Способ защиты доступности и конфиденциальности хранимых данных и система настраиваемой защиты хранимых данных
1 Область техники
Настоящее изобретение относится к области защиты данных, а именно к области настраиваемой защиты доступности, конфиденциальности и целостности данных.
2 Уровень техники
В настоящее время перед пользователями настольных компьютеров, серверов, ноутбуков, планшетных компьютеров, смартфонов (далее используется обобщающий термин - компьютеры) стоят различные задачи по защите хранящихся данных. Среди задач защиты особенно выделяются задача защиты доступности данных (защита от утраты данных), задача защиты конфиденциальности данных и защита целостности (защита от несанкционированного или случайного изменения). Объект защиты (защищаемые данные) и степень актуальности той или иной из обозначенных задач определяются, как правило, владельцем защищаемых данных на основании собственного опыта, существующих стандартов и практик в области защиты данных и информационной безопасности или на основе требований законодательства. Например, для обычных пользователей (физических лиц) объектами защиты обычно являются такие данные как список контактов с адресами и телефонами, номера банковских карт, PIN-коды, номер счетов,
личные фотографии, учетные данные для доступа к Интернет-банкингу и другим WEB-сервисам. Для организаций (юридических лиц) объектами защиты являются, например, данные, составляющие коммерческую тайну, персональные данные работников, клиентов и т.п. Далее под пользователями компьютеров понимаются как физические лица, так и юридические лица. В отношении однотипных данных для различных пользователей степень актуальности задач защиты может быть разная. Например, в отношении номеров банковских пластиковых карт для одних пользователей - физических лиц актуальна защита конфиденциальности и доступности, для других пользователей - физических лиц достаточно только защиты конфиденциальности номеров карт, а для юридического лица, перечисляющего заработную плату на пластиковые карты, особенно важна защита целостности данных.
Для пользователей компьютеров типичными причинами нарушения доступности хранящихся данных обычно являются: случайное стирание данных, преднамеренное стирание данных в результате несанкционированного доступа к компьютеру, потеря носителя данных, кража носителя данных, выход из строя носителя данных, шифрование данных вредоносной программой. К причинам нарушения конфиденциальности можно отнести несанкционированное копирование данных, потерю носителя данных, кражу носителя данных, ненадлежащее стирание данных при утилизации носителей или при их сервисном обслуживании (ремонте). Целостность данных нарушается обычно в результате преднамеренного несанкционированного изменения данных (например, посредством действия вредоносного кода) или выхода из строя части носителя (например, отдельных ячеек, секторов).
Как правило, указанные выше задачи защиты данных решаются с помощью различных средств защиты, а иногда и с помощью различных методов защиты. Далее для раскрытия сути изобретения приводится краткое описание существующих способов защиты данных от утраты, защиты конфиденциальности и целостности.
Существующие способы защиты от утраты данных. Защита данных от утраты обеспечивается за счет средств резервного копирования данных, например, с использованием программно-аппаратной или исключительно программной реализации технологии RAID (Redundant Array of Independent Disks), описанной в различных патентных документах, например, патентах США №№7392458 (публ. 24.06.2008), 7437658 (публ. 14.10.2008), 7600176 (публ. 06.10.2009); в заявках на патент США №№2009/0132851 (публ. 21.05.2009), 20100229033, (публ. 09.09.2010), 201101145677 (публ. 16.06.2011), 20110167294 (публ. 07.07.2011), 20110264949 (публ. 27.10.2011). В технологии RAID в режимах, предназначенных для защиты данных от частичной утраты, применяется заранее подобранный помехоустойчивый код: в режиме RAID-1, например, применяется код двукратного повторения, а в режиме RAID-6 используется код Рида-Соломона. При этом закодированные данные распределяются между носителями (дисками), обычно находящимися в одном конструктивном блоке (RAID-массиве). В зависимости от реализации технологии RAID, один набор носителей, входящий в RAID-массив, может задействоваться для создания хранилища как только в одном режиме, так и для создания нескольких хранилищ, каждое из которых может иметь свой RAID-режим. В патенте RU 2502124 C1 (публ. 20.12.2013) предложен способ распределенного хранения данных по нескольким носителям, характеризующийся тем, что позволяет на базе набора носителей данных (жестких дисков, флэш-накопителей и т.п.) построить запоминающее устройство (хранилище), устойчивое к утрате данных даже при выходе из строя большого количества частей запоминающего устройства. Согласно описанию RU 2502124 C1, память носителей данных, входящих в состав защищенного запоминающего устройства, задействуется полностью, а сами носители размещены в одном конструктивном блоке.
Кроме описанных выше способов, где защищенное хранилище (ЗХ) строится на базе носителей, размещенных предпочтительно в одном конструктивном блоке или в непосредственной близости друг от друга, имеются также
способы построения сетевых хранилищ. Так, в патенте RU 2501072 C2 (публ. 10.12.2013) с целью защиты данных от утраты предложен способ распределенного хранения данных, согласно которому, хранилище представляет собой сеть узлов (сетевое хранилище), в которой выход из строя узла отслеживается специальным узлом (группой узлов), и на основе данных из доступных узлов генерируются данные для нового узла. В этом случае узлы, составляющие сетевое защищенное хранилище, могут быть географически разнесены. Отметим, что в RU 2501072 C2 узлы сети, могут быть задействованы только для создания одного сетевого хранилища.
В патенте US 7418439 B2 (публ. 26.08.2008) предложен способ построения гибридной системы, защищенной от утраты данных, позволяющей защитить данные от утраты на базе как локальных носителей информации, так и на базе сетевых носителей. В US 7418439 B2 именно предложена виртуальная файловая система, предназначенная для создания хранилищ, защищенных от утраты данных. В основе изобретения US 7418439 B2 лежит способ построения файловой системы над файловыми системами существующих носителей (как локальных, так и сетевых) таким образом, что любой запрос к виртуальной файловой системе на изменение данных в файле дублируется (зеркалируется) для нижележащих файловых систем. За счет этого на разных носителях хранится идентичная копия файла. Этот способ позволяет на базе одного набора носителей создавать произвольное количество хранилищ с поддержкой зеркалирования. Недостатком описанного в US 7418439 B2 способа является то, что для защиты данных от утраты используется только зеркалирование, что, как отмечено, например, в RU 2501072 C2, часто не является оптимальной и дешевой стратегией защиты данных от утраты.
Существующие способы защиты от конфиденциальности и целостности данных. Защита конфиденциальности и целостности данных, как правило, обеспечивается применением криптографических преобразований к данным, таких как ГОСТ 21147-89, AES, 3DES, RSA, ГОСТ Р 34.11-2012, SHA. Кроме программных реализаций этих алгоритмов, существуют также
и аппаратные решения. В частности, для защиты конфиденциальности данных, в US 8239690 В2 (публ. 07.08.2013) предложена конструкция защищенного съемного Flash-носителя, на котором выделяется специальная защищенная область, в которой хранится информация для аутентификации пользователя и доступ к которой может получить только специальным образом разработанная программа, хранящаяся на устройстве. Данные на Flash-носителе шифруются с использованием ключа, получаемого вычислением хэш-функции от пароля, который вводит владелец Flash-носителя при аутентификации на устройстве. Способы защиты конфиденциальности и целостности данных, в частности, средство, описанное в US 8239690 В2, в свою очередь, не решают задачу защиты доступности данных.
Средства защиты конфиденциальности и целостности, основанные на программной или аппаратной реализации, в частности, отмеченных выше алгоритмов, используют секретные ключи или секретные пароли, на основе которых вырабатываются секретные ключи. Надежность защиты конфиденциальности и целостности в таких решениях основана на том допущении, что секретный ключ всегда остается в секрете, а пароль пользователем выбран так, что его вычислительно сложно подобрать. Однако на практике пользователями не всегда выполняются требования в отношении обеспечения секретности ключей или выбора сложных паролей, что может привести к ослаблению защиты конфиденциальности и целостности данных. В частности, если система парольной аутентификации настроена на использование только сложных паролей, например, в соответствии с рекомендациями из [?], то пользователь в часто не запоминает пароль, а записывает его [?]. При этом, в корпоративной среде пользователь в меньшей степени мотивирован на защиту корпоративных данных, поэтому записанный им пароль обычно оставляется, например, приклеенным к экрану монитора, или под клавиатурой. В случае же собственных информационных активов (учетные данные для доступа к Интернет-банкингу, переписка с партнерами и т.п.) пользователь заинтересован в их защите и, таким образом, либо запоминает сложный пароль, либо обеспечивает защиту записанного пароля:
хранит пароль, например, в личном кошельке или в личном телефоне. Таким образом, использование криптографических преобразований для надежной защиты конфиденциальности и целостности приводит к необходимости управлять жизненным циклом криптографических ключей или паролей, что приводит к необходимости пользователям запоминать сложные пароли. Это в свою очередь приводит к ослаблению защиты, так как из-за неудобств, связанных с запоминанием сложного пароля, пользователь обычно выбирает простой и, таким образом, легко подбираемый пароль. В то же время пользователь готов испытывать неудобства при использовании сложного пароля обычно с случае собственной заинтересованности в защите данных.
Существующие решения комплексной защиты доступности, конфиденциальности и целостности данных. Одновременное решение задач защиты доступности, конфиденциальности и целостности обычно достигается за счет последовательного применения сначала криптографического преобразования к данным, а затем применения технологии резервного копирования данных. Защита конфиденциальности и целостности данных актуальна как для систем типа RAID, где все носители размещены в одном конструктивном блоке, так и для распределенных систем хранения, то есть для сетевых хранилищ. Так в патенте США US 20050081048 А1 (публ. 14.04.2005) предложен метод защиты данных в RAID-массивах, согласно которому перед записью на RAID-массив (после чтения с RAID-массива) данные шифруются (расшифровываются) специально выделенным устройством, подключенным к PCI-шине. Ключ шифрования/расшифрования считывается с внешнего запоминающего устройства и/или запрашивается у пользователя. В патенте США US 8209551 В2 (публ. 26.06.2012) предложен метод защиты информации для RAID-массивов, согласно которому перед записью в массив данные разбиваются на несколько сегментов, часть из которых шифруется, а часть остается в открытом виде, после чего от шифрованных и нешифрованных данных вычисляются контрольные суммы. Шифрованные сегменты, сегменты в открытом виде и контрольные суммы далее
распределяются по дискам RAID-массива. При этом восстановление незашифрованных данных невозможно без знания секретного ключа, известного легальному пользователю. В патенте США US 7752676 В2 (публ. 06.07.2010) предложен метод защиты данных в сетевом хранилище, согласно которому, пользовательский запрос на чтение(запись) данных сначала проходит процедуру авторизации, и только в случае разрешения операции выполняется соответственно расшифрование (шифрование) данных на сетевом хранилище. Ключи шифрования/расшифрования хранятся на стороне клиента.
Другой вариант комбинированной защиты предложен в патенте US 20110107103 A1 (публ. 05.05.2011), согласно которому данные хранятся в облаке, а модуль шифрования хранится не на стороне клиента, а на стороне провайдера облачного хранилища. Это решение предназначено, как правило, для защиты резервных копий данных в облаке, хотя оригинальные данные хранятся на стороне клиента в исходном виде. При этом для обеспечения защиты конфиденциальности данных файл с данными сначала разбивается на части, а затем каждая часть преобразуется с помощью криптографического алгоритма и записывается на один или несколько носителей в облаке. Защита от утраты обеспечивается в случае, когда данные утрачиваются на стороне клиента. В этом случае резервная копия восстанавливается из облака. Недостатком этого решения является то, что модуль шифрования находится на стороне провайдера, тем самым потенциально провайдер имеет возможность получить доступ к данным пользователя. Кроме этого, на стороне клиента данные от нарушения конфиденциальности не защищаются.
Отметим, что конфиденциальность в отмеченных выше комбинированных решениях обеспечивается также за счет использования шифрования на основе секретных ключей, которые генерируются или защищаются с помощью паролей, проблемы использования которых отмечены выше. Таким образом, обеспечение конфиденциальности данных в таких комбинированных решениях связано с использованием криптографических ключей или
паролей, что приводит к введению дополнительных организационных мер в отношении либо использования носителей, на которых хранятся криптографические ключи, либо в отношении сложности паролей. Однако, запоминание сложных паролей создает неудобства у пользователей систем защиты, что приводит к послаблению системы защиты, так как пользователи часто игнорируют требования к сложности при выборе пароля.
Проблема запоминания сложного пароля или криптографического ключа может быть разрешена, например, с использованием методов распределения секрета, когда секрет (в данном случае пароль или криптографический ключ) распределяется между устройствами, принадлежащими пользователю.
Системы защищенного хранения данных без использования секретных ключей предложены, например, в патентах US 6363481 В1 (публ. 26.03.2002), US 7945784 В1 (публ. 17.05.2011) и US 8345861 В2 (публ. 01.01.2013). Общим принципом построения таких систем является использование (n,k)-схем разделения секрета. Защищаемые данные с помощью выбранной (n,k)-схемы разделения секрета разделяются на n частей, которые записываются на n носителей данных. При этом по любым k-1 частям нельзя получить какой-либо информации о защищаемых данных, а любые k частей дают возможность однозначно восстановить защищаемые данные. Таким образом, подобные системы защиты позволяют одновременно решать задачи защиты доступности и конфиденциальности данных: утрата не более чем n-k носителей (частей) позволяет однозначно восстановить данные по оставшимся k частям, а несанкционированный доступ (несанкционированное ознакомление, копирование) к не более чем k-1 носителям не дает возможности восстановить защищаемые данные. Общий принцип построения таких распределенных систем без привязки к конкретным схемам разделения секрета описан в US 6363481 В1, а в US 7945784 В1 и US 8345861 В2 описаны некоторые модификации этой системы и предложены конкретные (n,k)-схемы разделения секрета. Отметим, что в US 6363481 В1 рассматриваются различные варианты построения
распределенного хранения с использованием секретных ключей: 1) шифрование защищаемых данных перед применением схемы разделения секрета, 2) шифрование отдельных частей после применения схемы разделения секрета, 3) шифрование защищаемых данных и использование схемы разделения секрета для ключа шифрования, 4) шифрование защищаемых данных с последующим применением схемы разделения секрета к шифрованным данным и использование схемы разделения секрета для ключа шифрования. Системы распределенного хранения, описанные в патентах US 6363481 B1, US 7945784 В1 и US 8345861 В2 могут быть применены на практике в том случае, если получение злоумышленником доступа к k частям и выход и строя n-k носителей являются маловероятными событиями. К недостатку этих систем можно отнести их применимость преимущественно для защиты статичных данных, например, архивных копий документов (см. US 7945784 B1). В частности, описанная в патенте US 6363481 B1 процедура записи данных в защищенное распределенное хранилище подходит для случая записи нового файла (блока данных). Однако процедура обновления данных в файле (в блоке данных) не описана и представляется нетривиальной. Так как в US 6363481 B1 допускается применение различных (n,k)-схем разделения секрета к различным частям одного файла, то процедура обновления становится еще более нетривиальной в случае, когда необходимо обновить часть файла, частично перекрывающуюся с частями, к которым применены различные (n,k)-схемы разделения секрета. Отметим, что в системах, использующих (n,k)-схемы распределения секрета, требуется n носителей, что однако не всегда осуществимо при большом значении n. Также отметим, что эти распределенные защищенные системы хранения данных предназначены только для защиты конфиденциальности и доступности данных, и не предусматривают защиту целостности данных.
В патенте RU 2485584 С2 (публ. 20.06.2013) предложен другой способ построения комбинированной защиты, не требующий управления жизненным циклом секретных ключей или паролей. Этот способ является наиболее близким к предлагаемому способу одновременной защиты доступности
и конфиденциальности хранящихся данных. Описанный в патенте RU 2485584 С2 способ обеспечивает одновременную защиту доступности и конфиденциальности данных за счет разделения кодового слова на две части, одна из которых (конфиденциальная), состоящая из символов полезных данных и случайных символов, помещается в защищенную область (например, в чип на смарт-карте), а вторая часть - контрольная сумма - помещается в незащищенную область. Согласно RU 2485584 С2, несанкционированный доступ к контрольной сумме в незащищенной области не несет какой-либо информации за счет вставки блоков случайных данных в блок полезных данных перед кодированием. Способ организации защиты, описанный в RU 2485584 С2, предпочтительно предусматривает явное выделение защищенной (и тем самым, более дорогой) области и незащищенной области, что не позволяет применять этот метод в среде, где заранее неизвестно, какая область хранения является защищенной, а какая не является таковой. Например, этот способ не подходит, когда в качестве областей хранения конфиденциальной информации и контрольной суммы должны быть выбраны два одинаково используемых ("равноправных") Flash-носителя. Использование способа, описанного в RU 2485584 С2, в таком случае приводит к необходимости применения особых организационных защитных мер при обращении с Flash-носителем, на котором сохраняется конфиденциальная информация, что меняет его статус "равноправности" у используемых носителей. Также, согласно описанию RU 2485584 С2, способ кодирования подходит для устройств, в которых из строя выходят отдельные ячейки памяти. Таким образом, выход из строя полностью незащищенной области не позволяет обнаруживать и исправлять ошибки в защищенной области, а выход из строя полностью защищенной области приводит к полной потере полезных данных.
К общему минусу комбинированных решений можно отнести и то, что комбинированные решения применимы в том случае, когда пользователь заранее знает, какая информация будет храниться в защищенных хранилищах и какие требования к каждому из этих хранилищ предъявляются.
Однако часто заранее пользователь не может предугадать, какая информация будет храниться, и какие требования к ней предъявляются. Обычно на компьютере хранится разнородная информация, к которой предъявляются различные требования по защите. Например, в отношении собранной на компьютере видеотеки предъявляется требование по обеспечению защиты только доступности данных (защита от утраты); в отношении информации о банковских счетах/PIN-кодах необходимо обеспечить защиту конфиденциальности, а в отношении фотографий обычно необходимо обеспечить защиту доступности данных и защиту конфиденциальности, возможно менее строгую, нежели в отношении банковских счетов/PIN-кодов. Если заранее пользователь может определить типы хранимой информации, требования к защите, то в этом случае подходящим вариантом будет одно из комбинированных средств защиты на основе технологии RAID. Но такие решения подходят в случае, когда хранимые объемы информации достаточно велики, чтобы выделять для них защищенные разделы в RAID-массивах. Если же информация небольшого объема, то выделять целый раздел под такую информацию не имеет смысла. Предпочтительнее в этом случае использовать средства шифрования отдельных файлов. Также, если нужно обеспечить гарантированное удаление определенных данных, то предпочтительнее использовать средства гарантированного удаления отдельных файлов, а не шифрованные разделы RAID-массивов. Эту задачу обычно решают специальные средства, которые реализуют алгоритмы гарантированного удаления файлов, например, алгоритм, описанный в ГОСТ Р 50739-95.
Все это приводит к тому, что если владельцу данных необходимо в отношении одних данных применять резервное копирование, в отношении других - шифрование и/или контроль целостности, а в отношении третьих - гарантированное удаление, то для решения поставленных задач необходимо применять три средства защиты, реализующие соответственно функции RAID-массива, функции вычисления криптографических преобразований и функции гарантированного удаления. Таким образом, нерешенной является задача разработки единого технического решения, позволяющего
пользователю в зависимости от его потребностей в степени защиты от утраты данных, степени защиты конфиденциальности и целостности данных, в зависимости от имеющихся носителей данных, а также в зависимости от удобства использования гибко управлять защищенными хранилищами. При этом актуальным является решение, во-первых, позволяющее обеспечивать конфиденциальность данных, не применяя секретных ключей для криптографического преобразования, таким образом, не требующее затрат на управление жизненным циклом криптографических ключей, и, во-вторых, не накладывающее жестких ограничений на тип и количество носителей, на основе которых строится защищенное хранилище.
