Изобретение относится к технологии получения объектного кода программ, используемой как в трансляторах с языков высокого уровня, так и в двоичных транслирующих системах. Изобретение может быть особенно эффективно использовано в промышленных компиляторах для архитектурных платформ с явно выраженным параллелизмом на уровне отдельных операций, ориентированных на статическое управление вычислениями. Возможно его использование в традиционных суперскалярных архитектурах.
В процессе трансляции исходная программа переводится с языка программирования в некоторую промежуточную программу, на базе которой выполняются оптимизации, ориентированные на конкретную архитектурную платформу, а также осуществляется генерация объектного кода программы. Целью проводимых оптимизаций является, как правило, повышение скорости работы программы. Одним из главных показателей при этом является достигнутый в ходе оптимизации параллелизм на уровне отдельных операций.
В современных микропроцессорах реализуются два подхода к параллельному выполнению отдельных операций. Первый из них это динамических подход, который принят во многих традиционных суперскалярных архитектурах. Процессор просматривает последовательность команд во время исполнения, определяет возможные зависимости между операциями, решает, какие из них и на каком оборудовании можно выполнить параллельно.
Второй подход чисто статистический, он принят в архитектурах с явно выраженным параллелизмом. Отдельные операции образуют в объектном коде явно выделенные группы, подготовленные компилятором, которые могут исполняться процессором параллельно. Аппаратура при этом подходе упрощается, однако анализ и генерация явного параллельного кода теперь возлагается на компилятор.
Методы, при помощи которых компиляторы оптимизируют код с целью повышения уровня параллелизма, традиционно объединяются термином "планирование операций". Локальное планирование переупорядочивает операции в пределах линейных участков, т. е. фрагментов линейного кода, оканчивающихся операцией перехода. Однако для достижения предельной производительности современных процессоров с высокой архитектурной скоростью локального планирования операций оказывается явно недостаточно.
Глобальное планирование позволяет перемещать операции через границы линейных участков, что дает больше возможностей распараллеливания. Известно несколько решений задачи глобального планирования операций в пределах совокупности линейных участков. Одним из них является алгоритм планирования трасс. Оптимизируют некоторый наиболее часто исполняемый путь в объектном коде программы (трассу). Линейные участки, вошедшие в трассу, оптимизируют за счет остальных редко исполняемых участков. Операции переносят через границы участков трассы, при необходимости добавляют компенсирующий код для сохранения семантики программы. Этот подход сводит глобальное планирование к задаче локального планирования, он описан в работе Р. Geoffrey Lowney et al., "The Multiflow Trace Scheduling Compiler", J. Supercomputing 7, 51 (1993). Сперва идентифицируется ациклический часто исполняемый путь на множестве линейных участков, т. е. трасса, затем отдельные операции перемещают в пределах трассы через границы участков: переходы и метки (места в трассе, куда возможен вход из-за ее пределов). Наконец, вставляют необходимый корректирующий код. Так операции, которые были перемещены ниже некоторого перехода в трассе, требуют построения своей копии на определенном линейном участке вне трассы. Хотя такой способ в целом уменьшает количество операций внутри трассы, но это уменьшение происходит за счет увеличения кода за ее пределами.
Другим методом глобального планирования является так называемое "фильтрование", как это описано в работе A. Nicolau, "Percolation Scheduling: A Parallel Computation Technique", Technical Report, Cornell University (1984). Основой этого решения является набор базовых преобразований, применяемых к информационно-управляющему графу программы. При помощи "жадного" алгоритма операции перемещаются вверх по графу управления, на сколько это возможно с учетом зависимостей. Поскольку при такой технике оптимизации никак не учитывается реальная аппаратура, возможна ситуация, при которой оборудование будет загружено операциями с редко исполняемых участков исходной программы, результат которых требуется редко.
Как и техника планирования трасс, фильтрование требует компенсирующего кода.
Еще один подход, известный как "техника часового", описан в работе S. А. Mahlke, "Sentinel scheduling for VLIW and superscalar processors". Annual Symposium on Programming Languages and Operating Systems, vol. 27, p. 238 (1992). Здесь используется профиль программы, на базе которого совокупность линейных участков, удовлетворяющую определенным требованиям, планируют как один большой участок (суперблок).
