Область техники
[0001] Настоящее раскрытие относится к области основанных на машинном обучении моделей, реализующих генерирование видеоклипов на основе текстовых описаний (“prompts”) и дополнительной обуславливающей синтетической информации, определяющей в генерируемых кадрах видеоклипов динамику (например, желаемое размещение) объекта/объектов, соответствующих концепциям, передаваемым текстовым описанием.
Уровень техники
[0002] Существуют генеративные модели преобразования текстового описания в видеоклип. На вход такие модели получают текстовое описание, а на выходе такие модели обычно генерируют видеоклип, в котором объекты и их размещения в той или иной степени соответствуют концепциям, которые описываются текстовым описанием. Однако качество видеоклипов, генерируемых такими моделями, и концептуальное соответствие этих видеоклипов переданному текстовому описанию оставляют желать лучшего.
[0003] Для улучшения качества генерируемых видеоклипов и их соответствия передаваемым текстовым описаниям были предложены модели преобразования текстовых описаний в видеоклипы, которые в дополнение к текстовым описаниям обуславливаются последовательностью референсных видеоклипов. Тем не менее, недостатком таких моделей является необходимость отыскивать соответствующие текстовым описаниям референсные видеоклипы. Количество видеоклипов, находящихся в открытом доступе, которые можно было бы рассматривать в качестве соответствующих определенным текстовым описаниям и, соответственно, применимых в качестве соответствующих референсных, является сильно ограниченным и недостаточным для покрытия всего многообразия возможных концепций, передаваемых различными возможными формулировками текстовых описаний. Таким образом, было бы полезно обеспечить модель преобразования текстового описания в видеоклип, которая генерировала бы видеоклип аналогичного качества, но без использования на стадии вывода (“inference”) реальных референсных видеоклипов или какой-либо извлекаемой из них информации.
Сущность изобретения
[0004] В первом аспекте настоящего изобретения предусмотрен способ генерирования видеоклипа по текстовому описанию, включающий в себя этапы, на которых: принимают текстовое описание видеоклипа, подлежащего генерированию; получают векторное представление 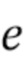 текстового описания согласно векторному пространству предобученной нейросетевой модели увязывания изображений и текстовых описаний на основе принятого текстового описания видеоклипа; получают векторное представление 2xNxL последовательности ключевых точек генерируемого видеоклипа, синтезируемое обучаемой диффузионной моделью движения на основе векторного представления текстового описания, где 2 - число координат, первая координата указывает высоту H кадра, а вторая координата указывает ширину W кадра, N - число ключевых точек на каждом кадре, и L - число кадров в видео; отображают векторное представление последовательности ключевых точек генерируемого видеоклипа в ряд L двумерных изображений ключевых точек генерируемого видеоклипа, причем каждое двумерное изображение ключевых точек из упомянутого ряда соответствует соответствующему кадру генерируемого видеоклипа; и генерируют последовательность кадров видеоклипа с помощью предобученной модели стабильной диффузии, при этом генерирование каждого кадра видеоклипа моделью стабильной диффузии дополнительно контролируется контролирующей нейросетевой моделью на основе двумерного изображения ключевых точек соответствующего кадра из упомянутого ряда.
текстового описания согласно векторному пространству предобученной нейросетевой модели увязывания изображений и текстовых описаний на основе принятого текстового описания видеоклипа; получают векторное представление 2xNxL последовательности ключевых точек генерируемого видеоклипа, синтезируемое обучаемой диффузионной моделью движения на основе векторного представления текстового описания, где 2 - число координат, первая координата указывает высоту H кадра, а вторая координата указывает ширину W кадра, N - число ключевых точек на каждом кадре, и L - число кадров в видео; отображают векторное представление последовательности ключевых точек генерируемого видеоклипа в ряд L двумерных изображений ключевых точек генерируемого видеоклипа, причем каждое двумерное изображение ключевых точек из упомянутого ряда соответствует соответствующему кадру генерируемого видеоклипа; и генерируют последовательность кадров видеоклипа с помощью предобученной модели стабильной диффузии, при этом генерирование каждого кадра видеоклипа моделью стабильной диффузии дополнительно контролируется контролирующей нейросетевой моделью на основе двумерного изображения ключевых точек соответствующего кадра из упомянутого ряда.
[0005] Согласно развитию первого аспекта настоящего изобретения нейросетевая модель увязывания изображений и текстовых описаний содержит кодер текстового описания и кодер изображения, причем кодер текстового описания выполнен с возможностью кодирования текстового описания в векторное пространство текстовое описание-изображение, а кодер изображения выполнен с возможностью кодирования изображения, которое упомянутое текстовое описание описывает, в то же самое векторное пространство текстовое описание-изображение.
[0006] Согласно развитию первого аспекта настоящего изобретения обучающие данные для обучения упомянутой диффузионной модели движения включают в себя: обучающий набор видеоклипов, векторные представления текстовых описаний всех видеоклипов из упомянутого набора видеоклипов, причем каждому видеоклипу из упомянутого набора видеоклипов соответствует свое векторное представление текстового описания, полученное кодером текстового описания нейросетевой модели увязывания изображений и текстовых описаний на основе по меньшей мере одного кадра соответствующего видеоклипа или на основе разметки, заранее обеспечиваемой человеком или автоматизированным методом, которая представляет собой текстовое описание соответствующего видеоклипа, и векторные представления последовательностей ключевых точек всех видеоклипов из упомянутого набора видеоклипов, причем каждому видеоклипу из упомянутого набора видеоклипов соответствует свое векторное представление последовательности ключевых точек, полученное моделью обнаружения ключевых точек на основе всех кадров соответствующего видеоклипа.
[0007] Согласно развитию первого аспекта настоящего изобретения в качестве ключевых точек модель обнаружения ключевых точек обучена обнаруживать, для каждого кадра видеоклипа, ключевые точки, определяющие позу человека в данном кадре видеоклипа.
[0008] Согласно развитию первого аспекта настоящего изобретения ключевые точки, определяющие позу человека в кадре видеоклипа, содержат: одну или более ключевых точек головы человека, одну или более ключевых точек корпуса человека, одну или более ключевых точек каждой верхней конечности человека, одну или более ключевых точек каждой нижней конечности человека.
[0009] Согласно развитию первого аспекта настоящего изобретения ключевые точки головы человека содержат ключевые точки лица человека, определяющие эмоцию человека.
[0010] Согласно развитию первого аспекта настоящего изобретения в качестве ключевых точек модель обнаружения ключевых точек обучена обнаруживать, для каждого кадра видеоклипа, ключевые точки, определяющие края одного или более объектов в данном кадре видеоклипа.
[0011] Согласно развитию первого аспекта настоящего изобретения обучение диффузионной модели движения содержит прямой процесс и обратный процесс и выполняется итеративно до тех пор, пока не будет удовлетворено любое из следующих условий завершения обучения, - достигнут признак сходимости функции потерь, - завершено предопределенное число n эпох обучения диффузионной модели движения.
[0012] Согласно развитию первого аспекта настоящего изобретения во время прямого процесса последовательно выполняют T временных шагов диффузии, на каждом из которых к векторному представлению последовательности ключевых точек случайного видеоклипа из обучающих данных добавляют гауссовский шум, для получения зашумленных векторных представлений последовательности ключевых точек упомянутого видеоклипа в числе T.
[0013] Согласно развитию первого аспекта настоящего изобретения во время обратного процесса диффузионную модель движения обучают выполнением следующих этапов, на которых: случайным образом выбирают временной шаг t из семплируемого диапазона временных шагов [1, T-1], который включает в себя все временные шаги t кроме самого первого несемплируемого временного шага t=0; прогнозируют обучаемой диффузионной моделью движения шум, который необходимо удалить из зашумленного векторного представления последовательности ключевых точек видеоклипа, соответствующего временному шагу t, для получения векторного представления последовательности ключевых точек видеоклипа, соответствующего временному шагу t-1; вычисляют значение функции потерь между спрогнозированным шумом и фактическим шумом, который был прибавлен к векторному представлению последовательности ключевых точек видеоклипа во время прямого процесса на временном шаге t-1; и выполняют обратное распространение ошибки путем вычисления, на основе вычисленного значения функции потерь, градиента и обновления весов обучаемой диффузионной модели движения на основе вычисленного градиента.
[0014] Согласно развитию первого аспекта настоящего изобретения значение функции потерь вычисляется как среднеквадратичная ошибка (MSE) между спрогнозированным шумом и шумом, фактически прибавленным к представлению ключевых точек видеоклипа на определенном временном шаге прямого процесса.
[0015] Согласно развитию первого аспекта настоящего изобретения диффузионная модель движения основана на архитектуре трансформер с механизмом самовнимания, причем векторное представление текстового описания видеоклипа, представление ключевых точек которого в данный момент используют при обучении диффузионной модели движения, дополнительно подают на вход обучаемой диффузионной модели движения, с которой в данный момент выполняют обратный процесс, в качестве условия обучения диффузионной модели движения, учитываемого через механизм самовнимания.
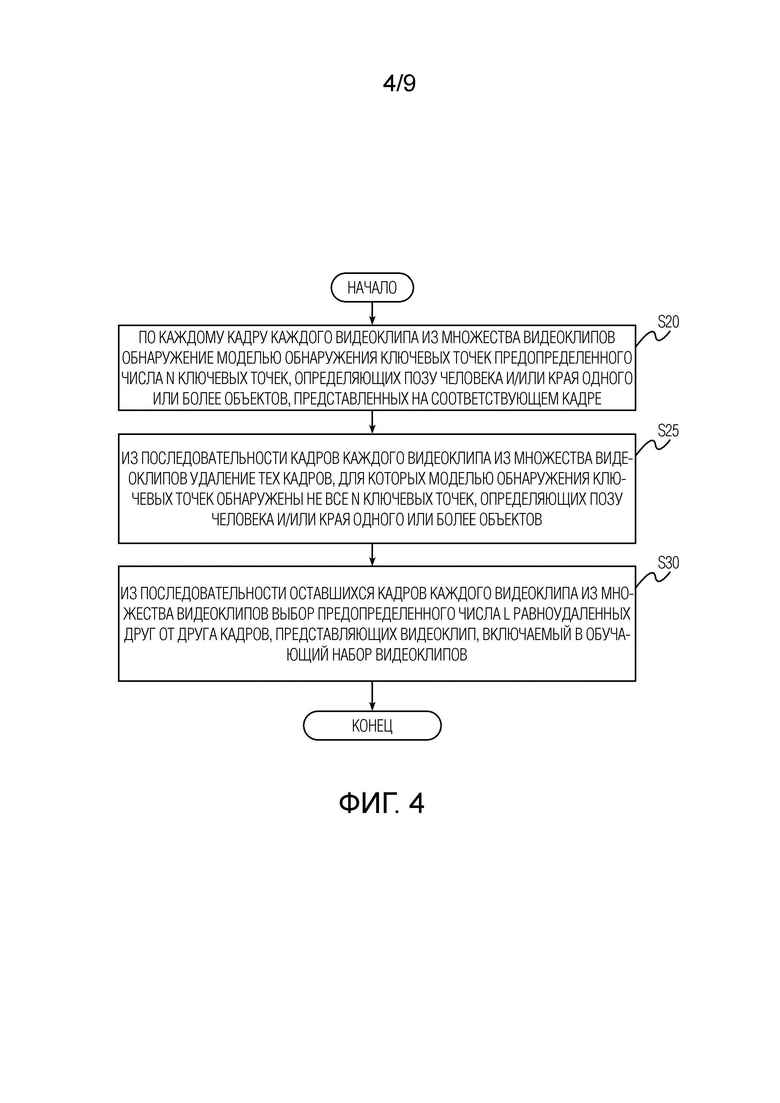
[0016] Согласно развитию первого аспекта настоящего изобретения формирование обучающего набора видеоклипов содержит этапы, на которых: по каждому кадру каждого видеоклипа из множества видеоклипов обнаруживают моделью обнаружения ключевых точек предопределенное число N ключевых точек, определяющих позу человека и/или края одного или более объектов, представленных на соответствующем кадре; из последовательности кадров каждого видеоклипа из множества видеоклипов удаляют те кадры, для которых моделью обнаружения ключевых точек обнаружены не все N ключевых точек, определяющих позу человека и/или края одного или более объектов; и из последовательности оставшихся кадров каждого видеоклипа из множества видеоклипов выбирают предопределенное число L равноудаленных друг от друга кадров, представляющих видеоклип, включаемый в обучающий набор видеоклипов.
