Перекрестные ссылки на родственные заявки
[0001] По данной заявке испрашивается приоритет на основании предварительной заявки на патент США 63/038,046, поданной 11 июня 2020 г., и заявки на патент EP 20179449.2, поданной 11 июня 2020 г., которые настоящим включены в данный документ путём ссылки.
Область техники, к которой относится изобретение
[0002] Данное изобретение относится в общем к обработке аудиосигналов и в частности к технологиям разделения аудиоисточников.
Уровень техники
[0003] Двухканальные аудиомиксы (например, стереомиксы) создаются посредством смешивания нескольких аудиоисточников. Имеется несколько примеров, в которых желательно обнаруживать и извлекать отдельные аудиоисточники из двухканальных микширований, в том числе, но не ограничиваясь: варианты применения для повторного микшироваения, в которых аудиоисточники перебазируются в двухканальном микшировании, варианты применения для повышающего микширования, в которых аудиоисточники располагаются или перебазируются в объемном звуковом микшировании, и варианты применения для улучшения характеристик аудиоисточников, в которых определенные аудиоисточники (например, речь/диалог) усиливаются и добавляются обратно в двухканальное или объемное звуковое микширование.
Раскрытие изобретения
[0004] Подробности раскрытых реализаций изложены на сопровождающих чертежах и в нижеприведенном описании. Другие признаки, задачи и преимущества должны стать очевидными из описания, чертежей и формулы изобретения.
[0005] В варианте осуществления, способ содержит: получение, с использованием одного или более процессоров, представления в частотной области первого набора выборок из множества уровневых и пространственных распределений целевых источников во множестве подполос частот; получение, с использованием одного или более процессоров, представления в частотной области второго набора выборок из множества уровневых и пространственных распределений фонов во множестве подполос частот; суммирование, с использованием одного или более процессоров, первого и второго наборов выборок для создания комбинированного набора выборок; обнаружение, с использованием одного или более процессоров, уровневых и пространственных параметров для каждой выборки в комбинированном наборе выборок для каждой подполосы частот во множестве подполос частот; в каждой подполосе частот из множества подполос частот, взвешивание обнаруженных уровневых и пространственных параметров посредством их соответствующих уровневых и пространственных распределений для целевого источника и фонов; сохранение, с использованием одного или более процессоров, взвешенных уровневых, пространственных параметров и отношения сигнала к шуму (SNR) во множестве подполос частот для каждой выборки в комбинированном наборе выборок в таблице; и переиндексацию, с использованием одного или более процессоров, таблицы посредством взвешенных уровневых параметров, пространственных параметров и подполосы частот таким образом, что таблица включает в себя целевое SNR в процентилях взвешенных уровневых и пространственных параметров и подполосы частот, и таким образом, что для данного ввода квантованных обнаруженных пространственных и уровневых параметров и подполосы частот, из таблицы получается оцененное SNR, ассоциированное с квантованными обнаруженными пространственными и уровневыми параметрами и подполосой частот.
[0006] В варианте осуществления, способ дополнительно содержит сглаживание данных, которые индексируются для одного или более обнаруженных уровневых, одного или более пространственных параметров или подполосы частот.
[0007] В варианте осуществления, представление в частотной области представляет собой представление в области кратковременного преобразования Фурье (STFT).
[0008] В варианте осуществления, пространственные параметры включают в себя панорамирование и разность фаз между двумя каналами сведенного аудиосигнала.
[0009] В варианте осуществления, целевой источник амплитудно панорамируется с использованием закона постоянной мощности.
[0010] В варианте осуществления, целевое SNR в процентилях составляет 25-ый процентиль.
[0011] В варианте осуществления, способ содержит: преобразование, с использованием одного или более процессоров, одного или более кадров двухканального аудиосигнала временной области в представление в частотно-временной области, включающее в себя множество частотно-временных мозаичных элементов, при этом частотная область представления в частотно-временной области включает в себя множество частотных элементов разрешения, сгруппированных во множество подполос частот; для каждого частотно-временного мозаичного элемента: вычисление, с использованием одного или более процессоров, пространственных параметров и уровня для частотно-временного мозаичного элемента; формирование, с использованием одного или более процессоров, отношения сигнала к шуму (SNR) в процентилях для каждого частотного элемента разрешения в частотно-временному мозаичному элементу; формирование, с использованием одного или более процессоров, дробного значения для элемента разрешения на основе SNR для элемента разрешения; и применение, с использованием одного или более процессоров, дробных значений для элементов разрешения в частотно-временном мозаичном элементе для формирования модифицированного частотно-временного мозаичного элемента оцененного аудиоисточника.
[0012] В варианте осуществления, кадры множества частотно-временных мозаичных элементов собираются во множество порций, причем каждая порция включает в себя множество подполос частот, при этом способ содержит: для каждой подполосы частот в каждой порции: вычисление, с использованием одного или более процессоров, пространственных параметров и уровня для каждого частотно-временного мозаичного элемента в порции; формирование, с использованием одного или более процессоров, отношения сигнала к шуму (SNR) в процентилях для каждого частотного элемента разрешения в частотно-временном мозаичном элементе; формирование, с использованием одного или более процессоров, дробного значения для элемента разрешения на основе SNR для элемента разрешения; и применение, с использованием одного или более процессоров, дробных значений для элементов разрешения в частотно-временном мозаичном элементе для формирования модифицированного частотно-временного мозаичного элемента оцененного аудиоисточника.
[0013] В варианте осуществления, способ включает в себя преобразование, с использованием одного или более процессоров, модифицированного частотно-временного мозаичного элемента во множество сигналов аудиоисточников временной области.
[0014] В варианте осуществления, пространственные параметры включают в себя панорамирование и разность фаз между каналами для каждого из частотно-временных мозаичных элементов.
[0015] В варианте осуществления, дробные значения получаются из таблицы поиска или функции для системы пространственно-уровневых фильтров (SLF), обученной для панорамированного целевого источника.
[0016] В варианте осуществления, преобразование одного или более кадров двухканального аудиосигнала временной области в сигнал частотной области содержит применение короткого частотно-временного преобразования (STFT) к двухканальному аудиосигналу временной области.
[0017] В варианте осуществления, несколько частотных элементов разрешения группируются в октавные подполосы частот или приблизительно октавные подполосы частот.
[0018] Конкретные варианты осуществления, раскрытые в данном документе, обеспечивают одно или более из следующих преимуществ. Раскрытые варианты осуществления обеспечивают возможность извлечения (разделения источников) целевого источника из записи микширования, которая состоит из источника плюс некоторые фоны. Более конкретно, раскрытые варианты осуществления обеспечивают возможность извлечения источника, который сводится (исключительно или главным образом) с использованием амплитудного панорамирования, которое представляет собой наиболее распространенный способ, которым диалог сводится в телепередачах и фильмах. Способность извлекать такие источники обеспечивает улучшение диалогов (которое извлекает и затем усиливает диалог в микшировании) или повышающее микширование. Дополнительно, высококачественная оценка источника может извлекаться практически без обучающих данных или времени задержки, признак, который отличает означенное от большинства других подходов к разделению источников.
Краткое описание чертежей
[0019] На прилагаемых чертежах, упоминаемых ниже, различные варианты осуществления проиллюстрированы на блок-схемах, блок-схемах способа и других схемах. Каждый блок на блок-схемах или блок могут представлять модуль, программу или часть кода, который содержит одну или более выполняемых инструкций для выполнения указанных логических функций. Хотя эти блоки проиллюстрированы в конкретных последовательностях для выполнения этапов способов, они не обязательно могут выполняться строго в соответствии с проиллюстрированной последовательностью. Например, они могут выполняться в обратной последовательности или одновременно, в зависимости от характера соответствующих операций. Также следует отметить, что блок-схемы и/или каждый блок на блок-схемах и их сочетания могут быть реализованы посредством специализированной системы на основе программного обеспечения или аппаратного обеспечения для выполнения указанных функций/операций, либо посредством сочетания специализированных аппаратных средств и компьютерных инструкций.