Особенностью еще одного подхода к глобальному планированию является попытка ограничить дублирование кода. Хотя операции по-прежнему перемещают через границы линейных участков, область применения оптимизации ограничивается цикловыми регионами. Такой способ описан в работе D. Bernstein, M. Rodeh, "Global instruction Scheduling for superscalar machines". Conference on Programming Language Design and Implementation, SIGPLAN'91, p. 241 (1991).
Наиболее близким аналогом данного изобретения является способ получения объектного кода, описанный в патенте США 5557761. Согласно данному способу сначала выбирают два линейных участка объектного кода исходной программы: источник и приемник. Затем осуществляют построение максимального множества операций в пределах участка-источника, которые можно переместить на участок-приемник без нарушения зависимостей между операциями и с учетом доступных аппаратных ресурсов. Для этого используют специальную модель оценки общей стоимости такого переноса операций, на основе которой принимают окончательное решение об оптимизации выбранной пары линейных участков. Программу в целом оптимизируют путем выполнения вышеуказанных операций по отношению ко всевозможным парам линейных участков, связанных по управлению.
Недостатками перечисленных способов, при которых обеспечивается увеличение степени параллелизма исходной программы, являются: плохо контролируемое разрастание кода, слабая привязка оптимизации к параметрам и характеристикам целевой архитектурной платформы, отсутствие четкой стратегии оптимизации.
Задачей, на решение которой направлено настоящее изобретение, является устранение указанных недостатков и обеспечение возможности сокращения времени выполнения объектного кода исходной программы, особенно при статическом распараллеливании вычислений.
Настоящее изобретение представляет собой способ получения объектного кода, заключающийся в том, что:
по исходной программе в ЭВМ с выбранной архитектурной платформой получают неоптимизированный объектный код в виде совокупности линейных участков и соответствующий указанному коду профиль программы с информацией о числе исполнений каждого линейного участка неоптимизированного объектного кода, причем указанную информацию получают с помощью счетчика и сохраняют на носителе;
в указанной ЭВМ переводят исходную программу или неоптимизированный объектный код в первичную промежуточную программу, имеющую совокупность линейных участков, соответствующую совокупности линейных участков неоптимизированного объектного кода;
каждый линейный участок первичной промежуточной программы планируют и затем определяют время исполнения полученного спланированного участка в тактах;
определяют полное время исполнения первичной промежуточной программы по следующей формуле:
где Т - полное время исполнения первичной промежуточной программы в тактах;
Lj - время исполнения j-го спланированного линейного участка первичной промежуточной программы в тактах;
Nj - число исполнений упомянутого j-го линейного участка;
j = 1...m - число линейных участков;
для каждого спланированного линейного участка первичной промежуточной программы определяют ожидаемое уменьшение полного времени исполнения первичной промежуточной программы в результате выноса совокупности операций, спланированных в первом такте указанного участка, с учетом числа исполнений указанного участка, полученного из сохраненного профиля программы;
осуществляют оптимизацию первичной промежуточной программы путем выполнения заданного числа циклов следующих действий, определяемого из условия завершения оптимизации:
- устанавливают последовательность спланированных линейных участков текущей промежуточной программы по убыванию ожидаемого уменьшения полного времени исполнения текущей промежуточной программы;
- переносят совокупность операций, спланированных в первом такте первого линейного участка указанной последовательности, на предшествующие ему по управлению спланированные линейные участки текущей промежуточной программы, включая в их число тот же спланированный участок в случае программного цикла, при этом получают преобразованную промежуточную программу, имеющую по меньшей мере два модифицированных участка;
- определяют полное время исполнения преобразованной промежуточной программы, полученное с учетом планирования ее участков, и реальное уменьшение указанного времени по сравнению с полным временем исполнения текущей промежуточной программы и полученное реальное уменьшение сравнивают с ожидаемым уменьшением полного времени исполнения текущей промежуточной программы для следующего линейного участка указанной последовательности; при этом:
- если первое из упомянутых уменьшений не меньше второго, сохраняют преобразованную промежуточную программу, после чего выполняют для нее указанный цикл действий, полагая ее текущей промежуточной программой в данном цикле, причем реальное уменьшение полного времени исполнения полученной последующей преобразованной промежуточной программы определяют по сравнению с полным временем исполнения предыдущей преобразованной промежуточной программы,
- если первое из упомянутых уменьшений меньше второго, восстанавливают состояние модифицированных участков, причем при положительном значении реального уменьшения его запоминают и выполняют указанный цикл действий с учетом этого значения, а при отсутствии реального уменьшения выполняют указанный цикл действий, осуществляя его с действия по переносу совокупности операций, спланированных в первом такте следующего линейного участка последней полученной последовательности спланированных линейных участков для текущей промежуточной программы;
- на основе полученной в результате оптимизации совокупности линейных участков последней преобразованной промежуточной программы формируют в указанной ЭВМ с помощью компилятора оптимизированный объектный код, который сохраняют на носителе информации.
