах min_input и max_input линейно отображаются в другие значения. Фиг. 11 показывает пример отображения. Точки P1, P2 поворота могут определяться в кодере, и линейная аппроксимация может использоваться, чтобы аппроксимировать кусочно-линейное отображение.
[279] Существует много способов сигнализировать линейный формирователь. В примере способа сигнализации линейного формирователя, исходный диапазон яркости может делиться на равное число бинов. То есть, отображение яркости между минимальным и максимальным бинами может равномерно распределяться. Например, все бины могут иметь одно и то же кодовое слово LMCS (lmcsCW). По этой причине, минимальный и максимальный индексы бинов могут сигнализироваться. Поэтому должен сигнализироваться только один набор reshape_model_bin_delta_abs_CW (или reshaper_model_delta_abs_CW, lmcs_delta_abs_CW) и reshaper_model_bin_delta_sign_CW_flag (или reshaper_model_delta_sign_CW_flag_sign_CW_flag).
[280] Следующие таблицы показывают примерный синтаксис и семантику сигнализации линейного формирователя в соответствии с этим примером.
[281] [Таблица 17]

[282] [Таблица 18]

[283] Со ссылкой на Таблицы 17 и 18, синтаксический элемент log2_lmcs_num_bins_minus4 может представлять собой информацию о числе бинов. На основе этой информации, число бинов может сигнализироваться, чтобы разрешать лучшее управление минимальной и максимальной точками поворота. В другом существующем примере, кодер и/или декодер может выводить (специфицировать) (фиксированное) число бинов без сигнализации, например, число бинов выводится как 16 или 32. Однако, в соответствии с примерами Таблиц 17 и 18, log2_lmcs_num_bins_minus4 plus 4 может представлять двоичный логарифм числа бинов. Число бинов, выведенное на основе синтаксического элемента, может быть в диапазоне от 4 до значения битовой глубины яркости BitDepthY.
[284] В Таблице 18, ScaleCoeffSingle может упоминаться как один коэффициент прямого масштабирования яркости, и InvScaleCoeffSingle может упоминаться как один коэффициент обратного масштабирования яркости. (Прямое) отображение на предсказании выборки яркости может выполняться на основе одного коэффициента прямого масштабирования яркости, и (обратное) отображение на восстановленных выборках яркости может выполняться на основе одного коэффициента обратного масштабирования яркости. ChromaScaleCoeffSingle, как описано выше, может упоминаться как один коэффициент остаточного масштабирования цветности. ScaleCoeffSingle, InvScaleCoeffSingle и ChromaScaleCoeffSingle могут использоваться для прямого отображения яркости, обратного отображения яркости и остаточного масштабирования цветности, соответственно. ScaleCoeffSingle, InvScaleCoeffSingle и ChromaScaleCoeffSingle могут одинаково применяться ко всем бинам (отображениям PWL 16 бинов) как один коэффициент.
[285] Со ссылкой на Таблицу 18, FP_PREC и CSCALE_FP_PREC могут быть постоянными значениями для битового сдвига. FP_PREC и CSCALE_FP_PREC могут или не могут быть одинаковыми. Например, FP_PREC может быть больше или равно CSCALE_FP_PREC. В одном примере, FP_PREC и CSCALE_FP_PREC могут оба составлять 11. В другом примере, FP_PREC может составлять 15, и CSCALE_FP_PREC может составлять 11.
[286] В другом примере способа сигнализации линейного формирователя, кодовое слово LMCS (lmcsCWlinearALL) может выводиться на основе следующих уравнений в Таблице 19. Также в этом примере, могут использоваться синтаксические элементы линейного повторного формирования в Таблице 17. Следующая таблица показывает пример семантики, описанной в соответствии с этим примером.
[287] [Таблица 19]

[288] Со ссылкой на Таблицу 19, FP_PREC и CSCALE_FP_PREC могут быть постоянными значениями для битового сдвига. FP_PREC и CSCALE_FP_PREC могут или не могут быть одинаковыми. Например, FP_PREC может быть больше или равным CSCALE_FP_PREC. В одном примере, FP_PREC и CSCALE_FP_PREC могут оба составлять 11. В другом примере, FP_PREC может составлять 15, и CSCALE_FP_PREC может составлять 11.
[289] В Таблице 19, lmcs_max_bin_idx может использоваться взаимозаменяемо с LmcsMaxBinIdx. lmcs_max_bin_idx и LmcsMaxBinIdx могут выводиться на основе lmcs_delta_max_bin_idx синтаксиса Таблиц 17 и 18, описанных выше. Например, Таблица 19 может интерпретироваться со ссылкой на Таблицу 18.
[290] В другом варианте осуществления в соответствии с настоящим документом, может быть предложен другой пример способа для сигнализации линейного формирователя. Точки P1, P2 поворота модели линейного формирователя могут сигнализироваться явно. Следующие таблицы показывают пример синтаксиса и семантики для явной сигнализации модели линейного формирователя в соответствии с этим примером.
[291] [Таблица 20]

[292] [Таблица 21]

[293] Со ссылкой на Таблицы 20 и 21, входное значение первой точки поворота может выводиться на основе синтаксического элемента lmcs_min_input, и входное значение второй точки поворота может выводиться на основе синтаксического элемента lmcs_max_input. Отображенное значение первой точки поворота может представлять собой предопределенное значение (значение, известное кодеру и декодеру), например, отображенное значение первой точки поворота равно 0. Отображенное значение второй точки поворота может выводиться на основе синтаксического элемента lmcs_max_mapped. То есть, модель линейного формирователя может явно (непосредственно) сигнализироваться на основе информации, сигнализированной в синтаксисе Таблицы 20.
[294] Альтернативно, lmcs_max_input и lmcs_max_mapped могут сигнализироваться как значения дельта. Следующие таблицы показывают пример синтаксиса и семантики для сигнализации модели линейного формирователя как значений дельта.
[295] [Таблица 22]

[296] [Таблица 23]

[297] Со ссылкой на Таблицу 23, входное значение первой точки поворота может выводиться на основе синтаксического элемента lmcs_min_input. Например, lmcs_min_input может иметь отображенное значение 0. lmcs_max_input_delta может специфицировать разность между входным значением второй точки поворота и максимальным значением яркости (т.е., (1<<bitdepthY)-1). lmcs_max_mapped_delta может специфицировать разность между отображенным значением второй точки поворота и максимальным значением яркости (т.е., (1<<bitdepthY)-1).
[298] В соответствии с вариантом осуществления настоящего документа, прямое отображение для выборки предсказания яркости, обратное отображение для выборок восстановления яркости и остаточное масштабирование цветности могут выполняться на основе вышеописанных примеров линейного формирователя. В одном примере, только один обратный коэффициент масштабирования может требоваться для обратного масштабирования для (восстановленных) выборок (пикселов) яркости в обратном отображении на основе линейного формирователя. Это также истинно для прямого отображения и остаточного масштабирования цветности. То есть, этапы для определения ScaleCoeff[i], InvScaleCoeff[i] и ChromaScaleCoeff[i], где i является индексом бина, могут быть заменены на только один коэффициент. Здесь, один коэффициент является представлением фиксированной точки (прямого) наклона или обратного наклона линейного отображения. В одном примере, коэффициент масштабирования обратного отображения яркости (коэффициент обратного масштабирования в обратном отображении для выборок восстановления яркости) может выводиться на основе по меньшей мере одного из следующих уравнений.
[299] [Уравнение 17]

[300] [Уравнение 18]

[301] [Уравнение 19]
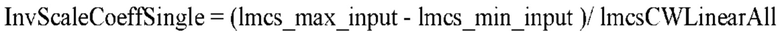
[302] lmcsCWLinear из Уравнения 17 может выводиться из Таблиц 17 и 18, описанных выше. lmcsCWLinearALL из Уравнений 18 и 19 может выводиться из по меньшей мере одной из Таблиц 19-23, описанных выше. В Уравнении 17 или 18, OrgCW может выводиться из Таблицы 8 или 18.
[303] Следующие таблицы описывают уравнения и синтаксис (условные утверждения), указывающие процесс прямого отображения для выборок яркости (т.е. выборок предсказания яркости) в восстановлении картинки. В следующих таблицах и уравнениях, FP_PREC является постоянным значением для битового сдвига и может быть предопределенным значением. Например, FP_PREC может составлять 11 или 15.
[304] [Таблица 24]

[305] [Таблица 25]

[306] Таблица 24 может быть предназначена для вывода прямых отображенных выборок яркости в процессе отображения яркости на основе Таблицы 7 и 8, описанных выше. То есть, Таблица 24 может быть описана вместе с Таблицами 7 и 8. В Таблице 24, прямые отображенные выборки (предсказания) яркости PredMAPSamples[i][j] в качестве выхода могут выводиться из выборок (предсказания) яркости predSamples[i][j] в качестве входа. idxY из Таблицы 24 может называться индексом (прямого) отображения, и индекс отображения может выводиться на основе выборок яркости предсказания.
[307] Таблица 25 может быть предназначена для вывода прямых отображенных выборок яркости в отображении яркости на основе линейного формирователя. Например, lmcs_min_input, lmcs_max_input, lmcs_max_mapped и ScaleCoeffSingle из Таблицы 25 могут выводиться по меньшей мере из одной из Таблиц 20-23. В Таблице 25, в случае ‘lmcs_min_input < predSamples[i][j] < lmcs_max_input’, прямые отображенные выборки (предсказания) яркости PredMAPSamples[i][j] могут выводиться как выход из входа, выборки (предсказания) яркости predSamples[i][j]. В сравнении между Таблицей 24 и Таблицей 25, изменение от существующего LMCS в соответствии с применением линейного формирователя можно видеть с точки зрения прямого отображения.
[308] Следующие уравнения описывают процесс обратного отображения для выборок яркости (т.е. выборок восстановления яркости). В следующих уравнениях, ‘lumaSample’ как вход может представлять собой выборку восстановления яркости до обратного отображения (до модификации). ‘invSample’ как выход может представлять собой обратную отображенную (модифицированную) выборку восстановления яркости. В других случаях, усеченное invSample может упоминаться как модифицированная выборка восстановления яркости.
[309] [Уравнение 20]
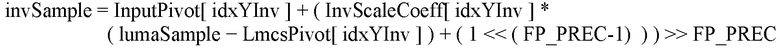
[310] [Уравнение 21]

