ПЕРЕКРЕСТНАЯ ССЫЛКА НА СВЯЗАННЫЕ ЗАЯВКИ
[0001] Данная патентная заявка испрашивает приоритет по. предварительной патентной заявке США №. 62/871,524, поданной 8 июля 2019 года Ye-Kui Wang, et. al. и озаглавленной «Constraints for Mixed NAL Unit Types within One Picture in Video Coding», которая настоящим включена в данный документ по ссылке.
ОБЛАСТЬ ТЕХНИКИ
[0002] Настоящее раскрытие в целом относится к кодированию/декодированию видео и, в частности, относится к кодированию/декодированию субизображений из изображений при кодировании/декодировании видео.
УРОВЕНЬ ТЕХНИКИ
[0003] Объем видеоданных, необходимых для представления даже относительно короткого видео, может быть значительным, что может привести к трудностям, когда эти данные должны передаваться в потоковом режиме или иным образом передаваться по сети связи с ограниченной пропускной способностью. Таким образом, видеоданные обычно сжимаются перед передачей по современным телекоммуникационным сетям. Размер видео также может быть проблемой, когда видео сохраняется на запоминающем устройстве, поскольку ресурсы памяти могут быть ограничены. Устройства сжатия видео часто используют программное и/или аппаратное обеспечение в источнике для кодирования/декодирования видеоданных перед передачей или сохранением, тем самым уменьшая количество данных, необходимых для представления цифровых видеоизображений. Сжатые данные затем принимаются устройством декомпрессии видео получателя, которое декодирует видеоданные. С ограниченными сетевыми ресурсами и постоянно растущими потребностями в видео более высокого качества, желательны улучшенные методики сжатия и декомпрессии, которые улучшают степень сжатия с минимальными потерями качества изображения или вообще без таких потерь.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
[0004] В варианте осуществления раскрытие включает в себя способ, реализуемый в декодере, причем способ содержит: прием, приемником декодера, битового потока, содержащего текущее изображение, включающее в себя множество единиц уровня сетевой абстракции (NAL) уровня кодирования/декодирования видео (VCL), которые не имеют одного и того же типа единицы NAL; получение, процессором декодера, активных записей списков опорных изображений для слайсов, расположенных в субизображении A (subpicA) в последующих изображениях, следующих за текущим изображением в порядке декодирования, при этом активные записи не включают в себя ссылку на какое-либо опорное изображение, предшествующее текущему изображению в порядке декодирования, когда subpicA в текущем изображении ассоциировано с типом единицы NAL интра-точки произвольного доступа (IRAP); декодирование, процессором, последующих изображений на основе активных записей списков опорных изображений; и пересылку процессором последующих изображений для отображения как части декодированной видеопоследовательности.
[0005] Системы кодирования/декодирования (coding) видео могут кодировать (encode) видео, используя IRAP-изображения и не-IRAP-изображения. IRAP-изображения являются изображениями, кодируемыми/декодируемыми согласно интра-предсказанию, которые служат в качестве точек произвольного доступа для видеопоследовательности. IRAP-изображение может быть декодировано без предварительного декодирования каких-либо других изображений. Соответственно, декодер может начинать декодирование видеопоследовательности с любого IRAP-изображения. В то же время декодер обычно не может начинать декодирование видеопоследовательности с не-IRAP-изображения. IRAP-изображения также могут обновлять DPB. Это связано с тем, что IRAP-изображение может действовать в качестве начальной точки для кодируемой/декодируемой видеопоследовательности (CVS), и изображения в этой CVS не ссылаются на изображения в предшествующей CVS. Таким образом, IRAP-изображения также могут разрывать/останавливать цепочки интер-предсказания и останавливать ошибки кодирования/декодирования, связанные с интер-предсказанием, поскольку такие ошибки не могут распространяться через IRAP-изображение.
[0006] В некоторых случаях для кодирования/декодирования видео виртуальной реальности (VR) могут использоваться системы кодирования/декодирования видео. Видео VR может включать в себя сферу видеоконтента, отображаемую так, как если бы пользователь находился в центре этой сферы. Пользователю отображается только участок сферы, называемый окном просмотра. Оставшаяся часть изображения отбрасывается без рендеринга. Все изображение обычно передается таким образом, что другое окно просмотра может быть динамически выбрано и отображено в ответ на движение головы пользователя. Такой подход может привести к очень большим размерам видеофайлов. Чтобы повысить эффективность кодирования/декодирования, некоторые системы делят изображения на субизображения. Видео может быть закодировано в двух или более разрешениях. Каждое разрешение кодируется в различном наборе битовых подпотоков, соответствующих субизображениям. Когда пользователь осуществляет потоковую передачу видео VR, система кодирования/декодирования может объединять битовые подпотоки в битовый поток для передачи на основе текущего окна просмотра, используемого пользователем. В частности, текущее окно просмотра получается из битового подпотока высокого разрешения, а окна просмотра, которые не просматриваются, получают из битового потока(потоков) низкого разрешения. Таким образом, для пользователя отображается видео наивысшего качества, а видео более низкого качества отбрасывается. В случае, если пользователь выбирает новое окно просмотра, пользователю отображается видео более низкого разрешения. Декодер может запросить, чтобы новое окно просмотра получило видео более высокого разрешения. Затем кодер может надлежащим образом изменить процесс объединения. Как только IRAP-изображение достигнуто, декодер может начинать декодирование видеопоследовательности более высокого разрешения в новом окне просмотра. Такой подход значительно увеличивает сжатие видео, не оказывая негативного влияния на впечатления пользователя от просмотра.
[0007] Одна проблема с вышеупомянутым подходом заключается в том, что продолжительность времени, необходимая для изменения разрешений, основана на продолжительности времени до момента, когда будет достигнуто IRAP-изображение. Это связано с тем, что, как описано выше, декодер не может начинать декодирование другой видеопоследовательности с не-IRAP-изображения. Одним из подходов к уменьшению такой задержки является включение большего числа IRAP-изображений. Однако это приводит к увеличению размера файла. Чтобы сбалансировать функциональность с эффективностью кодирования/декодирования, разные окна просмотра/субизображения могут включать в себя IRAP-изображения с разными частотами. Например, области просмотра, которые чаще всего просматриваются, могут иметь больше IRAP-изображений, чем другие области просмотра. Такой подход приводит к другим проблемам. В частности, изображения, следующие за IRAP-изображением, ограничены так, чтобы не ссылаться на изображения, которые предшествуют IRAP-изображению. Однако это ограничение делается на уровне изображений. Изображение, которое включает в себя смешанные единицы NAL, в том числе как IRAP-, так и не-IRAP-субизображения, может не рассматриваться в качестве IRAP-изображения на уровне изображений. Соответственно, такие ограничения на уровне изображений могут не быть подходящими. Это может привести к тому, что части изображений, которые следуют за IRAP-субизображением, неправильно ссылаются на изображения, которые предшествуют IRAP-изображению. В этом случае IRAP-субизображение не будет функционировать должным образом в качестве точки доступа, поскольку опорное изображение/субизображение может быть недоступным, что помешает декодированию субизображений, следующих за IRAP-субизображением. Кроме того, IRAP-субизображение не должно препятствовать такой ссылке не-IRAP-субизображения, поскольку это противоречило бы цели использования смешанных единиц NAL (например, интер-кодируемых/декодируемых последовательностей разной длины в зависимости от положения субизображения).
[0008] Настоящий пример включает в себя механизмы для смягчения ошибок кодирования/декодирования, когда изображения включают в себя как единицы NAL IRAP, так и единицы NAL не-IRAP. В частности, субизображение в текущем изображении может содержать единицу NAL IRAP. Когда это происходит, ссылка слайсов в изображении, следующем за текущим изображением, которые также содержатся в упомянутом субизображении, на опорные изображения, предшествующие текущему изображению, ограничивается. Это гарантирует, что единицы NAL IRAP остановят распространение интер-предсказания на уровне субизображений. Соответственно, декодер может начинать декодирование с IRAP-субизображения. Слайсы, ассоциированные с субизображением в более поздних изображениях, всегда могут быть декодированы, поскольку такие слайсы не ссылаются на какие-либо данные, которые предшествуют IRAP-субизображению (которое не было декодировано). Такое ограничение не применяется к единицам NAL не-IRAP. Соответственно, интер-предсказание не разрывается для субизображений, содержащих не-IRAP-данные. Таким образом, раскрытые механизмы позволяют реализовать дополнительную функциональность. Например, раскрытые механизмы поддерживают динамические изменения разрешения на уровне субизображений при использовании битовых потоков субизображений. Следовательно, раскрытые механизмы позволяют передавать битовые потоки субизображений более низкого разрешения при потоковой передаче видео VR без значительного ухудшения восприятия пользователем. Соответственно, раскрытые механизмы повышают эффективность кодирования/декодирования и, следовательно, уменьшают использование сетевых ресурсов, ресурсов памяти и/или ресурсов обработки в кодере и декодере.
[0009] Опционально, в любом из предшествующих аспектов, другая реализация аспекта обеспечивает, что тип единицы NAL IRAP представляет собой тип единицы NAL чистого произвольного доступа (CRA).
[0010] Опционально, в любом из предшествующих аспектов, другая реализация аспекта обеспечивает, что тип единицы NAL IRAP представляет собой тип единицы NAL мгновенного обновления декодера (IDR).
[0011] Опционально, в любом из предшествующих аспектов, другая реализация аспекта обеспечивает, что дополнительно содержится определение процессором того, что все слайсы текущего изображения, расположенные в subpicA, ассоциированы с одним и тем же типом единицы NAL.
[0012] Опционально, в любом из предшествующих аспектов, другая реализация аспекта обеспечивает, что дополнительно содержится определение процессором того, что первое значение типа единицы NAL для единиц NAL VCL текущего изображения отличается от второго значения типа единицы NAL для единиц NAL VCL текущего изображения на основе флага.
[0013] Опционально, в любом из предшествующих аспектов, другая реализация аспекта обеспечивает, что битовый поток включает в себя набор параметров изображения (PPS), и при этом флаг получают из PPS.
[0014] Опционально, в любом из предшествующих аспектов, другая реализация аспекта обеспечивает, что флаг представляет собой mixed_nalu_types_in_pic_flag, и при этом mixed_nalu_types_in_pic_flag равняется единице при специфицировании того, что каждое изображение, ссылающееся на PPS, имеет более одной единицы NAL VCL, и эти единицы NAL VCL не имеют одного и того же значения типа единицы NAL (nal_unit_type).
[0015] В варианте осуществления раскрытие включает в себя способ, реализуемый в кодере, причем способ содержит: определение процессором кодера того, что текущее изображение включает в себя множество единиц NAL VCL, которые не имеют одного и того же типа единицы NAL; определение процессором того, что subpicA в текущем изображении ассоциировано с типом единицы NAL IRAP; генерирование, процессором, активных записей списков опорных изображений для слайсов, расположенных в subpicA в последующих изображениях, следующих за текущим изображением в порядке декодирования, при этом активные записи не включают в себя ссылку на какое-либо опорное изображение, предшествующее текущему изображению в порядке декодирования, когда subpicA в текущем изображении ассоциировано с типом единицы NAL IRAP; кодирование, процессором, последующих изображений в битовый поток на основе списков опорных изображений; и сохранение памятью, соединенной с процессором, битового потока для передачи на декодер.
[0016] Системы кодирования/декодирования (coding) видео могут кодировать (encode) видео, используя IRAP-изображения и не-IRAP-изображения. IRAP-изображения являются изображениями, кодируемыми/декодируемыми согласно интра-предсказанию, которые служат в качестве точек произвольного доступа для видеопоследовательности. IRAP-изображение может быть декодировано без предварительного декодирования каких-либо других изображений. Соответственно, декодер может начинать декодирование видеопоследовательности с любого IRAP-изображения. В то же время декодер обычно не может начинать декодирование видеопоследовательности с не-IRAP-изображения. IRAP-изображения также могут обновлять DPB. Это связано с тем, что IRAP-изображение может действовать в качестве начальной точки для кодируемой/декодируемой видеопоследовательности (CVS), и изображения в этой CVS не ссылаются на изображения в предшествующей CVS. Таким образом, IRAP-изображения также могут разрывать цепочки интер-предсказания и останавливать ошибки кодирования/декодирования, связанные с интер-предсказанием, поскольку такие ошибки не могут распространяться через IRAP-изображение.
[0017] В некоторых случаях для кодирования/декодирования видео виртуальной реальности (VR) могут использоваться системы кодирования/декодирования видео. Видео VR может включать в себя сферу видеоконтента, отображаемую так, как если бы пользователь находился в центре этой сферы. Пользователю отображается только участок сферы, называемый окном просмотра. Оставшаяся часть изображения отбрасывается без рендеринга. Все изображение обычно передается таким образом, что другое окно просмотра может быть динамически выбрано и отображено в ответ на движение головы пользователя. Такой подход может привести к очень большим размерам видеофайлов. Чтобы повысить эффективность кодирования/декодирования, некоторые системы делят изображения на субизображения. Видео может быть закодировано в двух или более разрешениях. Каждое разрешение кодируется в различном наборе битовых подпотоков, соответствующих субизображениям. Когда пользователь осуществляет потоковую передачу видео VR, система кодирования/декодирования может объединять битовые подпотоки в битовый поток для передачи на основе текущего окна просмотра, используемого пользователем. В частности, текущее окно просмотра получается из битового подпотока высокого разрешения, а окна просмотра, которые не просматриваются, получают из битового потока(потоков) низкого разрешения. Таким образом, для пользователя отображается видео наивысшего качества, а видео более низкого качества отбрасывается. В случае, если пользователь выбирает новое окно просмотра, пользователю отображается видео более низкого разрешения. Декодер может запросить, чтобы новое окно просмотра получило видео более высокого разрешения. Затем кодер может надлежащим образом изменить процесс объединения. Как только IRAP-изображение достигнуто, декодер может начинать декодирование видеопоследовательности более высокого разрешения в новом окне просмотра. Такой подход значительно увеличивает сжатие видео, не оказывая негативного влияния на впечатления пользователя от просмотра.
[0018] Одна проблема с вышеупомянутым подходом заключается в том, что продолжительность времени, необходимая для изменения разрешений, основана на продолжительности времени до момента, когда будет достигнуто IRAP-изображение. Это связано с тем, что, как описано выше, декодер не может начинать декодирование другой видеопоследовательности с не-IRAP-изображения. Одним из подходов к уменьшению такой задержки является включение большего числа IRAP-изображений. Однако это приводит к увеличению размера файла. Чтобы сбалансировать функциональность с эффективностью кодирования/декодирования, разные окна просмотра/субизображения могут включать в себя IRAP-изображения с разными частотами. Например, области просмотра, которые чаще всего просматриваются, могут иметь больше IRAP-изображений, чем другие области просмотра. Такой подход приводит к другим проблемам. В частности, изображения, следующие за IRAP-изображением, ограничены так, чтобы не ссылаться на изображения, которые предшествуют IRAP-изображению. Однако это ограничение делается на уровне изображений. Изображение, которое включает в себя смешанные единицы NAL, в том числе как IRAP-, так и не-IRAP-субизображения, может не рассматриваться в качестве IRAP-изображения на уровне изображений. Соответственно, такие ограничения на уровне изображений могут не быть подходящими. Это может привести к тому, что части изображений, которые следуют за IRAP-субизображением, неправильно ссылаются на изображения, которые предшествуют IRAP-изображению. В этом случае IRAP-субизображение не будет функционировать должным образом в качестве точки доступа, поскольку опорное изображение/субизображение может быть недоступным, что помешает декодированию субизображений, следующих за IRAP-субизображением. Кроме того, IRAP-субизображение не должно препятствовать такой ссылке не-IRAP-субизображения, поскольку это противоречило бы цели использования смешанных единиц NAL (например, интер-кодируемых/декодируемых последовательностей разной длины в зависимости от положения субизображения).
[0019] Настоящий пример включает в себя механизмы для смягчения ошибок кодирования/декодирования, когда изображения включают в себя как единицы NAL IRAP, так и единицы NAL не-IRAP. В частности, субизображение в текущем изображении может содержать единицу NAL IRAP. Когда это происходит, ссылка слайсов в изображении, следующем за текущим изображением, которые также содержатся в упомянутом субизображении, на опорные изображения, предшествующие текущему изображению, ограничивается. Это гарантирует, что единицы NAL IRAP остановят распространение интер-предсказания на уровне субизображений. Соответственно, декодер может начинать декодирование с IRAP-субизображения. Слайсы, ассоциированные с субизображением в более поздних изображениях, всегда могут быть декодированы, поскольку такие слайсы не ссылаются на какие-либо данные, которые предшествуют IRAP-субизображению (которое не было декодировано). Такое ограничение не применяется к единицам NAL не-IRAP. Соответственно, интер-предсказание не разрывается для субизображений, содержащих не-IRAP-данные. Таким образом, раскрытые механизмы позволяют реализовать дополнительную функциональность. Например, раскрытые механизмы поддерживают динамические изменения разрешения на уровне субизображений при использовании битовых потоков субизображений. Следовательно, раскрытые механизмы позволяют передавать битовые потоки субизображений более низкого разрешения при потоковой передаче видео VR без значительного ухудшения восприятия пользователем. Соответственно, раскрытые механизмы повышают эффективность кодирования/декодирования и, следовательно, уменьшают использование сетевых ресурсов, ресурсов памяти и/или ресурсов обработки в кодере и декодере.
[0020] Опционально, в любом из предшествующих аспектов, другая реализация аспекта обеспечивает, что тип единицы NAL IRAP представляет собой тип единицы NAL CRA.
[0021] Опционально, в любом из предшествующих аспектов, другая реализация аспекта обеспечивает, что тип единицы NAL IRAP представляет собой тип единицы NAL IDR.
[0022] Опционально, в любом из предшествующих аспектов, другая реализация аспекта обеспечивает, что дополнительно содержится кодирование в битовый поток, процессором, текущего изображения посредством обеспечения того, что все слайсы текущего изображения, расположенные в subpicA, ассоциированы с одним и тем же типом единицы NAL.
[0023] Опционально, в любом из предшествующих аспектов, другая реализация аспекта обеспечивает, что дополнительно содержится кодирование в битовый поток, процессором, флага, указывающего, что первое значение типа единицы NAL для единиц NAL VCL текущего изображения отличается от второго значения типа единицы NAL для единиц NAL VCL текущего изображения.
[0024] Опционально, в любом из предшествующих аспектов, другая реализация аспекта обеспечивает, что флаг кодируется в PPS в битовом потоке.
[0025] Опционально, в любом из предшествующих аспектов, другая реализация аспекта обеспечивает, что флаг представляет собой mixed_nalu_types_in_pic_flag, и при этом mixed_nalu_types_in_pic_flag устанавливается равным единице при специфицировании того, что каждое изображение, ссылающееся на PPS, имеет более одной единицы NAL VCL, и эти единицы NAL VCL не имеют одного и того же значения nal_unit_type.
[0026] В одном варианте осуществления данное раскрытие включает в себя устройство кодирования/декодирования видео, содержащее: процессор, приемник, соединенный с процессором, память, соединенную с процессором, и передатчик, соединенный с процессором, при этом процессор, приемник, память и передатчик выполнены с возможностью осуществления способа по любому из предшествующих аспектов.
[0027] В одном варианте осуществления данное раскрытие включает в себя долговременный считываемый компьютером носитель, содержащий компьютерный программный продукт для использования устройством кодирования/декодирования видео, причем компьютерный программный продукт содержит исполняемые компьютером инструкции, хранящиеся на долговременном считываемом компьютером носителе, так что при исполнении процессор побуждает устройство кодирования/декодирования видео выполнять способ по любому из предшествующих аспектов.
[0028] В варианте осуществления данное раскрытие включает в себя декодер, содержащий: средство приема для приема битового потока, содержащего текущее изображение, включающее в себя множество единиц NAL VCL, которые не имеют одного и того же типа единицы NAL; средство получения для получения активных записей списков опорных изображений для слайсов, расположенных в subpicA в последующих изображениях, следующих за текущим изображением в порядке декодирования; средство определения для определения того, что активные записи не включают в себя ссылку на какое-либо опорное изображение, предшествующее текущему изображению в порядке декодирования, когда subpicA в текущем изображении ассоциировано с типом единицы NAL IRAP; средство декодирования для декодирования последующих изображений на основе активных записей списков опорных изображений; и средство пересылки для пересылки последующих изображений для отображения как части декодированной видеопоследовательности.
[0029] Опционально, в любом из предшествующих аспектов, другая реализация аспекта обеспечивает, что декодер дополнительно выполнен с возможностью выполнения способа по любому из предшествующих аспектов.
[0030] В варианте осуществления раскрытие включает в себя кодер, содержащий: средство определения для: определения того, что текущее изображение включает в себя множество единиц NAL VCL, которые не имеют одного и того же типа единицы NAL; и определения того, что subpicA в текущем изображении ассоциировано с типом единицы NAL IRAP; средство генерирования для генерирования активных записей списков опорных изображений для слайсов, расположенных в subpicA в последующих изображениях, следующих за текущим изображением в порядке декодирования, при этом активные записи не включают в себя ссылку на какое-либо опорное изображение, предшествующее текущему изображению в порядке декодирования, когда subpicA в текущем изображении ассоциировано с типом единицы NAL IRAP; средство кодирования для кодирования последующих изображений в битовый поток на основе списков опорных изображений; и средство хранения для сохранения битового потока для передачи на декодер.
[0031] Опционально, в любом из предшествующих аспектов, другая реализация аспекта обеспечивает, что кодер дополнительно выполнен с возможностью выполнения способа по любому из предшествующих аспектов.
[0032] Для ясности любой из вышеупомянутых вариантов осуществления изобретения может быть объединен с любым одним или более другими вышеупомянутыми вариантами осуществления, чтобы создать новый вариант осуществления в рамках объема настоящего раскрытия.
[0033] Эти и другие особенности будут более понятны из следующего подробного описания, рассматриваемого вместе с сопроводительными чертежами и формулой изобретения.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0034] Для более полного понимания этого раскрытия теперь обратимся к нижеследующему краткому описанию, рассматриваемому в связи с сопроводительными чертежами и подробным описанием, при этом одинаковые ссылочные позиции представляют одинаковые части.
[0035] ФИГ. 1 представляет собой блок-схему последовательности операций примерного способа кодирования/декодирования видеосигнала.
[0036] ФИГ. 2 представляет собой схематичное представление примерной системы кодирования и декодирования (кодека) для кодирования/декодирования видео.
[0037] ФИГ. 3 представляет собой схематичное представление, иллюстрирующее примерный видеокодер.
[0038] ФИГ. 4 представляет собой схематичное представление, иллюстрирующее примерный видеодекодер.
[0039] ФИГ. 5 представляет собой схематичное представление, иллюстрирующее множество видеопотоков субизображений, выделенных из видеопотока изображений виртуальной реальности (VR).
[0040] ФИГ. 6 представляет собой схематичное представление, иллюстрирующее ограничения, используемые, когда текущее изображение включает в себя смешанные типы единиц уровня сетевой абстракции (NAL).
[0041] ФИГ. 7 представляет собой схематичное представление, иллюстрирующее примерную структуру списков опорных изображений, содержащую списки опорных изображений.
[0042] ФИГ. 8 представляет собой схематичное представление, иллюстрирующее примерный битовый поток, содержащий изображения со смешанными типами единиц NAL.
[0043] ФИГ. 9 представляет собой схематичное представление примерного устройства кодирования/декодирования видео.
[0044] ФИГ. 10 представляет собой блок-схему последовательности операций примерного способа кодирования видеопоследовательности, содержащей изображение со смешанными типами единиц NAL, в битовый поток.
[0045] ФИГ. 11 представляет собой блок-схему последовательности операций примерного способа декодирования видеопоследовательности, содержащей изображение со смешанными типами единиц NAL, из битового потока.
[0046] ФИГ. 12 представляет собой схематичное представление примерной системы для кодирования/декодирования видеопоследовательности, содержащей изображение со смешанными типами единиц NAL, в битовый поток.
ПОДРОБНОЕ ОПИСАНИЕ
[0047] Прежде всего следует понимать, что, хотя иллюстративная реализация одного или более вариантов осуществления представлена ниже, раскрытые системы и/или способы могут быть реализованы с использованием любого числа методик, известных в настоящее время или уже существующих. Раскрытие никоим образом не должно быть ограничено иллюстративными реализациями, чертежами и методиками, проиллюстрированными ниже, в том числе примерными конструкциями и реализациями, проиллюстрированными и описанными в настоящем документе, но может быть изменено в пределах объема прилагаемой формулы изобретения вместе с полным объемом ее эквивалентов.
