Настоящее изобретение относится к кодированию источников, в частности к кодированию источников звука, при котором аудиосигнал обрабатывается, по меньшей мере, двумя различными аудиокодерами, использующими два различных алгоритма кодирования.
В области технологии низкоскоростного кодирования звуковых и речевых сигналов традиционно используют ряд подходов, дающих проверенный максимально высокий по качеству акустики результат для каждой скорости передачи двоичных данных. Кодеры обычных музыкальных/звуковых сигналов предназначаются для оптимизации субъективно оцениваемого качества путем формирования спектральной (и временной) геометрии ошибки квантования в зависимости от кривой порога маскирования, которую оценивают на основании входного сигнала с помощью перцепционной модели ("перцепционное аудиокодирование"). Вместе с тем, как показала практика, кодирование речи на очень низких битрейтах весьма эффективно, когда оно базируется на модели воспроизведения человеческой речи, то есть на использовании кодирования с линейным предсказанием (LPC) для моделирования резонансных эффектов речевого тракта человека в комплексе с продуктивным кодированием остаточного/возбуждаемого сигнала.
Эти два разных подхода с применением обычных аудиокодеров (формата MPEG-1, уровня 3, или формата усовершенствованного аудиокодирования MPEG-2/4, ААС), как правило, для голосовых сигналов при очень низких скоростях передачи данных не дают такой же положительный результат, как специализированные речевые LPC-кодеры, из-за того что при этом не используется модель источника речи. И, наоборот, линейно-предикативные кодеры речи в большинстве случаев не дают должных результатов при приложении к обычным музыкальным сигналам из-за неспособности гибко формировать огибающую спектра искажения кодирования в соответствии с кривой порога маскирования. Далее представлены варианты реализации концепции объединения преимуществ аудиокодирования на основе LPC и аудиокодирования на основе чувственного восприятия в унифицированную систему кодирования общих звуковых и речевых сигналов.
Традиционно в аудиокодерах перцепционного типа используют банки фильтров, помогающие эффективно кодировать аудиосигналы и формировать шумы квантования в соответствии с оцениваемой кривой маскирования.
На фиг.16а представлена блок-схема базовой монофонической перцепционной системы кодирования. Банк фильтров анализа 1600 предназначен для отображения отсчетов временной области в виде спектральных составляющих. В зависимости от числа спектральных составляющих систему можно также назвать кодером поддиапазонов (при небольшом количестве поддиапазонов, например 32) или кодером-преобразователем (при большом количестве частотных линий, например 512). Перцепционная ("психоакустическая") модель 1602 предназначена для оценки фактического порога маскирования с временной зависимостью. Спектральные составляющие ("поддиапазона" или "частотной области") квантуются и кодируются на шаге 1604 таким образом, что шум квантования скрыт за реально передаваемым сигналом, и не воспринимается после декодирования. Это достигается варьированием глубины квантования спектральных величин по времени и частоте.
Спектральные коэффициенты и значения поддиапазонов после квантования или энтропийного кодирования вводятся вместе с сопутствующей информацией в форматер битстрима 1606, формирующий кодированный аудиосигнал, готовый для передачи или сохранения в памяти. Битстрим на выходе элемента 1606 может быть передан через Интернет или сохранен на любом машиночитаемом носителе информации.
Закодированный битстрим поступает на интерфейс ввода данных декодера 1610. Блок 1610 отделяет прошедшие энтропийное кодирование и квантованные значения спектра/поддиапазона от побочной информации. Кодированные параметры спектра вводятся в энтропийный декодер, например декодер Хаффмана, расположенный между 1610 и 1620. Выходные данные энтропийного декодера представляют собой квантованные значения спектра. Эти квантованные спектральные величины вводятся в реквантователь, который выполняет "обратное" квантование, что показано в виде элемента 1620 на фиг.16а. Выходные данные элемента 1620 поступают в банк фильтров синтеза 1622, который выполняет синтез-фильтрование, включающее в себя частотно-временное преобразование и, как правило, операцию устранения эффекта наложения во временной области, такого как перекрытие, и операцию сложения и/или оконного преобразования синтезирования, для получения в итоге выходного аудиосигнала.
На фиг.16b, 16c представлен принцип кодирования, альтернативный перцепционному принципу кодирования на фиг.16a, полностью основанному на использовании банков фильтров, отличающийся тем, что со стороны кодера применен предварительный фильтр (предфильтр), а со стороны декодера применен последующий фильтр (постфильтр).
В публикации (В.Edler, G.Schuller: "Audio coding using a psychoacoustic pre- and post-filter", ICASSP 2000, Volume 2, 5-9 June 2000 Page(s): II881-II884 vol.2) был предложен аудиокодер перцепционного типа, в котором разделение аспектов устранения несущественной информации (то есть ограничение шума по перцептивным критериям) и устранение избыточности (то есть получение математически более сжатого представления информации) путем использования так называемого предварительного фильтра (предфильтра) вместо переменного квантования спектральных коэффициентов по частоте. Этот принцип проиллюстрирован на фиг.16B. Входной сигнал анализируется перцепционной моделью 1602 для оценочного расчета кривой порога маскирования по частоте. Пороговое значение маскирования преобразовывается в набор коэффициентов предварительного фильтра так, что диапазон его частотных характеристик обратно пропорционален пороговому значению маскирования. В процессе предфильтрации этот набор коэффициентов применяется к входному сигналу для получения выходного сигнала, в котором все частотные составляющие представлены в соответствии с их перцепционным значением ("перцепционное отбеливание"). Далее этот сигнал кодируется аудиокодером 1632 любого типа, который производит "белый" шум квантования, то есть не задействует никакие средства ограничения воспринимаемого шума. Транслируемый/сохраняемый аудиосигнала содержит как поток битов кодера, так и кодированную версию коэффициентов предфильтрования. С помощью декодера (1634) на фиг.16С битовый поток кодера расшифровывается как перцептивно отбеленный аудиосигнал, который содержит аддитивный белый шум квантования. Затем этот сигнал проходит процесс постфильтрования 1640 в соответствии с полученными коэффициентами фильтрации. Так как осуществляемая постфильтром функция обратного фильтрования аналогична функции предварительного фильтра, он реконструирует из перцептивно отбеленного сигнала первоначальный входной аудиосигнал. Аддитивный белый шум квантования, формируемый постфильтром, подобен кривой маскирования и, таким образом, на выходе декодера имеет сенсорную окраску, что и требуется.
Поскольку при подобной компоновке снижение слышимых помех достигается за счет пред-/пост-фильтрации, а не за счет частотно-зависимого квантования спектральных коэффициентов, подход в целом может быть объединен путем использования для представления аудиосигнала, прошедшего предварительное фильтрование, метода кодирования без применения банков фильтров, а не аудиокодера на базе банков фильтров. В (G.Schuller, B.Yu, D.Huang, and B.Edler, "Perceptual Audio Coding using Adaptive Pre- and Post-Filters and Lossless Compression", IEEE Transactions on Speech and Audio Processing, September 2002, pp.379-390) такой подход представлен для ядра кодирования во временной области с использованием прогностического и энтропийного кодирования.
Для желаемого ограничения спектра шумов способом пред-/пост-фильтрации необходимо, чтобы разрешающая способность пред-/постфильтра по частоте была адаптирована к частотному разрешению слуховой системы человека. В идеале разрешение по частоте должно соответствовать известным перцепционным частотным шкалам, таким как BARK или ERB (Zwicker, E. and Н.Fastl, "Psychoacoustics, Facts and Models", Springer Verlag, Berlin).
Это особенно важно для минимизации порядка модели пред-/постфильтра и, следовательно, снижения соотнесенной вычислительной сложности и скорости передачи протокольной информации.
Адаптация частотного разрешения пред-/постфильтра может быть достигнута применением известной концепции неравномерного частотного распределения (M.Karjalainen, A.Härmä, U.K.Laine, "Realizable warped IIR filters and their properties", IEEE ICASSP 1997, pp.2205-2208, vol.3). По существу единичные задержки в структуре фильтра замещаются всепропускающими фильтрами (первого или более высокого порядка), что в результате дает неравномерную деформацию ("неравномерное распределение") частотной характеристики фильтра. Было показано, что даже при использовании всепропускающего фильтра первого порядка, например
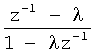 ,
,
благодаря надлежащему подбору частотно независимых коэффициентов, возможна весьма точная аппроксимация перцептуальных частотных шкал (J.O.Smith, J.S.Abel, "Bark and ERB Bilinear Transforms", IEEE Transactions on Speech and Audio Processing, Volume 7, Issue 6, Nov. 1999, pp.697-708). В силу этого в наиболее известных системах для неравномерного частотного распределения не применяются всепропускающие фильтры более высокого порядка. Поскольку всепропускающий фильтр первого порядка полностью определяется одним скалярным параметром (именуемым далее "фактор неравномерности" - 1<λ<1), что и определяет деформацию частотной шкалы. В частности, для фактора неравномерности λ=0 деформация не эффективна, то есть фильтр работает на нормальной шкале частот. Чем выше фактор неравномерности, тем больше частотное разрешение смещение в низкочастотную область спектра (из-за необходимости аппроксимации перцептуальной частотной шкалы) и тем дальше находится от высокочастотного участка спектра.
При применении пред-/постфильтра со смещением разрешения по частоте в аудиокодерах чаще всего используют порядок фильтра между 8 и 20 при стандартных частотах дискретизации в пределах 48 кГц или 44,1 кГц (S.Wabnik, G.Schuller, U.Krämer, J.Hirschfeld, "Frequency Warping in Low Delay Audio Coding", IEEE International Conference on Acoustics, Speech, and Signal Processing, March 18-23, 2005, Philadelphia, PA, USA).
Описаны также некоторые другие случаи фильтрования со смещением частотного разрешения, например, при имитации импульсных характеристик помещения (Härmä, Aki; Karjalainen, Matti; Savioja, Lauri; Välimäki, Vesa; Laine, Unto K.; Huopaniemi, Jyri, "Frequency-Warped Signal Processing for Audio Applications", Journal of the AES, Volume 48 Number 11 pp.1011-1031; November 2000) и параметрическом моделировании шумовой составляющей в аудиосигнале (под эквивалентным названием фильтрация Лагуерре/Кауца (Laguerre/Kauz)) (E.Schuijers, W.Oomen, В.den Brinker, J.Breebaart, "Advances in Parametric Coding for High-Quality Audio", 114th Convention, Amsterdam, The Netherlands 2003, preprint 5852).
Традиционно эффективное кодирование речи базировалось на линейно-предиктивном кодировании (LPC-кодирование) с моделированием резонансных эффектов человеческого голосового тракта совместно с продуктивным кодированием остаточного/инициирующего сигнала. Параметры LPC-кодирования и возбуждения транслируются от кодера к декодеру. Этот принцип иллюстрируется на фиг.17А и 17B.
На фиг.17а показан кодер линейно-прогностической кодек-системы. Входной речевой сигнал вводится в LPC-анализатор 1701, на выходе которого формируются коэффициенты фильтра кодирования с линейным предсказанием. На основании этих коэффициентов LPC-фильтрации производится настройка LPC-фильтра 1703. LPC-фильтр дает на выходе аудиосигнал отбеленного спектра, называемый также "сигналом ошибки предсказания". Этот спектрально отбеленный звуковой сигнал вводится в кодер остаточного возбуждения 1705, который генерирует параметры возбуждения. Таким образом, входной речевой сигнал кодируется в виде параметров возбуждения, с одной стороны, и в виде коэффициентов кодирования с линейным предсказанием, с другой стороны.
Далее, как показано на фиг.17B, параметры возбуждения вводятся в декодер возбуждения 1707, генерирующий сигнал возбуждения, который может быть введен в обратный фильтр кодирования с линейным предсказанием. Настройка обратного LPC-фильтра выполняется с использованием переданных коэффициентов LPC-фильтра. Таким образом, инверсный LPC-фильтр 1709 генерирует реконструируемый или синтезируемый выходной голосовой сигнал.
Длительное время предлагались различные методы эффективной и достоверной передачи остаточного (возбуждающего) сигнала, такие как многоимпульсное возбуждение (МРЕ), регулярное импульсное возбуждение (RPE) и линейное предсказание с кодовым возбуждением (CELP).
С помощью кодирования с линейным предсказанием делается попытка оценки текущей величины отсчета последовательности на основании отслеживания и линейного объединения некоторого числа величин прошлых измерений. Для ограничения избыточности входного сигнала LPC-фильтр кодера "отбеливает" входной сигнал в пределах огибающей его спектра, то есть представляет собой инверсную модель огибающей спектра сигнала. И наоборот, LPC-фильтр декодера является моделью огибающей спектра сигнала. В частности, хорошо известен авторегрессивный линейный прогнозирующий анализ, моделирующий огибающую спектра сигнала с помощью полюсной аппроксимации.
Как правило, узкополосные речевые кодеры (то есть речевые кодеры с частотой дискретизации 8 kHz), используют LPC-фильтры с порядком между 8 и 12. Благодаря конструктивным особенностям LPC-фильтра равномерное частотное разрешение эффективно во всем диапазоне частот. Это не соответствует шкале перцептивных частот. Некоторые публикации, обращая внимание на то, что неравномерная чувствительность по частоте при применении методов с деформированной частотной осью дает преимущества и при кодировании речи, предлагают заменить равномерный LPC-анализ неравномерным анализом с предсказанием, например (K.Tokuda, H.Matsumura, T.Kobayashi and S.Imai, "Speech coding based on adaptive mel-cepstral analysis," Proc. IEEE ICASSP′94, pp.197-200, Apr. 1994; K.Koishida, K.Tokuda, T.Kobayashi and S.Imai, "CELP coding based on mel-cepstral analysis," Proc. IEEE ICASSP′95, pp.33-36, 1995). Известны и другие варианты комбинирования неравномерного LPC-кодирования и CELP-кодирования (линейно-предиктивного кодирования с кодовым возбуждением, например (Aki Härmä, Unto K.Laine, Matti Karjalainen, "Warped low-delay CELP for wideband audio coding", 17th International AES Conference, Florence, Italy, 1999).
С целью объединения преимуществ традиционного LPC/CELP метода кодирования (оптимального для голосовых сигналов) и аудиокодирования на базе традиционного перцептуального подхода с использованием банков фильтров (оптимального для музыки) предлагается способ комбинированного кодирования, объединяющий эти два решения. В (B.Bessette, R.Lefebvre, R.Salami, "UNIVERSAL SPEECH/AUDIO CODING USING HYBRID ACELP/TCX TECHNIQUES," Proc. IEEE ICASSP 2005, pp.301-304, 2005) представлен кодер AMR-WB+, в котором два альтернативных ядра кодирования обрабатывают остаточный (разностный) сигнал кодирования с линейным предсказанием (LPC-сигнал). Одно базируется на методе ACELP (линейного предсказания с возбуждением алгебраическим кодом) и, следовательно, весьма эффективно для кодирования речевых сигналов. Второе ядро кодирования базируется на технологии ТСХ (возбуждение, управляемое кодом преобразования), то есть на методе кодирования с применением банков фильтров, напоминающем традиционные алгоритмы кодирования звука, дающие хорошее качество музыкальных сигналов. В зависимости от характеристик входных сигналов на короткий отрезок времени выбирается один из этих двух режимов кодирования для передачи остаточного сигнала LPC. Таким образом, фреймы длительностью 80 мс могут быть разбиты на подфреймы по 40 или 20 мс, в течение которых принимается решение о выборе одного из двух режимов кодирования.
Ограниченность этого метода в том, что в его основе лежит жесткий выбор и переключение между двумя кодерами/алгоритмами кодирования с абсолютно разными характеристиками вводимого искажения кодирования. Такое резкое переключение с одного режима на другой может стать причиной раздражающего воздействия сигнала при восприятии из-за его прерывистости. В частности, при плавном переходе от голосового сигнала к музыкальному за счет взаимного наложения (например, после объявления в радиопрограмме) точка перехода может быть ощутима. Так же и при наложении речи на музыку (например, при чтении сообщения на музыкальном фоне) резкое переключение может быть различимо на слух. Следовательно, при такой компоновке проблематично получить кодер, который смог бы обеспечить плавный переход между характеристиками двух составляющих кодеров.
Недавно описан метод коммутируемого кодирования, при котором ядро кодирования с использованием банков фильтров способно работать в пределах перцептивно (с помощью чувственного восприятия) взвешенной частотной шкалы, обеспечивая плавное переключение фильтра кодера между традиционным режимом LPC (необходимым для кодирования речи на основе алгоритма CELP) и режимом со смещаемым частотным разрешением, который напоминает перцептуальное аудиокодирование, основанное на применении пред-/пост-фильтрациии, что описано для EP 1873754.
Используя фильтр с переменным неравномерным частотным распределением, можно создать гибридный кодер речи/звука, который обеспечит высокое качество кодирования речи и звука с применением конфигурации, показанной на фиг.17C.
Режим кодирования ("речевой" или "музыкальный") выбирается специальным модулем 1726, который анализирует входной сигнал и может быть осуществлен на базе известных методик распознавания голосовых и музыкальных сигналов. Модуль выбора определяет алгоритм кодирования / и соответствующий ему оптимальный коэффициент неравномерности частотного разрешения для фильтра 1722. В дополнение к этому в зависимости от выбранного режима модуль рассчитывает набор коэффициентов фильтра, удовлетворяющих входному сигналу в выбранном режиме кодирования, то есть для кодирования речи выполняется анализ LPC (без или с низким коэффициентом деформации), тогда как для кодирования музыки делается оценка кривой маскирования, и ее обратные величины преобразуются в коэффициенты спектрального искажения.
Фильтр 1722 с изменяющимися во времени характеристиками частотного деформирования используется как общий фильтр кодера/декодера и применяется к сигналу в зависимости от выбора режима кодирования/коэффициент деформации и набора коэффициентов фильтрации, рассчитанных модулем выбора.
Выходной сигнал звена фильтрации кодируется или ядром кодирования речи 1724 (например, кодером CELP), или ядром универсального аудиокодера 1726 (например, на основе банков фильтров, или предиктивный аудиокодер), или обоими в зависимости от режима кодирования.
Передаваемые/сохраняемые данные включают в себя указание на выбранный режим кодирования (или на коэффициент деформации), коэффициенты фильтров в закодированной форме и информацию, содержащуюся в речи/возбуждении и универсальном аудиокодере.
Соответствующий декодер суммирует выходные данные декодера остаточного/возбуждающего сигнала и универсального аудиодекодера, и результат фильтруется фильтром синтеза с изменяемым во времени неравномерным частотным разрешением в зависимости от режима кодирования, коэффициента неравномерности и коэффициентов фильтрации.
Однако рассмотренные выше ограничения, относящиеся к кодированию с коммутацией режимов CELP/банки фильтров, распространяются и на данную схему из-за необходимости жесткого выбора между двумя алгоритмами кодирования.
Подобная конфигурация затрудняет создание кодера, способного осуществлять плавный переход между характеристиками двух составных кодеров.
