Изобретение относится к области обработки цифровых данных с помощью электронных устройств, а именно к способам временной синхронизации работы вычислительной системы, предназначенных для массивно-параллельных вычислительных систем с распределенной памятью (Massive Parallel Processing (МРР)) и может быть использовано для сокращения времени обработки цифровых данных вычислительными системами МРР.
Известен способ построения программы, заключающийся в определении в исходном коде программы на ассемблере помеченные циклы и классифицируют их на несколько предопределенных типов, выравнивают адреса начала помеченных циклов, если это требуется для цикла данного типа путем добавления ассемблерных инструкций и, сохраняя исходный код на ассемблере в памяти, строят путем компиляции и компоновки модифицированный ассемблерный код для устройства назначения [1].
Известен способ создания параллельной программы с временной параметризацией многопроцессорных вычислительных систем с одинаковым доступом к памяти, заключающийся в том, что для реализации способа устройство управления, блок выборки инструкций и арифметико-логическое устройство выполняют следующие операции: получает упорядоченный выбор лексем исходной последовательной программы и формирует для лексемы ее дескриптора; получает упорядоченный выбор дескрипторов лексем из сформированного на предшествующем этапе множества дескрипторов; формирует новые структуры спецификации программы с детализацией до операций/функций; формирует новые структуры спецификации программы с детализацией до фрагментов; проверяет эквивалентности текстовой спецификации программы задачи и ее представления новыми структурами спецификации; рассчитывает для операторов новой спецификации значения приоритетов; формирует множества операторов-претендентов на начало выполнения в момент времени; назначает операторы для реализации на свободный процессор; разрабатывает текстовые спецификации нитей параллельной программы с временной параметризацией; оценивает корректность результатов разработки параллельных программ с временной параметризацией; компилирует созданный параллельный код с временной параметризацией [2].
Недостатком данных способов является отсутствие учета конкретной архитектуры массивно-параллельных вычислительных систем с распределенной памятью и отсутствие учета параметра времени.
Одним из возможных путей повышения эффективности обработки информации является организация распределения данных программы между вычислительными узлами. Однако при распределении данных программы между вычислительными узлами возникают проблемы синхронизации вычислительных узлов, что приводит к снижению эффективности цифровой обработки информации, что необходимо учитывать при выборе моментов времени начала выполнения фрагментов/операторов при параллельном выполнении исходной программы.
Цель изобретения - повысить эффективность цифровой обработки информации (снижение времени решения задачи) за счет временной синхронизации работы массивно-параллельной вычислительной системы с распределенной памятью.
Указанная цель достигается способом временной синхронизации работы массивно-параллельной вычислительной системы с распределенной памятью, заключающимся в выполнении следующих процедур:
1. Упорядоченный выбор лексем исходной последовательной программы, определение их принадлежности к тому или иному классу лексем языка программирования высокого уровня, проверке принадлежности лексемы сформированному (к рассматриваемому моменту времени) множеству лексем, включении лексемы в формируемое множество лексем соответствующего типа (в случае ее отсутствия в составе множества), формировании для лексемы ее дескриптора, задающего числовое кодирование необходимых атрибутов.
2. Упорядоченный выбор дескрипторов лексем из сформированного на предшествующем этапе множества дескрипторов, определении соответствующей рассматриваемому дескриптору конструкции языка программирования высокого уровня, формировании для этой конструкции постфиксной спецификации на основе метода формирования обратной польской записи в соответствии с алгоритмом Дейкстры на основе применения «механизма стека» с приоритетами, позволяющего изменить порядок следования символов операндов и операций.
3. Формирование новых структур спецификации программы, описывающих исходную программу с детализацией до операций/функций:
- выделение из множества элементов постфиксной спецификации программы подмножества операторов операций/функций программы;
- сквозную нумерацию операторов;
- сквозную нумерацию входов для каждого оператора и выходов;
- ввод числового кодирования типов операторов на основе постфиксного представления каждой операции/функции;
- формирование для каждого оператора сформированной числовой спецификации множества номеров его операндов и задание его мощности;
- формирование для каждого оператора множества его внешних операторов (использующих результаты выполнения оператора) и задание его мощности;
- формирование, исходя из постфиксного представления операций/функций, для каждого оператора соответствующих меток.
