Область техники
Изобретение относится к электронной технике и может быть использовано в синтезе речи по тексту.
Предшествующий уровень техники
Задача конверсии - преобразование голоса диктора, являющегося в данном случае источником, в голос другого диктора (целевого); анализ речевых сигналов исходного и целевого дикторов; обучение модуля конверсии голоса с целью получения функции конверсии и синтез речевого сигнала. Процесс обучения предполагает найти согласованную разметку акустического пространства характеристических векторов целевого и исходного дикторов. Набор элементов данных характеристических векторов определяется моделями представления речевого сигнала.
Известен способ конверсии голоса, базирующийся на методах линейного предсказания и векторного квантования, который основан на дискретном представлении пространства спектральных параметров двух дикторов, полученных векторным квантованием: исходное и целевое акустическое пространства разделяются на не перекрывающиеся классы. Объединение в кластеры акустического пространства выполняется на основе оценки векторной кодовой книги для каждого из них. Как только исходная и целевая кодовая книги сформированы, тогда строится кодовая книга отображения, на основании которой выполняется конверсия исходного диктора в целевого. На этапе конверсии речевой сигнал исходного диктора анализируется с помощью метода линейного предсказания, спектральные параметры векторно квантуются с использованием его кодовой книги [Abe, M., Nakamura, S., Shikano, К. and Kuwabara, H. "Voice conversion through vector quantization", in Proc. of the Int. Conf. on Acoust., Speech and Sig. Proc. ICASSP, New York, USA, Apr. 1988, vol.1, pp.655-658].
Хотя системы конверсии голоса на основе кодовой книги отображения образуют преобразованные голоса, подходящие к целевому голосу, следует отметить, что качество синтезированного речевого сигнала недостаточно высоко, как требуется в приложениях. Основная проблема данного подхода - представление всего спектра с конечным множеством кодовых векторов. Это приводит к спектральной неоднородности в преобразованной речи, в конвертированном речевом сигнале присутствует большое количество артефактов.
Известен также способ конверсии голоса, построенный на основе принципа сегментации кодовой книги векторного квантования [US, 6615174].
В этом способе в фазе обучения строится параллельная кодовая книга спектральных параметров речевого сигнала, которая включает пару кодовых книг, одна для исходного диктора и другая - для целевого диктора, причем i-й вектор кодовой книги исходного диктора связан с i-м вектором кодовой книги целевого диктора. При построении кодовых книг формируется орфографическая транскрипция: речевой сигнал источника и целевого дикторов автоматически сегментированы с использованием регулировки для фонетического перевода орфографической транскрипции (как в задаче синтеза речи по тексту), спектральные параметры исходного и целевого дикторов вычисляются по фреймам, и каждый вектор спектральных параметров помечается соответствующей фонетической частью. Затем для установления однозначного отображения исходной и целевой кодовых книг оцениваются центроидные вектора для каждой фонемы кодовых книг исходного и целевого дикторов.
В фазе конверсии на основе теории формирующего фильтра спектр X(ω) исходного диктора представляется, как:
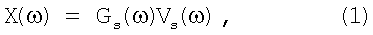
где Gs(ω) - возбуждение исходного диктора, Vs(ω) - передаточная функция вокального тракта для входного фрейма речи x(n).
Спектр речевого сигнала целевого диктора Y(ω) может быть сформулирован, как:
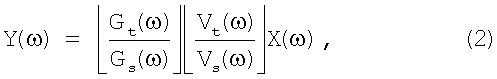
где Gt(ω) - кодовая книга целевого диктора, Vt(ω) - спектры возбуждения. С другой стороны, выражение (2) можно представить как произведение фильтра возбуждения Hg(ω) и фильтра вокального тракта Hv(ω):

Для того чтобы осуществить конверсию голоса исходного диктора в целевой, необходимо найти оба фильтра Hg(ω) и Hv(ω). Эти фильтры определяются взвешенной комбинацией спектральных параметров из соответствующих кодовых книг:

Значение γ для каждого фрейма находится тем или иным методом оптимизации при минимизации взвешенного расстояния между спектральными параметрами конвертированного исходного диктора приближенного вектора 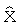 и соответствующим вектором спектральных параметров целевого диктора. Параметр γ рассматривается здесь как информация о фонетическом содержании текущего фрейма речи.
и соответствующим вектором спектральных параметров целевого диктора. Параметр γ рассматривается здесь как информация о фонетическом содержании текущего фрейма речи.
Однако взвешенное представление кодовой книги целевого диктора приводит к расширению полосы пропускания формант из-за интерполяции спектральных параметров. Поэтому необходима постобработка для изменения полосы пропускания пропорционально наиболее вероятному вектору спектральных параметров кодовой книги целевого диктора. Более того, данный способ также не обеспечивает высокое качество конвертированного речевого сигнала.
Наиболее близким к предлагаемому способу является способ конверсии голоса, включающий фазу обучения, заключающуюся в динамическом выравнивании речевых сигналов текстов целевого и исходного дикторов, в формировании соответствующих кодовых книг отображения и функции конверсии речевых сигналов, а также фазу конверсии, заключающуюся в определении параметров речевого сигнала исходного диктора, в конверсии параметров речевого сигнала исходного диктора в параметры речевого сигнала целевого диктора и в синтезе конвертированного речевого сигнала [Stylianou Y., Сарре О., Moulines E. "Continuous probabilistic transform for voice conversion", IEEE Trans. on Speech and Audio Processing, vol.6, №2, pp.131-142, March 1998].
Этот способ базируется на представлении речевого сигнала суммой гармоник и шума, а также описанием спектральных огибающих речевого сигнала исходного диктора на основе моделей гауссовых смесей. Функция конверсии в данном способе представляет собой параметрическую функцию вероятностного классификатора, которая определяется путем оптимизации по среднеквадратическому критерию на обучающем множестве речевых данных (фонетически сбалансированный текст).
В фазе обучения обучающее множество речевых данных (озвученный фонетически сбалансированный текст) исходного и целевого дикторов подвергаются гармоническому анализу для получения гармоник основного тона и шумовой компоненты, далее спектральные огибающие данных компонент с помощью динамической временной трансформации согласуются (фонетически сбалансированный текст может быть озвучен исходным и целевым дикторами за разное время), спектральная огибающая исходного диктора представляется компонентами моделей гауссовых смесей (более 100) и вычисляется функция конверсии.
Фаза конверсии состоит из следующих этапов: гармонический анализ вокализованного фрейма речевого сигнала исходного диктора (для определения спектральной огибающей); трансформация данной спектральной огибающей с помощью функции конверсии; синтез конвертированного речевого сигнала исходного диктора как сумма конвертированной гармонической компоненты речевого сигнала на основе трансформированной спектральной огибающей вокализованного фрейма речевого сигнала и шумовой компоненты, предварительно отфильтрованной корректирующим фильтром в зависимости от результата классификации речевого фрейма исходного диктора: вокализованный он или нет. При синтезе также учитываются просодические параметры исходного и целевого дикторов, также используется временное масштабирование.
Использование декомпозиции речевого сигнала на гармоники и шум позволяет осуществлять модификацию речевых сигналов с достаточно высоким качеством. В сравнении со способом конверсии голоса, использующего векторное квантование, здесь синтезированный конвертированный речевой сигнал более близко согласован с речевым сигналом целевого диктора.
Однако данный способ обладает двумя существенными недостатками.
Во-первых, результирующая матрица в функции конверсии, основанная на матрице условных вероятностей, неудовлетворительно обусловлена. Следовательно, обратная матрица может быть вычислена только приближенно, с определенной степенью ошибки, что приводит к появлению артефактов в конвертируемом речевом сигнале в виде «бормотании» и приглушенности речи, т.е. речь недостаточно близка к натуральной.
