[1] Настоящее техническое решение, в общем, относится к способам модификации, обучения и использования языковых моделей, направленных на работу с таблицами, а именно к способу и системе получения векторных представлений данных в таблице с учетом структуры таблицы и ее содержания.
УРОВЕНЬ ТЕХНИКИ
[2] Языковая модель - это распределение вероятностей по последовательностям слов. Языковые модели генерируют вероятности путем обучения на корпусе текстов на одном или нескольких языках. Учитывая, что языки могут использоваться для выражения огромного множества верных предложений (так называемая цифровая бесконечность), языковое моделирование сталкивается с проблемой задания ненулевых вероятностей лингвистически верным последовательностям, которые могут никогда не встретиться в обучающих данных. Для преодоления этой проблемы было разработано несколько подходов к моделированию, таких как применение марковских цепей или использование нейронных архитектур, таких как рекуррентные нейронные сети или трансформеры.
[3] Языковые модели полезны для решения множества задач вычислительной лингвистики; от первоначальных применений в распознавании речи для того, чтобы избежать генерации бессмысленных (то есть маловероятные) последовательностей слов, до более широкого использования в машинном переводе (например, оценка переводов-кандидатов), генерации естественного языка (генерация текста, более похожего на человеческий), разметки частей речи, синтаксического анализа, оптического распознавания символов, распознавания рукописного ввода, грамматических выводов, поиска информации и других приложений.
[4] Существует большое количество архитектур, направленных на работу с документами, работающие на визуальной, текстовой информации и информации о расположении текста (layout) на странице, такие как:
1. TableNet - end-to-end модель глубинного обучения, предназначенная для обнаружения таблиц и для распознавания структур.
2. Donut - энкодер-декодер архитектура на основе трансформера, работающий без OCR, энкодер принимает на вход изображение, декодер принимает на вход текст и выход энкодера для генерации текста.
3. DiT - трансформенная архитектура для предобучения на изображениях документов.
4. UDoP - Модель объединяет текст, изображение и layout с использованием одной модели на основе трансформера в общее пространство.
5. DocLLM - легковесное расширение для традиционных LLM, для работы с документами, объединяющий текстовый запрос и layout, не используя визуальный энкодер.
[5] При этом они не специализированы для выполнения задачи выделения именованных сущностей в таблице, поэтому требуют большего кол-ва данных и вычислительных мощностей, для получения сравнимого результата на конкретной задаче.
[6] Существующие языковые модели, направленных на работу с таблицами, таких как: TaBERT (Yin и др., 2020), TURL (Deng и др. 2020), TAPAS (Herzig и др., 2020), TabNER (Koleva и др., 2022) - требуют доработок в стандартной архитектуре трансформеров (Vaswani и др., 2017 -https://arxiv.org/pdf/1706.03762.pdf) и предобучения на большом объеме данных для решения задачи получения векторных представлений данных в таблице с учетом структуры таблицы и ее содержания.
[7] TaBERT добавляет механизм вертикального внимания, для контекстуализации эмбединга колонки, требующий предобучения (в известных примерах дообучение происходило на web-страницах с парсингом данных из html). Структура передаваемого в энкодер текста, не соответствует стандартной структуре подаваемый в трансформер: токен [SEP] несет иной смысл, чем в базовом трансформере, выполняя роль не разделителя между текстом, связь которых нужно установить, а разделителем между строками таблицы.
[8] В TURL эмбединг токенов в табличной части получается путем сложения вектора слова w, типа токена (заголовок или контент) t, и позиционного эмбединга р: x∧t=w+t+p.Это не соответствует стандартной схеме трансформеров и требует дополнительного предобучения на большом объеме табличных данных. Предназначено для работы только с плоской таблицей из-за механизма внимания (видимости), основанного на колонках и строках.
[9] В TAPAS эмбединг токенов в табличной части получается путем сложения вектора слова w, позиционного эмбединга р, эмбединга сегмента s, эмбединг колонки с, эмбединг строки в таблице r и эмбединг ранга rg: x∧t=w+p+c+s+r+rg. Это не соответствует стандартной схеме трансформеров и требует дополнительного переобучения на большом объеме табличных данных.
[10] В TabNER эмбединг токенов в табличной части получается путем сложения вектора слова w, позиционного эмбединга pos, эмбединга сегмента seg: x∧t=w+seg+pos, где эмбединг сегмента указывает - относится ли текст к заголовку или контенту таблицы, а не указывает отношение к семантической части, как в стандартном трансформере, что приводит к смещению распределения и невозможности использовать открытые модели. Также предполагает использование выходных эмбедингов модели для выделения именованных сущностей на уровне токенов, что увеличивает вероятность различения выделяемых сущностей.
РАСКРЫТИЕ ИЗОБРЕТЕНИЯ
[11] Данное техническое решение направлено на устранение недостатков, присущих существующим решениям, известным из уровня техники.
[12] Решаемой технической проблемой в данном техническом решении является то, что архитектуры моделей, используемые для работы с документами, не используют структурные элементы таблиц в документе при построении представлений данных (эмбедингов) и решении целевой задачи (классификации, NER, вопросной-ответные системы и т.д.), как правило, заменяя использование структуры таблицы, большим кол-вом данных используемым на этапах предобучения и обучения, специфичных для конкретной сферы, лишая возможности использовать открытые к использованию модели, на выбранном языке, либо принуждают к использованию большого кол-ва данных и вычислительных мощностей для обобщения знаний находящихся в таблицах. SOTA архитектуры моделей, которые учитывают структуру таблицы при обучении, как правило, вносят изменения в архитектуру стандартных моделей, что делает невозможным использование открытых моделей без дополнительного предобучения, которое требует большое кол-во ресурсов и данных, а так же необходимость их предобрабатывать и отбирать данные соответствующие требуемой структуре, лишая возможности использовать обучение на больших неструктурированных датасетах.
[13] Основным техническим результатом, проявляющимся при решении вышеуказанной проблемы, является ускорение процесса обучения языковой модели при работе с табличными документами за счет обеспечения возможности использования любого предварительно обученного трансформера для получения представлений на уровне ячейки для таблицы, что позволяет использовать как открытые модели, обученные на большом объеме данных, так и специализированные модели, предобученные на неструктурированных данных, специфичных для домена документов, без предварительной подготовки и очистки корпуса.
[14] Дополнительным техническим результатом, проявляющимся при решении вышеуказанной проблемы, является повышение точности решения задач языковой модели при работе с табличными документами за счет использования структурированности табличных данных и возможности работы с таблицами со сложной структурой.