[311] Со ссылкой на Уравнение 20, индекс idxInv может выводиться на основе Таблицы 10, описанной выше. То есть, Уравнение 20 может быть предназначено для вывода обратных отображенных выборок яркости в процессе отображения яркости на основе Таблиц 7 и 8, описанных выше. Уравнение 20 может быть описано вместе с Таблицей 9, описанной выше.
[312] Уравнение 21 может быть предназначено для вывода обратно отображенных выборок яркости в отображении яркости на основе линейного формирователя. Например, lmcs_min_input из Уравнения 21 может выводиться в соответствии с по меньшей мере одной из Таблиц 20-23. В сравнении между Уравнением 20 и Уравнением 21, изменение от существующего LMCS в соответствии с применением линейного формирователя можно видеть с точки зрения прямого отображения.
[313] На основе вышеописанных примеров линейного формирователя, процесс идентификации кусочного индекса может опускаться. То есть, в настоящих примерах, поскольку существует только один фрагмент, имеющий действительные переформированные пикселы яркости, процесс идентификации кусочного индекса, используемый для обратного отображения яркости и остаточного масштабирования цветности, может быть устранен. Соответственно, сложность обратного отображения яркости может быть уменьшена. К тому же, проблемы задержки, вызываемые зависимостью от идентификации кусочного индекса яркости во время остаточного масштабирования цветности, могут быть устранены.
[314] В соответствии с вариантом осуществления использования линейного формирователя, описанным выше, следующие преимущества могут быть обеспечены для LMCS: i) можно упростить схему формирователя кодера, предотвращая возможный артефакт, вызванный резкими изменениями между кусочными линейными фрагментами, ii) процесс обратного отображения декодера, в котором процесс идентификации кусочного индекса может быть устранен, может упрощаться за счет устранения процесса идентификации кусочного индекса, iii) путем устранения процесса идентификации кусочного индекса, можно устранить проблему задержки в остаточном масштабировании цветности, вызываемую зависимостью от соответствующих блоков яркости, iv) можно уменьшить перекрытие сигнализации и сделать частое обновление формирователя более рациональным, v) для множества мест, которые требовались для контура из 16 фрагментов, контур можно устранить. Например, чтобы вывести InvScaleCoeff[i], число операций деления на lmcsCW[i] может быть уменьшено до 1.
[315] В другом варианте осуществления в соответствии с настоящим документом, предложено LMCS на основе гибких бинов. Здесь, гибкие бины могут относиться к числу бинов, не фиксированному на предопределенное (предварительно определенное, конкретное) число. В существующем варианте осуществления, число бинов в LMCS фиксировано в 16, и 16 бинов равномерно распределены для входных значений выборки. В этом варианте осуществления, предложено гибкое число бинов, и фрагменты (бины) могут не распределяться одинаково с точки зрения исходных значений пикселов.
[316] Следующие таблицы показывают примерный синтаксис для данных LMCS (поля данных) в соответствии с этим вариантом осуществления и семантику для синтаксических элементов, включенных в него.
[317] [Таблица 26]

[318] [Таблица 27]

[319] Со ссылкой на Таблицу 26, информация о числе бинов lmcs_num_bins_minus1 может сигнализироваться. Со ссылкой на Таблицу 27, lmcs_num_bins_minus1+1 может быть равно числу бинов, из которого число бинов может находиться в диапазоне от 1 до (1<<BitDepthY)-1. Например, lmcs_num_bins_minus1 или lmcs_num_bins_minus1+1 могут быть кратны степени 2.
[320] В варианте осуществления, описанном вместе с таблицами 26 и 27, число точек поворота может выводиться на основе lmcs_num_bins_minus1 (информации о числе бинов), независимо от того, является ли формирователь линейным или нет (сигнализация lmcs_num_bins_minus1), и входные значения и отображенные значения точек поворота (LmcsPivot_input[i], LmcsPivot_mapped[i]) могут выводиться на основе суммирования сигнализированных значений кодовых слов (lmcs_delta_input_cw[i], lmcs_delta_mapped_cw[i]) (здесь, исходное входное значение LmcsPivot_input[0] и исходное выходное значение LmcsPivot_mapped[0] равны 0).
[321] Фиг. 12 показывает пример линейного прямого отображения в варианте осуществления настоящего документа. Фиг. 13 показывает пример обратного прямого отображения в варианте осуществления настоящего документа. В варианте осуществления в соответствии с фиг. 12 и фиг. 13, предложен способ для поддержки как регулярного LMCS, так и линейного LMCS. В примере в соответствии с этим вариантом осуществления, регулярное LMCS и/или линейное LMCS может указываться на основе синтаксического элемента lmcs_is_linear. В кодере, после того как линия линейного LMCS определена, отображенное значение (т.е., отображенное значение в pL на фиг. 12 и фиг. 13) может делиться на равные фрагменты (т.е., LmcsMaxBinIdx-lmcs_min_bin_idx+1). Кодовое слово в бине LmcsMaxBinIdx может сигнализироваться с использованием синтаксисов для данных lmcs или режима формирователя, описанных выше.
[322] Следующие таблицы показывают примерный синтаксис для данных LMCS (поля данных) и семантику для синтаксических элементов, включенных в него, в соответствии с примером этого варианта осуществления.
[323] [Таблица 28]

[324] [Таблица 29]

[325] 
[326] Следующие таблицы примерно показывают синтаксис для данных LMCS (поля данных) и семантику для синтаксических элементов, включенных в него, в соответствии с другим примером этого варианта осуществления.
[327] [Таблица 30]

[328] [Таблица 31]

[329] 
[330] Со ссылкой на Таблицы 28-31, когда lmcs_is_linear_flag истинно, все lmcsDeltaCW[i] между lmcs_min_bin_idx и LmcsMaxBinIdx могут иметь одинаковые значения. То есть, lmcsCW[i] всех фрагментов между lmcs_min_bin_idx и LmcsMaxBinIdx может иметь одинаковые значения. Масштабирование и обратное масштабирование и масштабирование цветности всех фрагментов между lmcs_min_bin_idx и lmcsMaxBinIdx могут быть одинаковыми. Тогда, если линейный формирователь является истинным, то нет необходимости выводить индекс фрагмента, можно использовать масштабирование, обратное масштабирование из только одного из фрагментов.
[331] Следующая таблица показывает примерный процесс идентификации кусочного индекса в соответствии с настоящим вариантом осуществления.
[332] [Таблица 32]

[333] В соответствии с другим вариантом осуществления настоящего документа, применение регулярного 16-кусочного PWL LMCS и линейного LMCS может зависеть от синтаксиса более высокого уровня (т.е., уровня последовательности).
[334] Следующие таблицы показывают синтаксис для SPS в соответствии с настоящим вариантом осуществления и семантику для синтаксических элементов, включенных в него.
[335] [Таблица 33]

[336] [Таблица 34]

[337] Со ссылкой на Таблицы 33 и 34, включение регулярного LMCS и/или линейного LMCS может определяться (сигнализироваться) синтаксическим элементом, включенным в SPS. Со ссылкой на Таблицу 34, на основе синтаксического элемента sps_linear_lmcs_enabled_flag, одно из регулярного LMCS или линейного LMCS может использоваться в единицах последовательности.
[338] К тому же, то, следует ли включить только линейное LMCS или регулярное LMCS или оба, может также зависеть от уровня профиля. В одном примере, для конкретного профиля (т.е., профиля SDR), может быть разрешено только линейное LMCS, для другого профиля (т.е., профиля HDR), может быть разрешено только регулярное LMCS, и для другого профиля, могут быть разрешены регулярное LMCS и/или линейное LMCS.
[339] В соответствии с другим вариантом осуществления настоящего документа, процесс идентификации кусочного индекса LMCS может использоваться в обратном отображении яркости и остаточном масштабировании цветности. В этом варианте осуществления, процесс идентификации кусочного индекса может использоваться для блоков с включенным остаточным масштабированием цветности и также вызываться для всех выборок яркости в переформированной (отображенной) области. Настоящий вариант осуществления нацелен на поддержание сложности низкой.
[340] Следующая таблица показывает процесс идентификации (процесс выведения) существующего кусочного индекса функции.
[341] [Таблица 35]

[342] В примере, в процессе идентификации кусочного индекса, входные выборки могут классифицироваться на по меньшей мере две категории. Например, входные выборки могут классифицироваться на три категории, первую, вторую и третью категории. Например, первая категория может представлять выборки (их значения), меньшие, чем LmcsPivot[lmcs_min_bin_idx+1], и вторая категория может представлять выборки (их значения), большие или равные (значениям) LmcsPivot[LmcsMaxBinIdx], третья категория может указывать выборки (их значения) между LmcsPivot[lmcs_min_bin_idx+1] и LmcsPivot[LmcsMaxBinIdx].
[343] В этом варианте осуществления, предложено оптимизировать процесс идентификации путем устранения классификаций на категории. То есть, поскольку входом в процесс идентификации кусочного индекса являются значения яркости в переформированной (отображенной) области, не должно быть значений помимо отображенных значений в точках поворота lmcs_min_bin_idx и LmcsMaxBinIdx+1. Соответственно, условный процесс для классификации выборок на категории в существующем процессе идентификации кусочного индекса не нужен. Что касается деталей, конкретные примеры будут описаны ниже при помощи таблиц.
[344] В примере в соответствии с этим вариантом осуществления, процесс идентификации, включенный в Таблицу 35, может заменяться на процесс Таблиц 36 или 37 ниже. Со ссылкой на Таблицы 36 и 37, первые две категории Таблицы 35 могут быть удалены, и для последней категории, граничное значение (второе граничное значение или конечная точка) в итерации для контура изменяется с LmcsMaxBinIdx на LmcsMaxBinIdx+1. То есть, процесс идентификации может быть упрощен, и сложность для вывода кусочного индекса может быть уменьшена. Соответственно, связанное с LMCS кодирование может эффективно выполняться в соответствии с настоящим вариантом осуществления.
[345] [Таблица 36]

[346] [Таблица 37]