Во-вторых, принятое в этом способе представление речевого сигнала в виде декомпозиции на гармоники + шум в большой степени зависит от точности определения вокализованности речевого фрейма и частоты основного тона, что приводит к прослушиванию в конвертируемом речевом сигнале исходного диктора, т.к. в данном способе невокализованные речевые фреймы исходного диктора без преобразования передаются на выход системы конверсии голоса. Более того, в данном представлении речевого сигнала предполагается, что частотный диапазон разделяется на гармоническую часть и шумовую относительно гармоники частоты основного тона, уровень которой ниже некоего заданного порога. Следовательно, в синтезированном речевом сигнале будет отсутствовать естественная шумовая компонента речи в низкочастотной части частотного диапазона, что приведет также к определенным артефактам в реконструированном речевом сигнале.
Раскрытие изобретения
Решаемая изобретением задача - повышение качества и технико-эксплуатационных характеристик.
Технический результат, который может быть получен при осуществлении заявленного способа, - повышение степени совпадения голоса целевого диктора в конвертированном речевом сигнале за счет улучшения разборчивости и узнаваемости голоса непосредственно целевого диктора.
Для решения поставленной задачи с достижением указанного технического результата в известном способе конверсии голоса, включающем фазу обучения, заключающуюся в динамическом выравнивании речевых сигналов текстов целевого и исходного дикторов, в формировании соответствующих кодовых книг отображения и функции конверсии речевых сигналов, а также фазу конверсии, заключающуюся в определении параметров речевого сигнала исходного диктора, в конверсии параметров речевого сигнала исходного диктора в параметры речевого сигнала целевого диктора и в синтезе конвертированного речевого сигнала, согласно заявленному способу в фазе обучения в речевом сигнале целевого и исходного дикторов в фрейме анализа выделяют гармоники основного тона, шумовую компоненту и переходную компоненту, при этом вокализованный фрейм речевого сигнала представляют в виде гармоник основного тона и шумовой компоненты, а переходная компонента состоит из невокализованных фреймов речевого сигнала, обрабатывают фрейм речевого сигнала исходного диктора и определяют его вокализованность, если фрейм речевого сигнала вокализован, то определяют его частоту основного тона, если основной тон не выявлен, то фрейм является переходным, а если фрейм не вокализован и не является переходным, то обрабатываемый фрейм представляют как паузу речевого сигнала, далее переходный фрейм формируют с помощью линейного предсказателя с возбуждением по его кодовой книге, определяют коэффициенты фильтра линейного предсказателя и параметры долговременного фильтра линейного предсказателя, которые затем на основании соответствующих кодовых книг отображения конвертируют в параметры целевого диктора и синтезируют переходный фрейм целевого диктора, в фазе конверсии, если фрейм речевого сигнала исходного диктора вокализован, то определяют частоту основного тона речевого сигнала и временной контур ее изменения и с помощью дискретного преобразования Фурье, согласованного с частотой основного тона, далее производят разделение фрейма речевого сигнала исходного диктора на компоненты - на гармоники частоты основного тона и на шумовую компоненту, равную остаточному шуму от разности фрейма исходного диктора и ресинтезированного фрейма по гармоникам основного тона, эти упомянутые компоненты на основании кодовых книг отображения конвертируют в параметры целевого диктора, при этом дополнительно учитывают конверсию частоты основного тона для исходного диктора, синтезируют компоненту гармоник основного тона и шумовую компоненту целевого диктора, которые суммируют с синтезированной переходной компонентой и паузой речевого сигнала.
Возможен дополнительный вариант осуществления способа, в котором целесообразно, чтобы при определении частоты основного тона осуществляли низкочастотную фильтрацию фрейма речевого сигнала исходного диктора фильтром с частотой среза 1000 Гц, далее вычисляют нормализованную функцию автокорреляции и определяют параметры, близкие к частоте основного тона, при этом пики автокорреляционной функции на 30% ниже ее максимального значения номинируют, как не соответствующие частоте основного тона, далее динамическим программированием параметров вычисляют весовые функции с учетом временного контура частоты основного тона в предыдущих фреймах речевого сигнала исходного диктора, при этом определяют максимально сглаженный временной контур изменения частоты основного тона, параметр с минимальным значением весовой функции выбирают в качестве начальной оценки частоты основного тона на данном фрейме речевого сигнала исходного диктора, оценки частоты основного тона уточняют путем определения гармоник частоты основного тона и шумовой компоненты фрейма речевого сигнала исходного диктора, вычисляют отношение мощности гармоники основного тона к мощности шумовой компоненты, в интервале изменения частоты основного тона определяют значение частоты основного тона, для которой значение отношения мощности гармоник основного тона к мощности шумовой компоненты для данного фрейма речевого сигнала исходного диктора максимально, и этот параметр частоты основного тона полагают истинным.
Таким образом, в заявленном текстозависимом способе конверсии голоса, состоящим из фазы обучения: динамическом выравнивании речевых тестов целевого и исходного дикторов, построении соответствующих кодовых книг отображения и функции конверсии, и фазы конверсии: определении параметров речевого сигнала исходного диктора, их конверсии в параметры целевого диктора и синтезе конвертированного речевого сигнала, обработку речевого сигнала целевого и исходного дикторов на фрейме анализа ведут на основании представления речевого сигнала: гармоники основного тона, шум и переходный, согласно которой вокализованный фрейм речевого сигнала представляется в виде периодической (гармоник основного тона) и апериодической (шумовой) компонент, а также переходной компоненты, в которую включаются невокализованные фреймы. Обработка фрейма речевого сигнала исходного диктора начинается с определения речевых пауз и его вокализованности. Если это не речевая пауза, то определяется частота основного тона или, если основной тон не выявлен, то констатируется, что фрейм - переходный. Переходный фрейм обрабатывается по методу линейного предсказания: находятся коэффициенты фильтра предсказателя и параметры долговременного фильтра предсказателя, которые затем на основании соответствующих кодовых книг отображения, формируемых на стадии фазы обучения, конвертируются в параметры целевого диктора и далее синтезируется переходный фрейм целевого диктора с помощью линейного предсказателя с возбуждением по его кодовой книге. В случае вокализованности фрейма речевого сигнала исходного диктора и определения частоты основного тона на основании дискретного преобразования Фурье, согласованного с частотой основного тона, осуществляется декомпозиция фрейма на периодическую (гармоники частоты основного тона) и апериодическую (остаточный шум от разности исходного фрейма и ресинтезированного фрейма по гармоникам основного тона) компоненты, которые на основании кодовых книг отображения, сформированных в фазе обучения, конвертируются в параметры целевого диктора и с учетом конверсии просодических параметров (частоты основного тона) исходного диктора в целевого синтезируются соответствующие гармонические и шумовые компоненты целевого диктора, которые суммируются с конвертированной переходной компонентой и речевой паузой.
При этом анализ речевого сигнала в соответствии с принятым выше представлением речевого сигнала, когда вокализованный фрейм речевого сигнала представляется в виде периодической (гармоник основного тона) и апериодической (шумовой) компонент основан на дискретном преобразовании Фурье, базовые функции (синус и косинус) которого согласованы с контуром изменения частоты основного тона на анализируемом фрейме речевого сигнала, результат анализа:
частота основного тона и временной контур ее изменения на фрейме анализа, амплитуды и фазы гармоник основного тона являются исходными данными для синтеза периодической компоненты с помощью синусоидальных генераторов с частотной модуляцией, выходной сигнал которых вычитается из исходного фрейма для получения сигнала остатка - шумовой компоненты, огибающие частотных характеристик периодической и шумовой компонент определяется по методу линейного предсказания.