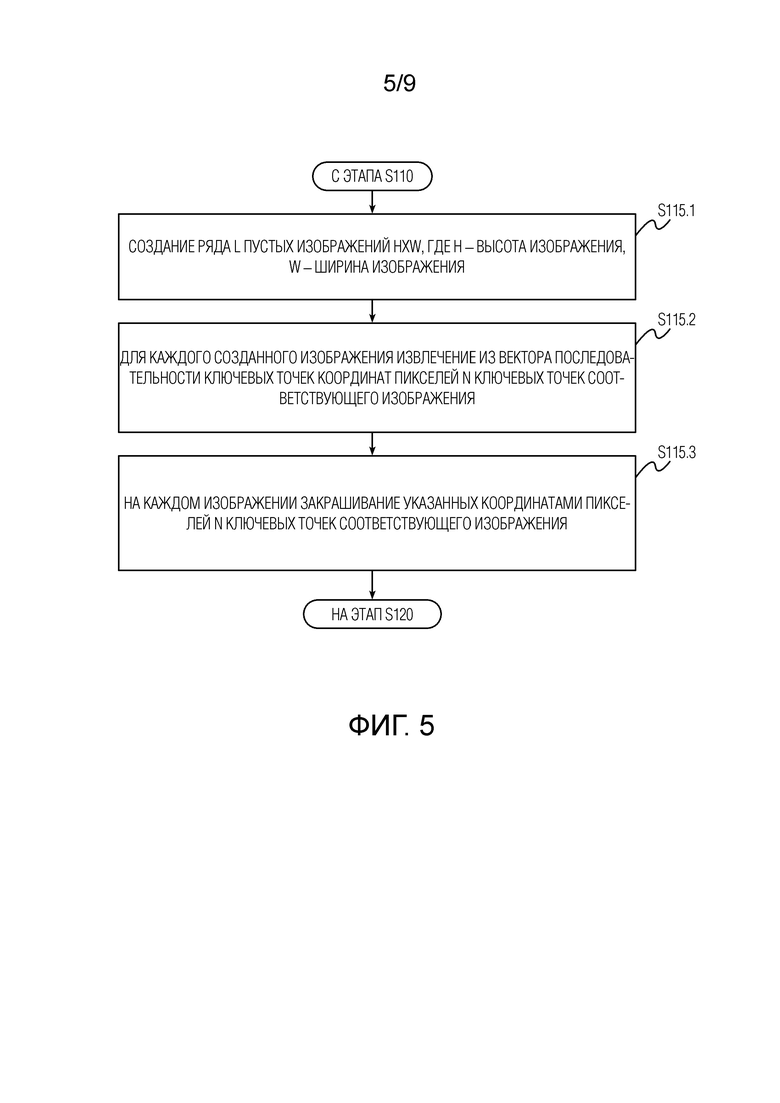
[0017] Согласно развитию первого аспекта настоящего изобретения отображение векторного представления последовательности ключевых точек генерируемого видеоклипа в ряд L двумерных изображений ключевых точек включает этапы, на которых: создают ряд L пустых изображений HxW, где H - высота изображения, W - ширина изображения; для каждого созданного изображения извлекают из векторного представления последовательности ключевых точек координаты пикселей N ключевых точек соответствующего изображения; на каждом изображении закрашивают указанные координатами пиксели N ключевых точек соответствующего изображения.
[0018] Согласно развитию первого аспекта настоящего изобретения способ дополнительно содержит обработку L двумерных изображений ключевых точек видеоклипа скользящей средней с размером окна, равным n двумерных изображений ключевых точек видеоклипа, при этом n < L. Согласно развитию первого аспекта настоящего изобретения векторное представление текстового описания, получаемое согласно векторному пространству предобученной нейросетевой модели увязывания изображений и текстовых описаний, содержит векторное представление, кодирующее принятое текстовое описание всего видеоклипа, и последовательность векторных представлений, дополнительно генерируемых предобученной нейросетевой моделью увязывания изображений и текстовых описаний, причем каждое векторное представление из упомянутой последовательности кодирует вероятное текстовое описание соответствующего кадра видеоклипа.
[0019] Во втором аспекте настоящего изобретения предусмотрено пользовательское электронное устройство, выполненное с возможностью генерирования видеоклипа по текстовому описанию, причем устройство содержит процессор и память, в которой хранятся исполняемые компьютером инструкции, которые при выполнении процессором заставляют устройство выполнять способ по первому аспекту настоящего изобретения или по любому развитию первого аспекта настоящего изобретения.
[0020] В третьем аспекте настоящего изобретения предусмотрен долговременный (non-transitory) машиночитаемый носитель, хранящий исполняемые компьютером инструкции, которые при исполнении устройством побуждают устройство выполнять способ по первому аспекту настоящего изобретения или по любому развитию первого аспекта настоящего изобретения.
[0021] Технические решения согласно приведенным выше аспектам настоящего изобретения обеспечивают возможность синтезирования, по текстовому описанию, видеоклипа без использования на стадии вывода реальных референсных видеоклипов. Кроме того, видеоклипы или их отдельные кадры, или последовательности ключевых точек, синтезируемые согласно раскрытым здесь техническим решениям, сами могут использоваться в качестве обучающих данных для других нейросетевых моделей, основанных на машинном обучении. Кроме того, достаточно высокое качество генерируемых видеоклипов обеспечивается за счет применения именно диффузионных моделей как для синтеза последовательности ключевых точек, так и для генерирования конечного видеоклипа на основе синтезированной последовательности его ключевых точек, соответствующей пользовательскому запросу.
Краткое описание чертежей
[0022] Эти и другие аспекты настоящего изобретения будут подробно описаны далее со ссылками на прилагаемые чертежи, на которых:
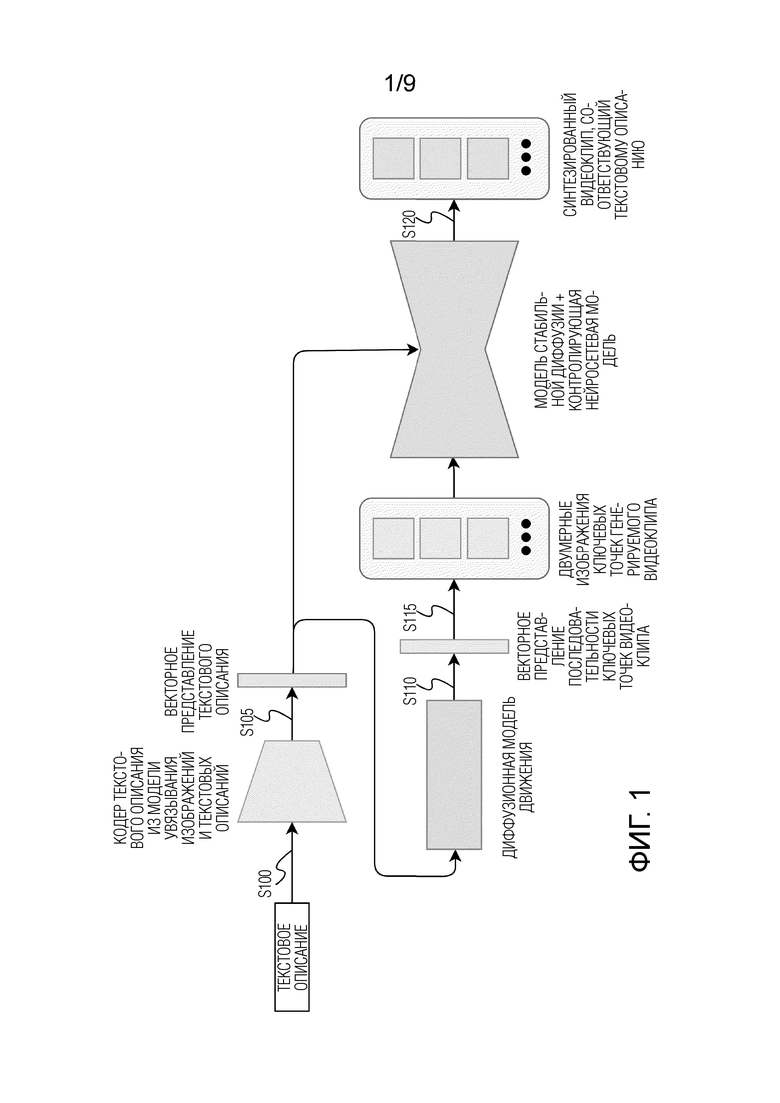
[ФИГ. 1] Фиг. 1 иллюстрирует схематичное представление последовательности операций генерирования видеоклипа по текстовому описанию и основные компоненты системы генерирования видеоклипа по текстовому описанию, которыми выполняются упомянутые операции.
[ФИГ. 2] Фиг. 2 иллюстрирует процесс диффузии диффузионной модели движения согласно варианту осуществления настоящего изобретения.
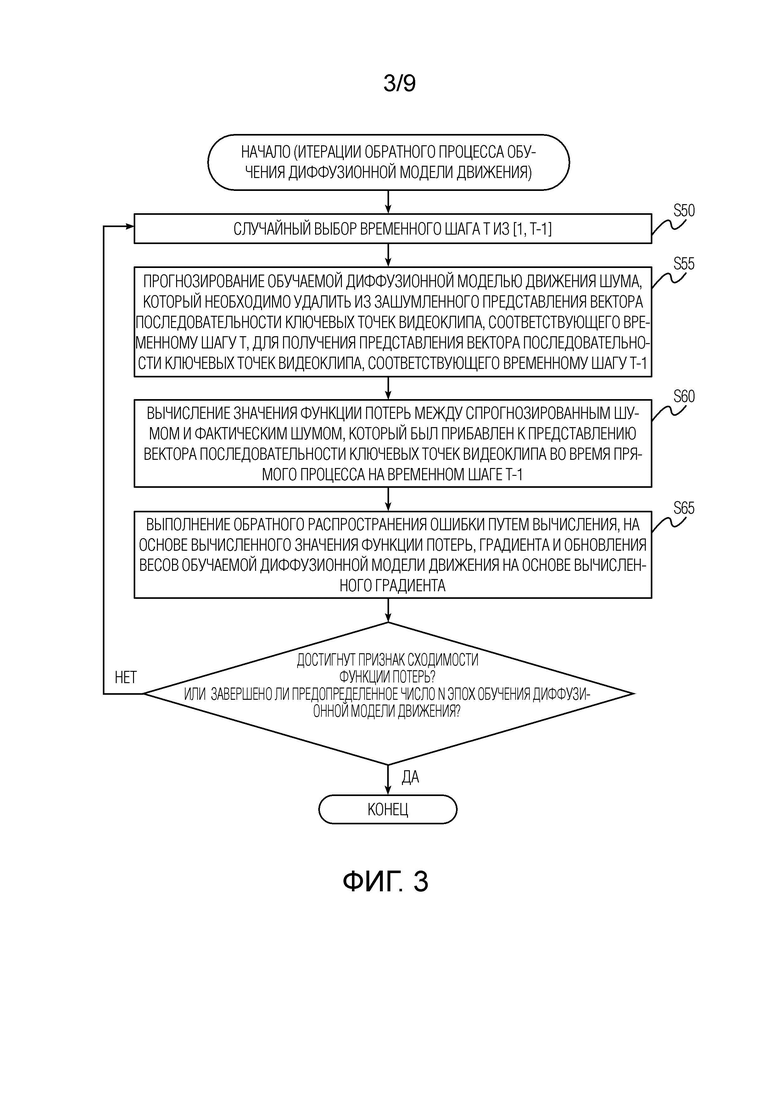
[ФИГ. 3] Фиг. 3 иллюстрирует последовательность операций, выполняемых во время обратного процесса при обучении диффузионной модели движения согласно варианту осуществления настоящего изобретения.
[ФИГ. 4] Фиг. 4 иллюстрирует неограничивающую реализацию последовательности операций формирования обучающих данных, используемых при обучении диффузионной модели движения, согласно варианту осуществления настоящего изобретения.
[ФИГ. 5] Фиг. 5 иллюстрирует неограничивающую реализацию последовательности операций отображения векторного представления последовательности ключевых точек видеоклипа в ряд двумерных изображений ключевых точек видеоклипа.
[ФИГ. 6] Фиг. 6 иллюстрирует неограничивающий пример ряда двумерных изображений 01-16 ключевых точек видеоклипа, полученного операцией отображения, схематично представленной на Фиг. 5.
