Изобретение относится к радиотехнике и может быть использовано в качестве системы воспроизведения караоке.
Известны устройства воспроизведения фонограмм записей песен певцов (проигрыватели). Также существуют устройства, которые имеют устройство ввода информации (микрофон) и позволяют одновременно воспроизводить поступающий с устройства ввода сигнал (голос человека) и музыкальную фонограмму (караоке). Но не все желающие могут спеть так, что бы это удовлетворяло самого исполнителя и окружающих.
Известно устройство обработки речевой информации для модуляции входного голосового сигнала путем его преобразования в выходной голосовой сигнал, содержащее устройство ввода, выполненное с возможностью введения звукового сигнала, представляющего собой входной голосовой сигнал с характерным частотным спектром, устройство обработки звукового сигнала, выполненное с процессором, обеспечивающим изменение частотного спектра входного голосового сигнала, базу данных параметров, в которой сохраняется несколько наборов параметров, каждый из которых индивидуально характеризует изменение частотного спектра процессором, устройство управления, которое выбирает из базы данных параметров нужный набор параметров и настраивает процессор с помощью выбранного набора параметров, и устройство воспроизведения, выполненное с возможностью вывода звукового сигнала, обработанного процессором и представляющим собой голосовой сигнал с выходными характеристиками частотного спектра, соответствующими выбранному набору параметров (Патент США №5847303, G10H 1/36, опубл. 08.12.1998).
В этом устройстве осуществляется конвертация частотного диапазона, которая позволяет мужчинам петь под караоке женским голосом и наоборот. Кроме того, устройство позволяет петь песню под караоке голосом выбранного профессионального певца/певицы за счет изменения частотного спектра. Таким образом, устройство позволяет изменять речевые характеристики в соответствии с набором заранее заданных параметров, хранящихся в базе данных вычислительного устройства, например компьютера.
Ограничением этого технического решения является то, что устройство не позволяет осуществить качественное воспроизведение входного голосового сигнала непосредственно пользователя караоке, по мастерству исполнения не уступающее профессиональному исполнителю, так чтобы на выходе караоке сохранялось звучание голоса пользователя караоке.
Так же известно устройство - преобразователь голосовых сигналов путем модуляции частот и амплитуд компонентов синусоидальной волны, содержащее средства извлечения только детерминированных компонентов из входящего голосового сигнала, детерминирующие составляющие, включая совокупность составляющих синусоидальных колебаний, которые перечисляются последовательно, где входящий голосовой сигнал включает детерминированные элементы и остаточные элементы; средства отделения для разделения компонентов синусоидальной волны на координаты значения частоты и координаты значения амплитуды, которые перечисляются последовательно, также как и компоненты синусоидальной волны; запоминающее устройство для хранения информации об исходной высоте/тоне эталонного звукового сигнала, информацию высоты звука, включая первичную высоту, представляющую совпадение высоты дискретного сигнала по музыкальной шкале, и вторичную высоту, представляющую дробный шаг, изменяющийся в соответствии с дискретным сигналом, и хранимую информацию об амплитуде эталонного сигнала, представляющего координаты амплитуды компонентов синусоидальной волны, содержащиеся в эталонном звуковом сигнале, которые перечисляются последовательно; первое средство модуляции для модуляции координат значения частоты компонентов синусоидальной волны входящего голосового сигнала в соответствии с первичной информацией об эталонной высоте звучания, извлеченной из запоминающего устройства, для генерирования модулированных координат значения частоты; первичная модуляция означает дальнейшую модуляцию координат частоты компонентов синусоидальной волны входящего звукового сигнала на основе вторичной информации о высоте звучания, извлеченной из запоминающего устройства, для дальнейшей модуляции координат значения частоты; средства контроля для установления контрольных параметров для отслеживания уровня модуляции координат частоты на основании первичной и вторичной информации о высоте звучания таким образом, чтобы степень влияния высоты эталонного звукового сигнала на исходящий звуковой сигнал определялась на основании заданных параметров; второе средство модуляции для модуляции координат значения амплитуды компонентов синусоидальной волны входящего голосового сигнала в соответствии с информацией об амплитуде эталонного сигнала, представленного координатами значения амплитуды, которые пронумерованы в соответствии с координатами амплитуды входящего голосового сигнала, извлеченными из памяти запоминающего устройства, так, что каждая координата амплитуды входящего голосового сигнала смешивается с соответствующей координатой амплитуды эталонного сигнала посредством установленной пропорции; средства комбинирования для сложения каждой координаты модулированной частоты и координат значения далее модулированной амплитуды для синтезирования компонентов синусоидальной волны выходящего голосового сигнала с высотой звучания и тоном, отличными от высоты и тона входящего голосового сигнала; и средства смешивания для смешивания компонентов синтезированной синусоидальной волны, где компоненты модифицированной частоты участвуют в синтезе выходного голосового сигнала, имеющего отличия в высоте звучания от входящего голосового сигнала и испытывающего влияние эталонного голосового сигнала (Патент США №7117154, G10L 13/00, опубл. 03.10.2006).
Ограничением этого технического решения является то, что устройство не позволяет осуществить качественное воспроизведение входного голосового сигнала непосредственно пользователя караоке, по мастерству исполнения не уступающее профессиональному исполнителю, так чтобы на выходе караоке сохранялось звучание голоса пользователя караоке. Кроме того, недостатком данного изобретения является преобразование только части голосового сигнала, а точнее его локализованной (гармонической) части. Не менее важная, не локализованная часть голосового сигнала в данном изобретение остается без изменения, что не позволяет достичь хорошего качества целенаправленного преобразования голосового сигнала.
Наиболее близким является техническое решение по патенту США №6836761, G10L 13/00, опубл.28.11.2004 «Голосовой конвертер для очищения при помощи фрейм - синтеза с временной корректировкой» - устройство для изменения входящего голосового сигнала в выходящий голосовой сигнал в соответствии с целевым голосовым сигналом.