Синтез же периодической (гармоник основного тона) и апериодической (шумовой) компонент основан на формировании суммарного сигнала шумовой и периодической компонент, где шумовой сигнал представляет собой выход формирующего фильтра с частотной характеристикой, определенной на этапе анализа, с возбуждением белым шумом, а периодическая компонента образуется суммированием частотно-модулированных синусоидальных сигналов, представляющих собой гармоники частоты основного тона, с учетом огибающей частотной характеристики периодической компоненты фрейма речевого сигнала и приращения частоты основного тона на фрейме анализа.
Кроме того, оценка частоты основного тона основана на низкочастотной фильтрации исходного речевого фрейма с частотой среза 1000 Гц, вычислении нормализованной функции автокорреляции и определении параметров, близких к частоте основного тона, т.е. «кандидатов» на частоту основного тона (все пики автокорреляционной функции на 30% ниже ее максимального значения не номинируются на кандидатов). Далее на основе динамического программирования для «кандидатов» вычисляются весовые функции с учетом контура частоты основного тона на предыдущих речевых фреймах с целью найти максимально сглаженный контур изменения основного тона. «Кандидат» с минимальным значением весовой функции выбирается как начальная оценка частоты основного тона на текущем фрейме речевого сигнала, которая уточняется с помощью процедуры анализа через синтез: согласно способу анализа речевого сигнала для найденной оценки частоты основного тона определяются периодическая (гармоническая) и шумовая компоненты фрейма речевого сигнала, вычисляется отношение мощности гармонической компоненты к мощности шумовой компоненты для определенной оценки частоты основного тона, на заданном интервале изменения частоты основного тона определяется оптимальное значение частоты основного тона, для которой максимизируется значение отношения мощности гармонической компоненты к мощности шумовой компоненты для текущего фрейма.
Так же, как в ближайшем аналоге, согласно предложенному способу конверсии голоса процесс обработки речи включает две фазы: фазу обучения и фазу конверсии речевого сигнала исходного диктора в речевой сигнал целевого диктора.
В фазе обучения предварительно формируется обучающее множество тестовых речевых сигналов (озвученный фонетически сбалансированный текст как для целевого диктора, так и для исходного диктора), которые затем подвергаются анализу для выделения огибающих частотных характеристик периодической (гармоник основного тона) и апериодической (шумовой) компонент, которые определяются соответствующими векторами линейных спектральных частот, а также переходной компоненты, состоящей из невокализованных фреймов, для которых находятся коэффициенты фильтра предсказателя и параметры долговременного фильтра предсказателя. Речевые паузы из обучающего множества исключаются.
Далее спектральные огибающие данных компонент с помощью метода динамической временной трансформации выравниваются (фонетически сбалансированный текст может быть озвучен исходным и целевым дикторами за разное время), строятся соответствующие кодовые книги векторного квантования для каждой компоненты тестовых речевых сигналов целевого и исходного дикторов согласно методу К-средних и кодовые книги отображения параметров исходного диктора в целевого.