Анализ предшествующего уровня техники и возможностей, которые возникают при совместном использовании существующих технических решений, позволяет получить новый результат: способ защиты доступности, конфиденциальности и целостности хранимых данных (СЗДиКХД) и систему настраиваемой защиты хранимых данных (СНЗХД).
3 Раскрытие изобретения
3.1 Сущность изобретения
Предлагается способ защиты доступности и конфиденциальности хранимых данных (СЗДиКХД), основанный на предварительном случайном кодировании данных, разделении кодовых слов на части и распределении частей по имеющимся носителям данных. В качестве метода случайного кодирования используется обобщенный метод кодового зашумления [2]. С целью повышения конфиденциальности данных предлагается регулярная смена кодеков путем выбора используемого кодека из заранее известного множества кодеков с использованием генератора псевдослучайных или случайных чисел. Это позволяет усилить защиту от статистических атак (см., например, [4], [5]) и атак многократного перехвата (см. [6], [7]), которым подвержен классический метод кодового зашумления (см., например, [1], [2]). После кодирования полученные кодовые слова разделяются
на произвольное количество частей, каждая из которых записывается на соответствующий носитель.
Также предлагается система настраиваемой защиты хранимых данных (СНЗХД) на основе последовательного применения преобразования данных, разделения на части преобразованных данных и распределения частей по носителям данных. В системе может использоваться любой алгоритм преобразования данных, как для защиты доступности данных, так и для защиты конфиденциальности и целостности данных. Преобразованные данные могут разделяться на произвольное число частей, которое ограничено только количеством доступных носителей данных. При этом система позволяет на базе одного набора носителей данных создавать различные защищенные распределенные хранилища, в которых используются разнотипные алгоритмы преобразования данных.
3.2 Технический результат
Технический результат СЗДиКХД заключается в повышении защищенности конфиденциальности данных за счет применения случайного кодирования с регулярной псевдослучайной сменой кодеков и за счет распределения частей кодовых слов по нескольким носителям данных. Технический результат СНЗХД заключается в повышении конфиденциальности данных, при использовании блока усиленной защиты, и в оптимальном использовании носителей данных за счет возможности создания на базе одного набора носителей нескольких защищенных хранилищ с разными требованиями к защищенности доступности, конфиденциальности и целостности данных.
4 Краткое описание чертежей
Изобретение поясняется чертежами:
На Фиг. 1 изображены функциональные блоки, задействованные в СЗДиКХД.
На Фиг. 2 изображена схема кодирования данных в СЗДиКХД.
На Фиг. 3 изображена схема декодирования данных в СЗДиКХД.
На Фиг. 4 изображен компьютер с типичным набором подключаемых носителей данных.
На Фиг. 5 изображена структура древовидной системы хранения файлов на защищенном хранилище и вспомогательных хранилищах, на основе которых строится защищенное хранилище.
На Фиг. 6 изображена структура СНЗХД.
На Фиг. 7 изображены некоторые примеры разбиения кодового слова.
На Фиг. 8 изображены функциональные блоки агента распределенной защиты СНЗХД.
На Фиг. 9 изображена последовательность записи данных на защищенное хранилище.
На Фиг. 10 изображена последовательность чтения данных с защищенного хранилища.
На Фиг. 11 изображено соответствие между считываемыми/записываемыми данными и представлением данных в защищенном хранилище в виде последовательности информационных блоков.
На Фиг. 12 изображены варианты применения СНЗХД для организации защищенных хранилищ.
На Фиг. 13 изображена схема типичного компьютера, на базе которого могут быть осуществлены СЗДиКХД и СНЗХД.
На Фиг. 14 изображена последовательность операций открытия защищенного хранилища.
На Фиг. 15 изображена последовательность операций закрытия защищенного хранилища.
На Фиг. 16 изображена последовательность операций сброса данных из кэша.
На Фиг. 17 изображена последовательность операций открытия файла на защищенном хранилище.
На Фиг. 18 изображена последовательность операций закрытия файла на защищенном хранилище.
На Фиг. 19 изображена последовательность операций чтения данных из файла на защищенном хранилище.
На Фиг. 20 изображена последовательность операций записи данных в файл на защищенном хранилище.
4.1 Подробное описание изобретения
4.1.1 Способ защиты доступности и конфиденциальности хранимых данных
Вариант применения кодового зашумления для распределения данных по носителям описан в работе [8]. Этот метод позволяет обеспечить защиту от частичного наблюдения данных и от частичной утраты данных. Для полноты раскрытия сути изобретения приведем описание метода кодового зашумления, который, в отличие от классических алгоритмов шифрования, типа ГОСТ 21147-89, AES, 3DES, RSA, на практике пока не используется для защищенного хранения данных. Пусть 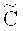 - линейный [n, l,
- линейный [n, l, 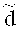 ]-код длины n, размерности l (над полем Галуа F, |F|=q, q - степень простого числа) с кодовым расстоянием
]-код длины n, размерности l (над полем Галуа F, |F|=q, q - степень простого числа) с кодовым расстоянием 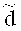 ; С - линейный [n, m, d]-код, являющийся подкодом кода
; С - линейный [n, m, d]-код, являющийся подкодом кода 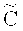 . Кодирование выполняется блоками по k:=l-m символов поля F в блоки по n символов того же поля. В дальнейшем предполагается, что в памяти компьютера, где адресуемой ячейкой памяти обычно является байт (восемь двоичных разрядов), k символов поля F занимают k1 байтов, а n символов поля F занимают n1 байтов. Для простоты реализации на компьютере предпочтительно использовать линейные коды
. Кодирование выполняется блоками по k:=l-m символов поля F в блоки по n символов того же поля. В дальнейшем предполагается, что в памяти компьютера, где адресуемой ячейкой памяти обычно является байт (восемь двоичных разрядов), k символов поля F занимают k1 байтов, а n символов поля F занимают n1 байтов. Для простоты реализации на компьютере предпочтительно использовать линейные коды 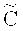 и С над полями Галуа характеристики 2 такие, для которых размерности соответственно m и l и длина n в битовом представлении кратны 8. Не ограничивая список вариантов, примерами подходящих пар кодов (
и С над полями Галуа характеристики 2 такие, для которых размерности соответственно m и l и длина n в битовом представлении кратны 8. Не ограничивая список вариантов, примерами подходящих пар кодов (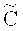 , С) являются: пара (RM(5,5), RM(2,5)), где RM(r,w) - двоичный код Рида-Маллера, размерности
, С) являются: пара (RM(5,5), RM(2,5)), где RM(r,w) - двоичный код Рида-Маллера, размерности 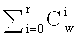 и длины 2w; множество пар
и длины 2w; множество пар 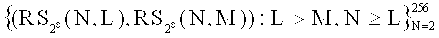 , где
, где  - код Рида-Соломона длины N и размерности L над полем F мощности 256, а
- код Рида-Соломона длины N и размерности L над полем F мощности 256, а  - его подкод размерности М.
- его подкод размерности М.
Опишем правила кодирования и декодирования данных. Пусть  - порождающая матрица кода
- порождающая матрица кода 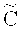 ,
, 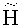 - соответствующая проверочная матрица, G и Н - соответственно порождающая и проверочная матрицы базового кода С. Так как С - подкод кода
- соответствующая проверочная матрица, G и Н - соответственно порождающая и проверочная матрицы базового кода С. Так как С - подкод кода 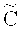 , то, без потери общности, матрицы
, то, без потери общности, матрицы 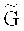 и Н представимы в виде:
и Н представимы в виде:

где G* - (k×n)-матрица, 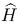 - (k×n)-матрица. Кодирование информационного вектора S=(s1, …, sk)∈Fk выполняется по правилу:
- (k×n)-матрица. Кодирование информационного вектора S=(s1, …, sk)∈Fk выполняется по правилу:
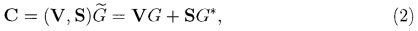
где V∈Fm - случайный (или псевдослучайный) вектор, а запись (а, b) для векторов над одним полем обозначает приписывание справа вектора b к вектору а. Код С принято называть базовым кодом, а пару (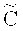 ,С) - факторным кодом [факторным, кодеком) [9]. Матрицу
,С) - факторным кодом [факторным, кодеком) [9]. Матрицу 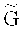 будем называть порождающей матрицей факторного кода (
будем называть порождающей матрицей факторного кода (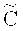 ,С). Генерация псевдослучайного вектора V длины m выполняется любым криптографически стойким генератором псевдослучайных чисел, например, проходящим все тесты NIST [3] на проверку случайности генерируемой последовательности. Предпочтительными в использовании являются генераторы, требующие небольшое число тактов процессора для генерации очередного значения псевдослучайной последовательности. Не ограничивая список вариантов, возможными генераторами могут быть алгоритмы ISAAK, ISAAK+, RC4. Так как для декодирования данных в методе кодового зашумления не используется генерируемая псевдослучайная последовательность, то ре-инициализация (повторная инициализация) генератора псевдослучайных чисел может производиться в любое время по усмотрению кодирующей стороны. Это позволяет повысить стойкость кодового зашумления и исключить возможную атаку анализа данных, закодированных периодической последовательностью.
,С). Генерация псевдослучайного вектора V длины m выполняется любым криптографически стойким генератором псевдослучайных чисел, например, проходящим все тесты NIST [3] на проверку случайности генерируемой последовательности. Предпочтительными в использовании являются генераторы, требующие небольшое число тактов процессора для генерации очередного значения псевдослучайной последовательности. Не ограничивая список вариантов, возможными генераторами могут быть алгоритмы ISAAK, ISAAK+, RC4. Так как для декодирования данных в методе кодового зашумления не используется генерируемая псевдослучайная последовательность, то ре-инициализация (повторная инициализация) генератора псевдослучайных чисел может производиться в любое время по усмотрению кодирующей стороны. Это позволяет повысить стойкость кодового зашумления и исключить возможную атаку анализа данных, закодированных периодической последовательностью.
При передаче по каналу кодовое слово С может быть испорчено, то есть получатель вместо С получит испорченное слово С′. Здесь и далее под каналом передачи данных понимаются как пространственно-временные каналы передачи данных (системы связи), так и временные каналы (системы хранения). В системах хранения, например, могут выйти из строя отдельные ячейки памяти, что можно рассматривать как помеху типа стирания. Если количество стертых символов кодового слова не превышает 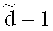 , то исходное кодовое слово может быть восстановлено однозначно. В общем случае для декодирования имеющегося слова С′, возможно испорченного, сначала применяется алгоритм декодирования кода
, то исходное кодовое слово может быть восстановлено однозначно. В общем случае для декодирования имеющегося слова С′, возможно испорченного, сначала применяется алгоритм декодирования кода 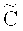 для восстановления по слову С′ истинного кодового слова С. Далее, согласно [7], матрицу Н вида (1) всегда можно выбрать так, что извлечение информационного вектора S из соответствующего декодированного кодового вектора С выполняется по правилу:
для восстановления по слову С′ истинного кодового слова С. Далее, согласно [7], матрицу Н вида (1) всегда можно выбрать так, что извлечение информационного вектора S из соответствующего декодированного кодового вектора С выполняется по правилу:

Показателем защищенности от частичного наблюдения является количество возможных информационных слов, которые может получить наблюдатель по подслушанным данным. Это количество определяется следующим образом. Для кода K и его подкода L последовательность
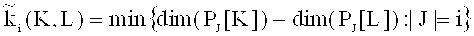 , i=0, …, n
, i=0, …, n
называется относительным обратным профилем размерность/длина [10], где PJ[М] - проекция кода М на множество номеров координат J. Известно, что если количество нестертых символов µ такое, что  , то по нестертым данным восстановить данные невозможно в теоретико-информационном смысле, где С⊥ и
, то по нестертым данным восстановить данные невозможно в теоретико-информационном смысле, где С⊥ и 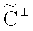 - дуальные коды соответственно к кодам С и
- дуальные коды соответственно к кодам С и  . В общем случае количество претендентов при подслушивании не более µ символов определяется как
. В общем случае количество претендентов при подслушивании не более µ символов определяется как 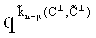 .
.
Отметим, что если защита данных от частичной утраты не требуется (например, вероятность стирания символа пренебрежимо мала), код 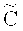 может быть размерности n, тогда матрица
может быть размерности n, тогда матрица 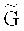 будет квадратной, и, согласно,
будет квадратной, и, согласно,
[1], будет обеспечена защита данных в теоретико-информационном смысле, если злоумышленнику будет доступно менее d(C⊥) символов каждого кодового слова, где d(С⊥) - кодовое расстояние для кода C⊥.
Метод кодового зашумления в ряде случаев подвержен статистической атаке и атак многократного перехвата (см. [4], [5], [6], [7]). С целью защиты от таких атак повышения конфиденциальности предлагается обобщение метода кодового зашумления. Пусть FCq(n, k, µ, ν) - конечное множество факторных кодеков мощности L, преобразующих информационные векторы длины k (над полем F) в кодовые векторы длины n так, что утрата не более ν символов кодового слова позволяет однозначно восстановить информационное слово, а подслушивание не более µ символов кодового слова не дает наблюдателю какой-либо информации о закодированном сообщении. Примером набора FCq(n, k, µ, ν) может быть подмножество кодеков, соответствующих кодам, комбинаторно-эквивалентным (полученным перестановкой столбцов в проверочной матрице) какому-то помехоустойчивому коду. Отличием от классического метода кодового зашумления является то, что в предлагаемом методе для каждого информационного блока длины k факторный кодек не фиксирован, а выбирается случайно или псевдослучайно из набора FCq(n, k, µ, ν). Далее поясняется эта идея для построения способа защиты доступности и конфиденциальности данных в системах хранения.
Пусть имеется t(>0) носителей данных (хранилищ), из которых к любым ttap(≥0) имеет доступ несанкционированный наблюдатель (т.е. на этих хранилищах данные могут быть подсмотрены) и из которых любые terr(≥0) могут выйти из строя (т.е. данные на этих хранилищах могут быть утрачены).
На основе тройки (t, ttap, terr) выбирается такой набор кодеков FCq(n, k, µ, ν) и такое правило разбиения кодовых слов на t частей, чтобы:
- объединение t частей давало возможность однозначно восстановить все кодовое слово;
- любые ttap частей в совокупности содержали не более µ различных
кодовых символов;
- любые terr частей в совокупности содержали не более ν различных кодовых символов.
Предпочтительно для ускорения операций использовать такие кодеки (и соответственно, такое поле F) и такие правила разбиения, чтобы длина кодового слова, а также длины частей кодового слова (после разбиения) при машинном представлении в виде последовательности нулей и единиц были кратны 8. Однако другие значения этих параметров не должны представлять сложностей для специалистов, компетентных в области прикладного программирования.
Не ограничивая других вариантов разбиения, возможно разбиение на равные части по
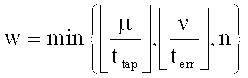
символов поля F, если 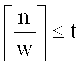 . В случае, если n не делится нацело на w, то
. В случае, если n не делится нацело на w, то 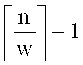 частей будут иметь длину w символов, а одна часть будет иметь длину
частей будут иметь длину w символов, а одна часть будет иметь длину 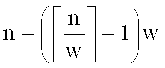 символов. Отметим, что если ttap=0 и/или terr=0, то это означает, что угрозы нарушения конфиденциальности нет и/или нет угрозы утраты данных. В частности, если ttap=terr=0, то w=n.
символов. Отметим, что если ttap=0 и/или terr=0, то это означает, что угрозы нарушения конфиденциальности нет и/или нет угрозы утраты данных. В частности, если ttap=terr=0, то w=n.
Набор кодеков FCq(n, k, µ, ν) показан на Фиг. 1 в виде блока 100; кодеки в этом наборе могут быть реализованы как на программном уровне, так и на программно-аппаратном уровне. Настройка конкретных параметров n, k, µ, ν и кодеков в наборе осуществляется на основе конфигурации кодеков 108, поступаемой от пользователя. Отметим, что все компоненты блока защиты 111 настраиваются посредством модуля управления 112. Кодеки должны реализовывать единый интерфейс кодирования блока данных (encode_data), декодирования блока данных (decode_data), чтения (get_codec_config) и настройки параметров кодеков (set_codec_config). Единство интерфейса предпочтительно для цели универсальности модуля факторного кодирования 102. Пусть факторные кодеки уникальным образом занумерованы натуральными числами из диапазона [1, L]: FCq(n, k, µ, ν)={ƒ1; …; ƒL}. Перед кодированием очередного информационного
слова S(∈Fk) (101.1 на Фиг. 2), поступившего от источника запросов ввода/вывода 101, модуль факторного кодирования 102 запрашивает у генератора псевдослучайных чисел (ПСЧ) 103 число r (103.1 на Фиг. 2) из диапазона натуральных чисел [1, L]. На основе полученного числа r модуль 102 выбирает в наборе 100 кодек ƒr с номером r и кодирует информационный блок S с помощью кодека ƒr в кодовый блок С. Кодовое слово С (102.1 на Фиг. 2) поступает на блок разбиения данных 104, а номер факторного кодека r поступает на блок разделения секрета 105, где реализуется какая-либо (t, t-terr)-схема разделения секрета. Алгоритм схемы разделения секрета может быть любым, например это может быть схема Шамира (алгоритм 109 схемы разделения секрета задается пользователем). В блоке 104 кодовое слово разбивается на t частей: C1, …, Ct (104.1 на Фиг. 2). Разбиение может выполняться как на равные части, так и на части различной длины. В общем случае допускается также разбиение и на частично пересекающиеся части. Параметры разбиения настраиваются на основе конфигурации 110, задаваемой пользователем. В блоке 105 с помощью (t, t-terr)-схемы разделения секрета номеру факторного кодека r в соответствие ставится t частей: R1, …, Rt (105.1 на Фиг. 2), при этом предпочтительно, чтобы в битовом представлении каждая часть Ri имела длину, кратную 8. Части C1, …, Ct и части R1, …, Rt поступают на блок слияния 106, выходом которого является вектор вида: (С1, R1, С2, R2, …, Ct, Rt) (106.1 на Фиг. 2). который получается путем приписывания битовых представлений частей Ci и Ri друг к другу, i=1, …, t. Далее в модуле распределения по хранилищам 107 пары вида (Ci, Ri) (i=1, …, n) (107.1-107.t на Фиг. 2) записываются соответственно на t хранилищ 113.1, …, 113.t.
При считывании данных (см. Фиг. 3), из хранилищ 113.1, …, 113.t считываются пары (Ci, Ri) [i=1, …, t). По любым не менее t-terr частям из набора R1, …, Rt в модуле 105 восстанавливается номер r факторного кодека, а далее в модуле 102 по номеру r выбирается факторный кодек ƒr, который в дальнейшем используется для извлечения информационного вектора из слова, собранного из соответствующих считанных частей Ci,
i∈{1; …; t}.
Например, пусть FCq(n, k, µ, ν) - множество из ста кодеков, комбинаторно-эквивалентных факторному (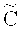 , С), где
, С), где 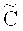 - код Рида-Соломона
- код Рида-Соломона  размерности 160 и длины 240 над полем
размерности 160 и длины 240 над полем 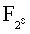 , С - код Рида-Соломона
, С - код Рида-Соломона 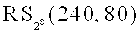 размерности 80 и длины 240 над тем же полем. В этом случае n=240, k=80, µ=80, ν=80, L=100. Если t=2, при этом ttap=1 или terr=1, то указанное множество FCq(n, k, µ, ν) не подходит для данной тройки (t, ttap, terr), так как кодовое слово длины 240 нельзя разбить на две части так, чтобы кража любой из них не несла какой-либо информации укравшему о закодированном слове. Зато множество FCq(n, k, µ, ν) подходит, например, для тройки (3, 1, 1): в этом случае кодовое слово можно разбить на 3 части по 80 символов, и потеря одной части или несанкционированное ознакомление с одной частью не приведут соответственно к утрате данных или нарушению конфиденциальности данных. Так как L=100, то для схемы разделения секрета можно использовать, например, (3,2)-схему Шамира, при этом каждая часть будет представлена не более чем одним символом поля , для представления которого в памяти требуется не более одного байта.
