Область техники
Область техники относится в целом к способам представления данных секвенирования генома, полученных секвенатором, а в частности к реализованным на компьютере способам сжатия таких данных секвенирования генома. В описании предложен способ сжатия на основе эталонной последовательности, который обеспечивает быстрое сжатие и распаковку, в то же время исключая потерю информации, и который имеет высокий коэффициент сжатия.
Предпосылки создания изобретения
В настоящее время секвенаторы следующего поколения генерируют большие объемы данных секвенирования по доступной цене. Современные системы за один цикл продолжительностью 36 ч генерируют более 6 миллиардов последовательностей длиной 150 нуклеотидов, что достаточно для секвенирования 20 полных геномов человека. В результате этого открывается множество новых перспектив для диагностики генетических заболеваний или разработки персонализированной медицины, целью которой является адаптация лечения с учетом специфики генома человека.
Однако также возникают новые проблемы, в частности, связанные со стоимостью хранения больших объемов данных. Самым распространенным форматом файла для исходных (без выравнивания) данных последовательности является формат FASTQ, в котором хранятся данные последовательности (строка нуклеотидов А, С, Т, G, также называемая прочтением), значения качества (вероятности ошибки платформы секвенирования в последовательности для каждого нуклеотида) и названия последовательностей. Это обычный текстовой файл ASCII, который часто сжимают с помощью стандартного алгоритма сжатия LZ (алгоритм Lempel-Ziv, реализованный в программном обеспечении gzip). Тем не менее использование таких способов сжатия сопряжено с рядом проблем:
- низкий коэффициент сжатия, поскольку не в полной мере используется повторяемость данных;
- медленное сжатие и распаковка.
Также существуют способы сжатия, специально разработанные для кодирования FASTQ, которые подразделяются на использующие эталонную последовательность и не использующие ее. Тем не менее ни один из них в полной мере не удовлетворяет требованиям, поскольку а) способы на основе эталонных последовательностей обеспечивают оптимальные коэффициенты сжатия, но они медленные, b) способы без эталонных последовательностей быстрее, но имеют меньшие коэффициенты сжатия. Примером такого способа без эталонных последовательностей является программное обеспечение SPRING, которое представляет собой программу сжатия без эталонных последовательностей для файлов FASTQ (адрес в Интернете: github.com/shubhamchandak94/SPRING). Однако способ сжатия, предлагаемый программным обеспечением SPRING, имеет низкий коэффициент сжатия.
Предложен ряд способов, относящихся к способам сжатия с эталонными последовательностями, где применяются выравнивания последовательностей и которые должны работать быстрее с хорошими коэффициентами сжатия. Однако такие способы страдают от ряда проблем, причем особенно серьезной проблемой является то, что они не позволяют полностью исключить потери. Такой известный способ сжатия на основе эталонной последовательности, например, описан в патентном документе WO 2018/068829 А1. В описанном способе после выравнивания с одной или более эталонными последовательностями последовательности нуклеотидов классифицируются в соответствии со степенями точности соответствия (создавая таким образом классы выравненных прочтений), а затем кодируются в виде множества слоев элементов синтаксиса с использованием разных исходных моделей и энтропийных кодеров для каждого слоя, в которые осуществляется разделение данных. Таким образом, классы данных кодируются раздельно и структурируются в разные слои элементов синтаксиса, при этом каждый слой включает в себя дескрипторы, которые уникальным образом отражают классифицированные и выравненные прочтения указанного слоя. Способ предназначен для того, чтобы получать источники четкой информации с пониженной энтропией информации, таким образом обеспечивая увеличение показателей сжатия, а также выборочный доступ к конкретным классам сжатых данных. Однако такой способ сжатия приводит к переупорядочению прочтений в таком порядке, который отличается от получаемого в конце стадии выравнивания прочтений (т.е. изменяется порядок прочтений в соответствии с их классами). Поэтому в процессе сжатия теряется определенная информация, в особенности порядок исходной последовательности. Таким образом, это может влиять на воспроизводимость некоторых результатов анализа, поскольку некоторые программы последующего анализа могут зависеть от порядка прочтений. Кроме того, распаковка данных в порядке, который отличается от исходного порядка прочтений, в значительной степени усложняет проверку идентичности распакованного файла с исходным файлом. Более того, такой способ сжатия является сравнительно медленным, в особенности в сравнении с существующими в данной области техники способами сжатия без эталонной последовательности.
Изложение сущности изобретения
Настоящее изобретение решает проблему существующих технологий предшествующего уровня техники путем обеспечения систем, способов, компьютерных программ и аппаратных схем для сжатия данных последовательности генома. В одном аспекте реализованные на компьютере способы сжатия данных последовательности генома, полученных с помощью секвенатора, в которых указанные данные последовательности генома включают в себя прочтения последовательностей нуклеотидов или оснований, которые были выравнены с эталонной последовательностью, с формированием таким образом выравненных прочтений, при этом указанные выравненные прочтения хранятся в виде списка прочтений в исходном файле, включают в себя стадии, на которых:
- определяют для каждого выравненного прочтения, насколько точно или неточно указанное прочтение сопоставляется с указанной эталонной последовательностью, или же указанное прочтение не сопоставляется с указанной эталонной последовательностью,
- кодируют прочтения в соответствии с указанным определением, причем прочтения, которые определены как точно сопоставленные, кодируются в соответствии с первым процессом кодирования, а прочтения, которые определены как несопоставленные, кодируются в соответствии со вторым процессом кодирования,
- при этом стадия определения для каждого неточно сопоставленного прочтения включает в себя сравнение количества несоответствий между указанным прочтением и указанной эталонной последовательностью с учетом порогового значения,
- при этом на стадии кодирования прочтения, которые определены как неточно сопоставленные, кодируются в соответствии со вторым процессом кодирования или с третьим процессом кодирования, при этом неточно сопоставленные прочтения кодируются в соответствии со вторым процессом кодирования, если указанное количество несоответствий превышает пороговое значение, а если указанное количество несоответствий меньше порогового значения, то такие неточно сопоставленные прочтения кодируются в соответствии с третьим процессом кодирования,
- при этом в указанном втором процессе кодирования каждый нуклеотид или основание прочтения кодируются по отдельности,
- при этом указанные первый и третий процессы кодирования включают в себя четко заданные наборы дескрипторов, и каждый набор дескрипторов уникальным образом представляет прочтения, связанные с соответствующим процессом кодирования, и каждый из указанных первого и третьего процессов кодирования представляет собой процесс кодирования с понижением энтропии источника информации.
Настоящее изобретение позволяет преодолеть недостатки способов сжатия предшествующего уровня техники, что обеспечивает быстрое сжатие и распаковку и одновременно исключает потерю информации и обеспечивает высокий коэффициент сжатия. Более конкретно, в настоящем изобретении основное внимание уделяется кодированию наиболее часто встречающихся случаев наиболее компактным образом, даже если это означает применение режимов кодирования со сниженными характеристиками для редких наименее часто встречающихся случаев. Это обеспечивает значительное улучшение показателей сжатия. Более того, благодаря формату представления геномной информации, который используется в настоящем изобретении, сжатие, выполняемое по способам, описанным в настоящем документе, осуществляется быстрее. Не в последнюю очередь настоящее изобретение позволяет сохранить исходный порядок прочтений как таковой и не приводит к переупорядочению прочтений в соответствии с их классами. Следовательно, в ходе процесса не происходит потери информации, что упрощает последующий анализ, а также эффективные проверки конформации после стадии распаковки.
Эти и другие признаки и преимущества настоящего изобретения станут более очевидны из прилагаемых графических материалов и последующего подробного описания. Кроме того, несмотря на то что в настоящем документе могут упоминаться превышенные или не превышенные пороговые значения, следует понимать, что такие пороговые значения могут концептуально использоваться так, чтобы определить, удовлетворяется ли, соблюдается ли или регистрируется ли иным образом такое пороговое значение, независимо от того, описываются ли величины или значения, используемые для оценки таких пороговых значений, с использованием положительных или отрицательных значений.
В соответствии с одним инновационным аспектом настоящего описания раскрыт способ сжатия данных геномной последовательности. В одном аспекте способ может включать в себя выполнение одной или более операций посредством исполнения инструкций программного обеспечения одним или более компьютерами, при этом операции включают в себя получение одним или более компьютерами записи прочтения; определение одним или более компьютерами соответствия записи прочтения такому прочтению, которое точно сопоставляется с эталонной последовательностью или неточно сопоставляется с эталонной последовательностью; на основании определения одним или более компьютерами соответствия записи прочтения такому прочтению, которое неточно сопоставляется с эталонной последовательностью, определение одним или более компьютерами того, насколько количество несоответствий неточно сопоставленного прочтения удовлетворяет заданному пороговому количеству несоответствий; и на основании определения того, что количество несоответствий удовлетворяет заданному пороговому количеству несоответствий, кодирование одним или более компьютерами каждого несоответствия неточно сопоставленного прочтения в запись размером 1 байт.
Другие аспекты включают в себя соответствующие системы, аппарат и компьютерные программы для выполнения операций из способов, описанных в настоящем документе, согласно определению в инструкциях, закодированных на машиночитаемых устройствах хранения данных.
Эти и другие версии могут необязательно включать в себя один или более из приведенных ниже признаков. Например, в некоторых вариантах реализации определение одним или более компьютерами того, насколько количество несоответствий неточно сопоставленного прочтения удовлетворяет заданному пороговому количеству несоответствий, может включать в себя определение одним или более компьютерами того, превышает ли количество несоответствий неточно сопоставленных прочтений заданное пороговое количество несоответствий.
В некоторых вариантах реализации каждая запись прочтения может включать в себя данные, указывающие на абсолютное положение начала выравненного прочтения по отношению к эталонной последовательности, данные, указывающие на точное или неточное сопоставление прочтения, данные, указывающие на длину прочтения, данные, указывающие на точное или неточное сопоставление прочтения, данные, указывающие на количество несоответствий, выявленных в прочтении, и данные, указывающие на относительное положение каждого из указанных возможных несоответствий в прочтении.
В некоторых вариантах реализации кодирование каждого несоответствия неточно сопоставленного прочтения в запись размером 1 байт для каждого конкретного несоответствия включает в себя: кодирование одним или более компьютерами первых двух битов байта, чтобы включить данные, представляющие альтернативный нуклеотид или основание, присутствующие в прочтении вместо соответствующего эталонного нуклеотида или основания в эталонной последовательности; и кодирование одним или более компьютерами шести остальных битов байта, чтобы включить данные, представляющие положение несоответствия в эталонной последовательности, при этом указанное положение вычисляется в виде смещения относительно предыдущего несоответствия прочтения.
В некоторых вариантах реализации способ может дополнительно включать в себя определение одним или более компьютерами того, превышает ли смещение максимальное кодируемое значение, и на основании определения того, что смещение превышает максимальное кодированное значение, вставку одним или более компьютерами по меньшей мере одного фиктивного несоответствия между конкретным несоответствием и предыдущим несоответствием.
В некоторых вариантах реализации на основании определения того, что количество несоответствий не удовлетворяет заданному пороговому количеству несоответствий, кодирование одним или более компьютерами списка положений эталонной последовательности, соответствующих положению каждого из несоответствий относительно эталонной последовательности, с использованием процесса кодирования с понижением энтропии информации.
В некоторых вариантах реализации на основании определения того, что запись прочтения соответствует прочтению, которое точно сопоставляется с эталонной последовательностью, способ может дополнительно включать в себя кодирование одним или более компьютерами по меньшей мере участка записи прочтения с использованием кодирования с понижением энтропии информации.
В некоторых вариантах реализации один или более компьютеров могут включать в себя один или более аппаратных процессоров.
В некоторых вариантах реализации один или более аппаратных процессоров могут включать в себя одну или более программируемых пользователем вентильных матриц (FPGA).
В некоторых вариантах реализации способ сжатия данных геномной последовательности может быть реализован с помощью одного или более аппаратных процессоров. В таких вариантах реализации аппаратные процессоры могут включать в себя аппаратную систему обработки, которая выполнена с возможностью выполнения одной или более операций. В одном аспекте операции могут включают в себя получение аппаратной системой обработки записи прочтения; определение аппаратной системой обработки соответствия записи прочтения такому прочтению, которое точно сопоставляется с эталонной последовательностью или неточно сопоставляется с эталонной последовательностью; на основании определения аппаратной системой обработки соответствия записи прочтения такому прочтению, которое неточно сопоставляется с эталонной последовательностью, определение аппаратной системой обработки того, насколько количество несоответствий неточно сопоставленного прочтения удовлетворяет заданному пороговому количеству несоответствий; и на основании определения того, что количество несоответствий удовлетворяет заданному пороговому количеству несоответствий, кодирование аппаратной системой обработки каждого несоответствия неточно сопоставленного прочтения в запись размером 1 байт.
В некоторых вариантах реализации каждая запись прочтения может содержать данные, указывающие на абсолютное положение начала выравненного прочтения по отношению к эталонной последовательности, данные, указывающие на точное или неточное сопоставление прочтения, данные, указывающие на длину прочтения, данные, указывающие на точное или неточное сопоставление прочтения, данные, указывающие на количество несоответствий, выявленных в прочтении, и данные, указывающие на относительное положение указанных возможных несоответствий в прочтении.
В некоторых вариантах реализации определение аппаратной системой обработки того, насколько количество несоответствий неточно сопоставленного прочтения удовлетворяет заданному пороговому количеству несоответствий, может включать в себя определение аппаратной системой обработки того, превышает ли количество несоответствий неточно сопоставленных прочтений заданное пороговое количество несоответствий.
В некоторых вариантах реализации кодирование каждого несоответствия неточно сопоставленного прочтения в запись размером 1 байт для каждого конкретного несоответствия может включать в себя кодирование аппаратной системой обработки первых двух битов байта, чтобы включить данные об альтернативном нуклеотиде или основании, присутствующем в прочтении вместо соответствующего эталонного нуклеотида или основания эталонной последовательности; и кодирование аппаратной системой обработки шести остальных битов байта, чтобы включить данные о положении несоответствия в эталонной последовательности, при этом указанное положение вычисляется как смещение относительно предыдущего несоответствия прочтения.
В некоторых вариантах реализации аппаратная система обработки дополнительно выполнена с возможностью выполнения операций, которые включают в себя определение аппаратной системой обработки, превышает ли смещение максимальное кодируемое значение, и на основании определения того, что смещение превышает максимальное кодированное значение, вставку аппаратной системой обработки по меньшей мере одного фиктивного несоответствия между конкретным несоответствием и предыдущим несоответствием.
В некоторых вариантах реализации на основании определения того, что количество несоответствий не удовлетворяет заданному пороговому количеству несоответствий, аппаратная система обработки дополнительно выполнена с возможностью выполнять операции, которые включают в себя кодирование аппаратной системой обработки списка положений эталонной последовательности, соответствующих положению каждого из несоответствий относительно эталонной последовательности, с использованием процесса кодирования с понижением энтропии информации.
В некоторых вариантах реализации на основании определения того, что запись прочтения соответствует прочтению, которое точно сопоставляется с эталонной последовательностью, аппаратная система обработки дополнительно выполнена с возможностью выполнять операции, которые включают в себя кодирование аппаратной системой обработки по меньшей мере участка записи прочтения с использованием кодирования с понижением энтропии информации.
В некоторых вариантах реализации аппаратная система обработки включает в себя одну или более программируемых пользователем вентильных матриц (FPGA).
В соответствии с другим инновационным аспектом настоящего изобретения описан способ сжатия данных геномной последовательности. В одном аспекте способ может включать в себя операции получения доступа с помощью одного или более процессоров к устройству хранения данных, хранящему множество записей прочтений так, чтобы сохранялся порядок последовательностей записей прочтений, созданный модулем сопоставления и выравнивания, причем для каждой конкретной записи прочтения из множества записей прочтений осуществляется: получение с помощью одного или более процессоров конкретной записи прочтения, определение с помощью одного или более процессоров того, соответствует ли конкретная запись прочтения тому прочтению, которое точно сопоставлено с эталонной последовательностью или неточно сопоставлено с эталонной последовательностью, на основании определения с помощью одного или более процессоров того, что конкретная запись прочтения соответствует прочтению, которое неточно сопоставлено с эталонной последовательностью, определение с помощью одного или более процессоров того, насколько количество несоответствий неточно сопоставленного прочтения удовлетворяет заданному пороговому количеству несоответствий, кодирование с помощью одного или более процессоров каждого несоответствия неточно сопоставленного прочтения в сжатую запись, имеющую заданный размер сжатой записи, и сохранение с помощью одного или более процессоров сжатой записи в устройстве хранения данных при сохранении порядка последовательности записей прочтения.
Другие аспекты включают в себя соответствующие системы, аппарат и компьютерные программы для выполнения операций из способов, описанных в настоящем документе, согласно определению в инструкциях, закодированных на машиночитаемых устройствах хранения данных.
Эти и другие версии могут необязательно включать в себя один или более из приведенных ниже признаков. Например, в некоторых вариантах реализации каждая запись прочтения из множества записей прочтений может включать в себя данные, указывающие на абсолютное положение начала выравненного прочтения по отношению к эталонной последовательности, данные, указывающие на длину прочтения, данные, указывающие на точное или неточное сопоставление прочтения, данные, указывающие на количество несоответствий, выявленных в прочтении, данные, указывающие на то, включает ли прочтение по меньшей мере одно неопределенное основание N, данные, указывающие на количество неопределенных оснований N в прочтении, данные, указывающие на то, является прочтение сопоставленным или несопоставленным, данные, указывающие на положение записи прочтения в последовательности записей прочтений, выводимой модулем сопоставления и выравнивания, и данные, указывающие на относительное положение указанных возможных несоответствий в прочтении.
В некоторых вариантах реализации заданный размер сжатой записи составляет один байт.
В некоторых вариантах реализации кодирование каждого несоответствия неточно сопоставленного прочтения в сжатую запись размером один байт может включать в себя кодирование для каждого конкретного несоответствия с помощью одного или более процессоров первых двух битов байта, чтобы включить данные об альтернативном нуклеотиде или основании, присутствующем в прочтении вместо соответствующего эталонного нуклеотида или основания в эталонной последовательности, и кодирование с помощью одного или более процессоров шести остальных битов байта, чтобы включить данные о положении несоответствия в эталонной последовательности, при этом указанное положение вычисляется как смещение относительно предыдущего несоответствия прочтения.
В некоторых вариантах реализации способ может дополнительно включать в себя определение с помощью одного или более процессоров того, превышает ли смещение максимальное кодируемое значение, и на основании определения того, что смещение превышает максимальное кодированное значение, вставку с помощью одного или более процессоров по меньшей мере одного фиктивного несоответствия между конкретным несоответствием и предыдущим несоответствием.
В некоторых вариантах реализации на основании определения того, что количество несоответствий не удовлетворяет заданному пороговому количеству несоответствий, способ может дополнительно включать в себя кодирование с помощью одного или более процессоров списка положений эталонной последовательности, соответствующих положению каждого из несоответствий относительно эталонной последовательности, с использованием способа кодирования с понижением энтропии информации.
В некоторых вариантах реализации на основании определения того, что запись прочтения соответствует прочтению, которое точно сопоставляется с эталонной последовательностью, способ может дополнительно включать в себя кодирование с помощью одного или более процессоров по меньшей мере участка записи прочтения с использованием кодирования с понижением энтропии информации.
В некоторых вариантах реализации определение с помощью одного или более компьютеров того, удовлетворяет ли количество несоответствий неточно сопоставленного прочтения заданному пороговому количеству несоответствий, может включать в себя определение с помощью одного или более процессоров того, превышает ли количество несоответствий неточно сопоставленных прочтений эталонное пороговое значение количества несоответствий.
В соответствии с другим инновационным аспектом настоящего изобретения описан аппаратный процессор. В одном аспекте аппаратный процессор может включать в себя аппаратную систему обработки, которая выполнена с возможностью выполнения одной или более операций. В одном аспекте операции, с возможностью осуществления которых выполнена аппаратная система обработки, включают в себя получение доступа аппаратной системой обработки к устройству хранения данных, хранящему множество записей прочтений, так, чтобы сохранялся порядок последовательностей записей прочтений, созданный модулем сопоставления и выравнивания, причем для каждой конкретной записи прочтения из множества записей прочтений операции могут включать в себя: получение аппаратной системой обработки записи прочтения; определение аппаратной системой обработки соответствия конкретной записи прочтения такому прочтению, которое точно сопоставляется с эталонной последовательностью или неточно сопоставляется с эталонной последовательностью; на основании определения аппаратной системой обработки соответствия конкретной записи прочтения такому прочтению, которое неточно сопоставляется с эталонной последовательностью, определение аппаратной системой обработки того, насколько количество несоответствий неточно сопоставленного прочтения удовлетворяет заданному пороговому количеству несоответствий; и на основании определения того, что количество несоответствий удовлетворяет заданному пороговому количеству несоответствий, кодирование аппаратной системой обработки каждого несоответствия неточно сопоставленного прочтения в сжатую запись, имеющую заданный размер сжатой записи, и сохранение аппаратной системой обработки сжатой записи в устройстве хранения данных при сохранении порядка последовательности записей прочтения.