4. Формирование новых структур спецификации программы, описывающих исходную программу с детализацией до фрагментов:
- выделение из множества операторов основной структуры подмножеств операторов, имеющих одинаковое значение номера фрагмента:
- определение для каждого подмножества номеров и типов входных и выходных операторов, фиксация их управляющих связей и соответствующих меток передач управления;
- формирование в числовом формате основной, связной и временной структуры, специфицирующих типы и схему управляющих связей фрагментов.
Результатами являются следующие сформированные новые структуры спецификации программы на этом уровне:
- основная структура фрагментов: номер фрагмента; метки фрагментов; типы фрагментов; указатели на номер фрагмента; мощность сопряженного множества для фрагмента; указатель на начало последовательности номеров фрагментов, образующих внешнее множество фрагмента; мощность внешнего множества для фрагмента; метки фрагментов безусловного перехода и условного перехода по значению «истина»; метки фрагментов условного перехода по значению «ложь» программы.
- связная структура фрагментов: номер строк структуры связей; указатель на продолжение последовательности номеров фрагментов, образующих сопряженное множество фрагмента для рассматриваемого фрагмента; сопряженное множество фрагмента для рассматриваемого фрагмента; указатель на продолжение последовательности номеров фрагмента, образующих внешнее множество фрагмента для рассматриваемого фрагмента; внешнее множество фрагмента.
- временная структура фрагментов: количество вершин; номер вершины графа; момент времени, в который начинается выполнение инструкции параллельного алгоритма, интерпретируемой вершиной, соответствующей временной параллельной схемой.
5. Оценка корректности сформированных новых структур спецификаций исходной программы с целью проверки эквивалентности текстовой спецификации программы задачи и ее представления новыми структурами спецификации, т.е. оценка равенства количеств сопряженных и внешних связей в основной и связной структурах новой спецификации, оценка соответствия количеств операторов различных типов в основной и связной структурах и исходной программе, оценка соответствия количества входов, выходов и величин их разрядности в основной и связной структурах и в исходной программе, оценка корректности семантики входов и выходов операторов основной и связной структур по сравнению с семантикой (единицами измерения) операндов и результатов выполнения инструкций/функций программы, оценка эквивалентности схем управления, задаваемых основной и связной структурами и текстом программы.
6. Расширение множества операторов и множества связей операторов основной и связной структур новой спецификации исходной программы за счет введения дополнительных переменных, представляющих результаты промежуточных вычислений правых частей операторов присваивания, и соответствующих этим переменным операторов записи данных в память, что обеспечивает переход к конструктивным основному и связному структурам новой спецификации, отображающим полный состав и связи операторов, подлежащих выполнению при решении задачи.
7. Реализация цикла по временным ярусам новой спецификации задачи с целью формирования для задачи множества фрагментов (начало фрагментации).
8. Формирование для множества операторов каждого яруса множества операторов ранжированных по убыванию мощностей их сопряженных множеств операторов.
9. Формирование первого фрагмента включает:
- текущее значение количества фрагментов;
- в первый фрагмент входит множество операторов, имеющих максимальную мощность сопряженного множества;
- сложность каждого фрагмента равна сумме мощностей сопряженного и внешнего множеств операторов, входящих в фрагмент.
10. Формирование для текущего оператора принадлежащему определенному временному ярусу множества пересечений сопряженных множеств и проверку равенства сопряженного множества пустому множеству с целью проверки факта использования текущими и выходными операторами общих исходных данных.
11. Проверка достижения текущего количества фрагментов заданному и включение текущих операторов в состав следующего фрагмента.
12. Расчет сложности фрагментации для текущего фрагмента путем сложения сложности фрагментации фрагмента, рассчитанной на предыдущих этапах и мощности сопряженного и внешнего множеств операторов, включенных в фрагмент.
13. Проверка окончания рассмотрения всех операторов временных ярусов.
14. Формирование для операторов временных ярусов множеств пересечений его сопряженного множества и подмножеств операторов каждого из фрагмента текущего множества сформированных фрагментов.