размерности 80 и длины 240 над тем же полем. В этом случае n=240, k=80, µ=80, ν=80, L=100. Если t=2, при этом ttap=1 или terr=1, то указанное множество FCq(n, k, µ, ν) не подходит для данной тройки (t, ttap, terr), так как кодовое слово длины 240 нельзя разбить на две части так, чтобы кража любой из них не несла какой-либо информации укравшему о закодированном слове. Зато множество FCq(n, k, µ, ν) подходит, например, для тройки (3, 1, 1): в этом случае кодовое слово можно разбить на 3 части по 80 символов, и потеря одной части или несанкционированное ознакомление с одной частью не приведут соответственно к утрате данных или нарушению конфиденциальности данных. Так как L=100, то для схемы разделения секрета можно использовать, например, (3,2)-схему Шамира, при этом каждая часть будет представлена не более чем одним символом поля , для представления которого в памяти требуется не более одного байта.
4.1.2 Система настраиваемой защиты хранимых данных
Далее, как и ранее, под компьютером понимается любое устройство, имеющее, как минимум, один процессор с программным управлением, запоминающее устройство для долговременного и оперативного хранения программы и промежуточных результатов, а также интерфейсы для подключения носителей данных и сетевые интерфейсы для подключения к сети передачи данных. На Фиг. 4. в качестве примера показан настольный компьютер 400, включающий, кроме периферийных устройств ввода данных (на Фиг. 4 не показаны), монитор 401 и системный блок 402. Устройства хранения данных, подключаемые к компьютеру 400, здесь условно делятся на встроенные устройства хранения данных 403, съемные устройства хранения данных 405, подключаемые не по сети устройства 411, одной из функций которых
является хранение данных, и сетевые хранилища 414. Набор встроенных устройств 403, как правило, состоит из внутренних жестких дисков 404, подключаемых, например, по интерфейсам ATA, SATA, SAS, Fibre Channel и т.п.. К встроенным устройствам хранения относится также встроенная память, которая не предполагается к извлечению при штатной работе компьютера (встроенная память планшетного компьютера, смартфона и т.п.). К съемным устройствам 405, в частности, относятся съемные жесткие диски 406, подключаемые, в частности, по интерфейсам USB, eSATA, SCSI, FireWire; Flash-накопители, подключаемые по USB-интерфейсу 407, но SD-интерфейсу 408 и по mini- или microSD-интерфейсам (на Фиг. 4 не показаны); гибкие магнитные диски 409; оптические диски 410. Приведенный перечень съемных устройств не является окончательным и может быть расширен устройствами хранения данных, подключаемыми к внешним интерфейсам компьютера. К подключаемым не по сети устройствам 411 относятся устройства, хранение данных для которых не является единственной функцией. К таким устройствам могут относиться, например, смартфоны 412, планшетные компьютеры 413, устройства для чтения электронных книг, аудиоплееры (на Фиг. 4 не показаны). Набор сетевых хранилищ, например, включает в себя файловые серверы (NAS - network area storage) 415, сети хранения (SAN - storage area network, на Фиг. 4 не показана), облачные хранилища 416, доступные по локальной сети передачи данных или по сети передачи данных общего пользования.
На базе компьютера и имеющегося набора носителей данных предлагается построить систему настраиваемой защиты хранимых данных (СНЗХД). Для построения какого-нибудь защищенного хранилища, которое будем обозначать SStor, необходимо TSStor(≥1) носителей данных. Под носителями данных далее понимаются, не ограничивая использование других вариантов, системы хранения, такие как, локальные файловые системы, сетевые файловые системы, реестр операционной системы Windows и другие системы, в которых хранение организовано на базе структур, логически совпадающих со структурой хранения данных в файловых системах. При
этом реестр операционной системы рассматривается как встроенный носитель данных (входит в группу 403). Каждому защищенному хранилищу SStor ставится в соответствие tSStor(≥1) хранилищ, каждое из которых представляет собой выделенную область на одном из TSStor носителей данных. Каждая такая область адресуется структурой, специфичной для носителя данных. Например, если носителем данных является локальная или сетевая файловая система, то такой структурой может быть каталог. Если носителем данных является, например, реестр операционной системы Windows, то такой структурой может являться ветка реестра. Адрес выделенной области на носителе будем называть точкой монтирования хранилища. В рамках одного защищенного хранилища SStor из tSStor хранилищ выбирается одно хранилище, называемое в дальнейшем базовым хранилищем защищенного хранилища SStor), которое будет адресовать защищенное хранилище SStor. Другими словами, с точки зрения пользователя, работа с защищаемыми данными в защищенном хранилище SStor выполняется посредством отправки запросов ввода/вывода к базовому хранилищу. Остальные tSStor-1 хранилищ называются вспомогательными хранилищами защищенного хранилища SStor. Числа tSStor и TSStor связаны только неравенством TSStor≤tSStor. Таким образом, на базе одного носителя данных может быть выделено несколько хранилищ. В этом случае области, адресуемые точками монтировал хранилищ в рамках одного защищенного хранилища SStor, не должны пересекаться.
Далее под защищенным, хранилищем, понимается система, состоящая из точки монтирования базового хранилища и точек монтирования вспомогательных хранилищ, в которой пользовательские запросы ввода/вывода направляются в адрес базового хранилища, а данные преобразуются и распределяются по вспомогательным хранилищам в соответствии с конфигурацией, описывающей защищенное хранилище.
При размещении защищаемого файла в защищенном хранилище SStor выполняется преобразование данных защищаемого файла с помощью заданного в конфигурации защищенного хранилища алгоритма преобразования,
разбиение преобразованных данных на части выбранного размера и распределение частей по вспомогательным хранилищам (и, возможно, на базовое хранилище). Чтение данных из защищаемого файла, размещенного в защищенном хранилище, выполняется в обратном порядке: чтение частичных данных на вспомогательных хранилищах (и, возможно, с базового хранилища), сбор частей данных в единое целое, обратное преобразование данных. Обычно алгоритмы преобразования данных в системах хранения выполняют преобразование поблочно. Однако в СНЗХД могут быть применены и алгоритмы, не ориентированные на преобразование данных поблочно. Для простоты, но не ограничивая при этом других вариантов алгоритмов преобразования, далее изобретение раскрывается применительно к блочным алгоритмам. Таким образом, защищаемый файл представим в виде последовательности информационных блоков. Преобразованные информационные блоки с помощью выбранного алгоритма преобразования будем называть кодовыми блоками.
Предпочтительным вариантом организации данных на вспомогательных хранилищах является реализация, при которой на вспомогательных хранилищах 500.2-500.tSStor (см. Фиг. 5), начиная соответственно с точек монтирования 501.2-501.tSStor, полностью повторяется структура файловой системы (или ее аналога), имеющаяся на базовом хранилище 500.1, начиная с точки монтирования 501.1. Таким образом, каждому размещаемому в защищенном хранилище файлу соответствует один файл в базовом хранилище, начиная с точки монтирования 501.1 и по одному файлу на вспомогательных хранилищах. Файлы, размещаемые в защищенном хранилище (но до помещения в защищенное хранилище), называются здесь защищаемыми файлами; файлы, размещенные в защищенном хранилище, называются защищенными файлами; файлы, размещаемые в базовом хранилище защищенного хранилища SStor, называются базовыми файлами, а соответствующие файлы на вспомогательных хранилищах - вспомогательными файлами. Таким образом, каждому защищенному файлу соответствует один базовый файл и несколько вспомогательных.
В базовом файле могут храниться либо только метаданные, либо метаданные и данные, подвергнутые преобразованию. Метаданные представляют собой служебные данные, например, об истинном размере защищаемого файла, времени последней модификации и т.п. Метаданные о размере файла необходимы, например, в том случае, когда преобразование выполняется блоками, размер которых больше одного байта. Если не хранить истинный размер файла, то размер защищенного файла будет всегда кратен длине кодового слова, то есть будут утеряны данные об истинном размере файла (в случае, если бы он не размещался в защищенном хранилище). Предпочтительной является реализация, когда в начале базового файла на защищенном хранилище выделяется область фиксированного размера для хранения метаданных.
Если базовое хранилище не выступает в роли одного из вспомогательных хранилищ, то базовые файлы содержат только метаданные. Если же базовое хранилище выступает в качестве одного из вспомогательных хранилищ, то базовые файлы кроме метаданных содержат данные, подвергнутые преобразованию.
Допускается реализация защищенного хранилища, когда носитель данных для хранилищ 500.1-500.tSStor один и тот же (т.е. TSStor=1). Такая реализация, например, имеет смысл в случае, когда необходимо дублирование данных в нескольких каталогах на одном носителе данных.
Далее для простоты, но не ограничивая общности, полагается, что точки монтирования защищенных и вспомогательных хранилищ представляют собой каталоги файловых систем.
СНЗХД состоит из двух подсистем (см. Фиг. 6): клиентский агент 600 и агент распределенной защиты 601. Каждая из подсистем 600 и 601 представляет собой программное средство, устанавливаемое на компьютер. Возможны два варианта: обе подсистемы устанавливаются на один компьютер, либо каждая из подсистем устанавливается на отдельный компьютер. Подсистемы 600 и 601 взаимодействуют посредством канала связи 602. Канал связи 602, в случае установки подсистем на разные компьютеры, может
представлять собой любой канал связи, посредством которого два компьютера могут обмениваться данными, например, через Wi-Fi, Bluetooth, USB-кабель, через проводную локальную сеть. В случае установки подсистем: на один компьютер роль канала связи 602 может выполнять прикладной программный интерфейс, посредством которого взаимодействуют подсистемы 600 и 601. Клиентский агент 600 включает модуль перехвата данных 603 и модуль управления 604. Модуль 603 перехватывает запросы 606 чтения/записи защищаемых данных, адресованные защищенному хранилищу SStor и отправляет их по каналу связи 602 агенту распределенной защиты 601. Модуль 603 может быть реализован как программная компонента (например, как драйвер), встраиваемая в реализуемый операционной системой процесс обработки запросов ввода/вывода, или реализована как программная компонента, использующая прикладной программный интерфейс операционной системы по работе с системами хранения данных и реализующая пользовательский графический и/или командный интерфейс работы с файлами на защищенных хранилищах. Модуль управления 604 получает конфигурацию 605 защищенного хранилища SStor, на основе которой настраиваются модуль перехвата данных 603 и агент распределенной защиты 601.
В агенте распределенной защиты модуль получения данных 607 (при операции записи данных в защищенное хранилище SStor) принимает запросы ввода/вывода от модуля перехвата данных 603 и далее передает их модулю защиты 608, где по указанному в конфигурации 605 алгоритму защиты происходит обработка запроса. Данные, в зависимости от конфигурации 605, могут также подвергаться усиленной защите в блоке 609. В блоке 610 реализуется схема распределения данных по tSStor хранилищам. В случае, когда подсистемы 600 и 601 устанавливаются на разные компьютеры, то в подсистеме 600 необходим модуль 613, принимающий от агента распределенной защиты 601 запросы на чтение/запись данных в защищенном хранилище, так как базовое хранилище защищенного хранилища SStor предпочтительно расположено на компьютере, где установлен клиентский
агент.
Конфигурация 605 защищенного хранилища SStor содержит пять основных разделов:
- параметры базового хранилища 605.1, где описываются такие параметры, как точка монтирования базового хранилища, признак того, может ли базовое хранилище выступать в качестве вспомогательного хранилища (содержать части кодовых блоков);
- параметры преобразования данных 605.2, где описываются такие параметры, как название алгоритма преобразования, длина информационного блока k; длина кодового блока n; длина ключа, ключевой контейнер, если алгоритм преобразования использует секретные ключи; в общем случае, предлагаемое изобретение позволяет использовать любой метод, преобразующий информационный блок данных длины k (k≥1) в кодовый блок данных длины n (n≥k) независимо от других блоков с использованием или без использования ключа; в частности, такими алгоритмами преобразования могут быть и традиционные алгоритмы симметричного или асимметричного преобразования, такие как ГОСТ 21147-89, AES, 3DES, RSA, алгоритмы контроля целостности типа SHA, ГОСТ Р 34.11-2012 и другие, алгоритмы защиты от ошибок и утраты данных, например, основанные на помехоустойчивых кодах Рида-Соломона, и другие;
- параметр усиленной защиты 605.3: число Q - количество перестановок битов в байте (Q≤250), алгоритм P генерации перестановок на основе целого числа из диапазона от 0 до Q и алгоритм Г генерации n псевдослучайных символов поля F по целому числу из диапазона от 0 до Q; усиленная защита может применяться для защиты от статистической атаки; если входным параметром алгоритма P является число 0, то алгоритм P генерирует перестановки, которые не приводят к изменению порядка бит, т.е. тождественные перестановки.
- параметры схемы разделения секрета 605.4, где описывается алгоритм схемы разделения секрета (могут использоваться, например, схемы, описанные в патентах US 7945784 B1, US 8345861 В2 и другие);
- параметры разбиения данных 605.5, где описываются количество вспомогательных хранилищ tSStor, правило П разбиения кодовых блоков на части, а также точки монтирования вспомогательных хранилищ.
В модуле защиты 608 имеется набор (база) 608.1 алгоритмов защиты данных (см. Фиг. 8). Каждый из этих алгоритмов характеризуется четверкой (n, k, µ, ν), где k - длина (в символах поля F) информационного блока, n - длина кодового блока после применения защиты, µ - максимальное количество символов кодового блока, по которым нельзя получить какой-либо информации об исходном информационном блоке, ν - максимальное число такое, что по любым n-ν кодовым символам однозначно за полиномиальное время (от n) восстанавливается информационный блок.
У пользователя, создающего защищенное хранилище SStor, имеется tSStor хранилищ, из которых любые ttap могут быть украдены/скопированы и terr могут выйти из строя или быть потеряны (вероятности этих событий таковы, что ими нельзя пренебречь). Тогда для пользователя с его набором условий (tSStor, ttap, terr) подходящим алгоритмом защиты является один из алгоритмов в наборе 608.1 с параметрами (n, k, µ, ν) такой, что при разбиении кодового вектора на tSStor частей:
- объединение tSStor частей давало возможность однозначно восстановить все кодовое слово длины n;
- любые ttap частей в совокупности содержат не более µ различных кодовых символов;
- любые terr частей в совокупности содержат не более ν различных кодовых символов.
Предпочтительно для ускорения операций использовать такие кодеки (и соответственно, поле F) и такие правила разбиения, чтобы длина кодового слова, а также длины частей кодового слова (после разбиения)при машинном представлении в виде последовательности нулей и единиц были кратны 8. Однако другие значения этих параметров не должны представлять сложностей для специалистов, компетентных в области прикладного программирования.
По заданной тройке (tSStor, ttap, terr) пользователь может сам выбирать подходящий алгоритм защиты. Например, при формировании параметров хранилища SStor, после задания тройки (tSStor, ttap, terr), в модуле 601 может формироваться список подходящих алгоритмов и передаваться в модуль 600, где пользователь из списка выбирает один алгоритм защиты. Выбранный алгоритм сохраняется в разделе 605.2 конфигурации 605 при создании защищенного хранилища SStor. Отметим, что возможна реализация, когда на разных хранилищах хранятся части разной длины, если количество хранилищ tSStor позволяет это сделать. После выбора подходящего алгоритма защиты выбирается схема разбиения кодового слова и сохраняется в разделе 605.5 конфигурации 605. Параметры разбиения на части, в частности, описывают состав каждой части, а именно указываются номера символов кодового слова, из значений которых образуется каждая часть. Если, например, tSStor=4, ttap=1, terr=0, то подходящим алгоритмом преобразования может быть, например, алгоритм, для которого n=8, k=4, µ=4, ν=0. В этом случае разбиение кодового слова, не ограничивая других возможных вариантов, например, может быть выполнено, как показано на Фиг. 7. Оба эти варианта не будут нарушать того условия, что несанкционированный доступ к любым ttap хранилищам не дает какой-либо информации злоумышленнику об информационном блоке. В частности, на Фиг. 7а кодовое слово 700 разбивается на две непересекающиеся части: одному вспомогательному хранилищу соответствует часть 700.1, состоящая из первого, третьего, четвертого и шестого кодовых символов; второму хранилищу соответствует часть 700.2, состоящая из второго, пятого, седьмого и восьмого кодовых символов. Разбиение того же кодового слова на Фиг. 7б выполнено таким образом, что все три части 701.1, 701.2 и 701.3 имеют один общий кодовый символ, при этом часть 701.2 длиннее остальных на один кодовый символ. Параметры разбиения в конфигурации 605 предпочтительно описываются в разделе описания каждого задействованного вспомогательного хранилища и задают правило разбиения П. Так. для разбиения, показанного на Фиг. 7А, в конфигурации защищенного
хранилища для первого вспомогательного хранилища будет указано множество {1; 3; 4; 6}, а для второго - {2; 5; 7; 8}. При использовании разбиения, показанного на Фиг. 7Б, в конфигурации защищенного хранилища для первого, второго и третьего вспомогательного хранилища будут указаны соответственно множества {1; 3; 4}, {2; 4; 5; 8} и {4; 6; 7}.
Опишем схему защиты данных. Все функциональные блоки агента распределенной защиты настраиваются на параметры из конфигурации 605 через модуль управления 611. При записи данных в защищенный файл каждый информационный блок S 800 (см. Фиг. 9), принятый модулем 607, передается в модуль защиты данных 608. На основе параметров 605.2 из конфигурации 605 модуль преобразования 608.2 настраивается на один из алгоритмов А защиты из набора 608.1. Информационный блок S проходит процедуру защиты 801 и, таким образом, преобразуется в кодовый блок С, который далее в модуле 608.3 на основе параметров разбиения данных 605.5 проходит этап разбиения 802 на tSStor частей: 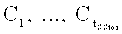 , каждая из которых имеет длину li байт при представлении частей в виде последовательностей нулей и единиц, i=1, …, tSStor. Далее выполняется проверка на равенство нулю параметра Q из раздела 605.3 конфигурации 605. Если Q=0, то блок усиленной защиты не применяется. Например, блок усиленной защиты не имеет смысла применять, если алгоритм A реализует СЗДиКХД, в который защита от статистических атак уже заложена. Если Q>0, то в модуле 609.1 с помощью генератора 601.1 генерируется случайно или псевдослучайно число r из диапазона от 0 до 250 (занимает в памяти 1 байт), по которому однозначным образом генерируется tSStor перестановок
, каждая из которых имеет длину li байт при представлении частей в виде последовательностей нулей и единиц, i=1, …, tSStor. Далее выполняется проверка на равенство нулю параметра Q из раздела 605.3 конфигурации 605. Если Q=0, то блок усиленной защиты не применяется. Например, блок усиленной защиты не имеет смысла применять, если алгоритм A реализует СЗДиКХД, в который защита от статистических атак уже заложена. Если Q>0, то в модуле 609.1 с помощью генератора 601.1 генерируется случайно или псевдослучайно число r из диапазона от 0 до 250 (занимает в памяти 1 байт), по которому однозначным образом генерируется tSStor перестановок 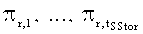 , каждая из которых переставляющая биты внутри li байтов частей (стадия 804 на блок-схеме). К каждому байту (в машинном представлении) блока Ci применяется перестановка πr,i, i=1, …, tSStor (стадия 805 на блок-схеме). Применение перестановки πr,i к байтам части Ci будем обозначать πr,i(Ci). На выходе стадии 805 получаем блок
, каждая из которых переставляющая биты внутри li байтов частей (стадия 804 на блок-схеме). К каждому байту (в машинном представлении) блока Ci применяется перестановка πr,i, i=1, …, tSStor (стадия 805 на блок-схеме). Применение перестановки πr,i к байтам части Ci будем обозначать πr,i(Ci). На выходе стадии 805 получаем блок  , i=1, …, tSStor.
