Область техники
Изобретение относится к области техники воспроизведения аудио. В частности, в данном документе описывается воспроизведение многоканального аудио с воспроизведением приподнятых или опущенных по высоте звуков.
Уровень техники
Для воспроизведения звука предусмотрены различные виды систем, которые отличаются относительно их сложности и качества воспроизведения. Ориентир для звука фильма представляет собой кинотеатры. Кинотеатры предоставляют многоканальный объемный звук, с громкоговорителями, установленными не только перед слушателем (обычно позади экрана), но дополнительно по бокам и сзади, а в последнее время также и на потолке. Боковые и задние громкоговорители предоставляют воспроизведение горизонтально огибающего звука, которое дополнительно может улучшаться посредством вертикально охватывающего звука с использованием высотных и потолочных громкоговорителей.
При использовании новейших технологий кодирования, иммерсивный, интерактивный и объектно-ориентированный аудиоконтент может не только использоваться в профессиональных окружениях, но также может легко передаваться в дом потребителя, что добавляет дополнительные признаки и размерности, например, высотное воспроизведение.
Улучшенные компоновки для воспроизведения для реалистичного воспроизведения звука используют громкоговорители, не только смонтированные в горизонтальной плоскости (обычно на или близко к высоте ушей слушателя), но дополнительно также громкоговорители, разбросанные в вертикальном направлении. Эти громкоговорители, например, являются приподнятыми (смонтированы на потолке или под некоторым углом выше уровня головы) либо размещаются ниже высоты уха слушателя (например, на полу либо под некоторым промежуточным или конкретным углом).
Зачастую неудобно или невозможно устанавливать громкоговорители в направлениях вверх или вниз.
В домашнем окружении, с большой вероятностью только энтузиасты устанавливают число громкоговорителей, требуемое для того, чтобы реплицировать компоновки громкоговорителей, которые используются в профессиональных окружениях, научно-исследовательских лабораториях или кинотеатрах. Здесь, термин «компоновка громкоговорителей» также включает в себя такие устройства и топологии, как звуковые панели, телевизоры со встроенными громкоговорителями, бумбоксы, звуковые пластины, массивы громкоговорителей, интеллектуальные динамики и т.д.
Тем не менее, при рендеринге звука для восприятия иммерсивного звука или виртуальной реальности, часто желательно подготавливать посредством рендеринга звук также в направлениях высоты (вверх или вниз) (обозначаются как «направления вверх и вниз» ниже по тексту. Конечно, не всегда оба направления должны обрабатываться, так что это является эквивалентным» направлениям либо вверх, либо вниз» или «направлениям вверх/вниз»).
Следовательно, возникает потребность в том, чтобы подготавливать посредством рендеринга звук в направлениях вверх и вниз без наличия высотных громкоговорителей, например, верхних громкоговорителей и/или нижних громкоговорителей.
Удобная альтернатива этим достаточно комплексным компоновкам представляет собой компактные системы воспроизведения, которые используют средство обработки сигналов для того, чтобы формировать сравнимое или аналогичное пространственное слуховое восприятие относительно улучшенных компоновок громкоговорителей. Здесь, термин «системы воспроизведения» включает в себя все устройства и топологии для воспроизведения аудио, к примеру, компоновки, содержащие определенное число отдельных громкоговорителей, звуковых панелей, телевизоров со встроенными громкоговорителями, бумбоксов, звуковых пластин, массивов громкоговорителей, интеллектуальных динамиков и т.д.
Ниже по тексту представляются практический способ и оборудование для того, чтобы достигать этого.
Сущность изобретения
Цель настоящего изобретения заключается в том, чтобы предоставлять более эффективный рендеринг аудиообъектов, который обеспечивает возможность трехмерного панорамирования, при этом повышение эффективности относится, например, к стабильности рендеринга, повышенной точности панорамирования, эффективности вычислений и/или пригодности с большим числом компоновок громкоговорителей, изменяющимся числом громкоговорителей, изменяющимися позициями громкоговорителей, изменяющимися позициями слушателей, изменяющимися позициями объектов.
Это цель достигается посредством предмета изобретения в независимых пунктах формулы изобретения.
Более эффективный рендеринг аудиообъектов, который обеспечивает возможность трехмерного панорамирования, достигается посредством выполнения панорамирования в двух каскадах, а именно по меньшей мере одного горизонтального внутрислойного панорамирования, приводящего к первой виртуальной позиции (динамика) и второй виртуальной или реальной позиции (динамика), которая вертикально смещается, и другого панорамирования вертикально между двумя позициями. Хотя кажется, что действие таким способом увеличивает вычислительную сложность, эта каскадная обработка увеличивает, фактически, стабильность рендеринга и точность локализации намеченной виртуальной позиции. Кроме того, каскадная обработка обеспечивает возможность выполнять, согласно варианту осуществления, панорамирование посредством использования только усилений амплитудного панорамирования, т.е. фазовая обработка не требуется, за счет этого снижая вычислительную сложность. Еще дополнительно, рендеринг является гибким относительно применимости для множества компоновок громкоговорителей.
Варианты осуществления настоящей заявки относятся к оборудованию для формирования сигналов громкоговорителей для множества громкоговорителей таким образом, что применение сигналов громкоговорителей во множестве громкоговорителей подготавливает посредством рендеринга по меньшей мере один аудиообъект в намеченной виртуальной позиции. Оборудование содержит интерфейс, выполненный с возможностью принимать входной аудиосигнал, который представляет по меньшей мере один аудиообъект. Он может представлять собой одно из канально-ориентированного аудиосигнала, объектно-ориентированного аудиосигнала и/или сцено-ориентированного аудиосигнала. Модуль определения первых усилений панорамирования выполнен с возможностью определять, в зависимости от намеченной виртуальной позиции, первые усиления панорамирования для первого набора громкоговорителей из множества громкоговорителей, которые размещаются в первом наборе слоев из одного или более первых горизонтальных слоев, причем первые усиления панорамирования задают извлечение первых частичных сигналов громкоговорителей по меньшей мере из одного входного аудиосигнала, которые ассоциированы с рендерингом по меньшей мере одного аудиообъекта в первой виртуальной позиции при применении первых частичных сигналов громкоговорителей к первому набору громкоговорителей. Означенное представляет собой вышеуказанное внутрислойное панорамирование. Модуль определения усилений вертикального панорамирования выполнен с возможностью определять, в зависимости от намеченной виртуальной позиции, дополнительные усиления панорамирования для панорамирования (или постепенного нарастания/затухания) между первыми частичными сигналами громкоговорителей и одним или более вторых частичных сигналов громкоговорителей, которое должно применяться ко второму набору из одного или более громкоговорителей и ассоциировано с рендерингом по меньшей мере одного аудиообъекта во второй позиции, которая вертикально смещается относительно первой позиции, с тем чтобы панорамироваться между первой виртуальной позицией и второй позицией. Означенное представляет собой вертикальное панорамирование. Один или более вторых частичных сигналов громкоговорителей могут представлять собой результат другого внутрислойного панорамирования, причем в этом случае, вторая позиция представляет собой вторую виртуальную позицию, или вторая позиция может представлять собой реальную позицию другого из громкоговорителей, который позиционируется с вертикальным смещением по отношению к первому набору громкоговорителей. Оборудование выполнено с возможностью составлять сигналы громкоговорителей из первых частичных сигналов громкоговорителей и одного или более вторых частичных сигналов громкоговорителей с использованием первых усилений панорамирования и дополнительных усилений панорамирования. Таким образом, в составлении, первое и дополнительные усиления панорамирования фактически применяются ко входному аудиосигналу, за счет этого приводя к сигналам громкоговорителей. Возможно, могут быть предусмотрены один или более сигналов громкоговорителей, для формирования которых должно использоваться только одно из усилений панорамирования, к примеру, для вышеуказанного второго громкоговорителя, позиционированного в позиции реального громкоговорителя и снабжаемого вторым частичным сигналом громкоговорителя.
Согласно некоторым вариантам осуществления, как описано выше, второй набор из одного или более громкоговорителей содержит более одного громкоговорителя, и один или более вторых частичных сигналов громкоговорителей содержат более одного вторых частичных сигналов громкоговорителей, и оборудование дополнительно содержит модуль определения вторых усилений панорамирования, выполненный с возможностью определять, в зависимости от намеченной виртуальной позиции, вторые усиления панорамирования для второго набора громкоговорителей, причем вторые усиления панорамирования задают извлечение вторых частичных сигналов громкоговорителей по меньшей мере из одного входного аудиосигнала, при этом оборудование выполнено с возможностью составлять сигналы громкоговорителей из первых и вторых частичных сигналов громкоговорителей с использованием первых и вторых усилений панорамирования и дополнительных усилений панорамирования. Здесь, согласно варианту осуществления, вторые частичные сигналы громкоговорителей могут извлекаться по меньшей мере из одного аудиосигнала посредством формирования спектра, так что вторая позиция представляет собой виртуальную позицию выше или ниже второго набора слоев, к примеру, не между или внутри любого из одного или более первых горизонтальных слоев и одного или более вторых горизонтальных слоев, в которых размещается второй набор громкоговорителей, а на одной стороне, вертикально, относительно этих горизонтальных слоев. В соответствии с соответствующими вариантами осуществления, в результате получается оборудование, которое служит для формирования сигналов громкоговорителей для множества громкоговорителей таким образом, что применение сигналов громкоговорителей во множестве громкоговорителей подготавливает посредством рендеринга по меньшей мере один аудиообъект в намеченной виртуальной позиции, при этом множество громкоговорителей распределяются в один или более горизонтальных слоев, причем оборудование содержит интерфейс, выполненный с возможностью принимать входной аудиосигнал, который представляет по меньшей мере один аудиообъект, модуль определения первых наборов сигналов громкоговорителей, выполненный с возможностью определять, в зависимости от намеченной виртуальной позиции, первые усиления панорамирования, например, в качестве упомянутых усилений чистого амплитудного панорамирования таким образом, что первая виртуальная позиция находится между позициями первого набора громкоговорителей для первого набора громкоговорителей из множества громкоговорителей, и использовать первые усиления панорамирования для того, чтобы извлекать первые частичные сигналы громкоговорителей по меньшей мере из одного входного аудиосигнала, которые ассоциированы с рендерингом по меньшей мере одного аудиообъекта в первой виртуальной позиции при применении первых частичных сигналов громкоговорителей к первому набору громкоговорителей, модуль определения вторых наборов сигналов громкоговорителей, выполненный с возможностью, посредством формирования спектра, извлекать вторые частичные сигналы громкоговорителей по меньшей мере из одного аудиосигнала, причем вторые частичные сигналы громкоговорителей ассоциированы с рендерингом по меньшей мере одного аудиообъекта во второй виртуальной позиции при применении вторых частичных сигналов громкоговорителей ко второму набору громкоговорителей, причем вторая виртуальная позиция находится выше или ниже одного или более горизонтальных слоев, например, не между или внутри любого из одного или более горизонтальных слоев, а на одной стороне, вертикально, относительно одного или более горизонтальных слоев, и модуль определения усилений вертикального панорамирования, выполненный с возможностью, в зависимости от намеченной виртуальной позиции, определять вторые усиления панорамирования для первых и вторых частичных сигналов громкоговорителей, с тем чтобы панорамироваться между первыми и вторыми виртуальными позициями, и модуль составления, выполненный с возможностью составлять сигналы громкоговорителей из первых и вторых частичных сигналов громкоговорителей с использованием вторых усилений панорамирования.
Варианты осуществления, изложенные в данном документе, в силу этого раскрывают концепцию для рендеринга по меньшей мере одного аудиообъекта в набор громкоговорителей по меньшей мере из одного входного аудиосигнала. Вкратце, входные аудиосигналы могут содержать информацию относительно аудиообъектов, которые должны выводиться посредством громкоговорителей. Например, такой аудиообъект может представлять собой звук вертолета, летящего в фильме, звук инструмента, играющего в оркестре, или звук голоса. Аудиообъект подготавливается посредством рендеринга с использованием громкоговорителей. Входной аудиосигнал обрабатывается, чтобы определять то, как аудиообъект должен выводиться в отдельных громкоговорителях. Для этого, каждый входной аудиосигнал ассоциирован с информацией позиции по меньшей мере одного аудиообъекта. Такая информация позиции может быть статической, например, скрипка расположена слева от оркестра, динамик находится перед слушателем, или динамической, например, вертолет летит справа налево. Набор громкоговорителей, используемых для того, чтобы подготавливать посредством рендеринга аудиообъект, может содержать одну или более групп громкоговорителей, причем каждая группа расположена в одном горизонтальном слое. Дополнительный громкоговоритель может представлять собой физический или виртуальный громкоговоритель, расположенный выше или ниже одной или более групп.
Это означает то, что для набора громкоговорителей, может задаваться ассоциирование со слоями и позициями, смещенными по отношению к слоям выше или ниже слоев. Например, компоновка может содержать четыре громкоговорителя в одном слое, например, все на идентичной высоте, и один физический или виртуальный громкоговоритель, более высокий, например, приподнятый, выше четырех других громкоговорителей. Эта компоновка в таком случае должна иметь один слой. Также являются возможными дополнительные один или более слоев.
Преимущественные варианты осуществления представляют собой предмет зависимых пунктов формулы изобретения. В частности, предпочтительные варианты осуществления настоящей заявки описываются ниже со ссылкой на чертежи, на которых:
Фиг. 1 показывает блок-схему оборудования для рендеринга аудио в соответствии с вариантом осуществления;
Фиг. 2 показывает другой вариант осуществления для оборудования для рендеринга аудио, описанного здесь как содержащего возможность горизонтального панорамирования для обоих наборов частичных сигналов громкоговорителей, а также частотной коррекции для одного из них;
Фиг. 3 схематично показывает примерную компоновку громкоговорителей и слушателя, позиционированного между громкоговорителями, с дополнительной иллюстрацией учета виртуального верхнего громкоговорителя для рендеринга аудио;
Фиг. 4 показывает принципиальную схему сценария по фиг. 3, с иллюстрацией первого (горизонтального) панорамирования;
Фиг. 5а показывает сценарий по фиг. 3, с иллюстрацией использования частотной коррекции или формирования спектра для того, чтобы предоставлять монауральную сигнальную метку, чтобы достигать виртуального верхнего громкоговорителя;
Фиг. 5b показывает ситуацию по фиг. 5а3, с иллюстрацией панорамирования между громкоговорителями, набранными с возможностью участвовать в рендеринге виртуального верхнего громкоговорителя, и усилений, используемых для того, чтобы располагать виртуальный верхний громкоговоритель;
Фиг. 6 показывает блок-схему оборудования для рендеринга аудио, варьируемого по сравнению с вариантом осуществления по фиг. 2 за счет другого порядка между горизонтальным панорамированием и частотной коррекцией для рендеринга верхнего/нижнего виртуального громкоговорителя;
Фиг. 7 показывает блок-схему другого варианта осуществления для оборудования для рендеринга аудио либо, если рассматривать по-другому, блок-схему элементов оборудования по фиг. 1, участвующих в рендеринге аудиообъекта для намеченной виртуальной позиции между двумя доступными слоями громкоговорителей;
Фиг. 8 показывает блок-схему, иллюстрирующую, в дополнение к элементам по фиг. 7, возможность учета позиции слушателя;
Фиг. 9 показывает схематичный вид сверху возможной компоновки громкоговорителей, здесь 5.0-компоновки громкоговорителей;
Фиг. 10 показывает другой схематичный трехмерный вид другого примера для компоновки громкоговорителей, здесь 5.0+2Н-компоновки громкоговорителей;
Фиг. 11, 12 показывают принципиальные схемы таким образом, чтобы иллюстрировать двухкаскадный процесс при выполнении рендеринга аудио объекта в намеченной виртуальной позиции между двумя доступными слоями, здесь для примера с использованием 5.0+4Н-компоновки громкоговорителей;
Фиг. 13, 14 иллюстрируют двухкаскадный рендеринг объекта в намеченной виртуальной позиции, вертикально смещенной по отношению к доступным слоям, здесь для примера по отношению к верхней части всех слоев, и
Фиг. 15 показывает примеры для формирующих функций, используемых в частотной коррекции или формировании спектра таким образом, чтобы формировать монауральную сигнальную метку для рендеринга сигнала виртуального верхнего/нижнего громкоговорителя.
Нижеприведенное описание начинается с описания варианта осуществления оборудования для формирования сигналов громкоговорителей для множества громкоговорителей. Более конкретные варианты осуществления приводятся ниже наряду с описанием подробностей, которые могут, отдельно или в группах, применяться к оборудованию по фиг. 1.
Оборудование по фиг. 1, в общем, указывается с использованием ссылки с номером 10 и служит для формирования сигналов 12 громкоговорителей для множества громкоговорителей 14 таким способом, что применение сигналов 12 громкоговорителей в или ко множеству громкоговорителей 14 подготавливает посредством рендеринга по меньшей мере один аудиообъект в намеченной виртуальной позиции.
Оборудование 10 может быть сконфигурировано для определенной компоновки громкоговорителей 14, т.е. для определенных позиций, в которых множество громкоговорителей 14 позиционируются либо позиционируются и ориентируются. Тем не менее, оборудование альтернативно может быть конфигурируемым для различных компоновок громкоговорителей для громкоговорителей 14. Аналогично, число громкоговорителей 14 может составлять два или более, и оборудование может проектироваться для заданного числа громкоговорителей 14 либо может быть конфигурируемым с возможностью решать проблемы, связанные с любым числом громкоговорителей 14.
Оборудование 10 содержит интерфейс 16, в котором оборудование 10 принимает аудиосигнал 18, который представляет по меньшей мере один аудиообъект. На настоящий момент предположим, что входной аудиосигнал 18 представляет собой моноаудиосигнал, который представляет аудиообъект, такой как звук вертолета и т.п. Ниже предоставляются дополнительные примеры и дополнительные сведения. В любом случае, аудиосигнал 18 может представлять аудиообъект во временной области, в частотной области или в любой другой области, и он может представлять аудиообъект сжатым способом или без сжатия.
Как проиллюстрировано на фиг. 1, оборудование 10 дополнительно содержит ввод на основе позиции для приема намеченной виртуальной позиции. Таким образом, во вводе 20 на основе позиции, оборудование 10 уведомляется в отношении намеченной виртуальной позиции, в которую аудиообъект должен фактически подготавливаться посредством рендеринга посредством применения сигналов 12 громкоговорителей в громкоговорителях 14. Таким образом, оборудование 10 принимает во вводе 20 информацию намеченной виртуальной позиции, и эта информация может предоставляться относительно компоновки/позиции громкоговорителей 14, относительно позиции и/или ориентации головы слушателя и/или относительно координат реального мира. Эта информация, например, может быть основана на декартовых системах координат или на полярных системах координат. Она, например, может быть основана на помещение-центрической системе координат или на слушателе-центрической системе координат, в качестве декартовой или полярной системы координат.