[15] Указанные технические результаты достигаются благодаря осуществлению способа получения векторных представлений данных в таблице с учетом структуры таблицы и ее содержания, реализуемого с помощью процессора и устройства хранения данных, включающего следующие шаги:
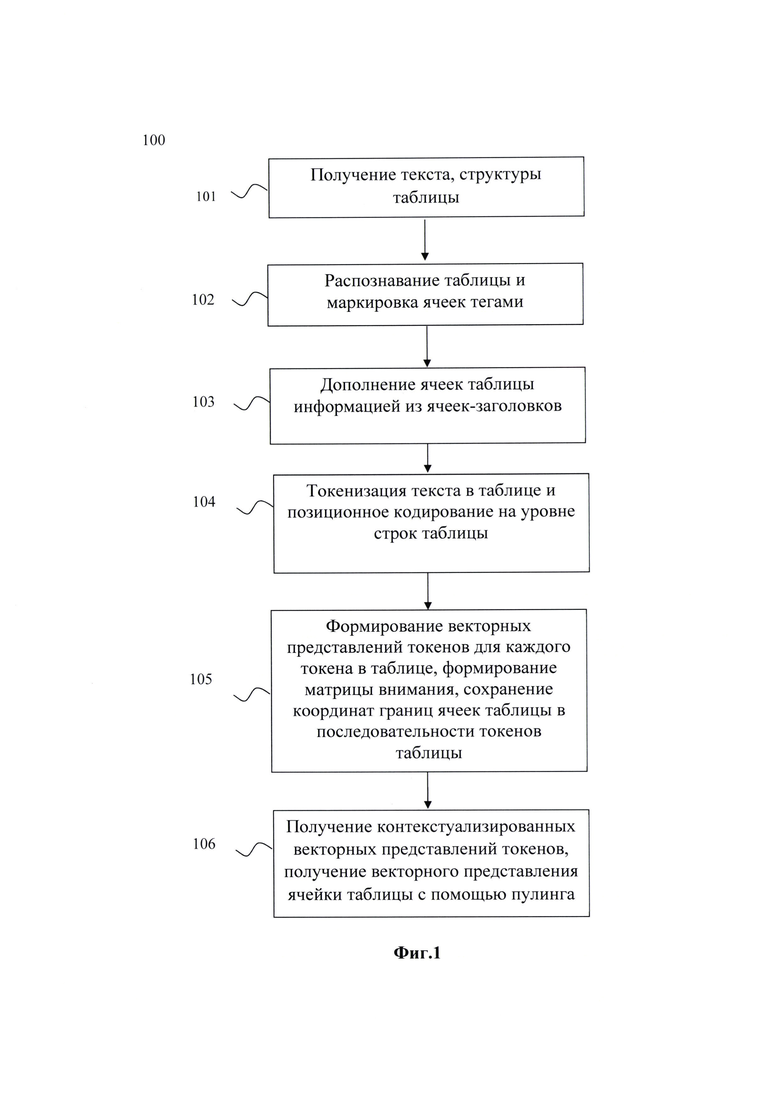
• получают данные, включающие: текст, структуру таблицы;
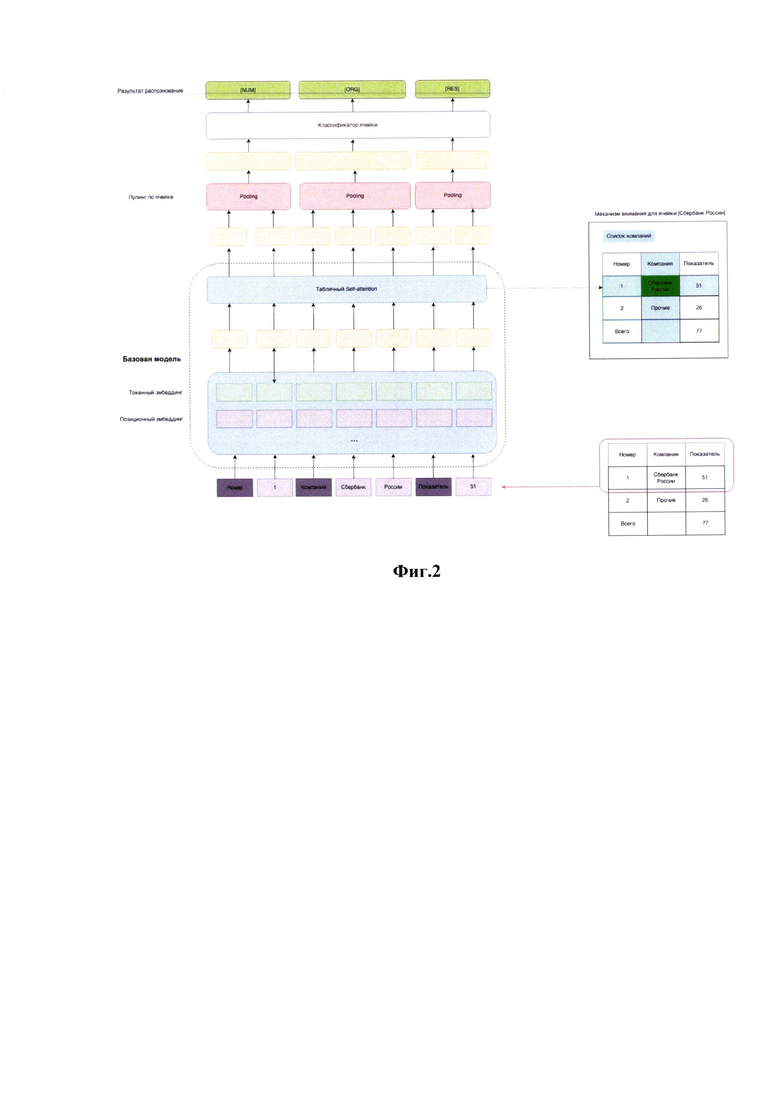
• таблица определяется как набор из списка ячеек заголовков таблицы и списка ячеек тела таблицы;
• каждую ячейку тела таблицы помечают тегами, характеризующими: идентификатор таблицы, список атомарных колонок к которым относится ячейка, список атомарных строк к которым относится ячейка.
• данные каждой ячейки тела таблицы дополняются информацией из соответствующих ячеек заголовков;
• производят токенизацию текста в таблице;
• производят позиционное кодирование на уровне строк таблицы;
• формируют векторные представления токенов для каждого токена в таблице путем агрегации векторных представлений токенов и позиционных векторных представлений;
• формируют матрицу внимания, используя принадлежность ячейки к колонке или строке таблицы;
• сохраняют координаты границ ячеек таблицы в последовательности токенов таблицы;
• базовая модель получает на вход подготовленные текстовые и позиционные векторные представления токенов и матрицу внимания и обрабатывает их, получая контекстуализированные векторные представления токенов;
• используя сохраненные координаты границ ячеек таблицы, используют пулинг для получения векторного представления ячейки таблицы.
[16] В одном из частных примеров осуществления способа базовая модель дообучается под выполнение конкретной задачи.
[17] В другом частном примере осуществления способа базовая модель предобучена на неструктурированном тексте под домен, без необходимости наличия информации о таблицах.
[18] Кроме того, заявленный технический результат достигается за счет работы системы получения векторных представлений данных в таблице с учетом структуры таблицы и ее содержания, содержащей:
по меньшей мере одно устройство обработки данных;
по меньшей мере одно устройство хранения данных;
по меньшей мере одну программу, где одна или более программ хранятся на одном или более устройствах хранения данных и исполняются на одном и более устройствах обработки данных, причем одна или более программ обеспечивает выполнение следующих шагов:
• получают данные, включающие: текст, структуру таблицы;
• таблица определяется как набор из списка ячеек заголовков таблицы и списка ячеек тела таблицы;
• каждую ячейку тела таблицы помечают тегами, характеризующими: идентификатор таблицы, список атомарных колонок к которым относится ячейка, список атомарных строк к которым относится ячейка.