Эти и другие версии могут необязательно включать в себя один или более из приведенных ниже признаков. Например, в некоторых вариантах реализации каждая запись прочтения из множества записей прочтений, к которым может получать доступ аппаратная система обработки, может включать в себя данные, указывающие на абсолютное положение начала выравненного прочтения по отношению к эталонной последовательности, данные, указывающие на длину прочтения, данные, указывающие на точное или неточное сопоставление прочтения, данные, указывающие на количество несоответствий, выявленных в прочтении, данные, указывающие на то, включает ли прочтение по меньшей мере одно неопределенное основание N, данные, указывающие на количество неопределенных оснований N в прочтении, данные, указывающие на то, является прочтение сопоставленным или несопоставленным, данные, указывающие на положение записи прочтения в последовательности записей прочтений, выводимой модулем сопоставления и выравнивания, и данные, указывающие на относительное положение указанных возможных несоответствий в прочтении.
В некоторых вариантах реализации заданный размер сжатой записи, созданной аппаратной системой обработки, может составлять один байт.
В некоторых вариантах реализации кодирование каждого несоответствия неточно сопоставленного прочтения в сжатую запись размером один байт для каждого конкретного несоответствия может включать в себя: кодирование аппаратной системой обработки первых двух битов байта, чтобы включить данные об альтернативном нуклеотиде или основании, присутствующем в прочтении вместо соответствующего эталонного нуклеотида или основания эталонной последовательности; и кодирование аппаратной системой обработки шести остальных битов байта, чтобы включить данные о положении несоответствия в эталонной последовательности, при этом указанное положение вычисляется как смещение относительно предыдущего несоответствия прочтения.
В некоторых вариантах реализации аппаратный процессор может быть дополнительно выполнен с возможностью включения аппаратной системы обработки, выполненной с возможностью выполнения операций, которые включают в себя определение аппаратной системой обработки того, превышает ли смещение максимальное кодируемое значение, и на основании определения того, что смещение превышает максимальное кодированное значение, вставку аппаратной системой обработки по меньшей мере одного фиктивного несоответствия между конкретным несоответствием и предыдущим несоответствием.
В некоторых вариантах реализации аппаратный процессор может быть дополнительно выполнен с возможностью включения аппаратной системы обработки, выполненной с возможностью осуществления операций, которые включают в себя на основании определения того, что количество несоответствий не удовлетворяет заданному пороговому количеству несоответствий, кодирование аппаратной системой обработки списка положений эталонной последовательности, соответствующих положению каждого из несоответствий относительно эталонной последовательности, с использованием способа кодирования с понижением энтропии информации.
В некоторых вариантах реализации аппаратный процессор может быть дополнительно выполнен с возможностью включения аппаратной системы обработки, выполненной с возможностью осуществления операций, которые включают в себя на основании определения того, что запись прочтения соответствует прочтению, которое точно сопоставляется с эталонной последовательностью, кодирование аппаратной системой обработки по меньшей мере участка записи прочтения с использованием кодирования с понижением энтропии информации.
В некоторых вариантах реализации определение аппаратной системой обработки того, удовлетворяет ли количество несоответствий неточно сопоставленного прочтения заданному пороговому количеству несоответствий, включает в себя:
определение аппаратной системой обработки того, превышает ли количество несоответствий неточно сопоставленного прочтения заданное пороговое количество несоответствий.
В соответствии с другим инновационным аспектом настоящего описания реализованный на компьютере способ сжатия данных последовательности генома, полученных с помощью секвенатора, причем указанные данные последовательности генома включают в себя прочтения последовательностей нуклеотидов или оснований, которые были выравнены с эталонной последовательностью, с формированием таким образом выравненных прочтений, при этом указанные выравненные прочтения хранятся в виде списка прочтений в исходном файле. В одном аспекте способ может включать в себя действия для каждого выравненного прочтения, определение того, насколько точно или неточно указанное прочтение сопоставляется с указанной эталонной последовательностью, или же установление того, что указанное прочтение не сопоставляется с указанной эталонной последовательностью; кодирование прочтения в соответствии с указанным определением, при этом те прочтения, которые отнесены к точно сопоставленным, кодируются в соответствии с первым процессом кодирования, а те прочтения, которые отнесены к неточно сопоставленным, кодируется в соответствии со вторым процессом кодирования, при этом стадия определения для каждого неточно сопоставленного прочтения включает в себя сравнение количества несоответствий между указанным прочтением и указанной эталонной последовательностью с учетом порогового значения, при этом на стадии кодирования те прочтения, которые определены как неточно сопоставленные, кодируются в соответствии со вторым процессом кодирования или с третьим процессом кодирования, при этом неточно сопоставленные прочтения кодируются в соответствии со вторым процессом кодирования, если указанное количество несоответствий превышает пороговое значение, а если указанное количество несоответствий меньше порогового значения, то такие неточно сопоставленные прочтения кодируются в соответствии с третьим процессом кодирования, при этом в указанном втором процессе кодирования каждый нуклеотид или основание прочтения кодируются по отдельности, при этом указанные первый и третий процессы кодирования включают в себя четко заданные наборы дескрипторов, и каждый набор дескрипторов уникальным образом представляет прочтения, связанные с соответствующим процессом кодирования, и каждый из указанных первого и третьего процессов кодирования представляет собой процесс кодирования с понижением энтропии источника информации.
Другие аспекты включают в себя соответствующие системы, аппарат и компьютерные программы для выполнения операций из способов, описанных в настоящем документе, согласно определению в инструкциях, закодированных на машиночитаемых устройствах хранения данных.
Эти и другие версии могут необязательно включать в себя один или более из приведенных ниже признаков. Например, в некоторых вариантах реализации, если прочтение отнесено к неточно сопоставленным с эталонной последовательностью и его количество несоответствий меньше порогового значения, то стадия определения может включать в себя определение того, насколько глобально или локально прочтение сопоставляется с указанной эталонной последовательностью, и при этом третий процесс кодирования включает в себя первый дополнительный процесс кодирования и второй дополнительный процесс кодирования, при этом те прочтения, которые определены как глобально сопоставленные, кодируются в соответствии с первым дополнительным процессом кодирования, а те прочтения, которые определены как локально сопоставленные, кодируются в соответствии со вторым дополнительным процессом кодирования, причем указанные первый и второй дополнительные процессы кодирования включают в себя четко заданные наборы дескрипторов, при этом каждый набор дескрипторов уникальным образом представляет прочтения, связанные с соответствующим дополнительным процессом кодирования.
В некоторых вариантах реализации указанные дескрипторы указанного первого дополнительного процесса кодирования могут включать в себя стартовое положение выравнивания в эталонной последовательности, длину прочтения и список несоответствий в виде замен символов, и при этом указанные дескрипторы указанного второго дополнительного процесса кодирования включают в себя стартовое положение локального выравнивания в эталонной последовательности, длину прочтения, список несоответствий в виде замен символов, а также длину отсеченных участков, которые не являются частью выравнивания.
В некоторых вариантах реализации на стадии кодирования отсеченные участки прочтения, которые должны кодироваться в соответствии со вторым дополнительным процессом кодирования, конкатенируются, при этом каждый нуклеотид или основание указанных отсеченных участков кодируются по отдельности.
В некоторых вариантах реализации на стадии кодирования каждое несоответствие неточно сопоставленного прочтения кодируется 1 байтом.
В некоторых вариантах реализации на стадии кодирования каждое несоответствие неточно сопоставленного прочтения кодирование выполняется следующим образом: два первых бита байта используются для кодирования альтернативного нуклеотида или основания, присутствующих в прочтении вместо соответствующего эталонного нуклеотида или основания эталонной последовательности; а шесть последних битов байта используются для кодирования положения несоответствия в эталонной последовательности, при этом положение вычисляется как смещение относительно предыдущего несоответствия прочтения.
В некоторых вариантах реализации на стадии кодирования, если смещение, вычисляемое между определенным несоответствием и предшествующим несоответствием больше максимального кодируемого значения, то на стадии кодирования по меньшей мере одно фиктивное несоответствие вставляется между указанными двумя несоответствиями, до тех пор, пока каждое смещение между каждым из указанных несоответствий и указанным по меньшей мере одним фиктивным несоответствием не будет меньше указанного максимального кодируемого значения, при этом фиктивное несоответствие определяется как несоответствие, для которого биты байта используются для кодирования несоответствия или для кодирования нуклеотида или основания, которые равны соответствующему эталонному нуклеотиду или основанию в эталонной последовательности.
В некоторых вариантах осуществления начальная стадия разделения списка прочтений на блоки прочтений, при этом каждый блок начинается с заголовка, содержащего информацию, необходимую для декодирования блока, причем указанный способ сжатия реализуется поблочно.
В некоторых вариантах реализации блоки прочтений характеризуются одинаковым размером блока.
В некоторых вариантах реализации конечной стадией является формирование сжатого файла, содержащего список кодированных прочтений, при этом указанные кодированные прочтения хранятся в сжатом файле в том же порядке, что и прочтения, хранившиеся в исходном файле.
В некоторых вариантах реализации указанное пороговое значение составляет 31.
В некоторых вариантах реализации для каждого выравненного прочтения выполняется стадия определения того, включает ли указанное прочтение по меньшей мере одно несоответствие, соответствующее случаю, когда секвенатор не смог распознать какое-либо основание или нуклеотид.
В некоторых вариантах реализации для каждого прочтения, содержащего по меньшей мере одно несоответствие, соответствующее случаю, когда секвенатор не смог распознать какое-либо основание или нуклеотид, выполняется стадия определения количества таких несоответствий и стадия сопоставления указанного количества с эталонным пороговым значением.
В некоторых вариантах реализации на стадии кодирования, если количество таких несоответствий больше эталонного порогового значения, каждый нуклеотид или основание прочтения, которые должны кодироваться в соответствии со вторым процессом кодирования, индивидуальным образом кодируется в 4 битах, и если количество таких несоответствий меньше эталонного порогового значения, каждый нуклеотид или основание прочтения, которые должны кодироваться в соответствии со вторым процессом кодирования, индивидуальным образом кодируется в 2 битах, а стадия кодирования дополнительно включает в себя кодирование списка положений вдоль эталонной последовательности, причем указанные положения соответствуют положениям таких несоответствий в эталонной последовательности.
Краткое описание графических материалов
На Фиг. 1 представлена блок-схема, иллюстрирующая пример способа сжатия, описанного в настоящем документе.
На Фиг. 1А представлена блок-схема, иллюстрирующая более подробный пример способа сжатия, показанного на Фиг. 1.
На Фиг. 2 представлена схема, иллюстрирующая пример системы для реализации одного или более способов сжатия, описанных в настоящем документе.
На Фиг. 2А представлена схема, иллюстрирующая другой пример системы для реализации способа сжатия, описанного в настоящем документе.
На Фиг. 2В представлена блок-схема, иллюстрирующая пример системы для реализации способа сжатия, описанного в настоящем документе.
На Фиг. 3 представлена схема, иллюстрирующая первый пример прочтения, которое глобально сопоставляется с эталонной последовательностью.
На Фиг. 4 представлена схема, иллюстрирующая второй пример прочтения, которое глобально сопоставляется с эталонной последовательностью, в том случае, когда требуется вставка фиктивного несоответствия.
На Фиг. 5 представлена схема примера вычислительных компонентов, которые можно использовать для реализации системы для осуществления способа сжатия, показанного на ФИГ. 1 и 1А.
На Фиг. 6 представлено множество столбчатых диаграмм, иллюстрирующих экспериментальные результаты настоящего изобретения.
На Фиг. 7 представлено множество столбчатых диаграмм, иллюстрирующих дополнительные экспериментальные результаты настоящего изобретения.
На Фиг. 8 представлено множество столбчатых диаграмм, иллюстрирующих экспериментальные результаты настоящего изобретения.
Подробное описание
К геномным последовательностям, упоминаемым в настоящем изобретении, относятся, для примера и без ограничения, нуклеотидные последовательности, последовательности дезоксирибонуклеиновой кислоты (ДНК), последовательности рибонуклеиновой кислоты (РНК) и аминокислотные последовательности. Несмотря на приведенное в настоящем документе достаточно подробное описание геномной информации в форме нуклеотидной последовательности, следует понимать, что способ сжатия в соответствии с изобретением может быть реализован также и для других геномных последовательностей, хотя и с рядом изменений, как будет очевидно специалисту в данной области.
Информацию о секвенировании генома получают с помощью секвенаторов в форме последовательностей нуклеотидов (или, в более общем случае, оснований), представленной в виде строки букв из определенного набора терминов. Наименьший набор терминов представлен пятью символами: {А, С, G, Т, N}, которые представляют собой 4 типа нуклеотидов, присутствующих в ДНК, а именно аденин, цитозин, гуанин и тимин. В РНК тимин заменен на урацил (U). N указывает на то, что секвенатор не смог распознать какое-либо основание, поэтому истинная природа положения остается неопределенной. Таким образом, для целей настоящего изобретения символ «N» относится к неопределенному основанию, а число «N» в прочтении относится к количеству неопределенных оснований в прочтении.
Нуклеотидные последовательности, получаемые секвенаторами, могут называться «прочтениями». Прочтения последовательностей могут иметь длину от нескольких десятков до нескольких тысяч нуклеотидов. Некоторые технологии позволяют получать прочтения последовательностей в парах, при этом первое прочтение пары относится к одной цепочке ДНК, а второе прочтение пары относится к другой цепочке ДНК. В тексте настоящего описания термин «эталонная последовательность» означает любую последовательность, относительно которой может быть выполнено выравнивание/сопоставление прочтений, содержащих последовательности нуклеотидов или оснований, полученные секвенатором. Одним из примеров такой эталонной последовательности фактически может быть эталонный геном, т.е. последовательность, построенная учеными в качестве репрезентативного примера набора генов того или иного вида. Однако эталонная последовательность может также состоять из синтетической последовательности, сконструированной лишь для того, чтобы улучшить степень сжатия прочтений в связи с их последующей обработкой.
В некоторых случаях секвенаторы могут вносить ошибки в прочтения последовательностей и, в частности, использовать неверный символ (т.е. представляющий другую нуклеиновую кислоту) для обозначения нуклеиновой кислоты или основания, в действительности присутствующего в секвенируемом образце. Этот тип ошибки замены может быть определен модулем сопоставления и выравнивания как «несоответствие». Это связано с тем, что ошибка замены в прочтении может не соответствовать определенному положению относительно эталонной последовательности, когда прочтение было выравнено относительно эталонной последовательности. Однако значение понятия «несоответствие» не ограничивается такими сценариями. Также «несоответствие» может представлять собой любое основание или нуклеотид прочтения, распознанные секвенатором, которые не соответствуют определенному положению относительно эталонной последовательности, когда прочтение было выравнено относительно эталонной последовательности с пороговым уровнем точности. Такие несоответствия могут включать в себя потенциальные варианты, варианты или другие различия между выравненным прочтением и положением относительно эталонной последовательности.
Настоящее изобретение относится к способу сжатия на основе эталонных последовательностей, входные данные которого представляют собой прочтения нуклеотидов или оснований, причем такие прочтения предварительно выравниваются модулем сопоставления и выравнивания относительно эталонной последовательности с получением таким образом выравненных прочтений. В некоторых вариантах реализации ранее выравненные прочтения могут включать в себя прочтения, выравненные с использованием программного модуля сопоставления и выравнивания, который выполняет сопоставление и выравнивание принятых прочтений относительно эталонной последовательности. Например, в некоторых вариантах реализации программный сопоставитель может выполнять на основе хеш-таблицы сопоставление и выравнивание принятых прочтений путем исполнения программных инструкций с использованием одного или более процессоров, таких как одного или более центральных процессоров (ЦП), одного или более графических процессоров (ГП) или любой их комбинации. В других вариантах реализации ранее выравненные прочтения могут включать в себя прочтения, выравненные с использованием аппаратного модуля сопоставления и выравнивания, который выполняет сопоставление и выравнивание принятых прочтений относительно эталонной последовательности. Например, в некоторых вариантах реализации аппаратный модуль сопоставления и выравнивания может выполнять на основе хеш-таблицы сопоставление и выравнивание с использованием одного или более аппаратных процессоров, таких как одной или более программируемых пользователем вентильных матриц (FPGA), имеющих жестко смонтированную цифровую логическую схему, выполненную с возможностью выполнения сопоставления и выравнивания принятых прочтений на основе хеш-таблицы.
Затем выравненные прочтения хранятся в виде списка прочтений в исходном файле. Способ выравнивания прочтений и их хранения в исходном файле после выравнивания не имеет критического значения для изобретения и не входит в цель настоящего описания. После этого каждое прочтение кодируется в виде положения на эталонной последовательности и в виде списка различий с указанной эталонной последовательностью. Затем каждое прочтение может реконструироваться на основе кодированной информации выравнивания и эталонной последовательности с использованием надлежащего программного обеспечения для распаковки, выполненного в соответствии с настоящим изобретением, как описано в настоящем документе.
В некоторых вариантах реализации модуль сжатия настоящего изобретения может быть реализован посредством исполнения программных инструкций одним или более центральными процессорами (ЦП), одного или более графическими процессорами (ГП), исполнения жестко смонтированных цифровых логических схем в одном или более аппаратных процессорах, или комбинации обоих вариантов для обработки и сжатия выравненных прочтений. Прочтения могут быть выравнены относительно эталонной последовательности до сжатия прочтений без учета определенных типов ошибок, внесенных в прочтения последовательностей, таких как, например, ошибки вставки или ошибки делеции. Ошибка вставки проявляется в виде вставки в одно прочтение последовательности одного или более дополнительных символов, которые не относятся к какой-либо фактически присутствующей нуклеиновой кислоте. Ошибка делеции проявляется в виде удаления из одного прочтения последовательности одного или более символов, относящихся к нуклеиновым кислотам, которые фактически присутствуют в секвенированном образце. Точнее, в случае ошибки вставки или ошибки делеции в заданном прочтении последовательности программное обеспечение для выравнивания будет рассматривать полученные ошибочные нуклеиновые кислоты как ошибки замены, также называемые «несоответствиями». Такой предпочтительный выбор для конфигурации программного обеспечения для выравнивания позволяет выполнять более быстрое последующее кодирование, обеспечивая существенно более взвешенный компромисс между скоростью и коэффициентом сжатия.
Для каждого выравненного прочтения модуль сопоставления и выравнивания может генерировать и обеспечивать запись прочтения. В некоторых вариантах реализации каждая запись прочтения может быть обеспечена непосредственно в качестве входных данных в модуль сжатия из модуля сопоставления и выравнивания. В других вариантах реализации каждая запись прочтения, сгенерированная модулем сопоставления и центрирования, может быть выведена и сохранена в запоминающем устройстве или на другом устройстве хранения данных. В таких вариантах реализации модуль сжатия может позднее получать доступ к сохраненным записям прочтения и сжимать хранящиеся записи прочтения.
Каждая запись прочтения, сгенерированная, обеспеченная или сохраненная модулем сопоставления и выравнивания, включает в себя данные, сгенерированные модулем сопоставления и выравнивания, которые описывают прочтение, представленное записью прочтения. Такие записи прочтения могут включать в себя по меньшей мере следующую информацию: абсолютное положение начала выравненного прочтения по отношению к эталонной последовательности, длину прочтения, тип выравнивания прочтения, например, является ли прочтение сопоставленным прочтением или несопоставленным прочтением, количество несоответствий, выявленных в прочтении, данные, указывающие на точное или неточное сопоставление прочтения, данные, указывающие на относительное положение указанных возможных несоответствий в прочтении, или т.п.
Хотя пример, описанный в настоящем документе, указывает на то, что данные в записи прочтения и данные, включенные в них, генерируются модулем сопоставления и выравнивания, этот никоим образом не ограничивает настоящее изобретение. Вместо этого для генерирования записи прочтения и содержащихся в нем данных можно использовать другие промежуточные модули, расположенные между модулем сопоставления и выравнивания и модулем сжатия.