Фаза конверсии заключается в определении параметров речевого сигнала исходного диктора (периодической, шумовой и переходной компонент), их конверсии в параметры целевого диктора с помощью кодовых книг отображения, сформированных в фазе обучения, и синтезе конвертированного речевого сигнала с учетом конверсии просодических параметров (частоты основного тона и временных масштабов) исходного диктора в целевого. При этом конвертированный сигнал представляет собой сумму с учетом фазового выравнивания конвертированных гармонических и шумовых компонент, а также конвертированной переходной компоненты и речевых пауз.
Таким образом, существенными признаками настоящего изобретения являются: представление речевого сигнала целевого и исходного дикторов на фрейме анализа в виде гармоник основного тона, шума и переходной компоненты (вокализованный фрейм речевого сигнала образуется из периодической (гармоник основного тона) и апериодической (шумовой) компонент, а переходная компонента включает невокализованные фреймы); динамическом выравнивании речевых текстов целевого и исходного дикторов, построении соответствующих обучающих книг и функции конверсии, последующим определении параметров речевого сигнала исходного диктора, их конверсии и синтезе конвертированного речевого сигнала. Это позволяет осуществлять конверсию речевых сигналов с достаточно высокой разборчивостью и узнаваемостью целевого диктора. Качество конверсии в меньшей степени зависит от точности определения вокализованности речевого фрейма и частоты основного тона, потому что наличие переходной компоненты, которая также конвертируется, не приводит к прослушиванию в восстановленном речевом сигнале исходного диктора, а также здесь весь частотный диапазон вокализованного фрейма разделяется на гармоническую и шумовую компоненты, следовательно, в синтезированном речевом сигнале будет присутствовать естественная шумовая компонента речи в низкочастотной части частотного диапазона и будет меньше артефактов.
Указанные преимущества, а также особенности настоящего изобретения поясняются лучшим вариантом его осуществления со ссылками на прилагаемые чертежи.
Краткий перечень чертежей
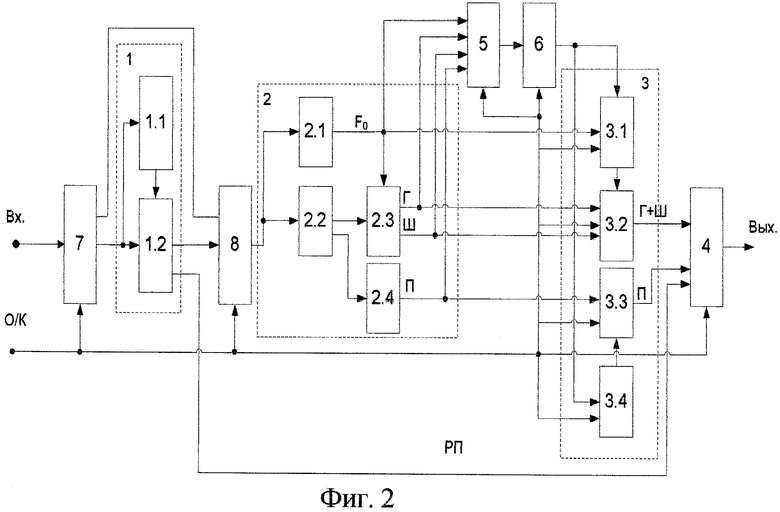
Фиг.1 изображает возможный вариант выполнения устройства для осуществления заявленного способа;
Фиг.2 - то же, что фиг.1, более детально;
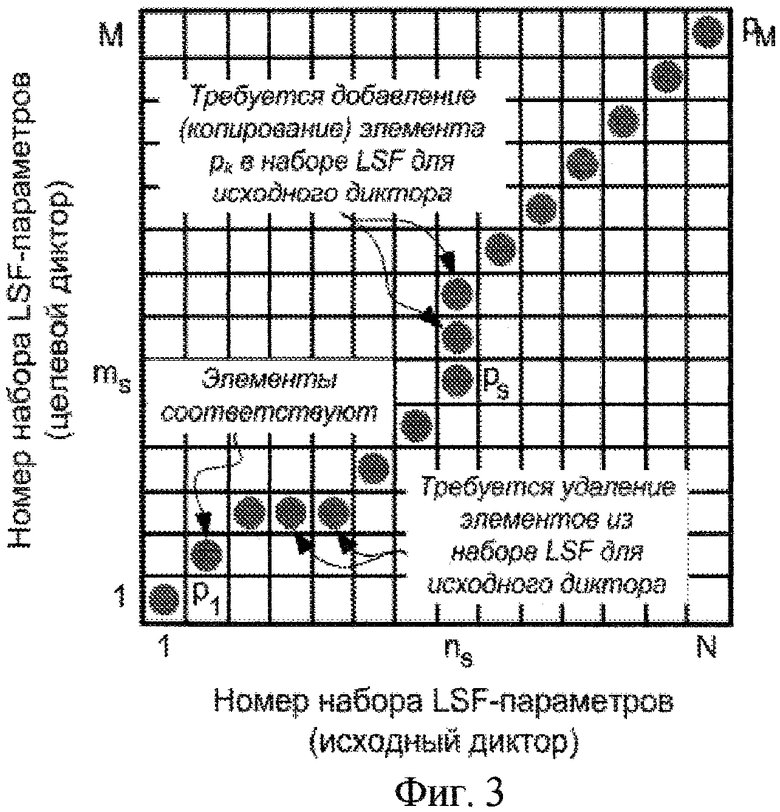
Фиг.3 - иллюстрация работы блока динамической временной трансформации на фиг.1 и 2;
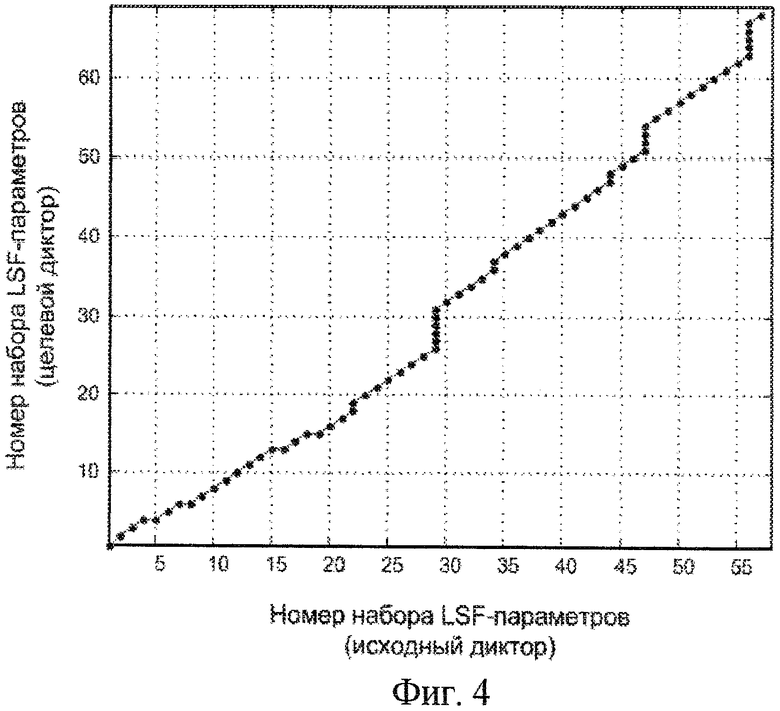
Фиг.4 - функция сопоставления для двух наборов LSF-параметров исходного и целевого мужских дикторов с длиной N=57 и М=68 соответственно, где N - число фреймов анализа обучающей последовательности исходного диктора, а М - количество фреймов анализа обучающей последовательности целевого диктора;
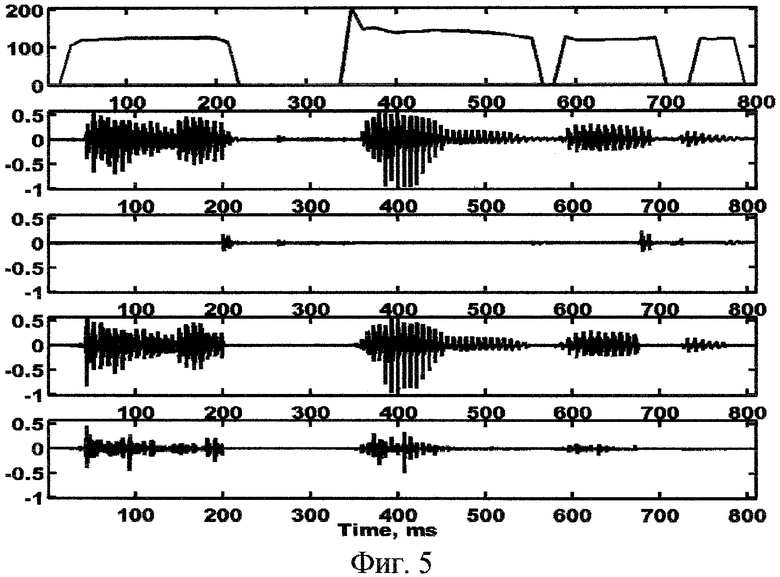
Фиг.5 - иллюстрация работы блока декомпозиции речевого сигнала на гармоническую и шумовую компоненты и переходный фрейм на фиг.1 и 2;
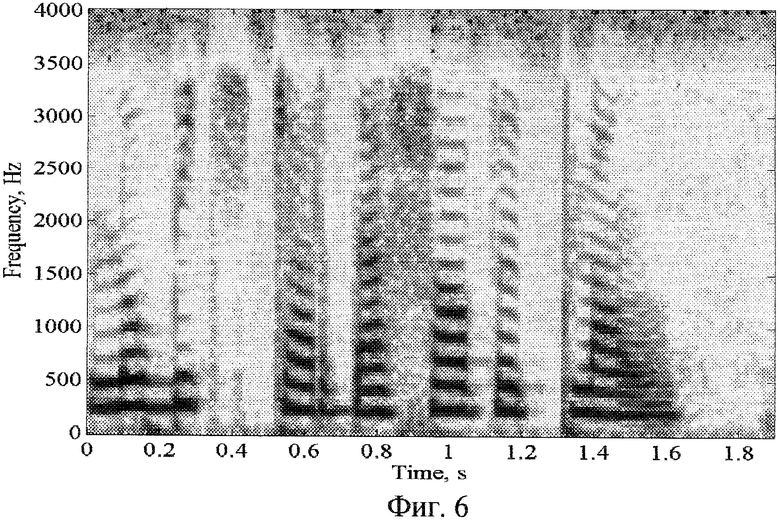
Фиг.6 - спектрограмма фразы целевого диктора;
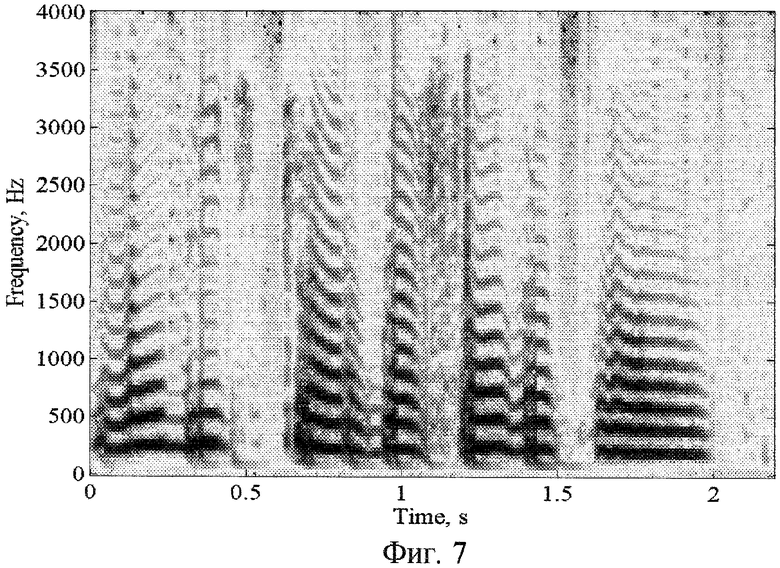
Фиг.7 - спектрограмма конвертированного речевого сигнала на основе модели гармоники-шум-переходный;
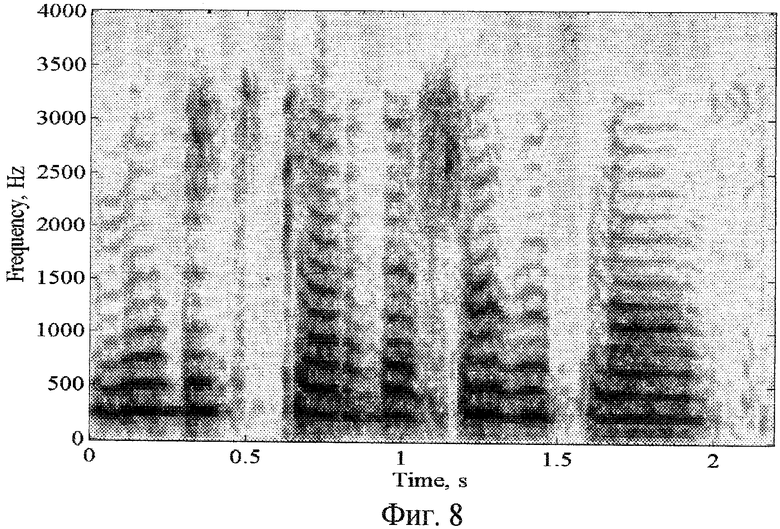
Фиг.8 - спектрограмма конвертированного речевого сигнала на основе векторного квантования и линейного предсказания.
