ОБЛАСТЬ ТЕХНИКИ
[0001] Заявленное решение относится к области информационных технологий, а именно к способу и системе формирования запросов к базе данных на естественном языке.
УРОВЕНЬ ТЕХНИКИ
[0002] Данные занимают центральное место в информационном обществе. Именно информация является основой для принятия решений, развития бизнеса и научных исследований. Многие организации инвестируют огромные средства в системы, способные хранить, обрабатывать и анализировать данные.
[0003] Одной из главных проблем, с которыми сталкиваются компании, это непосредственная работа с базами данных с помощью языка SQL (Structured Query Language). He все знают этот язык, и не у всех есть время изучать его. Поэтому на рынке появляются инструменты, позволяющие писать запрос на естественном языке и получать ответ на языке запросов.
[0004] Для написания программного кода сейчас широко применяются большие языковые модели или LLM (Large Language Model), которые предобучены на большом количестве текстовых документов на разных языках, в связи с чем они хорошо справляются с задачами разбора естественного языка и перевода.
[0005] При работе с языками программирования, к которым относится и SQL, проблемой является:
- необходимость строго соответствовать синтаксису языка;
- использовать только те структуры данных, которые представлены в имеющихся БД;
- понимание семантики таблиц и полей данных БД в контексте заданного вопроса.
[0006] Для решения данных проблем известен ряд способов, среди которых:
- RAG с использованием всей структуры БД (повышение показателей модели за счет RAG - https://arxiv.org/pdf/2307.05074);
- Prompt-engineering;
- Few-shot (добавление примеров, например в публикации рассмотрено влияние подсказок на качество ответов «Enhancing Few-shot Text-to-SQL Capabilities of Large Language Models: A Study on Prompt Design Strategies» https://arxiv.org/pdf/2305.12586);
- Обучение на примерах пар вопрос - SQL-запрос;
- Повторные запросы для корректировки ответа (повышение точности модели за счет самокорекции «DIN-SQL: Decomposed In-Context Learning of Text-to-SQL with Self-Correction» - https://arxiv.org/pdf/2304.11015).
[0007] В патент США 10,747,761 B2 (Salesforce Inc, 18.08.2020) рассматривается подход в части формирования запросов на основе естественного языка, при котором для каждой части запроса (список колонок, наличие группировок, тип агрегации, и т.д.) обучается отдельная нейросетевая модель. Каждая такая модель обучается на основе только ограниченного количества запросов для конкретной БД и не умеет обрабатывать конструкции естественного языка, которые отсутствовали в обучающей выборке.
[0008] Ключевыми недостатками известных из уровня техники подходов является необходимость подготовки человеком обучающей выборки, которая требует больших трудозатрат и компетенций в предметной области БД, что также приводит к возможным ошибкам, неточностям в рамках обучения модели, и, соответственно, снижает точность преобразования команд запросов с естественного языка на язык SQL.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
[0009] Заявленное изобретение позволяет решить техническую проблему в части повышения точности преобразования команд для работы с базами данных с естественного языка на язык SQL.
[0010] Техническим результатом является повышение точности преобразования команд обращений к базе данных с естественного языка на язык SQL.
[0011] Дополнительным техническим результатом является обеспечение возможности формирования исполнимых команд, за счет их предварительной проверки и корректировки в случае наличия ошибок.
[0012] Заявленный технический результат достигается за счет способа формирования запросов к базе данных (БД) на естественном языке, выполняемого с помощью процессора и содержащего этапы, на которых:
получают данные о БД пользователя, включающие в себя по меньшей мере:
структуру БД, описание таблиц и колонок, примеры значений колонок;
выполняют индексацию полученных данных о БД пользователя в векторную БД;
выполняют преобразование данных пользовательской БД в граф;
выявляют подграфы в БД, содержащие таблицы, связанные по ключу;
формируют шаблоны обращений к таблицам по выявленным подграфам;
выполняют нормализацию описаний таблиц и полей пользовательской БД;
выполняют обучение адаптеров модели машинного обучения с помощью нормализованной структуры БД;
получают пользовательский запрос, содержащий команду запроса к БД на естественном языке;
выполняют векторизацию полученного запроса и его последующую обработку векторной БД;
добавляют в контекст пользовательского запроса параметры структуры БД, хранящиеся в векторной БД;
генерируют запрос к большой языковой модели (LLM) на основании обработанного векторной БД запроса пользователя;
при этом, LLM выполняет
преобразование обработанного запроса пользователя в SQL-выражение;
проверку исполнимости SQL-выражение на основании данных о БД пользователя;
выполняют сформированное SQL-выражение;
передают результат выполнения SQL-выражения пользователю.
