Область техники, к которой относится изобретение
[001] Настоящая технология относится к способам машинного обучения, в частности, к способам и системам для обучения и использования моделей машинного обучения с целью ранжирования результатов поиска.
Уровень техники
[002] В настоящее время веб-поиск является одной из ключевых технологий, с использованием которой ежедневно обрабатываются миллиарды пользовательских запросов. Современные системы веб-поиска, как правило, ранжируют результаты поиска, исходя из их релевантности поисковому запросу. Для определения релевантности результатов поиска запросу зачастую используются алгоритмы машинного обучения (MLA, Machine Learning Algorithm), обученные оценивать различные показатели релевантности на основе множества признаков. Такое определение релевантности можно рассматривать, по меньшей мере частично, как задачу понимания языка, поскольку релевантность документа поисковому запросу отчасти относится к семантическому пониманию как запроса, так и результатов поиска, даже в тех случаях, когда запрос и результаты не содержат общих слов или когда результатами являются изображения, музыка или другой нетекстовый контент.
[003] Последние достижения в области нейронной обработки естественного языка включают в себя использование моделей машинного обучения на основе трансформера, как описано в статье Vaswani et al., «Attention Is All You Need», Advances in neural information processing systems, pages 5998-6008, 2017. Трансформер представляет собой модель глубокого обучения (то есть искусственную нейронную сеть или другую модель машинного обучения с несколькими слоями), в которой применяется механизм «внимания» для придания большего веса одним частям входных данных в сравнении с другими. При обработке естественного языка такой механизм внимания обеспечивает определение контекста для слов во входных данных, поскольку одно и то же слово может иметь разные значения в зависимости от контекста. Таким образом, модели машинного обучения на основе трансформера способны учитывать семантику (то есть смысл) слов в конкретном контексте, например, ключевых слов в поисковом запросе. Трансформеры также способны параллельно обрабатывать множество слов или токенов естественного языка, что позволяет применять параллельное обучение.
[004] Трансформеры легли в основу и других достижений в области обработки естественного языка, в частности, систем с предварительным обучением, которые могут заранее обучаться на большом наборе данных, а затем оптимизироваться для использования в конкретных задачах. Примерами таких систем являются двунаправленные представления кодировщиков на основе трансформеров (BERT, Bidirectional Encoder Representations from Transformers), описанные в статье Devlin et al., «BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding», Proceedings of NAACL-HLT 2019, pages 4171-4186, 2019, и генеративный предварительно обучаемый трансформер (GPT, Generative Pre-trained Transformer), описанный в статье Radford et al., «Improving Language Understanding by Generative Pre-Training», 2018.
[005] В общем случае для выполнения задач поискового ранжирования трансформеры могут обучаться определению параметров релевантности результатов поиска, выдаваемых цифровой платформой (например, поисковой системой) конкретному пользователю. Например, такие параметры релевантности могут быть представлены значениями вероятности взаимодействия пользователя с результатами поиска (например, нажатия кнопки мыши). В частности, в ответ на отправку пользователем поискового запроса цифровая платформа может находить набор цифровых документов (например, веб-документов), удовлетворяющих этому поисковому запросу. Кроме того, и поисковый запрос, и набор цифровых документов могут передаваться в модель машинного обучения на основе трансформера, обученную с использованием особым образом организованных обучающих данных, для выполнения ранжирования.
[006] Несмотря на то, что модели машинного обучения на основе трансформеров демонстрируют высокую эффективность при подборе релевантных результатов поиска на основе семантических связей между ними и поисковым запросом, «улавливание» лексических связей между поисковым запросом и цифровыми документами может быть сложной задачей для таких моделей. Иными словами, в связи с тем, что при использовании механизма внимания некоторым ключевым словам поискового запроса присваивается больший вес, чем другим, модели машинного обучения на основе трансформеров могут игнорировать цифровые документы, содержащие слова, полностью совпадающие с ключевыми словами поискового запроса (или присваивать таким документам низкие ранги).
[007] Например, пользователь может отправить на цифровую платформу поисковый запрос с текстом «Macarons recipe Cedric Grolet» (Рецепт десерта «макарон» Седрика Гроле), а цифровая платформа может обеспечить нахождение множества цифровых документов, удовлетворяющих этому поисковому запросу. Кроме того, модель машинного обучения на основе трансформера может ранжировать цифровые документы таким образом, чтобы в первые (лучшие) результаты поиска на странице результатов поиска (SERP, Search Engine Results Page) цифровой платформы попадали цифровые документы (например, текстовые документы, изображения, видео и пр.), содержащие информацию, относящуюся только к рецептам традиционных французских десертов «макарон», и/или информацию, относящуюся только к известному французскому кондитеру Седрику Гроле. При этом модель машинного обучения на основе трансформера может присвоить сравнительно низкий приоритет цифровым документам, которые содержат информацию о рецептах десертов «макарон» именно от Седрика Гроле, вследствие чего такие цифровые документы могут не появиться на странице результатов поиска. В результате взаимодействие с цифровой платформой может оставить негативные впечатления у пользователя.
[008] Таким образом, в данной области существует потребность в учете как семантических, так и лексических аспектов связей между поисковым запросом и цифровыми документами при ранжировании цифровых документов. В известных технических решениях был предложен ряд способов для решения этой технической задачи.
[009] В статье Gao et al., «COIL: Revisit Exact Lexical Match in Information Retrieval with Contextualized Inverted List», Carnegie Mellon University, 2021, раскрыта архитектура контекстуализированного поиска точного соответствия, в которой устанавливается лексико-семантическое соответствие на основе контекстуализированного инвертированного списка (COIL, Contextualized Inverted List). Оценка списка COIL формируется на основе контекстуализированных представлений частично совпадающих токенов в запросах и документах. Архитектура обеспечивает хранение контекстуализированных представлений токенов в инвертированных списках, сочетая эффективность точного соответствия с широкими возможностями представления глубоких языковых моделей.
[010] В патенте US11475067B2 «Systems, apparatuses, and methods to generate synthetic queries from customer data for training of document querying machine learning models», выданном 18 октября 2022 года и принадлежащем компании Amazon Technologies Inc., раскрыты методы формирования синтезированных запросов на основе данных клиента с целью обучения моделей машинного обучения для запроса документов в качестве сервиса. Такой сервис может получать один или несколько документов от пользователя, формировать множество пар вопросов и ответов на основе одного или нескольких документов пользователя с использованием модели машинного обучения, обученной прогнозированию вопроса по ответу, и сохранять множество пар вопросов и ответов, сформированных на основе одного или нескольких документов пользователя. Пары вопросов и ответов могут использоваться для обучения другой модели машинного обучения, например, модели ранжирования документов, модели ранжирования фрагментов, модели «вопрос-ответ» или модели часто задаваемых вопросов (FAQ, Frequently Asked Question).
Раскрытие изобретения
[011] Разработчики настоящей технологии установили, что эффективность учета как семантических, так и лексических связей между поисковыми запросами и ранжируемыми цифровыми документами повышается, если входные данные модели машинного обучения на основе трансформера, помимо поискового запроса и собственно ранжируемых цифровых документов, включают в себя ряд фраз из цифровых документов-кандидатов, которые были определены как лексически связанные с поисковым запросом.
[012] В частности, различные аспекты и варианты осуществления настоящей технологии относятся к способам и системам, которые предусматривают (а) получение поискового запроса, (б) нахождение в поисковом индексе цифровой платформы множества цифровых документов-кандидатов, соответствующих поисковому запросу и семантически связанных с ним, и (в) нахождение во множестве цифровых документов-кандидатов множества фраз-кандидатов, лексически связанных с поисковым запросом, то есть содержащих по меньшей мере одно слово, которое либо полностью совпадает с одним из ключевых слов поискового запроса, либо является его грамматическим производным. Кроме того, в соответствии с некоторыми не имеющими ограничительного характера вариантами осуществления настоящей технологии, поисковый запрос и найденные таким способом фразы, лексически связанные с ним, передаются в модель машинного обучения на основе трансформера, обученную формированию векторных представлений входных фраз, с целью формирования первого векторного представления поискового запроса и второго векторного представления множества фраз-кандидатов.
[013] Кроме того, описанные здесь способы и системы относятся к передаче сформированных таким способом векторных представлений, наряду с векторными представлениями документов и поискового запроса, в модель машинного обучения для ранжирования, особым образом предварительно обученную определению приоритетов цифровых документов на основе таких векторных представлений. Соответственно, при ранжировании цифровых документов для их представления на странице результатов поиска цифровой платформы эти способы и системы позволяют учитывать не только семантические связи между поисковым запросом и содержимым удовлетворяющих ему цифровых документов, но и лексику ключевых слов поиска. Таким образом, помимо цифровых документов, семантически (то есть по смыслу) релевантных поисковому запросу, на странице результатов поиска цифровой платформы могут быть представлены и цифровые документы, лексически релевантные поисковому запросу, то есть содержащие слова, полностью совпадающие с одним или несколькими ключевыми словами поискового запроса или являющиеся их производными. Это способствует улучшению впечатлений пользователей, взаимодействующих с цифровой платформой.
[014] В частности, в соответствии с первым широким аспектом настоящей технологии реализован компьютерный способ ранжирования цифровых документов на цифровой платформе. Способ предусматривает получение поискового запроса, отправленного пользователем на цифровую платформу, формирование первого векторного представления, характеризующего поисковый запрос, нахождение в поисковом индексе цифровой платформы множества цифровых документов-кандидатов, удовлетворяющих поисковому запросу, получение для каждого цифрового документа-кандидата из множества цифровых документов-кандидатов второго векторного представления, сформированного до поступления поискового запроса, нахождение для каждого документа-кандидата из множества цифровых документов-кандидатов по меньшей мере одной фразы-кандидата, лексически связанной с по меньшей мере одним ключевым словом поискового запроса, формирование третьего векторного представления, характеризующего по меньшей мере одну фразу-кандидат, определение на основе первого, второго и третьего векторных представлений для каждого документа-кандидата из множества цифровых документов-кандидатов значения параметра ранжирования, характеризующего релевантность этого документа-кандидата из множества цифровых документов-кандидатов поисковому запросу, и ранжирование множества цифровых документов-кандидатов на основе связанных с ними значений параметра ранжирования.
[015] В некоторых вариантах реализации способа нахождение множества цифровых документов-кандидатов предусматривает применение функции ранжирования.
[016] В некоторых вариантах реализации способа функция ранжирования представляет собой функцию ранжирования Okapi BM25.
[017] В некоторых вариантах реализации способа нахождение по меньшей мере одной фразы-кандидата предусматривает формирование для каждой фразы документа-кандидата из множества цифровых документов-кандидатов векторного представления фразы, определение в пространстве векторных представлений значения расстояния между первым векторным представлением, характеризующим поисковый запрос, и векторным представлением фразы, ранжирование фраз из множества цифровых документов-кандидатов в зависимости от значений расстояния, связанных с векторными представлениями фраз, с целью формирования ранжированного списка фраз для поискового запроса и выбор из ранжированного списка фраз заданного количества приоритетных фраз.
[018] В некоторых вариантах реализации способа формирование векторного представления фразы предусматривает определение для каждого ключевого слова поискового запроса значения отношения частоты ключевого слова к обратной частоте документа (TF-IDF, Term Frequency-Inverse Document Frequency) в документе-кандидате из множества цифровых документов-кандидатов.
[019] В некоторых вариантах реализации способа формирование векторного представления фразы предусматривает применение к ней алгоритма векторного представления текста.
[020] В некоторых вариантах реализации способа алгоритм векторного представления текста представляет собой алгоритм векторного представления слов FastText.
[021] В некоторых вариантах реализации способа определение значения параметра ранжирования предусматривает передачу первого, второго и третьего векторных представлений в объединенную модель машинного обучения, обученную определению значения параметра ранжирования для каждого документа из множества цифровых документов на основе векторных представлений (а) поискового запроса, используемого для нахождения множества цифровых документов, (б) каждого документа из множества цифровых документов, удовлетворяющих этому поисковому запросу, и (в) по меньшей мере одной фразы-кандидата, определенной во множестве цифровых документов как лексически связанной с по меньшей мере одним ключевым словом этого поискового запроса.
[022] В некоторых вариантах реализации способа он дополнительно предусматривает обучение объединенной модели машинного обучения путем формирования обучающего набора данных, содержащего множество обучающих цифровых объектов, каждый из которых содержит (а) обучающее векторное представление обучающего поискового запроса, (б) обучающие векторные представления множества обучающих цифровых документов-кандидатов, удовлетворяющих обучающему поисковому запросу, (в) обучающее векторное представление по меньшей мере одной обучающей фразы-кандидата, найденной во множестве обучающих цифровых документов, лексически связанной с по меньшей мере одним ключевым словом из обучающего поискового запроса, и (г) метку для каждого обучающего документа из множества обучающих цифровых документов, характеризующую степень релевантности этого документа из множества обучающих цифровых документов обучающему поисковому запросу, передачи множества обучающих цифровых объектов в объединенную модель машинного обучения и сведения к минимуму на каждой итерации обучения расхождения между текущим обучающим прогнозом, сформированным объединенной моделью машинного обучения, и меткой.
[023] В некоторых вариантах реализации способа метка задается человеком-оценщиком.
[024] В некоторых вариантах реализации способа метка формируется моделью машинного обучения, предварительно обученной на основе меток, сформированных людьми-оценщиками, для определения степени релевантности цифрового документа поисковому запросу.
[025] В некоторых вариантах реализации способа объединенная модель машинного обучения содержит глубокую модель машинного обучения для определения семантической близости.
[026] В некоторых вариантах реализации способа получение второго векторного представления предусматривает получение второго векторного представления от второй модели машинного обучения, обученной формированию векторных представлений входных цифровых документов.
[027] В некоторых вариантах реализации способа он дополнительно предусматривает обучение второй модели машинного обучения путем передачи в нее множества цифровых документов из поискового индекса цифровой платформы.
[028] В некоторых вариантах реализации способа он дополнительно предусматривает сокращение объема представлений для каждого из первого, второго и третьего векторных представлений перед определением значения параметра ранжирования.
[029] В некоторых вариантах реализации способа формирование первого, второго и третьего векторных представлений предусматривает применение модели машинного обучения на основе трансформера, а сокращение объема представлений предусматривает последовательное усечение выходных данных каждого промежуточного слоя модели машинного обучения на основе трансформера до заданной длины каждого из первого, второго и третьего векторных представлений.
[030] В некоторых вариантах реализации способа для каждого из первого, второго и третьего векторных представлений задается своя отличная от других длина.
[031] В некоторых вариантах реализации способа формирование первого и третьего векторных представлений осуществляется независимо от формирования второго векторного представления.
[032] В некоторых вариантах реализации способа формирование первого векторного представления, характеризующего поисковый запрос, и третьего векторного представления, характеризующего по меньшей мере одну фразу-кандидат, предусматривает применение модели машинного обучения, обученной формированию векторных представлений входных фраз.
[033] В некоторых вариантах реализации способа он дополнительно предусматривает обучение модели машинного обучения путем формирования обучающего набора данных, содержащего множество обучающих цифровых объектов, каждый из которых содержит обучающий поисковый запрос и множество обучающих фраз-кандидатов, найденных во множестве обучающих цифровых документов, удовлетворяющих обучающему поисковому запросу, и лексически связанных с по меньшей мере одним ключевым словом из обучающего поискового запроса, и передачи множества обучающих цифровых объектов в модель машинного обучения.
[034] В некоторых вариантах реализации способа модель машинного обучения представляет собой модель машинного обучения на основе трансформера.
[035] В некоторых вариантах реализации способа в процессе нахождения по меньшей мере одной фразы-кандидата, лексически связанной с по меньшей мере одним ключевым словом из поискового запроса, для каждого документа-кандидата из множества цифровых документов-кандидатов способ дополнительно предусматривает использование необработанной версии этого документа-кандидата из множества цифровых документов-кандидатов.
[036] В некоторых вариантах реализации способа необработанная версия находится в поисковом индексе.
