ОБЛАСТЬ ИЗОБРЕТЕНИЯ
Настоящее изобретение относится к области извлечения данных из изображений документов с помощью оптического распознавания символов (OCR). В частности, настоящее изобретение относится к применению подхода с использованием графа, подхода с использованием каскадной классификации, а также подхода с использованием уменьшенного алфавита, направленных на сокращение ошибок связанных с идентификации полей при обработке текстовой информации на изображениях документов.
УРОВЕНЬ ТЕХНИКИ
Для слабоструктурированных документов, таких как чеки, визитные карточки, паспорта (разных стран), банковские карты характерно различное расположение полей в разных экземплярах. Известные методы идентификации таких полей в слабоструктурированных документах основаны на «жадном алгоритме», когда поиск всех полей в тексте осуществляется в заданном порядке. Если фрагмент текста идентифицируется как некое поле, он не рассматривается в рамках исполнения дальнейших механизмов поиска. Такой подход предъявляет высокие требования к качеству работы первых механизмов поиска полей и ухудшает работу последующих механизмов поиска полей. В рамках первого механизма поиска поля принимается решение о том, является ли текстовый фрагмент искомым полем слабоструктурированного документа или нет, не имея информации о результатах последующих механизмов поиска или о документе в целом. В результате поля зачастую идентифицируются некорректно.
Для решения данной проблемы предлагается метод настоящего изобретения с использованием структуры графа. Граф позволяет сохранять результаты всех механизмов поиска и осуществлять исследование различных сочетаний полей в ходе дальнейшего анализа результатов поиска. Кроме того, наш метод позволяет организовать работу механизмов поиска поля, используя каскадную классификацию, что позволяет экономить вычислительные ресурсы и вычислять только то число признаков, которое требуется для отображения. Наш метод также основан на применении принципа уменьшенного алфавита для создания электронных словарей ключевых слов, что сокращает число ошибок при идентификации полей механизмами поиска, использующими электронные словари ключевых слов.
РАСКРЫТИЕ ИЗОБРЕТЕНИЯ
Настоящее изобретение относится к методу извлечения данных из полей на изображении документа. В одном варианте реализации получается текстовое представление изображения документа. Строится граф для хранения признаков текстовых фрагментов документа и связей между ними. Для вычисления признаков текстовых фрагментов документа и связей между ними осуществляется каскадная классификация. Формируется набор гипотез о принадлежности текстовых фрагментов полям на изображении документа. Выбирается комбинация гипотез. И на основе выбранной комбинации гипотез осуществляется извлечение данных из полей на изображении документа.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
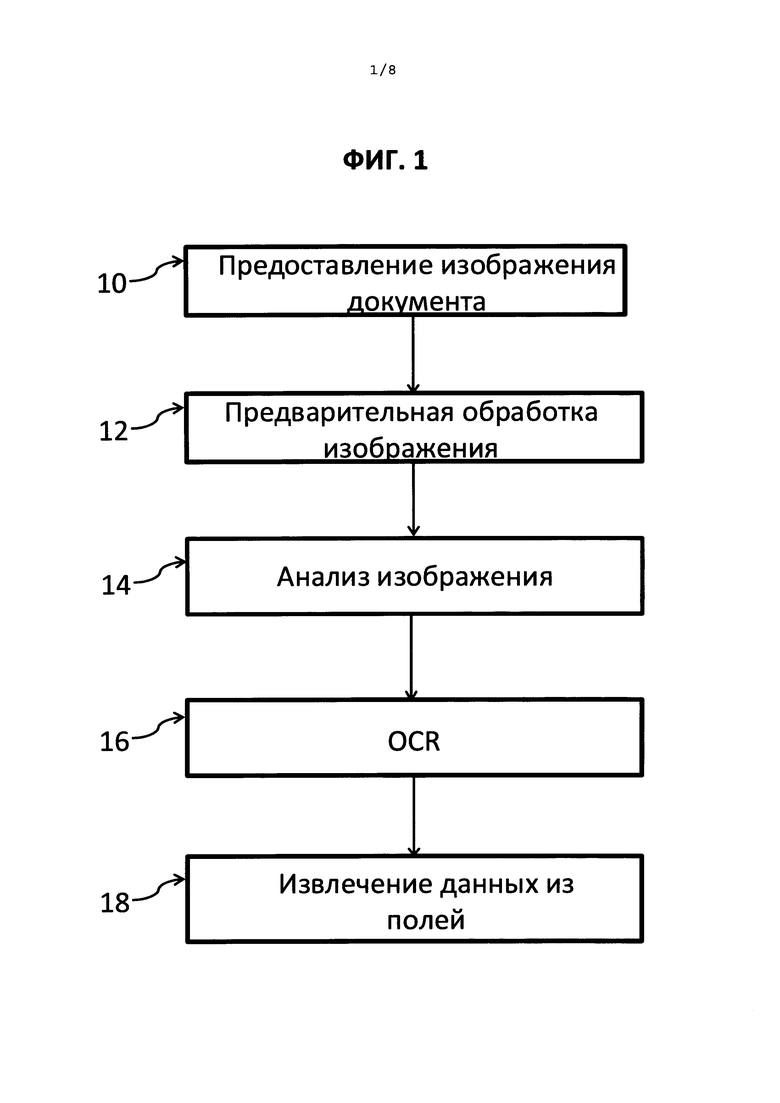
На Фиг. 1 показан метод автоматического извлечения значимой информации из слабоструктурированного документа.
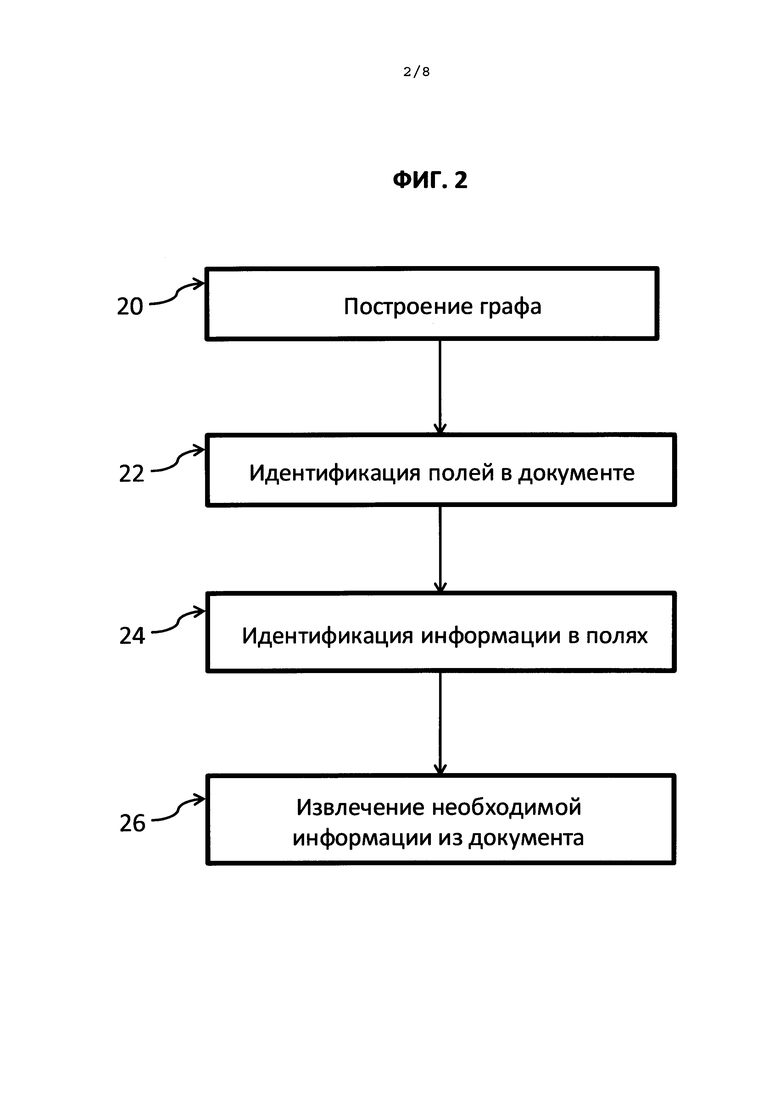
На Фиг. 2 показаны ключевые этапы извлечения сущностей.
