Изобретение относится к электронной технике, преимущественно с использованием программно управляемых электронных устройств обработки информации, и может быть использовано в синтезе речи.
Известно устройство для определения и коррекции акцента, включающее в себя: (а) средства для ввода нежелательных речевых образов, в которых упомянутые выше речевые образы оцифровываются, анализируются и сохраняются в цифровой памяти в виде библиотеки нежелательных речевых образов; (b) средства для ввода правильных речевых образов, соответствующих упомянутым выше нежелательным речевым образам, в которых упомянутые выше правильные речевые образы оцифровываются, анализируются и сохраняются в цифровой памяти в виде библиотеки правильных речевых образов; (с) средства для активного распознавания поступающих речевых образов, сравнения упомянутых выше распознанных речевых образов с нежелательными речевыми образами, сохраненными в цифровой памяти в виде библиотеки нежелательных речевых образов, и удаления и постановки в очередь замены нежелательных речевых образов, выявленных в упомянутых выше поступающих речевых образах; (d) средства для анализа упомянутых выше нежелательных речевых образов, выявленных в поступающих речевых образах, и определения однозначно соответствующих им правильных речевых образов; и (е) средства для замены упомянутых выше нежелательных речевых образов, выявленных в поступающих речевых образах, упомянутыми выше правильными речевыми образами, которые признаны однозначно соответствующими упомянутым выше нежелательным речевым образам, с получением в результате выходных речевых образов, в которых упомянутые выше нежелательные речевые образы удалены и заменены упомянутыми выше правильными речевыми образами (Заявка на патент США №20070038455. G10L 13/00, опубл. 15.02.2007).
В этом устройстве входной аудиосигнал анализируется на наличие предварительно заданных нежелательных речевых образов, т.е. фонем или фонемных групп, которые нуждаются в исправлении, например, представляющих собой иностранный акцент. Эти нежелательные образы затем изменяются или полностью заменяются предварительно сохраненными звуковыми образами, скорректированными на тональность голоса пользователя. Уровень коррекции речи, т.е. набор подлежащих изменению фонем может задаваться нужным образом. Устройство работает в двух режимах: первый - режим обучения, т.е. сохранение нежелательных фонем и звуковых образов для их замены, а второй - режим исправления, т.е. в котором осуществляется изменение фонем на основе сохраненной информации. Для осуществления этого изобретения используется программное обеспечение и оборудование на базе компьютера. Оборудование, принцип действия которого основан на параллельной обработке сигналов, позволяет корректировать акцент в реальном времени с различными уровнями сложности, вплоть до сверхсложных систем коррекции различных акцентов у нескольких пользователей, базирующихся на многоконтурной архитектуре, состоящей из нескольких микросхем и плат.
Ограничением этого устройства является возможность только коррекции нежелательных фонем и невозможность регулирования других речевых характеристик, например, изменения тембра голоса.
Известно устройство обработки речевой информации для модуляции входного голосового сигнала путем преобразования его в выходной голосовой сигнал, содержащее устройство ввода, выполненное с возможностью введения звукового сигнала, представляющего собой входной голосовой сигнал с характерным частотным спектром, устройство обработки звукового сигнала, выполненное с процессором, обеспечивающим изменение частотного спектра входного голосового сигнала, базу данных параметров, в которой сохраняется несколько наборов параметров, каждый из которых индивидуально характеризует изменение частотного спектра процессором, устройство управления, которое выбирает из базы данных параметров нужный набор параметров и настраивает процессор с помощью выбранного набора параметров, и устройство воспроизведения, выполненное с возможностью вывода звукового сигнала, обработанного процессором и представляющим собой голосовой сигнал с выходными характеристиками частотного спектра, соответствующими выбранному набору параметров (Патент США №5847303, G10H 1/36, опубл. 08.12.1998).
В этом устройстве осуществляется конвертация частотного диапазона, которая позволяет мужчинам петь караоке женским голосом и наоборот. Кроме того, устройство позволяет петь песню караоке голосом выбранного профессионального певца/певицы за счет изменения частотного спектра. Таким образом, устройство позволяет изменять речевые характеристики в соответствии с набором заранее заданных параметров, хранящихся в базе данных вычислительного устройства, например, компьютера.
Ограничениями устройства являются: звуковой сигнал можно преобразовать только в заранее заданный звуковой сигнал, характеризующийся заранее сохраненными параметрами в базе данных; невозможность воспроизведения измененного звукового сигнала в другой точке пространства, т.к. устройство предназначено только для использования в караоке, данное устройство в режиме реального времени может использовать только один пользователь.
Известно устройство для конвертации входящего голосового сигнала в выходящий голосовой сигнал в соответствии с целевым голосовым сигналом, содержащее источник входящего звукового сигнала, запоминающее устройство, которое временно хранит исходные данные, которые соотносятся и берутся из целевого голоса, анализирующее устройство, которое анализирует входящий голосовой сигнал и извлекает из него ряд фреймов входящих данных, представляющих входящий голосовой сигнал, производящее устройство, которое производит ряд фреймов целевых данных, представляющих собой целевой голосовой сигнал, основанный на исходных данных, корректируя фреймы целевых данных относительно фреймов входящих данных, и синтезирующее устройство, которое синтезирует выходящий голосовой сигнал в соответствии с фреймами целевых данных и фреймами входящих данных, при этом производящее устройство выполнено на базе характеристического анализатора, который выполнен обеспечивающим извлечение из входящего голосового сигнала характеристического вектора, являющегося характеристикой выходного голосового сигнала, и на базе корректирующего процессора, при этом запоминающее устройство сохраняет данные характеристических векторов для использования при распознавании их, содержащихся во входящем голосовом сигнале, и сохраняет данные функции преобразования, которые являются частью исходных данных и представляют собой характеристику целевого поведения голосового сигнала, причем корректирующий процессор определяет данные распознавания характеристических векторов и данные функции преобразования в отношении данных выходной корректировки, соответствующей информации о тоне данных функции преобразования, информации об амплитуде данных целевого поведения и информации о форме огибающего спектра характеристического вектора, при этом анализирующее устройство, характеристический анализатор, корректирующий процессор и синтезирующее устройство соединены последовательно, выход данных характеристических векторов запоминающего устройства подсоединен к входу данных характеристического анализатора, а выход данных функции преобразования запоминающего устройства подсоединен к входу данных корректирующего процессора, при этом в устройство введены переключатель режима обучения/эксплуатации и анализатор входного сигнала, источник входящего звукового сигнала подсоединен к входу переключателя режима обучения/эксплуатации, запоминающее устройство снабжено блоком фонограмм, обеспечивающим хранение данных базы фонограмм профессиональных исполнителей, вход/выход переключателя режима обучения/эксплуатации подсоединен к входу/выходу анализатора входного сигнала, а его выход - к входу блока фонограмм запоминающего устройства, первый выход данных блока фонограмм подсоединен к входу анализатора входного сигнала, а второй выход данных блока фонограмм - к входу анализирующего устройства, анализатор входного сигнала выполнен обеспечивающим разложение входящего голосового сигнала, поступающего на его вход/выход через переключатель режима обучения/эксплуатации от источника входящего звукового сигнала, на синусоидальные компоненты сигнала, шумовые компоненты сигнала и остаточные компоненты сигнала и выполнен с возможностью формирования наборов характеристических векторов и функций преобразования для каждой упомянутой компоненты по отдельности и передачи их в запоминающее устройство, анализирующее устройство выполнено обеспечивающим разложение входящего голосового сигнала с блока фонограмм на синусоидальные компоненты сигнала, шумовые компоненты сигнала и остаточные компоненты сигнала, а характеристический анализатор и корректирующий процессор выполнены с возможностью обработки упомянутых компонент по отдельности (Патент РФ №2393548, G10L 13/00, опубл. 27.06.2010).
Устройство позволяет обеспечить в караоке исполнение песни голосом пользователя, но в манере и с качественным уровнем исполнения профессионального певца (например, не хуже уровня исполнения известного исполнителя данной песни), при этом минимизируются ошибки, допускаемые пользователем при исполнении.
Ограничением устройства являются невозможность контроля режима обучения для получения наиболее высокого качества воспроизведения в режиме эксплуатации.
Известен способ конверсии голоса, включающий фазу обучения, заключающуюся в динамическом выравнивании речевых сигналов текстов целевого и исходного дикторов, в формировании соответствующих кодовых книг отображения и функции конверсии речевых сигналов, а также фазу конверсии, заключающуюся в определении параметров речевого сигнала исходного диктора, в конверсии параметров речевого сигнала исходного диктора в параметры речевого сигнала целевого диктора и в синтезе конвертированного речевого сигнала, причем в фазе обучения в речевом сигнале целевого и исходного дикторов в фрейме анализа выделяют гармоники основного тона, шумовую компоненту и переходную компоненту, при этом вокализованный фрейм речевого сигнала представляют в виде гармоник основного тона и шумовой компоненты, а переходная компонента состоит из невокализованных фреймов речевого сигнала, обрабатывают фрейм речевого сигнала исходного диктора и определяют его вокализованность, если фрейм речевого сигнала вокализован, то определяют его частоту основного тона, если основной тон не выявлен, то фрейм является переходным, а если фрейм не вокализован и не является переходным, то обрабатываемый фрейм представляют как паузу речевого сигнала, далее переходный фрейм формируют с помощью линейного предсказателя с возбуждением по его кодовой книге, определяют коэффициенты фильтра линейного предсказателя и параметры долговременного фильтра линейного предсказателя, которые затем на основании соответствующих кодовых книг отображения конвертируют в параметры целевого диктора и синтезируют переходный фрейм целевого диктора, в фазе конверсии, если фрейм речевого сигнала исходного диктора вокализован, то определяют частоту основного тона речевого сигнала и временной контур ее изменения и с помощью дискретного преобразования Фурье, согласованного с частотой основного тона, далее производят разделение фрейма речевого сигнала исходного диктора на компоненты - на гармоники частоты основного тона и на шумовую компоненту, равную остаточному шуму от разности фрейма исходного диктора и ресинтезированного фрейма по гармоникам основного тона, эти упомянутые компоненты на основании кодовых книг отображения конвертируют в параметры целевого диктора, при этом дополнительно учитывают конверсию частоты основного тона для исходного диктора, синтезируют компоненту гармоник основного тона и шумовую компоненту целевого диктора, которые суммируют с синтезированной переходной компонентой и паузой речевого сигнала (Патент РФ №2427044, G10L 21/00, опубл. 20.08.2011).
Способ позволяет повысить степень совпадения голоса целевого диктора в конвертированном речевом сигнале за счет улучшения разборчивости и узнаваемости голоса непосредственно целевого диктора.
Ограничением известного технического решения является то, что он является полностью текстозависимым и невозможно контролировать процесс (фазу) обучения для наиболее качественного воспроизведения речевого сигнала до и после его конвертирования.
В процессе проведения патентного поиска с точки зрения достигаемого технического результата аналогов заявленному техническому решению не выявлено.
Решаемая изобретением задача - повышение качества и технико-эксплуатационных характеристик.
Технический результат, который может быть получен при осуществлении заявленных способа и устройства, - повышение качества фазы обучения и темпа ее проведения, улучшение степени совпадения голоса пользователя (целевого диктора) в конвертированном речевом сигнале за счет улучшения точности, разборчивости и узнаваемости голоса непосредственно пользователя, обеспечение возможности одноразового проведения фазы обучения для конкретного аудиоматериала, и использования этих данных фазы обучения для переозвучивания других аудиоматериалов.
В заявленном техническом решении в фазе обучения могут применяться следующие базы:
- Универсальная. Предназначена для переозвучивания голосом пользователя любых аудиоматериалов (аудиокниг). То есть пользователь единожды обучает программно управляемое электронное устройство обработки информации по данной базе и далее имеет возможность переозвучивать любые аудиокниги без дообучения устройства. Таким образом, при последующем воспроизведении аудиоматериалов получают текстонезависимость.