Лучший вариант осуществления изобретения
Специалистам понятно, что заявленный текстозависимый способ конверсии голоса может быть осуществлен при помощи различных устройств, не изменяющих его сущности, изложенной в независимом пункте формулы изобретения.
В качестве одного из вариантов осуществления заявленного способа на фиг.1 и 2 показано возможное устройство, которое позволяет в полной мере реализовать этот способ.
На фиг.1 и 2 показаны блок 1 определения речевых пауз, блок 2 декомпозиции речевого сигнала на гармоническую и шумовую компоненты и переходный фрейм, блок 3 конверсии, выходной сумматор 4, блок 5 динамической временной трансформации, блок 6 тренировки кодовых книг, коммутатор 7, мультиплексор 8. Кроме того, на фигурах обозначены: Вх. - (вход устройства), О/К - (управляющий сигнал: высокий уровень - фаза обучения, низкий уровень - фаза конверсии), F0 - (частота основного тона), Г - (гармоническая компонента), Ш - (шумовая компонента), П - (переходная компонента), РП - (речевая пауза). Вых. - (выход устройства).
Режимы работы устройства (фаза обучения и фаза конверсии) определяются управляющим сигналом (О/К) (фиг.1, 2). Причем в фазе обучения, например, сигнал О/К имеет высокий уровень, блокируется работа блока 3 конверсии и выходного сумматора 4, а блок 5 динамической временной трансформации и блок 6 тренировки кодовых книг - активны. В фазе обучения вход устройства через первый выход коммутатора 7 и мультиплексора 8 соединен с блоком 2 декомпозиции речевого сигнала на гармоническую и шумовую компоненты и переходный фрейм. Результат декомпозиции - огибающие гармонической, шумовой и переходного фрейма поступают в память блока 5. В фазе обучения последовательно в блоке 2 определяются огибающие компонент декомпозиции входного речевого сигнала как исходного, так и целевого дикторов. Далее в блоке 6 тренировки кодовых книг на основании алгоритма К-средних для фазы конверсии формируются соответствующие кодовые книги отображения гармонической, шумовой компонент и переходного фрейма.
В режиме работы устройства - фаза конверсии - управляющий сигнал О/К меняет свое значение на инверсное, т.е., например, на низкий уровень. При этом блок 3 конверсии и выходной сумматор 4 активны, а блок 5 блокируется. Содержимое памяти блока 6 тренировки кодовых книг переписывается в блок 3 конверсии, а именно в блоки 3.1 и 3.2 (фиг.2) - кодовые книги отображения. Далее входной речевой сигнал исходного диктора через коммутатор 7, блок 1 определения речевых пауз и мультиплексор 8 поступает на анализ в блок 2. Результаты анализа в блоке 3 конверсии конвертируются в параметры целевого диктора, синтезируется сумма компонент гармонической и шумовой, формируется переходный фрейм и суммируются с речевой паузой в выходном сумматоре 4, на выходе которого получается конвертируемый речевой сигнал, близкий к сигналу целевого диктора.
Вокализованный фрейм речевого сигнала в блоке 2 (фиг.1) декомпозиции речевого сигнала на гармоническую, шумовую компоненты и переходный фрейм разделяется на гармоническую и шумовую компоненты:
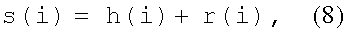
где h(i) - гармоническая компонента, a r(i) - шумовая.
Гармоническая компонента может быть определена следующим образом [Petrovsky, A., Zubricki, P. and Sawicki, A. "Tonal and noise components separation based on a pitch synchronous DFT analyzer as a speech coding method," in Proc. European Conf. Circuit Theory and Design, Cracow, Poland, Sep. 2003, vol.3, pp.169-172], [Zubricki, P., Pavlovec, A. and Petrovsky, A. "Analysis-by-synthesis parameters estimation in the harmonic coding framework by pitch tracking modified DFT" in "New trends in audio and video", Dobrucki, A., Petrovsky, A. and Skarbek, W. Eds. Byalystok 2006, pp.233-246], [Levine, S. and Smith, J.O. "A sines+transients+noise audio representation for data compression and time/pitch scale modifications" in Proc. 105th Corn. Audio Eng. Soc., preprint #4781, Sep. 1998):
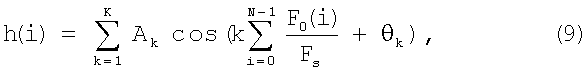
где Ak - амплитуда k-ой гармоники частоты основного тона, К - число всех гармоник, F0(i) - мгновенная оценка частоты основного тона. θk - начальная фаза k-ой гармоники, Fs - частота дискретизации, N - длина фрейма в отсчетах речевого сигнала.
Ядро гармонического анализатора 2.3 (фиг.2) составляет дискретное преобразование Фурье, базовые функции (синус и косинус) которого согласованы с контуром изменения частоты основного тона на анализируемом фрейме речевого сигнала [Zubricki, P., Pavlovec, A. and Petrovsky, A. "Analysis-by-synthesis parameters estimation in the harmonic coding framework by pitch tracking modified DFT" in "New trends in audio and video", Dobrucki, A., Petrovsky, A. and Skarbek, W. Eds. Byalystok 2006, pp.233-246.]:
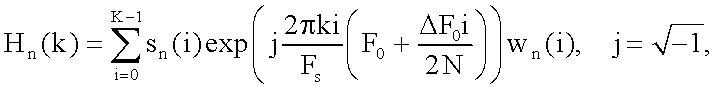
где Sn(i) - i-ый отсчет n-ого фрейма, F0 - частота основного тона, ΔF0 - изменение частоты основного тона на фрейме анализа, wn(i) - временное окно.
Таким образом, амплитуды и фазы гармоник могут быть найдены следующим образом:
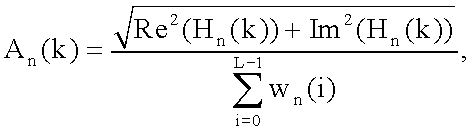
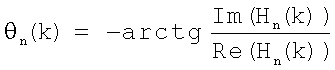 .
.
Неортогональность данного преобразования может привести к ошибкам анализа, выражающимся в просачивании энергии в соседние спектральные отсчеты. Для устранения данного недостатка предлагается использовать зависимое от времени окно, которое изменяет свою форму синхронно с контуром изменения частоты основного тона. Хорошие точностные характеристики показывает гармонический анализ при использовании в качестве такого зависимого от времени окна - окна Кайзера [Sercov, V. and Petrovsky, A. "An improved speech model with allowance for time-varying pitch harmonic amplitudes and frequencies in low bit-rate MBE coders", in Proc. of the European Conf. on Speech Communication and Technology EUROSPEECH, Budapest, Hungary, Sep. 1999, pp.1479-1482].
