ПЕРЕКРЕСТНЫЕ ССЫЛКИ НА СМЕЖНЫЕ ЗАЯВКИ
[0001] Данная заявка испрашивает преимущество по предварительной заявке на патент США №62/988,374, поданной 11 марта 2020 г., которая полностью включена в настоящий документ путем ссылки.
ПРЕДПОСЫЛКИ СОЗДАНИЯ ИЗОБРЕТЕНИЯ
[0002] Данное описание относится к анализу нуклеотидных последовательностей.
[0003] Секвенатор нуклеиновых кислот представляет собой инструмент, выполненный с возможностью автоматизации процесса секвенирования нуклеиновых кислот. Секвенирование нуклеиновых кислот представляет собой процесс определения порядка нуклеотидов в нуклеотидной последовательности. К нуклеиновым кислотам могут относиться дезоксирибонуклеиновая кислота (ДНК) или рибонуклеиновая кислота (РНК).
[0004] Секвенатор нуклеиновых кислот выполнен с возможностью приема образца нуклеиновой кислоты и генерирования выходных данных, называемых одним или более «чтениями», каждое из которых отражает порядок нуклеотидов в образце нуклеиновой кислоты. Нуклеотиды в образце ДНК могут включать одно или более оснований, включающих гуанин (G), цитозин (С), аденин (А) и тимин (Т) в любой комбинации. Нуклеотиды в образце РНК могут включать одно или более оснований, включающих G, С, А и урацил (U) в любой комбинации.
[0005] Прочтения, генерируемые секвенатором ДНК, могут быть сопоставлены (картированы) с известной последовательностью нуклеотидов эталонного генома с помощью модуля картирования и выравнивания. Картирование прочтений с известной последовательностью нуклеотидов эталонного генома может быть выполнено системой картирования и выравнивания, в которой используют индекс хеш-таблицы.
ИЗЛОЖЕНИЕ СУЩНОСТИ ИЗОБРЕТЕНИЯ
[0006] Настоящее описание относится к системам, способам и компьютерным программам для выполнения инкрементного вторичного анализа. Инкрементным вторичным анализом называется способ выполнения одной или более операций вторичного анализа над прочтением нуклеиновой кислоты образца до завершения секвенирования этого образца секвенатором нуклеиновых кислот. Одна или более операций вторичного анализа может включать картирование прочтения нуклеиновой кислоты, выравнивание прочтения нуклеиновой кислоты, распознавание вариантов или любую их комбинацию.
[0007] В соответствии с одним инновационным аспектом настоящего описания описан способ выполнения инкрементного вторичного анализа прочтений нуклеотидной последовательности. В одном аспекте способ включает действия (i) получения первых данных, описывающих множество первых прочтений, сгенерированных секвенатором нуклеиновых кислот во время первого интервала прочтения, причем каждое из первых прочтений представляет собой первую упорядоченную последовательность нуклеотидов, (ii) получения вторых данных, описывающих множество вторых прочтений, сгенерированных секвенатором нуклеиновых кислот во время второго интервала прочтения, выполняемого после первого интервала прочтения, причем каждое из вторых прочтений представляет собой вторую упорядоченную последовательность нуклеотидов, при этом во время получения вторых данных: (а) предоставление посредством секвенатора нуклеиновых кислот первых данных в качестве входных данных в блок картирования и выравнивания, (b) получение результатов выравнивания от блока картирования и выравнивания; и (с) сохранение полученных результатов выравнивания, а затем (iii) подачи команды блоку картирования и выравнивания начать выравнивание вторых данных, представляющих второе множество прочтений, с эталонной последовательностью.
[0008] Другие версии включают соответствующие системы, аппарат и компьютерные программы для выполнения действий из способов, определяемых командами, закодированными на машиночитаемых устройствах хранения.
[0009] Эти и другие версии могут необязательно могут включать один или более из приведенных ниже признаков. Например, в некоторых вариантах реализации по меньшей мере часть блока картирования и выравнивания реализована с использованием программируемого логического устройства.
[0010] В некоторых вариантах реализации программируемая схема представляет собой программируемую пользователем вентильную матрицу (FPGA).
[0011] В некоторых вариантах реализации по меньшей мере часть блока картирования и выравнивания реализована с использованием специализированной интегральной схемы (ASIC).
[0012] В некоторых вариантах реализации блок картирования и выравнивания включен в секвенатор нуклеиновых кислот.
[0013] В некоторых вариантах реализации одно или более первых прочтений включают в себя данные, представляющие первый идентификатор образца, а одно или более вторых прочтений включают в себя данные, представляющие второй идентификатор образца.
[0014] В некоторых вариантах реализации способ может дополнительно включать во время получения вторых данных: организацию одного или более первых прочтений в соответствующие группы на основе по меньшей мере первого идентификатора образца или второго идентификатора образца, а также генерирование статистики организации, причем статистика организации показывает число первых прочтений, соответствующих каждому идентификатору образца.
[0015] В некоторых вариантах реализации способ может дополнительно включать обеспечение выходных данных, которые представляют сохраненные результаты выравнивания, соответствующие множеству первых прочтений, до или во время выравнивания второй части кластера прочтений.
[0016] В некоторых вариантах реализации способ может дополнительно включать подачу команды модулю картирования и выравнивания начать дальнейшее выравнивание данных, представляющих первое множество прочтений, с эталонной последовательностью.
[0017] В некоторых вариантах реализации способ может дополнительно включать во время получения вторых данных определение набора вероятных вариантов для первых данных, представляющих первое множество прочтений, которое было выравнено с эталонной последовательностью.
[0018] В некоторых вариантах реализации по меньшей мере часть вторых данных, представляющих второе множество прочтений, выравнивают во время того, как получают по меньшей мере другую часть вторых данных, представляющих второе множество прочтений.
[0019] В некоторых вариантах реализации блок картирования и выравнивания получает команду начать выравнивание вторых данных, представляющих второе множество прочтений, за предварительно заданное число циклов секвенирования до полного получения вторых данных.
[0020] В соответствии с другим инновационным аспектом настоящего описания описан другой способ выполнения инкрементного вторичного анализа прочтения нуклеотидной последовательности. В одном аспекте способ может включать действия (i) генерирования множества первых идентификаторов объектов, причем каждый первый идентификатор объекта соответствует конкретному прочтению, которое будет сгенерировано во время первого интервала прочтения, (ii) генерирования множества вторых идентификаторов объектов, причем каждый второй идентификатор объекта соответствует конкретному прочтению, которое будет сгенерировано во время второго интервала прочтения, (iii) получения первых данных, описывающих множество первых прочтений, сгенерированных секвенатором нуклеиновых кислот на основе множества разных образцов во время первого интервала прочтения, причем каждое из множества первых прочтений соответствует по меньшей мере первому или второму идентификаторам объекта, причем во время получения первых данных способ также включает: организацию множества первых прочтений в организованные группы на основе первого или второго идентификатора объекта, связанного с каждым из первых прочтений, предоставление посредством секвенатора нуклеиновых кислот организованного множества прочтений блоку картирования и выравнивания, выполненному с возможностью выравнивания распознаваний оснований с эталонной последовательностью, получение результатов выравнивания от блока картирования и выравнивания и сохранение полученных результатов выравнивания, (iv) получения вторых данных, описывающих множество вторых прочтений, сгенерированных секвенатором нуклеиновых кислот на основе множества разных образцов во время второго интервала прочтения, выполняемого после первого интервала прочтения, причем каждое из множества вторых прочтений соответствует по меньшей мере первому или второму идентификаторам объектов, и (v) предоставления посредством секвенатора нуклеиновых кислот вторых данных блоку картирования и выравнивания, выполненному с возможностью выравнивания вторых данных с эталонной последовательностью.
[0021] Другие версии включают соответствующие системы, аппарат и компьютерные программы для выполнения действий из способов, определяемых командами, закодированными на машиночитаемых устройствах хранения.
[0022] Эти и другие версии могут необязательно могут включать один или более из приведенных ниже признаков. Например, в некоторых вариантах реализации по меньшей мере часть блока картирования и выравнивания реализована с использованием программируемого логического устройства.
[0023] В некоторых вариантах реализации программируемая схема представляет собой программируемую пользователем вентильную матрицу (FPGA).
[0024] В некоторых вариантах реализации по меньшей мере часть блока картирования и выравнивания реализована с использованием специализированной интегральной схемы (ASIC).
[0025] В некоторых вариантах реализации блок картирования и выравнивания включен в секвенатор нуклеиновых кислот.
[0026] В некоторых вариантах реализации организация множества первых прочтений включает генерирование данных, указывающих число прочтений, соответствующих каждому идентификатору объекта.
[0027] В некоторых вариантах реализации во время получения вторых данных для каждого упорядоченного набора первых прочтений определяют набор вероятных вариантов для этого упорядоченного набора первых прочтений, которые были выравнены с эталонной последовательностью.
[0028] В соответствии с другим инновационным аспектом настоящего описания описан другой способ выполнения инкрементного вторичного анализа прочтения нуклеотидной последовательности. В одном аспекте способ может включать действия получения первых данных, описывающих множество первых прочтений, сгенерированных секвенатором нуклеиновых кислот во время первого интервала прочтения первого прогона секвенирования, получения вторых данных, содержащих множество вторых прочтений, сгенерированных секвенатором нуклеиновых кислот во время второго интервала прочтения первого прогона секвенирования, выполняемого после первого интервала прочтения, причем во время получения по меньшей мере части вторых данных: инициирования выполнения одной или более операций вторичного анализа на первых данных или вторых данных с использованием секвенатора нуклеиновых кислот для выполнения второго прогона секвенирования, причем во время использования секвенатора нуклеиновых кислот для выполнения второго прогона секвенирования: продолжения выполнения одной или более операций вторичного анализа на по меньшей мере первых данных или вторых данных, и сохранения данных результатов, представляющих результаты операций вторичного анализа.
[0029] Другие версии включают соответствующие системы, аппарат и компьютерные программы для выполнения действий из способов, определяемых командами, закодированными на машиночитаемых устройствах хранения.
[0030] В соответствии с другим инновационным аспектом настоящего описания описан способ выполнения вторичного анализа прочтений нуклеотидной последовательности. В одном аспекте способ может включать действия получения одного или более атрибутов геномной обработки, определения на основе одного или более атрибутов геномной обработки типа переключения контекста обработки для программируемой схемы, причем тип переключения контекста обработки определяет циклы реконфигурирования программируемой схемы, и подачи команды контроллеру программируемой схемы выполнять вторичный анализ с использованием заданного типа переключения контекста.
[0031] Другие версии включают соответствующие системы, аппарат и компьютерные программы для выполнения действий из способов, определяемых командами, закодированными на машиночитаемых устройствах хранения.
[0032] Если не указано иное, все технические и научные термины, используемые в настоящем документе, имеют общепринятое значение, понятное любому обычному специалисту в данной области, к которой относится настоящее изобретение. В настоящем документе описаны примеры способов и материалов, хотя для проверки или анализа настоящего изобретения можно использовать подходящие способы и материалы, подобные или эквивалентные описанным ниже. Все публикации, заявки на патенты, патенты и другие упоминаемые в настоящем документе литературные источники включены в настоящий документ в полном объеме путем ссылки. В случае противоречий настоящее описание, включая определения, будет иметь приоритет. Кроме того, материалы, способы и примеры приведены только для иллюстрации и не имеют ограничительного характера.
[0033] Прочие признаки и преимущества изобретения будут понятны из представленного ниже подробного описания, а также из формулы изобретения.
КРАТКОЕ ОПИСАНИЕ ГРАФИЧЕСКИХ МАТЕРИАЛОВ
[0034] На ФИГ. 1А представлено схематическое изображение примера рабочего процесса предшествующего уровня техники, описывающего линейную последовательность операций вторичного анализа.
[0035] На ФИГ. 1В представлена контекстуальная схема примера системы для выполнения инкрементного вторичного анализа одного или более образцов с использованием блока вторичного анализа, расположенного в секвенаторе нуклеиновых кислот.
[0036] На ФИГ. 2 представлена блок-схема примера процесса выполнения инкрементного вторичного анализа в соответствии со схемой рабочего процесса, показанной на ФИГ. 1В.
[0037] На ФИГ. 3 представлена контекстуальная схема примера системы для выполнения инкрементного вторичного анализа одного или более образцов с использованием блока вторичного анализа, расположенного удаленно от секвенатора нуклеиновых кислот.
[0038] На ФИГ. 4 представлена блок-схема примера процесса выполнения инкрементного вторичного анализа в соответствии со схемой рабочего процесса, показанной на ФИГ. 3.
[0039] На ФИГ. 5 представлена контекстуальная схема примера системы для выполнения инкрементного вторичного анализа одного или более образцов с использованием блока вторичного анализа в секвенаторе нуклеиновых кислот.
[0040] На ФИГ. 6 представлена блок-схема примера процесса выполнения инкрементного вторичного анализа в соответствии со схемой рабочего процесса, показанной на ФИГ. 5.
[0041] На ФИГ. 7 представлен пример схемы процесса, описывающей рабочую последовательность операций, выполняемых в ходе выполнения инкрементного вторичного анализа с использованием блока вторичного анализа.
[0042] На ФИГ. 8 представлена блок-схема примера процесса выполнения инкрементного вторичного анализа в соответствии со схемой рабочего процесса, показанной на ФИГ. 7.
[0043] На ФИГ. 9 представлена блок-схема примера процесса выполнения динамического переключения контекста программируемой схемы.
[0044] На ФИГ. 10 показана структурная схема примера системных компонентов, которые можно использовать для выполнения инкрементного вторичного анализа.
ПОДРОБНОЕ ОПИСАНИЕ
[0045] Секвенирование нуклеиновых кислот биологического образца с помощью секвенатора нуклеиновых кислот представляет собой трудоемкую и дорогостоящую задачу. Традиционные системы используют линейный рабочий процесс, такой как линейный рабочий процесс, показанный на ФИГ. 1А. В таких традиционных линейных рабочих процессах последовательно выполняют операции, которые включают (i) первичный анализ для получения прочтений секвенирования нуклеиновых кислот, (ii) вторичный анализ сгенерированных прочтений секвенирования нуклеиновых кислот для генерирования выравненных прочтений и вариантов и в некоторых случаях (iii) третичный анализ с использованием результатов вторичного анализа, таких как варианты, идентифицированные во время распознавания вариантов. Третичный анализ может включать, например, классификацию идентифицированных вариантов, определение значимости идентифицированных вариантов, определение диагноза на основе идентифицированных вариантов, определение лечения на основе идентифицированных вариантов или т.п.
[0046] Со ссылкой на ФИГ. 1А описан обычный рабочий процесс 170А, который выполняет прогон 172А секвенирования одного или более образцов. Прогон 172А секвенирования включает операцию кластеризации в период времени Т1, первый интервал прочтения «Прочтение 1», который включает операции секвенирования для генерирования первых прочтений образца за период времени Т2А, и второй интервал прочтения «Прочтение 2», который включает операции секвенирования для генерирования вторых прочтений образца за другой период времени Т2В. Во время прогона 172А секвенирования первый первичный анализ 100А обрабатывает данные для генерации первого и второго прочтений. Первичный анализ 100А может включать, например, обработку изображений для генерирования последовательности нуклеотидов или оснований каждого из прочтений. После завершения первого первичного анализа 100А начинается вторичный анализ 100В. В этом примере, показанном на ФИГ. 1А, вторичный анализ 100В выполняется с использованием программных ресурсов секвенатора нуклеиновых кислот и включает демультиплексирование прочтений, сгенерированных во время первичного анализа 100А первого прогона 172А секвенирования, картирование и выравнивание демультиплексированных прочтений, а затем распознавание вариантов - все это в период времени Т3. Только после завершения вторичного анализа секвенатор нуклеиновых кислот может выполнять следующий первичный анализ 100С. Соответственно, при применении традиционных рабочих процессов с использованием традиционного программного обеспечения для вторичного анализа в секвенаторе нуклеиновых кислот это занимает по меньшей мере TSUM=T1+Т2А+Т2В+Т3 - в некоторых случаях приблизительно 56-99 часов - после запуска первого первичного анализа 100А первого прогона 172А секвенирования и до выполнения второго первичного анализа 100С второго прогона 172В секвенирования. Более того, это приводит к периодам простоя секвенатора, при которых секвенатор не выполняет вторичный анализ и расходует реагенты, в некоторых случаях, по меньшей мере 30-48 часов, что уменьшает пропускную способность прибора, число нуклеотидов, обрабатываемых за данный интервал времени, и отрицательно влияет на потоки дохода от продажи реагентов.
[0047] Традиционные системы работают таким образом, поскольку традиционные секвенаторы нуклеиновых кислот не имеют вычислительных ресурсов для параллельного выполнения операций первичного анализа и вторичного анализа. Вместо этого программные вычислительные ресурсы традиционных секвенаторов нуклеиновых кислот направляются на операции секвенирования во время первичного анализа, а затем эти же вычислительные ресурсы направляются на операции демультиплексирования, картирования, выравнивания и распознавания вариантов во время вторичного анализа. В некоторых вариантах реализации демультиплексирование может включать операции сортировки.
[0048] Настоящее описание решает эти проблемы путем передачи нагрузки аспектов операций вторичного анализа на программируемый логический блок, имеющий аппаратную цифровую логику, выполненную с возможностью выполнения одной или более операций вторичного анализа с использованием аппаратных схем. Это резко снижает время Т3, которое требуется для выполнения операций вторичного анализа. Более того, настоящее изобретение параллелизует операции секвенирования, такие как кластеризация, первичный анализ, другие операции секвенирования или их комбинация, и вторичный анализ, как описано в настоящем документе, для уменьшения общего времени обработки TSUM от начала первого прогона 172А секвенирования до начала второго прогона 172В секвенирования путем модификации традиционных устройств секвенирования нуклеиновых кислот для выполнения параллелизованных рабочих операций, описанных в настоящем документе.
[0049] Использование методик настоящего описания дает множество других преимуществ. Во-первых, настоящее описание можно использовать для экономии реагентов, используемых секвенатором нуклеиновых кислот во время прогонов секвенирования. Например, начиная операции вторичного анализа во время прогона секвенирования и завершая по меньшей мере часть операций вторичного анализа до завершения секвенирования, настоящее описание может генерировать статистику, такую как статистика выравнивания, статистика демультиплексирования или т.п., и оценивать сгенерированные статистические данные для измерения качества прочтений, генерируемых во время первичного анализа. Если статистика указывает на то, что качество прочтений, генерируемых секвенатором нуклеиновых кислот, является низким, то первичный анализ может быть завершен, а входные данные для секвенирования могут быть переконфигурированы, и может быть повторно запущен другой прогон секвенирования с использованием секвенатора нуклеиновых кислот. Таким образом, этот способ может сэкономить по меньшей мере часть реагента, который был бы израсходован для завершения целого прогона секвенирования первого первичного анализа путем прекращения прогона секвенирования первичного анализа без использования всего реагента для завершения низкокачественного прогона секвенирования.
[0050] Во-вторых, параллелизованные рабочие процессы данного описания могут позволить начинать третичный анализ раньше, чем традиционные системы, тем самым позволяя быстрее идентифицировать определенные диагнозы и способы лечения. Например, традиционные рабочие процессы с использованием традиционных вычислительных архитектур могут в некоторых случаях занимать TSUM = приблизительно 56-99 часов до начала третичного анализа. Однако в некоторых вариантах реализации настоящего изобретения третичный анализ может быть запущен всего через 2-12 часов или через несколько часов после завершения секвенирования. В некоторых случаях это может давать особое преимущество, например, для обеспечения более быстрого определения, связаны ли симптомы пациента с вирусом или бактериями. Однако существует множество сценариев, в которых определение лечения за часы, а не за 3-4 дня, как в некоторых случаях, может дать существенное преимущество - например, дать пациенту возможность получить антибиотики (или другой тип лекарственного средства или лечения), прежде чем инфекция (или иное заболевание) вызовет необратимое повреждение.
[0051] Эти и другие преимущества станут очевидными из признаков, представленных в настоящем описании.
[0052] На ФИГ. 1В представлена контекстуальная схема примера системы 100 для выполнения инкрементного вторичного анализа одного образца 105 с использованием блока 140 вторичного анализа, расположенного в секвенаторе нуклеиновых кислот. Система 100 включает в себя секвенатор 110 нуклеиновых кислот, одну или более проточных ячеек 120, один или более блоков 140 вторичного анализа, один или более блоков 150 обработки и одно или более запоминающих устройств 160. В примере, показанном на ФИГ. 1В, блок 140 вторичного анализа расположен внутри секвенатора 110. Тем не менее настоящее описание не ограничено этим. Вместо этого блок 140 вторичного анализа может быть расположен внутри одного или более удаленных компьютеров, которые соединены с возможностью обмена данными с секвенатором 110 с использованием одной или более проводных или беспроводных сетей, таких как LAN, WAN, сотовая сеть, Интернет или любая их комбинация. Блок 140 вторичного анализа может включать в себя запоминающее устройство 140, программируемую схему 142, блок 150 обработки, запоминающее устройство 160 или любую их комбинацию. Для целей настоящего описания вторичный анализ может включать операции картирования, операции выравнивания, операции распознавания вариантов или любое их подмножество или комбинацию. В некоторых вариантах реализации блок 150 обработки и/или запоминающее устройство 160 могут быть использованы секвенатором нуклеиновых кислот для выполнения других операций, которые не связаны со вторичным анализом.
[0053] Один или более блоков 150 обработки секвенатора 110 нуклеиновых кислот могут включать в себя один или более процессоров, выполненных с возможностью выполнения программных команд для реализации функциональных возможностей, определенных в этих программных командах. Например, один или более блоков 150 обработки могут получать и исполнять программные команды, заставляющие блок 162 демультиплексирования, хранящийся в запоминающем устройстве 160, реализовывать функциональные возможности блока 162 демультиплексирования. Один или более блоков 150 обработки могут включать в себя один или более центральных процессоров (ЦП), один или более графических процессоров (ГП) или любую их комбинацию.
[0054] В настоящем описании термин «блок» используется для описания программного модуля, аппаратного модуля или их комбинации, которая используется для выполнения указанной функции. Определение того, является ли конкретный «блок», описанный в настоящем документе, аппаратным, программным или их комбинацией, может быть выполнено на основе контекста его применения. Например, блок 142а «картирования и выравнивания», размещенный в программируемой схеме 142, представляет собой аппаратный блок, функциональные возможности которого реализованы с помощью аппаратных цифровых логических элементов или аппаратных цифровых логических блоков. В качестве другого примера «блок демультиплексирования» 162, размещенный в запоминающем устройстве 160, представляет собой программный блок, функциональные возможности которого реализованы блоком 150 обработки, исполняющим программные команды, определяющие блок 162 демультиплексирования. В качестве другого примера «блок обработки» 150 может представлять собой аппаратное устройство, реализующее функциональные возможности путем обработки программных команд, и, таким образом, функциональные возможности «блока обработки» 150 представляют собой комбинацию аппаратного и программного обеспечения. Аналогичным образом «блок вторичного анализа» 140 может включать в себя комбинацию аппаратного обеспечения и программного обеспечения, которая используется для взаимодействия с аппаратной программируемой схемой 142а.
