Область техники, к которой относится изобретение
[01] Настоящая технология в целом относится к способам и системам для обработки естественного языка (NLP, Natural Language Processing), и в частности к способам и системам для проверки точности фактов в медиаконтенте.
Уровень техники
[02] Различные глобальные и локальные сети (такие как сеть Интернет, локальные сети и т.п.) обеспечивают пользователю доступ к огромному объему информации. Информация включает в себя множество контекстно-зависимых тем, таких как сведения о знаменитых людях, о природе, о науке и технологиях, об образовании, новости и текущие события, карты, финансовая информация и ресурсы, информация о дорожном движении, информация об играх и развлечениях и т.д. Пользователи применяют разнообразные клиентские устройства (настольный компьютер, ноутбук, смартфон, планшет и т.п.) для получения доступа к богатому информационному содержимому (такому как изображения, аудиоматериалы, видеоматериалы, анимация и другой мультимедийный контент из таких сетей).
[03] В общем случае пользователь может иметь доступ к ресурсу через сеть связи двумя основными способами. Пользователь может осуществлять непосредственный доступ к конкретному ресурсу путем ввода адреса ресурса с клавиатуры (обычно универсального указателя ресурсов (URL, Universal Resource Locator) вида www.webpage.com) либо путем перехода по ссылке, доступной в сообщении электронной почты или на другом веб-ресурсе. В другом случае пользователь может выполнять поиск интересующего ресурса с использованием поисковой системы. Последний вариант особенно удобен, когда пользователю известна интересующая тема, но не известен точный адрес представляющего интерес ресурса.
[04] Пользователю доступно множество поисковых систем, упрощающих поиск, таких как поисковая система Yandex™, поисковая система Google™, поисковая система Yahoo™ и т.п. В общем случае поисковая система способна получать поисковый запрос от пользователя, выполнять поиск на его основе и предоставлять пользователю страницу ранжированных результатов поисковой системы (SERP, Search Engine Results Page). Страница SERP может, например, содержать результаты общего поиска и результаты вертикального поиска из онлайн-контента конкретного вида, такого как изображения, видеоматериалы, новости и т.п.
[05] Кроме того, поисковая система может формировать и добавлять на страницу SERP краткую сводку результатов поиска, содержащую некоторые их части, и таким образом предоставлять пользователю иллюстративный обзор объекта поиска, полученного на основе поискового запроса.
[06] Например, чтобы найти любимую знаменитость, пользователь может отправить поисковой системе соответствующий запрос, такой как «Keanu Reeves» («Киану Ривз») или «Matrix lead actor» («Ведущий актер в Матрице»). В ответ на отправленный запрос поисковая система может определить, что объектом поиска пользователя является Киану Ривз, и предоставить страницу SERP не только с ранжированными результатами поиска, но и с карточкой объекта, содержащей, например, краткую сводку биографии Киану Ривза. Карточка объекта может содержать текстовую часть с основными сведениями о соответствующем человеке, его изображение, рекламный ролик о новом фильме, над которым он работал, и т.д.
[07] Поисковая система способна формировать такую карточку объекта на основе предоставленных результатов поиска. Тем не менее, такой подход к формированию сводной информации об объектах поиска может быть ошибочным, поскольку некоторые источники из числа результатов поиска могут содержать ложную или противоречивую информацию об объекте поиска. В результате пользователю может быть предоставлена не заслуживающая доверия карточка объекта поиска, что может негативно повлиять на впечатление пользователя от использования поисковой системы.
[08] Для решения описанной выше технической проблемы были предложены некоторые известные подходы.
[09] В патенте US9454562B2 «Optimized Narrative Generation and Fact Checking Method and System Based on Language usage» (Lucas J. Myslinski, выдан 27 сентября 2016 г.) описана система проверки фактов, анализирующая и определяющая точность фактов информации и/или характеристики информации путем сравнения этой информации с исходной информацией. Система проверки фактов автоматически контролирует информацию, обрабатывает информацию, проверяет информацию на наличие фактологических ошибок оптимизированным образом и/или сообщает о состоянии этой информации. В некоторых вариантах осуществления изобретения система проверки фактов формирует, агрегирует и/или обобщает контент.
Раскрытие изобретения
[010] Целью настоящего изобретения является устранение по меньшей мере некоторых недостатков известных решений.
[011] Разработчики настоящей технологии установили, что точность фактов части заранее сформированных сводных данных объекта поиска (в этом документе также называется сниппетом) может быть проверена на основе контекста, обеспечиваемого другими частями этой сводки, например, смежными с рассматриваемой частью. В частности, разработчики разработали способы и системы для обучения алгоритма машинного обучения (MLA, Machine-Learning Algorithm), способного определять значение вероятности, указывающее на то, подтверждает ли контент по меньшей мере одной другой части заранее сформированной сводки данную ее часть. В по меньшей мере некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии контент данной части может быть определен как фактически точный в случае положительного результата такого определения.
[012] Например, рассматриваемая часть может содержать упоминание о дате рождения объекта поиска, например, «Keanu Reeves, born September 2, 1964» («Киану Ривз родился 2 сентября 1964 г.»). Другая часть заранее сформированной сводки может содержать упоминание о фактическом возрасте объекта поиска, например, «By the age of 57, he has starred in more than 60 films and shows» («К 57 годам он снялся более чем в 60 фильмах и сериалах»). Получив обе эти части, алгоритм MLA, обученный согласно не имеющим ограничительного характера вариантам осуществления настоящей технологии, может определить, что контент другой части, вероятно, подтверждает контент рассматриваемой части. Далее может быть сделано заключение, что контент рассматриваемой части заранее сформированной сводки фактически точен.
[013] Таким образом, не имеющие ограничительного характера варианты осуществления настоящей технологии позволяют обеспечивать более достоверные карточки объектов поиска, в результате чего повышается удовлетворенность пользователя от взаимодействия с поисковыми системами.
[014] В частности, согласно первому аспекту настоящей технологии реализован компьютерный способ проверки фактов контента сниппета из множества сниппетов. Множество сниппетов сформировано для объекта поиска порождающей моделью машинного обучения. Объект поиска определен на основе соответствующего поискового запроса. Способ выполняется сервером. Способ включает в себя: определение сервером для рассматриваемого сниппета по меньшей мере одного другого сниппета из множества сниппетов, обеспечивающего контекст для рассматриваемого сниппета; формирование сервером для рассматриваемого сниппета соответствующего целевого вектора, представляющего рассматриваемый сниппет, с использованием алгоритма векторизации текста; формирование сервером для по меньшей мере одного другого сниппета соответствующего вектора контекста, представляющего по меньшей мере один сниппет контекста, с использованием алгоритма векторизации текста; предоставление сервером соответствующего целевого вектора и соответствующего вектора контекста для модели NLP с целью определения значения вероятности, указывающего на то, подтверждает ли контент по меньшей мере одного другого сниппета точность фактов контента рассматриваемого сниппета, при этом модель NLP обучена определению того, подтверждают ли сниппеты этапа использования точность фактов рассматриваемого сниппета; и определение сервером того, что факты контента рассматриваемого сниппета являются точными, если это значение вероятности не меньше порогового значения вероятности.
[015] В некоторых вариантах осуществления способа порождающая модель способна формировать множество сниппетов на основе образцовых цифровых документов из множества цифровых документов, которые соответствуют соответствующему поисковому запросу.
[016] В некоторых вариантах осуществления способа цифровому документу из множества цифровых документов заранее назначен параметр релевантности, указывающий на то, насколько этот цифровой документ релевантен соответствующему поисковому запросу, а образцовые цифровые документы определены как связанные с N наибольшими соответствующими параметрами релевантности.
[017] В некоторых вариантах осуществления способа определение по меньшей мере одного другого сниппета для рассматриваемого сниппета включает в себя определение по меньшей мере одного другого сниппета, контент которого семантически связан с по меньшей мере одним фактом об объекте поиска в рассматриваемом сниппете.
[018] В некоторых вариантах осуществления способа порождающая модель машинного обучения способна формировать множество сниппетов, представляющих собой связный текст для объекта поиска.
[019] В некоторых вариантах осуществления способа порождающая модель машинного обучения представляет собой модель машинного обучения на основе трансформера.
[020] В некоторых вариантах осуществления способа модель NLP заранее обучена определению наличия семантической связи между двумя следующими друг за другом сниппетами из множества сниппетов.
[021] В некоторых вариантах осуществления способа модель NLP путем применения в отношении нее добавочной модели машинного обучения точно настраивается для определения значения вероятности того, что контент по меньшей мере одного другого сниппета подтверждает точность фактов контента рассматриваемого сниппета. Добавочная модель машинного обучения обучается формированию векторных представлений для модели NLP. Обучение добавочной модели машинного обучения включает в себя: получение сервером множества обучающих объектов, каждый из которых содержит (а) соответствующий первый обучающий сниппет; (б) по меньшей мере одну обучающую подводку (prompt), сформированную на основе соответствующего первого обучающего сниппета; (в) соответствующий второй сниппет, определенный как контекстно-связанный с соответствующим первым сниппетом; и (г) соответствующую метку, указывающую на то, подтверждает ли контент соответствующего второго обучающего сниппета факты контента соответствующего первого обучающего сниппета; и предоставление сервером множества обучающих объектов для добавочной модели машинного обучения с целью ее обучения формированию (а) соответствующего целевого вектора для рассматриваемого сниппета и (б) соответствующего вектора контекста для по меньшей мере одного сниппета контекста.
[022] В некоторых вариантах осуществления способа по меньшей мере одна подводка содержит вопрос, на который отвечает соответствующий первый обучающий сниппет.
[023] В некоторых вариантах осуществления способа по меньшей мере одна обучающая подводка содержит перефразированный соответствующий первый обучающий сниппет.
[024] В некоторых вариантах осуществления способа соответствующая метка назначена оценщиком-человеком.
[025] В некоторых вариантах осуществления способа модель NLP точно настраивается сервером, при этом ее веса, определенные после предварительного обучения модели NLP, фиксируются.
[026] В некоторых вариантах осуществления способа добавочная модель машинного обучения содержит нейронную сеть с долгой краткосрочной памятью (LSTM, Long Short-Term Memory).
[027] В некоторых вариантах осуществления способа точная настройка модели NLP включает в себя применение метода подбора подводок (P-tuning).
[028] В некоторых вариантах осуществления способа модель NLP содержит модель машинного обучения на основе трансформера.
[029] Согласно второму аспекту настоящей технологии реализован сервер для проверки фактов контента сниппета из множества сниппетов. Множество сниппетов сформировано для объекта поиска порождающей моделью машинного обучения. Объект поиска определен на основе соответствующего поискового запроса. Сервер содержит процессор и машиночитаемую физическую память, хранящую команды. Процессор при выполнении команд способен: определять для рассматриваемого сниппета по меньшей мере один другой сниппет из множества сниппетов, обеспечивающий контекст для рассматриваемого сниппета; формировать для рассматриваемого сниппета соответствующий целевой вектор, представляющий рассматриваемый сниппет, с использованием алгоритма векторизации текста; формировать для по меньшей мере одного другого сниппета соответствующий вектор контекста, представляющий по меньшей мере один сниппет контекста, с использованием алгоритма векторизации текста; предоставлять соответствующий целевой вектор и соответствующий вектор контекста для модели NLP с целью определения значения вероятности, указывающего на то, подтверждает ли контент по меньшей мере одного другого сниппета точность фактов контента рассматриваемого сниппета, при этом модель NLP обучена определению того, подтверждают ли сниппеты этапа использования точность фактов рассматриваемого сниппета; и определять, что факты контента рассматриваемого сниппета являются точным, если упомянутое значение вероятности не меньше порогового значения вероятности.
[030] В некоторых вариантах осуществления сервера с целью определения по меньшей мере одного другого сниппета для рассматриваемого сниппета процессор способен определять по меньшей мере один другой сниппет, контент которого семантически связан с по меньшей мере одним фактом об объекте поиска в рассматриваемом сниппете.
