Перекрестные ссылки на смежные заявки
Настоящее описание основано на предварительной заявке на патент Китая № 2023103874726, поданной в Национальное управление интеллектуальной собственности Китая 12 апреля 2023 г. и озаглавленной «Method for Detecting Hyperspectral Image Anomaly Based On Teacher-Student Model, Computer Storage Medium and Device», описание которой полностью включено в настоящий документ путем ссылки, и испрашивает приоритет по ней.
ОБЛАСТЬ ТЕХНИКИ
Настоящее описание относится к способу обнаружения аномалии изображения, в частности к способу обнаружения аномалии гиперспектрального изображения на основе модели «обучающий-обучаемый», компьютерному носителю данных и устройству.
ПРЕДПОСЫЛКИ СОЗДАНИЯ ИЗОБРЕТЕНИЯ
С развитием пилотируемой аэрокосмической техники бортовые системы визуализации становятся все более совершенными и создается все больше изображений гиперспектрального разрешения (далее — гиперспектральные изображения). Гиперспектральные изображения, как правило, обладают очень высокой информативностью, имея сотни последовательных узких полос, составляющих их спектральные размерности, при этом диапазон длин волн включает ультрафиолетовый, видимый, ближний инфракрасный, короткий инфракрасный и средний инфракрасный диапазоны. Гиперспектральные изображения имеют большее количество полос, чем мультиспектральные, так что они содержат более подробную информацию об объекте. Гиперспектральные изображения часто используют для различных задач обнаружения, таких как классификация изображений, обнаружение объекта и обнаружение аномалий.
Целью обнаружения аномалии изображения, по существу, является идентификация аномальных объектов, признаки которых значительно отличаются от соседних пикселей или глобального фона. Аномальная цель может представлять собой аномалию спектрального признака или аномалию пространственного признака; аномалия не относится к конкретному пикселю, она может представлять собой пиксель, или множество пикселей, или признак, или множество разных признаков. В практических применениях обнаружение аномалии изображения может представлять собой быструю и простую работу по отсеиванию до обнаружения объекта; сначала подозрительные объекты со значительными отличиями от фона быстро отсеивают с последующим уточненным обнаружением объекта, например сопоставлением с априорной информацией об объектах для различения объектов.
В существующих способах обнаружения аномалий на основе глубокого обучения приоритет отдают генеративным моделям, таким как автокодировщики или генеративно-состязательные сети. В этих способах стараются не использовать какие-либо предварительные знания об изображении, обучаться с нуля и обнаруживать аномалии путем сравнения исходного изображения с восстановленным изображением, однако существуют следующие проблемы: при сравнении используется простое сравнение на уровне пикселей, информация в пространственной области не учитывается, при восстановлении изображения обязательно присутствуют дефекты, и эти проблемы в некоторой степени ограничивают эффективность обнаружения этими способами.
Andrews et al. пытались сместить векторы эмбеддинга предварительно обученной сети в задачу обнаружения аномалии посредством выполнения подгонки неглубокого машинного обучения на признаках обучающих данных без аномалии и достигли хороших результатов; однако они применяют этот способ только для классификации изображений и не учитывают проблему обнаружения аномалии (см. Jerone TA Andrews, Thomas Tanay, Edward J Morton, and Lewis D Griffin. Transfer RepresentationLearning for Anomaly Detection. In Anomaly Detection Workshop at ICML 2016, 2016).
Аналогичные эксперименты выполняли Burlina et al., и, согласно их результатам, эффективность применения таких отличительных векторов эмбеддинга выше по сравнению с пространством признаков, полученным из генеративных моделей, но не в полной мере использует информацию о пространственной и спектральной областях (см. Philippe Burlina, Neil Joshi, and I-Jeng Wang. Where’s Wally Now Deep Generative and Discriminative Embeddings for Novelty Detection. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2019).
ИЗЛОЖЕНИЕ СУЩНОСТИ ИЗОБРЕТЕНИЯ
Целью настоящего описания является решение технических проблем, связанных с тем, что информация сравнения не является исчерпывающей и эффективность обнаружения ограничена из-за дефектов восстановленного изображения при обнаружении существующей аномалии гиперспектрального изображения, и предложение способа обнаружения аномалии гиперспектрального изображения на основе модели «обучающий-обучаемый», компьютерного носителя данных и устройства.
Технические решения, предложенные в настоящем описании, представляют собой:
способ обнаружения аномалии гиперспектрального изображения на основе модели «обучающий-обучаемый», включающий следующие стадии:
стадию S1 — построение модели обучающей сети и модели обучаемой сети;
стадию S2 — повторяющееся множество раз обучение модели обучающей сети с помощью меченых обучающих данных модели обучающей сети с проверочными аномальными данными, причем функция потерь Losst на момент обучения имеет вид: 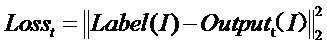 , до тех пор, пока функция потерь Losst не перестанет падать более чем на 0,1 процента за 5 циклов обучения, завершая обучение модели обучающей сети;
, до тех пор, пока функция потерь Losst не перестанет падать более чем на 0,1 процента за 5 циклов обучения, завершая обучение модели обучающей сети;
где 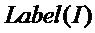 представляет собой метку обучающих данных модели обучающей сети, а
представляет собой метку обучающих данных модели обучающей сети, а 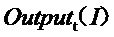 представляет собой выводимые данные обучающих данных модели обучающей сети через модель обучающей сети;
представляет собой выводимые данные обучающих данных модели обучающей сети через модель обучающей сети;
стадию S3 — выбор нормальных данных для формирования обучающих данных модели обучаемой сети;
стадию S4 — ввод обучающих данных модели обучаемой сети в модель обучающей сети, обученную на стадии S2, и получение эмбеддинга, выведенного моделью обучающей сети; одновременно ввод обучающих данных модели обучаемой сети в модель обучаемой сети, получение эмбеддинга, выведенного моделью обучаемой сети, выполнение обучения модели обучаемой сети множество раз, причем функция потерь Losss на момент обучения имеет вид: 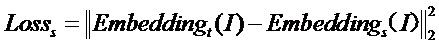 , до тех пор, пока функция потерь Losss не перестанет падать более чем на 0,1 процента за 5 циклов обучения, завершение обучения модели обучаемой сети;
, до тех пор, пока функция потерь Losss не перестанет падать более чем на 0,1 процента за 5 циклов обучения, завершение обучения модели обучаемой сети;
где 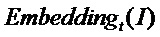 представляет собой эмбеддинг, выведенный моделью обучающей сети, а
представляет собой эмбеддинг, выведенный моделью обучающей сети, а 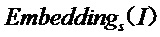 представляет собой эмбеддинг, выведенный моделью обучаемой сети;
представляет собой эмбеддинг, выведенный моделью обучаемой сети;
стадию S5 — ввод подлежащих обнаружению данных в модель обучающей сети, обученную на стадии S2, и в модель обучаемой сети, обученную на стадии S4, для обнаружения аномалии, и функция оценки аномалии имеет вид:
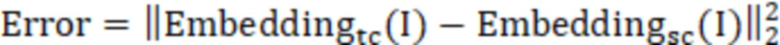 ,
,
где Error представляет собой оценку аномалии, 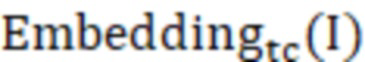 представляет собой эмбеддинг, выведенный моделью обучающей сети после ввода подлежащих обнаружению данных, а
представляет собой эмбеддинг, выведенный моделью обучающей сети после ввода подлежащих обнаружению данных, а 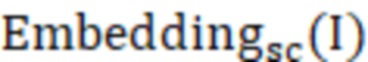 представляет собой эмбеддинг, выведенный моделью обучаемой сети после ввода подлежащих обнаружению данных; и
представляет собой эмбеддинг, выведенный моделью обучаемой сети после ввода подлежащих обнаружению данных; и
вычисление для получения оценки аномалии и определение того, что соответствующий пиксель представляет собой аномальный пиксель, в соответствии с предварительно заданным пороговым значением T оценки аномалии, в случае если оценка аномалии больше или равна пороговому значению T; в случае если оценка аномалии меньше порогового значения T, определение того, что соответствующий пиксель представляет собой нормальный пиксель.
