ОБЛАСТЬ ТЕХНИКИ
[1] Заявленное решение относится к области глубокого обучения, в частности к тензорному компилятору нейронных сетей и способу компиляции нейронных сетей.
УРОВЕНЬ ТЕХНИКИ
[2] В настоящее время практически любую нейронную сеть можно исполнить на центральном процессоре (CPU) - для этого существует множество различных инструментов, например, таких как PyTorch, TensorFlow, MXNet и пр. Данные библиотеки предоставляют как механизмы построения моделей, так и возможность для их запуска без каких-либо дополнительных зависимостей. Однако CPU не является устройством, оптимизированным для подобных вычислений, поэтому отдельные компании предлагают программно-аппаратные архитектуры для собственных графических ускорителей (GPU): Nvidia cuDNN, Intel oneDNN, ARMCompute и т.п. Комбинации данных методов позволяют значительно сократить время исполнения моделей, что является очень важным критерием для многих пользователей, особенно для задач вычислений в реальном времени. Кроме того, на рынке существуют также специализированные ИИ-ускорители (Intel Nervana NNP, Google TPU, Huawei Ascend 310/910 и др.), которые занимают конкурирующие позиции в рейтинге производительности в сравнении с GPU в задачах глубокого обучения. Очевидно, что графические ускорители остаются процессорами общего назначения, в то время как ИИ-ускорители созданы исключительно для данных задач и исполнения нейронных сетей. В связи с этим можно сформулировать следующие преимущества ИИ-ускорителей:
• обеспечение значительно большей пропускной способности за счёт особенностей архитектуры внутреннего устройства,
• демонстрация наилучших показателей энергоэффективности.
[3] Для обеспечения работы графических и тензорных процессоров требуются специальные инструменты, конечная задача которых - формирование соответствующих машинных инструкций для той или иной архитектуры устройства. В качестве таких инструментов можно выделить:
[4] OpenVINO - широкий набор инструментов разработки и анализа, упрощающих выполнение задач машинного обучения. Ключевая ценность - встроенный механизм конвертации представлений моделей нейронных сетей, а также возможность организации и подключения своего собственного пространства - плагина. В соответствии с официальной документацией OpenVINO, версия 2024 года поддерживает импорт семи различных форматах (ONNX, PaddlePaddle, TensorFlow, PyTorch, MXNet, Caffe), преобразуя их в собственное представление OpenVINO IR. Таким образом, спектр задач по оптимизациям представлений модели нейронной сети фокусируется только на данном формате, что значительно упрощает процесс разработки.
[5] MLIR - программная платформа для разработки компиляторов, являющаяся надстройкой над LLVM. Данное ПО содержит в себе большой набор инструментов для оптимизаций последовательностей операций на разных уровнях их представлений. С использованием данных средств MLIR возможна организация многоуровневой архитектуры диалектов, позволяющих трансформировать представления наиболее оптимальным образом с учетом архитектурных особенностей аппаратной части для последующей трансляции в машинный код. Для связи OpenVINO IR с верхним диалектом компилятора предполагается использование адаптера с интерфейсным диалектом CHHL (HLD).
[6] Указанные ранее компании также разрабатывают аналогичные продукты для своих платформ, тем не менее их использование для достижения наших поставленных целей невозможно по следующим причинам:
• ИИ-ускорители обладают уникальной архитектурой, отличающейся от архитектур существующих устройств на рынке, данный факт обуславливает невозможность исполнения машинного кода, подготовленного сторонними инструментами, на наших платформах;
• поставляемые инструменты являются решениями с закрытым исходным кодом, что делает невозможным их адаптацию для наших устройств.
[7] В связи с вышеописанным, предлагается реализация собственного механизма для предоставления возможности проведения вычислений на базе заявляемого устройства.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
[8] Заявленное решение позволяет решить техническую проблему в части создания способа и устройства для компиляции нейронных сетей (тензорного компилятора) для обеспечения работоспособности и взаимодействия вычислительных устройств за счёт организации механизмов перевода представлений моделей нейронных сетей в машинный код, поддерживаемый архитектурой вычислительного устройства.
[9] На этапе проектирования заявленного решения были выдвинуты следующие требования к функциональности:
• возможность загрузки моделей нейронных сетей в наиболее популярных форматах их представления;
• возможность интеграции с различными ML-инструментами разработчика для обучения;
• поддержка гетерогенного исполнения.
[10] С учетом особенностей архитектуры векторного вычислительного устройства, реализация собственного тензорного компилятора позволит проводить высокопроизводительные вычисления, достигаемые за счет:
• большого набора разработанных оптимизаций и (специфичных для векторного вычислительного устройства) трансформаций над графом операций модели нейронной сети, а также микроядер, обеспечивающих:
ο высокую пропускную способность за счет организации оптимальной работы систолических массивов (для вычисления матричных операций);
ο сокращение потребляемых ресурсов (памяти);
ο высокий показатель утилизации векторного вычислительного устройства (высоким показателем считается максимально приближенное значение к теоретической оценке для конкретной модели нейронной сети).
• разработанных специальных механизмов, позволяющих сократить накладные расходы при работе с памятью за счет организации очерёдных вычислений на последовательно и/или параллельно соединенных внутренних устройствах, а также (в целях увеличения скорости исполнения) распределить и синхронизировать вычислительную нагрузку на:
ο параллельных внутренних функциональных элементах векторного вычислительного устройства;
ο несколько независимых устройств одной архитектуры.
• высокого показателя энергоэффективности самого векторного вычислительного устройства.
[11] Техническим результатом является повышение производительности процесса компиляции нейронных сетей.
[12] Заявленный технический результат достигается за счет выполнения способа компиляции нейронных сетей, выполняемого по меньшей мере одним процессором, и содержащего этапы, на которых:
a) получают по меньшей мере одну модель нейронной сети и преобразуют её в унифицированный формат, представляющий ориентированный граф, где вершины графа являются операциями модели нейронной сети,
b) определяют возможности выполнения операций модели нейронной сети на по меньшей мере одном основном или вспомогательном вычислительном устройстве на основании анализа операций модели нейронной сети и информации об архитектуре указанных вычислительных устройств,
c) разделяют ориентированный граф на основной подграф и подграфы предварительной обработки и постобработки на основании возможности выполнения операций модели нейронной сети, определенной на этапе b),
d) формируют последовательность запуска операций модели нейронной сети на основании взаимодействия участков основного подграфа с подграфами предварительной обработки и постобработки,
e) осуществляют трансформации операций модели нейронной сети основного подграфа для оптимизации их исполнения, в результате получая оптимизированный унифицированный формат,
f) преобразуют оптимизированный унифицированный формат в высокоуровневый диалект путём применения трансформаций для сокращения количества вычислений и/или объема используемых данных,
g) преобразуют высокоуровневый диалект в диалект общего уровня путём распределения операций модели нейронной сети между аппаратными блоками основного вычислительного устройства с учетом иерархии памяти, размеров тензоров и используемых типов данных,
h) преобразуют диалект общего уровня в низкоуровневый диалект, состоящий из набора команд, доступных для выполнения на основном вычислительном устройстве,
i) осуществляют генерацию бинарного потока данных на основе низкоуровневого диалекта и разбиение бинарного потока данных на отдельные инструкции для параллельной обработки на аппаратных блоках основного вычислительного устройства,
j) выполняют инструкции, полученные на этапе i), на основном вычислительном устройстве, а также выполняют операции из подграфов предварительной обработки и постобработки на вспомогательном вычислительном устройстве на основании последовательности запуска, сформированной на этапе d).
[13] В одном из частных примеров реализации основное вычислительное устройство является векторным вычислительным устройством.
[14] В другом частном примере реализации вспомогательное вычислительное устройство является центральным процессорным устройством (CPU).
[15] В другом частном примере реализации этап определения возможности выполнения операций модели нейронной сети на основном или вспомогательном вычислительном устройстве дополнительно содержит:
• применение предварительных преобразований для нахождения операций модели нейронной сети, не поддерживаемых основным вычислительным устройством,
• локализацию найденных не поддерживаемых операций модели нейронной сети.
[16] В другом частном примере реализации основной подграф содержит операции модели нейронной сети, поддерживаемые основным вычислительным устройством, а подграфы предварительной обработки и постобработки содержат операций модели нейронной сети, не поддерживаемые основным вычислительным устройством.
[17] В другом частном примере реализации обеспечение взаимодействия участков основного подграфа с подграфами предварительной обработки и постобработки включает связывание параметров и результатов разных участков подграфов.
[18] В другом частном примере реализации связывание параметров и результатов разных участков подграфов включает связывание результата предыдущей по порядку исполнения операции с входным параметром следующей операции посредством ссылки.
[19] В другом частном примере реализации трансформации операций модели нейронной сети, осуществляемые на этапе e), включают по меньшей мере одно из:
• трансформации для движения и слияния операций транспонирования,
• трансформации для декомпозиции операций выравнивания дисперсии,
• трансформации для релаксации операций.
[20] В другом частном примере реализации трансформации для сокращения количества вычислений и/или объема используемых данных на этапе преобразования оптимизированного унифицированного формата в высокоуровневый диалект включают по меньшей мере одно из:
• нормализация операций,
• сворачивание констант,
• вывод размеров,
• упрощение цепочек операций,
• выравнивание глубин тензоров.
[21] В другом частном примере реализации этапы преобразования высокоуровневого диалекта в диалект общего уровня и преобразования диалекта общего уровня в низкоуровневый диалект дополнительно содержат выравнивание тензоров для работы с данными.
