ОБЛАСТЬ ТЕХНИКИ
Изобретение относится к области машинного интеллекта, в частности машинного обучения целенаправленному поведению, более конкретно - к т.н. глубокому обучению с подкреплением (deep reinforcement learning), с автоматическим построением иерархии все более абстрактных признаков.
УРОВЕНЬ ТЕХНИКИ
Можно выделить два базовых подхода к созданию систем искусственного интеллекта, наделенных когнитивными способностями, сопоставимыми с человеческими. Это:
• Логический (символьный) интеллект, задачей которого является разработка «интеллектуальных» алгоритмов, способных решать те или иные типы «творческих» задач. Например, выдача обоснованных рекомендаций экспертными системами, с использованием баз экспертных знаний и формальных правил выводов.
• Машинное обучение, или автоматическое порождение «интеллектуальных» алгоритмов в процессе обучения на больших объемах данных. Сложность таких алгоритмов лимитируется уже не объемом накопленных знаний, а объемами доступных данных и наличием вычислительных ресурсов. Как правило, результатом обучения является распределенная система со множеством настроечных параметров (например, искусственная нейросеть), а не свод логических правил. Такой вид машинного интеллекта называют еще распределенным интеллектом.
В последние годы прогресс в машинном обучении был связан в основном с т.н. глубоким обучением нейросетей с большим числом слоев, в которых каждый следующий слой обучается распознавать все более сложные признаки. Глубокое обучение лежит в основе лучших современных систем распознавания речи, машинного зрения, машинного перевода и многих других практических применений прикладного (узкого) искусственного интеллекта [1].
Основные успехи были достигнуты при обучении с учителем, когда обучающейся системе даются образцы правильного поведения, например, правильная классификация обучающего набора сенсорных образов.
Более сложная постановка задачи, характерная для обучения роботов и программных агентов - обучение с подкреплением, где образцы правильного поведения отсутствуют. Поведение роботов во всех мыслимых ситуациях нельзя запрограммировать, и они должны будут самостоятельно вырабатывать алгоритмы своего поведения, ориентируясь лишь на редкие подкрепляющие сигналы извне - награды за решение тех или иных задач [2].
Примером подобной системы является программа AlphaGo Zero, самостоятельно научившаяся игре в Го лучше профессиональных чемпионов - людей [3]. Однако для ее обучения потребовались очень серьезные вычислительные ресурсы (5 тысяч TFLOPS-лет). Подобная дороговизна обучения с подкреплением сдерживает развитие практических применений, в частности - в робототехнике.
AlphaGo Zero сочетает в себе логический и распределенный интеллект: глубокая нейросеть обучается оценивать позицию и предсказывать перспективные ходы, а логическая компонента производит просчет и отбор вариантов по заданному алгоритму (но не учится).
Данное изобретение также объединяет сильные стороны логического и распределенного подходов, только в виде иерархической системы, где на каждом уровне иерархии присутствуют два типа обучения - символьное и распределенное. Такой способ обучения оказывается более быстрым и экономным с точки зрения вычислительных затрат, чем традиционное глубокое обучение.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
Сложность обучения с подкреплением обусловлена прежде всего тем, что награды зависят не от отдельных действий, а от их последовательностей, и могут отстоять далеко по времени от конкретных действий. Получение награды не атрибутируется явно к тому или иному действию, что затрудняет оценки отдельных действий и, соответственно, обучение. Например, в случае игры в Го, награда (выигрыш) становится известна лишь в самом конце партии, без указания на то, какие именно ходы были наиболее полезны для ее получения.
В данном изобретении предложен метод обучения не отдельным действиям, а их наиболее полезным комбинациям, т.е. используются элементы дискретного символьного обучения, отсутствующего в традиционных глубоких нейронных сетях. Такое обучение ограничено относительно короткими последовательностями действий, т.к. их разнообразие экспоненциально возрастает с ростом их длины. Данное изобретение обходит эту проблему за счет иерархического планирования поведения одновременно на многих временных масштабах.
А именно предложенная в данном изобретении система представлена иерархией обучающихся вычислительных слоев (уровней вычислений). Более высокие уровни работают на больших временных масштабах, что позволяет верхним уровням «дотянуться» до произвольно удаленных по времени наград и нащупать грубый план их достижения, а более низким уровням - найти оптимальные способы реализации этого плана.
Идея иерархической обработки информации не нова (см. например [4]). На ней, в частности, основаны многие современные системы машинного перевода, в которых последовательные слои рекуррентных нейросетей анализируют иерархию контекстов, раскрывающих смыслы слов и фраз в переводимых текстах [5]. Однако алгоритмы градиентного обучения таких глубоких нейросетей, как мы уже отмечали, очень затратны.
В данном изобретении предлагается использовать комбинацию дискретного и аналогового обучения.
• Аналоговое или градиентное обучение нейросетей используется для кодирования и декодирования действий на разных уровнях планирования. Кодирование отображает множество цепочек действий на более низком уровне иерархии, встречающихся в сходных контекстах, в одно дискретное действие на более высоком уровне. Декодирование производит обратное преобразование действия более высокого уровня во множество способов его реализации на более низком уровне.
• Дискретное или символьное обучение используется для отбора наиболее перспективных комбинаций дискретных действий - паттернов поведения с максимальными ожидаемыми подкреплениями на каждом уровне иерархии.
В предлагаемом подходе рост сложности обучающейся системы, т.е. числа ее параметров, в ходе обучения происходит постепенно, пропорционально количеству обработанных системой данных. В итоге вычислительная сложность обучения оказывается на порядки ниже, чем сложность обучения глубоких нейросетей с фиксированным заранее числом параметров [6], что открывает широкие возможности практических применений изобретения, особенно в робототехнике и в мобильных устройствах, где возможности бортовых вычислительных систем очевидным образом ограничены.
Дополнительная сложность обучения с подкреплением связана с тем, что у системы отсутствуют образцы правильного поведения и она вынуждена генерировать их сама. При этом возникает известная дилемма между использованием уже известных навыков поведения и генерацией новых (exploration-exploitation tradeoff) [7]. Одним из решений является применение т.н. Томпсоновского сэмплирования из соответствующих вероятностных распределений (Thompson sampling) [8]. В частности, в контексте обучения с подкреплением этот метод используется для дополнения реальных примеров взаимодействия с внешним миром искусственно сгенерированными примерами [9].
В предложенном изобретении предлагается более экономный метод Томпсоновского сэмплирования - при извлечении данных из памяти системы. Экономия связана с тем, что память хранит результаты обучения, т.е. очень компактное сжатое представление исходных данных.
Для этого был разработан компьютерно реализуемый способ машинного обучения целенаправленному поведению, содержащий следующие этапы: получают из внешней среды сенсорную информацию, в том числе подкрепляющие сигналы, и генерируют управляющие сигналы с целью максимизации суммы ожидаемых в будущем подкрепляющих сигналов, при этом управляющие сигналы генерируют в соответствии с иерархией согласованных вложенных друг в друга планов, которые автоматически создают в процессе обучения и постоянно адаптируют к изменяющимся внешним обстоятельствам. Внешние подкрепляющие сигналы могут быть дополнены внутренними подкреплениями в случаях осуществления прогнозируемого системой хода развития событий.
Управляющие сигналы на каждом уровне иерархии могут представлять собой цепочки элементарных дискретных действий - паттерны поведения данного уровня, которые характеризуются наибольшим ожидаемым суммарным подкреплением с учетом статистической неопределенности определяемой при помощи Томпсоновского сэмплирования данных из памяти данного уровня.
На каждом уровне иерархии новые паттерны поведения могут создаваться путем добавления в память наиболее выгодных комбинаций из уже известных паттернов.