[037] В соответствии со вторым широким аспектом настоящей технологии реализован сервер для ранжирования цифровых документов на цифровой платформе. Сервер содержит по меньшей мере один процессор и по меньшей мере одну долговременную машиночитаемую память, хранящую исполняемые команды, при исполнении которых по меньшей мере одним процессором на сервере обеспечиваются получение поискового запроса, отправленного пользователем на цифровую платформу, формирование первого векторного представления, характеризующего поисковый запрос, нахождение в поисковом индексе цифровой платформы множества цифровых документов-кандидатов, удовлетворяющих поисковому запросу, получение для каждого цифрового документа-кандидата из множества цифровых документов-кандидатов второго векторного представления, сформированного до поступления поискового запроса, нахождение для каждого документа-кандидата из множества цифровых документов-кандидатов по меньшей мере одной фразы-кандидата, лексически связанной с по меньшей мере одним ключевым словом поискового запроса, формирование третьего векторного представления, характеризующего по меньшей мере одну фразу-кандидат, определение на основе первого, второго и третьего векторных представлений для каждого документа-кандидата из множества цифровых документов-кандидатов значения параметра ранжирования, характеризующего релевантность этого документа-кандидата из множества цифровых документов-кандидатов поисковому запросу, и ранжирование множества цифровых документов-кандидатов на основе связанных с ними значений параметра ранжирования.
[038] В контексте настоящего описания «сервер» представляет собой компьютерную программу, выполняемую на соответствующих аппаратных средствах и способную принимать по сети запросы (например, от клиентских устройств), выполнять эти запросы или инициировать их выполнение. Такие аппаратные средства могут быть реализованы в виде одного физического компьютера или одной физической компьютерной системы, что не имеет существенного значения для настоящей технологии. В данном контексте употребление выражения «сервер» не означает, что какая-либо конкретная задача или все задачи (например, принятые команды или запросы) принимаются, выполняются или запускаются на одном и том же сервере (т.е. одними и теми же программными и/или аппаратными средствами), а означает, что участвовать в приеме, передаче, выполнении или инициировании выполнения каких-либо задач или запросов либо результатов каких-либо задач или запросов может любое количество программных или аппаратных средств, и все эти программные и аппаратные средства могут представлять собой один сервер или несколько серверов, причем выражение «по меньшей мере один сервер» охватывает оба этих случая.
[039] В контексте настоящего описания «клиентское устройство» представляет собой любые компьютерные аппаратные средства, способные обеспечивать работу программного обеспечения, подходящего для решения поставленной задачи. Таким образом, примерами (не имеющими ограничительного характера) клиентских устройств являются персональные компьютеры (настольные компьютеры, ноутбуки, нетбуки и т.п.), смартфоны и планшеты, а также сетевое оборудование, например, маршрутизаторы, коммутаторы и шлюзы. При этом следует отметить, что устройство, выступающее в данном контексте в качестве клиентского, может выступать в качестве сервера для других клиентских устройств. Употребление выражения «клиентское устройство» не исключает использования нескольких клиентских устройств для приема/передачи, выполнения или инициирования выполнения каких-либо задач или запросов, результатов каких-либо задач или запросов либо шагов какого-либо описанного здесь способа.
[040] В контексте настоящего описания термин «база данных» означает любой структурированный набор данных, независимо от его конкретной структуры, программного обеспечения для управления базой данных и компьютерных аппаратных средств для хранения таких данных, их применения или обеспечения их использования иным способом. База данных может размещаться в тех же аппаратных средствах, в которых реализован процесс, обеспечивающий хранение или использование информации, хранящейся в базе данных, либо в отдельных аппаратных средствах, таких как специализированный сервер или группа серверов.
[041] В контексте настоящего описания выражение «информация» включает в себя информацию любого рода или вида, допускающую хранение в базе данных. Таким образом, информация включает в себя, среди прочего, аудиовизуальные произведения (изображения, фильмы, звукозаписи, презентации и т.д.), данные (данные о местоположении, числовые данные и т.д.), текст (отзывы, комментарии, вопросы, сообщения и т.д.), документы, электронные таблицы, списки слов и т.д.
[042] В контексте настоящего описания выражение «компонент» означает программное обеспечение (подходящее для конкретных аппаратных средств), необходимое и достаточное для выполнения конкретных упоминаемых функций.
[043] В контексте настоящего описания выражение «компьютерный носитель информации» предназначено для обозначения носителей любого рода и вида, включая ОЗУ, ПЗУ, диски (CD-ROM, DVD, дискеты, жесткие диски и т.п.), USB-накопители, твердотельные накопители, ленточные накопители и т.д.
[044] В контексте настоящего описания числительные «первый», «второй», «третий» и т.д. служат лишь для указания на различие между существительными, к которым они относятся, а не для описания каких-либо определенных взаимосвязей между этими существительными. Таким образом, следует понимать, что, например, термины «первый сервер» и «третий сервер» не предполагают существования каких-либо определенных порядка, типов, хронологии, иерархии или ранжирования серверов, а употребление этих терминов (само по себе) не подразумевает обязательного наличия какого-либо «второго сервера» в той или иной конкретной ситуации. Кроме того, как встречается в настоящем описании в другом контексте, ссылки на «первый» элемент и «второй» элемент не исключают того, что эти два элемента в действительности могут быть одним и тем же элементом. Так, например, в одних случаях «первый» и «второй» серверы могут представлять собой одни и те же программные и/или аппаратные средства, а в других случаях - разные программные и/или аппаратные средства.
[045] Каждый вариант осуществления настоящей технологии относится к по меньшей мере одной из вышеупомянутых целей и/или к одному из вышеупомянутых аспектов, но не обязательно ко всем ним. Следует понимать, что некоторые аспекты настоящей технологии, связанные с попыткой достижения вышеупомянутой цели, могут не соответствовать этой цели и/или могут соответствовать другим целям, не упомянутым здесь явным образом.
[046] Дополнительные и/или альтернативные признаки, аспекты и преимущества вариантов осуществления настоящей технологии содержатся в дальнейшем описании, на приложенных чертежах и в формуле изобретения.
Краткое описание чертежей
[047] Эти и другие признаки, аспекты и преимущества настоящей технологии содержатся в дальнейшем описании, в приложенной формуле изобретения и на следующих чертежах.
[048] На фиг. 1 схематически представлен пример компьютерной системы, пригодной для реализации некоторых не имеющих ограничительного характера вариантов осуществления систем и/или способов в соответствии с настоящей технологией.
[049] На фиг. 2 представлена сетевая компьютерная среда, пригодная для ранжирования цифровых документов на цифровой платформе, в соответствии с некоторыми не имеющими ограничительного характера вариантами осуществления настоящей технологии.
[050] На фиг. 3 представлена блок-схема архитектуры модели машинного обучения, запускаемой на сервере в составе сетевой компьютерной среды, показанной на фиг. 2, в соответствии с некоторыми не имеющими ограничительного характера вариантами осуществления настоящей технологии.
[051] На фиг. 4 схематически представлен пример цифрового документа, содержащего множество фраз-кандидатов, которые были определены сервером в составе сетевой компьютерной среды, показанной на фиг. 2, как лексически связанные с поисковым запросом, используемым для нахождения иллюстративного цифрового документа, в соответствии с некоторыми не имеющими ограничительного характера вариантами осуществления настоящей технологии.
[052] На фиг. 5 схематически представлена первая модель машинного обучения, реализованная на основе архитектуры модели машинного обучения, показанной на фиг. 3, для формирования векторных представлений входных фраз, в соответствии с некоторыми не имеющими ограничительного характера вариантами осуществления настоящей технологии.
[053] На фиг. 6 схематически представлена вторая модель машинного обучения, реализованная на основе архитектуры модели машинного обучения, показанной на фиг. 3, для формирования векторных представлений входных цифровых документов, в соответствии с некоторыми не имеющими ограничительного характера вариантами осуществления настоящей технологии.
[054] На фиг. 7 схематически представлен процесс обучения объединенной модели машинного обучения, способной формировать значения параметров ранжирования для цифровых документов на основе векторных представлений, сформированных первой и второй моделями машинного обучения, показанными на фиг. 5 и 6, соответственно, в соответствии с некоторыми не имеющими ограничительного характера вариантами осуществления настоящей технологии.
[055] На фиг. 8 схематически представлен процесс работы объединенной модели машинного обучения, показанной на фиг. 7, в соответствии с некоторыми не имеющими ограничительного характера вариантами осуществления настоящей технологии.
[056] На фиг. 9 представлена блок-схема способа ранжирования цифровых документов с использованием объединенной модели машинного обучения, показанной на фиг. 8, в соответствии с некоторыми не имеющими ограничительного характера вариантами осуществления настоящей технологии.
Осуществление изобретения
[057] Представленные здесь примеры и условный язык предназначены для обеспечения лучшего понимания принципов настоящей технологии, а не для ограничения ее объема до таких специально приведенных примеров и условий. Очевидно, что специалисты в данной области техники способны разработать различные способы и устройства, которые явно не описаны и не показаны, но реализуют принципы настоящей технологии в пределах ее существа и объема.
[058] Кроме того, чтобы способствовать лучшему пониманию, последующее описание может содержать упрощенные варианты реализации настоящей технологии. Специалисты в данной области должны понимать, что различные варианты осуществления настоящей технологии могут быть значительно сложнее.
[059] В некоторых случаях приводятся предположительно полезные примеры модификаций настоящей технологии. Они призваны лишь способствовать пониманию и также не определяют объема или границ настоящей технологии. Представленный перечень модификаций не является исчерпывающим и специалист в данной области способен разработать другие модификации в пределах объема настоящей технологии. Кроме того, если в некоторых случаях модификации не описаны, это не означает, что они невозможны и/или что описание содержит единственно возможный вариант реализации того или иного элемента настоящей технологии.
[060] При этом описание принципов, аспектов и вариантов реализации настоящей технологии, а также их конкретные примеры предназначены для охвата их структурных и функциональных эквивалентов, независимо от того, известны они в настоящее время или будут разработаны в будущем. Например, специалисты в данной области техники должны понимать, что все приведенные здесь блок-схемы соответствуют концептуальным представлениям иллюстративных принципиальных схем, реализующих принципы настоящей технологии. Также следует понимать, что все блок-схемы, схемы процессов, диаграммы изменения состояния, псевдокоды и т.п. соответствуют различным процессам, которые могут быть представлены на машиночитаемом физическом носителе информации и могут выполняться компьютером или процессором независимо от того, показан такой компьютер или процессор в явном виде или нет.
[061] Функции различных элементов, показанных на чертежах, включая все функциональные блоки, обозначенные как «процессор» или «графический процессор», могут быть реализованы с использованием специализированных аппаратных средств, а также аппаратных средств, способных обеспечивать работу соответствующего программного обеспечения. Если используется процессор, эти функции могут выполняться одним выделенным процессором, одним совместно используемым процессором и/или несколькими отдельными процессорами, некоторые из которых могут использоваться совместно. В некоторых вариантах реализации настоящей технологии процессор может представлять собой процессор общего назначения, например, центральный процессор (CPU), или процессор, предназначенный для решения конкретной задачи, например, графический процессор (GPU). Кроме того, явное использование термина «процессор» или «контроллер» не должно трактоваться как указание исключительно на аппаратные средства, способные обеспечивать работу программного обеспечения, и может подразумевать, среди прочего, аппаратные средства цифрового сигнального процессора (DSP), сетевой процессор, специализированную интегральную схему (ASIC), программируемую вентильную матрицу (FPGA), ПЗУ для хранения программного обеспечения, ОЗУ и/или энергонезависимое ЗУ. Также могут подразумеваться другие аппаратные средства, общего назначения и/или заказные.
[062] Программные модули или просто модули, реализация которых предполагается на базе программных средств, могут быть представлены здесь в виде любого сочетания элементов блок-схемы или других элементов, указывающих на выполнение шагов процесса и/или содержащих текстовое описание. Такие модули могут выполняться аппаратными средствами, показанными явно или подразумеваемыми.
[063] С учетом вышеизложенных принципов ниже рассмотрены некоторые не имеющие ограничительного характера примеры, иллюстрирующие различные варианты реализации аспектов настоящей технологии.
Компьютерная система
[064] На фиг. 1 изображена компьютерная система 100, пригодная для использования в некоторых вариантах осуществления настоящей технологии. Компьютерная система 100 содержит различные аппаратные элементы, включая один или несколько одноядерных или многоядерных процессоров, совместно представленных процессором 110, графический процессор 111, твердотельный накопитель 120, ОЗУ 130, интерфейс 140 дисплея и интерфейс 150 ввода/вывода.
[065] Связь между элементами компьютерной системы 100 может осуществляться через одну или несколько внутренних и/или внешних шин 160 (таких как шина PCI, шина USB, шина FireWire стандарта IEEE 1394, шина SCSI, шина Serial-ATA и т.д.), с которыми различные аппаратные элементы соединены электронными средствами.
[066] Интерфейс 150 ввода/вывода может быть соединен с сенсорным экраном 190 и/или с одной или несколькими внутренними и/или внешними шинами 160. Сенсорный экран 190 может быть частью дисплея. В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии сенсорный экран 190 представляет собой дисплей. Сенсорный экран 190 также может называться экраном 190. В вариантах осуществления, показанных на фиг. 1, сенсорный экран 190 содержит сенсорные средства 194 (например, сенсорные элементы, встроенные в слой дисплея и обеспечивающие фиксацию физического взаимодействия между пользователем и дисплеем) и контроллер 192 сенсорных средств ввода/вывода, обеспечивающий связь с интерфейсом 140 дисплея и/или с одной или несколькими внутренними и/или внешними шинами 160. В некоторых вариантах осуществления интерфейс 150 ввода/вывода может быть соединен с клавиатурой (не показана), мышью (не показана) или сенсорной панелью (не показана), которые обеспечивают взаимодействие пользователя с компьютерной системой 100 в дополнение к сенсорному экрану 190 или вместо него.
[067] Следует отметить, что в некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии часть элементов компьютерной системы 100 может отсутствовать. Например, может отсутствовать сенсорный экран 190, в том числе, в тех случаях, когда компьютерная система реализована в виде сервера, но не ограничиваясь ими.
[068] В соответствии с вариантами реализации настоящей технологии, на твердотельном накопителе 120 хранятся программные команды, пригодные для загрузки в ОЗУ 130 и исполнения процессором 110 и/или графическим процессором 111. Например, программные команды могут входить в состав библиотеки или приложения.
Сетевая компьютерная среда
[069] На фиг. 2 схематически представлена сетевая компьютерная среда 200, пригодная для использования с некоторыми не имеющими ограничительного характера вариантами осуществления систем и/или способов в соответствии с настоящей технологией. Сетевая компьютерная среда 200 содержит сервер 202, соединенный с электронным устройством 204 через сеть 208 связи. В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии электронное устройство 204 может быть связано с пользователем 216.
[070] В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии электронным устройством 204 может быть любое компьютерное аппаратное средство, способное обеспечивать работу программного обеспечения, подходящего для решения поставленной задачи. В связи с этим электронное устройство 204 может содержать некоторые или все элементы компьютерной системы 100, представленной на фиг. 1. Не имеющими ограничительного характера примерами электронного устройства 204 являются персональные компьютеры (настольные компьютеры, ноутбуки, нетбуки и т.п.), смартфоны и планшеты. Очевидно, что в некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии электронное устройство 204 может быть не единственным электронным устройством, связанным с пользователем 216, и пользователь 216 без отступления от существа и объема настоящей технологии также может быть связан с другими электронными устройствами (не показанными на фиг. 2), соединенными с сервером 202 через сеть 208 связи.
[071] В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 202 реализован как обычный компьютерный сервер и также может содержать некоторые или все элементы компьютерной системы 100, показанной на фиг. 1. В конкретном не имеющем ограничительного характера примере сервер 202 реализован в виде сервера Dell™ PowerEdge™, работающего под управлением операционной системы Microsoft™ Windows Server™, но он также может быть реализован на базе любых других подходящих видов аппаратных средств, программного обеспечения и/или микропрограммного обеспечения либо их сочетания. В показанных не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 202 представляет собой одиночный сервер. В других не имеющих ограничительного характера вариантах осуществления настоящей технологии (не показаны) функции сервера 202 могут быть распределены между несколькими серверами.