[0048] Нижеследующие термины определяются следующим образом до тех пор, пока они не используются в данном документе в противоположном контексте. В частности, следующие определения призваны внести дополнительную ясность в настоящее раскрытие. Однако термины могут быть описаны иначе в других контекстах. Соответственно, следующие определения следует рассматривать в качестве дополнения и не следует рассматривать их в качестве ограничивающих любые другие определения в описании, обеспеченном для таких терминов в настоящем документе.
[0049] Битовый поток представляет собой последовательность битов, включающих в себя видеоданные, которые сжаты для передачи между кодером и декодером. Кодер представляет собой устройство, которое выполнено с возможностью использования процессов кодирования для сжатия видеоданных в битовый поток. Декодер представляет собой устройство, которое выполнено с возможностью использования процессов декодирования для восстановления видеоданных из битового потока для отображения. Изображение представляет собой массив выборок яркости и/или массив выборок цветности, которые создают кадр или его поле. Изображение, которое кодируется или декодируется, может называться текущим изображением для ясности обсуждения, а любое изображение, следующее за текущим изображением, может называться последующим изображением. Субизображение является прямоугольной областью из одного или более слайсов в пределах последовательности изображений. Следует отметить, что квадрат является типом прямоугольника, и, следовательно, субизображение может включать в себя квадратную область. Слайс может быть определен как целое число полных тайлов или целое число последовательных строк полных единиц дерева кодирования/декодирования (CTU) в пределах тайла изображения, которые содержатся исключительно в одной единице уровня сетевой абстракции (NAL). Единица NAL представляет собой синтаксическую структуру, содержащую байты данных и указание типа содержащихся в ней данных. Единицы NAL включают в себя единицы NAL уровня кодирования/декодирования видео (VCL), которые содержат видеоданные, и единицы NAL не-VCL, которые содержат поддерживающие синтаксические данные. Тип единицы NAL является типом структуры данных, содержащейся в единице NAL. Тип единицы NAL интра-точки произвольного доступа (IRAP) представляет собой структуру данных, содержащую данные из IRAP-изображения или субизображения. IRAP-изображение/субизображение представляет собой изображение/суб-изображение, которое кодируется/декодируется согласно интра-предсказанию, которое указывает, что декодер может начинать декодирование видеопоследовательности с соответствующего изображения/субизображения, не ссылаясь на изображения, предшествующие упомянутому IRAP-изображению/субизображению. Тип единицы NAL чистого произвольного доступа (CRA) представляет собой структуру данных, содержащую данные из CRA-изображения или субизображения. CRA-изображение/субизображение представляет собой IRAP-изображение/субизображение, которое не обновляет буфер декодированных изображений (DPB). Тип единицы NAL мгновенного обновления декодирования (IDR) представляет собой структуру данных, содержащую данные из IDR-изображения или субизображения. IDR-изображение/субизображение представляет собой IRAP-изображение/субизображение, которое обновляет DPB. Опорное изображение представляет собой изображение, которое содержит опорные выборки, которые могут быть использованы при кодировании других изображений по ссылке согласно интер-предсказанию. Список опорных изображений представляет собой список опорных изображений, используемых для интер-предсказания и/или межуровневого предсказания. Некоторые системы кодирования/декодирования видео ссылаются на два списка изображений, которые можно обозначить как первый список опорных изображений и нулевой список опорных изображений. Структура списков опорных изображений представляет собой адресуемую синтаксическую структуру, которая содержит несколько списков опорных изображений. Активная запись представляет собой запись в списке опорных изображений, которая ссылается на опорные изображения, которые доступны для использования текущим изображением при выполнении интер-предсказания. Флаг представляет собой структуру данных, содержащую последовательность битов, которая может быть установлена для указания соответствующих данных. Набор параметров изображения (PPS) представляет собой набор параметров, который содержит данные уровня изображений, относящиеся к одному или более изображениям. Порядок декодирования представляет собой порядок, в котором синтаксические элементы обрабатываются посредством процесса декодирования. Декодированная видеопоследовательность представляет собой последовательность изображений, которые были восстановлены посредством декодера при подготовке для отображения пользователю.
[0050] В настоящем документе используются следующие аббревиатуры: кодируемая/декодируемая видеопоследовательность (CVS), буфер декодированных изображений (DPB), мгновенное обновление декодирования (IDR), интра-точка произвольного доступа (IRAP), младший значащий бит (LSB), старший значащий бит (MSB), уровень сетевой абстракции (NAL), счетчик порядка изображений (POC), полезные данные последовательности необработанных байтов (RBSP), набор параметров последовательности (SPS) и рабочий проект (WD).
[0051] Многие методики сжатия видео могут использоваться для уменьшения размера видеофайлов с минимальной потерей данных. Например, методики сжатия видео могут включать в себя выполнение пространственного (например интра-кадрового) предсказания и/или временного (например интер-кадрового) предсказания для сокращения или устранения избыточности данных в видеопоследовательностях. Для кодирования/декодирования видео на основе блоков видеослайс (например, видеоизображение или часть видеоизображения) может быть разделен на видеоблоки, которые также могут называться древовидными блоками, блоками дерева кодирования/декодирования (CTB), единицами дерева кодирования/декодирования (CTU), единицами кодирования/декодирования (CU) и/или узлами кодирования/декодирования. Видеоблоки в интра-кодируемом/декодируемом (I) слайсе изображения кодируются/декодируются с использованием пространственного предсказания по отношению к опорным выборкам в соседних блоках в том же самом изображении. Видеоблоки в слайсе интер-кодируемого/декодируемого однонаправленного предсказания (P) или двунаправленного предсказания (B) в изображении могут кодироваться/декодироваться посредством использования пространственного предсказания относительно опорных выборок в соседних блоках в том же самом изображении или временного предсказания относительно опорных выборок в других опорных изображениях. Изображения могут называться кадрами и/или картинками, а опорные изображения могут называться опорными кадрами и/или опорными картинками. Пространственное или временное предсказание приводит к предиктивному блоку, представляющему блок картинки. Остаточные данные представляют собой разности пикселей между исходным блоком картинки и предиктивным блоком. Соответственно, интер-кодируемый/декодируемый блок кодируется согласно вектору движения, который указывает на блок опорных выборок, формирующих предиктивный блок, и остаточным данным, указывающими разность между кодируемым/декодируемым блоком и предиктивным блоком. Интра-кодируемый/декодируемый блок кодируется согласно режиму интра-кодирования/декодирования и остаточным данным. Для дальнейшего сжатия остаточные данные могут быть преобразованы из пиксельной области в область преобразования. Это приводит к остаточным коэффициентам преобразования, которые могут быть квантованы. Квантованные коэффициенты преобразования могут изначально размещаться в двумерном массиве. Квантованные коэффициенты преобразования могут быть просканированы для создания одномерного вектора коэффициентов преобразования. Энтропийное кодирование/декодирование может быть применено для достижения еще большего сжатия. Такие методики сжатия видео обсуждаются более подробно ниже.
[0052] Чтобы обеспечить точное декодирование закодированного видео, видео кодируется и декодируется согласно соответствующим стандартам кодирования/декодирования видео. Стандарты кодирования/декодирования видео включают в себя H.261 Сектора стандартизации (ITU-T) Международного союза электросвязи (ITU), H.262 ITU-T Экспертной группы по движущимся изображениям (MPEG)-1, Часть 2, Международной организации по стандартизации/Международной электротехнической комиссии (ISO/IEC) или H.263 ITU-T MPEG-2, Часть 2, ISO/IEC, Усовершенствованное кодирование/декодирование видео (AVC) MPEG-4, Часть 2, ISO/IEC, также известное как H.264 ITU-T или MPEG-4, Часть 10, ISO/IEC, и Высокоэффективное кодирование/декодирование видео (HEVC), также известное как H.265 ITU-T или MPEG-H, Часть 2. AVC включает в себя такие расширения, как Масштабируемое кодирование/декодирование видео (SVC), Многоракурсное кодирование/декодирование видео (MVC) и Многоракурсное кодирование/декодирование видео плюс Глубина (MVC+D), а также трехмерное (3D) AVC (3D-AVC). HEVC включает такие расширения, как Масштабируемое HEVC (SHVC), Многоракурсное HEVC (MV-HEVC) и 3D HEVC (3D-HEVC). Совместная группа экспертов по видео (JVET) ITU-T и ISO/IEC приступила к разработке стандарта кодирования/декодирования видео, называемого Универсальным кодированием/декодированием видео (VVC). VVC включено в рабочий проект (WD), который включает в себя JVET-N1001-v10.
[0053] Системы кодирования/декодирования (coding) видео могут кодировать (encode) видео, используя IRAP-изображения и не-IRAP-изображения. IRAP-изображения являются изображениями, кодируемыми/декодируемыми согласно интра-предсказанию, которые служат в качестве точек произвольного доступа для видеопоследовательности. При интра-предсказании блоки изображения кодируются/декодируются посредством ссылки на другие блоки в том же самом изображении. Это отличается от не-IRAP-изображений, которые используют интер-предсказание. При интер-предсказании блоки текущего изображения кодируются/декодируются посредством ссылки на другие блоки в опорном изображении, которое отличается от текущего изображения. Поскольку IRAP-изображение кодируется/декодируется без ссылки на другие изображения, IRAP-изображение может быть декодировано без предварительного декодирования каких-либо других изображений. Соответственно, декодер может начинать декодирование видеопоследовательности с любого IRAP-изображения. Для сравнения, не-IRAP-изображение кодируется/декодируется со ссылкой на другие изображения, и, следовательно, декодер, как правило, не может начинать декодирование видеопоследовательности с не-IRAP-изображения. IRAP-изображения также могут обновлять DPB. Это связано с тем, что IRAP-изображение может действовать в качестве начальной точки для CVS, и изображения в этой CVS не ссылаются на изображения в предшествующей CVS. Таким образом, IRAP-изображения также могут останавливать ошибки кодирования/декодирования, связанные с интер-предсказанием, поскольку такие ошибки не могут распространяться через IRAP-изображение. Однако с точки зрения размера данных IRAP-изображения значительно больше, чем не-IRAP-изображения. Таким образом, видеопоследовательность обычно включает в себя множество не-IRAP-изображений с меньшим числом перемежающихся IRAP-изображений, чтобы сбалансировать эффективность кодирования с функциональностью. Например, CVS из шестидесяти кадров может включать в себя одно IRAP-изображение и пятьдесят девять не-IRAP-изображений.
[0054] В некоторых случаях системы кодирования/декодирования видео могут использоваться для кодирования/декодирования видео виртуальной реальности (VR), которое также может упоминаться как видео с углом обзора 360 градусов. Видео VR может включать в себя сферу видеоконтента, отображаемую так, как если бы пользователь находился в центре этой сферы. Пользователю отображается только участок сферы, называемый окном просмотра. Например, пользователь может использовать головной дисплей (HMD), который выбирает и отображает окно просмотра сферы на основе движения головы пользователя. Это создает впечатление физического присутствия в виртуальном пространстве, которое представлено посредством видео. Для достижения этого результата каждое изображение видеопоследовательности включает в себя всю сферу видеоданных в соответствующий момент времени. Однако пользователю отображается только небольшая часть (например, одно окно просмотра) изображения. Оставшаяся часть изображения отбрасывается без рендеринга. Все изображение обычно передается таким образом, что другое окно просмотра может быть динамически выбрано и отображено в ответ на движение головы пользователя. Такой подход может привести к очень большим размерам видеофайлов.
[0055] Чтобы повысить эффективность кодирования/декодирования, некоторые системы делят изображения на субизображения. Субизображение представляет собой определенную пространственную область изображения. Каждое субизображение содержит соответствующее окно просмотра изображения. Видео может быть закодировано в двух или более разрешениях. Каждое разрешение кодируется в отдельный битовый подпоток. Когда пользователь осуществляет потоковую передачу видео VR, система кодирования/декодирования может объединять битовые подпотоки в битовый поток для передачи на основе текущего окна просмотра, используемого пользователем. В частности, текущее окно просмотра получается из битового подпотока высокого разрешения, а окна просмотра, которые не просматриваются, получают из битового потока(потоков) низкого разрешения. Таким образом, для пользователя отображается видео наивысшего качества, а видео более низкого качества отбрасывается. В случае, если пользователь выбирает новое окно просмотра, пользователю отображается видео более низкого разрешения. Декодер может запросить, чтобы новое окно просмотра получило видео более высокого разрешения. Затем кодер может надлежащим образом изменить процесс объединения. Как только IRAP-изображение достигнуто, декодер может начинать декодирование видеопоследовательности более высокого разрешения в новом окне просмотра. Такой подход значительно увеличивает сжатие видео, не оказывая негативного влияния на впечатления пользователя от просмотра.
[0056] Одна проблема с вышеупомянутым подходом заключается в том, что продолжительность времени, необходимая для изменения разрешений, основана на продолжительности времени до момента, когда будет достигнуто IRAP-изображение. Это связано с тем, что, как описано выше, декодер не может начинать декодирование другой видеопоследовательности с не-IRAP-изображения. Одним из подходов к уменьшению такой задержки является включение большего числа IRAP-изображений. Однако это приводит к увеличению размера файла. Чтобы сбалансировать функциональность с эффективностью кодирования/декодирования, разные окна просмотра/субизображения могут включать в себя IRAP-изображения с разными частотами. Например, области просмотра, которые чаще всего просматриваются, могут иметь больше IRAP-изображений, чем другие области просмотра. Например, в контексте баскетбола окна просмотра, относящиеся к корзинам и/или центральной зоне, могут включать в себя IRAP-изображения с большей частотой, чем окна просмотра, через которые видны трибуны или потолок, поскольку такие окна просмотра с меньшей вероятностью будут просматриваться пользователем.
[0057] Такой подход приводит к другим проблемам. В частности, изображения, следующие за IRAP-изображением, ограничены так, чтобы не ссылаться на изображения, которые предшествуют IRAP-изображению. Однако это ограничение делается на уровне изображений. Изображение, которое включает в себя смешанные единицы NAL, в том числе как IRAP-, так и не-IRAP-субизображения, может не рассматриваться в качестве IRAP-изображения на уровне изображений. Соответственно, такие ограничения на уровне изображений могут не быть подходящими. Это может привести к тому, что части изображений, которые следуют за IRAP-субизображением, неправильно ссылаются на изображения, которые предшествуют IRAP-изображению. В этом случае IRAP-субизображение не будет функционировать должным образом в качестве точки доступа, поскольку опорное изображение/субизображение может быть недоступным, что помешает декодированию субизображений, следующих за IRAP-субизображением. Кроме того, IRAP-субизображение не должно препятствовать такой ссылке не-IRAP-субизображения, поскольку это противоречило бы цели использования смешанных единиц NAL (например, интер-кодируемых/декодируемых последовательностей разной длины в зависимости от положения субизображения).
[0058] В настоящем документе раскрыты механизмы для смягчения ошибок кодирования/декодирования, когда изображения включают в себя как единицы NAL IRAP, так и единицы NAL не-IRAP. В частности, субизображение в текущем изображении может содержать единицу NAL IRAP. Когда это происходит, ссылка слайсов в изображении, следующем за текущим изображением, которые также содержатся в упомянутом субизображении, на опорные изображения, предшествующие текущему изображению, ограничивается. Это гарантирует, что единицы NAL IRAP разрывают интер-предсказание (например останавливают цепочки ссылок при интер-предсказании) на уровне субизображений. Соответственно, декодер может начинать декодирование с IRAP-субизображения. Слайсы, ассоциированные с субизображением в более поздних изображениях, всегда могут быть декодированы, поскольку такие слайсы не ссылаются на какие-либо данные, которые предшествуют IRAP-субизображению (которое не было декодировано). Такое ограничение не применяется к единицам NAL не-IRAP. Соответственно, интер-предсказание не разрывается для субизображений, содержащих не-IRAP-данные. Таким образом, раскрытые механизмы позволяют реализовать дополнительную функциональность. Например, раскрытые механизмы поддерживают динамические изменения разрешения на уровне субизображений при использовании битовых потоков субизображений. Следовательно, раскрытые механизмы позволяют передавать битовые потоки субизображений более низкого разрешения при потоковой передаче видео VR без значительного ухудшения восприятия пользователем. Соответственно, раскрытые механизмы повышают эффективность кодирования/декодирования и, следовательно, уменьшают использование сетевых ресурсов, ресурсов памяти и/или ресурсов обработки в кодере и декодере.
[0059] ФИГ. 1 представляет собой блок-схему последовательности операций примерного рабочего способа 100 кодирования/декодирования видеосигнала. В частности, видеосигнал кодируется в кодере. Процесс кодирования сжимает видеосигнал, используя различные механизмы для уменьшения размера видеофайла. Меньший размер файла позволяет передавать сжатый видеофайл пользователю, уменьшая при этом ассоциированное с этим потребление ресурсов полосы пропускания. Затем декодер декодирует сжатый видеофайл, чтобы восстановить исходный видеосигнал для отображения конечному пользователю. Процесс декодирования как правило зеркально отражает процесс кодирования, что позволяет декодеру последовательно восстанавливать видеосигнал.
[0060] На этапе 101 видеосигнал вводится в кодер. Например, видеосигнал может представлять собой несжатый видеофайл, хранящийся в памяти. В качестве другого примера, видеофайл может быть захвачен устройством видеозахвата, таким как видеокамера, и закодирован для поддержки потоковой передачи видео в режиме реального времени. Видеофайл может включать в себя как аудиокомпонент, так и видеокомпонент. Видеокомпонент содержит ряд кадров изображений, которые при последовательном просмотре создают визуальное впечатление движения. Кадры содержат пиксели, которые выражены в показателях света, называемых в данном документе компонентами яркости (или выборками яркости), и цвета, которые называются компонентами цветности (или выборками цветности). В некоторых примерах кадры могут также содержать значения глубины для поддержки трехмерного просмотра.
[0061] На этапе 103 видео разделяется на блоки. Разделение включает в себя подразделение пикселей в каждом кадре на квадратные и/или прямоугольные блоки для сжатия. Например, в высокоэффективном кодировании/декодировании видео (HEVC) (также известном как H.265 и MPEG-H, Часть 2) кадр можно сначала разбить на единицы дерева кодирования/декодирования (CTU), которые представляют собой блоки предопределенного размера (например, шестьдесят четыре пикселя на шестьдесят четыре пикселя). CTU содержат выборки как яркости, так и цветности. Деревья кодирования/декодирования могут использоваться для разбиения CTU на блоки, а затем рекурсивного подразделения блоков до тех пор, пока не будут достигнуты конфигурации, которые поддерживают дальнейшее кодирование. Например, компоненты яркости кадра могут быть подразделены до тех пор, пока отдельные блоки не будут содержать относительно однородные значения освещения. Кроме того, компоненты цветности кадра могут быть подразделены до тех пор, пока отдельные блоки не будут содержать относительно однородные значения цвета. Соответственно, механизмы разделения различаются в зависимости от содержимого видеокадров.
[0062] На этапе 105 используются различные механизмы сжатия для сжатия блоков изображения, полученных разделением на этапе 103. Например, может быть использовано интер-предсказание и/или интра-предсказание. Интер-предсказание предназначено для получения преимущества от того факта, что объекты в общей сцене имеют тенденцию появляться в последовательных кадрах. Соответственно, блок, представляющий объект в опорном кадре, не нужно повторно описывать в смежных кадрах. В частности, объект, такой как стол, может оставаться в постоянном положении в течение нескольких кадров. Следовательно, стол описывается один раз, и смежные кадры могут ссылаться обратно на опорный кадр. Механизмы сопоставления образов могут использоваться для сопоставления объектов в нескольких кадрах. Кроме того, движущиеся объекты могут быть представлены в нескольких кадрах, например, из-за движения объекта или движения камеры. В качестве конкретного примера видео может показывать автомобиль, который движется по экрану в течение нескольких кадров. Векторы движения могут быть использованы для описания такого движения. Вектор движения представляет собой двумерный вектор, который обеспечивает смещение из координат объекта в кадре в координаты объекта в опорном кадре. Таким образом, интер-предсказание может кодировать блок изображения в текущем кадре в качестве набора векторов движения, указывающих смещение от соответствующего блока в опорном кадре.
[0063] Интра-предсказание кодирует блоки в общем кадре. Интра-предсказание получает преимущество от того факта, что компоненты цветности и яркости имеют тенденцию группироваться в кадре. Например, фрагмент зелени в части дерева имеет тенденцию располагаться рядом с аналогичными фрагментами зелени. Интра-предсказание использует несколько направленных режимов предсказания (например, тридцать три в HEVC), планарный режим и режим постоянного тока (DC). Направленные режимы указывают, что текущий блок аналогичен/совпадает с выборками соседнего блока в соответствующем направлении. Планарный режим указывает, что ряд блоков вдоль строки/столбца (например, плоскости) может быть интерполирован на основе соседних блоков на краях строки. Планарный режим, по сути, указывает на плавный переход света/цвета через строку/столбец, используя относительно постоянный наклон при изменении значений. Режим DC используется для сглаживания границ и указывает, что блок похож/аналогичен среднему значению, ассоциированному с выборками всех соседних блоков, ассоциированных с угловыми направлениями направленных режимов предсказания. Соответственно, блоки интра-предсказания могут представлять блоки изображения как значения различных реляционных режимов предсказания вместо фактических значений. Кроме того, блоки интер-предсказания могут представлять блоки изображения как значения векторов движения вместо фактических значений. В любом случае в некоторых случаях блоки предсказания могут не точно представлять блоки изображения. Любые различия хранятся в остаточных блоках. Преобразования могут быть применены к остаточным блокам для дальнейшего сжатия файла.
[0064] На этапе 107 могут применяться различные методики фильтрации. В HEVC фильтры применяются по схеме фильтрации внутри цикла. Основанное на блоках предсказание, рассмотренное выше, может привести к созданию блочных изображений в декодере. Кроме того, схема основанного на блоках предсказания может кодировать блок, а затем восстановить закодированный блок для последующего использования в качестве опорного блока. Схема фильтрации внутри цикла итеративно применяет к блокам/кадрам фильтры шумоподавления, фильтры деблокирования, адаптивные циклические фильтры и фильтры адаптивного к выборке смещения (SAO). Эти фильтры смягчают такие артефакты блочности, чтобы можно было точно восстановить закодированный файл. Кроме того, эти фильтры смягчают артефакты в восстановленных опорных блоках, так что артефакты с меньшей вероятностью создают дополнительные артефакты в последующих блоках, которые кодируются на основе этих восстановленных опорных блоков.
[0065] После разделения, сжатия и фильтрации видеосигнала полученные данные кодируются в битовый поток на этапе 109. Битовый поток включает в себя данные, рассмотренные выше, а также любые данные сигнализации, необходимые для поддержки надлежащего восстановления видеосигнала в декодере. Например, такие данные могут включать данные разделения, данные предсказания, остаточные блоки и различные флаги, обеспечивающие инструкции кодирования/декодирования, для декодера. Битовый поток может быть сохранен в памяти для передачи на декодер по запросу. Битовый поток также может быть широковещательно и/или многоадресно передан множеству декодеров. Создание битового потока является итеративным процессом. Соответственно, этапы 101, 103, 105, 107 и 109 могут происходить непрерывно и/или одновременно в отношении многих кадров и блоков. Порядок, показанный на ФИГ. 1, представлен для ясности и простоты обсуждения и не предназначен для ограничения процесса кодирования/декодирования видео определенным порядком.
[0066] Декодер принимает битовый поток и начинает процесс декодирования на этапе 111. В частности, декодер использует схему энтропийного декодирования для преобразования битового потока в соответствующие синтаксические и видео данные. Декодер использует синтаксические данные из битового потока для определения разделов для кадров на этапе 111. Разделение должно совпадать с результатами разделения на блоки на этапе 103. Теперь описывается энтропийное кодирование/декодирование, используемое на этапе 111. Кодер принимает множество решений во время процесса сжатия, например выбирает схемы разделения на блоки из нескольких возможных вариантов на основе пространственного расположения значений во входном изображении(-ях). Для сигнализации точных выборов может использоваться большое число бинов. Как используется в данном документе, бин представляет собой двоичное значение, которое обрабатывается как переменная (например, битовое значение, которое может изменяться в зависимости от контекста). Энтропийное кодирование позволяет кодеру отбрасывать любые опции, которые явно не подходят для конкретного случая, оставляя набор допустимых опций. Каждой допустимой опции затем назначается кодовое слово. Длина кодовых слов основана на числе допустимых опций (например, один бин для двух опций, два бина для трех-четырех опций и т. д.). Затем кодер кодирует кодовое слово для выбранной опции. Эта схема уменьшает размер кодовых слов, поскольку кодовые слова настолько велики, насколько это необходимо, чтобы однозначно указывать выбор из небольшого подмножества допустимых опций, в отличие от однозначного указания выбора из потенциально большого набора всех возможных опций. Затем декодер декодирует выбор, определяя набор допустимых опций аналогично кодеру. Посредством определения набора допустимых опций, декодер может считывать кодовое слово и определять выбор, сделанный кодером.