[0013] В одном из частных вариантов выполнения способа LLM дополнительно генерирует описание на естественном языке на основании пользовательского запроса.
[0014] В другом частном варианте выполнения способа на основании SQL-выражений, не прошедшие проверку на исполнимость, формируется корректирующее SQL-выражение, содержащее указание на по меньшей мере одну ошибку в сформированном SQL-выражении на основании структуры пользовательской БД.
[0015] В другом частном варианте выполнения способа выполняется проверка скорректированного SQL-выражения.
[0016] Заявленный технический результат также достигается за счет реализации системы для формирования запросов к базе данных (БД) на естественном языке, содержащей по меньшей мере один процессор и по меньшей мере одну память, содержащую машиночитаемые инструкции, которые при их исполнении процессором, выполняют вышеуказанный способ.
ОПИСАНИЕ ЧЕРТЕЖЕЙ
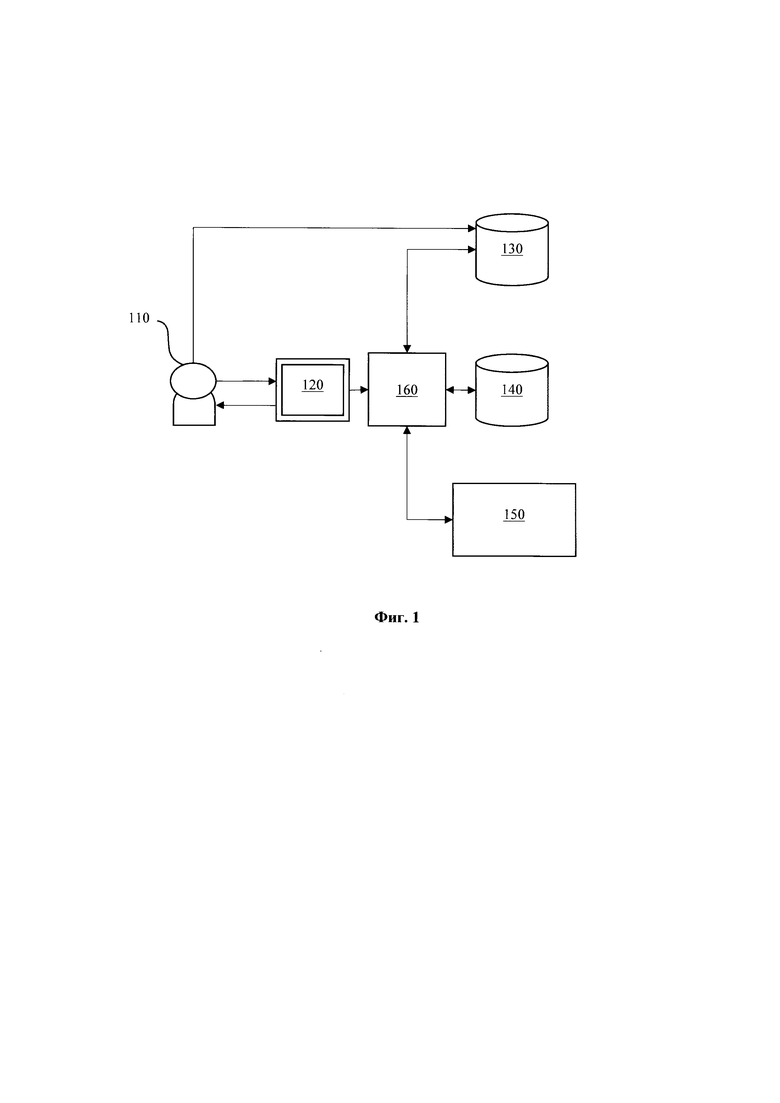
[0017] Фиг. 1 иллюстрирует общую схему заявленного решения.