[347] Со ссылкой на Таблицу 36, процесс сравнения, соответствующий условию оператора if (уравнению, соответствующему условию оператора if), может повторно выполняться на всех индексах бинов от минимального индекса бина до максимального индекса бина. Индекс бина, в случае, где уравнение, соответствующее условию оператора if, истинно, может выводиться как индекс обратного отображения для обратного отображения яркости (или индекс обратного масштабирования для остаточного масштабирования цветности). На основе индекса обратного отображения, могут выводиться модифицированные восстановленные выборки яркости (или масштабированные остаточные выборки цветности).
[348] Следующие чертежи поясняют конкретные примеры настоящей спецификации. Поскольку названия конкретных устройств, приведенные на чертежах, или названия конкретных сигналов/сообщений/полей представлены в качестве примера, технические признаки настоящей спецификации не ограничены конкретными названиями, используемыми в следующих чертежах.
[349] Фиг. 14 и фиг. 15 схематично показывают пример способа кодирования видео/изображения и связанные компоненты в соответствии с вариантом(ами) осуществления настоящего документа. Способ, раскрытый на фиг. 14, может выполняться устройством кодирования, раскрытым на фиг. 2. Конкретно, например, S1400 на фиг. 14 может выполняться процессором 230 остатка или предсказателем 220 устройства кодирования, S1410 может выполняться предсказателем 220 или сумматором 250 устройства кодирования. S1420 может выполняться процессором 230 остатка или сумматором 250 устройства кодирования, предсказателем 220 или процессором 230 остатка устройства кодирования, S1430 и/или S1440 могут выполняться процессором 230 остатка устройства кодирования, и S1450 может выполняться энтропийным кодером 240 устройства кодирования. Способ, раскрытый на фиг. 14, может включать в себя варианты осуществления, описанные выше в настоящем документе.
[350] Со ссылкой на фиг. 14, устройство кодирования может генерировать выборки яркости предсказания (S1410). Со ссылкой на выборки яркости предсказания, устройство кодирования может выводить выборки яркости предсказания текущего блока на основе режима предсказания. В этом случае, могут применяться различные способы предсказания, раскрытые в настоящем документе, такие как интер-предсказание или интра-предсказания.
[351] Устройство кодирования может выводить выборки цветности предсказания. Устройство кодирования может выводить остаточные выборки цветности на основе исходных выборок цветности и выборок цветности предсказания текущего блока. Например, устройство кодирования может выводить остаточные выборки цветности на основе разности между выборками цветности предсказания и исходными выборками цветности.
[352] Устройство кодирования может генерировать отображенные выборки яркости предсказания (S1410). Например, устройство кодирования может выводить входные значения и отображенные значения (выходные значения) точек поворота для отображения яркости и может генерировать отображенные выборки яркости предсказания на основе входных значений и отображенных значений. В одном примере, устройство кодирования может выводить индекс отображения (idxY) на основе первой выборки предсказания яркости и может генерировать первую отображенную выборку предсказания яркости на основе входного значения и отображенного значения точки поворота, соответствующей индексу отображения. В другом примере, линейное отображение (линейное повторное формирование, линейное LMCS) может использоваться, и отображенные выборки яркости предсказания могут генерироваться на основе коэффициента масштабирования прямого отображения, выведенного из двух точек поворота в линейном отображении, таким образом, процесс вывода индекса может опускаться вследствие линейного отображения.
[353] Устройство кодирования может генерировать масштабированные остаточные выборки цветности. Конкретно, устройство кодирования может выводить коэффициент остаточного масштабирования цветности и генерировать масштабированные остаточные выборки цветности на основе коэффициента остаточного масштабирования цветности. Здесь, остаточное масштабирование цветности стадии кодирования может называться прямым остаточным масштабированием цветности. Соответственно, коэффициент остаточного масштабирования цветности, выведенный устройством кодирования, может называться прямым коэффициентом остаточного масштабирования цветности, и могут генерироваться прямые масштабированные остаточные выборки цветности.
[354] Устройство кодирования может выводить связанную с LMCS информацию на основе отображенных выборок яркости предсказания (S1420). Кроме того, устройство кодирования может генерировать связанную с LMCS информацию на основе отображенных выборок яркости предсказания и/или масштабированных остаточных выборок цветности. Устройство кодирования может генерировать связанную с LMCS информацию для восстановленных выборок. Устройство кодирования может выводить связанные с LMCS параметры, которые могут применяться для фильтрации восстановленных выборок, и может генерировать связанную с LMCS информацию на основе связанных с LMCS параметров. Например, связанная с LMCS информация может включать в себя информацию об отображении яркости (т.е. прямое отображение, обратное отображение, линейное отображение), информацию об остаточном масштабировании цветности и/или индексы (т.е. максимальный индекс бина, минимальный индекс бина, индекс отображения), связанные с LMCS (или повторным формированием, повторным формирователем).
[355] Устройство кодирования может генерировать остаточные выборки яркости на основе отображенных выборок яркости предсказания (S1430). Например, устройство кодирования может выводить остаточные выборки яркости на основе разности между отображенными выборками яркости предсказания и исходными выборками яркости.
[356] Устройство кодирования может выводить информацию остатка (S1440). Устройство кодирования может выводить информацию остатка на основе масштабированных остаточных выборок цветности и/или остаточных выборок яркости. Устройство кодирования может выводить коэффициенты преобразования на основе масштабированных остаточных выборок цветности и/или процесса преобразования для остаточных выборок яркости. Например, процесс преобразования может включать в себя по меньшей мере одно из DCT, DST, GBT или CNT. Устройство кодирования может выводить квантованные коэффициенты преобразования на основе процесса квантования для коэффициентов преобразования. Квантованные коэффициенты преобразования могут иметь форму одномерного вектора на основе порядка сканирования коэффициентов. Устройство кодирования может генерировать информацию остатка, специфицирующую квантованные коэффициенты преобразования. Информация остатка может генерироваться посредством различных способов кодирования, такие как экспоненциальное кодирование Голомба, CAVLC, CABAC и тому подобное.
[357] Устройство кодирования может кодировать информацию изображения/видео (S1450). Информация изображения может включать в себя связанную с LMCS информацию и/или информацию остатка. Например, связанная с LMCS информация может включать в себя информацию о линейном LMCS. В одном примере, по меньшей мере одно кодовое слово LMCS может выводиться на основе информации о линейном LMCS. Закодированная информация видео/изображения может выводиться в форме битового потока. Битовый поток может передаваться на устройство декодирования через сеть или носитель хранения.
[358] Информация изображения/видео может включать в себя различную информацию в соответствии с вариантом осуществления настоящего документа. Например, информация изображения/видео может включать в себя информацию, раскрытую в по меньшей мере одной из Таблиц 1-37, описанных выше.
[359] В одном варианте осуществления, минимальный индекс бина (т.е., lmcs_min_bin_idx) и/или максимальный индекс бина (т.е., LmcsMaxBinIdx) могут выводиться на основе связанной с LMCS информации. Информация о минимальном индексе бина (т.е., lmcs_min_bin_idx) и/или максимальном индексе бина (т.е., LmcsMaxBinIdx) может быть включена в связанную с LMCS информацию. Первое отображенное значение (LmcsPivot[lmcs_min_bin_idx]) может выводиться на основе минимального индекса бина. Второе отображенное значение (LmcsPivot[LmcsMaxBinIdx] или LmcsPivot[LmcsMaxBinIdx+1]) может выводиться на основе максимального индекса бина. Значения восстановленных выборок яркости (т.е., lumaSample Таблицы 36 или 37) могут находиться в диапазоне от первого отображенного значения до второго отображенного значения. В одном примере, значения всех восстановленных выборок яркости могут находиться в диапазоне от первого отображенного значения до второго отображенного значения. В другом примере, значения некоторых из восстановленных выборок яркости могут находиться в диапазоне от первого отображенного значения до второго отображенного значения.
[360] В одном варианте осуществления, информация изображения может включать в себя набор параметров последовательности (SPS). SPS может включать в себя флаг включенного линейного LMCS, специфицирующий, включено ли линейное LMCS.
[361] В одном варианте осуществления, устройство кодирования может генерировать (выводить) кусочный индекс для остаточного масштабирования цветности. Устройство кодирования может выводить коэффициент остаточного масштабирования цветности на основе кусочного индекса. Устройство кодирования может генерировать масштабированные остаточные выборки цветности на основе остаточных выборок цветности и коэффициента остаточного масштабирования цветности.
[362] В одном варианте осуществления, коэффициент остаточного масштабирования цветности может представлять собой один коэффициент остаточного масштабирования цветности.
[363] В одном варианте осуществления, связанная с LMCS информация может включать в себя поле данных LMCS и информацию о линейном LMCS. Информация о линейном LMCS может называться информацией о линейном отображении. Поле данных LMCS может включать в себя флаг линейного LMCS, указывающий, применяется ли линейное LMCS. Когда значение флага линейного LMCS равно 1, отображенные выборки яркости предсказания могут генерироваться на основе информации о линейном LMCS.
[364] В одном варианте осуществления, информация о линейном LMCS включает в себя информацию о первой точке поворота (т.е. Р1 на фиг. 11) и информацию о второй точке поворота (т.е. Р2 на фиг. 11). Например, входное значение и отображенное значение первой точки поворота представляют собой минимальное входное значение и минимальное отображенное значение, соответственно. Входное значение и отображенное значение второй точки поворота представляют собой максимальное входное значение и максимальное отображенное значение, соответственно. Входные значения между минимальным входным значением и максимальным входным значением являются линейно отображенными.
[365] В одном варианте осуществления, информация изображения включает в себя информацию о максимальном входном значении и информацию о максимальном отображенном значении. Максимальное входное значение равно значению информации о максимальном входном значении (т.е., lmcs_max_input в Таблице 20). Максимальное отображенное значение равно значению информации о максимальном отображенном значении (т.е., lmcs_max_mapped в Таблице 20).
[366] В одном варианте осуществления, информация о линейном отображении включает в себя информацию о входном значении дельта второй точки поворота (т.е., lmcs_max_input_delta в Таблице 22) и информацию об отображенном значении дельта второй точки поворота (т.е., lmcs_max_mapped_delta в Таблице 22). Максимальное входное значение может выводиться на основе входного значения дельта второй точки поворота, и максимальное отображенное значение может выводиться на основе отображенного значения дельта второй точки поворота.
[367] В одном варианте осуществления, максимальное входное значение и максимальное отображенное значение могут выводиться на основе по меньшей мере одного уравнения, включенного в Таблицу 23, описанную выше.
[368] В одном варианте осуществления, генерация отображенных выборок яркости предсказания содержит вывод коэффициента масштабирования прямого отображения (т.е., ScaleCoeffSingle) для выборок яркости предсказания и генерацию отображенных выборок яркости предсказания на основе коэффициента масштабирования прямого отображения. Коэффициент масштабирования прямого отображения может представлять собой один коэффициент для выборок яркости предсказания.
[369] В одном варианте осуществления, коэффициент масштабирования прямого отображения может выводиться на основе по меньшей мере одного уравнения, включенного в Таблицы 21 и/или 23, описанные выше.
[370] В одном варианте осуществления, отображенные выборки яркости предсказания могут выводиться на основе по меньшей мере одного уравнения, включенного в Таблицу 25, описанную выше.
[371] В одном варианте осуществления, устройство кодирования может выводить коэффициент масштабирования обратного отображения (т.е., InvScaleCoeffSingle) для восстановленных выборок яркости (т.е., lumaSample). Также, устройство кодирования может генерировать модифицированные восстановленные выборки яркости (т.е., invSample) на основе восстановленных выборок яркости и коэффициента масштабирования обратного отображения. Коэффициент масштабирования обратного отображения может представлять собой один коэффициент для восстановленных выборок яркости.
[372] В одном варианте осуществления, коэффициент масштабирования обратного отображения может выводиться с использованием кусочного индекса, выведенного на основе восстановленных выборок яркости.
[373] В одном варианте осуществления, кусочный индекс может выводиться на основе Таблицы 36, описанной выше. То есть, процесс сравнения, включенный в Таблицу 36 (lumaSample<LmcsPivot[idxYInv+1]), может итеративно выполняться от кусочного индекса, который является минимальным индексом бина, до кусочного индекса, который является максимальным индексом бина.
[374] В одном варианте осуществления, модифицированные восстановленные выборки яркости могут генерироваться на основе отображенных значений на основе индексов бинов от минимального индекса бина до максимального индекса бина.
[375] В одном варианте осуществления, индексы бинов включают в себя первый индекс бина, указывающий первое отображенное значение. Первый индекс бина может быть выведен на основе отображенных значений на основе индексов бинов от минимального индекса бина до максимального индекса бина и сравнения между значениями восстановленных выборок яркости. По меньшей мере одна из модифицированных восстановленных выборок яркости может быть выведена на основе восстановленных выборок яркости и первого отображенного значения.