Еще один способ интегрирования ядра голосового кодирования с перцепционным аудиокодером общего назначения применяют в рамках стандарта MPEG-4 для кодирования звука с крупноступенчатым масштабированием (Grill, В., "A Bit Rate Scalable Perceptual Coder for MPEG-4 Audio", 103rd AES Convention, New York 1997, Preprint 4620) и (J.Herre, H.Purnhagen: "General Audio Coding", in F.Pereira, T.Ebrahimi (Eds.), "The MPEG-4 Book", Prentice Hall IMSC Multimedia Series, 2002. ISBN 0-13-061621-4). Принцип масштабируемого кодирования дает возможность создания конфигураций кодеков и форматов битстримов, обеспечивающих содержательное декодирование частей целого битстрима, давая на выходе сигнал с потерей качества. При этом скорость передачи/расшифровки данных может быть моментально адаптирована к текущей емкости канала без перекодирования входного сигнала.
Схема устройства аудиокодера стандарта MPEG-4 с крупноступенчатым масштабированием изображена на фиг.18 (Grill, В., "A Bit Rate Scalable Perceptual Coder for MPEG-4 Audio", 103rd AES Convention, New York 1997, Preprint 4620). Такая конфигурация включает в себя и так называемый корневой кодер 1802, и несколько уровней оптимизации на базе модуля перцептуального аудиокодирования 1804. Корневой кодер (обычно узкополосный речевой кодер) работает с меньшей частотой дискретизации, чем последующие уровни расширения. Масштабируемая комбинация этих компонентов работает по описанному ниже принципу.
Выполняется отсчет входного сигнала с понижением 1801 и его кодирование корневым кодером 1802. Образованный поток двоичных данных составляет часть корневого уровня 1804 масштабируемого битстрима. Выполняется его локальное декодирование 1806 и отсчет с повышением 1808 для достижения соответствия частоте дискретизации уровней перцептуальной адаптации, после чего он проходит банк фильтров анализа (МДКП [модифицированное дискретное косинусное преобразование]) 1810.
Во втором канале входной сигнал, компенсируемый задержкой (1812), проходит через банк фильтров анализа 1814 и используется для расчета остаточного сигнала ошибки кодирования. Разностный сигнал проходит частотно-селективное коммутационное устройство (FSS) 1816, что позволяет вернуться к исходному сигналу в пределах полосы коэффициента масштабирования, если есть возможность закодировать его более эффективно, чем разностный сигнал.
Ядро 1804 усовершенствованного метода аудиокодирования ААСС квантует/кодирует спектральные коэффициенты, подводя их к битстриму уровня оптимизации 1818. Далее могут следовать фазы усовершенствования (уровни оптимизации) путем перекодирования остаточного сигнала ошибки кодирования.
На фиг.19 показана конфигурация магистрально сопряженного масштабируемого декодера. Смешанный битовый поток делится 1902 на уровни кодирования. Далее выполняется декодирование 1904 потока двоичных данных корневого кодера (например, речевого кодера), при этом его выходной сигнал может быть выдан после дополнительной операции постфильтрации. Чтобы использовать сигнал корневого декодера в процессе масштабируемого декодирования, выполняется его отсчет с повышением 1908 до частоты дискретизации масштабируемого кодера, компенсирование задержкой 1910 относительно других уровней и декомпозиция с помощью банка фильтров анализа кодера (МДКП) 1912.
Далее битстримы более высокого уровня декодируются 1916 с применением усовершенствованного метода бесшумового декодирования ААС и обратного квантования и путем сложения 1918 всех коэффициентов спектральных составляющих. Частотно-селективное коммутирующее устройство 1920 интегрирует полученные спектральные коэффициенты с компонентой корневого уровня путем выбора их суммы или только коэффициентов, заимствуемых из уровней расширения, получаемых в виде сигналов кодера. В завершение результирующие данные преобразуются банком фильтров синтеза обратно во временную область (IMDCT) 1922.
Отличительной особенностью данной конфигурации является обязательное использование и декодирование кодера речи (корневого кодера). Если декодер имеет доступ не только к корневому уровню битстрима, но и к одному или более расширенным уровням, на этот декодер поступают также составляющие расширенных уровней аудиокодеров перцептуального типа, что обеспечивает хорошее качество неречевых/музыкальных сигналов.
Следовательно, эта масштабируемая конфигурация всегда включает в себя активный уровень, имеющий в своем составе речевой кодер, недостатком работы которого является неравноценное качество выходных речевых и звуковых сигналов.
Если входной сигнал является преимущественно речевым, перцептуальный аудиокодер уровня (уровней) оптимизации будет кодировать остаточный/разностный сигнал, который имеет свойства, отличные от свойств обычных акустических сигналов, и, следовательно, кодер такого типа будет иметь затруднения при кодировании. В качестве примера можно взять остаточный сигнал, содержащий импульсные составляющие, которые, естественно, возбуждают предэхо при кодировании перцептуальным аудиокодером, функционирующим на базе банков фильтров.
Если входной сигнал не является преимущественно речевым, для кодирования разностного сигнала часто требуется более высокий битрейт, чем для кодирования входного сигнала. В таких случаях частотно-избирательное коммутирующее устройство FSS выбирает для кодирования на уровне оптимизации исходный сигнал вместо разностного. В результате корневой уровень не участвует в формировании выходного сигнала, и битрейт корневого уровня работает вхолостую, поскольку не участвует в повышении суммарного качества. Другими словами, в таких случаях звучание результирующего сигнала бывает хуже, чем если бы весь битрейт был целиком выделен только перцептуальному аудиокодеру.
В http://www.hitech-projects.com/euprojects/ardor/summary.htm описан кодек ARDOR (адаптивный аудиокодер с оптимизацией зависимости характеристик искажения от скорости передачи).
В рамках этого проекта разработан кодек, кодирующий универсальное множество звуков с помощью наиболее адекватной комбинации моделей сигналов в зависимости от наличия ограничений и вспомогательных средств кодирования. Работа этого кодека может быть разделена на три этапа, соответствующие трем его компонентам, показанным на фиг.20.
Кодек ARDOR, базирующийся на механизме оптимизации 2004 на основе зависимости битрейта от параметров искажения, выбирает наиболее эффективный режим работы с учетом изменяющихся в реальном времени ограничений и типов входного сигнала. Для выполнения этой задачи в его распоряжении находится: свод стратегий ′субкодирования′ 2000, каждая из которых предназначена для высокоэффективного кодирования специфических составляющих входного сигнала, например тональных, шумовых или импульсных. Сопоставление битрейта и составляющих сигнала для каждой отдельной стратегии субкодирования базируется на новейшем способе измерения перцептивной дисторсии 2002, дающем критерий оценки чувственного восприятия для оптимизации взаимной зависимости битрейта и искажения. Иначе говоря, перцептуальная модель, базирующаяся на новейших сведениях о слуховой системе человека, обеспечивает для процедуры оптимизации информацию о сенсорной релевантности различных акустических составляющих. В рамках алгоритма оптимизации может, например, быть проигнорирована информация, не соответствующая параметрам восприятия. Как результат исходный сигнал не может быть восстановлен, но слуховая система не ощутит разницу.
Рассмотренные выше системы известного уровня техники подтверждают отсутствие на сегодняшний день оптимальной концепции кодирования, которая обеспечивала бы, с одной стороны, одинаково высокое качество сигналов общих звуковых частот и голосовых сигналов и, с другой стороны, низкий битрейт для всех видов сигналов. Так, методом масштабирования, описанным в контексте фиг.18 и фиг.19, введенным в стандарт MPEG-4, непрерывно обрабатывается весь аудиосигнал с использованием ядра речевого кодера при игнорировании аудиосигнала и, в частности, источника аудиосигнала. В силу этого, если акустический сигнал не является речевым, корневой кодер вносит ощутимые артефакты кодирования, и в результате частотно-селективное коммутирующее устройство (FSS) 1816 на фиг.18 обеспечит полное кодирование всего аудиосигнала с использованием ядра расширенного кодера ААС 1804. Таким образом, в этом случае в битстрим включены пустой выход речевого корневого кодера и дополнительный перцептуально закодированный вариант звукового сигнала. Это ведет не только к непроизводительному сужению полосы частот пропускания при передаче, но и к повышению неэффективного энергопотребления, что представляет отдельную проблему, когда речь идет о кодировании в устройствах мобильной связи, потребляющих энергию от элементов питания, энергоресурс которых ограничен. В основном перцепционный кодер-преобразователь игнорирует источник акустического сигнала, благодаря чему на его выходе (при умеренном битрейте) все возможные источники сигналов генерируются с малым количеством артефактов кодирования, в то время как при наличии нестационарных составляющих сигнала скорость передачи данных увеличивается, так как эффективность порога маскирования снижается по сравнению со стационарными аудиосигналами. Кроме того, в силу противоречия между временным и частотным разрешением, свойственного для преобразующих аудиокодеров, такая система кодирования представляет определенные трудности в отношении переходных или импульсных составляющих сигнала, поскольку эти элементы сигнала требуют высокой разрешающей способности по времени и не требуют высокого разрешения по частоте. При этом речевой кодер является характерным примером способа кодирования, целиком базирующегося на модели источника звука. Таким образом, речевой кодер идентичен модели источника голосовых сигналов и в силу этого предназначается для обеспечения высокоэффективного параметрического представления звуковых сигналов, имеющих источник, похожий на модель акустического источника, представленную алгоритмом кодирования. Звуки, имеющие источник, не соответствующий модели источника речевого кодера, на выходе содержат значительные артефакты или при возможности увеличения битрейта будут иметь резко возросший битрейт, значительно превышающий битрейт обычного аудиокодера. Цель данного изобретения - усовершенствованный метод кодирования звука, объединяющий в себе преимущества специализированного кодера и кодера общего назначения с максимально возможным устранением их недостатков.
Эта задача решается с использованием аудиокодера в соответствии с пунктом 1 формулы изобретения, способа кодирования звука в соответствии с пунктом 24, декодера закодированного аудиосигнала в соответствии с пунктом 25, способа декодирования в соответствии с пунктом 32, расширенного аудиосигнала в соответствии с пунктом 33 или компьютерной программы по пункту 34. Данное изобретение основано на заключении, что выделение импульсов из аудиосигнала обеспечивает высокоэффективное и высококачественное кодирование звука. В результате выделения импульсов из аудиосигнала образуются, с одной стороны, импульсный аудиосигнал и, с другой стороны, разностный сигнал, соответствующий аудиосигналу без импульсов. Импульсный аудиосигнал может быть закодирован импульсным кодером, таким как высокоэффективный голосовой кодер, который при чрезвычайно низких скоростях передачи данных обеспечивает голосовые сигналы высокого качества. Одновременно разностный сигнал, освобожденный от импульсоподобной составляющей, в основном содержит стационарную составляющую первоначального акустического сигнала. Такой сигнал близко соответствует параметрам кодера сигнала, например, общего назначения, и предпочтительно преобразующего аудиокодера с перцептуальным управлением. Закодированный сигнал импульсного типа и закодированный разностный сигнал поступают на выходной интерфейс. Эти два кодированных сигнала могут поступить на выходной интерфейс в любом реализуемом формате, который, однако, не обязательно должен быть масштабируемым, поскольку закодированный одиночный разностный сигнал или закодированный одиночный импульсный сигнал могут при определенных условиях не иметь существенное значение. Только оба сигнала вместе обеспечивают высококачественный акустический сигнал. Однако, с другой стороны, точное управление битрейтом такого комбинированного кодированного аудиосигнала может осуществляться при предпочтительном использовании импульсного аудиокодера с фиксированным битрейтом, например CELP или ACELP, где скорость передачи данных поддается жесткому контролю. Вместе с тем, при осуществлении кодера сигнала, например, в формате МР3 или МР4 управление им ведется в режиме постоянного битрейта, несмотря на то, что он выполняет функцию перцептуального кодирования, для которого изначально характерен переменный битрейт, что основано на реализации битового резервуара в кодерах стандарта MP3 или МР4. Таким образом обеспечивается постоянная скорость передачи закодированного выходного сигнала.
В силу того что остаточный аудиосигнал больше не содержит проблемные импульсные составляющие, скорость передачи закодированного разностного сигнала снижается благодаря тому, что этот разностный сигнал оптимизирован для кодера.
При этом импульсный кодер работает бесперебойно и эффективно, поскольку на него поступает сигнал, специально сформированный и выделенный из акустического сигнала так, чтобы полностью соответствовать модели источника для импульсного кодера. Следовательно, если селектор импульсов не обнаруживает в аудиосигнале импульсные составляющие, импульсный кодер остается незадействованным и не кодирует никакие другие элементы сигнала, не предназначенные для кодирования кодером импульсных сигналов. По этой же причине кодер импульсного типа не кодирует импульсный сигнал и не влияет на скорость вывода элементов сигналов в случае, если этот кодер импульсного типа требует высокий битрейт или не в состоянии обеспечить выходной сигнал допустимого качества. Особенно важно, что при приложении к мобильным устройствам в таких ситуациях импульсный кодер также не нуждается в потреблении энергоресурса. Так, кодер импульсного типа включается только тогда, когда аудиосигнал содержит импульсную составляющую, и импульсная составляющая, выбранная экстрактором импульса, полностью соответствует ожиданиям импульсного кодера.
Таким образом, при распределении акустического сигнала между двумя различными алгоритмами кодирования реализуется функция комбинированного кодирования, основное преимущество которой состоит в том, что кодер сигнала работает непрерывно, а кодер импульса действует как своего рода резервный блок, который активизируется, обеспечивает вывод данных и, соответственно, потребляет энергию, только когда сигнал включает в себя импульсные составляющие.
Импульсный кодер преимущественно предназначен для кодирования периодических последовательностей импульсов, называемых также "импульсными цугами". Эти "импульсы" или "цуги импульсов" представляют собой типовые шаблоны, полученные путем моделирования речевого тракта человека. Каждая импульсная последовательность включает в себя импульсы с временными интервалами между ними. Такой временной интервал называется "импульсным интервалом", и этот показатель соответствует "частоте основного тона" голосового сигнала.
Далее рассматриваются предпочтительные варианты осуществления данного изобретение в сопровождении иллюстративного материала, где:
на фиг.1 представлена блок-схема конструктивного решения аудиокодера в соответствии с настоящим изобретением;
на фиг.2 представлена блок-схема декодера, предназначенного для расшифровки кодированного аудиосигнала;
на фиг.3A представлено конструктивное решение в виде разомкнутого контура;
на фиг.3B представлен вариант конструктивного решения декодера;
на фиг.4А представлен вариант конструктивного решения кодера с разомкнутым контуром;
на фиг.4B представлен вариант конструктивного решения кодера с замкнутым контуром;
на фиг.4C представлено конструктивное решение, в котором селектор импульсов и кодер импульсов реализованы в структуре модифицированного кодера с линейным предсказанием, управляемым алгебраическим кодом ACELP;
на фиг.5А форма сигнала речевого сегмента во временной области представлена как сегмент импульсообразного сигнала;
на фиг.5B представлен спектр сегмента фиг.5А;
на фиг.5C представлен сегмент невокализованной речи во временной области как пример стационарного сегмента;
на фиг.5D показан спектр формы сигнала временной области фиг.5C;
на фиг.6 представлена блок-схема CELP-кодера синтеза;
на фиг. с 7А по 7D вокализованные и невокализованные сигналы возбуждения представлены в виде схем импульсообразных и стационарных сигналов;
на фиг.7Е представлена LPC-фаза кодера, на которой формируются данные краткосрочного предсказания и сигнал ошибки предсказания;
на фиг.8 представлен предпочтительный вариант конструктивного решения кодера с разомкнутым контуром фиг.4А;
на фиг.9А показана форма реального импульсного сигнала;
на фиг.9B представлен сигнал импульсного типа, улучшенный или оптимизированный на стадии усовершенствования импульсных характеристик на фиг.8;
на фиг.10 представлен усовершенствованный алгоритм CELP, реализуемый в рамках конструктивного решения на фиг.4C;
на фиг.11 представлен частный случай реализации алгоритма фиг.10;
на фиг.12 представлен частный случай реализации алгоритма фиг.11;
на фиг.13 представлен еще один вариант усовершенствованного алгоритма CELP в рамках конструктивного решения на фиг.4C;
на фиг.14 показаны непрерывный режим работы декодера сигналов и нестационарный режим работы импульсного декодера;
на фиг.15 представлено конструктивное решение кодера, в котором кодер сигнала включает в себя психоакустическую модель;
на фиг.16А представлен алгоритм кодирования/декодирования МР3 или МР4;
на фиг.16B представлен алгоритм кодирования с использованием входного фильтра;
на фиг.16C представлен алгоритм кодирования с использованием выходного фильтра;
на фиг.17А дана схема кодера с линейным предсказанием LPC;
на фиг.17B дана схема декодера с линейным предсказанием LPC;
на фиг.17C дана схема кодера, в котором реализован алгоритм коммутируемое кодирование с динамически регулируемым LPC-фильтром деформированным частотным разрешением;
на фиг.18 дана схема масштабируемого кодера MEPG-4;
на фиг.19 дана схема масштабируемого декодера MPEG-4; и
на фиг.20 дана принципиальная схема аудиокодера ARDOR.
Преимущество представляемых ниже технических решений заключается в том, они обеспечивают реализацию комбинированного метода, который расширяет функциональные возможности аудиокодера перцептуального типа, позволяя не только кодировать с оптимальным качеством сигналы общих звуковых частот, но и значительно повысить качество кодирования голосовых сигналов. Более того, они дают возможность избегать затруднения, связанные с быстрой коммутацией между режимом кодирования обычного звука (например, с использованием банков фильтров) и режимом голосового кодирования (например, с применением алгоритма CELP), описанными выше. Напротив, описываемые ниже варианты исполнения предусматривают ритмичное/бесперебойное комбинирование рабочих режимов и средств кодирования и достижение благодаря этому более плавного перехода/смешивания разнотипных сигналов.
Обоснованием представленных далее к рассмотрению конструктивных решений служат следующие соображения.
Общеизвестные аудиокодеры перцептуального типа, в которых используются банки фильтров, хорошо служат для воспроизведения сигналов, которые могут иметь достаточно сложную частотную структуру, но быть весьма статичными во времени. Кодирование переходных или импульсоподобных сигналов с помощью кодеров на базе банков фильтров приводит к размазыванию искажения кодирования во времени и в силу этого может вызывать артефакты предэха.
Значительная часть голосовых сигналов состоит из серий импульсов, продуцируемых человеческой голосовой щелью во время вокализованной речи с определенной частотой основного тона голоса. Поэтому структуры таких последовательностей импульсов представляют трудность при кодировании перцепционными аудиокодерами на базе банков фильтров на низких битрейтах.
В силу этого, чтобы достичь оптимального качества сигнала при использовании системы кодирования с применением банков фильтров, рекомендуется разложить входной сигнал кодера на импульсоподобные конструкции и другие, более стационарные составляющие. Импульсообразные структуры могут кодироваться специально предназначенным ядром кодирования (далее именуемым кодером импульсов), тогда как другие остаточные компоненты могут быть закодированы стандартным перцепционным аудиокодером на базе банков фильтров (далее именуемым кодером остатков). Кодер импульсов в основном состоит из функциональных блоков традиционных схем кодирования речи, таких как LPC-фильтр, с использованием информации о положении импульсов и т.д. и таких вспомогательных средств, как кодовые словари возбуждения, линейное предсказание с кодовым возбуждением CELP и т.п. Процесс разделения входного сигнала кодера должен отвечать двум условиям.
