Область техники
Данное изобретение относится к обработке данных и, более конкретно, к способу прохождения крупной базы данных, исходя из определенных пользователем критериев, выборки информации из базы данных, исходя из определенных пользователем критериев и предоставления информации в определенном пользователем формате.
Уровень техники
Прототипом для настоящего изобретения является система базы данных, раскрытая в публикации под названием "Parallel Oracle 7.1", Steve Bobrowski, DBMS, том 6, 13, cc. 89-91 (1993). В этой системе базы данных запросы в базу данных обрабатываются с использованием обработки посредством параллельных запросов, при которой один запрос в базу данных разделяется на несколько меньших подзадач, которые сами обрабатываются параллельно соответствующим числом процессоров. Хотя алгоритм обработки, предложенный в этой публикации, хорошо подходит для баз соотносимых данных, в которых данные связаны или соотносятся с другими данными в базе данных, такой алгоритм, как описанный в этой публикации, не решает проблемы, возникающие при обработках запросов в базу данных в случае больших баз данных о сделках или событиях, в которых записи данных могут соотноситься или не соотноситься друг с другом.
Пользователь крупной базы данных постоянно сталкивается с трудностью эффективного обращения к нужной информации в удобном формате. В общем, крупные коммерческие организации постоянно собирают и хранят данные во множестве форматов для множества видов использования. Многие их этих файлов обычно называют файлами сделок или файлами событий, поскольку каждая запись, или набор записей, содержит информацию об отдельном событии или сделке, которые могут происходить независимо от других событий или сделок в данном файле.
Например, крупная сеть розничных магазинов цепного подчинения может вести базы данных, содержащие информацию о покупателях, в которую входят адреса, номера телефонов и пр., и информацию ведущих счетов, которая может содержать для каждого покупателя перечень каждого вида закупленных товаров, дату покупки, цену и вид платежа. Эти файлы, которые могут корректировать ежедневно или еженедельно и которые могут охватить периоды сделок в несколько лет, у крупных компаний, по-видимому, являются довольно объемистыми. Как таковые эти файлы обычно хранят во внешних запоминающих устройствах, таких как накопители на магнитной ленте и накопители на дисках.
Сам по себе размер, например, файла счета ведущегося три года, с учетом того, что этот файл хранят на относительно медленных внешних запоминающихся устройствах, превращает выборку и обработку данных из этих файлов в требующую значительное время задачу. Поэтому эти файлы в их первоначальном виде не используются часто. Вместо этого для коммерческой организации обычно желательно оценивать данные в этих файлах и составлять сводные файлы, например, файлы итоговой суммы закупок в определенном периоде времени.
Поэтому та или иная корпорация будет составлять промежуточные "сводные файлы", которые содержат информацию, собранную из файлов событий или файлов сделок. С накоплением новых событий или сделок сводные файлы корректируют. Например, если файл сделок содержит сведения о ведомости заработной платы, которые указывают число часов, затраченных каждым работником на каждую работу, и также сумму из заработной платы, то сводный файл можно создать для ведения текущей суммы часов, которые затратил каждый работник на каждую работу. При введении в файл сделок новых записей по ведомости зарплаты сводный файл будет корректироваться простым суммированием новых данных по сделкам с ранее запомненными суммами в сводном файле.
В результате этого, если показатель запрашивает сведения о часах, затраченных работником Джоном Смитом на каждую из его работ, то система для предоставления запрошенной информации обратится к сводному файлу, а не к первоначальному файлу сделок - ведомости зарплаты. Поэтому в большинстве случаев для корректировки сводного файла и получения основной части текущей запрашиваемой информации системе придется проводить поиск в текущих записях (рабочих) дней. Это сокращает время обработки данных.
Эти основанные на "сводных файлах" системы, тем не менее, имеют определенные недостатки. Например, если нужный пользователю тип информации в сводном файле не держат, то информацию сразу получить нельзя. Тем самым значительная нагрузка налагается на составителей "сводного файла" в отношении предвидения или предположения будущей информации и нужд данной коммерческой организации и ведения сводной информации таким образом, чтобы она была доступной немедленно.
Дополнительная трудность возникает, когда данные в сводных файлах нужно изменять задним числом. Предположим, например, что решение спора о коллективном договоре с профсоюзом своим итогом имеет повышение, с обратной силой действия этого решения, почасовой оплаты с 7 долл./ч до 8 долл./ч. В указанной выше системе имеющегося уровня техники нужно подсчитать разницу выплат и затем нужно откорректировать все сводные файлы, содержащие производные сведения о заработной плате, чтобы это изменение задним числом было бы отражено.
Поэтому системы имеющегося уровня техники страдают от присущей им нехватки гибкости в связи с тем, что их выходные данные основаны на содержании сводных файлов, а не первоначальных файлов сделок или событий. Это значит есть необходимость в системе, которая может быстро составлять всю информацию в нужном формате из первоначальных файлов сделок или событий.
Сущность изобретения
Первым объектом изобретения является способ прохождения одного или более логического файла, выполняемый компьютером в системе, содержащей два или более процессора, причем указанные логические файлы содержат два или более физических файла базы данных сделок, согласно которому (способу) запоминают информацию базы данных сделок в запоминающих устройствах, отличающийся тем, что
генерируют один или более набор параметров для обработки указанных двух или более физических файлов базы данных сделок,
назначают соответствующую последовательность каждому из указанных двух или более физических файлов базы данных сделок, причем каждая последовательность содержит команды для обработки своего соответствующего одного файла из указанных двух или более файлов в соответствии с отобранными заранее параметрами обработки из числа указанного одного или более набора параметров обработки;
подвергают последовательному разовому прохождению каждого из числа указанных двух или более файлов базы данных сделок в соответствии с их соответствующей последовательностью, причем по меньшей мере две из указанных последовательностей приводят в рабочее состояние параллельно,
выбирают согласно указанным командам для каждой последовательности информацию из соответствующего одного физического файла из числа указанных двух или более физических файлов базы данных сделок, ассоциированных с указанной последовательностью, на основе отобранных заранее наборов из числа указанного одного или более наборов параметров обработки, ассоциированных с указанной последовательностью,
запоминают информацию, выбранную каждой последовательностью, в выходном файле.
Согласно заявленному способу указанные два или более файла находятся на одном или более внешнем носителе.
Набор входных буферов ассоциируют с каждым из указанных двух или более файлов, причем каждый набор входных буферов содержит два или более входных буфера, блоки данных из каждого из указанных двух или более файлов выбирают в соответствующие входные буферы из числа указанных двух или более входных буферов в том же порядке, в каком указанные блоки данных записывают на физическом носителе.
Один или более внешний носитель содержит один или более накопитель на ленте, накопитель на дисках, накопитель на жестких магнитных дисках, накопитель на оптических дисках, память на цилиндрических магнитных доменах (ЦМД) и флэш-память.
Вариантом заявленного первого объекта является выполняемый компьютером способ прохождения двух или более физических файлов базы данных сделок в системе, содержащей два или более процессора, которые соответствуют логическому файлу на основе одного или более определения представления, согласно которому (способу) запоминают информацию базы данных сделок в запоминающих устройствах, отличающийся тем, что
создают одно или более определение представления, причем каждое определение представления определяет набор параметров обработки для отобранных физических файлов из числа указанных двух или более физических файлов базы данных сделок,
создают логическую таблицу, содержащую набор логических таблиц для каждого из указанных двух или более физических файлов базы данных сделок,
преобразуют набор параметров для каждого определения представления в соответствующее множество записей логической таблицы, которое копируют в наборы логических таблиц, которые соответствуют отобранным физическим файлам из числа двух или более физических файлов, которые соответствуют наборам параметров, определенных каждым определением представления, ассоциируют соответствующую одну последовательность из множества последовательностей с каждым набором логических таблиц,
преобразуют записи логической таблицы каждой последовательности из числа указанного множества. последовательностей, соответствующих каждому определению представления, ассоциированному с каждой указанной последовательностью, в набор команд для указанной каждой последовательности,
задействуют каждую последовательность в соответствии с ее набором команд,
для обращения к каждой записи его соответствующего одного физического файла из числа указанных двух или более физических файлов базы данных сделок,
для выборки информации из указанной записи на основе определений представления, ассоциированных с указанной последовательностью, и
для хранения указанной информации в одном или более файле извлечений на основе определений представления, ассоциированных с указанной последовательностью, причем по меньшей мере две последовательности из указанного множества последовательностей задействуют параллельно.
Согласно заявленному варианту способа прохождения файла два или более файла находятся на одном или более внешнем носителе.
Один или более внешний носитель содержит один или более накопитель на лентах, накопитель на жестких дисках, накопитель на оптичесих дисках, память на цилиндрических магнитных доменах (ЦМД) или флэш-память.
Набор входных буферов ассоциируют с каждым из указанных двух или более файлов, причем каждый набор входных буферов содержит два или более входных буфера, блоки данных из каждого из указанных двух или более файлов выбирают в соответствующие входные буферы из числа указанных двух или более входных буферов в том же порядке, в каком записывают указанные блоки данных на физическом носителе.
Набор выходных буферов ассоциируют с каждым файлом извлечения из числа указанного одного или более файла извлечений, причем каждый набор выходных буферов содержит один или более выходной буфер, причем при приведении в рабочее состояние каждой последовательности для хранения указанной выбранной информации в одном или более файле извлечений, хранят указанную информацию, выбранную указанной каждой последовательностью в текущем одном выходном буфере из числа указанного одного или более выходного буфера, ассоциированного с одним файлом извлечений из числа указанного одного или более файла извлечений, определяют, заполнен ли текущий один выходной буфер из числа указанного одного или более выходного буфера и, если указанный текущий один выходной буфер из числа указанного одного или более выходного буфера определен как являющийся полным, то инициируют перенос текущего одного выходного буфера из числа указанного одного или более выходного буфера в его ассоциированный файл извлечений, и обозначают еще один выходной буфер из числа указанных выходных буферов в качестве текущего выходного буфера из числа указанного одного или более выходного буфера.
Вторым объектом изобретения является система параллельной обработки данных для прохождения логического файла базы данных, причем логический файл содержит два или более физических файла, содержащая (система) входной буфер для выборки блоков данных из указанных двух или более физических файлов базы данных сделок, выходной буфер для хранения блоков данных в одном или более файле извлечений, логическую таблицу, хранящую один или более набор параметров обработки, причем каждый набор параметров обработки соответствует соответствующему определению представления, каждое определение представления определяет критерии для выборки информации из одного или более файла логических записей, каждое определение представления также определяет формат обозначенного одного файла извлечений из числа указанных файлов извлечений, логическая таблица содержит по меньшей мере два набора логических таблиц, каждый набор логических таблиц ассоциирован с соответствующим файлом из числа указанных двух или более файлов базы данных сделок, каждый набор логических таблиц содержит соответствующий набор параметров обработки, ассоциированный с каждым определением представления, которое определяет критерии для выборки информации из соответствующего файла, ассоциированного с указанным набором логических таблиц, причем каждая последовательность последовательно обращается к записям из файла, ассоциированного с ее соответствующим набором логических таблиц, каждая последовательность применяет каждый из своих наборов параметров обработки к каждой записи, к которой обращаются, благодаря чему к каждой записи обращаются только один раз, каждая последовательность производит выборку информации из каждой записи, к которой совершено обращение, в соответствии с ее наборами параметров обработки и запоминает выбранную информацию в обозначенных файлах извлечений с помощью выходного буфера в соответствующих форматах, определенных определениями представления, соответствующими наборам параметров обработки.
Согласно заявленной системе входной буфер содержит соответствующий набор входных буферов для каждой последовательности, причем каждый соответствующий набор входных буферов содержит один, или более, входной буфер, причем каждый входной буфер предназначен для хранения выбранного блока данных, причем размер блока данных выбирают как функцию физического носителя, с которого был выбран данный блок данных.
Выходной буфер содержит соответствующий набор выходных буферов для каждого файла извлечений, причем каждый соответствующий выходной буфер содержит один, или более, выходной буфер, причем каждый выходной буфер предназначен для размещения блока данных для хранения в файле извлечений, ассоциированных с соответствующим выходным буфером, размер каждого блока данных выбран как функция физического носителя, в котором располагается файл извлечений.