В некоторых вариантах осуществления на стадии S1 построение модели обучающей сети и модели обучаемой сети предусматривает следующее:
архитектура модели обучающей сети включает в себя трехуровневую сверточную нейронную сеть, четыре линейных уровня и уровень нормализации, которые расположены последовательно; трехуровневая сверточная нейронная сеть используется для извлечения признаков, а сверточная нейронная сеть первого уровня представляет собой трехмерную свертку, используемую для одновременного извлечения пространственной информации и спектральной информации; и
архитектура модели обучаемой сети включает в себя одноуровневую сверточную нейронную сеть и два линейных уровня, которые расположены последовательно.
В некоторых вариантах осуществления на стадии S2 обучающие данные модели обучающей сети представляют собой один или более наборов данных; и
множество наборов данных соответствует множеству разных сценариев.
В некоторых вариантах осуществления на стадии S3 обучающие данные модели обучаемой сети удовлетворяют следующему:
подлежащие обнаружению данные содержат n типов фоновых данных, а обучающие данные модели обучаемой сети содержат нормальные данные из n типов фоновых данных.
В некоторых вариантах осуществления на стадии S4 эмбеддинг, выведенный моделью обучающей сети, выводится третьим линейным уровнем из четырех линейных уровней.
В некоторых вариантах осуществления на стадии S5 ввод подлежащих обнаружению данных в обученную модель обучающей сети со стадии S2 и обученную модель обучаемой сети со стадии S4 конкретно включает в себя:
ввод каждого подлежащего обнаружению пикселя и восьми смежных с ним пикселей в подлежащих обнаружению данных в квадрат данных размерами 3 * 3 в пространственной области в качестве блока ввода, который вводят в модель обучающей сети и модель обучаемой сети после завершения обучения.
В настоящем описании также предложен компьютерный носитель данных, содержащий в себе компьютерную программу, которая при исполнении процессором реализует стадии вышеописанного способа обнаружения аномалии гиперспектрального изображения на основе модели «обучающий-обучаемый».
В настоящем описании также предложено компьютерное устройство, содержащее процессор, запоминающее устройство, подключенное к процессору, и компьютерную программу, исполняемую процессором, и компьютерная программа при исполнении процессором реализует стадии вышеописанного способа обнаружения аномалии гиперспектрального изображения на основе модели «обучающий-обучаемый».
Преимущественные эффекты изобретения
Настоящее описание относится к способу обнаружения аномалии гиперспектрального изображения на основе модели «обучающий-обучаемый», при этом принимают сетевую модель «обучающий-обучаемый», полностью применяют информацию о пространственной и спектральной области в гиперспектральном изображении, вектор эмбеддинга модели обучающей сети переводят в задачу обнаружения гиперспектральной аномалии, получают более быстрое обнаружение аномалии на гиперспектральных изображениях в случае, когда получение меченых данных затруднено, и результаты обнаружения получают с высокой точностью, причем способ может быть широко применен для контроля различных видов внешних воздействий, и приспособляемость к внешним воздействиям сильна.
КРАТКОЕ ОПИСАНИЕ ГРАФИЧЕСКИХ МАТЕРИАЛОВ
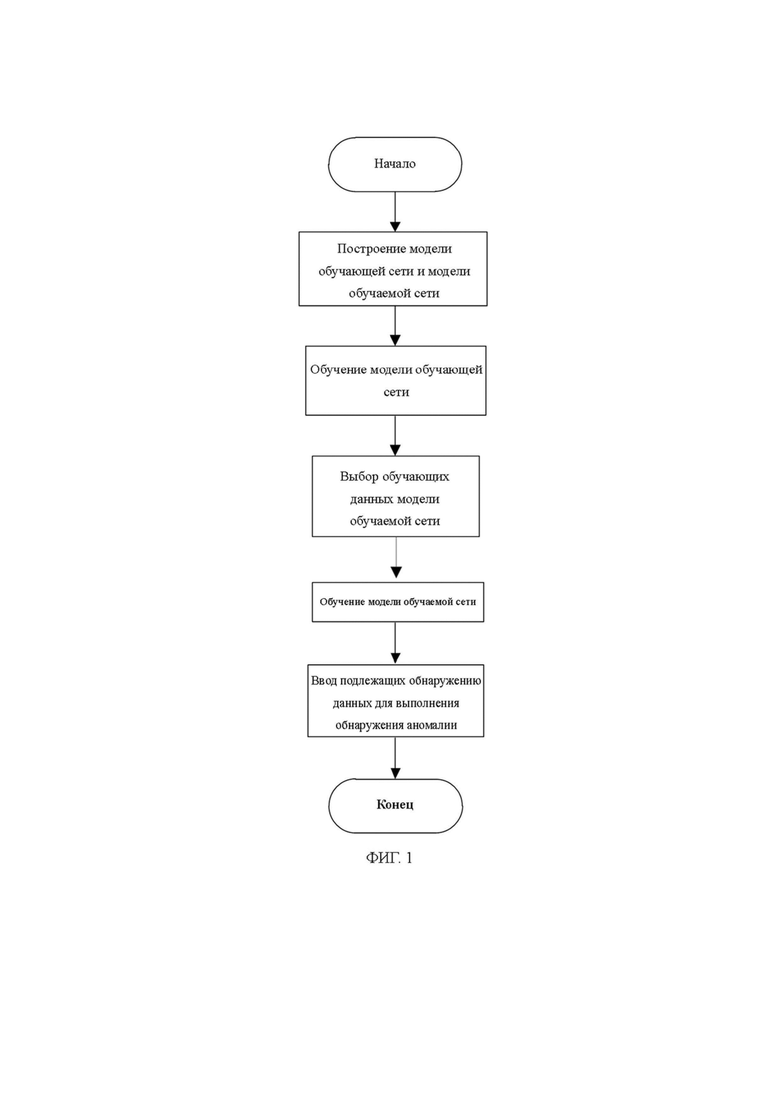
На ФИГ. 1 представлена блок-схема варианта осуществления способа обнаружения аномалии гиперспектрального изображения на основе модели «обучающий-обучаемый» в соответствии с настоящим описанием;
на ФИГ. 2 представлены гиперспектральное изображение (A) по первому сценарию для аэропорта и диаграмма (B) вероятности обнаружения по первому сценарию для аэропорта в наборе данных ABU в варианте осуществления настоящего описания;
