ОБЛАСТЬ ТЕХНИКИ
[001] Данное техническое решение, в общем, относится к области вычислительной техники, а в частности, к способам и системам оценки качества результатов таргетного секвенирования в области биоинформатики.
УРОВЕНЬ ТЕХНИКИ
[002] В настоящее время технология секвенирования нового поколения (NGS) широко применяется в клинической практике. Однако до сих пор стоимость одного исследования с использованием технологии NGS остается достаточно высокой, что ограничивает широкое применение данного метода. Одним из факторов, влияющих на стоимость, является выбор покрытия при секвенировании, то есть количество раз, которое был отсеквенирован каждый нуклеотид, в связи с чем проблема оценки качества результатов секвенирования является насущной.
[003] Из уровня техники известна научная статья "A quality control tool for high throughput sequence data" (опубл. январь 2014, автор: S. Andrews), в которой при оценке качества секвенирования опираются на оценку качества множества факторов. Например, таких как качество прочтения каждого нуклеотида чтения, процент встречаемости того или иного нуклеотида в каждой конкретной позиции чтения, GC контент, распределение k-мер, содержание перепредставленных последовательностей, содержание адаптерных последовательностей, покрытие различных частей референсной последовательности и т.д. Данные факторы рассматриваются и учитываются независимо друг от друга.
[004] Однако в уровне техники отсутствуют способы для интегральной оценки качества результатов таргетного секвенирования. В рутинной практике оценка качества секвенирования на основании разрозненных метрик, оценивающих разные характеристики, такие как процент ошибок секвенирования, процент коротких фрагментов, качество подготовки библиотеки секвенирования, а также наличие примесей в образце, имеет недостаточную масштабируемость, так как при увеличении числа образцов время на оценку качества каждого из них может быть неприемлемо большим.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
[005] Данное техническое решение направлено на устранение недостатков, свойственных решениям, известным из уровня техники.
[006] Технической задачей или проблемой, решаемой в данном техническом решении, является обеспечение оценки качества результатов таргетного секвенирования.
[007] Техническим результатом, проявляющимся при решении вышеуказанной технической задачи, является повышение скорости выполнения оценки качества результатов таргетного секвенирования.
[008] Дополнительным техническим результатом является повышение точности оценки качества результатов таргетного секвенирования.
[009] Указанный технический результат достигается благодаря использованию машинного обучения при формировании интегральной оценки качества путем объединения большого числа характеристик результатов секвенирования.
[0010] В целом указанный технический результат достигается за счет реализации интегрального способа для оценки качества результатов таргетного секвенирования, в котором получают по меньшей мере один образец по меньшей мере одного пользователя; выполняют таргетное секвенирование по меньшей мере одного образца, полученного на предыдущем шаге; получают из результатов секвенирования характеристики секвенирования; формируют интегральную характеристику секвенирования посредством использования алгоритма машинного обучения.
[0011] В некоторых вариантах реализации изобретения характеристикой секвенирования является среднее покрытие образца и/или число ампликонов, покрытых в среднем больше среднего покрытия образца, и/или процент пар нуклеотидов со значениями качества больше заранее заданного, и/или процент чтений, прошедших тримминг.
[0012] В некоторых вариантах реализации изобретения при формировании интегральной характеристики используют градиентный бустинг деревьев решений.
[0013] В некоторых вариантах реализации изобретения при формировании интегральной характеристики секвенирования используют меру качества, представляющую из себя число из диапазона от 0 до 1.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0014] Признаки и преимущества настоящего технического решения станут очевидными из приведенного ниже подробного описания и прилагаемых чертежей, на которых:
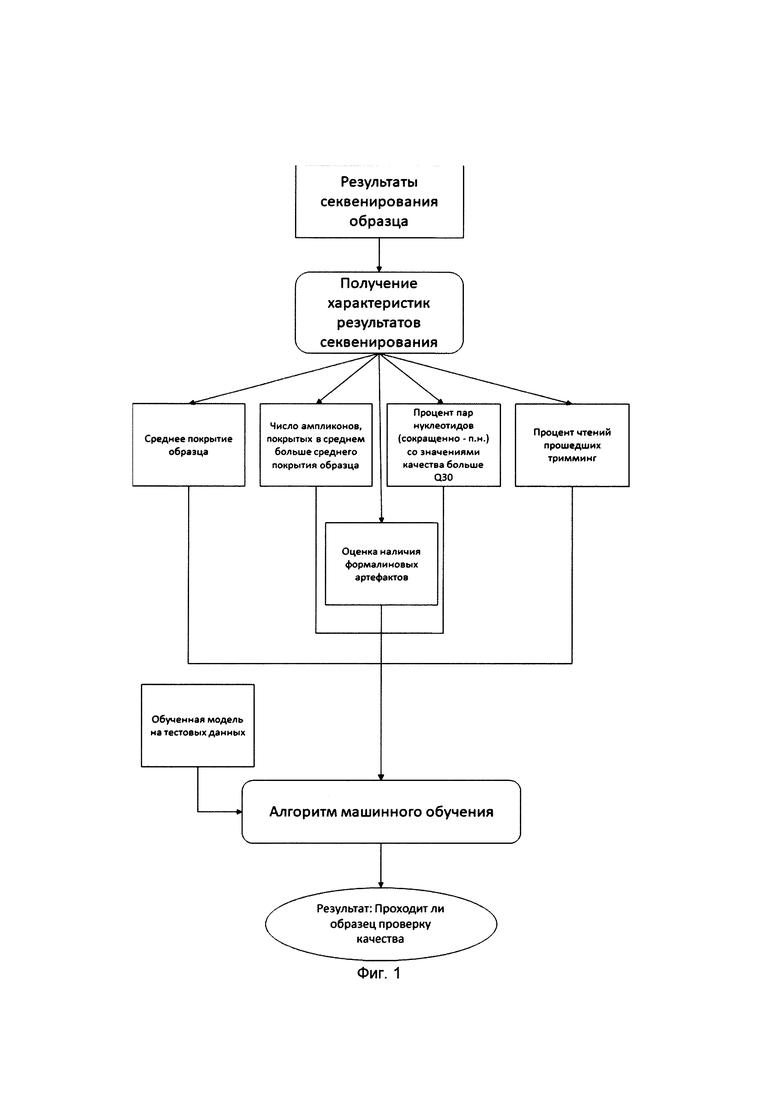
[0015] На Фиг. 1 показан пример реализации способ оценки качества результатов таргетного секвенирования.
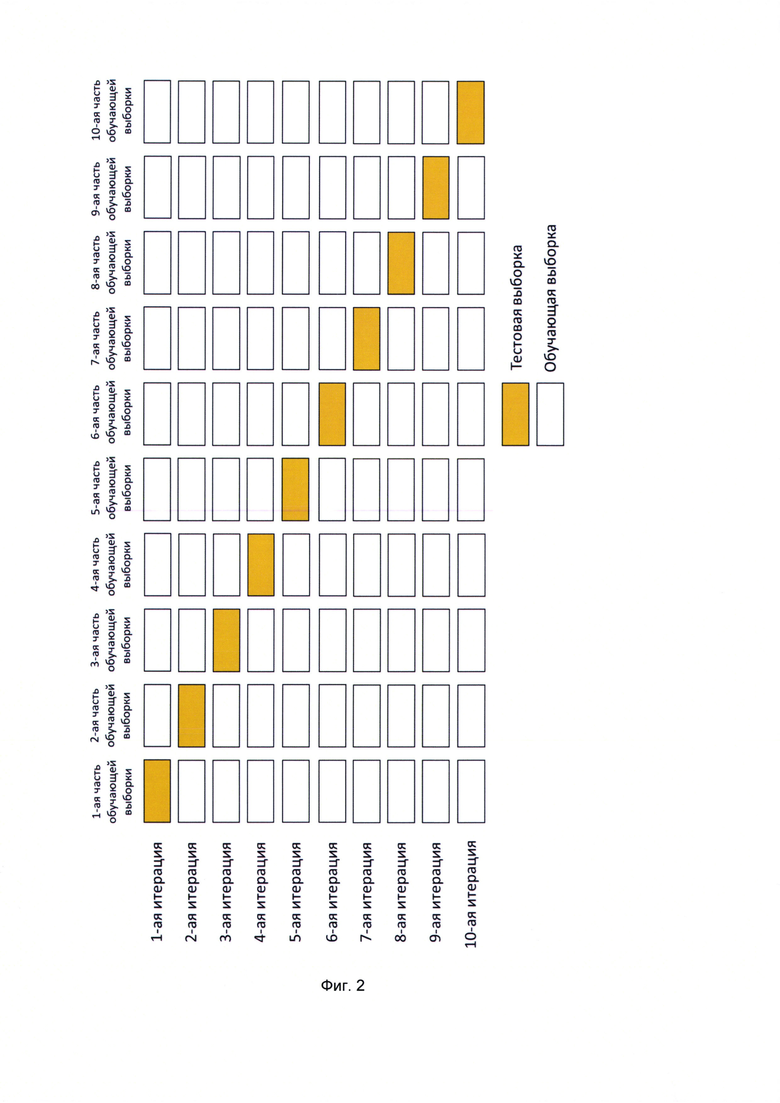
[0016] На Фиг. 2 представлена организация обучающей выборки при перекрестной проверке.