[0067] На этапе 113 декодер выполняет декодирование блоков. В частности, декодер применяет обратные преобразования для генерирования остаточных блоков. Затем декодер применяет остаточные блоки и соответствующие блоки предсказания для восстановления блоков изображения согласно разделению. Блоки предсказания могут включать в себя как блоки интра-предсказания, так и блоки интер-предсказания, генерируемые кодером на этапе 105. Затем восстановленные блоки изображения размещаются в кадры восстанавливаемого видеосигнала согласно данным разделения, определенным на этапе 111. Синтаксис для этапа 113 также может быть просигнализирован в битовом потоке посредством энтропийного кодирования/декодирования, как описано выше.
[0068] На этапе 115 фильтрация выполняется над кадрами восстановленного видеосигнала способом, аналогичным этапу 107 в кодере. Например, фильтры шумоподавления, фильтры деблокирования, адаптивные циклические фильтры и фильтры SAO могут быть применены к кадрам для удаления артефактов блочности. Как только кадры отфильтрованы, видеосигнал может быть выведен на дисплей на этапе 117 для просмотра конечным пользователем.
[0069] ФИГ. 2 представляет собой схематичное представление примерной системы 200 кодирования и декодирования (кодека) для кодирования/декодирования видео. В частности, система 200 кодека обеспечивает функциональные возможности для поддержки реализации рабочего способа 100. Система 200 кодека обобщена так, чтобы представлять компоненты, применяемые как в кодере, так и в декодере. Система 200 кодека принимает и разделяет видеосигнал, как описано в отношении этапов 101 и 103 в рабочем способе 100, в результате чего получается разделенный видеосигнал 201. Затем система 200 кодека сжимает разделенный видеосигнал 201 в закодированный битовый поток, действуя в качестве кодера, как описано в отношении этапов 105, 107 и 109 в способе 100. Действуя в качестве декодера, система 200 кодека генерирует выходной видеосигнал из битового потока, как описано в отношении этапов 111, 113, 115 и 117 в рабочем способе 100. Система 200 кодека включает в себя компонент 211 общего управления кодером/декодером, компонент 213 преобразования, масштабирования и квантования, компонент 215 интра-кадровой оценки, компонент 217 интра-кадрового предсказания, компонент 219 компенсации движения, компонент 221 оценки движения, компонент 229 обратного преобразования и масштабирования, компонент 227 анализа для управления фильтром, компонент 225 фильтров внутри цикла, компонент 223 буфера декодированных изображений и компонент 231 форматирования заголовка и контекстно-адаптивного двоичного арифметического кодирования/декодирования (CABAC). Такие компоненты соединены, как показано. На ФИГ. 2 черные линии указывают перемещение данных, подлежащих кодированию/декодированию, а пунктирные линии указывают перемещение управляющих данных, которые управляют работой других компонентов. Все компоненты системы 200 кодека могут присутствовать в кодере. Декодер может включать в себя подмножество компонентов системы 200 кодека. Например, декодер может включать в себя компонент 217 интра-кадрового предсказания, компонент 219 компенсации движения, компонент 229 обратного преобразования и масштабирования, компонент 225 фильтров внутри цикла и компонент 223 буфера декодированных изображений. Эти компоненты описаны далее.
[0070] Разделенный видеосигнал 201 представляет собой захваченную видеопоследовательность, которая была разделена на блоки пикселей деревом кодирования/декодирования. Дерево кодирования/декодирования использует различные режимы фрагментации для подразделения блока пикселей на более мелкие блоки пикселей. Затем эти блоки могут быть дополнительно подразделены на более мелкие блоки. Блоки могут называться узлами в дереве кодирования/декодирования. Более крупные родительские узлы подвергаются фрагментации на более мелкие дочерние узлы. Число раз, которое узел подразделяется, называется глубиной узла/дерева кодирования/декодирования. Полученные разделением блоки могут быть включены в единицы кодирования/декодирования (CU) в некоторых случаях. Например, CU может быть частью CTU, которая содержит блок яркости, блок(-и) цветности красного (Cr) и блок(-и) цветности синего (Cb) вместе с соответствующими инструкциями синтаксиса для CU. Режимы фрагментации могут включать двоичное дерево (BT), троичное дерево (TT) и квадратичное дерево (QT), используемые для разделения узла на два, три или четыре дочерних узла, соответственно, различных форм в зависимости от используемых режимов фрагментации. Разделенный видеосигнал 201 пересылается в компонент 211 общего управления кодером/декодером, компонент 213 преобразования, масштабирования и квантования, компонент 215 интра-кадровой оценки, компонент 227 анализа для управления фильтром и компонент 221 оценки движения для сжатия.
[0071] Компонент 211 общего управления кодером/декодером выполнен с возможностью принятия решений, связанных с кодированием изображений видеопоследовательности в битовый поток согласно ограничениям приложения. Например, компонент 211 общего управления кодером/декодером управляет оптимизацией битрейта/размера битового потока в зависимости от качества восстановления. Такие решения могут приниматься на основе доступности пространства хранения/полосы пропускания и запросов разрешения изображения. Компонент 211 общего управления кодером/декодером также управляет использованием буфера с учетом скорости передачи, чтобы смягчить проблемы недостаточного заполнения и переполнения буфера. Чтобы справиться с этими проблемами, компонент 211 общего управления кодером/декодером управляет разделением, предсказанием и фильтрацией посредством других компонентов. Например, компонент 211 общего управления кодером/декодером может динамически увеличивать сложность сжатия для увеличения разрешения и увеличения использования полосы пропускания или уменьшать сложность сжатия для уменьшения разрешения и использования полосы пропускания. Следовательно, компонент 211 общего управления кодером/декодером управляет другими компонентами системы 200 кодека, чтобы сбалансировать качество восстановления видеосигнала с учетом битрейта. Компонент 211 общего управления кодером/декодером создает управляющие данные, которые управляют работой других компонентов. Управляющие данные также пересылаются в компонент 231 форматирования заголовка и CABAC для кодирования в битовом потоке, чтобы сигнализировать параметры для декодирования в декодере.
[0072] Разделенный видеосигнал 201 также отправляется в компонент 221 оценки движения и компонент 219 компенсации движения для интер-предсказания. Кадр или слайс разделенного видеосигнала 201 может быть разбит на несколько видеоблоков. Компонент 221 оценки движения и компонент 219 компенсации движения выполняют кодирование с интер-предсказанием принятого видеоблока относительно одного или более блоков в одном или более опорных кадрах, чтобы обеспечить временное предсказание. Система 200 кодека может выполнять несколько проходов кодирования, например, для выбора надлежащего режима кодирования для каждого блока видеоданных.
[0073] Компонент 221 оценки движения и компонент 219 компенсации движения могут быть в высокой степени интегрированы, но показаны отдельно в концептуальных целях. Оценка движения, выполняемая компонентом 221 оценки движения, представляет собой процесс генерирования векторов движения, которые оценивают движение для видеоблоков. Вектор движения, например, может указать сдвиг кодируемого/декодируемого объекта относительно предиктивного блока. Предиктивный блок является блоком, который обнаружен как точно соответствующий блоку, который подлежит кодированию/декодированию, исходя из разности пикселей. Предиктивный блок также может именоваться опорным блоком. Такая разность пикселей может быть определена суммой абсолютных разностей (SAD), суммой квадратов разностей (SSD) или другими показателями различия. HEVC использует несколько кодируемых/декодируемых объектов, в том числе CTU, блоки дерева кодирования/декодирования (CTB) и CU. Например, CTU можно разбить на CTB, которые затем можно разбить на CB для включения в CU. CU может быть закодирована как единица предсказания (PU), содержащая данные предсказания, и/или единица преобразования (TU), содержащая преобразованные остаточные данные для CU. Компонент 221 оценки движения генерирует векторы движения, PU и TU с использованием анализа скорость-искажение в рамках процесса оптимизации скорость-искажение. Например, компонент 221 оценки движения может определять несколько опорных блоков, несколько векторов движения и т.д. для текущего блока/кадра и может выбирать опорные блоки, векторы движения и т.д., имеющие наилучшие характеристики скорость-искажение. Наилучшие характеристики скорость-искажение уравновешивают качество восстановления видео (например, объем потерь данных при сжатии) с эффективностью кодирования/декодирования (например, размер окончательного кодирования).
[0074] В некоторых примерах система 200 кодека может вычислять значения для положений субцелочисленных пикселей опорных изображений, сохраненных в компоненте 223 буфера декодированных изображений. Например, система 200 кодека может интерполировать значения положений одной четверти пикселя, положений одной восьмой пикселя или других положений дробных пикселей опорного изображения. Следовательно, компонент 221 оценки движения может выполнять поиск движения относительно положений полных пикселей и положений дробных пикселей и выводить вектор движения с точностью до дробных пикселей. Компонент 221 оценки движения вычисляет вектор движения для PU видеоблока в интер-кодируемом/декодируемом слайсе путем сравнения положения PU с положением предиктивного блока опорного изображения. Компонент 221 оценки движения выводит вычисленный вектор движения в качестве данных движения в компонент 231 форматирования заголовка и CABAC для кодирования и движения для компонента 219 компенсации движения.
[0075] Компенсация движения, выполняемая компонентом 219 компенсации движения, может включать в себя получение или генерирование предиктивного блока на основе вектора движения, определенного компонентом 221 оценки движения. Опять же, компонент 221 оценки движения и компонент 219 компенсации движения могут быть функционально интегрированы в некоторых примерах. После приема вектора движения для PU текущего блока видео компонент 219 компенсации движения может находить предиктивный блок, на который указывает вектор движения. Затем формируется остаточный видеоблок путем вычитания значений пикселей предиктивного блока из значений пикселей текущего кодируемого видеоблока, что формирует значения разности пикселей. В общем, компонент 221 оценки движения выполняет оценку движения относительно компонентов яркости, а компонент 219 компенсации движения использует векторы движения, вычисленные на основе компонентов яркости, как для компонентов цветности, так и для компонентов яркости. Предиктивный блок и остаточный блок пересылаются в компонент 213 преобразования, масштабирования и квантования.
[0076] Разделенный видеосигнал 201 также отправляется в компонент 215 интра-кадровой оценки и компонент 217 интра-кадрового предсказания. Как и в случае с компонентом 221 оценки движения и компонентом 219 компенсации движения, компонент 215 интра-кадровой оценки и компонент 217 интра-кадрового предсказания могут быть в высокой степени интегрированы, но в концептуальных целях проиллюстрированы отдельно. Компонент 215 интра-кадровой оценки и компонент 217 интра-кадрового предсказания осуществляют интра-предсказание текущего блока относительно блоков в текущем кадре, в качестве альтернативы интер-предсказанию, выполняемому компонентом 221 оценки движения и компонентом 219 компенсации движения между кадрами, как описано выше. В частности, компонент 215 интра-кадровой оценки определяет режим интра-предсказания для использования, чтобы кодировать текущий блок. В некоторых примерах компонент 215 интра-кадровой оценки выбирает надлежащий режим интра-предсказания для кодирования текущего блока из множества проверяемых режимов интра-предсказания. Выбранные режимы интра-предсказания затем пересылаются в компонент 231 форматирования заголовка и CABAC для кодирования.
[0077] Например, компонент 215 интра-кадровой оценки вычисляет значения скорость-искажение, используя анализ скорость-искажение для различных проверяемых режимов интра-предсказания, и выбирает режим интра-предсказания, имеющий лучшие характеристики скорость-искажение среди проверенных режимов. Анализ скорость-искажение обычно определяет степень искажения (или ошибку) между закодированным блоком и исходным незакодированным блоком, который был закодирован для получения упомянутого закодированного блока, а также битрейт (например, число битов), используемый для получения упомянутого закодированного блока. Компонент 215 интра-кадровой оценки вычисляет отношения по искажениям и скоростям для различных закодированных блоков, чтобы определить, какой режим интра-предсказания демонстрирует наилучшее значение скорость-искажение для блока. Кроме того, компонент 215 интра-кадровой оценки может быть выполнен с возможностью кодирования блоков глубины карты глубины с использованием режима моделирования глубины (DMM) на основе оптимизации скорость-искажение (RDO).
[0078] Компонент 217 интра-кадрового предсказания может генерировать остаточный блок из предиктивного блока на основе выбранных режимов интра-предсказания, определенных компонентом 215 интра-кадровой оценки, при реализации в кодере, или считывать остаточный блок из битового потока при реализации в декодере. Остаточный блок включает в себя разность значений между предиктивным блоком и исходным блоком, представленную в виде матрицы. Остаточный блок затем пересылается в компонент 213 преобразования, масштабирования и квантования. Компонент 215 интра-кадровой оценки и компонент 217 интра-кадрового предсказания могут работать как над компонентами яркости, так и над компонентами цветности.
[0079] Компонент 213 преобразования, масштабирования и квантования выполнен с возможностью дальнейшего сжатия остаточного блока. Компонент 213 преобразования, масштабирования и квантования применяет преобразование, такое как дискретное косинусное преобразование (DCT), дискретное синусное преобразование (DST) или концептуально аналогичное преобразование, к остаточному блоку, создавая видеоблок, содержащий остаточные значения коэффициентов преобразования. Также могут быть использованы вейвлет-преобразования, целочисленные преобразования, преобразования поддиапазонов или другие типы преобразований. Преобразование может переводить остаточную информацию из области значений пикселей в область преобразования, такую как частотная область. Компонент 213 преобразования, масштабирования и квантования также выполнен с возможностью масштабирования преобразованной остаточной информации, например на основе частоты. Такое масштабирование включает в себя применение коэффициента масштабирования к остаточной информации, так что информация разных частот квантуется с разными степенями детализации, что может повлиять на конечное визуальное качество восстановленного видео. Компонент 213 преобразования, масштабирования и квантования также выполнен с возможностью квантования коэффициентов преобразования для дальнейшего снижения битрейта. Процесс квантования может уменьшать битовую глубину, ассоциированную с некоторыми или всеми коэффициентами. Степень квантования может быть изменена посредством корректировки параметра квантования. В некоторых примерах компонент 213 преобразования, масштабирования и квантования может затем выполнять сканирование матрицы, включающей в себя квантованные коэффициенты преобразования. Квантованные коэффициенты преобразования пересылаются в компонент 231 форматирования заголовка и CABAC для кодирования в битовый поток.
[0080] Компонент 229 обратного преобразования и масштабирования применяет обратную операцию компонента 213 преобразования, масштабирования и квантования для поддержки оценки движения. Компонент 229 обратного преобразования и масштабирования применяет обратное масштабирование, преобразование и/или квантование для восстановления остаточного блока в пиксельной области, например для последующего использования в качестве опорного блока, который может стать предиктивным блоком для другого текущего блока. Компонент 221 оценки движения и/или компонент 219 компенсации движения могут вычислять опорный блок путем прибавления остаточного блока обратно к соответствующему предиктивному блоку для использования при оценке движения более позднего блока/кадра. Фильтры применяются к восстановленным опорным блокам для смягчения артефактов, создаваемых во время масштабирования, квантования и преобразования. В противном случае такие артефакты могут вызвать неточное предсказание (и создать дополнительные артефакты) при предсказании последующих блоков.
[0081] Компонент 227 анализа для управления фильтром и компонент 225 фильтров внутри цикла применяют фильтры к остаточным блокам и/или к восстановленным блокам изображения. Например, преобразованный остаточный блок из компонента 229 обратного преобразования и масштабирования может быть объединен с соответствующим блоком предсказания из компонента 217 интра-кадрового предсказания и/или компонента 219 компенсации движения для восстановления исходного блока изображения. Затем фильтры могут быть применены к восстановленному блоку изображения. В некоторых примерах фильтры могут быть применены к остаточным блокам. Как и в случае с другими компонентами на ФИГ. 2, компонент 227 анализа для управления фильтром и компонент 225 фильтров внутри цикла являются в высокой степени интегрируемыми и могут быть реализованы вместе, но представлены в концептуальных целях по-отдельности. Фильтры, применяемые к восстановленным опорным блокам, применяются к определенным пространственным областям и включают в себя несколько параметров для корректировки того, как такие фильтры применяются. Компонент 227 анализа для управления фильтром анализирует восстановленные опорные блоки для определения того, где такие фильтры должны применяться, и устанавливает соответствующие параметры. Такие данные пересылаются в компонент 231 форматирования заголовка и CABAC в качестве управляющих фильтром данных для кодирования. Компонент 225 фильтров внутри цикла применяет такие фильтры на основе управляющих фильтром данных. Фильтры могут включать в себя деблокирующий фильтр, фильтр шумоподавления, SAO-фильтр и адаптивный циклический фильтр. Такие фильтры могут применяться в пространственной/пиксельной области (например, к восстановленному блоку пикселей) или в частотной области, в зависимости от примера.
[0082] При работе в качестве кодера отфильтрованный восстановленный блок изображения, остаточный блок и/или блок предсказания сохраняются в компоненте 223 буфера декодированных изображений для последующего использования при оценке движения, как описано выше. При работе в качестве декодера компонент 223 буфера декодированных изображений сохраняет и пересылает восстановленные и отфильтрованные блоки на дисплей в ходе вывода видеосигнала. Компонент 223 буфера декодированных изображений может представлять собой любое запоминающее устройство, способное сохранять блоки предсказания, остаточные блоки и/или восстановленные блоки изображения.
[0083] Компонент 231 форматирования заголовка и CABAC принимает данные от различных компонентов системы 200 кодека и кодирует такие данные в кодируемый/декодируемый битовый поток для передачи на декодер. В частности, компонент 231 форматирования заголовка и CABAC генерирует различные заголовки для кодирования управляющих данных, таких как общие управляющие данные и управляющие фильтром данные. Кроме того, данные предсказания, включающие в себя данные движения и интра-предсказания, а также остаточные данные в форме данных квантованных коэффициентов преобразования, все кодируются в битовом потоке. Окончательный битовый поток включает в себя всю информацию, необходимую декодеру для восстановления исходного разделенного видеосигнала 201. Такая информация может также включать в себя таблицы индексов режимов интра-предсказания (также называемые таблицами отображения кодовых слов), определения контекстов кодирования для различных блоков, указания наиболее вероятных режимов интра-предсказания, указание информации разделения и т. д. Такие данные могут быть закодированы с помощью энтропийного кодирования. Например, информация может быть закодирована с использованием контекстно-адаптивного кодирования с переменной длиной слова (CAVLC), CABAC, синтаксического контекстно-адаптивного двоичного арифметического кодирования (SBAC), энтропийного кодирования с разделением вероятностных интервалов (PIPE) или другой методики энтропийного кодирования. После энтропийного кодирования кодированный битовый поток может быть передан на устройство (например, видеодекодер) или помещен в архив для последующей передачи или извлечения.
[0084] ФИГ. 3 представляет собой блок-схему, иллюстрирующую примерный видеокодер 300. Видеокодер 300 может использоваться для реализации функций кодирования системы 200 кодека и/или реализации этапов 101, 103, 105, 107 и/или 109 рабочего способа 100. Кодер 300 разделяет входной видеосигнал, в результате чего получается разделенный видеосигнал 301, который по существу аналогичен разделенному видеосигналу 201. Затем разделенный видеосигнал 301 сжимается и кодируется в битовый поток компонентами кодера 300.
[0085] В частности, разделенный видеосигнал 301 пересылается в компонент 317 интра-кадрового предсказания для интра-предсказания. Компонент 317 интра-кадрового предсказания может быть по существу аналогичен компоненту 215 интра-кадровой оценки и компоненту 217 интра-кадрового предсказания. Разделенный видеосигнал 301 также пересылается в компонент 321 компенсации движения для интер-предсказания на основе опорных блоков в компоненте 323 буфера декодированных изображений. Компонент 321 компенсации движения может быть по существу аналогичен компоненту 221 оценки движения и компоненту 219 компенсации движения. Блоки предсказания и остаточные блоки из компонента 317 интра-кадрового предсказания и компонента 321 компенсации движения пересылаются в компонент 313 преобразования и квантования для преобразования и квантования остаточных блоков. Компонент 313 преобразования и квантования может быть по существу аналогичен компоненту 213 преобразования, масштабирования и квантования. Преобразованные и квантованные остаточные блоки и соответствующие блоки предсказания (вместе с ассоциированными управляющими данными) пересылаются в компонент 331 энтропийного кодирования для кодирования в битовый поток. Компонент 331 энтропийного кодирования может быть по существу аналогичен компоненту 231 форматирования заголовка и CABAC.
[0086] Преобразованные и квантованные остаточные блоки и/или соответствующие блоки предсказания также пересылаются из компонента 313 преобразования и квантования в компонент 329 обратного преобразования и квантования для восстановления в опорные блоки для использования компонентом 321 компенсации движения. Компонент 329 обратного преобразования и квантования может быть по существу аналогичен компоненту 229 обратного преобразования и масштабирования. Фильтры внутри цикла в компоненте 325 фильтров внутри цикла также применяются к остаточным блокам и/или восстановленным опорным блокам, в зависимости от примера. Компонент 325 фильтров внутри цикла может быть по существу аналогичен компоненту 227 анализа для управления фильтром и компоненту 225 фильтров внутри цикла. Компонент 325 фильтров внутри цикла может включать в себя несколько фильтров, как описано в отношении компонента 225 фильтров внутри цикла. Затем отфильтрованные блоки сохраняются в компоненте 323 буфера декодированных изображений для использования в качестве опорных блоков компонентом 321 компенсации движения. Компонент 323 буфера декодированных изображений может быть по существу аналогичен компоненту 223 буфера декодированных изображений.
[0087] ФИГ. 4 представляет собой блок-схему, иллюстрирующую примерный видеодекодер 400. Видеодекодер 400 может использоваться для реализации функций декодирования системы 200 кодека и/или реализации этапов 111, 113, 115, и/или 117 рабочего способа 100. Декодер 400 принимает битовый поток, например от кодера 300, и генерирует восстановленный выходной видеосигнал на основе битового потока для отображения конечному пользователю.
[0088] Битовый поток принимается компонентом 433 энтропийного декодирования. Компонент 433 энтропийного декодирования выполнен с возможностью реализации схемы энтропийного декодирования, такой как декодирование CAVLC, CABAC, SBAC, PIPE, или других методик энтропийного декодирования. Например, компонент 433 энтропийного декодирования может использовать информацию заголовка для обеспечения контекста для интерпретации дополнительных данных, закодированных как кодовые слова в битовом потоке. Декодированная информация включает в себя любую требуемую информацию для декодирования видеосигнала, такую как общие управляющие данные, управляющие фильтром данные, информация разделения, данные движения, данные предсказания и квантованные коэффициенты преобразования из остаточных блоков. Квантованные коэффициенты преобразования пересылаются в компонент 429 обратного преобразования и квантования для восстановления в остаточные блоки. Компонент 429 обратного преобразования и квантования может быть аналогичен компоненту 329 обратного преобразования и квантования.
[0089] Восстановленные остаточные блоки и/или блоки предсказания пересылаются в компонент 417 интра-кадрового предсказания для восстановления в блоки изображения на основе операций интра-предсказания. Компонент 417 интра-кадрового предсказания может быть по существу аналогичен компоненту 215 интра-кадровой оценки и компоненту 217 интра-кадрового предсказания. В частности, компонент 417 интра-кадрового предсказания использует режимы предсказания для нахождения опорного блока в кадре и применяет остаточный блок к результату для восстановления интра-предсказанных блоков изображения. Восстановленные интра-предсказанные блоки изображения и/или остаточные блоки и соответствующие данные интер-предсказания пересылаются в компонент 423 буфера декодированных изображений через компонент 425 фильтров внутри цикла, которые могут быть по существу аналогичны компоненту 223 буфера декодированных изображений и компоненту 225 фильтров внутри цикла, соответственно. Компонент 425 фильтров внутри цикла фильтрует восстановленные блоки изображения, остаточные блоки и/или блоки предсказания, и такая информация сохраняется в компоненте 423 буфера декодированных изображений. Восстановленные блоки изображения из компонента 423 буфера декодированных изображений пересылаются в компонент 421 компенсации движения для интер-предсказания. Компонент 421 компенсации движения может быть по существу аналогичен компоненту 221 оценки движения и/или компоненту 219 компенсации движения. В частности, компонент 421 компенсации движения использует векторы движения из опорного блока для генерирования блока предсказания и применяет остаточный блок к результату для восстановления блока изображения. Получаемые в результате восстановленные блоки также можно переслать через компонент 425 фильтров внутри цикла в компонент 423 буфера декодированных изображений. Компонент 423 буфера декодированных изображений продолжает сохранять дополнительные восстановленные блоки изображения, которые могут быть восстановлены в кадры посредством информации разделения. Такие кадры также могут быть помещены в последовательность. Последовательность выводится на дисплей в виде восстановленного выходного видеосигнала.