Как проиллюстрировано на фиг. 1, оборудование 10 содержит модуль 22 определения первых усилений панорамирования, выполненный с возможностью определять, в зависимости от намеченной виртуальной позиции 21, принимаемой во вводе 20, первые усиления 24 панорамирования для первого набора 26 громкоговорителей из множества громкоговорителей 14. Этот набор 26 громкоговорителей размещается в первом наборе слоев из одного или более первых горизонтальных слоев. Таким образом, этот набор 26 громкоговорителей, квази-, размещается на аналогичных высотах. Первые усиления 24 панорамирования задают извлечение или участвуют в формировании первых частичных сигналов 2 8 громкоговорителей по меньшей мере из одного входного аудиосигнала 18, причем эти первые частичные сигналы 2 8 громкоговорителей ассоциированы с рендерингом по меньшей мере одного аудиообъекта в первой виртуальной позиции при применении первых частичных сигналов громкоговорителей к первому набору 26 громкоговорителей. Как подробнее указано ниже, модуль 22 определения первых усилений панорамирования, согласно варианту осуществления, может вычислять амплитудные усиления, по одному для каждого частичного сигнала громкоговорителя из первых частичных сигналов 28 громкоговорителей, так что первая виртуальная позиция панорамируется между громкоговорителями набора 26, что включает в себя возможный случай, в котором, иногда, первая виртуальная позиция совпадает с одной из позиций громкоговорителей, причем в этом случае только громкоговоритель в этой позиции может принимать ненулевое усиление панорамирования. Иными словами, модуль 22 определения первых усилений панорамирования служит для вычисления амплитудных усилений для горизонтального панорамирования в наборе 26 таким образом, что это горизонтальное панорамирование в результате приводит к позиции виртуального рендеринга в первом наборе слоев набора 26 громкоговорителей.
Оборудование 10 по фиг. 1 дополнительно содержит модуль 30 определения усилений вертикального панорамирования, который выполнен с возможностью определять, в зависимости от намеченной виртуальной позиции 21, дополнительные усиления панорамирования для панорамирования между первыми частичными сигналами 2 8 громкоговорителей, с одной стороны, и одним или более вторых частичных сигналов 34 громкоговорителей, с другой стороны. Один или более вторых частичных сигналов 34 громкоговорителей должны применяться ко второму набору 36 из одного или более громкоговорителей из громкоговорителей 14, который содержит только один громкоговоритель или более одного.
Фиг. 1 иллюстрирует случай, в котором число вторых частичных сигналов 34 громкоговорителей и громкоговорителей в наборе 36 больше одного, но также можно признать, что имеется только один громкоговоритель в наборе 36 и, соответственно, только один второй частичный сигнал 34 громкоговорителя. Во втором случае, один громкоговоритель набора 36 должен быть внешним для набора 26 громкоговорителей, для которых выделяются первые частичные сигналы 28 громкоговорителей. В случае набора 36, содержащего более одного громкоговорителя, наборы 26 и 36 могут быть взаимно непересекающимися, частично перекрываться, совпадать или полностью перекрываться, т.е. один может быть собственным поднабором другого. Ниже подробнее излагаются примеры. В любом случае, вторая позиция вертикально смещается относительно первой позиции. Ниже излагаются другие примеры того, как достигать вертикального смещения между первыми и вторыми позициями даже в случае совпадения первых и вторых наборов 26 и 36. Следует отметить, что в вариантах осуществления, приведенных относительно чертежей, каждый набор 26 и 36 состоит из громкоговорителей одного слоя или даже соответствует одному слою, так что в случае совпадения наборов 26 и 36, наборы слоев, т.е. слои наборов 26 и 32, также совпадают. Тем не менее, это соответствие между наборами и слоями может варьироваться таким образом, что любой из наборов 26 и 32 может состоять из громкоговорителей более чем одного слоя.
Дополнительные усиления 32 панорамирования, определенные посредством модуля 30 определения усилений вертикального панорамирования, в итоге приводят в результате к панорамированию между первой виртуальной позицией и второй позицией.
Как показано на фиг. 1, оборудование 10 дополнительно содержит модуль 40 составления, который дополнительно выполнен с возможностью составлять сигналы 12 громкоговорителей из входного аудиосигнала 18 с использованием первых усилений 24 панорамирования и дополнительных усилений 32 панорамирования. Как описано выше, первые усиления панорамирования могут представлять собой простые амплитудные усиления, и, соответственно, модуль 40 составления может содержать умножитель 42 для каждого частичного сигнала 28 громкоговорителя для умножения входного аудиосигнала 18 на соответствующее усиление 24 панорамирования. Усиления 24 панорамирования, соответственно, являются отдельными для частичных сигналов 28 громкоговорителей. Таким образом, имеется одно усиление 24 панорамирования в расчете на частичный входной сигнал 28. Аналогично и как подробнее указано ниже, усиления 32 панорамирования, выводимые посредством модуля 30 определения усилений вертикального панорамирования, также могут представлять собой простые амплитудные усиления. Здесь, имеется одно усиление 32 панорамирования в расчете на набор 28 и 34, соответственно. Соответственно, модуль 40 составления может содержать один умножитель 44а, 44b для каждого из наборов 28 и 34, соответственно, причем умножитель 4 4а умножает каждый сигнал громкоговорителя набора 28 на усиление 32 панорамирования, ассоциированное с этим набором 28, а умножитель 44b умножает каждый частичный сигнал громкоговорителя из набора 34 на усиление 32 панорамирования, ассоциированное с этим набором 34.
Дополнительная задача модуля 40 составления заключается в следующем: как упомянуто выше, наборы 26 и 36 громкоговорителей могут перекрываться или могут не перекрываться. В качестве задачи модуля 40 составления, модуль 40 составления корректно распределяет частичные сигналы 28 и 34 громкоговорителей, полученные посредством панорамирования с использованием усилений 24 и 32 панорамирования, на громкоговорители 14. Для этих частичных сигналов громкоговорителей наборов 28 и 34, которые принадлежат только одному из наборов 28 и 34, соответствующий частичный сигнал громкоговорителя становится одним из сигналов 12 громкоговорителей. Тем не менее, для этих одного или более частичных сигналов громкоговорителей, которые ассоциированы с идентичным громкоговорителем из громкоговорителей 14, тем не менее, модуль 40 составления суммирует их с использованием сумматора 46 таким образом, что сумма взаимно соответствующих частичных сигналов громкоговорителей из набора 28 и 34, соответственно, становится одним из сигналов 12 громкоговорителей.
Следует отметить, что вследствие ассоциативных и коммутативных свойств умножения, модуль 40 составления не ограничивается выполнением умножений для каждого частичного сигнала громкоговорителя в порядке, проиллюстрированном на фиг. 1. Таким образом, хотя модуль 4 0 составления по фиг. 1 проиллюстрирован как выполняющий отдельное умножение частичных сигналов громкоговорителя на первые усиления 24 панорамирования до умножения на глобальное для наборов усиление 32 панорамирования, умножения могут выполняться в другом порядке.
Фиг. 1 также иллюстрирует подробности, которые используются согласно вариантам осуществления, дополнительно описанным ниже. В частности, эти подробности связаны с извлечением или формированием частичных сигналов 34 громкоговорителей из входного аудиосигнала 18. Два последующих этапа обработки могут быть ассоциированы с извлечением/формированием частичных сигналов 34 громкоговорителей из входного аудиосигнала 18. Эти два этапа обработки и соответствующие элементы на фиг. 1, являются необязательными, и, соответственно, входной аудиосигнал может представлять один частичный сигнал 34 громкоговорителя непосредственно, который подвергается вертикальному панорамированию посредством соответствующего усиления 32 панорамирования. Если присутствует, только один или оба этапа обработки могут применяться и осуществляться в оборудовании 10.
Первый этап обработки соответствует горизонтальному панорамированию относительно частичных сигналов 34 громкоговорителей способом, практически соответствующим горизонтальному панорамированию, реализованному посредством элементов 22, 24 и 42 относительно частичных сигналов 28 громкоговорителей. Таким образом, как показано на фиг. 1, оборудование 10 может содержать модуль 52 определения вторых усилений панорамирования, выполненный с возможностью определять, в зависимости от намеченной виртуальной позиции 21, вторые усиления 54 панорамирования для второго набора 36 громкоговорителей, причем вторые усиления 54 панорамирования задают извлечение вторых частичных сигналов 34 громкоговорителей по меньшей мере из одного входного аудиосигнала 18. Модуль 4 0 составления должен содержать соответствующие умножители 56, а именно, по одному в расчете на частичный сигнал 34 громкоговорителя, который умножает соответствующее усиление 54 панорамирования на входной аудиосигнал. Другими словами, модуль 40 составления должен подвергать частичный сигнал 34 громкоговорителя для каждого громкоговорителя в наборе 36 умножению на усиление 54 панорамирования, ассоциированное с соответствующим громкоговорителем в наборе 36. Это должно приводить в результате к горизонтальному панорамированию и к позиции виртуального громкоговорителя, ассоциированной с частичными сигналами 34 громкоговорителей.
Дополнительно или альтернативно относительно элементов 52-56, оборудование 10 может содержать спектральный формирователь 58, который выполняет формирование спектра во входной аудиосигнал либо промежуточные или конечные продукты как результат горизонтального панорамирования в умножителях 56 и вертикального панорамирования в умножителе 4 4b таким образом, что вторые частичные сигналы 34 громкоговорителей извлекаются по меньшей мере из одного входного аудиосигнала посредством этого формирования спектра. Формирование спектра, например, для каждого из частичных сигналов 34 громкоговорителей является одинаковым, т.е. может использоваться идентичная функция формирования спектра. Как подробнее указано ниже, функция 60 формирования спектра, используемая посредством спектрального формирователя 58, выбирается таким образом, чтобы формировать такую психоакустическую сигнальную метку для слушателя, что вторая виртуальная позиция, ассоциированная со вторыми частичными сигналами 34 громкоговорителей, позиционируется выше или ниже второго набора 36 громкоговорителей.
Формирование спектра, выполняемое посредством спектрального формирователя 58, может выполняться в спектральной области посредством умножения спектра частичных сигналов громкоговорителей на формирующую функцию 60 либо может выполняться во временной области, к примеру, посредством фильтра временной области, такого IIR- или FIR-фильтр, причем фильтр временной области в таком случае должен иметь частотный отклик, соответствующий функции 60 формирования спектра. Дополнительные примечания приводятся относительно наборов 26 и 36. Оборудование может выбирать их в зависимости от текущей компоновки динамиков. Другими словами, оборудование может быть адаптивным к различным компоновкам. Оборудование может выбирать первый набор 26 громкоговорителей из множества громкоговорителей в зависимости от горизонтального компонента намеченной виртуальной позиции, к примеру, из одного слоя эти динамики, ближайшие к намеченной виртуальной позиции (в отношении своей вертикальной проекции в один слой) либо в зависимости от горизонтального компонента намеченной виртуальной позиции и вертикального компонента намеченной виртуальной позиции, к примеру, посредством выбора самого дальнего слоя, ближайшего к намеченной виртуальной позиции, и затем выбора динамиков в этом одном слое. Дополнительно или альтернативно, второй набор 36 громкоговорителей может выбираться из множества громкоговорителей в зависимости от вертикального компонента намеченной виртуальной позиции, к примеру, посредством выбора самого дальнего слоя, ближайшего к намеченной виртуальной позиции, и с использованием всех динамиков, принадлежащих этому слою для набора 36, либо в зависимости от горизонтального компонента намеченной виртуальной позиции и вертикального компонента намеченной виртуальной позиции, к примеру, посредством выбора самого дальнего слоя, ближайшего к намеченной виртуальной позиции, и выбора набора 36 из динамиков слоя таким образом, что он является ближайшим к намеченной виртуальной позиции (в отношении своей вертикальной проекции в один слой).
Как упомянуто выше относительно первых частичных сигналов 28 громкоговорителей, модуль 40 составления может быть выполнен с возможностью выполнять умножение 56 и 44b, а также формирование 58 спектра в любом порядке, т.е. может применять эти три задачи в любом порядке ко входному аудиосигналу 18, что приводит в результате к соответствующим частичным сигналам 34 громкоговорителей.
В завершение, следует отметить, что согласно примеру, имеется вероятность того, что число громкоговорителей в наборе 36 и в силу этого число частичных сигналов 34 громкоговорителей, соответственно, может составлять один, даже в случае использования спектрального формирователя 58.
Перед продолжением описания определенных подробностей и вариантов осуществления настоящей заявки, которые описываются ниже посредством многократного использования ссылок с номерами и описания, приведенного выше, необходимо отметить следующее относительно модуля 4 0 составления: в случае фиг. 1, модули 22, 30 и 52 определения усилений панорамирования формируют вид промежуточных модулей для вычисления усилений панорамирования на основе намеченной виртуальной позиции 21, тогда как фактическое применение усилений панорамирования выполнено посредством модуля 4 0 составления. Дополнительно, спектральный формирователь 58 показан как включенный в модуль 4 0 составления в качестве его субмодуля. Тем не менее, как описано выше, модификации по сравнению с иллюстрацией по фиг.1 являются целесообразными. Например, спектральный формирователь 58 может быть размещен выше элементов 52, 54 и 56 таким образом, что он становится, в завершение, модулем, внешним по отношению и, в частности, вышележащим по отношению к модулю 40 составления. Модуль 40 составления затем, в отношении первого набора 36 громкоговорителей, должен выполнять составление сигналов 12 громкоговорителей на основе предварительной версии определенной формы входного аудиосигнала 18. Дополнительно или альтернативно, большинство нижепоясненных вариантов осуществления используют составление, в котором вертикальное панорамирование применяется после горизонтального панорамирования, которое в свою очередь, реализуется посредством умножителей 42 и/или 56 и, если применимо, формирования 58 спектра, и в этом случае, модуль 40 составления и его составление могут заключать в себе только элементы 44а, 44b и, если применимо, сумматор 46, тогда как элементы 22, 24 и 42 формируют модуль 70 определения первых наборов сигналов громкоговорителей, и элементы 52, 54, 56, 58 и 60 (либо их части, если горизонтальное панорамирование или формирование спектра отсутствует) формируют модуль 72 определения вторых сигналов громкоговорителей.
Перед возобновлением описания с анонсированными дополнительными сведениями и дополнительными подробными вариантами осуществления, необходимо вкратце отметить достигаемые преимущества, получающиеся в результате концепции рендеринга аудио, как проиллюстрировано на фиг. 1. В частности, как указано выше, рендеринг аудио согласно концепции по фиг. 1 обеспечивает возможность для воспроизведения аудио обходиться без использования и ассоциированных вычислительно сложных задач для применения различных HRTF, которые точно адаптируются или выбираются на основе или согласно точному угловому варьированию намеченной виртуальной позиции 21. Все горизонтальное и вертикальное панорамирование осуществляется только посредством амплитудного панорамирования, и формирование 58 спектра может использовать одно формирование спектра или равную функцию 60 формирования спектра для всех частичных сигналов 34 громкоговорителей для всех громкоговорителей в наборе 36. В вариантах осуществления, подробнее описанных ниже, оборудование 10 может либо использовать непрерывно идентичную функцию 60 формирования спектра независимо от намеченной виртуальной позиции 21 (к примеру, в случае намеченной ограничения виртуальной позиции 21 позициями, которые находятся, по высоте, внутри, между или выше позиции слушателя или слоев громкоговорителей 14, либо наоборот, в случае ограничения позициями, которые находятся, по высоте, внутри, между или ниже позиции слушателя или слоев громкоговорителей 14), либо различать между двумя функциями 60 формирования спектра, одна из которых используется в случае нахождения намеченной виртуальной позиции 21 выше позиции слушателя или самого верхнего слоя громкоговорителей, соответственно, а другая в случае нахождения ниже позиции слушателя или самого нижнего слоя громкоговорителей, соответственно. Таким образом, вычислительная сложность рендеринга по фиг. 1 является низкой. Это также является истинным при использовании необязательного формирования 58 спектра.
Кроме того, хотя может казаться, что разложение трехмерного панорамирования на горизонтальное панорамирование, с одной стороны, и вертикальное панорамирование, с другой стороны, приводит к более сложной процедуре рендеринга, результирующая вычислительная сложность по-прежнему является низкой, тогда как точность рендеринга с точки зрения позиционирования намеченной виртуальной позиции по-прежнему является высокой даже при этой средней вычислительной сложности.
Таким образом, варианты осуществления, описанные в данном документе, предоставляют альтернативу достаточно комплексным компоновкам, изложенным во вводной части описания изобретения, и формируют компактное воспроизведение, которое использует средство обработки сигналов для того, чтобы формировать сравнимое или аналогичное пространственное слуховое восприятие в качестве более сложных компоновок громкоговорителей. Концепции, представленные выше и ниже по тексту, допускают:
- Перцепционную замену отсутствующих громкоговорителей/массивов громкоговорителей с учетом одного или более виртуальных громкоговорителей. В данном документе описывается формирование этих виртуальных громкоговорителей.
- Эффективный рендеринг звука в трехмерных компоновках громкоговорителей, при этом рендеринг может использоваться, если виртуальный громкоговоритель (1) используется, а также в сценариях, в которых необходимые громкоговорители доступны физически. Преимущество (2) заключается в гибкости и эффективности, что обеспечивает его применимость также в сценариях, в которых позиция слушателя отслеживается в реальном времени, и рендеринг адаптируется в реальном времени к текущей позиции слушателя.
Следует отметить, что варианты осуществления, описанные в данном документе, являются независимыми от окружения воспроизведения, и, например, также могут использоваться, например, в автомобильном окружении. Кроме того, варианты осуществления являются независимыми от конкретного типа электроакустического преобразователя или топологии, используемой для воспроизведения. Таким образом, варианты осуществления могут применяться, например, при воспроизведении в наушниках, а также при воспроизведении с использованием конкретных громкоговорителей, к примеру, массивов громкоговорителей, звуковых панелей, интеллектуальных динамиков и т.д.
Таким образом, приведенные непосредственно выше примечания проясняют то, что громкоговорители 14 могут представлять собой громкоговорители наушников или стереогромкоговорители, но могут, также, формировать массив громкоговорителей, звуковую панель или набор громкоговорителей, интеллектуальные динамики или набор интеллектуальных динамиков, из компоновки с объемным звуком либо могут представлять собой отдельные громкоговорители, при этом комбинации также могут быть целесообразными. Кроме того, описание проясняет то, что оборудование 10 работает адаптивно, с тем чтобы адаптировать, в реальном времени, составление сигналов 12 громкоговорителей в намеченную виртуальную позицию 21, которая может варьироваться во времени.
В этом отношении, необходимо кратко отметить, что хотя варианты осуществления оборудования рендеринга могут предварительно конфигурироваться для определенных компоновок громкоговорителей, т.е. что они ожидают то, что предварительно заданный набор громкоговорителей 14 позиционируется в предварительно заданных позициях, также имеется вероятность того, что оборудование, описанное в данном документе, является адаптивным к различным компоновкам громкоговорителей, отличающимся по числу громкоговорителей и/или позиций динамиков, с точки зрения инициализации оборудования и/или с точки зрения адаптации к перемещающимся позициям громкоговорителей. В первом случае, оборудование, после инициализации, может предполагать, что компоновка громкоговорителей является постоянной. Во втором случае, оборудование может даже адаптироваться к варьированиям компоновки динамиков во время выполнения. Даже число динамиков может варьироваться во время выполнения. Соответственно, оборудование может принимать информацию относительно позиций громкоговорителей, причем это необязательное обстоятельство, тем не менее, не показано явно на чертежах. Таким образом, аналогично необязательному приему информации позиции слушателя, оборудование по фиг. 1 (и по последующим показанным вариантам осуществления) может содержать дополнительный ввод на основе позиции для приема информации компоновки громкоговорителей, раскрывающей число динамиков 14 и их позиции. Эта информация может предоставляться относительно позиции и/или ориентации головы слушателя и/или относительно координат реального мира. Эта информация, например, может быть основана на декартовых системах координат или на полярных системах координат. Она, например, может быть основана на помещение-центрической системе координат или на слушателе-центрической системе координат, в качестве декартовой или полярной системы координат.
