Изобретение относится к области вычислительной техники и применяется для оптимизации программного кода.
Один из способов повысить скорость работы кода за счет использования возможностей архитектуры вычислительных комплексов - это спланировать одновременное исполнение нескольких операций в одном такте, то есть повысить параллельность кода.
Повышение скорости работы кода оптимизирующим компилятором достигается в значительной степени за счет планирования параллельного исполнения операций на устройствах вычислительных комплексов. Однако отсутствие информации о независимости чтений и записей существенно ограничивает возможности по изменению очередности исполнения. В этом случае нельзя менять исполнение чтения и записи местами, удалять повторные чтения и записи по тому же адресу, или одновременно исполнять зависимые операции, которые стоят до записи и после чтения. При динамическом планировании исполнения операций выявление информации о различии адресов чтений и записей может производится уже в процессе исполнения кода, что позволяет достаточно эффективно динамически спланировать исполнение операций. В случае же статического планирования основные доступные методы выявления независимости адресов - это применение различных методов анализа указателей и использование дополнительных правил работы с указателями (restrict, strict aliasing), информацию о соблюдении которых в исходном коде передается пользователем с помощью специальных опций или прагм. Несмотря на то, что анализ указателей - это обширный и развитый набор методов, его возможности весьма ограничены в случае передачи указателей между процедурами, наличия глобальных переменных и использования других типичных для программ С и С++ конструкций, и в случае использования в коде нерегулярно вычисляемых адресов от одного типа объектов.
Для обеспечения более высокой параллельности на уровне операций в процессорах со статическим планированием разработан механизм поддержки динамического разрыва зависимостей на уровне устройств, позволяющий выполнять часть операций спекулятивно (speculative), то есть заранее. А в случае последующего получения информации о том, что по адресу для чтений была произведена запись, перевыполнять часть операций уже с использованием правильного значения. Такой механизм реализован в процессорах Эльбрус с VLIW-архитектурой (DAM или Disambiguation of Accessing Memory), а также, с небольшими отличиями, для архитектуры Itanium (Advanced Load Address Table или ALAT).
Из уровня техники известен способ использования DAM и ALAT (прототип) для спекулятивного исполнения кода с помощью динамического разрыва зависимостей, который заключается в следующем: вместо исходного чтения до потенциально конфликтующей записи строится спекулятивная операция чтения (speculative load), а на месте исходной операции чтения строится операция проверочного чтения (check load). При этом адрес исходного чтения на уровне аппаратуры заносится в специальную таблицу, а потребители исходного чтения на вход получают данные, считанные спекулятивным чтением. В случае, если в дальнейшем произошел конфликт и данные по адресу спекулятивного чтения были изменены, то это отразится на операции проверочного чтения, которая проверяет данные в таблице. В результате будет произведен переход на код с повторным исполнением части операций (recovery code или компенсирующий код), в котором будут использованы данные, считанные проверочной операцией чтения, а затем произойдет обратный переход в точку проверки. Данный способ описан в «Руководство по эффективному программированию на платформе Эльбрус», Нейман-заде М. И., Королев С.Д. © 2020, АО «МЦСТ», стр. 90-91.
Недостатком указанного способа является то, что вместо каждого чтения исходного кода исполняется по 2 операции чтения - операция спекулятивного чтения и операция проверочного чтения, что замедляет исполнение даже в случае отсутствия конфликта по адресам. Кроме того, есть ограничение на количество доступных спекулятивных чтений, поскольку их требуется отслеживать в ограниченной по размеру таблице (32 для обеих описанных выше архитектур), а в случае нехватки этого размера могут остаться лишние зависимости по данным, что тоже отрицательно скажется на скорости работы кода.
Целью способа является повышение скорости исполнения кода за счет сокращения количества операций, создающихся при использовании механизма спекулятивных чтений, а также за счет обеспечения применимости механизма спекулятивного исполнения для большего числа чтений исходного кода.
Поставленная цель достигается за счет того, что при исполнении программного кода процессор для нескольких операций чтения по общему адресу исполняет только одну общую спекулятивную операцию чтения и одну общую операцию проверочного чтения, а сохранение данных от остальных чтений для компенсирующего кода реализует без использования спекулятивных операций.