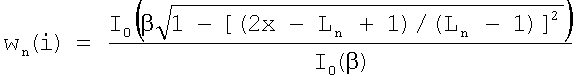 ,
,
где i=0…N-1, N длина окна, β параметр окна, I0() функция Бесселя нулевого порядка, x функция, отражающая зависимые от времени характеристики и определяемая, как:
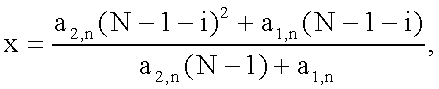
где a2,n и a1,n - параметры, обеспечивающие линейное изменение основного тона:
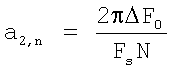 ,
, 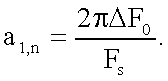
Оценка частоты основного тона в блоке 2.1 (фиг.2), определения F0 и переходных фреймов основана на низкочастотной фильтрации исходного речевого фрейма с частотой среза 1000 Гц, вычислении нормализованной автокорреляционной функции (НАКФ) для всех допустимых значений периода основного тона:
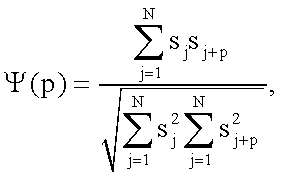
где p - отсчет НАКФ, ассоциируемый с периодом основного тона, sj - отсчеты речевого сигнала.
Пики автокорреляционной функции, расположенные внутри диапазона возможного периода основного тона (для частоты дискретизации 8 кГц этот диапазон определяется от 16 до 160 отсчета p НАКФ), рассматриваются как возможные параметры, близкие к частоте основного тона, - «кандидаты»: все пики автокорреляционной функции на 30% ниже ее максимального значения не номинируются на «кандидатов», далее на основе динамического программирования [Taikin, D. "Robust algorithm for pitch tracking" in "Speech Coding and Synthesis", Kleijn, W.B. and Palival, K.K. Eds. Elsevier, Amsterdam, Netherlands, 1995] для «кандидатов» вычисляются весовые функции с учетом контура частоты основного тона на предыдущих речевых фреймах с целью найти максимально сглаженный контур Di,j изменения основного тона
 ,
,
где di,j - локальная весовая функция j-ого «кандидата» в момент времени i, δi,j,k - весовое соотношение между k-ым «кандидатом» в момент времени i-1 и j-ым «кандидатом» в момент времени i, 1≤j≤Ii; I - число «кандидатов».
«Кандидат» с минимальным значением весовой функции Di,j выбирается как начальная оценка частоты основного тона на текущем фрейме речевого сигнала, которая уточняется с помощью процедуры анализа через синтез: согласно способу анализа речевого сигнала для найденной оценки частоты основного тона определяются периодическая (гармоническая) и шумовая компоненты фрейма речевого сигнала, вычисляется отношение мощности гармонической компоненты ЕH к мощности шумовой компоненты EN для определенной оценки частоты основного тона (Harmonic-to-Noise Ratio (HNR)):
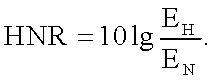
На заданном интервале изменения частоты основного тона от F0min до F0max определяется оптимальное значение частоты основного тона, для которой максимизируется значение отношения мощности гармонической компоненты к мощности шумовой компоненты для текущего фрейма:
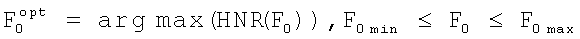 .
.
Синтез периодической компоненты осуществляется согласно [Talkin, D. "Robust algorithm for pitch tracking" in "Speech Coding and Synthesis", Kleijn, W.B. and Palival, K.K. Eds. Elsevier, Amsterdam, Netherlands, 1995] путем суммирования частотно-модулированных синусоидальных сигналов, представляющих собой гармоники частоты основного тона, с учетом огибающей частотной характеристики периодической компоненты фрейма речевого сигнала и приращения частоты основного тона на фрейме анализа (блок 3.2 фиг.2).
Принимая во внимание возможность использования [Talkin, D. "Robust algorithm for pitch tracking" in "Speech Coding and Synthesis", Kleijn, W.B. and Palival, K.K. Eds. Elsevier, Amsterdam, Netherlands, 1995], естественным было бы применить различные функции конверсии для огибающих спектра каждой компоненты. При этом этап обучения осуществляется раздельно для составляющих модели [Sercov, V. and Petrovsky, A. "An improved speech model with allowance for time-varying pitch harmonic amplitudes and frequencies in low bit-rate MBE coders", in Proc. of the European Conf, on Speech Communication and Technology EUROSPEECH, Budapest, Hungary, Sep. 1999, pp.1479-1482].
Из гармонического анализа для процесса конверсии выбираются такие параметры, как спектральная огибающая, представленная LSF-коэффициентами (Line Spectral Frequencies - LSF), и фундаментальная частота F0 (блоки 3.1 и 3.2, фиг.2). Анализ переходных фреймов, осуществляемый с помощью метода ACELP [ITU-T Rec. G.729, "Coding of speech at 8 kbit/s using conjugate-structure algebraic-code-excited linear - prediction (CS-ACELP)", Mar. 1996], предоставляет для модификации LSF - коэффициенты фильтра, моделирующего вокальный тракт, период основного тона Т0, коэффициенты усиления последовательностей адаптивного и фиксированного возбуждения Ga и Gf соответственно (блоки 3.3 и 3.4, фиг.2).
Для осуществления преобразования таких параметров, как фундаментальная частота F0 или период основного тона Т0, коэффициенты усиления последовательностей адаптивного и фиксированного возбуждения Ga и Gf в данном способе используется метод линейного преобразования математического ожидания и дисперсии, при этом предполагается, что математические ожидания этих параметров содержат существенную часть информации, специфической для каждого диктора. Задается также, что значения параметров каждого диктора подчиняются распределению Гаусса и имеют характерные средние значения и отклонения.
Обозначив модифицируемый параметр как 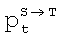 , можно определить линейное преобразование следующим образом [KY Lee, Y Zhao, Statistical Conversion Algorithms of Pitch Contours Based on Prosodic Phrases. Proceedings of the International Conference "Speech Prosody 2004". (SP 2004)", Nara, Japan March 23-26, 2004]:
, можно определить линейное преобразование следующим образом [KY Lee, Y Zhao, Statistical Conversion Algorithms of Pitch Contours Based on Prosodic Phrases. Proceedings of the International Conference "Speech Prosody 2004". (SP 2004)", Nara, Japan March 23-26, 2004]:
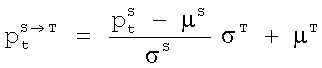 ,
,
где 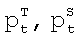 - один из параметров целевого и исходного дикторов соответственно, σs, µs, σT, µT - среднеквадратическое отклонение и математическое ожидание соответствующего параметра исходного и целевого дикторов соответственно.
- один из параметров целевого и исходного дикторов соответственно, σs, µs, σT, µT - среднеквадратическое отклонение и математическое ожидание соответствующего параметра исходного и целевого дикторов соответственно.
В ходе обучения для установления более точного сопоставления спектральных векторов исходного и целевого дикторов используется динамическая временная трансформация (DTW - Dynamic Time Warping) (блок 5, фиг.1 и 2) [Huang X., Acero A., Hon H-W. "Spoken Language Processing: a guide to theory, algorithms, and system development, Prentice Hall, NJ, 2001. - 980 р."].
Допустим, имеется две последовательности наборов. LSF-параметров: для целевого диктора - LSFtag и для исходного - LSFsource. Необходимо выполнить выравнивание данных двух последовательностей по времени, т.е. таким образом сопоставить их по длине путем вставки или удаления элементов из LSFsource, чтобы общее среднеквадратическое отклонение между элементами этих последовательностей стремилось к минимальному значению.