[22] Заявленный технический результат достигается также за счет реализации устройства для компиляции нейронных сетей, содержащего
по меньшей мере одно основное и вспомогательное вычислительные устройства, обеспечивающие возможность гетерогенного исполнения операций модели нейронной сети,
по меньшей мере один процессор,
по меньшей мере одну память, связанную с процессором и содержащую машиночитаемые инструкции, которые при их выполнении по меньшей мере одним процессором обеспечивают выполнение способа компиляции нейронных сетей.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
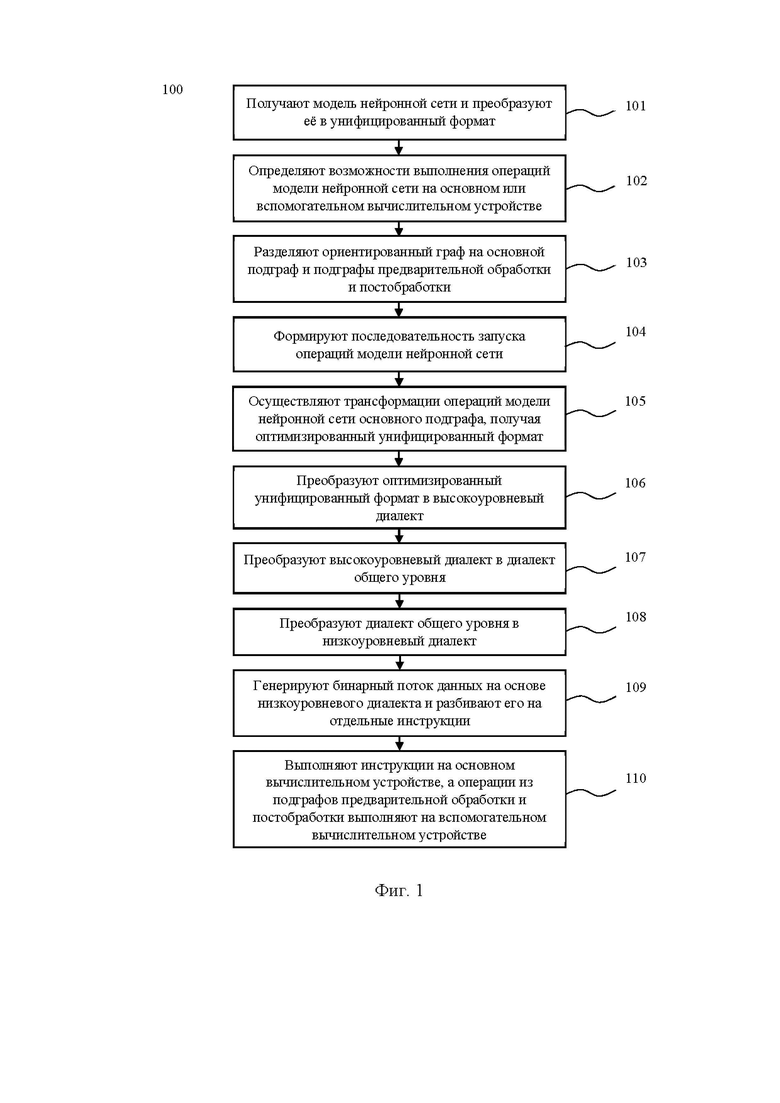
[23] На Фиг. 1 представлена блок-схема способа компиляции нейронных сетей.
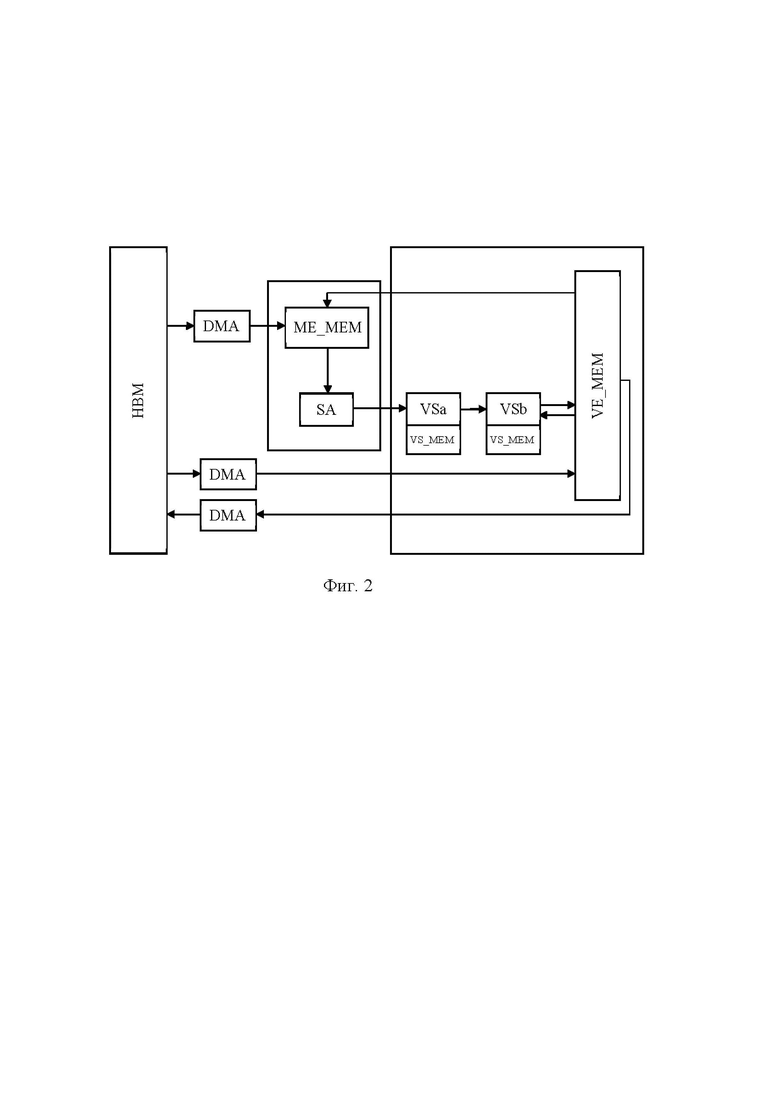
[24] На Фиг. 2 представлена общая схема векторного вычислительного устройства.
ОСУЩЕСТВЛЕНИЕ ИЗОБРЕТЕНИЯ
[25] Ниже будут описаны понятия и термины, необходимые для понимания настоящего изобретения.
[26] Компиляция - это процесс преобразования высокоуровневого исходного кода в низкоуровневый машинный код, который может быть выполнен целевой машиной [1].
[27] Тензорный компилятор - это инструмент, обеспечивающий проведение оптимизаций над графовым представлением модели нейронный сети, а также её трансляцию в машинный код с оптимизацией для дальнейшего исполнения на конкретном устройстве.
[28] Гетерогенное исполнение - это исполнение модели нейронной сети, при котором отдельные подграфы могут вычисляться на разных устройствах [2]. Наиболее частый пример - наличие небольших участков предварительной обработки и постобработки (препроцессинг и постпроцессинг), вычисление которых проводится на процессорах общего назначения, в то время как вычисление основного участка модели проводится на специальном устройстве, например, векторном вычислительном устройстве.
[29] Систолический массив (от англ. systolic array) - это однородная сеть тесно связанных блоков обработки данных (DPU), называемых ячейками или узлами. Каждый блок обработки данных независимо и параллельно вычисляет частичный результат как функцию данных, полученных от его вышестоящих соседей, сохраняет результат внутри себя и передает его нижестоящим узлам [3]. Блоки обработки данных служат для обработки данных, решающих узкоспециализированные задачи вычислений, и обладают высоким показателем пропускной способности.
[30] Векторный процессор - это процессор, в котором операндами некоторых команд могут выступать упорядоченные массивы данных - векторы [4].
[31] Высокопропускная память (от англ. High Bandwidth Memory, HBM) - это высокопроизводительный интерфейс ОЗУ для DRAM с многослойной компоновкой кристаллов в микросборке [5].
[32] Микроядро - это микропрограмма, позволяющая представить операцию или набор операций как набор низкоуровневых инструкций для дальнейшего исполнения. Как правило, обладает высоким показателем утилизации за счет прямой связи с архитектурой устройства. Данная микропрограмма встраивается в общий набор низкоуровневых инструкций (результат работы тензорного компилятора) в качестве выделенного блока, связанного как с предыдущими, так и с последующими инструкциями.
[33] Утилизация устройства - это отношение вычислительной сложности нагрузки к произведению числа тактов, потраченных устройством на решение задачи и пиковой производительности устройства. Чем выше данный показатель, тем более эффективно используются вычислительные ресурсы устройства при решении задачи (вычислениях).
[34] Трансформация - это специальный метод, имеющий определенный шаблон подграфа, выполняющий локализацию операций в соответствии с данным шаблоном, а также проводящий процедуры анализа и адаптации найденных участков в целях оптимизации их под конкретное устройство [6].
[35] Устройство сброса - это вспомогательное вычислительное устройство при гетерогенном исполнении. Тензорный компилятор обеспечивает не только оптимизацию графа модели нейронной сети, но и проводит анализ, позволяющий определить не поддерживаемые на устройстве операции. Данные операции "сбрасываются" для исполнения на вспомогательном вычислительном устройстве (по умолчанию - CPU).
[36] Релаксация операции - это переопределение набора допустимых входных и выходных типов данных для операции [7]. Под переопределением подразумевается создание нового набора допустимых типов данных.