Также для реализации предложенного способа была разработана компьютерная система для обучения иерархическому целесообразному поведению, содержащая по меньшей мере один процессор, компьютерную память, сетевую инфраструктуру, средства хранения информации, выполненные с возможностью осуществления иерархической послойной обработки входной сенсорной информации из более низкого уровня, включая внешнюю среду, как нулевой уровень, и управляющих сигналов с более высокого уровня, кроме верхнего уровня иерархии и выработки управляющих сигналов более низкому уровню, а также накопления опыта взаимодействия с внешней средой.
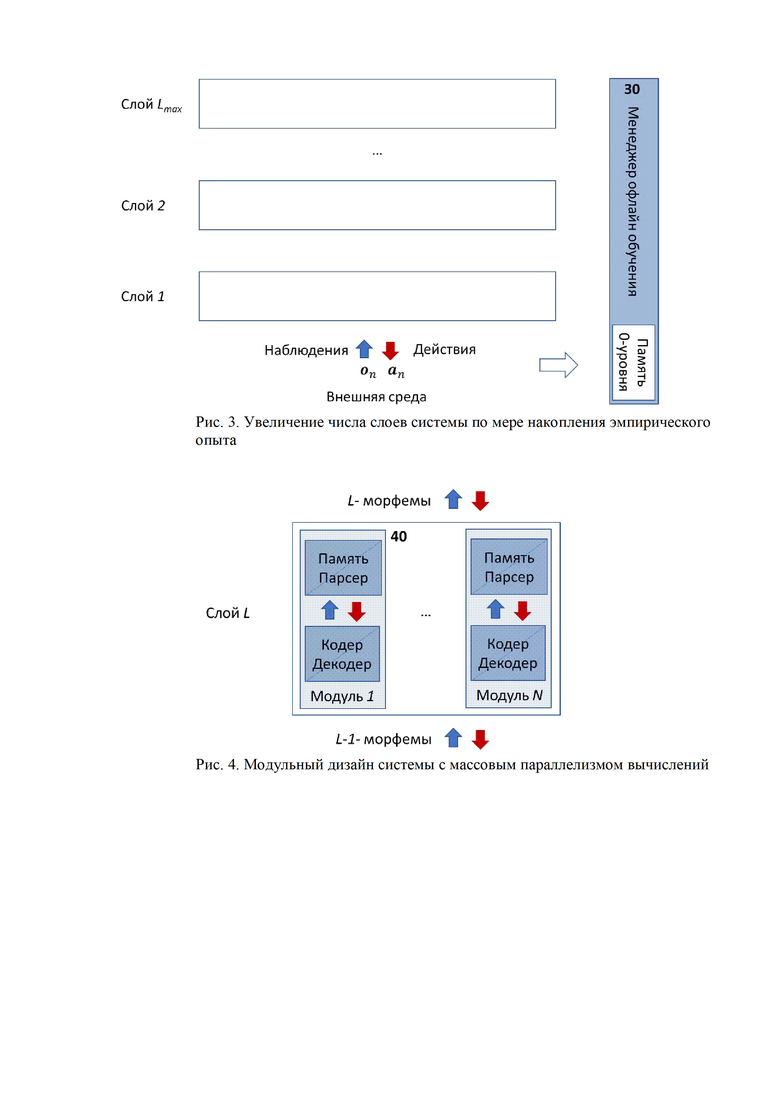
Количество уровней иерархии обработки информации может увеличиваться постепенно по мере накопления опыта взаимодействия с внешней средой.
Обработка информации на каждом иерархическом уровне может производится набором программно-аппаратных модулей, работающих параллельно и независимо друг от друга.
Вся система или ее отдельные компоненты могут быть реализованы аппаратно в виде специализированных микросхем соответствующей архитектуры.
Система может быть реализована в клиент-серверной архитектуре и все блоки соединены между собой стандартизированными каналами связи.
ПОЯСНЕНИЯ К РИСУНКАМ
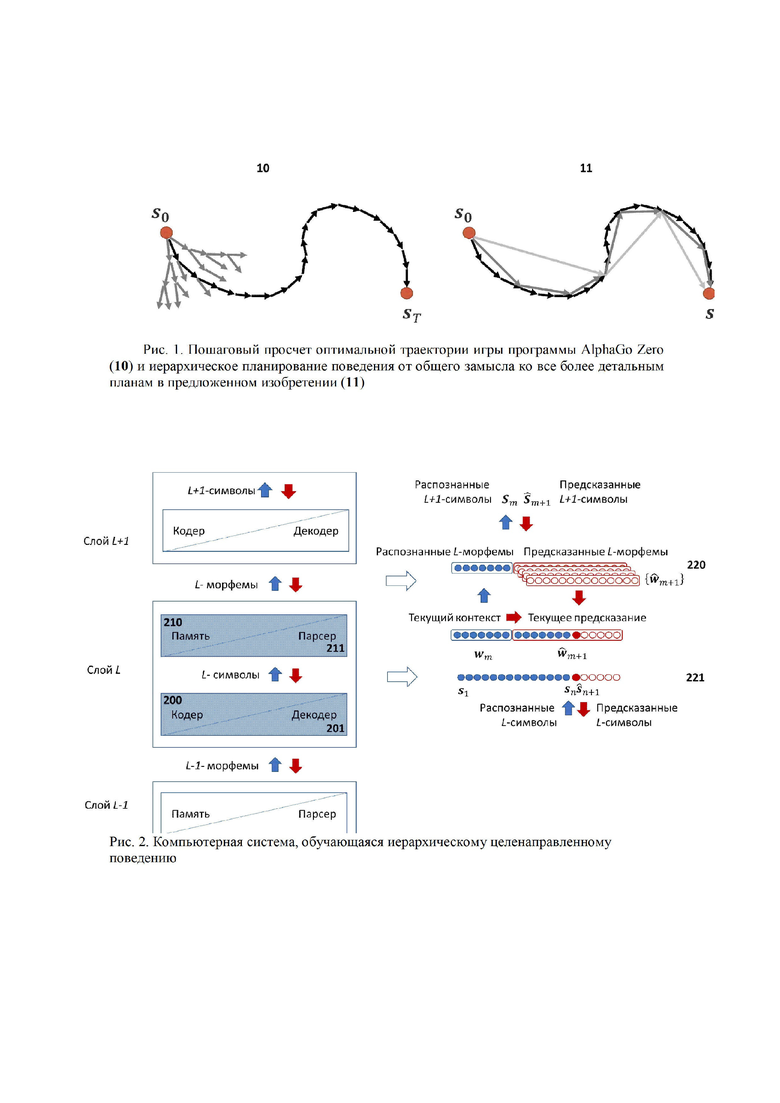
Рис. 1 иллюстрирует отличие предложенной в данном изобретении схемы иерархического планирования от системы AlphaGo Zero. Глубокая нейросеть AlphaGo Zero способна генерировать варианты своих ходов лишь на один шаг вперед. Для выбора лучшего варианта на каждом шаге производится просчет очень объемного дерева вариантов на десятки ходов вперед [10]. В данном изобретении предлагается гораздо более экономный подход к планированию поведения: от крупномасштабного замысла достижения цели - ко все более подробным планам его достижения. При этом разнообразие вариантов выбора на каждом уровне относительно невелико.
Предложенная в данном изобретении система состоит из набора вычислительных слоев, планирующих поведение на разных временных масштабах. Чем выше слой - тем большим временным масштабом он оперирует. Каждый слой кодирует текущее состояние взаимодействия системы с внешним миром определенным набором своих дискретных символов - состояний. Каждый такой символ кодирует на своем уровне абстракции сенсомоторную информацию - как входящую (наблюдения), так и исходящую (действия). Т.е. любой план действий сопровождается соответствующими предсказаниями наблюдений, которые постоянно сравниваются с реальностью, поставляя материал для обучения системы даже в отсутствие подкрепляющих сигналов, что выгодно отличает данное изобретение от обычного обучения с подкреплением.