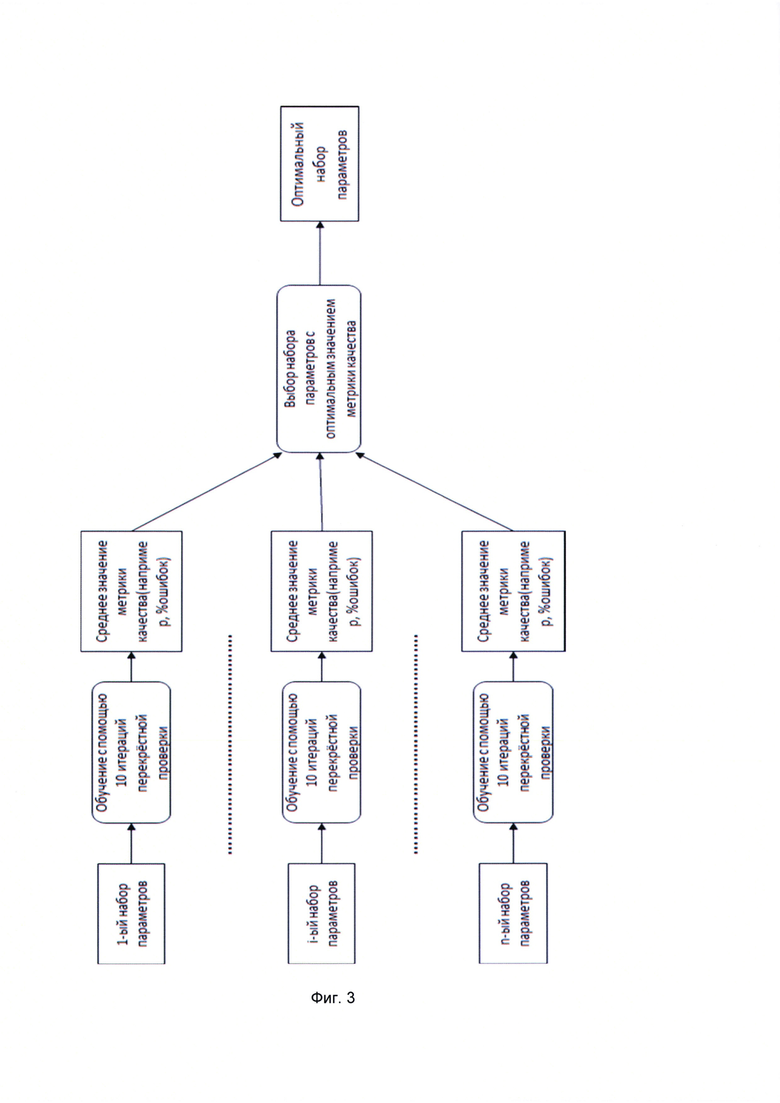
[0017] На Фиг. 3 продемонстрирован подбор параметров с помощью перекрестной проверки.
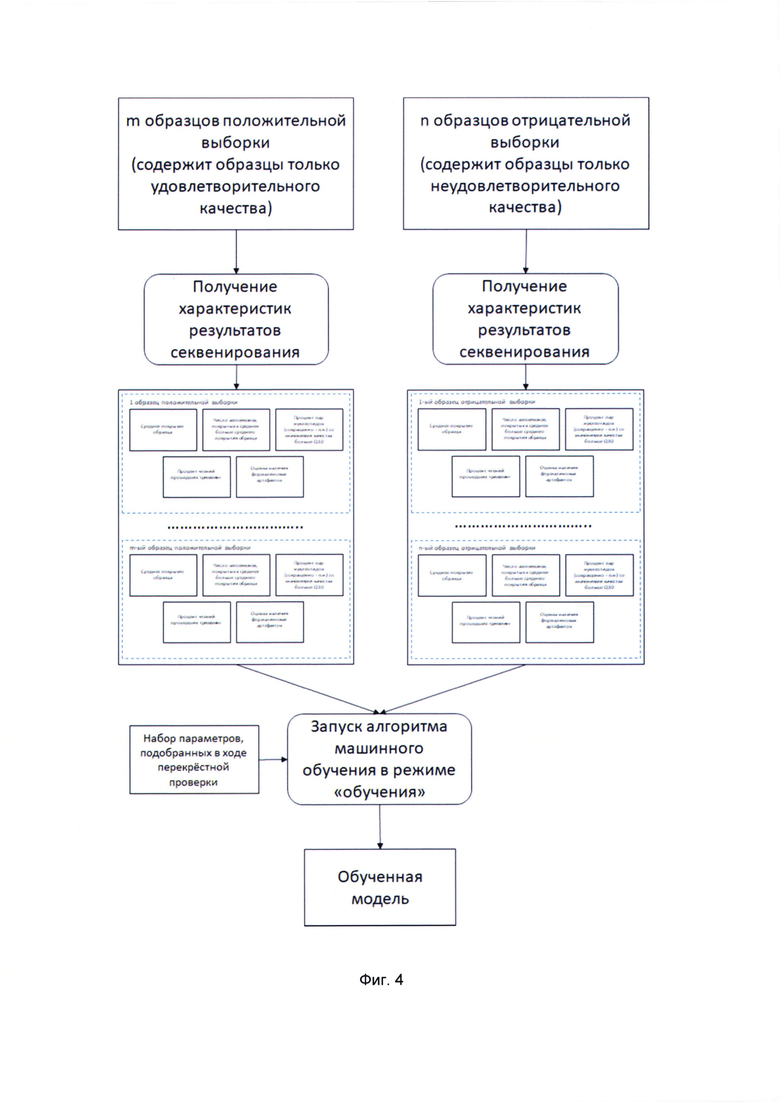
[0018] На Фиг. 4 показан процесс обучения модели с использованием обучающей выборки.
[0019] На Фиг. 5 показан пример расчета среднего покрытия.