- Специализированная. Подготавливается программно управляемым электронным устройством обработки информации под конкретную совокупность аудиоматериалов (то есть для одной группы аудиокниг нужна одна база, для другой группы - другая база. Текстозависимость).
Для решения поставленной задачи с достижением указанного технического результата способ переозвучивания аудиоматериалов заключается в том, что в программно управляемом электронном устройстве обработки информации формируют акустическую базу исходных аудиоматериалов, включающую параметрические файлы, и акустическую обучающую базу, включающую wav файлы обучающих фраз диктора и соответствующую акустической базе исходных аудиоматериалов, транспортируют данные из акустической базы исходных аудиоматериалов для отображения списка исходных аудиоматериалов на экране монитора, при выборе пользователем из списка акустической базы исходных аудиоматериалов по меньшей мере одного аудиоматериала, данные о нем передают для сохранения в оперативное запоминающее устройство программно управляемого электронного устройства обработки информации, и осуществляют выбор из акустической обучающей базы соответствующих wav файлов обучающих фраз диктора выбранному аудиоматериалу, которые преобразуют в звуковые фразы и передают их пользователю на устройство воспроизведения звука, пользователь посредством микрофона воспроизводит звуковые фразы, в процессе воспроизведения которых на экране монитора отображают текст воспроизводимой фразы и курсор, перемещающийся по тексту фразы в соответствии с тем, как пользователь должен ее воспроизвести, в соответствии с воспроизводимыми фразами создают wav файлы, которые сохраняют по порядку воспроизведения фраз в формируемой акустической базе целевого диктора, при этом программно управляемое электронное устройство обработки информации производит контроль скорости воспроизводимой фразы и ее громкости, по wav файлам сохраненным в акустической базе целевого диктора и wav файлам акустической обучающей базы формируют файл функции конверсии, затем параметрические файлы акустической базы исходных аудиоматериалов, используя файл функции конверсии, конвертируют и преобразуют в wav файл для сохранения в формируемой акустической базе конвертированных аудиоматериалов и предоставления пользователю конвертированных аудиоматериалов на экране монитора.
Возможны дополнительные варианты осуществления способа, в которых целесообразно, чтобы:
- при использовании в качестве управляемого электронного устройства обработки информации удаленного сервера или компьютера, функционирующего в многопользовательском режиме, дополнительно производили регистрацию пользователя;
- перед воспроизведением пользователем посредством микрофона звуковых фраз, производили запись фонового шума, которую сохраняют в виде wav файла в акустической базе целевого диктора, а программно управляемое электронное устройство обработки информации осуществляет шумоподавление фонового шума;
- при контроле скорости воспроизводимой фразы программно управляемое электронное устройство обработки информации осуществляет фильтрацию цифрового RAW-потока, соответствующего воспроизводимой фразе, рассчитывают мгновенную энергию и сглаживают результаты расчета мгновенной энергии, сравнивают значение сглаженного значения средней энергии с заданным пороговым значением, подсчитывают среднюю продолжительность пауз в wav файле, и программно управляемое электронное устройство обработки информации принимает решение о соответствии скорости речи эталонной;
- при контроле скорости воспроизводимой фразы программно управляемое электронное устройство обработки информации осуществляет оценку длительности слоговых сегментов, для этого производят нормирование речевого сигнала воспроизводимой фразы, фильтрацию, детектирование, перемножение огибающих сигналов воспроизводимой фразы, дифференцирование, сравнение полученного сигнала воспроизводимой фразы с пороговыми напряжениями и выделение логического сигнала, соответствующего наличию слогового сегмента, рассчитывают длительность слогового сегмента, после чего программно управляемое электронное устройство обработки информации принимает решение о соответствии скорости речи эталонной;
- при контроле громкости воспроизводимой фразы задают нижнюю границу диапазона громкости и верхнюю границу диапазона громкости, сравнивают громкость воспроизводимой фразы с границами диапазона громкости, при громкости воспроизводимой фразы вне упомянутых границ диапазона программно управляемое электронное устройство обработки информации отображает на экране монитора сообщение о нарушении громкости воспроизводимой фразы;
- после сохранения wav файлов в акустической базе целевого диктора и wav файлов в акустической обучающей базе программно управляемое электронное устройство обработки информации производит нормализацию wav файлов, их обрезку, шумоподавление и контроль соответствия воспроизведенного и отображенного текста воспроизводимой фразы.
Для решения поставленной задачи с достижением указанного технического результата устройство переозвучивания аудиоматериалов содержит блок управления, блок выбора аудиоматериалов, акустическую базу исходных аудиоматериалов, акустическую базу целевого диктора, блок обучения, блок воспроизведения фраз, блок записи фраз, акустическую обучающую базу, блок конверсии, базу функции конверсии, акустическую базу конвертированных аудиоматериалов, блок отображения результатов конверсии, монитор, клавиатуру, манипулятор, микрофон, устройство воспроизведения звука, при этом выход клавиатуры подсоединен к первому входу блока управления, к первому входу блока выбора аудиоматериалов, и к первому входу блока отображения результатов конверсии, выход манипулятора подсоединен к второму входу блока управления, к второму входу блока выбора аудиоматериалов, и к второму входу блока отображения результатов конверсии, вход монитора подсоединен к выходу блока выбора аудиоматериалов, к выходу блока обучения, к первому выходу блока воспроизведения фраз, к выходу блока записи фраз, к выходу блока конверсии, к выходу блока отображения результатов конверсии, вход устройства воспроизведения звука подсоединен к второму выходу блока воспроизведения фраз, выход микрофона подсоединен к входу блока записи фраз, первый вход/выход блока управления подсоединен к первому входу/выходу блока выбора аудиоматериалов, второй вход/выход блока управления - к первому входу/выходу акустической базы целевого диктора, третий вход/выход блока управления - к первому входу/выходу блока обучения, четвертый вход/выход блока управления - к первому входу/выходу блока конверсии, пятый вход/выход блока управления - к первому входу/выходу блока отображения результатов конверсии, второй вход/выход блока выбора аудиоматериалов подсоединен к первому входу/выходу акустической базы исходных аудиоматериалов, а второй вход/выход акустической базы исходных аудиоматериалов подсоединен к четвертому входу/выходу блока конверсии, второй вход/выход акустической базы целевого диктора подсоединен к первому входу/выходу блока записи фраз, а второй вход/выход блока записи фраз - к третьему входу/выходу блока обучения, второй вход/выход блока обучения подсоединен к первому входу/выходу блока воспроизведения фраз, а второй вход/выход блока воспроизведения фраз - к входу/выходу акустической обучающей базы, четвертый вход/выход блока обучения подсоединен к первому входу/выходу базы функций конверсии, второй вход/выход базы подсоединен к второму входу/выходу блока конверсии, третий вход/выход блока конверсии подсоединен к второму входу/выходу акустической базы конвертированных аудиоматериалов, а первый вход/выход акустической базы конвертированных аудиоматериалов подсоединен к второму входу/выходу блока отображения результатов конверсии.
Возможен дополнительный вариант выполнения устройства, в котором целесообразно, чтобы в устройство были введены блок авторизации/регистрации и база зарегистрированных пользователей, выход клавиатуры подсоединен к первому входу блока авторизации/регистрации, а выход манипулятора подсоединен к второму входу блока авторизации/регистрации, вход монитора подсоединен к выходу блока авторизации/регистрации, шестой вход/выход блока управления подсоединен к первому входу/выходу блока авторизации/регистрации, а второй вход/выход блока 20 авторизации/регистрации подсоединен к входу/выходу базы зарегистрированных пользователей.
Указанные преимущества заявленного технического решения, а также его особенности поясняются с помощью лучшего варианта выполнения со ссылками на прилагаемые фигуры.
Фиг.1 изображает функциональную схему заявленного устройства;
Фиг.2 - графический интерфейс формы выбора аудиоматериалов;
Фиг.3 - графический интерфейс формы авторизации/регистрации;
Фиг.4 - графический интерфейс формы записи фонового шума;
Фиг.5 - графический интерфейс формы воспроизведения фразы;
Фиг.6 - графический интерфейс формы воспроизведения (записи) прослушанной фразы;
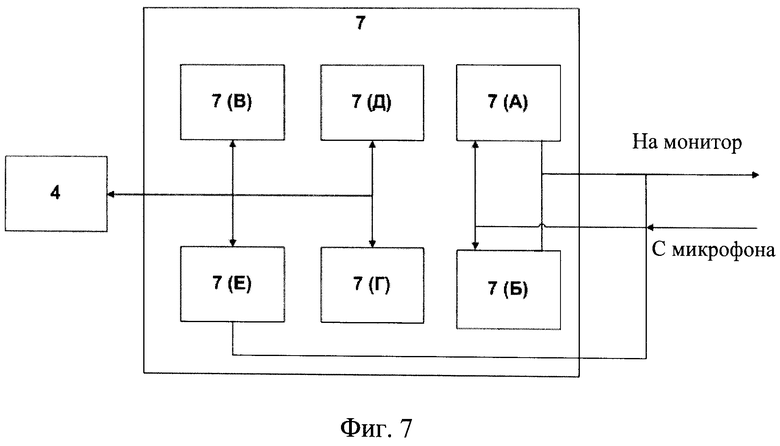
Фиг.7 - подблоки блока записи фраз на фиг.1;
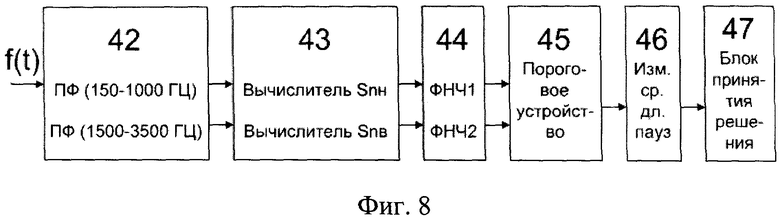
Фиг.8 - блок-схему алгоритма выделения и измерения длительности пауз;
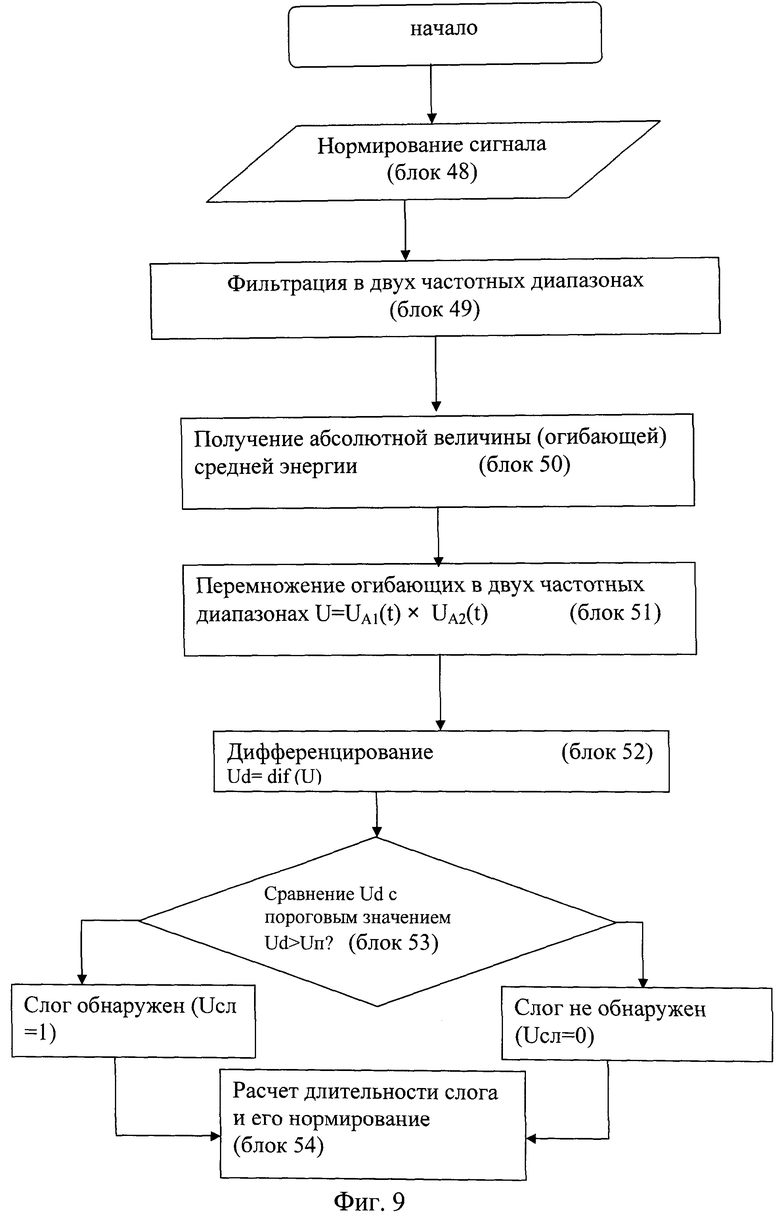
Фиг.9 - блок-схему алгоритма оценки длительности слоговых сегментов;
Фиг.10 - графический интерфейс формы конверсии аудиоматериалов;
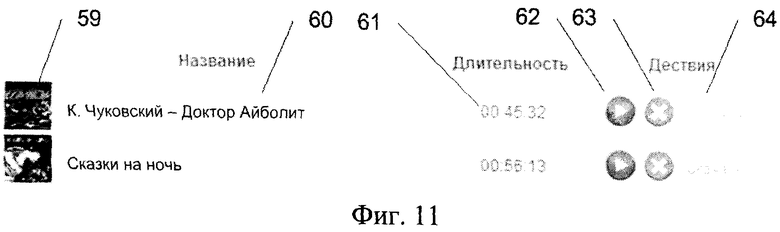
Фиг.11 - графический интерфейс формы результатов конверсии. Поскольку способ переозвучивания материалов детально раскрывается при описании работы устройства, то первоначально приводится описание самого устройства.