Анализируя конечную последовательность своих последних состояний (текущий контекст) каждый слой вырабатывает свой план действий (конечную последовательность следующих состояний), реализующий более общий план, полученный от более высокого слоя. Следующее действие из своего плана он передает нижележащему слою, а свой текущий контекст - вышележащему слою.
Нижележащий слой декодирует полученное свыше указание в свой план действий, вычисляет свое следующее состояние в соответствии с этим планом и передает его на слой ниже. Так формируется нисходящий поток команд, определяющих поведение системы.
Восходящий поток сигналов от внешней среды - текущие контексты разных уровней, сравнивается с нисходящим потоком предсказаний сверху, и там, где они расходятся между собой, происходит коррекция планов поведения.
Непосредственное взаимодействие системы с внешней средой происходит через самый низкий, первый уровень иерархии, который получает извне входные сенсорные сигналы - наблюдения и выдает на исполнение эффекторам управляющие сигналы - действия.
Некоторый выделенный класс входных сигналов т.н. подкрепляющие сигналы или подкрепления несут информацию о полученных системой внешних наградах, зависящих от предпринятых ею в прошлом действий. В дополнение к внешним подкреплениям система генерирует свои внутренние подкрепления в случае удачного предсказания ею внешних событий. Тем самым, система постоянно обучается предсказывать результаты своих собственных действий. Целью системы является планирование поведения с максимальным ожидаемым в будущем суммарным подкреплением (внешним и внутренним). Баланс между способностью системы планировать свое поведение и ее стремлением максимизировать внешние подкрепления может варьироваться в зависимости от решаемых системой задач.
Обучающаяся компьютерная система (см. Рис. 2) состоит из конечного числа вычислительных слоев, количество которых может возрастать при накоплении системой достаточного объема эмпирических данных. Каждый слой содержит один и тот же набор стандартных компонент: Кодер (200), Декодер (201), Парсер (211) и Память (210).
• Кодер представляет поступающие с предыдущего слоя данные в виде потока дискретных символов своего внутреннего алфавита - возможных состояний данного слоя. При этом конкретному состоянию данного слоя соответствует множество цепочек состояний более низкого слоя.
• Декодер производит обратную операцию - переводит выходной поток планируемых состояний данного слоя в поток инструкций для нижележащего слоя. Каждая такая инструкция представляет собой ранжированный набор возможных способов реализации нижележащим слоем текущего шага плана.
• Парсер группирует поступающие от Кодера символы в более крупные токены - морфемы, наиболее полезные с точки зрения суммарного подкрепления последовательности символов, составляющие словарь данного слоя. При этом Парсер использует накопленную в Памяти статистику наград, полученных при наблюдавшихся ранее сочетаниях различных морфем. Пользуясь этой статистикой, Парсер выбирает наиболее перспективные в данном контексте следующие морфемы, реализующие полученные с более высокого слоя инструкции, т.е. формирует оптимальный план действий данного слоя, как часть более общего плана. Предложенная иерархическая система способна обучаться многоуровневому планированию и демонстрировать целенаправленное поведение на все больших временных интервалах. Каждый слой системы учится компилировать свои планы, накапливая в своей Памяти наиболее полезные последовательности символов с максимальными суммарными наградами. А именно:
• Память хранит суммарные награды 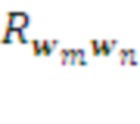 , полученные наблюдавшимися в прошлом сочетаниями известных ей морфем. Если эта величина превосходит некий заданный предел, т.е. комбинация морфем
, полученные наблюдавшимися в прошлом сочетаниями известных ей морфем. Если эта величина превосходит некий заданный предел, т.е. комбинация морфем 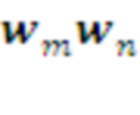 доказывает свою полезность, эта комбинация запоминается в Памяти как новая морфема в словаре данного слоя:
доказывает свою полезность, эта комбинация запоминается в Памяти как новая морфема в словаре данного слоя: 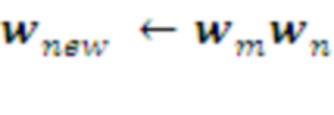 . Таким образом, объем Памяти возрастает с ростом числа обработанных системой данных.
. Таким образом, объем Памяти возрастает с ростом числа обработанных системой данных.
План L-го уровня, определяется по текущему контексту 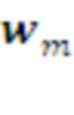 , как следующая морфема
, как следующая морфема 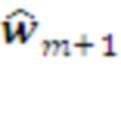 с максимальной предсказанной наградой, с учетом соответствия этой морфемы плану более высокого уровня (см. Рис. 2).
с максимальной предсказанной наградой, с учетом соответствия этой морфемы плану более высокого уровня (см. Рис. 2).
Каждый слой системы L (кроме последнего) получает сигналы от уровней (L+1) и (L-1), где внешняя среда считается нулевыми уровнем.
Слой L+1 определяет текущее состояние исполняемого плана (L+1)-уровня - 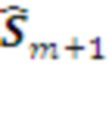 на Рис. 2. Декодер (L+1)-го слоя переводит этот символ в ранжированный набор морфем L-го уровня - возможных реализаций на L-ом уровне шага .
на Рис. 2. Декодер (L+1)-го слоя переводит этот символ в ранжированный набор морфем L-го уровня - возможных реализаций на L-ом уровне шага .
Кодер L-го слоя переводит текущий контекст (L-1)-уровня в дискретный входной символ 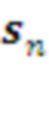 . Если он не соответствует предсказанию, текущий план L-го уровня корректируется. А именно, из ранжированного списка морфем-кандидатов выбирается та, которая соответствует текущему наблюдению. Если таковая в списке отсутствует, план действий L-го уровня выбирается из полного арсенала морфем, накопленных в Памяти L-го уровня без оглядки на план верхнего уровня. Последний будет скорректирован (L+1)-уровнем на его следующем шаге.
. Если он не соответствует предсказанию, текущий план L-го уровня корректируется. А именно, из ранжированного списка морфем-кандидатов выбирается та, которая соответствует текущему наблюдению. Если таковая в списке отсутствует, план действий L-го уровня выбирается из полного арсенала морфем, накопленных в Памяти L-го уровня без оглядки на план верхнего уровня. Последний будет скорректирован (L+1)-уровнем на его следующем шаге.
Следующее планируемое состояние 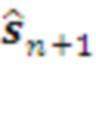 передается Декодеру для трансляции на уровень L-1.
передается Декодеру для трансляции на уровень L-1.
Память каждого слоя пополняется в процессе парсинга (разбора) поступающей извне информации, т.е. система постоянно обучается в режиме онлайн.
Кроме онлайн обучения, система периодически до-обучается в режиме офлайн под управлением специального модуля - Менеджера офлайн обучения (30 на Рис. 3). А именно, в определенные моменты времени система (или ее копия, если оригинал занят текущим управлением поведением) на время переходит в специальный режим «сна» для офлайн обучения, в процессе которого:
• Кодеры и Декодеры корректируют свои настроечные параметры, используя актуальные данные Памяти предыдущего слоя.
• К системе может быть добавлен очередной слой, если текущий слой верхнего уровня накопил достаточное количество данных для создания нового алфавита символов следующего слоя.
Для создания первого слоя и его периодического до-обучения в Менеджере офлайн обучения предусмотрена Память 0-го уровня, в которой хранится история взаимодействия системы с внешней средой - поток сенсорных наблюдений 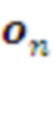 , и поток управляющих действий системы
, и поток управляющих действий системы 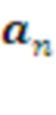 .
.
Резюмируя, предложенная в данном изобретении система осуществляет одновременное согласованное планирование поведения на многих масштабах времени. Каждый шаг уровня L+1 соответствует последовательности шагов уровня L. Причем планы более низких уровней вписываются в планы более высоких. Коррекция планов происходит там и тогда, когда их предсказания перестают соответствовать реальности. В целом, по мере накопления опыта и роста числа слоев, система обучается адаптивному целенаправленному поведению на все более долгих временных масштабах.
