Изобретение относится к средствам цифрового кодирования речевых сигналов и предназначено для их компактного представления в целях передачи и хранения.
Известен способ преобразования речи [Дж.Д.Маркел, А.X.Грэй. Линейное предсказание речи/Под ред. Ю.Н.Прохорова и B.C.Звездина. - М.: Связь, 1980, стр. 238-258; Y.Linde, A.Buzo, R.M. Gray. An Algorithm for Vector Quantizer Design// IEEE Transactions on Communication, vol. COM-28, N 1, January 1980, pp. 84-95], заключающийся в том, что идентифицируют вектор параметров огибающей спектра и параметров функции возбуждения методом кодирования с линейным предсказанием с последующим векторным квантованием вектора параметров огибающей спектра на передающей стороне, а также векторным деквантованием канального символа номера эталонного вектора восстановления с последующим синтезом речевого сигнала на основании значения компонентов вектора восстановления и параметров функции возбуждения. Идентификация вектора параметров огибающей спектра и параметров функции возбуждения при методе кодирования с линейным предсказанием осуществляется на временном интервале длительностью τ (длительность кадра). Длительность временного интервала τ выбирается из условия квазистационарности параметров речевого сигнала. Типичное значение длительности выбирается в диапазоне от 20 до 30 миллисекунд. После идентификации вектора параметров огибающей спектра данный вектор подвергается процедуре векторного квантования α′(•), в процессе которой ему ставится в соответствие канальный символ с номера эталонного вектора восстановления из конечного набора, обеспечивающий минимальное значение расстояния между входным вектором и вектором восстановления:
c = α′(a),
где a - вектор параметров огибающей спектра;
с - канальный символ.
Процедура векторного деквантования β′(•) зaключaeтcя в определении вектора восстановления a' в зависимости от значения пришедшего канального символа c*: a* = β′(c*). Недостатком данного способа является отсутствие учета межкадровых зависимостей речевого сигнала, что приводит к низкому уровню качества синтезированного сигнала и невысокому уровню коэффициента компрессии.
Известно устройство преобразования речи [Дж.Д.Маркел, А.X. Грэй. Линейное предсказание речи/ Под ред. Ю.Н. Прохорова и B.C. Звездина. - М.: Связь, 1980, стр. 238-258; Y. Linde, A. Buzo, R.M. Gray. An Algorithm for Vector Quantizer Design// IEEE Transactions on Communication, vol. COM-28, No. 1, January 1980, pp. 84-95], состоящее из последовательно соединенных кодера с линейным предсказанием, векторного квантователя, линий связи, векторного деквантователя и декодера с линейным предсказанием, которое реализует описанный выше способ. К недостаткам данного устройства относится: необходимость применения высокопроизводительного процессора для обеспечения работы в реальном масштабе времени ввиду большого количества векторов восстановления, не менее 1024 - 2048 векторов, среди которых необходимо определять эталонный вектор в каждом кадре; необходимость, по той же причине, применения элементной базы постоянной и оперативной памяти с высоким быстродействием; нерациональное использование пропускной способности линий связи вследствие завышения требуемой битовой скорости передачи при заданном уровне искажений.
Известен способ преобразования речи [Дж.Д. Маркел, А.X. Грэй. Линейное предсказание речи/Под ред. Ю. Н. Прохорова и B.C. Звездина. - М.: Связь, 1980, стр. 238-258; М.О. Dunham, R.M. Gray. An Algorithm for the Design of Labeled-Transition Finite-State Vector Quantization/ IEEE Transactions on Communication, vol. COM-33, No. 1, January 1985, pp. 83-89], который позволяет несколько улучшить качество передачи речи вследствие учета межкадровых линейных и нелинейных зависимостей в спектральных характеристиках речевого сигнала. Данный способ выбран в качестве прототипа и заключается в том, что идентифицируют вектор параметров огибающей спектра и параметры функции возбуждения методом кодирования с линейным предсказанием, осуществляют векторное квантование с конечным числом состояний, равным N, вектора параметров огибающей спектра на передающей стороне, а также векторное деквантование с конечным числом состояний, равным N, канального символа номера эталонного вектора восстановления с последующим синтезом речевого сигнала на основании значения компонентов вектора восстановления и параметров функции возбуждения. Идентификация вектора параметров огибающей спектра и параметров функции возбуждения при методе кодирования с линейным предсказанием осуществляется на временном интервале длительностью τ (длительность кадра). После идентификации вектора параметров огибающей спектра данный вектор подвергается процедуре векторного квантования с конечным числом состояний α(•), в процессе которой ему ставится в соответствие канальный символ с номера эталонного вектора восстановления из конечного набора, обеспечивающий минимальное значение расстояния между входным вектором и вектором восстановления:
c = α(a,Sn),
где a - вектор параметров огибающей спектра;
Sn - номер текущего состояния векторного квантователя, S = 1, 2,..., N;
N - число состояний квантователя;
n - номер рассматриваемого кадра;
с - канальный символ.