Устройство (фиг.1) переозвучивания аудиоматериалов содержит блок 1 управления, блок 2 выбора аудиоматериалов, акустическую базу 3 исходных аудиоматериалов, акустическую базу 4 целевого диктора, блок 5 обучения, блок 6 воспроизведения фраз, блок 7 записи фраз, акустическую обучающую базу 8, блок 9 конверсии, базу 10 функции конверсии, акустическую базу 11 конвертированных аудиоматериалов, блок 12 отображения результатов конверсии, монитор 13, клавиатуру 14, манипулятор 15 («мышь»), микрофон 16, устройство 17 воспроизведения звука, выполненное из динамиков 18 и/или наушников 19. Выход клавиатуры 14 подсоединен к первому входу блока 1 управления, к первому входу блока 2 выбора аудиоматериалов, и к первому входу блока 12 отображения результатов конверсии. Выход манипулятора 15 подсоединен ко второму входу блока 1 управления, к второму входу блока 2 выбора аудиоматериалов, и к второму входу блока 12 отображения результатов конверсии. Вход монитора 13 подсоединен к выходу блока 2 выбора аудиоматериалов, к выходу блока 5 обучения, к первому выходу блока 6 воспроизведения фраз, к выходу блока 7 записи фраз, к выходу блока 9 конверсии, к выходу блока 12 отображения результатов конверсии. Вход устройства 17 воспроизведения звука (динамиков 18 и/или наушников 19) подсоединен ко второму выходу блока 6 воспроизведения фраз. Выход микрофона 18 подсоединен к входу блока 9 записи фраз. Первый вход/выход блока 1 управления подсоединен к первому входу/выходу блока 2 выбора аудиоматериалов, второй вход/выход блока 1 управления - к первому входу/выходу акустической базы 4 целевого диктора, третий вход/выход блока 1 управления - к первому входу/выходу блока 5 обучения, четвертый вход/выход блока 1 управления - к первому входу/выходу блока 9 конверсии, пятый вход/выход блока 1 управления - к первому входу/выходу блока 12 отображения результатов конверсии. Второй вход/выход блока 2 выбора аудиоматериалов подсоединен к первому входу/выходу акустической базы 3 исходных аудиоматериалов, а второй вход/выход акустической базы 3 исходных аудиоматериалов подсоединен к четвертому входу/выходу блока 9 конверсии. Второй вход/выход акустической базы 4 целевого диктора подсоединен к первому входу/выходу блока 7 записи фраз, а второй вход/выход блока 7 записи фраз - к третьему входу/выходу блока 5 обучения. Второй вход/выход блока 5 обучения подсоединен к первому входу/выходу блока 6 воспроизведения фраз, а второй вход/выход блока 6 воспроизведения фраз - к входу/выходу акустической обучающей базы 8. Четвертый вход/выход блока 5 обучения подсоединен к первому входу/выходу базы 10 функций конверсии, второй вход/выход базы 10 подсоединен к второму входу/выходу блока 9 конверсии. Третий вход/выход блока 9 конверсии подсоединен к второму входу/выходу акустической базы 11 конвертированных аудиоматериалов, а первый вход/выход акустической базы 11 конвертированных аудиоматериалов подсоединен к второму входу/выходу блока 12 отображения результатов конверсии.
В устройство могут быть введены блок 20 авторизации/регистрации и база 21 зарегистрированных пользователей, выход клавиатуры 14 подсоединен к первому входу блока 20 авторизации/регистрации, а выход манипулятора 15 подсоединен к второму входу блока 20 авторизации/регистрации, вход монитора 13 подсоединен к выходу блока 20 авторизации/регистрации, шестой вход/выход блока 1 управления подсоединен к первому входу/выходу блока 20 авторизации/регистрации, а второй вход/выход блока 20 авторизации/регистрации подсоединен к входу/выходу базы 21 зарегистрированных пользователей.
Устройство может представлять собой удаленный сервер (на фиг.1 показано штрихпунктиром S), на котором установлено специализированное программное обеспечение (СПО) - блоки 1-12, тогда пользователь со своего компьютерного устройства (на фиг.1 условно показано штрих пунктиром С), при помощи монитора 13, клавиатуры 14, манипулятора 15 («мышь») имеет возможность, например, через сеть Интернет связаться с сайтом удаленного сервера S и осуществить запуск его функций, или устройство S посредством сети Интернет может быть установлено непосредственно на персональном компьютере пользователя или установлено на нем при помощи компакт диска (Compact Disc) или DVD диска (Digital Versatile Disc), тогда устройства S и С являются единым целым.
Работает устройство (фиг.1) следующим образом.
С помощью клавиатуры 14 и/или манипулятора 15 пользователь осуществляет запуск блока 1 управления, который с его первого входа/выхода передает на первый вход/выход блока 2 выбора аудиоматериалов команду на начало функционирования устройства. С второго входа/выхода блока 2 на первый вход/выход акустической базы 3 исходных аудиоматериалов направляется запрос на получение списка аудиоматериалов, содержащегося в ней. Аудиоматериалы, предназначенные для переозвучивания, хранятся в акустической базе 3 в виде параметрических аудиофайлов, например, с расширением war, которые могут быть получены и установлены в акустической базе 3 исходных аудиоматериалов при помощи сети Интернет, компакт дисков и т.п.
В акустической базе 11 конвертированных аудиоматериалов, в акустической обучающей базе 8 и в акустической базе 4 целевого диктора аудиоматериалы хранятся в виде WAV файлов (wav от англ. wave «волна»).
Преобразование WAV-аудиофайла в параметрический аудиофайл, например, с расширением war или наоборот осуществляется известным образом модулем параметризации (на фиг.1 не показан).
Параметрический файл с расширением war описывает аудиосигнал в виде параметров модели речеобразования. Модель речеобразования для использования в данном техническом решении состоит из частоты основного тона (1-ый параметр), вектора мгновенных амплитуд (2-ой параметр), вектора мгновенных фаз (3-ий параметр) и шумового остатка (это 4-ый параметр). Указанные параметры характеризуют акустический сигнал (один такой набор соответствует 5 мс) и нужны для выполнения процедуры конверсии. В процессе конверсии данные параметры изменяются с параметров, соответствующих исходному диктору, на параметры, соответствующие целевому диктору (пользователю), после чего из них формируется (синтезируется) выходной сигнал в формате wav.
Отличия параметрического аудиофайла от файла в формате wav заключаются в том, что wav описывает сигнал в виде последовательности временных отсчетов, в то время как параметрический аудиофайл описывает сигнал в виде набора параметров модели речеобразования, которые изменяются в процессе конверсии. Основное преимущество параметрического файла заключается в том, что сигнал в виде последовательности временных отсчетов не может быть непосредственно обработан так, как этого требует задача конверсии (например, нельзя оценить и изменить его тембр). Недостатки параметрического файла перед файлом в формате wav заключаются в том, что если не требуется модифицировать речь, то он требует больше дискового пространства и не обеспечивает полного восстановления исходного сигнала.
Принципиально важным поэтому с точки зрения быстродействия и осуществления конверсии является то, что в акустической базе 3 исходных аудиоматериалов файлы хранятся в виде параметрических фалов с расширением war (или эквивалентным), а в акустической базе 4 целевого диктора, в акустической обучающей базе 8 - в акустической базе 11 конвертированных аудиоматериалов - в виде wav файлов (или эквивалентных).
После обработки запроса с первого входа/выхода акустической базы 3 передается на второй вход/выход блока 2 выбора аудиоматериалов данные о списке аудиоматериалов, которые с выхода блока 2 поступают на монитор 13 пользователя и отображаются на его экране в графическом интерфейсе (фиг.2).
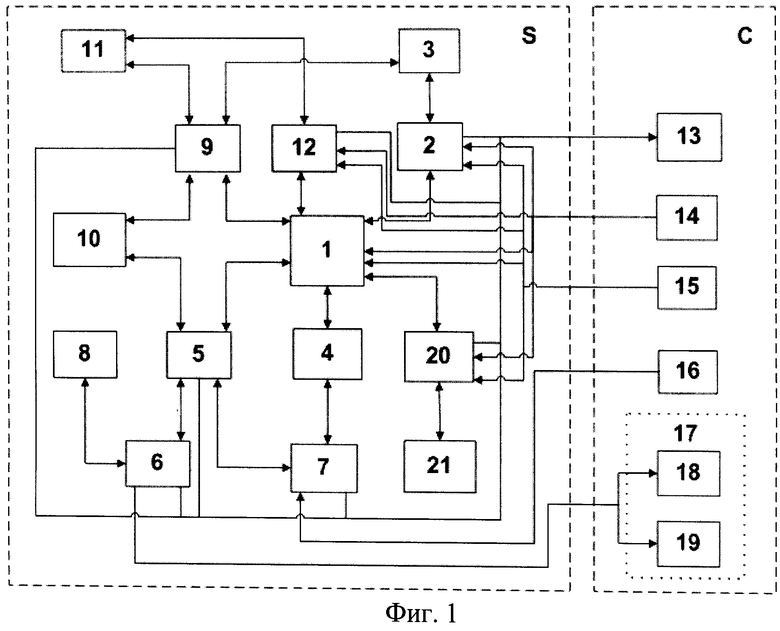
Графический интерфейс, содержащий список аудиоматериалов, может иметь различный внешний вид, форму и инструменты (на фиг.2 показан один из возможных вариантов его выполнения).