Последовательность, ассоциированная с одним, или более, входным буфером каждого набора входных буферов в заявленной системе может выполнять свои наборы параметров обработки на текущем одном входном буфере из числа указанного одного, или более, входного буфера, в то время как другой процессор выполнен с возможностью выборки следующего блока данных из указанного одного файла из числа указанных двух, или более, файлов, ассоциированных с данной последовательностью.
Каждая последовательность до запоминания выбранной информации в наборе выходных буферов, соответствующем обозначенному файлу извлечений, может определять, заполнен ли текущей выходной буфер данного набора выходных буферов, соответствующих обозначенному файлу извлечений, и если текущий выходной буфер не заполнен, то запоминать выбранную информацию в текущем выходном буфере; и если текущий выходной буфер заполнен, то инициировать перенос указанного текущего выходного буфера из числа одного, или более, выходного буфера в обозначенный файл извлечений и обозначать еще один выходной буфер из числа указанных выходных буферов в качестве текущего одного выходного буфера из числа одного, или более, выходного буфера.
В заявленной системе каждый набор входных буферов содержит множество входных буферов, а каждый набор выходных буферов содержит множество выходных буферов.
Физический носитель содержит один из следующих накопителей: накопитель на ленте, накопитель на дисках, накопитель на жестких магнитных дисках, накопитель на оптических дисках, память на цилиндрических магнитных доменах (ЦМД) и флэш-память.
В системе логическая таблица выполнена на языке, не имеющем процедур.
Таким образом, в соответствии с данным изобретением обеспечивают систему параллельной обработки данных для прохождения баз данных событий или сделок, которая может обрабатывать объемистые файлы событий или сделок быстро и эффективно, тем самым уменьшая потребность в ведении сводных файлов. В соответствии с данным изобретением определяют набор алгоритмов поиска в логической таблице, которую используют для прохождения множества физических файлов, содержащих отдельные события или сделки. Логическая таблица представляет собой осуществление "непроцедурного" языка. Но согласно данному изобретению можно будет выражать логическую таблицу таким процедурным языком, как "Паскаль" или "С".
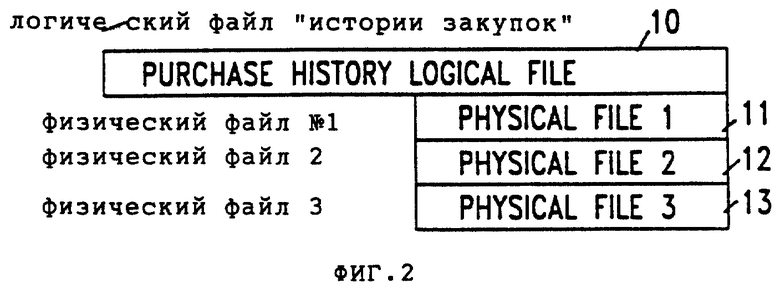
Каждое отдельное событие или сделку называют логической записью. Набор аналогично сформированных логических записей называют логическим файлом. Логический файл, например, может быть набором логических записей, содержащих информацию о событиях закупки (например, закупки с расчетом по кредитным карточкам), происходящих в течение некоторого периода времени, например трех лет. Этот логический файл "истории закупок", например, может включать в себя 3 физических файла: физический файл 1 с закупками в текущем календарном году (год 0), физический файл 2 с закупками по прошедшему календарному году (год -1), и физический файл 3 по закупкам в календарном году, предшествовавшем прошедшему году (год -2). Физические файлы можно хранить на ленте или диске.
В соответствии с данным изобретением в каждом физическом файле логического файла поиск производят согласно соответствующему алгоритму поиска по отдельной последовательности. В многопроцессорной системе отдельные последовательности можно выполнять на отдельных процессорах. Если число процессоров равно, или больше, числу последовательностей, то алгоритм поиска каждой последовательности может проходить свой соответствующий физический файл параллельно с алгоритмами прочих последовательностей. Например, если есть 3 последовательности и 3 процессора, то все 3 последовательности будут проходить свои соответствующие физические файлы параллельно. Далее, даже если число последовательностей превышает число процессоров, то по меньшей мере некоторые алгоритмы поиска будут идти параллельно. Например, если есть 4 последовательности в системе, которая имеет три процессора, то этим последовательностям придется совместно пользоваться процессорами, в связи с чем в любой данный момент времени могут выполняться только 3 последовательности.
В соответствии с данным изобретением алгоритм поиска вырабатывают в логической таблице из одного представления или нескольких. Представление определяют как определенный набор параметров, основанный на данной логической таблице, для создания файла извлечений. Само представление может определять, что некоторые данные или классы данных следует выбирать из логических записей логического файла, обрабатывать определенным способом и записывать в файл извлечений в определенном формате. В типичном случае применения может быть много представлений, определенных относительно одного логического файла и многих разных логических файлов, интересующих пользователя. В соответствии с данным изобретением все представления, которые можно определять относительно разных логических файлов и разных физических файлов, включают в объединенную логическую таблицу. Логическую таблицу организуют по "наборам", в которых каждый набор соответствует отличному от других физическому файлу и поэтому отличной от других последовательностей. Данный набор будет содержать каждое представление, которому требуется информация из физического файла, соответствующего этому набору.
В соответствии с данным изобретением логическую таблицу преобразуют в машинный код, при этом машинный код создает алгоритм поиска для каждой последовательности; каждая последовательность действует на своем соответствующем физическом файле. Затем последовательности исполняют параллельно согласно их соответствующему машинному коду для прохождения физических файлов с логическими записями. Помимо этого, поскольку алгоритм поиска, выполненный машинным кодом для каждой последовательности, будет извлекать всю нужную всеми представлениями информацию из соответствующего физического файла, то каждый физический файл будет проходить только раз независимо от числа представлений, которые определены, либо независимо от числа логических файлов, в которых производят поиск. В результате этого посредством параллелельного поиска в физических файлах и посредством прохождения каждого физического файла только один раз независимо от числа представлений согласно данному изобретению сильно сокращают обработочное время для прохождения крупной базы данных. Это дает возможность извлекать информацию не из сводных файлов, а из первоначальных файлов событий или сделок.
Например, предположим, что пользователь желает составить три отдельных сводки на основе информации, содержащейся в указанном выше логическом файле истории закупок: сводка 1 перечисляет все закупки, по номеру видов товара, сделанные лицами по имени Джон Смит в течение годов с 0 по -2 включительно: сводка 2 перечисляет по фамилии покупателя все покупки в течение годов с 0 по -1 на сумму свыше 500 долл., и сводка 3 перечисляет по каждому покупателю, накопительную сумму его закупок с расчетом по кредитной карточке в текущем году (0).
В соответствии с данным изобретением будут создавать логическую таблицу, разделять логическую таблицу на три части по одной каждому из трех физических файлов логического файла истории закупок.
Создают определение представления для сводки 1 и запоминают в каждом из трех наборов, так как для сводки 1 требуется информация из каждого из трех физических файлов. Определение представления для сводки 1, которую будут копировать в каждый из трех наборов, может включать в себя следующие параметры: выбрать все записи в физическом файле, "покупательским полем" которого является Джон Смит; ввести содержание покупательского поля всех выбранных записей в колонку 1 файла извлечений для представления 1, ввести содержание поля "вид товара" всех выбранных записей в колонку", ввести содержание "поля цены" всех выбранных записей в колонку 3, и отсортировать выбранные записи по содержанию поля "вид товара".
Создают определение представления для сводки 2 и запоминают его только в первом и втором наборах, так как для сводки 2 требуется информация только из физического файла 1 (год 0) и физического файла 2 (год -1). Определение представления для сводки 2, которую будут копировать в каждый из первых двух наборов, может содержать следующие параметры: выбрать все записи в физическом файле с "полем цены" свыше 500 долл., ввести содержание "покупательского поля" всех выбранных записей в колонку 1 файла извлечений для представления 2, ввести содержание поля 1"вида товара" всех выбранных записей в колонку 2, ввести содержание " поля цены " всех выбранных записей в колонку 3, и отсортировать выбранные записи по содержанию "покупательского поля".
Создают определение представления для сводки 3 и запоминают его только в первом множестве, так как для сводки 3 требуется информация только для физического файла 1 (год 0). Определение представления для сводки 3, которая будет присутствовать только в первом наборе, может включать в себя следующие параметры: выбрать все записи в физическом файле, ввести содержание "покупательского поля" всех выбранных записей в колонку 1 файла извлечений для представления 3, ввести содержание поля "вид товара" всех выбранных записей в колонку 2 файла извлечений, ввести содержание "поля цены" всех выбранных записей в колонку 3 файла извлечений, ввести "0" в колонку 4 для подготовки подсчета указанной выше текущей суммы, отсортировать выбранные записи по содержанию "покупательского поля", и ввести в колонку 4 каждой записи файла извлечений сумму содержания "поля цены" (колонка 3) записи и содержания колонки 4 для предыдущей записи для покупателя, идентифицированного в колонке 1 записи.
Указанные выше определения представления в логической таблице затем преобразуют в команды машинного кода для каждой из трех последовательностей - одна последовательность для каждого множества логической таблицы. Каждая из трех последовательностей будет проходить свой соответствующий физический файл следующим образом.
Последовательность 1 проходит физический файл 1. Последовательность 1 обращается к первой записи физического файла 1 и выполняет следующие этапы:
1. Если покупателя зовут Джон Смит - ввести содержание покупательского поля в колонку 1 извлекаемой записи, содержание поля "вид товара" в колонку 2, ввести содержание "поля цены" в колонку 3, собрать поля сортировки для подготовки для сортировки данной записи с предыдущими записями по содержанию поля "вид товара", и записать извлеченные записи в файл извлечений для представления 1.
2. Если "поле цены" превышает 500 долл., ввести содержание "покупательского поля" в колонку 1 извлекаемой записи, ввести содержание поля "вид товара" в колонку 2, ввести содержание "поля цены" в колонку 3, отсортировать запись с предыдущими записями для представления 2 по содержанию "покупательского поля", и записать извлеченные записи в файл извлечений для представления 2.
3. Ввести содержание "покупательского поля" в колонку 1 извлекаемой записи, ввести содержание поля "вида товара" в колонку 2, ввести содержание "поля цены" в колонку 3, собрать поля сортировки для подготовки сортирования данной записи с предыдущими записями для представления 3 по содержанию "покупательского поля", ввести "0" в колонку 4 для подготовки подсчета указанной выше текущей суммы и записать извлеченные в файл извлечений для представления 3.
4. Повторить этапы с 1 по 3 для всех остальных записей в физическом файле 1.
Последовательность 2 проходит физический файл 2. Последовательность 2 производит обращение к первой записи физического файла 2 и выполняет следующие этапы:
1. Если "покупательским полем" является Джон Смит, - ввести содержание "покупательского поля" в колонку 1 извлекаемой записи, ввести содержание "поля вида товара" в колонку 2, ввести содержание "цены поля" в колонку 3, собрать поля сортировки для подготовки сортировки записи с предыдущими записями по содержанию "поля вида товара", и записать извлеченные записи в файл извлечений для представления 1.
2. Если "поле цены" превышает 500 долл., - ввести содержание покупательского поля в колонку 1 извлекаемой записи, ввести содержание "поля вида товара" в колонку 2, ввести содержание "поля цены" в колонку 3, собрать поля сортировки для подготовки сортировки записи с предыдущими записями для представления 2 содержанием "покупательского поля", и записать извлеченные записи в файл извлечений для представления 2.
3. Повторить этапы с 1 по 2 для всех остальных записей в физическом файле 2.
Последовательность 3 будет проходить физический файл 3. Последовательность 3 будет производить выборку первой записи физического файла 3 и выполнять следующие этапы:
1. Если "покупательским полем" является Джон Смит, ввести содержание покупательского поля в колонку 1 извлекаемой записи, ввести содержание "поля вида товара" в колонку 2, ввести содержание "поля цены" в колонку 3, собрать поля сортировки для подготовки записи с предыдущими записями по содержанию "поля вида товара" и записать извлеченные записи в файл извлечений для представления 1.
2. Повторить этап 1 для всех остальных записей в физическом файле 3.
По завершении последовательностями указанной процедуры каждый файл извлечений сортируют в соответствии с полями сортировки, указанными каждым определением представления. Затем для каждой записи в файле извлечений для представления 3 к содержанию колонки 4 предыдущей записи прибавляют содержание колонки 3. Затем запоминают результат в колонке 4 записи, если запись не является первой записью в файле извлечений для покупателя, идентифицированного в колонке 1 записи.