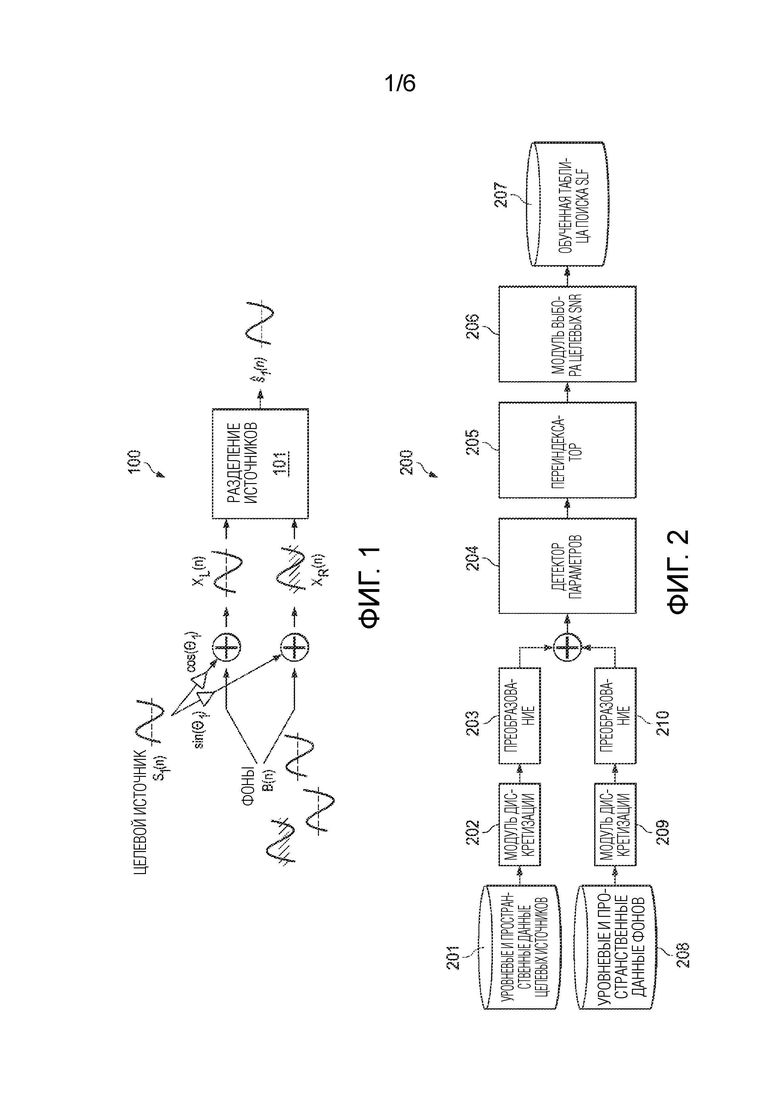
[0020] Фиг. 1 иллюстрирует модель прохождения сигналов для разделения источников, показывающую микширование во временной области в соответствии с вариантом осуществления.
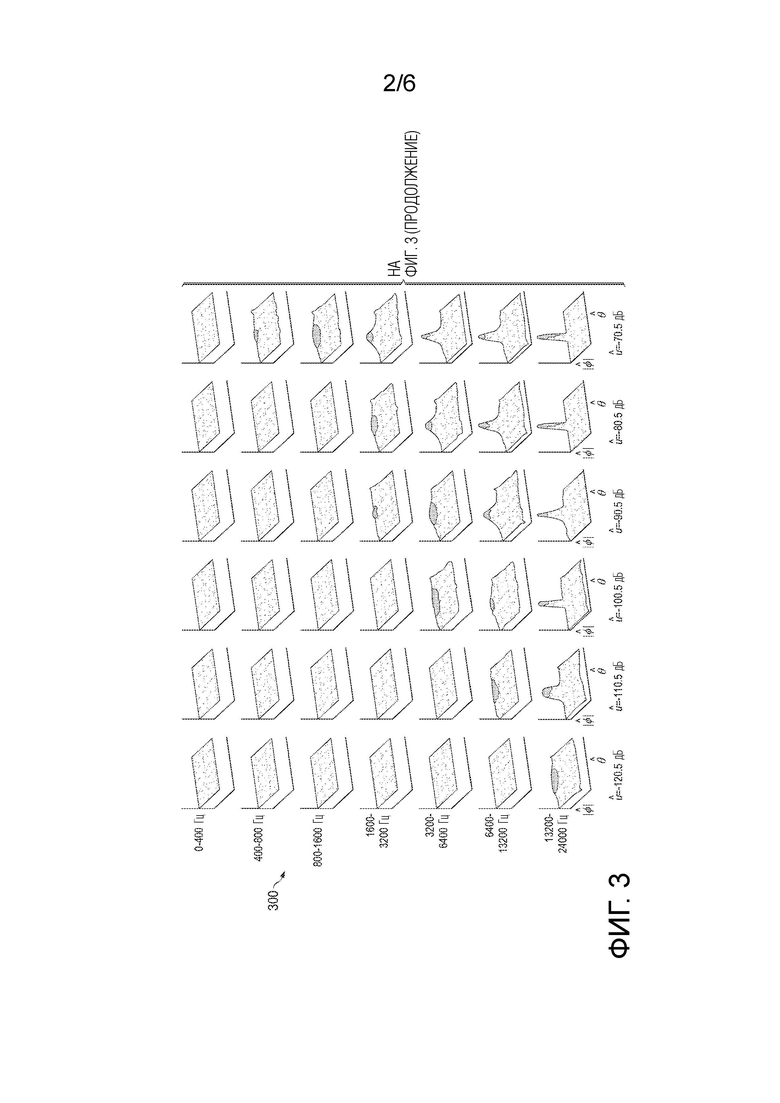
[0021] Фиг. 2 является блок-схемой системы для формирования таблицы поиска на основе пространственно-уровневых фильтров (SLF), обученную для извлечения панорамированных источников, согласно варианту осуществления.
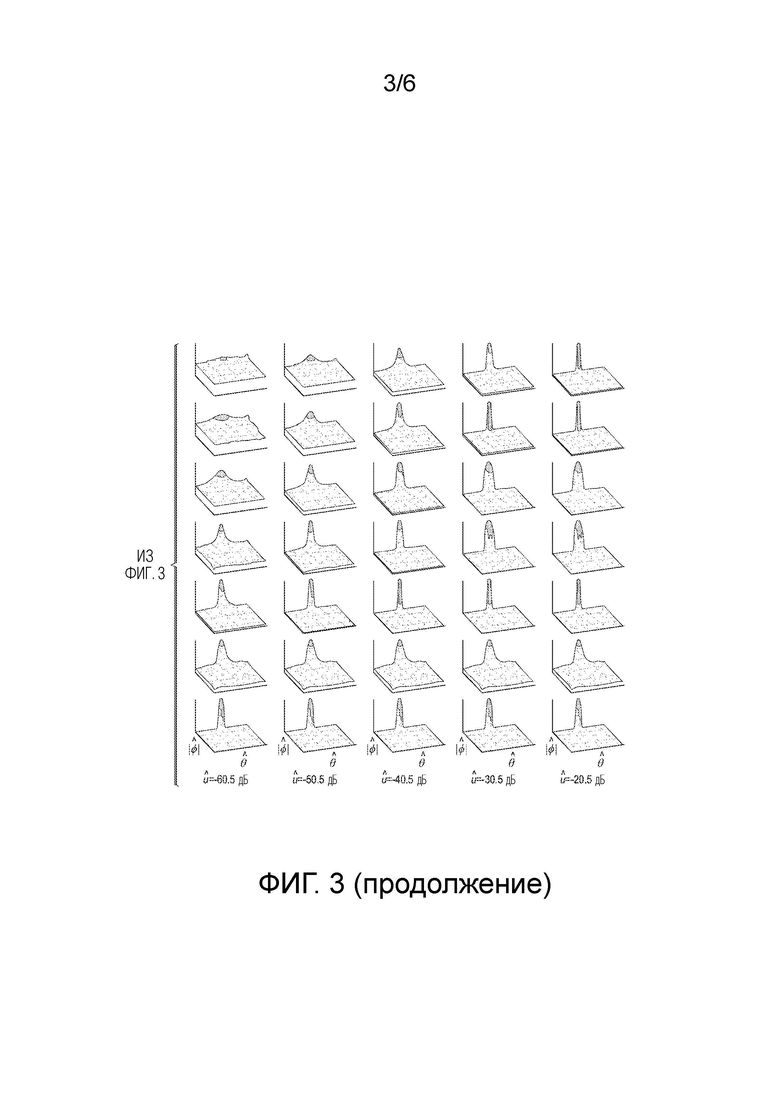
[0022] Фиг. 3 является визуальным изображением вводов и выводов таблицы поиска SLF, обученной для извлечения панорамированных источников в соответствии с вариантом осуществления.