[374] В одном варианте осуществления, индексы бинов включают в себя первый индекс бина, указывающий первое отображенное значение, и первый индекс бина может выводиться на основе уравнения сравнения, включенного в Таблицу 36 (lumaSample<LmcsPivot[idxYInv+1]). Например, в уравнении выше, lumaSample представляет значение целевой выборки яркости среди восстановленных выборок яркости, idxYInv представляет один из индексов бинов, и LmcsPivot[idxYinv+1] представляет одно из отображенных значений на основе индексов бинов от минимального индекса бина до максимального бина. По меньшей мере одна из восстановленных выборок яркости может выводиться на основе восстановленных выборок яркости и первого отображенного значения.
[377] В одном варианте осуществления, процесс сравнения (lumaSample<LmcsPivot[idxYInv+1]), включенный в Таблицу 36, может выполняться на всех из индексов бинов от минимального индекса бина до максимального индекса бина.
[378] В одном варианте осуществления, коэффициент масштабирования обратного отображения может быть выведен на основе по меньшей мере одного из уравнений, включенных в Таблицы 18, 19, 21 и 23, или уравнений 11 или 12, описанных выше.
[379] В одном варианте осуществления, модифицированные восстановленные выборки яркости могут выводиться на основе Уравнения 21, описанного выше.
[380] В одном варианте осуществления, связанная с LMCS информация может включать в себя информацию о числе бинов для вывода отображенных выборок яркости предсказания (т.е., lmcs_num_bins_minus1 в Таблице 26). Например, число точек поворота для отображения яркости может быть установлено равным числу бинов. В одном примере, устройство кодирования может генерировать входные значения дельта и отображенные значения дельта точек поворота по числу бинов, соответственно. В одном примере, входные значения и отображенные значения точек поворота выводятся на основе входных значений дельта (т.е., lmcs_delta_input_cw[i] в Таблице 26) и отображенных значений дельта (т.е., lmcs_delta_mapped_cw[i] в Таблице 26), и отображенные выборки яркости предсказания могут генерироваться на основе входных значений (т.е., LmcsPivot_input[i] Таблицы 27 или InputPivot[i] Таблицы 8) и отображенных значений (т.е., LmcsPivot_mapped[i] Таблицы 27 или LmcsPivot[i] Таблицы 8).
[381] В одном варианте осуществления, устройство кодирования может выводить кодовое слово дельта LMCS на основе по меньшей мере одного кодового слова LMCS и исходного кодового слова (OrgCW), включенных в связанную с LMCS информацию, и отображенные выборки предсказания яркости могут выводиться на основе по меньшей мере одного кодового слова LMCS и исходного кодового слова. В одном примере, информация о линейном отображении может включать в себя информацию о кодовом слове дельта LMCS.
[382] В одном варианте осуществления, по меньшей мере одно кодовое слово LMCS может выводиться на основе суммирования кодового слова дельта LMCS и OrgCW, например, OrgCW составляет (1<<BitDepthY)/16, где BitDepthY представляет битовую глубину яркости. Этот вариант осуществления может быть основан на Уравнении 12.
[383] В одном варианте осуществления, по меньшей мере одно кодовое слово LMCS может выводиться на основе суммирования кодового слова дельта LMCS и OrgCW*(lmcs_max_bin_idx-lmcs_min_bin_idx+1), например, lmcs_max_bin_idx и lmcs_min_bin_idx являются максимальным индексом бина и минимальным индексом бина, соответственно, и OrgCW может составлять (1<<BitDepthY)/16. Этот вариант осуществления может быть основан на Уравнениях 15 и 16.
[384] В одном варианте осуществления, по меньшей мере одно кодовое слово LMCS может быть кратно двум.
[385] В одном варианте осуществления, когда битовая глубина яркости (BitDepthY) восстановленных выборок яркости выше 10, по меньшей мере одно кодовое слово LMCS может быть кратно 1<<(BitDepthY-10).
[386] В одном варианте осуществления, по меньшей мере одно кодовое слово LMCS может находиться в диапазоне от (OrgCW>>1) до (OrgCW<<1)-1.
[387] Фиг. 16 и фиг. 17 схематично показывают пример способа декодирования изображения/видео и связанные компоненты в соответствии с вариантом осуществления настоящего документа. Способ, раскрытый на фиг. 16, может выполняться устройством декодирования, проиллюстрированным на фиг. 3. Конкретно, например, S1600 на фиг. 16 может выполняться энтропийным декодером 310 устройства декодирования, S1610 может выполняться предсказателем 330 устройства декодирования, S1620 может выполняться процессором 320 остатка, предсказателем 330 и/или сумматором 340 устройства декодирования, и S1630 может выполняться сумматором 340 устройства декодирования. Способ, раскрытый на фиг. 16, может включать в себя варианты осуществления, описанные выше в настоящем документе.
[388] Со ссылкой на фиг. 16, устройство декодирования может принимать/получать информацию видео/изображения (S1600). Информация видео/изображения может включать в себя связанную с LMCS информацию. Например, связанная с LMCS информация может включать в себя информацию об отображении яркости (т.е., прямом отображении, обратном отображении, линейном отображении), информацию об остаточном масштабировании цветности и/или индексы (т.е., максимальный индекс бина, минимальный индекс бина, индекс отображения), относящиеся к LMCS (или повторному формированию, формирователю). Устройство декодирования может принимать/ получать информацию изображения/видео через битовый поток.
[389] Информация изображения/видео может включать в себя различную информацию в соответствии с вариантом осуществления настоящего документа. Например, информация изображения/видео может включать в себя информацию, раскрытую в по меньшей мере одной из Таблиц 1-37, описанных выше.
[390] Устройство декодирования может генерировать выборки яркости предсказания (S1610). Устройство декодирования может выводить выборки яркости предсказания текущего блока на основе режима предсказания. В этом случае, могут применяться различные способы предсказания, раскрытые в настоящем документе, такие как интер-предсказание или интра-предсказание.
[391] Информация изображения может включать в себя информацию остатка. Устройство декодирования может генерировать остаточные выборки цветности и/или остаточные выборки яркости на основе информации остатка. Конкретно, устройство декодирования может выводить квантованные коэффициенты преобразования на основе информации остатка. Квантованные коэффициенты преобразования могут иметь форму одномерного вектора на основе порядка сканирования коэффициентов. Устройство декодирования может выводить коэффициенты преобразования на основе процесса деквантования для квантованных коэффициентов преобразования. Устройство декодирования может выводить остаточные выборки цветности и/или остаточные выборки яркости на основе коэффициентов преобразования.
[392] Устройство декодирования может генерировать отображенные выборки яркости предсказания (S1620). Например, устройство декодирования может выводить входные значения и отображенные значения (выходные значения) точек поворота для отображения яркости и может генерировать отображенные выборки яркости предсказания на основе входных значений и отображенных значений. В одном примере, устройство декодирования может выводить индекс (прямого) отображения (idxY) на основе первой выборки яркости предсказания, и первая отображенная выборка яркости предсказания может генерироваться на основе входного значения и отображенного значения точки поворота, соответствующей индексу отображения. В другом примере, линейное отображение (линейное повторное формирование, линейное LMCS) может использоваться, и отображенные выборки яркости предсказания могут генерироваться на основе коэффициента масштабирования прямого отображения, выведенного из двух точек поворота в линейном отображении, таким образом, процесс вывода индекса может опускаться вследствие линейного отображения.
[393] Устройство декодирования может генерировать восстановленные выборки яркости (S1630). Устройство декодирования может генерировать восстановленные выборки яркости на основе отображенных выборок яркости предсказания. Конкретно, устройство декодирования может суммировать остаточные выборки яркости с отображенными выборками яркости предсказания и может генерировать восстановленные выборки яркости на основе результата суммирования.
[394] Устройство декодирования может генерировать масштабированные остаточные выборки цветности. Конкретно, устройство декодирования может выводить коэффициент остаточного масштабирования цветности и генерировать масштабированные остаточные выборки цветности на основе коэффициента остаточного масштабирования цветности. Здесь, остаточное масштабирование цветности стороны декодирования может называться обратным остаточным масштабированием цветности, в противоположность стороне кодирования. Соответственно, коэффициент остаточного масштабирования цветности, выведенный устройством декодирования, может называться обратным коэффициентом остаточного масштабирования цветности, и могут генерироваться обратные масштабированные остаточные выборки цветности.
[395] Устройство декодирования может генерировать восстановленные выборки цветности. Устройство декодирования может генерировать восстановленные выборки цветности на основе масштабированных остаточных выборок цветности. Конкретно, устройство декодирования может выполнять процесс предсказания для компонента цветности и может генерировать выборки цветности предсказания. Устройство декодирования может генерировать восстановленные выборки цветности на основе суммирования выборок цветности предсказания и масштабированных остаточных выборок цветности.
[396] В одном варианте осуществления, минимальный индекс бина (т.е., lmcs_min_bin_idx) и/или максимальный индекс бина (т.е., LmcsMaxBinIdx) могут выводиться на основе связанной с LMCS информации. Первое отображенное значение (LmcsPivot[lmcs_min_bin_idx]) может выводиться на основе минимального индекса бина. Второе отображенное значение (LmcsPivot[LmcsMaxBinIdx] или LmcsPivot[LmcsMaxBinIdx+1]) может выводиться на основе максимального индекса бина. Значения восстановленных выборок яркости (т.е., lumaSample Таблицы 36 или 37) могут находиться в диапазоне от первого отображенного значения до второго отображенного значения. В одном примере, значения всех восстановленных выборок яркости могут находиться в диапазоне от первого отображенного значения до второго отображенного значения. В другом примере, значения некоторых из восстановленных выборок яркости могут находиться в диапазоне от первого отображенного значения до второго отображенного значения.
[397] В одном варианте осуществления, информация изображения может включать в себя набор параметров последовательности (SPS). SPS может включать в себя флаг включенного линейного LMCS, специфицирующий, включено ли линейное LMCS.
[398] В одном варианте осуществления, кусочный индекс (т.е., idxYInv в Таблицах 35, 36 или 37) может идентифицироваться на основе связанной с LMCS информации. Устройство декодирования может выводить коэффициент остаточного масштабирования цветности на основе кусочного индекса. Устройство декодирования может генерировать масштабированные остаточные выборки цветности на основе остаточных выборок цветности и коэффициента остаточного масштабирования цветности.
[399] В одном варианте осуществления, коэффициент остаточного масштабирования цветности может представлять собой один коэффициент остаточного масштабирования цветности.
[400] В одном варианте осуществления, связанная с информация может включать в себя поле данных LMCS и информацию о линейном LMCS. Информация о линейном LMCS может называться информацией о линейном отображении. Поле данных LMCS может включать в себя флаг линейного LMCS, указывающий, применяется ли линейное LMCS. Когда значение флага линейного LMCS равно 1, отображенные выборки яркости предсказания могут генерироваться на основе информации о линейном LMCS.
[401] В одном варианте осуществления, информация о линейном LMCS включает в себя информацию о первой точке поворота (т.е., P1 на фиг. 11) и информацию о второй точке поворота (т.е., P2 на фиг. 11). Например, входное значение и отображенное значение первой точки поворота являются минимальным входным значением и минимальным отображенным значением, соответственно. Входное значение и отображенное значение второй точки поворота являются максимальным входным значением и максимальным отображенным значением, соответственно. Входные значения между минимальным входным значением и максимальным входным значением являются линейно отображенными.
[402] В одном варианте осуществления, информация изображения включает в себя информацию о максимальном входном значении и информацию о максимальном отображенном значении. Максимальное входное значение равно значению информации о максимальном входном значении (т.е., lmcs_max_input в Таблице 20). Максимальное отображенное значение равно значению информации о максимальном отображенном значении (т.е., lmcs_max_mapped в Таблице 20).
[403] В одном варианте осуществления, информация о линейном отображении включает в себя информацию о входном значении дельта второй точки поворота (т.е., lmcs_max_input_delta в Таблице 22) и информацию об отображенном значении дельта второй точки поворота (т.е., lmcs_max_mapped_delta в Таблице 22). Максимальное входное значение может выводиться на основе входного значения дельта второй точки поворота, и максимальное отображенное значение может выводиться на основе отображенного значения дельта второй точки поворота.
[404] В одном варианте осуществления, максимальное входное значение и максимальное отображенное значение могут выводиться на основе по меньшей мере одного уравнения, включенного в Таблицу 23, описанную выше.
[405] В одном варианте осуществления, генерация отображенных выборок яркости предсказания содержит вывод коэффициента масштабирования прямого отображения (т.е., ScaleCoeffSingle) для выборок яркости предсказания и генерацию отображенных выборок яркости предсказания на основе коэффициента масштабирования прямого отображения. Коэффициент масштабирования прямого отображения может представлять собой один коэффициент для выборок яркости предсказания.
[406] В одном варианте осуществления, коэффициент масштабирования обратного отображения может выводиться с использованием кусочного индекса, выведенного на основе восстановленных выборок яркости.