• данные каждой ячейки тела таблицы дополняются информацией из соответствующих ячеек заголовков;
• производят токенизацию текста в таблице;
• производят позиционное кодирование на уровне строк таблицы;
• формируют векторные представления токенов для каждого токена в таблице путем агрегации векторных представлений токенов и позиционных векторных представлений;
• формируют матрицу внимания, используя принадлежность ячейки к колонке или строке таблицы;
• сохраняют координаты границ ячеек таблицы в последовательности токенов таблицы;
• базовая модель получает на вход подготовленные текстовые и позиционные векторные представления токенов и матрицу внимания, и обрабатывает их, получая контекстуализированные векторные представления токенов;
• используя сохраненные координаты границ ячеек таблицы, используют пулинг для получения векторного представления ячейки таблицы.
[19] В одном из частных примеров реализации системы базовая модель дообучается под выполнение конкретной задачи.
[20] В другом частном примере реализации системы базовая модель предобучена на неструктурированном тексте под домен, без необходимости наличия информации о таблицах.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[21] Признаки и преимущества настоящего технического решения станут очевидными из приводимого ниже подробного описания и прилагаемых чертежей, на которых:
[22] Фиг. 1 иллюстрирует блок-схему выполнения заявленного способа.
[23] Фиг. 2 иллюстрирует общую схему работы способа.
[24] Фиг. 3 иллюстрирует пример работы способа.
[25] Фиг. 4 иллюстрирует матрицу внимания.
[26] Фиг. 5 иллюстрирует систему для реализации заявленного способа.
ОСУЩЕСТВЛЕНИЕ ИЗОБРЕТЕНИЯ
[27] Ниже будут описаны термины и понятия, необходимые для реализации настоящего технического решения.
[28] Трансформер (англ. Transformer) - архитектура глубоких нейронных сетей, представленная в 2017 году исследователями из Google Brain. По аналогии с рекуррентными нейронными сетями (РНС) трансформеры предназначены для обработки последовательностей, таких как текст на естественном языке, и решения таких задач как машинный перевод и автоматическое реферирование. В отличие от РНС, трансформеры не требуют обработки последовательностей по порядку. Например, если входные данные - это текст, то трансформеру не требуется обрабатывать конец текста после обработки его начала. Благодаря этому трансформеры распараллеливаются легче, чем РНС, и могут быть быстрее обучены. Архитектура трансформера состоит из кодировщика и декодировщика. Кодировщик получает на вход векторизованую последовательность с позиционной информацией. Декодировщик получает на вход часть этой последовательности и выход кодировщика. Кодировщик и декодировщик состоят из слоев. Слои кодировщика последовательно передают результат следующему слою в качестве его входа. Слои декодировщика последовательно передают результат следующему слою вместе с результатом кодировщика в качестве его входа. Каждый кодировщик состоит из механизма самовнимания (вход из предыдущего слоя) и нейронной сети с прямой связью (вход из механизма самовнимания). Каждый декодировщик состоит из механизма самовнимания (вход из предыдущего слоя), механизма внимания к результатам кодирования (вход из механизма самовнимания и кодировщика) и нейронной сети с прямой связью (вход из механизма внимания).
[29] Эмбеддинг (англ. embedding) - это вектор, представленный в виде массива чисел, который получается в результате преобразования данных, например, текста. Комбинация этих чисел, составляющих вектор, действует как многомерная карта для измерения сходства.
Использование векторных представлений (эмбеддингов) позволяет:
• уменьшить размерность данных - с помощью эмбеддингов вы можете представить текстовые запросы в виде числовых векторов, что позволяет снизить размерность данных и ускорить их обработку;
• улучшить качество поиска - эмбеддинги позволяют оценивать сходство между текстовыми запросами на основе расстояния между соответствующими векторами. Это позволяет улучшить качество поиска и релевантность результатов;
• обеспечить универсальность - эмбеддинги можно использовать для различных задач обработки естественного языка, таких как Retrieval Augmented Generation (RAG), классификация текстов, кластеризация и других.
[30] Пулинг (Pooling) - это операция в обработке изображений и других данных, которая используется для уменьшения размерности данных и выделения наиболее значимых признаков. Существует несколько видов пулинга, включая max pooling (максимальное объединение) и average pooling (среднее объединение).
[31] Заявленное техническое решение может выполняться, например системой, машиночитаемым носителем, сервером и т.д. В данном техническом решении под системой подразумевается, в том числе компьютерная система, ЭВМ (электронно-вычислительная машина), ЧПУ (числовое программное управление), ГОЖ (программируемый логический контроллер), компьютеризированные системы управления и любые другие устройства, способные выполнять заданную, четко определенную последовательность операций (действий, инструкций).
[32] Под устройством обработки команд подразумевается электронный блок либо интегральная схема (микропроцессор), исполняющая машинные инструкции (программы).
[33] Устройство обработки команд считывает и выполняет машинные инструкции (программы) с одного или более устройства хранения данных, например таких устройств, как оперативно запоминающие устройства (ОЗУ) и/или постоянные запоминающие устройства (ПЗУ). В качестве ПЗУ могут выступать, но, не ограничиваясь, жесткие диски (HDD), флеш-память, твердотельные накопители (SSD), оптические носители данных (CD, DVD, BD, MD и т.п.) и др.
[34] Программа - последовательность инструкций, предназначенных для исполнения устройством управления вычислительной машины или устройством обработки команд.
[35] Термин «инструкции», используемый в этой заявке, может относиться, в общем, к программным инструкциям или программным командам, которые написаны на заданном языке программирования для осуществления конкретной функции, такой как, например, получение и обработка данных, формирование профиля пользователя, прием и передача сигналов, анализ принятых данных, идентификация пользователя и т.п.Инструкции могут быть осуществлены множеством способов, включающих в себя, например, объектно-ориентированные методы. Например, инструкции могут быть реализованы, посредством языка программирования С++, Java, Python, различных библиотек (например, Microsoft Foundation Classes) и т.д. Инструкции, осуществляющие процессы, описанные в этом решении, могут передаваться как по проводным, так и по беспроводным каналам передачи данных, например, Wi-Fi, Bluetooth, USB, WLAN, LAN и т.п.
[36] Представленный способ получения векторных представлений данных в таблице с учетом структуры таблицы и ее содержания (на Фиг. 1 представлена блок-схема выполнения способа) решает задачи ускорения процесса обучения языковой модели при работе с табличными документами и повышения точности решения задач языковой модели при работе с табличными документами за счет последовательного выполнения следующих шагов:
• получают данные, включающие: текст, структуру таблицы;
• таблица определяется как набор из списка ячеек заголовков таблицы и списка ячеек тела таблицы;
• каждую ячейку тела таблицы помечают тегами, характеризующими: идентификатор таблицы, список атомарных колонок к которым относится ячейка, список атомарных строк к которым относится ячейка.
• данные каждой ячейки тела таблицы дополняются информацией из соответствующих ячеек заголовков;
• производят токенизацию текста в таблице;
• производят позиционное кодирование на уровне строк таблицы;
• формируют векторные представления токенов для каждого токена в таблице путем агрегации векторных представлений токенов и позиционных векторных представлений;
• формируют матрицу внимания, используя принадлежность ячейки к колонке или строке таблицы;
• сохраняют координаты границ ячеек таблицы в последовательности токенов таблицы;
• базовая модель получает на вход подготовленные текстовые и позиционные векторные представления токенов и матрицу внимания и обрабатывает их, получая контекстуализированные векторные представления токенов;
• используя сохраненные координаты границ ячеек таблицы, используют пулинг для получения векторного представления ячейки таблицы.