Например, форма выбора аудиоматериалов имеет строку 22 фильтрации аудиоматериалов со следующими инструментами:
«Все» - кнопка 23, при нажатии которой с помощью манипулятора 15 в форме выбора аудиоматериалов отображается полный перечень аудиоматериалов из акустической базы 3 исходных аудиоматериалов;
«Новые» - кнопка 24, при нажатии которой в форме выбора аудиоматериалов отображается информация об N (задается в параметрах конфигурации устройства) аудиоматериалах, установленных последними (по времени) в акустическую базу 3 исходных аудиоматериалов;
«Популярные» - кнопка 25, при нажатии которой в форме выбора аудиоматериалов отображается информация об N аудиоматериалах, наиболее часто переозвучиваемых пользователями;
«Возраст» - выпадающий список 26 выбора диапазона возрастов. После выбора значения возраста в выпадающем списке 26 «Возраст», графический интерфейс выбора аудиоматериалов отображает перечень аудиоматериалов, рассчитанных (по интересу) для выбранного возраста;
«Поиск» - поле 27 ввода строки поиска аудиоматериалов. Поиск осуществляется по Наименованию аудиоматериалов (Текстовая строка, ассоциированная с каждым аудиоматериалом: каждому аудиоматериалу соответствует свое наименование. Наименование аудиоматериала храниться в акустической базе 3 исходных аудиоматериалов). После ввода поисковой строки (критерия поиска) в поле «Поиск» форма выбора аудиоматериалов отображает перечень аудиоматериалов, соответствующих введенному критерию поиска. Например, если в поле «Поиск» введено значение «доктор», то в графическом интерфейсе выбора аудиоматериалов отобразятся аудиоматериалы, у которых в названии содержится слово «доктор» («Доктор Айболит», «Доктор Живаго» и т.д.).
Область 28 содержит список аудиоматериалов, отфильтрованных согласно указанных в строке 22 фильтрации критериям. Каждая запись списка отображает информацию, ассоциированную с конкретным аудиоматериалом и хранящуюся в акустической базе 3 исходных аудиоматериалов. Данная информация включает:
Наименование 29 аудиоматериала;
Графическое изображение 30;
Краткое описание 31 содержимого аудиоматериала.
Форма графического интерфейса также содержит:
Кнопку 32 «Выбрать», при нажатии которой блок 2 выбора аудиоматериалов помещает соответствующий аудиоматериал в список аудиоматериалов на переозвучивание - «корзину» (термин «корзина» означает список аудиофайлов, выбранных пользователем для переозвучивания из акустической базы 3). «Корзина» храниться в оперативном запоминающем устройстве (ОЗУ) блока 2. При необходимости блок 1 оперативно извлекает «корзину» из блока 2. По существу блок 1 управления функционально является диспетчером процессов устройства, по аналогии с диспетчером процессов Windows, блок 1 синхронизирует работу остальных блоков 2-12 в соответствии с технологическими операциями, выполняемых ими, и последовательности их функционирования.
Кнопку 33 «Переозвучить», при нажатии которой запускается процесс переозвучивания аудиоматериалов, добавленных в список аудиоматериалов на переозвучивание («корзину»). Если «Корзина» пуста, кнопка «Переозвучить» недоступна.
Пользователь, с помощью клавиатуры 14 и/или манипулятора 15, добавляет в «корзину» при нажатии кнопки 32 «Выбрать» в отображенном на экране монитора 13 списке интересующие его аудиоматериалы.
Блок 2 выбора аудиоматериалов формирует список выбранных пользователем аудиоматериалов следующим образом.
При нажатии инструмента - кнопки 32 «Выбрать» операционная система устройства инициирует событие нажатия кнопки - выбран материал для переозвучивания. Сведения об осуществлении этого события (команда) передаются в блок 2 выбора аудиоматериалов, который перемещает выбранные аудиоматериалы в «корзину» - список, содержащий сведения о выбранных пользователем аудиоматериалах и хранящийся в ОЗУ блока 2).
Точно так же, как описано выше пользователь с помощью клавиатуры 14 и/или манипулятора 15, подает посредством кнопки 33 «Переозвучить» блоку 2 выбора аудиоматериалов команду запуска процесса переозвучивания аудиоматериалов в «корзине».
С первого входа/выхода блока 2 выбора аудиоматериалов передается на первый вход/выход блока 1 управления команда о завершении формирования «корзины», т.е. выбора пользователем, по меньшей мере, одного аудиоматериала для переозвучивания.
Возможно несколько вариантов исполнения устройства переозвучивания аудиоматериалов:
- в виде СПО, установленного на компьютере и функционирующего в однопользовательском режиме. В этом случае авторизация/регистрация не требуется и блок 20 авторизации/регистрации, а также база 21 зарегистрированных пользователей - не нужны;
- в виде СПО, установленного на компьютере и функционирующего в многопользовательском режиме (например, семья - мать, отец, дети пользуются данной программой). В данном случае авторизация/регистрация требуется;
- если устройство реализовано на базе удаленного сервера в виде web-приложения, авторизация/регистрация необходима.
Например, в случае использования удаленного сервера S после заполнения «корзины» блок 1 управления по цепи - шестой вход/выход блока 1-первый вход/выход блока 4 авторизации/регистрации активизирует функцию авторизации пользователя блока 20. Блок 20 инициирует форму авторизации/регистрации графического интерфейса, которая с его выхода поступает на вход монитора 13 для ее отображения пользователю.
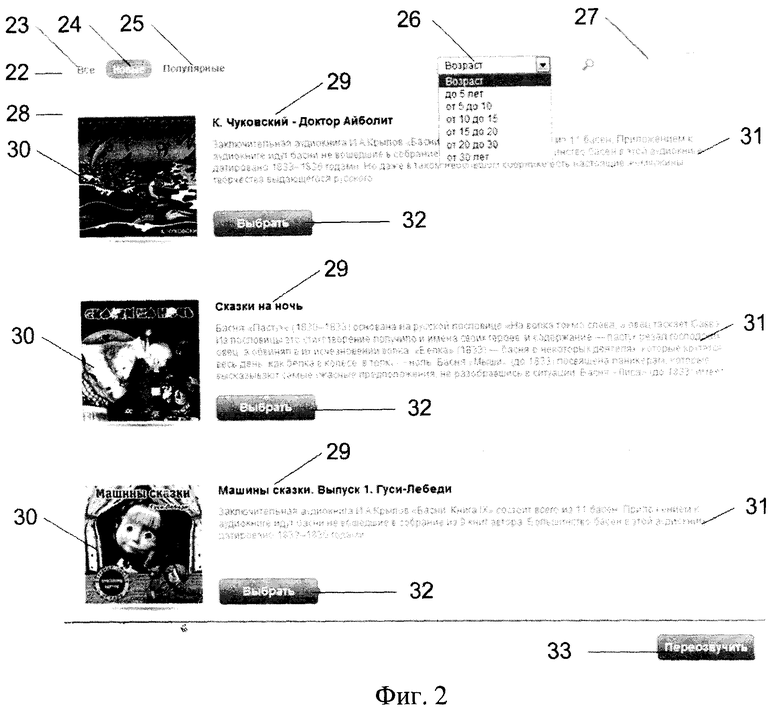
Форма авторизации/регистрации (фиг.3) имеет поля:
34 - «Email», предназначенное для ввода адреса электронной почты пользователя;
35 - «Пароль», предназначенное для ввода пароля пользователя.
Форма авторизации/регистрации также содержит инструменты (кнопки):
36 - «Войти», при нажатии кнопки 36 блок 20 авторизации/регистрации по его второму входу/выходу осуществляет проверку наличия в базе 21 зарегистрированных пользователей информации о пользователе с введенными учетными данными (email и пароль);
37 - «Регистрация», при нажатии кнопки 37 блок 20 авторизации/регистрации инициирует процесс регистрации пользователя в базе 21 зарегистрированных пользователей.
Пользователь посредством манипулятора 15 и клавиатуры 14 заполняет отображенную форму (Ошибка! Источник ссылки не найден.) - вводит свои учетные данные (email и пароль) и подает блоку 20 авторизации/регистрации команду авторизации. Блок 20 со своего второго входа/выхода передает на вход/выход базы 21 зарегистрированных пользователей запрос информации о наличии в базе 21 зарегистрированного пользователя с введенными учетными данными.
Если пользователь с введенными учетными данными отсутствует в базе 21, с выхода блока 20 на экран монитора 13 поступает сообщение об ошибке авторизации, например, «Пользователь с введенными учетными данными не зарегистрирован. Для продолжения работы необходимо ввести корректные учетные данные или зарегистрироваться». Пользователь посредством клавиатуры 14 и манипулятора 15 вводит свой email (логин) в поле 34 формы авторизации/регистрации и нажимает кнопку 37 «Регистрация». Блок 20 авторизации/регистрации генерирует пользователю пароль и уникальный идентификатор пользователя (ID). Сгенерированный пароль блок 20 отображает пользователю на экране монитора 13 (необходим пользователю при последующих авторизациях в устройстве). Данные о пользователе (введенный пользователем email, сгенерированные пароль и ID) поступают со второго входа/выхода блока 20 на вход/выход базы 21 зарегистрированных пользователей для сохранения в базе 21.
Если пользователь с введенными учетными данными уже был зарегистрирован в базе 21, то база 21 зарегистрированных пользователей передает со своего входа/выхода на второй вход/выход блока 20 уникальный ID пользователя. Блок 20 авторизации/регистрации хранит ID пользователя. При необходимости блок 1 оперативно извлекает ID из блока 20.
Список аудиофайлов («корзина») и ID пользователя - это значения, хранящиеся в глобальных переменных (в случае удаленного сервера web-приложения CloneBook), на протяжении всей сессии работы пользователя с устройством данные глобальные переменные доступны всем другим блокам компьютерного устройства.
Далее блок 1 управления со своего второго входа/выхода направляет запрос на первый вход/выход акустической базы 4 целевого диктора для проверки наличия в ней записей фраз пользователя с данным ID (с целью выяснения, обучал ли пользователь ранее заявленное устройство по образцу своего голоса). ID пользователя блок 1 оперативно извлекает из памяти блока 20 по цепи: шестой вход/выход блока 1 - первый вход/выход блока 20. Записи фраз пользователя сохраняются в акустической базе 21 в виде аудиофайлов в директории, наименование которой содержит только ID пользователя (в самой же директории пользователя хранятся записи его фраз).
Если ID этого пользователя не обнаружено в акустической базе 21 (пользователь не обучал устройство по образцу своего голоса), то по третьему входу/выходу блока 1 управления на первый вход/выход блока 5 обучения поступает команда на его функционирование, в соответствии с которой со второго входа/выхода блока 6 и с третьего его входа/выхода соответственно последовательно поступают команды на первый вход/выход блока 6 воспроизведения фраз (из обучающей базы) и на второй вход/выход блока 7 записи фраз (в базу) пользователя. Таким образом, блок 1 управляет блоком 5 (дает ему команду на начало работы), а блок 5, в свою очередь, управляет блоками 6 и 7.
Блок 6 воспроизведения фраз предназначен для воспроизведения пользователю фразы из обучающей базы 8, поэтому его второй вход/выход подсоединен к входу/выходу акустической обучающей базы 8, а его выход к устройству 17 воспроизведения звука (динамикам 18 и/или наушникам 19). Wav файлы обучающей базы 8 преобразуют драйвером в звуковые фразы. Пользователь, прослушав фразу, после сигнала устройства типа «готов к записи», должен повторить ее в микрофон 18. Блок 9 предназначен для записи воспроизведенной пользователем фразы и его вход подсоединен к выходу микрофона 16. Преобразование аналоговых сигналов микрофона 16 и устройства 17 воспроизведения звука в цифровые осуществляется с помощью драйверов соответствующих устройств. Например, звук от микрофона 16 преобразуется в цифровой raw-поток (аудиопоток) с помощью драйвера звуковой карты.
