Область техники, к которой относится изобретение
Изобретение относится к области способов передачи мультимедийной информации в сетях связи и запоминания ее в электронных устройствах, в частности к кодированию речи с целью, например, эффективной и надежной передачи речи высокого качества по линиям связи сетей с коммутацией пакетов, таких как IP-сети (включая Интернет).
Уровень техники
Характеристики систем передачи/запоминания речи в цифровой форме сильно зависят от методов сжатия (компрессии) речи, т.е. качества кодирования речевых сигналов. Эффективность такого кодирования является определяющими фактором как для передачи речи по цифровым каналам связи, так и в сетях с коммутацией каналов или пакетов. Кодирование речи при передаче по IP-сетям (системы IP-телефонии, Voice over IP) имеет следующие важные особенности.
1. Сети с коммутацией пакетов очень удобны для надежной передачи данных на базе протоколов IP, допускающей определенную переменную задержку, но для трафика реального времени (в частности, речи) они изначально не были рассчитаны. Использование протоколов UDP или RTP частично решает проблему задержек, но может приводить к нарушениям очередности и переменному времени доставки до получателя отдельных пакетов. К тому же при перегрузках сети часть пакетов, передаваемых по виртуальным каналам связи, может быть потеряна. Поэтому обеспечение определенной устойчивости к этому фактору влияния IP-сети на качество передачи речи очень важно.
Таким образом, кодирование речи для систем VoIP должно обеспечить достаточно качественную ее передачу в сетях IP в режиме реального времени в условиях, когда некоторая часть пакетов может быть потеряна.
2. Так как IP-сеть позволяет передавать пакеты с высокой скоростью, то это открывает возможности передачи широкополосной речи существенно более высокого качества, чем традиционная телефония. Очевидно, что речевой кодек для систем VoIP должен учитывать возможности IP-сети по передаче широкополосной речи с высоким качеством.
3. IP-сети допускают переменную скорость передачи информации. Поэтому целесообразно обеспечить условие, чтобы речевой трафик в IP-сети соответствовал реальной информативности речевого сообщения. Речь - именно такой источник с переменной информативностью (очевидно, что, например, информативность пауз в речевом потоке существенно ниже информативности активных речевых участков). В свою очередь, на речевых участках вокализованные части более важны, чем невокализованные, а участки перехода между самими вокализованными участками несут существенно больше информации, чем их квазистационарная часть. Это означает, что речевой кодек для VoIP должен обеспечить кодирование речи с заданным качеством и при этом скорость передаваемого битового потока должна меняться в зависимости от текущей информативности входного речевого сигнала.
4. Линии связи в IP-сети имеют, как известно, разную пропускную способность. Поэтому речевой кодек для систем VoIP должен обеспечивать передачу речи между абонентами (клиентами) одной сети или разных сетей, подключенными к сети IP цифровыми линиями связи с разной пропускной способностью без дополнительного перекодирования (транскодинга), вносящего дополнительные искажения в речь и задержки. Особенно это важно при организации многоточечной и циркулярной конференц-связи, когда в конференции одновременно участвуют несколько клиентов, подключенных к сети линиями связи с разной пропускной способностью, а сама конференц-связь организована по так называемой "tandem-free" схеме, когда микширование речевых сигналов проводится не на сервере, а непосредственно на стороне (компьютере) клиента. Решение этой проблемы возможно, если для кодирования речи используется способ так называемого масштабируемого кодирования (scalable coding). Впервые, по-видимому, он был предложен в 1971 г. автором данной заявки (см. АС 409477) и описан в статье В.А.Свириденко «Способ сжатия аналогового сообщения и его эффективность». - Автометрия, №3, 1974 г., стр.102-106, применительно к поэтапному кодированию с контролируемыми потерями непрерывных сообщений и сигналов, включая и речевые сигналы.
5. Число требований к речевому кодеку, предназначенному для эффективной работы в IP-сети, не исчерпывается указанным перечнем. К нему можно добавить требования малой алгоритмической задержки, что важно при интерактивной речевой связи, обеспечения определенного уровня шумостойкости кодека, устойчивости к ошибкам и снижения уровня акустического эха, способность кодека отвечать требованиям сетей связи нового поколения, способность кодека эффективно функционировать в интегрированных сетях при объединении сетей с разными архитектурами и возможностями (в частности, сети IP и сети мобильной радиосвязи) и другое.
К настоящему времени многие из этих факторов учтены в рамках разработки и реализации речевых кодеков для IP-сетей, включая кодеки в соответствии с Рекомендациями МСЭ-Т G.718, G.719, G.722.2 (AMR-WB), G.729.1, кодеки отдельных организаций, занятых проектированием и использованием систем VoIP и видеоконференцсвязи (Скайп, Поликом, ГИПС и др.), включая такие кодеки, как Speex, iSAC, iLBC, AMR-WB+ и другие.
Особо отметим положительные качества многоуровневого кодирования речевого источника, когда речь сначала кодируется кодером нижнего или базового уровня (base layer), который обеспечивает сжатие речи с допустимым речевым качеством, т.е. обеспечивает кодирование для самой низкой скорости передачи. Затем разница между исходной и восстановленной речью после базового уровня кодирования кодируется кодером первого уровня улучшения. Это дает некоторый заданный прирост битовой скорости и заданный прирост речевого качества в суммарном сигнале после двух уровней кодирования. Далее разница между исходной и восстановленной речью после базового и первого улучшающего уровня кодирования кодируется кодером второго уровня улучшения. И так поэтапно далее до тех пор, пока речевое качество восстановленной речи от всех уровней кодирования не будет достигать заданного качества, а суммарная скорость передачи не будет превышать заданного предела. Именно этот подход был представлен в АС 409477 применительно к любым непрерывным сигналам, включая и речевые сигналы.
Если вышележащие уровни кодирования практически не оказывают влияния на нижележащие уровни, то это обеспечивает независимость нижележащих уровней от вышележащих, что является полезным качеством.
Такой способ многоуровневого кодирования дает целый ряд важных преимуществ:
- обеспечивает масштабируемость битовой (двоичной) скорости (bit-rate scalability), когда речь кодируется с самым высоким качеством и наивысшей скоростью, а затем декомпозируется (разбирается) на потоки с различной скоростью и передается клиентам уже на тех скоростях, которые соответствуют текущим пропускным способностям линий связи, которыми они подключены к сети IP;
- достаточно использовать дополнительные средства защиты от потерь в канале связи, например используя корректирующее кодирование (forward error correcting) или некоторые формы маскировки потерянных пакетов (PLC - packet loss concealment) только информации самого нижнего уровня, чтобы обеспечить у получателя качество речи не ниже заданного допустимого уровня. Или, например, в случае IP-сети, результаты кодирования разных уровней могут быть разложены в разные пакеты, которым присваиваются разные приоритеты. Информации базового уровня назначается максимальный приоритет, а всем последующим соответственно назначаются приоритеты по убыванию. Тогда передача этой информации через IP-сеть с соответствующей архитектурой протоколов будет осуществляться с допустимой вероятностью потери пакетов базового уровня (за счет пакетов уровней улучшения, передаваемых с меньшим приоритетом). А это значит, что даже в условиях перегрузок в сети качество декодированной речи у получателя не будет снижаться ниже заданного уровня, а при отсутствии потерь будет достигать заданного максимального качества;
- возможно обеспечить определенную компенсацию в качестве декодированной речи при потере пакета, если всю информацию базового уровня или ее наиболее важную часть размещать не только в соответствующем кадре (или пакете), но и в смежном(ых) кадре(ах) или пакете(ах).
Следует отметить, что масштабирование может осуществляться еще и по ширине полосы обрабатываемой речи (bandwidth scalability). Например, кодирование базового уровня обеспечивает только минимально допустимую часть частотной полосы входной речи, например, в «телефонной» полосе 0,3…3,4 кГц, а каждый последующий улучшающий уровень кодирования постепенно расширяет полосу частот вплоть до полосы FM-радио (0,04…15 кГц) или, возможно, даже выше, до 0,02…20 кГц (при соответствующем увеличении частоты дискретизации). Таким образом, достигается способность передавать широкополосную (ШП) и даже сверхширокополосную (СШП) речь очень высокого качества, а в случае перегрузки сети или относительно низкой способности передавать широкополосную (ШП) и даже сверхширокополосную (СШП) речь очень высокого качества обеспечивать многоканальную ее передачу (например, стереопередачу), а в случае перегрузки сети или относительно низкой пропускной способности линии связи, которая подключает получателя к сети, отбрасывать часть или все уровни улучшения, сохранив речевое качество не ниже уровня обычной телефонной связи.
Одним из известных кодеков, использующих метод многоуровневого кодирования речи, является речевой кодек MPEG-4 CELP (ISO/IEC 14496-3), который содержит кодер базового уровня (Core Encoder) и набор средств масштабирования скорости передачи (Bit Rate Scalable (BRS) tools) и масштабирования полосы (Bandwidth Extension tool). Упрощенная блок-схема MPEG-4 CELP масштабируемого кодера показана на Фиг.1.
Этот кодек основан на многоимпульсном возбуждении (Multi Pulse Excitation (MPE)) - методе речевого кодирования, являющемся разновидностью хорошо известного CELP (Code Excited Linear Predictive) метода, предложенного М.Шредером и В.Аталом в 1985 г., который имеет разные варианты реализации (ACELP, RCELP, LD-CELP, VSELP и др.) и в настоящее время широко используется в разработке вокодеров.