[031] В некоторых вариантах осуществления сервера модель NLP заранее обучена определению наличия семантической связи между двумя следующими друг за другом сниппетами из множества сниппетов.
[032] В некоторых вариантах осуществления сервера модель NLP путем применения в отношении нее добавочной модели машинного обучения точно настроена для определения значения вероятности того, что контент по меньшей мере одного другого сниппета подтверждает точность фактов контента рассматриваемого сниппета, а процессор дополнительно способен обучать добавочную модель машинного обучения формированию векторных представлений для модели NLP путем: получения множества обучающих объектов, каждый из которых содержит (а) соответствующий первый обучающий сниппет; (б) по меньшей мере одну обучающую подводку, сформированную на основе соответствующего первого обучающего сниппета; (в) соответствующий второй сниппет, определенный как контекстно-связанный с соответствующим первым сниппетом; и (г) соответствующую метку, указывающую на то, подтверждает ли контент соответствующего второго обучающего сниппета факты контента соответствующего первого обучающего сниппета; и предоставления множества обучающих объектов для добавочной модели машинного обучения с целью ее обучения формированию (а) соответствующего целевого вектора для рассматриваемого сниппета и (б) соответствующего вектора контекста для по меньшей мере одного сниппета контекста.
[033] В некоторых вариантах осуществления сервера по меньшей мере одна подводка содержит вопрос, на который отвечает соответствующий первый обучающий сниппет.
[034] В контексте настоящего описания термин «сервер» означает компьютерную программу, выполняемую соответствующими аппаратными средствами и способную принимать запросы (например, от клиентских устройств) через сеть и выполнять эти запросы или инициировать их выполнение. Аппаратные средства могут представлять собой один физический компьютер или одну компьютерную систему, что не существенно для настоящей технологии. В настоящем контексте выражение «сервер» не означает, что каждая задача (например, принятая команда или запрос) или некоторая конкретная задача принимается, выполняется или запускается одним и тем же сервером (т.е. одними и теми же программными и/или аппаратными средствами). Это выражение означает, что любое количество программных средств или аппаратных средств может принимать, отправлять, выполнять или инициировать выполнение любой задачи или запроса либо результатов любых задач или запросов. Все эти программные и аппаратные средства могут представлять собой один сервер или несколько серверов, причем оба эти случая подразумеваются в выражении «по меньшей мере один сервер».
[035] В контексте настоящего описания термин «клиентское устройство» означает любое компьютерное аппаратное средство, способное выполнять программы, подходящие для решения поставленной задачи. Таким образом, некоторые (не имеющие ограничительного характера) примеры клиентских устройств включают в себя персональные компьютеры (настольные, ноутбуки, нетбуки и т.п.), смартфоны и планшеты, а также сетевое оборудование, такое как маршрутизаторы, коммутаторы и шлюзы. Следует отметить, что в данном контексте устройство, функционирующее как клиентское устройство, также может функционировать как сервер для других клиентских устройств. Использование выражения «клиентское устройство» не исключает использования нескольких клиентских устройств для приема, отправки, выполнения или инициирования выполнения любой задачи или запроса либо результатов любых задач или запросов, либо шагов любого описанного здесь способа.
[036] В контексте настоящего описания термин «база данных» означает любой структурированный набор данных, независимо от его конкретной структуры, программного обеспечения для управления базой данных или компьютерных аппаратных средств для хранения этих данных, их применения или обеспечения их использования иным способом. База данных может располагаться в тех же аппаратных средствах, где реализован процесс, обеспечивающий хранение или использование информации, хранящейся в базе данных, либо база данных может располагаться в отдельных аппаратных средствах, таких как специализированный сервер или множество серверов.
[037] В контексте настоящего описания выражение «информация» включает в себя информацию любого рода или вида, допускающую хранение в базе данных. Таким образом, информация включает в себя аудиовизуальные произведения (изображения, фильмы, звукозаписи, презентации и т.д.), данные (данные о местоположении, числовые данные и т.д.), текст (мнения, комментарии, вопросы, сообщения и т.д.), документы, электронные таблицы, списки слов и т.д., но не ограничивается ими.
[038] В контексте настоящего описания выражение «компонент» включает в себя обозначение программного обеспечения (подходящего для определенных аппаратных средств), необходимого и достаточного для выполнения определенной функции или нескольких функций.
[039] В контексте настоящего описания выражение «пригодный для использования в компьютере носитель информации» означает носители любого рода и вида, включая оперативное запоминающее устройство (ОЗУ), постоянное запоминающее устройство (ПЗУ), диски (CD-ROM, DVD, гибкие диски, жесткие диски и т.д.), USB-накопители, твердотельные накопители, накопители на магнитных лентах и т.д.
[040] В контексте настоящего описания числительные «первый», «второй», «третий» и т.д. используются лишь для указания на различие между существительными, к которым они относятся, но не для описания каких-либо определенных взаимосвязей между этими существительными. Например, должно быть понятно, что использование терминов «первый сервер» и «третий сервер» не подразумевает какого-либо определенного порядка, типа, хронологии, иерархии или классификации, в данном случае, серверов, а также что их использование (само по себе) не подразумевает наличие «второго сервера» в любой ситуации. Кроме того, как встречается в настоящем описании в другом контексте, ссылка на «первый» элемент и «второй» элемент не исключает того, что эти два элемента в действительности могут быть одним и тем же элементом. Таким образом, например, в некоторых случаях «первый» сервер и «второй» сервер могут представлять собой одно и то же программное и/или аппаратное средство, а в других случаях - разные программные и/или аппаратные средства.
[041] Каждый вариант осуществления настоящей технологии относится к по меньшей мере одной из вышеупомянутых целей и/или одному из вышеупомянутых аспектов, но не обязательно ко всем ним. Должно быть понятно, что некоторые аспекты настоящей технологии, связанные с попыткой достижения вышеупомянутой цели, могут не соответствовать этой цели и/или могут соответствовать другим целям, явным образом здесь не упомянутым.
[042] Дополнительные и/или альтернативные признаки, аспекты и преимущества вариантов осуществления настоящей технологии содержатся в дальнейшем описании, на приложенных чертежах и в формуле изобретения.
Краткое описание чертежей
[043] Эти и другие признаки, аспекты и преимущества настоящей технологии поясняются в дальнейшем описании, приложенной формуле изобретения и на следующих чертежах.
[044] На фиг. 1 представлена схема примера компьютерной системы для реализации некоторых не имеющих ограничительного характера вариантов осуществления систем и/или способов согласно настоящей технологии.
[045] На фиг. 2 представлена сетевая вычислительная среда, подходящая для обучения и использования модели машинного обучения с целью определения точности фактов сниппета из множества сниппетов, согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии.
[046] На фиг. 3 приведено схематическое изображение графического интерфейса пользователя (GUI, Graphical User Interface) браузерного приложения, обеспечивающего визуальное представление страницы SERP, предоставленной интерактивной поисковой платформой, размещенной на сервере в сетевой вычислительной среде, представленной на фиг. 2, согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии.
[047] На фиг. 4 приведена блок-схема архитектуры модели машинного обучения, выполняемой сервером в сетевой вычислительной среде, представленной на фиг. 2, согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии.
[048] На фиг. 5 приведена блок-схема другой конфигурации архитектуры модели машинного обучения, выполняемой сервером в сетевой вычислительной среде, представленной на фиг. 2, согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии.
[049] На фиг. 6 приведена блок-схема добавочной модели машинного обучения, используемой в качестве части конфигурации модели машинного обучения, представленной на фиг. 5, согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии.
[050] На фиг. 7 представлена блок-схема способа обучения модели машинного обучения, реализованной на основе архитектуры модели машинного обучения согласно фиг. 4 или 5, определению значения вероятности того, что контент одного сниппета подтверждает точность фактов контента другого сниппета, согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии.
Осуществление изобретения
[051] Представленные здесь примеры и условный язык предназначены для обеспечения лучшего понимания принципов настоящей технологии, а не для ограничения ее объема до таких специально приведенных примеров и условий. Очевидно, что специалисты в данной области техники способны разработать различные способы и устройства, которые явно не описаны и не показаны, но реализуют принципы настоящей технологии в пределах ее существа и объема.
[052] Кроме того, чтобы способствовать лучшему пониманию, последующее описание может содержать упрощенные варианты реализации настоящей технологии. Специалистам в данной области должно быть понятно, что другие варианты осуществления настоящей технологии могут быть значительно сложнее.
[053] В некоторых случаях приводятся полезные примеры модификаций настоящей технологии. Они способствуют пониманию, но также не определяют объема или границ настоящей технологии. Представленный перечень модификаций не является исчерпывающим и специалист в данной области может разработать другие модификации в пределах объема настоящей технологии. Кроме того, если в некоторых случаях модификации не описаны, это не означает, что они невозможны и/или что описание содержит единственно возможный вариант реализации того или иного элемента настоящей технологии.
[054] Более того, описание принципов, аспектов и вариантов реализации настоящей технологии, а также их конкретные примеры предназначены для охвата их структурных и функциональных эквивалентов, независимо от того, известны они в настоящее время или будут разработаны в будущем. Например, специалистам в данной области техники должно быть понятно, что любые описанные здесь структурные схемы соответствуют концептуальным представлениям иллюстративных принципиальных схем, реализующих основы настоящей технологии. Также должно быть понятно, что любые блок-схемы, схемы процессов, диаграммы изменения состояния, псевдокоды и т.п. соответствуют различным процессам, которые могут быть представлены на машиночитаемом физическом носителе информации и могут выполняться компьютером или процессором, независимо от того, показан такой компьютер или процессор явно или нет.
[055] Функции различных элементов, показанных на чертежах, включая любой функциональный блок, обозначенный как «процессор» или «графический процессор», могут быть реализованы с использованием специализированных аппаратных средств, а также с использованием аппаратных средств, способных выполнять соответствующее программное обеспечение. Если используется процессор, эти функции могут выполняться одним выделенным процессором, одним совместно используемым процессором и/или множеством отдельных процессоров, некоторые из которых могут использоваться совместно. В некоторых вариантах осуществления настоящей технологии процессор может представлять собой процессор общего назначения, такой как центральный процессор (CPU), или специализированный процессор, такой как графический процессор (GPU). Кроме того, явное использование термина «процессор» или «контроллер» не должно трактоваться как указание исключительно на аппаратные средства, способные выполнять программное обеспечение, и может подразумевать, помимо прочего, аппаратные средства цифрового сигнального процессора (DSP), сетевой процессор, специализированную интегральную схему (ASIC), программируемую вентильную матрицу (FPGA), ПЗУ для хранения программного обеспечения, ОЗУ и/или энергонезависимое запоминающее устройство. Также могут подразумеваться другие аппаратные средства, общего назначения и/или заказные.
[056] Программные модули или просто модули, реализация которых предполагается в виде программных средств, могут быть представлены здесь как любое сочетание элементов блок-схемы или других элементов, указывающих на выполнение шагов процесса и/или содержащих текстовое описание. Такие модули могут выполняться аппаратными средствами, показанными явно или подразумеваемыми.
[057] Далее с учетом вышеизложенных принципов рассмотрены некоторые не имеющие ограничительного характера примеры, иллюстрирующие различные варианты реализации аспектов настоящей технологии.
Компьютерная система
[058] На фиг. 1 представлена компьютерная система 100, пригодная для использования в некоторых вариантах осуществления настоящей технологии. Компьютерная система 100 содержит различные аппаратные элементы, включая один или несколько одно- или многоядерных процессоров, обобщенно представленных процессором 110, графический процессор 111, твердотельный накопитель 120, ОЗУ 130, интерфейс 140 дисплея и интерфейс 150 ввода-вывода.
[059] Связь между различными элементами компьютерной системы 100 может осуществляться через одну или несколько внутренних и/или внешних шин 160 (таких как шина PCI, шина USB, шина FireWire стандарта IEEE 1394, шина SCSI, шина Serial-ATA и т.д.), с которыми различные аппаратные элементы соединены электронным образом.