Известное устройство для изменения (конвертации) входящего голосового сигнала в выходящий голосовой сигнал в соответствии с целевым голосовым сигналом, содержащее источник входящего звукового сигнала, запоминающее устройство, которое временно хранит исходные данные, которые соотносятся и берутся из целевого голоса, анализирующее устройство, которое анализирует входящий голосовой сигнал и извлекает из него ряд фреймов входящих данных, представляющих входящий голосовой сигнал, производящее устройство, которое производит ряд фреймов целевых данных, представляющих собой целевой голосовой сигнал, основанный на исходных данных, корректируя фреймы целевых данных относительно фреймов входящих данных, и синтезирующее устройство, которое синтезирует выходящий голосовой сигнал в соответствии с фреймами целевых данных и фреймами входящих данных, при этом производящее устройство выполнено на базе характеристического анализатора, который выполнен обеспечивающим извлечение из входящего голосового сигнала характеристического вектора, являющегося характеристикой выходного голосового сигнала, и на базе корректирующего процессора, при этом запоминающее устройство сохраняет данные характеристических векторов для использования при распознавании их, содержащихся во входящем голосовом сигнале, и сохраняет данные функции преобразования, которые являются частью исходных данных и представляют собой характеристику целевого поведения голосового сигнала, причем корректирующий процессор, который определяет данные распознавания характеристических векторов и данные функции преобразования в отношении данных выходной корректировки, соответствующей информации о тоне данных функции преобразования поведения, информации об амплитуде данных целевого поведения и информации о форме огибающего спектра характеристического вектора, при этом анализирующее устройство, характеристический анализатор, корректирующий процессор и синтезирующее устройство соединены последовательно, выход данных характеристических векторов запоминающего устройства подсоединен к входу данных характеристического анализатора, а выход данных функции преобразования подсоединен к входу данных корректирующего процессора.
В этом устройстве целевым голосовым сигналом (который хотят получить) является голос профессионального певца, диктора.
Ограничением этого технического решения является то, что устройство не позволяет осуществить качественное воспроизведение входного голосового сигнала непосредственно пользователя караоке, по мастерству исполнения не уступающее профессиональному исполнителю, так чтобы на выходе караоке сохранялось звучание голоса пользователя караоке.
В этом техническом решении корректирующий процессор определяет временное соотношение между фреймами входящих данных и фреймами целевых данных в соответствии с характеристическим вектором и данные выходной корректировки, соответствующей определенному временному соотношению. Кроме того, в техническом решении используется более четырех методов анализа и преобразования, которые требуют производить сложную предварительную подготовку вводных данных. Такое выполнение корректирующего процессора и анализ усложняют конструкцию устройства. Несмотря на сложность проводимого анализа и преобразований при использовании этого изобретения у окружающих возникает ощущение, что пользователь голосом, похожим на голос профессионального певца (например, известного исполнителя данной песни), искажает манеру исполнения, допускает при исполнении ошибки, не характерные для данного певца.
Решаемая изобретением задача - повышение технико-эксплуатационных характеристик и обеспечение в караоке исполнения песни голосом пользователя, но в манере и с качественным уровнем исполнения профессионального певца (например, не хуже уровня исполнения известного исполнителя данной песни).
Технический результат, который может быть получен при выполнении устройства, - расширение функциональных возможностей воспроизведения, упрощение конструкции, создание качественной фонограммы звучания голоса пользователя, минимизирующей ошибки, допускаемые пользователем при исполнении.
Для решения поставленной задачи с достижением указанного технического результата в известном устройстве для конвертации входящего голосового сигнала в выходящий голосовой сигнал в соответствии с целевым голосовым сигналом, содержащем источник входящего звукового сигнала, запоминающее устройство, которое временно хранит исходные данные, которые соотносятся и берутся из целевого голоса, анализирующее устройство, которое анализирует входящий голосовой сигнал и извлекает из него ряд фреймов входящих данных, представляющих входящий голосовой сигнал, производящее устройство, которое производит ряд фреймов целевых данных, представляющих собой целевой голосовой сигнал, основанный на исходных данных, корректируя фреймы целевых данных относительно фреймов входящих данных, и синтезирующее устройство, которое синтезирует выходящий голосовой сигнал в соответствии с фреймами целевых данных и фреймами входящих данных, при этом производящее устройство выполнено на базе характеристического анализатора, который выполнен обеспечивающим извлечение из входящего голосового сигнала характеристического вектора, являющегося характеристикой выходного голосового сигнала, и на базе корректирующего процессора, при этом запоминающее устройство сохраняет данные характеристических векторов для использования при распознавании их, содержащихся во входящем голосовом сигнале, и сохраняет данные функции преобразования, которые являются частью исходных данных и представляют собой характеристику целевого поведения голосового сигнала, причем корректирующий процессор, который определяет данные распознавания характеристических векторов и данные функции преобразования в отношении данных выходной корректировки, соответствующей информации о тоне данных функции преобразования, информации об амплитуде данных целевого поведения и информации о форме огибающего спектра характеристического вектора, при этом анализирующее устройство, характеристический анализатор, корректирующий процессор и синтезирующее устройство соединены последовательно, выход данных характеристических векторов запоминающего устройства подсоединен к входу данных характеристического анализатора, а выход данных функции преобразования запоминающего устройства подсоединен к входу данных корректирующего процессора, согласно изобретению введены переключатель режима обучения/эксплуатации и анализатор входного сигнала, источник входящего звукового сигнала подсоединен к входу переключателя режима обучения/эксплуатации, запоминающее устройство снабжено блоком фонограмм, обеспечивающим хранение данных базы фонограмм профессиональных исполнителей, вход/выход переключателя режима обучения/эксплуатации подсоединен к входу/выходу анализатора входного сигнала, а его выход - к входу/выходу блока фонограмм запоминающего устройства, первый выход данных блока фонограмм подсоединен к входу анализатора входного сигнала, а второй выход данных блока фонограмм - к входу анализирующего устройства, анализатор входного сигнала выполнен обеспечивающим разложение входящего голосового сигнала, поступающего на его вход/выход через переключатель режима обучения/эксплуатации от источника входящего звукового сигнала, на синусоидальные компоненты сигнала, шумовые компоненты сигнала и остаточные компоненты сигнала и выполнен с возможностью формирования наборов характеристических векторов и функций преобразования для каждой упомянутой компоненты и передачи их в запоминающее устройство, анализирующее устройство выполнено обеспечивающим разложение входящего голосового сигнала с блока фонограмм на синусоидальные компоненты сигнала, шумовые компоненты сигнала и остаточные компоненты сигнала, а характеристический анализатор и корректирующий процессор выполнены с возможностью обработки упомянутых компонент.