[0090] ФИГ. 5 представляет собой схематичное представление, иллюстрирующее множество видеопотоков 501, 502, 503 субизображений, выделенных из видеопотока 500 изображений VR. Например, видеопотоки 501-503 субизображений и/или видеопоток 500 изображений VR могут быть закодированы кодером, таким как система 200 кодека и/или кодер 300, согласно способу 100. Кроме того, видеопотоки 501-503 субизображений и/или видеопоток 500 изображений VR могут быть декодированы декодером, таким как система 200 кодека и/или декодер 400.
[0091] Видеопоток 500 изображений VR включает в себя множество изображений, представляемых с течением времени. В частности, VR работает посредством кодирования/декодирования сферы видеоконтента, которая может отображаться так, как если бы пользователь находился в центре этой сферы. Каждое изображение включает в себя всю сферу. При этом пользователю отображается только часть изображения, известная как окно просмотра. Например, пользователь может использовать головной дисплей (HMD), который выбирает и отображает окно просмотра сферы на основе движения головы пользователя. Это создает впечатление физического присутствия в виртуальном пространстве, которое представлено посредством видео. Для достижения этого результата каждое изображение видеопоследовательности включает в себя всю сферу видеоданных в соответствующий момент времени. Однако пользователю отображается только небольшая часть (например, одно окно просмотра) изображения. Оставшаяся часть изображения отбрасывается без рендеринга. Все изображение обычно передается таким образом, что другое окно просмотра может быть динамически выбрано и отображено в ответ на движение головы пользователя.
[0092] В показанном примере каждое из изображений видеопотока 500 изображений VR может быть подразделено на субизображения на основе доступных окон просмотра. Соответственно, каждое изображение и соответствующее субизображение включает в себя значение порядка изображения в ходе представления. Видеопотоки 501-503 субизображений создаются, когда подразделение применяется последовательно во времени. Такое последовательное подразделение создает видеопотоки 501-503 субизображений, причем каждый поток содержит набор субизображений предопределенного размера, формы и пространственного положения относительно соответствующих изображений в видеопотоке 500 изображений VR. Кроме того, субизображения в видеопотоке 501-503 субизображений различаются по значению порядка изображения в течение времени представления. Таким образом, субизображения видеопотоков 501-503 субизображений могут быть выровнены на основе порядка изображений относительно времени представления. Затем субизображения из видеопотоков 501-503 субизображений при каждом значении счетчика порядка изображений могут быть объединены в пространственной области на основе предопределенного пространственного положения для восстановления видеопотока 500 изображений VR для отображения. В частности, каждый из видеопотоков 501-503 субизображений может быть закодирован в отдельные битовые подпотоки. Когда такие битовые подпотоки объединяются вместе, они приводят к битовому потоку, который включает в себя весь набор изображений за время представления. Получаемый в результате битовый поток может быть передан на декодер для декодирования и отображения на основе текущего выбранного пользователем окна просмотра.
[0093] Одна из проблем с видео VR заключается в том, что все видеопотоки 501-503 субизображений могут быть переданы пользователю с высоким качеством (например, с высоким разрешением). Это позволяет декодеру динамически выбирать текущее окно просмотра пользователя и отображать субизображение(я) из соответствующих видеопотоков 501-503 субизображений в реальном времени. Однако пользователь может просматривать только одно окно просмотра, например, из видеопотока 501 субизображений, в то время как видеопотоки 502-503 субизображений отбрасываются. Таким образом, передача видеопотоков 502-503 субизображений с высоким качеством может привести к растрате значительной части полосы пропускания. Чтобы повысить эффективность кодирования/декодирования, видео VR может быть закодировано во множество видеопотоков 500, где каждый видеопоток 500 кодируется с разным качеством/разрешением. Таким образом, декодер может передавать запрос текущего видеопотока 501 субизображений. В ответ кодер (или промежуточный слайсер, или другой сервер контента) может выбирать видеопоток 501 субизображений более высокого качества из видеопотока 500 более высокого качества и видеопотоки 502-503 субизображений более низкого качества из видеопотока 500 более низкого качества. Затем кодер может объединять такие битовые подпотоки вместе в полный кодированный битовый поток для передачи декодеру. Таким образом, декодер принимает ряд изображений, где текущее окно просмотра имеет более высокое качество, а другие окна просмотра имеют более низкое качество. Кроме того, субизображения наивысшего качества обычно отображаются пользователю (при отсутствии движения головы), а субизображения более низкого качества обычно отбрасываются, что балансирует функциональность с эффективностью кодирования/декодирования.
[0094] В случае, если пользователь переключается с просмотра видеопотока 501 субизображений на видеопоток 502 субизображений, декодер запрашивает передачу нового текущего видеопотока 502 субизображений с более высоким качеством. Затем кодер может надлежащим образом изменить механизм объединения. Декодер может начать декодирование новой CVS только с IRAP-изображения. Это связано с тем, что IRAP- изображение кодируется/декодируется в соответствии с интра-предсказанием, которое не ссылается на другое изображение. Следовательно, IRAP-изображение может быть декодировано, даже если изображения, которые предшествуют этому IRAP-изображению, не являются доступными. Не-IRAP-изображения кодируются/декодируются согласно интер-предсказанию. Таким образом, не-IRAP-изображения не могут быть декодированы без предварительного декодирования соответствующего набора опорных изображений на основе списка опорных изображений. Соответственно, декодер как правило не может начинать декодирование видеопоследовательности с не-IRAP-изображения. Из-за этих ограничений видеопоток 502 субизображений отображается с более низким качеством до тех пор, пока не будет достигнуто IRAP-изображение/субизображение. Затем IRAP-изображение может быть декодировано с более высоким качеством, чтобы начать декодирование версии более высокого качества видеопотока 502 субизображений. Такой подход значительно увеличивает сжатие видео, не оказывая негативного влияния на впечатления пользователя от просмотра.
[0095] Одна проблема с вышеупомянутым подходом заключается в том, что продолжительность времени, необходимая для изменения разрешений, основана на продолжительности времени до момента, когда в видеопотоке будет достигнуто IRAP-изображение. Это связано с тем, что декодер не может начинать декодирование другой версии видеопотока 502 субизображений с не-IRAP-изображения. Одним из подходов к уменьшению такой задержки является включение большего числа IRAP-изображений. Однако это приводит к увеличению размера файла. Чтобы сбалансировать функциональность с эффективностью кодирования/декодирования, разные видеопотоки 501-503 окон просмотра/субизображений могут включать в себя IRAP-изображения с разными частотами. Например, видеопотоки 501-503 окон просмотра/субизображений, которые чаще всего просматриваются, могут иметь больше IRAP-изображений, чем другие видеопотоки 501-503 окон просмотра/субизображений. Например, в контексте баскетбола, видеопотоки 501-503 окон просмотра/субизображений, относящиеся к корзинам и/или центральной зоне, могут включать в себя IRAP-изображения с большей частотой, чем видеопотоки 501-503 окон просмотра/субизображений, через которые просматриваются трибуны или потолок, поскольку такие видеопотоки 501-503 окон просмотра/субизображений с меньшей вероятностью будут просматриваться пользователем.
[0096] Такой подход приводит к дополнительным проблемам. В частности, субизображения из видеопотоков 501-503 субизображений, которые совместно используют некоторое POC, являются частью одного изображения. Как отмечалось выше, слайсы из изображения включаются в единицу NAL на основе типа изображения. В некоторых системах кодирования/декодирования видео все единицы NAL, относящиеся к одному изображению, ограничиваются включением одного и того же типа единиц NAL. Когда разные видеопотоки 501-503 субизображений имеют IRAP-изображения с разными частотами, некоторые из изображений включают в себя как IRAP-субизображения, так и не-IRAP-субизображения. Это нарушает ограничение, согласно которому каждое отдельное изображение должно использовать только единицы NAL одного и того же типа.
[0097] Эту проблему можно решить, убрав ограничение, согласно которому все единицы NAL для слайсов в изображении используют один и тот же тип единиц NAL. Например, изображение включается в единицу доступа. Убрав это ограничение, единица доступа может включать в себя как типы единиц NAL IRAP, так и типы единиц NAL не-IRAP. Кроме того, флаг может быть закодирован, чтобы указывать, когда единица доступа/изображение включает в себя смесь типов единиц NAL IRAP и типов единиц NAL не-IRAP. В некоторых примерах этот флаг представляет собой флаг смешанных типов единиц NAL в изображении (mixed_nalu_types_in_pic_flag). Кроме того, может применяться ограничение, требующее, чтобы одна/одно смешанная/смешанное единица доступа/изображение могла/могло содержать только один тип единицы NAL IRAP и один тип единицы NAL не-IRAP. Это предотвращает нежелательное смешение типов единиц NAL. Если бы такие смешения были разрешены, декодер должен был бы быть разработан для работы с такими смешениями. Это неоправданно увеличило бы требуемую сложность аппаратного обеспечения, не обеспечив дополнительных преимуществ для процесса кодирования/декодирования. Например, смешанное изображение может включать в себя один тип единицы NAL IRAP, выбранный из IDR_W_RADL, IDR_N_LP или CRA_NUT. Кроме того, смешанное изображение может включать в себя один тип единицы NAL не-IRAP, выбранный из TRAIL_NUT, RADL_NUT и RASL_NUT.
[0098] ФИГ. 6 представляет собой схематичное представление, иллюстрирующее ограничения 600, используемые, когда текущее изображение включает в себя смешанные типы единиц NAL. Ограничения 600 могут быть применены при кодировании/декодировании видеопотока 500 изображений VR. Таким образом, ограничения 600 могут использоваться кодером, таким как система 200 кодека и/или кодер 300, применяющим способ 100. Кроме того, ограничения 600 могут использоваться декодером, таким как система 200 кодека и/или декодер 400, применяющим способ 100. Ограничение 600 представляет собой требование, накладываемое на видеоданные, накладываемое на вспомогательные параметры и/или накладываемое на процесс, связанный с кодированием и/или декодированием видеоданных.
[0099] В частности, ФИГ. 6 изображает ряд изображений, которые были разбиты на субизображения. Субизображения обозначаются как субизображение A (subpicA) 601 и субизображение B (subpicB) 603. Субизображения и, следовательно, subpicA 601 и subpicB 603, представляют собой прямоугольные и/или квадратные области одного или более слайсов в последовательности изображений. SubpicA 601 и subpicB 603 могут содержаться в видеопотоках субизображений, таких как любые из видеопотоков 501-503 субизображений на ФИГ. 5. Для ясности показаны только два субизображения, но можно использовать любое количество субизображений.
[00100] Изображение представляет собой массив выборок яркости и/или массив выборок цветности, которые создают кадр или его поле. Изображения кодируются и/или декодируются в порядке 650 декодирования. Порядок декодирования представляет собой порядок, в котором синтаксические элементы обрабатываются посредством процесса декодирования. По мере продвижения по порядку декодирования процесс декодирования осуществляет переход по изображениям. Для ясности описания изображение, кодируемое/декодируемое в текущий, конкретный момент времени, называется текущим изображением 620. Изображение, которое уже было закодировано/декодировано, является предшествующим изображением 610. Изображение, которое еще не было декодировано, является последующим изображением 630 и/или 640. Как показано на ФИГ. 6, изображения последовательно разделяются на subpicA 601 и subpicB 603. Следовательно, каждое из предшествующего изображения 610, текущего изображения 620 и последующих изображений 630 и 640 разделяется на и/или включает в себя subpicA 601 и subpicB 603.
[00101] Как описано выше, в некоторых примерах IRAP-субизображения могут применяться с разными частотами. В показанном примере текущее изображение 620 включает в себя множество единиц NAL VCL, которые не имеют одного и того же типа единиц NAL. В частности, subpicA 601 в текущем изображении 620 включает в себя единицы 621 NAL IRAP, в то время как subpicB 603 в текущем изображении 620 включает в себя единицы 623 NAL не-IRAP. Единица 621 NAL IRAP представляет собой структуру данных, содержащую данные из IRAP-изображения или субизображения. IRAP-изображение/субизображение представляет собой изображение/суб-изображение, которое кодируется/декодируется согласно интра-предсказанию, которое указывает, что декодер может начинать декодирование видеопоследовательности с соответствующего изображения/субизображения, не ссылаясь на изображения, предшествующие упомянутому IRAP-изображению/субизображению. Единица 621 NAL IRAP может включать в себя единицу NAL CRA и/или единицу NAL IDR. CRA-изображение/субизображение представляет собой IRAP-изображение/субизображение, которое не обновляет DPB, а IDR-изображение/субизображение представляет собой IRAP-изображение/субизображение, которое обновляет DPB. Единица 623 NAL не-IRAP представляет собой любую единицу NAL VCL, которая не включает в себя IRAP-изображение/субизображение. Например, единица 623 NAL не-IRAP может включать в себя опережающие изображения, такие как опережающие изображения с пропуском произвольного доступа (RASL) или декодируемые опережающие изображения произвольного доступа (RADL), или замыкающие изображения. Опережающее изображение предшествует IRAP-изображению в порядке представления и появляется после этого IRAP-изображения в порядке 650 декодирования. Замыкающее изображение появляется после IRAP-изображения как в порядке представления, так и в порядке 650 декодирования. Единица 623 NAL не-IRAP может быть кодирована/декодирована согласно интер-предсказанию. Таким образом, текущее изображение 620 кодируется/декодируется согласно как интер-кадровому предсказанию в subpicB 603, так и интра-предсказанию в subpicA 601.
[00102] Предшествующее изображение 610 включает в себя единицу 611 NAL не-IRAP и единицу 613 NAL не-IRAP, последующее изображение 630 включает в себя единицу 631 NAL не-IRAP и единицу 633 NAL не-IRAP и последующее изображение 640 включает в себя единицу 641 NAL не-IRAP и единицу 643 NAL не-IRAP. Единицы 611, 613, 631, 633, 641 и 643 NAL не-IRAP могут быть аналогичны единице 623 NAL не-IRAP (например, могут быть кодированы/декодированы согласно интер-предсказанию), но могут содержать другие видеоданные.
[00103] Поскольку текущее изображение 620 включает в себя единицы NAL VCL, которые не имеют одного и того же типа единиц NAL, текущее изображение 620 представляет собой изображение смешанных единиц NAL. Наличие изображения смешанных единиц NAL может сигнализироваться флагом в наборе параметров в битовом потоке. Ограничения 600 применяются тогда, когда встречается изображение смешанных единиц NAL, такое как текущее изображение 620.
[00104] Во время кодирования кодер может определять, что subpicA 601 в текущем изображении 620 ассоциировано с типом единицы NAL IRAP и, следовательно, включает в себя единицу 621 NAL IRAP. Это указывает то, что subpicA 601 в текущем изображении 620 должно действовать как граница и предотвращает ссылку интер-предсказания в subpicA 601 через текущее изображение 620. Следовательно, единица 631 NAL не-IRAP не может ссылаться на единицу 611 NAL не-IRAP или любую другую единицу NAL, предшествующую единице 621 NAL IRAP. Кодер может кодировать текущее изображение 620 посредством обеспечения того, чтобы все слайсы текущего изображения, расположенные в subpicA 601, были ассоциированы с одним и тем же типом единицы NAL. Например, когда subpicA 601 содержит по меньшей мере один CRA-слайс (или IDR-слайс), все слайсы в subpicA 601 также должны быть CRA (или IDR). Слайсы текущего изображения 620 (включающего в себя единицу 621 NAL IRAP и единицу 623 NAL не-IRAP) затем кодируются на основе типа единицы NAL (например, интра-предсказание и интер-предсказание, соответственно). Последующие изображения 630 и 640, которые следуют за текущим изображением 620 в порядке 650 декодирования, также кодируются. Чтобы обеспечить, что единица 621 NAL IRAP предотвращает распространение интер-предсказания, единицам 631 и 641 NAL не-IRAP запрещается ссылка 632 на предшествующее изображение 610. Ссылка 632 управляется списком опорных изображений, где активные записи списка опорных изображений указывают опорные изображения, которые доступны для изображения, которое в настоящее время кодируется/декодируется. Таким образом, ограничения 600 гарантируют, что активные записи, ассоциированные со слайсами, расположенными в subpicA 601 на последующих изображениях 630 и 640 (например единицы 631 и 641 NAL не-IRAP), не обращаются к/не ссылаются 632 на какое-либо опорное изображение, предшествующее текущему изображению 620 в порядке 650 декодирования, когда subpicA 601 в текущем изображении 620 ассоциирован с единицей 621 NAL IRAP с типом единицы NAL IRAP. Единице 631 NAL не-IRAP все еще разрешается ссылаться на текущее изображение 620 и/или последующее изображение 640. Кроме того, единице 641 NAL не-IRAP все еще разрешается ссылаться на текущее изображение 620 и/или последующее изображение 630. Это останавливает распространение интер-предсказания для единиц 631 и 641 NAL не-IRAP, поскольку единицы 631 и 641 NAL не-IRAP следуют за единицей 621 NAL IRAP в subpicA 601. Затем последующее изображение 630 и/или 640 может быть закодировано на основе типа единицы NAL и в соответствии с ограничениями 600.
[00105] Такие ограничения 600 не применяются к единицам 633 и 643 NAL не-IRAP, поскольку они находятся в subpicB 603 и, следовательно, не следуют за единицей NAL IRAP в subpicB 603. Соответственно, единицы 633 и 643 NAL не-IRAP могут ссылаться 634 на предшествующее изображение 610. Соответственно, активные записи списков опорных изображений, ассоциированные с единицами 633 и 643 NAL не-IRAP, могут ссылаться на предшествующее изображение 610, текущее изображение 620 и/или последующие изображения 640 или 630, соответственно. Таким образом, интер-предсказание нарушается для subpicA 601 единицей 621 NAL IRAP, однако единица 621 NAL IRAP не останавливает распространение интер-предсказания для subpicB 603. Следовательно, путем применения ограничений 600 цепочки интер-предсказания могут быть остановлены (или нет) на основе 'субизображение за субизображением'. Как отмечено выше, показаны только два субизображения. Однако ограничения 600 могут быть применены к любому числу субизображений, чтобы остановить распространение цепочек ссылок при интер-предсказании, на основе 'субизображение за субизображением'.
[00106] ФИГ. 7 представляет собой схематичное представление, иллюстрирующее примерную структуру 700 списков опорных изображений (RPL), содержащую списки опорных изображений. Структура 700 RPL может применяться для сохранения указаний опорных изображений, используемых при однонаправленном интер-предсказании и/или двунаправленном интер-предсказании. Следовательно, структура 700 RPL может применяться системой 200 кодека, кодером 300 и/или декодером 400 при выполнении способа 100. Кроме того, структура 700 RPL может применяться при кодировании/декодировании видеопотока 500 изображений VR, и в этом случае структура 700 RPL может быть кодирована/декодирована согласно ограничениям 600.
[00107] Структура 700 RPL представляет собой адресуемую синтаксическую структуру, которая содержит несколько списков опорных изображений, таких как RPL 0 711 и RPL 1 712. Структура 700 RPL может быть кодирована/декодирована и/или извлечена для использования при кодировании/декодировании соответствующего слайса. Структура 700 RPL может быть сохранена в SPS и/или заголовке слайса битового потока, в зависимости от примера. Список опорных изображений, такой как RPL 0 711 и RPL 1 712, представляет собой список, указывающий опорные изображения, используемые для интер-предсказания. Каждый из RPL 0 711 и RPL 1 712 может включать в себя множество записей 715. Запись 715 структуры RPL представляет собой адресуемое местоположение в структуре 700 RPL, которое указывает опорное изображение, ассоциированное со списком опорных изображений, таким как RPL 0 711 и/или RPL 1 712. Каждая запись 715 может содержать значение счетчика порядка изображения (POC) (или другое значение-указатель), которое ссылается на изображение, используемое для интер-предсказания. В частности, ссылки на изображения, используемые посредством однонаправленного интер-предсказания, сохраняются в RPL 0 711, а ссылки на изображения, используемые посредством двунаправленного интер-предсказания, сохраняются как в RPL 0 711, так и в RPL 1 712. Например, двунаправленное интер-предсказание может использовать одно опорное изображение, указанное посредством RPL 0 711, и одно опорное изображение, указанное посредством RPL 1 712.
[00108] В конкретном примере структура 700 RPL может быть обозначена как ref_pic_list_struct(listIdx, rplsIdx), где индекс списка (listIdx) 721 идентифицирует список опорных изображений RPL 0 711 и/или RPL 1 712, а индекс структуры списков опорных изображений (rplsIdx) 725 идентифицирует запись 715 в списке опорных изображений. Соответственно, ref_pic_list_struct представляет собой синтаксическую структуру, которая возвращает запись 715 на основе listIdx 721 и rplsIdx 725. Кодер может кодировать часть структуры 700 RPL для каждого не-интра-кодируемого/декодируемого слайса в видеопоследовательности. Декодер, затем, может проанализировать соответствующую часть структуры 700 RPL перед декодированием каждого не-интра-кодируемого/декодируемого слайса в кодируемой/декодируемой видеопоследовательности. Записи 715, которые указывают опорные изображения, которые являются доступными для использования при кодировании/декодировании текущего изображения согласно интер-предсказанию, называются активными записями. Записи 715, которые не могут быть использованы для текущего изображения, называются неактивными записями.
[00109] ФИГ. 8 представляет собой схематичное представление, иллюстрирующее примерный битовый поток 800, содержащий изображения со смешанными типами единиц NAL. Например, битовый поток 800 может быть сгенерирован системой 200 кодека и/или кодером 300 для декодирования системой 200 кодека и/или декодером 400 согласно способу 100. Кроме того, битовый поток 800 может включать в себя видеопоток 500 изображений VR, который получен объединением нескольких видеопотоков 501-503 субизображений с множеством разрешений видео. Кроме того, битовый поток 800 может включать в себя структуру 700 RPL, кодируемую/декодируемую согласно ограничениям 600.
[00110] Битовый поток 800 включает в себя набор параметров последовательности (SPS) 810, множество наборов параметров изображения (PPS) 811, множество заголовков 815 слайсов и данные 820 изображения. SPS 810 содержит данные последовательности, общие для всех изображений в видеопоследовательности, содержащейся в битовом потоке 800. Такие данные могут включать размер изображения, битовую глубину, параметры инструмента кодирования/декодирования, ограничения битрейта и т. д. PPS 811 содержит параметры, которые применяются ко всему изображению. Следовательно, каждое изображение в видеопоследовательности может относиться к PPS 811. Следует отметить, что, хотя каждое изображение относится к PPS 811, в некоторых примерах один PPS 811 может содержать данные для нескольких изображений. Например, несколько схожих изображений могут быть кодированы/декодированы согласно схожим параметрам. В таком случае один PPS 811 может содержать данные для таких схожих изображений. PPS 811 может указывать инструменты кодирования/декодирования, доступные для слайсов в соответствующих изображениях, параметры квантования, смещения и т. д. Заголовок 815 слайса содержит параметры, которые являются специфичными для каждого слайса в изображении. Следовательно, в видеопоследовательности может быть один заголовок 815 слайса на каждый слайс. Заголовок 815 слайса может содержать информацию о типе слайса, счетчики порядка изображений (POC), списки опорных изображений, веса предсказания, точки переходов в тайлы, параметры деблокирования и т. д. Следует отметить, что заголовок 815 слайса также может упоминаться как заголовок группы тайлов в некоторых контекстах.
[00111] Данные 820 изображения содержат видеоданные, закодированные согласно интер-предсказанию и/или интра-предсказанию, а также соответствующие преобразованным и квантованным остаточным данным. Например, видеопоследовательность включает в себя множество изображений 821, кодируемых/декодируемых как данные 820 изображения. Изображение 821 является отдельным кадром видеопоследовательности и, следовательно, обычно отображается как одно целое при отображении видеопоследовательности. Однако субизображения 823 могут отображаться для реализации некоторых технологий, таких как виртуальная реальность. Каждое изображение 821 ссылается на PPS 811. Изображения 821 могут быть разбиты на субизображения 823, тайлы и/или слайсы. Субизображение 823 представляет собой пространственную область изображения 821, которая последовательно применяется на протяжении кодируемой/декодируемой видеопоследовательности. Соответственно, субизображение 823 может отображаться посредством HMD в контексте VR. Кроме того, субизображение 823 со специфицированным POC может быть получено из видеопотока 501-503 субизображений с соответствующим разрешением. Субизображение 823 может ссылаться на SPS 810. В некоторых системах слайсы 825 называются группами тайлов, содержащими тайлы. Слайсы 825 и/или группы тайлов с тайлами ссылаются на заголовок 815 слайса. Слайс 825 может быть определен как целое число полных тайлов или целое число последовательных строк полных единиц дерева кодирования/декодирования (CTU) в пределах тайла изображения 821, которые содержатся исключительно в одной единице NAL. Следовательно, слайсы 825 дополнительно разбиваются на CTU и/или блоки дерева кодирования/декодирования (CTB). CTU/CTB дополнительно разбиваются на блоки кодирования/декодирования на основе деревьев кодирования/декодирования. Затем блоки кодирования можно кодировать/декодировать согласно механизмам предсказания.