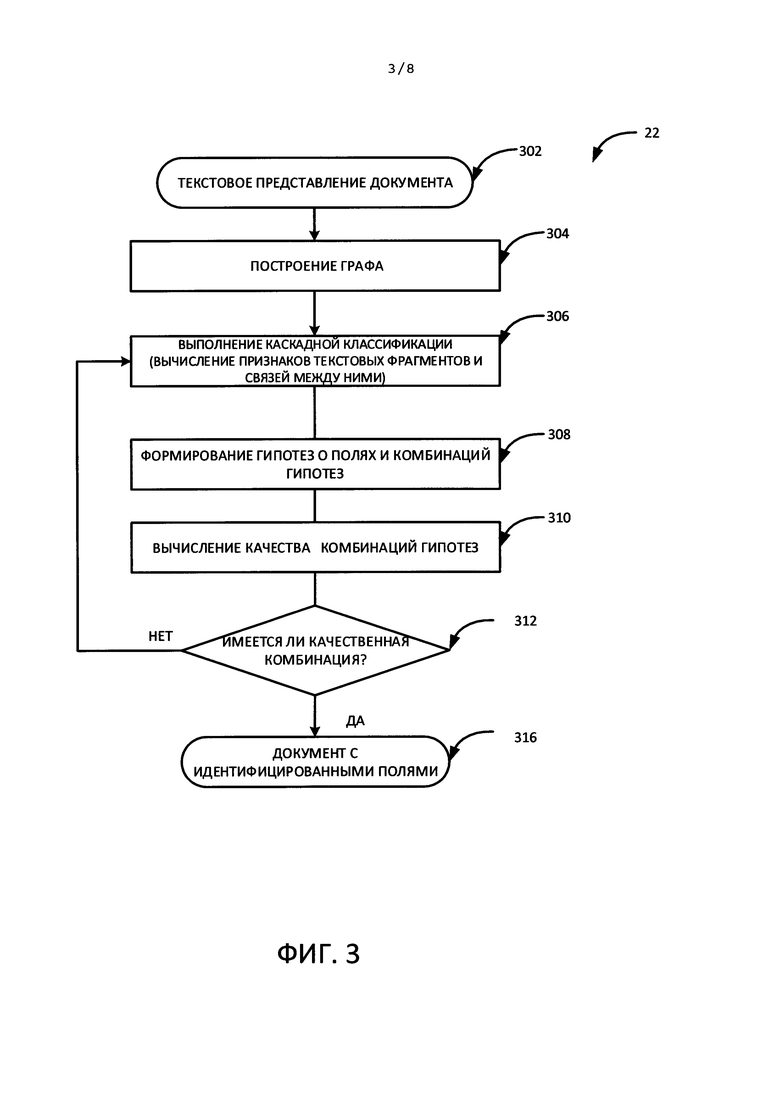
На Фиг. 3 показан метод идентификации полей в слабоструктурированном документе с использованием графа и каскадной классификации.
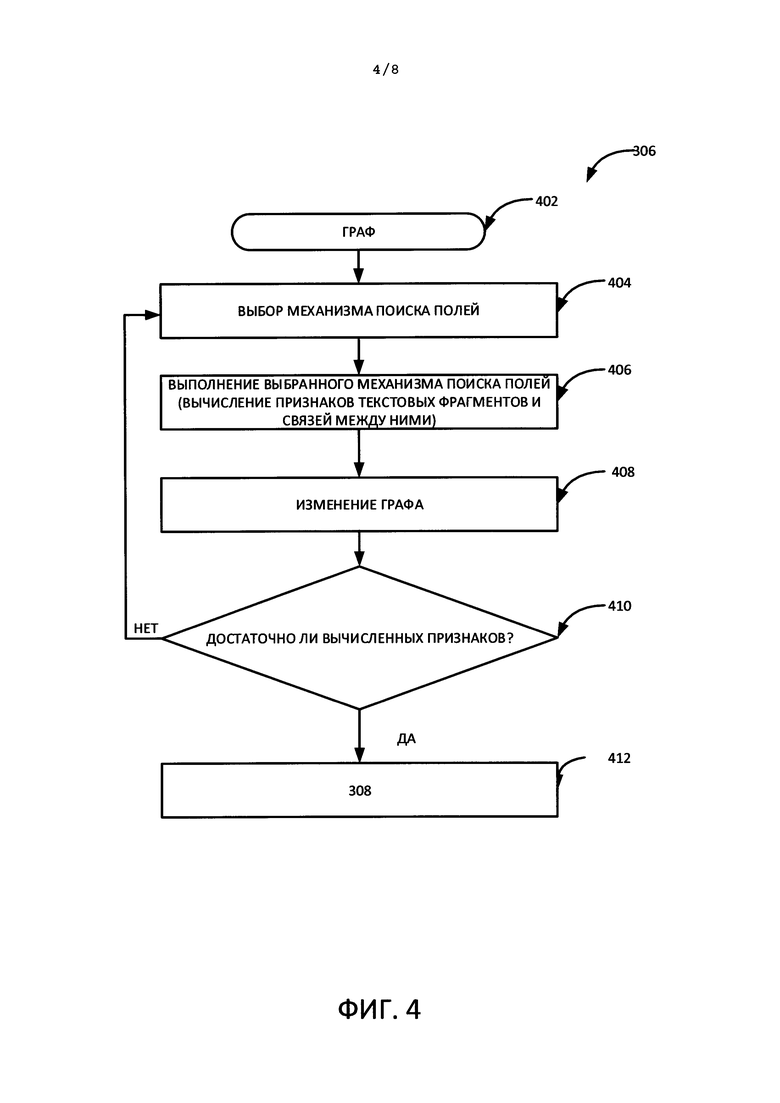
На Фиг. 4 показан метод каскадной классификации.
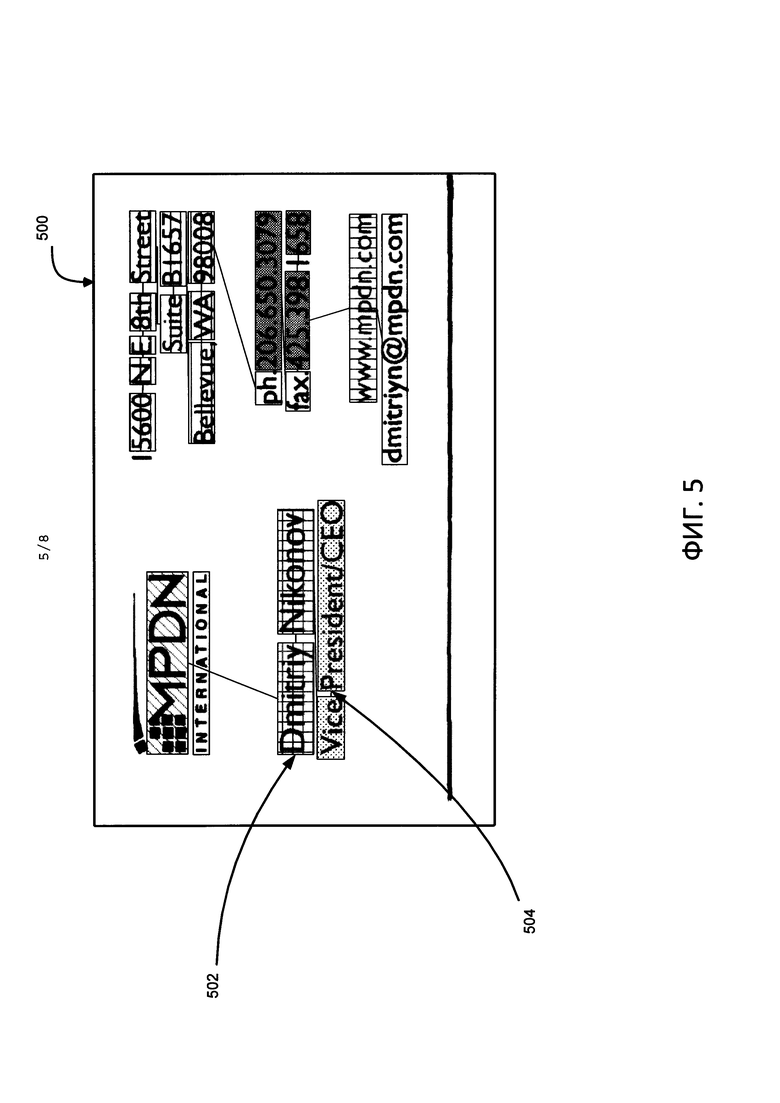
На Фиг. 5 приведен пример графа, построенного для визитной карточки.
