Область техники
Изобретение относится к области обработки данных.
Уровень техники
В настоящее время в традиционных системах автоматизации планово-расчетной и аналитической деятельности основной упор делается на документный оборот предприятий/обществ, то есть все исходные данные для таких систем принято получать из документов. Такой подход позволяет построить автоматизацию, однако эффективность такого подхода оставляет желать лучшего. Операционная деятельность большинства предприятий связана с товарооборотом, особенно это касается производств и торговых компаний, и основной сущностью, требующей цифровой обработки, являются именно товары и иные материальные ценности, а не документы. Конечно, документы отражают большинство информации о товарах и материальных ценностях, но они не представляют данных для автоматизации и несут больше правовые функции, нежели информационные.
Многие существующие системы идентификации привязаны к документам, то есть, например, сотрудник заполняет план продаж как отдельный документ, который хранится в базе данных в отдельной таблице, или в нескольких таблицах, то же самое касательно отчета по продажам, и после заполнения обоих документов, производится сведение данных для анализа, при том, что объекты числовых данных фигурируют в них одни и те же, при детальной аналитике эти документы разбираются обратно для частного анализа объектов (например, прибыльность отдельно взятого товара или услуги). Такой подход к обработке данных порождает необходимость регулярно собирать/разбирать массивы числовых данных (увеличение алгоритмической цепочки) об одних и тех же объектах, что ведет к усложнению работы с базой данных.
Вместе с тем, существующие решения по организации структуры баз данных и их наполнения недостаточно точны, имеют множественные дубликаты значений и вызывают трудности в визуальном восприятии идентификаторов и их распознавания при расчетах и других действиях с числовыми значениями, что ведет к увеличению значимости человеческого фактора и как следствие - ошибкам.
Так из патентного документа RU 2386166 С2 (Открытое Акционерное общество Таганрогский Авиационный научно-технический комплекс им. Г.М. Бериева, 10.04.2010) известен способ организации и функционирования базы данных нормативной документации, заключающийся в том, что, по меньшей мере, в одном хранилище данных сохраняют объекты нормативной документации, взаимодействуют с хранилищем данных следующим образом: весь объем нормативной документации и содержащейся в ней информации по любой предметной области деятельности помещают в отдельную область базы данных и представляют в виде трехмерного информационного пространства, выбирают три основных характеристических признака и присваивают их названия координатным осям X, Y, Z, определяют составляющие характеристических признаков и откладывают их на координатных осях, образованных ортами (единичными отрезками), которые определяют составляющие характеристических признаков, присваивают кодовые обозначения, исходя из обозначений, применяемых на практике, из орт образуют кластеры – области трехмерного пространства, ограниченные единичными поверхностями единичных отрезков, из кодов соответствующих орт характеристических признаков составляют код каждого кластера, получают трехмерное информационное пространство, состоящее из кластеров с присвоенными им кодами, помещают образованное трехмерное информационное пространство вместе с другими базами данных в общем хранилище информации в виде объектно-ориентированной или реляционной базы данных, каждый документ переводят в формат XML, определяют ключи и атрибуты, ссылки для критериев поиска и анализа и в отформатированном виде располагают в соответствующей области базы данных, а затем анализируют на предмет принадлежности документа, части документа или информации, содержащейся в документе, кластерам трехмерного информационного пространства, формируют по трем осям полный идентификационный номер документа или его части, состоящий из кода ортов в зависимости от принадлежности к одному или нескольким кластерам и идентификационного номера документа, при этом если документ по какой-либо оси принадлежит нескольким кластерам, то код орта по этой оси заменяют нулевым значением, затем полный идентификационный номер документа помещают в кластер или кластеры, к которым принадлежит документ или часть содержащейся в нем информации, через кластер формируют ключи, индексы и атрибуты и присоединяют их к документу в формате XML, по мере анализа документов заполняют таблицы принадлежности документов к характеристическим признакам, хранящиеся в базе данных и позволяющие по полному идентификационному номеру определить составляющие характеристических признаков, к которым принадлежит документ, затем проверяют наличие документов в кластере и анализируют достаточность информации в этих документах по критериям полноты документации, используя надстройки базы данных, результаты анализа помещают в проанализированный кластер и хранят вместе с полными идентификационными номерами документов, для анализа более широкой области, определяющей одну составляющую или весь характеристический признак, делают срез трехмерного информационного пространства в выбранной плоскости, используя надстройки базы данных, анализируют состояние обеспечения нормативной документацией любого направления выбранной области деятельности и принимают решение о необходимости создания нового или дополнения существующего документа, основываясь на том, что в каждом кластере трехмерного информационного пространства в идеальном случае должен содержаться только один документ, полностью описывающий ограниченную этим кластером область деятельности, используя базу шаблонов и критерии полноты документации, выполняют разработку или корректировку нормативных документов, в процессе разработки, и в окончательной редакции новый документ итеративно вновь подвергают проведенному анализу для определения качества и полноты информации и для помещения документа в трехмерное информационное пространство, с помощью средств базы данных выбирают и находят нормативные документы по одному, двум или трем характеристическим признакам, осуществляют доступ к информации по интересующему вопросу, вводят (удаляют) информацию, контролируют полноту и качество получаемой информации, при этом при разработке трехмерного информационного пространства областей деятельности, если часть объема нормативной документации и составляющие характеристических признаков совпадают, аналогичные кластеры новой базы данных получают путем замещения их на существующие.