Повсеместно используемые способы для рендеринга представляют собой технологии амплитудного панорамирования. Чтобы формировать восприятие слухового объекта в позициях, которые не покрываются громкоговорителями (например, не между двумя или более громкоговорителями), могут использоваться такие технологии рендеринга, как подавление перекрестных помех. Подавление перекрестных помех (ХТС)[1-7] имеет цель управлять сигналами в левое и в правое ухо слушателя посредством громкоговорителей. Это достигается посредством «подавления перекрестных помех между ушами», которое возникает, когда сигнал громкоговорителя достигает слушателя. После того как сигналы в уши могут непосредственно управляться, бинауральные технологии [8, 9] могут применяться для того, чтобы подготавливать посредством рендеринга звук в направлениях вверх и вниз. Предусмотрено два главных ограничения вышеупомянутой технологии. Во-первых, ХТС имеет ограничения, связанные с окрашиванием звука, чрезвычайно небольшой зоной наилучшего восприятия и высокой зависимостью от позиции громкоговорителей относительно слушателя. Во-вторых, без слежения за положением головы/отслеживания слушателя и/или индивидуализированных передаточных функций восприятия звука человеком (HRTF) или бинауральных импульсных откликов в помещении (BRIR), бинауральные технологии ограничены по достижимому качеству/производительности. Оба из указанного добавляют в систему высокую сложность, затраты и неудобство пользователей.
Предложены улучшения традиционного амплитудного панорамирования, с использованием виртуальных громкоговорителей в размерностях, не охватываемых компоновкой громкоговорителей, см., например [14, 15]. Высотное панорамирование с использованием таких технологий является не совсем реалистичным, поскольку тембр отклоняется от источников, истинно подготовленных посредством рендеринга на высоте.
Вертикальное полусферическое амплитудное панорамирование (VHAP) [10, 11] использует два поперечных громкоговорителя для того, чтобы подготавливать посредством рендеринга объекты с высотой и сверху слушателя. Поскольку громкоговорители должны находиться в поперечных направлениях на ±90 градусов, VHAP является негибким с точки зрения позиции слушателя.
В этом описании изобретения, термин «виртуальный громкоговоритель» используется для несуществующего громкоговорителя, который рассматривается во время процесса панорамирования объекта.
Концепция по фиг. 1 использует концепции для верхнего и/или нижнего рендеринга со следующими преимуществами по сравнению с вышеуказанными технологиями предшествующего уровня техники:
- Частотная коррекция (формирование 58 спектра) применяется к сигналам верхних/нижних виртуальных громкоговорителей для более верного верхнего/нижнего/высотного восприятия.
Любая компоновка громкоговорителей может использоваться для динамиков 14, и, несмотря на это, улучшение для (виртуального) верхнего и нижнего рендеринга является достижимым. Например, стереокомпоновка или 5.1-компоновка может использоваться в качестве основы для динамиков 14. Даже компоновки громкоговорителей с высотными громкоговорителями, например, 5.1+4Н, могут улучшаться с использованием концепции по фиг 1, к примеру, относительно верхнего рендеринга (например, громкоговорителя «гласа Божьего») или рендеринга нижнего слоя. В отличие от этого, VHAP требует, например, точной и конкретной компоновки громкоговорителей, с громкоговорителями с каждой стороны от слушателя (±90 градусов).
Кроме того, верхний и нижний рендеринг по фиг. 1 не базируются на конкретных позициях громкоговорителей относительно слушателя. Другими словами, схема по фиг. 1 может применяться также в сценарии, в котором слушатель перемещается, например, при отслеживаемом рендеринге.
Варианты осуществления, описанные в данном документе, предоставляют возможность очень простых реализаций виртуального высотного рендеринга.
Таким образом, панорамирование объектов согласно фиг. 1 может реализовываться способом, приводящим к оборудованию рендеринга или процессору панорамирования объектов согласно фиг. 2, которое формирует сигналы 12 громкоговорителей в выводе модуля 40 составления с двумя трактами, которые предоставляют частичные сигналы 34 громкоговорителей, с одной стороны, и частичные сигналы 28 громкоговорителей, с другой стороны, в модуль 40 составления, а именно, один тракт, содержащий модуль 70 определения частичных наборов громкоговорителей, который принимает входной аудиосигнал 18 и намеченную виртуальную позицию 21 и выводит частичные сигналы 28 громкоговорителей, и другой тракт, содержащий модуль 72, который формирует частичные сигналы 34 громкоговорителей на основе двух вводов 18 и 21, и причем это оборудование и т.д. подготавливает посредством рендеринга объект в трехмерном пространстве по любой компоновке громкоговорителей:
- С учетом по меньшей мере одного виртуального громкоговорителя (верхнего или нижнего) в вертикальном направлении (вверх или вниз). Это осуществляется или достигается посредством формирования 58 спектра, которое, как подробнее указано ниже, приводит к такой психоакустической сигнальной метке для слушателя, что звук, воспроизведенный посредством первых частичных сигналов 34 громкоговорителей, поступает сверху или снизу, соответственно.
- Посредством амплитудного панорамирования объекта, с учетом компоновки громкоговорителей плюс один или более виртуальных громкоговорителей. Амплитудное панорамирование выполняется посредством вертикального панорамирования в модуле 40 составления и горизонтального панорамирования в модуле 70 и в модуле 72.
- Посредством применения частотной коррекции к сигналам виртуальных и/или реальных громкоговорителей. Частотная коррекция осуществляется посредством этого формирования спектра в спектральном формирователе 58.
- Посредством воспроизведения каждого сигнала виртуального громкоговорителя по поднабору или всем громкоговорителям компоновки, как пояснено относительно фиг. 1, второй набор 36 громкоговорителей может совпадать с набором 26 и в силу этого включать все громкоговорители 14 либо может относиться только к поднабору громкоговорителей 14.
Ниже по тексту, концепция вариантов осуществления настоящей заявки визуализируется трехмерно. См. фиг. 3. На фиг. 3, слушатель указывается посредством ссылки с номером 100. Отдельные громкоговорители 14 различаются друг от друга посредством строчных букв. На фиг. 3, компоновка громкоговорителей содержит, примерно, четыре громкоговорителя. Фиг. 3 показывает один виртуальный громкоговоритель 102 сверху или выше слушателя 100. Фиг. 3, естественно, представляет собой просто пример. Виртуальный громкоговоритель 102 снизу или ниже слушателя 100 может рассматриваться, альтернативно. Кроме того, виртуальный громкоговоритель 102 может позиционироваться непосредственно выше слушателя 100, даже с предоставлением возможности слушателю 100 перемещаться горизонтально, а именно, посредством отслеживания позиции слушателя, либо позиция слушателя 100 может быть фиксированной по умолчанию независимо от нахождения слушателя 100, фактически, непосредственно ниже/выше виртуального громкоговорителя 102.
Другими словами, фиг. 3 показывает пример для позиционирования громкоговорителей 14, здесь примерных четырех громкоговорителей 14a-14d, и поясняет то, что варианты осуществления, показанные на фиг.1 и 2, могут заключать в себе виртуальный громкоговоритель, позиционированный в виртуальной позиции, которая представляет собой вышеуказанную виртуальную позицию рендеринга, ассоциированного с первыми частичными сигналами 34 громкоговорителей. Таким образом, фиг. 3 иллюстрирует то, что вариант осуществления по фиг. 2, аналогично варианту осуществления по фиг. 1, в отношении использования спектрального формирователя 58, дополнительно рассматривает виртуальный громкоговоритель 102 в дополнение к доступным громкоговорителям 14.
Фиг. 4, 5а и 5b показывают, с разложением на отдельные подконцепции или этапы, то, как проводится рендеринг в намеченной виртуальной позиции 104 с использованием доступных громкоговорителей 14a-14d и виртуального громкоговорителя 102.
Фиг. 4 иллюстрирует намеченную виртуальную позицию 104. Эта позиция 104 указывается как находящаяся вертикально выше слоя или плоскости, в которой находятся громкоговорители 14a-14d. Фиг. 4 также показывает проекцию намеченной виртуальной позиции 104 в слой или плоскость громкоговорителей 14a-14d, т.е. проекцию 104 вдоль вертикального направления в слой или плоскость громкоговорителей 14a-14d. Результирующая проецируемая позиция 106, т.е. проекция намеченной виртуальной позиции 104, в слой громкоговорителей 14a-14d, указывается с использованием ссылки с номером 106. Модуль 70 может использовать амплитудное панорамирование с тем, чтобы в результате приводить к частичным сигналам громкоговорителей, которые ассоциированы с рендерингом аудиообъекта в этой проецируемой виртуальной позиции 106. Таким образом, фиг. 4 иллюстрирует другое обстоятельство, еще не описанное относительно фиг. 1 и 2. В частности, оборудование по фиг. 1 и 2, соответственно, может быть выполнено с возможностью выбирать 26 из всех доступных громкоговорителей 14 или из группы громкоговорителей, к примеру, из группы громкоговорителей, принадлежащих определенному слою, к примеру, громкоговорителей 14a-14d здесь на фиг. 4. В частности, как проиллюстрировано посредством использования штриховки, только два громкоговорителя 14с и 14d могут выбираться, а именно, громкоговорители из группы громкоговорителей, принадлежащих горизонтальной плоскости слушателя 100, выбираются для того, чтобы принимать соответствующие частичные сигналы 28 громкоговорителей, которые являются ближайшими к защищенной виртуальной позиции 106. Согласно другому представлению, горизонтальное панорамирование, хотя и приводит в результате к ненулевым весовым коэффициентам только относительно поднабора соответствующего набора слоев громкоговорителей, непрерывно связано со всеми громкоговорителями соответствующего набора слоев. Здесь, только громкоговорители 14с и 14d должны быть ассоциированы с ненулевыми весовыми коэффициентами для горизонтального панорамирования, тогда как другие два динамика 14а и 14b должны быть ассоциированы с нулевыми весовыми коэффициентами, в силу этого не участвуя в горизонтальном панорамировании. Два громкоговорителя 14с и 14d из компоновки громкоговорителей в силу этого используются, в дополнение к виртуальному громкоговорителю 102. Фиг. 4 концентрируется на горизонтальном панорамировании, достигаемом посредством модуля 70 или посредством модуля 22 определения, соответственно, тогда как следующие чертежи концентрируются на модуле 72 и его доле в конечном рендеринге. Таким образом, следующие чертежи должны раскрывать то, как два громкоговорителя 14с и 14d из компоновки громкоговорителей наряду с виртуальным верхним громкоговорителем 102 используются для амплитудного панорамирования объекта в намеченной виртуальной позиции 104.
Следует отметить, что расстояние намеченной виртуальной позиции 104 не играет главную роль в контексте данной заявки, и что, соответственно, позиция 104 проиллюстрирована как находящаяся на большом расстоянии от слушателя только для более простого представления в перспективе. Визуальное представление, необязательно, может работать только в зависимости от направления к позиции 104.
Фиг. 5а показывает подконцепцию или этап, согласно которому частотная коррекция или формирование 58 спектра используется или применяется для/к сигналу(ам) громкоговорителя для виртуального громкоговорителя 102. С другой стороны, фиг. 3-5b концентрируются на примере, в котором этот виртуальный громкоговоритель 102 представляет собой виртуальный верхний громкоговоритель, но это представляет собой только пример. Частотная коррекция или формирование 58 спектра аналогично может использоваться для того, чтобы формировать виртуальный нижний громкоговоритель.
Фиг. 5b концентрируется на воспроизведении аудиообъекта в позиции виртуального громкоговорителя 102. Сигнал громкоговорителя, который должен применяться к виртуальному громкоговорителю 102 непосредственно, а именно, входной аудиосигнал подвергается частотной коррекции или формированию 58 спектра и горизонтальному панорамированию, здесь проиллюстрированному посредством соответствующих умножителей 56a-56d. Вторые умножители являются необязательными. Они требуются только в том случае, если позиция 102 виртуального громкоговорителя не является статической, а позиционируется таким образом, что она вертикально регулируется согласно позиции слушателя для слушателя 100, т.е. таким образом, что она горизонтально расположена таким образом, что ее вертикальная проекция в плоскость громкоговорителей 14a-14d совпадает с позицией слушателя 100 в этой плоскости или слое громкоговорителей 14a-14d. Фиг. 5b примерный иллюстрирует то, что набор 36 может охватывать все громкоговорители 14a-14d или по меньшей мере все громкоговорители соответствующей группы в одном горизонтальном слое. Таким образом, 5b иллюстрирует воспроизведение каждого второго частичного сигнала 34 громкоговорителя по поднабору или, как проиллюстрировано на фиг. 5b, по всем громкоговорителям 14a-14d компоновки. Поскольку виртуальный громкоговоритель(и) 102 недоступен физически, соответствующие частотно-скорректированные сигналы 34 воспроизводятся по упомянутому поднабору громкоговорителей. Усиления применяются в целом или для каждого громкоговорителя отдельно, чтобы регулировать уровень и результирующий вектор направления для виртуального направления. Альтернативная реализация, которая является преимущественной вследствие ее сниженных вычислительных затрат, уже упомянута выше и проиллюстрирована на фиг. 6. Таким образом, фиг. 6 показывает другой пример для оборудования для рендеринга или альтернативный вариант осуществления для процессора панорамирования объектов, а именно, пример, в котором, по сравнению с фиг. 2, частотная коррекция или формирование 58 спектра выполняется выше горизонтального панорамирования посредством элементов 52, 54 и 56 в модуле 72. Таким образом, частотная коррекция или формирование спектра с тем, чтобы приводить к психоакустическим сигнальным меткам для слушателя, которые приводят в результате к верхним или нижним громкоговорителям 102, применяется ко входному аудиосигналу 18 непосредственно, а не к каждому частичному сигналу 34 громкоговорителя отдельно. Таким образом, входной аудиосигнал 18 подвергается частотной коррекции или формированию спектра, при этом после панорамирования может применяться, к примеру, необязательно, горизонтальное панорамирование для того, чтобы управлять позицией виртуальной позиции 102 горизонтально, и вертикальное панорамирование, достигаемое с использованием коэффициентов или усилений вертикального панорамирования, предоставленных посредством модуля определения усилений вертикального панорамирования. Еще более низкая вычислительная сложность достигается, если усиление вертикального панорамирования для частичных сигналов 34 громкоговорителей применяется до необязательного горизонтального панорамирования между набором 36 громкоговорителей. Во втором случае, частотно-скорректированный или частотно-сформированный и совмещенный по уровню сигнал может копироваться и распределяться по громкоговорителям, которые выбраны для воспроизведения виртуального высотного громкоговорителя 102.
Согласно концепциям, изложенным выше, эффективное формирование виртуального высотного воспроизведения представляет собой часть алгоритма панорамирования, который предоставляет возможность использования соответствующего виртуального высотного динамика в произвольных компоновках громкоговорителей. Ниже описываются дополнительные сведения.
Алгоритм панорамирования/процессор панорамирования (объектов) или оборудование согласно любому из фиг. 1, 2 и 6 может использоваться для позиционирования воспринимаемого местоположения слуховых объектов в трехмерном пространстве воспроизведения как для статических, так и для перемещающихся источников звука.
Вследствие эффективности базовой концепции, она также может использоваться для статических, а также для перемещающихся позиций слушателя, т.е. также для вариантов применения, например, в которых позиция слушателя 100 отслеживается, и рендеринг посредством оборудования адаптируется к позиции слушателя. Ниже излагаются примеры адаптации. Кроме того, оборудование, как описано в данном документе, может даже применяться к сценариям со статическими, а также с перемещающимися громкоговорителями 14.
В типичных сценариях воспроизведения, позиции громкоговорителей являются фиксированными, но позиция слушателя 100 может непрерывно изменяться. В таком случае, углы, под которыми слушатель 100 видит громкоговорители 14, а также соответствующие углы между громкоговорителями изменяются в качестве функции от позиции слушателя 100.
Традиционным алгоритмам панорамирования, таким как VBAP, типично требуется инициализация для своей рассматриваемой инвариантной зоны наилучшего восприятия и позиций громкоговорителей. В ходе фазы инициализации, используются некоторые комплексные операции, такие как преобразование громкоговорителей в пару, триплет или квадруплет групп для панорамирования.
Поскольку в сценарии отслеживания, относительное позиционирование громкоговорителей 14 и слушателя 100 часто изменяется, нежелательно иметь комплексную фазу инициализации и фиксированное преобразование. Описанное панорамирование согласно фиг. 1, 2 и 6 разрешает эти проблемы и включает в себя несколько других новизн, связанных с панорамированием, в частности, в позициях, которые не находятся в зоне, которая покрывается/окружается посредством громкоговорителей.
В частности, следующие этапы помогают в достижении эффективного рендеринга и решении проблем, связанных с компоновками динамиков более чем с одним слоем динамиков 14a-d, как примерно показано на фиг. 3-5b, и могут добавляться в качестве функциональностей в оборудование, описанное в данном документе:
- Усиления амплитудного панорамирования вычисляются для горизонтального слоя громкоговорителей, к примеру, в любом из горизонтальных каскадов панорамирования в 70 и 72. Имеется вероятность того, что оборудование реагирует на то, составляет число слоев динамиков один или нет. Если только один слой существует, элементы 52, 54, 56 не используются или служат только для позиционирования позиции 102 верхнего/нижнего виртуального динамика непосредственно выше/ниже слушателя 100. Если более одного слоя существует, нижеуказанное является истинным.
- Если более одного слоя динамиков 14 присутствуют, то могут вычисляться усиления амплитудного панорамирования более чем для одного слоя громкоговорителей, к примеру, для высотного слоя и нижнего слоя с использованием модуля 70 и 72, соответственно. Это может осуществляться, например, если намеченная виртуальная позиция указывает на позицию вертикально между обоими слоями. Следует отметить, что даже более двух слоев могут трактоваться таким образом.
- При панорамировании, любая подготовленная посредством рендеринга горизонтальная/азимутальная виртуальная позиция объекта, к примеру, 106 на фиг. 4, а именно, в каждом слое, для которого выполняется горизонтальное панорамирование, рассматривается в рендеринге, а именно, при вертикальном панорамировании. Два слоя, т.е. две группы динамиков 14, каждый из которых ассоциирован с другим горизонтальным слоем на различных высотах, например, могут выбираться, причем один из них формирует набор 26 или используется для выбора набора 26 из него, и другой из них формирует набор 36 или используется для выбора набора 36 из него. Выбор из нескольких (более чем двух) доступных слоев может осуществляться так, как описано ниже, а именно, с учетом слоев, ближайших к намеченным виртуальным позициям. «Позиция подготовленного посредством рендеринга объекта», к примеру, 106 на фиг. 4 для одного примерного слоя, показанного на нем, в каждой одном из слоев в таком случае может использоваться в качестве виртуального громкоговорителя для вертикального панорамирования объекта между слоями. Ниже проиллюстрированы подробности.
- Если позиция объекта находится выше самого верхнего слоя или ниже самого нижнего слоя, то объект горизонтально панорамируется только в одном слое (т.е. в самом верхнем или в самом нижнем слое, соответственно). В этом случае, модуль 72 работает для виртуального верхнего/нижнего динамика 102, и горизонтальное панорамирование служит для регулирования горизонтальной позиции верхнего/нижнего динамика 102 в позицию 100 слушателя только в том случае, если этот вариант используется полностью (ниже описываются альтернативы, согласно которым эта адаптивность позиций слушателя не используется), и модуль 70 работает для горизонтального панорамирования в используемом вертикально крайнем внешнем слое динамиков или самой дальней группе динамиков 14, формирующих горизонтальный слой. Оба модуля 70 и 72 должны иметь свои наборы 26 и 36 динамиков 14, которые должны выбираться таким образом, что они соответствуют или представляют собой часть упомянутого вертикально крайнего внешнего слоя динамиков или самой дальней группы динамиков 14.