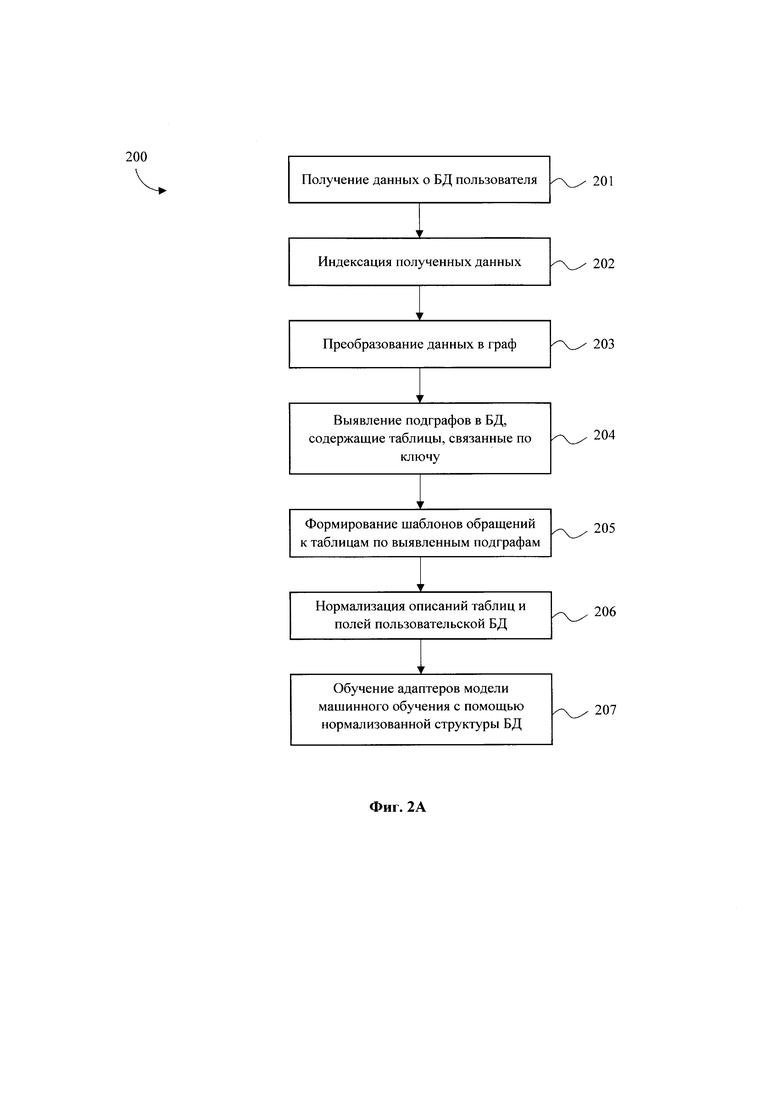
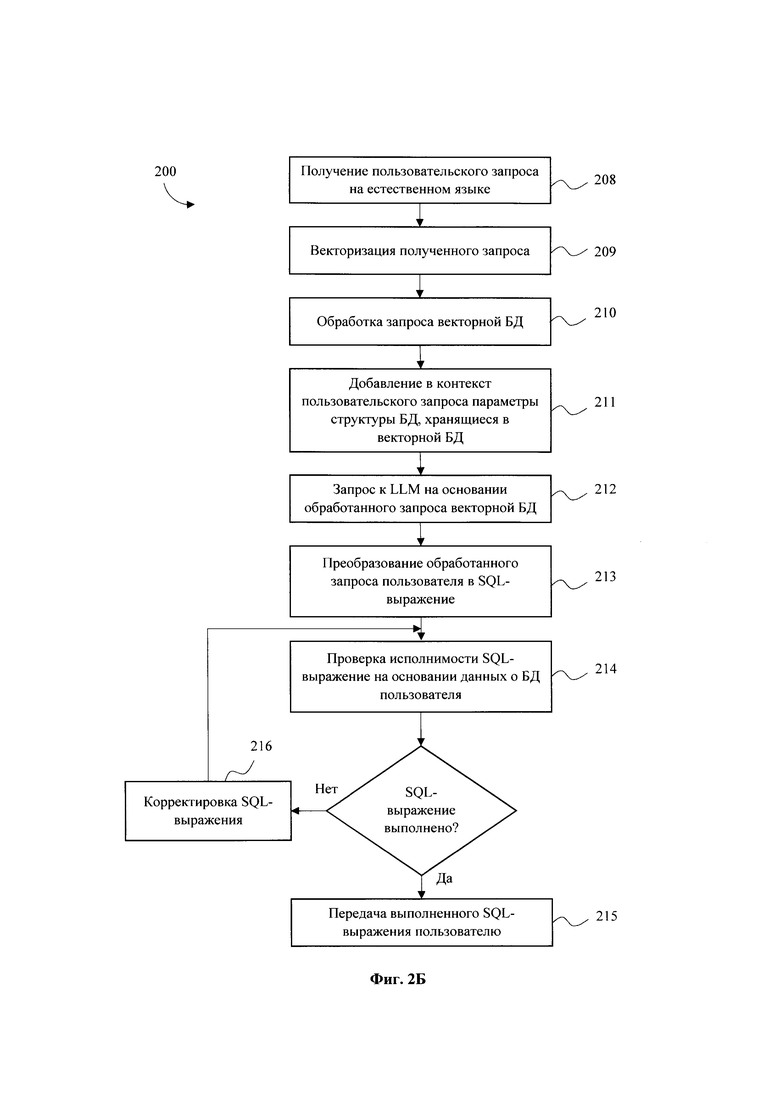
[0018] Фиг. 2А - Фиг. 2Б иллюстрирует блок-схему выполнения заявленного способа.