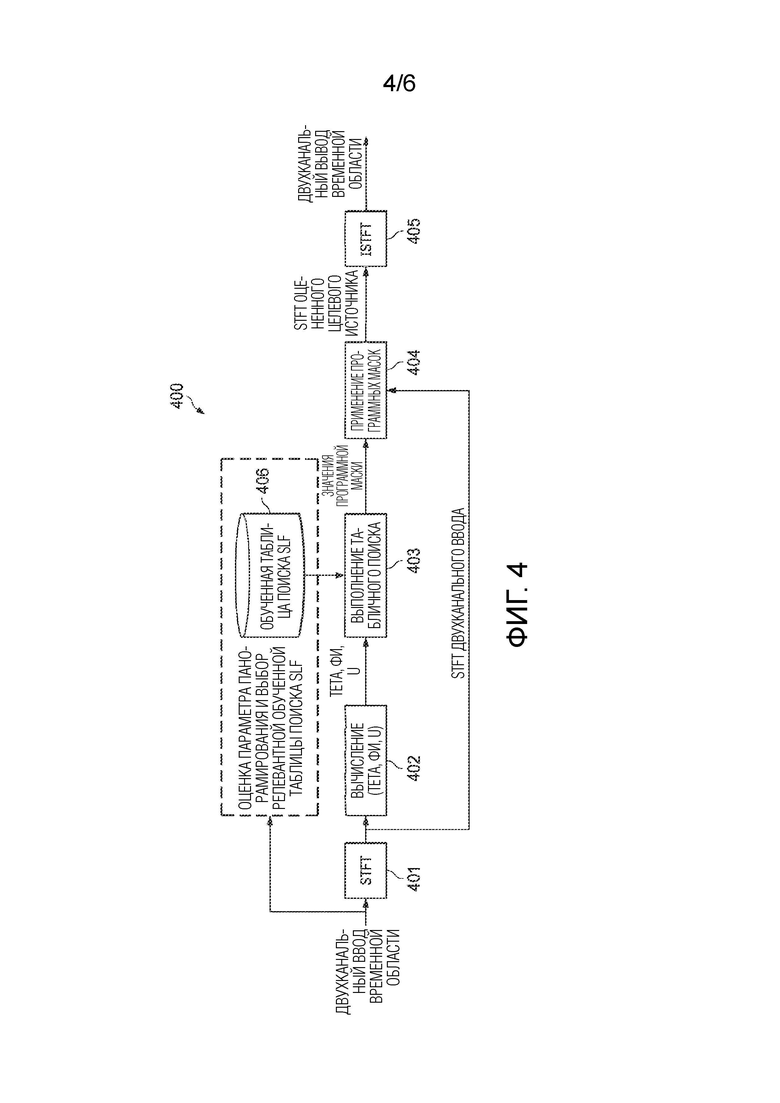
[0023] Фиг. 4 является блок-схемой системы для обнаружения и извлечения пространственно идентифицируемых подполосных аудиоисточников из двухканальных микшировании с использованием SLF, обученного для извлечения панорамированных источников, согласно варианту осуществления.
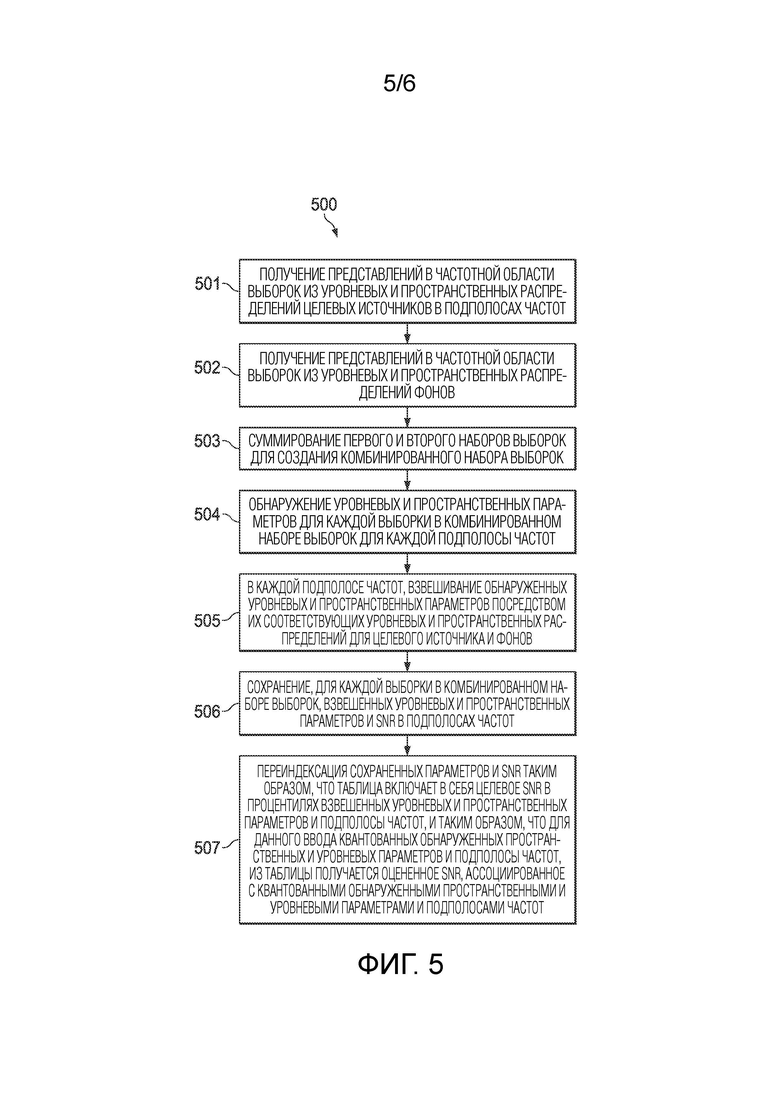
[0024] Фиг. 5 является блок-схемой процесса формирования таблицы поиска SLF, обученной для извлечения панорамированных источников в соответствии с вариантом осуществления.
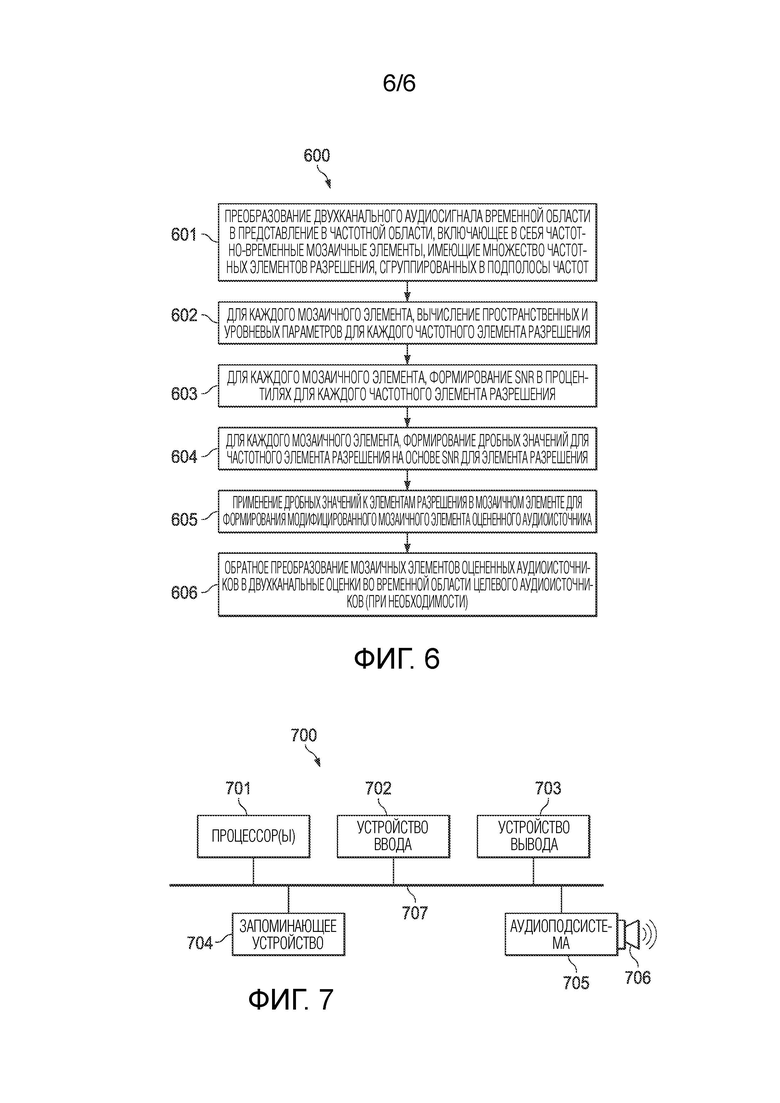
[0025] Фиг. 6 является блок-схемой процесса обнаружения и извлечения пространственно идентифицируемых подполосных аудиоисточников из двухканальных микширований с использованием SLF, обученного для извлечения панорамированных источников в соответствии с вариантом осуществления.
[0026] Фиг. 7 является блок-схемой архитектуры устройства для реализации систем и процессов, описанных в отношении фиг. 1-6, согласно варианту осуществления
[0027] Одинаковые условные обозначения, используемые на различных чертежах, указывают на аналогичные элементы.
Осуществление изобретения
Модель прохождения сигналов и предположения
[0028] Фиг. 1 иллюстрирует модель 100 прохождения сигналов для разделения источников, показывающую микширование во временной области в соответствии с вариантом осуществления. Модель 100 прохождения сигналов предполагает базовое микширование во временной области целевого источника, s1, и фонов, b, в два канала, в дальнейшем называемые «левым каналом» (x1 или XL) и «правым каналом» (x2 или XR), в зависимости от контекста. Два канала вводятся в системе 101 разделения источников, которая оценивает 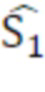 .
.
[0029] Целевой источник, s1 предположительно должен амплитудно панорамироваться с использованием закона постоянной мощности. Поскольку другие законы панорамирования могут быть преобразованы в закон постоянной мощности, использование закона постоянной мощности в модели 100 прохождения сигналов не является ограничивающим. При панорамировании по закону постоянной мощности, источник, s1, сводимый в левый/правый (L/R) каналы, описан следующим образом:
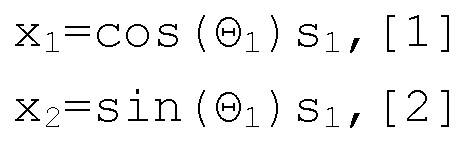
где Θ1 колеблется от 0 (источник, панорамированный крайним левым) до π/2 (источник, панорамированный крайним правым). Это может выражаться в области кратковременного преобразования Фурье (STFT) следующим образом:
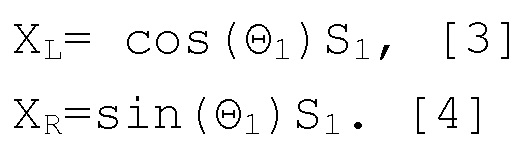
[0030] Продолжая в области STFT, суммирование фонов, B, с каждым каналом выражается следующим образом:
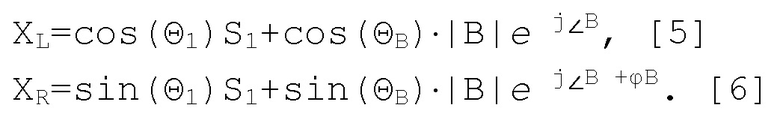
[0031] Фоны, B, включают в себя дополнительные параметры ∠B и φB. Эти параметры, соответственно, описывают разность фаз между S1 и фазой левого канала для B и межканальную разность фаз между фазой B в левом и правом каналах в пространстве STFT. Следует отметить, что нет необходимости включать параметр φS1 в уравнения [5] и [6], поскольку межканальная разность фаз для панорамированного источника по определению равна нулю. Цель S1 и фоны B предположительно не должны совместно использовать конкретное соотношение фаз в пространстве STFT, так что распределение по ∠B моделируется в качестве универсального.
[0032] Имеются ключевые пространственные разности между целевым источником и фонами. Пространственно, Θ1 трактуется в качестве конкретного одного значения («параметра панорамирования» для целевого источника S1), но ΘB and ΦB имеют статистическое распределение, которое обеспечивает возможность использования статистической модели (например, байесовской модели) для выполнения разделения источников.
[0033] Для дальнейшего анализа, «целевой источник» предположительно должен панорамироваться, что означает, что он может характеризироваться посредством Θ1. Межканальная разность фаз для целевого источника предположительно равна нулю. Также предусмотрено распределение по его уровню LS=|S1|, которое предположительно известно по меньшей мере по приблизительно октавным подполосам частот. Пространственная информация предположительно должна полностью указываться посредством параметра панорамирования источника.
[0034] Фоны, B, характеризуются как имеющие распределение по ΘB и также по межканальной разности φB фаз. Также предусмотрено распределение по фоновому уровню LB=|B|, которое предположительно должно быть известно по меньшей мере по приблизительно октавным подполосам частот.
[0035] Для целей этой модели, источник и фоны должны моделироваться только в моменты времени, в которые оба из означенного предположительно являются «активными». В этом смысле, источник и фон для текущих целей предположительно всегда «включены» или «выключены», и разделение должно предполагать, что как целевой источник, так и фон «включены». Можно показать, что если целевой источник является активным, а фоны не являются активными, то извлечение по-прежнему должно быть почти идеальным. Если целевой источник и параметры панорамирования не известны, они могут оцениваться с использованием технологий, известных специалистам в данной области техники. Для некоторых случаев, к примеру, для большей части музыки, может быть предусмотрена гармоническая взаимосвязь между целевым источником и фонами. Такие взаимосвязи отдельно не моделируются в модели 100 прохождения сигналов; распределения предположительно должны включать в себя определенную степень перекрытия гармоник, которая является подходящей для данного варианта применения.
Процесс обучения
[0036] Фиг. 2 является блок-схемой системы 200 для формирования таблицы поиска SLF, обученной для извлечения панорамированных источников, согласно варианту осуществления. SLF представляет собой систему, которая обучена для извлечения целевого источника с данным уровневым распределением и указанными пространственными параметрами, из микширования, которое включает в себя фоны с данным уровневым распределением и пространственными параметрами.
[0037] Система 200 включает в себя базу 201 данных параметров целевых источников, модуль 202 дискретизации распределений целевых источников, преобразование 203, детектор 204 параметров, переиндексатор 205, модуль 206 выбора целевых SNR, обученную таблицу 207 поиска SLF, базу 208 данных параметров фонов, модуль 209 дискретизации распределений фонов и преобразование 210. Модули 202, 209 дискретизации распределений и преобразования 203, 210 показаны как отдельные блоки на фиг. 2, но на практике модули 202, 209 дискретизации и преобразования 203, 210 могут комбинироваться в одиночные модули (например, программные модули), которые работают с базами 201, 208 данных целевых источников и фонов.
[0038] Цель процедуры обучения, реализованной посредством системы 200, состоит в создании байесовской модели, которая, с учетом двухканального ввода (например, стереоввода L/R), прогнозирует относительную долю энергии, принадлежащую целевому источнику, для каждого элемента разрешения или мозаичного элемента области STFT. Для помощи в достижении этой цели используются четыре параметра, которые являются обнаруживаемыми для двухканальных вводов в области STFT.
[0039] Первый параметр представляет собой b, который представляет приблизительно октавную подполосу частот. Этот параметр получается посредством тривиального преобразования из данного частотного элемента ω разрешения в подполосу b частот, которой он принадлежит. Примеры границ подполос частот приведены ниже.
[0040] Второй параметр представляет собой обнаруженное «панорамирование» для каждого мозаичного элемента (ω,t), которое задается следующим образом:
Θ(ω,t)=arctan(|XR(ω,t)|/|XL(ω,t)|), [7]
где «полный левый» составляет 0, и «полный правый» составляет π/2.
[0041] Третий параметр представляет собой обнаруженную «разность фаз» для каждого мозаичного элемента. Она задается следующим образом:
φ(ω,t)=angle(XL(ω,t)/XR(ω,t)), [8]
которая колеблется от -π до π, причем 0 означает то, что обнаруженная фаза является идентичной в обоих каналах.
[0042] Четвертый параметр представляет собой обнаруженный «уровень» для каждого мозаичного элемента, заданный следующим образом:
U(ω,t)=10*log10(|XR(ω,t)|2+|XL(ω,t)|2), [9]
который представляет собой просто «пифагорову» абсолютную величину двух каналов. Он может рассматриваться в качестве вида моноспектрограммы абсолютной величины.
[0043] Следует понимать, что каждый частотный элемент ω разрешения представляет конкретную частоту. Тем не менее, данные также могут группироваться в подполосах частот, которые представляют собой совокупности последовательных элементов разрешения, причем каждый частотный элемент ω разрешения принадлежит подполосе частот. Группировка данных в подполосах частот является, в частности, полезной для определенных задач оценки, выполняемых в системе. В варианте осуществления, используются октавные подполосы частот или приблизительно октавные подполосы частот, хотя могут использоваться другие определения подполос частот. Некоторые примеры формирования полос частот включают в себя задание краев полосы частот следующим образом, причем значения перечисляются в Гц:
[0,400,800,1600,3200,6400,13200,24000],
[0,375,750,1500,3000,6000,12000,24000], и
[0,375,750,1500,2625,4125,6375,10125,15375,24000].
[0044] Следует отметить, что если строго придерживаться определения «октавный», может быть предусмотрено бесконечное число таких полос частот, при этом наименьшая полоса частот приближается к инфинитезимальной ширине, так что некоторый вариант выбора требуется для обеспечения возможности конечного числа подполос частот. В варианте осуществления, наименьшая полоса частот выбирается равной по размеру второй полосе частот, хотя другие условные обозначения могут использоваться в других вариантах осуществления. В данном документе, термины «подполоса частот» и «полоса частот» могут использоваться взаимозаменяемо.