- Таким образом, если позиция 104, 21 объекта находится выше (ниже) самого верхнего (самого нижнего) слоя громкоговорителей (или в случае, если только один слой громкоговорителей (например, приблизительно на высоте ушей) доступен), то виртуальный вертикальный верхний (вертикальный нижний) громкоговоритель 102 рассматривается для того, чтобы перцепционно подготавливать посредством рендеринга слуховой объект выше (ниже) слоя(ев) громкоговорителей.
- Верхний или нижний частотный корректор, т.е. формирование 58 спектра с использованием соответствующей функции 60, применяется к объектному аудиосигналу и распределяется в громкоговорители, которые выбраны для воспроизведения направления вверх или вниз, т.е. в набор 36.
Этапы/функции/блоки, участвующие в рендеринге между двумя слоями или динамиками двух слоев, проиллюстрированы на фиг. 7. Если точнее, либо фиг. 7 иллюстрирует оборудование согласно дополнительному варианту осуществления, допускающему трехмерное панорамирование аудиообъекта, который должен подготавливаться посредством рендеринга между двумя слоями динамиков, либо фиг. 7 иллюстрирует взаимодействие этих частей оборудования по фиг. 1, которые участвуют в рендеринге в случае нахождения намеченной виртуальной позиции 21 между двумя такими слоями динамиков, тогда как другой элемент, показанный на фиг. 1, такой как спектральный формирователь/частотный корректор 58, не участвует в рендеринге в этом случае (а вместо этого в случае намеченной виртуальной позиции, находящейся перед всеми слоями динамиков для динамиков 14 либо ниже этих доступных слоев динамиков). Как показано, ввод представляет собой входной аудиосигнал 18. Горизонтальное панорамирование выполняется посредством модуля 70 относительно одного слоя, и элементы 52, 54 и 56 представляют собой часть модуля 72 для другого слоя. Соответствующие частичные сигналы 28 и 34 громкоговорителей, соответственно, составляются таким образом, что в результате получаются сигналы 12 громкоговорителей посредством модуля 40 составления, с дополнительным выполнением вертикального панорамирования с использованием усилений панорамирования, предоставленных посредством модуля 30 определения. Наборы 36 и 26 динамиков, для которых, соответственно, предназначены частичные сигналы 34 и 28 громкоговорителей, могут быть взаимно непересекающимися, как проиллюстрировано на фиг. 7, поскольку они принадлежат различным слоям. Тем не менее, следует отметить, что ассоциирование динамиков 14 со «слоями» может быть таким, что один динамик 14 может быть ассоциирован с различными слоями. Другими словами, группировка динамиков 14 в группы слоев динамиков может быть такой, что они перекрываются. До такой степени, иллюстрация по фиг. 7 представляет собой просто пример и может модифицироваться.
Ниже подробнее описывается взаимодействие отдельных элементов по фиг. 7. Как показано и как пояснено выше, панорамирование, горизонтальное и вертикальное панорамирования, управляется посредством позиционной информации 21. Она может в любом случае доставляться в качестве дополнительной информации, к примеру, в форме дополнительной информации в отдельном потоке данных, а именно, отдельном относительно входного аудиосигнала 18, например, в качестве аудиообъекта, включающего в себя по меньшей мере один канал аудиоинформации и ассоциированных метаданных, задающих намеченную позицию. Если входной аудиосигнал 18 представляет собой многоканальный файл без метаданных, намеченная позиция 21 различных элементов, включенных в аудиосигнал, может оцениваться и извлекаться на основе анализа сигналов с учетом известной целевой схемы размещения громкоговорителей, для которой сформирован сигнал. Например, входной аудиосигнал 18 может содержать канал, ассоциированный с позицией громкоговорителей сверху и/или снизу, но доступные динамики 14 не имеют таких динамиков. В этом случае, намеченная виртуальная позиция 21 представляет собой позицию для позиции динамика этого канала. Естественно, также доступны другие примеры. Это может осуществляться для всех передаваемых каналов. Взаимные позиции динамиков, к которым относятся каналы, могут поддерживаться посредством оборудования рендеринга.
В соответствии с вариантом осуществления, как горизонтальные панорамирования, а именно, один или более модулей 70 относительно частичных сигналов 28 громкоговорителей, так и панорамирование относительно других частичных сигналов 34 громкоговорителей посредством элементов 52-56 используют идентичный угол азимута для панорамирования. Таким образом, идентичный угол азимута используется для обоих слоев. Другими словами, горизонтальное панорамирование выполняется таким способом, что проецируемые виртуальные позиции 106, проиллюстрированные на фиг. 4, совпадают в вертикальной проекции друг на друга. Естественно, это может реализовываться по-другому. Ограничение не требуется, и различные углы азимута могут использоваться для различных слоев.
Преимущественный признак вариантов осуществления, поясненных в данном документе, представляет собой тот факт, что они не требуют широкомасштабной инициализации. Вместо этого, параметры панорамирования вычисляются непосредственно из данных или изменяющихся координат или позиций слушателя и громкоговорителей. Инициализация рендеринга не зависит от предварительно заданных пар, триплетов или квадруплетов громкоговорителей.
Фиг. 8 иллюстрирует тот факт, что как горизонтальное, так и вертикальное панорамирование могут управляться посредством информации относительно позиции слушателя, а именно, информации 110. Если точнее, предположим, что намеченная виртуальная позиция 21 представляется посредством телесных углов, указывающих определенное направление, из которого слушатель 100 должен воспринимать аудиообъект, который должен подготавливаться посредством рендеринга. В зависимости от позиции 110 слушателя, за исключением любой адаптации позиции виртуального верхнего/нижнего динамика к позиции слушателя, если имеется, горизонтальное панорамирование, которое зависит от позиции слушателя, может применяться, с тем чтобы достигать этого направления восприятия для слушателя. То же является истинным в случае информации 110 позиции слушателя, указывающей позицию слушателя 100 не только с точки зрения горизонтальной позиции, но также и с точки зрения высоты, к примеру, высоты позиции ушей слушателя.
Как очевидно из вышеприведенного описания, оборудование согласно вариантам осуществления настоящей заявки не ограничивается решением проблем, связанных с компоновками громкоговорителей, в которых доступные громкоговорители 14 размещаются только в одном слое. Второй пример проиллюстрирован на фиг. 3-5b. Наоборот, громкоговорители 14, доступные для оборудования, могут быть ассоциированы с различными слоями. Частичные сигналы 34 громкоговорителей, с одной стороны, и частичные сигналы 28 громкоговорителей, с другой стороны, которые пояснены выше, или, иными словами, два тракта, с которыми модуль 70 и 72, соответственно, последовательно соединяются, могут быть ассоциированы с одним или более таких слоев динамиков. Для нижеприведенного описания предполагается, что каждый из них ассоциирован с одним слоем динамиков. Таким образом, каждый ассоциирован с одной группой громкоговорителей, формирующих один слой. Некоторые громкоговорители могут быть ассоциированы более чем с одним слоем, как должно становиться очевидным из нижеприведенного описания и уже изложено выше. Атрибуция или ассоциирование слоев с отдельными трактами, а именно, с трактом модуля 70 и трактом модуля 72, может быть фиксированным или может подвергаться адаптации к намеченной виртуальной позиции 21 и/или к позиции 110 слушателя. Это уже пояснено выше: Если имеется более двух доступных слоев, два слоя могут выбираться в случае нахождения намеченной виртуальной позиции между парой этих слоев, и эти слои ассоциированы с двумя трактами. В случае намеченной виртуальной позиции 21, превышающей все доступные слои, и отсутствия реального верхнего или нижнего динамика, в таком случае крайний внешний слой, ближайший к намеченной виртуальной позиции, выбирается в качестве слоя громкоговорителей, для которого используются оба тракта.
С учетом произвольной компоновки громкоговорителей, инициализация может заключать в себе только то, что каждый громкоговоритель 14 классифицируется как принадлежащий одной или более следующих категорий:
Слой 1
Типично этот слой громкоговорителей используется для панорамирования объектов горизонтально (приблизительно на высоте ушей сидящего слушателя).
Слой 2-N
Необязательно, громкоговорители во втором слое могут задаваться, к примеру, громкоговорители в высотном (верхнем или нижнем) слое. Они представляют собой слои вертикально выше или ниже слоя 1. Слоев громкоговорителей в силу этого может быть больше двух. Различение между слоем 1, находящимся на высоте ушей, и любым другим слоем или другими слоями является необязательным.
Верхний
Громкоговоритель(и), по которому воспроизводится вертикальное направление вверх. Он может представлять собой выделенный громкоговоритель или поднабор громкоговорителей других слоев.
Нижний
Громкоговоритель(и), по которому воспроизводится вертикальное направление вниз. Он может представлять собой выделенный громкоговоритель или поднабор других слоев.
Вышеприведенное описание не ограничено регулярными компоновками, при этом регулярный, например, подразумевает, что в каждом слое присутствует равное число громкоговорителей, имеющих равные углы/расстояния между собой, или что все слои полностью окружают слушателя, или что все слои имеют громкоговорители, размещенные под совершенно идентичным вертикальным углом, при просмотре от слушателя.
Фактически, как упомянуто выше, любая произвольная компоновка может использоваться. Различные громкоговорители могут позиционироваться под различными/произвольными углами азимута и под различными/произвольными углами подъема (т.е. на различных высотах). Громкоговорители, считающиеся частью одного слоя, не обязательно должны находиться внутри плоскости. Варьирования в их вертикальном позиционировании разрешаются.
Фиг. 9 и 10 показывают примерные реализации/примерные классификации. Эти чертежи должны примерно иллюстрировать процедуру выделения различных доступных громкоговорителей различным слоям. Они представляют собой только примеры, различные преобразования в идентичной ситуации(ях) должны быть возможными и подчиняются пользовательским предпочтениям.
Фиг. 9 показывает классификацию с использованием 5.0-компоновки громкоговорителей. Здесь, а также на следующих чертежах, следующие идентификаторы используются для простоты для того, чтобы указывать доступные динамики 14: Горизонтально размещенные громкоговорители, которые обычно должны формировать компоновку, которая устанавливается приблизительно на высоте ушей слушателя, помечаются в форме «М_X», где М является индикатором для «середины», подсказывающим то, что этот слой обычно находится между верхним и нижним слоями громкоговорителей. В силу этого он должен представлять собой слой 1 в вышеуказанной системе обозначений. X идентифицирует конкретный громкоговоритель в этом слое, например, М_L должен представлять собой «левый передний громкоговоритель в среднем слое». Аналогично, громкоговоритель верхнего слоя идентифицируется в качестве «U_X», так что «U_Rs» должен представлять собой «правый громкоговоритель объемного звучания в верхнем слое». Громкоговорители в нижнем слое должны идентифицироваться посредством «L_X». U- и L-динамики в силу этого представляют собой динамики слоев 2…N в вышеуказанной системе обозначений. Громкоговоритель, смонтированный на потолке (т.е. либо непосредственно выше слушателя, либо непосредственно выше центра массива громкоговорителей), обозначается как «верхний». Соответственно, термин «нижний» используется для громкоговорителей непосредственно ниже слушателя либо непосредственно ниже центра массива громкоговорителей. На фиг. 9, классификация динамиков должна быть следующей:

Горизонтальное панорамирование посредством модуля 70 должно осуществляться с использованием всех доступных громкоговорителей (слой 1). Направления вверх и вниз подготавливаются посредством рендеринга с использованием модуля 72 по всем громкоговорителям, за исключением центрального (С). Таким образом, набор 36 должен содержать все громкоговорители, за исключением центрального, тогда как набор 28 должен охватывать все динамики.
Следует обратить внимание на то, что это представляет собой явное решение для этого примера. Конечно, центральный громкоговоритель также может использоваться для высотного рендеринга.
Дополнительная классификация с использованием 5.0+2Н-компоновки громкоговорителей проиллюстрирована на фиг. 10. Здесь, два слоя существуют в доступной компоновке, и классификация или ассоциирование должна быть следующей:

В этом примере, громкоговорители объемного звучания среднего слоя (М_Ls и М_Rs) используются для обоих слоев (слоя 1 и слоя 2), поскольку в противном случае слой 2 не должен окружать слушателя. Таким образом, динамики слоя 1 и слоя 2 должны использоваться для межслойного панорамирования, как проиллюстрировано на фиг.7 и 8, например, динамики слоя 1 для набора 26, а динамики слоя 2 для набора 36, или наоборот, и как только намеченная виртуальная позиция находится за пределами обоих слоев, к их верхней или нижней части, то динамики, принадлежащие классу «верхний», используются для набора 36 с активной частотной коррекцией 58 и с использованием динамиков слоя 2 для набора 26, или динамики класса «нижний» используются для набора 36 с активной частотной коррекцией 58 и с использованием динамиков слоя 1 для набора 26.
Альтернативные классификации в этой компоновке могут заключаться в том, чтобы принимать решение для рендеринга без слоя 2. Верхний может подготавливаться посредством рендеринга только с использованием приподнятых громкоговорителей U_L и U_R, либо альтернативно, верхний также может подготавливаться посредством рендеринга посредством комбинации U_L, U_R, М_Ls и М_Rs, как описано выше.
Дополнительные примеры являются легко извлекаемыми. Например, с громкоговорителями нижнего слоя либо с большим или меньшим числом приподнятых громкоговорителей, либо с большим или меньшим числом громкоговорителей в среднем слое, либо с более произвольными или нерегулярными компоновками громкоговорителей.
Ниже по тексту, случай рендеринга объекта в трехмерном поясняется для примерного случая, в котором объект панорамируется в направлении (при просмотре от слушателя), которое находится между двумя физически присутствующими слоями громкоговорителей (которые находятся на различной высоте). Это уже пояснено выше относительно фиг. 7 и 8, но проиллюстрировано более подробно на фиг. 11 и 12. 5.0+4Н-компоновка громкоговорителей примерно иллюстрируется здесь. Примеры для позиции слушателя 100 и позиции аудиообъекта 104 указываются. Динамики классифицируются на два отдельных слоя, различаемые с использованием различных типов линий, пунктирной для второго слоя и непрерывной для первого слоя.
Объект амплитудно панорамируется в первом слое посредством выдачи объектного сигнала в громкоговорители в этом слое с различными усилениями 24, например, посредством выдачи объектного сигнала в М_L и М_Ls таким образом, что он амплитудно панорамируется в позицию 1061 точки серого нижнего слоя на фиг. 11. Аналогично, объект амплитудно панорамируется во втором слое в позицию 1062 точки серого высотного слоя на фиг. 11. Как можно видеть, позиции 1061 и 1062 могут выбираться таким образом, что они вертикально накладываются друг на друга, и/или таким образом, что вертикальная проекция намеченной позиции 104 и позиции 1061 и 1062 также совпадают.
Фиг. 12 иллюстрирует рендеринг конечного направления объектов посредством применения амплитудного панорамирования между слоями, т.е. иллюстрирует вертикальное панорамирование. При рассмотрении виртуальных объектов в позициях 1061 и 1062 в качестве виртуальных громкоговорителей, амплитудное панорамирование посредством элементов 30 и 40 применяется для того, чтобы подготавливать посредством рендеринга виртуальный объект в намеченной позиции 104 между двумя слоями, появляющимися в направлении объекта. Результат этого амплитудного панорамирования между слоями представляет собой два коэффициента 32 усиления, с которыми взвешиваются сигналы 34 и 28 двух слоев.
Это взвешивание для горизонтального панорамирования между слоями (реальных) громкоговорителей дополнительно может быть частотно-зависимым, чтобы компенсировать такой эффект, что при вертикальном панорамировании различные частотные диапазоны могут восприниматься с различным подъемом [13].
Рендеринг объектов выше или ниже слоя или самого дальнего слоя дополнительно проверяется теперь, в качестве дополнительной информации относительно описания, изложенного выше.
Объект может иметь направление или позицию 104, которая не находится в пределах диапазона направлений между двумя слоями, как пояснено со ссылкой на фиг. 11 и 12. Этот случай поясняется со ссылкой на фиг. 13 и 14. Намеченная позиция 104 объекта находится выше или ниже (физически присутствующего) слоя, здесь выше любого доступного слоя и, в частности, выше верхнего слоя, указываемого с помощью пунктирных линий. В качестве примера, объект имеет направление/позицию 104 выше верхнего слоя громкоговорителей 5.0+4Н-компоновки, которая также использована в качестве примерной компоновки на фиг. 11 и 12.
В этом случае, горизонтальное амплитудное панорамирование применяется посредством модуля 70 к высотному слою, чтобы подготавливать посредством рендеринга объект в этом слое. Результирующая позиция 1061 подготовленного посредством рендеринга объекта указывается в качестве позиции 1061 точки серого высотного слоя на фиг.1 3.
После этого панорамирование применяется между позицией 1061 в высотном слое и вертикальным направлением/позицией 1062, указываемой в качестве позиции 1062 точки серого на фиг. 14. Результирующий трехмерный панорамированный виртуальный объект указывается в качестве позиции 104' точки серого.
Поскольку отсутствует реальный громкоговоритель в вертикальном направлении вверх или вниз, вертикальный сигнал в 1062 частотно корректируется посредством модуля 58, чтобы подражать окрашиванию верхнего или нижнего звука, соответственно, (дополнительную информацию относительно частотной коррекции см. в нижеприведенном пояснении). Вертикальный сигнал затем выдается в громкоговорители, предназначенные для направления вверх/вниз, т.е. в набор 36.
В отношении рендеринга виртуальных верхних или нижних громкоговорителей 102 можно сказать следующее.
В общем, различные подходы могут выбираться для того, чтобы подготавливать посредством рендеринга виртуальные вертикальные верхние или нижние громкоговорители.
В общем, два различных подходов могут выбираться:
- Виртуальный верхний/нижний всегда подготавливается посредством рендеринга выше фактической позиции прослушивания, как указано посредством 110.
- Виртуальный верхний/нижний динамик всегда подготавливается посредством рендеринга выше «зоны наилучшего восприятия» или центра массива (основных) громкоговорителей.
В качестве примеров вариантов применения, (1) может преимущественно выбираться, если позиция слушателя может отслеживаться, тогда как (2) может выбираться, если возможность для отслеживания слушателя не доступна.
Простая реализация использует идентичное усиление для каждого громкоговорителя, выбранного для верхнего или нижнего рендеринга, т.е. усиления 54 в таком случае должны выбираться равными. Эта схема работает хорошо. (Она, например, может использоваться в качестве простейшей реализации и является очень полезной, когда позиция слушателя не отслеживается и в силу этого неизвестна).
В частности, когда слушатель не расположен в центре в компоновке громкоговорителей, то следующие соображения могут улучшать верхний и нижний рендеринг:
- Если имеется высотный слой, и необходимо панорамироваться выше этого высотного слоя, коэффициенты 54 усиления, примененные к громкоговорителям 36 (высотного слоя), могут использоваться для направления вверх таким образом, что результирующий вектор направления панорамирования указывает вертикально вверх (или альтернативно к позиции 102 виртуального верхнего громкоговорителя), т.е. таким образом, что 102 находится непосредственно выше слушателя 100.
То же применимо для направления вниз, когда имеется нижний слои громкоговорителей.
- Если отсутствует высотный слой, и необходимо панорамироваться выше горизонтального слоя, усиления применяются к громкоговорителям таким образом, что вектор амплитудного панорамирования исчезает (отсутствует смещение в горизонтальном направлении). Проще говоря, можно применять усиления 54 к громкоговорителям таким образом, что амплитуда или мощность сигнала для слушателя является идентичной для каждого громкоговорителя на основе верхнего/нижнего рендеринга.