Важным частным случаем данного изобретения является модульный дизайн Системы, когда каждый ее слой состоит из конечного числа модулей (40 на Рис. 4), которые обучаются и работают независимо от других модулей того же слоя. Модульный дизайн позволяет эффективно распараллеливать вычисления и обобщает традиционную слоистую архитектуру глубоких нейронных сетей, в которых нейроны внутри каждого слоя не взаимодействуют друг с другом. Далее по тексту в том случае, если упоминаются модули, речь идет о частном случае модульного дизайна.
ОПРЕДЕЛЕНИЕ ОСНОВНЫХ ТЕРМИНОВ И ОПИСАНИЕ ЭЛЕМЕНТОВ СИСТЕМЫ
Термин / Элемент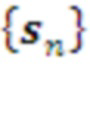 , описывающих дискретные состояния данного слоя системы. Здесь:
, описывающих дискретные состояния данного слоя системы. Здесь: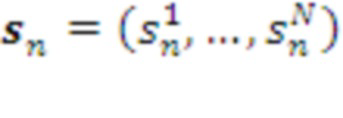 , где
, где 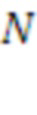 - размерность кода (число модулей) данного слоя
- размерность кода (число модулей) данного слоя
Каждый модуль имеет свой алфавит 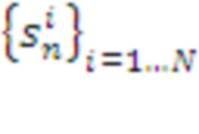
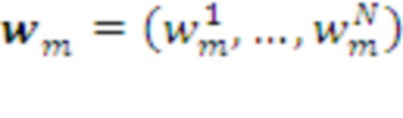 из символов Алфавита данного слоя. Каждая морфема состоит из двух более простых, т.е. представляет собой бинарное дерево с символами Алфавита в качестве его «листьев»
из символов Алфавита данного слоя. Каждая морфема состоит из двух более простых, т.е. представляет собой бинарное дерево с символами Алфавита в качестве его «листьев»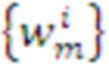 с достаточно большим накопленным подкреплением, используемых Парсером и Памятью данного слоя.
с достаточно большим накопленным подкреплением, используемых Парсером и Памятью данного слоя. 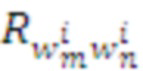 , полученных когда-либо системой при выборе паттерна поведения
, полученных когда-либо системой при выборе паттерна поведения 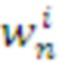 в контексте
в контексте 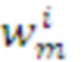 (Здесь - локальная память
(Здесь - локальная память  -го модуля)
-го модуля)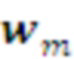 планов поведения
планов поведения 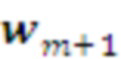 предыдущего слоя L символом
предыдущего слоя L символом 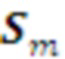 слоя L+1.
слоя L+1.
Кодер может быть реализован с помощью одно- или многослойной искусственной нейронной сети, отображающей строки Памяти, соответствующие морфеме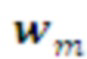 слоя L в символ слоя L+1
слоя L в символ слоя L+1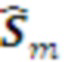 слоя L+1
слоя L+1 вероятностного распределения или ранжированного списка морфем
вероятностного распределения или ранжированного списка морфем 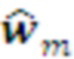 предыдущего слоя L
предыдущего слоя L
Декодер может быть реализован с помощью одно- или многослойной искусственной нейронной сети, отображающей символы слоя L+1 в вероятности или ранжированные списки строк Памяти слоя L, которые Кодер мог бы отобразить в символ
Слой L+1, если требуется, корректирует свой план, и Декодер передает вниз рекомендуемые к исполнению планы слоя L, т.е. морфемы , реализующие следующий шаг плана слоя L+1
Последняя распознанная морфема определяет текущий контекст.
Действуя совместно, Парсеры всех уровней составляют и реализуют долговременные планы с максимальным суммарным подкреплением
ДЕТАЛЬНОЕ ОПИСАНИЕ ЗАЯВЛЕННОГО ИЗОБРЕТЕНИЯ
Накопление Памяти 0-го уровня
Обучение Системы начинается с первичного накопления памяти 0-го уровня под управлением Менеджера офлайн обучения. Последний порождает случайные действия эффекторов Системы и воспринимает результаты этих действий от ее рецепторов. Память 0-го уровня накапливает историю взаимодействий со средой в виде множества многомерных векторов 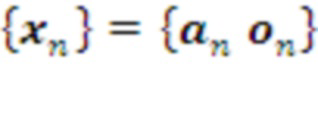 .
.
Смысл этого этапа - накопление данных о причинно-следственных связях между действиями Системы и их влиянием на внешний мир. В отсутствие у Системы априорных знаний ее действия случайны, т.е. все доступные состояния эффекторов равновероятны.
Создание Кодера и Декодера первого и последующих слоев
Когда память предыдущего уровня (начиная с нулевого) наполняется до уровня, удовлетворяющего некоторому критерию (например, число записей больше заданного предела), Менеджер офлайн обучения запускает алгоритм создания пары Кодер-Декодер следующего слоя Системы (начиная с первого).
Кодер представляет хранящиеся в Памяти строки таблицы накопленных подкреплений 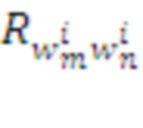 гораздо более компактными наборами дискретных символов (из алфавитов модулей соответствующего слоя) так, чтобы близкие вектора имели одинаковые или близкие коды - чтобы дискретные символы адекватно отражали реальность. Такой тип кодирования известен, как «locality sensitive hashing» или «learning to hash». Таким образом, Кодер приближает аналоговые данные с бесконечным разнообразием - дискретными данными с конечным числом состояний. Тем самым, у Системы появляется возможность запоминать комбинации действий, т.е. планировать поведение.
гораздо более компактными наборами дискретных символов (из алфавитов модулей соответствующего слоя) так, чтобы близкие вектора имели одинаковые или близкие коды - чтобы дискретные символы адекватно отражали реальность. Такой тип кодирования известен, как «locality sensitive hashing» или «learning to hash». Таким образом, Кодер приближает аналоговые данные с бесконечным разнообразием - дискретными данными с конечным числом состояний. Тем самым, у Системы появляется возможность запоминать комбинации действий, т.е. планировать поведение.
Задача Кодера - осуществить подобное дискретное кодирование с минимальными потерями, чтобы соответствующий Декодер мог по этому коду восстановить исходные вектора с минимальной потерей точности.
Для обучения пары Кодер-Декодер можно использовать любой из известных алгоритмов разреженного дискретного кодирования [11]. В случае модульного дизайна Кодер реализуется модулями, каждый из которых осуществляет свой вариант кластеризации данных 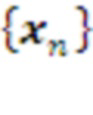 , использующих разные подпространства или разные обучающие подмножества данных. Кодом вектора
, использующих разные подпространства или разные обучающие подмножества данных. Кодом вектора 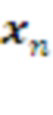 в этом случае является указание номера его кластера в каждом из модулей:
в этом случае является указание номера его кластера в каждом из модулей: 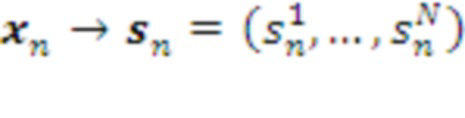 . Восстановленный Декодером исходный вектор в этом случае может быть представлен, например, усредненными координатами центроидов всех кластеров, соответствующих его коду.
. Восстановленный Декодером исходный вектор в этом случае может быть представлен, например, усредненными координатами центроидов всех кластеров, соответствующих его коду.
При формировании 1-го слоя кодируются вектора, представляющие историю взаимодействия Системы со средой: .