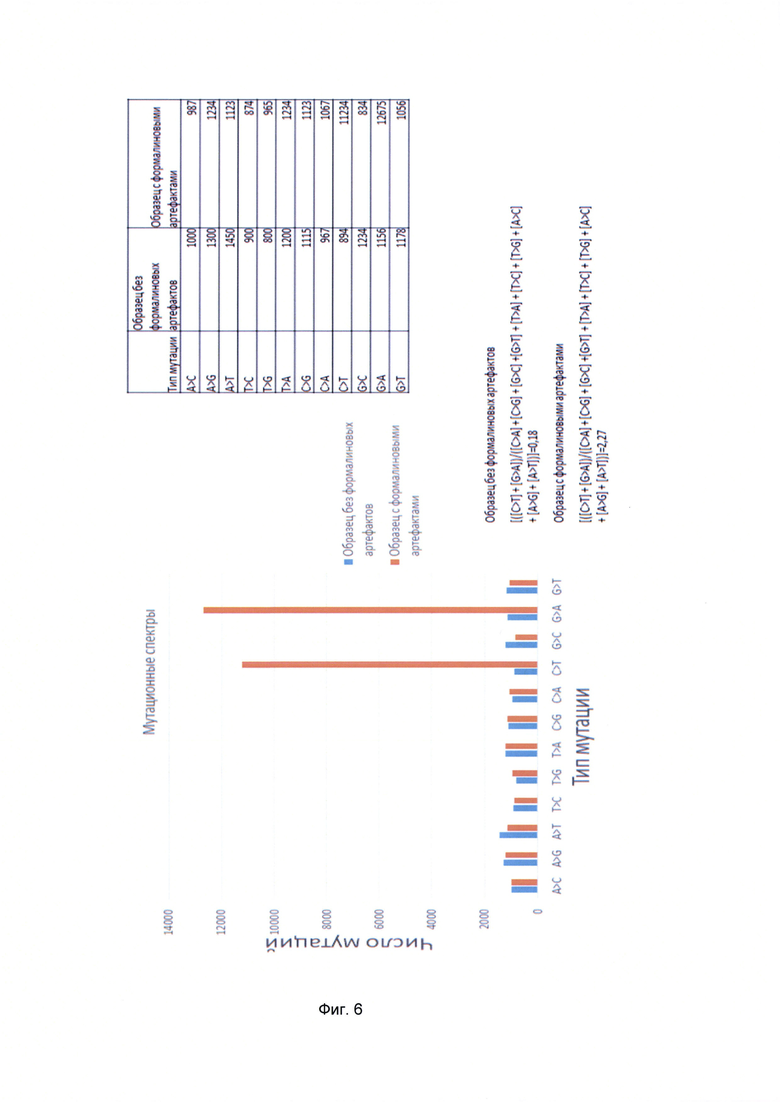
[0020] На Фиг. 6 показан пример пример оценки наличия формалиновых артефактов в образце.
[0021] На Фиг. 7 показан вариант реализации системы оценки качества результатов таргетного секвенирования.
ПОДРОБНОЕ ОПИСАНИЕ ИЗОБРЕТЕНИЯ
[0022] Данное техническое решение может быть реализовано на компьютере или другом устройстве обработки данных в виде автоматизированной системы или машиночитаемого носителя, содержащего инструкции для выполнения вышеупомянутого способа.
[0023] Техническое решение может быть реализовано в виде распределенной компьютерной системы, компоненты которой являются облачными или локальными серверами.
[0024] В данном решении под системой подразумевается компьютерная система или автоматизированная система (АС), ЭВМ (электронно-вычислительная машина), ЧПУ (числовое программное управление), ПЛК (программируемый логический контроллер), компьютеризированная система управления и любые другие устройства, способные выполнять заданную, четко определенную последовательность вычислительных операций (действий, инструкций).
[0025] Под устройством обработки команд подразумевается электронный блок либо интегральная схема (микропроцессор), исполняющая машинные инструкции (программы).
[0026] Устройство обработки команд считывает и выполняет машинные инструкции (программы) с одного или более устройства хранения данных. В роли устройства хранения данных могут выступать, но, не ограничиваясь, жесткие диски (HDD), флеш-память, ПЗУ (постоянное запоминающее устройство), твердотельные накопители (SSD), оптические приводы, облачные хранилища данных.
[0027] Программа - последовательность инструкций, предназначенных для исполнения устройством управления вычислительной машины или устройством обработки команд.
[0028] Секвенирование ДНК - определение последовательности нуклеотидов в молекуле ДНК. Под этим может подразумеваться как амликонное секвенирование (прочтение последовательностей выделенных фрагментов ДНК, полученных в результате ПЦР реакции - таких, как ген 16S рРНК или его фрагменты), так и полногеномное секвенирование (прочтение последовательностей всей ДНК, присутствующей в образце).
[0029] Чтения (иногда риды от англ. "reads") - данные, представляющие собой нуклеотидные последовательности фрагментов ДНК, полученные с помощью ДНК-секвенатора.
[0030] FASTA - формат записи последовательностей ДНК.
[0031] FASTQ - формат записи последовательностей ДНК, при котором записывается аппаратное качество прочтения каждой позиции.
[0032] Картирование прочтений - биоинформатический метод анализа результатов секвенирования нового поколения, состоящий в определении позиций в референсной базе геномов или генов, откуда с наибольшей вероятностью могло быть получено каждое конкретное короткое прочтение.
[0033] В результате секвенирования ДНК создается набор чтений. Длина чтения у современных секвенаторов составляет от нескольких сотен до нескольких тысяч нуклеотидов.
[0034] Ампликон (англ. «amplicon») - нуклеотидная последовательность ДНК, размноженная (амплифицированная) с помощью ПЦР.
[0035] Дерево решений - это бинарный алгоритм классификации, основанный на машинном обучении с учителем. Иными словами прежде чем производить классификацию строится дерево, представляющие из себя структуру у которой во внутренних узлах условия на признаки, а в листьях классы.
[0036] Обучающая выборка (англ. «training sample») - выборка, по которой производится настройка (оптимизация параметров) модели зависимости.
[0037] Кросс-валидация, которую иногда называют перекрестной проверкой, это техника валидации модели для проверки того, насколько успешно применяемый в модели статистический анализ способен работать на независимом наборе данных.
[0038] Способ оценки качества результатов таргетного секвенирования, реализуемый с помощью процессора, показанный на Фиг. 1 в виде блок-схемы, может включать следующие шаги.
[0039] Шаг 110: получают по меньшей мере один образец по меньшей мере одного пользователя.
[0040] В данном техническом решении под пользователем может пониматься пациент.
[0041] Предварительно подготавливают по крайней мере один образец ДНК пользователя для секвенирования. Образец должен представлять собой биологический материал, из которого возможно выделить ДНК. В качестве такого биоматериала для анализа мутаций, ассоциированных с онкологическими заболеваниями, могут быть использованы различные типы биологического материала, содержащие ДНК, например: образцы ткани опухоли (биопсийный или операционный материал) в виде замороженного препарата или парафинизированных блоков, циркулирующая ДНК из плазмы крови или других жидких сред человека, а также цельная кровь или защечный мазок, в качестве источника нормальной ткани для анализа наследственных мутаций.
[0042] К разным типам образцов предъявляются различные требования.
[0043] В некоторых вариантах реализации соответствие биоматериала требованиям определяется посредством процессора на основании ранее введенных параметров полученного образца и критериев пригодности биоматериала. Ниже приведены основные критерии пригодности биоматериала. Например, для образца «Парафинизированные образцы опухоли, фиксированные в формалине (парафиновые блоки)» показатели должны быть следующие. Объем ткани в блоке - не менее 10 мм3, а площадь поверхности ткани в блоке - не менее 5 мм2. Минимальное содержание опухоли по сопроводительным срезам с верхней и нижней поверхности анализируемого фрагмента, процент площади малигнизированной ткани должен быть не менее 10% (по учету клеточных ядер). Образцы, полученные после кислотной декальцинации костной ткани, непригодны для анализа из-за деградации ДНК. Использование незабуференного формалина при фиксации или слишком длительная фиксация ткани приводит к повреждению ДНК и может сделать образец непригодным для анализа.
[0044] Например, для образца «Жидкостная биопсия» (анализ циркулирующей ДНК) требования следующие:
[0045] Образец крови собирается в пробирку с К3ЭДТА (5-10 мл);
[0046] В течение 10 мин центрифугируется для осаждения клеточного осадка и отделения плазмы;
[0047] Отбирается плазма по 1 мл в микропробирки типа SafeLock (1,5 мл);
[0048] Строится центрифугирование на скорости 12-20 тыс. об./мин;
[0049] Немедленно замораживается при температуре -80°С или заморозить в жидком азоте.
[0050] Предварительно получают образец пользователя.