В некоторых вариантах реализации записи прочтений, обеспеченные модулем сопоставления и выравнивания или хранящиеся в нем, могут быть обеспечены или сохранены способом, который сохраняет последовательный порядок записей прочтений, генерируемых модулем сопоставления и выравнивания. Например, в некоторых вариантах реализации каждая запись прочтения может также включать в себя данные, указывающие на положение записей прочтений в последовательном порядке записей прочтений. Такие данные, указывающие на положение записей прочтений, могут включать в себя, например, sequence_id. В некоторых вариантах реализации этот sequence_id может представлять собой, например, число, которое начинается с «1» для первой записи прочтения, созданной модулем сопоставления и выравнивания, и которое затем увеличивается для каждой последующей записи прочтения, генерируемой модулем сопоставления и выравнивания. Затем модуль сжатия настоящего изобретения может получать доступ к этим записям прочтений и сжимать эти записи прочтений в их текущем последовательном порядке без необходимости изменения порядка записи прочтений в кластеры записей прочтений для сжатия. Сжатие записей прочтений таким образом, чтобы сохранить их начальный порядок, в котором они были сгенерированы модулем сопоставления и выравнивания, обеспечивает преимущества по сравнению с традиционными способами, поскольку позволяет сжимать записи прочтений без потерь данных, даже с сохранением последовательного порядка записей прочтений. Кроме того, сохранение порядка записей прочтений во время сжатия также упрощает валидацию сжатия записей прочтений.
Способ сжатия настоящего изобретения будет описан ниже со ссылкой на Фиг. 1. Например, в некоторых вариантах реализации способ может быть выполнен аппаратом 20, показанным на Фиг. 2. Аппарат 20 может включать в себя по меньшей мере один процессор 22 и по меньшей мере одно запоминающее устройство 24, функционально связанное с по меньшей мере одним процессором 22 с образованием вычислительного устройства. В запоминающем устройстве 24 может храниться код компьютерной программы или программное обеспечение 26, содержащее исполняемые на компьютере инструкции, которые при их исполнении процессором 22 приводят к тому, что процессор 22 выполняет операции модуля сжатия, включающие в себя исполнение стадий одного или более из способов сжатия, описанных в настоящем документе. Однако настоящее описание не обязательно ограничивается аппаратом 20.
Например, в некоторых вариантах реализации способы сжатия настоящего изобретения могут быть реализованы с помощью аппарата 20А, показанного на Фиг. 2А. Аппарат 20А аналогичен аппарату 20 в том, что аппарат 20А также включает в себя процессор 22 и по меньшей мере одно запоминающее устройство 24, функционально связанное с по меньшей мере одним процессором 22 с образованием вычислительного устройства. В запоминающем устройстве 24 аппарата 20А также хранится код компьютерной программы или программное обеспечение 26, содержащее исполняемые на компьютере инструкции, которые при их исполнении процессором 22 приводят к тому, что процессор 22 выполняет операции, включающие в себя стадии одного или более способов сжатия, описанных в настоящем документе. Кроме того, однако, аппарат 20А также включает в себя код компьютерной программы или программное обеспечение 28, содержащее исполняемые на компьютере инструкции, которые при их исполнении процессором 22 приводят к тому, что процессор 22 выполняет операции, реализующие функциональные возможности модуля сопоставления и выравнивания. Модуль сопоставления и выравнивания, функциональные возможности которого реализованы посредством исполнения инструкций компьютерной программы, может генерировать одно или более выравненных прочтений 29 и сохранять выравненные прочтения 29 в запоминающем устройстве 24. Затем процессор 22 может исполнять команды 26 программного обеспечения модуля сжатия для получения доступа к одному или более из выравненных прочтений 29 и сжатия одного или более выравненных прочтений 29 с использованием стадий одного или более способов сжатия, описанных в настоящем документе. В некоторых вариантах реализации аппарат 20А может представлять собой секвенатор нуклеиновой кислоты.
В другом примере в некоторых вариантах реализации способы сжатия настоящего изобретения могут быть реализованы с помощью аппарата 20В, показанного на Фиг. 2В. Аппарат 20В отличается от аппарата 20 тем, что аппарат 20В включает в себя один или более аппаратных процессоров 22В, таких как одну или более программируемых пользователем вентильных матриц (FPGA). В этом примере один или более аппаратных процессоров могут реализовывать функциональные возможности стадий одного или более способов сжатия, описанных в настоящем документе, и модуля сопоставления и выравнивания в аппаратной схеме одного или более аппаратных процессоров 22В. Например, аппаратный процессор 22В может включать в себя жестко смонтированные цифровые логические схемы 26В, выполненные в виде модуля сжатия для выполнения стадий одного или более из способов сжатия, описанных в настоящем документе. Аналогичным образом, аппаратный процессор 22В может включать в себя жестко смонтированные цифровые логические схемы 28В, выполненные с возможностью выполнения операций модуля сопоставления и выравнивания, который выполнен с возможностью генерирования выравненного прочтения 29В и сохранения выравненного прочтения 29В в запоминающем устройстве 24. Жестко смонтированные цифровые логические схемы 26В, выполненные в виде модуля сжатия для реализации функциональных возможностей стадий одного или более способов сжатия, описанных в настоящем документе, могут получать доступ к выравненному прочтению 29В из запоминающего устройства 24 и сжимать выравненное прочтение 29В с использованием способов сжатия, описанных в настоящем документе. В некоторых вариантах реализации аппарат 20В может представлять собой секвенатор нуклеиновой кислоты. Исходный файл, в котором хранятся записи выравненных прочтений в виде списка прочтений, например, хранится в запоминающем устройстве аппарата 20. В некоторых вариантах реализации список прочтений может включать в себя множество записей выравненных прочтений, хранящихся в запоминающем устройстве аппарата способом, который сохраняет порядок последовательностей записей прочтений, созданный модулем сопоставления и выравнивания. Этот порядок последовательностей записей выравненных прочтений может быть таким же, как порядок, полученный в конце стадии сопоставления и выравнивания.
В некоторых вариантах реализации исходный список выравненных прочтений может быть разделен на блоки прочтений. Например, в некоторых вариантах реализации список выравненных прочтений может быть разделен на блоки, состоящие из 50000 прочтений. Однако эту конкретную характеристику блоков, состоящих из 50000 прочтений, не следует рассматривать как ограничивающую объем настоящего изобретения, поскольку варианты реализации настоящего изобретения могут быть достигнуты таким же образом с использованием других характеристик.
В некоторых вариантах реализации блоки прочтений могут иметь одинаковый размер блока. Однако в других вариантах реализации блоки прочтений могут иметь различные размеры блоков. В любом случае каждый блок прочтений может начинаться с заголовка, содержащего информацию, необходимую для декодирования блока, такую как, например, размер содержимого блока в байтах, и/или идентификатор блока или его содержимого, и/или количество прочтений, содержащихся в блоке. Таким образом обеспечивается поддержка конкатенации сжатого файла, а также возможностей передачи (каждый блок прочтений содержит всю информацию, необходимую для декодирования прочтений блока). Кроме того, поскольку способ сжатия может осуществляться поблочно, это также позволяет выполнять многопоточную обработку блоков прочтений, таким образом обеспечивая распараллеливание и в результате этого определенный выигрыш по времени обработки. При одинаковой длине всех прочтений заданного блока длина прочтения также сохраняется в заголовке, в противном случае при выполнении способа сжатия в явной форме сохраняется список значений длины каждого прочтения.
Как показано на Фиг. 1, способ предпочтительно включает в себя начальную стадию 2, в которой аппарат получает запись выравненных прочтений из запоминающего устройства аппарата 20, 20А или 20В. В некоторых вариантах реализации это может включать в себя получение доступа с помощью аппарата к запоминающему устройству или другому устройству хранения данных, хранящему множество записей прочтений, способом, который сохраняет порядок последовательностей записей прочтений, созданный модулем сопоставления и выравнивания. Например, аппарат может определять на основе sequence_id предыдущей записи прочтения и sequence_id одной или более других записей прочтений, хранящихся в запоминающем устройстве, следующую запись прочтения для сжатия. В некоторых вариантах реализации sequence_id может представлять собой числовое значение, которое увеличивается для каждой последующей записи прочтения, генерируемой модулем сопоставления и выравнивания, а модуль сжатия может содержать счетчик, показания которого увеличиваются для каждой итерации процесса сжатия, показанного на ФИГ. 1, и обеспечивать указание на следующую запись прочтения, которая должна быть доступна на стадии 2.
Каждая запись прочтения содержит информацию о типе выравнивания прочтения. Информация о типе выравнивания прочтения может включать в себя любую информацию, которая описывает уровень сопоставления и выравнивания прочтения в эталонном геноме. В некоторых вариантах реализации типы выравнивания могут включать в себя точное выравнивание, неточное выравнивание или выравнивание «несопоставленного» прочтения. «Точное выравнивание» или «точно сопоставленное прочтение» может включать в себя прочтение, в котором каждый нуклеотид прочтения сопоставлен и выравнен по отношению к участку эталонного генома. В некоторых вариантах реализации «точное выравнивание» или «точно сопоставленное прочтение» может иметь нуль несоответствий и нуль неопределенных оснований «N». В других вариантах реализации «точное выравнивание» или «точно сопоставленное» прочтение может иметь нуль несоответствий, но потенциально одно или более неопределенных оснований «N». В общем случае определение «неточного выравнивания» или «неточно сопоставленного прочтения» зависит от значения «точно сопоставленного прочтения», реализованного в конкретном варианте реализации способов сжатия, описанных в настоящем документе. Если, например, используется вариант реализации, в котором точно сопоставленное прочтение может содержать нуль несоответствий и нуль неопределенных оснований N, то «неточное выравнивание» или «неточно сопоставленное прочтение» означает любое прочтение, которое соответствует по меньшей мере участку эталонной последовательности и включает в себя по меньшей мере одно несоответствие или по меньшей мере одно N. Однако если, например, используются варианты реализации, в которых точно сопоставленное прочтение может содержать нуль несоответствий по одному или более N, то «неточное выравнивание» или «неточно сопоставленное прочтение» означает любое прочтение, имеющее по меньшей мере одно несоответствие, отличное от неописанного основания N, тогда как по меньшей мере участок прочтения соответствует участку эталонной последовательности (в соответствии с другим данным определением неточно сопоставленного прочтения, где неточно сопоставленное прочтение может содержать одно или более N, при условии, что оно также содержит одно или более других несоответствий). Таким образом, то, каким образом какая-либо конкретная система или вариант реализации выполнен с возможностью распознавания точно сопоставленных прочтений, определяет значение неточно сопоставленных прочтений для этого варианта реализации. «Несопоставленное прочтение» может включать в себя прочтение, которое не было сопоставлено или выравнено с эталонным геномом.
В некоторых вариантах реализации каждая запись прочтения содержит множество битовых флагов, которые описывают атрибуты прочтения. В некоторых вариантах реализации множество битовых флагов можно хранить с использованием одного или более полей в начале записи прочтения. Однако в других вариантах реализации для хранения множества битовых флагов можно использовать другие поля записи прочтения. Каждый битовый флаг из множества битовых флагов может использовать одно из множества значений для указания значения соответствующего ему атрибута прочтения. В некоторых вариантах реализации для указания значений атрибутов прочтения для записи прочтения могут использоваться следующие битовые флаги:
- первый битовый флаг указывает на прямую или обратную ориентацию относительно эталонной последовательности,
- второй битовый флаг указывает на то, является ли выравнивание точным,
- третий битовый флаг указывает на то, содержит ли прочтение по меньшей мере одно N,
- четвертый битовый флаг указывает на разрядность кодирования данных о положении - 16 битов или 32 бита.
- пятый битовый флаг указывает на то, является ли прочтение сопоставленным или несопоставленным.
Следующие стадии 4-12 выполняются для каждого прочтения из множества прочтений. Если прочтения сгруппированы в блоки, то стадии 4-12 выполняются для каждого прочтения из каждого блока прочтений.
Способ сжатия настоящего изобретения может включать в себя следующую стадию 4 определения с помощью аппарата 20, 20А или 20В для каждого выравненного прочтения того, является ли указанное прочтение точно сопоставленным с эталонной последовательностью, неточно сопоставленным с эталонной последовательностью, или что указанное прочтение не сопоставлено с эталонной последовательностью. В некоторых вариантах реализации аппарат 20, 20А, 20В на основании информации, принятой от модуля сопоставления и выравнивания, может определять, является ли прочтение точно сопоставленным, неточно сопоставленным или несопоставленным прочтением. Эта информация может включать в себя информацию, такую как, например, является ли прочтение, представленное принятой записью прочтения, сопоставленным или несопоставленным, является ли прочтение, представленное принятой записью прочтения, точно сопоставленным или неточно сопоставленным, указание количества общих несоответствий, таких как варианты или ошибки секвенирования, неопределенные основания или любая их комбинация. В некоторых вариантах реализации эта информация может быть включена в саму полученную запись прочтения.
В некоторых вариантах реализации аппарат 20, 20А или 20В может сначала определять, является ли выравненное прочтение сопоставленным или несопоставленным. Если аппарат 20, 20А или 20В определяет, что выравненное прочтение является несопоставленным, то аппарат может продолжать выполнение способа, показанного на Фиг. 1, на стадии 6. Альтернативно, если аппарат 20, 20А или 20В определяет, что прочтение является сопоставленным, то аппарат 20, 20А или 20В может определить, является ли прочтение неточно сопоставленным или точно сопоставленным.
В некоторых вариантах реализации аппарат 20, 20А или 20В может определять, является ли прочтение неточно сопоставленным или точно сопоставленным, путем оценки общего количества несоответствий в прочтении. В некоторых вариантах реализации это общее количество несоответствий может быть обеспечено модулем сопоставления и выравнивания и получено из полученной записи прочтения. В таких вариантах реализации, если аппарат 20, 20А или 20В определяет, что общее количество несоответствий равно нулю, то аппарат 20, 20А или 20В может определить на стадии 4, что полученное выравненное прочтение является точно сопоставленным прочтением, и может продолжать исполнение способа, показанного на Фиг. 1, на стадии 6. Альтернативно, если на стадии 4 аппарат 20, 20А или 20В определяет, что общее количество несоответствий больше нуля, то аппарат 20, 20А или 20В может определить на стадии 4, что прочтение, соответствующее записи прочтения, является неточно сопоставленным прочтением, и аппарат 20, 20А или 20В может продолжить исполнение способа, показанного на Фиг. 1, на стадии 6.
Однако следует отметить, что приведенные выше варианты реализации представляют собой лишь примеры того, как аппарат 20, 20А или 20В может определить, является ли запись выравненного прочтения точно сопоставленной, неточно сопоставленной или несопоставленной. Например, в некоторых вариантах реализации такое определение может быть выполнено на основании информации, содержащейся в полученной записи прочтения, и без сравнения количества несоответствий с нулевым пороговым значением. В качестве примера запись прочтения может содержать битовые флаги в заголовке или другом участке записи прочтения, которые указывают на то, является прочтение сопоставленным или несопоставленным, точно сопоставленным, неточно сопоставленным или т.п. В таких вариантах реализации аппарат 20, 20А или 20В может выполнять определение, как на стадии 4, того, является ли запись выравненного прочтения сопоставленной, несопоставленной, точно сопоставленной или неточно сопоставленной, на основании битовых флагов полученной записи прочтения без сравнения количества несоответствий с нулевым пороговым значением. Другие варианты реализации также входят в объем настоящего изобретения. Например, можно предположить, что могут быть использованы варианты реализации, в которых информация, хранящаяся в структуре данных, отличной от полученной записи прочтения, может быть доступной и может считаться битовыми флагами прочтения или другими данными для указания на то, является ли конкретная запись прочтения сопоставленной, несопоставленной, точно сопоставленной или неточно сопоставленной.
В некоторых вариантах реализации эта стадия 4 может дополнительно включать в себя сравнение 4а для каждого неточно сопоставленного прочтения количества несоответствий между указанным прочтением и эталонной последовательностью относительно порогового значения. Это может включать в себя общее количество несоответствий, при этом общее количество несоответствий включает в себя сумму всех различий между выравненным прочтением и эталонной последовательностью, включая варианты, ошибки секвенирования и неопределенные основания N. В некоторых вариантах реализации количество несоответствий может быть обеспечено модулем сопоставления и выравнивания и получено из записи прочтения.
В некоторых вариантах реализации пороговое значение составляет 31. Это конкретное значение может быть выбрано так, чтобы обеспечить наилучший возможный компромисс для хранения количества несоответствий в достаточно компактной форме, что станет более понятно ниже в отношении стадии 12. Действительно, статистика наблюдений показывает, что в подавляющем большинстве случаев неточно сопоставленные прочтения включают в себя менее 31 несоответствия. Принцип, лежащий в основе такого выбора, заключается в кодировании в наиболее компактной форме наиболее часто встречающихся случаев, оставляя пространство для ряда очень незначительного количества случаев с низким качеством. Однако, хотя использование порогового значения, равного 31 несоответствию, в некоторых вариантах реализации, таких как варианты реализации коротких прочтений, где длина прочтений составляет приблизительно 150 нуклеотидов или оснований, может быть предпочтительным, настоящее изобретение не ограничивается только теми вариантами реализации, в которых пороговое значение равно 31. Вместо этого для других вариантов реализации может быть желательно использовать пороговое значение больше 31. Например, хотя аспекты (например, пороговое значение, равное 31 несоответствию) могут относиться к использованию сжатых записей прочтений, представляющих прочтения, созданные с помощью секвенаторов коротких прочтений, предполагается, что способы сжатия геномных данных настоящего изобретения могут быть использованы и в других вариантах реализации, например, для сжатия записей прочтений, генерируемых секвенаторами длинных прочтений. Таким образом, в таких вариантах реализации, где прочтения представлены записями прочтений, длина которых значительно превышает 150 нуклеотидов или оснований, в качестве порогового значения может быть задана величина, большая 31, чтобы обеспечить возможность применения способов сжатия настоящего изобретения для систем длинных прочтений.
Если определено, что прочтение является неточно сопоставленным и имеет количество несоответствий, которое меньше порогового значения, стадия 4 определения может также включать в себя дополнительное определение того, является ли прочтение глобально сопоставленным или локально сопоставленным по отношению к эталонной последовательности. «Глобально сопоставленное прочтение» представляет собой неточно сопоставленное прочтение, полная последовательность которого, включая начало и конец прочтения, неточно сопоставляется с эталонной последовательностью. «Локально сопоставленное прочтение» представляет собой неточно сопоставленное прочтение, содержащее сегмент нуклеотидов или оснований, которые неточно сопоставлены с эталонной последовательностью. Таким образом, указанный сегмент нуклеотидов или оснований соответствует участку исходного прочтения.
В некоторых вариантах реализации для каждого выравненного прочтения способ сжатия может дополнительно включать в себя стадию 6 определения того, включает ли указанное прочтение по меньшей мере одно неопределенное основание «N», т.е. включает ли указанное прочтение по меньшей мере одно несоответствие, соответствующее случаю, в котором секвенатор не смог распознать какое-либо основание или нуклеотид. Затем для каждого прочтения, содержащего по меньшей мере одно «N», способ включает в себя стадию 8 определения количества таких неопределенных оснований «N» и стадию 10 сравнения указанного количества неопределенных оснований «N» с эталонным пороговым значением. В некоторых вариантах реализации эталонное пороговое значение может быть равно 31. Однако в других вариантах реализации в качестве других эталонных пороговых значений могут быть заданы другие величины.
Независимо от результатов стадии 4 определения способ включает в себя следующую стадию 12 кодирования прочтений в соответствии с указанным определением. Точнее, прочтения, которые отнесены к точно сопоставленным с эталонной последовательностью, независимо от того, отсутствуют ли в них неопределенные основания «N» или количество неопределенных оснований «№>в них меньше эталонного порогового значения, кодируются в соответствии с первым способом кодирования. Прочтения, которые отнесены к несопоставленным, или прочтения, которые отнесены к точно сопоставленным, но в которых количество неопределенных оснований «№>больше эталонного порогового значения, кодируются в соответствии со вторым способом кодирования, где каждый нуклеотид или основание кодируются отдельно, независимо от того, были выравнены указанный нуклеотид или основание или нет. Прочтения, которые отнесены к неточно сопоставленным, кодируются в соответствии со вторым процессом кодирования или третьим процессом кодирования. Точнее, прочтения, которые отнесены к неточно сопоставленным с количеством несоответствий больше порогового значения, кодируются в соответствии со вторым процессом кодирования. Если установлено, что прочтение неточно сопоставлено с количеством несоответствий меньше порогового значения, и если указанное прочтение не содержит ни одного N или количество N в таком прочтении меньше эталонного порогового значения, то указанное прочтение кодируется в соответствии с третьим процессом кодирования. В противном случае, т.е. если количество N в таком прочтении больше эталонного порогового значения, то указанное прочтение кодируется в соответствии со вторым процессом кодирования.
