Настоящая заявка относится к устройству и способу для преобразования первого и второго входных каналов, по меньшей мере, в один выходной канал, и, в частности, к устройству и способу, подходящим для использования при преобразовании формата между различными конфигурациями каналов громкоговорителей.
Инструментальные средства пространственного кодирования аудио известны в данной области техники и стандартизированы, например, в стандарте объемного звучания MPEG. Пространственное кодирование аудио начинается с множества исходных входных, например, пяти или семи входных каналов, которые идентифицируются посредством их размещения в компоновке для воспроизведения, например, в качестве левого канала, центрального канала, правого канала, левого канала объемного звучания, правого канала объемного звучания и канала улучшения низких частот (LFE). Пространственный аудиокодер может извлекать один или более каналов понижающего микширования из исходных каналов и, дополнительно, может извлекать параметрические данные, связанные с пространственными сигнальными метками, такие как межканальные разности уровней в значениях канальной когерентности, межканальные разности фаз, межканальные разности времен и т.д. Один или более каналов понижающего микширования передаются вместе с параметрической вспомогательной информацией, указывающей пространственные сигнальные метки, в пространственный аудиодекодер для декодирования каналов понижающего микширования и ассоциированных параметрических данных, чтобы в итоге получать выходные каналы, которые являются аппроксимированной версией исходных входных каналов. Размещение каналов в выходной компоновке может быть фиксированным, например, как 5.1-формат, 7.1-формат и т.д.
Кроме того, инструментальные средства пространственного кодирования аудиообъектов известны в данной области техники и стандартизированы, например, в MPEG SAOC-стандарте (SAOC – пространственное кодирование аудиообъектов). В отличие от пространственного кодирования аудио, начинающегося с исходных каналов, пространственное кодирование аудиообъектов начинается с аудиообъектов, которые автоматически не выделяются для определенной компоновки для воспроизведения при рендеринге. Наоборот, размещение аудиообъектов в сцене для воспроизведения является гибким и может задаваться пользователем, например, посредством ввода определенной информации рендеринга в декодер по стандарту пространственного кодирования аудиообъектов. Альтернативно или дополнительно, информация рендеринга может передаваться в качестве дополнительной вспомогательной информации или метаданных; информация рендеринга может включать в себя информацию того, в какой позиции в компоновке для воспроизведения определенный должен быть размещен аудиообъект (например, во времени). Чтобы получать определенное сжатие данных, определенное число аудиообъектов кодируется с использованием SAOC-кодера, который вычисляет, из входных объектов, один или более транспортных каналов посредством понижающего микширования объектов в соответствии с определенной информацией понижающего микширования. Кроме того, SAOC-кодер вычисляет параметрическую вспомогательную информацию, представляющую межобъектные сигнальные метки, такую как разности уровней объектов (OLD), значения когерентности объектов и т.д. Аналогично SAC (SAC – пространственное кодирование аудио), межобъектные параметрические данные вычисляются для отдельных частотно-временных мозаичных фрагментов. Для определенного кадра (например, 1024 или 2048 выборок) аудиосигнала, рассматриваются множество полос частот (например, 24, 32 или 64 полосы частот), так что параметрические данные предоставляются для каждого кадра и каждой полосы частот. Например, когда аудио фрагмент имеет 20 кадров, и когда каждый кадр подразделяется на 32 полосы частот, число частотно-временных мозаичных фрагментов равно 640.
Требуемый формат воспроизведения, т.е. конфигурация выходных каналов (конфигурация выходных громкоговорителей) может отличаться от конфигурации входных каналов, при этом число выходных каналов, в общем, отличается от числа входных каналов. Таким образом, преобразование формата может требоваться для того, чтобы преобразовывать входные каналы из конфигурации входных каналов в выходные каналы из конфигурации выходных каналов.
Задача, лежащая в основе изобретения, заключается в том, чтобы предоставлять устройство и способ, которые разрешают улучшенное воспроизведение звука, в частности, в случае преобразования формата между различными конфигурациями каналов громкоговорителей.
Эта задача решается посредством устройства по п. 1 и способа по п. 12.
Варианты осуществления изобретения предоставляют устройство для преобразования первого входного канала и второго входного канала из конфигурации входных каналов, по меньшей мере, в один выходной канал из конфигурации выходных каналов, при этом каждый входной канал и каждый выходной канал имеет направление, в котором расположен ассоциированный громкоговоритель относительно центральной позиции слушателя, при этом устройство выполнено с возможностью:
- преобразовывать первый входной канал в первый выходной канал из конфигурации выходных каналов; и, по меньшей мере, одно из следующего:
a) преобразовывать второй входной канал в первый выходной канал, что содержит обработку второго входного канала посредством применения, по меньшей мере, одного из частотного корректирующего фильтра и декорреляционного фильтра ко второму входному каналу; и
b) несмотря на тот факт, что отклонение углов между направлением второго входного канала и направлением первого выходного канала меньше отклонения углов между направлением второго входного канала и второго выходного канала и/или меньше отклонения углов между направлением второго входного канала и направлением третьего выходного канала, преобразовывать второй входной канал во второй и третий выходные каналы посредством панорамирования между вторым и третьим выходными каналами.
Варианты осуществления изобретения предоставляют способ для преобразования первого входного канала и второго входного канала из конфигурации входных каналов, по меньшей мере, в один выходной канал из конфигурации выходных каналов, при этом каждый входной канал и каждый выходной канал имеет направление, в котором расположен ассоциированный громкоговоритель относительно центральной позиции слушателя, содержащий:
- преобразование первого входного канала в первый выходной канал из конфигурации выходных каналов; и, по меньшей мере, одно из следующего:
a) преобразование второго входного канала в первый выходной канал, содержащее обработку второго входного канала посредством применения, по меньшей мере, одного из частотного корректирующего фильтра и декорреляционного фильтра ко второму входному каналу; и
b) несмотря на тот факт, что отклонение углов между направлением второго входного канала и направлением первого выходного канала меньше отклонения углов между направлением второго входного канала и второго выходного канала и/или меньше отклонения углов между направлением второго входного канала и направлением третьего выходного канала, преобразование второго входного канала во второй и третий выходные каналы посредством панорамирования между вторым и третьим выходными каналами.
Варианты осуществления изобретения основаны на таких выявленных сведениях, что улучшенное воспроизведение аудио может достигаться даже в случае процесса понижающего микширования из определенного числа входных каналов в меньшее число выходных каналов, если используется подход, который спроектирован с возможностью пытаться сохранять пространственное разнесение, по меньшей мере, двух входных каналов, которые преобразуются, по меньшей мере, в один выходной канал. Согласно вариантам осуществления изобретения, это достигается посредством обработки одного из входных каналов, преобразованных в идентичный выходной канал, посредством применения, по меньшей мере, одного из частотного корректирующего фильтра и декорреляционного фильтра. В вариантах осуществления изобретения, это достигается посредством формирования фантомного источника для одного из входных каналов с использованием двух выходных каналов, по меньшей мере, один из которых имеет отклонение углов из входного канала, который превышает отклонение углов из входного канала в другой выходной канал.
В вариантах осуществления изобретения, частотный корректирующий фильтр применяется ко второму входному каналу и выполнен с возможностью повышать спектральную часть второго входного канала, который, как известно, создает у слушателя впечатление, что звук исходит из позиции, соответствующей позиции второго входного канала. В вариантах осуществления изобретения, угол подъема второго входного канала может превышать угол подъема одного или более выходных каналов, в которые преобразуется входной канал. Например, громкоговоритель, ассоциированный со вторым входным каналом, может находиться в позиции выше горизонтальной плоскости слушателя, в то время как громкоговорители, ассоциированные с одним или более выходных каналов, могут находиться в позиции в горизонтальной плоскости слушателя. Частотный корректирующий фильтр может быть выполнен с возможностью повышать спектральную часть второго канала в частотном диапазоне между 7 кГц и 10 кГц. Посредством обработки второго входного сигнала таким способом, у слушателя может создаваться впечатление, что звук исходит из приподнятой позиции, даже если он фактически не исходит из приподнятой позиции.
В вариантах осуществления изобретения, второй входной канал обрабатывается посредством применения частотного корректирующего фильтра, выполненного с возможностью обрабатывать второй входной канал, чтобы компенсировать разности тембра, вызываемые посредством различных позиций второго входного канала и, по меньшей мере, одного выходного канала, в который преобразуется второй входной канал. Таким образом, тембр второго входного канала, который воспроизводится посредством громкоговорителя в неправильной позиции, может манипулироваться таким образом, что у пользователя может складываться впечатление, что звук возникает из другой позиции, ближе к исходной позиции, т.е. из позиции второго входного канала.
В вариантах осуществления изобретения, декорреляционный фильтр применяется ко второму входному каналу. Применение декорреляционного фильтра ко второму входному каналу также может создавать у слушателя впечатление, что звуковые сигналы, воспроизведенные посредством первого выходного канала, возникают из различных входных каналов, расположенных в различных позициях в конфигурации входных каналов. Например, декорреляционный фильтр может быть выполнен с возможностью вводить частотно-зависимые задержки и/или рандомизированные фазы во второй входной канал. В вариантах осуществления изобретения, декорреляционный фильтр может представлять собой реверберационный фильтр, выполненный с возможностью вводить части сигнала реверберации во второй входной канал, так что у слушателя может складываться впечатление, что звуковые сигналы, воспроизведенные через первый выходной канал, возникают из различных позиций. В вариантах осуществления изобретения, декорреляционный фильтр может быть выполнен с возможностью свертывать второй входной канал с экспоненциально затухающей шумовой последовательностью, чтобы моделировать рассеянные отражения во втором входном сигнале.
В вариантах осуществления изобретения, коэффициенты частотного корректирующего фильтра и/или декорреляционного фильтра задаются на основе измеренной бинауральной импульсной характеристики в помещении (BRIR) для конкретного помещения для прослушивания или задаются на основе эмпирических знаний относительно акустики помещений (которые также могут учитывать конкретное помещение для прослушивания). Таким образом, соответствующая обработка, чтобы учитывать пространственное разнесение входных каналов, может быть адаптирована через конкретную обстановку, к примеру, конкретное помещение для прослушивания, в котором сигнал должен воспроизводиться посредством конфигурации выходных каналов.
Ниже поясняются варианты осуществления изобретения со ссылкой на прилагаемые чертежи, на которых:
Фиг. 1 показывает общее представление трехмерного аудиокодера трехмерной аудиосистемы;
Фиг. 2 показывает общее представление трехмерного аудиодекодера трехмерной аудиосистемы;
Фиг. 3 показывает пример для реализации преобразователя форматов, который может реализовываться в трехмерном аудиодекодере по фиг. 2;
Фиг. 4 показывает схематичный вид сверху конфигурации громкоговорителей;
Фиг. 5 показывает схематичный вид сзади другой конфигурации громкоговорителей;
Фиг. 6a и 6b показывают схематичные виды устройства для преобразования первого и второго входных каналов в выходной канал;
Фиг. 7a и 7b показывают схематичные виды устройства для преобразования первого и второго входных каналов в несколько выходных каналов;
Фиг. 8 показывает схематичный вид устройства для преобразования первого и второго канала в один выходной канал;
Фиг. 9 показывает схематичный вид устройства для преобразования первого и второго входных каналов в различные выходные каналы;
Фиг. 10 показывает блок-схему процессора сигналов для преобразования входных каналов из конфигурации входных каналов в выходные каналы из конфигурации выходных каналов;
Фиг. 11 показывает процессор сигналов; и
Фиг. 12 является схемой, показывающей так называемые полосы частот Блоерта.
Перед подробным описанием вариантов осуществления изобретательского подхода, приводится краткое представление системы трехмерных аудиокодеков, в которой может реализовываться изобретательский подход.
Фиг. 1 и 2 показывают алгоритмические блоки трехмерной аудиосистемы в соответствии с вариантами осуществления. Более конкретно, фиг. 1 показывает общее представление трехмерного аудиокодера 100. Аудиокодер 100 принимает в схеме 102 модуля предварительного рендеринга/микшера, которая необязательно может быть предоставлена, входные сигналы, более конкретно множество входных каналов, предоставляющих в аудиокодер 100 множество сигналов 104 каналов, множество сигналов 106 объектов и соответствующих метаданных 108 объектов. Сигналы 106 объектов, обработанные посредством модуля предварительного рендеринга/микшера 102 (см. сигналы 110), может предоставляться в SAOC-кодер 112 (SAOC–пространственное кодирование аудиообъектов). SAOC-кодер 112 формирует транспортные SAOC-каналы 114, предоставленные для входов USAC-кодера 116 (USAC– стандартизированное кодирование речи и аудио). Помимо этого, SAOC-SI 118 сигналов (SAOC-SI – вспомогательная информация SAOC) также предоставляется во входы USAC-кодера 116. USAC-кодер 116 дополнительно принимает сигналы 120 объектов непосредственно из модуля предварительного рендеринга/микшера, а также сигналы каналов и предварительно подготовленные посредством рендеринга сигналы 122 объектов. Информация 108 метаданных объектов применяется к OAM-кодеру 124 (OAM–метаданные объектов), предоставляющему сжатую информацию 126 метаданных объектов в USAC-кодер. USAC-кодер 116, на основе вышеуказанных входных сигналов, формирует сжатый выходной сигнал MP4, как показано на 128.