[0055] Секвенатор 110 нуклеиновых кислот представляет собой устройство, выполненное с возможностью осуществления операций секвенирования, таких как первичный анализ. Первичный анализ может включать размещение в секвенаторе 110 нуклеиновых кислот биологического образца 105, такого как образец крови, образец ткани, мокроты, и генерирование секвенатором 110 нуклеиновых кислот выходных данных, таких как одно или более прочтений 130-1, 130-2, 130-3, 130-4, 132-1, 132-2, 132-3, 132-4, 134-1, 134-2, 134-3, 134-4, каждое из которых представляет собой порядок нуклеотидов в нуклеотидной последовательности полученного биологического образца. Секвенирование секвенатором 110 нуклеиновых кислот может быть выполнено в несколько интервалов прочтения: первый интервал прочтения «Прочтение 1», который генерирует одно или более первых прочтений, представляющих порядок нуклеотидов из первого участка или конца фрагмента (или нити) нуклеотидной последовательности, который был клонально амплифицирован в клональную группу темплатных фрагментов нуклеиновых кислот, присоединенных к проточной ячейке 120, и второй интервал прочтения «Прочтение 2», который генерирует одно или более вторых прочтений, соответственно представляющих порядок нуклеотидов из второго участка, например второго конца фрагмента нуклеотидной последовательности, который был клонально амплифицирован в клональную группу темплатных фрагментов нуклеиновых кислот, присоединенных к проточной ячейке 120. Соответствующие клональные группы темплатных фрагментов нуклеиновых кислот, присоединенных к проточной ячейке 120, могут называться в настоящем документе кластерами, такими как кластер 1 122-1, кластер 2 122-2, кластер 3 122-3, кластер 4 122-4, кластер 5 122-5, кластер N 122-N.
[0056] В результате во время каждого интервала прочтения устройство 110 секвенирования нуклеиновых кислот будет генерировать по одному прочтению на каждый конец фрагмента нуклеиновой кислоты, клонально амплифицированной в соответствующем кластере. Таким образом, первый интервал прочтения цикла секвенирования будет формировать «Прочтение 1», а второй интервал прочтения цикла секвенирования будет формировать «Прочтение 2». В некоторых вариантах реализации нуклеотидная последовательность может секвенировать последовательность множества клонов фрагмента нуклеиновой кислоты в одном и том же кластере для визуализации и определения или идентификации последовательности прочтения.
[0057] Таким образом, каждое прочтение представляет собой часть конкретного фрагмента нуклеотидной последовательности. Например, предполагая, что короткий фрагмент нуклеотидной последовательности имеет приблизительно 600 нуклеотидов, первое прочтение может представлять 150 упорядоченных нуклеотидов для первого конца фрагмента нуклеотидной последовательности, а второе прочтение может представлять 150 упорядоченных нуклеотидов другого конца фрагмента нуклеотидной последовательности. Однако эти числа являются лишь примерами, и секвенатор 110 нуклеиновых кислот может быть сконфигурирован образом, соответствующим сущности и объему настоящего описания, позволяющим генерировать короткие последовательности нуклеиновых кислот и соответствующие прочтения иной длины, чем у тех, которые упомянуты в настоящем документе. Простой вариант этой концепции представлен со ссылкой на ФИГ. 1В, 3 и 5 для донесения принципов настоящего описания до специалиста в данной области. В частности, на этих фигурах показаны прочтения, сгенерированные секвенатором 110 нуклеиновых кислот, для соответствующих концов кластеризованных фрагментов нуклеотидной последовательности, темплат нуклеиновой кислоты которой был связан с проточной ячейкой 120 и клонально амплифицирован.
[0058] В некоторых вариантах реализации биологический образец может включать образец ДНК, а секвенатор 110 нуклеиновых кислот может обрабатывать ДНК. В таких вариантах реализации порядок секвенированных нуклеотидов в прочтении 130-1, 130-2, 130-3, 130-4, 132-1, 132-2, 132-3, 132-4, 134-1, 134-2, 134-3, 134-4, сгенерированном секвенатором нуклеиновых кислот, может включать один или более из гуанина (G), цитозина (С), аденина (А) и тимина (Т) в любой комбинации. В других вариантах реализации секвенатор 110 нуклеиновых кислот может обрабатывать РНК, а биологический образец может включать образец РНК. В таких вариантах реализации порядок секвенированных нуклеотидов в прочтении, сгенерированном секвенатором нуклеиновых кислот, может включать один или более из G, С, А и урацила (U) в любой комбинации. Соответственно, хотя в примере, показанном на ФИГ. 1В, описана обработка прочтения, состоящего из G, С, А и Т, на основе образца ДНК, настоящее описание не ограничивается этим. Вместо этого в других вариантах реализации процесс может обрабатывать прочтения, состоящие из С, G, А и U на основе образца РНК.
[0059] Однако секвенирование РНК не требует использования РНК-секвенатора. Например, в некоторых вариантах реализации секвенатор 110 нуклеиновых кислот может представлять собой ДНК-секвенатор, который секвенирует образец, и сгенерированные прочтения содержат один или более из G, С, А и Т. Затем в таких вариантах реализации секвенатор 110 нуклеиновых кислот может транскрибировать сгенерированные прочтения в кДНК для представления РНК секвенированного образца. В таких вариантах реализации прочтения будут представлены с использованием оснований, которые включают G, С, А и урацил (U) в любой комбинации.
[0060] В некоторых вариантах реализации секвенатор 110 нуклеиновых кислот может включать в себя секвенатор следующего поколения (NGS), который выполнен с возможностью генерирования прочтений последовательностей, например прочтений 130-1, 130-2, 130-3, 130-4, 132-1, 132-2, 132-3, 132-4, 134-1, 134-2, 134-3, 134-4, для данного образца таким образом, чтобы обеспечивать сверхвысокую пропускную способность, масштабируемость и скорость за счет использования технологии массового параллельного секвенирования. NGS позволяют быстро секвенировать целые геномы, обеспечивают возможность глубокого изучения секвенированных целевых областей, использования секвенирования РНК (RNA-Seq) для обнаружения новых вариантов РНК и сайтов сплайсинга или количественного определения мРНК для анализа генной экспрессии, проведения анализа эпигенетических факторов, таких как метилирование ДНК в масштабах генома и ДНК-белковые взаимодействия, секвенирования образцов опухолей для исследования редких соматических вариантов и субклонов опухоли, а также изучения разнообразия микроорганизмов у людей или в окружающей среде.
[0061] Способ генерирования прочтений последовательностей нуклеиновых кислот включает стадии подготовки образца, генерирования кластеров и секвенирования. Первая стадия включает подготовку образца, которая включает добавление последовательностей адаптера к концу каждого фрагмента ДНК. Посредством амплификации с уменьшенным количеством циклов добавляют дополнительные мотивы, такие как любые необходимые индексы, которые можно использовать для идентификации образца, от которого происходят прочтения, и области, комплементарные олигонуклеотидам проточной ячейки 120. Один или более примеров подготовки образца на твердой подложке описаны в патенте США №9,683,230, который полностью включен в настоящий документ путем ссылки. Вторая стадия включает кластеризацию, при которой каждый фрагмент ДНК изотермически амплифицируют, например с использованием реагента для амплификации. Один или более примеров изотермической амплификации нуклеиновых кислот на твердой подложке более подробно описаны в патенте США №7,972,820, который полностью включен в настоящий документ путем ссылки. Проточная ячейка 120 может включать в себя стеклянную плитку со множеством дорожек, причем каждая дорожка включает в себя «газон» из двух типов олигонуклеотидов. Первый из двух типов олигонуклеотидов обеспечивает гибридизацию с прикреплением к его комплементарным олигонуклеотидам на поверхности проточной ячейки. Полимераза создает комплементарную цепь для гибридизированного фрагмента. Фрагменты ДНК могут быть клонально амплифицированы с использованием методики, такой как мостиковая амплификация. В варианте реализации системы 100 и рабочего процесса 170В стадии кластеризации происходят в период времени Т1 рабочего процесса 170В. Тем не менее настоящее описание не ограничено этим. Вместо этого в некоторых вариантах реализации кластеризация может начинаться и/или выполняться до периода времени Т1 вне прибора. В таких вариантах реализации период времени Т1 может быть удален из расчета времени прогона, и прогон секвенирования может начинаться, например, с Т2А. Такие внеприборные и/или пред-Т1-кластеризации могут быть реализованы в системах 100, показанных на ФИГ. 1, системе 300, показанной на ФИГ. 3, системе 500, показанной на ФИГ. 5, системе 700, показанной на ФИГ. 7, или любом другом варианте реализации настоящего описания. После мостиковых амплификаций обратные фрагменты отщепляют, оставляя только прямые фрагменты.
[0062] Третья стадия включает выполнение операций секвенирования в периоды времени Т2А и Т2В посредством секвенатора 110 нуклеиновых кислот. В период времени Т2А секвенатор 110 нуклеиновых кислот выполняет X циклов операций секвенирования в течение первого интервала прочтения «Прочтение 1» с генерацией первого прочтения, которое соответствует первому концу каждого из фрагментов последовательности нуклеиновой кислоты, которые автоматически амплифицированы в соответствующие кластеры 122-1, 122-2, 122-3, 122-4, 122-5, 122-N, где X и N могут представлять собой любое положительное целое число больше нуля. Первое прочтение каждого кластера ДНК включает строку распознавания оснований, соответствующую участку соответствующей ДНК, ассоциированной с конкретным кластером. Например, прочтение 130-1 включает строку распознавания оснований, соответствующую первому концу фрагмента нуклеиновой кислоты, ассоциированного с кластером 1 122-1, прочтение 130-3 включает строку распознавания оснований, соответствующую первому концу фрагмента нуклеиновой кислоты, ассоциированного с кластером 2 122-2, прочтение 132-1 включает строку распознавания оснований, соответствующую первому концу фрагмента нуклеиновой кислоты, ассоциированного с кластером 3 122-3, прочтение 132-3 включает строку распознавания оснований, соответствующую первому концу фрагмента нуклеиновой кислоты, ассоциированного с кластером 4 122-4, прочтение 134-1 включает строку распознавания оснований, соответствующую первому концу фрагмента нуклеиновой кислоты, ассоциированного с кластером 5 122-5, и прочтение 134-3 включает строку распознавания оснований, соответствующую первому концу фрагмента нуклеиновой кислоты, ассоциированного с кластером N 122-N. Каждое распознавание оснований соответствует или представляет собой нуклеотид. Эти прочтения могут быть получены с использованием процесса секвенирования, такого как секвенирование путем синтеза. Данные, представляющие прочтения 130-1, 130-3, 132-1, 132-3, 134-1 и 134-3, могут быть выведены в запоминающее устройство 160 секвенатора 110 нуклеиновых кислот и/или введены в запоминающее устройство 144 блока 140 вторичного анализа.
[0063] В варианте реализации системы 100 и ФИГ. 1В эти первые прочтения 130-1, 130-3, 132-1, 132-3, 134-1 и 134-3, секвенированные за период времени Т2А первого интервала прочтения в рабочем процессе 170В, представляют собой ряд нуклеотидов на первом конце фрагмента ДНК, ассоциированного с каждым кластером. Например, в некоторых вариантах реализации фрагмент ДНК, секвенированный секвенатором 110 нуклеиновых кислот, может включать 600 нуклеотидов. Первые прочтения 130-1, 130-3, 132-1, 132-3, 134-1 и 134-3 кластера могут представлять собой, например, первые 150 нуклеотидов первого конца 600-нуклеотидного фрагмента ДНК, амплифицированного в соответствующем кластере. Каждый интервал прочтения является массово-параллельным процессом, который одновременно секвенирует сотни миллионов кластеров фрагментов ДНК. После завершения первого интервала прочтения в конце Т2А секвенатор 110 нуклеиновых кислот может инициировать второй интервал прочтения в период времени Т2В, в котором секвенируется противоположный конец каждого фрагмента ДНК в каждом кластере с генерированием вторых прочтений 130-2, 130-4, 132-2, 132-4, 134-2, 134-4. В качестве примера прочтение 130-2 включает строку распознавания оснований, соответствующую второму концу фрагмента нуклеиновой кислоты, ассоциированного с кластером 1 122-1, прочтение 130-4 включает строку распознавания оснований, соответствующую второму концу фрагмента нуклеиновой кислоты, ассоциированного с кластером 2 122-2, прочтение 132-2 включает строку распознавания оснований, соответствующую второму концу фрагмента нуклеиновой кислоты, ассоциированного с кластером 3 122-3, прочтение 132-4 включает строку распознавания оснований, соответствующую второму концу фрагмента нуклеиновой кислоты, ассоциированного с кластером 4 122-4, прочтение 134-2 включает строку распознавания оснований, соответствующую второму концу фрагмента нуклеиновой кислоты, ассоциированного с кластером 5 122-5, и прочтение 134-4 включает строку распознавания оснований, соответствующую второму концу фрагмента нуклеиновой кислоты, ассоциированного с кластером N 122-N. В данном варианте реализации системы 100 и ФИГ. 1 второй интервал прочтения начинается приблизительно во Время = T1+Т2А рабочего процесса 170В.
[0064] В традиционных системах, как описано со ссылкой на ФИГ. 1А, операции вторичного анализа, такие как картирование и выравнивание первых прочтений 130-1, 130-3, 132-1, 132-3, 134-1 и 134-3, не будут происходить до окончания второго интервала прочтения «Прочтение 2» по завершению Времени = T1+Т2А+Т2В. Однако система 100, показанная на ФИГ. 1В, как описано в настоящем описании, выполнена с возможностью инициирования операций вторичного анализа первых прочтений 130-1, 130-3, 132-1, 132-3, 134-1, 134-3, причем Время = T1+Т2А, причем вторичный анализ первых прочтений 130-1, 130-3, 132-1, 132-3, 134-1, 134-3 начинается и происходит во время второго интервала прочтения «Прочтение 2», в то время как секвенатор 110 нуклеиновых кислот выполняет операции секвенирования второго интервала прочтения «Прочтение 2» для генерирования вторых прочтений 130-2, 130-4, 132-2, 132-4, 134-2, 134-4.
[0065] Система 100 добивается этого преимущества в параллельной обработке путем переноса операций вторичного анализа первых прочтений в программируемую схему 142а блока 140 вторичного анализа. Перенос операций в блок 140 вторичного анализа освобождает блок 150 обработки и/или запоминающее устройство 160 секвенатора 110 нуклеиновых кислот для продолжения выполнения операций первичного анализа второго интервала прочтения «Прочтение 2» с генерацией вторых прочтений 130-2, 130-4, 132-2, 132-4, 134-2, 134-4 путем секвенирования противоположного конца кластера ДНК во время выполнения вторичного анализа одного или более первых прочтений. Соответственно, настоящее изобретение позволяет выполнять операции секвенирования, такие как первичный анализ, параллельно одной или более операциям вторичного анализа.
[0066] Блок 140 вторичного анализа включает в себя программируемую схему 142, которая может быть динамически сконфигурирована для включения одного или более рабочих блоков вторичного анализа, таких как блок 142а картирования и выравнивания, для выполнения одной или более операций вторичного анализа. Динамическое конфигурирование программируемой схемы 142 для включения операционного блока вторичного анализа, такого как блок 142а картирования и выравнивания, может включать, например, передачу одной или более команд на программируемую схему 142, которые вызывают перевод аппаратных логических элементов программируемой схемы 142 программируемой схемой 142 в такую аппаратную цифровую логическую конфигурацию, которая выполнена с возможностью осуществления в аппаратной логике функциональных возможностей блока 142а картирования и выравнивания. Аппаратные логические элементы программируемой схемы 142 могут быть реализованы с использованием скомпилированного кода на языке описания аппаратных средств или т.п. Создание исходных конфигураций программируемой схемы 142 и последующее реконфигурирование программируемой схемы 142 могут быть инициированы путем выполнения программных триггеров, которые выполняются секвенатором 110 нуклеиновых кислот или другим компьютером, на котором размещена программируемая схема 142. Например, в варианте реализации системы 100, показанной на ФИГ. 1В, в конце цикла интервала «Прочтение 1», секвенатор 110 нуклеиновых кислот или другой компьютер, на котором размещена программируемая схема 142, могут выполнять программные команды, которые инициируют изменение конфигурации программируемой схемы для выполнения операций картирования и выравнивания. Такое выполнение вышеупомянутых программных триггеров может, например, вызывать загрузку в память программируемой схемы 142 скомпилированного кода на языке описания аппаратных средств, который может быть выполнен контроллером программируемой схемы и вызывать изменение конфигурации логических элементов программируемой схемы 142. Сконфигурированные функциональные возможности блока 142а картирования и выравнивания могут включать получение одного или более прочтений, таких как первые прочтения 130-1, 130-3, 1S32-1, 132-3, 134-1, 134-3, картирование полученных первых прочтений 130-1, 130-3, 132-1, 132-3, 134-1, 134-3 в одну или более позиций эталонной последовательности, а затем выравнивание картированных первых прочтений 130-1, 130-3, 132-1, 132-3, 134-1, 134-3 с одной или более позициями эталонной последовательности. Эталонная последовательность может включать организованную последовательность нуклеотидов, соответствующих известному геному.
[0067] Конфигурирование аппаратных логических элементов программируемой схемы 142 в ответ на одну или более инструкций может включать в себя конфигурирование логических элементов, таких как элементы AND, элементы OR, элементы NOR, элементы XOR или любая их комбинация, для выполнения цифровых логических функций блока 142а картирования и выравнивания. Примеры применения программируемой логической схемы, такой как FPGA, для выполнения функций блока картирования и выравнивания более подробно описаны, например, в патенте США №9,679,104 или патентной публикации США №2020/0372031, содержание каждого из которых полностью включено в настоящий документ путем ссылки. Альтернативно или дополнительно конфигурация аппаратных логических элементов может включать в себя динамически конфигурируемые логические блоки, содержащие настраиваемые аппаратные логические блоки для выполнения сложных вычислительных операций, включая сложение, умножение, сопоставление или т.п. Точная конфигурация аппаратных логических элементов, логических блоков или их комбинации определяется полученными командами. Полученные команды могут включать в себя или быть производными от скомпилированного программного кода на языке описания аппаратных средств (HDL), который был написан субъектом и определяет схему компоновки операционного блока вторичного анализа, которая должна быть запрограммирована. Программный код HDL может включать в себя программный код, написанный на том или ином языке, таком как язык описания аппаратных средств на быстродействующих интегральных схемах (VHDL), Verilog или т.п. Субъектом может быть один или более людей-пользователей, подготовивших программный код HDL, один или более агентов искусственного интеллекта, генерирующих программный код HDL, или их комбинация.
[0068] В некоторых вариантах реализации программируемая схема 142 может включать в себя одну или более программируемых пользователем вентильных матриц (FPGA), одно или более сложных программируемых логических устройств (CPLD) или программируемых логических матриц (PLA) или их комбинацию, которые выполнены с возможностью динамического конфигурирования и переконфигурирования секвенатором 110 нуклеиновых кислот по мере необходимости для выполнения конкретного рабочего процесса. Например, в некоторых вариантах реализации может быть желательно использовать программируемую логическую схему 142 в качестве блока 142а выравнивания и картирования, как описано выше. Вместе с тем в других вариантах реализации может быть желательно использовать программируемую логическую схему 142 для выполнения функций распознавания вариантов или функций поддержки распознавания вариантов, таких как блок скрытой марковской модели (НММ). В других вариантах реализации программируемая схема 142 также может быть динамически сконфигурирована для поддержки общих вычислительных задач, таких как сжатие и распаковка, поскольку аппаратная логика программируемой схемы 142 способна выполнять эти задачи и другие указанные выше задачи намного быстрее выполнения тех же задач с использованием программных команд, выполняемых одним или более процессорами 150.
[0069] Программируемые схемы 142 представляют собой пример одного типа интегральной схемы, способной обеспечивать преимущества настоящего описания, описанные в настоящем документе. Однако в качестве аппаратной цифровой логики блока 140 вторичного анализа могут быть использованы другие типы интегральных схем, в которые можно перенести вторичный анализ секвенатора 110 нуклеиновых кислот для освобождения ресурсов секвенатора 110 нуклеиновых кислот для первичного анализа. Например, в некоторых вариантах реализации блок 140 вторичного анализа может быть выполнен с возможностью использования одной или более интегральных схем специального назначения (ASIC). Несмотря на невозможность перепрограммирования одна или более ASIC могут быть сконструированы с использованием специализированной аппаратной логической схемы одного или более операционных блоков вторичного анализа, таких как блок картирования и выравнивания, блок распознавания вариантов, вычислительный блок поддержки распознавания вариантов или т.п., для ускорения и параллелизации выполнения операций вторичного анализа. В некоторых вариантах реализации использование ASIC в качестве аппаратных логических схем блока 140 вторичного анализа, которые реализуют функциональные возможности одного или более блоков операций вторичного анализа, может обеспечивать еще более высокую скорость, чем применение программируемой схемы. Соответственно, специалисту в данной области будет очевидно, что в любом из вариантов осуществления, описанных в настоящем документе, вместо FPGA можно использовать ASIC.
[0070] В качестве примера в некоторых вариантах реализации программируемая логическая схема 142 может быть реализована с использованием FPGA, которая динамически сконфигурирована в качестве блока распаковки для доступа к данным, представляющим первые прочтения 130-1, 130-3, 132-1, 132-3, 134-1, 134-3, полученным от секвенатора нуклеиновых кислот и для распаковки данных, представляющих первые прочтения (например, если прочтения, полученные от секвенатора нуклеиновых кислот, сжаты). Блок распаковки может сохранять распакованные прочтения в запоминающем устройстве 144 или 160. Затем в таких вариантах реализации FPGA можно динамически переконфигурировать в качестве блока 142а картирования и выравнивания и использовать для выполнения картирования и выравнивания распакованных первых прочтений, сохраненных в запоминающем устройстве 144 или 160. Затем блок 142а картирования и выравнивания может сохранять данные, представляющие картированные и выравненные прочтения, в запоминающем устройстве 144 или 160. Затем FGPA может быть динамически реконфигурирована в блок распознавания вариантов или в блок, выполненный с возможностью выполнения вспомогательных функций для программного блока распознавания вариантов (например, блока НММ) и выполнения операций по распознаванию вариантов с генерированием выходных данных, которые могут быть использованы системой 100 секвенирования для создания файла в формате распознавания вариантов (VCF) на основе сохраненных данных, представляющих картированные и выравненные прочтения. Высокая скорость выполнения у таких аппаратных модулей, исполняемых с использованием FPGA, может уменьшать время вторичного анализа прочтений с 30-48 часов у традиционных способов до сроков порядка минут. Несмотря на то что такая последовательность операций описана как включающая операции распаковки, картирования и выравнивания и распознавания вариантов, настоящее описание не ограничивается выполнением всех этих операций. Вместо этого программируемая схема 142 может быть динамически сконфигурирована при необходимости для выполнения функций любого операционного блока в любом порядке для параллелизации вторичного анализа, выгруженного из секвенатора 110 нуклеиновых кислот.
[0071] Применительно к примеру, показанному на ФИГ. 1А, секвенатор 110 нуклеиновых кислот может конфигурировать программируемую схему 142 блока 140 вторичного анализа для включения блока 142а картирования и выравнивания. Секвенатор 110 нуклеиновых кислот может принимать образец 105, такой как нуклеиновая кислота, от объекта, такого как человек, животное, не являющееся человеком, или растение. Секвенатор 110 нуклеиновых кислот может подготавливать образец 105 и выполнять генерацию кластеров в период времени Т1 рабочего процесса 170В. Секвенатор 110 нуклеиновых кислот может выполнять операции секвенирования, такие как секвенирование путем синтеза, во время первого интервала прочтения, с генерированием первых прочтений 130-1, 130-3, 132-1, 132-3, 134-1, 134-3 в период времени Т2А, который идет после периода времени Т1. В конце периода времени T1+Т2А секвенатор ПО нуклеиновых кислот завершает секвенирование первых прочтений 130-1, 130-3, 132-1, 132-3, 134-1, 134-3 и начинает секвенирование вторых прочтений 130-2, 130-4, 132-2, 132-4, 134-2, 134-4.
[0072] Секвенатор 110 нуклеиновых кислот выполнен с возможностью параллелизации операций вторичного анализа, таких как картирование и выравнивание первых прочтений 130-1, 130-3, 132-1, 132-3, 134-1, 134-3, с операциями секвенирования, такими как секвенирование путем синтеза, для второго интервала прочтения с генерированием вторых прочтений 130-2, 130-4, 132-2, 132-4, 134-2, 134-4 в течение периода времени Т2В. Блок 142а картирования и выравнивания может генерировать результаты 149 картирования и выравнивания и сохранять результаты картирования и выравнивания в запоминающем устройстве 160 секвенатора 110 нуклеиновых кислот, запоминающем устройстве 144, каком-либо другом запоминающем устройстве, доступном для секвенатора 110 нуклеиновых кислот, каком-либо другом запоминающем устройстве, доступном для пользователя секвенатора 110 нуклеиновых кислот, или их комбинации. Результаты 149 могут включать данные, описывающие статистику картирования и выравнивания, такие как, например, оценка качества картирования (MAPQ), которая обеспечивает индикацию качества картирования, оценка выравнивания, которая обеспечивает индикацию качества выравнивания или т.п.