Краткое описание чертежей и схем, иллюстрирующих предлагаемый способ и его применение в процессе планирования машинного кода:
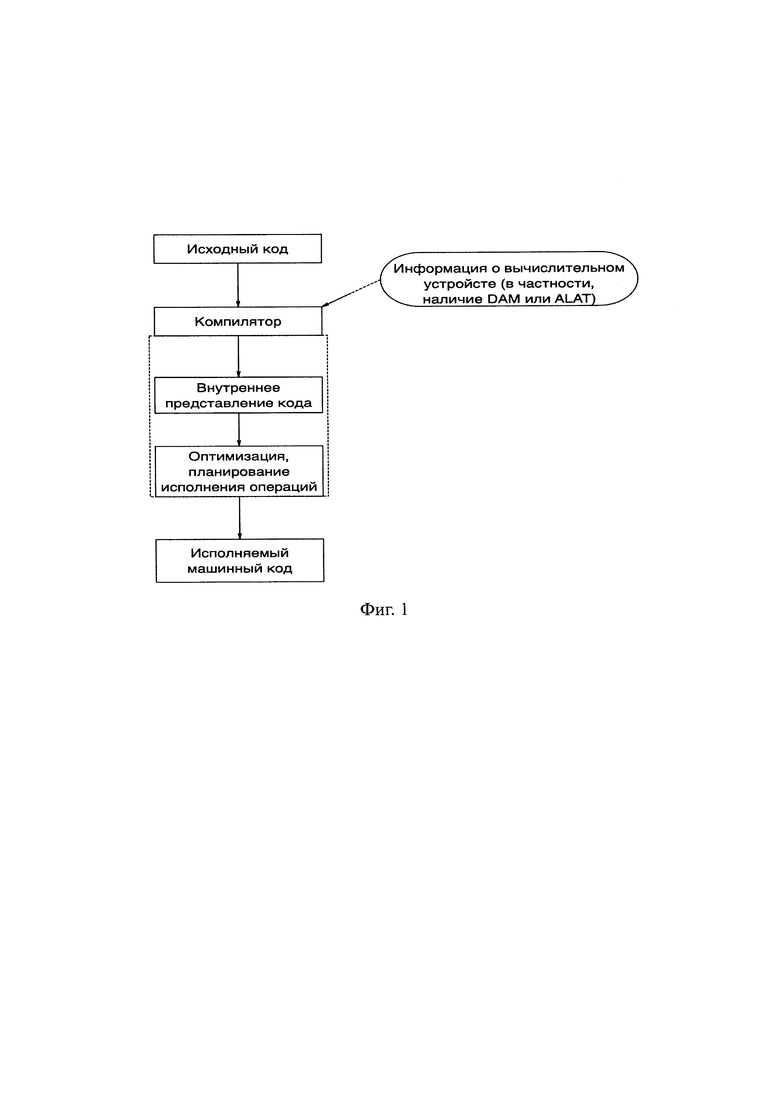
Фиг. 1 - Схема процесса компиляции кода с оптимизацией.