[00112] Наборы параметров и/или слайсы 825 кодируются/декодируются в единицах NAL. Единица NAL может быть определена как синтаксическая структура, содержащая указание типа данных, которые должны последовать, а также байты, содержащие эти данные в форме RBSP, перемежаемые, при необходимости, байтами предотвращения эмуляции. Более конкретно, единица NAL представляет собой единицу хранения, которая содержит набор параметров или слайс 825 изображения 821 и соответствующий заголовок 815 слайса. В частности, единицы 840 NAL VCL представляют собой единицы NAL, которые содержат слайс 825 изображения 821 и соответствующий заголовок 815 слайса. Кроме того, единицы 830 NAL не-VCL содержат наборы параметров, такие как SPS 810 и PPS 811. Могут применяться несколько типов единиц NAL. Например, SPS 810 и PPS 811 могут быть включены в тип 831 единицы NAL SPS (SPS_NUT) и тип 832 единицы NAL PPS (PPS_NUT) 832, соответственно, оба из которых являются единицами 830 NAL не-VCL. Таким образом, декодер может считывать SPS_NUT 831 из битового потока 800 для получения SPS 810, который кодирован кодером. Аналогично, декодер может считывать PPS_NUT 832 из битового потока 800 для получения PPS 811, который кодирован кодером.
[00113] Слайсы 825 IRAP-изображений/субизображений могут содержаться в единицах 845 NAL IRAP. Слайсы 825 не-IRAP-изображений/субизображений, например опережающие изображения и замыкающие изображения, могут быть включены в единицы 849 NAL не-IRAP. Например, слайс 825 может быть включен в одну единицу 840 NAL VCL. Затем единице 840 NAL VCL может быть назначен идентификатор типа на основе типа изображения 821 и/или субизображения 823, которое включает в себя слайс 825. Например, слайс 825, взятый из субизображения 823, которое является CRA-субизображением, включается в CRA_NUT 843. Битовый поток 800 включает в себя несколько типов единиц 845 NAL IRAP и, следовательно, типов изображений/субизображений, в том числе IDR без опережающих изображений, IDR с декодируемыми опережающими изображениями произвольного доступа (RADL) и CRA-изображения. Битовый поток 800 также включает в себя несколько типов единиц 849 NAL не-IRAP и, следовательно, типов изображений/субизображений, в том числе опережающие изображения с пропуском произвольного доступа (RASL), изображения RADL и замыкающие изображения.
[00114] Опережающее изображение представляет собой изображение, которое кодируется/декодируется после IRAP-изображения в порядке декодирования и перед этим изображением в порядке представления. Единица 845 NAL IRAP представляет собой любую единицу NAL, которая содержит слайс 825, взятый из IRAP-изображения или субизображения. Единица 849 NAL не-IRAP представляет собой любую единицу NAL, которая содержит слайс 825, взятый из любого изображения, которое не является IRAP-изображением или субизображением (например, опережающих изображений или замыкающих изображений). Единицы 845 NAL IRAP и единицы 849 NAL не-IRAP являются единицами 840 NAL VCL, поскольку и те, и другие содержат данные слайса. В примерном варианте осуществления единица 845 NAL IRAP может включать в себя слайсы 825 из IDR-изображения без опережающих изображений или IDR, ассоциированного с изображениями RADL, в единице 841 NAL IDR_N_LP или единице 842 NAL IDR_w_RADL, соответственно. Кроме того, единица 845 NAL IRAP может включать в себя слайсы 825 из CRA-изображения в CRA_NUT 843. В примерном варианте осуществления единица 849 NAL не-IRAP может включать в себя слайсы 825 из изображения RASL, изображения RADL или замыкающего изображения в RASL_NUT 846, RADL_NUT 847 или TRAIL_NUT 848, соответственно. В примерном варианте осуществления полный список возможных единиц NAL показан ниже отсортированным по типу единиц NAL.
slice_layer_rbsp( )
slice_layer_rbsp( )
slice_layer_rbsp( )
slice_layer_rbsp( )
8
IDR_N_LP
slice_layer_rbsp( )
slice_layer_rbsp( )
slice_layer_rbsp( )
12
RSV_IRAP_12
decoding_capability_information_rbsp( )
video_parameter_set_rbsp( )
seq_parameter_set_rbsp( )
pic_parameter_set_rbsp( )
18
SUFFIX_APS_NUT
adaptation_parameter_set_rbsp( )
picture_header_rbsp( )
access_unit_delimiter_rbsp( )
end_of_seq_rbsp( )
end_of_bitstream_rbsp( )
24
SUFFIX_SEI_NUT
sei_rbsp( )
filler_data_rbsp( )
27
RSV_NVCL_27
[00115] Как отмечено выше, видеопоток VR может включать в себя субизображения 823 с IRAP-изображениями на разных частотах. Это позволяет применять меньше IRAP-изображений для пространственных областей, на которые пользователь вряд ли будет смотреть, и использовать больше IRAP-изображений для пространственных областей, которые пользователь, вероятно, будет часто просматривать. Таким образом, пространственные области, к которым пользователь, вероятно, будет регулярно возвращаться, могут быть быстро настроены в более высокое разрешение. Когда этот подход приводит к изображению 821, которое включает в себя как единицы 845 NAL IRAP, так и единицы 849 NAL не-IRAP, изображение 821 упоминается как смешанное изображение. Это условие может сигнализироваться посредством флага 827 смешанных типов единиц NAL в изображении (mixed_nalu_types_in_pic_flag). Mixed_nalu_types_in_pic_flag 827 может быть установлен в PPS 811. Кроме того, mixed_nalu_types_in_pic_flag 827 может быть установлен равным единице при специфицировании того, что каждое изображение 821, ссылающееся на PPS, имеет более одной единицы 840 NAL VCL, и эти единицы 840 NAL VCL не имеют одного и того же значения типа единицы NAL (nal_unit_type). Кроме того, mixed_nalu_types_in_pic_flag 827 может быть установлен равным нулю, когда каждое изображение 821, ссылающееся на PPS 811, имеет одну или более единиц 840 NAL VCL, и эти единицы 840 NAL VCL каждого изображения 821, ссылающегося на PPS 811, все имеют одно и то же значение nal_unit_type.
[00116] Кроме того, могут быть применены различные ограничения, так что единицы 840 NAL VCL одного или более субизображений 823 изображения 821 все имеют первое конкретное значение типа единицы NAL, а все другие единицы 840 NAL VCL в изображении 821 имеют другое второе конкретное значение типа единицы NAL, когда установлен mixed_nalu_types_in_pic_flag 827. Например, ограничение может требовать, чтобы смешанное изображение 821 содержало единственный тип единицы 845 NAL IRAP и единственный тип единицы 849 NAL не-IRAP. Например, изображение 821 может включать в себя одну или более единиц 841 NAL IDR_N_LP, одну или более единиц NAL 842 IDR_w_RADL или один или более CRA_NUT 843, но не любую комбинацию таких единиц 845 NAL IRAP. Кроме того, изображение 821 может включать в себя одну или более RASL_NUTs 846, одну или более RADL_NUTs 847 или один или более TRAIL_NUTs 848, но не любую комбинацию таких единиц 845 NAL IRAP. Кроме того, субизображение 823 может быть ограничено только одним типом единицы 840 NAL VCL. Кроме того, ограничения 600 могут быть применены к субизображениям 823 на основе типа единиц 840 NAL VCL, которые применяются в битовом потоке 800.
[00117] Предшествующая информация теперь описывается более подробно ниже. В спецификации видеокодека типы изображений могут быть идентифицированы для определения процессов декодирования. Это может включать в себя извлечение идентификатора изображения (например, POC), пометку статуса опорных изображений в (DPB), вывод изображений из DPB и т. д.
[00118] В AVC и HEVC типы изображений могут быть идентифицированы по типу единицы NAL, который содержит кодируемое/декодируемое изображение. Типы изображений в AVC включают в себя IDR-изображения и не-IDR изображения. Типы изображений в HEVC включают в себя замыкающее изображение, изображение доступа к временному подуровню (TSA), изображение пошагового доступа к временному подуровню (STSA), декодируемое опережающее изображение произвольного доступа (RADL), опережающее изображение с пропуском произвольного доступа (RASL), изображение доступа с разорванной ссылкой (BLA), IDR и CRA. Каждый из этих типов изображений в HEVC можно дополнительно разделить на изображения подуровня, на которые осуществляется ссылка, или изображения подуровня, на которые не осуществляется ссылка. BLA-изображения также могут включать в себя BLA с опережающим изображением, BLA с RADL-изображением и BLA без опережающего изображения. IDR-изображения могут включать в себя IDR с RADL-изображением и IDR без опережающего изображения.
[00119] В HEVC, IDR-, BLA- и CRA-изображения являются IRAP-изображения. VVC применяет IDR- и CRA-изображения в качестве IRAP-изображений. IRAP-изображение обеспечивает следующие функциональности/преимущества. Наличие IRAP-изображения указывает, что процесс декодирования может начинаться с этого изображения. Эта функциональность поддерживает функцию произвольного доступа, которая позволяет процессу декодирования начинаться с положения в битовом потоке, когда в этом положении присутствует IRAP-изображение. Это положение может не быть в начале битового потока. Присутствие IRAP-изображения также может обновить процесс декодирования, так что кодируемые/декодируемые изображения после этого IRAP-изображения, за исключением RASL-изображения, кодируются/декодируются без какой-либо ссылки на изображения, предшествующие IRAP-изображению. Следовательно, IRAP-изображение предотвращает распространение ошибок, возникающих до упомянутого IRAP-изображения, на изображения, которые следуют за этим IRAP-изображением в порядке декодирования.
[00120] IRAP-изображения обеспечивают вышеупомянутые функциональности, но приводят к снижению эффективности сжатия. Наличие IRAP-изображения также вызывает резкий рост битрейта. Упомянутое снижение эффективности сжатия имеет две причины. Первая, поскольку IRAP-изображение является интра-предсказываемым и, следовательно, IRAP-изображение представлено большим числом битов, чем интер-предсказываемые изображения. Вторая, наличие IRAP-изображения может нарушить временное предсказание за счет обновления процесса декодирования, когда опорные изображения удаляются из DPB. Это может привести к менее эффективному кодированию/декодированию изображений, которые следуют за IRAP-изображением, поскольку для интер-предсказания доступно меньше опорных изображений.
[00121] IDR-изображения в HEVC могут извлекаться и сигнализироваться иначе, чем изображения других типов. Некоторые отличия заключаются в следующем. При сигнализации и извлечении значения POC IDR-изображения старший значащий бит (MSB) POC может быть установлен равным нулю вместо его извлечения из предыдущего ключевого изображения. Кроме того, заголовок слайса IDR-изображения может не содержать информации для помощи в управлении опорными изображениями. Для других типов изображений, таких как CRA и замыкающие, наборы опорных изображений (RPS) или списки опорных изображений могут быть применены для процесса пометки опорных изображений. Этот процесс применяется для определения статуса опорных изображений в DPB в качестве используемых для ссылки или неиспользуемых для ссылки. Для IDR-изображений такая информация может не сигнализироваться, поскольку наличие IDR указывает, что процесс декодирования должен помечать все опорные изображения в DPB в качестве неиспользуемых для ссылки.
[00122] В дополнение к типам изображений, идентификация изображения также применяется для нескольких целей. Это включают в себя идентификацию изображений собственно опорных изображений при интер-предсказании, идентификацию изображений для вывода из DPB, идентификацию изображений для масштабирования векторов движения, идентификацию изображений для взвешенного предсказания и т. д. В AVC и HEVC изображения могут быть идентифицированы посредством POC. В AVC и HEVC изображения в DPB могут быть помечены как используемые для краткосрочной ссылки, используемые для долгосрочной ссылки или неиспользуемые для ссылки. После того как изображение помечено как неиспользуемое для ссылки, оно больше не может использоваться для предсказания. Изображение может быть удалено из DPB, когда оно больше не нужно для вывода. AVC применяет краткосрочные и долгосрочные опорные изображения. Опорное изображение может быть помечено как неиспользуемое для ссылки, когда изображение больше не требуется для ссылки при предсказании. Преобразование между краткосрочным, долгосрочным и неиспользуемым для ссылки управляется процессом пометки декодированного опорного изображения. Процесс неявного скользящего окна и процесс операции явного контроля управления памятью (MMCO) могут применяться в качестве механизмов пометки декодированных опорных изображений. Процесс скользящего окна помечает краткосрочное опорное изображение как неиспользуемое для ссылки, когда количество опорных кадров равняется специфицированному максимальному числу в SPS. Кратковременные опорные изображения сохраняются в порядке 'первым введено, первым выведено', так что в DPB сохраняются самые недавно декодированные краткосрочные изображения. Процесс явного MMCO может включать в себя несколько MMCO-команд. MMCO-команда может помечать одно или более краткосрочных или долгосрочных опорных изображений в качестве неиспользуемых для ссылки или помечать все изображения в качестве неиспользуемых для ссылки. MMCO-команда может также помечать текущее опорное изображение или существующее краткосрочное опорное изображение в качестве долгосрочного и назначать этому долгосрочному опорному изображению индекс долгосрочного изображения. В AVC операции пометки опорных изображений, а также процессы вывода и удаления изображений из DPB выполняются после декодирования изображения.
[00123] HEVC применяет RPS для управления опорным изображением. RPS может включать в себя, для каждого слайса, полный набор опорных изображений, которые используются текущим изображением или любым последующим изображением. Таким образом, RPS сообщает о полном наборе всех изображений, которые должны храниться в DPB для использования текущими или последующими изображениями. Это отличается от схемы AVC, где сигнализируются только относительные изменения в DPB. RPS может не поддерживать информацию из более ранних изображений при декодировании, чтобы поддерживать правильный статус опорных изображений в DPB. Порядок декодирования изображения и операции DPB в HEVC используют преимущества RPS и повышают устойчивость к ошибкам. В AVC пометка изображения и операции буфера могут применяться после декодирования текущего изображения. В HEVC RPS сначала декодируется из заголовка слайса текущего изображения. Затем перед декодированием текущего изображения применяются пометка изображений и операции буфера.
[00124] VVC может напрямую сигнализировать и получать список опорных изображений ноль и список опорных изображений один. Списки опорных изображений не основаны на RPS, скользящем окне или MMCO-процессе, как в HEVC и AVC. Пометка опорных изображений выполняется непосредственно на основе списков опорных изображений ноль и один с использованием как активных, так и неактивных записей в списках опорных изображений. Только активные записи могут использоваться в качестве опорных индексов при интер-предсказании CTU для текущего изображения. Информация для извлечения двух списков опорных изображений сигнализируется синтаксическими элементами и синтаксическими структурами в SPS, PPS и заголовке слайса. Предопределенные RPL-структуры сигнализируются в SPS для использования по ссылке в заголовке слайса. Два списка опорных изображений генерируются для всех типов слайсов, в том числе слайсы с двунаправленным интер-предсказанием (B), однонаправленным интер-предсказанием (P) и интра-предсказанием (I). Эти два списка опорных изображений создаются без использования процесса инициализации списка опорных изображений или процесса модификации списка опорных изображений. Долгосрочные опорные изображения (LTRP) идентифицируются посредством LSB POC. Циклы дельта-MSB POC могут сигнализироваться для LTRP по желанию на основе 'изображение за изображением'.
[00125] HEVC может применять обычные слайсы, зависимые слайсы, тайлы и параллельную обработку волнового фронта (WPP) в качестве схем разделения. Эти схемы разделения могут применяться для согласования размера максимальной единицы передачи (MTU), параллельной обработки и уменьшенной сквозной задержки. Каждый обычный слайс может быть инкапсулирован в отдельную единицу NAL. Зависимость энтропийного кодирования/декодирования и предсказание в изображении, в том числе предсказание внутри выборки, предсказание информации движения и предсказание режима кодирования/декодирования, через границы слайсов могут быть запрещены. Таким образом, обычный слайс можно восстановить независимо от других обычных слайсов в том же самом изображении. Однако слайсы могут по-прежнему иметь некоторые взаимозависимости из-за операций циклической фильтрации.
[00126] Обычное распараллеливание на основе слайсов может не требовать значительного межпроцессорного или межъядерного взаимодействия. Одним исключением является то, что совместное использование данных между процессорами и/или ядрами может быть важным для компенсации движения при декодировании кодируемого/декодируемого с предсказанием изображения. Такой процесс может вовлекать больше ресурсов обработки, чем совместное использование данных между процессорами или ядрами из-за предсказания в изображении. Однако по той же причине использование обычных слайсов может привести к значительным издержкам на кодирование/декодирование из-за битовых затрат на заголовок слайса и из-за отсутствия предсказания через границы слайсов. Кроме того, обычные слайсы также служат механизмом для разделения битового потока для соответствия требованиям к размеру MTU из-за независимости обычных слайсов в изображении и из-за того, что каждый обычный слайс инкапсулируется в отдельной единице NAL. Во многих случаях цель распараллеливания и цель согласования размера MTU ставят противоречащие друг другу требования к размещению слайсов в изображении.
[00127] Зависимые слайсы имеют короткие заголовки слайсов и позволяют разделять битовый поток по границам древовидных блоков без нарушения какого-либо предсказания в изображении. Зависимые слайсы обеспечивают фрагментацию обычных слайсов на множество единиц NAL. Это обеспечивает уменьшенную сквозную задержку за счет того, что обеспечивается возможность передачи части обычного слайса до завершения кодирования всего обычного слайса.
[00128] При WPP изображение разделяется на отдельные ряды CTB. Энтропийное декодирование и предсказание могут использовать данные из CTB в других разделах. Параллельная обработка возможна посредством параллельного декодирования рядов CTB. Начало декодирования ряда CTB может быть задержано на один или два CTB, в зависимости от примера, чтобы гарантировать, что данные, относящиеся к CTB, находящемуся выше и справа от рассматриваемого CTB, будут доступны до того, как будет декодироваться рассматриваемое CTB. Такое ступенчатое начало создает вид волнового фронта. Этот процесс поддерживает распараллеливание с числом процессоров/ядер вплоть до числа содержащихся в изображении рядов CTB. Поскольку предсказание в изображении между соседними рядами древовидных блоков внутри изображения разрешено, межпроцессорное/межъядерное взаимодействие для обеспечения предсказания в изображении может быть существенным. Разделение WPP не приводит к созданию дополнительных единиц NAL. Таким образом, WPP может не использоваться для согласования размера MTU. Однако, если требуется согласование размера MTU, обычные слайсы с WPP можно использовать с некоторыми издержками на кодирование/декодирование.
[00129] Тайлы определяют горизонтальные и вертикальные границы, которые разделяют изображение на столбцы и строки тайлов. Порядок сканирования CTB может быть локальным в пределах тайла в порядке растрового сканирования CTB тайла. Соответственно, тайл может быть полностью декодирован перед декодированием верхнего левого CTB следующего тайла в порядке растрового сканирования тайлов изображения. Подобно обычным слайсам, тайлы разрушают зависимости предсказания в изображении, а также зависимости энтропийного декодирования. Однако тайлы могут не включаться в отдельные единицы NAL. Следовательно, тайлы могут не использоваться для согласования размера MTU. Каждый тайл может обрабатываться одним процессором/ядром. Межпроцессорное/межъядерное взаимодействие, применяемое для предсказания в изображении между блоками обработки, декодирующими соседние тайлы, может быть ограничено передачей совместно используемого заголовка слайса, когда слайс включает в себя более одного тайла, и связанным с циклической фильтрацией совместным использованием восстановленных выборок и метаданных. Когда в слайс включено более одного тайла или сегмента WPP, байтовое смещение точки перехода для каждого тайла или сегмента WPP, кроме первого в слайсе, может сигнализироваться в заголовке слайса.
[00130] Для простоты HEVC применяет конкретные ограничения на применение четырех различных схем разделения изображения. Кодируемая/декодируемая видеопоследовательность может не включать в себя тайлы и волновые фронты для большинства профилей, специфицированных в HEVC. Кроме того, одно или оба из следующих условий должны выполняться для каждого слайса и/или тайла. Все кодируемые/декодируемые древовидные блоки в слайсе включаются в один и тот же тайл. Кроме того, все кодируемые/декодируемые древовидные блоки в тайле включаются в один и тот же слайс. Кроме того, сегмент волнового фронта содержит ровно один ряд CTB. Когда используется WPP, слайс, начинающийся в ряду CTB, должен заканчиваться в той же самом ряду CTB.
[00131] HEVC может включать в себя сообщение дополнительной расширенной информации (SEI) временного набора тайлов с ограничением движения (MCTS), сообщение SEI набора информации извлечения MCTS и сообщение SEI вложения информации извлечения MCTS. Сообщение SEI временного MCTS указывает наличие MCTS в битовом потоке и сигнализирует этот MCTS. Для каждого MCTS векторы движения ограничены так, чтобы указывать на местоположения полной выборки внутри MCTS и на местоположения дробной выборки, которые применяют только местоположения полной выборки внутри MCTS для интерполяции. Использование векторов движения - кандидатов для временного предсказания векторов движения, извлекаемых из блоков за пределами MCTS, запрещается. Таким образом, каждый MCTS может быть декодирован независимо без присутствия тайлов, не включенных в MCTS. Сообщение SEI наборов информации извлечения MCTS обеспечивает дополнительную информацию, которую можно использовать при извлечении битового подпотока MCTS для генерирования соответствующего битового потока для MCTS-набора. Эта информация включает в себя некоторое число наборов информации извлечения, каждый из которых определяет число наборов MCTS и содержит RBSP-байты замещающих наборов параметров видео (VPS), SPS и PPS, которые подлежат использованию во время процесса извлечения битового подпотока MCTS. При извлечении битового подпотока согласно процессу извлечения битового подпотока MCTS наборы параметров, такие как VPS, SPS и PPS, могут быть перезаписаны или заменены. Заголовки слайсов также могут быть обновлены, поскольку один или более синтаксических элементов, связанных с адресом слайса, могут включать в себя разные значения после извлечения битового подпотока.
[00132] VVC может разделять изображения, как описано ниже. Изображения можно разбивать на группы тайлов и тайлы. Тайл может быть последовательностью CTU, которые охватывают прямоугольную область изображения. Группа тайлов, также известная как слайс, может содержать некоторое число тайлов изображения. Группы тайлов/слайсы могут быть сконфигурированы согласно режиму растрового сканирования и прямоугольному режиму. В режиме растрового сканирования группа тайлов/слайс содержит последовательность тайлов в порядке растрового сканирования относительно границ изображения. В прямоугольном режиме группа тайлов/слайс содержит некоторое число тайлов, которые в совокупности образуют прямоугольную область изображения. Тайлы в пределах прямоугольной группы тайлов включаются в порядке растрового сканирования относительно группы тайлов/слайса.
[00133] Видеоприложения с углом обзора 360 градусов (например, VR) могут отображать только часть сферы контента и, следовательно, могут отображать только подмножество всего изображения. Зависимая от окна просмотра доставка данных при обзоре в триста шестьдесят градусов может применяться для сокращения битрейта при доставке VR-видео через DASH. Кодирование/декодирование, зависящее от окна просмотра, может разбивать всю сферу/проецируемое изображение (например, с использованием проекции кубической карты) на многочисленные MCTS. Затем два или более битовых потока могут быть получены кодированием с разными пространственными разрешениями или на разных уровнях качества. MCTS из битового потока с более высоким разрешением/качеством отправляется(отправляются) в декодер для отображения окна просмотра (например, окна просмотра спереди). Остальные окна просмотра используют MCTS из битовых потоков с более низким разрешением/качеством. Эти MCTS упаковываются определенным образом, а затем отправляются в приемник для декодирования. Окно просмотра, которое обычно видит пользователь, представляется посредством MCTS с высоким разрешением/качеством, что обеспечивает положительные впечатления от просмотра. Когда пользователь разворачивается, чтобы увидеть другое окно просмотра (например, окно просмотра слева или справа), отображаемый контент поступает из окна просмотра с более низким разрешением/качеством. Это продолжается в течение короткого периода времени, пока система не сможет получить MCTS с высоким разрешением/качеством для этого окна просмотра.