Возможны дополнительные варианты выполнения устройства, в которых целесообразно, чтобы:
- запоминающее устройство было выполнено из трех блоков функции преобразования и из баз данных шести кодовых книг, каждые три из которых выполнены обеспечивающими хранение характеристических векторов синусоидальных компонент сигнала, шумовых компонент сигнала и остаточных компонент сигнала, при этом три из кодовых книг служат для хранения баз данных по фонограмме профессионального исполнителя, а три из кодовых книг - для хранения баз данных входного голосового сигнала, и входы трех блоков функции преобразования, и входы баз данных шести кодовых книг соответственно подсоединены к девяти выходам анализатора входного сигнала;
- характеристический анализатор был выполнен из трех квантователей, выход анализирующего устройства выполнен в виде трех раздельных выходов обработки синусоидальных компонент сигнала, шумовых компонент сигнала и остаточных компонент сигнала, и первые входы каждого из квантователей подсоединены к трем раздельным выходам анализирующего устройства, вторые входы каждого из квантователей подсоединены соответственно к выходам трех кодовых книг, служащих для хранения характеристических векторов синусоидальных компонент сигнала, шумовых компонент сигнала и остаточных компонент сигнала хранения баз данных по фонограмме профессионального исполнителя;
- корректирующий процессор был выполнен из трех преобразователей, каждый из трех первых входов которых соответственно подсоединен по отдельности к выходам квантователей, вторые входы преобразователей соответственно подсоединены по отдельности к выходам трех блоков памяти функции преобразования запоминающего устройства, а третьи входы преобразователей подсоединены по отдельности соответственно к выходам трех кодовых книг, служащих для хранения характеристических векторов синусоидальных компонент сигнала, шумовых компонент сигнала и остаточных компонент сигнала хранения баз данных по входному голосовому сигналу;
- синтезирующее устройство было выполнено из синтезатора звука и из цифро-аналогового преобразователя, соединенных последовательно, было выполнено из блока памяти базы данных музыкального звукового сигнала и из звукового генератора, соединенных последовательно, было выполнено из микшера и из громкоговорителя, выход звукового генератора и выход цифро-аналогового преобразователя подсоединены к входам микшера, выход которого подсоединен к громкоговорителю, а три входа синтезатора звука соответственно подсоединены по отдельности к выходам трех преобразователей корректирующего процессора;
- переключатель режима обучения/эксплуатации был выполнен цифровым, введен аналого-цифровой преобразователь, и вход переключателя режима обучения/эксплуатации подсоединен к источнику входящего звукового сигнала через аналого-цифровой преобразователь.
Указанные преимущества, а также особенности изобретения поясняются лучшим вариантом его выполнения со ссылками на прилагаемые чертежи.
Фиг.1 изображает обобщенную функциональную схему заявленного устройства;
Фиг.2 - обобщенную функциональную схему ближайшего аналога;
Фиг.3 - то же, что фиг.1, с входящими в состав функциональных блоков устройствами;
Фиг.4 - функциональная схема формирования функций преобразования;
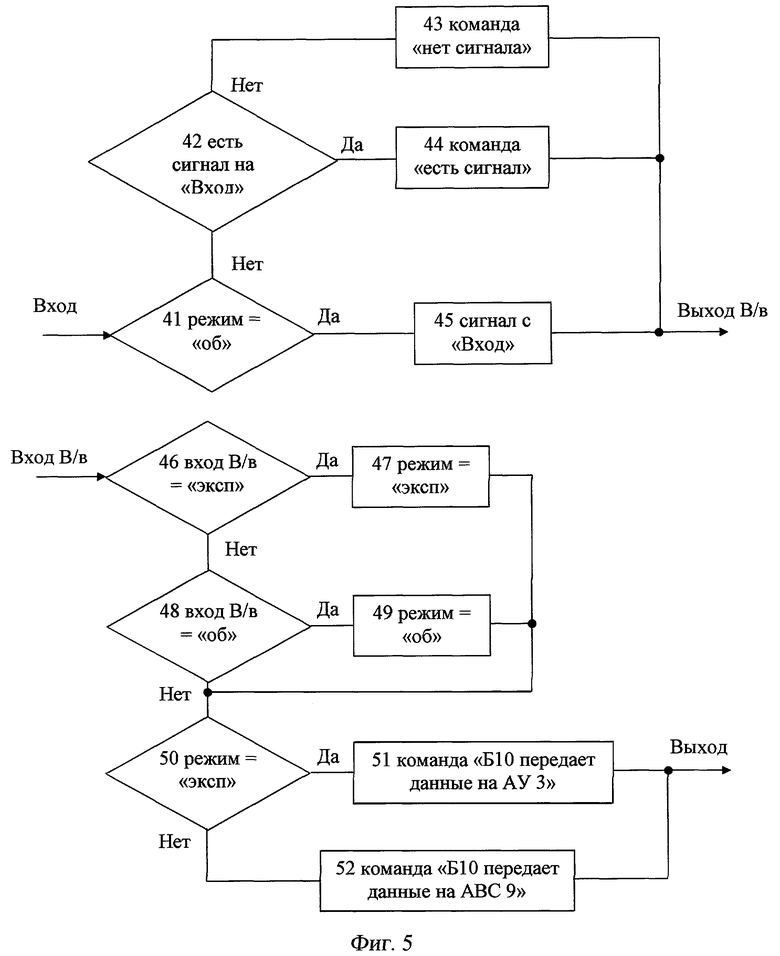
Фиг.5 - блок-схема алгоритма работы переключателя режима обучения/эксплуатации.