на ФИГ. 3 представлены гиперспектральное изображение (A) по второму сценарию для аэропорта и диаграмма (B) вероятности обнаружения по второму сценарию для аэропорта в наборе данных ABU в варианте осуществления настоящего описания;
на ФИГ. 4 представлены гиперспектральное изображение (A) по третьему сценарию для аэропорта и диаграмма (B) вероятности обнаружения по третьему сценарию для аэропорта в наборе данных ABU в варианте осуществления настоящего описания;
на ФИГ. 5 представлены гиперспектральное изображение (A) по четвертому сценарию для аэропорта и диаграмма (B) вероятности обнаружения по четвертому сценарию для аэропорта в наборе данных ABU в варианте осуществления настоящего описания;
на ФИГ. 6 представлены диаграммы вероятности обнаружения для сценариев со второго по четвертый, полученные с использованием глобального метода Рида — Сяоли (GRX); (a) — диаграмма вероятности обнаружения по второму сценарию, (b) — диаграмма вероятности обнаружения по третьему сценарию, и (c) — диаграмма вероятности обнаружения по четвертому сценарию;
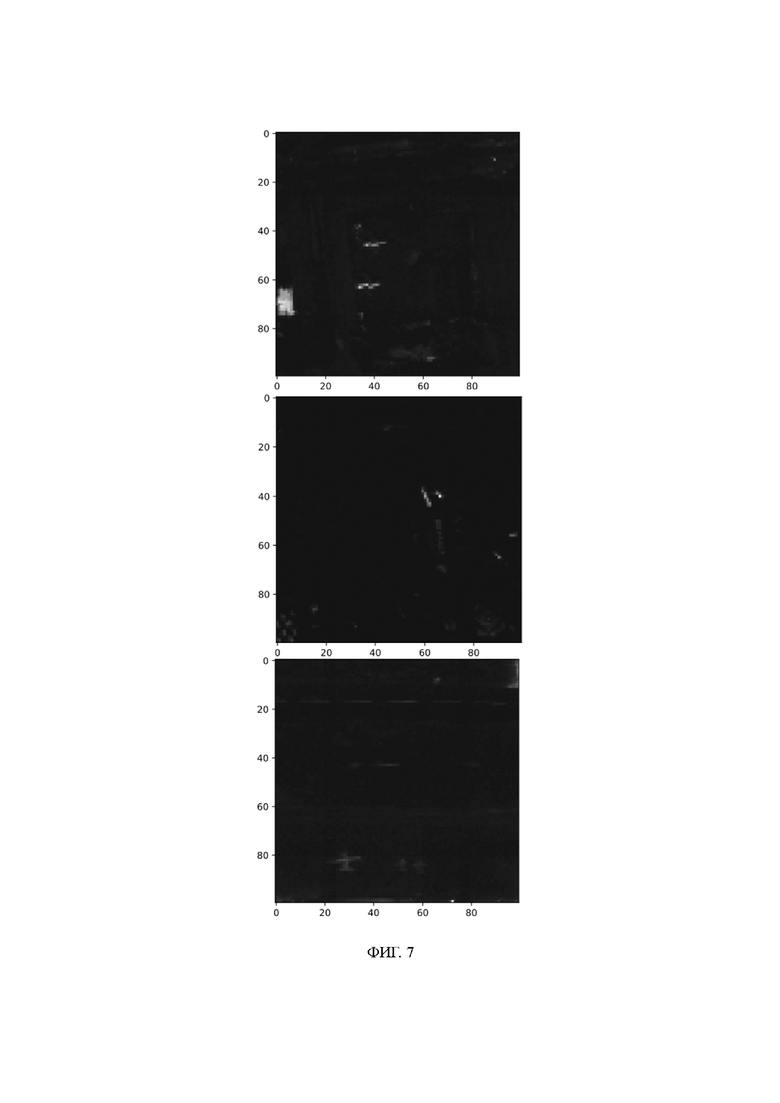
на ФИГ. 7 представлены диаграммы вероятности обнаружения для сценариев со второго по четвертый, полученные с использованием локального метода Рида — Сяоли (LRX); (a) — диаграмма вероятности обнаружения по второму сценарию, (b) — диаграмма вероятности обнаружения по третьему сценарию, и (c) — диаграмма вероятности обнаружения по четвертому сценарию;
на ФИГ. 8 представлены диаграммы вероятности обнаружения для сценариев со второго по четвертый, полученные с использованием метода обнаружения аномалии на основе совместных представлений (CRD); (a) — диаграмма вероятности обнаружения по второму сценарию, (b) — диаграмма вероятности обнаружения по третьему сценарию, и (c) — диаграмма вероятности обнаружения по четвертому сценарию;
на ФИГ. 9 представлены диаграммы вероятности обнаружения для сценариев со второго по четвертый, полученные с использованием метода Рида — Сяоли на основе энтропии для дробного преобразования Фурье (FrFE-RX); (a) — диаграмма вероятности обнаружения по второму сценарию, (b) — диаграмма вероятности обнаружения по третьему сценарию, и (c) — диаграмма вероятности обнаружения по четвертому сценарию;
на ФИГ. 10 представлены диаграммы вероятности обнаружения для сценариев со второго по четвертый, полученные с использованием метода извлечения признаков и очистки фона (FEBP); (a) — диаграмма вероятности обнаружения по второму сценарию, (b) — диаграмма вероятности обнаружения по третьему сценарию, и (c) — диаграмма вероятности обнаружения по четвертому сценарию;
на ФИГ. 11 представлены диаграммы вероятности обнаружения для сценариев со второго по четвертый, полученные с использованием метода автокодировщика (AE); (a) — диаграмма вероятности обнаружения по второму сценарию, (b) — диаграмма вероятности обнаружения по третьему сценарию, и (c) — диаграмма вероятности обнаружения по четвертому сценарию;
на ФИГ. 12 представлены диаграммы вероятности обнаружения для сценариев со второго по четвертый, полученные с использованием метода разреженного автокодировщика (SAE); (a) — диаграмма вероятности обнаружения по второму сценарию, (b) — диаграмма вероятности обнаружения по третьему сценарию, и (c) — диаграмма вероятности обнаружения по четвертому сценарию; и
на ФИГ. 13 представлены диаграммы вероятности обнаружения для сценариев со второго по четвертый, полученные с использованием метода обнаружения аномалии гиперспектрального изображения на основе модели «обучающий-обучаемый»; (a) — диаграмма вероятности обнаружения по второму сценарию, (b) — диаграмма вероятности обнаружения по третьему сценарию, и (c) — диаграмма вероятности обнаружения по четвертому сценарию.