Общее отклонение (расстояние) между последовательностями LSFtag и LSFsource можно определить, как: 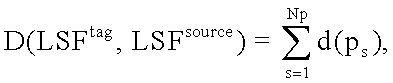
где d(ps) - расстояние между 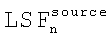 и
и 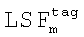 , ps - s-й элемент пути, Np - количество элементов в пути. Тогда процесс нахождения оптимального пути сводится к минимизации общего отклонения:
, ps - s-й элемент пути, Np - количество элементов в пути. Тогда процесс нахождения оптимального пути сводится к минимизации общего отклонения: 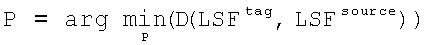 .
.
Таким образом, решение задачи сводится к нахождению функции выравнивания (пути):
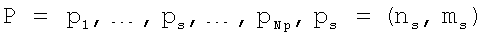 ,
,
где ns, и ms - номер набора LSF-параметров исходного и целевого диктора соответственно для пути ps.
Каждое значение функции выравнивания (пути) показывает, какой элемент последовательности LSFcource следует удалить, а какой вставить (фиг.3), чтобы достигнуть минимального значения общего отклонения.
Алгоритм для нахождения функции выравнивания (оптимального пути) может описывается следующим образом.
Шаг 1. Вычисление матрицы локальных среднеквадратических отклонений d, каждый элемент которой является евклидовым расстоянием между двумя соответствующими элементами последовательностей LSFcource и LSFtag, и определяется по следующему выражению:
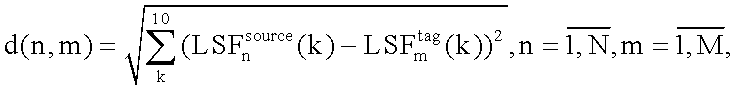
где n - номер LSF-параметров исходного диктора,
m - номер LSF-параметров целевого диктора,
N - число фреймов анализа обучающей последовательности исходного диктора,
М - количество фреймов анализа обучающей последовательности целевого диктора.
Шаг 2. Вычисление матрицы весов D, каждый элемент которой характеризует вклад соответствующего элемента матрицы d в общее среднеквадратическое отклонение.
Шаг 2.1. Пусть начальное условие D(1, 1)=d(1, 1). Вычисление первой строки матрицы D:
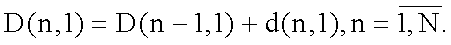
Шаг 2.2. Вычисление первого столбца матрицы D:
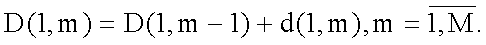
Шаг 2.3. Далее, двигаясь по матрице d слева направо, снизу вверх, вычисляются следующие элементы матрицы D:
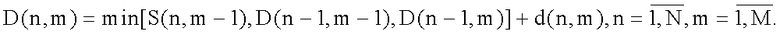
В процессе вычисления для каждой ячейки матрицы запоминают индекс соседней ячейки, которая вносит минимальный вклад в общую ошибку.
Шаг 3. Анализируя матрицу D в направлении от D(N, M} до D(1, 1) и учитывая определенные на предыдущих этапах индексы ячеек, которые вносят меньший вклад в общее отклонение по сравнению с соседними, определяют наилучшую функцию выравнивания (путь) 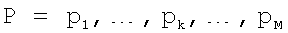 с точки зрения минимизации величины общего отклонения.
с точки зрения минимизации величины общего отклонения.
Полученная в результате осуществления алгоритма функции выравнивания (путь) 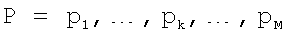 является обобщенной функцией сопоставления для обрабатываемых последовательностей, которая показывает, какие элементы необходимо удалить из исходной последовательности, а какие добавить. Например, на фиг.5 отображена функция сопоставления для двух наборов LSF-параметров исходного и целевого мужских дикторов с длиной N=57 и М=68 соответственно. Данным наборам соответствует фраза "Испорченный контакт".
является обобщенной функцией сопоставления для обрабатываемых последовательностей, которая показывает, какие элементы необходимо удалить из исходной последовательности, а какие добавить. Например, на фиг.5 отображена функция сопоставления для двух наборов LSF-параметров исходного и целевого мужских дикторов с длиной N=57 и М=68 соответственно. Данным наборам соответствует фраза "Испорченный контакт".
Функция конверсии векторов LSF для составляющих (8) (блок 3.2, фиг.2) имеет следующий вид:
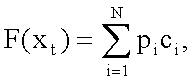
где pi - вес, характеризующий вероятность принадлежность вектора xt к i-му акустическому классу, представленному в кодовой книге (блок 3.1, фиг.2) размерности N центроидой сi.
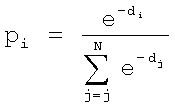 ,
,
где di - мера искажения: 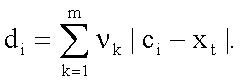
Здесь величина m представляет собой размерность вектора, a vk - вес, рассчитанный по формуле обратного гармонического среднего, с помощью которого учитывается перцептуальный фактор близости смежных LSF:
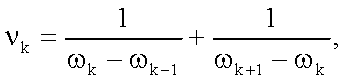 где ωk - k-й коэффициент LSF, ω0=0, ωm+1=π.
где ωk - k-й коэффициент LSF, ω0=0, ωm+1=π.
Блок 1 определения речевых пауз (фиг.1) состоит из детектора 1.1 определения вокализованности речевого фрейма исходного диктора (фиг.2), реализованного на энергетическом принципе, и коммутатора 1.2. Блок 2 декомпозиции речевого сигнала на гармоническую, шумовую и переходную компоненты состоит из определителя 2.1 частоты основного тона и переходного фрейма, коммутатора 2.2 режима анализа, управляемого определителем 2.1 частоты основного тона и переходного фрейма, гармонического анализатора 2.3 и анализатора переходного фрейма 2.4, который может быть реализован по указанному алгоритму ACELP [ITU-T Rec. G.729, "Coding of speech at 8 kbit/s using conjugate-structure algebrai-code-excited linear - prediction (CS-ACELP)", Mar. 1996].
Блок 2.1 соответствует определителю оценки частоты основного тона, описанному выше. Синтез периодической компоненты (блок 3.2) осуществляется согласно математическому выражению (9).
На фиг.4 проиллюстрирована работа блока 2 декомпозиции речевого сигнала на гармоническую, шумовую и переходную компоненты (сверху вниз на фиг.4 показаны контур частоты основного тона, исходный речевой сигнал, переходная компонента, гармоническая и соответственно шумовая компоненты речевого сигнала).
В блоке 3 конверсии на основании кодовых книг отображения, сформированных в фазе обучения, огибающие частотных характеристик периодической и шумовой компонент конвертируются в параметры целевого диктора. С учетом конверсии просодических параметров (частоты основного тона и временных масштабов (темпа речи)) исходного диктора в целевого синтезируются соответствующие гармонические и шумовые компоненты целевого диктора, которые с учетом фазового выравнивания суммируются в выходном сумматоре 4 с конвертированной переходной компонентой и речевой паузой.
На фиг.6-8 показаны спектрограммы конверсии мужского голоса в женский, голос для фразы из польской речевой базы [Grocholevski, S. "First Database for Spoken Polish", in Proc. Int. Conf. On Language Resources and Evaluation, Grenada, 1998, pp.1059-1062]. "Lubic czardaszowy plas" для схем конверсии аналогов на основе векторного квантования и линейного предсказания, также схемы конверсии данного изобретения.