[060] Интерфейс 150 ввода-вывода может соединяться с сенсорным экраном 190 и/или с одной или несколькими внутренними и/или внешними шинами 160. Сенсорный экран 190 может входить в состав дисплея. В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии сенсорный экран 190 представляет собой дисплей. Сенсорный экран 190 может также называться экраном 190. В представленных на фиг. 1 вариантах осуществления изобретения сенсорный экран 190 содержит сенсорные аппаратные средства 194 (например, чувствительные к нажатию ячейки, встроенные в слой дисплея и позволяющие обнаруживать физическое взаимодействие между пользователем и дисплеем) и контроллер 192 сенсорных средств ввода-вывода, который обеспечивает связь с интерфейсом 140 дисплея и/или с одной или несколькими внутренними и/или внешними шинами 160. В некоторых вариантах осуществления изобретения интерфейс 150 ввода-вывода может соединяться с клавиатурой (не показана), мышью (не показана) или сенсорной площадкой (не показана), которые обеспечивают взаимодействие пользователя с компьютерной системой 100 в дополнение к сенсорному экрану 190 или вместо него.
[061] Следует отметить, что в некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии некоторые элементы компьютерной системы 100 могут отсутствовать. Например, может отсутствовать сенсорный экран 190, в частности, если компьютерная система реализована в виде сервера (но не ограничиваясь этим).
[062] Согласно вариантам осуществления настоящей технологии, твердотельный накопитель 120 хранит программные команды, пригодные для загрузки в ОЗУ 130 и выполнения процессором 110 и/или графическим процессором 111. Программные команды могут, например, входить в состав библиотеки или приложения.
Сетевая вычислительная среда
[063] На фиг. 2 представлена схема сетевой вычислительной среды 200, пригодной для использования с некоторыми не имеющими ограничительного характера вариантами осуществления систем и/или способов согласно настоящей технологии. Сетевая вычислительная среда 200 содержит сервер 202, соединенный через сеть 208 связи с электронным устройством 204. В не имеющих ограничительного характера вариантах осуществления настоящей технологии электронное устройство 204 может быть связано с пользователем 220.
[064] В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии электронное устройство 204 может представлять собой любые компьютерные аппаратные средства, способные выполнять программы, подходящие для решения поставленной задачи. Таким образом, в качестве некоторых не имеющих ограничительного характера примеров электронного устройства 204 можно привести персональные компьютеры (настольные, ноутбуки, нетбуки и т.п.), смартфоны и планшеты. Должно быть понятно, что в некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии электронное устройство 204 может быть не единственным электронным устройством, связанным с пользователем 220, который может быть связан с другими электронными устройствами (не показаны на фиг. 2), способные через сеть 208 связи соединяться с сервером 202, без выхода за границы настоящей технологии.
[065] В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 202 реализован в виде традиционного компьютерного сервера и может содержать некоторые или все элементы компьютерной системы 100, представленной на фиг. 1. В конкретном не имеющем ограничительного характера примере сервер 202 реализован в виде сервера Dell™ PowerEdge™, работающего под управлением операционной системы Microsoft™ Windows Server™, но он также может быть реализован с использованием любых других подходящих аппаратных средств, прикладного программного обеспечения и/или встроенного программного обеспечения либо их сочетания. В представленных не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 202 представляет собой один сервер. В других не имеющих ограничительного характера вариантах осуществления настоящей технологии (не показаны) функции сервера 202 могут быть распределены между несколькими серверами.
[066] В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 202 может содержать интерактивную поисковую платформу 210. В общем случае интерактивная поисковая платформа 210 соответствует программной веб-системе, способной выполнять поиски в ответ на отправленные ей поисковые запросы. Виды результатов поиска, которые интерактивная поисковая платформа 210 способна предоставлять в ответ на поисковые запросы, обычно зависят от конкретного варианта реализации интерактивной поисковой платформы 210. Например, в некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии интерактивная поисковая платформа 210 может быть реализована в виде поисковой системы (такой как поисковая система Google™, поисковая система Yandex™ и т.п.), а результаты поиска могут включать в себя цифровые документы различных видов, такие как цифровые аудиодокументы (например, песни, записи речи, подкасты), цифровые видеодокументы (например, видеоклипы, фильмы, мультипликационные фильмы), текстовые цифровые документы и т.д. Кроме того, в некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии интерактивная поисковая платформа 210 может быть реализована в виде платформы интерактивных списков (такой как платформа интерактивных списков Yandex™ Market™), а результаты поиска могут включать в себя цифровые документы, содержащие рекламу различных элементов, таких как товары и услуги. Также возможны другие варианты реализации интерактивной поисковой платформы 210.
[067] Таким образом, в некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 202 может быть связан с поисковой базой 206 данных, способной хранить информацию о цифровых документах, которые потенциально доступны через сеть 208 связи, например, электронному устройству 204. С этой целью поисковая база 206 данных может быть предварительно наполнена указаниями на цифровые документы, например, с использованием процесса обхода (crawling), который в некоторых не имеющих ограничительного характера вариантах осуществления изобретения может, например, быть реализован сервером 202. В частности, в дополнительных не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 202 может хранить в поисковой базе 206 данных данные, указывающие на каждый поиск, выполненный пользователем 220 на интерактивной поисковой платформе 210, в частности, поисковые запросы и наборы соответствующих им цифровых документов, а также их метаданные.
[068] Кроме того, несмотря на то, что в представленных на фиг. 2 вариантах осуществления изобретения поисковая база 206 данных показана в виде одного элемента, должно быть понятно, что в других не имеющих ограничительного характера вариантах осуществления настоящей технологии функции поисковой базы 206 данных могут быть распределены между несколькими базами данных. В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии поисковая база 206 данных может быть доступна серверу 202 через сеть 208 связи, а не через прямую линию связи (отдельно не обозначена), как показано на фиг. 2.
[069] Таким образом, пользователь 220 с использованием электронного устройства 204 может обращаться, например, с помощью браузерного приложения 205 к интерактивной поисковой платформе 210, например, путем ввода соответствующего URL-адреса в адресную строку браузерного приложения 205. Пользователь 220 может отправлять поисковый запрос 212 интерактивной поисковой платформе 210, которая способна определять в поисковой базе 206 данных набор 214 цифровых документов, соответствующих поисковому запросу 212. Кроме того, чтобы способствовать навигации пользователя 220 в наборе 214 цифровых документов, может потребоваться их ранжирование, например, согласно степени их релевантности поисковому запросу 212.
[070] На фиг. 3 представлен интерфейс GUI браузерного приложения 205, обеспечивающего визуальное представление страницы 302 SERP интерактивной поисковой платформы 210, содержащей набор 214 цифровых документов, согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии (см. также фиг. 2).
[071] Предполагается, что в различных не имеющих ограничительного характера вариантах осуществления настоящей технологии интерактивная поисковая платформа 210 способна предоставлять набор 214 цифровых документов, содержащий цифровые документы различных видов, включая цифровые текстовые документы, такие как цифровые веб-документы, содержащие текстовый контент, или цифровые документы в одном из текстовых форматов, таком как *.txt, *.docx, *.rtf, цифровые графические документы, цифровые видеодокументы и т.д.
[072] В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии интерактивная поисковая платформа 210 способна формировать не только набор 214 цифровых документов, но и поисковую сводку 216 для объекта поиска, связанного с поисковым запросом 212, и добавлять поисковую сводку 216 на страницу 302 SERP. В частности, согласно некоторым не имеющим ограничительного характера вариантах осуществления настоящей технологии, интерактивная поисковая платформа 210 способна формировать поисковую сводку 216 в виде карточки объекта поиска, содержащей конкретные цифровые документы, наиболее точно представляющие объект поиска пользователя 220.
[073] Например, как показано на фиг. 3, интерактивная поисковая платформа 210 на основе отправленного ей поискового запроса 212 «Matrix Lead Actor» («Ведущий актер в Матрице») способна определить, что объектом поиска пользователя 220 является актер Киану Ривз, и дополнительно сформировать поисковую сводку 216 для этого объекта поиска. На способ определения интерактивной поисковой платформой 210 объекта поиска на основе поискового запроса 212 не накладывается каких-либо ограничений. В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии он может включать в себя определение объекта поиска на основе цифровых документов, идентифицированных как релевантные предыдущим поисковым запросам, отправленным пользователями сети 208 связи. В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии объекты поиска могут быть заранее связаны с соответствующими поисковыми запросами и соответствующими цифровыми документами в поисковой базе 206 данных.
[074] Таким образом интерактивная поисковая платформа 210 способна формировать поисковую сводку 216, содержащую множество 304 сниппетов, образующих текстовую сводку объекта поиска. В контексте данного описания термин «сниппет» соответствует части текста, такой как предложение или его часть, содержащей по меньшей мере один факт об объекте поиска. Например, как показано на фиг. 3, первый сниппет 306 может содержать факт о национальности Киану Ривз, определенного в качестве объекта поиска поискового запроса 212. Тем не менее, следует отметить, что в зависимости от формата поисковой сводки 216, интерактивная поисковая платформа 210 также может содержать изображение объекта поиска, как показано на фиг. 3, или цифровые документы других видов, такие такие как видео- или аудиодокументы, без выхода за границы настоящей технологии.
[075] Согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии, интерактивная поисковая платформа 210 способна формировать поисковую сводку 216 на основе цифровых документов из набора 214 цифровых документов, соответствующих поисковому запросу 212. Например, интерактивная поисковая платформа 210 может определять образцовые цифровые документы из набора 214 цифровых документов для формирования поисковой сводки 216. На выбор интерактивной поисковой платформой 210 образцовых цифровых документов для формирования поисковой сводки 216 не накладывается каких-либо ограничений. Например, в некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии интерактивная поисковая платформа 210 способна (а) ранжировать набор 214 цифровых документов и (б) выбирать N цифровых документов с наибольшим приоритетом (например, 10) из ранжированного набора цифровых в качестве образцовых цифровых документов. Кроме того, не накладывается каких-либо ограничений на способ ранжирования интерактивной поисковой платформой 210 набора 214 цифровых документов. Как описано выше, в некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии этот способ может включать в себя ранжирование набора 214 цифровых документов их степени релевантности поисковому запросу 212. С этой целью интерактивная поисковая платформа 210 может применять один из подходов, описанных в патентной заявке этого же заявителя US17/831473 «Multi-phase training of machine learning models for search results ranking», содержание которой полностью включено в настоящий документ посредством ссылки.
[076] Предполагается, что интерактивная поисковая платформа 210 способна определять соответствующий набор образцовых цифровых документов для каждой части поисковой сводки 216 в зависимости от формата поисковой сводки 216. В частности, для формирования множества 304 сниппетов, образующих текстовую сводку объекта поиска, интерактивная поисковая платформа 210 может, например, определять соответствующий набор образцовых цифровых документов из части набора 214 цифровых документов, представляющих собой результаты общего поиска, соответствующие поисковому запросу 212. При этом если формат поисковой сводки 216 включает в себя изображение объекта поиска, как показано на фиг. 3, то для определения этого изображения интерактивная поисковая платформа 210 способна выбирать соответствующий набор образцовых цифровых объектов в качестве части набора 214 цифровых документов, как представляющий собой результаты вертикального поиска цифровых графических документов, соответствующих поисковому запросу 212.
[077] Согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии, для формирования на основе соответствующего набора образцовых цифровых документов множества 304 сниппетов для объекта поиска интерактивная поисковая платформа 210 способна выполнять с использованием сервера 202 парсинг соответствующего набора образцовых цифровых документов, выбранных из набора 214 цифровых документов, как описано выше, с целью определения в нем множества 304 сниппетов. Например, в некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии с этой целью сервер 202 может применять порождающую модель машинного обучения (не показана).