[0073] В примере, показанном на ФИГ. 1А, сверхбыстрое выполнение блока 142а картирования и выравнивания, реализованного с использованием аппаратной цифровой логики программируемой схемы 142, позволяет блоку 142а картирования и выравнивания выполнять картирование и выравнивание первых прочтений 130-1, 130-3, 132-1, 132-3, 134-1, 134-3 за долю времени, необходимую секвенатору 110 нуклеиновых кислот для выполнения второго интервала прочтения. Например, в некоторых вариантах реализации программируемая схема 142 может выполнять картирование и выравнивание первых прочтений 130-1, 130-3, 132-1, 132-3, 134-1, 134-3 всего за минуты, при этом секвенирование вторых прочтений 130-2, 130-4, 132-2, 132-4, 134-2, 134-4 может занимать от 12 до 24 часов. Соответственно, результаты картирования и выравнивания 149 могут быть оценены секвенатором 110 нуклеиновых кислот и/или пользователем секвенатора 110 нуклеиновых кислот, и на основе качества картирования и выравнивания первых прочтений 130-1, 130-3, 132-1, 132-3, 134-1, 134-3, согласно статистике картирования и выравнивания, может быть определено, следует ли секвенатору 110 нуклеиновых кислот продолжать секвенирование вторых прочтений 130-2, 130-4, 132-2, 132-4, 134-2, 134-4.
[0074] Это определение того, следует ли продолжать секвенирование вторых прочтений 130-2, 130-4, 132-2, 132-4, 134-2, 134-4, может выполняться автоматически секвенатором 110 нуклеиновых кислот, вручную пользователем секвенатора 110 нуклеиновых кислот или на основе данных, содержащих определение, сделанное обоими способами. В качестве примера секвенатор 110 нуклеиновых кислот может быть выполнен с возможностью определения того, удовлетворяет ли статистика картирования и выравнивания, например оценки выравнивания первых прочтений 130-1, 130-3, 132-1, 132-3, 134-1 и 134-3, предварительно заданному пороговому значению. Если одна или более оценок выравнивания удовлетворяют предварительно заданному пороговому значению, то секвенатор 110 нуклеиновых кислот может продолжать секвенирование вторых прочтений 130-2, 130-4, 132-2, 132-4, 134-2, 134-4. Альтернативно, если определено, что одна или более оценок выравнивания не удовлетворяют предварительно заданному пороговому значению, то секвенатор 110 нуклеиновых кислот может прервать секвенирование вторых прочтений 130-2, 130-4, 132-2, 132-4, 134-2, 134-4.
[0075] В качестве другого примера в некоторых вариантах реализации результаты картирования и выравнивания 149 могут быть вручную рассмотрены пользователем секвенатора 110 нуклеиновых кислот. В таких случаях пользователь может определить, должен ли секвенатор 110 нуклеиновых кислот продолжать секвенирование вторых прочтений 130-2, 130-4, 132-2, 132-4, 134-2, 134-4 на основе качества выравнивания первых прочтений 130-1, 130-3, 132-1, 132-3, 134-1, 134-3, указанного оценками выравнивания.
[0076] В качестве еще одного примера, определение того, нужно ли продолжать секвенирование вторых прочтений на основе качества выравнивания первых прочтений, указанного оценками выравнивания в результатах 149 картирования и выравнивания, может проводить как секвенатор 110 нуклеиновых кислот, так и пользователь. В таких вариантах реализации могут быть получены данные, описывающие определения, сделанные секвенатором 110 нуклеиновых кислот и пользователем, и в некоторых вариантах реализации секвенатор 110 нуклеиновых кислот прервет второй интервал прочтения, только в случае, если и секвенатор 110 нуклеиновых кислот и пользователь согласны с тем, что второй интервал прочтения должен быть прерван.
[0077] В других вариантах реализации может быть вычислено средневзвешенное значение двух определений с получением агрегированной оценки, представляющего определение как секвенатора 110 нуклеиновых кислот, так и пользователя. В таких вариантах реализации секвенатор 110 нуклеиновых кислот может прерывать работу, только если агрегированная оценка не удовлетворяет предварительно заданному пороговому значению качества. В других вариантах реализации данные, представляющие статистику выравнивания, данные, представляющие определение пользователем того, следует ли продолжать секвенирование во втором интервале прочтения, данные, представляющие одно или более первых прочтений, другие данные, такие как данные, представляющие признаки образца 105, или их комбинация могут быть векторизованы и введены в агент искусственного интеллекта, такой как модель машинного обучения, которая была обучена определению того, должен ли секвенатор 110 нуклеиновых кислот продолжать первичный анализ второго интервала прочтения. В таких вариантах реализации модель машинного обучения может быть предварительно обучена на меченых обучающих данных с пометками «прервать второй интервал прочтения» или «продолжить второй интервал прочтения» или их соответствующих эквивалентах. Меченные обучающие данные могут включать в себя данные, представляющие те же типы входных данных, которые будут предоставлены модели машинного обучения во время работы. Такие типы входных данных могут включать в себя данные, представляющие статистику выравнивания, данные, представляющие определение пользователем того, следует ли продолжать секвенирование второго интервала прочтения, данные, представляющие одно или более из первых прочтений, другие данные, такие как данные, представляющие признаки образца 105, или их комбинацию.
[0078] Использование результатов 149 картирования и выравнивания, сгенерированных на основе картирования и выравнивания первых прочтений 130-1, 130-3, 132-1, 132-3, 134-1, 134-3 с одной или более эталонных последовательностей, обеспечивает экономию секвенатором 110 нуклеиновых кислот реагента, используемого во время второго интервала прочтения для генерирования вторых прочтений 130-2, 130-4, 132-2, 132-4, 134-2, 134-4. Например, низкие оценки выравнивания для первых прочтений 130-1, 130-3, 132-1, 132-3, 134-1, 134-3 могут указывать на наличие ряда проблем, таких как загрязненный образец 105, ошибки секвенирования, их комбинации или т.п. Соответственно, в таких случаях, вместо использования реагентов, которые могут быть очень дорогостоящими, для секвенирования вторых прочтений во время второго интервала прочтения, и вместо дополнительной траты времени на выполнение еще одного цикла первичного анализа, секвенатор 110 нуклеиновых кислот можно отключить, выполнить реконфигурацию, а затем использовать для начала первичного анализа другого образца за долю времени, которое было бы потрачено на завершение секвенатором 110 нуклеиновой кислоты низкокачественного прогона секвенирования. В некоторых вариантах реализации после определения того, что качество картирования и выравнивания первых прочтений является удовлетворительным, секвенатор 110 нуклеиновых кислот может отклонить результаты 149 картирования и выравнивания. В других вариантах реализации картирование и выравнивание первых прочтений, выполняемое параллельно со вторым интервалом прочтения, можно использовать в качестве результатов картирования и выравнивания для заключительных прогонов данных первых прочтений.
[0079] Продолжая пример, показанный на ФИГ. 1В, после того как было определено, что результаты картирования и выравнивания являются удовлетворительными, секвенатор 110 нуклеиновых кислот может продолжать выполнение второго интервала прочтения с генерированием вторых прочтений. После генерирования вторых прочтений 130-2, 130-4, 132-2, 132-4, 134-2, 134-4 секвенатор 110 нуклеиновых кислот может дать команду блоку 140 вторичного анализа начать заключительный прогон данных вторичного анализа. Заключительный прогон данных вторичного анализа может включать картирование и выравнивание первых прочтений 130-1, 130-3, 132-1, 132-3, 134-1, 134-3 и вторых прочтений 130-2, 130-4, 132-2, 132-4, 134-2, 134-4 с использованием блока 140 вторичного анализа. Поскольку эти операции вторичного анализа реализованы с использованием программируемой схемы 142а, эти операции вторичного анализа могут быть выполнены параллельно второму прогону секвенирования и за долю времени, необходимую для выполнения второго прогона секвенирования.
[0080] Это обеспечивает преимущество по сравнению с традиционными системами в плане возможности перейти к последующим прогонам секвенирования в то время, как вторичный анализ прочтений предшествующего прогона секвенирования еще выполняется. Таким образом, если традиционные секвенаторы нуклеиновых кислот должны ожидать прибл. 24-48 часов после завершения первого цикла секвенирования до начала второго цикла секвенирования, как показано на ФИГ. 1А, секвенатор 110 нуклеиновых кислот может использовать блок 142а картирования и выравнивания, реализованный в программируемой схеме 142, для параллелизации вторичного анализа прочтений первого прогона секвенирования и выполнения второго прогона секвенирования. Таким образом, секвенатор 110 нуклеиновых кислот, показанный на ФИГ. 1В может быть использован для выполнения большего количества прогонов секвенирования за более короткое время, чем традиционные системы, которые используют систему и рабочий процесс, описанный со ссылкой на ФИГ. 1А. Соответственно, параллелизация прогонов секвенирования и вторичного анализа посредством переноса вычислительных задач вторичного анализа в программируемую схему 142 блока 140 вторичного анализа может привести к увеличению дохода от дополнительных продаж реагентов.
[0081] В некоторых вариантах реализации секвенатор 110 нуклеиновых кислот может также иметь программное обеспечение, например блок 162 демультиплексирования и блок 164 распознавания вариантов, хранимые в запоминающем устройстве 160. Один или более процессоров 150 секвенатора нуклеиновых кислот может обрабатывать программные команды этих блоков для реализации функциональных возможностей этих блоков. Например, в некоторых вариантах реализации фрагменты ДНК из множества образцов могут быть секвенированы одновременно с использованием секвенатора 110 нуклеиновых кислот. В таких случаях блок 162 демультиплексирования может быть использован для осуществления методик демультиплексирования, которые организуют прочтения на основе индекса, такого как штрихкод, который был добавлен к каждому из сгенерированных прочтений, и идентификации образца, ассоциированного с каждым прочтением. В качестве другого примера процессор 150 может быть использован для выполнения блока 164 распознавания вариантов, который может анализировать картированные и выравненные прочтения для идентификации наличия любых вариантов, таких как однонуклеотидные полиморфизмы (SNP), вставки/делеции (инделы), структурные вариации или т.п. В некоторых вариантах реализации программируемая схема 142 может быть динамически реконфигурирована для облегчения обработки в рамках распознавания вариантов. Например, программируемая схема 142 может быть динамически реконфигурирована для включения блока НММ, который может быть использован для выполнения вычислений вероятностей, например вероятности появления варианта в одном или более эталонных положениях картированных и выравненных прочтений. В некоторых вариантах реализации блок 164 распознавания вариантов может быть выполнен с возможностью выполнения операций распознавания вариантов в картированных и выравненных прочтениях из интервала «Прочтение» 1 параллельно операциям секвенирования второго прогона секвенирования.
[0082] В примере, показанном на ФИГ. 1В, описан пример, имеющий прочтения с 8 нуклеотидами. Тем не менее настоящее описание не ограничено этим. Вместо этого такой простой пример представлен, чтобы простым для понимания образом объяснить признаки настоящего описания. На практике каждый из фрагментов ДНК настоящего описания может иметь в некоторых вариантах реализации, например, до 600 нуклеотидов, до 1000 нуклеотидов или более, и каждое прочтение фрагмента может иметь, например, 50 нуклеотидов, 75 нуклеотидов, 150 нуклеотидов, 200 нуклеотидов, 300 нуклеотидов, 500 нуклеотидов или более с каждого конца фрагмента ДНК. Однако можно использовать варианты реализации настоящего описания, которые имеют ДНК-фрагменты иной длины и прочтения иной длины. Аналогичным образом ничто на ФИГ. 1В или любой другой фигуре не следует интерпретировать как ограничение числа кластеров фрагментов. Например, секвенатор 110 нуклеиновых кислот может выполнять массово-параллельное секвенирование с одновременным секвенированием миллионов кластеров из множества фрагментов.
[0083] На ФИГ. 2 представлена блок-схема примера процесса 200 выполнения инкрементного вторичного анализа в соответствии с схемой рабочего процесса, показанной на ФИГ. 1В. По существу, процесс 200 включает получение первых данных, представляющих множество первых прочтений, сгенерированных секвенатором нуклеиновых кислот во время первого интервала (210) прочтения, получение вторых данных, представляющих множество вторых прочтений, сгенерированных секвенатором нуклеиновых кислот во время второго интервала прочтения, выполняемого после первого интервала (220) прочтения, во время получения вторых данных на стадии 220 (I) выполнение одной или более операций вторичного анализа на первых данных, представляющих множество первых прочтений, сгенерированных секвенатором нуклеиновых кислот, и (II) сохранение данных результатов вторичного анализа первого множества прочтений (230), и выполнение после этого вторичного анализа полученных вторых данных, представляющих второе множество прочтений, с эталонными данными. Для удобства эти стадии будут более подробно описаны ниже в качестве выполняемых системой секвенирования, такой как система 100, показанная на ФИГ. 1В.
[0084] Система секвенирования может начинать выполнение процесса 200 с получения 210 первых данных, представляющих множество первых прочтений, сгенерированных секвенатором нуклеиновых кислот во время первого интервала прочтения. Получение первых данных может включать сохранение первых данных, представляющих множество первых прочтений, в запоминающем устройстве, таком как запоминающее устройство блока вторичного анализа, после генерирования первых данных секвенатором нуклеиновых кислот. Запоминающее устройство блока вторичного анализа может представлять собой блок памяти, выполненный с возможностью доступа к нему интегральной схемы блока вторичного анализа, выполненной с возможностью выполнения операций вторичного анализа. Интегральная схема может включать в себя одну или более программируемых схем, одну или более ASIC или их комбинацию. Каждое прочтение из множества первых прочтений может состоять из упорядоченной последовательности нуклеотидов. В некоторых вариантах реализации упорядоченная последовательность нуклеотидов может соответствовать нуклеотидам первого конца фрагмента нуклеиновой кислоты. Секвенатор нуклеиновых кислот может включать в себя любое секвенатор нуклеиновых кислот, включая секвенатор, выполненный с возможностью секвенирования или ДНК, или РНК.
[0085] Система секвенирования может продолжать выполнение процесса 200 получением 220 вторых данных, представляющих множество вторых прочтений, сгенерированных секвенатором нуклеиновых кислот во время второго интервала прочтения, выполняемого после первого интервала прочтения. Получение вторых данных может включать сохранение вторых данных, представляющих множество вторых прочтений, в запоминающем устройстве блока вторичного анализа после генерирования вторых данных секвенатором. Запоминающее устройство блока вторичного анализа может представлять собой блок памяти, выполненный с возможностью доступа к нему интегральной схемы блока вторичного анализа, выполненной с возможностью выполнения операций вторичного анализа. Интегральная схема может включать в себя одну или более программируемых схем, одну или более ASIC или их комбинацию. В некоторых вариантах реализации по меньшей мере часть вторых данных получают во время генерирования другой части вторых секвенатором нуклеиновых кислот. Каждое прочтение из множества вторых прочтений может состоять из упорядоченной последовательности нуклеотидов. В некоторых вариантах реализации упорядоченная последовательность нуклеотидов может соответствовать нуклеотидам второго конца фрагмента нуклеиновой кислоты, который противоположен первому концу фрагмента нуклеиновой кислоты.
[0086] Во время того как система секвенирования получает вторые данные на стадии 220, система секвенирования может выполнять на стадии 230 одну или более операций вторичного анализа на первых данных, представляющих множество первых прочтений. В некоторых вариантах реализации выполнение одной или более операций вторичного анализа на первых данных, представляющих множество первых прочтений, может включать (i) предоставление секвенатором нуклеиновых кислот первых данных блоку картирования и выравнивания для выравнивания первых данных, представляющих множество первых прочтений, с эталонной последовательностью, (ii) выравнивание посредством блока картирования и выравнивания первых данных, представляющих множество первых прочтений, (iii) получение результатов выравнивания от блока картирования и выравнивания и (iv) сохранение полученных результатов выравнивания первых данных, представляющих множество первых прочтений, с эталонной последовательностью до завершения получения вторых данных на стадии 204. Результаты выравнивания могут включать в себя статистику выравнивания, которая описывает качество выравнивания первых данных, представляющих первое множество прочтений, с эталонной последовательностью. Статистика выравнивания может включать в себя, например, одну или более из оценки MAPQ, оценки выравнивания или т.п. В других вариантах реализации результаты выравнивания могут включать в себя картированные и выравненные прочтения, которые могут быть представлены в качестве входных данных в распознаватель вариантов для определения потенциальных вариантов.
[0087] В некоторых вариантах реализации выходные данные, описывающие результаты выравнивания, могут быть предоставлены для изучения одному или более пользователям-людям. Например, выходные данные, описывающие результаты выравнивания, могут быть выведены на дисплей, например, подключенный к секвенатору нуклеиновых кислот или размещенный в другом помещении или здании. Альтернативно или дополнительно выходные данные, описывающие результаты выравнивания, могут быть выведены с использованием принтера, соединенного, например, напрямую или опосредованно с возможностью обмена данными с секвенатором нуклеиновых кислот для печати отчета, описывающего результаты выравнивания.
[0088] В некоторых вариантах реализации по меньшей мере часть блока картирования и выравнивания реализована в интегральной схеме, такой как программируемая схема или ASIC, установленная в секвенаторе нуклеиновых кислот. Например, программируемая схема или ASIC может реализовывать функции поиска в таблице, алгоритм Смита-Уотермена или определение оценки качества. Однако в других вариантах реализации одна или более операций блока картирования и выравнивания могут быть выполнены в программном обеспечении, исполняемом секвенатором нуклеиновых кислот. Например, управление программируемой схемой и сортировка результатов выравнивания могут быть реализованы в программном обеспечении. В других вариантах реализации блок картирования и выравнивания может быть реализован в программируемой схеме, ASIC, исполняемом программном обеспечении или их комбинации на одном или более удаленных компьютерах, которые связаны с возможностью обмена данными с секвенатором нуклеиновых кислот с использованием одной или более сетей. В таких вариантах реализации данные, представляющие прочтения, результаты выравнивания и т.п., могут быть переданы между секвенатором нуклеиновых кислот и одним или более удаленными компьютерами, на которых размещается блок картирования и выравнивания, с использованием одной или более сетей.
[0089] Система секвенирования, другая система обработки или один или более пользователей-людей могут оценивать результаты выравнивания во время получения вторых данных на стадии 220. Например, результаты выравнивания могут быть оценены для определения того, имеет ли выравнивание достаточное качество для продолжения получения вторых данных на этапе 220. В некоторых вариантах реализации, если результаты выравнивания для первого множества прочтений не удовлетворяют предварительно заданному пороговому значению, то секвенатор нуклеиновых кислот может получить команду остановить получение вторых данных на стадии 220. Альтернативно, если определено, что результаты выравнивания для первого множества прочтений удовлетворяют предварительно заданному пороговому значению, то секвенатору нуклеиновых кислот может быть разрешено продолжить получение вторых данных на стадии 220.
[0090] В других вариантах реализации картированные и выравненные первые прочтения могут быть оценены для обнаружения потенциальных вариантов между картированными и выравненными первыми прочтениями и одной или более эталонными последовательностями во время получения вторых данных на стадии 220. Такие варианты реализации могут обеспечивать возможность проведения третичного анализа картированных и выравненных первых прочтений быстрее, чем в традиционных способах, которые не позволят начать третичный анализ до завершения как первого интервала прочтения, так и второго интервала прочтения. Таким образом, первоначальный диагноз для начала лечения может быть получен как минимум на 12-24 часа раньше или еще раньше, поскольку не нужно ждать завершения второго интервала прочтения, прежде чем переходить к третичному анализу.
[0091] Система секвенирования может продолжить выполнение процесса 200, давая на стадии 240 команду на выполнение операций вторичного анализа на вторых данных, например, давая команду блоку картирования и выравнивания начать выравнивание вторых данных, представляющих второе множество прочтений, с эталонной последовательностью. В некоторых вариантах реализации система 200 секвенирования может всегда переходить к стадии 240. Такие варианты реализации все равно обеспечивают технические преимущества ускорения третичного анализа и сокращения времени простоя секвенатора нуклеиновых кислот. Однако в других вариантах реализации выполнение процесса 200 может продолжаться только по команде блоку картирования и выравнивания начать выравнивание вторых данных, представляющих второе множество прочтений, с эталонной последовательностью, если полученные результаты выравнивания, описывающие качество выравнивания первых данных, представляющих множество первых прочтений, считаются удовлетворяющими предварительно заданному порогу качества.
[0092] В некоторых вариантах реализации система секвенирования может полагаться на результаты вторичного анализа картирования и выравнивания и/или распознавания вариантов для первых данных, выполненного на стадии 220 во время получения вторых данных. В других вариантах реализации эти исходные результаты выполненного на стадии 230 вторичного анализа, связанные с первыми данными, могут быть отброшены после их оценки для определения качества первого интервала прочтения. В таких случаях система секвенирования может инициировать вторую итерацию вторичного анализа первых данных либо до, либо после выполнения вторичного анализа вторых данных на стадии 240.
[0093] На ФИГ. 3 представлена контекстуальная схема примера системы 300 для выполнения инкрементного вторичного анализа одного или более образцов с использованием блока 340 вторичного анализа, расположенного удаленно от секвенатора 310 нуклеиновых кислот. Система 300, по существу, идентична системе 100, описанной со ссылкой на ФИГ. 1В, с несколькими изменениями. Одно изменение заключается в том, что блок 340 вторичного анализа расположен на одном или более компьютерах 320, которые удалены от секвенатора 310 нуклеиновых кислот. Для любого явно не упомянутого справочного номера на ФИГ. 3 компонент, обозначенный справочным номером, имеет те же признаки, что и соответствующий ему элемент, показанный на ФИГ. 1. Например, соответствующие кластеры 322-1, 322-2, 322-3, 322-4, 322-5, 322-N имеют тот же смысл, что и кластеры 122-1, 122-2, 122-3, 122-4, 122-5, 122-N соответственно, показанные на ФИГ. 1, если со ссылкой на ФИГ. 3 не описаны дополнительные или иные признаки.
[0094] Другим отличием между примером, показанным на ФИГ. 3, и примером, показанным на ФИГ. 1В, является то, что в примере, показанном на ФИГ. 3, обрабатываются несколько образцов. В результате, прочтения, полученные секвенатором 310 нуклеиновых кислот в системе 300, имеют индекс, который генерируется для каждого прочтения. Этот индекс представлен на ФИГ. 3 метками S1, S2 и S3, которые присоединены к каждому прочтению. В этом примере S2, S2, S3 представляют собой строки, используемые для идентификации прочтений, полученных на основе первого образца, второго образца или третьего образца соответственно. Хотя указанные индексы описаны в данном документе с использованием термина S1, S2, S3, настоящее описание не ограничивается использованием текстовых строк в качестве идентификатора образца, поскольку эти термины используются в качестве примеров для иллюстрации концепции индекса. Вместо этого в некоторых вариантах реализации в качестве идентификатора образца для прочтения могут быть использованы штрихкод или другие данные. В некоторых вариантах реализации идентификатор образца может быть сгенерирован посредством добавления синтетических нуклеотидов, представляющих индекс, к каждому сгенерированному прочтению.