, i=1, …, tSStor.
Для каждой части 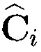 , состоящей из li байт:
, состоящей из li байт: 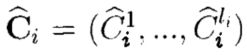 в модуле
в модуле
609.2 выполняется стадия гаммирования 805. Именно, по числу r с помощью алгоритма Г вырабатывается псевдослучайная последовательность Г(r)=(Г(r)1, .…, F(r)tSStor) длиной 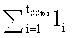 байт, где каждый блок Г(r)i имеет длину li байтов, i=1, …, tSStor. Затем выполняется побитовая операция XOR векторов (
байт, где каждый блок Г(r)i имеет длину li байтов, i=1, …, tSStor. Затем выполняется побитовая операция XOR векторов (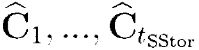 ) и Г(r), образуя при этом вектор вида:
) и Г(r), образуя при этом вектор вида:
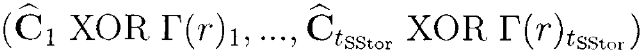 .
.
По числу r в модуле разделения секрета 609.3 выполняется стадия разделения секрета 807 (реализующая, например, алгоритм Шамира над полем F251), где генерируется tSStor частей (каждая длины 1 байт): 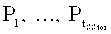 , каждая из которых в модуле 609.4 на этапе 808 приписывается справа к соответствующему вектору
, каждая из которых в модуле 609.4 на этапе 808 приписывается справа к соответствующему вектору  XOR Г(r)i, образуя пару вида
XOR Г(r)i, образуя пару вида 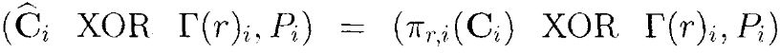 длиной li+1 байтов, i=1, …, tSStor.
длиной li+1 байтов, i=1, …, tSStor.
После этого, а равно также после того, как в проверке 803 установлено, что Q=0, итоговые части передаются в модуль распределения по вспомогательным хранилищам 610, где выполняется процедура 809 записи частей на хранилища.
Отметим, что применение модуля усиленной защиты 609 особенно представляется полезным в случае, когда в наборе алгоритмов защиты 608.1 ни один из алгоритмов не обеспечивает должной защиты от статистической атаки. Например, если в наборе 608.1 имеется только алгоритм простого факторного кодирования (который, как показано, например, в [6] и [7], не устойчив к атаке многократного перехвата), то используя модуль усиленной защиты, где для каждого кодового слова генерируется свой набор перестановок битов, то можно усилить защиту конфиденциальности данных от статистических атак. При этом использование схемы разделения секрета не позволяет при несанкционированном доступе к ttap частям (хранилищам) восстановить число, по которому генерируется набор перестановок. Такая конфигурация СНЗХД фактически является одной версией реализации СЗДиКХД. Злоумышленнику, в случае использования модуля усиленной
защиты, для проведения статистической атаки необходимо будет накапливать (перехватывать) существенно больший объем, что усложняет статистическую атаку.
Не ограничивая возможных вариантов алгоритмов Р генерации по числу r набора перестановок бит, здесь приводится следующий простой в реализации алгоритм P. Пусть r=(r1, …, r8) - битовая запись числа r. Тогда в байте b=(b1, …, b8) биты bi и bi+1 меняются местами, если ri не равен ri+1; в противном случае биты bi и bi+1 остаются на месте, i∈{1; 3; 5; 8}. Отметим, что этот алгоритм переставляет биты только внутри каждого байта, но не переставляет биты между байтами в рамках одной части Ci, i=1, …, tSStor. Для специалиста, компетентного в области программирования, разработка других алгоритмов перестановки бит, в том числе переставляющих биты между байтами, не должна вызвать затруднения.
Декодирование при чтении данных из защищаемого файла выполняется по следующему алгоритму (см. Фиг. 10). При запросе на считывание информационного блока из защищенного файла модуль распределения данных по хранилищам 610 выполняет процедуру считывания 901, в результате выполнения которой с t′(≥tSStor-terr) хранилищ считываются части кодового слова. Без потери общности полагаем, что считываются первые t′ частей: C1, …, Ct′. (Хотя, по возможности, для ускорения операции снятия защиты считывание должно выполняться со всех tSStor хранилищ.) Размеры частей и их порядковые номера при этом задаются в разделе 605.5 конфигурации 605. На основе значения Q из раздела 605.3 конфигурации 605 выполняется проверка 902 относительно использования модуля усиленной защиты 609. Если усиленная защита используется (Q>0), то от частей C1, …, Ct′ отделяются справа приписанные части 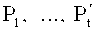 (этап 903 на, блок-схеме фиг. 9), по которым в модуле разделения секрета 609.3 восстанавливается число r (этап 904 на блок-схеме). По полученному числу r в модуле гаммирования 609.2 снимается гамма с частей кодовых слов (стадия 905 на блок-схеме) и применяются обратные перестановки бит в первых байтах частей Ci, i=1, …, t′ (этапы 906 и 907 на блок-схеме). Далее на этапе
(этап 903 на, блок-схеме фиг. 9), по которым в модуле разделения секрета 609.3 восстанавливается число r (этап 904 на блок-схеме). По полученному числу r в модуле гаммирования 609.2 снимается гамма с частей кодовых слов (стадия 905 на блок-схеме) и применяются обратные перестановки бит в первых байтах частей Ci, i=1, …, t′ (этапы 906 и 907 на блок-схеме). Далее на этапе
908 в блоке 608.3 выполняется сбор кодового слова из полученных частей  (кодовое слово может быть при этом восстановлено не полностью из-за отсутствия части хранилищ) и на основе алгоритма защиты в блоке 608.2 на этапе 909 восстанавливается информационный блок S (если стерто не более ν символов).
(кодовое слово может быть при этом восстановлено не полностью из-за отсутствия части хранилищ) и на основе алгоритма защиты в блоке 608.2 на этапе 909 восстанавливается информационный блок S (если стерто не более ν символов).
Запись и чтение данных могут выполняться не только по одному информационному блоку, а также последовательностями информационных блоков. В этом случае при записи операция защиты данных 801 выполняется итеративно для всех информационных слов из последовательности, формируя набор кодовых слов. Для каждого кодового слова из сформированной последовательности кодовых слов итеративно выполняются операции с 802 по 808. Результатом этого являются tSStor наборов частей кодовых слов. Каждый из наборов записывается на соответствующее вспомогательное хранилище в ходе выполнения этапа 809. При чтении набора информационных слов сначала со вспомогательных хранилищ считываются наборы частей кодовых слов (процедура 901), далее, путем итеративного применения операций с 902 по 908 формируется набор кодовых слов, а затем для каждого кодового слова из этого набора итеративно применяется блок снятия защиты 909 для формирования набора информационных слов.
Операции чтения/записи данных в СНЗХД выполняются блоками. Поэтому запросы чтения или записи, поступающие от инициатора запроса и адресованные защищенному хранилищу, должны быть подвергнуты процедуре выравнивания данных на границу блока (см. Фиг. 11). На защищенном хранилище, адресуемом точкой монтирования 1106 базового хранилища, работа с защищаемым файлом, представленным в рамках защищенного хранилища базовым файлом 1100, организована так, что, с точки зрения инициатора запросов ввода/вывода данных (которым, не ограничивая других вариантов, может быть, например, программа пользовательского уровня), работа с таким файлом ни чем не отличается от работы с файлом с использованием прикладного программного интерфейса операционной системы. Хотя при этом фактически в базовом файле 1100, размещенном в
базовом хранилище 1106, данные в исходном виде могут и не храниться. Базовый файл 1100 фактически содержит метаданные и, возможно, преобразованные данные, если базовое хранилище может выступать в роли вспомогательного хранилища. Далее рассматривается случай, когда базовый файл содержит только метаданные. Работа по преобразованию данных, считанных из вспомогательных файлов или записываемых во вспомогательные файлы, выполняется незаметно для пользователя. Если записываемый блок данных 1104 не выровнен на границу информационного блока, то перед записью из защищенного файла считываются информационные блоки 1102 и 1103. Считывание информационных блоков 1102 и 1103 реализуется путем считывания соответствующих частей кодовых слов: для получения информационного блока 1102 со вспомогательных хранилищ, адресуемых точками монтирования 1108.1, … ,1108.tSStor, из соответствующих вспомогательных файлов 1107.1, …, 1107.tSStor соответственно считываются части 1109.1, …, 1109.tSStor кодового блока, соответствующего информационному блоку 1102, а затем собранное кодовое слово преобразуется (декодируется) в информационное слово; для получения информационного слова 1103 со вспомогательных хранилищ, адресуемых точками монтирования 1108.1, …, 1108.tSStor из соответствующих вспомогательных файлов 1107.1, …, 1107.tSStor соответственно считываются части 1110.1, …, 1110.tSStor кодового блока, соответствующего информационному слову 1103, а затем собранное кодовое слово преобразуется в информационное слово. К блоку 1104 в начале приписывается часть 1105 из блока 1102, а в конце блока 1104 дописывается часть 1101 из блока 1103. Блок данных, состоящий из последовательно сцепленных блоков 1105, 1104 и 1101 далее подвергается преобразованию (возможно, с применением усиленной защиты) и распределению частей кодовых слов по соответствующим вспомогательным файлам. При считывании с защищенного хранилища с точкой монтирования 1106 блока данных 1104, невыровненного на границу информационного слова, считываются блоки 1102, 1103, а также блоки, размещенные между ними. Считывание информационных блоков выполняется по описанной выше
схеме считывания блока 1102 или 1103. Инициатору запроса на чтение данных возвращается только требуемый в запросе участок данных 1104; блоки 1105 и 1101 не возвращаются.
Рассмотрим пример организации защищенных хранилищ для детального раскрытия сути изобретения. Пример рассмотрим для случая, когда базовое хранилище также может содержать закодированные данные. Программно реализованная СНЗХД в виде модулей 600 и 601 полностью копируется в долговременную память компьютера 400. После запуска клиентский агент 600 перехватывает запросы ввода/вывода, адресованные защищенным хранилищам и передает агенту распределенной защиты 601. Если на компьютере 400 в отношении хранящихся видеофильмов, например, в каталоге С:\films необходимо обеспечить резервное копирование, то для этого можно организовать защищенное от утраты хранилище 1200 (см. Фиг. 12), где в качестве базового хранилища используется каталог С:\films на встроенном жестком диске 404 компьютера 400, а в качестве резервного хранилища используется, например, каталог \\server\films_copy на файловом сервере server 415. В качестве алгоритма защиты в этом случае выступает алгоритм зеркалирования данных (код двукратного повторения) и усиленная защита для такого хранилища не используется. Если также необходимо обеспечить конфиденциальность аутентификационных данных (например, паролей доступа к сервисам Интернет-банкинга, личной почте и т.п.), хранящихся на компьютере, то эти данные можно зашифровать и хранить на любом из устройств хранения, а пароль/ключ шифрования надежно хранить, например, в аппаратном криптографически защищенном токене. Для этих целей может быть организовано защищенное хранилище 1202 на основе выбранного на носителе 406 каталога, например, С:\auth_data. В качестве алгоритма защиты в этом случае может быть, например, один из классических алгоритмов, типа ГОСТ 21147-89, AES, 3DES, RSA, при этом блок усиленной защиты 609 использовать не имеет смысла, так как хранилище всего одно. Если пользователь не имеет возможности применять шифратор по каким-либо причинам (например,
нет аппаратно защищенного токена и/или неудобно запоминать сложный ключ/пароль), то он (пользователь) может, например, на базе смартфона 412 (представленного в операционной системе Windows, например, буквой диска D), Flash-носителя 407 (представленного в операционной системе Windows, например, буквой диска Е) и встроенного жесткого диска 404 с применением кодового зашумления [2] или СЗДиКХД организовать распределенное защищенное от несанкционированного ознакомления хранилище 1201, в котором закодированные данные разбиты на части, распределенные по вспомогательным хранилищам. (В частности, если для защиты используется классическое кодовое зашумление, то для защиты от статистических атак имеет смысл использовать блок усиленной защиты 609.) В этом случае, например, каталог С:\auth_data_dist полагается базовым хранилищем, а на смартфоне 412 и Flash-носителе 407 выбираются вспомогательные хранилища соответственно, например, D:\auth_data и Е:\auth_data. Так как пользователь заинтересован в осторожном обращении со своими устройствами (Flash-носителем 407 и смартфоном 412), то их потеря или их бесконтрольное оставление маловероятны. А несанкционированный доступ к частичным данным, например, хранящимся на встроенном жестком диске 404 компьютера 400, либо на смартфоне 412, либо на Flash-носителе 407, при подходящем выборе параметров кодового зашумления или СЗДиКХД не даст возможности получить полезную информацию о закодированных данных. По тем же причинам потеря одного из носителей не приводит к нарушению конфиденциальности данных. Одновременная потеря двух носителей (Flash-носителя 407 и смартфона 412) представляется крайне маловероятной, поэтому такое хранение обеспечивает защиту конфиденциальности данных. Отличительной особенностью использования описанного способа обеспечения конфиденциальности на основе кодового зашумления данных (или на основе СЗДиКХД) с последующим распределением данных по хранилищам на разных носителях данных является отсутствие необходимости в применении криптографических ключей и паролей, что не создает дополнительных нагрузок на пользователя,
часто возникающих при использовании паролей. Конфиденциальные данные могут быть раскодированы, когда будет подключено минимально необходимое количество хранилищ, среди которых распределены закодированные данные. Отметим, что параметры метода кодового зашумления (а также СЗДиКХД) могут быть выбраны так, что кража/потеря некоторых носителей не нарушат конфиденциальности данных в целом, но при этом легальному пользователю предоставляется возможность по оставшимся данным восстановить закодированные данные.
Таким образом, для рассмотренной в примере конфигурации, не ограничивая вариантов кодеков, для организации защищенного хранилища 1200, может быть выбран кодек двукратного повторения с длиной кодируемого блока 1 байт. Выходом такого кодека будет кодовое слово длины 2 байта, каждый из которых повторяет входной байт данных; первый байт, например, записывается в файл на базовом хранилище С:\films, а второй - в файл на вспомогательное хранилище \\server\films_сору. Хранилище 1202 (каталог С:\auth_data) полагается базовым и в его файлах, кроме полезных для пользователя данных, хранятся также и метаданные о защищаемых файлах; в качестве алгоритма защиты может быть выбран, например, алгоритм ГОСТ 21147-89. Для организации защищенного хранилища 1201, не ограничивая вариантов кодеков, может быть выбран кодек кодового зашумления, построенный на основе пары кодов ( ,С), где
,С), где  - код Рида-Соломона
- код Рида-Соломона 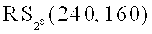 , С - код Рида-Соломона
, С - код Рида-Соломона  . Выходом кодека будет кодовое слово длины 240 байт, поставленное в соответствие информационному блоку длины 80 байт. Первые 80 байт кодового слова, например, записываются на вспомогательное хранилище С:\auth_data_dist, вторые 80 байт - на вспомогательное хранилище Е:\auth_data, а оставшиеся 80 байт - на вспомогательное хранилище D:\auth_data. Так как
. Выходом кодека будет кодовое слово длины 240 байт, поставленное в соответствие информационному блоку длины 80 байт. Первые 80 байт кодового слова, например, записываются на вспомогательное хранилище С:\auth_data_dist, вторые 80 байт - на вспомогательное хранилище Е:\auth_data, а оставшиеся 80 байт - на вспомогательное хранилище D:\auth_data. Так как 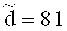 , то утрата (потеря/кража) любого одного вспомогательного хранилища (носителя данных) дает возможность владельцу оставшихся двух вспомогательных хранилищ восстановить закодированные данные. При этом по данным любого одного хранилища при
, то утрата (потеря/кража) любого одного вспомогательного хранилища (носителя данных) дает возможность владельцу оставшихся двух вспомогательных хранилищ восстановить закодированные данные. При этом по данным любого одного хранилища при
указанном разбиении нельзя восстановить закодированные данные [8]. Таким образом, утрата одного из вспомогательных хранилищ не нарушает конфиденциальности данных и при этом обеспечена защита от утраты одного хранилища. Если для организации защищенного хранилища 1201 задействуется блок усиленной защиты, то в этом случае подходит, например, (3,2)-схема разделения секрета Шамира. Указанное в примере разбиение не является единственно возможным и не ограничивает другие варианты разбиения. Разбиение может быть как на равные части, так и не на равные. Размер части кодового слова для вспомогательного хранилища, например, может быть определен, исходя из вероятности утраты (потери/кражи) этого вспомогательного хранилища или вспомогательного хранилища этого типа. В возможности такого выбора проявляется гибкость в настройке степени защиты данных с использованием системы настраиваемой защиты хранимых данных.
Рассмотрим еще один пример использования СНЗХД. Пусть у пользователя имеются часто создаваемые/удаляемые данные, которые не имеет смысла шифровать (например, из-за крайне малой вероятности несанкционированного доступа к компьютеру, или из-за нежелания пользователя запоминать пароли/ключи), но которые не должны быть восстановлены после их удаления штатными средствами операционной системы. В этом случае с использованием СНЗХД можно организовать защищенное хранилище с гарантированным удалением незашифрованных данных за одну перезапись. Такое защищенное хранилище можно организовать на базе одного вспомогательного хранилища (оно же и базовое); например, на носителе 406 выделить для таких данных каталог С:\sensative_data. Так как известно, что восстановление перезаписанных данных происходит с ошибками [12], то в качестве алгоритма защиты предлагается использовать кодек кодового зашумления с кодом  размерности и длины n. Тогда восстановление данных по испорченным кодовым словам может быть крайне затруднено при подборе параметров кодового зашумления [2]. Согласно [12], вероятность правильного восстановления стертого бита примерно равна 0,92, поэтому
размерности и длины n. Тогда восстановление данных по испорченным кодовым словам может быть крайне затруднено при подборе параметров кодового зашумления [2]. Согласно [12], вероятность правильного восстановления стертого бита примерно равна 0,92, поэтому
для обеспечения надежного стирания данных за одну итерацию можно перед записью данных на носитель кодировать их с помощью факторного кода  с базовым кодом С Рида-Маллера RM(2,5).
с базовым кодом С Рида-Маллера RM(2,5).
Отметим, что СНЗХД может быть распределена между двумя компьютерами 400 и 1203 (см. Фиг. 12), когда на компьютер 400 устанавливается только клиентский агент 600, а на компьютер 1203 устанавливается агент распределенной защиты 601. В качестве компьютера 1203 может выступать любое устройство, поддерживающее интерфейсы подключения съемных устройств хранения данных, сетевые интерфейсы, а также поддерживающее работу с локальными и сетевыми файловыми системами. Такой компьютер 1203 может не иметь устройств отображения данных (например, отсутствует дисплей).
Также отметим, что в СНЗХД вспомогательное хранилище может быть в свою очередь защищенным хранилищем, построенным на основе СНЗХД. Таким образом, может быть организован каскад (иерархия) произвольного количества защищенных хранилищ.