[407] В одном варианте осуществления, кусочный индекс может выводиться на основе Таблицы 36, описанной выше. То есть, процесс сравнения, включенный в Таблицу 36 (lumaSample<LmcsPivot[idxYInv+1]), может итеративно выполняться от кусочного индекса, который является минимальным индексом бина, до кусочного индекса, который является максимальным индексом бина.
[408] В одном варианте осуществления, модифицированные восстановленные выборки яркости могут генерироваться на основе отображенных значений на основе индексов бинов от минимального индекса бина до максимального индекса бина.
[409] В одном варианте осуществления, индексы бинов включают в себя первый индекс бина, указывающий первое отображенное значение. Первый индекс бина может быть выведен на основе отображенных значений на основе индексов бинов от минимального индекса бина до максимального индекса бина и сравнения между значениями восстановленных выборок яркости. По меньшей мере одна из модифицированных восстановленных выборок яркости может быть выведена на основе восстановленных выборок яркости и первого отображенного значения.
[410] В одном варианте осуществления, индексы бинов включают в себя первый индекс бина, указывающий первое отображенное значение, и первый индекс бина может выводиться на основе уравнения сравнения, включенного в Таблицу 36 (lumaSample<LmcsPivot[idxYInv+1]). Например, в уравнении выше, lumaSample представляет значение целевой выборки яркости среди восстановленных выборок яркости, idxYInv представляет один из индексов бинов, и LmcsPivot[idxYinv+1] представляет одно из отображенных значений на основе индексов бинов от минимального индекса бина до максимального бина. По меньшей мере одна из восстановленных выборок яркости может выводиться на основе восстановленных выборок яркости и первого отображенного значения.
[411] В одном варианте осуществления, процесс сравнения (lumaSample<LmcsPivot[idxYInv+1]), включенный в Таблицу 36, может выполняться на всех из индексов бинов от минимального индекса бина до максимального индекса бина.
[412] В одном варианте осуществления, коэффициент масштабирования прямого отображения может выводиться на основе по меньшей мере одного уравнения, включенного в Таблицы 21 и/или 23, описанные выше.
[413] В одном варианте осуществления, отображенные выборки яркости предсказания могут выводиться на основе по меньшей мере одного уравнения, включенного в Таблицу 25, описанную выше.
[414] В одном варианте осуществления, устройство декодирования может выводить коэффициент масштабирования обратного отображения (т.е., InvScaleCoeffSingle) для восстановленных выборок яркости (т.е., lumaSample). Также, устройство декодирования может генерировать модифицированные восстановленные выборки яркости (т.е., invSample) на основе восстановленных выборок яркости и коэффициента масштабирования обратного отображения. Коэффициент масштабирования обратного отображения может представлять собой один коэффициент для восстановленных выборок яркости.
[415] В одном варианте осуществления, коэффициент масштабирования обратного отображения может выводиться на основе по меньшей мере одного из уравнений, включенных в Таблицы 18, 19, 20 и 23, или Уравнений 11 или 12, описанных выше.
[416] В одном варианте осуществления, модифицированные восстановленные выборки яркости могут выводиться на основе Уравнения 21, описанного выше.
[417] В одном варианте осуществления, связанная с LMCS информация может включать в себя информацию о числе бинов для вывода отображенных выборок яркости предсказания (т.е., lmcs_num_bins_minus1 в Таблице 26). Например, число точек поворота для отображения яркости может быть установлено равным числу бинов. В одном примере, устройство декодирования может генерировать входные значения дельта и отображенные значения дельта точек поворота по числу бинов, соответственно. В одном примере, входные значения и отображенные значения точек поворота выводятся на основе входных значений дельта (т.е., lmcs_delta_input_cw[i] в Таблице 26) и отображенных значений дельта (т.е., lmcs_delta_mapped_cw[i] в Таблице 26), и отображенные выборки яркости предсказания могут генерироваться на основе входных значений (т.е., LmcsPivot_input[i] Таблицы 27 или InputPivot[i] Таблицы 8) и отображенных значений (т.е., LmcsPivot_mapped[i] Таблицы 27 или LmcsPivot[i] Таблицы 8).
[418] В одном варианте осуществления, устройство декодирования может выводить кодовое слово дельта LMCS на основе по меньшей мере одного кодового слова LMCS и исходного кодового слова (OrgCW), включенных в связанную с LMCS информацию, и отображенные выборки предсказания яркости могут выводиться на основе по меньшей мере одного кодового слова LMCS и исходного кодового слова. В одном примере, информация о линейном отображении может включать в себя информацию о кодовом слове дельта LMCS.
[419] В одном варианте осуществления, по меньшей мере одно кодовое слово LMCS может выводиться на основе суммирования кодового слова дельта LMCS и OrgCW, например, OrgCW составляет (1<<BitDepthY)/16, где BitDepthY представляет битовую глубину яркости. Этот вариант осуществления может быть основан на Уравнении 12.
[420] В одном варианте осуществления, по меньшей мере одно кодовое слово LMCS может выводиться на основе суммирования кодового слова дельта LMCS и OrgCW*(lmcs_max_bin_idx-lmcs_min_bin_idx+1), например, lmcs_max_bin_idx и lmcs_min_bin_idx являются максимальным индексом бина и минимальным индексом бина, соответственно, и OrgCW может составлять (1<<BitDepthY)/16. Этот вариант осуществления может быть основан на Уравнениях 15 и 16.
[421] В одном варианте осуществления, по меньшей мере одно кодовое слово LMCS может быть кратно двум.
[422] В одном варианте осуществления, когда битовая глубина яркости (BitDepthY) восстановленных выборок яркости выше 10, по меньшей мере одно кодовое слово LMCS может быть кратно 1<<(BitDepthY-10).
[423] В одном варианте осуществления, по меньшей мере одно кодовое слово LMCS может находиться в диапазоне от (OrgCW>>1) до (OrgCW<<1)-1.
[424] В вышеописанном варианте осуществления, способы описаны на основе блок-схемы последовательности операций, имеющей последовательность этапов или блоков. Настоящее раскрытие не ограничено порядком этапов или блоков выше. Некоторые этапы или блоки могут выполняться одновременно или в другом порядке относительно других этапов или блоков, как описано выше. Дополнительно, специалисты в данной области техники поймут, что этапы, показанные в блок-схеме последовательности операций выше, не являются исключительными, что дополнительные этапы могут быть включены или что один или более этапов в блок-схеме последовательности операций могут быть удалены без влияния на объем настоящего раскрытия.
[425] Способ в соответствии с вышеописанными вариантами осуществления настоящего документа может быть реализован в форме программного обеспечения, и устройство кодирования и/или устройство декодирования в соответствии с настоящим документом, например, может быть включено в устройство, которое выполняет обработку изображения телевизора, компьютера, смартфона, телевизионной приставки, устройства отображения и т.д.
[426] Когда варианты осуществления в настоящем документе реализованы в программном обеспечении, вышеописанный способ может быть реализован как модуль (процесс, функция и т.д.), который выполняет вышеописанную функцию. Модуль может храниться в памяти и исполняться процессором. Память может быть внутренней или внешней по отношению к процессору и может быть связана с процессором различными хорошо известными средствами. Процессор может включать в себя специализированную интегральную схему (ASIC), другие чипсеты, логические схемы и/или устройства обработки данных. Память может включать в себя постоянную память (ROM), память с произвольным доступом (RAM), флэш-память, карты памяти, носители хранения и/или другие устройства хранения. То есть, варианты осуществления, описанные в настоящем документе, могут реализовываться и выполняться на процессоре, микропроцессоре, контроллере или чипе. Например, функциональные блоки, показанные на каждом чертеже, могут реализовываться и выполняться на компьютере, процессоре, микропроцессоре, контроллере или чипе. В этом случае, информация об инструкциях или алгоритм для реализации могут храниться в цифровом носителе хранения.
[427] К тому же, устройство декодирования и устройство кодирования, к которым применяется настоящее раскрытие, могут быть включены в устройство передачи/приема мультимедийного вещания, мобильный терминал связи, устройство домашнего кинотеатра, устройство цифрового кинотеатра, камеру наблюдения, устройство для разговора по видео, устройство связи в реальном времени, такой как видеосвязь, мобильное устройство стриминга, носитель хранения, камеру-регистратор, устройство обеспечения услуги VoD, устройство доставки видео непосредственно от провайдера контента (OTT), устройство обеспечения услуги Интернет-стриминга, устройство трехмерного (3D) видео, устройство видео-телеконференции, пользовательское оборудование на транспорте (т.е., пользовательское оборудование наземного транспортного средства, пользовательское оборудование самолета, пользовательское оборудование корабля и т.д.) и медицинское видео-устройство и могут использоваться, чтобы обрабатывать сигналы видео и сигналы данных. Например, ОТТ-устройство доставки видео может включать в себя игровую консоль, проигрыватель blue-ray, телевизор с Интернет-доступом, систему домашнего кинотеатра, смартфон, планшетный PC, цифровой рекордер видео (DVR) и тому подобное.
[428] Более того, способ обработки, к которому применяется настоящий документ, может выполняться в форме программы, которая подлежит исполнению компьютером, и может храниться в считываемом компьютером носителе записи. Мультимедийные данные, имеющие структуру данных в соответствии с настоящим раскрытием, могут также храниться в считываемых компьютером носителях записи. Считываемые компьютером носители записи включают в себя все типы устройств хранения, в которых хранятся данные, считываемые компьютерной системой. Считываемые компьютером носители записи могут включать в себя, например, BD, универсальную последовательную шину (USB), ROM, PROM, EPROM, EEPROM, RAM, CD-ROM, магнитную ленту, флоппи-диск и устройство оптического хранения данных. Более того, считываемые компьютером носители записи включают в себя носители, реализуемые в форме несущей волны (т.е., передача через Интернет). К тому же, битовый поток, сгенерированный способом кодирования, может храниться в считываемом компьютером носителе записи или может передаваться по сетям проводной/беспроводной связи.
[429] К тому же, варианты осуществления настоящего документа могут быть реализованы при помощи компьютерного программного продукта в соответствии с программными кодами, и программные коды могут выполняться в компьютере посредством вариантов осуществления настоящего документа. Программные коды могут храниться на носителе, который может считываться компьютером.
[430] Фиг. 18 показывает пример системы стриминга контента, к которой могут применяться варианты осуществления, раскрытые в настоящем документе.
[431] Со ссылкой на фиг. 18, система стриминга контента, к которой применяется вариант(ы) осуществления настоящего документа, может в широком смысле включать в себя сервер кодирования, стриминговый сервер, веб-сервер, медиа-хранилище, устройство пользователя и устройство мультимедийного ввода.
[432] Сервер кодирования сжимает контент, введенный из устройств мультимедийного ввода, таких как смартфон, камера, камера-регистратор и т.д. в цифровые данные, чтобы сгенерировать битовый поток и передать битовый поток на стриминговый сервер. В качестве примера, когда устройства мультимедийного ввода, такие как смартфоны, камеры, камеры-регистраторы и т.д., непосредственно генерируют битовый поток, сервер кодирования может опускаться.
[433] Битовый поток может генерироваться способом кодирования или способом генерации битового потока, к которым применяется вариант(ы) осуществления настоящего раскрытия, и стриминговый сервер может временно хранить битовый поток в процессе передачи или приема битового потока.
[434] Стриминговый сервер передает мультимедийные данные на устройство пользователя на основе запроса пользователя через веб-сервер, и веб-сервер служит как носитель для информирования пользователя об услуге. Когда пользователь запрашивает желаемую услугу от веб-сервера, веб-сервер доставляет ее на стриминговый сервер, и стриминговый сервер передает мультимедийные данные пользователю. В этом случае, система стриминга контента может включать в себя отдельный сервер управления. В этом случае, сервер управления служит, чтобы управлять командой/откликом между устройствами в системе стриминга контента.
[435] Стриминговый сервер может принимать контент от хранения медиа и/или сервера кодирования. Например, когда контент принимается от сервера кодирования, контент может приниматься в реальном времени. В этом случае, чтобы обеспечить плавную стриминговую услугу, стриминговый сервер может хранить битовый поток в течение предопределенного времени.
[436] Примеры пользовательского устройства могут включать в себя мобильный телефон, смартфон, ноутбук, цифровой терминал вещания, персональный цифровой помощник (PDA), портативный мультимедийный проигрыватель (PMP), навигатор, тонкий PC, планшетные PC, ультрабуки, носимые устройства (например, умные часы, умные очки, наголовные дисплеи), цифровые телевизоры, настольный компьютер, цифровые указатели и тому подобное. Каждый сервер в системе стриминга контента может применяться как распределенный сервер, в этом случае, данные, принятые от каждого сервера, могут распределяться.
[437] Каждый сервер в системе стриминга контента может применяться как распределенный сервер, и в этом случае, данные, принятые от каждого сервера, могут распределяться и обрабатываться.
[438] Пункты формулы изобретения, описанные здесь, могут комбинироваться различными способами. Например, технические признаки пунктов формулы на способ согласно настоящему документу могут комбинироваться и реализовываться как устройство, и технические признаки пунктов формулы на устройство согласно настоящему документу могут комбинироваться и реализовываться как способ. К тому же, технические признаки пунктов формулы на способ согласно настоящему документу и технические признаки пунктов формулы на устройство могут комбинироваться для реализации как устройство, и технические признаки пунктов формулы на способ согласно настоящему документу и технические признаки пунктов формулы на устройство могут комбинироваться и реализовываться как способ.





