Настоящее изобретение относится к кодированию аудиосигналов, к обработке аудиосигналов и к декодированию аудиосигналов и, в частности, к оборудованию и способу для долговременного предсказания в частотной области тональных сигналов для кодировки аудио.
В области техники кодировки аудио, предсказание используется для того, чтобы удалять избыточность в аудиосигналах. Посредством вычитания предсказанных данных из исходных данных и затем квантования и кодирования остатка, который обычно демонстрирует более низкую энтропию, скорость передачи битов может уменьшаться для передачи и хранения аудиосигнала [1]. Долговременное предсказание (LTP) представляет собой один вид способа предсказания, направленного на удаление периодических компонентов в аудиосигналах [2].
В стандарте усовершенствованного кодирования аудио (AAC) уровня 2 Экспертной группы по киноизображению (MPEG), модифицированное дискретное косинусное преобразование (MDCT) используется в качестве частотно-временного преобразования для перцепционного аудиокодера с обратным адаптивным LTP [3].
Фиг. 4 иллюстрирует структуру перцепционного аудиокодера с преобразованием с обратным адаптивным LTP. Аудиокодер по фиг. 4 содержит MDCT-модуль 410, модуль 420 управления психоакустическими моделями, модуль 430 оценки основного тона, модуль 440 долговременного предсказания, квантователь 450 и модуль 460 восстановления после квантования.
Как показано на фиг. 4, модуль предсказания имеет восстановленные MDCT-кадры в качестве ввода. Чтобы выполнять традиционное долговременное предсказание во временной области (TDLTP), MDCT-коэффициенты восстановленного сигнала должны сначала преобразовываться во временную область. Предсказанный сегмент временной области затем преобразуется обратно в MDCT-область для вычисления остатков.
MDCT использует перекрывающиеся окна аналитического кодирования со взвешиванием, которые уменьшают эффекты блокирования, и по-прежнему предлагает идеальное восстановление через процедуру суммирования с перекрытием (OLA) на этапе синтеза в обратном преобразовании [4]. Поскольку восстановление без наложения спектров второй половины текущего кадра требует первую половину будущего кадра [4], запаздывание при предсказании должно тщательно выбираться [2].
Если только полностью восстановленные выборки в буфере используются для предсказания, могут присутствовать целые кратные периодов основного тона задержки между выбранным предыдущим запаздыванием основного тона и запаздыванием основного тона, которое должно предсказываться. Вследствие нестационарности аудиосигналов более длинная задержка может приводить к меньшей стабильности предсказания. Для сигналов с высокой фундаментальной частотой, период основного тона является небольшим, в силу чего отрицательный эффект этой дополнительной задержки на предсказание может быть более заметным.
Концепция предсказания в частотной области (FDP), которая работает непосредственно в MDCT-области, предложена в [5] (см. также [13]). В этом способе каждый гармонический компонент тонального сигнала трактуется отдельно во время предсказания. Предсказание элемента разрешения в текущем кадре получается посредством вычисления синусоидального изменения его соседних спектральных элементов разрешения в предыдущих кадрах.
Тем не менее, когда частотное разрешение этих MDCT-коэффициентов является относительно низким относительно фундаментальной частоты тонального сигнала, гармонические компоненты могут перекрываться в большой степени друг с другом на элементах разрешения, приводя к плохой производительности этого подхода на основе частотной области.
Задача настоящего изобретения заключается в том, чтобы предоставлять усовершенствованные концепции для кодирования, обработки и декодирования аудиосигналов. Задача настоящего изобретения достигается посредством кодера по п. 1, посредством декодера по п. 23, посредством оборудования по п. 45, посредством способа по п. 52, посредством способа по п. 53, посредством способа по п. 54 и посредством компьютерной программы по п. 55.
Предоставляется кодер для кодирования текущего кадра аудиосигнала в зависимости от одного или более предыдущих кадров аудиосигнала согласно варианту осуществления. Один или более предыдущих кадров предшествуют текущему кадру, при этом каждый из текущего кадра и одного или более предыдущих кадров содержит один или более гармонических компонентов аудиосигнала, при этом каждый из текущего кадра и одного или более предыдущих кадров содержит множество спектральных коэффициентов в частотной области или в области преобразования. Чтобы генерировать кодирование текущего кадра, выполнен с возможностью определять оценку двух гармонических параметров для каждого из одного или более гармонических компонентов самого предыдущего кадра из одного или более предыдущих кадров. Кроме того, выполнен с возможностью определять оценку двух гармонических параметров для каждого из одного или более гармонических компонентов самого предыдущего кадра с использованием первой группы из трех или более из множества спектральных коэффициентов каждого из одного или более предыдущих кадров аудиосигнала.
Кроме того, предоставляется декодер для восстановления текущего кадра аудиосигнала согласно варианту осуществления. Один или более предыдущих кадров аудиосигнала предшествуют текущему кадру, при этом каждый из текущего кадра и одного или более предыдущих кадров содержит один или более гармонических компонентов аудиосигнала, при этом каждый из текущего кадра и одного или более предыдущих кадров содержит множество спектральных коэффициентов в частотной области или в области преобразования. Декодер выполнен с возможностью принимать кодирование текущего кадра. Декодер выполнен с возможностью определять оценку двух гармонических параметров для каждого из одного или более гармонических компонентов самого предыдущего кадра из одного или более предыдущих кадров. Два гармонических параметра для каждого из одного или более гармонических компонентов самого предыдущего кадра зависят от первой группы из трех или более из множества восстановленных спектральных коэффициентов для каждого из одного или более предыдущих кадров аудиосигнала. Кроме того, Декодер выполнен с возможностью восстанавливать текущий кадр в зависимости от кодирования текущего кадра и в зависимости от оценки двух гармонических параметров для каждого из одного или более гармонических компонентов самого предыдущего кадра.
Кроме того, предоставляется оборудование для скрытия потерь кадров согласно варианту осуществления. Один или более предыдущих кадров аудиосигнала предшествуют текущему кадру аудиосигнала. Каждый из текущего кадра и одного или более предыдущих кадров содержит один или более гармонических компонентов аудиосигнала, при этом каждый из текущего кадра и одного или более предыдущих кадров содержит множество спектральных коэффициентов в частотной области или в области преобразования. Оборудование выполнено с возможностью определять оценку двух гармонических параметров для каждого из одного или более гармонических компонентов самого предыдущего кадра из одного или более предыдущих кадров, при этом два гармонических параметра для каждого из одного или более гармонических компонентов самого предыдущего кадра зависят от первой группы из трех или более из множества восстановленных спектральных коэффициентов для каждого из одного или более предыдущих кадров аудиосигнала. Если оборудование не принимает текущий кадр, либо если текущий кадр принимается посредством оборудования в поврежденном состоянии, оборудование выполнено с возможностью восстанавливать текущий кадр в зависимости от оценки двух гармонических параметров для каждого из одного или более гармонических компонентов самого предыдущего кадра.
Кроме того, предоставляется способ для кодирования текущего кадра аудиосигнала в зависимости от одного или более предыдущих кадров аудиосигнала согласно варианту осуществления. Один или более предыдущих кадров предшествуют текущему кадру. Каждый из текущего кадра и одного или более предыдущих кадров содержит один или более гармонических компонентов аудиосигнала. Каждый из текущего кадра и одного или более предыдущих кадров содержит множество спектральных коэффициентов в частотной области или в области преобразования. Чтобы генерировать кодирование текущего кадра, способ содержит определение оценки двух гармонических параметров для каждого из одного или более гармонических компонентов самого предыдущего кадра из одного или более предыдущих кадров. Определение оценки двух гармонических параметров для каждого из одного или более гармонических компонентов самого предыдущего кадра проводится с использованием первой группы из трех или более из множества спектральных коэффициентов каждого из одного или более предыдущих кадров аудиосигнала.
Кроме того, предоставляется способ для восстановления текущего кадра аудиосигнала согласно варианту осуществления. Один или более предыдущих кадров аудиосигнала предшествуют текущему кадру. Каждый из текущего кадра и одного или более предыдущих кадров содержит один или более гармонических компонентов аудиосигнала. Каждый из текущего кадра и одного или более предыдущих кадров содержит множество спектральных коэффициентов в частотной области или в области преобразования. Способ содержит прием кодирования текущего кадра. Кроме того, способ содержит определение оценки двух гармонических параметров для каждого из одного или более гармонических компонентов самого предыдущего кадра из одного или более предыдущих кадров, при этом два гармонических параметра для каждого из одного или более гармонических компонентов самого предыдущего кадра зависят от первой группы из трех или более из множества восстановленных спектральных коэффициентов для каждого из одного или более предыдущих кадров аудиосигнала. Кроме того, способ содержит восстановление текущего кадра в зависимости от кодирования текущего кадра и в зависимости от оценки двух гармонических параметров для каждого из одного или более гармонических компонентов самого предыдущего кадра.
Кроме того, предоставляется способ для скрытия потерь кадров согласно варианту осуществления. Один или более предыдущих кадров аудиосигнала предшествуют текущему кадру аудиосигнала, при этом каждый из текущего кадра и одного или более предыдущих кадров содержит один или более гармонических компонентов аудиосигнала, при этом каждый из текущего кадра и одного или более предыдущих кадров содержит множество спектральных коэффициентов в частотной области или в области преобразования. Способ содержит определение оценки двух гармонических параметров для каждого из одного или более гармонических компонентов самого предыдущего кадра из одного или более предыдущих кадров, при этом два гармонических параметра для каждого из одного или более гармонических компонентов самого предыдущего кадра зависят от первой группы из трех или более из множества восстановленных спектральных коэффициентов для каждого из одного или более предыдущих кадров аудиосигнала. Кроме того, способ содержит, если текущий кадр не принимается или если текущий кадр принимается в поврежденном состоянии, восстановление текущего кадра в зависимости от двух гармонических параметров для каждого из одного или более гармонических компонентов самого предыдущего кадра.
Кроме того, предоставляется компьютерная программа согласно варианту осуществления для реализации одного из вышеописанных способов, когда компьютерная программа выполняется посредством компьютера или процессора сигналов.
Долговременное предсказание (LTP) традиционно используется для того, чтобы предсказывать сигналы, которые имеют некоторую периодичность во временной области. В случае кодирования с преобразованием с обратной адаптацией в аудиокодере модуль декодера имеет в распоряжении, в общем, только частотные коэффициенты, в силу чего обратное преобразование требуется перед предсказанием. Варианты осуществления предоставляют концепции предсказания по методу наименьших квадратов в частотной области (FDLMSP), которые работают непосредственно в области модифицированного дискретного косинусного преобразования (MDCT) и которые, например, заметно уменьшают скорость передачи битов для кодирования аудио даже при очень низком частотном разрешении. Таким образом, некоторые варианты осуществления, например, могут использоваться в кодеке с преобразованием, чтобы повышать эффективность кодирования, в частности, в сценариях кодирования аудио с низкой задержкой.
Некоторые варианты осуществления предоставляют концепцию предсказания по методу наименьших квадратов в частотной области (FDLMSP), которая выполняет LTP непосредственно в MDCT-области. Тем не менее вместо выполнения предсказания отдельно относительно каждого элемента разрешения, эта новая концепция моделирует гармонические компоненты тонального сигнала в области преобразования с использованием системы действительнозначных линейных уравнений. Предсказание выполняется после решения по методу наименьших квадратов (LMS) системы линейных уравнений. Параметры гармоник затем используются для того, чтобы предсказывать текущий кадр, на основе характера набега фазы гармоник. Следует отметить, что эта концепция предсказания также может применяться к другим действительнозначным линейным преобразованиям или гребенкам фильтров, к примеру, к различным типам дискретного косинусного преобразования (DCT) или полифазного квадратурного фильтра (PQF) [6].
Ниже по тексту представляется модель прохождения сигналов, подробно поясняется процесс оценки и предсказания гармонических компонентов, описываются эксперименты для того, чтобы оценивать FDLMSP-концепцию по сравнению с TDLTP и FDP, и показываются и поясняются результаты.
Далее подробнее описываются варианты осуществления настоящего изобретения со ссылкой на чертежи, на которых:
Фиг. 1 иллюстрирует кодер для кодирования текущего кадра аудиосигнала в зависимости от одного или более предыдущих кадров аудиосигнала согласно варианту осуществления.
Фиг. 2 иллюстрирует декодер для декодирования кодирования текущего кадра аудиосигнала согласно варианту осуществления.
Фиг. 3 иллюстрирует систему согласно варианту осуществления.
Фиг. 4 иллюстрирует структуру перцепционного аудиокодера с преобразованием с обратным адаптивным LTP.
Фиг. 5 иллюстрирует экономию по скоростям передачи битов при предсказании по одиночным нотам с использованием трех концепций предсказания с различными полосами пропускания предсказания и MDCT-длинами.
Фиг. 6 иллюстрирует экономию по скоростям передачи битов в четырех различных рабочих режимах для шести различных элементов с полосой пропускания, ограниченной 4 кГц, и длиной MDCT-кадра в 64 и 512.
Фиг. 7 иллюстрирует оборудование для скрытия потерь кадров согласно варианту осуществления.
Фиг. 8 иллюстрирует принципиальную блок-схему кодера для кодирования аудиосигнала концепции FDP-предсказания согласно примеру.
Фиг. 9 показывает принципиальную блок-схему декодера 201 для декодирования кодированного сигнала 120 концепции FDP-предсказания согласно примеру.
Фиг. 1 иллюстрирует кодер 100 для кодирования текущего кадра аудиосигнала в зависимости от одного или более предыдущих кадров аудиосигнала согласно варианту осуществления.
Один или более предыдущих кадров предшествуют текущему кадру, при этом каждый из текущего кадра и одного или более предыдущих кадров содержит один или более гармонических компонентов аудиосигнала, при этом каждый из текущего кадра и одного или более предыдущих кадров содержит множество спектральных коэффициентов в частотной области или в области преобразования.
Чтобы генерировать кодирование текущего кадра, кодер 100 выполнен с возможностью определять оценку двух гармонических параметров для каждого из одного или более гармонических компонентов самого предыдущего кадра из одного или более предыдущих кадров. Кроме того, кодер 100 выполнен с возможностью определять оценку двух гармонических параметров для каждого из одного или более гармонических компонентов самого предыдущего кадра с использованием первой группы из трех или более из множества спектральных коэффициентов каждого из одного или более предыдущих кадров аудиосигнала.
Самый предыдущий кадр, например, может быть самым предыдущим относительно текущего кадра.
Самый предыдущий кадр, например, может представлять собой (называться) непосредственно предшествующий кадр. Непосредственно предшествующий кадр, например, может непосредственно предшествовать текущему кадру.
Текущий кадр содержит один или более гармонических компонентов аудиосигнала. Каждый из одного или более предыдущих кадров может содержать один или более гармонических компонентов аудиосигнала. Фундаментальная частота одного или более гармонических компонентов в текущем кадре и одного или более предыдущих кадров предполагается идентичной.
Согласно варианту осуществления кодер 100, например, может быть выполнен с возможностью оценивать два гармонических параметра для каждого из одного или более гармонических компонентов самого предыдущего кадра без использования второй группы из одного или более дополнительных спектральных коэффициентов из множества спектральных коэффициентов каждого из одного или более предыдущих кадров.
Согласно варианту осуществления кодер 100, например, может быть выполнен с возможностью определять коэффициент усиления и остаточный сигнал в качестве кодирования текущего кадра в зависимости от фундаментальной частоты одного или более гармонических компонентов текущего кадра и одного или более предыдущих кадров и в зависимости от оценки двух гармонических параметров для каждого из одного или более гармонических компонентов самого предыдущего кадра. Кодер 100, например, может быть выполнен с возможностью генерировать кодирование текущего кадра таким образом, что кодирование текущего кадра содержит коэффициент усиления и остаточный сигнал.
В варианте осуществления кодер 100, например, может быть выполнен с возможностью определять оценку двух гармонических параметров для каждого из одного или более гармонических компонентов текущего кадра в зависимости от оценки двух гармонических параметров для каждого из одного или более гармонических компонентов самого предыдущего кадра и в зависимости от фундаментальной частоты одного или более гармонических компонентов текущего кадра и одного или более предыдущих кадров. Фундаментальная частота, например, может предполагаться неизменной в течение текущего кадра и одного или более предыдущих кадров.
Согласно варианту осуществления два гармонических параметра для каждого из одного или более гармонических компонентов представляют собой первый параметр для косинусоидального субкомпонента и второй параметр для синусоидального субкомпонента для каждого из одного или более гармонических компонентов.
В варианте осуществления кодер 100, например, может быть выполнен с возможностью оценивать два гармонических параметра для каждого из одного или более гармонических компонентов самого предыдущего кадра посредством решения системы линейных уравнений, содержащей, по меньшей мере, три уравнения, при этом каждое, по меньшей мере, из трех уравнений зависит от спектрального коэффициента первой группы из трех или более из множества спектральных коэффициентов каждого из одного или более предыдущих кадров.
Согласно варианту осуществления кодер 100, например, может быть выполнен с возможностью решать систему линейных уравнений с использованием алгоритма на основе метода наименьших квадратов.
Согласно варианту осуществления система линейных уравнений задается следующим образом:
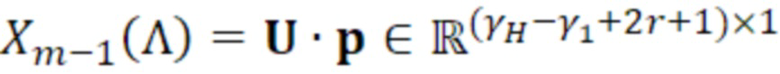
- при этом:
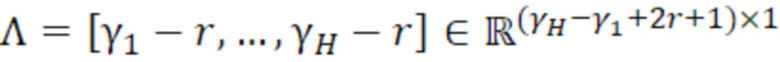
- при этом γ1 указывает первую полосу частот спектра одного из одного или более гармонических компонентов самого предыдущего кадра, имеющего наименьшую гармоническую компонентную частоту из числа одного или более гармонических компонентов, при этом γH указывает вторую полосу частот спектра одного из одного или более гармонических компонентов самого предыдущего кадра, имеющего наибольшую гармоническую компонентную частоту из числа одного или более гармонических компонентов, при этом r является целым числом, где r≥0.
В варианте осуществления r≥1.
Согласно варианту осуществления:
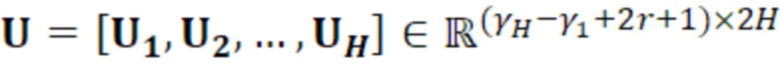
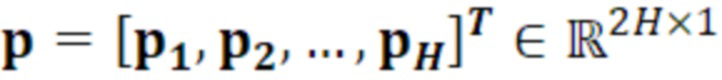
- при этом:
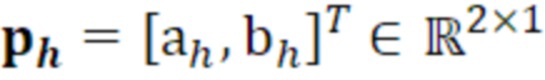
- при этом ah является параметром для косинусоидального субкомпонента для h-ого гармонического компонента самого предыдущего кадра, при этом bh является параметром для синусоидального субкомпонента для h-ого гармонического компонента самого предыдущего кадра, при этом, для каждого целочисленного значения, где 1≤h≤H:
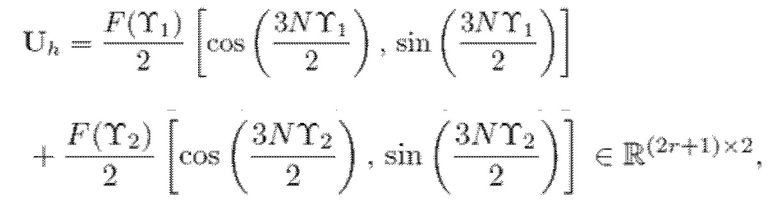
- при этом:
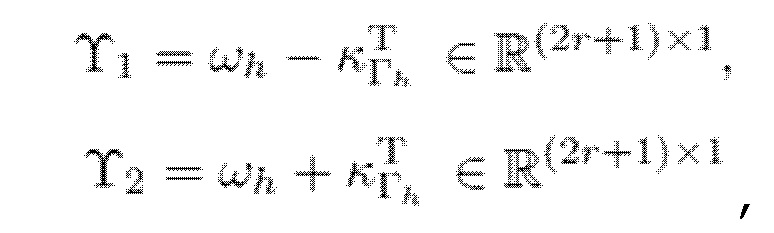
- при этом:
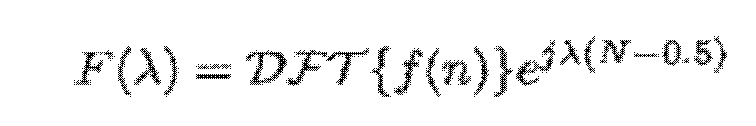
- при этом f(n) является функцией кодирования со взвешиванием во временной области,
при этом DFT является дискретным преобразованием Фурье, при этом:
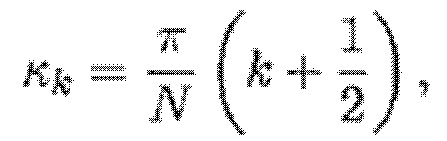
- при этом:
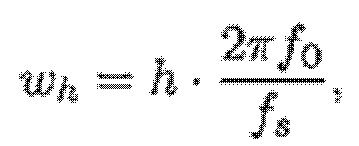
- при этом f0 является фундаментальной частотой одного или более гармонических компонентов текущего кадра и одного или более предыдущих кадров,
при этом fs является частотой дискретизации, и
при этом N зависит от длины блока преобразования для преобразования аудиосигнала временной области в частотную область или в спектральную область.
В варианте осуществления система линейных уравнений является разрешимой следующим образом:
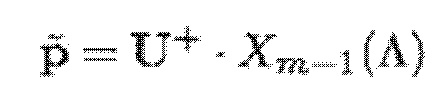
- при этом 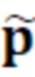 является первым вектором, содержащим оценку двух гармонических параметров для каждого из одного или более гармонических компонентов самого предыдущего кадра, при этом Xm-1(Λ) является вторым вектором, содержащим первую группу из трех или более из множества спектральных коэффициентов каждого из одного или более предыдущих кадров, при этом U+ является обратной матрицей Мура-Пенроуза
является первым вектором, содержащим оценку двух гармонических параметров для каждого из одного или более гармонических компонентов самого предыдущего кадра, при этом Xm-1(Λ) является вторым вектором, содержащим первую группу из трех или более из множества спектральных коэффициентов каждого из одного или более предыдущих кадров, при этом U+ является обратной матрицей Мура-Пенроуза 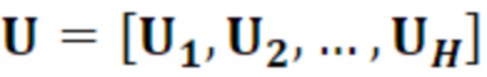 , при этом U содержит число третьих матриц или третьих векторов, при этом каждая из третьих матриц или третьих векторов вместе с оценкой двух гармонических параметров для гармонического компонента из одного или более гармонических компонентов самого предыдущего кадра указывает оценку упомянутого гармонического компонента, при этом H указывает число гармонических компонентов одного или более предыдущих кадров.
, при этом U содержит число третьих матриц или третьих векторов, при этом каждая из третьих матриц или третьих векторов вместе с оценкой двух гармонических параметров для гармонического компонента из одного или более гармонических компонентов самого предыдущего кадра указывает оценку упомянутого гармонического компонента, при этом H указывает число гармонических компонентов одного или более предыдущих кадров.
В варианте осуществления кодер 100, например, может быть выполнен с возможностью кодировать фундаментальную частоту гармонических компонентов, функцию кодирования со взвешиванием, коэффициент усиления и остаточный сигнал.
Согласно варианту осуществления кодер 100, например, может быть выполнен с возможностью определять число одного или более гармонических компонентов самого предыдущего кадра и фундаментальную частоту одного или более гармонических компонентов самого предыдущего кадра до оценки двух гармонических параметров для каждого из одного или более гармонических компонентов самого предыдущего кадра с использованием первой группы из трех или более из множества спектральных коэффициентов каждого из одного или более предыдущих кадров аудиосигнала.
Согласно варианту осуществления кодер 100, например, может быть выполнен с возможностью определять одну или более групп гармонических компонентов из одного или более гармонических компонентов и применять предсказание аудиосигнала к одной или более групп гармонических компонентов, при этом кодер 100, например, может быть выполнен с возможностью кодировать порядок относительно каждой из одной или более групп гармонических компонентов самого предыдущего кадра.