Каждая из указанных выше трех последовательностей действует независимо друг от друга и, если система содержит по меньшей мере 3 процессора, то каждая из трех последовательностей действует параллельно. Как показано выше, обращение к каждой записи каждого физического файла производят только раз, несмотря на то что последовательность 1, например, создает три отдельные сводки.
Поскольку физические файлы запоминают на внешних устройствах, таких как накопители на ленте и накопители на диске, то время, нужное для выборки данной записи на физическом файле, намного превышает время, нужное для последовательности, чтобы обработать данные, когда они выбраны. Поэтому посредством обращения к каждой записи физического файла только один раз и последовательным обращением к записям их физически записывают независимо от числа представлений, определенных относительно физического файла, при этом время обработки сокращается. Кроме этого посредством параллельной обработки файлов время обработки сокращается еще больше.
В соответствии с другим осуществлением данного изобретения время обработки еще больше сокращают выполнением свойства наложенного ввода/вывода по данному изобретению.
В соответствии с данным изобретением для каждой последовательности обеспечивают набор входных буферов, причем каждый набор входных буферов содержит один или более входной буфер; каждый входной буфер хранит один блок данных, при этом перенос блоков данных с физического носителя на входные буферы происходит в том же порядке, что и очередность запоминания блоков на физическом носителе, в целях сведения к минимуму задержек из-за переключения с одного блока на следующий. В соответствии с осуществлением данного изобретения размер блока данных выбирают как функцию природы физического носителя, на котором располагается физический файл. Размер блока данных устанавливают равным наибольшему размеру, который можно выбрать с его соответствующего физического носителя без необходимости механического перемещения рычага выборки, если данные хранятся на диске.
С помощью выбора размера блока данных таким образом система согласно данному изобретению выбирает максимальное количество данных во входной буфер в течение минимального возможного времени обработки.
В соответствии с еще одним осуществлением данного изобретения множество входных буферов обеспечивают в каждом наборе входных буферов для дальнейшего сокращения времени выборки данных. В соответствии с этим осуществлением данного изобретения после загрузки первого входного буфера его блоком данных - в то время как другие блоки данных загружают в следующие входные буферы - последовательность, соответствующая физическому файлу для этого набора входных буферов, проходит первый входной буфер в соответствии с его алгоритмом обработки, тем самым накладывая выборку блока данных на поиск. Лучше всего, чтобы число входных буферов в наборе входных буферов было выбрано так, чтобы к тому времени, когда последовательность пройдет последний из входных буферов, первый входной буфер уже будет перезагружен новым блоком данных с физического файла. В результате этого последовательности не придется ждать загрузки блоков данных в буферы до начала обработки блока данных.
В соответствии с еще одним осуществлением данного изобретения для каждого файла извлечений, к которому обращается логическая таблица, обеспечивают набор выходных буферов. В свою очередь каждый набор буферов содержит один или более выходной буфер, причем каждый из выходных буферов содержит один блок данных. Размер блока данных выбирают как функцию природы физического носителя, на котором располагается соответствующий файл извлечений, как описывается выше в отношении входных буферов. Для дальнейшего повышения скорости обработки могут обеспечивать множество выходных буферов, для чего создают возможность, чтобы один буфер записывался, когда другой буфер заполняют.
Краткое описание чертежей
Фиг. 1 - иллюстративное изображение системы процессора в соответствии с осуществлением данного изобретения.
Фиг. 2 - иллюстративное изображение логического файла в соответствии с осуществлением данного изобретения.
Фиг. 2А - более подробно изображает логические записи логического файла фиг. 2.
Фиг. 2В - иллюстративное изображение справочной таблицы в соответствии с данным изобретением.
Фиг.3 - изображение логической таблицы в соответствии с данным изобретением.
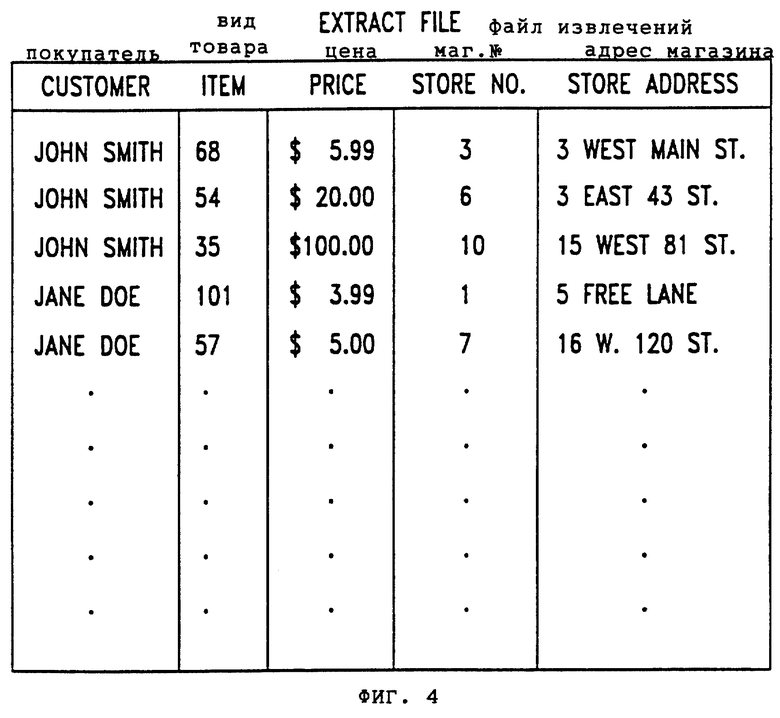
Фиг.4 - изображает файл извлечений в соответствии с данным изобретением.
Фиг.5 - экран Нормативных Параметров Определения Представления в соответствии с осуществлением данного изобретения.
Фиг.6 - экран Общих Параметров Колонки Определения Представления в соответствии с осуществлением данного изобретения.
Фиг.7 - экран Подсчетов Колонки Определения Представления в соответствии с осуществлением данного изобретения.
Фиг. 8 - экран Общих Параметров Сортировки Определения Представления в соответствии с осуществлением данного изобретения.
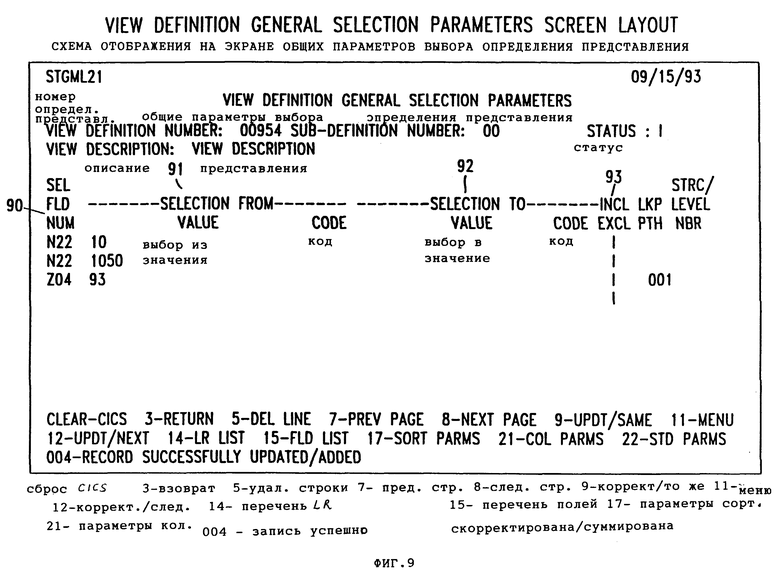
Фиг. 9 - экран Общих Параметров Выбора Определения Представления в соответствии с осуществлением данного изобретения.
Фиг. 10 - Параметры Выбора Колонки Определения Представления в соответствии с осуществлением данного изобретения.
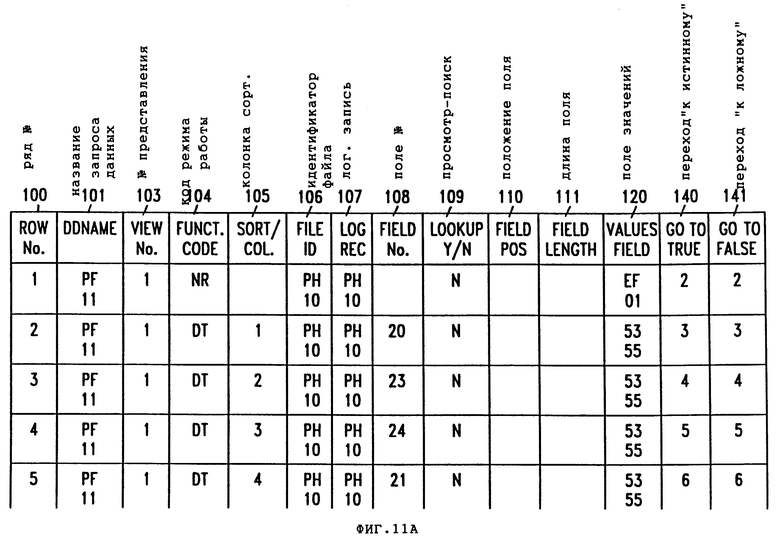
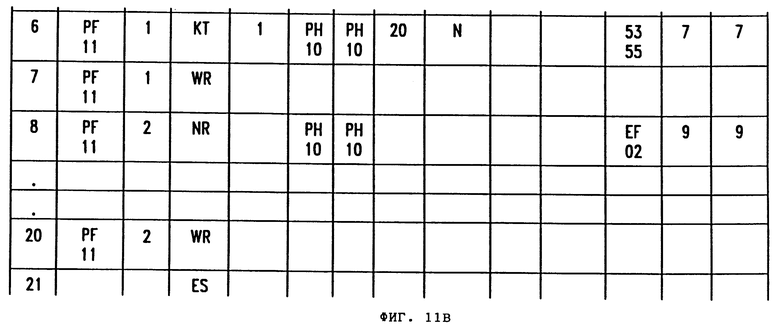
Фиг.11A-D - более подробное изображение логической таблицы фиг. 3.
Фиг. 11Е - приводимая в качестве иллюстрации часть логической таблицы фиг. 3, которая осуществляет поиск по справочной таблице.
Фиг. 12 - буферизация на входе в соответствии с осуществлением данного изобретения.
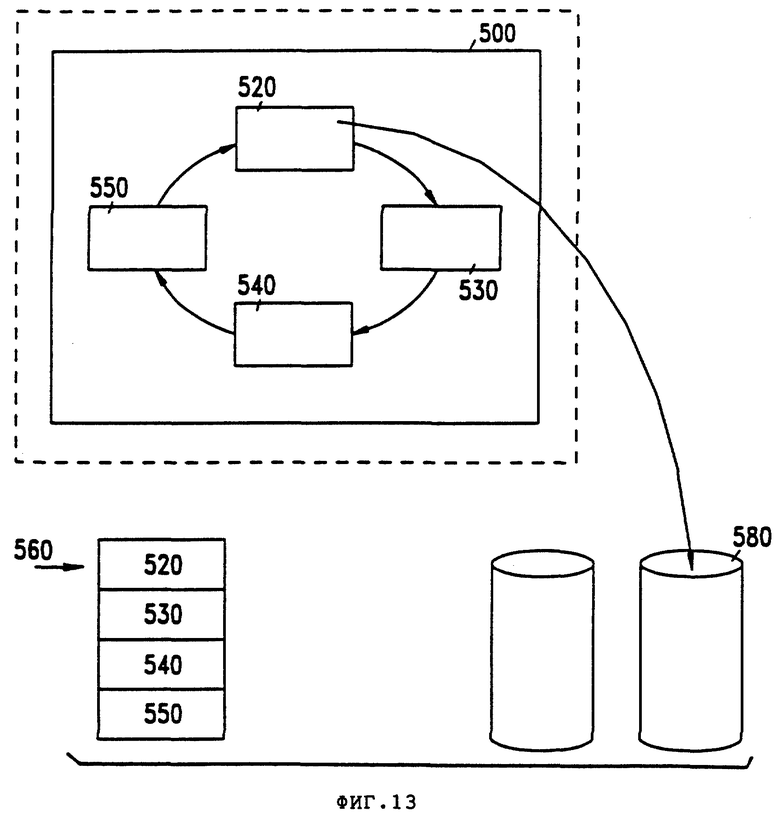
Фиг. 13 - буферизация на выходе в соответствии с осуществлением данного изобретения.