15. Определение номера фрагмента, имеющего максимальное значение пересечений, включение оператора временного яруса в состав фрагмента и проведение расчета сложности фрагментации (согласно шага 12) для текущего фрагмента.
16. Оценка мощностей множеств операторов, включенных в каждый из фрагментов с целью обеспечения равномерности количества операторов во фрагментах и равномерности загрузки ресурса.
17. Определение номер фрагмента, имеющего минимальное значение мощностей множеств оператора и включение оператора временного яруса в состав фрагмента и проведение расчета сложности фрагментации (согласно шага 12) для текущего фрагмента.
18. Расчет общей сложности фрагментации задачи, окончание фрагментации.
19. Кластеризация фрагментов в интересах минимизации суммарного времени обмена сообщениями.
20. Оценка текущего состояния ресурса процессоров и коммуникационной сети, заключающейся в определении состава свободного в текущий момент времени ресурса (с учетом возможности выполнения ранее начатых задач):
- количества и множества номеров свободных в текущий момент времени процессоров, имеющих признак занятости;
- количества и множества номеров свободных линий связи, имеющих признак занятости.
21. Установление взаимно однозначного соответствия между кластерами фрагментов и подмножеством свободных в текущий момент времени процессоров вычислительных узлов, сопоставляющее каждому кластеру фрагментов выделенный процессор и обеспечивающее минимизацию суммарной длины межпроцессорных связей.
22. Оценка конкретного типа процессоров (суперскалярные и со сверхдлинной командной строкой).
23. Формирование множество фрагментов для суперскалярных процессоров и процессоров со сверхдлинной командной строкой.
24. Оценка конкретной топологии (полносвязная, кольцо, гиперкуб, общая шина, решетка-тор и т.д.) коммуникационной сети вычислительной системы.
25. Оценка максимальных временных затрат на обмен сообщениями, т.е. на выполнение параллельного процесса с временной параметризацией в вычислительной системе, которые определяются величиной затрат процессорного времени и межпроцессорным обменом сообщениями:
- цикл по номерам фрагментов, фрагментных основной и связной структур новой спецификации;
- определение номера процессора, реализующего фрагмент;
- выделение для фрагмента его внешнего фрагментного множества и множества номеров внешних для процессора с номером процессоров, реализующих множество фрагментов;
- выделение из основной и связной структур новой спецификации топологии вычислительной системы внешнего множества номеров процессоров для основного процессора с соответствующим номером;
- формирование разности внешних множеств номеров процессоров, если она больше или равна пустому множеству, то это соответствует корректному закреплению основного и его внешних фрагментов за необходимым ресурсом топологии и время на реализацию обмена определяется как сумма общих затрат времени на обмен сообщениями при решении задачи и произведения времени передачи служебных данных на множество номеров внешних процессоров, реализующих внешнее фрагментное множество, при рассмотрении всех фрагментов задачи - завершение оценки временных коммуникационных затрат, в другом случае переход к выполнению цикла для очередного фрагмента;
- формирование разности внешних множеств номеров процессоров, если она меньше пустого множества, то это соответствует недостаточности для основного процессора с соответствующим номером требуемого количества смежных процессоров для выполнения всех фрагментов множества и необходимости выбора дополнительных процессоров из имеющегося ресурса для реализации оставшихся нераспределенных фрагментов множества внешних фрагментов для фрагментов (с обеспечением возможности минимального увеличения дополнительных временных затрат на обмен при реализации фрагмента):
- цикл по номерам процессоров, образующих внешнее множество процессоров для соответствующего основного процессора;
- выделение из основной и связной структур новой спецификации топологии вычислительной системы внешнего множества номеров процессоров для процессора с соответствующим номером;
- цикл по элементам внешнего множества процессора с соответствующим номером;
- проверка условия занятости процессора с соответствующим номером;
- при условии занятости процессора переход к следующему элементу внешнего множества процессора, в другом случае - назначение текущего незакрепленного фрагмента на процессор с его переводом в состояние занят;
- формирование текущего значения временных затрат на реализацию обмена определяется как как сумма общих затрат времени на обмен сообщениями при решении задачи и произведения времени передачи служебных данных на сумму сложностей обмена данными между фрагментами и их текущими внешними фрагментами;
- формирование параллельных фрагментов с временной параметризацией процесса решения задачи вычислительной системой с определением реальных временных затрат на параллельное выполнение задачи определяются возможностями совмещения выполнения во времени различных процессорных операций и операций обмена сообщениями и учитывают: количества вычислительных узлов и процессоров; значения длительностей выполнения различных типов операций, в т.ч. операций обращения к индивидуальной памяти процессора; количества портов приема/передачи данных произвольного процессора; топологии вычислительной системы; методы параллельной обработки данных;
- оценка показателей эффективности сформированных фрагментов с временной параметризацией процесса решения задачи вычислительной системой: последовательное и параллельное время решения задачи, прирост во времени, показатель эффективности распараллеливания, коэффициент загрузки оборудования.
