Изобретение относится к информатике, а именно - к способам распознавания документов.
Наиболее близким аналогом заявляемого изобретения является способ нейросетевого контроля текстовых данных на изображениях документов (патент на изобретение РФ №2806012), согласно которому осуществляют подачу на вход входного изображения текстового поля, причем для изображения известно, что в оригинальном документе текстовая информация на нем обладает свойством А, также известна ширина изображения текстового поля, при этом входное поле изображения в цветном пространстве RGB, содержащее текстовое поле документа, обрабатывают нейросетевым детектором контроля текстовых данных по следующему алгоритму: изображение поля преобразуют в одноканальное, после чего поступает на вход обученной полносверточной нейронной сети; на выходе нейронная сеть ставит в соответствие для каждой вертикальной линии, соответствующей середине рецептивного поля, значения и оценки уверенности для двух возможных классов: класс при котором свойство в текстовом поле отсутствует; класс А, при котором свойство в текстовом поле присутствует; производят подсчет сумм и значений оценок уверенности для двух возможных классов по всем вертикальным линиям изображения текстового поля: производят проверку на наличие в изображении аномалии, при этом если в рассматриваемом текстовом поле аномалия не найдена, то изображение рассматриваемого текстового поля обладает свойством А, если в рассматриваемом текстовом поле аномалия найдена, то изображение текстового поля считается обладающим свойством А при наличии аномалии, если выполнено условие в других случаях изображение текстового поля не обладает свойством А. Недостатком этого технического решения является ориентация на учет только текстовых полей изображения, хотя во многих документах (прежде всего, в деловых документах, предназначенных для обмена данными с организациями и физическими лицами) содержатся и другие примитивы - QR-коды, штрих-коды, слова статического текста, отрезки (линии подчеркивания), бар-коды, пометки (чек-боксы).
Технической задачей заявляемого изобретения является развитие методов автоматического распознавания цифровых документов.
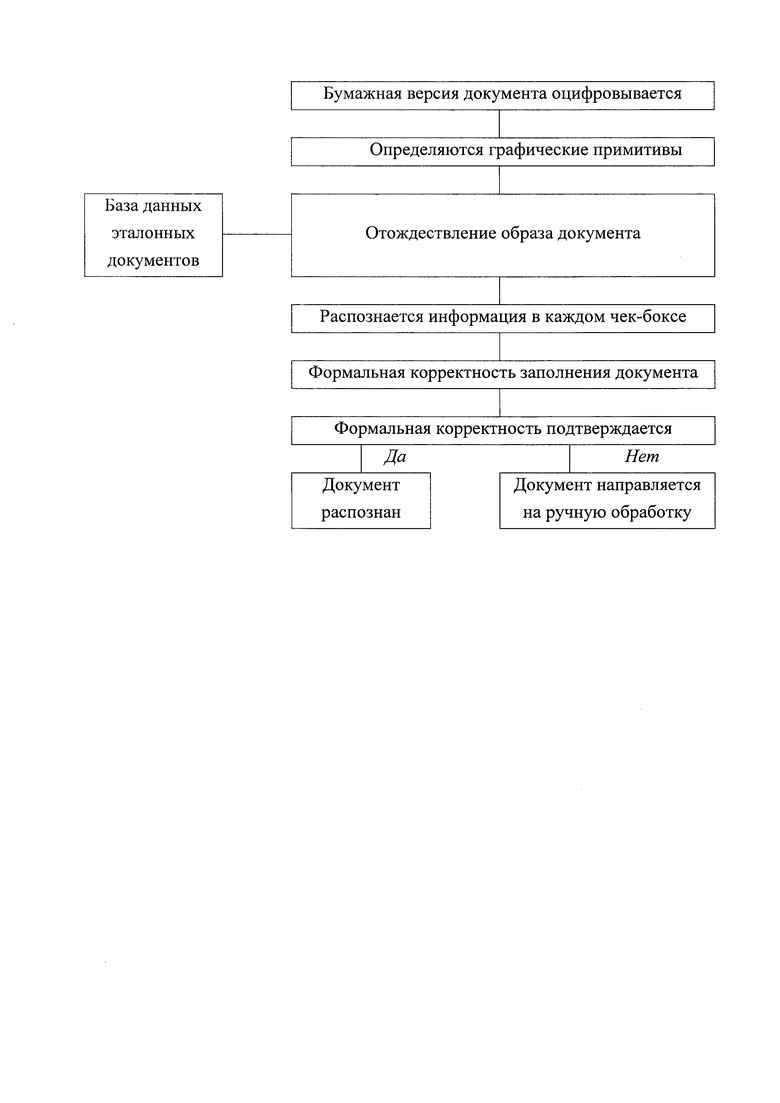
Решение технической задачи достигается за счет того, что формируется база данных эталонных документов, содержащая информацию о взаимном расположении графических примитивов в эталонном документе и указаниями на тип информации, содержащейся в каждом графическом примитиве: QR-код, штрих-код, отрезок, бар-код, тип - текстовая, цифровая или комбинированная - и язык информации в каждом чек-боксе; бумажная версия документа оцифровывается, тем самым формируется цифровой образ документа, на цифровом образе документа определяются графические примитивы, к которым относятся QR-коды, штрих-коды, слова статического текста, отрезки, бар-коды, чек-боксы; на основании взаимного расположения графических примитивов цифровой образ документа отождествляется с цифровым образом одного из эталонных документов, хранящихся в заранее сформированной базе данных эталонных документов, содержащей информацию о взаимном расположении графических примитивов в эталонном документе и указаниями на тип информации, содержащейся в каждом графическом примитиве: QR-коды, штрих-коды, отрезки, бар-коды, тип - текстовая, цифровая или комбинированная - и язык информации в каждом чек-боксе; по результатам отождествления распознается информация в каждом чек-боксе; проводится формальная корректность заполнения документа как соответствие