[078] В общем случае порождающая модель машинного обучения обучена определению в цифровых документах сниппетов, содержащих фактическую информацию о соответствующих объектах поиска. Обучение порождающей модели машинного обучения может, например, выполняться сервером 202 на основе соответствующего обучающего набора данных, содержащего множество обучающих цифровых объектов, каждый из которых содержит: (1) обучающую часть текста, определенную в обучающем цифровом документе; (2) указание на содержащуюся в ней фактическую информацию; и (3) соответствующий обучающий объект поиска, к которому относится фактическая информация, содержащаяся в обучающей части текста. В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии указание на фактическую информацию может быть предоставлено оценщиком-человеком. Таким образом, порождающая модель машинного обучения может быть обучена извлечению сниппетов фактической информации, относящейся к соответствующим объектам поиска, отфильтровывая части цифровых документов, не содержащие такой информации, такие как части, содержащие абстрактные описания, вводные конструкции, факты о других объектах и т.п.
[079] В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии порождающая модель машинного обучения может быть дополнительно обучена формированию множества 304 сниппетов, образующих связный текст. В частности, порождающая модель машинного обучения может быть дополнительно обучена преобразованию сниппетов из множества 304 сниппетов так, чтобы в целом они представляли собой связный текст. Для этого порождающая модель машинного обучения может быть точно настроена на основе другого обучающего набора данных, содержащего другое множество обучающих объектов, каждый из которых содержит: (1) первый обучающий сниппет; (2) второй обучающий сниппет, следующий непосредственно за первым обучающим сниппетом; и (3) перефразированный второй обучающий сниппет, образующий совместно с первым сниппетом фрагмент связного текста. В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии перефразированный второй обучающий сниппет может быть предоставлен оценщиком-человеком.
[080] На реализацию порождающей модели машинного обучения не накладывается каких-либо ограничений. В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии она может быть реализована в виде модели машинного обучения на основе трансформера, архитектура которой описана ниже со ссылкой на фиг. 4. Тем не менее, в других не имеющих ограничительного характера вариантах осуществления настоящей технологии порождающая модель машинного обучения может быть реализована на основе любой другой архитектуры нейронной сети (NN, Neural Network), такой как сеть NN вида LSTM (Long Short-Term Memory), сеть NN вида «вариационный автокодировщик» (Variational Autoencoder) и т.д.
[081] После формирования сервером 202 множества 304 сниппетов интерактивная поисковая платформа 210 способна включать их в поисковую сводку 216 для объекта поиска, определенного на основе поискового запроса 212. При этом несмотря на то, что каждый сниппет из множества 304 сниппетов, такой как первый сниппет 306, может содержать грамматически правильную часть текста, они могут быть неточными с точки зрения фактов. Например, документ из соответствующего набора образцовых цифровых документов, определенный в наборе 214 цифровых документов и используемый для формирования первого сниппета 306, содержит ложный факт о Киану Ривзе, а именно о том, что он является американским актером («American actor») (в отличие от фактически верного утверждения о том, что Киану Ривз является канадским актером («Canadian actor»)). Такие ошибочные сводки, предоставленные пользователю 220, могут негативно повлиять на удовлетворенность пользователя от взаимодействия с интерактивной поисковой платформой 210.
[082] Описанные в этом документе способы и системы предназначены для проверки фактов контента каждого сниппета из множества 304 сниппетов, например, первого сниппета 306. В частности, разработчики настоящей технологии разработали способы, включающие в себя определение того, являются ли факты контента первого сниппета 306 точными, на основе контента по меньшей мере одного другого сниппета из множества 304 сниппетов, такого как второй сниппет 308, обеспечивающий контекст для первого сниппета 306. Например, в некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 202 может определять второй сниппет как представляющий собой по меньшей мере один смежный сниппет, такой как второй сниппет 308.
[083] При этом в других не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 202 может определять второй сниппет 308, например, на основе его лингвистического анализа. В частности, сервер 202 может определять второй сниппет 308, например, как содержащий слова, семантически схожие со словами из первого сниппета 306.
[084] Для этого, согласно по меньшей мере некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии, сервер 202 может обучать и применять модель 218 NLP для определения значения вероятности, указывающего на то, подтверждает ли контент второго сниппета 308 точность фактов контента первого сниппета 306. Кроме того, эти способы могут включать в себя определение того, являются ли факты контента первого сниппета 306 точными, на основе определенного таким образом значения вероятности.
[085] Например, с использованием модели 218 NLP, обученной согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии, настоящие способы позволяют определять то, что контент второго сниппета 308 не подтверждает точность фактов контента первого сниппета 306. В частности, настоящие способы позволяют определять несоответствие между контентом второго сниппета 308 и первого сниппета 306, а именно, то, что родившийся в Ливане и выросший в Канаде человек очень маловероятно будет называться американцем («American»). Таким образом контент первого сниппета 306 может быть определен как неточный с точки зрения фактов.
[086] В общем случае можно сказать, что сервер 202 должен выполнять два процесса в отношении модели 218 NLP. Первый из двух процессов представляет собой процесс обучения, в котором сервер 202 на основе соответствующего обучающего набора данных обучает модель 218 NLP определению того, подтверждают ли сниппеты этапа использования точность фактов первого сниппета 306 (описано ниже со ссылкой на фиг. 4-6). Второй процесс представляет собой процесс этапа использования, в котором сервер 202 выполняет обученную таким образом модель 218 NLP (описано ниже).
[087] На реализацию модели 218 NLP не накладывается каких-либо ограничений. Например, в некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии модель 218 NLP может быть реализована на основе рекуррентной сети NN (RNN, Recurrent NN), сверточной сети NN (CNN, Convolutional NN) или сети NN вида LSTM. В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии модель 218 NLP может быть реализована в виде модели машинного обучения на основе трансформера, архитектура которой описана ниже со ссылкой на фиг. 4.
Сеть связи
[088] В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии сеть 208 связи может представлять собой сеть Интернет. В альтернативных не имеющих ограничительного характера вариантах осуществления настоящей технологии сеть 208 связи может быть реализована в виде любой подходящей локальной сети (LAN, Local Area Network), глобальной сети (WAN, Wide Area Network), частной сети связи и т.п. Очевидно, что варианты осуществления сети связи приведены лишь в иллюстративных целях. Реализация соответствующих линий связи (отдельно не обозначены) между сервером 202 и электронным устройством 204 с одной стороны и сетью 208 связи с другой стороны зависит, среди прочего, от реализации сервера 202 и электронного устройства 204. Лишь в качестве примера, не имеющего ограничительного характера, в тех вариантах осуществления настоящей технологии, где электронное устройство 204 реализовано в виде устройства беспроводной связи, такого как смартфон, линия связи может быть реализована в виде беспроводной линии связи. Примеры беспроводных линий связи включают в себя канал сети связи 3G, канал сети связи 4G и т.д. В сети 208 связи также может использоваться беспроводное соединение с сервером 202.
Архитектура модели машинного обучения
[089] На фиг. 4 представлена архитектура 400 модели машинного обучения, пригодная для использования в по меньшей мере некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии. Архитектура 400 модели машинного обучения основана на архитектуре модели нейронной сети на основе трансформера, как описано, например, в работе Vaswani et al. «Attention Is All You Need», Proceedings of 31st Conference on Neural Information Processing Systems (NIPS 2017), содержание которой полностью включено в настоящий документ посредством ссылки.
[090] Таким образом, архитектура 400 модели машинного обучения может содержать стек 402 слоев кодера и стек 403 слоев декодера, которые способны обрабатывать входные данные 412 и целевые данные 417 архитектуры 400 модели машинного обучения, соответственно.
[091] Кроме того, блок 404 кодера стека 402 слоев кодера содержит слой 406 многоголового внимания (MHA, Multi-Head Attention) кодера и слой 408 сети NN прямого распространения (FFNN, Feed-Forward NN) кодера. Слой 406 MHA кодера содержит зависимости между частями предоставленных ему входных данных 412. Например, если входные данные 412 содержат текстовые данные, такие как текстовое предложение, то слой 406 MHA кодера может содержать зависимости между словами предложения. В другом примере, где входные данные 412 стека 402 слоев кодера содержат аудиосигнал, например, представляющий фрагмент человеческой речи, слой 406 MHA кодера может содержать зависимости между конкретными звуками и/или акустическими признаками фрагмента человеческой речи. Такие зависимости могут использоваться слоем 406 MHA кодера для определения контекстной информации части входных данных 412 стека 402 слоев кодера (например, представляющей слово из первого сниппета 306), связанной с другой частью входных данных 412.
[092] Кроме того, слой 408 сети NN прямого распространения кодера способен преобразовывать свои входные данные из слоя 406 MHA кодера в формат, принимаемый одним или несколькими следующими слоями архитектуры 400 модели машинного обучения, такими как слой 409 MHA кодера-декодера (описано ниже). Слой 408 сети NN прямого распространения кодера обычно не содержит зависимостей слоя 406 MHA кодера, поэтому входные данные слоя 408 сети NN прямого распространения кодера могут обрабатываться параллельно.
[093] Кроме того, входные данные 412 стека 402 слоев кодера могут быть представлены множеством входных векторов 414, формируемых алгоритмом 410 векторизации входных данных. В общем случае алгоритм 410 векторизации входных данных способен формировать векторные представления фиксированной размерности для входных данных 412 в соответствующем пространстве векторных представлений. Иными словами, если входные данные 412 содержат текстовые данные, например, контент первого сниппета 306 или второго сниппета 308, то алгоритм 410 векторизации входных данных может формировать множество целевых векторов 419, в котором координаты векторов, представляющих слова первого сниппета 306 со схожим значением, располагаются ближе друг к другу в соответствующем пространстве векторных представлений. Таким образом, алгоритм 410 векторизации входных данных может быть реализован в виде алгоритма векторизации текста, включая, среди прочего, алгоритм векторизации текста вида «слово в вектор» (Word2Vec, Word to Vector), алгоритм векторизации текста на основе глобальных векторов для представления слов (GloVe, Global Vectors for Word Representation) и т.п.
[094] Следует отметить, что стек 402 слоев кодера может содержать несколько, например, 6 или 12, блоков кодера, реализованных подобно блоку 404 кодера.
[095] Блок 405 декодера стека 403 слоев декодера архитектуры 400 модели машинного обучения содержит (а) слой 407 MHA декодера и (б) слой 411 сети NN прямого распространения (FFNN) декодера, которые обычно могут быть реализованы подобно слою 406 MHA кодера и слою 408 сети NN прямого распространения кодера, соответственно. Тем не менее, архитектура блока 405 декодера отличается от архитектуры блока 404 кодера: блок 405 декодера дополнительно содержит слой 409 MHA кодера-декодера. Слой 409 MHA кодера-декодера способен (а) получать входные векторы от стека 402 слоев кодера и от слоя 407 MHA декодера и, следовательно, (б) определять в процессе обучения, как описано ниже, зависимости между входными данными 412 и целевыми данными 417 (такими, как текстовые данные) архитектуры 400 модели машинного обучения, введенным в стек 403 слоев декодера. Иными словами, выходные данные слоя 409 MHA кодера-декодера представляют собой векторы внимания, содержащие данные, указывающие на взаимосвязи между соответствующими частями входных данных 412 и целевых данных 417.
[096] Как и в случае входных данных 412, с целью подачи целевых данных 417 в блок 405 декодера, алгоритм 415 векторизации целевых данных может применяться в отношении целевых данных 417 для формирования множества целевых векторов 419, содержащих числовые представления соответствующих частей целевых данных 417. Предполагается, что в тех вариантах осуществления изобретения, где целевые данные 417 содержат текстовые данные, алгоритм 415 векторизации целевых данных может быть реализован подобно алгоритму 410 векторизации входных данных.