Анализ показывает, что представление речевого сигнала в виде суммы гармоник основного тона, шума и переходного фрейма позволяет осуществлять конверсию речевых сигналов с достаточно высокой разборчивостью и узнаваемостью целевого диктора. В сравнении со способом конверсии голоса, использующего векторное квантование, здесь синтезированный конвертированный речевой сигнал более близко согласован к речевому сигналу целевого диктора. Более того, в предлагаемом способе качество конверсии в меньшей степени зависит от точности определения вокализованности речевого фрейма и частоты основного тона, как в ближайшем аналоге, потому что имеется переходный фрейм, который также конвертируется. Это приводит к непрослушиванию в восстановленном речевом сигнале исходного диктора, а также по сравнению с ближайшим аналогом весь частотный диапазон вокализованного фрейма разделяется на гармоническую часть и шумовую компоненты. Следовательно, в синтезированном речевом сигнале присутствует естественная шумовая компонента речи в низкочастотной части частотного диапазона, и поэтому в заявленном техническом решении меньше артефактов.
Промышленная применимость
Наиболее успешно заявленный текстозависимый способ конверсии голоса промышленно применим в различного рода системах мультимедиа; синтез речи по тексту (устранение «компьютерного акцента»); виртуальное дублирование (восстановление звуковых дорожек кинофильмов); защита свидетелей (применение в судебной практике); оперативная смена диктора в коммуникационных системах (озвучивание SMS - сообщений в мобильных телефонах) и т.д.
Изобретение относится к электронной технике и может быть использовано при синтезировании речи по тексту. Техническим результатом является повышение степени совпадения голоса целевого диктора в конвертированном речевом сигнале. Указанный технический результат достигается тем, что в фазе обучения в речевом сигнале целевого и исходного дикторов в фрейме анализа выделяют гармоники основного тона, шумовую компоненту и переходную компоненту, определяют вокализованность фрейма речевого сигнала исходного диктора. Если фрейм речевого сигнала вокализован, определяют его частоту основного тона. Если основной тон не выявлен, то фрейм - переходной, если фрейм не вокализован и не переходной, то его представляют как паузу речевого сигнала. Переходный фрейм формируют с помощью линейного предсказателя с возбуждением по его кодовой книге. В фазе конверсии, если фрейм речевого сигнала исходного диктора вокализован, то определяют частоту основного тона речевого сигнала и временной контур ее изменения, и с помощью дискретного преобразования Фурье производят разделение фрейма на гармоники частоты основного тона и на шумовую компоненту, равную остаточному шуму от разности фрейма исходного диктора и ресинтезированного фрейма по гармоникам основного тона. Компоненты конвертируют в параметры целевого диктора, при этом дополнительно учитывают конверсию частоты основного тона для исходного диктора. Синтезируют компоненту гармоник основного тона и шумовую компоненту целевого диктора, которые суммируют с синтезированной переходной компонентой и паузой речевого сигнала. 1 з.п. ф-лы, 8 ил.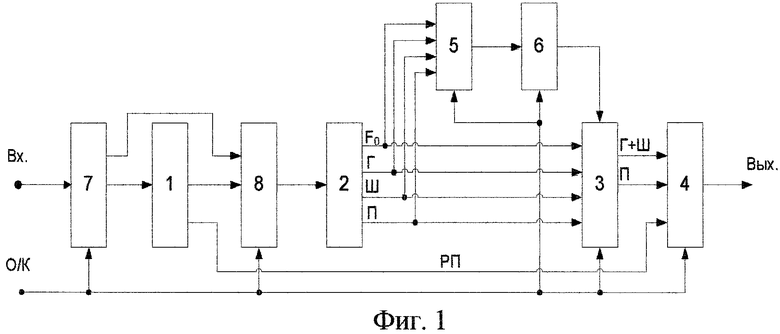
1. Способ конверсии голоса, включающий фазу обучения, заключающуюся в динамическом выравнивании речевых сигналов текстов целевого и исходного дикторов, в формировании соответствующих кодовых книг отображения и функции конверсии речевых сигналов, а также фазу конверсии, заключающуюся в определении параметров речевого сигнала исходного диктора, в конверсии параметров речевого сигнала исходного диктора в параметры речевого сигнала целевого диктора и в синтезе конвертированного речевого сигнала, отличающийся тем, что в фазе обучения в речевом сигнале целевого и исходного дикторов в фрейме анализа выделяют гармоники основного тона, шумовую компоненту и переходную компоненту, при этом вокализованный фрейм речевого сигнала представляют в виде гармоник основного тона и шумовой компоненты, а переходная компонента состоит из невокализованных фреймов речевого сигнала, обрабатывают фрейм речевого сигнала исходного диктора и определяют его вокализованность, если фрейм речевого сигнала вокализован, то определяют его частоту основного тона, если основной тон не выявлен, то фрейм является переходным, а если фрейм не вокализован и не является переходным, то обрабатываемый фрейм представляют как паузу речевого сигнала, далее переходный фрейм формируют с помощью линейного предсказателя с возбуждением по его кодовой книге, определяют коэффициенты фильтра линейного предсказателя и параметры долговременного фильтра линейного предсказателя, которые затем на основании соответствующих кодовых книг отображения конвертируют в параметры целевого диктора и синтезируют переходный фрейм целевого диктора, в фазе конверсии, если фрейм речевого сигнала исходного диктора вокализован, то определяют частоту основного тона речевого сигнала и временной контур ее изменения и с помощью дискретного преобразования Фурье, согласованного с частотой основного тона, далее производят разделение фрейма речевого сигнала исходного диктора на компоненты - на гармоники частоты основного тона и на шумовую компоненту, равную остаточному шуму от разности фрейма исходного диктора и ресинтезированного фрейма по гармоникам основного тона, эти упомянутые компоненты на основании кодовых книг отображения конвертируют в параметры целевого диктора, при этом дополнительно учитывают конверсию частоты основного тона для исходного диктора, синтезируют компоненту гармоник основного тона и шумовую компоненту целевого диктора, которые суммируют с синтезированной переходной компонентой и паузой речевого сигнала.
2. Способ по п.1, отличающийся тем, что при определении частоты основного тона осуществляют низкочастотную фильтрацию фрейма речевого сигнала исходного диктора фильтром с частотой среза 1000 Гц, вычисляют нормализованную функцию автокорреляции и определяют параметры, близкие к частоте основного тона, при этом пики автокорреляционной функции на 30% ниже ее максимального значения номинируют как не соответствующие частоте основного тона, далее динамическим программированием параметров вычисляют весовые функции с учетом временного контура частоты основного тона в предыдущих фреймах речевого сигнала исходного диктора, при этом определяют максимально сглаженный временной контур изменения частоты основного тона, параметр с минимальным значением весовой функции выбирают в качестве начальной оценки частоты основного тона на данном фрейме речевого сигнала исходного диктора, оценки частоты основного тона уточняют путем определения гармоник частоты основного тона и шумовой компоненты фрейма речевого сигнала исходного диктора, вычисляют отношение мощности гармоники основного тона к мощности шумовой компоненты, в интервале изменения частоты основного тона определяют значение частоты основного тона, для которой значение отношения мощности гармоник основного тона к мощности шумовой компоненты для данного фрейма речевого сигнала исходного диктора максимально, и этот параметр частоты основного тона полагают истинным.
| WO 2010031437 A1, 25.03.2010 | |||
| JP 2005266349 A, 29.09.2005 | |||
| СПОСОБ СЪЕМКИ ШКУР С ТУШ ЖИВОТНЫХ | 0 |
|
SU247067A1 |
| US 6615174 B1, 02.09.2003 | |||
| JP 2005266823 A, 29.09.2005 | |||
| CN 101359473 A, 04.02.2009 | |||
| 0 |
|
SU93173A1 | |