[072] В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии на сервере 202 может быть размещена цифровая платформа 210. В общем случае цифровая платформа 210 представляет собой веб-ресурс, способный управлять множеством цифровых документов, размещенных на цифровой платформе 210, то есть предоставлять доступ к ним, представлять их в той или иной форме и обеспечивать взаимодействие с ними. В целом, виды цифровых документов, размещаемых на цифровой платформе 210, зависят от ее конкретной реализации. Например, в некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии цифровая платформа 210 представляет собой платформу потокового аудио, такую как платформа потокового аудио Spotify™, Yandex™ Music™ и т.п., а множество цифровых документов может включать в себя различные цифровые аудиодокументы, например, аудиодорожки, аудиокниги, подкасты и т.п. В другом примере, где цифровая платформа 210 представляет собой платформу видеохостинга или платформу потокового видео, например, такую как платформа видеохостинга YouTube™ или платформа потокового видео Netflix™, множество цифровых документов может включать в себя различные цифровые видеодокументы, например, видеоклипы, фильмы, новостные видеоматериалы и т.п. В еще одном примере, где цифровая платформа реализована в виде онлайн-платформы объявлений, такой как онлайн-платформа объявлений Yandex™ Market™, онлайн-платформа объявлений Avito™ и т.п., множество цифровых документов может включать в себя объявления о продаже различных продуктов, например, товаров и услуг. В еще одном примере цифровая платформа 210 может быть реализована в виде поисковой системы, такой как поисковая система Google™, поисковая система Yandex™ и т.п., а множество цифровых документов может представлять собой веб-документ, который может содержать цифровые документы всех упомянутых выше видов. Очевидно, что возможны и другие варианты реализации цифровой платформы 210, а также другие виды размещаемых на ней цифровых документов.
[073] Соответственно, для предоставления доступа ко множеству цифровых документов пользователям цифровой платформы 210, таким как пользователь 216, цифровая платформа 210 может обеспечивать возможность поиска, позволяя пользователю 216 отправлять поисковые запросы на цифровую платформу 210 (например, через специальный пользовательский интерфейс), в ответ на которые цифровая платформа 210 может обеспечивать подбор соответствующих наборов цифровых документов.
[074] В соответствии с некоторыми не имеющими ограничительного характера вариантами осуществления настоящей технологии, сервер 202 может быть связан с базой 206 данных поискового индекса для обеспечения хранения множества цифровых документов, потенциально доступных через сеть 208 связи. В связи с этим в тех вариантах осуществления, в которых цифровая платформа 210 включает в себя потоковую платформу или онлайн-платформу объявлений, в базу 206 данных поискового индекса могут быть предварительно загружены ссылки на множество цифровых документов от поставщиков цифровых документов, таких как музыканты, звукозаписывающие студии и продавцы товаров. При этом в тех вариантах осуществления, в которых цифровая платформа 210 реализована в виде поисковой системы, ссылки на множество цифровых документов могут быть предварительно загружены в базу 206 данных поискового индекса с использованием процесса, называемого «обходом контента», который в некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии может быть, например, также реализован сервером 202. Кроме того, несмотря на то что в вариантах осуществления, показанных на фиг. 2, база данных 206 поискового индекса изображена как единое целое, следует понимать, что в других не имеющих ограничительного характера вариантах осуществления настоящей технологии функции базы 206 данных поискового индекса могут быть распределены между несколькими базами данных. В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии доступ к базе 206 данных поискового индекса может осуществляться сервером 202 через сеть 208 связи, а не через прямой канал связи (не обозначен отдельно), как показано на фиг. 2.
[075] Очевидно, что в некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии база 206 данных поискового индекса может дополнительно обеспечивать хранение предварительно сформированных векторных (то есть числовых) представлений каждого цифрового документа из множества цифровых документов. В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии векторные представления могут формироваться сторонним сервером (не показан), на котором выполняется, например, особым образом обученная модель машинного обучения. В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии векторные представления могут формироваться сервером 202, как подробно описано ниже.
[076] Таким образом, в соответствии с некоторыми не имеющими ограничительного характера вариантами осуществления настоящей технологии, пользователь 216, используя электронное устройство 204, может отправлять поисковый запрос 212 на цифровую платформу 210, а цифровая платформа 210 способен обеспечивать нахождение в базе 206 данных поискового индекса набора 214 цифровых документов, удовлетворяющих поисковому запросу 212.
[077] В соответствии с некоторыми не имеющими ограничительного характера вариантами осуществления настоящей технологии, сервер 202 способен находить набор 214 цифровых документов, используя математическую модель, способную оценивать релевантность документа из множества цифровых документов, размещенных на цифровой платформе 210, поисковому запросу 212. В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии математическая модель может выполнять функцию ранжирования. Например, функция ранжирования может быть реализована на основе модели «мешок слов» (bags-of-words) и включать в себя функцию ранжирования Okapi BM25. При этом следует отметить, что на способ нахождения сервером 202 набора 214 цифровых документов не накладывается ограничений. Например, в других не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 202 может применять для нахождения набора 214 цифровых документов подходы, основанные на машинном обучении, например, на модели машинного обучения на основе дерева решений.
[078] Кроме того, после нахождения сервером 202 набора 214 цифровых документов он способен ранжировать цифровые документы из набора 214 цифровых документов, например, в зависимости от степени их релевантности поисковому запросу 212, чтобы помочь пользователю 216 цифровой платформы 210 сориентироваться в наборе 214 цифровых документов. Таким образом, сервер 202 способен формировать ранжированный набор 220 цифровых документов.
[079] Разработчики настоящей технологии учли, что степень удовлетворенности пользователя 216 набором 214 цифровых документов может увеличиваться в тех случаях, когда ранги в наборе 214 цифровых документов определяются на основе как лексических, так и семантических связей между цифровыми документами из набора 214 цифровых документов и ключевыми словами поискового запроса 212.
[080] В контексте настоящей технологии термином «семантические связи» между ключевым словом поискового запроса 212 и цифровым документом из набора 214 цифровых документов обозначается соответствие цифрового документа семантике (то есть смыслу) ключевого слова поискового запроса 212. В частности, семантические связи между ключевым словом и цифровым документом могут определяться тем, содержит ли цифровой документ слова из семантического поля, в которое входит ключевое слово поискового запроса 212, то есть из лексического набора семантически сгруппированных слов, относящегося к соответствующей тематике. Например, семантическое поле слова «движение» может включать в себя слова «бежать», «идти», «лететь», «ехать», «гулять», «быстро» и др., в том числе разнообразные их производные во всех частях речи. Конкретным примером семантической связи между цифровым документом и ключевым словом поискового запроса 212 может быть наличие синонимов или антонимов этого ключевого слова в данном цифровом документе. При этом термин «семантические связи» не следует трактовать как ограниченный лишь семантическими связями между словами. Например, цифровой документ, содержащий изображение кошки или видеоклип с ней, считается семантически связанным с ключевым словом поискового запроса 212 «кошка» и другими ключевыми словами из того же семантического поля, такими как «кошачий наполнитель», «кошачья мята», «котенок», и наоборот, изображения или видеоклипы с такими объектами считаются семантически связанными со словом «кошка». В другом примере аудиозапись мяуканья кошки также считается семантически связанной со словом «кошка».
[081] В контексте настоящего описания термином «лексические связи» между ключевым словом поискового запроса 212 и цифровым документом обозначается соответствие цифрового документа лексике ключевого слова поискового запроса 212, то есть его лингвистической форме, зафиксированной в словаре. В частности, семантические связи между ключевым словом и цифровым документом могут определяться тем, (а) содержит ли цифровой документ слова, полностью совпадающие с ключевым словом поискового запроса 212, (б) содержит ли цифровой документ одну или несколько грамматических форм ключевого слова поискового запроса 212, например, форм, различающихся категориями числа и падежа (или склонения, например, кошка - кошки - кошек) для существительных и категориями лица, числа и времени (или спряжения, например, спят - спит - спал) для глаголов, и (в) содержит ли цифровой документ однокоренные слова, образованные от ключевого слова поискового запроса 212 в рамках данной части речи, например, действие - деятельность - деяние (существительное).
[082] В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии для определения степени релевантности цифрового документа из набора 214 цифровых документов поисковому запросу 212 с точки зрения семантики и лексики сервер 202 способен осуществлять обучение и последующее применение алгоритма 218 машинного обучения, включая объединенную модель 602 машинного обучения, подробное описание обучения и использования которой приведено ниже со ссылкой на фиг. 7 и 8. В частности, в соответствии с некоторыми не имеющими ограничительного характера вариантами осуществления настоящей технологии, объединенная модель 602 машинного обучения способна определять значение параметра ранжирования для каждого цифрового документа из набора 214 цифровых документов, исходя из степени релевантности этого цифрового документа поисковому запросу 212 с точки зрения лексики и семантики. Как поясняется в приведенном ниже описании, для этого объединенная модель 602 машинного обучения может получать (а) первое векторное представление поискового запроса 212, например, векторное представление 512 поискового запроса, показанное на фиг. 5, (б) второе векторное представление цифрового документа, например, векторное представление 516 документа для иллюстративного цифрового документа 402, показанного на фиг. 6, и (в) третье векторное представление по меньшей мере одной фразы-кандидата из набора 214 цифровых документов, лексически связанной с по меньшей мере одним ключевым словом поискового запроса 212, например, векторное представление 514 фраз, показанное на фиг. 5. Способ обеспечения получения первого, второго и третьего векторных представлений сервером 202 для их передачи в объединенную модель 602 машинного обучения подробно описан ниже со ссылкой на фиг. 4-6.
[083] В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии объединенная модель 602 машинного обучения может быть реализована на основе архитектуры нейронной сети. Например, в таких вариантах осуществления объединенная модель 602 машинного обучения может представлять собой модель машинного обучения на основе глубокой модели для определения семантической близости (DSSM, Deep Semantic Similarity Model), модель машинного обучения на основе нейронной сети с долговременной и кратковременной памятью (LS™, Long Short-Term Memory) или модель машинного обучения на основе трансформера.
[084] При этом следует понимать, что для реализации объединенной модели 602 машинного обучения могут использоваться и другие типы моделей машинного обучения, такие как, среди прочего, модель машинного обучения на основе дерева решений, модель машинного обучения на основе дерева решений с градиентным бустингом, модель машинного обучения на основе поиска ассоциативных правил, модель машинного обучения на основе индуктивного логического программирования, модель машинного обучения на основе машин опорных векторов, модель машинного обучения на основе кластеризации, байесовские сети, модель машинного обучения на основе обучения с подкреплением, модель машинного обучения на основе обучения представлениям, модель машинного обучения на основе обучения по метрикам и близости, модель машинного обучения на основе обучения по разреженному словарю, модель машинного обучения на основе генетических алгоритмов и т.п.
[085] Кроме того, используя определенные указанным способом значения параметра ранжирования, сервер 202 может обеспечивать ранжирование цифровых документов в наборе 214 цифровых документов, формируя ранжированный набор 220 цифровых документов. Таким образом, сервер 202 способен предоставлять пользователю 216 более релевантные цифровые документы, что способствует повышению степени удовлетворенности пользователя 216 от взаимодействия с цифровой платформой 210.
[086] Можно утверждать, что в общем случае сервер 202 выполняет два процесса в отношении объединенной модели 602 машинного обучения в алгоритме 218 машинного обучения. Первый из этих двух процессов представляет собой процесс обучения, в котором сервер 202 обеспечивает обучение объединенной модели 602 машинного обучения на основе обучающего набора данных, чтобы определить значение параметра ранжирования для каждого цифрового документа из набора 214 цифровых документов. Описание процесса обучения приведено ниже со ссылкой на фиг. 7. Второй процесс представляет собой процесс использования, в котором сервер 202 применяет объединенную модель 602 машинного обучения для ранжирования цифровых документов в наборе 214 цифровых документов, как это описано ниже со ссылкой на фиг. 8, в соответствии с некоторыми не имеющими ограничительного характера вариантами осуществления настоящей технологии.
[087] Пример архитектуры модели машинного обучения, которая может использоваться для реализации алгоритма 218 машинного обучения, включая объединенную модель 602 машинного обучения, описан ниже со ссылкой на фиг. 3.
Сеть связи
[088] В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии сеть 208 связи представляет собой сеть Интернет. В других не имеющих ограничительного характера вариантах осуществления настоящей технологии сеть 208 связи может быть реализована как любая подходящая локальная сеть (LAN, Local Area Network), глобальная сеть (WAN, Wide Area Network), частная сеть связи и т.п. Следует понимать, что варианты осуществления сети связи приведены лишь в иллюстративных целях. Способ реализации линий связи (отдельно не обозначены), соединяющих сервер 202 и электронное устройство 204 с сетью 208 связи, зависит, среди прочего, от реализации сервера 202 и электронного устройства 204. Для примера, среди прочего, можно отметить, что в тех вариантах осуществления настоящей технологии, где электронное устройство 204 реализовано в виде устройства беспроводной связи, такого как смартфон, линия связи может быть реализована в виде беспроводной линии связи. Примерами беспроводных линий связи могут служить, помимо прочего, канал сети связи 3G, канал сети связи 4G и т.п. В сети 208 связи также может использоваться беспроводное соединение с сервером 202.
Архитектура модели машинного обучения
[089] На фиг. 3 представлена блок-схема архитектуры 300 модели машинного обучения, используемой для реализации алгоритма 218 машинного обучения, в соответствии с некоторыми не имеющими ограничительного характера вариантами осуществления настоящей технологии. Как отмечалось выше, в некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии архитектура 300 модели машинного обучения может быть построена на основе модели машинного обучения BERT, как описано, например, в вышеупомянутой статье авторов Devlin et al. Аналогично BERT, архитектура 300 модели машинного обучения содержит стек 302 трансформеров, содержащий трансформерные блоки, например, трансформерные блоки 304, 306 и 308.
[090] Каждый из трансформерных блоков 304, 306 и 308 содержит блок энкодера трансформера, как описано, например, в вышеупомянутой статье авторов Vaswani et al. Каждый из трансформерных блоков 304, 306 и 308 имеет слой 320 многоголового внимания (для наглядности здесь показан только блок 304 трансформера) и слой 322 нейронной сети прямого распространения (для наглядности здесь также показан только блок 304 трансформера). Трансформерные блоки 304, 306 и 308 в целом имеют одинаковую структуру, но (после обучения) им присваиваются разные веса. В слое 320 многоголового внимания между входными данными блока трансформера существуют зависимости, которые могут использоваться, например, для передачи контекстной информации на каждый вход в зависимости от данных на всех остальных входах блока трансформера. В слое 322 нейронной сети прямого распространения, как правило, нет таких зависимостей, поэтому входные данные слоя 322 нейронной сети прямого распространения могут обрабатываться параллельно. Следует понимать, что на фиг. 3 показаны только три трансформерных блока (трансформерные блоки 304, 306 и 308), но в практических вариантах реализации описанной здесь технологии таких трансформерных блоков в стеке 302 трансформеров может быть гораздо больше. Например, в некоторых вариантах реализации в стеке 302 трансформеров может использоваться 12 трансформерных блоков.
[091] Входные данные 330 стека 302 трансформеров содержат токены, например, токен 332 [CLS] и токены 334. Токены 334 могут представлять собой, например, слова или части слов. Токен 332 [CLS] служит в качестве представления для классификации всего набора токенов 334. Каждый из токена 334 и токена 332 [CLS] представлен в виде вектора. В некоторых вариантах реализации каждый из этих векторов может иметь длину, например, 768 значений с плавающей запятой. Следует понимать, что для эффективного уменьшения размера (размерности) векторов могут использоваться разнообразные методы сжатия.
[092] В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии количество токенов 334, используемых в качестве входных данных 330 для стека 302 трансформеров, может быть фиксированным. Например, в одних не имеющих ограничительного характера вариантах осуществления настоящей технологии могут использоваться 1024 токена, а в других вариантах реализации стек 302 трансформеров может быть способен вмещать 512 токенов (помимо токена 332 [CLS]). Те входные данные 330, длина которых оказывается меньшей фиксированного количества токенов 334, могут быть расширены до фиксированной длины, например, путем добавления заполняющих токенов.
[093] В некоторых вариантах реализации входные данные 330 могут формироваться на основе обучающего цифрового объекта 336 с использованием токенизатора 338. Архитектура токенизатора 338, как правило, зависит от обучающего цифрового объекта 336, который служит входными данными для токенизатора 338. Например, в некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии в токенизаторе 338 могут использоваться известные методы кодирования, такие как кодирование пар байтов, а также предварительно обученные нейронные сети для формирования входных данных 330.
[094] В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии токенизатор 338 может быть реализован на основе схемы кодирования пар байтов WordPiece, например, используемой в моделях обучения BERT с достаточно большим объемом словаря. В частности, в некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии объем словаря может составлять приблизительно 120 000 токенов. В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии перед применением токенизатора 338 входные данные 330 могут подвергаться предварительной обработке. Например, все слова во входных данных 330 могут переводиться в нижний регистр, после чего может производиться нормализация Unicode NFC. Схема кодирования пар байтов WordPiece, которая может использоваться в некоторых вариантах реализации для создания словаря токенов, описана, например, в статье Rico Sennrich et al., «Neural Machine Translation of Rare Words with Subword Units», Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1715-1725, 2016.