После этого определяется номер следующего состояния Sn+1 согласно функции следующего состояния Sn+1 = fcc(Sn, c). Так как функция следующего состояния fcc определяет номер следующего состояния в зависимости от номера текущего состояния и значения канального символа, то последовательность состояний может быть точно отслежена векторным деквантователем с конечным числом состояний в случае отсутствия ошибок в канале связи. Процедура векторного деквантования с конечным числом состояний β(•) заключается в определении вектора восстановления a* в зависимости от значения пришедшего канального символа c* и номера текущего состояния S
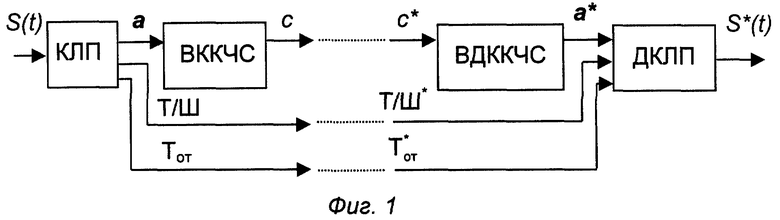
Известно устройство преобразования речи [Дж.Д. Маркел, А.X. Грэй. Линейное предсказание речи/ Под ред. Ю.Н. Прохорова и B.C. Звездина. - М.: Связь, 1980, стр. 238-258, М.О. Dunham, R.M. Gray. An Algorithm for the Design of Labeled-Transition Finite-State Vector Quantization// IEEE Transactions on Communication, vol. COM-33, N 1, January 1985, pp. 83-89], изображенное на фиг. 1, наиболее близкое к предлагаемому, выбранное в качестве прототипа и состоящее из кодера с линейным предсказанием (КЛП), векторного квантователя с конечным числом состояний (ВККЧС), линий связи, векторного деквантователя с конечным числом состояний (ВДККЧС) и декодера с линейным предсказанием (ДКЛП). Поступающий на вход КЛП аналоговый речевой сигнал S(t) дискретизуется по времени и квантуется по уровню. После этого на временном интервале, соответствующем длительности кадра τ, осуществляется идентификация вектора параметров огибающей спектра a и выделение параметров функции возбуждения. Количество и тип параметров огибающей спектра в зависимости от типа КЛП может быть разным. Функция возбуждения в простейшем случае представляется набором из двух параметров: тон/шум (Т/Ш) и высота основного тона (Тот), однако при любом представлении функции возбуждения необходимо выделять параметр тон/шум. Первый выход КПП (вектор параметров огибающей спектра a) соединен с входом ВККЧС, который ставит в соответствие входному вектору а канальный символ c, передаваемый в линию связи совместно с параметрами функции возбуждения (Т/Ш и Тот). Принятый по линии связи канальный символ с* поступает на вход ВДККЧС, в котором определяется соответствующий ему вектор восстановления a*. Выход ВДККЧС соединен с первым входом ДКПП. Принятые по каналу связи параметры тон/шум (Т/Ш*) и высота основного тона (T
Основной задачей, решаемой предлагаемыми способом преобразования речи и устройством, является повышение качества синтезированного речевого сигнала без увеличения битовой скорости передачи.
Указанный технический результат достигается тем, что в известном способе, заключающемся в том, что идентифицируют вектор параметров огибающей спектра, высоту основного тона и сигнал тон/шум в кодере с линейным предсказанием, формируют канальный символ вектора параметров огибающей спектра в векторном квантователе, передают канальный символ, высоту основного тона и сигнал тон/шум по линиям связи, затем формируют вектор восстановления на основании значения канального символа в векторном деквантователе и синтезируют речевой сигнал на основании значения вектора восстановления, высоты основного тона и сигнала тон/шум в декодере с линейным предсказанием, формирование же канального символа в векторном квантователе и вектора восстановления в векторном деквантователе производится с учетом значения сигнала тон/шум.
Указанный технический результат достигается тем, что в известном устройстве преобразования речи, содержащем кодер с линейным предсказанием (КЛП) с аналоговым входом и тремя выходами: для вектора параметров огибающей спектра, сигнала тон/шум и высоты основного тона, первый из которых через векторный квантователь речевых сигналов с конечным числом состояний (ВККЧС), линию связи и векторный деквантователь речевых сигналов с конечным числом состояний (ВДККЧС) связан с входом для вектора восстановления декодера с линейным предсказанием (ДКЛП), а два других через соответствующие линии связи - с соответствующими остальными выходами ДКЛП, причем ВККЧС состоит из векторных квантователей состояний (ВКС) по числу состояний ВККЧС, входы которых соединены с соответствующими выходами решающего устройства выбора ВКС (РУк1), вход которого является входом ВККЧС, а выходы ВКС соединены с соответствующими входами решающего устройства выбора канального символа (РУк2), управляющий вход для сигнала номера текущего состояния которого соединен с соответствующими входами РУк1 и блока определения номера следующего состояния (БОС) и через блок задержки на длительность кадра (Т) - с выходом БОС, второй управляющий вход которого соединен с выходом РУк2 и является выходом ВККЧС, ВДККЧС состоит из векторных деквантователей (ВДКС) по числу состояний ВДККЧС, входы которых соединены с соответствующими выходами решающего устройства выбора ВДКС (РУдк1), вход которого является входом ВДККЧС, а выходы ВДКС соединены с соответствующими входами решающего устройства выбора вектора восстановления (РУдк2), выход которого является выходом ВДККЧС, управляющий вход для сигнала номера текущего состояния РУдк2 соединен с управляющими входами РУдк1, БОС и через блок задержки на длительность кадра Т - с выходом БОС, другой вход которого соединен с входом РУдк1, БОС квантователя ВККЧС и деквантователя ВДККЧС включает в себя блок определения адреса номера следующего состояния (БОА НСС), два входа которого являются управляющими входами БОС, БОС и каждый ВКС в составе ВККЧС имеют дополнительные входы, которые объединены и образуют дополнительный вход ВККЧС, соединенный с выходом сигнала тон/шум КЛП, также БОС и каждый ВДКС в составе ВДККЧС имеют дополнительные входы, которые объединены и образуют дополнительный вход ВДККЧС, соединенный со входом сигнала тон/шум ДКЛП.