[0095] Применительно к примеру, показанному на ФИГ. 3, секвенатор 310 нуклеиновых кислот или удаленный компьютер 320 может конфигурировать программируемую схему 342 блока 340 вторичного анализа для включения блока 342а картирования и выравнивания. Секвенатор 310 нуклеиновых кислот может принимать множество образцов 105, 106, 107. Образцы 105, 106, 107 могут включать в себя, например, образцы нуклеиновой кислоты от разных объектов. Разные объекты могут представлять собой разных людей, разных животных, разные растения или т.п. Секвенатор 310 нуклеиновых кислот может подготавливать образцы 105, 106, 107 и выполнять генерацию кластеров в период времени Т1 рабочего процесса 370. Секвенатор 310 нуклеиновых кислот может выполнять операции секвенирования, такие как секвенирование путем синтеза, в первый интервал прочтения с генерированием первых прочтений 330-1, 330-3, 332-1, 332-3, 334-1, 334-3 в период времени Т2А, который идет после периода времени T1. B конце периода времени Т1+Т2А секвенатор 310 нуклеиновых кислот завершает секвенирование первых прочтений 330-1, 330-3, 332-1, 332-3, 334-1, 334-3 и начинает в период времени Т3А генерировать индексы для первых прочтений, сгенерированных во время первого интервала прочтения. В конце периода времени T1+Т2А+Т3А секвенатор 310 нуклеиновых кислот завершает генерирование индексов для первого цикла прочтения и начинает в период времени Т3В генерировать индексы для вторых прочтений, которые будут сгенерированы во время второго интервала прочтения. В конце периода времени Т1+Т2А+Т3А+Т3В секвенатор 310 нуклеиновых кислот начинает секвенирование вторых прочтений 330-2, 330-4, 332-2, 332-4, 334-2, 334-4.
[0096] Секвенатор 310 нуклеиновых кислот выполнен с возможностью параллелизации операций вторичного анализа, таких как картирование и выравнивание первых прочтений 330-1, 330-3, 332-1, 332-3, 334-1, 334-3, пока секвенатор 310 нуклеиновых кислот выполняет операции секвенирования, такие как секвенирование путем синтеза, для второго интервала прочтения с генерированием вторых прочтений 330-2, 330-4, 332-2, 332-4, 334-2, 334-4 в течение периода времени Т2В. Этот процесс аналогичен описанному со ссылкой на пример, показанный на ФИГ. 1В. Однако в примере, показанном на ФИГ. 3, секвенировали множество образцов. Соответственно, множество первых прочтений необходимо демультиплексировать на группы на основе индексов каждого прочтения, прежде чем переходить к другим операциям вторичного анализа, таким как картирование и выравнивание и распознавание вариантов. После демультиплексирования множества первых прочтений можно выполнять одну или более операций вторичного анализа на демультиплексированных группах первых прочтений. В некоторых вариантах реализации система 300 может генерировать на основе операций демультиплексирования статистику демультиплексирования, и сохраненную статистику можно оценивать для определения качества секвенированных прочтений.
[0097] В примере, показанном на ФИГ. 3, вторичный анализ первых прочтений не может быть начат до завершения периода времени T1+Т2А+T3A+T3B, поскольку организация первых прочтений в демультиплексированные группы невозможна, пока не будут завершены операции индексирования в периоды времени T3A и T3B. После завершения добавления второго индекса в конце периода времени T1+Т2А+T3A+T3B секвенатор 310 нуклеиновых кислот может предоставлять множество первых прочтений удаленному компьютеру 320 по сети 112. Удаленный компьютер 320 может принимать множество первых прочтений и сохранять множество первых прочтений в запоминающем устройстве 344. Пока секвенатор 310 нуклеиновых кислот выполняет второй интервал прочтения в период времени Т2В, блок 340 вторичного анализа может использовать блок 350 обработки для доступа к множеству первых прочтений в запоминающем устройстве 344 и использовать блок 362 демультиплексирования для демультиплексирования множества первых прочтений 330-1, 330-3, 332-1, 332-3, 334-1, 334-3 на группы на основе индексов или идентификатора образца каждого прочтения. Демультиплексирование может быть достигнуто с использованием операций демультиплексирования для организации первых прочтений на основе индекса. Демультиплексированные первые прочтения могут храниться в запоминающем устройстве 344. Блок 342а картирования и выравнивания может затем получать доступ к прочтениям, хранящимся в запоминающем устройстве 344, и выполнять операции картирования и выравнивания на демультиплексированных первых прочтениях во время второго интервала прочтения.
[0098] Блок 340 вторичного анализа может генерировать статистику, которую можно использовать для оценки качества прочтений, сгенерированных секвенатором нуклеиновых кислот. В некоторых вариантах реализации блок вторичного анализа может генерировать статистику демультиплексирования на основе операций демультиплексирования. Блок 342а картирования и выравнивания может генерировать результаты картирования и выравнивания и статистику для каждой группы первых прочтений, хранящихся в запоминающем устройстве 344. Блок 342а картирования и выравнивания может хранить результаты 359 в запоминающем устройстве 360 или передавать результаты 359 обратно в секвенатор 310 нуклеиновых кислот.
[0099] Результаты 359 могут включать в себя статистику демультиплексирования, результаты картирования и выравнивания, статистику картирования и выравнивания, статистику распознавания вариантов или любую их комбинацию. Статистика демультиплексирования может включать в себя число прочтений, соответствующих каждому идентификатору образца. Результаты картирования и выравнивания могут включать в себя данные, представляющие одно или более прочтений, картированных с эталонной последовательностью. Статистика картирования и выравнивания может включать в себя данные, описывающие, например, оценку MAPQ, которая обеспечивает индикацию качества картирования, оценку выравнивания, которая обеспечивает индикацию качества выравнивания или т.п. Секвенатор 310 нуклеиновых кислот может принимать результаты 359 и сохранять полученные результаты в запоминающем устройстве 160.
[0100] В примере, показанном на ФИГ. 3, сверхбыстрое выполнение блока 342а картирования и выравнивания, реализованного с использованием аппаратной логики программируемой схемы 342, позволяет блоку 342а картирования и выравнивания выполнять картирование и выравнивание соответствующих демультиплексированных групп первых прочтений 330-1, 330-3, 332-1, 332-3, 334-1, 334-3 за долю времени, необходимую секвенатору 310 нуклеиновых кислот для выполнения второго интервала прочтения. Например, в некоторых вариантах реализации программируемая схема 342а может выполнять картирование и выравнивание демультиплексированных групп первых прочтений 330-1, 330-3, 332-1, 332-3, 334-1, 334-3 всего за минуты, при этом секвенирование вторых прочтений 330-2, 330-4, 332-2, 332-4, 334-2, 334-4 во время второго интервала прочтения может занимать от 12 до 24 часов. Соответственно, результаты 359 могут быть оценены секвенатором 310 нуклеиновых кислот, удаленным компьютером 320, пользователем секвенатора 310 нуклеиновых кислот или удаленного компьютера 320, агентом или моделью искусственного интеллекта или их комбинацией, и на основе качества демультиплексирования первых прочтений 330-1, 330-3, 332-1, 332-3, 334-1, 334-3 и/или качества картирования и выравнивания демультиплексированных групп первых прочтений 330-1, 330-3, 332-1, 332-3, 334-1, 334-3 может быть определено, должен ли секвенатор 310 нуклеиновых кислот продолжать операции секвенирования во время второго интервала прочтения для генерирования вторых прочтений 330-2, 330-4, 332-2, 332-4, 334-2, 334-4.
[0101] Определение того, следует ли продолжать операции секвенирования во время второго интервала прочтения для генерирования вторых прочтений 330-2, 330-4, 332-2, 332-4, 334-2, 334-4, может выполняться автоматически секвенатором 310 нуклеиновых кислот, вручную пользователем секвенатора нуклеиновых кислот, автоматически агентом или моделью искусственного интеллекта или на основе данных, содержащих определение, сделанное комбинацией этих способов, как описано применительно к примеру, показанному на ФИГ. 1В. Альтернативно или дополнительно удаленный компьютер 320, пользователь компьютера 320 или агент или модель искусственного интеллекта или их комбинация, могут на основе результатов 359 определять, следует ли продолжать секвенирование во втором интервале прочтения для генерирования вторых прочтений 330-2, 330-4, 332-2, 332-4, 334-2, 334-4. Такой анализ результатов 359 может быть оценен удаленным компьютером 320, пользователем удаленного компьютера 320, агентом или моделью искусственного интеллекта или их комбинацией таким же образом, как описано применительно к оценке результатов 149 секвенатором 310 нуклеиновых кислот, пользователем секвенатора 310 нуклеиновых кислот или агентом или моделью искусственного интеллекта или их комбинацией в описании ФИГ. 1В. В случае агента или модели искусственного интеллекта модель искусственного интеллекта также может быть обучена на типах входных данных, которые включают в себя, в дополнение к другим типам входным данных, описанным в описании ФИГ. 1В, характеристики демультиплексирования.
[0102] В некоторых вариантах реализации статистика демультиплексирования может быть оценена отдельно или в сочетании со статистикой картирования и выравнивания для определения качества прочтений, сгенерированных секвенатором 310 нуклеиновых кислот. Например, секвенатор 310 нуклеиновых кислот или удаленный компьютер 320 может сохранять данные, представляющие ожидаемое число прочтений для каждого соответствующего идентификатора образца. Секвенатор 310 нуклеиновых кислот, удаленный компьютер 320, пользователь, агент искусственного интеллекта или их комбинация могут затем определять, включает ли в себя статистика демультиплексирования число прочтений, соответствующих каждому идентификатору образца, которое находится в пределах порогового значения ошибки ожидаемого числа прочтений для каждого идентификатора образца. Если статистика демультиплексирования находится в пределах порогового значения ошибки ожидаемого числа прочтений для каждого идентификатора образца, секвенатор 310 нуклеиновых кислот, удаленный компьютер 320, пользователь-человек, агент искусственного интеллекта или их комбинация могут определить, что операции секвенирования должны продолжаться. Альтернативно, если определяется, что статистика демультиплексирования не находится в пределах порогового значения ошибки ожидаемого числа прочтений для каждого идентификатора образца, то секвенатор 310 нуклеиновых кислот, удаленный компьютер 320, пользователь-человек, агент искусственного интеллекта или их комбинация могут определить, что прогон секвенирования следует прервать.
[0103] В некоторых вариантах реализации необязательно, чтобы результаты 359 передавались обратно в секвенатор 310 нуклеиновых кислот с удаленного компьютера 320. Вместо этого удаленный компьютер 320, пользователь удаленного компьютера 320 или агент или модель искусственного интеллекта могут передавать обратно в секвенатор 310 нуклеиновых кислот данные, указывающие, должен ли секвенатор 310 нуклеиновых кислот продолжать генерирование вторых прочтений 330-2, 330-4, 332-2, 332-4, 334-2, 334-4, на основе выполненного компьютером 320, пользователем компьютера 320 или агентом или моделью искусственного интеллекта анализа результатов 359. Затем секвенатор нуклеиновых кислот может определить, нужно ли продолжать или прерывать второй интервал прочтения на основе данных, принятых от удаленного компьютера 320, без фактического приема результатов 359.
[0104] В еще одном варианте реализации секвенатор нуклеиновых кислот может также учитывать множество определений, подобных описанному со ссылкой на ФИГ. 1В. Например, в некоторых вариантах реализации могут быть получены данные, описывающие определение секвенатором 310 нуклеиновых кислот, пользователем секвенатора 310 нуклеиновых кислот, удаленным компьютером 320, пользователем удаленного компьютера 320, агентом или моделью искусственного интеллекта или любой их комбинацией, и в таких вариантах реализации секвенатор 310 нуклеиновых кислот прервет второй интервал прочтения, только если секвенатор 310 нуклеиновых кислот, пользователь секвенатора 310 нуклеиновых кислот, удаленный компьютер 320, пользователь удаленного компьютера 320, агент или модель искусственного интеллекта или любая их комбинация согласны, что второй интервал прочтения должен быть прерван. В других вариантах реализации может быть сгенерирована агрегированная оценка на основе средневзвешенного значения определений одним или более из секвенатора 310 нуклеиновых кислот, пользователя секвенатора 310 нуклеиновых кислот, удаленного компьютера 320, пользователя удаленного компьютера 320, агента искусственного интеллекта или любой их комбинации, а затем на основе этой агрегированной оценки определяется, следует ли прерывать второй интервал прочтения. В таких вариантах реализации второй интервал прочтения может быть прерван, если агрегированная оценка падает ниже предварительно заданного порогового значения. В альтернативном варианте осуществления второй интервал прочтения может продолжаться, если агрегированная оценка оказывается выше предварительно заданного порогового значения.
[0105] Используя эти методики, система 300, показанная на ФИГ. 3, обеспечивает технологические преимущества, сходные с описанными со ссылкой на ФИГ. 1В. Таким образом, система 300 может экономить реагенты, используемые для генерирования вторых прочтений, если результаты 359 показывают, что выравнивание первых прочтений является низкокачественным. После определения того, что качество статистики демультиплексирования, результатов картирования и выравнивания, статистики картирования и выравнивания или их комбинации является удовлетворительным, секвенатор 310 нуклеиновых кислот может отклонить результаты 359. В других вариантах реализации картирование и выравнивание первых прочтений, выполняемое параллельно со вторым прочтением, можно использовать в качестве картирования и выравнивания первых прочтений в заключительном прогоне данных.
[0106] Продолжая пример, показанный на ФИГ. 3, после определения того, что результаты 359 являются удовлетворительными, секвенатор 310 нуклеиновых кислот может продолжать выполнение вторых прочтений. После генерирования вторых прочтений 330-2, 330-4, 332-2, 332-4, 334-2, 334-4 секвенатор 310 нуклеиновых кислот может передавать удаленному компьютеру 320 по сети 112 инструкции дать команду блоку 340 вторичного анализа начать заключительный прогон данных вторичного анализа. Заключительный прогон данных может включать в себя демультиплексирование вторых прочтений 330-2, 330-4, 332-2, 332-4, 334-2, 334-4 на организованные группы вторых прочтений на основе идентификаторов образца каждого второго прочтения, а затем картирование и выравнивание вторых прочтений 330-2, 330-4, 332-2, 332-4, 334-2, 334-4 с использованием блока 340 вторичного анализа. В некоторых вариантах реализации если результаты картирования и выравнивания организованного первого набора прочтений были отклонены, в заключительном прогоне данных можно выполнять операции картирования и выравнивания как на первых прочтениях, так и на вторых прочтениях. Поскольку эти операции реализованы с использованием программируемой схемы 342а, эти операции могут быть выполнены параллельно второму прогону 374 секвенирования и за долю времени, необходимую для выполнения второго прогона 374 секвенирования. По сравнению с традиционными системами это обеспечивает преимущество возможности продолжения последующих прогонов секвенирования во время выполнения вторичного анализа предшествующего прогона 372 секвенирования, в результате чего уменьшается время простоя секвенатора, которое имеет место в традиционных системах, показанных на ФИГ. 1А.
[0107] Помимо демультиплексирования и картирования с выравниванием блок 340 вторичного анализа также может выполнять операции распознавания вариантов. В качестве примера блок 350 обработки может быть использован для выполнения блока 364 распознавания вариантов, который может анализировать картированные и выравненные прочтения для идентификации наличия любых вариантов, таких как однонуклеотидные полиморфизмы (SNP), вставки/делеции (инделы), структурные вариации или т.п. В некоторых вариантах реализации программируемая схема 342 может быть динамически реконфигурирована, например, удаленным компьютером 320, для облегчения обработки в рамках распознавания вариантов. Например, программируемая схема 342 может быть динамически реконфигурирована для включения блока НММ, который может быть использован для выполнения вычислений вероятностей, например вероятности появления варианта в одном или более эталонных положениях картированных и выравненных прочтений. Примеры использования программируемой схемы, такой как FPGA, для выполнения операций распознавания вариантов более подробно описаны, например, в патентной публикации США №2016/0180019, патентной публикации США №2016/0306922 и патентной публикации США №2019-0259468, содержание каждой из которых полностью включено в настоящий документ путем ссылки.
[0108] В примере, показанном на ФИГ. 3, описан пример, имеющий прочтения с 8 нуклеотидами и 3 образца. Тем не менее настоящее описание не ограничено этим. Вместо этого такой простой пример представлен, чтобы простым для понимания образом объяснить признаки настоящего описания. На практике фрагменты ДНК настоящего описания могут иметь в некоторых вариантах реализации, например, до 600 нуклеотидов, до 800 нуклеотидов, до 1000 нуклеотидов или более, и каждое прочтение фрагмента может иметь, например, 50 нуклеотидов, 75 нуклеотидов, 150 нуклеотидов, 200 нуклеотидов, 300 нуклеотидов, 500 нуклеотидов или более с каждого конца нуклеотидного фрагмента ДНК. Аналогичным образом ничто на ФИГ. 3 или любой другой фигуре не следует интерпретировать как ограничение числа кластеров фрагментов. Например, секвенатор 310 нуклеиновых кислот может выполнять массово-параллельное секвенирование с одновременным секвенированием миллионов кластеров из множества фрагментов.
[0109] Хотя пример на ФИГ. 3 относится ко множеству образцов, которые используются для генерирования прочтений, имеющих индекс или идентификатор образца, настоящее описание не ограничено этим. Напротив, система 300 также может быть использована для обработки одного образца, при которой генерируются прочтения, которые не индексируются, поскольку все прочтения принадлежат одному образцу. В таких вариантах реализации могут выполняться такие же процессы, причем второй интервал прочтения «Прочтение 2» инициируется сразу после первого интервала прочтения «Прочтение 1» без генерирования каких-либо индексов. Затем после завершения первого интервала прочтения «Прочтение 1» может быть запущен второй интервал прочтения «Прочтение 2», тогда как вторичный анализ первых прочтений параллелизован со вторым интервалом прочтения. Единственное различие между реализацией с одним образцом и реализацией со множеством образцов заключается в том, что при одном образце не обязательно выполнять этапы генерирования индексов и демультиплексирования, поскольку все прочтения связаны с одним и тем же образцом.
[0110] На ФИГ. 4 представлена блок-схема примера процесса 400 выполнения инкрементного вторичного анализа в соответствии со схемой рабочего процесса, показанной на ФИГ. 3. Как правило, процесс 400 включает получение первых данных, описывающих множество первых прочтений, сгенерированных секвенатором нуклеиновых кислот из множества разных образцов во время первого интервала (410) прочтения, получение вторых данных, описывающих множество вторых прочтений, сгенерированных секвенатором нуклеиновых кислот из множества разных образцов во время второго интервала (420) прочтения, выполняемого после первого интервала (410) прочтения, во время получения вторых данных на стадии 420 (I) организацию множества первых прочтений в организованные группы на основе по меньшей мере первого или второго идентификатора образца, связанного с каждым из первых прочтений, (II) выполнение для каждой организованной группы первых прочтений операций вторичного анализа, и (III) сохранение для каждой группы первых прочтений (430) результатов вторичного анализа, и затем подачу команды блоку вторичного анализа начать (А) организацию множества вторых прочтений во множество организованных групп на основе по меньшей мере первого или второго идентификаторов (440) образца и (В) выполнение для каждой организованной группы вторых прочтений операций вторичного анализа над организованной группой вторых прочтений или организованной группой первых и вторых прочтений (450). Для удобства, но не в качестве ограничения, эти стадии будут более подробно описаны ниже в качестве выполняемых системой секвенирования, такой как система 300, показанная на ФИГ. 3.
[0111] Система секвенирования может начинать выполнение процесса 400 с получения 410 первых данных, описывающих множество первых прочтений, сгенерированных секвенатором нуклеиновых кислот из множества различных образцов во время первого интервала прочтения. Получение первых данных может включать сохранение первых данных, представляющих множество первых прочтений, в запоминающем устройстве, таком как запоминающее устройство блока вторичного анализа, после генерирования первых данных секвенатором. Запоминающее устройство блока вторичного анализа может представлять собой блок памяти, выполненный с возможностью доступа к нему интегральной схемы блока вторичного анализа, выполненной с возможностью выполнения операций вторичного анализа. Интегральная схема может включать в себя одну или более программируемых схем, одну или более ASIC или их комбинацию.
[0112] Каждое прочтение из множества первых прочтений может состоять из упорядоченной последовательности нуклеотидов. В некоторых вариантах реализации упорядоченная последовательность нуклеотидов может соответствовать нуклеотидам первого конца фрагмента нуклеиновой кислоты. Фрагмент нуклеиновой кислоты может быть клонально амплифицирован для облегчения секвенирования, и в таких вариантах реализации упорядоченная последовательность нуклеотидов может быть определена путем анализа множества клонов фрагмента нуклеиновой кислоты с генерированием нуклеотидов прочтения. Каждое первое прочтение может включать в себя данные, идентифицирующие образец, используемый для генерации этого первого прочтения. В некоторых вариантах реализации данные, идентифицирующие образец, могут включать в себя штрихкод. Секвенатор нуклеиновых кислот может включать в себя любое секвенатор нуклеиновых кислот, включая ДНК-секвенатор или РНК-секвенатор.
[0113] Система секвенирования может продолжать выполнение процесса 400 получением 420 вторых данных, описывающих множество вторых прочтений, сгенерированных секвенатором нуклеиновых кислот из множества различных образцов во время второго интервала прочтения, выполняемого после первого интервала прочтения. Получение вторых данных может включать сохранение вторых данных, представляющих множество первых прочтений, в запоминающем устройстве блока вторичного анализа после генерирования вторых данных секвенатором. Запоминающее устройство блока вторичного анализа может представлять собой блок памяти, выполненный с возможностью доступа к нему интегральной схемы блока вторичного анализа, выполненной с возможностью выполнения операций вторичного анализа. Интегральная схема может включать в себя одну или более программируемых схем, одну или более ASIC или их комбинацию.
[0114] В некоторых вариантах реализации по меньшей мере часть вторых данных получают во время генерирования другой части вторых секвенатором нуклеиновых кислот. Каждое прочтение из множества вторых прочтений может состоять из упорядоченной последовательности нуклеотидов. В некоторых вариантах реализации упорядоченная последовательность нуклеотидов может соответствовать нуклеотидам второго конца фрагмента нуклеиновой кислоты, который противоположен первому концу фрагмента нуклеиновой кислоты. Фрагмент нуклеиновой кислоты может быть клонально амплифицирован для облегчения секвенирования, и в таких вариантах реализации упорядоченная последовательность нуклеотидов может быть определена путем анализа множества клонов фрагмента нуклеиновой кислоты с генерированием нуклеотидов прочтения. Каждое второе прочтение может включать в себя данные, идентифицирующие образец, от которого получено второе прочтение. В некоторых вариантах реализации данные, идентифицирующие образец, могут включать в себя штрихкод.
[0115] Во время получения вторых данных на стадии 420 система секвенирования может использовать блок вторичного анализа для параллелизации дополнительной обработки множества первых прочтений. В некоторых вариантах реализации дополнительная параллелизованная обработка может включать (I) организацию данных, представляющих множество первых прочтений, в организованные группы на основе по меньшей мере первого или второго идентификаторов образца, связанных с каждым из первых прочтений, (II) выполнение для каждой организованной группы первых прочтений операций вторичного анализа над организованной группой первых прочтений и (III) сохранение результатов вторичного анализа каждой группы первых прочтений (430).
[0116] Организация множества первых прочтений в организованные группы на основе идентификатора образца необходима для обеспечения релевантной обработки вторичного анализа при секвенировании множества образцов. Сюда может входить выполнение одной или более операций демультиплексирования для картирования набора первых прочтений, имеющих разные первые идентификаторы образца, в соответствующие организованные группы, причем каждая организованная группа первых прочтений имеет один и тот же идентификатор образца. Можно сгенерировать статистику демультиплексирования, которая описывает качество операций демультиплексирования. Например, статистика демультиплексирования может указывать число первых прочтений, соответствующих каждому идентификатору образца. В некоторых вариантах реализации блок вторичного анализа может возвращать данные результатов, которые описывают статистику демультиплексирования, секвенатору нуклеиновых кислот, предоставлять данные результатов одному или более агентам или моделям-искусственному интеллекту или выводить данные результатов для одного или более пользователей-людей. В таких случаях система секвенирования может определить, продолжать процесс 400 или прерывать процесс 400 в данный момент времени на основании качества операции демультиплексирования, описанного статистикой демультиплексирования. Альтернативно такая статистика демультиплексирования может быть возвращено в виде данных результатов после выполнения операций картирования и выравнивания, как описано ниже.