- То же применимо для направления вниз, когда отсутствует нижний слой громкоговорителей.
Ниже по тексту, частотный корректор 58 (или спектральный формирователь) дополнительно примерно иллюстрируется с использованием дополнительных сведений. Основные сигнальные метки, позволяющие слушателю 100 локализовать источник звука в горизонтальной плоскости, представляют собой разности между входными сигналами в левое и правое ухо (интерауральные разности времен (ITD) и интерауральные разности уровней (ILD)). Первичные сигнальные метки для оценки вертикальной позиции источника звука представляют собой спектральные варьирования вследствие отражений, сформированных посредством головы, торса и ушных раковин слушателя. Такие сигнальные метки зачастую называются «монауральными сигнальными метками (МС)», называемыми «психоакустической сигнальной меткой» в вышеприведенном описании.
Конкретные ILD, ITD и МС, которые возникают вследствие уникальных признаков тела каждого человека и рассматриваемого направления падения, обычно обобщаются под термином «передаточные функции восприятия звука человеком (HRTF)». В частности, МС являются высокоиндивидуальными. Однако предусмотрены некоторые общие признаки, которые влияют на восприятие высоты в общем.
Посредством формирования частотного контента конкретного сигнала источника, который принимается из одного направления, такая иллюзия, что этот звук фактически исходит из другого подъема, и/или ориентация спереди назад на идентичном конусе неопределенности может поддерживаться. Это соответствует изменяющимся МС и является целью частотного корректора 58 (EQ).
Простая, но хорошо работающая реализация концепции использования виртуальных верхних/нижних громкоговорителей и частотной коррекции этих сигналов использует конкретный статический EQ для направления вверх и вниз, соответственно.
Фиг. 15 показывает два таких эвристически определенных частотных корректора в качестве примеров или, иными словами, показывает формирующую функцию 60а для рендеринга в виртуальном верхнем динамике и формирующую функцию 60b для рендеринга в виртуальном нижнем динамике. Они определены посредством анализа измеренных HRTF-данных, соответствующих сигнальным меткам, подразумевающим источник выше или ниже слушателя. HRTF многих субъектов рассмотрены, и EQ определены посредством игнорирования спектральных изменений, которые варьируются слишком сильно между субъектами.
Частотный корректор 60а для направления вверх типично имеет одну или более режекций и/или пиков. Типично, имеется режекция ниже 1 кГц и один или боле пиков в верхних частотах. Частотный корректор 60b для направления вниз включает в себя эффект «затенения за счет тела», т.е. полные высокие частоты затухают. Другими словами, посредством функции 60а, вторые частичные сигналы 34 громкоговорителей демпфируются, относительно по меньшей мере одного входного аудиосигнала 18, в режекционном спектральном диапазоне 120 между 200 и 1000 Гц и усиливаются в одном или более пиковых спектральных диапазонов 1221 и 1222 (здесь для примера имеется два), находящихся между 1000 и 10 кГц. Посредством функции 60b, вторые частичные сигналы 34 громкоговорителей демпфируются, относительно по меньшей мере одного аудиосигнала в спектральном диапазоне 124 выше 1000 Гц с уменьшением демпфирования в спектральном поддиапазоне 126 в спектральном диапазоне 124, причем этот поддиапазон расположен между 5 и 10 кГц. Дополнительно, функция 60b, как проиллюстрировано на фиг. 15, может приводить к усилению сигналов 34 в спектральном диапазоне 128 между 500 Гц и 1 кГц. Естественно, диапазоны и примеры могут варьироваться.
Эффективный полный спектр акустического сигнала, достигающего слушателя, определяется частично посредством не подвергнутого EQ сигнала 28 (амплитудного панорамирования в слое) и частично посредством подвергнутого EQ сигнала 34 (сигнала из виртуального верхнего/нижнего динамика). Таким образом, эффективная полная EQ представляет собой линейную комбинацию единицы и верхних/нижних EQ 60а/60b. Таким образом, подвергание EQ для слушателя постепенно нарастает по мере того, как источник 104 перемещается к верхней позиции (или, соответственно, к нижней позиции).
Такое непрерывное постепенное нарастание или затухание/изменение величины подвергания EQ является специфически преимущественным, поскольку слуховая система человека может использовать эти изменения спектра принимаемого сигнала, чтобы определять его местоположение. В частности, в отслеживаемых сценариях, эти изменения могут использоваться для того, чтобы отличать то, представляет собой конкретный спектральный признак свойство фактического сигнала либо он изменяется в то время, когда слушатель перемещается, и он в силу этого может интерпретироваться в качестве признака, связанного с местоположением источника.
Если обобщать, обеспечивается воспроизведение объектно-ориентированного аудио или многоканального аудио с воспроизведением приподнятых или опущенных по высоте звуков (верхних и нижних). Воспроизведение входных аудиосигналов (содержащих звук, предназначенный для воспроизведения по приподнятым или опущенным слоям громкоговорителей) по произвольным компоновкам громкоговорителей является возможным. Здесь, «компоновки громкоговорителей» также включают в себя такие устройства и топологии, как звуковые панели, телевизоры со встроенными громкоговорителями, бумбоксы, звуковые пластины, массивы громкоговорителей, интеллектуальные динамики и т.д. Нет необходимости иметь приподнятые или опущенные слои громкоговорителей. Таким образом, перцепционный эффект верхних или нижних звуков почти в любой произвольной компоновке громкоговорителей (даже без приподнятых или опущенных громкоговорителей) становится возможным.
Варианты осуществления являются вычислительно эффективными, так что они также могут преимущественно использоваться в сценариях, в которых (изменяющаяся) позиция слушателя известна и/или (постоянно) отслеживается посредством системы воспроизведения.
Варианты осуществления могут использоваться для входных форматных канально-ориентированных аудиосигналов, объектно-ориентированных аудиосигналов и сцено-ориентированных аудиосигналов (например, амбиофонических).
По сравнению со способами рендеринга, которые основаны на HRTF, следует подчеркнуть, что варианты осуществления не направлены на имитацию подробных конкретных бинауральных сигнальных меток для конкретных позиций объектов во всех возможных направлениях (чего может быть затруднительным достигать в широком диапазоне). Вместо этого, формируется хорошая имитация сигнальных меток, которые вызывают восприятие источника звука выше или ниже слушателя (т.е. формируют виртуальный источник выше или ниже) в одной конкретной позиции/направлении. Таким образом, необходимо попытаться подражать восприятию для двух направлений (вверх/вниз 102) очень хорошим/убедительным способом. Преимущество двух выбранных конкретных направлений заключается в том, что помимо спектральных сигнальных меток, две других доминирующих пространственных сигнальных аудиометки (т.е. ITD и ILD) являются минимальными; теоретически, ITD и ILD не возникают для источников звука идеально выше или ниже слушателя, т.е. скорость частиц в горизонтальном направлении является близкой к нулю для прямого звука из источника звука. Таким образом, двухкаскадный подход с панорамированием горизонтально и вертикально, потенциально с виртуальным рендерингом верхнего/нижнего динамика 102, является стабильным и приводит к высокой точности.
Ниже по тексту описываются некоторые дополнительные примерные критерии выбора того, как громкоговорители из множества громкоговорителей могут автоматически назначаться набору или слою громкоговорителей для воспроизведения виртуального громкоговорителя.
Критерии для выбора громкоговорителей для наборов/слоев:
- Выбор каждого слоя таким образом, что предпочтительно панорамирование на 360 градусов вокруг слушателя является возможным.
- Выбор громкоговорителей для воспроизведения виртуального высотного канала:
- Использование нескольких громкоговорителей таким образом, чтобы:
1) предпочтительно выбирать громкоговорители, которые уже находятся в приподнятых позициях,
2) с учетом 1), выбор (дополнительных) громкоговорителей, чтобы достигать массива, окружающего слушателя.
Выбранные громкоговорители должны максимально возможно хорошо обеспечивать то, что они могут воспроизводить сигнал для виртуального высотного канала таким образом, что: сформированное звуковое поле в позиции слушателя имеет нулевую или небольшую скорость частиц в горизонтальном направлении.
Если несколько подходящих громкоговорителей доступны, либо все они могут использоваться, либо процедура выбора может заключаться в следующем:
- Если возможно, выбор громкоговорителей, симметричных вокруг слушателя (в идеале максимально возможно (вращательно) симметричных)
- Если доступны громкоговорители, которые уже размещаются в приподнятых позициях (или вниз) к требуемой позиции подъема намеченного виртуального высотного источника:
- Угол подъема громкоговорителей должен быть максимально большим, т.е. всегда выбор громкоговорителей с самыми большими углами подъема (максимально возможно вертикальных)
- В идеале, выбор максимально возможно небольшого числа громкоговорителей, чтобы удовлетворять указанным выше критериям
- Конечно, громкоговорители также могут выбираться/назначаться пользователем «вручную».
Возможные входные параметры для (возможно адаптивного) рендеринга являются следующими:
- Углы (азимута и подъема) от позиции слушателя до громкоговорителей,
- Это имеет такое допущение, что все громкоговорители находятся на одинаково большом расстоянии и формируют аналогичный уровень в позиции прослушивания,
- Если они не находятся на одинаково большом расстоянии, уровень и/или задержка могут балансироваться, чтобы достигать равного уровня/времени поступления сигналов в позиции слушателя,
В сценарии, в котором слушатель отслеживается, также требуется расстояние до каждого громкоговорителя в дополнение к углам, так что уровень и/или задержка могут адаптироваться.
Такая адаптация уровня и задержки в отслеживаемом сценарии также может быть преимущественной для того, чтобы достигать вышеуказанного критерия «небольшая скорость частиц в горизонтальном направлении» для воспроизведения виртуальных высотных сигналов.
В качестве вывода, варианты осуществления, описанные в данном документе, могут необязательно дополняться посредством любого из важных моментов или аспектов, описанных здесь. Тем не менее, следует отметить, что важные моменты и аспекты, описанные здесь, могут использоваться отдельно или в комбинации и могут вводиться в любой из вариантов осуществления, описанных в данном документе, как отдельно, так и в комбинации. В качестве результата последнего, вышеприведенное описание, в числе прочего, включает в себя оборудование для формирования сигналов 12 громкоговорителей для множества громкоговорителей 14 таким образом, что применение сигналов 12 громкоговорителей во множестве громкоговорителей 14 подготавливает посредством рендеринга по меньшей мере один аудиообъект в намеченной виртуальной позиции 104, причем оборудование содержит интерфейс 16, выполненный с возможностью принимать входной аудиосигнал 18, который представляет по меньшей мере один аудиообъект, модуль 22 определения первых усилений панорамирования, выполненный с возможностью определять, в зависимости от намеченной виртуальной позиции, первые усиления 24 панорамирования для первого набора 26 громкоговорителей из множества громкоговорителей, которые размещаются в или формируют первый горизонтальный слой, причем первые усиления 24 панорамирования задают извлечение первых частичных сигналов 28 громкоговорителей по меньшей мере из одного входного аудиосигнала 18, которые ассоциированы с рендерингом по меньшей мере одного аудиообъекта в первой виртуальной позиции 106 при применении первых частичных сигналов 28 громкоговорителей к первому набору 26 громкоговорителей, модуль 30 определения усилений вертикального панорамирования, выполненный с возможностью определять, в зависимости от намеченной виртуальной позиции, дополнительные усиления 32 панорамирования для панорамирования между первыми частичными сигналами 28 громкоговорителей и вторыми частичными сигналами 34 громкоговорителей, которое должно применяться ко второму набору 36 громкоговорителей, который вертикально смещается относительно первого набора слоев таким образом, что он размещается или формирует второй горизонтальный слой и ассоциирован с рендерингом по меньшей мере одного аудиообъекта во второй позиции 102, с тем чтобы панорамироваться между первой виртуальной позицией 106 и второй позицией 102, при этом оборудование выполнено с возможностью составлять сигналы 12 громкоговорителей из входного аудиосигнала 18 с использованием первых усилений 2 4 панорамирования и дополнительных усилений 32 панорамирования. Также содержится модуль 52 определения вторых усилений панорамирования, который выполнен с возможностью определять, в зависимости от намеченной виртуальной позиции, вторые усиления 54 панорамирования для второго набора громкоговорителей, причем вторые усиления 54 панорамирования задают извлечение вторых частичных сигналов 34 громкоговорителей по меньшей мере из одного входного аудиосигнала, и оборудование выполнено с возможностью составлять сигналы 12 громкоговорителей из входного аудиосигнала 18 с использованием первых и вторых усилений панорамирования и дополнительных усилений панорамирования. Модули 22, 52 определения первых и вторых усилений панорамирования выполнены с возможностью выбирать первые и вторые наборы 26, 36 громкоговорителей из множества громкоговорителей таким образом, что первые и вторые наборы слоев имеют, из горизонтальных слоев, в которые распределяются множество громкоговорителей, намеченную виртуальную позицию 104 вертикально между ними. Следует отметить, что первый набор 26 громкоговорителей и второй набор 36 громкоговорителей могут частично перекрываться, т.е. один громкоговоритель может содержаться в обоих наборах 26 и 36. Если точнее, множество громкоговорителей могут распределяться в горизонтальные слои таким способом, что, для каждого горизонтального слоя, громкоговорители, принадлежащие этому горизонтальному слою, окружают, горизонтально (т.е. в горизонтальной проекции), позицию слушателя, или, иными словами, предоставляют возможность, горизонтально, панорамирования на 360 градусов вокруг позиции слушателя, и для достижения этого обстоятельства, например по меньшей мере одна пара горизонтальных слоев может совместно использовать один или более своих громкоговорителей. Таким образом, горизонтальность и вертикальная смещенность горизонтальных слоев могут абстрагироваться в той степени, что иногда, к примеру по меньшей мере для одной пары горизонтальных слоев, один или более громкоговорителей принадлежат более чем одному из горизонтальных слоев, соответственно. Иными словами, вышеприведенное описание, в числе прочего, включает в себя оборудование для формирования сигналов 12 громкоговорителей для множества громкоговорителей 14 таким образом, что применение сигналов 12 громкоговорителей во множестве громкоговорителей 14 подготавливает посредством рендеринга по меньшей мере один аудиообъект в намеченной виртуальной позиции 104, при этом множество громкоговорителей распределяются в один или более горизонтальных слоев, причем оборудование содержит интерфейс 16, выполненный с возможностью принимать входной аудиосигнал 18, который представляет по меньшей мере один аудиообъект, модуль 70 определения первых наборов сигналов громкоговорителей, выполненный с возможностью определять, в зависимости от намеченной виртуальной позиции, первые усиления 24 панорамирования для первого набора громкоговорителей 26 из множества громкоговорителей и использовать первые усиления 24 панорамирования для того, чтобы извлекать первые частичные сигналы 28 громкоговорителей по меньшей мере из одного входного аудиосигнала 18, которые ассоциированы с рендерингом по меньшей мере одного аудиообъекта в первой виртуальной позиции 106 при применении первых частичных сигналов громкоговорителей к первому набору 26 громкоговорителей, модуль 72 определения вторых наборов сигналов громкоговорителей, выполненный с возможностью, посредством формирования спектра, извлекать вторые частичные сигналы 34 громкоговорителей по меньшей мере из одного входного аудиосигнала 18, причем вторые частичные сигналы 34 громкоговорителей ассоциированы с рендерингом по меньшей мере одного аудиообъекта во второй виртуальной позиции 102 при применении вторых частичных сигналов 34 громкоговорителей ко второму набору громкоговорителей 36, причем вторая виртуальная позиция находится выше или ниже одного или более горизонтальных слоев, и модуль 30 определения усилений вертикального панорамирования, выполненный с возможностью, в зависимости от намеченной виртуальной позиции, определять дополнительные усиления 32 панорамирования для первых и вторых частичных сигналов громкоговорителей, с тем чтобы панорамироваться между первыми и вторыми виртуальными позициями, и модуль 4 0 составления, выполненный с возможностью составлять сигналы громкоговорителей из первых и вторых частичных сигналов громкоговорителей с использованием дополнительных усилений 32 панорамирования. С другой стороны, следует отметить, что первый набор 26 громкоговорителей и второй набор 36 громкоговорителей могут частично перекрываться, т.е. один громкоговоритель может содержаться в обоих наборах 26 и 36. Если точнее, множество громкоговорителей могут распределяться в горизонтальные слои таким способом, что, для каждого горизонтального слоя, громкоговорители, принадлежащие этому горизонтальному слою, окружают, горизонтально (т.е. в горизонтальной проекции), позицию слушателя, или, иными словами, предоставляют возможность, горизонтально, панорамирования на 360 градусов вокруг позиции слушателя, и для достижения этого обстоятельства, например по меньшей мере одна пара горизонтальных слоев может совместно использовать один или более своих громкоговорителей. Таким образом, горизонтальность и вертикальная смещенность горизонтальных слоев могут абстрагироваться в той степени, что иногда, к примеру по меньшей мере для одной пары горизонтальных слоев, один или более громкоговорителей принадлежат более чем одному из горизонтальных слоев, соответственно. Все другие модификации, описанные выше и упомянутые в нижеприведенной формуле изобретения, также являются целесообразными, такие как использование формирования 58 спектра таким образом, чтобы извлекать вторые частичные сигналы 34 громкоговорителей по меньшей мере из одного аудиосигнала 18, чтобы в результате получать вторую позицию, представляющую собой виртуальную позицию 102 выше самого верхнего или ниже самого нижнего из горизонтальных слоев.
Хотя некоторые аспекты описаны в контексте оборудования, очевидно, что эти аспекты также представляют описание соответствующего способа, при этом устройство или его часть соответствует этапу способа либо признаку этапа способа. Аналогично, аспекты, описанные в контексте этапа способа, также представляют описание соответствующего оборудования либо части оборудования, либо элемента или признака соответствующего оборудования. Некоторые или все этапы способа могут выполняться посредством (или с использованием) аппаратного оборудования, такого как, например, микропроцессор, программируемый компьютер либо электронная схема. В некоторых вариантах осуществления, один или более из самых важных этапов способа могут выполняться посредством этого оборудования.
В зависимости от определенных требований к реализации, варианты осуществления изобретения могут реализовываться в аппаратных средствах или в программном обеспечении. Реализация может выполняться с использованием цифрового носителя хранения данных, например, гибкого диска, DVD, Blu-Ray, CD, ROM, PROM, EPROM, EEPROM или флэш-памяти, имеющего сохраненные электронно считываемые управляющие сигналы, которые взаимодействуют (или допускают взаимодействие) с программируемой компьютерной системой таким образом, что осуществляется соответствующий способ. Следовательно, цифровой носитель хранения данных может быть машиночитаемым.
Некоторые варианты осуществления согласно изобретению содержат носитель данных, имеющий электронночитаемые управляющие сигналы, которые допускают взаимодействие с программируемой компьютерной системой таким образом, что осуществляется один из способов, описанных в данном документе.
В общем, варианты осуществления настоящего изобретения могут реализовываться как компьютерный программный продукт с программным кодом, при этом программный код выполнен с возможностью осуществления одного из способов, когда компьютерный программный продукт выполняется на компьютере. Программный код, например, может сохраняться на машиночитаемом носителе.
Другие варианты осуществления содержат компьютерную программу для осуществления одного из способов, описанных в данном документе, сохраненную на машиночитаемом носителе.
Другими словами, вариант осуществления изобретаемого способа в силу этого представляет собой компьютерную программу, имеющую программный код для осуществления одного из способов, описанных в данном документе, когда компьютерная программа выполняется на компьютере.