(Условие №1) Характеристики импульсоподобного сигнала для ввода в кодер импульсов.
Входной сигнал кодера импульсов предпочтительно должен включать в себя импульсные образования во избежание генерирования нежелательных искажений, так как кодер импульсов целенаправленно оптимизирован для пересылки импульсных структур, а не стационарных (или тональных) составляющих сигнала. Иначе говоря, ввод в кодер импульсов тональных составляющих сигнала приведет к искажениям, которые не могут быть легко компенсированы кодером на базе банков фильтров.
(Условие №2) Однородная во времени разностная составляющая выхода кодера импульсов, предназначенная для кодера разности.
Остаточный сигнал, кодируемый кодером остатков, преимущественно должен быть сгенерирован так, чтобы после разделения входного сигнала разностный сигнал был стационарным во времени даже в те моменты, когда кодер импульсов кодирует импульсы. В частности, требуется, чтобы огибающая времени разностной составляющей формировалась без "дыр".
В отличие от вышеупомянутых схем коммутирования при кодировании, благодаря параллельному, то есть одновременному, задействованию кодеров (кодера импульсов и кодера разности) и ассоциированных с ними декодеров, при необходимости достигается непрерывное координированное взаимодействие между кодированием импульса и кодированием остатков. Конкретно, рекомендуется такой режим, при котором кодер остатков постоянно находится в рабочем состоянии, в то время как кодер импульсов активизируется только, когда его работа считается целесообразной.
Согласно предлагаемой концепции для достижения максимальной эффективности работы входной сигнал должен быть расчленен на составляющие, которые оптимально адаптируются к параметрам соответствующего подкодера (кодера импульсов и кодера разностей). Далее в предпочтительных версиях исполнения принято следующее.
Одним из составных кодеров является аудиокодер на базе банков фильтров (однотипный общепринятым перцепционным аудиокодерам). Как следствие, этот составной кодер предназначается для обработки стационарных и тональных акустических сигналов (на спектрограмме соответствующих "горизонтальным построениям"), а не для аудиосигналов, которые включают в себя множество нестационарностей во временной области, таких как переходные состояния, пороги срабатывания или импульсы (которые на спектрограмме представлены "вертикальными построениями").
Попытка кодирования таких сигналов кодером на базе банков фильтров ведет к смазыванию во времени, предэхам и реверберации выходного сигнала.
Второй составной кодер представляет собой кодер импульсов, работающий во временной области. В силу этого данный составной кодер предназначается для обработки звуковых сигналов, которые имеют в своем составе множество нестационарных составляющих временной области, таких как переходные состояния, пороги срабатывания или импульсы (отображаемых на спектрограммах "вертикальными построениями"), а не для представления стационарных и тональных аудиосигналов (отображаемых на спектрограммах "горизонтальными построениями"). Попытка кодирования таких сигналов кодером импульсов временной области ведет к искажениям тональных составляющих сигнала или резкому звучанию из-за разрежения во временной области.
Декодированные выходные данные обоих аудиодекодеров суммируются для получения совокупного декодированного сигнала (при условии, что и импульсный кодер, и кодер на базе банков фильтров работают одновременно).
На фиг.1 представлена принципиальная схема аудиокодера, предназначенного для кодирования аудиосигнала 10, содержащего импульсную составляющую и стационарную составляющую. Как правило, различие между импульсной составляющей аудиосигнала и стационарной составляющей стационарного сигнала может быть установлено с помощью обработки сигналов, при которой измеряются импульсная и стационарная характеристики. Подобные измерения могут быть выполнены, например, путем анализа формы аудиосигнала. С этой целью может быть выполнено любое преобразование, например LPC-кодирование. Определить интуитивно, носит ли составляющая сигнала импульсный характер, можно, в частности, рассмотрев форму сигнала временной области и установив, равные или неравные интервалы между пиками имеет эта форма сигнала временной области, причем равные интервалы между пиками более приемлемы для кодера речи.
Для иллюстрации можно обратиться к фиг.5А-5D. Здесь показаны образцы сегментов или составляющих сигнала импульсного типа и образцы сегментов или составляющих стационарного сигнала. Так, в качестве образца составляющей импульсного сигнала приведен фрагмент озвученной речи, который на фиг.5А представлен во временной области, а на фиг.5B - в частотной области, и в качестве образца составляющей стационарного сигнала на фиг.5С и 5D приведен сегмент неозвученной речи. В целом, речь может быть классифицирована на вокализованную (озвученную), невокализованную (неозвученную) и смешанную. Графики отсчетов вокализованной и невокализованной речи в частотно-временной области показаны на фиг. с 5А по 5D. Вокализованная речь квазипериодична во временной области и гармонически структурирована в частотной области, в то время как невокализованная речь является неупорядоченной и широкополосной. Кроме того, энергия вокализованных сегментов, как правило, выше энергии невокализованных сегментов. Кратковременный спектр озвученной речи характеризуется формантной и тонкой структурой. Тонкая гармоническая структура является следствием квазипериодичности речи и может быть отнесена на счет вибрации голосовых связок. Формантная структура (огибающая спектра) обусловлена взаимодействием источника и речевого тракта. Речевой тракт составляют глотка и полость рта. Конфигурация огибающей спектра, "совпадающая" с кратковременным участком спектра вокализованной речи, зависит от характеристик передачи через речевой тракт и угла наклона спектра (6 дБ на октаву) под воздействием импульса зоны голосообразования. Огибающая спектра характеризуется рядом пиков, называемых формантами. Форманты представляют собой резонансные режимы речевого тракта. Средний речевой тракт формирует от трех до пяти формант ниже 5 кГц. Амплитуды и позиции первых трех формант, которые обычно ниже 3 кГц, важны как для синтеза речи, так и для восприятия. Верхние форманты важны также для воспроизведения широкополосной и неозвученной речи. Параметры речи имеют следующую зависимость от физической системы речеобразования. Вокализованная речь возникает при возбуждении речевого тракта квазипериодическими глоттальными воздушными импульсами, генерируемыми за счет вибрации голосовых связок. Частоту периодического импульса называют основной частотой или высотой тона. Неозвученную речь формируют путем форсированного пропускания потока воздуха через сужения в речевом тракте. Носовые звуки образуют за счет акустического взаимодействия носового и речевого трактов, а взрывные согласные звуки произносят путем резкого высвобождения воздушного потока под давлением, создаваемым позади препятствия, образуемого в тракте.
Таким образом, стационарная составляющая акустического сигнала может быть стационарной составляющей во временной области, как показано на фиг.5C, или стационарной составляющей в частотной области, которая отличается от импульсной составляющей, как видно, в частности, на фиг.5А, в силу того что стационарная составляющая во временной области не образует резкие повторяющиеся импульсы. При этом, как будет в общих чертах изложено позднее, стационарные составляющие и импульсные составляющие могут быть дифференцированы также посредством методов LPC, с помощью которых моделируются речевой тракт и возбуждение речевых трактов. При представлении сигнала в частотной области у сигналов импульсного типа заметно проявляются индивидуальные форманты, то есть выделяющиеся пики на фиг.5B, в то время как стационарный спектр является выраженно белым, как показано на фиг.5D, или в случае гармонических сигналов имеет довольно продолжительный минимальный уровень шума с несколькими преобладающими пиками, отображающими специфические тональные сигналы, которые могут встретиться, например, в музыкальном сигнале, но между которыми нет таких равномерных интервалов, как между импульсными сигналами на фиг.5B.
Кроме того, импульсоподобные составляющие и стационарные составляющие могут встречаться спорадически, что означает, что одна часть аудиосигнала во времени стационарна, а другая часть аудиосигнала во времени импульсообразна. И наоборот или вместе с тем, характеристика сигнала может быть различной в разных полосах частот. Поэтому звуковой сигнал можно определить как стационарный или как импульсный, кроме того, и частотно-избирательным путем так, что отдельная частотная полоса или несколько отдельных частотных полос будут рассматриваться как стационарные, а другие частотные полосы будут рассматриваться как импульсообразные. В подобном случае некоторая временная составляющая акустического сигнала может включать в себя и импульсный элемент, и стационарный элемент.
Версия кодера на фиг.1 содержит селектор импульсов 10 для выделения из аудиосигнала импульсной составляющей. В селектор импульсов 10 введен кодер импульсов для кодирования импульсного компонента с целью получения закодированного импульсного сигнала. В дальнейшем будет показано, что выделение импульса и собственно кодирование могут быть разделены между собой или скомбинированы с образованием общего алгоритма, такого как ACELP (линейного предсказания с управлением алгебраическим кодом) в видоизмененной форме, как описано в контексте фиг.4C.
На выход селектора импульсов 10 поступает закодированный импульсный сигнал 12 и, в некоторых реализациях, дополнительная служебная информация в виде параметров экстракции импульса или кодирования импульса.
Помимо этого, вариант реализации кодера на фиг.1 включает в себя кодер сигнала 16 для кодирования остаточного сигнала 18 аудиосигнала 10 с получением кодированного разностного сигнала 20. А именно, при получении остаточного сигнала 18 из аудиосигнала 10 импульсные составляющие аудиосигнала сокращаются или полностью удаляются. При этом звуковой сигнал продолжает содержать стационарную составляющую, так как селектор импульсов 10 ее не выделяет.
Далее, относящийся к изобретению аудиокодер включает в себя интерфейс 22 вывода кодированного импульсного сигнала 12, кодированного разностного сигнала 20 и при наличии сопутствующей информации 14 совокупно образующих кодированный сигнал 24. Для формирования полезного сигнала выходной интерфейс 22 не должен быть интерфейсом масштабируемого потока данных, который записывался бы таким образом, что закодированный разностный сигнал и закодированный импульсный сигнал могли быть декодированы независимо друг от друга. Вследствие того что ни кодированный импульсный сигнал, ни кодированный разностный сигнал не являются акустическими сигналами приемлемого качества, независимое воспроизведение одного сигнала без другого в предпочтительных вариантах осуществления не рекомендуется. В силу этого выходной интерфейс 22 может обеспечивать эффективный вывод двоичных данных, пренебрегая параметрами потока данных и его масштабируемостью при декодировании.
Предпочтительный вариант реализации относящегося к изобретению аудиодекодера включает в себя генератор разностного сигнала 26. Генератор разностного сигнала 26 принимает аудиосигнал 10 и параметры 28 выбранных импульсных составляющих сигнала и выводит разностный сигнал 18, который не содержит выбранные составляющие сигнала. В зависимости от конструктивного решения генератор разностного сигнала 26 или кодер сигнала 16 могут выдавать дополнительную информацию. Тем не менее, вывод и передача сопутствующей информации 14 не обязательны, поскольку декодер может иметь предварительно заданную конфигурацию, на базе которой кодер, работая как компонент изобретения, не должен в принудительном порядке генерировать и передавать какую-либо дополнительную служебную информацию. Однако, если в режимах работы кодера или декодера предусмотрена определенная гибкость или если генератор разностного сигнала рассчитан на выполнение дополнительных - помимо вычитания - функций, декодеру может потребоваться служебная информация, чтобы он, и в особенности комбинатор в его составе, игнорировал составляющие декодированного разностного сигнала, введенные со стороны кодера исключительно с целью формирования равномерного и неимпульсообразного разностного сигнала без разрывов.
На фиг.2 представлен предпочтительный вариант осуществления декодера, предназначенного для декодирования кодированного аудиосигнала 24, который представляет собой сигнал выходного интерфейса 22. Обычно кодированный аудиосигнал 24 состоит из кодированного импульсного сигнала и кодированного разностного сигнала. Декодер может включать в себя входной интерфейс 28 для извлечения из кодированного аудиосигнала 24 кодированного импульсного сигнала 12, кодированного разностного сигнала 20 и служебной информации 14. Кодированный импульсный сигнал 12 вводится в импульсный декодер 30 для декодирования с использованием алгоритма, соответствующего алгоритму кодирования генерируемого импульсного сигнала, то есть алгоритму кодирования, используемому в блоке 10 на фиг.1. Кроме того, декодер на фиг.2 включает в себя декодер 32 для декодирования кодированного разностного сигнала с использованием алгоритма декодирования, соответствующего алгоритму кодирования генерируемого разностного сигнала, то есть алгоритму кодирования, используемому в блоке 16 на фиг.1. Выходные сигналы обоих декодеров 30 и 32 вводятся в комбинатор сигналов 34, где декодированный импульсный сигнал и декодированный разностный сигнал совмещаются для получения декодированного выходного сигнала 36. В частности, декодер сигнала 32 и декодер импульса 30 рассчитаны на обеспечение одновременного вывода отдельных составляющих выходных значений декодированных аудиосигналов, относящихся к одному моменту времени.
Эта характеристика проиллюстрирована с помощью фиг.14. На фиг.14 схематично показан выход 140 декодера сигнала 32. На фиг.14 видно, что данные 140 декодера сигнала выводятся непрерывно. Это означает, что декодер сигнала (и соответствующий кодер сигнала) работает в постоянном режиме, бесперебойно обеспечивая выходной сигнал, пока на вход поступает звуковой сигнал. Естественно, по окончании фонограммы, при прекращении поступления входного сигнала для кодирования, декодер сигнала также прекращает генерировать выходной сигнал.
Во втором уровне на фиг.14 показан выходной сигнал импульсного декодера 142. Особое внимание на фиг.14 следует обратить на временные отрезки 143, в которые отсутствует выходной сигнал импульсного декодера, поскольку в них первоначальный звуковой сигнал не содержал стационарные составляющие. При этом в другие интервалы времени сигнал имеет стационарные составляющие и/или импульсные составляющие, причем импульсные составляющие генерирует декодер импульсного типа. Следовательно в отрезки времени 142 выходные значения генерируются обоими декодерами одновременно. Однако в моменты времени 143 в общем выходном сигнале содержится только продукт декодера остаточного сигнала и совсем не содержится выходной сигнал импульсного декодера.
На фиг.3A представлена рекомендуемая реализация кодера в варианте так называемого разомкнутого контура. Селектор импульсов 10 включает в себя основной селектор импульсов, генерирующий незакодированный импульсный сигнал, обозначенный линией 40. Селектор импульсов обозначен как 10а. Импульсный сигнал 40 пересылается на кодер импульсов 10b, который формирует на выходе закодированный импульсный сигнал 12. Параметры импульсного сигнала, передаваемые по линии 28, соответствуют незакодированному импульсному сигналу, извлеченному селектором импульсов 10а. На фиг.3A генератор остаточного сигнала 26 выполнен в виде устройства вычитания некодированного импульсного сигнала, проходящего по линии 28, из аудиосигнала 10 с получением разностного сигнала 18.
Аудиокодер сигнала 16 рекомендуется реализовывать на базе банка фильтров, что наиболее применимо для кодирования разностного сигнала, который уже не содержит импульсные составляющие или в котором импульсные составляющие понижены относительно исходного акустического сигнала 10. Таким образом, исходный аудиосигнал проходит первый этап 10а преобразования во входные сигналы составных кодеров. А именно, алгоритм разделения применяется для генерирования выходных сигналов по линиям 40 и 18, что удовлетворяет ранее рассмотренным условиям 1 (подача на кодер импульсов сигналов импульсного типа) и 2 (подача на кодер разностного сигнала временно выравненного остаточного сигнала). Таким образом, как показано на фиг.3A, селектор импульсов 10а выделяет импульсный сигнал из входного аудиосигнала 10.
Разностный сигнал 18 образуется путем исключения импульсного сигнала из входного аудиосигнала. Исключение может быть выполнено вычитанием, как показано на фиг.3A, или другими способами, например заменой импульсного участка аудиосигнала меньшим импульсным ("сглаженным") сигналом, который может быть выделен из первоначального акустического сигнала 10 соответствующим масштабированием во времени или интерполяцией в левую или правую сторону от импульсного участка. На последующих параллельно проходящих этапах кодирования 10b, 16 импульсный сигнал (при его наличии) кодируется специальным кодером импульсов 10b, а разностный сигнал кодируется преимущественно аудиокодером на базе банка фильтров 16.
При другом рекомендуемом варианте осуществления изобретения, в случае распознания временной составляющей аудиосигнала как импульсообразной (импульсоподобной), простое исключение этой временной составляющей и ее кодирование только импульсным кодером приводит к образованию разрыва в остаточном сигнале, поступающем на кодер обычных сигналов. Во избежание образования подобного разрыва, нарушающего работу кодера обычного сигнала, синтезируется сигнал-заполнитель этого "разрыва". Как будет разъяснено позже, такой сигнал может представлять собой сигнал интерполяции или взвешенный вариант исходного сигнала или шумовой сигнал, обладающий определенной энергией.
Одно из конструктивных решений предусматривает вычитание этого интерполированного/синтезированного сигнала из "исключенной" импульсной составляющей сигнала таким образом, что на кодер импульсов поступает только разность этого вычитания (также являющаяся импульсным сигналом). Благодаря такому конструктивному решению выход кодера разности и выход декодера импульсов могут быть совмещены для выработки декодером общего декодированного сигнала. При этом варианте все сигналы, получаемые обоими выходными декодерами, безотказно принимаются и совмещаются, формируя выходной сигнал, причем выбраковка сигнала на выходе любого из обоих декодеров исключена.
Позже будут рассмотрены варианты реализации генератора разностного сигнала 26 на принципах, отличных от вычитания.
Как сказано выше, возможно переменное по времени масштабирование аудиосигнала. В частности, при обнаружении импульсной составляющей аудиосигнала для масштабирования отсчетов во временной области этого аудиосигнала может быть применен масштабный коэффициент со значением меньше 0,5 или, например, даже меньше 0,1. В результате снижается энергия разностного сигнала во временном интервале, где аудиосигнал имеет форму импульса. При этом вместо простого обнуления оригинального аудиосигнала в интервале времени, когда он имеет форму импульса, генератор разностного сигнала 26 обеспечивает отсутствие в остаточном сигнале "разрывов", которые представляют собой нестационарности, осложняющие работу аудиокодера на базе банков фильтров 16. С другой стороны, закодированный разностный сигнал в момент импульсного состояния, когда он представляет собой исходный звуковой сигнал, умноженный на небольшой коэффициент масштабирования, не может быть обработан декодером или может быть обработан лишь в малой степени. Сообщение об этом событии может содержаться в сопутствующей служебной информации 14. Следовательно, бит протокольных данных, формируемый подобным генератором разностного сигнала, может содержать указание на то, какой масштабный коэффициент был использован для понижающего масштабирования импульсной составляющей аудиосигнала или какой масштабный коэффициент должен быть использован декодером для корректной реконструкции исходного аудиосигнала после раскодирования его отдельных составляющих.