ПОДРОБНОЕ ОПИСАНИЕ
Способ обнаружения аномалии гиперспектрального изображения на основе модели «обучающий-обучаемый», предлагаемый в настоящем варианте осуществления, дополнительно описан ниже со ссылкой на прилагаемые графические материалы.
На ФИГ. 1 представлены следующие стадии способа обнаружения аномалии гиперспектрального изображения на основе модели «обучающий-обучаемый»:
1. Построение модели обучающей сети и модели обучаемой сети;
построение соответствующих архитектур для модели обучающей сети и модели обучаемой сети соответственно для облегчения последующей реализации алгоритма обнаружения аномалии; структура модели обучающей сети включает в себя сверточный уровень, линейные уровни и конечный уровень нормализации. Структура модели обучаемой сети упрощена от модели обучающей сети.
В модели обучающей сети для извлечения признаков используют трехуровневую сверточную нейронную сеть, и первый уровень сверточной нейронной сети представляет собой трехмерную свертку, он может одновременно использовать пространственную информацию и спектральную информацию; далее следуют четыре линейных уровня. Линейные уровни, как правило, функционируют как классификаторы и могут выводить свои вероятности принадлежности к соответствующим классам на основе входной информации о признаке. Необходимо пояснить, что, когда модель обучающей сети обучена, последний линейный уровень реализует функцию вывода вероятностей принадлежности к различным классам в соответствии с входной информацией о признаке, здесь это двоичная классификация, т. е. аномалия и отсутствие аномалии; но при использовании модели обучающей сети и модели обучаемой сети для вывода эмбеддингов линейный уровень функционирует для скрининга требуемой информации о признаке.
Модель обучаемой сети включает в себя один сверточный уровень и два линейных уровня и упрощается от модели обучающей сети для сведения к минимуму количества параметров в сети, чтобы ускорить процесс обучения и зондирования при одновременном обеспечении обнаружения.
2. Обучение модели обучающей сети посредством множества меченых обучающих данных модели обучающей сети;
в некоторых вариантах осуществления подлежащий обнаружению пиксель и его восемь соседних пикселей образуют квадрат данных, имеющий размер 3 * 3, в пространственной области, квадрат данных вводят в модель обучающей сети, а затем выходной вектор, имеющий размер 2, берут из конца сети (два значения в векторе представляют вероятность аномалии и вероятность отсутствия аномалии соответственно).
Обучающие данные модели обучающей сети включают в себя аномальные данные, и обучающие данные модели обучающей сети выбирают для обучения модели обучающей сети, причем выбранные обучающие данные модели обучающей сети имеют тип, соответствующий набору данных, подлежащих обнаружению, и представляют собой набор гиперспектральных данных, и для удобства может быть выбран набор данных, уже имеющий метку. Может быть выбран один или более наборов обучающих данных модели обучающей сети. В данном варианте осуществления выбирают только один набор данных для обнаружения эффективности способа в наихудшем случае. Предпочтительно выбор обучающих данных модели обучающей сети в множестве разных сценариев позволяет модели обучающей сети усваивать как можно больше информации.
Следует подчеркнуть, что обучение модели обучающей сети не приводит к заметной точности ее результатов обнаружения (выводу вероятности аномалии в конце сети). Выходные данные в конце сети используют только во время обучения модели обучающей сети, и последующее обнаружение использует только эмбеддинг, выведенный линейным уровнем в середине. Роль данного обучения заключается только в том, чтобы модель обучающей сети усвоила определенные признаки аномальных и неаномальных данных и различия между ними. Другими словами, конечная цель данного обучения заключается в том, чтобы позволить модели обучающей сети различать эмбеддинги, выводимые соответствующими линейными уровнями модели обучающей сети, в определенной степени для обоих случаев: ввода аномальных данных и ввода неаномальных данных.
Функция потерь Losst для обучения модели обучающей сети имеет вид:
,
где представляет собой метку обучающих данных модели обучающей сети, а представляет собой выводимые данные обучающих данных модели обучающей сети через модель обучающей сети, причем выходные данные представляют собой вектор размером 2, второе значение которого в настоящем варианте осуществления принимают в качестве вероятности аномалии. Функция потерь представляет собой квадрат евклидовой нормы метки обучающих данных модели обучающей сети и выводимых данных обучающих данных модели обучающей сети через модель обучающей сети.
Обучение повторяют несколько раз на наборе данных, используемом до тех пор, пока функция потерь Losst не перестанет падать более чем на 0,1 процента за 5 циклов обучения, при этом обучение модели обучающей сети завершается.
3. Выбор неаномальных данных (нормальных данных) для формирования обучающих данных модели обучаемой сети;
неаномальные данные представляют собой данные в наборе данных, отличные от аномальных целевых данных, подлежащих обнаружению, которые также могут называться фоновыми данными. Такие данные разнообразны и относятся к различным категориям. Фоновые данные, по существу, составляют большой объем в изображении.
Основной принцип способа обнаружения аномалии гиперспектрального изображения на основе модели «обучающий-обучаемый» заключается в использовании различия в информации модели обучающей сети и модели обучаемой сети для обнаружения аномалий после формирования обучающих данных модели обучаемой сети с использованием неаномальных данных, только предшествующая информация о неаномальных данных присутствует в модели обучаемой сети, в то время как предшествующая информация как об аномальных данных, так и о неаномальных данных существует в модели обучающей сети, тем самым создавая различие в информации между моделью обучаемой сети и моделью обучающей сети.