Наиболее близким аналогом заявленного решения является патентный документ RU 2650032 С1 (Семенов Алексей Петрович, 06.04.2018), из которого известен способ формирования электронной базы данных, характеризующийся тем, что способ исполняют с помощью системы управления базой данных посредством электронного устройства по следующим этапам: данные организуют с помощью системы управления базой данных в единственную таблицу, содержащую, по крайней мере, четыре столбца и, по крайней мере, пять строк; формируют первую строку, отображающую корневой элемент, в первом столбце которой сохраняют первый идентификационный номер; формируют вторую строку, отображающую тип данных, в первом столбце которой сохраняют уникальный идентификационный номер типа данных, при этом уникальный идентификационный номер типа данных отличается от первого идентификационного номера, в третьем столбце сохраняют наименование используемого типа данных и в четвертом столбце сохраняют код типа данных; формируют третью строку, отображающую термин, в первом столбце которой сохраняют уникальный идентификационный номер термина, в третьем столбце сохраняют наименование термина и в четвертом столбце сохраняют код используемого типа данных; формируют четвертую строку, отображающую реквизит термина, в первом столбце которой сохраняют уникальный идентификационный номер реквизита термина, а во втором столбце сохраняют идентификационный номер родительского элемента реквизита термина, при этом реквизит термина зависит от родительского элемента; и формируют пятую строку, отображающую данные, в первом столбце которой сохраняют уникальный идентификационный номер данных, во втором столбце сохраняют идентификационный номер родительского элемента данных, при этом данные зависят от родительского элемента, в третьем столбце сохраняют данные и четвертом столбце сохраняют уникальный код типа данных.
При этом в случае необходимости обработки внушительных объемов данных из множества различных источников указанные способы оказываются неэффективными из-за их сложности и громоздкости, большое количество операций приведет к снижению быстродействия программного обеспечения и уменьшению скорости обработки данных. Более того, большое количество таблиц и данных в них затрудняет восприятие идентификаторов и их распознавание при расчетах и других действиях с числовыми значениями, усложняет работу с базой данных, увеличивает количество человеческих ошибок.
Таким образом, недостатками вышеуказанных аналогов в общем и прототипа в частности является сложность и громоздкость способов, большое количество операций, которое приводит к снижению быстродействия программного обеспечения и уменьшению скорости обработки данных, трудность в восприятии идентификаторов и их распознавании при расчетах и других действиях с числовыми значениями, увеличение количества человеческих ошибок, сложность в работе с базой данных.
Задача и технический результат
Задачей и техническим результатом предлагаемого изобретения является обеспечение более удобного визуального восприятия идентификаторов и их распознавания при расчетах и других действиях с числовыми значениями в базах данных, упрощение работы с базой данных, уменьшение значимости человеческого фактора, а, следовательно, уменьшение человеческих ошибок, а также повышение быстродействия программного обеспечения и значительное увеличение скорости обработки данных при работе с базами данных.
Раскрытие изобретения
Поставленная задача решается, а требуемый технический результат при использовании изобретения достигается тем, что способ формирования и структурирования электронной базы данных, реализуется с помощью системы управления базой данных и/или с помощью языков программирования посредством электронного устройства согласно следующим этапам: а) данные организуют в таблицу или таблицы с необходимой структурой, которая содержит, по крайней мере, один столбец для конечного идентификатора числовых значений и/или индекса, однозначно указывающего на конечный идентификатор числовых значений; б) создают таблицу, содержащую, по крайней мере, один столбец, и формируют в строках, по крайней мере, два базовых элемента идентификатора, один из которых определяет вид числового значения идентификатора; при этом столбец базового элемента идентификатора имеет текстовый тип данных, позволяющий хранить данные в виде набора символов естественного языка и/или иных символов, поддерживаемых электронными базами данных; в) используют таблицу, созданную на этапе б), с добавлением, по крайней мере, одного столбца или создают другую таблицу, содержащую, по крайней мере, Два столбца, и формируют в строках одной из указанных таблиц предварительный идентификатор, основанный на базовых элементах идентификатора, сформированных на этапе б), таким образом, чтобы строки отражали состав предварительного идентификатора в виде соотношения один предварительный идентификатор ко многим базовым элементам; при этом столбец предварительных идентификаторов имеет текстовый тип данных, позволяющий хранить данные в виде набора символов естественного языка и/или иных символов, поддерживаемых электронными базами данных; г) посредством конкатенации предварительного идентификатора с разделителем и/или с базовым элементом идентификатора, выражающего тип, определяющий вид числового значения, генерируют конечный идентификатор, основанный на сформированных на этапах б), в) значениях базовых элементов идентификатора, так чтобы, по крайней мере, один из них определял вид числового значения; д) на основе сгенерированных на этапе г) конечных идентификаторов формируют строки таблицы или таблиц, созданных на этапе а), чем закрепляют числовые значения за конечными идентификаторами в виде соотношения один конечный идентификатор ко многим числовым значениям, позволяющего определить их прямую взаимосвязь с объектом идентификации.
Сущность изобретения
Изобретение является способом построения/оптимизации организационной структуры данных предприятий/обществ, нуждающихся в последовательной обработке информации, и требующих тщательного анализа числовых данных.
Таблица базовых элементов идентификатора
Целью создания таблицы базовых элементов идентификатора является хранение и формирование базовых элементов идентификатора в базе данных. Таблица базовых элементов идентификатора носит условное название "Алфавит" в данном описании изобретения и содержит пять столбцов/колонок, достаточных для построения семантического идентификатора числовых данных.