[095] Кроме того, в некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии в дополнение к токенизатору 338 или вместо него для формирования входных данных 330 сервер 202 может использовать алгоритм векторного представления. В общем случае алгоритм векторного представления способен преобразовывать входные данные, такие как цифровой объект 336, в числовой вектор в пространстве векторных представлений. При этом конкретная реализация алгоритма векторного представления, как правило, зависит от типа данных цифрового объекта 336. Например, в тех не имеющих ограничительного характера вариантах осуществления настоящей технологии, в которых цифровой объект 336 содержит один из прошлых запросов и множество связанных с ним прошлых фраз-кандидатов, как описано ниже, алгоритм векторного представления может представлять собой алгоритм векторного представления текста.
[096] В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии алгоритм векторного представления текста может представлять собой, среди прочего, один из алгоритмов векторного представления текста Word2Vec, GloVe, FastText и т.п., который сервер 202 может использовать с целью формирования входных данных 330 для архитектуры 300 модели машинного обучения.
[097] В другом примере в тех не имеющих ограничительного характера вариантах осуществления настоящей технологии, в которых цифровой объект 336 содержит аудиозапись, алгоритм векторного представления может быть реализован как алгоритм векторного представления звука. В соответствии с некоторыми не имеющими ограничительного характера вариантами осуществления настоящей технологии, алгоритм векторного представления звука может представлять собой, среди прочего, алгоритм векторного представления звука Seq2Seq Autoencoder, алгоритм векторного представления звука типа «сверточная векторная регрессия», алгоритм векторного представления звука на основе буквенной n-граммы, алгоритм векторного представления звука на основе нейронной сети с долговременной и кратковременной памятью и т.п.
[098] В еще одном примере в тех не имеющих ограничительного характера вариантах осуществления настоящей технологии, в которых цифровой объект 336 содержит изображение, алгоритм векторного представления может быть реализован как алгоритм векторного представления изображения. Примерами алгоритма векторного представления изображения являются алгоритмы, реализованные на основе глубоких нейронных сетей, например, сверточных нейронных сетей, в том числе, среди прочего, алгоритма векторного представления изображения InceptionV3, алгоритма векторного представления изображения SqueezeNet и алгоритма векторного представления изображения DeepLoc.
[099] В дополнительных не имеющих ограничительного характера вариантах осуществления настоящей технологии после использования токенизатора 338 формирование входных данных 330 может дополнительно предусматривать применение сервером 202 алгоритма векторного представления положения (не показан), способного регистрировать данные о положении в частях входного обучающего цифрового объекта 336. Например, если входной обучающий цифровой объект 336 содержит текстовую фразу, алгоритм векторного представления положения может формировать вектор, указывающий на данные о положении среди слов в этой текстовой фразе. На способ реализации алгоритма векторного представления положения не накладывается ограничений и таким алгоритмом, среди прочего, может быть, например, синусоидальный алгоритм векторного представления положения (sinusoid positional embedding), алгоритм векторного представления положения на основе пакетирования кадров (frame stacking positional embedding) или сверточный алгоритм векторного представления положения (convolutional positional embedding).
[0100] Выходные данные 350 стека 302 трансформеров содержат выходные данные 352 [CLS] и вектор 354 выходных данных, содержащий выходное значение для каждого из токенов 334, содержащихся во входных данных 330 стека 302 трансформеров. Затем выходные данные 350 могут направляться в модуль 370 задачи. В некоторых вариантах реализации, как показано на фиг. 3, модуль 370 задачи использует только выходные данные 352 [CLS], которые служат представлением всего вектора 354 выходных данных. Это может быть наиболее целесообразно в тех случаях, когда модуль 370 задачи используется в качестве классификатора или для вывода метки или значения, характеризующего весь входной обучающий цифровой объект 336, например, с целью формирования коэффициента релевантности, в частности, значения параметра ранжирования для цифрового документа из набора 214 цифровых документов, как описано выше.
[0101] В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии (не показанных на фиг. 3) некоторые или все значения вектора 354 выходных данных и, возможно, выходные данные 352 [CLS] могут служить входными данными для модуля 370 задачи. Это может быть наиболее целесообразно в тех случаях, когда модуль 370 задачи используется для формирования меток или значений для каждого из токенов 334 входных данных 330, в частности, для прогнозирования маскированного или отсутствующего токена или для распознавания именованных сущностей. В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии модуль 370 задачи может содержать нейронную сеть прямого распространения (не показана), которая формирует результат 380, ориентированный на выполнение задачи, такой как коэффициент релевантности или вероятность перехода по ссылке. В модуле 370 задачи могут использоваться и другие модели. Например, собственно модуль 370 задачи может быть трансформером или нейронной сетью другого типа. Кроме того, результат 380, ориентированный на выполнение задачи, может служить входными данными для других моделей, таких как модель CatBoost, описанная в статье Dorogush et al., «CatBoost: gradient boosting with categorical features support», NIPS, 2017.
[0102] Следует понимать, что для облегчения понимания некоторых не имеющих ограничительного характера вариантов осуществления настоящей технологии архитектура модели 300 машинного обучения, описанная выше со ссылкой на фиг. 3, была упрощена. Например, в практическом варианте реализации архитектуры 300 модели машинного обучения каждый из трансформерных блоков 304, 306 и 308 может также выполнять операции нормализации слоя, а модуль 370 задачи - логистическую функцию нормализации softmax и т.д. Специалисту в данной области техники должно быть понятно, что такие операции широко используются в нейронных сетях и в моделях глубокого обучения, таких как модель с архитектурой 300 модели машинного обучения.
Формирование векторных представлений
[0103] Как указано выше, лексические связи между цифровым документом и поисковым запросом 212 могут определяться наличием в этом цифровом документе по меньшей мере одного слова, представленного в той же лингвистической форме, которую имеет по меньшей мере одно ключевое слово поискового запроса 212.
[0104] В связи с этим для ранжирования цифровых документов в наборе 214 цифровых документов с использованием объединенной модели 602 машинного обучения в некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 202 может сначала обеспечивать нахождение в каждом цифровом документе из набора 214 цифровых документов множества фраз-кандидатов, лексически связанных с по меньшей мере одним ключевым словом поискового запроса 212. Иными словами, как указано выше, каждая фраза-кандидат из множества фраз-кандидатов может содержать слова, которые (а) полностью совпадают с по меньшей мере одним ключевым словом поискового запроса, (б) представлены в одной или нескольких грамматических формах по меньшей мере одного ключевого слова поискового запроса 212 и/или (в) включают в себя одно или несколько однокоренных слов по меньшей мере одного ключевого слова поискового запроса 212 в рамках одной части речи.
[0105] На фиг. 4 схематически представлен иллюстративный цифровой документ 402 из набора 214 цифровых документов, содержащий множество 404 фраз-кандидатов, в соответствии с некоторыми не имеющими ограничительного характера вариантами осуществления настоящей технологии.
[0106] В примере на фиг. 4 предполагается, что цифровая платформа 210 представляет собой онлайн-платформу объявлений, для получения доступа к которой пользователю 216 необходимо ввести соответствующий URL-адрес онлайн-платформы объявлений в адресной строке приложения браузера на электронном устройстве 204. Пользователь 216 может отправить на цифровую платформу 210 поисковый запрос 212 с текстом «Macaron Recipe Pierre Herme» (Макарон Рецепт Пьер Эрме). Сервер 202, например, используя вышеупомянутую математическую модель, способен находить в базе 206 данных поискового индекса, хранящей множество цифровых документов, набор 214 цифровых документов, удовлетворяющих этому поисковому запросу. Кроме того, в иллюстративном цифровом документе 402 из набора 214 цифровых документов сервер 202 способен находить множество 404 фраз-кандидатов, которые содержат по меньшей мере одно слово, лексически связанное с по меньшей мере одним ключевым словом поискового запроса 212.
[0107] В соответствии с некоторыми не имеющими ограничительного характера вариантами осуществления настоящей технологии, сервер 202 способен находить в иллюстративном цифровом документе 402 множество 404 фраз-кандидатов путем вычисления значений метрики близости между поисковым запросом 212 и отдельными фразами иллюстративного цифрового документа 402. В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии метрика близости определяется расстоянием между векторами, представляющими поисковый запрос 212 и фразу иллюстративного цифрового документа 402 в пространстве векторных представлений. В связи с этим метрика близости может включать в себя, например, косинусоидальную метрику близости. В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 202 способен определять отдельные фразы в иллюстративном цифровом документе 402 как фразы-кандидаты для включения во множество 404 фраз-кандидатов, если их значения метрики близости к поисковому запросу 212 превышают заданный порог близости. В других не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 202 способен ранжировать фразы иллюстративного цифрового документа 402 в соответствии с их значениями метрики близости и выбирать N приоритетных фраз для включения во множество 404 фраз-кандидатов.
[0108] При этом на способ формирования сервером 202 векторов, представляющих поисковый запрос 212 и отдельные фразы иллюстративного цифрового документа 402, не накладывается ограничений. Например, в некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 202 способен формировать такие векторы путем определения для каждого ключевого слова поискового запроса 212 значения отношения частоты ключевого слова к обратной частоте документа (TF-IDF) применительно к каждой фразе в иллюстративном цифровом документе 402. При этом в других не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 202 способен применять к поисковому запросу и каждой фразе иллюстративного цифрового документа 402 один из вышеупомянутых алгоритмов векторного представления текста.
[0109] Соответственно, сервер 202 может, например, выбрать первую фразу-кандидат 401, поскольку она содержит слова, полностью совпадающие с ключевыми словами «Pierre Herme» (выделены) из поискового запроса 212. Кроме того, сервер 202 может выбрать вторую фразу-кандидат 403, поскольку она содержит форму множественного числа ключевого слова «Macaron» из поискового запроса 212. Подобным образом сервер 202 может выбрать третью и четвертую фразы-кандидаты 405, 407. Наконец, сервер 202 может выбрать пятую фразу-кандидат 409, поскольку она содержит притяжательную форму ключевых слов «Pierre Herme», форму множественного числа ключевого слова «Macaron» и слово, полностью совпадающее с ключевым словом «Macaron».
[0110] В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии множество 404 фраз-кандидатов для последующего использования при ранжировании набора 214 цифровых документов может содержать заданное количество фраз-кандидатов, например, 3, 5, 10, 100 или 147 000. В этих вариантах осуществления сервер 202 способен выбирать из иллюстративного цифрового документа 402 для включения во множество 404 фраз-кандидатов лишь те фразы-кандидаты, которые содержат наибольшее количество слов, лексически связанных с ключевыми словами поискового запроса 212. Например, если заданное количество фраз-кандидатов равно 3, сервер 202 может включить во множество 404 фраз-кандидатов пятую фразу-кандидат 409, вторую фразу-кандидат 403 и одну из первой, третьей и четвертой фраз-кандидатов 401, 405 и 407.
[0111] В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии каждая фраза-кандидат из множества 404 фраз-кандидатов может содержать как минимум заданное целевое количество слов, лексически связанных с по меньшей мере одним ключевым словом поискового запроса 212. В частности, в таких вариантах осуществления, если заданное целевое количество фраз-кандидатов, например, равно двум, сервер 202 может исключить из множества 404 фраз-кандидатов все фразы-кандидаты, за исключением второй и пятой фраз-кандидатов 403, 409.
[0112] Таким образом, используя подход, аналогичный описанному выше применительно к иллюстративному цифровому документу 402, сервер 202 способен анализировать и другие документы из набора 214 цифровых документов с целью подбора фраз-кандидатов для включения их во множество 404 фраз-кандидатов. В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 202 может проанализировать все цифровые документы из набора 214 цифровых документов. В других не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 202 может проанализировать только часть набора 214 цифровых документов с целью подбора фраз-кандидатов для множества 404 фраз-кандидатов. Сервер 202 способен определять такую часть набора 214 цифровых документов как N приоритетных цифровых документов, в наибольшей степени удовлетворяющих поисковому запросу 212.
[0113] В некоторых других не имеющих ограничительного характера вариантах осуществления настоящей технологии для определения множества 404 фраз-кандидатов сервер 202 способен (а) определять для каждой фразы в наборе 214 цифровых документов значение метрики близости к поисковому запросу 212, как указано выше, (б) ранжировать фразы в зависимости от значений метрики близости и (в) выбирать N (например, 3, 5 или 20) приоритетных фраз из набора 214 цифровых документов для включения их во множество 404 фраз-кандидатов.
[0114] Таким образом, в соответствии с некоторыми не имеющими ограничительного характера вариантами осуществления настоящей технологии, сервер 202 способен получать информацию о лексических связях между поисковым запросом 212 и набором 214 цифровых документов из их необработанных версий, сохраненных в базе 206 данных поискового индекса при ее заполнении, например, путем обхода контента сети 208 связи сервером 202, как указано выше.
[0115] Кроме того, в некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии для передачи множества 404 фраз-кандидатов и поискового запроса 212 в объединенную модель 602 машинного обучения сервер 202 способен определять их векторные представления. В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 202 способен определять векторные представления множества 404 фраз-кандидатов и поискового запроса 212, используя один из алгоритмов векторного представления текста, указанных выше для примера применительно к описанию архитектуры 300 модели машинного обучения. При этом в других не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 202 способен определять такие векторные представления, используя особым образом обученную модель машинного обучения.
[0116] Таким образом, в соответствии с некоторыми не имеющими ограничительного характера вариантами осуществления настоящей технологии, алгоритм 218 машинного обучения может включать в себя первую модель 502, схематически представленную на фиг. 5. В соответствии с некоторыми не имеющими ограничительного характера вариантами осуществления настоящей технологии, первая модель 502 машинного обучения может быть реализована в виде глубокой нейронной сети, такой как нейронная сеть с долговременной и кратковременной памятью или рекуррентная нейронная сеть. В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии первая модель 502 машинного обучения может быть реализована в виде модели машинного обучения на основе трансформера. В связи с этим первая модель 502 машинного обучения может включать в себя некоторые или все элементы описанной выше архитектуры 300 модели машинного обучения.
[0117] В соответствии с некоторыми не имеющими ограничительного характера вариантами осуществления настоящей технологии, первая модель 502 машинного обучения способна формировать векторные представления входных фраз. Например, первая модель 502 машинного обучения может получать поисковый запрос 212 для формирования векторного представления 512 поискового запроса и получать множество 404 фраз-кандидатов для формирования векторного представления 514 фраз.
[0118] Чтобы обучить первую модель 502 машинного обучения формированию векторных представлений входных фраз, сервер 202 может формировать первый обучающий набор данных, содержащий первое множество обучающих цифровых объектов, каждый из которых содержит обучающую фразу. Подобно поисковому запросу 212 и множеству 404 фраз-кандидатов, в некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии эта обучающая фраза может содержать один из обучающих поисковых запросов (например, один из прошлых запросов, отправленных пользователями цифровой платформы 210) и обучающее множество фраз-кандидатов, подобранных подобно множеству 404 фраз-кандидатов для поискового запроса 212. При этом в других не имеющих ограничительного характера вариантах осуществления настоящей технологии обучающей фразой может быть любая другая фраза, которую сервер 202 способен извлечь, например, из всего множества цифровых документов, размещенных на цифровой платформе 210. В другом примере сервер 202 способен извлекать обучающие фразы для обучения первой модели 502 машинного обучения из других ресурсов сети 208 связи, включая любую текстовую информацию.
[0119] Кроме того, сервер 202 способен передавать каждый обучающий цифровой объект из первого множества обучающих цифровых объектов в первую модель 502 машинного обучения, обучая первую модель 502 машинного обучения формированию векторных представлений входных фраз. Как указано выше применительно к описанию архитектуры 300 модели машинного обучения, сервер 202 способен передавать обучающую фразу в токенизатор 338 для формирования входных данных 330, а также передавать входные данные 330 в трансформерные блоки 304, 306 и 308 для формирования выходных данных 350, содержащих числовое представление обучающей фразы с учетом контекста слов в обучающей фразе. Иными словами, выходные данные 350 первой модели 502 машинного обучения могут содержать векторное представление обучающей фразы, включающее в себя совокупную семантику обучающей фразы. Таким образом, путем передачи первого множества обучающих цифровых объектов в первую модель 502 машинного обучения, сервер 202 может определять веса трансформерных блоков 304, 306 и 308, обучая первую модель 502 машинного обучения формированию векторных представлений входных фраз, таких как поисковый запрос 212 и множество 404 фраз-кандидатов.