[0051] Вышеуказанные первичные данные получают посредством использования набора для отбора проб, который может включать контейнер для образцов, имеющий компонент технологического реагента и сконфигурированный для приема образца из места сбора пользователем, которое может быть удаленным. Дополнительно или альтернативно набор для отбора проб может быть предоставлен непосредственно через устройство сбора образцов, установленное в помещении или на улице, которое предназначено для облегчения приема пробы от пользователя. В других вариантах осуществления набор для отбора проб может быть сдан в клинике или другом медицинском учреждении медицинскому лабораторному технику, а ранее доставлен пользователю, например, курьером. Однако предоставление набора (-ов) для отбора проб пользователя в систему может дополнительно или альтернативно выполняться любым другим подходящим способом, например, в замороженном виде в стерильном контейнере.
[0052] Шаг 120: выполняют таргетное секвенирование по меньшей мере одного образца, полученного на предыдущем шаге, посредством платформы секвенирования;
[0053] Получение данных высокопроизводительного таргетного секвенирования включает несколько этапов, которые могут отличаться в зависимости от конкретного используемого набора методов, выбранной технологии секвенирования и типа биологического материала. Геномная ДНК выделяется соответствующими наборами реагентов в зависимости от типа образца: с использованием сорбентного метода или метода гетерофазной экстракции. Концентрация выделенной двуцепочечной ДНК должна быть не менее 1 нг/мкл. ДНК может храниться при 37°С в течение 10-20 минут, при 2-8°С - в течение 12-24 часов, при -20°С - длительно.
[0054] При анализе спектрофотометрической чистоты препарата ДНК соотношение поглощения раствора на длинах волн 260 и 280 нм определяют в диапазоне 1,8-2,0.
[0055] Для приготовления ДНК-библиотеки получают биоматериал в объеме, эквивалентном не менее 50 нг ДНК. На следующем этапе выполняются манипуляции в соответствии с инструкцией производителя наборов для таргетного обогащения (если применимо) и набора для приготовления библиотек. Данное изобретение применимо для различных типов ДНК-библиотек, в том числе для полученных таргетным обогащением методом мультиплексной ПЦР или гибридизацией со специфичными РНК/ДНК-зондами.
[0056] Таргетное секвенирование выполняют в режиме, обеспечивающем среднюю кратность покрытия целевых регионов не менее 200х. Изобретение было испытано на платформах секвенирования lllumina и Torrent, однако учитывая унифицированный формат данных секвенирования может быть применено и для других платформ и технологий высокопроизводительного секвенирования.
[0057] Тем не менее результаты секвенирования имеют унифицированный формат и для них может быть применено данное изобретение.
[0058] Шаг 130: получают из результатов секвенирования характеристики секвенирования.
[0059] На данном шаги посредством использования процессора выполняют последовательно следующие шаги:
1) Картируют чтения на референсный геном Н.sapiens;
2) Осуществляют подсчет числа чтений покрывающих каждую позицию референса;
3) Определяют набор мутаций;
4) Определяют мутационный спектр для образца.
[0060] В данном техническом решении используется интегральная характеристика, которая позволяет количественно оценить качество образца на основании набора характеристик данных секвенирования.
[0061] В некоторых вариантах реализации изобретения используют среднее покрытие образца для общей интегральной характеристики. Данный параметр характеризует насколько полно была прочитана геномная последовательность. Чем больше его значение, тем больше вероятность того, что были прочитаны все целевые регионы и полнее представлена вся генетическая информация, содержащаяся в биологическом образце. Среднее покрытие образца определяется как число чтений умноженное на их длину и деленное на размер целевой прочитываемой нуклеотидной последовательности. Например, было прочитано 100 млн. чтений длиной 100 п. н. Был прочитан полностью геном человека длиной 4 млрд п. н.. В итоге среднее покрытие определяется как 100*10^6*100/4*10^9=2.5.
[0062] В некоторых вариантах реализации изобретения используют число ампликонов, покрытых в среднем больше среднего покрытия образца. Данный параметр характеризует насколько много целевых последовательностей покрытых больше, чем среднее значение покрытия. Таким образом можно понять, сколько ампликонов перепредставлены в образце и понять насколько неравномерно представлены целевые последовательности.
[0063] Также используют процент пар нуклеотидов (сокращенно - п. н.) со значениями качества больше Q30 (для секвенатора Иллюмина) и Q20 (для секвенатора lonTorrent). Значения качества показывает насколько хорошо прочитан определенный нуклеотид в последовательностях, полученных с использованием секвенатора. Порог в значении качества, отделяющих нуклеотиды прочитанные с высокой точностью специфичен для разных технологий секвенирования и посчитав процент нуклеотидов прочитанных со значениями качества выше этих порогов можно понять насколько удачен запуск.
[0064] Еще в одном варианте реализации используют процент чтений, прошедших тримминг, под которым понимается процесс удаления из последовательности чтения регионов, содержащих нуклеотиды с низкими значениями качества. Таким образом можно оценить процент сохранившихся чтений, после работы алгоритма удаления регионов чтений, прочитанных с низким качеством. И процент таких чтений достаточно велик, то можно судить о том что секвенирование было удачным.
[0065] Также могут использовать оценку наличия формалиновых артефактов по мутационным спектрам и общему количеству найденных мутаций, которая проводится следующим образом. Подсчитывается количество всех найденных однонуклеотидных замен и строится распределение числа замен, разных по их типам в образце. Если количество однонуклеотидных замен C>Т и G>A значительно преобладает над остальными, считается, что в исследуемом образце присутствуют формалиновые артефакты, как показано на Фиг. 6. Иными словами если отношение ([C>Т]+[G>A])/([C>A]+[C>G]+[G>C]+[G>T]+[Т>А]+[Т>С]+[T>G]+[А>С]+[A>G]+[А>Т]) больше 2 (в случае наличия формалиновых артефактов резко возрастает число замен типа C в T и G в A в биологических образцах, в связи с чем эмпирически определено, что число замен такого типа вырастает на порядок по сравнению с суммарным числом других замен), то определяют, что в образце присутствуют формалиновые артефакты, где [С>Т] - число замен С в Т, [G>A] - число замен G в А, и т.д.
[0066] Необходимо понимать, что вышеприведенный набор характеристик секвенирования не ограничен использованием, и могут быть добавлены дополнительные характеристики секвенирования, в связи с чем появится возможность учесть особенности новых технологий секвенирования, появившиеся в уровне техники.
[0067] Шаг 140: формируют интегральную характеристику секвенирования на основании полученных на предыдущем шаге характеристик секвенирования посредством использования алгоритма машинного обучения на процессоре.
[0068] Интегральная характеристика может быть получена с использованием алгоритма машинного обучения XGBoost (градиентный бустинг). В качестве альтернативных алгоритмов машинного обучения могут использовать случайные деревья, метод опорных векторов, нейронные сети и т.д. Примерный вариант реализации показан на градиентном бустинге деревьев решений.
[0069] Непосредственно само дерево решений строится по обучающей выборке. Обучающая выборка - это набор объектов, для которых точно известно к какому классу тот или иной объект относится. Бустинг же является одним из методов построения композиции простых классификаторов, причем каждый последующий строящийся классификатор пытается компенсировать недостатки предыдущей композиции алгоритмов. В случае XGBoost в качестве простого алгоритма классификации используется дерево решений, причем достаточно небольшой глубины.
[0070] Для обучения модели, а именно композиции деревьев решений используют обучающую выборку, имеющую минимум 2*N образцов с удовлетворительным качеством и N образцов с неудовлетворительным качеством, где N - количество характеристик секвенирования. Данные ограничения на число образцов связаны с тем, что если число образцов меньше чем число характеристик, то построенный ансамбль решающих деревьев сможет просто запомнить обучающую выборку и явно будет переобучен, то есть не сможет адекватно классифицировать объекты, не входящие в обучающую выборку. Причем эмпирически выяснено, что для получения удовлетворительного качества классификации необходима, как минимум двукратно превосходящая число признаков по объему обучающая выборка удовлетворяющих по качеству образцов.