Форма выполнения каждого ВКС в составе ВККЧС, обеспечивающая его дополнительным управляющим входом, заключается в том, что ВКС снабжен решающими устройствами выбора векторного квантователя (РУкс1) и выбора канального символа (РУкс2), двумя векторными квантователями: один для вокализованных (ВКВ), другой для невокализованных (ВКНВ) фрагментов речевого сигнала, причем вход РУкс1 является входом ВКС, а его выходы соединены с входами соответственно ВКВ и ВКНВ, выходы которых соединены с входами РУкс2, выход которого является выходом ВКС, управляющие же входы для сигнала тон/шум РУкс1 и РУкс2 объединены и образуют дополнительный вход ВКС (для подачи сигнала тон/шум).
Форма выполнения каждого ВДКС в составе ВДККЧС, обеспечивающая его дополнительным управляющим входом, заключается в том, что ВДКС снабжен решающими устройствами выбора векторного деквантователя (РУдкс1) и выбора вектора восстановления (РУдкс2), двумя векторными деквантователями: один для вокализованных (ВДКВ), другой для невокализованных (ВДКНВ) фрагментов речевого сигнала, причем вход РУдкс 1 является входом ВДКС, а его выходы соединены с входами соответственно ВДКВ и ВДКНВ, выходы которых соединены с входами РУдкс2, выход которого является выходом ВДКС, управляющие же входы для сигнала тон/шум РУдкс1 и РУдкс2 объединены и образуют дополнительный вход ВДКС (для подачи сигнала тон/шум).
Блоки задержки на длительность кадра Т в составе ВККЧС и ВДККЧС идентичны. Техническое решение построения блоков задержки на длительность 20 - 30 милисекунд имеет несколько известных вариантов и в простейшем случае может быть реализованно на регистре сдвига.
БОС в составе ВККЧС и ВДККЧС также идентичны и форма их выполнения, обеспечивающая их дополнительным управляющим входом, заключается в том, что БОС снабжен решающими устройствами определения блока памяти (РУ ОБП) и выбора номера состояния (РУ НС), двумя блоками памяти, имеющими матрицы номеров перехода состояний соответственно с вокализованных (БП ПС-В) и невокализованных (БП ПС-НВ) фрагментов речевого сигнала, выходы которых соединены с соответствующими входами РУ НС, выход которого является выходом БОС, а управляющий вход соединен с управляющим входом РУ ОБП и является дополнительным управляющим входом БОС (для подачи сигнала тон/шум). Вход РУ ОБП соединен с выходом БОА НСС, а его выходы - соответственно с входами БП ПС-В и БП ПС-НВ.
КЛП и ДКЛП по своей форме выполнения аналогичны используемым в прототипе [Дж. Д. Маркел, А.X.Грэй. Линейное предсказание речи/ Под ред. Ю.Н.Прохорова и B.C.Звездина. - М.: Связь, 1980, стр. 238 - 258].
Предлагаемые способ и устройство преобразования речи решают одну и ту же задачу - повышение качества синтезированного речевого сигнала без увеличения битовой скорости передачи, и устройство с вариантами выполнения его отдельных блоков позволяет реализовать этот способ, что свидетельствует о соблюдении требования единства изобретения.
На фиг. 1 изображена структурная схема устройства преобразования речи (прототип); на фиг.2 - структурная схема векторного квантователя с конечным числом состояний устройства прототипа; на фиг.3 - структурная схема векторного деквантователя с конечным числом состояний устройства прототипа; на фиг.4 - структурная схема блока определения номера следующего состояния устройства прототипа: на фиг. 5 - структурная схема предлагаемого устройства преобразования речи, с помощью которого реализуется предлагаемый способ; на фиг. 6 - структурная схема векторного квантователя с конечным числом состояний предлагаемого устройства (ВККЧС); на фиг.7 - структурная схема векторного деквантователя с конечным числом состояний предлагаемого устройства (ВДККЧС); на фиг. 8 - структурная схема векторного квантователя состояний в составе ВККЧС; на фиг. 9 - структурная схема векторного деквантователя состояний в составе ВДККЧС; на фиг. 10 - структурная схема блока определения номера следующего состояния в составе ВККЧС и ВДККЧС.