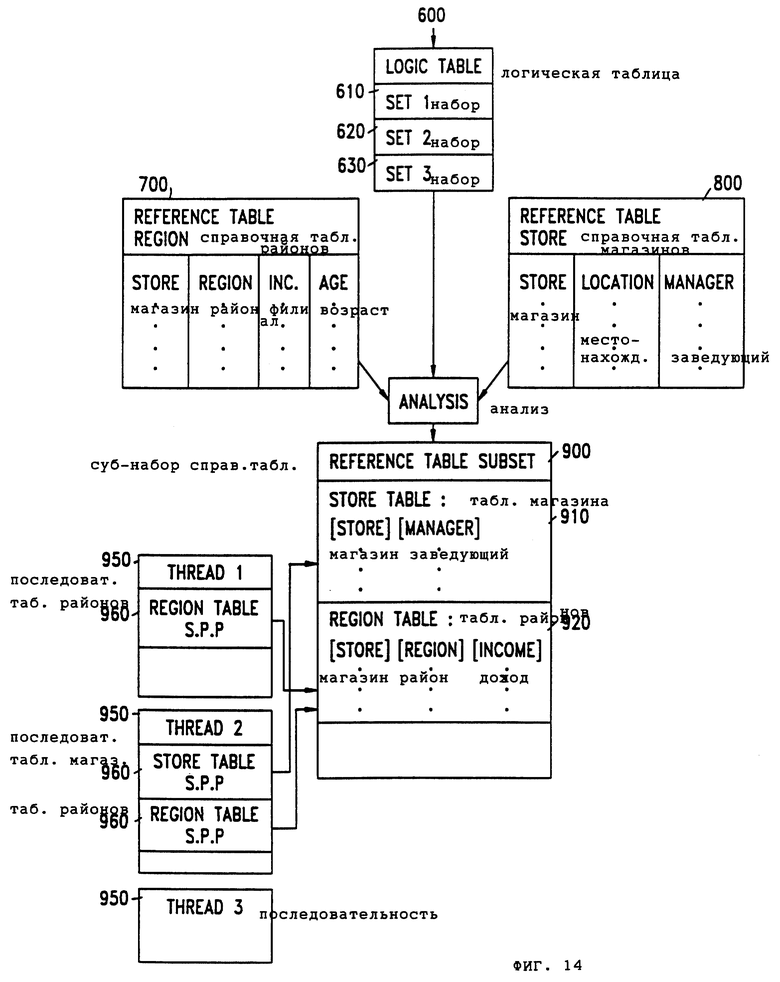
Фиг.14 - изображение субнабора справочной таблицы данного изобретения.
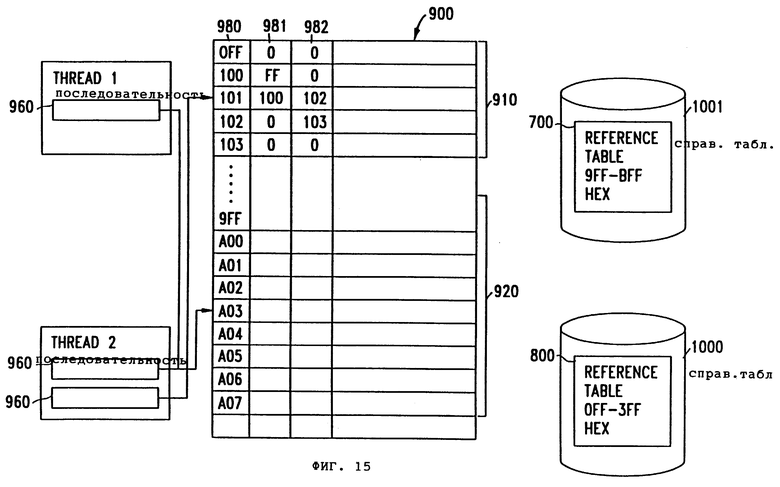
Фиг. 15 - более подробное изображение субнабора справочной таблицы фиг. 14.
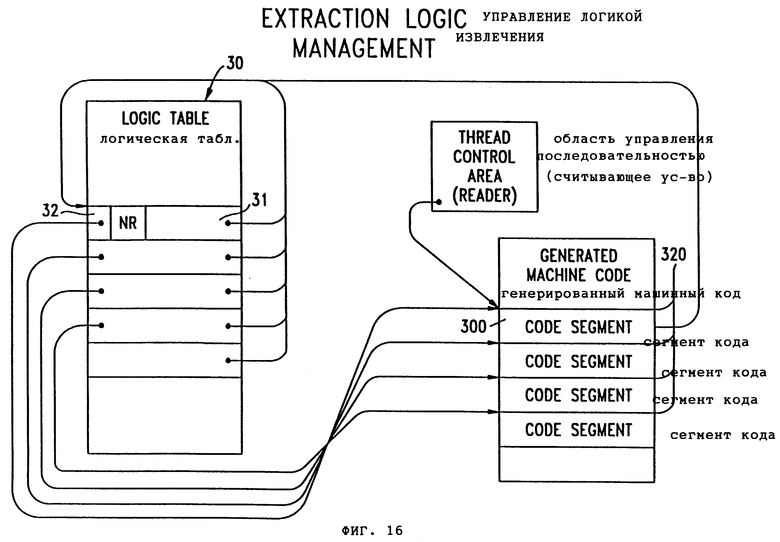
Фиг.16 - изображение выработки машинного кода по логической таблице.
Подробное описание изобретения
Как показано на фиг. 1, система процессора в соответствии с данным изобретением может содержать универсальную вычислительную машину 1 компании IBM (включая, например, 3 процессора А, В, С), связанную с разнообразными внешними запоминающими устройствами, такими как накопитель на дисках 2, накопитель на жестких магнитных дисках 3 и накопители на лентах 4, 5.
В соответствии с данным изобретением процессоры производят поиск в базе данных событий (или сделок) в соответствии с одним или более определением представления, которое содержится в логической таблице.
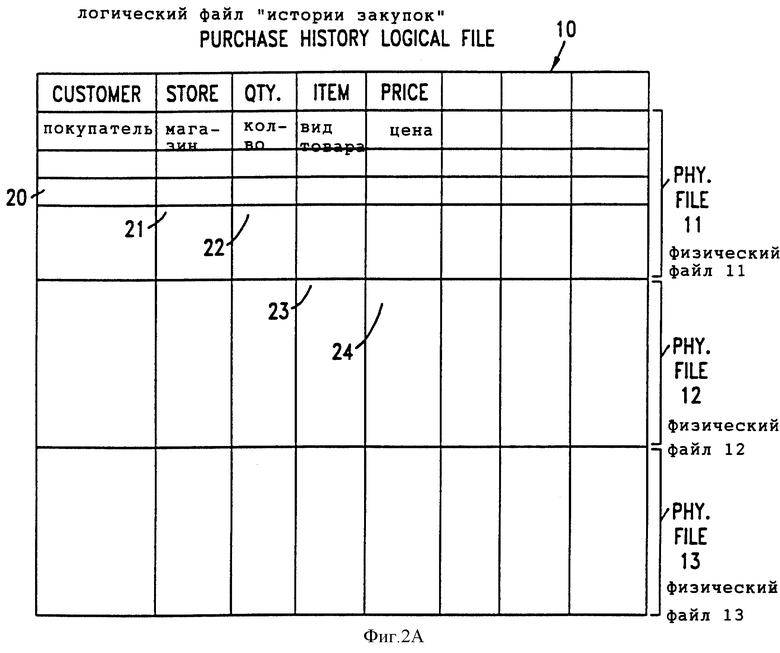
Как указывалось выше, базой данных событий является база данных, содержащая файлы, которые запоминают информацию о событиях. База данных событий может включать в себя множество логических файлов, причем каждый логический файл содержит множество логических записей. В свою очередь логический файл может располагаться во множестве физических файлов. Примером логического файла может быть файл с записями истории закупок. Как показано на фиг. 2, логический файл 10 истории закупок может располагаться в физическом файле 11, физическом файле 12 и физическом файле 13. На фиг. 2А показано, что логический файл 10 истории закупок может содержать колонки для: фамилии 20 покупателя, магазина 21, количества 22, вида товара 23 и цены 24. Каждый ряд логического файла 10 является отличной от других логической записью истории закупок. Несмотря на то, что на фиг. 2 и 2A это не изображено, нужно понимать, что каждый физический файл может содержать логические записи, принадлежащие к нескольким отличным друг от друга логическим файлам.
Физический файл 11 может содержать, например, все логические записи логического файла истории закупок для текущего календарного года (год 0), с физическим файлом 12, содержащим все записи логического файла истории закупок по предыдущему календарному году (год -1), и физическим файлом 13, содержащим все записи логического файла истории закупок по следующему предшествовавшему календарному году (год -2).
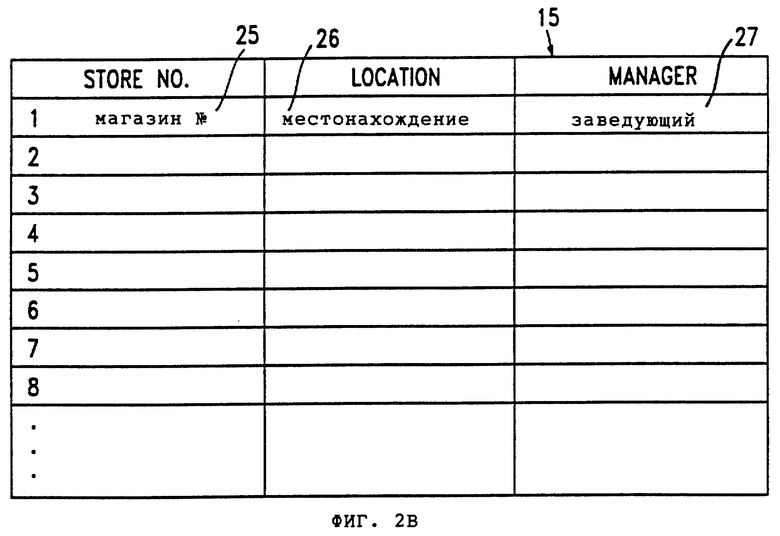
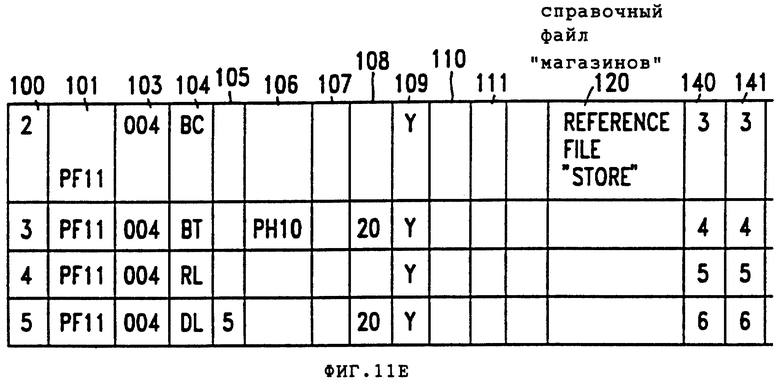
В соответствии с данным изобретением, в дополнение к базам данных событий и сделок, можно также производить поиск в справочных таблицах. Справочные таблицы содержат справочную информацию, а не информацию о событиях или сделках. Например, в то время как база данных событий может содержать информацию о сделках данного покупателя в сети магазинов цепного подчинения, справочная таблица может указывать местонахождение каждого магазина в цепи и фамилии заведующих каждым магазином. Обращаясь к фиг. 2В - справочная таблица магазина 15 содержит колонки для номера магазина 25, местонахождения 26, заведующего 27.
Как объяснялось выше, база данных содержит ряд логических файлов, причем каждый логический файл можно хранить в одном или нескольких физических файлах. В соответствии с данным изобретением для большей эффективности в физических файлах базы данных событий поиск производят параллельно. В соответствии с поиском в конкретном физическом файле каждое множество определений представления, относящихся к этому физическому файлу, объединяют с помощью логической таблицы для создания единого алгоритма поиска. Этот алгоритм применяют один раз по физическому файлу для получения результатов поиска для всех определений представления для этого физического файла, причем результаты поиска обрабатывают в соответствии с определениями представления и записывают в назначенные файлы извлечений.