Независимо от того, отнесено ли конкретное прочтение к точно сопоставленным, неточно сопоставленным или несопоставленным, если указанное прочтение содержит по меньшей мере одно N, но количество N меньше эталонного порогового значения, то стадия 12 кодирования включает в себя кодирование списка положений вдоль эталонной последовательности, при этом указанные положения соответствуют положениям N в эталонной последовательности. Затем список положений сохраняется в запоминающем устройстве вычислительного устройства, при этом указанное устройство осуществляет способ сжатия. Если прочтение содержит по меньшей мере одно значение N, но количество N меньше эталонного порогового значения, и оно должно кодироваться по второму процессу кодирования, то каждый нуклеотид или основание прочтения отдельно кодируется 2 битами.
Если прочтение содержит по меньшей мере одно значение N, но количество N больше эталонного порогового значения, то указанное прочтение во всех случаях кодируется по второму процессу кодирования, а каждый нуклеотид или основание прочтения отдельно кодируется 4 битами. В этом случае стадия 12 кодирования не включает в себя кодирование и хранение списка положений N в эталонной последовательности. Действительно, после этого каждое несоответствие N напрямую кодируется в соответствии со вторым процессом кодирования точно таким же образом, как и другие нуклеотиды или основания прочтения.
Первый и третий процессы кодирования включают в себя четко заданные наборы дескрипторов. Каждый набор дескрипторов уникальным образом представляет прочтения, связанные с соответствующим процессом кодирования, и каждый из первого и третьего процессов кодирования представляет собой процесс кодирования с понижением энтропии информации. Точнее, третий процесс кодирования включает в себя первый дополнительный процесс кодирования и второй дополнительный процесс кодирования. Неточно сопоставленные прочтения, которые на стадии 4 отнесены к глобально сопоставленным прочтениям, кодируются в соответствии с первым дополнительным способом кодирования. Неточно сопоставленные прочтения, которые на стадии 4 отнесены к локально сопоставленным прочтениям, кодируются в соответствии со вторым дополнительным способом кодирования. Первый и второй дополнительные процессы кодирования включают в себя четко заданные наборы дескрипторов, уникальным образом представляющие прочтения, связанные с соответствующим дополнительным процессом кодирования.
Таким образом, информация выравнивания, которая кодируется для каждого прочтения и которая позволяет восстанавливать полную последовательность прочтения в ходе распаковки данных, зависит от соответствующего процесса или дополнительного процесса кодирования, который использовался для указанного прочтения.
Например, в некоторых вариантах реализации первый набор дескрипторов, используемых для первого процесса кодирования, может включать в себя:
ο абсолютное положение начала точно сопоставленного прочтения относительно эталонной последовательности (в 16- или 32-битовой кодировке) и
ο длина прочтения (кодируемая посредством дифференциального кодирования относительно длины предыдущего прочтения с кодом переменной длины от 2 битов до 34 битов).
В качестве другого примера в некоторых вариантах реализации второй набор дескрипторов, используемых для первого дополнительного процесса кодирования, может включать в себя:
ο абсолютное положение начала неточно сопоставленного прочтения относительно эталонной последовательности (в 16- или 32-битовой кодировке),
ο длина прочтения (кодируемая посредством дифференциального кодирования относительно длины предыдущего прочтения с кодом переменной длины от 2 битов до 34 битов) и
ο список несоответствий прочтения.
В качестве другого примера в некоторых вариантах реализации третий набор дескрипторов, используемых для второго дополнительного процесса кодирования, может включать в себя:
ο абсолютное положение начала неточно сопоставленного участка прочтения относительно эталонной последовательности, также называемое положением начала локального выравнивания (в 16- или 32-битовой кодировке),
ο длина прочтения (кодируемая посредством дифференциального кодирования относительно длины предыдущего прочтения с кодом переменной длины от 2 битов до 34 битов),
ο список несоответствий прочтения и
ο длина отсеченных участков прочтения, которые не являются частью выравнивания (8-битовое кодирование для каждого отсеченного участка).
Предпочтительно список несоответствий, который кодируется в первом и втором дополнительных процессах, может включать в себя заголовок. Например, в некоторых вариантах реализации заголовок может быть закодирован с использованием битового флага и закодирован одним байтом. В таких вариантах реализации пять первых битов однобайтового заголовка могут быть использованы для кодирования количества несоответствий, содержащихся в прочтении. В вариантах реализации, в которых пороговое значение равно 31, количество несоответствий может находиться в диапазоне от 0 до 31. Один бит однобайтового заголовка может использоваться для кодирования информации о том, является ли неточно сопоставленное прочтение глобально или локально сопоставленным. Другой бит однобайтового заголовка может использоваться для кодирования информации о том, активирован ли 2-битовый режим для второго способа кодирования. Последний бит однобайтового заголовка может использоваться для кодирования информации о том, активирован ли 4-битовый режим для второго способа кодирования. В некоторых вариантах реализации для каждого прочтения, кодируемого в соответствии со вторым дополнительным способом кодирования на стадии 12 кодирования, выполняется конкатенация отсеченных участков указанного прочтения (т.е. тех участков, которые не являются частью локального выравнивания), и каждый нуклеотид или основание указанных отсеченных участков кодируется отдельно. В некоторых вариантах реализации каждый нуклеотид или основание таких отсеченных участков прочтения кодируется отдельно 2 битами.
В некоторых вариантах реализации каждое несоответствие, кодированное в списке несоответствий неточно сопоставленного прочтения (т.е. кодированное в соответствии с первым или вторым дополнительным способом кодирования), может кодироваться 1 байтом. Более конкретно, каждое несоответствие неточно сопоставленного прочтения, которое должно кодироваться в соответствии с первым или вторым дополнительным процессом кодирования, может кодироваться следующим образом:
ο первые два бита байта используются для кодирования альтернативного нуклеотида или основания, присутствующего в прочтении вместо соответствующего эталонного нуклеотида или основания эталонной последовательности,
ο шесть последних битов используются для кодирования положения несоответствия в эталонной последовательности, причем указанное положение вычисляется как смещение относительно предыдущего несоответствия прочтения. Данное вычисленное положение может представлять собой относительное положение несоответствия, исключая первое несоответствие прочтения, для которого кодируется абсолютное положение. Таким образом, диапазон такого смещения, которое кодируется 6 битами, может составлять [0-63].
Кодированная или сжатая запись, полученная в результате выполнения способа, показанного на Фиг. 1, может храниться в запоминающем устройстве или другом устройстве хранения данных аппарата. В некоторых вариантах реализации эта кодированная или сжатая запись может храниться в запоминающем устройстве или другом устройстве хранения данных аппарата таким образом, чтобы сохранять порядок последовательности записей прочтений. Это помогает обеспечить условия, при которых сжатие записей выравненных прочтений осуществляется без потерь данных, поскольку сохраняет даже начальный порядок последовательности записей выравненных прочтений.
Получение записи выравненного прочтения на стадии 102
Способ сжатия, показанный на ФИГ. 1, более подробно описан ниже со ссылкой на способ 100А сжатия, показанный на ФИГ. 1А. Исполнение способа 100А сжатия с помощью аппарата 20, 20А или 20В может начинаться с начальной стадии 102, которая включает в себя получение записи выровненного прочтения (также называемой ниже как «полученная запись прочтения» или «несопоставленное прочтение» / «сопоставленное прочтение» / «точно сопоставленное прочтение» / «неточно сопоставленное прочтение» на основе последующей классификации полученной записи прочтения во время исполнения способа 100А). В некоторых вариантах реализации запись выровненного прочтения может быть получена из множества записей выравненных прочтений, которые хранятся таким образом, чтобы сохранить их исходный порядок, обеспеченный секвенатором. Таким образом, полная операция, выполненная модулем сопоставления и выравнивания и модулем сжатия может сохранять записи прочтений в исходном порядке, обеспеченном секвенатором. В некоторых вариантах реализации записи выравненных прочтений могут храниться таким образом, чтобы сохранять их исходный порядок, с использованием sequence_id, который сохраняется с каждой записью выравненного прочтения и увеличивается для каждой последующей записи выравненного прочтения, созданной модулем сопоставления и выравнивания.
Определение на стадии 104 того, является ли прочтение, соответствующее записи выровненного прочтения, точно сопоставленным, неточно сопоставленным или несопоставленным
Способ сжатия настоящего изобретения может включать в себя следующую стадию 104 определения с помощью аппарата 20, 20А или 20В того, соответствует ли полученная запись прочтения тому прочтению, которое является точно сопоставленным с эталонной последовательностью, неточно сопоставленным с эталонной последовательностью или не сопоставленным с эталонной последовательностью. В некоторых вариантах реализации аппарат 20, 20А, 20В на основании информации, принятой от модуля сопоставления и выравнивания, может определять, является ли прочтение точно сопоставленным, неточно сопоставленным или несопоставленным прочтением. Эта информация может включать в себя информацию, такую как, например, является ли прочтение, представленное принятой записью прочтения, сопоставленным или несопоставленным, является ли прочтение, представленное принятой записью прочтения, точно сопоставленным или неточно сопоставленным, указание количества общих несоответствий, таких как варианты или ошибки секвенирования, неопределенные основания или любая их комбинация. В некоторых вариантах реализации эта информация может быть включена в саму запись прочтения.
В некоторых вариантах реализации на стадии 104 аппарат 20, 20А или 20В может сначала определять, является ли выравненное прочтение сопоставленным или несопоставленным. Если аппарат 20, 20А или 20В определяет, что выравненное прочтение является несопоставленным, то аппарат может продолжать исполнение способа 100А, показанного на Фиг. 1А, на стадии 120. Альтернативно, если аппарат 20, 20А или 20В определяет, что прочтение было сопоставленным, то аппарат 20, 20А или 20В может дополнительно определять на стадии 104, является ли прочтение неточно сопоставленным или точно сопоставленным.
В некоторых вариантах реализации аппарат 20, 20А или 20В может определять на стадии 104, является ли прочтение неточно сопоставленным или точно сопоставленным, путем оценки количества несоответствий в прочтении. В некоторых вариантах реализации количество несоответствий может быть обеспечено модулем сопоставления и выравнивания и получено из записи прочтения. Количество несоответствий можно подсчитать разными способами в разных вариантах реализации. В некоторых вариантах реализации количество несоответствий на стадии 104 может не включать в себя количество неопределенных оснований N. В других вариантах реализации количество несоответствий, определенных на стадии 104, может включать в себя сумму количества несоответствий и количества неопределенных оснований N.
В примере, показанном на Фиг. 1А, предполагается, что неопределенное основание N не является несоответствием. В результате этого точно сопоставленное прочтение может включать в себя 0 несоответствий и одно или более неопределенных оснований N. Таким образом, неточно сопоставленное прочтение в этом варианте реализации должно иметь по меньшей мере одно несоответствие и может иметь или не иметь какие-либо неопределенные основания N. Однако в других вариантах реализации способ, показанный на Фиг. 1 А, может быть изменен в части предположения о том, что присутствие N в прочтении может считаться несоответствием. В таких вариантах реализации прочтение можно определить как точно сопоставленное прочтение, только если определено, что прочтение имеет 0 несоответствий и 0 неопределенных оснований N, при этом прочтение, имеющее 0 несоответствий и одно или более неопределенных оснований N, классифицируется как неточно сопоставленное прочтение.
В первом варианте реализации на стадии 104, если аппарат 20, 20А или 20В определяет, что общее количество несоответствий равно нулю, а общее количество неопределенных оснований N больше или равно нулю, то аппарат 20, 20А или 20В может определить на стадии 4, что полученное выровненное прочтение является точно сопоставленным прочтением, и может продолжить исполнение способа 100А, показанного на Фиг. 1А, на стадии 116. Альтернативно в этом первом варианте реализации, если на стадии 104 аппарат 20, 20А или 20В определяет, что общее количество несоответствий больше нуля, а общее количество неопределенных оснований N больше или равно нулю, то аппарат 20, 20А или 20В может определить на стадии 104, что прочтение, соответствующее полученной записи прочтения, является неточно сопоставленным прочтением, и аппарат 20, 20А или 20В может продолжить исполнение способа 100А, показанного на Фиг. 1А, на стадии 106.
Во втором и альтернативном варианте реализации на стадии 104 аппарат 20, 20А или 20В определит, что прочтение является точно сопоставленным прочтением, только если общее количество несоответствий равно нулю и общее количество неопределенных оснований N равно нулю, и в таком сценарии аппарат 20, 20А или 20В может продолжить исполнение способа 100А, показанного на Фиг. 1А, на стадии 116. Альтернативно в этом втором варианте реализации, если на стадии 104 аппарат 20, 20А или 20В определит, что общее количество несоответствий больше нуля или общее количество неопределенных оснований N больше нуля, то аппарат 20, 20А или 20В может определить на стадии 104, что прочтение, соответствующее полученной записи прочтения, является неточно сопоставленным прочтением, и аппарат 20, 20А или 20В может продолжить исполнение способа 100А, показанного на Фиг. 1А, на стадии 106.
Однако следует отметить, что приведенные выше варианты реализации представляют собой лишь примеры того, как аппарат 20, 20А или 20В может определить на стадии 104, что прочтение, соответствующее полученной записи прочтения, является точно сопоставленным, неточно сопоставленным или несопоставленным. Например, вместо этого в некоторых вариантах реализации такое определение может быть выполнено на основании информации, содержащейся в полученной записи прочтения, и без сравнения количества несоответствий с пороговым значением, без сравнения количества неопределенных оснований N с пороговым значением или и без того, и без другого. В качестве примера запись прочтения может содержать битовые флаги в заголовке или другом участке записи прочтения, которые указывают на то, является прочтение сопоставленным или несопоставленным, точно сопоставленным, неточно сопоставленным или т.п. В таких вариантах реализации аппарат 20, 20А или 20В может выполнять определение, как на стадии 4, того, является ли запись выравненного прочтения сопоставленной, несопоставленной, точно сопоставленной или неточно сопоставленной, на основании битовых флагов записи прочтения без сравнения количества несоответствий или неопределенных оснований N с пороговыми значениями. Другие варианты реализации также входят в объем настоящего изобретения. Например, можно предположить, что могут использоваться варианты реализации, в которых информация, хранящаяся в структуре данных, отличной от записи прочтения, может быть доступной и может считаться битовыми флагами прочтения или другими данными для указания на то, является ли прочтение, соответствующее конкретной записи прочтения, сопоставленным, несопоставленным, точно сопоставленным или неточно сопоставленным.
Ветвь «неточно сопоставленное прочтение» на стадии 104
Если аппарат 20, 20А или 20В определяет на стадии 104, что прочтение, соответствующее полученной записи прочтения, является неточно сопоставленным прочтением, то аппарат 20, 20А или 20В может определять на стадии 106 то, превышает ли количество различий между указанным неточно сопоставленным прочтением и эталонной последовательностью первое пороговое значение. Этот показатель может включать в себя общее количество несоответствий, при этом общее количество несоответствий включает в себя сумму всех различий между выравненным прочтением и эталонной последовательностью, включая варианты, ошибки секвенирования и неопределенные основания N. В других вариантах реализации количество различий на стадии 106 может включать в себя только количество несоответствий и не учитывать количество неопределенных оснований N. В некоторых вариантах реализации количество несоответствий может быть обеспечено модулем сопоставления и выравниванием и получено из записи прочтения.
В некоторых вариантах реализации первое пороговое значение может составлять 31. Это конкретное значение может быть выбрано так, чтобы обеспечить наилучший возможный компромисс для хранения количества несоответствий в достаточно компактной форме, что станет более понятно ниже в отношении последующих стадий. Действительно, статистика наблюдений показывает, что в подавляющем большинстве случаев неточно сопоставленные прочтения включают в себя менее 31 несоответствия. Принцип, лежащий в основе такого выбора, заключается в кодировании в наиболее компактной форме наиболее часто встречающихся случаев, оставляя пространство для очень незначительного количества случаев с низким качеством. Однако несмотря на конкретные преимущества, которые могут быть достигнуты при использовании первого порогового значения, равного 31, настоящее описание не ограничивается только теми вариантами реализации, в которых первое пороговое значение равно 31. Вместо этого для других вариантов реализации может быть желательно использовать пороговое значение больше 31. Например, хотя аспекты (например, пороговое значение, равное 31 несоответствию) могут относиться к использованию сжатых записей прочтений, представляющих прочтения, созданные с помощью секвенаторов коротких прочтений, предполагается, что способы сжатия геномных данных настоящего изобретения могут быть использованы и в других вариантах реализации, например, для сжатия записей прочтений, генерируемых секвенаторами длинных прочтений. Таким образом, в таких вариантах реализации, где прочтения представлены записями прочтений, длина которых значительно превышает 150 нуклеотидов или оснований, в качестве порогового значения может быть задана величина, большая 31, чтобы обеспечить возможность применения способов сжатия настоящего изобретения для систем длинных прочтений.
Ветвь «ДА» стадии 106
Если аппарат 20, 20А или 20В определяет на стадии 106, что количество различий между неточно сопоставленным прочтением и эталонной последовательностью превышает первое пороговое значение, аппарат может продолжить исполнение способа 100А на стадии 114. На стадии 114 аппарат 20, 20А или 20В может определить, превышает ли количество неопределенных оснований «N» в неточно сопоставленном прочтении второе пороговое значение. В некоторых вариантах реализации второе пороговое значение также может быть равно 31. Однако, как и первые пороговые значения, второе пороговое значение настоящего изобретения не ограничено значением 31. Вместо этого любое численное значение, включая более высокие значения, чем 31, может быть использовано в качестве второго порогового значения на основании длины прочтений, выданной в варианте реализации. Более того, не существует требования по использованию в качестве первого порогового значения и второго порогового значения одного и того же порогового значения.
Ветвь «ДА» стадии 114
Если аппарат 20, 20А или 20В определяет, что количество неопределенных оснований «N» в неточно сопоставленном прочтении превышает второе пороговое значение, то аппарат 20, 20А или 20В может определить, что неточно сопоставленное прочтение следует кодировать с помощью второго модуля ПО кодирования для кодирования неточно сопоставленного прочтения с использованием второго способа кодирования. Второй способ кодирования является таким же, как второй способ кодирования, описанный выше применительно к Фиг. 1, в котором каждый нуклеотид или основание кодируется по отдельности, независимо от того, является ли указанный нуклеотид или основание выравненным или нет. В некоторых вариантах реализации, так как аппарат 20, 20А или 20В определяет, что количество неопределенных оснований «N» превысило второе пороговое значение на стадии 114, аппарат 20, 20А или 20В может использовать второй модуль кодирования для 4-битового кодирования 110а прочтения с использованием второго способа кодирования. После кодирования прочтения с использованием второго способа 110 кодирования с использованием 4-битового кодирования 110а аппарат 20, 20А или 20В может сохранить кодированное прочтение в запоминающем устройстве или другом устройстве хранения данных на стадии 122. Аппарат 20, 20А или 20В может определить на стадии 124, имеется ли другое, последовательно упорядоченное выравненное прочтение, которое должно быть сжатым. И если имеется другое, последовательно упорядоченное выравненное прочтение, которое должно быть сжатым, аппарат 20, 20А или 20В может исполнить операции стадии 102 для получения следующей последовательно упорядоченной записи выравненного прочтения и снова исполнить способ 100А. Аппарат 20, 20А или 20В может продолжить исполнять способ 100А в итеративном режиме до тех пор, пока на стадии 124 не будут идентифицированы новые последовательно упорядоченные записи выравненных прочтений. После определения такого условия способ 100А может быть завершен на стадии 126.