[0120] Кроме того, как наиболее наглядно показано на фиг. 5, в соответствии с некоторыми не имеющими ограничительного характера вариантами осуществления настоящей технологии, сервер 202 способен сокращать объем представлений (то есть количество значений в векторе 354 выходных данных) в выходных данных 350 первой модели 502 машинного обучения. В связи с этим в некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 202 способен усекать значения в выходных данных 350 до необходимой заданной длины. При этом в других не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 202 способен сокращать объем представлений выходных данных 350 первой модели 502 машинного обучения, последовательно усекая значения в выходных данных промежуточных слоев, то есть каждого из трансформерных блоков 304, 306 и 308, до тех пор, пока не будет достигнута необходимая заданная длина выходных данных 350. В различных не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 202 способен выбирать необходимую заданную длину выходных данных 350 для первой модели 502 машинного обучения и усеченные длины выходных данных трансформерных блоков 304, 306 и 308 на основе компромисса между скоростью и качеством формирования выходных данных 350 для последующей передачи на один из входов объединенной модели 602 машинного обучения. Например, необходимая заданная длина выходных данных 350 после усечения может составлять 8, 16 или 32 значения в соответствующих векторных представлениях.
[0121] В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 202 способен сокращать объем представлений в выходных данных 350 первой модели 502 машинного обучения для разных векторных представлений разными способами. Иными словами, для формирования векторного представления 512 поискового запроса сервер 202 может обеспечивать усечение значений выходных данных 350 первой моделью 502 машинного обучения до первой необходимой заданной длины, которая может составлять, например, 8 значений. Для формирования векторного представления 514 фраз сервер 202 может обеспечивать усечение значений выходных данных 350 первой моделью 502 машинного обучения до второй необходимой заданной длины, которая может составлять, например, 16 значений.
[0122] Таким образом, сервер 202 способен использовать первую модель 502 машинного обучения для формирования векторных представлений поисковых запросов и соответствующих множеств фраз-кандидатов, которые могут обеспечивать дальнейшее обучение объединенной модели 602 машинного обучения и ее использование для ранжирования цифровых документов, таких как набор 214 цифровых документов, с учетом их лексических связей с поисковым запросом 212, как описано ниже.
[0123] Кроме того, для определения семантических связей между цифровым документом из набора 214 цифровых документов и поисковым запросом 212 с использованием объединенной модели 602 машинного обучения сервер 202, в соответствии с некоторыми не имеющими ограничительного характера вариантами осуществления настоящей технологии, способен получать векторное представление цифрового документа.
[0124] Как указано выше, в некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии векторное представление цифрового документа может предварительно формироваться сторонним сервером и сохраняться в базе 206 данных поискового индекса в привязке к соответствующим цифровым документам цифровой платформы 210. При этом в некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 202 способен самостоятельно формировать векторное представление документа. В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 202 способен формировать векторное представление документа в зависимости от вида этого цифрового документа (то есть от того, какие данные он содержит - текст, аудио, видео и т.д.), используя одну из множества реализаций алгоритма векторного представления, указанных выше применительно к описанию архитектуры 300 модели машинного обучения.
[0125] В других не имеющих ограничительного характера вариантах осуществления настоящей технологии для формирования векторных представлений документов алгоритм 218 машинного обучения, размещенный на сервере 202, может включать в себя вторую модель 504 машинного обучения, схематически представленную на фиг. 6.
[0126] В соответствии с некоторыми не имеющими ограничительного характера вариантами осуществления настоящей технологии, вторая модель 504 машинного обучения, подобно первой модели 502 машинного обучения, может быть реализована в виде глубокой нейронной сети, такой как модель машинного обучения на основе трансформера. В связи с этим вторая модель 504 машинного обучения может включать в себя некоторые или все элементы описанной выше архитектуры 300 модели машинного обучения.
[0127] Например, вторая модель 504 машинного обучения способна получать иллюстративный цифровой документ 402 и формировать векторное представление 516 документа, в котором учитывается контекстная информация для элементов иллюстративного цифрового документа 402. Для этого в некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 202 может предварительно обучать вторую модель машинного обучения формированию векторных представлений различных цифровых документов.
[0128] В связи с этим, в соответствии с некоторыми не имеющими ограничительного характера вариантами осуществления настоящей технологии, сервер 202 способен (а) формировать второй обучающий набор данных, содержащий второе множество обучающих цифровых объектов, каждый из которых содержит один из множества цифровых документов, размещенных на цифровой платформе 210, (б) передавать каждый из второго множества обучающих цифровых объектов в токенизатор 338 для формирования входных данных 330 для второй модели 504 машинного обучения, (в) передавать входные данные 330 в трансформерные блоки 304, 306 и 308 для обеспечения формирования выходных данных 350, содержащих числовое представление цифрового документа. Таким образом, путем передачи всех цифровых документов из множества цифровых документов цифровой платформы 210, сервер 202 способен определять веса трансформерных блоков 304, 306 и 308 второй модели 504 машинного обучения, обучая вторую модель 504 машинного обучения формированию векторных представлений документов, например, векторного представления 516 документа для иллюстративного цифрового документа 402.
[0129] Очевидно, что при использовании второй модели 504 машинного обучения для ранжирования набора 214 цифровых документов формирование векторных представлений для каждого документа из набора 214 цифровых документов в реальном времени может представлять собой весьма ресурсоемкую задачу для сервера 202. Соответственно, в некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 202 способен (а) обеспечивать предварительное формирование второй моделью 504 машинного обучения векторных представлений документов для множества цифровых документов и сохранять их в привязке к соответствующим цифровым документам, например, в базе 206 данных поискового индекса, и (б) при необходимости использовать сформированное таким способом представление документа для цифрового документа из набора 214 цифровых документов в качестве входных данных для объединенной модели 602 машинного обучения, как описано ниже. Это позволяет экономить вычислительные ресурсы сервера 202 в режиме реального времени.
[0130] Кроме того, как и в случае с первой моделью 502 машинного обучения, в некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 202 способен обеспечивать сокращение второй моделью 504 машинного обучения объема представлений ее выходных данных 350, используя один из описанных выше методов усечения. Следует отметить, что итоговая длина векторного представления 516 документа может как совпадать с длинами векторных представлений 512, 514 поискового запроса и фраз, так и отличаться от них.
[0131] Таким образом, сервер 202 способен формировать векторные представления документов и затем на их основе обучать объединенную модель 602 машинного обучения и использовать ее для ранжирования набора 214 цифровых документов с учетом семантической связи цифрового документа из набора 214 цифровых документов с поисковым запросом 212.
[0132] Иными словами, после получения векторных представлений для (а) поисковых запросов, (б) множеств фраз-кандидатов, лексически связанных с поисковыми запросами, и (в) цифровых документов, например, путем обучения и использования первой и второй моделей 502, 504 машинного обучения, сервер 202 способен обучать объединенную модель 602 машинного обучения ранжированию цифровых документов на основе их лексических и семантических связей с соответствующими поисковыми запросами, как описано ниже.
Процесс обучения
[0133] На фиг. 7 схематически представлен процесс обучения объединенной модели 602 машинного обучения ранжированию набора 214 цифровых документов в соответствии с некоторыми не имеющими ограничительного характера вариантами осуществления настоящей технологии. Как указано выше, в некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии объединенная модель 602 машинного обучения может быть реализована в виде модели машинного обучения на основе глубокой модели для определения семантической близости. В других не имеющих ограничительного характера вариантах осуществления настоящей технологии объединенная модель 602 машинного обучения может представлять собой модель машинного обучения на основе трансформера. В таких вариантах осуществления объединенная модель 602 машинного обучения может включать в себя некоторые или все элементы описанной выше архитектуры 300 модели машинного обучения.
[0134] В соответствии с некоторыми не имеющими ограничительного характера вариантами осуществления настоящей технологии, для обучения объединенной модели 602 машинного обучения формированию значений параметра ранжирования сервер 202 способен формировать третий обучающий набор данных, содержащий третье множество обучающих цифровых объектов, каждый из которых содержит (а) векторное представление 613 обучающего поискового запроса для обучающего поискового запроса 603 (например, отправленного одним из пользователей цифровой платформы 210 в прошлом), (б) векторные представления обучающих документов из набора 616 обучающих цифровых документов, которые были определены в базе 206 данных поискового индекса как удовлетворяющие обучающему поисковому запросу 603, например, векторное представление 617 обучающего документа для обучающего цифрового документа (не обозначен отдельно), (в) метку 619, характеризующую степень релевантности обучающего цифрового документа, представленного векторным представлением 617 обучающего документа, обучающему поисковому запросу 603, и (г) векторное представление 615 обучающих фраз для множества обучающих 605 фраз-кандидатов, лексически связанных с обучающим поисковым запросом 603.
[0135] Как указано выше, сервер 202 способен формировать векторное представление 613 обучающего поискового запроса и векторное представление 615 обучающих фраз, используя первую модель 502 машинного обучения в режиме онлайн, то есть в реальном времени. В то же время сервер 202 способен получать векторные представления обучающих документов для набора 616 обучающих цифровых документов из базы 206 данных поискового индекса, которые сервер 202 может формировать, используя вторую модель 504 машинного обучения, до формирования векторных представлений 613, 615 обучающего поискового запроса и фраз.
[0136] Кроме того, в соответствии с некоторыми не имеющими ограничительного характера вариантами осуществления настоящей технологии, метка 619 может быть предоставлена человеком-оценщиком, который, например, может быть связан с краудсорсинговой платформой (не показана), такой как краудсорсинговая платформа Amazon™ Mechanical Turk™ или краудсорсинговая платформа Yandex™ Toloka™, с которой сервер 202 соединен через сеть 208 связи. Например, такой человек-оценщик может получать через интерфейс краудсорсинговой платформы инструкцию по формированию меток для присвоения метки 619 обучающему цифровому документу, представленному векторным представлением 617 обучающего документа. В соответствии с некоторыми не имеющими ограничительного характера вариантами осуществления настоящей технологии, метка 619 содержит значение параметра ранжирования, которое может быть выбрано, например, в диапазоне от 0 до 1, где 0 означает нерелевантность обучающего цифрового документа обучающему поисковому запросу 603, а 1 означает релевантность обучающего цифрового документа обучающему поисковому запросу 603. Например, соответствующая метка 619 может принимать значения 0,1, 0,25, 0,37 и т.п.
[0137] В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии метка 619 для обучающего цифрового документа может автоматически формироваться сервером 202, например, с использованием дополнительной модели машинного обучения, обученной определению степени релевантности обучающего цифрового документа обучающему поисковому запросу 603 на основе высококачественных меток, сформированных людьми-оценщиками. Например, высококачественные метки, формируемые людьми-оценщиками, могут предоставляться не людьми-оценщиками с краудсорсинговой платформы, а экспертами, формирующими метки более высокого качества, чем у таких людей-оценщиков.
[0138] Кроме того, в соответствии с некоторыми не имеющими ограничительного характера вариантами осуществления настоящей технологии, сервер 202 способен находить множество обучающих 605 фраз-кандидатов из набора 616 обучающих цифровых документов тем же способом, который описан выше со ссылкой на фиг. 4 применительно к подбору множества 404 фраз-кандидатов в иллюстративном цифровом документе 402. Кроме того, путем передачи множества обучающих 605 фраз-кандидатов в первую модель 502 машинного обучения сервер 202 способен формировать векторное представление 615 обучающих фраз.
[0139] В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии для предоставления информации о лексических связях между обучающим поисковым запросом 603 и набором 616 обучающих цифровых документов вместо векторного представления 615 обучающих фраз сервер 202 может использовать необработанные текстовые данные обучающего поискового запроса 603. В частности, в некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 202 в третьем множестве обучающих цифровых объектов способен включать количество вхождений того или иного ключевого слова из обучающего поискового запроса 603 в соответствующий документ из набора 616 обучающих цифровых документов. Иными словами, в таких вариантах осуществления каждый объект из третьего множества обучающих цифровых объектов содержит (а) векторное представление 613 обучающего поискового запроса для обучающего поискового запроса 603, (б) векторные представления обучающих документов для набора 616 обучающих цифровых документов, например, векторное представление 617 обучающего документа для некоторого обучающего цифрового документа, (в) метку 619, характеризующую степень релевантности обучающего цифрового документа, представленного векторным представлением 617 обучающего документа, обучающему поисковому запросу 603, и (г) целочисленные значения, характеризующие количество вхождений ключевых слов из обучающего поискового запроса 603 в обучающий цифровой документ.
[0140] В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 202 способен использовать необработанные текстовые данные из набора 616 обучающих цифровых документов для формирования третьего обучающего набора данных иным образом. В частности, в таких альтернативных вариантах осуществления вместо определения частоты вхождения каждого полного ключевого слова из обучающего поискового запроса 603 в обучающий цифровой документ сервер 202 способен (а) разделять ключевые слова из обучающего поискового запроса 603 на N-граммы, например, биграммы или триграммы, (б) определять частоту вхождения каждой N-граммы обучающего поискового запроса в обучающий цифровой документ и (в) включать в третье множество обучающих цифровых объектов целочисленные значения, характеризующие частоту вхождения каждой N-граммы из обучающего поискового запроса 603 в обучающий цифровой документ из набора 616 обучающих цифровых документов.
[0141] Иными словами, в отличие от вариантов осуществления, ориентированных на использование векторного представления 615 обучающих фраз для предоставления информации о лексических связях между обучающими цифровыми документами из набора 616 обучающих цифровых документов и обучающим поисковым запросом 603, в некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 202 способен использовать «необработанные» целочисленные значения, характеризующие частоты вхождения либо ключевых слов целиком, либо N-грамм обучающего поискового запроса 603 в каждый обучающий цифровой документ из набора 616 обучающих цифровых документов.
[0142] Кроме того, для обучения объединенной модели 602 машинного обучения на основе третьего обучающего набора данных сервер 202 способен (а) на данной итерации обучения передавать обучающий цифровой объект из третьего множества обучающих цифровых объектов в объединенную модель 602 машинного обучения, обеспечивая формирование объединенной моделью 602 машинного обучения текущего прогнозного значения параметра ранжирования, и (б) сводить к минимуму расхождение между (фактическим) значением параметра ранжирования, представленным меткой 619, и текущим прогнозным значением, сформированным объединенной моделью 602 машинного обучения на данной итерации обучения, корректируя веса узлов в объединенной модели 602 машинного обучения.
[0143] Например, в некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 202 способен определять расхождение между фактическим и текущим прогнозным значениями параметра ранжирования, используя функцию потерь, такую как функция потерь на основе перекрестной энтропии. Очевидно, что в других не имеющих ограничительного характера вариантах осуществления настоящей технологии возможны другие варианты реализации функции потерь, которые могут включать в себя, например, среди прочего, функцию потерь на основе среднеквадратической ошибки, функцию потерь Хьюбера, кусочно-линейную функцию потерь и т.д. При этом на способ сведения к минимуму функции потерь сервером 202 не накладывается ограничений и в некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии он, как правило, зависит от дифференцируемости функции потерь. Например, если функция потерь является непрерывно дифференцируемой, для ее минимизации могут использоваться, среди прочего, алгоритм градиентного спуска, алгоритм оптимизации Ньютона и пр. В тех вариантах осуществления, где функция потерь не является дифференцируемой, для ее минимизации сервер 202 может применять, например, прямые алгоритмы, стохастические алгоритмы и/или популяционные алгоритмы.
[0144] Таким образом, передача в объединенную модель 602 машинного обучения векторного представления 617 обучающего документа в составе объекта из третьего множества обучающих цифровых объектов позволяет объединенной модели 602 машинного обучения определять то, как цифровой документ из набора 214 цифровых документов семантически (то есть по смыслу) связан с поисковым запросом 212. С другой стороны, передача в объединенную модель 602 машинного обучения векторного представления 615 обучающих фраз для множества обучающих 605 фраз-кандидатов, лексически связанных с обучающим поисковым запросом 603, позволяет объединенной модели 602 машинного обучения определять то, как цифровой документ лексически (то есть по лингвистическим формам) связан с поисковым запросом 212.
[0145] Очевидно, что третье множество обучающих цифровых объектов может содержать тысячи, десятки тысяч или даже сотни тысяч обучающих цифровых объектов, сформированных на основе различных обучающих поисковых запросов, полученных, например, из архивных данных о взаимодействии пользователей с цифровой платформой 210. Таким образом, путем передачи всех обучающих цифровых объектов в объединенную модель машинного обучения и сведения к минимуму расхождения между фактическим и прогнозным значениями параметра ранжирования сервер 202 способен обучать объединенную модель 602 машинного обучения формированию значений параметра ранжирования для цифровых документов, подобранных для поисковых запросов в режиме использования, таких как набор 214 цифровых документов для поискового запроса 212, с учетом как семантических, так и лексических связей между ними. Ниже описано, как сервер 202 может использовать объединенную модель 602 машинного обучения после завершения описанного выше процесса обучения.