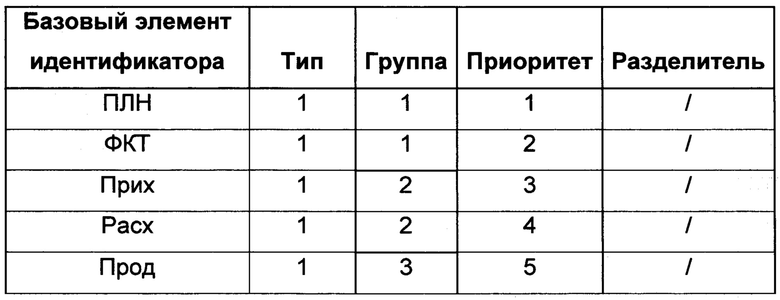
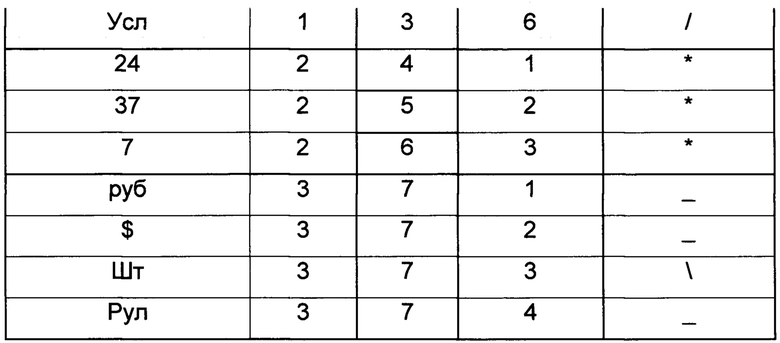
Таблица 1 - Пример заполнения таблицы базовых элементов идентификатора
Столбец базового элемента идентификатора имеет текстовый тип данных, позволяющий хранить данные в виде набора символов естественного языка и/или иных символов, поддерживаемых электронными базами данных. Столбцы типа, группы и приоритета могут иметь текстовый, цифровой, либо пользовательский тип данных, в зависимости от реализации изобретения, не могут иметь тип данных в виде даты или логических типов. Первый столбец содержит текстовое выражение базового элемента идентификатора, второй столбец содержит текстовое и/или цифровое выражение типа базового элемента идентификатора, третий столбец содержит текстовое и/или цифровое выражение групповой принадлежности базового элемента идентификатора, четвертый столбец содержит текстовое и/или цифровое выражение порядкового номера базового элемента идентификатора в пределах типа и имеет смысл приоритетного отношения между типами, пятый столбец содержит текстовое и/или цифровое выражение символа разделителя базового элемента идентификатора. Столбцы/колонки типа, группы, приоритета и разделителя могут отсутствовать в различных реализациях изобретения, при этом столбец базового элемента идентификатора присутствует всегда.
Базовый элемент идентификатора
Выражением базового элемента идентификатора является совокупность символов естественного языка и/или иных символов, поддерживаемых электронными базами данных. Базовый элемент идентификатора носит условное название "Буква" в данном описании изобретения. "Буква" может нести функцию групповой принадлежности, описательную функцию, функцию конечной идентификации вида числового значения, закрепляемого за идентификатором (таблица 2) и/или иные функции предусмотренные реализацией изобретения.
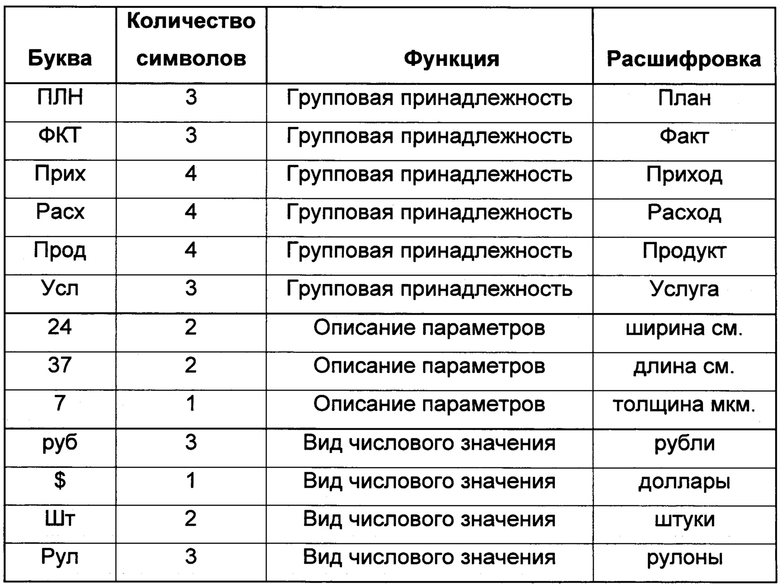
Таблица 2 - Примеры базовых элементов идентификатора - "Букв"
Примеры в таблице 2 приведены для понимания в пределах данного описания, и проведения аналогий в случае схожих применений, в различных реализациях изобретения "Буквы" могут быть сформированы в любом составе и количестве, но всегда выполняют указанные в данном описании функции.
Тип "Буквы"
Тип "Буквы" может быть сформирован на основе функциональной принадлежности, либо на основе иных нужд/предпочтений разработчика/пользователя базы данных, при этом тип, выполняющий функцию определения вида числового значения, создается всегда (примеры - таблица 2, строки 10-14) и является определяющим для формирования конечного идентификатора и привязки числовых данных. Тип "Буквы" может быть выражен в цифровом и/или ином виде, поддерживаемом полями столбца таблицы базы данных, и определяет первичную группировку и сортировку "Букв" для целей дальнейшего построения семантического идентификатора.
Группа "Буквы"
Группа "Буквы" формируется на основе нужд/предпочтений разработчика/пользователя базы данных и может быть выражена в цифровом и/или ином виде, поддерживаемом полями столбца таблицы базы данных, и определяет вторичную группировку "Букв" для целей дальнейшего построения семантического идентификатора. В различных реализациях изобретения столбец группы может иметь иные функции либо отсутствовать.
Приоритет "Буквы"
Приоритет "Буквы" формируется на основе нужд/предпочтений разработчика/пользователя базы данных и может быть выражен в цифровом и/или ином виде, поддерживаемом полями столбца таблицы базы данных и выполняет функцию порядковой сортировки в пределах типа в конечном идентификаторе. В различных реализациях изобретения столбец приоритета может иметь иные функции либо отсутствовать.