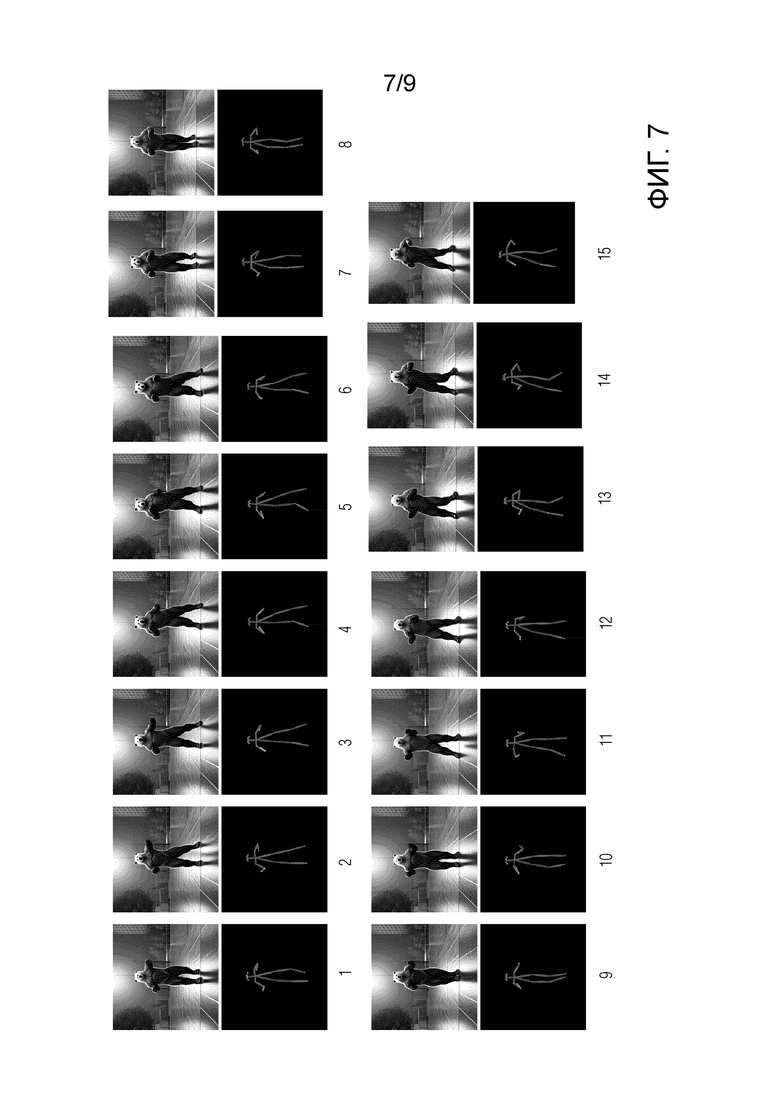
[ФИГ. 7] Фиг. 7 иллюстрирует неограничивающий пример другого ряда двумерных изображений 01-15 ключевых точек видеоклипа, причем каждое двумерное изображение ключевых точек видеоклипа (нижняя часть каждой картинки) представлено на этой фигуре в паре с соответствующим кадром видеоклипа (верхняя часть каждой картинки), сгенерированным моделью стабильной диффузии под контролем контролирующей нейросетевой модели.
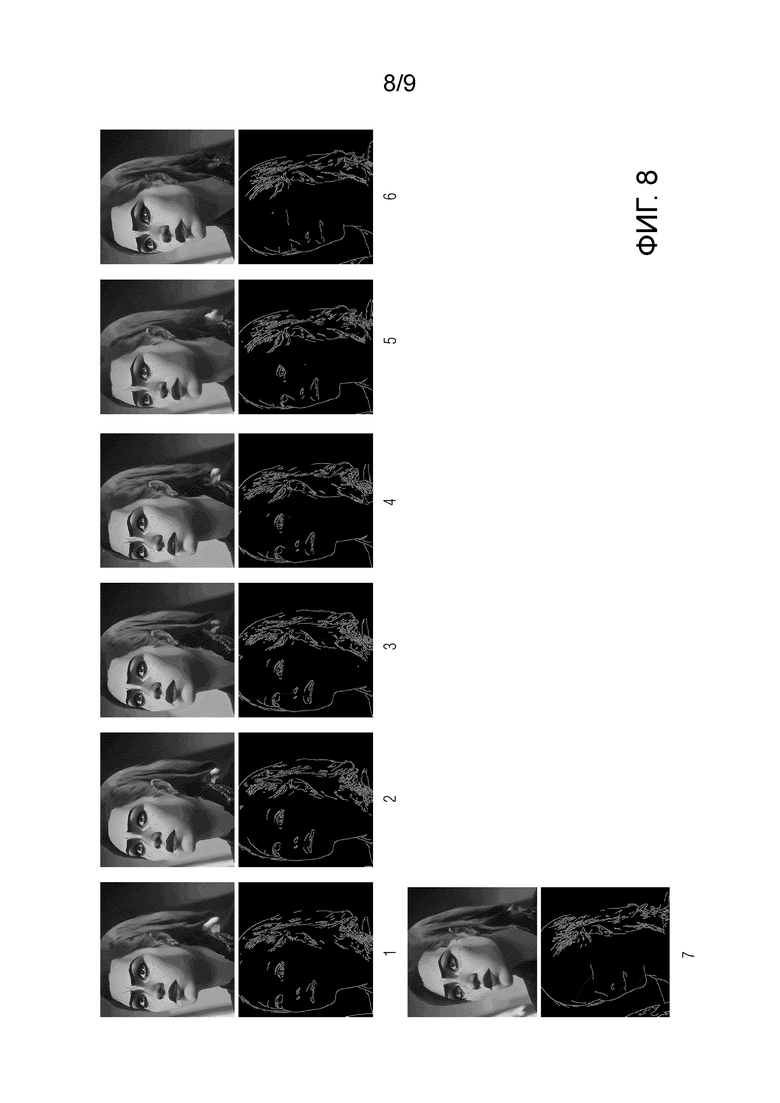
[ФИГ. 8] Фиг. 8 иллюстрирует неограничивающий пример другого ряда двумерных изображений 01-07 ключевых точек видеоклипа, причем каждое двумерное изображение ключевых точек видеоклипа (нижняя часть каждой картинки) представлено на этой фигуре в паре с соответствующим кадром видеоклипа (верхняя часть каждой картинки), сгенерированным моделью стабильной диффузии под контролем контролирующей нейросетевой модели.
[ФИГ. 9] Фиг. 9 иллюстрирует схематичное представление электронного устройства, выполненного с возможностью реализации способа по первому аспекту настоящего изобретения или по любому развитию первого аспекта настоящего изобретения, согласно варианту осуществления настоящего изобретения.
Подробное описание
[0023] Сначала со ссылкой на Фиг. 1 подробно опишем общую последовательность операций способа и соответствующие компоненты системы, которые эти операции реализуют. Способ начинается с этапа S100, на котором получают текстовое описание видеоклипа, подлежащего генерированию. Никакие ограничения на длину текстового описания, содержимое текстового описания или язык текстового описания не накладываются при условии, что нейросетевая модель увязывания изображений и текстовых описаний, используемая на следующем этапе S105, была предварительно обучена для поддержки таких длины, содержимого и языка вводимого текстового описания. Неограничивающими примерами текстовых описаний являются “девушка громко смеется”, “bear is dancing” и т.д. Текстовое описание представляет собой текст, который словами описывает видеоклип (например, его содержимое, характер, динамику, сцену и т.д.), который подлежит генерированию. Вместо термина “текстовое описание” могут использоваться эквивалентные термины, например, “текстовая подсказка”, “подсказка”, “промпт” и им подобные. Можно сказать, что текстовое описание служит в раскрытых здесь технических решениях отправной точкой или, выражаясь иначе, условием для генерирования видеоклипа. Под термином “векторное представление” здесь понимается тензор или вектор признаков, который в некоторых источниках могут называть “эмбеддингом”. Часть нейросетевой модели (например, входной слой) или отдельная нейросетевая модель может использоваться для извлечения из входных необработанных данных таких векторных представлений. Термины “генерирование” и “синтез” могут использоваться здесь взаимозаменяемо.
[0024] Текстовое описание видеоклипа, который следует сгенерировать, может вводиться пользователем через любое доступное на пользовательском электронном устройстве средство ввода/вывода (например, но без ограничения, клавиатуру, микрофон, сенсорный экран, мышь и т. д.). Альтернативно, текстовое описание видеоклипа, который следует сгенерировать, может приниматься из любого источника текстовых описаний, имеющегося на пользовательском электронном устройстве (например, из приложения), а сгенерированный видеоклип может передаваться обратно упомянутому источнику для его последующего использования (например, отображения, обработки и т. д.) упомянутым источником.
[0025] После выполнения этапа S100 способ переходит к выполнению этапа S105, на котором получают векторное представление текстового описания согласно векторному пространству предобученной нейросетевой модели увязывания изображений и текстовых описаний на основе принятого текстового описания видеоклипа. Для этого текстовое описание видеоклипа, подлежащего генерированию, пропускают через кодер текстовых описаний предобученной нейросетевой модели увязывания изображений и текстовых описаний. На выходе кодер обеспечивает векторное представление текстового описания, полученное согласно векторному пространству предобученной нейросетевой модели увязывания изображений и текстовых описаний и содержащее векторное представление, кодирующее текстовое описание всего видеоклипа (т.е. того, что принято на этапе S100), и (дополнительно) последовательность векторных представлений, каждое из которых кодирует текстовое описание соответствующего кадра видеоклипа. Неограничивающим примером модели увязывания изображений и текстовых описаний является модель CLIP (Contrastive Image-Language Pre-training), см. опубликованную в 2021г. статью “Learning Transferable Visual Models From Natural Language Supervision” за авторством Alec Radford и др.), или любая производная или по существу эквивалентная ей по функциональным возможностям нейросетевая модель, основанная на машинном обучении, например, но без ограничения упомянутыми, GLIP (Grounded Language-Image Pre-training), см. опубликованную в 2021г. статью “Grounded Language-Image Pre-training” за авторством Liunian Harold Li и др., или BLIP-2 (Bootstrapping Language-Image Pre-training), см. опубликованную 15 июня 2023г. статью “Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models” за авторством Junnan Li и др.
[0026] Нейросетевая модель увязывания изображений и текстовых описаний содержит упомянутый кодер текстовых описаний и кодер изображений. Кодер текстовых описаний кодирует текстовые описания в векторное пространство “текстовые описания-изображения”, а кодер изображений кодирует изображения в тоже самое векторное пространство “текстовые описания-изображения”. Благодаря кодированию изображений и соответствующих им текстовых описаний в одно векторное пространство обеспечивается увязывание признаков изображений с соответствующими им признаками текстовых описаний. Другими словами, таким образом модель обучается пониманию соответствий между различными зрительными образами из реального мира и соответствующими им текстовыми описаниями и наоборот. Кодер изображений может быть основан на архитектуре ResNet-50 или архитектуре визуальный трансформер с механизмом самовнимания. Кодер текстовых описаний может быть основан на архитектуре трансформер.
[0027] Нейросетевая модель увязывания изображений и текстовых описаний может быть обучена на парах (изображение, текстовое описание) согласно следующей неограничивающей реализации обучения. Изображением может быть любое изображение, в том числе любой кадр любого видеоклипа из обучающего множества видеоклипов, а соответствующее текстовое описание представляет собой текст, который словами описывает данный кадр (например, его содержимое, сцену и т.д.) или весь видеоклип (например, его содержимое, характер, динамику, сцену и т.д.), из которого данный кадр был выбран. Для пакета из K пар (изображение, текстовое описание), нейросетевую модель увязывания изображений и текстовых описаний обучают предсказывать, какие из K изображений × K текстовых описаний в пакете действительно образуют пары. Для этого CLIP изучает мультимодальное векторное пространство “текстовые описания-изображения” путем совместного обучения кодера изображений и кодера текстовых описаний с целью максимизации косинусного сходства векторных представлений текстовых описаний и изображений K реальных пар в пакете и одновременной с этим минимизации косинусного сходства векторных представлений K2 - K некорректных пар. Затем функцию симметричной кросс-энтропийной потери оптимизируют по этим показателям сходства.
[0028] После выполнения этапа S105 способ переходит к выполнению этапа S110, на котором обученной диффузионной моделью движения получают векторное представление 2xNxL последовательности ключевых точек генерируемого видеоклипа на основе векторного представления текстового описания, где 2 - число координат, первая координата указывает высоту H кадра, а вторая координата указывает ширину W кадра; N - число ключевых точек на каждом кадре; и L - число кадров в видео. Подаваемое на вход диффузионной модели движения векторное представление текстового описания служит в качестве условия синтеза векторного представления последовательности ключевых точек видеоклипа. Далее со ссылкой на Фиг. 2 и 3 будет подробно описана архитектура применяемой диффузионной модели движения, а также то, как и на каких данных эту диффузионную модель движения обучают.
[0029] В качестве обучающих данных для обучения диффузионной модели движения используют: обучающий набор видеоклипов, формируемый способом, который будет отдельно описан ниже со ссылкой на Фиг. 4; векторные представления текстовых описаний всех видеоклипов из упомянутого набора видеоклипов, причем каждому видеоклипу из упомянутого набора видеоклипов соответствует свое векторное представление текстового описания, которое могло быть получено кодером текстового описания обученной нейросетевой модели увязывания изображений и текстовых описаний на основе по меньшей мере одного кадра (например, первого кадра, последнего кадра или иного кадра, или их комбинации) соответствующего видеоклипа или на основе текстового описания, полученного в процессе ручной или автоматизированной разметки обучающих данных; и векторные представления последовательностей ключевых точек всех видеоклипов из упомянутого набора видеоклипов, причем каждому видеоклипу из упомянутого набора видеоклипов соответствует свое векторное представление последовательности ключевых точек, полученное обученной моделью обнаружения ключевых точек на основе всех кадров соответствующего видеоклипа. Для видеоклипа векторное представление последовательности ключевых точек хранит координаты пикселей одинакового числа ключевых точек для каждого кадра упомянутого видеоклипа, причем в разных видеоклипах, включаемых в обучающий набор видеоклипов, число кадров также будет одинаковым (и таким, которое было у обучающих видеоклипов, использованных при обучении модели), это достигается благодаря применению способа формирования обучающих данных, который будет описан ниже со ссылкой на Фиг. 4.