[37] Предлагаемый способ (на Фиг. 2 показана общая схема работы способа) вносит изменения в структуру работы стандартных моделей, не изменяя распределение входных эмбедингов (не добавляет новый вид позиционных, ранговых или других эмбедингов и не переопределяет использование стандартных видов эмбедингов и токенов), поэтому не требует дополнительного предобучения на большом объеме данных, и позволяет использовать открытые модели, на выбранном языке или делать предобучение для подгонки к домену (строительная документация, финансовые отчеты, юридические документы и т.д.) без необходимости специфичной предобработки или отбора данных. А также позволяет использовать в качестве базовой модели, использующие не только текстовые данные, но и модели с использованием информацию с картинки и layout, такие как UDOP и LayoutLMv3.
[38] Таким образом, у представленного технического решения следующие преимущества:
1) нет необходимости дополнительного предобучения, для подгонки к архитектуре базового эмбедера:
1. можно использовать открытые модели;
2. можно предобучать модели под домен на неструктурированом тексте;
3. возможность использовать в качестве базовой модели почти любой модели, основанной на архитектуре трансформер, следовательно, возможно использовать так же информацию об изображении и 2-d координат;
2) использует структурированность табличных данных;
3) Обеспечивает возможность работы с таблицей сложной структуры.
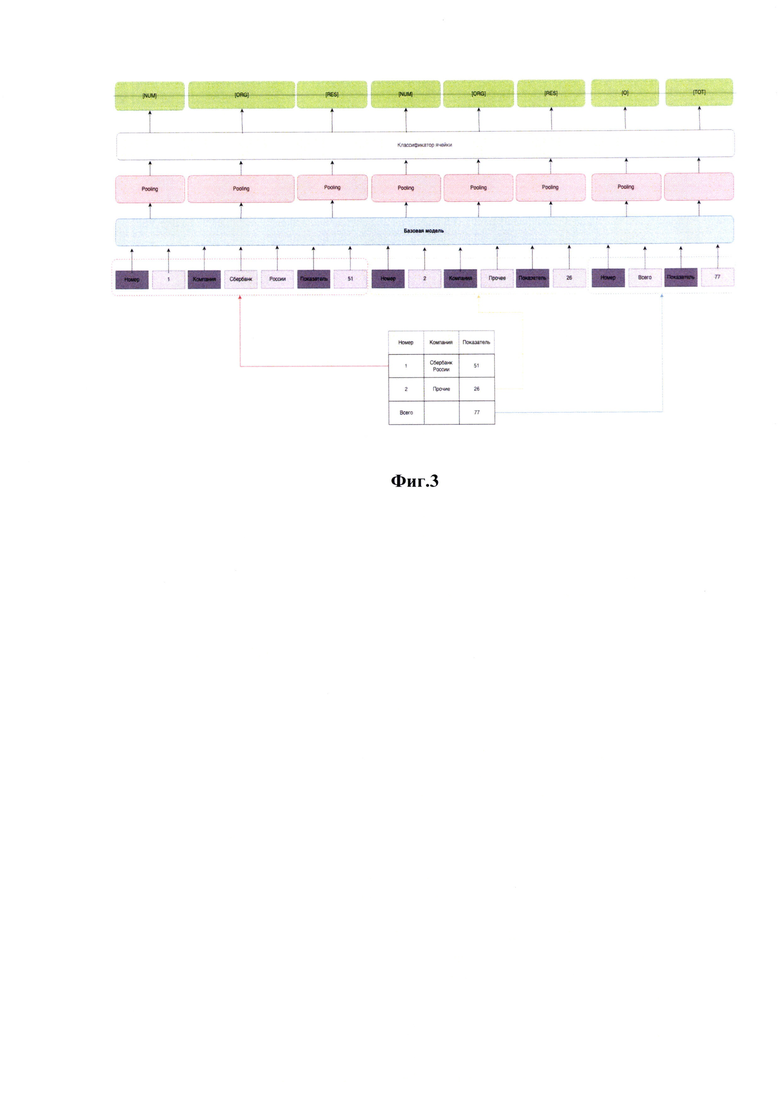
[39] В частном примере реализации заявленного технического решения (пример работы показан на Фиг. 3) в качестве основы для базового эмбедера токенов (ENC) может выступать почти любая модель на основе архитектуры трансформер и слоя классификации (например, ruBert-base: https://huggingface.co/ai -forever/ruBert-base).
Векторные представления токенов для каждого токена в линеаризованной таблице формируются путем агрегации вложений токенов и вложений позиций.
[40] Таблица определяется как кортеж Т=(С, H), где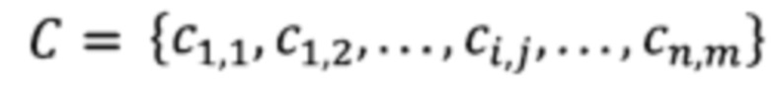 - это набор ячеек тела таблицы для n строк и m столбцов. Каждая ячейка
- это набор ячеек тела таблицы для n строк и m столбцов. Каждая ячейка 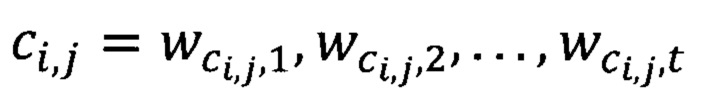 представляет собой последовательность токенов длины t. Заголовок таблицы
представляет собой последовательность токенов длины t. Заголовок таблицы 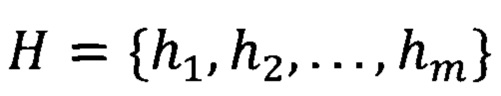 - это набор соответствующих ячеек заголовка столбца, где
- это набор соответствующих ячеек заголовка столбца, где 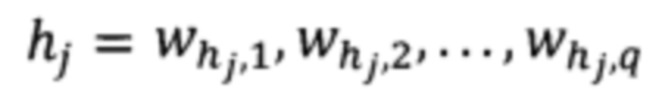 представляет собой последовательность заголовочных токенов длины q.
представляет собой последовательность заголовочных токенов длины q.
Используется T[i,:], чтобы обратиться к i-й строке (Н=Т[k,:]), где k-строка с окончанием заголовка таблицы (таблица может иметь сложную структуру) и 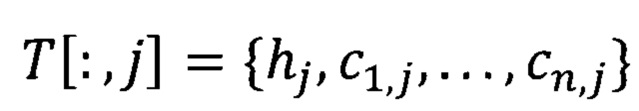 - чтобы обратиться к j-му столбцу Т.
- чтобы обратиться к j-му столбцу Т.
Приведем пример, когда у каждой помеченной ячейки есть последовательность тегов NER: 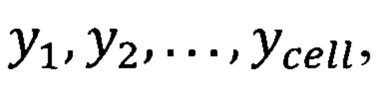 где каждый
где каждый 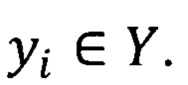
Используются теги IO, поэтому 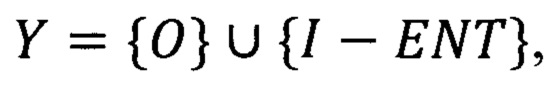 где, например, ENT ∈ {NUM,RES,0RG,T0T}.