[0071] Одним из признаков может быть среднее покрытие образца, которое оценивается как отношение суммарного покрытия образца к длине геномной последовательности образца. Допустим имеется референсная последовательность нуклеотидов, которая состоит из 10 пар нуклеотидов. Значения покрытий для каждой позиции из 10 пар могут быть следующими: 1 - покрытие 1, 2 -1, 3 - 3, 4 - 3, 5 - 3, 6 - 3, 7 - 3, 8 - 3, 9 - 3, 10 - 3. Таким образом, суммарное покрытие будет равно 26.
[0072] Еще одним признаком является число ампликонов, покрытых в среднем больше среднего покрытия образца. Оценивается данный признак следующим образом:
[0073] а) Для каждого ампликона оценивается его среднее покрытие;
[0074] б) Сравнивается среднее покрытие ампликона со средним покрытием образца. Затем определяется число ампликонов, для которых среднее покрытие больше среднего покрытия образца.
[0075] Еще одним признаком является процент п. н. со значениями качества больше Q30 (для секвенатора Иллюмина) и Q20 (для секвенатора lonTorrent). Значение качества определяет проприетарное программное обеспечение секвенатора. Данный признак для каждой прочитанной позиции образца указывает вероятность правильного прочтения в логарифмической шкале -10log как вероятность ошибки. Q30 - это вероятность ошибки 10^-3, а Q20 - это вероятность ошибки 10^-2.
[0076] Еще одним признаком для обучающей выборки является процент чтений, прошедших тримминг (процесс удаления из последовательности чтения регионов, содержащих нуклеотиды с низкими значениями качества).
[0077] Также в качестве признака используют оценку наличия формалиновых артефактов по мутационным спектрам и общему количеству найденных мутаций.
[0078] Процесс подбора параметров обучения модели производится с использованием перекрестной проверки, который используется процессор, как показано на Фиг. 4. Обучающая выборка делится, например, на 10 частей и для каждого этапа предсказания обучения осуществляется на 9 частях, после чего оценка предсказания производится на основе оставшейся части. Объектами обучающей выборки могут являться образцы, которые заранее классифицированы, например, пользователем или другим алгоритмом машинного обучения, как имеющие удовлетворительный уровень качества и неудовлетворительный уровень качества. В ходе данного процесса обучения подбираются параметры для алгоритма, конструирующего классификатор. Подбор параметров необходим для оптимизации построенного классификатора для чего и используется кросс - валидация. А именно обучающая выборка делится на набор подвыборок, набор подвыборок без одной используется для обучения, а исключенная подвыборка используется для определения качества кластеризации, и так повторяется для всех подвыборок в качестве тестовых, как показано на Фиг. 3. Делается вариация обучающей выборки и проверяются предсказания, на наборе данных для которых известна оценка качества. Для варианта реализации, когда используется XGBoost, перебираются следующие параметры (как показано на Фиг. 2):
[0079] eta (параметр XGBoost, указывающий во сколько раз необходимо уменьшить размер шага после каждой итерации) (диапазон значений от 0.01 до 0.4 с шагом 0.01);
[0080] min_child_weight (минимальный вес дочернего узла)(диапазон значений от 0.3 до 1 с шагом 0.01);
[0081] max_depth (максимальная глубина формируемых решающих деревьев)(от 3 до 10 с шагом 0.01); subsample (часть обучающей выборки, использующейся при обучении XGBoost) (от 0.3 до 1 с шагом 0.01);
[0082] colsample_bytree (часть обучающей выборки, использующейся при обучении на каждой итерации XGBoost)(от 0.3 до 1 с шагом 0.01);
[0083] colsample_bylevel (часть обучающей выборки, использующейся при обучении при каждом построении внутренних узлов в решающих деревьях на каждой итерации XGBoost)(от 0.3 до 1 с шагом 0.01);
[0084] параметр scale_pos_weight (величина, указывающая насколько более ценны экземпляры положительной обучающей выборки относительно отрицательной; в нашем случае положительная выборка - это образцы удовлетворительного качества, а отрицательная - это образцы неудовлетворительного качества) должен быть равен отношению величины положительной выборки к отрицательной или близок к данному отношению.
[0085] Перебор параметров осуществляется следующим образом, как показано на Фиг. 5.
[0086] Предварительно всем параметрам устанавливается минимальное значение.
[0087] Затем осуществляют кроссвалидацию, где определяется оценка качества классификации. В качестве такой оценки может использоваться величина AUC - площадь под ROC-кривой. ROC-кривая - это зависимость между чувствительностью и специфичностью алгоритма классификации.
[0088] Далее параметр eta увеличивается на 0.01, после чего снова проводится кросс - валидация и делается оценка качества классификации.
[0089] Если eta меньше 0.4, то алгоритм продолжается с выполнения перекрестной проверки.
[0090] Если min_child_weight меньше 1, то данный параметр увеличивается на 0.01 и алгоритм продолжается с выполнения перекрестной проверки и параметр eta устанавливается в 0.01.
[0091] Если max_depth меньше 10, то данный параметр увеличивается на 0.01 и алгоритм продолжается с выполнения перекрестной проверки, а параметр eta устанавливается в 0.01, параметр min_child_weight устанавливается в 0.3.
[0092] Если subsample меньше 1, то он увеличивается на 0.01 и алгоритм продолжается с выполнения перекрестной проверки, параметр eta устанавливается в 0.01, параметр min_child_weight устанавливается в 0.3 и параметр max_depth устанавливается в 3.
[0093] Если colsample_bytree меньше 1, то он увеличивается на 0.01, алгоритм продолжается с выполнения перекрестной проверки, параметр eta устанавливается в 0.01, параметр min_child_weight устанавливается в 0.3, параметр max_depth устанавливается в 3 и параметр subsample устанавливается в 0.3.
[0094] Если colsample_bylevel меньше 1, то он увеличивается на 0.01, алгоритм продолжается с выполнения перекрестной проверки, параметр eta устанавливается в 0.01, параметр min_child_weight устанавливается в 0.3, параметр max_depth устанавливается в 3, параметр subsample устанавливается в 0.3 и параметр colsample_bytree устанавливается в 0.3.
[0095] В итоге выбирается набор параметров, для которого величина AUC максимальна. И этот набор параметров становится результатом проведения кросс - валидации. Обучение производится на всем объеме обучающей выборки с этим набором параметров.
[0096] Полученная обученная модель XGBoost в дальнейшем может быть использована для оценки качества образцов, полученных с использованием тех же секвенаторов, с которых получены и образцы обучающей выборки. В случае смены оборудования для секвенирования необходимо производить переобучение модели, а именно необходимо сформировать обучающую выборку на образцах, полученных с использованием нового оборудования и провести формирование новой модели. В некоторых вариантах реализации формируют универсальные модели, подходящие для широкого круга секвенирующих установок, для чего используют достаточно большой набор образцов (например, как минимум 1^-10 тыс.* [число оцениваемых параметров] образцов в обучающей выборке), полученных с использованием нескольких разных секвенирующих установок, построенных как на основе одной технологии так и нескольких. Таким образом для оценки того, насколько качество образцов различается как в пределах секвенаторов, построенных на основе одной технологии, так и между разными технологиями, необходим набор образцов, полученных с использованием как можно более разнообразного оборудования. Оценку достаточности текущего количества образцов можно оценить по значению среднего параметра AUC в ходе кросс - валидации. Он должен быть не меньше 0.8 (классификаторы с AUC больше 0.8 считаются хорошими, как известно из источника информации [2]).
[0097] Для проведения анализа с использованием обученной XGBoost модели для анализируемого образца (набора чтений) определяются признаки, способом аналогичным способу применяемому при работе с обучающей выборкой, посредством использования процессора. Список признаков не задается, так как выше было показано, что этот набор гибко выбирается на этапе обучения. Далее на основе этих признаков производится оценка с использованием, построенного на основе XGBoost, классификатора качества образца. Признаки образца подаются на вход классификатора. На основе этих признаков он выдает значение в диапазоне от 0 до 1. Если значение, полученное с помощью классификатора превышает 0.5, то считается, что образец имеет удовлетворительный уровень качества. Если величина меньше 0.5, то неудовлетворительный. В случае если величина предсказанная XGBoost равна 0.5 то качество образца не удается оценить.
