Настоящее изобретение относится к области робототехники и искусственного интеллекта и может быть использовано в качестве способа для создания контроллеров управления шагающими роботами с целью повышения эффективности управления платформы за счет оптимизации контроллера управления под конкретную платформу с учетом динамических характеристик платформы, а также упрощение получения контроллеров управления для различных целевых задач.
Известен патент RU2755339C1 «Модифицированный интеллектуальный контроллер с адаптивным критиком». Изобретение состоит из блока расчета подкрепления, блок расчета временной разности, блока критика, решающей нейронной сети, блока отбора действий, блока действий, блока выбора действий, объекта управления. Повышение адаптационных свойств системы управления на базе интеллектуального контроллера достигается за счет выделения процесса обучения нейронной сети блока критика и решающей нейронной сети в отдельный блок обучения нейронных сетей, при этом данный блок обучает обе нейронные сети. Работа с блоком действий строится по новому принципу с использованием блока отбора действий, блока выбора действий, блока обучения нейронных сетей, блока расчета временной разности и блока расчета подкрепления. Блока отбора действий, ограничивающий возможные действия, не подходящие по минимально заданному подкреплению, а также возможность прямого обращения к блоку действий блока отбора действий, блока критика, блока расчета подкрепления и блока расчета временной разности повышают скоростные характеристики работы системы. Упрощение реализации для разработчика заключается в модернизации взаимодействия блоков расчета подкрепления, блока расчета временной разности и блока выбора действий с блоком действий, а также выделение процесса обучения нейронной сети блока критика и решающей нейронной сети в отдельный блок.
Недостатками данного контроллера являются недостаточные адаптационные свойства, сложность описания целевых задач контроллера для применения в робототехнике.
В качестве ближайшего аналога заявленному способу выбран патент RU2686030C1 «Непрерывное управление с помощью глубокого обучения с подкреплением». Способ описывает общий подход к обучению с подкреплением и состоит из нейронной сети-исполнителя, используемой для выбора действий, подлежащих выполнению агентом, запоминающего устройства повторного воспроизведения, в котором сохраняются экспериментальные кортежи данных, нейронной сети-критика, обрабатывающей учебное наблюдение и учебное действие в экспериментальных кортежах, прогнозной нейронной-сети исполнителя, прогнозной нейронной сети-критика. Многократно выполняя над множеством различных минипакетов экспериментальных кортежей процесс определения прогнозного вывода нейронной сети из учебного вознаграждения и следующего наблюдения, а также определения обновления параметров нейронной сети-критика через их прогнозные аналоги и определение обновления для нейронной сети-исполнителя с использованием нейронной сети-критика, система может обучить нейронную сеть-исполнителя определять выученные значения параметров нейронной сети-исполнителя и предоставлять возможность эффективного использования нейронной сети-исполнителя для выбора действий, подлежащих выполнению агентом при взаимодействии со средой.
Недостатками способа являются отсутствие централизованной системы описания целевых задач, замедляющее процесс получения различных контроллеров, недостаточная оптимизация метода для применения в задачах шагающих роботов
Таким образом, существует задача разработки такого способа для создания контроллеров управления шагающими роботами на основе обучения с подкреплением, который обеспечивает автоматизацию создания оптимальных контроллеров управления с учетом особенностей и динамических характеристик конкретных платформ, что особенно важно при использовании данной полезной модели в автономных шагающих роботах.
Техническим результатом заявленного изобретения является автоматизация процессов создания эффективных контроллеров управления за счет учета особенностей и динамических характеристик конкретных платформ для автономных шагающих роботов и упрощения получения конечного результата разработчиком данных контроллеров.
Поставленная задача решается, а заявленный технический результат достигается тем, что способ для создания контроллеров управления шагающими роботами на основе обучения с подкреплением, включает следующие этапы: инициализация, создание необходимых модулей, обмен данными между контроллером управления и агентом управления, подсчет наград и штрафов при получении ответного отклика менеджером обучения, сохранение данных в хранилище, оптимизация параметров контроллера управления через максимизацию получаемой итоговой награды с помощью алгоритма машинного обучения, экспорт контроллера управления в виде бинарного файла его внутренних параметров для дальнейшей загрузки на реального робота для генерации его движений.
Далее изобретение подробно поясняется со ссылкой на фигуры.