[37] Диалект - это задекларированный набор операций, отображающий множество операций представления модели нейронной сети.
[38] Промежуточное представление - это цепочка связанных операций (граф) из диалекта.
[39] Тензор - это многомерная структура данных, в частности, многомерный массив.
[40] Лэйаут (layout) - это схема или макет, описывающая размещение элементов входного тензора данных в памяти, а также способ хранения многомерных массивов [8].
[41] NCHW и NHWC - это два наиболее распространенных конкретных формата лэйаута. Данные акронимы описывают порядок размещения размерностей тензора, где N - количество выборок данных, H - высота данных, W - ширина, C - каналы данных. К примеру, тензор для представления двух изображений в формате RGB (т.е. 3 канала) размером 10 на 10 пикселей будет иметь вид (2,3,10,10) в NCHW и (2,10,10,3) в NHWC.
[42] Операция транспонирования - это операция, применяемая над тензором, которая проводит перемещение его размерностей [9]. К примеру, если взять двумерный тензор (матрицу) размерами AxB, то транспонировать её можно только единственным образом - в тензор BxA. Для больших тензоров, количество вариантов транспонирования становится равным числу перестановок от числа размерностей, поэтому данная операция имеет дополнительный одноименный параметр, регламентирующий конкретное правило перемещения размерностей. Перевод лэйаута NHWC в NCHW и наоборот также осуществляется при помощи данной операции с перестановками (0, 3, 1, 2) и (0, 2, 3, 1) соответственно.
[43] Генератор паттернов адресов (Address Pattern Generator, APG) - это механизм адресации, позволяющий за одну инструкцию/команду получить доступ на чтение и запись циклически по заданным значениям шага и количеству шагов.
[44] На Фиг. 1 представлен способ компиляции нейронных сетей, выполняемый по меньшей мере одним процессором.
[45] На первом этапе (101) получают по меньшей мере одну модель нейронной сети и преобразуют её в унифицированный формат, представляющий ориентированный граф, где вершины графа являются операциями модели нейронной сети.
[46] Заявленное решение поддерживает получение моделей нейронной сети в различных форматах. В качестве таких форматов могут выступать, но не ограничиваться указанными примерами, форматы ONNX, PaddlePaddle, TensorFlow, PyTorch, MXNet, Caffe или Kaldi. Конвертация или преобразование в унифицированный формат необходима для поддержки множественных представлений, т.е. обеспечения они своего единого набора представлений операций. В предпочтительном варианте исполнения в качестве унифицированного формата выступает, но не ограничивается им, формат OpenVINO IR [10].
[47] Вершины ориентированного графа являются операциями модели нейронной сети, например, такими как свертка, объединение и поэлементные операции с тензорами. Операции модели нейронной сети определяют, как обрабатываются входные данные для получения выходных данных.
[48] Данный этап (101), выполняемый устройством для компиляции нейронных сетей (тензорным компилятором нейронных сетей), является точкой входа и выхода, регламентирующей работу вложенных элементов и позволяющая взаимодействовать с устройством без необходимости изучать особенности его архитектуры.
[49] На этапе (102) определяют возможности выполнения операций модели нейронной сети на по меньшей мере одном основном или вспомогательном вычислительном устройстве на основании анализа операций модели нейронной сети и информации об архитектуре указанных вычислительных устройств.
[50] Основная задача, решаемая тензорным компилятором на данном этапе (102), - обеспечение гетерогенного исполнения, т.е. определение операций, которые будут исполняться на основном вычислительном устройстве и операций, которые будут исполняться на вспомогательном вычислительном устройстве (устройстве сброса). Для реализации данного механизма, нами был разработан отдельный набор шаблонов, при помощи которых выполняется локализация требующих внимания операций или подграфов на всем представлении модели нейронной сети, а также набор методов, способных анализировать найденные при помощи шаблонов области. В соответствии с информацией об архитектуре устройства и на основе анализа данных областей, принимается решение, возможно ли исполнить ту или иную операцию (с учетом потенциального проведения оптимизаций в дальнейшем).
[51] В частном примере реализации определения возможности выполнения операций модели нейронной сети на основном или вспомогательном вычислительном устройстве дополнительно содержит:
[59] применение предварительных преобразований для нахождения операций модели • нейронной сети, не поддерживаемых основным вычислительным устройством,
• локализацию найденных неподдерживаемых операций модели нейронной сети.
[52] Неподдерживаемые операции помечаются специальными маркерами, на основе которых происходит их обособление (локализация) от основного представления и размещение в двух вспомогательных подграфах: предварительной обработки и постобработки. Решение на размещение конкретной операции в том или ином подграфе проводится на основе вычисленных расстояний от неё и до начала и конца исходного графа.
[53] В предпочтительном варианте исполнения основное вычислительное устройство является ИИ-ускорителем, например, векторным вычислительным устройством. Более подробное описание векторного вычислительного устройства раскрыто далее со ссылкой на Фиг. 2. В качестве вспомогательного вычислительного устройства (устройства сброса) выступает, но не ограничивается им, центральное процессорное устройство (CPU).
[54] На Фиг. 2 представлен общий вид векторного вычислительного устройства, используемого при реализации способа компиляции нейронных сетей. В общем случае основное вычислительное устройство является векторным, т.е. поддерживает одновременные вычисления массива (вектора) данных.
[55] Векторное вычислительное устройство состоит из по меньшей мере следующих модулей (Фиг. 2):
[56] - Векторная память (Vector Memory, VE_MEM) - это общая память (например, SRAM) между вычислительными модулями (VSa, VSb), размер памяти обычно несколько десятков мегабайт. Поддерживается векторная адресация через APG (Address Pattern Generator), позволяющая разным портам одновременно читать и записывать данные в разные участки памяти со скоростью 1 вектор/такт.
[57] - Локальная матричная память (Matrix Engine Memory, ME_MEM) - это локальная память (например, SRAM) для данных в систолическом массиве меньшего объема по сравнению с векторной памятью (VE_MEM). Предназначена для более быстрого доступа систолического массива к необходимым данным. Для каждого систолического массива есть отдельная локальная память (ME_MEM). Скорость доступа составляет 1 вектор/такт. Локальная матричная память имеет возможности записи и чтения из глобальной памяти (HBM) в общую (VE_MEM).
[58] - Матричный умножитель на основе систолических массивов (Systolic Array, SA), который исполняет матричное умножение входных данных и весов. Входных данных и веса читаются из матричной памяти (ME_MEM). В общем случае, для инициализации весов (загрузки), необходимое количество машинных тактов равно размеру вектора. Веса могут обновляться во время вычисления результатов на предыдущих весах, тем самым сокращая простой конвейера между инструкциями. Для расчета матричного умножения и операций свертки на систолическом массиве необходимо, чтобы входные каналы (последняя размерность входных данных) и выходные каналы (последняя размерность результата) были кратны размеру вектора.
[59] - Высокопропускная глобальная память (High Bandwidth Memory, HBM) - это высокоскоростная внешняя память, объемом в несколько гигабайт с последовательной адресацией. Контроллер памяти позволяет также адресовать со скоростью 1 вектор/такт (к примеру, для размера вектора 128 и данных в формате FP24 [11] необходимая скорость глобальной памяти для устройства частотой 1ГГц: размер_вектора * 3 байта * 10^9 = 384 ГБ/с). В векторном вычислительном устройстве реализована поддержка чтения данных из высокопропускной глобальной памяти (HBM) и запись в векторную (VE_MEM) и матричную (ME_MEM) памяти, при этом запись в глобальную память (HBM) поддерживается только из векторной памяти (VE_MEM). В отличие от векторной и матричной памятей, не поддерживается одновременная запись и чтение между глобальной (HBM) и векторной памятью (VE_MEM). Чтение и запись из/в HBM производятся с помощью DMA (Direct Memory Access) контроллера прямого доступа к памяти.
[60] - Исполнительное устройство векторных операций (Vector Subunit, VS). В векторном вычислительном устройстве реализована возможность в режиме конвейеризации отправить данные из систолического массива на, по меньшей мере, два последовательных исполнительных устройства векторных операций (VSa, VSb). Первое исполнительное устройство векторных операций (VSa) используется для сложения результата операции свертки с постоянным смещением (bias), а также для суммирования результатов с выходом результатов вычислений систолического массива. Второе исполнительное устройство векторных операций (VSb) используется для вычисления функции активации (RELU, Sigmoid и пр), и дополнительных операций сложения, умножения, при этом данные подаются из векторной памяти (VE_MEM) дополнительно в оба исполнительных устройства векторных операций (VSa, VSb).
[61] - Локальная память векторного устройства (VS_MEM) - это SRAM память для векторных операций, которая позволяет хранить промежуточные результаты вычислений SA, и обеспечивает быстрый и практически бесконфликтный доступ к данным. Также в этой памяти эффективно хранить “bias” значение для возможности эффективного сложения. Размер VS_MEM памяти сопоставим с размером векторной памяти (VE_MEM), при этом размер VS_MEM памяти можно взять меньше в 2 раза, поскольку размер выходных данных приблизительно того же порядка, что и размер входных данных, но не нужна конвейеризация внутри VS_MEM памяти. Память VS_MEM встроена внутри каждого исполнительного устройства скалярных операций (VSa, VSb).
[62] Каждый из указанных модулей векторного вычислительного устройства имеет аппаратное воплощение, например, в виде системы на кристалле (System-on-a-Chip, SoC).