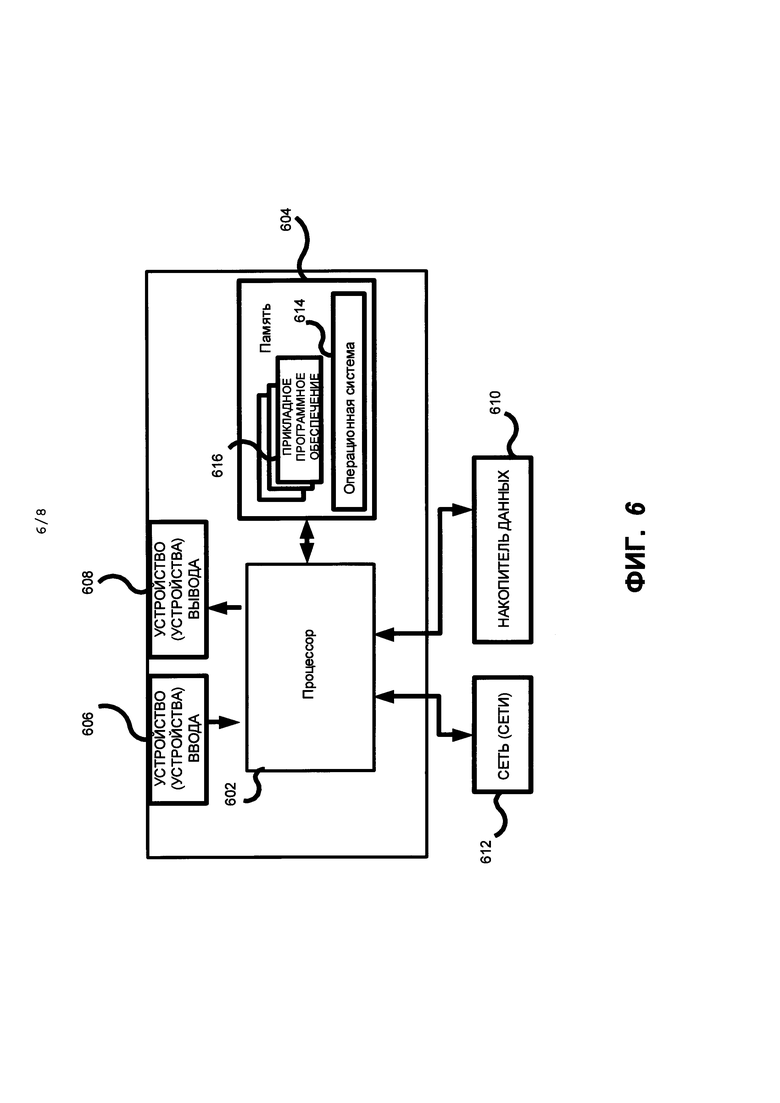
На Фиг. 6 приведена общая архитектурная схема различных видов компьютеров и прочих устройств с процессорным управлением.
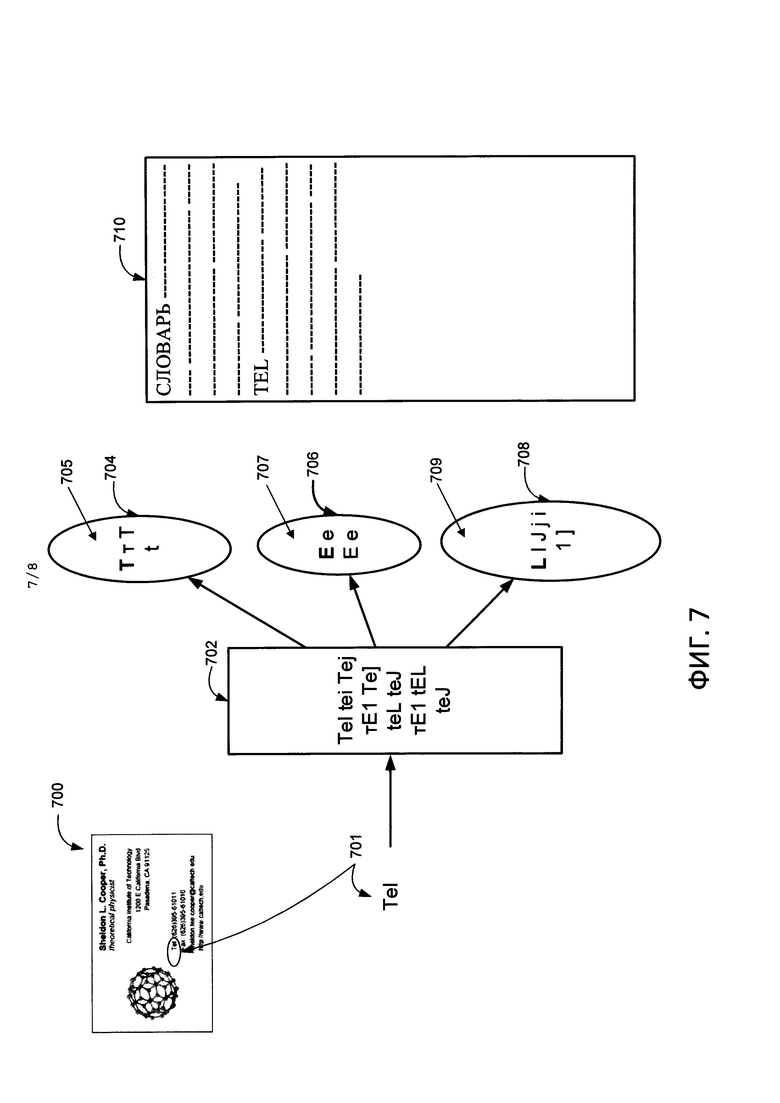
На Фиг. 7 приведен пример представления слова в словаре с применением техники уменьшенного алфавита.
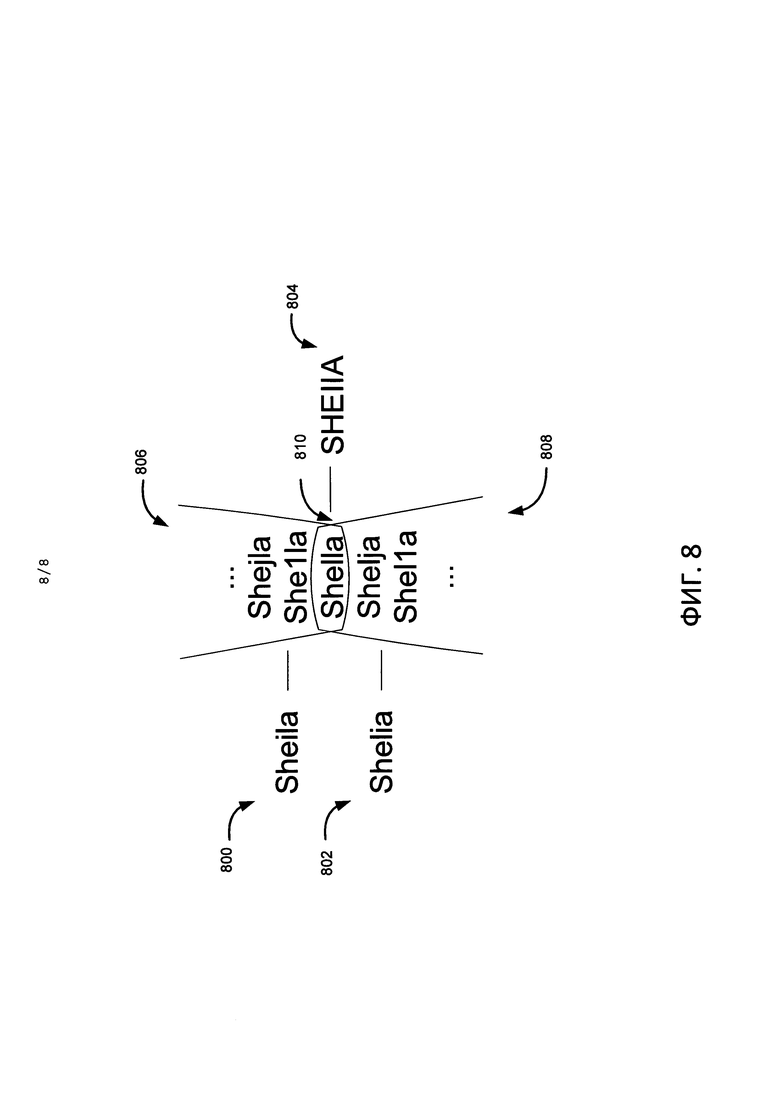
На Фиг. 8 приведен пример слова в составе уменьшенного алфавита, которое соответствует двум исходным словам.