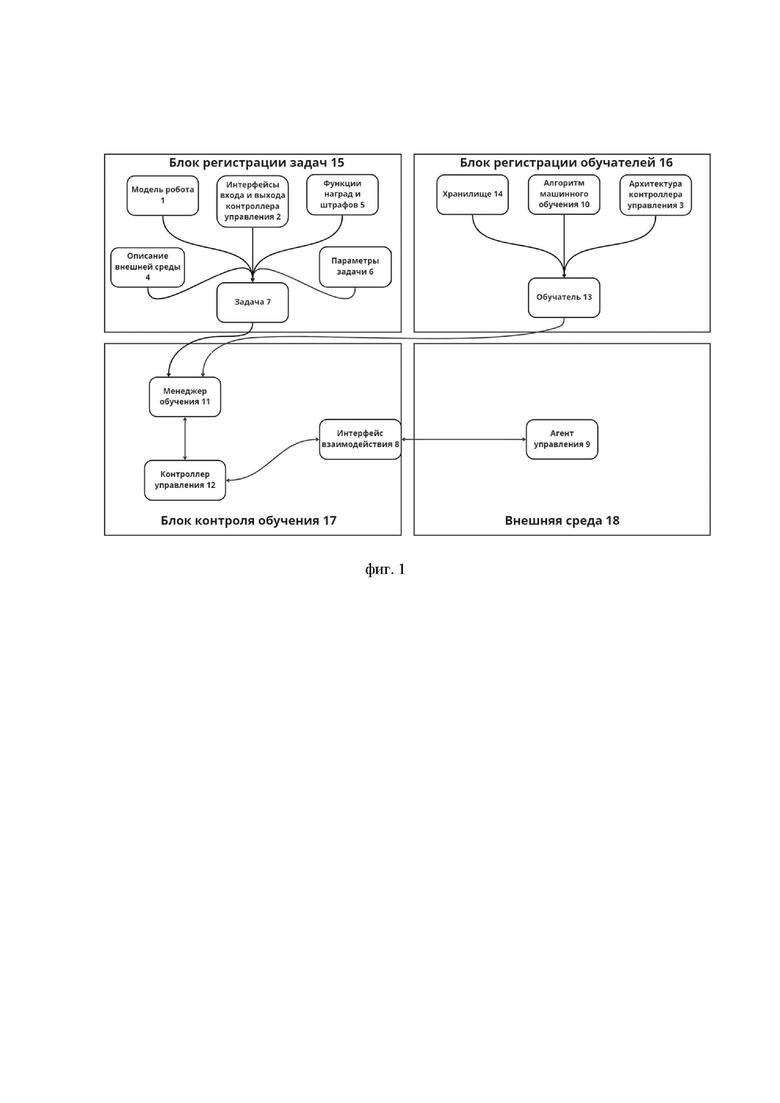
На фиг. 1 схематично показана взаимосвязь основных используемых блоков в способе для создания контроллеров управления шагающими роботами на основе обучения с подкреплением. На фигуре 1 ссылочными позициями отмечены:
1 – модель робота;
2 – интерфейсы входа и выхода контроллера управления;
3 - архитектура контроллера управления;
4 – описание внешней среды;
5 – функции наград и штрафов;
6 - параметры задачи;
7 – задача;
8 – интерфейс взаимодействия;
9 – агент управления;
10 – алгоритм машинного обучения;
11 - менеджер обучения;
12 – контроллер управления;
13 – обучатель;
14 – хранилище;
15 – блок регистрации задач;
16 – блок регистрации обучателей;
17 – блок контроля обучения;
18 – внешняя среда.
Блок регистрации задач (15) состоит из описания внешней среды (4), модели робота (1), функции наград и штрафов (5), интерфейсов (2) входов и выходов контроллера управления, параметров задачи (6) и задачи (7). Описание внешней среды (4) предназначено для описания физики, окружения робота, предметов для взаимодействия и других, необходимых для решения задачи, параметров. Модель робота (1) описывает собственно конструкцию робота, например, в нем могут быть заданы параметры моторов, датчиков, формат управления. Функции наград и штрафов (5) содержат описания функций от входов и выходов контроллера, привилегированной информации от среды, которая не может непосредственно участвовать в формировании управляющего воздействия, определяющие желаемое поведение контроллера управления. Интерфейсы (2) входа и выхода контроллера управления предназначены для определения количества входов и выходов, типа используемой контроллером информации, формата входных и выходных данных. Параметры (6) задачи содержат общие сведения о конфигурации задачи. Примером могут служить параметры влияния определенных наград и штрафов, усиления входов и выходов и т.д. Задача (7) описывает комплексную информацию о роботе, его интерфейсы управления (входы и выходы), внешней среде (18), в которой робот будет работать, наградах и штрафах, которые можно получить в процессе обучения, общих параметрах, относящимся к данной задаче. Задача формируется посредством выбора экземпляров модулей, содержащих требуемую информацию.