[097] Следует отметить, что стек 403 слоев декодера может содержать несколько, например, 6 или 12, блоков декодера, реализованных подобно блоку 405 декодера. Предполагается, что после обучения архитектуры 400 модели машинного обучения все блоки стека 402 слоев кодера и стека 403 слоев декодера имеют различные веса, используемые при формировании выходных данных 425. Для корректировки весов в процессе обучения в отношении архитектуры 400 модели машинного обучения может применяться алгоритм обратного распространения и могут определяться и минимизироваться различия между входными данными 412 и выходными данными 425. Такие различия могут выражаться функцией потерь, такой как функция потерь кросс-энтропии (Cross-Entropy Loss Function).
[098] Должно быть понятно, что в не имеющих ограничительного характера вариантах осуществления настоящей технологии также возможны другие варианты реализации функции потерь, например, функция потерь среднеквадратичной ошибки, функция потерь по Губеру, кусочно-линейная функция потерь и т.д.
[099] Выходные данные 425 архитектуры 400 модели машинного обучения могут содержать выходной вектор, соответствующий вектору из множества входных векторов 414. Например, как описано ниже, в тех вариантах осуществления изобретения, где входные данные 412 архитектуры 400 модели машинного обучения содержат первый сниппет 306 и второй сниппет 308, выходные данные 425 могут содержать значение вероятности, указывающее на то, имеется ли семантическая связь контента второго сниппета 308 с контентом первого сниппета 306.
[0100] Должно быть понятно, что архитектура 400 модели машинного обучения, описанная со ссылкой на фиг. 4, упрощена для лучшего понимания и что фактический вариант реализации архитектуры 400 модели машинного обучения может содержать дополнительные слои и/или блоки, например, как описано в вышеупомянутой работе Vaswani et al. В частности, в некоторых вариантах реализации архитектуры 400 модели машинного обучения каждый блок 404 кодера и каждый блок 405 декодера может также содержать слой операций нормализации. Кроме того, формирование выходных данных 425 может включать в себя применение функции нормализации softmax на выходе стека 403 слоев декодера и т.д. Специалистам в данной области должно быть известно, что такие операции широко используются в нейронных сетях и моделях глубокого обучения, таких как архитектура 400 модели машинного обучения.
Модель NLP
[0101] Согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии, модель 218 NLP может быть реализована на основе архитектуры 400 виде модели машинного обучения, описанной выше. В частности, в некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии модель 218 NLP также может содержать стек 402 слоев кодера и стек 403 слоев декодера, включая несколько блоков кодера и декодера. При этом соответствующие количества таких блоков в стеке 402 слоев кодера и в стеке 403 слоев декодера могут отличаться от их количеств в архитектуре 400 модели машинного обучения.
[0102] Например, в некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии модель 218 NLP может содержать один блок кодера и тринадцать блоков декодера, реализованных подобно блоку 404 кодера и блоку 405 декодера, соответственно, как описано выше. В других не имеющих ограничительного характера вариантах осуществления настоящей технологии модель 218 NLP может не содержать блоков кодера и содержать несколько блоков декодера, например, 6, 12 или 96 (в этом случае модель 218 NLP может называться заранее обученным генеративным трансформером (GPT, Generative Pre-trained Transformer)). При этом в других не имеющих ограничительного характера вариантах осуществления настоящей технологии модель 218 NLP может содержать только блоки кодера, например, 12, 24 или 36, и не содержать блоков декодера (в этом случае модель 218 может называться «Представления двунаправленного кодера из трансформеров» (BERT, Bidirectional Encoder Representations from Transformers)). Соответственно, в тех вариантах осуществления изобретения, где модель 218 NLP образована только блоками кодера или только блоками декодера, ее входные данные 412 и целевые данные 417 вводятся в виде единого вектора.
[0103] Также возможны другие конфигурации стека 402 слоев кодера и стека 403 слоев декодера для реализации модели 218 NLP без выхода за границы настоящей технологии.
[0104] Как описано выше, согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии, сервер 202 может обучать модель 218 NLP определению значения вероятности того, что контент по меньшей мере одного другого сниппета из множества 304 сниппетов подтверждает точность фактов первого сниппета 306. Для этого, согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии, сервер 202 может обучать модель NLP в ходе двух этапов. На первом этапе обучения (этап предварительного обучения) сервер 202 может на основе первого обучающего набора данных обучать модель 218 NLP определению первого значения вероятности того, что контент двух сниппетов этапа использования, таких как первый сниппет 306 и второй сниппет 308 из множества 304 сниппетов, семантически связан. Иными словами, на первом этапе обучения сервер 202 способен обучать модель 218 NLP определению того, связан ли контент первого сниппета 306 и контент второго сниппета 308 с одним и тем же признаком, таким как национальность объекта поиска, как описано выше со ссылкой на фиг. 3.
[0105] На втором этапе обучения, который следует после первого этапа обучения и здесь также называется этапом точной настройки, сервер 202 может обучать модель 218 NLP на основе второго обучающего набора данных определению второго значения вероятности, указывающего на то, подтверждает ли второй сниппет 308 точность фактов первого сниппета 306. Первый этап обучения и второй этап обучения описаны ниже со ссылкой на фиг. 5 и 6.
Процесс обучения
[0106] На первом этапе обучения сервер 202 может подавать первый обучающий набор данных в модель 218 NLP и таким образом обучать модель 218 NLP определению того, имеется ли семантическая связь между контентом двух сниппетов этапа использования (см. фиг. 4). В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии первый обучающий набор данных содержит первое множество обучающих цифровых объектов, каждый из которых содержит: (а) первый обучающий сниппет, (б) второй обучающий сниппет и (в) соответствующую метку, указывающую на то, связан ли семантически второй обучающий сниппет с первым обучающим сниппетом. Предполагается, что сервер 202 может формировать первое множество обучающих цифровых объектов на основе множества обучающих цифровых документов, где обучающие сниппеты заранее определены, например, порождающей моделью машинного обучения, описанной выше.
[0107] В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии второй обучающий сниппет может быть определен как сниппет, смежный с первым обучающим сниппетом. В других не имеющих ограничительного характера вариантах осуществления настоящей технологии второй обучающий сниппет может быть определен как сниппет, содержащий слова, семантически схожие со словами рассматриваемого обучающего сниппета. В других не имеющих ограничительного характера вариантах осуществления настоящей технологии второй обучающий сниппет может представлять собой перефразированный первый обучающий сниппет, предоставленный оценщиком-человеком. Например, для первого обучающего сниппета «Rachel McAdams is a Canadian actress» («Рейчел Макадамс - канадская актриса») может быть определен второй обучающий сниппет «She was born in London, Ontario, Canada» («Она родилась в Лондоне, Онтарио, Канада»).
[0108] В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии соответствующая метка, указывающая на то, связаны ли семантически первый и второй сниппеты, может быть назначена оценщиком-человеком, имеющим задание определять семантическую связь между обучающими сниппетами. Например, соответствующая метка может представлять собой бинарные значения, такие как «0» или «1», «YES» («Да») или «NO» (Нет») и т.п. В других не имеющих ограничительного характера вариантах осуществления настоящей технологии соответствующая метка может быть небинарной и принимать значения, указывающие на степень семантической связи между первым обучающим сниппетом и вторым обучающим сниппетом, например, 0,3, 0,7, 0,8 или «LOW» (Низкая»), «MODERATE» («Средняя»), «HIGH» («Высокая») и т.д.
[0109] Сервер 202 может подавать обучающий цифровой объект в модель 218 NLP путем предоставления первого и второго обучающих сниппетов в качестве части входных данных 412 и соответствующей метки в качестве целевых данных 417. Подобным образом сервер 202 может формировать и подавать в модель 218 NLP первое множество обучающих цифровых объектов, содержащее тысячи, сотни тысяч или даже миллионы схожих обучающих цифровых объектов. Таким образом сервер 202 может обучать модель 218 NLP формированию выходных данных 425, содержащих первое значение вероятности того, что контент двух сниппетов этапа использования, таких как первый сниппет 306 и второй сниппет 308, семантически связан. С использованием алгоритма обратного распространения сервер 202 может определять функцию потерь, представляющую различие между первым значением вероятности из выходных данных 425 и контрольным значением, на которое указывает соответствующая метка. Путем минимизации функции потерь сервер 202 может определять веса для узлов модели 218 NLP. На этом первый этап обучения модели 218 NLP завершается.
[0110] После первого этапа обучения сервер 202 может перейти ко второму этапу обучения, на котором сервер 202 способен обучать модель 218 NLP определению второго значения вероятности, указывающего на то, подтверждает ли контент второго сниппета 308 точность фактов контента первого сниппета 306. С этой целью сервер 202 может подавать второй обучающий набор данных в модель 218 NLP, предварительно обученную на первом этапе обучения. Согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии, второй обучающий набор данных содержит второе множество обучающих цифровых объектов, каждый из которых содержит: (а) первый обучающий сниппет, (б) второй обучающий сниппет, (в) по меньшей мере одну обучающую подводку, сформированную на основе первого обучающего сниппета, и (г) соответствующую метку, указывающую на то, подтверждает ли контент второго обучающего сниппета точность фактов первого обучающего сниппета.
[0111] Согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии, первый и второй обучающие сниппеты объекта из второго множества обучающих цифровых объектов могут быть определены подобно сниппетам объекта из первого множества обучающих цифровых объектов. Таким образом, в некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 202 может формировать объект из второго множества обучающих цифровых объектов на основе объекта из первого множества обучающих цифровых объектов.
[0112] В общем случае по меньшей мере одна подводка, сформированная, например, оценщиком-человеком на основе первого обучающего сниппета, может быть предназначена для предоставления более конкретного контекста для первого обучающего сниппета. В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии по меньшей мере одна подводка может содержать перефразированный первый обучающий сниппет. В описанном выше примере с первым обучающим сниппетом «Rachel McAdams is a Canadian actress» («Рейчел Макадамс - канадская актриса») по меньшей мере одна подводка может содержать перефразированный сниппет, такой как «Rachel McAdams is an actress from Canada» («Рейчел Макадамс - актриса из Канады») или «Rachel McAdams is an actress living and working in Canada» («Рейчел Макадамс - актриса, живущая и работающая в Канаде») и т.п. В других не имеющих ограничительного характера вариантах осуществления настоящей технологии по меньшей мере одна подводка может содержать вопрос, на который отвечает первый обучающий сниппет. В описанном выше примере по меньшей мере одна подводка может выглядеть следующим образом: «What is the origin of Rachel McAdams? Canadian» («Каково происхождение Рейчел Макадамс? Канадка») или «What country does Rachel McAdams come from? Canada» («Из какой страны родом Рейчел Макадамс? Канада») и т.п. Следует отметить, что формирование по меньшей мере одной обучающей подводки может выполняться автоматически, например, сервером 202, с использованием специализированной модели языка, заранее настроенной для формирования соответствующих подводок на основе введенных в нее сниппетов.
[0113] Подобно метке объекта из первого множества обучающих цифровых объектов, соответствующая метка объекта из второго множества обучающих цифровых объектов может быть назначена оценщиком-человеком, имеющим задание определять соответствие фактов первого обучающего сниппета и второго обучающего сниппета. Как и в случае первого множества обучающих цифровых объектов, соответствующая метка объекта из второго множества обучающих цифровых объектов может принимать бинарные или небинарные значения.
[0114] В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 202 может подавать объект из второго множества обучающих цифровых объектов в модель 218 NLP путем предоставления первого и второго обучающих сниппетов и по меньшей мере одной подводки в качестве части входных данных 412 и соответствующей метки в качестве целевых данных 417. Подобным образом сервер 202 может формировать и подавать в модель 218 NLP каждый другой объект из второго множества обучающих цифровых объектов, содержащего тысячи, сотни тысяч или даже миллионы сходных обучающих цифровых объектов. Таким образом сервер 202 способен обучать модель 218 NLP определению второго значения вероятности, указывающего на то, подтверждает ли контент второго сниппета 308 точность фактов контента первого сниппета 306 из множества 304 сниппетов, выдаваемых в поисковой сводке 216. Как и в случае первого этапа обучения, сервер 202 с использованием алгоритма обратного распространения и минимизации функции потерь может повторно определять веса для узлов модели 218 NLP.