Устройство для изменения входящего голосового сигнала в выходящий голосовой сигнал в соответствии с целевым голосовым сигналом (фиг.1) содержит источник 1 (И) входящего звукового сигнала, запоминающее устройство 2 (ЗУ), которое временно хранит исходные данные, которые соотносятся и берутся из целевого голоса, анализирующее устройство 3 (АУ), которое анализирует входящий голосовой сигнал и извлекает из него ряд фреймов входящих данных, представляющих входящий голосовой сигнал. Устройство также содержит производящее устройство 4 (ПУ), которое производит ряд фреймов целевых данных, представляющих собой целевой голосовой сигнал, основанный на исходных данных, корректируя фреймы целевых данных относительно фреймов входящих данных, и синтезирующее устройство 5 (СУ), которое синтезирует выходящий голосовой сигнал в соответствии с фреймами целевых данных и фреймами входящих данных. ПУ 4 выполнено на базе характеристического анализатора 6 (ХА), который выполнен обеспечивающим извлечение из входящего голосового сигнала характеристического вектора (ХВ), являющегося характеристикой выходного голосового сигнала, и на базе корректирующего процессора 7 (КП), ЗУ 2 сохраняет данные ХВ для использования при распознавании их, содержащихся во входящем голосовом сигнале, и сохраняет данные функции преобразования (ФП), которые являются частью исходных данных и представляют собой характеристику целевого поведения голосового сигнала. Причем КП 7 определяет данные распознавания ХВ и данные ФП в отношении данных выходной корректировки, соответствующей информации о тоне данных ФП, информации об амплитуде данных целевого поведения и информации о форме огибающего спектра ХВ. АУ 3, ХА 6, КП 7 и СУ 4 соединены последовательно. Выход данных ХВ ЗУ 2 подсоединен к входу данных ХА 6, а выход данных функции преобразования ЗУ 2 подсоединен к входу данных КП 7.
В устройство введены переключатель 8 (П) режима обучения/эксплуатации и анализатор входного сигнала 9 (АВС). И 1 входящего звукового сигнала подсоединен к входу П 8. ЗУ 2 снабжено блоком 10 фонограмм (Б), обеспечивающим хранение данных базы фонограмм профессиональных исполнителей. Вход/выход П 8 подсоединен к входу/выходу АВС 9, а выход П 8 - к входу Б 10 запоминающего устройства 2. Первый выход данных Б 10 подсоединен к входу АВС 9, а второй его выход данных - к входу АУ 3. АВС 9 выполнен обеспечивающим разложение входящего голосового сигнала, поступающего на его вход/выход через П 8 от источника 1 входящего звукового сигнала, на синусоидальные компоненты сигнала, шумовые компоненты сигнала и остаточные компоненты сигнала и выполнен с возможностью формирования наборов ХВ и ФП для каждой упомянутой компоненты по отдельности и передачи их в ЗУ 2. АУ 3 выполнено обеспечивающим разложение входящего голосового сигнала с Б 10 на синусоидальные компоненты сигнала, шумовые компоненты сигнала и остаточные компоненты сигнала, а ХА 6 и КП 7 выполнены с возможностью обработки упомянутых компонент по отдельности.
Сравнение обобщенных функциональных схем заявленного устройства (фиг.1) и ближайшего аналога (фиг.2) показывает, что изменены связи между элементами, так выход АУ 3 не соединен с входом ЗУ 2, И 1 не подсоединен непосредственно к входу АУ 3. При этом в заявленном устройстве корректирующий процессор 7 не определяет временное соотношение между фреймами входящих данных и фреймами целевых данных в соответствии с характеристическим вектором и данные выходной корректировки, соответствующей определенному временному соотношению. Не используется четыре метода анализа и преобразования. Это, несмотря на введение в заявленное техническое решение П 8 и АВС 9, упрощает обработку и конструкцию устройства в целом.
ЗУ 2 в заявленном техническом решении (фиг.3) целесообразно выполнить из трех блоков функции преобразования 11, 12, 13 (БФП) и из баз данных шести кодовых книг 14, 15, 16, 17, 18, 19 (КК). Каждая три из КК выполнена обеспечивающей хранение характеристических векторов синусоидальных компонент сигнала, шумовых компонент сигнала и остаточных компонент сигнала по отдельности. Три из КК 14, 15, 16 служат для хранения упомянутых баз данных по фонограмме профессионального исполнителя. Три КК 17, 18, 19 служат для хранения баз данных входного голосового сигнала. Входы трех БФП 11, 12, 13 и входы баз данных шести КК 14, 15, 16, 17, 18, 19 соответственно подсоединены по отдельности к девяти выходам АВС 9.
Характеристический анализатор 6 (фиг.3) выполнен из трех квантователей 20, 21, 22 (К). Выход АУ 3 выполнен в виде трех раздельных выходов обработки синусоидальных компонент сигнала, шумовых компонент сигнала и остаточных компонент сигнала по отдельности. Первые входы каждого из К 20, 21, 22 подсоединены по отдельности к трем раздельным выходам АУ 3. Вторые входы каждого из К 20, 21, 22 подсоединены по отдельности соответственно к выходам трех КК 14, 15, 16, служащих для хранения ХВ синусоидальных компонент сигнала, шумовых компонент сигнала и остаточных компонент сигнала хранения баз данных по фонограмме профессионального исполнителя.
Корректирующий процессор 7 (фиг.3) выполнен из трех преобразователей 23, 24, 25 (ПР). Каждый из трех первых входов ПР 23, 24, 25 соответственно подсоединен по отдельности к выходам К 20, 21, 22. Вторые входы ПР 23, 24, 25 соответственно подсоединены по отдельности к выходам трех БФП 11, 12, 13 запоминающего устройства 2. Третьи входы ПР 23, 24, 25 подсоединены по отдельности соответственно к выходам трех КК 1, 18, 19, служащих для хранения ХВ синусоидальных компонент сигнала, шумовых компонент сигнала и остаточных компонент сигнала хранения баз данных по входному голосовому сигналу.