Разделитель "Буквы"
Разделитель "Буквы "формируется на основе нужд/предпочтений разработчика/пользователя базы данных и может быть выражен в цифровом и/или ином виде, поддерживаемом полями столбца таблицы базы данных, и несет функцию визуального разделения "Букв" в идентификаторе. В различных реализациях изобретения разделитель может быть выражен одним или несколькими символами для всех "Букв", либо определенным заранее в коде приложения символом/символами, либо отсутствовать.
Таблица построения предварительных идентификаторов
Целью создания таблицы построения предварительных идентификаторов является формирование и хранение предварительных идентификаторов в базе данных. Таблица построения предварительных идентификаторов носит условное название "Словарь" в данном описании изобретения и содержит шесть столбцов, достаточных для построения семантического идентификатора цифровых данных и его дальнейшего хранения в базе данных.
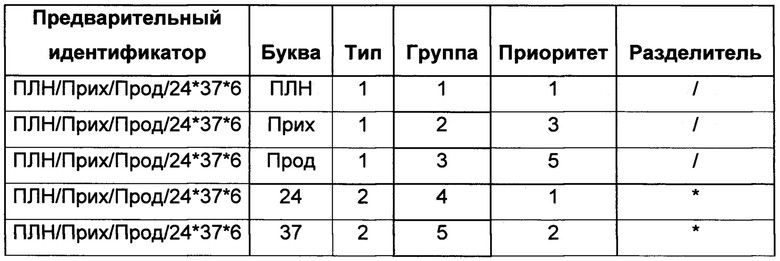

Таблица 3 - Примеры предварительных идентификаторов - "Слов"
Первый столбец таблицы предварительных идентификаторов имеет текстовый тип данных, позволяющий хранить данные в виде набора символов естественного языка и иных символов поддерживаемых электронными базами данных. Остальные пять столбцов - базового элемента идентификатора, типа, группы, приоритета и разделителя аналогичны столбцам/колонкам таблицы базовых элементов идентификатора, и подчиняются тем же правилам формирования. Столбцы типа, группы, приоритета и разделителя могут отсутствовать в различных реализациях изобретения, при этом столбец базового элемента идентификатора и столбец предварительного идентификатора присутствуют всегда.
Предварительный идентификатор
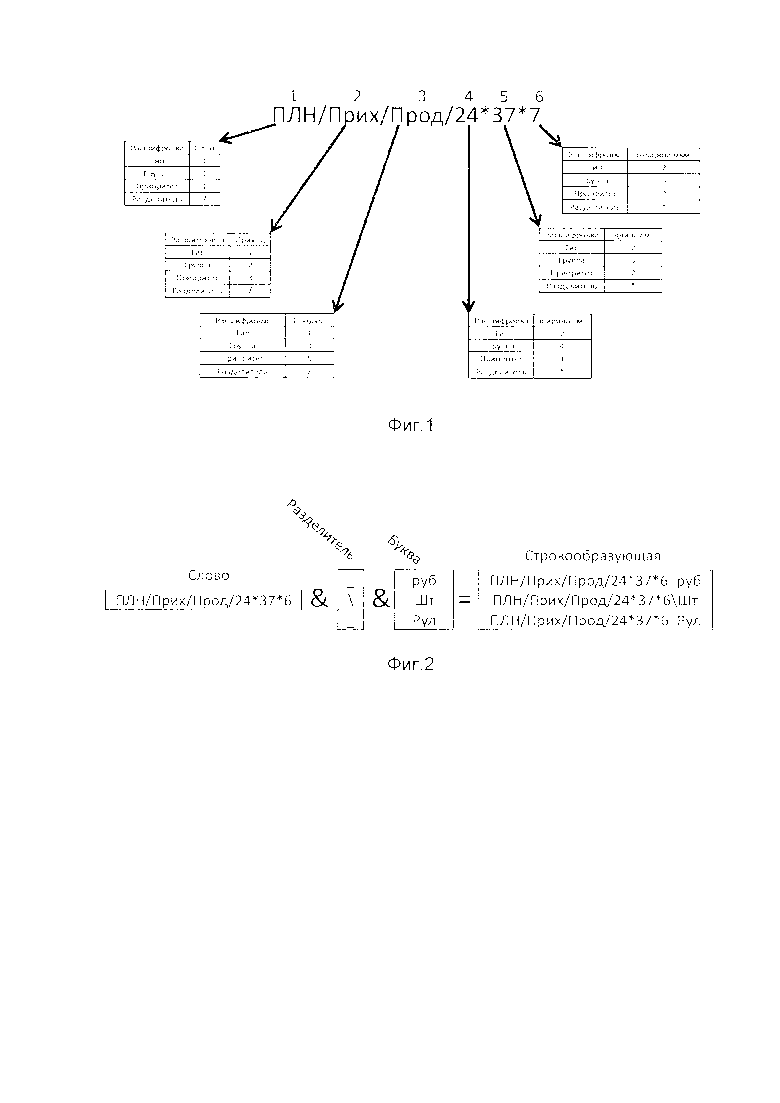
Выражением предварительного идентификатора служит совокупность сформированных в "Алфавите" (таблице базовых элементов идентификатора) элементов ("Букв") и разделителей, объединенных посредством операции конкатенации в коде приложения, либо коде базы данных, либо соединенных вручную, с использованием сортировки сначала по Типу, затем по Приоритету (либо же сортировка может не осуществляться), при помощи выбора по одному/нескольким элементам ("Буквам") в пределах Группы. "Буквы" определяющие вид числового значения не присоединяются к предварительному идентификатору. Предварительный идентификатор носит условное название "Слово" в данном описании изобретения. Результатом формирования "Слова" является текстовое выражение, позволяющее точно идентифицировать объект исчисления, его групповую принадлежность, свойства и вид числовых значений в дальнейших операциях со строками/ячейками базы данных (фиг. 1).