[63] На этапе (103) разделяют ориентированный граф на основной подграф и подграфы предварительной обработки и постобработки на основании возможности выполнения операций модели нейронной сети, определенной на предыдущем этапе (102). Таким образом, тензорный компилятор обеспечивает автономное формирование участков (подграфов) пред- и постобработки, а также их исполнение на вспомогательном вычислительном устройстве (по умолчанию - CPU), тем самым предоставляя возможность гетерогенного исполнения.
[64] В частном примере реализации основной подграф содержит операций модели нейронной сети, поддерживаемые основным вычислительным устройством, а подграфы предварительной обработки и постобработки содержат операции модели нейронной сети, не поддерживаемые основным вычислительным устройством.
[65] Гетерогенное исполнение позволяет использовать возможности ИИ-ускорителей для обработки самых тяжелых частей модели нейронной сети и выполнять неподдерживаемые операции на вспомогательных вычислительных устройствах, таких как CPU. Таким образом, поддержка заявленным тензорным компилятором гетерогенного исполнения способствует повышению производительности процесса компиляции нейронных сетей, в том числе, и потому что основное вычислительное устройство (векторное вычислительное устройство) не будет тратить время на обработку неподдерживаемых операций, т.к. они уйдут на исполнение CPU. Благодаря этому сократится время исполнения моделей и за счёт этого повысится общая производительность процесса компиляции нейронных сетей.
[66] Далее рассмотрим некоторые варианты применения гетерогенного исполнения:
• В отдельных моделях нейронных сетей (чаще всего на embedding-участках) могут встретиться специфические операции, не поддерживаемые основным вычислительным устройством на данный момент: тригонометрические функции (sin, cos и др.), операции gather с особым форматом входа (параметризованные индексы), операции приведения к запрещенным типам данных (которые невозможно представить, как вещественные) и прочие;
• После проведения всех оптимизаций над представлением, могут остаться операции неподлежащие выравниванию. Исполнение подобных операций невозможно на основном вычислительном устройстве (векторном вычислительном устройстве) ввиду особенности его векторных вычислений. Исключением являются операции, связанные с управлением размерностями, такие как транспонирования или изменения размерностей;
• Иногда исполнение некоторых операций на основном вычислительном устройстве лишено смысла, например, когда комбинации операций управления размерностями являются первыми или последними, т.е. расположены в начале или в конце исходного графа. В таком случае, выгоднее предварительно выполнить требуемую конфигурацию связанного параметра или результата на уровне вспомогательного вычислительного устройства, нежели проводить операцию на основном вычислительном устройстве.
[67] На этапе (104) формируют последовательность запуска операций модели нейронной сети на основании взаимодействия участков основного подграфа с подграфами предварительной обработки и постобработки.
[68] В частном примере реализации обеспечение взаимодействия участков основного подграфа с подграфами предварительной обработки и постобработки включает связывание параметров и результатов разных участков подграфов, при этом связывание параметров и результатов разных участков подграфов включает связывание результата, предыдущей по порядку исполнения операции, с входным параметром следующей операции посредством ссылки.
[69] Одной из ключевых особенностей тензорного компилятора является наличие набора трансформаций собственной разработки, укомплектованных в длинные последовательности, выполняющие как задачи подготовки гетерогенных участков, так и задачи оптимизации верхнеуровнего графа моделей нейронных сетей (учитывая при этом только те архитектурные особенности векторного вычислительного устройства, которые свойственные всем платформам семейства). Данные трансформации разделены на три основных блока:
[70] - Блок предварительных преобразований - содержит трансформации, применяемые до использования общих оптимизаций набора инструментов, а также обеспечивает первичное определение гарантированно не поддерживаемых устройством операций и обособление их в отдельные подграфы;
[71] - Блок основных преобразований - содержит обширный перечень трансформаций собственной разработки, перемешанных с базовыми преобразованиями набора инструментов. Данный набор обеспечивает:
• Принудительную конвертацию типов данных (векторное вычислительное устройство поддерживает только вещественный тип) и формата тензоров NCHW в NHWC (векторное вычислительное устройство поддерживает вычисление операций свертки только в формате NHWC);
• Адаптацию трансформерных блоков (сведение всевозможных форматов к единому для унификации их под нужды специального микроядра);
• Движение операций транспонирования (с целью уменьшения затрат на проведение транспонирований за счет их слияния);
• А также проводит прочие процессы оптимизации представления модели нейронной сети;
• Кроме того, в завершении он доукомплектовывает подграфы предварительной обработки и постобработки, определяя новые узлы для гетерогенного исполнения по заданным критериям;
[72] - Блок завершающих трансформаций - работает для подграфов, сброшенных на гетерогенное исполнение. В ходе основных преобразований, все операции при необходимости конвертируются в специфичный для векторного вычислительного устройства формат, позже, часть из них может быть сброшена (такое возможно, например, когда предполагалось на начальном этапе, что неподдерживаемая операция будет сконвертирована, но такого не произошло по какой-либо причине). Данный набор трансформаций обеспечивает возврат специфичных конструкций и операций в изначальный вид, тем самым оптимизируя подграфы предварительной обработки и постобработки для исполнения на вспомогательном вычислительном устройстве (устройстве сброса).
[73] По окончании преобразований, тензорный компилятор обеспечивает взаимодействие подграфов предварительной обработки и постобработки с основным подграфом за счет связывания параметров и результатов разных частей (т.е. результат предыдущего по порядку исполнения подграфа содержит ссылку на входной параметр следующего подграфа, что указывает тензорному компилятору порядок действий при работе с данными).
[74] На этапе (105) осуществляют трансформации операций модели нейронной сети основного подграфа для оптимизации их исполнения, в результате получая оптимизированный унифицированный формат.
[75] В одном из частных примеров реализации трансформации операций модели нейронной сети, осуществляемые на этапе (105), включают по меньшей мере одно из:
• трансформации для движения и слияния операций транспонирования,
• трансформации для декомпозиции операций выравнивания дисперсии,
• трансформации для релаксации операций.
[76] Одной из основных задач тензорного компилятора также является проведение оптимизаций над верхнеуровневым графом. Как указывалось ранее, набор инструментов, применяемых тензорным компилятором, уже содержит базу общих трансформаций (например, преобразования сворачивая констант, объединения однотипных операций или преобразования декомпозиции сложных операций), тем не менее, использование части из них ограничено или лишено смысла из-за особенностей аппаратной части векторного вычислительного устройства. К примеру, существуют композиционные операции, предположим, логарифм от функции активации softmax, который декомпозируется общими трансформациями на комбинации редуцирующих операций с целью поддержания вычислительной стабильности. Такое поведение приводит к большему числу вычислений, а в отдельных случаях (при проведении вычислений по оси каналов) может повлечь увеличение потребляемой памяти из-за необходимости выравнивания операций (как указывалось ранее - по причине векторных вычислений основного вычислительного устройства). Подобные оптимизации были принудительно отключены, при этом были разработаны собственные трансформации, проводящие подобные декомпозиции другими способами, более выгодными для векторного вычислительного устройства. Для поддержания вычислительной стабильности был разработан механизм, исключающий появления неопределенных вычислений. В частности, для данного примера, появление логарифма от нуля невозможно за счет проведения предварительного сложения с очень маленьким числом, близким к нулю.
[77] В дополнение к базовому набору на данный период времени нашей командой было разработано свыше 200 собственных трансформаций, обеспечивающих формирование графа операций, оптимального для векторного вычислительного устройства. Далее представлены примеры оптимизаций и адаптаций, реализуемые в заявленном решении:
[78] Семейства трансформаций для движения и слияния операций транспонирования
[79] Самый очевидный подграф для сверточных сетей - комбинации связанных операций свертки. Предположим, у нас имеется последовательность из N данных операций, разделенных смещениями - операциями сложений.
[80] Как уточнялось ранее, векторное вычислительное устройство проводит вычисление конволюций в формате NHWC, при этом выбранный унифицированный формат представлений всегда проводит данную операцию в формате NCHW. Данный факт требует перемещения оси каналов в конец, что вкупе с необходимостью поддержания целостности графа, приведёт к появлению двух операций транспонирования до и после каждой операции свертки. В сумме, число операций в последовательности увеличится на 2N.
[81] Для устранения подобных затрат, в заявленном решении реализованы отдельные наборы алгоритмов, позволяющие находить и сближать транспонирования друг к другу и проводить их слияния. Таким образом, все транспонирования, заключенные между каждыми двумя узлами свертки, будут компенсированы, а операции сложения соответствующим образом переведены в формат NHWC.
[82] В результате останется лишь две операции транспонирования: перед первой сверткой и после последней. При наилучших обстоятельствах, данные операции могут быть перемещены до самого начала и до самого конца графа, где обеспечат предварительную конфигурацию параметра или результата, либо они могут быть слиты с другими транспонированиями, если таковые присутствуют в исходном графе. В противном случае, если на их пути есть неразрешенные операции, например, сложные операции изменения размерностей, при которых, предположим, происходит выделение новой оси из смежных, то движение операции транспонирования будет заблокировано. Тем не менее, даже для таких случаев есть отдельный набор трансформаций, имеющий шаблон поиска в виде подграфа транспонирование-изменение размерностей-транспонирование, обеспечивающих разрешение подобных комбинаций.
[83] В конечном счете, при любых обстоятельствах, все операции будут приведены в формат, поддерживаемый основным вычислительным устройством, при этом число операций транспонирований, в большинстве случаев уменьшится в сравнении с исходным представлением, обеспечивая тем самым снижение числа накладных (вычислительных) расходов.