5 Осуществление изобретения
На Фиг. 13 показана типичная схема компьютера 400. На базе таких компьютеров могут быть осуществлены СЗДиКХД и СНЗХД. Компьютер представляет собой систему функциональных блоков - процессор 400.1, оперативную память 400.3, статическую память 400.7, сетевые интерфейсы 400.8, устройство отображения данных 400.9, устройства ввода данных 400.10 и интерфейсы подключения носителей данных 400.11 -, взаимодействующих по алгоритмам, известным специалисту в этой области, посредством системной шины 400.12. Процессор 400.1 выполняет инструкции 400.2, загруженные из оперативной памяти 400.3. В оперативную память инструкции загружаются или из статической памяти 400.7 (например, во время загрузки операционной системы), или с носителей данных (не показаны), подключенных через интерфейсы в наборе 400.11. В оперативную память загружается (частично или полностью) операционная система
400.4 (например, Windows, Linux, QNX), и другие программные модули 400.5 (драйверы файловых систем, драйверы устройств, приложения пользовательского уровня и т.п.). Также в оперативной памяти 400.3 хранятся данные 400.6, используемые программными модулями. В наборе сетевых интерфейсов 400.8 могут быть, например, такие интерфейсы как RJ-45, Wi-Fi-модуль, СОМ-порт, USB и другие интерфейсы, посредством которых возможен прием/передача данных между компьютерами.
5.1 Осуществление СЗДиКХД
В показанной на Фиг. 1 схеме СЗДиКХД компоненты 100, 102-107, 112 блока 111 могут быть реализованы как аппаратно (например, с помощью программируемой аппаратной логики), так и программно в виде программных модулей, выполняемых на компьютере 400. Данные конфигурации 108-110, которые в предпочтительной реализации представляют собой структурированный файл с параметрами (например, в XML-формате), загружаются в блок 111 либо через аппаратный интерфейс (при аппаратной реализации), посредством которого блок 111 подключен к источнику запросов 101, либо через прикладной программный интерфейс, предоставляемый блоком 111 (при программной реализации). При аппаратной реализации блок 111 подключается к источнику запросов 101, например, через USB-интерфейс. Отметим, что интерфейсом подключения может быть любой другой стандартный интерфейс: COM, LPT, RJ-45, SCSI, PCI и т.п. В качестве источника запросов 101 в одном примерном варианте реализации может быть компьютер 400. В этом случае устройство 111, с точки зрения компьютера 400, представляет собой носитель данных, например, Flash-носитель. Работа с устройством 111 выполняется как с обычным Flash-носителем. За реализацию логики представления блока 111 как носителя данных отвечает блок управления 112. К блоку 111 (при его аппаратной реализации) носители данных подключаются также по стандартным интерфейсам, например, по USB-интерфейсам. За распределение данных по этим носителям отвечает блок 107. Этот же блок 107 взаимодействует с блоком 112 и сигнализирует
о подключенных носителях данных. Например, если подключены все необходимые носители данных, то блок 111 представляется инициатору запросов (в примере - компьютеру 400), как один носитель данных. Если же подключены не все носители данных, то блок 111 не должен определяться как носитель данных.
При программной реализации в среде Windows версии не ниже 4.0 блок 111 может быть реализован в виде, например, фильтрующего драйвера файловой системы, перехватывающего запросы от менеджера ввода-вывода операционной системы. Менеджер ввода-вывода в этом случае представляется как источник запросов 101. Модуль 107 в этом случае также может реализовываться как драйвер, использующий интерфейсы файловых систем, интерфейсы сетевой подсистемы и интерфейсы других систем, позволяющих организовать хранение данных по типу файловых систем. Кодеки 100 при этом могут быть реализованы как программные сервисы уровня ядра или пользовательского уровня с интерфейсом доступа из режима ядра. Для специалиста в данной области не должна представлять труда программная реализация блока 111 и на прикладном уровне (не на уровне ядра), а также в другой операционной среде.
5.2 Осуществление СНЗХД
Модули 600 и 601 представляют собой программные модули, исполняемые на компьютере типа 400. Ранее отмечалось, что эти модули могут быть размещены на разных компьютерах. Отметим, что для модуля 601 компьютер 400 может не содержать дисплей 400.9 и/или устройств ввода данных 400.10. Каждый из модулей 603, 604 и 613 может реализовываться в виде одного из программных модулей 400.5, как на прикладном уровне, так и на уровне ядра операционной системы. Для прозрачной работы агента 600 предпочтительным вариантом реализации является реализация модуля 603 в виде драйвера, перехватывающего файловые операции создания, записи, чтения, закрытия, удаления, переименования файла, например, в виде фильтрующего драйвера операционной системы Windows версии
не ниже 4.0. Другим вариантом реализации модуля 603 может быть программная компонента прикладного уровня, использующая прикладной программный интерфейс операционной системы по работе с системами хранения данных и реализующая пользовательский графический и/или командный интерфейс работы с файлами на защищенных хранилищах. Модуль доступа к локальным хранилищам 613 предпочтительно реализуется как сетевой модуль, принимающий и передающий данные по протоколу, например, TCP/IP, и взаимодействующий посредством программного интерфейса (прикладного уровня или уровня ядра) с драйверами локальных файловых систем и другими модулями, которые позволяют организовать хранение данных.
Набор алгоритмов защиты 608.1 может включать любое количество кодеков, реализующих любые алгоритмы преобразования данных по заранее установленному интерфейсу. Интерфейс кодеков состоит из функций выполнения прямого и обратного преобразования данных, функции загрузки ключа и функций создания кодера и декодера по заданным из конфигурации 605 параметрам.
Конфигурация 605 защищенного хранилища SStor содержит следующие обязательные параметры: точку монтирования защищенного хранилища - базовое хранилище; количество tSStor вспомогательных хранилищ; точки монтирования вспомогательных хранилищ; параметры алгоритма преобразования; параметры разбиения кодового слова на части; параметры схемы разделения секрета; параметры алгоритма гаммирования данных.
СНЗХД позволяет на базе одного набора носителей информации создавать любое количество защищенных хранилищ с различными алгоритмами защиты. Модуль 600 подключается к инициатору запросов ввода/вывода с помощью используемого в компьютере программного интерфейса ввода/вывода данных. В момент подключения или загрузки модуля 600 в модуле 603 инициализируются список открытых защищенных хранилищ 603.1, а также кэш 603.2 для хранения метаданных об открытых/созданных в недавнее время файлах на базовых хранилищах. Назначение кэша объясняется
далее.
В набор алгоритмов защиты 608.1 добавляется информация о новом алгоритме защиты в момент получения модулем 608 от соответствующего модуля реализации алгоритма защиты запроса на регистрацию. Если в наборе 608.1 такого модуля нет, то в список добавляется интерфейс нового алгоритма. Запрос на регистрацию интерфейса алгоритма инициируется модулем, реализующим этот интерфейс, после того, как этим модулем будет установлено, что модуль 608 загружен и готов принимать запросы. Поиск алгоритма защиты в модуле 608 в списке 608.1 может осуществляться по любому набору свойств алгоритма, уникально его идентифицирующего, предпочтительно, по имени алгоритма (например, RM_CODEC - название кодека для кода Рида-Маллера), длине информационного блока, длине кодового блока.
В список защищенных хранилищ 603.1 включаются вновь открываемые хранилища, каждое из которых должно иметь уникальный набор свойств для однозначного нахождения хранилища, например, уникальное имя хранилища. Модуль 603, при перехвате запросов ввода/вывода использует список 603.1 для того, чтобы определить, к какому хранилищу адресован запрос. В структуре, описывающей защищенное хранилище, кроме списка, вспомогательных хранилищ, из которых оно состоит, содержится признак, сигнализирующий, в каком режиме находится защищенное хранилище: в режиме "только чтение" или в режиме "чтение/запись". На основе значения этого признака в модуле 603 принимается решение о возможности выполнения операции записи на защищенное хранилище. Операция записи данных может быть запрещена в случае, когда не все вспомогательные хранилища подключены, однако параметры используемого кодека таковы, что по имеющемуся набору вспомогательных хранилищ данные можно однозначно восстановить (считать). Модуль кэша 603.2 предназначен для ускорения обработки запросов на открытие файлов. Так как при открытии файла необходимо считывать метаданные, а операции открытия файла могут выполняться довольно часто, то предпочтительно метаданные некоторое время
хранить в кэше 603.2. Кэш 603.2 предпочтительно реализуется в виде хранилища в оперативной памяти 400.3, например, в виде однонаправленного списка, каждый элемент которого кроме ссылки на следующий элемент в списке содержит метаданные о соответствующем файле. Для повышения скорости работы кэшируемые данные могут храниться в виде дерева, повторяющего древовидную структуру размещения файлов на защищенном хранилище, начиная с точки монтирования базового хранилища.
Создание или открытие существующего защищенного хранилища инициируется отправкой конфигурации 605 модулю управления 604 СНЗХД, который проводит разбор параметров конфигурации и выполняет ряд проверок перед созданием защищенного хранилища (см. Фиг. 14). Среди основных проверок должны быть проверка 1402 на наличие точки монтирования защищенного хранилища на базовом хранилище. В случае отсутствия такой точки монтирования сигнализируется ошибка создания/открытия защищенного хранилища. В противном случае выполняется поверка 1404 наличия указанного в конфигурации алгоритма защиты в списке зарегистрированных в системе алгоритмов 608.1. Если соответствующий модуль отсутствует, то сообщается об ошибке создания/открытия защищенного хранилища. В противном случае выполняется проверка 1403 о наличии вспомогательных хранилищ, указанных в конфигурации, и интерфейсов доступа к ним. При отсутствии хотя бы одного хранилища пользователю должно быть отправлено сообщение об ошибке открытия хранилища в штатном режиме. При этом, на основе параметров алгоритма защиты из конфигурации выполняется проверка 1410, могут ли данные быть восстановлены без отсутствующих вспомогательных хранилищ. Фактически выполняется проверка, что число отсутствующих хранилищ не больше terr. Если данные могут быть восстановлены, то для защищенного хранилища устанавливается признак "только чтение" (блок 1409) и далее предпочтительно в памяти 400.3 компьютера 400, на котором установлен клиентский агент 600, создается структура, описывающая параметры защищенного хранилища, которая добавляется в список открытых/созданных защищенных хранилищ
603.1. В таком режиме пользователю предоставляется возможность восстановить все данные, которые ранее были записаны на защищенном хранилище. Если при проверке 1403 выяснится, что все вспомогательные хранилища и интерфейсы к ним имеются, то защищенное хранилище создается/открывается с возможностью чтения и записи данных (блок 1405). После добавления хранилища в список открытых/созданных хранилищ пользователю сообщается об успехе открытия/создания хранилища (блок 1406) и открытие хранилища завершается 1408. Отправка сообщения об ошибке создания и причине ошибки создания выполняется в блоке 1407.
Закрытие защищенного хранилища начинается с отправки запроса на закрытие 1501 (см. Фиг. 15). Модуль управления 604 СНЗХД определяет в проверке 1502, имеется ли в списке открытых/созданных защищенных хранилищ закрываемое защищенное хранилище. При этом поиск хранилища выполняется по точке монтирования, хотя уникальный набор признаков хранилища, по которому осуществляется поиск, может быть и другим. Перед удалением, в зависимости от реализации, могут также выполняться операции по завершению всех текущих операций с файлами и выполняется проверка 1507, не является ли защищенное хранилище вспомогательным для какого-либо другого открытого/созданного хранилища. Закрытие хранилища предпочтительно выполнять только тогда, когда оно не является вспомогательным для некоторых других открытых хранилищ. Если хранилище найдено и оно не является вспомогательным для других, то соответствующая структура защищенного хранилища удаляется (блок 1503) из списка 603.1, размещенного в оперативной памяти, а пользователю возвращается результат успешного удаления хранилища. Если же закрываемого хранилища нет в списке или оно является вспомогательным для какого-то другого хранилища, то пользователю возвращается на этапе 1504 сообщение об ошибке закрытия хранилища и причина ошибки; алгоритм закрытия защищенного хранилища заканчивается 1506.
Так как операция открытия/создания в отношении одного файла выполняется часто, то, как выше указывалось, считывание и записывание
метаданных может приводить к замедлению в работе с файлами на защищенном хранилище. В СНЗХД, а именно в модуле перехвата запросов ввода/вывода 603 для уменьшения операций чтения/записи метаданных предусмотрен блок кэширования 603.2 метаданных об открываемых файлах. Алгоритм его работы показан на Фиг. 16. При операции открытия файла (эта операция описывается далее подробно) модуль перехвата запросов ввода/вывода 603 сначала проверяет, имеются ли для соответствующего файла метаданные в кэше, и только если таких данных в кэше нет, выполняется считывание метаданных из базового файла. Каждому открываемому/создаваемому файлу на защищенном хранилище соответствует запись в кэше, хранящая метаданные (например, истинный размер файла, время последней модификации и т.п.). Кроме метаданных, запись о файле в кэше содержит счетчик ссылок на данный файл. Этот счетчик увеличивается на единицу каждый раз, когда открывается соответствующий файл, и уменьшается при закрытии файла. Время жизни каждой записи в кэше задается (например, в секундах) параметром из конфигурации 605 защищенного хранилища и определяется как интервал времени, в течение которого к файлу не было обращений. Периодически модуль перехвата запросов ввода/вывода 603, предпочтительно в фоновом режиме, проводит поиск в кэше записей с истекшим временем жизни и выполняет их сброс. При программной реализации такая периодическая проверка может быть реализована в виде потока уровня ядра или прикладного уровня. Не ограничивая других вариантов реализации, начало работы 1600 потока инициируется, например, при создании/открытии защищенного хранилища. Поток в цикле с началом 1601 и окончанием 1610 выполняет поиск 1602 в кэше всех записей с истекшим временем жизни. Не ограничивая вариантов реализации, кэш может быть организован в соответствии со структурой размещения файлов в файловой системе, например, в виде дерева. Для каждой такой найденной записи в цикле 1603 выполняется проверка 1604 равенства нулю количества ссылок на запись. Если количество ссылок не равно нулю, то осуществляется переход к следующей записи. В противном случае из
записи в кэше в базовый файл на защищенном хранилище сбрасываются (записываются) метаданные (фаза 1605) и из кэша удаляется соответствующая запись (фаза 1606). После отработки цикла 1603 выполняется проверка 1607: получен ли сигнал на закрытие защищенного хранилища. Если такой сигнал получен, то выполняется принудительный сброс всех записей из кэша и осуществляется выход из цикла с границами 1601 и 1610; работа потока по сбросу данных из кэша завершается 1611. Если сигнала на закрытие защищенного хранилища не получено, то осуществляется приостановка потока на время, заданное в конфигурации 605 при создании/открытии защищенного хранилища; далее процедура сброса данных повторяется.
Далее, не ограничивая вариантов реализации, рассматриваются алгоритмы создания/открытия и закрытия файлов на защищенных хранилищах, когда в базовом хранилище базовые файлы содержат только метаданные. То есть в базовых файлах не содержатся преобразованные данные или их части.
При отработке открытия/создания файла (см. Фиг. 17) модуль перехвата запросов ввода/вывода 603 анализирует запрос 1701 и выполняет проверку 1702: адресован ли запрос какому-либо защищенному хранилищу. Например, в среде Windows версии не ниже 4.0, где модуль 603 реализуется, например, в виде фильтрующего драйвера, запрос 1701 представляется в виде IRP-запроса (Input/output Request Packet). При этом фактически выполняется поиск защищенного хранилища в списке 603.1. Если запрос не адресован ни одному защищенному хранилищу, то запрос отправляется далее без промежуточной обработки (например, следующему драйверу в стэке драйверов). В противном случае на базовом хранилище выполняется попытка 1704 открытия/создания файла. Создание/открытие файла предпочтительно выполняется с использованием штатных функций операционной среды (операционной системы). Если файл в базовом хранилище не создан или не открыт, то открытие/создание файла в защищенном хранилище завершается с ошибкой. Если файл создан/открыт, то проверяется
1706 наличие в кэше записи с метаданными об открываемом файле. Если такой записи в кэше нет, то такая запись создается (фаза 1707) и счетчик ссылок на запись устанавливается равным 0. Далее выполняется проверка 1709, где определяется, открывается существующий файл или создается новый. Если открывается существующий файл, то метаданные считываются из базового файла в базовом хранилище и заносятся в созданную ранее запись в кэше. Если при проверке 1709 определено, что создается новый файл, или при проверке 1706 выяснится, что запись в кэше имеется, то выполняется блок 1708 создания и отправки запросов на создание/открытие соответствующих вспомогательных файлов на вспомогательных хранилищах. Блок 1708 выполняется в модуле 601. После того, как в блоке 1710 получен сигнал, что запросы к вспомогательным хранилищам обработаны, выполняется проверка 1713, где определяется статус завершения обработки этих запросов. Если не на всех вспомогательных хранилищах файлы успешно открыты/созданы, то выполняется проверка 1717, в ходе которой определяется, может ли используемый в защищенном хранилище алгоритм защиты по имеющемуся набору данных восстановить исходные данные. Если алгоритм защиты не может однозначно восстановить данные (для каждого кодового слова количество недостающих кодовых символов больше ν), то необходимо закрыть/удалить файл (блок 1716) на базовом хранилище и вспомогательных хранилищах (удаление выполняется в случае, когда создавался новый файл) и завершить (в блоке 1712) обработку запроса с ошибкой, вернуть причину неуспеха открытия/создания файла на вспомогательных хранилищах. Отметим, что функции блока 1716 частично выполняются в модуле 600 (при закрытии/удалении базового файла), а частично - в модуле 601 (при закрытии/удалении вспомогательных файлов). При создании/открытии файла на защищенном хранилище предпочтительно создается специальная структура, описывающая этот файл. Такая структура создается каждый раз в модуле перехвата 603 запросов ввода/вывода, когда приходит запрос на создание/открытие файла, и удаляется при поступлении запроса на закрытие файла; структура содержит
ссылку на объект, описывающий открытый файл на защищенном хранилище. Если алгоритм защиты может восстановить исходные данные по неполному набору вспомогательных файлов, то пометить структуру, описывающую открываемый на защищенном хранилище файл атрибутом "только чтение" и увеличить на единицу количество ссылок на запись в кэше. Если при проверке 1713 установлено, что на всех вспомогательных хранилищах файлы созданы/открыты успешно, то увеличить на единицу количество ссылок на запись в кэше и завершить обработку запроса (фаза 1715).
При закрытии файла (см. Фиг. 18) модуль перехвата запросов ввода/вывода 603 для запроса 1801 на закрытие файла выполняет проверку 1802: адресован ли запрос какому-либо защищенному хранилищу. В случае, если запрос не адресован защищенному хранилищу, запрос отправляется в блоке 1803 далее без обработки в модуле перехвата запросов ввода/вывода. Если запрос адресован защищенному хранилищу, то для всех вспомогательных хранилищ создаются в блоке 1804 (выполняется в модуле 601) запросы на закрытие соответствующих файлов. После отправки запросов, в блоке 1705 ожидается завершение обработки запросов вспомогательными хранилищами. Далее в блоке 1808 закрывается базовый файл на базовом хранилище и уменьшается на единицу в блоке 1809 количество ссылок на запись в кэше. Если на всех хранилищах (и вспомогательных, и базовом) закрытие выполнено успешно, завершить обработку запроса с успехом. В противном случае сигнализировать о том, что не на всех хранилищах файлы закрыты успешно, вернуть причину неуспеха и завершить обработку запроса (фаза 1810).