Ветвь «НЕТ» стадии 114
Если на стадии 114 аппарат 20, 20А или 20В определяет, что количество неопределенных оснований «N» в неточно сопоставленном прочтении не превышает второе пороговое значение, то аппарат 20, 20А или 20В может определить, что неточно сопоставленное прочтение следует кодировать с помощью второго модуля 110 кодирования для кодирования неточно сопоставленного прочтения с использованием второго способа кодирования. Второй способ кодирования является таким же, как второй способ кодирования, описанный выше применительно к Фиг. 1, в котором каждый нуклеотид или основание кодируется по отдельности, независимо от того, является ли указанный нуклеотид или основание выравненным или нет. В некоторых вариантах реализации, так как аппарат 20, 20А или 20В определяет, что количество неопределенных оснований «N» не превысило второе пороговое значение на стадии 114, аппарат 20, 20А или 20В может использовать второй модуль кодирования для 2-битового кодирования 110b прочтения с использованием второго способа кодирования. После кодирования прочтения с использованием второго способа 110 кодирования с использованием 2-битового кодирования 110b аппарат 20, 20А или 20В может сохранить кодированное прочтение в запоминающем устройстве или другом устройстве хранения данных на стадии 122. Аппарат 20, 20А или 20В может определить на стадии 124, имеется ли другое, последовательно упорядоченное выравненное прочтение, которое должно быть сжатым. И если имеется другое, последовательно упорядоченное выравненное прочтение, которое должно быть сжатым, аппарат 20, 20А или 20В может исполнить операции стадии 102 для получения следующей последовательно упорядоченной записи выравненного прочтения и снова исполнить способ 100А. Аппарат 20, 20А или 20В может продолжить исполнять способ 100А в итеративном режиме до тех пор, пока на стадии 124 не будут идентифицированы новые последовательно упорядоченные записи выравненных прочтений. После определения такого условия способ 100А может быть завершен на стадии 126.
Ветвь «НЕТ» стадии 106
Если аппарат 20, 20А или 20В определяет на стадии 106, что количество различий между неточно сопоставленным прочтением и эталонной последовательностью не превышает первое пороговое значение, то аппарат 20, 20А или 20В может продолжать исполнение способа 100А на стадии 108. На стадии 108 аппарат 20, 20А или 20В может определить, превышает ли количество неопределенных оснований «N», включенных в неточно сопоставленное прочтение, второе пороговое значение.
Ветвь «ДА» стадии 108
Если на стадии 108 аппарат 20, 20А или 20В определяет, что количество неопределенных оснований «N» в неточно сопоставленном прочтении превышает второе пороговое значение, то аппарат 20, 20А или 20В может определить на стадии 108, что неточно сопоставленное прочтение следует кодировать с помощью второго модуля 110 кодирования для кодирования неточно сопоставленного прочтения с использованием второго способа кодирования. Второй способ кодирования является таким же, как второй способ кодирования, описанный выше применительно к Фиг. 1, в котором каждый нуклеотид или основание кодируется по отдельности, независимо от того, является ли указанный нуклеотид или основание выравненным или нет. В некоторых вариантах реализации, так как аппарат 20, 20А или 20В определяет, что количество неопределенных оснований «№>превысило второе пороговое значение на стадии 108, аппарат 20, 20А или 20В может использовать второй модуль кодирования для 4-битового кодирования 110а прочтения с использованием второго способа кодирования. После кодирования прочтения с использованием второго способа 110 кодирования с использованием 4-битового кодирования 110а аппарат 20, 20А или 20В может сохранить кодированное прочтение в запоминающем устройстве или другом устройстве хранения данных на стадии 122. Аппарат 20, 20А или 20В может определить на стадии 124, имеется ли другое, последовательно упорядоченное выравненное прочтение, которое должно быть сжатым. И если имеется другое, последовательно упорядоченное выравненное прочтение, которое должно быть сжатым, аппарат 20, 20А или 20В может исполнить операции стадии 102 для получения следующей последовательно упорядоченной записи выравненного прочтения и снова исполнить способ 100А. Аппарат 20, 20А или 20В может продолжить исполнять способ 100А в итеративном режиме до тех пор, пока на стадии 124 не будут идентифицированы новые последовательно упорядоченные записи выравненных прочтений. После определения такого условия способ 100А может быть завершен на стадии 126.
Ветвь «НЕТ» стадии 108
Если на стадии 108 аппарат 20, 20А или 20В определяет, что неточно сопоставленное прочтение включает в себя количество неопределенных оснований «N», которое не удовлетворяет второму пороговому значению, то аппарат 20, 20А или 20В может использовать третий модуль 112 кодирования для кодирования неточно сопоставленного прочтения с использованием третьего способа кодирования. Третий способ кодирования, показанный на Фиг. 1А, аналогичен третьему способу кодирования, описанному выше со ссылкой на способ, показанный на Фиг. 1, и использует те же дескрипторы, что и третий способ кодирования, описанный выше. После кодирования прочтения с использованием третьего способа кодирования третьего модуля 112 кодирования аппарат 20, 20А или 20В может сохранить кодированное прочтение в запоминающем устройстве или другом устройстве хранения данных на стадии 122. Аппарат 20, 20А или 20В может определить на стадии 124, имеется ли другое, последовательно упорядоченное выравненное прочтение, которое должно быть сжатым. И если имеется другое, последовательно упорядоченное выравненное прочтение, которое должно быть сжатым, аппарат 20, 20А или 20В может исполнить операции стадии 102 для получения следующей последовательно упорядоченной записи выравненного прочтения и снова исполнить способ 100А. Аппарат 20, 20А или 20В может продолжить исполнять способ 100А в итеративном режиме до тех пор, пока на стадии 124 не будут идентифицированы новые последовательно упорядоченные записи выравненных прочтений. После определения такого условия способ 100А может быть завершен на стадии 126.
Ветвь «точно сопоставленное прочтение» на стадии 104
Альтернативно, если на стадии 104 определено, что прочтение, соответствующее полученной записи прочтения, является точно сопоставленным прочтением, то аппарат 20, 20А или 20В может определять на стадии 116, превышает ли количество неопределенных оснований «N», включенных в точно сопоставленное прочтение, второе пороговое значение. В некоторых вариантах реализации второе пороговое значение также может быть равно 31. Однако, как и в случае первых пороговых значений, настоящее изобретение не ограничено вторым пороговым значением, равным 31. Вместо этого любое численное значение, включая более высокие значения, чем 31, может быть использовано в качестве второго порогового значения на основании длины прочтений, выданной в варианте реализации. Более того, не существует требования по использованию в качестве первого порогового значения и второго порогового значения одного и того же порогового значения.
Ветвь «НЕТ» стадии 116
Если аппарат 20, 20А или 20В определяет на стадии 116, что количество неопределенных оснований «N», включенных в точно сопоставленное прочтение, не превышает второе пороговое значение, то аппарат 20, 20А или 20В может определить, что следует кодировать прочтение с помощью первого модуля 122 кодирования с использованием первого способа кодирования. Если точно сопоставленное прочтение не включает в себя какие-либо неопределенные основания «N», то первый модуль 122 кодирования исполняет первый способ кодирования, который аналогичен первому способу кодирования, описанному выше со ссылкой на Фиг. 1, и использует те же дескрипторы, что и первый способ кодирования, описанный выше. Альтернативно, если точно сопоставленное прочтение включает в себя одно или более «N», первый модуль 122 кодирования кодирует точно сопоставленное прочтение с использованием первого способа кодирования, описанного выше со ссылкой на Фиг. 1, и с использованием тех же дескрипторов для первого способа кодирования, описанного выше. Кроме того, в конкретном варианте реализации, в котором точно сопоставленное прочтение включает в себя одно или более N (но меньше второго порогового значения N), первый модуль 118 кодирования также может хранить список положений неопределенных оснований N в прочтении.
После кодирования прочтения с использованием первого модуля 118 кодирования аппарат 20, 20А или 20В может сохранить кодированное прочтение в запоминающем устройстве или другом устройстве хранения данных на стадии 122. Аппарат 20, 20А или 20В может определить на стадии 124, имеется ли другое, последовательно упорядоченное выравненное прочтение, которое должно быть сжатым. И если имеется другое, последовательно упорядоченное выравненное прочтение, которое должно быть сжатым, аппарат 20, 20А или 20В может исполнить операции стадии 102 для получения следующей последовательно упорядоченной записи выравненного прочтения и снова исполнить способ 100А. Аппарат 20, 20А или 20В может продолжить исполнять способ 100А в итеративном режиме до тех пор, пока на стадии 124 не будут идентифицированы новые последовательно упорядоченные записи выравненных прочтений. После определения такого условия способ 100А может быть завершен на стадии 126.
Ветвь «ДА» стадии 116
Однако если аппарат определяет на стадии 116, что прочтение включает в себя количество неопределенных оснований «N», превышающее второе пороговое значение, то аппарат 20, 20А или 20В может использовать второй модуль 110 кодирования для 4-битового кодирования 110а прочтения с использованием второго способа кодирования. Второй способ кодирования, показанный на Фиг. 1А, аналогичен второму способу кодирования, описанному выше применительно к Фиг. 1, в котором каждый нуклеотид или основание кодируется по отдельности, независимо от того, выравнен ли указанный нуклеотид или основание или нет. После кодирования прочтения с использованием второго способа ПО кодирования с использованием 4-битового кодирования 110а аппарат 20, 20А или 20В может сохранить кодированное прочтение в запоминающем устройстве или другом устройстве хранения данных на стадии 122. Аппарат 20, 20А или 20В может определить на стадии 124, имеется ли другое, последовательно упорядоченное выравненное прочтение, которое должно быть сжатым. И если имеется другое, последовательно упорядоченное выравненное прочтение, которое должно быть сжатым, аппарат 20, 20А или 20В может исполнить операции стадии 102 для получения следующей последовательно упорядоченной записи выравненного прочтения и снова исполнить способ 100А. Аппарат 20, 20А или 20В может продолжить исполнять способ 100 А в итеративном режиме до тех пор, пока на стадии 124 не будут идентифицированы новые последовательно упорядоченные записи выравненных прочтений. После определения такого условия способ 100А может быть завершен на стадии 126.
Ветвь «несопоставленное прочтение» стадии 104
Альтернативно, если на стадии 104 определено, что прочтение, соответствующее полученной записи прочтения, является несопоставленным прочтением, то аппарат 20, 20А или 20В может определить на стадии 120, превышает ли количество неопределенных оснований «N», включенных несопоставленное прочтение, второе пороговое значение. В некоторых вариантах реализации второе пороговое значение также может быть равно 31. Однако, как и в случае первых пороговых значений, настоящее изобретение не ограничено вторым пороговым значением, равным 31. Вместо этого любое численное значение, включая более высокие значения, чем 31, может быть использовано в качестве второго порогового значения на основании длины прочтений, выданной в варианте реализации. Более того, не существует требования по использованию в качестве первого порогового значения и второго порогового значения одного и того же порогового значения.
Ветвь «НЕТ» стадии 120
Если аппарат 20, 20А или 20В определяет на стадии 120, что количество неопределенных оснований «N», включенных в несопоставленное прочтение, не превышает второе пороговое значение, то аппарат 20, 20А или 20В может определить, что следует кодировать прочтение с помощью второго модуля 110 кодирования с использованием второго способа кодирования. Второй способ кодирования является таким же, как второй способ кодирования, описанный выше применительно к Фиг. 1, в котором каждый нуклеотид или основание кодируется по отдельности, независимо от того, является ли указанный нуклеотид или основание выравненным или нет. В некоторых вариантах реализации, так как аппарат 20, 20А или 20В определяет, что количество неопределенных оснований «N» не превысило второе пороговое значение на стадии 120, аппарат 20, 20А или 20В может использовать второй модуль кодирования для 2-битового 110b кодирования прочтения с использованием второго способа кодирования. После кодирования прочтения с использованием второго способа 110 кодирования с использованием 2-битового кодирования 110b аппарат 20, 20А или 20В может сохранить кодированное прочтение в запоминающем устройстве или другом устройстве хранения данных на стадии 122. Аппарат 20, 20А или 20В может определить на стадии 124, имеется ли другое, последовательно упорядоченное выравненное прочтение, которое должно быть сжатым. И если имеется другое, последовательно упорядоченное выравненное прочтение, которое должно быть сжатым, аппарат 20, 20А или 20В может исполнить операции стадии 102 для получения следующей последовательно упорядоченной записи выравненного прочтения и снова исполнить способ 100А. Аппарат 20, 20А или 20В может продолжить исполнять способ 100А в итеративном режиме до тех пор, пока на стадии 124 не будут идентифицированы новые последовательно упорядоченные записи выравненных прочтений. После определения такого условия способ 100А может быть завершен на стадии 126.
Ветвь «ДА» стадии 120
Однако если аппарат определяет на стадии 120, что несопоставленное прочтение включает в себя количество неопределенных оснований «N», превышающее второе пороговое значение, то аппарат 20, 20А или 20В может использовать второй модуль 110 кодирования для 4-битового 110а кодирования прочтения с использованием второго способа кодирования. Второй способ кодирования, показанный на Фиг. 1А, аналогичен второму способу кодирования, описанному выше применительно к Фиг. 1, в котором каждый нуклеотид или основание кодируется по отдельности, независимо от того, выравнен ли указанный нуклеотид или основание или нет. После кодирования прочтения с использованием второго способа 110 кодирования с помощью 4-битового кодирования 110а аппарат 20, 20А или 20В может сохранить кодированное прочтение в запоминающем устройстве или другом устройстве хранения данных на стадии 122. Аппарат 20, 20А или 20В может определить на стадии 124, имеется ли другое, последовательно упорядоченное выравненное прочтение, которое должно быть сжатым. И если имеется другое, последовательно упорядоченное выравненное прочтение, которое должно быть сжатым, аппарат 20, 20А или 20В может исполнить операции стадии 102 для получения следующей последовательно упорядоченной записи выравненного прочтения и снова исполнить способ 100А. Аппарат 20, 20А или 20В может продолжить исполнять способ 100А в итеративном режиме до тех пор, пока на стадии 124 не будут идентифицированы новые последовательно упорядоченные записи выравненных прочтений. После определения такого условия способ 100А может быть завершен на стадии 126.
На Фиг. 3 представлен пример кодирования несоответствий прочтения с использованием первого дополнительного процесса кодирования. Прочтение представляет собой неточно сопоставленное прочтение, которое глобально сопоставляется с эталонной последовательностью. Прочтение содержит два несоответствия:
ο первое несоответствие, находящееся в 12-м положении прочтения, которое представляет собой замену нуклеотида А в эталонной последовательности на нуклеотид Т в прочтении, и
ο второе несоответствие, находящееся в 21-м положении прочтения, которое представляет собой замену нуклеотида С в эталонной последовательности на нуклеотид G в прочтении.
Затем список несоответствий кодируется следующим образом:
ο <12, Т>, значение «12», соответствующее абсолютному положению первого несоответствия в прочтении, и
ο <9, G>, значение «9», соответствующее относительному положению второго несоответствия в прочтении, т.е. смещению между вторым несоответствием и первым несоответствием.
<12, Т> может быть, например, преобразовано в значение «51» (кодируемое 1 байтом), а<9, G> может быть преобразовано в значение «38» (кодируемое 1 байтом). Такое байтовое кодирование получают следующим образом:
положение смещения х 4 + код нуклеотида (при А=0, С=1, G=2, Т=3)
Предпочтительно для каждого неточно сопоставленного прочтения, которое должно кодироваться в соответствии с первым или вторым дополнительным процессом кодирования, если смещение, вычисленное между заданным несоответствием прочтения и предшествующим несоответствием прочтения, больше максимального кодируемого значения, то по меньшей мере одно «фиктивное» несоответствие вставляется между указанными двумя несоответствиями, до тех пор, пока каждое смещение между каждым из указанных несоответствий и по меньшей мере одно «фиктивное» несоответствие не окажутся меньше указанного максимального кодируемого значения. «Фиктивное» несоответствие определяется как несоответствие, для которого биты байта, используемые для кодирования несоответствия, кодируют нуклеотид или основание, которые эквивалентны соответствующим эталонным нуклеотиду или основанию в эталонной последовательности. В некоторых вариантах реализации максимальное кодируемое значение равно 63, что соответствует максимальному значению, которое кодируется 6 битами. Однако настоящее изобретение не ограничено вариантами реализации, имеющими максимальное кодируемое значение 63. В вариантах реализации для кодирования значения можно использовать максимальное кодируемое значение, превышающее 63, и дополнительные биты. В таких вариантах реализации это может потребовать, например, регулировки других битовых длин в заголовке для прочтения, увеличения размера заголовка за величину один байт или комбинации обоих условий. Соответственно, признаки алгоритма настоящего изобретения являются гибкими для конкретных случаев применения, но варианты реализации, которые могут возникать в результате изменений конструкции, могут приводить к соответствующим компромиссам в эксплуатационных характеристиках, которые могут быть приемлемыми и даже преимущественными при определенных обстоятельствах для любого конкретного варианта реализации.
На Фиг. 4 представлен пример кодирования несоответствий прочтения с использованием первого дополнительного процесса кодирования в случае, когда требуется вставка «фиктивного» несоответствия. Прочтение представляет собой неточно сопоставленное прочтение, которое глобально сопоставляется с эталонной последовательностью. Прочтение содержит два несоответствия:
ο первое несоответствие, находящееся в 22-м положении прочтения, которое представляет собой замену нуклеотида А в эталонной последовательности на нуклеотид Т в прочтении, и
ο второе несоответствие, находящееся в 134-м положении прочтения, которое представляет собой замену нуклеотида С в эталонной последовательности на нуклеотид G в прочтении.
Положение смещения между вторым и первым несоответствием составляет 112, что превышает максимальное кодируемое значение, равное 63. Таким образом, между двумя несоответствиями необходимо вставить «фиктивное» несоответствие, так чтобы каждое смещение между каждым из несоответствий и «фиктивным» несоответствием было меньше, чем указанное максимальное кодируемое значение. «Фиктивное» несоответствие с нуклеотидом Т (соответствующее «настоящему» нуклеотиду Т в эталонной последовательности), например, вводится в 85-е положение прочтения. Положение смещения, вычисляемое между «фиктивным» несоответствием и первым несоответствием, составляет 63, что совпадает с максимальным кодируемым значением. Положение смещения, вычисляемое между вторым несоответствием и «фиктивным» несоответствием, составляет 49, что меньше 63.
Затем список несоответствий кодируется следующим образом:
ο <22, Т>, значение «22», соответствующее абсолютному положению
первого несоответствия в прочтении,
ο <63, Т>, значение «63», соответствующее относительному положению «фиктивного» несоответствия в прочтении, т.е. смещению между «фиктивным» несоответствием и первым несоответствием, и
ο <49, G>, значение «49», соответствующее относительному положению второго несоответствия в прочтении, т.е. смещению между вторым несоответствием и «фиктивным» несоответствием.
Например, <22, Т> может быть преобразовано в значение «91» (кодируется 1 байтом), <63, Т> может быть преобразовано в значение «255» (кодируется 1 байтом), а <49, G> может быть преобразовано в значение «198» (кодируется 1 байтом). Такое байтовое кодирование получают следующим образом:
положение смещения х 4 + код нуклеотида (при А=0, С=1, G=2, Т=3)
Способ включает в себя конечную стадию 14 формирования сжатого файла, содержащего список кодированных прочтений. Кодированные прочтения хранятся в сжатом файле в том же порядке, что и прочтения, хранившиеся в исходном файле без сжатия. Затем каждое прочтение может реконструироваться на основе кодированной информации выравнивания и эталонной последовательности с использованием надлежащего программного обеспечения для распаковки и/или способа, выполненного в соответствии с настоящим изобретением.
Несмотря на то что обладающие признаками изобретения методики, раскрываемые в настоящем документе, описаны со ссылкой на пример архитектуры вычислительного устройства 20 (показано на Фиг. 2 для целей иллюстрации), они могут быть реализованы в аппаратном обеспечении, программном обеспечении, микропрограммном обеспечении или в любой их комбинации. При реализации в программном обеспечении код компьютерной программы может храниться на машиночитаемом носителе или исполняться аппаратным блоком обработки, включающим один или более процессоров, как в случае с устройством 20 на Фиг. 2. Следует понимать, что термин «процессор» при использовании в настоящем документе включает в себя одно или более устройств обработки, включая сигнальный процессор, микропроцессор, микроконтроллер, специализированную интегральную схему (ASIC), программируемую пользователем вентильную матрицу (FPGA) или систему обработки другого типа, а также участки или комбинации таких элементов системы. Также термин «запоминающее устройство» при использовании в настоящем документе включает в себя электронное запоминающее устройство, связанное с процессором, такое как оперативное запоминающее устройство (ОЗУ), постоянное запоминающее устройство (ПЗУ) или запоминающие устройства другого типа, в любой комбинации.
Соответственно, инструкции программного обеспечения или код для реализации методологий и протоколов, описанных в настоящем документе, могут храниться в одном или более из связанных запоминающих устройств, например ОЗУ, встроенное или съемное запоминающее устройство, а затем, при готовности к использованию, загружаться в ОЗУ и исполняться процессором.