Следовательно, дополнительный вариант осуществления изобретаемых способов представляет собой носитель хранения данных (цифровой носитель хранения данных или машиночитаемый носитель), содержащий записанную компьютерную программу для осуществления одного из способов, описанных в данном документе. Носитель данных, цифровой носитель хранения данных или носитель с записанными данными типично является материальным и/или энергонезависимым.
Следовательно, дополнительный вариант осуществления изобретаемого способа представляет собой поток данных или последовательность сигналов, представляющих компьютерную программу для осуществления одного из способов, описанных в данном документе. Поток данных или последовательность сигналов, например, может быть выполнена с возможностью передачи через соединение для передачи данных, например, через Интернет.
Дополнительный вариант осуществления содержит средство обработки, например, компьютер или программируемое логическое устройство, выполненное с возможностью осуществлять один из способов, описанных в данном документе.
Дополнительный вариант осуществления содержит компьютер, имеющий установленную компьютерную программу для осуществления одного из способов, описанных в данном документе.
Дополнительный вариант осуществления согласно изобретению содержит оборудование или систему, выполненную с возможностью передавать (например, электронно или оптически) компьютерную программу для осуществления одного из способов, описанных в данном документе, в приемное устройство. Приемное устройство, например, может представлять собой компьютер, мобильное устройство, запоминающее устройство и т.п. Оборудование или система, например, может содержать файловый сервер для передачи компьютерной программы в приемное устройство.
В некоторых вариантах осуществления, программируемое логическое устройство (например, программируемая пользователем вентильная матрица) может использоваться для того, чтобы выполнять часть или все из функциональностей способов, описанных в данном документе. В некоторых вариантах осуществления, программируемая пользователем вентильная матрица может взаимодействовать с микропроцессором, чтобы осуществлять один из способов, описанных в данном документе. В общем, способы предпочтительно осуществляются посредством любого аппаратного оборудования.
Оборудование, описанное в данном документе, может реализовываться с использованием аппаратного оборудования либо с использованием компьютера, либо с использованием комбинации аппаратного оборудования и компьютера.
Оборудование, описанное в данном документе, или любые компоненты оборудования, описанного в данном документе, могут реализовываться по меньшей мере частично в аппаратных средствах и/или в программном обеспечении.
Способы, описанные в данном документе, могут осуществляться с использованием аппаратного оборудования либо с использованием компьютера, либо с использованием комбинации аппаратного оборудования и компьютера.
Способы, описанные в данном документе, либо любые части способов, описанных в данном документе, могут выполняться по меньшей мере частично посредством аппаратных средств и/или посредством программного обеспечения.
Вышеописанные варианты осуществления являются просто иллюстративными в отношении принципов настоящего изобретения. Следует понимать, что модификации и изменения компоновок и подробностей, описанных в данном документе, должны быть очевидными для специалистов в данной области техники. Следовательно, они подразумеваются как ограниченные только посредством объема нижеприведенной формулы изобретения, а не посредством конкретных подробностей, представленных посредством описания и пояснения вариантов осуществления в данном документе.
Библиографический список
[1] А.В. S и S.M. R «Apparent sound source translator», февраль 1966 г. Патент (США) 3236949.
[2] Philip A Nelson, Hareo Hamada и Stephen J Elliott «Adaptive inverse filters for stereophonic sound reproduction», IEEE Transactions on Signal Processing, 40(7):1621-1632, 1992 г.
[3] P. A. Nelson и J. F. W. Rose «Errors in two-point sound reproduction», The Journal of the Acoustical Society of America, 118(1):193, 2005 г.
[4] Takashi Takeuchi и Philip A. Nelson «Optimal source distribution for binaural synthesis over loudspeakers», The Journal of the Acoustical Society of America, 112(6):2786, 2002 г.
[5] Hironori Tokuno, Ole Kirkeby, Philip A Nelson и Hareo Hamada «Inverse filter of sound reproduction systems using regularization», IEICE Transactions on Fundamentals of Electronics, Communications and Computer Sciences, 80(5):809-820, 1997 г.
[6] Ole Kirkeby, Philip A. Nelson, Hareo Hamada и Felipe Orduna-Bustamante «Fast deconvolution of multichannel systems using regularization», IEEE Transactions on Speech and Audio Processing, 6(2):189-194, 1998 г.
[7] Edgar Y Choueiri «Optimal crosstalk cancellation for binaural audio with two loudspeakers», Princeton University, стр. 28, 2008 г.
[8] В. В. Bauer «Stereophonic earphones and binaural loudspeakers», J. Audio Eng. Soc, 9:148-151, 1961 г.
[9] J. Huopaniemi «Virtual Acoustics and 3D Sound in Multimedia Signal Processing», PhD thesis, Laboratory of Acoustics and Audio Signal Processing, Helsinki University of Technology, Финляндия, 1999 г., Rep. 53.
[10] Hyunkook Lee «Sound source and loudspeaker base angle dependency of phantom image elevation effect», J. Audio Eng. Soc, 65(9):733-748, 2017 г.
[11] Hyunkook Lee, Dale Johnson и Maksims Mironovs Virtual hemispherical amplitude panning (VHAP): A method for 3d panning without elevated loudspeakers», In Audio Engineering Society Convention 144, май 2018 г.
[12] Young Woo Lee и др. «Virtual height Speaker Rendering for Samsung 10.2-channel Vertical Surround System», In Audio Engineering Society Convention 131, октябрь 2011 г.
[13] Reinhard Gretzki и Andreas Silzle «A new method for elevation panning reducing the size of the resulting auditory events», TecniAcustica, Bilbao, 2003 г.
[14] Christian BorB «A Polygon-Based Panning Method for 3D Loudspeaker Setups», Audio Engineering Society Convention 137, октябрь 2014 г.
[15] MPEG-H Standard, ISO/IEC 23008-3:2015 (E).

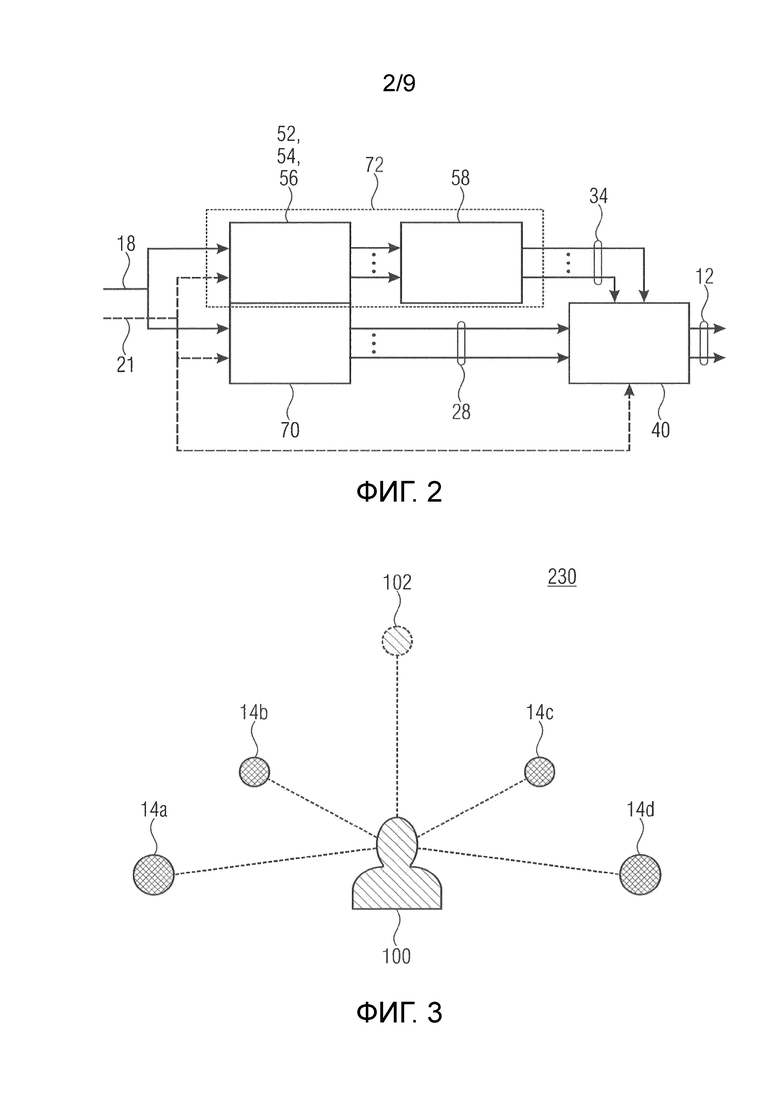

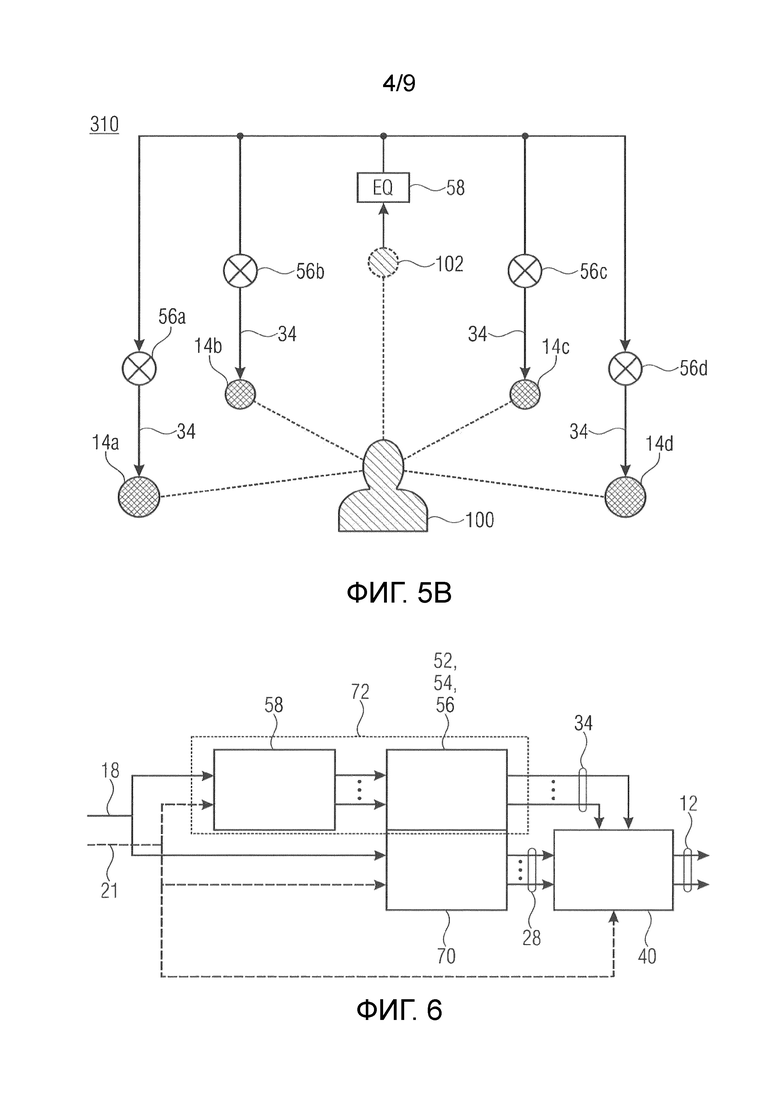

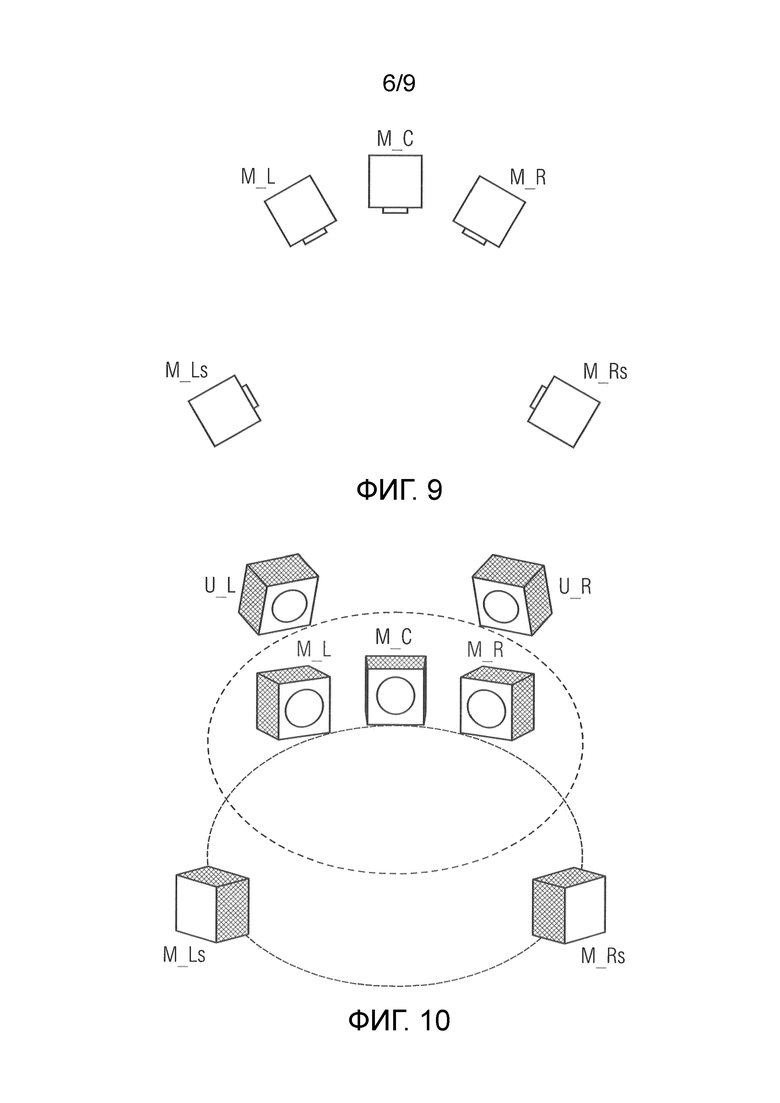
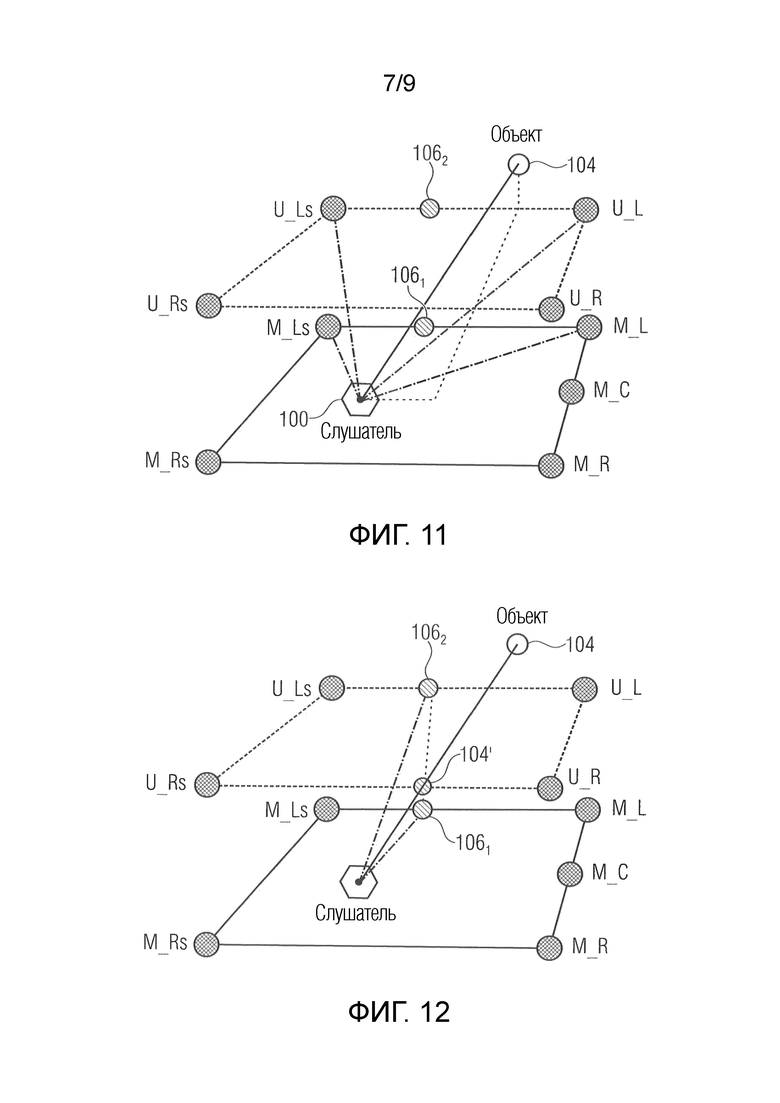
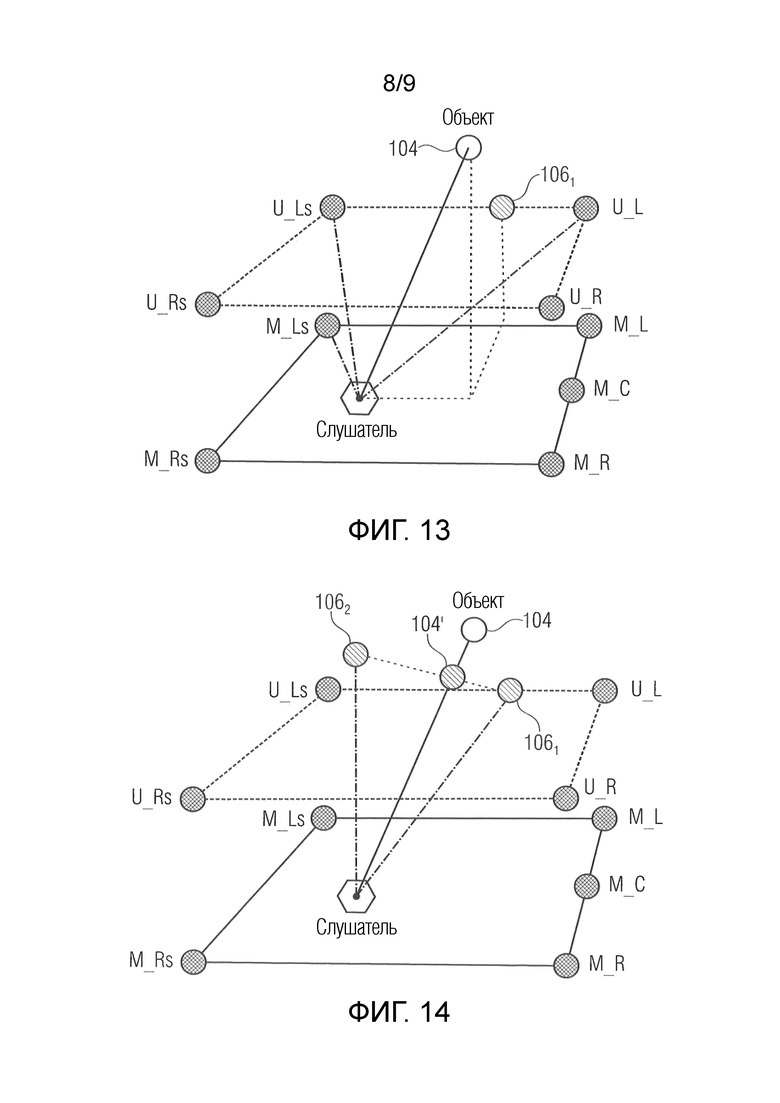
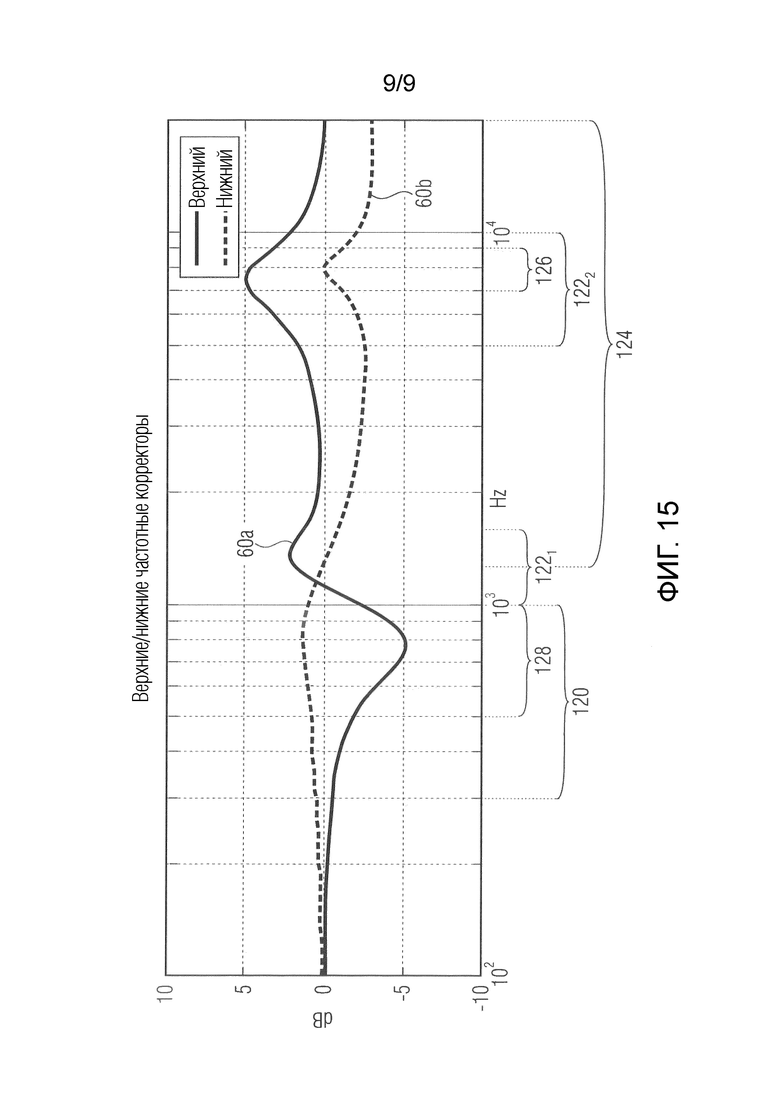
Изобретение относится к области техники воспроизведения аудио, в частности к воспроизведению многоканального аудио с воспроизведением приподнятых или опущенных по высоте звуков. Техническим результатом является получение более эффективного рендеринга аудиообъектов, который обеспечивает возможность трехмерного панорамирования при обеспечении стабильности рендеринга, повышенной точности панорамирования, эффективности вычислений с большим числом компоновок громкоговорителей, изменяющимся числом громкоговорителей, изменяющимися позициями громкоговорителей, изменяющимися позициями слушателей, изменяющимися позициями объектов. Посредством заявленного оборудования выполняют панорамирование в двух каскадах, а именно по меньшей мере одного горизонтального внутрислойного панорамирования, приводящего к первой виртуальной позиции динамика и второй виртуальной или реальной позиции динамика, которая вертикально смещается, и другого панорамирования вертикально между двумя позициями. Такая каскадная обработка увеличивает стабильность рендеринга и определения местоположения намеченной виртуальной позиции. Кроме того, каскадная обработка обеспечивает возможность выполнять, согласно варианту осуществления, панорамирование посредством использования только усилений амплитудного панорамирования, т.е. фазовая обработка не требуется, за счет этого снижая вычислительную сложность. Еще дополнительно рендеринг является гибким относительно применимости для множества компоновок громкоговорителей. Помимо оборудования для формирования сигналов громкоговорителей заявлены также способы для формирования сигналов громкоговорителей, системы для воспроизведения аудио и машиночитаемые цифровые носители хранения данных. 8 н. и 39 з.п. ф-лы, 16 ил., 2 табл.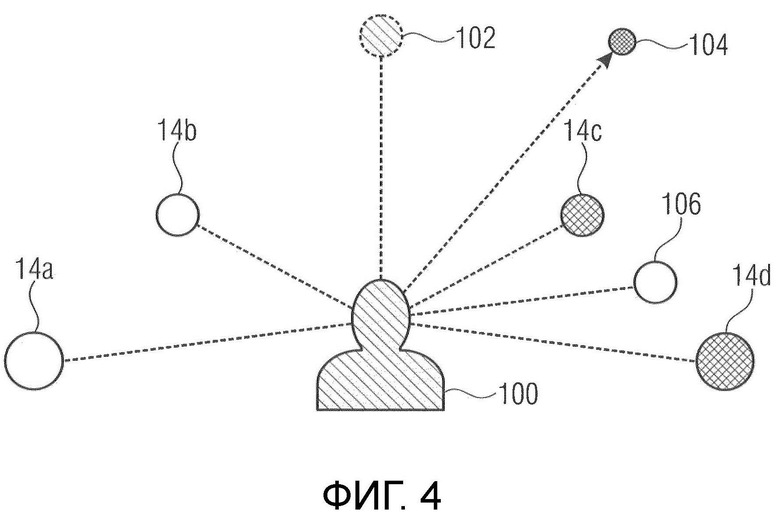
1. Оборудование для формирования сигналов (12) громкоговорителей для множества громкоговорителей (14) таким образом, что применение сигналов (12) громкоговорителей во множестве громкоговорителей (14) подготавливает посредством рендеринга по меньшей мере один аудиообъект в намеченной виртуальной позиции (104), причем оборудование содержит:
- интерфейс (16), выполненный с возможностью принимать входной аудиосигнал (18), который представляет по меньшей мере один аудиообъект,
- модуль (22) определения первых усилений панорамирования, выполненный с возможностью определять, в зависимости от намеченной виртуальной позиции, первые усиления (24) панорамирования для первого набора (26) громкоговорителей из множества громкоговорителей, которые размещаются в первом горизонтальном слое, причем первые усиления (24) панорамирования задают извлечение первых частичных сигналов (28) громкоговорителей по меньшей мере из одного входного аудиосигнала (18), которые ассоциированы с рендерингом по меньшей мере одного аудиообъекта в первой виртуальной позиции (106) при применении первых частичных сигналов (28) громкоговорителей к первому набору (26) громкоговорителей,
- модуль (30) определения усилений вертикального панорамирования, выполненный с возможностью определять, в зависимости от намеченной виртуальной позиции, дополнительные усиления (32) панорамирования для панорамирования между первыми частичными сигналами (28) громкоговорителей и одним или более вторых частичных сигналов (34) громкоговорителей, которое должно применяться ко второму набору (36) из одного или более громкоговорителей, который размещается во втором горизонтальном слое, который вертикально смещается относительно первого набора слоев и ассоциирован с рендерингом по меньшей мере одного аудиообъекта во второй позиции (102), с тем чтобы панорамироваться между первой виртуальной позицией (106) и второй позицией (102),
- при этом оборудование выполнено с возможностью составлять сигналы (12) громкоговорителей из входного аудиосигнала (18) с использованием первых усилений (24) панорамирования и дополнительных усилений (32) панорамирования,
- при этом оборудование является адаптивным к различным компоновкам множества громкоговорителей (14) и выполнено с возможностью ассоциировать множество громкоговорителей (14) со множеством горизонтальных слоев таким образом, что один из громкоговорителей может быть ассоциирован с различными из горизонтальных слоев, и выбирать первый горизонтальный слой и второй горизонтальный слой из множества горизонтальных слоев таким образом, что намеченная виртуальная позиция находится между первым горизонтальным слоем и вторым горизонтальным слоем.
2. Оборудование по п. 1, в котором второй набор (36) из одного или более громкоговорителей содержит более одного громкоговорителя, один или более вторых частичных сигналов (34) громкоговорителей содержат более одного вторых частичных сигналов громкоговорителей, и оборудование дополнительно содержит:
- модуль (52) определения вторых усилений панорамирования, выполненный с возможностью определять, в зависимости от намеченной виртуальной позиции, вторые усиления (54) панорамирования для второго набора громкоговорителей, причем вторые усиления (54) панорамирования задают извлечение вторых частичных сигналов (34) громкоговорителей по меньшей мере из одного входного аудиосигнала, и
- при этом оборудование выполнено с возможностью составлять сигналы (12) громкоговорителей из входного аудиосигнала (18) с использованием первых и вторых усилений панорамирования и дополнительных усилений панорамирования.
3. Оборудование по п. 2,
- в котором второй набор (36) громкоговорителей находится в пределах второго набора слоев из одного или более горизонтальных слоев, и первые и вторые наборы слоев вертикально смещаются относительно друг друга.