Для записи фразы пользователем блоком 7 задается время ΔТ, в течение которого пользователь должен повторить фразу, воспроизведенную блоком 6 (время ΔT определяется продолжительностью фразы, записанной в акустической обучающей базе 8).
Перед воспроизведением фраз пользователем и записи их в акустическую базу 4, с выхода блока 7 передается на экран монитора 13 графический интерфейс записи фонового шума.
Графический интерфейс записи фонового шума (Ошибка! Источник ссылки не найден.) содержит:
Кнопку 38 «Начать запись», при нажатии которой запускается процесс записи фонового шума. Фоновый шум считывается при помощи микрофона 16 и передается на вход блока 7 записи фраз, который в виде аудио-потока передается с первого входа/выхода блока 7 на второй вход/выход акустической базы 4 целевого диктора, и аудио-поток сохраняется в форме аудиофайла. Аудиофайл с фоновым шумом сохраняется в акустической базе 4 в директории пользователя (наименование которой содержит ID пользователя).
Аудиофайл с фоновым шумом сохраняется в акустической базе 4 в директории, наименование которой содержит только ID пользователя. Данную директорию создает (перед сохранением первой записанной пользователем фразы) акустическая база 4. ID пользователя акустическая база 4 запрашивает у блока 1 управления по цепи «первый вход/выход базы 4» - «второй вход/выход блока I». Блок 1 управления оперативно извлекает ID пользователя из блока 4 по цепи «шестой вход/выход блока 1» - «первый вход/выход блока 20».
На экране монитора 13 формируется индикатор 39 (фиг.4) процесса записи фонового шума.
Пользователь посредством манипулятора 15 нажимает кнопку 38. В период, когда осуществляется запись фонового шума (курсор индикатора 39 перемещается от 0 до 100%), пользователь должен соблюдать тишину.
После завершения записи фонового шума блок 6 воспроизведения фраз с его выхода передает на экран монитора 13 для отображения графический интерфейс воспроизведения фразы (Ошибка! Источник ссылки не найден.). Конкретную фразу блок 6 воспроизведения фраз получает из акустической обучающей базы 8 в виде файла и воспроизводит пользователю с помощью устройства 17 воспроизведения звука.
Акустическая обучающая база 8 содержит определенное количество аудиофайлов с фразами, количество которых (реализованных на практике), например, составляет тридцать шесть. Блок 6 последовательно их воспроизводит. Причем последовательность их воспроизведения не важна. Информация о том, какие фразы блок 8 уже воспроизвел, а какие еще нужно воспроизвести, храниться в самом блоке 8.
Выбор обучающих фраз для конкретного аудиоматериала осуществляется следующим образом.
В акустической базе 3 исходных аудиоматериалов каждому аудиоматериалу сопоставляется перечень фраз из акустической обучающей базы 8. Сопоставление осуществляется в виде перечня вида: «аудиоматериал-01.wav» - «фразы из базы 10: 001. wav, 005.wav, 007.wav…». фразы для аудиоматериала акустической базы 3 подбираются с помощью аллофонного анализа текста, например, автоматизированным способом (Национальная Академия Наук Белоруссии, Объединенный институт проблем информатики. Б.М.Лобанов, Л.И.Цирульник. «Компьютерный синтез и клонирование речи», Минск, Белорусская наука, 2008 г., стр.198-243) и сохраняются в акустической обучающей базе 8.
На графическом интерфейсе воспроизведения фразы (Ошибка! Источник ссылки не найден.) отображают индикатор 40 воспроизводимой фразы, содержащий:
- Текст воспроизводимой фразы (для примера на фиг.5 это текст - «Идет холодная зима»). Данный текст сопоставлен с конкретной фразой и хранится вместе с ней в акустической обучающей базе 8 в текстовом файле. Блок 6 воспроизведения фраз загружает этот текст вместе с воспроизводимым аудиофайлом и отображает в графическом интерфейсе воспроизведения фразы в индикаторе 40;
- Курсор, перемещающийся по тексту фразы по мере его воспроизведения.
В процессе воспроизведения фразы местоположение курсора синхронизировано с воспроизведением фразы. То есть в начале воспроизведения фразы курсор располагается у первого символа текста фразы, в конце воспроизведения - у последнего символа. Скорость движения курсора учитывает темп речи диктором фразы из акустической обучающей базы 8. То есть, если диктор акустической фразы «тянет» букву в слове, курсор «снижает» скорость перемещения на данной букве (например, если слово «Ножницы» диктор произносит с задержкой на букве «о», то есть «Но-о-о-о-ожницы», то курсор на букве «о» также замедляет перемещение).
Информация о местоположении курсора (скорости его движения по тексту) содержится в параметрическом файле скорости курсора. Параметрический файл скорости курсора представляет собой набор пар значений-соответствий: «положение курсора- м. сек». Каждой фразе (звуковому файлу) из акустической обучающей базы 8 соответствует свой параметрический файл скорости курсора, например, с расширением car.
Блок 5 обучения формирует команду на запуск блока 6 воспроизведения фраз по цепи «второй вход/выход блока 5 - первый вход/выход блока 6». Команда - воспроизвести очередную фразу из акустической обучающей базы 8. Очередность устанавливает блок 6. После того как блок 6 воспроизвел фразу и вернул блоку 5 результат работы (результатом является номер воспроизведенной фразы, например, «001.wav»), блок 5 создает команду на запуск блока 7 записи фраз (по цепи «третий вход/выход блока 5 - второй вход/выход блока 7»). Блок 7 записывает фразу пользователя и возвращает результат блоку 5 по той же цепи. Результатом является номер записанной в базе 4 фразы. Напр., «002.wav». Этот цикл повторяется по каждой фразе из обучающей акустической базы 8.
После прослушивания фразы пользователем происходит запись этой же фразы пользователем. Пользователь должен произнести прослушанную фразу в том же темпе. Блок 7 записи фраз отображает на экране монитора 13 пользователю следующий возможный графический интерфейс записи фразы (Ошибка! Источник ссылки не найден.).
Графический интерфейс записи фразы имеет индикатор 41 записываемой фразы, содержащий:
- Текст воспроизводимой фразы (для примера на Ошибка! Источник ссылки не найден, это текст «Идет холодная зима»);
- Курсор, перемещающийся по тексту фразы в соответствии с тем, как пользователь должен ее воспроизвести. Скорость воспроизведения фразы по тексту содержится в параметрическом файле скорости курсора (описан выше).
Пользователь произносит прослушанную фразу в микрофон 16. Аудио-поток от выхода микрофона 16 поступает на блок 7 записи фраз, который посредством его первого входа/выхода, поступает на второй вход/выход акустической базы 4 целевого диктора и сохраняется в базе 4 в форме аудиофайла. Аудиофайл сохраняется в акустической базе 4 в директории, наименование которой содержит только ID пользователя. Данную директорию создает (перед сохранением первой записанной пользователем фразы) акустическая база 4. ID пользователя акустическая база 4 запрашивает у блока 1 управления по цепи «первый вход/выход акустической базы 4» - «второй вход/выход блока I». Блок 1 управления оперативно извлекает ID пользователя из блока 20 по цепи «шестой вход/выход блока 1» - «первый вход/выход блока 20».
В процессе записи фразы блок 7 записи фраз осуществляет (фиг.7) контроль скорости речи пользователя. Если обучающий компьютерное устройство пользователь говорит слишком быстро или слишком медленно (нарушает темп речи), блок 7(А) контроля скорости речи из состава блока 9 записи фраз отображает на экране монитора 13 предупреждающее сообщение о нарушении темпа речи: Например, «Вы говорите слишком быстро, говорите медленнее» (если пользователь говорит быстро), или «Вы говорите слишком медленно, говорите быстрее» (если пользователь говорит медленно). Текст предупреждающих сообщений содержится в программе блока 7(А).
Блок 7(А) контроля скорости речи (является собственной разработкой) определяет скорость (темп) речи следующим образом.
Определение темпа речи основано на использовании двух алгоритмов:
определения длительности пауз и выделении, а также оценке длительности слоговых сегментов в речевом сигнале. Локализация пауз проводится методом цифровой фильтрации в двух спектральных диапазонах, соответствующих локализации максимумов энергии для вокализованных и шумных (невокализованных) звуков, фильтрами Лернера четвертого порядка, «взвешивания» кратковременной энергии речевого сигнала в двух частотных диапазонах с использованием прямоугольного окна длительностью 20 мс.
Определение длительности слоговых сегментов основано на уточненной слуховой модели, учитывающей спектральное распределение гласных звуков, фильтрации в двух взаимно коррелированных спектральных диапазонах. Принятие решения о принадлежности сегмента речи к слогу, содержащему гласный звук, и локализация гласного звука проводится программно реализованной комбинационной логической схемой.
Заключение о скорости речи говорящего (темпе речи) производится на основании анализа обоими алгоритмами на интервале накопления информации: всего файла для режима ОффЛайн, или чтением потока (файла) с выводом результатов каждые 15 с.
В общем случае алгоритм определения темпа речи состоит из следующих этапов:
- Нормирование речевого сигнала. Обеспечивает выравнивание слабых (тихих) сигналов с целью исключения зависимости результатов измерения от громкости входного речевого сигнала.
- Выделение и измерение длительности пауз. Формирование первичных признаков темпа. (Алгоритм 1)
- Оценка длительности слоговых сегментов. Формирование главных признаков. (Алгоритм 2)
- Принятие решения о скорости воспроизводимой фразы.
1. Нормирование входного речевого сигнала воспроизводимой фразы
Нормирование входного речевого сигнала проводится с целью исключения зависимости результатов измерений от амплитуды (громкости) записанного или вводимого сигнала.
Нормирование производится следующим образом:
- на интервалах длительностью 1 с производится поиск максимального абсолютного значения амплитуды.
- находится среднее значение в полученном массиве.
- определяется коэффициент пересчета по формуле, равный отношению максимально возможного значения амплитуды к найденному среднему значению.
- каждое значение входного сигнала умножается на коэффициент пересчета.
2. Выделение и измерение длительности пауз. (Алгоритм 1)
Метод основан на измерении мгновенной энергии в двух частотных диапазонах, соответствующих максимальному сосредоточению энергии вокализованных (диапазон частот 150-1000 Гц) и невокализованных (диапазон частот 1500-3500 Гц) звуков.
Блок-схема Алгоритма 1 представлена на Ошибка! Источник ссылки не найден..
2.1. Фильтрация
Блок 42 осуществляет фильтрацию второго порядка (фильтром Лернера) входного речевого сигнала (воспроизводимой фразы пользователя) в выходной речевой сигнал.;
Входной речевой сигнал представляет собой цифровой raw-поток (англ. raw-сырой) - аудиопоток - значение сигнала от 0 до 32768, является безразмерной величиной.
Формула типового звена фильтрации второго порядка (фильтра Лернера) эквивалентна разностному уравнению во временной области вида
Y(n)=(2×Y1-X1)×K1-Y2×K2+X(n); где
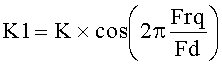 ;
;
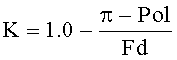 ;
;
K2=K×K
X(n) - текущее значение входного сигнала;
Y(n) - текущее значение выходного сигнала;
Y1 - значение выходного сигнала, задержанное на один период дискретизации;
Y2 - значение выходного сигнала, задержанное на два периода дискретизации;
Pol - полоса пропускания в Гц;
Pol=850 Гц для первого и 2000 Гц для второго полосовых фильтров;
Fd - частота дискретизации в Гц. Fd=8000 Гц;
Frq - средняя частота полосы фильтра в Гц, Frq=575 Гц для первого и 2500 Гц для второго полосовых фильтров;
K, K1, K2 - коэффициенты фильтрации.