Неаномальные данные, составляющие обучающие данные модели обучаемой сети, должны быть как можно более репрезентативными при выборе, т. е. они должны быть репрезентативными по отношению к фоновым данным в подлежащих обнаружению данных; например, в подлежащих обнаружению данных существует n типов фоновых данных, при этом идеально, чтобы существовало определенное количество n типов фоновых данных в обучающих данных модели обучаемой сети; чем более репрезентативны данные в обучающих данных модели обучаемой сети по отношению к фоновым данным в подлежащих обнаружению данных, тем лучше будет результат обнаружения.
4. Обучение модели обучаемой сети на обучающих данных модели обучаемой сети с помощью псевдометки, сгенерированной моделью обучающей сети;
сначала, если говорить о средствах ввода данных, модель обучаемой сети имеет структуру, аналогичную структуре модели обучающей сети, так что модель обучаемой сети имеет такие же средства ввода данных, что и модель обучающей сети, и подлежащий обнаружению пиксель и восемь соседних пикселей образуют в качестве блока ввода квадрат данных размерами 3 * 3 в пространственной области. Следует подчеркнуть, что в этом квадрате данных только центральный пиксель должен представлять собой неаномальные данные из обучающих данных, а остальные соседние пиксели могут представлять собой аномальные данные, однако усвоение признаков аномальных данных в пространственной области также является неизбежным процессом для модели обучаемой сети и не препятствует формированию различия в информации с моделью обучающей сети.
Функция потерь Losss при обучении имеет вид:
,
где представляет собой эмбеддинг, выведенный моделью обучающей сети (эмбеддинг представляет собой вектор, извлеченный и преобразованный из входных данных, содержащий некоторую информацию о признаке входных данных), и используется в настоящем документе в качестве псевдометки, причем эмбеддинг модели обучающей сети выводится третьим линейным уровнем, из которого вектор эмбеддинга размером 512 (подразумевающий информацию о признаке входных данных) берется по требованию; представляет собой эмбеддинг, выведенный моделью обучаемой сети; функция потерь представляет собой квадрат евклидовой нормы их обоих.
Из функции потерь можно видеть, что цель данного обучения заключается в том, чтобы сделать эмбеддинг, выведенный моделью обучаемой сети, как можно ближе к эмбеддингу, выведенному моделью обучающей сети, т. е. это процесс, с помощью которого модель обучаемой сети усваивает априорные знания в модели обучающей сети. Следует подчеркнуть, что обучающие данные модели обучаемой сети содержат только неаномальные данные, поэтому знания, усвоенные моделью обучаемой сети, связаны только с неаномальными данными, что представляет собой процесс формирования различия в информации модели обучаемой сети и модели обучающей сети.
Процесс обучения повторяют несколько раз на обучающих данных до тех пор, пока функция потерь Losss не перестанет падать более чем на 0,1 процента за 5 циклов обучения, при этом обучение модели обучаемой сети завершается.
5. Ввод подлежащих обнаружению данных, использование обученной модели обучающей сети и модели обучаемой сети для обнаружения аномалий;
во-первых, если говорить о формате ввода данных, в соответствии со способом обучения на стадии 2 и стадии 4 подлежащий обнаружению пиксель и его восемь соседних пикселей, которые образуют квадрат размерами 3 * 3 в пространственной области, вводят в модель обучающей сети и модель обучаемой сети для получения эмбеддинга, выведенного моделью обучающей сети, и эмбеддинга, выведенного моделью обучаемой сети, соответственно.
Из-за различия в информации между моделью обучающей сети и моделью обучаемой сети эмбеддинги, выводимые ими, также будут отличаться. Когда входной подлежащий обнаружению пиксель представляет собой неаномальные данные, эмбеддинги, выводимые моделью обучающей сети и моделью обучаемой сети, очень близки, как и при обучении; когда входной подлежащий обнаружению пиксель представляет собой аномальные данные, эмбеддинг, выведенный моделью обучаемой сети, в это время получает отклонение, поскольку предыдущая информация об аномальных данных в модели обучаемой сети отсутствует.
Во-вторых, для обнаружения аномалии можно найти евклидову норму эмбеддинга, выведенного моделью обучающей сети, и эмбеддинга, выведенного моделью обучаемой сети. Евклидова норма также известна как евклидово расстояние, которое измеряет истинное расстояние между двумя точками в многомерном пространстве, при этом чем больше это расстояние, тем больше вероятность того, что пиксель представляет собой аномальный пиксель.
Конкретная функция оценки аномалии имеет вид:
,
где  представляет собой эмбеддинг, выведенный моделью обучающей сети, а
представляет собой эмбеддинг, выведенный моделью обучающей сети, а 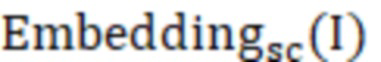 представляет собой эмбеддинг, выведенный моделью обучаемой сети; оценка Error аномалии представляет собой квадрат евклидовой нормы их обоих.
представляет собой эмбеддинг, выведенный моделью обучаемой сети; оценка Error аномалии представляет собой квадрат евклидовой нормы их обоих.
Наконец, в соответствии с предварительно заданным пороговым значением T оценки аномалии, в случае если оценка аномалии больше или равна пороговому значению T, соответствующий пиксель представляет собой аномальный пиксель; в случае если оценка аномалии меньше порогового значения T, соответствующий пиксель представляет собой нормальный пиксель. В частности, после нормализации оценки аномалии в диапазоне всех подлежащих обнаружению данных оценка аномалии находится в диапазоне от 0 до 1. Чем ближе оценка аномалии к 1, тем выше вероятность, что данные являются аномальными. В одном варианте реализации, как правило, значение 0,5 можно использовать в качестве порогового значения для отличения аномального от неаномального: если значение больше или равно 0,5, то пиксель считается аномальным пикселем, в противном случае он является неаномальным пикселем.
Результат настоящего способа дополнительно проиллюстрирован ниже посредством испытания методом моделирования.
1. Условия моделирования
Испытание методом моделирования варианта осуществления проводили на операционной системе Linux с использованием программного обеспечения PyCharm.
