ПЕРЕКРЕСТНАЯ ССЫЛКА НА РОДСТВЕННУЮ ЗАЯВКУ
[0001] Данная заявка испрашивает преимущество по предварительной заявке на патент США №62/944,304, поданной 5 декабря 2019 г., которая полностью включена в настоящий документ путем ссылки.
ПРЕДПОСЫЛКИ СОЗДАНИЯ ИЗОБРЕТЕНИЯ
[0002] Слияния генов можно использовать в качестве онкогенных факторов, которые являются важными диагностическими и терапевтическими мишенями при лечении таких заболеваний, как рак.
ИЗЛОЖЕНИЕ СУЩНОСТИ ИЗОБРЕТЕНИЯ
[0003] В соответствии с одним инновационным аспектом настоящего описания приводится реализованный на компьютере способ идентификации одного или более слияний генов в биологическом образце. В одном аспекте способ может включать операции по получению одним или более компьютерами первых данных, которые представляют множество выравненных считываний от блока выравнивания считываний, идентификации одним или более компьютерами множества потенциальных слияний генов, включенных в полученные первые данные, фильтрацию множества потенциальных слияний генов одним или более компьютерами для определения отфильтрованного набора потенциального слияния генов, для каждого конкретного потенциального слияния генов из отфильтрованного набора потенциальных слияний генов: генерирование входных данных одним или более компьютерами для ввода в модель машинного обучения, причем генерирование таких входных данных включает извлечение характерных данных, отличающих конкретное потенциальное слияние генов от данных, которые включают: (i) один или более сегментов эталонной последовательности, с которыми выравнивали конкретное потенциальное слияние генов с помощью блока выравнивания считываний, и (ii) данные, сгенерированные на основании выходной информации блока выравнивания считываний, направляемые одним или более компьютерами сгенерированные входные данные в качестве ввода для модели машинного обучения, причем модель машинного обучения была обучена генерировать выходные данные, отражающие вероятность того, что потенциальное слияние генов представляет собой подтвержденное слияние генов, исходя из результатов применения модели машинного обучения для обработки входных данных, представляющих собой (i) один или более сегментов эталонной последовательности, с которыми выравнивали конкретное потенциальное слияние генов с помощью блока выравнивания считываний, и (ii) данные, сгенерированные на основании выходной информации блока выравнивания считываний, получение одним или более компьютерами выходных данных, сгенерированных моделью машинного обучения после обработки сгенерированных входных данных моделью машинного обучения, и на основании выходных данных определение, является ли конкретное потенциальное слияние генов подтвержденным потенциальным слиянием генов, одним или более компьютерами.
[0004] Другие версии включают соответствующие системы, аппарат и компьютерные программы для выполнения действий из способов, определяемых командами, закодированными на машиночитаемых устройствах хранения.
[0005] Эти и другие версии могут необязательно включать один или более из приведенных ниже признаков. Например, в некоторых вариантах реализации генерирование входных данных дополнительно включает извлечение характерных данных, которые включают данные аннотации, описывающие аннотации сегментов эталонной последовательности, с которыми выравнивали конкретное потенциальное слияние генов с помощью блока выравнивания считываний. В таких вариантах реализации модель машинного обучения обучена генерировать выходные данные, отражающие вероятность того, что потенциальное слияние генов является подтвержденным потенциальным слиянием генов на основании результатов применения модели машинного обучения для обработки входных данных, представляющих собой: (i) один или более сегментов эталонной последовательности, с которыми выравнивали конкретное потенциальное слияние генов с помощью блока выравнивания считываний, (ii) данные аннотации, описывающие аннотации сегментов эталонной последовательности, с которыми выравнивали конкретное потенциальное слияние генов с помощью блока выравнивания считываний, и (iii) данные, сгенерированные на основании выходной информации блока выравнивания считываний.
[0006] В некоторых вариантах реализации идентификация множества потенциальных слияний генов, содержащихся в полученных первых данных, одним или более компьютерами может включать идентификацию множества выравниваний расщепленных считываний одним или более компьютерами.
[0007] В некоторых вариантах реализации идентификация множества потенциальных слияний генов, содержащихся в полученных первых данных, одним или более компьютерами может включать идентификацию множества выравниваний дискордантных пар считываний одним или более компьютерами.
[0008] В некоторых вариантах реализации блок выравнивания считываний реализуют с использованием набора из одного или более модулей обработки, которые выполнены с возможностью использования аппаратных логических схем, физически организованных с возможностью выполнения операций с использованием аппаратных логических схем, для: (i) приема данных, представляющих первое считывание, (ii) сопоставления данных, представляющих первое считывание, с одним или более участками эталонной последовательности для идентификации одной или более совпадающих позиций эталонной последовательности, (iii) генерирования одной или более оценок выравнивания, соответствующих каждой из совпадающих позиций эталонной последовательности для первого считывания, (iv) выбора одного или более потенциальных выравниваний для первого считывания на основании одной или более оценок выравнивания и (v) вывода данных, представляющих потенциальное выравнивание для первого считывания.
[0009] В некоторых вариантах реализации блок выравнивания считываний реализуют с использованием набора из одного или более модулей обработки посредством использования одного или более центральных процессоров (CPU) или одного или более графических процессоров (GPU) для выполнения программных команд, которые инициируют выполнение одним или более CPU или одним или более GPU функций: (i) приема данных, представляющих первое считывание, (ii) сопоставления данных, представляющих первое считывание, с одним или более участками эталонной последовательности для идентификации одной или более совпадающих позиций эталонной последовательности для первого считывания, (iii) генерирования одной или более оценок выравнивания, соответствующих каждой из совпадающих позиций эталонной последовательности для первого считывания, (iv) выбора одного или более потенциальных выравниваний для первого считывания на основании одной или более оценок выравнивания и (v) вывода данных, представляющих потенциальное выравнивание для первого считывания.
[0010] В некоторых вариантах реализации способ может дополнительно включать получение блоком выравнивания считываний множества считываний, которые еще не были выравнены, выравнивание блоком выравнивания считываний первого подмножества из множества считываний и сохранение блоком выравнивания считываний первого подмножества выравненных считываний в запоминающем устройстве. В таких вариантах реализации получение одним или более компьютерами первых данных, которые представляют множество выравненных считываний от блока выравнивания считываний, может включать получение одним или более компьютерами первого подмножества выравненных считываний из запоминающего устройства и выполнение одной или более операций по п. 1, в то время как блок выравнивания считываний проводит выравнивание второго подмножества из множества считываний, которые еще не были выравнены.
[0011] В некоторых вариантах реализации данные, сгенерированные на основании выходной информации блока выравнивания считываний, могут включать любое одно или более из числа частоты встречаемости вариантов аллелей, числа уникальных выравниваний считываний, охвата считываний транскрипта, показателя MAPQ или данных, указывающих на гомологию между родительскими генами.
[0012] В некоторых вариантах реализации определение, соответствует ли конкретное потенциальное слияние подтвержденному потенциальному слиянию генов на основании выходных данных, может включать определение, удовлетворяют ли выходные данные предварительно заданному пороговому значению, одним или более компьютерами и определение того, что конкретное потенциальное слияние соответствует подтвержденному потенциальному слиянию генов, на основании определения того, что выходные данные удовлетворяют предварительно заданным пороговым значениям.
[0013] В некоторых вариантах реализации определение, соответствует ли конкретное потенциальное слияние подтвержденному потенциальному слиянию генов на основании выходных данных, может включать определение, удовлетворяют ли выходные данные предварительно заданному пороговому значению, одним или более компьютерами и определение несоответствия конкретного потенциального слияния подтвержденному потенциальному слиянию генов на основании определения несоответствия выходных данных предварительно заданным пороговым значениям.
[0014] Эти и другие инновационные аспекты настоящего описания очевидны в свете подробного описания, прилагаемых графических материалов и пунктов формулы изобретения.
КРАТКОЕ ОПИСАНИЕ ГРАФИЧЕСКИХ МАТЕРИАЛОВ
[0015] На ФИГ. 1 показана блок-схема примера системы для быстрого обнаружения подтвержденных слияний генов.
[0016] На ФИГ. 2 показана последовательность операций примера процесса проведения быстрого обнаружения подтвержденных слияний генов.
[0017] На ФИГ. 3 показана блок-схема другого примера системы для быстрого обнаружения подтвержденных слияний генов.
[0018] На ФИГ. 4 показана блок-схема системных компонентов, которые можно использовать для реализации системы быстрого обнаружения подтвержденных слияний генов.
ПОДРОБНОЕ ОПИСАНИЕ
[0019] Настоящее описание относится к системам, способам, устройствам, компьютерным программам или любой их комбинации для быстрого обнаружения слияний генов. Наличие определенных слияний генов может быть важными показателями конкретного заболевания, показателем, который предполагает использование конкретного лекарственного средства при конкретном заболевании, или их комбинации. Например, определенные слияния генов могут быть показателями определенной формы рака, например острых и хронических миелоидных лейкозов, миелодиспластических синдромов (МДС), сарком мягких тканей или их лечения. Настоящее описание позволяет быстро выявить точные слияния генов с помощью модуля фильтрации для снижения числа потенциальных слияний генов (также называемых в настоящем документе «потенциальными слияниями»), с последующей обработкой, чтобы определить, является ли каждое потенциальное слияние подтвержденным слиянием генов. Такой модуль фильтрации позволяет с высокой точностью выбирать потенциальные слияния для последующего анализа и одновременно сокращать вычислительные ресурсы, которые необходимо расходовать для выявления подтвержденных слияний генов, поскольку для дальнейшей обработки можно использовать только отфильтрованное подмножество потенциальных слияний генов, как описано в настоящем документе.
[0020] Сокращенный набор потенциальных слияний генов также обеспечивает другие технологические преимущества. Например, описанные в настоящем документе способы и системы обеспечивают сокращение времени прогона по сравнению со стандартными способами обработки и оценки всех потенциальных слияний генов. Сокращение времени прогона для выполнения операций также напрямую приводит к снижению расходов на ресурсы обработки (например, ресурсы CPU или GPU), использование запоминающего устройства и энергопотребление. Несмотря на то что модуль фильтрации обеспечивает сокращение времени прогона по сравнению с традиционными способами, описанные в настоящем документе способы и системы также в состоянии использовать другие подходы для сокращения времени прогона. Например, в некоторых вариантах реализации можно добиться еще большего сокращения времени прогона за счет использования аппаратно-ускоренного блока выравнивания считываний для картирования, выравнивания и генерирования метаданных, используемых для обработки потенциальных слияний генов.
[0021] На ФИГ. 1 показана блок-схема примера системы 100 для быстрого обнаружения подтвержденных слияний генов. Система 100 может включать секвенатор 110 нуклеиновых кислот, запоминающее устройство 120, блок 130 вторичного анализа, модуль 140 идентификации потенциального слияния, модуль 150 фильтрации потенциальных слияний, модуль 160 генерации набора признаков, модель 170 машинного обучения, модуль 180 определения слияния генов, модуль 190 выходного прикладного программного интерфейса (API) и дисплей 195 вывода. В примере, показанном на ФИГ. 1, каждый из этих компонентов описан как реализуемый в рамках секвенатора 110 нуклеиновых кислот. Вместе с тем настоящее описание не ограничивается такими вариантами осуществления.
[0022] Вместо этого в некоторых вариантах реализации один или более компонентов, показанных на ФИГ. 1, могут быть реализованы на компьютере вне секвенатора 110 нуклеиновых кислот. Например, в некоторых вариантах реализации модули вторичного анализа могут быть реализованы в рамках секвенатора 110 нуклеиновых кислот и модуля 140 идентификации потенциального слияния, модуля 150 фильтрации потенциальных слияний, модуля 160 генерации набора признаков, модели 170 машинного обучения, модуля 180 определения слияния генов, модуля 190 выходного прикладного программного интерфейса (API), которые могут быть реализованы в одном или более разных компьютерах. В таких вариантах реализации один или более разных компьютеров и секвенатор нуклеиновых кислот могут быть соединены с возможностью связи с использованием одной или более проводных сетей, одной или более беспроводных сетей или их комбинации.
[0023] Для целей данного описания термин «модуль» включает один или более программных компонентов, один или более аппаратных компонентов или любую их комбинацию, которые можно использовать для осуществления функциональных возможностей, относящихся к соответствующему модулю в данном описании. Как правило, приведенный в настоящем документе термин «модуль» использует один или более процессоров для выполнения программных команд для реализации функциональных возможностей модуля, описанного в настоящем документе. Процессор может включать центральный процессор (CPU), графический процессор (GPU) или т.п.
[0024] Аналогичным образом используемый в настоящем документе термин «блок» включает один или более программных компонентов, один или более аппаратных компонентов или любую их комбинацию, которые можно использовать для осуществления функциональных возможностей, относящихся к соответствующему блоку в настоящем описании. Как правило, приведенный в настоящем документе «блок» использует один или более аппаратных компонентов, таких как зашитые цифровые логические элементы или зашитые цифровые логические блоки, организованные в виде модулей обработки, для выполнения операций, которые осуществляют функциональные возможности описанного в настоящем документе блока. Такие зашитые цифровые логические элементы или зашитые цифровые логические схемы могут включать программируемую пользователем матрицу логических элементов (FPGA), интегральную схему прикладного назначения (ASIC) или т.п.
[0025] Секвенатор 110 нуклеиновых кислот (также называемый в настоящем документе секвенатором 110) выполнен с возможностью проведения анализа первичной нуклеотидной последовательности. Выполнение первичного анализа может включать введение в секвенатор 110 биологического образца 105, такого как образец крови, образец ткани, мокрота или образец нуклеиновой кислоты, и генерирование секвенатором 110 выходных данных, таких как одно или более считываний 112, каждое из которых представляет собой порядок нуклеотидов нуклеотидной последовательности полученного биологического образца. В некоторых вариантах реализации секвенирование с помощью секвенатора 110 нуклеиновых кислот можно выполнять в ходе множества циклов считывания, при этом в первом цикле считывания «Read 1» генерируют одно или более первых считываний, представляющих порядок нуклеотидов от первого конца фрагмента нуклеотидной последовательности, и во втором цикле считывания «Read 2» генерируют одно или более вторых считываний соответственно, представляющих порядок нуклеотидов с других концов одного из фрагментов нуклеотидной последовательности. В некоторых вариантах реализации считывания могут представлять собой короткие считывания длиной приблизительно от 80 до 120 нуклеотидов. При этом настоящее описание не ограничивается считываниями с какой-либо конкретным количеством нуклеотидов. Напротив, настоящее описание можно использовать для считывания любого количества нуклеотидов.