Фильтр 4-го порядка реализуется путем каскадного последовательного соединения двух звеньев второго порядка указанного типа.
2.2. Расчет мгновенной энергии речевого сигнала
Расчет мгновенной энергии речевого сигнала производится блоком 43.
Расчет мгновенной энергии производится на интервалах (в окне) длительностью 20 мс), что соответствует для частоты дискретизации Fd=8000 Гц 160 отсчетам входного речевого сигнала.
Последовательность действий при вычислении мгновенной энергии следующая:
- Вычисляется модуль Ynв=Abs (Y(n)) - выпрямление выходного сигнала фильтра;
- затем вычисляется значение мгновенной величины энергии в окне 20 мс (160 отсчетов) по формуле 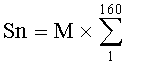 Yna×Yna, где
Yna×Yna, где
Sn - значение мгновенной энергии в n-ом окне (Snв - для диапозона 1500-3500 Гц и Snн - для диапозона 150-1000 Гц);
Yn - выходное значение фильтра;
Ynв - выпрямленное выходное значение;
М - масштабный коэффициент, ограничивающий переполнение. Экспериментально было установлено, что величина М для выполнения задач конверсии может быть принята 160.
Мгновенная энергия рассчитывается в двух частотных диапазонах, соответствующих полосовым фильтрам (см. п.2.1).
2.3. Расчет ФНЧ
Сглаживание (усреднение) результатов расчета мгновенной энергии производится блоком 44, для чего используется фильтр нижних частот (ФНЧ) первого порядка, соответствующий разностному уравнению вида Y(n)=(1-k)Y1-1+Sn,
Y(n) - текущее выходное значение ФНЧ;
Sn - текущее входное значение ФНЧ (значение мгновенной энергии);
Y1 - задержанное на период дискретизации значение выходного сигнала;
k - коэффициент, определяющий постоянную времени или частоту среза ФНЧ.
2.4. Пороговое устройство
Пороговое устройство (блок 44) сравнивает текущее значение сглаженного значения средней энергии в заданной полосе с пороговым значением (определяется экспериментально), за начальный уровень может быть принято значение 50 мВ. За паузу принимается значение энергии меньше уровня порогов в обоих спектральных диапазонах. С этого момента начинается отсчет длительности паузы.
2.5. Счетчик средней продолжительности пауз в файле
Средняя продолжительность паузы в обрабатываемом файле или на анализируемом участке (блок 45) определяется как сумма длин всех пауз, деленная на их количество
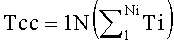
Где
Tcc - средняя продолжительность паузы в обрабатываемом файле или на анализируемом участке.
Ti - i-я пауза в обрабатываемом файле или на анализируемом участке;
N, Ni - кол-во пауз в обрабатываемом файле или на анализируемом участке;
2.6. Блок принятия решения
Блок 47 осуществляет принятие решения о соответствии скорости (темпа) речи. Заключение о темпе речи принимается исходя из следующих положений:
- При превышении средней длины паузы Тсс эталона или значения 600 мс темп считается медленным. За эталон принимается файл в формате wav с параметрами записи 16 бит 8000 Гц, полученный экспериментальным путем. Хранится в блоке 7(А) контроля скорости речи.
- При значении Tcc, меньшем средней длины паузы эталона или значения 300 мс, темп считается быстрым.
- В противном случае - соответствующим эталону.
3. Оценка длительности слоговых сегментов (Алгоритм 2)
Метод выделения признаков слоговых сегментов воспроизводимой фразы основан на формировании первичных параметров, использующих огибающие сигналов в частотных диапазонах А1=800-2500 Гц и А2=250-540 Гц. Результирующий параметр, который в дальнейшем используется для выделения признаков слогов, получается корреляционным методом и определяется так:
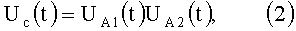
где UA1(t) - огибающая энергии в полосе частот A1, a UA2(t) - огибающая энергии в полосе А2.
Диапазон частот первого полосового фильтра, равный 250 - 540 Гц, выбран в виду того, что в нем отсутствует энергия высокоэнергетических фрикативных звуков типа /ш/ и /ч/, которые создают ошибочные слоговые ядра, а также сосредоточена значительная часть энергии всех звонких звуков, в том числе и гласных. Однако в этом диапазоне энергия сонорных звуков типа /л/, /м/, /н/ сравнима с энергией гласных, из-за чего определение слоговых сегментов только с учетом огибающей речевого сигнала в этом диапазоне сопровождается ошибками. Поэтому диапазон частот второго полосового фильтра, выбран в пределах 800-2500 Гц, в котором энергия гласных звуков минимум в два раза превышает энергию сонорных звуков.
Благодаря операции умножения огибающих UA1(t) и UA2(t) в результирующей временной функции происходит усиление участков кривой в области гласных звуков из-за корреляции их энергий в обоих диапазонах. Кроме того, ошибочные максимумы энергии, предопределенные наличием в диапазоне 800-2500 Гц значительной части энергии фрикативных звуков, устраняются путем их умножения на практически нулевое значение амплитуды фрикативных звуков в диапазоне 250-540 Гц.
Последовательность операций при работе алгоритма 2 следующая (фиг.9):
- Нормирование воспроизводимой фразы (сигнала) производится блоком 48. Нормирование речевого сигнала обеспечивает выравнивание слабых (тихих) сигналов с целью исключения зависимости результатов измерения от громкости входного речевого сигнала.
Нормирование воспроизводимой фразы (входного речевого сигнала) проводится с целью исключения зависимости результатов измерений от амплитуды (громкости) записанного или вводимого сигнала.
Нормирование производится следующим образом:
- на интервалах длительностью 1 с производится поиск максимального абсолютного значения амплитуды,
- находится среднее значение в полученном массиве,
- определяется коэффициент пересчета по формуле, равный отношению максимально возможного значения амплитуды к найденному среднему значению,
- каждое значение входного сигнала умножается на коэффициент пересчета.
- Фильтрация воспроизводимой фразы (сигнала) двумя полосовыми фильтрами Лернера четвертого порядка в диапазонах 250-540 Гц и 800-2500Гц соответственно (блок 49).
- Детектирование выходных сигналов фильтров для получения огибающих (блок 50).
- Перемножение огибающих выходных сигналов фильтров (блок 51).
- Дифференцирование результирующего сигнала (блок 52).
- Сравнение полученного сигнала с пороговыми напряжениями и выделение логического сигнала, соответствующего наличию слогового сегмента (блок 53).
- Расчет длительности слогового сегмента (блок 54).
4. Механизм принятия решения о скорости речи
Принятие решения о скорости (темпе речи) основывается на результате расчета длительности пауз и слоговых сегментов. При этом реализуется следующая комбинационная логика:
- паузы длинные, слоги длинные - темп медленный. Критерием «длинные» является отклонение длительности от эталонных на 30%. Эталонный файл в формате wav с параметрами записи 16 бит 8000 Гц, получен экспериментальным путем. Хранится в блоке 7(А) контроля скорости речи,
- паузы короткие или отсутствуют, слоги короткие - темп быстрый. Критерием «короткие» является отклонение длительности от эталонных на 30%,
- паузы длинные, слоги короткие - темп быстрый, т.е. приоритетным является анализ слогов, при этом выводится предупреждение о длинных паузах,
- паузы короткие или отсутствуют, слоги длинные - темп медленный.
Блок 7 записи фраз (фиг.7) осуществляет контроль громкости речи пользователя. Если пользователь говорит слишком громко или слишком тихо, блок 7(Б) контроля громкости речи (из состава блока 7 записи фраз) отображает на экране монитора 13 предупреждающее сообщение о нарушении громкости воспроизводимой фразы, например: «Вы говорите слишком громко, говорите тише» (если пользователь говорит громко) или «Вы говорите слишком тихо, говорите громче» (если пользователь говорит тихо). Текст предупреждающих сообщений содержится в тексте программы блока 7 записи фраз. Блок 7(Б) контроля громкости речи контролирует громкость речи говорящего следующим образом: осуществляется проверка нахождения текущего значения уровня сигнала говорящего в допустимом диапазоне уровней сигналов. Диапазон уровней сигналов задан в тексте программы блока 7(Б) в виде постоянных значений. При использовании wav файлов уровень громкости сигнала не имеет единиц измерения. Значение изменяется от 0 (нет звука) до 32768 (MAX громкость).
Например, пусть задано:
- «нижняя граница диапазона» равна 8000;
- «верхняя граница диапазона» равна 28000;
Если текущее значение уровня сигнала превышает верхнюю границу диапазона, на экран монитора 13 передается предупреждающее сообщение «слишком громко». Если текущее значение уровня сигнала меньше нижней границы диапазона, формируется предупреждение «слишком тихо».
После записи фразы, соответствующей и удовлетворяющей заданным параметрам блоков 7(А) и 7(Б) блок 7 записи фраз обрабатывает сохраненный аудиофайл (с фразой пользователя) в следующей последовательности:
- Нормализация, осуществляется Блоком нормализации 7(В) (из состава блока 9 записи фраз) следующим образом: в записанной фразе выделяется наибольшее значение уровня сигнала Lф. Далее вычисляется коэффициент k, равный отношению предельного значения уровня сигнала (Lmax=32 000) к наибольшему значению уровня сигнала в записанной фразе: k=Lmax/Lф. Далее уровни сигнала в записанной фразе увеличиваются на значение коэффициента k. Нормализация производится для приведения громкости сигнала к максимуму.
- Обрезка, заключается в удалении из записанной фразы пауз (участков записи, на которых речь отсутствует более 500 мс). Обрезку выполняет блок 7 (Д) обрезки (из состава блока 7 записи фраз), звуковые файлы на вход блока 7 (Д) подаются в виде WAV файлов.
- Шумоподавление, реализовано в виде стандартного алгоритма устранения шумов из полезного сигнала на основе метода спектрального вычитания. Шумоподавление выполняет блок 7 (Г) шумоподавления (из состава блока 7 записи фраз).
- Контроль соответствия произнесенного и заданного текста фразы. То есть производится преобразование речи пользователя в текст (технология STT -speech-to-text) и сравнение полученного текста с текстом, который он должен был произнести. Алгоритм преобразования речи в текст реализован в блоке 7 (Е) контроля соответствия из состава блока 7 записи фраз. Записанная фраза (та, которую надиктовал пользователь) «переводится» в текст. Полученный текст сравнивается с тем текстом, который должен быть прочитан (содержится в акустической обучающей базе 8). Если есть несоответствие произнесенного и заданного текста, блок 7 (Е) контроля соответствия отображает пользователю на экране монитора 13 сообщение о необходимости перезаписать соответствующую фразу. В данном случае блок 7 записи фраз запускает процесс перезаписи данной фразы: воспроизведение фразы пользователю (Ошибка! Источник ссылки не найден.), запись фразы пользователя (Ошибка! Источник ссылки не найден.).
Для всех содержащихся в акустической обучающей базе 8 фразам блок 5 обучения аналогичным образом последовательно:
- воспроизводит фразы пользователю (Ошибка! Источник ссылки не найден.);
- записывает фразы пользователя (Ошибка! Источник ссылки не найден.). Результатом является набор аудиофайлов с фразами пользователя, записанных в акустической базе 4 целевого диктора.