[00134] Задержка возникает между моментом, когда пользователь разворачивается, и временем, когда отображается представление окна просмотра с более высоким разрешением/качеством. Эта задержка зависит от того, насколько быстро система может получить MCTS с более высоким разрешением/качеством для этого окна просмотра. Это зависит от IRAP-периода, который представляет собой интервал между появлением двух IRAP. Это связано с тем, что MCTS нового окна просмотра могут декодироваться только начиная с IRAP-изображения. Если IRAP-период кодируется/декодируется каждую секунду, то применяется следующее. В лучшем случае упомянутая задержка аналогична задержке двусторонней передачи данных по сети, когда пользователь разворачивается, чтобы увидеть новое окно просмотра непосредственно перед началом получения системой нового сегмента/IRAP-периодом. В этом сценарии система может сразу же запросить MCTS с более высоким разрешением/качеством для нового окна просмотра. Таким образом, единственной задержкой является задержка двусторонней передачи данных по сети, которая включает в себя задержку запроса на получение плюс время передачи запрошенного MCTS. Это предполагает, что минимальная задержка буферизации может быть установлена равной нулю или другому пренебрежимо малому значению. Например, задержка двусторонней передачи данных по сети может составлять около двухсот миллисекунд. Наихудшим сценарием задержки является IRAP-период плюс задержка двусторонней передачи данных по сети, когда пользователь разворачивается, чтобы увидеть новое окно просмотра, сразу после того, как система уже сделала запрос следующего сегмента. Чтобы улучшить описанный выше сценарий наихудшего случая, можно кодировать битовые потоки с более частыми IRAP-изображениями, чтобы IRAP-период был короче. Это уменьшает общую задержку. Однако большее количество IRAP-изображений увеличивает требование к полосе пропускания и, следовательно, снижает эффективность сжатия.
[00135] Смешанные типы единиц NAL могут использоваться в изображении путем добавления флага PPS, который специфицирует, имеют ли все единицы NAL VCL изображения один и тот же тип единицы NAL. Также может быть добавлено ограничение, требующее, чтобы для любого конкретного изображения либо все единицы NAL VCL имели один и тот же тип единицы NAL, либо некоторые единицы NAL VCL имели конкретный тип NAL IRAP, а остальные имели конкретный тип единицы NAL VCL не-IRAP. Ниже приведено примерное описание такого механизма.
[00136] IRAP-изображение представляет собой кодируемое/декодируемое изображение, для которого mixed_nalu_types_in_pic_flag равняется нулю, а каждая единица NAL VCL имеет NalUnitType в диапазоне IDR_W_RADL - CRA_NUT включительно.
[00137] Пример RBSP-синтаксиса PPS выглядит следующим образом.
[00138] Пример семантики заголовка единицы NAL выглядит следующим образом. IDR-изображение, имеющее NalUnitType, равный IDR_N_LP, не имеет ассоциированных опережающих изображений, присутствующих в битовом потоке. IDR-изображение, имеющее NalUnitType, равный IDR_W_RADL, не имеет ассоциированных RASL-изображений, присутствующих в битовом потоке, но может иметь ассоциированные RADL-изображения в битовом потоке. Для единиц NAL VCL любого конкретного изображения применяется следующее. Если mixed_nalu_types_in_pic_flag равен нулю, все единицы NAL VCL должны иметь одинаковое значение nal_unit_type. В противном случае некоторые из единиц NAL VCL должны иметь конкретное значение типа единицы NAL IRAP (например, значение nal_unit_type в диапазоне IDR_W_RADL - CRA_NUT включительно), в то время как все другие единицы NAL VCL должны иметь конкретный тип единицы NAL VCL не-IRAP (например, значение nal_unit_type, находящееся в диапазоне TRAIL_NUT - RSV_VCL_15, включительно, или равное GRA_NUT).
[00139] Пример RBSP-семантики PPS выглядит следующим образом. pps_seq_parameter_set_id специфицирует значение sps_seq_parameter_set_id для активного SPS. Значение pps_seq_parameter_set_id должно быть в диапазоне от нуля до пятнадцати включительно. mixed_nalu_types_in_pic_flag может быть установлен равным единице для специфицирования того, что каждое изображение, ссылающееся на PPS, имеет множество единиц NAL VCL, и эти единицы NAL не имеют одного и того же значения nal_unit_type. mixed_nalu_types_in_pic_flag может быть установлен равным нулю для специфицирования, что единицы NAL VCL каждого изображения, ссылающегося на PPS, имеют одно и то же значение nal_unit_type. Когда sps_idr_rpl_present_flag равен нулю, значение mixed_nalu_types_in_pic_flag должно равняться нулю.
[00140] Изображения можно разбивать на субизображения. Указание наличия субизображений может быть указано в SPS вместе с другой информацией об уровне-последовательности этих субизображений. То, обрабатываются ли границы субизображения как границы изображения в процессе декодирования (за исключением операций фильтрации внутри цикла), может управляться посредством битового потока. То, запрещается ли фильтрация внутри цикла через границы субизображения, может управляться битовым потоком для каждого субизображения. Процессы деблокирующего фильтра (DBF), SAO и адаптивного циклического фильтра (ALF) обновляются для управления операциями фильтрации внутри цикла через границы субизображений. Ширина, высота, смещение по горизонтали и смещение по вертикали субизображений могут сигнализироваться в единицах выборок яркости в SPS. Границы субизображений могут быть ограничены границами слайсов. Обработка субизображения в качестве изображения в процессе декодирования (за исключением операций фильтрации внутри цикла) специфицируется посредством обновления: синтаксиса coding_tree_unit(), процесса выведения для расширенного временного предсказания векторов движения яркости, процесса билинейной интерполяции выборок яркости, процесса интерполяционной фильтрации с восемью отводами выборок яркости и процесса интерполяции выборок цветности. Идентификаторы (ID) субизображений явно специфицируются в SPS и включаются в заголовки групп тайлов, чтобы обеспечить возможность извлечения последовательностей субизображений без необходимости изменять единицы NAL VCL. Наборы выходных субизображений (OSPS) могут специфицировать нормативные точки извлечения и согласования для субизображений и их наборов.
[00141] Предыдущие системы имеют определенные проблемы. Битовый поток может содержать изображения как с IRAP-, так и с не-IRAP-слайсами. Ошибки будут возникать, если слайсы в изображениях, которые следуют за таким изображением в порядке декодирования и охватывают аналогичные области изображения IRAP-слайсов в изображении, будут ссылаться на изображения, предшествующие упомянутому изображению в порядке декодирования для интер-предсказания.
[00142] Настоящее раскрытие включает в себя усовершенствованные методики поддержки основанного на субизображениях или MCTS произвольного доступа при кодировании/декодировании видео. Более конкретно, этот документ раскрывает способы, которые налагают некоторые ограничения на IRAP-слайсы в пределах изображения, имеющего как IRAP-, так и не-IRAP-слайсы. Описание методик VVC. Однако данные методики могут также применяться и к спецификациям других кодеков видео/мультимедиа.
[00143] Например, добавляются ограничения, чтобы гарантировать, что слайсы в изображениях, которые (1) следуют за некоторым изображением со смешанными единицами NAL в порядке декодирования, и которые (2) охватывают аналогичные области IRAP-слайсов в этом изображении, не ссылаются на опорные изображения, которые являются более ранними, чем упомянутое изображение со смешанными единицами NAL, в порядке декодирования для интер-предсказания. Примерная реализация заключается в следующем.
[00144] IRAP-изображение может быть определено как кодируемое/декодируемое изображение, для которого mixed_nalu_types_in_pic_flag равняется нулю, а каждая единица NAL VCL имеет NalUnitType в диапазоне IDR_W_RADL - CRA_NUT включительно.
[00145] Пример RBSP-синтаксиса PPS выглядит следующим образом.
[00146] Пример семантики заголовка единицы NAL выглядит следующим образом. IDR-изображение, имеющее NalUnitType, равный IDR_N_LP, не имеет ассоциированных опережающих изображений, присутствующих в битовом потоке. IDR-изображение, имеющее NalUnitType, равный IDR_W_RADL, не имеет ассоциированных RASL-изображений, присутствующих в битовом потоке, но может иметь ассоциированные RADL-изображения в битовом потоке. Для единиц NAL VCL любого конкретного изображения применяется следующее. Если mixed_nalu_types_in_pic_flag равен нулю, все единицы NAL VCL должны иметь одинаковое значение nal_unit_type. В противном случае некоторые из единиц NAL VCL должны иметь конкретное значение типа единицы NAL IRAP (например, значение nal_unit_type в диапазоне IDR_W_RADL - CRA_NUT включительно), в то время как все другие единицы NAL VCL должны иметь конкретный тип единицы NAL VCL не-IRAP (например, значение nal_unit_type, находящееся в диапазоне TRAIL_NUT - RSV_VCL_15, включительно, или равное GRA_NUT).
[00147] Пример RBSP-семантики PPS выглядит следующим образом. pps_seq_parameter_set_id специфицирует значение sps_seq_parameter_set_id для активного SPS. Значение pps_seq_parameter_set_id должно быть в диапазоне от нуля до пятнадцати включительно. mixed_nalu_types_in_pic_flag может быть установлен равным единице для специфицирования того, что каждое изображение, ссылающееся на PPS, имеет множество единиц NAL VCL, и эти единицы NAL не имеют одного и того же значения nal_unit_type. mixed_nalu_types_in_pic_flag может быть установлен равным нулю для специфицирования, что единицы NAL VCL каждого изображения, ссылающегося на PPS, имеют одно и то же значение nal_unit_type. Когда sps_idr_rpl_present_flag равен нулю, значение mixed_nalu_types_in_pic_flag должно равняться нулю. Для каждого IRAP-слайса в изображении picA, которое также имеет по меньшей мере один не-IRAP-слайс, применяется следующее. IRAP-слайс должен принадлежать к субизображению subpicA и границы этого субизображения обрабатываются как границы изображения в процессе декодирования (за исключением операций фильтрации в цикле). Например, значение sub_pic_treated_as_pic_flag[ i ] для subpicA должно быть равно единице. IRAP-слайс не должен принадлежать к субизображению в том же самом изображении, содержащем один или более не-IRAP-слайсов. Для всех единиц доступа (AU) к следующему уровню в порядке декодирования ни RefPicList[ 0 ], ни RefPicList[ 1 ] слайса в subpicA не должны включать в активную запись какое-либо изображение, предшествующее picA в порядке декодирования.
[00148] ФИГ. 9 представляет собой схематичное представление примерного устройства 900 кодирования/декодирования видео. Устройство 900 кодирования/декодирования видео подходит для реализации раскрытых примеров/вариантов осуществления, которые описаны в данном документе. Устройство 900 кодирования/декодирования видео содержит нисходящие порты 920, восходящие порты 950 и/или блоки приемопередатчика (Tx/Rx) 910, в том числе передатчики и/или приемники для передачи данных в восходящем потоке и/или нисходящем потоке по сети. Устройство 900 кодирования/декодирования видео также включает в себя процессор 930, включающий в себя логический блок и/или центральный процессор (CPU), для обработки данных и память 932 для сохранения данных. Устройство 900 кодирования/декодирования видео может также содержать электрические, оптико-электрические (OE) компоненты, электрико-оптические (EO) компоненты и/или компоненты беспроводной связи, соединенные с восходящими портами 950 и/или нисходящими портами 920, для передачи данных через сети электрической, оптической или беспроводной связи. Устройство 900 кодирования/декодирования видео может также включать в себя устройства 960 ввода и/или вывода (I/O) для передачи данных пользователю и от пользователя. Устройства 960 I/O могут включать в себя устройства вывода, такие как дисплей, для отображения видеоданных, динамики для вывода аудиоданных и т.д. Устройства 960 I/O могут также включать в себя устройства ввода, такие как клавиатура, мышь, шаровой манипулятор и т. д., и/или соответствующие интерфейсы для взаимодействия с такими устройствами вывода.
[00149] Процессор 930 реализуется аппаратным обеспечением и программным обеспечением. Процессор 930 может быть реализован в виде одного или более ядер (например, в форме многоядерного процессора), микросхем CPU, программируемых пользователем вентильных матриц (FPGA), специализированных интегральных схем (ASIC) и процессоров цифровых сигналов (DSP). Процессор 930 осуществляет связь с нисходящими портами 920, Tx/Rx 910, восходящими портами 950 и памятью 932. Процессор 930 содержит модуль 914 кодирования/декодирования. Модуль 914 кодирования/декодирования реализует описанные в данном документе варианты осуществления, такие как способы 100, 1000 и 1100, которые могут использовать видеопоток 500 изображений VR, битовый поток 800 и/или структуру 700 RPL, кодируемые/декодируемые согласно ограничениям 600. Модуль 914 кодирования/декодирования может также реализовывать любой другой способ/механизм, описанный в данном документе. Кроме того, модуль 914 кодирования/декодирования может реализовать систему 200 кодека, кодер 300 и/или декодер 400. Например, модуль 914 кодирования/декодирования может кодировать/декодировать видео VR, включающее в себя текущее изображение, как с единицами NAL IRAP, так и с единицами NAL не-IRAP. Например, единицы NAL IRAP могут содержаться в субизображении. Когда это происходит, модуль 914 кодирования/декодирования может ограничивать слайсы в изображении, следующем за текущим изображением, которые также содержатся в упомянутом субизображении. Таким слайсам может быть запрещено ссылаться на опорные изображения, предшествующие текущему изображению. Следовательно, модуль 914 кодирования/декодирования побуждает устройство 900 кодирования/декодирования видео обеспечивать дополнительную функциональность и/или эффективность кодирования/декодирования при кодировании/декодировании видеоданных. Таким образом, модуль 914 кодирования/декодирования улучшает функциональность устройства 900 кодирования/декодирования видео, а также решает проблемы, которые характерны для областей техники кодирования/декодирования видео. Кроме того, модуль 914 кодирования/декодирования осуществляет перевод устройства 900 кодирования/декодирования видео в другое состояние. В качестве альтернативы, модуль 914 кодирования/декодирования может быть реализован как инструкции, хранящиеся в памяти 932 и исполняемые процессором 930 (например, как компьютерный программный продукт, хранящийся на долговременном носителе).
[00150] Память 932 содержит память одного или более типов, например диски, ленточные накопители, твердотельные накопители, постоянное запоминающее устройство (ROM), оперативное запоминающее устройство (RAM), флэш-память, троичное запоминающее устройство с адресацией по содержимому (TCAM), статическое оперативное запоминающее устройство (SRAM) и т. д. Память 932 может использоваться в качестве устройства хранения данных переполнения для хранения программ, когда такие программы выбираются для исполнения, и для хранения инструкций и данных, которые считываются во время исполнения программы.
[00151] ФИГ. 10 представляет собой блок-схему последовательности операций примерного способа 1000 кодирования видеопоследовательности, содержащей изображение со смешанными типами единиц NAL, в битовый поток, такой как битовый поток 800, содержащий видеопоток 500 изображений VR со структурой 700 RPL. Способ 1000 может кодировать такой битовый поток согласно ограничениям 600. Способ 1000 может быть использован кодером, таким как система 200 кодека, кодер 300 и/или устройство 900 кодирования/декодирования видео при выполнении способа 100.
[00152] Способ 1000 может начинаться, когда кодер принимает видеопоследовательность, включающую в себя множество изображений, таких как изображения VR, и определяет, что следует кодировать эту видеопоследовательность в битовый поток, например на основе пользовательского ввода. Битовый поток может включать видеоданные VR. Видеоданные VR могут включать в себя изображения, каждое из которых представляет сферу контента в соответствующий момент в видеопоследовательности. Изображения могут быть разделены на набор субизображений. Например, каждое субизображение может содержать видеоданные, соответствующие окну просмотра видео VR. Кроме того, различные субизображения могут содержать единицы NAL IRAP и единицы NAL не-IRAP с переменными частотами. На этапе 1001 кодер определяет, что текущее изображение включает в себя множество единиц NAL VCL, которые не имеют одного и того же типа единицы NAL. Например, единицы NAL VCL могут включать в себя единицу NAL IRAP с типом единицы NAL IRAP и единицу NAL не-IRAP с типом единицы NAL не-IRAP. Например, тип единицы NAL IRAP может включать в себя тип единицы NAL IDR или тип единицы NAL CRA. Кроме того, тип единицы NAL не-IRAP может включать в себя тип замыкающей единицы NAL, тип единицы NAL RASL и/или тип единицы NAL RADL.
[00153] На этапе 1003 кодер кодирует флаг в битовый поток. Этот флаг указывает, что первое значение типа единицы NAL для единиц NAL VCL текущего изображения отличается от второго значения типа единицы NAL для единиц NAL VCL текущего изображения. В примере флаг может быть кодирован в PPS в битовом потоке. В качестве конкретного примера флагом может быть mixed_nalu_types_in_pic_flag 827. mixed_nalu_types_in_pic_flag может быть установлен равным единице при специфицировании того, что каждое изображение, ссылающееся на PPS, имеет более одной единицы NAL VCL, и эти единицы NAL VCL не имеют одного и того же значения nal_unit_type.
[00154] На этапе 1005 кодер определяет, что subpicA в текущем изображении ассоциировано с типом единицы NAL IRAP. На этапе 1007 кодер кодирует текущее изображение в битовый поток. Например, кодер обеспечивает, что все слайсы текущего изображения, расположенные в subpicA, ассоциированы с одним и тем же типом единицы NAL (например, типом единицы NAL IRAP). Кодер может кодировать subpicA согласно интра-предсказанию. Кодер также может определить, что субизображение B (subpicB) содержит слайсы типа единицы NAL не-IRAP. Следовательно, кодер может кодировать subpicB текущего согласно интер-предсказанию.
[00155] На этапе 1009 кодер может осуществить подготовку к кодированию последующих изображений, следующих за текущим изображением в порядке декодирования. Например, кодер может сгенерировать активные записи списков опорных изображений для слайсов, расположенных в subpicA в последующих изображениях. Активные записи для некоторого специфицируемого последующего изображения указывают изображения, которые могут использоваться в качестве опорных изображений при выполнении процессов кодирования с интер-предсказанием над этим специфицированным последующим изображением. В частности, активные записи для subpicA в последующих изображениях ограничиваются таким образом, чтобы такие активные записи не ссылались ни на какое опорное изображение, предшествующее текущему изображению в порядке декодирования. Это ограничение применяется, когда subpicA в текущем изображении ассоциировано с типом единицы NAL IRAP. Это ограничение гарантирует, что слайсы в субизображении, которые следуют за IRAP-субизображением, не ссылаются на изображения, предшествующие упомянутому IRAP-субизображению, что в противном случае могло бы вызывать ошибки кодирования/декодирования, если IRAP-субизображение использовалось бы в качестве точки произвольного доступа. Слайсы последующих изображений, которые не следуют за IRAP-субизображением (например, которые расположены в subpicB и следуют за единицей NAL не-IRAP), могут продолжать ссылаться на изображения, которые предшествуют текущему изображению.
[00156] На этапе 1011 кодер кодирует последующие изображения в битовый поток на основе списков опорных изображений. Например, кодер может кодировать последующие изображения на основе интер-предсказания и/или интра-предсказания в зависимости от типов NAL, ассоциированных со слайсами в соответствующих субизображениях. В процессах интер-предсказания используются списки опорных изображений. Списки опорных изображений могут включать в себя список опорных изображений ноль и список опорных изображений один. Кроме того, списки опорных изображений могут быть кодированы/декодированы в структуре списков опорных изображений. Структура списков опорных изображений также может быть закодирована в битовый поток. Кодер также может сохранять битовый поток для передачи на декодер.
[00157] ФИГ. 11 представляет собой блок-схему последовательности операций примерного способа 1100 декодирования видеопоследовательности, содержащей изображение со смешанными типами единиц NAL, из битового потока, такого как битовый поток 800, содержащий видеопоток 500 изображений VR со структурой 700 RPL. Способ 1100 может декодировать такой битовый поток согласно ограничениям 600. Способ 1100 может быть использован декодером, таким как система 200 кодека, декодер 400 и/или устройство 900 кодирования/декодирования видео при выполнении способа 100.
[00158] Способ 1100 может начинаться, когда декодер начинает прием битового потока кодированных данных, представляющих видеопоследовательность, например в результате выполнения способа 1000. Битовый поток может включать в себя видеопоследовательность VR, включающую в себя множество изображений, таких как изображения VR. Битовый поток может включать видеоданные VR. Видеоданные VR могут включать в себя изображения, каждое из которых представляет сферу контента в соответствующий момент в видеопоследовательности. Изображения могут быть разделены на набор субизображений. Например, каждое субизображение может содержать видеоданные, соответствующие окну просмотра видео VR. Кроме того, различные субизображения могут содержать единицы NAL IRAP и единицы NAL не-IRAP с переменными частотами. На этапе 1101 декодер принимает битовый поток. Битовый поток, содержит текущее изображение, включающее в себя множество единиц NAL VCL, которые не имеют одного и того же типа единицы NAL. Например, единицы NAL VCL могут включать в себя единицу NAL IRAP с типом единицы NAL IRAP и единицу NAL не-IRAP с типом единицы NAL не-IRAP. Например, тип единицы NAL IRAP может включать в себя тип единицы NAL IDR или тип единицы NAL CRA. Кроме того, тип единицы NAL не-IRAP может включать в себя тип замыкающей единицы NAL, тип единицы NAL RASL и/или тип единицы NAL RADL.
[00159] На этапе 1103 декодер определяет, что первое значение типа единицы NAL для единиц NAL VCL текущего изображения отличается от второго значения типа единицы NAL для единиц NAL VCL текущего изображения, на основе флага. В примере битовый поток может содержать PPS, ассоциированный с текущим изображением. Флаг может быть получен из PPS. В качестве конкретного примера флагом может быть mixed_nalu_types_in_pic_flag 827. mixed_nalu_types_in_pic_flag может быть установлен равным единице при специфицировании того, что каждое изображение, ссылающееся на PPS, имеет более одной единицы NAL VCL, и эти единицы NAL VCL не имеют одного и того же значения nal_unit_type.
[00160] На этапе 1105 декодер может определить, что все слайсы текущего изображения, расположенные в subpicA, ассоциированы с одним и тем же типом единицы NAL. Декодер также может декодировать subpicA и/или текущее изображение на основе типов единиц NAL для слайсов. Например, subpicA в текущем изображении может содержать единицы NAL IRAP. В таком случае subpicA может быть декодировано согласно интра-предсказанию. Декодер также может определить, что subpicB содержит слайсы типа единицы NAL не-IRAP. Следовательно, декодер может декодировать subpicB текущего согласно интер-предсказанию.
[00161] На этапе 1107 декодер может получить активные записи списков опорных изображений для слайсов, расположенных в subpicA в последующих изображениях, следующих за текущим изображением в порядке декодирования. Активные записи для некоторого специфицируемого последующего изображения указывают изображения, которые могут использоваться в качестве опорных изображений при выполнении процессов декодирования с интер-предсказанием над этим специфицированным последующим изображением.
[00162] На этапе 1109 декодер может определить, что активные записи не включают в себя ссылку на какое-либо опорное изображение, предшествующее текущему изображению в порядке декодирования, когда subpicA в текущем изображении ассоциировано с типом единицы NAL интра-точки произвольного доступа (IRAP). Это ограничение гарантирует, что слайсы в субизображении, которые следуют за IRAP-субизображением, не ссылаются на изображения, предшествующие упомянутому IRAP-субизображению, что в противном случае могло бы вызывать ошибки кодирования/декодирования, когда IRAP-субизображение использовалось бы в качестве точки произвольного доступа. Слайсы последующих изображений, которые не следуют за IRAP-субизображением (например, которые расположены в subpicB и следуют за единицей NAL не-IRAP), могут продолжать ссылаться на изображения, которые предшествуют текущему изображению.
[00163] На этапе 1111 декодер может декодировать последующие изображения на основе активных записей списков опорных изображений. Например, декодер может декодировать последующие изображения на основе интер-предсказания и/или интра-предсказания в зависимости от типов NAL, ассоциированных со слайсами в соответствующих субизображениях. В процессах интер-предсказания используются списки опорных изображений. Списки опорных изображений могут включать в себя список опорных изображений ноль и список опорных изображений один. Кроме того, списки опорных изображений могут быть получены из структуры списков опорных изображений, которая кодируется в битовый поток. Декодер может пересылать текущее изображение, последующие изображения и/или их субизображения (например subpicA или subpicB) для отображения как часть декодируемой видеопоследовательности.
[00164] ФИГ. 12 представляет собой схематичное представление примерной системы 1200 для кодирования/декодирования видеопоследовательности, содержащей изображение со смешанными типами единиц NAL, в битовый поток, такой как битовый поток 800, содержащий видеопоток 500 изображений VR со структурой 700 RPL, и кодируемой/декодируемой согласно ограничениям 600. Система 1200 может быть реализована с помощью кодера и декодера, такого как система 200 кодека, кодер 300, декодер 400 и/или устройство 900 кодирования/декодирования видео. Кроме того, система 1200 может использоваться при реализации способов 100, 1000 и/или 1100.
[00165] Система 1200 включает в себя видеокодер 1202. Видеокодер 1202 содержит модуль 1201 определения для определения того, что текущее изображение включает в себя множество единиц NAL VCL, которые не имеют одного и того же типа единицы NAL. Модуль 1201 определения дополнительно предназначен для определения, что subpicA в текущем изображении ассоциировано с типом единицы NAL IRAP. Видеокодер 1202 дополнительно содержит модуль 1203 генерирования для генерирования активных записей списков опорных изображений для слайсов, расположенных в subpicA в последующих изображениях, следующих за текущим изображением в порядке декодирования, при этом активные записи не ссылаются на какое-либо опорное изображение, предшествующее текущему изображению в порядке декодирования, когда subpicA в текущем изображении ассоциировано с типом единицы NAL IRAP. Видеокодер 1202 дополнительно содержит модуль 1205 кодирования для кодирования последующих изображений в битовый поток на основе списков опорных изображений. Видеокодер 1202 дополнительно содержит модуль 1207 хранения для сохранения битового потока для передачи на декодер. Видеокодер 1202 дополнительно содержит модуль 1209 передачи для передачи битового потока на видеодекодер 1210. Видеокодер 1202 может быть дополнительно выполнен с возможностью выполнения любого из этапов способа 1000.
[00166] Система 1200 также включает в себя видеодекодер 1210. Видеодекодер 1210 содержит модуль 1211 приема для приема битового потока, содержащего текущее изображение, включающее в себя множество единиц NAL VCL, которые не имеют одного и того же типа единицы NAL. Видеодекодер 1210 дополнительно содержит модуль 1213 получения для получения активных записей списков опорных изображений для слайсов, расположенных в subpicA в последующих изображениях, следующих за текущим изображением в порядке декодирования. Видеодекодер 1210 дополнительно содержит модуль 1215 определения для определения, что активные записи не ссылаются на какое-либо опорное изображение, предшествующее текущему изображению в порядке декодирования, когда subpicA в текущем изображении ассоциировано с типом единицы NAL IRAP. Видеодекодер 1210 дополнительно содержит модуль 1217 декодирования для декодирования последующих изображений на основе активных записей списков опорных изображений. Видеодекодер 1210 дополнительно содержит модуль 1217 пересылки для пересылки последующих изображений для отображения как части декодируемой видеопоследовательности. Видеодекодер 1210 может быть дополнительно выполнен с возможностью выполнения любого из этапов способа 1100.
[00167] Первый компонент напрямую связан со вторым компонентом, когда между первым компонентом и вторым компонентом нет промежуточных компонентов, за исключением линии, дорожки или другой среды. Первый компонент опосредованно связан со вторым компонентом, когда между первым компонентом и вторым компонентом есть промежуточные компоненты, отличные от линии, дорожки или другой среды. Термин «связанные» и его варианты включают в себя как непосредственно связанные, так и опосредованно связанные. Использование термина «примерно» означает диапазон, включающий ±10% от идущего далее числа, если не указано иное.
[00168] Также следует понимать, что этапы иллюстративных способов, изложенных в настоящем документе, не обязательно должны выполняться в описанном порядке, и порядок этапов таких способов следует понимать как просто иллюстративный. Подобным образом в такие способы могут быть включены дополнительные этапы, а некоторые этапы могут быть исключены или объединены в способах, соответствующих различным вариантам осуществления настоящего раскрытия.
[00169] Хотя в настоящем раскрытии обеспечено несколько вариантов осуществления, нужно понимать, что раскрытые системы и способы могут быть воплощены во многих других конкретных формах, не выходя за рамки сущности или объема настоящего раскрытия. Настоящие примеры следует рассматривать как иллюстративные, а не ограничительные, и есть намерение не ограничиваться приведенными в данном документе деталями. Например, различные элементы или компоненты могут быть объединены или интегрированы в другую систему, или определенные функции могут быть опущены или не реализованы.
[00170] Кроме того, методики, системы, подсистемы и способы, описанные и проиллюстрированные в различных вариантах осуществления как дискретные или отдельные, могут быть объединены или интегрированы с другими системами, компонентами, технологиями или способами без отклонения от объема настоящего раскрытия. Другие примеры изменений, замен и модификаций могут быть определены специалистом в данной области техники и могут быть выполнены без отклонения от сущности и объема, раскрытых в данном документе.
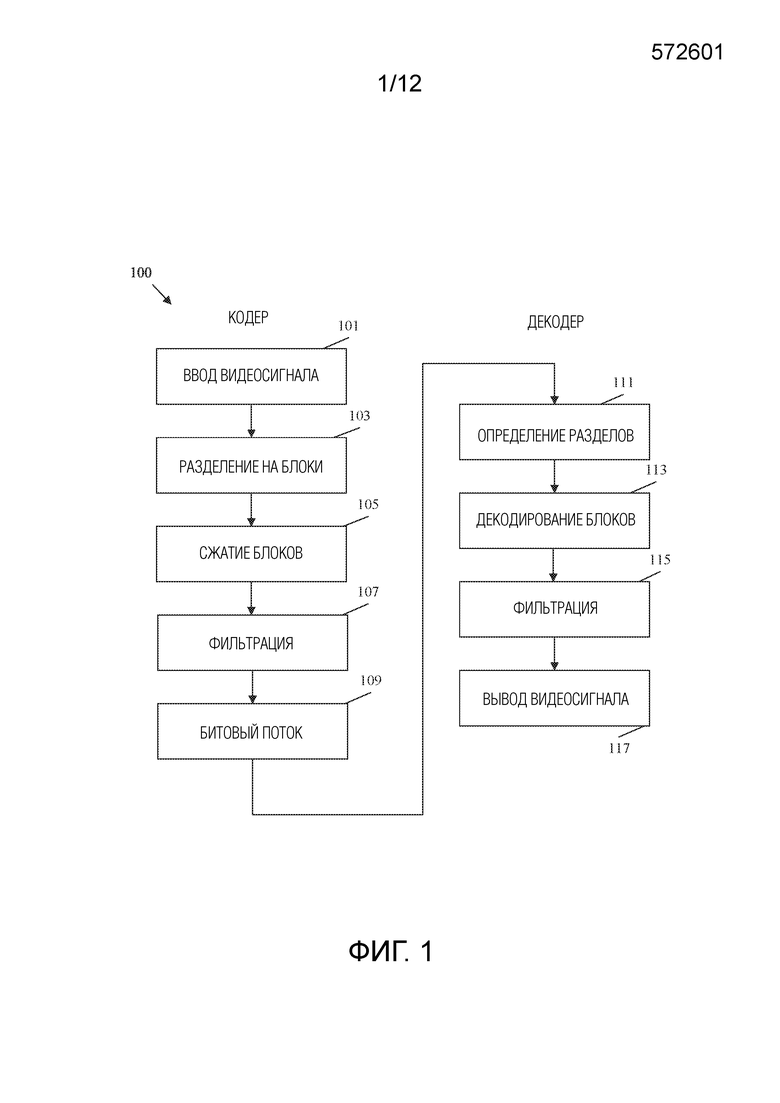
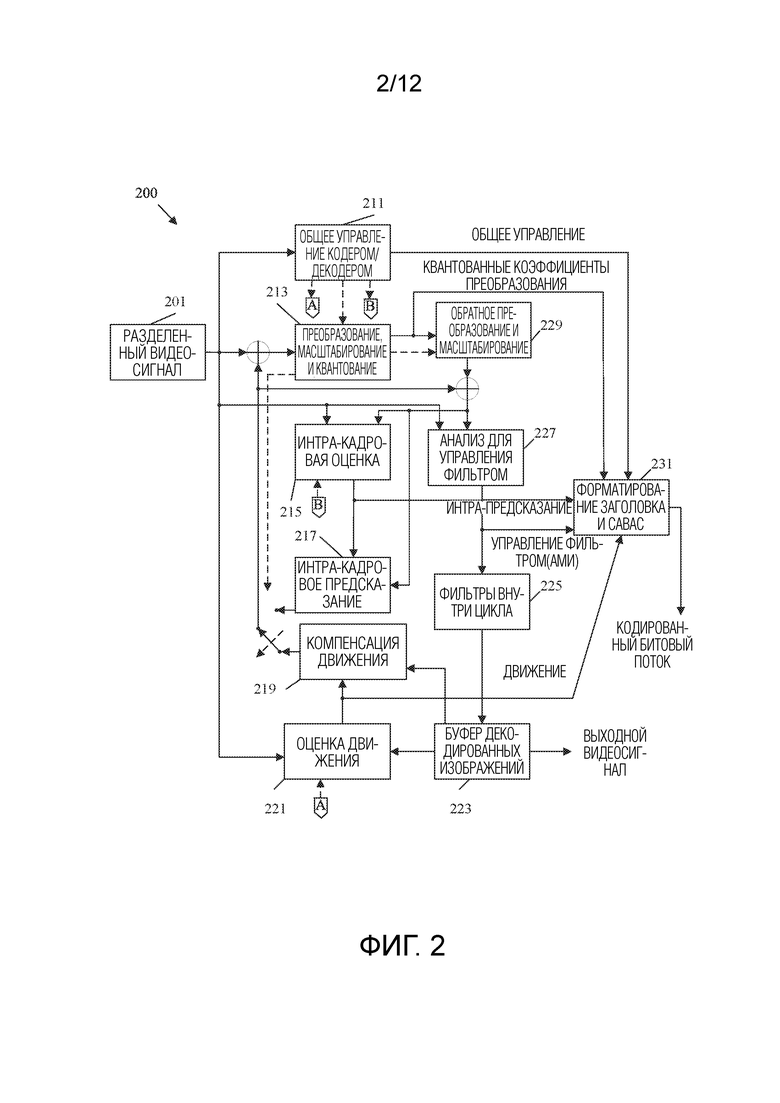
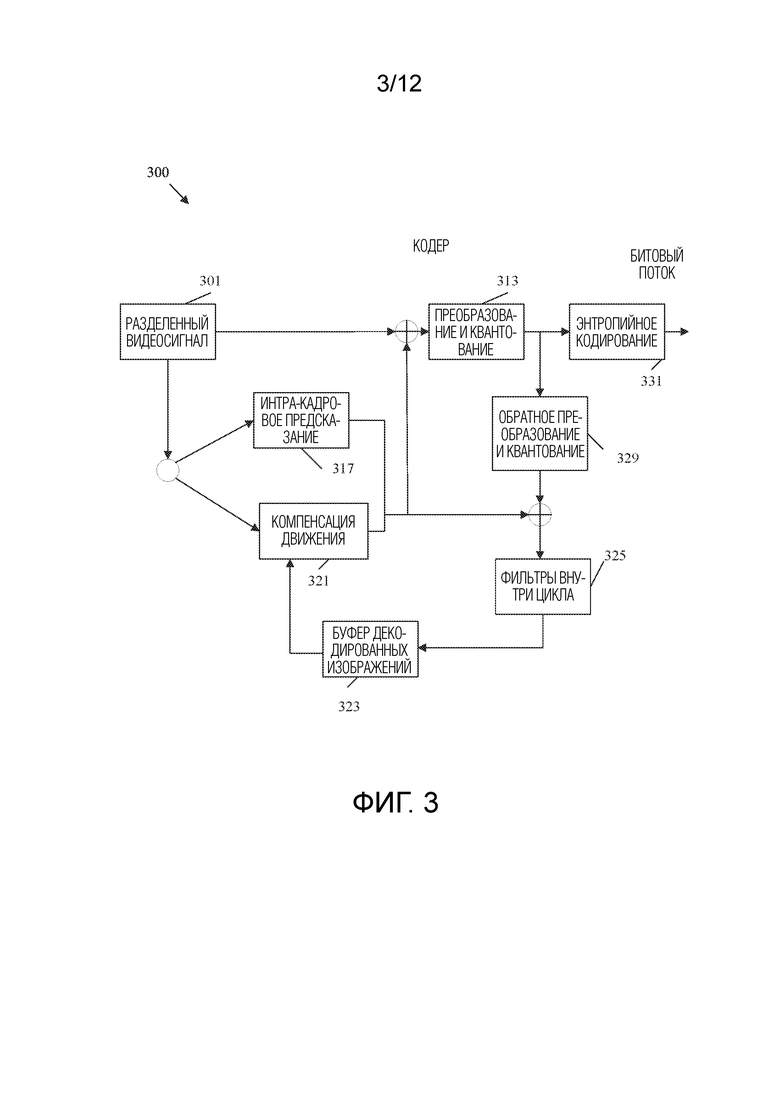
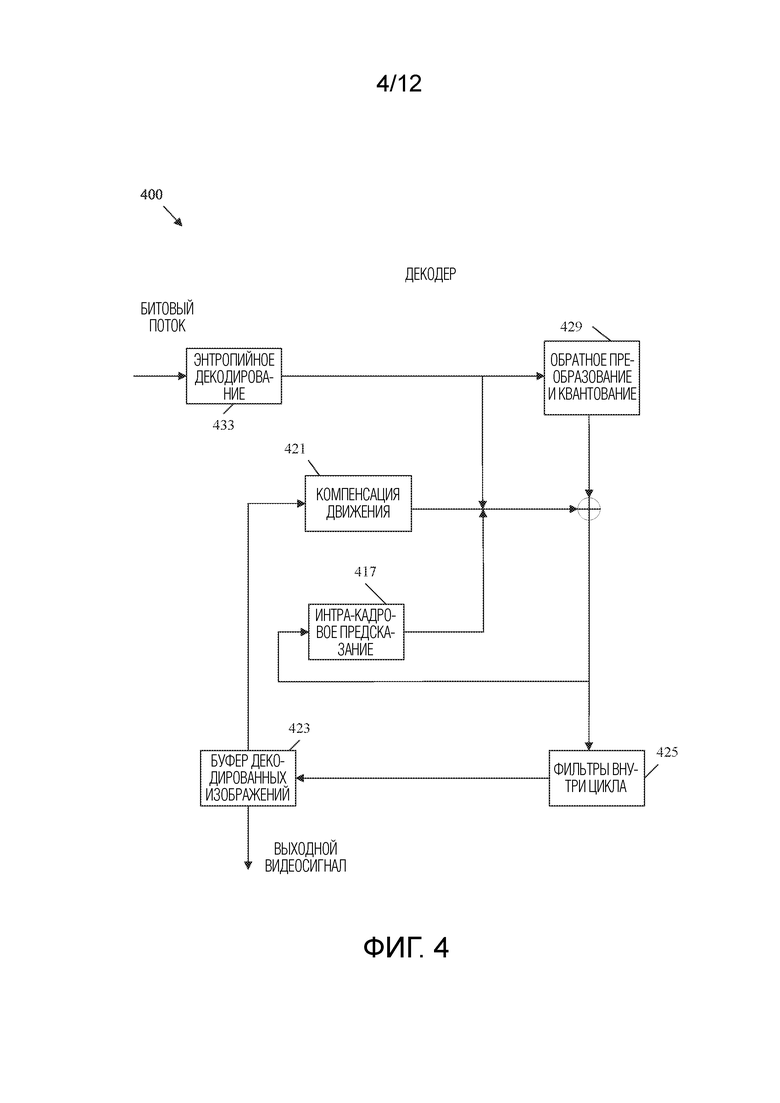
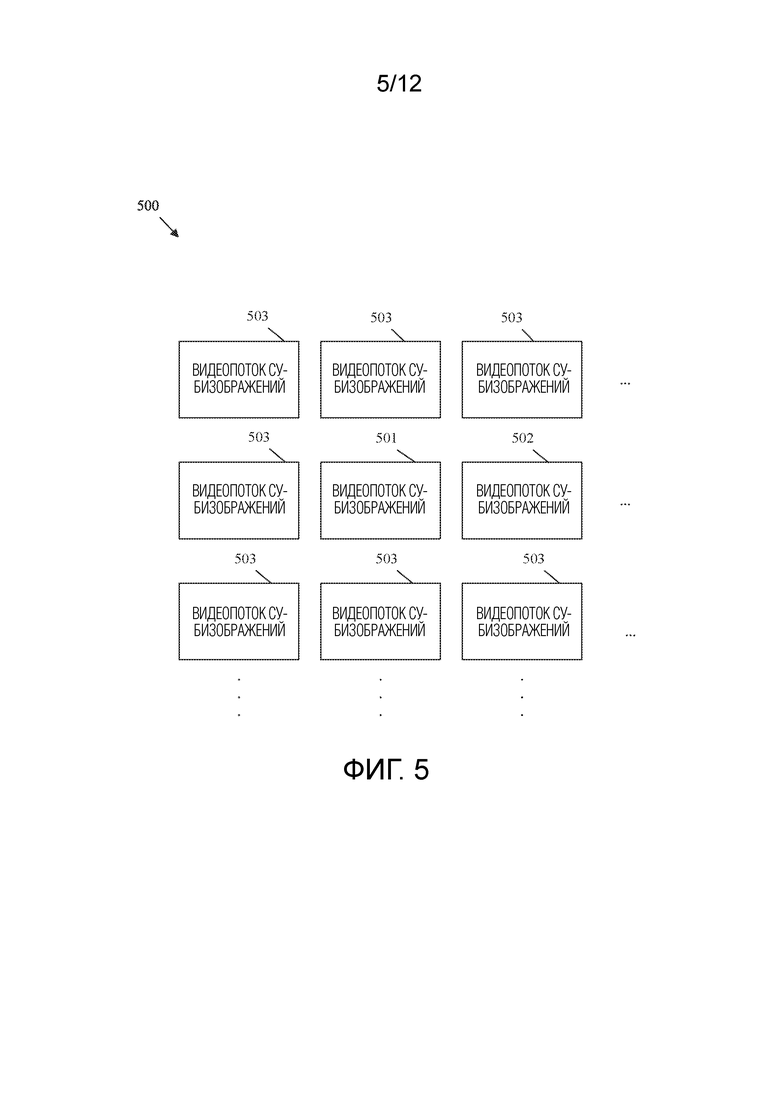
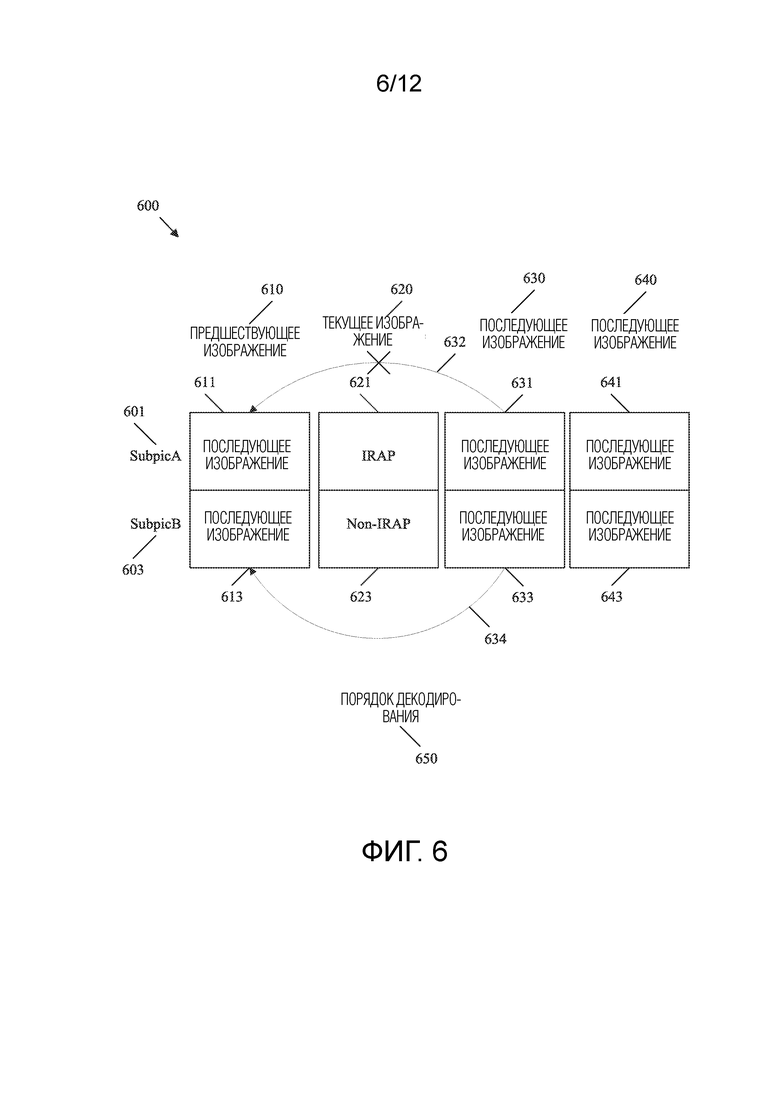
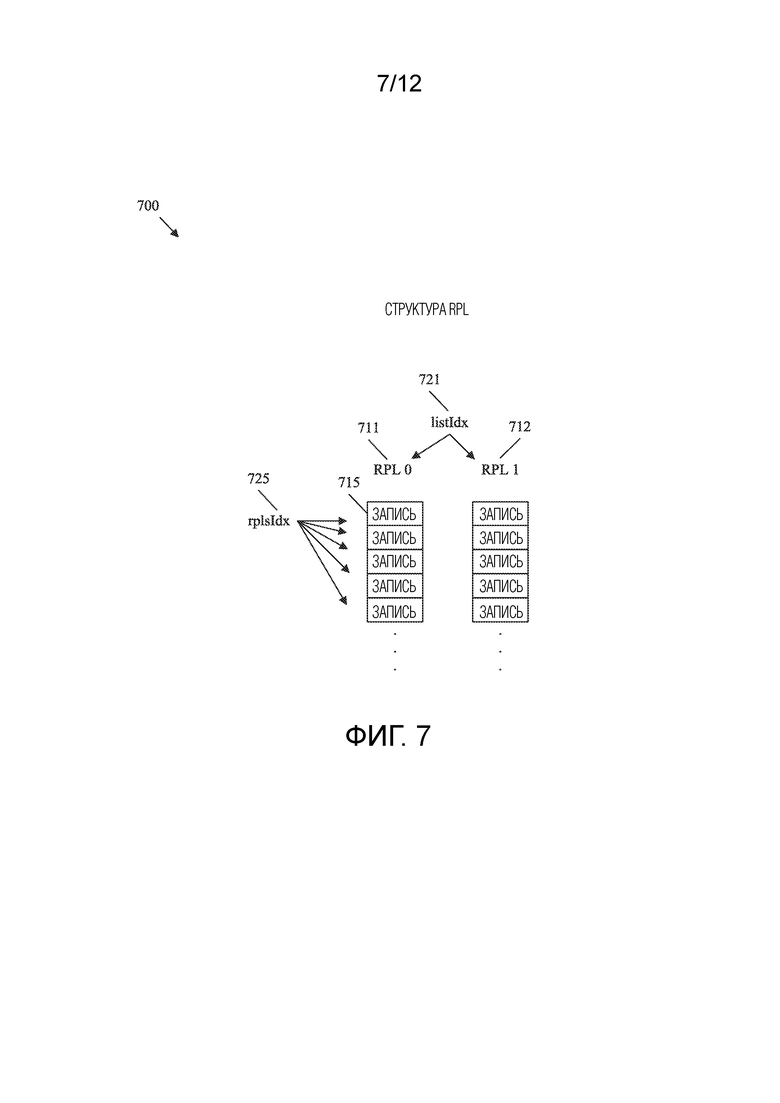
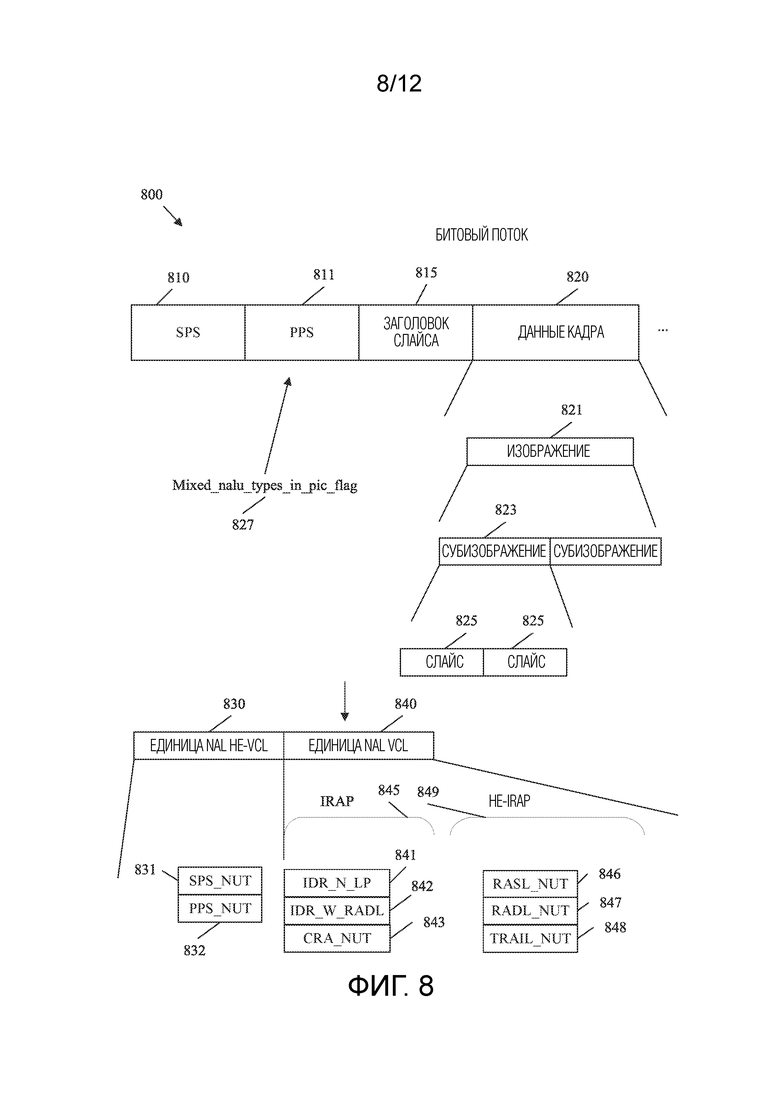
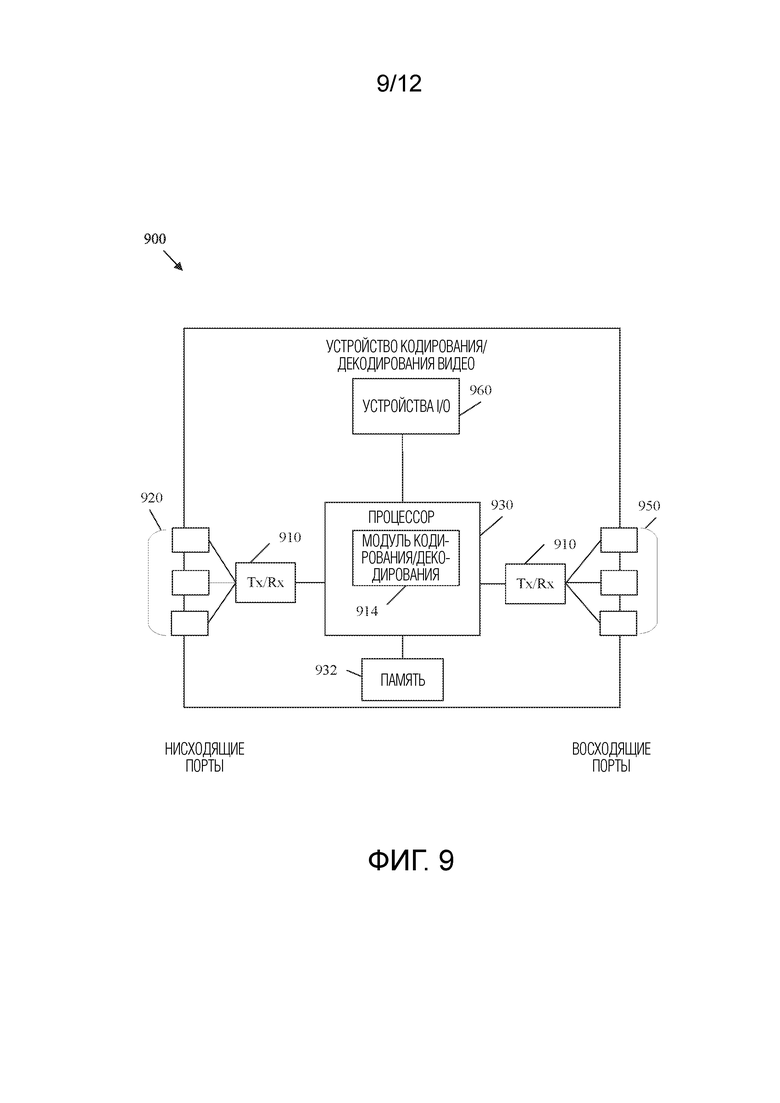
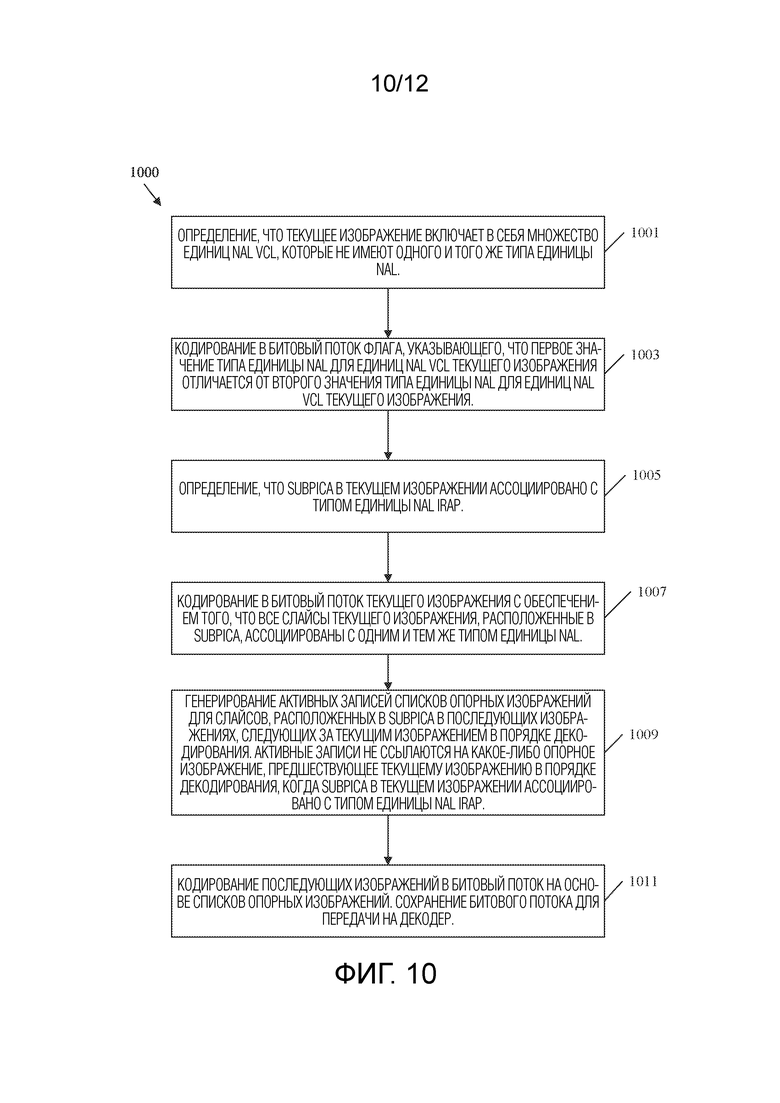
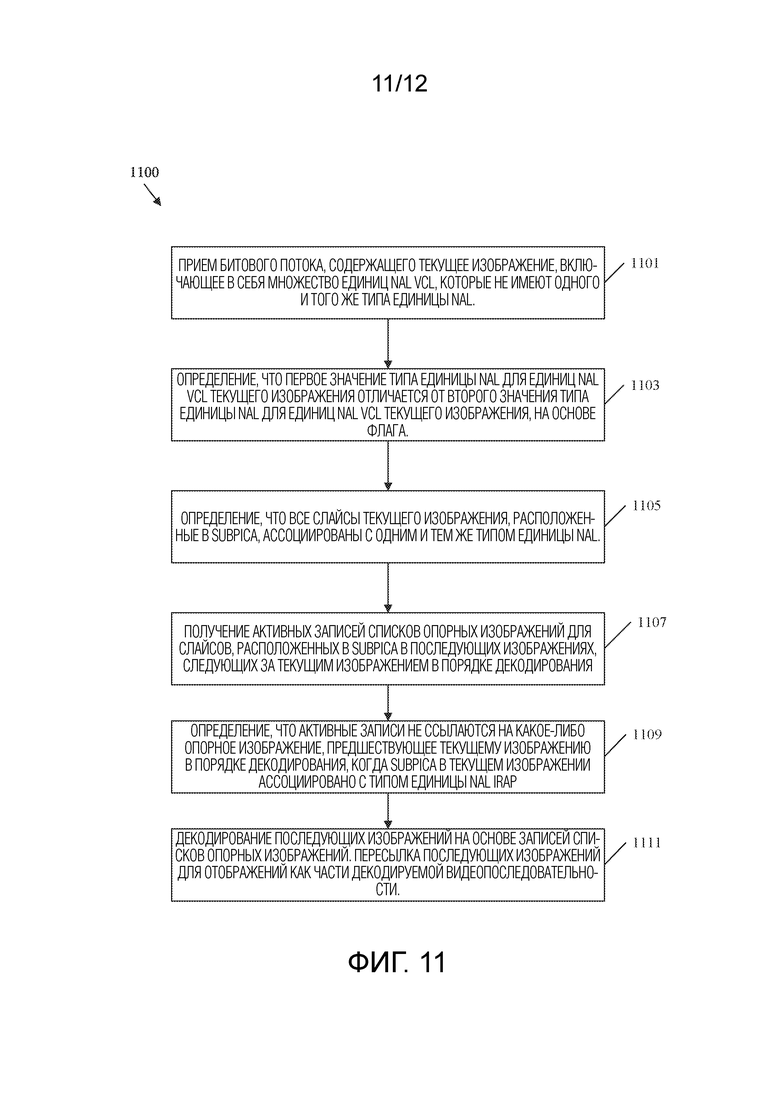
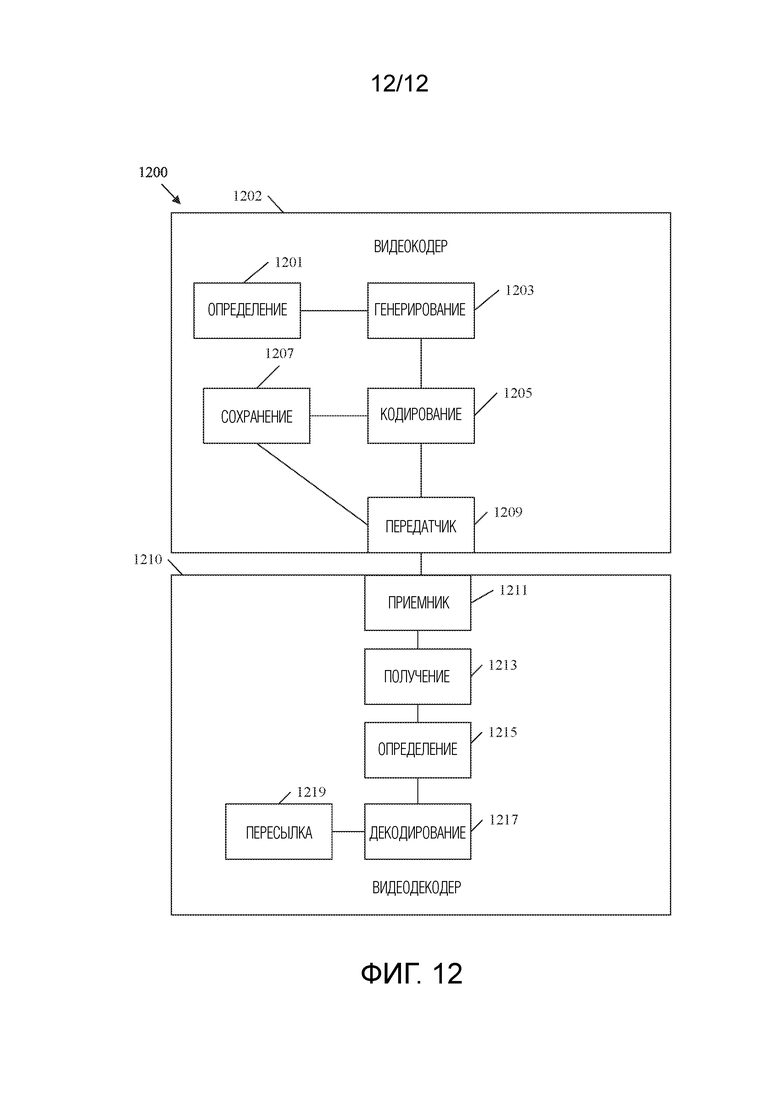
Изобретение относится к средствам для кодирования/декодирования видео. Технический результат заключается в повышении эффективности кодирования/декодирования видео. Принимают битовый поток, содержащий текущее изображение, включающее в себя множество единиц уровня сетевой абстракции (NAL) уровня кодирования/декодирования видео (VCL), которые не имеют одного и того же типа единицы NAL. Получают активные записи списков опорных изображений для слайсов, расположенных в субизображении A (subpicA) в последующих изображениях, следующих за текущим изображением в порядке декодирования. Активные записи не включают в себя ссылку на какое-либо опорное изображение, предшествующее текущему изображению в порядке декодирования, когда subpicA в текущем изображении ассоциировано с типом единицы NAL интра-точки произвольного доступа (IRAP). Каждое из текущего изображения и последующих изображений разделено на субизображения subpicA и subpicB. SubpicB в текущем изображении содержит единицы NAL не-IRAP, все слайсы текущего изображения, расположенные в subpicA, ассоциированы с одним и тем же типом единицы NAL. Декодируют последующие изображения на основе активных записей списков опорных изображений. 6 н. и 12 з.п. ф-лы, 12 ил.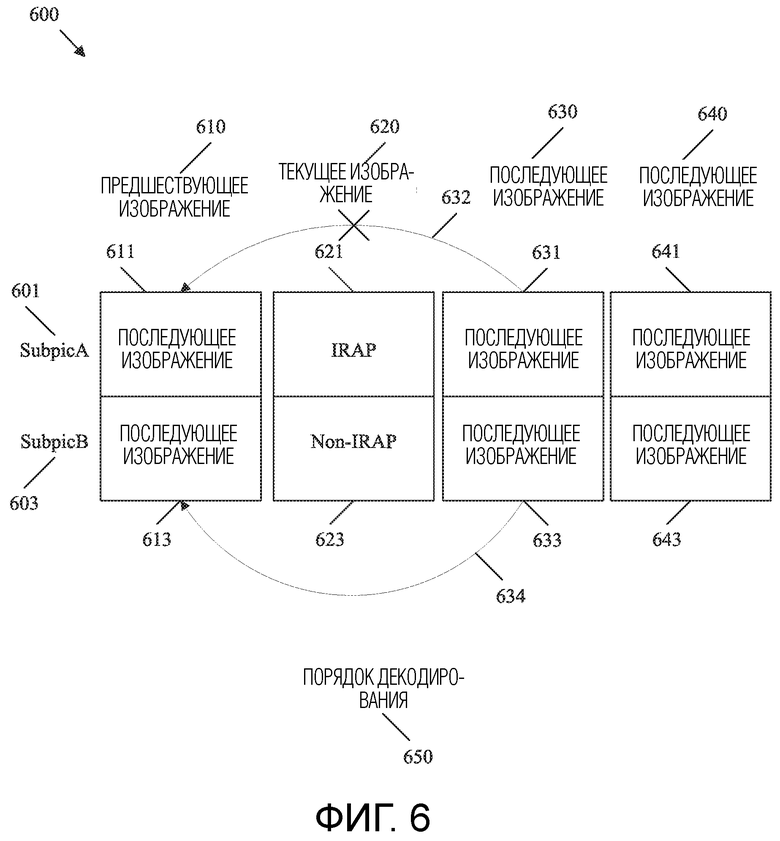
1. Способ кодирования/декодирования видео, реализуемый в декодере, причем способ содержит:
прием, приемником декодера, битового потока, содержащего текущее изображение, включающее в себя множество единиц уровня сетевой абстракции (NAL) уровня кодирования/декодирования видео (VCL), которые не имеют одного и того же типа единицы NAL;
получение, процессором декодера, активных записей списков опорных изображений для слайсов, расположенных в субизображении A (subpicA) в последующих изображениях, следующих за текущим изображением в порядке декодирования, при этом активные записи не включают в себя ссылку на какое-либо опорное изображение, предшествующее текущему изображению в порядке декодирования, когда subpicA в текущем изображении ассоциировано с типом единицы NAL интра-точки произвольного доступа (IRAP); при этом каждое из текущего изображения и последующих изображений разделено на субизображения, и субизображения содержат subpicA и subpicB, причем субизображения представляют собой прямоугольные или квадратные области одного или более слайсов; при этом subpicB в текущем изображении содержит единицы NAL не-IRAP, все слайсы текущего изображения, расположенные в subpicA, ассоциированы с одним и тем же типом единицы NAL; и