Прочие столбцы "Словаря"
Остальные столбцы словаря выполняют функцию закрепления за "Словом" (предварительным идентификатором) "Букв" (базовых элементов идентификатора) и дальнейшего хранения сформированной структуры в базе данных. В различных реализациях изобретения могут отсутствовать столбцы Типа, Группы, Приоритета и Разделителя, но столбцы предварительного идентификатора и "Букв" присутствуют всегда.
Построение конечного идентификатора и привязка числовых значений.
Предварительный идентификатор "Слово" позволяет визуально определять объекты исчисления в базах данных, и имеет неоспоримые преимущества по сравнению с традиционной идентификацией в виде числовых артикулов/индексов и/или идентификаторов, поскольку является семантически читаемым, не требующим дополнительной расшифровки его смысла, групповых принадлежностей, и свойств объекта им идентифицируемого. Вместе с тем позволяет выполнять те же функции, что и традиционные артикулы/индексы/идентификаторы, выражаемые цифровой кодировкой, как то - уникальная идентификация строк базы данных, обращение в запросах на языках SQL и NoSQL.
Конечный идентификатор
Само "Слово" идентифицирует объект исчисления, но не вид исчисления как такового, поэтому для формирования конечного идентификатора и привязки к нему числовых данных производится конкатенация "Слова" с разделителем "Буквы", выражающей тип, определяющий вид числового значения, либо с разделителем, определенным в коде приложения/базы данных, в случае если присутствие разделителя определено пользователем/разработчиком, а затем с самой "Буквой" определяющей вид числового значения (таблица 2, строки 10-14). Конкатенация производится в коде приложения, либо коде базы данных, либо вручную. Таким образом на одно "Слово" приходится ровно столько конечных идентификаторов, сколько типов числового значения было определено в структуре "Слова" (фиг. 2.).
Конечный идентификатор носит условное название "Строкообразующая" в данном описании изобретения. "Строкообразующая" несет функцию уникальной идентификации массива числовых значений для целей фильтрации, группировки, сортировки и осуществления математических операций над элементами массива. Массив числовых данных может быть выражен в любом виде, позволяющем хранить числовые данные в цифровом виде на носителях информации ЭВМ.
Для хранения "Строкообразующих" может быть создана отдельная таблицы/таблицы, либо возможна их генерация "на лету" в коде приложения/базы данных.
Привязка числовых данных
Под привязкой числовых данных понимается соотношение конечного идентификатора ("Строкообразующей") с набором числовых данных, позволяющее определить их прямую взаимосвязь с объектом идентификации. Под объектом идентификации понимается любой материальный/нематериальный объект, который может быть выражен численно.
Привязка числовых данных осуществляется при помощи организации четкой взаимосвязи числовых данных со "Строкообразующей" в таблицах/коде базы данных, либо коде приложения.
Взаимосвязь числовых данных со "Строкообразующей" может быть организована посредством хранения числовых данных в одной строке таблицы со "Строкообразующей", посредством построения многоступенчатой связи из идентификаторов/артикулов/индексов и/или их комбинаций, хранящихся в строках таблиц базы данных и достоверно определяющих связь числовых данных со "Строкообразующей", посредством сохранения в коде приложения/базы данных "Строкообразующей", ее "Букв" и/или их совокупности, и создания на их основе таблиц и их строк/столбцов. В различных реализациях возможны иные способы организации взаимосвязи числовых данных со "Строкообразующей", но во всех случаях данная взаимосвязь всегда определяется достоверно.
Осуществление изобретения
Способ реализуют следующим образом.
Принимают решение о целях расчетной системы будущей базы данных/приложения, например, ведение складского учета, финансовое планирование, комплексный анализ деятельности предприятия. Исходя из принятого решения, определяют массивы числовых данных, требующие структуризации, например: план продаж, отчет по продажам, сведение плана с фактом продаж. Определяют требуемые параметры фильтрации, группировки, сортировки, например: изометрические пропорции товара (ширина, длина, толщина и т.п.), направление перемещения (приход, расход), вид данных об объекте (план, факт). Определяют требуемые виды исчисления, например, рубли, штуки, килограммы.
С помощью СУБД, и ее средств и/или внешних средств работы с СУБД (например, ODBC драйвер) создания/кодирования таблиц, создают таблицы, необходимые для реализации целей по принятому решению, например, как следующая таблица:

Таблица 4 - Пример целевой таблицы "Наличие товара на складе с учетом остатка в цеху"
В данном примере слово идентифицирует числовые данные как план прихода продукта в рублевом, штучном и упаковочном (рулон) выражении. Как видно на примере, при использовании семантического идентификатора, отпадает надобность в создании отдельных таблиц по плану, факту, приходу, расходу, и расшифровкам артикула, все эти функции выполняет сам идентификатор, позволяющий точно идентифицировать данные. Например, вместо "Буквы" ПЛН - план, может быть использована "Буква" ФКТ - факт, и тогда строки будут идентифицировать фактические данные. Находясь в одной таблице, такие "Строкообразующие" позволят с легкостью получить отчетные результаты по схождению плана с фактом, путем выполнения простых SQL запросов, при этом одного взгляда на "Строкообразующую" достаточно, чтобы определить какие именно данные она идентифицирует. Единственное необходимое условие для реализации идентификации - присутствие в целевых таблицах столбца, содержащего "Строкообразующие" или какой-либо индекс, указывающий на "Строкообразующую", в случае, если разработчик/пользователь решит использовать дополнительную индексацию, что также допустимо.