Смоделированные экспериментальные данные для этого эксперимента представляют собой набор данных, названный «аэропорт-пляж-город» (ABU), содержащий гиперспектральные изображения по четырем сценариям для аэропорта; четырем сценариям для пляжа и пяти сценариям для города, причем в настоящем эксперименте брали гиперспектральные изображения сценариев для аэропорта для эксперимента. Схематические представления этого набора данных показаны на ФИГ. 2–5, демонстрируя визуальный результат гиперспектральных изображений сценариев для аэропорта с первого по четвертый и соответствующих им диаграмм вероятности обнаружения. Чем он ярче, тем выше вероятность аномальной цели, а подробная информация об изображении сценариев для аэропорта с первого по четвертый приведена в таблице 1.
В таблице 1 представлена подробная информация о гиперспектральных изображениях сценариев для аэропорта в ABU.
2. Содержание моделирования
Сначала подлежащий обнаружению пиксель и его соседние пиксели упаковывали в один блок ввода в соответствии с вышеуказанным способом, этот блок I ввода вводили в обученную модель обучающей сети и модель обучаемой сети для получения соответственно эмбеддинга , выведенного моделью обучающей сети, и эмбеддинга , выведенного моделью обучаемой сети, евклидову норму разности двух эмбеддингов возводили в квадрат и получали оценку 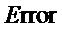 аномалии.
аномалии.
В качестве индикатора для оценки результатов обнаружения по сравнению с существующими способами выбирали площадь под кривой (AUC) рабочей характеристики приемника (ROC). В частности, для выходного набора данных обнаружения и набора эталонных данных значение AUC вычисляли по следующей формуле:
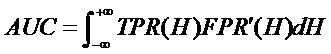
Определенное пороговое значение устанавливали равным H, при этом TPR (H) определяет частоту истинно положительных результатов, т. е. частоту, с которой встречаются правильные положительные результаты среди всех положительных образцов; FPR (H) определяет частоту, с которой встречаются ложноположительные результаты среди всех доступных отрицательных образцов. Смысл данной формулы заключается в вычислении площади под кривой с TPR (H) по вертикальной оси и FPR (H) по горизонтальной оси. Преимущество AUC в качестве индикатора заключается в том, что он зависит только от порядка пикселей, а не от абсолютного значения обнаружения. Таким образом, AUC используется в настоящем документе для оценки объективной эффективности разных способов.
Конечные результаты получали с использованием процедуры данного примера на базе данных ABU и оценивали с использованием индекса AUC, как показано в таблице 2. Следует отметить, что abu-аэропорт-1 используют в качестве обучающих данных модели обучающей сети и, следовательно, не используют в настоящем документе в качестве тестового изображения для обеспечения достоверности результатов. Обучающие данные модели обучающей сети выбирают только одно изображение для проверки эффективности способа в наихудшем случае. Каждое изображение имеет семьдесят процентов фоновых пикселей в качестве обучающих данных модели обучаемой сети для обучения модели обучаемой сети, оставляя тридцать процентов фоновых пикселей и аномальных пикселей в качестве тестового набора данных. Следует подчеркнуть, что в таблице 2 представлен перечень результатов оценки, полученных с использованием разных классических способов обнаружения (сравнительных способов) и с использованием способа обнаружения в соответствии с вариантом осуществления настоящего описания, и «Способ изобр.» в таблице 2 представляет собой способ обнаружения аномалии гиперспектрального изображения на основе модели «обучающий-обучаемый», предложенной в варианте осуществления.
Таблица 2. Результаты оценки разными способами
Все данные в таблице 2 сгенерированы в тестовом наборе, и данные в тестовом наборе никак не соприкасаются с сетью в модели, тем самым обеспечивая достаточно надежные результаты. Результаты обнаружения представлены на ФИГ. 6–13. Здесь следует отметить, что на показанных результирующих диаграммах 70% фоновых пикселей каждой диаграммы используются в качестве обучающих данных. Таким образом, результирующие диаграммы предназначены только для справки. Точная эффективность может быть измерена с помощью значений AUC в таблице 2. Более того, согласно данным экспериментальным испытаниям, значения AUC, полученные на тестовом наборе, и значения AUC, полученные на всей диаграмме, очень близки, поэтому результирующая диаграмма представляет собой эталонное значение.
Как видно из таблицы 2 и ФИГ. 6–13, способ согласно настоящему варианту осуществления обеспечивает хороший результат. Как видно из данных графических материалов, большинство классических способов ошибочно идентифицируют большое количество фоновых пикселей в качестве аномальных точек. Напротив, в результате обнаружения способом, предложенным в данном варианте осуществления, меньшее количество фоновых пикселей ошибочно идентифицируются как аномальные пиксели. Исходя из таблицы, способ, предложенный в данном варианте осуществления, принимает наибольшее значение на диаграммах аэропорта-2 и аэропорта-4 в сценариях для аэропортов и опережает второе значение на большую величину на диаграмме аэропорта-2.
Хотя данный способ может показывать лучший результат не во всех случаях, однако средний результат является лучшим, и среднее значение AUC, измеренное способом, предложенным в данном варианте осуществления, составляет 0,9679, что значительно лучше по сравнению со вторым результатом 0,9572 для CRD.
В настоящих вариантах осуществления также предложен машиночитаемый носитель данных, содержащий в себе компьютерную программу, которая при исполнении процессором реализует стадии вышеупомянутого способа обнаружения аномалии гиперспектрального изображения на основе модели «обучающий-обучаемый». Машиночитаемый носитель данных может представлять собой считываемый носитель сигнала или считываемый носитель данных. В настоящем варианте осуществления также предложено компьютерное устройство, включающее в себя процессор, запоминающее устройство, подключенное к процессору, и компьютерную программу, исполняемую процессором, причем процессор при исполнении компьютерной программы реализует стадии вышеупомянутого способа обнаружения аномалии гиперспектрального изображения на основе модели «обучающий-обучаемый»; компьютерное устройство в настоящем документе может представлять собой вычислительное устройство, такое как компьютер, ноутбук, карманный компьютер и любые облачные серверы, а процессор может представлять собой процессор общего назначения, процессор обработки цифровых сигналов, специализированную интегральную схему или любое другое программируемое логическое устройство.