26. Разработка текстовых спецификаций нитей параллельной программы с временной параметризацией включает разработку следующих объектов:
- текстовых спецификаций временных нитей параллельной программы со встроенными средствами (операторами sleep) временной синхронизации параллельных процессов вычислительных узлов;
- текстовых спецификаций временных нитей параллельной программы со встроенными средствами (операторами send, receive), учитывающими время передачи/приема данных в буферы передающей и принимающей сторон, времени приема пересылаемых данных в память;
- структур временной спецификации параллельной программы в виде индивидуальных текстов нитей программ процессоров вычислительной системы со встроенными средствами (операторами sleep, send, receive);
- оценок суммарного количества обращений к каждому данному, необходимое для выполнения исходной программы.
Исходные данные этапа разработки текстовых спецификаций временных нитей параллельной программы: новые структуры (основная, связная, временная) параллельного процесса с временной параметризацией, удовлетворяющей заданным требованиям (время реализации параллельной программы на заданном ресурсе, коэффициент загрузки процессоров от топологии вычислительной системы, типа и числа процессоров); закрепление операторов за нитями или процессорами; характеристики архитектуры вычислительной системы: тип топологии вычислительной системы, количество вычислительных узлов, количество и тип процессоров, значения длительностей выполнения различных типов операций и операций обращения к индивидуальной памяти процессора, количество портов одновременного параллельного ввода-вывода, методы параллельной обработки данных.
Основные этапы разработки текстовых спецификаций временных нитей программ параллельной программы включают:
- цикл по номерам операторов основной структуры;
- определение номера процессора, реализующего оператор;
- формирование текстовой спецификации оператора/операции, включающее:
1) определение с помощью основной структуры типа процессорной команды;
2) выборка из связной структуры имен сопряженных операторов и запись текстовой спецификации оператора;
3) выборка из связной структуры имен сопряженных операторов, замена имен операторов на их действительные адреса и запись текстовой спецификации оператора;
4) временная параметризация операторов процессорных нитей программ;
5) представление текстовых спецификаций нитей программ с временной параметризацией каждого из процессоров вычислительного узла для программ в виде совокупности строк следующего вида: номера команд нитей программ процессоров; признак класса операции; имя операции; адреса первого и второго операндов; имена фрагментов; значение текущего дискретного времени, соответствующего началу реализации операторов задачи, содержащего конкретное данное, используемое при выполнении операции.
27. Оценка корректности результатов разработки параллельных программ с временной параметризацией, т.е. оценка корректности типов данных, типов операций/функций над данными, связей операций по данным и по управлению, корректность единиц измерения физических величин, корректность моментов начала и длительности вычислительных операций/функций и операторов передач управления и синхронизации временных параллельных процессов.
28. Компилирование созданного параллельного кода с временной параметризацией.
Таким образом, для повышения эффективности цифровой обработки информации (снижения времени решения задачи) следует разработать временные нити программы с учетом требования оптимизации равномерности загрузки вычислительных узлов в процессе параллельного решения задачи, тем самым, обеспечить необходимую временную синхронизацию работы вычислительных узлов.
Новыми признаками, обладающими существенными отличиями, являются:
1. Учет архитектуры массивно-параллельных вычислительных систем с распределенной памятью.
2. Учет вариантов фрагментации задач.