Предлагаемый способ преобразования речевого сигнала осуществляют следующим образом. В процедуры векторного квантования и векторного деквантования в качестве управляющего параметра вводят значение сигнала тон/шум - Т/Ш и Т/Ш* соответственно. Таким образом, процедуры векторного квантования и векторного деквантования приобретают вид:  и
и  соответственно. Кроме того, функция следующего состояния приобретает вид:
соответственно. Кроме того, функция следующего состояния приобретает вид:  и
и  для процедуры векторного квантования и процедуры векторного деквантования соответственно, где:
для процедуры векторного квантования и процедуры векторного деквантования соответственно, где: процедура векторного квантования;
процедура векторного квантования;
a - вектор параметров огибающей речевого сигнала;
Sn - номер текущего состояния векторного квантования, S = 1, 2,...,N;
N - число состояний;
n - номер рассматриваемого кадра;
Т/Ш - сигнал тон/шум при векторном квантовании;
c - канальный символ на входе линии связи; процедура векторного деквантования;
процедура векторного деквантования;
c* - канальный символ на выходе линии связи;
S
a* - вектор восстановления параметров огибающей речевого сигнала;
Т/Ш* - сигнал тон/шум при векторном деквантовании;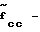 функция следующего состояния векторных квантования и деквантования;
функция следующего состояния векторных квантования и деквантования;
Sn+1 - номер следующего состояния векторного квантования;
S
Использование сигнала тон/шум в качестве дополнительного управляющего параметра при векторном квантовании и деквантовании позволяет разделить множество эталонных кодовых векторов восстановления для вокализованных и невокализованных фрагментов речевого сигнала, что обеспечивает возможность вдвое увеличить общее количество эталонных кодовых векторов восстановления без увеличения битовой скорости передачи. Это приводит к повышению качества синтезированного речевого сигнала. Использование сигнала тон/шум в качестве дополнительного управляющего параметра в функции следующего состояния позволяет разделить фонемные переходы с вокализованного и фонемные переходы с невокализованного фрагментов речевого сигнала, что приводит к более точному описанию последовательности фонемных переходов речевого сигнала и, следовательно, к повышению качества синтезированного речевого сигнала.
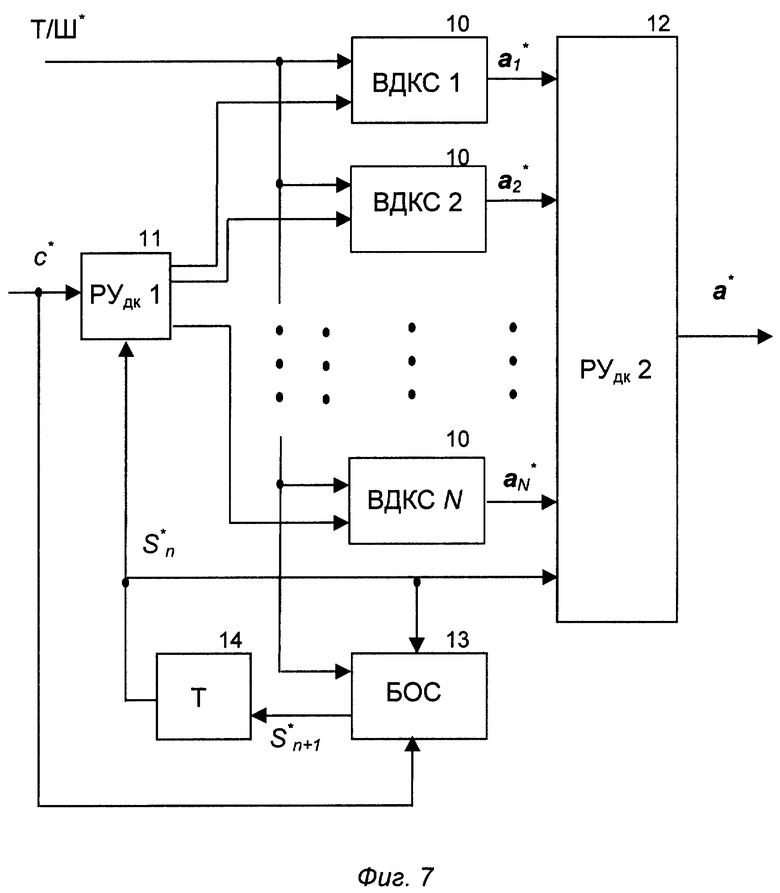
Предлагаемое устройство содержит кодер с линейным предсказанием (КЛП) 1, векторный квантователь речевых сигналов с конечным числом состояний (ВККЧС) 2, векторный деквантователь речевых сигналов с конечным числом состояний (ВДККЧС) 3 и векторный декодер с линейным предсказанием (ДКЛП) 4. Аналоговый вход КЛП 1 для речевого сигнала S(t) является входом устройства. Выход КЛП 1 для вектора параметров огибающей спектра а соединен со входом ВККЧС 2, выход которого через линию связи соединен со входом ВДККЧС 3. Выход ВДККЧС 3 соединен со входом ДКЛП 4 для вектора восстановления а*. Выходы КЛП 1 для речевого сигнала тон/шум (Т/Ш) и высоты основного тона (Тот) через соответствующие линии связи соединены непосредственно с соответствующими остальными входами ДКЛП 4, выход которого является выходом