Синтезирующее устройство 5 (фиг.3) выполнено идентично ближайшему аналогу (США №6836761, fig 10) и выполнено из синтезатора 26 звука (СЗ) и из цифро-аналогового преобразователя 27 (ЦАП) - блока обратного преобразования Фурье, соединенных последовательно, и из блока памяти 28 базы данных музыкального звукового сигнала (БП) и из звукового генератора 29 (ЗГ), соединенных последовательно, из микшера 30 (М) и из громкоговорителя 31 (Г). Выход ЗГ 29 и выход ЦАП 27 подсоединены к входам М 30. Выход М 30 подсоединен к Г 31, а три входа СЗ 26 соответственно подсоединены по отдельности к выходам трех соответствующих ПР 23, 24, 25 корректирующего процессора 7.
Переключатель 8 режима обучения/эксплуатации выполнен цифровым, введен аналого-цифровой преобразователь 32 (АЦП) - блок прямого преобразования Фурье, и вход П 8 подсоединен к источнику 1 входящего звукового сигнала через АЦП 32.
Устройство для конвертации входящего голосового сигнала в выходящий голосовой сигнал в соответствии с целевым голосовым сигналом, где входящим голосовым сигналом является фонограмма профессионального певца, целевым голосовым сигналом является голос пользователя караоке, а выходным голосовым сигналом является конвертированная фонограмма профессионально певца, в соответствии с частотными характеристиками пользователя караоке, работает следующим образом.
1) Режим Обучения.
При выборе пользователем новой песни или при начале эксплуатации П 8 находиться в режиме «обучение». Пользователь караоке начинает петь.
В Б 10 заранее записываются и хранятся фонограммы профессиональных певцов. И 1 передает голос пользователя караоке SV на вход П 8 через АЦП 32 (фиг 3). П 8, при нахождении в состоянии «обучение» и наличии входного сигнала с И 1, передает через его вход/выход входной голосовой сигнал на АВС 9, а через выход П 8 на Б 10 команду с выхода П 8 о начале передачи с выхода Б 10 на вход АВС 9 выбранной пользователем фонограммы профессионального певца. АВС 9 при одновременном поступлении на него сигналов с Б 10 и П 8 начинает процесс обучения устройства, в результате которого производиться формирование характеристических векторов для занесения их в КК 14, 15, 16, 17, 18, 19 и корректирующих данных, которые необходимы для работы корректирующего процессора, данные сохраняются в БФП 11, 12 и 13 в виде функций преобразования (зависимостей характеристических векторов пользователя караоке от характеристических векторов профессионального исполнителя).
АВС 9 производит разложение спектров звуковых сигналов, поступивших с Б 10 и П 8 на спектры, соответствующие синусоидальным компонентам, шумовым компонентам и остаточным компонентам. Выделение от спектра сигнала синусоидных компонентов производиться аналогично (АУ) ближайшего аналога (США №6836761, fig.14).
В спектральном модельном синтезе (анализе) форма колебаний голоса (фрейм) получена путем увеличения сэмплированной формы колебаний на функцию окна, сперва отделенным в качестве сегмента, и затем синусоидальные компоненты и остаточные компоненты извлекаются из частотного спектра, полученного с помощью быстрого преобразования по Фурье АЦП 32 (FFT).
Синусоидальный компонент является компонентом частотного (обертонового) эквивалента фундаментальной частоты (основного тона) или кратной единицы фундаментальной частоты. Частота сохраняется как "Fi", средняя амплитуда каждого компонента сохраняется как "Ai", и огибающие спектра сохраняются как огибающие.
Остаточные компоненты представляют собой остающийся входной сигнал, из которого исключены синусоидальные компоненты, и остаточные компоненты сохранены как данные частотной области.
После выделения из спектров звуковых сигналов спектров синусоидных компонентов оставшийся сигнал проверяется на наличие в нем шумовой составляющей. Выделение шумовых компонентов производится путем дальнейшего анализа изменения амплитуд колебаний звуковой волны анализируемого фрейма, полученного в результате отделения синусоидальных компонентов по описанной выше процедуре по выделению остаточных компонент. Все последовательные pitch-и отклонения амплитуды не более 5-10% относительно 3 предыдущих pitch-ей полагают шумовыми компонентами. Весь остальные спектральные компоненты спектра звукового сигнала считают остаточными компонентами.
Шумовые и остаточные компоненты сохраняются как данные частотной области, аналогично остаточным компонентам (США №6836761, fig.14).
Для каждого из двух сигналов и каждого из трех компонентов АВС 9 формирует характеристические вектора, которые сохраняются в КК 14-19. Создание характеристических векторов и формирование КК может производиться любым известным способом, например, как описано в ближайшем аналоге, с использованием коэффициентов мел-кепстра, скрытых Марковских моделях и однолинейного алгоритма Витерби.
Кодовые книги 14-19 хранят информацию о векторах, разбитых на число символов для каждого характеристического вектора (Fig.11). Сборник кодов КК 14-19 генерируется путем нахождения набора, называемого прогнозируемым вектором (кодом) К с использованием квантования, которое обеспечивает минимальное искажение от всех прогнозируемых векторов в огромном количестве расчетных наборов, например по алгоритму (LGB), описанному в ближайшем аналоге.