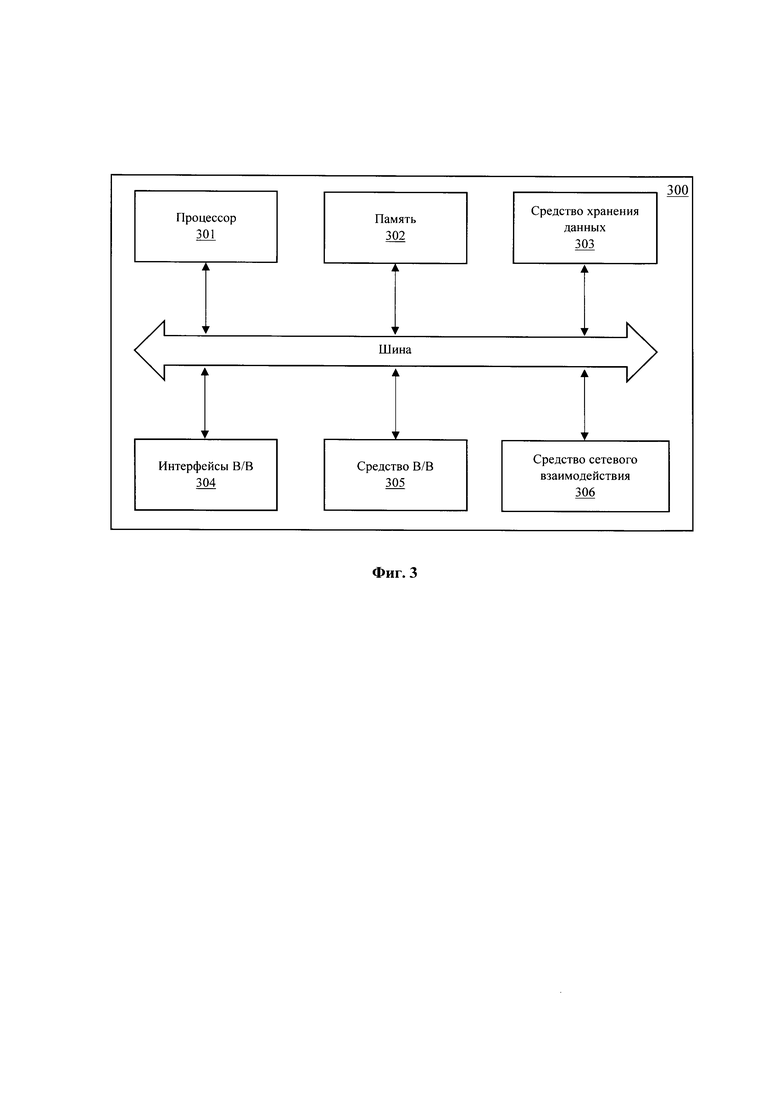
[0019] Фиг. 3 иллюстрирует общий вид вычислительного устройства.
ОСУЩЕСТВЛЕНИЕ ИЗОБРЕТЕНИЯ
[0020] Как показано на Фиг. 1 заявленное решение представляет собой автоматизированное решение, реализуемое посредством получения запросов от пользователей (110), направляемых через графический интерфейс (120), для их последующей обработки с помощью управляющего сервера (160). Запросы пользователей (110) представляю собой текстовый запрос (промпт), направляемый в форму интерфейса (120) для их последующего преобразования из текстовой формы в SQL-выражение.
[0021] Сервер (160) связан с пользовательской БД (130), к которой необходимо формировать SQL запросы, векторной БД (140) и LLM (150).
[0022] Далее с отсылками на Фиг. 2А - 2Б рассмотрим детальное выполнение заявленного способа (200) формирования запросов на языке SQL к пользовательской БД (130). На первом этапе (201) сначала происходит сбор данных о пользовательской БД (130), к которой в последующем будут формироваться необходимые запросы. Собираемые данные включают в себя структуру БД, описание таблиц и колонок, примеры значений колонок.
[0023] Данные примеры структуры БД (130) необходимы для последующего дообучения модели машинного обучения, входящей в состав векторной БД (140) и помогает модели делать более точные SQL-запросы. Ниже приведен пример данных о пользовательской БД (130).
[0024] Пример 1.
Таблица: companies,
Колонка: company_street,
Описание: улица работодателя,
Примеры значений: 'ул. Ленина, 1', 'пр. Мира, 2', 'ул. Радищева, 3'.