Блок регистрации обучателей (16) содержит в себе хранилище (14), алгоритм машинного обучения (10), архитектуру (3) контроллера управления и обучатель (13). Хранилище (14) предназначено для хранения данных о состояниях, действиях и наградах. Алгоритм машинного обучения (10) содержит непосредственно алгоритм по оптимизации контроллера управления по данным из хранилища. Архитектура (3) контроллера управления содержит информацию о внутреннем устройстве контроллера. Обучатель (13) содержит сведения о процессах изменения внутренних параметров контроллера с целью его оптимизации на основе использования заданного алгоритма обучения, описанного в алгоритме машинного обучения (10) и архитектуры (3) контроллера управления.
Блок контроля обучения (17) содержит менеджер обучения (11), интерфейс взаимодействия (8) и контроллер управления (12). Менеджер обучения (11) описывает основной цикл обучения, инициализирует выбранные задачи и обучатели для создания и обучения контроллеров управления, а также экспортирует готовый контроллер для применения на реальном роботе. Интерфейс взаимодействия (8) предназначен для получения данных из внешней среды (18) непосредственно в которой действует агент. Это могут быть интерфейсы для подключения к виртуальным или реальным датчикам робота, камерам, лидарам, средствам локализации и т.д.
Модульность, реализованная в способе, позволяет достичь уровня гибкости, позволяющей пользователю беспрепятственно внедрить своего робота, задачу и условия среды, для получения эффективного контроллера, подготовленного непосредственно под заданную конфигурацию.
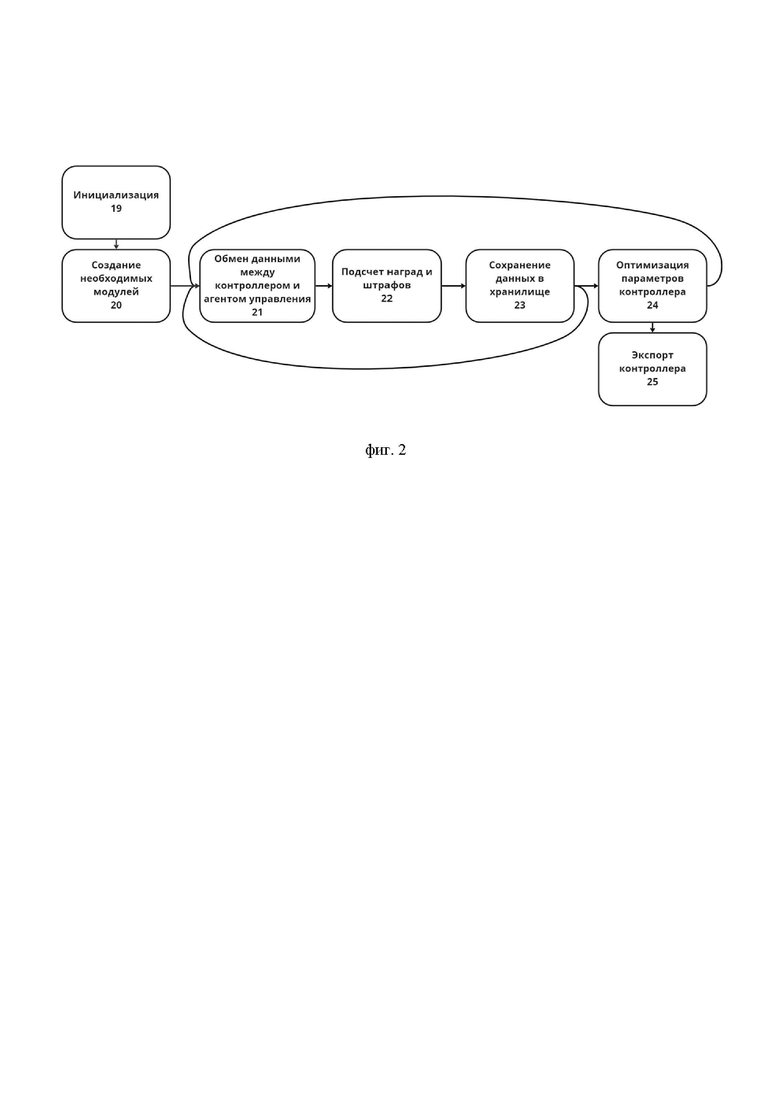
На фиг. 2 схематично приведена общая блок-схема способа для создания контроллеров управления шагающими роботами на основе обучения с подкреплением. На фигуре 2 ссылочными позициями отмечены:
19 – инициализация;
20 – создание необходимых модулей;
21 – обмен данными между контроллером управления и агентом управления;
22 –подсчет наград и штрафов;
23 – сохранение данных в хранилище;
24 – оптимизация параметров контроллера управления;
25 – экспорт контроллера управления.