После осуществления выбора состава и структуры целевой таблицы/таблиц и ее/их создания, формируют таблицу базовых элементов идентификатора ("Алфавит") и таблицу предварительных идентификаторов ("Словарь"). Формируют базовые элементы ("Буквы") в таблице "Алфавит", и указывают типы, групповые принадлежности, приоритеты и разделители, согласно правилам формирования, указанным в подразделе описания "Таблица базовых элементов идентификатора". Затем, на основе значений, заполненной таблицы "Алфавит", в таблице "Словарь" формируют предварительные идентификаторы ("Слова"), согласно правилам формирования, указанным в подразделе описания "Таблица построения предварительных идентификаторов". После того как сформированы обе таблицы, производится генерация конечного идентификатора "Строкообразующей", согласно правилам формирования, указанным в подразделе описания "Построение конечного идентификатора и привязка числовых значений".
Таким образом, при использовании принципа построения "Строкообразующих", все операции с данными, относящимися к объектам идентификации, получают единый идентификатор, позволяющий точно определять принадлежность данных и их признаков к объекту идентификации, без лишнего увеличения объемов базы данных и алгоритмических цепочек, а также за счет оптимизации процессов выборки, что приведет к повышению быстродействия программного обеспечения и значительному увеличению скорости обработки базы данных с ним связанных.
Небольшое количество операций, таблиц, отсутствие множественных дубликатов значений, применение конечных идентификаторов "Строкообразующих" обеспечивают упрощение работы с базой данных, уменьшение значимости человеческого фактора, а, следовательно, уменьшение человеческих ошибок.
Также использование для столбца базового элемента идентификатора и столбца предварительных идентификаторов текстового типа данных, позволяющего хранить данные в виде набора символов естественного языка и/или иных символов, поддерживаемых электронными базами данных, как и применение конечных идентификаторов "Строкообразующих", позволяет визуально определять объекты исчисления, виды числовых значений и в результате обеспечивать более удобное визуальное восприятие идентификаторов и их распознавание при расчетах и других действиях с числовыми значениями.
Таким образом, признаки, характеризующие то, что создают таблицу, содержащую, по крайней мере, один столбец, и формируют в строках, по крайней мере, два базовых элемента идентификатора, один из которых определяет вид числового значения идентификатора; при этом столбец базового элемента идентификатора имеет текстовый тип данных, позволяющий хранить данные в виде набора символов естественного языка и/или иных символов, поддерживаемых электронными базами данных; в) используют таблицу, созданную на этапе б), с добавлением, по крайней мере, одного столбца или создают другую таблицу, содержащую, по крайней мере, два столбца, и формируют в строках одной из указанных таблиц предварительный идентификатор, основанный на базовых элементах идентификатора, сформированных на этапе б), таким образом, чтобы строки отражали состав предварительного идентификатора в виде соотношения один предварительный идентификатор ко многим базовым элементам; при этом столбец предварительных идентификаторов имеет текстовый тип данных, позволяющий хранить данные в виде набора символов естественного языка и/или иных символов, поддерживаемых электронными базами данных; г) посредством конкатенации предварительного идентификатора с разделителем и/или с базовым элементом идентификатора, выражающего тип, определяющий вид числового значения, генерируют конечный идентификатор, основанный на сформированных на этапах б), в) значениях базовых элементов идентификатора, так чтобы, по крайней мере, один из них определял вид числового значения; д) на основе сгенерированных на этапе г) конечных идентификаторов формируют строки таблицы или таблиц, созданных на этапе а), чем закрепляют числовые значения за конечными идентификаторами в виде соотношения один конечный идентификатор ко многим числовым значениям, позволяющего определить их прямую взаимосвязь с объектом идентификации, являются существенными с точки зрения технического результата, а именно с точки зрения обеспечения более удобного визуального восприятия идентификаторов и их распознавания при расчетах и других действиях с числовыми значениями в базах данных, упрощения работы с базой данных, уменьшения значимости человеческого фактора, а, следовательно, уменьшения человеческих ошибок, а также повышения быстродействия программного обеспечения и значительное увеличение скорости обработки данных при работе с базами данных.
Таким образом, обеспечивается достижение требуемого технического результата, а именно обеспечение более удобного визуального восприятия идентификаторов и их распознавания при расчетах и других действиях с числовыми значениями в базах данных, упрощение работы с базой данных, уменьшение значимости человеческого фактора, а, следовательно, уменьшение человеческих ошибок, а также повышение быстродействия программного обеспечения и значительное увеличение скорости обработки данных при работе с базами данных.
Реализации заявляемого изобретения имеют, по меньшей мере, один из вышеупомянутых объектов и/или аспектов, но необязательно содержат все из них. Следует понимать, что некоторые аспекты настоящего изобретения, которые возникли в результате попыток достичь вышеупомянутого объекта реализации, могут не удовлетворять этому объекту и/или могут удовлетворять другим объектам, не указанным здесь конкретно.
Указанный порядок заполнения строк и столбцов дан в качестве примера и служит для целей описания сущности изобретения. В каждом конкретном случае порядок строк и столбцов и порядок их заполнения может быть иным в зависимости решений разработчика/пользователя.
Изобретение может быть реализовано с использованием любых электронных устройств, позволяющих устанавливать и запускать программное обеспечение, например, персональные компьютеры, смартфоны, планшеты, ноутбуки.
Изобретение может быть реализовано как с применением клиент-серверной технологии организации пользовательских интерфейсов, так и в локальных приложениях, при этом сервер и клиент могут представлять из себя как аппаратный комплекс, так и программный, например, разделение физических электронных устройств на клиент и сервер, либо разделение программных продуктов на клиент и сервер.
Изобретение может быть реализовано с использованием любых реляционных и нереляционных СУБД, поддерживающих хранение таблиц и текстовых и/или числовых данных в них, например - MySQL, Microsoft Access, Oracle Database, Hbase и др.