ОПИСАНИЕ ПРЕДПОЧТИТЕЛЬНЫХ ВАРИАНТОВ РЕАЛИЗАЦИИ ИЗОБРЕТЕНИЯ
В контексте настоящего изобретения термин «поле» означает содержащуюся в документе информацию, которую необходимо идентифицировать и извлечь из документа.
На ФИГ. 1 приведено общее иллюстративное описание метода автоматического извлечения значимой информации из изображения слабоструктурированного документа. Слабоструктурированный документ - это документ, содержащий набор информационных полей (элементов документа, предназначенных для извлечения данных), оформление, количество и расположение которых могут существенно отличаться в различных версиях данного документа. Примером такого слабоструктурированного документа может быть товарный чек или визитная карточка, при том что настоящий метод и соответствующая система не ограничиваются товарными чеками или визитными карточками. На этапе 10 предоставляется изображение документа, подлежащее вводу в систему. На этапе 12 осуществляется предварительная обработка изображения, которая предназначена для уменьшения шума и различных дефектов изображения, а также корректировки качества изображения с целью его подготовки к дальнейшей обработке. Дальнейшая обработка на этапе 14 включает анализ документа для определения физической структуры анализируемого документа, как, например, текстовые блоки, наличие или отсутствие таблицы и так далее. На этапе 16 осуществляется оптическое распознавание символов (преобразование машинописного или печатного текста в машинокодированный текст). Этап 18 метода обработки документа согласно настоящему изобретению представляет собой этап извлечения сущности (поля).
На ФИГ. 2 показаны ключевые этапы этапа 18 - извлечение сущностей (полей), показанного на ФИГ. 1. Этап 20 на ФИГ. 2 иллюстрирует построение графа как структуры для хранения числовых характеристик фрагментов текста и связей между ними. На этапе 22 на ФИГ. 2 осуществляется идентификация полей на изображении документа с применением метода каскадной классификации. Поля в документе могут простыми (без внутренней структуры, например, стоимость товаров) и составными (с внутренней структурой, например, поле адреса). Следовательно, на этапе 24 на ФИГ. 2 осуществляется идентификация компонентов полей с использованием, например, регулярных выражений, ключевых слов и прочей представляющей интерес информации. Извлечение желаемой идентифицированной информации (данных) показано на этапе 26 ФИГ. 2.
Структура, используемая для хранения различных характеристик текстового представления изображения документа, представлена в виде графа. Текстовое представление является результатом оптического распознавания символов (OCR) изображения документа. На ФИГ. 5 показан граф, построенный для визитной карточки. Текстовое представление визитной карточки (500) представлено в виде графа. Вершины (502) такого графа включают текстовые фрагменты анализируемого документа. Вершины графа также включают числовые характеристики текстовых фрагментов. В ходе анализа документа вершины графа сопоставляются с полями в документе. Вершины графа соединяются ребрами (504), которые хранят числовые характеристики логических связей между текстовыми фрагментами. В одном из вариантов реализации изобретения каждой вершине графа соответствует одно слово в тексте, а ребра графа задают линейный порядок слов в тексте. Линейный порядок - это предполагаемый порядок чтения текста в документе, который зависит от языка документа (например, в случае англоязычных документов порядок чтения текста - слева направо, в случае документов на иврите - справа налево). Каждое слово сопоставлено с соответствующей вершиной. В ходе анализа текста, подробное описание которого приводится ниже, две или более вершины могут сливаться либо одна вершина может быть разделена на две или более вершин. Также могут удаляться и добавляться ребра между вершинами и изменяться числовые характеристики вершин (текстовые фрагменты) и ребер (связи).
На ФИГ. 3 показан метод извлечения данных из слабоструктурированного документа с использованием графа и каскадной классификации. В качестве иллюстративного примера система извлечения данных из слабоструктурированного документа получает текстовое представление изображения документа (302). Текстовое представление является результатом оптического распознавания символов (OCR) изображения документа. На этапе 304 строится граф, представляющий распознанный текст документа. Каждой вершине графа соответствует слово, словосочетание или фрагмент текстового представления (такой, как, например, фрагмент «www» в адресе «HYPERLINK "http://%c2%bb"Ошибка! Недопустимый объект гиперссылки.» или окончание фамилии), то есть число вершин графа равняется либо превышает число слов в текстовом представлении изображения документа и каждая вершина соединена со всеми другими вершинам посредством ребер.
На этапе 306 осуществляется каскадная классификация выделенных текстовых фрагментов документа. Каскадная классификация - это метод сбора информации о признаках текстовых фрагментов, включая подсчет признаков текстовых фрагментов, а также о связях между текстовыми фрагментами. Каскадная классификация - это итеративный процесс. Процесс каскадной классификации осуществляется до тех пор, пока собранная информация о текстовых фрагментах и связях между ними не станет достаточной для формирования гипотез о принадлежности текстовых фрагментов определенному полю документа. Каждая итерация в рамках каскадной классификации представляет собой выполнение определенного механизма.
Механизм - это компьютерная программная функция, которая отвечает за обработку графа, подсчет определенных признаков для вершин и ребер графа и создание новых признаков. Вычисление признаков и создание признаков осуществляются исходя из предшествующих данных (рассчитанных предыдущими механизмами). При запуске определенного механизма применяется каскадный принцип, когда вершины, соответствующие текстовым фрагментам, которые не подлежат обработке данным конкретным механизмом, игнорируются.
Так, если в ходе обработки текстового представления изображения визитной карточки первый механизм в каскадной классификации включает определение размера шрифта, по которому текстовые фрагменты (вершины) на визитных карточках разделяются на текстовые фрагменты с соответствующим шрифтом «мелкий» и текстовые фрагменты с соответствующим шрифтом «крупный», а следующий механизм заключается, например, в поиске имен в документе, то вершины со значением «мелкий» признака «размер» будут отсекаться, и второй механизм будет рассчитывать значения только для вершин со значением признака «размер шрифта», определенным как «крупный».
В качестве еще одного примера, если в ходе выполнения предыдущих механизмов текстовый фрагмент был идентифицирован как класс чисел, а следующий механизм заключается в поиске ключевых слов, данный следующий механизм не будет применяться к текстовому фрагменту «число». Ключевые слова - это соотнесенные с определенными полями слова, которые могут использоваться для выявления полей.
На Фиг. 4 показана блок-схема каскадной классификации текстовых фрагментов. В качестве входных данных система получает граф (402). Вершинами графа являются текстовые фрагменты. Вершины графа соединяются ребрами (логические связи между текстовыми фрагментами), которые задают линейный порядок распознанного текста в рамках документа. Могут также быть и ребра, не являющимися связями линейного порядка.
На этапе 404 для поиска поля выбирается механизм из множества различных механизмов исходя из принципа экономии ресурсов. Это значит, что сначала выбираются наиболее ресурсосберегающие механизмы, а наиболее ресурсоемкие механизмы выбираются позже. Ресурсосберегающие механизмы - это, например, поиск текстовых фрагментов, состоящих из букв, или текстовых фрагментов, включающих числа, либо идентификация текстового фрагмента по размеру шрифта и т.д. Примером ресурсоемкого механизма является поиск полей с использованием крупного электронного словаря.
На этапе 406 запускается механизм, выбранный на этапе 404. Механизм анализирует все текстовые фрагменты (или некоторую часть фрагментов) и генерирует значение признака или значения признаков (числовые характеристики). Более подробная информация о механизмах и признаках, которые они идентифицируют, представлена ниже.