Метод MPE, как и многие другие методы кодирования речи, опирается на модель речеобразования «источник-фильтр», в которой речевой тракт представлен в виде полюсного фильтра с изменяемыми во времени параметрами, на вход которого подается сигнал источника возбуждения, характеризующий работу голосовых связок, и параметры воздушной струи, поступающей на вход речевого тракта. Сам CELP-метод базируется на четырех главных принципах: использование упомянутой модели речеобразования «источник-фильтр» на основе линейного предсказания (ЛП); использование адаптивной и фиксированной кодовой книг в качестве источника возбуждения для ЛП-модели; реализации поиска оптимального сигнала возбуждения в замкнутой петле с учетом взвешенного разностного сигнала на основе восприятия речи человеком; векторного квантования.
В кодеке MPEG-4 CELP входной речевой сигнал в цифровой форме с частотой дискретизации 16 кГц, достаточной для передачи речи в полосе 7…8 кГц, поступает на блок 101, понижающий частоту дискретизации до 8 кГц, что достаточно для кодирования речи в полосе не более 4 кГц (например, «телефонного канала»), и далее в кодер базового уровня (блок 102), на выходе которого выделяются параметры модели речеобразования, которые передаются во вне через мультиплексор (блок 106). Часть параметров образует информацию об импульсах возбуждения, которая передается на блок масштабирования по скорости (блок 103), куда одновременно от блока 102 поступает «остаток», представляющий собой разность между исходным речевым сигналом с частотой дискретизации 8 кГц и синтезированном в кодере сигналом. Подобная информация и «остатки» поступают и на более высокие по уровню средства масштабирования по скорости вплоть до средства уровня N (блок 104), выходы которых также подаются на блок 106. Но если есть возможность передать более широкополосный сигнал (полосой 7…8 кГц), то в работу включается блок 105 - средство расширения полосы, на основной вход которого подается исходный речевой сигнал (16 кГц), на его информационные входы подается информация о параметрах источника возбуждения и коэффициентах синтезирующего ЛП-фильтра от блока 104, а на выходе, подключенном к блоку 106, формируются параметры речевого сигнала для широкой полосы (до 8 кГц).
Упрощенная блок-схема MPEG-4 CELP кодера базового уровня кодирования показана на Фиг.2. Он включает блоки 201, 202, 203 и 204 для синтеза речевого сигнала, причем блоки 201 и 202 в совокупности моделируют «источник» и включают фиксированную и адаптивную кодовую книги, сигналы которых объединяются в блоке 203 для формирования сигнала возбуждения, а цифровой фильтр (блок 204), ЛП-коэффициенты (LPC) которого определяют огибающую спектра синтезируемой речи, формирует из этого сигнала возбуждения синтезируемый в кодере речевой сигнал. Последний вычитается из исходной речи в блоке 205 для формирования сигнала ошибки или «остатка», который подается на взвешивающий фильтр (блок 208), выход которого запитывает блок 209 для минимизации мощности этого остатка с целью формирования сигнала выбора «оптимального сигнала возбуждения», подаваемого на управляющий вход 1 блока 201 и блок 202, где реализуется поиск этого «оптимального сигнала» в кодовых книгах. Сигнал возбуждения из блока 203 подается также на формирователь управляющего сигнала для адаптивной кодовой книги (блок 210), выход которого поступает на второй управляющий вход блока 201. Оценка коэффициентов LPC производится в блоке 206, куда подается речевой сигнал. Эти коэффициенты квантуются векторным квантователем (блок 207) и подаются на блок 204. На выходе кодера формируются «остаток» (выход блока 205) и параметры речевого сигнала в виде основного тона (второй выход блока 201), информации об импульсах возбуждения (второй выход блока 202), линейных спектральных частотах (LSF), называемых также линейными спектральными парами (LSP), представляющими собой коэффициенты LPC в более удобной для передачи форме из-за меньшей чувствительности к шуму квантования, на втором выходе блока 207.
Данный кодер содержит адаптивную и несколько фиксированных кодовых книг (для простоты на Фиг.2 показана только одна фиксированная кодовая книга). Сумма выходных сигналов этих двух книг формирует сигнал возбуждения синтезирующего LPC-фильтра. Кодирование речи проводится покадрово. Т.е. входной речевой сигнал делится на отдельные кадры (frames) и для каждого кадра выполняется анализ параметров LPC-фильтра. Далее кадр разбивается на подкадры и для каждого из них проводится оптимизация параметров адаптивной и фиксированной кодовых книг методом «анализ синтезом» по критерию минимума взвешенной среднеквадратической погрешности (ошибки) между входным и синтезированным сигналом. Взвешивание проводится так называемым «фильтром восприятия», представляющим собой, как правило, полюсно-нулевой фильтр, параметры которого получаются из коэффициентов LPC-фильтра. Задача взвешивания состоит в повышении веса погрешности в формантных областях спектра речевого сигнала, которые наиболее важны при восприятии речевого сигнала, и снизить вес в менее значимых областях этого спектра для восприятия речи человеком. Взвешенный речевой сигнал может быть получен как:

где:
x(n) - очередной отсчет входного речевого сигнала,
ak, bk - коэффициенты LPC-фильтра K-го порядка,
γ1, γ2 - константы, определяющие степень взвешивания
Уравнение (1) отражает последовательную фильтрацию входного сигнала соответственно нулевым и полюсным LPC-фильтрами, импульсные характеристики которых скорректированы константами γ1, γ2.
В основе алгоритма кодека лежит известный метод линейного предсказания, в котором речевой сигнал представлен следующим уравнением, отражающим фильтрацию сигнала возбуждения полюсным LPC-фильтром:
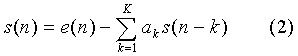
где:
s(n) - очередной отсчет синтезированного речевого сигнала,
е(n) - очередной отсчет сигнала возбуждения (excitation),
ak - коэффициенты LPC-фильтра K-го порядка (в кодекс MPEG-4 CELP: K=10 для базового кодера (Core Encoder) и K=20 для средства расширения полосы (Bandwidth Extension Tool)).
LPC-фильтр отражает характеристики голосового тракта речевого сигнала и формирует спектральную огибающую кодируемого отрезка синтезированного сигнала, опираясь на так называемые кратковременные корреляции в речевом сигнале. Коэффициенты фильтра ak находятся путем решения системы автокорреляционных уравнений предсказания на базе метода минимизации энергии погрешности (ошибки) предсказания, на основе рекурсивного алгоритма Левинсона-Дарбина.
Сигнал возбуждения е(n) находится для каждого подкадра, как описано ниже.
Вначале находится оценка периода основного тона (ОТ), так называемая «открытая петля ОТ» (Open Loop Pitch), как временная задержка, на которой отрезок прошлых отсчетов во времени взвешенного речевого сигнала имеет минимальное среднеквадратичное отклонение от отрезка текущих отсчетов:
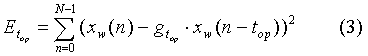
где:
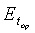 - среднеквадратическая ошибка, подвергаемая минимизации,
- среднеквадратическая ошибка, подвергаемая минимизации,
top - («оптимальная») оценка задержки, при которой среднеквадратическая ошибка минимальна. Для вокализованных участков эта задержка практически равна длительности периода основного тона речи;
xw(n) - очередной отсчет взвешенного входного речевого сигнала,
 - коэффициент усиления предсказания для оптимальной задержки top, который может быть рассчитан как:
- коэффициент усиления предсказания для оптимальной задержки top, который может быть рассчитан как:
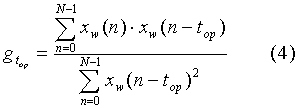
N - число отсчетов взвешенного речевого сигнала, участвующих в оценке коэффициента усиления.
Сравнение значения коэффициента усиления предсказания с порогами дает возможность дополнительно оценить степень вокализованности текущего отрезка речевого сигнала, которая может быть использована в дальнейшем.
Далее все процедуры оптимизации проводятся известным методом «анализ синтезом».
Для этого процедура синтеза текущего отрезка взвешенной речи представляется в форме:
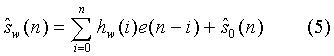
где:
е(n-i) - сигнал возбуждения синтезирующего фильтра,
hw - отсчеты импульсного отклика взвешенного синтезирующего фильтра, которые вычисляются путем последовательной фильтрации вектора коэффициентов нулевого взвешивающего фильтра, дополненного нулями, соответственно синтезирующим и взвешивающим полюсными фильтрами:
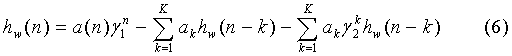
где:
ak - коэффициенты LPC-фильтра для текущего подкадра, полученные, как правило, линейной интерполяцией из LPC-коэффициентов, вычисленных для прошлого и текущего кадров и пересчитанных в LSF-область.
а(n)=ak для всех n=(k-1)<K,
а(n)=0 для всех n≥K,
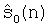 - вклад прошлого возбуждения в текущий вектор синтезированного сигнала за счет памяти взвешенного синтезирующего фильтра, так называемый «звон».
- вклад прошлого возбуждения в текущий вектор синтезированного сигнала за счет памяти взвешенного синтезирующего фильтра, так называемый «звон».
Затем вычисляется целевой сигнал как взвешенный входной речевой сигнал за вычетом «звона»:

Этот «звон» вычисляется, как правило, путем последовательной фильтрации «целевого» сигнала взвешивающим и синтезирующим фильтрами. Однако часто используется эквивалентная процедура получения целевого сигнала, которая заключается в нахождении сигнала LPC-остатка:
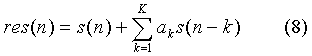
а затем последовательной фильтрации сигнала остатка взвешивающим и синтезирующим фильтрами:
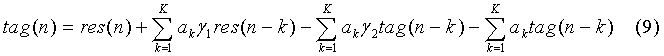
Обновление памяти фильтра для следующего подкадра выполняется после нахождения сигнала возбуждения путем фильтрации разности между остатком и найденным сигналом возбуждения взвешивающим и синтезирующим фильтрами.