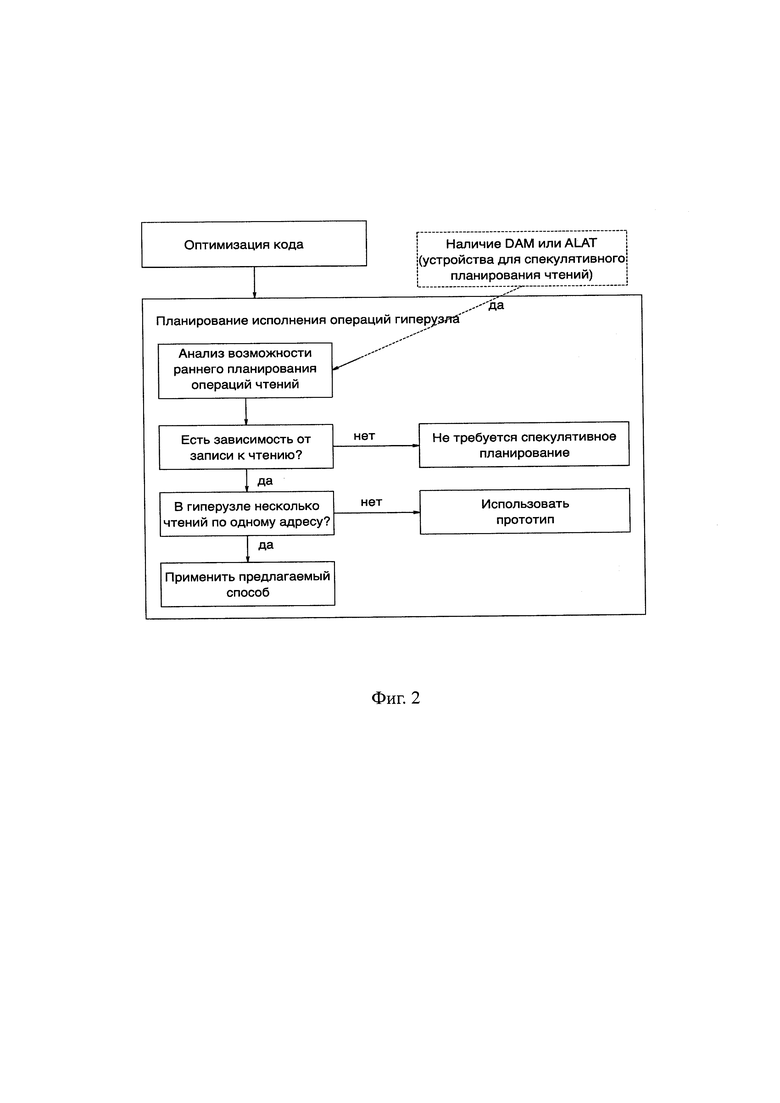
Фиг. 2 - Схема спекулятивного исполнения кода с указанием точки отличия от прототипа.
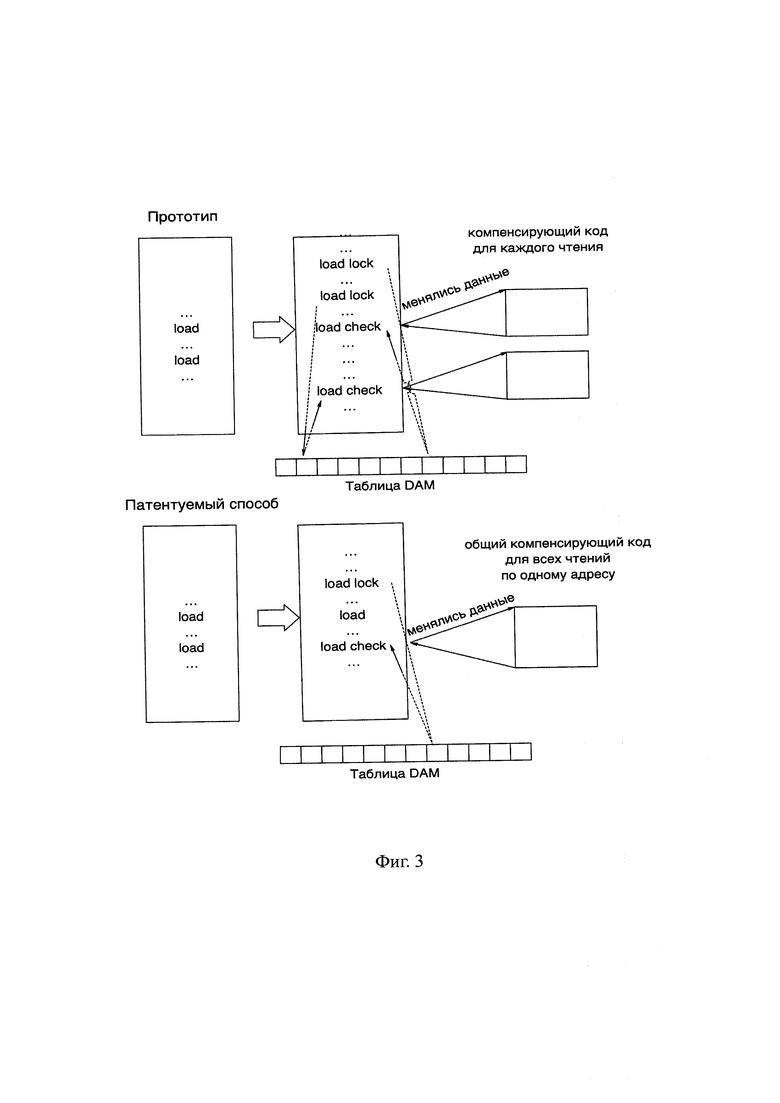
Фиг. 3 - Сравнительная схема работы прототипа и предлагаемого способа.