При поступлении запроса 1901 на чтение данных (см. Фиг. 19) в модуле 603 выполняется проверка 1902, в ходе которой выясняется, адресован ли запрос какому-либо защищенному хранилищу. Если запрос не адресован ни одному защищенному хранилищу, то запрос отправляется в блоке 1903 без промежуточной обработки далее (по стеку отработки запросов). Если же запрос адресован какому-то базовому файлу на каком-то защищенном хранилище, то для каждого соответствующего вспомогательного файла в
блоке 1904 создается запрос на чтение данных: при этом считываемые данные на вспомогательных хранилищах соответствующим образом выравниваются, если это необходимо; блок 1904 выполняется в модуле 601. Далее в блоке 1905 ожидается завершение обработки этих запросов. В проверке 1906 проверяется статус завершения обработки запросов. Если не со всех вспомогательных файлов чтение завершено успешно, то в проверке 1908 (на основе конфигурации 605.2) проверяется возможность извлечь данные (информационные блоки) из имеющихся данных. Если такой возможности нет, то в блоке 1910 инициатору запроса возвращается ошибка с указанием причины ошибки; обработка запроса на чтение завершается 1913. Если со всех вспомогательных файлов данные успешно считаны (проверка 1906), то выполняется переход на блок 1907. На этот же блок выполняется переход и в случае истинности выражения в проверке 1908. В блоке 1907 считанные данные объединяются в массив кодовых слов (возможно, частичных кодовых слов) в соответствии с параметрами разбиения и далее извлекаются информационные блоки (снимается защита с кодовых блоков). Если в ходе проверке 1911 выясняется, что декодирование выполнено с ошибкой, то выполняется переход на блок 1910, в котором обработка запроса на чтение завершается с ошибкой и возвращается причина ошибки; алгоритм обработки запроса на чтение завершается 1913. Если в ходе проверки 1911 выясняется, что данные декодированы корректно, то в блоке 1912 из декодированных данных формируется буфер (требуемого объема и размещенный по требуемому смещению от начала файла) и возвращается инициатору запроса; алгоритм обработки запроса на чтение завершается (фаза 1913).
Не ограничивая вариантов реализации записи данных, далее для примера описан алгоритм записи данных (см. Фиг. 20) без поддержки атомарности операции записи: при ошибке записи данных в какой-либо вспомогательный файл во вспомогательных файлах, в которые данные были записаны успешно, перезаписанные данные не восстанавливаются. Полагается, что возникновение ошибки при записи в какой-либо вспомогательный
файл является маловероятной. Для смягчения последствий от возникновения такой ошибки в СНЗХД предусмотрен, как показано в алгоритме 2000, механизм создания резервных копий вспомогательных файлов на вспомогательных хранилищах.
При получении модулем перехвата 603 запросов ввода/вывода запроса на запись 2001, в проверке 2002 выясняется, кому адресован запрос. Если запрос адресован ни одному защищенному хранилищу, то в блоке 2003 запрос отправляется далее по стеку обработки запросов и алгоритм завершается (фаза 2013). Если же запрос адресован какому-либо защищенному хранилищу, то выполняется проверка 2008, в ходе которой выясняется, сколько времени Δbackup (в секундах) прошло с момента последнего резервного копирования вспомогательных файлов, соответствующих базовому файлу, которому адресован запрос на изменение данных. Если Δbackup больше периода резервного копирования, указанного в конфигурации 605 при создании защищенного хранилища, то в блоке 2009 выполняется операция создания резервных копий соответствующих вспомогательных файлов. Период создания резервных копий выбирается пользователем, исходя из степени критичности данных и объемов данных, хранящихся на защищенных хранилищах. Большие объемы данных могут привести к ощутимым задержкам при создании резервных копий, поэтому период резервного копирования предпочтительно должен быть выбран так, чтобы подобные задержки не создавали неудобств пользователю. На вспомогательных хранилищах, не ограничивая вариантов реализации, имя файла резервной копии состоит из имени копируемого файла, даты/времени копирования и истинного объема данных на защищенном хранилище на момент копирования. Такой формат имен файлов позволяет восстановить данные, находившиеся в защищенном хранилище на момент резервного копирования. В другом варианте реализации резервного копирования в резервные копии вспомогательных файлов заносятся метаданные из базового файла и к имени вспомогательных файлов дописывается дата и время создания копии. После создания резервных копий осуществляется переход на блок 2004. На
этот же блок выполняется переход после проверки 2008, если в ходе нее выяснилось, что время создания резервных копий не наступило. В блоке 2004 выполняется преобразование (кодирование) информационных блоков в кодовые блоки по алгоритму, заданному в конфигурации G05 защищенного хранилища. Далее в блоке 2005 закодированные данные разбиваются на tSStor-1 массивов в соответствии с конфигурацией, указанной при создании защищенного хранилища. В блоке 2006 создаются запросы для записи полученных массивов данных в tSStor-1 соответствующих вспомогательных файлов. После окончания ожидания в блоке 2007 обработки запросов на вспомогательных хранилищах, в проверке 2010 выясняется, на все ли хранилища запись проведена успешно: если да, то в блоке 2012 обработка запроса завершается с успехом, если нет, то в блоке 2011 обработка завершается с ошибкой и указывается причина ошибки: алгоритм обработки запроса на залгись данных заканчивается 2013.
Список литературы
[1] Ozarov Н., Wyner A.D. Wire-Тар Channel II. // BLTj, 63, - 1984, - pp. 2135-2157.
[2] Яковлев В.А. Защита информации на основе кодового зашумления. Под ред. В.И. Коржика. - СПб., 1993. - 244 с.
[3] A Statistical Test Suite for Random and Pseudorandom Number Generators for Cryptographic Applications. // http://csrc.nist.gov/publications/nistpubs/800-22-rev1a/SP800-22rev1a.pdf. Последнее обращение 17.06.2016.