[0026] В некоторых вариантах реализации биологический образец 105 может включать образец ДНК, а секвенатор 110 нуклеиновых кислот может включать секвенатор ДНК. В таких вариантах реализации порядок секвенированных нуклеотидов в считывании, полученном секвенатором нуклеиновых кислот, может включать один или более из гуанина (G), цитозина (С), аденина (А) и тимина (Т) в любой комбинации. В некоторых вариантах реализации секвенатор 110 нуклеиновых кислот можно использовать для получения считываний РНК биологического образца 105. В таких вариантах реализации это может происходить с использованием протоколов RNA-seq. В качестве примера, биологический образец 105 может быть предварительно обработан с применением обратной транскрипции с образованием комплементарной ДНК (кДНК) с помощью фермента обратной транскриптазы. В других вариантах реализации секвенатор 110 нуклеиновых кислот может включать секвенатор РНК, а биологический образец может включать образец РНК. Считывания РНК, полученные с использованием кДНК или с помощью секвенатора РНК, могут состоять из С, G, А и урацила (U). Описанный в настоящем документе пример на ФИГ. 1 приводится со ссылкой на генерирование и анализ считываний РНК. При этом настоящее описание можно использовать для получения и анализа любого типа считываний нуклеотидной последовательностей, включая считывания ДНК или РНК.
[0027] Секвенатор 110 может включать секвенатор следующего поколения (NGS), который выполнен с возможностью генерирования считываний последовательностей, таких как считывания 112-1, 112-2, 112-n, где «n» представляет собой любое положительное целое число больше 0, для данного образца таким образом, чтобы обеспечивать сверхвысокую производительность, масштабируемость и скорость за счет использования технологии массового параллельного секвенирования. NGS позволяют быстро секвенировать целые геномы, обеспечивают возможность глубокого изучения секвенированных целевых областей, использования секвенирования РНК (RNA-Seq) для обнаружения новых вариантов РНК и сайтов сплайсинга или количественно определять мРНК для анализа генной экспрессии, проводить анализ эпигенетических факторов, таких как метилирование ДНК в масштабах генома и ДНК-белковые взаимодействия, секвенирование образцов опухолей для исследования редких соматических вариантов и субклонов опухоли, а также изучение разнообразия микроорганизмов, например, у людей или в окружающей среде.
[0028] Секвенатор 110 может секвенировать биологический образец 105 и генерировать соответствующий набор считываний, представленных в виде набора А, С, Т и G. Затем секвенатор может выполнять обратную транскрипцию для построения последовательности кДНК, отражающую соответствующую последовательность РНК. Такие считывания последовательности РНК 112-1, 112-2, 112-n выводят секвенатором 110 и сохраняют в запоминающем устройстве 120. В некоторых вариантах реализации считывания последовательности РНК 112-1, 112-2, 112-n можно сжимать в форме записи данных меньшего объема перед сохранением считываний 112-1, 112-2, 112-n в запоминающем устройстве 120. Доступ к запоминающему устройству 120 можно осуществлять каждым из показанных на ФИГ. 1 компонентов, включая блок 130 вторичного анализа, модуль 140 идентификации потенциального слияния, модуль 150 фильтрации потенциальных слияний, модуль 160 генерации набора признаков, модель 170 машинного обучения, модуль 180 определения слияния генов и модуль 190 выходного API. Несмотря на то что соответствующие модули могут быть показаны как обеспечивающие передачу выходных данных от первого модуля на второй модуль, практическое осуществление такой функции может включать сохранение выходных данных первым модулем в запоминающем устройстве, таком как запоминающее устройство 120, и доступ второго модуля к хранящимся выходным данным в запоминающем устройстве и обработку доступных выходных данных в качестве входных данных для второго модуля.
[0029] Блок 130 вторичного анализа может получать доступ к считываниям 112-1, 112-2, 112-n, хранящимся в запоминающем устройстве 120, и выполнять одну или более операций вторичного анализа считываний 112-1, 112-2, 112-n. В некоторых вариантах реализации считывания 112-1, 112-2, 112-n могут храниться в запоминающем устройстве 120 в сжатых записях данных. В таких вариантах реализации блок вторичного анализа может выполнять операции распаковки сжатых записей считывания до выполнения операций вторичного анализа записей считывания. Операции вторичного анализа могут включать картирование одного или более считываний с эталонным геномом, выравнивание одного или более считываний с эталонным геномом или обе перечисленные операции. В некоторых вариантах реализации операции вторичного анализа могут также включать операции распознавания вариантов. В дополнение к выполнению операций вторичного анализа блок 130 вторичного анализа также может быть выполнен с возможностью проведения операций сортировки. Операции сортировки могут включать, например, упорядочение считываний, которые были выравнены блоком вторичного анализа, на основании позиций в эталонном геноме, с которым были сопоставлены выравненные считывания.
[0030] В некоторых вариантах реализации, таких как пример, приведенный на ФИГ. 1, блок 130 вторичного анализа может включать запоминающее устройство 132 и программируемое логическое устройство 134. Программируемое логическое устройство 134 может содержать аппаратные логические схемы, которые могут быть динамически конфигурированы для включения одного или более операционных блоков вторичного анализа, таких как блок 136 выравнивания считываний, и могут быть использованы для выполнения одной или более операций вторичного анализа с использованием аппаратных логических схем. Динамическое конфигурирование программируемого логического устройства 134 для включения операционного блока вторичного анализа, такой как блок 136 выравнивания считываний, может включать, например, передачу одной или более команд на программируемое логическое устройство 134, которые инициируют перевод аппаратных логических элементов программируемого логического устройства 134 программируемым логическим устройством 134 в такую аппаратную цифровую логическую конфигурацию, которая выполнена с возможностью осуществления функциональных возможностей блока 136 выравнивания считываний в аппаратной логике.
[0031] Одна или более операций, приводящих к динамической конфигурации программируемого логического устройства 134, могут включать компилируемый код языка описания аппаратных средств, одну или более команд для программируемого логического устройства 134 для его собственной конфигурации на основании компилируемого кода языка описания аппаратных средств или т.п. Такие операции, которые приводят к динамической конфигурации программируемого логического устройства 134, можно генерировать и передавать на программируемое логическое устройство 134 посредством управляющей программы, выполняемой секвенатором 110 или другим компьютером, на котором размещена управляющая программа. В некоторых вариантах реализации управляющая программа может представлять собой программный модуль, команды которого хранятся в запоминающем устройстве, таком как запоминающее устройство 120. Функциональные возможности управляющей программы по генерированию и передаче кода команд языка описания аппаратных средств или других команд для конфигурирования программируемого логического устройства 134 могут быть реализованы посредством выполнения программного модуля управляющей программы с помощью одного или более процессоров, таких как один или более CPU или один или более GPU.
[0032] Функциональные возможности блока 136 выравнивания считываний могут включать получение одного или более первых считываний, таких как считывания РНК 112-1, 112-2, 112-n, которые хранились в запоминающем устройстве 120 секвенатора 110, картирование полученных первых считываний 112-1, 112-2, 112-n с одной или более позициями эталонной последовательности и последующее выравнивание картированных первых считываний 112-1, 112-2, 112-n с эталонной последовательностью. Таким образом, на стадии картирования можно идентифицировать набор потенциальных позиций эталонной последовательности для каждого конкретного считывания из полученных первых считываний, которые соответствуют конкретному считыванию. Затем на стадии выравнивания можно генерировать оценку каждой потенциальной позиции эталонной последовательности и выбирать конкретную позицию эталонной последовательности с самой высокой оценкой выравнивания в качестве правильного выравнивания для конкретного считывания. Эталонная последовательность может включать организованную последовательность нуклеотидов, соответствующих известному геному.
[0033] Конфигурация аппаратных логических элементов программируемого логического устройства 134 в ответ на одну или более команд управляющей программы может включать конфигурирование логических элементов, таких как элементы AND, элементы OR, элементы NOR, элементы XOR или любая их комбинация, для выполнения цифровых логических функций блока 136 выравнивания считываний. В альтернативном или дополнительном варианте осуществления конфигурация аппаратных логических элементов может включать динамически конфигурируемые логические блоки, содержащие настраиваемые аппаратные логические блоки для выполнения сложных вычислительных операций, включая сложение, умножение, сопоставление или т.п. Точная конфигурация аппаратных логических элементов, логических блоков или их комбинации определяется командами, получаемыми от управляющей программы. Полученные команды могут включать (или быть выведены из него) компилированный программный код языка описания аппаратных средств (HDL), который был записан субъектом и определяет схему компоновки операционного блока вторичного анализа, которая должна быть запрограммирована в программируемое логическое устройство 134. Программный код HDL может включать программный код, написанный на том или ином языке, таком как язык описания аппаратных средств на быстродействующих интегральных схемах (VHDL), Verilog или т.п. Субъектом может быть один или более людей-пользователей, подготовивших программный код HDL, один или более агентов искусственного интеллекта, генерирующих программный код HDL, или их комбинация.
[0034] Программируемое логическое устройство 134 может включать программируемое логическое устройство любого типа. Например, программируемое логическое устройство 134 может включать одну или более программируемых пользователем матриц логических элементов (FPGA), одно или более сложных программируемых логических устройств (CPLD) или одну или более программируемых логических матриц (PLA) или их комбинацию, которые выполнены с возможностью динамического конфигурирования и переконфигурирования управляющей программой по мере необходимости для выполнения конкретной последовательности рабочих операций. Например, в некоторых вариантах реализации может быть желательно использовать программируемое логическое устройство 134 в качестве блока 136 выравнивания считываний, как описано выше. Вместе с тем в других вариантах реализации может быть желательно использовать программируемое логическое устройство 134 для выполнения функций распознавания вариантов или функций поддержки распознавания вариантов, таких как блок скрытой марковской модели (НММ). В других вариантах реализации программируемое логическое устройство 134 также может быть динамически конфигурировано для поддержки общих вычислительных задач, таких как сжатие и распаковка, поскольку аппаратная логика программируемого логического устройства 134 способна выполнять эти задачи и другие указанные выше задачи намного быстрее выполнения тех же задач с использованием программных команд, выполняемых одним или более процессоров 150. В некоторых вариантах реализации программируемое логическое устройство 134 может быть динамически переконфигурировано в процессе прогона для выполнения различных операций.
[0035] В качестве примера в некоторых вариантах реализации программируемое логическое устройство 134 может быть реализовано с использованием FPGA, которая динамически конфигурирована в виде блока распаковки для доступа к данным, представляющим сжатую версию первых считываний 112-1, 112-2, 112-n, хранящихся в запоминающем устройстве 120 или 132. Блок 130 вторичного анализа может использовать блок распаковки для распаковки сжатых данных, представляющих первые считывания 112-1, 112-2, 122-n (например, если считывания, полученные от секвенатора нуклеиновых кислот, были сжаты). Блок распаковки может хранить распакованные считывания в запоминающем устройстве 120 или 132. Затем в таких вариантах реализации FPGA можно динамически переконфигурировать в качестве блока 136 выравнивания считываний и использовать для выполнения картирования и выравнивания распакованных первых считываний 112-1,112-2, 112-n, уже сохраненных в запоминающем устройстве 132 или 120. Затем блок 136 выравнивания считываний может сохранять данные, представляющие картированные и выравненные считывания в запоминающем устройстве 132 или 120. Несмотря на то что такая последовательность операций описана как включающая операции распаковки, картирования и выравнивания, настоящее описание не ограничивается выполнением этих операций или только этими операциями. Напротив, программируемое логическое устройство 134 может быть динамически сконфигурировано для осуществления при необходимости функциональных возможностей любого операционного блока в любом порядке для реализации функциональных возможностей, описанных в настоящем документе.
[0036] В примере на ФИГ. 1 описан блок 130 вторичного анализа, который использует аппаратное логическое устройство в форме программируемого логического устройства 134 для осуществления блока 136 выравнивания считываний. Вместе с тем настоящее описание не ограничивается применением программируемых логических устройств для осуществления блока 136 выравнивания считываний. Напротив, другие виды интегральных схем можно использовать для осуществления блока 136 выравнивания считываний в аппаратной цифровой логической схеме блока 130 вторичного анализа. Например, в некоторых вариантах реализации блок 143 вторичного анализа может быть выполнен с возможностью использования одной или более специализированных интегральных схем (ASIC) для реализации функциональных возможностей одного или более операционных блоков вторичного анализа. Несмотря на невозможность перепрограммирования одна или более специализированных интегральных схем (ASIC) могут быть сконструированы с использованием специализированной аппаратной логической схемы одного или более операционных блоков вторичного анализа, таких как блок 136 выравнивания считываний, блок распознавания вариантов, вычислительный блок поддержки распознавания вариантов или т.п., для ускорения и распараллеливания выполнения операций вторичного анализа. В некоторых вариантах реализации использование одной или более ASIC в качестве аппаратных логических схем блока 130 вторичного анализа, которые реализуют функциональные возможности одного или более блоков операций вторичного анализа, может обеспечивать еще более высокую скорость, чем применение программируемого логического устройства, такого как FPGA. Соответственно, специалисту в данной области будет очевидно, что в любом из вариантов осуществления, описанных в настоящем документе, вместо программируемого логического устройства, такого как FPGA, можно использовать ASIC. Для тех вариантов реализации, в которых будут использовать ASIC, необходимо применять специализированную ASIC или специализированные логические группы из одной ASIC для каждого блока операций вторичного анализа, которые должны проводить ASIC. В качестве примера используют одну или более ASIC для выравнивания считывания, одну или более ASIC для распаковки, одну или более ASIC для сжатия или их комбинации. Кроме того, такие же функциональные возможности можно также обеспечивать при использовании специализированных логических групп в одной и той же ASIC.