[0025] Пример 2. Таблица:
companies,
Колонка: name,
Описание: название работодателя,
Примеры значений: 'ООО Рога и Копыта', 'ООО Яблоко', 'ЗАО Вектор'.
[0026] Пример 3.
Таблица: companies,
Колонка: company_type,
Описание: организационная форма компании,
Категории: ['ЗАО', 'ПАО', 'ИП', 'ООО']
Примеры значений: 'ЗАО', 'ПАО', 'ИП', 'ООО'
[0027] Сбор данных из пользовательской БД (130) может выполняться отдельным скриптом, который обращается к БД (130) посредством сервера (160) и сканирует ее таким образом, что получает все значения каждого атрибута и сохраняет в отдельную базу данных - с целью последующего изъятия и подставления в промпт при формировании SQL-запросов. Сохранение примеров значений в отдельную БД происходит, чтобы исключить постоянное сканирование базы данных (130).
[0028] Полученная на этапе (201) информация о пользовательской БД (130) далее проходит процедуру индексации на этапе (202). Полученные данные пользовательской БД (130) векторизуются с помощью эмбеддинг модели (модель, делающая векторное представление текста), входящей в состав векторной БД (140).
[0029] В случае подкладывания всех параметрам по всем таблицам пользовательской БД (130) в промпт возникает проблема слишком большого контекста. Все языковые модели ограничены размером подаваемых символов на вход. Тем самым при превышении определенного размера промпта модель не может генерировать текст на поданный вопрос. Данную проблему решает применение векторной БД (140).
[0030] Перед формированием промпта дополнительно сохраняется текстовое описание на натуральном языке в векторную БД (140). Далее производится векторное представление изначального вопроса, сформированному пользователем (110), и по этому представлению производится поиск ближайших представлений в векторном пространстве БД (140). Набор таких ближайших представлений будет хранить в себе информацию о текстовом описании таблиц и колонок, которые семантически наиболее похожи на изначальный вопрос, следовательно, информация из этих таблиц и колонок наиболее необходима для ответа.
[0031] Следующим шагом из векторной БД (140) с данными структуры пользовательской БД (130) берутся именно те таблиц и колонки, которые наиболее необходимы для ответа. Таким образом применение векторной БД (140) позволяет сократить количество информации, подаваемой на вход в LLM (150).
[0032] Для генерации запросов структура БД (130) на этапе (203) преобразуется в графовое представление, по которому на этапе (204) находятся подграфы таблиц, связанных по ключу. Для каждого подграфа генерируется множество запросов по списку шаблонов на этапе (205), применимых для данного подмножества таблиц.
[0033] Генерация синтетических наборов данных основана на обратном преобразовании SQL-выражения в текстовое описание. Как правило, LLM меньше ошибается, когда преобразует структурированный текст в естественный язык.
[0034] На вход LLM подаются синтаксически корректные SQL-запросы, сгенерированные по заранее запрограммированным шаблонам, представляющим наиболее распространенные запросы пользователей.
[0035] Для ряда запросов LLM недостаточно хорошо преобразует SQL в текст, в этом случае для улучшения генерации параллельно с запросом генерируется описание на естественном языке путем склейки строк без учета связи слов в предложении и корректировкой данного запроса средствами LLM.
[0036] Для генерации синтетических наборов данных необходимо использовать краткие, но однозначные названия таблиц и их атрибутов. В описании базы данных, представленной пользователем, часто встречаются шаблонные фразы вида «В этой таблице описаны...», «Данный атрибут является внешним ключом на таблицу...», которые не позволяют сгенерировать качественное описание SQL запроса на основе склейки строк без учета связи слов. На этапе (206) при нормализации такие описания подлежат обнаружению и исправлению при помощи специального запроса к LLM. Также нормализации подлежат различные аббревиатуры (например, RUR, USD), которые могут быть ошибочно трактованы LLM.
[0037] Имея сгенерированные данные, на этапе (207) полученные пары SQL-Описание используются для обучения LORA-адаптера к LLM. Использование адаптера с правильно подобранными параметрами обучения позволяет экономить ресурсы на дообучение модели и менять адаптеры по мере необходимости без перезагрузки LLM целиком.
[0038] После обучения адаптеров модели на основании структуры пользовательской БД (130), пользователь формирует на этапе (208) запрос через интерфейс (120) на естественном языке, например, «Отобразить данные за 2024 год из таблицы Вакансии». Полученный пользовательский запрос на этапе (209) преобразовывается в векторную форму с помощью обработки моделью векторной БД (140). Далее на этапе (210) векторизованный запрос обрабатывается векторной БД (140) на предмет поиска ближайших векторных представлений, позволяющих выявить релевантные сведения для последующего генерирования SQL-запроса.