[0045] Для понимания того, каким образом следует построить байесовскую систему на основе этих четырех параметров, сначала напомним правило Байеса:
p(A|B)=p(B|A)p(A)/p(B).[10]
[0046] В этом случае, цель процесса обучения состоит в обеспечении возможности оценки распределения на SNR для каждого мозаичного элемента спектрограммы, с учетом некоторых наблюдений. Наблюдения b, Θ, φ, U описаны выше. Правило Байеса задается следующим образом:
p(SNR|b,Θ,φ,U)=p(b,Θ,φ,U|SNR)p(SNR)/p(b,Θ,φ,U). [11]
[0047] Теперь цель состоит в обучении байесовской системы, которая может формировать все величины в правой части уравнения [11] таким образом, что величина в левой части уравнения [11] может оцениваться. Для этого, p(SNR) оценивается посредством рассмотрения уровневых распределений по целевому источнику в фоне.
[0048] Условная вероятность p(b,Θ,φ,U|SNR) оценивается из распределений по параметрам (Θ,φ,U) в каждой полосе b частот при микшировании цели и фонов при различных SNR. Процедура формирования этих данных заключает в себе формирование множества выборок данных из баз 201, 208 данных, для целевого источника и фонов, соответственно, посредством дискретизации из их известных или предполагаемых пространственных и уровневых распределений с использованием модулей 202, 209 дискретизации распределений. Преобразования 203, 210 создают значения в области STFT со свойствами выборок.
[0049] Напомним, что целевой источник предположительно должен иметь конкретный параметр панорамирования, так что процедура обучения, описанная здесь, явно указывает параметр панорамирования целевого источника, который необходимо впоследствии извлекать. Примерные варианты осуществления, описанные в данном документе, предполагают, что целевой источник имеет Θ1=π/4, что соответствует центральному панорамированному источнику. При формировании обучающих данных, предполагается, что случайное соотношение фаз существует между целью и фонами, как отмечено выше. На практике, это может реализовываться посредством задания одного значения фазы равным нулю, а другого - а различным выборкам на единичной окружности.
[0050] Для создания обучающих данных представления в частотной области, выводимые посредством модулей преобразования 203, 210, суммируются между собой (как показано в модели 100 прохождения сигналов по фиг. 1), для создания комбинированного представления в частотной области. Следует отметить, что предусмотрено очень большое число комбинаций элементов данных целей и фонов при выполнении байесовского обучения, при этом такое очень большое число комбинаций должно иметь гораздо меньшее число соотношений одинаково квантованных целей к фонам.
[0051] Для эффективного использования этой реальности процесс обучения отдельно создает набор равномерно дискретизированных данных для каждого из следующего: SNR целей к фонам (0-37 дБ, хотя большие диапазоны могут выбираться), разности фаз между целью и фонами (0-2π), фон Θ (0-π/2) и абсолютная величина фона φ (0-π). Для всех возможных комбинаций этих данных, процесс обучения вычисляет обнаруженные значения (Θ, φ, U) и сохраняет их в storeThetaHat, storePhiHat и storeUdBHat, соответственно. Следует отметить, что такие вычисления по-прежнему не рассматривают конкретные пространственные и уровневые распределения для каждого из цели и фонов. Они представляют собой просто таблицы поиска, преобразующие из всех потенциальных комбинаций релевантных входных атрибутов в обнаруженные Θ, φ и U. Использование этих таблиц должно повышать эффективность впоследствии в процессе обучения.
[0052] Далее, включаются конкретные пространственные и уровневые данные для цели и фонов. Напомним, что цель состоит в получении p(b,Θ,φ,U|SNR). На практике, распределение по каждой переменной (Θ,φ,U) может представляться посредством квантованной функции плотности распределения вероятностей (pdf), и SNR также может квантоваться. В варианте осуществления, используется квантование 51 уровня для абсолютной величины φ (0-π), 51 уровня для Θ (0-π/2), приращений в 1 дБ для U (примерный диапазон 0-127 дБ) и приращений в 1 дБ для DNR (примерный диапазон от -40 дБ до +60 дБ). С учетом такого квантования, информация p(b,Θ,φ,U|SNR) может сохраняться в многомерном массиве storePopularity следующего размера: 7 полос частот, на 101 обученный SNR (от -40 до 60), на 51 элемент разрешения Θ, на 51 элемент разрешения φ, на 128 уровней в дБ (например, 0-128). Для каждого элемента, значение, сохраненное в массиве, затем представляет вероятность (или, аналогичным образом, «популярность») конкретной комбинации, относительно других комбинаций в массиве. Например, элемент массива (4, 49, 26, 26, 90) представляет то, насколько «популярным» является наличие, для полосы 4 частот и DNR на+8 дБ (49-ое значение), обнаруженного значения Θ в π/4 (26-ое значение), значения абсолютной величины φ в π/2 (26-ое значение) и уровня U в 89 дБ (90-е значение).
[0053] Для получения p(b,Θ,φ,U|SNR), процесс обучения исчерпывающе (или через дискретизацию) циклически проходит по всем возможным комбинациям пространственных и уровневых данных для цели и источника. В это время, когда конкретное SNR, разность фаз, фон Θ и фон φ наблюдаются в обучающих данных, данные, ранее сохраненные в storeThetaHat, storePhiHat и storeUdBHat, используются для поиска результирующего Θ, φ и U, соответственно, таким образом, чтобы уменьшить обучающие вычисления. Этот поиск также может называться «обнаружением параметров» и выполняется посредством блока 204 по фиг. 2. Важно, что популярность каждой такой комбинации, как указано посредством значений пространственных и уровневых распределений на цели и фонах, также используется; они взвешивают долю в массиве storePopularity и в силу этого включают p(SNR) требуемым образом. За счет циклического прохождения по всем таким комбинациям и с учетом их популярности, вышеописанный массив storePopularity создается. Этот массив может быть разреженным или зашумленным, так что он должен сглаживаться с использованием технологий, знакомых специалистам в данной области техники. Примерная технология должна заключаться в сглаживании по одной или более размерностей таблицы.
[0054] На этой стадии получаются данные, необходимые для байесовского анализа, но они не обеспечиваются в требуемом формате таблицы поиска или функции. Конечный этап в процессе обучения заключается в получении применимого p(SNR|b,Θ,φ,U) из данных p(b,Θ,φ,U|SNR)p(SNR) в storePopularity, который имеет размер: 7 полос частот, на 101 обученный SNR (от -40 до 60), на 51 элемент разрешения Θ, на 51 элемент разрешения φ, на 128 уровней в дБ (например, 0-128). Для понимания того, каким образом это соответствует p(b,Θ,φ,U|SNR)p(SNR), напомним, что p(b,Θ,φ,U|SNR)p(SNR) может одинаково представляться в качестве p(b,Θ,φ,U, SNR) или эквивалентно p(b, SNR,Θ,φ,U). Пять индексов являются идентичными индексам в storePopularity.
[0055] Эта переиндексация или повторное преобразование осуществляется посредством блоков 205 и 206 на фиг. 2. Следует иметь в виду, что требуемый p(SNR|b,Θ,φ,U) представляет собой не набор одиночных значений, а набор распределений по SNR, с учетом некоторых обнаруженных (Θ,φ,U) для каждой полосы b частот. Для сохранения управляемости размера представления принимается решение в отношении того, каким образом должны быть кратко описаны эти распределения; типичные способы достижения этого включают в себя взятие среднего, медианного значения или других параметров. С учетом потребностей практических вариантов применения, для которых проектируется эта система, в варианте осуществления используется 25-ый и 50-ый процентиль каждого распределения SNR.
[0056] Для получения p(SNR|b,Θ,φ,U) процесс обучения работает с возможностью выполнения переиндексации (блок 205) и выбор целевых SNR (блок 206). Базовая цель состоит в получении и характеризации всех данных SNR из storePopularity, которые соответствуют данному обнаруженному триплету (Θ,φ,U) в полосе b частот. Поскольку полосы частот трактуются как независимые, эквивалентно можно рассматривать цель в качестве выполнения каждого из N отдельных упражнений для нахождения p(SNR|Θ,φ,U) для каждой из N полос частот. Блок 205 выполняет эту задачу. Он циклически проходит по каждой полосе частот и по каждому дискретизированному уровню распределения для следующих переменных: обнаруженный Θ, обнаруженный φ, обнаруженный уровень. Для каждого такого значения, из storePopularity создается буфер, состоящий из всех SNR и того, насколько популярными они являются с учетом конкретной комбинации обнаруженных значений Θ, φ и U. Более конкретно, буфер представляет собой поднабор storePopularity следующим образом: storePopularitySmoothed (индекс полосы частот, (все данные), индекс Θ, индекс φ, индекс U). Следующий блок 206 анализирует буфер значений и, в варианте осуществления, обнаруживает и записывает значения 25-ого процентиля и 50-ого процентиля в обученной таблице поиска SLF (207). В частности, эти значения записываются в новых массивах, соответственно, percentile25SNRvalues и percentile50SNRvalues, каждый из которых индексируется посредством (индекс полосы частот, обнаруженный индекс Θ, обнаруженный индекс φ, обнаруженный индекс U), что фактически представляет собой представление, искомое для p(SNR|b,Θ,φ,U).