Другой способ генерации разностного сигнала состоит в исключении импульсной составляющей исходного акустического сигнала и интерполяции изъятого участка с использованием аудиосигнала в начале или в конце импульсной составляющей для формирования непрерывного аудиосигнала, который при этом уже не является импульсообразным. Параметры интерполяции также могут содержаться в специальном бите служебной информации 14, включающей в себя характеристики кодирования импульса или кодирования сигнала или генерирования остаточного сигнала. Комбинатор в составе декодера может полностью исключить или, по крайней мере, до определенной степени ослабить раскодированный интерполированный элемент. Требуемые показатели могут быть заданы с помощью сопутствующих протокольных данных 14.
В дополнение к этому рекомендуется дополнять разностный сигнал функцией плавного нарастания и затухания. В силу этого коэффициент изменяющегося во времени масштабирования не просто устанавливается на некое малое значение, но постепенно до него снижается, а в конце импульсной составляющей или при приближении к такому концу низкий масштабный коэффициент постепенно возрастает до расчетного показателя, то есть до невысокого коэффициента масштабирования 1, заданного для составляющей аудиосигнала, не имеющей импульсные характеристики.
На фиг.3B представлена схема декодера, который соответствует кодеру на фиг.3A, где декодер звукового сигнала 32 с фиг.2 реализован на базе банка фильтров и где комбинатор сигнала 34 реализован как сумматор отсчетов.
И наоборот, выполняемое комбинатором сигнала 34 совмещение может быть выполнено также в частотной области или в подполосовой области при условии, что импульсный декодер 30 и аудиодекодер на базе банков фильтров 32 генерируют выходные сигналы в частотной или подполосовой области.
Кроме того, комбинатор 34 не обязательно должен суммировать отсчеты, им можно управлять посредством служебной информации 14, как пояснялось в связи с фиг.1, 2 и 3A, для масштабирования во времени с целью компенсации процессов нарастания и затухания, выполняемых кодером, и для обработки составляющих сигнала, сгенерированных кодером для выравнивания разностных сигналов, например, с помощью вставки, интерполяции или переменного по времени масштабирования. Если генератор разностного сигнала 26 предусматривает вычитание отсчетов, как показано на фиг.3A, комбинатору 34 в составе декодера не требуется сопутствующая служебная информация, а для суммирования отсчетов ему не требуются такие дополнительные преобразования, как наплыв, затухание или масштабирование сигнала.
Что касается сигналов вокализованной речи, сигналы возбуждения, то есть импульсы голосовой щели, проходят в речевом тракте человека процесс фильтрации, который может быть инвертирован фильтром LPC. Поэтому перед началом процедуры выборки соответствующих глоттальных (гортанных) импульсов, как правило, выполняется LPC-анализ, а перед расчетом остаточного сигнала - LPC-синтез, как показано на фиг.4а, что представляет собой реализацию в виде разомкнутого контура.
А именно, звуковой сигнал 8 поступает в блок анализа LPC 10а. Блок анализа LPC генерирует реальный импульсный сигнал, как, например, показано на фиг.9А. Далее реальный импульсный сигнал проходит фазу выделения импульса 10c, что видно, например, на фиг.9А, на выходе которой формируется совершенный импульсный сигнал, или импульсный сигнал, по крайней мере, более совершенный, чем реальный импульсный сигнал на входе селектора импульсов 10c. Затем этот импульсный сигнал поступает в кодер импульсов 10b. Кодер импульсов 10b формирует высококачественное представление входного импульсного сигнала, поскольку он специально предназначен для обработки таких импульсных сигналов и благодаря тому, что входной импульсный сигнал 48 идеален, или почти идеален. В варианте реализации на фиг.4А импульсный сигнал 48, соответствующий "параметрам импульсного сигнала" 28 на фиг.1, вводят в синтезатор LPC 26b для "преобразования" идеального импульсного сигнала, существующего в "области LPC", обратно во временную область. Далее выходной сигнал синтезатора LPC 26b вводится в вычитатель 26а для генерирования разностного сигнала 18, который представляет собой исходный аудиосигнал, который при этом не содержит импульсную составляющую, представленную идеальным импульсным сигналом 48 или 28. Таким образом, генератор разностного сигнала 26 на фиг.1 реализован на фиг.4А в виде синтезатора LPC 26b и вычитатель 26а.
Назначение и функциональные возможности анализатора LPC 10а и синтезатора LPC 26b более подробно будут рассмотрены ниже применительно к фиг. с 7А по 7Е, фиг.8 и фиг.9А-9B.
На фиг.7А схематически представлена модель линейной системы речеобразования. Эта система предполагает двухступенчатое возбуждение, то есть импульсный цуг для вокализованной речи на фиг.7А и случайные помехи для невокализованной речи на фиг.7D. Речевой тракт смоделирован как всеполюсный преобразующий фильтр 70, который обрабатывает импульсы, данные на фиг.7С или фиг.7D, сгенерированные глоттальной моделью 72. Всеполюсная передаточная функция формируется каскадом нескольких двухполюсных резонаторов формант. Модель голосообразования представляет собой двухполюсный фильтр нижних частот, а модель губного звукоиспускания 74 представлена как L(z)=1-z-1. И, наконец, коэффициент коррекции спектра 76 введен для компенсации низкочастотных эффектов высших полюсов. При передаче индивидуальных особенностей речи фаза коррекции спектра опускается, при этом нулевая установка функции губного звукоизлучения в значительной степени компенсируется одним из глоттальных полюсов. Таким образом, конфигурация фиг.7А может быть приведена к всеполюсной модели, показанной на фиг.7B, включающей в себя фазу усиления 77, канал прямой связи 78, канал обратной связи 79 и операцию суммирования 80. Канал обратной связи 79 включает в себя фильтр прогнозирования 81, при этом полностью модель для синтеза акустического истока, схема которой дана на фиг.7B, может быть представлена с помощью функций z-области следующим образом: S(z)=g/(1-A(z))·X(z), где g - коэффициент усиления (выигрыша от) предсказания, A(z) - фильтр с предсказанием, определяемый анализом LPC, X(z) - сигнал возбуждения и S(z) - выходной сигнал синтезированной речи.
На фиг.7C и 7D представлены графики синтезированной вокализованной и невокализованной речи во временной области с использованием линейной модели акустического источника. Акустический источник и параметры возбуждения в приведенном выше уравнении неизвестны и должны быть выведены из конечного множества речевых отсчетов. Коэффициенты A(z) получают посредством линейного предсказания. В начальном линейном предикторе p-порядка данный отсчет речевой последовательности предсказывается с использованием линейной комбинации t предшествующих отсчетов. Коэффициенты предиктора могут быть определены с помощью известных алгоритмов, таких как алгоритм Левинсона-Дарбина, или общепринятого метода автокорреляции или метода отражения.
На фиг.7Е представлена более детальная схема реализации блока анализа линейно-предиктивного кодирования LPC 10а на фиг.4А. Аудиосигнал вводится в блок определения параметров фильтра A(z). Эти данные выводятся в виде краткосрочного предсказания, необходимого для декодера. В варианте исполнения на фиг.4А данные краткосрочного предсказания могут быть использованы для выходного сигнала кодера импульсов. Однако, когда требуется только сигнал ошибки предсказания 84, в выводе информации краткосрочного предсказания нет необходимости. Тем не менее, данные краткосрочного предсказания требуются действующему фильтру прогнозирования 85. В вычитатель 86 вводится текущий отсчет аудиосигнала, где производится вычитание предсказанного значения текущего отсчета, в результате чего для этого отсчета генерируется сигнал ошибки предсказания 84. Последовательность таких отсчетов сигнала ошибки предсказания схематично изображена на фиг.9А, где для упрощения опущены элементы питания и т.д. В силу этого график на фиг.9А можно рассматривать как разновидность импульсного сигнала.
Далее будет подробнее рассмотрена фиг.8. Фиг.8 аналогична фиг.4А, но на ней блоки 10а и 26b представлены более детально. Рассмотрим дополнительно основные функции звена оптимизации импульсных характеристик 10С. Фаза LPC-анализа 10а на фиг.8 может быть осуществлена в варианте, детально отображенном на фиг.7Е, где данные краткосрочного предсказания A(z) вводятся на стадии синтеза 26b, а сигнал ошибки предсказания, являющийся "реальным импульсным сигналом", выводится по линии 84. Если предполагается смешанный сигнал, то есть сигнал, содержащий голосовые и прочие составляющие, реальный импульсоподобный сигнал можно рассматривать как наложение возбуждающих сигналов, показанных на фиг.7C и 7D, которые в сглаженном виде соответствуют графику на фиг.9А. Образуется реальный импульсоподобный сигнал, дополнительно включающий в себя, стационарные составляющие. Эти стационарные составляющие устраняются на стадии оптимизации импульсных характеристик 10с, на выходе которой формируется сигнал, подобный, например, сигналу на фиг.9B. И наоборот, выходной сигнал блока 10с может быть сформирован простой выборкой пиков, то есть выделением из сигнала на фиг.9А импульса, начиная с некоего отсчета слева от пика и кончая некоторым отсчетом справа от пика, с удалением всех отсчетов сигнала между пиками. Это означает, что блок 10с генерирует сигнал, подобный сигналу на фиг.7C, с тем отличием, что импульсы не являются идеальными импульсами Дирака, но имеют определенную ширину импульса. Более того, блок оптимизации импульсной характеристики 10с может преобразовывать пики, формируя у каждого из них одинаковую высоту и форму, что видно на графике фиг.9B.
Сигнал, сгенерированный блоком 10c, идеально соответствует кодеру импульсов 10b, который обеспечивает кодирование, требующее малого битового объема и представляющее идеальный сигнал импульсного типа, не имеющий, или имеющий очень мало, ошибок квантования.
Блок LPC-синтеза 26b на фиг.8 может быть осуществлен в варианте, полностью идентичном всеполюсной модели, представленной на фиг.7B, с единичным усилением или с усилением, отличным от 1, так чтобы передаточная функция, указанная для блока 26b, обеспечивала на выходе блока 10с образ идеального импульсного сигнала во временной области, позволяя блоку 26а комбинировать отсчеты, например вычитать. После этого выходной сигнал блока 26а будет представлять собой разностный сигнал, который в идеальном случае будет содержать только стационарную составляющую аудиосигнала без признаков импульсной составляющей. Любая потеря данных при выполнении блоком 10с операции оптимизации импульсной характеристики, например при селекции пиков, не создает проблем, поскольку такая "ошибка" учтена в разностном сигнале и не вызывает потерь. Однако следует обратить внимание на то, что положения импульсов, выбранных на ступени 10с, точно соответствуют положениям импульсов аудиосигнала 8, благодаря чему совмещение обоих сигналов блоком 26а, особенно при вычитании, дает в результате не два тесно совпадающих импульса, а сигнал без признаков импульса, поскольку импульс был удален из оригинального аудиосигнала 8 при комбинировании в блоке 26а.
Эта особенность дает преимущество при так называемом "открытом контуре" конструкции и может оказаться недостатком при "закрытом контуре", показанном на фиг.4B.
Фиг.4B отличается от фиг.4А тем, что выходной сигнал импульсного кодера вводится в импульсный декодер 26е, который является частью генератора разностного сигнала 26 на фиг.1. Если кодер импульсов 10b вводит в позиции импульсов ошибки квантования и импульсный декодер 26c не компенсирует эти ошибки, то блок 26а в результате выполнения операции вычитания выдает разностный сигнал, который содержит не только оригинальные импульсы исходного аудиосигнала, но и в непосредственной близости от них - сопутствующие импульсы, внесенные при вычитании. Во избежание подобной ситуации для комбинатора 26 может быть предусмотрено выполнение не только вычитания отсчетов, но и анализа выходного сигнала импульсного декодера 26c с целью синхронизации процедуры вычитания.
Кроме того, режим "замкнутого контура" можно рассматривать как каскадное дробление сигнала. Один из двух составных кодеров (предпочтительно кодер импульсов) настраивают на прием соответствующих составляющих входного сигнала (предпочтительно голосообразующих импульсов). При этом на другой кодер-компонент 16 поступает остаточный сигнал, представляющий собой разность между исходным сигналом и декодированным сигналом, полученным от первого кодера-компонента. Первым кодируется и декодируется импульсный сигнал, и квантованный выходной сигнал вычитается из входного аудиосигнала для генерации в режиме замкнутого контура разностного сигнала, который кодируется аудиокодером на базе банков фильтров.
В качестве примера эффективного кодера импульсов могут быть использованы кодеры CELP (линейный предиктивный с кодовым возбуждением) или ACELP (линейный предиктивный с алгебраическим кодовым возбуждением), как показано на фиг.4C, что будет рассмотрено позже. При этом рекомендуется, чтобы в алгоритм CELP или ACELP были внесены изменения, настраивающие кодер на моделирование только импульсных составляющих входного сигнала и исключающие моделирование тональных или очень стабильных составляющих сигнала. Иными словами, если для моделирования импульсных составляющих сигнала уже использован определенный набор импульсов, введение большего числа импульсов для моделирования других компонентов сигнала контрпродуктивно и пагубно отражается на качестве итогового выходного сигнал. Таким образом, соответствующий препроцессор или контроллер, например блок 1000 на фиг.10, останавливает процесс аллокации импульсов сразу же после того, как смоделированы все фактически встречающиеся импульсы.
В дополнение к этому, желательно, чтобы остаточный сигнал после выделения из выходного сигнала кодера импульсов имел достаточно пологую структуру во времени, чтобы удовлетворять условию номер 2, отвечая требованиям кодирования кодером на базе банков фильтров 16 на фиг.4C.
Так, фиг.4С служит иллюстрацией подхода, при котором модифицированный кодер ACELP 10 одновременно выполняет функции селектора импульсов и кодера импульсов. Генератор разностного сигнала 26 на фиг.1 для извлечения импульсных составляющих из аудиосигнала вновь использует вычитатель 26а, тем не менее допустимо применение других методов, например обсуждавшихся ранее выравнивания или интерполяции.
Недостаток разомкнутого контура, представленного на фиг.4b, при котором сигнал сначала разделяется на импульсный сигнал и остаточный сигнал с последующим раздельным кодированием каждой из двух составляющих и с наличием потерь при квантовании как кодером импульсов, так и аудиокодером на базе банков фильтров, заключается в том, что ошибки квантования обоих кодеров необходимо в индивидуальном порядке контролировать и перцептуально оптимизировать. Это происходит вследствие того, что на выходе декодера обе ошибки квантования суммируются.
При этом преимущество разомкнутого контура состоит в том, что при выделении импульса формируется чистый импульсный сигнал, не искаженный ошибками квантования. В силу этого квантование с использованием импульсного кодера не воздействует на разностный сигнал.
При этом оба конструктивных решения могут быть интегрированы для получения некоего гибридного алгоритма. Таким образом, элементы разомкнутого и замкнутого контуров могут быть реализованы совместно.
Как правило, эффективный кодер импульсов обеспечивает квантование как отдельных значений, так и позиций импульсов. Одна из задач смешанного открытого/закрытого контура состоит в использовании значений квантованных импульсов и точных/неквантованных позиций импульсов для вычисления остаточного сигнала. Затем позиция импульса квантуется в режиме разомкнутого контура. С другой стороны, может быть применен итеративный процесс анализа через синтез CELP для выявления сигналов импульсного типа, однако для фактического кодирования импульсного сигнала используется специальный инструментарий кодирования, который выполняет или не выполняет квантование позиций импульсов с небольшой ошибкой квантования.
Далее, в контексте фиг.6, будет рассмотрен кодер CELP, выполняющий "анализ через синтез", для представления изменений, которые необходимо внести в данный алгоритм, что отображено на фиг.10-13. Данный линейный предиктивный кодер с мультикодовым управлением CELP подробно рассматривается в "Speech Coding: А Tutorial Review", Andreas Spanias, Proceedings of the IEEE, Vol.82, No.10, October 1994, pages 1541-1582 ("Кодирование речи: обзор программы обучения", Андреас Спаниас, Научные труды ИИЭЭ, Изд.82, №10, октябрь 1994, с.1541-1582). Кодер CELP, как показано на фиг.6, включает в себя долгосрочный предиктор 60 и краткосрочный предиктор 62. В дополнение к этому используется кодовый словарь 64. Кроме того, в схему включены перцептуальный взвешивающий фильтр W(z) 66 и контроллер минимизации ошибок 68. s(n) представляет собой сигнал возбуждения, генерируемый, например, на этапе LPC-анализа 10а. Этот сигнал, который показан линией 84 на фиг.7Е, называют также "сигналом ошибки предсказания". Перцептуально взвешенный сигнал ошибки предсказания вводится в вычитатель 69, который вычисляет ошибку между синтезированным сигналом на выходе блока 66 и фактическим взвешенным сигналом ошибки предсказания s(w)(n). Обычно краткосрочное предсказание A(z) вычисляется на стадии анализа LPC, как показано на фиг.7Е, и на основании этой информации рассчитываются данные долгосрочного предсказания AL(z), включая коэффициент усиления долгосрочного предсказания g и индекс векторного квантования, то есть ссылки на кодовую таблицу. Возбуждение кодируется с помощью алгоритма CELP с использованием кодового словаря, например гауссовых последовательностей. Алгоритм линейного предсказания с управлением алгебраическим кодом ACELP, где буква "A" означает "алгебраический", содержит специальную алгебраически построенную книгу шифров.
Таблица кодов содержит некоторое количество векторов, из которых каждый вектор представляет определенную длину отсчета. Коэффициент усиления g масштабирует вектор возбуждения, а отсчеты возбуждения фильтруются фильтром долгосрочного синтеза и фильтром краткосрочного синтеза. "Оптимальный" вектор выбирается из расчета минимизации перцептуально взвешенной среднеквадратической ошибки. Процедура поиска в рамках алгоритма линейного предсказания с кодовым управлением CELP очевидна из схемы на фиг.6.
Ниже, в контексте фиг.10, описывается пример применения алгоритма ACELP, дополнительно иллюстрирующий изменения, вносимые в методику в соответствии с применяемым вариантом осуществления настоящего изобретения, рассмотренные в связи с фиг.4C.
В публикации "A simulation tool for introducing Algebraic CELP (ACELP) coding concepts in a DSP course", Frontiers in Education Conference, Boston, Massachusetts, 2002, Venkatraman Atti and Andreas Spanias, представлена методика обучения внедрению линейного предиктивного кодирования с мультикодовым управлением (CELP) в рамках университетского курса. Базовый алгоритм ACELP состоит из нескольких фаз, включая предварительную обработку и анализ LPC 1000, анализ основного тона 1002 в режиме разомкнутого контура, анализ основного тона 1004 в режиме замкнутого контура и поиск по алгебраической (фиксированной) шифровальной книге 1006.