декодирование, процессором, последующих изображений на основе активных записей списков опорных изображений.
2. Способ по п. 1, в котором тип единицы NAL IRAP представляет собой тип единицы NAL чистого произвольного доступа (CRA).
3. Способ по п. 1, в котором тип единицы NAL IRAP представляет собой тип единицы NAL мгновенного обновления декодера (IDR).
4. Способ по любому из пп. 1-3, дополнительно содержащий определение процессором того, что первое значение типа единицы NAL для единиц NAL VCL текущего изображения отличается от второго значения типа единицы NAL для единиц NAL VCL текущего изображения на основе флага.
5. Способ по п. 4, в котором битовый поток включает в себя набор параметров изображения (PPS), и в котором флаг получают из PPS.
6. Способ по п. 4 или 5, в котором флаг представляет собой mixed_nalu_types_in_pic_flag, и при этом mixed_nalu_types_in_pic_flag равняется единице при специфицировании того, что каждое изображение, ссылающееся на PPS, имеет более одной единицы NAL VCL, и эти единицы NAL VCL не имеют одного и того же значения типа единицы NAL (nal_unit_type).
7. Способ кодирования/декодирования видео, реализуемый в кодере, причем способ содержит:
определение процессором кодера того, что текущее изображение включает в себя множество единиц уровня сетевой абстракции (NAL) уровня кодирования/декодирования видео (VCL), которые не имеют одного и того же типа единицы NAL;
определение процессором того, что субизображение A (subpicA) в текущем изображении ассоциировано с типом единицы NAL интра-точки произвольного доступа (IRAP);
генерирование, процессором, активных записей списков опорных изображений для слайсов, расположенных в subpicA в последующих изображениях, следующих за текущим изображением в порядке декодирования, при этом активные записи не включают в себя ссылку на какое-либо опорное изображение, предшествующее текущему изображению в порядке декодирования, когда subpicA в текущем изображении ассоциировано с типом единицы NAL IRAP; при этом каждое из текущего изображения и последующих изображений разделяется на субизображения, и субизображения содержат subpicA и subpicB, причем субизображения представляют собой прямоугольные или квадратные области одного или более слайсов; при этом subpicB в текущем изображении содержит единицы NAL не-IRAP, все слайсы текущего изображения, расположенные в subpicA, ассоциированы с одним и тем же типом единицы NAL; и
кодирование, процессором, последующих изображений в битовый поток на основе списков опорных изображений.
8. Способ по п. 7, в котором тип единицы NAL IRAP представляет собой тип единицы NAL чистого произвольного доступа (CRA).
9. Способ по п. 7, в котором тип единицы NAL IRAP представляет собой тип единицы NAL мгновенного обновления декодера (IDR).
10. Способ по п. 8 или 9, дополнительно содержащий кодирование в битовый поток, процессором, флага, указывающего, что первое значение типа единицы NAL для единиц NAL VCL текущего изображения отличается от второго значения типа единицы NAL для единиц NAL VCL текущего изображения.
11. Способ по п. 10, в котором флаг кодируется в набор параметров изображения (PPS) в битовом потоке.
12. Способ по п. 10 или 11, в котором флаг представляет собой mixed_nalu_types_in_pic_flag, и при этом mixed_nalu_types_in_pic_flag устанавливается равным единице при специфицировании того, что каждое изображение, ссылающееся на PPS, имеет более одной единицы NAL VCL, и эти единицы NAL VCL не имеют одного и того же значения типа единицы NAL (nal_unit_type).
13. Устройство кодирования/декодирования видео, содержащее:
процессор, приемник, соединенный с процессором, память, соединенную с процессором, и передатчик, соединенный с процессором, при этом процессор, приемник, память и передатчик выполнены с возможностью осуществления способа по любому из пп. 1-12.
14. Долговременный считываемый компьютером носитель, содержащий компьютерный программный продукт для использования устройством кодирования/декодирования видео, причем компьютерный программный продукт содержит исполняемые компьютером инструкции, хранящиеся на долговременном считываемом компьютером носителе, так что при исполнении процессор побуждает устройство кодирования/декодирования видео выполнять способ по любому из пп. 1-12.
15. Декодер, содержащий:
средство приема для приема битового потока, содержащего текущее изображение, включающее в себя множество единиц уровня сетевой абстракции (NAL) уровня кодирования/декодирования видео (VCL), которые не имеют одного и того же типа единицы NAL;
средство получения для получения активных записей списков опорных изображений для слайсов, расположенных в субизображении A (subpicA) в последующих изображениях, следующих за текущим изображением в порядке декодирования;
средство определения для определения того, что активные записи не включают в себя ссылку на какое-либо опорное изображение, предшествующее текущему изображению в порядке декодирования, когда subpicA в текущем изображении ассоциировано с типом единицы NAL интра-точки произвольного доступа (IRAP); при этом каждое из текущего изображения и последующих изображений разделено на субизображения, и субизображения содержат subpicA и subpicB, причем субизображения представляют собой прямоугольные или квадратные области одного или более слайсов; при этом subpicB в текущем изображении содержит единицы NAL не-IRAP, все слайсы текущего изображения, расположенные в subpicA, ассоциированы с одним и тем же типом единицы NAL;
средство декодирования для декодирования последующих изображений на основе активных записей списков опорных изображений; и
средство пересылки для пересылки последующих изображений для отображения как части декодированной видеопоследовательности.
16. Декодер по п. 15, в котором декодер дополнительно выполнен с возможностью выполнения способа по любому из пп. 1-6.
17. Кодер, содержащий:
средство определения для:
определения того, что текущее изображение включает в себя множество единиц уровня сетевой абстракции (NAL) уровня кодирования/декодирования видео (VCL), которые не имеют одного и того же типа единицы NAL; и
определения того, что субизображение A (subpicA) в текущем изображении ассоциировано с типом единицы NAL интра-точки произвольного доступа (IRAP);
средство генерирования для генерирования активных записей списков опорных изображений для слайсов, расположенных в subpicA в последующих изображениях, следующих за текущим изображением в порядке декодирования, при этом активные записи не включают в себя ссылку на какое-либо опорное изображение, предшествующее текущему изображению в порядке декодирования, когда subpicA в текущем изображении ассоциировано с типом единицы NAL IRAP; при этом каждое из текущего изображения и последующих изображений разделено на субизображения, и субизображения содержат subpicA и subpicB, причем субизображения представляют собой прямоугольные или квадратные области одного или более слайсов; при этом subpicB в текущем изображении содержит единицы NAL не-IRAP, все слайсы текущего изображения, расположенные в subpicA, ассоциированы с одним и тем же типом единицы NAL;
средство кодирования для кодирования последующих изображений в битовый поток на основе списков опорных изображений; и
средство хранения для сохранения битового потока для передачи на декодер.
18. Кодер по п. 17, при этом кодер дополнительно выполнен с возможностью выполнения способа по любому из пп. 7-12.
| Станок для придания концам круглых радиаторных трубок шестигранного сечения | 1924 |
|
SU2019A1 |
| Ye-Kui Wang et al | |||
| Способ гальванического снятия позолоты с серебряных изделий без заметного изменения их формы | 1923 |
|
SU12A1 |
| Способ защиты переносных электрических установок от опасностей, связанных с заземлением одной из фаз | 1924 |
|
SU2014A1 |
| Устройство для закрепления лыж на раме мотоциклов и велосипедов взамен переднего колеса | 1924 |
|
SU2015A1 |
| Автомобиль-сани, движущиеся на полозьях посредством устанавливающихся по высоте колес с шинами | 1924 |
|
SU2017A1 |
| Автомобиль-сани, движущиеся на полозьях посредством устанавливающихся по высоте колес с шинами | 1924 |
|
SU2017A1 |
| СТРУКТУРЫ ФОРМАТА ФАЙЛА МНОГОУРОВНЕВОГО ВИДЕО | 2014 |
|
RU2676876C2 |