| название | год | авторы | номер документа |
|---|---|---|---|
| Способ обработки изображений магнитно-резонансной томографии для формирования обучающих данных | 2023 |
|
RU2813480C1 |
| СПОСОБ ОЦЕНКИ КАЧЕСТВА АНАЛИЗА МЕДИЦИНСКОГО ИЗОБРАЖЕНИЯ | 2023 |
|
RU2838577C1 |
| СПОСОБЫ И СИСТЕМЫ ИДЕНТИФИКАЦИИ ПОЛЕЙ В ДОКУМЕНТЕ | 2020 |
|
RU2760471C1 |
| СПОСОБЫ И СИСТЕМЫ ИДЕНТИФИКАЦИИ ПОЛЕЙ В ДОКУМЕНТЕ | 2021 |
|
RU2774653C1 |
| ОБУЧАЕМЫЕ ВИЗУАЛЬНЫЕ МАРКЕРЫ И СПОСОБ ИХ ПРОДУЦИРОВАНИЯ | 2016 |
|
RU2665273C2 |
| МОРСКОЙ ТРЕНАЖЕР ДЛЯ ОБУЧЕНИЯ, ТРЕНИРОВКИ И ПОВЫШЕНИЯ КВАЛИФИКАЦИИ ОПЕРАТОРОВ И СПЕЦИАЛИСТОВ ПО ПРИМЕНЕНИЮ ГИДРОФИЗИЧЕСКИХ КОМПЛЕКСОВ ОБНАРУЖЕНИЯ И КЛАССИФИКАЦИИ АНОМАЛИЙ ВОДНОЙ СРЕДЫ | 2010 |
|
RU2445710C2 |
| Способ и система для предупреждения о предстоящих аномалиях в процессе бурения | 2021 |
|
RU2772851C1 |
| СПОСОБ ОБРАБОТКИ ИЗОБРАЖЕНИЙ ОБУЧЕННЫМИ НЕЙРОННЫМИ СЕТЯМИ | 2021 |
|
RU2779281C1 |
| СИСТЕМА И СПОСОБ ОСУЩЕСТВЛЕНИЯ КОЛИЧЕСТВЕННОЙ ГИСТОПАТОЛОГИЧЕСКОЙ ОЦЕНКИ НЕКЛАССИФИЦИРОВАННОГО ИЗОБРАЖЕНИЯ ТКАНИ НА ПРЕДМЕТНОМ СТЕКЛЕ, КЛАССИФИКАТОР ТКАНИ ДЛЯ ОСУЩЕСТВЛЕНИЯ КОЛИЧЕСТВЕННОЙ ГИСТОПАТОЛОГИЧЕСКОЙ ОЦЕНКИ И СПОСОБ ЕГО ОБУЧЕНИЯ | 2019 |
|
RU2799788C2 |
| СПОСОБ ОБНАРУЖЕНИЯ ЧЕЛОВЕЧЕСКИХ ОБЪЕКТОВ В ВИДЕО (ВАРИАНТЫ) | 2013 |
|
RU2635066C2 |











Изобретение относится к области вычислительной техники для обнаружения аномалии гиперспектрального изображения. Технический результат заключается в повышении точности обнаружения существующей аномалии гиперспектрального изображения. Технический результат достигается за счет того, что подлежащие обнаружению данные содержат n типов фоновых данных, а обучающие данные модели обучаемой сети содержат нормальные данные из n типов фоновых данных; вводят обучающие данные модели обучаемой сети в модель обучающей сети, обученную на стадии S2, и получают эмбеддинг, выведенный моделью обучающей сети; одновременно вводят обучающие данные модели обучаемой сети в модель обучаемой сети, получают эмбеддинг, выведенный моделью обучаемой сети, выполняют обучение на модели обучаемой сети множество раз; вводят подлежащие обнаружению данные в модель обучающей сети, обученную на стадии S2, и в модель обучаемой сети, обученную на стадии S4, для обнаружения аномалии; вычисляют для получения оценки аномалии и определяют то, что соответствующий пиксель представляет собой аномальный пиксель, в соответствии с предварительно заданным пороговым значением T оценки аномалии, в случае если оценка аномалии больше или равна пороговому значению T; в случае если оценка аномалии меньше порогового значения T, определяют то, что соответствующий пиксель представляет собой нормальный пиксель; отсеивают аномальные пиксели из экспериментальных данных и выполняют последующее обнаружение объектов. 3 н. и 3 з.п. ф-лы, 13 ил., 2 табл.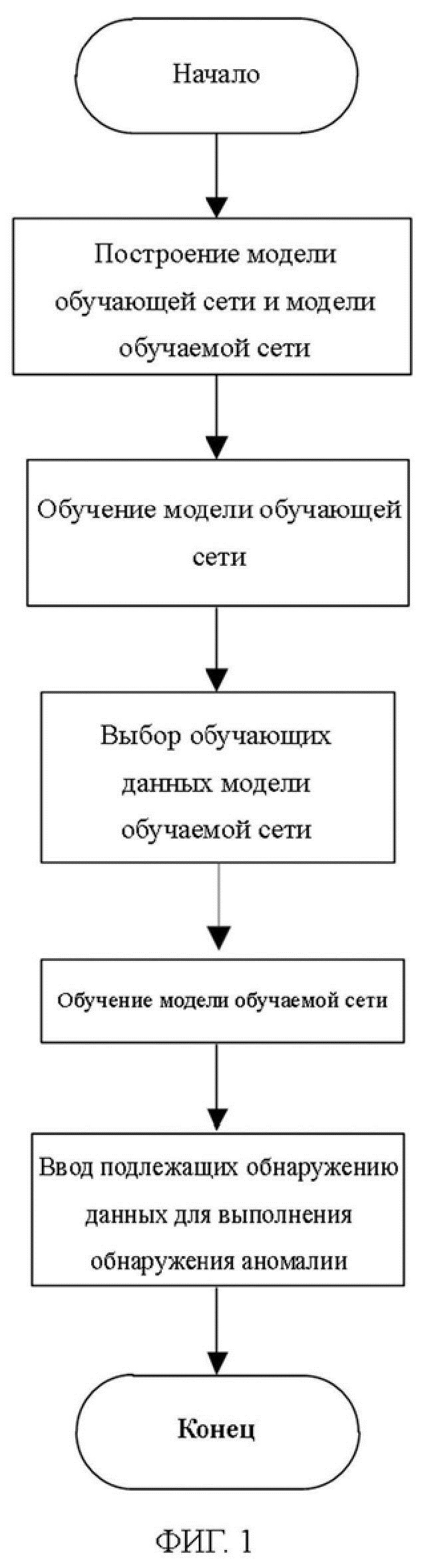
1. Способ обнаружения аномалии гиперспектрального изображения на основе модели «обучающий-обучаемый», применяемый для обнаружения аномалий гиперспектральных изображений сценариев, в том числе сценариев для аэропорта, включающий:
стадию S1 - построение модели обучающей сети и модели обучаемой сети;
стадию S2 - повторяющееся множество раз обучение модели обучающей сети с помощью меченых обучающих данных модели обучающей сети с проверочными аномальными данными, причем функция потерь Losst на момент обучения имеет вид: 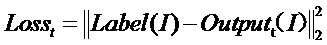 , до тех пор, пока функция потерь Losst не перестанет падать более чем на 0,1 процента за 5 циклов обучения, завершая обучение модели обучающей сети;
, до тех пор, пока функция потерь Losst не перестанет падать более чем на 0,1 процента за 5 циклов обучения, завершая обучение модели обучающей сети;
где 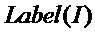 представляет собой метку обучающих данных модели обучающей сети, а
представляет собой метку обучающих данных модели обучающей сети, а 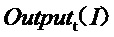 представляет собой выводимые данные обучающих данных модели обучающей сети через модель обучающей сети;
представляет собой выводимые данные обучающих данных модели обучающей сети через модель обучающей сети;
при этом на стадии S2 обучающие данные модели обучающей сети представляют собой один или более наборов данных; и
множество наборов данных соответствует множеству разных сценариев;
стадию S3 - выбор нормальных данных для формирования обучающих данных модели обучаемой сети;
при этом на стадии S3 обучающие данные модели обучаемой сети удовлетворяют следующему:
подлежащие обнаружению данные содержат n типов фоновых данных, а обучающие данные модели обучаемой сети содержат нормальные данные из n типов фоновых данных;