3. Учет параметра времени начала выполнения фрагментов/операторов параллельного алгоритма.
Данные признаки обладают существенными отличиями, так как в известных способах не обнаружены.
Применение новых признаков, в совокупности с известными позволит повысить эффективность цифровой обработки информации за счет оптимизации равномерности загрузки вычислительных узлов в процессе параллельного решения задачи.
Способ временной синхронизации работы массивно-параллельной вычислительной системы с распределенной памятью реализуется следующим образом.
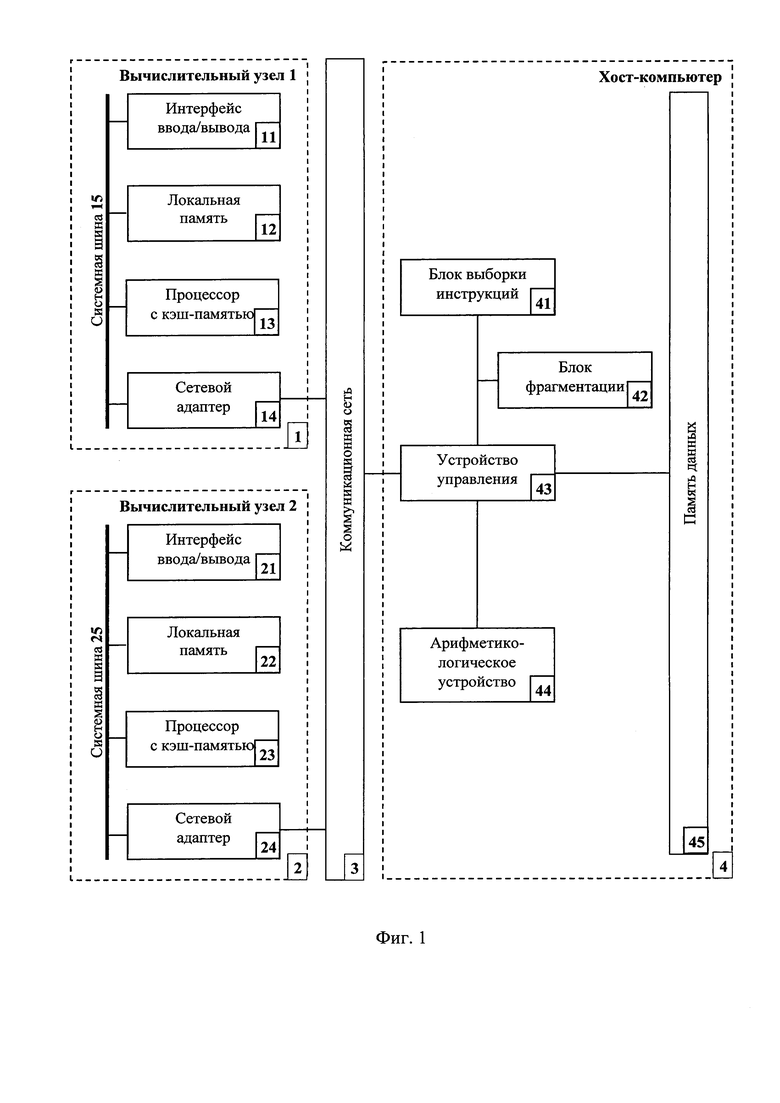
На фиг. 1 показана схема основных компонентов массивно-параллельной вычислительной системы с распределенной памятью, состоящей из коммуникационной сети 3, вычислительных узлов 1, 2, которые включают интерфейсы ввода/вывода 11, 21, локальные памяти 12, 22, процессоры с кэш-памятью 13, 23, сетевые адаптеры 14, 24, системные шины 15, 25, и хост-компьютера 4, который включает блок выборки инструкции 41, блок фрагментации 42, устройство управления 43, арифметико-логическое устройство 44, память данных 45. Вычислительная система содержит два вычислительных узла 1, 2 и хост-компьютер 4, выполненные с возможностью оптимизации фрагментации задач и оптимизации обмена сообщений между вычислительными узлами 1, 2, предназначенными для создания параллельного кода с временной параметризацией посредством коммуникационной сети 3.