[0057] Вследствие потенциальной разреженности обучающих данных, некоторые буферы, из которых вычисляются SNR в процентилях, могут иметь слишком мало точек данных, из которых можно давать в результате надежные значения SNR в процентилях. Для разрешения этого могут использоваться две примерных технологии, хотя могут использоваться другие. Одна технология заключается в совместном использовании данных из смежных полос частот, значения Θ, значения φ или значения U (с предпочтением совместному использованию полосы частот и уровня U) перед вычислением SNR в процентилях. Другая технология заключается в вычислении SNR в процентилях, хотя бы и из разреженных данных, затем, если они появляются нестабильными, в замене или сглаживании значений SNR в процентилях со значениями SNR из смежных значений U или при необходимости, полос частот.
[0058] На этой стадии переиндексация является полной, и описывается применение обученной системы. Система имеет переиндексированную таблицу, так что индексы в таблице представляют квантованные значения Θ, φ и U и индекс b в рассматриваемой полосе частот. Для использования такой таблицы для получения значения программной маски функция квантует входные значения Θ, φ и U, соответственно, в 51, 51 и 128 уровней. Преобразование из обнаруженных значений Θ, φ и U в их индексы является тривиальным и придерживается идентичного квантования, используемого при выполнении вышеприведенных квантованных распределений. Функция осуществляет доступ к значениям таблицы, соответствующим этим квантованным индексным уровням (а также к индексу для полосы b частот, соответствующему рассматриваемому частотному элементу ω разрешения).
[0059] Следует отметить, что, хотя percentile25SNRvalues и percentile50SNRvalues в этом случае получаются из таблицы с конкретными индексами, значения SNR на практике могут задаваться посредством более общих функций, которые принимают произвольные (не обязательно квантованные) значения Θ, φ, U и b. На практике, функция, которая нацелена на получение значений программной маски из Θ, φ, U и b, не должна обязательно осуществлять доступ к таблице для вывода значения программной маски. Она может непосредственно вычислять значение программной маски посредством использования кривых или общих функций (включающих в себя обученные нейронные сети), которые аппроксимируют и или интерполируют значения в таблице. Из проверки по фиг. 3 (представления системы SNR в 25-ый процентиль) нетрудно видеть, что кривые могут подгоняться к данным, представленным в таблице. В варианте осуществления с использованием таблицы, следует понимать, что таблица представляет собой не ограничивающий способ для получения значений программной маски, а вместо этого рекомендованный эффективный способ для достижения этого. Такие функции, как функции, извлекаемые из подгонки кривых по методу наименьших квадратов или нейронных сетей, аппроксимирующих или интерполирующих таблицу, могут конструироваться с использованием технологий, знакомых специалистам в данной области техники.
[0060] Фиг. 3 является визуальным изображением вводов и выводов таблицы поиска SLF, обученной для извлечения панорамированных источников в соответствии с вариантом осуществления. Более конкретно, фиг. 3 показывает визуальное представление обученной четырехмерной (4D) таблицы поиска SLF с 25-ым процентилем для центрального панорамированного целевого источника, как описано в отношении фиг. 2. Таблица поиска SLF является большой, но также и повторяющейся. Технологии, которые знакомы специалистам в данной области техники, могут использоваться для уменьшения времени поиска и объема запоминающего устройства, требуемого для сохранения информации в этой таблице (например, для энтропийного кодирования), либо, как упомянуто выше, для преобразования информации в таблице в непрерывные функции.
[0061] Как упомянуто выше, визуальное представление на фиг. 3 является четырехмерным. Четыре входные переменные представляют собой модифицированные левую-правую Θ и входную-выходную φ ось каждого подграфика и индексы вертикальных (подполоса b частот) и горизонтальных (уровень U) подграфиков. Следует отметить, что по практическим причинам, размерность горизонтальных подграфиков (уровень U) не иллюстрирует все уровни, сохраненные в таблице поиска SLF; достижение этого требует того, что 128 левых-правых подграфиков в качестве приращений в 1 дБ должны использоваться в диапазоне в 128 дБ в таблице. На практике, более точные или более приблизительные приращения могут использоваться для большей точности или большей эффективности поиска, соответственно. При просмотре фиг. 3, следует отметить, что имеется множество «неотображаемых» подграфиков слева направо.
[0062] Выходная переменная таблицы SLF поиска представляет собой значение программной маски между 0 и 1 включительно и показывается на вертикальной оси каждого подграфика. Значение программной маски представляет долю соответствующего входного STFT, которая должна передаваться в вывод. Поскольку имеется один (четырехмерный) ввод в расчете на мозаичный элемент STFT, также имеется один вывод в расчете на мозаичный элемент STFT. Результат применения таблицы/функции SLF представляет собой представление размера STFT, состоящее из значений между 0 и 1.
[0063] Как отмечено выше, могут использоваться значения программной маски, сформированные посредством percentile25SNRvalues или percentile50SNRvalues, хотя могут использоваться другие процентили. Вообще говоря, использование percentile25SNRvalues приводит к решению по разделению источников, которое балансирует между включением некоторых фонов и вызыванием некоторых артефактов в оценке источников. Использование percentile50SNRvalues приводит к решению, которое имеет меньшее количество артефактов, но также и большее количество фонов. Применение параметров программной маски показывается в блоке 404 по фиг. 4.
[0064] В варианте осуществления, значения программной маски и/или значения сигналов сглаживаются по времени и частоте с использованием технологий, знакомых специалистам в данной области техники. При условии 4096-точечного FFT, может использоваться сглаживание в зависимости от частоты, которое использует сглаживающую функцию [0,17 0,33 1,0 0,33 0,17]/sum([0,17 0,33 1,0 0,33 0,17]). Для более высоких или более низких FFT-размеров, должно выполняться некоторое обоснованное масштабирование диапазона сглаживания и коэффициентов. При условии размера перескоков в 1024 выборки, может использоваться сглаживающая функция в зависимости от времени приблизительно в [0,1 0,55 1,0 0,55 0,1]/sum([0,1 0,55 1,0 0,55 0,1]). Если размер перескоков или длина кадра изменяется, сглаживание может надлежащим образом регулироваться.
Примерные варианты применения
[0065] Фиг. 4 является блок-схемой системы 400 для обнаружения и извлечения пространственно идентифицируемых подполосных аудиоисточников из двухканальных микширований с использованием SLF, согласно варианту осуществления. Система 400 включает в себя преобразование 401, модуль 402 вычисления параметров, табличный поиск 403, модуль 404 применения программных масок и обратное преобразование 405. Табличный поиск 403 работает с базой 406 данных, которая сохраняет таблицу поиска SLF, обученную для обнаружения панорамированных источников, как описано в отношении фиг. 2. Для этого примерного варианта применения, предполагается, что либо целевой источник, который должен извлекаться, имеет известный параметр панорамирования, либо обнаружение такого параметра выполняется с использованием любого числа технологий, известных специалистам в данной области техники. Одна примерная технология для обнаружения параметра панорамирования, заключается в выделения пиков из взвешенной по уровню гистограммы для значений тета.
[0066] Обращаясь к фиг. 4, преобразование 401 применяется к двухканальному входному сигналу (например, к сигналу стереомикширования). В варианте осуществления, система 400 использует параметры STFT, включающие в себя тип функции кодирования со взвешиванием и размер перескоков, которые, как известно, являются относительно оптимальными для задач разделения источников для специалистов в данной области техники. Тем не менее, могут использоваться другие параметры STFT. Из представления STFT модуль 402 вычисления параметров вычисляет значения для параметров (Θ,φ,U) для каждой октавной подполосы b частот. Эти значения используются табличным поиском 403 для выполнения табличного поиска для таблицы поиска SLF, сохраненной в базе 406 данных. Табличный поиск формирует SNR в процентилях (например, 25-ый процентиль) для каждого мозаичного элемента STFT или элемента разрешения. Из SNR, система 400 вычисляет долю ввода STFT, которая должна выводиться в качестве байесовской оценки. Например, если оцененное SNR в процентилях равно 0 дБ, доля передаваемого ввода должна составлять 0,5 или 50%, поскольку целевой источник и фон оценочно должны иметь идентичный уровень U. Общая формула придерживается предположения касательно фильтра Винера и является следующей: доля ввода=10hathathat(SNR/20)/(10hathathat(SNR/20)+1). Затем, модуль 404 применения программных масок умножает входное STFT для каждого канала на это дробное значение между 0 и 1 для каждого мозаичного элемента STFT. Обратное преобразование 405 затем инвертирует представление STFT для получения двухканального сигнала временной области, представляющего оцененный целевой источник.