Найденные векторы импульсного отклика взвешенного синтезирующего фильтра hw(n) и целевого сигнала tag(n) используются для нахождения параметров адаптивной и фиксированной кодовых книг.
Вначале оптимизируется адаптивная кодовая книга (Adaptive Codebook), опираясь на значение Open Loop Pitch top. Как правило, адаптивная кодовая книга реализуется в виде Pitch-предиктора, а суть оптимизации состоит в уточнении оптимальной задержки и вычислении усиления предсказания, при которых сигнал прошлого возбуждения, профильтрованный взвешенным синтезирующим фильтром, имеет минимальное среднеквадратичное отклонение от вектора целевого сигнала:
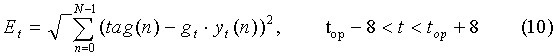
где:
top - значение оптимальной задержки, найденное методом Open-Loop,
yt(n) - сигнал прошлого возбуждения, профильтрованный взвешенным синтезирующим фильтром hw:

Следует отметить, что при задержках t менее длины анализируемого подкадра сигнал прошлого возбуждения еще не сформирован. В этом случае, как правило, вычисленный ранее LPC-остаток res(n) используется в качестве расширения сигнала прошлого возбуждения.
Усиление предиктора основного тона (или Pitch-предиктора) вычисляется как:
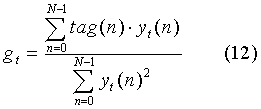
Параметры адаптивной кодовой книги (t, gt) далее кодируются для передачи.
Таким образом, адаптивная кодовая книга обеспечивает в текущее возбуждение вклад от прошлого возбуждения на временном интервале задержки t, равном периоду «основного тона» речевого сигнала, используя тем самым так называемые «долговременные корреляции» в речевом сигнале. Вклад этой книги, оцениваемый как коэффициент усиления gt, тем сильнее, чем сильнее сохраняется стационарный и периодичный (с периодом «основного тона») характер текущего речевого сигнала в сравнении с предыдущим во времени речевым сигналом. Соответственно на переходных участках речевого сигнала от вокализованных (огласованных) до целиком невокализованных (неогласованных) эффективность адаптивной кодовой книги сильно падает.
Далее проводится оптимизация фиксированной кодовой книги (Fixed Codebook) также по критерию минимума среднеквадратической ошибки между взвешенным синтезированным сигналом и целевым вектором:
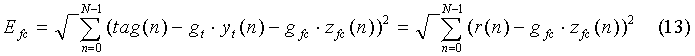
где:
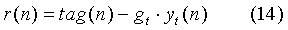
- новый целевой вектор, необходимый для оптимизации фиксированной кодовой книги, который получен после вычета из первого целевого вектора вклада адаптивной кодовой книги,
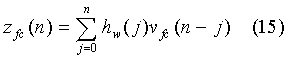
- вклад фиксированной кодовой книги во взвешенном синтезированном сигнале,
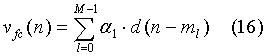
- вектор сигнала многоимпульсного возбуждения, состоящий из М единичных импульсов d с позициями ml, 0≤l<М и знаками αl(±1).
Суть оптимизации сводится к нахождению таких позиций из М импульсов, их знаков и усиления gfc, которые обеспечивают минимальную среднеквадратическую ошибку Efc (формула 10).
Классический алгоритм поиска позиций импульсов в МРЕ-методе заключается в нахождении позиции импульса по критерию максимума выражения:
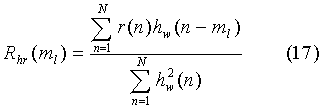
а затем его амплитуды из выражения:
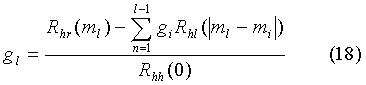
где:
l - текущее количество импульсов,
mi - позиция i-го импульса.
Таким образом, используя выражения (17) и (18), проводится последовательное нахождение позиций всех М импульсов, а затем и их общее усиление как:
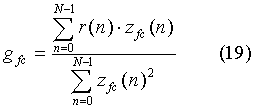
Далее найденные оптимальные позиции, знаки и усиление импульсов кодируются для передачи.
Итак, фиксированная кодовая книга обеспечивает вклад в текущее возбуждение стохастической составляющей возбуждения, моделирующей шумовую компоненту источника возбуждения. Одновременно важным свойством фиксированной кодовой книги является то, что она фактически обеспечивает сигнал прошлого возбуждения недостающими импульсами, необходимыми для того, чтобы сделать текущий суммарный сигнал возбуждения более близким к реальному сигналу.
Особенно это свойство фиксированной кодовой книги проявляется при сильной разряженности книги, когда количество импульсов возбуждения недостаточно для того, чтобы сразу хорошо описать реальный сигнал. Поэтому при сильной разряженности кодовых книг (свойственной низкоскоростным кодекам) как неогласованные, так и огласованные участки речи формируются недостаточно качественно. Однако вышеупомянутое свойство фиксированной кодовой книги позволяет уже через несколько интервалов анализа достаточно хорошо «насытить» огласованный сигнал недостающими импульсами. Но часть речевого сигнала в начале новых огласованных участков остается недостаточно хорошо восстановленной.
Блок-схема средства масштабирования скорости передачи MPEG-4 CELP кодека представлена на Фиг.3.
Это средство масштабирования представляет собой фактически дополнительный кодер, в котором также присутствуют источник многоимпульсного возбуждения (блок 302) на базе кодовой книги, оптимизируемый методом «анализ синтезом» аналогично кодеру базового уровня со стороны блока 306, выход которого заведен на первый управляющий вход блока 302, и со стороны блока 301, выход которого заведен на второй управляющий вход блока 302, и синтезирующий LPC-фильтр (блок 303), выход которого подается на блок вычитания 304. Информация о возбуждении текущего уровня улучшения суммируется в блоке 305 и подается на следующий уровень улучшения.
В то же время имеются и следующие принципиальные отличия:
- оптимизация проводится на базе минимизации ошибки между синтезированным сигналом и сигналом остатка (а не со входным речевым сигналом), полученным на предыдущем уровне кодирования (например, на базовом уровне, если текущее масштабирующее средство является первым улучшающим уровнем),
- в качестве сигнала возбуждения используется только фиксированная кодовая книга (как уже отмечалось, в кодере MPEG-4 CELP используется МРЕ в качестве фиксированной кодовой книги),
- это средство работает автономно, т.е. не оказывает никакого влияния на предыдущие уровни, включая базовый уровень. (В частности, сформированный на данном уровне сигнал возбуждения не участвует в обновлении памяти адаптивной кодовой книги базового уровня.)
Последняя особенность обеспечивает масштабируемость кодирования, поскольку обеспечивает независимость каждого уровня кодирования от более высоких (последующих) уровней кодирования. В то же время плата за такую независимость - это более низкое качество речи в сравнении с другими CELP-подобными кодеками на одинаковой скорости. Причина этому - более низкая эффективность адаптивной кодовой книги в масштабируемом кодеке, поскольку в обновлении памяти адаптивной кодовой книги участвует фиксированная книга только одного базового уровня, имеющая очень ограниченное количество импульсов возбуждения. Это не позволяет быстро «насытить» огласованный сигнал недостающими импульсами и, как следствие, не позволяет в полной мере использовать долговременные корреляции в речевом сигнале, что приводит к снижению эффективности кодирования по качеству ШП-речи. Это снижение эффективности кодирования тем больше, чем ниже скорость кодека, используемого в базовом уровне кодирования. В такой ситуации даже наличие нескольких улучшающих уровней кодирования, добавляющих недостающие импульсы в сигнал возбуждения, не обеспечивает адекватное повышение эффективности кодирования, поскольку вклад прошлого возбуждения не используется в полной мере, особенно в начале огласованных участков.
С другой стороны, как отмечалось выше, виртуальный цифровой канал, по которому передаются речевые пакеты в IP-сети, не является идеальным из-за возможных ошибок в нем и в первую очередь из-за потери пакетов. В таких условиях важно, чтобы потери части информации в речевом трафике не приводили к размножению ошибки, т.е. требуется независимость текущей информации от предыдущей информации. В этой связи наличие адаптивной кодовой книги сказывается отрицательно, поскольку потеря информации о параметрах текущего предиктора, которым обычно является адаптивная кодовая книга, а также потеря импульсов фиксированной кодовой книги, которые используются для обновления ее памяти, приводят к тому, что на протяжении длительного времени (теоретически стремящегося к бесконечности) состояние адаптивной кодовой книги декодера остается не соответствующим состоянию адаптивной кодовой книги кодера. Это приводит к рассогласованию их работы и резкому снижению качества восстанавливаемого речевого сигнала на стороне получателя при наличии указанных потерь.