В соответствии с данным изобретением создают логическую таблицу, которая управляет методом обработки логического файла(ов). Логическая таблица представляет собой осуществление непроцедурного языка. Но в соответствии с данным изобретением логическую таблицу можно выразить таким процедурным языком, как "Паскаль" или "С". Логическая таблица, кроме логических файлов, может также производить поиск в множестве справочных таблиц. Как объяснялось выше, в противоположность логическим файлам справочные таблицы записей событий не содержат. Вместо этого они содержат справочную информацию, которая может быть полезной, чтобы облегчить представление и истолкование данных файла событий из логических записей.
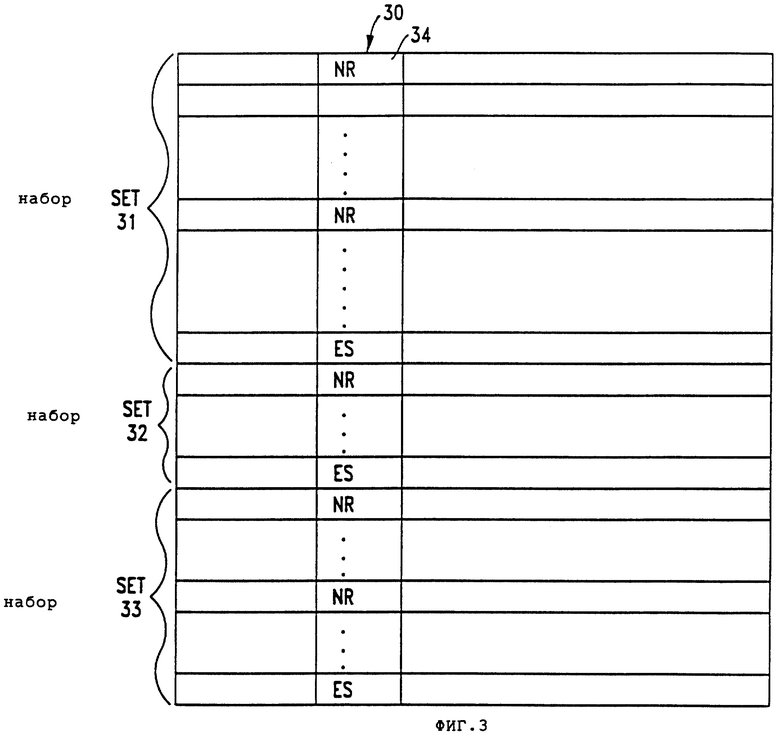
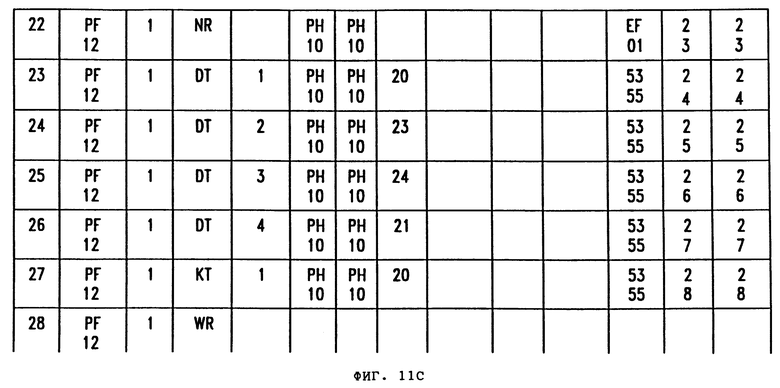
Как показано на фиг. 3, логическая таблица 30 состоит из некоторого числа записей. Каждая запись содержит поле 34 кода режима работы, и, в общем, к записям или рядам логической таблицы здесь будут обращаться с помощью их поля кода режима работы.
Логическую таблицу можно разделить на множество "наборов". Поле "ES" (ряд "ES") кода режима работы указывает конец набора. Фиг.3, например, изображает приводимую в качестве примера логическую таблицу "непроцедурного языка" с 3 наборами, где первый набор соответствует физическому файлу 11, второй набор соответствует физическому файлу 12, и третий набор 33 соответствует физическому файлу 13 Логического Файла Истории Закупок. В соответствии с излагаемым ниже более подробным объяснением каждый набор соответствует отдельной последовательности в системе параллельной обработки данных.
Запись "NR" (новый запрос) кода режима работы обозначает начало нового представления. Как указывалось выше, последующие записи, которые могут появляться между двумя рядами NR, уточняют это представление.
Определение представления определяет метод обработки конкретного логического файла. Помимо этого определение представления управляет методом форматирования для пользователя результатов поиска. В соответствии с осуществлением данного изобретения пользователь создает определение представления с помощью ряда экранов. После создания определения представления его включают в логическую таблицу в ряде NR и одном или более дополнительном ряде логической таблицы.
В соответствии с осуществлением данного изобретения меню определения представления дает пользователю возможность отобразить перечень имевшихся к данному моменту определений представления, отобразить конкретное имеющееся определение представления или создать новое определение представления. Меню определения представления может содержать множество экранов, таких как те, которые описываются ниже со ссылкой на фиг. 5-10. Обращение к этим экранам производят из главного меню (не показано) либо из других экранов. Например, к экрану Общих Параметров Колонки Определения Представления на фиг. 6 обращение может быть из экрана Нормативных Параметров Определения Представления фиг. 5 путем ввода числа "21" из меню 46 в нижней части фиг. 5.
При создании нового определения представления или редактирования имеющегося определения представления пользователь вводит Экран Нормативных Параметров Определения Представления, который излагает нормативные параметры, применяемые для определения представления. Как показано на фиг. 5 - Экран Нормативных Параметров Определения Представления указывает Логическую Запись 40, диапазон данных поиска 41 и файл извлечений 42.
Чтобы определить, какие колонки будут включены в файл извлечений, обращаются к Экрану Общих Параметров Колонки Определения Представления. Каждую колонку в определении представления идентифицируют и последовательно нумеруют. Как показано на фиг. 6, поле 50 идентификатора колонки идентифицирует номер ( напр. , с 1 по 999 ) колонки, атрибуты которого определены в остальной части экрана. Поле 51 Номера Поля обозначает поле, из которого в колонке появляется логическая запись или справочная таблица. Кроме этого из этого экрана можно определить заголовок 52 колонки, ширину 53 колонки и пр.
На фиг. 7 показан Экран Подсчетов Колонки Определения Представления, который обеспечивает назначение подсчетов колонкам, указанным в Экране Общих Параметров Колонки Определения Представления. Поле 60 идентификатора колонки обозначает колонку, в которой должно появиться подсчитанное значение, а поля оператора 61, кода 62 и значения 63 определяют выполняемый подсчет. Поле 61 оператора дает обозначения для сложения, вычитания, умножения и деления. Поле кода дает обозначения для текущего значения колонки ( CL ), предыдущего значения колонки (PL) или постоянной величины (СО). Поле 63 значения указывает значение постоянной величины, определенной в поле 62 кода. Предположим, например, что пользователь желает вести текущую сумму колонки 3 в колонке 4. Обращаясь к фиг. 7 - это можно выполнить следующим образом: идентификатором колонки будет колонка 4, в первой записи оператором будет "+", и кодом будет "CL 03", а во второй записи оператором будет "+", и кодом будет"PL 04".
На фиг. 8 показан Экран Общих Параметров Сортировки Определения Представления, который используют для управления уровнями сортировки для определения представления. "Уровни сортировки" определения представления указывают колонку из логической записи или справочного файла, по которым будут сортировать результаты поиска. Например, если после 70 сортировки по фиг. 8 является "фамилией покупателя", то результаты поиска будут сортировать по фамилии покупателя, если она записана в файле извлечений. Если второе поле 70 сортировки было бы определено как номер магазина, то результаты поиска сначала сортировали по фамилии покупателя и затем - по номеру магазина.
Для исключения некоторой информации из файла извлечений пользователь вводит Экран Общих Параметров Определения Представления (фиг. 9). Этот экран дает пользователю возможность включить или исключить из файла извлечений логические записи, которые имеют поля, содержащие отобранные данные. Например, если пользователя не интересуют сделки на сумму менее 200 долл., то тогда номер поля для поля "сумма" записи сделки вводится в поле FLD NUM 90, поле 81 "отбор из" устанавливают на"0", поле 82 "отбор для" устанавливают на "200" и поле 83 включения/исключения устанавливают на "Е" для исключения. В тех случаях, когда несколько критериев отбора устанавливают для одного номера ("Field No. "), тогда для результатов поиска будут применять логику "ИЛИ". В тех случаях, когда устанавливают разные номера поля, применяют логику "И". Например, предположим, что пользователь был заинтересован только в сделке, в которой проданный в магазине 93 вид товара имел цену 10 долл. или 1050 долл. Исходя из того что Z04 представляет поле магазина и Н22 представляет поле цены, и обращаясь к фиг. 9, указанный выше пример можно выполнить следующим образом: если данные в поле Н22 логической записи - либо 10, либо 1050 и данные в поле Z04 этой записи - 93, тогда эту запись включат в файл извлечений.
Показанный на фиг. 10 Экран Параметров Выбора Колонки действует в том же порядке, что и Экран Общих Параметров Выбора, за тем исключением, что Экран Параметров Выбора Колонки дает возможность пользователю включить или исключить данные из конкретной колонки путем указания идентификатора 85 колонки.
Простой пример может помочь проиллюстрировать изложенные выше свойства. Предположим, что пользователь желает создать документ, в котором за последние 3 года по каждому покупателю перечисляется каждый закупленный вид товара, сумма закупки, адрес и номер магазина, в котором данный вид товара был закуплен.
Пользователь вводит меню Стандартных Параметров Определения Представления и вводит идентификатор для Логического Файла Истории Закупок (фиг. 2A) в табл. (LR) Номер Поля 40. В Поле 41 активного диапазона дат пользователь вводит 01011991-99999999 (1-го января 1991 до настоящего времени). Остальные записи могут оставаться в изображенных значениях по умолчанию.
Затем пользователь вводит Экран Параметров Колонки Определения Представления (фиг. 6). Для идентификатора колонки: 001 (колонка 1), код для "покупателя": РН 20 (Логическая Запись Истории Закупок (L. R. 20) вводят в Поле Номер 51. В поле 52 Заголовка Колонки пользователь может затем ввести "ПОКУПАТЕЛЬ" (CUSTOMER). Затем пользователь нажимает "1" для "новой колонки" и вводит информацию для кол. 2 (Идентификатор: 002): поле 51=РН 23, предоставляющее "вид товара"; Поле 52="Вид Товара" (ITEM ); затем - основа "1" для ввода информации для колонки 3 ( Идентификатор: 003 ); Поле 51=РН (представляющее "цену"); Поле 52="ЦЕНА"; затем снова "1" для ввода информации для колонки 4 (Идентификатор: 004); Поле 51=РН 21 (предоставляющее "магазин"); Поле 52="МАГАЗИН НОМЕР" (STORE No.). Затем пользователь нажимает "1" для ввода информации для колонки 5 (Идентификатор: 005). Поскольку пятая колонка предназначается для адресов магазина, Поле Nо. 51 будет обращаться к колонке 2 (местонахождение 26 ) справочной таблицы 15 магазинов (RS 26), а маршрутом 54 поиска будет РН 21, т.е. адрес магазина или местонахождение (RS 26) для номера магазина (РН 21) вводят в пятую колонку. Заголовком колонки в Поле 53 может быть, например, "МЕСТОНАХОЖДЕНИЕ МАГАЗИНА" (STORE LOCATION).
Затем пользователь введет экран Общих Параметров Сортировки (фиг. 8). Поле 70 Сортировки будет определяться как РН 20 (покупатель) для указания того, что файл извлечений будет сортирован по фамилии покупателя.
Полученный файл извлечений для упомянутого примера будет иметь 5 колонок, которые будут называться: ПОКУПАТЕЛЬ, ЦЕНА, НОМЕР МАГАЗИНА и МЕСТОНАХОЖДЕНИЕ МАГАЗИНА. Полученные таким образом записи, выбранные из Логического Файла Истории Закупок и справочной таблицы магазинов, будут перечислены по имени покупателя, как это изображено на фиг. 4.
Определение представления, которое определено изложенным выше образом, автоматически преобразуют в различные записи в логической таблице. Снова используя изложенный выше пример и проиллюстрированный на фиг. 3-10: далее следует описание преобразования информационного ввода в экраны представления (фиг. 5-10) в логическую таблицу. Фиг.11 изображает логическую таблицу фиг. 3 более подробно.