Процесс использования
[0146] На фиг. 8 схематически представлен процесс использования объединенной модели 602 машинного обучения для ранжирования цифровых документов в соответствии с некоторыми не имеющими ограничительного характера вариантами осуществления настоящей технологии.
[0147] В частности, в соответствии с некоторыми не имеющими ограничительного характера вариантами осуществления настоящей технологии, чтобы использовать объединенную модель 602 машинного обучения для ранжирования цифровых документов, сервер 202 способен (а) получать поисковый запрос 212, отправленный пользователем 216 на цифровую платформу 210, (б) формировать, используя первую модель 502 машинного обучения, векторное представление 512 поискового запроса, как описано выше, (в) находить, используя, например, математическую модель, в базе 206 данных поискового индекса набор 214 цифровых документов, удовлетворяющих поисковому запросу 212, и соответствующие им векторные представления документов, такие как векторное представление 516 документа для иллюстративного цифрового документа 402, (г) находить в наборе 214 цифровых документов множество 404 фраз-кандидатов, лексически связанных с поисковым запросом 212, и (д) формировать, используя первую модель 502 машинного обучения, векторное представление 514 фраз, характеризующее множество 404 фраз-кандидатов.
[0148] Как указано выше, в некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 202 способен формировать векторные представления документов для отдельных документов из множества цифровых документов на цифровой платформе 210, используя вторую модель 504 машинного обучения, до запуска объединенной модели 602 машинного обучения в режиме использования и сохранять такие векторные представления документов в базе 206 данных поискового индекса для последующего использования. Таким образом, после подбора сервером 202 набора цифровых документов для ранжирования, например, набора 214 цифровых документов, сервер 202 способен получать соответствующие векторные представления документов без необходимости их формирования в реальном времени. Это позволяет экономить вычислительные ресурсы сервера 202 во время работы объединенной модели 602 машинного обучения, что повышает эффективность формирования ранжированного набора 220 цифровых документов.
[0149] Кроме того, сервер 202 способен передавать (а) векторное представление 512 поискового запроса, (б) векторное представление 514 фраз и (в) векторные представления документов для набора 214 цифровых документов в объединенную модель 602 машинного обучения, обеспечивая формирование объединенной моделью 602 машинного обучения значений 702 параметра ранжирования для набора 214 цифровых документов. Кроме того, сервер 202 способен ранжировать набор 214 цифровых документов в зависимости от значений 702 параметра ранжирования, формируя ранжированный набор 220 цифровых документов. Наконец, сервер 202 способен передавать ранжированный набор 220 цифровых документов в электронное устройство 204 для его представления пользователю 216.
[0150] Как указано выше в описании процесса обучения, в некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии для предоставления информации о лексических связях между поисковым запросом 212 и набором 214 цифровых документов вместо векторного представления 514 фраз для множества 404 фраз-кандидатов сервер 202 способен формировать и дополнительно передавать в объединенную модель 602 машинного обучения векторы частоты в режиме использования, каждый из которых содержит значения, характеризующие количество вхождений ключевых слов поискового запроса 212 в иллюстративный цифровой документ 402. Например, как показано на фиг. 4, где представлен поисковый запрос 212 с текстом «Macaron Recipe Pierre Herme», вектор частоты в режиме использования для иллюстративного цифрового документа 402 может содержать следующие значения: [5, 0, 2], поскольку (а) лингвистические формы ключевого слова «Macaron» встречаются в иллюстративном цифровом документе 402 пять раз, (б) какие-либо формы ключевого слова «Recipe» в документе отсутствуют и (в) различные формы ключевых слов «Pierre Herme» в иллюстративном цифровом документе 402 встречаются дважды.
[0151] Таким образом, передача векторного представления 514 фраз или векторов частот в режиме использования вместе с векторными представлениями документов для набора 214 цифровых документов позволяет объединенной модели 602 машинного обучения формировать значения 702 параметра ранжирования, учитывая не только семантические связи между отдельными документами из набора 214 цифровых документов и поисковым запросом 212, но и лексические связи между ними. Иными словами, передача векторного представления 514 фраз в объединенную модель 602 машинного обучения позволяет переориентировать объединенную модель 602 машинного обучения с определения степени релевантности каждого из набора 214 цифровых документов поисковому запросу 212 исключительно на основе семантических связей между ними на определение степени релевантности каждого из набора 214 цифровых документов поисковому запросу 212 на основе как семантических, так и лексических связей между ними.
[0152] Это позволяет ранжировать набор 214 цифровых документов так, чтобы цифровым документам, связанным с поисковым запросом 212 как семантически, так и лексически, присваивалось более высокое значение параметра ранжирования, чем связанным с поисковым запросом 212 только семантически или только лексически. Как следствие, степень удовлетворенности пользователя 216 ранжированным набором 220 цифровых документов может быть увеличена.
Способ
[0153] С учетом описанной выше архитектуры и приведенных примеров возможна реализация способа ранжирования цифровых документов, таких как набор 214 цифровых документов. На фиг. 9 представлена блок-схема способа 800 в соответствии с некоторыми не имеющими ограничительного характера вариантами осуществления настоящей технологии. Способ 800 может быть реализован сервером 202.
Шаг 802: получение поискового запроса, отправленного пользователем на цифровую платформу.
[0154] Способ 800 начинается с шага 802, на котором сервер 202 может получать поисковый запрос 212, который пользователь 216 электронного устройства 204 отправил на цифровую платформу 210.
[0155] Следующим шагом в способе 800 является шаг 804.
Шаг 804: формирование первого векторного представления, характеризующего поисковый запрос.
[0156] На шаге 804, в соответствии с некоторыми не имеющими ограничительного характера вариантами осуществления настоящей технологии, сервер 202 может формировать векторное представление 512 поискового запроса для поискового запроса 212, полученного на шаге 802. Для этого в соответствии с некоторыми не имеющими ограничительного характера вариантами осуществления настоящей технологии сервер 202 может использовать первую модель 502 машинного обучения, обученную формированию векторных представлений входных фраз, как описано выше со ссылкой на фиг. 5.
[0157] Следующим шагом в способе 800 является шаг 806.
Шаг 806: нахождение в поисковом индексе цифровой платформы множества цифровых документов-кандидатов, удовлетворяющих поисковому запросу.
[0158] На шаге 806, в соответствии с некоторыми не имеющими ограничительного характера вариантами осуществления настоящей технологии, сервер 202 может находить в базе 206 данных поискового индекса цифровой платформы 210 набор 214 цифровых документов, удовлетворяющих поисковому запросу 212. В связи с этим, как описано выше, сервер 202 может применять математическую модель, которая может включать в себя, например, функцию ранжирования Okapi BM25.
[0159] Следующим шагом в способе 800 является шаг 808.
Шаг 808: получение для каждого цифрового документа-кандидата из множества цифровых документов-кандидатов второго векторного представления, сформированного до поступления поискового запроса.
[0160] На шаге 808, в соответствии с некоторыми не имеющими ограничительного характера вариантами осуществления настоящей технологии, сервер 202 может получать для каждого цифрового документа из набора 214 цифровых документов векторное представление документа, такое как векторное представление 516 документа для иллюстративного цифрового документа 402 из набора 214 цифровых документов.
[0161] Как указано выше, перед получением поискового запроса 212 на шаге 802, в соответствии с некоторыми не имеющими ограничительного характера вариантами осуществления настоящей технологии, сервер 202 может формировать векторное представление 516 документа, используя вторую модель 504 машинного обучения, обученную формированию векторных представлений входных цифровых документов, как описано выше со ссылкой на фиг. 6. Кроме того, сервер 202 может сохранять векторное представление 516 документа в базе 206 данных поискового индекса в привязке к иллюстративному цифровому документу 402 для его последующего использования при ранжировании цифровых документов.
[0162] Следующим шагом в способе 800 является шаг 810.
Шаг 810: нахождение для каждого документа-кандидата из множества цифровых документов-кандидатов по меньшей мере одной фразы-кандидата, лексически связанной с по меньшей мере одним ключевым словом поискового запроса.
[0163] На шаге 810, в соответствии с некоторыми не имеющими ограничительного характера вариантами осуществления настоящей технологии, сервер 202 может находить в цифровом документе из набора 214 цифровых документов по меньшей мере одну фразу-кандидат, лексически связанную с поисковым запросом 212, например, множество 404 фраз-кандидатов, найденных в иллюстративном цифровом документе 402, как описано выше со ссылкой на фиг. 4.
[0164] В частности, в некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 202 может (а) формировать для каждой фразы иллюстративного цифрового документа 402 вектор, содержащий числовое представление фразы в пространстве векторных представлений, (б) определять, используя такие векторы, для каждой фразы иллюстративного цифрового документа 402 значение метрики близости к поисковому запросу 212, (в) ранжировать фразы иллюстративного цифрового документа 402 в зависимости от значений метрики близости и (г) выбирать для включения во множество фраз-кандидатов N приоритетных фраз, лексически связанных с поисковым запросом 212. Как указано выше, в некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии метрика близости может характеризовать расстояние между вектором, представляющим фразу иллюстративного цифрового документа 402, и вектором, представляющим поисковый запрос 212, в пространстве векторных представлений. В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии метрика близости может представлять собой косинусоидальную метрику близости.
[0165] Следующим шагом в способе 800 является шаг 812.
Шаг 812: формирование третьего векторного представления, характеризующего по меньшей мере одну фразу-кандидат.
[0166] На шаге 812, в соответствии с некоторыми не имеющими ограничительного характера вариантами осуществления настоящей технологии, сервер 202 может формировать векторное представление 514 фраз для множества 404 фраз-кандидатов, лексически связанных с поисковым запросом 212. Для этого сервер 202 может использовать первую модель 502 машинного обучения, обученную формированию векторных представлений входных фраз, как описано выше со ссылкой на фиг. 5.
[0167] В других не имеющих ограничительного характера вариантах осуществления вместо векторного представления 514 фраз сервер 202 способен формировать векторы частоты в режиме использования, каждый из которых содержит значения, характеризующие количество вхождений ключевых слов поискового запроса 212 в иллюстративный цифровой документ 402, как описано выше со ссылкой на фиг. 4 и 8.
[0168] Следующим шагом в способе 800 является шаг 814.
Шаг 814: определение на основе первого, второго и третьего векторных представлений значения параметра ранжирования для каждого документа-кандидата из множества цифровых документов-кандидатов.
[0169] На шаге 814 на основе векторного представления 512 поискового запроса, векторных представлений документов для каждого документа из набора 214 цифровых документов и векторного представления 514 фраз (или векторов частоты вхождения ключевых слов из поискового запроса 212 в режиме использования) для множества 404 фраз-кандидатов, лексически связанных с поисковым запросом 202, сервер 202 может ранжировать набор 214 цифровых документов с учетом их лексических и семантических связей с поисковым запросом 212.
[0170] Для этого, в соответствии с некоторыми не имеющими ограничительного характера вариантами осуществления настоящей технологии, сервер 202 может использовать объединенную модель 602 машинного обучения, обученную, как описано выше со ссылкой на фиг. 7. В частности, как описано выше со ссылкой на фиг. 8, сервер 202 может передавать (а) векторное представление 512 поискового запроса, (б) векторное представление 514 фраз и (в) векторные представления документов для набора 214 цифровых документов в объединенную модель 602 машинного обучения, обеспечивая формирование объединенной моделью 602 машинного обучения значений 702 параметра ранжирования для набора 214 цифровых документов. Как указано выше, значение параметра ранжирования характеризует степень релевантности цифрового документа поисковому запросу 212.
Шаг 816: ранжирование множества цифровых документов-кандидатов на основе связанных с ними значений параметра ранжирования.
[0171] Наконец, на шаге 816, в соответствии с некоторыми не имеющими ограничительного характера вариантами осуществления настоящей технологии, сервер 202 может ранжировать набор 214 цифровых документов в зависимости от значений 702 параметра ранжирования, определенных на шаге 814, формируя ранжированный набор 220 цифровых документов. Кроме того, сервер 202 может передавать ранжированный набор 220 цифровых документов в электронное устройство 204 для его представления пользователю 216.
[0172] На этом реализация способа 800 завершается.
[0173] Таким образом, некоторые варианты осуществления способа 800 дают возможность вводить в объединенную модель 602 машинного обучения информацию, характеризующую лексические связи между цифровыми документами и поисковым запросом 212, что дополнительно позволяет ранжировать набор 214 цифровых документов так, чтобы цифровым документам, связанным с поисковым запросом 212 как семантически, так и лексически, присваивалось более высокое значение параметра ранжирования, чем цифровым документам, связанным с поисковым запросом 212 только семантически или только лексически. Это позволяет увеличить степень удовлетворенности пользователя 216 ранжированным набором 220 цифровых документов.