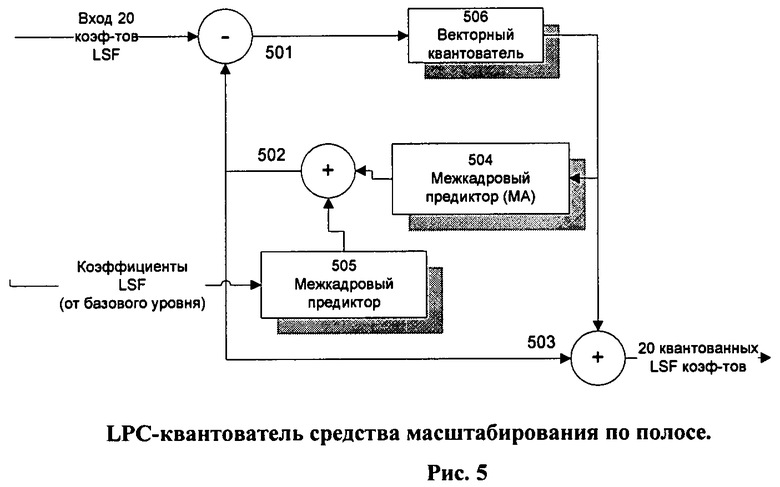
MPEG-4 CELP кодек обладает также средством масштабирования по ширине полосы (см. блок 105 на Фиг.1), которое представляет собой отдельный MP-CELP кодек, работающий с речевым сигналом с вдвое большей шириной полосы речевого сигнала и, соответственно, с удвоенной частотой выборки, в сравнении с базовым кодеком. Блок-схема средства масштабирования по полосе показана на Фиг.4.
Алгоритм работы этого кодера аналогичен алгоритму кодера базового уровня, за исключением нескольких особенностей:
- частота выборки всех сигналов 16 кГц,
- порядок LPC-предсказания 20, т.е. вдвое больше, чем в базовом кодере,
- поиск по адаптивной кодовой книге проводится вокруг значения частоты основного тона, найденного при кодировании базового уровня,
- сигнал возбуждения формируется из трех составляющих:
• прошлого возбуждения из адаптивной кодовой книги,
• возбуждения из кодера базового уровня после преобразования его на удвоенную частоту выборки,
• многоимпульсного возбуждения из фиксированной кодовой книги,
- квантование LPC коэффициентов в LSF-области проводится с предсказанием (предиктивно) с учетом коэффициентов LSF, ранее квантованных в кодере базового уровня.
Блок-схема предиктивного квантователя коэффициентов LSF показана на Фиг.5.
При квантовании используется корреляция между десятью коэффициентами, квантованными на базовом уровне (в узкой полосе - NB), и первыми десятью коэффициентами, квантованными в средстве масштабирования полосы (в широкой полосе - WB). Кроме того, используется корреляция между смежными кадрами, чтобы повысить эффективность кодирования.
Квантование коэффициентов LSF в средстве расширения полосы (Bandwidth Extension Tool) выполняется в соответствии со следующими выражениями:
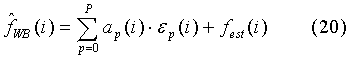
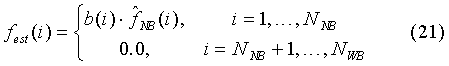
где:
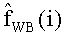 - квантованные LSFs,
- квантованные LSFs,
ap(i) - коэффициенты междкадрового предсказания порядка Р,
εp(i) - квантованная предсказанная ошибка с предыдущего кадра на расстоянии р,
b(i) - оценочные коэффициенты во внутрикадровом предсказании, при котором квантованные LSF из базового кодера (узкополосного - УП или NB) трансформируются в соответствующие коэффициенты модуля расширения полосы (широкополосного - ШП или WB).
Следует отметить, что все вычисления в блоке 105 (средство масштабирования или расширения по полосе) проводятся аналогично кодеру базового уровня. Т.е. последовательно оптимизируются каждая из трех составляющих возбуждения на основе критерия минимума среднеквадратического отклонения взвешенного синтезированного сигнала от целевого вектора. Найденные параметры затем квантуются для передачи по каналу связи.
Таким образом, MPEG-4 CELP кодек обеспечивает масштабируемость как по битовой скорости, так и по полосе обрабатываемого речевого сигнала.
Однако при работе в канале с изменяемой пропускной способностью (IP-сеть, например) резкие переходы с узкой полосы на широкую и наоборот приводят к заметным артефактам в звучании речи. Кроме того, чтобы обеспечить плавность в изменении скорости при переходе количество импульсов возбуждения, добавляемых в блоке 105 (средстве расширения полосы), должно быть минимальным. Однако при недостаточном количестве импульсов возбуждения качество широкополосной речи сильно страдает, поскольку большая разряженность импульсов не обеспечивает правильное формирование сигнала в верхней части спектра.
Также существенным недостатком является использование разных синтезирующих фильтров в базовом кодере и в кодере расширения. Такой подход приводит к необходимости:
- повторно проводить LPC-анализ в средстве расширения и усложняет квантование коэффициентов фильтра,
- ресэмплировать (повторно дискретизировать) как входной речевой сигнал, так и сигнал возбуждения, что требует дополнительной временной задержки в фильтрах, дополнительных вычислений и приводит к дополнительным искажениям речи,
а также затрудняет построение кодека с плавным масштабированием и большим количеством уровней улучшения из-за возрастающей сложности.
Кроме того, использование корреляции между кадрами при квантовании коэффициентов LSF делает данный кодек очень уязвимым к потерям в канале из-за размножения (распространимости) ошибок.
Все это резко ограничивает возможности использования такого кодека для передачи речи по IP-сети.
Раскрытие изобретения
Цель данного изобретения - создание такого способа и реализующего его устройства многоуровневого кодирования речи, ориентированного на передачу речи высокого качества по сети с коммутацией пакетов (например, IP-сети), которые устраняют отмеченные выше недостатки, присущие другим масштабируемым (многоуровневым) речевым кодекам, подобным MPEG-4 CELP. Для достижения этой цели предлагаются следующие улучшения.
1. Для передачи речи очень высокого качества ширина частотной полосы обрабатываемого речевого сигнала должна быть достаточно широкой. Соответственно, синтезирующий фильтр речевого кодера должен иметь адекватный этой полосе порядок. Например, для кодирования входного сигнала, имеющего частотную полосу 0,04…15 кГц (полосу FM-radio), порядок синтезирующего LPC-фильтра должен быть около 40. В то же время необходимо обеспечить плавную масштабируемость кодека по полосе, начиная с минимально допустимой частотной полосы, например 0,04…3,4 кГц, плавно расширяя ее от уровня к уровню до полной ширины полосы. Обычно для кодирования такой узкополосной речи достаточен порядок фильтра, равный 10. Решение этой задачи способом, рассмотренным выше (в MPEG-4 CELP кодеке), характеризуется рядом отмеченных выше существенных недостатков.
Предлагается на всех уровнях кодирования, включая базовый уровень, использовать единую максимальную частоту выборки (например, 32 кГц) и единый синтезирующий фильтр максимального порядка (например, 40). Для того чтобы минимизировать избыточность, возникающую при этом на нижних уровнях кодирования, предлагается применить такое кодирование (квантование) параметров этого фильтра, которое обеспечивает восстановление с необходимой точностью огибающей только той части спектра, которая выбрана как рабочая для заданного уровня кодирования. Сигнал, синтезируемый за пределами этой рабочей полосы, просто не использовать, т.е. отфильтровывать.
Полюсный фильтр высокого порядка позволяет помимо более тонкой оценки огибающей спектра речевого сигнала в его максимумах довольно точно оценивать и «нули» спектра, что позволяет более точно передавать некоторые типы вокализованных звуков (в частности, назальных звуков).
Как известно, для формирования огибающей спектра в минимально заданной полосе 0,04…3,4 кГц (кодирование базового уровня) требуется передать с высокой точностью только первые 8-12 коэффициентов фильтра, а все последующие коэффициенты достаточно передать с более низкой точностью, но чтобы уровень спектральных искажений в рабочей полосе 0,04-3,4 кГц не превышал заданный уровень. На каждом из последующих уровней кодирования рабочая полоса расширяется и, соответственно, повышается точность кодирования все большего числа коэффициентов. При этом на каждом последующем уровне кодирования квантуется только ошибка между неквантованными параметрами фильтра и квантованными параметрами на предыдущих уровнях. Таким образом, достигается плавность расширения полосы от уровня к уровню при контролируемой дополнительной избыточности и сохранении «классического» алгоритма кодирования с многоимпульсным возбуждением, без дополнительных операций LPC-анализа, сложного квантования и ресэмплирования.
В качестве примера такого квантователя параметров синтезирующего фильтра может служить векторный квантователь LSF, в котором поиск по кодовой книге ведется на основе критерия минимума взвешенной среднеквадратической ошибки между вектором исходных коэффициентов и вектором квантованных коэффициентов:
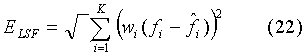
где:
K - порядок синтезирующего фильтра (например, 40),
fi, 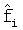 - соответственно неквантованные и квантованные коэффициенты LSF,
- соответственно неквантованные и квантованные коэффициенты LSF,
wi - вектор весовых коэффициентов, который и задает точность квантования отдельных LSF-коэффициентов.
Вектор весовых коэффициентов является переменным и для каждого нового вектора LSF, подлежащего квантованию, должен рассчитываться исходя из заданных спектральных искажений в рабочей полосе частот как:

где:
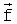 - вектор квантуемых LSF-коэффициентов,
- вектор квантуемых LSF-коэффициентов,
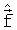 - вектор квантованных LSF-коэффициентов.
- вектор квантованных LSF-коэффициентов.