[84] Декомпозиция операции выравнивания дисперсии
[85] Довольно часто встречаемая операция - операция выравнивания дисперсии с предварительным выделением групп. По нашим наблюдениям, число групп в различных моделях нейронных сетей, всегда составляет 32.
[86] Как правило, подобная операция располагается между двумя операциями свертки, а значит, учитывая ранее описанную трансформацию, произойдёт адаптация данного участка под формат NHWC, что приведет к перемещению групп в последнюю ось.
[87] Ввиду необходимости выравнивания данных для проведения векторных вычислений, данная ось впоследствии будет выровнена до размера вектора, что приведет к четырехкратному увеличению затрат памяти и соответствующему увеличению вычислительной нагрузки.
[88] По умолчанию, общий набор трансформаций декомпозирует данную операцию на комбинации операций редуцирования, возведения в степень, вычитания, деления и взятия корня. Данные операции проводятся над ранее выделенными группами.
[89] Вместо подобного подхода, было решено использовать собственную трансформацию для разложения данной операции. Мы, в свою очередь, сперва избавляемся от процедуры выделения групп, т.е. проводим межканальное выравнивание за две отдельные операции: отдельно сглаживаем каналы (вне групп; операция редуцирования), а затем сглаживаем отдельно группы за счет проведения операции матричного умножения со специально подготовленной константой.
[90] За счет подобной оптимизации, в качестве последней оси выбираются не выделенные группы, а исходная ось каналов, что исключает необходимость выравнивания данных, тем самым сокращая расходы по памяти.
[91] При этом появляется одна дополнительная операция матричного умножения, но описываемая трансформация позволяет также сократить размер множителя, за счет предварительной операции изменения размерностей, уменьшая размер как множителя, так и значение оси каналов данных до минимально допустимых - до размера вектора устройства. Таким образом, дополнительная вычислительная нагрузка сводится к минимуму, в сравнении с вышеописанным четырехкратным увеличением, при этом логика работы операции выравнивания дисперсии сохраняется.
[92] Семейство трансформаций релаксации операций
[93] Для отдельно взятых операций по умолчанию существует определенный перечень поддерживаемых входных и выходных типов данных. В связи с этим, многие модели нейронных сетей используют, к примеру, целочисленные или логические типы данных. Как уточнялось ранее, векторное вычислительное устройство поддерживает исключительно вещественный тип. В связи с этим, был реализован специальный механизм (посредством организации отдельного набора трансформаций), позволяющих находить операции с неподдерживаемым типом данных и проводить для них процедуру релаксации.
[94] Данный набор трансформаций также обеспечивает обособление найденных узлов операциями конвертации типов данных для поддержания целостности представления модели.
[95] После проведения процедур релаксации, трансформации гарантируют слияние операций конвертации типов, а также обеспечивают конфигурацию связанного с ними параметра или результата представления модели нейронной сети.
[96] В результате граф структурно остается таким же, каким был изначально, но с переопределенными типами входных и выходных типов данных найденных операций, обеспечивая возможность загрузки тензоров на устройство.
[97] В результате применения к основному подграфу всех трансформаций, необходимых для оптимизации исполнения операций модели нейронной сети, на выходе, в качестве результата применения трансформаций, получаем оптимизированный унифицированный формат. Кроме того, осуществление трансформаций операций модели нейронной сети способствует повышению производительности процесса компиляции нейронных сетей за счёт оптимизации исполнения операций модели нейронной сети.
[98] В альтернативном варианте воплощения заявленного изобретения тензорный компилятор имеет отдельный формат работы в динамическом режиме, когда отдельные размерности входных тензоров не заданы. Для этого указанные выше блоки трансформаций адаптируются для работы с подобного рода операциями. По завершении преобразований, тензорный компилятор сохраняет сформированный граф с динамическим форматом, и преобразует динамически определенные участки в специальные шаблонные заглушки, позволяя в дальнейшем перекомпилировать только их. Кроме того, тензорный компилятор обеспечивает переаллокацию входных и выходных тензоров при подаче пользовательских данных, а также настройку соответствующих memhandler`ов. Вместе с тем, динамический режим работы поддерживает выполнение асинхронных запросов на исполнение, что позволяет обрабатывать сразу несколько пользовательских входных данных и автономно распределять процессы перекомпиляции.
[99] Кроме того, для обеспечения оптимальной работы LLM-моделей, тензорный компилятор поддерживает специальный режим работы с KV-кэшом, реализованный посредством использования специального интерфейса, входящего в состав набора инструментов (например, OpenVINO State API с использованием специальных операций: ReadValue и Assign). Данный механизм позволяет тензорному компилятору сохранять состояния переменных между запросами на исполнения, что позволяет организовать своеобразную работу memhandler`ов и избавить векторное вычислительное устройство от лишних вычислений.
[100] На этапе (106) преобразуют оптимизированный унифицированный формат (полученный в результате осуществления трансформации операций модели нейронной сети) в высокоуровневый диалект путём применения трансформаций для сокращения количества вычислений и/или объема используемых данных.
[101] В одном из частных примеров реализации трансформации для сокращения количества вычислений и/или объема используемых данных на этапе преобразования оптимизированного унифицированного формата в высокоуровневый диалект включают по меньшей мере одно из:
• нормализация операций,
• сворачивание констант,
• вывод размеров,
• упрощение цепочек операций,
• выравнивание глубин тензоров.
[102] Одной из задач тензорного компилятора нейронных сетей является интеграция с разными форматами нейронных сетей. Поэтому при построении архитектуры тензорного компилятора должна быть использована компонента, реализующая эту функцию, - фронтенд компилятора. Результатом работы фронтенда компилятора является сгенерированный верхнеуровневый граф, состоящий из связанных между собой операций из набора, т.е. оптимизированный унифицированный формат. Существует большое разнообразие различных инструментов для обучения и оптимизации нейронных сетей: OpenVINO, TVM, XLA и каждый из них имеет свой собственный фронтенд и как следствие свой собственный набор уникальных операций.
[103] Как было сказано выше, верхняя часть тензорного компилятора базируется на наборе инструментов оптимизации, при этом архитектура тензорного компилятора изначально спроектирована для готовности к любым изменениям, в том числе, замены одного набора функций оптимизации на любой другой, позволяющий обеспечить взаимодействие с разными форматами нейронных сетей. Данная возможность реализована в тензорном компиляторе для совместимости фронтенда и высокоуровневого диалекта компилятора. Суть её заключается в преобразовании оптимизированного унифицированного формата (верхнеуровневого представления) в высокоуровневый диалект (граф операций высокоуровневого диалекта), при этом тензорный компилятор гарантирует, что преобразование будет выполнено корректно и все операции фронтенда (оптимизированного унифицированного формата) будут отображены в соответствующие операции диалекта высокого уровня (высокоуровневого диалекта), если такое преобразование является возможным.
[104] Высокоуровневый диалект - это набор операций, максимально приближенный к их представлению в инструментах глубокого обучения, предназначенный для выполнения дополнительных преобразований графа нейронной сети и задач ускорения исполнения. Преобразования, выполняемые над графом высокоуровневого диалекта схожи с теми, которые могут быть выполнены над графом фронтенда (оптимизированного унифицированного формата), многие из них осуществляются для повышения производительности вычислений за счет сокращения количества вычислений или объема используемых данных. Примерами таких трансформаций являются: нормализация операций, сворачивание констант, вывод размеров, упрощение цепочек операций, выравнивание глубин тензоров (матриц). В целом, высокоуровневый диалект предполагает выполнение трансформаций, которые могут быть выполнены универсально, независимо от целевой архитектуры, т.е. графовое представление, полученное после всех преобразований, остается возможным для исполнения на любом вычислительном устройстве, но с разной производительностью.
[105] В основе этой идеи лежит создание унифицированного диалекта для всего множества операций, которыми могут быть представлены нейронные сети: матричные умножения, векторные операции, функции активации. Диалект таких высокоуровневых операций называется диалектом высокого уровня. Создание собственного диалекта высокого уровня позволяет абстрагироваться от конкретной имплементации операции на конкретном устройстве, сохранив при этом определение. Таким образом, достигается эффект единого универсального определения операции с возможностью различных реализаций в различных архитектурах аппаратных ускорителей нейронных сетей. Также, набор высокоуровневых операций позволяет избежать внешних зависимостей в компиляторе. Так как диалект высокоуровневых операций создан с нуля, определение операций сделано максимально универсально и состоит из меньшего набора операций, чем набор операций в инструментах глубокого обучения, при этом высокоуровневый диалект тем не менее достаточно полно описывает модель и к нему (высокоуровневому диалекту) могут быть легко сконвертированы описания моделей различных инструментов глубокого обучения.
[106] Операции диалекта высокого уровня представляют собой операции, описанные в рамках правил диалекта. Операции содержат названия, связанные с ней входные и выходные тензора, а также дополнительные свойства, задающие константные параметры операции. Для формирования новой операции необходимо описать операцию в файле диалекта, т.е. описать ее входные и выходные параметры, описать ее свойства, а также, опционально, операции трансформаций. Например, операция сверточного слоя может принимать на вход данные и ядро свертки, а выдавать в качестве выхода тензор, помимо этого используются различные свойства: шаг, дополнение и другие. Также существует возможность задавать необходимые преобразования, которые будут применяться к операции при обработке диалекта, например, нормализация.