[0067] Хотя вышеприведенные примерные варианты осуществления используют частотно-временные представления STFT (например, мозаичные элементы), может использоваться любое подходящее частотно-временное представление.
[0068] Хотя примерный вариант применения для разделения источников, описанный выше, использует таблицу поиска SLF, другие варианты осуществления могут использовать функцию SLF вместо таблицы поиска.
Примерные процессы
[0069] Фиг. 5 является блок-схемой процесса 500 формирования таблицы поиска SLF, обученной для извлечения панорамированных источников в соответствии с вариантом осуществления. Процесс 500 может быть реализован, например, посредством архитектуры 700 устройства, описанной в отношении фиг. 7.
[0070] Процесс 500 начинается посредством получения представлений в частотной области выборок из уровневых и пространственных распределений целевых источников в подполосах частот (501), получения представлений в частотной области выборок из уровневых и пространственных распределений фонов (502) и суммирования первого и второго наборов выборок для создания комбинированного набора выборок (503), как описано в отношении фиг. 2.
[0071] Процесс 500 продолжается посредством обнаружения уровневых и пространственных параметров для каждой выборки в комбинированном наборе выборок для каждой подполосы частот (504), и в каждой подполосе частот, взвешивания обнаруженных уровневых и пространственных параметров посредством их соответствующих уровневых и пространственных распределений для целевого источника и фона(ов) (505), как описано в отношении фиг. 2.
[0072] Процесс 500 продолжается посредством сохранения, для каждой выборки в комбинированном наборе выборок, взвешенных уровневых и пространственных параметров и SNR с подполосами частот в таблице (506), как описано в отношении фиг. 2 и 3.
[0073] Процесс 500 продолжается посредством переиндексации сохраненных параметров и SNR таким образом, что таблица включает в себя целевое SNR в процентилях взвешенных уровневых и пространственных параметров и подполосы частот, и таким образом, что для данного ввода квантованных обнаруженных пространственных и уровневых параметров и подполосы частот, оцененное SNR, ассоциированное с квантованными обнаруженными пространственными и уровневыми параметрами и подполосами частот, получается из таблицы (507), как описано в отношении фиг. 2 и 3. Таблица поиска SLF затем сохраняется в базе данных для использования в варианте применения для разделения источников, к примеру, как описано в отношении фиг. 4 и 6.
[0074] Фиг. 6 является блок-схемой последовательности операций способа для процесса 600 обнаружения и извлечения пространственно идентифицируемых подполосных аудиоисточников из двухканальных микширований с использованием SLF, обученного для обнаружения панорамированных источников, в соответствии с вариантом осуществления. Процесс 600 может быть реализован, например, посредством архитектуры 700 устройства, описанной в отношении фиг. 7.
[0075] Процесс 600 может начинаться посредством преобразования двухканального аудиосигнала временной области в представление в частотной области, включающее в себя частотно-временные мозаичные элементы, имеющие множество частотных элементов разрешения, сгруппированных в подполосы частот (601). Например, STFT может использоваться для создания представления STFT каждого канала двухканального аудиосигнала временной области.
[0076] Процесс 600 продолжается посредством вычисления пространственных и уровневых параметров для каждого частотного элемента разрешения (602). Например, параметры (Θ,φ,U) могут вычисляться с использованием уравнений [7]-[9].
[0077] Процесс 600 продолжается посредством формирования, для каждого мозаичного элемента, SNR в процентилях для каждого частотного элемента разрешения в мозаичном элементе (603), формирования дробного значения для частотного элемента разрешения на основе SNR для частотного элемента разрешения (604) и применения дробных значений к их соответствующим частотным элементам разрешения в мозаичном элементе для формирования модифицированного мозаичного элемента оцененного аудиоисточника (605), как описано в отношении фиг. 4. Таблица поиска/функция SLF обучается для обнаружения панорамированных источников, как описано в отношении фиг. 2 и 5. Дробные значения, описанные выше, также называются данном документе «значениями программной маски» и составляют действительные числа между 0 и 1 включительно и представляют долю соответствующего входного STFT, которая передается в вывод. Результат применения таблицы/функции SLF представляет собой представление размера STFT, состоящее из значений между 0 и 1. В варианте осуществления, значения программной маски и/или значения SNR сглаживаются по времени и частоте с использованием технологий, знакомых специалистам в данной области техники.
[0078] Процесс 600 продолжается посредством выполняемого при необходимости обратного преобразования частотно-временного мозаичного элемента оцененного целевого аудиоисточника в двухканальную оценку во временной области целевого аудиоисточника (606), как описано в отношении фиг. 4. Следует отметить, что некоторые варианты осуществления могут использовать частотно-временной мозаичный элемент оцененного аудиоисточника в частотной области, и другие варианты осуществления могут использовать двухканальную оценку во временной области оцененного аудиоисточника.
Примерная архитектура устройства
[0079] Фиг. 7 является блок-схемой архитектуры 700 устройства для реализации систем и процессов, описанных в отношении фиг. 1-6, согласно варианту осуществления
Архитектура 700 устройства может использоваться в любом компьютере или электронном устройстве, которое допускает выполнение математических вычислений, описанных выше.
[0080] В показанном примере, архитектура 700 устройства включает в себя один или более процессоров 701 (например, CPU, микросхемы DSP, ASIC), одно или более устройств 702 ввода (например, клавиатуру, мышь, сенсорную поверхность), одно или более устройств вывода (например, светодиодный/ЖК дисплей), запоминающее устройство 704 (например, RAM, ROM, флэш-память) и аудиоподсистему 706 (например, мультимедийный проигрыватель, звукоусилитель и вспомогательную схему), соединенную с громкоговорителем 706. Каждый из этих компонентов соединен с одной или более шин 707 (например, системной, подачи мощности, периферийной и т.д.). В варианте осуществления, признаки и процессы, описанные в данном документе, могут быть реализованы в виде программных инструкций, сохраненных в запоминающем устройстве 704 или на любом другом машиночитаемом носителе и выполняемые одним или более процессорами 701. Также возможны другие архитектуры с большим или меньшим числом компонентов, например архитектуры, которые используют сочетание программного обеспечения и аппаратных средств для реализации признаков и процессов, описанных здесь.