Фиг. 2 показывает общее представление трехмерного аудиодекодера 200 трехмерной аудиосистемы. Кодированный сигнал 128 (MP4), сформированный посредством аудиокодера 100 по фиг. 1, принимается в аудиодекодере 200, более конкретно в USAC-декодере 202. USAC-декодер 202 декодирует принимаемый сигнал 128 в сигналы 204 каналов, предварительно подготовленные посредством рендеринга сигналы 206 объектов, сигналы 208 объектов и сигналы 210 транспортных SAOC-каналов. Дополнительно, сжатая информация 212 метаданных объектов и SAOC-SI 214 сигналов выводится посредством USAC-декодера. Сигналы 208 объектов предоставляются в модуль 216 рендеринга объектов, выводящий подготовленные посредством рендеринга сигналы 218 объектов. Сигналы 210 транспортных SAOC-каналов предоставляются в SAOC-декодер 220, выводящий подготовленные посредством рендеринга сигналы 222 объектов. Сжатая метаинформация 212 объектов предоставляется в OAM-декодер 224, выводящий соответствующие управляющие сигналы в модуль 216 рендеринга объектов и SAOC-декодер 220 для формирования подготовленных посредством рендеринга сигналов 218 объектов и подготовленных посредством рендеринга сигналов 222 объектов. Декодер дополнительно содержит микшер 226, принимающий, как показано на фиг. 2, входные сигналы 204, 206, 218 и 222 для вывода сигналов 228 каналов. Сигналы каналов могут непосредственно выводиться в громкоговоритель, например, 32-канальный громкоговоритель, как указано на 230. Альтернативно, сигналы 228 могут предоставляться в схему 232 преобразования форматов, принимающую в качестве управляющего ввода сигнал схемы размещения для воспроизведения, указывающий способ, которым должны преобразовываться сигналы 228 каналов. В варианте осуществления, проиллюстрированном на фиг. 2, предполагается, что преобразование должно выполняться таким образом, что сигналы могут предоставляться в акустическую 5.1-систему, как указано на 234. Кроме того, сигналы 228 каналов предоставляются в модуль 236 бинаурального рендеринга, формирующий два выходных сигнала, например, для наушника, как указано на 238.
Система кодирования/декодирования, проиллюстрированная на фиг. 1 и 2, может быть основана на MPEG-D USAC-кодеке для кодирования сигналов каналов и объектов (см. сигналы 104 и 106). Чтобы повышать эффективность для кодирования большого количества объектов, может использоваться MPEG SAOC-технология. Три типа модулей рендеринга могут выполнять задачи рендеринга объектов в каналы, рендеринга каналов в наушники или рендеринга каналов в другую компоновку громкоговорителей (см. фиг. 2, ссылки с номерами 230, 234 и 238). Когда сигналы объектов явно передаются или параметрически кодируются с использованием SAOC, соответствующая информация 108 метаданных объектов сжимается (см. сигнал 126) и мультиплексируется в трехмерный поток 128 аудиобитов.
Фиг. 1 и 2 показывают алгоритмические блоки для полной трехмерной аудиосистемы, которая подробнее описывается ниже.
Модуль 102 предварительного рендеринга/микшер необязательно может быть предоставлен для того, чтобы преобразовывать сцену ввода каналов плюс объектов в сцену каналов перед кодированием. Функционально, он является идентичным модулю рендеринга объектов/микшеру, который подробно описывается ниже. Предварительный рендеринг объектов может требоваться для того, чтобы обеспечивать детерминированную энтропию сигналов на входе кодера, которая по существу является независимой от числа одновременно активных сигналов объектов. При предварительном рендеринге объектов, не требуется передача метаданных объектов. Сигналы дискретных объектов подготовлены посредством рендеринга в схему размещения каналов, которую кодер выполнен с возможностью использовать. Весовые коэффициенты объектов для каждого канала получаются из ассоциированных метаданных объектов (OAM).
USAC-кодер 116 представляет собой базовый кодек для сигналов каналов громкоговорителя, сигналов дискретных объектов, сигналов понижающего микширования объектов и предварительно подготовленных посредством рендеринга сигналов. Он основан на MPEG-D USAC-технологии. Он обрабатывает кодирование вышеуказанных сигналов посредством создания информации преобразования каналов и объектов на основе геометрической и семантической информации назначения входных каналов и объектов. Эта информация преобразования описывает то, как входные каналы и объекты преобразуются в USAC-канальные элементы, такие как элементы канальных пар (CPE), одноканальные элементы (SCE), низкочастотные эффекты (LFE) и элементы канальных четверок (QCE), и CPE, SCE и LFE и соответствующая информация передается в декодер. Все дополнительные SAOC-данные 114, 118 в форме рабочих данных или метаданные 126 объектов рассматриваются при управлении скоростью кодеров. Кодирование объектов является возможным различными способами, в зависимости от требований по искажению в зависимости от скорости передачи и требований по интерактивности для модуля рендеринга. В соответствии с вариантами осуществления, возможны следующие варианты кодирования объектов:
Предварительно подготовленные посредством рендеринга объекты: Сигналы объектов подготавливаются посредством рендеринга и сводятся в 22.2-канальные сигналы перед кодированием. Последующая цепочка кодирования видит 22.2-канальные сигналы.
Формы сигналов дискретных объектов: Объекты предоставляются в качестве монофонических форм сигнала в кодер. Кодер использует одноканальные элементы (SCE), чтобы передавать объекты в дополнение к сигналам каналов. Декодированные объекты подготавливаются посредством рендеринга и сводятся на стороне приемного устройства. Сжатая информация метаданных объектов передается в приемное устройство/модуль рендеринга.
Формы сигналов параметрических объектов: Свойства объектов и их взаимосвязь между собой описываются посредством SAOC-параметров. Понижающее микширование сигналов объектов кодируется с помощью USAC. Параметрическая информация передается совместно. Число каналов понижающего микширования выбирается в зависимости от числа объектов и полной скорости передачи данных. Сжатая информация метаданных объектов передается в модуль SAOC-рендеринга.
SAOC-кодер 112 и SAOC-декодер 220 для сигналов объектов могут быть основаны на MPEG SAOC-технологии. Система допускает повторное создание, модификацию и рендеринг определенного числа аудиообъектов на основе меньшего числа передаваемых каналов и дополнительных параметрических данных, таких как OLD, IOC (межобъектная когерентность), DMG (усиления при понижающем микшировании). Дополнительные параметрические данные демонстрируют значительно более низкую скорость передачи данных, чем требуется для передачи всех объектов по отдельности, что делает кодирование очень эффективным. SAOC-кодер 112 принимает в качестве ввода сигналы объектов/каналов в качестве монофонических форм сигнала и выводит параметрическую информацию (которая пакетирована в трехмерный поток 128 аудиобитов) и транспортные SAOC-каналы (которые кодируются с использованием одноканальных элементов и передаются). SAOC-декодер 220 восстанавливает сигналы объектов/каналов из декодированных транспортных SAOC-каналов 210 и параметрической информации 214 и формирует выходную аудиосцену на основе схемы размещения для воспроизведения, распакованной информации метаданных объектов и необязательно на основе информации пользовательского взаимодействия.
Кодек метаданных объектов (см. OAM-кодер 124 и OAM-декодер 224) предоставляется таким образом, что для каждого объекта, ассоциированные метаданные, которые указывают геометрическую позицию и объем объектов в трехмерном пространстве, эффективно кодируются посредством квантования свойств объектов во времени и пространстве. Сжатые метаданные 126 объектов (cOAM) передаются в приемное устройство 200 в качестве вспомогательной информации.
Модуль 216 рендеринга объектов использует сжатые метаданные объектов для того, чтобы формировать формы сигналов объектов согласно данному формату воспроизведения. Каждый объект подготавливается посредством рендеринга в определенный выходной канал 218 согласно своим метаданным. Вывод этого блока получается в результате суммы частичных результатов. Если декодируются как канальный контент, так и дискретные/параметрические объекты, канальные формы сигналов и подготовленные посредством рендеринга формы сигналов объектов сводятся посредством микшера 226 перед выводом результирующих форм 228 сигналов или перед их подачей в модуль постпроцессора, такой как модуль 236 бинаурального рендеринга или модуль 232 рендеринга громкоговорителей.
Модуль 236 бинаурального рендеринга формирует бинауральное понижающее микширование многоканального аудиоматериала таким образом, что каждый входной канал представлен посредством виртуального источника звука. Обработка осуществляется покадрово в области QMF (гребенки квадратурных зеркальных фильтров), и бинаурализация основана на измеренных бинауральных импульсных характеристиках в помещении.
Модуль 232 рендеринга громкоговорителей преобразует между конфигурацией 228 передаваемых каналов и требуемым форматом воспроизведения. Он также может называться "преобразователем форматов". Преобразователь форматов выполняет преобразования в меньшие числа выходных каналов, т.е. он создает понижающего микширования.
Возможная реализация преобразователя 232 форматов показана на фиг. 3. В вариантах осуществления изобретения, процессор сигналов представляет собой такой преобразователь форматов. Преобразователь 232 форматов, также называемый "модулем рендеринга громкоговорителей", преобразует между конфигурацией каналов передающего устройства и требуемым форматом воспроизведения посредством преобразования (входных) каналов передающего устройства из конфигурации (входных) каналов передающего устройства в (выходные) каналы требуемого формата воспроизведения (конфигурации выходных каналов). Преобразователь 232 форматов, в общем, выполняет преобразования в меньшее число выходных каналов, т.е. он выполняет процесс 240 понижающего микширования (DMX). Понижающий микшер 240, который предпочтительно работает в QMF-области, принимает выходные сигналы 228 микшера и выводит сигналы 234 громкоговорителей. Может предоставляться конфигуратор 242, также называемый "контроллером", который принимает, в качестве управляющего ввода, сигнал 246, указывающий схему размещения выходов микшера (конфигурацию входных каналов), т.е. схему размещения, для которой определяются данные, представленные посредством выходного сигнала 228 микшера, и сигнал 248, указывающий требуемую схему размещения для воспроизведения (конфигурацию выходных каналов). На основе этой информации, контроллер 242, предпочтительно автоматически, формирует матрицы понижающего микширования для данной комбинации форматов ввода и вывода и применяет эти матрицы к понижающему микшеру 240. Преобразователь 232 форматов обеспечивает возможность стандартных конфигураций громкоговорителей, а также случайных конфигураций с нестандартными позициями громкоговорителей.
Варианты осуществления настоящего изобретения относятся к реализации модуля 232 рендеринга громкоговорителей, т.е. к устройствам и способам для реализации части функциональности модуля 232 рендеринга громкоговорителей.
Теперь следует обратиться к фиг. 4 и 5. Фиг. 4 показывает конфигурацию громкоговорителей, представляющую 5.1-формат, содержащий шесть громкоговорителей, представляющих левый канал LC, центральный канал CC, правый канал RC, левый канал LSC объемного звучания, правый канал LRC объемного звучания и канал LFC улучшения низких частот. Фиг. 5 показывает другую конфигурацию громкоговорителей, содержащую громкоговорители, представляющие левый канал LC, центральный канал CC, правый канал RC и приподнятый центральный канал ECC.
Далее, канал улучшения низких частот не рассматривается, поскольку точная позиция громкоговорителя (сабвуфера), ассоциированного с каналом улучшения низких частот, не является важной.
Каналы размещаются в конкретных направлениях относительно центральной позиции P слушателя. Направление каждого канала задается посредством азимутального угла α и угла β подъема, см. фиг. 5. Азимутальный угол представляет угол канала в горизонтальной плоскости 300 слушателя и может представлять направление соответствующего канала относительно переднего центрального направления 302. Как можно видеть на фиг. 4, переднее центральное направление 302 может задаваться как предполагаемое направление просмотра слушателя, расположенного в центральной позиции P слушателя. Заднее центральное направление 304 содержит азимутальный угол 180° относительно переднего центрального направления 300. Все азимутальные углы слева от переднего центрального направления между передним центральным направлением и задним центральным направлением находятся на левой стороне переднего центрального направления, и все азимутальные углы справа от переднего центрального направления между передним центральным направлением и задним центральным направлением находятся на правой стороне переднего центрального направления. Громкоговорители, расположенные перед виртуальной линией 306, которая является ортогональной к переднему центральному направлению 302 и передает центральную позицию P слушателя, являются передними громкоговорителями, и громкоговорители, расположенные позади виртуальной линии 306, являются задними громкоговорителями. В 5.1-формате азимутальный угол α канала LC составляет 30° влево, α CC составляет 0°, α RC составляет 30° вправо, α LSC составляет 110° влево, и α RSC составляет 110° вправо.
Угол β подъема канала задает угол между горизонтальной плоскостью 300 слушателя и направлением виртуальной соединительной линии между центральной позицией слушателя и громкоговорителем, ассоциированным с каналом. В конфигурации, показанной на фиг. 4, все громкоговорители размещаются в горизонтальной плоскости 300 слушателя, и в силу этого все углы подъема являются нулевыми. На фиг. 5, угол β подъема канала ECC может составлять 30°. Громкоговоритель, расположенный строго выше центральной позиции слушателя, должен иметь угол подъема в 90°. Громкоговорители, размещаемые ниже горизонтальной плоскости 300 слушателя, имеют отрицательный угол подъема. На фиг. 5, LC имеет направление x1, CC имеет направление x2, RC имеет направление x3, и ECC имеет направление x4.