устройства. ВККЧС 2 состоит из векторных квантователей (ВКС) 5 по числу N состояний ВККЧС 2, решающих устройств выбора ВКС (РУк1) 6 и выбора канального символа (РУк 2) 7, блока определения номера следующего состояния (БОС) 8 и блока задержки на длительность кадра (Т) 9. Вход РУк1 (6) является входом ВККЧС 2. Выходы РУк1 (6) соединены соответственно со входами ВКС 5, выходы которых соединены с соответствующими выходами РУк2 (7), выход которого соединен с выходом БОС 8 и является выходом ВККЧС 2. Управляющий вход для сигнала номера текущего состояния (Sn) РУк2 (7) соединен с соответствующими входами РУк1 (6) и БОС 8 и через блок Т9 с выходом БОС 8. БОС 8 и каждый ВКС 5 снабжены дополнительными управляющими входами, которые объединены и образуют дополнительный управляющий вход ВККЧС 2 для сигнала Т/Ш, который соединен с выходом Т/Ш КПП 1. ВДККЧС 3 состоит из векторных деквантователей (ВДКС) 10 по числу N состояний ВДККЧС 3, решающих устройств выбора ВДКС (РУдк1) 11 и выбора вектора восстановления (РУдк2) 12, блока определения номера следующего состояния (БОС) 13 и блока задержки на длительность кадра (Т) 14. Вход РУдк1 (11) является входом ВДККЧС 3. Выходы РУдк1 (11) соединены соответственно со входами ВДКС 10, выходы которых соединены с соответствующими входами РУдк2 (12), выход которого является выходом ВДККЧС 3, а управляющий вход для сигнала номера текущего состояния (S
Блоки Т9 и 14 идентичны. Длительность кадра выбирается из условия квазистационарности речевого сигнала, что имеет место при длительности кадра 20 - 30 милисекунд.
БОС 8 и 13 также идентичны. Число N состояний ВККЧС 2 и ВДККЧС 3 одинаково для квантователя и деквантователя и выбирается оптимальным из соображений минимизации искажений, вносимых устройством. Методика выбора количества состояний приведена в [М. О. Dunham, R.M. Gray. An Algorithm for the Design of Labeled-Transition Finite-State Vector Quantization// IEEE Transactions on Communication, vol. COM-33, N 1, January 1985, pp. 83-89].
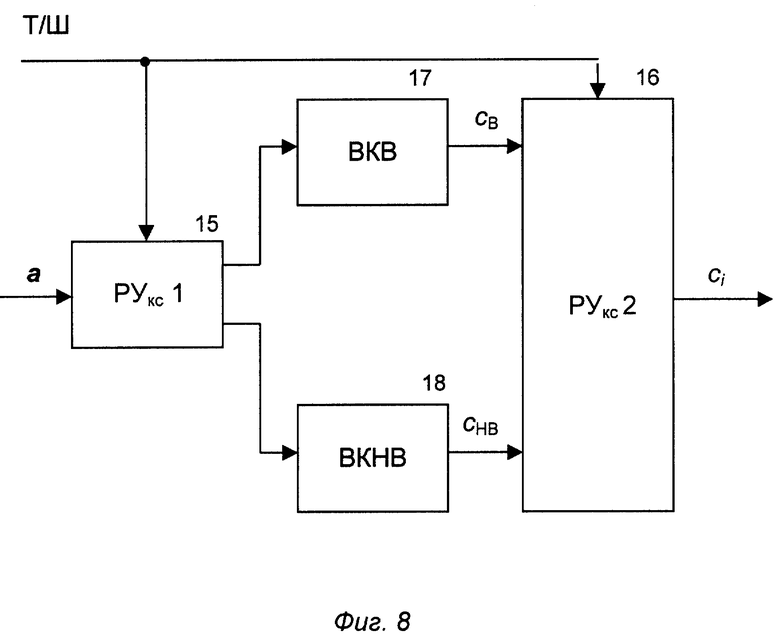
Каждый BKC 5 состоит из решающих устройств выбора векторного квантователя (РУкс1) 15 и выбора канального символа (РУкс2) 16, двух векторных квантователей: для вокализованных (ВКВ) 17 и невокализованных (ВКНВ) 18 фрагментов речевого сигнала. Вход РУкс1 (15) является входом BKC 5. Выходы РУкс1 (15) соединены соответственно с входами ВКВ 17 и ВКНВ 18, выходы которых соединены с соответствующими входами РУкс2 (16), выход которого является выходом BKC 5. Управляющие входы РУкс1 (15) и РУкс2 (16) объединены и образуют дополнительный управляющий вход BKC 5 для сигнала T/Ш.
Каждый ВДКС 10 состоит из решающих устройств выбора векторного деквантователя (РУдкс1) 19 и выбора вектора восстановления (РУдкс2) 20, двух векторных деквантователей: для вокализованных (ВДКВ) 21 и невокализованных (ВДКНВ) 22 фрагментов речевого сигнала. Вход РУдкс1 (19) является входом ВДКС 10. Выходы РУдкс1 (19) соединены соответственно со входами ВДКВ 21 и ВДКНВ 22, выходы которых соединены с соответствующими входами РУдкс2 (20), выход которого является выходом ВДКС 10. Управляющие входы РУдкс1 (19) и РУдкс2 (20) объединены и образуют дополнительный управляющий вход ВДКС 10 для сигнала Т/Ш*.