[0030] В качестве ключевых точек модель обнаружения ключевых точек обучают обнаруживать, для каждого кадра видеоклипа, ключевые точки, определяющие позу человека в данном кадре видеоклипа. Такие ключевые точки могут содержать, но без ограничения упомянутым, одну или более ключевых точек головы человека, одну или более ключевых точек корпуса человека, одну или более ключевых точек каждой верхней конечности человека, одну или более ключевых точек каждой нижней конечности человека (см. представления таких ключевых точек, проиллюстрированные на Фиг. 7 на черном фоне под соответствующим кадром генерируемого видеоклипа). Ключевые точки головы человека могут опционально содержать ключевые точки лица человека, определяющие эмоцию человека (см. представления таких ключевых точек для генерируемого видео на Фиг. 6). Неограничивающим примером модели обнаружения таких ключевых точек может быть модель OpenPose, описанная в опубликованной в 2018г. статье “OpenPose: Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields” за авторством Zhe Cao и др., или любая производная или по существу эквивалентная ей по функциональным возможностям нейросетевая модель, основанная на машинном обучении.
[0031] Модель обнаружения ключевых точек может быть основана на архитектуре многослойной сверточной нейронной сети (CNN) с двумя ветвями. Первую ветвь обучают предсказывать для кадра видеоклипа карты достоверности (confidence map) расположения различных частей тела одного или более людей на исходном кадре видеоклипа. Вторую ветвь обучают предсказывать для упомянутого кадра видеоклипа поля сходства фрагментов (part affinity fields, PAFs), которые представляют степень связи между различными частями тела одного или более людей на исходном кадре видеоклипа. Затем прогнозы из обеих ветвей и характеристики исходного кадра видеоклипа объединяются и используются для получения прогнозов ключевых точек, определяющих позу человека в кадре видеоклипа. Для обучения такой основанной на CNN модели обнаружения ключевых точек может, но без ограничения упомянутым, использоваться функция L2 потерь, вычисляемых между прогнозами карт достоверности и полей сходства фрагментов, получаемыми обучаемой моделью, и референсными (истинными) картами достоверности и полями сходства фрагментов. Затем вычисленное значение функции потерь может использоваться для вычисления градиентов и обновления на их основе весов обучаемой модели при выполнении обратного распространения ошибки. Неограничивающими примерами применимой здесь сети CNN являются VGG-16 или VGG-19.
[0032] Альтернативно, в качестве ключевых точек модель обнаружения ключевых точек обучают обнаруживать, для каждого кадра видеоклипа, ключевые точки, определяющие края одного или более объектов в данном кадре видеоклипа (см. представления таких ключевых точек для генерируемого видео на Фиг. 8). Кадры, на которых обнаруживаются ключевые точки не всех объектов, относительно других кадров (например, соседних по времени кадров) того же самого видеоклипа, могут исключаться из последовательности кадров. Для обнаружения ключевых точек в этой неограничивающей реализации может применяться оператор Кэнни, представляющий собой средство обнаружения границ объектов на изображении, или любое производное или по существу эквивалентное ему по функциональным возможностям средство, в том числе любая основанная на машинном обучении нейросетевая или регрессионная модель обнаружения границ объектов на изображении.
[0033] Вернемся к описанию диффузионной модели движения, которая применяется на этапе S110 для получения векторного представления последовательности ключевых точек генерируемого видеоклипа. Диффузионные модели представляют собой класс моделей, часто используемых при генеративном моделировании изображений. Согласно принятой формулировке устраняющие шум диффузионно-вероятностные модели (Denoising Diffusion Probabilistic Models, DDPM) представляют собой модели скрытых переменных вида 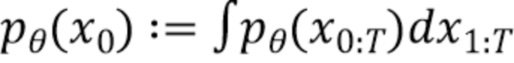 , где
, где 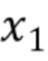 ,…,
,…,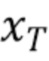 представляют собой скрытые переменные аналогичной размерности, что и данные
представляют собой скрытые переменные аналогичной размерности, что и данные 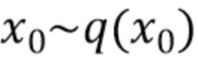 . Обучение диффузионной модели движения содержит прямой процесс (иначе называемый процессом диффузии) и обратный процесс (иначе называемый генеративным процессом), причем обучение выполняется итеративно до тех пор, пока не будет удовлетворено любое из следующих условий завершения обучения: достигнут признак сходимости функции потерь и/или завершено предопределенное число n эпох обучения диффузионной модели движения. Неограничивающим примером достижения признака сходимости функции потерь может являться то, что за некоторое предопределенное число последних эпох обучения абсолютная разница в значениях функции потерь изменяется меньше, чем на предопределенное пороговое значение (например, меньше, чем на 10-8). Кроме того, обучение может завершаться по прошествии предопределенного числа эпох, итераций или предопределенного времени.
. Обучение диффузионной модели движения содержит прямой процесс (иначе называемый процессом диффузии) и обратный процесс (иначе называемый генеративным процессом), причем обучение выполняется итеративно до тех пор, пока не будет удовлетворено любое из следующих условий завершения обучения: достигнут признак сходимости функции потерь и/или завершено предопределенное число n эпох обучения диффузионной модели движения. Неограничивающим примером достижения признака сходимости функции потерь может являться то, что за некоторое предопределенное число последних эпох обучения абсолютная разница в значениях функции потерь изменяется меньше, чем на предопределенное пороговое значение (например, меньше, чем на 10-8). Кроме того, обучение может завершаться по прошествии предопределенного числа эпох, итераций или предопределенного времени.
[0034] Прямой процесс представляет собой цепь Маркова с гауссовскими переходами, обычно определяемую как последовательность случайных событий с конечным или счетным числом исходов, где вероятность наступления каждого события зависит от состояния, достигнутого в предыдущем событии. В ходе основанного на цепи Маркова прямого процесса к данным добавляется гауссовский шум в соответствии с планом изменения данных (от англ. “variance schedule”) 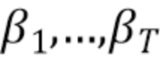 :
:
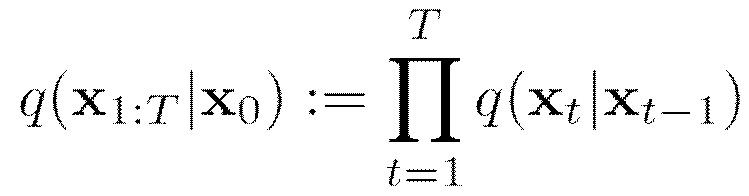 (мат. выражение 1),
(мат. выражение 1),
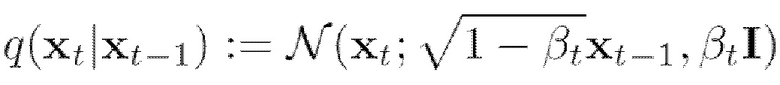 (мат. выражение 2),
(мат. выражение 2),
где
q представляет собой функцию перехода от зашумленного представления последовательности ключевых точек на временном шаге t, к менее зашумленному представлению последовательности ключевых точек на шаге t-1,
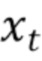 представляет собой представление последовательности ключевых точек на временном шаге t,
представляет собой представление последовательности ключевых точек на временном шаге t,
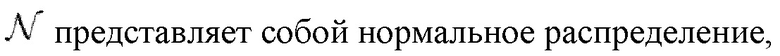
I представляет собой единичную матрицу.
[0035] Выборка для произвольного временного шага t (т.е. для процесса диффузии: для t=0 будет представлять собой незашумленное векторное представление последовательности ключевых точек из обучающих данных, а для t>0 представляет собой зашумленное векторное представление последовательности ключевых точек из обучающих данных; в общем случае x является представлением изображения последовательности ключевых точек в форме тензора) во время прямого процесса может быть сделана согласно следующему мат. выражению 3, представленному в аналитической форме:
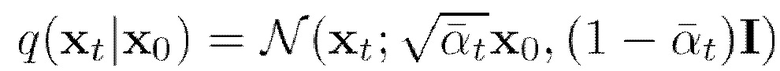 (мат. выражение 3),
(мат. выражение 3),
 представляет собой степень зашумленности (т.е. долю шума в представлении последовательности ключевых точек) и определяется как:
представляет собой степень зашумленности (т.е. долю шума в представлении последовательности ключевых точек) и определяется как:
 (мат. выражение 4),
(мат. выражение 4),
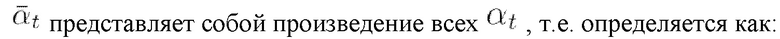
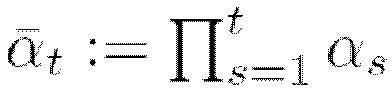 (мат. выражение 5).
(мат. выражение 5).
[0036] Таким образом, во время прямого процесса последовательно выполняют T временных шагов диффузии, на каждом из которых к векторному представлению последовательности ключевых точек случайного видеоклипа из обучающих данных добавляют гауссовский шум, для получения зашумленных векторных представлений последовательности ключевых точек упомянутого видеоклипа в числе T. Другими словами, прямой процесс диффузии обеспечивает зашумление векторного представления последовательности ключевых точек. Т.е. не используя модель делают T шагов интерполяции от векторного представления последовательности ключевых точек к шуму ~N(0, 1). Таким образом, векторное представление последовательности ключевых точек на временном шаге t, который выбирается из диапазона временных шагов [0, T-1], представляет собой смесь незашумленного (исходного) векторного представления последовательности ключевых точек и векторного представления случайного шума для данного временного шага t (согласно плану изменения данных) и определяется следующим образом:
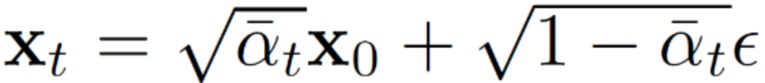 (мат. выражение 6),
(мат. выражение 6),
где ∈ представляет собой случайный (добавляемый) шум.
[0037] Обратный процесс представляет собой совместное распределение 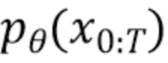 , также определяемое как цепь Маркова с выучиваемыми гауссовскими переходами между зашумленными векторными представлениями последовательности ключевых точек и менее зашумленными (вплоть до полностью обесшумленного) векторными представлениями последовательности ключевых точек, начинающуюся с
, также определяемое как цепь Маркова с выучиваемыми гауссовскими переходами между зашумленными векторными представлениями последовательности ключевых точек и менее зашумленными (вплоть до полностью обесшумленного) векторными представлениями последовательности ключевых точек, начинающуюся с 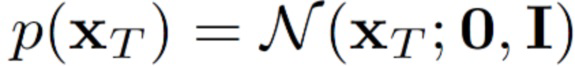 :
:
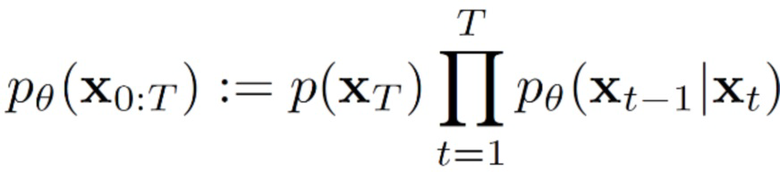 (мат. выражение 7)
(мат. выражение 7)
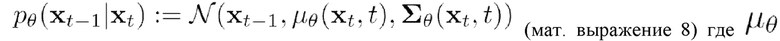 представляет собой математическое ожидание нормального распределения. Обучение в ходе обратного процесса эквивалентно обучению устранению шума из зашумленного векторного представления последовательности ключевых точек
представляет собой математическое ожидание нормального распределения. Обучение в ходе обратного процесса эквивалентно обучению устранению шума из зашумленного векторного представления последовательности ключевых точек 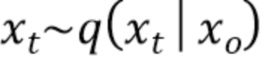 для получения оценки
для получения оценки 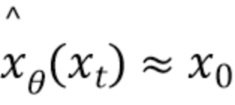 для всех временных шагов, причем этой оценкой в данном случае является представление последовательности ключевых точек, из которого удалили спрогнозированный шум.
для всех временных шагов, причем этой оценкой в данном случае является представление последовательности ключевых точек, из которого удалили спрогнозированный шум.