Рассмотрим пошаговое выполнение предложенного способа временной синхронизации работы массивно-параллельной вычислительной системы с распределенной памятью в описанной выше системе (Фиг. 1). В память данных 45 загружается последовательный код программы. Из памяти данных 45 устройство управления 43 получает упорядоченный выбор лексем исходной последовательной программы, формирует дескрипторы лексем (шаг 1). Блок выборки инструкций 41 получает упорядоченный выбор дескрипторов лексем, формирует для этой конструкции постфиксную спецификацию (шаг 2). Формирует новые структуры спецификации программы с детализацией до операций/функций (шаг 3). Формирует новые структуры спецификации программы с детализацией до фрагментов (шаг 4). Устройство управления 43 проверяет эквивалентность текстовой спецификации программы задачи и ее представления новыми структурами спецификации (шаг 5). Расширяет множества операторов и множества связной структур новой спецификации исходной программы (шаг 6). Блок фрагментации 42 реализует цикл по временным ярусам новой спецификации задачи (шаг 7). Формирует для множества операторов каждого яруса множества операторов ранжированных по убыванию мощностей их сопряженных множеств операторов (шаг 8). Формирует первый фрагмент (шаг 9). Формирует для текущего оператора принадлежащему определенному временному ярусу множества пересечений сопряженных множеств и проверяет равенства сопряженного множества пустому множеству (шаг 10). Проверяет достижения текущего количества фрагментов заданному и включает текущие операторы в состав следующего фрагмента (шаг 11). Арифметико-логическое устройство 44 рассчитывает сложность фрагментации для текущего фрагмента (шаг 12). Устройство управления 43 проверяет окончание рассмотрения всех операторов временных ярусов (шаг 13). Формирует для операторов временных ярусов множеств пересечений его сопряженного множества и подмножеств операторов каждого из фрагмента текущего множества сформированных фрагментов (шаг 14). Блок фрагментации 42 определяет номер фрагмента, имеющего максимальное значение пересечений, включает оператор временного яруса в состав фрагмента и арифметико-логическое устройство 44 рассчитывает сложность фрагментации для текущего фрагмента (шаг 15). Устройство управления 43 оценивает мощность множеств операторов, включенных в каждый из фрагментов (шаг 16). Блок фрагментации 42 определяет номер фрагмента, имеющего минимальное значение мощностей множеств оператора, включает оператор временного яруса в состав фрагмента и арифметико-логическое устройство 44 рассчитывает сложность фрагментации для текущего фрагмента (шаг 17). Рассчитывает общую сложность фрагментации задачи (шаг 18). Устройство управления 43 кластеризует фрагменты (шаг 19). Оценивает текущее состояния ресурса процессоров с кэш-памятью 13 и коммуникационной сети 3 (шаг 20). Устанавливает взаимно однозначного соответствия между кластерами фрагментов и подмножеством свободных в текущий момент времени процессоров с кэшпамятью 13, 23 вычислительных узлов 1, 2 (шаг 21). Устройство управления 6 оценивает конкретный тип процессоров с кэш-памятью 13, 23 (шаг 22). Формирует множество фрагментов для суперскалярных процессоров и процессоров со сверхдлинной командной строкой (шаг 23). Оценивает конкретный тип топологии коммуникационной сети 3 (шаг 24). Оценивает максимальные временные затраты на обмен сообщениями (шаг 25). Блок выборки инструкций 41 разрабатывает текстовые спецификации нитей параллельной программы с временной параметризацией, учитывающими время передачи/приема данных в буферы передающей и принимающей сторон и добавляет встроенные средства (операторы sleep, send, receive) временной синхронизации в код для каждого процессора с кэш-памятью 13, 23 вычислительных узлов 1, 2 (шаг 26). Устройство управления 43 оценивает корректность результатов разработки параллельных программ с временной параметризацией (шаг 27) и через коммуникационную сеть 3 подает команду процессорам с кэш-памятью 13, 23 на компилирование созданного параллельного кода с временной параметризацией (шаг 28). Ниже приведен пример созданного параллельного кода с временной параметризацией (фиг. 2).