распознанной информации ожидаемой информации; если формальная корректность подтверждается, то документ считается успешно распознанным и информация из документа заносится в таблицу «номер документа - графический примитив - информация, содержащаяся в графическом примитиве», иначе - документ направляется на ручную обработку, причем информация о взаимном расположении графических примитивов в каждом эталонном документе, хранящемся в базе данных эталонных документов, содержит: минимальные расстояния от середины каждого из четырех ребер эталонного документа до ближайшей точки каждого графического примитива, минимальные расстояния от каждого из четырех углов эталонного документа до ближайшей точки каждого графического примитива.
Технический результат, достигаемый указанной совокупностью признаков, заключается в повышении качества распознавания документов.
Разработанный способ ориентирован на повышение качества распознавания условно жестких деловых документов за счет привязки полей при их распознавании. Условно жестким деловым документом считается документ, имеющий жесткую структуру, характеризуемую наличием примитивов с четким расположением в документе, а задача распознавания документа может быть сведена только к распознаванию информации, находящейся в QR-кодах, штрих-кодах, бар-кодах и чек-боксах, а также в словах статического текста.
Реализация заявленного способа заключается в следующем (см. фигуру).
Оцифрованный документ определяется как совокупность полей и статической информации. Причем многие документы характеризуются относительно простой структурой и ограниченным словарем статических текстов. Поля документа (области распознавания) определяются как объект, который ограничен несколькими статическими элементами, такими как слова статического текста, отрезки (линии подчеркивания); бар-коды, пометки (чек-боксы).
Извлечение информации из распознанных деловых документов имеет ряд особенностей: малый объем словаря слов статического текста; возможное значительное число ошибок распознавания; возможные ошибки детектирования графических элементов.
Постановка задачи распознавания документа состоит в следующем. На основании распознавания текстовых объектов и найденных графических примитивов найти границы полей (областей заполнения) и извлечь информацию из областей полей.
Распознавание образа документа реализуется в виде следующих этапов:
нормализация образа страницы, в том числе, поиск области документа и его приведение к прямоугольному виду;
распознавание слов;
извлечение графических объектов;
классификация типа документа;
поиск локальных особенностей;
поиск границ полей документа известного типа с помощью границ локальных особенностей;
извлечение или распознавание содержимого полей в найденных границах с помощью атрибутов полей;
постобработка распознанных полей с помощью словарных моделей.
Критерием качества решения задачи распознавания является извлечение информации из границ максимального числа полей с наименьшим числом ошибок для каждого поля. Извлекаемая информация может иметь вид не только набора символов, но и границ найденного поля.
В документы, при создании которых использовалась жесткая форма, в процессе печати и оцифровке в изображении этих документов могут быть внесены неустранимые искажения:
замятия страниц, приводящие к сильному искажению геометрической формы страницы и областей изображения;
применение шрифтов и других статических элементов малого размера, что приводит к значительным потерям точек, которые могли бы быть взяты в качестве ключевых (опорных) точек и т.п.