[0037] Кроме того, в примерах настоящего описания, представленных со ссылкой на системы 100 и 300 на ФИГ. 1 и 3 соответственно, описаны со ссылкой на использование аппаратной реализации блока 136 выравнивания считываний в программируемом логическом устройстве. Кроме того, выше указано, что одну или более ASIC можно использовать для осуществления модуля выравнивания считываний или других блоков операций вторичного анализа. Вместе с тем настоящее описание не ограничивается использованием аппаратных блоков для реализации таких операций вторичного анализа. Напротив, в некоторых вариантах реализации любая из операций, описанных в настоящем документе, выполняемых программируемым логическим устройством, таких как выравнивание считываний, сжатие или распаковка, также может быть реализована с использованием одного или более программных модулей.
[0038] Как показано в примере на ФИГ. 1, реализация системы 100 может начинаться с секвенатора 110 для секвенирования биологического образца 105. Секвенирование биологического образца может включать генерирование секвенатором 110 считанных последовательностей, которые представляют собой данные, отражающие упорядоченные последовательности нуклеотидов, присутствующих в биологическом образце 105. Если система 100 выполнена с возможностью обработки считываний ДНК, считывания, генерируемые секвенатором 110, можно сохранять в запоминающем устройстве 120.
[0039] В альтернативном варианте реализации в некоторых вариантах реализации, если система 100 выполнена с возможностью обработки считываний РНК, секвенатор 110 может быть выполнен с возможностью проведения предварительной обработки биологического образца 110 с использованием обратной транскрипции для образования комплементарной ДНК (кДНК) с помощью фермента обратной транскриптазы. В таких вариантах реализации, таких как вариант реализации в примере, представленном на ФИГ. 1, считывания, сгенерированные секвенатором 110, включают считывания РНК 112-1, 112-2, 112-n. В других вариантах реализации секвенатор 110 нуклеиновых кислот может включать секвенатор РНК, а биологический образец может включать образец РНК. Независимо от того, генерируют ли считывания РНК с помощью секвенатора ДНК с использованием кДНК или с помощью секвенатора РНК, каждое из считываний РНК включает последовательность нуклеотидов, состоящую из С, G, А и U. Считывания 112-1, 112-2, 112-n могут храниться в запоминающем устройстве 120 в сжатом или распакованном формате.
[0040] Реализация системы 100 может быть продолжена с использованием блока 130 вторичного анализа, получающего считывания 112-1, 112-2, 112-n, хранящихся в запоминающем устройстве 120. В некоторых вариантах реализации блоку 130 вторичного анализа можно предоставлять доступ к считываниям 112-1, 112-2, 122-n в запоминающем устройстве 120, и он может сохранять доступные считывания 112-1, 112-2, 112-n в запоминающем устройстве 132 блока 130 вторичного анализа. В других вариантах реализации после того, как управляющая программа регистрирует завершение секвенирования считываний 112-1, 112-2, 112-n и доступность блока 130 вторичного анализа для выполнения операций вторичного анализа, управляющая программа может загружать считывания 112-1, 112-2, 112-n в память 132 блока 130 вторичного анализа.
[0041] В случае сжатия считываний 112-1, 112-2, 112-n блок 130 вторичного анализа может динамически конфигурировать программируемое логическое устройство 134 как блок распаковки для доступа к считываниям 112-1, 112-2, 112-n в запоминающем устройстве 132 или 120, распаковки считываний 112-1, 112-2, 112-n, а затем сохранять распакованные считывания 112-1, 112-2, 112-n в запоминающем устройстве 1320 или 120. В некоторых вариантах реализации блок вторичного анализа может динамически изменять конфигурацию программируемого логического устройства и выполнять распаковку в соответствии с командами управляющей программы.
[0042] Если считывания 112-1, 112-2, 122-n не были сжаты, блок 130 вторичного анализа может получать доступ к считываниям из запоминающего устройства 132 или 120 и выполнять операции выравнивания считываний. В некоторых вариантах реализации блок 130 вторичного анализа может принимать от управляющей программы команду, инструктирующую блок 130 вторичного анализа конфигурировать или повторно конфигурировать программируемое логическое устройство 134 так, чтобы включать блок 136 выравнивания считываний, а затем использовать блок 136 выравнивания считываний для проведения выравнивания считываний 112-1, 112-2, 112-n. В альтернативном варианте реализации в других вариантах реализации программируемое логическое устройство может уже быть выполнено с возможностью включения блока 136 выравнивания считываний и использования блока 136 выравнивания считываний для проведения выравнивания считываний 112-1, 112-2, 112-n. В других вариантах реализации блок 130 вторичного анализа может включать ASIC, которая выполнена с возможностью проведения выравнивания считываний, а затем использовать ASIC для проведения выравнивания считываний 112-1, 112-2, 112-n.
[0043] Блок 130 вторичного анализа может быть выполнен с возможностью проведения операций выравнивания считываний параллельно с анализом слияния генов. Например, блок 140 вторичного анализа может получать первый пакет считываний, сгенерированный секвенатором 110, которые не были выравнены, использовать блок 136 выравнивания считываний для выравнивания первого пакета считываний, использовать модуль сортировки, который может быть реализован в аппаратной конфигурации программируемого логического устройства 136 или может быть реализован в программном обеспечении посредством выполнения программных команд для сортировки выравненных считываний, а затем выводить первый пакет выравненных и отсортированных считываний для хранения в запоминающем устройстве 132, 130. В некоторых вариантах реализации память 132 может функционировать как локальный кэш для блока 132 вторичного анализа, в который загружают данные, подлежащие обработке в блоке выравнивания считываний, после чего выгружают данные, которые выводит блок 136 выравнивания считываний. Поэтому после вывода первого пакета выравненных считываний из блока 136 выравнивания считываний в память 132, первый пакет выравненных считываний может проходить сортировку, а затем загружаться в память 120. Затем модуль 140 идентификации потенциального слияния может получать доступ к первому пакету выравненных и отсортированных считываний из запоминающего устройства 120 и начинать обработку первого пакета выравненных и отсортированных считываний, в то время как блок 130 вторичного анализа выполняет операции выравнивания второго пакета считываний, которые были подготовлены секвенатором 110 и не были выравнены ранее. Такой процесс можно выполнять итеративно, пока система 100 не обработает каждый пакет считываний. Несмотря на то что данный пример описан с использованием выравненных и отсортированных пакетов, настоящее описание не требует, чтобы пакеты выравненных считываний также были отсортированы. Напротив, использование выравненных и отсортированных считываний можно осуществлять в системе 100 или системе 300 для улучшения показателей, например сокращения времени прогона, как это описано ниже.
[0044] Модуль 140 идентификации потенциального слияния может получать пакет выравненных и отсортированных считываний, которые были выравнены блоком 136 выравнивания считываний, и определять, содержит ли пакет выравненных и отсортированных считываний один или более потенциальных генов слияния. В некоторых вариантах реализации, если полученный пакет включает выравненные и отсортированные считывания, модуль 140 идентификации потенциального слияния может оценивать отсортированные считывания пакета, причем геномный интервал, соответствующий пакету, перекрывает точку разрыва по меньшей мере одного потенциального слияния. За счет этого может сокращаться число потенциальных слияний, которые требуют дальнейшего анализа. В других вариантах реализации, если полученный пакет включает выравненные считывания, которые не были отсортированы, модуль 140 идентификации потенциального слияния может оценивать каждое из выравненных считываний в пакете, чтобы определить, является ли выравненное считывание потенциальным слиянием. В некоторых вариантах реализации проводимая модулем 140 идентификации потенциального слияния операция определения того, включает ли пакет считываний одно или более потенциальных слияний, предусматривает определение модулем 140 идентификации потенциального слияния, при том что пакет считываний включает одно или более выравниваний расщепленных считываний, одной или более дискордантных пар считываний, одно или более выравниваний с ограниченным клиппированием или их комбинацию.
[0045] В некоторых вариантах реализации модуль 140 идентификации потенциального слияния может быть выполнен с возможностью идентификации выравниваний расщепленных считываний как потенциальных слияний. Модуль 140 идентификации потенциального слияния может идентифицировать выравнивания расщепленных считываний посредством анализа генов эталонной последовательности, с которой проводили выравнивание каждого конкретного считывания в пакете выравненных считываний. Если модуль 140 идентификации потенциального слияния устанавливает соответствие того или иного считывания единичному гену, модуль 140 идентификации потенциального слияния может определять, что такое считывание не является расщепленным. В альтернативном варианте осуществления, если модуль 140 идентификации потенциального слияния определяет, что считывание совпадает с двумя различными генами, то считывание можно считать расщепленным. В таких вариантах реализации расщепленное считывание может быть отнесено к потенциальным слияниям. Считывание можно считать соответствующим двум различным считываниям, если, например, первое подмножество нуклеотидов считывания выравнивают с первым родительским геном эталонного генома, а второе подмножество нуклеотидов считывания выравнивают со вторым родительским геном эталонного генома. В некоторых вариантах реализации первое подмножество нуклеотидов может быть префиксом считывания, а второе подмножество нуклеотидов может быть суффиксом считывания. Если модуль 140 идентификации потенциального слияния выполнен с возможностью идентификации расщепленных считываний, данные идентификации расщепленных считываний, при наличии таковых, могут храниться в запоминающем устройстве 120.
[0046] В некоторых вариантах реализации модуль 140 идентификации потенциального слияния может быть выполнен с возможностью идентификации выравниваний дискордантных пар считываний как потенциальных слияний. Модуль 140 идентификации потенциального слияния может идентифицировать дискордантные пары считываний посредством анализа генов эталонной последовательности, с которой выравнивали каждую конкретную пару считывания в пакете выравненных считываний. Если пару считывания выравнивают с эталонной последовательностью, а ориентация и диапазон выравнивания соответствуют ожидаемой ориентации и диапазону, пара считывания не относится к дискордантным считываниям. В альтернативном варианте осуществления, если пару считывания выравнивают с эталонной последовательностью, а ориентация и диапазон выравнивания соответствуют ожидаемым ориентации и диапазону, пара считывания будет отнесена к дискордантным считываниям. В таких вариантах реализации, если одно считывание в паре соответствует одному родительскому гену, а другое соответствует другому родительскому гену, дискордантное считыванием может быть отнесено к потенциальным слияниям. Если модуль 140 идентификации потенциального слияния выполнен с возможностью идентификации дискордантных считываний, данные идентификации дискордантных считываний, при наличии таковых, могут храниться в запоминающем устройстве 120.
[0047] В некоторых вариантах реализации модуль 140 идентификации потенциального слияния может быть выполнен с возможностью идентификации выравниваний с ограниченным клиппированием как потенциальных слияний. Модуль 140 идентификации потенциального слияния может идентифицировать выравнивания с ограниченным клиппированием посредством анализа генов эталонной последовательности, с которой выравнивали каждое конкретное считывание в пакете выравненных считываний. В некоторых вариантах реализации модуль 140 идентификации потенциального слияния может определять, полностью ли выравнивается считывание с единичной позицией в эталонном геноме. Если модуль 140 идентификации потенциального слияния устанавливает полное соответствие выравнивания того или иного считывания с единичной позицией в эталонном геноме, модуль 140 идентификации потенциального слияния может определять, что такое считывание не является расщепленным. В альтернативном варианте осуществления, если модуль 140 идентификации потенциального слияния устанавливает, что лишь участок того или иного считывания выравнивается с эталонным геномом, модуль 140 идентификации потенциального слияния может определять, что такое считывание является расщепленным. Если выравненный участок считывания соответствует одному родительскому гену, а невыравненный участок содержит последовательность, аналогичную другому родительскому гену, считывание ограниченным клиппированием будет отнесено к потенциальным слияниям. Если модуль 140 идентификации потенциального слияния выполнен с возможностью идентификации считываний с ограниченным клиппированием, данные идентификации считываний с ограниченным клиппированием как потенциального слияния, при наличии таковых, могут храниться в запоминающем устройстве 120.
[0048] Модуль 150 фильтрации потенциальных слияний может получать данные, описывающие набор потенциальных слияний, идентифицированных модулем 140 идентификации потенциального слияния. В некоторых вариантах реализации модуль фильтрации потенциальных слияний может получать доступ к запоминающему устройству 120 и получать данные, описывающие потенциальные слияния, из запоминающего устройства 120. В других вариантах реализации модуль фильтрации потенциальных слияний может получать данные, описывающие потенциальные слияния, из выходной информации предыдущего модуля, такого как модуль 140 идентификации потенциального слияния. Модуль 150 фильтрации потенциальных слияний может использовать один или более фильтров для фильтрации данных, описывающих набор потенциальных слияний, для идентификации отфильтрованного набора потенциальных слияний генов, который меньше полного набора потенциальных слияний генов. В некоторых вариантах реализации такие фильтры применяют в пределах одной стадии. Например, можно применять каждый из одного или более фильтров, и каждое потенциальное слияние в наборе потенциальных слияний можно оценивать после каждого из одного или более фильтров. Вместе с тем в других вариантах реализации можно использовать многостадийные подходы к фильтрации. В таких вариантах реализации первый набор из одного или более фильтров применяют в отношении исходного набора потенциальных слияний, идентифицированных модулем 140 идентификации потенциального слияния. Затем второй набор одного или более фильтров применяют к первому набору отфильтрованных потенциальных слияний, которые остаются после первой стадии фильтрации. При необходимости, чтобы получать оптимальный отфильтрованный набор потенциальных кандидатов, можно также применять дополнительные стадии фильтрации.