Позиция конкретного канала в пространстве, т.е. позиция громкоговорителя, ассоциированная с конкретным каналом, задается посредством азимутального угла, угла подъема и расстояния громкоговорителя от центральной позиции слушателя. Следует отметить, что термин "позиция громкоговорителя" зачастую описывается специалистами в данной области техники посредством ссылки только на азимутальный угол и угол подъема.
Обычно, преобразование формата между различными конфигурациями каналов громкоговорителей выполняется в качестве процесса понижающего микширования, который преобразует определенное число входных каналов в определенное число выходных каналов, при этом число выходных каналов, в общем, меньше числа входных каналов, при этом позиции выходных каналов могут отличаться от позиций входных каналов. Один или более входных каналов могут сводиться вместе в идентичный выходной канал. Одновременно, один или более входных каналов могут быть подготовлены посредством рендеринга более чем для одного выходного канала. Это преобразование из входных каналов в выходной канал типично определяется посредством набора коэффициентов понижающего микширования или альтернативно формулируется в качестве матрицы понижающего микширования. Выбор коэффициентов понижающего микширования значительно влияет на достижимое качество выводимого звука при понижающем микшировании. Плохие варианты выбора могут приводить к несбалансированному сведению или плохому пространственному воспроизведению входной звуковой сцены.
Каждый канал имеет ассоциированный аудиосигнал, который должен воспроизводиться посредством ассоциированного громкоговорителя. Такая идея, что конкретный канал обрабатывается (к примеру, посредством применения коэффициента, посредством применения частотного корректирующего фильтра или посредством применения декорреляционного фильтра), означает то, что обрабатывается соответствующий аудиосигнал, ассоциированный с этим каналом. В контексте данной заявки, термин "частотный корректирующий фильтр" предназначен, чтобы охватывать любое средство для того, чтобы применять частотную коррекцию к сигналу таким образом, что достигается частотно-зависимое взвешивание частей сигнала. Например, частотный корректирующий фильтр может быть выполнен с возможностью применять частотно-зависимые коэффициенты усиления к полосам частот сигнала. В контексте данной заявки, термин "декорреляционный фильтр" предназначен, чтобы охватывать любое средство для того, чтобы применять декорреляцию к сигналу, к примеру, посредством введения частотно-зависимых задержек и/или рандомизированных фаз в сигнал. Например, декорреляционный фильтр может быть выполнен с возможностью применять коэффициенты частотно-зависимой задержки к полосам частот сигнала и/или применять рандомизированные фазовые коэффициенты к сигналу.
В вариантах осуществления изобретения, преобразование входного канала в один или более выходных каналов включает в себя применение, по меньшей мере, одного коэффициента, который должен применяться к входному каналу, для каждого выходного канала, в который преобразуется входной канал. По меньшей мере, один коэффициент может включать в себя коэффициент усиления, т.е. значение усиления, которое должно применяться к входному сигналу, ассоциированному с входным каналом, и/или коэффициент задержки, т.е. значение задержки, которое должно применяться к входному сигналу, ассоциированному с входным каналом. В вариантах осуществления изобретения, преобразование может включать в себя применение частотно-избирательных коэффициентов, т.е. различных коэффициентов для различных полос частот входных каналов. В вариантах осуществления изобретения, преобразование входных каналов в выходные каналы включает в себя формирование одной или более матриц коэффициентов из коэффициентов. Каждая матрица задает коэффициент, который должен применяться к каждому входному каналу из конфигурации входных каналов для каждого выходного канала из конфигурации выходных каналов. Для выходных каналов, в которые не преобразуется входной канал, соответствующий коэффициент в матрице коэффициентов является нулевым. В вариантах осуществления изобретения, могут формироваться отдельные матрицы коэффициентов для коэффициентов усиления и коэффициентов задержки. В вариантах осуществления изобретения, матрица коэффициентов для каждой полосы частот может формироваться в случае, если коэффициенты являются частотно-избирательными. В вариантах осуществления изобретения, преобразование дополнительно может включать в себя применение извлеченных коэффициентов ко входным сигналам, ассоциированным с входными каналами.
Чтобы получать хорошие коэффициенты понижающего микширования, эксперт (например, звукооператор) может вручную настраивать коэффициенты, с учетом своих экспертных знаний. Другая возможность состоит в том, чтобы автоматически извлекать коэффициенты понижающего микширования для данной комбинации входных и выходных конфигураций посредством трактовки каждого входного канала как виртуального источника звука, позиция которого в пространстве задается посредством позиции в пространстве, ассоциированной с конкретным каналом, т.е. позиции громкоговорителя, ассоциированной с конкретным входным каналом. Каждый виртуальный источник может воспроизводиться посредством общего алгоритма панорамирования, такого как панорамирование по теореме тангенсов в двумерном случае или векторное амплитудное панорамирование (VBAP) в трехмерном случае, см работу V. Pulkki: "Virtual Sound Source Positioning Using Vector Base Amplitude Panning", Journal of the Audio Engineering Society, издание 45, стр. 456-466, 1997 год. Другой проект для математического, т.е. автоматического извлечения коэффициентов понижающего микширования для данной комбинации входных и выходных конфигураций приведен в работе автора A. Ando: "Conversion of Multichannel Sound Signal Maintaining Physical Properties of Sound in Reproduced Sound Field", IEEE Transactions on Audio, Speech and Language Processing, издание 19, номер. 6, август 2011 года.
Соответственно, существующие подходы на основе понижающего микширования в основном основаны на трех стратегиях извлечения коэффициентов понижающего микширования. Первая стратегия представляет собой прямое преобразование отброшенных входных каналов в выходные каналы в идентичной или сравнимой азимутальной позиции. Смещения подъема отбрасываются. Например, установившейся практикой является то, чтобы подготавливать посредством рендеринга высотные каналы непосредственно с горизонтальными каналами в идентичной или сравнимой азимутальной позиции, если высотный уровень не присутствует в конфигурации выходных каналов. Вторая стратегия представляет собой использование общих алгоритмов панорамирования, которые трактуют входные каналы как виртуальные источники звука и сохраняют информацию азимута посредством введения фантомных источников в позициях отброшенных входных каналов. Смещения подъема отбрасываются. В способах предшествующего уровня техники, панорамирование используется только в том случае, если отсутствует доступный выходной громкоговоритель в требуемой выходной позиции, например, под требуемым азимутальным углом. Третья стратегия представляет собой внедрение экспертных знаний для извлечения оптимальных коэффициентов понижающего микширования в эмпирическом, художественном или психоакустическом смысле. Может использоваться отдельное или комбинированное применение различных стратегий.
Варианты осуществления изобретения предоставляют техническое решение, позволяющее улучшать или оптимизировать процесс понижающего микширования таким образом, что могут получаться выходные сигналы понижающего микширования более высокого качества, чем без использования этого решения. В вариантах осуществления, решение может повышать качество понижающего микширования в случаях, если пространственное разнесение, внутренне присущее в конфигурации входных каналов, теряется в ходе понижающего микширования без применения предлагаемого решения.
С этой целью, варианты осуществления изобретения обеспечивают возможность сохранения пространственного разнесения, которое является внутренне присущим в конфигурации входных каналов, и которое не сохраняется посредством простого подхода на основе понижающего микширования (DMX). В сценариях понижающего микширования, в которых уменьшается число акустических каналов, варианты осуществления изобретения в основном направлены на уменьшение потерь разнесения и огибания, которые неявно возникают при преобразовании из большего в меньшее число каналов.
Авторы изобретения выяснили, что в зависимости от конкретной конфигурации, внутренне присущее пространственное разнесение и пространственное огибание конфигурации входных каналов зачастую значительно снижается или полностью теряется в конфигурации выходных каналов. Кроме того, если акустические события одновременно воспроизводятся из нескольких динамиков во входной конфигурации, они становятся более когерентными, уплотненными и сфокусированными в выходной конфигурации. Это может приводить к перцепционно более давящему пространственному впечатлению, которое зачастую кажется менее приятным, чем для конфигурации входных каналов. Варианты осуществления изобретения направлены на явное сохранение пространственного разнесения в конфигурации выходных каналов в первый раз. Варианты осуществления изобретения направлены на сохранение воспринимаемого местоположения акустического события максимально близким по сравнению со случаем использования исходной конфигурации громкоговорителей входных каналов.
Соответственно, варианты осуществления изобретения предоставляют конкретный подход преобразования первого входного канала и второго входного канала, которые ассоциированы с различными позициями громкоговорителей конфигурации входных каналов, и, следовательно, содержат пространственное разнесение, по меньшей мере, в один выходной канал. В вариантах осуществления изобретения, первый и второй входные каналы имеют различные подъемы относительно горизонтальной плоскости слушателя. Таким образом, смещения подъема между первым входным каналом и вторым входным каналом могут учитываться, чтобы улучшать воспроизведение звука с использованием громкоговорителей конфигурации выходных каналов.
В контексте данной заявки, разнесение может описываться следующим образом. Различные громкоговорители конфигурации входных каналов приводят к различным акустическим каналам из громкоговорителей в уши, к примеру, в уши слушателя в позиции P. Предусмотрено определенное число прямых акустических трактов и определенное число непрямых акустических трактов, также известных как отражения или реверберация, которые являются следствием различной степени оживленности помещения для прослушивания и которые добавляют дополнительную декорреляцию и изменения тембра в воспринимаемые сигналы из различных позиций громкоговорителей. Акустические каналы могут полностью моделироваться посредством BRIR, которые являются характерными для каждого помещения для прослушивания. Восприятие при прослушивании конфигурации входных каналов строго зависит от характерной комбинации различных входных каналов и разнообразных BRIR, которые соответствуют конкретным позициям громкоговорителей. Таким образом, разнесение и огибание являются результатом различных модификаций сигналов, которые внутренне применяются ко всем сигналам громкоговорителей посредством помещения для прослушивания.
Далее приводится обоснование необходимости подходов на основе понижающего микширования, которые сохраняют пространственное разнесение конфигурации входных каналов. Конфигурация входных каналов может использовать большее число громкоговорителей, чем для конфигурации выходных каналов, либо может использовать, по меньшей мере, один громкоговоритель, не присутствующий в конфигурации выходных громкоговорителей. Просто в качестве иллюстрации, конфигурация входных каналов может использовать громкоговорители LC, CC, RC, ECC, как показано на фиг. 5, в то время как конфигурация выходных каналов может использовать только громкоговорители LC, CC и RC, т.е. не использует громкоговоритель ECC. Таким образом, конфигурация входных каналов может использовать более высокое число уровней воспроизведения, чем конфигурация выходных каналов. Например, конфигурация входных каналов может предоставлять горизонтальные (LC, CC, RC) и высотные (ECC) динамики, тогда как выходная конфигурация может только предоставлять горизонтальные динамики (LC, CC, RC). Таким образом, число акустических каналов из громкоговорителя в уши уменьшается с конфигурацией выходных каналов в ситуациях понижающего микширования. В частности, трехмерные (например, 22.2) в двумерные (например, 5.1) понижающего микширования (DMX) затрагиваются больше всего вследствие отсутствия различных уровней для воспроизведения в конфигурации выходных каналов. Степени свободы, чтобы достигать аналогичного восприятия при прослушивании с конфигурацией выходных каналов относительно разнесения и огибания, уменьшаются, и, следовательно, ограничиваются. Варианты осуществления изобретения предоставляют подходы на основе понижающего микширования, которые улучшают сохранение пространственного разнесения конфигурации входных каналов, при этом описанные устройства и способы не ограничены каким-либо конкретным видом подхода на основе понижающего микширования и могут применяться в различных контекстах и вариантах применения.
Далее описываются варианты осуществления изобретения со ссылкой на конкретный сценарий, показанный на фиг. 5. Тем не менее, описанные проблемы и решения могут быть легко адаптированы к другим сценариям с аналогичными условиями. Без потери общности, допускаются следующие конфигурации входных и выходных каналов:
Конфигурация входных каналов: четыре громкоговорителя LC, CC, RC и ECC в позициях x1=(α1, β1), x2=(α2, β1), x3=(α3, β1) и x4=(α4, β2), где α2≈α4 или α2=α4.
Конфигурация выходных каналов: три громкоговорителя в позиции x1=(α1, β1), x2=(α2, β1) и x3=(α3, β1), т.е. громкоговоритель в позиции x4 отбрасывается в понижающем микшировании; α представляет азимутальный угол, и β представляет угол подъема.
Как пояснено выше, простой DMX-подход должен приоритезировать сохранение направленной информации азимута и просто игнорировать все смещения подъема. Таким образом, сигналы из громкоговорителя ECC в позиции x4 должны просто передаваться в громкоговоритель CC в позиции x2. Тем не менее, при этом теряются характеристики. Во-первых, теряются разности тембра вследствие различных BRIR, которые внутренне применяются в позициях x2 и x4 воспроизведения. Во-вторых, теряется пространственное разнесение входных сигналов, которые воспроизводятся в различных позициях x2 и x4. В-третьих, теряется внутренне присущая декорреляция входных сигналов вследствие различных акустических трактов распространения из позиций x2 и x4 в уши слушателей.