Последним этапом анализа является формирование функций преобразования в БФП 11, 12 и 13. В рамках получения функции преобразования по каждому компоненту сигнала (синусоидальный, шумовой, остаточный) необходимы исходные данные, содержащих два набора пар характеризующих векторов (КК), соответствующих огибающим спектра профессионального певца и пользователя караоке конкретного фрейма в конкретный промежуток времени. Для формирования функции преобразования для БФП 11 используются КК 14 и 17, для БФП 12 - КК 15 и 18, для БФП 13 - КК 16 и 19. Чтобы обеспечить взаимнооднозначное отображение между кадрами речи профессионально исполнителя и пользователя караоке, спектры голосовых сигналов анализируются с фиксированной частотой кадров блоками 33 и 34 асинхронного анализа (Фиг.4). Блоки 33 и 34 асинхронного анализа выдают на выход данные в виде огибающей спектра фрейма, например в 10 мс, которые подаются на блок 35 синхронизации по времени. Блок 35 для синхронизации двух фреймов по времени использует известный алгоритм Динамической трансформации временной шкалы (Dynamic Time Warping, DTW) (Berndt D.J., Clifford J. Using dynamic time warping to find patterns in time series // Workshop on Knowledge Discovery in Databases. USA: AAAI Press, 1994. P.229-248).
Синхронизированные данные оптимизируются по принципу обратной связи с использованием алгоритма максимизации ожидания блоком 36 с использованием однолинейного алгоритма Витерби аналогично описанному в ближайшем аналоге.
В итоге функция преобразования представляет из себя данные по подмене кодов КК 14-16 профессионально певца на коды КК 17-19 пользователя караоке так, чтобы смысловая составляющая речи не менялась, а менялись только частотные характеристики звукового сигнала.
Функции преобразования заявляемого изобретения отличаются от функции преобразования ближайшего аналога тем, что функции преобразования формируются так, чтобы в исходном голосовом сигнале (фонограмма профессионального диктора) были изменены частотные характеристики голоса в соответствии с данными целевого голосового сигнала (голоса пользователя караоке), без изменения смысловой нагрузки.
По окончанию формирования КК 14-19 и БФП 11-13 АВС 9 по его входу/выходу передает на П 8 команду на переключение в режим "эксплуатация".
Таким образом, в отличие от ближайшего аналога в заявленном техническом изобретении получают иные функции преобразования, которые в дальнейшем позволяют воспроизвести фонограмму профессионального певца с частотными характеристиками голоса пользователя караоке. Причем за счет того, что АВС 9 выполнен обеспечивающим разложение входящего голосового сигнала, поступающего на его вход/выход через П 8 от источника 1 входящего звукового сигнала, на синусоидальные компоненты сигнала, шумовые компоненты сигнала и остаточные компоненты сигнала и выполнен с возможностью формирования наборов ХВ и ФП для каждой упомянутой компоненты по отдельности и передачи их в ЗУ 2, а также последующей обработке сигналов в АУ 3, ХА 6, КП 7 по отдельности удается улучшить качество воспроизведения выходного голосового сигнала.
2) Режим Эксплуатации.
При поступлении с АВС 9 по его входу/выходу на П 8 команды на переключение в режим "эксплуатация" П 8 переходит в упомянутый режим и с И 1 передается голос пользователя караоке SV на вход П 8 через АЦП 32. П 8 при нахождении в состоянии «эксплуатация» и наличии входного сигнала с И 1 передает через выход П 8 на вход Б 10 команду о начале передачи с выхода Б 10 на вход АУ 3 выбранной пользователем фонограммы певца.
АУ 3 производит разложение звукового сигнала поступившего с Б 10 на спектры синусоидальных компонент, шумовых компонент и остаточных компонент аналогично АВС 9.
С соответствующих выходов АУ 3 полученные данные о спектрах поступают на К 20, 21 и 22. Символьное квантование производится на основание трех соответствующих КК 14, 15 и 16, которые хранятся в ЗУ 2. В процессе работы К 20, 21, 22 производится сравнение поступающих спектров голосового сигнала с АУ 3 с характеристическими векторами, хранящимися в КК 14, 15, 16. В результате чего К 20, 21, 22 определяет коды характеризирующих векторов, наиболее соответствующих спектрам голосового сигнала, поступившего с АУ 3, и передают их на ПР 23, 24 и 25 соответственно. Процесс символьного квантования производится аналогично ближайшему аналогу.
Квантование может производиться, например, с интервалом в 10 мс. Каждый такой интервал является фреймом.
ПР 23, получив от К 20 характеристический вектор из КК 14, характеризующий сигнал, поступивший с АУ 3 в данный интервал квантования, в соответствии с данными БФП 11 и КК 17 производит преобразование путем определения временного указателя для входящего голоса, основанного на определенном переходе состояния, определяет целевой фрейм, соответствующий временному указателю, и выдает спектральные частотные компоненты входящего голоса, сохраненные в БФП 11, и спектральные частотные компоненты цели, сохраненные в КК 17, синтезирующему устройству СЗ 26.
Аналогичным образом работают ПР 24 и 25. Они используют данные, поступаемые с К 21, БФП 12, КК 18 и К 22, БФП 13, КК 19 соответственно.
СУ 5 служит для синтеза звука выходного голосового сигнала профессионального певца со спектральными характеристиками пользователя караоке. СЗ 26 на основании данных от ПР 23, 24 и 25, поступающих на его три входа, генерирует спектры новых частотных компонент. Полученный частотный спектр голосового сигнала поступает на вход ЦАП 27 - блок обратного преобразования Фурье.
В конкретном конструкционном исполнении в заявленном техническом решении представлен аппарат караоке, обладающий функцией имитации, в котором средство хранения данных музыкального отрывка базы данных музыкального звукового сопровождения БП 28 хранит данные музыкального отрывка караоке, включая данные MIDI, данные времени, данные текста песни. Устройство включает в себя ЗГ 29 для генерирования музыкального звукового сигнала из выходных данных, подаваемых с БП 28 на вход ЗГ 9. М 30 смешивает звуковые сигналы, поступающие из ЦАП 27 и ЗГ 29, и звуковой сигнал с М 30, соответствующий голосу пользователя караоке, поступает на Г 31 для его воспроизведения.
Итак, если певец караоке поет песню, новый голос, который конвертируется из фонограммы профессионального певца для имитации манеры и качества исполнения профессионального певца, но с частотными характеристиками голоса пользователя караоке, выводится под аккомпанемент музыкальных звуков музыки караоке через Г 31.
Для перевода переключателя 8 в режим обучения или эксплуатации используется цифровое логическое устройство, которое функционирует в соответствии с блок-схемой фиг.5.