стадию S4 - ввод обучающих данных модели обучаемой сети в модель обучающей сети, обученную на стадии S2, и получение эмбеддинга, выведенного моделью обучающей сети; одновременно ввод обучающих данных модели обучаемой сети в модель обучаемой сети, получение эмбеддинга, выведенного моделью обучаемой сети, выполнение обучения на модели обучаемой сети множество раз, при этом функция потерь Losss на момент обучения имеет вид: 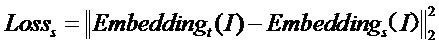 , до тех пор, пока функция потерь Losss не перестанет падать более чем на 0,1 процента за 5 циклов обучения, завершая обучение модели обучаемой сети;
, до тех пор, пока функция потерь Losss не перестанет падать более чем на 0,1 процента за 5 циклов обучения, завершая обучение модели обучаемой сети;
где 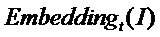 представляет собой эмбеддинг, выведенный моделью обучающей сети, а
представляет собой эмбеддинг, выведенный моделью обучающей сети, а 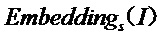 представляет собой эмбеддинг, выведенный моделью обучаемой сети;
представляет собой эмбеддинг, выведенный моделью обучаемой сети;
стадию S5 - ввод подлежащих обнаружению данных в модель обучающей сети, обученную на стадии S2, и в модель обучаемой сети, обученную на стадии S4, для обнаружения аномалии, и функция оценки аномалии имеет вид:
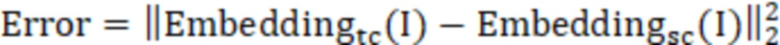 ,
,
где Error представляет собой оценку аномалии,  представляет собой эмбеддинг, выведенный моделью обучающей сети после ввода подлежащих обнаружению данных, а
представляет собой эмбеддинг, выведенный моделью обучающей сети после ввода подлежащих обнаружению данных, а 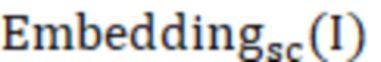 представляет собой эмбеддинг, выведенный моделью обучаемой сети после ввода подлежащих обнаружению данных; и
представляет собой эмбеддинг, выведенный моделью обучаемой сети после ввода подлежащих обнаружению данных; и
вычисление для получения оценки аномалии и определение того, что соответствующий пиксель представляет собой аномальный пиксель, в соответствии с предварительно заданным пороговым значением T оценки аномалии, в случае если оценка аномалии больше или равна пороговому значению T; в случае если оценка аномалии меньше порогового значения T, определение того, что соответствующий пиксель представляет собой нормальный пиксель;
при этом способ дополнительно включает:
отсеивание аномальных пикселей из экспериментальных данных и последующее обнаружение объектов, при этом, в случае если способ применяют по сценарию для аэропорта, обнаруженные объекты включают объекты в виде самолетов и объекты в виде взлетно-посадочных полос.
2. Способ по п. 1, в котором:
на стадии S1 построение модели обучающей сети и модели обучаемой сети предусматривает следующее:
архитектура модели обучающей сети включает в себя трехуровневую сверточную нейронную сеть, четыре линейных уровня и уровень нормализации, которые расположены последовательно; трехуровневая сверточная нейронная сеть используется для извлечения признаков, причем сверточная нейронная сеть первого уровня представляет собой трехмерную свертку, используемую для одновременного извлечения пространственной информации и спектральной информации; и
архитектура модели обучаемой сети включает в себя одноуровневую сверточную нейронную сеть и два линейных уровня, которые расположены последовательно.
3. Способ по п. 1, в котором:
на стадии S4 эмбеддинг, выведенный моделью обучающей сети, выводится третьим линейным уровнем из четырех линейных уровней.
4. Способ по п. 3, в котором:
на стадии S5 ввод подлежащих обнаружению данных в обученную модель обучающей сети со стадии S2 и обученную модель обучаемой сети со стадии S4 предусматривает следующее:
ввод каждого подлежащего обнаружению пикселя и восьми смежных с ним пикселей в подлежащих обнаружению данных в квадрат данных размерами 3×3 в пространственной области в качестве блока ввода и ввод модели обучающей сети и модели обучаемой сети, обучение которых завершено.
5. Компьютерный носитель данных, содержащий в себе компьютерную программу, в котором компьютерная программа при исполнении процессором реализует стадии способа обнаружения аномалии гиперспектрального изображения на основе модели «обучающий-обучаемый» по любому из пп. 1-4.
6. Компьютерное устройство, содержащее процессор, запоминающее устройство, подключенное к процессору, и компьютерную программу, исполняемую процессором, в котором компьютерная программа при исполнении процессором реализует стадии способа обнаружения аномалии гиперспектрального изображения на основе модели «обучающий-обучаемый» по любому из пп. 1-4.
| Способ восстановления спиралей из вольфрамовой проволоки для электрических ламп накаливания, наполненных газом | 1924 |
|
SU2020A1 |
| Способ получения продуктов конденсации фенолов с формальдегидом | 1924 |
|
SU2022A1 |
| CN 107563355 B, 09.01.2018 | |||
| CN 104408705 A, 11.03.2015 | |||
| СПОСОБ ИДЕНТИФИКАЦИИ ОБЪЕКТОВ НА ЦИФРОВЫХ ИЗОБРАЖЕНИЯХ ПОДСТИЛАЮЩЕЙ ПОВЕРХНОСТИ МЕТОДОМ НЕЧЕТКОЙ ТРИАНГУЛЯЦИИ ДЕЛОНЕ | 2018 |
|
RU2729557C2 |