Полное время исполнения преобразованной промежуточной программы в ходе оптимизации можно определить либо по формуле:
где Top - полное время исполнения преобразованной промежуточной программы в тактах с учетом дублирования операций в процессе оптимизации;
Lj - время исполнения j-го спланированного линейного участка преобразованной промежуточной программы в тактах;
Nj - число исполнений упомянутого j-го линейного участка;
Кoр - положительное число, характеризующее замедление работы преобразованной промежуточной программы на выбранной архитектурной платформе из-за увеличения размеров кода;
Rj - число операций на j-м линейном участке с учетом результатов переноса;
j = 1...m - число линейных участков в совокупности;
либо по формуле
где Tmem - полное время исполнения преобразованной промежуточной программы в тактах с учетом увеличения числа обращений в память в процессе оптимизации;
Lj - время исполнения j-го спланированного линейного участка преобразованной промежуточной программы в тактах:
Nj - число исполнений упомянутого j-го линейного участка;
Kmem - положительное число, характеризующее замедление работы преобразованной промежуточной программы в процессе оптимизации на выбранной архитектурной платформе из-за увеличения числа обращений в память;
Mj - число операций обращения в память на j-м линейном участке с учетом результатов переноса;
j = 1...m - число линейных участков в совокупности.
При этом условием завершения оптимизации первичной промежуточной программы может быть, например, отсутствие реального уменьшения полного времени исполнения преобразованной промежуточной программы для всех линейных участков либо отсутствие реального уменьшения полного времени исполнения преобразованной промежуточной программы для заданного числа оптимизируемых линейных участков.
На фиг.1 изображена общая схема получения объектного кода программы.
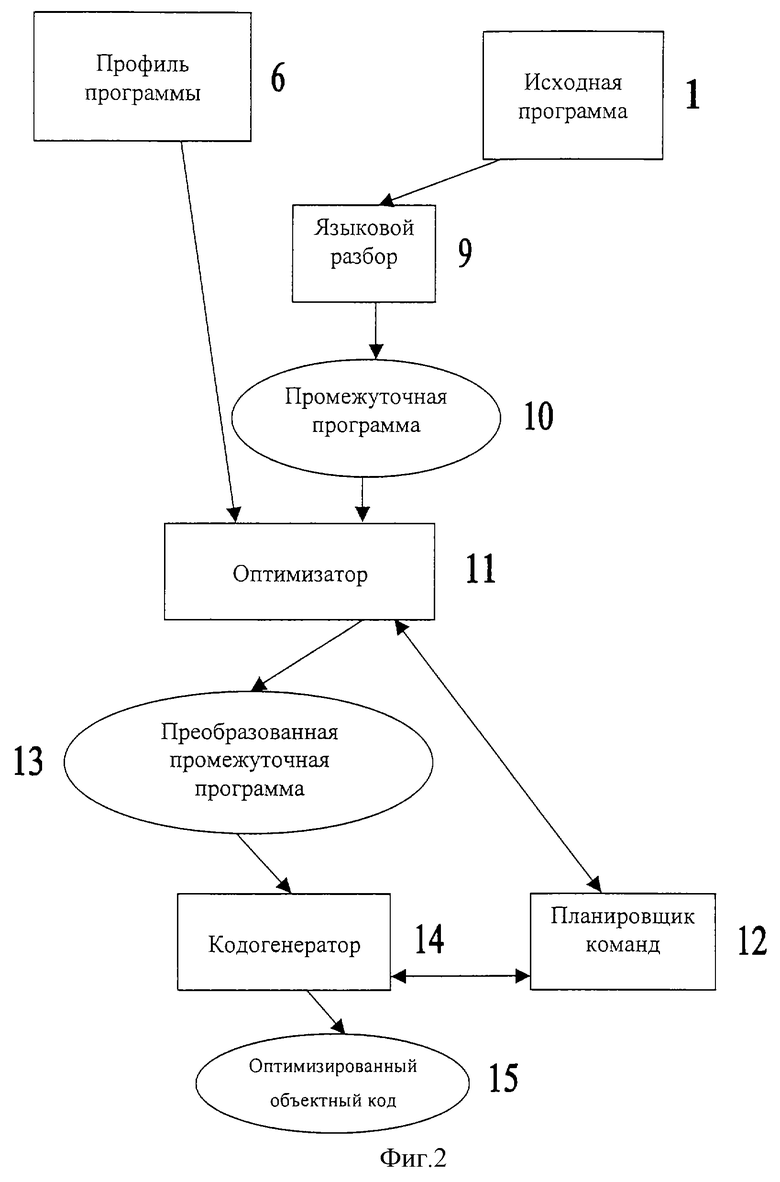
На фиг.2 - схема работы компилятора для случая с использованием исходной программы.