Переключатель 8 оснащен двумя входами: на вход поступают данные с И 1, а на вход входа/выхода поступают данные с АВС 9. Также у переключателя 8 имеется два выхода: выход входа/выхода подключен к входу АВС 9, а выход подключен к входу Б 10.
Переключатель 8 как логическое устройство может находиться в двух состояниях: «Обучение» и «Эксплуатация». Состояние по умолчанию - «Обучение». Данные, поступаемые на вход входа/выхода переключателя 8, являются управляющими состояния переключателя. Переключатель 8 всегда находится в статусе анализа обработки входящих данных. Не зависимо от наличия входных данных или их отсутствия переключатель 8 постоянно производит анализ данных своего состояния и входных данных по двух логическим цепочкам:
- Блок 41 производит проверку текущего состояния переключателя 8. Если текущий режим переключателя «Обучение», то блок 45 обеспечивает передачу входящего сигнала с входа на выход входа/выхода, чем достигается прямая коммутация сигнала от И 1 на АВС 9. Если же текущий режим переключателя «Эксплуатация», то блок 42 проверяет наличие сигнала И 1 на входе переключателя 8. Если сигнала нет, то блок 43 формирует команду «Нет сигнала» для АВС 9, которая передается на выход входа/выхода переключателя 8. Иначе блок 44 формирует команду «Есть сигнала» для АВС 9, которая передается на выход входа/выхода переключателя 8.
- Блок 46 постоянно производит проверку поступающего управляющего сигнала на вход входа/выхода переключателя 8. Если входящий сигнал на вход входа/выхода переключателя 8 соответствует команде перевода переключателя 8 в режим «Эксплуатация», то блок 47 переводит переключатель 8 в режим «Эксплуатация». Иначе блок 48 производит проверку поступающего управляющего сигнала на вход входа/выхода переключателя 8. Если входящий сигнал соответствует команде перевода переключателя 8 в режим «Обучение», то блок 49 переводит переключатель 8 в режим «Обучение». Далее блок 50 производит проверку текущего режима работы переключателя 8. Если текущий режим переключателя 8 - «Эксплуатация», то блок 51 формирует команду для Б 10, которая информирует Б 10 о необходимости передачи данных (фонограммы профессионального певца) на выход Б 10, подключенному к входу АУ 3. Данная команда передается на выход переключателя 8. Если текущий режим переключателя 8 - «Обучение», то блок 52 формирует команду для Б 10, которая информирует Б 10 о необходимости передачи данных (фонограммы профессионального певца) на выход Б 10, подсоединенного к входу АВС 9. Данная команда передается на выход переключателя 8.
Изобретенное устройство (фиг.1) может представлять собой компьютер с центральным процессором для контроля и функционирования средств 1-32 устройства.
В результате достигается эффект того, что окружающие слушают фонограмму не профессионального певца (оригинала), а фонограмму песни, которую исполняет пользователь, но с умением профессионального певца.
Наиболее успешно заявленное устройство для конвертации входящего голосового сигнала в выходящий голосовой сигнал в соответствии с целевым голосовым сигналом промышленно применимо в цифровых электронных системах воспроизведения звука.



Изобретение относится к радиотехнике и может быть использовано в качестве системы воспроизведения караоке. Техническим результатом является обеспечение исполнения песни голосом пользователя, но в манере и с качественным уровнем исполнения профессионального певца с минимизацией ошибок исполнения и с повышением его качества. Указанный технический результат достигается тем, что устройство содержит источник (И) входящего звукового сигнала, запоминающее устройство (ЗУ), анализирующее устройство (АУ), производящее устройство (ПУ) и синтезирующее устройство (СУ). ПУ выполнено на базе характеристического анализатора (ХА) и корректирующего процессора (КП). Введены переключатель (П) режима обучения/эксплуатации и анализатор входного сигнала (ABC). И подсоединен к входу П. ЗУ снабжено блоком фонограмм (Б). Вход/выход П подсоединен к входу/выходу ABC, а его выход - к входу Б. Первый выход данных Б подсоединен к входу ABC, а второй выход данных Б - к входу АУ. ABC выполнен обеспечивающим разложение входящего голосового сигнала на синусоидальные компоненты сигнала (С), шумовые компоненты сигнала (Ш) и остаточные компоненты сигнала (О) и выполнен с возможностью формирования наборов характеристических векторов и функций преобразования для каждой упомянутой компоненты и передачи их в ЗУ. АУ выполнено обеспечивающим разложение входящего голосового сигнала с Б на С, Ш и О. ХА и КП выполнены с возможностью обработки упомянутых компонент. 5 з.п. ф-лы, 5 ил.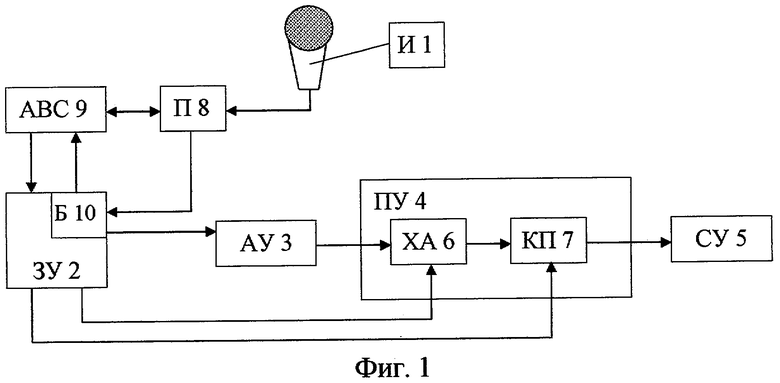
1. Устройство для конвертации входящего голосового сигнала в выходящий голосовой сигнал в соответствии с целевым голосовым сигналом, содержащее источник входящего звукового сигнала, запоминающее устройство, которое временно хранит исходные данные, которые соотносятся и берутся из целевого голоса, анализирующее устройство, которое анализирует входящий голосовой сигнал и извлекает из него ряд фреймов входящих данных, представляющих входящий голосовой сигнал, производящее устройство, которое производит ряд фреймов целевых данных, представляющих собой целевой голосовой сигнал, основанный на исходных данных, корректируя фреймы целевых данных относительно фреймов входящих данных, и синтезирующее устройство, которое синтезирует выходящий голосовой сигнал в соответствии с фреймами целевых данных и фреймами входящих данных, при этом производящее устройство выполнено на базе характеристического анализатора, который выполнен обеспечивающим извлечение из входящего голосового сигнала характеристического вектора, являющегося характеристикой выходного голосового сигнала, и на базе корректирующего процессора, при этом запоминающее устройство