При формировании 2-го и последующих слоев многомерные вектора соответствуют контекстам 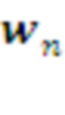 предыдущего слоя и представляют собой хранящиеся в Памяти предыдущего слоя суммарные накопленные подкрепления, соответствующие всем известным вариантам продолжения данного контекста
предыдущего слоя и представляют собой хранящиеся в Памяти предыдущего слоя суммарные накопленные подкрепления, соответствующие всем известным вариантам продолжения данного контекста 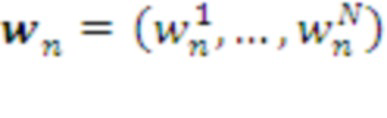 , а именно:
, а именно: 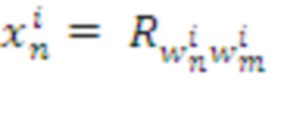 (
(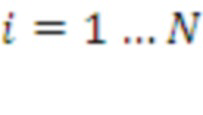 ). Здесь
). Здесь 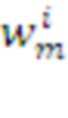 - морфемы из Словаря
- морфемы из Словаря  -го модуля данного слоя. Т.е. размерность вектора равна суммарному размеру Словаря всех модулей данного слоя.
-го модуля данного слоя. Т.е. размерность вектора равна суммарному размеру Словаря всех модулей данного слоя.
Парсинг потока символов в слое
Данные c предыдущего слоя, поступающие в данный слой через его Кодер, представляют собой поток дискретных символов , где  маркирует дискретные моменты времени данного слоя, а - размерность кода (число модулей) этого слоя.
маркирует дискретные моменты времени данного слоя, а - размерность кода (число модулей) этого слоя.
Парсер группирует поступающие от Кодера наборы символов в более крупные токены - морфемы , где 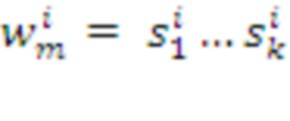 - морфема длины
- морфема длины  из Словаря -го модуля данного слоя. Морфемы представляют собой наиболее полезные с точки зрения суммарного подкрепления последовательности символов и служат ключами к Памяти, хранящей статистику наград , полученных Системой при наблюдавшихся ранее слияниях известных морфем (см. ниже). Каждая известная морфема данного модуля образуется конкатенацией двух его более коротких морфем,
из Словаря -го модуля данного слоя. Морфемы представляют собой наиболее полезные с точки зрения суммарного подкрепления последовательности символов и служат ключами к Памяти, хранящей статистику наград , полученных Системой при наблюдавшихся ранее слияниях известных морфем (см. ниже). Каждая известная морфема данного модуля образуется конкатенацией двух его более коротких морфем, 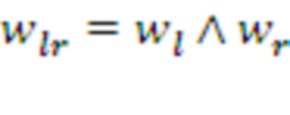 , т.е. представляет собой бинарное дерево с символами Алфавита данного модуля в качестве своих листьев. Набор морфем в Словарях модулей постоянно пополняется, как это будет описано ниже.
, т.е. представляет собой бинарное дерево с символами Алфавита данного модуля в качестве своих листьев. Набор морфем в Словарях модулей постоянно пополняется, как это будет описано ниже.
Парсер представляет собой конечный автомат, преобразующий входную последовательность символов 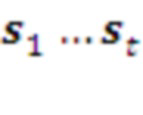 в более короткую последовательность распознанных им морфем
в более короткую последовательность распознанных им морфем 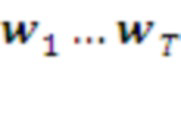 . Возможны различные варианты алгоритмов парсинга, т.е. нахождения локальных оптимумов сложной комбинаторной задачи - построения оптимальной структуры данных [12].
. Возможны различные варианты алгоритмов парсинга, т.е. нахождения локальных оптимумов сложной комбинаторной задачи - построения оптимальной структуры данных [12].
В качестве примера приведем алгоритм Парсера -го порядка, который работает с последней распознанной морфемой (текущим контекстом) и следующими символами, поступающими из входящего потока. На каждом следующем шаге Парсер находит наилучший вариант разбора последовательности длиной 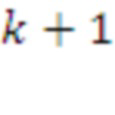 , дающий максимальную ожидаемую награду
, дающий максимальную ожидаемую награду 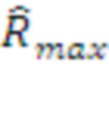 - бинарное дерево с максимальной суммой ожидаемых наград всех его ветвлений, согласно эмпирическим оценкам наград из Памяти данного слоя.
- бинарное дерево с максимальной суммой ожидаемых наград всех его ветвлений, согласно эмпирическим оценкам наград из Памяти данного слоя.
Например, Рис. 5 иллюстрирует алгоритм работы Парсера 2-го порядка, на каждом шаге которого происходит сравнение двух вариантов дерева разбора (500 и 510). В выбранном варианте с наибольшим подкреплением происходит либо слияние поступающих символов (501), либо расширение контекста 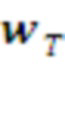 (511). Если слияние невозможно (соответствующие морфемы отсутствуют в Словаре), прежний контекст считается распознанным и передается на более высокий уровень, и начинается формирование нового текущего контекста
(511). Если слияние невозможно (соответствующие морфемы отсутствуют в Словаре), прежний контекст считается распознанным и передается на более высокий уровень, и начинается формирование нового текущего контекста 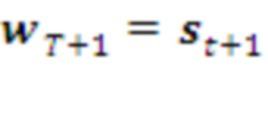 (502 или 512). Из них выбирается тот, которому соответствует максимальная оценка суммарной награды:
(502 или 512). Из них выбирается тот, которому соответствует максимальная оценка суммарной награды:
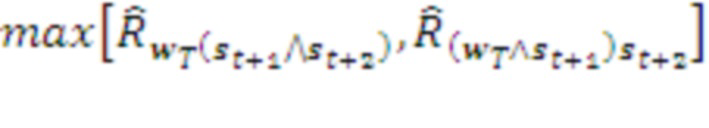
Здесь операция max производится в каждом модуле независимо, а значения 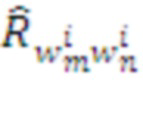 получаются из хранимых в Памяти модулей значений с помощью процедуры Томпсоновского сэмплирования - выбора случайной величины
получаются из хранимых в Памяти модулей значений с помощью процедуры Томпсоновского сэмплирования - выбора случайной величины 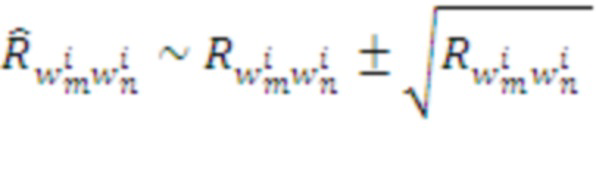 , отражающей разброс оценок ожидаемых наград при конечном размере выборки.
, отражающей разброс оценок ожидаемых наград при конечном размере выборки.
Каждый шаг парсинга (с образованием новой морфемы или без него) сопровождается коррекцией параметров Памяти:
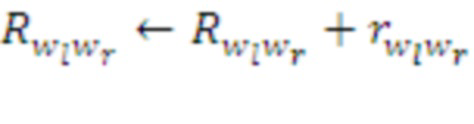
Где 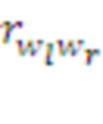 - суммарное подкрепление, полученное в данном эпизоде парой морфем
- суммарное подкрепление, полученное в данном эпизоде парой морфем 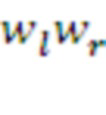 :
:
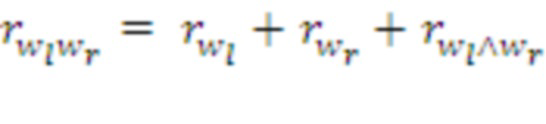
Здесь 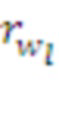 ,
, 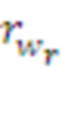 - подкрепления, полученные морфемами
- подкрепления, полученные морфемами 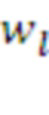 ,
, 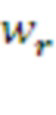 до их слияния, а
до их слияния, а 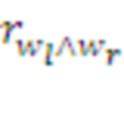 - подкрепление непосредственно в момент их слияния.
- подкрепление непосредственно в момент их слияния.