Изобретение может быть реализовано с использованием любых языков программирования, как низкого так и высокого уровня, например, Assembler, С++, Visual basic, Java, PHP и др.
В контексте данного описания таблицы, созданные в рамках способа структурирования данных, представляющего собой распределение данных по строкам и столбцам, могут быть реализованы с помощью средств СУБД либо языков программирования.
В контексте данного описания конкатенация - операция склеивания объектов линейной структуры. Например, конкатенация слов «микро» и «мир» даст слово «микромир».
В контексте данного описания, SQL (structured query language) -формальный непроцедурный язык программирования, применяемый для создания, модификации и управления данными в произвольной реляционной базе данных, управляемой соответствующей системой управления базами данных (СУБД).
В контексте данного описания, NoSQL - термин, обозначающий ряд подходов, направленных на реализацию хранилищ баз данных, имеющих существенные отличия от моделей, используемых в традиционных реляционных СУБД с доступом к данным средствами языка SQL.
В контексте данного описания интерфейс - это совокупность средств, при помощи которых пользователь взаимодействует с приложением, запущенным в аппаратном комплексе электронного устройства.
В контексте данного описания база данных - представленная в объективной форме совокупность самостоятельных данных.
В контексте данного описания система управления базой данных (СУБД) - совокупность программных и лингвистических средств общего или специального назначения, обеспечивающих управление созданием и использованием баз данных.
В контексте данного описания «электронное устройство» представляет собой любое компьютерное оборудование, которое может запускать программное обеспечение для соответствующей задачи. В контексте данного описания термин «электронное устройство» означает, что устройство может функционировать в качестве сервера для других электронных устройств, однако это не обязательно в отношении данного изобретения. Таким образом, некоторыми (не ограничивающими) примерами электронных устройств являются персональные компьютеры (настольные компьютеры, ноутбуки, нетбуки и т.д.), смартфоны и планшеты, а также сетевое оборудование, такое как маршрутизаторы, коммутаторы и шлюзы. Следует понимать, что в данном контексте тот факт, что устройство функционирует как электронное устройство, не означает, что оно не может функционировать в качестве сервера для других электронных устройств. Использование выражения «электронное устройство» не исключает использование нескольких электронных устройств при приеме/отправке, выполнении или вызове выполнения какой-либо задачи или запроса или последствий любой задачи или запроса или этапов любого описанного здесь способа.
Приведенные здесь примеры и условный язык в основном предназначены для того, чтобы помочь читателю понять принципы заявляемого изобретения и не ограничивать сферу его применения указанными примерами и условиями. Понятно, что специалисты в данной области техники могут разработать различные устройства, которые, хотя они явно не описаны или показаны здесь, тем не менее, воплощают принципы заявляемого изобретения и включены в его сущность и сферу применения.
Учитывая новизну совокупности существенных признаков, техническое решение поставленной задачи, изобретательский уровень и существенность всех общих и частных признаков изобретения, доказанных в разделе «Уровень техники» и «Раскрытие изобретения», доказанную в разделе «Осуществление изобретения» техническую осуществимость и промышленную применимость изобретения, решение поставленных изобретательских задач и уверенное достижение требуемого технического результата при реализации и использовании изобретения, по нашему мнению, заявленное изобретение удовлетворяет всем требованиям охраноспособности, предъявляемым к изобретениям.
Проведенный анализ показывает также, что все общие и частные признаки изобретения являются существенными, так как каждый из них необходим, а все вместе они не только достаточны для достижения цели изобретения, но и позволяют реализовать изобретение промышленным способом.
| название | год | авторы | номер документа |
|---|---|---|---|
| ЭЛЕКТРОННАЯ БАЗА ДАННЫХ И СПОСОБ ЕЁ ФОРМИРОВАНИЯ | 2017 |
|
RU2650032C1 |
| СПОСОБ АВТОМАТИЧЕСКОГО АНАЛИЗА ВЫГРУЗОК ИЗ БАЗ ДАННЫХ | 2024 |
|
RU2821442C1 |
| Способ оптического распознавания текстовых строк, основанный на полносверточной ИНС, квазисимвологиях и динамическом программировании | 2024 |
|
RU2837307C1 |
| СПОСОБЫ И СИСТЕМЫ ЭФФЕКТИВНОГО АВТОМАТИЧЕСКОГО РАСПОЗНАВАНИЯ СИМВОЛОВ С ИСПОЛЬЗОВАНИЕМ ЛЕСА РЕШЕНИЙ | 2014 |
|
RU2582064C1 |
| ОТОБРАЖЕНИЕ МОДЕЛИ ФАЙЛОВОЙ СИСТЕМЫ В ОБЪЕКТ БАЗЫ ДАННЫХ | 2006 |
|
RU2409847C2 |
| ОБФУСКАЦИЯ ПОЛЬЗОВАТЕЛЬСКОГО КОНТЕНТА В СТРУКТУРИРОВАННЫХ ФАЙЛАХ ПОЛЬЗОВАТЕЛЬСКИХ ДАННЫХ | 2018 |