сохраняет данные характеристических векторов для использования при распознавании их, содержащихся во входящем голосовом сигнале, и сохраняет данные функции преобразования, которые являются частью исходных данных и представляют собой характеристику целевого поведения голосового сигнала, причем корректирующий процессор определяет данные распознавания характеристических векторов и данные функции преобразования в отношении данных выходной корректировки, соответствующей информации о тоне данных функции преобразования, информации об амплитуде данных целевого поведения и информации о форме огибающего спектра характеристического вектора, при этом анализирующее устройство, характеристический анализатор, корректирующий процессор и синтезирующее устройство соединены последовательно, выход данных характеристических векторов запоминающего устройства подсоединен к входу данных характеристического анализатора, а выход данных функции преобразования запоминающего устройства подсоединен к входу данных корректирующего процессора, отличающееся тем, что введены переключатель режима обучения/эксплуатации и анализатор входного сигнала, источник входящего звукового сигнала подсоединен к входу переключателя режима обучения/эксплуатации, запоминающее устройство снабжено блоком фонограмм, обеспечивающим хранение данных базы фонограмм профессиональных исполнителей, вход/выход переключателя режима обучения/эксплуатации подсоединен к входу/выходу анализатора входного сигнала, а его выход - к входу блока фонограмм запоминающего устройства, первый выход данных блока фонограмм подсоединен к входу анализатора входного сигнала, а второй выход данных блока фонограмм - к входу анализирующего устройства, анализатор входного сигнала выполнен обеспечивающим разложение входящего голосового сигнала, поступающего на его вход/выход через переключатель режима обучения/эксплуатации от источника входящего звукового сигнала, на синусоидальные компоненты сигнала, шумовые компоненты сигнала и остаточные компоненты сигнала и выполнен с возможностью формирования наборов характеристических векторов и функций преобразования для каждой упомянутой компоненты по отдельности и передачи их в запоминающее устройство, анализирующее устройство выполнено обеспечивающим разложение входящего голосового сигнала с блока фонограмм на синусоидальные компоненты сигнала, шумовые компоненты сигнала и остаточные компоненты сигнала, а характеристический анализатор и корректирующий процессор выполнены с возможностью обработки упомянутых компонент по отдельности.
2. Устройство по п.1, отличающееся тем, что запоминающее устройство выполнено из трех блоков функции преобразования и из баз данных шести кодовых книг, каждые три из которых выполнены обеспечивающими хранение характеристических векторов синусоидальных компонент сигнала, шумовых компонент сигнала и остаточных компонент сигнала по отдельности, при этом три из кодовых книг служат для хранения баз данных по фонограмме профессионального исполнителя, а три из кодовых книг - для хранения баз данных входного голосового сигнала, и входы трех блоков функции преобразования и входы баз данных шести кодовых книг соответственно подсоединены к девяти выходам анализатора входного сигнала.
3. Устройство по п.2, отличающееся тем, что характеристический анализатор выполнен из трех квантователей, выход анализирующего устройства выполнен в виде трех раздельных выходов обработки синусоидальных компонент сигнала, шумовых компонент сигнала и остаточных компонент сигнала по отдельности, и первые входы каждого из квантователей подсоединены по отдельности к трем раздельным выходам анализирующего устройства, вторые входы каждого из квантователей подсоединены по отдельности соответственно к выходам трех кодовых книг, служащих для хранения характеристических векторов синусоидальных компонент сигнала, шумовых компонент сигнала и остаточных компонент сигнала хранения баз данных по фонограмме профессионального исполнителя.
4. Устройство по п.3, отличающееся тем, что корректирующий процессор выполнен из трех преобразователей, каждый из трех первых входов которых соответственно подсоединен по отдельности к выходам квантователей, вторые входы преобразователей соответственно подсоединены по отдельности к выходам трех блоков памяти функции преобразования запоминающего устройства, а третьи входы преобразователей подсоединены по отдельности соответственно к выходам трех кодовых книг, служащих для хранения характеристических векторов синусоидальных компонент сигнала, шумовых компонент сигнала и остаточных компонент сигнала хранения баз данных по входному голосовому сигналу.
5. Устройство по п.4, отличающееся тем, что синтезирующее устройство выполнено из синтезатора звука и из цифроаналогового преобразователя, соединенных последовательно, выполнено из блока памяти базы данных музыкального звукового сигнала и из звукового генератора, соединенных последовательно, выполнено из микшера и из громкоговорителя, выход звукового генератора и выход цифроаналогового преобразователя подсоединены к входам микшера, выход которого подсоединен к громкоговорителю, а три входа синтезатора звука соответственно подсоединены по отдельности к выходам трех преобразователей корректирующего процессора.
6. Устройство по п.4, отличающееся тем, что переключатель режима обучения/эксплуатации выполнен цифровым, введен аналого-цифровой преобразователь и вход переключателя режима обучения/эксплуатации подсоединен к источнику входящего звукового сигнала через аналого-цифровой преобразователь.
| US 6836761 В1, 28.12.2004 | |||
| US 5847303 А1, 08.12.1998 | |||
| US 7117154 В2, 03.10.2006 | |||
| Способ обезвоживания и обессоливания нефти | 1981 |
|
SU982713A1 |
| KR 2008037178 А, 30.04.2008 | |||
| Способ формовки стаканообразных изделий | 1944 |
|
SU66103A1 |