Кроме коррекции значений параметров Памяти, в ходе обучения увеличивается и объем Словаря. А именно, список морфем пополняется комбинациями уже известных морфем, которые преодолели заданный порог накопленных при их слияниях подкреплений:
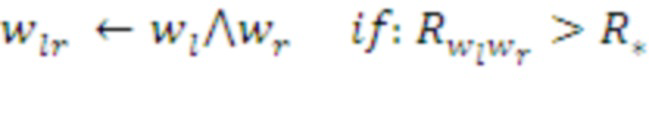
Впоследствии слияния таких морфем порождают новую морфему - их конкатенацию.
Формирование долговременного плана поведения в верхнем слое
Планирование поведения происходит сверху-вниз, начиная с верхнего слоя. Парсер верхнего слоя составляет план действий, предсказывая оптимальную морфему, следующую за последней распознанной им морфемой, представляющей актуальный контекст.
В момент, когда очередная морфема распознана, т.е. сформирован новый контекст , Парсер делает предсказание о следующей возможной морфеме. Для этого он запрашивает у Памяти ранжированный список оценок 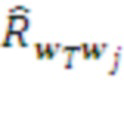 ожидаемого подкрепления для морфем-кандидатов
ожидаемого подкрепления для морфем-кандидатов 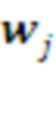 и выбирает из них те, для которых ожидаемая награда максимальна. Соответствующая морфема становится его текущим планом действий, посимвольно транслируемым нижележащему слою:
и выбирает из них те, для которых ожидаемая награда максимальна. Соответствующая морфема становится его текущим планом действий, посимвольно транслируемым нижележащему слою:
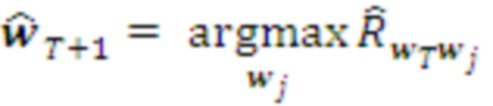
Верхний слой учитывает наиболее широкий контекст и формирует соответствующий ему долговременный план. Остальные слои стремятся его осуществить, адаптируясь к постоянно меняющейся обстановке.
Согласование планов между слоями Системы
Планирование поведения в остальных слоях Системы происходит путем согласования плана, спущенного сверху, и оперативной информации, полученной снизу.
Вышележащий слой передает нижележащему на исполнение очередной шаг своего текущего плана через свой Декодер. Последний декодирует этот шаг в возможные варианты его реализации 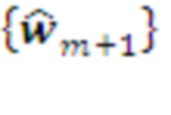 на уровне
на уровне  (220 на Рис. 2), ранжированные по степени их соответствия спущенному сверху плану. Например, когда кодирование осуществляется с помощью модулей, варианты реализации ранжируются по числу модулей, «голосующих» за каждый из них, т.е. количество общих компонент у и
(220 на Рис. 2), ранжированные по степени их соответствия спущенному сверху плану. Например, когда кодирование осуществляется с помощью модулей, варианты реализации ранжируются по числу модулей, «голосующих» за каждый из них, т.е. количество общих компонент у и 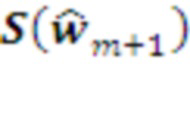 .
.
Планирование в простейшем случае сводится к выбору первого из ранжированного списка набора морфем 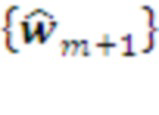 уровня , который и становится текущим планом уровня , транслируемым посимвольно
уровня , который и становится текущим планом уровня , транслируемым посимвольно 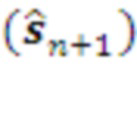 нижележащему уровню
нижележащему уровню 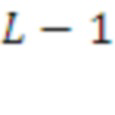 (221 на Рис. 2). Возможны и более сложные алгоритмы согласования планов, основанные не на ранжировании списка, а на присвоении им различных весов, исходя из вероятностного подхода.
(221 на Рис. 2). Возможны и более сложные алгоритмы согласования планов, основанные не на ранжировании списка, а на присвоении им различных весов, исходя из вероятностного подхода.
Навстречу с уровня через Кодер уровня поступает оперативная информация 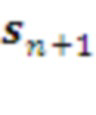 из внешнего мира. Если
из внешнего мира. Если 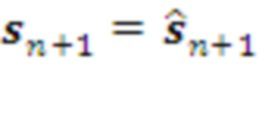 , текущий план остается неизменным. В противном случае
, текущий план остается неизменным. В противном случае 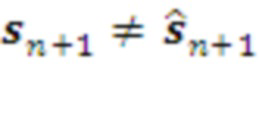 он корректируется. А именно, из ранжированного списка выбирается первый член, соответствующий текущим наблюдениям
он корректируется. А именно, из ранжированного списка выбирается первый член, соответствующий текущим наблюдениям 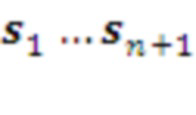 . Если таковой отсутствует, оптимальный план уровня формируется им самостоятельно, как в случае верхнего уровня:
. Если таковой отсутствует, оптимальный план уровня формируется им самостоятельно, как в случае верхнего уровня:
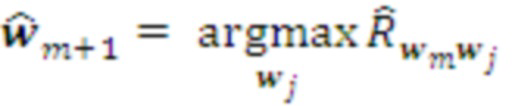
Декодер 1-го слоя декодирует очередной шаг своего плана в сенсомоторный вектор 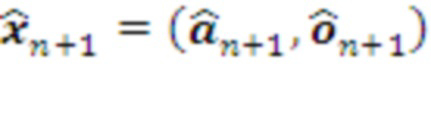 , соответствующий следующим действиям
, соответствующий следующим действиям 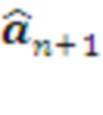 актуаторов и предсказанию следующих наблюдений сенсоров
актуаторов и предсказанию следующих наблюдений сенсоров 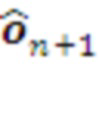 .
.
Таким образом каждый слой Системы стремится к достижению долговременных планов, спущенных сверху, с учетом актуальной информации, полученной снизу.
Дообучение Системы в режиме офлайн
В определенные моменты времени, по расписанию или в соответствии с заданными критериями (например, количеству обновлений содержания Памяти), система (или ее копия, пока оригинал занят текущим управлением поведением) на время переходит в специальный режим «сна» для офлайн обучения под управлением Менеджера офлайн обучения. В этом режиме корректируются настроечные параметры Кодеров и Декодеров слоев (всех или выборочно), т.е. корректируются значения дискретных символов в соответствии с обновленным содержанием Памяти слоев.
Например, в описанном выше случае, когда кодирование сводится к кластеризации векторов, соответствующих строкам Памяти, корректируются координаты центроидов соответствующих кластеров. Например, проводится одна или несколько итераций алгоритма K-means [13], начиная с текущих положений центроидов кластеров.
ПРИМЕРЫ РЕАЛИЗАЦИИ ПРЕДЛОЖЕННОГО ИЗОБРЕТЕНИЯ
ПРИМЕР 1. Предлагаемое изобретение представляет собой универсальный обучающийся контроллер, способный управлять объектами самого разного рода. В частности, компания Google использовала алгоритмы обучения с подкреплением своей дочерней компании DeepMind для управления системой охлаждения своих дата центров, добившись за счет этого 40% экономии электроэнергии [14].
Рассмотрим на этом примере применение предлагаемого изобретения в сравнении с традиционным подходом теории управления. Последний характеризуется:
• наличием упрощенной модели управляемого объекта (как правило, линейной),
• заранее рассчитанным по этой модели «оптимальным» планом управления (как следствие, являющимся лишь приближением оптимального),
• петлей обратной связи, минимизирующей отклонение реальной ситуации от запланированной.
Использование предложенного в данном изобретении способа управления с упреждением с помощью обучающегося контроллера позволяет:
• обойтись без предварительного создания упрощенной модели управляемого объекта (Система сама создаст соответствующую сложную нелинейную модель в своем внутреннем представлении в ходе взаимодействия с объектом управления),
• обойтись без приближенного решения задачи оптимизации (Система сама найдет оптимальный по заданному критерию способ управления объектом без упрощающих предположений),
• осуществлять управление не реактивно (после обнаружения отклонений), а проактивно (прогнозируя возможные сценарии развития событий).