[0039] В момент обработки запроса векторной БД (140) на этапе (211) в контекст пользовательского запроса добавляются параметры структуры БД (130), хранящиеся в векторной БД (140). По итогу работы векторной БД (140) на этапе (212) формируется запрос к LLM (150), которая на этапе (213) преобразовывает запрос пользователя (110) с естественного языка в SQL-выражение на основании полученной ранее информации о структуре пользовательской БД (130).
[0040] Перед тем как передать пользователю (110) сформированный SQL-запрос проводится проверка на его корректность и исполнимость с помощью его применения на этапе (214) к пользовательской БД (130). Все SQL-запросы, сгенерированные LLM (150), проверяются на выполнение к пользовательской БД (130). Неуспешное выполнение возможно в случаях: неправильного SQL синтаксиса запроса и некорректного выполнения к конкретной базе данных. Все эти ошибки при выполнении отображаются в соответствующем сообщении из БД, которое описывает ошибку. Таким образом формируется некоторое текстовое описание полученной ошибки.
[0041] Если ошибки были выявлены, то на этапе (216) автоматически формируется корректирующее SQL-выражение, которое представляет собой промпт в LLM (150), в котором указывается структура пользовательской БД, сообщение об ошибке и инструкцию по исправлению содержащее указание на по меньшей мере одну ошибку в сформированном SQL-выражении на основании структуры пользовательской БД.
[0042] Пример исправления SQL-запроса.
Исправь SQL-запрос:
SELECT COUNT(*) FROM vacancies WHERE vacancies.departments_name = 'finance'
Замени отсутствующие в базе данных колонки
'departments_name'
на наиболее подходящие из схемы БД:
TABLE vacancies(vacancy_id, date added, level, direction, department_name, company_id, salary_from, salary_to, salary_currency, name, work_location, schedule_type)
Запрос должен отвечать на вопрос
Сколько вакансий предлагает департамент 'finance'?
[0043] После этого LLM (150) формирует исправленный SQL запрос, который заново проверяется на его исполнимость, либо модель возвращает SQL-запрос в таком же виде. Это позволяет, используя LLM (150), производить исправление ошибок при выполнении сгенерированных запросов к пользовательской БД (130), что дополнительно позволяет повысить точность перевода запросов на естественном языке в SQL код.
[0044] После того как сформированный SQL-запрос проходит проверку на исполнимость, на этапе (215) осуществляется его выполнение и передача пользователю (110) посредством графического интерфейса (120).
[0045] На Фиг. 3 представлен общий вид вычислительного устройства (300), с помощью которого может быть реализовано заявленное решение. В общем случае, вычислительное устройство (300) содержит объединенные общей шиной информационного обмена один или несколько процессоров (301), средства памяти, такие как ОЗУ (302) и ПЗУ (303), интерфейсы ввода / вывода (304), устройства ввода / вывода (305), и устройство для сетевого взаимодействия (306).
[0046] Процессор (301) (или несколько процессоров, многоядерный процессор) могут выбираться из ассортимента устройств, широко применяемых в текущее время, например, компаний Intel™, AMD™, Apple™, Samsung Exynos™, MediaTEK™, Qualcomm Snapdragon™ и т.п. Под процессором также необходимо учитывать графический процессор, например, GPU NVIDIA или ATI, который также является пригодным для полного или частичного выполнения способа (200). При этом, средством памяти может выступать доступный объем памяти графической карты или графического процессора.
[0047] ОЗУ (302) представляет собой оперативную память и предназначено для хранения исполняемых процессором (301) машиночитаемых инструкций для выполнение необходимых операций по логической обработке данных. ОЗУ (302), как правило, содержит исполняемые инструкции операционной системы и соответствующих программных компонент (приложения, программные модули и т.п.).
[0048] ПЗУ (303) представляет собой одно или более устройств постоянного хранения данных, например, жесткий диск (HDD), твердотельный накопитель данных (SSD), флэш-память (EEPROM, NAND и т.п.), оптические носители информации (CD-R/RW, DVD-R/RW, BlueRay Disc, MD) и др.
[0049] Для организации работы компонентов устройства (300) и организации работы внешних подключаемых устройств применяются различные виды интерфейсов В/В (304). Выбор соответствующих интерфейсов зависит от конкретного исполнения вычислительного устройства, которые могут представлять собой, не ограничиваясь: PCI, AGP, PS/2, IrDa, FireWire, LPT, COM, SATA, IDE, Lightning, USB (2.0, 3.0, 3.1, micro, mini, type C), TRS/Audio jack (2.5, 3.5, 6.35), HDMI, DVI, VGA, Display Port, RJ45, RS232 и т.п.