В варианте осуществления кодер 100, например, может быть выполнен с возможностью применять:
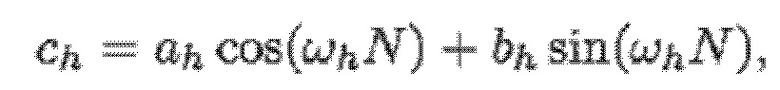 и:
и:
- при этом кодер 100, например, может быть выполнен с возможностью применять:
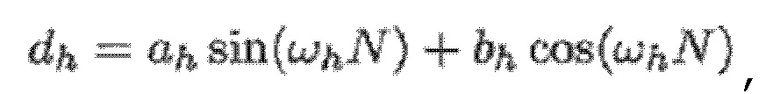
- при этом ah является параметром для косинусоидального субкомпонента для h-ого гармонического компонента из упомянутых одного или более гармонических компонентов самого предыдущего кадра, при этом bh является параметром для синусоидального субкомпонента для h-ого гармонического компонента из упомянутых одного или более гармонических компонентов самого предыдущего кадра, при этом ch является параметром для косинусоидального субкомпонента для h-ого гармонического компонента из упомянутых одного или более гармонических компонентов текущего кадра, при этом dh является параметром для синусоидального субкомпонента для h-ого гармонического компонента из упомянутых одного или более гармонических компонентов текущего кадра, при этом N зависит от длины блока преобразования для преобразования аудиосигнала временной области в частотную область или в спектральную область, и при этом:
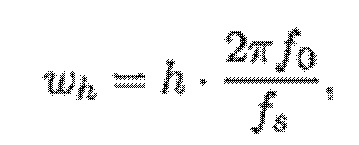
- при этом f0 является фундаментальной частотой одного или более гармонических компонентов самого предыдущего кадра, представляющей собой фундаментальную частоту одного или более гармонических компонентов текущего кадра, при этом fs является частотой дискретизации, и при этом h является индексом, указывающим один из одного или более гармонических компонентов самого предыдущего кадра.
Согласно варианту осуществления кодер 100, например, может быть выполнен с возможностью определять остаточный сигнал в зависимости от множества спектральных коэффициентов текущего кадра в частотной области или в области преобразования и в зависимости от оценки двух гармонических параметров для каждого из одного или более гармонических компонентов текущего кадра, и при этом кодер 100, например, может быть выполнен с возможностью кодировать остаточный сигнал.
В варианте осуществления кодер 100, например, может быть выполнен с возможностью определять спектральное предсказание одного или более из множества спектральных коэффициентов текущего кадра в зависимости от оценки двух гармонических параметров для каждого из одного или более гармонических компонентов текущего кадра. Кодер 100, например, может быть выполнен с возможностью определять остаточный сигнал и коэффициент усиления в зависимости от множества спектральных коэффициентов текущего кадра в частотной области или в области преобразования и в зависимости от спектрального предсказания трех или более из множества спектральных коэффициентов текущего кадра, при этом кодер 100, например, может быть выполнен с возможностью генерировать кодирование текущего кадра таким образом, что кодирование текущего кадра содержит остаточный сигнал и коэффициент усиления.
Согласно варианту осуществления кодер 100, например, может быть выполнен с возможностью определять остаточный сигнал текущего кадра следующим образом:
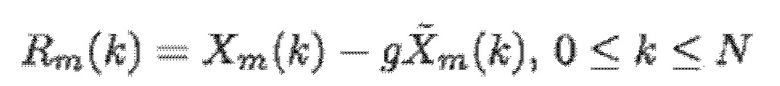
- при этом m является индексом кадра, при этом k является частотным индексом, при этом Rm(k) указывает k-ую выборку остаточного сигнала в спектральной области или в области преобразования, при этом Xm(k) указывает k-ую выборку спектральных коэффициентов текущего кадра в спектральной области или в области преобразования, при этом 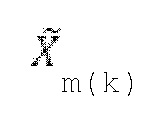 указывает k-ую выборку спектрального предсказания текущего кадра в спектральной области или в области преобразования, и при этом g является коэффициентом усиления.
указывает k-ую выборку спектрального предсказания текущего кадра в спектральной области или в области преобразования, и при этом g является коэффициентом усиления.
Фиг. 2 иллюстрирует декодер 200 для восстановления текущего кадра аудиосигнала согласно варианту осуществления.
Один или более предыдущих кадров аудиосигнала предшествуют текущему кадру, при этом каждый из текущего кадра и одного или более предыдущих кадров содержит один или более гармонических компонентов аудиосигнала, при этом каждый из текущего кадра и одного или более предыдущих кадров содержит множество спектральных коэффициентов в частотной области или в области преобразования.
Декодер 200 выполнен с возможностью принимать кодирование текущего кадра.
Кроме того, декодер 200 выполнен с возможностью определять оценку двух гармонических параметров для каждого из одного или более гармонических компонентов самого предыдущего кадра из одного или более предыдущих кадров. Два гармонических параметра для каждого из одного или более гармонических компонентов самого предыдущего кадра зависят от первой группы из трех или более из множества восстановленных спектральных коэффициентов для каждого из одного или более предыдущих кадров аудиосигнала.
Кроме того, декодер 200 выполнен с возможностью восстанавливать текущий кадр в зависимости от кодирования текущего кадра и в зависимости от оценки двух гармонических параметров для каждого из одного или более гармонических компонентов самого предыдущего кадра.
Самый предыдущий кадр, например, может быть самым предыдущим относительно текущего кадра.
Самый предыдущий кадр, например, может представлять собой (называться) непосредственно предшествующий кадр. Непосредственно предшествующий кадр, например, может непосредственно предшествовать текущему кадру.
Текущий кадр содержит один или более гармонических компонентов аудиосигнала. Каждый из одного или более предыдущих кадров может содержать один или более гармонических компонентов аудиосигнала. Фундаментальная частота одного или более гармонических компонентов в текущем кадре и одного или более предыдущих кадров предполагается идентичной.
Согласно варианту осуществления два гармонических параметра для каждого из одного или более гармонических компонентов самого предыдущего кадра не зависят от второй группы из одного или более дополнительных спектральных коэффициентов из множества спектральных коэффициентов одного или более предыдущих кадров.
В варианте осуществления декодер 200, например, может быть выполнен с возможностью определять оценку двух гармонических параметров для каждого из одного или более гармонических компонентов текущего кадра в зависимости от оценки двух гармонических параметров для каждого из одного или более гармонических компонентов самого предыдущего кадра и в зависимости от фундаментальной частоты одного или более гармонических компонентов текущего кадра и одного или более предыдущих кадров.
Согласно варианту осуществления декодер 100, например, может быть выполнен с возможностью принимать кодирование текущего кадра, содержащее коэффициент усиления и остаточный сигнал. Декодер 200, например, может быть выполнен с возможностью восстанавливать текущий кадр в зависимости от коэффициента усиления, в зависимости от остаточного сигнала и в зависимости от фундаментальной частоты одного или более гармонических компонентов текущего кадра и одного или более предыдущих кадров. Фундаментальная частота, например, может предполагаться неизменной в течение текущего кадра и одного или более предыдущих кадров.
Согласно варианту осуществления два гармонических параметра для каждого из одного или более гармонических компонентов представляют собой первый параметр для косинусоидального субкомпонента и второй параметр для синусоидального субкомпонента для каждого из одного или более гармонических компонентов.
В варианте осуществления два гармонических параметра для каждого из одного или более гармонических компонентов самого предыдущего кадра зависят от системы линейных уравнений, содержащей, по меньшей мере, три уравнения, при этом каждое, по меньшей мере, из трех уравнений зависит от спектрального коэффициента первой группы из трех или более из множества восстановленных спектральных коэффициентов для каждого из одного или более предыдущих кадров.
Согласно варианту осуществления система линейных уравнений является разрешимой с использованием алгоритма на основе метода наименьших квадратов.
Согласно варианту осуществления система линейных уравнений задается следующим образом:
- при этом:
- при этом γ1 указывает первую полосу частот спектра одного из одного или более гармонических компонентов самого предыдущего кадра, имеющего наименьшую гармоническую компонентную частоту из числа одного или более гармонических компонентов, при этом γH указывает вторую полосу частот спектра одного из одного или более гармонических компонентов самого предыдущего кадра, имеющего наибольшую гармоническую компонентную частоту из числа одного или более гармонических компонентов, при этом r является целым числом, где r≥0.
В варианте осуществления r≥1.
Согласно варианту осуществления:
- при этом:
- при этом ah является параметром для косинусоидального субкомпонента для h-ого гармонического компонента самого предыдущего кадра, при этом bh является параметром для синусоидального субкомпонента для h-ого гармонического компонента самого предыдущего кадра, при этом, для каждого целочисленного значения, где 1≤h≤H:
- при этом:
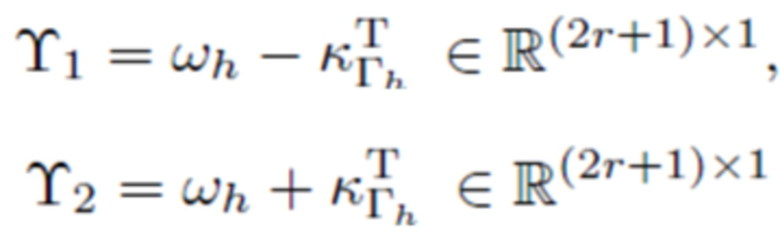 ,
,
- при этом:
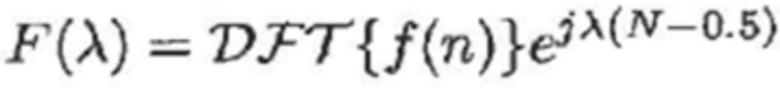
- при этом f(n) является функцией кодирования со взвешиванием во временной области, при этом DFT является дискретным преобразованием Фурье, при этом:
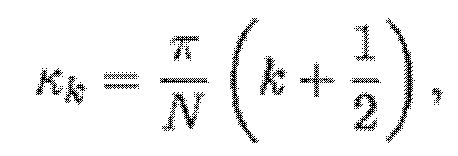
- при этом:
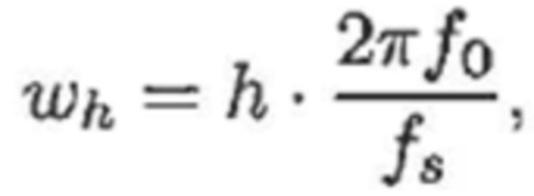
- при этом f0 является фундаментальной частотой одного или более гармонических компонентов текущего кадра и одного или более предыдущих кадров, при этом fs является частотой дискретизации, и при этом N зависит от длины блока преобразования для преобразования аудиосигнала временной области в частотную область или в спектральную область.
В варианте осуществления система линейных уравнений является разрешимой следующим образом:
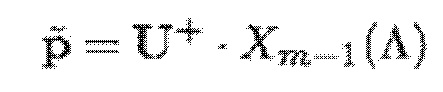
- при этом является первым вектором, содержащим оценку двух гармонических параметров для каждого из одного или более гармонических компонентов самого предыдущего кадра, при этом Xm-1(Λ) является вторым вектором, содержащим первую группу из трех или более из множества восстановленных спектральных коэффициентов для каждого из одного или более предыдущих кадров, при этом U+ является обратной матрицей Мура-Пенроуза , при этом U содержит число третьих матриц или третьих векторов, при этом каждая из третьих матриц или третьих векторов вместе с оценкой двух гармонических параметров для гармонического компонента из одного или более гармонических компонентов самого предыдущего кадра указывает оценку упомянутого гармонического компонента, при этом H указывает число гармонических компонентов одного или более предыдущих кадров.
В варианте осуществления, при этом декодер 200, например, может быть выполнен с возможностью принимать фундаментальную частоту гармонических компонентов, функцию кодирования со взвешиванием, коэффициент усиления и остаточный сигнал. Декодер 200, например, может быть выполнен с возможностью восстанавливать текущий кадр в зависимости от фундаментальной частоты одного или более гармонических компонентов самого предыдущего кадра, в зависимости от порядка гармонических компонентов, в зависимости от функции кодирования со взвешиванием, в зависимости от коэффициента усиления и в зависимости от остаточного сигнала.
Должны передаваться только фундаментальная частота, порядок гармонических компонентов, функция кодирования со взвешиванием, коэффициент усиления и остаток. Декодер 200, например, может вычислять U на основе этой принимаемой информации и затем проводить оценку гармонических параметров и текущее кадровое предсказание. Декодер, например, может затем восстанавливать текущий кадр посредством суммирования передаваемых остаточных спектров с предсказанными спектрами, масштабируемыми на передаваемый коэффициент усиления.
Согласно варианту осуществления декодер 200, например, может быть выполнен с возможностью принимать число одного или более гармонических компонентов самого предыдущего кадра и фундаментальную частоту одного или более гармонических компонентов самого предыдущего кадра. Декодер 200, например, может быть выполнен с возможностью декодировать кодирование текущего кадра в зависимости от числа одного или более гармонических компонентов самого предыдущего кадра и в зависимости от фундаментальной частоты одного или более гармонических компонентов текущего кадра и одного или более предыдущих кадров.
Согласно варианту осуществления декодер 200 выполнен с возможностью декодировать кодирование текущего кадра в зависимости от одной или более групп гармонических компонентов, при этом декодер 200 выполнен с возможностью применять предсказание аудиосигнала к одной или более групп гармонических компонентов.
Согласно варианту осуществления декодер 200, например, может быть выполнен с возможностью определять два гармонических параметра для каждого из одного или более гармонических компонентов текущего кадра в зависимости от двух гармонических параметров для каждого из упомянутых одного из одного или более гармонических компонентов самого предыдущего кадра.
В варианте осуществления:
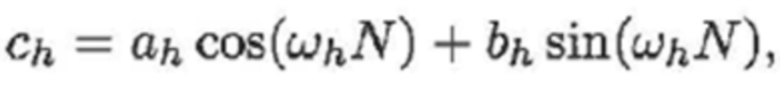 и
и
- при этом декодер 200, например, может быть выполнен с возможностью применять:
- при этом ah является параметром для косинусоидального субкомпонента для h-ого гармонического компонента из упомянутых одного или более гармонических компонентов самого предыдущего кадра, при этом bh является параметром для синусоидального субкомпонента для h-ого гармонического компонента из упомянутых одного или более гармонических компонентов самого предыдущего кадра, при этом ch является параметром для косинусоидального субкомпонента для h-ого гармонического компонента из упомянутых одного или более гармонических компонентов текущего кадра, при этом dh является параметром для синусоидального субкомпонента для h-ого гармонического компонента из упомянутых одного или более гармонических компонентов текущего кадра, при этом N зависит от длины блока преобразования для преобразования аудиосигнала временной области в частотную область или в спектральную область, и при этом:
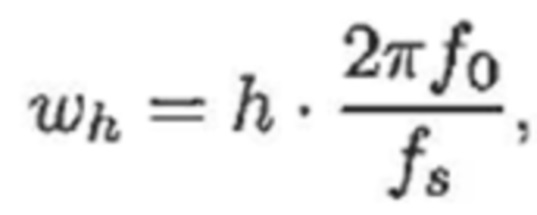
- при этом f0 является фундаментальной частотой одного или более гармонических компонентов самого предыдущего кадра, представляющей собой фундаментальную частоту одного или более гармонических компонентов текущего кадра, при этом fs является частотой дискретизации, и при этом h является индексом, указывающим один из одного или более гармонических компонентов самого предыдущего кадра.
Согласно варианту осуществления декодер 200, например, может быть выполнен с возможностью принимать остаточный сигнал, при этом остаточный сигнал зависит от множества спектральных коэффициентов текущего кадра в частотной области или в области преобразования, и при этом остаточный сигнал зависит от оценки двух гармонических параметров для каждого из одного или более гармонических компонентов текущего кадра.
В варианте осуществления декодер 200, например, может быть выполнен с возможностью определять спектральное предсказание одного или более из множества спектральных коэффициентов текущего кадра в зависимости от оценки двух гармонических параметров для каждого из одного или более гармонических компонентов текущего кадра, и при этом декодер 200, например, может быть выполнен с возможностью определять текущий кадр аудиосигнала в зависимости от спектрального предсказания текущего кадра и в зависимости от остаточного сигнала, и в зависимости от коэффициента усиления.
Согласно варианту осуществления в котором остаточный сигнал текущего кадра задается следующим образом:
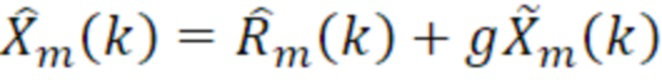
- при этом m является индексом кадра, при этом k является частотным индексом, при этом 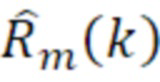 является принимаемым остатком после восстановления после квантования, при этом
является принимаемым остатком после восстановления после квантования, при этом 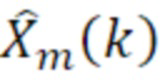 является восстановленным текущим кадром, при этом указывает спектральное предсказание текущего кадра в спектральной области или в области преобразования, и при этом g является коэффициентом усиления.
является восстановленным текущим кадром, при этом указывает спектральное предсказание текущего кадра в спектральной области или в области преобразования, и при этом g является коэффициентом усиления.
Фиг. 3 иллюстрирует систему согласно варианту осуществления.
Система содержит кодер 100 согласно одному из вышеописанных вариантов осуществления для кодирования текущего кадра аудиосигнала.
Кроме того, система содержит декодер 200 согласно одному из вышеописанных вариантов осуществления для декодирования кодирования текущего кадра аудиосигнала.
Фиг. 7 иллюстрирует оборудование 700 для скрытия потерь кадров согласно варианту осуществления.
Один или более предыдущих кадров предыдущих кадров аудиосигнала предшествуют текущему кадру аудиосигнала. Каждый из текущего кадра и одного или более предыдущих кадров содержит один или более гармонических компонентов аудиосигнала, при этом каждый из текущего кадра и одного или более предыдущих кадров содержит множество спектральных коэффициентов в частотной области или в области преобразования.
Оборудование 700 выполнено с возможностью определять оценку двух гармонических параметров для каждого из одного или более гармонических компонентов самого предыдущего кадра из одного или более предыдущих кадров, при этом два гармонических параметра для каждого из одного или более гармонических компонентов самого предыдущего кадра зависят от первой группы из трех или более из множества восстановленных спектральных коэффициентов для каждого из одного или более предыдущих кадров аудиосигнала.
Если оборудование 700 не принимает текущий кадр, либо если текущий кадр принимается посредством оборудования 700 в поврежденном состоянии, оборудование 700 выполнено с возможностью восстанавливать текущий кадр в зависимости от оценки двух гармонических параметров для каждого из одного или более гармонических компонентов самого предыдущего кадра.
Самый предыдущий кадр, например, может быть самым предыдущим относительно текущего кадра.
Самый предыдущий кадр, например, может представлять собой (называться) непосредственно предшествующий кадр. Непосредственно предшествующий кадр, например, может непосредственно предшествовать текущему кадру.
Текущий кадр содержит один или более гармонических компонентов аудиосигнала. Каждый из одного или более предыдущих кадров может содержать один или более гармонических компонентов аудиосигнала. Фундаментальная частота одного или более гармонических компонентов в текущем кадре и одного или более предыдущих кадров предполагается идентичной.
Согласно варианту осуществления оборудование 700, например, может быть выполнено с возможностью принимать число одного или более гармонических компонентов самого предыдущего кадра. Оборудование 700, например, может быть выполнено с возможностью декодировать кодирование текущего кадра в зависимости от числа одного или более гармонических компонентов самого предыдущего кадра и в зависимости от фундаментальной частоты одного или более гармонических компонентов текущего кадра и одного или более предыдущих кадров.
В варианте осуществления чтобы восстанавливать текущий кадр, оборудование 700, например, может быть выполнено с возможностью определять оценку двух гармонических параметров для каждого из одного или более гармонических компонентов текущего кадра в зависимости от оценки двух гармонических параметров для каждого из одного или более гармонических компонентов самого предыдущего кадра.
В варианте осуществления оборудование 700 выполнено с возможностью применять:
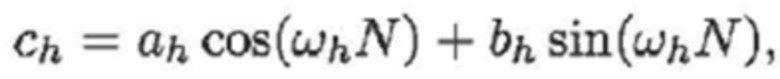 и
и
- при этом оборудование 700 выполнено с возможностью применять:
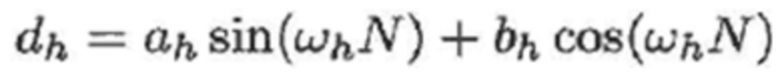 ,
,
- при этом ah является параметром для косинусоидального субкомпонента для h-ого гармонического компонента из упомянутых одного или более гармонических компонентов самого предыдущего кадра, при этом bh является параметром для синусоидального субкомпонента для h-ого гармонического компонента из упомянутых одного или более гармонических компонентов самого предыдущего кадра, при этом ch является параметром для косинусоидального субкомпонента для h-ого гармонического компонента из упомянутых одного или более гармонических компонентов текущего кадра, при этом dh является параметром для синусоидального субкомпонента для h-ого гармонического компонента из упомянутых одного или более гармонических компонентов текущего кадра, при этом N зависит от длины блока преобразования для преобразования аудиосигнала временной области в частотную область или в спектральную область, и при этом:
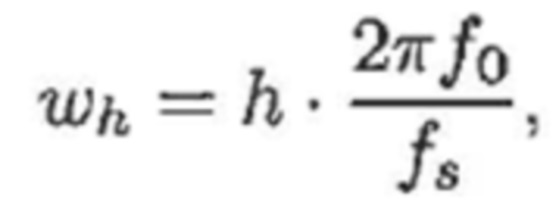
- при этом f0 является фундаментальной частотой одного или более гармонических компонентов самого предыдущего кадра, представляющей собой фундаментальную частоту одного или более гармонических компонентов текущего кадра, при этом fs является частотой дискретизации, и при этом h является индексом, указывающим один из одного или более гармонических компонентов самого предыдущего кадра.
Согласно варианту осуществления оборудование 700, например, может быть выполнено с возможностью определять спектральное предсказание трех или более из множества спектральных коэффициентов текущего кадра в зависимости от оценки двух гармонических параметров для каждого из одного или более гармонических компонентов текущего кадра.
Ниже по тексту предоставляются предпочтительные варианты осуществления.
Сначала описывается модель прохождения сигналов.
При условии, что гармоническая часть в цифровом аудиосигнале представляет собой следующее:
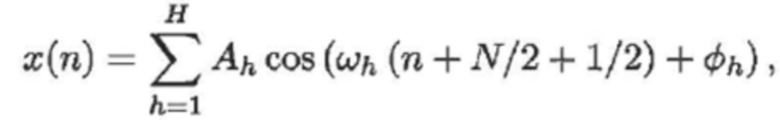 (1)
(1)
- где:
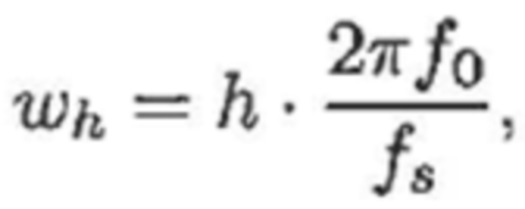 (2)
(2)
- где f0 является фундаментальной частотой одного или более гармонических компонентов, и H является числом гармонических компонентов. Без потери общности, выражение фазового компонента намеренно разделяется на две части, при этом часть, обозначаемая посредством ωh*(N/2+1/2), является удобной впоследствии для математических извлечений, когда MDCT-преобразование применяется к x(n) с N в качестве длины MDCT-кадра, и ϕh является остатком фазового компонента; fs, например, является частотой дискретизации.