[0098] В результате применения разработанного технического решения к данным, полученным в результате секвенирования получают посредством процессора меру качества, представляющую из себя число из диапазона от 0 до 1.
[0099] Ниже показан пример реализации описанного выше технического решения посредством процессора.
[00100] Для обучения используются следующие признаки: среднее покрытие, % чтений, прошедших тримминг.
[00101] Для обучения используются следующие объекты:
[00102] Положительная выборка (удовлетворительное качество):
[00103] Первый объект: среднее покрытие - 500х, % чтения после тримминга 90%
[00104] Второй объект: среднее покрытие - 400х, % чтения после тримминга 80%
[00105] Третий объект: среднее покрытие - 600х, % чтения после тримминга 70%
[00106] Четвертый объект: среднее покрытие - 400х, % чтения после тримминга 75%
[00107] Отрицательная выборка (неудовлетворительное качество):
[00108] Первый объект: среднее покрытие - 100х, % чтения после тримминга 40%
[00109] Второй объект: среднее покрытие - 400х, % чтения после тримминга 30%
[00110] Далее строится классификатор с использованием данной обучающей выборки.
[00111] Берутся объекты, для которых оценивается качество. Допустим это два объекта с такими признаками:
Первый объект: среднее покрытие - 400х, % чтения после тримминга 78%
[00112] Второй объект: среднее покрытие - 100х, % чтения после тримминга 34%
[00113] Данные объекты подаются на вход классификатора построенного в пункте 3. Для первого объекта получаем оценку 0.87. Для второго 0.34. 0.87>0.5 - первый тестируемый объект удовлетворительного качества. 0.34<0.5 - второй тестируемый объект неудовлетворительного качества.
[00114] Ссылаясь на Фиг. 7, данное техническое решение может быть реализовано в виде вычислительной системы 700, которая содержит один или более из следующих компонент:
- компонент 701 обработки, содержащий по меньшей мере один процессор 702,
- память 703,
- компонент 704 питания,
- компонент 705 мультимедиа,
- компонент 706 аудио,
- интерфейс 707 ввода / вывода (I / О),
- сенсорный компонент 708,
- компонент 709 передачи данных.
[00115] Компонент 701 обработки в основном управляет всеми операциями системы 700, например, формирует интегральную характеристику секвенирования посредством использования алгоритма машинного обучения, а также управляет дисплеем, телефонным звонком, передачей данных, работой камеры и операцией записи мобильного устройства связи пользователя. Модуль 701 обработки может включать в себя один или более процессоров 702, реализующих инструкции для завершения всех или части шагов из указанных выше способов. Кроме того, модуль 701 обработки может включать в себя один или более модулей для удобного процесса взаимодействия между другими модулями 701 обработки и другими модулями. Например, модуль 701 обработки может включать в себя мультимедийный модуль для удобного облегченного взаимодействия между компонентом 705 мультимедиа и компонентом 701 обработки.
[00116] Память 703 выполнена с возможностью хранения различных типов данных для поддержки работы системы 700, например, базу данных с профилями пользователей. Примеры таких данных включают в себя инструкции из любого приложения или способа, контактные данные, данные адресной книги, сообщения, изображения, видео, и т.д., и все они работают на системе 700. Память 703 может быть реализована в виде любого типа энергозависимого запоминающего устройства, энергонезависимого запоминающего устройства или их комбинации, например, статического оперативного запоминающего устройства (СОЗУ), Электрически-Стираемого Программируемого постоянного запоминающего устройства (ЭСППЗУ), Стираемого Программируемого постоянного запоминающего устройства (СППЗУ), Программируемого постоянного запоминающего устройства (ППЗУ), постоянного запоминающего устройства (ПЗУ), магнитной памяти, флэш-памяти, магнитного диска или оптического диска и другого, не ограничиваясь.
[00117] Компонент 704 питания обеспечивает электричеством различные компоненты системы 700. Компонент 704 питания может включать систему управления электропитанием, один или более источник питания, и другие узлы для генерации, управления и распределения электроэнергии к системе 400.
[00118] Компонент 705 мультимедиа включает в себя экран, обеспечивающий выходной интерфейс между системой 700, которая может быть установлена на мобильном устройстве связи пользователя и пользователем. В некоторых вариантах реализации, экран может быть жидкокристаллическим дисплеем (ЖКД) или сенсорной панелью (СП). Если экран включает в себя сенсорную панель, экран может быть реализован в виде сенсорного экрана для приема входного сигнала от пользователя. Сенсорная панель включает один или более сенсорных датчиков в смысле жестов, прикосновения и скольжения сенсорной панели. Сенсорный датчик может не только чувствовать границу прикосновения пользователя или жест перелистывания, но и определять длительность времени и давления, связанных с режимом работы на прикосновение и скольжение. В некоторых вариантах осуществления компонент 705 мультимедиа включает одну фронтальную камеру и/или одну заднюю камеру. Когда система 700 находится в режиме работы, например, режиме съемки или режиме видео, фронтальная камера и/или задняя камера могут получать данные мультимедиа извне. Каждая фронтальная камера и задняя камера может быть одной фиксированной оптической системой объектива или может иметь фокусное расстояние или оптический зум.
[00119] Компонент 706 аудио выполнен с возможностью выходного и/или входного аудио сигнала. Например, компонент 706 аудио включает один микрофон (MIC), который выполнен с возможностью получать внешний аудио сигнал, когда система 700 находится в режиме работы, например, режиме вызова, режима записи и режима распознавания речи. Полученный аудио сигнал может быть далее сохранен в памяти 703 или направлен по компоненту 709 передачи данных. В некоторых вариантах осуществления компонент 706 аудио также включает в себя один динамик выполненный с возможностью вывода аудио сигнала.
[00120] Интерфейс 707 ввода / вывода (I / О) обеспечивает интерфейс между компонентом 701 обработки и любым периферийным интерфейсным модулем. Вышеуказанным периферийным интерфейсным модулем может быть клавиатура, руль, кнопка, и т.д. Эти кнопки могут включать, но не ограничиваясь, кнопку запуска, кнопку регулировки громкости, начальную кнопку и кнопку блокировки.
[00121] Сенсорный компонент 708 содержит один или более сенсоров и выполнен с возможностью обеспечения различных аспектов оценки состояния системы 700. Например, сенсорный компонент 708 может обнаружить состояния вкл/выкл системы 700, относительное расположение компонентов, например, дисплея и кнопочной панели, одного компонента системы 700, наличие или отсутствие контакта между пользователем и системой 700, а также ориентацию или ускорение/замедление и изменение температуры системы 700. Сенсорный компонент 708 содержит бесконтактный датчик, выполненный с возможностью обнаружения присутствия объекта, находящегося поблизости, когда нет физического контакта. Сенсорный компонент 708 содержит оптический датчик (например, КМОП или ПЗС-датчик изображения) выполненный с возможностью использования в визуализации приложения. В некоторых вариантах сенсорный компонент 708 содержит датчик ускорения, датчик гироскопа, магнитный датчик, датчик давления или датчик температуры.
[00122] Компонент 709 передачи данных выполнен с возможностью облегчения проводной или беспроводной связи между системой 700 и другими устройствами. Система 700 может получить доступ к беспроводной сети на основе стандарта связи, таких как WiFi, 2G, 3G, 5G, или их комбинации. В одном примерном варианте компонент 709 передачи данных получает широковещательный сигнал или трансляцию, связанную с ними информацию из внешней широковещательной системы управления через широковещательный канал. В одном варианте осуществления компонент 709 передачи данных содержит модуль коммуникации ближнего поля (NFC), чтобы облегчить ближнюю связь. Например, модуль NFC может быть основан на технологии радиочастотной идентификации (RFID), технологии ассоциации передачи данных в инфракрасном диапазоне (IrDA), сверхширокополосных (UWB) технологии, Bluetooth (ВТ) технологии и других технологиях.
[00123] В примерном варианте осуществления система 700 может быть реализована посредством одной или более Специализированных Интегральных Схем (СИС), Цифрового Сигнального Процессора (ЦСП), Устройств Цифровой Обработки Сигнала (УЦОС), Программируемым Логическим Устройством (ПЛУ), логической микросхемой, программируемой в условиях эксплуатации (ППВМ), контроллера, микроконтроллера, микропроцессора или других электронных компонентов, и может быть сконфигурирован для реализации способа отображения альбома.