В данном примере система управления представляет собой очень сложный объект, состоящий из многих тысяч кулеров, теплообменников, насосов и градирен, который очень сложно описать с помощью уравнений, и еще сложнее рассчитать для такой модели оптимальный план. К тому же, для каждого дата центра комбинация его элементов управления и сенсоров, как правило, уникальна [15].
Предлагаемая в данном изобретении Система может быть использована для оптимизации энергопотребления дата центром следующим образом.
• На стадии предварительного обучения Система обучается копировать существующий алгоритм управления дата центром. На этом этапе Система ничем реально не управляет и игнорирует показания потребления электроэнергии, получая подкрепления лишь в случае удачно предсказанных следующие действия эффекторов 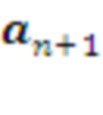 и показаний рецепторов
и показаний рецепторов 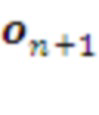 . После того, как Система обучится копировать существующую управляющую систему, ее можно без существенного риска допустить до реального управления.
. После того, как Система обучится копировать существующую управляющую систему, ее можно без существенного риска допустить до реального управления.
• На стадии оптимизации Система получает отрицательные подкрепления пропорционально реальному уровню энергопотребления дата центра, и постепенно корректирует свое управление таким образом, чтобы его минимизировать. При этом, у нее формируется иерархическая модель управления, основанная на долгосрочном планировании, например, с учетом прогнозирования дневных, недельных и годовых колебаний внешней температуры и уровня нагрузок данного дата центра.
В итоге любой сколь угодно сложно устроенный дата центр с помощью предлагаемого изобретения сможет обучаться подбирать оптимальный для себя режим энергопотребления.
Аналогичные применения могут относиться и к управлению другими сложными системами, например к оптимизации сложных многостадийных процессов нефтепереработки для достижения более глубоких стадий переработки нефтей [16].
ПРИМЕР 2. Предлагаемое изобретение может работать как с аналоговыми данными (как в Примере 1), так и с символьной информацией. Например, обе компоненты информационного обмена с внешней средой 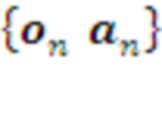 могут быть символами, осуществляющими прием и передачу текстовой информации. В этом случае предлагаемое изобретение описывает устройство и метод построения т.н. языковой модели (language model), способной обучаться понимать и генерировать сообщения на естественных языках.
могут быть символами, осуществляющими прием и передачу текстовой информации. В этом случае предлагаемое изобретение описывает устройство и метод построения т.н. языковой модели (language model), способной обучаться понимать и генерировать сообщения на естественных языках.
Языковые модели широко применяются на практике в системах автоматической обработки текстов и речи, например, в машинном переводе [17]. Повышению качества языковых моделей способствовало развитие в последние годы методов глубокого обучения [18]. Лучшие языковые модели сегодня способны генерировать тексты, которые трудно отличить от созданных человеком [19].
В качестве языковой модели предлагаемое изобретение можно использовать, как диалоговый человеко-машинный интерфейс на естественном языке для различных информационных сервисов. Например, следующим образом.
• На стадии предварительного обучения Система самостоятельно обучается воспроизводить входной поток символов с минимальными ошибками, т.е. учится генерировать тексты на естественном языке, обучаясь на больших объемах текстовой информации. На этом этапе в Системе формируется иерархия языковых понятий, помогающих ей правильно воспроизводить известные слова, понимать их смысл, составлять из них грамматически правильные фразы и предложения и сопрягать отдельные предложения в связные тексты. После того, как Система обучится генерировать связные тексты, основанные на информации из обучающей выборки, ее можно обучить выдавать эту информацию в процессе диалога с пользователем.
• Для этого предварительно обученная Система дообучается в режиме диалога, получая подкрепления всякий раз, когда она генерирует правильные реплики, например, ответы на заданные пользователем вопросы. Для обучения можно использовать как накопленные записи диалогов, так и реальные диалоги с пользователями. На этом этапе в Системе формируются и усиливаются паттерны, соответствующие культуре ведения диалогов (когда можно начинать отвечать на вопрос, насколько краткими должны быть ответы, как задавать уточняющие вопросы и т.д.).
Обученную таким образом Систему можно использовать в качестве интеллектуальных агентов для обслуживания пользователей на естественном языке в информационно-справочных системах и голосовых интерфейсах на мобильных устройствах.
Источники информации
1. Schmidhuber J. Deep learning in neural networks: An overview //Neural networks. - 2015. - Т. 61. - С. 85-117.
2. Mousavi S.S., Schukat M., Howley E. Deep reinforcement learning: an overview //Proceedings of SAI Intelligent Systems Conference. - Springer, Cham, 2016. - С. 426-440.
3. Silver D. et al. Mastering the game of Go without human knowledge //Nature. - 2017. - Т. 550. - №. 7676. - С. 354.
4. Commons, M.L., and White, M.S. 2006. Intelligent control with hierarchical stacked neural networks. U.S. Pat. No. 7,152,051, filed Sep. 30, 2002, and issued Dec. 19, 2006.
5. Wu Y. et al. Google's neural machine translation system: Bridging the gap between human and machine translation //arXiv preprint arXiv:1609.08144. - 2016.
6. Shumsky, S.A. Scalable Natural Language Understanding: From Scratch, On the Fly. The Proceedings of the 2018 International Conference on Artificial Intelligence Applications and Innovations, 30 Oct - 2 Nov 2018, Nicosia, Cyprus. ISBN: 978-1-7281-0412-6.
7. Ghavamzadeh, M. et al. Bayesian reinforcement learning: A survey. Foundations and Trends® in Machine Learning 8.5-6 (2015): 359-483.
8. Agrawal S., Goyal N. Further optimal regret bounds for Thompson sampling //Artificial Intelligence and Statistics. - 2013. - С. 99-107.
9. Osband, I.D.M., Van Roy, B. Systems and Methods for Providing Reinforcement Learning in a Deep Learning System, 2016. US20170032245A1.
10. Graepel T.K.H., et al. Selecting actions to be performed by a reinforcement learning agent using tree search, 2016. US20180032864A1.
11. Wang J. et al. A survey on learning to hash // IEEE Transactions on Pattern Analysis and Machine Intelligence. - 2018. - Т. 40. - №. 4. - С. 769-790.
12. Gonzalez R.C., Thomason M.G. Syntactic pattern recognition: An introduction. - 1978.
13. Kanungo T. et al. An efficient k-means clustering algorithm: Analysis and implementation // IEEE Transactions on Pattern Analysis & Machine Intelligence. - 2002. - №. 7. - С. 881-892.
14. Evans R. and Gao J. DeepMind AI Reduces Google Data Centre Cooling Bill by 40%// DeepMind. - 2016 https://deepmind.com/blog/deepmind-ai-reduces-google-data-centre-cooling-bill-40/.
15. Dayarathna M., Wen Y., Fan R. Data center energy consumption modeling: A survey //IEEE Communications Surveys & Tutorials. - 2015. - Т. 18. - № 1. - С. 732-794.
16. Галиев Р.Г., Хавкин В.А., Данилов А.М. О задачах российской нефтепереработки //Мир нефтепродуктов. Вестник нефтяных компаний. - 2009. - №. 2. - С. 3-7.
17. Brants T. et al. Large language models in machine translation // Proceedings of the 2007 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning (EMNLP-CoNLL). - 2007. - С. 858-867.