Гармонический компонент определяется посредством трех параметров: частота, амплитуда и фаза. При условии, что информация частоты ωh известна, оценка амплитуды и фазы представляет собой задачу нелинейной регрессии. Тем не менее она может превращаться в задачу линейной регрессии посредством перезаписи уравнения (1) следующим образом:
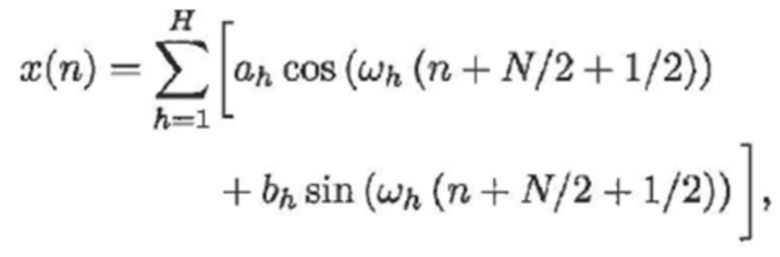 (3)
(3)
и неизвестные параметры гармоники теперь представляют собой ah и bh:
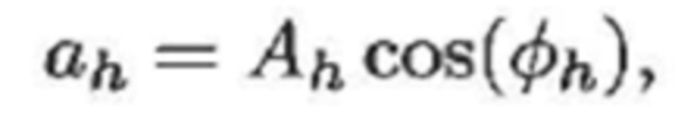 (4a)
(4a)
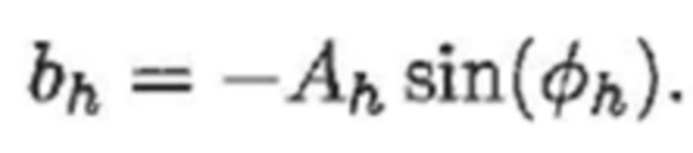 (4b)
(4b)
Преобразование блока x(n) с длиной 2N в MDCT-область:
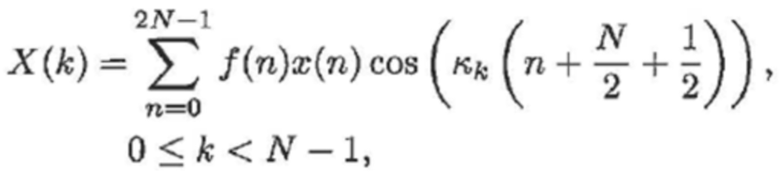 (5)
(5)
- где:
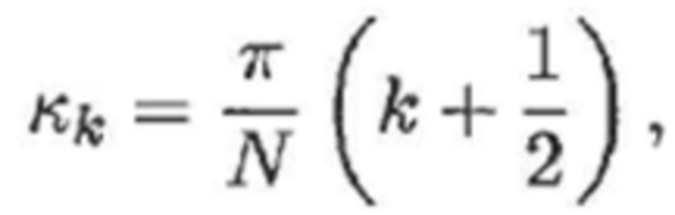 (6)
(6)
- где f(n) является функцией аналитического кодирования со взвешиванием, и κk является частотой модуляции в полосе k частот.
При подстановке уравнения (3) в уравнение (5) и с некоторыми математическими извлечениями на основе тригонометрии, получается следующее:
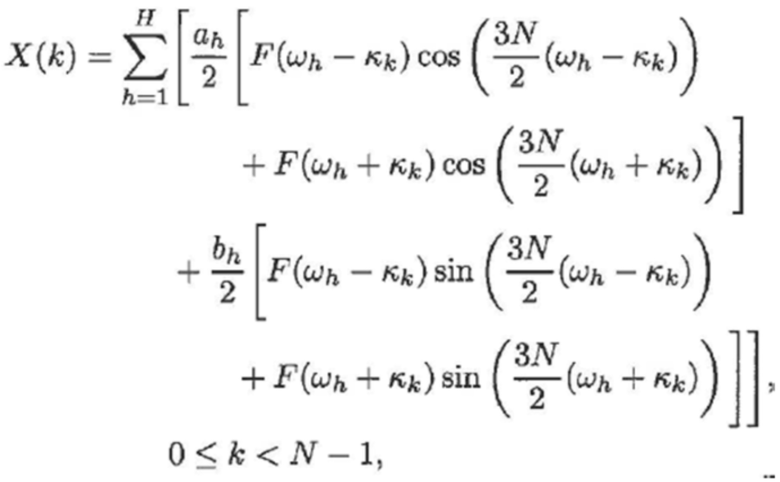 (7)
(7)
- где F() является действительнозначной функцией, полученной посредством добавления члена сдвига фаз в преобразование Фурье функции кодирования со взвешиванием:
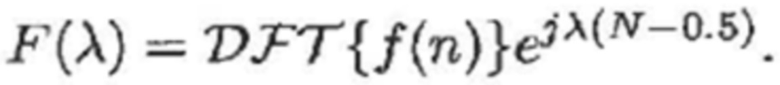 (8)
(8)
Ниже по тексту описывается оценка и предсказание гармоник.
На основе предполагаемой модели прохождения сигналов, описанной выше посредством уравнений (3)-(8), с таким дополнительным предположением, что частота гармонических компонентов не изменяется быстро между смежными кадрами, предложенный FDLMSP-подход может разделяться на три этапа. Например, чтобы предсказывать m-ый кадр, во-первых, информация частоты всех гармонических компонентов в m-ом кадре оценивается. Эта информация частоты впоследствии передастся как часть вспомогательной информации, чтобы помогать предсказанию в декодере 200. Затем параметры каждого гармонического компонента в m-1-ом кадре, обозначаемые посредством ah, bh, с h=[1..., H], оцениваются только с использованием предшествующих кадров.
В конце, m-ый кадр предсказывается на основе оцененных гармонических параметров. Остаточный спектр затем вычисляется и дополнительно обрабатывается, например, квантуется и передается. Информация основного тона в каждом кадре может получаться посредством модуля оценки основного тона.
Сначала подробно описывается оценка гармоник.
Преобразования обычно имеют ограниченное частотное разрешение, в силу чего каждый гармонический компонент должен разбрасываться по нескольким смежным элементам разрешения вокруг полосы частот, в которой находится ее центральная частота. Для гармонического компонента с частотой ωh в m-1-ом кадре, он должен центрироваться в полосе MDCT-частот с индексом γh полосы частот, где:
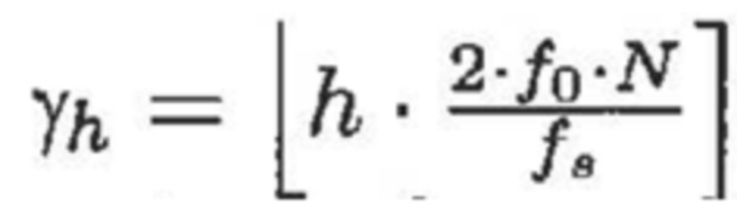
 и разбрасывается по элементам разрешения:
и разбрасывается по элементам разрешения:
Γh=γh-r, ..., γh+r,
- где r является числом соседних элементов разрешения на каждой стороне.
Параметры ah и bh этого гармонического компонента могут оцениваться посредством решения такой системы линейных уравнений, сформированной из уравнения (7):
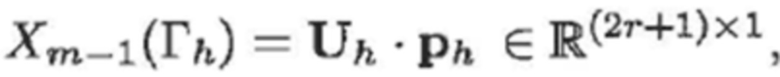 (9)
(9)
- где:
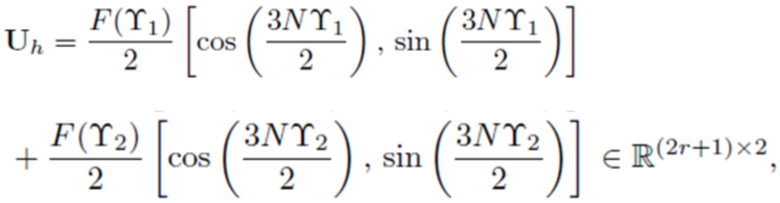 (10a)
(10a)
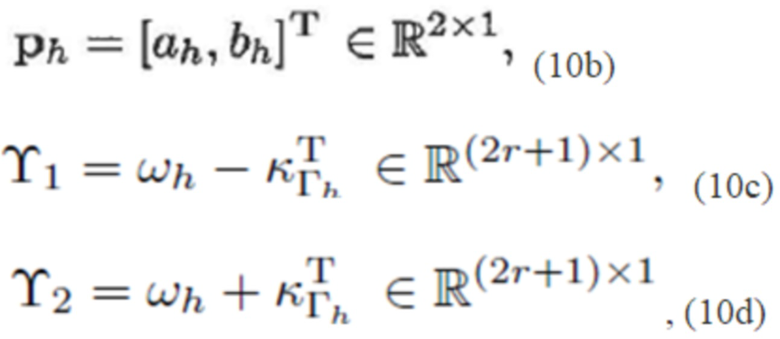
Uh является действительнозначной матрицей, которая является независимой от сигнала x(n) и может вычисляться после того, как известны f0, N и функция f(n) кодирования со взвешиванием.
При условии, что информация частоты всех гармонических компонентов в одном кадре известна, следующая система линейных уравнений посредством объединения уравнения (9) по всем гармоническим компонентам получается:
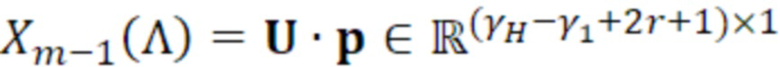 (11)
(11)
- где:
(12a)
(12b)
(12c)
Как матрица U, так и MDCT-коэффициенты являются действительнозначными, и в силу этого имеется система действительнозначных линейных уравнений. Оценка 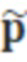 гармонических параметров может получаться посредством решения по методу наименьших квадратов (LMS) системы линейных уравнений с псевдоинверсией U:
гармонических параметров может получаться посредством решения по методу наименьших квадратов (LMS) системы линейных уравнений с псевдоинверсией U:
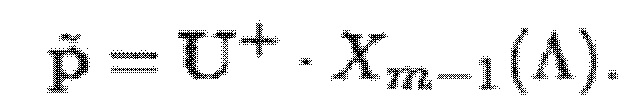 (13)
(13)
U+, например, является обратной матрицей Мура-Пенроуза U.
(U+, например, является псевдообратной матрицей U).
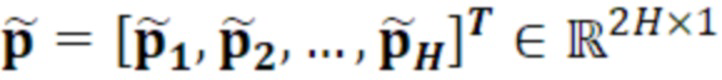 например, является оценкой гармонических параметров p.
например, является оценкой гармонических параметров p.
Относительно объединения уравнения (9) по всем гармоническим компонентам, аналогично, в то время как уравнение (10b) остается неисправленным, уравнения (10a) и (10c) становятся следующими:
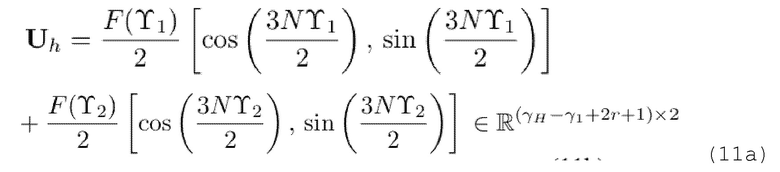
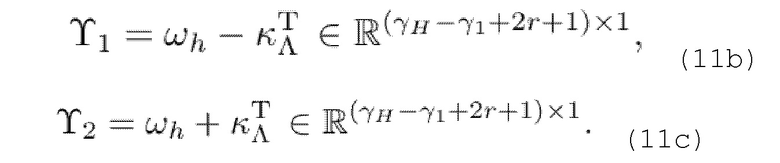
Поскольку Λ отличается от Γh, размерности 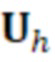 и γ изменяются.
и γ изменяются.
Оценка 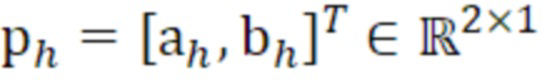 уравнения (10b), например, может упоминаться следующим образом:
уравнения (10b), например, может упоминаться следующим образом:
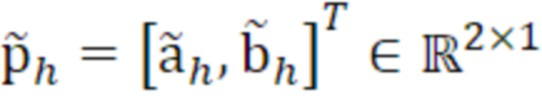 (11d)
(11d)
В случае если число параметров, которые должны оцениваться, превышает число элементов MDCT-разрешения, которые охватывают гармоники, в результате должна получаться недоопределенная система линейных уравнений. Это исключается за счет размещения в стеке матрицы U вертикально и вектора X горизонтально с соответствующими значениями из более предыдущих кадров. Тем не менее, дополнительная задержка не вводится, поскольку (самые) предыдущие кадры уже находятся в буфере. Наоборот, при этом расширении, этот предложенный подход является применимым к сценариям с крайне низким частотным разрешением, в которых гармонические компоненты плотно разнесены. Коэффициент масштабирования может применяться к определенному числу используемых предыдущих кадров, чтобы гарантировать переопределенную систему линейных уравнений, что также повышает устойчивость этой концепции предсказания к шуму в сигнале.
Далее подробно описывается предсказание.
При условии, что частоты и амплитуды синусоид не изменяются, m-ый кадр во временной области может записываться следующим образом:
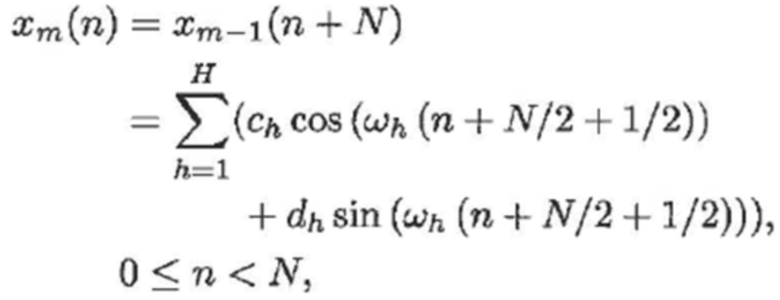 (14)
(14)
- где:
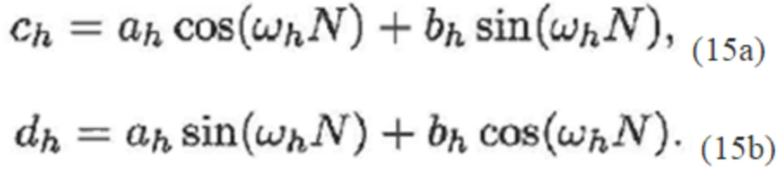
В силу наличия оценки гармонических параметров для каждого из одного или более гармонических компонентов в m-1-ом кадре, на основе уравнений (5)-(9), предсказание текущего MDCT-кадра представляет собой следующее:
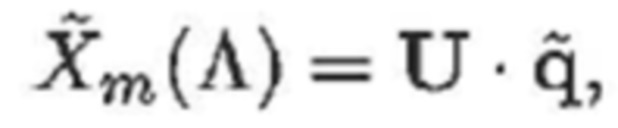 (16)
(16)
- где:
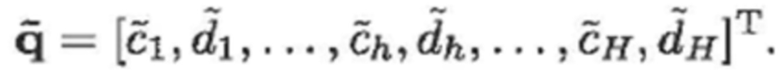 (17)
(17)
Для элементов разрешения, в которых предсказание не выполняется, значение предсказания задается равным нулю.
Тем не менее, вследствие нестационарности сигнала, амплитуда гармоник может немного варьироваться между последовательными кадрами. Коэффициент усиления вводится, чтобы приспосабливаться к этому изменению амплитуды, и должен передаваться как часть вспомогательной информации в декодер 200.
Остаточный спектр в таком случае представляет собой следующее:
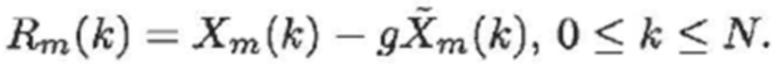 (18)
(18)
Ниже по тексту оцениваются вышеприведенные концепции.
Чтобы оценивать производительность этой предложенной FDLMSP-концепции, окружение кодера в Python скомпоновано согласно фиг. 4. Предоставленная концепция реализуется согласно вышеприведенному описанию, где r равно 2. Для сравнения, TDLTP и FDP повторно реализованы согласно справочной литературе [2], [5]. Это направлено на использование экспериментов, чтобы оценивать эти три концепции предсказания в трех различных аспектах: (i) производительность относительно различных частотных разрешений MDCT-коэффициентов, (ii) чувствительность к негармоничности [7] тестовых материалов и (iii) общая производительность и компетентность по сравнению друг с другом в идентичных сценариях кодирования. Негармоничность тона обычно подразумевает, что его гармоники высшего порядка более не разнесены равномерно. Поскольку гармоничность в полосах верхних частот является перцепционно менее важной [8], влияние этого фактора посредством использования различных полос пропускания предсказания оценено.
Для эксперимента, использованы частота дискретизации в 16 кГц и длины MDCT-кадров в 64, 128, 256 и 512. Предсказания выполняются для ограниченных полос пропускания в 1 кГц, 2 кГц, 4 кГц и 8 кГц. Синусоидальная функция кодирования со взвешиванием в качестве функции аналитического кодирования со взвешиванием выбрана, поскольку она удовлетворяет ограничениям для идеального восстановления [9]. Этот подход также может обрабатывать функции асимметричного кодирования со взвешиванием при переключении между различными длинами кадров. Чтобы повышать точность оценки гармоник, функция F(ω) вычисляется для интерполированной передаточной функции из функции аналитического кодирования со взвешиванием. В TDLTP, для каждого кадра 3-отводный фильтр предсказания вычисляется на основе концепции автокорреляции с использованием полностью восстановленных данных и исходной временной области. При поиске предыдущего полностью восстановленного запаздывания основного тона из буферных данных, также следует принимать во внимание, что запаздывание основного тона может не быть целым кратным интервала дискретизации. Число соседних временных или спектральных элементов разрешения в FDP ограничено 2.
YIN-алгоритм [10] используется для оценки основного тона. Диапазон поиска f0 задается равным [20, ..., 1000] Гц, и гармоническое пороговое значение составляет 0,25. Комплексная перцепционная модель на основе гребенки фильтров с бесконечным импульсным откликом (IIR), предложенная в [11], используется для того, чтобы вычислять пороговые значения маскирования для квантования. Более точный поиск основного тона вокруг YIN-оценки (± 0,5 Гц с размером шага в 0,02 Гц) и поиск оптимального коэффициента усиления в [0,5, ..., 2], с размером шага в 0,01, выполняется объединенно в каждом кадре посредством минимизации перцепционной энтропии (PE) [12] квантованного остатка, которая является аппроксимацией энтропии квантованного остаточного спектра с учетом перцепционной модели.
Кодер имеет четыре рабочих режима: "FDLMSP", "TDLTP", "FDP" и "адаптивное MDCT LTP (AMLTP)", соответственно. В AMLTP-режиме, кодер переключается между различными концепциями предсказания на основе кадров с PE-минимизацией в качестве критериев. Для всех четырех рабочих режимов, предсказание не выполняется в кадре, если PE остаточного спектра выше спектра исходного сигнала.
Для каждого режима, кодер тестируется на шести различных материалах: три одиночных ноты с длительностью в 1-2 секунды: басовая нота (f0 приблизительно в 50 Гц); клавесиновая нота (f0 приблизительно в 88 Гц) и нота камертона-дудки (f0 приблизительно в 290 Гц). Эти тестовые материалы имеют относительно регулярную гармоническую структуру и медленно варьирующуюся временную огибающую. Кодер также тестируется на более сложных тестовых материалах: фрагмент игры трубы (длиной ~5 секунд, f0 варьируется между 300 Гц и 700 Гц), женский вокал (длиной ~10 секунд, f0 варьируется между 200 Гц и 300 Гц) и мужская речь (длиной ~8 секунд; f0 варьируется между 100 Гц и 220 Гц). Эти три тестовых материала имеют широко варьирующуюся огибающую и быстро изменяющиеся основные тона вдоль времени и менее регулярную гармоническую структуру. В ходе эксперимента, отмечено, что басовая нота имеет гораздо более сильную гармонику второго порядка, чем гармоника первого порядка, приводя к постоянно неправильным оценкам основного тона. Таким образом, диапазон поиска f0 этой басовой ноты в модуле YIN-оценки основного тона для корректной оценки основного тона отрегулирован.
Средняя PE квантованного остаточного спектра и квантованного спектра исходного сигнала оценена. На основе оцененных PE, экономия по скорости передачи битов (BS) [в битах в секунду] в передаче сигнала посредством применения предсказания вычислена без учета потребления по скорости передачи битов вспомогательной информации. Сначала проанализировано поведение каждой концепции, и это сравнение ограничено предсказанием по одиночным нотам для рационального логического вывода и анализа. После этого сравнивается производительность четырех режимов для идентичных конфигураций параметров.
Фиг. 5 иллюстрирует экономию по скоростям передачи битов при предсказании по одиночным нотам с использованием трех концепций предсказания с различными полосами пропускания предсказания и MDCT-длинами.
Сначала ниже описывается концепция FDP-предсказания из предшествующего уровня техники. Концепция FDP-предсказания описывается подробнее в [5] и в [13] (WO 2016 142357 A1, опубликован в сентябре 2016 года).
Фиг. 8 показывает принципиальную блок-схему кодера 101 для кодирования аудиосигнала 102 концепции FDP-предсказания согласно примеру. Кодер 101 выполнен с возможностью кодировать аудиосигнал 102 в области преобразования или области 104 гребенки фильтров (например, в частотной области или в спектральной области), при этом кодер 101 выполнен с возможностью определять спектральные коэффициенты 106_t0_f1-106_t0_f6 аудиосигнала 102 для текущего кадра 108_t0 и спектральные коэффициенты 106_t-1_f1-106_t-1_f6 аудиосигнала, по меньшей мере, для одного предыдущего кадра 108_t-1. Дополнительно, кодер 101 выполнен с возможностью избирательно применять кодирование с предсказанием ко множеству отдельных спектральных коэффициентов 106_t0_f2 или к группам спектральных коэффициентов 106_t0_f4 и 106_t0_f5, при этом кодер 101 выполнен с возможностью определять значение разнесения, при этом кодер 101 выполнен с возможностью выбирать множество отдельных спектральных коэффициентов 106_t0_f2 или группы спектральных коэффициентов 106_t0_f4 и 106_t0_f5, к которым применяется кодирование с предсказанием, на основе значения разнесения.
Другими словами, кодер 101 выполнен с возможностью избирательно применять кодирование с предсказанием ко множеству отдельных спектральных коэффициентов 106_t0_f2 или к группам спектральных коэффициентов 106_t0_f4 и 106_t0_f5, выбранных на основе одного значения разнесения, передаваемого в качестве вспомогательной информации.
Это значение разнесения может соответствовать частоте (например, фундаментальной частоте гармонического тона (аудиосигнала 102)), которая задает вместе со своими целыми кратными центры всех групп спектральных коэффициентов, для которых применяется предсказание: Первая группа может центрироваться вокруг этой частоты, вторая группа может центрироваться вокруг этой частоты, умноженной на два, третья группа может центрироваться вокруг этой частоты, умноженной на три, и т.д. Знание этих центральных частот обеспечивает вычисление коэффициентов предсказания для предсказания соответствующих синусоидальных сигнальных компонентов (например, фундаментального и обертонов гармонических сигналов). Таким образом, усложненная и подверженная ошибкам обратная адаптация коэффициентов предсказания более не требуется.
В примерах кодер 101 может быть выполнен с возможностью определять одно значение разнесения в расчете на кадр.
В примерах множество отдельных спектральных коэффициентов 106_t0_f2 или группы спектральных коэффициентов 106_t0_f4 и 106_t0_f5 могут разделяться, по меньшей мере, посредством одного спектрального коэффициента 106_t0_f3.