[4] Иванов В.А. Статистические методы оценки эффективности кодового зашумления // Труды по дискретной математике. М.: ФИЗМАТЛИТ, 2002. Том 6. сс. 48-63.
[5] Деундяк В.М., Косолапов Ю.В. О стойкости кодового зашумления к статистическому анализу наблюдаемых данных многократного повторения.
// Моделирование и анализ информационных систем. Т. 19, №4 (2012), сс. 110-127.
[6] Газарян Ю.О., Винничук И.И., Косолапов Ю.В. Стойкость кодового зашумления в рамках модели многократного частичного наблюдения кодовых сообщений. // В сб. "Материалы XII Международной научно-практической конференции "Информационная безопасность", ч. 3, Таганрог: ЮФУ, 2012., сс. 258-263.
[7] Деундяк В.М., Косолапов Ю.В. Об одном методе снятия неопределенности в канале с помехами в случае применения кодового зашумления. II Известия ЮФУ. Технические науки. №2(151), - 2014, сс. 197-208.
[8] Arunkumar Subramanian, Steven W. McLaughlin. MDS codes on the erasure-erasure wiretap channel. // arXv:0902.3286v1 [cs.IT] 19 Feb. 2009. P. 1-4. Последнее обращение 13.11.2013.
[9] Деундяк B.M., Косолапов Ю.В. Математическая модель канала с перехватом второго типа. // Известия высших учебных заведений, Северо-Кавказский регион, серия Естественные науки, 3(145), - 2008, сс. 3-8.
[10] Yuan Luo, Chaichana Mitrpant, A.J. Hav Vinck, Kefei Chen. Some New characters on the wire-tap channel of type II. // IEEE Transactions on information theory, vol. 51, No. 3, 2005. P. 1222-1229.
[11] Mihir Bellare, Stefano Tessaro, Alexander Vardy A Cryptographic Treatment of the Wiretap Channel. // arXiv:1201.2205, http://arxiv.org/abs/1201.2205, 2012. Последнее обращение 10.01.2014.
[12] Wright С, Kleiman D., Shyaam Sundhar R.S. Overwriting Hard Drive Data: The Great Wiping Controversy. // ICISS ′08 Proceedings of the 4th International Conference on Information Systems Security, - 2008, pp. 243-257.
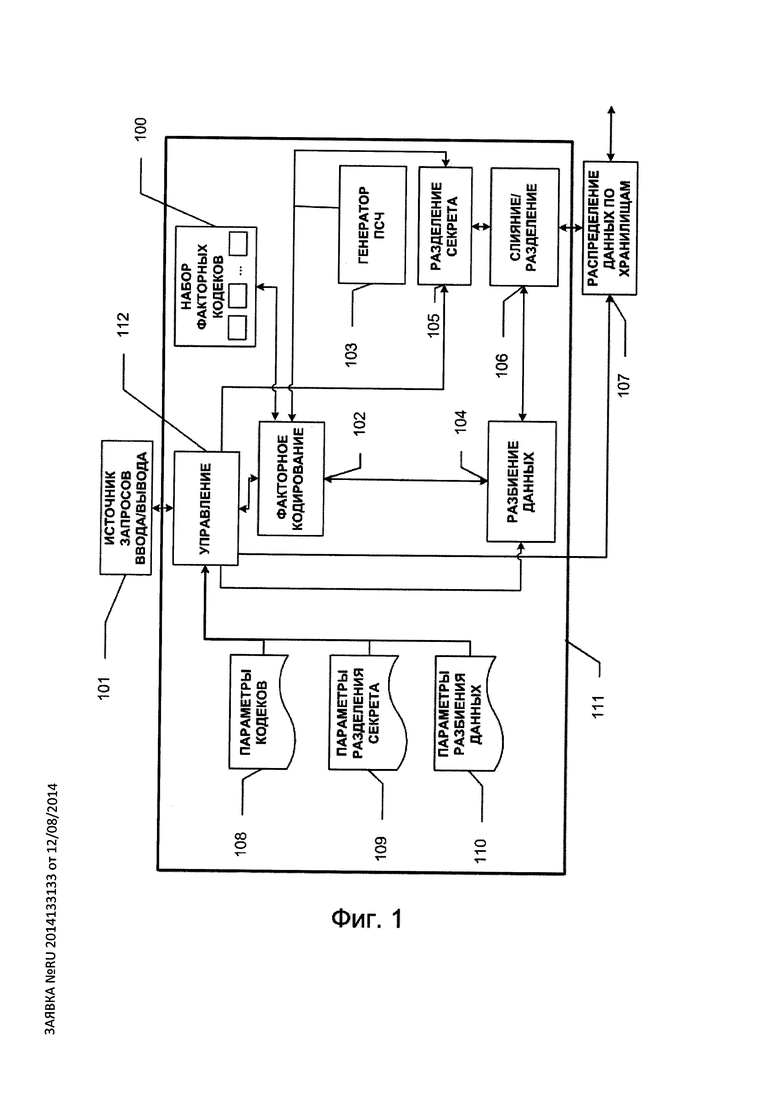
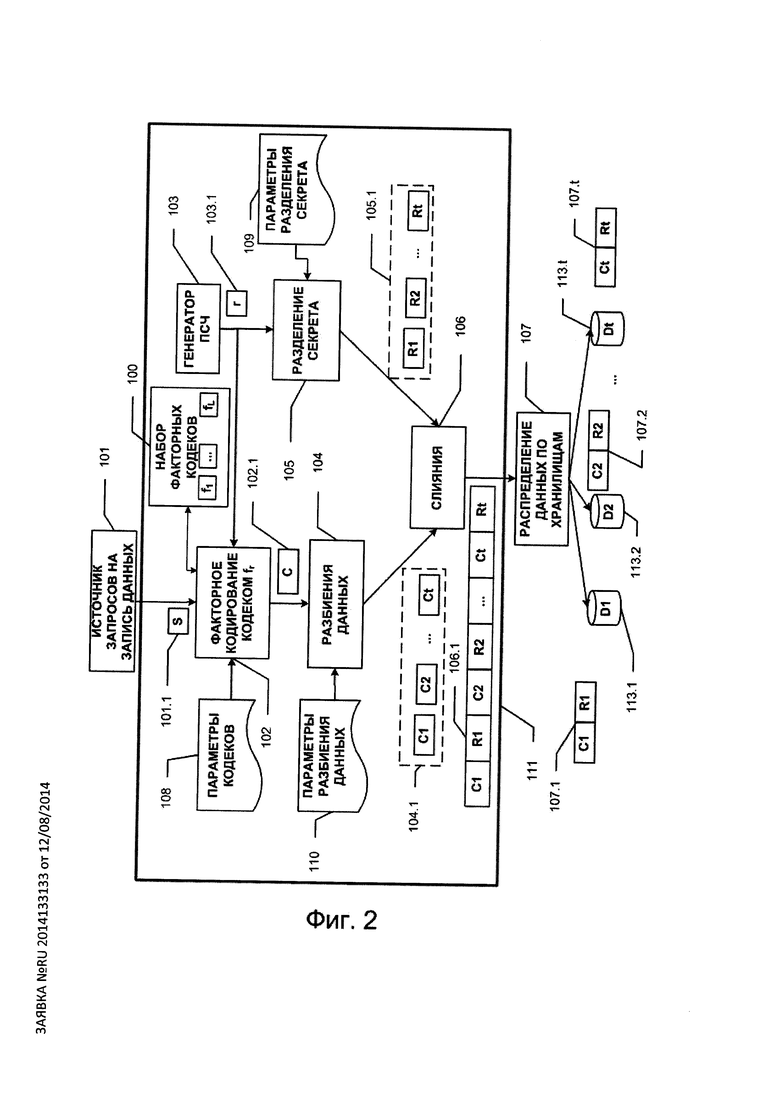
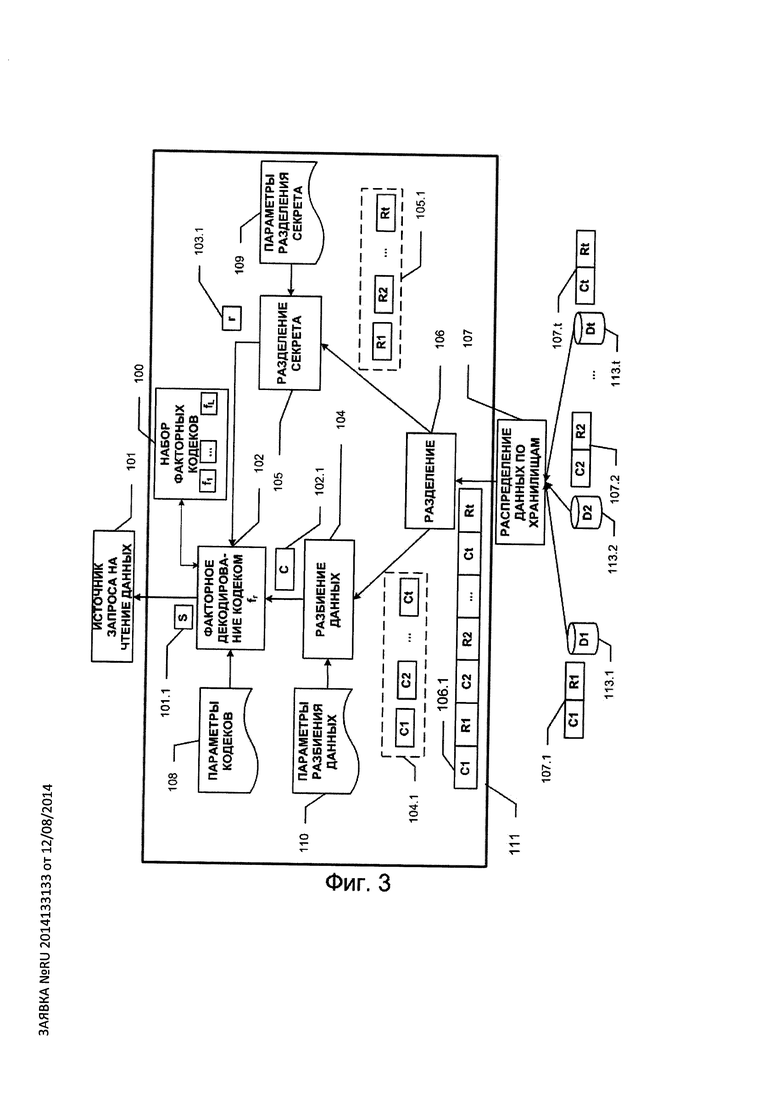
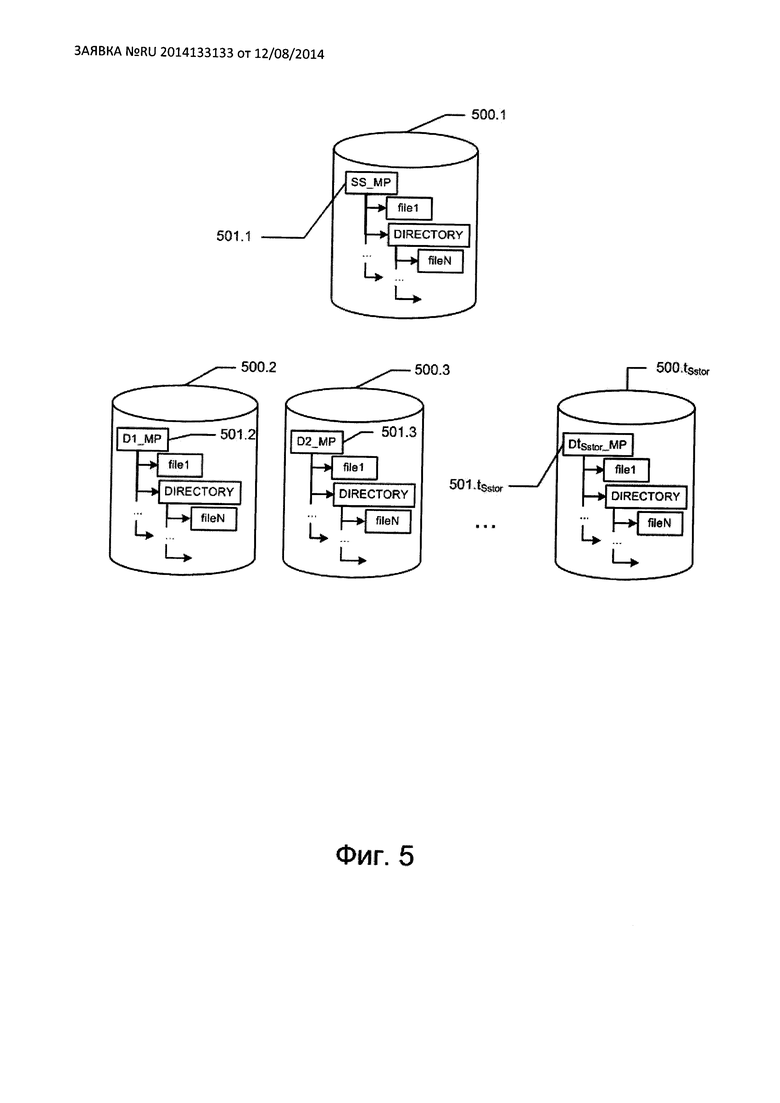
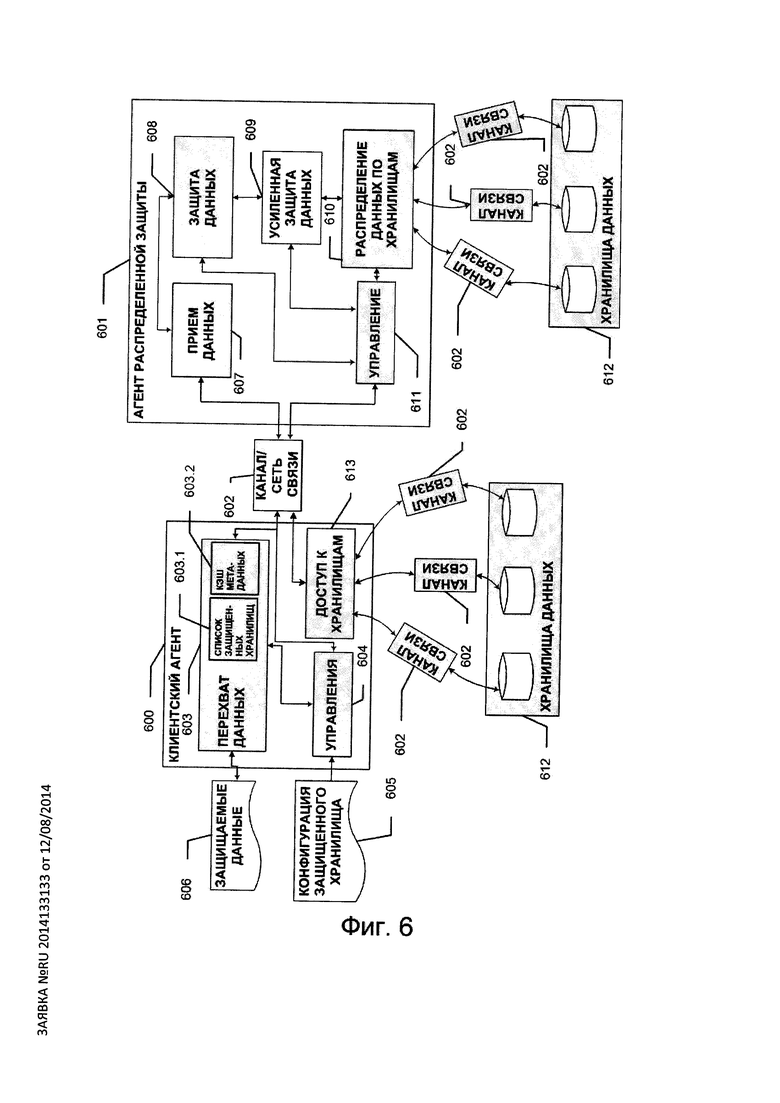

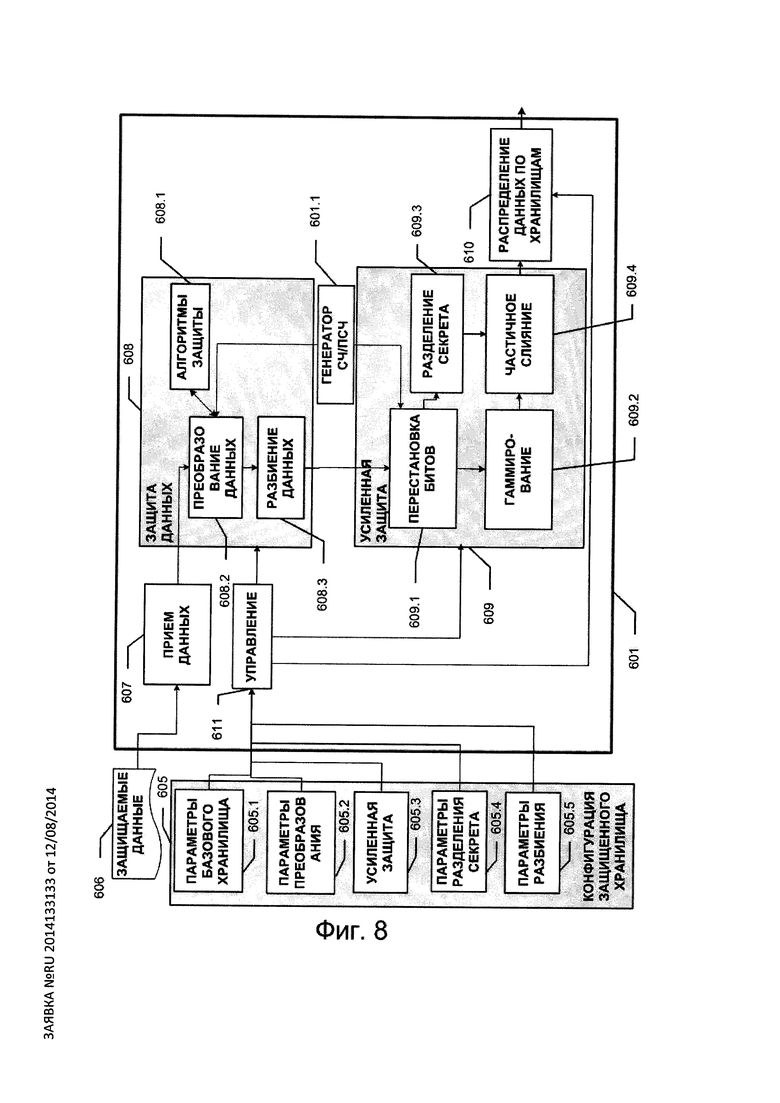
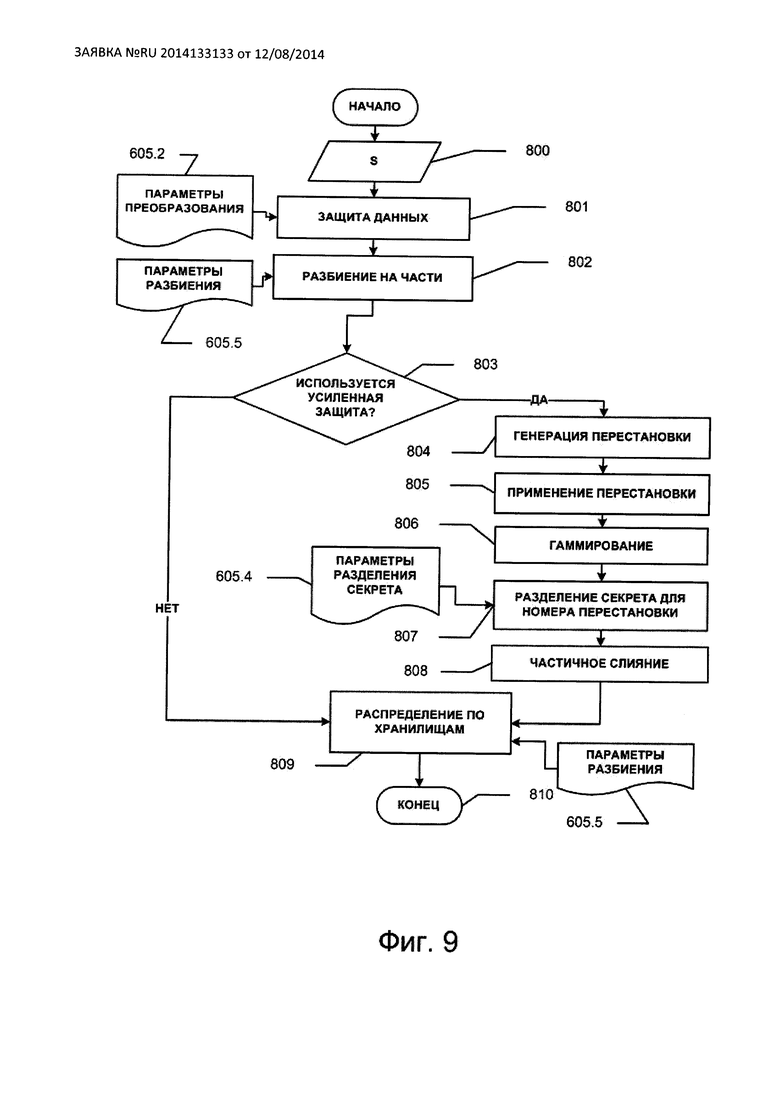
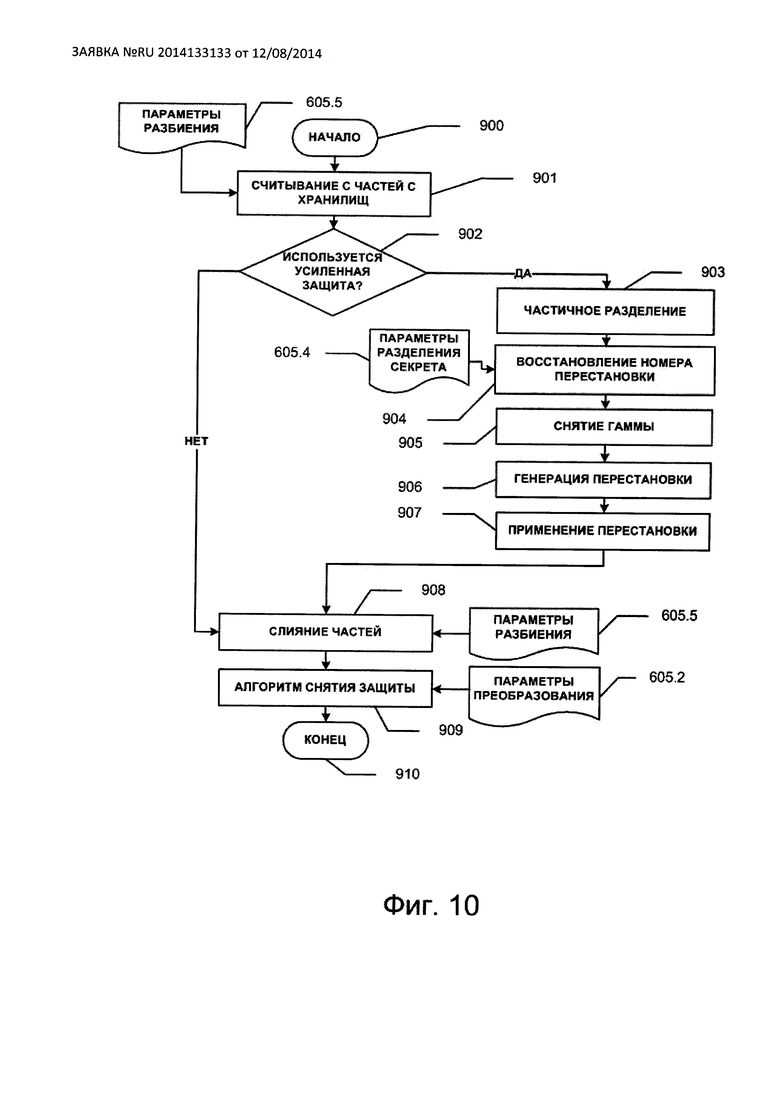


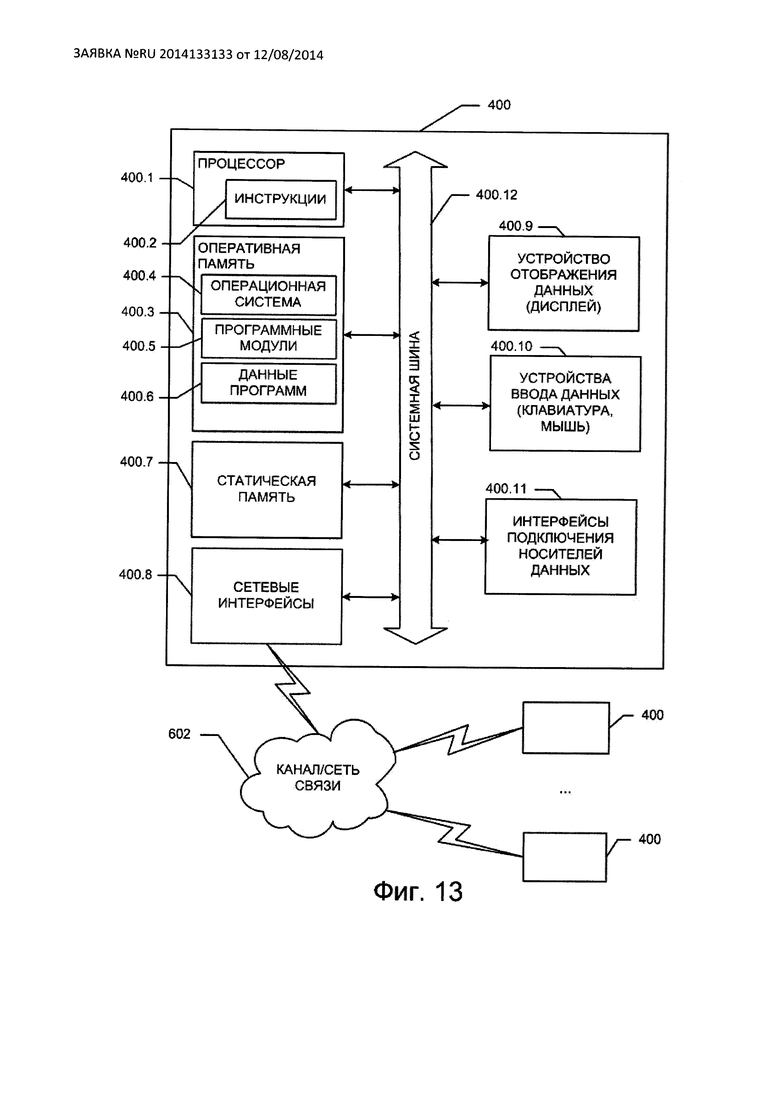
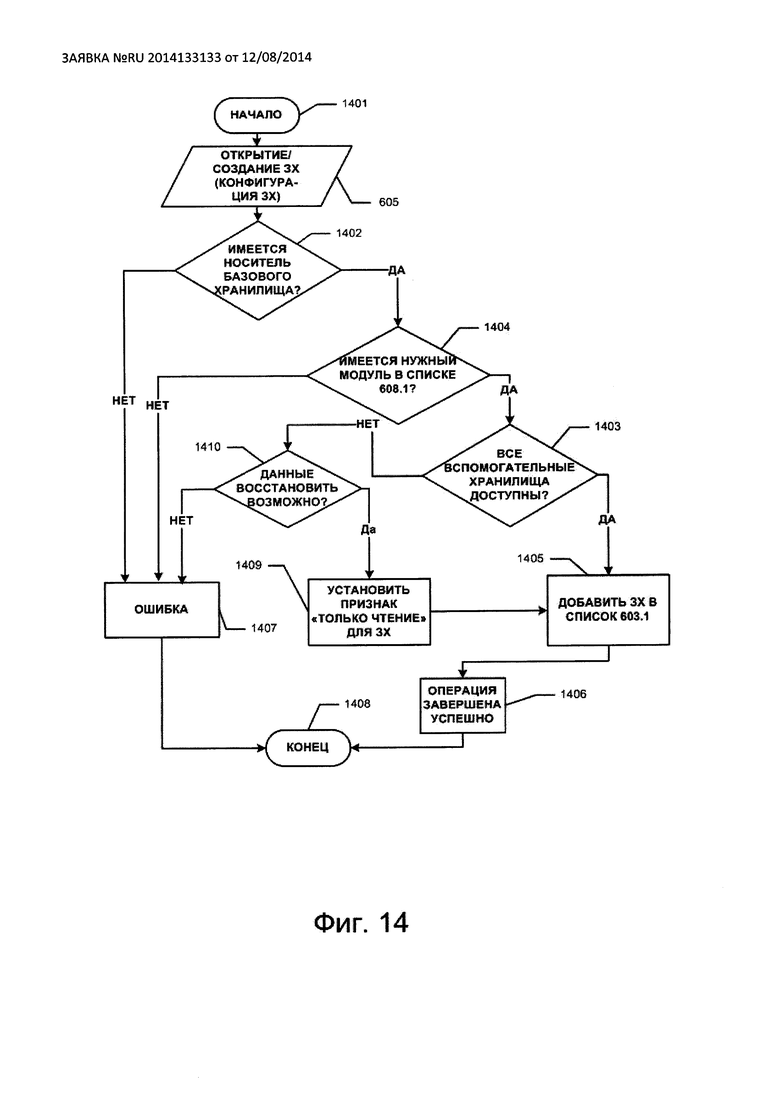

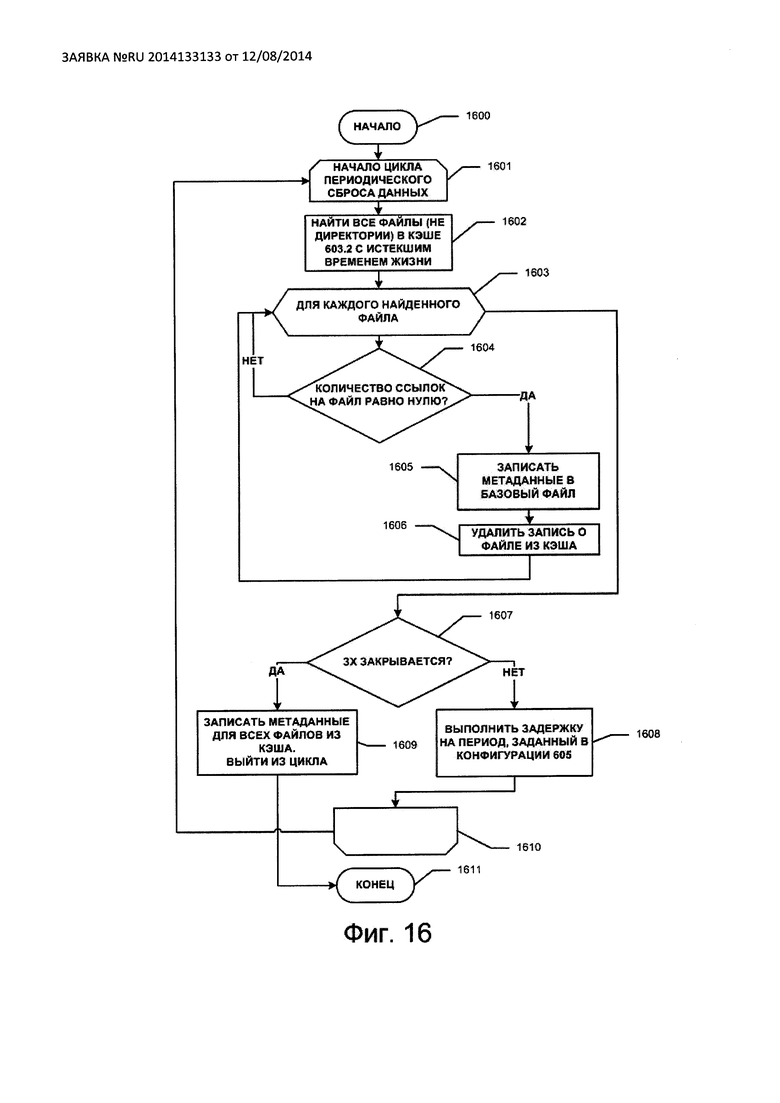
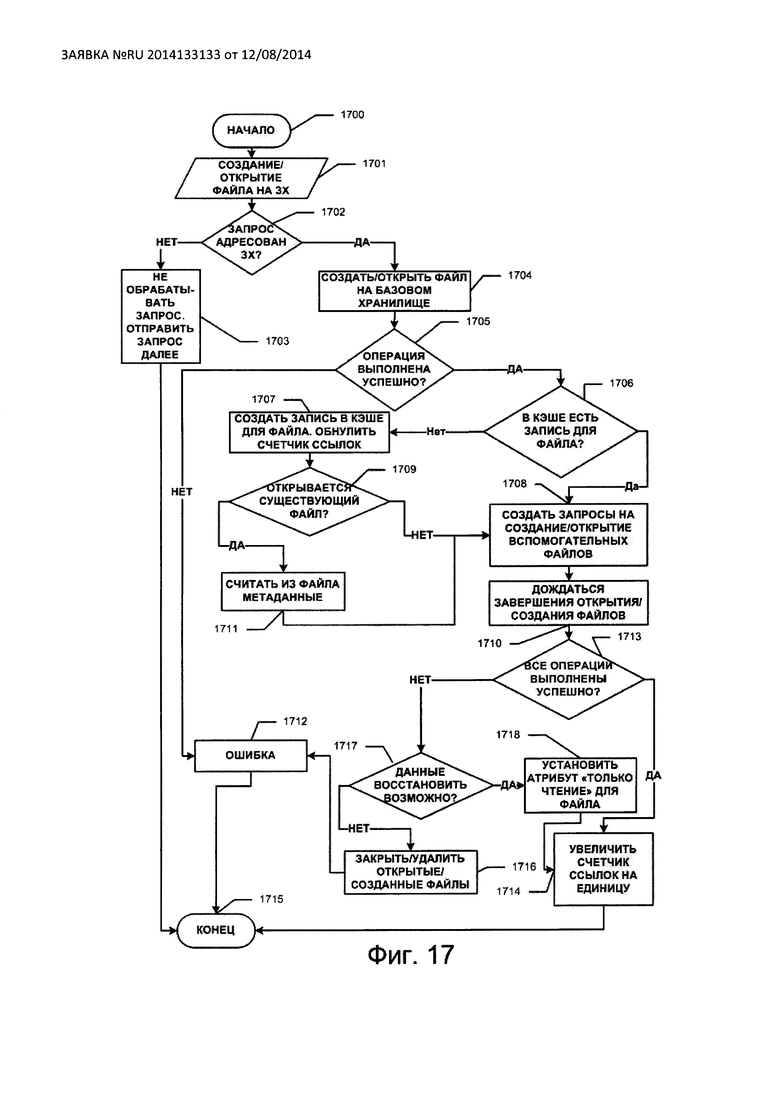
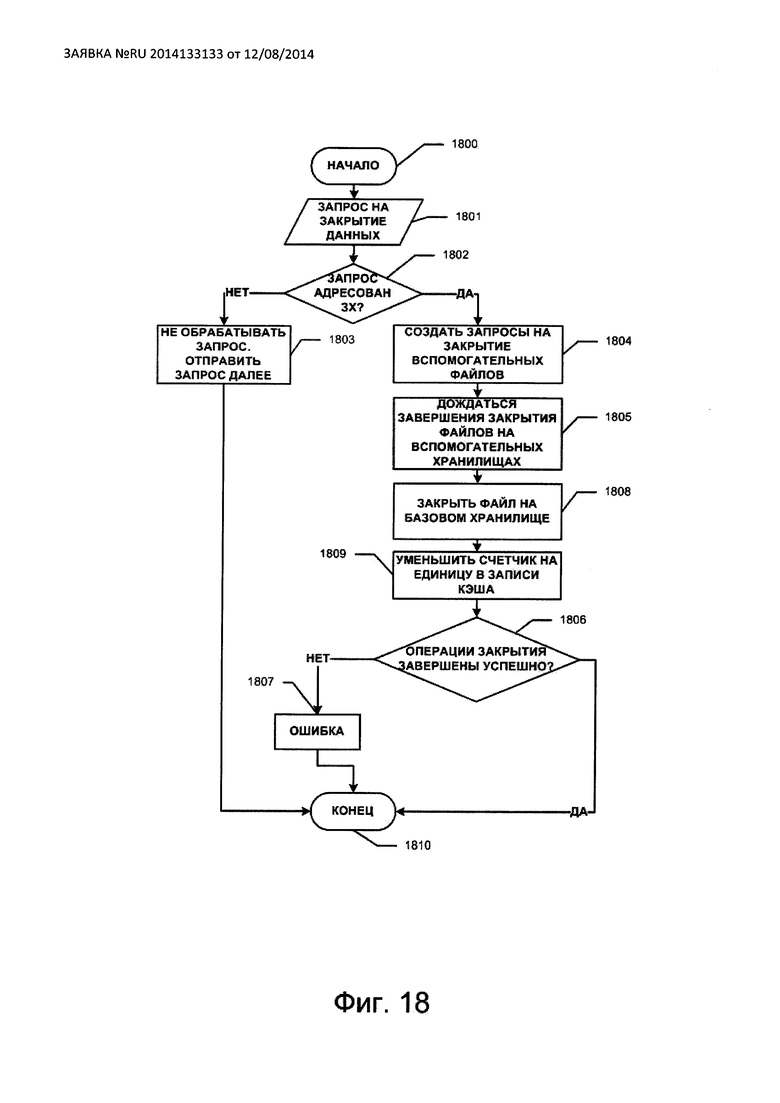
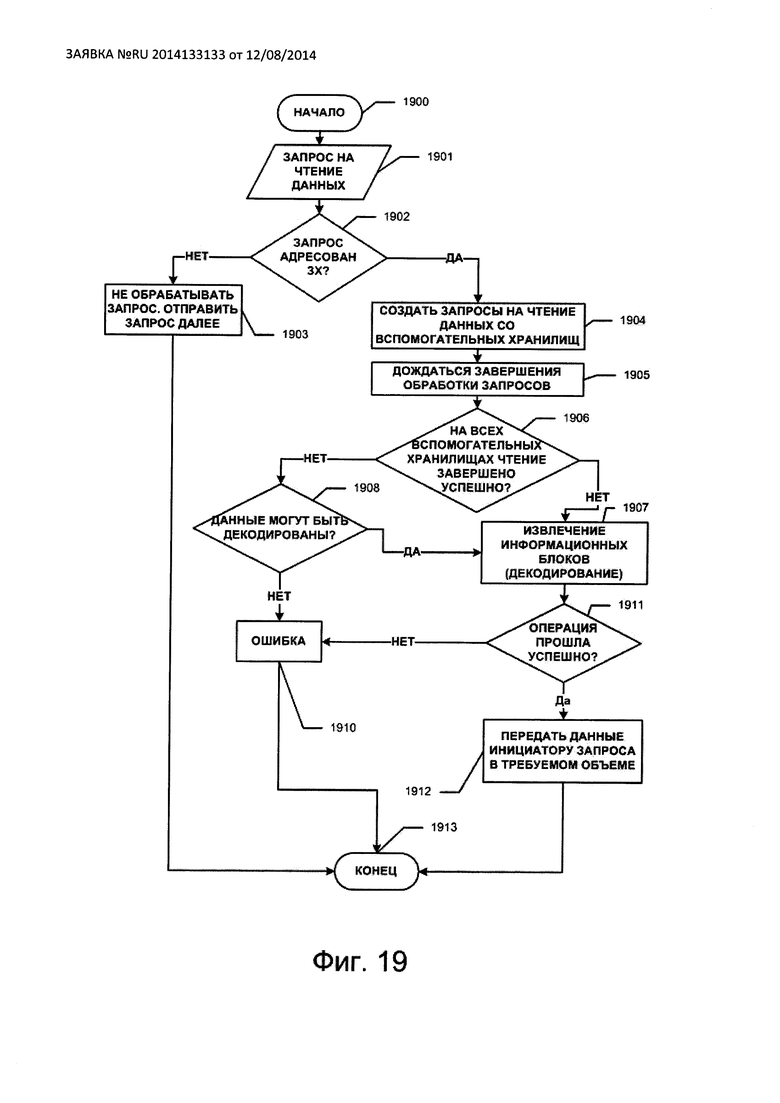
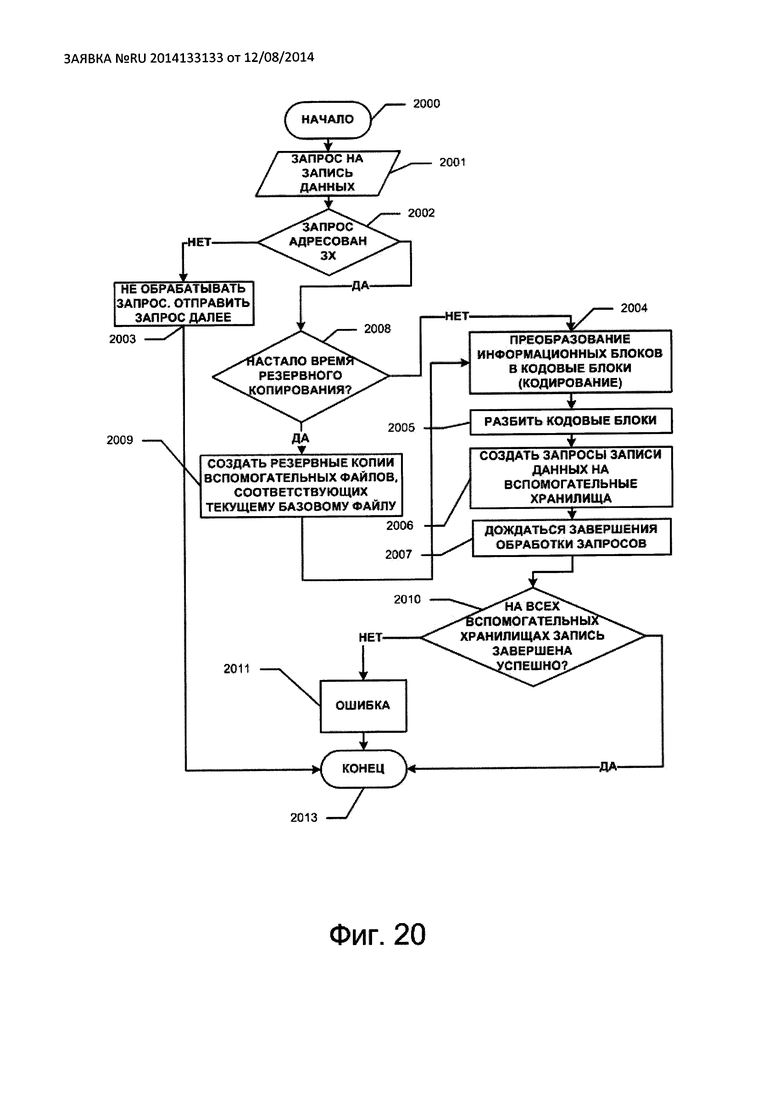
Группа изобретений относится к области защиты данных, записанных в хранилище с долговременной памятью, и может быть использована для защиты доступности и конфиденциальности данных. Техническим результатом является повышение защищенности данных. В способе защиты доступности и конфиденциальности хранимых данных для каждого информационного блока из множества обратимых случайных преобразований выбирается случайным или псевдослучайным образом номер r одного кодирующего правила, которое затем применяется к кодовому блоку; полученное кодовое слово разбивается на t частей, к каждой из которых дописывается часть секрета, полученная по числу r с помощью подходящей схемы разделения секрета, после чего полученные части объединяются. 4 н. и 5 з.п. ф-лы, 20 ил.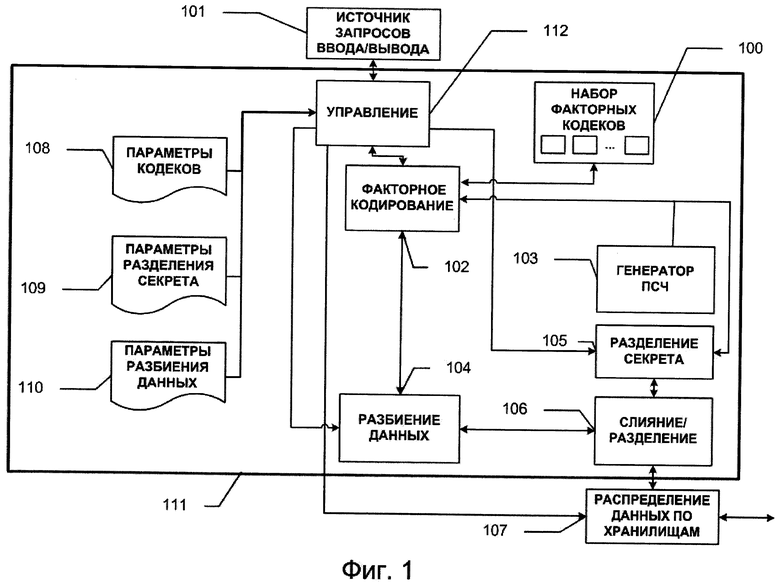
1. Способ защиты доступности и конфиденциальности хранимых данных, характеризующийся тем, что при операции записи данных:
• каждый информационный блок S длины k символов конечного поля F кодируют в кодовый блок С длины n символов поля F с помощью кодека ƒr, случайным или псевдослучайным образом выбранным из занумерованного набора кодеков FCq(n, k, µ, ν), преобразующих информационные векторы длины k (над полем F) в кодовые векторы длины n (над тем же полем F) так, что утрата не более ν символов кодового слова позволяет однозначно восстановить информационное слово, а подслушивание (наблюдение) не более µ символов кодового слова не дает наблюдателю какой-либо информации о закодированном сообщении;
• кодовый блок С разбивают на Т частей (C1, …, CT) таким образом, чтобы объединение любых terr частей в совокупности давало не более ν различных кодовых символов, а объединение любых ttap частей в совокупности давало не более µ различных кодовых символов;
• по номеру r выбранного кодека, используя (Т, T-terr)-схему разделения секрета, получают Т частей: R1, …, RT;
• пары (Ci, Ri), где i=1, …, Т, по порядку объединяются в блок (С1, R1, …, CT, RT);
• каждую пару (Ci, Ri), где i=1, …, T, записывают на одно из Т хранилищ так, чтобы на одно хранилище была записана только одна пара указанного вида,
а при чтении защищаемых данных
• с, по крайней мере, T-terr хранилищ считывают пары вида (Ci, Ri), где i∈{1; …; Т};
• по считанным частям Ri, используя (T, Т-terr)-схему разделения секрета, получают номер r использованного при кодировании кодека ƒr;
• по считанным частям Ci формируют (в порядке встречаемости кодовых символов) частичный кодовый блок С′, в котором неизвестно, самое многое, ν кодовых символов;
• из блока С′, используя обратное преобразование k ƒr(∈FCq(n, k, µ, ν)), извлекают информационный блок S.
2. Способ защиты доступности и конфиденциальности хранимых данных по п. 1, в котором в качестве набора FCq(n, k, µ, ν) выступает множество кодеков, построенных путем всевозможных перестановок столбцов порождающей матрицы 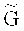
3. Система настраиваемой защиты хранимых данных, характеризующаяся тем, что она состоит из:
• компьютера, на котором установлен клиентский агент, включающий подмодуль перехвата данных, подмодуль управления и модуль доступа к носителям данных, подключаемым к компьютеру;
• компьютера, на котором установлен агентский модуль распределенной защиты, включающий подмодуль защиты данных (содержащий базу алгоритмов защиты), подмодуль усиленной защиты данных (включающий набор алгоритмов схем разделения секрета, алгоритмов генерации последовательностей и алгоритмов генерации перестановок) и модуль распределения данных по носителям данных;