На этапе 408 граф изменяется исходя из значений признаков, идентифицированных данным механизмом, по всем или части текстовых фрагментов. То есть обновляются значения признаков в вершинах (текстовых фрагментах) и ребрах графа (логические связи между текстовыми фрагментами). Кроме того, на данном этапе в структуру графа могут вноситься любые изменения. Так, может возникнуть необходимость в разделении текстового фрагмента, содержащего как буквы, так и числа, на две вершины, с тем чтобы отделить буквы от чисел. Это будет сделано путем создания новой вершины, добавления ребра от старой вершины к новой вершине и переносом в новую вершину ребер, которые ранее брали начало от старой вершины.
На этапе 410 определяется, является ли информация (вычисленные признаки) по текстовым фрагментам и связям между ними достаточной для формирования одной или более гипотез о типах полей, соотнесенных с данными текстовыми фрагментами.
Если информация о текстовых фрагментах и связях между ними является недостаточной, осуществляется переход на этап выбора следующего механизма поиска (404). Следующий механизм выбирается исходя из подсчитанных ранее признаков. В одном из вариантов реализации изобретения каждый последующий механизм является более ресурсоемким, чем предыдущий. Примером более ресурсоемкого механизма может быть механизм поиска текстового фрагмента, соответствующего определенному регулярному выражению. Регулярное выражение - это последовательность символов, которая образует шаблон поиска, в основном предназначенный для сопоставления шаблона со строками.
Если информация о текстовых фрагментах и связях между ними является достаточной, каскадная классификация текстовых фрагментов завершается.
Возвращаясь к Фиг. 3, на этапе 308 формируются гипотезы о принадлежности текстовых фрагментов определенным полям документа и комбинации этих гипотез. Формирование гипотез основано на информации о текстовых фрагментах и связях между ними, вычисленной в ходе каскадной классификации 306. При формировании гипотез им присваиваются определенные уровни уверенности. Уровень уверенности для гипотезы зависит от значения признаков текстовых фрагментов и связей между ними. В одном из вариантов реализации изобретения уверенность гипотезы измеряется в процентах от 0 до 100%. Для одного текстового фрагмента может быть сформировано несколько гипотез с различными или одинаковыми уровнями уверенности. Следовательно, может быть сформировано несколько комбинаций гипотез о полях документа. На этапе 310 осуществляется вычисление качества различных комбинаций гипотез о полях документа. Вычисленное качество комбинаций гипотез может использоваться для сравнения комбинаций гипотез. Для оценки качества комбинации гипотез учитывается несколько показателей. Первым показателем является совокупный показатель уровней уверенности для комбинации гипотез. Совокупный показатель уровней уверенности для всех гипотез в составе одной комбинации гипотез вычисляется как сумма уровней уверенности, вычисленная по каждому текстовому фрагменту в отношении данной гипотезы. Чем выше совокупный показатель уровней уверенности для всех гипотез в составе комбинации, тем выше качество данной комбинации.
Вторым показателем является совокупный показатель штрафов совместимости различных гипотез в составе одной комбинации. Совокупный показатель штрафов для комбинации гипотез вычисляется как сумма штрафов. В рамках данного показателя штрафы комбинациям гипотез присваиваются исходя из определенных правил, описывающих конкретные поля, их характеристики и расположение относительно друг друга (геометрия полей) и возможную структуру документа. Данные правила, как правило, создаются отдельно для каждого вида документа. Так, в случае с визитной карточкой поле имени не может быть пустым, не может быть два поля имени или несколько полей адреса, расположенных в различных частях документа, и т.д. Чем меньше совокупный показатель штрафов совместимости гипотез, тем выше качество данной комбинации. Вычисленное качество комбинации гипотез по меньшей мере частично основано на совокупном показателе уровней уверенности и совокупном показателе штрафов.
В одном из вариантов реализации изобретения на этапе 312 определяется, превышает ли вычисленное качество комбинации гипотез предопределенное пороговое значение или имеется ли комбинация гипотез для всего документа достаточного качества. В случае отсутствия такой комбинации, осуществляется возврат на этап 306, и процесс получения дополнительных характеристик текстовых фрагментов и связей между ними с использованием каскадной классификации возобновляется. В таком случае в одном из вариантов реализации изобретения применяются все более сложные (ресурсоемкие) механизмы, например, механизмы, использующие более крупный глоссарий. При наличии подходящей комбинации гипотез анализ текста документа считается завершенным, т.е. поля на изображении документа идентифицированы. В другом варианте реализации настоящего изобретения на этапе 312 выбирается комбинация гипотез с наиболее высоким вычисленным качеством.
В рамках описанного выше метода сравнение комбинаций гипотез для каждой комбинации гипотез вычисляется значение качества, т.е. каждой комбинации присваивается числовой показатель качества, который определяет качество всей комбинации гипотез. Лучшая комбинация гипотез определяется путем сравнения данных показателей качества комбинаций друг с другом и с предопределенным пороговыми значением. Такое сопоставление может быть не совсем точным. Существует альтернативный подход к сравнению комбинаций гипотез. Данный подход заключается в сравнении набора признаков или вектора признаков одной комбинации гипотез с набором признаков или вектором признаков другой комбинации гипотез. Вектор признаков комбинации гипотез может включать перечень полей и связей между ними, идентифицированных в составе данной комбинации гипотез. Выбор лучшей комбинации основывается на наборе правил, хранящихся в системе по каждому виду документа. Например, в результате выполнения механизмов по обработке документа вида «визитная карточка» сформировано две комбинации гипотез. Вектор признаков первой комбинации гипотез может включать следующее: документ содержит два логически связанных поля, где первое поле - это «Имя», а второе поле - «Фамилия». Вектор признаков второй комбинации гипотез может включать следующее: документ содержит два логически связанных поля, где первое поле - это «Имя», а второе поле - «Должность (специальность)». Набор правил по визитным карточкам может включать правило, согласно которому лучшей комбинацией гипотез по визитным карточкам является комбинация, в которой есть как поле «Имя», так и поле «Фамилия», при этом данные поля расположены рядом друг с другом (логически связаны). В данном примере предпочтение отдается первой комбинации гипотез, так как вектор признаков данной комбинации больше соответствует правилам. Данный альтернативный подход к сопоставлению комбинаций гипотез является более точным и позволяет учитывать больше нюансов.
Выполнение механизмов для установления новых или дополнительных признаков должно осуществляться в таком порядке, который необходим для обеспечения высокого качества классификации. Порядок выполнения классификаторов определяется либо вручную, либо автоматически.
В качестве примера метода каскадной классификации, используемого в настоящем изобретении, рассматривается необходимость распознавания некого множества товарных чеков из нескольких различных магазинов. Поля в товарных чеках из одного и того же магазина, как правило, имеют одинаковую геометрическую структуру: расположение полей, шрифт и другие признаки таких товарных чеков от одного и того же продавца не различаются. Такие признаки обычно отличаются по расположению и шрифтам на товарных чеках из разных магазинов или от разных продавцов. Для классификации товарных чеков из разных магазинов сначала необходимо выполнить механизм поиска продавцов, использующий словарь наименований продавцов, т.е. добавить идентификационные данные продавца в каскадный классификатор, и, если продавец был идентифицирован, остальные поля будут идентифицироваться по шаблону, соотнесенному с данным продавцом. Если, например, кассовые аппараты продавца не изменились с момента создания шаблона, использование текущего шаблона существенным образом ускорит процесс извлечения данных.
Для установления новых признаков метод настоящего изобретения предполагает использование различных эвристик для более точного выбора нескольких возможных мест расположения того или иного вида определенного поля на чеке. Например, поле, соответствующее наименованию продавца часто расположено рядом с полем, соответствующим адресу. Таким образом, если расположение, соответствующее полю наименование продавца, известно, то, скорее всего, текст адреса расположен рядом с наименованием продавца, так можно идентифицировать и ввести соответствующий признак. И наоборот, если найдено поле наименования продавца, то можно найти поле адреса, используя признак «Текстовый фрагмент располагается рядом с наименованием продавца».
Для поиска поля наименования продавца на товарных чеках можно использовать признак «Текстовый фрагмент располагается в первой строке».