В соответствии с фиг. 11 каждый ряд логической таблицы содержит множество полей. Первое поле 100 содержит номер ряда логической таблицы. Вторым полем является поле 101 названия запроса данных, которое идентифицирует физический файл, являющийся источником логических записей для представления. Значение этого поля генерирует из Таблицы (LR) номер 40 из Экрана Нормативных Параметров (фиг. 5). Это поле будет иметь одинаковое значение для каждого ряда набора в логической таблице. Третьим полем является представление номер 103, которое содержит номер представления (позиции 45 на фиг. 5), последовательно назначаемый каждому представлению системой процессора.
Как показано на фиг. 5, записи в меню Нормативных Параметров преобразуют в записи логической таблицы следующим образом. Новый ряд запроса создают вводом "NR" в поле 104 кода режима работы. Автоматически генерированный Номер Определения Представления вводят поле 103 номера представления для каждого ряда, относящегося к этому представлению. Значение поля 40 Номера Таблицы (LR) преобразуют в поля 101 и 107 каждого ряда логической таблицы с полем 101, указывающим файл, где находятся логические записи, и полем 107, указывающим тип логической записи. Значение поля 41 активного диапазона данных используют для определения тех физических файлов логической записи, которые будут нужны для этого представления. Если для представления требуется не один физический файл, то все ряды для представления будут копироваться в другие наборы, как объясняется ниже. Поле 42 идентификатора файла извлечений копируют в соответствующий номер поля файла извлечений в значениях поля 120 ряда NR.
Как показывает экран Нормативных Параметров Колонки по фиг. 6, каждое поле 50 идентификатора колонки копируют в отдельный ряд логической таблицы. На фиг. 11 показано, что ряд 2 содержит код режима работы DT для указания того, что эта строка определяет колонку, содержание которой будут выбирать из логической записи. Поле 105 номера сортировки-колонки указывает, что ряд 3 определяет первую колонку файла извлечений (идентификатор 001 колонки из поля 50 фиг. 6). Поле 108 номера поля выводят из поля 51 Номера Поля экрана Общих Параметров Колонки. Ряд 2 также содержит информацию о формате колонки в поле 120 значений, например: ширину колонки для колонки 1 из поля 53 ширины колонки. Ряды с 3 по 5, аналогично, указывают содержание колонок 2, 3 и 4 файла извлечений.
Ряд 6 содержит информацию о критериях сортировки, указанных в меню Общих Параметров Сортировки фиг. 8. Код КТ режима работы указывает, что файл извлечений будут сортировать по полю из логической записи. Поле 105 сортировки-колонки указывает номер сортировки (в этом случае "1", поскольку это - первая сортировка), а Поле Nо. 108 указывает поле логической записи, по которому будет сортироваться файл извлечений. Эту запись получают из поля 70 сортировки экрана Общих Параметров Сортировки фиг. 8.
Ряд 7 является строкой записывания записи (WR). Строка WR дает системе команду записать строку данных в файл извлечений, идентифицированный в предыдущей строке NR (ряд 1).
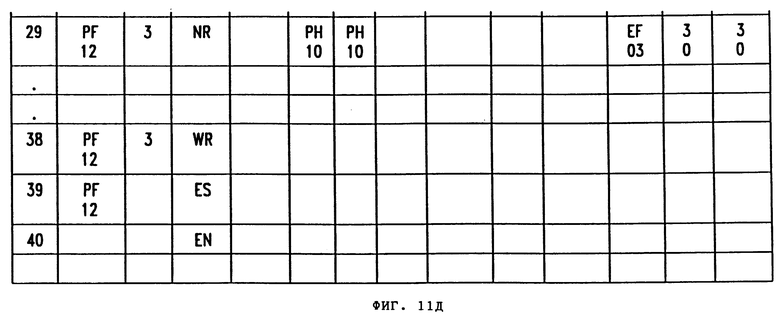
Ряд 8 является строкой NR для второго представления (представление Номер 2). Это определение представления содержится в рядах 8-20. Ряд 21 указывает конец множества (ES). Этим завершаются записи логической таблицы для физического файла 11.
Ряд 21 начинает второй набор, который соответствует физическому файлу 12 логического файла 10. В примере фиг. 11 активный диапазон дат, введенный в поле 41 меню нормативных параметров для представления 1, указывал, что для поиска был нужен второй физический файл логических записей. Поэтому определение представления рядов 1-7 набора 1 автоматически копируют в строки 22-28 набора 2. Но поле 101 названия запроса данных изменяют, чтобы идентифицировать физический файл 12 вместо физического файла 11. Поскольку активный диапазон дат представления 2 не требует информации из физического файла 2, ряды 8-20 не копируют в набор 2. Аналогично, поскольку активный диапазон дат представления 3 требует информацию из физического файла 2, но не физического файла 1, представление 3 появляется только во втором наборе. Ряд 40 является концом строки (EN) логической таблицы, которая указывает, что конец логической таблицы достигнут.
Для выполнения некоторых других упомянутых выше в связи с фиг. 5-10 функций обеспечивают дополнительные поля функций. Например, значения выбора, указанные в экране Общих Параметров Выбора или Параметров Выбора Колонки, которые выбирают единое значение, можно выполнить с помощью кода режима работы SE, введя поле Nо. 80 или 90 (фиг. 9 или 10) в поле номер 108 и введя выбираемое значение в поле 120 значений. Аналогично, значения выбора, указанные в экране Общих Параметров Выбора или Параметров Выбора Колонки, которые указывают диапазон значений, можно выполнить с помощью кода режима работы ST, введя поле Nо. 80 в поле номер 108 и введя диапазон значений, которые выбирают в поле 120 значений или исключают их из этого поля. Для выполнения Общих Параметров Выбора строка ST или SE непосредственно следует за строкой NR. Для выполнения Параметров Выбора Колонки строка ST или SE непосредственно предшествует строке DT, которая создает колонку.
Поле (83, 93) включения/исключения меню Общих Параметров Выбора или Параметров Выбора Колонки выполняют с помощью поля 140 перехода GO-TO-TRUE (к истинному) и поля 141 перехода GO-TO-FALSE (к ложному). Например, если мы желаем исключить логическую запись с помощью упомянутых строк ST или SE, то функцию исключения можно выполнить переходом GO-TO-FALSE к последующей строке и переходом GO-TO-TRUE к следующему ряду NR (следующее представление). В результате этого, если логическая запись удовлетворяет критериям выбора, определенным строкой ST или SE, то последовательность переходит к следующему ряду NR и запись будет исключена. В противном случае последовательность пойдет к следующему ряду логической таблицы. Аналогично, функцию включения можно выполнить переходом GO-TO-FAISE к следующему ряду NR и переходом GO-TO-TRUE к последующей строке.
В тех случаях, когда упомянутые функции должны выполняться с помощью информации из справочной таблицы, а не из логической записи, процедура является аналогичной. Но для использования справочной таблицы для того, чтобы соотнести данные в справочной таблице с данными логической записи, нужно выполнить одну или несколько функций поиска-просмотра.
Предположим, например, что пользователь желает отобразить - наряду с каждым номером магазина, извлеченным из Логического Файла 10 Истории Закупок, - соответствующее местонахождение магазина в колонке 5. Информация местонахождения магазинов содержится в Справочной Таблице 15 Магазинов. Как показано на фиг. 11А, в ряде 2 (как указано в колонке 100) код режима работы " ВС " (колонка 104) используют для обозначения обращения к справочной таблице, из которой получают адрес магазина. Номер справочной таблицы магазина справочной таблицы магазинов вводят в поле 120 значения, а поле 109 просмотра-поиска устанавливают на "Y". Затем, в ряде 3, код режима работы "ВТ" (колонка 104), взятый с номером поля, указанным в поле 108, идентифицирует колонку логической записи, из которой составляют ключ, т.е. колонку номера магазина, представленную кодом "20". Текущее содержание колонки номера магазина затем используют для просмотра-поиска записи в справочной таблицы магазинов. Если, например, содержание колонки номера магазина идентифицировало магазин No. 9, тогда в ряде 4 код режима работы RL (колонка 104) используют для запуска поиска в справочной таблицы магазинов для записи по магазину 9 и считывания всей записи для магазина 9 из справочной таблицы магазинов.
Наконец, в строке 5 код режима работы DL (который соответствует коду режима работы DT, упомянутому выше в отношении данных, выборку которых произвели из логических записей) дает команду системе запомнить отобранное поле из выбранной записи справочной таблицы как содержание колонки 5 (колонка сортировки 105=5). Отобранное поле из выбранной записи идентифицируют в колонке 108. В этом примере поле "20" записи справочной таблицы содержит информацию местонахождения магазинов. Поскольку код режима работы DL применим только к колонкам, выработанным из данных справочной таблицы, система знает, что содержание колонки 108 идентифицирует отобранное поле выбранной записи справочной таблицы.
Показанная на фиг. 3 логическая таблица содержит множество наборов. Каждый набор в свою очередь может включать в себя множество представлений. Каждое множество представлений должно соответствовать физическому файлу, к которому обратилось множество. В соответствии с тем, как это объяснялось выше со ссылкой на фиг. 5, определение представления может также включать в себя ограничения по датам. Например, если данное определение представления включило в себя ограничение по датам, которое запрашивает поиск только файлов для текущего года, тогда это определение представления появится только в первом наборе. Если второе определение представления не имело ограничения по датам, тогда это определение представления так же, как все последующие записи для этого определения представления, будут автоматически копироваться во второй и третий наборы (исходя из того, что Логический Файл имеет 3 Физических файла).
В соответствии с данным изобретением каждый набор Логической Таблицы соответствует отдельной "последовательности". Последовательностью является единый последовательный ход управления. Как таковая, одна последовательность может в любой конкретный момент иметь только одну точку исполнения, т.е. в любой момент времени одна последовательность может исполнять самое большее одну команду. Но при обеспечении многих последовательностей единая программа может иметь многие точки исполнения - одну на каждую последовательность. В соответствии с данным изобретением множество последовательностей - одна для каждого набора в логической таблице - идет параллельно.
Например, если Логическая Таблица имеет три последовательности (т.е. три набора) и в компьютере есть три процессора, то тот или иной процессор может вести каждую последовательность. Поскольку каждая последовательность соответствует разным Физическим Файлам 11-13 Логического Файла 10, каждая последовательность может обрабатывать свои соответствующие физические файлы 11-13 параллельно другим последовательностям, тем самым значительно повышая производительность.
После создания логической таблицы она по существу действует как исходная программа, которая согласованно управляет методом обработки базы данных системой; при этом поля переходов GO-TO-TRUE и GO-TRUE-FALSE управляют последовательностью, в которой ряды Логической Таблицы выполняются системой.
Более конкретно, записи Логической Таблицы переводят в машинный код следующим образом: как показано на фиг. 16, каждая строка 31 логической таблицы в логической таблице 30 имеет прилагаемый к ней адресный префикс 320, который соответствует начальному адресу 320 сегмента машинного кода, который содержит команды для выполнения строки логической таблицы. Префикс 320 каждой строки логической таблицы дает возможность сегментам 300 кода возможность обращения к логической таблице и использования в качестве данных полей строк 31 логической таблицы.
Для каждой последовательности, содержащей команды машинного кода, выработанные из их соответствующего набора логической таблицы, делают один проход по соответствующему физическому файлу согласно последовательности команд, генерированной в логической таблице указанным выше образом. Во время этого одного прохода все представления в соответствующем наборе обрабатывают в такой последовательности, которая диктуется записями логической таблицы, конкретно: полями 140-141 перехода GO-TO-TRUE/FALSE рядов логической таблицы.
Обращаясь, например, к логической таблице по фиг. 11, можно видеть, что в наборе 31 ряды 1-6 составляют представление 16, а ряды 8-20 составляют представление 2: в наборе 32 ряды 22-28 копируют из рядов 1-6 и определяют представление 1, а ряды 29-38 определяют представление 3. Каждый из рядов 1-40 будет преобразовывать в сегменты машинного кода 300 - как это изображено на фиг. 16.