[107] На этапе (107) преобразуют высокоуровневый диалект в диалект общего уровня путём распределения операций модели нейронной сети между аппаратными блоками основного вычислительного устройства с учетом иерархии памяти, размеров тензоров и используемых типов данных.
[108] Операции, выраженные с помощью высокоуровневого диалекта, имеют тензорный вид и никак не отображают специфики устройства. Поэтому для того, чтобы операции нейронных сетей можно было разложить на аппаратные блоки вычислительного устройства и организовать параллельность вычислений используется многоуровневый граф. Переходы между разными уровнями осуществляются с помощью этапов преобразования, называемые понижением. Написание этапов преобразования часто выглядит объемно и сложно для понимания, поэтому в тензорном компиляторе предлагается для написания микроядер использовать специальный преобразователь графовых представлений. Преобразователь позволяет выполнить конвертацию из диалекта высокого уровня в набор операций общего уровня. С помощью преобразователя можно описать схему вычислений с учетом иерархии памяти и размеров тензоров, используемых типов данных, без необходимости глубокого погружения в архитектуру ускорителя. Логика работы преобразователя состоит в автоматической генерации платформенно зависимого кода и наличии механизма автоматического распределения вычислений между элементами векторного вычислительного устройства (матричными умножителями, различными видами памяти и другими исполнительными устройствами, поддерживающими параллелизм).
[109] Преобразователь осуществляет работу с многомерными массивами данных, расположенные в памяти основного вычислительного устройства по определенному адресу и иерархией памяти, которая используется для хранения тензоров следующего вида:
1. Глобальная память векторного вычислительного устройства (HBM).
2. Разделяемая векторная память (VE_MEM).
3. Локальная память исполнительного устройства. Конкретный тип локальной памяти определяется из контекста операции, которая выполняется над тензором. Может быть локальной памятью Matrix Engine (ME_MEM) или локальной векторной памятью (VS_MEM).
[110] В тензорном компиляторе для всех тензоров доступна индексация для следующих целей:
• адресации элементов тензоров в операциях чтения и записи элементов;
• указания диапазонов циклов, причем диапазоном цикла может быть любая линейная комбинация индексов внешних циклов.
[111] Любой уникальный индекс, используемый в тензорных выражениях порождает вложенный цикл. Для адресации элементов тензоров и указания диапазонов циклов может быть использована линейная комбинация индексов. Линейная комбинация - это выражение вида: a*i + b*j + ... + c*k + d, где i, j, k - индексы, a, b, c, d - целые числа произвольного знака.
[112] Над индексами и линейными комбинациями индексов введены следующие операции:
• преобразование любого индекса в выражение,
• преобразование любого целого числа в выражение,
• сложение, вычитание линейных комбинаций индексов,
• сложение и вычитание произвольного целого числа из индексного выражения,
• умножение и деление линейных комбинаций на целое число.
[113] Результатом адресации данных по индексам является подмножество значений тензора, на которые указывают индексы или линейная комбинация индексов. По умолчанию, диапазоны индексов определяются из размерностей тензора.
[114] Результатом работы преобразователя является сгенерированный граф общего или низкого уровней.
[115] На примере операции сложения работа преобразователя будет выглядеть так (для других операций аналогично):
1. Принять на вход операцию на диалекте высокого уровня с двумя входами и одним выходом;
2. Преобразовать операнды в комбинацию операций чтения и/или записи в/из матричную, векторную или глобальную памяти;
3. Преобразовать команду сложения и подготовить ее для вычисления на исполнительном устройство векторных операций;
4. Преобразовать результат в комбинацию операций чтения и/или записи в/из матричную, векторную или глобальную памяти.
[116] Таким образом, осуществляется воздействие преобразователем на операцию диалекта высокого уровня и генерируется граф на диалекте общего или низкого уровней с отображением на исполнительные устройства внутри основного вычислительного устройства.
[117] Преобразователь тензорного компилятора эффективно применяется в устройствах, снабженных векторной, матричной и/или глобальной памятью, но не ограничивается только указанными видами памятей.
[118] На этапе (108) преобразуют диалект общего уровня в низкоуровневый диалект, состоящий из набора команд, доступных для выполнения на основном вычислительном устройстве.
[119] Диалект общего уровня предназначен для формирования промежуточного представления, включающего специфику исполнения и оптимизации вычислений нейронных сетей. Граф, построенный с использованием диалекта общего уровня, включает в себя иерархию памяти основного вычислительного устройства, инструкции загрузки и сохранения, набор операций, поддерживаемых основным вычислительным устройством, а также атрибуты задающие обходы тензоров в памяти. Например, с использованием генератора паттернов адресов (APG) может быть описан тензор любой вложенности и любых размеров. Модификации графа общего уровня позволяют выполнять декомпозиции операций нейронных сетей на список операций, поддерживаемых основным вычислительным устройством. Операции, которые описаны в диалекте высокого уровня, не всегда могут быть представлены в диалекте общего уровня, в таком случае выполняется их разложение на поддерживаемые операции, либо используются аппроксимации.
[120] Ещё одной функцией диалекта среднего уровня является расширяемость тензорного компилятора под другие архитектуры устройств, решающие задачи ускорения инференса нейронных сетей. В случае необходимости поддержки дополнительных устройств может быть создан ещё один диалект, состоящих из операций, отражающих специфику новой архитектуры.
[121] Таким образом, реализуется подход понижения представления операции. На самом верху компилятора, в части фронтенда, операция максимально далека от специфики основного вычислительного устройства и больше является арифметической, однако в процессе преобразования фронтенд → высокоуровневый диалект → диалект общего уровня → низкоуровневый диалект происходит «понижение» операции, её разложение и все операции становятся уже строго архитектурно зависимыми. Они учитывают типы данных, используемые в вычислениях, связи между исполнительными устройствами внутри процессора, позволяя генерировать низкоуровневый код с максимальной производительностью вычислений за счет сокращения вычислений и повышения параллелизма работы устройства.
[122] В одном из частных примеров реализации этапы преобразования высокоуровневого диалекта в диалект общего уровня и преобразования диалекта общего уровня в низкоуровневый диалект дополнительно содержат выравнивание тензоров для работы с данными.
[123] В предыдущих разделах множество раз уточнялось, что основное вычислительное устройство проводит исключительно векторные вычисления - это требует выравнивания тензоров для работы с данными. Для этого был реализован отдельный механизм выравнивания, позволяющий тензорам быть консистентными на каждом участке графа модели нейронной сети. Под термином консистентности понимается возможность обработки тензора устройством, т.е. это условия, при которых размер данных должен быть кратен размеру вектора устройства. Описываемый механизм обеспечивает проверку всех операций для выбранного графа, а также их адаптацию под заданные требования при необходимости.
[124] Примеры сценариев поведения:
[125] - Поэлементные операции: самый простой случай, в качестве примера операций подобного рода можно выделить операции сложения, вычитания, умножения, а также функции активации и т.п. Ввиду отсутствия возможных зависимостей данных друг от друга, в случае, когда их размер некратен размеру вектора, достаточно укомплектовать тензор в размерах, чуть больших, чем требуется и удовлетворяющих условию консистентности;
[126] - Операции свертки: в случае, если операции свертки не удовлетворяют критерию, невозможно выровнять размер данных, как это делается для поэлементных операций, так как это нарушит логику работы. В данном случае консистентность не является достаточным условием и требуется соблюсти условие выровненности оси каналов. Для решения этой проблемы сперва проводится попытка приведения операции к полосатому формату - отдельная трансформация, позволяющая выровнять ось каналов за счет переконфигурации размерностей, а также обновления параметров и атрибутов самой свертки. Если же это выполнить невозможно ввиду специфичного формата операции, предпринимается введение предварительной операции выравнивания оси каналов до требуемых размеров для соблюдения поставленного условия. Последний способ наименее эффективен и влечет за собой появление лишних накладных расходов, размер которых зависит от разницы исходного и выровненного числа каналов, тем не менее, он всегда гарантирует возможность исполнения операции на устройстве;
[127] - Константные скаляры: отдельные операции иногда работают со скалярными константами, например, операции деления, при которых для исключения неопределенностей, проводится предварительное сложение с очень малой величиной. В таком случае для константы выделяется участок памяти, соответствующий размеру вектора и само значение скаляра копируется соответствующее число раз. В целях сокращения расходов памяти, размер константы всегда остается неизменным и читается столько раз, сколько требуется для проведения операции (в зависимости от размера тензора параметризованного операнда).
[128] На этапе (109) осуществляют генерацию бинарного потока данных на основе низкоуровневого диалекта и разбиение бинарного потока данных на отдельные инструкции для параллельной обработки на аппаратных блоках основного вычислительного устройства.
[129] Низкоуровневый диалект предназначен для представления ассемблерной программы в виде графа инструкций конкретной архитектуры основного вычислительного устройства. Каждая архитектура имеет свой независимый низкоуровневый диалект, который может быть получен из диалекта общего уровня.
[130] Низкоуровневый диалект состоит из операций, однозначно отображаемых для операций модуля генерации кода и, соответственно, команд, доступных для выполнения на основном вычислительном устройстве. Каждая новая архитектура вычислительного устройства должна быть представлена в виде самостоятельного низкоуровневого диалекта.
[131] Генератор кода - это библиотека примитивов, используемая для создания бинарных программ. Генератор кода состоит из набора интерфейсов, которые вызываются напрямую в момент выполнения этапа кодогенерации в процессе компиляции. Интерфейсы библиотеки предполагают возможность написания бинарных программ, как с использованием языка ассемблера, так и с помощью специальных интерфейсов.