[00124] В примерном варианте осуществления, энергонезависимый компьютерно-читаемый носитель, содержит инструкции также предусмотренные, например, память 703 включает инструкции, где инструкции выполняются процессором 701 системы 700 для реализации описанных выше способов автоматизированного конструирования мультимодального сервиса грузоперевозок. Например, энергонезависимым компьютерно-читаемым носителем может быть ПЗУ, оперативное запоминающее устройство (ОЗУ), компакт-диск, магнитная лента, дискеты, оптические устройства хранения данных и тому подобное.
[00125] Вычислительная система 700 может включать в себя интерфейс дисплея, который передает графику, текст и другие данные из коммуникационной инфраструктуры (или из буфера кадра, не показан) для отображения на компоненте 705 мультимедиа. Вычислительная система 700 дополнительно включает в себя устройства ввода или периферийные устройства. Периферийные устройства могут включать в себя одно или несколько устройств для взаимодействия с мобильным устройством связи пользователя, такие как клавиатура, микрофон, носимое устройство, камера, один или более звуковых динамиков и другие датчики. Периферийные устройства могут быть внешними или внутренними по отношению к мобильному устройству связи пользователя. Сенсорный экран может отображать, как правило, графику и текст, а также предоставляет пользовательский интерфейс (например, но не ограничиваясь ими, графический пользовательский интерфейс (GUI)), через который пользователь может взаимодействовать с мобильным устройством связи пользователя, например, получать доступ и взаимодействовать с приложениями, запущенными на устройстве.
[00126] Элементы заявляемого технического решения находятся в функциональной взаимосвязи, а их совместное использование приводит к созданию нового и уникального технического решения. Таким образом, все блоки функционально связаны.
[00127] Все блоки, используемые в системе, могут быть реализованы с помощью электронных компонент, используемых для создания цифровых интегральных схем, что очевидно для специалиста в данном уровне техники. Не ограничиваюсь, могут быть использоваться микросхемы, логика работы которых определяется при изготовлении, или программируемые логические интегральные схемы (ПЛИС), логика работы которых задается посредством программирования. Для программирования используются программаторы и отладочные среды, позволяющие задать желаемую структуру цифрового устройства в виде принципиальной электрической схемы или программы на специальных языках описания аппаратуры: Verilog, VHDL, AHDL и др. Альтернативой ПЛИС могут быть программируемые логические контроллеры (ПЛК), базовые матричные кристаллы (БМК), требующие заводского производственного процесса для программирования; ASIC - специализированные заказные большие интегральные схемы (БИС), которые при мелкосерийном и единичном производстве существенно дороже.
[00128] Обычно, сама микросхема ПЛИС состоит из следующих компонент:
- конфигурируемых логических блоков, реализующих требуемую логическую функцию;
- программируемых электронных связей между конфигурируемыми логическими блоками;
- программируемых блоков ввода/вывода, обеспечивающих связь внешнего вывода микросхемы с внутренней логикой.
[00129] Также блоки могут быть реализованы с помощью постоянных запоминающих устройств.
[00130] Таким образом, реализация всех используемых блоков достигается стандартными средствами, базирующимися на классических принципах реализации основ вычислительной техники.
[00131] Как будет понятно специалисту в данной области техники, аспекты настоящего технического решения могут быть выполнены в виде системы, способа или компьютерного программного продукта. Соответственно, различные аспекты настоящего технического решения могут быть реализованы исключительно как аппаратное обеспечение, как программное обеспечение (включая прикладное программное обеспечение и так далее) или как вариант осуществления, сочетающий в себе программные и аппаратные аспекты, которые в общем случае могут упоминаться как «модуль», «система» или «архитектура». Кроме того, аспекты настоящего технического решения могут принимать форму компьютерного программного продукта, реализованного на одном или нескольких машиночитаемых носителях, имеющих машиночитаемый программный код, который на них реализован.
[00132] Также может быть использована любая комбинация одного или нескольких машиночитаемых носителей. Машиночитаемый носитель хранилища может представлять собой, без ограничений, электронную, магнитную, оптическую, электромагнитную, инфракрасную или полупроводниковую систему, аппарат, устройство или любую подходящую их комбинацию. Конкретнее, примеры (неисчерпывающий список) машиночитаемого носителя хранилища включают в себя: электрическое соединение с помощью одного или нескольких проводов, портативную компьютерную дискету; жесткий диск, оперативную память (ОЗУ), постоянную память (ПЗУ), стираемую программируемую постоянную память (EPROM или Flash-память), оптоволоконное соединение, постоянную память на компакт-диске (CD-ROM), оптическое устройство хранения, магнитное устройство хранения или любую комбинацию вышеперечисленного. В контексте настоящего описания, машиночитаемый носитель хранилища может представлять собой любой гибкий носитель данных, который может содержать или хранить программу для использования самой системой, устройством, аппаратом или в соединении с ними.
[00133] Программный код, встроенный в машиночитаемый носитель, может быть передан с помощью любого носителя, включая, без ограничений, беспроводную, проводную, оптоволоконную, инфракрасную и любую другую подходящую сеть или комбинацию вышеперечисленного.
[00134] Компьютерный программный код для выполнения операций для шагов настоящего технического решения может быть написан на любом языке программирования или комбинаций языков программирования, включая объектно-ориентированный язык программирования, например Java, Smalltalk, С++ и так далее, и обычные процедурные языки программирования, например язык программирования «С» или аналогичные языки программирования. Программный код может выполняться на компьютере пользователя полностью, частично, или же как отдельный пакет программного обеспечения, частично на компьютере пользователя и частично на удаленном компьютере, или же полностью на удаленном компьютере. В последнем случае, удаленный компьютер может быть соединен с компьютером пользователя через сеть любого типа, включая локальную сеть (LAN), глобальную сеть (WAN) или соединение с внешним компьютером (например, через Интернет с помощью Интернет-провайдеров).
[00135] Аспекты настоящего технического решения были описаны подробно со ссылкой на блок-схемы, принципиальные схемы и/или диаграммы способов, устройств (систем) и компьютерных программных продуктов в соответствии с вариантами осуществления настоящего технического решения. Следует иметь в виду, что каждый блок из блок-схемы и/или диаграмм, а также комбинации блоков из блок-схемы и/или диаграмм, могут быть реализованы компьютерными программными инструкциями. Эти компьютерные программные инструкции могут быть предоставлены процессору компьютера общего назначения, компьютера специального назначения или другому устройству обработки данных для создания процедуры, таким образом, чтобы инструкции, выполняемые процессором компьютера или другим программируемым устройством обработки данных, создавали средства для реализации функций/действий, указанных в блоке или блоках блок-схемы и/или диаграммы.
[00136] Эти компьютерные программные инструкции также могут храниться на машиночитаемом носителе, который может управлять компьютером, отличным от программируемого устройства обработки данных или отличным от устройств, которые функционируют конкретным образом, таким образом, что инструкции, хранящиеся на машиночитаемом носителе, создают устройство, включающее инструкции, которые осуществляют функции/действия, указанные в блоке блок-схемы и/или диаграммы.