На шаге инициализации (19) осуществляется: получение данных о модели робота (1) из файла, определение формата интерфейсов (2) входа и выхода контроллера управления для данной модели и внутренней архитектуры (3) контроллера управления для создания экземпляра контроллера управления (12), получение описания внешней среды (4) и определение ее состояния на момент начала обучения, определение функций наград и штрафов (5), которые можно получить в процессе обучения, получение конфигурационных файлов для определения параметров (6) задачи. На основе этих данных происходит формирование задачи (7) и инициализация интерфейса взаимодействия (8) контроллера управления и агента управления (9), представляющего собой реального робота или модели робота внутри симуляции, определение алгоритма машинного обучения (10).
Конструкция робота, для которого формируется задача, описывается моделью робота (1) в формате URDF, MJCF или аналогичном формате. Одна и та же конструкция может быть использована для разных задач, что упрощает получение контроллеров управления для одной и той же целевой платформы.
Затем на шаге (20) осуществляется создание необходимых модулей: менеджера обучения (11) с учетом функции наград и штрафов (5) для процесса обучения, контроллера управления (12) на основе архитектуры (3) контроллера управления и интерфейсов (2) входа и выхода контроллера управления, а также обучателя (13) с использованием менеджера обучения (11), контроллера управления (12) и заданного алгоритма машинного обучения (10).
Менеджер обучения (11) содержит внутри себя цикл обмена данными между контроллером управления и агентом управления (9). При получении текущего состояния агента управления (9) через интерфейс взаимодействия (8) и отправке его на вход контроллера управления (12), формат которого описан в задаче (7), осуществляется получение команд из интерфейса (2) выхода контроллера управления (12) для целевого управления. Затем на шаге (21) осуществляется обмен данными между контроллером управления (12) и агентом управления (9). При получении ответного отклика менеджером обучения (11) ведется подсчет наград и штрафов на шаге (22), т.е. рассчитывается общая оценка текущего действия агента управления (9) с помощью функции наград и штрафов (5), описанных в задаче (7). Информация о состоянии агента управления (9) во внешней среде до выполнения действия, действие агента, текущая награда агента и состояние агента в среде после действия сохраняются на шаге (23) в хранилище (14).
Оптимизация параметров контроллера на шаге (23) для улучшения желаемого движения достигается за счет максимизации получаемой награды с помощью алгоритмов машинного обучения, описанных в алгоритме машинного обучения (10). Для этого из данных, собранных во время одной итерации цикла обмена между агентом и средой и хранящихся в хранилище, формируется выборка, являющейся обучающей для данного контроллера. Переход между шагами (21) и (24) происходит при сборе достаточного количества данных, описанного в параметрах задачи (6), для формирования обучающей выборки. Контроллер управления (12) с обновленными внутренними параметрами используется в следующей итерации цикла обмена.
Процесс завершается на шаге (25) экспортом контроллера управления при достижении целей задачи, описанных в параметрах задачи (6), либо после достижения максимального числа итераций, также описанных в параметрах задачи (6).