[0049] В некоторых вариантах реализации модуль 150 фильтрации потенциальных слияний может фильтровать набор потенциальных слияний для учета дублирующих потенциальных слияний, которые являются следствием высокой глубины охвата при секвенировании с коротким считыванием. Например, накопление данных в результате 30-кратного секвенирования, может приводить к тому, что модуль 140 идентификации потенциального слияния идентифицирует до 30 потенциальных слияний, которые дублируют друг друга. Модуль 150 фильтрации потенциальных слияний может удалять такие дубликаты потенциальных слияний за счет применения фильтра к параметрам потенциальных слияний для выявления дублирования. Например, модуль 150 фильтрации потенциальных слияний может определять, выравнено ли множество потенциальных слияний с одним и тем же родительским геном, выравнено ли оно с участком эталонного генома, включающим один и тот же или подобный точечный разрыв, или их комбинацию. Если модуль 150 фильтрации потенциальных слияний идентифицирует множество потенциальных слияний, которые выравнены с одним и тем же родительским геном, выравнено с участком эталонного генома, включающим один и тот же или подобный точечный разрыв, или их комбинация, модуль 150 фильтрации потенциальных слияний может определять, являются ли потенциальные слияния дублирующими, и выбирать только одно потенциальное слияние в качестве репрезентативного потенциального слияния. В таких случаях оставшиеся потенциальные слияния, которые были выравнены с одним и тем же родительским геном, выравнены с участком эталонного генома, включающим один и тот же или подобный точечный разрыв, или их комбинацию, можно исключать без дальнейшего последующего анализа. Затем репрезентативное потенциальное слияние можно добавлять к набору фильтрованных потенциальных слияний в запоминающем устройстве, таком как запоминающее устройство 120.
[0050] В альтернативном или дополнительном варианте осуществления модуль 150 фильтрации потенциальных слияний может фильтровать набор потенциальных слияний на основании одного или более устанавливаемых правилами условий. Например, модуль 150 фильтрации потенциальных слияний может анализировать каждое потенциальное слияние и определять, соответствует ли потенциальное слияние одному или более параметров, удовлетворяющих одному или более устанавливаемых правилами условий, используемым модулями 150 фильтрации. В некоторых вариантах реализации одно или более устанавливаемых правилами условий может включать позицию выравнивания каждого участка потенциального слияния, расстояние перекрывания выравнивания относительно точечного разрыва, охватываемого потенциальным слиянием, ориентацию выравнивания потенциального слияния, качество выравнивания считывания потенциального слияния, дополнительное совмещение положения потенциального слияния или любую их комбинацию.
[0051] В качестве примера, модуль 150 фильтрации потенциальных слияний может использовать одно или более из устанавливаемых правил условий для фильтрации потенциальных слияний на основании положения выравнивания. Например, в некоторых вариантах реализации модуль 150 фильтрации потенциальных слияний может быть выполнен с возможностью использования устанавливаемого правилами условия, которое отфильтровывает потенциальные слияния со считыванием, выравненным с эталонной последовательностью так, что охват выравнивания пересекает точечный разрыв слияния на более чем предварительно заданное число нуклеотидов. В некоторых вариантах реализации предварительно заданное число нуклеотидов для такого устанавливаемого правилами условия может составлять 8 нуклеотидов. В альтернативном или дополнительном варианте осуществления модуль 150 фильтрации потенциальных слияний может быть выполнен с возможностью фильтрации потенциальных слияний со считыванием, выравненным с эталонной последовательностью так, что охват выравнивания на эталонной последовательности не достигает предварительно заданного предельного числа нуклеотидов от точечного разрыва слияний. В некоторых вариантах реализации предварительно заданное пороговое число нуклеотидов для такого устанавливаемого правилами условия может составлять 50 нуклеотидов. В альтернативном или дополнительном варианте осуществления модуль 150 фильтрации потенциальных слияний может быть выполнен с возможностью использования устанавливаемого правилами условия, которое отфильтровывает потенциальные слияния со считыванием, выравненным с эталонной последовательностью, так, что выравненные участки считывания в двух точечных разрывах имеют общее по меньшей мере предварительно заданное число нуклеотидов. В некоторых вариантах реализации предварительно заданное число общих нуклеотидов может включать по меньшей мере 8 нуклеотидов.
[0052] В качестве другого примера, модуль 150 фильтрации потенциальных слияний может использовать одно или более из устанавливаемых правилами условий для фильтрации потенциальных слияний на основании ориентации. В некоторых вариантах реализации, например, модуль 150 фильтрации потенциальных слияний может быть выполнен с возможностью применения устанавливаемого правилами условия, которое отфильтровывает потенциальные слияния с ориентацией выравнивания, указывающей на обращение нуклеотидной последовательности по меньшей мере одного из родительских генов в транскрипте слияния.
[0053] В качестве другого примера, модуль 150 фильтрации потенциальных слияний можно использовать одно или более устанавливаемых правилами условий для фильтрации потенциальных слияний на основании качества картирования. Например, в некоторых вариантах реализации модуль 150 фильтрации потенциальных слияний может быть выполнен с возможностью использования устанавливаемого правилами условия, которое отфильтровывает потенциальные слияния с выравненным считыванием с оценкой качества картирования, не удовлетворяющей предварительно заданному пороговому значению.
[0054] В качестве другого примера, модуль 150 фильтрации потенциальных слияний может использовать одно или более устанавливаемых правилами условий для фильтрации потенциальных слияний на основании положений дополнительного картирования. В некоторых вариантах реализации, например, модуль 150 фильтрации потенциальных слияний может быть выполнен с возможностью применения устанавливаемого правилами условия, которое отфильтровывает потенциальные слияния на основании определения того, что участок считывания потенциального слияния соответствует множеству положений эталонной последовательности. В некоторых вариантах реализации модуль 150 фильтрации потенциальных слияний может быть выполнен с возможностью исключения положений, аннотированных в качестве гомологичных генов.
[0055] Потенциальные слияния, которые удовлетворяют каждому из одного или более установленных правилами условий, можно добавлять к набору отфильтрованных потенциальных слияний в запоминающем устройстве, таком как запоминающее устройство 120. Потенциальные слияния, которые не удовлетворяют каждому из одного или более установленных правилами условий, могут быть исключены без дальнейшего последующего анализа. В некоторых вариантах реализации установленное правилами условие по результатам фильтрации потенциальных слияний можно применять в качестве фильтра второй стадии после применения на первой стадии фильтра для устранения дублирования. В других вариантах реализации фильтрацию потенциальных слияний на основании установленного правилами условия можно применять в качестве первой стадии фильтрации, а затем в качестве фильтра второй стадии можно применять фильтр удаления дублирования. В других вариантах реализации фильтрацию на основании установленного правилами условия можно применять в качестве одной стадии фильтрации без предварительной фильтрации с удалением дублирования. Фильтрация потенциальных слияний на основании одного или более из таких установленных правилами условий может значительно сокращать число потенциальных слияний, которые должны будут проходить дополнительную последующую обработку.
[0056] Последующую обработку можно проводить для каждого потенциального слияния в отфильтрованном наборе потенциальных слияний, выводимых модулем 150 фильтрации потенциальных слияний. Последующая обработка включает выполнение операций модуля 160 генерации набора признаков, модели 170 машинного обучения, модуля 180 определения слияния генов и модуля 190 выходного API. Такую последующую обработку можно использовать, чтобы определить, соответствует ли потенциальное слияние подтвержденному потенциальному слиянию генов.
[0057] Модуль 160 генерации набора признаков может опираться на данные из множества источников данных для идентификации набора атрибутов данных, на основании которых проводят выделение признаков. К таким источникам данных относятся данные атрибутов, хранящиеся в памяти 120, о потенциальном слиянии, которые включают (i) считывание(-я) потенциального слияния, (ii) участок(-и) позиций эталонной последовательности, с которым выравнивали считывания потенциальных слияний, и (iii) аннотации сегментов эталонного генома, с которыми выравнивали конкретное потенциальное выравнивание. В некоторых вариантах реализации аннотации могут включать аннотации экзонов гена, аннотации, указывающие на присутствие гомологичных генов, аннотации, указывающие на список обогащенных генов, или их комбинацию.
[0058] Источники данных, которые может использовать модуль 160 генерации набора признаков, могут также включать данные, сгенерированные блоком 136 выравнивания считываний в процессе выравнивания. В некоторых вариантах реализации модуль 160 генерации набора признаков может получать данные о признаках на основании данных, сгенерированных блоком 136 выравнивания считываний при выравнивании потенциального слияния. Например, модуль 160 генерации набора признаков на основании данных, сгенерированных блоком 136 выравнивания считываний, может получать информацию, такую как частота встречаемости вариантов аллелей, число уникальных выравниваний считываний, охват считываний транскрипта, показатель MAPQ, данные, указывающие на гомологию между родительскими генами, или их комбинация.
[0059] Модуль 160 генерации набора признаков можно использовать для генерирования данных признаков, которые представляют один или более из вышеупомянутых атрибутов потенциального слияния, полученных из множества источников данных, и кодирования данных признаков в одну или более структур 162 данных для ввода в модель 170 машинного обучения. Например, в некоторых вариантах реализации весь набор признаков, полученных из атрибутов потенциального слияния, может быть закодирован в единичный вектор 162, включенный в модуль 170 машинного обучения. Например, в сценарии выравниваний расщепленных считываний или с ограниченным клиппированием каждый из признаков, полученных из атрибутов такого рода потенциальных слияний, может быть закодирован в единичных векторах 162.
[0060] В других вариантах реализации данные признаков могут представлять собой полученные из атрибутов потенциальных слияний и могут быть закодированы для ввода в виде множества векторов. В таком сценарии входной вектор 162 может включать пару входных векторов 162а, 162b. Например, в сценарии расщепленного считывания потенциального слияния каждый из признаков, извлеченный из атрибутов, относящийся к префиксу расщепленного считывания, включая признаки, представляющие нуклеотиды префикса расщепленного считывания, признаки, представляющие сегмент эталонной последовательности, с которой выравнивают префикс, и любые другие признаки, извлеченные из вышеупомянутых атрибутов, относящихся к префиксу, или любая их комбинация могут быть закодированы во входном векторе 162а. Аналогичным образом в таком варианте реализации каждый из признаков, извлеченный из атрибутов, относящихся к суффиксу расщепленного считывания, включая признаки, представляющие нуклеотиды префикса расщепленного считывания, признаки, представляющие сегмент эталонной последовательности, с которой выравнивается суффикс, и любые другие признаки, извлеченные из вышеупомянутых атрибутов, относящихся к суффиксу, или любая их комбинация могут быть закодированы во входном векторе 162b. В качестве другого примера, если дискордантная пара считывания идентифицирована в качестве потенциального слияния, извлеченные признаки, представляющие первое считывание дискордантной пары считывания, извлеченные признаки, представляющие участок эталонной последовательности, с которой их выравнивали, признаки, извлеченные из атрибутов, относящихся к первому считыванию дискордантной пары считывания, или любая их комбинация, могут быть закодированы во входном векторе 162а. Аналогичным образом в таком примере извлеченные признаки, представляющие второе считывание дискордантной пары считывания, извлеченные признаки, представляющие участок эталонной последовательности, с которой их выравнивали, признаки, извлеченные из атрибутов, относящихся ко второму считыванию дискордантной пары считывания, или любая их комбинация, могут быть закодированы во входном векторе 162b.
[0061] Каждый из одного или более векторов 162 может численно представлять собой сгенерированные данные признаков, причем такие данные признаков включают любой из признаков, полученных от потенциальных слияний, или любой из признаков, полученных из данных блока 136 выравнивания считываний, относящихся к потенциальному слиянию и сохраненных в запоминающем устройстве 120. Например, каждый вектор 162 или 162а, 162b может включать множество полей, каждое из которых соответствует конкретному признаку конкретного считывания конкретного потенциального слияния. В зависимости от конкретного потенциального слияния это может приводить к одному или более входных векторов, как это описано выше. Модуль 160 генерации набора признаков может определять численное значение для каждого из полей, которое описывает степень проявления конкретного признака в атрибутах конкретного считывания потенциального слияния. Установленные численные значения для каждого из полей можно использовать для кодирования подготовленных данных признаков, отражающих атрибуты считываний потенциального слияния, в один или более соответствующих векторов 162. Построенные один или более векторов 162а, 162b, которые численно отражают соответствующие считывания потенциального слияния, вводят в качестве исходной информации в модель 170 машинного обучения. В некоторых вариантах реализации, даже если для того или иного потенциального слияния генерируют множество концептуальных векторов, такое множество концептуальных векторов может быть свернуто в единичный вектор 162, который можно вводить в модель 170 машинного обучения. В таких вариантах реализации, если было целесообразно получать множество векторов в (i) определенных вариантах реализации расщепленных считываний, причем признаки префикса присваивали первому вектору, а признаки суффикса присваивали второму вектору, или (ii) в реализациях с дискордантной парой, тогда первый участок единичного вектора может соответствовать концептуальному первому вектору, а второй участок единичного вектора может соответствовать концептуальному второму вектору.
[0062] Модель 170 машинного обучения может включать глубокую нейронную сеть, обучаемую для вычисления вероятности того, что потенциальное слияние соответствует подтвержденному слиянию генов, на основании обработки исходной информации одного или более входных векторов 162, которые отражают признаки того или иного потенциального слияния. Подтвержденное слияние генов представляет собой химерный транскрипт, который содержит последовательность из множества генов из-за перестройки в геноме, связывающую префикс одного родительского гена с суффиксом другого родительского гена. В контексте настоящего описания подтвержденное слияние генов будет считаться предсказанным моделью 170, если, например, выходные данные 178, подготовленные моделью машинного обучения, удовлетворяют предварительно заданному пороговому значению. Модель 170 машинного обучения может включать входной слой 172 для приема входных данных, один или более скрытых слоев 174а, 174b, 174с для обработки входных данных, полученных через входной слой 172, и выходной слой 176 для выдачи выходных данных 178. Каждый скрытый слой 174а, 174b, 174с включает один или более весовых коэффициентов или других параметров. Весовые коэффициенты или другие параметры каждого соответствующего скрытого слоя 174а, 174b, 174с могут быть скорректированы в процессе обучения так, чтобы обученная глубокая нейронная сеть создавала желаемые целевые выходные данные 178 с указанием вероятности того, что один или более входных векторов 162 представляют собой подтвержденное слияние генов на основании модели 170 машинного обучения, обрабатывающей один или более входных векторов 162.