После первичной обработки исходного кода компилятор формирует промежуточное представление, а также получает информацию о наличии различных вычислительных устройств, с учетом которых может принимать решения об использовании механизма спекулятивного планирования (Фиг. 1). На этапе планирования операций сформированных в процессе компиляции гиперузлов в случае наличия потенциальных конфликтов между операциями записи и чтения необходимо произвести проверку наличия нескольких операций чтения по одному адресу (Фиг. 2). Если они нашлись, то к ним предлагается применять способ исполнения процессором программ с использованием таблицы адресов спекулятивности по данным. Для остальных чтений при этом используется традиционный способ (прототип).
Осуществление способа исполнения процессором программ с использованием таблицы адресов спекулятивности по данным заключается в следующем:
1) Строится одна операция спекулятивного чтения по общему адресу перед потенциально конфликтующими с чтениями операциями записи.
2) Вместо результатов исходных чтений для всех соответствующих потребителей в основном коде (не компенсирующем) используется результат построенного спекулятивного чтения.
3) В точке самого последнего исходного чтения по общему адресу строится операция проверочного чтения, во всех остальных точках чтений по общему адресу строятся обычные (не спекулятивные) чтения, результат которых будет использоваться на общем компенсирующем коде (Фиг 3).
4) Строится компенсирующий код для всех спекулятивно исполненных операций. В нем для того потребителя чтения (use), который использовал результат последнего чтения, используется результат проверочного чтения. Для остальных потребителей используются результаты соответствующих обычных чтений.
При применении описанного способа к n исходным чтениям по общему адресу строится 1 операция спекулятивного чтения (speculative load), 1 операция проверочного чтения (check load) и (n-1) обычная операция чтения (load), то есть суммарно n+1 операция чтения. При этом в таблице (DAM или ALAT) для всех n исходных чтений создается только одна запись.
В случае же использования прототипа для n исходных чтений по общему адресу строится n спекулятивных операций чтения и n проверочных чтений, то есть 2*n операций чтения. При этом в таблице (DAM или ALAT) для каждого исходного чтения создается своя запись, то есть для n чтений создается n записей.
Итого применение описанного способа для каждой группы из п чтений по общему адресу позволяет по сравнению с прототипом сократить суммарное количество требуемых операций чтения с 2*n до (n+1) операций, а также сократить использование таблицы (DAM или ALAT) с n записей до одной. Сокращение суммарного количества операций чтения позволяет ускорить исполнение кода за счет меньшего количества требуемых вычислений. Сокращение использования таблицы позволяет спланировать спекулятивное исполнение большего количества чтений исходного кода по сравнению с прототипом, то есть ускорять исполнение кода за счет повышения его спекулятивности.
Разработанный способ позволяет максимально минимизировать использование операций спекулятивного чтения и операций проверок результата чтения, что повышает скорость исполнения итогового машинного кода на архитектурах с динамическим механизмом разрыва зависимостей по типу DAM или ALAT.