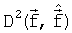 - взвешенные спектральные искажения, которые могут быть рассчитаны как:
- взвешенные спектральные искажения, которые могут быть рассчитаны как:
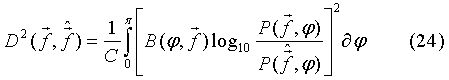
где:
С - нормирующая константа,
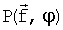 ,
, 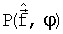 - энергетические LPC-спектры соответственно неквантованных и квантованных LPC, которые могут быть рассчитаны как:
- энергетические LPC-спектры соответственно неквантованных и квантованных LPC, которые могут быть рассчитаны как:
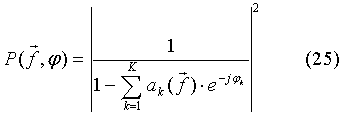
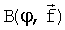 - функция взвешивания по частоте, которая определяется рабочей шириной частотной полосы и важностью восприятия слушателем отдельных участков спектра внутри рабочей полосы и может быть рассчитана, например, как:
- функция взвешивания по частоте, которая определяется рабочей шириной частотной полосы и важностью восприятия слушателем отдельных участков спектра внутри рабочей полосы и может быть рассчитана, например, как:
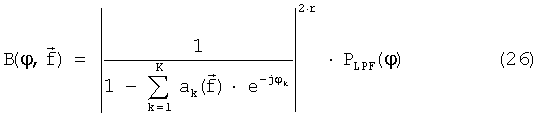
где:
 - неквантованные LPC-коэффициенты, выраженные как функция вектора LSF,
- неквантованные LPC-коэффициенты, выраженные как функция вектора LSF,
r - эмпирическая константа (≈0,15),
PLPF(φ) - спектральная характеристика фильтра нижних частот (LPF), который определяет рабочую частотную полосу, фиксированную для текущего уровня кодирования.
Вычисление второй производной (23) и интеграла (24) может быть выполнено любым из соответствующих реализационных алгоритмов, при выборе из которых целесообразно учесть снижение вычислительных затрат.
Обучение кодовых книг квантователя может быть выполнено любым из известных оптимизационных алгоритмов (например, с помощью алгоритма Ллойда).
2. Как известно, использование предсказания при кодировании параметров речевого сигнала (параметров возбуждения и LPC-фильтра) позволяет увеличить эффективность кодирования с учетом корреляционной связи (избыточности) между текущими и прошлыми сигналами или параметрами. Предиктивное кодирование позволяет использовать эту избыточность и существенно повысить тем самым качество восстановленного речевого сигнала по сравнению с непредиктивным кодированием при одинаковой степени сжатия (одинаковой битовой скорости).
С другой стороны, как отмечалось выше, предиктивное кодирование весьма чувствительно к ошибкам и потерям информации при передаче речевого потока по каналу связи из-за эффекта размножения ошибок.
Одним из известных компромиссных вариантов решения этой проблемы является чередование во времени непредиктивного и предиктивного кодирования. В этом случае распространение ошибки невозможно далее, чем на расстояние между смежными кадрами с непредиктивно кодированными параметрами. Однако подобное компромиссное решение без учета самого речевого сигнала и типа кодирования (предиктивный или непредиктивный) для данного конкретного отрезка кодируемого сигнала может не дать требуемого качества. Кроме того, действие даже одиночной ошибки приводит к деградации качества соответствующего участка сигнала из-за эффекта ее размножения, хотя и ограничивается по времени.
Целесообразно связать выбор типа кодирования с характером кодируемого сигнала через некоторый критерий стационарности. Идея такого подхода заключается в том, чтобы обнаруживать начальный участок квазистационарного отрезка сигнала, в рамках которого его статистические характеристики практически неизменны, и кодировать его непредиктивно, но достаточно точно, а последующие за ним участки внутри этого квазистационарного отрезка кодировать предиктивно по отношению к начальному непредиктивно кодированному участку.
Подобный подход известен из кодирования видеопоследовательностей, когда ключевые кадры (фреймы) кодируются непредиктивно, а промежуточные кадры кодируются предиктивно относительно ключевых кадров. При этом возможна автоматическая расстановка ключевых кадров на основе некоторого критерия отличия текущего кадра от последнего ключевого.
Предлагается применить подобный подход (в дополнение к вышеописанному улучшению по п.1) к кодированию параметров речевых сигналов в масштабируемом речевом кодеке с целью обеспечить компромисс между эффективностью кодирования и устойчивостью к потерям (размножению ошибки). Для этого при кодировании параметров синтезирующего фильтра целесообразно опираться на некоторый критерий отличий текущих параметров синтезирующего фильтра от тех кодированных параметров синтезирующего фильтра, которые в прошлом были последними закодированы непредиктивно. Если критерий отличий не выполняется, то текущие параметры синтезирующего фильтра квантуются предиктивно относительно тех кодированных параметров синтезирующего фильтра, которые последними были закодированы непредиктивно. Если критерий отличий выполняется, то текущие параметры квантуются непредиктивно.
При таком подходе искажение или потеря любых предиктивно кодированных параметров не приводят к размножению ошибки, поскольку каждые последующие предиктивно кодированные параметры слабо зависят от предыдущих предиктивно кодированных параметров. Однако потеря непредиктивно кодированных параметров приведет к искажению всего участка, который предиктивно кодирован по отношению к ним. Тем не менее, во-первых, вероятность попадания ошибки на непредиктивно квантованные параметры существенно ниже, чем на промежуточные предиктивно квантованные, а во-вторых, непредиктивно квантованные параметры могут быть дополнительно защищены одним из способов (например, корректирующим кодом или дублированием). Поэтому предложенный способ кодирования параметров синтезирующего фильтра обеспечивает более высокую устойчивость к потерям, поскольку снижает вероятность распространения ошибки.
Вместе с тем, подобная схема кодирования сохраняет высокую эффективность, т.к. использует сильные корреляционные связи внутри квазистационарных участков и не использует предиктивное кодирование там, где его эффективность низка.
Более важно в сетях IP обеспечить устойчивость к потере кадров, характерной для подобных сетей. Существуют различные механизмы для этого, базирующиеся на интерполяции потерянной информации по ближайшим кадрам (переданным до потерянного и/или после потерянного) или на ее повторении. С учетом предлагаемого подхода формирования непредиктивно кодированных ключевых кадров целесообразно использовать механизм повторения путем сохранения некоторой минимально необходимой информации из непредиктивно кодированного кадра в таком виде: важная часть группы параметров базового уровня (в первую очередь чувствительные к ошибкам/потерям биты) непредиктивно кодированного кадра или все такие параметры повторяются в следующем (или даже в двух или более следующих) предиктивно кодированном(ых) кадре(ах). Тогда при потере непредиктивно кодированного кадра его базовая часть может быть восстановлена с некоторой задержкой (большей частью на один кадр) по информации о ней в следующем(их) предиктивно кодированном(ых) кадре(ах). Квантование параметров базового уровня, которые повторяются в следующим кадре за непредиктивно кодированном кадром, может быть и более грубым с целью уменьшения такой вводимой контролируемой избыточности.
В качестве примера квантователя параметров синтезирующего фильтра может служить переключаемый (предиктивный/непредиктивный) векторный квантователь LSF, построенный одним из известных способов. В качестве критерия отличия, по которому происходит переключение с одного типа квантователя на другой, может быть использован простой критерий сравнения взвешенной среднеквадратической ошибки между текущими коэффициентами LSF и ранее непредиктивно квантованными LSF с заданным порогом:

(где if - это «если», then - «тогда», Threshold означает «порог», a otherwise означает «иначе»).
Весовой вектор wi обеспечивает взвешивание LSF-коэффициентов по их значимости по восприятию слушателем.
3. В соответствии с предыдущими рассуждениями, адаптивная кодовая книга также является источником размножения ошибки. Поэтому разумно или не использовать адаптивную кодовую книгу там, где ее эффективность невысокая, решив тем самым компромисс между эффективностью кодирования и устойчивостью к потерям, или использовать указанный выше механизм введения контролируемой избыточности для ослабления влияния потерь кадров.
В первом случае в дополнение к улучшению по п.1 предлагается не использовать вклад адаптивной кодовой книги в текущий сигнал возбуждения в том случае, если не выполняется некоторый критерий эффективности этой адаптивной кодовой книги.
В качестве такого критерия может быть использована, например, среднеквадратическая ошибка между входным и предсказанным речевым сигналом, нормированная по энергии входного сигнала, которая сравнивается с заданным порогом:
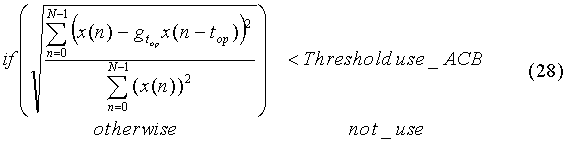
где:
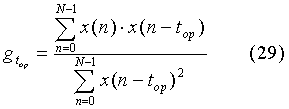
(use - означает «использовать», not_use - «не использовать»).
T.e. если нормированная ошибка не превышает заданный порог, то адаптивная кодовая книга (АКК) применяется для формирования возбуждения текущего подкадра. В противном случае адаптивная кодовая книга не используется. Флаг использования адаптивной кодовой книги передается в линию связи вместе с другими речевыми параметрами.
Во втором случае флаг использования АКК и информация о вкладе АКК повторяются в следующем кадре, что снизит ущерб от потери предыдущего кадра за счет локализации ошибки.
4. Как отмечалось выше, эффективность адаптивной кодовой книги остается низкой в начале огласованных стационарных участков, особенно когда количество импульсов возбуждения, формируемых фиксированной кодовой книгой, малое. Только после нескольких интервалов анализа адаптивная кодовая книга «насыщает» сигнал возбуждения. В результате качество речи на значительной части этих стационарных участков сильно страдает. Эта проблема особенно обостряется при кодировании речи на базовом уровне, где минимальная битовая скорость может быть достигнута только при очень малом количестве импульсов возбуждения, формируемых фиксированной кодовой книгой. Обычный подход, в котором количество импульсов возбуждения, формируемых фиксированной кодовой книгой, не зависит от входного сигнала, вынуждает смириться либо с недостаточным речевым качеством в начале огласованных стационарных участков, если используется малое количество импульсов, либо с завышенной битовой скоростью при использовании большего количества импульсов.