• канала, связывающего клиентский агент и агент распределенной защиты;
• множества конфигураций защищенных хранилищ, где конфигурация каждого защищенного хранилища SStor включает:
- точки монтирования (каталоги) tSStor (∈N) хранилищ на носителях данных;
- нумерацию хранилищ числами от 1 до tSStor;
- базовое хранилище защищенного хранилища SStor (одно из tSStor хранилищ);
- число ttap хранилищ, несанкционированный доступ к которым не должен компрометировать закодированные данные;
- число terr хранилищ, утрата которых не должна приводить к потере закодированных данных;
- наименование алгоритма S для (tSStor, tSStor-terr)-схемы разделения секрета;
- наименование алгоритма A преобразования информационных блоков длины k символов поля F (в машинном представлении k1 байтов) в кодовые блоки длины n символов поля F (в машинном представлении n1 байтов), подходящий для тройки параметров (tSStor, ttap, terr);
- количество перестановок Q(∈{0; 250}), используемых для усиления защиты от статистических атак;
- наименование алгоритма P генерации по числу r(∈{0; …; Q})tSStor перестановок бит в байте; при этом алгоритм P при Q=0 генерирует перестановки, которые не приводят к изменению порядка бит в байтах (тождественные перестановки);
- правило П разбиения кодовых блоков длины n символов поля F (n1 байтов соответственно) на tSStor частей, каждая из которых в машинном представлении занимает li байтов, i=1, …, tSStor.
- наименование алгоритма Г генерации последовательности псевдослучайных чисел, который по числу r(∈{0; …; Q}) генерирует псевдослучайную последовательность Г(r) длиной 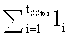
и что каждому файлу FILE, размещаемому в защищенном хранилище SStor, ставят в соответствие tSStor файлов: один файл FILEm на базовом хранилище (базовый файл), и по одному файлу на каждом из оставшихся tSStor-1 хранилищ (вспомогательные файлы); при этом в начале базового файла резервируют область фиксированной длины для метаданных о защищаемом файле FILE (об истинном размере файла, времени последней модификации);
4. Система настраиваемой защиты хранимых данных по п. 3, характеризующаяся тем, что при записи файла в защищенное хранилище SStor (или при записи блока данных в файл, размещенный в защищенном хранилище SStor):
• при необходимости записываемые данные выравнивают на границу информационного блока длины k1 байтов;
• записываемые данные представляют в виде последовательности k1-байтных информационных блоков (k1≥1);
• каждый информационный блок S преобразуют с помощью алгоритма A в соответствующий n1-байтный кодовый блок (n1≥k1);
• для каждого кодового блока С:
- используя правило разбиения П, разбивают блок С на tSStor частей:
- случайно или псевдослучайно выбирают число r(∈{0; …; Q}), по которому генерируют tSStor перестановок: 
- с помощью перестановки πr,i переставляют биты всех li байтов части Ci, i=1, …, tSStor, в результате получают блок πr,i(Ci);
- выполняют операцию побитового XOR векторов 
- по числу r, используя схему разделения секрета S, генерируют tSStor частей, каждая из которых занимает один байт: 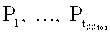
- в файл на i-м хранилище (i=1, …, tSStor) записывают соответствующую пару (πr,i(Ci) XOR Г(r)i, Pi);
5. Система настраиваемой защиты хранимых данных по п. 3, характеризующаяся тем, что при чтении данных из файла FILE, размещенного в защищенном хранилище SStor:
• границы буфера считываемых данных выравнивают на границу информационного блока длины k1 байтов;
• для каждого информационного блока S длины k символом поля F (k1 байтов в машинном представлении), считываемого в выровненный буфер:
- из, по крайней мере, t′≥tSStor-terr файлов, размещенных на хранилищах, считывают соответствующие информационному блоку S пары (πr,i(Ci) XOR Г(r)i, Pi) в машинном представлении занимающие соответственно li+1 байтов, i∈{1; …; tSStor};
- по совокупности, по меньшей мере, t′ частей Pi, используя схему разделения секрета S, находят число r;
- по числу r, используя алгоритм Г, находят последовательность псевдослучайных чисел Г(r), с помощью которой снимают гамму и получают блоки πr,i(Ci), i∈{1; …; tSStor};
- по числу r, используя алгоритм P, находят необходимые перестановки πr,i битов в байтах и получают блоки Ci;
- используя алгоритм A и алгоритм разбиения П, по имеющемуся набору частей кодового блока восстанавливают информационный блок S;
• из декодированных информационных блоков S формируют буфер считанных данных и инициатору возвращают буфер в рамках тех границ, которые заданы инициатором.
6. Система настраиваемой защиты хранимых данных по любому из пп. 3-5, отличающаяся тем, что используется (tSStor-1, tSStor-1-terr)-схема разделения секрета S, алгоритм P генерирует tSStor-1 перестановок, правило П разбивает кодовое слово на tSStor-1 частей, алгоритм Г генерирует последовательность длины 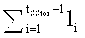
7. Система настраиваемой защиты хранимых данных по п. 3, отличающаяся тем, что при создании защищенного хранилища задают период времени в секундах, по истечении которого с момента последней модификации защищенного файла FILE должны создаваться резервные копии соответствующих файлов на базовом и вспомогательных хранилищах.
8. Машиночитаемый носитель, на котором сохранен компьютерный программный продукт, который при выполнении процессором с программным управлением побуждает процессор осуществлять способ по одному из пп. 1-2.
9. Машиночитаемый носитель, на котором сохранен компьютерный программный продукт, который при выполнении процессором с программным управлением побуждает процессор осуществлять систему по одному из пп. 3-7.
| СПОСОБ И УСТРОЙСТВО ДЛЯ КОДИРОВАНИЯ СЛОВ ДАННЫХ | 2008 |
|
RU2485584C2 |
| БЕЗОПАСНОЕ ХРАНЕНИЕ ДАННЫХ С ЗАЩИТОЙ ЦЕЛОСТНОСТИ | 2006 |
|
RU2399087C2 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ ЗАЩИТЫ В СИСТЕМЕ ОБРАБОТКИ ДАННЫХ | 2004 |
|
RU2356170C2 |
| US 2010046739 A1, 25.02.2010 | |||
| US 7945784 B1, 17.05.2011 | |||
| US 6363481 B1, 26.03.2002 | |||
| US 2013346748 A1, 26.12.2013. | |||