[132] Помимо того, что команды необходимо правильным образом закодировать, чтобы целевая архитектура смогла их исполнить, также нужно уметь читать бинарный поток данных и разбивать его на отдельные инструкции для исполнительных устройств. Данная возможность необходима для отладки бинарного кода, который генерирует тензорный компилятор, поиска узких мест и интерпретации набора байт в человекочитаемом виде.
[133] Разделение бинарной инструкции на структуры, ее определяющие, выполняет декодер, результат работы которого может быть передан в дизассемблер.
[134] Дизассемблер - это часть генератора кода, переводящая декодированные инструкции в исходный ассемблерный вид. Таким образом, генератор кода обеспечивает возможность полного цикла генерации бинарного кода и его последующей обработки в задачах широкого спектра.
[135] Архитектура компилятора предполагает работу в двух режимах:
• режим динамической оптимизации,
• режим макрокернелов.
[136] Режим динамической оптимизации основан на принципе общих оптимизирующих алгоритмов, т.е. алгоритмов, которыми будет обработана исходная нейронная сеть вне зависимости от её топологии. Таким образом, стратегии вычислений строятся максимально универсально. Например, один из механизмов синхронизации потоков внутри устройства - планирование тегов анализирует весь граф целиком, что затратно по ресурсам, однако обеспечивает достаточную степень параллелизма исполнительных процессорных устройств.
[137] Режим макрокернелов, наоборот, предполагает, что все стратегии вычислений строятся вручную. При таком подходе каждая операция имеет свою реализацию на диалекте общего уровня или ниже. Это позволяет достигать максимальной производительности для конкретных операций. Нейронные сети - это целые наборы различных операций и шаблонных паттернов, поэтому при использовании похода с макрокернелами всегда можно выделить блок, требующий ускорения и написать для него высокопроизводительный код.
[138] Поскольку на данном уровне тензорный компилятор имеет доступ ко всей информации об архитектуре конкретного вычислительного устройства, тензорный компилятор содержит в себе специальный механизм, обеспечивающий распределение вычислительной нагрузки, а также регламентирующий работу независимых компонентов устройства при переводе операций на низкоуровневый диалект.
[139] Алгоритм планирует загрузку входных данных небольшими порциями из глобальной памяти, распределяя эти загруженные участки на независимые (параллельные) внутренние компоненты. После этого он компонует вычисленные результаты в глобальную память так, чтобы сохранить целостность данных, проводя при необходимости вспомогательные арифметические операции. Кроме того, на этом же этапе, определяются специальные элементы синхронизации, гарантирующие корректную работу независимых внутренних компонент, которые исключают возникновения гонки данных [12]. Конкретные размеры порций, а также сам алгоритм распределения являются специфичными для каждого типа операций и определяются вспомогательными алгоритмами анализа, которые проводят необходимые расчеты для нахождения наиболее оптимальных параметров (под оптимальными параметрами подразумеваются те параметры, при которых достигается наиболее допустимая утилизация устройства для конкретных условий).
[140] Для примера рассмотрим случай, когда, необходимо сложить два тензора размерами (256, 512, 128). Размеры данных тензоров в векторах составляют 131072, что в сумме выходит за рамки допустимой памяти устройства векторных вычислений, поэтому исполнение операции на одном внутреннем компоненте за один проход физически невозможно. Предлагается разделить входную память на 4 участка и распределить работу на два независимых устройства векторных вычислений с очередью 2. При этом, инструкции формируются в формате конвейера, т.е. когда загружаются данные, например, для третьего участка, для второго участка в этот момент происходит вычисление суммы, что позволяет исключить эффект бутылочного горлышка при параллельном вычислении операции. Результат вычислений последовательно укомплектовывается в глобальную память, необходимости проводить дополнительные операции для отдельных промежуточных порций результата нет. В итоге скорость исполнения данной операции повышается на 72% в сравнении с теоретической оценкой при одном проходе (вероятно, полагается, что увеличение будет на 100%, но это невозможно, так как число инструкций для обращения к памяти устройства сильно возрастает, что приводит к появлению дополнительных накладных расходов).
[141] Для операций, использующих матричный умножитель (к примеру - свертка), реализованы более сложные алгоритмы распределения вычислений, учитывающие также особенности работы систолических массивов.
[142] Таким образом, данный алгоритм не только позволяет вычислять операции, не помещающиеся в память конкретных внутренних компонент, но и позволяет более эффективно использовать вычислительные ресурсы основного вычислительного устройства.
[143] Также стоит отметить специальный подход к чтению входных данных. Указанный алгоритм реализует чтение данных из глобальной памяти независимо по младшим адресам памяти и по старшим, синхронизируя выполнение операции чтения на стороне принимающего компонента, тем самым позволяя сократить время на её выполнение до двух раз.
[144] На этапе (110) выполняют инструкции, полученные на этапе (109), на основном вычислительном устройстве, а также выполняют операции из подграфов предварительной обработки и постобработки на вспомогательном вычислительном устройстве на основании последовательности запуска, сформированной на этапе (104).
[145] В рамках заявленного тензорного компилятора, исполняющая среда представляет собой устройство, способное выполнить бинарный код, полученный в результате компиляции. Исполняющая среда позволяет проводить инференс нейронных сетей и проводить оценку производительности скомпилированных нейронных сетей.
[146] Для обеспечения повышения производительности процесса компиляции нейронных сетей выполнение инструкций, полученных разбиением бинарного потока данных (этап 109), осуществляют на основном вычислительном устройстве, а операции из подграфов предварительной обработки и постобработки (содержащие операций модели нейронной сети, не поддерживаемые основным вычислительным устройством) выполняют на вспомогательном вычислительном устройстве, при этом синхронизация выполнения вышеуказанных инструкций и операций осуществляется строго на основании последовательности запуска, сформированной на этапе (104).
[147] Тензорный компилятор (устройство для компиляции нейронных сетей) может быть реализован на базе вычислительной системы, содержащей
• по меньшей мере одно основное и вспомогательное вычислительные устройства, обеспечивающие возможность гетерогенного исполнения операций модели нейронной сети,
• по меньшей мере один процессор,
• по меньшей мере одну память, связанную с процессором и содержащую машиночитаемые инструкции, которые при их выполнении по меньшей мере одним процессором обеспечивают выполнение способа компиляции нейронных сетей.
[148] Основное вычислительные устройства было описано ранее со ссылкой на Фиг. 2 и, в частном случае реализации, является векторным вычислительным устройством. Вспомогательное вычислительное устройство является центральным процессорным устройством (CPU). Процессор (или несколько процессоров, многоядерный процессор) могут выбираться из ассортимента устройств, широко применяемых в текущее время, например, компаний Intel™, AMD™, Apple™, Samsung Exynos™, MediaTEK™, Qualcomm Snapdragon™ и т.п. В качестве процессора может также применяться графический процессор, например, Nvidia, AMD, Graphcore и пр. Память, связанная с процессором, может представлять собой оперативную память, предназначенную для хранения исполняемых процессором машиночитаемых инструкций.
[149] Дополнительно устройство для компиляции нейронных сетей может содержать одно или более устройств постоянного хранения данных, например, жесткий диск (HDD), твердотельный накопитель данных (SSD), флэш-память (EEPROM, NAND и т.п.), оптические носители информации (CD-R/RW, DVD-R/RW, Blu-Ray Disc, MD) и др.
[150] Элементы устройства для компиляции нейронных сетей могут быть объединены общей шиной информационного обмена.
[151] Представленные материалы заявки раскрывают предпочтительные примеры реализации технического решения и не должны трактоваться как ограничивающие иные, частные примеры его воплощения, не выходящие за пределы испрашиваемой правовой охраны, которые являются очевидными для специалистов соответствующей области техники.