Далее блок 5 обучения формирует файл функции конверсии по записанным фразам, не имеющий расширения (функция конверсии необходима для конверсии голоса исходного диктора в голос соответствующего пользователя). При этом блок 5 обучения оценивает величину «примерного» времени получения функции конверсии с учетом времени конверсии аудиоматериалов. Полученное время блок обучения 5 отображает пользователю на экране монитора 13 в виде текста: «Подождите. Осталось 01:20:45». Отображаемое время обновляется на экране монитора 13 с периодичностью, заданной настройками блока 5 обучения. «Примерное» время вычисляется блоком 5 обучения на основе статистических данных, накопленных в его внутренней памяти. Статистические данные включают следующие сведения о уже выполненных задачах получения функции конверсии и самой конверсии: объем записанных аудиофайлов с фразами пользователя, фактическое время получения функции конверсии и самой конверсии, количество задач конверсии, исполняемых параллельно с данной (одновременно устройством могут пользоваться сразу несколько пользователей, поэтому возможна ситуация, когда конверсии разных пользователей пересекаются по времени, т.е. задачи конверсии могут выполняться параллельно).
При подсчете примерного времени конверсии блок 5 обучения определяет наиболее близкое значение из статистических данных по следующим критериям: объем аудиоматериалов, количество выполняемых задач конверсии. Созданный файл функции конверсии блок 5 обучения сохраняет в базе 10 функций конверсии под ID соответствующего пользователя.
Далее блок 7 обучения производит оценку функции конверсии путем последовательных приближений. В качестве входных параметров выступают амплитудные спектральные огибающие речевых сигналов исходного и целевого дикторов (пользователя). Для вычисления определения ошибки конверсии последовательность амплитудных спектральных огибающих исходного диктора (сохраненные в wav файлах) преобразовывается при помощи текущей функции конверсии и рассчитывается расстояние полученной последовательности от целевой. Ошибка нормируется, т.е. делиться на число огибающих в последовательности.
Ошибка конверсии в данной терминологии - Евклидова норма амплитудных спектральных огибающих речевых сигналов исходного и целевого дикторов, другими словами, среднеквадратическое значение ошибки конверсии тембральной составляющей, которая определяется огибающей спектра. Она может быть получена только после определения функции конверсии и выполнения самой процедуры конверсии.
То есть блок 7 дополнительно вычисляет значение "среднеквадратическое значение ошибки конверсии тембральной составляющей". Полученное значение сравнивается с порогами:
- от d11 до d12: хорошая конверсия;
- от d21 до d22: удовлетворительная конверсия;
- от d31 до d32: плохая конверсия - фразы нужно перезаписать.
d11, d12; d21, d22; d31, d32 - нижнее и верхнее значение «среднеквадратической ошибки конверсии» соответственно для «хорошей», «удовлетворительной» и «плохой» конверсии (выбираются экспериментальным путем).
Если фразы нужно перезаписать, блок 5 обучения отображает на экране монитора 13 сообщение о необходимости перезаписать фразы. Блок 5 обучения перезаписывает фразы: со второго входа/выхода блока 5 и с третьего его входа/выхода соответственно последовательно поступают команды на первый вход/выход блока 6 воспроизведения фраз из акустической обучающей базы 8 и на второй вход/выход блока 7 записи фраз в акустическую базу 4 целевого диктора (пользователя).
Конверсию аудиоматериалов выполняет блок 9 конверсии, который по цепи «первый вход/выход блока 9 конверсии - пятый вход/выход блока 1 управления» запрашивает и принимает от блока 1 управления данные аудиоматериалов «корзины».
Блок 1 оперативно извлекает эти аудиоматериалы из памяти блока 2 выбора аудиоматериалов по цепи «первый вход/выход блока 1» - «первый вход/выход блока 2» и конвертирует содержащиеся в «корзине» аудиоматериалы, используя полученный файл функции конверсии из базы 10 функций конверсии. Блок 9 конвертирует параметрический файл блока 2 и преобразует его в wav файл для сохранения в акустической базе 11 конвертированных аудиоматериалов.
Блок 9 конверсии отображает посредством выхода, подсоединенного к входу монитора 13 на его экране графический интерфейс конверсии аудиоматериалов (Ошибка! Источник ссылки не найден.).
Графический интерфейс конверсии аудиоматериалов (Ошибка! Источник ссылки не найден.) имеет:
- Графическое изображение 55, ассоциированное с конвертируемым аудиоматериалом (см. выше);
- Наименование 56 конвертируемого аудиоматериала;
- Поле 56 примерного времени конверсии аудиоматериала, вычисленное блоком 9 конверсии на основе статистических данных, накопленных в его внутренней памяти;
Индикатор 58 процесса конверсии (0% - начало осуществления конверсии; 100% - конверсия выполнена).
Блок конверсии 9 передает с его третьего входа/выхода переозвученные голосом пользователя аудиоматериалы на второй вход/выход акустической базы 9 конвертированных аудиоматериалов для их сохранения в виде аудиофайлов.
По цепи «шестой вход/выход блока 1 управления» - «первый вход/выход акустической базы 11» осуществляется:
- запрос и получения блоком 1 информации от блока 11 о конвертированном материале для ее отображения на экране монитора 13 в графическом интерфейсе результатов конверсии аудиоматериалов;
- управления акустической базой 11 (осуществляется по команде пользователя через блок 1 управления):
- удаление аудиофайла конвертированного аудиоматериала из акустической базы 11 конвертированных аудиоматериалов;
- воспроизведения конвертированного аудиоматериала пользователю через устройство 17 воспроизведения звука;
- перезаписи аудиофайла конвертированного аудиоматериала из акустической базы 11 конвертированных аудиоматериалов на съемный носитель пользователя.
Процесс переозвучивания завершен. Пользователь может прослушать переозвученные аудиоматериалы с устройства 17 воспроизведения звука (динамиков 18 и/или наушников 19), а также перезаписать аудиофайлы с переозвученными аудиоматериалами на съемный носитель.
По завершении переозвучивания блок 1 управления со своего пятого входа/выхода передает на первый вход/выход блока 12 отображения результатов конверсии команду на запуск блока 12. Параметром команды является ID пользователя, аудиоматериалы которого были переконвертированы устройством. Со второго входа/выхода блока 12 на первый вход/выход акустической базы 11 конвертированных аудиоматериалов направляется запрос на получение списка конвертированных аудиоматериалов пользователя с заданным ID. Конвертированные аудиоматериалы хранятся в акустической базе 11 в виде аудиофайлов в директории, наименование которой содержит только ID пользователя. После обработки запроса с первого входа/выхода акустической базы 11 передаются на второй вход/выход блока 12 данные о списке конвертированных аудиоматериалов, которые с выхода блока 12 поступают на монитор 13 пользователя и отображаются на его экране в графическом интерфейсе результатов конверсии аудиоматериалов (Ошибка! Источник ссылки не найден.).
Графический интерфейс, содержащий список конвертированных аудиоматериалов, может иметь различный внешний вид, форму и инструменты (на Ошибка! Источник ссылки не найден, показан один из возможных вариантов его выполнения.).
Например, графический интерфейс результатов конверсии аудиоматериалов имеет:
- Графическое изображение 59, ассоциированное с конвертируемым аудиоматериалом;
- Наименование 60 конвертируемого аудиоматериала;
- Поле 61 продолжительности записи в формате чч.мм.сс.;
- Кнопку 62 воспроизведения конвертированного аудиоматериала через устройство 17 воспроизведения звука;
- Кнопку 63 удаления аудиофайла конвертированного аудиоматериала из акустической базы 11 конвертированных аудиоматериалов;
- Кнопку 64 перезаписи аудиофайла конвертированного аудиоматериала из акустической базы 11 конвертированных аудиоматериалов на съемный носитель пользователя.
При нажатии инструмента - кнопки 62 «Воспроизвести» операционная система устройства генерирует событие - воспроизвести выбранный конвертированный аудиоматериал с помощью устройства 17. Сведения об осуществлении этого события (команда) передаются в блок 12 отображения конвертированных аудиоматериалов, который запрашивает конкретный конвертированный аудиоматериал из акустической базы 13 (по цепи «второй вход/выход блока 14 - первый вход/выход акустической базы 13») в виде файла и воспроизводит пользователю с помощью устройства 17 воспроизведения звука.
Таким образом устройство реализует следующий способ переозвучивания аудиоматериалов:
- в программно управляемом электронном устройстве обработки информации формируют акустическую базу исходных аудиоматериалов, включающую параметрические файлы, и акустическую обучающую базу, включающую wav файлы обучающих фраз диктора и соответствующую акустической базе исходных аудиоматериалов;
- транспортируют данные из акустической базы исходных аудиоматериалов для отображения списка исходных аудиоматериалов на экране монитора;
- при выборе пользователем из списка акустической базы исходных аудиоматериалов по меньшей мере одного аудиоматериала, данные о нем передают для сохранения в оперативное запоминающее устройство программно управляемого электронного устройства обработки информации;
- осуществляют выбор из акустической обучающей базы соответствующих wav файлов обучающих фраз диктора выбранному аудиоматериалу, которые преобразуют в звуковые фразы и передают их пользователю на устройство воспроизведения звука;
- пользователь посредством микрофона воспроизводит звуковые фразы, в процессе воспроизведения которых на экране монитора отображают текст воспроизводимой фразы и курсор, перемещающийся по тексту фразы в соответствии с тем, как пользователь должен ее воспроизвести;
- в соответствии с воспроизводимыми фразами создают wav файлы, которые сохраняют по порядку воспроизведения фраз в формируемой акустической базе целевого диктора;
- программно управляемое электронное устройство обработки информации производит контроль скорости воспроизводимой фразы и ее громкости;
- по wav файлам сохраненным в акустической базе целевого диктора и wav файлам акустической обучающей базы формируют файл функции конверсии;
- параметрические файлы акустической базы исходных аудиоматериалов, используя файл функции конверсии, конвертируют и преобразуют в wav файл для сохранения в формируемой акустической базе конвертированных аудиоматериалов и предоставления пользователю данных о конвертированных аудиоматериалах на экране монитора.
Таким образом, заявленные способ и устройство позволяют повысить качество проведения фазы обучения, улучшить степень совпадения голоса пользователя (целевого диктора) в конвертированном речевом сигнале за счет улучшения точности, разборчивости и узнаваемости голоса непосредственно пользователя, обеспечить возможность одноразового проведения фазы обучения для конкретного аудиоматериала, и использования этих данных фазы обучения для переозвучивания других аудиоматериалов.