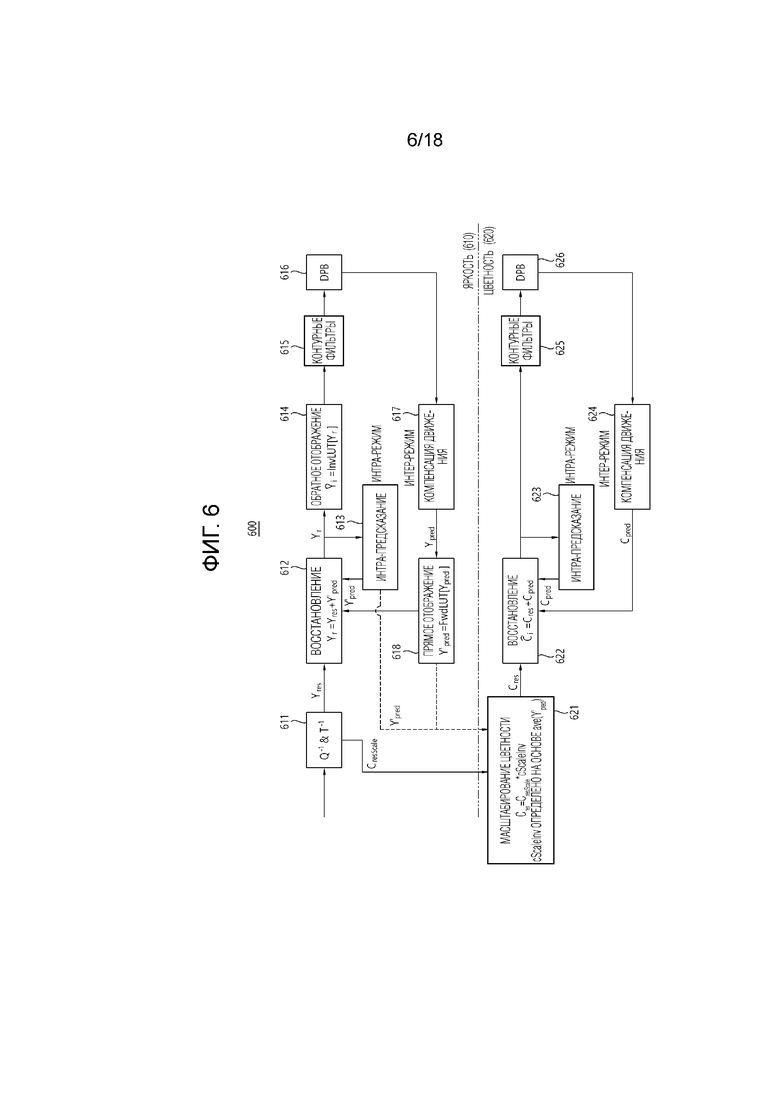
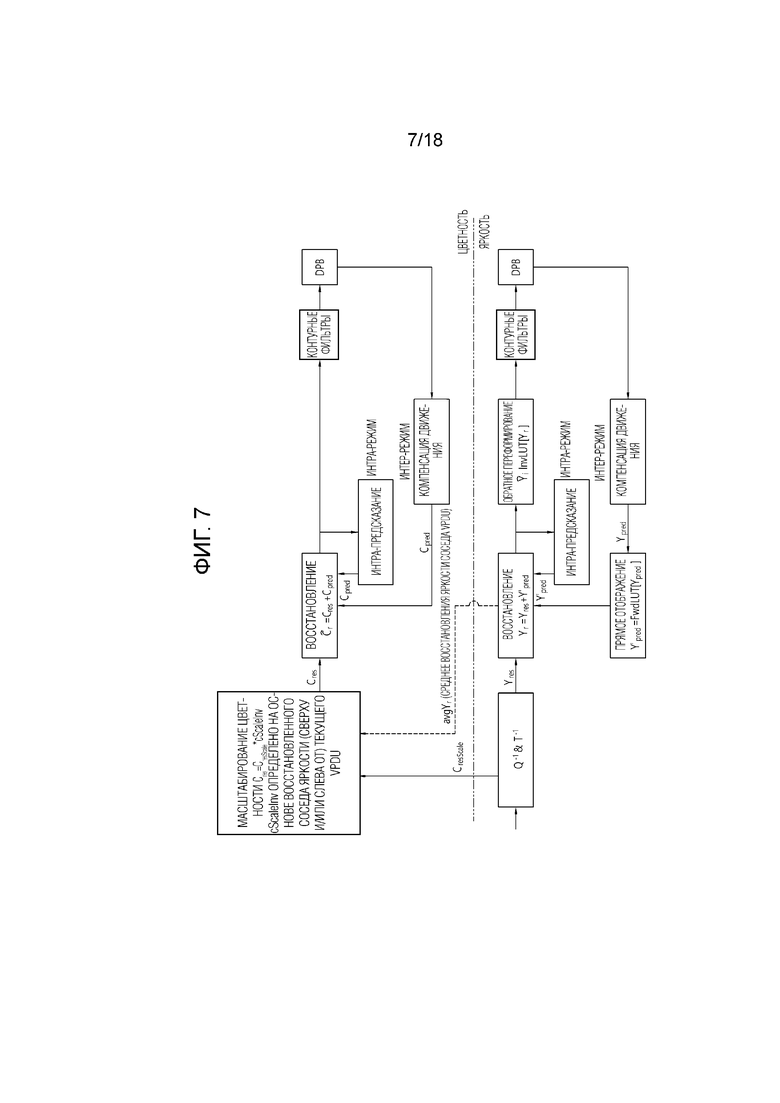