Стадия предварительной обработки и LPC-анализа включает в себя фильтрацию верхних частот и масштабирование входного сигнала. Для выполнения высокочастотной фильтрации применен фильтр с полюсами и нулями второго порядка с критической частотой 140 Гц. Масштабирование выполняется для снижения вероятности переполнения при операциях с фиксированной точкой. Затем предварительно обработанный сигнал проходит оконное преобразование с использованием асимметричного окна в 30 мс (240 отсчетов). Кроме того, применяется определенное перекрытие. Далее с помощью алгоритма Левинсона-Дарбина из коэффициентов автокорреляции, соответствующих речи, прошедшей оконное преобразование, рассчитываются коэффициенты линейного предсказания. Коэффициенты линейного предсказания преобразуются в линейные спектральные пары, которые затем квантуются и пересылаются. Алгоритм Левинсона-Дарбина дополнительно выводит коэффициенты отражения, которые используются в блоке анализа основного тона с открытым контуром для вычисления высоты тона Тор разомкнутого контура путем нахождения максимума автокорреляции взвешенного голосового сигнала и путем считывания задержки на таком максимуме. На основе рассчитанной высоты основного тона открытого контура вступает в действие фаза 1004 нахождения основного тона замкнутого контура, на которой определяется узкий диапазон отсчетов в районе Тор с целью вывода конечных точных данных задержки высоты тона и выигрыша от долгосрочного предсказания. Этот коэффициент выигрыша от долгосрочного предсказания дополнительно используется в поиске по фиксированной алгебраической таблице кодов и в конечном итоге выводится вместе с другой параметрической информацией в виде квантованных величин усиления. Алгебраическая таблица кодов состоит из набора чередующихся перестановочных кодов, содержащих несколько ненулевых элементов, определенным образом структурированных в кодовую таблицу, в которой по ссылке размещены положение импульса, число импульсов, глубина чередования и количество битов, описывающих положения импульсов. Вектор поиска по кодовой таблице определяется путем размещения выбранного количества единичных импульсных сигналов в определенных локациях, где выполняется также перемножение с их знаками. На основе вектора кодовой таблицы выполняется определенная оптимизация, при которой ведется отбор из всех имеющихся в наличии кодовых векторов наиболее подходящего кодового вектора. После этого положения импульсов и время импульсов, полученные с помощью оптимального вектора кода, кодируются и передаются вместе с квантованными значениями усиления в качестве параметров кодирования.
Скорость передачи выходного сигнала ACELP зависит от количества выделенных импульсов. Для небольшого количества импульсов, например для моноимпульса, требуется низкий битрейт. Для большего количества импульсов битрейт возрастает от 7,4 Кбит/с до 8,6 Кбит/с на пять импульсов и до 12,6 Кбит/с на десять импульсов.
В предпочтительном варианте осуществления настоящего изобретения, как уже говорилось в контексте фиг.4C, в усовершенствованный кодер ACELP 10 должен быть введен блок управления количеством импульсов 1000. Блок управления количеством импульсов, в частности, измеряет коэффициент усиления долгосрочного предсказания (LTP) на выходе анализатора основного тона замкнутого цикла и в случае низкого показателя LTP регулирует количество импульсов. Низкий коэффициент усиления долгосрочного предсказания служит показателем того, что фактически обрабатываемый сигнал не является выраженной импульсной последовательностью, а высокий коэффициент усиления LTP показывает, что данный сигнал представляет собой последовательность импульсов и поэтому легко применим кодером ACELP.
На фиг.11 представлено предпочтительное осуществление блока 1000, показанного на фиг.10. А именно, блок 1010 определяет, не превышает ли усиление LTP заданное для него пороговое значение. Если да, устанавливается, что сигнал импульсного типа 1011. Тогда используется заданное или присущее количество импульсов, что показано в рамке 1012. При этом алгоритм кодирования ACELP применяется без каких-либо модификаций с прямым импульсным регулированием или прямым управлением количеством импульсов, но изменение положения импульса, вводимое этим кодером, частично или полностью ограничивается периодической сеткой, построенной на полученной ранее информации, что делается для того, чтобы устранить недостатки замкнутого цикла, что отображено в рамке 1013. Так, если показатель выигрыша от долгосрочного предиктора (LTP) высок, что означает, что сигнал периодичен и импульсы размещены в предшествующих фреймах, то есть сигнал имеет форму импульса, таблица алгебраических кодов используется для коррекции геометрии импульсов путем ограничения возможных положений импульса рамками периодической сетки, построенной на предшествующих позициях импульсов и интервалом LTP. В частности, количество импульсов, распределенных в соответствии с таблицей алгебраических кодов, может быть постоянным для этого режима, что показано элементом 1011.
Если установлено, что показатель выигрыша от долгосрочного предиктора (LTP) низок, что отображено элементом 1014, количество импульсов при оптимизации кодовой таблицы варьируется, как показано в рамке 1015. Определяя точнее, управление алгебраической таблицей кодов осуществляется так, что импульсы могут быть позиционированы таким образом, что энергия остатка сводится к минимуму, и положения импульсов образуют периодическую последовательность импульсов с периодом, равным интервалу LTP. Однако процесс останавливается, если энергетическая разность становится ниже установленной пороговой величины, в результате чего количество импульсов в алгебраической кодовой таблице становится непостоянным.
Ниже рассматривается фиг.12, представляющая предпочтительный вариант разрешения задачи изменения количества импульсов, возникающей в связи со звеном 1015. Оптимизация начинается с использования малого количества импульсов, например с моноимпульса, что отражено элементом 1016. Затем с этим небольшим количеством импульсов выполняется оптимизация, как показано в рамке 1017. Для наиболее подходящего кодового вектора блок 1018 вычисляет энергию сигнала ошибки, которая в блоке 1019 сравнивается с пороговым значением энергии ошибки (THR). Предельное значение задается заранее и может быть установлено на показатель, обеспечивающий кодирование кодером ACELP с определенной точностью только импульсной составляющей сигнала и предупреждающий кодирование неимпульсных составляющих сигнала, которое кодер также может начать выполнять в случае, если не будет применен относящийся к изобретению контроллер 1000 на фиг.10.