Таким образом, предлагаемый способ позволит снизить время решения задачи на двух вычислительных узлах до 24% при работе массивно-параллельной вычислительной системы с распределенной памятью, то есть повысить эффективность цифровой обработки информации за счет временной синхронизации работы массивно-параллельной вычислительной системы с распределенной памятью.
Источники информации
1. Яковлев СВ., Сафонов И.В., Быкова Т.В. Способ построения программы. Патент на изобретение №2406112, бюл. №34, 2010 г.(аналог).
2. Викторов Д.С., Брежнев Д.Ю., Толмачев А.А., Калачников А.С., Якунина Г.Р. Способ автоматического создания параллельной программы с временной параметризацией многопроцессорных вычислительных систем с одинаковым доступом к памяти. Патент на изобретение №2786347, бюл. №35, 2022 г. (прототип).

Изобретение относится к области вычислительной техники для обработки цифровых данных. Технический результат заключается в повышении эффективности цифровой обработки информации (снижение времени решения задачи) вычислительной системы. Технический результат достигается за счет определения номера фрагмента, имеющего минимальное значение мощностей множеств операторов, включения оператора временного яруса в состав фрагмента и расчета сложности фрагментации для текущего фрагмента; расчета общей сложности фрагментации задачи; кластеризации фрагментов; оценки текущего состояния ресурса процессоров с кэш-памятью и коммуникационной сети; установки взаимно однозначного соответствия между кластерами фрагментов и подмножеством свободных в текущий момент времени процессоров с кэш-памятью вычислительных узлов; оценки конкретного типа процессоров с кэш-памятью; формирования множества фрагментов для суперскалярных процессоров и процессоров со сверхдлинной командной строкой; оценки конкретного типа топологии коммуникационной сети; оценки максимальных временных затрат на обмен сообщениями; разработки текстовых спецификаций нитей параллельной программы с временной параметризацией, учитывающих время передачи/приема данных в буферы передающей и принимающей сторон, и добавления встроенных средств временной синхронизации в код для каждого процессора с кэш-памятью вычислительных узлов; оценки корректности результатов разработки параллельных программ с временной параметризацией; компиляции созданного параллельного кода с временной параметризацией. 2 ил.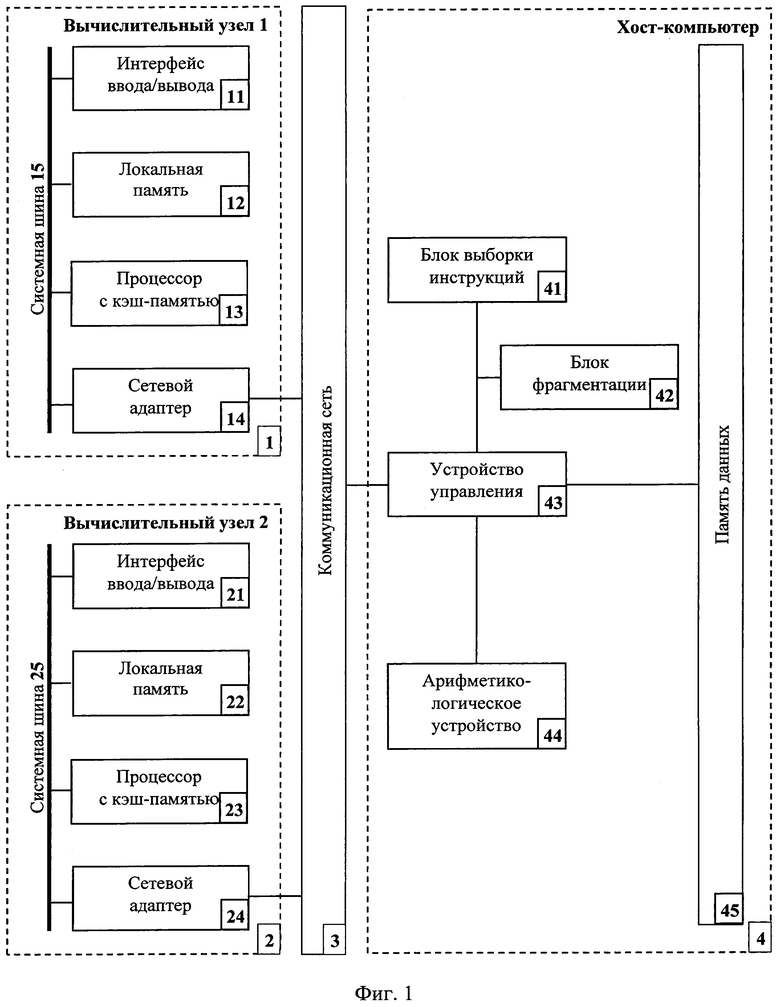
Способ временной синхронизации работы массивно-параллельной вычислительной системы с распределенной памятью, заключающийся в том, что для реализации способа коммуникационная сеть, вычислительные узлы, которые включают интерфейсы ввода/вывода, локальные памяти, процессоры с кэш-памятью, сетевые адаптеры, системные шины и хост-компьютер, который включает блок выборки инструкции, блок фрагментации, устройство управления, арифметико-логическое устройство, память данных, выполняют следующие операции: получают упорядоченный выбор лексем исходной последовательной программы и формируют для лексем их дескрипторы; получают упорядоченный выбор дескрипторов лексем из сформированного на предшествующем этапе множества дескрипторов; формируют новые структуры спецификации программы с детализацией до