[152] Источники информации:
[1] How Compilers Work | Baeldung on Computer Science. https://www.baeldung.com/cs/how-compilers-work
[2] Heterogeneous Execution - ONE (On-device Neural Engine) 1.29.0 documentation. https://nnfw.readthedocs.io/en/stable/runtime/heterogeneous-execution.html
[3] Систолический массив - Википедия. https://ru.wikipedia.org/wiki/Систолический_массив
[4] Векторный процессор - Википедия. https://ru.wikipedia.org/wiki/Векторный_процессор
[5] Высокопропускная память - Википедия. https://ru.wikipedia.org/wiki/ Высокопропускная память
[6] Overview of Transformations API - OpenVINO™ documentation - Version (2023.3). https://docs.openvino.ai/2023.3/openvino_docs_transformations.html
[7] Class ov::op::TypeRelaxed - OpenVINO™ documentation - Version (2023.3). https://docs.openvino.ai/2023.3/api/c_cpp_api/classov_1_1op_1_1_type_relaxed.html
[8] Layout API Overview - OpenVINO™ documentation - Version (2023.3). https://docs.openvino.ai/2023.3/openvino_docs_OV_UG_Layout_Overview.html
[9] Transpose - OpenVINO™ documentation - Version (2024). https://docs.openvino.ai/2024/documentation/openvino-ir-format/operation-sets/operation-specs/movement/transpose-1.html
[10] OpenVINO IR format - OpenVINO™ documentation - Version (2023.3). https://docs.openvino.ai/2023.3/openvino_ir.html
[11] Minifloat - Wikipedia. https://en.wikipedia.org/wiki/Minifloat
[12] Параллельные вычисления и многопоточное программирование. Лекция 6: Потоки. Гонка данных и другие проблемы. https://intuit.ru/studies/courses/10554/1092/lecture/27095
| название | год | авторы | номер документа |
|---|---|---|---|
| Система классификации трафика | 2018 |
|
RU2697648C2 |
| ЯЗЫК РАЗМЕТКИ И ОБЪЕКТНАЯ МОДЕЛЬ ДЛЯ ВЕКТОРНОЙ ГРАФИКИ | 2003 |
|
RU2321892C2 |
| СИСТЕМА СЖАТИЯ ИСКУССТВЕННЫХ НЕЙРОННЫХ СЕТЕЙ НА ОСНОВЕ ИТЕРАТИВНОГО ПРИМЕНЕНИЯ ТЕНЗОРНЫХ АППРОКСИМАЦИЙ | 2019 |
|
RU2734579C1 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ СОВМЕСТНОГО ВЫПОЛНЕНИЯ ДЕБАЙЕРИЗАЦИИ И УСТРАНЕНИЯ ШУМОВ ИЗОБРАЖЕНИЯ С ПОМОЩЬЮ НЕЙРОННОЙ СЕТИ | 2020 |
|
RU2764395C1 |
| Метод построения процессоров для вывода в сверточных нейронных сетях, основанный на потоковых вычислениях | 2020 |
|
RU2732201C1 |
| СПОСОБ И СИСТЕМА МОДИФИКАЦИИ ПРОГРАММНОГО КОДА | 2023 |
|
RU2824522C1 |
| УСТРОЙСТВО МАТРИЧНЫХ ВЫЧИСЛЕНИЙ | 2025 |
|
RU2838831C1 |
| СИСТЕМА И СПОСОБ СТАТИЧЕСКОГО АНАЛИЗА ИСПОЛНЯЕМОГО ДВОИЧНОГО КОДА И ИСХОДНОГО КОДА С ИСПОЛЬЗОВАНИЕМ НЕЧЕТКОЙ ЛОГИКИ | 2021 |
|
RU2783152C1 |
| СПОСОБ И СИСТЕМА ДЛЯ ВЫПОЛНЕНИЯ ПРОГРАММНОГО КОДА С ПОМОЩЬЮ НЕЙРОННЫХ СЕТЕЙ | 2024 |
|
RU2834580C1 |
| СПОСОБ РАЗДЕЛЕНИЯ ОПЕРАЦИИ СВЕРТКИ НА УСТРОЙСТВЕ С МАТРИЧНЫМИ УМНОЖИТЕЛЯМИ НА ОСНОВЕ СИСТОЛИЧЕСКИХ МАССИВОВ | 2024 |
|
RU2830039C1 |
Изобретение относится к области глубокого обучения, в частности к способу и устройству для компиляции нейронных сетей. Техническим результатом является повышение производительности процесса компиляции нейронных сетей. Способ выполняется по меньшей мере одним процессором и содержит этапы, на которых: a) получают модель нейронной сети и преобразуют ее в унифицированный формат, представляющий ориентированный граф, где вершины графа являются операциями модели нейронной сети, b) определяют возможности выполнения операций модели нейронной сети на основном или вспомогательном вычислительном устройстве, c) разделяют ориентированный граф на основной подграф и подграфы предварительной обработки и постобработки, d) формируют последовательность запуска операций модели нейронной сети на основании взаимодействия участков основного подграфа с подграфами предварительной обработки и постобработки, e) осуществляют трансформации операций модели нейронной сети основного подграфа для оптимизации их исполнения, в результате получая оптимизированный унифицированный формат, f) преобразуют оптимизированный унифицированный формат в высокоуровневый диалект, g) преобразуют высокоуровневый диалект в диалект общего уровня, h) преобразуют диалект общего уровня в низкоуровневый диалект, i) осуществляют генерацию бинарного потока данных на основе низкоуровневого диалекта и разбиение бинарного потока данных на отдельные инструкции для параллельной обработки на аппаратных блоках основного вычислительного устройства, j) выполняют инструкции, полученные на этапе i), на основном вычислительном устройстве, а также выполняют операции из подграфов предварительной обработки и постобработки на вспомогательном вычислительном устройстве на основании последовательности запуска, сформированной на этапе d). 2 н. и 11 з.п. ф-лы, 2 ил.
1. Способ компиляции нейронных сетей, выполняемый по меньшей мере одним процессором, содержащий этапы, на которых:
a) получают по меньшей мере одну модель нейронной сети и преобразуют её в унифицированный формат, представляющий ориентированный граф, где вершины графа являются операциями модели нейронной сети,
b) определяют возможности выполнения операций модели нейронной сети на по меньшей мере одном основном или вспомогательном вычислительном устройстве на основании анализа операций модели нейронной сети и информации об архитектуре указанных вычислительных устройств,
c) разделяют ориентированный граф на основной подграф и подграфы предварительной обработки и постобработки на основании возможности выполнения операций модели нейронной сети, определенной на этапе b),
d) формируют последовательность запуска операций модели нейронной сети на основании взаимодействия участков основного подграфа с подграфами предварительной обработки и постобработки,
e) осуществляют трансформации операций модели нейронной сети основного подграфа для оптимизации их исполнения, в результате получая оптимизированный унифицированный формат,
f) преобразуют оптимизированный унифицированный формат в высокоуровневый диалект путём применения трансформаций для сокращения количества вычислений и/или объема используемых данных,
g) преобразуют высокоуровневый диалект в диалект общего уровня путём распределения операций модели нейронной сети между аппаратными блоками основного вычислительного устройства с учетом иерархии памяти, размеров тензоров и используемых типов данных,
h) преобразуют диалект общего уровня в низкоуровневый диалект, состоящий из набора команд, доступных для выполнения на основном вычислительном устройстве,
i) осуществляют генерацию бинарного потока данных на основе низкоуровневого диалекта и разбиение бинарного потока данных на отдельные инструкции для параллельной обработки на аппаратных блоках основного вычислительного устройства,
j) выполняют инструкции, полученные на этапе i), на основном вычислительном устройстве, а также выполняют операции из подграфов предварительной обработки и постобработки на вспомогательном вычислительном устройстве на основании последовательности запуска, сформированной на этапе d).
2. Способ по п.1, характеризующийся тем, основное вычислительное устройство является векторным вычислительным устройством.
3. Способ по п.1, характеризующийся тем, что вспомогательное вычислительное устройство является центральным процессорным устройством (CPU).
4. Способ по любому из пп.1-3, характеризующийся тем, что этап определения возможности выполнения операций модели нейронной сети на основном или вспомогательном вычислительном устройстве дополнительно содержит:
• применение предварительных преобразований для нахождения операций модели нейронной сети, не поддерживаемых основным вычислительным устройством,
• локализацию найденных неподдерживаемых операций модели нейронной сети.
5. Способ по п.1, характеризующийся тем, что основной подграф содержит операции модели нейронной сети, поддерживаемые основным вычислительным устройством, а подграфы предварительной обработки и постобработки содержат операции модели нейронной сети, не поддерживаемые основным вычислительным устройством.
6. Способ по п.1, характеризующийся тем, что обеспечение взаимодействия участков основного подграфа с подграфами предварительной обработки и постобработки включает связывание параметров и результатов разных участков подграфов.
7. Способ по п.6, характеризующийся тем, что связывание параметров и результатов разных участков подграфов включает связывание результата предыдущей по порядку исполнения операции с входным параметром следующей операции посредством ссылки.
8. Способ по п.1, характеризующийся тем, что трансформации операций модели нейронной сети, осуществляемые на этапе e), включают по меньшей мере одно из:
• трансформации для движения и слияния операций транспонирования,
• трансформации для декомпозиции операций выравнивания дисперсии,
• трансформации для релаксации операций.
9. Способ по п.1, характеризующийся тем, что трансформации для сокращения количества вычислений и/или объема используемых данных на этапе преобразования оптимизированного унифицированного формата в высокоуровневый диалект включают по меньшей мере одно из:
• нормализация операций,
• сворачивание констант,
• вывод размеров,
• упрощение цепочек операций,
• выравнивание глубин тензоров.
10. Способ по п.1, характеризующийся тем, что этапы преобразования высокоуровневого диалекта в диалект общего уровня и преобразования диалекта общего уровня в низкоуровневый диалект дополнительно содержат выравнивание тензоров для работы с данными.
11. Устройство для компиляции нейронных сетей, содержащее
по меньшей мере одно основное и вспомогательное вычислительные устройства, обеспечивающие возможность гетерогенного исполнения операций модели нейронной сети,
по меньшей мере один процессор,
по меньшей мере одну память, связанную с процессором и содержащую машиночитаемые инструкции, которые при их выполнении по меньшей мере одним процессором обеспечивают выполнение способа по любому из пп.1-10.
12. Устройство по п.11, характеризующееся тем, что основное вычислительное устройство является векторным вычислительным устройством.
13. Устройство по п.11, характеризующееся тем, что вспомогательное вычислительное устройство является центральным процессорным устройством (CPU).
| US 11977475 B1, 07.05.2024 | |||
| US 20230053289 A1, 16.02.2023 | |||
| В | |||
| ВИНОГРАДОВ, Разработка тензорного компилятора под RISC-V CPU с помощью OpenVINO и MLIR, 16.01.2024, URL: https://web.archive.org/web/20240116180908/https://engineer.yadro.com/article/tensor-compiler/ | |||
| N | |||
| ROTEM и др | |||
| Glow: Graph Lowering Compiler Techniques for Neural Networks, |