[0115] В других не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 202 может выполнять второй этап обучения без повторного определения весов узлов модели 218 NLP. В этих вариантах осуществления изобретения сервер 202 после первого этапа обучения может применять метод P-tuning для точной настройки модели 218 NLP. В частности, в этих вариантах осуществления изобретения сервер 202 может обучать другую модель машинного обучения формированию векторов для ввода в модель 218 NLP, на основе которых модель 218 NLP способна определять второе значение вероятности.
[0116] На фиг. 5 приведена схема модели 218 NLP с применяемой в отношении нее добавочной моделью 502 согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии.
[0117] Как показано на фиг. 5, вместо непосредственного использования множества входных векторов 414 и множества целевых векторов 419 в качестве входных данных стека 402 слоев кодера и стека 403 слоев декодера, соответственно, модель 218 NLP способна вводить эти векторы в добавочную модель 502. Сервер 202 может обучать добавочную модель 502 формированию на основе входных векторов 414 и целевых векторов 419 дополнительных входных векторов 504 и дополнительных целевых векторов 509, соответственно, которые далее используются для формирования выходных данных 425 модели 218 NLP.
[0118] На реализацию добавочной модели 502 не накладывается каких-либо ограничений. В одном примере, согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии, добавочная модель 502 может быть реализована на основе сети NN, такой как многослойная сеть NN прямого распространения, содержащая, например, 6 или 12 слоев. В других не имеющих ограничительного характера вариантах осуществления настоящей технологии добавочная модель 502 может быть реализована на основе сети NN вида LSTM.
[0119] На фиг. 6 представлена схема архитектуры добавочной модели 502, реализованной на основе двунаправленной сети 602 NN вида LSTM, согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии.
[0120] В общем случае двунаправленная сеть 602 NN вида LSTM представляет собой сеть NN, содержащую так называемые узлы памяти, такие как узел 603 памяти, способные выучивать долгосрочные зависимости между их весами в течение нескольких операций обучения. Иными словами, на итерации обучения узел 603 памяти формирует свой текущий вес не только на основе текущего веса узла из предыдущего слоя, но и на основе своего предыдущего веса из предыдущей итерации обучения.
[0121] В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии добавочная модель 502 может дополнительно содержать многослойный перцептрон 604, который, например, может содержать два или три слоя перцептрона (отдельно не обозначены). Несмотря на то, что в вариантах осуществления изобретения согласно фиг. 6 слои многослойного перцептрона 604 содержат 128, 384 и 320 узлов, соответственно, должно быть понятно, что другие количества узлов также возможны без выхода за границы настоящей технологии.
[0122] В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 202 может обучать добавочную модель 502 на основе второго обучающего набора данных, описанного выше. В частности, для объекта из второго множества обучающих цифровых объектов сервер 202 путем применения алгоритма 410 векторизации входных данных и алгоритма 415 векторизации целевых данных может формировать соответствующие конфигурации множества входных векторов 414 и множества целевых векторов 419, которые затем вводятся для обучения добавочной модели 502 формированию дополнительных входных векторов 504 и дополнительных целевых векторов 509.
[0123] В других не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 202 может обучать добавочную модель 502 на основе третьего обучающего набора данных. Третий обучающий набор данных может быть сформирован подобно второму обучающему набору данных. При этом третий обучающий набор данных может содержать меньше обучающих цифровых объектов, чем второй обучающий набор данных. Иными словами, третий набор данных может быть меньшим по размеру, чем второй обучающий набор данных.
[0124] Как и в случае обучения модели 218 NLP, сервер 202 с использованием алгоритма обратного распространения и минимизации функции потерь может определять веса узлов добавочной модели 502. Обучение добавочной модели 502 более подробно описано, например, в статье «GPT Understands, too» (Liu et al.), содержание которой полностью включено в настоящий документ посредством ссылки.
[0125] В результате сервер 202 может обучать добавочную модель 502 формированию векторных представлений для модели 218 NLP, предварительно обученной на первом этапе обучения, как описано выше. На основе этих векторных представлений модель 218 NLP далее способна определять второе значение вероятности того, подтверждает ли контент второго сниппета 308 точность фактов контента первого сниппета 306.
[0126] Такой подход к точной настройке модели 218 NLP для определения второго значения вероятности позволяет избежать после первого этапа обучения повторной корректировки весов всех узлов модели 218 NLP, т.е. более чем ста миллиардов узлов в некоторых вариантах реализации изобретения. Вместо этого данный подход предусматривает обучение только добавочной модели 502, обычно содержащей значительно меньше узлов. Иными словами, в этих вариантах осуществления изобретения этап точной настройки выполняется при фиксированных весах узлов модели 218 NLP, определенных на первом этапе обучения. В результате эти способы и системы позволяют экономить вычислительные ресурсы сервера 202 при обучении модели 218 NLP. Кроме того, этот подход к точной настройке модели 218 NLP может быть особенно полезным в случае недоступности высококачественных данных для выполнения второго этапа обучения.
Процесс использования
[0127] В ходе этапа использования, сформировав в ответ на получение поискового запроса 212 поисковую сводку 216, содержащую множество 304 сниппетов, как описано выше со ссылкой на фиг. 3, сервер 202 далее может выбрать из множества 304 сниппетов первый сниппет 306 для проверки его фактов. Затем сервер 202 может определить второй сниппет 308 из множества 304 сниппетов, контекстно-связанный с первым сниппетом 306. Например, сервер 202 может определить второй сниппет 308 как один из смежных сниппетов первого сниппета 306.
[0128] Далее сервер 202 может подать первый сниппет 306 и второй сниппет 308 в качестве входных данных 412 в модель 218 NLP, обученную согласно одному из описанных выше подходов. В ответ модель 218 NLP может сформировать выходные данные 425, содержащие второе значение вероятности, указывающее на то, подтверждает ли контент второго сниппета 308 факты контента первого сниппета 306.
[0129] Затем сервер 202 может сравнить второе значение вероятности с заранее заданным порогом вероятности, который, например, может быть равен 0,85 или 0,95. Если второе значение вероятности не меньше заранее заданного порога вероятности, то сервер 202 может определить, что контент второго сниппета 308 подтверждает факты контента первого сниппета 306. Таким образом в некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 202 может определять, что факты контента первого сниппета 306 являются точными.
[0130] Если второе значение вероятности меньше заранее заданного порога вероятности, сервер 202 может определить, что контент второго сниппета 308 не подтверждает фактов контента первого сниппета 306. Таким образом в некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 202 может определять, что факты контента первого сниппета 306 являются неточными. Затем сервер 202 может, например, удалить первый сниппет 306 из множества 304 сниппетов. В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 202 также может удалить цифровой документ, из которого был получен первый сниппет 306, из соответствующего набора образцовых цифровых документов, используемых для формирования множества 304 сниппетов.
[0131] В других не имеющих ограничительного характера вариантах осуществления настоящей технологии, если определено, что второе значение вероятности меньше заранее заданного порога вероятности, сервер 202 может дополнительно определять точность фактов контента первого сниппета 306 на основе по меньшей мере других сниппетов из множества 304 сниппетов. Сервер 202 может определять, являются факты контента первого сниппета 306 точными или неточными, на основе сравнения количества сниппетов, контент которых подтверждает точность фактов контента первого сниппета 306, с количеством сниппетов, контент которых не дает такого подтверждения.
[0132] Например, на основе второго значения вероятности, предоставленного моделью 218 NLP, сервер 202 может определить, что контент второго сниппета 308 не подтверждает факты контента первого сниппета 306. Иными словами, сервер 202 может определить, что тот факт, что Киану Ривз родился в Бейруте и вырос в Канаде, противоречит утверждению о том, что он - американский актер. После этого сервер 202 может определить, что факты контента первого сниппета 306 не являются точными и затем удалить первый сниппет 306 из множества 304 сниппетов, выдаваемых в поисковой сводке 216.
[0133] Таким образом, описанные способы и системы позволяют проверять факты контента поисковых сводок, формируемых на основе предоставляемых пользователям результатов поиска, в результате чего возможно повышение удовлетворенности пользователей от взаимодействия с поисковыми системами.
Способ
[0134] Описанные выше архитектура и примеры позволяют выполнять способ проверки фактов контента сниппета, такого как первый сниппет 306 из множества 304 сниппетов. На фиг. 7 представлена блок-схема способа 700 согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии. Способ 700 может выполняться сервером 202.
[0135] Как описано выше со ссылкой на фиг. 2, в некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии сервером 202, выполняющим порождающую модель машинного обучения, обученную получению сниппетов фактической информации из цифровых документов, может быть сформировано множество 304 сниппетов. Для формирования множества 304 сниппетов сервер 202 может определять в наборе 214 цифровых документов, соответствующих поисковому запросу 212, набор образцовых цифровых документов. Например, сервер 202 может определять соответствующий набор образцовых цифровых документов в виде N цифровых документов с наибольшим рангом (например, 10, 20 и т.д.) из набора 214 цифровых документов, ранжированных согласно степени релевантности цифровых документов поисковому запросу 212. Затем сервер 202 может подавать соответствующий набор образцовых цифровых документов в порождающую модель машинного обучения для формирования множества 304 сниппетов. Как описано выше, порождающая модель машинного обучения способна формировать множество 304 сниппетов, представляющих собой связный текст.
Шаг 702: определение сервером для рассматриваемого сниппета по меньшей мере одного другого сниппета из множества сниппетов.
[0136] Согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии, на шаге 702 сервер 202 может определять во множестве 304 сниппетов по меньшей мере один другой сниппет, такой как второй сниппет 308, обеспечивающий контекст для первого сниппета 306. Например, в некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 202 может определять второй сниппет 308 как представляющий собой один из смежных сниппетов первого сниппета 306. В других не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 202 может определять второй сниппет 308 на основе лингвистического анализа множества 304 сниппетов. Например, сервер 202 может определять второй сниппет 308 как семантически связанный с первым сниппетом 306, т.е. сниппет, содержащий слова, семантически схожие со словами из первого сниппета 306.
[0137] Затем способ 700 переходит к шагу 704.
Шаг 704: формирование сервером для рассматриваемого сниппета соответствующего целевого вектора, представляющего рассматриваемый сниппет, с использованием алгоритма векторизации текста, и формирование сервером для по меньшей мере одного другого сниппета соответствующего вектора контекста, представляющего по меньшей мере один сниппет контекста, с использованием алгоритма векторизации текста.
[0138] На шаге 704 перед применением модели 218 NLP в отношении первого и второго сниппетов 306, 308 сервер 202 может применить в отношении них алгоритмы векторизации текста, такие как алгоритм 410 векторизации входных данных, описанный выше со ссылкой на фиг. 4.
[0139] Таким образом, сервер 202 может формировать на основе первого и второго сниппетов 306, 308 множество входных векторов 414 для последующего их ввода в модель 218 NLP.
[0140] Затем способ 700 продолжается на шаге 706.
Шаг 706: предоставление сервером соответствующего целевого вектора и соответствующего вектора контекста для модели NLP с целью определения значения вероятности, указывающего на то, подтверждает ли контент по меньшей мере одного другого сниппета точность фактов контента рассматриваемого сниппета.
[0141] На шаге 706 сервер 202 может предоставлять множество входных векторов 414 модели 218 NLP для определения соответствующего значения вероятности того, что контент второго сниппета 308 подтверждает факты контента первого сниппета 306.
[0142] Как описано выше со ссылкой на фиг. 4-6, сервер 202 может обучать модель 218 NLP определению соответствующих значений вероятности того, что контент другого сниппета из множества 304 сниппетов подтверждает факты контента первого сниппета 306. В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии модель 218 NLP может представлять собой модель машинного обучения на основе трансформера, архитектура которой подробно описана выше со ссылкой на фиг. 4.