Одним из примеров использования эвристики в рамках метода настоящего изобретения является случай варьирования признаков некого текстового фрагмента, представленного в виде последовательности чисел (например, «…428»). Примеры соответствующих признаков включают: признак телефонного номера, признак цены приобретенного товара или товаров, или признак адреса (номер дома, часть почтового индекса и тому подобное).
Кроме того, признаки могут быть в виде регулярного выражения. Примером такого признака является «Текстовый фрагмент соответствует регулярному выражению формата даты» (например, ДД/ММ/ГГГГ).
Признаки также могут быть в виде часто встречающихся ключевых слов в таких документах, как товарные чеки: сочетание «тел.», соответствующее телефонному номеру, сочетание «итого», соответствующее итоговой цене покупки, и так далее.
Аналогичным образом можно использовать такие ключевые слова, как «спасибо, что выбрали», чтобы найти поле наименования продавца (соответствующий признак - «Текстовый фрагмент расположен после фразы «спасибо, что выбрали»). Аналогичным образом ключевое слово «адрес» может использоваться, чтобы найти поле адреса на товарных чеках или визитных карточках (соответствующий признак - «Текстовый фрагмент расположен после названия поля, указывающего на адрес» (такое как “адрес”)). Ключевое слово «компания» может использоваться, чтобы найти поле наименования компании на визитной карточке (соответствующий признак - «Текстовый фрагмент расположен после названия поля указывающего на компанию» (такое как “компания”)).
Метод и система настоящего изобретения также предполагают использование бинарных признаков при идентификации желаемых полей документа. Извлечение различных сущностей из документа, такого как товарный чек, происходит автоматически путем обучения системы распознаванию бинарных признаков (т.е. путем классификации). Например, бинарным признаком для сущности, соответствующей полю наименования продавца, может быть: близость поля адреса, наличие кавычек, близкое расположение таких слов, как «компания», «ООО».
Ключевые слова могут быть частью поля. Примерами таких признаков являются: «Текстовый фрагмент содержит ключевое слово? указывающее на улицу» (такое как «ул.», «проспект», «проезд»), «Текстовый фрагмент содержит слова, обозначающие род занятий» (такие как «агент», «брокер», «программист») или «Текстовый фрагмент содержит наименование города».
Чтобы найти веб-адрес на визитной карточке могут использоваться следующие признаки: «Текстовый фрагмент расположен после ярлыка “url”» (такого как «web:», «url:»), «Текстовый фрагмент содержит символы “www”» (возможно, не в точности «www», а что-то похожее, как, например, «11w»), «Текстовый фрагмент включает доменное имя» (такое как «соm», «net»). Помимо перечисленных примеров признаков текстовых фрагментов, механизмы также могут вычислять признаки-связи (ребра) между текстовыми фрагментами. Примерами таких признаков являются: «Ребро находится между двумя совместимыми текстовыми фрагментами» (такими как несколько колонок), «Ребро находится между аналогичными горизонтальными строками», «Ребро находится между словами», «Ребро находится над знаком препинания», «Ребро выводится искателем».
В случаях, когда необходима идентификация и извлечение только некоторых из полей (например, при необходимости только полей, соответствующих наименованию продавца и итоговой цене покупки), метод каскадной классификации запускает выполнение только тех своих механизмов, которые необходимы для корректной идентификации данных полей.
В качестве иллюстрации метода настоящего изобретения рассмотрим пример идентификации телефонного номера продавца на товарном чеке. Для быстрой идентификации телефонного номера могут использоваться регулярные выражения возможных символов (в данном случае цифры), а также данные о типичном порядке их расположения.
Если все анализируемые текстовые фрагменты документа были успешно классифицированы, то есть в документе не осталось ни одного не идентифицированного фрагмента или было принято решение остановки каскадной классификации, процесс идентификации может быть завершен. Идентификация может быть завершена при условии отсутствия конфликтов в ходе классификации, т.е. отсутствия случаев совпадения одного текстового фрагмента с несколькими противоречащими друг другу классами (видами), как, например, «соответствует телефонному номеру» и «не соответствует телефонному номеру».
В случае возникновения конфликтов в процессе классификации могут быть использованы другие методы классификации. В число таких других методов входят классификация по ключевым словам, геометрии полей в документе и так далее. Например, очень легко спутать телефонный номер и номер факса, однако механизм классификации по ключевому слову, точно указывающий на телефонный номер или номер факса, может эффективно использоваться для корректной идентификации желаемого номера.
В настоящем изобретении предусматривается возможность использования электронного словаря (словаря) в рамках предлагаемого метода, однако в определенных вариантах реализации данного метода использование словаря не требуется. Следующий пример помогает проиллюстрировать вариант реализации изобретения с использованием словаря. При извлечении данных из полей слабоструктурированных документов с использованием метода настоящего изобретения многие механизмы поиска используют специализированные словари. Например, чтобы идентифицировать поле «имя», механизм поиска использует специализированный словарь имен; чтобы идентифицировать поле «адрес», механизм поиска использует специализированные словари улиц и городов, чтобы идентифицировать поле «профессия», механизм поиска использует специализированный словарь профессий, должностей и родов занятий; чтобы идентифицировать поля, которые, как правило, сопровождаются ключевыми словами, такими как «Тел.», «Факс», «т.», «ф.», «Итого» и т.д., привлекается механизм поиска, использующий специализированный словарь ключевых слов. Слова, входящие в состав специализированного словаря, могут отличаться в зависимости от языка (страны). Словарные слова используются как признаки полей.
Из-за OCR ошибок в тексте, полученном в результате распознавания изображения документа, бывает невозможно найти в словаре некорректно распознанное слово/ключевое слово. Это в первую очередь относится к коротким словам на китайском, корейском и японском языках. Если для идентификации поля механизмом поиска используется словарь, а в слове имеется ошибка OCR, данное слово не будет найдено в словаре. Это означает, что не будет надлежащим образом вычислен с помощью специализированного словаря соответствующий признак, и поле может быть идентифицировано некорректно.
Вышеописанная проблема, связанная с использованием словаря, решается в рамках настоящего изобретения путем применения принципа уменьшенного алфавита. Суть принципа уменьшенного алфавита заключается в следующем. Предположим, имеется исходный алфавит А. Далее «алфавит» - родовое понятие, обозначающее совокупность символов, которые могут включать числа, буквы, знаки препинания и (или) математические и специальные символы. При составлении уменьшенного алфавита сначала группируются символы из алфавита А, которые можно легко спутать друг с другом. Из каждой из полученных групп выбирается символ-метапредставитель. Совокупность символов-метапредставителей групп составляет новый алфавит Б, при этом множество символов алфавита Б является подмножеством множества символов алфавита А. При составлении алфавита Б из алфавита А преобразовали множество символов алфавита А в множество символов алфавита Б (f: А->Б). Теперь поиск слова выполняется в специализированном словаре, использующем алфавит Б.
Объединение символов в группы может осуществляться на основании статистики ошибок OCR. То есть при наличии эталонного текста и распознанной версии того же текста мы можем идентифицировать символы, которые были некорректно распознаны (перепутаны в процессе распознавания). Например, исходя из этих данных в отдельную группу могут быть помещены следующие символы как легко путающиеся друг с другом: «YyUu», «АаАа», «HhHн», «ОоОо0», «UuИи» и т.д. из английского и русского алфавитов. В одну группу помещаются такие символы, которые можно легко спутать друг с другом.
Для каждой такой группы выбирается либо создается символ-метапредставитель. Например, группа символов «YyУу» может быть представлена одним символом «Y».
Каждый символ из исходного алфавита с кодированием UTF32 представляется 4 байтами. Символ из уменьшенного алфавита может быть представлен меньшим числом байтов. В результате замена символов исходного алфавита на символы уменьшенного алфавита может существенно сократить размер памяти, необходимый для хранения словаря.
Символы-метапредставители различных групп образуют уменьшенный словарь. Таким образом, в состав уменьшенного словаря включаются символы/знаки/буквы, которые либо невозможно, либо трудно спутать с любым другим символом. Результаты процесса распознавания слабоструктурированного документа и слов в специализированном словаре могут быть представлены с помощью уменьшенного алфавита. Заменяя буквы в специализированном словаре на соответствующие символы-метапредставители, преобразуем специализированный словарь в словарь на основе уменьшенного алфавита.