Варианты осуществления изобретения направлены на сохранение или имитацию одной или более описанных характеристик посредством применения стратегий, поясненных в данном документе, отдельно или в комбинации для процесса понижающего микширования.
Фиг. 6a и 6b показывают схематичные виды для пояснения устройства 10 для реализации стратегии, в которой первый входной канал 12 и второй входной канал 14 преобразуются в идентичный выходной канал 16, при этом обработка второго входного канала выполняется посредством применения, по меньшей мере, одного из частотного корректирующего фильтра и декорреляционного фильтра ко второму входному каналу. Эта обработка указывается на фиг. 6a посредством блока 18.
Специалистам в данной области техники должно быть понятным, что устройства, поясненные и описанные в настоящей заявке, могут реализовываться посредством соответствующих компьютеров или процессоров, сконфигурированных и/или запрограммированных с возможностью получать описанную функциональность. Альтернативно, устройства могут реализовываться как другие программируемые аппаратные структуры, к примеру, как программируемые пользователем вентильные матрицы и т.п.
Первый входной канал 12 на фиг. 6a может быть ассоциирован с центральным громкоговорителем CC в направлении x2, и второй входной канал 14 может быть ассоциирован с приподнятым центральным громкоговорителем ECC в позиции x4 (в конфигурации входных каналов, соответственно). Выходной канал 16 может быть ассоциирован с центральным громкоговорителем ECC в позиции x2 (в конфигурации выходных каналов). Фиг. 6b иллюстрирует то, что канал 14, ассоциированный с громкоговорителем в позиции x4, преобразуется в первый выходной канал 16, ассоциированный с громкоговорителем CC в позиции x2, и то, что это преобразование содержит обработку 18 второго входного канала 14, т.е. обработку аудиосигнала, ассоциированного со вторым входным каналом 14. Обработка второго входного канала содержит применение, по меньшей мере, одного из частотного корректирующего фильтра и декорреляционного фильтра ко второму входному каналу, чтобы сохранять различные характеристики между первым и вторым входными каналами в конфигурации входных каналов. В вариантах осуществления, частотный корректирующий фильтр и/или декорреляционный фильтр могут быть выполнены с возможностью сохранять характеристики относительно разностей тембра вследствие различных BRIR, которые внутренне применяются в различных позициях x2 и x4 громкоговорителей, ассоциированных с первым и вторым входными каналами. В вариантах осуществления изобретения, частотный корректирующий фильтр и/или декорреляционный фильтр выполнены с возможностью сохранять пространственное разнесение входных сигналов, которые воспроизводятся в различных позициях, так что пространственное разнесение первого и второго входного канала остается воспринимаемым несмотря на тот факт, что первый и второй входные каналы преобразуются в идентичный выходной канал.
В вариантах осуществления изобретения, декорреляционный фильтр выполнен с возможностью сохранять внутренне присущую декорреляцию входных сигналов вследствие различных акустических трактов распространения из различных позиций громкоговорителей, ассоциированных с первым и вторым входными каналами с ушами слушателя.
В варианте осуществления изобретения, частотный корректирующий фильтр применяется ко второму входному каналу, т.е. к аудиосигналу, ассоциированному со вторым входным каналом в позиции x4, если он микширован с понижением в громкоговоритель CC в позиции x2. Частотный корректирующий фильтр компенсирует изменения тембра различных акустических каналов и может извлекаться на основе эмпирических экспертных знаний и/или измеренных BRIR-данных и т.п. Например, предполагается, что конфигурация входных каналов предоставляет канал гласа Божьего (VoG) при подъеме в 90°. Если конфигурация выходных каналов предоставляет только громкоговорители на одном уровне, и VoG-канал отбрасывается, как, например, в выходной 5.1-конфигурации, очень простой подход заключается в том, чтобы распределять VoG-канал во все выходные громкоговорители, чтобы сохранять направленную информацию VoG-канала, по меньшей мере, в зоне наилучшего восприятия. Тем не менее, исходный VoG-громкоговоритель воспринимается достаточно по-разному вследствие различной BRIR. Посредством применения выделенного частотного корректирующего фильтра к VoG-каналу перед распределением во все выходные громкоговорители может компенсироваться разность тембра.
В вариантах осуществления изобретения, частотный корректирующий фильтр может быть выполнен с возможностью осуществлять частотно-зависимое взвешивание соответствующего входного канала, чтобы учитывать психоакустические выявленные сведения относительно направленного восприятия аудиосигналов. Примером таких выявленных сведений являются так называемые полосы частот Блоерта, представляющие полосы частот определения направления. Фиг. 12 показывает три графика 20, 22 и 24, представляющие вероятность того, что распознается конкретное направление аудиосигналов. Как видно из графика 20, аудиосигналы сверху могут распознаваться с высокой вероятностью в полосе 1200 частот между 7 кГц и 10 кГц или. Как видно из графика 22, аудиосигналы сзади могут распознаваться с высокой вероятностью в полосе 1202 частот приблизительно от 0,7 кГц приблизительно до 2 кГц и в полосе 1204 частот приблизительно от 10 кГц приблизительно до 12,5 кГц. Как видно из графика 24, аудиосигналы спереди могут распознаваться с высокой вероятностью в полосе 1206 частот приблизительно от 0,3 кГц до 0,6 кГц и в полосе 1208 частот приблизительно от 2,5 приблизительно до 5,5 кГц.
В вариантах осуществления изобретения, частотный корректирующий фильтр сконфигурирован с использованием этого распознавания. Другими словами, частотный корректирующий фильтр может быть выполнен с возможностью применять более высокие коэффициенты усиления (повышение) к полосам частот, которые, как известно, создают у пользователя впечатление, что звук исходит из конкретных направлений, по сравнению с другими полосами частот. Более конкретно, в случае если входной канал преобразуется в нижний выходной канал, спектральная часть входного канала в диапазоне полосы 1200 частот между 7 кГц и 10 кГц может быть повышена, по сравнению с другими спектральными частями вторых входных каналов, так что у слушателя может складываться впечатление, что соответствующий сигнал возникает из приподнятой позиции. Аналогично, частотный корректирующий фильтр может быть выполнен с возможностью повышать другие спектральные части второго входного канала, как показано на фиг. 12. Например, в случае если входной канал преобразуется в выходной канал, размещаемый в более выдвинутой вперед позиции, полосы 1206 и 1208 частот могут быть повышены, а в случае, если входной канал преобразуется в выходной канал, размещаемый в находящейся дальше сзади позиции, полосы 1202 и 1204 частот могут быть повышены.
В вариантах осуществления изобретения, устройство выполнено с возможностью применять декорреляционный фильтр ко второму входному каналу. Например, декорреляционный/реверберационный фильтр может применяться к входному сигналу, ассоциированному со вторым входным каналом (ассоциированному с громкоговорителем в позиции x4), если он микширован с понижением в громкоговоритель в позиции x2. Такой декорреляционный/реверберационный фильтр может извлекаться из BRIR-измерений или эмпирических знаний относительно акустики помещений и т.п. Если входной канал преобразуется в несколько выходных каналов, сигнал фильтра может воспроизводиться по нескольким громкоговорителям, причем для каждого громкоговорителя могут применяться различные фильтры. Фильтр(ы) также может моделировать только ранние отражения.
Фиг. 8 показывает схематичный вид устройства 30, содержащего фильтр 32, который может представлять частотный корректирующий фильтр или декорреляционный фильтр. Устройство 30 принимает определенное число входных каналов 34 и выводит определенное число выходных каналов 36. Входные каналы 34 представляют конфигурацию входных каналов, и выходные каналы 36 представляют конфигурацию выходных каналов. Как показано на фиг. 8, третий входной канал 38 непосредственно преобразуется во второй выходной канал 42, и четвертый входной канал 40 непосредственно преобразуется в третий выходной канал 44. Третий входной канал 38 может представлять собой левый канал, ассоциированный с левым громкоговорителем LC. Четвертый входной канал 40 может представлять собой правый входной канал, ассоциированный с правым громкоговорителем RC. Второй выходной канал 42 может представлять собой левый канал, ассоциированный с левым громкоговорителем LC, и третий выходной канал 44 может представлять собой правый канал, ассоциированный с правым громкоговорителем RC. Первый входной канал 12 может представлять собой центральный горизонтальный канал, ассоциированный с центральным громкоговорителем CC, и второй входной канал 14 может представлять собой высотный центральный канал, ассоциированный с приподнятым центральным громкоговорителем ECC. Фильтр 32 применяется ко второму входному каналу 14, т.е. к высотному центральному каналу. Фильтр 32 может представлять собой декорреляционный или реверберационный фильтр. После фильтрации второй входной канал маршрутизируется в горизонтальный центральный громкоговоритель, т.е. в первый выходной канал 16, ассоциированный с громкоговорителем CC в позиции x2. Таким образом, оба входных канала 12 и 14 преобразуются в первый выходной канал 16, как указано посредством блока 46 на фиг. 8. В вариантах осуществления изобретения, первый входной канал 12 и обработанная версия второго входного канала 14 могут добавляться в блоке 46 и предоставляться в громкоговоритель, ассоциированный с выходным каналом 16, т.е. в центральный горизонтальный громкоговоритель CC в описанном варианте осуществления.
В вариантах осуществления изобретения, фильтр 32 может представлять собой декорреляционный или реверберационный фильтр, чтобы моделировать дополнительный эффект помещения, воспринимаемый, когда присутствуют два отдельных акустических канала. Декорреляция может обладать дополнительным преимуществом в том, что артефакты подавления DMX могут уменьшаться посредством этого уведомления. В вариантах осуществления изобретения, фильтр 32 может представлять собой частотный корректирующий фильтр и может быть выполнен с возможностью осуществлять частотную коррекцию тембра. В других вариантах осуществления изобретения, декорреляционный фильтр и реверберационный фильтр могут применяться для того, чтобы применять частотную коррекцию и декорреляцию тембра перед понижающим микшированием сигнала приподнятого громкоговорителя. В вариантах осуществления изобретения, фильтр 32 может быть выполнен с возможностью комбинировать обе функциональности, т.е. частотную коррекцию и декорреляцию тембра.
В вариантах осуществления изобретения, декорреляционный фильтр может реализовываться как реверберационный фильтр, вводящий реверберации во второй входной канал. В вариантах осуществления изобретений, декорреляционный фильтр может быть выполнен с возможностью свертывать второй входной канал с экспоненциально затухающей шумовой последовательностью. В вариантах осуществления изобретения, может использоваться любой декорреляционный фильтр, который декоррелирует второй входной канал, чтобы сохранять впечатление для слушателя в том, что сигнал из первого входного канала и второго входного канала возникает из громкоговорителей в различных позициях.
Фиг. 7a показывает схематичный вид устройства 50 согласно другому варианту осуществления. Устройство 50 выполнено с возможностью принимать первый входной канал 12 и второй входной канал 14. Устройство 50 выполнено с возможностью преобразовывать первый входной канал 12 непосредственно в первый выходной канал 16. Устройство 50 дополнительно выполнено с возможностью формировать фантомный источник посредством панорамирования между вторым и третьим выходными каналами, которые могут представлять собой второй выходной канал 42 и третий выходной канал 44. Это указывается на фиг. 7a посредством блока 52. Таким образом, формируется фантомный источник, имеющий азимутальный угол, соответствующий азимутальному углу второго входного канала.
При рассмотрении обстановки на фиг. 5, первый входной канал 12 может быть ассоциирован с горизонтальным центральным громкоговорителем CC, второй входной канал 14 может быть ассоциирован с приподнятым центральным громкоговорителем ECC, первый выходной канал 16 может быть ассоциирован с центральным громкоговорителем CC, второй выходной канал 42 может быть ассоциирован с левым громкоговорителем LC, и третий выходной канал 44 может быть ассоциирован с правым громкоговорителем RC. Таким образом, в варианте осуществления, показанном на фиг. 7a, фантомный источник размещен в позиции x2 посредством панорамирования громкоговорителей в позициях x1 и x3 вместо прямого применения соответствующего сигнала в громкоговоритель в позиции x2. Таким образом, панорамирование между громкоговорителями в позициях x1 и x3 выполняется несмотря на тот факт, что имеется другой громкоговоритель в позиции x2, которая ближе к позиции x4, чем позиции x1 и x3. Другими словами, панорамирование между громкоговорителями в позициях x1 и x3 выполняется несмотря на тот факт, что отклонения Δα азимутальных углов между соответствующими каналами 42, 44 и каналом 14 превышают отклонение азимутальных углов между каналами 14 и 16, которое составляет 0°, см. фиг. 7b. За счет этого, пространственное разнесение, введенное посредством громкоговорителей в позициях x2 и x4, сохраняется посредством использования дискретного громкоговорителя в позиции x2 для сигнала, первоначально назначаемого соответствующему входному каналу и фантомному источнику в идентичной позиции. Сигнал фантомного источника соответствует сигналу громкоговорителя в позиции x4 исходной конфигурации входных каналов.
Фиг. 7b схематично показывает преобразование входного канала, ассоциированного с громкоговорителем в позиции x4, посредством панорамирования 52 между громкоговорителем в позициях x1 и x3.