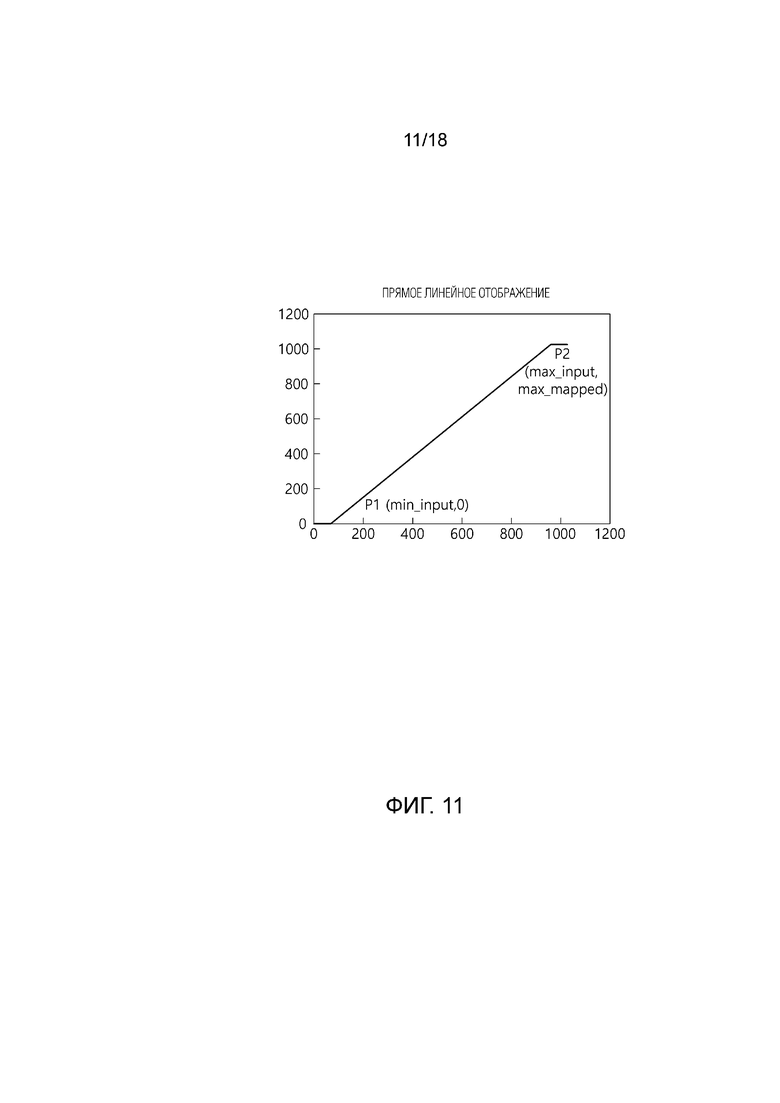
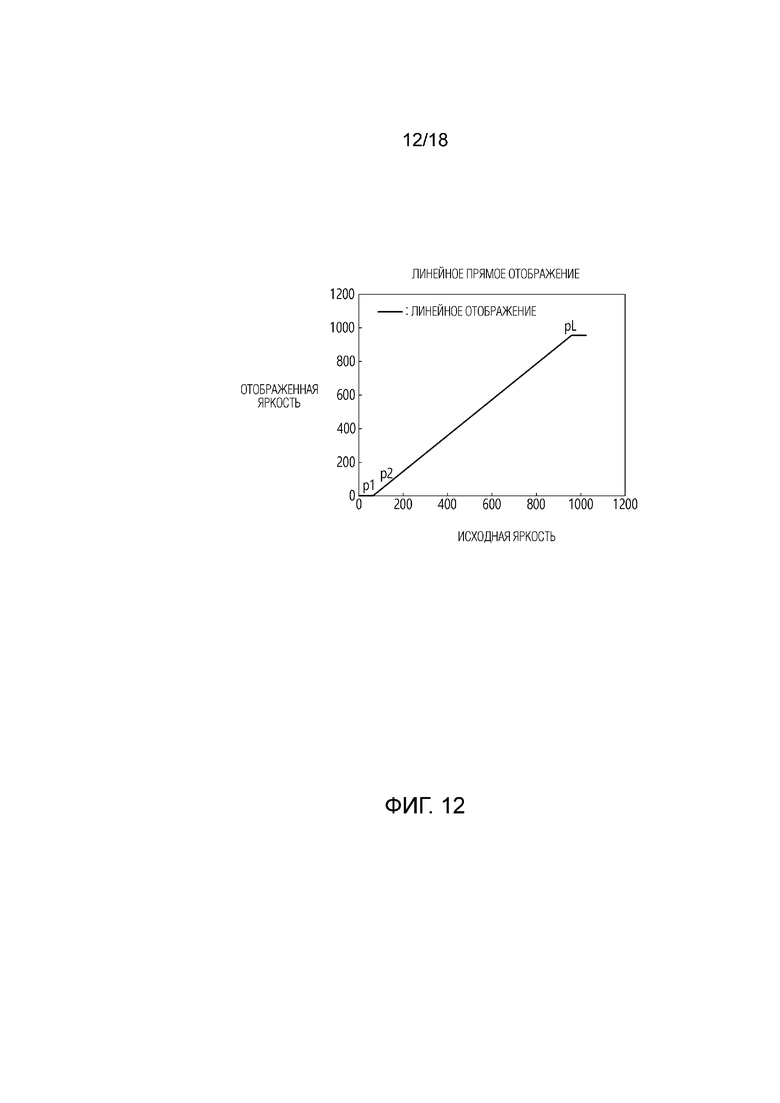
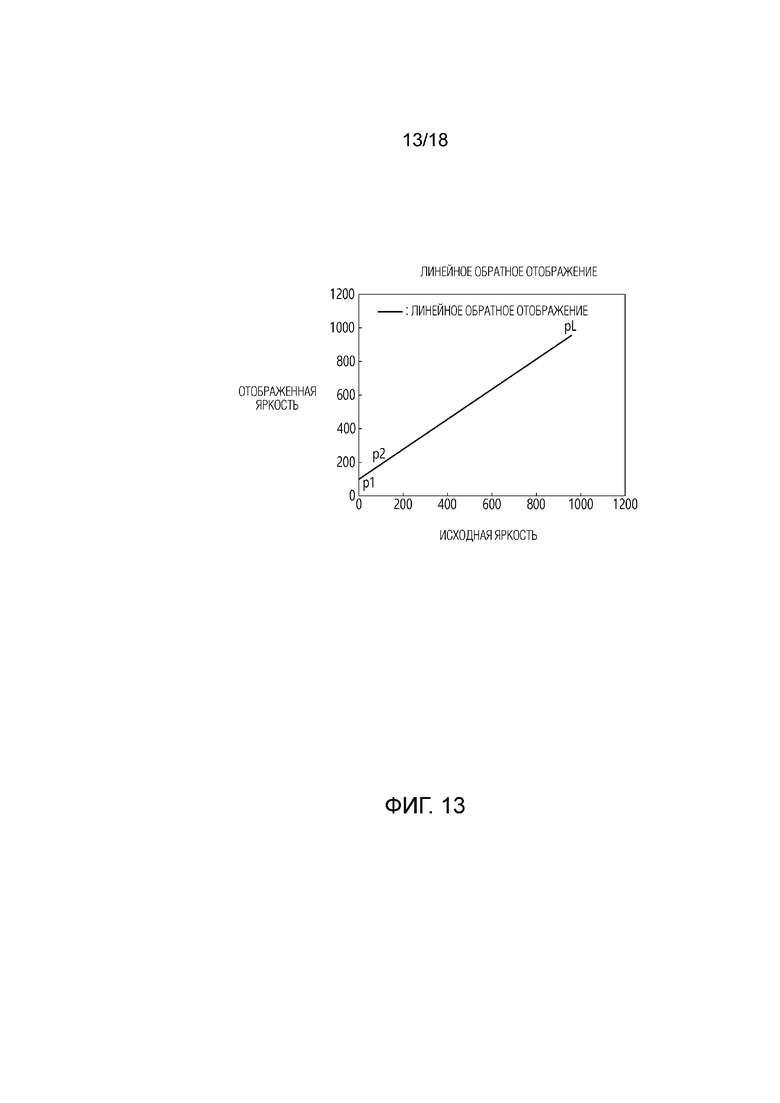