[0117] После того как множество первых прочтений были организованы, система секвенирования может выполнять для каждой организованной группы первых прочтений одну или более операций вторичного анализа над организованной группой первых прочтений. Выполнение операций вторичного анализа над организованной группой первых прочтений может включать в себя для каждой организованной группы первых прочтений (I) предоставление секвенатором нуклеиновых кислот организованной группы первых прочтений блоку картирования и выравнивания для выравнивания организованной группы первых прочтений с эталонной последовательностью, (II) выравнивание с использованием блока картирования и выравнивания организованной группы первых прочтений с эталонной последовательностью, (iii) получение результата от блока картирования и выравнивания и (iv) сохранение полученных данных результатов до завершения получения вторых данных на стадии 420.
[0118] Данные результатов могут включать в себя статистику демультиплексирования или статистику картирования и выравнивания. Статистика демультиплексирования может включать в себя данные, описывающие качество операции демультиплексирования, такие как число первых прочтений, соответствующих каждому идентификатору образца. Статистика картирования и выравнивания может включать в себя данные, описывающие качество выравнивания для каждой организованной группы первых прочтений с соответствующей эталонной последовательностью. Статистика картирования и выравнивания может включать в себя, например, одну или более из оценки MAPQ, оценки выравнивания или т.п. В других вариантах реализации результаты картирования и выравнивания могут включать в себя картированные и выравненные прочтения для каждой организованной группы первых прочтений, которые могут быть предоставлены в качестве входных данных распознавателю вариантов для определения потенциальных вариантов путем сравнения картированных и выравненных прочтений каждой организованной группы первых прочтений с соответствующей эталонной последовательностью.
[0119] В некоторых вариантах реализации выходные данные, описывающие данные результатов для каждой организованной группы первых прочтений, могут быть предоставлены для изучения одному или более пользователям-людям. Например, выходные данные, описывающие данные результатов для каждой организованной группы первых прочтений, могут быть выведены на дисплей, соединенный, например, с секвенатором нуклеиновых кислот или находящийся в другом помещении или здании. Альтернативно или дополнительно выходные данные, описывающие данные результатов для каждой организованной группы первых прочтений, могут быть выведены с использованием принтера, соединенного, например, напрямую или опосредованно с возможностью обмена данными с секвенатором нуклеиновых кислот для печати отчета, описывающего результаты выравнивания для каждой организованной группы первых прочтений.
[0120] В некоторых вариантах реализации система секвенирования, удаленный компьютер, один или более пользователей-людей, агент или модель искусственного интеллекта или их комбинация могут оценивать данные результатов во время получения вторых данных на стадии 420. Например, данные результатов могут быть оценены для определения того, имеют ли демультиплексированные первые прочтения и/или картирование и выравнивание первых прочтений достаточное качество для продолжения получения вторых данных на стадии 420. В некоторых вариантах реализации, если данные результатов для организованной группы первых прочтений не удовлетворяют одному или более предварительно заданным правилам или пороговым значениям, то секвенатор нуклеиновых кислот может получить команду остановить получение вторых данных на стадии 420. Альтернативно, если определено, что данные результатов для организованной группы первых прочтений удовлетворяют одному или более предварительно заданным правилам или пороговым значениям, то секвенатору нуклеиновых кислот может быть разрешено продолжить получение вторых данных на стадии 420.
[0121] В некоторых вариантах реализации каждая организованная группа картированных и выравненных первых прочтений может быть оценена для обнаружения потенциальных вариантов во время получения вторых данных на стадии 420. Такие варианты реализации могут обеспечивать возможность проведения третичного анализа идентифицированных для каждой группы вариантов быстрее, чем в традиционных способах, которые не позволят начать третичный анализ до завершения как первого интервала прочтения, так и второго интервала прочтения. Таким образом, первоначальный диагноз для начала лечения может быть получен как минимум на 12-24 часа раньше или еще раньше, чем в традиционных способах, поскольку не нужно ждать завершения второго интервала прочтения, прежде чем переходить к третичному анализу.
[0122] Система секвенирования может продолжать выполнение процесса 400 путем подачи на стадии 430 команды блоку картирования и выравнивания начать организовывать множество вторых прочтений во множество организованных групп вторых прочтений на основе по меньшей мере первого или второго идентификатора образца. Организация множества вторых прочтений в организованные группы на основе вторых идентификаторов образца необходима для обеспечения релевантной обработки вторичного анализа вторых прочтений. Сюда может входить выполнение одной или более операций демультиплексирования для картирования набора вторых прочтений, имеющих разные идентификаторы образца, в разные организованные группы, причем каждая организованная группа вторых прочтений имеет один и тот же второй идентификатор образца. Система секвенирования может продолжать выполнение процесса 400, осуществляющего для каждой организованной группы вторых прочтений операции вторичного анализа над организованной группой вторых прочтений (стадия 440). В некоторых вариантах реализации операции вторичного анализа могут быть выполнены над комбинацией первых и вторых прочтений.
[0123] В некоторых вариантах реализации система секвенирования может переходить к стадиям 430 и 440. Такие варианты реализации все еще обеспечивают технические преимущества ускорения третичного анализа и сокращения времени простоя секвенатора нуклеиновых кислот. Однако в других вариантах реализации выполнение процесса 400 системой секвенирования может продолжаться только при организации множества вторых прочтений во множество организованных групп (430), и операции вторичного анализа, такие как картирование и выравнивание и/или распознавание вариантов, выполняют, если определено, что полученные данные результатов для каждой из организованных групп первых прочтений, описывающие качество демультиплексирования первых прочтений и/или качество картирования и выравнивания первых прочтений, удовлетворяют одному или более предварительно заданным правилам или пороговым значениям качества.
[0124] В некоторых вариантах реализации система секвенирования может полагаться на результаты вторичного анализа картирования и выравнивания и/или распознавания вариантов для организованных групп первых прочтений, выполненного на стадии 420, во время получения вторых данных. В других вариантах реализации эти исходные результаты выполненного на стадии 420 вторичного анализа, связанные с организованными группами первых прочтений, могут быть отброшены после их оценки для определения качества первого интервала прочтения. В таких случаях система секвенирования может инициировать вторую итерацию вторичного анализа организованных групп первых прочтений либо до, либо после завершения вторичного анализа организованных групп вторых прочтений на стадиях 430 и 440.
[0125] На ФИГ. 5 представлена контекстуальная схема примера системы 500 для выполнения инкрементного вторичного анализа одного или более образцов с использованием блока вторичного анализа в секвенаторе нуклеиновых кислот. Система 500 по существу совпадает с системой 300, описанной со ссылкой на ФИГ. 3, с несколькими различиями. Одно различие заключается в том, что блок 540 вторичного анализа расположен внутри секвенатора 510 нуклеиновых кислот. Для любого явно не упомянутого справочного номера на ФИГ. 5 компонент, обозначенный справочным номером, имеет те же признаки, что и соответствующий ему элемент, показанный на ФИГ. 1 или 3. В качестве примера соответствующие кластеры 522-1, 522-2, 522-3, 522-4, 522-5, 522-N имеют тот же смысл, что и кластеры 122-1, 122-2, 122-3, 122-4, 122-5, 122-N соответственно, показанные ФИГ. 1, если со ссылкой на ФИГ. 5 не описаны дополнительные или иные признаки.
[0126] Другое различие между примером, показанным на ФИГ. 5, и примером, показанным на ФИГ. 3, заключается в том, что секвенатор нуклеиновых кислот выполнен с возможностью генерирования идентификаторов или индексов образцов для каждого прочтения до первого интервала прочтения. Это проиллюстрировано рабочим процессом 570, в котором показано, что индексы IND1 и IND2 генерируют после стадии кластеризации и до получения первого прочтения в первом интервале прочтения «ПРОЧТЕНИЕ 1» рабочего процесса 570. Это отличается от генерирования идентификаторов или индексов образцов в примере, показанном на ФИГ. 3, поскольку индексы согласно ФИГ. 3 генерируют после первого интервала прочтения. Хотя в варианте реализации, показанном на ФИГ. 5 и 6 описаны сгенерированные отдельные идентификаторы или индексы образцов для «ПРОЧТЕНИЯ 1» и «ПРОЧТЕНИЯ 2», настоящее описание не ограничено этим. Напротив, варианты реализации настоящего описания могут генерировать только один идентификатор или индекс образца, который относится как к «ПРОЧТЕНИЮ 1», так и к «ПРОЧТЕНИЮ 2» конкретного фрагмента.
[0127] Преимущество генерирования идентификатора образца до первых интервалов прочтения, состоит в том, что организацию прочтений в демультиплексированные группы, имеющие один и тот же идентификатор образца, можно выполнять в режиме реального времени, по мере генерирования прочтений. Имея все сгенерированные идентификаторы образца и возможность организации прочтений на основе идентификаторов образца в режиме реального времени, система 500 способна начинать вторичный анализ организованных групп первых прочтений во время первого интервала прочтения. В таком сценарии данные результатов вторичного анализа, включающие в себя статистику демультиплексирования и/или статистику картирования и выравнивания для каждой организованной группы первых прочтений, могут быть получены и оценены во время первого интервала прочтения, таким образом обеспечивая возможность прерывания первого интервала прочтения, если данные результатов оказываются неудовлетворительными, в результате чего экономится реагент.
[0128] Более того, возможность начинать выполнение вторичного анализа организованных групп первых прочтений во время первого интервала прочтения позволяет еще быстрее переходить к операциям третичного анализа, чем в примерах систем, описанных со ссылкой на ФИГ. 1В и ФИГ. 3. Система, показанная на ФИГ. 5, может переходить к третичному анализу быстрее, чем системы, показанные на ФИГ. 1В и ФИГ. 3, поскольку начальный набор вариантов на основе картированных и выравненных первых прочтений, используемых в качестве входных данных для третичного анализа, может быть идентифицирован во время первого интервала прочтения. Это позволяет начинать третичный анализ в течении около нескольких часов или менее после начала первого интервала прочтения. В этом отличие от примеров, показанных на ФИГ. 1В и ФИГ. 3, в которых, соответственно, третичный анализ с использованием в качестве входных данных идентифицированных вариантов картированных и выравненных прочтений не может быть начат до завершения секвенирования.
[0129] Применительно к примеру, показанному на ФИГ. 5, секвенатор 510 нуклеиновых кислот может сконфигурировать программируемую схему 542 блока 540 вторичного анализа для включения блока 542а картирования и выравнивания. Секвенатор 510 нуклеиновых кислот может принимать множество образцов 105, 106, 107. Образцы 105, 106, 107 могут включать в себя, например, образцы нуклеиновой кислоты разных видов. Разные виды могут представлять собой разных людей, разных животных, разные растения или т.п. Секвенатор 510 нуклеиновых кислот может подготавливать образцы 105, 106, 107 и выполнять генерирование кластеров в период времени Т1 рабочего процесса 570.
[0130] По завершении стадии кластеризации секвенатор 510 нуклеиновых кислот начинает генерировать индексы или идентификаторы образца для каждого первого прочтения, которое будет создано секвенатором 510 нуклеиновых кислот в период времени Т2А. В конце периода времени Т2А секвенатор 510 нуклеиновых кислот начинает генерировать индексы или идентификаторы образца для каждого второго прочтения, которое будет создано секвенатором 510 нуклеиновых кислот в период времени Т2В. Индекс или идентификатор образца для каждого прочтения может включать в себя любые данные, которые могут быть использованы для создания логической взаимосвязи между прочтением и образцом. Таким образом, в конце периода времени T1+Т2А+Т2В в примере, показанном на ФИГ. 5, индексы или идентификаторы образца созданы для каждого первого прочтения, которое будет сгенерировано секвенатором 510 нуклеиновых кислот во время первого интервала прочтения, и индексы или идентификаторы образца также были созданы для каждого второго прочтения, которое будут сгенерировано секвенатором 510 нуклеиновых кислот во время второго интервала прочтения.
[0131] Секвенатор 510 нуклеиновых кислот выполнен с возможностью параллелизации операций вторичного анализа, таких как картирование и выравнивание по меньшей мере части первых прочтений 530-1, 530-3, 532-1, 532-3, 534-1, 534-3, пока секвенатор 510 нуклеиновых кислот продолжает выполнять операции секвенирования, такие как секвенирование путем синтеза, для первого интервала прочтения в течение периода времени Т3. Начало вторичного анализа по меньшей мере части первых прочтений во время первого интервала прочтения не может быть достигнуто в примере, показанном на ФИГ. 3, поскольку индексы или идентификаторы образца для каждого прочтения не генерируются, пока не будет завершен первый интервал прочтения. Напротив, в примере, показанном на ФИГ. 5, индексы или идентификаторы образца для каждого прочтения, которое должно быть сгенерировано секвенатором 510 нуклеиновых кислот, создают заранее.
[0132] В примере, показанном на ФИГ. 5, первый интервал прочтения не начинается до завершения периода времени T1+Т2А+Т2В рабочего процесса 570. После истечения периода времени T1+Т2А+Т2В секвенатор 570 нуклеиновых кислот может начинать первый интервал прочтения. Начало первого интервала прочтения может включать инициирование операций первичного анализа при секвенировании, таком как секвенирование путем синтеза, с генерированием одного или более первых прочтений 530-1, 530-3, 532-1, 532-3, 534-1, 534-3. После истечения периода времени ТХ с начала первого интервала прочтения «Прочтение 1» одно или более первых прочтений 530-1, 530-3, 532-1, которые были сгенерированы за период времени ТХ, могут быть впоследствии сохранены в запоминающем устройстве 544 блока 540 вторичного анализа или другом запоминающем устройстве, доступном для блока 540 вторичного анализа и/или блока 150 обработки.
[0133] Поскольку секвенатор 510 нуклеиновых кислот секвенирует множество образцов, секвенатор 510 нуклеиновых кислот должен выполнять операцию организации для организации одного или более первых прочтений 530-1, 530-3, 532-1 в одну или более организованных групп первых прочтений. Организация первых прочтений может быть достигнута с использованием блока 562 демультиплексирования. Например, блок 550 обработки может получать доступ к одному или более прочтениям, хранящимся в запоминающем устройстве 544, запоминающем устройстве 560 или другом запоминающем устройстве, и осуществлять запрограммированные функциональные возможности блока 562 демультиплексирования с демультиплексированием одного или более первых прочтений 530-1, 530-3, 532-1 в одну или более организованных групп первых прочтений. Демультиплексирование может быть осуществлено для соответствующих первых прочтений с использованием одной или более операций демультиплексирования с организацией одного или более первых прочтений 530-1, 530-3, 532-1 на основе индекса или идентификатора образца. Демультиплексированные первые прочтения могут храниться в запоминающем устройстве 544 или в другом запоминающем устройстве, доступном для блока 542а картирования и выравнивания.
[0134] Блок 542а картирования и выравнивания может получать доступ к организованным первым прочтениям, хранящимся в запоминающем устройстве 544, и выполнять операции картирования и выравнивания в реальном времени на демультиплексированных первых прочтениях во время первого интервала прочтения. Блок 540 вторичного анализа может генерировать результаты 549 для каждой группы первых прочтений, хранящихся в запоминающем устройстве 544. Результаты 549 могут включать в себя статистику демультиплексирования, статистику картирования и выравнивания, результаты картирования и выравнивания или их комбинацию. Блок 540 вторичного анализа может сохранять полученные результаты в запоминающем устройстве 560. Статистика демультиплексирования может включать в себя данные, описывающие качество демультиплексирования, такие как число записей, соответствующих каждому идентификатору образца. Статистика картирования и выравнивания, например оценка MAPQ, которая обеспечивает индикацию качества картирования для каждой группы первых прочтений, оценка выравнивания, которая обеспечивает индикацию качества выравнивания для каждой группы первых прочтений, или т.п. Результаты 549 картирования и выравнивания могут включать в себя данные, описывающие картированные и выравненные прочтения. В некоторых вариантах реализации эти результаты картирования и выравнивания могут динамически обновляться по мере того, как большее количество первых прочтений генерируется, картируется и выравнивается с соответствующими эталонными последовательностями.
[0135] В примере, показанном на ФИГ. 5, сверхбыстрое выполнение блока 542а картирования и выравнивания, реализованного с использованием аппаратной логики программируемой схемы 542, позволяет блоку 542а картирования и выравнивания выполнять картирование и выравнивание соответствующих демультиплексированных групп первых прочтений 530-1, 530-3, 532-1, 532-3, 534-1, 534-3 за долю времени, необходимую секвенатору 510 нуклеиновых кислот для выполнения первого интервала прочтения. Например, в некоторых вариантах реализации программируемая схема 542а может выполнять картирование и выравнивание демультиплексированных групп первых прочтений, сгенерированных в период времени ТХ, в аппаратной логике во время первого интервала прочтения «Прочтение 1» за минуты или менее, при этом выполнение всего первого интервала прочтения с использованием программного обеспечения, исполняемого блоком 150 обработки, может занимать от 12 до 24 часов. Таким образом, секвенатор 510 нуклеиновых кислот или один или более пользователей-людей могут оценивать результаты 549 вторичного анализа первых прочтений, например первых прочтений, полученных за период времени ТХ, в период времени Т3, когда остальные первые прочтения генерируются секвенатором 510 нуклеиновых кислот. Затем секвенатор 510 нуклеиновых кислот, пользователь секвенатора 510 нуклеиновых кислот, агент или модель искусственного интеллекта или их комбинация могут на основе качества операции демультиплексирования и/или операции картирования и выравнивания по результатам 549 определить, должен ли секвенатор 510 нуклеиновых кислот продолжать выполнение операций секвенирования первого интервала прочтения. Это определение того, следует ли продолжать операции секвенирования во время первого интервала прочтения может автоматически выполняться секвенатором 510 нуклеиновых кислот, выполняться автоматически агентом или моделью искусственного интеллекта, выполняться пользователем секвенатора нуклеиновых кислот или выполняться на основе данных, описывающих определение, выполненное каждым из этих объектов, как описано со ссылкой например ФИГ. 1В.
[0136] Используя эти методики, система 500, показанная на ФИГ. 5, обеспечивает технологические преимущества, еще лучшие, чем описанные со ссылкой на ФИГ. 1В. Таким образом, система 500 позволяет экономить реагенты, которые использовались бы для продолжения генерирования дополнительных прочтений во время первого интервала прочтения, если бы результаты 549 не указывали на то, что демультиплексирование по меньшей мере части первых прочтений, уже сгенерированных за время первого интервала прочтения и/или выравнивание части первых прочтений, уже сгенерированных во время первого интервала прочтения, является низкокачественным. Когда определено, что качество демультиплексирования уже сгенерированных первых прочтений и/или картирования и выравнивания уже сгенерированных первых прочтений является удовлетворительным, секвенатор 510 нуклеиновых кислот может отбросить результаты 549 картирования и выравнивания. В других вариантах реализации картирование и выравнивание уже сгенерированных первых прочтений, выполняемое параллельно с первым интервалом прочтения, можно использовать в качестве результатов картирования и выравнивания для заключительных прогонов данных первых прочтений.
[0137] Помимо демультиплексирования и картирования и выравнивания блок 540 вторичного анализа также может выполнять операции распознавания вариантов для одной или более групп картированных и выравненных первых прочтений во время первого интервала прочтения «Прочтение 1». В качестве примера блок 550 обработки может быть использован для выполнения блока 564 распознавания вариантов, который может анализировать картированные и выравненные прочтения для идентификации наличия любых вариантов, таких как однонуклеотидные полиморфизмы (SNP), вставки/делеции (инделы), структурные вариации или т.п. В некоторых вариантах реализации программируемая схема 542 может быть динамически реконфигурирована, например, секвенатором 510 нуклеиновых кислот, для облегчения обработки в рамках распознавания вариантов. Например, программируемая схема 542 может быть динамически реконфигурирована для включения блока НММ, который может быть использован для выполнения вычислений вероятностей, например вероятности появления варианта в одном или более эталонных положениях картированных и выравненных прочтений. Секвенатор 510 нуклеиновых кислот или другое компьютерное устройство может затем выполнять одну или более операций третичного анализа во время первого интервала прочтения «Прочтение 1» с использованием любых идентифицированных вариантов. Это может помочь ускорить лечение существа на основе третичного анализа. Существо может включать в себя пациента, человека, субъекта, растение, животное или т.п.
[0138] В примере системы 500, если определение выполняется для прерывания первого интервала прочтения на основе определения того, что статистика демультиплексирования и/или статистика картирования и выравнивания имеют низкое качество, система 500 может также прерывать второй интервал прочтения «Прочтение 2». Таким образом, система 500 обеспечивает дополнительные преимущества по сравнению с примерами системы, показанными на ФИГ. 1В или ФИГ. 3, в том смысле, что можно сэкономить еще больше реагента в случае низкокачественных результатов демультиплексирования и/или результатов картирования и выравнивания.
[0139] Однако, применительно к примеру системы 500, если определено, что результаты демультиплексирования и/или результаты картирования и выравнивания удовлетворяют пороговому уровню качества, то система 500 может начинать выполнение второго интервала прочтения «Прочтения 2», как показано в рабочем процессе 570. В некоторых вариантах реализации система 500 может генерировать второй интервал прочтения «Прочтение 2» без параллелизации вторичного анализа вторых прочтений. Такое исполнение может быть предпочтительным, поскольку, например, система 500 уже оценила качество секвенирования во время первого интервала прочтения «Прочтение 1». Однако в других вариантах реализации система 500 может параллелизовать вторичный анализ вторых прочтений таким же образом, каким параллелизован вторичный анализ первых прочтений с первым интервалом прочтения.
[0140] В примере, показанном на ФИГ. 5, описан пример, имеющий прочтения с 8 нуклеотидами и 3 образца. Тем не менее настоящее описание не ограничено этим. Вместо этого такой простой пример представлен, чтобы простым для понимания образом объяснить признаки настоящего описания. На практике фрагменты ДНК настоящего описания могут иметь в некоторых вариантах реализации, например, до 600 нуклеотидов, до 800 нуклеотидов, до 1000 нуклеотидов или более, и каждое прочтение фрагмента может иметь, например, 50 нуклеотидов, 75 нуклеотидов, 150 нуклеотидов, 200 нуклеотидов, 300 нуклеотидов, 500 нуклеотидов или более с каждого конца фрагмента ДНК. Аналогичным образом ничто на ФИГ. 5 или любой другой фигуре не следует интерпретировать как ограничение числа кластеров фрагментов. Например, секвенатор 510 нуклеиновых кислот может выполнять массово-параллельное секвенирование с одновременным секвенированием миллионов кластеров из множества фрагментов.
[0141] Хотя пример на ФИГ. 5 относится ко множеству образцов, которые используются для генерирования прочтений, имеющих индекс или идентификатор образца, настоящее описание не ограничено этим. Напротив, система 500 также может быть использована для обработки одного образца, при которой генерируются прочтения, которые не индексируются, поскольку все прочтения принадлежат одному образцу. В таких вариантах реализации такие же процессы могут быть осуществлены с инициированием первого интервала прочтения сразу после стадии кластеризации. Затем, после того как часть первых прочтений сгенерирована во время первого интервала прочтения «Прочтение 1», система 500 может предоставить сгенерированную часть первых прочтений в блок 542а картирования и выравнивания для проведения картирования и выравнивания во время того, как в ходе первого интервала прочтения генерируется оставшаяся часть первых прочтений, без необходимости в стадии демультиплексирования. В этом варианте реализации первые прочтения не обязательно должны подвергаться демультиплексированию, поскольку все они связаны с одним и тем же образцом. Таким образом, часть картированных и выравненных первых прочтений далее можно проанализировать на варианты с использованием первого интервала прочтения «Прочтение 1», как описано выше. Определения в отношении продолжения первого интервала прочтения и второго интервала прочтения могут осуществляться сходным образом, как объяснено для примера, показанного на ФИГ. 5. В целом существенное различие между вариантом реализации системы 500 с одним образцом, показанной на ФИГ. 5, и вариантами реализации системы со множеством образцов, показанной на ФИГ. 5, заключается в том, что в варианте реализации с одним образцом не требуется выполнять стадии демультиплексирования.
[0142] На ФИГ. 6 представлена блок-схема примера процесса 600 выполнения инкрементного вторичного анализа в соответствии со схемой рабочего процесса, показанной на ФИГ. 5. По существу, процесс 600 включает генерирование множества первых идентификаторов образца, причем каждый первый идентификатор образца соответствует конкретному прочтению, которое будет сгенерировано во время первого интервала прочтения (610), генерирование множества вторых идентификаторов образца, причем каждый второй идентификатор образца соответствует конкретному прочтению, которое будет сгенерировано во время второго интервала прочтения (620), получение первых данных, описывающих множество первых прочтений, сгенерированных секвенатором нуклеиновых кислот на множестве разных образцов во время первого интервала прочтения, причем каждое из множества первых прочтений соответствует по меньшей мере одному из первого и второго идентификаторов образца (630), причем во время получения первых данных на стадии 630 (I) организацию множества первых прочтений в организованные группы на основе по меньшей мере первого или второго идентификатора образца, связанного с каждым из первых прочтений, (II) выполнение для каждой организованной группы первых прочтений операций вторичного анализа над организованной группой первых прочтений и (III) сохранение результатов вторичного анализа для каждой группы первых прочтений (640), получение вторых данных, описывающих множество вторых прочтений, сгенерированных секвенатором нуклеиновых кислот, по множеству разных образцов во время второго интервала прочтения, выполняемого после первого интервала прочтения, причем каждое из множества вторых прочтений соответствует по меньшей мере одному из первого или второго идентификаторов образца (650), и выполнение вторичного анализа полученных вторых данных (660). Для удобства и без ограничений эти стадии будут более подробно описаны ниже в качестве выполняемых системой секвенирования, такой как система 500, показанная на ФИГ. 5.
[0143] Система секвенирования может начинать выполнение процесса 600 с генерирования 610 множества первых идентификаторов образца, причем каждый первый идентификатор образца соответствует конкретному прочтению, которое будет сгенерировано во время первого интервала прочтения. В некоторых вариантах реализации каждый первый идентификатор образца может включать в себя последовательность индексной метки. Последовательность индексной метки может быть присоединена к целевым полинуклеотидам каждого образца перед иммобилизацией соответствующих образцов для секвенирования. Индексная метка может представлять собой синтетическую последовательность нуклеотидов, которая добавляется к мишени в рамках этапа подготовки темплата. Соответственно, специфичная для библиотеки индексная метка представляет собой метку нуклеотидной последовательности, которая присоединяется к каждой из целевых молекул образца, и присутствие которой служит указателем или используется для идентификации объекта, из которого выделяли молекулы-мишени. В некоторых вариантах реализации последовательность индексной метки может включать в себя штрихкод, встроенный в синтетическую последовательность.
[0144] Система секвенирования может продолжать выполнение процесса 600 на стадии 620 генерированием множества вторых идентификаторов образца, причем каждый второй идентификатор образца соответствует конкретному прочтению, которое будет сгенерировано во время второго интервала прочтения, происходящего после первого интервала прочтения. В некоторых вариантах реализации каждый второй идентификатор образца может включать в себя последовательность индексной метки. Последовательность индексной метки может быть присоединена к целевым полинуклеотидам каждого образца перед иммобилизацией соответствующих образцов для секвенирования. Индексная метка может представлять собой синтетическую последовательность нуклеотидов, которая добавляется к мишени в рамках этапа подготовки темплата. Соответственно, специфичная для библиотеки индексная метка представляет собой метку нуклеотидной последовательности, которая присоединяется к каждой из целевых молекул образца, и присутствие которой служит указателем или используется для идентификации объекта, из которого выделяли молекулы-мишени. В некоторых вариантах реализации последовательность индексной метки может включать в себя штрихкод, встроенный в синтетическую последовательность.
[0145] Система секвенирования может продолжать выполнение процесса 600 на стадии 630 получением первых данных, описывающих множество первых прочтений, генерируемых секвенатором нуклеиновых кислот из множества разных образцов во время первого интервала прочтения, причем каждое из множества первых прочтений соответствует одному из первых идентификаторов образца. Получение первых данных может включать сохранение первых данных, представляющих одно или более первых прочтений, в запоминающем устройстве блока вторичного анализа после генерирования первых данных секвенатором. Запоминающее устройство блока вторичного анализа может представлять собой блок памяти, выполненный с возможностью доступа к нему интегральной схемы блока вторичного анализа, выполненной с возможностью выполнения операций вторичного анализа. Интегральная схема может включать в себя одну или более программируемых схем, одну или более ASIC или их комбинацию. В некотором варианте реализации по меньшей мере часть первых данных получают во время генерирования другой части первых данных секвенатором нуклеиновых кислот. Таким образом, данные, представляющие первый набор из одного или более прочтений, можно получать и сохранять в запоминающем устройстве блока вторичного анализа, в то время как одно или более других первых прочтений генерируются секвенатором нуклеиновых кислот во время первого интервала прочтения.
[0146] Каждое прочтение из множества первых прочтений может состоять из упорядоченной последовательности нуклеотидов. В некоторых вариантах реализации упорядоченная последовательность нуклеотидов может соответствовать нуклеотидам первого конца фрагмента нуклеиновой кислоты. Фрагмент нуклеиновой кислоты может быть клонально амплифицирован для облегчения секвенирования, и в таких вариантах реализации упорядоченная последовательность нуклеотидов может быть определена путем анализа множества клонов фрагмента нуклеиновой кислоты с генерированием нуклеотидов прочтения. Каждый первый идентификатор образца каждого первого прочтения, сгенерированный заранее во время первого интервала прочтения, соответствует конкретному образцу, из которого получено первое прочтение. Первый идентификатор образца может быть использован системой секвенирования для определения образца, связанного с любым конкретным первым прочтением. В некоторых вариантах реализации данные, идентифицирующие образец, могут включать в себя штрихкод.
[0147] Во время получения первых данных на стадии 630 во время первого интервала прочтения система секвенирования может использовать блок вторичного анализа для параллелизации в реальном времени дополнительной обработки одного или более из первых прочтений, которое уже было сгенерировано секвенатором нуклеиновых кислот. В некоторых вариантах реализации дополнительная обработка может включать (I) организацию множества первых прочтений в организованные группы на основе по меньшей мере первого или второго идентификаторов образца, связанных с каждым из первых прочтений, (II) выполнение для каждой организованной группы первых прочтений операций вторичного анализа над организованной группой первых прочтений и (III) сохранение результатов вторичного анализа каждой группы первых прочтений (стадия 640).
[0148] Организация одного или более первых прочтений в организованные группы на основе идентификатора образца необходима для обеспечения релевантной обработки вторичного анализа при секвенировании множества образцов. Сюда может входить выполнение одной или более операций демультиплексирования для картирования одного или более первых прочтений с разными первыми идентификаторами образца в соответствующие организованные группы, причем каждая организованная группа первых прочтений имеет один и тот же идентификатор образца. Можно сгенерировать статистику демультиплексирования, которая описывает качество операций демультиплексирования. Например, статистика демультиплексирования может указывать число первых прочтений, соответствующих каждому идентификатору образца. В некоторых вариантах реализации блок вторичного анализа может возвращать данные результатов, которые описывают статистику демультиплексирования, секвенатору нуклеиновых кислот, предоставлять данные результатов одному или более агентам или моделям-искусственному интеллекту или выводить данные результатов для одного или более пользователей-людей. В таких случаях система секвенирования может определить, продолжать процесс 600 или прерывать процесс 600 в данный момент времени на основании качества операции демультиплексирования, описанного статистикой демультиплексирования. Альтернативно такая статистика демультиплексирования может быть возвращено в виде данных результатов после выполнения операций картирования и выравнивания, как описано ниже.
[0149] После того как одно или более первых прочтений были организованы, система секвенирования может выполнить для каждой организованной группы первых прочтений одну или более операций вторичного анализа над организованной группой первых прочтений параллельно с оставшейся частью первого интервала прочтения с использованием блока вторичного анализа. Выполнение операций вторичного анализа над организованной группой первых прочтений может включать для каждой организованной группы первых прочтений (I) предоставление секвенатором нуклеиновых кислот организованной группы первых прочтений блоку картирования и выравнивания для выравнивания организованной группы первых прочтений с эталонной последовательностью, (II) выравнивание с использованием блока картирования и выравнивания организованной группы первых прочтений с эталонной последовательностью, (III) получение данных результатов от блока картирования и выравнивания и (IV) сохранение полученных данных результатов выравнивания до завершения получения первых данных на стадии 630.
[0150] Данные результатов могут включать в себя статистику демультиплексирования или статистику картирования и выравнивания. Статистика демультиплексирования может включать в себя данные, описывающие качество операции демультиплексирования, такие как число первых прочтений, соответствующих каждому идентификатору образца. Статистика картирования и выравнивания может включать в себя данные, описывающие качество выравнивания для каждой организованной группы первых прочтений с соответствующей эталонной последовательностью. Статистика картирования и выравнивания может включать в себя, например, одну или более из оценки MAPQ, оценки выравнивания или т.п. В других вариантах реализации результаты картирования и выравнивания могут включать в себя картированные и выравненные прочтения для каждой организованной группы первых прочтений, которые могут быть предоставлены в качестве входных данных распознавателю вариантов для определения потенциальных вариантов путем сравнения картированных и выравненных прочтений каждой организованной группы первых прочтений с соответствующей эталонной последовательностью.
[0151] В некоторых вариантах реализации выходные данные, описывающие данные результатов для каждой организованной группы первых прочтений, могут быть предоставлены для изучения одному или более пользователям-людям. Например, выходные данные, описывающие результаты для каждой организованной группы первых прочтений, могут быть выведены на дисплей, например, соединенный с секвенатором нуклеиновых кислот или находящийся в другом помещении или здании. Альтернативно или дополнительно выходные данные, описывающие результаты выравнивания для каждой организованной группы первых прочтений, могут быть выведены с использованием принтера, соединенного, например, напрямую или опосредованно с возможностью обмена данными с секвенатором нуклеиновых кислот для печати отчета, описывающего результаты выравнивания для каждой организованной группы первых прочтений.
[0152] В некоторых вариантах реализации система секвенирования, один или более пользователей-людей, один или более агентов или моделей искусственного интеллекта или их комбинация могут оценивать результаты выравнивания во время получения первых данных на стадии 630. Например, результаты могут быть оценены для определения того, имеет ли демультиплексирование полученных первых прочтений и/или картирование и выравнивание полученных первых прочтений или их комбинация достаточное качество для продолжения получения первых данных на стадии 630. В некоторых вариантах реализации, если результаты для организованной группы первых прочтений не удовлетворяют одному или более предварительно заданным правилам или пороговым значениям, то секвенатор нуклеиновых кислот может получить команду остановить получение первых данных во время первого интервала прочтения на стадии 630. Альтернативно, если определено, что результаты для организованной группы первых прочтений удовлетворяют одному или более предварительно заданным правилам или пороговым значениям, то секвенатору нуклеиновых кислот может быть разрешено продолжить получение первых данных в ходе первого интервала прочтения на стадии 630.
[0153] В некоторых вариантах реализации каждая организованная группа картированных и выравненных первых прочтений может быть оценена для обнаружения потенциальных вариантов во время получения первых данных на стадии 630. Такие варианты реализации могут обеспечивать возможность проведения третичного анализа выявленных для каждой группы вариантов быстрее, чем в традиционных способах, которые не позволят начать третичный анализ до завершения как первого интервала прочтения на стадии 630, так и второго интервала прочтения на стадии 650. Таким образом, первоначальный диагноз, чтобы начать лечение, может быть получен на несколько дней раньше, чем в традиционных способах, показанных на ФИГ. 1А, без необходимости ждать завершения первого интервала прочтения, второго интервала прочтения и картирования и выравнивания первого и второго прочтений, прежде чем переходить к третичному анализу.
[0154] После завершения стадии 630, система секвенирования может продолжать выполнение процесса 600 получением 650 вторых данных, описывающих множество вторых прочтений, генерируемых секвенатором нуклеиновых кислот из множества разных образцов во время второго интервала прочтения, происходящего после первого интервала прочтения, причем каждое из множества вторых прочтений соответствует по меньшей мере первому или второму идентификатору образца. Получение вторых данных может включать в себя сохранение вторых данных, представляющих одно или более вторых прочтений, сгенерированных во время второго интервала прочтения, в запоминающем устройстве устройства блока вторичного анализа после генерирования вторых данных секвенатором. Запоминающее устройство блока вторичного анализа может представлять собой блок памяти, выполненный с возможностью доступа к нему интегральной схемы блока вторичного анализа, выполненной с возможностью выполнения операций вторичного анализа. Интегральная схема может включать в себя одну или более программируемых схем, одну или более ASIC или их комбинацию. В некоторых вариантах реализации по меньшей мере часть вторых данных получают во время генерирования другой части вторых секвенатором нуклеиновых кислот. Таким образом, данные, представляющие второй набор из одного или более прочтений, можно получать и сохранять в запоминающем устройстве секвенатора, в то время как одно или более других вторых прочтений генерируются секвенатором нуклеиновых кислот во время второго интервала прочтения.
[0155] Каждое прочтение из множества вторых прочтений может состоять из упорядоченной последовательности нуклеотидов. В некоторых вариантах реализации упорядоченная последовательность нуклеотидов может соответствовать нуклеотидам второго конца фрагмента нуклеиновой кислоты, который противоположен первому концу фрагмента нуклеиновой кислоты. Фрагмент нуклеиновой кислоты может быть клонально амплифицирован для облегчения секвенирования, и в таких вариантах реализации упорядоченная последовательность нуклеотидов может быть определена путем анализа множества клонов фрагмента нуклеиновой кислоты с генерированием нуклеотидов прочтения. Каждый второй идентификатор образца каждого второго прочтения, сгенерированный заранее во время второго интервала прочтения, соответствует конкретному идентификатору второго прочтения. Второй идентификатор образца может быть использован системой секвенирования для определения образца, связанного с любым конкретным вторым прочтением. В некоторых вариантах реализации данные, идентифицирующие образец, могут включать в себя штрихкод.
[0156] Система секвенирования может продолжить выполнение процесса 600 выполнением 660 вторичного анализа полученных вторых данных. В некоторых вариантах реализации система секвенирования может перейти к стадии 660 после завершения стадии 650. В контексте процесса 600 это может происходить при сохранении по меньшей мере некоторых преимуществ настоящего описания, таких как ускоренный третичный анализ, поскольку качество секвенирования может быть оценено во время первого интервала прочтения на стадии 640, а также сокращение времени простоя секвенатора нуклеиновых кислот. Тем не менее настоящее описание не ограничено этим. Напротив, в некоторых вариантах реализации система секвенирования может параллелизировать вторичный анализ вторых прочтений таким же образом, каким параллелизирован вторичный анализ первых прочтений с первым интервалом прочтения.
[0157] В некоторых вариантах реализации система секвенирования может полагаться на результаты вторичного анализа картирования и выравнивания и/или распознавания вариантов для организованных групп первых прочтений, выполненного на стадии 640, во время получения первых данных в течение первого интервала прочтения. В других вариантах реализации эти исходные результаты выполненного на стадии 640 вторичного анализа, связанные с организованными группами первых прочтений, могут быть отброшены после их оценки для определения качества первого интервала прочтения. В таких случаях система секвенирования может инициировать вторую итерацию вторичного анализа организованных групп первых прочтений либо до, либо после завершения вторичного анализа организованных групп вторых прочтений на стадии 660.
[0158] На ФИГ. 7 представлен пример схемы 770 процесса, описывающей рабочую последовательность операций, выполняемых в ходе выполнения инкрементного вторичного анализа с использованием блока вторичного анализа. Схема 770 рабочего процесса аналогична схеме 370 рабочего процесса, показанной на ФИГ. 3. Однако на ФИГ. 7 последовательность 710 дополнительных операций, которые должны быть выполнены во время заключительного прогона данных, наложены поверх схемы 770 рабочего процесса.
[0159] В некоторых вариантах реализации заключительный прогон данных может включать в себя вторичный анализ или другую дополнительную обработку, которая даст результаты вторичного анализа, имеющие пороговый уровень достоверности. В традиционных системах секвенирования заключительный прогон данных не может быть обеспечен традиционными системами секвенирования до тех пор, пока не будет завершен как первый интервал прочтения, так и второй интервал прочтения. Кроме того, такие традиционные системы также имеют время простоя секвенатора между завершением первого прогона секвенирования и началом второго прогона секвенирования, как показано на ФИГ. 1А. Хотя описан пример реализации, в котором используется пороговый уровень достоверности, могут быть использованы другие варианты реализации, которые не используют такие пороги.
[0160] В примере, показанном на ФИГ. 7, система секвенирования, такая как система секвенирования, показанная на ФИГ. 3 или 5, может быть выполнена с возможностью запуска заключительного прогона данных в период времени TY до завершения второго интервала прочтения. Период времени TY может представлять собой, например, предварительно заданное число одного или более циклов секвенирования от конца второго интервала прочтения, где цикл представляет собой время, требуемое для генерирования одной нуклеиновой кислоты из прочтения. В некоторых вариантах реализации секвенатор нуклеиновых кислот может быть выполнен с возможностью обнаружения прохождения предварительно заданного числа циклов секвенирования от конца второго интервала прочтения «Прочтение 2» и запуска выполнения вторичного анализа на одном или более первых прочтениях, сгенерированных во время первого интервала прочтения «Прочтение 1» Первые прочтения могут включать в себя один или более организованных наборов прочтений, которые были ранее демультиплексированы в конце периода времени T3B в рабочем процессе, показанном на ФИГ. 7. Запуск выполнения вторичного анализа может включать, например, подачу команды блоку вторичного анализа выполнять картирование и выравнивание и/или распознавание вариантов картированных и выравненных прочтений.
[0161] После запуска блок вторичного анализа может продолжать выполнять операции вторичного анализа прочтений, генерируемых в течение первого и второго интервалов прочтения первого прогона секвенирования, до тех пор, пока не будут завершены запущенные операции вторичного анализа. Как показано на ФИГ. 7, выполнение операций вторичного анализа с использованием блока вторичного анализа может начинаться во время первого прогона секвенирования и продолжаться во время второго прогона секвенирования, который начинается после завершения первого прогона секвенирования. Операции вторичного анализа на прочтениях, сгенерированных во время первого прогона секвенирования, будут завершены во время второго прогона секвенирования. Таким образом, эта параллелизация вторичного анализа, соответствующего первому прогону секвенирования, с операциями второго прогона секвенирования позволяет секвенатору нуклеиновых кислот продолжать прогоны секвенирования без простоев или небольшим временем простоя секвенатора с увеличением потребления реагентов и получаемых от этого доходов. Операции второго прогона секвенирования, перекрывающиеся со вторичным анализом первого прогона секвенирования, могут включать, без ограничений, настройку, кластеризацию или первичный анализ второго прогона секвенирования.
[0162] В примере, показанном на ФИГ. 7, параллелизация вторичного анализа первого прогона секвенирования и операций второго прогона секвенирования выполняется не для оценки качества прочтений, сгенерированных секвенатором нуклеиновых кислот, чтобы определить, следует ли продолжить второй интервал прочтения. Вместо этого параллелизация вторичного анализа и операций второго прогона секвенирования выполняется как часть заключительного прогона данных, что позволяет сделать конечные результаты подходящими для применения в последующих операциях, например во время третичного анализа.
[0163] На ФИГ. 8 представлена блок-схема примера процесса 800 выполнения инкрементного вторичного анализа в соответствии со схемой рабочего процесса, показанной на ФИГ. 7. В целом получение первых данных, описывающих множество первых прочтений, сгенерированных секвенатором нуклеиновых кислот во время первого интервала прочтения первого прогона секвенирования (810), получение вторых данных, описывающих множество вторых прочтений, сгенерированных секвенатором нуклеиновых кислот во время второго интервала прочтения первого прогона секвенирования, выполняемого после первого интервала прочтения (820), причем во время получения по меньшей мере части вторых данных на стадии 820: инициирование выполнения одной или более операций вторичного анализа над по меньшей мере первыми данными или вторыми данными (830) с использованием секвенатора нуклеиновых кислот для выполнения второго прогона секвенирования (840), причем во время использования секвенатора нуклеиновых кислот для выполнения второго прогона секвенирования на стадии 840: (I) продолжение выполнения одной или более операций вторичного анализа на первых данных или вторых данных и (II) сохранение данных, представляющих результаты операций вторичного анализа (850). Для удобства и без ограничения эти стадии будут более подробно описаны ниже как выполняемые системой секвенирования, такой как система 100, 300 или 500, показанная на ФИГ. 1А, 3 или 5 соответственно.
[0164] Система секвенирования может начинать выполнение процесса 800 на стадии 810 с получения первых данных, описывающих множество первых прочтений, сгенерированных секвенатором нуклеиновых кислот во время первого интервала прочтения первого прогона секвенирования. Получение первых данных может включать сохранение первых данных, описывающих множество первых прочтений, в запоминающем устройстве, таком как запоминающее устройство блока вторичного анализа, после генерирования первых данных секвенатором нуклеиновых кислот. Запоминающее устройство блока вторичного анализа может представлять собой блок памяти, выполненный с возможностью доступа к нему интегральной схемы блока вторичного анализа, выполненной с возможностью выполнения операций вторичного анализа. Интегральная схема может включать в себя одну или более программируемых схем, одну или более ASIC или их комбинацию.
[0165] Каждое прочтение из множества первых прочтений может состоять из упорядоченной последовательности нуклеотидов. В некоторых вариантах реализации упорядоченная последовательность нуклеотидов может соответствовать нуклеотидам первого конца фрагмента нуклеиновой кислоты. Фрагмент нуклеиновой кислоты может быть клонально амплифицирован для облегчения секвенирования, и в таких вариантах реализации упорядоченная последовательность нуклеотидов может быть определена путем анализа множества клонов фрагмента нуклеиновой кислоты с генерированием нуклеотидов прочтения. Секвенатор нуклеиновых кислот может включать в себя любое секвенатор нуклеиновых кислот, включая ДНК-секвенатор или РНК-секвенатор. Первый прогон секвенирования может включать полное выполнение первичного анализа одного или более биологических образцов секвенатором нуклеиновых кислот. Пример стадий полного первого прогона секвенирования показан на ФИГ. 7 и включает стадию кластеризации, первый интервал прочтения и второй интервал прочтения. В некоторых вариантах реализации, например, показанном на ФИГ. 7, первичный анализ также может включать одну или более стадий индексирования.
[0166] Система секвенирования может продолжать выполнение процесса 800 на стадии 820 получением вторых данных, описывающих множество вторых прочтений, сгенерированных секвенатором нуклеиновых кислот во время второго интервала прочтения первого прогона секвенирования, выполняемого после первого интервала прочтения. Получение вторых данных может включать сохранение вторых данных, представляющих множество вторых прочтений, в запоминающем устройстве блока вторичного анализа после генерирования вторых данных секвенатором. Запоминающее устройство блока вторичного анализа может представлять собой блок памяти, выполненный с возможностью доступа к нему интегральной схемы блока вторичного анализа, выполненной с возможностью выполнения операций вторичного анализа. Интегральная схема может включать в себя одну или более программируемых схем, одну или более ASIC или их комбинацию. В некоторых вариантах реализации по меньшей мере часть вторых данных получают во время генерирования другой части вторых секвенатором нуклеиновых кислот. Каждое прочтение из множества вторых прочтений может состоять из упорядоченной последовательности нуклеотидов. В некоторых вариантах реализации упорядоченная последовательность нуклеотидов может соответствовать нуклеотидам второго конца фрагмента нуклеиновой кислоты, который противоположен первому концу фрагмента нуклеиновой кислоты. Фрагмент нуклеиновой кислоты может быть клонально амплифицирован для облегчения секвенирования, и в таких вариантах реализации упорядоченная последовательность нуклеотидов может быть определена путем анализа множества клонов фрагмента нуклеиновой кислоты с генерированием нуклеотидов прочтения.