На Фиг. 7 приведен пример слова, представленного в специализированном словаре с применением принципа уменьшенного алфавита. Как показано на Фиг. 7, визитная карточка 700 содержит поле телефонного номера, и это поле сопровождается ключевым словом «Tel» (701). При распознавании «Tel» может быть распознано с различными ошибками. На Фиг. 7 перечислены некоторые варианты ошибочного распознавания слова «Tel» 702. Исходя из данных примеров и сопоставления различных версий распознавания можно идентифицировать группы символов (704, 706 и 708). В данных группах идентифицируются символы-метапредставители. На Фиг. 7 идентифицированные символы-метапредставители (705, 706, 709) выделены жирным шрифтом. Для групп 704, 706 и 708 это «Т», «Е» и «L» соответственно. В словаре на основе уменьшенного алфавита 710 слово «Tel» будет представлено с помощью данных символов-метапредставителей в виде слова «TEL».
Словарь на основе уменьшенного алфавита не только обеспечивает корректную идентификацию полей документа (несмотря на возможные ошибки OCR в словах/ключевых словах), но и позволяет исправлять данные ошибки. Это обусловлено специальной структурой словаря на основе уменьшенного алфавита. Структурной единицей словаря на основе уменьшенного алфавита является слово уменьшенного алфавита. В одном из вариантов реализации изобретения слова в словаре на основе уменьшенного алфавита хранятся вместе с соответствующим исходным словом (словами) и соотнесенным с данным исходным словом множеством (множествами) версий распознавания данного исходного слова с ошибками OCR. Если слово в уменьшенном алфавите соотнесено только с одним исходным словом и, соответственно, только с одним множеством версий распознавания данного исходного слова с ошибками OCR, орфографические ошибки в исходном слове могут быть исправлены с помощью словаря на основе уменьшенного алфавита.
На Фиг. 8 показан более сложный случай, когда одно слово уменьшенного алфавита соответствует двум исходным словам. Этими двумя исходными словами на Фиг. 8 являются «Sheila» (800) и «Shelia» (802). С помощью уменьшенного алфавита слова «Sheila» и «Shelia» (800 и 802) могут быть представлены в виде слова «SHEIIA» (804) ввиду пересечения множеств версий распознавания данных двух исходных слов (806 и 808). В данном случае неверное написание исходного слова может быть исправлено с помощью словаря на основе уменьшенного алфавита, если ошибочные версии распознавания не попадают в пересекающееся подмножество (810).
Если алфавит состоит из иероглифов, такой алфавит также может быть разделен на несколько групп, при этом результатом распознавания иероглифа будет группа, содержащая данный иероглиф, а не код данного иероглифа. В результате слова вводятся в словарь с помощью определенного суженного алфавита.
Таким образом, даже если символ в ключевом слове был неверно распознан, соответствующее ключевое слово все равно будет найдено в словаре, соотнесено с полем контрольного слова, и будет корректно идентифицировано.
На ФИГ. 6 показан пример вычислительного средства для реализации принципов и систем настоящего изобретения в соответствии с одним из вариантов реализации настоящего изобретения. Как показано на ФИГ. 6, данный пример вычислительного средства включает по меньшей мере один процессор 602, соединенный с запоминающим устройством 604. Процессор 602 может представлять собой один или несколько процессоров (например, микропроцессоров), а запоминающее устройство 604 может представлять собой оперативные запоминающие устройства (ОЗУ), включающие основное запоминающее устройство вычислительного средства, а также любые вспомогательные уровни памяти, например, кэш-память, энергонезависимые или резервные виды памяти (например, программируемая или флэш-память), постоянные запоминающие устройства и т.д. Кроме того, может считаться, что запоминающее устройство 604 включает запоминающее устройство, физически расположенное где-либо в ином месте в вычислительном средстве, например, любая кэш-память в процессоре 602, а также любой объем памяти, используемый в качестве виртуальной памяти, например, хранящейся на съемном накопителе 610.
Как правило, вычислительное средство имеет ряд входов и выходов для обмена информацией с внешними устройствами. В качестве интерфейса пользователя или оператора вычислительное средство может содержать одно или более пользовательских устройств ввода 606 (например, клавиатуру, мышь, устройство обработки изображений, сканер и микрофон), а также одно или более устройств вывода 608 (например, панель жидкокристаллического дисплея (LCD) и устройство воспроизведения звука (динамик)). Для реализации настоящего изобретения вычислительное средство, как правило, содержит как минимум одно устройство с экраном.
Для дополнительного хранения вычислительное средство может также содержать одно или более устройство большой емкости 610, например, накопитель на гибком диске или на другом съемном диске, накопитель на жестком диске, запоминающее устройство с прямым доступом (ЗУПД), оптический привод (например, привод оптических дисков (формата CD), привод с цифровым универсальным диском (формата DVD)) и (или) стример и т.д. Более того, вычислительное средство может включать интерфейс с одной сетью или более сетями 612 (например, с локальной сетью (LAN), глобальной сетью (WAN), беспроводной сетью и (или) сетью Интернет и т.д.) для обмена информацией с другими компьютерами, подключенными к этим сетям. Следует иметь в виду, что вычислительное средство обычно содержит необходимые аналоговые и (или) цифровые интерфейсы между процессором 602 и каждым из компонентов 604, 606, 608 и 612, что хорошо известно специалистам в данной области.
Вычислительное средство работает под управлением операционной системы 614, на нем выполняются различные компьютерные программные приложения, компоненты, программы, объекты, модули и т.д. для реализации описанных выше способов. Более того, различные приложения, компоненты, программы, объекты и т.п., совместно именуемые на ФИГ. 6 прикладным программным обеспечением 616, также могут выполняться в одном или более процессорах в другом компьютере, подключенном к вычислительному средству через сеть 612, например, в распределенной вычислительной среде, в результате чего обработка, необходимая для реализации функций компьютерной программы, может быть распределена по нескольким компьютерам в сети.
В целом, стандартные программы, выполняемые для реализации вариантов осуществления настоящего изобретения, могут быть реализованы как часть операционной системы или конкретного приложения, компонента, программы, объекта, модуля или последовательности команд, которые называются «программа для компьютера». Обычно программа для компьютера содержит один набор команд или несколько наборов команд, записанных в различные моменты времени в различных запоминающих устройствах и системах хранения в компьютере; после считывания и выполнения одним или несколькими процессорами в компьютере эти команды приводят к тому, что компьютер выполняет операции, необходимые для выполнения элементов, связанных с различными аспектами настоящего изобретения. Кроме того, несмотря на то, что это изобретение описано в контексте полностью работоспособных компьютеров и компьютерных систем, специалистам в данной области техники будет понятно, что различные варианты осуществления этого изобретения могут распространяться в виде программного продукта в различных формах, и что это изобретение в равной степени применимо для фактического распространения независимо от используемого конкретного типа машиночитаемых носителей. Примеры машиночитаемых носителей включают в том числе: записываемые носители, такие как энергонезависимые и энергозависимые устройства памяти, гибкие диски и другие съемные диски, накопители на жестких дисках, оптические диски (например, постоянные запоминающие устройства на компакт-диске (формата CD-ROM), накопители на цифровом универсальном диске (формата DVD), флэш-память и т.д.) и т.п. Другой тип распространения можно реализовать в виде загрузки из сети Интернет.
Аспекты настоящего раскрытия были описаны выше в отношении методов машинной интерпретации информации в текстовых документах. Тем не менее, было предусмотрено, что части данного описания могут быть альтернативно или дополнительно реализованы в виде отдельных программных продуктов или элементов других программных продуктов.
Все утверждения, принципы цитирования, аспекты и варианты реализации настоящего изобретения и соответствующие конкретные примеры охватывают как структурные и функциональные эквиваленты раскрытия изобретения.
Специалистам в данной области техники должно быть очевидно, что возможны различные модификации устройств, способов и программных продуктов настоящего изобретения без отхода от сущности или объема раскрытия изобретения. Таким образом, подразумевается, что настоящее изобретение включает модификации, которые включены в объем настоящего изобретения, а также их эквиваленты.