Последовательность 1 взаимосвязывают с физическим файлом 11 и она соответствует набору 31, который включает в себя представления 1 и 2. Последовательность 1 будет производить обращение к первой записи физического файла 11 и выполнять следующие этапы:
1. Назначение файла извлечений No. 01 для представления 1 (ряд 1 "nr"); создание извлекаемой записи для представления 1 посредством: введения покупательского поля 20 в колонку 1 извлекаемой записи (ряд 2 "DT"); введения поля 23 вида товара в колонку 2 извлекаемой записи (ряд 3 "DT"), введения поля 24 цены в колонку 3 извлекаемой записи (ряд 4 "DT"); введения поля 21 номера магазина в колонку 4 извлекаемой записи (ряд 4 "DT"); введения фамилии 20 покупателя (ряд 5 "КТ") в ключ сортировки для подготовки сортировки извлекаемой записи с извлекаемыми записями, записанными ранее в файл извлечений; записывания извлекаемой записи в соответствующее место в назначенном файле извлечений (ряд 7 "WR").
2. Назначение файла извлечений No. 02 для представления (ряд 8 "nr"); создание извлекаемой записи для представления 2 путем исполнения команд рядов 8-19 (не показаны); записывание извлекаемой записи в соответствующее место в файле извлечений 02 (ряд 20 "WR").
3. Повторение этапов 1-2 для следующей записи в физическом файле 11.
Последовательность 2 взаимосвязывают с физическим файлом 12 и она соответствует набору 32, который включает в себя представления 1 и 3. Последовательность 2 будет действовать параллельно последовательности 1, производя обращение к первой записи физического файла 12 и выполняя следующие этапы:
1. Назначение файла извлечений No. 01 для представления 1 (ряд 22 "NR"); создание извлекаемой записи для представления 1 посредством: введения покупательского поля 20 в колонку 1 извлекаемой записи (ряд 23 "DT"); введения поля 23 позиции в колонку 2 извлекаемой записи (ряд 24 "DT"), введения поля 24 цены в колонку 3 извлекаемой записи (ряд 25 "DT"); введения поля 21 номера магазина в колонку 4 извлекаемой записи (ряд 26 "DT"); введения фамилии 20 покупателя (ряд 27 "КТ") в ключ сортировки для подготовки сортировки извлекаемой записи с извлекаемыми записями, записанными ранее в файл извлечений; записывания извлекаемой записи в соответствующее место в назначенном файле извлечений (ряд 28 "WR").
2. Назначение файла извлечений No. 03 для представления 3 (ряд 29 " nr "); создание извлекаемой записи для представления 3 путем исполнения команд рядов 30-38 (не показаны); записывание извлекаемой записи в соответствующее место в файле извлечений 03 (ряд 38 "WR").
3. Повторение этапов 1-2 для следующей записи в физическом файле 12.
По завершении последовательностями изложенной выше процедуры каждый файл извлечений сортируют в соответствии с полями сортировки, указанными каждым определением представлениями.
Итак, данное изобретение создает программу для конкретных пользователей, которая проходит логический файл базы данных событий. Помимо этого посредством генерирования отдельных последовательностей для каждого отдельного физического файла, поиск по которому осуществляют в пределах логической записи, некоторые или все физические файлы можно обрабатывать одновременно отдельными последовательностями, тем самым повышая скорость поиска в базе данных. Кроме этого, время обработки сокращается еще больше, поскольку каждый физический файл проходит только раз независимо от числа представлений, указанных по каждому физическому файлу.
Время обработки в соответствии с данными изобретением далее сокращают путем эффективного управления входными буферами, выходными буферами и информацией справочного файла. Конкретно, с помощью наложенного ввода/вывода в соответствии с осуществлением данного изобретения общее время обработки для прохождения логического файла сокращают выбором размера входных и выходных буферов, исходя из природы физического носителя, в котором хранят физические файлы логического файла. Кроме этого, путем создания субнабора справочной таблицы в главном запоминающем устройстве, содержащем только отобранные части справочных таблиц, нужных для Логической Таблицы, можно значительно уменьшить необходимость в обращении к справочным таблицам из внешних запоминающих устройств и в некоторых случаях полностью ее устранить.
После создания логической таблицы (перед генерацией машинного кода или обработки логических записей) для процесса назначают входные и выходные буферы.
Для обработки логической записи 10 данные о событиях, содержащиеся в физических файлах 11-13, должны быть загружены из их внешнего носителя (например, накопителя на дисках или ленте) во входные буферы в главном запоминающем устройстве.
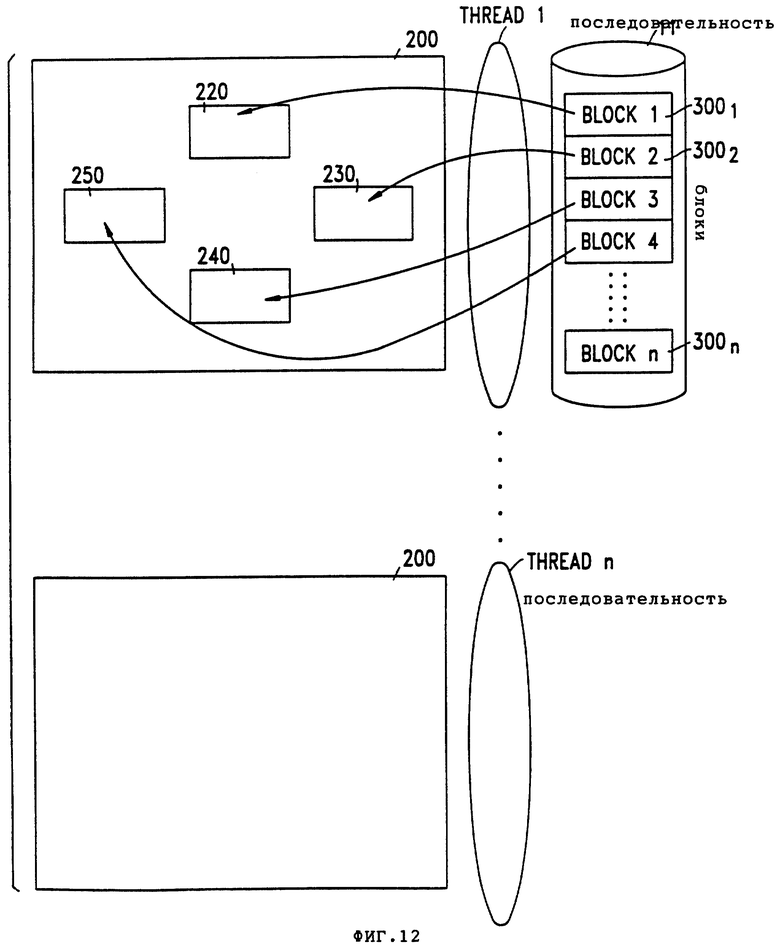
В соответствии с осуществлением данного изобретения время обработки также сокращают обеспечением функции наложенного ввода/вывода для входных буферов. Обращаясь к фиг. 12 - набор 200 входных буферов назначают каждому набору 31-33 Логической Таблицы 30, благодаря чему каждая последовательность действует на отдельном наборе входных буферов. В соответствии с осуществлением данного изобретения множество буферов 220, 230, 240, 250 назначают для каждой последовательности и каждый буфер 220-240 хранит блок данных 300n.
Размер блока данных 300n выбирают как функцию физических характеристик файла 11 для обеспечения последующего сокращения времени обработки. Одна из наиболее трудоемких по затрачиваемому времени задач, связанных с обработкой крупного файла, это - перенос данных с внешних устройств и на них. Помимо этого одна из наиболее трудоемких по затрачиваемому времени задач, связанных с переносом на диск или ленту, это - перемещение механических узлов самого накопителя.
Поэтому переносом блоков данных с физического файла ко входным буферам в том же порядке, в котором их записывают, задержки, связанные с переключением с одного блока на следующий, сокращают до минимума.
После загрузки последовательностью блока 3001 в буфер 220 начинается обработка буфера 220. Но в то время, когда последовательность 1 обрабатывает буфер 220, другой процессор в системе заполняет буфер 230 блоком 3002. Лучше всего, чтобы к тому времени, когда последовательность 1 завершит обработку блока 3004, буфер 220 будет перезагружен блоком 5. Скорость обработки также повышается в результате этого наложенного ввода/вывода в соответствии с осуществлением данного изобретения.
В дополнение к назначению входных буферов также назначают наборы 400 выходных буферов исходя из логической таблицы, как изображено на фиг. 13. Каждый набор 500 выходных буферов соответствует отдельному файлу извлечений.
Как излагалось выше, каждое представление назначает файл извлечений для хранения результатов процесса для этого представления. Номер файла извлечений выбирают из Экрана Нормативных Параметров Определения Представления, и он появляется в поле No. Файла Извлечений поля 120 значений соответствующей строки NR логической таблицы. Набор 500 выходных буферов будут назначать каждому файлу извлечений, обозначенному в логической таблице.
Поскольку выходные буферы 500 отделены не номером последовательности, а номером файла извлечений, то выходной буфер 500 для файла извлечений может хранить данные из некоторого числа разных последовательностей и некоторого числа разных представлений. Но все данные для того или иного конкретного представления предпочтительно записывают в набор 500 выходных буферов одного файла извлечений, так как данные будут в конечном счете записаны в один выходной файл.
Как показано на фиг. 13, Файл извлечений 1000 содержит набор 500 выходных буферов. Набор 500 выходных буферов в свою очередь содержит множество буферов 520, 530, 540, 550. Как и в случае с буферами 220-250 фиг. 12, буферы 520-550, каждый из них, содержит один блок данных, в котором размер блока данных задан как функция природы физического носителя, на который записывают Файл Извлечений 1000.
Файл Извлечений 1000 обрабатывают следующим способом.
Например, указатель 560 указывает буфер 520. Когда указатель 560 указывает на буфер 520, то любая последовательность, выполняющая функцию записи ( строка WR логической таблицы ) в Файл Извлечений 1000, будет записывать данные в следующее имеющееся местонахождение в буфере 520. Если эта последовательность определяет, что буфер 520 заполнен, то тогда последовательность будет перемещать указатель к буферу 530 и затем инициировать перенос блока данных в буфер 520 обозначенному внешнему носителю.
В результате этого, в то время когда содержание буфера 520 записывают во внешний носитель 580, данные все еще можно будет записывать в буфер 530. При этом, поскольку размер буферов 520-550 устанавливают как функцию физических характеристик внешнего носителя 580, поэтому время, необходимое для переноса данных с буфера 520-550, сводится к минимуму.
В соответствии с вышеизложенным согласно другому осуществлению данного изобретения время обработки также сокращают созданием субнабора справочной таблицы в главном запоминающем устройстве, которое содержит только отобранные части справочных таблиц, нужных логической таблице, тем самым сокращая или устраняя необходимость обращения к справочным таблицам из внешних запоминающих устройств и сокращая время обработки.
После вышеизложенного распределения по назначению входных и выходных буферов (и до выработки машинного кода и поиска) система загружает некоторые или все нужные данные из справочных таблиц в главное запоминающее устройство.
Подобно логическим записям справочные таблицы хранят на внешних носителях, таких как жесткие диски или ленты. После выработки логической таблицы система определяет, какие колонки из каких справочных таблиц нужны для завершения процесса. После того как это определено, система формирует субнабор справочной таблицы в главном запоминающем устройстве, которое содержит только нужные для обработки колонки справочных таблиц.
Обращаясь к фиг. 14, предположим, что логическая таблица 600 содержит строки, которые обращаются к Справочной Таблице 700 Районов и Справочной Таблице 800 Магазинов. Справочная Таблица 700 Районов Содержит колонки для "магазина", "района", "среднего дохода "и" среднего возраста "Справочная Таблица 800 Магазинов содержит колонки для "магазина", " местонахождения" и "заведующего". Предположим, что логическая таблица 600 содержит только строки, которые обращаются к колонкам магазина и заведующего в Справочной Таблице Магазинов и колонкам магазина, района и дохода Справочной Таблицы Районов.
В соответствии с упомянутым осуществлением данного изобретения субнабор 900 справочных таблиц создают в памяти, причем субнабор 900 справочных таблиц содержит часть 910 таблицы магазинов и часть 920 таблицы районов; колонки магазина и заведующего справочной таблицы 800 хранят в части 910 таблицы магазинов, а колонки магазинов, районов и дохода справочной таблицы 800 районов хранят в части 920 таблицы районов.