На фиг. 3 и 4 представлена работа алгоритма, по которому осуществляют оптимизацию объектного кода.
На фиг. 5 дан пример состояния трех линейных участков программного кода до и после работы одной итерации алгоритма оптимизации.
Получение объектного кода программы, написанной на языке высокого уровня, может быть представлено последовательностью действий, изображенной на фиг. 1. Исходную программу (1) подают на вход стандартной компоненты программного обеспечения ЭВМ - компилятора (2). Результатом работы компилятора является файл неоптимизированного объектного кода (3) исходной программы, представляющего собой совокупность линейных участков. Файл записывают на каком-либо носителе информации. Полученный код может быть исполнен аппаратными средствами (4) данной ЭВМ за некоторое время То, характеризующее скорость работы программы. Настоящее изобретение позволяет оптимизировать объектный код программы, при этом оптимизированный код, выполняющий все действия, предусмотренные исходной программой, будет выполнен на той же аппаратуре за время Т<То.
Оптимизирующие преобразования неоптимизированного объектного кода, значительно повышающие скорость работы, можно выполнить, если известна информация о поведении программы и отдельных ее частей в ходе исполнения (прогона). Технологией оптимизации предусмотрен такой пробный или тренировочный прогон неоптимизированного кода программы, условно обозначенный позицией (5). Результатом этого прогона является профиль программы (6), характеризующий поведение отдельных частей программы. Необходимой составной частью профиля программы, используемого в настоящем изобретении, является информация о числе исполнений каждого линейного участка неоптимизированного кода, получаемая с помощью счетчика.
Для выполнения оптимизирующих преобразований неоптимизированного кода программы в качестве исходных данных используют либо непосредственно неоптимизированный объектный код (3), либо исходную программу (1) на языке высокого уровня. Кроме того, используют профиль программы (6), сохраненный на подходящем носителе, которым может быть, например, жесткий диск или магнитная лента. Компилятор (2), используя дополнительную информацию, преобразует неоптимизированный объектный код (3) или исходную программу (1) в оптимизированный объектный код программы (7), также сохраняемый на носителе информации. Прогоны данного кода, обозначенные условно как (8), покажут меньшее время исполнения программы.
На фиг.2 изображена упрощенная структурная схема компилятора (2), используемого в способе получения объектного кода программы по настоящему изобретению. Показан пример осуществления с использованием исходной программы. Исходную программу (1) переводят при помощи компоненты языкового разбора (9) в первичную промежуточную программу (10) в виде совокупности линейных участков, соответствующей совокупности линейных участков неоптимизированного объектного кода. Компонента оптимизатора (11), получая профиль программы (6), при взаимодействии с планировщиком команд (12) реализует итеративный алгоритм модификации линейных участков. В результате получают преобразованную в процессе оптимизации промежуточную программу (13). Генератор кода (14) получает оптимизированный объектный код (15) исходной программы.