В вариантах осуществления, описанных относительно фиг. 7a и 7b, предполагается, что конфигурация входных каналов предоставляет высотный и горизонтальный уровень, включающие в себя высотный центральный громкоговоритель и горизонтальный центральный громкоговоритель. Кроме того, предполагается, что конфигурация выходных каналов предоставляет только горизонтальный уровень, включающий в себя горизонтальный центральный громкоговоритель и левый и правый горизонтальные громкоговорители, которые могут реализовывать фантомный источник в позиции горизонтального центрального громкоговорителя. Как поясняется, в общем простом подходе, высотный центральный входной канал должен воспроизводиться с помощью горизонтального центрального выходного громкоговорителя. Вместо этого, согласно описанному варианту осуществления изобретения, высотный центральный входной канал намеренно панорамируется между горизонтальными левым и правым выходными громкоговорителями. Таким образом, пространственное разнесение высотного центрального громкоговорителя и горизонтального центрального громкоговорителя конфигурации входных каналов сохраняется посредством использования горизонтального центрального громкоговорителя и фантомного источника, обеспечиваемого сигналами посредством высотного центрального входного канала.
В вариантах осуществления изобретения, в дополнение к панорамированию, частотный корректирующий фильтр может применяться для того, чтобы компенсировать возможные изменения тембра вследствие различных BRIR.
На фиг. 9 показан вариант осуществления устройства 60, реализующего подход на основе панорамирования. На фиг. 9, входные каналы и выходные каналы соответствуют входным каналам и выходному каналу, показанным на фиг. 8, и их повторное описание опускается. Устройство 60 выполнено с возможностью формировать фантомный источник посредством панорамирования между вторым и третьим выходными каналами 42 и 44, как показано на фиг. 9 посредством блоков 62.
В вариантах осуществления изобретения, панорамирование может достигаться с использованием стандартных алгоритмов панорамирования, к примеру, общих алгоритмов панорамирования, таких как панорамирование по теореме тангенсов в двумерном случае или векторное амплитудное панорамирование в трехмерном случае, см работу V. Pulkki: "Virtual Sound Source Positioning Using Vector Base Amplitude Panning", Journal of the Audio Engineering Society, издание 45, стр. 456-466, 1997 год, и не должны подробнее описываться в данном документе. Панорамирующие усиления применяемой теоремы для панорамирования определяют усиления, которые применяются при преобразовании входных каналов в выходные каналы. Соответствующие получаемые сигналы добавляются во второй и третий выходные каналы 42 и 44, см. блоки 64 сумматора на фиг. 9. Таким образом, второй входной канал 14 преобразуется во второй и третий выходные каналы 42 и 44 посредством панорамирования, чтобы формировать фантомный источник в позиции x2, первый входной канал 12 непосредственно преобразуется в первый выходной канал 16, и третий и четвертый входные каналы 38 и 40 также преобразуются непосредственно во второй и третий выходные каналы 42 и 44.
В альтернативных вариантах осуществления, блок 62 может модифицироваться, чтобы дополнительно предоставлять функциональность частотного корректирующего фильтра в дополнение к функциональности панорамирования. Таким образом, возможные изменения тембра вследствие различных BRIR могут компенсироваться в дополнение к сохранению пространственного разнесения посредством подхода на основе панорамирования.
Фиг. 10 показывает систему для формирования DMX-матрицы, в которой может быть осуществлено настоящее изобретение. Система содержит наборы правил, описывающие потенциальные преобразования входных-выходных каналов, блок 400 и модуль 402 выбора, который выбирает наиболее подходящие правила для данной комбинации конфигурации 404 входных каналов и комбинации 406 конфигурации выходных каналов на основе наборов 400 правил. Система может содержать надлежащий интерфейс, чтобы принимать информацию относительно конфигурации 404 входных каналов и конфигурации 406 выходных каналов. Конфигурация входных каналов задает каналы, присутствующие во входной компоновке, при этом каждый входной канал имеет ассоциированное направление или позицию. Конфигурация выходных каналов задает каналы, присутствующие в выходной компоновке, при этом каждый выходной канал имеет ассоциированное направление или позицию. Модуль 402 выбора предоставляет выбранные правила 408 в модуль 410 оценки. Модуль 410 оценки принимает выбранные правила 408 и оценивает выбранные правила 408, чтобы извлекать DMX-коэффициенты 412 на основе выбранных правил 408. DMX-матрица 414 может формироваться из извлеченных коэффициентов понижающего микширования. Модуль 410 оценки может быть выполнен с возможностью извлекать матрицу понижающего микширования из коэффициентов понижающего микширования. Модуль 410 оценки может принимать информацию относительно конфигурации входных каналов и конфигурации выходных каналов, к примеру, информацию относительно геометрии выходной компоновки (например, позиций каналов) и информацию относительно геометрии входной компоновки (например, позиций каналов) и учитывать информацию при извлечении DMX-коэффициентов. Как показано на фиг. 11, система может реализовываться в процессоре 420 сигналов, содержащем процессор 422, запрограммированный или выполненный с возможностью выступать в качестве модуля 402 выбора и модуля 410 оценки, и запоминающее устройство 424, выполненное с возможностью сохранять, по меньшей мере, часть наборов 400 правил преобразования. Другая часть правил преобразования может проверяться посредством процессора без осуществления доступа к правилам, сохраненным в запоминающем устройстве 422. В любом случае, правила предоставляются в процессор, чтобы осуществлять описанные способы. Процессор сигналов может включать в себя входной интерфейс 426 для приема входных сигналов 228, ассоциированных с входными каналами, и выходной интерфейс 428 для вывода выходных сигналов 234, ассоциированных с выходными каналами.
Некоторые правила 400 могут быть спроектированы таким образом, что процессор 420 сигналов реализует вариант осуществления изобретения. Примерные правила для преобразования входного канала в один или более выходных каналов приведены в таблице 1.
Правила преобразования
Метки, используемые в таблице 1 для соответствующих каналов, должны быть интерпретированы следующим образом. Символы "CH" означают "канал". Символ "M" означает "горизонтальную плоскость слушателя", т.е. угол подъема в 0°. Она представляет собой плоскость, в которой громкоговорители расположены в нормальной двумерной компоновке, к примеру, в стерео- или 5.1. Символ "L" означает более низкую плоскость, т.е. угол подъема <0°. Символ "U" означает более высокую плоскость, т.е. угол подъема >0°, к примеру, в 30°, в качестве верхнего громкоговорителя в трехмерной компоновке. Символ "T" означает верхний канал, т.е. угол подъема в 90°, который также известен как канал "гласа Божьего". После одной из меток M/L/U/ находится метка для левого (L) или правого (R), после которой следует азимутальный угол. Например, CH_M_L030 и CH_M_R030 представляют левый и правый канал традиционной стереокомпоновки. Азимутальный угол и угол подъема для каждого канала указываются в таблице 1, за исключением LFE-каналов и последнего пустого канала.
Таблица 1 показывает матрицу правил, в которой одно или более правил ассоциированы с каждым входным каналом (исходным каналом). Как можно видеть из таблицы 1, каждое правило задает один или более выходных каналов (целевых каналов), в которые должен преобразовываться входной канал. Помимо этого, каждое правило задает значение G усиления в третьем столбце. Каждое правило дополнительно задает EQ-индекс, указывающий то, должен ли применяться частотный корректирующий фильтр, и если да, то какой конкретный частотный корректирующий фильтр (EQ-индекс 1-4) должен применяться. Преобразование входного канала в один выходной канал выполняется с усилением G, приведенным в столбце 3 таблицы 1. Преобразование входного канала в два выходных канала (указываемых во втором столбце) выполняется посредством применения панорамирования между двумя выходными каналами, при этом панорамирующие усиления g1 и g2, получающиеся в результате применения теоремы для панорамирования, дополнительно умножаются на усиление, заданное по соответствующему правилу (столбец три в таблице 1). Специальные правила применяются для верхнего канала. Согласно первому правилу, верхний канал преобразуется во все выходные каналы верхней плоскости, указываемые посредством ALL_U, и согласно второму (менее приоритезированному) правилу, верхний канал преобразуется во все выходные каналы горизонтальной плоскости слушателя, указываемые посредством ALL_M.
При рассмотрении правил, указываемых в таблице 1, правила, задающие преобразование канала CH_U_000 в левый и правый каналы, представляют реализацию варианта осуществления изобретения. Помимо этого, правила, задающие то, что должна применяться частотная коррекция, представляют реализации вариантов осуществления изобретения.
Как можно видеть из таблицы 1, один из частотных корректирующих фильтров 1-4 применяется, если приподнятый входной канал преобразуется в один или более нижних каналов. Значения GEQ усиления частотного корректора могут определяться следующим образом на основе нормализованных центральных частот, приведенных в таблице 2, и на основе параметров, приведенных в таблице 3.
Нормализованные центральные частоты 77 полос частот гребенки фильтров
Параметры частотного корректора
GEQ состоит из значений усиления в расчете на полосу k частот и индекс e частотного корректора. Пять предварительно заданных частотных корректоров являются комбинациями различных пиковых фильтров. Как можно видеть из таблицы 3, частотные корректоры GEQ,1, GEQ,2 и GEQ,5 включают в себя один пиковый фильтр, частотный корректор GEQ,3 включает в себя три пиковых фильтра, и частотный корректор GEQ,4 включает в себя два пиковых фильтра. Каждый частотный корректор представляет собой последовательный каскад одного или более пиковых фильтров и усиления:
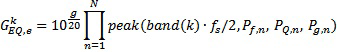 ,
,
где band(k) является нормализованной центральной частотой полосы j частот, указываемой в таблице 2, fs является частотой дискретизации, и функция peak() предназначена для отрицательного G:
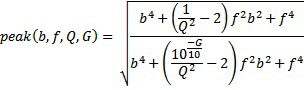
уравнение 1
и в противном случае:
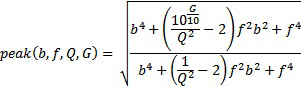
уравнение 2
Параметры для частотных корректоров указываются в таблице 3. В вышеприведенных уравнениях 1 и 2, b задается посредством band(k)*fs/2, Q задается посредством PQ для соответствующего пикового фильтра (1-n), G задается посредством Pg для соответствующего пикового фильтра, и f задается посредством Pf для соответствующего пикового фильтра.
В качестве примера, значения GEQ,4 усиления частотного корректора для частотного корректора, имеющего индекс 4, вычисляются с помощью параметров фильтрации, извлеченных из соответствующей строки таблицы 3. Таблица 3 перечисляет два набора параметров для пиковых фильтров для GEQ,4, т.е. наборы параметров для n=1 и n=2. Параметры являются пиковой частотой Pf в Гц, коэффициентом PQ качества пикового фильтра, усилением Pg (в дБ), которое применяется на пиковой частоте, и общим усилением g в дБ, которое применяется к каскаду из двух пиковых фильтров (каскаду фильтров для параметров n=1 и n=2).
Таким образом:
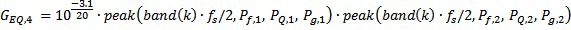
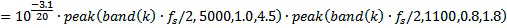
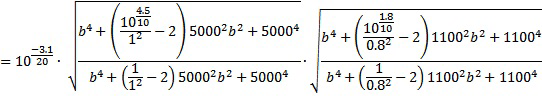
Определение частотного корректора, как указано выше, задает нуль-фазовые усиления GEQ,4 независимо для каждой полосы k частот. Каждая полоса k частот указывается посредством своей нормализованной центральной частоты band(k), где 0<=band<=1. Следует отметить, что нормализованная частота band=1 соответствует ненормализованной частоте fs/2, где fs обозначает частоту дискретизации. Следовательно, 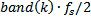 обозначает ненормализованную центральную частоту полосы k частот в Гц.
обозначает ненормализованную центральную частоту полосы k частот в Гц.
Таким образом, описан другой частотный корректирующий фильтр, который может использоваться в вариантах осуществления изобретения. Тем не менее, очевидно, что описание этих частотных корректирующих фильтров служит в качестве иллюстрации, и что другие частотные корректирующие фильтры или декорреляционные фильтры могут использоваться в других вариантах осуществления.
Таблица 4 показывает примерные каналы, имеющие ассоциированные соответствующий азимутальный угол и угол подъема.
Каналы с соответствующими азимутальными углами и углами подъема
В вариантах осуществления изобретения, панорамирование между двумя целевыми каналами может достигаться посредством применения амплитудного панорамирования по теореме тангенсов. При панорамировании исходного канала в первый и второй целевой канал, коэффициент G1 усиления вычисляется для первого целевого канала, и коэффициент G2 усиления вычисляется для второго целевого канала:
G1=(значение столбца усиления в таблице 4)*g1, и
G2=(значение столбца усиления таблицы 4)*g2.
Усиления g1 и g2 вычисляются посредством применения амплитудного панорамирования по теореме тангенсов следующим образом:
- разворачивание азимутальных углов исходных и целевых каналов таким образом, что они являются положительными,
- азимутальные углы целевых каналов составляют α1 и α2 (см. таблицу 4),
- азимутальный угол исходного канала (цель панорамирования) составляет αsrc.
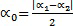
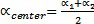
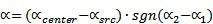
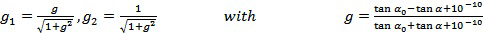
В других вариантах осуществления, могут применяться другие теоремы для панорамирования.