ИСПОЛЬЗУЕМЫЕ ИСТОЧНИКИ ИНФОРМАЦИИ
1. Andrews S., FastQC A. A quality control tool for high throughput sequence data. 2010 // Google Scholar. - 2015.
2. Mieczyslaw A. Klopotek, Slawomir T. Wierzchon, Krzysztof Trojanowski Intelligent Information Processing and Web Mining: Proceedings of the International IIS: IIPWM'05 Conference held in Gdansk, Poland, June 13-16, 2005 page 276.
| название | год | авторы | номер документа |
|---|---|---|---|
| РАСЧЕТ БРЕМЕНИ ОПУХОЛЕВЫХ МУТАЦИЙ С ИСПОЛЬЗОВАНИЕМ ДАННЫХ РНК СЕКВЕНИРОВАНИЯ ОПУХОЛЕЙ И КОНТРОЛИРУЕМОГО МАШИННОГО ОБУЧЕНИЯ | 2020 |
|
RU2759205C1 |
| СПОСОБ И СИСТЕМА КОРРЕКЦИИ НЕЖЕЛАТЕЛЬНЫХ КОВАРИАЦИОННЫХ ЭФФЕКТОВ В МИКРОБИОМНЫХ ДАННЫХ | 2019 |
|
RU2742003C1 |
| СПОСОБ И СИСТЕМА ГЕНЕРАЦИИ ИНДИВИДУАЛЬНЫХ РЕКОМЕНДАЦИЙ ПО ДИЕТЕ НА ОСНОВАНИИ АНАЛИЗА СОСТАВА МИКРОБИОТЫ | 2019 |
|
RU2724498C1 |
| Способ обработки данных полногеномного секвенирования | 2023 |
|
RU2806429C1 |
| Способ неинвазивного пренатального скрининга анеуплоидий плода | 2019 |
|
RU2712175C1 |
| Способ и система поиска аналогов месторождений нефти и газа | 2020 |
|
RU2745492C1 |
| Способ малоинвазивной диагностики рака легкого по фрагментированной свободно циркулирующей ДНК на основе методов машинного обучения | 2023 |
|
RU2820322C1 |
| СПОСОБ ОПРЕДЕЛЕНИЯ АНЕУПЛОИДИИ ПЛОДА В ОБРАЗЦЕ КРОВИ БЕРЕМЕННОЙ ЖЕНЩИНЫ | 2021 |
|
RU2777072C1 |
| СИСТЕМА И СПОСОБ ИНТЕРПРЕТАЦИИ ДАННЫХ И ПРЕДОСТАВЛЕНИЯ РЕКОМЕНДАЦИЙ ПОЛЬЗОВАТЕЛЮ НА ОСНОВЕ ЕГО ГЕНЕТИЧЕСКИХ ДАННЫХ И ДАННЫХ О СОСТАВЕ МИКРОБИОТЫ КИШЕЧНИКА | 2017 |
|
RU2699284C2 |
| Способ анализа митохондриальной ДНК для неинвазивного пренатального тестирования | 2021 |
|
RU2772912C1 |

Изобретение относится к области биотехнологии. Предложен компьютерно-реализуемый интегральный способ для оценки качества результатов таргетного секвенирования. Способ включает получение образца пользователя, таргетное секвенирование образца, получение из результатов секвенирования характеристики секвенирования и формирование интегральной характеристики секвенирования посредством использования алгоритма машинного обучения. Изобретение обеспечивает повышение скорости выполнения оценки качества результатов таргетного секвенирования. 5 з.п. ф-лы, 7 ил.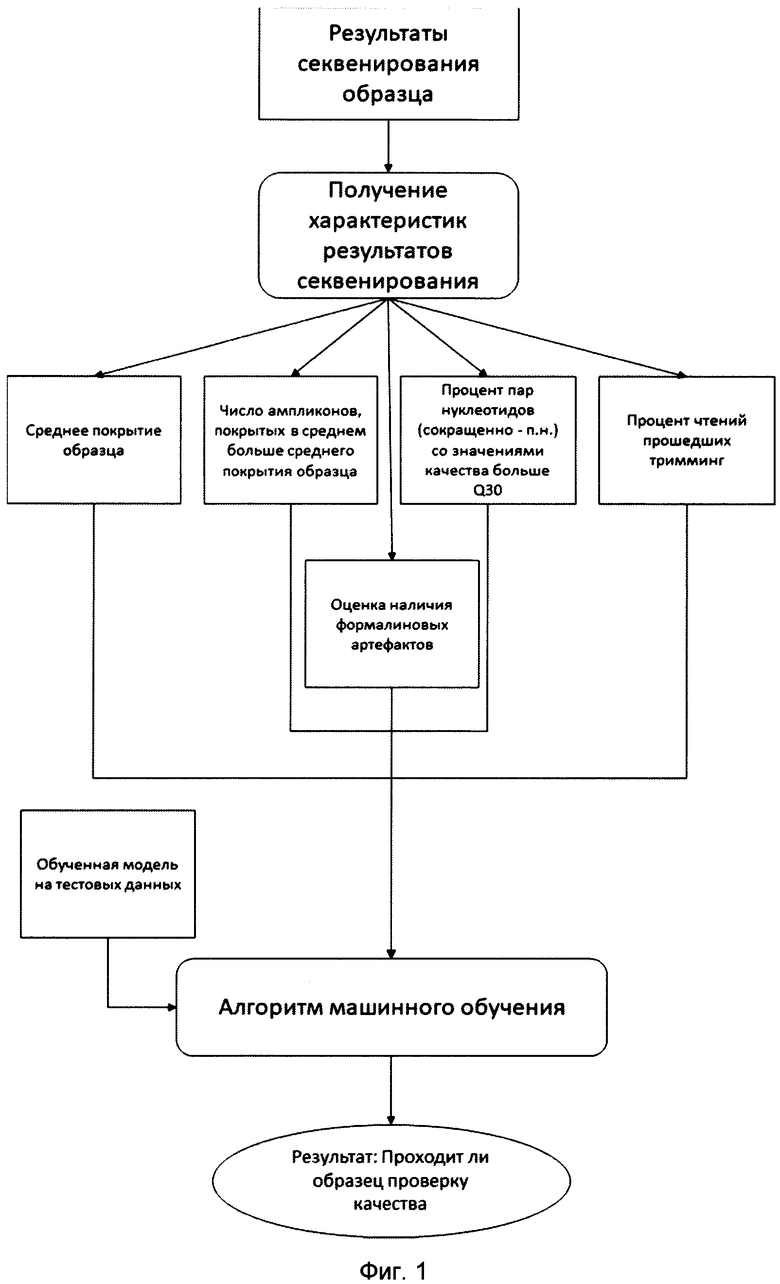
1. Компьютерно-реализуемый интегральный способ для оценки качества результатов таргетного секвенирования, реализуемый с помощью процессора, включающий следующие шаги:
• получают данные о по меньшей мере одном образце по меньшей мере одного пользователя;
• выполняют таргетное секвенирование данных по меньшей мере одного образца, полученного на предыдущем шаге, посредством платформы секвенирования;
• получают из результатов секвенирования характеристики секвенирования, причем:
картируют чтения на референсный геном;
осуществляют подсчет числа чтений, покрывающих каждую позицию референса;
определяют набор мутаций;
определяют мутационный спектр для образца, по которому были получены данные;
• формируют интегральную характеристику секвенирования на основании полученных на предыдущем шаге характеристик секвенирования посредством использования алгоритма машинного обучения на процессоре.
2. Способ по п. 1, характеризующийся тем, что характеристикой секвенирования является среднее покрытие образца и/или число ампликонов, покрытых в среднем больше среднего покрытия образца, и/или процент пар нуклеотидов со значениями качества больше заранее заданного, и/или процент чтений, прошедших тримминг.
3. Способ по п. 1, характеризующийся тем, что при формировании интегральной характеристики используют градиентный бустинг деревьев решений.
4. Способ по п. 1, характеризующийся тем, что при формировании интегральной характеристики секвенирования используют меру качества, представляющую из себя число из диапазона от 0 до 1.
5. Способ по п. 1, характеризующийся тем, что при формировании интегральной характеристики используют случайные деревья или метод опорных векторов, или искусственные нейронные сети.
6. Способ по п. 3, характеризующийся тем, что при обучении деревьев решений подбирают параметры обучения модели с использованием перекрестной проверки.
| БАРХАТОВ И.М | |||
| и др | |||
| Секвенирование нового поколения и области его применения в онкогематологии // Фундаментальные исследования в практической медицине на современном этапе, ОНКОГЕМАТОЛОГИЯ, том.11, 2016, стр.56-63 | |||
| CROWGEY E.L | |||
| et al | |||
| An Integrated Approach for Analyzing Clinical Genomic Variant Data from Next-Generation Sequencing // Journal of |