[0050] Для обеспечения взаимодействия пользователя с вычислительным устройством (300) применяются различные средства (305) В/В информации, например, клавиатура, дисплей (монитор), сенсорный дисплей, тач-пад, джойстик, манипулятор мышь, световое перо, стилус, сенсорная панель, трекбол, динамики, микрофон, средства дополненной реальности, оптические сенсоры, планшет, световые индикаторы, проектор, камера, средства биометрической идентификации (сканер сетчатки глаза, сканер отпечатков пальцев, модуль распознавания голоса) и т.п.
[0051] Средство сетевого взаимодействия (306) обеспечивает передачу данных устройством (300) посредством внутренней или внешней вычислительной сети, например, Интранет, Интернет, ЛВС и т.п. В качестве одного или более средств (306) может использоваться, но не ограничиваться: Ethernet карта, GSM модем, GPRS модем, LTE модем, 5G модем, модуль спутниковой связи, NFC модуль, Bluetooth и/или BLE модуль, Wi-Fi модуль и др.
[0052] Дополнительно могут применяться также средства спутниковой навигации в составе устройства (300), например, GPS, ГЛОНАСС, BeiDou, Galileo.
[0053] Представленные материалы заявки раскрывают предпочтительные примеры реализации технического решения и не должны трактоваться как ограничивающие иные, частные примеры его воплощения, не выходящие за пределы испрашиваемой правовой охраны, которые являются очевидными для специалистов соответствующей области техники.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ И СИСТЕМА ГЕНЕРАЦИИ ОТВЕТА НА ПОИСКОВЫЙ ЗАПРОС | 2024 |
|
RU2834217C1 |
| СПОСОБ И СИСТЕМА ГЕНЕРАЦИИ ЗАПРОСОВ ДЛЯ ОБРАЩЕНИЯ К НЕЙРОСЕТЕВОЙ ЯЗЫКОВОЙ МОДЕЛИ | 2024 |
|
RU2826816C1 |
| СПОСОБ ЗАЩИЩЕННОГО ДОСТУПА К БАЗЕ ДАННЫХ | 2019 |
|
RU2709288C1 |
| СПОСОБ И СИСТЕМА ДЛЯ ВЫСТРАИВАНИЯ ДИАЛОГА С ПОЛЬЗОВАТЕЛЕМ В УДОБНОМ ДЛЯ ПОЛЬЗОВАТЕЛЯ КАНАЛЕ | 2018 |
|
RU2688758C1 |
| ГОЛОСОВАЯ СВЯЗЬ НА ЕСТЕСТВЕННОМ ЯЗЫКЕ МЕЖДУ ЧЕЛОВЕКОМ И УСТРОЙСТВОМ | 2014 |
|
RU2583150C1 |
| СПОСОБ ПРОВЕДЕНИЯ МИГРАЦИИ И РЕПЛИКАЦИИ ДАННЫХ С ИСПОЛЬЗОВАНИЕМ ТЕХНОЛОГИИ ЗАЩИЩЕННОГО ДОСТУПА К БАЗЕ ДАННЫХ | 2020 |
|
RU2745679C1 |
| СПОСОБ И СИСТЕМА ОБУЧЕНИЯ СИСТЕМЫ ЧАТ-БОТА | 2023 |
|
RU2820264C1 |
| ПОИСК ИЗОБРАЖЕНИЙ НА ЕСТЕСТВЕННОМ ЯЗЫКЕ | 2015 |
|
RU2688271C2 |
| Способ комбинирования большой языковой модели и агента безопасности | 2023 |
|
RU2825975C1 |
| СПОСОБ И СИСТЕМА ДЛЯ ФОРМИРОВАНИЯ ТЕКСТОВЫХ ПОДСКАЗОК | 2024 |
|
RU2841233C1 |
Изобретение относится к области информационных технологий. Технический результат заключается в повышении точности преобразования команд обращений к базе данных с естественного языка на язык SQL. Технический результат достигается за счет этапов, на которых: получают данные о БД пользователя, включающие в себя по меньшей мере: структуру БД, описание таблиц и колонок, примеры значений колонок; выполняют индексацию полученных данных о БД пользователя в векторную БД; выполняют преобразование данных пользовательской БД в граф; выявляют подграфы в БД, содержащие таблицы, связанные по ключу; формируют шаблоны