|
RU2772300C2 |
| УСТРОЙСТВА И СПОСОБЫ, КОТОРЫЕ СТРОЯТ ИЕРАРХИЧЕСКИ УПОРЯДОЧЕННУЮ СТРУКТУРУ ДАННЫХ, СОДЕРЖАЩУЮ НЕПАРАМЕТРИЗОВАННЫЕ СИМВОЛЫ, ДЛЯ ПРЕОБРАЗОВАНИЯ ИЗОБРАЖЕНИЙ ДОКУМЕНТОВ В ЭЛЕКТРОННЫЕ ДОКУМЕНТЫ | 2013 |
|
RU2625533C1 |
| СПОСОБ И СИСТЕМА ОПРЕДЕЛЕНИЯ ОРИЕНТАЦИИ ИЗОБРАЖЕНИЯ ТЕКСТА | 2015 |
|
RU2626656C2 |
| СПОСОБ УПРАВЛЕНИЯ АВТОМАТИЗИРОВАННОЙ СИСТЕМОЙ ПРАВОВЫХ КОНСУЛЬТАЦИЙ | 2019 |
|
RU2718978C1 |
| РАСШИРЯЕМЫЙ ЯЗЫК ЗАПРОСОВ С ПОДДЕРЖКОЙ ДЛЯ РАСШИРЕНИЯ ТИПОВ ДАННЫХ | 2007 |
|
RU2434276C2 |
Изобретение относится к способу формирования и структурирования базы данных. Технический результат - увеличение скорости обработки данных при работе с базами данных. Данные организуют в таблицу или таблицы с необходимой структурой, которая содержит, по крайней мере, один столбец для конечного идентификатора числовых значений и/или индекса, однозначно указывающего на конечный идентификатор числовых значений. Создают таблицу, содержащую, по крайней мере, один столбец, и формируют в строках, по крайней мере, два базовых элемента идентификатора, один из которых определяет вид числового значения идентификатора. Используют таблицу с добавлением, по крайней мере, одного столбца или создают другую таблицу, содержащую, по крайней мере, два столбца, и формируют в строках одной из указанных таблиц предварительный идентификатор, основанный на базовых элементах идентификатора таким образом, чтобы строки отражали состав предварительного идентификатора в виде отношения один предварительный идентификатор ко многим базовым элементам. Посредством конкатенации предварительного идентификатора с разделителем и/или с базовым элементом идентификатора генерируют конечный идентификатор, основанный на значениях базовых элементов идентификатора, так чтобы, по крайней мере, один из них определял вид числового значения. На основе сгенерированных конечных идентификаторов формируют строки таблицы или таблиц, чем закрепляют числовые значения за конечными идентификаторами в виде отношения один конечный идентификатор ко многим числовым значениям, позволяющего определить их прямую взаимосвязь с объектом идентификации. 2 ил., 4 табл.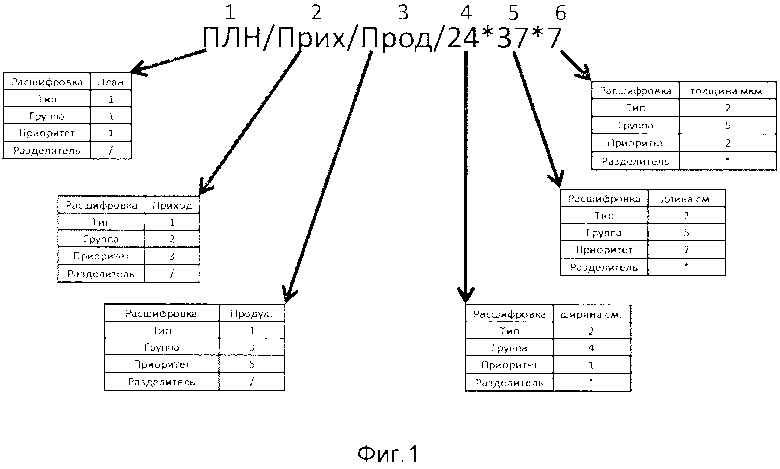
Способ формирования и структурирования электронной базы данных, реализуемый с помощью системы управления базой данных и/или с помощью языков программирования посредством электронного устройства согласно следующим этапам:
а) данные организуют в таблицу или таблицы с необходимой структурой, которая содержит, по крайней мере, один столбец для конечного идентификатора числовых значений и/или индекса, однозначно указывающего на конечный идентификатор числовых значений;
б) создают таблицу, содержащую, по крайней мере, один столбец, и формируют в строках, по крайней мере, два базовых элемента идентификатора, один из которых определяет вид числового значения идентификатора; при этом столбец базового элемента идентификатора имеет текстовый тип данных, позволяющий хранить данные в виде набора символов естественного языка и/или иных символов, поддерживаемых электронными базами данных;
в) используют таблицу, созданную на этапе б), с добавлением, по крайней мере, одного столбца или создают другую таблицу, содержащую, по крайней мере, два столбца, и формируют в строках одной из указанных таблиц предварительный идентификатор, основанный на базовых элементах идентификатора, сформированных на этапе б), таким образом, чтобы строки отражали состав предварительного идентификатора в виде отношения один предварительный идентификатор ко многим базовым элементам; при этом столбец предварительных идентификаторов имеет текстовый тип данных, позволяющий хранить данные в виде набора символов естественного языка и/или иных символов, поддерживаемых электронными базами данных;
г) посредством конкатенации предварительного идентификатора с разделителем и/или с базовым элементом идентификатора, выражающего тип, определяющий вид числового значения, генерируют конечный идентификатор, основанный на сформированных на этапах б), в) значениях базовых элементов идентификатора, так чтобы, по крайней мере, один из них определял вид числового значения;
д) на основе сгенерированных на этапе г) конечных идентификаторов формируют строки таблицы или таблиц, созданных на этапе а), чем закрепляют числовые значения за конечными идентификаторами в виде отношения один конечный идентификатор ко многим числовым значениям, позволяющего определить их прямую взаимосвязь с объектом идентификации.
| ЭЛЕКТРОННАЯ БАЗА ДАННЫХ И СПОСОБ ЕЁ ФОРМИРОВАНИЯ | 2017 |
|
RU2650032C1 |
| СПОСОБ И СИСТЕМА ОРГАНИЗАЦИИ И ФУНКЦИОНИРОВАНИЯ БАЗЫ ДАННЫХ НОРМАТИВНОЙ ДОКУМЕНТАЦИИ | 2008 |
|
RU2386166C2 |
| US 6505205 B1, 07.01.2003 | |||
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |

