Область техники, к которой относится изобретение
Настоящее изобретение относится к области компьютерных технологий, а более конкретно к системе и способу сканирования документов в многопользовательской структуре с использованием веб-браузера в качестве интерфейса сканирования.
Уровень техники
В настоящее время в различных учреждениях и организациях распространено объединение персональных рабочих мест в компьютерные сети. Оконечными узлами в таких персональных сетях могут быть серверы, персональные компьютеры, а также сетевые ресурсы в виде сетевых принтеров, сетевых сканеров и подобных устройств.
Учреждения и организации всегда стоят перевод вопросом организации оптимального документооборота. Одним из таких вопросов является вопрос сканирования документов на сканере, подключенном к сети. Для этих целей уже были предложены многочисленные решения.
Одним из подходов в этой области является использование веб-браузера для предоставления интерфейса сканирования.
Так в документе RU 2611962 раскрыта система и способ сканирования документов, в которой сканер соединен с сервером через сеть, причем одним из компонентов такой системы является веб-браузер. Однако в данной системе веб-браузер расположен непосредственно на сканере, что означает необходимость внесения изменения в само устройство сканера для создания такой системы. А для учреждения или организации это означает приобретение нового оборудования, что влечет не всегда желательные материальные затраты.
В документе US 9143633 раскрыта система сканирования документов, включающая в себя сканер, рабочую станцию и сервер, в которой на рабочей станции находится веб-браузер, а на сервере расположен апплет сканирования, который при необходимости сканирования доставляется в веб-браузер на рабочую станцию. Предложен также соответствующий способ сканирования. Однако в данной системе апплет сканирования, загружаемый с сервера, после завершения сканирования отправляет полученное изображение непосредственно на сервер для дальнейшей обработки и хранения. Такая система создает очень большую нагрузку на канал соединения рабочей станции и сервера. При значительном объеме сканируемого документа создается большое количество изображений, которые требуется отправить на сервер, что обычно приводит к отказу системы. Кроме того, данная система и способ сканирования являются браузер-специфичными, поскольку, как отмечено в этом документе, для Safari требуется устанавливать специфичное время задержки в 10 секунд.
На современном рынке практически отсутствуют решения, позволяющие осуществлять безотказное сетевое сканирование документов, содержащих 2000 страниц и более, используя при этом веб-браузер для предоставления интерфейса сканирования.
Таким образом, до сих пор сохраняется потребность в системе и способе сетевого сканирования для учреждений и организаций, в которых есть необходимость в сканировании большого количества документов, либо документов большого объема. Особенная необходимость существует в таких системах, где интерфейс сканирования находится в веб-браузере, поскольку часто многие операции на рабочей станции в учреждениях производятся из веб-браузера и создание интерфейса сканирования непосредственно в веб-браузере позволяет продолжать работу пользователя в одном окне, избегая переключения между окнами различных приложений, а тем более дополнительного запуска отдельного приложения для сканирования.
Раскрытие сущности изобретения
Задачей настоящего изобретения является преодоление недостатков уровня техники путем предоставления способа и системы для сканирования документов с использованием интерфейса веб-браузера, которые позволят сканировать большие количества документов, либо документы большого объема без внесения конструктивных изменений в сканер.
Таким образом, настоящее изобретение направлено на расширение арсенала технических средств для сканирования, а также на повышение эффективности и удобства сканирования документов, особенно для тех, кто регулярно работает с большими объемами документов.
Данная задача решается тем, что предложена система сканирования документов, включающая в себя по меньшей мере один сервер, по меньшей мере один персональный компьютер и по меньшей мере один сканер, где указанный сканер подключен к указанному персональному компьютеру, на котором имеется драйвер указанного сканера, и указанный сканер способен взаимодействовать с указанным персональным компьютером по соответствующему протоколу сканирования, отличающаяся тем, что на персональном компьютере установлен компонент сканирования, выполненный с возможностью управления процессом сканирования из браузера, запущенного на персональном компьютере, а также осуществления записи файлов в память персонального компьютера, а на сервере расположено клиент-серверное приложение, выполненное с возможностью приема и хранения в базе данных, расположенной на сервере, отсканированных документов, при этом клиентская часть этого приложения выполнена с возможностью формирования интерфейса в браузере, причем этот интерфейс позволяет пользователю персонального компьютера взаимодействовать как с указанным сервером, так и с указанным компонентом сканирования.
Благодаря такой организации системы сканирования, пользователь персонального компьютера может осуществлять сканирование документов непосредственно через браузер без необходимости открывания и использования дополнительного программного обеспечения. При этом настоящее изобретение решает вопрос преодоления ограниченного функционала стандартного браузера. Функционал стандартных браузеров ограничен, поскольку из соображений безопасности браузеры не могут выполнять своими средствами некоторые функции, например запись файла на диск. Однако, благодаря системе сканирования, предложенной согласно данному изобретению, это ограничение преодолевается, поскольку функцию записи файла на диск в этой системе осуществляет компонент сканирования. Таким образом, настоящее изобретение обеспечивает более рациональный и удобный для пользователя подход к сканированию документов.
При этом у пользователя сохраняется возможность использовать стандартное оборудование и программное обеспечение. Входящий в систему сканирования компонент сканирования обеспечивает работу с любым браузером. Входящий в систему сканирования компонент сканирования обеспечивает работу также с любым сканером, драйвер которого поддерживает стандартный протокол сканирования, причем компонент является универсальным, поскольку он, в свою очередь, также совместим со стандартными протоколами сканирования.
Настоящая система сканирования устраняет возможность прерывания процесса сканирования документа и необходимости вмешательства пользователя в сам процесс сканирования. Это может значительно сократить время и усилия, необходимые для сканирования больших документов, и сделать весь процесс более эффективным.
Кроме того, благодаря использованию настоящей системы сканирования канал связи между клиентом и сервером не перегружается большим трафиком документов, которые представляют собой отдельные изображения, полученные со сканера. Это гарантирует, что система останется отзывчивой и работоспособной даже при больших нагрузках.
Может быть предусмотрено, что используется протокол сканирования TWAIN или SANE. Это означает, что пользователи могут воспользоваться преимуществами установленного стандарта TWAIN или SANE, который широко поддерживается различными производителями и моделями сканеров. Таким образом, настоящее изобретение обеспечивает более гибкий и совместимый подход к сканированию документов, поскольку оно может работать с широким спектром сканеров, поддерживающих протокол TWAIN или SANE. Это также обеспечивает легкую интеграцию с различными существующими системами управления документами, поддерживающими протокол TWAIN или SANE.
Может быть предусмотрено, что компонент сканирования выполнен с возможностью работы по http-протоколу.
Настоящее изобретение также относится к способу сканирования документов, при котором:
- на персональном компьютере запускают браузер,
- в браузере с помощью http-запроса к приложению, расположенному на сервере, открывают клиентскую часть этого приложения с получением в браузере соответствующего интерфейса сканирования,
- из этого интерфейса с помощью http-запроса обращаются к компоненту сканирования, расположенному на том же персональном компьютере, для получения доступа к сканеру, который соединен с этим персональным компьютером по соответствующему протоколу сканирования с использованием своего драйвера,
- осуществляют сканирование документов с помощью сканера,
- файл изображения отсканированной страницы документа передают через драйвер в компонент сканирования и с помощью этого компонента сканирования сохраняют этот файл изображения на персональном компьютере,
- из файлов изображений с помощью этого компонента сканирования создают файл формата pdf, причем компонент сканирования сначала распределяет файлы изображений по пакетам, устанавливая размер пакета на основании объема памяти и размера изображений, затем получает из каждого пакета файла формата pdf, затем объединяет полученные файлы формата pdf в результирующий файл формата pdf, а затем сохраняет результирующий файла формата pdf на персональном компьютере,
- из браузера с помощью http-запроса обращаются к компоненту сканирования для получения этого результирующего файла,
- результирующий файл с помощью http-запроса отправляют на сервер.
Этот способ обеспечивает несколько технических преимуществ по сравнению с предшествующим уровнем техники. Например, он позволяет пользователям воспользоваться уже открытым окном браузера для осуществления сканирования, что повышает удобство пользователя и экономит время на сканирование. При этом все ограничения браузера (например, запрет на запись файла) снимаются благодаря использованию в способе компонента сканирования, который осуществляет необходимую запись. Предложенный способ сканирования позволяет сканировать большие документы без прерывания процесса вручную, а также снижает нагрузку на канал между клиентом и сервером, пропуская через канал только результирующий файл.
После передачи файла изображения отсканированной страницы через драйвер в компонент сканирования с сохранением файла скана страницы на персональном компьютере можно осуществить обработку файла скана страницы через браузер посредством компонента сканирования.
Таким образом, у пользователя сохраняется возможность работы с изображением до отправки его на сервер, следовательно, снижение нагрузки на канал персональный компьютер – сервер происходит без потери качества процесса сканирования.
Указанную обработку файла скана страницы можно проводить до окончания сканирования всех страниц документа.
Это экономит время, позволяя заранее обработать выбранные страницы, не дожидаясь сканирования всего документа. Такая оптимизация процесса сканирования достигается за счет соответствующей функции компонента сканирования, задействованного в предлагаемом способе, и оказывает положительное влияние на общую скорость процесса сканирования.
Если в файле изображение отсутствует, такой файл можно удалить.
Это уменьшает беспорядок и экономит место для хранения, сохраняя только сканы, содержащие информацию. Кроме того, это позволяет устранить необходимость последующей обработки итогового файла документа ручным способом, оптимизируя таким образом процесс сканирования. Наличие пустых страниц является известной проблемой в данной области, а предложенный способ позволяет автоматизировать процесс их удаления, благодаря возможности локальной работы с отдельными файлами изображений.
После передачи файла изображения отсканированной страницы через драйвер в компонент сканирования с сохранением файла изображения отсканированной страницы на персональном компьютере, в браузере можно осуществлять увеличение и уменьшение масштаба изображения посредством компонента сканирования.
Таким образом оптимизируется процесс сканирования с получением результирующего файла требуемого качества.
После передачи файла изображения отсканированной страницы через драйвер в компонент сканирования с сохранением файла изображения отсканированной страницы на персональном компьютере можно сохранить в браузере кэш миниатюры страницы.
Это сокращает время загрузки, обеспечивая более быстрый доступ к ранее просмотренным страницам. Кроме того, это обеспечивает более удобный интерфейс, предоставляя легкодоступный способ навигации по отсканированным страницам.
Результирующий файл, отправленный на сервер, можно выгружать с сервера обратно на персональный компьютер. Предпочтительно этот персональный компьютер не является тем же самым компьютером, с которого файл был отправлен. Таким образом достигается возможность работы с документом в многопользовательской среде.
Таким образом, настоящее изобретение позволяет пользователям сканировать документы с помощью своего веб-браузера. При этом канал связи между клиентом и сервером не перегружен большим потоком документов, что обеспечивает эффективную связь. Возможности обработки изображений в этом изобретении позволяют пользователям обрабатывать отсканированные изображения различными способами перед их сохранением. Оценки размера пакета относительно размера памяти и размера изображения могут позволить пользователям принимать обоснованные решения о том, как они хотят обрабатывать свои сканы, например выбирать между форматами jpeg и pdf в зависимости от желаемого уровня сжатия. Пакетное склеивание изображений jpeg может позволить пользователям обрабатывать несколько изображений одновременно, а склеивание pdf-файлов на диске упрощает организацию и управление отсканированными документами, поскольку при склейке pdf-файлов не происходит загрузки файла в память – файлы присоединяются друг к другу с использованием переформатирования.
В целом, это изобретение обеспечивает различные технические преимущества, такие как улучшенная доступность через веб-браузеры, эффективная связь между клиентом и сервером, удобные возможности обработки изображений, а также лучшая организация и управление отсканированными документами. Реализация этих функций может быть оценена специалистом в данной области техники и может привести к более производительным процессам сканирования с лучшим использованием вычислительной мощности, емкости хранилища или полосы пропускания.
Таким образом, изобретение позволяет реализовать сканирование документов на выделенный сервер для общей работы с нескольких рабочих мест. Оно расширяет арсенал технических средств для сканирования документов через интерфейс веб-браузера. Техническим результатом данного изобретения является снижение нагрузки на канал связи с сервером и обеспечение легковесного приложения на клиентской части. Техническим эффектом является возможность работы с объемными (многостраничными) документами.
Краткое описание графических материалов
На Фигуре показано устройство системы сканирования документов
Осуществление изобретения
Система сканирования согласно изобретению представляет собой совокупность модулей, которые, взаимодействуя друг с другом, выполняют общее назначение, а именно сканирование документов.
Поскольку такая система рассчитана на функционирование в учреждении или организации, где работает хотя бы несколько, а скорее всего, много пользователей, и не одному единственному пользователю, а нескольким из них обычно требуется доступ к отсканированному документу, то такой документ удобно хранить на сервере, обеспечивающем доступ к документу.
Сервером называется компьютер, выделенный из группы персональных компьютеров (или рабочих станций) для выполнения какой-либо сервисной задачи без непосредственного участия человека. В данном случае одной из задач такого сервера будет хранение документа.
Персональный компьютер – это персональная электронная вычислительная машина. Такая машина предназначена обычно для использования одним пользователем. Хотя у каждого персонального компьютера могут быть разные пользователи, но они не используют такой персональный компьютер одновременно. Персональный компьютер может быть как стационарным (чаще всего настольным), так и портативным (ноутбук, планшет). Персональный компьютер является средством автоматизации деятельности и предназначен для пользователей, не обладающих специальными знаниями в области вычислительной техники и программирования. Персональный компьютер – это основа автоматизированного рабочего места, иначе называемого рабочей станцией. Персональный компьютер как рабочая станция является местом работы специалиста, имеет набор необходимого программного обеспечения, и, по необходимости, дополняемые вспомогательным оборудованием, таким как: сканер, печатающее устройство, внешнее устройство хранения данных на магнитных и(или) оптических носителях, сканер штрих-кода и прочим. В общем, рабочая станция – это комплекс аппаратных и программных средств, предназначенных для решения определённого круга задач.
В данном описании «персональный компьютер», «автоматизированное рабочее место» и «рабочая станция» являются взаимозаменяемыми терминами.
В локальных сетях компьютеры подразделяются на рабочие станции и серверы. На рабочих станциях пользователи решают прикладные задачи (работают в базах данных, создают документы, делают расчёты). Сервер обслуживает сеть и предоставляет собственные ресурсы всем узлам сети, в том числе и рабочим станциям.
Сканер в контексте данного описания – это устройство ввода, которое создаёт цифровую копию объекта (например, рисунка или текста). Процесс получения этой копии называется сканированием. Такая копия затем обычно передаётся в электронно-вычислительную машину. Сканеры бывают разных типов: планшетные, ручные, листопротяжные (протяжные), планетарные или книжные сканеры, слайд-сканеры, сканеры штрих-кода.
Для целей настоящего изобретения подходят сканеры, которые могут обеспечить задачи сканирования большого количества документов, либо документов большого объема. Предпочтительны сканеры, которые имеют высокое качество и приемлемую скорость сканирования. Однако могут использоваться любые сканеры, совместимые с задачами пользователя.
Согласно данному изобретению применяются сканеры, которые подключаются к персональному компьютеру непосредственно через интерфейс TWAIN или SANE.
Сканер может быть как самостоятельным устройством, так и являться частью многофункционального устройства, которое включает в себя, например, принтер, или другие устройства ввода-вывода.
Сканер подключается к персональному компьютеру с помощью проводной или беспроводной связи.
Хотя сказано, что в системе имеется по меньшей мере один сервер, по меньшей мере один персональный компьютер и по меньшей мере один сканер, из постановки задачи следует, что в наибольшей степени эффект изобретения раскрывается, когда в системе находится более одного персонального компьютера. Более того, чем больше персональных компьютеров находится в сети, на базе которой работает предложенная система, тем больше пользы можно извлечь из предложенной системы сканирования документов.
На персональном компьютере должен быть установлен драйвер сканера. Драйвер — это программный компонент, который позволяет операционной системе и устройству взаимодействовать.
Команды сканирования на персональном компьютере обычно выполняются через некоторое компьютерное приложение, то есть компьютерную программу, предназначенную для выполнения задач сканирования. Например, приложение «Сканер Windows» позволяет сканировать изображения и документы и сохранять их на компьютере. Существуют много иных подобных программ (приложений). Когда такому приложению требуется считывать данные с устройства, оно вызывает функцию, реализованную операционной системой. Затем операционная система вызывает функцию, реализованную драйвером сканера. Драйвер сканера обеспечивает взаимодействие с оборудованием устройства для получения данных. Когда драйвер получает данные, он возвращает их операционной системе, а затем возвращает их приложению.
Для того, чтобы различные сканеры, для которых существуют собственные драйверы, единообразно взаимодействовали с приложением и операционной системой, были разработаны стандартные протоколы взаимодействия, такие как TWAIN, ISIS, SANE и WIA.
На персональном компьютере, согласно настоящему изобретению, также должен находиться браузер.
Браузер — это программа, которая способна воспринимать действия пользователя на локальном компьютере, обрабатывать их, отправлять соответствующий запрос на сервер, чтобы затем получить с сервера ответ, например в виде данных, и продемонстрировать его пользователю на экране персонального компьютера.
Обычно принято говорить о браузере как о веб-браузере, а полученные данные демонстрируются в виде веб-страницы, поскольку серверы, на которые отправляются запросы, расположены в сетевой структуре, имеющей название «веб».
В контексте настоящего описания термины «браузер» и «веб-браузер» считаются равнозначными. При этом сервер, с которым взаимодействует браузер, может находится не только в веб-структуре, но в любой сети, в частности в локальной сети.
Согласно настоящему изобретению, на сервере, который входит в состав предлагаемой системы сканирования, расположено приложение, имеющее клиентскую и серверную части. Клиентскую часть этого приложения можно открыть в браузере, расположенном на персональном компьютере. Эта клиентская часть и используется в качестве интерфейса, предоставляемого пользователю персонального компьютера, в частности для работы со сканером.
Серверная часть приложения включает в себя микросервисы, которые, в том числе, обеспечивают прием файлов со стороны клиентской части, а также их запись в базу данных, расположенную на сервере. Микросервисы в контексте данного изобретения — это компоненты, выполняемые в отдельном процессе и коммуницирующие между собой через запросы.
При этом на персональном компьютере установлен компонент (утилита, сервис) сканирования.
Компонент сканирования, находящийся на персональном компьютере, содержит несколько модулей, включая http-сервер для прослушивания запросов от браузера, а также модули, реализующие функции связи с драйвером сканера, обработки изображений, оценки размера пакета относительно объема памяти и размера изображения, пакетной склейки изображений формата jpeg, склейки файлов формата pdf на диске и сохранение файлов на персональный диск.
Специалисту в области техники будет ясно, как реализовать каждую из функций компонента сканирования. При этом объединение в компоненте этих функций, и использование такого компонента в рамках системы с размещением этого компонента на персональном компьютере привело к желаемым преимуществам и техническим эффектам, которые до сих пор не достигались в уровне техники.
Компонент сканирования согласно настоящему изобретению обеспечивает связь со сканером через TWAIN/SANE драйвер.
Компонент сканирования обеспечивает обработку каждого изображения, полученного со сканера, и формирование конечного документа, который составляется из отдельных изображений. При этом устраняется возможность прерывания процесса сканирования документа и необходимости вмешательства пользователя в сам процесс сканирования. Это может значительно сократить время и усилия, необходимые для сканирования больших документов, и сделать весь процесс более эффективным.
Кроме того, благодаря использованию компонента сканирования для нескольких стадий обработки документов, канал между клиентом и сервером не перегружается большим трафиком файлов, которые представляют собой отдельные изображения, полученные со сканера. Это гарантирует, что система останется отзывчивой и работоспособной даже при больших нагрузках.
Так как компонент сканирования фактически изолирован от браузера, в данной системе сканирования не требуется учет вида браузера, и, как следствие, не требуется разработка плагинов под все существующие виды браузеров. То есть система будет работать с любым браузером без установки в нем плагина
В компонент может быть добавлен модуль пропуска пустых страниц при сканировании.
Эта функция позволяет пользователям экономить время, автоматически игнорируя пустые страницы и обрабатывая только соответствующий контент. Компонент будет обладать преимуществом возможности сэкономить время и усилия при сканировании документов с пустыми страницами.
В компонент сканирования может быть добавлен модуль состояния сканирования, который позволяет пользователям работать с файлами сканирования до завершения процесса сканирования.
Эта функция обеспечивает дополнительную гибкость и контроль над процессом сканирования, что упрощает управление отсканированными документами. Работа системы и способа будет улучшена благодаря этой функции компонента сканирования, что сделает их более удобными и дружелюбными к пользователю.
Взаимодействие с компонентом сканирования из браузера может осуществляться с помощью JavaScript.
Возможности JavaScript в браузере ограничены ради безопасности пользователя. Например, JavaScript на веб-странице не может читать/записывать произвольные файлы на жёстком диске, копировать их или запускать программы, он не имеет прямого доступа к системным функциям ОС. Однако компонент сканирования позволяет преодолеть ограничения как браузера, так и функционала JavaScript.
Компонент сканирования способен работать по http-протоколу, осуществляя http-запросы, а также по twain/sane-протоколу, осуществляя twain/sane-запросы. Таким образом компонентом сканирования осуществляются обращения к серверу, к сканеру, к процессу сканирования, к локальному диску и т.п.
Основой протокола http является технология «клиент-сервер», то есть предполагается существование «клиентов», которые инициируют соединение и посылают запрос, и «серверов», которые ожидают соединения для получения запроса, производят необходимые действия и возвращают обратно сообщение с результатом.
Протоколы twain/sane — стандартные протоколы, определяющие взаимодействие между программами и устройствами захвата изображения, такими как сканеры.
Способ по изобретению подразумевает обработку изображения непосредственно на персональном компьютере пользователя. Это позволяет сократить объем трафика между персональным компьютером и сервером.
С целью экономии ресурсов формирование результирующего pdf файла происходит постепенно. То есть сначала, примерно через каждые 50 изображений, из изображений, создаваемых сканером, с помощью компоненты сканирования создаются файлы размером примерно 100–150 МБ. Затем из них формируется результирующий файл. И на сервер происходит уже отправка окончательно сформированного документа.
При этом предусмотрена возможность также получать файлы документов с сервера на персональный компьютер. Эта возможность может быть реализована в приложении, размещенном на сервере.
Формирование pdf файла из изображений может быть выполнено с помощью известных pdf процессоров.
Обработка изображений может быть выполнена с помощью программ для чтения и редактирования файлов графических форматов.
Для обработки изображения могут быть также использованы инструменты машинного обучения на основе нейросетей.
Система по изобретению может работать на различных операционных системах, таких как Windows, Linux, но не ограничиваясь ими. Аббревиатура «ОС» подразумевает любую соответствующую операционную систему.
Система по изобретению может быть реализована следующим образом со ссылкой на прилагаемую Фигуру.
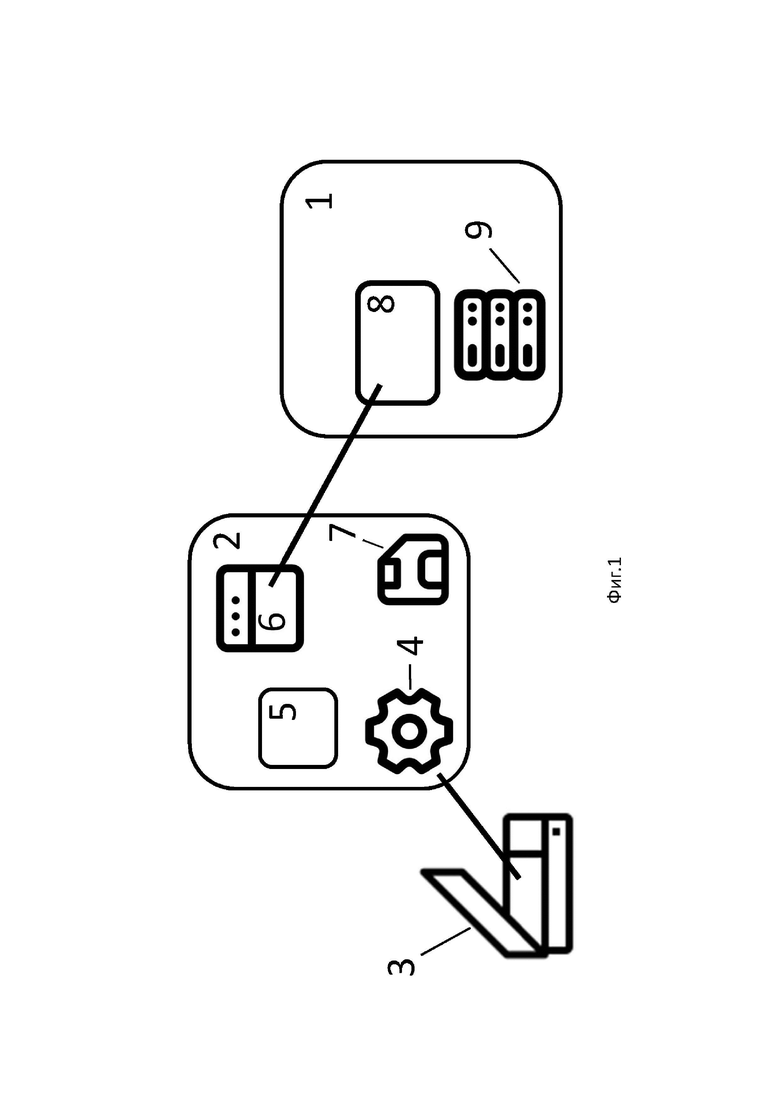
Система сканирования документов состоит из по меньшей мере одного сервера 1, по меньшей мере одного персонального компьютера 2 и по меньшей мере одного сканера 3. Сканер 3 подключен к персональному компьютеру 2. На персональном компьютере 2 установлен драйвер 4 для сканера 3. Сканер 3 способен взаимодействовать с персональным компьютером 2 по соответствующему протоколу сканирования. На персональном компьютере 2 также установлен компонент сканирования 5 и браузер 6. Компонент сканирования 5 предоставляет возможность управлять процессом сканирования из браузера 6. Компонент сканирования 5 также предоставляет возможность записи файлов в память 7 персонального компьютера 2. При этом на сервере 1 находится клиент-серверное приложение 8 и база данных 9. Приложение 8 включает микросервисы для различных целей. В частности, микросервисы обеспечивают прием и хранение отсканированных документов в базе данных 9. Приложение 8 также обеспечивает формирование в браузере 6 интерфейса, позволяющего пользователю персонального компьютера 2 взаимодействовать с указанным компонентом сканирования 5.
Способ по изобретению в системе по изобретению может быть реализован следующим образом со ссылкой на прилагаемую Фигуру.
На персональном компьютере 2 из браузера 6 выполняется http-запрос к приложению 8.
Приложение 8 возвращает в браузер 6 интерфейс для работы со сканером. Этот интерфейс далее называется далее также «js-приложением», если в конкретной реализации приложение использует JavaScript.
Таким образом, в конкретной реализации пользователь с помощью браузера 6 открывает js-приложение.
Далее пользователь имеет возможность выбрать сканер для использования из тех сканеров, которые доступны с данного персонального компьютера 2. Эта возможность реализуется из указанного приложения, открытого в браузере 6.
Для этого пользователь сначала запрашивает список доступных сканеров. Такой запрос осуществляется путем нажатия соответствующей кнопки на экране (в js-приложении).
По нажатию пользователем кнопки браузер 6 отправляет http-запрос к компоненту 5 на получение списка доступных сканеров.
Компонент 5 через стандартные средства операционной системы (TWAIN/SANE-драйверы) запрашивает список доступных в операционной системе сканеров. Список доступных сканеров возвращается в компонент 5.
Компонент 5 возвращает этот список сканеров далее в браузер 6 (в рамках ответа на его http-запрос).
Пользователь выбирает нужный сканер. Его выбор сохраняется в браузере в контексте js-приложения в виде «id сканера».
Далее пользователь имеет возможность изменить настройки выбранного сканера. Эта возможность реализуется из указанного приложения, открытого в браузере 6.
Для этого пользователь нажимает кнопку изменения настроек выбранного сканера в интерфейсе js-приложения.
По нажатию пользователем кнопки браузер отправляет http-запрос в компонент 5 на получение списка доступных вариантов настроек (DPI, яркость, контрастность, и прочее) для выбранного сканера. Для идентификации сканера используется сохраненный в браузере идентификатор «id сканера».
Компонент 5 через стандартные средства операционной системы (TWAIN/SANE-драйверы) запрашивает список доступных вариантов настроек и их значений для сканера с данным «id сканера». Список доступных настроек и их значения возвращаются в компонент 5.
Компонент 5 возвращает этот список сканеров далее в браузер 6 (в рамках ответа на его http-запрос).
Далее пользователь имеет возможность изменить какие-то значения (например, DPI) и подтвердить выбор.
Затем пользователь может приступить непосредственно к сканированию документов.
Для этого пользователь нажимает кнопку сканирования в интерфейсе js-приложения, а браузер выполняет инициирование процесса сканирования через http-запрос к компоненту 5.
Компонент 5 запускает отдельный процесс сканирования и возвращает подтверждение, что сканирование инициировано в виде успешного ответа с идентификатором «id процесса сканирования» на http-запрос.
Этот отдельный процесс сканирования инициирует сканирование через нативный запрос (twain-запрос) через драйвер операционной системы.
Сканер начинает сканировать и возвращает изображения отсканированных страниц через драйвер 4 в компонент 5 в рамках ответа на http-запрос. Изображения отсканированных страниц представляют собой файлы формата jpg. Они сохраняются отдельным процессом сканирования на локальном диске 7 персонального компьютера 2 через компонент 5 путем стандартного вызова функции операционной системы для сохранения на диске.
В ходе процесса сканирования на стороне браузера 6 реализуются периодические проверки статуса сканирования документа для возможности продолжения работы с уже отсканированными страницами документа. Для этого js-приложение из браузера 6 выполняет http-запрос к компоненту 5 на проверку статуса процесса сканирования по «id процесса сканирования», полученному ранее.
В ответ на такой http-запрос браузера 6 компонент 5 опрашивает отдельный процесс сканирования (нативный запрос от компонента 5) и получает от него список отсканированных страниц документа и общий статус процесса сканирования (в процессе/завершен). Список страниц возвращается в браузер 6 в ответ на его http-запрос.
Браузер 6 посредством js-приложения производит показ изображений отсканированных страниц документа через http-запрос к компоненту 5. Компонент 5 обращается к локальному диску 7 (нативный запрос компонента 5) и возвращает файл в браузер 6 в ответ на его http-запрос.
Далее пользователь имеет возможность производить работу с полученным изображением отсканированной страницы (обрезка, повороты и прочее). Эта возможность реализуется из указанного js-приложения, открытого в браузере 6.
При этом браузер инициирует http-запрос на соответствующую операцию к компоненту 5. В рамках данного запроса компонент 5 считывает файл изображения отсканированной страницы (нативный запрос от компонента 5) и выполняет необходимую операцию (масштабирование, обрезка, поворот). При необходимости измененный файл при этом сохраняется обратно на диск 7 (нативный вызов от компонента 5). Далее компонент 5 возвращает измененный файл в браузер 6 рамках ответа на его http-запрос.
Далее пользователь имеет возможность инициировать создание файла документа в формате pdf. Эта возможность реализуется из указанного js-приложения, открытого в браузере 6.
Для этого пользователь нажимает на соответствующую кнопку в интерфейсе. По нажатию пользователем кнопки браузер выполняет http-запрос к компоненту 5 с перечнем страниц к включению в pdf-файл.
Компонент 5 подготавливает результирующий pdf файл в два этапа.
На первом этапе происходит создание промежуточных pdf-файлов на основе jpg-файлов изображений отсканированных страниц (нативный запрос от компонента 5). Компонент производит расчет оптимального размера пакета jpg-файлов в зависимости от размера памяти и размера изображений. Созданные промежуточные pdf-файлы сохраняются во временной папке на диске 7 (нативный запрос от компонента 5).
На втором этапе промежуточные pdf-файлы соединяются между собой и создается результирующий файл без повышенных требований к памяти (нативный запрос от компонента 5). При дисковой склейке память используется только для хранения одного текущего pdf-файла. Результирующий файл формируется на диске.
Готовый результирующий файл передается компонентом 5 обратно в браузер в рамках ответа на его http-запрос и затем отправляется браузером на сервер 1 через http-запрос к серверу 1.
Таким образом осуществляется сканирование документа любого объема локальным сканером 3 и размещение его на хранение на сервере 1 с общим доступом.
При необходимости файл документа может быть потом получен на любой персональный компьютер 2 из компьютеров, входящих в описанную систему.
Модификации и улучшения вышеописанного варианта осуществления настоящего технического решения будут ясны специалистам в данной области техники. Описание представлено только в качестве примера и не несет никаких ограничений. Таким образом, объем настоящего технического решения ограничен только объемом прилагаемой формулы изобретения.
Изобретение относится к области компьютерных технологий, а более конкретно к системе и способу сканирования документов с использованием веб-браузера в качестве интерфейса сканирования. Технический результат - расширение арсенала технических средств для сканирования документов из веб-браузера, обеспечивающего сканирование больших документов без прерывания процесса и снижение нагрузки на канал между клиентом и сервером за счет пропускания через канал только результирующего файла. Система сканирования включает в себя сервер, персональный компьютер и сканер, причем на персональном компьютере установлен компонент сканирования, который дает возможность управления процессом сканирования из браузера, а также осуществления записи файлов в память персонального компьютера, а на сервере расположено клиент-серверное приложение, обеспечивающее прием и хранение в базе данных, расположенной на сервере, отсканированных документов, при этом клиентская часть этого приложения формирует в браузере интерфейс, который позволяет пользователю персонального компьютера взаимодействовать как с сервером, так и с компонентом сканирования. 2 н. и 7 з.п. ф-лы, 1 ил.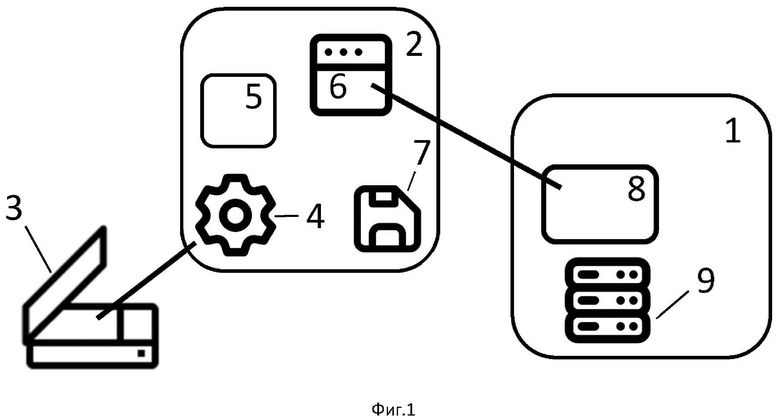
1. Система сканирования документов, включающая в себя по меньшей мере один сервер, по меньшей мере один персональный компьютер и по меньшей мере один сканер, где указанный сканер подключен к указанному персональному компьютеру, на котором имеется драйвер указанного сканера, и указанный сканер способен взаимодействовать с указанным персональным компьютером по соответствующему протоколу сканирования, отличающаяся тем, что на персональном компьютере установлен компонент сканирования, который предоставляет возможность управления процессом сканирования из браузера, открытого на персональном компьютере, а также осуществления записи файлов в память персонального компьютера, где компонент сканирования сначала распределяет файлы изображений по пакетам, устанавливая размер пакета на основании объема памяти и размера изображений, затем получает из каждого пакета файла формата pdf, затем объединяет полученные файлы формата pdf в результирующий файл формата pdf, а на сервере расположено клиент-серверное приложение, обеспечивающее прием и хранение в базе данных, расположенной на сервере, отсканированных документов, при этом клиентская часть этого приложения выполнена с возможностью формирования интерфейса в браузере, причем этот интерфейс позволяет пользователю персонального компьютера взаимодействовать как с указанным сервером, так и с указанным компонентом сканирования.
2. Система по п.1, отличающаяся тем, что протокол сканирования представляет собой TWAIN или SANE.
3. Система по п.1, отличающаяся тем, что компонент сканирования выполнен с возможностью работы по http-протоколу.
4. Способ сканирования документов, при котором:
- на персональном компьютере запускают браузер,
- в браузере с помощью http-запроса к приложению, расположенному на сервере, открывают клиентскую часть этого приложения с получением в браузере соответствующего интерфейса сканирования,
- из этого интерфейса с помощью http-запроса обращаются к компоненту сканирования, расположенному на том же персональном компьютере, для получения доступа к сканеру, который соединен с этим персональным компьютером по соответствующему протоколу сканирования с использованием своего драйвера,
- осуществляют сканирование документов с помощью сканера,
- файл изображения отсканированной страницы документа передают через драйвер в компонент сканирования и с помощью этого компонента сканирования сохраняют этот файл изображения на персональном компьютере,
- из файлов изображений с помощью этого компонента сканирования создают файл формата pdf, причем компонент сканирования сначала распределяет файлы изображений по пакетам, устанавливая размер пакета на основании объема памяти и размера изображений, затем получает из каждого пакета файла формата pdf, затем объединяет полученные файлы формата pdf в результирующий файл формата pdf, а затем сохраняет результирующий файла формата pdf на персональном компьютере,
- из браузера с помощью http-запроса обращаются к компоненту сканирования для получения этого результирующего файла,
- результирующий файл с помощью http-запроса отправляют на сервер.
5. Способ по п.4, где после передачи файла изображения отсканированной страницы через драйвер в компонент сканирования с сохранением файла скана страницы на персональном компьютере осуществляют обработку файла скана страницы через браузер посредством компонента сканирования.
6. Способ по п.5, где указанную обработку файла изображения отсканированной страницы проводят до окончания сканирования всех страниц документа.
7. Способ по п.4, где после передачи файла изображения отсканированной страницы через драйвер в компонент сканирования с сохранением файла изображения отсканированной страницы на персональном компьютере в браузере осуществляют увеличение и уменьшение масштаба изображения посредством компонента сканирования.
8. Способ по п.4, где после передачи файла изображения отсканированной страницы через драйвер в компонент сканирования с сохранением файла изображения отсканированной страницы на персональном компьютере в браузере сохраняют кэш миниатюры страницы.
9. Способ по п.4, где дополнительно результирующий файл, отправленный на сервер, выгружают с сервера обратно на персональный компьютер.
| Способ регенерирования сульфо-кислот, употребленных при гидролизе жиров | 1924 |
|
SU2021A1 |
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| Многоступенчатая активно-реактивная турбина | 1924 |
|
SU2013A1 |
| УСТРОЙСТВО ОБРАБОТКИ ИЗОБРАЖЕНИЯ, СПОСОБ ОБРАБОТКИ ИЗОБРАЖЕНИЯ, ВЕБСЕРВЕР, СПОСОБ УПРАВЛЕНИЯ ИМ И НОСИТЕЛЬ ХРАНЕНИЯ ДАННЫХ | 2013 |
|
RU2611962C2 |