где, например, ENT ∈ {NUM,RES,0RG,T0T}.
Позиционное кодирование происходит на уровне строки таблицы, где токены заголовка таблицы hj учитывает в расчет порядка, таким образом сохраняется распределение во входном слое базовой модели.
Используется маска внимания к таблице (матрицу видимости) αi,j, но на уровне токена, а не ячейки. Эта маска позволяет каждому токену обращаться исключительно к токенам в той же строке или столбце, αi,j - это симметричная бинарная матрица, определенная как:
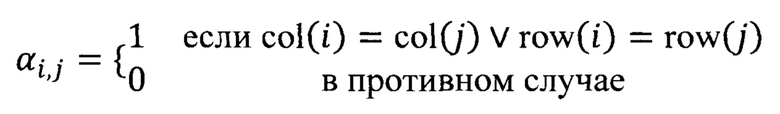
Здесь row (col) - функции, отображающие линеаризованные индексы токенов обратно в индексы строк (столбцов) в таблице.
Классификация происходит на уровне ячеек (что не отменяет возможность делать классификацию, на уровне токенов, но это повышает вероятность ошибки и разрыва сущности внутри ячейки, а значит требует большого кол-ва данных для получения сопоставимого результата), поэтому сохраняются не только координаты исходных слов в последовательности токенов (bpe как правило, зависит от модели), но и координаты границ ячеек таблицы в последовательности токенов.
Выход слоя кодировщика токенов - это последовательность представлений токенов:
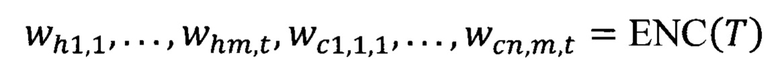
Используя сохраненные границы ячеек (или слов) таблицы, осуществляется пулинг (https://arxiv.org/abs/2009.07485 - максимальный, средневзвешенный, или другие виды пулинга) для получения представления ячейки таблицы. Предпочитаемый метод пулинга может зависеть от архитектуры и способа предобучения базового эмбедера.
Затем эти представления передаются в слой классификации с активацией Softmax для присвоения оценки каждому токену класса 
[41] В качестве подробного примера реализации представлено описание частного варианта осуществления способа:
Шаг 1: получают данные, включающие: текст, структуру таблицы;
На вход приходит:
1) Изображение в виде таблицы, пример ниже:

2) Результаты полнотекстового распознавания картинки включающую текст, его расположение и структуру таблицы с помощью, например, таких средств как SberOCR, Tesseract, ABBYY FineReader или другие).
Ниже показан пример получаемого полнотекстового распознавания (с помощью SberOCR). Общая информация:

Ниже показан пример получаемого полнотекстового распознавания (с помощью SberOCR). Отдельная ячейка:

Шаг 2: таблица определяется как набор из списка ячеек заголовков таблицы и списка ячеек тела таблиц.
Ниже пример визуального представления таблицы в виде заголовка и последовательности нумерованных ячеек и колонок:

Шаг 3: каждую ячейку тела таблицы помечают тегами, характеризующими: идентификатор таблицы, список атомарных колонок к которым относится ячейка, список атомарных строк к которым относится ячейка.
Текст разбивается на последовательности. Каждая последовательность содержит в себе информацию о таблице (table_id), колонке (column_idxs) и строке таблицы (row_idxs). Для нетабличных последовательностей эти значения равны None. Ниже показан пример считанных последовательностей:

Шаг 4: данные каждой ячейки тела таблицы дополняются информацией из соответствующих ячеек заголовков. Ячейки-заголовки ограничиваются нижним значением строки или определяются вручную:

Данные каждой ячейки тела таблицы дополняются информацией из соответствующих ячеек заголовков:

Шаг 5: производят токенизацию текста в таблице.
Текст разбивается на значимые для модели части текста (токены) и дополняются служебными токенами необходимые для работы модели - ниже пример значимых для модели токенов и полученных из исходного текста:

Шаг 6: производят позиционное кодирование на уровне строк таблицы. Позиционное кодирование происходит на уровне строки таблицы, где токены заголовка таблицы учитывает в расчет порядка, таким образом сохраняется распределение во входном слое базовой модели.
Шаг 7: формируют векторные представления токенов для каждого токена в таблице путем агрегации векторных представлений токенов и позиционных векторных представлений - ниже пример векторных представлений, получаемых из первой части модели трансформера - энкодера:

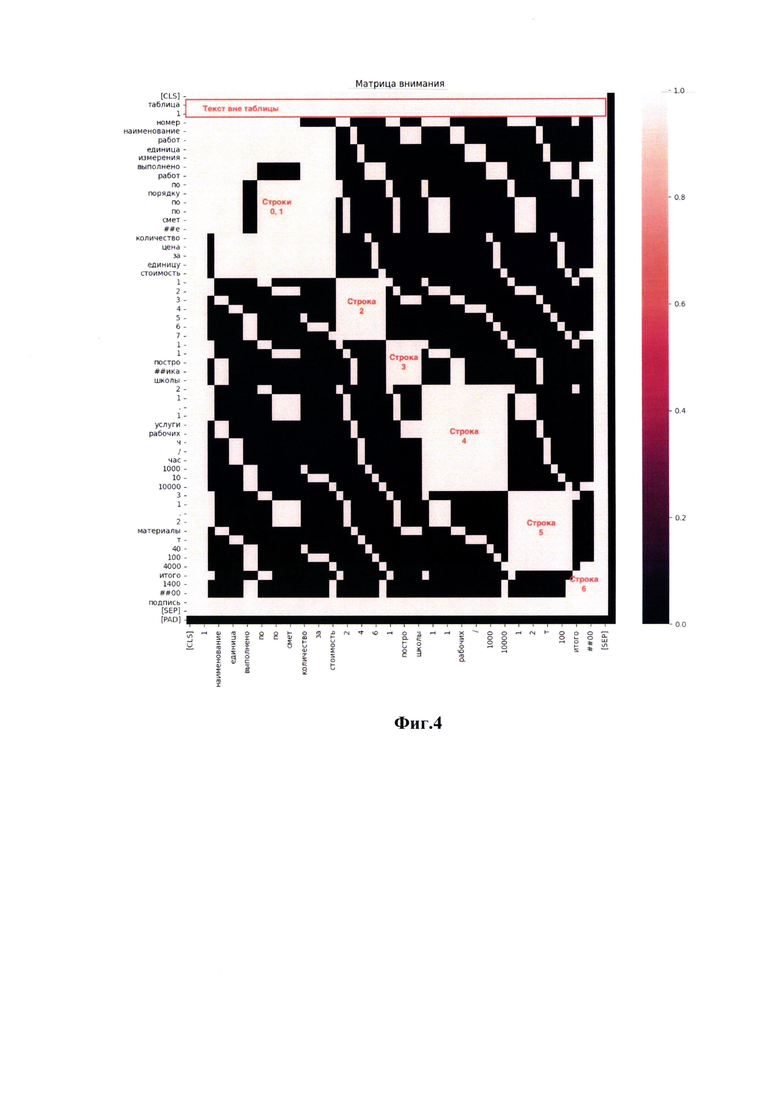
Шаг 8: формируют матрицу внимания, используя принадлежность ячейки к колонке или строке таблицы. Матрица внимания передается в модель трансформера. Матрица внимания состоит из 0 и 1. Где значение 1 означает, что токены обуславливается друг на друга, то есть зависимы. Значение 0 означает независимость токенов для модели и необязательность для проведения расчетов для этих токенов. Каждый токен в и вне таблицы обуславливается на все токены вне таблицы. Внутри таблицы токены обуславливаются только на токены находящиеся в одной строке или колонке. На Фиг. 4 изображена матрица внимания, где белый цвет - 1, черный - 0.