БОС 8 и 13 каждый состоит из блока определения адреса номера следующего состояния (БОА НСС) 23, решающих устройств определения блока памяти (РУ ОБП) 24 и выбора номера состояния (РУНС) 25, двух блоков памяти: один имеет матрицы номеров перехода состояний с вокализованных (БП ПС-В) 26, другой имеет матрицы номеров перехода состояний с невокализованных (БП ПС-НВ) 27 фрагментов речевого сигнала. Входы БОА НСС 23 (Sn, с - для квантователя, S
Предлагаемое устройство работает следующим образом.
На вход КЛП 1 устройства поступает аналоговый речевой сигнал S(t), который дискретизуется по времени, квантуется по уровню и разделяется на последовательность кадров выбранной длительности.
После этого на длительности кадра осуществляется идентификация вектора параметров огибающей спектра a и выделение параметров функции возбуждения. С первого выхода КЛП 1 вектор параметров огибающей спектра a подается на вход ВККЧС 2, который ставит в соответствие входному вектору а канальный символ с, передаваемый в линию связи совместно с параметрами функции возбуждения Т/Ш и Тот с соответствующих выходов КЛП 1. Сигнал Т/Ш с КЛП 1 подается на управляющий вход ВККЧС 2. Принятый по линии связи канальный символ с* поступает на вход ВДККЧС 3, в котором определяется соответствующий ему вектор восстановления a*. С выхода ВДККЧС 3 вектор восстановления а* подается на первый вход ДКЛП 4. Принятый по линии связи параметр тон/шум (Т/Ш*) поступает на управляющий вход ВДККЧС 3 и на второй вход ДКЛП 4. Принятый по линии связи параметр высоты основного тона T
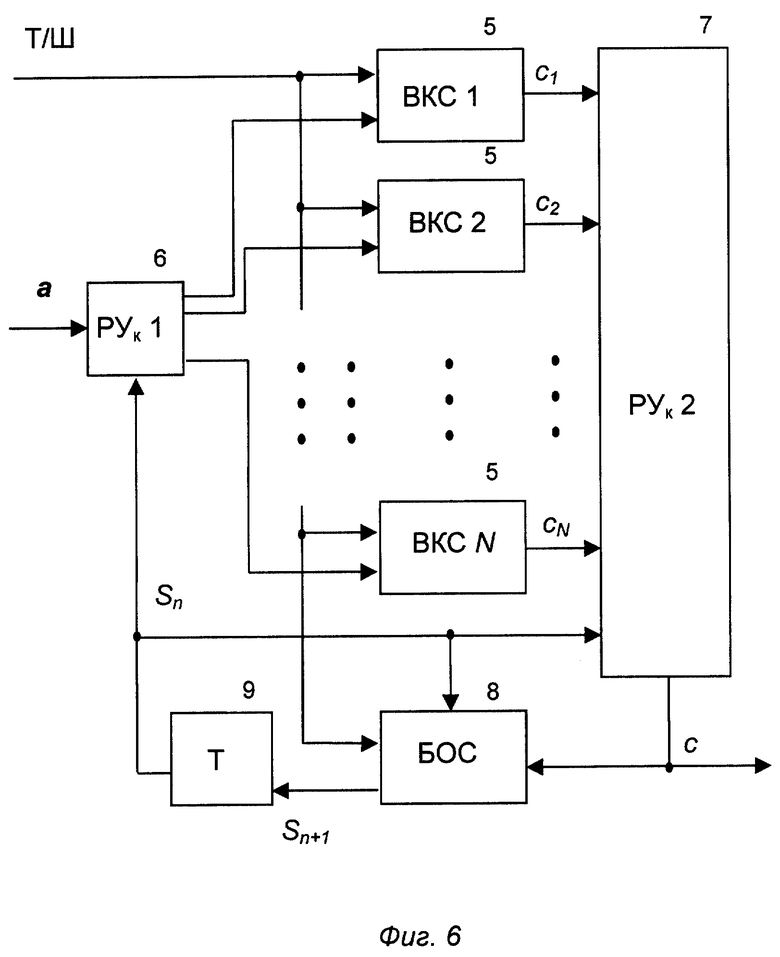
Работает ВККЧС 2 следующим образом. На вход РУк1 (6) поступает вектор параметров a. В зависимости от сигнала Sn на управляющем входе РУк1 (6) передает вектор а на один из N выходов, соединенных с входами ВКС 1,... ВКС N (5). Далее в ВКС 5 сигнал поступает на вход РУкс1 (15). РУкс1 (15) в зависимости от значения сигнала на управляющем входе Т/Ш передает вектор параметров а на вход соответствующего векторного квантователя (17, 18). После процедуры квантования РУкс2 (16) в зависимости от значения сигнала Т/Ш на управляющем входе передает на выход ВКС соответствующий канальный символ сi, который поступает на соответствующий вход РУк2 (7), которое в соответствии с сигналом Sn на своем управляющем входе передает канальный символ c на БОС (8), а также в линии связи. Блок БОС (8) в зависимости от значения сигналов Sn, c и Т/Ш на управляющих входах формирует на выходе управляющий сигнал Sn+1. Сигнал Sn+1 поступает на блок Т 9, где задерживается на длительность кадра. Таким образом, квантователь ВККЧС 2 готов к обработке речевого сигнала на следующем кадре, соответственно описанному выше. Поскольку БОС 8 в составе ВККЧС 2 и БОС 13 в составе ВДККЧС 3 идентичны, на фиг.10 без скобок приведены сигналы в ВККЧС 2, а в скобках - в ВДККЧС 3. Работает блок БОС (8, 13) следующим образом. В зависимости от значения управляющих сигналов номера текущего состояния Sn(S
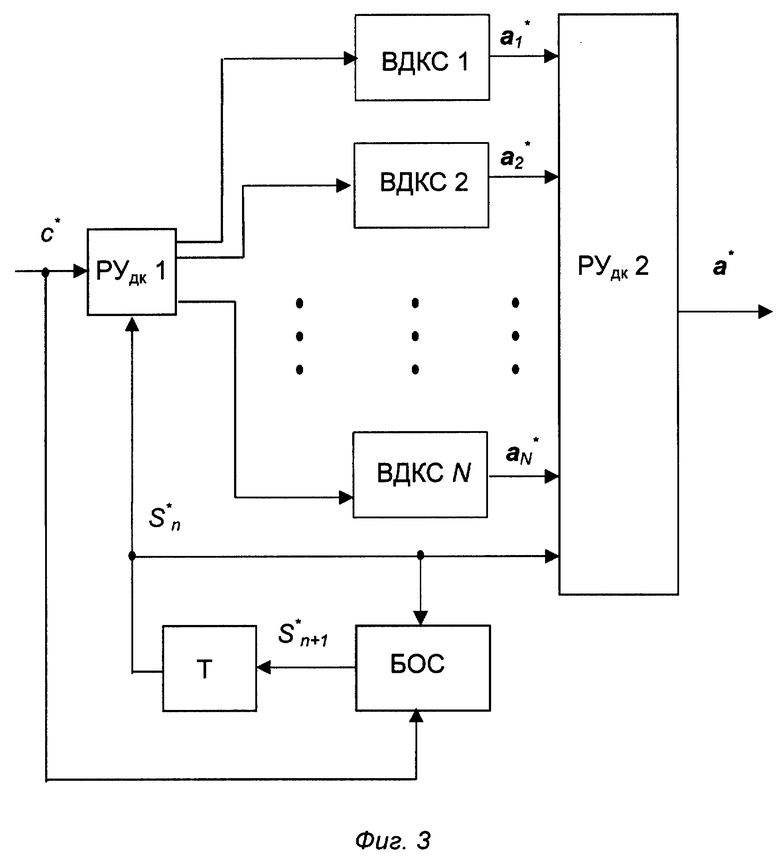
Векторный деквантователь ВДККЧС 3 (фиг. 7) работает следующим образом. На вход РУдк (11) поступает канальный символ с*. В зависимости от сигнала S
В ДКЛП 4 на основании значения сигналов а*, поступающего с ВДККЧС 3, и Т/Ш*, T
Приведенные сведения показывают, что при осуществлении заявленной группы изобретений с использованием конкретных вариантов выполнения средства, воплощающие изобретения при их осуществлении, предназначены для использования в промышленности, а именно: в производстве и эксплуатации аппаратуры и программных средств для интегрированных сетей обмена информацией, информационно-вычислительных систем и автоматизированных систем управления, а также аппаратуры диспетчерской и громкоговорящей связи.
Кроме того, средства, воплощающие изобретения при их осуществлении, способны обеспечить более качественную передачу речевой информации и более компактное представление речевых сигналов в целях хранения за счет использования сигнала тон/шум в качестве дополнительного управляющего параметра в функции следующего состояния, что позволяет разделить фонемные переходы с вокализованного и фонемные переходы с невокализованного фрагментов речевого сигнала, а это в свою очередь приводит к более точному описанию последовательности фонемных переходов речевого сигнала и, следовательно, к повышению качества синтезированного речевого сигнала.