Если на шаге 1019 будет установлено, что достигнут порог, выполнение операции останавливается. Однако, если на стадии сопоставления блоком 1019 будет определено, что пороговый уровень энергии сигнала ошибки еще не достигнут, количество импульсов возрастет, например, на 1, что показано в рамке 1020. После этого операции 1017, 1018 и 1019 повторяются, но с большим количеством импульсов. Данная последовательность действий выполняется до тех пор, пока не будет сформирован окончательный критерий, как, например, максимально допустимое число импульсов. Тем не менее, выполнение алгоритма, как правило, останавливается в силу срабатывания порогового критерия, так как в большинстве случаев количество импульсов неимпульсного типа меньше количества импульсов, которые были бы размещены алгоритмом кодирования в случае импульсного сигнала.
Другая версия кодера ACELP представлена на фиг.13. В представленном варианте основной функцией является выбор между вокализованным и невокализованным типом речевого сигнала, что отражено в рамке 1300. В зависимости от принятого решения такой кодер обращается в случае вокализованной составляющей к первой таблице кодов, в случае невокализованной составляющей - к второй таблице кодов. В соответствии с конструктивным решением данного изобретения анализ через синтез алгоритма CELP применяется только для распознавания параметров кодирования импульса в случае, если блоком 1300 была распознана озвученная составляющая, как отображено в элементе 1310. При обнаружении кодером CELP неозвученной составляющей его выходной сигнал, содержащий такие неозвученные составляющие, не вычисляется или, по меньшей мере, игнорируется и не включается в закодированный импульсный сигнал. В соответствии с концепцией настоящего изобретения подобные невокализованные составляющие сигнала кодирует кодер остатков, и поэтому техническая особенность такого кодера состоит в игнорировании невокализованной составляющей выходного сигнала кодера, что отражено элементом 1320.
Концепция данного изобретения предусматривает его интегрирование преимущественно с технологией коммутируемого кодирования с динамически регулируемым LPC-фильтром с деформированным частотным разрешением, как показано на фиг.17. В импульсном кодере применяется фильтр LPC, где кодер импульсов представлен в виде блока 1724. Если кодер остатков на базе банка фильтров содержит устройство пред-/постфильтрования, возможно осуществление кодера импульсов 1724 и кодера разности в комбинированном частотно-временном исполнении, которое не отображено на фиг.17C, поскольку обработка входного аудиосигнала без входного фильтра 1722 не практикуется, но должна была бы быть применена для обеспечения ввода в универсальный аудиокодер 1726, который соответствовал бы кодеру разностного сигнала 16 на фиг.1. Благодаря этому можно обходиться без использования двух фильтров анализа со стороны кодера и двух фильтров синтеза со стороны декодера. Этот подход может включать в себя динамическую адаптацию универсального фильтра со смещаемым частотным разрешением, что обсуждалось в контексте фиг.17C. В силу этого данное изобретение может быть интегрировано в структуру, отображенную на фиг.17C, путем преобразования выходного сигнала 1722 предварительного фильтра перед вводом этого сигнала в универсальный аудиокодер 1726 и путем дополнительного выделения импульсов из аудиосигнала перед его введением в кодер остаточного возбуждения 1724. В силу этого блоки 10c, 26b, и 26а должны размещаться на выходе варьируемого во времени фильтра с неравномерным частотным разрешением 1722 и на входе кодера разности/кодера возбуждения 1724, который соответствовал бы кодеру импульсов 10b на фиг.4А, а также на входе универсального аудиокодера 1726, который соответствовал бы аудиокодеру на базе банков фильтров 16 на фиг.4А. Конечно, замкнутый цикл на фиг.4B также может быть дополнительно введен в систему кодирования на фиг.17C.
Желательно применение психоакустически управляемого кодера сигнала 16 на фиг.1.
Рекомендуется введение психоакустической модели 1602, которая, например, аналогична соответствующему элементу на фиг.16А, в конструкцию на фиг.15 таким образом, чтобы ее вход был сопряжен с исходным аудиосигналом 8. Благодаря этому психоакустические данные порога маскирования линии 1500 отражали бы положение оригинального акустического сигнала лучше, чем разностный сигнал на выходе генератора разностного сигнала 26. При этом управление квантователем 1604а осуществляется с использованием данных порога маскирования 1500, источником которых является не фактически квантованный сигнал, а оригинальный звуковой сигнал до вычисления разностного сигнала 18. Желательно, чтобы эта последовательность операций выполнялась после ввода выходных данных генератора разностного сигнала 26 в психоакустическую модель, поскольку маскирующий эффект импульсной составляющей сигнала также участвует в процессе преобразования, и в дальнейшем скорость передачи данных может снизиться. Вместе с тем, сопряжение входа психоакустической модели с выходом генератора разностного сигнала 18 желательно также потому, что разностный сигнал представляет собой реальный звуковой сигнал и, следовательно, имеет порог маскирования. Однако, несмотря на то что такое техническое решение в целом возможно и целесообразно в определенных приложениях, оно приведет к росту битрейта по сравнению с ситуацией, когда в психоакустическую модель 1602 вводится исходный аудиосигнал.
В целом, предпочтительные варианты реализации настоящего изобретения отличаются рядом аспектов, которые можно свести в следующую схему.
Кодирование: способ разделения сигнала; наличие уровня банка фильтров обязательно; наличие уровня оптимизации речи произвольно; анализ сигнала (выделение импульса) перед кодированием; обработка кодером импульсов только определенных составляющих входного сигнала; настройка кодера импульсов на обработку только импульсов; и уровень банка фильтров представлен немодифицируемым кодером на базе банков фильтров. Декодирование: наличие уровня банка фильтров обязательно; и наличие уровня оптимизации речи произвольно.
Как правило, способ кодирования импульса выбирается в качестве дополнения к методу кодирования с использованием банков фильтров, когда базовая модель источника импульсов (например, возбуждение голосообразующих импульсов) хорошо подходит для входного сигнала, и кодирование импульса может начаться в любой удобный момент времени; и это не требует анализа зависимости искажения от битрейта при кодировании и декодировании, и поэтому такой подход значительно более эффективен в технологии кодирования. Предпочтительным методом кодирования импульса или кодирования последовательности импульсов является волновая интерполяция, описанная в "Speech coding below 4 kB/s using waveform interpolation", W.B.Kleijn, Globecom ′91, pages 1879 to 1883, или в "A speech coder based on decomposition of characteristic waveforms", W.B.Kleijn and J.Haagen, ICASSP 1995, pages 508 to 511.