[0063] Модель 170 машинного обучения можно обучать несколькими различными способами. В одном варианте реализации модель 170 машинного обучения можно обучать различать (i) один или более входных векторов, содержащих признаки, полученные из атрибутов подтвержденных потенциальных слияний, и (ii) один или более входных векторов, содержащих признаки, полученные из атрибутов неподтвержденных потенциальных слияний. В некоторых вариантах реализации такое обучение можно проводить с использованием меченых пар обучающих векторов. Каждый обучающий вектор может представлять собой обучающее потенциальное слияние и может состоять из тех же типов данных признаков, что и один или более входных векторов 162, упомянутых выше. В таких вариантах реализации один или более входных векторов 162, содержащих признаки, полученные из атрибутов потенциальных слияний, могут быть помечены как подтвержденные слияния генов или неподтвержденные слияния генов. В некоторых вариантах реализации метка подтвержденного слияния генов и метка неподтвержденного слияния генов могут быть представлены в виде численного значения. Например, в некоторых вариантах реализации меткой подтвержденного слияния генов может быть «1», а меткой неподтвержденного слияния генов может быть «0». В других вариантах реализации, например, меткой подтвержденного слияния генов может быть число от «0» до «1», удовлетворяющее предварительно заданному пороговому значению, а меткой неподтвержденного слияния генов может быть число от «0» до «1», не удовлетворяющее предварительно заданному пороговому значению. В таких вариантах реализации значение, при котором такое число удовлетворяет или не удовлетворяет предварительно заданному пороговому значению, указывает на уровень достоверности того, что обучающая пара входных векторов представляет собой подтвержденное слияние генов или неподтвержденное слияние генов. В некоторых вариантах реализации соответствие предварительно заданному пороговому значению может включать превышение предварительно заданного порогового значения. Вместе с тем конфигурацию вариантов реализации можно также выбирать таким образом, чтобы соответствие пороговому значению означало отсутствие превышения предварительно заданного порогового значения. Такие варианты реализации могут включать, например, варианты реализации, в которых исключается использование компаратора и параметров.
[0064] В процессе обучения каждый меченый набор из одного или более обучающих векторов в качестве входных данных вводят в модель 170 машинного обучения для обработки моделью 170 машинного обучения, а затем выходные данные обучения, подготовленные моделью 170 машинного обучения, используют, чтобы определять прогнозируемую метку для каждого меченого набора из одного или более обучающих векторов. Прогнозируемую метку, полученную моделью 170 машинного обучения на основании обработки моделью машинного обучения одного или более меченых обучающих векторов, соответствующих паре считываний обучающего потенциального слияния, можно сравнивать с обучающей меткой для одного или более обучающих векторов, соответствующих одному или более считываний (или участков считываний) обучающего потенциального слияния. Затем параметры модели 170 машинного обучения можно скорректировать на основании различий между прогнозируемыми метками и обучающими метками. Данный процесс может итеративно продолжаться для каждого из множества меченых обучающих векторов, отвечающих соответствующему обучающему потенциальному слиянию, пока прогнозируемые метки потенциального слияния, полученные моделью 170 машинного обучения на основании обработки набора из одного или более обучающих векторов, соответствующих обучающему потенциальному слиянию, в пределах предварительно заданного уровня ошибки не будут совпадать с обучающими метками набора одного или более обучающих векторов, относящихся к соответствующему обучающему потенциальному слиянию.
[0065] В некоторых вариантах реализации меченые обучающие потенциальные слияния могут быть получены из библиотеки обучающих потенциальных слияний, которые были проанализированы и помечены одним или более людьми-пользователями. Вместе с тем в других вариантах реализации меченые обучающие потенциальные слияния могут включать обучающее потенциальное слияние, которое было сгенерировано и помечено симулятором. В таких вариантах реализации симулятор может быть использован для генерирования распределений различных категорий обучающих потенциальных слияний, которые могут быть использованы для обучения модели 170 машинного обучения. Как правило, если прогон модели 170 машинного обучения предусматривает введение одного входного вектора 162, в котором каждый извлеченный признак потенциального слияния кодируют одним входным вектором 162, модель 170 машинного обучения необходимо обучать с использованием одного входного вектора с теми же признаками, что и входной вектор 162, с использованием описанного выше процесса обучения. Аналогичным образом, если прогон модуля 170 машинного обучения предусматривает введение двух обучающих векторов 162а, 162b, как описано выше, то модель 170 машинного обучения необходимо обучать с использованием двух входных векторов, каждый из которых имеет одинаковые соответствующие признаки упомянутых выше входных векторов 162а, 162b. Таким образом, тип входных векторов, подлежащих обработке в ходе прогона, совпадает с типом векторов, которые нужно применять для обучения модели 170 с использованием описанного выше процесса обучения.
[0066] В процессе обработки входных данных 162, которые соответствуют признакам, полученным из атрибутов потенциального слияния, выходные данные каждого скрытого слоя 174а, 174b, 174с могут включать вектор активации. Выходной вектор активации, выводимый каждым соответствующим скрытым слоем, может быть распространен через последующие слои глубокой нейронной сети и использован выходным слоем для генерирования выходных данных 178. В примере, показанном на ФИГ. 1, модель 170 машинного обучения обучена генерировать выходные данные 178, которые представляют собой комбинированный показатель, получаемые моделью 170 машинного обучения на основании обработки моделью машинного обучения отдельных входных векторов 162а, 162b, каждый из которых соответствует одному из считываний потенциального слияния. Такой комбинированный показатель 178 в конечном итоге генерируется выходным слоем 176 обученной модели машинного обучения на основании вычислений, выполненных выходным слоем 176 обученной модели 170 машинного обучения с вектором активации, полученным от конечного скрытого слоя 174с.
[0067] Модуль 180 определения слияния генов может оценивать выходные данные 178, подготовленные обученной моделью 170 машинного обучения, чтобы определить, указывают ли они на то, что потенциальное слияние, соответствующее одному или более входных векторов 162, является подтвержденным потенциальным слиянием. В некоторых вариантах реализации выходные данные 178 могут быть переданы в модуль 180 определения слияния генов обученной моделью 170 машинного обучения. В других вариантах реализации система 100 может сохранять выходные данные 178 обученной модели 170 машинного обучения в запоминающем устройстве, таком как запоминающее устройство 120, для последующего доступа модуля 180 определения слияния генов. Модуль 180 определения слияния генов может получать выходные данные 178, подготовленные моделью 170 машинного обучения, и оценивать выходные данные 178, чтобы на основании выходных данных 178 определять, является ли потенциальное слияние, соответствующее паре 162 входных векторов 162а, 162b, подтвержденным слиянием генов. В некоторых вариантах реализации модуль 180 определения слияния генов может устанавливать, является ли потенциальное слияние, соответствующее одному или более входных векторов 162, подтвержденным слиянием генов, посредством сравнения выходных данных 178, подготовленных моделью машинного обучения, с предварительно заданным пороговым значением. Если модуль 180 определения слияния генов устанавливает, что выходные данные 178 удовлетворяют предварительно заданному пороговому значению, то модуль 180 определения слияния генов может считать, что потенциальное слияние, соответствующее одному или более входных векторов 162, является подтвержденным слиянием генов. В альтернативном варианте осуществления, если модуль 180 определения слияния генов устанавливает, что выходные данные 178 не удовлетворяют предварительно заданному пороговому значению, модуль 180 определения слияния генов может считать, что потенциальное слияние, соответствующее одному или более входных векторов 162, не является подтвержденным слиянием генов.
[0068] В некоторых вариантах реализации модуль 180 определения слияния генов может генерировать выходные данные 182, которые указывают на результаты решения, принятого модулем 180 определения слияния генов, на основании проведенной модулем 180 определения слияния генов оценки выходных данных 178, подготовленных моделью 170 машинного обучения. Такие выходные данные 182 могут включать данные идентификации потенциального слияния генов, которые соответствуют одному или более входных векторов 162, и данные, содержащие решение, принятое модулем 180 определения слияния генов. Данные, содержащие решение модуля 180 определения слияния генов, могут включать данные, сообщающие, является ли потенциальное слияние генов, которое соответствует одному или более входных векторов 162, подтвержденным слиянием генов или неподтвержденным слиянием генов. В некоторых вариантах реализации выходные данные 182 могут содержать только список подтвержденных слияний генов, идентифицированных на основании выходных данных 178, список неподтвержденных слияний генов, идентифицированных на основании выходных данных 178, данные о том, что подтвержденных слияний генов не обнаружено, или любую их комбинацию. В некоторых вариантах реализации такие выходные данные 182 могут сохраняться в запоминающем устройстве 182 для последующего использования другим вычислительным модулем, для последующего вывода на пользовательское устройство и т.п.
[0069] В альтернативном или дополнительном варианте осуществления модуль 180 определения слияния генов может генерировать выходные данные 184, которые можно передавать в качестве входных данных на модуль 190 выходного прикладного программного интерфейса (API). Выходные данные 184 могут содержать инструкцию для выходного API по выдаче на дисплей вывода сообщений о том, является ли потенциальное слияние генов, которое соответствует одному или более входных векторов 162, подтвержденным слиянием генов или неподтвержденным слиянием генов. В некоторых вариантах реализации команды могут инструктировать модуль 190 выходного API получать доступ к выходным данным 182, хранящимся в запоминающем устройстве 120, и генерировать преобразованные данные, что после преобразования вычислительным устройством, связанным с дисплеем 195 вывода, инструктирует дисплей 195 вывода отображать (i) данные идентификации потенциального слияния, которые соответствуют одному или более входных векторов 162, и (ii) данные, указывающие, является ли идентифицированное потенциальное слияние подтвержденным слиянием генов или неподтвержденным слиянием генов. При этом дисплей 195 вывода может получать инструкции на отображение любых выходных данных 182, хранящихся в запоминающем устройстве 184. В некоторых вариантах реализации такую выходную информацию можно выводить в форме отчета.
[0070] В некоторых вариантах реализации модуль 180 определения слияния генов сохраняет выходные данные 182 для каждого потенциального слияния генов в запоминающем устройстве 120 по результатам последующей обработки, проводимой для каждого потенциального слияния из отфильтрованного набора потенциальных слияния генов. В таких вариантах реализации модуль 180 определения слияния генов может только инструктировать модуль 190 выходного API выводить результаты анализа слияния генов, хранящиеся в запоминающем устройстве 120 для каждого потенциального слияния из отфильтрованного набора потенциальных слияний генов, после завершения последующей обработки каждого потенциального слияния. В таком сценарии выходные данные 192, передаваемые для отображения на дисплее 195 вывода, будут включать список подтвержденных слияний генов, список неподтвержденных слияний генов или оба списка. В других вариантах реализации модуль 180 определения слияния генов может подавать команду на модуль 190 выходного API для вывода данных результатов с указанием списка идентифицированных слияний генов, если таковые выявлены, после завершения дальнейшей обработки для данного конкретного потенциального слияния.
[0071] Модуль 190 выходного APIR может выводить выходные данные 192 в других формах. Например, в некоторых вариантах реализации выходные данные 192 могут представлять собой данные, которые вывод отчета другим устройством, таким как принтер, включающего (i) данные, идентифицирующие потенциальное слияние, которое соответствует одному или более векторов 162, и (ii) данные, указывающие, является ли идентифицированное потенциальное слияние подтвержденным геном. В других вариантах реализации выходные данные 192 могут инициировать вывод громкоговорителем звуковых данных, включающих (i) данные, идентифицирующие потенциальное слияние, которое соответствует одному или более векторов 162, и (ii) данные, указывающие, является ли идентифицированное потенциальное слияние подтвержденным геном. Модуль 190 выходного APIR может также выводить выходные данные в других формах.
[0072] В некоторых вариантах реализации дисплей 195 вывода может представлять собой дисплейную панель секвенатора 110. В других вариантах реализации дисплей 195 вывода может представлять собой дисплейную панель пользовательского устройства, которое связано с секвенатором 110 через одну или более сетей. Действительно, секвенатор 110 можно использовать для передачи выходных данных 192 на любое устройство с любым дисплеем.
[0073] На ФИГ. 2 показан пример последовательности операций процесса 200 проведения быстрого обнаружения подтвержденных слияний генов. Система, например система 100, может начинать выполнение процесса 200 с использованием одного или более компьютеров для получения первых данных, представляющих множество выравненных считываний, от блока (210) выравнивания считываний. Система может идентифицировать множество потенциальных слияний генов, включенных в полученные первые данные (220). Система может фильтровать множество потенциальных слияний генов для генерирования отфильтрованного набора потенциальных слияний генов (230).
[0074] Система может извлекать конкретное потенциальное слияние генов из отфильтрованного набора потенциальных слияний генов (240). Система может генерировать входные данные для ввода в модель машинного обучения, причем генерирование входных данных включает извлечение характерных данных, представляющих конкретное потенциальное слияние генов, из данных, включающих (i) один или более сегментов эталонной последовательности, с которыми выравнивали конкретное потенциальное слияние генов с помощью блока выравнивания считываний, и (ii) данные, сгенерированные на основании выходной информации блока выравнивания считываний (250).
[0075] Система может передавать подготовленные входные данные в качестве входных данных в модель машинного обучения, причем модель машинного обучения обучена генерировать выходные данные, отражающие вероятность того, что потенциальное слияние генов представляет собой подтвержденное слияние генов, исходя из результатов применения модели машинного обучения для обработки входных данных, представляющих собой (i) сегменты эталонного генома, с которыми выравнивали конкретное потенциальное слияние генов с помощью блока выравнивания считываний, и (ii) данные, сгенерированные на основании выходной информации блока (260) выравнивания считываний. Система может получать выходные данные, сгенерированные моделью машинного обучения по результатам модели машинного обучения, обрабатывающей входные данные (270). Система может определять, является ли потенциальное слияние подтвержденным слиянием генов на основании выходных данных (280).
[0076] После завершения стадии 280 система может определять, следует ли проводить оценку другого потенциального слияния из отфильтрованного набора потенциальных слияний (290). Если система устанавливает, что существует другое потенциальное слияние из оцениваемого отфильтрованного набора потенциальных слияний, система может продолжать выполнение процесса 200 на стадии 240. В альтернативном варианте осуществления, если система устанавливает, что не существует другого потенциального слияния из оцениваемого отфильтрованного набора потенциальных слияний, система может завершать выполнение процесса на стадии 295. Другое потенциальное слияние может присутствовать в отфильтрованном наборе потенциальных слияний, если набор потенциальных слияний не был исчерпан.