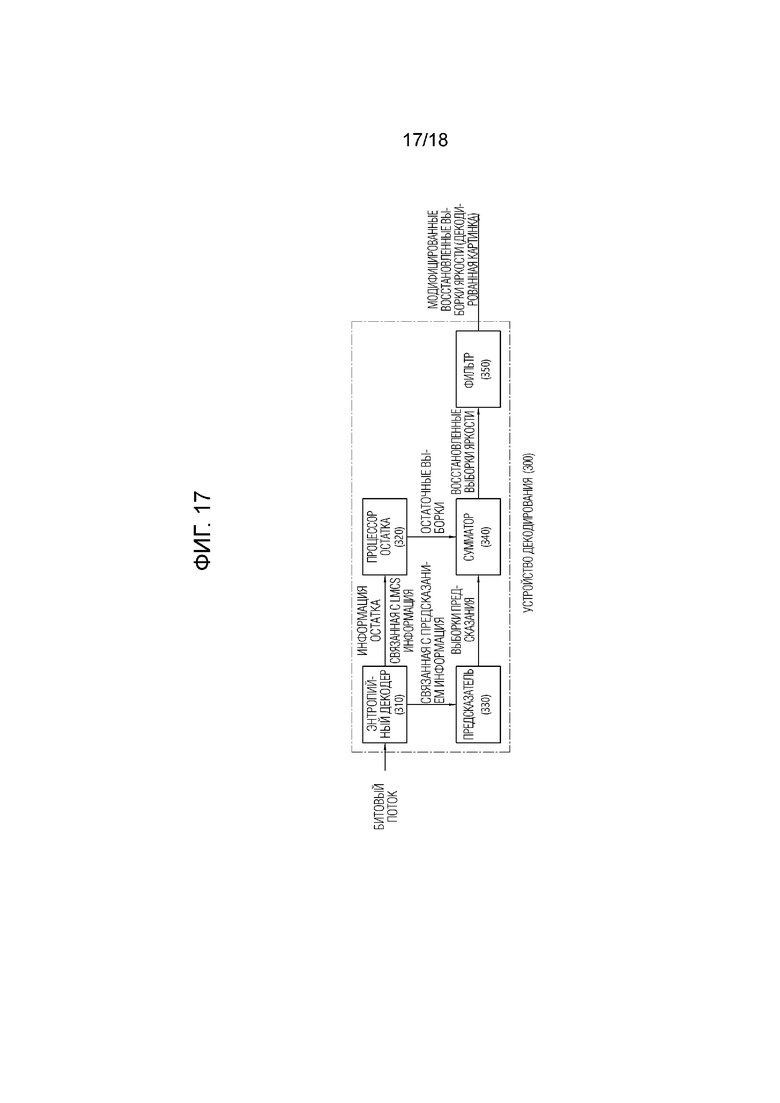

Изобретение относится к средствам для кодирования видео. Технический результат заключается в повышении эффективности кодирования видео. Генерируют выборку яркости предсказания, отображенную выборку яркости предсказания на основе выборки яркости предсказания; информацию, связанную с отображением яркости с масштабированием цветности (LMCS) на основе отображенной выборки яркости предсказания; и остаточную выборку яркости на основе отображенной выборки яркости предсказания. Выводят информацию остатка на основе остаточной выборки яркости. Выполняют кодирование информации изображения, включающей в себя связанную с LMCS информацию и информацию остатка. Причем дополнительно выполняют генерацию восстановленной выборки яркости на основе выборки яркости предсказания и остаточной выборки яркости. Выводят индекс кусочной функции на основе связанной с LMCS информацией. Генерируют модифицированную восстановленную выборку яркости на основе восстановленной выборки яркости и индекса кусочной функции. Причем минимальный индекс бина и максимальный индекс бина выводятся на основе связанной с LMCS информации. 4 н.п. ф-лы, 18 ил.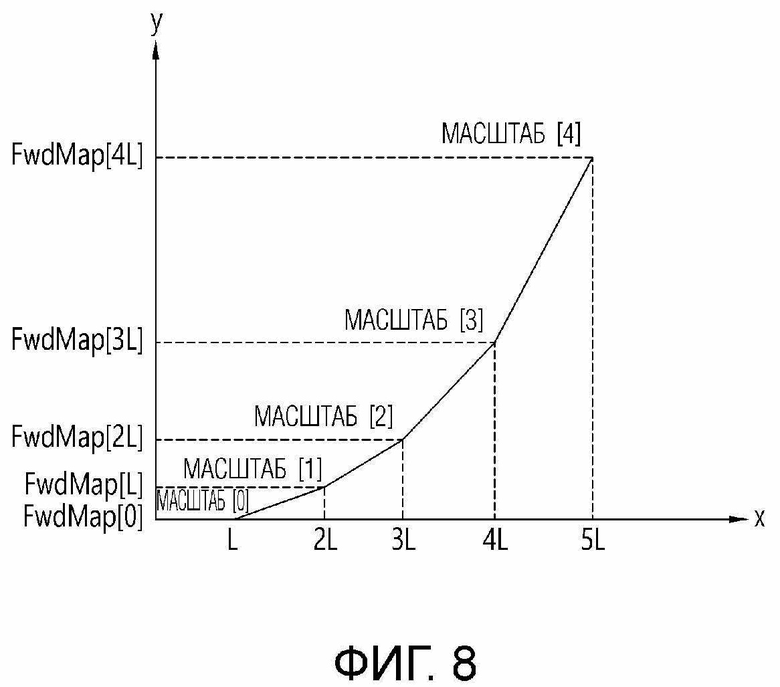
1. Способ декодирования изображения, выполняемый устройством декодирования, причем способ содержит:
получение информации изображения, включающей в себя информацию, связанную с предсказанием, информацию остатка и информацию, связанную с отображением яркости с масштабированием цветности (LMCS), из битового потока;
генерацию выборки яркости предсказания на основе информации, связанной с предсказанием;
генерацию остаточной выборки яркости на основе информации остатка;
генерацию восстановленной выборки яркости на основе выборки яркости предсказания и остаточной выборки яркости;
вывод индекса кусочной функции на основе связанной с LMCS информацией; и
генерацию модифицированной восстановленной выборки яркости на основе восстановленной выборки яркости и индекса кусочной функции,
причем минимальный индекс бина и максимальный индекс бина выводятся на основе связанной с LMCS информацией,
причем вывод индекса кусочной функции содержит:
определение того, является ли первое отображенное значение, в случае, когда индекс кусочной функции равен минимальному индексу бина, больше значения восстановленной выборки яркости;
определение того, является ли второе отображенное значение, в случае, когда индекс кусочной функции равен максимальному индексу бина -1, больше значения восстановленной выборки яркости; и
определение того, является ли третье отображенное значение, в случае, когда индекс кусочной функции равен максимальному индексу бина, больше значения восстановленной выборки яркости на основе определения того, что второе отображенное значение, в случае, когда индекс кусочной функции равен максимальному индексу бина -1, не больше значения восстановленной выборки яркости.
2. Способ кодирования изображения, выполняемый устройством кодирования, причем способ содержит:
генерацию выборки яркости предсказания;
генерацию отображенной выборки яркости предсказания на основе выборки яркости предсказания;
генерацию информации, связанной с отображением яркости с масштабированием цветности (LMCS) на основе отображенной выборки яркости предсказания;
генерацию остаточной выборки яркости на основе отображенной выборки яркости предсказания;
вывод информации остатка на основе остаточной выборки яркости; и
кодирование информации изображения, включающей в себя связанную с LMCS информацию и информацию остатка,
причем способ кодирования изображения также содержит:
генерацию восстановленной выборки яркости на основе выборки яркости предсказания и остаточной выборки яркости;
вывод индекса кусочной функции на основе связанной с LMCS информацией; и
генерацию модифицированной восстановленной выборки яркости на основе восстановленной выборки яркости и индекса кусочной функции,
причем минимальный индекс бина и максимальный индекс бина выводятся на основе связанной с LMCS информации,
причем вывод индекса кусочной функции содержит:
определение того, является ли первое отображенное значение, в случае, когда индекс кусочной функции равен минимальному индексу бина, больше значения восстановленной выборки яркости;
определение того, является ли второе отображенное значение, в случае, когда индекс кусочной функции равен максимальному индексу бина -1, больше значения восстановленной выборки яркости; и
определение того, является ли третье отображенное значение, в случае, когда индекс кусочной функции равен максимальному индексу бина, больше значения восстановленной выборки яркости на основе определения того, что второе отображенное значение, в случае, когда индекс кусочной функции равен максимальному индексу бина -1, не больше значения восстановленной выборки яркости.
3. Считываемый компьютером цифровой носитель хранения, хранящий инструкции, которые при исполнении побуждают выполнять способ кодирования изображения по п. 2.
4. Способ передачи данных для информации изображения, содержащий:
получение битового потока информации изображения, включающей в себя информацию, связанную с отображением яркости с масштабированием цветности (LMCS), и информацию остатка, причем информация, связанная с LMCS генерируется путем генерации выборки яркости предсказания, генерации отображенной выборки яркости предсказания на основе выборки яркости предсказания, и вывод информации, связанной с LMCS на основе отображенной выборки яркости предсказания, и причем информация остатка генерируется путем генерации остаточной выборки яркости на основе отображенной выборки яркости предсказания, и вывод информации остатка основан на остаточной выборке яркости; и
передачу данных, содержащих битовый поток информации изображения, включающей в себя связанную с LMCS информацию и информацию остатка,
причем восстановленная выборка яркости генерируется на основе выборки яркости предсказания и остаточной выборки яркости;
причем индекс кусочной функции выводится на основе связанной с LMCS информацией; и
причем модифицированная восстановленная выборка яркости генерируется на основе восстановленной выборки яркости и индекса кусочной функции,
причем минимальный индекс бина и максимальный индекс бина выводятся на основе связанной с LMCS информацией,
причем для вывода индекса кусочной функции,
определяется то, является ли первое отображенное значение, в случае, когда индекс кусочной функции равен минимальному индексу бина, больше значения восстановленной выборки яркости;
определяется то, является ли второе отображенное значение, в случае, когда индекс кусочной функции равен максимальному индексу бина -1, больше значения восстановленной выборки яркости; и
определяется то, является ли третье отображенное значение, в случае, когда индекс кусочной функции равен максимальному индексу бина, больше значения восстановленной выборки яркости на основе определения того, что второе отображенное значение, в случае, когда индекс кусочной функции равен максимальному индексу бина -1, не больше значения восстановленной выборки яркости.
| Автомобиль-сани, движущиеся на полозьях посредством устанавливающихся по высоте колес с шинами | 1924 |
|
SU2017A1 |
| Способ получения цианистых соединений | 1924 |
|
SU2018A1 |
| Способ получения цианистых соединений | 1924 |
|
SU2018A1 |
| Способ получения цианистых соединений | 1924 |
|
SU2018A1 |
| Способ получения цианистых соединений | 1924 |
|
SU2018A1 |
| US 9661338 B2, 23.05.2017 | |||
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| СПОСОБ И УСТРОЙСТВО КОДИРОВАНИЯ ИЗОБРАЖЕНИЙ С ЭФФЕКТОМ ГЛУБИНЫ ПРИ КОДИРОВАНИИ ВИДЕО | 2015 |
|
RU2661331C2 |