Способ привязки полей условно жестких деловых документов при их распознавании, характеризующийся тем, что:
на оцифрованной бумажной версии (цифровом образе) документа (информация о взаимном расположении графических примитивов в каждом эталонном документе, хранящемся в базе данных эталонных документов, содержит: минимальные расстояния от середины каждого из четырех ребер эталонного документа до ближайшей точки каждого графического примитива, минимальные расстояния от каждого из четырех углов эталонного документа до ближайшей точки каждого графического примитива) определяются графические примитивы, к которым относятся QR-коды, штрих-коды, слова статического текста, отрезки, бар-коды, чек-боксы;
на основании взаимного расположения графических примитивов (углы и нормализованные расстояния между ними) цифровой образ текущего документа отождествляется с цифровым образом одного из эталонных документов, хранящихся в заранее сформированной базе данных эталонных документов. База данных эталонных документов содержит информацию о взаимном расположении графических примитивов в каждом эталонном документе, а также указания на тип информации, содержащейся в каждом графическом примитиве: QR-коды, штрих-коды, отрезки, бар-коды, тип -текстовая, цифровая или комбинированная - и язык информации в каждом чек-боксе.
Текущий цифровой образ документа отождествляется с одним из образов, хранимым в базе данных, по результатам отождествления распознается информация в каждом чек-боксе - априорные сведения об информации повышают качество распознавания.
Затем проводится проверка формальной корректности заполнения документа как соответствие распознанной информации ожидаемой информации.
Если формальная корректность подтверждается, то информация из документа заносится в таблицу «номер документа - графический примитив -информация, содержащаяся в графическом примитиве», иначе - документ направляется на ручную обработку.
Качество заявляемого способа проверено на собственном тестовом датасете, содержащем 418 изображений условно жесткого документа. Документы были напечатаны на листах размера А4 и оцифрованы камерами мобильных устройств в различных условиях освещения и съемки. В процессе оцифровки образы документов были подвергнуты проективным искажениям и нелинейным деформациям листов.
В качестве альтернативного способа распознавания использовался SDK Smart Document Engine (https://smartengines.com/).
В результате показано, что средняя точность распознавания одной пометки увеличилась с 87.85% до 88.94%) - то есть на тестовом датасете доля ошибок распознавания пометок уменьшилась более, чем в 2 раза.
Этим доказано достижение заявленного технического результата.
| название | год | авторы | номер документа |
|---|---|---|---|
| Устройство для распознавания условно жестких деловых документов с автоматической привязкой их полей | 2024 |
|
RU2828182C1 |
| КЛАССИФИКАЦИЯ ИЗОБРАЖЕНИЙ ДОКУМЕНТОВ НА ОСНОВАНИИ КОНТЕНТА | 2014 |
|
RU2571545C1 |
| СПОСОБ ОБРАБОТКИ ИЗОБРАЖЕНИЙ С ИСПОЛЬЗОВАНИЕМ АДАПТИВНЫХ ТЕХНОЛОГИЙ НА ОСНОВЕ НЕЙРОСЕТЕЙ И КОМПЬЮТЕРНОГО ЗРЕНИЯ | 2020 |
|
RU2744769C1 |
| СИСТЕМА КОМПЬЮТЕРНОГО ЗРЕНИЯ В РИТЕЙЛЕ | 2022 |
|
RU2785327C1 |
| СИСТЕМА АВТОМАТИЗАЦИИ ВВОДА И КОНТРОЛЯ ДОКУМЕНТОВ | 2002 |
|
RU2232419C1 |
| СПОСОБ РАСПОЗНАВАНИЯ ПЛАТЕЖНЫХ ДОКУМЕНТОВ | 2016 |
|
RU2652946C1 |
| Система определения стоимости весового товара | 2021 |
|
RU2809136C2 |
| АВТОМАТИЗАЦИЯ ФОРМИРОВАНИЯ ДОКУМЕНТА | 2017 |
|
RU2714609C1 |
| Способ использования кодов для доступа к данным | 2015 |
|
RU2619526C1 |