В примерах кодер 101 может быть выполнен с возможностью применять кодирование с предсказанием ко множеству отдельных спектральных коэффициентов, которые разделяются, по меньшей мере, посредством одного спектрального коэффициента, к примеру, к двум отдельным спектральным коэффициентам, которые разделяются, по меньшей мере, посредством одного спектрального коэффициента. Дополнительно, кодер 101 может быть выполнен с возможностью применять кодирование с предсказанием ко множеству групп спектральных коэффициентов (причем каждая из групп содержит, по меньшей мере, два спектральных коэффициента), которые разделяются, по меньшей мере, посредством одного спектрального коэффициента, к примеру, к двум группам спектральных коэффициентов, которые разделяются, по меньшей мере, посредством одного спектрального коэффициента. Дополнительно, кодер 101 может быть выполнен с возможностью применять кодирование с предсказанием ко множеству отдельных спектральных коэффициентов и/или к группам спектральных коэффициентов, которые разделяются, по меньшей мере, посредством одного спектрального коэффициента, к примеру, по меньшей мере, к одному отдельному спектральному коэффициенту и, по меньшей мере, к одной группе спектральных коэффициентов, которые разделяются, по меньшей мере, посредством одного спектрального коэффициента.
В примере показанном на фиг. 8, кодер 101 выполнен с возможностью определять шесть спектральных коэффициентов 106_t0_f1-106_t0_f6 для текущего кадра 108_t0 и шесть спектральных коэффициентов 106_t-1_f1-106_t-1_f6 для (самого) предыдущего кадра 108_t-1. В силу этого, кодер 101 выполнен с возможностью избирательно применять кодирование с предсказанием к отдельному второму спектральному коэффициенту 106_t0_f2 текущего кадра и к группе спектральных коэффициентов, состоящей из четвертого и пятого спектральных коэффициентов 106_t0_f4 и 106_t0_f5 текущего кадра 108_t0. Как можно видеть, отдельный второй спектральный коэффициент 106_t0_f2 и группа спектральных коэффициентов, состоящая из четвертого и пятого спектральных коэффициентов 106_t0_f4 и 106_t0_f5, разделяются друг от друга посредством третьего спектрального коэффициента 106_t0_f3.
Следует отметить, что термин "избирательно" при использовании в данном документе означает применение кодирования с предсказанием (только) к выбранным спектральным коэффициентам. Другими словами, кодирование с предсказанием не обязательно применяется ко всем спектральным коэффициентам, а вместо этого только к выбранным отдельным спектральным коэффициентам или к группам спектральных коэффициентов, причем выбранные отдельные спектральные коэффициенты и/или к группы спектральных коэффициентов могут разделяться друг от друга, по меньшей мере, посредством одного спектрального коэффициента. Другими словами, кодирование с предсказанием может деактивироваться, по меньшей мере, для одного спектрального коэффициента, посредством которого разделяются выбранное множество отдельных спектральных коэффициентов или группы спектральных коэффициентов.
В примерах кодер 101 может быть выполнен с возможностью избирательно применять кодирование с предсказанием ко множеству отдельных спектральных коэффициентов 106_t0_f2 или к группам спектральных коэффициентов 106_t0_f4 и 106_t0_f5 текущего кадра 108_t0 на основе, по меньшей мере, соответствующего множества отдельных спектральных коэффициентов 106_t-1_f2 или групп спектральных коэффициентов 106_t-1_f4 и 106_t-1_f5 предыдущего кадра 108_t-1.
Например, кодер 101 может быть выполнен с возможностью кодировать с предсказанием множество отдельных спектральных коэффициентов 106_t0_f2 или группы спектральных коэффициентов 106_t0_f4 и 106_t0_f5 текущего кадра 108_t0 посредством кодирования ошибок предсказания между множеством предсказанных отдельных спектральных коэффициентов 110_t0_f2 или группами предсказанных спектральных коэффициентов 110_t0_f4 и 110_t0_f5 текущего кадра 108_t0 и множеством отдельных спектральных коэффициентов 106_t0_f2 или группами спектральных коэффициентов 106_t0_f4 и 106_t0_f5 текущего кадра (либо их квантованными версиями).
На фиг. 8 кодер 101 кодирует отдельный спектральный коэффициент 106_t0_f2 и группу спектральных коэффициентов, состоящую из спектральных коэффициентов 106_t0_f4 и 106_t0_f5, посредством кодирования ошибок предсказания между предсказанным отдельным спектральным коэффициентом 110_t0_f2 текущего кадра 108_t0 и отдельным спектральным коэффициентом 106_t0_f2 текущего кадра 108_t0 и между группой предсказанных спектральных коэффициентов 110_t0_f4 и 110_t0_f5 текущего кадра и группой спектральных коэффициентов 106_t0_f4 и 106_t0_f5 текущего кадра.
Другими словами, второй спектральный коэффициент 106_t0_f2 кодируется посредством кодирования ошибки предсказания (или разности) между предсказанным вторым спектральным коэффициентом 110_t0_f2 и (фактическим или определенным) вторым спектральным коэффициентом 106_t0_f2, при этом четвертый спектральный коэффициент 106_t0_f4 кодируется посредством кодирования ошибки предсказания (или разности) между предсказанным четвертым спектральным коэффициентом 110_t0_f4 и (фактическим или определенным) четвертым спектральным коэффициентом 106_t0_f4, и при этом пятый спектральный коэффициент 106_t0_f5 кодируется посредством кодирования ошибки предсказания (или разности) между предсказанным пятым спектральным коэффициентом 110_t0_f5 и (фактическим или определенным) пятым спектральным коэффициентом 106_t0_f5.
В примере кодер 101 может быть выполнен с возможностью определять множество предсказанных отдельных спектральных коэффициентов 110_t0_f2 или группы предсказанных спектральных коэффициентов 110_t0_f4 и 110_t0_f5 для текущего кадра 108_t0 посредством соответствующих фактических версий множества отдельных спектральных коэффициентов 106_t-1_f2 или групп спектральных коэффициентов 106_t-1_f4 и 106_t-1_f5 предыдущего кадра 108_t-1.
Другими словами, кодер 101, в вышеописанном процессе определения может использовать непосредственно множество фактических отдельных спектральных коэффициентов 106_t-1_f2 или группы фактических спектральных коэффициентов 106_t-1_f4 и 106_t-1_f5 предыдущего кадра 108_t-1, причем 106_t-1_f2, 106_t-1_f4 и 106_t-1_f5 представляют исходные еще не квантованные спектральные коэффициенты или группы спектральных коэффициентов, соответственно, по мере того, как они получаются посредством кодера 101 таким образом, что упомянутый кодер может работать в области преобразования или области 104 гребенки фильтров.
Например, кодер 101 может быть выполнен с возможностью определять второй предсказанный спектральный коэффициент 110_t0_f2 текущего кадра 108_t0 на основе соответствующей еще не квантованной версии второго спектрального коэффициента 106_t-1_f2 предыдущего кадра 10 108_t-1, предсказанный четвертый спектральный коэффициент 110_t0_f4 текущего кадра 108_t0 на основе соответствующей еще не квантованной версии четвертого спектрального коэффициента 106_t-1_f4 предыдущего кадра 108_t-1 и предсказанный пятый спектральный коэффициент 110_t0_f5 текущего кадра 108_t0 на основе соответствующей еще не квантованной версии пятого спектрального коэффициента 106_t-1_f5 предыдущего кадра.
За счет этого подхода, схема кодирования и декодирования с предсказанием может демонстрировать вид гармонического формирования шума квантования, поскольку соответствующий декодер, пример которого описывается ниже относительно фиг. 11, может использовать, на вышеуказанном этапе определения, только передаваемые квантованные версии множества отдельных спектральных коэффициентов 106_t-1_f2 или множества групп спектральных коэффициентов 106_t-1_f4 и 106_t-1_f5 предыдущего кадра 108_t-1, для декодирования с предсказанием.
Хотя такое гармоническое формирование шума, поскольку оно, например, традиционно выполняется посредством долговременного предсказания (LTP) во временной области, может быть субъективно преимущественным для кодирования с предсказанием, в некоторых случаях оно может быть нежелательным, поскольку оно может приводить к нежелательной, чрезмерной величине тональности, введенной в декодированный аудиосигнал. По этой причине, далее описывается альтернативная схема кодирования с предсказанием, которая полностью синхронизируется с соответствующим декодированием и, по сути, использует только любые возможные усиления для предсказания, но не приводит к формированию шума квантования. Согласно этому альтернативному примеру кодирования, кодер 101 может быть выполнен с возможностью определять множество предсказанных отдельных спектральных коэффициентов 110_t0_f2 или группы предсказанных спектральных коэффициентов 110_t0_f4 и 110_t0_f5 для текущего кадра 108_t0 с использованием соответствующих квантованных версий множества отдельных спектральных коэффициентов 106_t-1_f2 или групп спектральных коэффициентов 106_t-1_f4 и 106_t-1_f5 предыдущего кадра 108_t-1.
Например, кодер 101 может быть выполнен с возможностью определять второй предсказанный спектральный коэффициент 110_t0_f2 текущего кадра 108_t0 на основе соответствующей квантованной версии второго спектрального коэффициента 106_t-1_f2 предыдущего кадра 108_t-1, предсказанный четвертый спектральный коэффициент 110_t0_f4 текущего кадра 108_t0 на основе соответствующей квантованной версии четвертого спектрального коэффициента 106_t-1_f4 предыдущего кадра 108_t-1 и предсказанный пятый спектральный коэффициент 110_t0_f5 текущего кадра 108_t0 на основе соответствующей квантованной версии пятого спектрального коэффициента 106_t-1_f5 предыдущего кадра.
Дополнительно, кодер 101 может быть выполнен с возможностью извлекать коэффициенты 112_f2, 114_f2, 112_f4, 114_f4, 112_f5 и 114_f5 предсказания из значения разнесения и вычислять множество предсказанных отдельных спектральных коэффициентов 110_t0_f2 или группы предсказанных спектральных коэффициентов 110_t0_f4 и 110_t0_f5 для текущего кадра 108_t0 с использованием соответствующих квантованных версий множества отдельных спектральных коэффициентов 106_t-1_f2 и 106_t-2_f2 или групп спектральных коэффициентов 106_t-1_f4, 106_t-2_f4, 106_t-1_f5 и 106_t-2_f5, по меньшей мере, двух предыдущих кадров 108_t-1 и 108_t-2 и с использованием извлеченных коэффициентов 112_f2, 114_f2, 112_f4, 114_f4, 112_f5 и 114_f5 предсказания.
Например, кодер 101 может быть выполнен с возможностью извлекать коэффициенты 112_f2 и 114_f2 предсказания для второго спектрального коэффициента 106_t0_f2 из значения разнесения, извлекать коэффициенты 112_f4 и 114_f4 предсказания для четвертого спектрального коэффициента 106_t0_f4 из значения разнесения и извлекать коэффициенты 112_f5 и 114_f5 предсказания для пятого спектрального коэффициента 106_t0_f5 из значения разнесения.
Например, извлечение коэффициентов предсказания может извлекаться следующим способом: Если значение разнесения соответствует частоте f0 либо ее кодированной версии, центральная частота K-ой группы спектральных коэффициентов, для которых активируется предсказание, составляет fc=K*f0. Если частота дискретизации составляет f, и размер перескока при преобразовании (сдвиг между последовательными кадрами) составляет N, идеальные коэффициенты предиктора в K-ой группе при условии синусоидального сигнала с частотой fc представляют собой следующее:
p1=2*cos(N*2*pi*fc/fs) и p2=-1.
Например, если оба спектральных коэффициента 106_t0_f4 и 106_t0_f5 находятся в этой группе, коэффициенты предсказания представляют собой следующее:
112_f4=112_f5=2*cos(N*2*pi*fc/fs) и 114_f4=114_f5=-1.
По причинам стабильности, может вводиться коэффициент d демпфирования, приводящий к модифицированным коэффициентам предсказания:
112_f4'=112_f5'=d*2*cos(N*2*pi*fc/fs), 114_f4'=114_f5'=d2.
Поскольку значение разнесения передается в кодированном аудиосигнале 120, декодер может извлекать совершенно идентичные коэффициенты предсказания 212_f4=212_f5=2*cos(N*2*pi*fc/fs) и 114_f4=114_f5=-1. Если коэффициент демпфирования используется, коэффициенты могут модифицироваться соответствующим образом.
Как указано на фиг. 8, кодер 101 может быть выполнен с возможностью предоставлять кодированный аудиосигнал 120. В силу этого, кодер 101 может быть выполнен с возможностью включать в квантованные версии кодированного аудиосигнала 120 ошибки предсказания для множества отдельных спектральных коэффициентов 106_t0_f2 или групп спектральных коэффициентов 106_t0_f4 и 106_t0_f5, к которым применяется кодирование с предсказанием. Дополнительно, кодер 101 может быть выполнен с возможностью не включать коэффициенты 112_f2-114_f5 предсказания в кодированный аудиосигнал 120.
Таким образом, кодер 101 может использовать коэффициенты 112_f2-14_f5 предсказания только для вычисления множества предсказанных отдельных спектральных коэффициентов 110_t0_f2 или групп предсказанных спектральных коэффициентов 110_t0_f4 и 110_t0_f5 и, из них, ошибок предсказания между предсказанным отдельным спектральным коэффициентом 110_t0_f2 или группой предсказанных спектральных коэффициентов 110_t0_f4 и 110_t0_f5 и отдельным спектральным коэффициентом 106_t0_f2 или группой предсказанных спектральных коэффициентов 110_t0_f4 и 110_t0_f5 текущего кадра, но не должен предоставлять ни отдельные спектральные коэффициенты 106_t0_f4 (либо их квантованную версию) или группы спектральных коэффициентов 106_t0_f4 и 106_t0_f5 (либо их квантованные версии), ни коэффициенты 112_f2-114_f5 предсказания в кодированном аудиосигнале 120. Следовательно, декодер, пример которого описывается ниже относительно фиг. 11, может извлекать коэффициенты 112_f2-114_f5 предсказания для вычисления множества предсказанных отдельных спектральных коэффициентов или групп предсказанных спектральных коэффициентов для текущего кадра из значения разнесения.
Другими словами, кодер 101 может быть выполнен с возможностью предоставлять кодированный аудиосигнал 120, включающий в себя квантованные версии ошибок предсказания вместо квантованных версий множества отдельных спектральных коэффициентов 106_t0_f2 или групп спектральных коэффициентов 106_t0_f4 и 106_t0_f5 для множества отдельных спектральных коэффициентов 106_t0_f2 или групп спектральных коэффициентов 106_t0_f4 и 106_t0_f5, к которым применяется кодирование с предсказанием.
Дополнительно, кодер 101 может быть выполнен с возможностью предоставлять кодированный аудиосигнал 102, включающий в себя квантованные версии спектральных коэффициентов 106_t0_f3, посредством которых разделяются множество отдельных спектральных коэффициентов 106_t0_f2 или группы спектральных коэффициентов 106_t0_f4 и 106_t0_f5 таким образом, что возникает чередование спектральных коэффициентов 106_t0_f2 или групп спектральных коэффициентов 106_t0_f4 и 106_t0_f5, для которых квантованные версии ошибок предсказания включаются в кодированный аудиосигнал 120, и спектральных коэффициентов 106_t0_f3 или групп спектральных коэффициентов, для которых квантованные версии предоставляются без использования кодирования с предсказанием.
В примерах кодер 101 может быть дополнительно выполнен с возможностью энтропийно кодировать квантованные версии ошибок предсказания и квантованные версии спектральных коэффициентов 106_t0_f3, посредством которых разделяются множество отдельных спектральных коэффициентов 106_t0_f2 или группы спектральных коэффициентов 106_t0_f4 и 106_t0_f5, и включать энтропийно кодированные версии в кодированный аудиосигнал 120 (вместо их неэнтропийно кодированных версий).
В примерах кодер 101 может быть выполнен с возможностью выбирать группы 116_1-116_6 спектральных коэффициентов (или отдельные спектральные коэффициенты), спектрально размещаемые согласно гармонической сетке, заданной посредством значения разнесения для кодирования с предсказанием. В силу этого, гармоническая сетка, заданная посредством значения разнесения, описывает периодическое спектральное распределение (равноотстоящее разнесение) гармоник в аудиосигнале 102. Другими словами, гармоническая сетка, заданная посредством значения разнесения, может представлять собой последовательность значений разнесения, описывающих равноотстоящее разнесение гармоник аудиосигнала.
Дополнительно, кодер 101 может быть выполнен с возможностью выбирать спектральные коэффициенты (например, только те спектральные коэффициенты), спектральные индексы которых равны или находятся в диапазоне (например, предварительно определенном или переменном) вокруг множества спектральных индексов, извлекаемых на основе значения разнесения, для кодирования с предсказанием.
Из значения разнесения, могут извлекаться индексы (или номера) спектральных коэффициентов, которые представляют гармоники аудиосигнала 102. Например, при условии, что четвертый спектральный коэффициент 106_t0_f4 представляет мгновенную фундаментальную частоту аудиосигнала 102, и при условии, что значение разнесения равно пяти, спектральный коэффициент, имеющий индекс девять, может извлекаться на основе значения разнесения. Такой извлеченный спектральный коэффициент, имеющий индекс девять, т.е. девятый спектральный коэффициент 106_t0_f9, представляет вторую гармонику. Аналогично, могут извлекаться спектральные коэффициенты, имеющие индексы 14, 19, 24 и 29, представляющие третью-шестую гармоники 124_3-124_6. Тем не менее, не только спектральные коэффициенты, имеющие индексы, которые равны множеству спектральных индексов, извлекаемых на основе значения разнесения, могут кодироваться с предсказанием, но также и спектральные коэффициенты, имеющие индексы в данном диапазоне вокруг множества спектральных индексов, извлекаемых на основе значения разнесения.
Дополнительно, кодер 101 может быть выполнен с возможностью выбирать группы 116_1-116_6 спектральных коэффициентов (или множество отдельных спектральных коэффициентов), к которым применяется кодирование с предсказанием, таким образом, что возникает периодическое чередование, периодическое с допуском в +/-1 спектральный коэффициент, между группами 116_1-116_6 спектральных коэффициентов (или множеством отдельных спектральных коэффициентов), к которым применяется кодирование с предсказанием, и спектральными коэффициентами, посредством которых разделяются группы спектральных коэффициентов (или множество отдельных спектральных коэффициентов), к которым применяется кодирование с предсказанием. Допуск в +/-1 спектральный коэффициент может требоваться, когда расстояние между двумя гармониками аудиосигнала 102 равно не целочисленному значению разнесения (целочисленному относительно индексов или номеров спектральных коэффициентов), а вместо этого его доле или кратному.
Другими словами, аудиосигнал 102 может содержать, по меньшей мере, два гармонических сигнальных компонента 124_1-124_6, при этом кодер 101 может быть выполнен с возможностью избирательно применять кодирование с предсказанием к этому множеству групп 116_1-116_6 спектральных коэффициентов (или к отдельным спектральным коэффициентам), которые представляют, по меньшей мере, два гармонических сигнальных компонента 124_1-124_6 или спектральные окружения вокруг, по меньшей мере, двух гармонических сигнальных компонентов 124_1-124_6 аудиосигнала 102. Спектральные окружения вокруг, по меньшей мере, двух гармонических сигнальных компонентов 124_1-124_6 могут составлять, например, +/-1, 2, 3, 4 или 5 спектральных компонентов.
В силу этого, кодер 101 может быть выполнен с возможностью не применять кодирование с предсказанием к этим группам 118_1-118_5 спектральных коэффициентов (или ко множеству отдельных спектральных коэффициентов), которые не представляют, по меньшей мере, два гармонических сигнальных компонента 124_1-124_6 или спектральные окружения, по меньшей мере, двух гармонических сигнальных компонентов 124_1-124_6 аудиосигнала 102. Другими словами, кодер 101 может быть выполнен с возможностью не применять кодирование с предсказанием к этому множеству групп 118_1-118_5 спектральных коэффициентов (или к отдельным спектральным коэффициентам), которые принадлежат нетональному фоновому шуму между сигнальными гармониками 124_1-124_6.
Дополнительно, кодер 101 может быть выполнен с возможностью определять гармоническое значение разнесения, указывающее спектральное разнесение, по меньшей мере, между двумя гармоническими сигнальными компонентами 124_1-124_6 аудиосигнала 102, причем гармоническое значение разнесения указывает это множество отдельных спектральных коэффициентов или группы спектральных коэффициентов, которые представляют, по меньшей мере, два гармонических сигнальных компонента 124_1-124_6 аудиосигнала 102.
Кроме того, кодер 101 может быть выполнен с возможностью предоставлять кодированный аудиосигнал 120 таким образом, что кодированный аудиосигнал 120 включает в себя значение разнесения (например, одно значение разнесения в расчете на кадр) или (альтернативно) параметр, из которого может непосредственно извлекаться значение разнесения.
Примеры разрешают вышеуказанные две проблемы FDP-способа посредством введения в FDP-процесс гармонического значения разнесения, передаваемого в служебных сигналах из кодера 101 (передающего устройства) в соответствующий декодер (приемное устройство) таким образом, что оба из них могут работать полностью синхронизированно. Упомянутое гармоническое значение разнесения может служить в качестве индикатора мгновенной фундаментальной частоты (или основного тона) одного или более спектров, ассоциированных с кадром, который выполнен с возможностью кодироваться, и идентифицирует то, какие спектральные элементы разрешения (спектральные коэффициенты) должны предсказываться. Более конкретно, только эти спектральные коэффициенты вокруг расположенных гармонических сигнальных компонентов (с точки зрения их индексации) в целые кратные фундаментального основного тона (заданного посредством гармонического значения разнесения) должны подвергаться предсказанию.
Фиг. 9 показывает принципиальную блок-схему декодера 201 для декодирования кодированного сигнала 120 концепции FDP-предсказания согласно примеру. Декодер 201 выполнен с возможностью декодировать кодированный аудиосигнал 120 в области преобразования или области 204 гребенки фильтров, при этом декодер 201 выполнен с возможностью синтаксически анализировать кодированный аудиосигнал 120, чтобы получать кодированные спектральные коэффициенты 206_t0_f1-206_t0_f6 аудиосигнала для текущего кадра 208_t0 и кодированные спектральные коэффициенты 206_t-1_f0-06_t-1_f6, по меньшей мере, для одного предыдущего кадра 208_t-1, и при этом декодер 201 выполнен с возможностью избирательно применять декодирование с предсказанием ко множеству отдельных кодированных спектральных коэффициентов или к группам кодированных спектральных коэффициентов, которые разделяются, по меньшей мере, посредством одного кодированного спектрального коэффициента.
В примерах декодер 201 может быть выполнен с возможностью применять декодирование с предсказанием ко множеству отдельных кодированных спектральных коэффициентов, которые разделяются, по меньшей мере, посредством одного кодированного спектрального коэффициента, к примеру, к двум отдельным кодированным спектральным коэффициентам, которые разделяются, по меньшей мере, посредством одного кодированного спектрального коэффициента. Дополнительно, декодер 201 может быть выполнен с возможностью применять декодирование с предсказанием ко множеству групп кодированных спектральных коэффициентов (причем каждая из групп содержит, по меньшей мере, два кодированных спектральных коэффициента), которые разделяются, по меньшей мере, посредством одного кодированного спектрального коэффициента, к примеру, к двум группам кодированных спектральных коэффициентов, которые разделяются, по меньшей мере, посредством одного кодированного спектрального коэффициента. Дополнительно, декодер 201 может быть выполнен с возможностью применять декодирование с предсказанием ко множеству отдельных кодированных спектральных коэффициентов и/или к группам кодированных спектральных коэффициентов, которые разделяются, по меньшей мере, посредством одного кодированного спектрального коэффициента, к примеру, по меньшей мере, к одному отдельному кодированному спектральному коэффициенту и, по меньшей мере, к одной группе кодированных спектральных коэффициентов, которые разделяются, по меньшей мере, посредством одного кодированного спектрального коэффициента.
В примере, показанном на фиг. 9, декодер 201 выполнен с возможностью определять шесть кодированных спектральных коэффициентов 206_t0_f1-206_t0_f6 для текущего кадра 208_t0 и шесть кодированных спектральных коэффициентов 206_t-1_f1-206_t-1_f6 для предыдущего кадра 208_t-1. В силу этого, декодер 201 выполнен с возможностью избирательно применять декодирование с предсказанием к отдельному второму кодированному спектральному коэффициенту 206_t0_f2 текущего кадра и к группе кодированных спектральных коэффициентов, состоящей из четвертого и пятого кодированных спектральных коэффициентов 206_t0_f4 и 206_t0_f5 текущего кадра 208_t0. Как можно видеть, отдельный второй кодированный спектральный коэффициент 206_t0_f2 и группа кодированных спектральных коэффициентов, состоящая из четвертого и пятого кодированных спектральных коэффициентов 206_t0_f4 и 206_t0_f5, разделяются друг от друга посредством третьего кодированного спектрального коэффициента 206_t0_f3.
Следует отметить, что термин "избирательно" при использовании в данном документе означает применение декодирования с предсказанием (только) к выбранным кодированным спектральным коэффициентам. Другими словами, декодирование с предсказанием применяется не ко всем кодированным спектральным коэффициентам, а вместо этого только к выбранным отдельным кодированным спектральным коэффициентам или к группам кодированных спектральных коэффициентов, причем выбранные отдельные кодированные спектральные коэффициенты и/или группы кодированных спектральных коэффициентов разделяются друг от друга, по меньшей мере, посредством одного кодированного спектрального коэффициента. Другими словами, декодирование с предсказанием не применяется, по меньшей мере, к одному кодированному спектральному коэффициенту, посредством которого разделяются выбранное множество отдельных кодированных спектральных коэффициентов или группы кодированных спектральных коэффициентов.
В примерах декодер 201 может быть выполнен с возможностью не применять декодирование с предсказанием, по меньшей мере, к одному кодированному спектральному коэффициенту 206_t0_f3, посредством которого разделяются отдельные кодированные спектральные коэффициенты 206_t0_f2 или группа спектральных коэффициентов 206_t0_f4 и 206_t0_f5.
Декодер 201 может быть выполнен с возможностью энтропийно декодировать кодированные спектральные коэффициенты, чтобы получать квантованные ошибки предсказания для спектральных коэффициентов 206_t0_f2, 2016_t0_f4 и 206_t0_f5, к которым должно применяться декодирование с предсказанием, и для квантованных спектральных коэффициентов 206_t0_f3, по меньшей мере, для одного спектрального коэффициента, к которым не должно применяться декодирование с предсказанием. В силу этого, декодер 201 может быть выполнен с возможностью применять квантованные ошибки предсказания ко множеству предсказанных отдельных спектральных коэффициентов 210_t0_f2 или к группам предсказанных спектральных коэффициентов 210_t0_f4 и 210_t0_f5, чтобы получать, для текущего кадра 208_t0, декодированные спектральные коэффициенты, ассоциированные с кодированными спектральными коэффициентами 206_t0_f2, 206_t0_f4 и 206_t0_f5, к которым применяется декодирование с предсказанием.
Например, декодер 201 может быть выполнен с возможностью получать вторую квантованную ошибку предсказания для второго квантованного спектрального коэффициента 206_t0_f2 и применять вторую квантованную ошибку предсказания к предсказанному второму спектральному коэффициенту 210_t0_f2, чтобы получать второй декодированный спектральный коэффициент, ассоциированный со вторым кодированным спектральным коэффициентом 206_t0_f2, при этом декодер 201 может быть выполнен с возможностью получать четвертую квантованную ошибку предсказания для четвертого квантованного спектрального коэффициента 206_t0_f4 и применять четвертую квантованную ошибку предсказания к предсказанному четвертому спектральному коэффициенту 210_t0_f4, чтобы получать четвертый декодированный спектральный коэффициент, ассоциированный с четвертым кодированным спектральным коэффициентом 206_t0_f4, и при этом декодер 201 может быть выполнен с возможностью получать пятую квантованную ошибку предсказания для пятого квантованного спектрального коэффициента 206_t0_f5 и применять пятую квантованную ошибку предсказания к предсказанному пятому спектральному коэффициенту 210_t0_f5, чтобы получать пятый декодированный спектральный коэффициент, ассоциированный с пятым кодированным спектральным коэффициентом 206_t0_f5.
Дополнительно, декодер 201 может быть выполнен с возможностью определять множество предсказанных отдельных спектральных коэффициентов 210_t0_f2 или группы предсказанных спектральных коэффициентов 210_t0_f4 и 210_t0_f5 для текущего кадра 208_t0 на основе соответствующего множества отдельных кодированных спектральных коэффициентов 206_t-1_f2 (например, с использованием множества ранее декодированных спектральных коэффициентов, ассоциированных с множеством отдельных кодированных спектральных коэффициентов 206_t-1_f2) или групп кодированных спектральных коэффициентов 206_t-1_f4 и 206_t-1_f5 (например, с использованием групп ранее декодированных спектральных коэффициентов, ассоциированных с группами кодированных спектральных коэффициентов 206_t-1_f4 и 206_t-1_f5) предыдущего кадра 208_t-1.
Например, декодер 201 может быть выполнен с возможностью определять второй предсказанный спектральный коэффициент 210_t0_f2 текущего кадра 208_t0 с использованием ранее декодированного (квантованного) второго спектрального коэффициента, ассоциированного со вторым кодированным спектральным коэффициентом 206_t-1_f2 предыдущего кадра 208_t-1, четвертый предсказанный спектральный коэффициент 210_t0_f4 текущего кадра 208_t0 с использованием ранее декодированного (квантованного) четвертого спектрального коэффициента, ассоциированного с четвертым кодированным спектральным коэффициентом 206_t-1_f4 предыдущего кадра 208_t-1, и пятый предсказанный спектральный коэффициент 210_t0_f5 текущего кадра 208_t0 с использованием ранее декодированного (квантованного) пятого спектрального коэффициента, ассоциированного с пятым кодированным спектральным коэффициентом 206_t-1_f5 предыдущего кадра 208_t-1.
Кроме того, декодер 201 может быть выполнен с возможностью извлекать коэффициенты предсказания из значения разнесения, и при этом декодер 201 может быть выполнен с возможностью вычислять множество предсказанных отдельных спектральных коэффициентов 210_t0_f2 или группы предсказанных спектральных коэффициентов 210_t0_f4 и 210_t0_f5 для текущего кадра 208_t0 с использованием соответствующего множества ранее декодированных отдельных спектральных коэффициентов или групп ранее декодированных спектральных коэффициентов, по меньшей мере, двух предыдущих кадров 208_t-1 и 208_t-2 и с использованием извлеченных коэффициентов предсказания.
Например, декодер 201 может быть выполнен с возможностью извлекать коэффициенты 212_f2 и 214_f2 предсказания для второго кодированного спектрального коэффициента 206_t0_f2 из значения разнесения, извлекать коэффициенты 212_f4 и 214_f4 предсказания для четвертого кодированного спектрального коэффициента 206_t0_f4 из значения разнесения и извлекать коэффициенты 212_f5 и 214_f5 предсказания для пятого кодированного спектрального коэффициента 206_t0_f5 из значения разнесения.
Следует отметить, что декодер 201 может быть выполнен с возможностью декодировать кодированный аудиосигнал 120, чтобы получать квантованные ошибки предсказания, вместо множества отдельных квантованных спектральных коэффициентов или групп квантованных спектральных коэффициентов для множества отдельных кодированных спектральных коэффициентов или групп кодированных спектральных коэффициентов, к которым применяется декодирование с предсказанием.
Дополнительно, декодер 201 может быть выполнен с возможностью декодировать кодированный аудиосигнал 120, чтобы получать квантованные спектральные коэффициенты, посредством которых разделяются множество отдельных спектральных коэффициентов или группы спектральных коэффициентов таким образом, что возникает чередование кодированных спектральных коэффициентов 206_t0_f2 или групп кодированных спектральных коэффициентов 206_t0_f4 и 206_t0_f5, для которых получаются квантованные ошибки предсказания, и кодированных спектральных коэффициентов 206_t0_f3 или групп кодированных спектральных коэффициентов, для которых получаются квантованные спектральные коэффициенты.
Декодер 201 может быть выполнен с возможностью предоставлять декодированный аудиосигнал 220 с использованием декодированных спектральных коэффициентов, ассоциированных с кодированными спектральными коэффициентами 206_t0_f2, 206_t0_f4 и 206_t0_f5, к которым применяется декодирование с предсказанием, и с использованием энтропийно декодированных спектральных коэффициентов, ассоциированных с кодированными спектральными коэффициентами 206_t0_f1, 206_t0_f3 и 206_t0_f6, к которым не применяется декодирование с предсказанием.
В примерах декодер 201 может быть выполнен с возможностью получать значение разнесения, при этом декодер 201 может быть выполнен с возможностью выбирать множество отдельных кодированных спектральных коэффициентов 206_t0_f2 или группы кодированных спектральных коэффициентов 206_t0_f4 и 206_t0_f5, к которым применяется декодирование с предсказанием, на основе значения разнесения.
Как уже упомянуто выше относительно описания соответствующего кодера 101, значение разнесения, например, может представлять собой разнесение (или расстояние) между двумя характеристическими частотами аудиосигнала. Дополнительно, значение разнесения может составлять целое число спектральных коэффициентов (или индексов спектральных коэффициентов), аппроксимирующее разнесение между двумя характеристическими частотами аудиосигнала. Естественно, значение разнесения также может составлять долю или кратное целого числа спектральных коэффициентов, описывающее разнесение между двумя характеристическими частотами аудиосигнала.
Декодер 201 может быть выполнен с возможностью выбирать отдельные спектральные коэффициенты или группы спектральных коэффициентов, спектрально размещаемые согласно гармонической сетке, заданной посредством значения разнесения для декодирования с предсказанием. Гармоническая сетка, заданная посредством значения разнесения, может описывать периодическое спектральное распределение (равноотстоящее разнесение) гармоник в аудиосигнале 102. Другими словами, гармоническая сетка, заданная посредством значения разнесения, может представлять собой последовательность значений разнесения, описывающих равноотстоящее разнесение гармоник аудиосигнала 102.
Кроме того, декодер 201 может быть выполнен с возможностью выбирать спектральные коэффициенты (например, только те спектральные коэффициенты), спектральные индексы которых равны или находятся в диапазоне (например, предварительно определенном или переменном диапазоне) вокруг множества спектральных индексов, извлекаемых на основе значения разнесения для декодирования с предсказанием. В силу этого, декодер 201 может быть выполнен с возможностью задавать ширину диапазона в зависимости от значения разнесения.
В примерах кодированный аудиосигнал может содержать значение разнесения либо его кодированную версию (например, параметр, из которого значение разнесения может непосредственно извлекаться), при этом декодер 201 может быть выполнен с возможностью извлекать значение разнесения либо его кодированную версию из кодированного аудиосигнала, чтобы получать значение разнесения.
Альтернативно, декодер 201 может быть выполнен с возможностью определять значение разнесения отдельно, т.е. кодированный аудиосигнал не включает в себя значение разнесения. В этом случае, декодер 201 может быть выполнен с возможностью определять мгновенную фундаментальную частоту (кодированного аудиосигнала 120, представляющего аудиосигнал 102) и извлекать значение разнесения из мгновенной фундаментальной частоты либо из ее доли или кратного.
В примерах декодер 201 может быть выполнен с возможностью выбирать множество отдельных спектральных коэффициентов или группы спектральных коэффициентов, к которым применяется декодирование с предсказанием, таким образом, что возникает периодическое чередование, периодическое с допуском в +/-1 спектральный коэффициент, между множеством отдельных спектральных коэффициентов или группами спектральных коэффициентов, к которым применяется декодирование с предсказанием, и спектральными коэффициентами, посредством которых разделяются множество отдельных спектральных коэффициентов или группы спектральных коэффициентов, к которым применяется декодирование с предсказанием.
В примерах аудиосигнал 102, представленный посредством кодированного аудиосигнала 120, содержит, по меньшей мере, два гармонических сигнальных компонента, при этом декодер 201 выполнен с возможностью избирательно применять декодирование с предсказанием к этому множеству отдельных кодированных спектральных коэффициентов 206_t0_f2 или к группам кодированных спектральных коэффициентов 206_t0_f4 и 206_t0_f5, которые представляют, по меньшей мере, два гармонических сигнальных компонента или спектральные окружения вокруг, по меньшей мере, двух гармонических сигнальных компонентов аудиосигнала 102. Спектральные окружения вокруг, по меньшей мере, двух гармонических сигнальных компонентов могут составлять, например, +/-1, 2, 3, 4 или 5 спектральных компонентов.
В силу этого декодер 201 может быть выполнен с возможностью идентифицировать, по меньшей мере, два гармонических сигнальных компонента и избирательно применять декодирование с предсказанием к этому множеству отдельных кодированных спектральных коэффициентов 206_t0_f2 или к группам кодированных спектральных коэффициентов 206_t0_f4 и 206_t0_f5, которые ассоциированы с идентифицированными гармоническими сигнальными компонентами, например, которые представляют идентифицированные гармонические сигнальные компоненты или которые окружают идентифицированные гармонические сигнальные компоненты.
Альтернативно, кодированный аудиосигнал 120 может содержать информацию (например, значение разнесения), идентифицирующую, по меньшей мере, два гармонических сигнальных компонента. В этом случае, декодер 201 может быть выполнен с возможностью избирательно применять декодирование с предсказанием к этому множеству отдельных кодированных спектральных коэффициентов 206_t0_f2 или к группам кодированных спектральных коэффициентов 206_t0_f4 и 206_t0_f5, которые ассоциированы с идентифицированными гармоническими сигнальными компонентами, например, которые представляют идентифицированные гармонические сигнальные компоненты или которые окружают идентифицированные гармонические сигнальные компоненты.
В обеих вышеуказанных альтернативах, декодер 201 может быть выполнен с возможностью не применять декодирование с предсказанием к этому множеству отдельных кодированных спектральных коэффициентов 206_t0_f3, 206_t0_f1 и 206_t0_f6 или к группам кодированных спектральных коэффициентов, которые не представляют, по меньшей мере, два гармонических сигнальных компонента или спектральные окружения, по меньшей мере, двух гармонических сигнальных компонентов аудиосигнала 102.
Другими словами, декодер 201 может быть выполнен с возможностью не применять декодирование с предсказанием к этому множеству отдельных кодированных спектральных коэффициентов 206_t0_f3, 206_t0_f1, 206_t0_f6 или к группам кодированных спектральных коэффициентов, которые принадлежат нетональному фоновому шуму между сигнальными гармониками аудиосигнала 102.
Идея конкретных вариантов осуществления теперь заключается в том, чтобы предоставлять кодер и декодер, имеющие различные рабочие режимы.
Согласно варианту осуществления кодер 100, например, может работать в первом режиме и, например, может работать, по меньшей мере, в одном из второго режима и третьего режима, и четвертого режима.
Если кодер 100 находится в первом режиме, кодер 100, например, может быть выполнен с возможностью кодировать текущий кадр посредством определения оценки двух гармонических параметров для каждого из одного или более гармонических компонентов самого предыдущего кадра с использованием первой группы из трех или более из множества спектральных коэффициентов каждого из одного или более предыдущих кадров аудиосигнала.
Если кодер 100 находится во втором режиме, кодер 100, например, может быть выполнен с возможностью кодировать аудиосигнал в области преобразования или в области гребенки фильтров, и кодер, например, может быть выполнен с возможностью определять множество спектральных коэффициентов 106_t0_f1:106_t0_f6; 106_t-1_f1:106_t-1_f6 аудиосигнала 102 для текущего кадра 108_t0 и, по меньшей мере, для предыдущего кадра 108_t-1, при этом кодер 100, например, может быть выполнен с возможностью избирательно применять кодирование с предсказанием ко множеству отдельных спектральных коэффициентов 106_t0_f2 или к группам спектральных коэффициентов 106_t0_f4, 106_t0_f5, кодер 100, например, может быть выполнен с возможностью определять значение разнесения, кодер 100, например, может быть выполнен с возможностью выбирать множество отдельных спектральных коэффициентов 106_t0_f2 или группы спектральных коэффициентов 106_t0_f4, 106_t0_f5, к которым, например, может применяться кодирование с предсказанием, на основе значения разнесения.
В варианте осуществления в каждом из первого режима и второго режима, и третьего режима, и четвертого режима, кодер 100, например, может быть выполнен с возможностью детализировать фундаментальную частоту для того, чтобы получать детализированную фундаментальную частоту, и выполнен с возможностью адаптировать коэффициент усиления для того, чтобы получать адаптированный коэффициент усиления на основе кадров, в зависимости от критерия минимизации. Кроме того, кодер 100, например, может быть выполнен с возможностью кодировать детализированную фундаментальную частоту и адаптированный коэффициент усиления вместо исходной фундаментальной частоты и коэффициента усиления.
В варианте осуществления кодер 100, например, может быть выполнен с возможностью устанавливать себя в первый режим или, по меньшей мере, в один из второго режима и третьего режима, и четвертого режима, в зависимости от текущего кадра аудиосигнала. Кодер 100, например, может быть выполнен с возможностью кодировать то, кодирован ли текущий кадр в первом режиме или во втором режиме, или в третьем режиме, или в четвертом режиме.
Относительно декодера согласно варианту осуществления, декодер 200, например, может работать в первом режиме и, например, может работать, по меньшей мере, в одном из второго режима и третьего режима, и четвертого режима.
Если декодер 200 находится в первом режиме, декодер 200, например, может быть выполнен с возможностью определять оценку двух гармонических параметров для каждого из одного или более гармонических компонентов самого предыдущего кадра, при этом два гармонических параметра для каждого из одного или более гармонических компонентов самого предыдущего кадра зависят от первой группы из трех или более из множества восстановленных спектральных коэффициентов для каждого из одного или более предыдущих кадров аудиосигнала, и декодер 200, например, может быть выполнен с возможностью декодировать кодирование текущего кадра в зависимости от оценки двух гармонических параметров для каждого из одного или более гармонических компонентов самого предыдущего кадра.
Если декодер 200 находится во втором режиме, декодер 200, например, может быть выполнен с возможностью синтаксически анализировать кодирование аудиосигнала 120, чтобы получать кодированные спектральные коэффициенты 206_t0_f1:206_t0_f6; 206_t-1_f1:206_t-1_f6 аудиосигнала 120 для текущего кадра 208_t0 и, по меньшей мере, для предыдущего кадра 208_t-1, и декодер 200, например, может быть выполнен с возможностью избирательно применять декодирование с предсказанием ко множеству отдельных кодированных спектральных коэффициентов 206_t0_f2 или к группам кодированных спектральных коэффициентов 206_t0_f4, 206_t0_f5, при этом декодер 200, например, может быть выполнен с возможностью получать значение разнесения, при этом декодер 200, например, может быть выполнен с возможностью выбирать множество отдельных кодированных спектральных коэффициентов 206_t0_f2 или группы кодированных спектральных коэффициентов 206_t0_f4, 206_t0_f5, к которым, например, может применяться декодирование с предсказанием, на основе значения разнесения.
Если декодер 200 находится в третьем режиме, декодер 200, например, может быть выполнен с возможностью декодировать аудиосигнал посредством использования долговременного предсказания во временной области.
Если декодер 200 находится в четвертом режиме, декодер 200, например, может декодировать аудиосигнал посредством использования долговременного предсказания с адаптивным модифицированным дискретным косинусным преобразованием, при этом, если декодер 200 использует долговременное предсказание с адаптивным модифицированным дискретным косинусным преобразованием, декодер 200, например, может быть выполнен с возможностью выбирать либо долговременное предсказание во временной области, либо предсказание в частотной области, либо предсказание по методу наименьших квадратов в частотной области в качестве способа предсказания на основе кадров в зависимости от критерия минимизации.
Согласно варианту осуществления в каждом из первого режима и второго режима, и третьего режима, и четвертого режима, декодер 200, например, может быть выполнен с возможностью декодировать аудиосигнал в зависимости от детализированной фундаментальной частоты и в зависимости от адаптированного коэффициента усиления, которые определены на основе кадров.
В варианте осуществления декодер 200, например, может быть выполнен с возможностью принимать и декодировать кодирование, содержащее индикатор относительно того, кодирован текущий кадр в первом режиме или во втором режиме, или в третьем режиме, или в четвертом режиме. Декодер 200, например, может быть выполнен с возможностью устанавливать себя в первый режим или во второй режим, или в третий режим, или в четвертый режим в зависимости от индикатора.
На фиг. 5 можно видеть, что BS всех трех концепций значительно падает для ноты дудки, когда длина кадра увеличивается, поскольку избыточность в исходном сигнале в значительной степени удалена посредством самого преобразования. Производительность FDP ухудшается значительно для низкотональной басовой ноты вследствие сильно перекрывающихся гармоник для MDCT-коэффициентов. Производительность TDLTP, в целом, является хорошей. Но она ухудшается, когда длина кадра является большой, при этом требуется большая задержка в нахождении совпадающего предыдущего периода основного тона. FDLMSP предлагает относительно хорошую и стабильную производительность относительно различных нот и различных длин кадров. Фиг. 5 также показывает то, что BS падает, когда полоса пропускания предсказания увеличивается до 8 кГц, что получается в результате негармоничности тонов в полосах верхних частот. Поскольку негармоничность зависит от спектральных характеристик каждого отдельного звукового материала, предварительное вычисление и сравнение относительно потребления по скорости передачи битов могут выполняться для каждой полосы частот, чтобы получать более высокую эффективность кодирования. Решение по предсказанию затем может приниматься и передаваться в служебных сигналах в каждом кадре в качестве вспомогательной информации.
Фиг. 6 иллюстрирует экономию по скоростям передачи битов в четырех различных рабочих режимах для шести различных элементов с полосой пропускания, ограниченной 4 кГц, и длиной MDCT-кадра в 64 и 512.
Как показано на фиг. 6, FDLMSP превосходит TDLTP и FDP во множестве сценариев и предлагает, в общем, хорошую производительность. AMLTP работает лучше всего и выбирает в большинстве случаев FDLMSP или TDLTP, что указывает то, что FDLMSP может комбинироваться с TDLTP, чтобы значительно улучшать BS.
Предоставлен новый подход для LTP в MDCT-области. Новый подход моделирует каждый MDCT-кадр в качестве гипотезы гармонических компонентов и оценивает параметры всех гармонических компонентов из предыдущих кадров с использованием LMS-концепции. Предсказание затем выполняется на основе оцененных гармонических параметров. Этот подход предлагает конкурентную производительность по сравнению со своими равноправными концепциями и также может использоваться совместно для того, чтобы повышать эффективность кодирования аудио.
Вышеуказанные концепции, например, могут использоваться для того, чтобы анализировать влияние точности информации основного тона на предсказание, например, посредством использования различных алгоритмов оценки основного тона или посредством применения различных размеров шагов квантования. Вышеуказанные концепции также могут использоваться для того, чтобы определять или детализировать информацию основного тона аудиосигнала на основе кадров с использованием критериев минимизации. Влияние негармоничности и других сложных характеристик сигналов на предсказание, например, может учитываться. Вышеуказанные концепции, например, могут использоваться для скрытия ошибок.
Хотя некоторые аспекты описаны в контексте оборудования, очевидно, что эти аспекты также представляют описание соответствующего способа, при этом блок или устройство соответствует этапу способа либо признаку этапа способа. Аналогично, аспекты, описанные в контексте этапа способа, также представляют описание соответствующего блока или элемента, или признака соответствующего оборудования. Некоторые или все этапы способа могут выполняться посредством (или с использованием) аппаратного оборудования, такого как, например, микропроцессор, программируемый компьютер либо электронная схема. В некоторых вариантах осуществления, один или более из самых важных этапов способа могут выполняться посредством этого оборудования.
В зависимости от определенных требований к реализации, варианты осуществления изобретения могут реализовываться в аппаратных средствах либо в программном обеспечении, либо, по меньшей мере, частично в аппаратных средствах, либо, по меньшей мере, частично в программном обеспечении. Реализация может выполняться с использованием цифрового носителя хранения данных, например, гибкого диска, DVD, Blu-Ray, CD, ROM, PROM, EPROM, EEPROM или флэш-памяти, имеющего сохраненные электронно считываемые управляющие сигналы, которые взаимодействуют (или допускают взаимодействие) с программируемой компьютерной системой таким образом, что осуществляется соответствующий способ. Следовательно, цифровой носитель хранения данных может быть машиночитаемым.
Некоторые варианты осуществления согласно изобретению содержат носитель данных, имеющий электронно-считываемые управляющие сигналы, которые допускают взаимодействие с программируемой компьютерной системой таким образом, что осуществляется один из способов, описанных в данном документе.
В общем, варианты осуществления настоящего изобретения могут реализовываться как компьютерный программный продукт с программным кодом, при этом программный код выполнен с возможностью осуществления одного из способов, когда компьютерный программный продукт работает на компьютере. Программный код, например, может сохраняться на машиночитаемом носителе.
Другие варианты осуществления содержат компьютерную программу для осуществления одного из способов, описанных в данном документе, сохраненную на машиночитаемом носителе.
Другими словами, вариант осуществления изобретаемого способа в силу этого представляет собой компьютерную программу, имеющую программный код для осуществления одного из способов, описанных в данном документе, когда компьютерная программа работает на компьютере.
Следовательно, дополнительный вариант осуществления изобретательских способов представляет собой носитель хранения данных (цифровой носитель хранения данных или машиночитаемый носитель), содержащий записанную компьютерную программу для осуществления одного из способов, описанных в данном документе. Носитель данных, цифровой носитель хранения данных или носитель с записанными данными типично является материальным и/или энергонезависимым.
Следовательно, дополнительный вариант осуществления изобретаемого способа представляет собой поток данных или последовательность сигналов, представляющих компьютерную программу для осуществления одного из способов, описанных в данном документе. Поток данных или последовательность сигналов, например, может быть выполнена с возможностью передачи через соединение для передачи данных, например, через Интернет.
Дополнительный вариант осуществления содержит средство обработки, например, компьютер или программируемое логическое устройство, выполненное с возможностью осуществлять один из способов, описанных в данном документе.
Дополнительный вариант осуществления содержит компьютер, имеющий установленную компьютерную программу для осуществления одного из способов, описанных в данном документе.
Дополнительный вариант осуществления согласно изобретению содержит оборудование или систему, выполненную с возможностью передавать (например, электронно или оптически) компьютерную программу для осуществления одного из способов, описанных в данном документе, в приемное устройство. Приемное устройство, например, может представлять собой компьютер, мобильное устройство, запоминающее устройство и т.п. Оборудование или система, например, может содержать файловый сервер для передачи компьютерной программы в приемное устройство.
В некоторых вариантах осуществления, программируемое логическое устройство (например, программируемая пользователем вентильная матрица) может использоваться для того, чтобы выполнять часть или все из функциональных возможностей способов, описанных в данном документе. В некоторых вариантах осуществления, программируемая пользователем вентильная матрица может взаимодействовать с микропроцессором, чтобы осуществлять один из способов, описанных в данном документе. В общем, способы предпочтительно осуществляются посредством любого аппаратного оборудования.
Оборудование, описанное в данном документе, может реализовываться с использованием аппаратного оборудования либо с использованием компьютера, либо с использованием комбинации аппаратного оборудования и компьютера.
Способы, описанные в данном документе, могут осуществляться с использованием аппаратного оборудования либо с использованием компьютера, либо с использованием комбинации аппаратного оборудования и компьютера.
Вышеописанные варианты осуществления являются просто иллюстративными в отношении принципов настоящего изобретения. Следует понимать, что модификации и изменения компоновок и подробностей, описанных в данном документе, должны быть очевидными для специалистов в данной области техники. Следовательно, они подразумеваются как ограниченные только посредством объема нижеприведенной формулы изобретения, а не посредством конкретных подробностей, представленных посредством описания и пояснения вариантов осуществления в данном документе.
Библиографический список
[1] Jürgen Herre и Sascha Dick "Psychoacoustic models for perceptual audio coding the tutorial review", Applied Sciences, издание 9, стр. 2854, ITT, 2019 год.
[2] Juha Ojanperä, Mauri Väänänen и Lin Yin "Long Term Predictor for Transform Domain Perceptual Audio Coding", in Audio Engineering Society Convention 107, сентябрь 1999 года.
[3] Hendrik Fuchs "Improving mpeg audio coding by backward adaptive linear stereo prediction", in Audio Engineering Society Convention 99, октябрь 1995 года.
[4] J. Princen, A. Johnson и A. Bradley "Subband/transform coding using filter bank designs based on time domain aliasing cancellation", in ICASSP '87. IEEE International Conference on Acoustics, Speech and Signal Processing, апрель 1987 года, издание 12, стр. 2161-2164.
[5] Christian Helmrich "Efficient Perceptual Audio Coding Using Cosine and Sine Modulated Lapped Transforms", doctoral thesis, Friedrich-Alexander-Universität Erlangen-Nürnberg (FAU), 2017 год, глава 3.3: "Frequency-Domain Prediction with Very Low Complexity".
[6] J. Rothweiler "Polyphase quadrature filters-a new subband coding technique", in ICASSP '83. IEEE International C01iference on Acoustics, Speech and Signal Processing, апрель 1983 года, издание 8, стр. 1280-1283.
[7] Albrecht Schneider и Klaus Frieler "Perception of harmonic and inharmonic sounds: Results from ear models" in "Computer Music Modeling and Retrieval. Genesis of Meaning in Sound and Music,", Sølvi Ystad, Richard Kronland-Martinet and Kristoffer Jensen, Eds., Berlin, Heidelberg, 2009 год, стр. 18-44, Springer Berlin Heidelberg.
[8] Hugo Fastl и Eberhard Zwicker "Psychoacoustics: Facts and Models", Springer-Verlag, Berlin, Heidelberg, 2006 год, глава 7.2: "Just-Noticeable Changes in Frequency".
[9] John P. Princen и Alan Bernard Bradley "Analysis/synthesis filter bank design based on time domain aliasing cancellation", IEEE Transactions on Acoustics, Speech and Signal Processing, издание 34, номер 5, стр. 1153-1161, октябрь 1986 года.
[10] Alain de Cheveign и Hideki Kawahara "Yin, the fundamental frequency estimator for speech and music", The Journal of the Acoustical Society of America, издание 111, стр. 1917-30, 05-2002 года.
[11] Armin Taghipour "Psychoacoustics of detection of tonality and asymmetry of masking: implementation of tonality estimation methods in the psychoacoustic model for perceptual audio coding", doctoral thesis, Friedrich-Alexander-Universität Erlangen-Nürnberg (FAU), 2016 год, глава 4: "The Psychoacoustic model".
[12] J.D. Johnston "Estimation of perceptual entropy using noise masking criteria", in ICASSP-88' International Conference on Acoustics, Speech and Signal Processing, апрель 1988 года, стр. 2524-2527, издание 5.
[13] WO 2016 142357 A1, опубликован в сентябре 2016 года.
| название | год | авторы | номер документа |
|---|---|---|---|
| АУДИОКОДЕР, АУДИОДЕКОДЕР, СПОСОБ КОДИРОВАНИЯ АУДИОСИГНАЛА И СПОСОБ ДЕКОДИРОВАНИЯ КОДИРОВАННОГО АУДИОСИГНАЛА | 2016 |
|
RU2707151C2 |
| РЕГУЛИРОВКА УРОВНЯ ВО ВРЕМЕННОЙ ОБЛАСТИ ДЛЯ ДЕКОДИРОВАНИЯ ИЛИ КОДИРОВАНИЯ АУДИОСИГНАЛОВ | 2014 |
|
RU2608878C1 |
| ДЕКОДЕР ДЛЯ ДЕКОДИРОВАНИЯ КОДИРОВАННОГО АУДИОСИГНАЛА И КОДЕР ДЛЯ КОДИРОВАНИЯ АУДИОСИГНАЛА | 2016 |
|
RU2691231C2 |
| АУДИОКОДЕР, АУДИОДЕКОДЕР И СВЯЗАННЫЕ СПОСОБЫ ОБРАБОТКИ МНОГОКАНАЛЬНЫХ АУДИОСИГНАЛОВ С ИСПОЛЬЗОВАНИЕМ КОМПЛЕКСНОГО ПРЕДСКАЗАНИЯ | 2011 |
|
RU2577195C2 |
| ДЕКОДЕР И СПОСОБ ДЕКОДИРОВАНИЯ С ВЫБОРОМ РЕЖИМА СКРЫТИЯ ОШИБОК, А ТАКЖЕ КОДЕР И СПОСОБ КОДИРОВАНИЯ | 2020 |
|
RU2807683C2 |
| АУДИОКОДЕР И ДЕКОДЕР | 2015 |
|
RU2696292C2 |
| КОДИРОВАНИЕ И ДЕКОДИРОВАНИЕ ИМПУЛЬСНЫХ И ОСТАТОЧНЫХ ЧАСТЕЙ ЗВУКОВОГО СИГНАЛА | 2022 |
|
RU2825308C2 |
| УПРАВЛЕНИЕ ПОЛОСОЙ ЧАСТОТ В КОДЕРАХ И/ИЛИ ДЕКОДЕРАХ | 2018 |
|
RU2752520C1 |
| УСТРОЙСТВО И СПОСОБ ДЛЯ КОДИРОВАНИЯ И ДЕКОДИРОВАНИЯ АУДИОСИГНАЛА С ИСПОЛЬЗОВАНИЕМ ВЫРОВНЕННОЙ ЧАСТИ ОПЕРЕЖАЮЩЕГО ПРОСМОТРА | 2012 |
|
RU2574849C2 |
| АУДИОКОДЕР ДЛЯ КОДИРОВАНИЯ АУДИОСИГНАЛА, СПОСОБ ДЛЯ КОДИРОВАНИЯ АУДИОСИГНАЛА И КОМПЬЮТЕРНАЯ ПРОГРАММА, УЧИТЫВАЮЩИЕ ДЕТЕКТИРУЕМУЮ СПЕКТРАЛЬНУЮ ОБЛАСТЬ ПИКОВ В ВЕРХНЕМ ЧАСТОТНОМ ДИАПАЗОНЕ | 2017 |
|
RU2719008C1 |
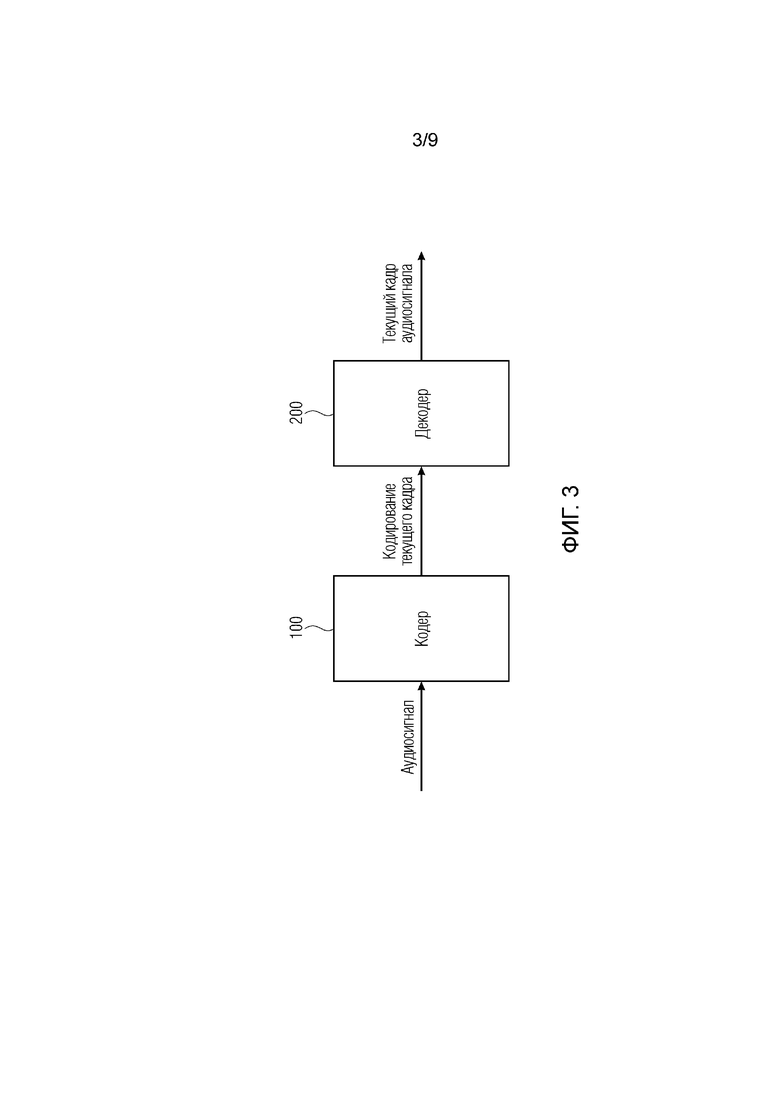
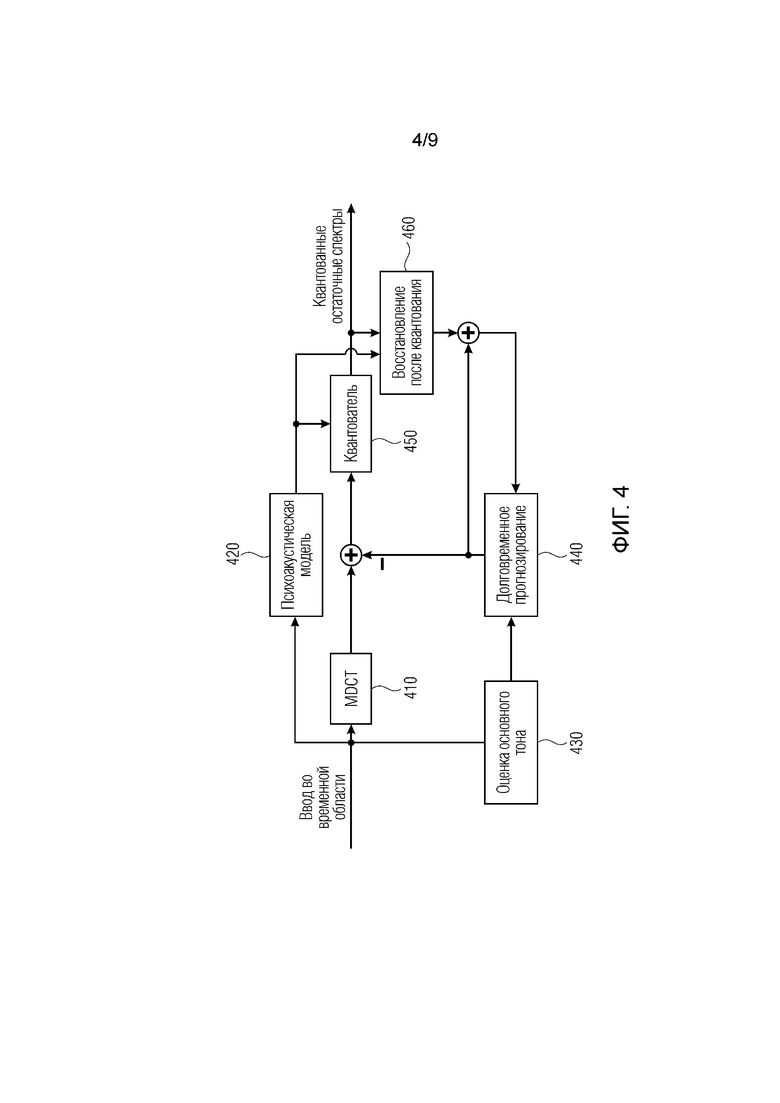
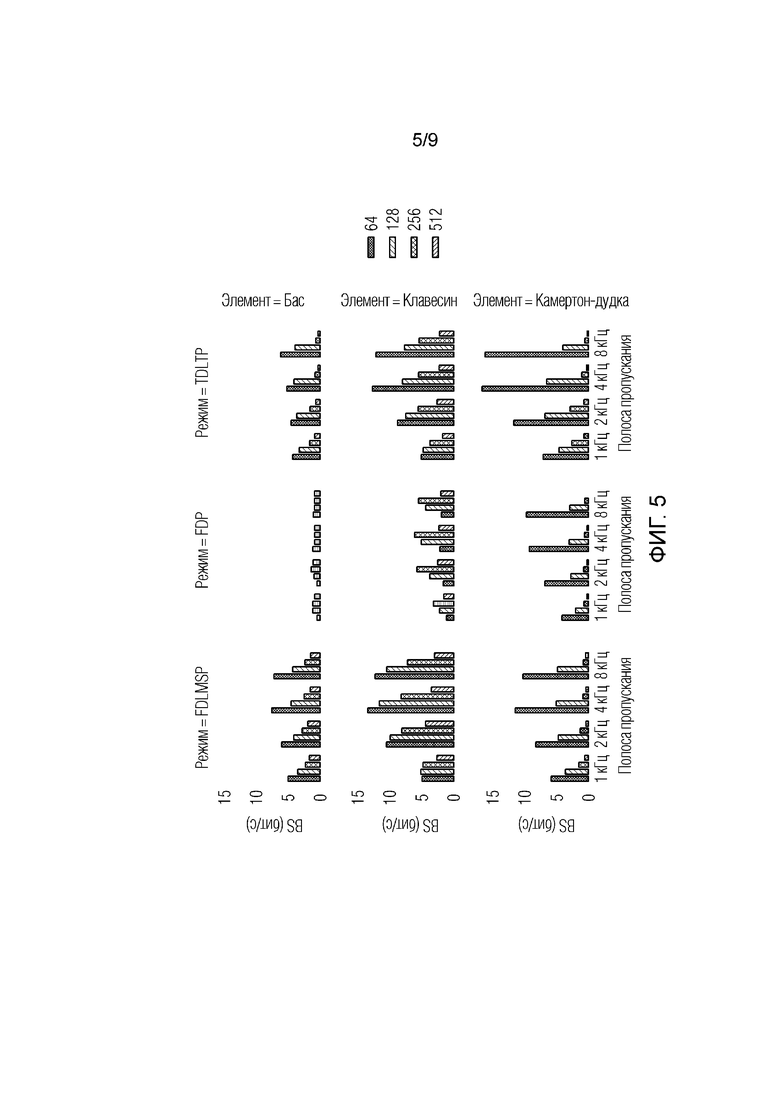
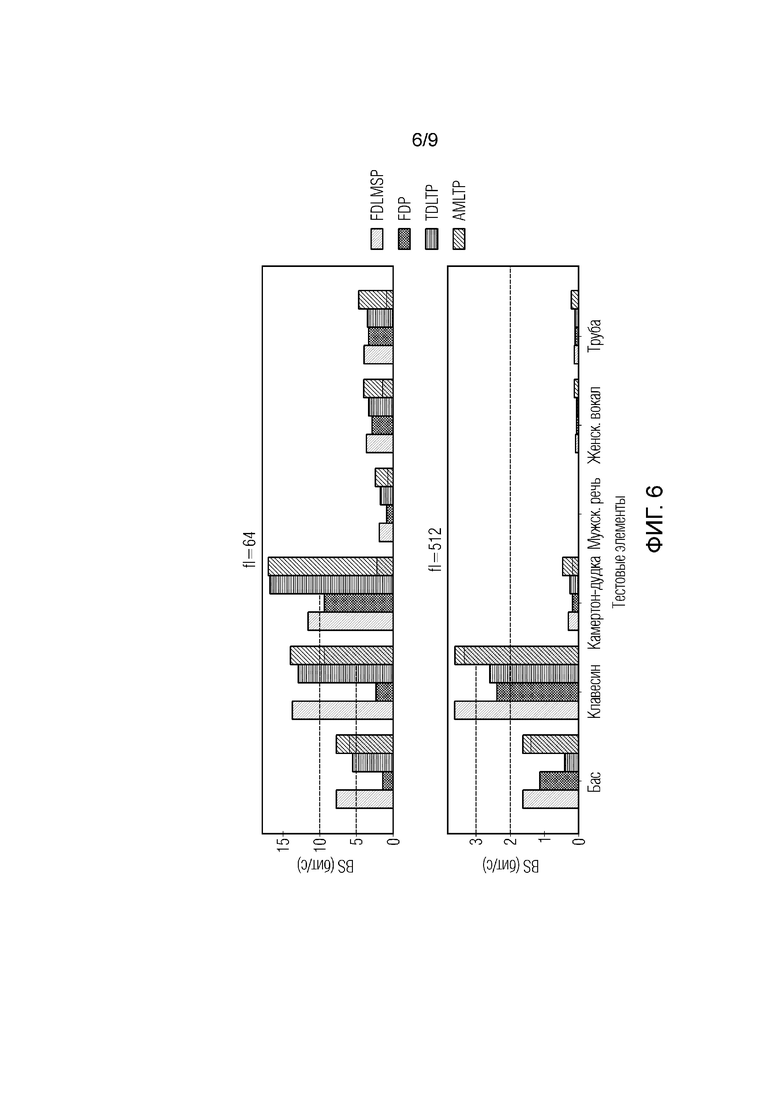
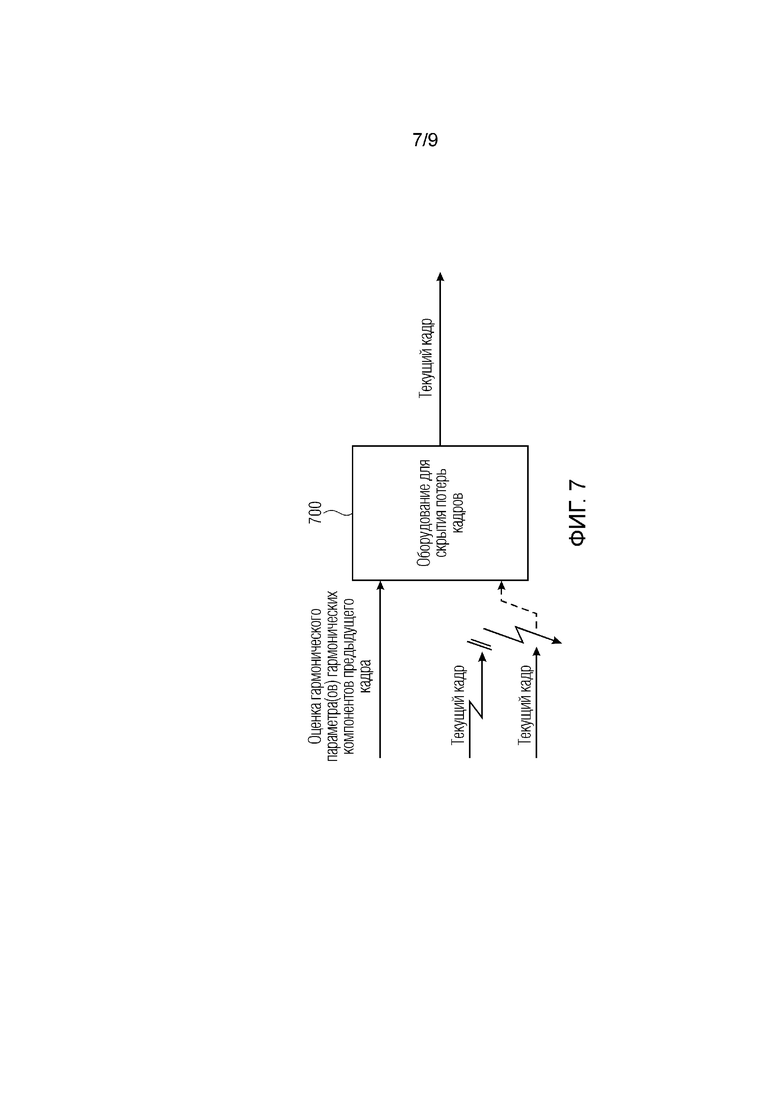
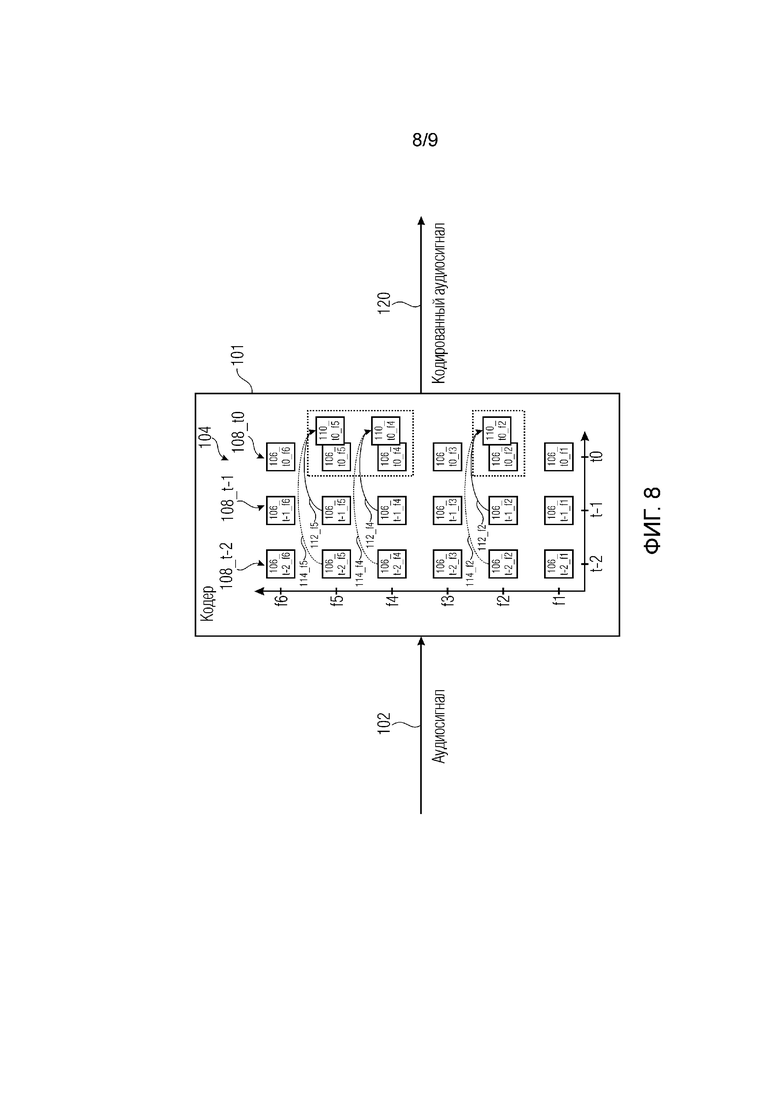
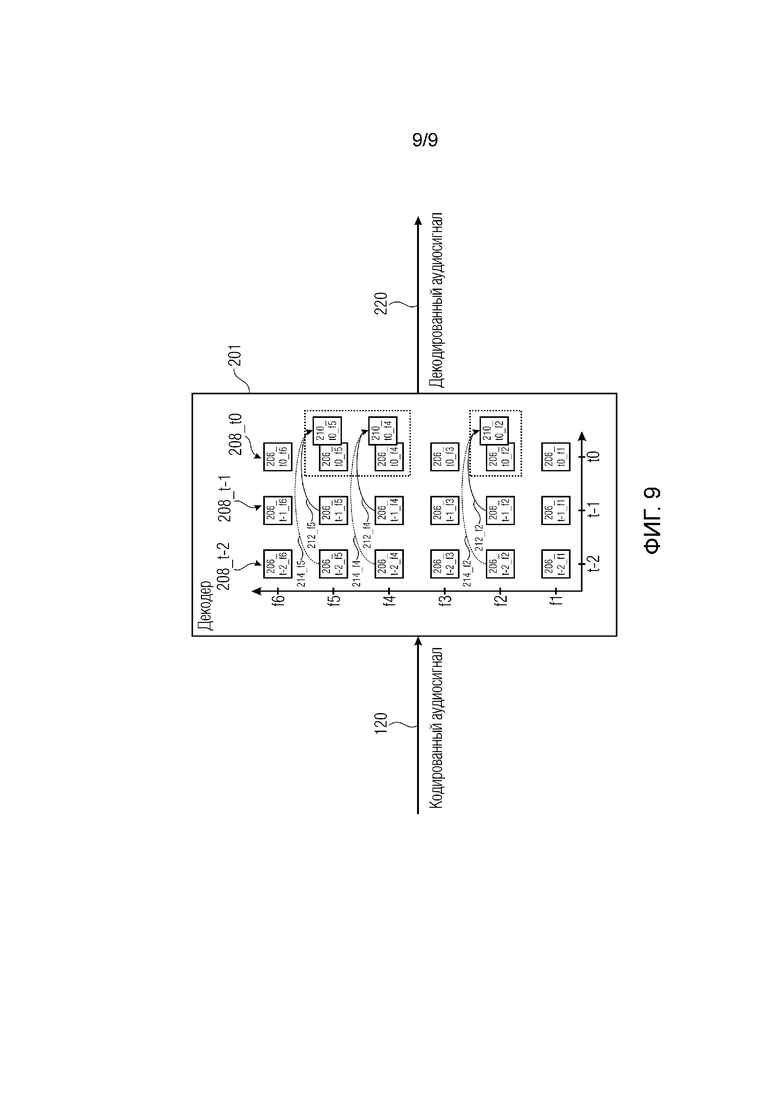
Изобретение относится к области вычислительной техники для обработки аудиоданных. Технический результат заключается в исключении перекрытия гармонических компонентов на элементах разрешения, когда частотное разрешение MDCT-коэффициентов является низким относительно фундаментальной частоты тонального сигнала. Технический результат достигается за счет определения оценки двух гармонических параметров для каждого из одного или более гармонических компонентов самого предыдущего кадра из одного или более предыдущих кадров, при этом два гармонических параметра для каждого из одного или более гармонических компонентов самого предыдущего кадра зависят от первой группы из трех или более из множества восстановленных спектральных коэффициентов для каждого из одного или более предыдущих кадров аудиосигнала. 10 н. и 47 з.п. ф-лы, 9 ил.
1. Кодер (100) для кодирования текущего кадра аудиосигнала в зависимости от одного или более предыдущих кадров аудиосигнала, при этом один или более предыдущих кадров предшествуют текущему кадру, при этом каждый из текущего кадра и одного или более предыдущих кадров содержит один или более гармонических компонентов аудиосигнала, при этом каждый из текущего кадра и одного или более предыдущих кадров содержит множество спектральных коэффициентов в частотной области или в области преобразования,
- при том для того, чтобы генерировать кодирование текущего кадра, кодер (100) выполнен с возможностью определять оценку двух гармонических параметров для каждого из одного или более гармонических компонентов самого предыдущего кадра из одного или более предыдущих кадров, при этом кодер (100) выполнен с возможностью определять оценку двух гармонических параметров для каждого из одного или более гармонических компонентов самого предыдущего кадра с использованием первой группы из трех или более из множества спектральных коэффициентов каждого из одного или более предыдущих кадров аудиосигнала.
2. Кодер (100) по п. 1,
- при этом кодер (100) выполнен с возможностью оценивать два гармонических параметра для каждого из одного или более гармонических компонентов самого предыдущего кадра без использования второй группы из одного или более дополнительных спектральных коэффициентов из множества спектральных коэффициентов каждого из одного или более предыдущих кадров.
3. Кодер (100) по п. 1 или 2,
- при этом кодер (100) выполнен с возможностью определять коэффициент усиления и остаточный сигнал в качестве кодирования текущего кадра в зависимости от фундаментальной частоты одного или более гармонических компонентов текущего кадра и одного или более предыдущих кадров и в зависимости от оценки двух гармонических параметров для каждого из одного или более гармонических компонентов самого предыдущего кадра,
- при этом кодер (100) выполнен с возможностью генерировать кодирование текущего кадра таким образом, что кодирование текущего кадра содержит коэффициент усиления и остаточный сигнал.
4. Кодер (100) по п. 3,
- при этом кодер (100) выполнен с возможностью определять оценку двух гармонических параметров для каждого из одного или более гармонических компонентов текущего кадра в зависимости от оценки двух гармонических параметров для каждого из одного или более гармонических компонентов самого предыдущего кадра и в зависимости от фундаментальной частоты одного или более гармонических компонентов текущего кадра и одного или более предыдущих кадров.
5. Кодер (100) по п. 3 или 4,
- в котором два гармонических параметра для каждого из одного или более гармонических компонентов представляют собой первый параметр для косинусоидального субкомпонента и второй параметр для синусоидального субкомпонента для каждого из одного или более гармонических компонентов.
6. Кодер (100) по одному из пп. 3-5,
- при этом кодер (100) выполнен с возможностью оценивать два гармонических параметра для каждого из одного или более гармонических компонентов самого предыдущего кадра посредством решения системы линейных уравнений, содержащей, по меньшей мере, три уравнения, при этом каждое, по меньшей мере, из трех уравнений зависит от спектрального коэффициента первой группы из трех или более из множества спектральных коэффициентов каждого из одного или более предыдущих кадров.
7. Кодер (100) по п. 6,
- при этом кодер (100) выполнен с возможностью решать систему линейных уравнений с использованием алгоритма на основе метода наименьших квадратов.
8. Кодер (100) по п. 6 или 7,
- в котором система линейных уравнений задается следующим образом:
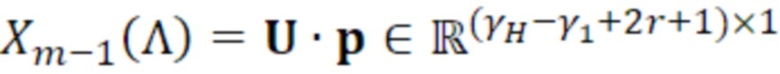
- при этом:
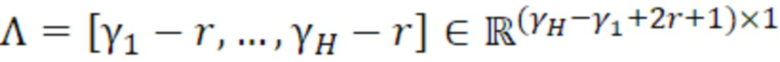
- при этом γ1 указывает первую полосу частот спектра одного из одного или более гармонических компонентов самого предыдущего кадра, имеющего наименьшую гармоническую компонентную частоту из числа одного или более гармонических компонентов,
- при этом γH указывает вторую полосу частот спектра одного из одного или более гармонических компонентов самого предыдущего кадра, имеющего наибольшую гармоническую компонентную частоту из числа одного или более гармонических компонентов,
- при этом r является целым числом, где r≥0.
9. Кодер (100) по п. 8, в котором r≥1.
10. Кодер (100) по п. 8 или 9,
- в котором:
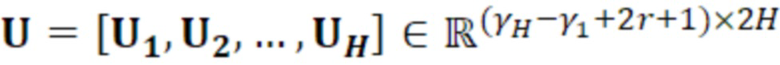
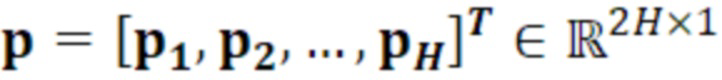
- при этом:
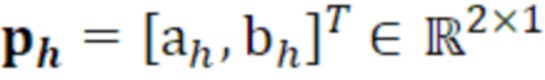
- при этом ah является параметром для косинусоидального субкомпонента для h-ого гармонического компонента самого предыдущего кадра,
- при этом bh является параметром для синусоидального субкомпонента для h-ого гармонического компонента самого предыдущего кадра,
- при этом для каждого целочисленного значения, где 1≤h≤H:
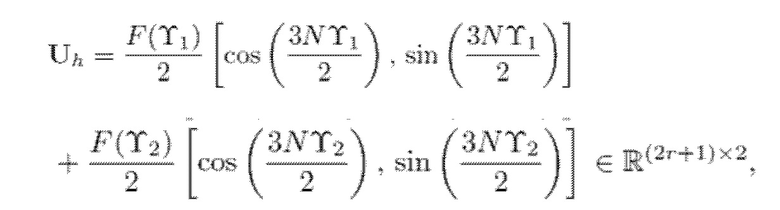
- при этом:
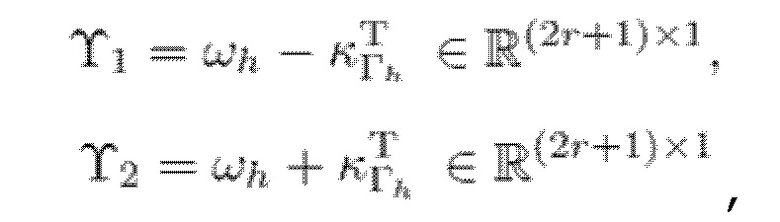
- при этом:
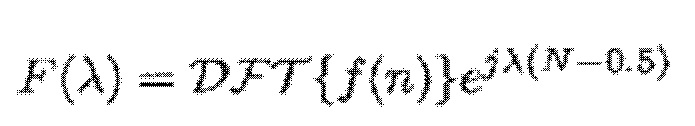
- при этом f(n) является функцией кодирования со взвешиванием во временной области,
- при этом DFT является дискретным преобразованием Фурье,
- при этом:
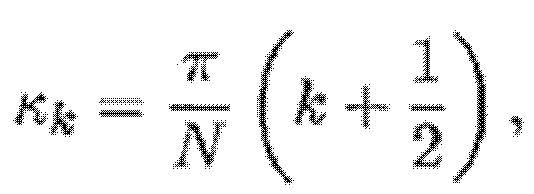
- при этом:
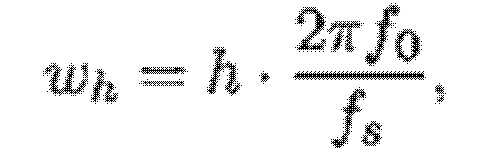
- при этом f0 является фундаментальной частотой одного или более гармонических компонентов текущего кадра и одного или более предыдущих кадров,
- при этом fs является частотой дискретизации, и
- при этом N зависит от длины блока преобразования для преобразования аудиосигнала временной области в частотную область или в спектральную область.
11. Кодер (100) по одному из пп. 6-10,
- в котором система линейных уравнений является разрешимой следующим образом:
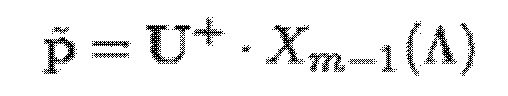
- при этом 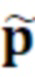 является первым вектором, содержащим оценку двух гармонических параметров для каждого из одного или более гармонических компонентов самого предыдущего кадра,
является первым вектором, содержащим оценку двух гармонических параметров для каждого из одного или более гармонических компонентов самого предыдущего кадра,
- при этом Xm-1(Λ) является вторым вектором, содержащим первую группу из трех или более из множества спектральных коэффициентов каждого из одного или более предыдущих кадров,
- при этом U+ является обратной матрицей Мура-Пенроуза 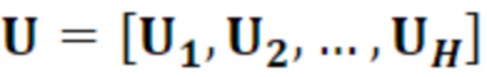 ,
,
- при этом U содержит число третьих матриц или третьих векторов,
- при этом каждая из третьих матриц или третьих векторов вместе с оценкой двух гармонических параметров для гармонического компонента из одного или более гармонических компонентов самого предыдущего кадра указывает оценку упомянутого гармонического компонента,
- при этом H указывает число гармонических компонентов одного или более предыдущих кадров.
12. Кодер (100) по одному из пп. 3-11,
- при этом кодер (100) выполнен с возможностью кодировать фундаментальную частоту гармонических компонентов, функцию кодирования со взвешиванием, коэффициент усиления и остаточный сигнал.
13. Кодер (100) по п. 12,
- при этом кодер (100) выполнен с возможностью определять число одного или более гармонических компонентов самого предыдущего кадра до оценки двух гармонических параметров для каждого из одного или более гармонических компонентов самого предыдущего кадра с использованием первой группы из трех или более из множества спектральных коэффициентов каждого из одного или более предыдущих кадров аудиосигнала.
14. Кодер (100) по п. 13,
- при этом кодер (100) выполнен с возможностью определять одну или более групп гармонических компонентов из одного или более гармонических компонентов и применять предсказание аудиосигнала к одной или более групп гармонических компонентов, при этом кодер (100) выполнен с возможностью кодировать порядок для каждой из одной или более групп гармонических компонентов самого предыдущего кадра.
15. Кодер (100) по одному из пп. 3-14,
- при этом кодер (100) выполнен с возможностью определять два гармонических параметра для каждого из одного или более гармонических компонентов текущего кадра в зависимости от двух гармонических параметров для каждого из упомянутых одного из одного или более гармонических компонентов самого предыдущего кадра.
16. Кодер (100) по п. 15,
- при этом кодер (100) выполнен с возможностью применять:
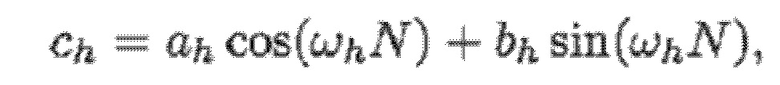 и
и
- при этом кодер (100) выполнен с возможностью применять:
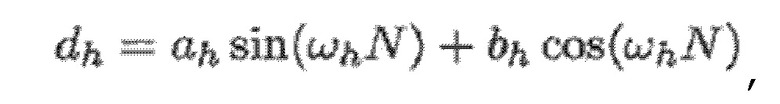
- при этом ah является параметром для косинусоидального субкомпонента для h-ого гармонического компонента из упомянутых одного или более гармонических компонентов самого предыдущего кадра,
- при этом bh является параметром для синусоидального субкомпонента для h-ого гармонического компонента из упомянутых одного или более гармонических компонентов самого предыдущего кадра,
- при этом ch является параметром для косинусоидального субкомпонента для h-ого гармонического компонента из упомянутых одного или более гармонических компонентов текущего кадра,
- при этом dh является параметром для синусоидального субкомпонента для h-ого гармонического компонента из упомянутых одного или более гармонических компонентов текущего кадра,
- при этом N зависит от длины блока преобразования для преобразования аудиосигнала временной области в частотную область или в спектральную область, и
- при этом:

- при этом f0 является фундаментальной частотой одного или более гармонических компонентов самого предыдущего кадра, представляющей собой фундаментальную частоту одного или более гармонических компонентов текущего кадра,
- при этом fs является частотой дискретизации, и
- при этом h является индексом, указывающим один из одного или более гармонических компонентов самого предыдущего кадра.
17. Кодер (100) по одному из пп. 3-16,
- при этом кодер (100) выполнен с возможностью определять остаточный сигнал в зависимости от множества спектральных коэффициентов текущего кадра в частотной области или в области преобразования и в зависимости от оценки двух гармонических параметров для каждого из одного или более гармонических компонентов текущего кадра, и
- при этом кодер (100) выполнен с возможностью кодировать остаточный сигнал.
18. Кодер (100) по п. 17,
- при этом кодер (100) выполнен с возможностью определять спектральное предсказание одного или более из множества спектральных коэффициентов текущего кадра в зависимости от оценки двух гармонических параметров для каждого из одного или более гармонических компонентов текущего кадра, и
- при этом кодер (100) выполнен с возможностью определять остаточный сигнал и коэффициент усиления в зависимости от множества спектральных коэффициентов текущего кадра в частотной области или в области преобразования и в зависимости от спектрального предсказания трех или более из множества спектральных коэффициентов текущего кадра, при этом кодер (100) выполнен с возможностью кодировать порядок для каждой из одной или более групп гармонических компонентов самого предыдущего кадра.
19. Кодер (100) по п. 18,
- при этом кодер (100) выполнен с возможностью определять остаточный сигнал текущего кадра следующим образом:
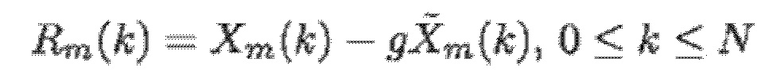
- при этом m является индексом кадра,
- при этом k является частотным индексом,
- при этом Rm(k) указывает k-ую выборку остаточного сигнала в спектральной области или в области преобразования,
- при этом Xm(k) указывает k-ую выборку спектральных коэффициентов текущего кадра в спектральной области или в области преобразования,
- при этом  указывает k-ую выборку спектрального предсказания текущего кадра в спектральной области или в области преобразования, и
указывает k-ую выборку спектрального предсказания текущего кадра в спектральной области или в области преобразования, и
- при этом g является коэффициентом усиления.
20. Кодер (100) по одному из предшествующих пунктов,
- при этом кодер (100) работает в первом режиме и работает, по меньшей мере, в одном из второго режима и третьего режима, и четвертого режима,
- при этом, если кодер (100) находится в первом режиме, кодер (100) выполнен с возможностью кодировать текущий кадр посредством определения оценки двух гармонических параметров для каждого из одного или более гармонических компонентов самого предыдущего кадра с использованием первой группы из трех или более из множества спектральных коэффициентов каждого из одного или более предыдущих кадров аудиосигнала,
- при этом, если кодер (100) находится во втором режиме, кодер (100) выполнен с возможностью кодировать аудиосигнал в области преобразования или в области гребенки фильтров, и кодер выполнен с возможностью определять множество спектральных коэффициентов (106_t0_f1:106_t0_f6; 106_t-1_f1:106_t-1_f6) аудиосигнала (102) для текущего кадра (108_t0) и, по меньшей мере, для самого предыдущего кадра (108_t-1), при этом кодер (100) выполнен с возможностью избирательно применять кодирование с предсказанием ко множеству отдельных спектральных коэффициентов (106_t0_f2) или к группам спектральных коэффициентов (106_t0_f4, 106_t0_f5), кодер (100) выполнен с возможностью определять значение разнесения, кодер (100) выполнен с возможностью выбирать множество отдельных спектральных коэффициентов (106_t0_f2) или группы спектральных коэффициентов (106_t0_f4, 106_t0_f5), к которым применяется кодирование с предсказанием, на основе значения разнесения,
- при этом, если кодер (100) находится в третьем режиме, кодер (100) выполнен с возможностью кодировать аудиосигнал посредством использования долговременного предсказания во временной области, и
- при этом, если кодер (100) находится в четвертом режиме, кодер (100) выполнен с возможностью кодировать аудиосигнал посредством использования долговременного предсказания с адаптивным модифицированным дискретным косинусным преобразованием, при этом, если кодер (100) использует долговременное предсказание с адаптивным модифицированным дискретным косинусным преобразованием, кодер (100) выполнен с возможностью выбирать либо долговременное предсказание во временной области, либо предсказание в частотной области, либо предсказание по методу наименьших квадратов в частотной области в качестве способа предсказания на основе кадров в зависимости от критерия минимизации.
21. Кодер (100) по п. 20,
- при этом в каждом из первого режима, и второго режима, и третьего режима, и четвертого режима кодер (100) выполнен с возможностью детализировать фундаментальную частоту для того, чтобы получать детализированную фундаментальную частоту, и выполнен с возможностью адаптировать коэффициент усиления для того, чтобы получать адаптированный коэффициент усиления на основе кадров, в зависимости от критерия минимизации,
- при этом кодер (100) выполнен с возможностью кодировать детализированную фундаментальную частоту и адаптированный коэффициент усиления вместо исходной фундаментальной частоты и коэффициента усиления.
22. Кодер (100) по п. 20 или 21,
- при этом кодер (100) выполнен с возможностью устанавливать себя в первый режим или, по меньшей мере, в один из второго режима и третьего режима, и четвертого режима, и
- при этом кодер (100) выполнен с возможностью кодировать то, кодирован ли текущий кадр в первом режиме или во втором режиме, или в третьем режиме, или в четвертом режиме.
23. Декодер (200) для восстановления текущего кадра аудиосигнала, при этом один или более предыдущих кадров аудиосигнала предшествуют текущему кадру, при этом каждый из текущего кадра и одного или более предыдущих кадров содержит один или более гармонических компонентов аудиосигнала, при этом каждый из текущего кадра и одного или более предыдущих кадров содержит множество спектральных коэффициентов в частотной области или в области преобразования,
- при этом декодер (200) выполнен с возможностью принимать кодирование текущего кадра,
- при этом декодер (200) выполнен с возможностью определять оценку двух гармонических параметров для каждого из одного или более гармонических компонентов самого предыдущего кадра из одного или более предыдущих кадров, при этом два гармонических параметра для каждого из одного или более гармонических компонентов самого предыдущего кадра зависят от первой группы из трех или более из множества восстановленных спектральных коэффициентов для каждого из одного или более предыдущих кадров аудиосигнала,
- при этом декодер (200) выполнен с возможностью восстанавливать текущий кадр в зависимости от кодирования текущего кадра и в зависимости от оценки двух гармонических параметров для каждого из одного или более гармонических компонентов самого предыдущего кадра.
24. Декодер (200) по п. 23,
- в котором два гармонических параметра для каждого из одного или более гармонических компонентов самого предыдущего кадра не зависят от второй группы из одного или более дополнительных спектральных коэффициентов из множества восстановленных спектральных коэффициентов для каждого из одного или более предыдущих кадров.
25. Декодер (200) по п. 23 или 24,
- при этом декодер (100) выполнен с возможностью принимать кодирование текущего кадра, содержащее коэффициент усиления и остаточный сигнал,
- при этом декодер (200) выполнен с возможностью восстанавливать текущий кадр в зависимости от коэффициента усиления, в зависимости от остаточного сигнала и в зависимости от фундаментальной частоты одного или более гармонических компонентов текущего кадра и одного или более предыдущих кадров.
26. Декодер (200) по п. 25,
- при этом декодер (200) выполнен с возможностью определять оценку двух гармонических параметров для каждого из одного или более гармонических компонентов текущего кадра в зависимости от оценки двух гармонических параметров для каждого из одного или более гармонических компонентов самого предыдущего кадра и в зависимости от фундаментальной частоты одного или более гармонических компонентов текущего кадра и одного или более предыдущих кадров.
27. Декодер (200) по п. 25 или 26,
- в котором два гармонических параметра для каждого из одного или более гармонических компонентов представляют собой первый параметр для косинусоидального субкомпонента и второй параметр для синусоидального субкомпонента для каждого из одного или более гармонических компонентов.
28. Декодер (200) по одному из пп. 25-27,
- в котором два гармонических параметра для каждого из одного или более гармонических компонентов самого предыдущего кадра зависят от системы линейных уравнений, содержащей, по меньшей мере, три уравнения, при этом каждое, по меньшей мере, из трех уравнений зависит от спектрального коэффициента первой группы из трех или более из множества восстановленных спектральных коэффициентов для каждого из одного или более предыдущих кадров.
29. Декодер (200) по п. 28,
- в котором система линейных уравнений является разрешимой с использованием алгоритма на основе метода наименьших квадратов.
30. Декодер (200) по п. 28 или 29,
- в котором система линейных уравнений задается следующим образом:
- при этом:
- при этом γ1 указывает первую полосу частот спектра одного из одного или более гармонических компонентов самого предыдущего кадра, имеющего наименьшую гармоническую компонентную частоту из числа одного или более гармонических компонентов,
- при этом γH указывает вторую полосу частот спектра одного из одного или более гармонических компонентов самого предыдущего кадра, имеющего наибольшую гармоническую компонентную частоту из числа одного или более гармонических компонентов,
- при этом r является целым числом, где r≥0.
31. Декодер (200) по п. 30, в котором r≥1.
32. Декодер (200) по п. 30 или 31,
- в котором:
- при этом:
- при этом ah является параметром для косинусоидального субкомпонента для h-ого гармонического компонента самого предыдущего кадра,
- при этом bh является параметром для синусоидального субкомпонента для h-ого гармонического компонента самого предыдущего кадра,
- при этом для каждого целочисленного значения, где 1≤h≤H:
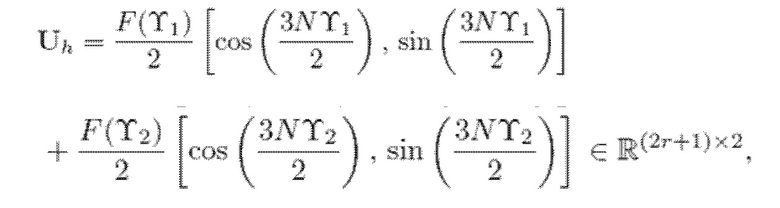
- при этом:

- при этом:
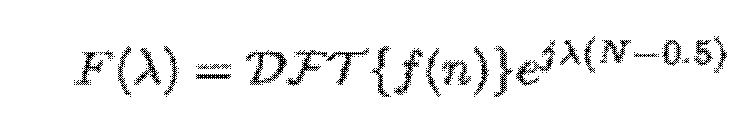
- при этом f(n) является функцией кодирования со взвешиванием во временной области,
- при этом DFT является дискретным преобразованием Фурье,
- при этом:
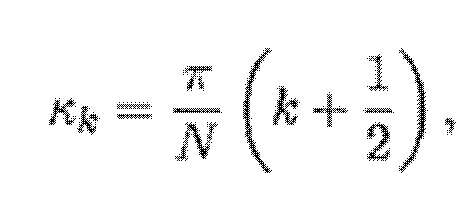
- при этом:
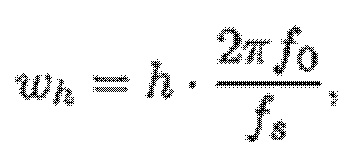
- при этом f0 является фундаментальной частотой одного или более гармонических компонентов текущего кадра и одного или более предыдущих кадров,
- при этом fs является частотой дискретизации, и
- при этом N зависит от длины блока преобразования для преобразования аудиосигнала временной области в частотную область или в спектральную область.
33. Декодер (200) по одному из пп. 28-32,
- в котором система линейных уравнений является разрешимой следующим образом:
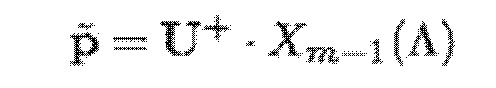
- при этом является первым вектором, содержащим оценку двух гармонических параметров для каждого из одного или более гармонических компонентов самого предыдущего кадра,
- при этом Xm-1(Λ) является вторым вектором, содержащим первую группу из трех или более из множества восстановленных спектральных коэффициентов для каждого из одного или более предыдущих кадров,
- при этом U+ является обратной матрицей Мура-Пенроуза 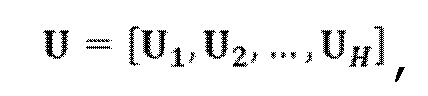
- при этом U содержит число третьих матриц или третьих векторов,
- при этом каждая из третьих матриц или третьих векторов вместе с оценкой двух гармонических параметров для гармонического компонента из одного или более гармонических компонентов самого предыдущего кадра указывает оценку упомянутого гармонического компонента,
- при этом H указывает число гармонических компонентов одного или более предыдущих кадров.
34. Декодер (200) по одному из пп. 25-33,
- при этом декодер (200) выполнен с возможностью принимать фундаментальную частоту гармонических компонентов, функцию кодирования со взвешиванием, коэффициент усиления и остаточный сигнал,
- при этом декодер (200) выполнен с возможностью восстанавливать текущий кадр в зависимости от фундаментальной частоты одного или более гармонических компонентов самого предыдущего кадра, в зависимости от функции кодирования со взвешиванием, в зависимости от коэффициента усиления и в зависимости от остаточного сигнала.
35. Декодер (200) по п. 34,
- при этом декодер (200) выполнен с возможностью принимать упомянутое число одного или более гармонических компонентов самого предыдущего кадра, и
- при этом декодер (200) выполнен с возможностью декодировать кодирование текущего кадра в зависимости от упомянутого числа одного или более гармонических компонентов самого предыдущего кадра.
36. Декодер (200) по п. 35,
- при этом декодер (200) выполнен с возможностью декодировать кодирование текущего кадра в зависимости от одной или более групп гармонических компонентов,
- при этом декодер (200) выполнен с возможностью применять предсказание аудиосигнала к одной или более групп гармонических компонентов.
37. Декодер (200) по одному из пп. 25-36,
- при этом декодер (200) выполнен с возможностью определять два гармонических параметра для каждого из одного или более гармонических компонентов текущего кадра в зависимости от двух гармонических параметров для каждого из упомянутых одного из одного или более гармонических компонентов самого предыдущего кадра.
38. Декодер (200) по п. 37,
- при этом декодер (200) выполнен с возможностью применять:
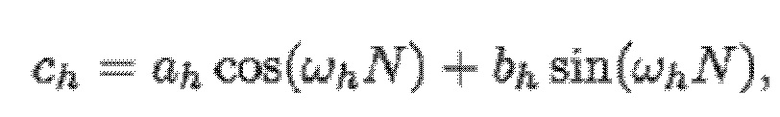 и
и
- при этом декодер (200) выполнен с возможностью применять:
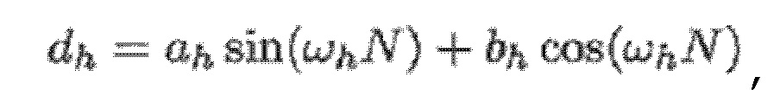
- при этом ah является параметром для косинусоидального субкомпонента для h-ого гармонического компонента из одного или более гармонических компонентов самого предыдущего кадра,
- при этом bh является параметром для синусоидального субкомпонента для h-ого гармонического компонента из одного или более гармонических компонентов самого предыдущего кадра,
- при этом ch является параметром для косинусоидального субкомпонента для h-ого гармонического компонента из одного или более гармонических компонентов текущего кадра,
- при этом dh является параметром для синусоидального субкомпонента для h-ого гармонического компонента из одного или более гармонических компонентов текущего кадра,
- при этом N зависит от длины блока преобразования для преобразования аудиосигнала временной области в частотную область или в спектральную область, и
- при этом:
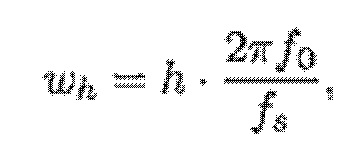
- при этом f0 является фундаментальной частотой одного или более гармонических компонентов самого предыдущего кадра, представляющей собой фундаментальную частоту одного или более гармонических компонентов текущего кадра,
- при этом fs является частотой дискретизации, и
- при этом h является индексом, указывающим один из одного или более гармонических компонентов самого предыдущего кадра.
39. Декодер (200) по одному из пп. 25-38,
- при этом декодер (200) выполнен с возможностью принимать остаточный сигнал, при этом остаточный сигнал зависит от множества спектральных коэффициентов текущего кадра в частотной области или в области преобразования, и при этом остаточный сигнал зависит от оценки двух гармонических параметров для каждого из одного или более гармонических компонентов текущего кадра.
40. Декодер (200) по п. 39,
- при этом декодер (200) выполнен с возможностью определять спектральное предсказание одного или более из множества спектральных коэффициентов текущего кадра в зависимости от оценки двух гармонических параметров для каждого из одного или более гармонических компонентов текущего кадра, и при этом декодер (200) выполнен с возможностью определять текущий кадр аудиосигнала в зависимости от спектрального предсказания текущего кадра и в зависимости от остаточного сигнала, и в зависимости от коэффициента усиления.
41. Декодер (200) по п. 40,
- при этом остаточный сигнал текущего кадра задается следующим образом:
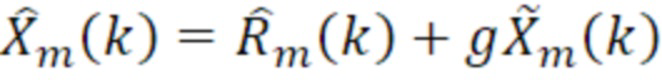
- при этом m является индексом кадра,
- при этом k является частотным индексом,
- при этом 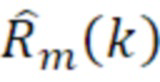 является принимаемым остатком после восстановления после квантования,
является принимаемым остатком после восстановления после квантования,
- при этом 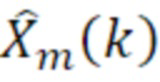 является восстановленным текущим кадром,
является восстановленным текущим кадром,
- при этом указывает спектральное предсказание текущего кадра в спектральной области или в области преобразования, и
- при этом g является коэффициентом усиления.
42. Декодер (200) по одному из пп. 23-41,
- при этом декодер (200) работает в первом режиме и работает, по меньшей мере, в одном из второго режима и третьего режима, и четвертого режима,
- при этом, если декодер (200) находится в первом режиме, декодер (200) выполнен с возможностью определять оценку двух гармонических параметров для каждого из одного или более гармонических компонентов самого предыдущего кадра, при этом два гармонических параметра для каждого из одного или более гармонических компонентов самого предыдущего кадра зависят от первой группы из трех или более из множества восстановленных спектральных коэффициентов для каждого из одного или более предыдущих кадров аудиосигнала, и декодер (200) выполнен с возможностью декодировать кодирование текущего кадра в зависимости от оценки двух гармонических параметров для каждого из одного или более гармонических компонентов самого предыдущего кадра,
- при этом, если декодер (200) находится во втором режиме, декодер (200) выполнен с возможностью синтаксически анализировать кодирование аудиосигнала (120), чтобы получать кодированные спектральные коэффициенты (206_t0_f1:206_t0_f6; 206_t-1_f1:206_t-1_f6) аудиосигнала (120) для текущего кадра (208_t0) и, по меньшей мере, для самого предыдущего кадра (208_t-1), и декодер (200) выполнен с возможностью избирательно применять декодирование с предсказанием ко множеству отдельных кодированных спектральных коэффициентов (206_t0_f2) или к группам кодированных спектральных коэффициентов (206_t0_f4, 206_t0_f5), при этом декодер (200) выполнен с возможностью получать значение разнесения, при этом декодер (200) выполнен с возможностью выбирать множество отдельных кодированных спектральных коэффициентов (206_t0_f2) или группы кодированных спектральных коэффициентов (206_t0_f4, 206_t0_f5), к которым применяется декодирование с предсказанием, на основе значения разнесения,
- при этом, если декодер (200) находится в третьем режиме, декодер (200) выполнен с возможностью декодировать аудиосигнал посредством использования долговременного предсказания во временной области, и
- при этом, если декодер (200) находится в четвертом режиме, декодер (200) выполнен с возможностью декодировать аудиосигнал посредством использования долговременного предсказания с адаптивным модифицированным дискретным косинусным преобразованием, при этом, если декодер (200) использует долговременное предсказание с адаптивным модифицированным дискретным косинусным преобразованием, декодер (200) выполнен с возможностью выбирать либо долговременное предсказание во временной области, либо предсказание в частотной области, либо предсказание по методу наименьших квадратов в частотной области в качестве способа предсказания на основе кадров в зависимости от критерия минимизации.
43. Декодер (200) по п. 42,
- при этом в каждом из первого режима, и второго режима, и третьего режима, и четвертого режима декодер (200) выполнен с возможностью декодировать аудиосигнал в зависимости от детализированной фундаментальной частоты и в зависимости от адаптированного коэффициента усиления, которые определены на основе кадров.
44. Декодер (200) по п. 42 или 43,
- при этом декодер (200) выполнен с возможностью принимать и декодировать кодирование, содержащее индикатор относительно того, кодирован текущий кадр в первом режиме или во втором режиме, или в третьем режиме, или в четвертом режиме, и
- при этом декодер (200) выполнен с возможностью устанавливать себя в первый режим или во второй режим, или в третий режим, или в четвертый режим в зависимости от индикатора.
45. Оборудование (700) для скрытия потерь кадров, в котором один или более предыдущих кадров аудиосигнала предшествуют текущему кадру аудиосигнала, при этом каждый из текущего кадра и одного или более предыдущих кадров содержит один или более гармонических компонентов аудиосигнала, при этом каждый из текущего кадра и одного или более предыдущих кадров содержит множество спектральных коэффициентов в частотной области или в области преобразования,
- при этом оборудование (700) выполнено с возможностью определять оценку двух гармонических параметров для каждого из одного или более гармонических компонентов самого предыдущего кадра из одного или более предыдущих кадров, при этом два гармонических параметра для каждого из одного или более гармонических компонентов самого предыдущего кадра зависят от первой группы из трех или более из множества восстановленных спектральных коэффициентов для каждого из одного или более предыдущих кадров аудиосигнала,
- при этом, если оборудование (700) не принимает текущий кадр, либо если текущий кадр принимается посредством оборудования (700) в поврежденном состоянии, оборудование (700) выполнено с возможностью восстанавливать текущий кадр в зависимости от оценки двух гармонических параметров для каждого из одного или более гармонических компонентов самого предыдущего кадра.
46. Оборудование (700) по п. 45,
- при этом оборудование (700) выполнено с возможностью принимать упомянутое число одного или более гармонических компонентов самого предыдущего кадра, и
- при этом оборудование (700) должно декодировать кодирование текущего кадра в зависимости от упомянутого числа одного или более гармонических компонентов самого предыдущего кадра и в зависимости от фундаментальной частоты одного или более гармонических компонентов текущего кадра и одного или более предыдущих кадров.
47. Оборудование (700) по п. 45 или 46,
- при этом для того, чтобы восстанавливать текущий кадр, оборудование (700) выполнено с возможностью определять оценку двух гармонических параметров для каждого из одного или более гармонических компонентов текущего кадра в зависимости от оценки двух гармонических параметров для каждого из одного или более гармонических компонентов самого предыдущего кадра.
48. Оборудование (700) по п. 47,
- в котором декодер (200) выполнен с возможностью определять два гармонических параметра для каждого из одного или более гармонических компонентов текущего кадра в зависимости от двух гармонических параметров для каждого из упомянутых одного из одного или более гармонических компонентов самого предыдущего кадра.
49. Оборудование (700) по п. 48,
- при этом оборудование (700) выполнено с возможностью применять:
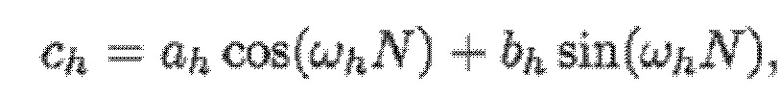 и
и
- при этом оборудование (700) выполнено с возможностью применять:
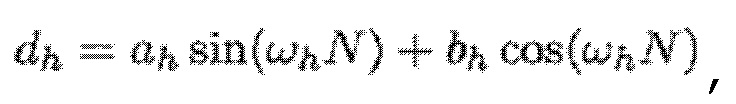
- при этом ah является параметром для косинусоидального субкомпонента для h-ого гармонического компонента из одного или более гармонических компонентов самого предыдущего кадра,
- при этом bh является параметром для синусоидального субкомпонента для h-ого гармонического компонента из одного или более гармонических компонентов самого предыдущего кадра,
- при этом ch является параметром для косинусоидального субкомпонента для h-ого гармонического компонента из одного или более гармонических компонентов текущего кадра,
- при этом dh является параметром для синусоидального субкомпонента для h-ого гармонического компонента из одного или более гармонических компонентов текущего кадра,
- при этом N зависит от длины блока преобразования для преобразования аудиосигнала временной области в частотную область или в спектральную область, и
- при этом:
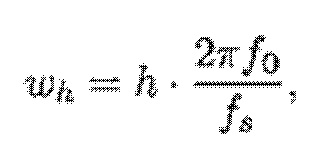
- при этом f0 является фундаментальной частотой одного или более гармонических компонентов самого предыдущего кадра, представляющей собой фундаментальную частоту одного или более гармонических компонентов текущего кадра,
- при этом fs является частотой дискретизации, и
- при этом h является индексом, указывающим один из одного или более гармонических компонентов самого предыдущего кадра.
50. Оборудование (700) по п. 48 или 49,
- при этом оборудование (700) выполнено с возможностью определять спектральное предсказание одного или более из множества спектральных коэффициентов текущего кадра в зависимости от оценки двух гармонических параметров для каждого из одного или более гармонических компонентов текущего кадра.
51. Система для кодирования и декодирования текущего кадра аудиосигнала, содержащая:
- кодер (100) по одному из пп. 1-22 для кодирования текущего кадра аудиосигнала, и
- декодер (200) по одному из пп. 23-44 для декодирования кодирования текущего кадра аудиосигнала.
52. Способ для кодирования текущего кадра аудиосигнала в зависимости от одного или более предыдущих кадров аудиосигнала, при этом один или более предыдущих кадров предшествуют текущему кадру, при этом каждый из текущего кадра и одного или более предыдущих кадров содержит один или более гармонических компонентов аудиосигнала, при этом каждый из текущего кадра и одного или более предыдущих кадров содержит множество спектральных коэффициентов в частотной области или в области преобразования,
- при том для того, чтобы генерировать кодирование текущего кадра, способ содержит этап, на котором определяют оценку двух гармонических параметров для каждого из одного или более гармонических компонентов самого предыдущего кадра из одного или более предыдущих кадров,
- при этом определение оценки двух гармонических параметров для каждого из одного или более гармонических компонентов самого предыдущего кадра проводится с использованием первой группы из трех или более из множества спектральных коэффициентов каждого из одного или более предыдущих кадров аудиосигнала.
53. Способ для восстановления текущего кадра аудиосигнала, при этом один или более предыдущих кадров аудиосигнала предшествуют текущему кадру, при этом каждый из текущего кадра и одного или более предыдущих кадров содержит один или более гармонических компонентов аудиосигнала, при этом каждый из текущего кадра и одного или более предыдущих кадров содержит множество спектральных коэффициентов в частотной области или в области преобразования,
- при этом способ содержит этап, на котором принимают кодирование текущего кадра,
- при этом способ содержит этап, на котором определяют оценку двух гармонических параметров для каждого из одного или более гармонических компонентов самого предыдущего кадра из одного или более предыдущих кадров, при этом два гармонических параметра для каждого из одного или более гармонических компонентов самого предыдущего кадра зависят от первой группы из трех или более из множества восстановленных спектральных коэффициентов для каждого из одного или более предыдущих кадров аудиосигнала,
- при этом способ содержит этап, на котором восстанавливают текущий кадр в зависимости от кодирования текущего кадра и в зависимости от оценки двух гармонических параметров для каждого из одного или более гармонических компонентов самого предыдущего кадра.
54. Способ для скрытия потерь кадров, при этом один или более предыдущих кадров аудиосигнала предшествуют текущему кадру аудиосигнала, при этом каждый из текущего кадра и одного или более предыдущих кадров содержит один или более гармонических компонентов аудиосигнала, при этом каждый из текущего кадра и одного или более предыдущих кадров содержит множество спектральных коэффициентов в частотной области или в области преобразования,
- при этом способ содержит этап, на котором определяют оценку двух гармонических параметров для каждого из одного или более гармонических компонентов самого предыдущего кадра из одного или более предыдущих кадров, при этом два гармонических параметра для каждого из одного или более гармонических компонентов самого предыдущего кадра зависят от первой группы из трех или более из множества восстановленных спектральных коэффициентов для каждого из одного или более предыдущих кадров аудиосигнала,
- при этом способ содержит, если текущий кадр не принимается или если текущий кадр принимается в поврежденном состоянии, этап, на котором восстанавливают текущий кадр в зависимости от двух гармонических параметров для каждого из одного или более гармонических компонентов самого предыдущего кадра.
55. Машиночитаемый носитель, содержащий компьютерную программу для реализации способа по п. 52, когда компьютерная программа выполняется посредством компьютера или процессора сигналов.
56. Машиночитаемый носитель, содержащий компьютерную программу для реализации способа по п. 53, когда компьютерная программа выполняется посредством компьютера или процессора сигналов.
57. Машиночитаемый носитель, содержащий компьютерную программу для реализации способа по п. 54, когда компьютерная программа выполняется посредством компьютера или процессора сигналов.
| Способ обработки целлюлозных материалов, с целью тонкого измельчения или переведения в коллоидальный раствор | 1923 |
|
SU2005A1 |
| Колосоуборка | 1923 |
|
SU2009A1 |
| Способ защиты переносных электрических установок от опасностей, связанных с заземлением одной из фаз | 1924 |
|
SU2014A1 |
| Автомобиль-сани, движущиеся на полозьях посредством устанавливающихся по высоте колес с шинами | 1924 |
|
SU2017A1 |
| ДЕКОДИРОВАНИЕ БИТОВЫХ АУДИОПОТОКОВ С МЕТАДАННЫМИ РАСШИРЕННОГО КОПИРОВАНИЯ СПЕКТРАЛЬНОЙ ПОЛОСЫ ПО МЕНЬШЕЙ МЕРЕ В ОДНОМ ЗАПОЛНЯЮЩЕМ ЭЛЕМЕНТЕ | 2016 |
|
RU2665887C1 |