| название | год | авторы | номер документа |
|---|---|---|---|
| VLIW-ПРОЦЕССОР С УЛУЧШЕННОЙ ПРОИЗВОДИТЕЛЬНОСТЬЮ ПРИ ЗАДЕРЖКЕ ОБНОВЛЕНИЯ ОПЕРАНДОВ | 2023 |
|
RU2816092C1 |
| СПОСОБ КОНВЕЙЕРНОЙ ОБРАБОТКИ КОМАНД ДЛЯ КОМПЬЮТЕРА С VLIW-ПРОЦЕССОРОМ И ОПТИМИЗИРУЮЩИМ КОМПИЛЯТОРОМ И КОМПЬЮТЕР ДЛЯ ОСУЩЕСТВЛЕНИЯ СПОСОБА | 2024 |
|
RU2820021C1 |
| ПРЕДСТАВЛЕНИЕ ФИЛЬТРАЦИИ НАБЛЮДЕНИЯ, АССОЦИИРОВАННОЙ С БУФЕРОМ ДАННЫХ | 2013 |
|
RU2608000C2 |
| ОБРАБОТКА ТРАНЗАКЦИЙ | 2013 |
|
RU2606878C2 |
| ОПТИМИЗИРОВАННАЯ ДЛЯ ПОТОКОВ МНОГОПРОЦЕССОРНАЯ АРХИТЕКТУРА | 2007 |
|
RU2427895C2 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ УСОВЕРШЕНСТВОВАННЫХ ТЕХНОЛОГИЙ ПРОПУСКА БЛОКИРОВКИ | 2014 |
|
RU2595925C2 |
| ОПТИМИЗАЦИЯ ОПЕРАЦИЙ ПРОГРАММНОЙ ТРАНЗАКЦИОННОЙ ПАМЯТИ | 2006 |
|
RU2433453C2 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ КОМПИЛЯЦИИ НЕЙРОННЫХ СЕТЕЙ | 2024 |
|
RU2835757C1 |
| СПОСОБ АВТОМАТИЧЕСКОГО РАСПАРАЛЛЕЛИВАНИЯ ПРОГРАММ | 2009 |
|
RU2411569C2 |
| УСТРОЙСТВО И СПОСОБ РЕВЕРСИРОВАНИЯ И ПЕРЕСТАНОВКИ БИТОВ В РЕГИСТРЕ МАСКИ | 2014 |
|
RU2636669C2 |
Изобретение относится к вычислительной технике. Технический результат заключается в повышении скорости исполнения итогового машинного кода на архитектурах с динамическим механизмом разрыва зависимостей. Способ исполнения процессором программ с использованием таблицы адресов спекулятивности по данным включает вычислительный комплекс, содержащий процессор с архитектурой VLIW, реализующий механизм DAM или ALAT, поддерживающий исполнение операций спекулятивного чтения с занесением в таблицу адресов спекулятивности по данным, проверочного и обычного чтений, компилятор, транслирующий программный код процессору, причем при исполнении программного кода процессор для нескольких операций чтения по общему адресу исполняет только одну общую спекулятивную операцию чтения и одну общую операцию проверочного чтения, а сохранение данных от остальных чтений для компенсирующего кода реализует без использования спекулятивных операций. 3 ил.
Способ исполнения процессором программ с использованием таблицы адресов спекулятивности по данным, включающий вычислительный комплекс, содержащий процессор с архитектурой VLIW, реализующий механизм DAM или ALAT, поддерживающий исполнение операций спекулятивного чтения с занесением в таблицу адресов спекулятивности по данным, проверочного и обычного чтений, компилятор, транслирующий программный код процессору, отличающийся тем, что при исполнении программного кода процессор для нескольких операций чтения по общему адресу исполняет только одну общую спекулятивную операцию чтения и одну общую операцию проверочного чтения, а сохранение данных от остальных чтений для компенсирующего кода реализует без использования спекулятивных операций.
| Способ защиты переносных электрических установок от опасностей, связанных с заземлением одной из фаз | 1924 |
|
SU2014A1 |
| Способ приготовления мыла | 1923 |
|
SU2004A1 |
| Пресс для выдавливания из деревянных дисков заготовок для ниточных катушек | 1923 |
|
SU2007A1 |
| Способ обработки целлюлозных материалов, с целью тонкого измельчения или переведения в коллоидальный раствор | 1923 |
|
SU2005A1 |
| СПОСОБ ВЫПОЛНЕНИЯ УПРЕЖДАЮЩЕГО ЧТЕНИЯ В СИСТЕМАХ ХРАНЕНИЯ ДАННЫХ | 2017 |
|
RU2672726C1 |