[0077] На ФИГ. 3 показана блок-схема другого примера системы 300 для быстрого обнаружения подтвержденных слияний генов. Система 300 выполняет те же функции, что и система 100, поскольку система 300 использует секвенатор 110 для генерирования считываний 112 последовательностей РНК (или ДНК), использует блок 130 вторичного анализа для выравнивания считываний 112 последовательностей РНК с эталонной последовательностью, использует модуль 140 идентификации потенциального слияния для идентификации потенциального слияния, использует модуль 150 фильтрации потенциальных слияний для генерирования отфильтрованного набора потенциальных слияний для дальнейшего анализа, а затем проводит последующий анализ отфильтрованного набора потенциальных слияний, чтобы определять подтвержденные слияния генов с помощью модуля 160 генерации набора признаков, модели 170 машинного обучения, модуля 190 определения слияния генов и модуля 190 выходного API. Каждый из этих функциональных блоков, модулей или модели выполняет те же функции, которые были для них описаны при рассмотрении системы 100 на ФИГ. 1.
[0078] Различие между системой 300 и системой 100 заключается в том, что идентификацию потенциального слияния, фильтрацию потенциального слияния и дальнейший анализ отфильтрованного набора потенциальных слияний проводят на другом компьютере 320, а не на секвенаторе 110. Соответственно, различия между системой 300 и системой 100 заключаются в способе упаковки выравненных считываний и их передачи на компьютер 320 для анализа слияния генов с использованием сети 310, распаковки компьютером 320, а также в способе упаковки и передачи результатов анализа слияния генов на другое устройство с соответствующим дисплеем для вывода.
[0079] Более подробно, секвенатор 110 может секвенировать биологический образец 105 и генерировать считывания РНК 112-1, 112-2, 112-n, где «n» представляет собой любое положительное целое число больше 0, как описано со ссылкой на систему 100. Несмотря на то что в качестве примера используют считывания РНК, система может также выполнять те же процедуры со считываниями ДНК. Секвенатор 110 может хранить считывания 112-1, 112-2, 112-n в запоминающем устройстве 120. В некоторых вариантах реализации считывания 112-1, 112-2, 112-n могут быть в сжатом формате.
[0080] Блок 130 вторичного анализа может получать считывания 112-1, 112-2, 112-n и сохранять считывания 112-1, 112-2, 122-n в запоминающем устройстве 132 блока 130 вторичного анализа. В некоторых вариантах реализации сюда может входить передача управляющей программой секвенатора 110 считываний 112-1, 112-2, 112-n в память 132 блока 130 вторичного анализа. В других вариантах реализации блок 130 вторичного анализа может запрашивать считывания 112-1, 112-2, 122-n.В случае сжатых считываний 112-1, 112-2, 112-n программируемое логическое устройство 134 блока 130 вторичного анализа можно переводить в состояние В для работы в качестве блока 138 распаковки и может быть использовано для распаковки считываний 112-1, 112-2, 112-n. Затем программируемое логическое устройство 134 может быть переконфигурировано в состояние А для работы в качестве блока выравнивания считываний и использовано для выравнивания считываний 112-1, 112-2, 112-n с эталонной последовательностью.
[0081] Блок 130 вторичного анализа можно возвращать в состояние В для работы в качестве блока сжатия, и такой блок сжатия можно использовать для сжатия выравненных считываний для подготовки выравненных считываний к передаче на компьютер 320. В данном примере сжатие первого пакета выравненных считываний включает сжатие не только выравненных считываний, но также и данных, подготовленных блоком 136 выравнивания считываний, относящихся к выравненным считываниям, которые будут использовать для анализа слияния генов. Такие данные описаны со ссылкой на систему 100, показанную на ФИГ. 1, и могут включать, например, частоту встречаемости вариантов аллелей, число уникальных выравниваний считываний, охват считываний транскрипта, показатель MAPQ, данные, указывающие на гомологию между родительскими генами, или их комбинацию. Кроме того, другие данные, которые могут сжиматься в выравненные считывания первого пакета, могут включать (i) считывания потенциального слияния, (ii) участок, с которым выравнивали считывания потенциальных слияний, и (iii) аннотации сегментов эталонного генома, с которыми выравнивали конкретное потенциальное слияние генов. В некоторых вариантах реализации аннотации могут включать аннотации экзонов гена, аннотации, указывающие на присутствие гомологичных генов, аннотации, указывающие на список обогащенных генов, или их комбинацию.
[0082] После сжатия выравненных считываний блок 130 вторичного анализа может сохранять первый пакет сжатых считываний в запоминающем устройстве 120. Затем секвенатор 110 может передавать первый пакет 125 выравненных считываний на компьютер 320 по сети 310 для анализа слияния генов. Сеть 310 может включать одну или более проводных сетей, одну или более беспроводных сетей или их комбинацию. В различных вариантах реализации сеть 310 может представлять собой одну или более из проводной сети Ethernet, проводной оптической сети, LAN, WAN, сотовой сети, Интернета или их комбинации. В некоторых вариантах реализации компьютер 320 может представлять собой удаленный облачный сервер. Вместе с тем в других вариантах реализации компьютер 320 может связываться с секвенатором 110 посредством прямого соединения, такого как прямое соединение Ethernet, соединение USB-C или т.п. Несмотря на то что в данном примере на ФИГ. 300 до передачи сжимают первый пакет считываний, сжатие не является обязательным. Напротив, сжатие применяют в качестве способа снижения использования пропускной способности сети и сокращения затрат на хранение, что может обеспечивать значительные технологические преимущества и уменьшать расходы при работе с геномами с большими размерами данных.
[0083] В некоторых вариантах реализации первый пакет выравненных считываний включает полный набор считываний, полученный для пробы 105. В других вариантах реализации первый пакет выравненных считываний представляет собой лишь участок полного набора считываний, подготовленных для пробы 105, и для упрощения параллельной обработки можно использовать систему пакетной обработки. Например, в некоторых вариантах реализации после того, как блок вторичного анализа сохраняет первый пакет выравненных считываний в запоминающем устройстве 120, в блок 130 вторичного анализа поступает второй пакет считываний, которые еще не были выравнены, для хранения в запоминающем устройстве 132. Затем блок 130 вторичного анализа может выполнять распаковку, если второй пакет считываний был сжат, и выравнивание второго пакета считываний, в то время как компьютер 320 проводит анализ слияния генов первого пакета считываний. Такая параллельная обработка, которую обеспечивает пакетная обработка считываний, может значительно сокращать время прогона системы 300, необходимое для определения подтвержденных слияний генов для считываний пробы 105.
[0084] Компьютер 320 может получать первый пакет считываний 125 по сети 310 и сохранять первый пакет считываний в запоминающем устройстве 320. В случае сжатого первого пакета 125 считываний компьютер 320 может использовать модуль сжатия/распаковки 325 для распаковки первого пакета считываний и сохранения первого пакета считываний в запоминающем устройстве 320. Затем компьютер 320 может организовать процесс поточного анализа слияний генов с использованием модуля 140 идентификации потенциального слияния, модуля 150 фильтрации потенциальных слияний, модуля 160 генерации набора признаков, модели 170 машинного обучения, модуля 180 определения слияния генов и модуля 190 выходного API таким же образом, как описано со ссылкой на систему 100 на ФИГ. 1.
[0085] Выходные данные 192 можно передавать на множество различных устройств через сеть 310. В качестве примера выходные данные можно передавать на секвенатор для вывода на дисплей 195 секвенатора. В альтернативном или дополнительном варианте осуществления выходные данные 192 можно выводить для отображения на дисплее пользовательского устройства 330 через сеть 310. Пользовательское устройство 330 может включать смартфон, планшетный компьютер, ноутбук, настольный компьютер или любой другой компьютер с дисплеем. В альтернативном или дополнительном варианте осуществления выходные данные 192 можно также передавать для вывода на принтер 340 по сети 310. В таких вариантах реализации выходные данные могут представлять собой печатную копию отчета о выявленных подтвержденных слияниях генов.
[0086] На ФИГ. 4 показана блок-схема системных компонентов, которые можно использовать для осуществления системы быстрого обнаружения слияний генов.
[0087] Вычислительное устройство 400 должно представлять собой различные формы цифровых компьютеров, таких как ноутбуки, настольные компьютеры, рабочие станции, карманные персональные компьютеры, серверы, блейд-серверы, мэйнфреймы и другие подходящие компьютеры. Вычислительное устройство 450 должно представлять собой различные формы мобильных устройств, таких как карманные персональные компьютеры, сотовые телефоны, смартфоны и другие аналогичные вычислительные устройства. Кроме того, вычислительное устройство 400 или 450 может включать флэш-накопители с универсальной последовательной шиной (USB). Во флэш-накопителях USB можно хранить операционные системы и другие приложения. Флэш-накопители USB могут включать компоненты ввода/вывода, такие как беспроводной передатчик или USB-разъем, который может быть вставлен в USB-порт другого вычислительного устройства. Представленные здесь компоненты, их соединения и взаимоотношения, а также их функции являются только примерами и не предназначены для ограничения вариантов реализации изобретения, описанных и/или заявленных в настоящем документе.
[0088] Вычислительное устройство 400 включает процессор 402, память 404, устройство 406 хранения, высокоскоростной интерфейс 408, соединяющийся с памятью 404 и высокоскоростными расширительными портами 410, и низкоскоростной интерфейс 412, соединяющийся с низкоскоростной шиной 414 и устройством 408 хранения. Все компоненты 402, 404, 406, 408, 410 и 412 соединены друг с другом с помощью различных шин, и могут быть установлены на общей материнской плате или при необходимости другими способами. Процессор 402 может обрабатывать команды, предназначенные для выполнения в вычислительном устройстве 400, включая команды, хранящиеся в запоминающем устройстве 404 или на устройстве 408 хранения, для отображения графической информации графического пользовательского интерфейса на внешнем устройстве ввода/вывода, таком как дисплей 416, соединенный с высокоскоростным интерфейсом 408. В других вариантах реализации при необходимости можно использовать множество процессоров и/или множество шин вместе с множеством запоминающих устройств и типов памяти. Кроме того, множество вычислительных устройств 400 могут быть соединены, причем каждое устройство обеспечивает участок необходимых операций, например это может быть банк серверов, группа блейд-серверов или многопроцессорная система.
[0089] Информация в запоминающем устройстве 404 хранится в вычислительном устройстве 400. В одном варианте реализации память 404 представляет собой блок или блоки энергозависимой памяти. В другом варианте реализации память 404 представляет собой блок или блоки энергонезависимой памяти. Память 404 может также представлять собой другую форму машиночитаемого носителя, такую как магнитный или оптический диск.
[0090] Устройство 408 хранения выполнено с возможностью обеспечения большой емкости хранения для вычислительного устройства 400. В одном варианте реализации устройство 408 хранения может представлять собой или содержать машиночитаемый носитель, такой как устройство с гибким диском, устройство с жестким диском, устройство с оптическим диском или устройство с лентой, флэш-память или другое аналогичное твердотельное запоминающее устройство или массив устройств, включая устройства в сети хранения данных или в других конфигурациях. Компьютерный программный продукт может быть на практике реализован на носителе информации. Компьютерный программный продукт может также содержать команды, которые при их исполнении осуществляют один или более способов, таких как описанные выше. Носитель информации представляет собой компьютерочитаемый или машиночитаемый носитель, такой как память 404, устройство 408 хранения данных или память на процессоре 402.
[0091] Высокоскоростной контроллер 408 управляет операциями с большой пропускной способностью для вычислительного устройства 400, а низкоскоростной контроллер 412 управляет операциями с меньшей пропускной способностью. Такое распределение функций является лишь примером. В одном варианте реализации высокоскоростной контроллер 408 соединен с памятью 404, дисплеем 416, например, через графический процессор или ускоритель, и с высокоскоростными расширительными портами 410, в которые можно устанавливать различные платы расширения (не показаны). В варианте реализации низкоскоростной контроллер 412 соединен с устройством 408 хранения и низкоскоростным расширительным портом 414. Низкоскоростной расширительный порт, который может включать различные коммуникационные порты, например USB, Bluetooth, Ethernet, беспроводной Ethernet, может быть соединен с одним или более устройствами ввода/вывода, такими как клавиатура, указательное устройство, пара микрофон/динамик, сканер или сетевое устройство, такое как коммутатор или маршрутизатор, например, с помощью сетевого адаптера. Вычислительное устройство 400 может быть реализовано в нескольких различных формах, как показано на фигуре. Например, оно может быть реализовано как стандартный сервер 420 или многократно, в виде группы таких серверов. Оно может также быть реализовано как часть стоечной серверной системы 424. Кроме того, оно может быть реализовано на персональном компьютере, таком как ноутбук 422. В альтернативном варианте осуществления компоненты вычислительного устройства 400 могут быть объединены с другими компонентами в мобильном устройстве (не показано), таком как устройство 450. Каждое из таких устройств может содержать одно или более вычислительных устройств 400, 450, и вся система может состоять из множества вычислительных устройств 400, 450, взаимодействующих друг с другом.
[0092] Вычислительное устройство 400 может быть реализовано в нескольких различных формах, как показано на фигуре. Например, оно может быть реализовано как стандартный сервер 420 или многократно, в виде группы таких серверов. Оно может также быть реализовано как часть стоечной серверной системы 424. Кроме того, оно может быть реализовано на персональном компьютере, таком как ноутбук 422. В альтернативном варианте осуществления компоненты вычислительного устройства 400 могут быть объединены с другими компонентами в мобильном устройстве (не показано), таком как устройство 450. Каждое из таких устройств может содержать одно или более вычислительных устройств 400, 450, и вся система может состоять из множества вычислительных устройств 400, 450, взаимодействующих друг с другом.
[0093] Вычислительное устройство 450 включает процессор 452, память 464 и устройство ввода/вывода, такое как, помимо прочего, дисплей 454, коммуникационный интерфейс 466 и приемопередатчик 468. Устройство 450 может также быть снабжено устройством хранения, таким как микропривод или другое устройство, для обеспечения дополнительной возможности хранения. Все компоненты 450, 452, 464, 454, 466 и 468 соединяют друг с другом с помощью различных шин, и некоторые из компонентов могут быть установлены на общей материнской плате или иными способами, в зависимости от ситуации.