В принципе, варианты осуществления изобретения направлены на моделирование более высокого числа акустических каналов в конфигурации входных каналов посредством измененных преобразований канала и модификаций сигналов в конфигурации выходных каналов. По сравнению с простыми подходами, которые зачастую представляются как пространственно более давящие, менее разнообразные и менее огибающие, чем для конфигурации входных каналов, пространственное разнесение и общее восприятие при прослушивании могут улучшаться и быть более приятными посредством использования вариантов осуществления изобретения.
Другими словами, в вариантах осуществления изобретения, два или более входных канала сводятся вместе в варианте применения для понижающего микширования, при этом процессор применяется к одному из входных сигналов, чтобы сохранять различные характеристики различных трактов передачи из исходных входных каналов в уши слушателя. В вариантах осуществления изобретения, процессор может заключать в себе фильтры, которые модифицируют характеристики сигналов, например, частотные корректирующие фильтры или декорреляционные фильтры. Частотные корректирующие фильтры, в частности, могут компенсировать потери различных тембров входных каналов с различным подъемом, назначаемым им. В вариантах осуществления изобретения, процессор может маршрутизировать, по меньшей мере, один из входных сигналов в несколько выходных громкоговорителей, чтобы формировать различный тракт передачи для слушателя, за счет этого сохраняя пространственное разнесение входных каналов. В вариантах осуществления изобретения, модификации фильтрации и маршрутизации могут применяться отдельно или в комбинации. В вариантах осуществления изобретения, вывод процессора может воспроизводиться в одном или нескольких громкоговорителей.
Хотя некоторые аспекты описаны в контексте устройства, очевидно, что эти аспекты также представляют описание соответствующего способа, при этом блок или устройство соответствует этапу способа либо признаку этапа способа. Аналогично, аспекты, описанные в контексте этапа способа, также представляют описание соответствующего блока или элемента, или признака соответствующего устройства. Некоторые или все этапы способа могут быть выполнены посредством (или с использованием) устройства, такого как, например, микропроцессор, программируемый компьютер либо электронная схема. В некоторых вариантах осуществления, некоторые из одного или более самых важных этапов способа могут выполняться посредством этого устройства. В вариантах осуществления изобретения, способы, описанные в данном документе, являются процессорно-реализованными или компьютерно-реализованными.
В зависимости от конкретных требований к реализации, варианты осуществления изобретения могут быть реализованы в аппаратных средствах или в программном обеспечении. Реализация может выполняться с использованием некратковременного носителя хранения данных, такого как цифровой носитель хранения данных, например, гибкий диск, DVD, Blu-Ray, CD, ROM, PROM, EPROM, EEPROM или флэш-память, имеющего сохраненные электронно-читаемые управляющие сигналы, которые взаимодействуют (или допускают взаимодействие) с программируемой компьютерной системой таким образом, что осуществляется соответствующий способ. Следовательно, цифровой носитель хранения данных может быть компьютерно-читаемым.
Некоторые варианты осуществления согласно изобретению содержат носитель данных, имеющий электронно-читаемые управляющие сигналы, которые допускают взаимодействие с программируемой компьютерной системой таким образом, что осуществляется один из способов, описанных в данном документе.
В общем, варианты осуществления настоящего изобретения могут быть реализованы как компьютерный программный продукт с программным кодом, при этом программный код выполнен с возможностью осуществления одного из способов, когда компьютерный программный продукт исполняется на компьютере. Программный код, например, может быть сохранен на компьютерно-читаемом носителе.
Другие варианты осуществления содержат компьютерную программу для осуществления одного из способов, описанных в данном документе, сохраненную на компьютерно-читаемом носителе.
Другими словами, следовательно, вариант осуществления изобретательского способа представляет собой компьютерную программу, имеющую программный код для осуществления одного из способов, описанных в данном документе, когда компьютерная программа исполняется на компьютере.