Шаг 9: сохраняют координаты границ ячеек таблицы в последовательности токенов таблицы.
Границы последовательностей (строки вне таблиц и ячейки в таблице) сохраняются в виде списка, где первое значение указывает на первый токен последовательности (ячейки или строки), второе значение указывает на последний токен последовательности (ячейки или строки) и будут использованы после получения векторных представлений токенов для получения векторных представлений ячеек.
Ниже показан пример списка границ последовательностей, указываемые в токенах:

Шаг 10: базовая модель получает на вход подготовленные текстовые и позиционные векторные представления токенов и матрицу внимания, и обрабатывает их, получая контекстуализированные векторные представления токенов.
Модели трансформера на вход подаются индексы токенов, матрица внимания и прочие необходимые для работы конкретной модели. На выходе мы получаем список из векторных представлений каждого токена, обогащенного контекстуальной информацией важной для данного токена. Количество выходных векторов равно кол-ву токенов.
Первым этапом модели является получение неконтекстуализированных векторных представлений слов из словаря. К ним, как правило, добавляется векторное представление позиции.
Далее эти векторные представления подаются на вход основной части модели трансформера, осуществляющую контекстуализацию векторных представлений слов путем механизма self-attention.
В качестве базовой модели использовалась модель BertModel из библиотеки transformers:
https://github.com/huggingface/transformers/blob/main/transformers/models/bert/modeling_bert.py#L956.
Ниже приведен пример списка из векторных представлений токенов на выходе модели трансформера: 
Шаг 11: используя сохраненные координаты границ ячеек таблицы, используют пулинг для получения векторного представления ячейки таблицы. По сохраненным координатам границы ячеек производится пулинг. После применения пулинга токенов в границах сохраненных токенов получаем кол-во векторов равное кол-ву ячеек таблицы + кол-во внетабличных последовательностей (строк) - ниже пример списка из векторных представлений последовательностей (ячеек и строк):

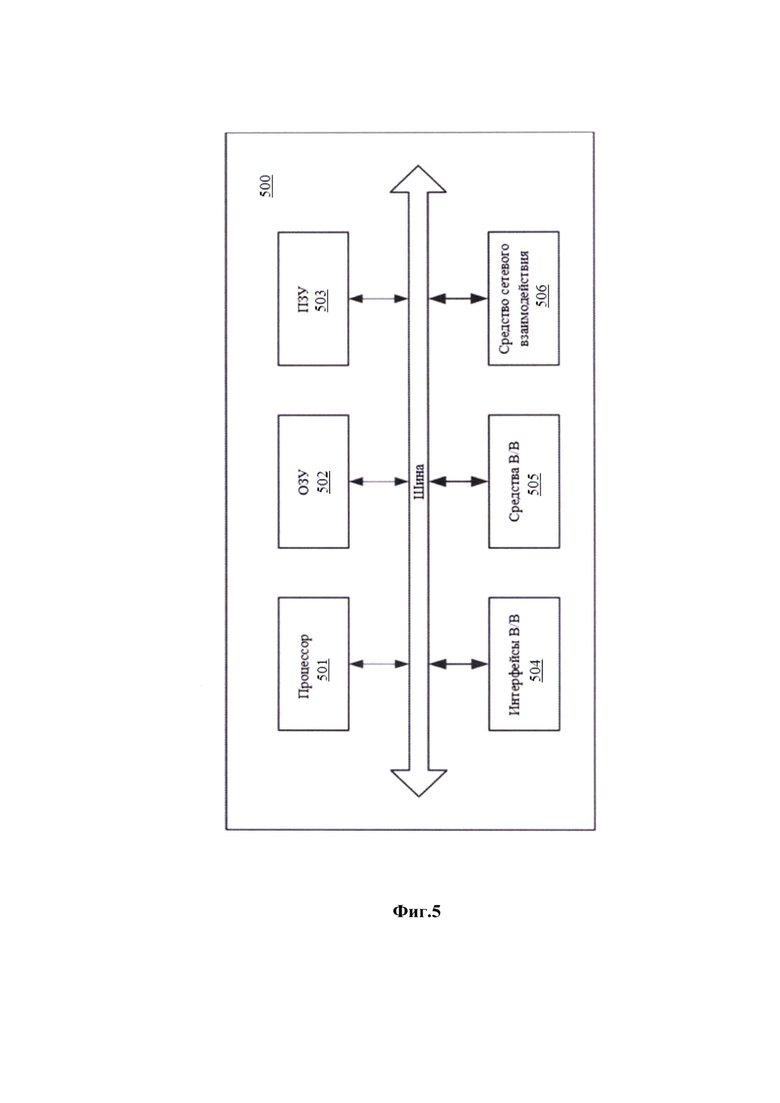
[42] В общем виде (см. Фиг. 5) система получения векторных представлений данных в таблице с учетом структуры таблицы и ее содержания (500) содержит объединенные общей шиной информационного обмена один или несколько процессоров (501), средства памяти, такие как ОЗУ (502) и ПЗУ (503) и интерфейсы ввода/вывода (504).
[43] Процессор (501) (или несколько процессоров, многоядерный процессор и т.п.) может выбираться из ассортимента устройств, широко применяемых в настоящее время, например, таких производителей, как: Intel™, AMD™, Apple™, Samsung Exynos™, MediaTEK™, Qualcomm Snapdragon™ и т.п. Под процессором или одним из используемых процессоров в системе (500) также необходимо учитывать графический процессор, например, GPU NVIDIA с программной моделью, совместимой с CUDA, или Graphcore, тип которых также является пригодным для полного или частичного выполнения способа, а также может применяться для обучения и применения моделей машинного обучения в различных информационных системах.
[44] ОЗУ (502) представляет собой оперативную память и предназначено для хранения исполняемых процессором (501) машиночитаемых инструкций для выполнения необходимых операций по логической обработке данных. ОЗУ (502), как правило, содержит исполняемые инструкции операционной системы и соответствующих программных компонент (приложения, программные модули и т.п.). При этом, в качестве ОЗУ (502) может выступать доступный объем памяти графической карты или графического процессора.
[45] ПЗУ (503) представляет собой одно или более устройств постоянного хранения данных, например, жесткий диск (HDD), твердотельный накопитель данных (SSD), флэш-память (EEPROM, NAND и т.п.), оптические носители информации (CD-R/RW, DVD-R/RW, BlueRay Disc, MD) и др.
[46] Для организации работы компонентов устройства (500) и организации работы внешних подключаемых устройств применяются различные виды интерфейсов В/В (504). Выбор соответствующих интерфейсов зависит от конкретного исполнения вычислительного устройства, которые могут представлять собой, не ограничиваясь: PCI, AGP, PS/2, IrDa, Fire Wire, LPT, COM, SATA, IDE, Lightning, USB (2.0, 3.0, 3.1, micro, mini, type C), TRS/Audio jack (2.5, 3.5, 6.35), HDMI, DVI, VGA, Display Port, RJ45, RS232 и т.п.