[0038] Один проход обратного процесса обучения диффузионной модели движения проиллюстрирован на Фиг. 3. Сначала на этапе S50 случайным образом выбирают из [1, T-1] временной шаг t. Затем на этапе S55 прогнозируют обучаемой диффузионной моделью движения шум, который необходимо удалить из зашумленного векторного представления последовательности ключевых точек видеоклипа, соответствующего временному шагу t, для получения векторного представления последовательности ключевых точек видеоклипа, соответствующего временному шагу t-1. После этого на этапе S60 вычисляют значение функции потерь между спрогнозированным шумом и фактическим шумом, который был прибавлен к векторному представлению последовательности ключевых точек видеоклипа во время прямого процесса на временном шаге t-1, и на этапе S65 выполняют обратное распространение ошибки путем вычисления, на основе вычисленного значения функции потерь, градиента и обновления весов обучаемой диффузионной модели движения на основе вычисленного градиента.
[0039] На этапе S60 значение функции потерь вычисляется как среднеквадратичная ошибка (MSE) между спрогнозированным шумом и шумом, фактически прибавленным к представлению ключевых точек видеоклипа на соответствующем временном шаге прямого процесса. Другими словами, обучаемая диффузионная модель движения оптимизируется путем минимизации среднеквадратической ошибки прогнозирования шума согласно 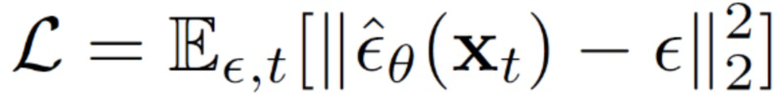 (мат. выражение 9) по временным шагам t, равномерно выбираемым из [1,…,T], при этом определяется согласно мат. выражению 6 и
(мат. выражение 9) по временным шагам t, равномерно выбираемым из [1,…,T], при этом определяется согласно мат. выражению 6 и 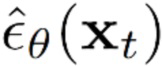 представляет собой оценку добавленного шума ∈, получаемую обучаемой диффузионной моделью движения.
представляет собой оценку добавленного шума ∈, получаемую обучаемой диффузионной моделью движения.
[0040] Обученную диффузионную модель движения используют (на стадии использования, также упоминаемой в некоторых источниках как стадия инференса) для получения на этапе S110 векторного представления 2xNxL последовательности ключевых точек генерируемого видеоклипа согласно итеративной процедуре DDPM (устранения шума), определяемой следующим образом:
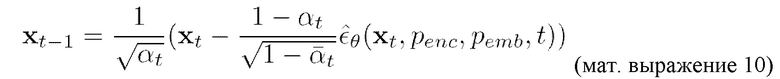
 представляет собой обученную диффузионную модель движения с параметрами (весами) θ,
представляет собой обученную диффузионную модель движения с параметрами (весами) θ,
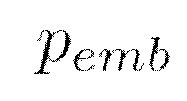 представляет собой векторное представление, кодирующее текстовое описание всего видеоклипа согласно векторному пространству предобученной нейросетевой модели увязывания изображений и текстовых описаний,
представляет собой векторное представление, кодирующее текстовое описание всего видеоклипа согласно векторному пространству предобученной нейросетевой модели увязывания изображений и текстовых описаний,
 представляет собой последовательность векторных представлений, каждое из которых кодирует текстовое описание соответствующего кадра видеоклипа согласно векторному пространству предобученной нейросетевой модели увязывания изображений и текстовых описаний, и
представляет собой последовательность векторных представлений, каждое из которых кодирует текстовое описание соответствующего кадра видеоклипа согласно векторному пространству предобученной нейросетевой модели увязывания изображений и текстовых описаний, и
представляет собой зашумленное векторное представление последовательности ключевых точек.
[0041] Для получения на этапе S110 векторного представления последовательности ключевых точек итеративным образом выполняют согласно мат. выражению 10 устранение шума, начиная с временного шага t=T=[предопределенное значение (например, но без ограничения упомянутым значением, 1000)], и до тех пор, пока не будет достигнут временной шаг t=0. Векторное представление, получаемое согласно этой итеративной процедуре на временном шаге t=0, является векторным представлением 2xNxL последовательности ключевых точек генерируемого видеоклипа, получаемым на этапе S110.
[0042] Как схематично показано на Фиг. 2 диффузионная модель движения основана на архитектуре трансформер с механизмом самовнимания. В качестве модели шумоподавления в процессе диффузии для генерирования векторного представления последовательности ключевых точек видеоклипа используется трансформер с декодером, использующимся для предсказания следующего токена во входной последовательности. Как показано на Фиг. 2, входные данные модели содержат: вектор-энкодинг текстового описания всего видеоклипа, последовательность векторов-энкодингов текстовых описаний кадров видеоклипов, векторное представление временного шага диффузии, зашумленное векторное представление последовательности ключевых точек видеоклипа и выученные запросы (queries), которые представляют собой окончательную последовательность получаемых обучением векторов, которая позволяет трансформеру понять то, какую информацию необходимо извлекать из входной последовательности, чтобы для каждого кадра и для соответствующего временного шага t предсказывать вектор с шумом, который необходимо вычитать из представления последовательности ключевых точек для получения менее зашумленного (и в конечном итоге - чистого, синтезированного) представления последовательности ключевых точек.
[0043] Вывод проиллюстрированной диффузионной модели движения, основанной на архитектуре трансформер с механизмом самовнимания, а именно вектор последовательности синтезированных ключевых точек видеоклипа, используется на этапе S115 для получения ряда двумерных изображений ключевых точек генерируемого видеоклипа, каждое из которых соответствует соответствующему кадру генерируемого видеоклипа. Все вводимые данные, представленные в векторной форме, проецируются в одну и ту же размерность (f)=512 с использованием обучаемых линейных слоев, обеспечивающих линейное преобразование над входными данными, а затем конкатенируются в одно векторное представление последовательности длиной L+2+N+N, где L - число кадров в видео, N - число ключевых точек на каждом кадре. Это векторное представление входной последовательности данных далее обрабатывается моделью трансформера, которая выводит последовательность, имеющую ту же форму, что и входная последовательность ((L+2+N+N) × размерность), последние N × размерность (которая может равняться 2xL) векторов в векторном представлении выходной последовательности соответствуют синтезированному векторному представлению 2xNxL последовательности ключевых точек. Эти 2xNxL последних векторов впоследствии дополнительно проецируются в предопределенную размерность ключевых точек посредством обученного линейного слоя проецирования выходных данных. В результате предлагаемая здесь архитектура трансформера имеет следующие обучаемые части: сам трансформер, линейные слои проецирования входных данных, линейный слой проецирования выходных данных, последовательность получаемых обучением векторов. Все эти элементы обучаются сквозным образом с помощью функции потерь MSE, определяемой согласно мат. выражению 9 выше.
[0044] Декодер проиллюстрированного на Фиг. 2 трансформера содержит предопределенное число M последовательных блоков, каждый из которых содержит компонент многомерного самовнимания (MHSA) и компонент многослойного перцептрона (MLP). В неограничивающем примере реализации M=12. Механизм самовнимания был предложен вместе с первой архитектурой трансформера в опубликованной в 2017г. статье “Attention Is All You Need” за авторством Ashish Vaswani и др. Ключевой особенностью этого механизма является то, что признаки более высоких уровней аккумулируют информацию из всех элементов последовательности более низкого уровня признаков. Работа однофокусного самовнимания определяется следующим образом:
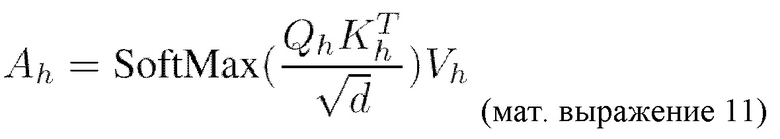
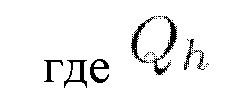 представляет собой матрицу запросов (Query) и вычисляется как
представляет собой матрицу запросов (Query) и вычисляется как 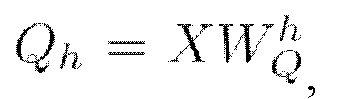 (мат. выражение 12), где X является представлением входной последовательности,
(мат. выражение 12), где X является представлением входной последовательности,  представляет собой получаемую обучением матрицу весов запросов,
представляет собой получаемую обучением матрицу весов запросов,
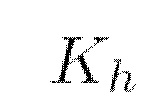 представляет собой матрицу ключей (Keys) и вычисляется как
представляет собой матрицу ключей (Keys) и вычисляется как 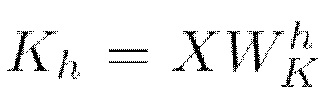 (мат. выражение 13), где X является представлением входной последовательности,
(мат. выражение 13), где X является представлением входной последовательности, 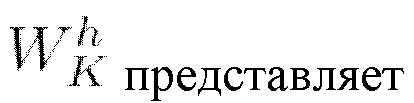 собой получаемую обучением матрицу весов ключей,
собой получаемую обучением матрицу весов ключей,
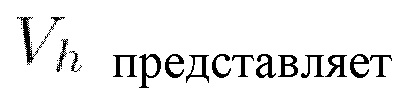 собой матрицу значений (Value) и вычисляется как
собой матрицу значений (Value) и вычисляется как 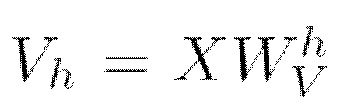 (мат. выражение 14), где X является представлением входной последовательности,
(мат. выражение 14), где X является представлением входной последовательности, 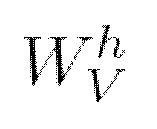 представляет собой получаемую обучением матрицу весов значений,
представляет собой получаемую обучением матрицу весов значений,
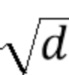 представляет собой нормировочную константу, определяемую как квадратный корень из размерности ключей и значений.
представляет собой нормировочную константу, определяемую как квадратный корень из размерности ключей и значений.
[0045] При перемножении представления xi каждого элемента входной последовательности на 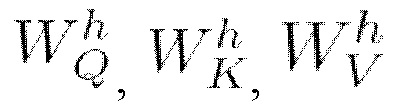 получают вектор-строки qi, ki, vi, где i представляет собой номер элемента, которые называются, соответственно запросами, ключами и значениями. Их роли можно условно описать следующим образом: qi - запрос к базе данных; ki - ключи хранящихся в базе значений, по которым будет осуществляться поиск; vi - сами значения. Таким образом матрицы
получают вектор-строки qi, ki, vi, где i представляет собой номер элемента, которые называются, соответственно запросами, ключами и значениями. Их роли можно условно описать следующим образом: qi - запрос к базе данных; ki - ключи хранящихся в базе значений, по которым будет осуществляться поиск; vi - сами значения. Таким образом матрицы 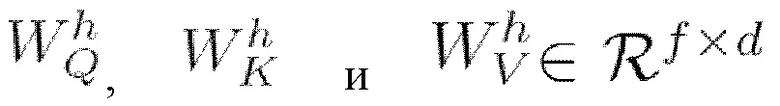 проецируют входную последовательность
проецируют входную последовательность 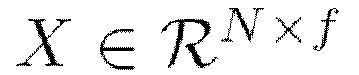 в выходной тензор с размерностью d, с длиной последовательности N и изначальной размерностью векторного представления элемента последовательности f=512. Другими словами, после применения матриц
в выходной тензор с размерностью d, с длиной последовательности N и изначальной размерностью векторного представления элемента последовательности f=512. Другими словами, после применения матриц 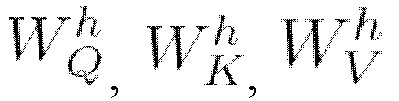 к входной последовательности X получают три последовательности длины N с пониженной размерностью d (f является изначальной размерностью векторов в последовательности). Матрица внимания, определяемая в мат. выражении 11 как
к входной последовательности X получают три последовательности длины N с пониженной размерностью d (f является изначальной размерностью векторов в последовательности). Матрица внимания, определяемая в мат. выражении 11 как 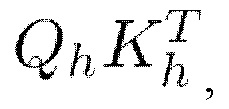 отвечает за выучивание оценок соответствия между токенами в последовательности. Согласно вышеупомянутому близость запроса qi к ключу ki может определяться как скалярное произведение между каждым элементом/токеном в матрице запросов
отвечает за выучивание оценок соответствия между токенами в последовательности. Согласно вышеупомянутому близость запроса qi к ключу ki может определяться как скалярное произведение между каждым элементом/токеном в матрице запросов 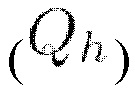 и каждым элементом/токеном в матрице ключей
и каждым элементом/токеном в матрице ключей 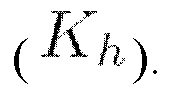 Работа однофокусного самовнимания приводит в результате к процессу автономного определения соответствий, посредством которого токены входной последовательности выучиваются аккумулировать информацию друг из друга.
Работа однофокусного самовнимания приводит в результате к процессу автономного определения соответствий, посредством которого токены входной последовательности выучиваются аккумулировать информацию друг из друга.