Как ранее указывалось, сети с коммутацией пакетов (например, IP-сеть) не накладывают требование на постоянство битовой скорости. Разумно использовать эту возможность и управлять количеством импульсов возбуждения в кодеке в зависимости от информативности (стационарности) входного сигнала.
Предлагается, в дополнение к улучшению по п.1, связать количество импульсов возбуждения, формируемого фиксированной кодовой книгой, с некоторым критерием начала вокализованного (огласованного) стационарного участка.
В качестве этого критерия начала огласованного стационарного участка может быть использован, например, критерий сравнения усиления предсказания, вычисленного по формуле (29), с заданным порогом:
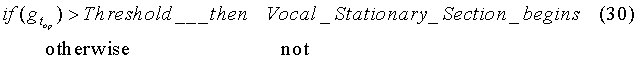
где Vocal_Stationary_Section_begins означает «начался стационарный огласованный участок речи», otherwise означает «иначе», not означает «нет».
Анализ очень большого речевого материала показывает, что точность предсказания резко увеличивается в самом начале огласованных стационарных участков, когда новая стационарная речевая волна еще только начинает развиваться. Увеличивая количество импульсов возбуждения, формируемых фиксированной кодовой книгой, удается более точно сформировать эту развивающуюся речевую волну на данном подкадре (или кадре). Сигнал возбуждения в последующих подкадрах (или кадрах) формируется также с более высокой точностью, но уже за счет адаптивной кодовой книги при минимальном вкладе фиксированной кодовой книги. Таким образом, кратковременный «впрыск» дополнительных импульсов в начале огласованных стационарных участков несущественно повышает среднюю битовую скорость кодированной речи, но позволяет значительно повысить качество синтезированной речи, поскольку эффективность предсказателя адаптивной кодовой книги становится очень высокой уже с самого начала огласованного стационарного участка.
Краткое описание чертежей
На Фиг.1 представлена упрощенная блок-схема речевого кодера MPEG-4 CELP, работающего в режиме масштабирования битовой скорости и частотной полосы.
На Фиг.2 дана упрощенная блок-схема речевого CELP-кодера с многоимпульсным возбуждением (MP-CELP), являющегося кодером базового уровня в MPEG-4 CELP.
На Фиг.3 показана упрощенная блок-схема средства масштабирования битовой скорости (Bit Rate Scalable tool) речевого кодера MPEG-4 CELP.
На Фиг.4 представлена упрощенная блок-схема средства расширения частотной полосы (Bandwidth Extension Tool) речевого кодера MPEG-4 CELP.
На Фиг.5 показана упрощенная блок-схема LPC-квантователя (квантователя LSF коэффициентов) средства расширения частотной полосы (Bandwidth Extension Tool) речевого кодера MPEG-4 CELP.
На Фиг.6 показана упрощенная блок-схема масштабируемого речевого кодера, использующего заявляемый способ кодирования.
На Фиг.7 показана упрощенная блок-схема MP-CELP кодера базового уровня, использующего заявляемый способ кодирования.
На Фиг.8 показана упрощенная блок-схема LPC-квантователя MP-CELP кодера базового уровня, использующего заявляемый способ кодирования.
На Фиг.9 показана упрощенная блок-схема MP-CELP кодера улучшающего уровня, использующего заявляемый способ кодирования.
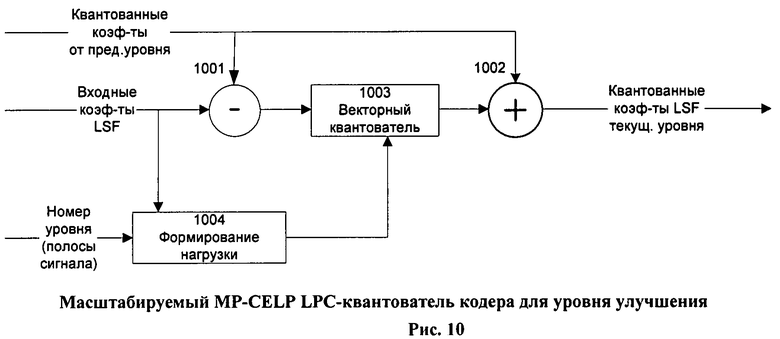
На Фиг.10 показана упрощенная блок-схема LPC-квантователя MP-CELP кодера уровня улучшения, использующего заявляемый способ кодирования.
Осуществление изобретения
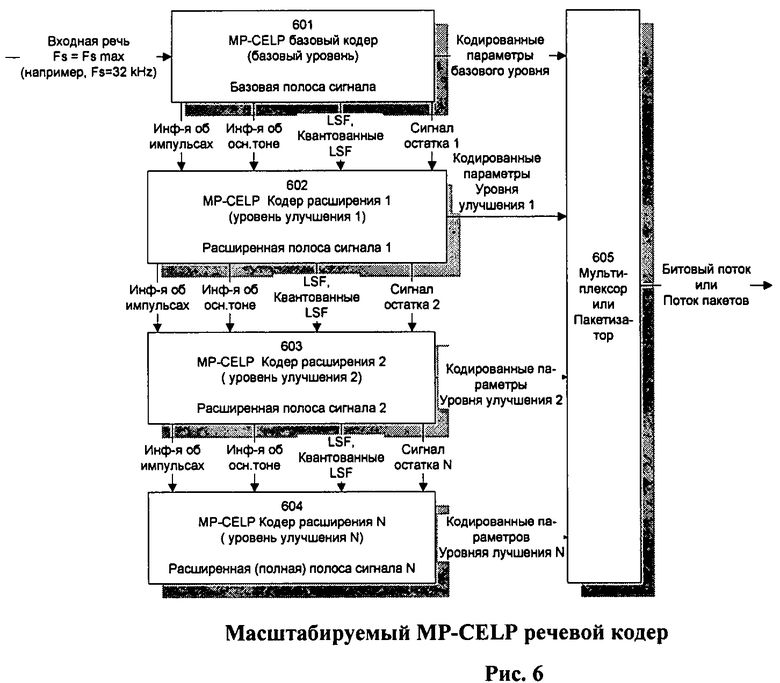
Блок-схема масштабируемого речевого кодера, в котором использован метод кодирования в соответствии с предлагаемым изобретением, показана на Фиг.6.
Как видно из Фиг.6, масштабируемый кодер содержит MP-CELP кодер базового уровня кодирования (блок 601), на который поступает речевой сигнал в цифровой форме, с максимальной частотой дискретизации (например, с частотой 32 кГц), и набор из N MP-CELP кодеров улучшающих уровней кодирования (блоки 602, 603 и 604). Важной особенностью данной схемы является отсутствие каких-либо преобразователей частоты выборки входного речевого сигнала. Т.е. кодеры всех уровней работают с сигналами входной (максимальной) частоты дискретизации (или выборки).
Тем не менее для того чтобы обеспечить низкую битовую скорость, кодер базового уровня кодирует речевой сигнал, используя очень малое количество импульсов возбуждения и только в узкой (базовой) полосе частот, например 0,04…3,4 кГц. Результатом работы кодера базового уровня (блок 601) является набор кодированных параметров базового уровня, передаваемые в канал через блок 605, реализующий мультиплексирование или пакетизацию битового потока и корректирующего (помехоустойчивого) кодирования всех или части кодированных параметров речевого сигнала для борьбы с ошибками в цифровом канале связи, а также ряд параметров (квантованные и неквантованные коэффициенты LSF, информация об основном тоне и о позициях импульсов возбуждения и др.), передаваемых на кодер последующего улучшающего уровня (блок 602), включая сигнал остатка. Этот сигнал остатка получен как разница между взвешенным входным речевым сигналом и взвешенным синтезированным сигналом базового уровня за вычетом «звона» взвешенного синтезирующего фильтра и служит входным целевым вектором для кодера следующего улучшающего уровня. Каждый из последующих улучшающих уровней (блоки 603 и 604) кодирует этот сигнал остатка, поступающий с предыдущего уровня улучшения наряду с информацией об ОТ и позициях импульсов возбуждения, а также о квантованных и неквантованных коэффициентах LSF. Выходы всех последовательно соединенных блоков 601, 602, 603 и 604 поступают на соответствующие входы блока 605. При этом речевое качество суммы сигналов, синтезированных на всех предыдущих уровнях кодирования, плавно повышается от уровня к уровню за счет как дополнительных импульсов в сигнале возбуждения, так и за счет расширения частотной полосы. Суммарный синтезированный сигнал всех уровней сформирован, таким образом, максимальным числом импульсов возбуждения и имеет максимальную ширину частотной полосы. Речевое качество этого сигнала близко качеству исходного речевого сигнала.