[0081] Хотя этот документ содержит множество конкретных подробностей реализации, их не следует рассматривать как ограничения объема того, что может быть заявлено, а следует рассматривать в качестве описания признаков, которые могут относиться к конкретным вариантам осуществления. Определенные признаки, которые описаны в данном описании в контексте отдельных вариантов осуществления, также могут быть реализованы в сочетании в одном варианте осуществления. Напротив, различные признаки, которые описаны в контексте одного варианта осуществления, также могут быть реализованы во множестве вариантов осуществления по отдельности либо в любом подходящем подсочетании. Кроме того, хотя признаки могут быть описаны выше как действующие в определенных сочетаниях и даже могут быть первоначально заявлены в таком виде, один или более признаков из заявленного сочетания в некоторых случаях могут быть исключены из сочетания, и заявленное сочетание может относиться к подсочетанию или к вариации подсочетания. Логические последовательности операций, проиллюстрированные на чертежах, не требуют конкретного показанного порядка или последовательного порядка для достижения желаемых результатов. Кроме того, могут быть предусмотрены другие этапы, или этапы могут быть исключены из описанных последовательностей операций, и другие компоненты могут быть добавлены в описанные системы или удалены из них. Соответственно, другие варианты реализации входят в объем прилагаемой формулы изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| ПРОСТРАНСТВЕННЫЙ АУДИО ПРОЦЕССОР И СПОСОБ ОБЕСПЕЧЕНИЯ ПРОСТРАНСТВЕННЫХ ПАРАМЕТРОВ НА ОСНОВЕ АКУСТИЧЕСКОГО ВХОДНОГО СИГНАЛА | 2011 |
|
RU2596592C2 |
| ТРАНСКОДИРОВЩИК АУДИО ФОРМАТА | 2010 |
|
RU2519295C2 |
| СПОСОБ И УСТРОЙСТВО УЛУЧШЕНИЯ РЕЧЕВОГО СИГНАЛА С ИСПОЛЬЗОВАНИЕМ БЫСТРОЙ СВЕРТКИ ФУРЬЕ | 2022 |
|
RU2795573C1 |
| АППАРАТ И СПОСОБ УЛУЧШЕНИЯ АУДИОСИГНАЛА, СИСТЕМА УЛУЧШЕНИЯ ЗВУКА | 2015 |
|
RU2666316C2 |
| ИНТЕГРАЛЬНОЕ ПАРАМЕТРИЧЕСКОЕ АУДИОКОДИРОВАНИЕ ДЛЯ КАЖДОЙ ПОЛОСЫ ЧАСТОТ | 2022 |
|
RU2834366C2 |
| СПОСОБ ПЕЛЕНГАЦИИ РАДИОСИГНАЛОВ И ПЕЛЕНГАТОР ДЛЯ ЕГО ОСУЩЕСТВЛЕНИЯ | 2009 |
|
RU2419805C1 |
| ПРОЦЕССОР ДЛЯ ФОРМИРОВАНИЯ СПЕКТРА ПРОГНОЗИРОВАНИЯ НА ОСНОВЕ ДОЛГОСРОЧНОГО ПРОГНОЗИРОВАНИЯ И/ИЛИ ГАРМОНИЧЕСКОЙ ПОСТФИЛЬТРАЦИИ | 2022 |
|
RU2826967C2 |
| УСТРАНЕНИЕ ПОЗИЦИОННОЙ НЕОДНОЗНАЧНОСТИ ПРИ ФОРМИРОВАНИИ ПРОСТРАНСТВЕННОГО ЗВУКА | 2009 |
|
RU2529591C2 |
| Аудиоустройство и способ для него | 2020 |
|
RU2804014C2 |
| УСТРОЙСТВО ДЛЯ ФОРМИРОВАНИЯ ВЫХОДНОГО ПРОСТРАНСТВЕННОГО МНОГОКАНАЛЬНОГО АУДИО СИГНАЛА | 2009 |
|
RU2537044C2 |
Изобретение относится к области вычислительной техники для обработки аудиоданных. Технический результат заключается в обеспечении возможности обнаружения и извлечения отдельных аудиоисточников из двухканальных микширований. Технический результат достигается за счет того, что в каждой подполосе частот из множества подполос частот взвешивают обнаруженные уровневые и пространственные параметры посредством их соответствующих уровневых и пространственных распределений для целевого источника и фонов; сохраняют, с использованием одного или более процессоров, взвешенные уровневые, пространственные параметры и отношение сигнала к шуму (SNR) во множестве подполос частот для каждой выборки в комбинированном наборе выборок в таблице; и повторно индексируют, с использованием одного или более процессоров, таблицу посредством взвешенных уровневых параметров, пространственных параметров и подполосы частот таким образом, что таблица включает в себя целевое SNR в процентилях взвешенных уровневых и пространственных параметров и подполосы частот, и таким образом, что для данного ввода квантованных обнаруженных пространственных и уровневых параметров и подполосы частот из таблицы получается оцененное SNR, ассоциированное с квантованными обнаруженными пространственными и уровневыми параметрами и подполосой частот. 4 н. и 9 з.п. ф-лы, 7 ил.
1. Способ обработки аудиосигнала, содержащий этапы, на которых:
получают, с использованием одного или более процессоров, представление в частотной области первого набора выборок из множества уровневых и пространственных распределений целевых источников во множестве подполос частот;
получают, с использованием одного или более процессоров, представление в частотной области второго набора выборок из множества уровневых и пространственных распределений фонов во множестве подполос частот;
суммируют, с использованием одного или более процессоров, первый и второй наборы выборок для создания комбинированного набора выборок;
обнаруживают, с использованием одного или более процессоров, уровневые и пространственные параметры для каждой выборки в комбинированном наборе выборок для каждой подполосы частот во множестве подполос частот;
в каждой подполосе частот из множества подполос частот взвешивают обнаруженные уровневые и пространственные параметры посредством их соответствующих уровневых и пространственных распределений для целевого источника и фонов;
сохраняют, с использованием одного или более процессоров, взвешенные уровневые, пространственные параметры и отношение сигнала к шуму (SNR) во множестве подполос частот для каждой выборки в комбинированном наборе выборок в таблице; и
повторно индексируют, с использованием одного или более процессоров, таблицу посредством взвешенных уровневых параметров, пространственных параметров и подполосы частот таким образом, что таблица включает в себя целевое SNR в процентилях взвешенных уровневых и пространственных параметров и подполосы частот, и таким образом, что для данного ввода квантованных обнаруженных пространственных и уровневых параметров и подполосы частот из таблицы получается оцененное SNR, ассоциированное с квантованными обнаруженными пространственными и уровневыми параметрами и подполосой частот.
2. Способ по п. 1, дополнительно содержащий этап, на котором:
сглаживают данные, которые индексируются для одного или более обнаруженных уровневых, одного или более пространственных параметров или подполосы частот.
3. Способ по любому из предшествующих пп. 1 или 2, в котором представление в частотной области представляет собой представление в области кратковременного преобразования Фурье (STFT).
4. Способ по любому из предшествующих пп. 1-3, в котором пространственные параметры включают в себя панорамирование и разность фаз между двумя каналами сведенного аудиосигнала.
5. Способ по любому из предшествующих пп. 1-4, в котором целевой источник амплитудно панорамируется с использованием закона постоянной мощности.
6. Способ по любому из предшествующих пп. 1-5, в котором целевое SNR в процентилях составляет 25-й процентиль.
7. Способ обработки аудиосигнала, содержащий этапы, на которых:
преобразуют, с использованием одного или более
процессоров, один или более кадров двухканального аудиосигнала временной области в представление в частотно-временной области, включающее в себя множество частотно-временных мозаичных элементов, при этом частотная область представления в частотно-временной области, включает в себя множество частотных элементов разрешения, сгруппированных во множество подполос частот;
для каждого частотно-временного мозаичного элемента:
вычисляют, с использованием одного или более процессоров, пространственные параметры и уровень для частотно-временного мозаичного элемента;
формируют, с использованием одного или более процессоров, отношение сигнала к шуму (SNR) в процентилях для каждого частотного элемента разрешения в частотно-временном мозаичном элементе;
формируют, с использованием одного или более процессоров, дробное значение для элемента разрешения на основе SNR для элемента разрешения; и
применяют, с использованием одного или более процессоров, дробные значения для элементов разрешения в частотно-временном мозаичном элементе для формирования модифицированного частотновременного мозаичного элемента оцененного аудиоисточника.
8. Способ по п. 7, дополнительно содержащий этап, на котором:
преобразуют, с использованием одного или более процессоров, модифицированный частотно-временной мозаичный элемент во множество сигналов аудиоисточников временной области.
9. Способ по п. 7 или 8, в котором дробные значения получаются из таблицы поиска или функции для системы пространственно-уровневой фильтрации (SLF), обученной для панорамированного целевого источника.
10. Способ по любому из предшествующих пп. 7-9, в котором преобразование одного или более кадров двухканального аудиосигнала временной области в сигнал частотной области содержит этап, на котором применяют короткое частотно-временное преобразование (STFT) к двухканальному аудиосигналу временной области.
11. Способ по любому из предшествующих пп. 7-10, в котором несколько частотных элементов разрешения группируются в октавные подполосы частот или приблизительно октавные подполосы частот.
12. Устройство обработки аудиосигнала, содержащее:
один или более процессоров;
запоминающее устройство, сохраняющее инструкции, которые при выполнении одним или более процессорами предписывают одному или более процессорам осуществлять любой из предшествующих способов по пп. 1-11.
13. Постоянный машиночитаемый носитель хранения данных, на котором сохранены инструкции, которые при выполнении одним или более процессорами предписывают одному или более процессорам осуществлять любой из предшествующих способов по пп. 1-11.
| US 20200075030 A1, 05.03.2020 | |||
| US 20190098399 A1, 28.03.2019 | |||
| ПРОСТРАНСТВЕННЫЙ АУДИО ПРОЦЕССОР И СПОСОБ ОБЕСПЕЧЕНИЯ ПРОСТРАНСТВЕННЫХ ПАРАМЕТРОВ НА ОСНОВЕ АКУСТИЧЕСКОГО ВХОДНОГО СИГНАЛА | 2011 |
|
RU2596592C2 |
| ИЗВЛЕЧЕНИЕ РЕВЕРБЕРИРУЮЩЕГО ЗВУКА С ИСПОЛЬЗОВАНИЕМ МИКРОФОННЫХ МАССИВОВ | 2014 |
|
RU2640742C1 |
| УСТРОЙСТВО ОБРАБОТКИ СИГНАЛОВ ДЛЯ УСИЛЕНИЯ РЕЧЕВОГО КОМПОНЕНТА В МНОГОКАНАЛЬНОМ ЗВУКОВОМ СИГНАЛЕ | 2014 |
|
RU2673390C1 |