[0094] Процессор 452 может выполнять команды, имеющиеся в вычислительном устройстве 450, включая команды, хранящиеся в запоминающем устройстве 464. Процессор может быть реализован в виде набора микросхем, включая отдельные и многокомпонентные аналоговые и цифровые процессоры. Кроме того, процессор может быть реализован с использованием любой из ряда архитектур. Например, процессор 410 может представлять собой процессор CISC (вычислительное устройство с полным набором команд), процессор RISC (вычислительное устройство с сокращенным набором команд) или процессор MISC (вычислительное устройство с минимальным набором команд). Процессор может обеспечивать, например, координацию других компонентов устройства 450, таких как управление пользовательскими интерфейсами, запуск приложений устройством 450, и беспроводную связь с устройством 450.
[0095] Процессор 452 может обмениваться данными с пользователем через интерфейс 458 управления и интерфейс 456 дисплея, соединенный с дисплеем 454. Дисплей 454 может представлять собой, например, дисплей типа TFT (жидкокристаллический дисплей на тонкопленочных транзисторах) или типа OLED (на органических светоизлучающих диодах), или другие подходящие технологии отображения. Интерфейс 456 дисплея может содержать соответствующую схему для приведения дисплея 454 в действие и для представления графической и другой информации пользователю. Интерфейс 458 управления может принимать команды от пользователя и преобразовывать их для передачи процессору 452. Кроме того, может быть предусмотрен внешний интерфейс 462, сообщающийся с процессором 452 для обеспечения устройства 450 связью ближнего радиуса действия с другими устройствами. В некоторых вариантах реализации внешний интерфейс 462 может обеспечивать, например, проводную связь, или в других вариантах реализации беспроводную связь, и можно также использовать множество интерфейсов.
[0096] Информация в запоминающем устройстве 464 хранится в вычислительном устройстве 450. Запоминающее устройство 464 может быть реализована в виде одного или более машиночитаемых носителей или носителей, блока или блоков энергозависимой памяти, или блока или блоков энергонезависимой памяти. Кроме того, может быть предусмотрена расширительная память 474, соединенная с устройством 450 посредством расширительного интерфейса 472, который может включать, например, интерфейс карты SIMM (модуль с однорядным расположением микросхем памяти). Такая расширительная память 474 может обеспечивать устройство 450 дополнительным пространством хранения или может также хранить приложения или другую информацию для устройства 450. В частности, расширительная память 474 может включать команды для выполнения или для дополнения описанных выше процессов, а может также включать защищенную информацию. Таким образом, например, расширительная память 474 может быть обеспечена в качестве защищенного модуля для устройства 450 и может быть запрограммирована командами, которые позволяют использовать устройство 450 защищенным образом. Кроме того, с помощью плат SIMM можно передавать безопасные приложения, а также дополнительную информацию, например размещать идентификационную информацию на карте SIMM без возможности компрометации.
[0097] Память может включать, например, флэш-память и/или память NVRAM, как описано ниже. В одном варианте реализации компьютерный программный продукт на практике реализован на носителе информации. Компьютерный программный продукт содержит команды, при исполнении которых осуществляется один или более способов, такие как описанные выше. Информационный носитель представляет собой компьютерочитаемый или машиночитаемый носитель, такой как запоминающее устройство 464, расширительная память 474 или память на процессоре 452, причем информация может быть принята, например, посредством приемопередатчика 468 или внешнего интерфейса 462.
[0098] Устройство 450 может обмениваться данными беспроводным способом через коммуникационный интерфейс 466, в который при необходимости может быть включена схема для обработки цифровых сигналов. Коммуникационный интерфейс 466 связи может обеспечивать связь в различных режимах или протоколах, таких как, помимо прочего, голосовые звонки GSM, SMS, EMS или MMS сообщения, CDMA, TDMA, PDC, WCDMA, CDMA2000 или GPRS. Такую передачу данных можно осуществлять, например, при помощи радиочастотного приемопередатчика 468. Кроме того, возможна связь ближнего радиуса действия, например, с помощью Bluetooth, Wi-Fi или другого подобного приемопередатчика (не показан). Кроме того, модуль 470 приемника GPS (глобальной системы позиционирования) может передавать дополнительные относящиеся к навигации и местоположению беспроводные данные на устройство 450, которые можно использовать при необходимости в приложениях, работающих на устройстве 450.
[0099] Устройство 450 может также передавать звуковой сигнал с использованием аудиокодека 460, который может принимать речевую информацию от пользователя и преобразовывать ее в пригодную для использования цифровую информацию. Аудиокодек 460 может также генерировать звуковой сигнал для пользователя, например, через динамик, например через гарнитуру устройства 450. Такой звуковой сигнал может представлять собой звук от голосовых телефонных звонков, может представлять собой записанный звук, например голосовые сообщения, музыкальные файлы и т.п., а может также включать звук, создаваемый приложениями, работающими на устройстве 450.
[0100] Вычислительное устройство 450 может быть реализовано в нескольких различных формах, как показано на фигуре. Например, оно может быть реализовано в виде сотового телефона 480. Оно может также быть реализовано как часть смартфона 482, карманного персонального компьютера или другого подобного мобильного устройства.
[0101] Различные варианты реализации систем и способов, описанных в настоящем документе, могут быть реализованы в виде цифровой электронной схемы, интегральной схемы, специально разработанных ASIC (интегральных схем прикладного назначения), компьютерного аппаратного обеспечения, микропрограммного обеспечения, программного обеспечения и/или в виде комбинации таких вариантов реализации. Данные различные реализации могут включать реализацию в одной или более компьютерных программах, выполненных с возможностью исполнения и/или интерпретации в программируемой системе, включающей по меньшей мере один программируемый процессор, который может быть специализированным или общего назначения, присоединенный к системе хранения для приема от нее данных и команд и передачи в нее данных и команд, по меньшей мере одно устройство ввода и по меньшей мере одно устройство вывода.
[0102] Эти компьютерные программы (также именуемые программами, программным обеспечением, программными приложениями или кодом), включают машинные команды для программируемого процессора и могут быть реализованы на высокоуровневом процедурном и/или объектно-ориентированном языке программирования, и/или на ассемблерном/машинном языке. Используемые в настоящем документе термины «машиночитаемый носитель», «компьютерочитаемый носитель» относятся к любому компьютерному программному продукту, аппарату и/или устройству, например такому как магнитные диски, оптические диски, запоминающее устройство, программируемые логические устройства (PLD), используемые для передачи машинных команд и/или данных на программируемый процессор, включая машиночитаемый носитель, который принимает машинные команды в качестве машиночитаемого сигнала. Термин «машиночитаемый сигнал» относится к любому сигналу, используемому для передачи машинных команд и/или данных на программируемый процессор.
[0103] Для обеспечения взаимодействия с пользователем описанные в настоящем документе системы и методы могут быть реализованы на компьютере, имеющем устройство отображения, например КЛТ- (катодно-лучевая трубка) или ЖК-(жидкокристаллический) монитор, для отображения информации пользователю, и клавиатуру и указывающее устройство, например мышь или трекбол, с помощью которых пользователь может вводить в компьютер входные данные. Для обеспечения взаимодействия с пользователем также можно использовать и другие типы устройств; обратная связь, предоставляемая пользователю, может иметь любую осязаемую форму, например визуальная обратная связь, слуховая обратная связь или тактильная обратная связь; и входные данные от пользователя могут поступать в любой форме, включая звуковые, речевые или тактильные входные данные.
[0104] Описанные в настоящем документе системы и методы могут быть реализованы в компьютерной системе, которая включает серверный компонент, например сервер данных, или включает промежуточный компонент, например сервер приложений, или включает клиентский компонент (например, компьютер-клиент с графическим интерфейсом пользователя или веб-браузером, с помощью которых пользователь может взаимодействовать с реализацией описанных в настоящем документе систем и методов), либо любую комбинацию таких серверных, промежуточных и клиентских компонентов. Компоненты системы могут быть связаны между собой любой формой или средой цифрового обмена данными, например сетью связи. К примерам сетей связи относятся локальная вычислительная сеть (LAN), глобальная сеть (WAN) и Интернет.
[0105] Компьютерная система может включать клиенты и серверы. Клиент и сервер по существу удалены друг от друга и, как правило, взаимодействуют через сеть связи. Функциональная зависимость клиента и сервера возникает благодаря компьютерным программам, выполняемым на соответствующих компьютерах и имеющим функциональную зависимость клиент-сервер друг от друга.
ДРУГИЕ ВАРИАНТЫ ОСУЩЕСТВЛЕНИЯ
[0106] Описан ряд вариантов осуществления. Тем не менее будет очевидно, что возможны различные модификации без отклонения от сущности и объема изобретения. Кроме того, логические потоки, изображенные на фигурах, не требуют показанного определенного или последовательного порядка для достижения желаемых результатов. Кроме того, могут быть предусмотрены и другие стадии, или же стадии могут быть исключены из описанных потоков, и в описанные системы могут быть добавлены или удалены из них другие компоненты. Соответственно, нижеследующая формула изобретения охватывает другие варианты осуществления.
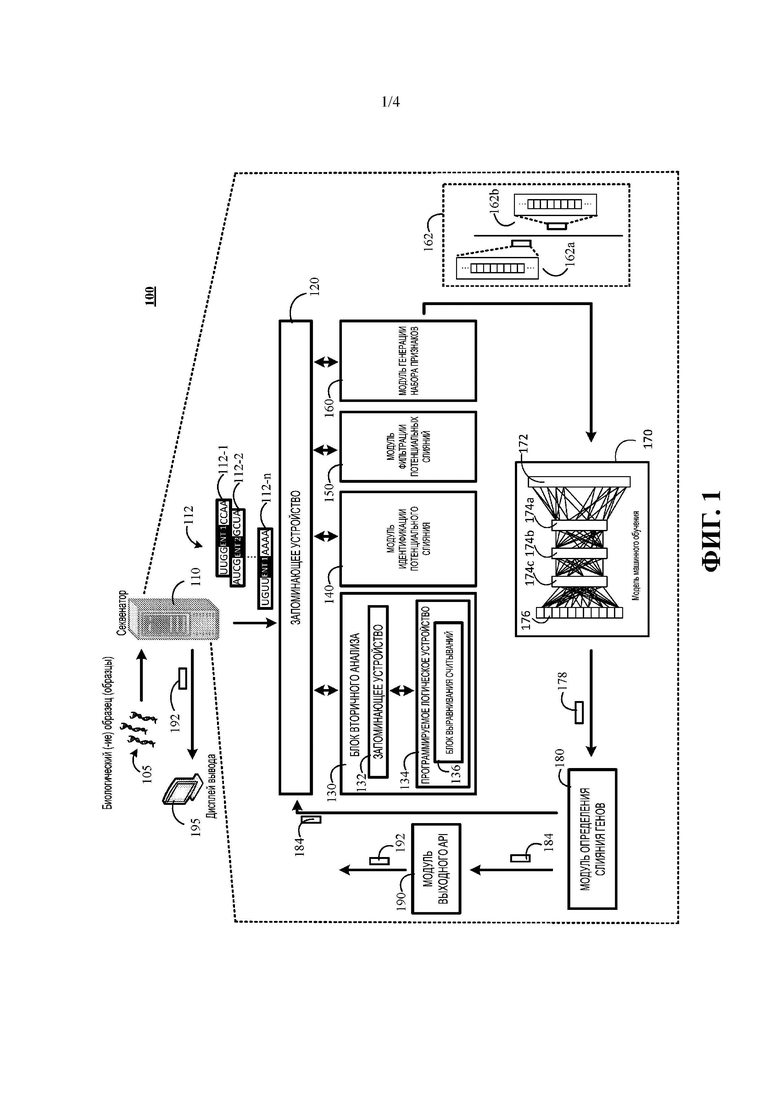
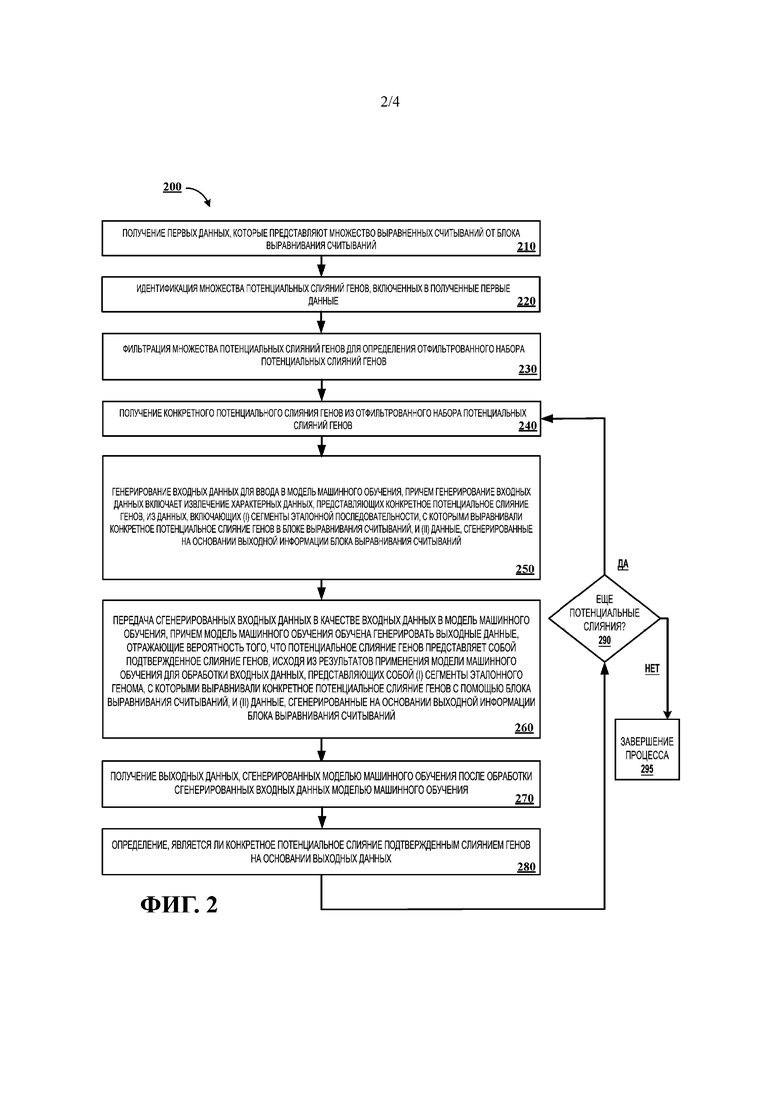
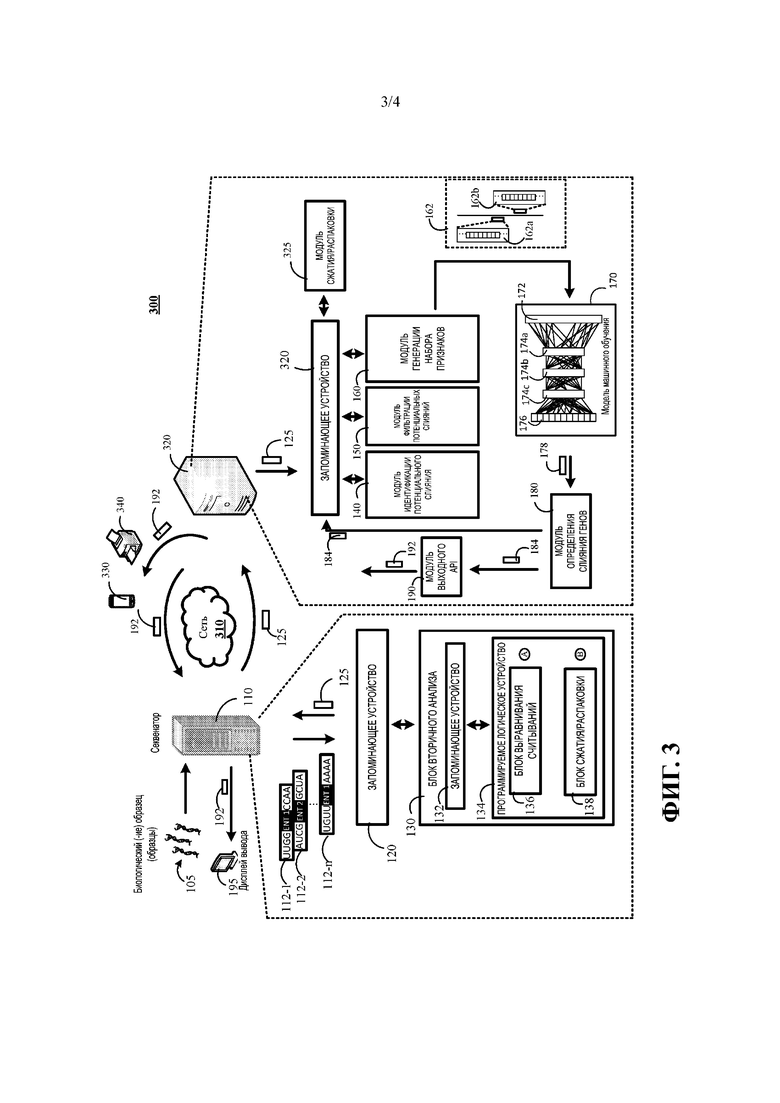
Изобретение относится к биотехнологии. Описан способ идентификации одного или более слияний генов в биологическом образце. Способ включает операции по получению первых данных, которые представляют множество выравненных считываний, идентификации множества потенциальных слияний, включенных в полученные первые данные, фильтрации множества потенциальных слияний для определения отфильтрованного набора потенциальных слияний, для каждого конкретного потенциального слияния из отфильтрованного набора кандидатов на слияние: генерирование входных данных одним или более компьютерами для ввода в модель машинного обучения, которые включают извлеченные данные признаков, представляющих конкретное потенциальное слияние, передачу сгенерированных входных данных в качестве входных данных в модель машинного обучения, которая была обучена генерировать выходные данные, отражающие вероятность того, что потенциальное слияние является подтвержденным слиянием генов, и определение того, соответствует ли конкретное потенциальное слияние подтвержденному слиянию генов на основании выходных данных. Также представлена система для идентификации одного или более слияний генов в биологическом образце, содержащая один или более компьютеров и одно или более устройств хранения, на которых хранятся команды, при исполнении которых одним или более компьютерами один или более компьютеров выполняют операции, включающие описанный способ. Кроме того, представлен энергонезависимый машиночитаемый носитель для идентификации одного или более слияний генов в биологическом образце, на котором хранится программное обеспечение, содержащее команды, выполненные с возможностью исполнения одним или более компьютерами, за счет исполнения которых один или более компьютеров выполняют операции, включающие описанный способ. 3 н. и 10 з.п. ф-лы, 4 ил.