[47] Для обеспечения взаимодействия пользователя с устройством (500) применяются различные средства (505) В/В информации, например, клавиатура, дисплей (монитор), сенсорный дисплей, тач-пад, джойстик, манипулятор мышь, световое перо, стилус, сенсорная панель, трекбол, динамики, микрофон, средства дополненной реальности, оптические сенсоры, планшет, световые индикаторы, проектор, камера, средства биометрической идентификации (сканер сетчатки глаза, сканер отпечатков пальцев, модуль распознавания голоса) и т.п.
[48] Средство сетевого взаимодействия (506) обеспечивает передачу данных посредством внутренней или внешней вычислительной сети, например, Интранет, Интернет, ЛВС и т.п. В качестве одного или более средств (506) может использоваться, но не ограничиваться: Ethernet карта, GSM модем, GPRS модем, LTE модем, 5G модем, модуль спутниковой связи, NFC модуль, Bluetooth и/или BLE модуль, Wi-Fi модуль и др.
[49] Конкретный выбор элементов устройства (500) для реализации различных программно-аппаратных архитектурных решений может варьироваться с сохранением обеспечиваемого требуемого функционала. В частности, подобная реализация может быть выполнена с помощью электронных компонент, используемых для создания цифровых интегральных схем. Не ограничиваюсь, могут быть использоваться микросхемы, логика работы которых определяется при изготовлении, или программируемые логические интегральные схемы (ПЛИС), логика работы которых задается посредством программирования. Для программирования используются программаторы и отладочные среды, позволяющие задать желаемую структуру цифрового устройства в виде принципиальной электрической схемы или программы на специальных языках описания аппаратуры: Verilog, VHDL, AHDL и др. Альтернативой ПЛИС являются: программируемые логические контроллеры (ПЛК), базовые матричные кристаллы (БМК), требующие заводского производственного процесса для программирования; ASIC - специализированные заказные большие интегральные схемы (БИС), которые при мелкосерийном и единичном производстве существенно дороже. Таким образом, реализация может быть достигнута стандартными средствами, базирующимися на классических принципах реализации основ вычислительной техники.
[50] Представленные материалы заявки раскрывают предпочтительные примеры реализации технического решения и не должны трактоваться как ограничивающие иные, частные примеры его воплощения, не выходящие за пределы испрашиваемой правовой охраны, которые являются очевидными для специалистов соответствующей области техники.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ И СИСТЕМА КЛАССИФИКАЦИИ ТЕКСТА | 2022 |
|
RU2818693C2 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ ОПРЕДЕЛЕНИЯ МОШЕННИЧЕСКИХ ТРАНЗАКЦИЙ ПОЛЬЗОВАТЕЛЯ | 2024 |
|
RU2839053C1 |
| НАСТРАИВАЕМЫЕ ТАБЛИЧНЫЕ СТИЛИ ДИНАМИЧЕСКИХ ТАБЛИЦ | 2006 |
|
RU2419851C2 |
| СПОСОБ И СИСТЕМА ВЫЯВЛЕНИЯ ОБФУСЦИРОВАННЫХ ВРЕДОНОСНЫХ КОМАНД В СИСТЕМНОЙ КОНСОЛИ ОПЕРАЦИОННОЙ СИСТЕМЫ | 2024 |
|
RU2838483C1 |
| СПОСОБ И СИСТЕМА ОБУЧЕНИЯ СИСТЕМЫ ЧАТ-БОТА | 2023 |
|
RU2820264C1 |
| СПОСОБ И СИСТЕМА ПОЛУЧЕНИЯ ВЕКТОРНОГО ПРЕДСТАВЛЕНИЯ ЭЛЕКТРОННОГО ТЕКСТОВОГО ДОКУМЕНТА ДЛЯ КЛАССИФИКАЦИИ ПО КАТЕГОРИЯМ КОНФИДЕНЦИАЛЬНОЙ ИНФОРМАЦИИ | 2021 |
|
RU2775358C1 |
| СПОСОБ И УСТРОЙСТВО ГЕНЕРИРОВАНИЯ ВИДЕОКЛИПА ПО ТЕКСТОВОМУ ОПИСАНИЮ И ПОСЛЕДОВАТЕЛЬНОСТИ КЛЮЧЕВЫХ ТОЧЕК, СИНТЕЗИРУЕМОЙ ДИФФУЗИОННОЙ МОДЕЛЬЮ | 2024 |
|
RU2823216C1 |
| ИЗВЛЕЧЕНИЕ ИНФОРМАЦИИ ИЗ СТРУКТУРИРОВАННЫХ ДОКУМЕНТОВ, СОДЕРЖАЩИХ ТЕКСТ НА ЕСТЕСТВЕННОМ ЯЗЫКЕ | 2015 |
|
RU2607976C1 |
| СИСТЕМА И СПОСОБ ОБУЧЕНИЯ МОДЕЛЕЙ МАШИННОГО ОБУЧЕНИЯ ДЛЯ РАНЖИРОВАНИЯ РЕЗУЛЬТАТОВ ПОИСКА | 2023 |
|
RU2829065C1 |
| СПОСОБ ПРОГНОЗИРОВАНИЯ ДИАГНОЗА НА ОСНОВЕ ОБРАБОТКИ ДАННЫХ, СОДЕРЖАЩИХ МЕДИЦИНСКИЕ ЗНАНИЯ | 2019 |
|
RU2723674C1 |
Группа изобретений относится к области обработки данных и может быть использована для получения векторных представлений данных в таблице с учетом структуры таблицы и ее содержания. Техническим результатом является ускорение процесса обучения языковой модели при работе с табличными документами. Способ содержит следующие этапы: получают данные, включающие: текст, структуру таблицы; таблица определяется как набор из списка ячеек заголовков таблицы и списка ячеек тела таблицы; каждую ячейку тела таблицы помечают тегами, характеризующими: идентификатор таблицы, список атомарных колонок, к которым относится ячейка, список атомарных строк, к которым относится ячейка; данные каждой ячейки тела таблицы дополняются информацией из соответствующих ячеек заголовков; производят токенизацию текста в таблице; производят позиционное кодирование на уровне строк таблицы; формируют векторные представления токенов для каждого токена в таблице путем агрегации векторных представлений токенов и позиционных векторных представлений; формируют матрицу внимания, используя принадлежность ячейки к колонке или строке таблицы; сохраняют координаты границ ячеек таблицы в последовательности токенов таблицы; базовая модель получает на вход подготовленные текстовые и позиционные векторные представления токенов и матрицу внимания и обрабатывает их, получая контекстуализированные векторные представления токенов; используя сохраненные координаты границ ячеек таблицы, используют пулинг для получения векторного представления ячейки таблицы. 2 н. и 4 з.п. ф-лы, 5 ил.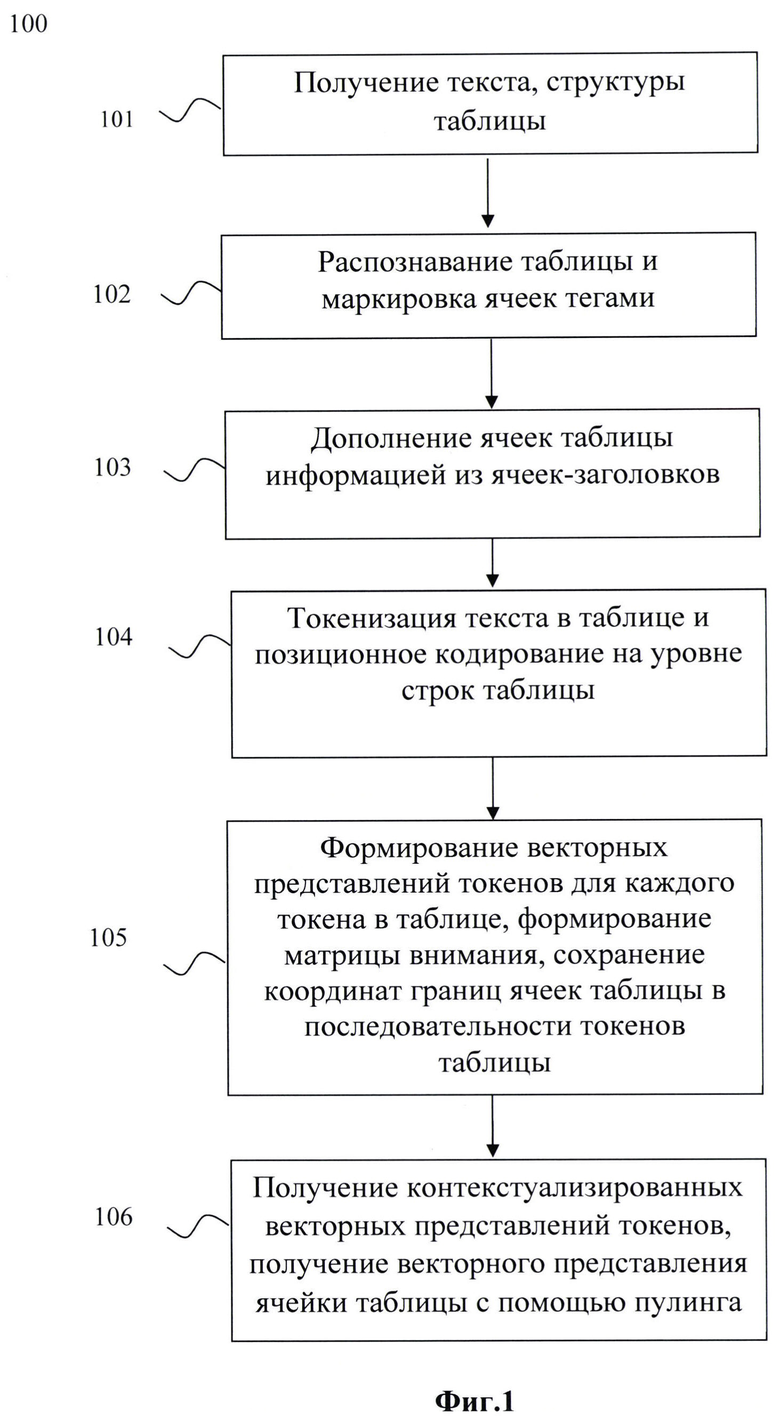