Изобретение относится к области извлечения данных из изображений документов с помощью оптического распознавания символов (OCR). Техническим результатом является экономия вычислительных ресурсов. В способе извлечения данных из полей на изображении документа получают текстовое представление изображения документа. Строится граф для хранения признаков текстовых фрагментов документа и связей между ними. Для вычисления признаков текстовых фрагментов документа и связей между ними осуществляется каскадная классификация. Формируется набор гипотез о принадлежности текстовых фрагментов полям на изображении документа. Выбирается комбинация гипотез. И на основе выбранной комбинации гипотез осуществляется извлечение данных из полей на изображении документа. 14 з.п. ф-лы, 8 ил.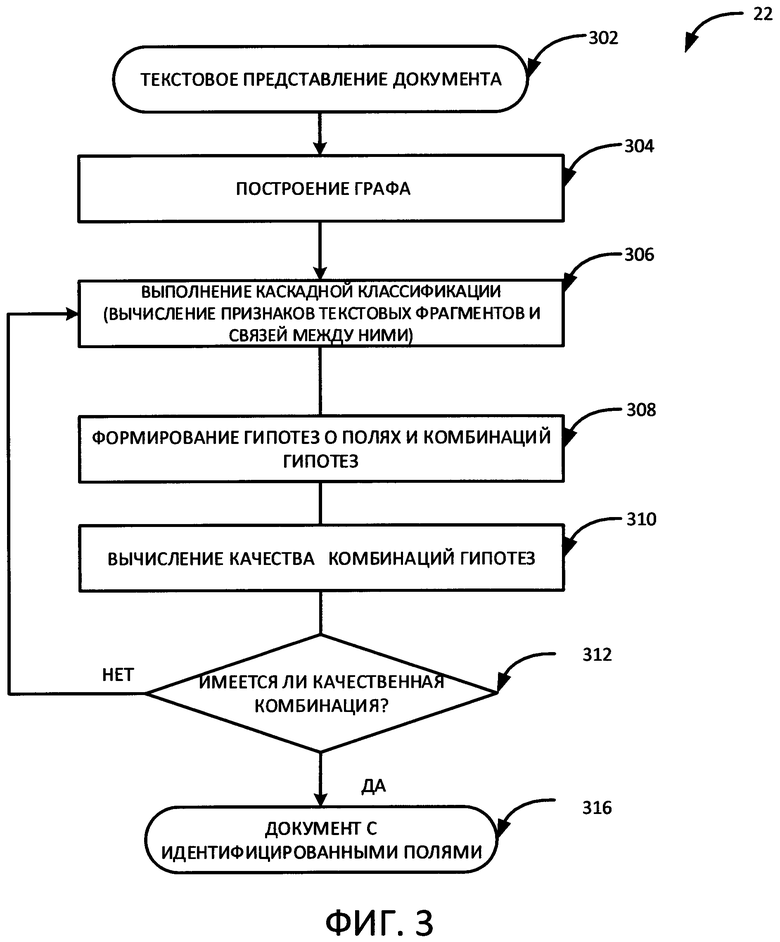
1. Способ извлечения данных из одного или более полей на изображении документа, способ включающий:
получение текстового представления изображения документа;
построение графа для хранения одного или более значений признаков одного или более текстовых фрагментов в текстовом представлении изображения документа и одной или более связей между одним или более текстовыми фрагментами;
вычисление одного или более признаков одного или более текстовых фрагментов и одной или более связей с использованием каскадной классификации;
формирование одной или более гипотез об одном или более текстовых фрагментах, принадлежащих одному или более полям на изображении документа;
формирование одной или более комбинаций гипотез;
выбор комбинации гипотез; и
извлечение данных из одного или более поля на изображении документа, основываясь на выбранной комбинации гипотез.
2. Способ по п. 1, отличающийся тем, что текстовое представление изображения документа является результатом оптического распознавания символов (OCR).
3. Способ по п. 1, отличающийся тем, что граф включает вершины, ребра и значения признаков вершин и ребер, а также тем, что построение графа далее включает:
сопоставление вершин графа со словами, комбинациями слов, фрагментами слов текстового представления изображения документа;
связывание вершин в линейном порядке с помощью ребер.
4. Способ по п. 1, отличающийся тем, что вычисление одного или более признаков одного или более текстовых фрагментов и одной или более связей включает получение значений признаков одного или более текстовых фрагментов и одной или более связей.
5. Способ по п. 1, отличающийся тем, что вычисление одного или более признаков одного или более текстовых фрагментов и одной или более связей включает:
выбор механизма для вычисления одного или более признаков одного и более текстовых фрагментов и одной или более связей;
запуск выбранного механизма для вычисления одного или более признаков одного и более текстовых фрагментов и одной или более связей;
изменение графа, основываясь на вычисленном по крайней мере одном признаке для одного или более текстовых фрагментов или одной или более связей.
6. Способ по п. 5, отличающийся тем, что изменение графа включает одно или более из: объединение вершин, разделение вершин, удаление ребер, добавление ребер, изменение значений признаков вершин и изменение значений признаков связей.
7. Способ по п. 1, отличающийся тем, что формирование одной или более гипотез об одном или более текстовом фрагменте, принадлежащем одному или более полям на изображении документа, по крайней мере частично основывается на подсчете одного или более признаков одного или более текстовых фрагментов и одной или более связей.
8. Способ по п. 1, отличающийся тем, что выбор комбинации гипотез основывается на вычисленном качестве одной или более комбинаций гипотез.
9. Способ по п. 8, отличающийся тем, что выбор комбинации гипотез, основанный на вычисленном качестве одной или более комбинаций гипотез, включает:
для каждой комбинации гипотез:
вычисление суммарного показателя уровней уверенности для комбинации гипотез;
вычисление суммарного показателя штрафов для комбинации гипотез;
выбор комбинации гипотез с наивысшим вычисленным качеством, заключающимся в том, что вычисленное качество по крайне мере частично основывается на суммарном показателе уровней уверенности и суммарном показателе штрафов.
10. Способ по п. 1, отличающийся тем, что выбор комбинации гипотез основывается на сравнении вектора признаков одной комбинации с вектором признаков другой комбинации.
11. Способ по п. 5, отличающийся тем, что запуск выбранного механизма далее включает использование одного или более электронных словарей.
12. Способ по п. 5, отличающийся тем, что запуск выбранного механизма далее включает использование уменьшенного алфавита.
13. Способ по п. 1, отличающийся тем, что изображение документа представляет собой чек или визитную карточку.
14. Способ по п. 1, отличающийся тем, что вычисление одного или более признаков одного или более текстовых фрагментов или одной или более связей далее включает:
объединение легко путающихся символов из первого алфавита в группы на основании статистики по OCR ошибкам;
выбор символа-метапредставителя для каждой группы;
посторонние уменьшенного алфавита с использованием символов-метапредставителей групп;
преобразование текстового представления изображения документа с использованием уменьшенного алфавита; и
преобразование одного или более электронных словарей с использованием уменьшенного алфавита.
15. Способ по п. 14, отличающийся тем, что вычисление одного или более признаков одного или более текстовых фрагментов и одной или более связей далее включает поиск слова из преобразованного текстового представления изображения документа в одном или более преобразованных электронных словарях.
| Пресс для выдавливания из деревянных дисков заготовок для ниточных катушек | 1923 |
|
SU2007A1 |
| Устройство для закрепления лыж на раме мотоциклов и велосипедов взамен переднего колеса | 1924 |
|
SU2015A1 |
| Способ защиты переносных электрических установок от опасностей, связанных с заземлением одной из фаз | 1924 |
|
SU2014A1 |
| СПОСОБ ВЫДЕЛЕНИЯ СТРОКИ ЗНАКОВ И УСТРОЙСТВО ВЫДЕЛЕНИЯ СТРОКИ ЗНАКОВ | 2011 |
|
RU2557461C2 |
| СПОСОБ РАСПОЗНАВАНИЯ ТЕКСТОВОЙ ИНФОРМАЦИИ ИЗ ГРАФИЧЕСКОГО ФАЙЛА С ИСПОЛЬЗОВАНИЕМ СЛОВАРЕЙ И ДОПОЛНИТЕЛЬНЫХ ДАННЫХ | 2005 |
|
RU2295154C1 |
| СПОСОБ РАСПОЗНАВАНИЯ ТЕКСТОВОЙ ИНФОРМАЦИИ ИЗ ВЕКТОРНО-РАСТРОВОГО ИЗОБРАЖЕНИЯ | 2005 |
|
RU2309456C2 |