[0046] Самовнимание часто используется в режиме многомерного внимания (т.е. с множеством фокусов внимания, также упоминаемых в некоторых источниках как “головы внимания”). Использование такого режима улучшает возможность модели фокусироваться на разных позициях обрабатываемой последовательности и обеспечивает множество “репрезентативных подпространств” для слоя внимания. В этом сценарии проиллюстрированная на Фиг. 2 архитектура трансформера может использовать, но без ограничения упомянутым, H=8 параллельных фокусов внимания с независимыми матрицами 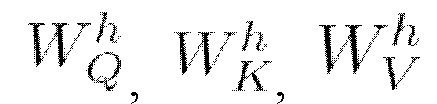 весов. Выходные данные фокусов внимания затем конкатенируются и умножаются на матрицу
весов. Выходные данные фокусов внимания затем конкатенируются и умножаются на матрицу 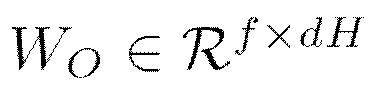 весов, которая отображает конкатенированные выходные данные для их соответствия выходной форме согласно следующему:
весов, которая отображает конкатенированные выходные данные для их соответствия выходной форме согласно следующему:
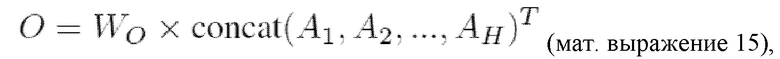
где AH представляет собой выходные данные соответствующего фокуса H внимания. Другими словами, Wo представляет собой обучаемую матрицу весов, отвечающую за проецирование полученных данных в размерность выходной последовательности, т.е. из d в f.
[0047] В дополнение к подслоям внимания каждый из слоев декодера трансформера содержит полносвязную сеть прямого распространения (MLP), которая одинаковым образом применяется к каждому токену (т.е. r вектору в последовательности) по отдельности. Эта MLP содержит два компонента линейного преобразования с компонентом GELU (Gaussian Error Linear Unit)-активации между ними. Такая MLP расширяет размерность токенов f=512 до размерности fh=2048, применяет к ней вводимую посредством GELU нелинейность и проецирует fh обратно в f:
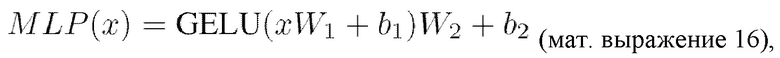
где W1, b1, W2, b2 представляют собой параметры первого и второго линейного слоя, соответственно.
[0048] Целью данной манипуляции, выполняемой посредством MLP, является захват высокоуровневых особенностей в признаковой карте токенов. GELU-активацию в мат. выражении 16 следует рассматривать в качестве предпочтительной функции активации для MLP, но не следует ограничивать настоящее изобретение только этой функцией активации, поскольку в других вариантах осуществления могут применяться другие функции активации, например, ReLU (Rectified Linear Activation Unit) или ELU (Exponential Linear Unit).
[0049] Таким образом, описанная выше архитектура трансформер используется в настоящем изобретении не по назначению, поскольку в нее подается не упорядоченная последовательность [x0, x1, x2, x3], а неупорядоченный набор разных переменных 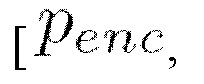
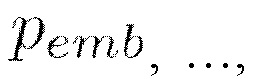 time_emb, noised_sequence, learned_queries], а механизм самовнимания по сути в каждый элемент на выходе записывает взвешенную сумму остальных элементов. В данном изобретении последний элемент последовательности на выходе трансформера является сгенерированным на этапе S110 векторным представлением последовательности ключевых точек. Получаемые обучением веса трансформера зависят от того, какой элемент был в последовательности на входе в трансформер. Т.е. learned_queries представляют собой последовательность обучаемых векторов (внизу слева на Фиг. 2), которая позволяет трансформеру понять, как правильно скомбинировать информацию из [
time_emb, noised_sequence, learned_queries], а механизм самовнимания по сути в каждый элемент на выходе записывает взвешенную сумму остальных элементов. В данном изобретении последний элемент последовательности на выходе трансформера является сгенерированным на этапе S110 векторным представлением последовательности ключевых точек. Получаемые обучением веса трансформера зависят от того, какой элемент был в последовательности на входе в трансформер. Т.е. learned_queries представляют собой последовательность обучаемых векторов (внизу слева на Фиг. 2), которая позволяет трансформеру понять, как правильно скомбинировать информацию из [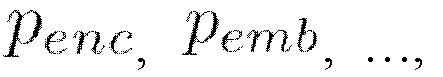 time_emb, noised_sequence, learned_queries], чтобы предсказать шум, который нужно вычесть из noised_sequence на временном шаге, соответствующем time_emb, чтобы синтезировать требуемое векторное представление последовательности ключевых точек.
time_emb, noised_sequence, learned_queries], чтобы предсказать шум, который нужно вычесть из noised_sequence на временном шаге, соответствующем time_emb, чтобы синтезировать требуемое векторное представление последовательности ключевых точек.
[0050] Кроме того, справедливо отметить, что показанное на Фиг. 2, применимо как для иллюстрации стадии обучения, так и для иллюстрации стадии использования. Другими словами, векторное представление текстового описания видеоклипа, представление ключевых точек которого в данный момент используют при обучении диффузионной модели движения, дополнительно подают на вход обучаемой диффузионной модели движения, с которой в данный момент выполняют обратный процесс, в качестве условия обучения диффузионной модели движения, учитываемого через вышеописанный механизм самовнимания. Аналогично, при использовании уже обученной диффузионной модели движения, векторное представление текстового описания видеоклипа, подлежащего генерированию, подают на этапе S110 на вход диффузионной модели движения в качестве условия получения векторного представления последовательности ключевых точек видеоклипа, подлежащего генерированию, которое учитывается через механизм самовнимания обученной диффузионной модели движения.
[0051] Вернемся к описанию Фиг. 1. после получения на этапе S110 включающего в себя  векторного представления текстового описания видеоклипа, подлежащего генерированию, способ переходит к выполнению этапа S115, на котором отображают векторное представление последовательности ключевых точек генерируемого видеоклипа в ряд L двумерных изображений ключевых точек генерируемого видеоклипа. Каждое двумерное изображение ключевых точек из упомянутого ряда соответствует соответствующему кадру генерируемого видеоклипа. Неограничивающие иллюстрации двумерных изображений ключевых точек, генерируемых на данном этапе, показаны на Фиг. 6, а также на Фиг. 7 и Фиг. 8, на которых такие двумерные изображения ключевых точек показаны на черном фоне под соответствующим кадром генерируемого видеоклипа. Выбор черного цвета для фона изображений ключевых точек не является ограничением, главное, чтобы на этих изображениях пиксели ключевых точек были выделены любым (желательно высококонтрастным образом) от всех остальных пикселей этих изображений. Таким образом, в другом неограничивающем примере в качестве фона может выступать белый цвет, а в качестве цвета для закрашивания пикселей ключевых точек может применяться черный цвет.
векторного представления текстового описания видеоклипа, подлежащего генерированию, способ переходит к выполнению этапа S115, на котором отображают векторное представление последовательности ключевых точек генерируемого видеоклипа в ряд L двумерных изображений ключевых точек генерируемого видеоклипа. Каждое двумерное изображение ключевых точек из упомянутого ряда соответствует соответствующему кадру генерируемого видеоклипа. Неограничивающие иллюстрации двумерных изображений ключевых точек, генерируемых на данном этапе, показаны на Фиг. 6, а также на Фиг. 7 и Фиг. 8, на которых такие двумерные изображения ключевых точек показаны на черном фоне под соответствующим кадром генерируемого видеоклипа. Выбор черного цвета для фона изображений ключевых точек не является ограничением, главное, чтобы на этих изображениях пиксели ключевых точек были выделены любым (желательно высококонтрастным образом) от всех остальных пикселей этих изображений. Таким образом, в другом неограничивающем примере в качестве фона может выступать белый цвет, а в качестве цвета для закрашивания пикселей ключевых точек может применяться черный цвет.
[0052] Неограничивающая реализация данного этапа S115 описана далее со ссылкой на Фиг. 5. Отображение S115 векторного представления последовательности ключевых точек генерируемого видеоклипа в ряд L двумерных изображений ключевых точек начинается с выполнения этапа S115.1, на котором создают ряд L пустых изображений HxW, где H - высота изображения, W - ширина изображения. Число L соответствует числу кадров генерируемого видеоклипа и числу кадров каждого видеоклипа в использованном обучающем наборе видеоклипов. Значения H и W соответственно соответствуют высоте и ширине каждого кадра генерируемого видеоклипа, а также высоте и ширине каждого кадра каждого видеоклипа в использованном обучающем наборе видеоклипов. Затем отображение S115 переходит к этапу S115.2, на котором для каждого созданного изображения из ряда L извлекают из представления последовательности ключевых точек координаты пикселей N ключевых точек соответствующего изображения. Согласно конфигурации модели обнаружения ключевых точек, которая применялась для сбора обучающих данных, или согласно самой структуре ключевых точек в обучающих данных, одна ключевая точка может быть представлена одним пикселем или, альтернативно, одна ключевая точка может быть представлена несколькими или даже множеством пикселей. Таким образом, это не следует интерпретировать в качестве ограничения настоящего изобретения. Наконец, после выполнения этапа S115.2 отображение S115 переходит к этапу S115.3, на котором на каждом изображении из ряда L изображений закрашивают указанные координатами пиксели N ключевых точек соответствующего изображения. При этом закрашивание само по себе здесь следует интерпретировать в широком смысле как выделение пикселей N ключевых точек (в том числе любое изменение значений цветности или интенсивности этих пикселей), указанных координатами, относительно всех других пикселей изображения.
[0053] Вернемся к описанию Фиг. 1. после отображения на этапе S115 векторного представления последовательности ключевых точек генерируемого видеоклипа в ряд L двумерных изображений ключевых точек генерируемого видеоклипа, способ переходит к этапу S120, на котором генерируют последовательность кадров видеоклипа с помощью предобученной модели стабильной диффузии. При этом генерирование каждого кадра видеоклипа моделью стабильной диффузии дополнительно контролируется контролирующей нейросетевой моделью на основе двумерного изображения ключевых точек соответствующего кадра из упомянутого ряда L двумерных изображений ключевых точек, полученного на предыдущем этапе S115. В неограничивающем примере реализации в качестве используемой на данном этапе модели стабильной диффузии может использоваться диффузионный генератор Stable Diffusion (SD), описанный в опубликованной в 2021г. статье “High-Resolution Image Synthesis with Latent Diffusion Models” за авторством Robin Rombach и др. или любой производный или по существу эквивалентный по функциональным возможностям диффузионный генератор. В качестве используемой на данном этапе контролирующей нейросетевой модели может использоваться модель ControlNet, описанная в опубликованной в 2023г. статье “Adding Conditional Control to Text-to-Image Diffusion Models” за авторством Lvmin Zhang и др. или любая производная или по существу эквивалентная по функциональным возможностям нейросетевая модель. Неограничивающие примеры генерируемых таким образом кадров показаны на Фиг. 7 и Фиг. 8, см. в частности соответствующие кадры, показанные на этих фигурах над соответствующими двумерными изображениями ключевых точек, которые выступали на этапе S120 в качестве учитываемых через контролирующую нейросетевую модель условий синтеза моделью стабильной диффузии соответствующих кадров видеоклипа.
[0054] Теперь перейдем к описанию Фиг. 4, на которой показана блок-схема последовательности операций процедуры формирования обучающего набора видеоклипов, используемых для обучения диффузионной модели движения, описанной выше со ссылками на Фиг. 2 и Фиг. 3. Формирование обучающего набора видеоклипов начинается с выполнения этапа S20, на котором по каждому кадру каждого видеоклипа из множества видеоклипов обнаруживают обученной моделью обнаружения ключевых точек предопределенное число N ключевых точек, определяющих позу человека и/или края одного или более объектов, представленных на соответствующем кадре. Поэте этого на этапе S25 из последовательности кадров каждого видеоклипа из множества видеоклипов удаляют те кадры, для которых моделью обнаружения ключевых точек обнаружены не все N ключевых точек, определяющих позу человека и/или края одного или более объектов. Этап S25 может быть реализован любым известным из уровня техники способом.
[0055] В качестве неограничивающего примера реализации данного этапа из последовательности кадров каждого видеоклипа из множества видеоклипов могут быть удалены те кадры, на которых число пикселей, представляющих ключевые точки, обнаруживаемые моделью обнаружения ключевых точек, отличается на предопределенную величину от числа пикселей, представляющих ключевые точки на уже обработанных моделью обнаружения ключевых точек кадрах. Данная реализация может использоваться тогда, когда в качестве модели обнаружения ключевых точек используется оператор Кэнни для обнаружения краев объектов на изображениях. В другом неограничивающем примере реализации данного этапа, если поза/размещение любого объекта (в том числе человека) на изображении должна, согласно предварительно конфигурации обученной модели обнаружения ключевых точек, определяться, например, предопределенным числом ключевых точек, например 16 ключевыми точками как показано на каждом двумерном изображении ключевых точек на Фиг. 7 для изображений танцующего медведя, тогда из последовательности кадров могут отбираться только те кадры, на которых все эти 16 ключевых точек этого объекта обнаружены, а те кадры, на которых обнаруживаются не все эти 16 ключевых точек объекта, могут удаляться из последовательности кадров.