[0143] Как описано выше, сервер 202 может обучать модель 218 NLP в ходе двух этапов. На первом этапе обучения (этап предварительного обучения) сервер 202 может обучать модель 218 NLP на основе первого обучающего набора данных определению первого значения вероятности того, что контент двух сниппетов этапа использования, таких как первый сниппет 306 и второй сниппет 308 из множества 304 сниппетов, семантически связан. Иными словами, на первом этапе обучения сервер 202 способен обучать модель 218 NLP определению того, связан ли контент первого сниппета 306 и второго сниппета 308 с одним и тем же признаком, таким как национальность объекта поиска, как описано выше со ссылкой на фиг. 3.
[0144] В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии первый обучающий набор данных содержит первое множество обучающих цифровых объектов, каждый из которых содержит: (а) первый обучающий сниппет, (б) второй обучающий сниппет и (в) соответствующую метку, указывающую на то, связан ли семантически второй обучающий сниппет с первым обучающим сниппетом. Путем предоставления первого множества обучающих цифровых объектов для модели 218 NLP сервер 202 может определять веса для узлов модели 218 NLP и таким образом обучать ее определению первого значения вероятности того, является ли второй сниппет 308 семантически связанным с первым сниппетом 306.
[0145] На втором этапе обучения, следующим за первым этапом обучения и также называемым здесь этапом точной настройки, сервер 202 может обучать модель 218 NLP на основе второго обучающего набора данных определению второго значения вероятности, указывающего на то, подтверждает ли второй сниппет 308 точность фактов первого сниппета 306.
[0146] Согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии, второй обучающий набор данных содержит второе множество обучающих цифровых объектов, каждый из которых содержит: (а) первый обучающий сниппет, (б) второй обучающий сниппет, (в) по меньшей мере одну обучающую подводку, сформированную на основе первого обучающего сниппета, и (г) соответствующую метку, указывающую на то, подтверждает ли контент второго обучающего сниппета точность фактов первого обучающего сниппета. Как описано выше, по меньшей мере одна подводка, сформированная на основе первого обучающего сниппета, может содержать перефразированный первый обучающий сниппет или вопросы, на которые отвечает первый обучающий сниппет. Путем предоставления второго множества обучающих цифровых объектов для модели 218 NLP сервер 202 может повторно определять (или иныи образом корректировать) веса узлов модели 218 NLP и таким образом обучать ее определению второго значения вероятности того, подтверждает ли контент второго сниппета 308 точность фактов первого сниппета 306.
[0147] В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 202 может выполнять второй этап обучения путем применения метода P-tuning без повторного определения весов узлов модели 218 NLP. В частности, в этих вариантах осуществления изобретения сервер 202 может обучать другую модель машинного обучения, такую как добавочная модель 502, описанная выше со ссылкой на фиг. 5 и 6, формированию векторов для ввода в модель 218 NLP, на основе которых модель 218 NLP способна определять второе значение вероятности без повторной корректировки весов узлов.
[0148] Как подробно описано выше со ссылкой на фиг. 6, добавочная модель 502 может быть реализована на основе сети NN вида LSTM, такой как двунаправленная сеть 602 вида LSTM.
[0149] В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 202 может обучать добавочную модель 502 на основе второго обучающего набора данных. В других не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 202 может обучать добавочную модель 502 на основе третьего обучающего набора данных, который может быть сформирован подобно второму набору данных, но может быть меньшим по размеру, чем второй обучающий набор данных.
[0150] Путем подачи второго или третьего набора данных в добавочную модель 502 сервер 202 может определять веса узлов добавочной модели 502 и таким образом обучать ее формированию на основе множества входных векторов 414 и множества целевых векторов 419 дополнительных входных векторов 504 и дополнительных целевых векторов 509. Затем сервер 202 может вводить дополнительные входные векторы 504 и дополнительные целевые векторы 509 в стек 402 слоев кодера и стек 403 слоев декодера модели 218 NLP, соответственно. Таким образом, на основе дополнительных входных векторов 504 и дополнительных целевых векторов 509 модель 218 NLP затем способна определять второе значение вероятности того, подтверждает ли контент второго сниппета 308 точность фактов контента первого сниппета 306.
[0151] Такой подход к точной настройке модели 218 NLP для определения второго значения вероятности позволяет избежать после первого этапа обучения повторной корректировки весов всех узлов модели 218 NLP, т.е. более чем ста миллиардов узлов в некоторых вариантах реализации изобретения. Вместо этого данный подход предусматривает обучение только добавочной модели 502, обычно содержащей значительно меньше узлов. В результате настоящие способы и системы позволяют экономить вычислительные ресурсы сервера 202 при обучении модели 218 NLP. Кроме того, этот подход к точной настройке модели 218 NLP может быть особенно полезным в случае недоступности высококачественных данных для выполнения второго этапа обучения.
[0152] Способ 700 продолжается на шаге 708.
Шаг 708: определение сервером того, что факты контента рассматриваемого сниппета являются точными, если значение вероятности не меньше порогового значения вероятности.
[0153] На шаге 708 согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии сервер 202 может сравнить второе значение вероятности с заранее заданным порогом вероятности, который, например, может быть равен 0,85 или 0,95. Если второе значение вероятности превышает или равно заданному порогу вероятности, то сервер 202 может определить, что контент второго сниппета 308 подтверждает факты контента первого сниппета 306. Таким образом в некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 202 может определять, что факты контента первого сниппета 306 являются точными.
[0154] Если второе значение вероятности меньше заранее заданного порога вероятности, сервер 202 может определить, что контент второго сниппета 308 не подтверждает фактов контента первого сниппета 306. Таким образом, в некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 202 может определять, что факты контента первого сниппета 306 не являются точными. Затем сервер 202 может, например, удалить первый сниппет из множества 304 сниппетов. В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 202 также может удалить цифровой документ, из которого был получен первый сниппет 306, из соответствующего набора образцовых цифровых документов, используемых для формирования множества 304 сниппетов.
[0155] При этом в других не имеющих ограничительного характера вариантах осуществления настоящей технологии, если определено, что второе значение вероятности меньше заранее заданного порога вероятности, сервер 202 может дополнительно определять точность фактов контента первого сниппета 306 на основе по меньшей мере других сниппетов из множества 304 сниппетов. Сервер 202 может определять, являются ли факты контента первого сниппета 306 точными или неточными, на основе сравнения количества сниппетов, контент которых подтверждает точность фактов контента первого сниппета 306, с количеством сниппетов, контент которых не дает такого подтверждения.
[0156] Таким образом, некоторые варианты осуществления способа 700 позволяют проверять факты информации до предоставления ее пользователям интерактивных поисковых платформ, что позволяет повышать удовлетворенность пользователей от взаимодействия с ними.
[0157] На этом выполнение способа 700 завершается.
[0158] Также должно быть понятно, что несмотря на описание здесь вариантов осуществления изобретения со ссылкой на конкретные особенности и структуры, без выхода за границы таких технологий могут быть реализованы различные модификации и сочетания. Например, различные оптимизации, применяемые в нейронных сетях, включая трансформеры, могут подобным образом применяться и в настоящей технологии. Кроме того, также могут применяться оптимизации, ускоряющие определение релевантности на этапе использования. Например, в некоторых вариантах осуществления изобретения трансформерная модель может быть разделена так, что некоторые блоки трансформеров поделены между обработкой запроса и обработкой документа, поэтому представления документов могут быть предварительно рассчитаны в автономном режиме и сохранены в индексе поиска документов. Описание и чертежи следует рассматривать лишь как иллюстрацию обсуждаемых вариантов реализации или осуществления изобретения, принципы которого определенны приложенной формулой изобретения, которая охватывает все модификации, изменения, сочетания или эквиваленты в пределах объема настоящего изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ И СЕРВЕР ДЛЯ ОБУЧЕНИЯ НЕЙРОННОЙ СЕТИ ФОРМИРОВАНИЮ ТЕКСТОВОЙ ВЫХОДНОЙ ПОСЛЕДОВАТЕЛЬНОСТИ | 2020 |
|
RU2798362C2 |
| СИСТЕМА И СПОСОБ ОБУЧЕНИЯ МОДЕЛЕЙ МАШИННОГО ОБУЧЕНИЯ ДЛЯ РАНЖИРОВАНИЯ РЕЗУЛЬТАТОВ ПОИСКА | 2023 |
|
RU2829065C1 |
| МНОГОЭТАПНОЕ ОБУЧЕНИЕ МОДЕЛЕЙ МАШИННОГО ОБУЧЕНИЯ ДЛЯ РАНЖИРОВАНИЯ РЕЗУЛЬТАТОВ | 2021 |
|
RU2831678C2 |
| СИСТЕМА И СПОСОБ ОБУЧЕНИЯ МОДЕЛЕЙ МАШИННОГО ОБУЧЕНИЯ ДЛЯ РАНЖИРОВАНИЯ РЕЗУЛЬТАТОВ ПОИСКА | 2023 |
|
RU2832419C2 |
| СИСТЕМА И СПОСОБ РАНЖИРОВАНИЯ РЕЗУЛЬТАТОВ ПОИСКА В ПОИСКОВОЙ СИСТЕМЕ | 2024 |
|
RU2839310C1 |