Следовательно, дополнительный вариант осуществления изобретательского способа представляет собой носитель хранения данных (цифровой носитель хранения данных или компьютерно-читаемый носитель), содержащий записанную компьютерную программу для осуществления одного из способов, описанных в данном документе. Носитель данных, цифровой носитель хранения данных или носитель с записанными данными типично является материальным и/или некратковременным.
Следовательно, дополнительный вариант осуществления изобретательского способа представляет собой поток данных или последовательность сигналов, представляющих компьютерную программу для осуществления одного из способов, описанных в данном документе. Поток данных или последовательность сигналов, например, может быть выполнена с возможностью передачи через соединение для передачи данных, например, через Интернет.
Дополнительный вариант осуществления содержит средство обработки, например, компьютер или программируемое логическое устройство, запрограммированное, сконфигурированное или выполненное с возможностью осуществлять один из способов, описанных в данном документе.
Дополнительный вариант осуществления содержит компьютер, имеющий установленную компьютерную программу для осуществления одного из способов, описанных в данном документе.
Дополнительный вариант осуществления согласно изобретению содержит устройство или систему, выполненную с возможностью передавать (например, электронно или оптически) компьютерную программу для осуществления одного из способов, описанных в данном документе, в приемное устройство. Приемное устройство, например, может представлять собой компьютер, мобильное устройство, запоминающее устройство и т.п. Устройство или система, например, может содержать файловый сервер для передачи компьютерной программы в приемное устройство.
В некоторых вариантах осуществления, программируемое логическое устройство (например, программируемая пользователем вентильная матрица) может быть использовано для того, чтобы выполнять часть или все из функциональностей способов, описанных в данном документе. В некоторых вариантах осуществления, программируемая пользователем вентильная матрица может взаимодействовать с микропроцессором, чтобы осуществлять один из способов, описанных в данном документе. В общем, способы предпочтительно осуществляются посредством любого устройства.
Вышеописанные варианты осуществления являются просто иллюстративными в отношении принципов настоящего изобретения. Следует понимать, что модификации и изменения компоновок и подробностей, описанных в данном документе, должны быть очевидными для специалистов в данной области техники. Следовательно, они подразумеваются как ограниченные только посредством объема нижеприведенной формулы изобретения, а не посредством конкретных подробностей, представленных посредством описания и пояснения вариантов осуществления в данном документе.
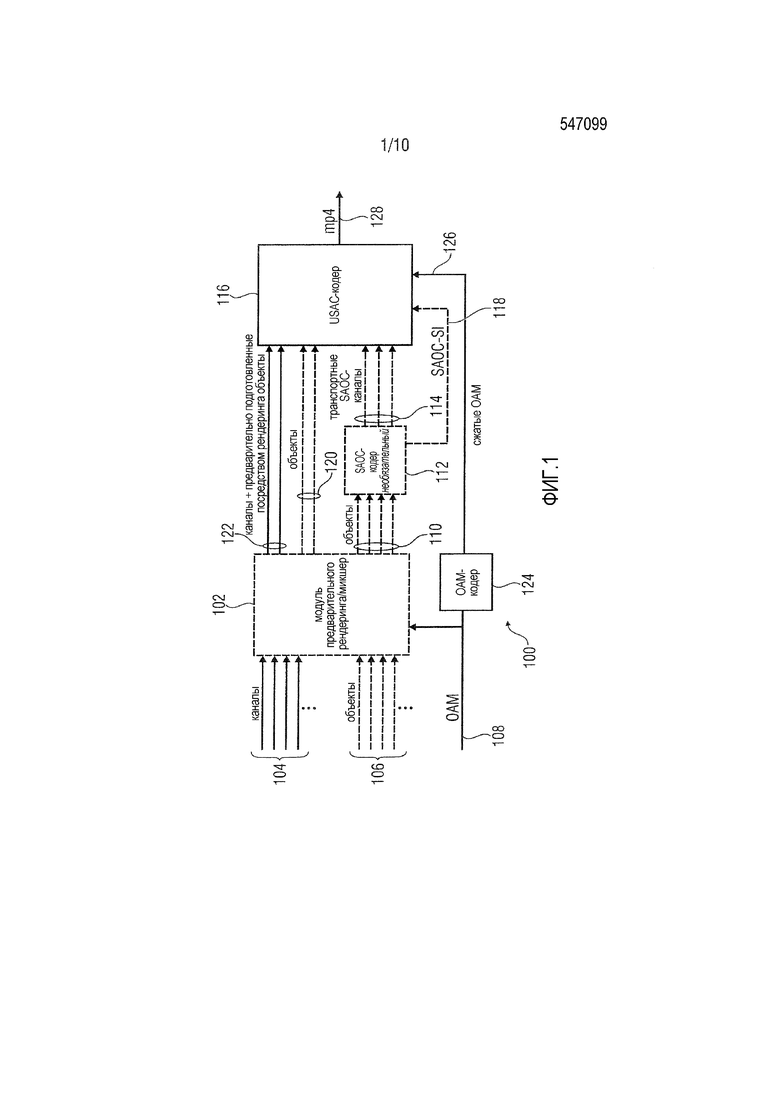
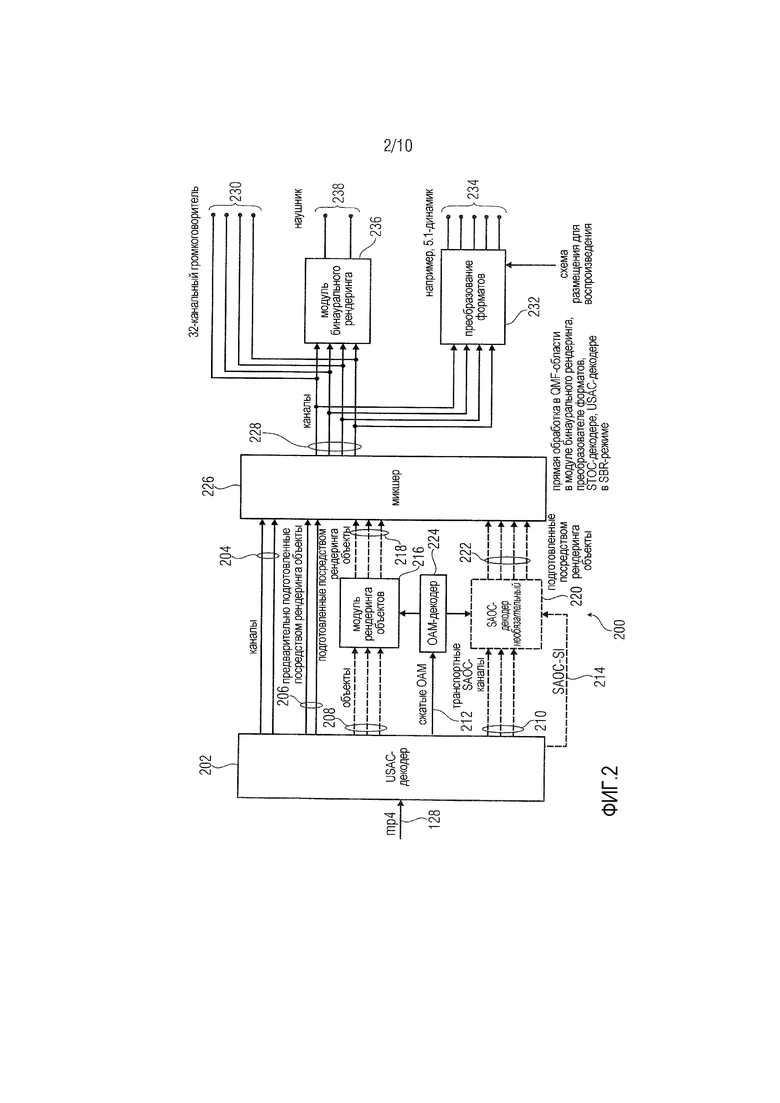
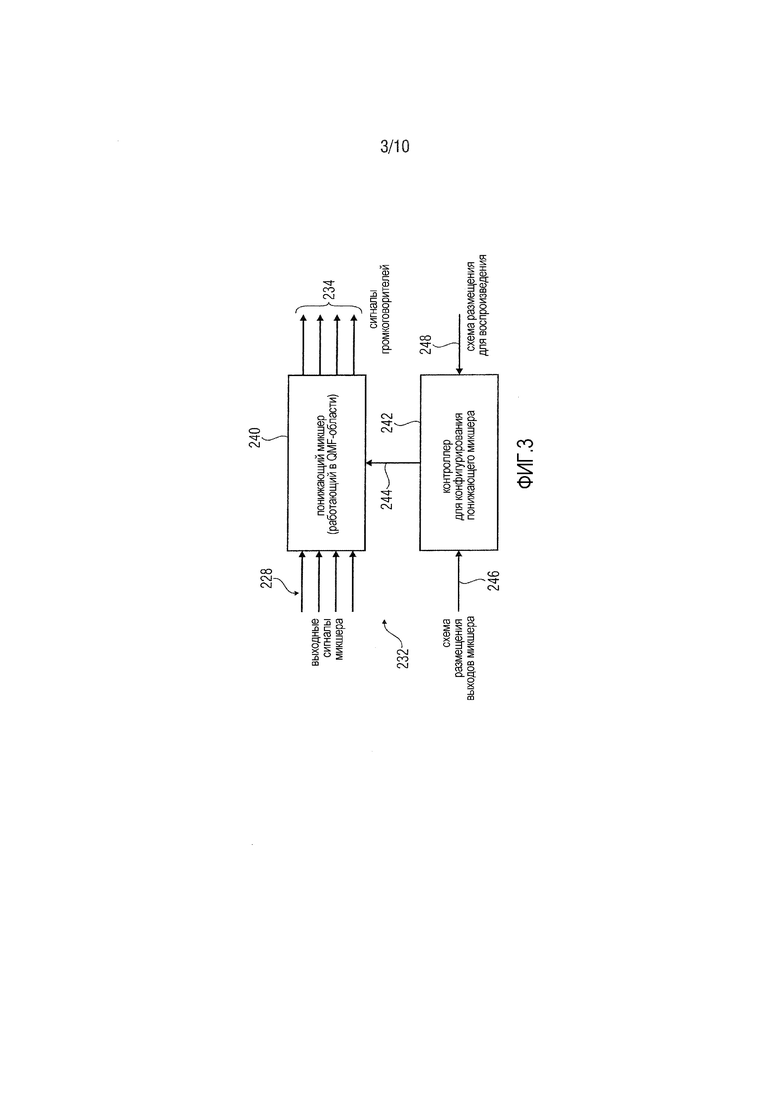
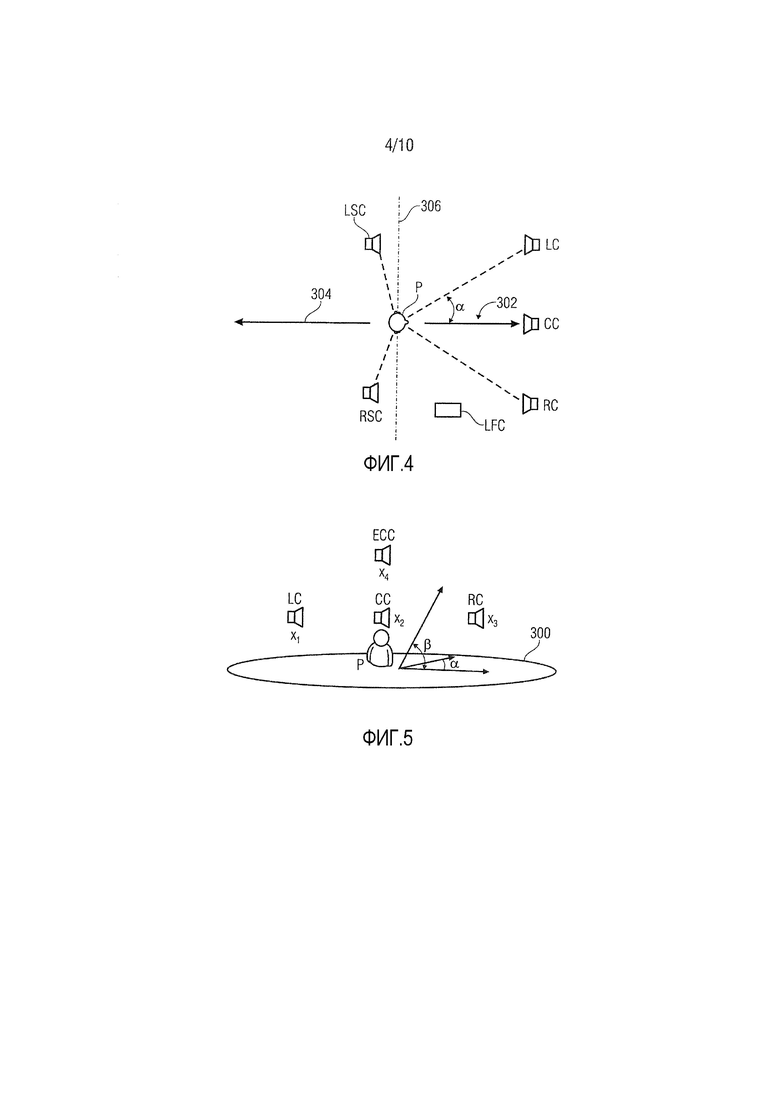
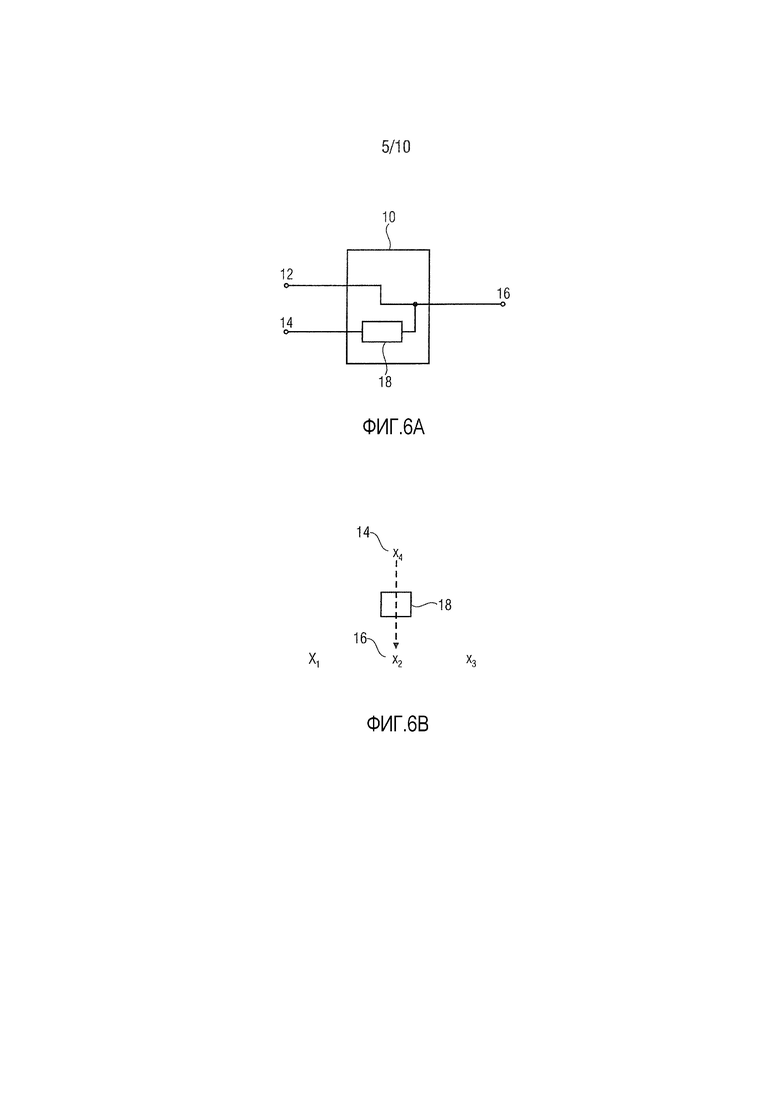
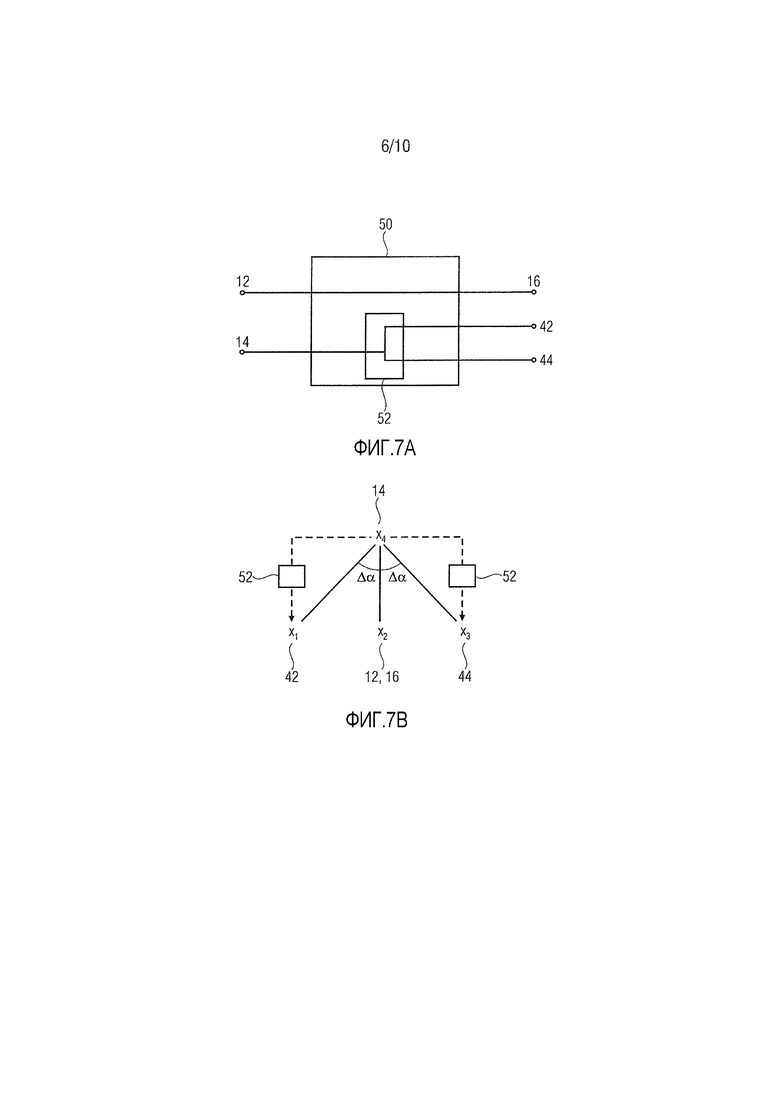
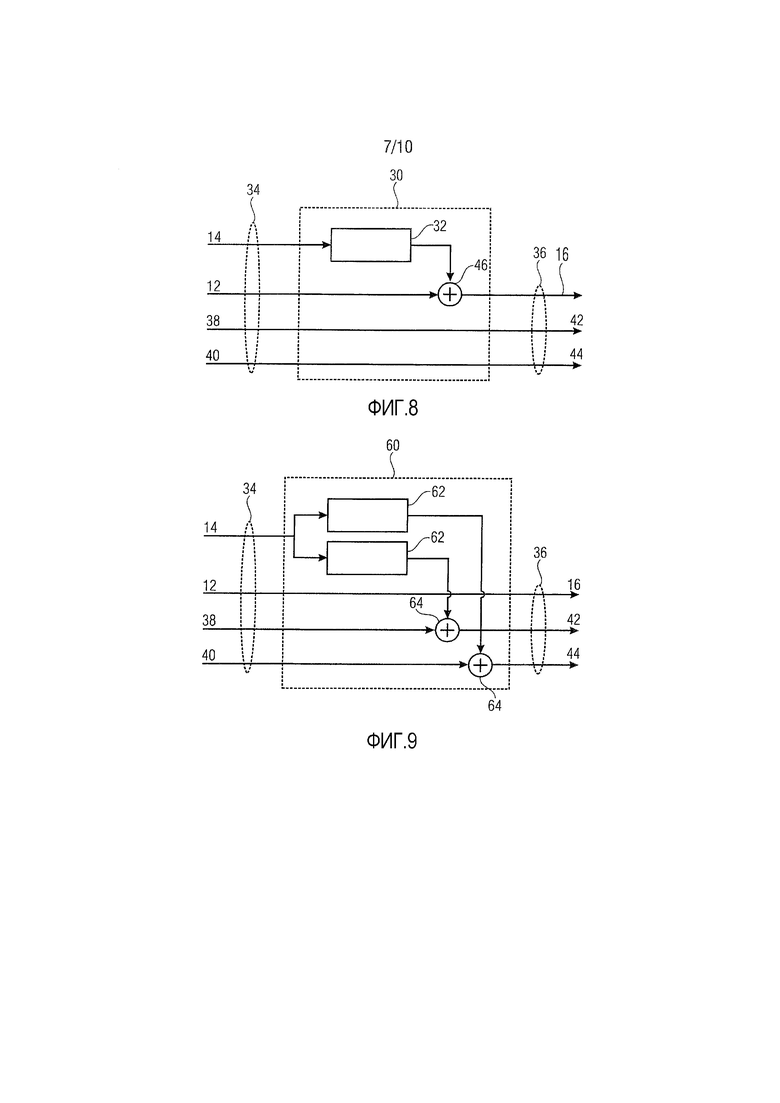
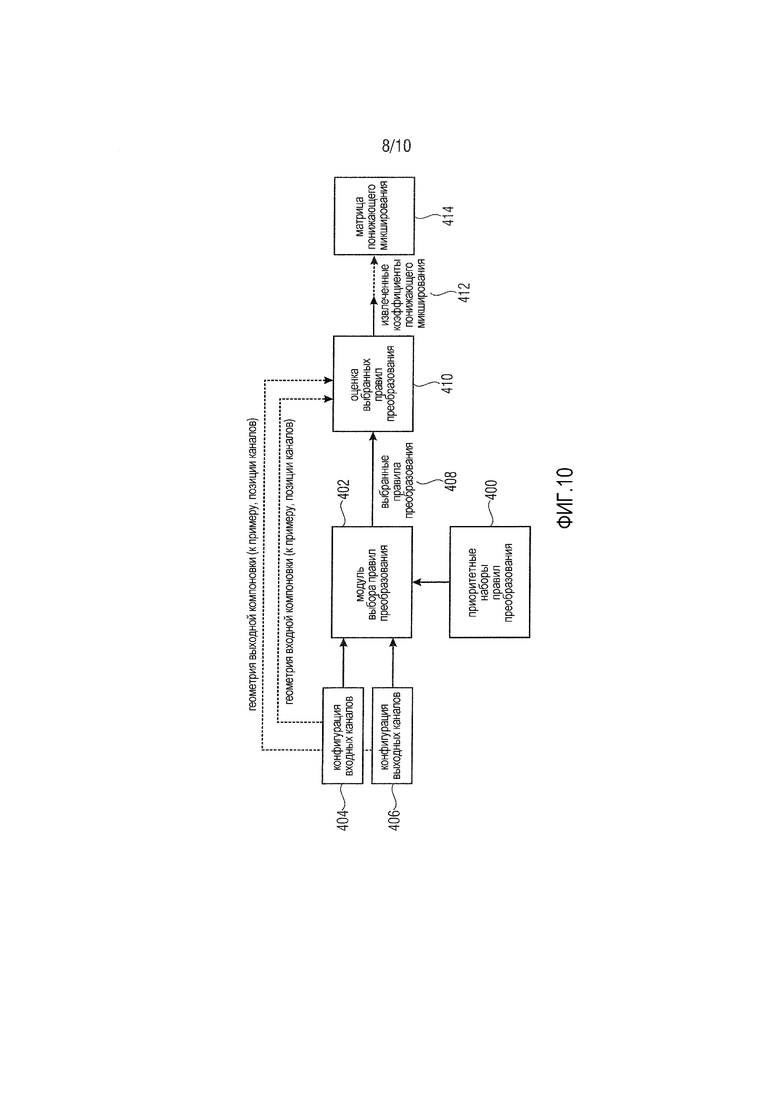
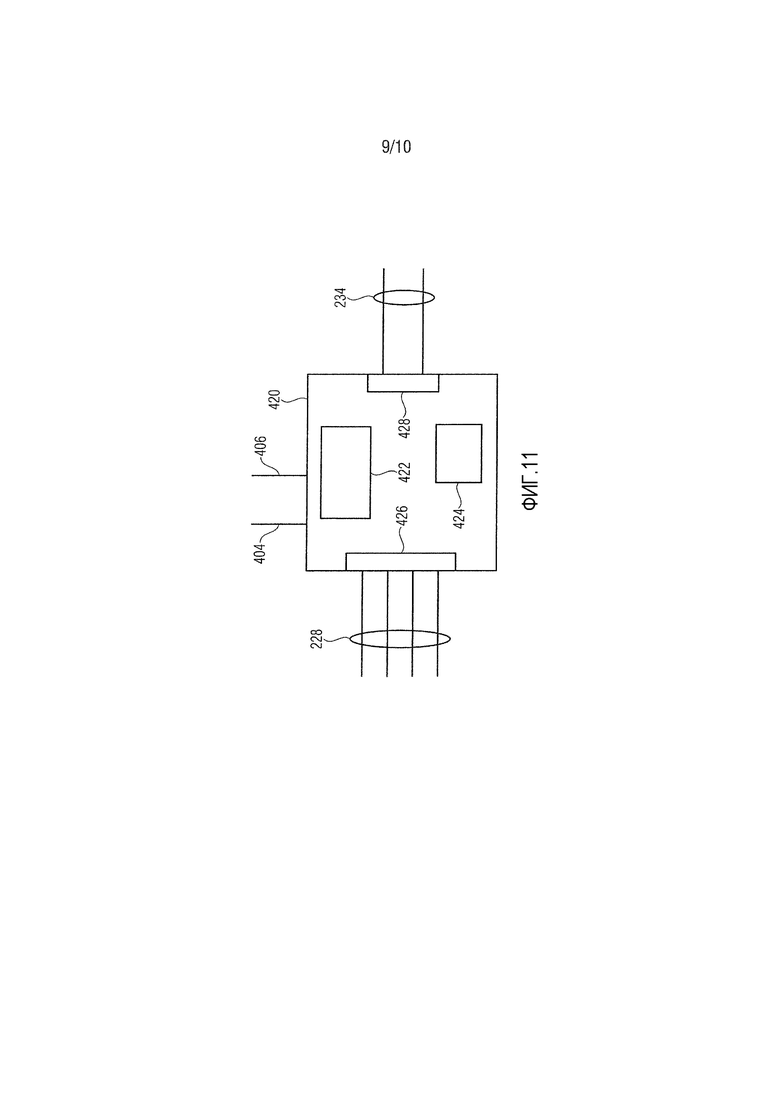
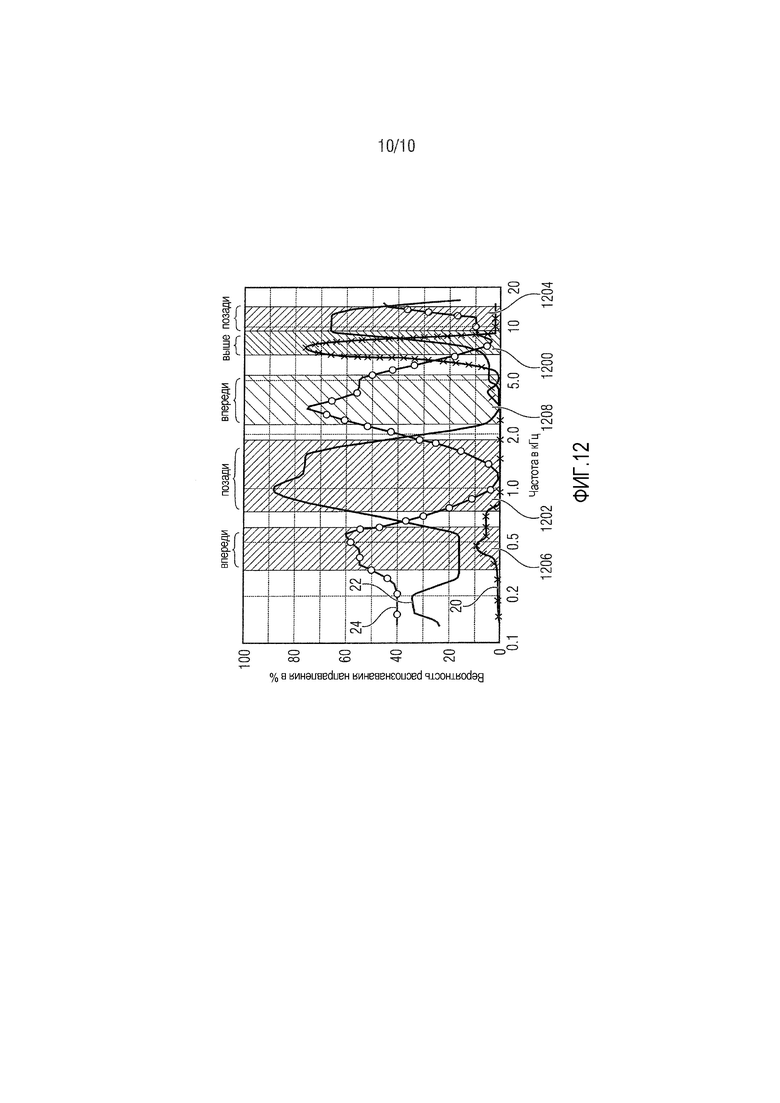
Изобретение относится к области кодирования аудиосигналов и предназначено для преобразования первого и второго входных каналов в один выходной канал, и в частности, предназначено для использования при преобразовании формата между различными конфигурациями каналов громкоговорителей. Технический результат - улучшенное воспроизведение звука в случае преобразования формата между различными конфигурациями каналов громкоговорителей. Пространственное кодирование аудио начинается с множества исходных входных, например пяти или семи, каналов, которые идентифицируются посредством их размещения в компоновке для воспроизведения в качестве левого канала, центрального канала, правого канала, левого канала объемного звучания, правого канала объемного звучания и канала улучшения низких частот (LFE). В устройстве каждый входной канал и каждый выходной канал имеют направление, в котором расположен ассоциированный громкоговоритель относительно центральной позиции слушателя, при этом устройство выполнено с возможностью преобразовывать первый входной канал в первый выходной канал из конфигурации выходных каналов. 3 н. и 1 з.п. ф-лы, 14 ил., 4 табл.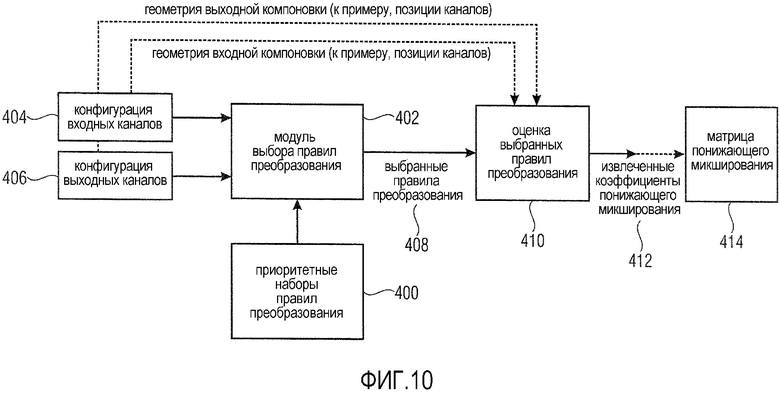