4. Оборудование по любому из пп. 2, 3,
- в котором второй набор (36) громкоговорителей находится в пределах второго набора слоев из одного или более горизонтальных слоев, и первые и вторые наборы слоев вертикально смещаются относительно друг друга, при этом намеченная виртуальная позиция (104) находится вертикально между ними.
5. Оборудование по любому из пп. 2-4,
- в котором второй набор (36) громкоговорителей находится в пределах второго набора слоев из одного или более горизонтальных слоев, и модули (22, 52) определения первых и вторых усилений панорамирования выполнены с возможностью выбирать первые и вторые наборы (26, 36) громкоговорителей из множества громкоговорителей таким образом, что первые и вторые наборы слоев, из горизонтальных слоев, в которые распределяются множество громкоговорителей, являются вертикально ближайшими к намеченной виртуальной позиции (104) и вертикально смещаются относительно друг друга, при этом намеченная виртуальная позиция (104) находится вертикально между ними.
6. Оборудование по любому из пп. 2-5, в котором модули (22, 52) определения первых и вторых усилений панорамирования выполнены с возможностью извлекать первые и вторые усиления (24, 54) панорамирования таким образом, что первая виртуальная позиция (1061) и вторая позиция (1062) совпадают в вертикальной проекции.
7. Оборудование по п. 6, в котором:
- формирование (58) спектра подражает свойствам передаточной функции восприятия звука человеком (HRTF) вдоль направления восприятия из второй позиции (102).
8. Оборудование по любому из пп. 6, 7, сконфигурированное:
- таким образом, что вторая позиция находится вертикально выше второго набора слоев, а также с возможностью выполнять формирование (58) спектра таким образом, что вторые частичные сигналы (34) громкоговорителей демпфируются, относительно по меньшей мере одного входного аудиосигнала, в режекционном спектральном диапазоне (120) между 200 и 1000 Гц и усиливаются в одном или более пиковых спектральных диапазонов (1221, 1222) между 1000 и 10 кГц, или
- таким образом, что вторая позиция находится вертикально ниже второго набора слоев, а также с возможностью выполнять формирование спектра таким образом, что вторые частичные сигналы (34) громкоговорителей демпфируются, относительно по меньшей мере одного аудиосигнала в спектральном диапазоне выше 1000 Гц.
9. Оборудование по любому из пп. 6-8, сконфигурированное:
- таким образом, что вторая позиция находится вертикально выше второго набора слоев, а также с возможностью выполнять формирование (58) спектра таким образом, что вторые частичные сигналы (34) громкоговорителей демпфируются, относительно по меньшей мере одного входного аудиосигнала, в режекционном спектральном диапазоне (120) между 200 и 1000 Гц и усиливаются в одном или более пиковых спектральных диапазонов (1221, 1222) между 1000 и 10 кГц, или
- таким образом, что вторая позиция находится вертикально ниже второго набора слоев, а также с возможностью выполнять формирование спектра таким образом, что вторые частичные сигналы (34) громкоговорителей демпфируются, относительно по меньшей мере одного аудиосигнала в спектральном диапазоне (124) выше 1000 Гц с промежуточным уменьшением демпфирования в спектральном поддиапазоне (126) в спектральном диапазоне, расположенном между 5 и 10 кГц, и усиливаются (128) между 500 Гц и 1 кГц.
10. Оборудование по пп. 6-9, выполненное с возможностью:
- если намеченная виртуальная позиция (104) находится вертикально выше второго набора слоев, позиционировать вторую позицию таким образом, что она находится вертикально выше второго набора слоев, выполнять формирование спектра таким образом, что вторые частичные сигналы громкоговорителей демпфируются, относительно по меньшей мере одного аудиосигнала в режекционном спектральном диапазоне между 200 и 1000 Гц и усиливаются в одном или более пиковых спектральных диапазонов между 1000 и 10 кГц, и
- если намеченная виртуальная позиция находится вертикально ниже второго набора слоев, позиционировать вторую позицию таким образом, что она находится вертикально ниже второго набора слоев, выполнять формирование спектра таким образом, что вторые частичные сигналы громкоговорителей демпфируются, относительно по меньшей мере одного аудиосигнала в спектральном диапазоне выше 1000 Гц.
11. Оборудование по пп. 6-10,
- в котором множество громкоговорителей (14) формируют компоновку, в которой громкоговорители ассоциированы с горизонтальными слоями, и оборудование выполнено с возможностью реагировать на изменение намеченной виртуальной позиции таким образом, что:
- если намеченная виртуальная позиция находится между двумя горизонтальными слоями:
- выбирать первый набор слоев в качестве первого из двух горизонтальных слоев и второй набор слоев в качестве второго из двух горизонтальных слоев, и первый набор (26) из громкоговорителей, ассоциированный с первым горизонтальным слоем, и второй набор (36) из громкоговорителей, ассоциированный со вторым горизонтальным слоем, при этом модуль (22, 52) определения первых и вторых усилений панорамирования выполнен с возможностью определять, в зависимости от намеченной виртуальной позиции, первые и вторые усиления панорамирования и то, что формирование (58) спектра отключается, так что первая виртуальная позиция находится в пределах первого горизонтального слоя, и вторая виртуальная позиция находится в пределах второго горизонтального слоя, и
- если намеченная виртуальная позиция вертикально смещается по отношению ко всем горизонтальным слоям в направлении выше или ниже горизонтальных слоев:
- выбирать первый набор слоев и второй набор слоев в качестве самого дальнего слоя из горизонтальных слоев, ближайших к намеченной виртуальной позиции, и первый набор (26) и второй набор (36) из громкоговорителей, ассоциированные с самым дальним слоем, при этом модуль (22) определения первых усилений панорамирования выполнен с возможностью определять, в зависимости от намеченной виртуальной позиции, первые усиления панорамирования и использование формирования (58) спектра, так что вторая позиция представляет собой виртуальную позицию (102), вертикально смещенную относительно самого дальнего слоя к направлению, в котором находится намеченная виртуальная позиция (104).
12. Оборудование по п. 11,
- при этом оборудование выполнено с возможностью реагировать на изменение намеченной виртуальной позиции таким образом, что:
- если намеченная виртуальная позиция находится между двумя горизонтальными слоями:
- модуль (22, 52) определения первых и вторых усилений панорамирования выполнен с возможностью определять, в зависимости от намеченной виртуальной позиции, первые и вторые усиления панорамирования таким образом, что первая виртуальная позиция (1061) и вторая позиция (1062) совпадают в вертикальной проекции, и формирование (58) спектра отключается, и/или
- если намеченная виртуальная позиция вертикально смещается по отношению ко всем горизонтальным слоям в направлении выше или ниже горизонтальных слоев:
- модуль (22) определения первых усилений панорамирования выполнен с возможностью определять, в зависимости от намеченной виртуальной позиции, первые усиления панорамирования таким образом, что первая виртуальная позиция (106) совпадает в вертикальной проекции с намеченной виртуальной позицией.
13. Оборудование по пп. 6-12,
- в котором множество громкоговорителей (14) формируют компоновку, в которой громкоговорители ассоциированы с одним или более горизонтальных слоев, и оборудование выполнено с возможностью реагировать на число одного или более горизонтальных слоев и изменение намеченной виртуальной позиции таким образом, что:
- если число одного или более горизонтальных слоев больше одного:
- если намеченная виртуальная позиция находится между двумя горизонтальными слоями:
- выбирать первый набор слоев в качестве первого из двух горизонтальных слоев и второй набор слоев в качестве второго из двух горизонтальных слоев, и первый набор (26) из громкоговорителей, ассоциированный с первым горизонтальным слоем, и второй набор (36) из громкоговорителей, ассоциированный со вторым горизонтальным слоем, при этом модуль (22, 52) определения первых и вторых усилений панорамирования выполнен с возможностью определять, в зависимости от намеченной виртуальной позиции, первые и вторые усиления панорамирования и то, что формирование (58) спектра отключается, так что первая виртуальная позиция находится в пределах первого горизонтального слоя, и вторая виртуальная позиция находится в пределах второго горизонтального слоя, и
- если намеченная виртуальная позиция вертикально смещается по отношению ко всем горизонтальным слоям в направлении выше или ниже горизонтальных слоев:
- выбирать первый набор слоев и второй набор слоев в качестве самого дальнего слоя из горизонтальных слоев, ближайших к намеченной виртуальной позиции, и первый набор (26) и второй набор (36) из громкоговорителей, ассоциированные с самым дальним слоем, при этом модуль (22) определения первых усилений панорамирования выполнен с возможностью определять, в зависимости от намеченной виртуальной позиции, первые усиления панорамирования и то, что формирование (58) спектра используется, так что вторая позиция представляет собой виртуальную позицию (102), вертикально смещенную относительно самого дальнего слоя к направлению, в котором намеченная виртуальная позиция (104) находится, и
- если число одного или более горизонтальных слоев равно одному:
- если намеченная виртуальная позиция находится в пределах одного горизонтального слоя:
- составлять сигналы (12) громкоговорителей чисто из первых частичных сигналов громкоговорителей, и
- если намеченная виртуальная позиция вертикально смещается по отношению к одному горизонтальному слою:
- выбирать первый набор слоев и второй набор слоев в качестве одного горизонтального слоя и первый набор (26) и второй набор (36) из громкоговорителей, ассоциированные с одним горизонтальным слоем, при этом модуль (22) определения первых усилений панорамирования выполнен с возможностью определять, в зависимости от намеченной виртуальной позиции, первые усиления панорамирования и то, что формирование (58) спектра используется, так что вторая позиция представляет собой виртуальную позицию (102), вертикально смещенную относительно одного горизонтального слоя к направлению, в котором находится намеченная виртуальная позиция (104).
14. Оборудование по п. 13,
- при этом оборудование выполнено с возможностью реагировать на число одного или более горизонтальных слоев и изменение намеченной виртуальной позиции таким образом, что:
- если число одного или более горизонтальных слоев больше одного:
- если намеченная виртуальная позиция находится между двумя горизонтальными слоями:
- модуль (22, 52) определения первых и вторых усилений панорамирования выполнен с возможностью определять, в зависимости от намеченной виртуальной позиции, первые и вторые усиления панорамирования таким образом, что первая виртуальная позиция (1061) и вторая позиция (1062) совпадают в вертикальной проекции, и/или
- если намеченная виртуальная позиция вертикально смещается по отношению ко всем горизонтальным слоям в направлении выше или ниже горизонтальных слоев:
- модуль (22) определения первых усилений панорамирования выполнен с возможностью определять, в зависимости от намеченной виртуальной позиции, первые усиления панорамирования таким образом, что первая виртуальная позиция (106) совпадает в вертикальной проекции с намеченной виртуальной позицией, и/или
- если число одного или более горизонтальных слоев равно одному:
- если намеченная виртуальная позиция вертикально смещается по отношению к одному горизонтальному слою:
- модуль (22) определения первых усилений панорамирования выполнен с возможностью определять, в зависимости от намеченной виртуальной позиции, первые усиления панорамирования таким образом, что первая виртуальная позиция (106) совпадает в вертикальной проекции с намеченной виртуальной позицией.