18. Jozefowicz R. et al. Exploring the limits of language modeling // arXiv preprint arXiv:1602.02410. - 2016.
19. Radford A. et al. Language models are unsupervised multitask learners // OpenAI Blog. - 2019. - Т. 1. - С. 8.
| название | год | авторы | номер документа |
|---|---|---|---|
| Компьютерная система и способ для обнаружения вредоносных программ с использованием машинного обучения | 2021 |
|
RU2802860C1 |
| СПОСОБ И УСТРОЙСТВО АДАПТИВНОГО АВТОМАТИЗИРОВАННОГО УПРАВЛЕНИЯ СИСТЕМОЙ ОТОПЛЕНИЯ, ВЕНТИЛЯЦИИ И КОНДИЦИОНИРОВАНИЯ | 2021 |
|
RU2784191C1 |
| СПОСОБ АВТОМАТИЗАЦИИ СКВОЗНОГО (END-TO-END) ТЕСТИРОВАНИЯ С ПОМОЩЬЮ МОДЕЛИ МАШИННОГО ОБУЧЕНИЯ | 2024 |
|
RU2839253C1 |
| ОПТИЧЕСКОЕ РАСПОЗНАВАНИЕ СИМВОЛОВ ПОСРЕДСТВОМ КОМБИНАЦИИ МОДЕЛЕЙ НЕЙРОННЫХ СЕТЕЙ | 2020 |
|
RU2768211C1 |
| Способ для создания контроллеров управления шагающими роботами на основе обучения с подкреплением | 2022 |
|
RU2816639C1 |
| СПОСОБ И СИСТЕМА ДЛЯ ОБУЧЕНИЯ МОДЕЛИ МАШИННОГО ОБУЧЕНИЯ ДЛЯ ПЕРЕВОДА | 2023 |
|
RU2835121C1 |
| СПОСОБ И СИСТЕМА ОБУЧЕНИЯ СИСТЕМЫ ЧАТ-БОТА | 2023 |
|
RU2820264C1 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ ЭНТРОПИЙНОГО КОДИРОВАНИЯ С ИСПОЛЬЗОВАНИЕМ ИЕРАРХИЧЕСКОЙ ЕДИНИЦЫ ДАННЫХ И СПОСОБ И УСТРОЙСТВО ДЛЯ ДЕКОДИРОВАНИЯ | 2012 |
|
RU2597494C2 |
| СПОСОБ ВЫРАВНИВАНИЯ ПО СЛОЯМ В КОДИРОВАННОМ ВИДЕОПОТОКЕ | 2020 |
|
RU2803890C1 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ ЭНТРОПИЙНОГО КОДИРОВАНИЯ С ИСПОЛЬЗОВАНИЕМ ИЕРАРХИЧЕСКОЙ ЕДИНИЦЫ ДАННЫХ И СПОСОБ И УСТРОЙСТВО ДЛЯ ДЕКОДИРОВАНИЯ | 2012 |
|
RU2635893C1 |

Изобретение относится к способу и системе машинного обучения с подкреплением, т.е. формирования алгоритма целенаправленного поведения системы с максимальным ожидаемым долговременным выигрышем на основании внешних подкрепляющих сигналов. Предложен метод поэтапного обучения все более сложным и протяженным во времени поведенческим навыкам и использования их для составления и коррекции долговременных планов. Целенаправленное поведение формируется иерархической обучающейся системой, в которой каждый иерархический уровень ответственен за свой временной масштаб поведения. Технический результат заключается в сокращении времени обучения системы. 2 н. и 6 з.п. ф-лы, 5 ил. 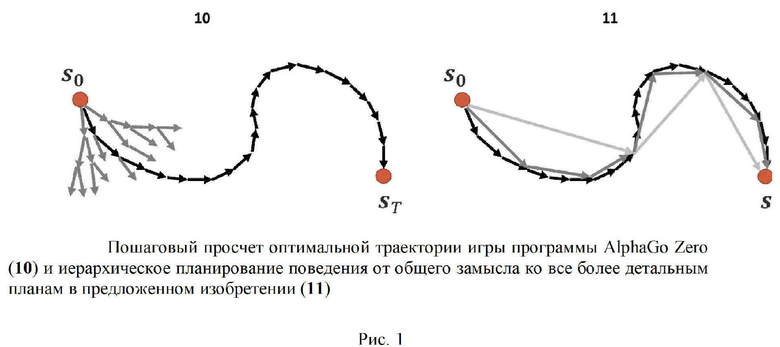
1. Компьютерно-реализуемый способ машинного обучения обучающейся системы с подкреплением, содержащий по меньшей мере один процессор и средства хранения информации, управляющие поведением управляемой системы на основе входной информации от сенсоров управляемой системы, включая подкрепляющие сигналы о значимых для достижения заданной цели результатах поведения, генерируя управляющие сигналы актуаторам управляемой системы, определяющим ее поведение, где обучающаяся система состоит из конечного числа вычислительных слоев, каждый из которых содержит: Кодер (200), кодирующий поступающую с нижележащего слоя входную информацию одним из входных состояний данного слоя; Память (210), хранящую статистику типовых цепочек состояний данного слоя; Парсер (211), разбивающий поток входных состояний на типовые цепочки состояний, хранимые в Памяти, передающий информацию о них вышележащему слою, принимающий от вышележащего слоя, если таковой существует, набор рекомендованных цепочек выходных состояний (220), и сопоставляя его с входной информацией, выбирающий выходное состояние данного слоя (221); Декодер (201), переводящий выходное состояние данного слоя в управляющий сигнал для нижележащего слоя, представляющий собой набор рекомендованных цепочек выходных состояний нижележащего слоя; отличается тем, что вычислительные слои, в совокупности, реализуют иерархию автоматически генерируемых вложенных друг в друга разномасштабных планов достижения цели, адаптирующихся к изменяющимся внешним обстоятельствам путем коррекции управляющих сигналов вышележащих вычислительных слоев с учетом входной информации от нижележащих, и постепенно увеличивают количество уровней иерархии по мере накопления информации о взаимодействии с внешней средой.
2. Способ по п.1, отличающийся тем, что управляющая система наряду с управляющими сигналами генерирует прогноз входных сенсорных сигналов на следующем шаге, и в случаях осуществления прогнозируемого хода развития событий внешние подкрепляющие сигналы дополняют внутренними подкреплениями.
3. Способ по любому из пп.1, 2, отличающийся тем, что управляющие сигналы на каждом уровне иерархии генерируются с учетом статистической неопределенности содержания Памяти при помощи Томпсоновского сэмплирования данных из Памяти каждого уровня.
4. Способ по любому из пп.1, 2, отличающийся тем, что на каждом уровне иерархии новые типовые цепочки символов создают путем добавления в Память комбинаций из уже известных цепочек символов с наибольшей суммой подкреплений.
5. Система для обучения иерархическому целесообразному поведению, содержащая по меньшей мере один процессор, компьютерную память, сетевую инфраструктуру, средства хранения информации, выполненные с возможностью осуществления иерархической послойной обработки входной сенсорной информации из более низкого уровня, включая внешнюю среду, как нулевой уровень, и управляющих сигналов с более высокого уровня и выработки управляющих сигналов более низкому уровню, а также накопления опыта взаимодействия с внешней средой, реализующая компьютерно-реализуемый способ машинного обучения обучающейся системы по п.1 формулы.
6. Система п.5, отличающаяся тем, что обработка информации на каждом иерархическом уровне производится набором программно-аппаратных модулей, работающих параллельно и независимо друг от друга.
7. Система по любому из пп.5, 6, отличающаяся тем, что система или ее отдельные компоненты реализованы аппаратно в виде специализированных микросхем соответствующей архитектуры.
8. Система по любому из пп.5-7, отличающаяся тем, что система реализована в клиент-серверной архитектуре и все блоки соединены между собой стандартизированными каналами связи.
| Автомобиль-сани, движущиеся на полозьях посредством устанавливающихся по высоте колес с шинами | 1924 |
|
SU2017A1 |
| Способ получения цианистых соединений | 1924 |
|
SU2018A1 |
| СИСТЕМА И СПОСОБ ДЛЯ ХРАНЕНИЯ И ОБРАБОТКИ ДАННЫХ | 2017 |
|
RU2670781C9 |
| СПОСОБ ИНТЕРПРЕТАЦИИ ИСКУССТВЕННЫХ НЕЙРОННЫХ СЕТЕЙ | 2018 |
|
RU2689818C1 |