1. Устройство (10; 30; 50; 60) для преобразования первого входного канала (12) громкоговорителя и второго входного канала (14) громкоговорителя из конфигурации входных каналов громкоговорителей в выходные каналы (16, 42, 44) громкоговорителей из конфигурации выходных каналов громкоговорителей, при этом каждый входной канал громкоговорителя и каждый выходной канал громкоговорителя имеет направление относительно центральной позиции (P) слушателя, при этом первый и второй входные каналы (12, 14) громкоговорителей имеют различные углы подъема относительно горизонтальной плоскости (300) слушателя, при этом устройство выполнено с возможностью:
преобразовывать первый входной канал (12) громкоговорителя в первый выходной канал (16) громкоговорителя из конфигурации выходных каналов громкоговорителей; и
несмотря на тот факт, что отклонение азимутальных углов между направлением второго входного канала (14) громкоговорителя и направлением первого выходного канала (16) громкоговорителя меньше отклонения азимутальных углов между направлением второго входного канала (14) громкоговорителя и второго выходного канала (42) громкоговорителя и/или меньше отклонения азимутальных углов между направлением второго входного канала (14) громкоговорителя и направлением третьего выходного канала (44) громкоговорителя, преобразовывать второй входной канал (14) громкоговорителя во второй и третий выходные каналы (42, 44) громкоговорителей посредством панорамирования (52, 62) между вторым и третьим выходными каналами (42, 44) громкоговорителей, чтобы формировать фантомный источник в позиции громкоговорителя, ассоциированного с первым выходным каналом громкоговорителя.
2. Устройство по п. 1, выполненное с возможностью обрабатывать второй входной канал (14) громкоговорителя посредством применения по меньшей мере одного из частотного корректирующего фильтра и декорреляционного фильтра ко второму входному каналу (14) громкоговорителя.
3. Способ преобразования первого входного канала (12) громкоговорителя и второго входного канала (14) громкоговорителя из конфигурации входных каналов громкоговорителей в выходные каналы громкоговорителей из конфигурации выходных каналов громкоговорителей, при этом каждый входной канал громкоговорителя и каждый выходной канал громкоговорителя имеет направление относительно центральной позиции (P) слушателя, при этом первый и второй входные каналы (12, 14) громкоговорителей имеют различные углы подъема относительно горизонтальной плоскости (300) слушателя, при этом способ содержит:
преобразование первого входного канала (12) громкоговорителя в первый выходной канал (16) громкоговорителя из конфигурации выходных каналов громкоговорителей; и
несмотря на тот факт, что отклонение азимутальных углов между направлением второго входного канала (14) громкоговорителя и направлением первого выходного канала (16) громкоговорителя меньше отклонения азимутальных углов между направлением второго входного канала (14) громкоговорителя и второго выходного канала (42) громкоговорителя и/или меньше отклонения азимутальных углов между направлением второго входного канала (14) громкоговорителя и направлением третьего выходного канала (44) громкоговорителя, преобразование второго входного канала (14) громкоговорителя во второй и третий выходные каналы (42, 44) громкоговорителей посредством панорамирования (52, 62) между вторым и третьим выходными каналами (42, 44) громкоговорителей, чтобы формировать фантомный источник в позиции громкоговорителя, ассоциированного с первым выходным каналом громкоговорителя.
4. Цифровой носитель данных, на котором записана компьютерная программа для осуществления, при выполнении на компьютере или процессоре, способа по п. 3.
| Многоступенчатая активно-реактивная турбина | 1924 |
|
SU2013A1 |
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ ВОСПРОИЗВЕДЕНИЯ ОБШИРНОГО МОНОФОНИЧЕСКОГО ЗВУКА | 2006 |
|
RU2330390C2 |
| УСТРОЙСТВО И СПОСОБ СОЗДАНИЯ МНОГОКАНАЛЬНОГО ВЫХОДНОГО СИГНАЛА ИЛИ ФОРМИРОВАНИЯ НИЗВЕДЕННОГО СИГНАЛА | 2005 |
|
RU2329548C2 |
| Колосоуборка | 1923 |
|
SU2009A1 |