На фиг.3 представлена подготовка к началу работы итеративного алгоритма оптимизации, который реализует функцию оптимизатора (11). Каждый линейный участок первичной промежуточной программы (10) исходной программы (1), совокупность которых обозначена как множество {В}, планируют (16) с получением значения времени его исполнения L(j) в тактах. Аналогичные действия по планированию осуществляют и по отношению к линейным участкам преобразованных промежуточных программ, получаемых в процессе оптимизации. Из профиля программы (6) берут соответствующие числа исполнений (17) каждого линейного участка. Теперь каждому спланированному участку B(j) из множества {В} (j = 1. . m) соответствует некоторое число N(j), характеризующее число исполнений этого участка. Далее определяют (18) полное время Т исполнения первичной промежуточной программы по следующей формуле:
где Т - полное время исполнения первичной промежуточной программы в тактах;
Lj - время исполнения j-го спланированного линейного участка промежуточной (первичной или преобразованной) программы в тактах;
Nj - число исполнений упомянутого j-го линейного участка;
j = 1...m - число линейных участков;
Поскольку дальнейшая оптимизация участков идет с учетом результатов планирования, в качестве множества операций, выносимых с выбранного участка, берется совокупность операций, спланированных в первом такте данного участка. Максимальный ожидаемый эффект, в данном случае максимальное ожидаемое уменьшение полного времени исполнения первичной промежуточной программы, при таком выносе равно одному машинному такту, умноженному на число исполнений оптимизируемого участка. Таким образом, для каждого участка B(j) можно определить ожидаемый эффект оптимизации P(j), который сперва полагается равным P(j)= N(j) (19). После подсчета возможного эффекта участки сортируют (20) так, что P(j)>=P(j+1). Тем самым устанавливают последовательность спланированных линейных участков первичной промежуточной программы по убыванию ожидаемого уменьшения полного времени ее исполнения. Выбирают участок с номером j=1 как первый претендент на модификацию (21).
На фиг.4 показана блок-схема итеративного алгоритма оптимизации. Сперва запоминают (22) значение возможного эффекта оптимизации D=P(j+1) для участка B(j+1), следующего по порядку в полученной упомянутой последовательности за выбранным линейным участком. Это необходимо для принятия решения о продолжении оптимизации участка B(j) или переходе к участку B(j+1). Затем множество операций, спланированных в первом такте участка B(j), переносят (23) на участки {В'}, предшествующие по управлению, включая и сам участок B(j), если он является программным циклом. Модифицированные участки {B(j), B'} перепланируют (24). С учетом результатов планирования определяют (25) значение полного времени Т' исполнения преобразованной в процессе оптимизации промежуточной программы. При получении реального уменьшения указанного времени по сравнению с полным временем исполнения первичной промежуточной программы сравнивают (26) это реальное уменьшение с ожидаемым уменьшением D полного времени исполнения первичной промежуточной программы для участка B(j+1). Если T-T'>= D, то принимают решение о сохранении (27, 30) результатов проделанной оптимизации, после чего заново сортируют (31) множество участков с получением новой последовательности спланированных линейных участков по убыванию ожидаемого уменьшения полного времени исполнения полученной преобразованной промежуточной программы, при этом учитывается полученное на шаге 30 реальное уменьшение. Снова выбирают участок с максимальным ожидаемым эффектом (32), и итерацию алгоритма повторяют уже по отношению к ранее полученной преобразованной промежуточной программе, которую при этом полагают текущей промежуточной программой. Если полученное реальное уменьшение меньше D, то участки B(j) {В'} восстанавливают (28) к исходному виду. При этом, если определено (29), что полученное реальное уменьшение имеет положительное значение, то оно запоминается P(j)=T-T' (30) и множество участков заново сортируется с учетом этого нового значения (31). Снова выбирается участок с максимальным ожидаемым эффектом (32), и итерация алгоритма повторяется. Если же на проверке (29) эффект оптимизации оказался нулевым, то принимают решение о переходе к следующему участку j=j+1 (33) полученной перед этим последовательности спланированных линейных участков для первичной промежуточной программы (или, применительно к последующим циклам действий по оптимизации, для текущей промежуточной программы) или окончании работы алгоритма, если это был последний участок упорядоченной последовательности.