Описанные ниже конструктивные решения даны как иллюстрация основных принципов настоящего изобретения. Подразумевается, что для специалистов в данной области возможность внесения изменений и усовершенствований в компоновку и элементы описанной конструкции очевидна. В силу этого представленные описания и пояснения вариантов реализации изобретения ограничиваются только рамками патентных требований, а не конкретными деталями.
В зависимости от конкретных требований к реализации относящихся к изобретению методов эти методы могут быть осуществлены как в виде аппаратных средств, так и в виде программного обеспечения. Изобретение может быть реализовано с использованием цифрового накопителя данных, в частности диска, DVD-диска или CD-диска, содержащего электронно считываемые управляющие сигналы, совместимого с программируемыми компьютерными системами с целью осуществления методов, имеющих отношение к изобретению. Таким образом, в целом настоящее изобретение представляет собой компьютерный программный продукт с хранящимся на машиночитаемом носителе кодом программы, с помощью которого практически выполняются изобретенные методы при условии исполнения компьютерного программного продукта на компьютере. Иначе говоря, методы, относящиеся к изобретению, представляют собой, таким образом, компьютерную программу с присвоенным ей кодом программы, предназначенную для реализации, по меньшей мере, одного из относящихся к изобретению методов при выполнении компьютерной программы на компьютере.
| название | год | авторы | номер документа |
|---|---|---|---|
| АУДИОКОДЕР И АУДИОДЕКОДЕР ДЛЯ КОДИРОВАНИЯ И ДЕКОДИРОВАНИЯ ОТСЧЕТОВ АУДИОСИГНАЛА | 2009 |
|
RU2515704C2 |
| АУДИОКОДЕР ДЛЯ КОДИРОВАНИЯ МНОГОКАНАЛЬНОГО СИГНАЛА И АУДИОДЕКОДЕР ДЛЯ ДЕКОДИРОВАНИЯ КОДИРОВАННОГО АУДИОСИГНАЛА | 2016 |
|
RU2679571C1 |
| АУДИОКОДЕР ДЛЯ КОДИРОВАНИЯ МНОГОКАНАЛЬНОГО СИГНАЛА И АУДИОДЕКОДЕР ДЛЯ ДЕКОДИРОВАНИЯ КОДИРОВАННОГО АУДИОСИГНАЛА | 2016 |
|
RU2680195C1 |
| КОДЕР АУДИОСИГНАЛА, ДЕКОДЕР АУДИОСИГНАЛА, СПОСОБ КОДИРОВАНИЯ ИЛИ ДЕКОДИРОВАНИЯ АУДИОСИГНАЛА С УДАЛЕНИЕМ АЛИАСИНГА (НАЛОЖЕНИЯ СПЕКТРОВ) | 2010 |
|
RU2591011C2 |
| КОДЕР АУДИОСИГНАЛА, ДЕКОДЕР АУДИОСИГНАЛА, СПОСОБ КОДИРОВАННОГО ПРЕДСТАВЛЕНИЯ АУДИОКОНТЕНТА, СПОСОБ ДЕКОДИРОВАННОГО ПРЕДСТАВЛЕНИЯ АУДИОКОНТЕНТА И КОМПЬЮТЕРНАЯ ПРОГРАММА ДЛЯ ПРИЛОЖЕНИЙ С МАЛОЙ ЗАДЕРЖКОЙ | 2010 |
|
RU2596594C2 |
| УСТРОЙСТВО И СПОСОБ ДЛЯ КОДИРОВАНИЯ И ДЕКОДИРОВАНИЯ АУДИОСИГНАЛА С ИСПОЛЬЗОВАНИЕМ ВЫРОВНЕННОЙ ЧАСТИ ОПЕРЕЖАЮЩЕГО ПРОСМОТРА | 2012 |
|
RU2574849C2 |
| АУДИОКОДЕР И СПОСОБ ДЛЯ КОДИРОВАНИЯ АУДИОСИГНАЛА | 2016 |
|
RU2707144C2 |
| СХЕМА АУДИОКОДИРОВАНИЯ/ДЕКОДИРОВАНИЯ С ПЕРЕКЛЮЧЕНИЕМ БАЙПАС | 2009 |
|
RU2483364C2 |
| УСТРОЙСТВО И СПОСОБ ДЕКОДИРОВАНИЯ КОДИРОВАННОГО ЗВУКОВОГО СИГНАЛА | 2009 |
|
RU2483366C2 |
| КОДЕР И ДЕКОДЕР АУДИОСИГНАЛА, ИСПОЛЬЗУЮЩИЕ ПРОЦЕССОР ЧАСТОТНОЙ ОБЛАСТИ, ПРОЦЕССОР ВРЕМЕННОЙ ОБЛАСТИ И КРОССПРОЦЕССОР ДЛЯ НЕПРЕРЫВНОЙ ИНИЦИАЛИЗАЦИИ | 2015 |
|
RU2668397C2 |
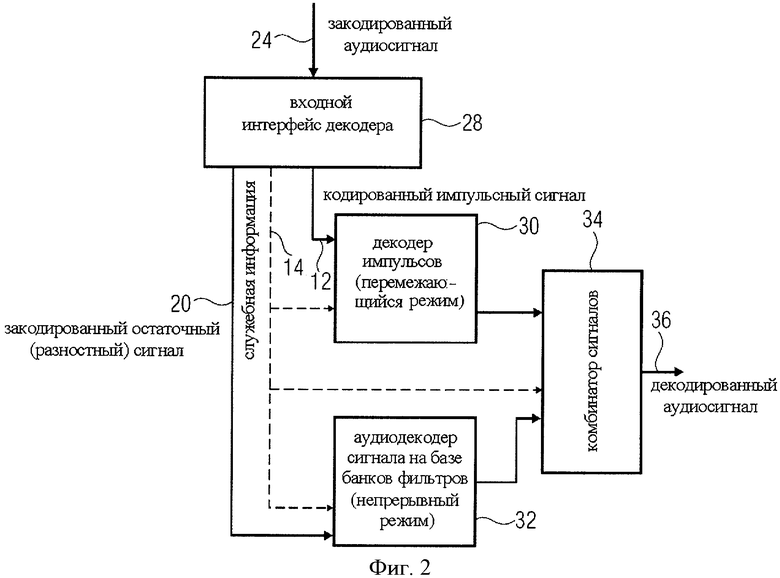
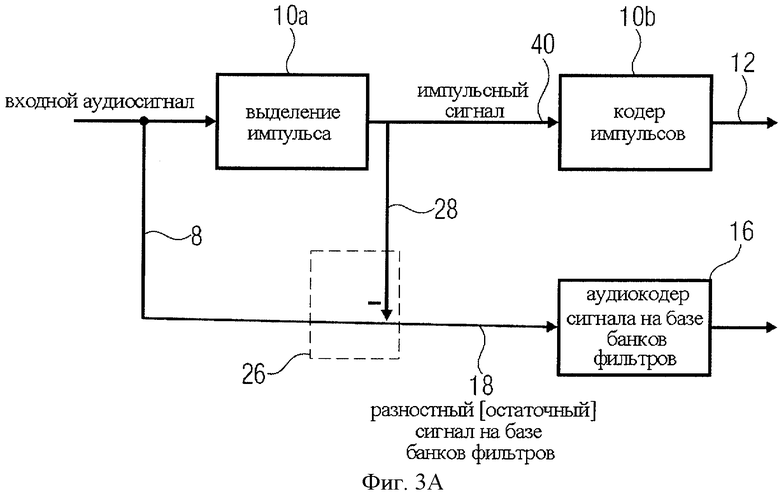
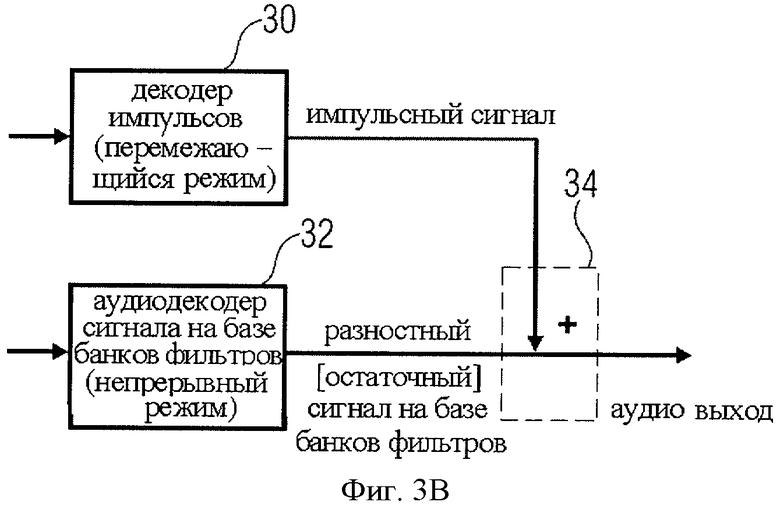
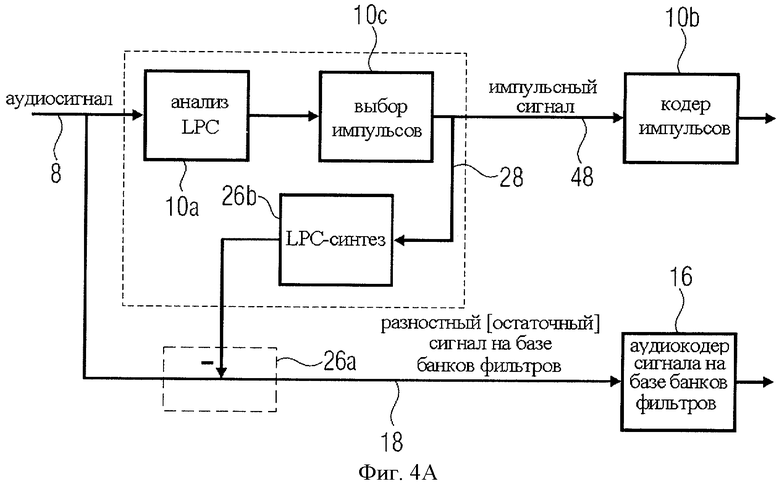
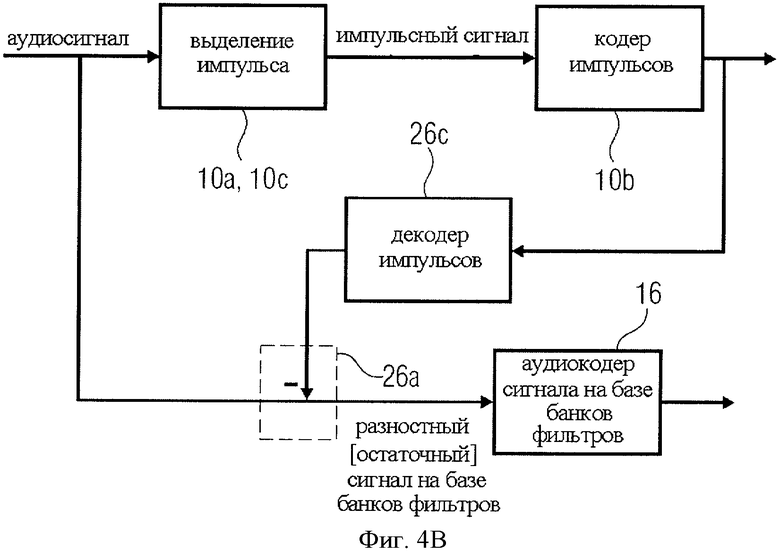
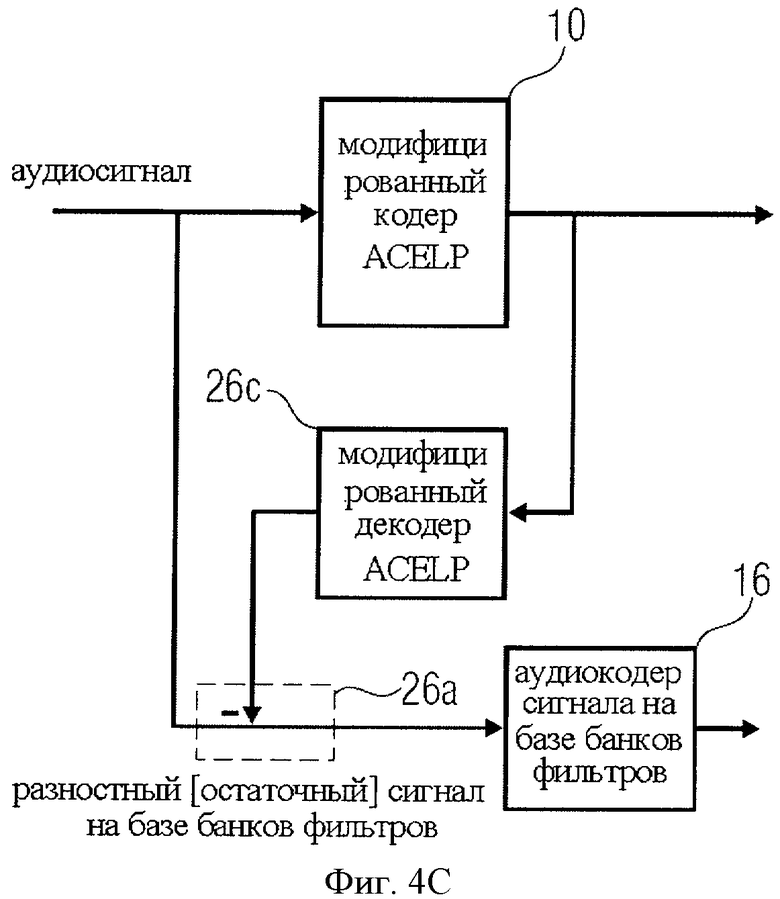
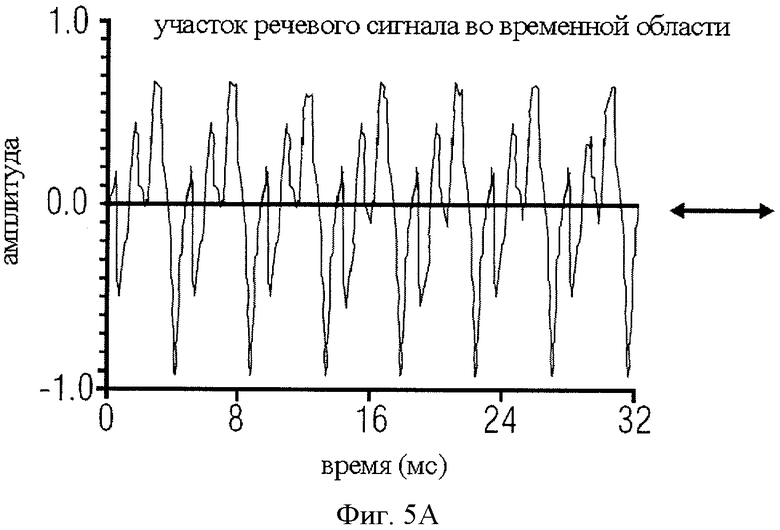
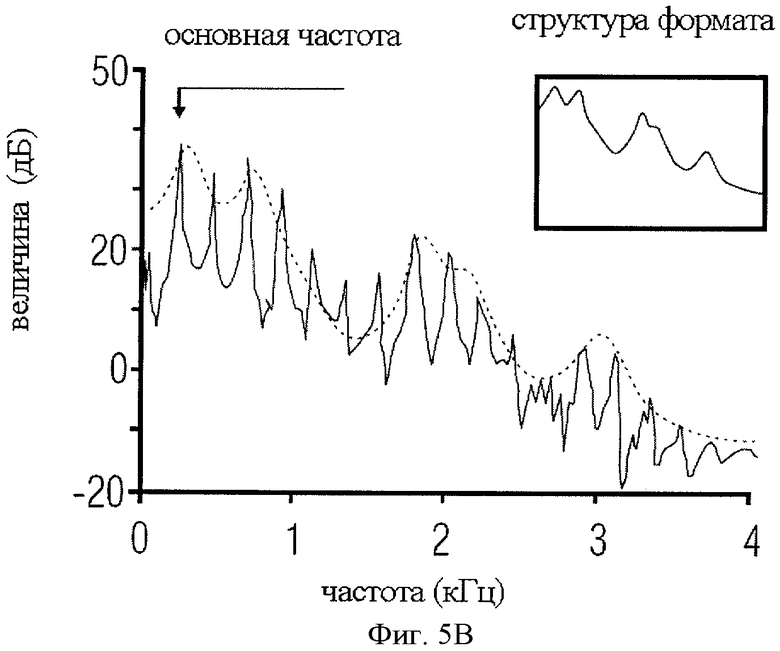
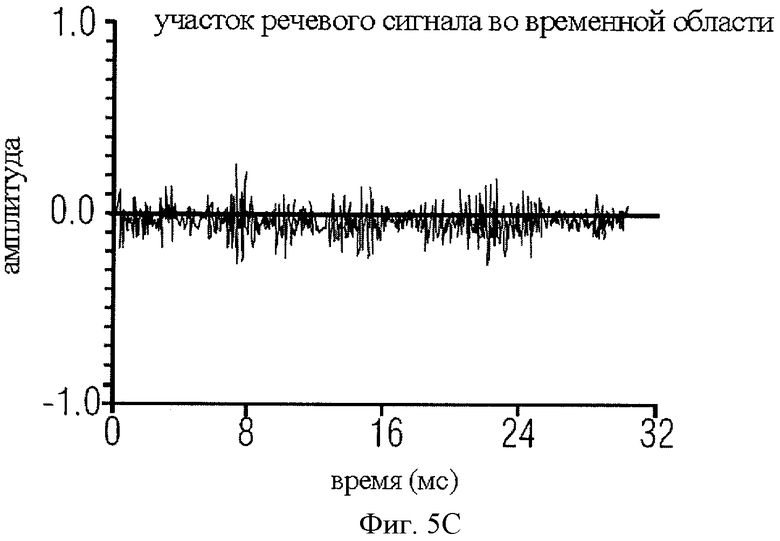
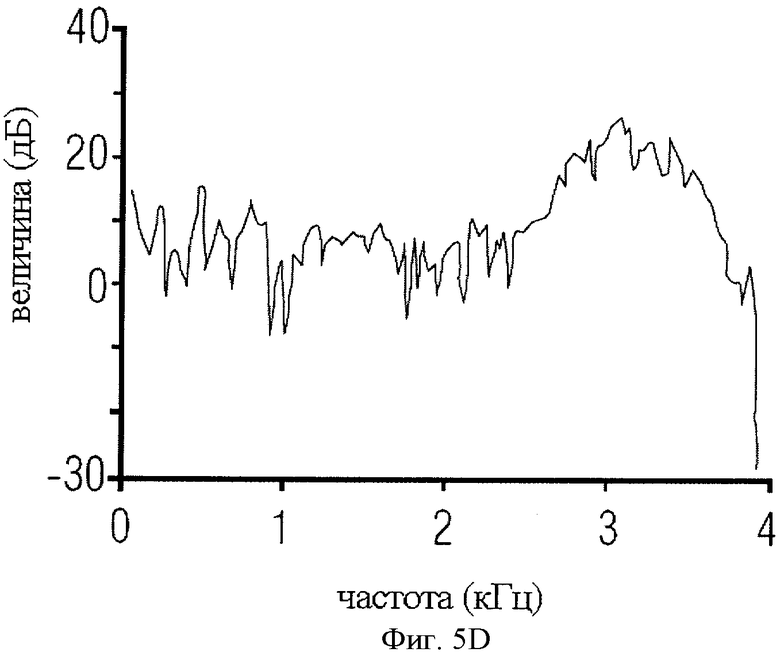
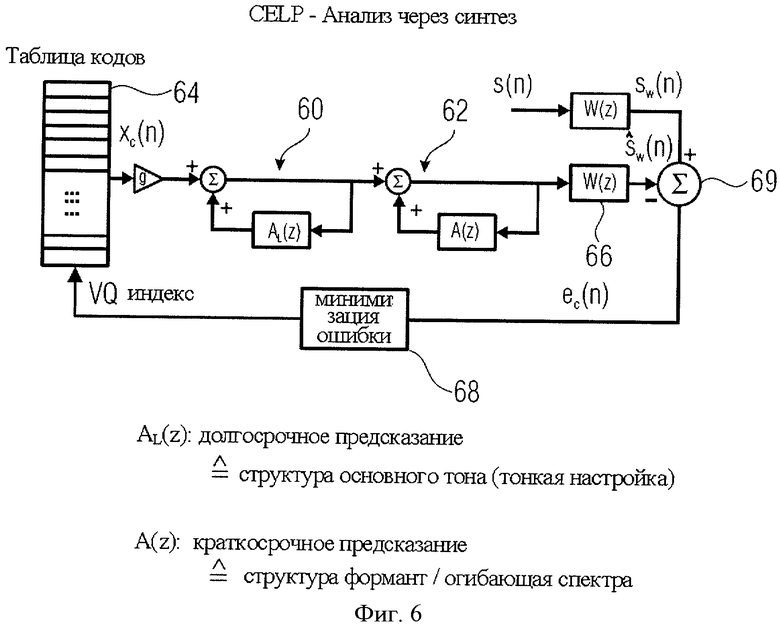
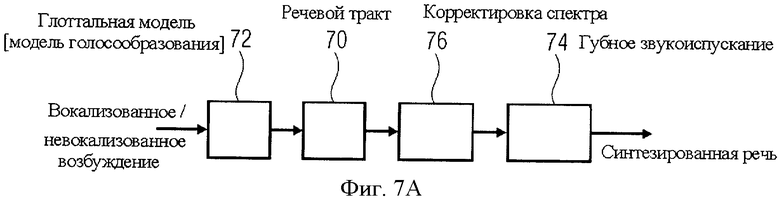
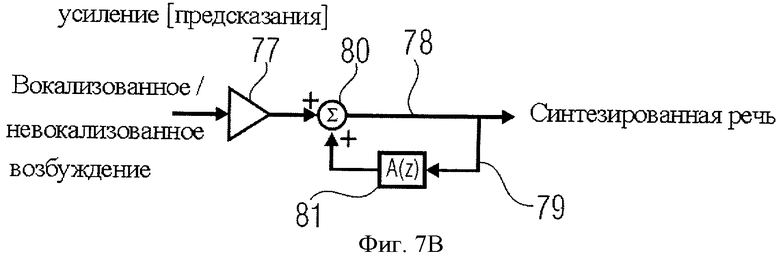


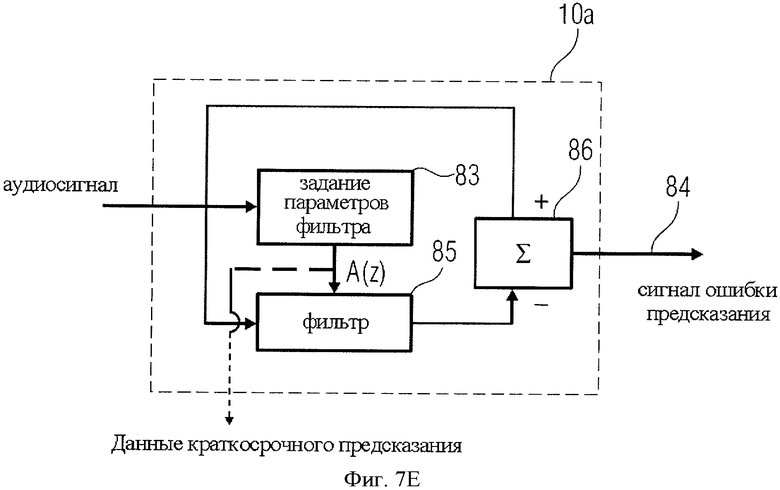
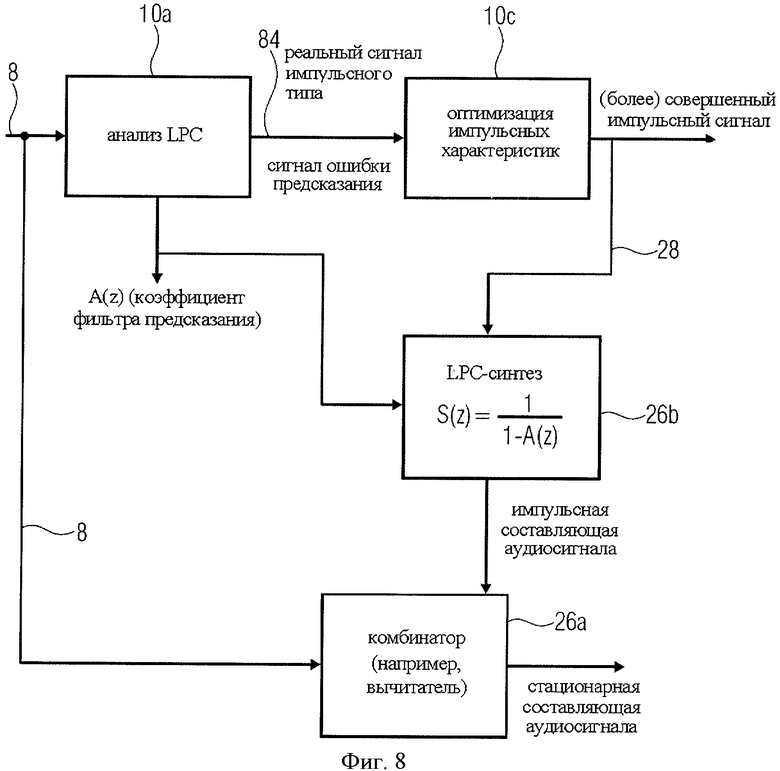
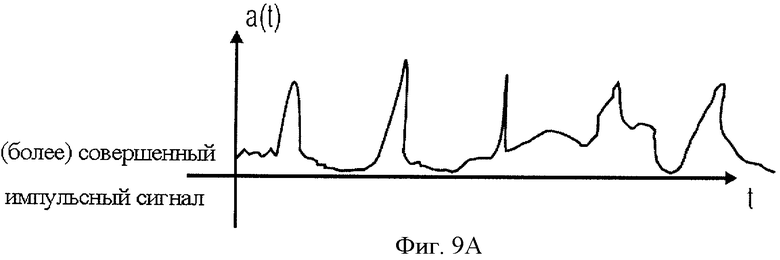
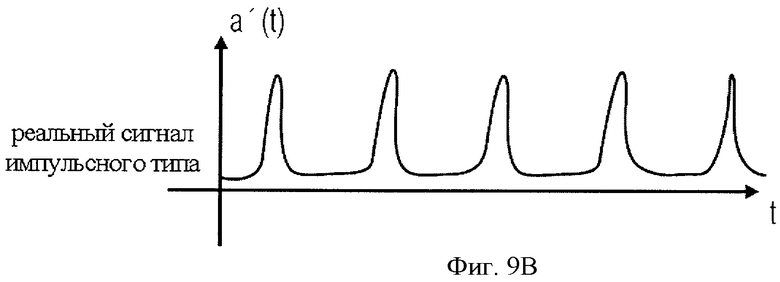
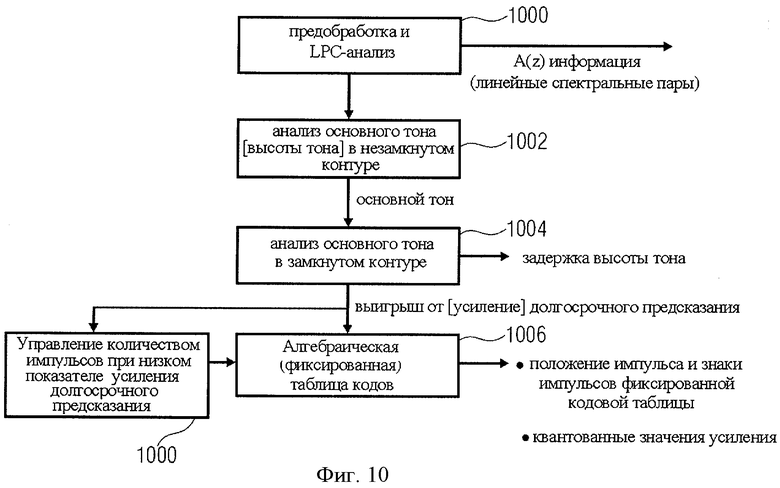
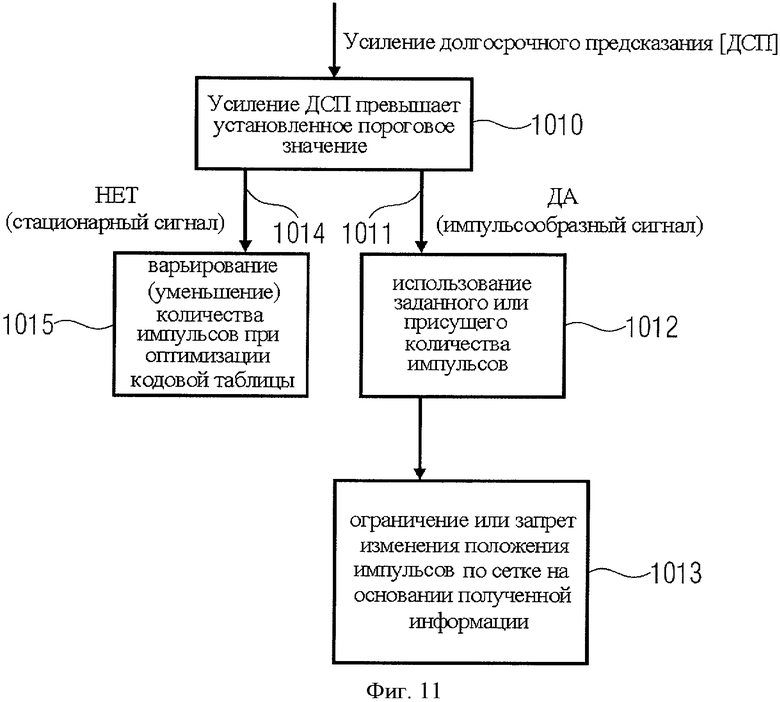
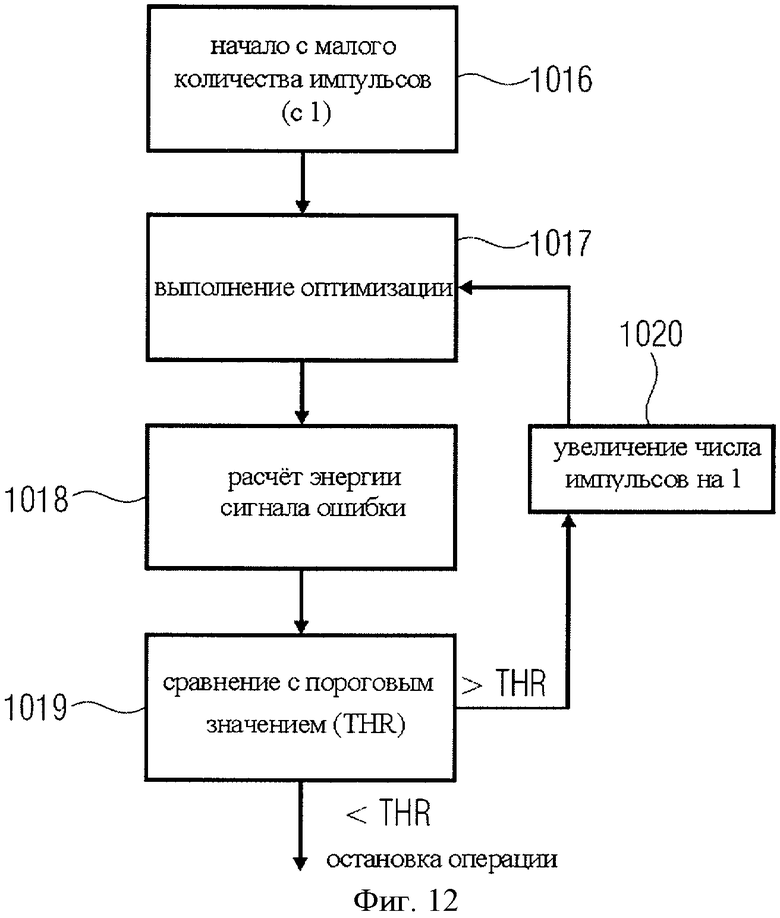
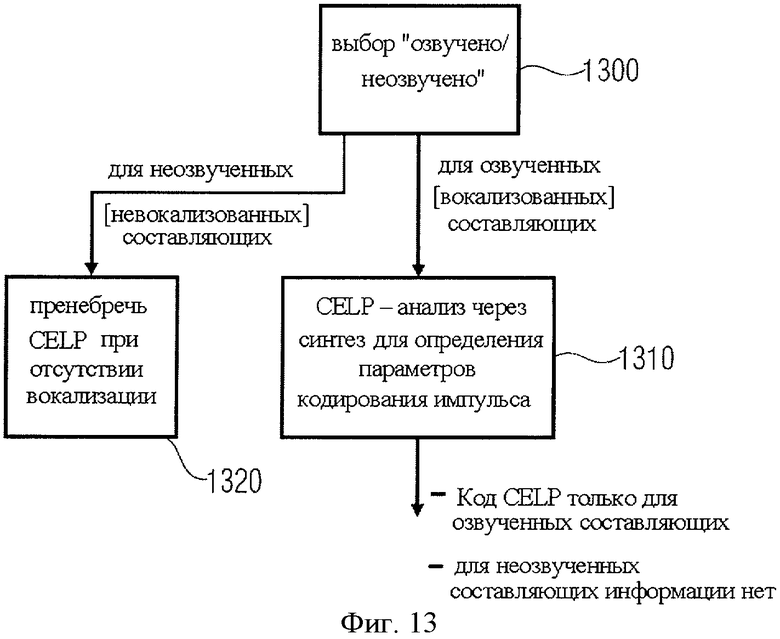
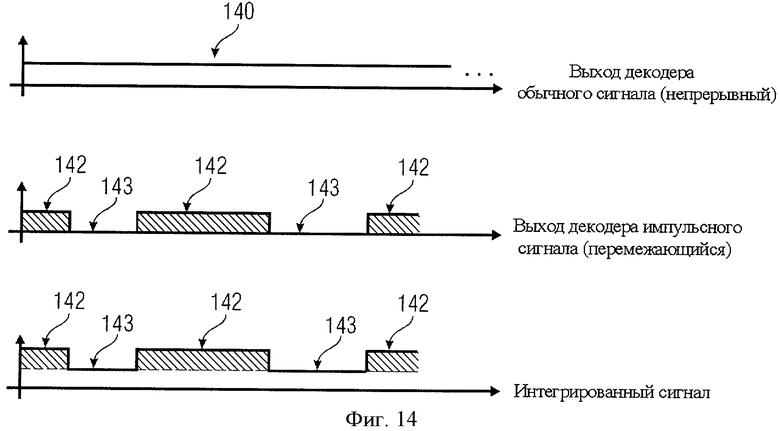
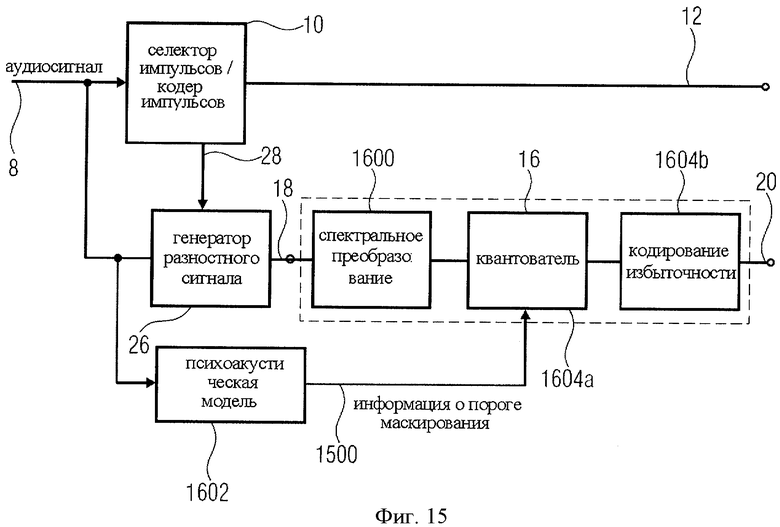
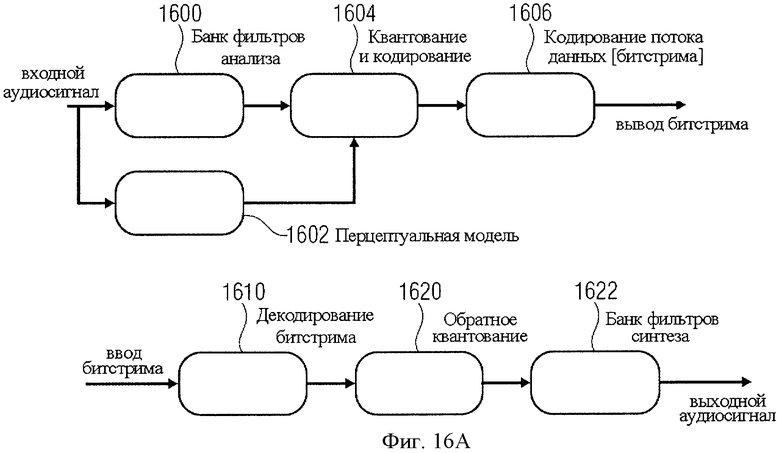
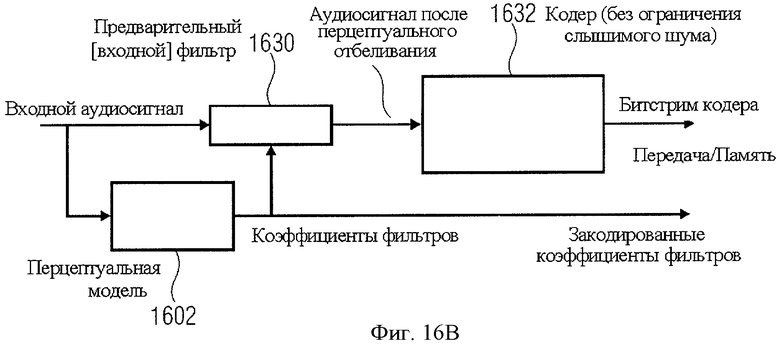
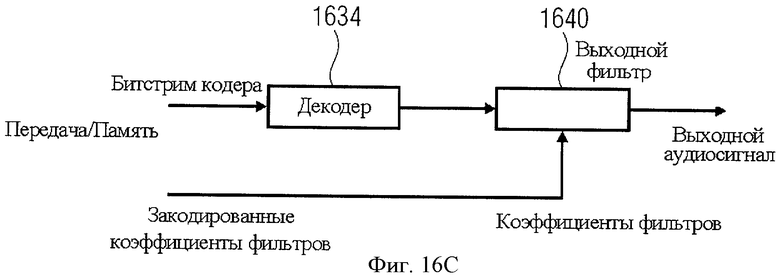
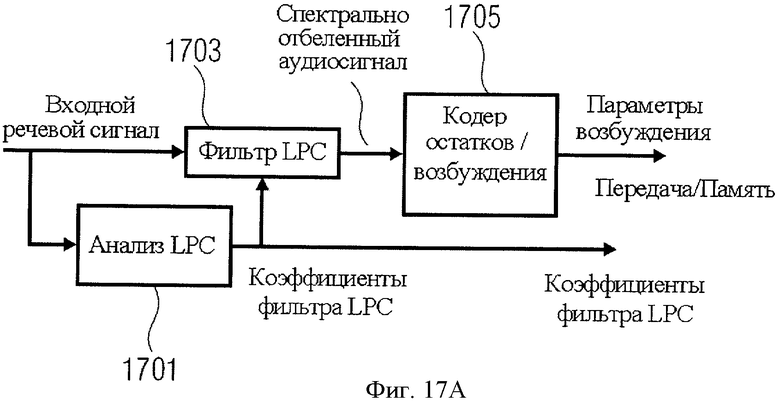
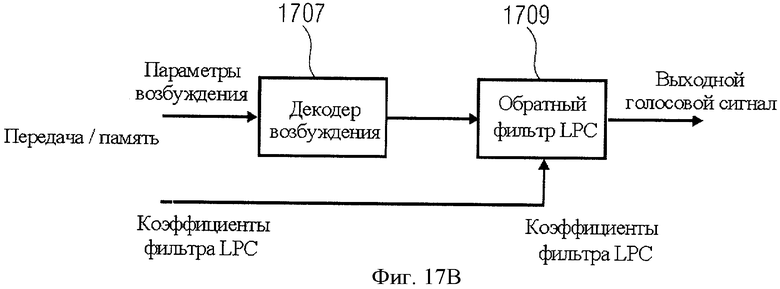
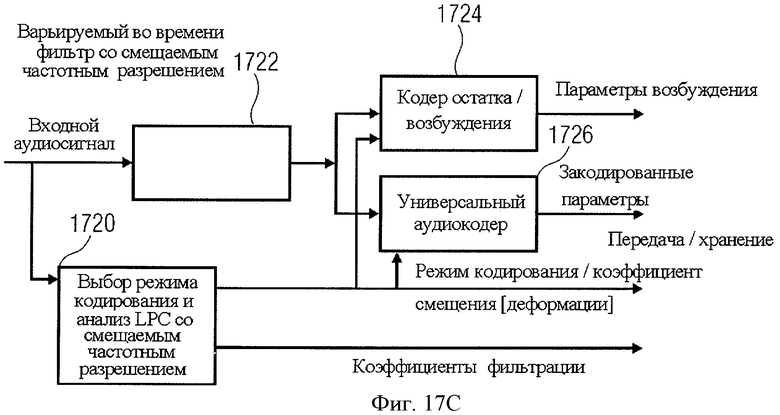
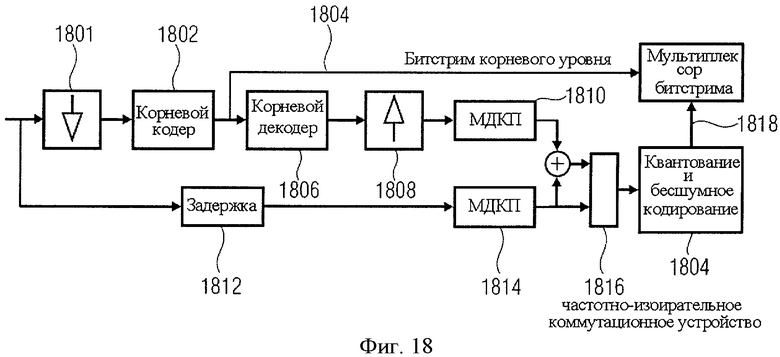
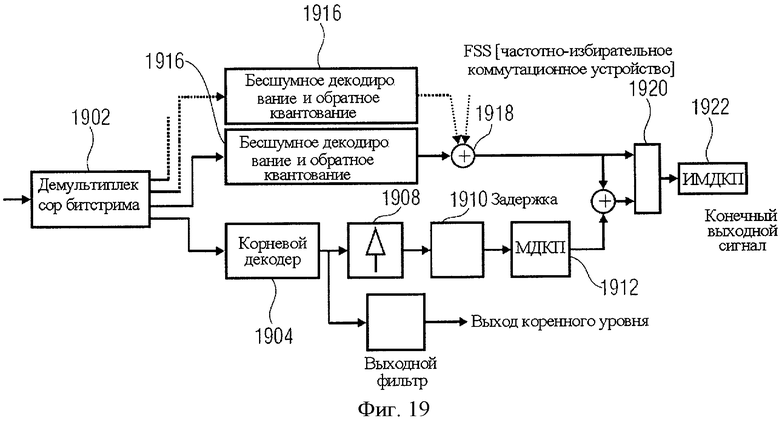
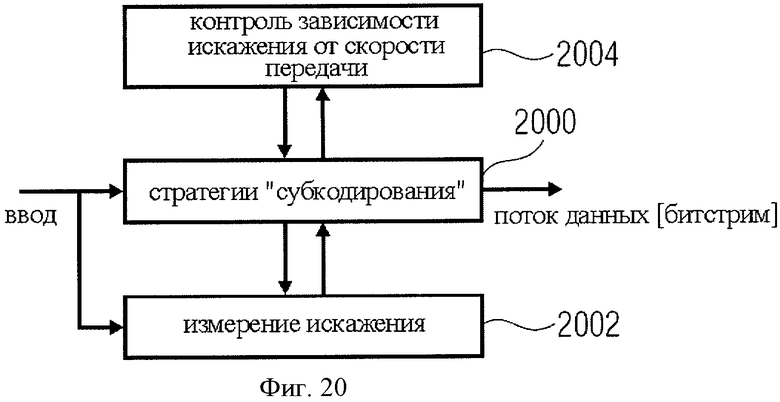
Изобретение относится к кодированию источников, в частности к кодированию источников звука, при котором аудиосигнал обрабатывается, по меньшей мере, двумя различными аудиокодерами, использующими два различных алгоритма кодирования. Техническим результатом является повышение эффективности и качества кодирования звука. Указанный технический результат достигается тем, что аудиокодер для кодирования аудиосигнала (8), имеющего импульсную составляющую и стационарную составляющую, включает селектор импульсов (10), предназначенный для выделения из аудиосигнала импульсной составляющей, имеющий в своем составе кодер импульсов для кодирования импульсных составляющих с формированием кодированных импульсных сигналов; кодер сигналов (16), предназначенный для кодирования разностного сигнала, выделенного из аудиосигнала, с формированием кодированного разностного сигнала (20), извлеченного из аудиосигнала таким образом, что импульсная составляющая сокращается или удаляется из данного аудиосигнала; и выходной интерфейс (22), предназначенный для вывода кодированного импульсного сигнала (12) и кодированного разностного сигнала (20) с формированием кодированного сигнала (24). Импульсный кодер импульсов сконфигурирован таким образом, что не кодирует импульсный сигнал в случае, когда селектор импульсов не способен обнаружить импульсную составляющую сигнала. 7 н. и 26 з.п. ф-лы, 35 ил.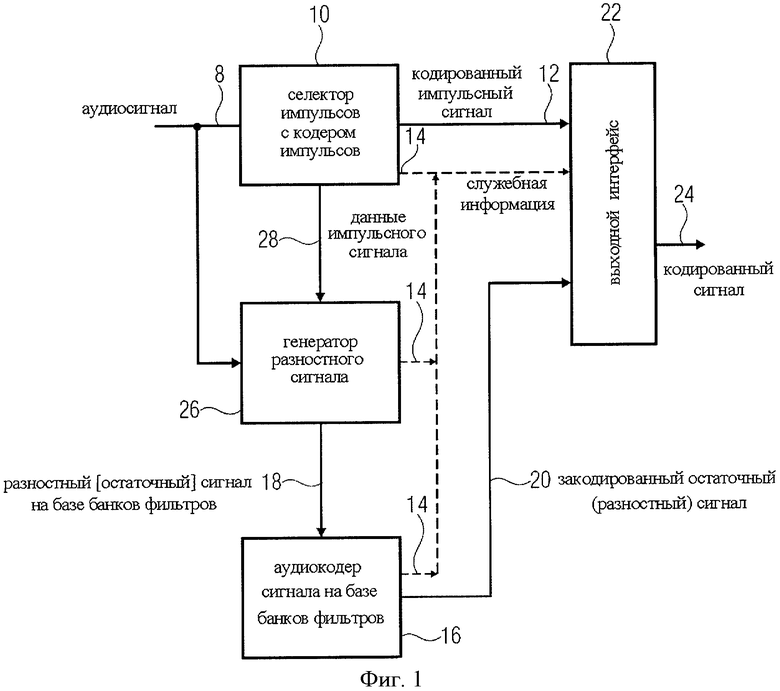
1. Аудиокодер для кодирования аудиосигнала (8), имеющего импульсную составляющую и стационарную составляющую, характеризующийся тем, что включает селектор импульсов (10), предназначенный для выделения из аудиосигнала импульсной составляющей, имеющий в своем составе кодер импульсов для кодирования импульсных составляющих с формированием кодированных импульсных сигналов; кодер сигналов (16), предназначенный для кодирования разностного сигнала, выделенного из аудиосигнала, с формированием кодированного разностного сигнала (20), извлеченного из аудиосигнала таким образом, что импульсная составляющая сокращается или удаляется из данного аудиосигнала; и выходной интерфейс (22), предназначенный для вывода кодированного импульсного сигнала (12) и кодированного разностного сигнала (20) с формированием кодированного сигнала (24), при этом импульсный кодер импульсов сконфигурирован таким образом, что не кодирует импульсный сигнал в случае, когда селектор импульсов не способен обнаружить импульсную составляющую сигнала.