обращений к таблицам по выявленным подграфам; выполняют нормализацию описаний таблиц и полей пользовательской БД; выполняют обучение адаптеров модели машинного обучения с помощью нормализованной структуры БД; получают пользовательский запрос, содержащий команду запроса к БД на естественном языке; выполняют векторизацию полученного запроса и его последующую обработку векторной БД; добавляют в контекст пользовательского запроса параметры структуры БД, хранящиеся в векторной БД; генерируют запрос к большой языковой модели (LLM) на основании обработанного векторной БД запроса пользователя. 2 н. и 3 з.п. ф-лы, 4 ил.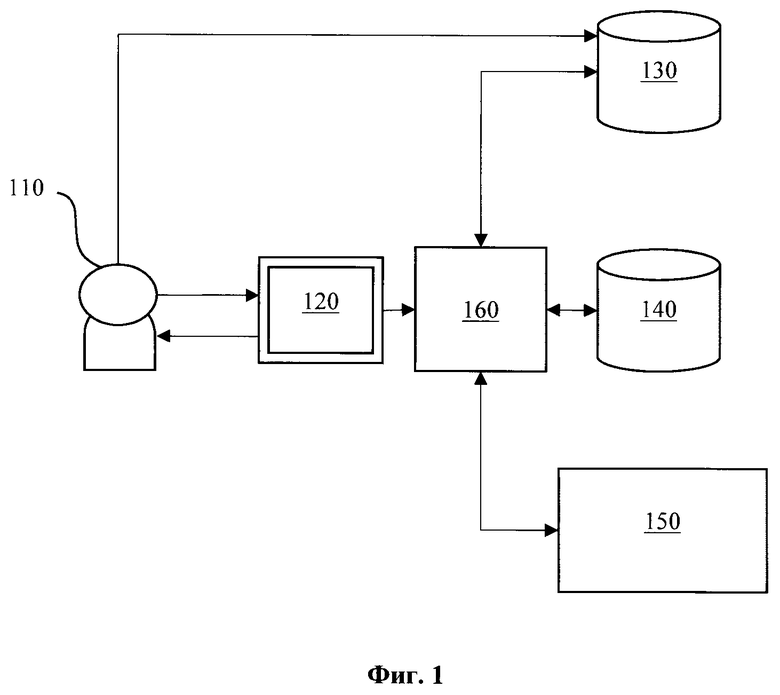
1. Способ формирования запросов к базе данных (БД) на естественном языке, выполняемый с помощью процессора и содержащий этапы, на которых:
получают данные о БД пользователя, включающие в себя по меньшей мере:
структуру БД, описание таблиц и колонок, примеры значений колонок;
выполняют индексацию полученных данных о БД пользователя в векторную БД;
выполняют преобразование данных пользовательской БД в граф;
выявляют подграфы в БД, содержащие таблицы, связанные по ключу;
формируют шаблоны обращений к таблицам по выявленным подграфам;
выполняют нормализацию описаний таблиц и полей пользовательской БД;
выполняют обучение адаптеров модели машинного обучения с помощью нормализованной структуры БД;
получают пользовательский запрос, содержащий команду запроса к БД на естественном языке;
выполняют векторизацию полученного запроса и его последующую обработку векторной БД;
добавляют в контекст пользовательского запроса параметры структуры БД, хранящиеся в векторной БД;
генерируют запрос к большой языковой модели (LLM) на основании обработанного векторной БД запроса пользователя;
при этом LLM выполняет
преобразование обработанного запроса пользователя в SQL-выражение;
проверку исполнимости SQL-выражения на основании данных о БД пользователя;
выполняют сформированное SQL-выражение;
передают результат выполнения SQL-выражения пользователю.
2. Способ по п. 1, в котором LLM дополнительно генерирует описание на естественном языке на основании пользовательского запроса.
3. Способ по п. 1, в котором на основании SQL-выражений, не прошедших проверку на исполнимость, формируется корректирующее SQL-выражение, содержащее указание на по меньшей мере одну ошибку в сформированном SQL-выражении на основании структуры пользовательской БД.
4. Способ по п. 3, в котором выполняется проверка скорректированного SQL-выражения.
5. Система для формирования запросов к базе данных (БД) на естественном языке, содержащая по меньшей мере один процессор и по меньшей мере одну память, содержащую машиночитаемые инструкции, которые при их исполнении процессором выполняют способ по любому из пп. 1-4.
| US 20160179883 A1, 23.06.2016 | |||
| US 20220414228 A1, 29.12.2022 | |||
| US 20210209104 A1, 08.07.2021 | |||
| US 20180210966 A1, 26.07.2018 | |||
| Способ формирования и структурирования электронной базы данных | 2018 |
|
RU2696295C1 |