1. Способ получения векторных представлений данных в таблице с учетом структуры таблицы и ее содержания, реализуемый с помощью процессора и устройства хранения данных, включающий следующие шаги:
- получают данные, включающие: текст, структуру таблицы;
- таблица определяется как набор из списка ячеек заголовков таблицы и списка ячеек тела таблицы;
- каждую ячейку тела таблицы помечают тегами, характеризующими: идентификатор таблицы, список атомарных колонок к которым относится ячейка, список атомарных строк к которым относится ячейка.
- данные каждой ячейки тела таблицы дополняются информацией из соответствующих ячеек заголовков;
- производят токенизацию текста в таблице;
- производят позиционное кодирование на уровне строк таблицы;
- формируют векторные представления токенов для каждого токена в таблице путем агрегации векторных представлений токенов и позиционных векторных представлений;
- формируют матрицу внимания, используя принадлежность ячейки к колонке или строке таблицы;
- сохраняют координаты границ ячеек таблицы в последовательности токенов таблицы;
- базовая модель получает на вход подготовленные текстовые и позиционные векторные представления токенов и матрицу внимания и обрабатывает их, получая контекстуализированные векторные представления токенов;
- используя сохраненные координаты границ ячеек таблицы, используют пулинг для получения векторного представления ячейки таблицы.
2. Способ по п. 1, характеризующийся тем, что базовая модель дообучается под выполнение конкретной задачи.
3. Способ по п. 1, характеризующийся тем, что базовая модель предобучена на неструктурированном тексте под домен, без необходимости наличия информации о таблицах.
4. Система получения векторных представлений данных в таблице с учетом структуры таблицы и ее содержания, используемых для машинного обучения, содержащая:
по меньшей мере одно устройство обработки данных;
по меньшей мере одно устройство хранения данных;
по меньшей мере одну программу, где одна или более программ хранятся на одном или более устройствах хранения данных и исполняются на одном и более устройствах обработки данных, причем одна или более программ обеспечивает выполнение следующих шагов:
- получают данные, включающие: текст, структуру таблицы;
- таблица определяется как набор из списка ячеек заголовков таблицы и списка ячеек тела таблицы;
- каждую ячейку тела таблицы помечают тегами, характеризующими: идентификатор таблицы, список атомарных колонок, к которым относится ячейка, список атомарных строк, к которым относится ячейка.
- данные каждой ячейки тела таблицы дополняются информацией из соответствующих ячеек заголовков;
- производят токенизацию текста в таблице;
- производят позиционное кодирование на уровне строк таблицы;
- формируют векторные представления токенов для каждого токена в таблице путем агрегации векторных представлений токенов и позиционных векторных представлений;
- формируют матрицу внимания, используя принадлежность ячейки к колонке или строке таблицы;
- сохраняют координаты границ ячеек таблицы в последовательности токенов таблицы;
- базовая модель получает на вход подготовленные текстовые и позиционные векторные представления токенов и матрицу внимания и обрабатывает их, получая контекстуализированные векторные представления токенов;
- используя сохраненные координаты границ ячеек таблицы, используют пулинг для получения векторного представления ячейки таблицы.
5. Система по п. 4, характеризующаяся тем, что базовая модель дообучается для выполнения конкретной задачи.
6. Система по п. 4, характеризующаяся тем, что базовая модель предобучена на неструктурированном тексте под домен, без необходимости наличия информации о таблицах.
| СПОСОБ И СИСТЕМА ПОЛУЧЕНИЯ ВЕКТОРНОГО ПРЕДСТАВЛЕНИЯ ЭЛЕКТРОННОГО ДОКУМЕНТА | 2021 |
|
RU2775351C1 |
| СПОСОБ И СИСТЕМА ПОЛУЧЕНИЯ ВЕКТОРНОГО ПРЕДСТАВЛЕНИЯ ЭЛЕКТРОННОГО ТЕКСТОВОГО ДОКУМЕНТА ДЛЯ КЛАССИФИКАЦИИ ПО КАТЕГОРИЯМ КОНФИДЕНЦИАЛЬНОЙ ИНФОРМАЦИИ | 2021 |
|
RU2775358C1 |
| US 20210224612 A1, 22.07.2021 | |||
| EP 4318322 A1, 07.02.2024 | |||
| CN 115204300 A, 18.10.2022. | |||