Чтобы учесть специфику работы программы на конкретной архитектурной платформе и контролировать различные характеристики программы в процессе оптимизации, т. е. в ходе переноса операций, полное время исполнения преобразованной промежуточной программы в процессе оптимизации можно определить как с учетом разрастания ее кода, так и с учетом увеличения обращений программы в память. Поэтому в первом случае указанное время определяют по формуле
где Top - полное время исполнения преобразованной промежуточной программы в тактах с учетом дублирования операций в процессе оптимизации;
Lj - время исполнения j-го спланированного линейного участка преобразованной промежуточной программы в тактах;
Nj - число исполнений упомянутого j-го линейного участка;
Кор - положительное число, характеризующее замедление работы преобразованной промежуточной программы на выбранной архитектурной платформе из-за увеличения размеров кода;
Rj - число операций на j-м линейном участке с учетом результатов переноса;
j = 1...m - число линейных участков в совокупности.
Во втором случае указанное время определяют по формуле
где Tmem - полное время исполнения преобразованной промежуточной программы в тактах с учетом увеличения числа обращений в память в процессе оптимизации;
Lj - время исполнения j-го спланированного линейного участка преобразованной промежуточной программы в тактах;
Nj - число исполнений упомянутого j-го линейного участка;
Kmem - положительное число, характеризующее замедление работы преобразованной промежуточной программы в процессе оптимизации на выбранной архитектурной платформе из-за увеличения числа обращений в память;
Mj - число операций обращения в память на j-м линейном участке с учетом результатов переноса;
j = 1...m - число линейных участков в совокупности.
Следует также отметить, что планирование линейных участков при осуществлении способа получения объектного кода по настоящему изобретению обеспечивает учет возможностей архитектурной платформы и знание времени выполнения участков до и после оптимизации на выбранной архитектуре с точностью до одного машинного такта.
Фиг. 5 иллюстрирует результаты работы одной итерации алгоритма при модификации участка (34) с переносом операции (35) на участки, предшествующие по управлению (34), (36) и (37) с длинами, т.е. временем исполнения участков, в 2, 4, 2 такта и счетчиками N1, N2, N3 соответственно. До оптимизирующего преобразования имелось некоторое значение Т1 полного времени исполнения текущей промежуточной программы (первичной или преобразованной). В результате переноса исходная операция (35) продублирована (38), (39), (40) и помещена на каждый из участков, предшествующих по управлению. По результатам планирования операций длина участка (41) стала на один такт короче по сравнению с исходным участком (36). Длины остальных линейных участков не изменились. Новое значение полного времени исполнения преобразованной вышеописанным образом промежуточной программы в результате этого оптимизирующего преобразования стало равно T2 = T1-N2, оно меньше предыдущего значения. Поэтому результаты оптимизации в данном случае будут сохранены в преобразованной промежуточной программе.
Предлагаемый способ получения объектного кода был применен в оптимизирующем компиляторе с языков С, Фортран-77 для получения параллельного кода микропроцессора "Эльбрус-3М". Для программ целочисленных вычислений, которые трудно поддаются оптимизации традиционными методами, было получено ускорение исполнения кода на модели архитектуры микропроцессора в 1,5-2,2 раза. Предпочтительно использовались задачи пакета замеров производительности SPEC CPU95, известного специалистам в данной области. Пакет задач поставляется компанией Standard Performance Evaluation Corporation (SPEC) и рекомендуется для сравнения производительности архитектурных платформ и вычислительных систем.



Изобретение относится к области оптимизирующей компиляции программ для повышения уровня параллелизма при исполнении на современных архитектурных платформах. Технический результат заключается в обеспечении возможности сокращения времени выполнения объектного кода исходной программы, особенно при статическом распараллеливании вычислений. Способ реализует итеративный алгоритм на базе использования профиля программы с пошаговым контролем за ходом оптимизации путем оценки целевой функции, характеризующей время исполнения программы, который последовательно применяется ко всем линейным участкам исходной программы, начиная с участков, потенциально дающих наибольшее ускорение. 4 з.п.ф-лы, 5 ил.