[0167] Во время получения по меньшей мере части вторых данных на стадии 820 система секвенирования может продолжать выполнение процесса 800 стадии 830 инициированием выполнения одной или более операций вторичного анализа на первых данных или вторых данных. Инициирование выполнения одной или более операций вторичного анализа может включать динамическое конфигурирование программируемой схемы для включения в нее аппаратной логики для выполнения операции вторичного анализа, а затем выполнение по меньшей мере одной операции вторичного анализа для одного или более прочтений, сгенерированных во время первого прогона секвенирования. Например, система секвенирования может динамически конфигурировать программируемую схему в качестве блока картирования и выравнивания, а затем использовать аппаратную логику блока картирования и выравнивания для выполнения картирования и выравнивания по меньшей мере одного прочтения, сгенерированного во время первого прогона секвенирования. В других вариантах реализации инициирование выполнения одной или более операций вторичного анализа может включать подачу команды ASIC на исполнение цифровой логики для выполнения операции вторичного анализа на одном или более прочтениях, сгенерированных во время первого прогона секвенирования.
[0168] В некоторых вариантах реализации, например, когда во время первого прогона секвенирования было секвенировано множество образцов, перед картированием и выравниванием может потребоваться, чтобы первые прочтения или вторые прочтения были организованы в демультиплексированные группы. В таких вариантах реализации по меньшей мере часть организации первых прочтений и/или вторых прочтений также можно выполнять на стадии 820.
[0169] Система секвенирования может продолжать работу процесса 800 на стадии 840 использованием секвенатора нуклеиновых кислот для выполнения второго прогона секвенирования. Второй прогон секвенирования может включать полное выполнение первичного анализа одного или более биологических образцов секвенатором нуклеиновых кислот. В некоторых вариантах реализации второй прогон секвенирования может секвенировать один или более биологических образцов, отличных от биологических образцов, секвенированных во время первого прогона секвенирования. Второй прогон секвенирования может включать этап кластеризации, первый интервал прочтения и второй интервал прочтения. В некоторых вариантах реализации первичный анализ может также включать одну или более стадий индексирования.
[0170] Во время использования секвенатора нуклеиновых кислот для выполнения второго прогона секвенирования на стадии 840: (I) продолжение 850 выполнения одной или более операций вторичного анализа над первыми данными или вторыми данными и (II) сохранение результатов, представляющих результаты операций вторичного анализа. Продолжение выполнения одной или более операций вторичного анализа на первых данных или вторых данных, полученных на стадиях 810 или 820 соответственно, может включать продолжение выполнения вторичного анализа первых и вторых данных до завершения вторичного анализа первых и вторых данных. Например, аппаратный блок картирования и выравнивания, который может быть сконфигурирован на стадии 830 во время первого прогона секвенирования, может продолжать выполнение операций картирования и выравнивания первых прочтений и/или вторых прочтений во время второго прогона секвенирования до завершения операций картирования и выравнивания на первых прочтениях и/или вторых прочтениях.
[0171] На ФИГ. 9 представлена блок-схема примера процесса 900 выполнения динамического переключения контекста программируемой схемы. По существу, процесс 900 может включать получение одного или более атрибутов геномной обработки (910), определение на основе одного или более атрибутов геномной обработки типа переключения контекста обработки для программируемой схемы, причем тип переключения контекста обработки определяет реконфигурирование программируемой схемы (920), и подачу команды контроллеру программируемой схемы на выполнение вторичного анализа с использованием заданного типа переключения контекста (930). Для удобства и без ограничения эти стадии будут более подробно описаны ниже как выполняемые системой секвенирования, такой как система 100, 300 или 500, показанная на ФИГ. 1А, 3 или 5 соответственно.
[0172] Система секвенирования может начинать выполнение процесса 900 на стадии 910 с получения одного или более атрибутов геномной обработки. В некоторых вариантах реализации один или более атрибутов обработки могут включать в себя идентификатор обработки, который идентифицирует обработку, выбранную пользователем секвенатора нуклеиновых кислот. Геномные обработки могут включать, например, обработку для полногеномного секвенирования, обработку для обогащения, обработку для РНК, ампликонную обработку, обработку для РНК одиночных клеток или т.п. Альтернативно или дополнительно один или более атрибутов обработки могут включать в себя данные, описывающие число образцов, секвенированных секвенатором нуклеиновых кислот. Альтернативно или дополнительно один или более атрибутов обработки могут включать в себя предварительно заданный временной порог для выполнения обработки. Альтернативно или дополнительно один или более атрибутов обработки могут включать в себя некоторое количество имеющихся вычислительных ресурсов, доступных для секвенатора нуклеиновых кислот.
[0173] Система секвенирования может продолжать выполнение процесса 900 на стадии 920 определением на основе одного или более атрибутов геномной обработки типа переключения контекста обработки для программируемой схемы, причем тип переключения контекста обработки определяет реконфигурирование программируемой схемы. Определение типа переключения контекста обработки может включать выбор конкретного типа переключения контекста обработки из множества типов переключений контекста на основе одного или более атрибутов обработки.
[0174] Тип переключения контекста определяет, как программируемая схема будет динамически реконфигурирована в реальном времени. В качестве примера первый контекст программируемой схемы может включать в себя перемежающиеся операции выравнивания и распознавания вариантов программируемой схемой. В таких вариантах реализации программируемая схема может быть сконфигурирована как блок картирования и выравнивания для выравнивания прочтений, соответствующих первому образцу, с эталонной последовательностью, динамически реконфигурирована как блок распознавания вариантов для выполнения операций распознавания вариантов на прочтениях, соответствующих первому выравненному образцу, динамически реконфигурирована для картирования и выравнивания прочтений, соответствующих второму образцу, с эталонной последовательностью, динамически реконфигурирована как блок распознавания вариантов для выполнения операций распознавания вариантов, соответствующих второму выравненному образцу, и т.д. В этом контексте программируемая схема может динамически переключаться назад и вперед между операциями картирования и выравнивания и операциями распознавания вариантов. Этот первый контекст программируемой схемы является предпочтительным, когда имеется только один образец или небольшое количество образцов.
[0175] В качестве другого примера второй контекст программируемой схемы может включать в себя выполнение программируемой схемой всех необходимых выравниваний, а затем выполнение всех необходимых операций распознавания вариантов на выравненных прочтениях. В таких вариантах реализации программируемая схема может быть сконфигурирована как блок картирования и выравнивания и выравнивать первый образец, выравнивать второй образец, выравнивать третий и т.д. пока все образцы не будут выравнены, а затем динамически реконфигурирована как блок распознавания вариантов для выполнения операций распознавания вариантов на первом выравненном образце, выполнения операций распознавания вариантов на втором выравненном образце, выполнения операций распознавания вариантов на третьем выравненном образце и т.д. Поскольку переключение контекста представляет собой дорогостоящую вычислительную функцию, этот второй контекст программируемой схемы может быть выбран, когда обработка включает большее число образцов.
[0176] В некоторых вариантах реализации система секвенирования может принимать решение о типах переключения контекста несколькими способами. Например, в некоторых вариантах реализации система секвенирования может получать данные, такие как идентификатор обработки, который указывает на выбор обработки пользователем секвенатора нуклеиновых кислот. В некоторых вариантах реализации система секвенирования может быть запрограммирована для автоматического выбора конкретного типа переключения контекста, который логически связан с полученным идентификатором обработки. Логическая взаимосвязь может включать, например, картирование один-к-одному между идентификатором обработки и типом переключения контекста.
[0177] Альтернативно или дополнительно система секвенирования может выбирать между вышеупомянутыми типами переключения контекста в зависимости от числа образцов. Например, можно установить предварительно заданное пороговое значение числа образцов. Затем, если секвенатор нуклеиновых кислот определяет, что конкретная обработка включает число образцов, превышающее пороговое значение, то секвенатор нуклеиновых кислот может выбирать второй программируемый контекст. Альтернативно, если секвенатор нуклеиновых кислот определяет, что число образцов не превышает пороговое значение числа образцов, то секвенатор нуклеиновых кислот может выбирать первый программируемый контекст.
[0178] Альтернативно или дополнительно система секвенирования может выбирать между вышеупомянутыми типами переключения контекста в зависимости от предполагаемого времени выполнения вторичного анализа. Например, секвенатор нуклеиновой кислоты может быть запрограммирован для анализа данных, описывающих принятую обработку, и оценивать предполагаемое время выполнения вторичного анализа с использованием заданного по умолчанию контекста программируемой схемы, причем заданный по умолчанию контекст программируемой схемы представляет собой первый контекст программируемой схемы. В таких вариантах реализации, если предполагаемое время выполнения вторичного анализа меньше предварительно заданного порогового значения времени, то секвенатор нуклеиновых кислот может выбирать первый контекст программируемой схемы. Альтернативно, если предполагаемое время вторичного анализа больше предварительно заданного порогового значения времени, то секвенатор нуклеиновых кислот может выбирать второй контекст программируемой схемы.
[0179] Эти вышеупомянутые варианты реализации представляют собой только примеры типов переключения контекста программируемой схемы и переключения контекста, которые могут быть использованы в настоящем описании. Ни один из этих примеров не следует рассматривать как ограничивающий объем настоящего описания. Напротив, в объем настоящего описания входят другие типы контекстов программируемых схем и типы переключения контекста.
[0180] Система секвенирования может продолжать выполнение процесса 900 на стадии 930 подачей команды контроллеру программируемой схемы на выполнение вторичного анализа с использованием определенного типа переключения контекста. Контроллер программируемой схемы может включать в себя программное обеспечение, аппаратное обеспечение или их комбинацию, которые конфигурируют программируемую логику программируемой схемы. В зависимости от принятых инструкций контроллер программируемой схемы может динамически конфигурировать программируемую схему для включения в нее аппаратной цифровой логики, которая выполнена с возможностью выполнения типа переключения контекста, идентифицированного командами.
[0181] На ФИГ. 10 показана структурная схема примера системных компонентов, которые можно использовать для выполнения инкрементного вторичного анализа.
[0182] Предполагается, что вычислительное устройство 1000 представляет собой различные формы цифровых компьютеров, таких как ноутбуки, настольные компьютеры, рабочие станции, карманные персональные компьютеры, серверы, блейд-серверы, мэйнфреймы и другие подходящие компьютеры. В некоторых вариантах реализации вычислительное устройство 1000 может представлять собой секвенатор нуклеиновых кислот, такой как секвенатор нуклеиновых кислот, показанный на ФИГ. 1, 3 или 5. Предполагается, что мобильное вычислительное устройство 1050 представляет собой различные формы мобильных устройств, таких как карманные персональные компьютеры, сотовые телефоны, смартфоны, мобильные встроенные радиосистемы, диагностические вычислительные радиокоммуникационные устройства и другие аналогичные вычислительные устройства. Представленные в настоящем документе компоненты, их соединения и взаимоотношения, а также их функции являются только примерами и не носят ограничительного характера.
[0183] Вычислительное устройство 1000 включает в себя процессор 1002, запоминающее устройство 1004, устройство 1006 хранения данных, высокоскоростной интерфейс 1008, соединенный с запоминающим устройством 1004, несколько высокоскоростных портов 1010 расширения и низкоскоростной интерфейс 1012, соединяющийся с низкоскоростным портом 1014 расширения и устройством 1006 хранения данных. Каждое из процессора 1002, запоминающего устройства 1004, устройства 1006 хранения данных, высокоскоростного интерфейса 1008, высокоскоростных портов 1010 расширения и низкоскоростного интерфейса 1012 взаимно соединены с использованием различных шин и могут быть смонтированы на общей материнской плате или иным подходящим способом. Процессор 1002 может обрабатывать команды, предназначенные для исполнения внутри вычислительного устройства 1000, включая команды, хранящиеся в запоминающем устройстве 1004 или на устройстве 1006 хранения данных, для отображения графической информации графического интерфейса пользователя (ГИП) на внешнем устройстве ввода/вывода, таком как дисплей 1016, соединенный с высокоскоростным интерфейсом 1008. В других вариантах реализации при необходимости можно использовать множество процессоров и/или множество шин вместе со множеством запоминающих устройств и типов запоминающих устройств. Дополнительно могут быть соединены множество вычислительных устройств, причем каждое устройство обеспечивает часть операций (например, банк серверов, группа блейд-серверов или многопроцессорная система). В некоторых вариантах реализации процессор 1002 представляет собой однопоточный процессор. В некоторых вариантах реализации процессор 1002 представляет собой многопоточный процессор. В некоторых вариантах реализации процессор 1002 представляет собой квантовый компьютер.
[0184] Информация в запоминающем устройстве 1004 хранится внутри вычислительного устройства 1000. В некоторых вариантах реализации запоминающее устройство 1004 представляет собой блок или блоки энергозависимого запоминающего устройства. В некоторых вариантах реализации запоминающее устройство 1004 представляет собой блок или блоки энергонезависимого запоминающего устройства. Запоминающее устройство 1004 может также представлять собой другую форму машиночитаемого носителя, такую как магнитный или оптический диск.
[0185] Устройство 1006 хранения данных выполнено с возможностью обеспечения большой емкости хранения данных для вычислительного устройства 1000. В некоторых вариантах реализации устройство 1006 хранения данных может представлять собой или включать в себя машиночитаемый носитель, такой как устройство с гибким диском, устройство с жестким диском, устройство с оптическим диском или устройство с лентой, флеш-память или другое аналогичное твердотельное запоминающее устройство или массив устройств, включая устройства в сети хранения данных или в других конфигурациях. Команды могут храниться на носителе информации. Команды, если они выполняются одним или более устройствами обработки (например, процессором 1002), выполняют один или более способов, таких как описанные выше. Команды также могут храниться на одном или более запоминающих устройствах, таких как машиночитаемые носители (например, запоминающее устройство 1004, устройство 1006 хранения данных или память на процессоре 1002). Высокоскоростной интерфейс 1008 управляет операциями, требующими высокой пропускной способности, для вычислительного устройства 1000, а низкоскоростной интерфейс 1012 управляет операциями, требующими меньшей пропускной способности. Такое распределение функций является лишь примером. В некоторых вариантах реализации высокоскоростной интерфейс 1008 соединен с запоминающим устройством 1004, дисплеем 1016 (например, через графический процессор или ускоритель) и с высокоскоростными портами 1010 расширения, в которые можно устанавливать различные платы расширения (не показаны). В варианте реализации низкоскоростной интерфейс 1012 соединен с устройством 1006 хранения данных и низкоскоростным портом 1014 расширения. Низкоскоростной порт 1014 расширения, который может включать в себя различные коммуникационные порты (например USB, Bluetooth, Ethernet, беспроводной Ethernet) может быть соединен с одним или более устройствами ввода/вывода, такими как клавиатура, указательное устройство, сканер или сетевое устройство, такое как коммутатор или маршрутизатор, например, с помощью сетевого адаптера.
[0186] Вычислительное устройство 1000 может быть реализовано в ряде разных форм, как показано на фигуре. Например, оно может быть реализовано в виде стандартного сервера 1020 или многократно в виде группы таких серверов. Кроме того, оно может быть реализовано на персональном компьютере, таком как ноутбук 1022. Оно также может быть реализовано в рамках стоечной серверной системы 1024. Альтернативно компоненты вычислительного устройства 1000 могут быть объединены с другими компонентами в мобильном устройстве, таком как мобильное вычислительное устройство 1050. Каждое из таких устройств может включать в себя одно или более вычислительных устройств 1000, или мобильных вычислительных устройств 1050, и вся система может состоять из множества вычислительных устройств, взаимодействующих друг с другом.
[0187] Мобильное вычислительное устройство 1050 включает в себя, помимо прочих компонентов, процессор 1052, запоминающее устройство 1064, устройство ввода/вывода, такое как дисплей 1054, коммуникационный интерфейс 1066 и приемопередатчик 1068. Мобильное вычислительное устройство 1050 также может быть оснащено устройством хранения данных, таким как микродиск или другое устройство, для обеспечения дополнительной возможности хранения. Каждый из процессора 1052, запоминающего устройства 1064, дисплея 1054, коммуникационного интерфейса 1066 и приемопередатчика 1068 соединены друг с другом с помощью различных шин, и некоторые из компонентов могут быть при необходимости смонтированы на общей материнской плате или иными подходящими способами.
[0188] Процессор 1052 может исполнять команды внутри мобильного вычислительного устройства 1050, включая команды, хранящиеся в запоминающем устройстве 1064. Процессор 1052 может быть реализован в виде набора микросхем, который включает в себя отдельные и многокомпонентные аналоговые и цифровые процессоры. Процессор 1052 может обеспечивать, например, координацию других компонентов мобильного вычислительного устройства 1050, такую как управление пользовательскими интерфейсами, запуск приложений мобильным вычислительным устройством 1050 и беспроводная связь с помощью мобильного вычислительного устройства 1050.
[0189] Процессор 1052 может обмениваться данными с пользователем через интерфейс 1058 управления и интерфейс 1056 дисплея, соединенный с дисплеем 1054. Дисплей 1054 может представлять собой, например, дисплей типа TFT (жидкокристаллический дисплей на тонкопленочных транзисторах) или типа OLED (на органических с вето излучающих диодах) или использовать другие подходящие технологии отображения. Интерфейс 1056 дисплея может включать в себя соответствующую схему для использования дисплея 1054 для представления графической и другой информации пользователю. Интерфейс 1058 управления может принимать команды от пользователя и преобразовывать их для передачи на процессор 1052. Кроме того, внешний интерфейс 1062 может обеспечивать связь с процессором 1052 для обеспечения мобильного вычислительного устройства 1050 связью ближнего радиуса действия с другими устройствами. В некоторых вариантах реализации внешний интерфейс 1062 может обеспечивать, например, проводную связь, или в других вариантах реализации беспроводную связь, а также можно использовать множество интерфейсов.
[0190] Информация в запоминающем устройстве 1064 хранится внутри мобильного вычислительного устройства 1050. Запоминающее устройство 1064 может быть реализовано в виде одного или более машиночитаемых носителей, блоков энергозависимого запоминающего устройства или блоков энергонезависимого запоминающего устройства. Также может быть предусмотрено запоминающее устройство 1074 расширения, соединенное с мобильным вычислительным устройством 1050 посредством расширительного интерфейса 1072, который может включать в себя, например, интерфейс карты SIMM (модуль запоминающего устройства с однорядным расположением микросхем). Такое запоминающее устройство 1074 расширения может обеспечивать мобильное вычислительное устройство 1050 дополнительным пространством хранения данных или может также хранить приложения или другую информацию для мобильного вычислительного устройства 1050. В частности, запоминающее устройство 1074 расширения может включать в себя команды для выполнения или для дополнения описанных выше процессов, а также может включать в себя защищенную информацию. Таким образом, например, запоминающее устройство 1074 расширения может быть предусмотрено в качестве модуля защиты для мобильного вычислительного устройства 1050 и может быть запрограммировано командами, которые позволяют использовать мобильное вычислительное устройство 1050 безопасным образом. Дополнительно с помощью карт SIMM можно передавать безопасные приложения, а также дополнительную информацию, например размещать идентификационную информацию на карте SIMM без риска подвергнуться хакерским атакам.
[0191] Запоминающее устройство может включать в себя, например, флеш-память и/или память NVRAM (энергонезависимое оперативное запоминающее устройство), как описано ниже. В некоторых вариантах реализации на носителе информации хранятся команды, например команды, которые, если они выполняются одним или более устройствами обработки (например, процессором 1052), выполняют один или более способов, таких как описанные выше. Команды также могут храниться на одном или более устройствах хранения, таких как один или более компьютерочитаемых или машиночитаемых носителей (например, запоминающее устройство 1064, запоминающее устройство 1074 расширения или память на процессоре 1052). В некоторых вариантах реализации команды могут быть приняты в распространяемом сигнале, например, через приемопередатчик 1068 или внешний интерфейс 1062.
[0192] Мобильное вычислительное устройство 1050 может обмениваться данными беспроводным образом через интерфейс 1066 связи, который может включать в себя, в некоторых случаях, схему цифровой обработки сигналов. Интерфейс 1066 связи может обеспечивать обмен данными в различных режимах или протоколах, таких как, среди прочих, голосовые сигналы GSM (глобальная система мобильных коммуникаций), SMS (служба коротких сообщений), EMS (улучшенная служба сообщений) или обмен данными MMS (служба обмена мультимедийными сообщениями), CDMA (многостанционный доступ с кодовым разделением каналов), TDMA (многостанционный доступ с временным разделением каналов), PDC (персональная цифровая сотовая связь), WCDMA (широкополосный многостанционный доступ с кодовым разделением каналов), CDMA2000 или GPRS (общая служба пакетной радиопередачи), LTE, сотовая сеть 5G/6G. Такая связь может происходить, например, через приемопередатчик 1068 с использованием радиочастоты. Кроме того, возможна связь ближнего радиуса действия, например, с использованием Bluetooth, Wi-Fi или другого подобного приемопередатчика (не показан). Кроме того, модуль 1070 приемника GPS (глобальной системы позиционирования) может обеспечивать для мобильного вычислительного устройства 1050 дополнительные относящиеся к навигации и местоположению беспроводные данные, которые при необходимости можно использовать в приложениях, работающих на мобильном вычислительном устройстве 1050.
[0193] Мобильное вычислительное устройство 1050 может также передавать звуковой сигнал с использованием аудиокодека 1060, который может принимать речевую информацию от пользователя и преобразовывать ее в пригодную для использования цифровую информацию. Аудиокодек 1060 может также генерировать звуковой сигнал для пользователя, например, через динамик, например через гарнитуру мобильного вычислительного устройства 1050. Такой звуковой сигнал может включать в себя звук от голосовых телефонных звонков, может включать в себя записанный звук (например, среди прочего, голосовые сообщения, музыкальные файлы и т.д.), а может также включать в себя звук, генерируемый приложениями, работающими на мобильном вычислительном устройстве 1050.
[0194] Мобильное вычислительное устройство 1050 может быть реализовано в ряде разных форм, как показано на фигуре. Например, оно может быть реализовано в виде сотового телефона 1080. Оно может также быть реализовано в составе смартфона 1082, карманного персонального компьютера или другого аналогичного мобильного устройства.
[0195] Описан ряд вариантов реализации. Тем не менее будет очевидно, что возможны разные модификации без отклонения от сущности и объема описания. Например, можно использовать различные формы потоков, показанные выше, с изменением порядка, добавлением или удалением этапов.
[0196] Варианты осуществления изобретения и все функциональные операции, описанные в настоящем описании, могут быть реализованы в цифровой электронной схеме или в компьютерном программном обеспечении, микропрограммном обеспечении или аппаратном обеспечении, включая структуры, описанные в настоящем описании, и их структурные эквиваленты, или в комбинациях одного или более из них. Варианты осуществления изобретения могут быть реализованы в виде одного или более компьютерных программных продуктов, например одного или более модулей из компьютерных программных команд, закодированных на машиночитаемом носителе для выполнения или управления работой устройства обработки данных. Машиночитаемый носитель может представлять собой машиночитаемое устройство хранения, машиночитаемую основу для хранения, запоминающее устройство, композицию объектов, приводящую в действие машиночитаемый распространяемый сигнал, или комбинацию одного или более из них. Термин «устройство обработки данных» может охватывать все аппараты, устройства и машины для обработки данных, включая в качестве примера программируемый процессор, компьютер или множество процессоров или компьютеров. Устройство может включать в себя, помимо аппаратного обеспечения, код, который создает среду исполнения для рассматриваемой компьютерной программы, например код, который составляет микропрограммное обеспечение процессора, стек протоколов, систему управления базой данных, операционную систему или комбинацию одного или более из них. Распространяемый сигнал представляет собой искусственно генерируемый сигнал, например, генерируемый устройством электрический, оптический или электромагнитный сигнал, генерируемый для кодирования информации для передачи в подходящее приемное устройство.