2. Аудиокодер по п.1, характеризующийся тем, что включает в свой состав кодер импульсов (10b) и кодер сигналов (16), из которых кодер импульсов (10b) более адаптирован для импульсных сигналов, чем кодер сигналов (16), а кодер сигналов (16) более адаптирован для стационарных сигналов, чем кодер импульсов (10b).
3. Аудиокодер по п.1 или 2, характеризующийся тем, что дополнительно включает генератор разностного сигнала (26), предназначенный для получения аудиосигнала (8) и информации (28) о выделенных импульсных составляющих сигнала и для вывода разностного сигнала (18), который не содержит выделенные составляющие сигнала.
4. Аудиокодер по п.3, характеризующийся тем, что генератор разностного сигнала (26) включает вычитающее устройство (26a) для вычитания извлеченных составляющих (28) аудиосигнала (8) с формированием разностного сигнала (18).
5. Аудиокодер по п.3, характеризующийся тем, что селектор импульсов (10) предназначен для извлечения параметрического представления импульсных составляющих сигнала; и генератор разностного сигнала (26) предназначен для синтезирования (26c) формы сигнала с использованием параметрического представления и для вычитания (26а) формы сигнала из аудиосигнала (8).
6. Аудиокодер по п.3, характеризующийся тем, что генератор разностного сигнала (26) содержит импульсный декодер (26с), предназначенный для вычисления декодированного импульсного сигнала, и вычитающее устройство (26а), предназначенное для вычитания декодированного импульсного сигнала из аудиосигнала (8).
7. Аудиокодер по п.3, характеризующийся тем, что селектор импульсов (10) включает блок (10а) для выполнения LPC анализа аудиосигнала (8) с возможностью получения сигнала ошибки предсказания (84), селектор импульсов (10) включает процессор сигнала ошибки предсказания (10c), предназначенный для обработки сигнала ошибки предсказания с улучшением импульсной характеристики этого сигнала, генератор разностного сигнала (26) предназначен для LPC синтеза (26b) с учетом оптимизированного сигнала ошибки предсказания и для вычитания из аудиосигнала сигнала, полученного в результате синтеза LPC, с получением разностного сигнала (18).
8. Аудиокодер по п.1, характеризующийся тем, что селектор импульсов (10) включает блок (1300) принятия решения импульс/не импульс, и который выполняет функцию идентификации импульсной составляющей аудиосигнала и передачи ее на кодер импульсов (10b), но не на кодер сигнала (16).
9. Аудиокодер по п.1, характеризующийся тем, что блок принятия решения импульс/не импульс выполнен с возможностью распознавания вокализованного/невокализованного сигнала.
10. Аудиокодер по п.1, характеризующийся тем, что аудиосигнал имеет формантную структуру и тонкую гармоническую структуру; селектор импульсов (10) выполнен с возможностью преобразования аудиосигнала таким образом, что обработанный аудиосигнал реконструирует только тонкую гармоническую структуру, и, кроме того, данный селектор импульсов при преобразовании сигнала тонкой гармонической структуры оптимизирует импульсную характеристику сигнала тонкой гармонической структуры (10c); оптимизированный сигнал тонкой гармонической структуры кодируется кодером импульсов (10b).
11. Аудиокодер по п.1, характеризующийся тем, что кодер сигнала (16) представляет собой кодер-преобразователь или кодер на базе банков фильтров общего назначения, а кодер импульсов представляет собой кодер, работающий во временной области.
12. Аудиокодер по п.1, характеризующийся тем, что селектор импульсов (10) содержит кодер ACELP (10), выполняющий операции LPC-анализа (1000) с целью получения краткосрочного предсказания, определения основного тона (1002, 1004) с целью получения показателей высоты основного тона и коэффициента усиления устройства долгосрочного предсказания, и получения данных кодового словаря с целью определения позиций ряда импульсов для параметрического представления разностного сигнала; селектор импульсов (10) осуществляет управление (1000) кодером ACELP (10) по показателям выигрыша от долгосрочного предсказания, позиционируя переменное число импульсов для первого коэффициента усиления устройства долгосрочного предсказания или фиксированное число импульсов для второго коэффициента усиления устройства долгосрочного предсказания, причем второй коэффициент усиления устройства долгосрочного предсказания больше, чем первый коэффициент усиления устройства долгосрочного предсказания.
13. Аудиокодер по п.12, характеризующийся тем, что максимум переменного числа импульсов равно или меньше фиксированного числа импульсов.
14. Аудиокодер по п.12, характеризующийся тем, что селектор импульсов (10) выполнен с возможностью управления (1000) кодером ACELP, последовательно распределяя импульсы, начиная с малого числа импульсов (1016) и переходя к большему числу импульсов (1020), при этом последовательное размещение импульсов прекращается, если энергия сигнала ошибки становится ниже заданного порогового значения энергии (1019).
15. Аудиокодер по п.12, характеризующийся тем, что селектор импульсов (10) выполнен с возможностью управления (1000) кодером ACELP (10) таким образом, что в случае превышения значением выигрыша от долгосрочного предсказания пороговой величины возможные положения импульсов распределяются в виде решетки, которая базируется, по крайней мере, на одной позиции импульса предшествующего фрейма (1013).
16. Аудиокодер по п.3, характеризующийся тем, что кодер импульсов (10b) представляет собой кодер с линейным предсказанием с кодовым возбуждением (CELP), который вычисляет положения импульсов и значения квантованных импульсов, генератор разностного сигнала (26) выполнен с возможностью использования позиции неквантованных импульсов и значения квантованных импульсов для вычисления сигнала, который должен быть вычтен из аудиосигнала (8) для нахождения разностного сигнала.
17. Аудиокодер по п.3, характеризующийся тем, что селектор импульсов предназначен для синтеза линейного предсказания с кодовым возбуждением CELP с целью определения положения неквантованных импульсов в сигнале ошибки предсказания, и в составе которого кодер импульсов (10b) кодирует положение импульса с точностью, превышающей точность данных квантования краткосрочного предсказания.
18. Аудиокодер по п.3, характеризующийся тем, что селектор импульсов (10) предназначен для определения составляющей сигнала как импульсной, генератор разностного сигнала (26) предназначен для замены составляющей акустического сигнала синтезированным сигналом без импульсной составляющей или с усеченной импульсной составляющей.
19. Аудиокодер по п.18, характеризующийся тем, что генератор разностного сигнала (26) предназначен для вычисления синтезированного сигнала путем экстраполяции на основании границы между импульсным и неимпульсным сигналом.
20. Аудиокодер по п.18, характеризующийся тем, что генератор разностного сигнала вычисляет синтезированный сигнал путем взвешивания импульсной составляющей аудиосигнала с применением весового коэффициента, меньшего 0,5.
21. Аудиокодер по п.1, характеризующийся тем, что кодер сигнала (16) является аудиокодером с психоакустическим управлением, в котором психоакустический порог маскирования (1500), используемый для квантования звука (1604а), вычисляется по аудиосигналу (8), при этом данный кодер сигнала (16) предназначен для преобразования разностного сигнала в спектральную форму отображения (1600) и квантования (1604а) величины спектрального представления, используя психоакустический порог маскирования (1500).
22. Аудиокодер по п.1, характеризующийся тем, что селектор импульсов (10) предназначен для извлечения из аудиосигнала импульсного сигнала для получения выделенного импульсного сигнала; селектор импульсов (10) с помощью (10с) выделенных импульсных сигналов предназначен для формирования оптимизированного импульсного сигнала, который имеет более идеальную форму импульсного сигнала по сравнению с формой выделенного импульсного сигнала; кодер импульсов (10b) предназначен для кодирования оптимизированного импульсного сигнала с целью получения кодированного оптимизированного импульсного сигнала; аудиокодер содержит вычислитель разностного сигнала (26), предназначенный для вычитания импульсного сигнала, или оптимизированного импульсного сигнала, или сигнала, полученного декодированием кодированного оптимизированного импульсного сигнала из аудиосигнала с целью получения разностного сигнала.
23. Способ кодирования аудиосигнала (8), содержащего импульсную составляющую и стационарную составляющую, характеризующийся тем, что включает в себя вычленение (10) из аудиосигнала импульсной составляющей, стадию извлечения, включающую операцию кодирования импульсных составляющих с получением кодированного импульсного сигнала; кодирование (16) разностного сигнала, полученного из аудиосигнала с формированием кодированного разностного сигнала (20), причем разностный сигнал выводится из акустического сигнала так, что импульсная составляющая сокращается или удаляется из аудиосигнала; и вывод (22) для передачи или сохранения в памяти кодированного импульсного сигнала (12) и кодированного разностного сигнала (20) с целью формирования кодированного сигнала (24), при этом операция импульсного кодирования не осуществляется, если на стадии извлечения импульса не обнаружено импульсной составляющей в аудиосигнале.
24. Декодер для декодирования закодированного аудиосигнала (24), содержащего закодированный импульсный сигнал (12) и закодированный разностный сигнал (20), характеризующийся тем, что содержит импульсный декодер (30) для декодирования закодированного импульсного сигнала с использованием алгоритма декодирования, соответствующего алгоритму кодирования, использованному для генерации кодированного импульсного сигнала, с формированием декодированного сигнала импульсного типа; декодер сигнала (32) для декодирования закодированного разностного сигнала (20) с использованием алгоритма декодирования, соответствующего алгоритму кодирования, используемому для генерации кодированного разностного сигнала (20), с формированием декодированного разностного сигнала; и комбинатор сигнала (34) для объединения декодированного импульсного сигнала и декодированного разностного сигнала с формированием декодированного выходного сигнала (36), причем декодер сигналов (32) и декодер импульсов (30) генерируют выходные значения, относящиеся к тому же моменту времени, что и декодированный сигнал, причем импульсный декодер (30) получает закодированный импульсный сигнал и формирует декодированный импульсный сигнал в заданные интервалы времени (142), разделенные периодами (143), в которые декодер сигнала генерирует декодированный разностный сигнал, а импульсный декодер (30) не генерирует декодированный сигнал импульсного типа таким образом, что декодированный выходной сигнал имеет периоды (143), в которые декодированный выходной сигнал идентичен декодированному разностному сигналу, а декодированный выходной сигнал имеет определенные временные составляющие (142), в течение которых декодированный выходной сигнал состоит из декодированного разностного сигнала и декодированного импульсного сигнала или состоит только из декодированного импульсного сигнала.
25. Декодер по п.24, характеризующийся тем, что декодер импульсов (30) представляет собой декодер временной области, а декодер сигнала (32) представляет собой банк фильтров или декодер-преобразователь.
26. Декодер по п.24, характеризующийся тем, что закодированный аудиосигнал содержит служебную информацию (14), включающую в себя характеристики кодирования или декодирования, соответствующие разностному сигналу; комбинатор (34) предназначен для интегрирования декодированного разностного сигнала и декодированного импульсного сигнала в соответствии со служебной информацией (14).
27. Декодер по п.24, характеризующийся тем, что если служебная информация (14) содержит указания на то, что одновременно с импульсной составляющей в разностном сигнале сгенерирован искусственный сигнал, комбинатор (34) выполнен с возможностью блокирования или, по меньшей мере, ослабления декодированного разностного сигнала во время прохождения импульсной составляющей в соответствии со служебной информацией.
28. Декодер по п.24, характеризующийся тем, что если служебная информация указывает, что импульсный сигнал перед вычитанием из аудиосигнала ослаблен согласно коэффициенту ослабления, комбинатор (34) выполнен с возможностью ослабления декодированного разностного сигнала согласно коэффициенту ослабления и использования ослабленного декодированного сигнала для совмещения с декодированным сигналом импульсного типа.
29. Декодер по п.24, характеризующийся тем, что если закодированный импульсный сигнал включает в себя сигнал в форме последовательности импульсов, декодер для декодирования (30) закодированного импульсного сигнала выполнен с возможностью использования алгоритма декодирования, соответствующего алгоритму кодирования, причем алгоритм кодирования предусматривает большую эффективность или меньшую ошибку кодирования при кодировании сигнала в виде последовательности импульсов, чем при кодировании сигнала, не являющегося импульсной последовательностью.
30. Способ декодирования кодированного аудиосигнала (24), содержащего закодированный импульсный сигнал (12) и закодированный разностный сигнал (20), характеризующийся тем, что декодирование (30) закодированного импульсного сигнала с использованием алгоритма декодирования, соответствующего алгоритму кодирования, предназначено для генерирования кодированного импульсного сигнала с формированием декодированного импульсного сигнала; декодирование (32) закодированного разностного сигнала (20) с использованием алгоритма декодирования, соответствующего алгоритму кодирования, предназначено для генерирования закодированного разностного сигнала (20) с формированием декодированного разностного сигнала; совмещение (34) декодированного импульсного сигнала и декодированного разностного сигнала с формированием декодированного выходного сигнала (36), где фазы декодирования (32, 30) формируют выходные значения, относящиеся к тому же моменту времени, что и декодированный сигнал, причем при декодировании (30) закодированного импульсного сигнала импульсный сигнал принимается, и формируется декодированный сигнал импульсного типа в установленные интервалы времени (142), которые разделены периодами (143), в течение которых выполняется декодирование (32) закодированного разностного сигнала, а операция декодирования (30) закодированного импульсного сигнала не выполняется, вследствие чего декодированный выходной сигнал имеет периоды (143), в которые декодированный выходной сигнал идентичен декодированному разностному сигналу, а декодированный выходной сигнал имеет определенные интервалы времени (142), в течение которых декодированный выходной сигнал состоит из декодированного разностного сигнала и декодированного импульсного сигнала или состоит только из импульсного сигнала.
31. Машиночитаемый носитель информации, содержащий кодированный аудиосигнал (24), характеризующийся тем, что включает закодированный импульсный сигнал (12), закодированный разностный сигнал (20) и служебную информацию (14), содержащую характеристики кодирования или декодирования, относящиеся к закодированному разностному сигналу или к закодированному импульсному сигналу, причем закодированный импульсный сигнал содержит заданные временные составляющие (142) аудиосигнала, в которых аудиосигнал представлен только кодированным импульсным сигналом или представлен кодированным разностным сигналом и кодированным импульсным сигналом, при этом заданные временные составляющие (142) разделены периодами (143), в течение которых аудиосигнал представлен только закодированным разностным сигналом, а незакодированным импульсным сигналом (12).
32. Машиночитаемый носитель информации, содержащий сохраненную на нем компьютерную программу, имеющую программный код, предназначенную для реализации способа в соответствии с п.23 с применением вычислительной техники.
33. Машиночитаемый носитель информации, содержащий сохраненную на нем компьютерную программу, имеющую программный код, предназначенную для реализации способа в соответствии с п.30 с применением вычислительной техники.
| RAMPRASHAD S A, A two stage hybrid embedded speech/audio coding structure, Acoustics, speech and signal processing, Proceedings of the 1998 IEEE International Conference on Seattle, 12.05.1998, c.337-340 | |||
| СПОСОБ РЕГЕНЕРАЦИИ ОТРАБОТАННОГО ТОПЛИВА | 2009 |
|
RU2403634C1 |
| WO 2006030340 A2, 23.03.2003 | |||
| WO 2004082288 A1, 23.09.2004 | |||
| JP 3905706 B2, 18.04.2007 | |||
| СПОСОБ И УСТРОЙСТВО КОДИРОВАНИЯ АУДИОСИГНАЛА С ИСПОЛЬЗОВАНИЕМ ИЗВЛЕЧЕНИЯ ГАРМОНИК | 2002 |
|
RU2289858C2 |
| RU 2005113877 A, 10.10.2005. | |||