1. Реализованный на компьютере способ идентификации одного или более слияний генов в биологическом образце (105), включающий:
для каждой позиции эталонной последовательности из множества позиций эталонной последовательности:
получение первых данных, которые представляют накопление выравненных считываний, полученных путем секвенирования с коротким считыванием и имеющих высокую глубину охвата в указанной позиции эталонной последовательности, от блока выравнивания считываний, одним или более компьютерами;
идентификацию множества потенциальных слияний генов, включенных в полученные первые данные, одним или более компьютерами (140);
фильтрацию множества потенциальных слияний генов одним или более компьютерами (150) для удаления дубликатов потенциальных слияний, которые являются следствием высокой глубины охвата, в указанной позиции эталонной последовательности, с определением, таким образом, отфильтрованного набора потенциальных слияний генов;
для каждого конкретного потенциального слияния генов из отфильтрованного набора потенциальных слияний генов:
генерирование входных данных (162) одним или более компьютерами (160) для ввода в модель (170) машинного обучения, причем генерирование входных данных включает извлечение характерных данных, отличающих конкретное потенциальное слияние генов от данных, включающих:
(i) один или более сегментов эталонной последовательности, с которыми выравнивали конкретное потенциальное слияние генов с помощью блока (136) выравнивания считываний, и
(ii) данные, сгенерированные на основании выходной информации блока (136) выравнивания считываний, причем данные, сгенерированные на основании выходной информации блока выравнивания считываний, включают одно или более из числа частоты встречаемости вариантов аллелей, числа уникальных выравниваний считываний, показателя MAPQ или данных, указывающих на гомологию между родительскими генами;
передачу одним или более компьютерами сгенерированных входных данных (162) в качестве входных данных в модель (170) машинного обучения, при этом модель машинного обучения обучена с использованием меченых обучающих векторов, где каждый меченый обучающий вектор представляет обучающее потенциальное слияние и содержит (i) один или более сегментов эталонной последовательности, с которыми выравнивали обучающее потенциальное слияние генов, и (ii) одно или более из числа частоты встречаемости вариантов аллелей, числа уникальных выравниваний считываний, показателя MAPQ или данных, указывающих на гомологию между родительскими генами, генерировать выходные данные (178), отражающие вероятность того, что потенциальное слияние генов представляет собой подтвержденное слияние генов, исходя из результатов применения модели (170) машинного обучения для обработки входных данных (162), представляющих собой (i) один или более сегментов эталонной последовательности, с которыми выравнивали конкретное потенциальное слияние генов с помощью блока (136) выравнивания считываний, и (ii) данные, сгенерированные на основании выходной информации блока (136) выравнивания считываний, где данные, сгенерированные на основании выходной информации блока выравнивания считываний, включают любое одно или более из числа частоты встречаемости вариантов аллелей, числа уникальных выравниваний считываний, показателя MAPQ или данных, указывающих на гомологию между родительскими генами;
получение одним или более компьютерами (180) выходных данных (178), сгенерированных моделью (170) машинного обучения после обработки сгенерированных входных данных (162) моделью машинного обучения; и
определение, является ли конкретное потенциальное слияние подтвержденным слиянием генов на основании выходных данных (178), одним или более компьютерами (180).
2. Способ по п. 1,
в котором генерирование входных данных (162) дополнительно включает извлечение характерных данных, которые включают данные аннотации, описывающие аннотации сегментов эталонной последовательности, с которыми выравнивали конкретное потенциальное слияние генов с помощью блока (136) выравнивания считываний; и
при этом модель (170) машинного обучения обучена генерировать выходные данные (178), отражающие вероятность того, что потенциальное слияние генов является подтвержденным потенциальным слиянием генов на основании результатов применения модели (170) машинного обучения для обработки входных данных (162), представляющих собой:
(i) один или более сегментов эталонной последовательности, с которыми выравнивали конкретное потенциальное слияние генов с помощью блока (136) выравнивания считываний,
(ii) данные аннотации, описывающие аннотации сегментов эталонной последовательности, с которыми выравнивали конкретное потенциальное слияние генов с помощью блока (136) выравнивания считываний, и
(iii) данные, сгенерированные на основании выходной информации блока (136) выравнивания считываний.
3. Способ по любому из предшествующих пунктов, в котором идентификация множества потенциальных слияний генов, включенных в полученные первые данные, одним или более компьютерами (140) включает идентификацию множества выравниваний расщепленных считываний одним или более компьютерами.
4. Способ по любому из предшествующих пунктов, в котором идентификация множества потенциальных слияний генов, включенных в полученные первые данные, одним или более компьютерами (140) включает идентификацию множества выравниваний дискордантных пар считываний одним или более компьютерами.
5. Способ по любому из предшествующих пунктов, в котором блок (136) выравнивания считываний реализуют с использованием набора из одного или более модулей обработки, которые выполнены с возможностью использования аппаратных логических схем, физически организованных с возможностью выполнения операций с использованием аппаратных логических схем, для:
(i) приема данных, представляющих первое считывание,
(ii) сопоставления данных, представляющих первое считывание, с одним или более участками эталонной последовательности для идентификации одной или более совпадающих позиций эталонной последовательности,
(iii) генерирования одной или более оценок выравнивания, соответствующих каждой из совпадающих позиций эталонной последовательности для первого считывания,
(iv) выбора одного или более потенциальных выравниваний для первого считывания на основании одной или более оценок выравнивания, и
(v) вывода данных, представляющих потенциальное выравнивание для первого считывания.
6. Способ по любому из пп. 1-4, в котором блок (136) выравнивания считываний реализуют с использованием набора из одного или более модулей обработки посредством использования одного или более центральных процессоров, т.е. CPU, или одного или более графических процессоров, т.е. GPU, для выполнения программных команд, которые инициируют выполнение одним или более CPU или одним или более GPU функций:
(i) приема данных, представляющих первое считывание,
(ii) сопоставления данных, представляющих первое считывание, с одним или более участками эталонной последовательности для идентификации одной или более совпадающих позиций эталонной последовательности для первого считывания,
(iii) генерирования одной или более оценок выравнивания, соответствующих каждой из совпадающих позиций эталонной последовательности для первого считывания,
(iv) выбора одного или более потенциальных выравниваний для первого считывания на основании одной или более оценок выравнивания, и
(v) вывода данных, представляющих потенциальное выравнивание для первого считывания.
7. Способ по любому из предшествующих пунктов, в котором получение одним или более компьютерами первых данных, которые представляют накопление выравненных считываний от блока (136) выравнивания считываний, включает получение одним или более компьютерами накопления выравненных считываний из запоминающего устройства (120) и выполнение одной или более операций по п. 1, в то время как блок (136) выравнивания считываний выравнивает второе накопление считываний, которые еще не были выравнены.
8. Способ по любому из предшествующих пунктов, в котором данные, сгенерированные на основании выходной информации блока выравнивания считываний, включают любое одно или более из числа частоты встречаемости вариантов аллелей, числа уникальных выравниваний считываний, показателя MAPQ или данных, указывающих на гомологию между родительскими генами.
9. Способ по любому из предшествующих пунктов, в котором определение того, соответствует ли конкретное потенциальное слияние подтвержденному потенциальному слиянию генов на основании выходных данных (178), включает:
определение одним или более компьютерами (180), удовлетворяют ли выходные данные (178) предварительно заданному пороговому значению; и
определение того, что конкретное потенциальное слияние соответствует подтвержденному потенциальному слиянию генов, на основании определения того, что выходные данные (178) удовлетворяют предварительно заданным пороговым значениям.
10. Способ по п. 1, в котором определение того, соответствует ли конкретное потенциальное слияние подтвержденному слиянию генов на основании выходных данных (178), включает:
определение одним или более компьютерами (180), удовлетворяют ли выходные данные (178) предварительно заданному пороговому значению; и
определение того, что конкретное потенциальное слияние не соответствует подтвержденному потенциальному слиянию генов, на основании определения того, что выходные данные (178) не удовлетворяют предварительно заданным пороговым значениям.
11. Способ по п. 1, в котором высокая глубина охвата в указанной позиции эталонной последовательности равна 30x охвату.
12. Система (100) для идентификации одного или более слияний генов в биологическом образце, содержащая:
один или более компьютеров и одно или более устройств хранения, на которых хранятся команды, при исполнении которых одним или более компьютерами один или более компьютеров выполняют операции, включающие способ по любому из пп. 1-11.
13. Энергонезависимый машиночитаемый носитель для идентификации одного или более слияний генов в биологическом образце, на котором хранится программное обеспечение, содержащее команды, выполненные с возможностью исполнения одним или более компьютерами, за счет исполнения которых один или более компьютеров выполняют операции, включающие способ по любому из пп. 1-11.
| ANDREW MCPHERSON | |||
| et al | |||
| "deFuse: An Algorithm for Gene Fusion Discovery in Tumor RNA-Seq Data", PLOS COMPUTATIONAL BIOLOGY, Vol | |||
| Способ восстановления хромовой кислоты, в частности для получения хромовых квасцов | 1921 |
|
SU7A1 |
| Кипятильник для воды | 1921 |
|
SU5A1 |
| Печь для непрерывного получения сернистого натрия | 1921 |
|
SU1A1 |
| FRANCESCO ABATE | |||
| et al | |||
| "Pegasus: a comprehensive annotation and prediction tool for detection of driver gene fusions in cancer", BMC | |||