Использование: в средствах цифрового кодирования речевых сигналов для их комплексного представления в целях передачи и хранения. Сущность изобретения: способ преобразования речи, основанный на векторных квантовании и деквантовании, снабжен дополнительным управлением с помощью сигнала тон/шум, который используют в качестве управляющего параметра: Т/Ш, Т/Ш* соответственно. Устройство преобразования речи и варианты практической реализации блоков в составе векторного квантователя с конечным числом состояний и векторного деквантователя с конечным числом состояний, обеспечивающие дополнительное управление сигналом тон/шум в процедуре векторного квантования и деквантования, что позволяет разделить множество эталонных кодовых векторов на два подмножества, соответствующие вокализованным и невокализованным фрагментам речевого сигнала, что повышает качество синтезированного речевого сигнала без увеличения битовой скорости передачи и приводит к более точному описанию последовательности переходов речевого сигнала и, следовательно, повышению разборчивости и натуральности синтезированного речевого сигнала, в чем и состоит технический результат, достигаемый при осуществлении заявленных изобретений. 2 с. и 3 з.п.ф-лы, 10 ил.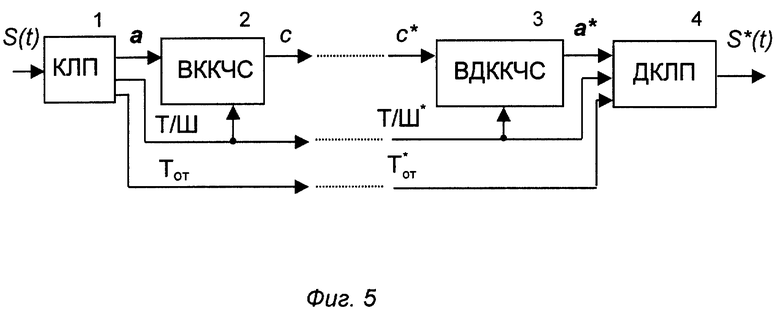
c = α(a, Sn),
где α - процедура векторного квантования;
N - число состояний векторного квантователя;
n - номер рассматриваемого кадра,
передают канальный символ, высоту основного тона и сигнал тон/шум по линиям связи, формируют вектор восстановления а* в векторном деквантователе с конечным числом состояний на основании принятого канального символа вектора параметров огибающей спектра с* и номера текущего состояния S
a*= β(c*,S
где β - процедура векторного деквантования, причем номер следующего состояния Sn+1 определяют в векторном квантователе на основании номера текущего состояния Sn и канального символа с
Sn+1 = fcc(Sn, c),
где fcc - функция следующего состояния,
а номер следующего состояния S
S
синтезируют речевой сигнал на основании значения вектора восстановления а*, принятой высоты основного тона T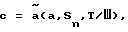
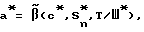
где 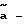 процедура векторного квантования с учетом воздействия сигнала тон/шум;
процедура векторного квантования с учетом воздействия сигнала тон/шум;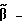 процедура векторного деквантования с учетом воздействия сигнала тон/шум,
процедура векторного деквантования с учетом воздействия сигнала тон/шум,
причем номер следующего состояния Sn+1 определяют в векторном квантователе с учетом воздействия сигнала тон/шум
где  функция следующего состояния с учетом воздействия сигнала тон/шум,
функция следующего состояния с учетом воздействия сигнала тон/шум,
а номер следующего состояния S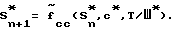
2. Устройство преобразования речи, содержащее кодер с линейным предсказанием (КЛП) с аналоговым входом для речевого сигнала, выход для вектора параметров огибающей спектра которого через последовательно соединенные векторный квантователь речевых сигналов с конечным числом состояний (ВККЧС), линию связи и векторный деквантователь речевых сигналов с конечным числом состояний (ВДККЧС) соединен со входом для вектора восстановления декодера с линейным предсказанием (ДКЛП), а выходы сигналов тон/шум и высоты основного тока КЛП через соответствующие линии связи соединены с соответствующими входами ДКЛП, ВККЧС состоит из векторных квантователей состояний (ВКС) по числу состояний ВККЧС, входы которых соединены с соответствующими выходами решающего устройства выбора ВКС (РУк1), вход которого является входом ВККЧС, а выходы - с соответствующими входами решающего устройства выбора канального символа (РУк2), управляющий вход для сигнала номера текущего состояния которого соединен с соответствующими входами РУк1 и блока определения номера следующего состояния (БОС) и через блок задержки на длительность кадра (Т) - с выходом БОС, второй управляющий вход которого соединен с выходом РУк2 и является выходом ВККЧС, а ВДККЧС состоит из векторных деквантователей состояний (ВДКС) по числу состояний ВДККЧС, входы которых соединены с соответствующими выходами решающего устройства выбора ВДКС (РУдк1), вход которого является входом ВДККЧС, а выходы - с соответствующими входами решающего устройства выбора вектора восстановления (РУдк2), выход которого является выходом ВДККЧС и управляющий вход для сигнала номера текущего состояния которого соединен с управляющими входами РУдк1, БОС и через блок задержки на длительность кадра Т - с выходом БОС, другой вход которого соединен с входом РУдк1, БОС квантователя ВККЧС и деквантователя ВДККЧС включает в себя блок определения адреса номера следующего состояния (БОА НСС), два входа которого являются управляющими входами БОС, отличающееся тем, что БОС и каждый ВКС в составе ВККЧС имеют дополнительные входы, которые объединены и образуют дополнительный вход ВККЧС, соединенный с выходом сигнала тон/шум КЛП, также БОС и каждый ВДКС в составе ВДККЧС имеют дополнительные входы, которые объединены и образуют дополнительный вход ВДККЧС, соединенный с входом сигнала тон/шум ДКЛП.
| Цифровой синтезатор речи | 1983 |
|
SU1297098A1 |
| EP 0532225 A, 17.03.1993 | |||
| Домовый номерной фонарь, служащий одновременно для указания названия улицы и номера дома и для освещения прилежащего участка улицы | 1917 |
|
SU93A1 |