| СПОСОБ И СИСТЕМА ДЛЯ РАСПОЗНАВАНИЯ РЕЧЕВОГО ФРАГМЕНТА ПОЛЬЗОВАТЕЛЯ | 2021 |
|
RU2808582C2 |
| СПОСОБ СОЗДАНИЯ ОБУЧАЮЩЕГО ОБЪЕКТА ДЛЯ ОБУЧЕНИЯ АЛГОРИТМА МАШИННОГО ОБУЧЕНИЯ | 2016 |
|
RU2637883C1 |
| СПОСОБ И СЕРВЕР ДЛЯ ПОВТОРНОГО ОБУЧЕНИЯ АЛГОРИТМА МАШИННОГО ОБУЧЕНИЯ | 2019 |
|
RU2743932C2 |
| Способ и система для формирования карточки объекта | 2018 |
|
RU2739554C1 |
| Способ и система для хранения множества документов | 2018 |
|
RU2744028C2 |
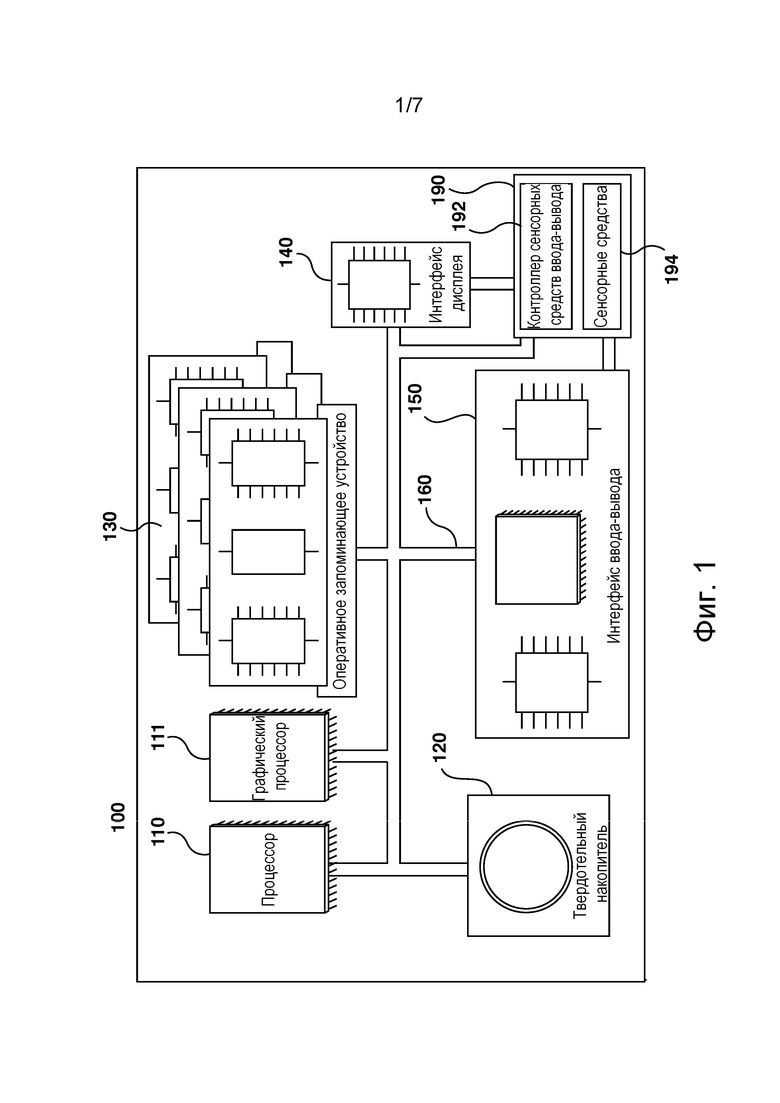




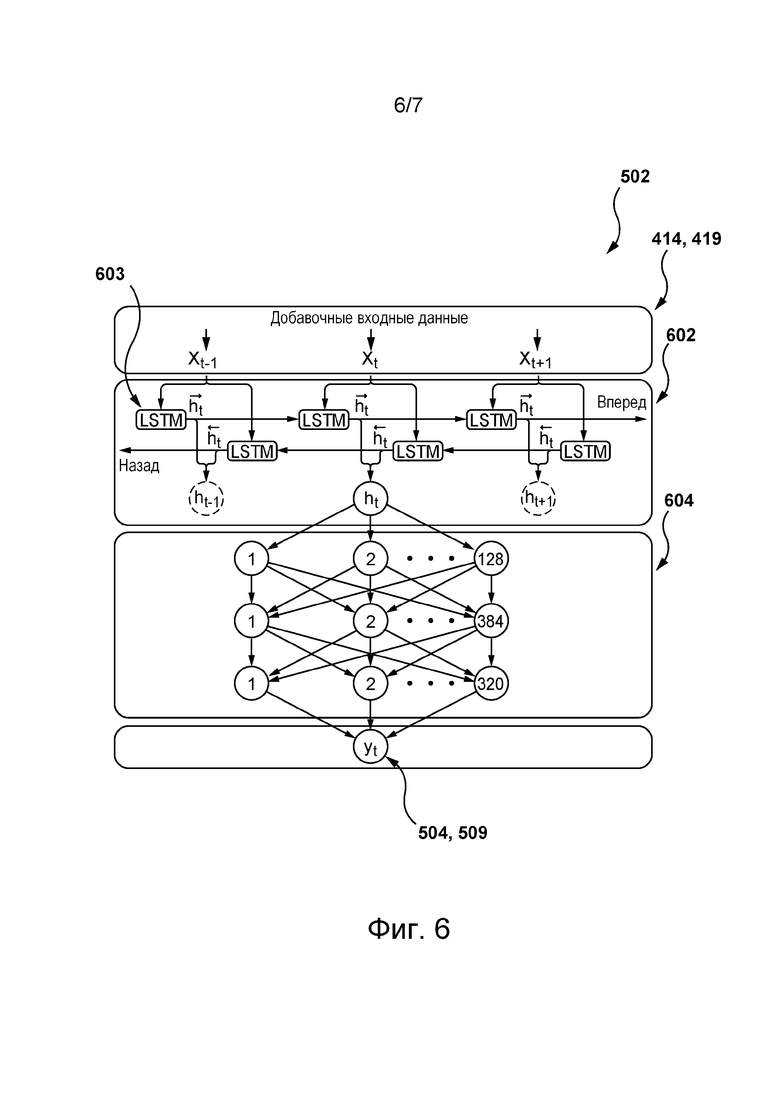

Изобретение относится к вычислительной технике. Технический результат заключается в обеспечении более достоверных карточек объектов поиска. Компьютерный способ проверки фактов контента сниппета из множества сниппетов включает в себя определение для рассматриваемого сниппета по меньшей мере одного другого сниппета из множества сниппетов, обеспечивающего контекст для рассматриваемого сниппета; формирование для рассматриваемого сниппета целевого вектора; формирование для по меньшей мере одного другого сниппета вектора контекста; предоставление целевого вектора и вектора контекста модели обработки естественного языка для определения значения вероятности, указывающего на то, подтверждает ли контент по меньшей мере одного другого сниппета точность фактов контента рассматриваемого сниппета; определение сервером того, что факты контента рассматриваемого сниппета являются точными, если значение вероятности не меньше порогового значения вероятности. 2 н. и 18 з.п. ф-лы, 7 ил.
1. Компьютерный способ проверки фактов контента сниппета из множества сниппетов, сформированного порождающей моделью машинного обучения для объекта поиска, определенного на основе поискового запроса, выполняемый сервером и включающий в себя:
определение сервером для рассматриваемого сниппета по меньшей мере одного другого сниппета из множества сниппетов, обеспечивающего контекст для рассматриваемого сниппета;
формирование сервером для рассматриваемого сниппета целевого вектора, представляющего рассматриваемый сниппет, с использованием алгоритма векторизации текста;
формирование сервером для по меньшей мере одного другого сниппета вектора контекста, представляющего по меньшей мере один сниппет контекста, с использованием алгоритма векторизации текста;
предоставление сервером целевого вектора и вектора контекста для модели NLP с целью определения значения вероятности, указывающего на то, подтверждает ли контент по меньшей мере одного другого сниппета точность фактов контента рассматриваемого сниппета, при этом модель NLP обучена определению того, подтверждают ли сниппеты этапа использования точность фактов рассматриваемого сниппета; и
определение сервером того, что факты контента рассматриваемого сниппета являются точными, если значение вероятности не меньше порогового значения вероятности.
2. Способ по п. 1, отличающийся тем, что порождающая модель способна формировать множество сниппетов на основе образцовых цифровых документов из множества цифровых документов, соответствующих поисковому запросу.
3. Способ по п. 2, отличающийся тем, что рассматриваемому цифровому документу из множества цифровых документов заранее назначен параметр релевантности, указывающий на то, насколько рассматриваемый цифровой документ релевантен соответствующему поисковому запросу, а образцовые цифровые документы определены как связанные с N наибольшими соответствующими параметрами релевантности.
4. Способ по п. 1, отличающийся тем, что определение по меньшей мере одного другого сниппета для рассматриваемого сниппета включает в себя определение по меньшей мере одного другого сниппета, контент которого семантически связан с по меньшей мере одним фактом об объекте поиска в рассматриваемом сниппете.
5. Способ по п. 1, отличающийся тем, что порождающая модель машинного обучения способна формировать множество сниппетов, представляющих собой связный текст для объекта поиска.
6. Способ по п. 1, отличающийся тем, что порождающая модель машинного обучения представляет собой модель машинного обучения на основе трансформера.
7. Способ по п. 1, отличающийся тем, что модель NLP заранее обучена определению наличия семантической связи между двумя следующими друг за другом сниппетами из множества сниппетов.
8. Способ по п. 7, отличающийся тем, что модель NLP путем применения в отношении нее добавочной модели машинного обучения дополнительно точно настраивается для определения значения вероятности того, что контент по меньшей мере одного другого сниппета подтверждает точность фактов контента рассматриваемого сниппета, при этом добавочная модель машинного обучения обучается формированию векторных представлений для модели NLP и обучение добавочной модели машинного обучения включает в себя:
получение сервером множества обучающих объектов, каждый из которых содержит (а) первый обучающий сниппет; (б) по меньшей мере одну обучающую подводку, сформированную на основе первого обучающего сниппета; (в) второй сниппет, определенный как контекстно-связанный с первым сниппетом; и (г) метку, указывающую на то, подтверждает ли контент второго обучающего сниппета факты контента первого обучающего сниппета; и
предоставление сервером множества обучающих объектов для добавочной модели машинного обучения с целью ее обучения формированию (а) целевого вектора для рассматриваемого сниппета и (б) вектора контекста для по меньшей мере одного сниппета контекста.
9. Способ по п. 8, отличающийся тем, что по меньшей мере одна обучающая подводка содержит вопрос, на который отвечает первый обучающий сниппет.
10. Способ по п. 8, отличающийся тем, что по меньшей мере одна обучающая подводка содержит перефразированный первый обучающий сниппет.
11. Способ по п. 8, отличающийся тем, что метка назначена оценщиком-человеком.
12. Способ по п. 8, отличающийся тем, что модель NLP точно настраивается сервером, при этом ее веса, определенные после предварительного обучения модели NLP, фиксируются.
13. Способ по п. 8, отличающийся тем, что добавочная модель машинного обучения содержит нейронную сеть LSTM.
14. Способ по п. 8, отличающийся тем, что точная настройка модели NLP включает в себя применение метода P-tuning.
15. Способ по п. 8, отличающийся тем, что модель NLP содержит модель машинного обучения на основе трансформера.
16. Сервер для проверки фактов контента сниппета из множества сниппетов, сформированного порождающей моделью машинного обучения для объекта поиска, определенного на основе поискового запроса, при этом сервер содержит машиночитаемую физическую память, хранящую команды, и процессор, способный при выполнении команд:
определять для рассматриваемого сниппета по меньшей мере один другой сниппет из множества сниппетов, обеспечивающего контекст для рассматриваемого сниппета;
формировать для рассматриваемого сниппета целевой вектор, представляющий рассматриваемый сниппет, с использованием алгоритма векторизации текста;
формировать для по меньшей мере одного другого сниппета вектор контекста, представляющий по меньшей мере один сниппет контекста, с использованием алгоритма векторизации текста;
предоставлять целевой вектор и вектор контекста для модели NLP с целью определения значения вероятности, указывающего на то, подтверждает ли контент по меньшей мере одного другого сниппета точность фактов контента рассматриваемого сниппета, при этом модель NLP обучена определению того, подтверждают ли сниппеты этапа использования точность фактов рассматриваемого сниппета; и
определять, что факты контента рассматриваемого сниппета являются точными, если значение вероятности не меньше порогового значения вероятности.
17. Сервер по п. 16, отличающийся тем, что для определения по меньшей мере одного другого сниппета для рассматриваемого сниппета процессор способен определять по меньшей мере один другой сниппет, контент которого семантически связан с по меньшей мере одним фактом об объекте поиска в рассматриваемом сниппете.
18. Сервер по п. 16, отличающийся тем, что модель NLP заранее обучена определению наличия семантической связи между двумя следующими друг за другом сниппетами из множества сниппетов.
19. Сервер по п. 18, отличающийся тем, что модель NLP путем применения в отношении нее добавочной модели машинного обучения дополнительно точно настроена для определения значения вероятности того, что контент по меньшей мере одного другого сниппета подтверждает точность фактов контента рассматриваемого сниппета, а процессор дополнительно способен обучать добавочную модель машинного обучения формированию векторных представлений для модели NLP путем:
получения множества обучающих объектов, каждый из которых содержит (а) первый обучающий сниппет; (б) по меньшей мере одну обучающую подводку, сформированную на основе первого обучающего сниппета; (в) второй сниппет, определенный как контекстно-связанный с первым сниппетом; и (г) метку, указывающую на то, подтверждает ли контент второго обучающего сниппета факты контента первого обучающего сниппета; и
предоставления множества обучающих объектов для добавочной модели машинного обучения с целью ее обучения формированию (а) соответствующего целевого вектора для рассматриваемого сниппета и (б) соответствующего вектора контекста для по меньшей мере одного сниппета контекста.
20. Сервер по п. 19, отличающийся тем, что по меньшей мере одна подводка содержит вопрос, на который отвечает соответствующий первый обучающий сниппет.
| US 20200202073 A1, 25.06.2020 | |||
| US 20160078149 A1, 17.03.2016 | |||
| US 20130151641 A1, 13.06.2013 | |||
| US 20160070742 A1, 10.03.2016 | |||
| СПОСОБ (ВАРИАНТЫ) И СЕРВЕР РАНЖИРОВАНИЯ ПОИСКОВЫХ РЕЗУЛЬТАТОВ НА ОСНОВЕ ПАРАМЕТРА ПОЛЕЗНОСТИ | 2015 |
|
RU2632138C2 |