операций/функций; формируют новые структуры спецификации программы с детализацией до фрагментов; проверяют эквивалентности текстовой спецификации программы задачи и ее представления новыми структурами спецификации; расширяют множества операторов и множества связей операторов основной и связной структур новой спецификации исходной программы; реализуют цикл по временным ярусам новой спецификации задачи; формируют для множества операторов каждого яруса множества операторов ранжированных по убыванию мощностей их сопряженных множеств операторов; формируют первый фрагмент; формируют для текущего оператора, принадлежащего определенному временному ярусу, множества пересечений сопряженных множеств и проверяют равенства сопряженного множества пустому множеству; проверяют достижения текущего количества фрагментов заданному и включают текущих операторов в состав следующего фрагмента; рассчитывают сложность фрагментации для текущего фрагмента; проверяют окончание рассмотрения всех операторов временных ярусов; формируют для операторов временных ярусов множества пересечений его сопряженного множества и подмножества операторов каждого из фрагмента текущего множества сформированных фрагментов; определяют номер фрагмента, имеющего максимальное значение пересечений, включают оператора временного яруса в состав фрагмента и рассчитывают сложность фрагментации для текущего фрагмента; оценивают мощность множеств операторов, включенных в каждый из фрагментов; определяют номер фрагмента, имеющего минимальное значение мощностей множеств оператора, включают оператора временного яруса в состав фрагмента и рассчитывают сложность фрагментации для текущего фрагмента; рассчитывают общую сложность фрагментации задачи; кластеризуют фрагменты; оценивают текущее состояния ресурса процессоров с кэш-памятью и коммуникационной сети; устанавливают взаимно однозначное соответствие между кластерами фрагментов и подмножеством свободных в текущий момент времени процессоров с кэш-памятью вычислительных узлов; оценивают конкретный тип процессоров с кэш-памятью; формируют множество фрагментов для суперскалярных процессоров и процессоров со сверхдлинной командной строкой; оценивают конкретный тип топологии коммуникационной сети; оценивают максимальные временные затраты на обмен сообщениями; разрабатывают текстовые спецификации нитей параллельной программы с временной параметризацией, учитывающие время передачи/приема данных в буферы передающей и принимающей сторон и добавляют встроенные средства временной синхронизации в код для каждого процессора с кэш-памятью вычислительных узлов; оценивают корректность результатов разработки параллельных программ с временной параметризацией; компилируют созданный параллельный код с временной параметризацией.
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| Колосоуборка | 1923 |
|
SU2009A1 |
| Способ защиты переносных электрических установок от опасностей, связанных с заземлением одной из фаз | 1924 |
|
SU2014A1 |
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| Способ автоматического создания параллельной программы с временной параметризацией многопроцессорных вычислительных систем с одинаковым доступом к памяти | 2022 |
|
RU2786347C1 |