[0056] Вернемся к описанию последовательности этапов по Фиг. 4. На последнем этапе S30 из последовательности оставшихся кадров каждого видеоклипа из множества видеоклипов выбирают предопределенное число L равноудаленных друг от друга кадров, представляющих видеоклип, включаемый в обучающий набор видеоклипов. Как уже указывалось выше, число L соответствует числу кадров генерируемого видеоклипа и числу кадров каждого видеоклипа в использованном обучающем наборе видеоклипов. Дополнительно, L двумерных изображений ключевых точек видеоклипа может быть дополнительно обработано экспоненциальной скользящей средней с размером окна, равным n двумерных изображений ключевых точек видеоклипа, при этом n < L. Вместо экспоненциальной скользящей средней может использоваться любой другой вид скользящей средней. Эта дополнительная обработка, применимая к стадии обучения диффузионной модели движения в рамках конвейера, показанного на Фиг. 1, или к стадии использования этого конвейера, позволяет избежать резких перемещений или рывков объектов на кадрах генерируемого видеоклипа.
[0057] Любые аспекты любой из нейросетевых моделей, описанных выше, могут осуществляться на практике с помощью библиотек для машинного обучения, таких как, например, но без ограничения упомянутым, Tensorflow, Pytorch, Keras. Обучение любой из нейросетевых моделей, описанных выше, может проводится онлайн, т.е. на том же самом устройстве, на котором обучаемая модель впоследствии используется, или офлайн, т.е. на другом устройстве (например, на компьютерном сервере, приспособленном для эффективного выполнения такого обучения). Кроме того, использование конвейера обученных нейросетевых моделей, подробно описанного выше и проиллюстрированного со ссылкой на Фиг. 1, также может выполняться онлайн, когда веса и параметры нейросетевых моделей загружаются и используются непосредственно на конечном пользовательском электронном устройстве, или офлайн, когда конечное пользовательское отправляет запрос (например, через приложение) в форме текстового описания видеоклипа, подлежащего генерированию, одному или нескольким компьютерным серверам, хранящим веса и другие параметры нейросетевых моделей, в том числе, опционально, последовательность полученных обучением векторов, а также исполняемые компьютером инструкции для исполнения этих нейросетевых моделей по требованию, а в ответ принимает сгенерированный видеоклип.
[0058] Таким образом, настоящее изобретение также предусматривает электронное устройство 400, схематично показанное на Фиг. 9, которым может быть любое из вышеупомянутого пользовательского электронного устройства или вышеупомянутого компьютерного сервера. Данное электронное устройство может быть выполнено с возможностью реализации любого из вышеописанных аспектов настоящего изобретения или их развитий. Электронное устройство содержит процессор 405 и память 410, в которой хранятся исполняемые компьютером инструкции, а также веса и параметры нейросетевых моделей предложенного здесь конвейера обработки, показанного на Фиг. 1. Когда электронным устройством 400 является пользовательское электронное устройство, этим пользовательским электронным устройством может быть, но без ограничения упомянутым, мобильный телефон, смартфон, планшет, ноутбук, персональный компьютер, носимое электронное устройство пользователя (например, очки, часы), AR/VR-гарнитура, устройство ‘интернета вещей’ (IoT), размещаемое в транспортном средстве оборудование или любое другое электронное устройство с поддержкой мобильной или иной связи. Пользовательское электронное устройство может называться иначе, например, как пользовательский терминал, устройство пользователя, абонентское устройство и т.д.
[0059] Электронное устройство 400 показано на Фиг. 9 в относительно упрощенном, схематичном виде, поэтому на этой фигуре показаны не все фактически содержащиеся в нем компоненты, а только те, благодаря которым настоящее изобретение может быть реализовано. Как известно электронное устройство может содержать другие не показанные на Фиг. 9 компоненты, например, блок питания, батарею, различные интерфейсы, средства ввода/вывода, модуль связи, различные межсоединения, а также любую подходящую для этого операционную систему (Windows, Linux, Android, iOS, HarmonyOS и т.д.), и т.д. Модуль связи может содержать связанные друг с другом приемопередатчик и антенну.
[0060] Процессор 405 электронного устройства UE 400 может представлять собой центральный процессор, специализированный процессор, другой блок обработки, например, блок графической обработки (GPU), нейронный процессор, или их комбинацию. Процессор 405 может быть реализован как микросхема, например, как FPGA, ASIC, SoC и т.д. Память 410 может включать в себя оперативную и постоянную память, хранящую исполняемые процессором инструкции, а также веса и параметры, в том числе, опционально, последовательность полученных обучением векторов, проиллюстрированных на Фиг. 1 нейросетевых моделей, используемых в настоящем изобретении для генерирования видеоклипов по текстовым описаниям.
[0061] Оперативная память может включать в себя оперативную память любого класса, например, но без ограничения упомянутой, FB DIMM (Fully Buffered DIMM), DDR SDRAM REG (Registered) ECC, DDR3 SDRAM, DDR2 SDRAM, DDR SDRAM, RDRAM (RIMM, Rambus), SRAM, ESDRAM, SDRAM, SO-DIMM, DIMM, SIMM. Постоянная память может включать в себя постоянную память любого класса, например, но без ограничения упомянутой, MROM, PROM, EPROM, EEPROM, EAROM. Постоянная память может реализовываться как, но без ограничения упомянутым, флэш-память, HDD, SSD.
[0062] Настоящее изобретение дополнительно предусматривает машиночитаемый носитель, хранящий исполняемые компьютером инструкции, а также веса и параметры в том числе, опционально, последовательность полученных обучением векторов, нейросетевых моделей предложенного здесь конвейера обработки, показанного на Фиг. 1. Упомянутые инструкции при исполнении устройством, оборудованным по меньшей мере процессором и памятью, побуждают это устройство генерировать видеоклип по текстовому описанию, который впоследствии может быть отображен на экране или передан для любых целей в любой другой источник как в самом устройстве, так и за пределами устройства, например по сети связи. Этот машиночитаемый носитель может представлять собой любой долговременный (non-transitory) машиночитаемый носитель, память, область памяти, запоминающее устройство и т. д, например, но без ограничения упомянутым, жесткий диск, оптический носитель, полупроводниковый носитель, твердотельный (SSD) накопитель или им подобные.
[0063] Раскрытые в настоящей заявке технические решения обеспечивают возможность синтезирования, по текстовому описанию, видеоклипа без использования на стадии вывода реальных референсных видеоклипов. Кроме того, раскрытые в настоящей заявке технические решения позволяют получать синтетические обучающие данные в виде сгенерированных видеоклипов, соответствующих требуемым текстовым описаниям, в любом требуемом объеме. Эти синтетические видеоклипы могут использоваться для обучения любых других нейросетевых моделей. При этом качество видеоклипов, генерируемых согласно настоящему раскрытию, не уступает качеству видеоклипов, генерируемых известными из уровня техники техническими решениями, которые используют на стадии вывода реальные референсные видео. Достаточно высокое качество генерируемых видеоклипов обеспечивается за счет применения именно диффузионных моделей как для синтеза последовательности ключевых точек, так и для генерирования конечного видеоклипа на основе синтезированной последовательности его ключевых точек, соответствующей пользовательскому запросу.
[0064] Специалисту в данной области техники может быть понятно, что различные иллюстративные логические блоки (функциональные блоки или модули) и этапы (операции), используемые в вариантах осуществления раскрытого технического решения, могут быть реализованы электронными аппаратными средствами, компьютерным программным обеспечением или их комбинацией. Реализуются ли функции с помощью аппаратного или программного обеспечения, зависит от конкретных приложений и требований к конструкции всей системы. Специалист в данной области техники может использовать различные способы реализации описанных функций для каждого конкретного применения, но не следует считать, что такая реализация будет выходить за рамки вариантов осуществления, раскрытых в данной заявке.
[0065] Также следует отметить, что порядок этапов любого раскрытого способа не является строгим, т.к. некоторые один или несколько этапов могут быть переставлены в фактическом порядке выполнения и/или объединены с другим одним или несколькими этапами, и/или разбиты на большее число подэтапов.
[0066] Во всех материалах настоящей заявки ссылка на элемент в единственном числе не исключает наличия множества таких элементов в фактической реализации изобретения, и, наоборот, ссылка на элемент во множественном числе не исключает наличия только одного такого элемента при фактическом осуществлении изобретения. Любое указанное выше конкретное значение или диапазон значений не следует интерпретировать в ограничительном смысле, вместо этого следует рассматривать такое конкретное значение или такой диапазон значений как представляющие середину определенного бóльшего диапазона, вплоть до, приблизительно, 50% или более % в обе стороны от конкретно указанного значения или от границ конкретно указанного меньшего диапазона. Если в данной заявке говорится о том, что любой элемент “содержит” или “включает в себя” ряд компонентов, этот ряд компонентов не следует интерпретировать в качестве единственно возможного содержимого данного элемента. Вместо этого указанный элемент может “содержать” или “включать в себя” другие компоненты, которые явным образом не перечислены.
[0067] Хотя данное раскрытие показано и описано со ссылкой на его конкретные варианты осуществления и примеры, специалисты в данной области техники поймут, что различные изменения по форме и содержанию могут вноситься без отступления от сущности и объема данного раскрытия, определяемого прилагаемой формулой изобретения и ее эквивалентами. Другими словами, приведенное выше подробное описание основано на конкретных примерах и возможных неограничивающих реализациях настоящего изобретения, но его не следует интерпретировать так, что осуществимы только явно раскрытые реализации. Предполагается, что любое изменение или замена, которые могут быть осуществлены в данном раскрытии обычным специалистом без внесения в технологию творческого и/или технического вклада, должны подпадать под объем охраны (с учетом эквивалентов), обеспечиваемый приводимой далее формулой настоящего изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ СИНТЕЗА ВИДЕО ИЗ ВХОДНОГО КАДРА АВТОРЕГРЕССИОННЫМ МЕТОДОМ, ПОЛЬЗОВАТЕЛЬСКОЕ ЭЛЕКТРОННОЕ УСТРОЙСТВО И СЧИТЫВАЕМЫЙ КОМПЬЮТЕРОМ НОСИТЕЛЬ ДЛЯ ЕГО РЕАЛИЗАЦИИ | 2023 |
|
RU2829010C1 |
| СПОСОБ И СИСТЕМА ФОРМИРОВАНИЯ ОБУЧАЮЩИХ ДАННЫХ ДЛЯ АЛГОРИТМА МАШИННОГО ОБУЧЕНИЯ | 2023 |
|
RU2831408C2 |
| СПОСОБ И СИСТЕМА ОБУЧЕНИЯ СИСТЕМЫ ЧАТ-БОТА | 2023 |
|
RU2820264C1 |
| СПОСОБ И СИСТЕМА ПОЛУЧЕНИЯ ВЕКТОРНЫХ ПРЕДСТАВЛЕНИЙ ДАННЫХ В ТАБЛИЦЕ С УЧЁТОМ СТРУКТУРЫ ТАБЛИЦЫ И ЕЁ СОДЕРЖАНИЯ | 2024 |
|
RU2839037C1 |
| Способ управления бортовыми системами беспилотных транспортных средств при помощи нейронных сетей на основе архитектуры трансформеров | 2024 |
|
RU2841111C1 |
| СПОСОБ И СИСТЕМА ОПРЕДЕЛЕНИЯ ПОДЛИННОСТИ ЛИЦА НА ИЗОБРАЖЕНИИ | 2024 |
|
RU2840316C1 |
| СПОСОБ И СИСТЕМА ДЛЯ РАСПОЗНАВАНИЯ РЕЧЕВОГО ФРАГМЕНТА ПОЛЬЗОВАТЕЛЯ | 2021 |
|
RU2808582C2 |
| СИСТЕМА И СПОСОБ ОБУЧЕНИЯ МОДЕЛЕЙ МАШИННОГО ОБУЧЕНИЯ ДЛЯ РАНЖИРОВАНИЯ РЕЗУЛЬТАТОВ ПОИСКА | 2023 |
|
RU2829065C1 |
| СПОСОБ И СИСТЕМА ПОИСКА ГРАФИЧЕСКИХ ИЗОБРАЖЕНИЙ | 2022 |
|
RU2807639C1 |
| СПОСОБЫ И СЕРВЕРЫ ДЛЯ ОБУЧЕНИЯ МОДЕЛИ ОБНАРУЖЕНИЮ СМЕНЫ ДИКТОРА | 2024 |
|
RU2841235C1 |


Изобретение относится к области основанных на машинном обучении моделей, реализующих синтез видеоклипов на основе текстовых описаний. Технический результат заключается в возможности синтезирования по текстовому описанию видеоклипа высокого качества без использования референсных видеоклипов. Способ генерирования видеоклипа по текстовому описанию включает в себя этапы, на которых: принимают текстовое описание видеоклипа, подлежащего генерированию; получают векторное представление 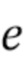 текстового описания согласно векторному пространству предобученной нейросетевой модели увязывания изображений и текстовых описаний на основе принятого текстового описания видеоклипа; получают векторное представление 2×N×L последовательности ключевых точек генерируемого видеоклипа, синтезируемое обучаемой диффузионной моделью движения на основе векторного представления текстового описания, где 2 - число координат, первая координата указывает высоту H кадра, а вторая координата указывает ширину W кадра, N - число ключевых точек на каждом кадре, и L - число кадров в видео; отображают векторное представление последовательности ключевых точек генерируемого видеоклипа в ряд L двумерных изображений ключевых точек генерируемого видеоклипа, причем каждое двумерное изображение ключевых точек из упомянутого ряда соответствует соответствующему кадру генерируемого видеоклипа, и генерируют последовательность кадров видеоклипа с помощью предобученной модели стабильной диффузии, при этом генерирование каждого кадра видеоклипа моделью стабильной диффузии дополнительно контролируется контролирующей нейросетевой моделью на основе двумерного изображения ключевых точек соответствующего кадра из упомянутого ряда. 3 н. и 15 з.п. ф-лы, 9 ил.