Заявленный способ позволяет автоматизировано создавать оптимальные контролеры управления для шагающих роботехнических платформ для применения в описанных пользователем задачах. Способ обеспечивает автоматизацию процессов создания эффективных контроллеров управления с целью повышения стабильности движений робота в различных окружающих его условиях при моделировании походки робота в симуляторе и в реальной среде. Способ позволяет получать обученные модели для их применения на различных моделях шагающих роботов.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ И СИСТЕМА МАШИННОГО ОБУЧЕНИЯ ИЕРАРХИЧЕСКИ ОРГАНИЗОВАННОМУ ЦЕЛЕНАПРАВЛЕННОМУ ПОВЕДЕНИЮ | 2019 |
|
RU2755935C2 |
| Модифицированный интеллектуальный контроллер с адаптивным критиком | 2024 |
|
RU2836598C1 |
| НЕПРЕРЫВНОЕ УПРАВЛЕНИЕ С ПОМОЩЬЮ ГЛУБОКОГО ОБУЧЕНИЯ С ПОДКРЕПЛЕНИЕМ | 2016 |
|
RU2686030C1 |
| МОДИФИЦИРОВАННЫЙ ИНТЕЛЛЕКТУАЛЬНЫЙ КОНТРОЛЛЕР С АДАПТИВНЫМ КРИТИКОМ | 2013 |
|
RU2523218C1 |
| ИНТЕЛЛЕКТУАЛЬНЫЙ КОНТРОЛЛЕР С НЕЙРОННОЙ СЕТЬЮ И ПРАВИЛАМИ САМОМОДИФИКАЦИИ | 2003 |
|
RU2266558C2 |
| Модифицированный интеллектуальный контроллер с адаптивным критиком | 2020 |
|
RU2755339C1 |
| МОДИФИЦИРОВАННЫЙ ИНТЕЛЛЕКТУАЛЬНЫЙ КОНТРОЛЛЕР С АДАПТИВНЫМ КРИТИКОМ | 2011 |
|
RU2450336C1 |
| МОДИФИЦИРОВАННЫЙ ИНТЕЛЛЕКТУАЛЬНЫЙ КОНТРОЛЛЕР | 2011 |
|
RU2458390C1 |
| КОНТРОЛИРУЮЩАЯ СИСТЕМА ДЛЯ КОНТРОЛЯ ТЕПЛОВОЙ ОБРАБОТКИ | 2013 |
|
RU2653733C2 |
| Способ рентгеновского исследования образца | 2023 |
|
RU2812088C1 |
Изобретение относится к области робототехники и искусственного интеллекта и может быть использовано для создания контроллеров управления шагающими роботами. Техническим результатом является автоматизация процессов создания эффективных контроллеров управления за счет учета особенностей и динамических характеристик конкретных платформ для автономных шагающих роботов. Способ содержит этапы: инициализация, создание необходимых модулей, обмен данными между контроллером управления и агентом управления, подсчет наград и штрафов, сохранение данных в хранилище, оптимизация параметров контроллера управления, экспорт контроллера управления для загрузки на реального робота. 2 ил.
1. Способ для создания контроллеров управления шагающими роботами на основе обучения с подкреплением, включающий следующие этапы:
a) инициализация, в процессе которой осуществляется получение данных о модели робота (1) из файла, определение формата интерфейсов входа и входа контроллера управления (2) для данной модели и внутренней архитектуры контроллера управления (3) для создания экземпляра контроллера управления, получение описания внешней среды (4) и определение ее состояния на момент начала обучения, определение функций наград и штрафов (5), которые можно получить в процессе обучения, получение конфигурационных файлов для определения параметров задачи (6), на основе этих данных происходит формирование задачи (7) и инициализация интерфейса взаимодействия (8) контроллера управления и агента управления (9), представляющего собой реального робота или модели робота внутри симуляции, определение алгоритма машинного обучения (10);
b) создание необходимых модулей: менеджера обучения (11) с учетом функций наград и штрафов (5) для процесса обучения, контроллера управления (12) на основе архитектуры контроллера управления (3) и интерфейсов входа и выхода контроллера (2), а также обучателя (13) с использованием менеджера обучения (11), контроллера управления (12) и заданного алгоритма машинного обучения (10);
c) обмен данными между контроллером управления (12) и агентом управления (9), при котором осуществляется получение текущего состояния агента во внешней среде (4) через интерфейс взаимодействия (8) и отправка команд из контроллера управления (12) агенту управления (9) для последующего выполнения; обмен прекращается при сборе достаточного количества данных, описанного в параметрах задачи (6), для формирования обучающей выборки, контроллер управления (12) с обновленными внутренними параметрами используется в последующих итерациях цикла обмена данными;
d) подсчет наград и штрафов при получении ответного отклика менеджером обучения (11), представляющий собой общую оценку текущего действия агента (9) с помощью функций наград и штрафов (5), описанных в задаче (7);
e) сохранение данных в хранилище (14), а именно информации о состоянии агента управления (9) в среде до выполнения действия, действие агента, текущая награда агента (9) управления и состояние агента (9) во внешней среде (4) после действия;
f) оптимизация параметров контроллера управления (12) через максимизацию получаемой итоговой награды с помощью алгоритма машинного обучения (10);
g) экспорт контроллера управления (12) в виде бинарного файла его внутренних параметров для дальнейшей загрузки на реального робота для генерации его движений.
| НЕПРЕРЫВНОЕ УПРАВЛЕНИЕ С ПОМОЩЬЮ ГЛУБОКОГО ОБУЧЕНИЯ С ПОДКРЕПЛЕНИЕМ | 2016 |
|
RU2686030C1 |
| US 10786900 B1, 29.09.2020 | |||
| US 10828775 B2, 10.11.2020 | |||
| US 20210122037 A1, 29.04.2021 | |||
| WO 2022223056 A1, 27.10.2022. | |||