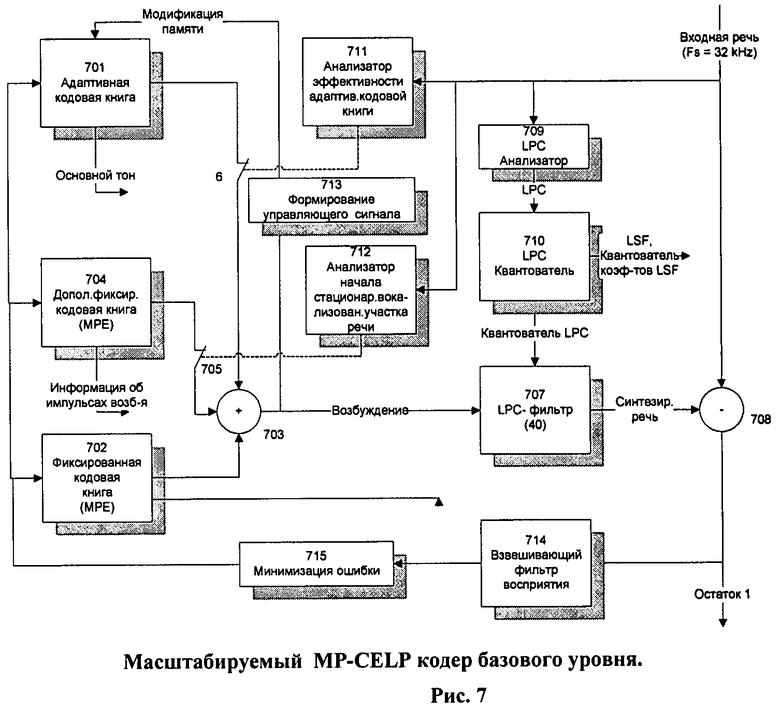
Блок-схема базового MP-CELP кодера, использующего способ кодирования в соответствии с настоящей заявкой на изобретение, показана на Фиг.7.
Как видно из Фиг.7, эта блок-схема похожа на блок-схему MPEG-4 CELP кодера, показанную на Фиг.2. Поэтому при кодировании все основные вычисления выполняются аналогично, в соответствии с выражениями (1)-(19). В то же время базовый кодер, использующий заявляемый метод, имеет следующие существенные отличия.
Во-первых, частота выборки входного сигнала соответствует максимальной ширине частотной полосы, выбранной для всех уровней кодирования, например 32 кГц. Соответственно, порядок LPC-фильтра также выбран исходя из максимальной ширины частотной полосы, например 40-й.
Кроме того, на блок-схеме присутствует дополнительный блок 711 «анализатора эффективности адаптивной кодовой книги» (Adaptive Codebook's Effectiveness Analyzer), который исключает вклад адаптивной кодовой книги из сигнала возбуждения в том случае, когда эффективность кодовой книги низка. Работа анализатора может быть осуществлена, например, в соответствии с выражением (28).
Также на блок-схеме присутствует дополнительный блок 712 «анализатора начала стационарного огласованного участка» (Analyzer of the Stationary Voiced Section Beginning), который управляет вкладом дополнительной фиксированной кодовой книги в сигнал возбуждения в начале огласованных стационарных участков. Этот анализатор может быть реализован, например, в соответствии с выражением (30). На блоки 711 и 712 подается входная речь с максимальной частотой дискретизации. Выход блока 711 управляет переключателем 706, а выход блока 12 управляет переключателем 705. Дополнительная фиксированная кодовая книга (блок 704), на которую также подается сигнал поиска оптимального кодового слова, как и на блоки 701 и 702, позволяет при обнаружении стационарного участка речи через переключатель 705 обеспечить дополнительный «впрыск» импульсов возбуждения.
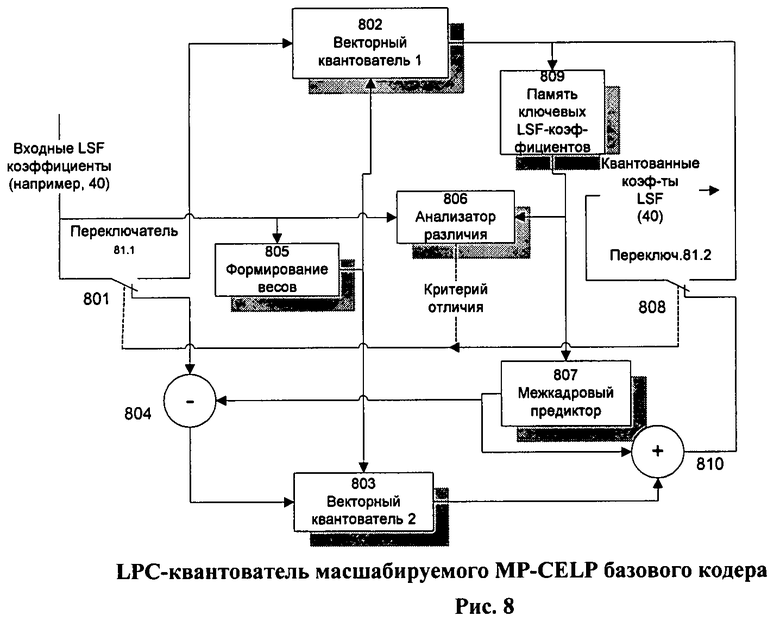
Остальные особенности заключаются в реализации отдельных модулей базового кодера, в первую очередь LPC-квантователя. Блок-схема квантователя показана на Фиг.8.
Квантователь, на вход которого поступают коэффициенты LSP через переключатель 81.1 (блок 801), состоит из двух частей: непредиктивного векторного квантователя 1 (блок 802) и предиктивного векторного квантователя 2 (блок 803) с межкадровым предиктором (блок 807), выход которого поступает на блок вычитаний 804 и блок суммирования 810. Переключение входов и выходов этих квантователей обеспечивается с помощью условных переключателей соответственно с номером 81.1 (блок 801) и номером 81.2 (блок 808), управляемых сигналом "критерий различий" (Distinction Criterion) с выхода блока 806. Этот сигнал формируется «анализатором различий» (блок 806) как результат сравнительного анализа текущих входных LSF-коэффициентов и последних по времени «ключевых LSF- коэффициентов», хранимых в памяти блока 809 (Key LSF's memory), например, в соответствии с выражением (27). В зависимости от этого параметра и соответственно положения переключателей 81.1 и 81.2, текущие LSF-коэффициенты квантуются либо непредиктивно и затем сохраняются в памяти как новые «ключевые LSF», либо предиктивно по отношению к последним «ключевым LSF», хранимым в памяти блока 809, выход которого подключен ко входам блоков 806 и 807. Выходом квантователя являются квантованные коэффициенты LSF, которые могут в зависимости от положения переключателя 81.2 поступать с выхода блока 802 или блока 803 через сумматор 810.
Главной особенностью квантователя является наличие блока «формирования весов» (блок 805). Именно этот блок, используя текущие входные LSF-коэффициенты и ширину рабочей полосы частот (Base Bandwidth), принятую на базовом уровне кодирования (например, 0,04…3,4 кГц), адаптивно формирует для каждого текущего вектора LSF-коэффициентов взвешивающий вектор, который используется в обоих векторных квантователях 1 и 2. Этот взвешивающий вектор может быть сформирован в соответствии с выражением (23). Таким образом, несмотря на то что порядок фильтра максимальный, эффективно кодируется речевой сигнал только в рабочей принятой для базового уровня полосе частот. Сигнал, синтезированный за пределами рабочей частотной полосы, отфильтровывается в декодере базового уровня.
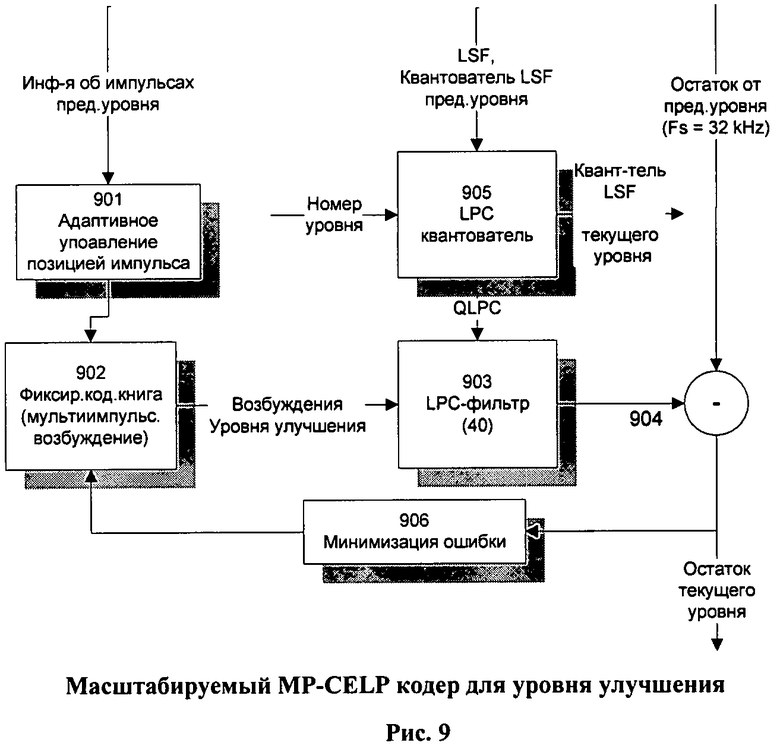
Блок-схема MP-CELP кодера улучшающего уровня показана на Фиг.9.
Очевидно, что блок-схема кодера уровня улучшения очень похожа на блок-схему средства масштабирования скорости кодера MPEG-4 CELP, показанную на Фиг.3. Формирование сигнала возбуждения синтезирующего фильтра может быть осуществлено «классическим» методом поиска позиций импульсов, принятым в МРЕ-методе, например, в соответствии с выражениями (17)-(19). В то же время имеются и следующие существенные отличия.
Во-первых, частота выборки сигнала остатка, поступающего на вход кодера с предыдущего уровня, всегда равна максимальной (например, 32 кГц) частоте, несмотря на ширину частотной полосы, которая принята как «рабочая» на данном уровне кодирования. Соответственно, порядок синтезирующего фильтра также всегда остается максимального порядка (например, 40-го).
Во-вторых, на блок-схеме присутствует LPC-квантователь, на вход которого поступают неквантованные LSF-коэффициенты и LSF-коэффициенты, квантованные в кодере предыдущего уровня. Кроме того, на вход квантователя поступает номер данного уровня улучшения, который косвенно задает ширину рабочей полосы частот для данного уровня кодирования.
Блок-схема этого LPC-квантователя показана на Фиг.10.
Из него следует, что векторный квантователь (блок 1003) квантует ошибку (разницу), формируемую блоком вычитания 1001, между входными LSF-коэффициентами и LSF-коэффициентами, квантованными на предыдущих уровнях кодирования. Особенность квантователя - наличие блока формирования весов (Weights Forming) 1004, который формирует вектор весовых коэффициентов, опираясь на текущие значения входных LSF-коэффициентов и ширину частотной полосы, принятой как рабочая для данного уровня кодирования. Формирование вектора весовых коэффициентов может быть осуществлено, например, в соответствии с выражением (23). Выходом LPC-квантователя служат квантованные LSF-коэффициенты текущего уровня, которые получаются на выходе блока суммирования 1002, на два входа которого поступают соответственно входной сигнал LSF-квантователя, т.е. квантованные коэффициенты LSF предыдущего уровня, и выходной сигнал блока 1003. Несмотря на то что на Фиг.10 показан простой векторный квантователь, использование в улучшающем уровне кодирования переключаемого предиктивно/непредиктивного квантования, подобно базовому уровню, также не исключается.



Изобретение относится к области способов передачи мультимедийной информации в сетях связи и запоминания в электронных устройствах, в частности к кодированию речи. Техническим результатом является повышение качества речи и обеспечение устойчивости к потерям речевых кадров, передаваемых в сети пакетной коммутации. Указанный результат достигается тем, что в способе многоуровневого масштабируемого по частотной полосе и скорости передачи кодирования речи на базе «анализа синтезом» для каждого кадра или подкадра речи кодируют параметры источника многоимпульсного возбуждения и синтезирующего фильтра. Способ включает кодирование базового уровня и кодирование одного или более уровней улучшения. Параметры синтезирующего фильтра определяют только один раз на этапе анализа при кодировании базового уровня, затем кодируют эти параметры таким образом, что только базовая часть речевого сигнала может быть восстановлена с заданным качеством в определенной ограниченной части частотной полосы сигнала, и хотя бы на одном последующем улучшающем уровне кодирования указанная часть частотной полосы расширяется. 3 н. и 6 з.п. ф-лы, 10 ил.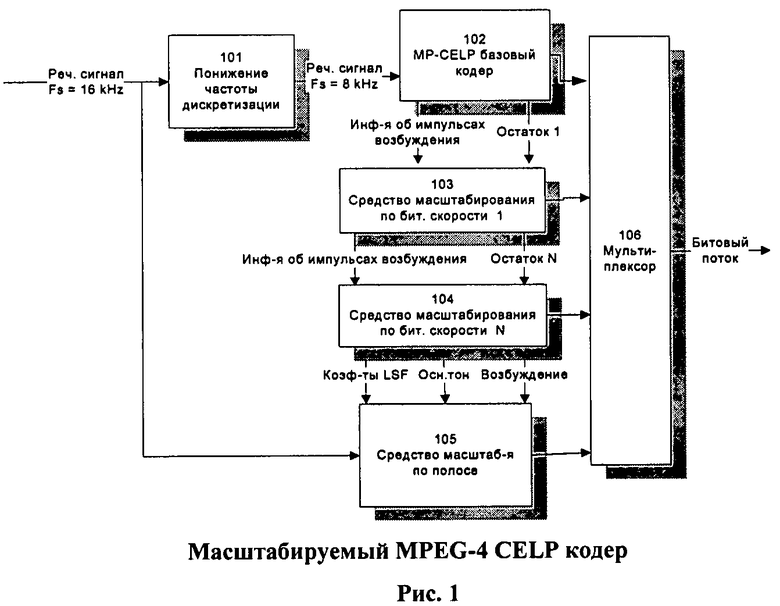
1. Способ многоуровневого масштабируемого по частотной полосе и скорости передачи кодирования речи на базе «анализа синтезом», в котором для каждого кадра или подкадра речи кодируют параметры источника многоимпульсного возбуждения и синтезирующего фильтра, включающий кодирование базового уровня и кодирование одного или более уровней улучшения, отличающийся тем, что для повышения качества речи и обеспечения устойчивости к потерям речевых кадров, передаваемых в сети пакетной коммутации, параметры вышеназванного синтезирующего фильтра определяют только один раз на этапе анализа при кодировании базового уровня, затем кодируют эти параметры таким образом, что только базовая часть речевого сигнала может быть восстановлена с заданным качеством в определенной ограниченной части частотной полосы сигнала, и хотя бы на одном последующем улучшающем уровне кодирования указанная часть частотной полосы расширяется.
2. Способ по п.1, где при кодировании очередного речевого кадра или подкадра текущие параметры вышеназванного синтезирующего фильтра кодируют на основе метода предиктивного кодирования, который опирается на ранее закодированные прошлые параметры синтезирующего фильтра, которые последними были закодированы без использования предсказания при кодировании одного из прошлых кадров или подкадров, если не выполнен заданный критерий отличия вышеназванных текущих параметров синтезирующего фильтра от вышеназванных прошлых параметров синтезирующего фильтра, а
в противном случае, если вышеназванный критерий отличия выполнен, то эти указанные текущие параметры синтезирующего фильтра кодируют без использования предсказания.
3. Способ по п.1, в котором сигнал возбуждения синтезирующего фильтра формируют с помощью хотя бы одной фиксированной кодовой книги и с помощью адаптивной кодовой книги, если выполнен заданный критерий эффективности адаптивной кодовой книги, а
в противном случае, если вышеназванный заданный критерий эффективности не выполнен, сигнал возбуждения вышеназванного синтезирующего фильтра формируют без использования указанной адаптивной кодовой книги, причем информация об использовании адаптивной кодовой книги повторяется в следующем или следующих кадрах.
4. Способ по п.3, в котором память адаптивной кодовой книги обнуляется, если вышеназванный заданный критерий эффективности адаптивной кодовой книги не выполняется.
5. Способ по п.1, в котором к сигналу возбуждения синтезирующего фильтра дополнительно добавляют один или более импульсов возбуждения в том случае, если выполнен заданный критерий, характеризующий начало огласованного стационарного участка речевого сигнала.
6. Способ по п.1, или 2, или 3, или 4, или 5, в котором часть параметров или все параметры, представленные на одном или более уровнях кодирования, дополнительно защищают корректирующим кодом, и/или часть или все параметры базового уровня повторяются в следующем или следующих кадрах для повышения устойчивости к ошибкам и потерям кадров.
7. Способ по п.6, в котором корректирующее кодирование или повторение на базовом уровне в следующем или следующих кадрах применяют только к тем параметрам, которые были кодированы без использования предсказания.
8. Устройство, реализующие способ кодирования речи по п.1, или 2, или 3, или 4, или 5, или 7 и содержащее последовательно соединенные базовый кодер, на вход которого поступает речевой сигнал с максимальной частотой дискретизации, а выход подсоединен к первому входу блока мультиплексирования или пакетизации и канального кодирования непредиктивных параметров речевого сигнала, выход которого представляет собой битовый поток или поток пакетов, и серию кодеров расширения 1, 2,…,N, выходы которых подключены соответственно ко второму, третьему,…, (N+1)-му входам указанного блока мультиплексирования или пакетизации и канального кодирования, причем на четыре информационных входа всех кодеров расширения от первого до N-гo поступают соответственно информация об импульсах возбуждения, информация об основном тоне, квантованные и неквантованные коэффициенты LSF, сигнал остатка от базового блока или кодера расширения нижнего уровня.
9. Устройство, реализующие способ по п.6 и содержащее последовательно соединенные базовый кодер, на вход которого поступает речевой сигнал с максимальной частотой дискретизации, а выход подсоединен к первому входу блока мультиплексирования или пакетизации с повторением всех или части параметров базового уровня или канального кодирования всех или части параметров речевого сигнала базового уровня и всех или части уровней расширения, выход которого представляет собой битовый поток или поток пакетов, и серию кодеров расширения 1, 2,…,N, выходы которых подключены соответственно ко второму, третьему,…, (N+1)-му входам указанного блока мультиплексирования или пакетизации и канального кодирования, причем на четыре информационных входа всех кодеров расширения от первого до N-ro поступают соответственно информация об импульсах возбуждения, информация об основном тоне, квантованные и неквантованные коэффициенты LSF, сигнал остатка от базового блока или кодера расширения нижнего уровня.
| Пресс для выдавливания из деревянных дисков заготовок для ниточных катушек | 1923 |
|
SU2007A1 |
| Способ контроля качества фритюрного жира | 1990 |
|
SU1793373A1 |
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |
| Способ и приспособление для нагревания хлебопекарных камер | 1923 |
|
SU2003A1 |
| Колосоуборка | 1923 |
|
SU2009A1 |
| Способ удержания растянутой ленты в заданном положении на врашающемся шкиве шахтного подъемника и устройство для его осуществления | 1988 |
|
SU1785984A1 |
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |
| МНОГОРЕЖИМНОЕ УСТРОЙСТВО КОДИРОВАНИЯ | 2000 |
|
RU2262748C2 |
| RU 2007140382 A, 10.05.2009. | |||