| МЕТОД И СИСТЕМА ИЗВЛЕЧЕНИЯ ДАННЫХ ИЗ ИЗОБРАЖЕНИЙ СЛАБОСТРУКТУРИРОВАННЫХ ДОКУМЕНТОВ | 2015 |
|
RU2613846C2 |
Изобретение относится к способам распознавания документов. Технический результат заключается в повышении качества распознавания документов. В способе привязки полей условно жестких деловых документов при их распознавании на оцифрованной бумажной версии документа определяются графические примитивы с учетом информации о взаимном расположении графических примитивов в каждом эталонном документе, а именно минимальные расстояния от середины каждого из четырех ребер эталонного документа до ближайшей точки каждого графического примитива, минимальные расстояния от каждого из четырех углов эталонного документа до ближайшей точки каждого графического примитива, на основании взаимного расположения графических примитивов цифровой образ текущего документа отождествляется с цифровым образом одного из эталонных документов, хранящихся в заранее сформированной базе данных эталонных документов. Далее распознается информация и проводится проверка формальной корректности заполнения документа. 1 ил.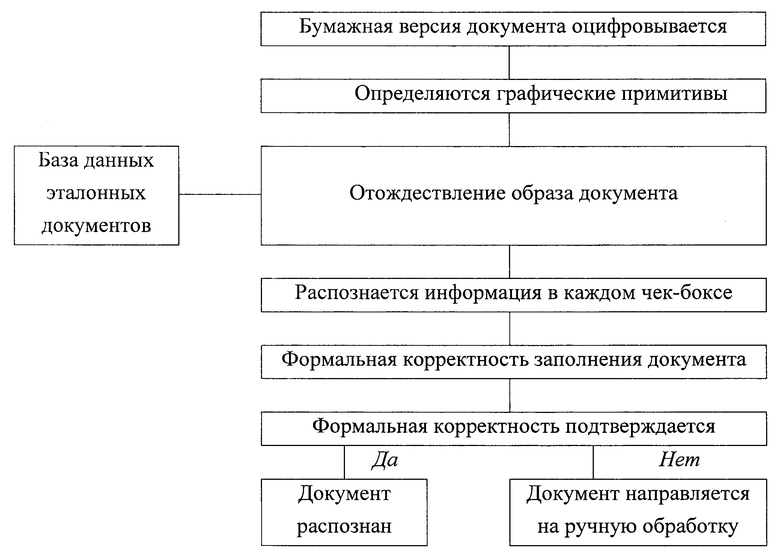
Способ привязки полей условно жестких деловых документов при их распознавании, характеризующийся тем, что: формируется база данных эталонных документов, содержащая информацию о взаимном расположении графических примитивов в эталонном документе и с указаниями на тип информации, содержащейся в каждом графическом примитиве: QR-код, штрихкод, отрезок, бар-код, тип: текстовая, цифровая или комбинированная, и язык информации в каждом чек-боксе; бумажная версия документа оцифровывается, тем самым формируется цифровой образ документа, на цифровом образе документа определяются графические примитивы, к которым относятся QR-коды, штрихкоды, слова статического текста, отрезки, бар-коды, чек-боксы; на основании взаимного расположения графических примитивов цифровой образ документа отождествляется с цифровым образом одного из эталонных документов, хранящихся в заранее сформированной базе данных эталонных документов, содержащей информацию о взаимном расположении графических примитивов в эталонном документе и с указаниями на тип информации, содержащейся в каждом графическом примитиве: QR-коды, штрихкоды, отрезки, бар-коды, тип: текстовая, цифровая или комбинированная, и язык информации в каждом чек-боксе; по результатам отождествления распознается информация в каждом чек-боксе; проводится формальная корректность заполнения документа как соответствие распознанной информации ожидаемой информации; если формальная корректность подтверждается, то документ считается успешно распознанным и информация из документа заносится в таблицу «номер документа - графический примитив - информация, содержащаяся в графическом примитиве», иначе документ направляется на ручную обработку, причем информация о взаимном расположении графических примитивов в каждом эталонном документе, хранящемся в базе данных эталонных документов, содержит: минимальные расстояния от середины каждого из четырех ребер эталонного документа до ближайшей точки каждого графического примитива, минимальные расстояния от каждого из четырех углов эталонного документа до ближайшей точки каждого графического примитива.
| ИДЕНТИФИКАЦИЯ ПОЛЕЙ НА ИЗОБРАЖЕНИИ С ИСПОЛЬЗОВАНИЕМ ИСКУССТВЕННОГО ИНТЕЛЛЕКТА | 2018 |
|
RU2695489C1 |
| US 20200019768 A1, 16.01.2020 | |||
| US 20060164682 A1, 27.07.2006 | |||
| US 8326015 B2, 04.12.2012 | |||
| СПОСОБ РАСПОЗНАВАНИЯ ПЛАТЕЖНЫХ ДОКУМЕНТОВ | 2016 |
|
RU2652946C1 |