[0174] Также следует понимать, что представленные в настоящем документе варианты осуществления описаны со ссылкой на конкретные признаки и структуры, но без отступления от существа этого описания возможны их различные модификации и комбинации. Например, различные оптимизации, применимые к нейронным сетям, включая трансформеры и/или BERT, могут быть применены и в описанной технологии. Кроме того, могут использоваться оптимизации, ускоряющие определение релевантности в режиме использования. Например, в некоторых вариантах реализации модель трансформера может быть разделена так, чтобы обеспечивалось распределение некоторых трансформерных блоков между задачами обработки запроса и обработки документа, позволяющее заранее вычислять представления документов в автономном режиме и сохранять их в поисковом индексе документов. Описание и, соответственно, чертежи следует рассматривать лишь как иллюстрацию представленных вариантов реализации или осуществления и их принципов, определяемых приложенной формулой изобретения, при этом предполагается, что они охватывают все модификации, вариации, комбинации и эквиваленты в пределах существа и объема настоящего изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| СИСТЕМА И СПОСОБ ОБУЧЕНИЯ МОДЕЛЕЙ МАШИННОГО ОБУЧЕНИЯ ДЛЯ РАНЖИРОВАНИЯ РЕЗУЛЬТАТОВ ПОИСКА | 2023 |
|
RU2832419C2 |
| МНОГОЭТАПНОЕ ОБУЧЕНИЕ МОДЕЛЕЙ МАШИННОГО ОБУЧЕНИЯ ДЛЯ РАНЖИРОВАНИЯ РЕЗУЛЬТАТОВ | 2021 |
|
RU2831678C2 |
| СПОСОБ И СИСТЕМА ФОРМИРОВАНИЯ ОБУЧАЮЩИХ ДАННЫХ ДЛЯ АЛГОРИТМА МАШИННОГО ОБУЧЕНИЯ | 2023 |
|
RU2831408C2 |
| СПОСОБ И СИСТЕМА ДЛЯ ФОРМИРОВАНИЯ ТЕКСТОВЫХ ПОДСКАЗОК | 2024 |
|
RU2841233C1 |
| СПОСОБ И СИСТЕМА ДЛЯ ПРОВЕРКИ МЕДИАКОНТЕНТА | 2022 |
|
RU2815896C2 |
| СПОСОБ И СИСТЕМА ОБУЧЕНИЯ СИСТЕМЫ ЧАТ-БОТА | 2023 |
|
RU2820264C1 |
| СПОСОБ И СИСТЕМА ДЛЯ ОБУЧЕНИЯ МОДЕЛИ МАШИННОГО ОБУЧЕНИЯ ДЛЯ ПЕРЕВОДА | 2023 |
|
RU2835121C1 |
| СПОСОБ И СЕРВЕР ДЛЯ ФОРМИРОВАНИЯ МОДЕЛИ МАШИННОГО ОБУЧЕНИЯ | 2022 |
|
RU2828354C2 |
| СПОСОБ И СЕРВЕР ДЛЯ ПОВТОРНОГО ОБУЧЕНИЯ АЛГОРИТМА МАШИННОГО ОБУЧЕНИЯ | 2019 |
|
RU2743932C2 |
| Способ и сервер для формирования расширенного запроса | 2021 |
|
RU2813582C2 |
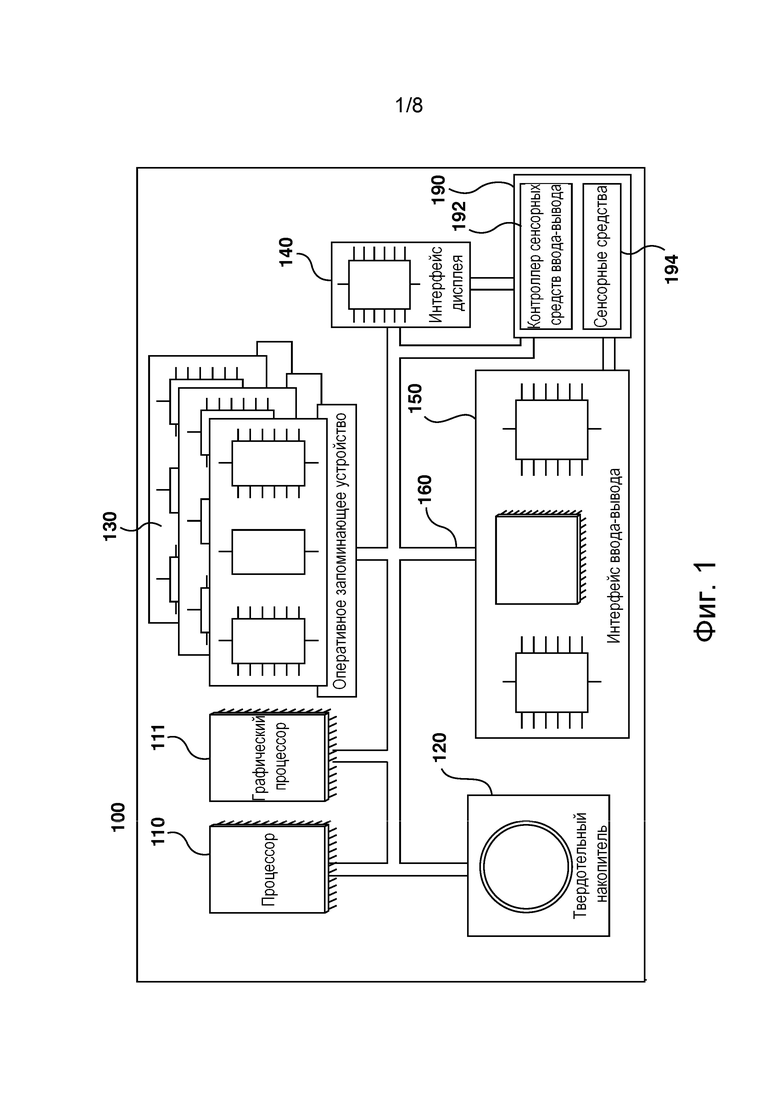
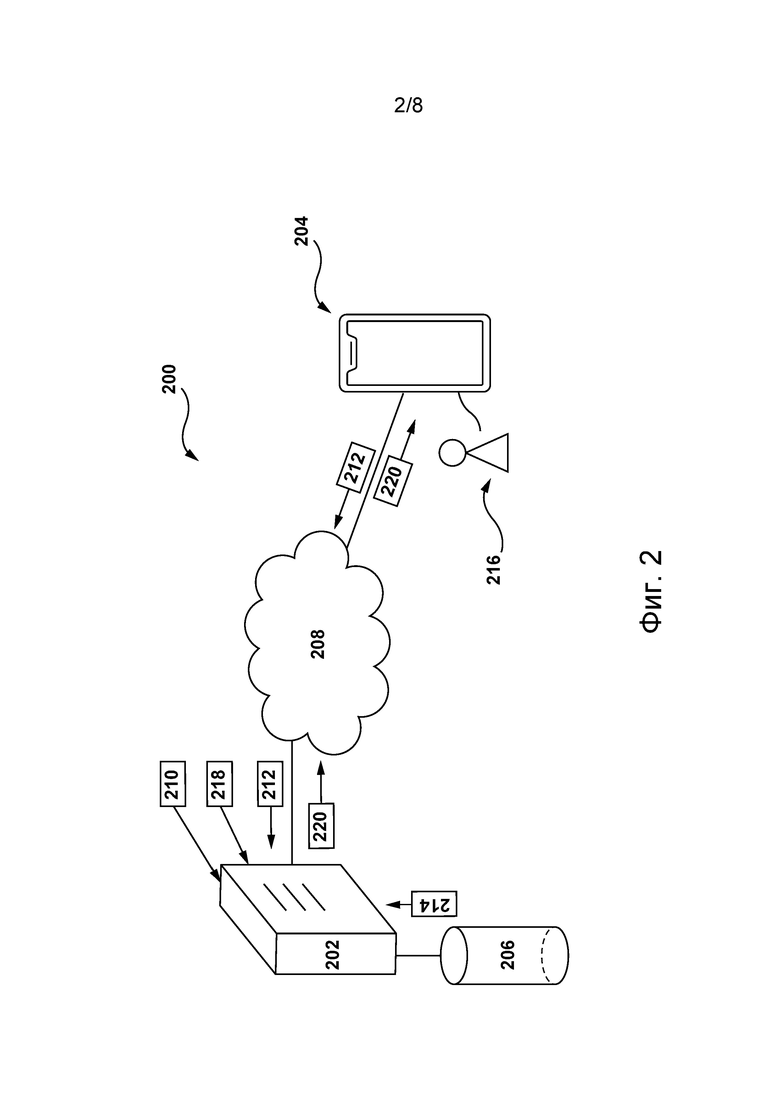
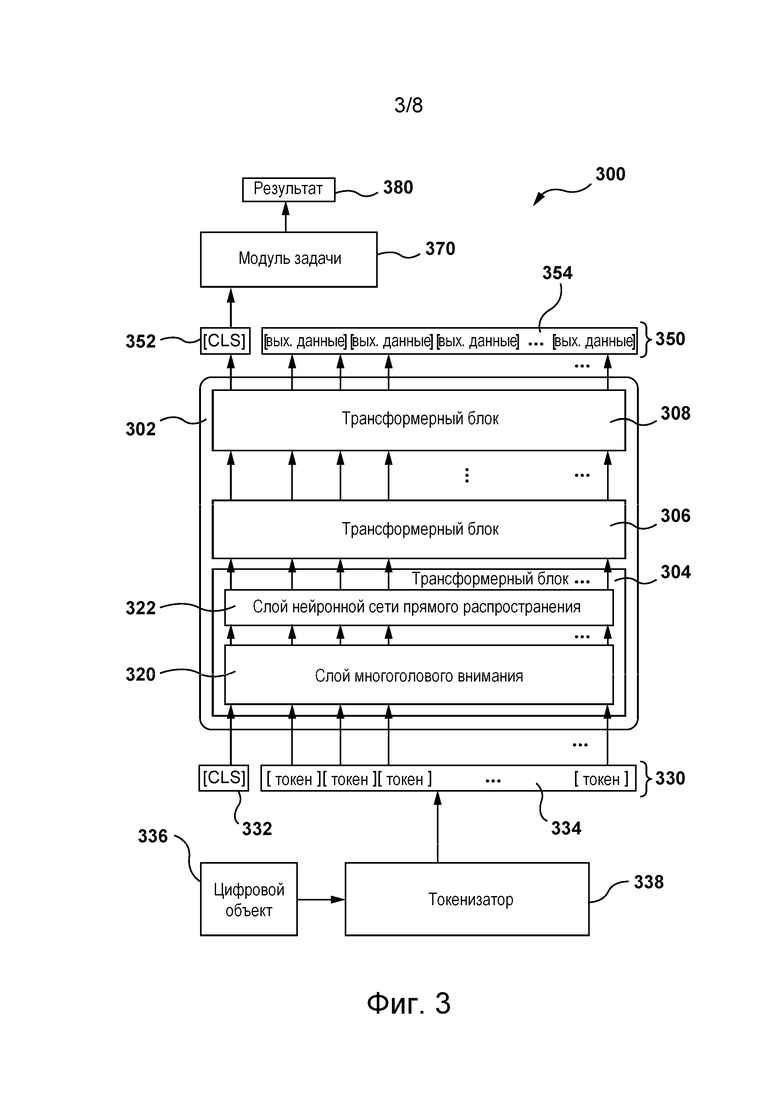
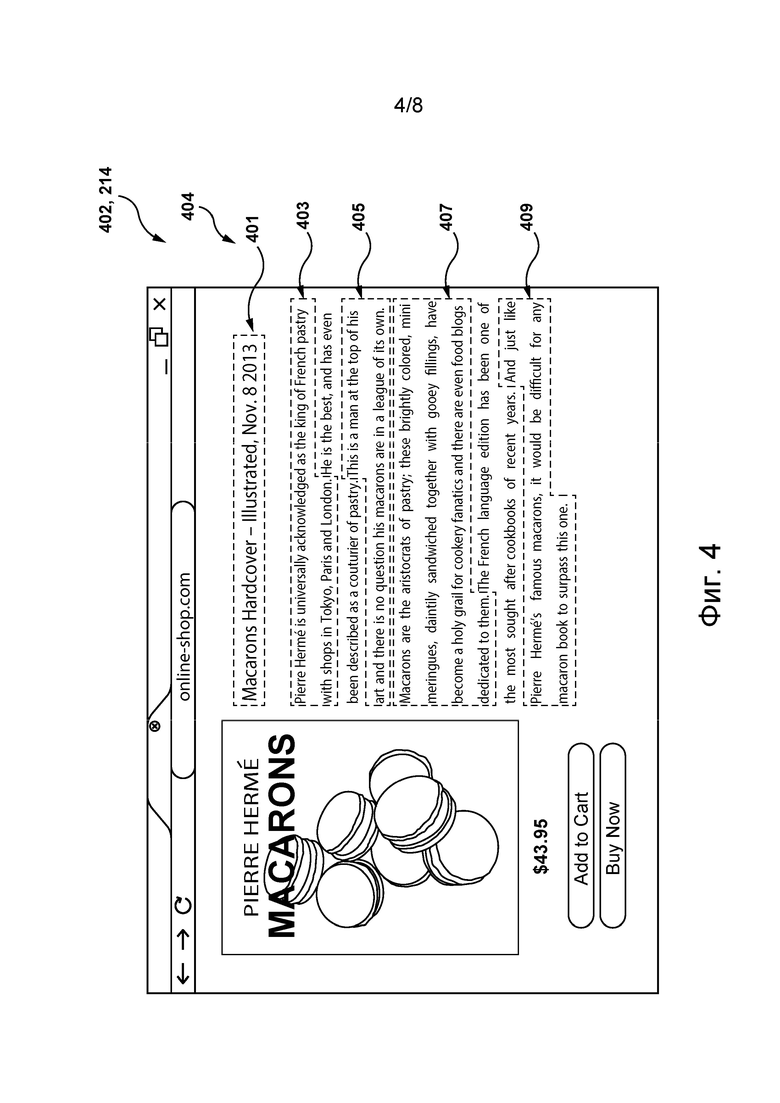
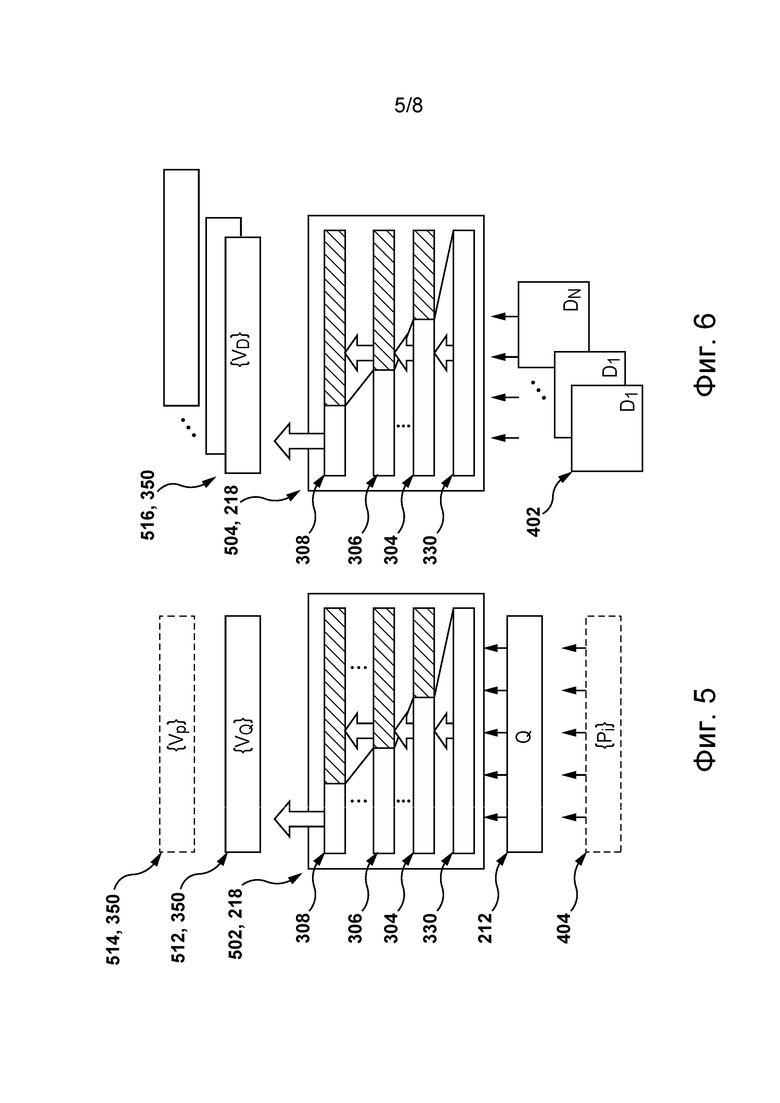
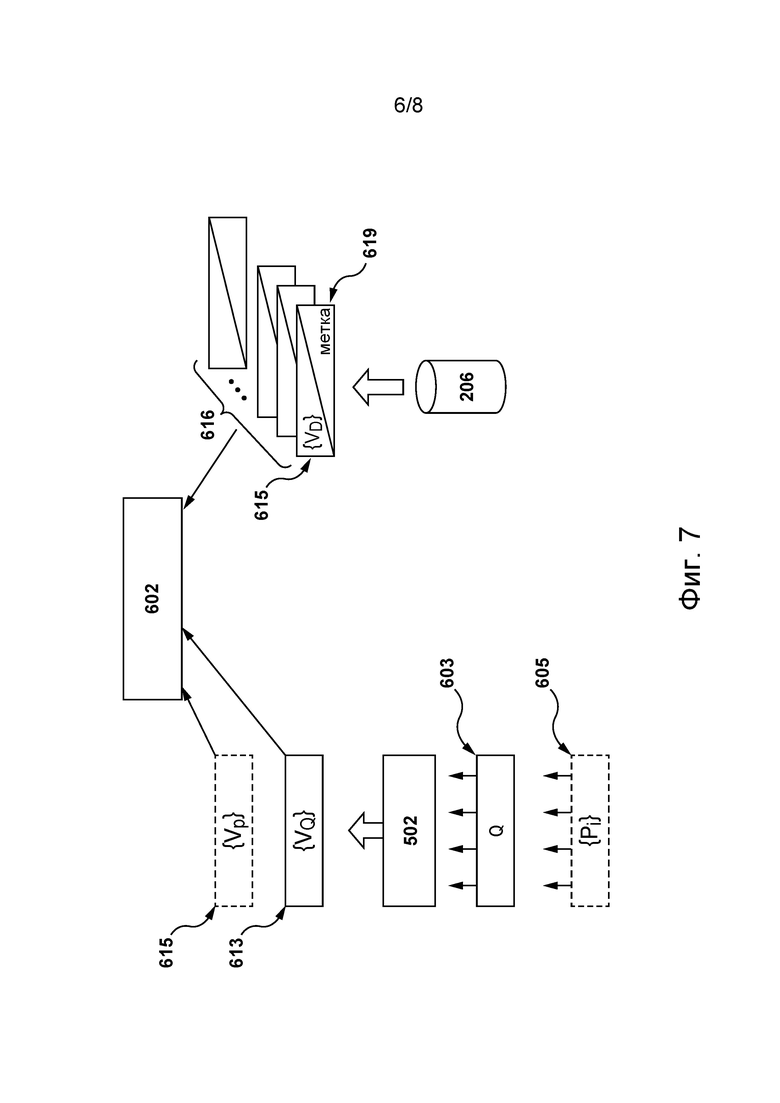
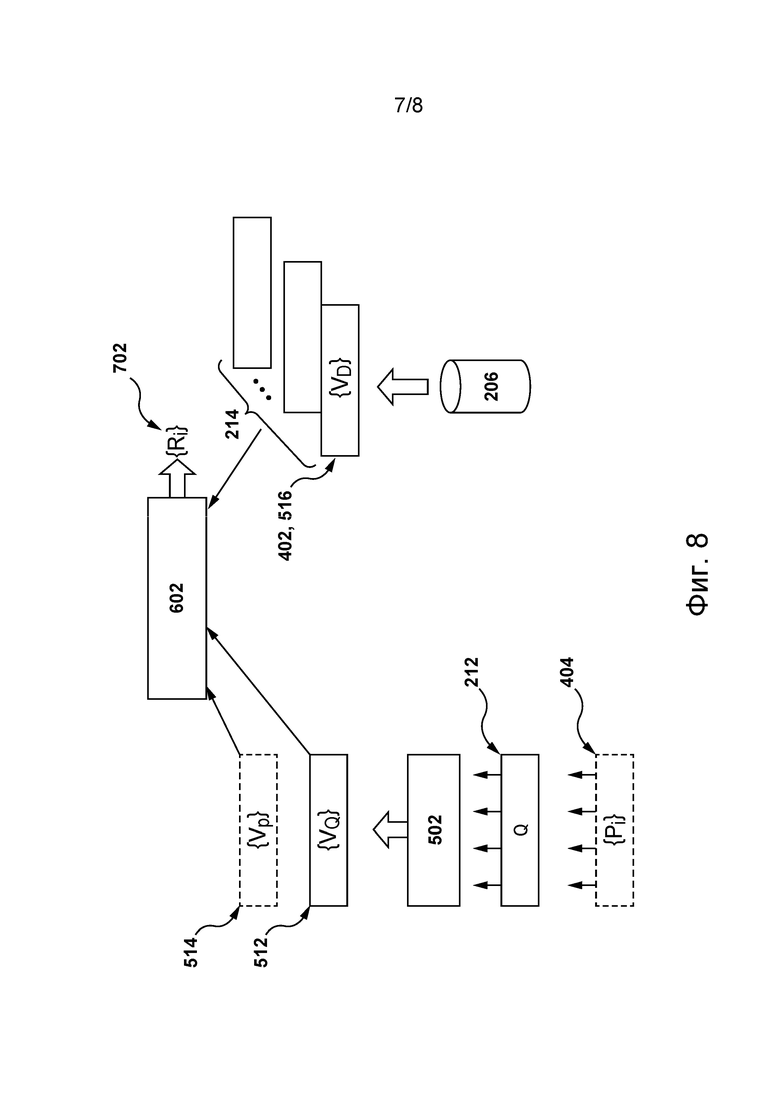
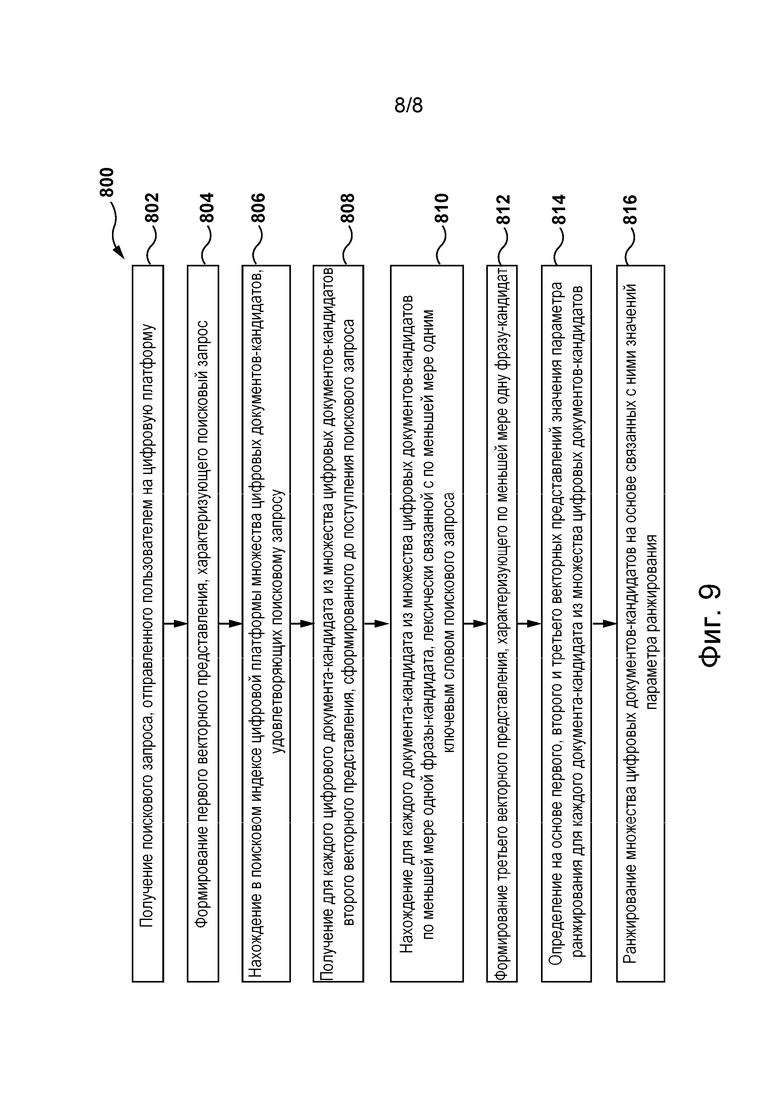
Изобретение относится к способу и серверу для ранжирования цифровых документов на цифровой платформе. Технический результат заключается в повышении релевантности ранжируемых цифровых документов поисковому запросу. Способ предусматривает получение поискового запроса, отправленного на цифровую платформу, формирование первого векторного представления, характеризующего поисковый запрос, нахождение множества цифровых документов-кандидатов, удовлетворяющих поисковому запросу, получение для каждого цифрового документа-кандидата из множества цифровых документов-кандидатов второго векторного представления, нахождение в каждом документе-кандидате из множества цифровых документов-кандидатов по меньшей мере одной фразы-кандидата, лексически связанной с поисковым запросом, формирование третьего векторного представления, характеризующего по меньшей мере одну фразу-кандидат, определение на основе первого, второго и третьего векторных представлений для каждого документа-кандидата из множества цифровых документов-кандидатов значения параметра ранжирования и ранжирование множества цифровых документов-кандидатов в зависимости от связанных с ними значений параметра ранжирования. 2 н. и 18 з.п. ф-лы, 9 ил.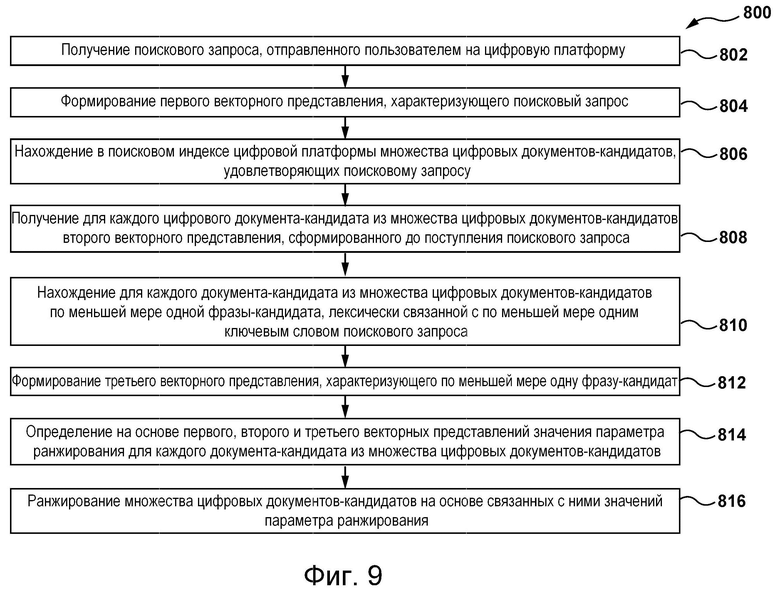
1. Компьютерный способ ранжирования цифровых документов на цифровой платформе, предусматривающий:
- получение поискового запроса, отправленного пользователем на цифровую платформу;
- формирование первого векторного представления, характеризующего поисковый запрос;
- нахождение в поисковом индексе цифровой платформы множества цифровых документов-кандидатов, удовлетворяющих поисковому запросу;
- получение для каждого цифрового документа-кандидата из множества цифровых документов-кандидатов второго векторного представления, сформированного до поступления поискового запроса;
- нахождение для каждого документа-кандидата из множества цифровых документов-кандидатов по меньшей мере одной фразы-кандидата, лексически связанной с по меньшей мере одним ключевым словом поискового запроса;
- формирование третьего векторного представления, характеризующего по меньшей мере одну фразу-кандидат;
- определение на основе первого, второго и третьего векторных представлений для каждого документа-кандидата из множества цифровых документов-кандидатов значения параметра ранжирования, характеризующего релевантность этого документа-кандидата из множества цифровых документов-кандидатов поисковому запросу; и
- ранжирование множества цифровых документов-кандидатов на основе связанных с ними значений параметра ранжирования.
2. Способ по п. 1, в котором нахождение множества цифровых документов-кандидатов предусматривает применение функции ранжирования.
3. Способ по п. 2, в котором функция ранжирования представляет собой функцию ранжирования Okapi BM25.
4. Способ по п. 1, в котором нахождение по меньшей мере одной фразы-кандидата предусматривает:
- формирование для каждой фразы документа-кандидата из множества цифровых документов-кандидатов векторного представления фразы;
- определение в пространстве векторных представлений значения расстояния между первым векторным представлением, характеризующим поисковый запрос, и векторным представлением фразы;
- ранжирование фраз из множества цифровых документов-кандидатов в зависимости от значений расстояния, связанных с векторными представлениями фраз, с целью формирования ранжированного списка фраз для поискового запроса; и
- выбор из ранжированного списка фраз заданного количества приоритетных фраз.
5. Способ по п. 4, в котором формирование векторного представления фразы предусматривает определение для каждого ключевого слова поискового запроса значения отношения частоты ключевого слова к обратной частоте документа в документе-кандидате из множества цифровых документов-кандидатов.
6. Способ по п. 4, в котором формирование векторного представления фразы предусматривает применение к ней алгоритма векторного представления текста.
7. Способ по п. 6, в котором алгоритм векторного представления текста представляет собой алгоритм векторного представления слов FastText.