где Т - полное время исполнения первичной промежуточной программы в тактах;
Lj - время исполнения j-того спланированного линейного участка первичной промежуточной программы в тактах;
Nj - число исполнений упомянутого j-того линейного участка;
j=1...m - число линейных участков;
для каждого спланированного линейного участка первичной промежуточной программы определяют ожидаемое уменьшение полного времени исполнения первичной промежуточной программы в результате выноса совокупности операций, спланированных в первом такте указанного участка, с учетом числа исполнений указанного участка, полученного из сохраненного профиля программы, осуществляют оптимизацию первичной промежуточной программы путем выполнения заданного числа циклов следующих действий, определяемого из условия завершения оптимизации: устанавливают последовательность спланированных линейных участков текущей промежуточной программы по убыванию ожидаемого уменьшения полного времени исполнения текущей промежуточной программы, переносят совокупность операций, спланированных в первом такте первого линейного участка указанной последовательности, на предшествующие ему по управлению спланированные линейные участки текущей промежуточной программы, включая в их число тот же спланированный участок в случае программного цикла, при этом получают преобразованную промежуточную программу, имеющую по меньшей мере два модифицированных участка, определяют полное время исполнения преобразованной промежуточной программы, полученное с учетом планирования ее участков, и реальное уменьшение указанного времени по сравнению с полным временем исполнения текущей промежуточной программы и полученное реальное уменьшение сравнивают с ожидаемым уменьшением полного времени исполнения текущей промежуточной программы для следующего линейного участка указанной последовательности, при этом, если первое из упомянутых уменьшений не меньше второго, сохраняют преобразованную промежуточную программу, после чего выполняют для нее указанный цикл действий, полагая ее текущей промежуточной программой в данном цикле, причем реальное уменьшение полного времени исполнения полученной последующей преобразованной промежуточной программы определяют по сравнению с полным временем исполнения предыдущей преобразованной промежуточной программы, если первое из упомянутых уменьшений меньше второго, восстанавливают состояние модифицированных участков, причем при положительном значении реального уменьшения его запоминают и выполняют указанный цикл действий с учетом этого значения, а при отсутствии реального уменьшения выполняют указанный цикл действий, осуществляя его с действия по переносу совокупности операций, спланированных в первом такте следующего линейного участка последней полученной последовательности спланированных линейных участков для текущей промежуточной программы, на основе полученной в результате оптимизации совокупности линейных участков последней преобразованной промежуточной программы формируют в указанной ЭВМ с помощью компилятора оптимизированный объектный код, который сохраняют на носителе информации.
где Тор - полное время исполнения преобразованной промежуточной программы в тактах с учетом дублирования операций в процессе оптимизации;
Lj - время исполнения j-того спланированного линейного участка преобразованной промежуточной программы в тактах;
Nj - число исполнений упомянутого j-того линейного участка;
Kop - положительное число, характеризующее замедление работы преобразованной промежуточной программы на выбранной архитектурной платформе из-за увеличения размеров кода;
Rj - число операций на j-том линейном участке с учетом результатов переноса;
j=1...m - число линейных участков в совокупности.
Tmem
где Тmem - полное время исполнения преобразованной промежуточной программы в тактах с учетом увеличения числа обращений в память в процессе оптимизации;
Lj - время исполнения j-того спланированного линейного участка преобразованной промежуточной программы в тактах;
Nj - число исполнений упомянутого j-того линейного участка;
Kmem - положительное число, характеризующее замедление работы преобразованной промежуточной программы в процессе оптимизации на выбранной архитектурной платформе из-за увеличения числа обращений в память;
Mj - число операций обращения в память на j-ом линейном участке с учетом результатов переноса;
j=1...m - число линейных участков в совокупности.
| DE 19840029 С1, 20.04.2000 | |||
| СПОСОБ И УСТРОЙСТВО ДЛЯ ДОСТОВЕРНОЙ ОЦЕНКИ СЕМАНТИЧЕСКИХ ПРИЗНАКОВ В СИНТАКСИЧЕСКОМ АНАЛИЗЕ ПРИ ПРОХОДЕ ВПЕРЕД СЛЕВА НАПРАВО | 1995 |
|
RU2115158C1 |
| СПЕЦИАЛИЗИРОВАННЫЙ ПРОЦЕССОР | 1995 |
|
RU2147378C1 |
| DE 4206567 С1, 27.05.1993 | |||
| Бесколесный шариковый ход для железнодорожных вагонов | 1917 |
|
SU97A1 |
| Способ холодной прокатки труб | 1977 |
|
SU751459A1 |
| Автоматический огнетушитель | 0 |
|
SU92A1 |