Наиболее успешно заявленные способ переозвучивания аудиоматериалов и реализующее его устройство промышленно применимы в программно управляемых электронных устройствах обработки информации при синтезе речи.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ АВТОМАТИЗИРОВАННОЙ ОБРАБОТКИ ТЕКСТА И КОМПЬЮТЕРНОЕ УСТРОЙСТВО ДЛЯ РЕАЛИЗАЦИИ ЭТОГО СПОСОБА | 2011 |
|
RU2460154C1 |
| ТЕКСТОЗАВИСИМЫЙ СПОСОБ КОНВЕРСИИ ГОЛОСА | 2010 |
|
RU2427044C1 |
| СПОСОБ ОБМЕНА СООБЩЕНИЯМИ И УСТРОЙСТВА ДЛЯ ЕГО РЕАЛИЗАЦИИ | 2007 |
|
RU2324296C1 |
| ТРЕНАЖЕР ДЛЯ РАЗВИТИЯ РЕЧИ И ОТРАБОТКИ ПРОИЗНОШЕНИЯ ПРИ ИЗУЧЕНИИ ИНОСТРАННЫХ ЯЗЫКОВ | 2020 |
|
RU2747910C1 |
| СПОСОБ КОМПЕНСАЦИИ ПОТЕРИ СЛУХА В ТЕЛЕФОННОЙ СИСТЕМЕ И В МОБИЛЬНОМ ТЕЛЕФОННОМ АППАРАТЕ | 2013 |
|
RU2568281C2 |
| УСТРОЙСТВО ДЛЯ ИЗМЕНЕНИЯ ВХОДЯЩЕГО ГОЛОСОВОГО СИГНАЛА В ВЫХОДЯЩИЙ ГОЛОСОВОЙ СИГНАЛ В СООТВЕТСТВИИ С ЦЕЛЕВЫМ ГОЛОСОВЫМ СИГНАЛОМ | 2008 |
|
RU2393548C1 |
| СПОСОБ СЛУХОРЕЧЕВОЙ РЕАБИЛИТАЦИИ И УСТРОЙСТВО ДЛЯ ЕГО РЕАЛИЗАЦИИ | 2013 |
|
RU2525366C1 |
| СПОСОБ ОБУЧЕНИЯ И СИГНАЛОГРАММА ДЛЯ ЕГО РЕАЛИЗАЦИИ | 1995 |
|
RU2107327C1 |
| СПОСОБ МОДИФИКАЦИИ ГОЛОСА С ВИЗУАЛЬНОЙ И ЗВУКОВОЙ ОБРАТНОЙ СВЯЗЬЮ | 2024 |
|
RU2836637C1 |
| СПОСОБ ОБУЧЕНИЯ ИНОСТРАННОМУ ЯЗЫКУ ШЕХТЕРА И.Ю. | 2003 |
|
RU2220457C1 |




Способ и устройство позволяют повысить качество проведения фазы обучения, улучшить степень совпадения голоса пользователя (целевого диктора) в конвертированном речевом сигнале, обеспечить возможность одноразового проведения фазы обучения для различных аудиоматериалов. Указанный технический результат достигается тем, что в программно управляемом электронном устройстве обработки информации (ПУЭУОИ) формируют акустическую базу исходных аудиоматериалов (АБИА) и акустическую обучающую базу (АОБ). Передают данные из АБИА для отображения списка исходных аудиоматериалов на экране монитора. При выборе из списка АБИА по меньшей мере одного аудиоматериала, данные о нем передают для сохранения в ОЗУ ПУЭУОИ. Осуществляют выбор из АОБ обучающих фраз диктора файлы, которые преобразуют в звуковые фразы и передают их пользователю на устройство воспроизведения звука. Пользователь посредством микрофона воспроизводит звуковые фразы, в процессе воспроизведения которых на экране монитора отображают текст воспроизводимой фразы и курсор, перемещающийся по тексту фразы в соответствии с тем, как пользователь должен ее воспроизвести. Создают файлы в соответствии с воспроизводимыми фразами, которые сохраняют по порядку воспроизведения фраз в формируемой акустической базе целевого диктора (АБЦД). ПУЭУОИ производит контроль скорости воспроизводимой фразы и ее громкости. Формируют файл функции конверсии. Файлы АБИА, используя файл функции конверсии, конвертируют для сохранения в формируемой акустической базе конвертированных аудиоматериалов (АБКА) и предоставления пользователю данных о конвертированных аудиоматериалах на экране монитора. Устройство содержит соответствующие функциональные блоки, реализующие способ. 2 н. и 11 з.п. ф-лы, 11 ил.
1. Способ переозвучивания аудиоматериалов, заключающийся в том, что в программно управляемом, электронном устройстве обработки информации формируют акустическую базу исходных аудиоматериалов и акустическую обучающую базу, включающую аудиофайлы обучающих фраз диктора и соответствующую акустической базе исходных аудиоматериалов, транспортируют данные из акустической базы исходных аудиоматериалов для отображения списка исходных аудиоматериалов на экране монитора, при выборе пользователем из списка акустической базы исходных аудиоматериалов по меньшей мере одного аудиоматериала, данные о нем передают для сохранения в оперативное запоминающее устройство программно управляемого электронного устройства обработки информации, и осуществляют выбор из акустической обучающей базы соответствующих аудиофайлов обучающих фраз диктора выбранному аудиоматериалу, которые преобразуют в звуковые фразы для отображения пользователю, пользователь посредством микрофона воспроизводит звуковые фразы, в соответствии с воспроизводимыми фразами создают аудиофайлы, которые сохраняют по порядку воспроизведения фраз в формируемой акустической базе целевого диктора, формируют файл функции конверсии, затем файлы акустической базы исходных аудиоматериалов, используя файл функции конверсии, конвертируют и преобразуют в аудиофайл для сохранения в формируемой акустической базе конвертированных аудиоматериалов и предоставления пользователю данных о конвертированных аудиоматериалах на экране монитора.
2. Способ по п.1, отличающийся тем, что при использовании в качестве управляемого электронного устройства обработки информации удаленного сервера или компьютера, функционирующего в многопользовательском режиме, дополнительно производят регистрацию пользователя.
3. Способ по п.1, отличающийся тем, что перед воспроизведением пользователем посредством микрофона звуковых фраз, производят запись фонового шума, которую сохраняют в виде аудиофайла в акустической базе целевого диктора, а программно управляемое электронное устройство обработки информации осуществляет шумоподавление фонового шума.
4. Способ по п.1, отличающийся тем, что при формировании акустической базы целевого диктора программно управляемое электронное устройство обработки информации производит контроль скорости воспроизводимой пользователем фразы и ее громкости.
5. Способ по п.1, отличающийся тем, что при контроле скорости воспроизводимой фразы программно управляемое электронное устройство обработки информации осуществляет фильтрацию цифрового RAW-потока, соответствующего воспроизводимой фразе, рассчитывают мгновенную энергию и сглаживают результаты расчета мгновенной энергии, сравнивают значение сглаженного значения средней энергии с заданным пороговьм значением, подсчитывают среднюю продолжительность пауз в аудиофайле, и программно управляемое электронное устройство обработки информации принимает решение о соответствии скорости речи эталонной.
6. Способ по п.1, отличающийся тем, что при контроле скорости воспроизводимой фразы программно управляемое электронное устройство обработки информации осуществляет оценку длительности слоговых сегментов, для этого производят нормирование речевого сигнала воспроизводимой фразы, фильтрацию, детектирование, перемножение огибающих сигналов воспроизводимой фразы, дифференцирование, сравнение полученного сигнала воспроизводимой фразы с пороговыми напряжениями и выделение логического сигнала, соответствующего наличию слогового сегмента, рассчитывают длительность слогового сегмента, после чего программно управляемое электронное устройство обработки информации принимает решение о соответствии скорости речи эталонной.
7. Способ по п.1, отличающийся тем, что при контроле громкости воспроизводимой фразы задают нижнюю границу диапазона громкости и верхнюю границу диапазона громкости, сравнивают громкость воспроизводимой фразы с границами диапазона громкости, при громкости воспроизводимой фразы вне упомянутых границ диапазона программно управляемое электронное устройство обработки информации отображает на экране монитора сообщение о нарушении громкости воспроизводимой фразы.
8. Способ по п.1, отличающийся тем, что при формировании акустической базы исходных аудиоматериалов используют параметрические файлы, а акустической обучающей базы - wav файлы. Кроме параметрических файлов могут быть использованы любые файлы, содержащие аудиопоток.
9. Способ по п.1, отличающийся тем, что звуковые фразы для отображения пользователю передают на устройство воспроизведения звука.
10. Способ по п.1, отличающийся тем, что в процессе воспроизведения звуковых фраз пользователем на экране монитора отображают текст воспроизводимой фразы и курсор, перемещающийся по тексту фразы в соответствии с тем, как пользователь должен ее воспроизвести.
11. Способ по п.1, отличающийся тем, что после сохранения аудиофайлов в акустической базе целевого диктора и аудиофайлов в акустической обучающей базе программно управляемое электронное устройство обработки информации производит нормализацию аудиофайлов, их обрезку, шумоподавление и контроль соответствия воспроизведенного и отображенного текста воспроизводимой фразы.
12. Устройство переозвучивания аудиоматериалов, содержащее блок управления, блок выбора аудиоматериалов, акустическую базу исходных аудиоматериалов, акустическую базу целевого диктора, блок обучения, блок воспроизведения фраз, блок записи фраз, акустическую обучающую базу, блок конверсии, базу функций конверсии, акустическую базу конвертированных аудиоматериалов, блок отображения результатов конверсии, монитор, клавиатуру, манипулятор, микрофон, устройство воспроизведения звука, при этом выход клавиатуры подсоединен к первому входу блока управления, к первому входу блока выбора аудиоматериалов, и к первому входу блока отображения результатов конверсии, выход манипулятора подсоединен к второму входу блока управления, к второму входу блока выбора аудиоматериалов, и к второму входу блока отображения результатов конверсии, вход монитора подсоединен к выходу блока выбора аудиоматериалов, к выходу блока обучения, к первому выходу блока воспроизведения фраз, к выходу блока записи фраз, к выходу блока конверсии, к выходу блока отображения результатов конверсии, вход устройства воспроизведения звука подсоединен к. второму выходу блока воспроизведения фраз, выход микрофона подсоединен к входу блока записи фраз, первый вход/выход блока управления подсоединен к первому входу/выходу блока выбора аудиоматериалов, второй вход/выход блока управления - к первому входу/выходу акустической базы целевого диктора, третий вход/выход блока управления - к первому входу/выходу блока обучения, четвертый вход/выход блока управления - к первому входу/выходу блока конверсии, пятый вход/выход блока управления - к первому входу/выходу блока отображения результатов конверсии, второй вход/выход блока выбора аудиоматериалов подсоединен к первому входу/выходу акустической базы исходных аудиоматериалов, а второй вход/выход акустической базы исходных аудиоматериалов подсоединен к четвертому входу/выходу блока конверсии, второй вход/выход акустической базы целевого диктора подсоединен к первому входу/выходу блока записи фраз, а второй вход/выход блока записи фраз - к третьему входу/выходу блока обучения, второй вход/выход блока обучения подсоединен к первому входу/выходу блока воспроизведения фраз, а второй вход/выход блока воспроизведения фраз - к входу/выходу акустической обучающей базы, четвертый вход/выход блока обучения подсоединен к первому входу/выходу базы функций конверсии, второй вход/выход базы подсоединен к второму входу/выходу блока конверсии, третий вход/выход блока конверсии подсоединен к второму входу/выходу акустической базы конвертированных аудиоматериалов, а первый вход/выход акустической базы конвертированных аудиоматериалов подсоединен к второму входу/выходу блока отображения результатов конверсии.
13. Устройство по п.12, отличающееся тем, что введены блок авторизации/регистрации и база зарегистрированных пользователей, выход клавиатуры подсоединен к первому входу блока авторизации/регистрации, а выход манипулятора подсоединен к, второму входу блока авторизации/регистрации, вход монитора подсоединен к выходу блока авторизации/регистрации, шестой вход/выход блока управления подсоединен к первому входу/выходу блока авторизации/регистрации, а второй вход/выход блока авторизации/регистрации подсоединен к входу/выходу базы зарегистрированных пользователей.
| ТЕКСТОЗАВИСИМЫЙ СПОСОБ КОНВЕРСИИ ГОЛОСА | 2010 |
|
RU2427044C1 |
| УСТРОЙСТВО ДЛЯ ИЗМЕНЕНИЯ ВХОДЯЩЕГО ГОЛОСОВОГО СИГНАЛА В ВЫХОДЯЩИЙ ГОЛОСОВОЙ СИГНАЛ В СООТВЕТСТВИИ С ЦЕЛЕВЫМ ГОЛОСОВЫМ СИГНАЛОМ | 2008 |
|
RU2393548C1 |
| RU 2009131086 A, 20.02.2011 | |||
| Способ формовки стаканообразных изделий | 1944 |
|
SU66103A1 |
| US 5847303 A1, 08.12.1998 | |||
| US 20070038455 A1, 15.02.2007 | |||
| US 6615174 B1, 02.09.2003 | |||
| JP 2005266823 A, 29.09.2005 | |||
| JP 2005266349 A, 29.09.2005 | |||
| WO 2010031437 A1, 25.03.2010 | |||