Методики настоящего описания могут быть реализованы в широком разнообразии устройств или аппаратов, включая, например, мобильные телефоны, компьютеры, сервера, планшетные компьютеры и аналогичные устройства.
Несмотря на то что представленные для иллюстрации варианты осуществления настоящего изобретения были описаны в настоящем документе со ссылкой на приложенные графические материалы, следует понимать, что изобретение не ограничено этими вариантами осуществления и что различные другие изменения и модификации могут быть реализованы специалистом в данной области, не выходя за рамки объема или сущности изобретения.
На Фиг. 5 представлена схема примера вычислительных компонентов, которые можно использовать для реализации системы для осуществления способа сжатия, показанного на ФИГ. 1 и 1А.
Вычислительное устройство 500 должно представлять собой различные формы цифровых компьютеров, таких как ноутбуки, настольные компьютеры, рабочие станции, карманные персональные компьютеры, серверы, блейд-серверы, мэйнфреймы и другие подходящие компьютеры. Вычислительное устройство 550 должно представлять собой различные формы мобильных устройств, таких как карманные персональные компьютеры, сотовые телефоны, смартфоны и другие аналогичные вычислительные устройства. Кроме того, вычислительное устройство 500 или 550 может включать в себя флэш-накопители с универсальной последовательной шиной (USB). Во флэш-накопителях USB можно хранить операционные системы и другие приложения. Флэш-накопители USB могут включать в себя компоненты ввода/вывода, такие как беспроводной передатчик или USB-разъем, который может быть вставлен в USB-порт другого вычислительного устройства. Представленные здесь компоненты, их соединения и взаимоотношения, а также их функции являются только примерами и не предназначены для ограничения вариантов реализации изобретения, описанных и/или заявленных в настоящем документе.
Вычислительное устройство 500 включает в себя процессор 502, запоминающее устройство 504, устройство 508 хранения данных, высокоскоростной интерфейс 508, соединяющийся с запоминающим устройством 504 и высокоскоростными расширительными портами 510, и низкоскоростной интерфейс 512, соединяющийся с низкоскоростной шиной 514 и устройством 508 хранения данных. Каждый из компонентов 502, 504, 508, 508, 510 и 512 соединен друг с другом с помощью различных шин и может быть установлен на общей материнской плате или при необходимости другими способами. Процессор 502 может обрабатывать инструкции, предназначенные для исполнения внутри вычислительного устройства 500, включая инструкции, хранящиеся в запоминающем устройстве 504 или на устройстве 508 хранения данных, для отображения графической информации графического интерфейса пользователя (ГИП) на внешнем устройстве ввода/вывода, таком как дисплей 516, соединенный с высокоскоростным интерфейсом 508. В других вариантах реализации при необходимости можно использовать множество процессоров и/или множество шин вместе с множеством запоминающих устройств и типов памяти. Кроме того, могут быть соединены множество вычислительных устройств 500, причем каждое устройство обеспечивает участки необходимых операций, например, как банк серверов, группа блейд-серверов или многопроцессорная система.
Запоминающее устройство 504 хранит информацию внутри вычислительного устройства 500. В одном варианте реализации запоминающее устройство 504 представляет собой блок или блоки энергозависимого запоминающего устройства. В другом варианте реализации запоминающее устройство 504 представляет собой блок или блоки энергонезависимого запоминающего устройства. Запоминающее устройство 504 может также представлять собой другую форму машиночитаемого носителя, такую как магнитный или оптический диск.
Устройство 508 хранения данных выполнено с возможностью обеспечения большой емкости хранения данных для вычислительного устройства 500. В одном варианте реализации устройство 508 хранения данных может представлять собой или содержать машиночитаемый носитель, такой как устройство с гибким диском, устройство с жестким диском, устройство с оптическим диском или устройство с лентой, флэш-память или другое аналогичное твердотельное запоминающее устройство или массив устройств, включая устройства в сети хранения данных или в других конфигурациях. Компьютерный программный продукт может быть на практике реализован на носителе информации. Компьютерный программный продукт может также содержать команды, которые при их исполнении осуществляют один или более способов, таких как описанные выше. Носитель информации представляет собой читаемый компьютером или машиночитаемый носитель, такой как запоминающее устройство 504, устройство 508 хранения данных или запоминающее устройство на процессоре 502.
Высокоскоростной контроллер 508 управляет операциями с большой пропускной способностью для вычислительного устройства 500, а низкоскоростной контроллер 512 управляет операциями с меньшей пропускной способностью. Такое распределение функций является лишь примером. В одном варианте реализации высокоскоростной контроллер 508 соединен с запоминающим устройством 504, дисплеем 516, например, через графический процессор или ускоритель, и с высокоскоростными расширительными портами 510, в которые можно устанавливать различные платы расширения (не показаны). В варианте реализации низкоскоростной контроллер 512 соединен с устройством 508 хранения данных и низкоскоростным расширительным портом 514. Низкоскоростной расширительный порт, который может включать в себя различные коммуникационные порты, например USB, Bluetooth, Ethernet, беспроводной Ethernet, может быть соединен с одним или более устройствами ввода/вывода, такими как клавиатура, указательное устройство, пара микрофон/динамик, сканер или сетевое устройство, такое как коммутатор или маршрутизатор, например, с помощью сетевого адаптера. Вычислительное устройство 500 может быть реализовано в ряде разных форм, как показано на фигуре. Например, оно может быть реализовано как стандартный сервер 520 или многократно в виде группы таких серверов. Оно также может быть реализовано в рамках стоечной серверной системы 524. Кроме того, оно может быть реализовано на персональном компьютере, таком как ноутбук 522. Альтернативно компоненты вычислительного устройства 500 могут быть объединены с другими компонентами в мобильном устройстве (не показано), таком как устройство 550. Каждое из таких устройств может содержать одно или более вычислительных устройств 500, 550, и вся система может состоять из множества вычислительных устройств 500, 550, взаимодействующих друг с другом.
Вычислительное устройство 500 может быть реализовано в ряде разных форм, как показано на фигуре. Например, оно может быть реализовано как стандартный сервер 520 или многократно в виде группы таких серверов. Оно также может быть реализовано в рамках стоечной серверной системы 524. Кроме того, оно может быть реализовано на персональном компьютере, таком как ноутбук 522. Альтернативно компоненты вычислительного устройства 500 могут быть объединены с другими компонентами в мобильном устройстве (не показано), таком как устройство 550. Каждое из таких устройств может содержать одно или более вычислительных устройств 500, 550, и вся система может состоять из множества вычислительных устройств 500, 550, взаимодействующих друг с другом.
Вычислительное устройство 550 включает в себя, помимо прочих компонентов, процессор 552, запоминающее устройство 564 и устройство ввода/вывода, такое как дисплей 554, коммуникационный интерфейс 566 и приемопередатчик 568. Устройство 550 также может быть оснащено устройством хранения данных, таким как микродиск или другое устройство, для обеспечения дополнительной возможности хранения. Каждый из компонентов 550, 552, 564, 554, 566 и 568 соединен друг с другом с помощью различных шин, и некоторые из компонентов могут быть установлены на общей материнской плате или иными способами, в зависимости от ситуации.
Процессор 552 может исполнять инструкции внутри вычислительного устройства 550, включая инструкции, хранящиеся в запоминающем устройстве 564. Процессор может быть реализован в виде набора микросхем, который включает в себя отдельные и многокомпонентные аналоговые и цифровые процессоры. Кроме того, процессор может быть реализован с использованием любой из ряда архитектур. Например, процессор 510 может представлять собой процессор CISC (вычислительное устройство с полным набором команд), процессор RISC (вычислительное устройство с сокращенным набором команд) или процессор MISC (вычислительное устройство с минимальным набором команд). Процессор может обеспечивать, например, координацию других компонентов устройства 550, таких как управление пользовательскими интерфейсами, запуск приложений устройством 550 и беспроводная связь с устройством 550.
Процессор 552 может обмениваться данными с пользователем через интерфейс 558 управления и интерфейс 556 дисплея, соединенный с дисплеем 554. Дисплей 554 может представлять собой, например, дисплей типа TFT (жидкокристаллический дисплей на тонкопленочных транзисторах) или типа OLED (на органических светоизлучающих диодах), или использовать другие подходящие технологии отображения. Интерфейс 556 дисплея может содержать соответствующую схему для использования дисплея 554 для представления графической и другой информации пользователю. Интерфейс 558 управления может принимать команды от пользователя и преобразовывать их для передачи на процессор 552. Кроме того, может быть обеспечен внешний интерфейс 562, сообщающийся с процессором 552, для обеспечения устройства 550 связью ближнего радиуса действия с другими устройствами. В некоторых вариантах реализации внешний интерфейс 562 может обеспечивать, например, проводную связь, или, в других вариантах реализации, беспроводную связь, а также можно использовать множество интерфейсов.
Информация в запоминающем устройстве 564 хранится внутри вычислительного устройства 550. Запоминающее устройство 564 может быть реализовано в виде одного или более машиночитаемых носителей, блоков энергозависимого запоминающего устройства или блоков энергонезависимого запоминающего устройства. Также может быть предусмотрено расширительное запоминающее устройство 574, соединенное с устройством 550 посредством расширительного интерфейса 572, который может включать в себя, например, интерфейс карты SIMM (модуль запоминающего устройства с однорядным расположением микросхем). Такое расширительное запоминающее устройство 574 может обеспечивать устройство 550 дополнительным пространством хранения данных или может также хранить приложения или другую информацию для устройства 550. В частности, расширительное запоминающее устройство 574 может включать в себя инструкции для выполнения или для дополнения описанных выше процессов, а также может включать в себя защищенную информацию. Таким образом, например, расширительное запоминающее устройство 574 может быть предусмотрено в качестве модуля защиты для устройства 550 и может быть запрограммировано инструкциями, которые позволяют использовать устройство 550 безопасным образом. Кроме того, с помощью плат SIMM можно передавать безопасные приложения, а также дополнительную информацию, например размещать идентификационную информацию на карте SIMM без возможности компрометации.
Память может включать в себя, например, флэш-память и/или память NVRAM, как описано ниже. В одном варианте реализации компьютерный программный продукт на практике реализован на носителе информации. Компьютерный программный продукт содержит инструкции, при исполнении которых осуществляется один или более способов, такие как описанные выше. Носитель информации представляет собой читаемый компьютером или машиночитаемый носитель, такой как запоминающее устройство 564, расширительное запоминающее устройство 574 или запоминающее устройство на процессоре 552, причем информация может быть принята, например, посредством приемопередатчика 568 или внешнего интерфейса 562.
Устройство 550 может обмениваться данными беспроводным образом через коммуникационный интерфейс 566, в который при необходимости может быть включена схема для цифровой обработки сигналов. Коммуникационный интерфейс 566 может обеспечивать связь в различных режимах или протоколах, таких как, помимо прочего, голосовые звонки GSM, SMS, EMS или MMS сообщения, CDMA, TDMA, PDC, WCDMA, CDMA2000 или GPRS. Такую передачу данных можно осуществлять, например, при помощи радиочастотного приемопередатчика 568. Кроме того, возможна связь ближнего радиуса действия, например, с помощью Bluetooth, Wi-Fi или другого подобного приемопередатчика (не показан). Кроме того, модуль 570 приемника GPS (глобальной системы позиционирования) может обеспечивать для устройства 550 дополнительные относящиеся к навигации и местоположению беспроводные данные, которые при необходимости можно использовать в приложениях, работающих на устройстве 550.
Устройство 550 может также передавать звуковой сигнал с использованием аудиокодека 560, который может принимать речевую информацию от пользователя и преобразовывать ее в пригодную для использования цифровую информацию. Аудиокодек 560 может также генерировать звуковой сигнал для пользователя, например через динамик, например через гарнитуру устройства 550. Такой звуковой сигнал может представлять собой звук от голосовых телефонных звонков, может представлять собой записанный звук, например голосовые сообщения, музыкальные файлы и т.д., а может также включать в себя звук, создаваемый приложениями, работающими на устройстве 550.
Вычислительное устройство 550 может быть реализовано в ряде разных форм, как показано на фигуре. Например, оно может быть реализовано в виде сотового телефона 580. Оно может также быть реализовано в составе смартфона 582, карманного персонального компьютера или другого аналогичного мобильного устройства.
Различные варианты реализации систем и способов, описанных в настоящем документе, могут быть реализованы в виде цифровой электронной схемы, интегральной схемы, специально разработанных ASIC (интегральных схем прикладного назначения), компьютерного аппаратного обеспечения, микропрограммного обеспечения, программного обеспечения и/или в виде комбинации таких вариантов реализации. Данные различные реализации могут включать в себя реализацию в одной или более компьютерных программах, выполненных с возможностью исполнения и/или интерпретации в программируемой системе, включающей в себя по меньшей мере один программируемый процессор, который может быть специализированным или общего назначения, присоединенный к системе хранения для приема от нее данных и инструкций и передачи в нее данных и инструкций, по меньшей мере одно устройство ввода и по меньшей мере одно устройство вывода.
Эти компьютерные программы (также называемые программами, программным обеспечением, программными приложениями или кодом), включают в себя машинные инструкции для программируемого процессора и могут быть реализованы на высокоуровневом процедурном и/или объектно-ориентированном языке программирования, и/или на ассемблерном/машинном языке. Используемые в настоящем документе термины «машиночитаемый носитель», «читаемый компьютером носитель» относятся к любому компьютерному программному продукту, аппарату и/или устройству, например таким как магнитные диски, оптические диски, запоминающее устройство, программируемые логические устройства (PLD), используемые для передачи машинных инструкций и/или данных на программируемый процессор, включая машиночитаемый носитель, который принимает машинные инструкции в качестве машиночитаемого сигнала. Термин «машиночитаемый сигнал» относится к любому сигналу, используемому для передачи машинных инструкций и/или данных на программируемый процессор.
Для обеспечения взаимодействия с пользователем описанные в настоящем документе системы и методы могут быть реализованы на компьютере, имеющем устройство отображения, например КЛТ- (катодно-лучевая трубка) или ЖК-(жидкокристаллический) монитор, для отображения информации пользователю, и клавиатуру и указывающее устройство, например мышь или трекбол, с помощью которых пользователь может вводить в компьютер входные данные. Для обеспечения взаимодействия с пользователем также можно использовать и другие типы устройств; обратная связь, предоставляемая пользователю, может иметь любую осязаемую форму, например визуальная обратная связь, слуховая обратная связь или тактильная обратная связь; и входные данные от пользователя могут поступать в любой форме, включая звуковые, речевые или тактильные входные данные.
Описанные в настоящем документе системы и методы могут быть реализованы в компьютерной системе, которая включает в себя серверный компонент, например сервер данных, или включает в себя промежуточный компонент, например сервер приложений, или включает в себя клиентский компонент (например, компьютер-клиент с графическим интерфейсом пользователя или веб-браузером, с помощью которых пользователь может взаимодействовать с реализацией описанных в настоящем документе систем и методов), либо любую комбинацию таких серверных, промежуточных и клиентских компонентов. Компоненты системы могут быть связаны между собой любой формой или средой цифрового обмена данными, например сетью связи. К примерам сетей связи относятся локальная вычислительная сеть (LAN), глобальная сеть (WAN) и Интернет.
Компьютерная система может включать в себя клиенты и серверы. Клиент и сервер по существу удалены друг от друга и, как правило, взаимодействуют через сеть связи. Функциональная зависимость клиента и сервера возникает благодаря компьютерным программам, выполняемым на соответствующих компьютерах и имеющим связь типа «клиент - сервер» друг с другом.
ДРУГИЕ ВАРИАНТЫ ОСУЩЕСТВЛЕНИЯ
Описан ряд вариантов осуществления. Тем не менее будет очевидно, что возможны различные модификации без отклонения от сущности и объема изобретения. Кроме того, логические потоки, изображенные на фигурах, не требуют показанного определенного или последовательного порядка для достижения желаемых результатов. Кроме того, могут быть предусмотрены и другие стадии, или же стадии могут быть исключены из описанных потоков, и в описанные системы могут быть добавлены или удалены из них другие компоненты. Соответственно, нижеследующая формула изобретения охватывает другие варианты осуществления.
ЭКСПЕРИМЕНТАЛЬНЫЕ РЕЗУЛЬТАТЫ
Статистические и численные примеры способа сжатия в соответствии с изобретением
Приведенный ниже сравнительный пример был реализован для файла данных без сжатия размером 35 770 МБ, который содержал 48 миллионов прочтений или последовательностей нуклеотидов. Результаты этого сравнительного примера также графически представлены на Фиг. 6.
Приведенные ниже результаты указывают на размер сжатой версии несжатого файла размером 35 770 МБ, содержащего 48 миллионов прочтений, после сжатия с использованием каждого соответствующего алгоритма. Эти результаты представлены на диаграмме 610.
ο размер файла, сжатого с использованием программного обеспечения gzip: 6649 МБ (612)
ο размер файла, сжатого с использованием программного обеспечения без эталонной последовательности SPRING: 1402 МБ (614)
ο размер файла, сжатого с использованием способа сжатия на основе эталонной последовательности в соответствии с настоящим изобретением: 1179 МБ (616)
Приведенные ниже результаты указывают на количество времени, необходимое для сравнения несжатого файла размером 35 770 МБ, содержащего 48 миллионов прочтений, с использованием каждого соответствующего алгоритма. Эти результаты представлены на диаграмме 620.
ο время сжатия с использованием программного обеспечение без эталонной последовательности SPRING: 1722 с (622)
ο время сжатия с использованием способа сжатия на основе эталонной последовательности в соответствии с настоящим изобретением: 181 с (624)
Приведенные ниже результаты указывают на средний размер в битах/нуклеотид сжатой версии несжатого файла размером 35 770 МБ, содержащего 48 миллионов прочтений, после сжатия с использованием каждого соответствующего алгоритма. Эти результаты представлены на диаграмме 630.
ο средний размер битов/нуклеотидов в файле данных без сжатия (кодирование ASCII): 8 битов/нуклеотид (630)
ο средний размер битов/нуклеотидов в файле, который был сжат с кодированием, адаптированным для 4 возможных символов А, Т, С, G: 2 бита/нуклеотид (634)
ο средний размер битов/нуклеотидов в файле, который был сжат с использованием способа сжатия на основе эталонной последовательности в соответствии с настоящим изобретением: 0,33 бита/нуклеотид (636)
На Фиг. 7 показаны дополнительные сравнительные результаты, полученные при использовании разных алгоритмов сжатия для сжатия образцов прочтений, полученных с использованием WXS novaseq и эталонного генома SRR8604734.
На диаграмме 710 показано сравнение полученного размера сжатия (МБ) между сжатием с помощью алгоритма gzip прочтений WXS novaseq с использованием эталонного генома SRR8604734 (712), сжатием с помощью алгоритма Spring прочтений WXS novaseq с использованием эталонного генома SRR8604734 (716) и сжатием с помощью алгоритма настоящего изобретения прочтений WXS novaseq с использованием эталонного генома SRR8604734 (716). Измерения представлены в мегабайтах.
На диаграмме 720 показано сравнение скоростей сжатия с помощью алгоритмов сжатия, показанных на диаграмме 720, при сжатии прочтений WXS novaseq с использованием эталонного генома SRR8604734. Скорости сжатия с помощью алгоритма Spring прочтений WXS novaseq с использованием эталонного генома SRR8604734, показанные на диаграмме (722), сравниваются со скоростью сжатия с помощью алгоритма настоящего изобретения прочтений WXS novaseq с использованием эталонного генома SRR8604734, показанной на диаграмме 724. Измерения представлены в секундах.
На диаграмме 730 показано сравнение используемой памяти алгоритмами сжатия, представленными на диаграмме 730, при сжатии прочтений WXS novaseq с использованием эталонного генома SRR8604734. При сжатии с помощью алгоритма Spring использовалось 13 428 МБ памяти при сжатии прочтений WXS novaseq с использованием эталонного генома SRR8604734 732, а при сжатии с помощью алгоритма настоящего изобретения использовалось 3604 МБ памяти при сжатии прочтений WXS novaseq с использованием эталонного генома SRR8604734 (734). Измерения представлены в мегабайтах.
На Фиг. 8 показаны дополнительные сравнительные результаты, полученные при использовании разных алгоритмов сжатия для сжатия образцов прочтений, полученных с использованием разных секвенаторов и разных эталонных геномов при разных коэффициентах сжатия.