15. Оборудование по любому из пп. 1-14,
- в котором первый набор (26) громкоговорителей включается во второй набор (36) из одного или более громкоговорителей, и/или
- при этом второй набор (36) из одного или более громкоговорителей включается в первый набор (26) громкоговорителей, и/или
- при этом первый набор (26) громкоговорителей и второй набор (36) из одного или более громкоговорителей совпадают, и/или
- при этом первый набор (26) громкоговорителей и второй набор (36) из одного или более громкоговорителей частично перекрываются, и/или
- при этом первый набор (26) громкоговорителей и второй набор (36) из одного или более громкоговорителей представляют собой непересекающиеся наборы.
16. Оборудование по любому из пп. 1-15,
- выполненное с возможностью выбирать первый набор (26) громкоговорителей из множества громкоговорителей в зависимости от горизонтального компонента намеченной виртуальной позиции или в зависимости от горизонтального компонента намеченной виртуальной позиции и вертикального компонента намеченной виртуальной позиции, и/или
- выполненное с возможностью выбирать второй набор (36) из одного или более громкоговорителей из множества громкоговорителей в зависимости от вертикального компонента намеченной виртуальной позиции или в зависимости от горизонтального компонента намеченной виртуальной позиции и вертикального компонента намеченной виртуальной позиции.
17. Оборудование по любому из пп. 1-16, в котором второй набор из одного или более громкоговорителей содержит один или более громкоговорителей, в или горизонтально окружающих вторую позицию и горизонтально размещаемых между первым набором громкоговорителей.
18. Оборудование по любому из пп. 1-17,
- в котором модули (22, 52) определения первых и/или вторых усилений панорамирования выполнены с возможностью определять первые и/или вторые усиления (24, 54) панорамирования дополнительно в зависимости от позиции слушателя.
19. Оборудование по любому предшествующему пункту,
- в котором множество громкоговорителей означают любое одно из либо комбинацию одного или более массивов громкоговорителей, одной или более звуковых панелей, одного или более интеллектуальных динамиков, одного или более стереодинамиков, одной или более компоновок с объемным звуком либо одного или более наборов отдельных громкоговорителей.
20. Оборудование по любому предшествующему пункту,
- в котором входной аудиосигнал представляет собой одно из канально-ориентированного аудиосигнала, объектно-ориентированного аудиосигнала и/или сцено-ориентированного аудиосигнала.
21. Оборудование по любому предшествующему пункту,
- выполненное с возможностью извлекать намеченную виртуальную позицию из входного аудиосигнала.
22. Оборудование по любому предшествующему пункту,
- в котором усиления панорамирования представляют собой усиления амплитудного панорамирования.
23. Оборудование по любому из пп. 1-22,
- в котором входной аудиосигнал представляет собой канально-ориентированный аудиосигнал, задающий аудиосигнал для каждой из конкретных для сигнала позиций громкоговорителей,
- при этом оборудование выполнено с возможностью трактовать каждый выбор одного или более (или всех) из аудиосигналов для конкретных для сигнала позиций громкоговорителей в качестве одного по меньшей мере из одного аудиообъекта.
24. Оборудование по п. 23, выполненное с возможностью:
- извлекать намеченную виртуальную позицию одного аудиообъекта из позиции громкоговорителей соответствующего аудиосигнала.
25. Оборудование по п. 24,
- в котором намеченная виртуальная позиция одного аудиообъекта извлекается из позиции громкоговорителей соответствующего аудиосигнала таким способом, что взаимная позиционная взаимосвязь между конкретной для сигнала позицией громкоговорителя поддерживается.
26. Оборудование по любому из пп. 1-25,
- в котором входной аудиосигнал представляет собой объектно-ориентированный аудиосигнал, задающий один или более аудиообъектов для рендеринга,
- при этом оборудование выполнено с возможностью использовать выбор из одного или более (или всех) из одного или более аудиообъектов для рендеринга в качестве одного по меньшей мере из одного аудиообъекта.
27. Оборудование по любому предшествующему пункту,
- выполненное с возможностью принимать информацию относительно изменения множества громкоговорителей с точки зрения позиции громкоговорителей и учитывать изменение при последующем формировании сигналов громкоговорителей, и/или
- выполненное с возможностью принимать информацию относительно изменения множества громкоговорителей с точки зрения числа громкоговорителей и учитывать изменение при последующем формировании сигналов громкоговорителей.
28. Оборудование для формирования сигналов (12) громкоговорителей для множества громкоговорителей (14) таким образом, что применение сигналов (12) громкоговорителей во множестве громкоговорителей (14) подготавливает посредством рендеринга по меньшей мере один аудиообъект в намеченной виртуальной позиции (104), при этом множество громкоговорителей распределяются в один или более горизонтальных слоев, причем оборудование содержит:
- интерфейс (16), выполненный с возможностью принимать входной аудиосигнал (18), который представляет по меньшей мере один аудиообъект,
- модуль (70) определения первых наборов сигналов громкоговорителей, выполненный с возможностью определять, в зависимости от намеченной виртуальной позиции, первые усиления (24) панорамирования для первого набора громкоговорителей (26) из множества громкоговорителей и использовать первые усиления (24) панорамирования для того, чтобы извлекать первые частичные сигналы (28) громкоговорителей по меньшей мере из одного входного аудиосигнала (18), которые ассоциированы с рендерингом по меньшей мере одного аудиообъекта в первой виртуальной позиции (106) при применении первых частичных сигналов громкоговорителей к первому набору (26) громкоговорителей,
- модуль (72) определения вторых наборов сигналов громкоговорителей, выполненный с возможностью, посредством формирования спектра и посредством усилений панорамирования, извлекать вторые частичные сигналы (34) громкоговорителей по меньшей мере из одного входного аудиосигнала (18), причем вторые частичные сигналы (34) громкоговорителей ассоциированы с рендерингом по меньшей мере одного аудиообъекта во второй виртуальной позиции (102) при применении вторых частичных сигналов (34) громкоговорителей ко второму набору громкоговорителей (36) из множества громкоговорителей, при этом усиления панорамирования выбираются таким образом, что вторая виртуальная позиция находится выше или ниже одного или более горизонтальных слоев и соответствует горизонтальной позиции, которая совпадает с позицией слушателя вдоль вертикальной проекции, и
- модуль (30) определения усилений вертикального панорамирования, выполненный с возможностью, в зависимости от намеченной виртуальной позиции, определять дополнительные усиления (32) панорамирования для первых и вторых частичных сигналов громкоговорителей, с тем, чтобы панорамироваться между первыми и вторыми виртуальными позициями, и
- модуль (40) составления, выполненный с возможностью составлять сигналы громкоговорителей из первых и вторых частичных сигналов громкоговорителей с использованием дополнительных усилений (32) панорамирования.
29. Оборудование по п. 28,
- в котором первый набор громкоговорителей находится в пределах одного или более горизонтальных слоев, которые являются, из числа одного или более горизонтальных слоев, вертикально ближайшими к намеченной виртуальной позиции.
30. Оборудование по п. 28 или 29,
- в котором модуль (70) определения первых наборов сигналов громкоговорителей выполнен с возможностью выбирать первый набор громкоговорителей (26) из множества громкоговорителей таким образом, что первый набор громкоговорителей находится в пределах одного или более горизонтальных слоев, которые являются, из числа одного или более горизонтальных слоев, вертикально ближайшими к намеченной виртуальной позиции.
31. Оборудование по п. 28 или 29,
- в котором модуль (70) определения первых наборов сигналов громкоговорителей сконфигурирован таким образом, что первый набор громкоговорителей находится в пределах одного горизонтального слоя, а также с возможностью определять первые усиления панорамирования дополнительно в зависимости от позиций первого набора громкоговорителей в одном горизонтальном слое.
32. Оборудование по п. 28,
- в котором модуль (70) определения первых наборов сигналов громкоговорителей сконфигурирован таким образом, что первые усиления панорамирования реализуют чистое амплитудное панорамирование таким образом, что первая виртуальная позиция находится между позициями набора первых громкоговорителей.
33. Оборудование по любому из пп. 28-32,
- в котором модуль (70) определения первых наборов сигналов громкоговорителей выполнен с возможностью определять первые усиления панорамирования дополнительно в зависимости от позиции слушателя.
34. Оборудование по любому из пп. 28-33,
- в котором модуль (72) определения вторых наборов сигналов громкоговорителей сконфигурирован таким образом, что формирование спектра подражает свойствам передаточной функции восприятия звука человеком (HRTF) вдоль направления восприятия из второй виртуальной позиции.
35. Оборудование по любому из пп. 28-34,
- в котором модуль (72) определения вторых наборов сигналов громкоговорителей выполнен с возможностью извлекать вторые частичные сигналы громкоговорителей по меньшей мере из одного аудиосигнала:
- таким образом, что вторые частичные сигналы громкоговорителей формируются по меньшей мере из одного аудиосигнала с использованием коэффициента амплитудного усиления, который является одинаковым для всех вторых частичных сигналов громкоговорителей, или
- посредством панорамирования с использованием усилений панорамирования, которые соответствуют горизонтальной центральной позиции или позиции в зоне наилучшего восприятия между вторым набором громкоговорителей.
36. Оборудование по любому из пп. 28-35,
- в котором первый набор громкоговорителей включается во второй набор громкоговорителей, и/или
- при этом второй набор (36) громкоговорителей включается в первый набор (26) громкоговорителей, и/или
- при этом первый набор громкоговорителей и второй набор громкоговорителей совпадают, и/или
- при этом первый набор (26) громкоговорителей и второй набор (36) громкоговорителей частично перекрываются, и/или
- при этом первый набор громкоговорителей и второй набор громкоговорителей являются взаимоисключающими.
37. Оборудование по любому из пп. 28-36,
- выполненное с возможностью выбирать первый набор (26) громкоговорителей из множества громкоговорителей в зависимости от горизонтального компонента намеченной виртуальной позиции или в зависимости от горизонтального компонента намеченной виртуальной позиции и вертикального компонента намеченной виртуальной позиции, и/или
- выполненное с возможностью выбирать второй набор (36) громкоговорителей из множества громкоговорителей в зависимости от вертикального компонента намеченной виртуальной позиции или в зависимости от горизонтального компонента намеченной виртуальной позиции и вертикального компонента намеченной виртуальной позиции.
38. Оборудование по любому из пп. 28-37,
- в котором модуль (72) определения вторых наборов сигналов громкоговорителей сконфигурирован таким образом, что вторая виртуальная позиция находится вертикально выше одного или более горизонтальных слоев, а также с возможностью выполнять формирование спектра таким образом, что вторые частичные сигналы громкоговорителей демпфируются, относительно по меньшей мере одного аудиосигнала в режекционном спектральном диапазоне между 200 и 1000 Гц и усиливаются в одном или более пиковых спектральных диапазонов между 1000 и 10 кГц, или
- при этом модуль (72) определения вторых наборов сигналов громкоговорителей сконфигурирован таким образом, что вторая виртуальная позиция находится вертикально ниже одного или более горизонтальных слоев, а также с возможностью выполнять формирование спектра таким образом, что вторые частичные сигналы громкоговорителей демпфируются, относительно по меньшей мере одного аудиосигнала в спектральном диапазоне выше 1000 Гц.
39. Оборудование по любому из пп. 28-38,
- в котором модуль (72) определения вторых наборов сигналов громкоговорителей сконфигурирован таким образом, что вторая виртуальная позиция находится вертикально выше одного или более горизонтальных слоев, а также с возможностью выполнять формирование спектра таким образом, что вторые частичные сигналы громкоговорителей демпфируются, относительно по меньшей мере одного аудиосигнала в режекционном спектральном диапазоне между 200 и 1000 Гц и усиливаются в одном или более пиковых спектральных диапазонов между 1000 и 10 кГц, или
- при этом модуль (72) определения вторых наборов сигналов громкоговорителей сконфигурирован таким образом, что вторая виртуальная позиция находится вертикально ниже одного или более горизонтальных слоев, а также с возможностью выполнять формирование спектра таким образом, что вторые частичные сигналы громкоговорителей демпфируются, относительно по меньшей мере одного аудиосигнала в спектральном диапазоне выше 1000 Гц с промежуточным уменьшением демпфирования в спектральном поддиапазоне в спектральном диапазоне, расположенном между 5 и 10 кГц, и усиливаются между 500 Гц и 1 кГц.
40. Оборудование по любому из пп. 28-39,
- в котором модуль (72) определения вторых наборов сигналов громкоговорителей выполнен с возможностью:
- если намеченная виртуальная позиция находится вертикально выше одного или более горизонтальных слоев, позиционировать вторую виртуальную позицию таким образом, что она находится вертикально выше одного или более горизонтальных слоев, выполнять формирование спектра таким образом, что вторые частичные сигналы громкоговорителей демпфируются, относительно по меньшей мере одного аудиосигнала в режекционном спектральном диапазоне между 200 и 1000 Гц и усиливаются в одном или более пиковых спектральных диапазонов между 1000 и 10 кГц, и
- если намеченная виртуальная позиция находится вертикально ниже одного или более горизонтальных слоев, позиционировать вторую виртуальную позицию таким образом, что она находится вертикально ниже одного или более горизонтальных слоев, выполнять формирование спектра таким образом, что вторые частичные сигналы громкоговорителей демпфируются, относительно по меньшей мере одного аудиосигнала в спектральном диапазоне выше 1000 Гц.
41. Оборудование по любому из пп. 28-40,
- в котором модуль составления выполнен с возможностью реагировать на изменение намеченной виртуальной позиции из внутрислойной позиции, которая находится вертикально внутри или между одним или более слоев, в позицию, вертикально смещенную от одного или более горизонтальных слоев, посредством:
- управления дополнительными усилениями панорамирования таким образом, чтобы выполнять постепенное нарастание/затухание из составления сигналов громкоговорителей чисто из первых частичных сигналов громкоговорителей в составление сигналов громкоговорителей из первых и вторых частичных сигналов громкоговорителей таким образом, что дополнительные усиления панорамирования панорамируются из первой виртуальной позиции ко второй виртуальной позиции.
42. Система воспроизведения аудио, содержащая:
- множество громкоговорителей, и
- оборудование по одному из пп. 1-27.
43. Система воспроизведения аудио, содержащая:
- множество громкоговорителей, и
- оборудование по одному из пп. 28-41.
44. Способ для формирования сигналов (12) громкоговорителей для множества громкоговорителей (14) таким образом, что применение сигналов (12) громкоговорителей во множестве громкоговорителей (14) подготавливает посредством рендеринга по меньшей мере один аудиообъект в намеченной виртуальной позиции (104), при этом способ содержит этапы, на которых:
- принимают входной аудиосигнал (18), который представляет по меньшей мере один аудиообъект,
- ассоциируют множество громкоговорителей (14) со множеством горизонтальных слоев таким образом, что один из громкоговорителей может быть ассоциирован с различными из горизонтальных слоев, и выбирают первый горизонтальный слой и второй горизонтальный слой из множества горизонтальных слоев таким образом, что намеченная виртуальная позиция находится между первым горизонтальным слоем и вторым горизонтальным слоем, чтобы иметь возможность адаптироваться к различным компоновкам множества громкоговорителей (14);
- определяют, в зависимости от намеченной виртуальной позиции, первые усиления (24) панорамирования для первого набора (26) громкоговорителей из множества громкоговорителей, которые размещаются в первом горизонтальном слое, причем первые усиления (24) панорамирования задают извлечение первых частичных сигналов (28) громкоговорителей по меньшей мере из одного входного аудиосигнала (18), которые ассоциированы с рендерингом по меньшей мере одного аудиообъекта в первой виртуальной позиции (106) при применении первых частичных сигналов (28) громкоговорителей к первому набору (26) громкоговорителей,
- определяют, в зависимости от намеченной виртуальной позиции, дополнительные усиления (32) панорамирования для панорамирования между первыми частичными сигналами (28) громкоговорителей и одним или более вторых частичных сигналов (34) громкоговорителей, которое должно применяться ко второму набору (36) из одного или более громкоговорителей, который размещается во втором горизонтальном слое, который вертикально смещен относительно первого набора слоев и ассоциирован с рендерингом по меньшей мере одного аудиообъекта во второй позиции (102), с тем чтобы панорамироваться между первой виртуальной позицией (106) и второй позицией (102),
- составляют сигналы (12) громкоговорителей из входного аудиосигнала (18) с использованием первых усилений (24) панорамирования и дополнительных усилений (32) панорамирования.
45. Способ для формирования сигналов (12) громкоговорителей для множества громкоговорителей (14) таким образом, что применение сигналов (12) громкоговорителей во множестве громкоговорителей (14) подготавливает посредством рендеринга по меньшей мере один аудиообъект в намеченной виртуальной позиции (104), при этом множество громкоговорителей распределяются в один или более горизонтальных слоев, при этом способ содержит этапы, на которых:
- принимают входной аудиосигнал (18), который представляет по меньшей мере один аудиообъект,
- определяют, в зависимости от намеченной виртуальной позиции, первые усиления (24) панорамирования для первого набора громкоговорителей (26) из множества громкоговорителей и используют первые усиления (24) панорамирования для того, чтобы извлекать первые частичные сигналы (28) громкоговорителей по меньшей мере из одного входного аудиосигнала (18), которые ассоциированы с рендерингом по меньшей мере одного аудиообъекта в первой виртуальной позиции (106) при применении первых частичных сигналов громкоговорителей к первому набору (26) громкоговорителей,
- посредством формирования спектра и посредством усилений панорамирования, извлекают вторые частичные сигналы (34) громкоговорителей по меньшей мере из одного входного аудиосигнала (18), причем вторые частичные сигналы (34) громкоговорителей ассоциированы с рендерингом по меньшей мере одного аудиообъекта во второй виртуальной позиции (102) при применении вторых частичных сигналов (34) громкоговорителей ко второму набору громкоговорителей (36) из множества громкоговорителей, при этом усиления панорамирования выбирают таким образом, что вторая виртуальная позиция находится выше или ниже одного или более горизонтальных слоев и соответствует горизонтальной позиции, которая совпадает с позицией слушателя вдоль вертикальной проекции, и
- в зависимости от намеченной виртуальной позиции, определяют дополнительные усиления (32) панорамирования для первых и вторых частичных сигналов громкоговорителей, с тем чтобы панорамироваться между первыми и вторыми виртуальными позициями, и
- составляют сигналы громкоговорителей из первых и вторых частичных сигналов громкоговорителей с использованием дополнительных усилений (32) панорамирования.
46. Машиночитаемый цифровой носитель хранения данных, имеющий сохраненную компьютерную программу, имеющую программный код для осуществления, при выполнении на компьютере, способа по п. 44.
47. Машиночитаемый цифровой носитель хранения данных, имеющий сохраненную компьютерную программу, имеющую программный код для осуществления, при выполнении на компьютере, способа по п. 45.
| US 2016044433 A, 11.02.2016 | |||
| WO 2020201107 A1, 08.10.2020 | |||
| BUKVIC IVICA ICO | |||
| Переносная печь для варки пищи и отопления в окопах, походных помещениях и т.п. | 1921 |
|
SU3A1 |
| Аппарат для очищения воды при помощи химических реактивов | 1917 |
|
SU2A1 |
| Коридорная многокамерная вагонеточная углевыжигательная печь | 1921 |
|
SU36A1 |
| Печь-кухня, могущая работать, как самостоятельно, так и в комбинации с разного рода нагревательными приборами | 1921 |
|
SU10A1 |
| US 2014119581 A1, 01.05.2014 | |||
| US | |||