[0197] Компьютерная программа (также называемая программой, программным обеспечением, приложением, скриптом или кодом) может быть написана на языке программирования любого типа, включая компилируемые или интерпретируемые языки, и может устанавливаться в любой форме, включая автономную программу или модуль, компонент, подпрограмму или другой элемент, пригодный для использования в вычислительной среде. Компьютерная программа не обязательно соответствует файлу в файловой системе. Программа может храниться в части файла, который содержит другие программы или данные (например, один или более скриптов, хранящихся в документе на языке разметки), в одном файле, предназначенном для рассматриваемой программы, или во множестве согласованных файлов (например, файлов, которые содержат один или более модулей, подпрограмм или частей кода). Компьютерную программу можно устанавливать для исполнения на одном компьютере или на множестве компьютеров, находящихся в одном месте или распределенных во множестве мест, объединенных сетью связи.
[0198] Процессы и логические потоки, представленные в настоящем описании, может выполнять один или более программируемых процессоров, исполняющих одну или более компьютерных программ, для выполнения функций путем использования входных данных и генерирования выходных данных. Процессы и логические потоки также могут быть выполнены на логической схеме специального назначения, например программируемой пользователем вентильной матрице (FPGA) или интегральной схеме специального назначения (ASIC), и аппарат может быть реализован в таком виде.
[0199] Подходящие для исполнения компьютерной программы процессоры в качестве примера включают в себя процессоры как общего, так и специального назначения, а также любой один или более процессоров цифрового компьютера любого типа. В целом процессор будет принимать команды и данные от постоянного запоминающего устройства и/или оперативного запоминающего устройства. Существенными элементами компьютера являются процессор для выполнения команд и одно или более запоминающих устройств для хранения команд и данных. В целом компьютер также будет включать в себя одно или более устройств хранения данных, например магнитный, магнитооптический или оптический диски, или будет функционально соединен с возможностью получения данных от них, или передачи данных на них, или для обеих целей. Однако компьютер не обязательно должен иметь такие устройства. Кроме того, компьютер может быть встроен в другое устройство, несколькими примерами которых могут быть: планшетный компьютер, мобильный телефон, карманный персональный компьютер (PDA), мобильный аудиоплеер, приемник системы глобальной позиционирования (GPS). Машиночитаемые носители, подходящие для хранения команд компьютерной программы и данных, включают в себя все формы энергонезависимых запоминающих устройств, носителей и запоминающих устройств, включая, например, полупроводниковые запоминающие устройства, например ЭППЗУ, ЭСППЗУ и устройства флеш-памяти; магнитные диски, например внутренние жесткие диски или съемные диски; магнитооптические диски; и диски CD-ROM и DVD-ROM. Процессор и запоминающее устройство могут быть дополнены специализированной логической электронной схемой или встроены в нее.
[0200] Для обеспечения взаимодействия с пользователем варианты осуществления изобретения могут быть реализованы на компьютере с устройством отображения, например катодно-лучевой трубкой (КЛТ) или жидкокристаллическим (ЖК) монитором, для отображения информации для пользователя, а также клавиатурой и указывающим устройством, например мышью или трекболом, с помощью которых пользователь может вводить в компьютер входные данные. Для обеспечения взаимодействия с пользователем также можно использовать и другие типы устройств; обратная связь, предоставляемая пользователю, может иметь любую осязаемую форму, например визуальная обратная связь, слуховая обратная связь или тактильная обратная связь; и входные данные от пользователя могут поступать в любой форме, включая звуковые, речевые или тактильные входные данные.
[0201] Варианты осуществления изобретения могут быть реализованы в компьютерной системе, которая включает в себя серверный компонент, например сервер данных, или включает в себя промежуточный компонент, например сервер приложений, или включает в себя клиентский компонент, например компьютер-клиент с графическим интерфейсом пользователя или веб-браузером, с помощью которых пользователь может взаимодействовать с реализацией изобретения, либо любую комбинацию одного или более таких серверных, промежуточных или клиентских компонентов. Компоненты системы могут быть связаны между собой любой формой или средой цифрового обмена данными, например сетью связи. К примерам сетей связи относятся локальная вычислительная сеть (LAN) и глобальная сеть (WAN), например Интернет.
[0202] Компьютерная система может включать в себя клиенты и серверы. Клиент и сервер, по существу, удалены друг от друга и, как правило, взаимодействуют через сеть связи. Функциональная зависимость клиента и сервера возникает благодаря компьютерным программам, выполняемым на соответствующих компьютерах и имеющим связь типа «клиент - сервер» друг с другом.
[0203] Хотя данное описание содержит много конкретных деталей, их не следует рассматривать как ограничения объема изобретения или возможной формулы изобретения, а скорее как описания признаков, специфичных для конкретных вариантов осуществления изобретения. Определенные признаки, описанные в настоящем описании в контексте отдельных вариантов осуществления, также могут быть реализованы в комбинации в одном варианте осуществления. И наоборот, различные признаки, описанные в контексте одного варианта осуществления, также могут быть реализованы во множестве вариантов осуществления по отдельности или в любой подходящей подкомбинации. Кроме того, хотя признаки могут быть описаны выше как действующие в определенных комбинациях, и даже изначально включенные в формулу изобретения в таком качестве, один или более признаков из заявленной комбинации могут в некоторых случаях быть исключены из комбинации, а заявленная комбинация может относится к подкомбинации или варианту подкомбинации.
[0204] Аналогичным образом, хотя операции изображены на чертежах в конкретном порядке, не следует считать, что для достижения желаемых результатов требуется выполнение таких операций в этом конкретном показанном порядке, или в последовательном порядке, или выполнение всех проиллюстрированных операций. В определенных обстоятельствах преимуществом может быть многозадачность и параллельная обработка. Более того, разделение различных компонентов системы в описанных выше вариантах осуществления не следует понимать как необходимость такого разделения во всех вариантах осуществления, и следует понимать, что описанные программные компоненты и системы могут, по существу, быть интегрированы в один программный продукт или упакованы во множество программных продуктов.
[0205] В каждом случае, когда указан конкретный формат файла, в качестве замены могут выступать другие типы или форматы файлов. Например, файл HTML может быть заменен на XML, JSON, простой текст или другие типы файлов. Более того, при упоминании конкретной структуры данных, такой как таблица или хеш-таблица, вместо упомянутой структуры данных можно использовать другие структуры данных (такие как электронные таблицы, реляционные базы данных или структурированные файлы).
ДРУГИЕ ВАРИАНТЫ ОСУЩЕСТВЛЕНИЯ
[0206] Следует понимать, что, хотя настоящее изобретение описано подробно, приводимое выше описание предназначено для иллюстрации и не ограничивает объем настоящего изобретения, который определяется объемом прилагаемой формулы изобретения. Другие аспекты, преимущества и модификации входят в объем следующей формулы изобретения.
[0207] Описаны конкретные варианты осуществления изобретения. Нижеследующая формула изобретения охватывает другие варианты осуществления. Например, этапы, указанные в формуле изобретения, могут быть выполнены в другом порядке и тем не менее достигать желаемых результатов.
[0208] Описан ряд вариантов осуществления. Тем не менее будет очевидно, что возможны различные модификации без отклонения от сущности и объема изобретения. Кроме того, логические потоки, изображенные на фигурах, не требуют показанного определенного или последовательного порядка для достижения желаемых результатов. Кроме того, могут быть предусмотрены и другие этапы, или же этапы могут быть исключены из описанных потоков, и в описанные системы могут быть добавлены или удалены из них другие компоненты. Соответственно, нижеследующая формула изобретения охватывает другие варианты осуществления.

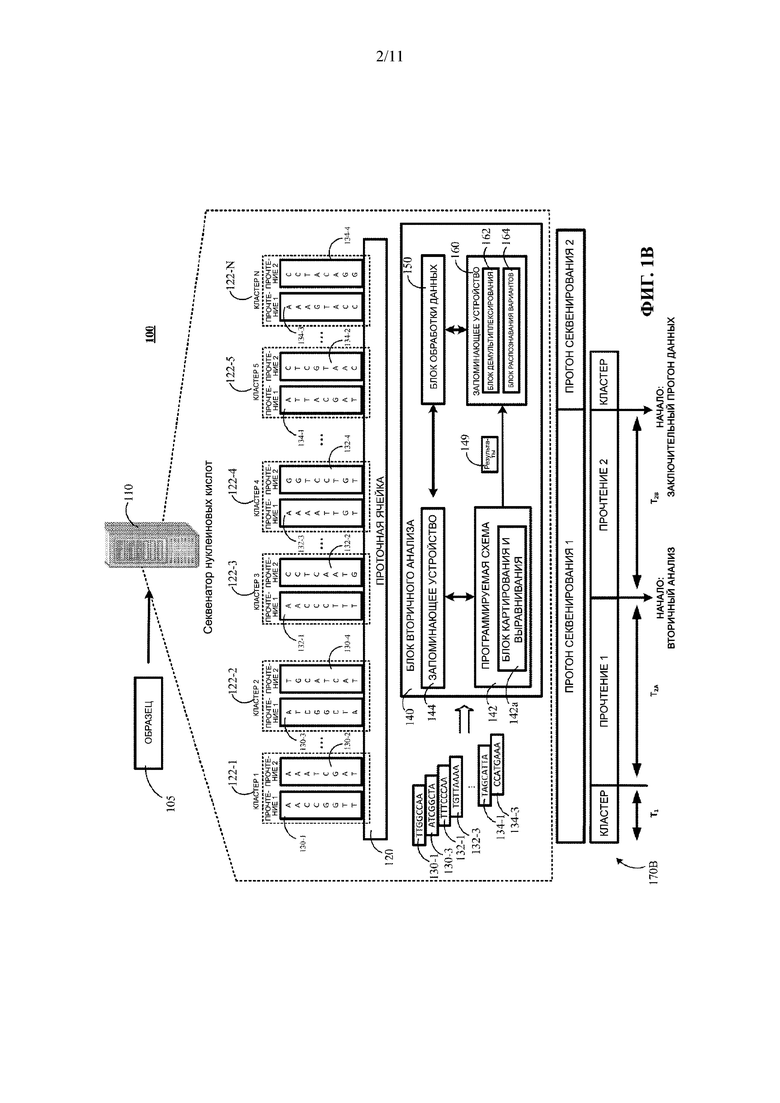

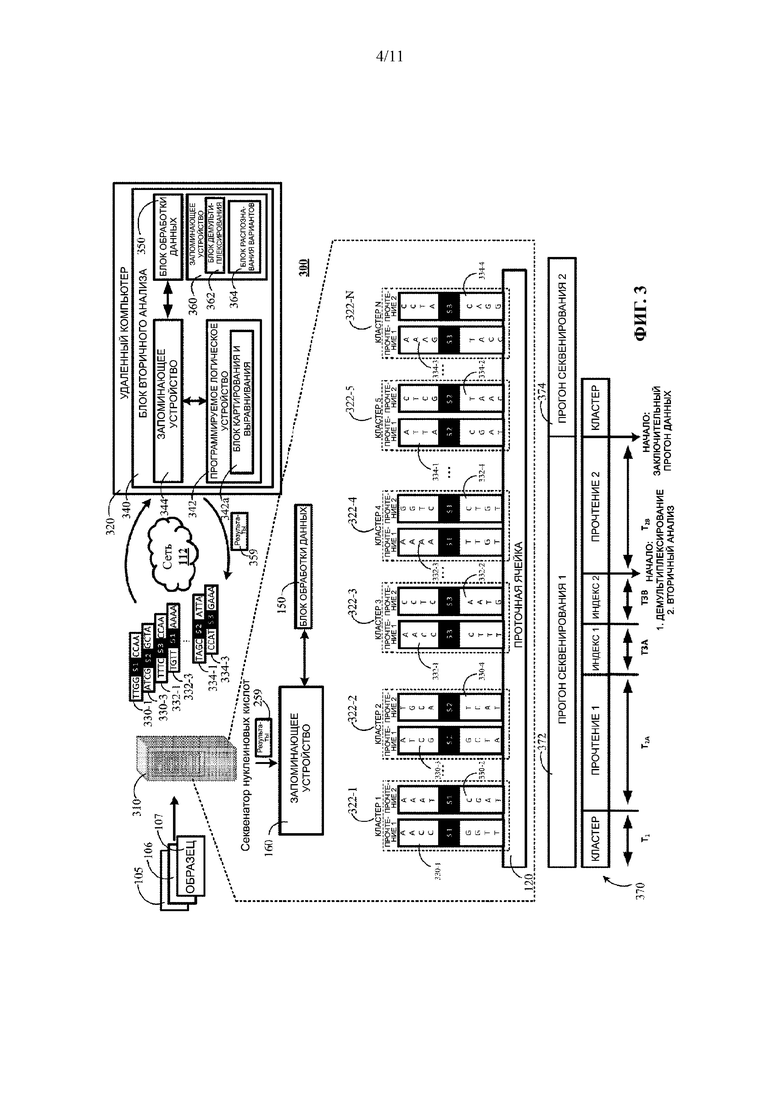






Изобретение относится к биотехнологии. Описан способ выполнения инкрементного вторичного анализа прочтений нуклеотидной последовательности, включающий: (i) получение первых данных, описывающих множество первых прочтений, сгенерированных секвенатором нуклеиновых кислот во время первого интервала прочтения, причем каждое из первых прочтений представляет первую упорядоченную последовательность нуклеотидов; (ii) получение вторых данных, описывающих множество вторых прочтений, сгенерированных секвенатором нуклеиновых кислот во время второго интервала прочтения, выполняемого после первого интервала прочтения, при этом каждое из вторых прочтений представляет вторую упорядоченную последовательность нуклеотидов, причем во время получения вторых данных способ также включает: (a) предоставление секвенатором нуклеиновых кислот первых данных в качестве входных данных блоку картирования и выравнивания; (b) получение от блока картирования и выравнивания результатов выравнивания первых данных, представляющих собой первое множество прочтений, с эталонной последовательностью; и (c) сохранение полученных результатов выравнивания; (d) определение на основе данных, описывающих качество сохраненных результатов выравнивания, необходимости прекращения операции секвенирования; а затем (iii) подачу команды блоку картирования и выравнивания начать выравнивание вторых данных, представляющих второе множество прочтений, с эталонной последовательностью. Раскрыта система для выполнения инкрементного вторичного анализа прочтений нуклеотидной последовательности. Также раскрыт соответствующий машиночитаемый носитель данных. Изобретение расширяет арсенал средств для анализа информации, получаемой с помощью секвенирования. 3 н. и 22 з.п. ф-лы, 10 ил.
1. Способ выполнения инкрементного вторичного анализа прочтений нуклеотидной последовательности, включающий:
(i) получение первых данных, описывающих множество первых прочтений, сгенерированных секвенатором нуклеиновых кислот во время первого интервала прочтения, причем каждое из первых прочтений представляет первую упорядоченную последовательность нуклеотидов;
(ii) получение вторых данных, описывающих множество вторых прочтений, сгенерированных секвенатором нуклеиновых кислот во время второго интервала прочтения, выполняемого после первого интервала прочтения, при этом каждое из вторых прочтений представляет вторую упорядоченную последовательность нуклеотидов, причем во время получения вторых данных способ также включает:
(a) предоставление секвенатором нуклеиновых кислот первых данных в качестве входных данных блоку картирования и выравнивания;
(b) получение от блока картирования и выравнивания результатов выравнивания первых данных, представляющих собой первое множество прочтений, с эталонной последовательностью; и
(c) сохранение полученных результатов выравнивания;
(d) определение на основе данных, описывающих качество сохраненных результатов выравнивания, необходимости прекращения операции секвенирования; а затем
(iii) подачу команды блоку картирования и выравнивания начать выравнивание вторых данных, представляющих второе множество прочтений, с эталонной последовательностью.
2. Способ по п. 1, в котором одно или более первых прочтений включают в себя данные, представляющие первый идентификатор образца, при этом одно или более вторых прочтений включают в себя данные, представляющие второй идентификатор образца, и способ дополнительно включает:
во время получения вторых данных:
организацию одного или более первых прочтений в соответствующие группы на основе по меньшей мере первого идентификатора образца или второго идентификатора образца; и
генерирование статистики организации, причем статистика организации указывает число первых прочтений, соответствующих каждому идентификатору образца.
3. Способ по п. 1, дополнительно включающий:
обеспечение выходных данных, которые представляют сохраненные результаты выравнивания, соответствующие множеству первых прочтений, до или во время выравнивания второй части кластера прочтений.
4. Способ по п. 1, дополнительно включающий:
подачу команды модулю картирования и выравнивания начать дальнейшее выравнивание данных, представляющих первое множество прочтений, с эталонной последовательностью.
5. Способ по п. 1, дополнительно включающий:
во время получения вторых данных определение набора вероятных вариантов для первых данных, представляющих первое множество прочтений, которое было выравнено с эталонной последовательностью.
6. Способ по п. 1, в котором по меньшей мере часть вторых данных, представляющих второе множество прочтений, выравнивают во время того, как получают по меньшей мере другую часть вторых данных, представляющих второе множество прочтений.
7. Способ по п. 1, в котором блок картирования и выравнивания получает команду начать выравнивание вторых данных, представляющих второе множество прочтений, за предварительно заданное число циклов секвенирования до полного получения вторых данных.
8. Система для выполнения инкрементного вторичного анализа прочтений нуклеотидной последовательности, содержащая:
секвенатор нуклеиновых кислот; и
одно или более запоминающих устройств, хранящих команды, которые при исполнении одним или более процессорами секвенатора нуклеиновых кислот приводят к осуществлению секвенатором нуклеиновых кислот операций, включающих:
(i) получение первых данных, описывающих множество первых прочтений, сгенерированных секвенатором нуклеиновых кислот во время первого интервала прочтения, причем каждое из первых прочтений представляет первую упорядоченную последовательность нуклеотидов;
(ii) получение вторых данных, описывающих множество вторых прочтений, сгенерированных секвенатором нуклеиновых кислот во время второго интервала прочтения, выполняемого после первого интервала прочтения, при этом каждое из вторых прочтений представляет вторую упорядоченную последовательность нуклеотидов, причем во время получения вторых данных:
(a) предоставление секвенатором нуклеиновых кислот первых данных в качестве входных данных блоку картирования и выравнивания;
(b) получение от блока картирования и выравнивания результатов выравнивания первых данных, представляющих собой первое множество прочтений, с эталонной последовательностью; и
(c) сохранение полученных результатов выравнивания;
(d) определение на основе данных, описывающих качество сохраненных результатов выравнивания, необходимости прекращения операции секвенирования; а затем
(iii) подачу команды блоку картирования и выравнивания начать выравнивание вторых данных, представляющих второе множество прочтений, с эталонной последовательностью.
9. Система по п. 8, в которой по меньшей мере часть блока картирования и выравнивания реализована с использованием программируемого логического устройства.
10. Система по п. 9, в которой программируемая схема представляет собой программируемую пользователем вентильную матрицу (FPGA).
11. Система по п. 8, в которой по меньшей мере часть блока картирования и выравнивания реализована с использованием интегральной схемы специального назначения (ASIC).
12. Система по п. 8, в которой блок картирования и выравнивания включен в секвенатор нуклеиновых кислот.
13. Система по п. 8, в которой одно или более первых прочтений включают в себя данные, представляющие первый идентификатор образца, при этом одно или более вторых прочтений включают в себя данные, представляющие второй идентификатор образца, причем операции дополнительно включают:
во время получения вторых данных:
организацию одного или более первых прочтений в соответствующие группы на основе по меньшей мере первого идентификатора образца или второго идентификатора образца; и
генерирование статистики организации, причем статистика организации указывает число первых прочтений, соответствующих каждому идентификатору образца.
14. Система по п. 8, причем операции дополнительно включают:
обеспечение выходных данных, которые представляют сохраненные результаты выравнивания, соответствующие множеству первых прочтений, до или во время выравнивания второй части кластера прочтений.
15. Система по п. 8, причем операции дополнительно включают:
подачу команды модулю картирования и выравнивания начать дальнейшее выравнивание данных, представляющих первое множество прочтений, с эталонной последовательностью.
16. Система по п. 8, причем операции дополнительно включают:
во время получения вторых данных определение набора вероятных вариантов для первых данных, представляющих первое множество прочтений, которое было выравнено с эталонной последовательностью.
17. Система по п. 8, причем по меньшей мере часть вторых данных, представляющих второе множество прочтений, выравнивают во время того, как получают по меньшей мере другую часть вторых данных, представляющих второе множество прочтений.
18. Система по п. 8, в которой блок картирования и выравнивания получает команду начать выравнивание вторых данных, представляющих второе множество прочтений за предварительно заданное число циклов секвенирования до полного получения вторых данных.
19. Машиночитаемый носитель данных, на котором хранятся команды, которые при исполнении одним или более компьютерами приводят к выполнению одним или более компьютерами операций, включающих:
(i) получение первых данных, описывающих множество первых прочтений, сгенерированных секвенатором нуклеиновых кислот во время первого интервала прочтения, причем каждое из первых прочтений представляет первую упорядоченную последовательность нуклеотидов;
(ii) получение вторых данных, описывающих множество вторых прочтений,
сгенерированных секвенатором нуклеиновых кислот во время второго интервала прочтения, выполняемого после первого интервала прочтения, при этом каждое из вторых прочтений представляет вторую упорядоченную последовательность нуклеотидов, причем во время получения вторых данных:
(a) предоставление секвенатором нуклеиновых кислот первых данных в качестве входных данных блоку картирования и выравнивания;
(b) получение от блока картирования и выравнивания результатов выравнивания первых данных, представляющих собой первое множество прочтений, с эталонной последовательностью; и
(c) сохранение полученных результатов выравнивания;
(d) определение на основе данных, описывающих качество сохраненных результатов выравнивания, необходимости прекращения операции секвенирования; а затем
(iii) подачу команды блоку картирования и выравнивания начать выравнивание вторых данных, представляющих второе множество прочтений, с эталонной последовательностью.
20. Машиночитаемый носитель данных по п. 19, в котором одно или более первых прочтений включают в себя данные, представляющие первый идентификатор образца, при этом одно или более вторых прочтений включают в себя данные, представляющие второй идентификатор образца, причем операции дополнительно включают:
во время получения вторых данных:
организацию одного или более первых прочтений в соответствующие группы на основе по меньшей мере первого идентификатора образца или второго идентификатора образца; и
генерирование статистики организации, причем статистика организации указывает число первых прочтений, соответствующих каждому идентификатору образца.
21. Машиночитаемый носитель данных по п. 19, причем операции дополнительно включают:
обеспечение выходных данных, которые представляют сохраненные результаты выравнивания, соответствующие множеству первых прочтений, до или во время выравнивания второй части кластера прочтений.
22. Машиночитаемый носитель данных по п. 19, причем операции дополнительно включают:
подачу команды модулю картирования и выравнивания начать дальнейшее выравнивание данных, представляющих первое множество прочтений, с эталонной последовательностью.
23. Машиночитаемый носитель данных по п. 19, причем операции дополнительно включают:
во время получения вторых данных определение набора вероятных вариантов для первых данных, представляющих первое множество прочтений, которое было выравнено с эталонной последовательностью.
24. Машиночитаемый носитель данных по п. 19, причем по меньшей мере часть вторых данных, представляющих второе множество прочтений, выравнивают во время того, как получают по меньшей мере другую часть вторых данных, представляющих второе множество прочтений.
25. Машиночитаемый носитель данных по п. 19, причем блок картирования и выравнивания получает команду начать выравнивание вторых данных, представляющих второе множество прочтений, за предварительно заданное число циклов секвенирования до полного получения вторых данных.
| WO 2018068014 A1, 12.04.2018 | |||
| WO 2016179437 A1, 10.11.2016 | |||
| RU 2016141308 A, 22.05.2018. |