8. Способ по п. 1, в котором определение значения параметра ранжирования предусматривает передачу первого, второго и третьего векторных представлений в объединенную модель машинного обучения, обученную определению значения параметра ранжирования для каждого документа из множества цифровых документов на основе векторных представлений (а) поискового запроса, используемого для нахождения множества цифровых документов, (б) каждого документа из множества цифровых документов, удовлетворяющих этому поисковому запросу, и (в) по меньшей мере одной фразы-кандидата, определенной во множестве цифровых документов как лексически связанной с по меньшей мере одним ключевым словом этого поискового запроса.
9. Способ по п. 8, дополнительно предусматривающий обучение объединенной модели машинного обучения путем:
- формирования обучающего набора данных, содержащего множество обучающих цифровых объектов, каждый из которых содержит (а) обучающее векторное представление обучающего поискового запроса, (б) обучающие векторные представления множества обучающих цифровых документов-кандидатов, удовлетворяющих обучающему поисковому запросу, (в) обучающее векторное представление по меньшей мере одной обучающей фразы-кандидата, найденной во множестве обучающих цифровых документов, лексически связанной с по меньшей мере одним ключевым словом из обучающего поискового запроса, и (г) метку для каждого обучающего документа из множества обучающих цифровых документов, характеризующую степень релевантности этого обучающего документа из множества обучающих цифровых документов обучающему поисковому запросу;
- передачи множества обучающих цифровых объектов в объединенную модель машинного обучения; и
- сведения к минимуму расхождения между текущим обучающим прогнозом, сформированным объединенной моделью машинного обучения, и меткой на каждой итерации обучения.
10. Способ по п. 9, в котором метка формируется моделью машинного обучения, предварительно обученной на основе меток, сформированных человеком-оценщиком, для определения степени релевантности цифрового документа поисковому запросу.
11. Способ по п. 8, в котором объединенная модель машинного обучения содержит глубокую модель машинного обучения для определения семантической близости.
12. Способ по п. 1, в котором получение второго векторного представления предусматривает получение второго векторного представления от второй модели машинного обучения, обученной формированию векторных представлений входных цифровых документов.
13. Способ по п. 12, дополнительно предусматривающий обучение второй модели машинного обучения путем передачи в нее множества цифровых документов из поискового индекса цифровой платформы.
14. Способ по п. 1, дополнительно предусматривающий сокращение объема представлений для каждого из первого, второго и третьего векторных представлений перед определением значения параметра ранжирования.
15. Способ по п. 14, в котором формирование первого, второго и третьего векторных представлений предусматривает применение модели машинного обучения на основе трансформера, а сокращение объема представлений предусматривает последовательное усечение выходных данных каждого промежуточного слоя модели машинного обучения на основе трансформера до заданной длины каждого из первого, второго и третьего векторных представлений.
16. Способ по п. 1, в котором формирование первого и третьего векторных представлений осуществляется независимо от формирования второго векторного представления.
17. Способ по п. 1, в котором формирование первого векторного представления, характеризующего поисковый запрос, и третьего векторного представления, характеризующего по меньшей мере одну фразу-кандидат, предусматривает применение модели машинного обучения, обученной формированию векторных представлений входных фраз.
18. Способ по п. 17, дополнительно предусматривающий обучение модели машинного обучения путем:
- формирования обучающего набора данных, содержащего множество обучающих цифровых объектов, каждый из которых содержит обучающий поисковый запрос и множество обучающих фраз-кандидатов, найденных во множестве обучающих цифровых документов, удовлетворяющих обучающему поисковому запросу, и лексически связанных с по меньшей мере одним ключевым словом из обучающего поискового запроса; и
- передачи множества обучающих цифровых объектов в модель машинного обучения.
19. Способ по п. 1, в котором в процессе нахождения по меньшей мере одной фразы-кандидата, лексически связанной с по меньшей мере одним ключевым словом из поискового запроса, для каждого документа-кандидата из множества цифровых документов-кандидатов способ дополнительно предусматривает использование необработанной версии этого документа-кандидата из множества цифровых документов-кандидатов.
20. Сервер для ранжирования цифровых документов на цифровой платформе, содержащий по меньшей мере один процессор и по меньшей мере одну долговременную машиночитаемую память, хранящую исполняемые команды, при исполнении которых по меньшей мере одним процессором на сервере обеспечиваются:
- получение поискового запроса, отправленного пользователем на цифровую платформу;
- формирование первого векторного представления, характеризующего поисковый запрос;
- нахождение в поисковом индексе цифровой платформы множества цифровых документов-кандидатов, удовлетворяющих поисковому запросу;
- получение для каждого цифрового документа-кандидата из множества цифровых документов-кандидатов второго векторного представления, сформированного до поступления поискового запроса;
- нахождение для каждого документа-кандидата из множества цифровых документов-кандидатов по меньшей мере одной фразы-кандидата, лексически связанной с по меньшей мере одним ключевым словом поискового запроса;
- формирование третьего векторного представления, характеризующего по меньшей мере одну фразу-кандидат;
- определение на основе первого, второго и третьего векторных представлений для каждого документа-кандидата из множества цифровых документов-кандидатов значения параметра ранжирования, характеризующего релевантность этого документа-кандидата из множества цифровых документов-кандидатов поисковому запросу; и
- ранжирование множества цифровых документов-кандидатов на основе связанных с ними значений параметра ранжирования.
| RU 2018122689 A, 24.12.2019 | |||
| RU 2021133942 A, 30.06.2023 | |||
| RU 2021135486 A, 05.10.2023 | |||
| СПОСОБ И СИСТЕМА ГЕНЕРИРОВАНИЯ ПРИЗНАКА ДЛЯ РАНЖИРОВАНИЯ ДОКУМЕНТА | 2018 |
|
RU2733481C2 |
| Способы и серверы для ранжирования цифровых документов в ответ на запрос | 2020 |
|
RU2775815C2 |
| СИСТЕМА И СПОСОБ ФОРМИРОВАНИЯ ОБУЧАЮЩЕГО НАБОРА ДЛЯ АЛГОРИТМА МАШИННОГО ОБУЧЕНИЯ | 2017 |
|
RU2711125C2 |
| СПОСОБ И СИСТЕМА ДЛЯ РАСШИРЕНИЯ ПОИСКОВЫХ ЗАПРОСОВ С ЦЕЛЬЮ РАНЖИРОВАНИЯ РЕЗУЛЬТАТОВ ПОИСКА | 2018 |
|
RU2720905C2 |
| US 20200005149 A1, 02.01.2020 | |||
| US 20210097472 A1, 01.04.2021 | |||
| US 20200257712 A1, 13.08.2020 | |||
| US 11475067 B2, 18.10.2022. | |||