Если нужная таблица не может поместиться в пространстве, выделенном для субнабора 900 справочных таблиц, тогда обращение к этой справочной таблице можно осуществить из физического запоминающего устройства во время поиска.
Благодаря тому что в субнаборе 900 справочных таблиц хранится наибольшее возможное число справочных таблиц, время обработки также сокращают устранением необходимости в выборке информации из внешнего носителя во время поиска.
После выработки субнабора 900 справочных таблиц: для каждой последовательности формируют набор указателей параметров обработки. Каждая последовательность 950 содержит указатель 960 параметра обработки для каждой справочной таблицы (910, 920 ) в субнаборе 900 справочных таблиц, который эта последовательность должна завершить в своем поиске. В изображенном на фиг. 14 примере логическая таблица содержит три набора: Haбоp1 610, который соответствует последовательности 1 950 и для которого требуется справочная таблица районов; набор 2 620, который соответствует последовательности 2 950 и для которого требуется справочная таблица магазинов и справочная таблица районов; и набор 3 630, который соответствует последовательности 3 950 и для которого не требуется какая-либо справочная таблица в субнаборе 900 справочных таблиц.
Указатели 960 параметра обработки первоначально устанавливают в среднюю точку их соответствующих таблиц в субнаборе справочных таблиц. В первой точке в поиске, в который производится обращение к справочной таблице, т.е. в первой строке RL набора в логической таблице, производят обращение к записи в средней точке. Если эта запись не соответствует запросу, то указатель 960 параметра обработки перемещают к средней точке между предыдущим положением и началом части (910 или 920) справочной таблицы, если предыдущее положение было слишком низким, и к средней точке между предыдущим положением и концом части (910 или 920) справочной таблицы, если предыдущее положение было слишком высоким, до тех пор, пока не достигнут нужной записи. Таким образом, двоичный поиск проводят по данной части субнабора справочных таблиц для отыскания запрошенной записи.
Как показано на фиг. 15, справочная таблица магазинов 800 расположена в адресных местоположениях Off-103 Hex во внешнем носителе 1000, а справочная таблица районов 700 расположена в адресных местоположениях Off-a07 Hex во внешнем носителе 1001. Когда справочную таблицу магазинов 800 и справочную таблицу регионов 700 копируют в субнабор 900 справочной таблицы, то для каждого местоположения 985 справочной таблицы результаты указанного выше двоичного поиска заранее кодируют в первый и второй префиксы 981 и 982 этого местоположения 985.
Например, поскольку местоположение справочной таблицы расположено на полпути между местоположением 101 справочной таблицы и началом части 910 справочной таблицы является местоположение 100, то первым префиксом 981 местоположения 101 справочной таблицы будет 100. Аналогично, поскольку местоположение справочной таблицы на полпути между местоположением 101 справочной таблицы и концом части 910 таблицы магазинов является 102, то вторым префиксом 981 местоположения 101 справочной таблицы будет 102.
Первоначально указатели 960 параметра обработки будут установлены на среднюю точку их соответствующих частей 910, 920 справочной таблицы, т.е. на 101 hex для справочной таблицы магазинов и на а03 для справочной таблицы районов.
Когда последовательность 2 в первый раз обращается к субнабору справочной таблицы для таблицы магазинов, она будет обращаться к местоположению 101 Hex. Предположим, например, что последовательность 2 в соответствии с записями второго набора логической таблицы ищет соответствующий адрес магазина для магазина номер 94.
Если местоположение 101 Hex имеет запись магазина для 94, то местоположение магазина будет выбрано и указатель 960 для части 910 таблицы магазинов останется на 101 hex. Но если местоположение 101 Hex имеет, например, запись для магазина 74, то тогда указатель 960 будет установлен на значение, запомненное во втором префиксе местоположения 101 hex (которое, как упоминалось выше, соответствует средней точке между 101 Hex и 103 Hex), и этот процесс будет повторяться до тех пор, пока не будет отыскана запись для магазина 94.
Итак, введение первого и второго префиксов в субнабор справочной таблицы еще в большей степени ускорит обработку системой в соответствии с данным изобретением, потому что оно устраняет необходимость подсчитывать во время процесса поиска следующее местоположение субнабора справочной таблицы для обращения к нему в соответствии с двоичным поиском.
Несмотря на то что данное изобретение описывалось выше относительно создания представлений из одного логического файла, будет также возможно в соответствии с данным изобретением создавать сверхпредставление, которое содержит информацию из множества логических файлов. Согласно этому аспекту данного изобретения логическую таблицу создают для каждого логического файла, причем каждая логическая таблица будет содержать отдельные представления, которые обозначают и форматируют информацию своих соответствующих логических записей. Каждое представление в сверхпредставлении обозначает для выхода один и тот же файл извлечений, и, кроме этого, каждое представление в сверхпредставлении имеет по меньшей мере одно поле, общее с другими представлениями в сверхпредставлении.
Каждую логическую таблицу обрабатывают в машинный код и применяют в качестве алгоритма поиска для ее соответствующих логических файлов - как изложено выше. После прохождения всех логических файлов, обозначенных в сверхпредставлении, обозначенный файл извлечений для сверхпредставления сортируют по номеру представления и общему полю представлений сверхпредставления и запоминают в обозначенном выходном файле. Предположим, например, что общим полем представлений сверхпредставлений являлось поле фамилий покупателей, тогда выходной файл будет иметь следующий формат:
ПОКУПАТЕЛЬ 1...ПРЕДСТАВЛЕНИЕ 1 ВЫХОД ФАЙЛА ИЗВЛЕЧЕНИЙ
ПОКУПАТЕЛЬ 1...ПРЕДСТАВЛЕНИЕ 2 ВЫХОД ФАЙЛА ИЗВЛЕЧЕНИЙ
-
-
-
ПОКУПАТЕЛЬ 1...ПРЕДСТАВЛЕНИЕ N ВЫХОД ФАЙЛА ИЗВЛЕЧЕНИЙ
ПОКУПАТЕЛЬ 2...ПРЕДСТАВЛЕНИЕ 1 ВЫХОД ФАЙЛА ИЗВЛЕЧЕНИЙ
ПОКУПАТЕЛЬ 2...ПРЕДСТАВЛЕНИЕ 2 ВЫХОД ФАЙЛА ИЗВЛЕЧЕНИЙ
ПОКУПАТЕЛЬ 2...ПРЕДСТАВЛЕНИЕ 3 ВЫХОД ФАЙЛА ИЗВЛЕЧЕНИЙ
-
-
-
ПОКУПАТЕЛЬ 2...ПРЕДСТАВЛЕНИЕ N ВЫХОД ФАЙЛА ИЗВЛЕЧЕНИЙ
Изложенным выше образом можно создать выходной файл, который содержит информацию из множества представлений. Естественно, после выработки этого выходного файла (или любого файла извлечений, полученного указанным выше образом) содержание файла можно обрабатывать обычным способом для получения сводок или других документов в любом нужном формате.
| название | год | авторы | номер документа |
|---|---|---|---|
| УСТРОЙСТВО АВТОМАТИЗИРОВАННОЙ ОБРАБОТКИ ДАННЫХ ПРОТОКОЛА ИЗМЕНЕНИЯ ЦЕН | 1999 |
|
RU2251728C2 |
| ВСТАВКА ИДЕНТИФИКАЦИОННОЙ МЕТКИ В ДАННЫЕ | 2004 |
|
RU2339091C2 |
| СПОСОБ И УСТРОЙСТВО ОСУЩЕСТВЛЕНИЯ ФИНАНСОВЫХ СДЕЛОК | 1996 |
|
RU2134901C1 |
| ИЗВЛЕЧЕНИЕ ЖЕЛАЕМЫХ ДАННЫХ ИЗ ПОТОКА ДАННЫХ | 1998 |
|
RU2193285C2 |
| СПОСОБ И СИСТЕМА АВТОМАТИЧЕСКОЙ ГЕНЕРАЦИИ ПРОГРАММНОГО КОДА ДЛЯ КОРПОРАТИВНОГО ХРАНИЛИЩА ДАННЫХ | 2017 |
|
RU2683690C1 |
| СПОСОБЫ И СИСТЕМЫ ЗАГРУЗКИ ДАННЫХ В ХРАНИЛИЩА ВРЕМЕННЫХ ДАННЫХ | 2012 |
|
RU2599538C2 |
| СИСТЕМЫ И СПОСОБЫ МАНИПУЛИРОВАНИЯ ДАННЫМИ В СИСТЕМЕ ХРАНЕНИЯ ДАННЫХ | 2006 |
|
RU2413984C2 |
| АДРЕСАЦИЯ РЕГИСТРОВ В УСТРОЙСТВЕ ОБРАБОТКИ ДАННЫХ | 1997 |
|
RU2193228C2 |
| СПОСОБ ОБРАБОТКИ ПОТРЕБИТЕЛЬСКОГО ЗАКАЗА, КОМПЬЮТЕРНАЯ СИСТЕМА ДЛЯ ЕГО ОСУЩЕСТВЛЕНИЯ И МАШИНОЧИТАЕМЫЙ НОСИТЕЛЬ (ВАРИАНТЫ) | 2006 |
|
RU2491633C2 |
| ПРИСВОЕНИЕ ПРИМЕНИМЫХ НА ПРАКТИКЕ АТРИБУТОВ ДАННЫХ, КОТОРЫЕ ОПИСЫВАЮТ ИДЕНТИЧНОСТЬ ЛИЧНОСТИ | 2011 |
|
RU2547213C2 |





Изобретение относится к устройствам обработки данных. Техническим результатом является уменьшение затраченного времени на составление всей необходимой информации в нужном формате из первоначальных файлов сделок или событий. Система содержит входной буфер для выборки блоков данных из указанных двух или более физических файлов базы данных сделок, выходной буфер для хранения блоков данных в одном или более файлов извлечений, наборы логических таблиц, хранящих один или более наборов параметров обработки. Способы описывают работу указанной системы. 3 с. и 17 з.п.ф-лы, 22 ил.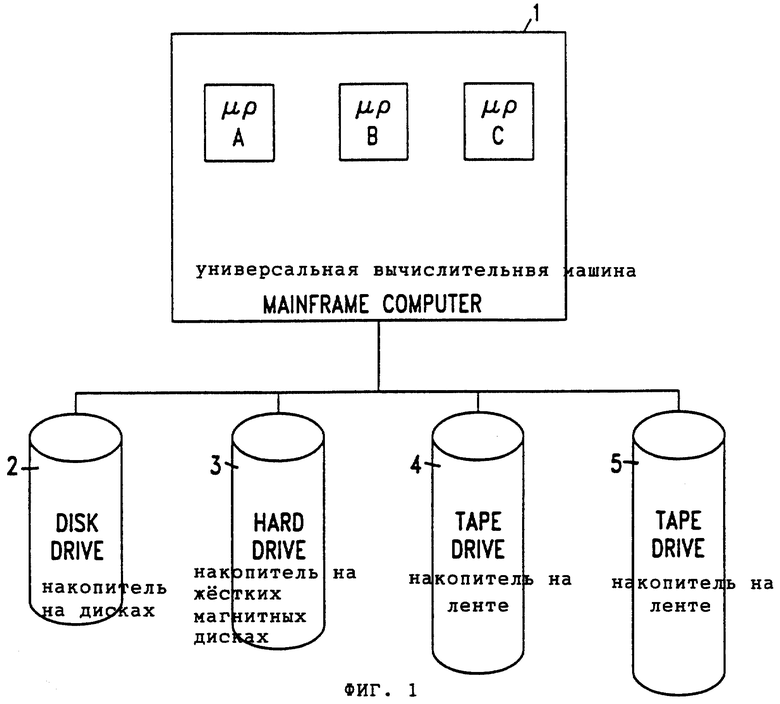
| BOBROWSKI STEVE, Parallel Oracle 7.1, DBMS, т | |||
| Приспособление для точного наложения листов бумаги при снятии оттисков | 1922 |
|
SU6A1 |
| Способ размножения копий рисунков, текста и т.п. | 1921 |
|
SU89A1 |
| Вычислительная система | 1989 |
|
SU1633417A1 |
| US 4918593 А, 17.04.1990 | |||
| US 4876643 А, 24.10.1989 | |||
| DE 3320191 Al, 08.12.1983 | |||
| Многопроцессорная система обработки данных | 1986 |
|
SU1436714A1 |