На диаграмме 810 показан исходный размер (812) в гигабайтах (ГБ) файла прочтений, генерируемого с использованием Novaseq. При использовании алгоритма gzip для сжатия прочтений Novaseq размером 100 ГБ gzip сжал исходные данные до 17,7 ГБ (814). Настоящее изобретение позволило сжать тот же исходный размер 812 файла прочтений, сгенерированных с помощью Novaseq, размером 100 ГБ в сжатый файл размером 3,4 ГБ (816). Эталонный геном, используемый для сжатия с помощью gzip и настоящего изобретения, как показано на 810, представлял собой SRR6882909, а коэффициент сжатия составил 5,2х.
На диаграмме 820 показан исходный размер (822) в гигабайтах (ГБ) файла прочтений, сгенерированного с использованием Hiseq X Ten. При использовании gzip для сжатия прочтений Hiseq X Ten размером 100 ГБ gzip сжал исходные данные до 24,9 ГБ (824). Настоящее изобретение позволило сжать тот же исходный размер 822 файла прочтений, сгенерированных с помощью Hiseq X Ten, размером 100 ГБ в сжатый файл размером 8,1 ГБ (826). Эталонный геном, используемый для сжатия с помощью gzip и настоящего изобретения, как показано на 820, представлял собой SRR7725247, а коэффициент сжатия составил 3х.
На диаграмме 830 показан исходный размер (832) в гигабайтах (ГБ) файла прочтений, сгенерированных с помощью Hiseq 2000. При использовании gzip для сжатия прочтений Hiseq 2000 размером 100 ГБ gzip сжал исходные данные до 27,6 ГБ (834). Настоящее изобретение позволило сжать тот же исходный размер 832 файла прочтений, сгенерированных с помощью Hiseq 2000, размером 100 ГБ в сжатый файл размером 11,3 ГБ (836). Эталонный геном, используемый для сжатия с помощью gzip и настоящего изобретения, как показано на 830, представлял собой ERR 174324, а коэффициент сжатия составил 2,4х.
Приведенные выше численные примеры показывают, что настоящее изобретение обеспечивает быстрое сжатие и распаковку, обеспечивая высокий коэффициент сжатия.
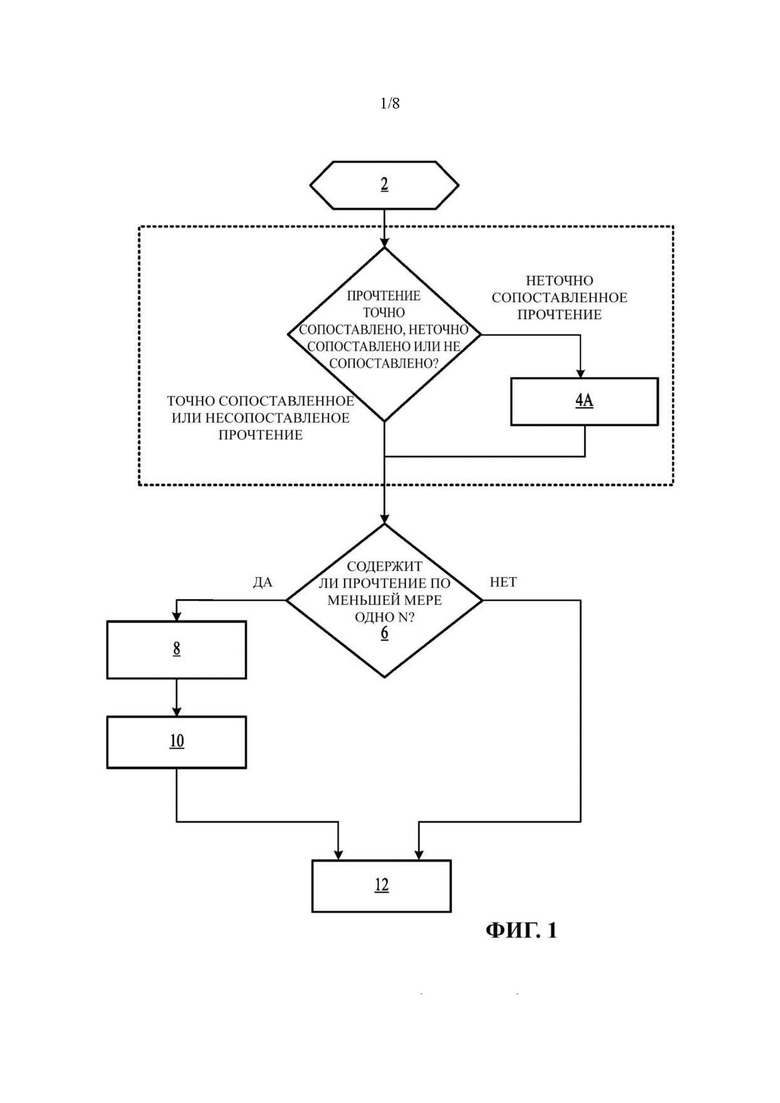
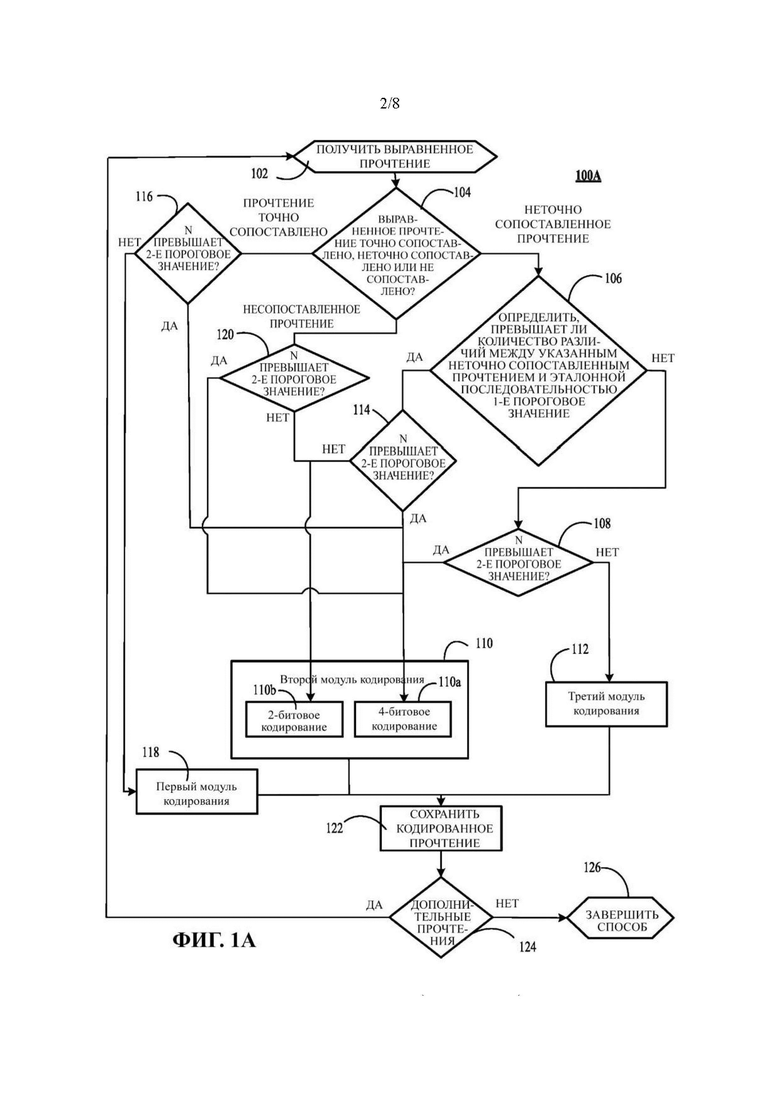
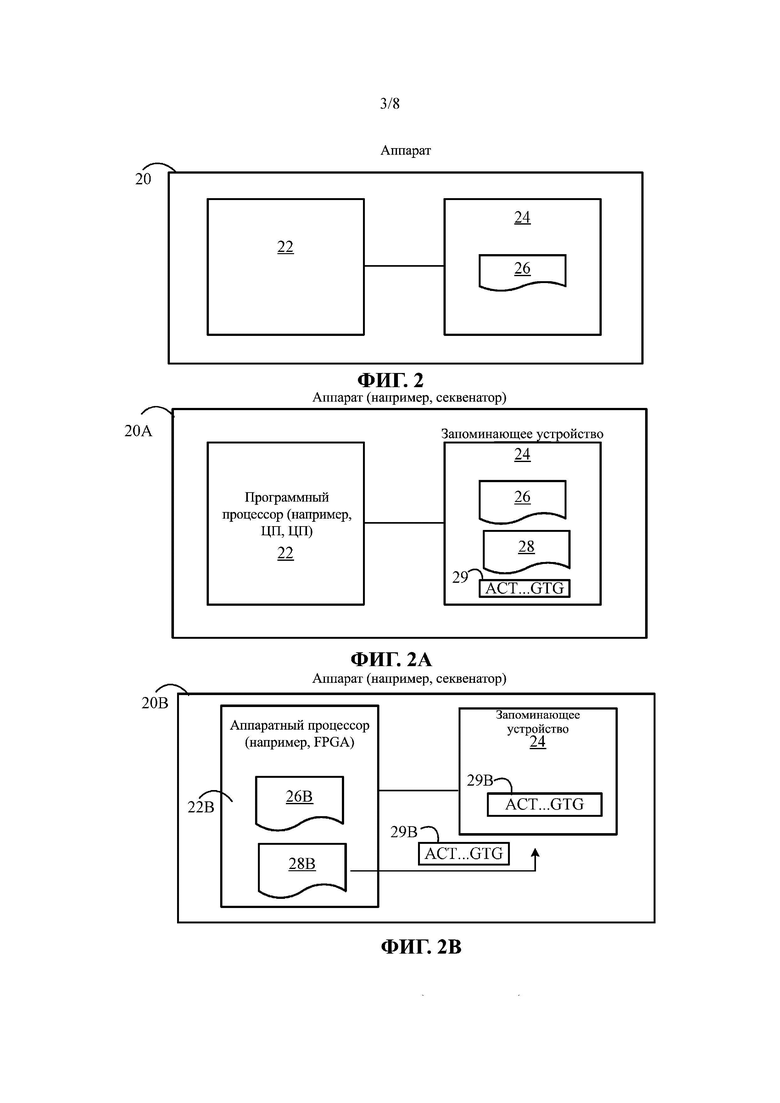
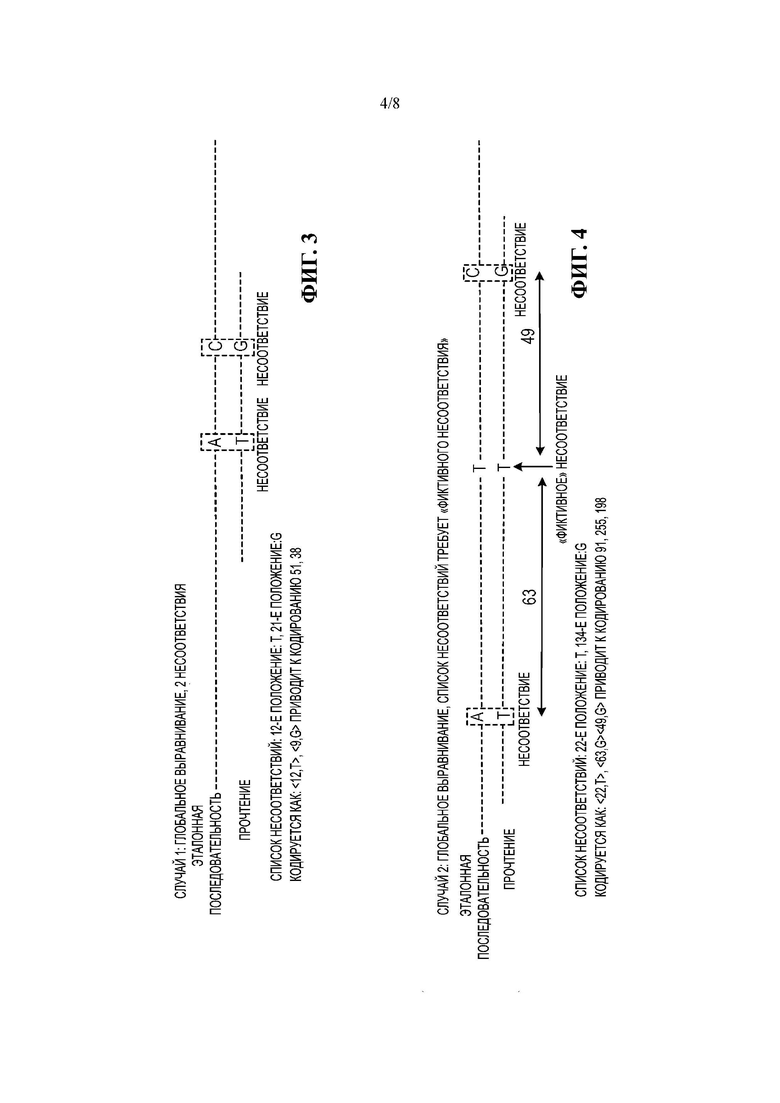
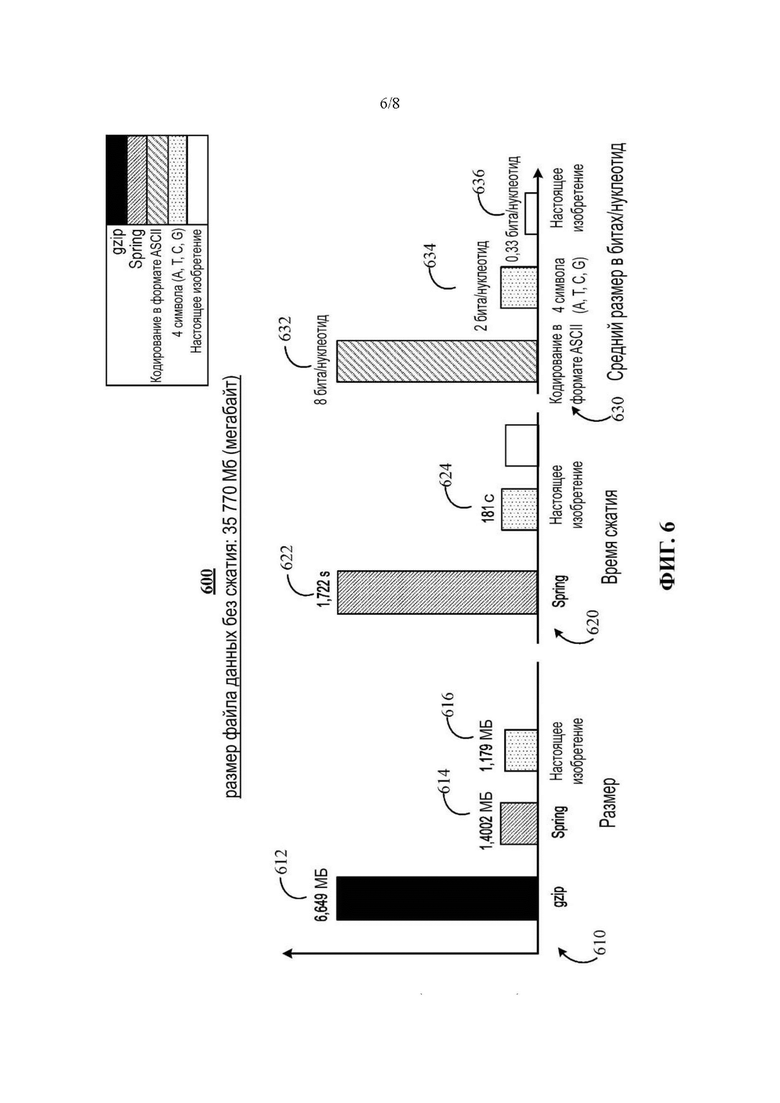
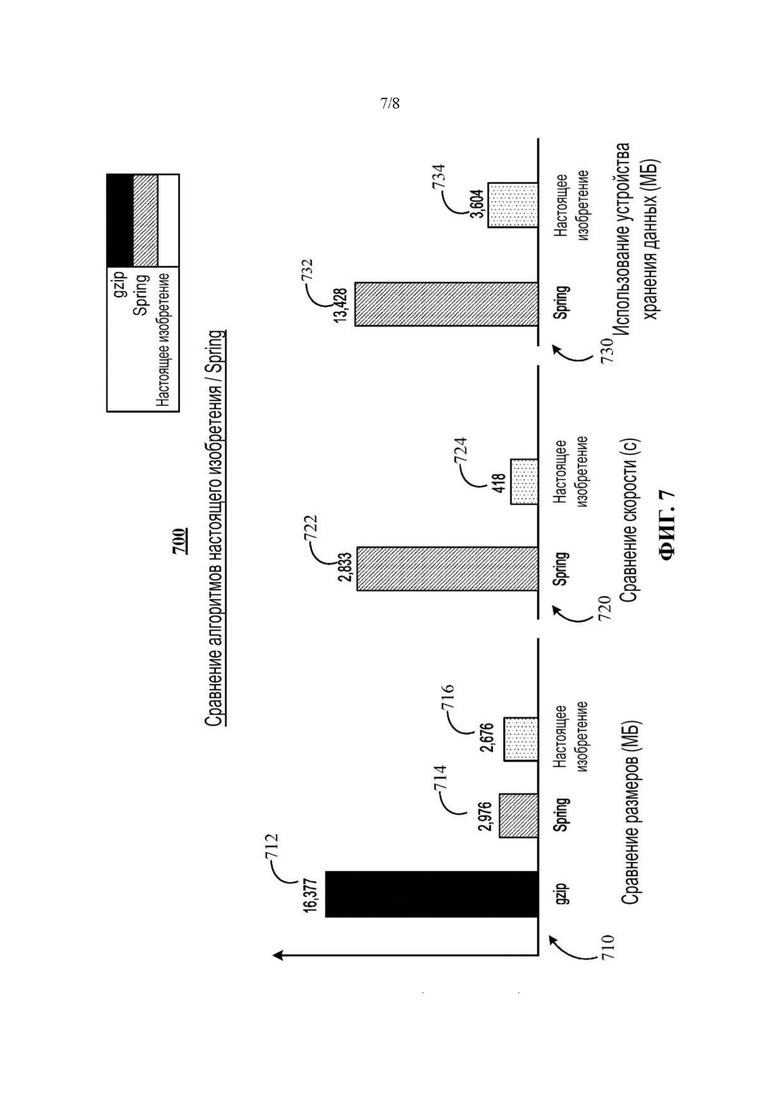
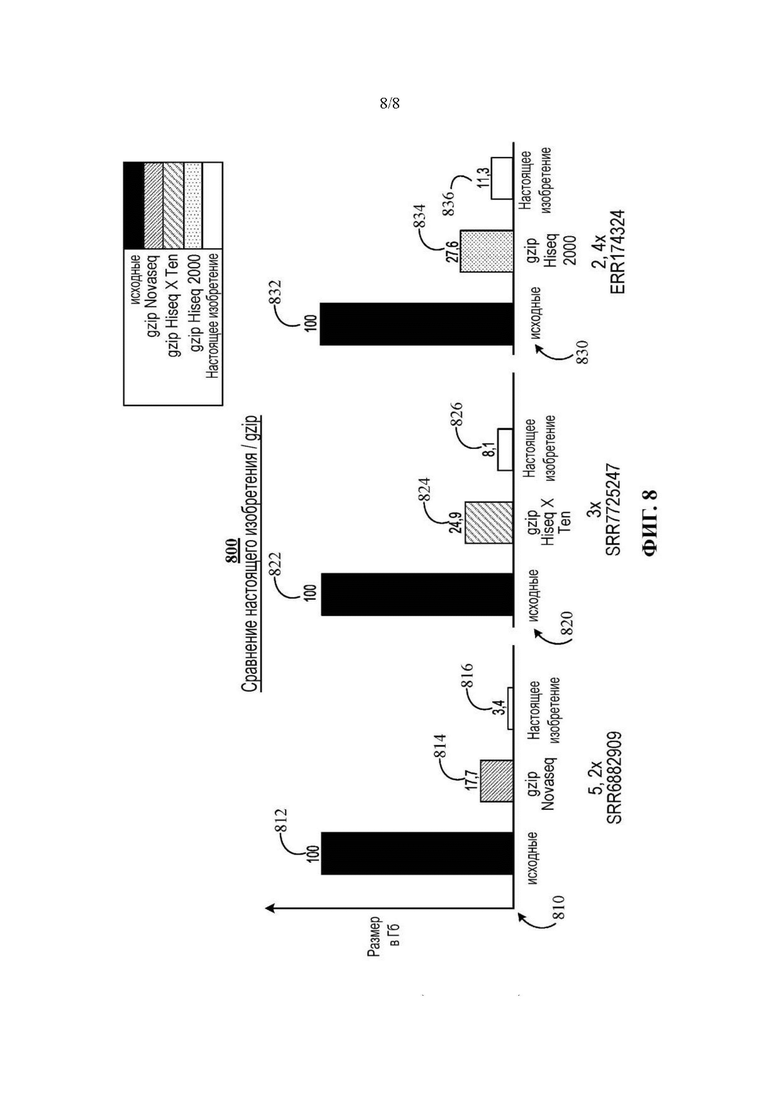
Группа изобретений относится к процессу сжатия данных последовательности генома, полученных секвенатором, на основе эталонной последовательности. Для последовательностей нуклеотидов или оснований, которые ранее были выравнены с эталонной последовательностью, определяется то, насколько они точно сопоставляются, неточно сопоставляются или не сопоставляются с эталонной последовательностью; после чего они кодируются в зависимости от указанного определения. Для каждой неточно сопоставленной последовательности стадия определения включает в себя сравнение количества несоответствий между указанной последовательностью и эталонной последовательностью с учетом эталонного порогового значения и в зависимости от результата указанного сравнения - кодирование неточно сопоставленных последовательностей с использованием однозначно заданных процессов кодирования указанного способа сжатия данных последовательности генома, полученных секвенатором. Группа изобретений включает реализуемый на компьютере способ сжатия данных геномной последовательности, систему сжатия данных последовательности генома, машиночитаемое устройство хранения данных для сжатия данных последовательности генома и аппаратный процессор для сжатия данных последовательности генома. Группа изобретений обеспечивает быстрое сжатие и распаковку данных, в то же время исключая потерю информации, и обеспечивает высокий коэффициент сжатия. 4 н. и 28 з.п. ф-лы, 7 ил.