текстового описания согласно векторному пространству предобученной нейросетевой модели увязывания изображений и текстовых описаний на основе принятого текстового описания видеоклипа; получают векторное представление 2×N×L последовательности ключевых точек генерируемого видеоклипа, синтезируемое обучаемой диффузионной моделью движения на основе векторного представления текстового описания, где 2 - число координат, первая координата указывает высоту H кадра, а вторая координата указывает ширину W кадра, N - число ключевых точек на каждом кадре, и L - число кадров в видео; отображают векторное представление последовательности ключевых точек генерируемого видеоклипа в ряд L двумерных изображений ключевых точек генерируемого видеоклипа, причем каждое двумерное изображение ключевых точек из упомянутого ряда соответствует соответствующему кадру генерируемого видеоклипа, и генерируют последовательность кадров видеоклипа с помощью предобученной модели стабильной диффузии, при этом генерирование каждого кадра видеоклипа моделью стабильной диффузии дополнительно контролируется контролирующей нейросетевой моделью на основе двумерного изображения ключевых точек соответствующего кадра из упомянутого ряда. 3 н. и 15 з.п. ф-лы, 9 ил.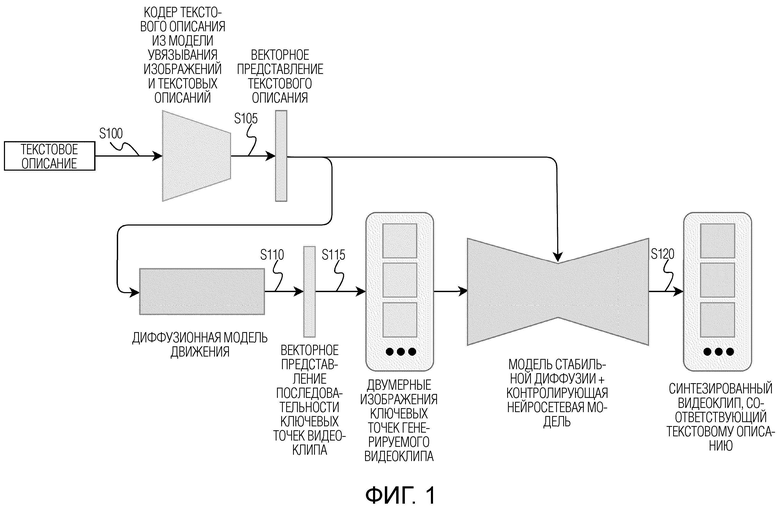
1. Способ генерирования видеоклипа по текстовому описанию, содержащий этапы, на которых:
принимают (S100) текстовое описание видеоклипа, подлежащего генерированию,
получают (S105) векторное представление 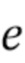 текстового описания согласно векторному пространству предобученной нейросетевой модели увязывания изображений и текстовых описаний на основе принятого текстового описания видеоклипа,
текстового описания согласно векторному пространству предобученной нейросетевой модели увязывания изображений и текстовых описаний на основе принятого текстового описания видеоклипа,
получают (S110) векторное представление 2×N×L последовательности ключевых точек генерируемого видеоклипа, синтезируемое обученной диффузионной моделью движения на основе векторного представления текстового описания, где 2 - число координат, первая координата указывает высоту H кадра, а вторая координата указывает ширину W кадра; N - число ключевых точек на каждом кадре; и L - число кадров в видео,
отображают (S115) векторное представление последовательности ключевых точек генерируемого видеоклипа в ряд L двумерных изображений ключевых точек генерируемого видеоклипа, причем каждое двумерное изображение ключевых точек из упомянутого ряда соответствует соответствующему кадру генерируемого видеоклипа, и
генерируют (S120) последовательность кадров видеоклипа с помощью предобученной модели стабильной диффузии, при этом генерирование каждого кадра видеоклипа моделью стабильной диффузии дополнительно контролируется контролирующей нейросетевой моделью на основе двумерного изображения ключевых точек соответствующего кадра из упомянутого ряда.
2. Способ по п. 1, в котором нейросетевая модель увязывания изображений и текстовых описаний содержит кодер текстового описания и кодер изображения, причем кодер текстового описания выполнен с возможностью кодирования текстового описания в векторное пространство текстовое описание-изображение, а кодер изображения выполнен с возможностью кодирования изображения, которое упомянутое текстовое описание описывает, в то же самое векторное пространство текстовое описание-изображение.
3. Способ по п. 1, в котором обучающие данные для обучения упомянутой диффузионной модели движения содержат:
обучающий набор видеоклипов,
векторные представления текстовых описаний всех видеоклипов из упомянутого набора видеоклипов, причем каждому видеоклипу из упомянутого набора видеоклипов соответствует свое векторное представление текстового описания, полученное кодером текстового описания нейросетевой модели увязывания изображений и текстовых описаний на основе по меньшей мере одного кадра соответствующего видеоклипа или на основе разметки, представляющей собой текстовое описание соответствующего видеоклипа, и
векторные представления последовательностей ключевых точек всех видеоклипов из упомянутого набора видеоклипов, причем каждому видеоклипу из упомянутого набора видеоклипов соответствует свое векторное представление последовательности ключевых точек, полученное моделью обнаружения ключевых точек на основе всех кадров соответствующего видеоклипа.
4. Способ по п. 1, в котором в качестве ключевых точек модель обнаружения ключевых точек обучена обнаруживать, для каждого кадра видеоклипа, ключевые точки, определяющие позу человека в данном кадре видеоклипа.
5. Способ по п. 4, в котором ключевые точки, определяющие позу человека в кадре видеоклипа, содержат:
одну или более ключевых точек головы человека,
одну или более ключевых точек корпуса человека,
одну или более ключевых точек каждой верхней конечности человека,
одну или более ключевых точек каждой нижней конечности человека.
6. Способ по п. 5, в котором ключевые точки головы человека содержат ключевые точки лица человека, определяющие эмоцию человека.
7. Способ по п. 1, в котором в качестве ключевых точек модель обнаружения ключевых точек обучена обнаруживать, для каждого кадра видеоклипа, ключевые точки, определяющие края одного или более объектов в данном кадре видеоклипа.
8. Способ по п. 5, в котором обучение диффузионной модели движения содержит прямой процесс и обратный процесс и выполняется итеративно до тех пор, пока не будет удовлетворено любое из следующих условий завершения обучения:
- достигнут признак сходимости функции потерь,
- завершено предопределенное число n эпох обучения диффузионной модели движения.
9. Способ по п. 8, в котором во время прямого процесса последовательно выполняют T временных шагов диффузии, на каждом из которых к векторному представлению последовательности ключевых точек случайного видеоклипа из обучающих данных добавляют гауссовский шум, для получения зашумленных векторных представлений последовательности ключевых точек упомянутого видеоклипа в числе T.
10. Способ по п. 9, в котором во время обратного процесса диффузионную модель движения обучают выполнением следующих этапов, на которых:
случайным образом выбирают (S50) из [1, T-1] временной шаг t,
прогнозируют (S55) обучаемой диффузионной моделью движения шум, который необходимо удалить из зашумленного векторного представления последовательности ключевых точек видеоклипа, соответствующего временному шагу t, для получения векторного представления последовательности ключевых точек видеоклипа, соответствующего временному шагу t-1,
вычисляют (S60) значение функции потерь между спрогнозированным шумом и фактическим шумом, который был прибавлен к векторному представлению последовательности ключевых точек видеоклипа во время прямого процесса на временном шаге t-1, и
выполняют (S65) обратное распространение ошибки путем вычисления, на основе вычисленного значения функции потерь, градиента и обновления весов обучаемой диффузионной модели движения на основе вычисленного градиента.
11. Способ по п. 10, в котором значение функции потерь вычисляется как среднеквадратичная ошибка (MSE) между спрогнозированным шумом и шумом, фактически прибавленным к представлению ключевых точек видеоклипа на определенном временном шаге прямого процесса.
12. Способ по п. 10, в котором диффузионная модель движения основана на архитектуре трансформер с механизмом самовнимания,
причем векторное представление текстового описания видеоклипа, представление ключевых точек которого в данный момент используют при обучении диффузионной модели движения, дополнительно подают на вход обучаемой диффузионной модели движения, с которой в данный момент выполняют обратный процесс, в качестве условия обучения диффузионной модели движения, учитываемого через механизм самовнимания.
13. Способ по п. 3, в котором формирование обучающего набора видеоклипов содержит этапы, на которых:
по каждому кадру каждого видеоклипа из множества видеоклипов обнаруживают (S20) моделью обнаружения ключевых точек предопределенное число N ключевых точек, определяющих позу человека и/или края одного или более объектов, представленных на соответствующем кадре;
из последовательности кадров каждого видеоклипа из множества видеоклипов удаляют (S25) те кадры, для которых моделью обнаружения ключевых точек обнаружены не все N ключевых точек, определяющих позу человека и/или края одного или более объектов, и
из последовательности оставшихся кадров каждого видеоклипа из множества видеоклипов выбирают (S30) предопределенное число L равноудаленных друг от друга кадров, представляющих видеоклип, включаемый в обучающий набор видеоклипов.
14. Способ по п. 1, в котором отображение (S115) векторного представления последовательности ключевых точек генерируемого видеоклипа в ряд L двумерных изображений ключевых точек содержит этапы, на которых:
создают (S115.1) ряд L пустых изображений H×W, где H - высота изображения, W - ширина изображения,
для каждого созданного изображения извлекают (S115.2) из векторного представления последовательности ключевых точек координаты пикселей N ключевых точек соответствующего изображения,
на каждом изображении закрашивают (S115.3) указанные координатами пиксели N ключевых точек соответствующего изображения.
15. Способ по п. 1, дополнительно содержащий обработку L двумерных изображений ключевых точек видеоклипа скользящей средней с размером окна, равным n двумерных изображений ключевых точек видеоклипа, при этом n < L.
16. Способ по п. 1, в котором векторное представление текстового описания, получаемое согласно векторному пространству предобученной нейросетевой модели увязывания изображений и текстовых описаний, содержит векторное представление, кодирующее текстовое описание всего видеоклипа, и последовательность векторных представлений, каждое из которых кодирует текстовое описание соответствующего кадра видеоклипа.
17. Электронное устройство (400), выполненное с возможностью генерирования видеоклипа по текстовому описанию, причем устройство содержит процессор (405) и память (410), в которой хранятся исполняемые компьютером инструкции, которые при выполнении процессором заставляют устройство выполнять способ по любому из пп. 1-16.
18. Машиночитаемый носитель, хранящий исполняемые компьютером инструкции, которые при исполнении устройством побуждают устройство выполнять способ по любому из пп. 1-16.
| Передача между двумя параллельными валами | 1933 |
|
SU39495A1 |
| СПОСОБ И СИСТЕМА АВТОМАТИЗИРОВАННОГО ГЕНЕРИРОВАНИЯ ВИДЕОПОТОКА С ЦИФРОВЫМ АВАТАРОМ НА ОСНОВЕ ТЕКСТА | 2020 |
|
RU2748779C1 |
| US 11809688 B1, 07.11.2023 | |||
| US 20200342909 A1, 29.10.2020 | |||
| WO 2012154618 A2, 15.11.2012 | |||
| US 20130124206 A1, 16.05.2013 | |||
| Lvmin Zhang и др., "Adding Conditional Control to Text-to-Image Diffusion Models", 26.11.2023, URL: https://arxiv.org/pdf/2302.05543 | |||
| Gyeongrok Oh и др., "MTVG : Multi-text | |||