1. Реализуемый на компьютере способ сжатия данных геномной последовательности, включающий:
получение доступа одним или более процессорами к устройству хранения данных, хранящему множество записей прочтений так, чтобы сохранялся порядок последовательностей записей прочтений, созданный модулем сопоставления и выравнивания, причем каждая из множества записей прочтений соответствует точно сопоставленному прочтению или неточно сопоставленному прочтению;
для каждой конкретной записи прочтения из множества записей прочтений:
получение одним или более процессорами конкретной записи прочтения, сгенерированной на основании выходных данных, полученных модулем сопоставления и выравнивания, при этом конкретная запись прочтения включает в себя данные, указывающие на то, является ли прочтение, соответствующее конкретной записи прочтения, точно сопоставленным или неточно сопоставленным;
определение одним или более процессорами и на основании конкретной записи прочтения того, соответствует ли конкретная запись прочтения прочтению, которое точно сопоставлено с эталонной последовательностью или неточно сопоставлено с эталонной последовательностью;
на основании определения одним или более процессорами того, что конкретная запись прочтения соответствует прочтению, которое неточно сопоставлено с эталонной последовательностью, определение одним или более процессорами того, насколько количество несоответствий неточно сопоставленного прочтения удовлетворяет заданному пороговому количеству несоответствий;
на основании определения того, что количество несоответствий удовлетворяет заданному пороговому количеству несоответствий, кодирование одним или более процессорами каждого несоответствия неточно сопоставленного прочтения в сжатую запись, имеющую заданный размер сжатой записи; и
сохранение одним или более процессорами сжатой записи в устройстве хранения данных при сохранении порядка последовательностей множества записей прочтения.
2. Реализуемый на компьютере способ по п. 1, где каждая запись прочтения из множества записей прочтений дополнительно включает в себя:
данные, указывающие на абсолютное положение начала выравненного прочтения по отношению к эталонной последовательности,
данные, указывающие на длину прочтения,
данные, указывающие на количество несоответствий, выявленных в прочтении,
данные, указывающие на то, включает ли прочтение по меньшей мере одно неопределенное основание N,
данные, указывающие на количество неопределенных оснований N в прочтении,
данные, указывающие на то, является прочтение сопоставленным или несопоставленным,
данные, указывающие на положение записи прочтения в последовательности записей прочтений, выводимой модулем сопоставления и выравнивания, и
данные, указывающие на относительное положение указанных возможных несоответствий в прочтении.
3. Реализуемый на компьютере способ по п. 1, где заданный размер сжатой записи составляет один байт.
4. Реализуемый на компьютере способ по п. 3, где кодирование каждого несоответствия неточно сопоставленного прочтения в сжатую запись размером один байт для каждого конкретного несоответствия включает в себя:
кодирование одним или более процессорами первых двух битов байта, чтобы включить данные, отражающие альтернативный нуклеотид или основание, присутствующие в прочтении вместо соответствующего эталонного нуклеотида или основания в эталонной последовательности; и
кодирование одним или более процессорами шести последних битов байта, чтобы включить данные, отражающие положение несоответствия в эталонной последовательности, причем указанное положение вычисляется как смещение относительно предыдущего несоответствия прочтения.
5. Реализуемый на компьютере способ по п. 4, дополнительно включающий:
определение одним или более процессорами того, превышает ли смещение максимальное кодируемое значение;
на основании определения того, что смещение превышает максимальное кодированное значение, вставку одним или более процессорами по меньшей мере одного фиктивного несоответствия между конкретным несоответствием и предыдущим несоответствием.
6. Реализуемый на компьютере способ по п. 1, дополнительно включающий
на основании определения того, что количество несоответствий не удовлетворяет заданному пороговому количеству несоответствий, кодирование одним или более процессорами списка положений эталонной последовательности, соответствующих положению каждого из несоответствий относительно эталонной последовательности, с использованием процесса кодирования с понижением энтропии информации.
7. Реализуемый на компьютере способ по п. 1, дополнительно включающий
на основании определения того, что запись прочтения соответствует прочтению, которое точно сопоставлено с эталонной последовательностью, кодирование одним или более процессорами по меньшей мере участка записи прочтения с использованием кодирования с понижением энтропии информации.
8. Реализуемый на компьютере способ по п. 1, где определение одним или более компьютерами того, насколько количество несоответствий неточно сопоставленного прочтения удовлетворяет заданному пороговому количеству несоответствий, включает в себя
определение одним или более процессорами того, превышает ли количество несоответствий неточно сопоставленного прочтения эталонное пороговое значение.
9. Система сжатия данных последовательности генома, включающая в себя
один или более компьютеров и одно или более устройств хранения данных, на которых хранятся инструкции, при исполнении которых одним или более компьютерами один или более компьютеров выполняют операции, включающие в себя:
получение доступа одним или более компьютерами к устройству хранения данных, хранящему множество записей прочтений так, чтобы сохранялся порядок последовательностей записей прочтений, созданный модулем сопоставления и выравнивания, причем каждая из множества записей прочтений соответствует точно сопоставленному прочтению или неточно сопоставленному прочтению;
для каждой конкретной записи прочтения из множества записей прочтений:
получение одним или более компьютерами конкретной записи прочтения, сгенерированной на основании выходных данных, полученных модулем сопоставления и выравнивания, при этом конкретная запись прочтения включает в себя данные, указывающие на то, является ли прочтение, соответствующее конкретной записи прочтения, точно сопоставленным или неточно сопоставленным;
определение одним или более компьютерами и на основании конкретной записи прочтения, соответствует ли конкретная запись прочтения прочтению, которое точно сопоставлено с эталонной последовательностью или неточно сопоставлено с эталонной последовательностью;
на основании определения одним или более компьютерами того, что конкретная запись прочтения соответствует прочтению, которое неточно сопоставлено с эталонной последовательностью, определение одним или более компьютерами того, насколько количество несоответствий неточно сопоставленного прочтения удовлетворяет заданному пороговому количеству несоответствий;
на основании определения того, что количество несоответствий удовлетворяет заданному пороговому количеству несоответствий, кодирование одним или более компьютерами каждого несоответствия неточно сопоставленного прочтения в сжатую запись, имеющую заданный размер сжатой записи; и
сохранение одним или более компьютерами сжатой записи в устройстве хранения данных при сохранении порядка последовательностей множества записей прочтения.
10. Система по п. 9, где каждая запись прочтения из множества записей прочтений дополнительно включает в себя:
данные, указывающие на абсолютное положение начала выравненного прочтения по отношению к эталонной последовательности,
данные, указывающие на длину прочтения,
данные, указывающие на количество несоответствий, выявленных в прочтении,
данные, указывающие на то, включает ли прочтение по меньшей мере одно неопределенное основание N,
данные, указывающие на количество неопределенных оснований N в прочтении,
данные, указывающие на то, является прочтение сопоставленным или несопоставленным,
данные, указывающие на положение записи прочтения в последовательности записей прочтений, выводимой модулем сопоставления и выравнивания, и
данные, указывающие на относительное положение указанных возможных несоответствий в прочтении.
11. Система по п. 9, где заданный размер сжатой записи составляет один байт.
12. Система по п. 11, где кодирование каждого несоответствия неточно сопоставленного прочтения в сжатую запись размером один байт для каждого конкретного несоответствия включает в себя:
кодирование одним или более компьютерами первых двух битов байта, чтобы включить данные, отражающие альтернативный нуклеотид или основание, присутствующие в прочтении вместо соответствующего эталонного нуклеотида или основания в эталонной последовательности; и
кодирование одним или более компьютерами шести последних битов байта, чтобы включить данные, отражающие положение несоответствия в эталонной последовательности, причем указанное положение вычисляется как смещение относительно предыдущего несоответствия прочтения.
13. Система по п. 12, где операции дополнительно включают в себя:
определение одним или более компьютерами того, превышает ли смещение максимальное кодируемое значение;
на основании определения того, что смещение превышает максимальное кодированное значение, вставку одним или более компьютерами по меньшей мере одного фиктивного несоответствия между конкретным несоответствием и предыдущим несоответствием.
14. Система по п. 12, где операции дополнительно включают в себя
на основании определения того, что количество несоответствий не удовлетворяет заданному пороговому количеству несоответствий, кодирование одним или более компьютерами списка положений эталонной последовательности, соответствующих положению каждого из несоответствий относительно эталонной последовательности, с использованием процесса кодирования с понижением энтропии информации.
15. Система по п. 12, где операции дополнительно включают в себя
на основании определения того, что запись прочтения соответствует прочтению, которое точно сопоставлено с эталонной последовательностью, кодирование одним или более компьютерами по меньшей мере участка записи прочтения с использованием кодирования с понижением энтропии информации.
16. Система по п. 12, где определение одним или более компьютерами того, насколько количество несоответствий неточно сопоставленного прочтения удовлетворяет заданному пороговому количеству несоответствий, включает в себя
определение одним или более компьютерами того, превышает ли количество несоответствий неточно сопоставленного прочтения заданное пороговое количество несоответствий.
17. Машиночитаемое устройство хранения данных для сжатия данных последовательности генома, имеющее хранящиеся в нем инструкции, которые при их исполнении аппаратом для обработки данных приводят к тому, что аппарат для обработки данных выполняет операции сжатия данных геномной последовательности, включающие в себя:
получение доступа к устройству хранения данных, хранящему множество записей прочтений так, чтобы сохранялся порядок последовательностей записей прочтений, созданный модулем сопоставления и выравнивания, причем каждая из множества записей прочтений соответствует точно сопоставленному прочтению или неточно сопоставленному прочтению;
для каждой конкретной записи прочтения из множества записей прочтений:
получение конкретной записи прочтения, сгенерированной на основании выходных данных, полученных модулем сопоставления и выравнивания, при этом конкретная запись прочтения включает в себя данные, указывающие на то, является ли прочтение, соответствующее конкретной записи прочтения, точно сопоставленным или неточно сопоставленным;
определение на основании конкретной записи прочтения того, соответствует ли конкретная запись прочтения прочтению, которое точно сопоставлено с эталонной последовательностью или неточно сопоставлено с эталонной последовательностью;
на основании определения того, что конкретная запись прочтения соответствует прочтению, которое неточно сопоставлено с эталонной последовательностью, определение того, насколько количество несоответствий неточно сопоставленного прочтения удовлетворяет заданному пороговому количеству несоответствий;
на основании определения того, что количество несоответствий удовлетворяет заданному пороговому количеству несоответствий, кодирование каждого несоответствия неточно сопоставленного прочтения в сжатую запись, имеющую заданный размер сжатой записи; и
сохранение сжатой записи в устройстве хранения данных при сохранении порядка последовательностей множества записей прочтения.
18. Машиночитаемое устройство хранения данных по п. 17, где каждая запись прочтения из множества записей прочтений содержит:
данные, указывающие на абсолютное положение начала выравненного прочтения по отношению к эталонной последовательности,
данные, указывающие на длину прочтения,
данные, указывающие на количество несоответствий, выявленных в прочтении,
данные, указывающие на то, включает ли прочтение по меньшей мере одно неопределенное основание N,
данные, указывающие на количество неопределенных оснований N в прочтении,
данные, указывающие на то, является прочтение сопоставленным или несопоставленным,
данные, указывающие на положение записи прочтения в последовательности записей прочтений, выводимой модулем сопоставления и выравнивания, и
данные, указывающие на относительное положение указанных возможных несоответствий в прочтении.
19. Машиночитаемое устройство хранения данных по п. 17, где заданный размер сжатой записи составляет один байт.
20. Машиночитаемое устройство хранения данных по п. 19, где кодирование каждого несоответствия неточно сопоставленного прочтения в сжатую запись размером один байт для каждого конкретного несоответствия включает в себя:
кодирование первых двух битов байта так, чтобы включить данные, отражающие альтернативный нуклеотид или основание, присутствующие в прочтении вместо соответствующего эталонного нуклеотида или основания в эталонной последовательности; и
кодирование шести последних битов байта, чтобы включить данные, отражающие положение несоответствия в эталонной последовательности, причем указанное положение вычисляется как смещение относительно предыдущего несоответствия прочтения.
21. Машиночитаемое устройство хранения данных по п. 20, где операции дополнительно включают в себя:
определение того, превышает ли смещение максимальное кодируемое значение;
на основании определения того, что смещение превышает максимальное кодированное значение, вставку по меньшей мере одного фиктивного несоответствия между конкретным несоответствием и предыдущим несоответствием.
22. Машиночитаемое устройство хранения данных по п. 20, где операции дополнительно включают в себя
на основании определения того, что количество несоответствий не удовлетворяет заданному пороговому количеству несоответствий, кодирование списка положений эталонной последовательности, соответствующих положению каждого из несоответствий относительно эталонной последовательности, с использованием процесса кодирования с понижением энтропии информации.
23. Машиночитаемое устройство хранения данных по п. 20, где операции дополнительно включают в себя
на основании определения того, что запись прочтения соответствует прочтению, которое точно сопоставлено с эталонной последовательностью, кодирование по меньшей мере участка записи прочтения с использованием кодирования с понижением энтропии информации.
24. Машиночитаемое устройство хранения данных по п. 20, где определение того, насколько количество несоответствий неточно сопоставленного прочтения удовлетворяет заданному пороговому количеству несоответствий, включает в себя
определение того, превышает ли количество несоответствий неточно сопоставленного прочтения заданное пороговое количество несоответствий.
25. Аппаратный процессор для сжатия данных последовательности генома, который включает в себя аппаратную систему обработки, которая выполнена с возможностью выполнения одной или более операций, причем одна или более операций включают в себя:
получение доступа аппаратной системой обработки к устройству хранения данных, хранящему множество записей прочтений так, чтобы сохранялся порядок последовательностей записей прочтений, созданный модулем сопоставления и выравнивания, при этом каждая из множества записей прочтений соответствует точно сопоставленному прочтению или неточно сопоставленному прочтению;
для каждой конкретной записи прочтения из множества записей прочтений:
получение аппаратной системой обработки конкретной записи прочтения, сгенерированной на основании выходных данных, полученных модулем сопоставления и выравнивания, причем конкретная запись прочтения включает в себя данные, указывающие на то, является ли прочтение, соответствующее конкретной записи прочтения, точно сопоставленным или неточно сопоставленным;
определение аппаратной системой обработки и на основании конкретной записи прочтения того, соответствует ли конкретная запись прочтения прочтению, которое точно сопоставлено с эталонной последовательностью или неточно сопоставлено с эталонной последовательностью;
на основании определения аппаратной системой обработки того, что конкретная запись прочтения соответствует прочтению, которое неточно сопоставлено с эталонной последовательностью, определение аппаратной системой обработки того, насколько количество несоответствий неточно сопоставленного прочтения удовлетворяет заданному пороговому количеству несоответствий;
на основании определения того, что количество несоответствий удовлетворяет заданному пороговому количеству несоответствий, кодирование аппаратной системой обработки каждого несоответствия неточно сопоставленного прочтения в сжатую запись, имеющую заданный размер сжатой записи; и
сохранение аппаратной системой обработки сжатой записи в устройстве хранения данных при сохранении порядка последовательностей множества записей прочтения.
26. Аппаратный процессор по п. 25, где каждая запись прочтения из множества записей прочтений дополнительно включает в себя:
данные, указывающие на абсолютное положение начала выравненного прочтения по отношению к эталонной последовательности,
данные, указывающие на длину прочтения,
данные, указывающие на количество несоответствий, выявленных в прочтении,
данные, указывающие на то, включает ли прочтение по меньшей мере одно неопределенное основание N,
данные, указывающие на количество неопределенных оснований N в прочтении,
данные, указывающие на то, является прочтение сопоставленным или несопоставленным,
данные, указывающие на положение записи прочтения в последовательности записей прочтений, выводимой модулем сопоставления и выравнивания, и
данные, указывающие на относительное положение указанных возможных несоответствий в прочтении.
27. Аппаратный процессор по п. 25, где заданный размер сжатой записи составляет один байт.
28. Аппаратный процессор по п. 27, где кодирование каждого несоответствия неточно сопоставленного прочтения в сжатую запись размером один байт для каждого конкретного несоответствия включает в себя:
кодирование аппаратной системой обработки первых двух битов байта, чтобы включить данные, отражающие альтернативный нуклеотид или основание, присутствующие в прочтении вместо соответствующего эталонного нуклеотида или основания в эталонной последовательности; и
кодирование аппаратной системой обработки шести последних битов байта, чтобы включить данные, отражающие положение несоответствия в эталонной последовательности, причем указанное положение вычисляется как смещение относительно предыдущего несоответствия прочтения.
29. Аппаратный процессор по п. 28, дополнительно содержащий:
определение аппаратной системой обработки того, превышает ли смещение максимальное кодируемое значение;
на основании определения того, что смещение превышает максимальное кодированное значение, вставку аппаратной системой обработки по меньшей мере одного фиктивного несоответствия между конкретным несоответствием и предыдущим несоответствием.
30. Аппаратный процессор по п. 28, дополнительно содержащий
на основании определения того, что количество несоответствий не удовлетворяет заданному пороговому количеству несоответствий, кодирование аппаратной системой обработки списка положений эталонной последовательности, соответствующих положению каждого из несоответствий относительно эталонной последовательности, с использованием процесса кодирования с понижением энтропии информации.
31. Аппаратный процессор по п. 28, дополнительно содержащий
на основании определения того, что запись прочтения соответствует прочтению, которое точно сопоставлено с эталонной последовательностью, кодирование аппаратной системой обработки по меньшей мере участка записи прочтения с использованием кодирования с понижением энтропии информации.
32. Аппаратный процессор по п. 28, где определение аппаратной системой обработки того, насколько количество несоответствий неточно сопоставленного прочтения удовлетворяет заданному пороговому количеству несоответствий, включает в себя
определение аппаратной системой обработки того, превышает ли количество несоответствий неточно сопоставленного прочтения заданное пороговое количество несоответствий.
| SEBASTIAN WANDELT et al.: Adaptive efficient compression of genomes | |||
| Algorithms for molecular biology | |||
| BIOMED CENTRAL LTD, LO, vol | |||
| Способ восстановления хромовой кислоты, в частности для получения хромовых квасцов | 1921 |
|
SU7A1 |
| Печь для непрерывного получения сернистого натрия | 1921 |
|
SU1A1 |
| Способ обработки медных солей нафтеновых кислот | 1923 |
|
SU30A1 |
| US 2015227686 A1, 13.08.2015 | |||
| SEBASTIAN WANDELT et al | |||
| Fresco, IEEE/ACM transactions on computational biology and bioinformatics | |||
| IEEE SERVICE CENTER, NEW YORK, NY, US, vol | |||
| Печь-кухня, могущая работать, как самостоятельно, так и в комбинации с разного рода нагревательными приборами | 1921 |
|
SU10A1 |
| Кипятильник для воды | 1921 |
|
SU5A1 |

